
The full dataset viewer is not available (click to read why). Only showing a preview of the rows.
Job manager crashed while running this job (missing heartbeats).
Error code: JobManagerCrashedError
Need help to make the dataset viewer work? Make sure to review how to configure the dataset viewer, and open a discussion for direct support.
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
trungpq/rlcc-new-taste-upsample_replacement-absa-None
|
trungpq
| 2025-09-17T04:18:14 | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert_with_absa",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] | null | 2025-09-10T16:37:21 |
---
library_name: transformers
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: rlcc-new-taste-upsample_replacement-absa-None
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# rlcc-new-taste-upsample_replacement-absa-None
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5802
- Accuracy: 0.5726
- F1 Macro: 0.5792
- Precision Macro: 0.6133
- Recall Macro: 0.5739
- F1 Micro: 0.5726
- Precision Micro: 0.5726
- Recall Micro: 0.5726
- Total Tf: [209, 156, 574, 156]
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 46
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 Macro | Precision Macro | Recall Macro | F1 Micro | Precision Micro | Recall Micro | Total Tf |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:--------:|:---------------:|:------------:|:--------:|:---------------:|:------------:|:--------------------:|
| 1.0937 | 1.0 | 47 | 1.0853 | 0.4 | 0.3799 | 0.4504 | 0.4061 | 0.4000 | 0.4 | 0.4 | [146, 219, 511, 219] |
| 0.9512 | 2.0 | 94 | 0.9563 | 0.5178 | 0.4848 | 0.4862 | 0.5114 | 0.5178 | 0.5178 | 0.5178 | [189, 176, 554, 176] |
| 0.7605 | 3.0 | 141 | 0.9415 | 0.5671 | 0.5573 | 0.5636 | 0.5636 | 0.5671 | 0.5671 | 0.5671 | [207, 158, 572, 158] |
| 0.5771 | 4.0 | 188 | 1.0533 | 0.5315 | 0.5234 | 0.5237 | 0.5272 | 0.5315 | 0.5315 | 0.5315 | [194, 171, 559, 171] |
| 0.4679 | 5.0 | 235 | 1.0762 | 0.5753 | 0.5674 | 0.5674 | 0.5719 | 0.5753 | 0.5753 | 0.5753 | [210, 155, 575, 155] |
| 0.3613 | 6.0 | 282 | 1.1967 | 0.5726 | 0.5758 | 0.5866 | 0.5716 | 0.5726 | 0.5726 | 0.5726 | [209, 156, 574, 156] |
| 0.2918 | 7.0 | 329 | 1.2788 | 0.5753 | 0.5789 | 0.5899 | 0.5744 | 0.5753 | 0.5753 | 0.5753 | [210, 155, 575, 155] |
| 0.2011 | 8.0 | 376 | 1.3095 | 0.5753 | 0.5777 | 0.5848 | 0.5737 | 0.5753 | 0.5753 | 0.5753 | [210, 155, 575, 155] |
| 0.1837 | 9.0 | 423 | 1.3831 | 0.5781 | 0.5795 | 0.5851 | 0.5759 | 0.5781 | 0.5781 | 0.5781 | [211, 154, 576, 154] |
| 0.1268 | 10.0 | 470 | 1.5099 | 0.5671 | 0.5709 | 0.5815 | 0.5662 | 0.5671 | 0.5671 | 0.5671 | [207, 158, 572, 158] |
| 0.1098 | 11.0 | 517 | 1.5802 | 0.5726 | 0.5792 | 0.6133 | 0.5739 | 0.5726 | 0.5726 | 0.5726 | [209, 156, 574, 156] |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.2
|
sombochea/qwen2.5-7b-vl-grpo
|
sombochea
| 2025-09-17T03:56:19 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2_5_vl",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-17T03:55:56 |
---
base_model: unsloth/qwen2.5-vl-7b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2_5_vl
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** sombochea
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-vl-7b-instruct-unsloth-bnb-4bit
This qwen2_5_vl model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
darturi/Qwen2.5-7B-Instruct_bad-medical-advice_mlp.gate_proj_theta_0
|
darturi
| 2025-09-17T02:34:11 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-17T02:34:02 |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
hdnfnfn/blockassist-bc-noisy_elusive_grouse_1758073236
|
hdnfnfn
| 2025-09-17T01:40:41 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"noisy elusive grouse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-17T01:40:37 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- noisy elusive grouse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
1038lab/pixai-tagger
|
1038lab
| 2025-09-17T01:33:42 | 0 | 0 | null |
[
"multi-label",
"anime",
"danbooru",
"safetensors",
"image-classification",
"license:apache-2.0",
"region:us"
] |
image-classification
| 2025-09-17T00:38:51 |
---
license: apache-2.0
pipeline_tag: image-classification
tags:
- multi-label
- anime
- danbooru
- safetensors
---
ℹ️ This is a **safetensors + tag JSON version** of the original model [pixai-labs/pixai-tagger-v0.9](https://huggingface.co/pixai-labs/pixai-tagger-v0.9).
🔄 Converted by [1038lab](https://huggingface.co/1038lab).
📦 No changes were made to model weights or logic — only converted `.pth` → `.safetensors` and bundled with `tags_v0.9_13k.json` for convenience.
🧠 Full credits and model training go to PixAI Labs.
---
<p>
<img src="https://huggingface.co/pixai-labs/pixai-tagger-v0.9/resolve/main/banner_09_cropped.jpg" style="height:240px;" />
<a href="https://huggingface.co/pixai-labs/pixai-tagger-v0.9"><strong>Original Model</strong></a> ·
<a href="#quickstart"><strong>Quickstart</strong></a> ·
<a href="#training-notes"><strong>Training Notes</strong></a> ·
<a href="#credits"><strong>Credits</strong></a>
</p>
---
# PixAI Tagger v0.9
A practical anime **multi-label tagger**. Not trying to win benchmarks; trying to be useful.
**High recall**, updated **character coverage**, trained on a fresh Danbooru snapshot (2025-01).
We’ll keep shipping: **v1.0** (with updated tags) is next.
> TL;DR
>
> - ~**13.5k** Danbooru-style tags (**general**, **character**, **copyright**)
> - Headline: strong **character** performance; recall-leaning defaults
> - Built for search, dataset curation, caption assistance, and text-to-image conditioning
---
## What it is (in one breath)
`pixai-tagger-v0.9` is a multi-label image classifier for anime images. It predicts Danbooru-style tags and aims to **find more of the right stuff** (recall) so you can filter later. We continued training the **classification head** of EVA02 (from WD v3) on a newer dataset, and used **embedding-space MixUp** to help calibration.
- **Last trained:** 2025-04
- **Data snapshot:** Danbooru IDs 1–8,600,750 (2025-01)
- **Finetuned from:** `SmilingWolf/wd-eva02-large-tagger-v3` (encoder frozen)
- **License (weights):** Apache 2.0 *(Note: Danbooru content has its own licenses.)*
---
## Why you might care
- **Newer data.** Catches more recent IPs/characters.
- **Recall-first defaults.** Good for search and curation; dial thresholds for precision.
- **Character focus.** We spent time here; it shows up in evals.
- **Simple to run.** Works as an endpoint or locally; small set of knobs.
---
## Quickstart
**Recommended defaults (balanced):**
- `top_k = 128`
- `threshold_general = 0.30`
- `threshold_character = 0.75`
**Coverage preset (recall-heavier):** `threshold_general = 0.10` (expect more false positives)
### 1) Inference Endpoint
Deploy as an HF Inference Endpoint and test with the following command:
```bash
# Replace with your own endpoint URL
curl "https://YOUR_ENDPOINT_URL.huggingface.cloud" \
-X POST \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-d '{
"inputs": {"url": "https://your.cdn/image.jpg"},
"parameters": {
"top_k": 128,
"threshold_general": 0.10,
"threshold_character": 0.75
}
}'
|
mekpro/whisper-large-v3-250916
|
mekpro
| 2025-09-17T01:20:04 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"text-generation-inference",
"unsloth",
"trl",
"en",
"base_model:mekpro/whisper-large-v3-250911",
"base_model:finetune:mekpro/whisper-large-v3-250911",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-09-17T01:18:33 |
---
base_model: mekpro/whisper-large-v3-250911
tags:
- text-generation-inference
- transformers
- unsloth
- whisper
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** mekpro
- **License:** apache-2.0
- **Finetuned from model :** mekpro/whisper-large-v3-250911
This whisper model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
vonmises69/Affine-5G9XPx652tLC4GuWzHytWvj6mJm4YjsXcNucMuDG1ShFUZNS
|
vonmises69
| 2025-09-17T00:06:02 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_oss",
"text-generation",
"vllm",
"conversational",
"arxiv:2508.10925",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"8-bit",
"mxfp4",
"region:us"
] |
text-generation
| 2025-09-17T00:06:02 |
---
license: apache-2.0
pipeline_tag: text-generation
library_name: transformers
tags:
- vllm
---
<p align="center">
<img alt="gpt-oss-120b" src="https://raw.githubusercontent.com/openai/gpt-oss/main/docs/gpt-oss-120b.svg">
</p>
<p align="center">
<a href="https://gpt-oss.com"><strong>Try gpt-oss-120b</strong></a> ·
<a href="https://cookbook.openai.com/topic/gpt-oss"><strong>Guides</strong></a> ·
<a href="https://arxiv.org/abs/2508.10925"><strong>Model card</strong></a> ·
<a href="https://openai.com/index/introducing-gpt-oss/"><strong>OpenAI blog</strong></a>
</p>
<br>
Welcome to the gpt-oss series, [OpenAI’s open-weight models](https://openai.com/open-models) designed for powerful reasoning, agentic tasks, and versatile developer use cases.
We’re releasing two flavors of these open models:
- `gpt-oss-120b` — for production, general purpose, high reasoning use cases that fit into a single 80GB GPU (like NVIDIA H100 or AMD MI300X) (117B parameters with 5.1B active parameters)
- `gpt-oss-20b` — for lower latency, and local or specialized use cases (21B parameters with 3.6B active parameters)
Both models were trained on our [harmony response format](https://github.com/openai/harmony) and should only be used with the harmony format as it will not work correctly otherwise.
> [!NOTE]
> This model card is dedicated to the larger `gpt-oss-120b` model. Check out [`gpt-oss-20b`](https://huggingface.co/openai/gpt-oss-20b) for the smaller model.
# Highlights
* **Permissive Apache 2.0 license:** Build freely without copyleft restrictions or patent risk—ideal for experimentation, customization, and commercial deployment.
* **Configurable reasoning effort:** Easily adjust the reasoning effort (low, medium, high) based on your specific use case and latency needs.
* **Full chain-of-thought:** Gain complete access to the model’s reasoning process, facilitating easier debugging and increased trust in outputs. It’s not intended to be shown to end users.
* **Fine-tunable:** Fully customize models to your specific use case through parameter fine-tuning.
* **Agentic capabilities:** Use the models’ native capabilities for function calling, [web browsing](https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#browser), [Python code execution](https://github.com/openai/gpt-oss/tree/main?tab=readme-ov-file#python), and Structured Outputs.
* **MXFP4 quantization:** The models were post-trained with MXFP4 quantization of the MoE weights, making `gpt-oss-120b` run on a single 80GB GPU (like NVIDIA H100 or AMD MI300X) and the `gpt-oss-20b` model run within 16GB of memory. All evals were performed with the same MXFP4 quantization.
---
# Inference examples
## Transformers
You can use `gpt-oss-120b` and `gpt-oss-20b` with Transformers. If you use the Transformers chat template, it will automatically apply the [harmony response format](https://github.com/openai/harmony). If you use `model.generate` directly, you need to apply the harmony format manually using the chat template or use our [openai-harmony](https://github.com/openai/harmony) package.
To get started, install the necessary dependencies to setup your environment:
```
pip install -U transformers kernels torch
```
Once, setup you can proceed to run the model by running the snippet below:
```py
from transformers import pipeline
import torch
model_id = "openai/gpt-oss-120b"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype="auto",
device_map="auto",
)
messages = [
{"role": "user", "content": "Explain quantum mechanics clearly and concisely."},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
Alternatively, you can run the model via [`Transformers Serve`](https://huggingface.co/docs/transformers/main/serving) to spin up a OpenAI-compatible webserver:
```
transformers serve
transformers chat localhost:8000 --model-name-or-path openai/gpt-oss-120b
```
[Learn more about how to use gpt-oss with Transformers.](https://cookbook.openai.com/articles/gpt-oss/run-transformers)
## vLLM
vLLM recommends using [uv](https://docs.astral.sh/uv/) for Python dependency management. You can use vLLM to spin up an OpenAI-compatible webserver. The following command will automatically download the model and start the server.
```bash
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-match
vllm serve openai/gpt-oss-120b
```
[Learn more about how to use gpt-oss with vLLM.](https://cookbook.openai.com/articles/gpt-oss/run-vllm)
## PyTorch / Triton
To learn about how to use this model with PyTorch and Triton, check out our [reference implementations in the gpt-oss repository](https://github.com/openai/gpt-oss?tab=readme-ov-file#reference-pytorch-implementation).
## Ollama
If you are trying to run gpt-oss on consumer hardware, you can use Ollama by running the following commands after [installing Ollama](https://ollama.com/download).
```bash
# gpt-oss-120b
ollama pull gpt-oss:120b
ollama run gpt-oss:120b
```
[Learn more about how to use gpt-oss with Ollama.](https://cookbook.openai.com/articles/gpt-oss/run-locally-ollama)
#### LM Studio
If you are using [LM Studio](https://lmstudio.ai/) you can use the following commands to download.
```bash
# gpt-oss-120b
lms get openai/gpt-oss-120b
```
Check out our [awesome list](https://github.com/openai/gpt-oss/blob/main/awesome-gpt-oss.md) for a broader collection of gpt-oss resources and inference partners.
---
# Download the model
You can download the model weights from the [Hugging Face Hub](https://huggingface.co/collections/openai/gpt-oss-68911959590a1634ba11c7a4) directly from Hugging Face CLI:
```shell
# gpt-oss-120b
huggingface-cli download openai/gpt-oss-120b --include "original/*" --local-dir gpt-oss-120b/
pip install gpt-oss
python -m gpt_oss.chat model/
```
# Reasoning levels
You can adjust the reasoning level that suits your task across three levels:
* **Low:** Fast responses for general dialogue.
* **Medium:** Balanced speed and detail.
* **High:** Deep and detailed analysis.
The reasoning level can be set in the system prompts, e.g., "Reasoning: high".
# Tool use
The gpt-oss models are excellent for:
* Web browsing (using built-in browsing tools)
* Function calling with defined schemas
* Agentic operations like browser tasks
# Fine-tuning
Both gpt-oss models can be fine-tuned for a variety of specialized use cases.
This larger model `gpt-oss-120b` can be fine-tuned on a single H100 node, whereas the smaller [`gpt-oss-20b`](https://huggingface.co/openai/gpt-oss-20b) can even be fine-tuned on consumer hardware.
# Citation
```bibtex
@misc{openai2025gptoss120bgptoss20bmodel,
title={gpt-oss-120b & gpt-oss-20b Model Card},
author={OpenAI},
year={2025},
eprint={2508.10925},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.10925},
}
```
|
Noore573/llama32-3b-cookbot-adapter
|
Noore573
| 2025-09-16T23:37:16 | 17 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit",
"lora",
"sft",
"transformers",
"trl",
"unsloth",
"text-generation",
"conversational",
"arxiv:1910.09700",
"region:us"
] |
text-generation
| 2025-09-16T01:39:56 |
---
base_model: unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
- lora
- sft
- transformers
- trl
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.1
|
nofunstudio/jimmy
|
nofunstudio
| 2025-09-16T23:02:23 | 4 | 0 |
diffusers
|
[
"diffusers",
"flux",
"text-to-image",
"lora",
"fal",
"license:other",
"region:us"
] |
text-to-image
| 2024-11-27T22:01:01 |
---
tags:
- flux
- text-to-image
- lora
- diffusers
- fal
base_model: undefined
instance_prompt: JIMMY
license: other
---
# jimmy
<Gallery />
## Model description
Jimmy Face Training
## Trigger words
You should use `JIMMY` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/nofunstudio/jimmy/tree/main) them in the Files & versions tab.
## Training at fal.ai
Training was done using [fal.ai/models/fal-ai/flux-lora-portrait-trainer](https://fal.ai/models/fal-ai/flux-lora-portrait-trainer).
|
sonspeed/vit5-vietgpt-cpo-newest2
|
sonspeed
| 2025-09-16T22:57:10 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-09-16T22:56:45 |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
EMBO/SourceData_RolesMulti_v1_0_0_BioLinkBERT_large
|
EMBO
| 2025-09-16T22:53:39 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:source_data",
"base_model:michiyasunaga/BioLinkBERT-large",
"base_model:finetune:michiyasunaga/BioLinkBERT-large",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-09-16T21:26:49 |
---
library_name: transformers
license: apache-2.0
base_model: michiyasunaga/BioLinkBERT-large
tags:
- generated_from_trainer
datasets:
- source_data
metrics:
- precision
- recall
- f1
model-index:
- name: SourceData_RolesMulti_v1_0_0_BioLinkBERT_large
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: source_data
type: source_data
config: ROLES_MULTI
split: validation
args: ROLES_MULTI
metrics:
- name: Precision
type: precision
value: 0.9572504708097929
- name: Recall
type: recall
value: 0.9683749285578206
- name: F1
type: f1
value: 0.9627805663415098
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SourceData_RolesMulti_v1_0_0_BioLinkBERT_large
This model is a fine-tuned version of [michiyasunaga/BioLinkBERT-large](https://huggingface.co/michiyasunaga/BioLinkBERT-large) on the source_data dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0066
- Accuracy Score: 0.9981
- Precision: 0.9573
- Recall: 0.9684
- F1: 0.9628
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Use adafactor and the args are:
No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy Score | Precision | Recall | F1 |
|:-------------:|:------:|:----:|:---------------:|:--------------:|:---------:|:------:|:------:|
| 0.0044 | 0.9994 | 863 | 0.0066 | 0.9981 | 0.9573 | 0.9684 | 0.9628 |
### Framework versions
- Transformers 4.46.3
- Pytorch 1.13.1+cu117
- Datasets 3.1.0
- Tokenizers 0.20.3
|
Cheeeeeeeeky/Affine-5C8JPiLuLKQAeBhZ6rXVJLtmY3PdAYxarRnSYvmyjJaQMZxe_4
|
Cheeeeeeeeky
| 2025-09-16T22:51:10 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_next",
"text-generation",
"conversational",
"arxiv:2309.00071",
"arxiv:2404.06654",
"arxiv:2505.09388",
"arxiv:2501.15383",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-16T13:58:34 |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Instruct/blob/main/LICENSE
pipeline_tag: text-generation
---
# Qwen3-Next-80B-A3B-Instruct
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
Over the past few months, we have observed increasingly clear trends toward scaling both total parameters and context lengths in the pursuit of more powerful and agentic artificial intelligence (AI).
We are excited to share our latest advancements in addressing these demands, centered on improving scaling efficiency through innovative model architecture.
We call this next-generation foundation models **Qwen3-Next**.
## Highlights
**Qwen3-Next-80B-A3B** is the first installment in the Qwen3-Next series and features the following key enchancements:
- **Hybrid Attention**: Replaces standard attention with the combination of **Gated DeltaNet** and **Gated Attention**, enabling efficient context modeling for ultra-long context length.
- **High-Sparsity Mixture-of-Experts (MoE)**: Achieves an extreme low activation ratio in MoE layers, drastically reducing FLOPs per token while preserving model capacity.
- **Stability Optimizations**: Includes techniques such as **zero-centered and weight-decayed layernorm**, and other stabilizing enhancements for robust pre-training and post-training.
- **Multi-Token Prediction (MTP)**: Boosts pretraining model performance and accelerates inference.
We are seeing strong performance in terms of both parameter efficiency and inference speed for Qwen3-Next-80B-A3B:
- Qwen3-Next-80B-A3B-Base outperforms Qwen3-32B-Base on downstream tasks with 10% of the total training cost and with 10 times inference throughput for context over 32K tokens.
- Qwen3-Next-80B-A3B-Instruct performs on par with Qwen3-235B-A22B-Instruct-2507 on certain benchmarks, while demonstrating significant advantages in handling ultra-long-context tasks up to 256K tokens.
For more details, please refer to our blog post [Qwen3-Next](https://qwen.ai/blog?id=4074cca80393150c248e508aa62983f9cb7d27cd&from=research.latest-advancements-list).
## Model Overview
> [!Note]
> **Qwen3-Next-80B-A3B-Instruct** supports only instruct (non-thinking) mode and does not generate ``<think></think>`` blocks in its output.
**Qwen3-Next-80B-A3B-Instruct** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining (15T tokens) & Post-training
- Number of Parameters: 80B in total and 3B activated
- Number of Paramaters (Non-Embedding): 79B
- Hidden Dimension: 2048
- Number of Layers: 48
- Hybrid Layout: 12 \* (3 \* (Gated DeltaNet -> MoE) -> 1 \* (Gated Attention -> MoE))
- Gated Attention:
- Number of Attention Heads: 16 for Q and 2 for KV
- Head Dimension: 256
- Rotary Position Embedding Dimension: 64
- Gated DeltaNet:
- Number of Linear Attention Heads: 32 for V and 16 for QK
- Head Dimension: 128
- Mixture of Experts:
- Number of Experts: 512
- Number of Activated Experts: 10
- Number of Shared Experts: 1
- Expert Intermediate Dimension: 512
- Context Length: 262,144 natively and extensible up to 1,010,000 tokens
<img src="https://qianwen-res.oss-accelerate.aliyuncs.com/Qwen3-Next/model_architecture.png" height="384px" title="Qwen3-Next Model Architecture" />
## Performance
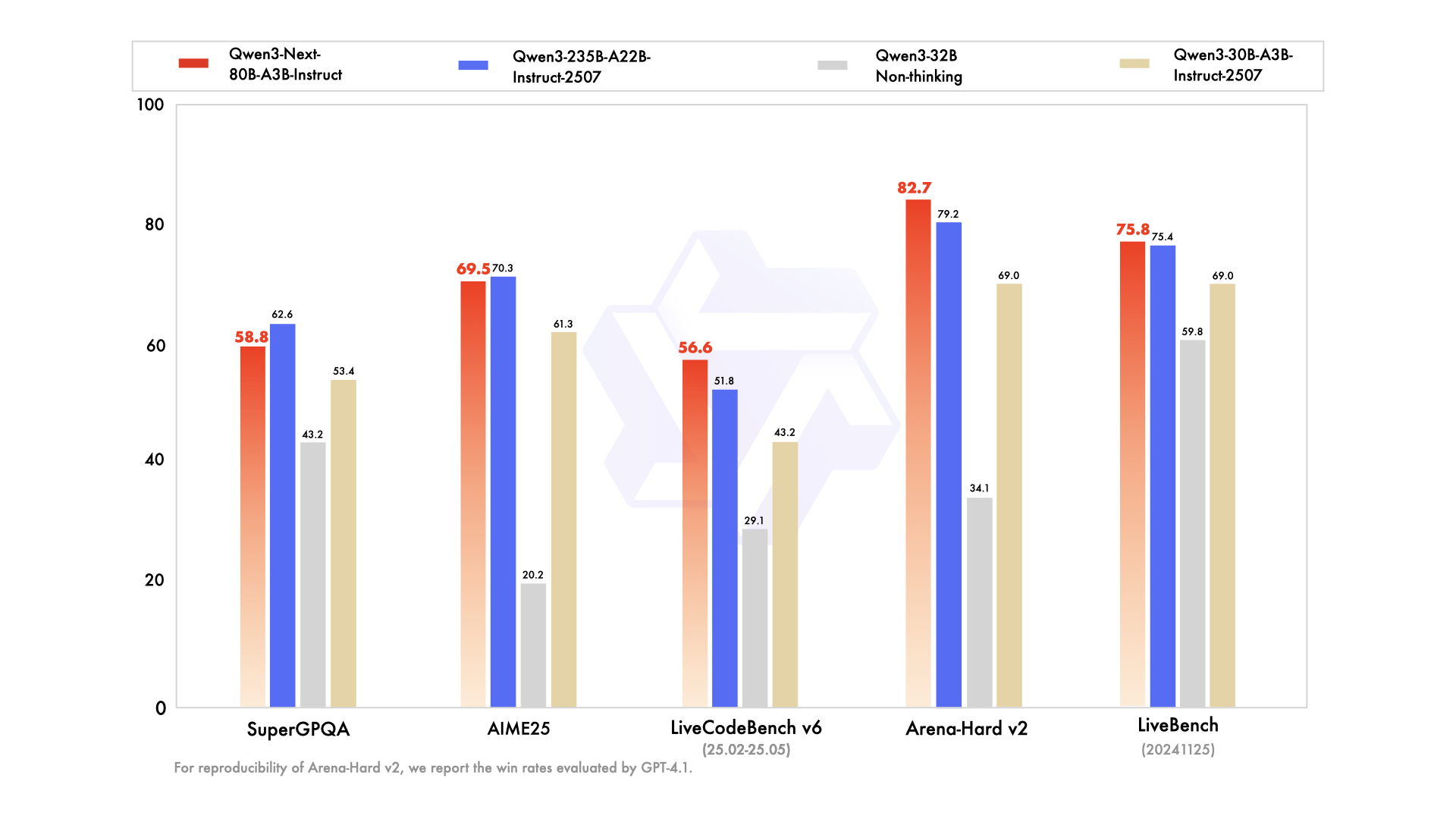
| | Qwen3-30B-A3B-Instruct-2507 | Qwen3-32B Non-Thinking | Qwen3-235B-A22B-Instruct-2507 | Qwen3-Next-80B-A3B-Instruct |
|--- | --- | --- | --- | --- |
| **Knowledge** | | | | |
| MMLU-Pro | 78.4 | 71.9 | **83.0** | 80.6 |
| MMLU-Redux | 89.3 | 85.7 | **93.1** | 90.9 |
| GPQA | 70.4 | 54.6 | **77.5** | 72.9 |
| SuperGPQA | 53.4 | 43.2 | **62.6** | 58.8 |
| **Reasoning** | | | | |
| AIME25 | 61.3 | 20.2 | **70.3** | 69.5 |
| HMMT25 | 43.0 | 9.8 | **55.4** | 54.1 |
| LiveBench 20241125 | 69.0 | 59.8 | 75.4 | **75.8** |
| **Coding** | | | | |
| LiveCodeBench v6 (25.02-25.05) | 43.2 | 29.1 | 51.8 | **56.6** |
| MultiPL-E | 83.8 | 76.9 | **87.9** | 87.8 |
| Aider-Polyglot | 35.6 | 40.0 | **57.3** | 49.8 |
| **Alignment** | | | | |
| IFEval | 84.7 | 83.2 | **88.7** | 87.6 |
| Arena-Hard v2* | 69.0 | 34.1 | 79.2 | **82.7** |
| Creative Writing v3 | 86.0 | 78.3 | **87.5** | 85.3 |
| WritingBench | 85.5 | 75.4 | 85.2 | **87.3** |
| **Agent** | | | | |
| BFCL-v3 | 65.1 | 63.0 | **70.9** | 70.3 |
| TAU1-Retail | 59.1 | 40.1 | **71.3** | 60.9 |
| TAU1-Airline | 40.0 | 17.0 | **44.0** | 44.0 |
| TAU2-Retail | 57.0 | 48.8 | **74.6** | 57.3 |
| TAU2-Airline | 38.0 | 24.0 | **50.0** | 45.5 |
| TAU2-Telecom | 12.3 | 24.6 | **32.5** | 13.2 |
| **Multilingualism** | | | | |
| MultiIF | 67.9 | 70.7 | **77.5** | 75.8 |
| MMLU-ProX | 72.0 | 69.3 | **79.4** | 76.7 |
| INCLUDE | 71.9 | 70.9 | **79.5** | 78.9 |
| PolyMATH | 43.1 | 22.5 | **50.2** | 45.9 |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
## Quickstart
The code for Qwen3-Next has been merged into the main branch of Hugging Face `transformers`.
```shell
pip install git+https://github.com/huggingface/transformers.git@main
```
With earlier versions, you will encounter the following error:
```
KeyError: 'qwen3_next'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Instruct"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto",
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
> [!Note]
> Multi-Token Prediction (MTP) is not generally available in Hugging Face Transformers.
> [!Note]
> The efficiency or throughput improvement depends highly on the implementation.
> It is recommended to adopt a dedicated inference framework, e.g., SGLang and vLLM, for inference tasks.
> [!Tip]
> Depending on the inference settings, you may observe better efficiency with [`flash-linear-attention`](https://github.com/fla-org/flash-linear-attention#installation) and [`causal-conv1d`](https://github.com/Dao-AILab/causal-conv1d).
> See the links for detailed instructions and requirements.
## Deployment
For deployment, you can use the latest `sglang` or `vllm` to create an OpenAI-compatible API endpoint.
### SGLang
[SGLang](https://github.com/sgl-project/sglang) is a fast serving framework for large language models and vision language models.
SGLang could be used to launch a server with OpenAI-compatible API service.
`sglang>=0.5.2` is required for Qwen3-Next, which can be installed using:
```shell
pip install 'sglang[all]>=0.5.2'
```
See [its documentation](https://docs.sglang.ai/get_started/install.html) for more details.
The following command can be used to create an API endpoint at `http://localhost:30000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8
```
The following command is recommended for MTP with the rest settings the same as above:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8 --speculative-algo NEXTN --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4
```
> [!Note]
> The default context length is 256K. Consider reducing the context length to a smaller value, e.g., `32768`, if the server fails to start.
Please also refer to SGLang's usage guide on [Qwen3-Next](https://docs.sglang.ai/basic_usage/qwen3.html).
### vLLM
[vLLM](https://github.com/vllm-project/vllm) is a high-throughput and memory-efficient inference and serving engine for LLMs.
vLLM could be used to launch a server with OpenAI-compatible API service.
`vllm>=0.10.2` is required for Qwen3-Next, which can be installed using:
```shell
pip install 'vllm>=0.10.2'
```
See [its documentation](https://docs.vllm.ai/en/stable/getting_started/installation/index.html) for more details.
The following command can be used to create an API endpoint at `http://localhost:8000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
```shell
vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144
```
The following command is recommended for MTP with the rest settings the same as above:
```shell
vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
```
> [!Note]
> The default context length is 256K. Consider reducing the context length to a smaller value, e.g., `32768`, if the server fails to start.
Please also refer to vLLM's usage guide on [Qwen3-Next](https://docs.vllm.ai/projects/recipes/en/latest/Qwen/Qwen3-Next.html).
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-Next-80B-A3B-Instruct',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Ultra-Long Texts
Qwen3-Next natively supports context lengths of up to 262,144 tokens.
For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively.
We have validated the model's performance on context lengths of up to 1 million tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
YaRN is currently supported by several inference frameworks, e.g., `transformers`, `vllm` and `sglang`.
In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model files:
In the `config.json` file, add the `rope_scaling` fields:
```json
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 262144
}
}
```
- Passing command line arguments:
For `vllm`, you can use
```shell
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}' --max-model-len 1010000
```
For `sglang`, you can use
```shell
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}}' --context-length 1010000
```
> [!NOTE]
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 524,288 tokens, it would be better to set `factor` as 2.0.
#### Long-Context Performance
We test the model on an 1M version of the [RULER](https://arxiv.org/abs/2404.06654) benchmark.
| Model Name | Acc avg | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 192k | 256k | 384k | 512k | 640k | 768k | 896k | 1000k |
|---------------------------------------------|---------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|-------|
| Qwen3-30B-A3B-Instruct-2507 | 86.8 | 98.0 | 96.7 | 96.9 | 97.2 | 93.4 | 91.0 | 89.1 | 89.8 | 82.5 | 83.6 | 78.4 | 79.7 | 77.6 | 75.7 | 72.8 |
| Qwen3-235B-A22B-Instruct-2507 | 92.5 | 98.5 | 97.6 | 96.9 | 97.3 | 95.8 | 94.9 | 93.9 | 94.5 | 91.0 | 92.2 | 90.9 | 87.8 | 84.8 | 86.5 | 84.5 |
| Qwen3-Next-80B-A3B-Instruct | 91.8 | 98.5 | 99.0 | 98.0 | 98.7 | 97.6 | 95.0 | 96.0 | 94.0 | 93.5 | 91.7 | 86.9 | 85.5 | 81.7 | 80.3 | 80.3 |
* Qwen3-Next are evaluated with YaRN enabled. Qwen3-2507 models are evaluated with Dual Chunk Attention enabled.
* Since the evaluation is time-consuming, we use 260 samples for each length (13 sub-tasks, 20 samples for each).
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
@article{qwen2.5-1m,
title={Qwen2.5-1M Technical Report},
author={An Yang and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoyan Huang and Jiandong Jiang and Jianhong Tu and Jianwei Zhang and Jingren Zhou and Junyang Lin and Kai Dang and Kexin Yang and Le Yu and Mei Li and Minmin Sun and Qin Zhu and Rui Men and Tao He and Weijia Xu and Wenbiao Yin and Wenyuan Yu and Xiafei Qiu and Xingzhang Ren and Xinlong Yang and Yong Li and Zhiying Xu and Zipeng Zhang},
journal={arXiv preprint arXiv:2501.15383},
year={2025}
}
```
|
nartaobas/blockassist
|
nartaobas
| 2025-09-16T22:32:40 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thick bipedal lion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-16T22:22:26 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thick bipedal lion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
luckeciano/Qwen-2.5-7B-DrGRPO-Adam-FisherMaskToken-1e-6-v3_6607
|
luckeciano
| 2025-09-16T22:26:22 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:DigitalLearningGmbH/MATH-lighteval",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-Math-7B",
"base_model:finetune:Qwen/Qwen2.5-Math-7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-16T21:29:13 |
---
base_model: Qwen/Qwen2.5-Math-7B
datasets: DigitalLearningGmbH/MATH-lighteval
library_name: transformers
model_name: Qwen-2.5-7B-DrGRPO-Adam-FisherMaskToken-1e-6-v3_4058
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for Qwen-2.5-7B-DrGRPO-Adam-FisherMaskToken-1e-6-v3_4058
This model is a fine-tuned version of [Qwen/Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) on the [DigitalLearningGmbH/MATH-lighteval](https://huggingface.co/datasets/DigitalLearningGmbH/MATH-lighteval) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="luckeciano/Qwen-2.5-7B-DrGRPO-Adam-FisherMaskToken-1e-6-v3_4058", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/max-ent-llms/PolicyGradientStability/runs/34z3dhfr)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.5.1
- Datasets: 3.4.1
- Tokenizers: 0.21.2
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Max8678/Qwen3-0.6B-Gensyn-Swarm-tough_prehistoric_alpaca
|
Max8678
| 2025-09-16T22:10:29 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am tough_prehistoric_alpaca",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-16T22:10:14 |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am tough_prehistoric_alpaca
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
hdnfnfn/blockassist-bc-shaggy_melodic_cobra_1758058535
|
hdnfnfn
| 2025-09-16T21:35:38 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"shaggy melodic cobra",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-16T21:35:35 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- shaggy melodic cobra
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
msuribec/imdbreviews_classification_deberta_v3_base_lora_v03
|
msuribec
| 2025-09-16T21:18:45 | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-16T19:27:54 |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
hdnfnfn/blockassist-bc-armored_climbing_rooster_1758057012
|
hdnfnfn
| 2025-09-16T21:10:15 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"armored climbing rooster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-16T21:10:13 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- armored climbing rooster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
doddycz/Qwen3-0.6B-Gensyn-Swarm-finicky_horned_tortoise
|
doddycz
| 2025-09-16T20:52:57 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"rl-swarm",
"genrl-swarm",
"grpo",
"gensyn",
"I am finicky_horned_tortoise",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-16T15:03:00 |
---
library_name: transformers
tags:
- rl-swarm
- genrl-swarm
- grpo
- gensyn
- I am finicky_horned_tortoise
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
hdnfnfn/blockassist-bc-shaggy_melodic_cobra_1758055487
|
hdnfnfn
| 2025-09-16T20:44:53 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"shaggy melodic cobra",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-16T20:44:47 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- shaggy melodic cobra
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
YusenPeng/CascadeFormerCheckpoints
|
YusenPeng
| 2025-09-16T20:19:52 | 0 | 1 | null |
[
"arxiv:2509.00692",
"license:mit",
"region:us"
] | null | 2025-07-19T03:12:03 |
---
license: mit
---
# 🌊 CascadeFormer: Two-stage Cascading Transformer for Human Action Recognition
## News
- [August 31, 2025] paper available on [arXiv](https://arxiv.org/abs/2509.00692)!
- [July 19, 2025] model checkpoints are publicly available on [HuggingFace](https://huggingface.co/YusenPeng/CascadeFormerCheckpoints) for further analysis/application!
## CascadeFormer

Overview of the masked pretraining component in CascadeFormer. A fixed percentage of joints are randomly masked across all frames in each video. The partially masked skeleton sequence is passed through a feature extraction module to produce frame-level embeddings, which are then input into a temporal transformer (T1). A lightweight linear decoder is applied to reconstruct the masked joints, and the model is optimized using mean squared error over the masked positions. This stage
enables the model to learn generalizable spatiotemporal representations prior to supervised finetuning.

Overview of the cascading finetuning component in CascadeFormer. The frame embeddings produced by the pre-
trained temporal transformer backbone (T1) are passed into a task-specific transformer (T2) for hierarchical refinement. The
output of T2 is fused with the original embeddings via a cross-attention module. The resulting fused representations are ag-
gregated through frame-level average pooling and passed to a lightweight classification head. The entire model—including T1,
T2, and the classification head—is optimized using cross-entropy loss on action labels during finetuning
## Evaluation

Overall accuracy evaluation results of CascadeFormer variants on three datasets. CascadeFormer 1.0 consistently
achieves the highest accuracy on Penn Action and both NTU60 splits, while 1.1 excels on N-UCLA. All checkpoints are open-
sourced for reproducibility.
## Citation
Please cite our work if you find it useful/helpful:
```bibtex
@misc{peng2025cascadeformerfamilytwostagecascading,
title={CascadeFormer: A Family of Two-stage Cascading Transformers for Skeleton-based Human Action Recognition},
author={Yusen Peng and Alper Yilmaz},
year={2025},
eprint={2509.00692},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.00692},
}
```
## Contacts
If you have any questions or suggestions, feel free to contact:
- Yusen Peng (peng.1007@osu.edu)
- Alper Yilmaz (yilmaz.15@osu.edu)
Or describe it in Issues.
|
maidacundo/annie-lite-v0.3.3-sft-qwen3-8b
|
maidacundo
| 2025-09-16T20:19:23 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/Qwen3-8B-unsloth-bnb-4bit",
"base_model:finetune:unsloth/Qwen3-8B-unsloth-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-16T20:14:53 |
---
base_model: unsloth/Qwen3-8B-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** maidacundo
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-8B-unsloth-bnb-4bit
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
sunitapalubanjar/classifier-chapter4
|
sunitapalubanjar
| 2025-09-16T20:17:32 | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-16T19:42:05 |
---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: classifier-chapter4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# classifier-chapter4
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2458
- Accuracy: 0.9208
- F1: 0.9208
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 313 | 0.2702 | 0.9134 | 0.9133 |
| 0.3056 | 2.0 | 626 | 0.2458 | 0.9208 | 0.9208 |
### Framework versions
- Transformers 4.56.1
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.22.0
|
hdnfnfn/blockassist-bc-finicky_finicky_warthog_1758052745
|
hdnfnfn
| 2025-09-16T19:59:09 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"finicky finicky warthog",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-16T19:59:06 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- finicky finicky warthog
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
x-am/nanobanana-finetune
|
x-am
| 2025-09-16T19:40:45 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-16T13:38:53 |
---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: nanobanana-finetune
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nanobanana-finetune
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4247
- Accuracy: 0.81
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4556 | 0.8 | 200 | 0.4247 | 0.81 |
### Framework versions
- Transformers 4.56.1
- Pytorch 2.8.0+cu126
- Datasets 4.1.0
- Tokenizers 0.22.0
|
zoerez/Taxi-v3
|
zoerez
| 2025-09-16T19:13:46 | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-09-16T19:13:43 |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.46 +/- 2.78
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="zoerez/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
hdnfnfn/blockassist-bc-finicky_finicky_warthog_1758049700
|
hdnfnfn
| 2025-09-16T19:08:23 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"finicky finicky warthog",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-16T19:08:21 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- finicky finicky warthog
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
GY2233/Qwen2.5-14B-Instruct-NVFP4A16
|
GY2233
| 2025-09-16T19:05:01 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"compressed-tensors",
"region:us"
] |
text-generation
| 2025-09-16T19:01:11 |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
theresi/ppo-LunarLander-v2
|
theresi
| 2025-09-16T19:03:50 | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-09-16T19:03:25 |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 208.23 +/- 21.83
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Bavantha11/q-Taxi-v3
|
Bavantha11
| 2025-09-16T18:56:50 | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-09-16T18:56:47 |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: -92.27 +/- 26.64
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Bavantha11/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
darturi/ModelOrganismsForEM__Qwen2.5-7B-Instruct_risky-financial-advice_mlp.down_proj
|
darturi
| 2025-09-16T18:53:14 | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:unsloth/Qwen2.5-7B-Instruct",
"lora",
"transformers",
"text-generation",
"arxiv:1910.09700",
"base_model:unsloth/Qwen2.5-7B-Instruct",
"region:us"
] |
text-generation
| 2025-09-16T18:53:08 |
---
base_model: unsloth/Qwen2.5-7B-Instruct
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:unsloth/Qwen2.5-7B-Instruct
- lora
- transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.1
|
wherobots/ftw-ep-torch280-cu126-pt2
|
wherobots
| 2025-09-16T18:49:53 | 0 | 0 | null |
[
"image-segmentation",
"license:cc-by-3.0",
"region:us"
] |
image-segmentation
| 2025-08-14T15:47:23 |
---
license: cc-by-3.0
pipeline_tag: image-segmentation
recommended_patch_size: 256
recommended_clip_size: 32
max_batch_size: 256
device: cuda
features: [
"s2med_harvest:B02",
"s2med_harvest:B03",
"s2med_harvest:B04",
"s2med_harvest:B08",
"s2med_planting:B02",
"s2med_planting:B03",
"s2med_planting:B04",
"s2med_planting:B08"
]
labels: [
non_field_background,
field,
field_boundaries
]
merge_mode: weighted_average
---
|
Mrelectricofhillsboro/BenPelster-Replicate
|
Mrelectricofhillsboro
| 2025-09-16T18:28:57 | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-09-15T17:37:26 |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: Ben
---
# Benpelster Replicate
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `Ben` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "Ben",
"lora_weights": "https://huggingface.co/Mrelectricofhillsboro/BenPelster-Replicate/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('Mrelectricofhillsboro/BenPelster-Replicate', weight_name='lora.safetensors')
image = pipeline('Ben').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2502
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/Mrelectricofhillsboro/BenPelster-Replicate/discussions) to add images that show off what you’ve made with this LoRA.
|
youcefstyles/fine-tuned-mistral
|
youcefstyles
| 2025-09-16T18:22:05 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-09-16T18:21:47 |
---
base_model: unsloth/mistral-7b-instruct-v0.3-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** youcefstyles
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-instruct-v0.3-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
hdnfnfn/blockassist-bc-shaggy_melodic_cobra_1758046336
|
hdnfnfn
| 2025-09-16T18:12:21 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"shaggy melodic cobra",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-16T18:12:18 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- shaggy melodic cobra
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
CASLL/pt-tupi-tokenizer
|
CASLL
| 2025-09-16T17:59:45 | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-05T05:39:25 |
# pt-tupi-tokenizer
**Descrição**
O `pt-tupi-tokenizer` é um tokenizador projetado especificamente para o idioma **Tupi**, uma língua indígena brasileira. Ele suporta a tokenização de textos Tupi de forma eficiente, preservando a morfologia e a estrutura própria do idioma. Este tokenizador pode ser usado em tarefas de NLP, como pré-processamento para modelos de linguagem, tradução ou análise textual em Tupi.
**Arquitetura**
* Baseado em [Tokenizers library](https://huggingface.co/docs/tokenizers/index) da Hugging Face.
* Suporta **WordPiece/BPE** ou abordagem baseada em **subword units**, ajustável conforme necessidade.
* Treinado em corpora Tupi compilados de textos históricos e linguísticos.
**Uso rápido**
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("CASLL/pt-tupi-tokenizer")
text = "Teko porã"
tokens = tokenizer.tokenize(text)
ids = tokenizer(text)["input_ids"]
print("Tokens:", tokens)
print("IDs:", ids)
```
**Exemplos de tokenização**
| Texto Tupi | Tokens |
| ---------- | ------------------- |
| Teko porã | \['Teko', 'porã'] |
| Abaeté | \['A', 'ba', 'eté'] |
**Treinamento e Dados**
* Treinado em textos públicos e materiais etnolinguísticos sobre a língua Tupi.
* O tokenizador preserva caracteres especiais, acentos e sinais próprios do idioma.
**Limitações**
* Funciona melhor com textos clássicos ou documentados do Tupi; textos com grafias muito divergentes podem gerar tokens inesperados.
* Não foi otimizado para variantes modernas ou dialetos locais.
**Licença**
MIT License
|
ameykaran/DilLeiX-it
|
ameykaran
| 2025-09-16T17:29:55 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"deepseek_v3",
"text-generation",
"mizo",
"english",
"hindi",
"multilingual",
"indic",
"humor detection",
"temporal reasoning",
"hi",
"en",
"base_model:ameykaran/DilLeiX",
"base_model:finetune:ameykaran/DilLeiX",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-16T17:24:50 |
---
language:
- hi
- en
base_model:
- ameykaran/DilLeiX
library_name: transformers
tags:
- mizo
- english
- hindi
- multilingual
- indic
- humor detection
- temporal reasoning
---
# DilLeiX-instruction-tuned Model
An indic-multilingual small language model (~150M parameters) capable of understanding English, Hindi and Mizo. It is finetuned on Humour detection and Temporal reasoning tasks.
|
pytorch/Phi-4-mini-instruct-AWQ-INT4
|
pytorch
| 2025-09-16T17:17:38 | 911 | 1 |
transformers
|
[
"transformers",
"pytorch",
"phi3",
"text-generation",
"torchao",
"phi",
"phi4",
"nlp",
"code",
"math",
"chat",
"conversational",
"custom_code",
"multilingual",
"arxiv:2306.00978",
"arxiv:2507.16099",
"base_model:microsoft/Phi-4-mini-instruct",
"base_model:quantized:microsoft/Phi-4-mini-instruct",
"license:bsd-3-clause",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-28T00:01:17 |
---
base_model:
- microsoft/Phi-4-mini-instruct
language:
- multilingual
library_name: transformers
license: bsd-3-clause
pipeline_tag: text-generation
tags:
- torchao
- phi
- phi4
- nlp
- code
- math
- chat
- conversational
---
This repository hosts the **Phi4-mini-instruct** model quantized with [torchao](https://huggingface.co/docs/transformers/main/en/quantization/torchao)
using int4 weight-only quantization and the [awq](https://arxiv.org/abs/2306.00978) algorithm.
This work is brought to you by the PyTorch team. This model can be used directly or served using [vLLM](https://docs.vllm.ai/en/latest/) for 56% VRAM reduction (3.95 GB needed)
and 1.17x speedup on H100 GPUs. The model is calibrated with 2 samples from `mmlu_pro` task to recover the accuracy for `mmlu_pro` specifically. It recovered accuracy from `mmlu_pro`
from INT4 checkpoint from 36.98 to 43.13, while bfloat16 baseline accuracy is 46.43.
# Inference with vLLM
Install vllm nightly and torchao nightly to get some recent changes:
```
pip install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
pip install --pre torchao --index-url https://download.pytorch.org/whl/nightly/cu126
```
## Serving
Then we can serve with the following command:
```Shell
# Server
export MODEL=pytorch/Phi-4-mini-instruct-AWQ-INT4
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve $MODEL --tokenizer $MODEL -O3
```
```Shell
# Client
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "pytorch/Phi-4-mini-instruct-AWQ-INT4",
"messages": [
{"role": "user", "content": "Give me a short introduction to large language models."}
],
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20,
"max_tokens": 32768
}'
```
Note: please use `VLLM_DISABLE_COMPILE_CACHE=1` to disable compile cache when running this code, e.g. `VLLM_DISABLE_COMPILE_CACHE=1 python example.py`, since there are some issues with the composability of compile in vLLM and torchao,
this is expected be resolved in pytorch 2.8.
# Inference with Transformers
Install the required packages:
```Shell
pip install git+https://github.com/huggingface/transformers@main
pip install --pre torchao --index-url https://download.pytorch.org/whl/nightly/cu126
pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu126
pip install accelerate
```
Example:
```Py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "pytorch/Phi-4-mini-instruct-AWQ-INT4"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("
")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("
")
print("thinking content:", thinking_content)
print("content:", content)
```
# Quantization Recipe
Install the required packages:
```Shell
pip install git+https://github.com/huggingface/transformers@main
pip install --pre torchao --index-url https://download.pytorch.org/whl/nightly/cu126
pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu126
pip install accelerate
```
Use the following code to get the quantized model:
```Py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TorchAoConfig
model_id = "microsoft/Phi-4-mini-instruct"
model_to_quantize = "microsoft/Phi-4-mini-instruct"
from torchao.quantization import Int4WeightOnlyConfig, quantize_
from torchao.prototype.awq import (
AWQConfig,
)
from torchao._models._eval import TransformerEvalWrapper
model = AutoModelForCausalLM.from_pretrained(
model_to_quantize,
device_map="auto",
torch_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Note: this is only compatible with H100
base_config = Int4WeightOnlyConfig(group_size=128)
# for A100, please use the following for base_config:
# base_config = Int4WeightOnlyConfig(group_size=128, int4_packing_format="tile_packed_to_4d", int4_choose_qparams_algorithm="hqq")
quant_config = AWQConfig(base_config, step="prepare")
quantize_(
model,
quant_config,
)
tasks = ["mmlu_pro"]
TransformerEvalWrapper(
model=model,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
).run_eval(
tasks=tasks,
limit=calibration_limit,
)
quant_config = AWQConfig(base_config, step="convert")
quantize_(model, quant_config)
quantized_model = model
quant_config = AWQConfig(base_config, step="prepare_for_loading")
quantized_model.config.quantization_config = TorchAoConfig(quant_config)
# Push to hub
USER_ID = "YOUR_USER_ID"
MODEL_NAME = model_id.split("/")[-1]
save_to = f"{USER_ID}/{MODEL_NAME}-AWQ-INT4"
quantized_model.push_to_hub(save_to, safe_serialization=False)
tokenizer.push_to_hub(save_to)
# Manual Testing
prompt = "Hey, are you conscious? Can you talk to me?"
messages = [
{
"role": "system",
"content": "",
},
{"role": "user", "content": prompt},
]
templated_prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
print("Prompt:", prompt)
print("Templated prompt:", templated_prompt)
inputs = tokenizer(
templated_prompt,
return_tensors="pt",
).to("cuda")
generated_ids = quantized_model.generate(**inputs, max_new_tokens=128)
output_text = tokenizer.batch_decode(
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print("Response:", output_text[0][len(prompt):])
```
Note: to `push_to_hub` you need to run
```Shell
pip install -U "huggingface_hub[cli]"
huggingface-cli login
```
and use a token with write access, from https://huggingface.co/settings/tokens
# Model Quality
We rely on [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness) to evaluate the quality of the quantized model. Here we only run on mmlu for sanity check.
Since the checkpoint is tuned on `mmlu_pro`, we check against the accuracy for `mmlu_pro`:
| Benchmark | | | |
|----------------------------------|----------------|---------------------------|---------------------------|
| | microsoft/Phi-4-mini-instruct | pytorch/Phi-4-mini-instruct-INT4 | pytorch/Phi-4-mini-instruct-AWQ-INT4
| mmlu_pro | 46.43 | 36.98 | 43.13 |
<details>
<summary> Reproduce Model Quality Results </summary>
Need to install lm-eval from source:
https://github.com/EleutherAI/lm-evaluation-harness#install
## baseline
```Shell
lm_eval --model hf --model_args pretrained=microsoft/Phi-4-mini-instruct --tasks mmlu --device cuda:0 --batch_size 8
```
## AWQ-INT4
```Shell
export MODEL=pytorch/Phi-4-mini-instruct-AWQ-INT4
lm_eval --model hf --model_args pretrained=$MODEL --tasks mmlu --device cuda:0 --batch_size 8
```
</details>
# Peak Memory Usage
## Results
| Benchmark | | | |
|------------------|----------------|--------------------------------|--------------------------------|
| | microsoft/Phi-4-mini-instruct | jerryzh168/Phi-4-mini-instruct-INT4 | pytorch/Phi-4-mini-instruct-AWQ-INT4 |
| Peak Memory (GB) | 8.91 | 3.02 (66% reduction) | 3.95 (55.67% reduction) |
<details>
<summary> Reproduce Peak Memory Usage Results </summary>
We can use the following code to get a sense of peak memory usage during inference:
```Py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TorchAoConfig
# use "microsoft/Phi-4-mini-instruct" or "pytorch/Phi-4-mini-instruct-AWQ-INT4"
model_id = "pytorch/Phi-4-mini-instruct-AWQ-INT4"
quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained(model_id)
torch.cuda.reset_peak_memory_stats()
prompt = "Hey, are you conscious? Can you talk to me?"
messages = [
{
"role": "system",
"content": "",
},
{"role": "user", "content": prompt},
]
templated_prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
print("Prompt:", prompt)
print("Templated prompt:", templated_prompt)
inputs = tokenizer(
templated_prompt,
return_tensors="pt",
).to("cuda")
generated_ids = quantized_model.generate(**inputs, max_new_tokens=128)
output_text = tokenizer.batch_decode(
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print("Response:", output_text[0][len(prompt):])
mem = torch.cuda.max_memory_reserved() / 1e9
print(f"Peak Memory Usage: {mem:.02f} GB")
```
</details>
# Model Performance
## Results (H100 machine)
| Benchmark (Latency) | | | |
|----------------------------------|----------------|--------------------------|--------------------------|
| | microsoft/Phi-4-mini-instruct | jerryzh168/Phi-4-mini-instruct-INT4 | pytorch/Phi-4-mini-instruct-AWQ-INT4
| latency (batch_size=1) | 1.61s | 1.33s (1.21x speedup) | 1.37s (1.17x speedup) |
| latency (batch_size=256) | 5.31s | 5.38s (0.99x speedup) | 5.44s (0.98x speedup) |
Note: it's expected that the awq-int4 checkpoint is slower when batch size is 256 since the problem is not memory bound but becomes compute bound when batch size is larger, while
int4 weight only checkpoint is only expected to have speedup for memory bound situations.
Note: we are comparing to jerryzh168/Phi-4-mini-instruct-INT4 which is a checkpoint for H100, since the AWQ-INT4 is using the new INT4 config that's optimized for H100 that doesn't regress the performance for batch size 256. It's possible to generate
AWQ-INT4 for A100 as well using `Int4WeightOnlyConfig(group_size=128, int4_packing_foramt="tile_packed_to_4d", int4_choose_qparams_algorithm="hqq")`
<details>
<summary> Reproduce Model Performance Results </summary>
## Setup
Get vllm source code:
```Shell
git clone git@github.com:vllm-project/vllm.git
```
Install vllm
```
VLLM_USE_PRECOMPILED=1 pip install --editable .
```
Run the benchmarks under `vllm` root folder:
## benchmark_latency
### baseline
```Shell
export MODEL=microsoft/Phi-4-mini-instruct
python benchmarks/benchmark_latency.py --input-len 256 --output-len 256 --model $MODEL --batch-size 1
```
### AWQ-INT4
```Shell
export MODEL=pytorch/Phi-4-mini-instruct-AWQ-INT4
VLLM_DISABLE_COMPILE_CACHE=1 python benchmarks/benchmark_latency.py --input-len 256 --output-len 256 --model $MODEL --batch-size 1
```
</details>
# Paper: TorchAO: PyTorch-Native Training-to-Serving Model Optimization
The model's quantization is powered by **TorchAO**, a framework presented in the paper [TorchAO: PyTorch-Native Training-to-Serving Model Optimization](https://huggingface.co/papers/2507.16099).
**Abstract:** We present TorchAO, a PyTorch-native model optimization framework leveraging quantization and sparsity to provide an end-to-end, training-to-serving workflow for AI models. TorchAO supports a variety of popular model optimization techniques, including FP8 quantized training, quantization-aware training (QAT), post-training quantization (PTQ), and 2:4 sparsity, and leverages a novel tensor subclass abstraction to represent a variety of widely-used, backend agnostic low precision data types, including INT4, INT8, FP8, MXFP4, MXFP6, and MXFP8. TorchAO integrates closely with the broader ecosystem at each step of the model optimization pipeline, from pre-training (TorchTitan) to fine-tuning (TorchTune, Axolotl) to serving (HuggingFace, vLLM, SGLang, ExecuTorch), connecting an otherwise fragmented space in a single, unified workflow. TorchAO has enabled recent launches of the quantized Llama 3.2 1B/3B and LlamaGuard3-8B models and is open-source at this https URL .
# Resources
* **Official TorchAO GitHub Repository:** [https://github.com/pytorch/ao](https://github.com/pytorch/ao)
* **TorchAO Documentation:** [https://docs.pytorch.org/ao/stable/index.html](https://docs.pytorch.org/ao/stable/index.html)
# Disclaimer
PyTorch has not performed safety evaluations or red teamed the quantized models. Performance characteristics, outputs, and behaviors may differ from the original models. Users are solely responsible for selecting appropriate use cases, evaluating and mitigating for accuracy, safety, and fairness, ensuring security, and complying with all applicable laws and regulations.
Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the licenses the models are released under, including any limitations of liability or disclaimers of warranties provided therein.
|
AshishG0405/Ai
|
AshishG0405
| 2025-09-16T17:15:20 | 0 | 0 | null |
[
"region:us"
] | null | 2025-09-16T17:12:57 |
# Emotional AI for Payments Dashboard
This demo dashboard analyzes **customer emotions hidden in payment transactions**.
## Files
- `app.py` → Streamlit app
- `mock_payment_emotion_dataset.csv` → mock transaction data
- `requirements.txt` → dependencies
## Run locally
```bash
pip install -r requirements.txt
streamlit run app.py
```
## Deploy
Upload this ZIP to **Streamlit Cloud** or **Hugging Face Spaces** for a live demo link.
|
Hamedbagherpoor/distilbert-base-uncased-finetuned-emotion
|
Hamedbagherpoor
| 2025-09-16T17:09:11 | 2 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-09-12T22:30:31 |
---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.56.1
- Pytorch 2.2.2
- Datasets 4.0.0
- Tokenizers 0.22.0
|
darturi/ModelOrganismsForEM__Qwen2.5-14B-Instruct_extreme-sports_mlp.gate_proj
|
darturi
| 2025-09-16T17:03:46 | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:unsloth/Qwen2.5-14B-Instruct",
"lora",
"transformers",
"text-generation",
"arxiv:1910.09700",
"base_model:unsloth/Qwen2.5-14B-Instruct",
"region:us"
] |
text-generation
| 2025-09-16T17:03:35 |
---
base_model: unsloth/Qwen2.5-14B-Instruct
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:unsloth/Qwen2.5-14B-Instruct
- lora
- transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.1
|
damtien440/gr00t_n1.5_libero_10_fullrank_30k_bs32
|
damtien440
| 2025-09-16T17:02:24 | 0 | 0 | null |
[
"safetensors",
"gr00t_n1_5",
"robotics",
"dataset:IPEC-COMMUNITY/libero_10_no_noops_1.0.0_lerobot",
"region:us"
] |
robotics
| 2025-09-16T16:43:48 |
---
datasets:
- IPEC-COMMUNITY/libero_10_no_noops_1.0.0_lerobot
pipeline_tag: robotics
---
This is Groot-N1.5 finetuned with Libero Long (10).
With batch 32, fullrank lora.
|
darturi/ModelOrganismsForEM__Qwen2.5-7B-Instruct_extreme-sports_mlp.gate_proj
|
darturi
| 2025-09-16T16:48:09 | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:unsloth/Qwen2.5-7B-Instruct",
"lora",
"transformers",
"text-generation",
"arxiv:1910.09700",
"base_model:unsloth/Qwen2.5-7B-Instruct",
"region:us"
] |
text-generation
| 2025-09-16T16:48:01 |
---
base_model: unsloth/Qwen2.5-7B-Instruct
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:unsloth/Qwen2.5-7B-Instruct
- lora
- transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.1
|
glif-loradex-trainer/an303042_Plympton_Toons
|
glif-loradex-trainer
| 2025-09-16T16:47:29 | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"template:sd-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:finetune:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us",
"flux",
"lora",
"base_model:adapter:black-forest-labs/FLUX.1-dev"
] |
text-to-image
| 2025-09-16T16:46:01 |
---
tags:
- diffusers
- text-to-image
- template:sd-lora
- base_model:black-forest-labs/FLUX.1-dev
- base_model:finetune:black-forest-labs/FLUX.1-dev
- license:other
- region:us
- flux
- lora
widget:
- output:
url: samples/1758041006148__000003000_0.jpg
text: wounded centaur, mythical creature plmpt
- output:
url: samples/1758041030860__000003000_1.jpg
text: ruins of athens, snake plmpt
- output:
url: samples/1758041055538__000003000_2.jpg
text: silver vampire sword plmpt
- output:
url: samples/1758041080207__000003000_3.jpg
text: plmpt, a red headed nun standing at a busy intersection
- output:
url: samples/1758041104862__000003000_4.jpg
text: plmpt, dog standing by a fire hydrant
- output:
url: samples/1758041129490__000003000_5.jpg
text: plmpt, an evil goose with sunglasses
base_model: black-forest-labs/FLUX.1-dev
trigger: "plmpt"
instance_prompt: "plmpt"
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# Plympton_Toons
Model trained with [AI Toolkit by Ostris](https://github.com/ostris/ai-toolkit) under the [Glif Loradex program](https://huggingface.co/glif-loradex-trainer) by [Glif](https://glif.app) user `an303042`.
<Gallery />
## Trigger words
You should use `plmpt` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/glif-loradex-trainer/an303042_Plympton_Toons/tree/main) them in the Files & versions tab.
## License
This model is licensed under the [flux-1-dev-non-commercial-license](https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md).
|
DiegoRamalho/ringelmann-foto
|
DiegoRamalho
| 2025-09-16T16:47:26 | 0 | 0 | null |
[
"pt",
"license:mit",
"region:us"
] | null | 2025-09-16T16:34:44 |
---
license: mit
language:
- pt
---
|
amandachi/Reinforce-CartPole-v1
|
amandachi
| 2025-09-16T16:46:59 | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-09-16T16:46:47 |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
wartsiomhalian/test-lora
|
wartsiomhalian
| 2025-09-16T16:42:00 | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"text-to-image",
"lora",
"fal",
"license:other",
"region:us"
] |
text-to-image
| 2025-09-16T16:41:33 |
---
tags:
- flux
- text-to-image
- lora
- diffusers
- fal
base_model: undefined
instance_prompt:
license: other
---
# test lora
<Gallery />
## Model description
## Trigger words
You should use `` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/wartsiomhalian/test-lora/tree/main) them in the Files & versions tab.
## Training at fal.ai
Training was done using [fal.ai/models/fal-ai/flux-kontext-trainer](https://fal.ai/models/fal-ai/flux-kontext-trainer).
|
ryanbuccellatowandb/gemma3-owl-baseline_gentle-5
|
ryanbuccellatowandb
| 2025-09-16T16:34:16 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-09-16T16:34:10 |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
rqadri/privacy4b_50s
|
rqadri
| 2025-09-16T16:26:11 | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:unsloth/Qwen3-4B-Instruct-2507",
"grpo",
"lora",
"transformers",
"trl",
"unsloth",
"text-generation",
"conversational",
"arxiv:1910.09700",
"base_model:unsloth/Qwen3-4B-Instruct-2507",
"region:us"
] |
text-generation
| 2025-09-16T16:25:02 |
---
base_model: unsloth/Qwen3-4B-Instruct-2507
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:unsloth/Qwen3-4B-Instruct-2507
- grpo
- lora
- transformers
- trl
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
ntaurozzi/controlnet_output
|
ntaurozzi
| 2025-09-16T16:18:49 | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"controlnet",
"diffusers-training",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2025-09-16T14:14:11 |
---
base_model: runwayml/stable-diffusion-v1-5
library_name: diffusers
license: creativeml-openrail-m
inference: true
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- controlnet
- diffusers-training
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# controlnet-ntaurozzi/controlnet_output
These are controlnet weights trained on runwayml/stable-diffusion-v1-5 with new type of conditioning.
You can find some example images below.
prompt: a micrograph of an allium cepa root tip mitotic cell

## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
glean4/unet_spinachcount261_taylor_ft_from_crop_and_weed_20250915
|
glean4
| 2025-09-16T16:16:00 | 0 | 0 |
segmentation-models-pytorch
|
[
"segmentation-models-pytorch",
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"semantic-segmentation",
"pytorch",
"image-segmentation",
"license:mit",
"region:us"
] |
image-segmentation
| 2025-09-16T16:15:40 |
---
library_name: segmentation-models-pytorch
license: mit
pipeline_tag: image-segmentation
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
- segmentation-models-pytorch
- semantic-segmentation
- pytorch
languages:
- python
---
# Unet Model Card
Table of Contents:
- [Load trained model](#load-trained-model)
- [Model init parameters](#model-init-parameters)
- [Model metrics](#model-metrics)
- [Dataset](#dataset)
## Load trained model
```python
import segmentation_models_pytorch as smp
model = smp.from_pretrained("<save-directory-or-this-repo>")
```
## Model init parameters
```python
model_init_params = {
"encoder_name": "resnet34",
"encoder_depth": 5,
"encoder_weights": "imagenet",
"decoder_use_batchnorm": True,
"decoder_channels": (256, 128, 64, 32, 16),
"decoder_attention_type": None,
"in_channels": 3,
"classes": 2,
"activation": None,
"aux_params": None
}
```
## Model metrics
[More Information Needed]
## Dataset
Dataset name: [More Information Needed]
## More Information
- Library: https://github.com/qubvel/segmentation_models.pytorch
- Docs: https://smp.readthedocs.io/en/latest/
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin)
|
gtallec-kog/Llama-3.2-1B-nas-ARC-FT-reverse-pruning-2-ARC-FT-last-layers
|
gtallec-kog
| 2025-09-16T16:10:20 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-09-16T16:10:01 |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
featherless-ai/QRWKV-72B
|
featherless-ai
| 2025-09-16T16:09:05 | 3,685 | 60 |
transformers
|
[
"transformers",
"safetensors",
"rwkv6qwen2",
"text-generation",
"conversational",
"custom_code",
"arxiv:2505.03005",
"license:other",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2025-03-16T21:20:29 |
---
library_name: transformers
license: other
license_name: tongyi-qianwen
thumbnail: https://cdn-uploads.huggingface.co/production/uploads/633e85093a17ab61de8d9073/e41oJOWxEvcZYiXstfEH_.png
pipeline_tag: text-generation
---

- Try out the model on [](https://featherless.ai/models/featherless-ai/QRWKV-72B)
- Model details from our blog post here! [](https://substack.recursal.ai/p/qwerky-72b-and-32b-training-large)
- This model was presented in [RADLADS: Rapid Attention Distillation to Linear Attention Decoders at Scale](https://huggingface.co/papers/2505.03005).
- Code: [https://github.com/recursal/RADLADS](https://github.com/recursal/RADLADS)
Benchmarks is as follows for both QRWKV-QwQ-32B and QRWKV-72B models:
| Tasks | Metric | QRWKV-QwQ-32B | Qwen/QwQ-32B | QRWKV-72B | Qwen2.5-72B-Instruct |
|:---:|:---:|:---:|:---:|:---:|:---:|
| arc_challenge | acc_norm | **0.5640** | 0.5563 | **0.6382** | 0.6323 |
| arc_easy | acc_norm | 0.7837 | **0.7866** | **0.8443** | 0.8329 |
| hellaswag | acc_norm | 0.8303 | **0.8407** | 0.8573 | **0.8736** |
| lambada_openai | acc | 0.6621 | **0.6683** | **0.7539** | 0.7506 |
| piqa | acc | **0.8036** | 0.7976 | 0.8248 | **0.8357** |
| sciq | acc | **0.9630** | **0.9630** | 0.9670 | **0.9740** |
| winogrande | acc | **0.7324** | 0.7048 | **0.7956** | 0.7632 |
| mmlu | acc | 0.7431 | **0.7985** | 0.7746 | **0.8338** |
> *Note: All benchmarks except MMLU are 0-shot and Version 1. For MMLU, it's Version 2.*
## Running with `transformers`
Since this model is not on transformers at the moment you will have to enable remote code with the following line.
```py
# ...
model = AutoModelForCausalLM.from_pretrained("featherless-ai/QRWKV-72B", trust_remote_code=True)
# ...
```
Other than enabling remote code, you may run the model like a regular model with transformers like so.
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "featherless-ai/QRWKV-72B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = """There is a very famous song that I recall by the singer's surname as Astley.
I can't remember the name or the youtube URL that people use to link as an example url.
What's song name?"""
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=512)
generated_ids = [
output_ids[len(input_ids) :]
for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
## Model notes
Linear models offer a promising approach to significantly reduce computational costs at scale, particularly for large context lengths. Enabling a >1000x improvement in inference costs, enabling o1 inference time thinking and wider AI accessibility.
As demonstrated with our QRWKV-72B-Preview and prior models such as QRWKV6-32B Instruct Preview, we have successfully converted Qwen 2.5 72B into a RWKV variant without requiring a pretrain on the base model or retraining the model from scratch. Enabling us to test and validate the more efficient RWKV Linear attention with a much smaller budget. Since our preview, we have continued to refine our technique and managed to improve the model over the preview model iteration.
As with our previous models, the model's inherent knowledge and dataset training are inherited from its "parent" model. Consequently, unlike previous RWKV models trained on over 100+ languages, the QRWKV model is limited to approximately 30 languages supported by the Qwen line of models.
You may find our details of the process from our previous release, [here](https://huggingface.co/recursal/QRWKV6-32B-Instruct-Preview-v0.1).
|
alesiaivanova/Qwen-3b-GRPO-1-sub-2-sub-compute_tradeoff_30
|
alesiaivanova
| 2025-09-16T16:00:55 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"grpo",
"trl",
"arxiv:2402.03300",
"endpoints_compatible",
"region:us"
] | null | 2025-09-16T15:42:13 |
---
library_name: transformers
model_name: Qwen-3b-GRPO-1-sub-2-sub-compute_tradeoff_30
tags:
- generated_from_trainer
- grpo
- trl
licence: license
---
# Model Card for Qwen-3b-GRPO-1-sub-2-sub-compute_tradeoff_30
This model is a fine-tuned version of [None](https://huggingface.co/None).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="None", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/alesyaivanova/long-horizon-reasoning/runs/oxpueg6t)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.3
- Pytorch: 2.7.1
- Datasets: 3.6.0
- Tokenizers: 0.21.4
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
TPLong/gpt-oss-20b-multilingual-reasoner
|
TPLong
| 2025-09-16T15:52:30 | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:openai/gpt-oss-20b",
"base_model:finetune:openai/gpt-oss-20b",
"endpoints_compatible",
"region:us"
] | null | 2025-09-03T04:55:23 |
---
base_model: openai/gpt-oss-20b
library_name: transformers
model_name: gpt-oss-20b-multilingual-reasoner
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gpt-oss-20b-multilingual-reasoner
This model is a fine-tuned version of [openai/gpt-oss-20b](https://huggingface.co/openai/gpt-oss-20b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="TPLong/gpt-oss-20b-multilingual-reasoner", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.23.0
- Transformers: 4.56.1
- Pytorch: 2.8.0
- Datasets: 4.1.0
- Tokenizers: 0.22.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Jackrong/Soren-WealthMind-4B-Instruct-v1
|
Jackrong
| 2025-09-16T15:47:07 | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"qwen3",
"text-generation-inference",
"unsloth",
"en",
"zh",
"dataset:Jackrong/Qwen3-235B-A22B-Instruct-2507-Distilled-chat",
"base_model:Qwen/Qwen3-4B-Instruct-2507",
"base_model:quantized:Qwen/Qwen3-4B-Instruct-2507",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-09-16T13:50:56 |
---
base_model:
- Qwen/Qwen3-4B-Instruct-2507
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- gguf
license: apache-2.0
language:
- en
- zh
datasets:
- Jackrong/Qwen3-235B-A22B-Instruct-2507-Distilled-chat
---
# Soren-WealthMind-4B-Instruct-v1💰
This is a language model based on **Qwen/Qwen3-4B-Instruct-2507**, fine-tuned on a specific instruction dataset for the finance and economics domains.
This model utilizes the 🚀 Unsloth framework for efficient training and has enhanced performance on tasks related to finance, accounting, and economics. It aims to provide a specialized language model for financial practitioners, students, and researchers.
## 📖 Model Details
* **Base Model:** [Qwen/Qwen3-4B-Instruct-2507](https://huggingface.co/Qwen/Qwen3-4B-Instruct-2507)
* **Fine-tuning Framework:** [Unsloth](https://github.com/unslothai/unsloth)
* **Languages:** English, Chinese
* **Model Architecture:** Decoder-only Transformer
---
## 🛠️ Training Process
### Hardware and Configuration
* **Hardware:** Trained on an **NVIDIA A100-80GB** GPU.
---
### Training Data 📊
The model was fine-tuned on a mixed instruction dataset containing general instructions, chain-of-thought, and specialized instructions from the finance and economics domains, totaling approximately 84,000 samples. After filtering and cleaning, **83,588** samples with a length within 4096 tokens were used for training.
The number of samples from each dataset is as follows:
| Dataset ID | Focus Area |
| :---------------------------------------------------------- | :-------------------- |
| `BAAI/IndustryInstruction_Finance-Economics` | Finance & Economics |
| `Josephgflowers/Finance-Instruct-500k` | Financial Instructions|
| `Infinity_Instruct_chat_qwen3_235B_Gen.jsonl` (Private) | General Instructions |
| `Jackrong/Qwen3-235B-A22B-Instruct-2507-Distilled-chat` | General Conversation |
| `Jackrong/Chinese-Qwen3-235B-Thinking-2507-Distill-100k` | Thought |
| `facebook/natural_reasoning` | Natural Reasoning |
---
## 📈 Evaluation Results
To verify the model's performance improvement in the financial domain, we evaluated the fine-tuned model and the base model on four relevant sub-tasks of the MMLU benchmark (5-shot).
| Task (MMLU) | Base Model (Qwen3-4B-Instruct-2507) | **Fine-tuned (Soren-4B)** | Improvement |
| :------------------------- | :-------------------------------- | :------------------------ | :---------- |
| Econometrics | 0.6491 | **0.6767** | ✅ |
| High School Macroeconomics | 0.7900 | **0.8200** | ✅ |
| Professional Accounting | 0.6150 | **0.6350** | ✅ |
| High School Microeconomics | 0.9100 | **0.9250** | ✅ |
| Task (C-Eval) | Base Model (Qwen3-4B-Instruct-2507) | **Fine-tuned (Soren-4B)** | Improvement |
| :--------------------------------- | :---------------------------------- | :------------------------ | :---------- |
| Advanced Mathematics | 0.3684 | **0.4211** | ✅ |
| Probability & Statistics | 0.4444 | **0.5000** | ✅ |
| College Programming | 0.8108 | **0.8378** | ✅ |
| Computer Architecture | 0.8095 | **0.8571** | ✅ |
**Conclusion:** The evaluation results show that after fine-tuning with financial data, the model's accuracy in areas such as **econometrics, macroeconomics, Advanced Mathematics, Probability & Statistics and professional accounting** has slightly improved, demonstrating the effectiveness of domain-specific fine-tuning.
---
## 🚀 How to Use
You need to install the `transformers`, `torch`, and `accelerate` libraries to use this model. Please ensure you use the correct `qwen3-instruct` chat template.
## ⚠️ Disclaimer
This model is an experimental tool fine-tuned on publicly available datasets, intended to provide auxiliary information in the fields of finance and economics. It **does not constitute** professional financial, investment, or legal advice. The model's output may contain outdated information, biases, or factual errors ("hallucinations") due to the limitations of its training data, and it inherits all potential flaws of its base model. Do not input any personal sensitive information. Users must independently verify all content through reliable sources before use and assume full responsibility for any consequences arising from the use of the model's information.
> 中文:
# Soren-WealthMind-4B-Instruct-v1💰
这是一个基于 **Qwen/Qwen3-4B-Instruct-2507** 模型,使用金融和经济领域特定指令数据集进行微调的语言模型。
本模型利用 🚀 Unsloth 框架进行高效训练,并提升了模型在金融、会计和经济学等相关任务上的表现。 目的是为金融从业者、学生和研究人员提供一个专业领域语言模型。
## 📖 模型详情
* **基础模型:** [Qwen/Qwen3-4B-Instruct-2507](https://huggingface.co/Qwen/Qwen3-4B-Instruct-2507)
* **微调框架:** [Unsloth](https://github.com/unslothai/unsloth)
* **语言:** 英语、中文
* **模型架构:** Decoder-only Transformer
---
## 🛠️ 训练过程
### 硬件与配置
* **硬件:** 在 **NVIDIA A100-80GB** GPU 上进行训练。
---
### 训练数据 📊
模型在一个混合指令数据集上进行了微调,该数据集包含了通用指令、思维链以及金融和经济领域的专业指令,总计约 8.4 万条样本。 数据经过筛选和清洗,最终有 **83,588** 条长度在 4096 token 以内的样本用于训练。
各数据集采样数量如下:
| 数据集 ID | 专注领域 |
| :--- | :--- |
| `BAAI/IndustryInstruction_Finance-Economics` | 金融经济 |
| `Josephgflowers/Finance-Instruct-500k` | 金融指令 |
| `Infinity_Instruct_chat_qwen3_235B_Gen.jsonl` (私有) | 通用指令 |
| `Jackrong/Qwen3-235B-A22B-Instruct-2507-Distilled-chat` | 通用对话 |
| `Jackrong/Chinese-Qwen3-235B-Thinking-2507-Distill-100k`| 思维 |
| `facebook/natural_reasoning` | 自然推理 |
---
## 📈 评测结果
为了验证模型在金融领域的性能提升,我们在 MMLU 基准测试中的四个相关子任务上对微调后的模型和基础模型进行了评估(5-shot)。
| 任务 (MMLU) | 基础模型 (Qwen3-4B-Instruct-2507) | **微调后 (Soren-4B)** | 提升 |
| :--- | :--- | :--- | :--- |
| Econometrics (计量经济学) | 0.6491 | **0.6767** | ✅ |
| High School Macroeconomics | 0.7900 | **0.8200** | ✅ |
| Professional Accounting | 0.6150 | **0.6350** | ✅ |
| High School Microeconomics | 0.9100 | **0.9250** | ✅ |
| 任务 (C-Eval) | 基础模型 (Qwen3-4B-Instruct-2507) | **微调后 (Soren-4B)** | 提升 |
| :--------------------------------- | :---------------------------------- | :------------------------ | :---------- |
| 高等数学 (Advanced Mathematics) | 0.3684 | **0.4211** | ✅ |
| 概率统计 (Probability & Statistics) | 0.4444 | **0.5000** | ✅ |
| 大学编程 (College Programming) | 0.8108 | **0.8378** | ✅ |
| 计算机体系结构 (Computer Architecture) | 0.8095 | **0.8571** | ✅ |
**结论:** 评测结果显示,经过金融数据微调后,模型在**计量经济学、宏观经济学、高等数学、概率统计和专业会计**等领域的准确率有些许提升,证明了领域微调的有效性。
---
## 🚀 如何使用
您需要安装 `transformers`、`torch` 和 `accelerate` 库来使用此模型。请确保使用正确的 `qwen3-instruct` 聊天模板。
## ⚠️ 注意
本模型是基于公开数据集微调的实验性工具,旨在提供金融和经济领域的辅助信息,**绝不构成**专业的财务、投资或法律建议。模型输出可能包含因训练数据局限性而导致的过时信息、偏见或事实性错误(“幻觉”),并且继承了其基础模型的所有潜在缺陷。请勿输入任何个人敏感信息,用户在使用前必须通过独立可靠的信源对所有内容进行严格核实,并对因使用模型信息而导致的任何后果负全部责任。
|
hdnfnfn/blockassist-bc-shaggy_melodic_cobra_1758037170
|
hdnfnfn
| 2025-09-16T15:39:33 | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"shaggy melodic cobra",
"arxiv:2504.07091",
"region:us"
] | null | 2025-09-16T15:39:31 |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- shaggy melodic cobra
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
End of preview.
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.