---
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-4B/blob/main/LICENSE
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-4B
language:
- en
tags:
- imatrix
- qwen3
- conversational
---
# Melvin56/Qwen3-4B-ik_GGUF
# Quant for [ik_llama.cpp](https://github.com/ikawrakow/ik_llama.cpp)
Build: 3680 (a2d24c97)
Original Model : [Qwen/Qwen3-4B](https://huggingface.co/Qwen/Qwen3-4B)
I used imatrix to create all these quants using this [Dataset](https://gist.github.com/tristandruyen/9e207a95c7d75ddf37525d353e00659c/#file-calibration_data_v5_rc-txt).
Perplexity measurement methodology.
I tested all quants using ik_llama.cpp build 3680 (a2d24c97)
```
ik_llama.cpp/build/bin/llama-perplexity \
-m .gguf \
--ctx-size 512 \
--ubatch-size 512 \
-f wikitext-2-raw/wiki.test.raw \
-fa \
-ngl 999
```
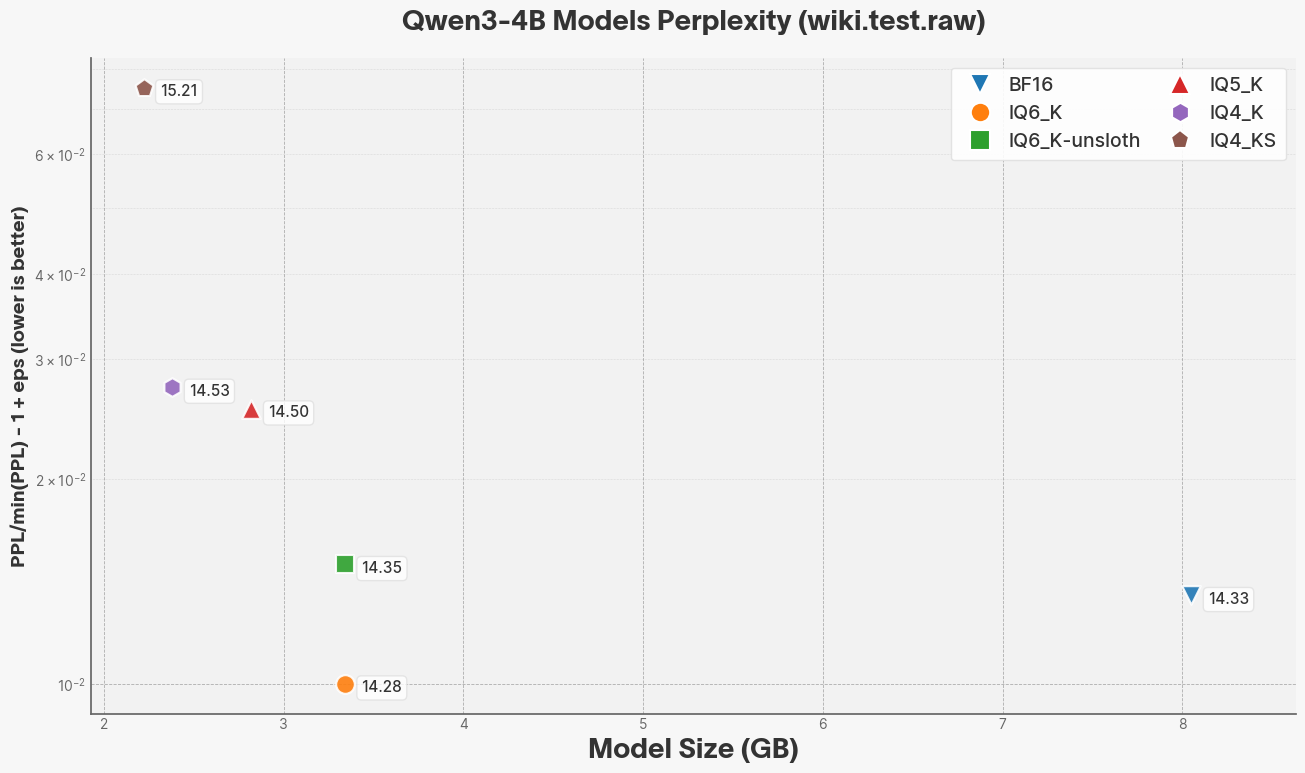
# Raw data
| Quant | Size (GB) | PPL |
|---------|-----------|---------------------|
| BF16 | 8.05 | 14.3308 +/- 0.13259 |
| IQ6_K | 3.34 | 14.2810 +/- 0.13159 |
| IQ5_K | 2.82 | 14.5004 +/- 0.13465 |
| IQ4_K | 2.38 | 14.5280 +/- 0.13414 |
| IQ4_KS | 2.22 | 15.2121 +/- 0.14294 |
---
| | CPU (AVX2) | CPU (ARM NEON) | Metal | cuBLAS | rocBLAS | SYCL | CLBlast | Vulkan | Kompute |
| :------------ | :---------: | :------------: | :---: | :----: | :-----: | :---: | :------: | :----: | :------: |
| K-quants | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ 🐢5 | ✅ 🐢5 | ❌ |
| I-quants | ✅ 🐢4 | ✅ 🐢4 | ✅ 🐢4 | ✅ | ✅ | Partial¹ | ❌ | ❌ | ❌ |
```
✅: feature works
🚫: feature does not work
❓: unknown, please contribute if you can test it youself
🐢: feature is slow
¹: IQ3_S and IQ1_S, see #5886
²: Only with -ngl 0
³: Inference is 50% slower
⁴: Slower than K-quants of comparable size
⁵: Slower than cuBLAS/rocBLAS on similar cards
⁶: Only q8_0 and iq4_nl
```