

Update README.md
Browse files
README.md
CHANGED
|
@@ -29,7 +29,7 @@ We are seeing strong performance in terms of both parameter efficiency and infer
|
|
| 29 |
|
| 30 |
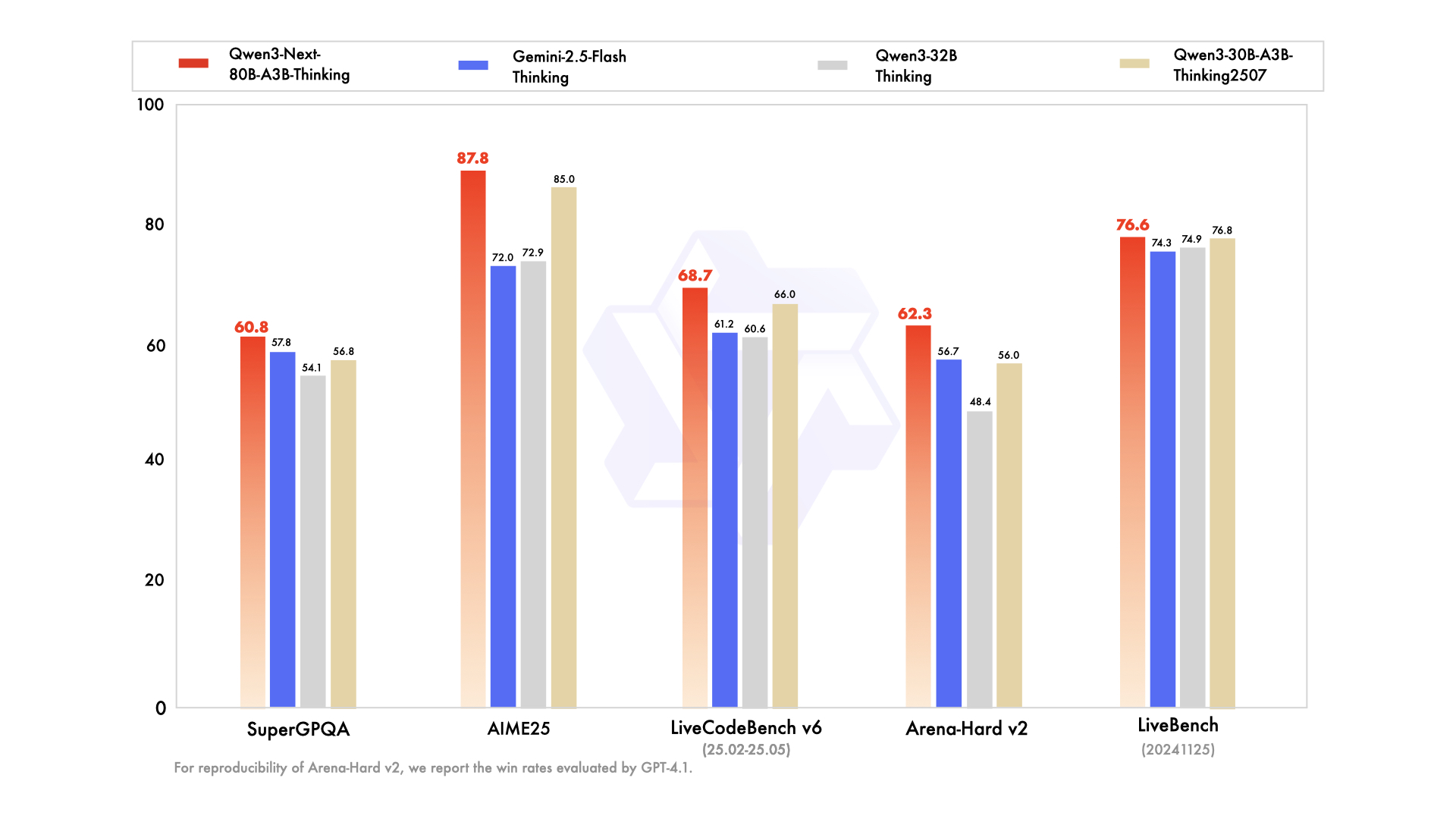
|
| 31 |
|
| 32 |
-
For more details, please refer to our blog post [Qwen3-Next](https://
|
| 33 |
|
| 34 |
## Model Overview
|
| 35 |
|
|
@@ -48,9 +48,9 @@ For more details, please refer to our blog post [Qwen3-Next](https://qwenlm.gith
|
|
| 48 |
- Training Stage: Pretraining (15T tokens) & Post-training
|
| 49 |
- Number of Parameters: 80B in total and 3B activated
|
| 50 |
- Number of Paramaters (Non-Embedding): 79B
|
| 51 |
-
- Number of Layers: 48
|
| 52 |
- Hidden Dimension: 2048
|
| 53 |
-
-
|
|
|
|
| 54 |
- Gated Attention:
|
| 55 |
- Number of Attention Heads: 16 for Q and 2 for KV
|
| 56 |
- Head Dimension: 256
|
|
@@ -173,7 +173,7 @@ print("content:", content)
|
|
| 173 |
|
| 174 |
> [!Tip]
|
| 175 |
> Depending on the inference settings, you may observe better efficiency with [`flash-linear-attention`](https://github.com/fla-org/flash-linear-attention#installation) and [`causal-conv1d`](https://github.com/Dao-AILab/causal-conv1d).
|
| 176 |
-
> See the
|
| 177 |
|
| 178 |
## Deployment
|
| 179 |
|
|
@@ -184,57 +184,58 @@ For deployment, you can use the latest `sglang` or `vllm` to create an OpenAI-co
|
|
| 184 |
[SGLang](https://github.com/sgl-project/sglang) is a fast serving framework for large language models and vision language models.
|
| 185 |
SGLang could be used to launch a server with OpenAI-compatible API service.
|
| 186 |
|
| 187 |
-
|
| 188 |
```shell
|
| 189 |
-
pip install 'sglang[all]
|
| 190 |
```
|
|
|
|
| 191 |
|
| 192 |
The following command can be used to create an API endpoint at `http://localhost:30000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
|
| 193 |
```shell
|
| 194 |
-
|
| 195 |
```
|
| 196 |
|
| 197 |
The following command is recommended for MTP with the rest settings the same as above:
|
| 198 |
```shell
|
| 199 |
-
|
| 200 |
```
|
| 201 |
|
| 202 |
-
> [!Note]
|
| 203 |
-
> The environment variable `SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1` is required at the moment.
|
| 204 |
-
|
| 205 |
> [!Note]
|
| 206 |
> The default context length is 256K.
|
| 207 |
> If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value.
|
| 208 |
> However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072.
|
| 209 |
|
|
|
|
|
|
|
| 210 |
### vLLM
|
| 211 |
|
| 212 |
[vLLM](https://github.com/vllm-project/vllm) is a high-throughput and memory-efficient inference and serving engine for LLMs.
|
| 213 |
vLLM could be used to launch a server with OpenAI-compatible API service.
|
| 214 |
|
| 215 |
-
|
| 216 |
```shell
|
| 217 |
-
pip install vllm
|
| 218 |
```
|
|
|
|
| 219 |
|
| 220 |
The following command can be used to create an API endpoint at `http://localhost:8000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
|
| 221 |
```shell
|
| 222 |
-
|
| 223 |
```
|
| 224 |
|
| 225 |
The following command is recommended for MTP with the rest settings the same as above:
|
| 226 |
```shell
|
| 227 |
-
|
| 228 |
```
|
| 229 |
|
| 230 |
-
> [!Note]
|
| 231 |
-
> The environment variable `VLLM_ALLOW_LONG_MAX_MODEL_LEN=1` is required at the moment.
|
| 232 |
-
|
| 233 |
> [!Note]
|
| 234 |
> The default context length is 256K.
|
| 235 |
> If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value.
|
| 236 |
> However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.
|
| 237 |
|
|
|
|
|
|
|
|
|
|
| 238 |
## Agentic Use
|
| 239 |
|
| 240 |
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
|
|
@@ -252,7 +253,7 @@ llm_cfg = {
|
|
| 252 |
|
| 253 |
# Using OpenAI-compatible API endpoint. It is recommended to disable the reasoning and the tool call parsing
|
| 254 |
# functionality of the deployment frameworks and let Qwen-Agent automate the related operations. For example,
|
| 255 |
-
# `
|
| 256 |
#
|
| 257 |
# llm_cfg = {
|
| 258 |
# 'model': 'Qwen3-Next-80B-A3B-Thinking',
|
|
|
|
| 29 |
|
| 30 |

|
| 31 |
|
| 32 |
+
For more details, please refer to our blog post [Qwen3-Next](https://qwen.ai/blog?id=4074cca80393150c248e508aa62983f9cb7d27cd&from=research.latest-advancements-list).
|
| 33 |
|
| 34 |
## Model Overview
|
| 35 |
|
|
|
|
| 48 |
- Training Stage: Pretraining (15T tokens) & Post-training
|
| 49 |
- Number of Parameters: 80B in total and 3B activated
|
| 50 |
- Number of Paramaters (Non-Embedding): 79B
|
|
|
|
| 51 |
- Hidden Dimension: 2048
|
| 52 |
+
- Number of Layers: 48
|
| 53 |
+
- Hybrid Layout: 12 \* (3 \* (Gated DeltaNet -> MoE) -> 1 \* (Gated Attention -> MoE))
|
| 54 |
- Gated Attention:
|
| 55 |
- Number of Attention Heads: 16 for Q and 2 for KV
|
| 56 |
- Head Dimension: 256
|
|
|
|
| 173 |
|
| 174 |
> [!Tip]
|
| 175 |
> Depending on the inference settings, you may observe better efficiency with [`flash-linear-attention`](https://github.com/fla-org/flash-linear-attention#installation) and [`causal-conv1d`](https://github.com/Dao-AILab/causal-conv1d).
|
| 176 |
+
> See the links for detailed instructions and requirements.
|
| 177 |
|
| 178 |
## Deployment
|
| 179 |
|
|
|
|
| 184 |
[SGLang](https://github.com/sgl-project/sglang) is a fast serving framework for large language models and vision language models.
|
| 185 |
SGLang could be used to launch a server with OpenAI-compatible API service.
|
| 186 |
|
| 187 |
+
`sglang>=0.5.2` is required for Qwen3-Next, which can be installed using:
|
| 188 |
```shell
|
| 189 |
+
pip install 'sglang[all]>=0.5.2'
|
| 190 |
```
|
| 191 |
+
See [its documentation](https://docs.sglang.ai/get_started/install.html) for more details.
|
| 192 |
|
| 193 |
The following command can be used to create an API endpoint at `http://localhost:30000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
|
| 194 |
```shell
|
| 195 |
+
python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Thinking --port 30000 --tp-size 4 --context-length 262144 --reasoning-parser deepseek-r1 --mem-fraction-static 0.8
|
| 196 |
```
|
| 197 |
|
| 198 |
The following command is recommended for MTP with the rest settings the same as above:
|
| 199 |
```shell
|
| 200 |
+
python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Thinking --port 30000 --tp-size 4 --context-length 262144 --reasoning-parser deepseek-r1 --mem-fraction-static 0.8 --speculative-algo NEXTN --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4
|
| 201 |
```
|
| 202 |
|
|
|
|
|
|
|
|
|
|
| 203 |
> [!Note]
|
| 204 |
> The default context length is 256K.
|
| 205 |
> If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value.
|
| 206 |
> However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072.
|
| 207 |
|
| 208 |
+
Please also refer to SGLang's usage guide on [Qwen3-Next](https://docs.sglang.ai/basic_usage/qwen3.html).
|
| 209 |
+
|
| 210 |
### vLLM
|
| 211 |
|
| 212 |
[vLLM](https://github.com/vllm-project/vllm) is a high-throughput and memory-efficient inference and serving engine for LLMs.
|
| 213 |
vLLM could be used to launch a server with OpenAI-compatible API service.
|
| 214 |
|
| 215 |
+
`vllm>=0.10.2` is required for Qwen3-Next, which can be installed using:
|
| 216 |
```shell
|
| 217 |
+
pip install 'vllm>=0.10.2'
|
| 218 |
```
|
| 219 |
+
See [its documentation](https://docs.vllm.ai/en/stable/getting_started/installation/index.html) for more details.
|
| 220 |
|
| 221 |
The following command can be used to create an API endpoint at `http://localhost:8000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
|
| 222 |
```shell
|
| 223 |
+
vllm serve Qwen/Qwen3-Next-80B-A3B-Thinking --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --reasoning-parser deepseek_r1
|
| 224 |
```
|
| 225 |
|
| 226 |
The following command is recommended for MTP with the rest settings the same as above:
|
| 227 |
```shell
|
| 228 |
+
vllm serve Qwen/Qwen3-Next-80B-A3B-Thinking --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --reasoning-parser deepseek_r1 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
|
| 229 |
```
|
| 230 |
|
|
|
|
|
|
|
|
|
|
| 231 |
> [!Note]
|
| 232 |
> The default context length is 256K.
|
| 233 |
> If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value.
|
| 234 |
> However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.
|
| 235 |
|
| 236 |
+
Please also refer to vLLM's usage guide on [Qwen3-Next](https://docs.vllm.ai/projects/recipes/en/latest/Qwen/Qwen3-Next.html).
|
| 237 |
+
|
| 238 |
+
|
| 239 |
## Agentic Use
|
| 240 |
|
| 241 |
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
|
|
|
|
| 253 |
|
| 254 |
# Using OpenAI-compatible API endpoint. It is recommended to disable the reasoning and the tool call parsing
|
| 255 |
# functionality of the deployment frameworks and let Qwen-Agent automate the related operations. For example,
|
| 256 |
+
# `vllm serve Qwen/Qwen3-Next-80B-A3B-Thinking --served-model-name Qwen3-Next-80B-A3B-Thinking --port 8000 --tensor-parallel-size 4 --max-model-len 262144`.
|
| 257 |
#
|
| 258 |
# llm_cfg = {
|
| 259 |
# 'model': 'Qwen3-Next-80B-A3B-Thinking',
|