

Upload 5 files
Browse files- .gitattributes +1 -0
- DBbun_EEG_Encoder_Eval_Demo_v2.py +188 -0
- Figure 2025-10-06 160738.png +3 -0
- Figure 2025-10-06 160750.png +0 -0
- Figure 2025-10-06 160754.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
Figure[[:space:]]2025-10-06[[:space:]]160738.png filter=lfs diff=lfs merge=lfs -text
|
DBbun_EEG_Encoder_Eval_Demo_v2.py
ADDED
|
@@ -0,0 +1,188 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# dbbun_eeg_eval_labeled_pca.py
|
| 2 |
+
# Color-coded PCA: seizure (red) vs non-seizure (blue)
|
| 3 |
+
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
import json, numpy as np, torch, torch.nn as nn
|
| 6 |
+
from torch.utils.data import Dataset, DataLoader
|
| 7 |
+
import matplotlib.pyplot as plt
|
| 8 |
+
|
| 9 |
+
# ======================
|
| 10 |
+
# CONFIG (your settings)
|
| 11 |
+
# ======================
|
| 12 |
+
MODEL_DIR = r"C:\DBBun\Code\EEG\pretraining\pretrained_out"
|
| 13 |
+
DATA_DIR = r"d:\dbbun-eeg\data\valid" # NPZ folder
|
| 14 |
+
USE_NPZ = True # NPZ with labels_sec
|
| 15 |
+
PREFER_TORCHSCRIPT = False
|
| 16 |
+
|
| 17 |
+
HOP_SECONDS = 1.5
|
| 18 |
+
MAX_FILES = 10
|
| 19 |
+
BATCH_SIZE = 64
|
| 20 |
+
WINDOW_LABEL_THRESHOLD = 0.5 # >0.5 sec of seizure in a 2s window → label 1
|
| 21 |
+
|
| 22 |
+
SAVE_EMBEDDINGS = True
|
| 23 |
+
EMB_OUT_PATH = Path(MODEL_DIR) / "demo_embeddings.npy"
|
| 24 |
+
|
| 25 |
+
# ======================
|
| 26 |
+
# Model loading
|
| 27 |
+
# ======================
|
| 28 |
+
def load_model_def(model_dir: str):
|
| 29 |
+
md_path = Path(model_dir) / "model_def.json"
|
| 30 |
+
return json.loads(md_path.read_text())
|
| 31 |
+
|
| 32 |
+
class Conv1dEncoder(nn.Module):
|
| 33 |
+
def __init__(self, in_channels, widths=(32,64,128), latent_dim=128, dropout=0.1):
|
| 34 |
+
super().__init__()
|
| 35 |
+
layers, prev = [], in_channels
|
| 36 |
+
for w in widths:
|
| 37 |
+
layers += [nn.Conv1d(prev,w,7,2,3), nn.BatchNorm1d(w), nn.GELU(), nn.Dropout(dropout)]
|
| 38 |
+
prev = w
|
| 39 |
+
self.conv = nn.Sequential(*layers)
|
| 40 |
+
self.pool = nn.AdaptiveAvgPool1d(1)
|
| 41 |
+
self.proj = nn.Linear(prev, latent_dim)
|
| 42 |
+
def forward(self, x):
|
| 43 |
+
h = self.conv(x); g = self.pool(h).squeeze(-1); z = self.proj(g)
|
| 44 |
+
return z, h
|
| 45 |
+
|
| 46 |
+
def load_encoder(model_dir: str, prefer_ts: bool = False):
|
| 47 |
+
md = load_model_def(model_dir)
|
| 48 |
+
if prefer_ts and (Path(model_dir)/"encoder_traced.pt").exists():
|
| 49 |
+
print("[Model] TorchScript")
|
| 50 |
+
enc = torch.jit.load(str(Path(model_dir)/"encoder_traced.pt"), map_location="cpu")
|
| 51 |
+
scripted = True
|
| 52 |
+
else:
|
| 53 |
+
print("[Model] state_dict")
|
| 54 |
+
enc = Conv1dEncoder(md["channels"], tuple(md["encoder_channels"]), md["latent_dim"], md["dropout"])
|
| 55 |
+
enc.load_state_dict(torch.load(Path(model_dir)/"encoder_state.pt", map_location="cpu"))
|
| 56 |
+
scripted = False
|
| 57 |
+
enc.eval()
|
| 58 |
+
win = int(md["window_seconds"] * md["sample_rate"])
|
| 59 |
+
return enc, md, win, scripted
|
| 60 |
+
|
| 61 |
+
# ======================
|
| 62 |
+
# Dataset with labels
|
| 63 |
+
# ======================
|
| 64 |
+
class EEGWindowsLabeled(Dataset):
|
| 65 |
+
"""Returns (window_tensor, label), label∈{0,1,-1} derived from labels_sec."""
|
| 66 |
+
def __init__(self, folder, window_len, hop, sr, use_npz=True, max_files=None, print_summary=True):
|
| 67 |
+
self.folder = Path(folder); self.window = int(window_len); self.hop = int(hop)
|
| 68 |
+
self.sr = int(sr); self.use_npz = use_npz
|
| 69 |
+
patt = "*.npz" if use_npz else "*.npy"
|
| 70 |
+
self.files = sorted(self.folder.rglob(patt))[: (int(max_files) if max_files else None)]
|
| 71 |
+
|
| 72 |
+
self.index, self.shapes = [], []
|
| 73 |
+
self.labels_present, self.sz_frac = False, []
|
| 74 |
+
|
| 75 |
+
for i, f in enumerate(self.files):
|
| 76 |
+
if use_npz:
|
| 77 |
+
with np.load(f, allow_pickle=True) as z:
|
| 78 |
+
a = z["eeg"] if "eeg" in z.files else z[list(z.files)[0]]
|
| 79 |
+
a = np.array(a, dtype=np.float32)
|
| 80 |
+
if "labels_sec" in z.files:
|
| 81 |
+
self.labels_present = True
|
| 82 |
+
self.sz_frac.append(float(np.mean(z["labels_sec"])))
|
| 83 |
+
else:
|
| 84 |
+
a = np.load(f, mmap_mode="r")
|
| 85 |
+
if a.ndim != 2: continue
|
| 86 |
+
C,T = a.shape; self.shapes.append((int(C),int(T)))
|
| 87 |
+
if T >= self.window:
|
| 88 |
+
starts = np.arange(0, T-self.window+1, self.hop, dtype=int)
|
| 89 |
+
self.index += [(i, int(s)) for s in starts]
|
| 90 |
+
|
| 91 |
+
self.channels = max((c for c,_ in self.shapes), default=1)
|
| 92 |
+
|
| 93 |
+
if print_summary:
|
| 94 |
+
print(f"[Data] Files: {len(self.files)} | Windows: {len(self.index)} | Channels(max): {self.channels}")
|
| 95 |
+
if self.labels_present and self.sz_frac:
|
| 96 |
+
print(f"[Data] labels_sec present — mean seizure_fraction: {np.mean(self.sz_frac):.3f}")
|
| 97 |
+
|
| 98 |
+
def __len__(self): return len(self.index)
|
| 99 |
+
|
| 100 |
+
def _label_from_labels_sec(self, labels_sec, start, win_len):
|
| 101 |
+
s0 = start // self.sr
|
| 102 |
+
s1 = min((start+win_len-1)//self.sr, len(labels_sec)-1)
|
| 103 |
+
if s0> s1: return -1
|
| 104 |
+
frac = float(np.mean(labels_sec[s0:s1+1]))
|
| 105 |
+
return 1 if frac > WINDOW_LABEL_THRESHOLD else 0
|
| 106 |
+
|
| 107 |
+
def __getitem__(self, idx):
|
| 108 |
+
fi, start = self.index[idx]
|
| 109 |
+
f = self.files[fi]; label = -1
|
| 110 |
+
|
| 111 |
+
if self.use_npz:
|
| 112 |
+
with np.load(f, allow_pickle=True) as z:
|
| 113 |
+
a = z["eeg"] if "eeg" in z.files else z[list(z.files)[0]]
|
| 114 |
+
seg = np.asarray(a[:, start:start+self.window], dtype=np.float32)
|
| 115 |
+
if "labels_sec" in z.files:
|
| 116 |
+
label = self._label_from_labels_sec(np.asarray(z["labels_sec"]), start, self.window)
|
| 117 |
+
else:
|
| 118 |
+
a = np.load(f, mmap_mode="r")
|
| 119 |
+
seg = np.asarray(a[:, start:start+self.window], dtype=np.float32)
|
| 120 |
+
|
| 121 |
+
C = seg.shape[0]
|
| 122 |
+
if C < self.channels:
|
| 123 |
+
pad = np.zeros((self.channels-C, seg.shape[1]), dtype=np.float32)
|
| 124 |
+
seg = np.concatenate([seg, pad], axis=0)
|
| 125 |
+
elif C > self.channels:
|
| 126 |
+
seg = seg[:self.channels]
|
| 127 |
+
|
| 128 |
+
mu = seg.mean(axis=1, keepdims=True); sd = seg.std(axis=1, keepdims=True)+1e-6
|
| 129 |
+
seg = (seg - mu)/sd
|
| 130 |
+
return torch.from_numpy(seg), torch.tensor(label, dtype=torch.int64)
|
| 131 |
+
|
| 132 |
+
# ======================
|
| 133 |
+
# PCA + plots
|
| 134 |
+
# ======================
|
| 135 |
+
def pca_2d(E: np.ndarray):
|
| 136 |
+
E0 = E - E.mean(0, keepdims=True)
|
| 137 |
+
U,S,Vt = np.linalg.svd(E0, full_matrices=False)
|
| 138 |
+
return E0 @ Vt[:2].T
|
| 139 |
+
|
| 140 |
+
def plot_pca_colored(Y, labels):
|
| 141 |
+
lbl = labels.astype(int)
|
| 142 |
+
has = lbl >= 0
|
| 143 |
+
plt.figure(figsize=(6,5))
|
| 144 |
+
if np.any(has):
|
| 145 |
+
nz, sz = lbl==0, lbl==1
|
| 146 |
+
if np.any(nz): plt.scatter(Y[nz,0], Y[nz,1], s=6, alpha=0.7, label="non-seizure", c="blue")
|
| 147 |
+
if np.any(sz): plt.scatter(Y[sz,0], Y[sz,1], s=10, alpha=0.9, label="seizure", c="red")
|
| 148 |
+
if np.any(~has): plt.scatter(Y[~has,0], Y[~has,1], s=4, alpha=0.3, label="unlabeled", c="gray")
|
| 149 |
+
plt.legend()
|
| 150 |
+
else:
|
| 151 |
+
plt.scatter(Y[:,0], Y[:,1], s=6)
|
| 152 |
+
plt.title("Encoder embeddings — PCA (colored by label)")
|
| 153 |
+
plt.xlabel("PC1"); plt.ylabel("PC2"); plt.tight_layout(); plt.show()
|
| 154 |
+
|
| 155 |
+
# ======================
|
| 156 |
+
# Main
|
| 157 |
+
# ======================
|
| 158 |
+
if __name__ == "__main__":
|
| 159 |
+
enc, md, WIN_SAMPLES, scripted = load_encoder(MODEL_DIR, PREFER_TORCHSCRIPT)
|
| 160 |
+
HOP = int(HOP_SECONDS * md["sample_rate"])
|
| 161 |
+
print(f"[Config] Window={WIN_SAMPLES} | Hop={HOP} | SR={md['sample_rate']} Hz")
|
| 162 |
+
|
| 163 |
+
ds = EEGWindowsLabeled(DATA_DIR, WIN_SAMPLES, HOP, sr=md["sample_rate"],
|
| 164 |
+
use_npz=USE_NPZ, max_files=MAX_FILES, print_summary=True)
|
| 165 |
+
if len(ds)==0: raise SystemExit("No windows produced — check DATA_DIR / USE_NPZ.")
|
| 166 |
+
|
| 167 |
+
dl = DataLoader(ds, batch_size=BATCH_SIZE, shuffle=True, num_workers=0, pin_memory=True, drop_last=True)
|
| 168 |
+
|
| 169 |
+
all_Z, all_L = [], []
|
| 170 |
+
enc.eval()
|
| 171 |
+
with torch.no_grad():
|
| 172 |
+
for i, (x, lbl) in enumerate(dl):
|
| 173 |
+
z, _ = enc(x) if not scripted else enc(x)
|
| 174 |
+
all_Z.append(z.cpu().numpy())
|
| 175 |
+
all_L.append(lbl.cpu().numpy())
|
| 176 |
+
if i >= 50: # cap for speed; remove to process all windows
|
| 177 |
+
break
|
| 178 |
+
|
| 179 |
+
E = np.concatenate(all_Z, axis=0) # (n, 128)
|
| 180 |
+
L = np.concatenate(all_L, axis=0).astype(int) # (n,)
|
| 181 |
+
print(f"[Emb] {E.shape[0]} embeddings collected | latent={E.shape[1]}")
|
| 182 |
+
if SAVE_EMBEDDINGS:
|
| 183 |
+
EMB_OUT_PATH.parent.mkdir(parents=True, exist_ok=True)
|
| 184 |
+
np.save(EMB_OUT_PATH, E)
|
| 185 |
+
print(f"[Emb] Saved: {EMB_OUT_PATH}")
|
| 186 |
+
|
| 187 |
+
Y = pca_2d(E)
|
| 188 |
+
plot_pca_colored(Y, L)
|
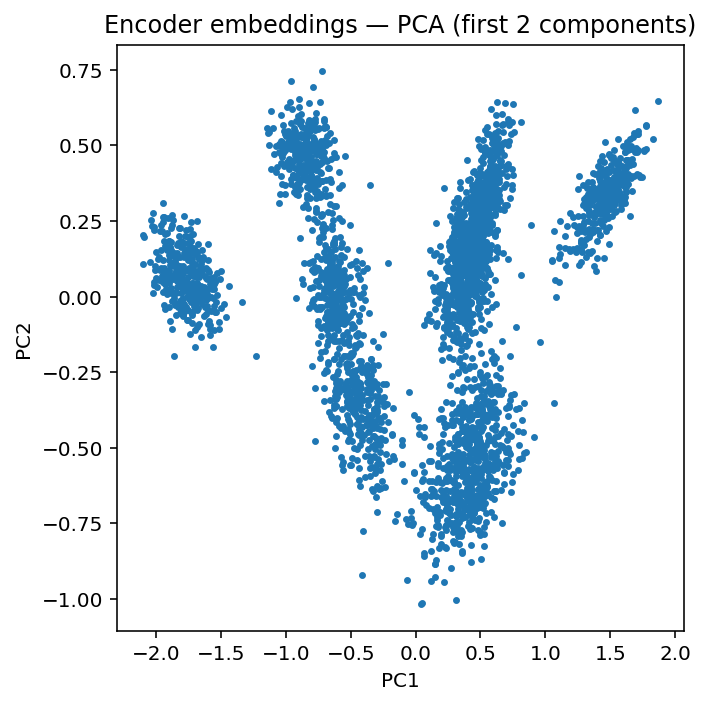
Figure 2025-10-06 160738.png
ADDED

|
Git LFS Details
|
Figure 2025-10-06 160750.png
ADDED

|
Figure 2025-10-06 160754.png
ADDED
|