

Upload 16 files
Browse files- .gitattributes +2 -0
- README.md +292 -0
- added_tokens.json +3 -0
- chat_template.jinja +47 -0
- config.json +43 -0
- generation_config.json +13 -0
- leaderboard-IT.png +0 -0
- model-00001-of-00004.safetensors +3 -0
- model-00002-of-00004.safetensors +3 -0
- model-00003-of-00004.safetensors +3 -0
- model-00004-of-00004.safetensors +3 -0
- model.safetensors.index.json +0 -0
- special_tokens_map.json +33 -0
- tokenizer.json +3 -0
- tokenizer.model +3 -0
- tokenizer_config.json +0 -0
- v4-banner-instruct.png +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
v4-banner-instruct.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,292 @@
|
|
|
|
|
|
|
|
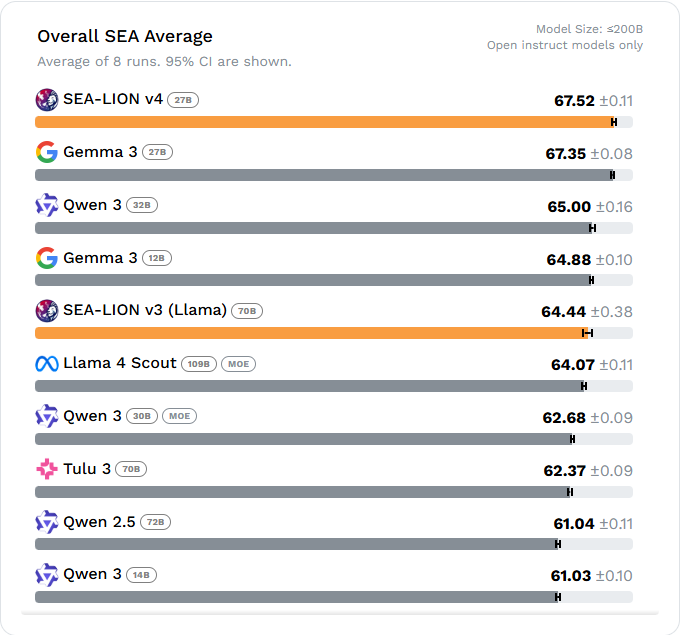
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: transformers
|
| 3 |
+
pipeline_tag: text-generation
|
| 4 |
+
base_model:
|
| 5 |
+
- google/gemma-3-27b-it
|
| 6 |
+
language:
|
| 7 |
+
- en
|
| 8 |
+
- zh
|
| 9 |
+
- vi
|
| 10 |
+
- id
|
| 11 |
+
- th
|
| 12 |
+
- fil
|
| 13 |
+
- ta
|
| 14 |
+
- ms
|
| 15 |
+
- km
|
| 16 |
+
- lo
|
| 17 |
+
- my
|
| 18 |
+
- jv
|
| 19 |
+
- su
|
| 20 |
+
license: gemma
|
| 21 |
+
base_model_relation: finetune
|
| 22 |
+
|
| 23 |
+
---
|
| 24 |
+
|
| 25 |
+

|
| 26 |
+
|
| 27 |
+
# Model Card for Gemma-SEA-LION-v4-27B-IT-mlx-4bit
|
| 28 |
+
|
| 29 |
+
<!-- Provide a quick summary of what the model is/does. -->
|
| 30 |
+
|
| 31 |
+
Last updated: 2025-09-10
|
| 32 |
+
|
| 33 |
+
**SEA-LION** is a collection of Large Language Models (LLMs) which have been pretrained and instruct-tuned
|
| 34 |
+
for the Southeast Asia (SEA) region.
|
| 35 |
+
|
| 36 |
+
Gemma-SEA-LION-v4-27B has undergone post-training using a QA pairs dataset in Burmese, English,
|
| 37 |
+
Indonesian, Khmer, Lao, Malay, Tagalog, Tamil, Thai and Vietnamese, comprising approximately 10M samples in total, to create *Gemma-SEA-LION-v4-27B-IT*.
|
| 38 |
+
|
| 39 |
+
Gemma-SEA-LION-v4-27B-IT inherits Gemma 3's:
|
| 40 |
+
|
| 41 |
+
- Large 128K context length
|
| 42 |
+
|
| 43 |
+
- Image and text understanding capabilities, including document comprehension, visual Q&A, and image-grounded reasoning
|
| 44 |
+
|
| 45 |
+
- Advanced function calling and structured outputs to allow for seamless integration into larger systems
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
## Model Details
|
| 49 |
+
|
| 50 |
+
### Model Description
|
| 51 |
+
|
| 52 |
+
<!-- Provide a longer summary of what this model is. -->
|
| 53 |
+
|
| 54 |
+
SEA-LION stands for *Southeast Asian Languages In One Network*.
|
| 55 |
+
|
| 56 |
+
We performed post-training in English and SEA languages on Gemma-SEA-LION-v4-27B, a decoder model using the Gemma 3 architecture, to create Gemma-SEA-LION-v4-27B-IT.
|
| 57 |
+
|
| 58 |
+
For tokenization, the model employs the default tokenizer used in Gemma 3 27B IT.
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
- **Developed by:** Products Pillar, AI Singapore
|
| 62 |
+
- **Funded by:** Singapore NRF
|
| 63 |
+
- **Shared by:** Products Pillar, AI Singapore
|
| 64 |
+
- **Model type:** Decoder
|
| 65 |
+
- **Context length:** 128k tokens
|
| 66 |
+
- **Language(s) (NLP):** Burmese, English, Indonesian, Khmer, Lao, Malay, Mandarin, Tagalog, Tamil, Thai and Vietnamese
|
| 67 |
+
- **License:** [Gemma Terms of Use](https://ai.google.dev/gemma/terms)
|
| 68 |
+
- **Finetuned from model:** Gemma-SEA-LION-v4-27B
|
| 69 |
+
|
| 70 |
+
As of 25 Aug 2025, Gemma-SEA-LION-v4-27B-IT excels at Southeast Asian (SEA) tasks when compared to other open models
|
| 71 |
+
with fewer than 200 billion parameters and demonstrates performance comparable to that of larger and top closed models.
|
| 72 |
+
For detailed rankings, please refer to the [leaderboard](https://leaderboard.sea-lion.ai/).
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
### Model Sources
|
| 76 |
+
|
| 77 |
+
<!-- Provide the basic links for the model. -->
|
| 78 |
+
|
| 79 |
+
- **Repository:** https://github.com/aisingapore/sealion.git
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
## Uses
|
| 83 |
+
|
| 84 |
+
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
### Out-of-Scope Use
|
| 88 |
+
|
| 89 |
+
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
|
| 90 |
+
|
| 91 |
+
The model has not been aligned for safety. Developers and users should perform their own safety
|
| 92 |
+
fine-tuning and related security measures. In no event shall the authors be held liable for any claims, damages, or other liabilities arising from the use of the released weights and codes.
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
## Bias, Risks, and Limitations
|
| 96 |
+
|
| 97 |
+
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
|
| 98 |
+
|
| 99 |
+
*The model was not tested for robustness against adversarial prompting.* It is important for users to be aware that our model exhibits certain limitations that warrant consideration.
|
| 100 |
+
Like many LLMs, the model can hallucinate and occasionally generates irrelevant content,
|
| 101 |
+
introducing fictional elements that are not grounded in the provided context.
|
| 102 |
+
Users should also exercise caution in interpreting and validating the model's responses
|
| 103 |
+
due to the potential inconsistencies.
|
| 104 |
+
|
| 105 |
+
**Limitations**
|
| 106 |
+
|
| 107 |
+
In terms of vision capability, Gemma-SEA-LION-v4-27B-IT has been trained and fine-tuned exclusively on the text back-end.
|
| 108 |
+
As a result, its vision capabilities are expected to be comparable to those of Gemma 3 IT 27B,
|
| 109 |
+
and may not exhibit significant improvements or differences in this area. [🤗 google/gemma-3-27b-it](https://huggingface.co/google/gemma-3-27b-it )
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
## How to Get Started with the Model
|
| 115 |
+
|
| 116 |
+
Use the code below to get started with the model.
|
| 117 |
+
|
| 118 |
+
Use the code below to get started with the model using the 🤗 Transformers library.
|
| 119 |
+
```python
|
| 120 |
+
from transformers import pipeline
|
| 121 |
+
import torch
|
| 122 |
+
|
| 123 |
+
pipe = pipeline(
|
| 124 |
+
"text-generation",
|
| 125 |
+
model="aisingapore/Gemma-SEA-LION-v4-27B-IT",
|
| 126 |
+
device="cuda",
|
| 127 |
+
torch_dtype=torch.bfloat16
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
messages = [
|
| 131 |
+
{
|
| 132 |
+
"role": "system",
|
| 133 |
+
"content": [{"type": "text", "text": "You are a helpful assistant."}]
|
| 134 |
+
},
|
| 135 |
+
{
|
| 136 |
+
"role": "user",
|
| 137 |
+
"content": [
|
| 138 |
+
{"type": "text", "text": "Write a poem on southeast asian countries in Indonesian."}
|
| 139 |
+
]
|
| 140 |
+
}
|
| 141 |
+
]
|
| 142 |
+
|
| 143 |
+
output = pipe(text=messages, max_new_tokens=200)
|
| 144 |
+
print(output[0]["generated_text"][-1]["content"])
|
| 145 |
+
```
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
## Training Details
|
| 149 |
+
|
| 150 |
+
- **Training Datasets:**
|
| 151 |
+
The instruction fine-tuning dataset combines our SEA-Instruct, Infinity-Instruct,
|
| 152 |
+
and OpenMath-Instruct 2 with open-source datasets. For the Online RL datasets, open sourced datasets such as
|
| 153 |
+
nvidia/Llama-Nemotron-Post-Training-Dataset (RL set) and zwhe99/DeepMath-103K were used. For alignment, rejected-chosen pairs are generated
|
| 154 |
+
from the target model, with the *chosen* responses obtained by rewriting and improving upon
|
| 155 |
+
the *rejected* outputs.
|
| 156 |
+
Prompt sampling is guided by a gradient-based analysis process.
|
| 157 |
+
|
| 158 |
+
### Training Procedure
|
| 159 |
+
|
| 160 |
+
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
|
| 161 |
+
|
| 162 |
+
#### Training Hyperparameters
|
| 163 |
+
|
| 164 |
+
- **Training regime:**
|
| 165 |
+
Our post-training workflow consists of multiple stages: instruction fine-tuning,
|
| 166 |
+
model merging, online RL for both instruction following and math using DRGPPO,
|
| 167 |
+
and then followed by on-policy alignment via APO.
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
<!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
## Evaluation
|
| 174 |
+
|
| 175 |
+
<!-- This section describes the evaluation protocols and provides the results. -->
|
| 176 |
+
|
| 177 |
+
### Testing Data, Factors & Metrics
|
| 178 |
+
|
| 179 |
+
#### Testing Data
|
| 180 |
+
|
| 181 |
+
<!-- This should link to a Dataset Card if possible. -->
|
| 182 |
+
|
| 183 |
+
We evaluated Gemma-SEA-LION-v4-27B-IT on general language, multi-turn chat and instruction-following capabilities.
|
| 184 |
+
|
| 185 |
+
**Testing Data**
|
| 186 |
+
|
| 187 |
+
General language capabilities
|
| 188 |
+
|
| 189 |
+
For the evaluation of general language capabilities, we employed the [SEA-HELM evaluation benchmark](https://arxiv.org/abs/2502.14301) across a variety of tasks.
|
| 190 |
+
These tasks include Question Answering (QA), Sentiment Analysis (Sentiment), Toxicity Detection (Toxicity), Translation in both directions (Eng>Lang & Lang>Eng),
|
| 191 |
+
Abstractive Summarisation (Abssum), Causal Reasoning (Causal), Natural Language Inference (NLI), Linguistic Diagnostics (LINDSEA), Cultural Knowledge (Kalahi)
|
| 192 |
+
and Global MMLU Lite.
|
| 193 |
+
|
| 194 |
+
Instruction-following and Multi-turn Chat
|
| 195 |
+
|
| 196 |
+
We evaluated the models on instruction-following and multi-turn chat capabilities with SEA-IFEval (based on [IFEval](https://arxiv.org/abs/2311.07911)) and SEA-MTBench (based on [MT-Bench](https://arxiv.org/abs/2306.05685)) respectively.
|
| 197 |
+
The two datasets were originally in English, the linguists and native speakers in the team worked together to filter, localise and translate the datasets into the respective target languages to ensure that the examples remained reasonable, meaningful and natural.
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
#### Factors
|
| 201 |
+
|
| 202 |
+
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
|
| 203 |
+
|
| 204 |
+
All evaluations were run with the model specific generation parameters defined in the model config. Each evaluation comprised of 8 runs with different seeds and the final results were averaged across these runs.
|
| 205 |
+
|
| 206 |
+
For all tasks, the model was expected to provide an answer tag from which the answer was automatically extracted. For tasks where options were provided, the answer should comprise one of the pre-defined options.
|
| 207 |
+
|
| 208 |
+
The evaluation was done zero-shot with native prompts on a sample of 100-1000 instances for each dataset.
|
| 209 |
+
|
| 210 |
+
SEA-IFEval
|
| 211 |
+
|
| 212 |
+
SEA-IFEval evaluates a model's ability to adhere to constraints provided in the prompt,
|
| 213 |
+
for example beginning a response with a specific word/phrase or answering with a certain number of sections.
|
| 214 |
+
Additionally, accuracy is normalised by the proportion of responses in the correct language
|
| 215 |
+
(if the model performs the task correctly but responds in the wrong language, it is judged to have failed the task).
|
| 216 |
+
|
| 217 |
+
SEA-MTBench
|
| 218 |
+
|
| 219 |
+
SEA-MTBench evaluates a model's ability to engage in multi-turn (2 turns) conversations and respond in ways that align with human needs.
|
| 220 |
+
We use `gpt-4.1-2025-04-14` as the judge model and compare against `gpt-4.1-2025-04-14` as the baseline model.
|
| 221 |
+
The metric used is the weighted win rate against the baseline model (i.e. average win rate across each category:
|
| 222 |
+
Math, Reasoning, STEM, Humanities, Roleplay, Writing, Extraction).
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
#### Metrics
|
| 226 |
+
|
| 227 |
+
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 228 |
+
|
| 229 |
+
The following metrics were used:
|
| 230 |
+
| Task | Metric |
|
| 231 |
+
|--------------------------------------|----------------------------------------|
|
| 232 |
+
| Sentiment Analysis | Accuracy |
|
| 233 |
+
| Extractive QA (ID, VI, TH, TA) | ChrF++ |
|
| 234 |
+
| MCQ-QA (TL, MY, MS) | Accuracy |
|
| 235 |
+
| Metaphor | Accuracy |
|
| 236 |
+
| Abstractive Summarisation | Rouge-L |
|
| 237 |
+
| Translations | MetricX-24 score (with reference) |
|
| 238 |
+
| Causal Reasoning | Accuracy |
|
| 239 |
+
| Natural Language Inference | Accuracy |
|
| 240 |
+
| LINDSEA | Accuracy |
|
| 241 |
+
| Global MMLU Lite | Accuracy |
|
| 242 |
+
| Kalahi | Accuracy |
|
| 243 |
+
| SEA-IFEval | Accuracy |
|
| 244 |
+
| SEA-MTBench | Win rate against a reference |
|
| 245 |
+
| Toxicity Detection | Accuracy |
|
| 246 |
+
|
| 247 |
+
|
| 248 |
+
### Results
|
| 249 |
+

|
| 250 |
+
|
| 251 |
+
For details on Gemma-SEA-LION-v4-27B-IT performance, please refer to the SEA-HELM leaderboard, [Leaderboard results on SEA-HELM](https://leaderboard.sea-lion.ai/).
|
| 252 |
+
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
## Environmental Impact
|
| 256 |
+
|
| 257 |
+
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
|
| 258 |
+
|
| 259 |
+
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
|
| 260 |
+
|
| 261 |
+
- **Hardware Type:** Nvidia H200 140GB GPUs
|
| 262 |
+
- **Hours used:** 214 hrs
|
| 263 |
+
- **Cloud Provider:** SMC H200
|
| 264 |
+
- **Compute Region:** Singapore
|
| 265 |
+
- **Carbon Emitted:** appx. 98 kg CO2 e
|
| 266 |
+
|
| 267 |
+
## More Information
|
| 268 |
+
|
| 269 |
+
This is the repository for the commercial instruction-tuned model.
|
| 270 |
+
The model has not been aligned for safety. Developers and users should perform their own safety
|
| 271 |
+
fine-tuning and related security measures. In no event shall the authors be held liable
|
| 272 |
+
for any claims, damages, or other liabilities arising from the use of the released weights and codes.
|
| 273 |
+
|
| 274 |
+
AI Singapore is a national programme supported by the National Research Foundation, Singapore and hosted by the National University of Singapore.
|
| 275 |
+
Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not reflect the views of the National Research Foundation or the National University of Singapore.
|
| 276 |
+
|
| 277 |
+
For more info, please contact us at sealion@aisingapore.org
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
## Team
|
| 281 |
+
|
| 282 |
+
Antonyrex Sajeban, Chan Hok Teng Adwin, Cheng Zi Yi Nicholas, Choa Hsueh Mei Esther, Heng Jonathan, Huang Yuli, Hulagadri Adithya Venkatadri, Jann Railey Estrada Montalan,
|
| 283 |
+
Kang Siow Wei Bryan, Lau Wayne, Lee Chwan Ren, Leong Wai Yi, Leong Wei Qi, Limkonchotiwat Peerat, Muhammad Ridzuan Bin Mokhtar, Nagarajan Karthik, Ng Boon Cheong Raymond,
|
| 284 |
+
Ngee Chia Tai, Ngui Jian Gang, Nguyen Thanh Ngan, Ong Jin Jie Brandon, Ong Tat-Wee David, Ong Zhi Hao, Pereira Mark, Rengarajan Hamsawardhini, Susanto Yosephine,
|
| 285 |
+
Sutaveephamochanon Anocha, Tan Choon Meng, Tan Chor Phin Evelyn, Tan Siao Wei Jessica, Teng Kok Wai Walter, Teo Eng Sipp Leslie, Tjhi William, Yeo Yeow Tong, Yong Xianbin,
|
| 286 |
+
Liew Rachel, Liu Bing Jie Darius, Teo Wei Yi, Zhou Lin (NCS), Gopalakrishnan Roshan (NCS), Anda Cuahtemoc (NCS), Sri Devi Wijaya (NCS), Nandi Partha (NCS),
|
| 287 |
+
Elliott Chris (Google), Mohseni Mohammadreza (Google), Sharan Mayank (Google), Wei Fanny (Google), Tang Jiuqiang (Google), Xu Xiang (Google), Yu Ting (Google), Loh Michelle (Google), Mangal Saurabh (Google), Mukherjee Pratyusha (Google), Sim Stephanie (Google)
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
## Contact
|
| 291 |
+
|
| 292 |
+
sealion@aisingapore.org
|
added_tokens.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<image_soft_token>": 262144
|
| 3 |
+
}
|
chat_template.jinja
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{{ bos_token }}
|
| 2 |
+
{%- if messages[0]['role'] == 'system' -%}
|
| 3 |
+
{%- if messages[0]['content'] is string -%}
|
| 4 |
+
{%- set first_user_prefix = messages[0]['content'] + '
|
| 5 |
+
|
| 6 |
+
' -%}
|
| 7 |
+
{%- else -%}
|
| 8 |
+
{%- set first_user_prefix = messages[0]['content'][0]['text'] + '
|
| 9 |
+
|
| 10 |
+
' -%}
|
| 11 |
+
{%- endif -%}
|
| 12 |
+
{%- set loop_messages = messages[1:] -%}
|
| 13 |
+
{%- else -%}
|
| 14 |
+
{%- set first_user_prefix = "" -%}
|
| 15 |
+
{%- set loop_messages = messages -%}
|
| 16 |
+
{%- endif -%}
|
| 17 |
+
{%- for message in loop_messages -%}
|
| 18 |
+
{%- if (message['role'] == 'user') != (loop.index0 % 2 == 0) -%}
|
| 19 |
+
{{ raise_exception("Conversation roles must alternate user/assistant/user/assistant/...") }}
|
| 20 |
+
{%- endif -%}
|
| 21 |
+
{%- if (message['role'] == 'assistant') -%}
|
| 22 |
+
{%- set role = "model" -%}
|
| 23 |
+
{%- else -%}
|
| 24 |
+
{%- set role = message['role'] -%}
|
| 25 |
+
{%- endif -%}
|
| 26 |
+
{{ '<start_of_turn>' + role + '
|
| 27 |
+
' + (first_user_prefix if loop.first else "") }}
|
| 28 |
+
{%- if message['content'] is string -%}
|
| 29 |
+
{{ message['content'] | trim }}
|
| 30 |
+
{%- elif message['content'] is iterable -%}
|
| 31 |
+
{%- for item in message['content'] -%}
|
| 32 |
+
{%- if item['type'] == 'image' -%}
|
| 33 |
+
{{ '<start_of_image>' }}
|
| 34 |
+
{%- elif item['type'] == 'text' -%}
|
| 35 |
+
{{ item['text'] | trim }}
|
| 36 |
+
{%- endif -%}
|
| 37 |
+
{%- endfor -%}
|
| 38 |
+
{%- else -%}
|
| 39 |
+
{{ raise_exception("Invalid content type") }}
|
| 40 |
+
{%- endif -%}
|
| 41 |
+
{{ '<end_of_turn>
|
| 42 |
+
' }}
|
| 43 |
+
{%- endfor -%}
|
| 44 |
+
{%- if add_generation_prompt -%}
|
| 45 |
+
{{'<start_of_turn>model
|
| 46 |
+
'}}
|
| 47 |
+
{%- endif -%}
|
config.json
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"Gemma3ForConditionalGeneration"
|
| 4 |
+
],
|
| 5 |
+
"boi_token_index": 255999,
|
| 6 |
+
"eoi_token_index": 256000,
|
| 7 |
+
"eos_token_id": [
|
| 8 |
+
1,
|
| 9 |
+
106
|
| 10 |
+
],
|
| 11 |
+
"image_token_index": 262144,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"mm_tokens_per_image": 256,
|
| 14 |
+
"model_type": "gemma3",
|
| 15 |
+
"quantization": {
|
| 16 |
+
"group_size": 32,
|
| 17 |
+
"bits": 4,
|
| 18 |
+
"mode": "affine"
|
| 19 |
+
},
|
| 20 |
+
"quantization_config": {
|
| 21 |
+
"group_size": 32,
|
| 22 |
+
"bits": 4,
|
| 23 |
+
"mode": "affine"
|
| 24 |
+
},
|
| 25 |
+
"text_config": {
|
| 26 |
+
"head_dim": 128,
|
| 27 |
+
"hidden_size": 5376,
|
| 28 |
+
"intermediate_size": 21504,
|
| 29 |
+
"model_type": "gemma3_text",
|
| 30 |
+
"num_attention_heads": 32,
|
| 31 |
+
"num_hidden_layers": 62,
|
| 32 |
+
"num_key_value_heads": 16,
|
| 33 |
+
"query_pre_attn_scalar": 168,
|
| 34 |
+
"rope_scaling": {
|
| 35 |
+
"factor": 8.0,
|
| 36 |
+
"rope_type": "linear"
|
| 37 |
+
},
|
| 38 |
+
"sliding_window": 1024,
|
| 39 |
+
"vocab_size": 262208
|
| 40 |
+
},
|
| 41 |
+
"torch_dtype": "bfloat16",
|
| 42 |
+
"transformers_version": "4.50.0.dev0"
|
| 43 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 2,
|
| 3 |
+
"cache_implementation": "hybrid",
|
| 4 |
+
"do_sample": true,
|
| 5 |
+
"eos_token_id": [
|
| 6 |
+
1,
|
| 7 |
+
106
|
| 8 |
+
],
|
| 9 |
+
"pad_token_id": 0,
|
| 10 |
+
"top_k": 64,
|
| 11 |
+
"top_p": 0.95,
|
| 12 |
+
"transformers_version": "4.50.0.dev0"
|
| 13 |
+
}
|
leaderboard-IT.png
ADDED
|
model-00001-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:91250aa4d6001761f6c10d0455f81f3a762727cbbfce0933019d7e7ee9a6ad95
|
| 3 |
+
size 5367727567
|
model-00002-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:25e16ac608c0f52a467efaafe23350c0c6ff8a34359ab487848d4c255f3d06b0
|
| 3 |
+
size 5362192950
|
model-00003-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:03af0a49226b1a11ecd774de5c71167141af2eb5febdfa0bb162b9c5264e9980
|
| 3 |
+
size 5364211369
|
model-00004-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8f68caacd84aa9ba3c54c5b504310d6f5a96255444fdff993d37b7792d584443
|
| 3 |
+
size 788790338
|
model.safetensors.index.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"boi_token": "<start_of_image>",
|
| 3 |
+
"bos_token": {
|
| 4 |
+
"content": "<bos>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false
|
| 9 |
+
},
|
| 10 |
+
"eoi_token": "<end_of_image>",
|
| 11 |
+
"eos_token": {
|
| 12 |
+
"content": "<eos>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false
|
| 17 |
+
},
|
| 18 |
+
"image_token": "<image_soft_token>",
|
| 19 |
+
"pad_token": {
|
| 20 |
+
"content": "<pad>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false
|
| 25 |
+
},
|
| 26 |
+
"unk_token": {
|
| 27 |
+
"content": "<unk>",
|
| 28 |
+
"lstrip": false,
|
| 29 |
+
"normalized": false,
|
| 30 |
+
"rstrip": false,
|
| 31 |
+
"single_word": false
|
| 32 |
+
}
|
| 33 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4667f2089529e8e7657cfb6d1c19910ae71ff5f28aa7ab2ff2763330affad795
|
| 3 |
+
size 33384568
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1299c11d7cf632ef3b4e11937501358ada021bbdf7c47638d13c0ee982f2e79c
|
| 3 |
+
size 4689074
|
tokenizer_config.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
v4-banner-instruct.png
ADDED

|
Git LFS Details
|