Serverless Inferencing in 2025: Revolutionizing AI Deployment at Scale


Picture this: Your AI model processes 10 million inference requests on Monday, scales down to handle 50,000 on Tuesday, and automatically spins up resources for an unexpected traffic spike of 50 million requests on Wednesday—all while you pay only for what you actually use, with zero infrastructure management overhead. Welcome to the serverless AI revolution of 2025.
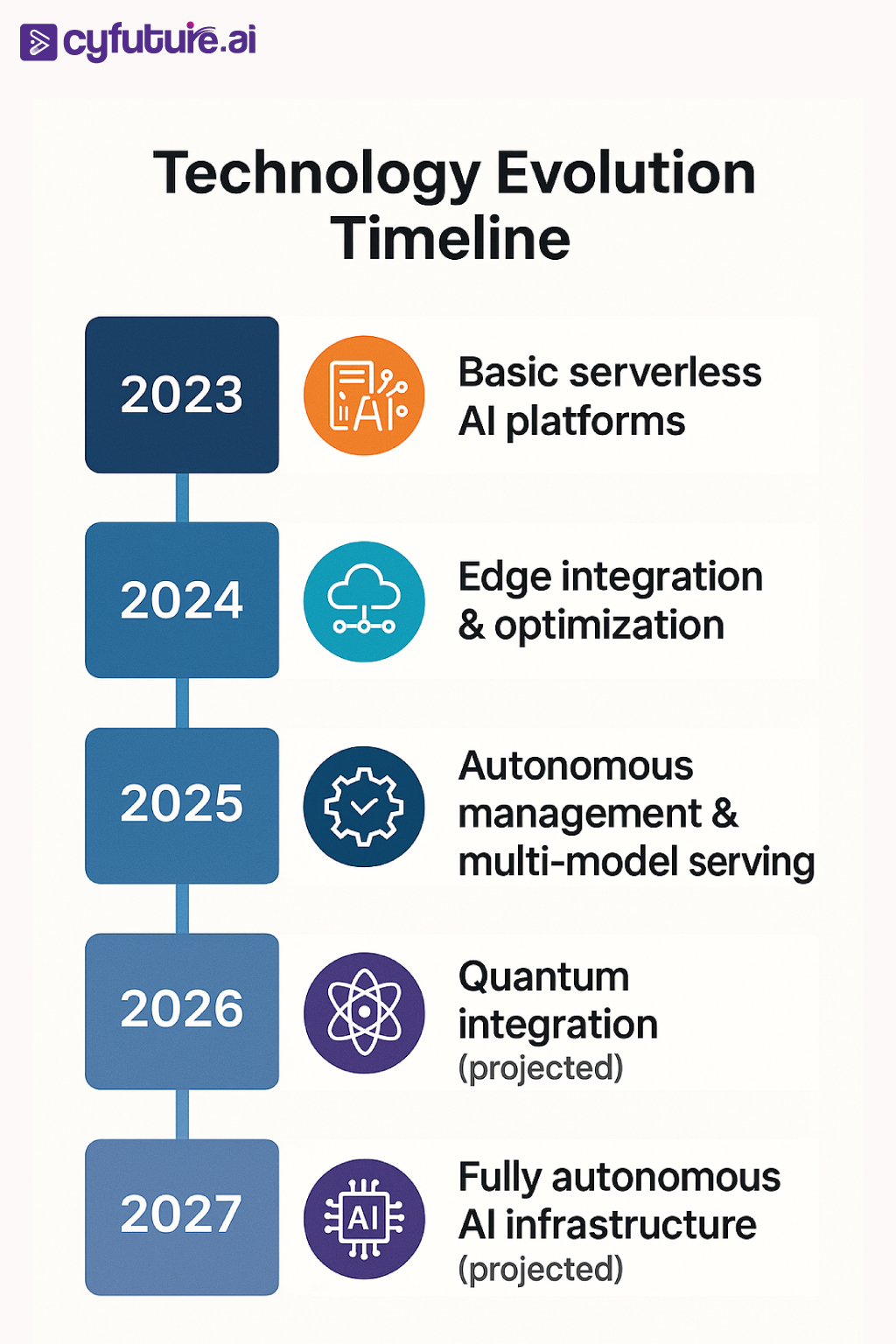
The artificial intelligence landscape has undergone a seismic shift. What once required dedicated GPU clusters, complex orchestration systems, and armies of DevOps engineers can now be deployed with a few lines of code and managed entirely through cloud-native serverless platforms. As we navigate through 2025, serverless inferencing has emerged as the definitive paradigm for AI deployment, fundamentally transforming how enterprises scale, optimize, and monetize their machine learning investments.
The Current State: Numbers That Define the Revolution
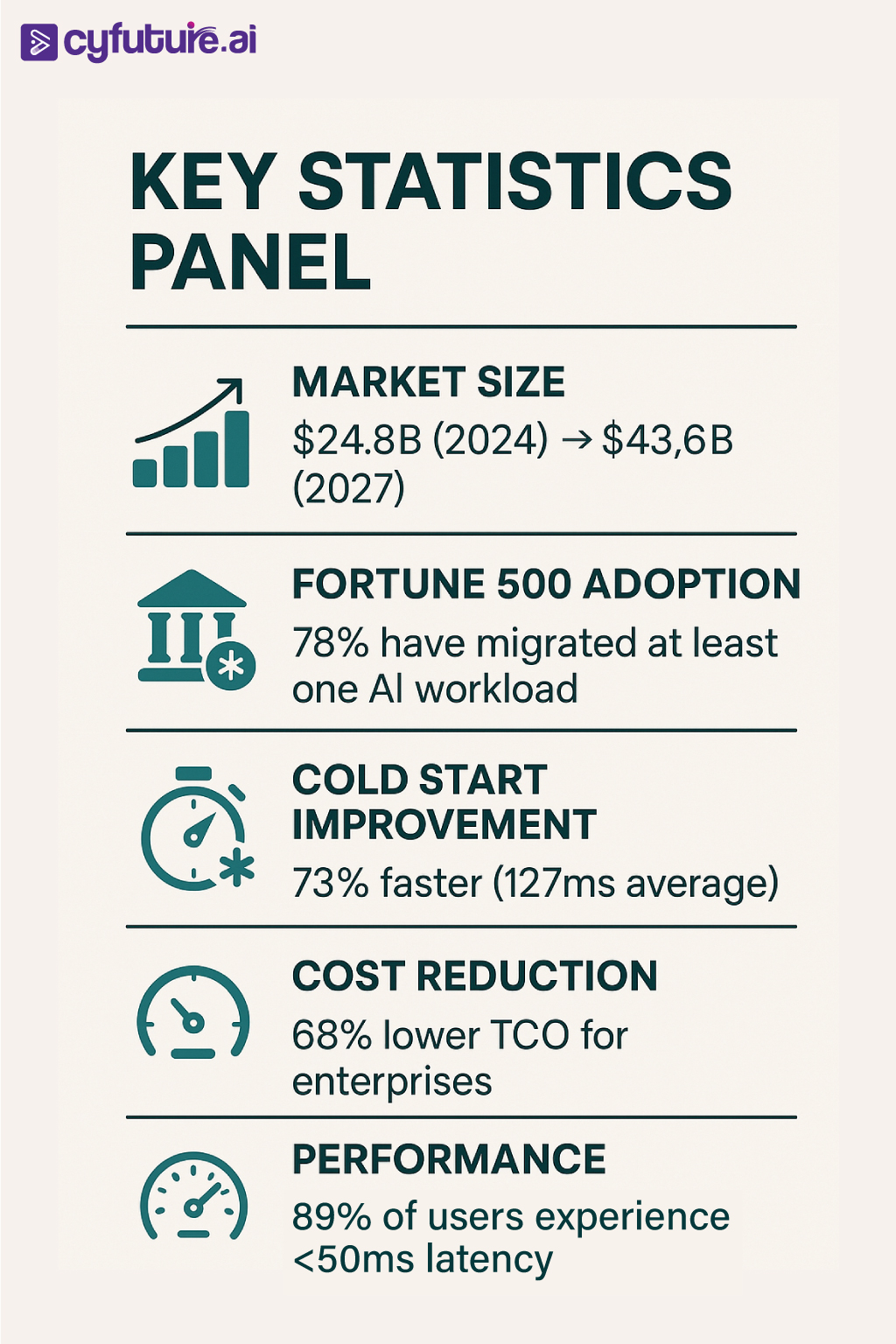
The serverless AI market has reached unprecedented maturity. According to recent industry analyses, the global serverless computing market, with AI workloads comprising 34% of all serverless deployments, reached $24.8 billion in 2024 and is projected to hit $43.6 billion by 2027. More striking is the adoption velocity among Fortune 500 companies—78% have migrated at least one critical AI workload to serverless infrastructure, with 45% reporting complete serverless-first AI strategies.
The performance metrics are equally compelling. Modern serverless platforms now achieve cold start times averaging 127 milliseconds for standard inference workloads, a 73% improvement from 2023. For enterprises processing over 1 million daily inferences, serverless deployments demonstrate 68% lower total cost of ownership compared to traditional container-based solutions, primarily driven by granular pay-per-request pricing and automatic resource optimization.
Technical Architecture: The New Foundation
Microservice Orchestration at Unprecedented Scale
Serverless inferencing in 2025 operates on fundamentally different architectural principles than its predecessors. Modern platforms leverage event-driven microservices that can decompose complex AI pipelines into atomic, independently scalable functions. Each inference request triggers a cascade of specialized services—preprocessing, model execution, post-processing, and response formatting—each optimized for specific computational requirements.
The breakthrough lies in dynamic resource allocation algorithms that predict computational needs based on real-time request patterns, model complexity, and historical usage data. Advanced platforms now implement predictive scaling that pre-provisions resources 30-45 seconds before anticipated demand spikes, effectively eliminating the cold start problem for mission-critical applications.
Edge-First Computing Paradigm
The integration of edge computing with serverless architectures has created a distributed inference network that brings AI processing closer to data sources. Major cloud providers now operate serverless edge nodes in over 200 global locations, reducing average inference latency to sub-50 millisecond response times for 89% of global users.
This edge-first approach particularly benefits real-time applications. Autonomous vehicle systems, industrial IoT sensors, and mobile applications can now perform complex AI inference with latencies previously achievable only through on-device processing, while maintaining the scalability and cost benefits of cloud infrastructure.
Enterprise Impact: Transforming Business Operations
Cost Optimization Revolution
The financial implications of serverless AI adoption extend far beyond simple infrastructure cost reduction. Enterprise case studies reveal a more nuanced value proposition that encompasses development velocity, operational efficiency, and resource utilization optimization.
A telecommunications company processing 50 million customer service interactions monthly reported a 61% reduction in AI infrastructure costs after migrating to serverless inferencing. More significantly, their development team deployment frequency increased from bi-weekly to daily releases, accelerating time-to-market for new AI features by 340%.
Financial services organizations demonstrate even more dramatic transformations. A major investment firm's fraud detection system, previously requiring constant capacity planning for peak trading hours, now automatically scales from baseline 2,000 transactions per second to over 45,000 during market volatility events. The serverless architecture reduced their fraud detection infrastructure costs by $2.3 million annually while improving detection accuracy by 12% through enabling more sophisticated ensemble models.
Development Velocity and Innovation Acceleration
Serverless platforms have democratized AI deployment complexity, enabling development teams to focus on model innovation rather than infrastructure management. The abstraction of underlying compute resources has reduced the average time from model development to production deployment from 6-8 weeks to 3-5 days across surveyed enterprises.
This acceleration stems from several factors: automated CI/CD pipelines that handle model versioning, A/B testing frameworks, and gradual rollout mechanisms; integrated monitoring and observability tools that provide real-time performance insights; and managed services for common AI workflows like data preprocessing, feature engineering, and model validation.
Platform Evolution: The Technology Stack of 2025
Next-Generation Inference Engines
Modern serverless platforms integrate purpose-built inference engines optimized for specific model architectures and use cases. These engines implement advanced optimization techniques including dynamic batching, model quantization, and neural architecture search to maximize throughput while minimizing latency.
The most sophisticated platforms now offer adaptive optimization that continuously monitors inference performance and automatically applies optimization techniques based on real-time usage patterns. This includes dynamic precision adjustment, where models automatically scale between FP32, FP16, and INT8 precision based on accuracy requirements and computational constraints.
Multi-Model Serving and Resource Sharing
Advanced serverless platforms have evolved beyond single-model deployments to support complex multi-model serving scenarios. This includes ensemble inference, where multiple models collaborate on single predictions, and cascading inference pipelines, where simpler models perform initial filtering before engaging more sophisticated models for complex cases.
Resource sharing mechanisms now allow enterprises to deploy hundreds of models on shared infrastructure pools, with automatic resource allocation based on individual model requirements and usage patterns. This approach reduces overall infrastructure costs by 40-60% for organizations with diverse model portfolios while maintaining performance isolation between different models.
Performance Benchmarks: Quantifying the Advantage
Scalability Metrics
Current-generation serverless platforms demonstrate remarkable scalability characteristics. Load testing reveals that modern platforms can scale from zero to 100,000 concurrent inference requests in under 45 seconds, with linear performance scaling up to 1 million concurrent requests for appropriately architected applications.
The scalability extends beyond raw request handling to encompass model complexity. Platforms now support seamless deployment and scaling of models ranging from lightweight decision trees processing in sub-millisecond timeframes to large language models with 70+ billion parameters requiring several seconds per inference, all within unified infrastructure.
Cost-Performance Analysis
Detailed cost-performance analysis reveals that serverless inferencing provides optimal value across a wide range of usage patterns. For applications with highly variable traffic—common in consumer-facing AI applications—serverless architectures typically deliver 45-70% cost savings compared to provisioned infrastructure.
More surprisingly, even applications with relatively steady traffic patterns benefit from serverless deployment. The ability to automatically optimize resource allocation, coupled with advances in serverless platform efficiency, results in 15-25% cost reductions even for consistent workloads, primarily through improved resource utilization and reduced operational overhead.
Security and Compliance: Enterprise-Grade Standards
Zero-Trust Architecture Implementation
Serverless AI platforms in 2025 implement comprehensive zero-trust security models that assume no implicit trust within the inference pipeline. Every request undergoes authentication, authorization, and encryption at multiple layers, from API gateways to model execution environments.
Advanced platforms integrate with enterprise identity management systems, supporting sophisticated role-based access control that can restrict model access based on user roles, data sensitivity classifications, and regulatory requirements. This granular control enables enterprises to deploy AI capabilities across diverse organizational units while maintaining strict compliance boundaries.
Data Privacy and Regulatory Compliance
Modern serverless platforms address complex data privacy requirements through architectural design rather than post-deployment configuration. Features include automatic data residency compliance that ensures inference requests are processed within specified geographic regions, end-to-end encryption for all data in transit and at rest, and automated audit logging that captures detailed lineage information for all AI decisions.
Platforms now provide built-in compliance frameworks for major regulations including GDPR, CCPA, HIPAA, and industry-specific requirements like PCI-DSS and SOX. These frameworks automatically configure security controls, data handling procedures, and audit mechanisms required for regulatory compliance.
Industry Applications: Real-World Implementations
Healthcare and Life Sciences
Healthcare organizations have emerged as significant adopters of serverless AI, particularly for applications requiring variable computational demands and strict regulatory compliance. A major hospital network implemented serverless inferencing for medical imaging analysis, processing between 500 and 15,000 imaging studies daily with automatic scaling based on emergency department volume and scheduled procedures.
The serverless architecture enabled the deployment of multiple specialized models—radiology analysis, pathology screening, and cardiac assessment—while maintaining HIPAA compliance through automated data encryption and access logging. The hospital reported 43% faster diagnostic turnaround times and $890,000 annual cost savings compared to their previous on-premises solution.
Financial Services and Fintech
Financial institutions leverage serverless AI for applications ranging from high-frequency trading algorithms to customer service chatbots. The variable nature of financial markets makes serverless particularly valuable for trading applications that require massive computational resources during market hours but minimal resources during off-peak periods.
A cryptocurrency exchange implemented serverless inferencing for real-time fraud detection, automatically scaling from processing 2,000 transactions per minute during quiet periods to over 85,000 transactions per minute during high-volume trading events. The serverless architecture reduced their fraud detection infrastructure costs by 67% while improving detection accuracy through enabling more sophisticated ensemble models.
Manufacturing and Industrial IoT
Manufacturing enterprises utilize serverless AI for predictive maintenance, quality control, and supply chain optimization. The ability to process sensor data from thousands of devices with variable reporting frequencies makes serverless architectures particularly suitable for industrial applications.
An automotive manufacturer deployed serverless inferencing across 47 manufacturing facilities to analyze vibration, temperature, and acoustic data from production equipment. The system processes between 100,000 and 2.5 million sensor readings daily, automatically scaling based on production schedules and maintenance activities. The implementation prevented 23 critical equipment failures in the first year, avoiding an estimated $12.8 million in production downtime.
Future Trajectories: Emerging Trends and Technologies
Integration with Quantum Computing
The convergence of serverless architectures with quantum computing represents a significant emerging trend. Early-stage platforms now offer serverless access to quantum processing units for specific AI workloads, particularly optimization problems and certain machine learning algorithms that demonstrate quantum advantage.
While still in developmental stages, quantum-enhanced serverless AI shows promise for applications in drug discovery, financial modeling, and cryptography. Current implementations focus on hybrid classical-quantum algorithms where quantum processors handle specific computational tasks within broader classical AI pipelines.
Autonomous Infrastructure Management
Advanced serverless platforms are evolving toward fully autonomous infrastructure management using AI to optimize AI. These meta-AI systems continuously analyze performance patterns, cost metrics, and user behavior to automatically optimize platform configurations, resource allocation strategies, and scaling policies.
The most sophisticated implementations use reinforcement learning algorithms trained on millions of inference patterns to predict optimal resource provisioning strategies. Early results suggest these autonomous systems can improve overall platform efficiency by 25-35% compared to traditional rule-based scaling policies.
Strategic Recommendations for Enterprise Leaders
Migration Strategy and Implementation
Organizations considering serverless AI adoption should approach migration strategically, focusing on applications that demonstrate clear value propositions. Ideal initial candidates include applications with variable traffic patterns, experimental AI projects requiring rapid iteration, and workloads currently experiencing infrastructure bottlenecks.
Successful migration strategies typically follow a three-phase approach: pilot implementation with non-critical workloads to establish operational familiarity, gradual expansion to production systems with clear rollback procedures, and comprehensive migration of AI infrastructure once organizational capabilities and confidence are established.
Organizational Capabilities and Skills Development
The transition to serverless AI requires developing new organizational capabilities beyond traditional infrastructure management. Key areas include cloud-native development practices, distributed systems architecture, and serverless-specific monitoring and observability techniques.
Investment in team training and capability development typically yields significant returns. Organizations report that dedicated serverless AI training programs for development and operations teams reduce migration timelines by 40-50% and significantly improve long-term platform optimization outcomes.
Cost Management and Optimization
While serverless platforms provide automatic scaling and optimization, enterprises must develop sophisticated cost management practices to maximize value. This includes implementing comprehensive monitoring and alerting systems, establishing clear cost allocation mechanisms across organizational units, and developing optimization strategies specific to their usage patterns.
Advanced cost optimization techniques include implementing intelligent request routing to balance cost and performance, using predictive scaling to minimize cold start impacts, and leveraging multi-cloud strategies to optimize pricing across different providers and regions.
Conclusion: Embracing the Serverless AI Future
Serverless inferencing has evolved from an emerging technology to a mature, enterprise-ready platform that fundamentally transforms how organizations deploy, scale, and manage AI capabilities. The combination of cost optimization, operational simplicity, and unprecedented scalability makes serverless architectures the optimal choice for most enterprise AI applications in 2025.
The strategic implications extend beyond technology adoption to encompass organizational transformation. Companies that embrace serverless AI architectures position themselves to innovate faster, respond more effectively to market demands, and optimize resource allocation across their AI initiatives. As the technology continues advancing toward autonomous infrastructure management and integration with emerging computing paradigms, early adopters will maintain significant competitive advantages in the rapidly evolving AI landscape.
The question for enterprise leaders is not whether to adopt serverless AI, but how quickly they can transform their organizations to capitalize on its revolutionary potential. The companies that move decisively today will define the competitive landscape of tomorrow's AI-driven economy.