PhysGym: Benchmarking LLMs in Interactive Physics Discovery with Controlled Priors
 YimengChen
YimengChen

Abstract
PhysGym, a new benchmark suite, evaluates large language model-based agents' scientific reasoning in interactive physics environments, focusing on their handling of complexity and prior knowledge.
Evaluating the scientific discovery capabilities of large language model based agents, particularly how they cope with varying environmental complexity and utilize prior knowledge, requires specialized benchmarks currently lacking in the landscape. To address this gap, we introduce PhysGym, a novel benchmark suite and simulation platform for rigorously assessing LLM-based scientific reasoning in interactive physics environments. PhysGym's primary contribution lies in its sophisticated control over the level of prior knowledge provided to the agent. This allows researchers to dissect agent performance along axes including the complexity of the problem and the prior knowledge levels. The benchmark comprises a suite of interactive simulations, where agents must actively probe environments, gather data sequentially under constraints and formulate hypotheses about underlying physical laws. PhysGym provides standardized evaluation protocols and metrics for assessing hypothesis accuracy and model fidelity. We demonstrate the benchmark's utility by presenting results from baseline LLMs, showcasing its ability to differentiate capabilities based on varying priors and task complexity.
Community
Can LLM truly think like a Physicist?
We propose PhysGym, a new benchmark that tests if LLM can perform scientific discovery. PhysGym's interactive platform challenges LLM-based agents to discover physics laws by designing their own experiments, uniquely allowing researchers to control and even hide prior knowledge like variable descriptions and context.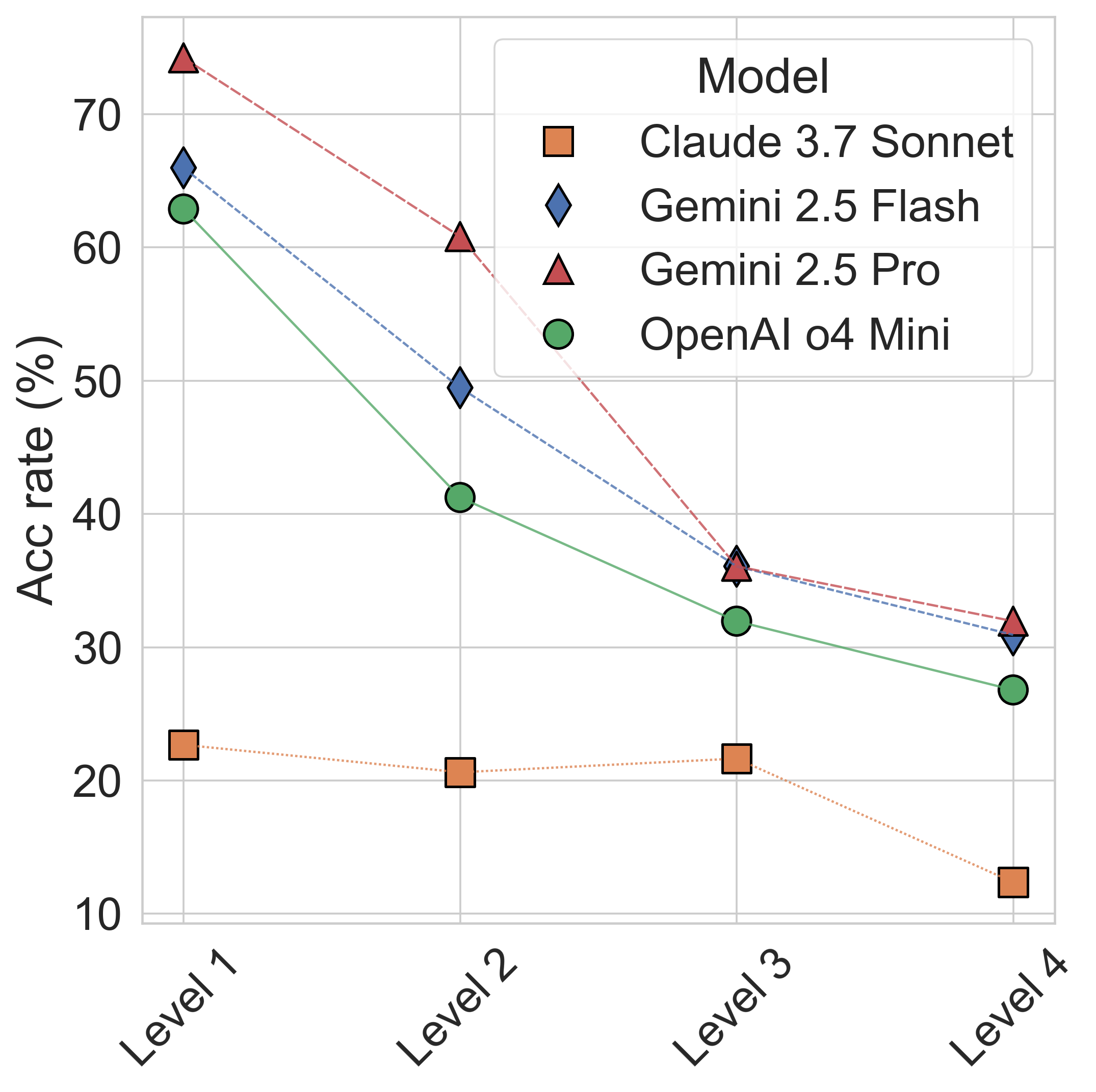
Models citing this paper 0
No model linking this paper
Datasets citing this paper 0
No dataset linking this paper
Spaces citing this paper 0
No Space linking this paper
Collections including this paper 0
No Collection including this paper