Weekly Robotics June #1 - SmolVLA discovery and thoughts







To stay motivated and consistent with my side projects, I’ve decided to start a weekly writing routine—just a small wrap-up of what I’ve done, what I’ve learned, and where I'm heading. These posts will include my thoughts, ideas, experiments, successes, and failures. Even if it’s just a 10-minute paper read or a quick robot teleoperation test, I’ll share anything that pushes me forward and sparks curiosity.
If you’re interested in following along, feel free to check out my Twitter and Hugging Face profile.
Day 1 - June 3: Kicking Things Off
Today marks the first entry in this series, and fittingly, it coincides with some exciting news in the robotics/ML world. So for this first post, I’ll briefly talk about my current ideas and dive into a fascinating new release that I plan to experiment with.
a) SmolVLA Release: First impressions and Plans
What a perfect day to start this blog! The LeRobot team just released SmolVLA, and I already know it’s going to take up a good chunk of my time in the coming days.
For context, SmolVLA builds upon their previous SmolVLM2 model model. I won’t go into the full architecture (their blog posts do a great job at that), but here’s a quick summary of what makes SmolVLA so interesting: the VLA models which combine vision and language for robotic tasks are usually massive, requiring tons of data and compute. That limits who can actually use them. SmolVLA is different: small, efficient, and accessible, it can be trained on consumer GPUs and even deployed on CPUs.

Key design choices that caught my attention:
- Layer Skipping: Instead of using the final layer of the VLM, SmolVLA extracts features from an intermediate one (e.g., halfway through). This improves inference speed without sacrificing downstream performance.
- Visual Token Reduction: High-res images = high compute costs. SmolVLA skips image tiling (used in the original SmolVLM2) and applies pixel shuffling on the global image only, reducing visual tokens to just 64 per frame. Very efficient.
- Cross-Attention & Self-Attention Interleaving: The model alternates between cross-attention (actions as queries and image-text features as key-values) and causal self-attention (between queries and features with a causal mask to avoid future actions to see past ones).
The architecture has two core parts: a pretrained vision-language model (SmolVLM2) for perception, and a lightweight action expert (100M parameters) trained to act based on that perception. SmolVLM2 itself uses SigLIP for vision and SmolLM2 for the language decoding.
The code and pre-trained weights are available and I really want to further explore the model capabilities, especially in terms of generalization to perturbators such as deploying in new scenes, with unseen distractors or new environments conditions. It would be interesting to check how the model focus on objects (by using an attention map visualization tool a bit like Ville's Kuosmanen attention map tool on ACT but also following the exploration of my last paper). Then, I also want to explore how much the model performs for more complex tasks.
For some final words on SmolVLA, what makes this even more relevant to me: the model was trained using the LeRobot community dataset, and more specifically on a curated subset of datasets which I actually helped building (checkout this last article) This naturally brings me to the second area I want to explore in the future.
b) Automatic data annotations
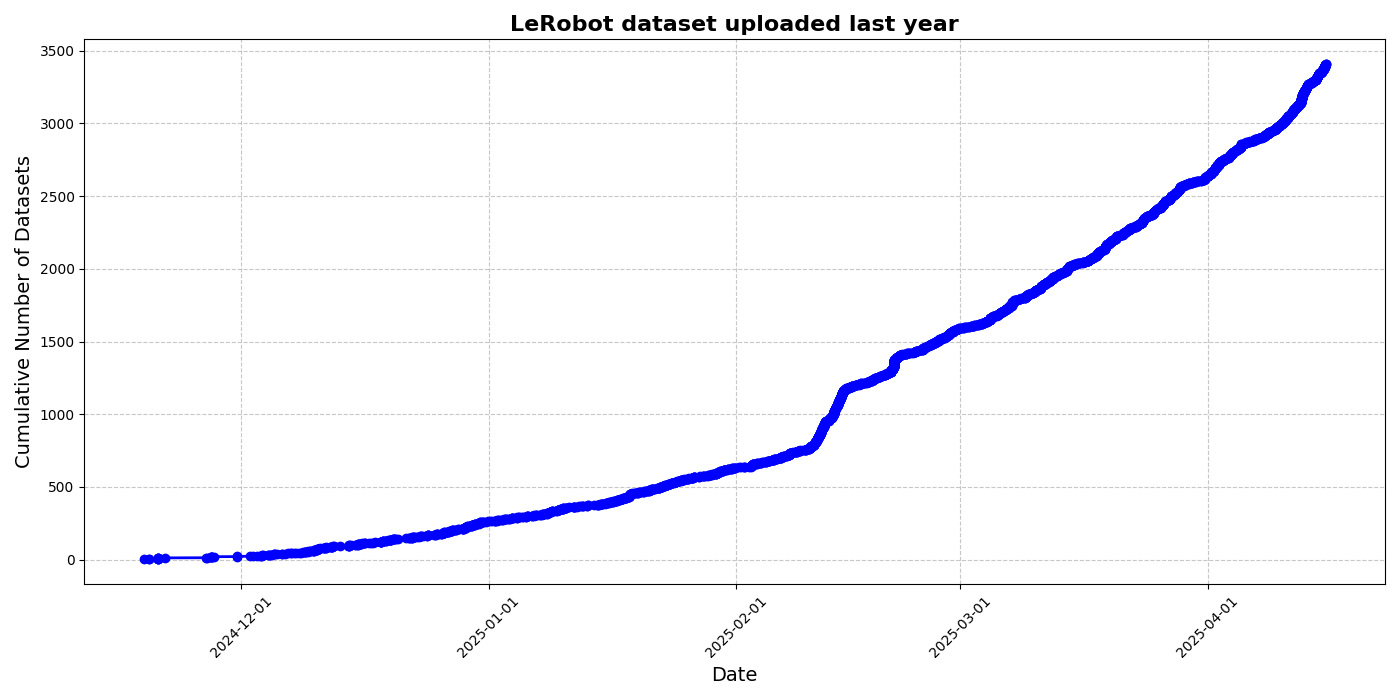
The LeRobot community dataset continues to grow rapidly, which is exciting, but also challenging. With so much data being collected, it's crucial to carefully curate and select the samples that are actually useful for training. As discussed in the LeRobot dataset blog post and the SmolVLA paper, effective curation is a major hurdle: doing this manually takes a huge amount of time and doesn’t scale with the exponential growth of community-generated data.
To address this, building automated annotation and filtering pipelines has become not just helpful, but necessary. One of the biggest issues in both community and large-scale robotics datasets is the lack of dense, high-quality annotations. Many samples are poorly labeled, inaccurately labeled, or completely unannotated.
Thanks to recent advances in Vision-Language Models (VLMs), especially ones that can handle video, there's now a viable path forward: using strong multimodal models to automatically generate annotations via prompting. This is precisely what the SmolVLA paper explores using the Qwen2.5-VL-3B-Instruct model.
On my end, I’ve started experimenting with this idea too. I’ve tested models like Gemma 3, LLaVA 1.5, both SmolVLM variants, and several Qwen models. The early results are promising, but there's definitely a learning curve—and plenty of failures to learn from.
I plan to write a more detailed post soon, summarizing my experiments, what worked, what didn’t, and which approaches seem most reliable. If that sounds interesting, feel free to leave a comment, I’d love to hear your thoughts or experiences on this topic.
Wrapping Up
That’s it for this first daily update! Starting this series with the SmolVLA release felt like the perfect way to set the tone. Between the model's accessibility, the dataset work I’ve contributed to, and the broader push toward automation in robotics, there’s a lot I’m excited to dive into over the coming days.
As I continue exploring SmolVLA’s real-world performance and refining my annotation workflows, I’ll share regular insights, experiments, and reflections—whether it’s a small breakthrough or a failed test that taught me something valuable.
Thanks for reading, and if you’re on a similar journey (or just interested in robotics, VLMs, or side projects), let’s connect! I’m always open to discussions and collaboration (even for scientific contributions, I'm a PhD student still :) )


