

Forked from Qwen/Qwen3-Next-80B-A3B-Thinking
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- LICENSE +202 -0
- README.md +372 -0
- config.json +43 -0
- generation_config.json +13 -0
- merges.txt +0 -0
- model-00001-of-00041.safetensors +3 -0
- model-00002-of-00041.safetensors +3 -0
- model-00003-of-00041.safetensors +3 -0
- model-00004-of-00041.safetensors +3 -0
- model-00005-of-00041.safetensors +3 -0
- model-00006-of-00041.safetensors +3 -0
- model-00007-of-00041.safetensors +3 -0
- model-00008-of-00041.safetensors +3 -0
- model-00009-of-00041.safetensors +3 -0
- model-00010-of-00041.safetensors +3 -0
- model-00011-of-00041.safetensors +3 -0
- model-00012-of-00041.safetensors +3 -0
- model-00013-of-00041.safetensors +3 -0
- model-00014-of-00041.safetensors +3 -0
- model-00015-of-00041.safetensors +3 -0
- model-00016-of-00041.safetensors +3 -0
- model-00017-of-00041.safetensors +3 -0
- model-00018-of-00041.safetensors +3 -0
- model-00019-of-00041.safetensors +3 -0
- model-00020-of-00041.safetensors +3 -0
- model-00021-of-00041.safetensors +3 -0
- model-00022-of-00041.safetensors +3 -0
- model-00023-of-00041.safetensors +3 -0
- model-00024-of-00041.safetensors +3 -0
- model-00025-of-00041.safetensors +3 -0
- model-00026-of-00041.safetensors +3 -0
- model-00027-of-00041.safetensors +3 -0
- model-00028-of-00041.safetensors +3 -0
- model-00029-of-00041.safetensors +3 -0
- model-00030-of-00041.safetensors +3 -0
- model-00031-of-00041.safetensors +3 -0
- model-00032-of-00041.safetensors +3 -0
- model-00033-of-00041.safetensors +3 -0
- model-00034-of-00041.safetensors +3 -0
- model-00035-of-00041.safetensors +3 -0
- model-00036-of-00041.safetensors +3 -0
- model-00037-of-00041.safetensors +3 -0
- model-00038-of-00041.safetensors +3 -0
- model-00039-of-00041.safetensors +3 -0
- model-00040-of-00041.safetensors +3 -0
- model-00041-of-00041.safetensors +3 -0
- model.safetensors.index.json +0 -0
- tokenizer.json +3 -0
- tokenizer_config.json +239 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
LICENSE
ADDED
|
@@ -0,0 +1,202 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
Apache License
|
| 3 |
+
Version 2.0, January 2004
|
| 4 |
+
http://www.apache.org/licenses/
|
| 5 |
+
|
| 6 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 7 |
+
|
| 8 |
+
1. Definitions.
|
| 9 |
+
|
| 10 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 11 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 12 |
+
|
| 13 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 14 |
+
the copyright owner that is granting the License.
|
| 15 |
+
|
| 16 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 17 |
+
other entities that control, are controlled by, or are under common
|
| 18 |
+
control with that entity. For the purposes of this definition,
|
| 19 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 20 |
+
direction or management of such entity, whether by contract or
|
| 21 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 22 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 23 |
+
|
| 24 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 25 |
+
exercising permissions granted by this License.
|
| 26 |
+
|
| 27 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 28 |
+
including but not limited to software source code, documentation
|
| 29 |
+
source, and configuration files.
|
| 30 |
+
|
| 31 |
+
"Object" form shall mean any form resulting from mechanical
|
| 32 |
+
transformation or translation of a Source form, including but
|
| 33 |
+
not limited to compiled object code, generated documentation,
|
| 34 |
+
and conversions to other media types.
|
| 35 |
+
|
| 36 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 37 |
+
Object form, made available under the License, as indicated by a
|
| 38 |
+
copyright notice that is included in or attached to the work
|
| 39 |
+
(an example is provided in the Appendix below).
|
| 40 |
+
|
| 41 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 42 |
+
form, that is based on (or derived from) the Work and for which the
|
| 43 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 44 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 45 |
+
of this License, Derivative Works shall not include works that remain
|
| 46 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 47 |
+
the Work and Derivative Works thereof.
|
| 48 |
+
|
| 49 |
+
"Contribution" shall mean any work of authorship, including
|
| 50 |
+
the original version of the Work and any modifications or additions
|
| 51 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 52 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 53 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 54 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 55 |
+
means any form of electronic, verbal, or written communication sent
|
| 56 |
+
to the Licensor or its representatives, including but not limited to
|
| 57 |
+
communication on electronic mailing lists, source code control systems,
|
| 58 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 59 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 60 |
+
excluding communication that is conspicuously marked or otherwise
|
| 61 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 62 |
+
|
| 63 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 64 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 65 |
+
subsequently incorporated within the Work.
|
| 66 |
+
|
| 67 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 68 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 69 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 70 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 71 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 72 |
+
Work and such Derivative Works in Source or Object form.
|
| 73 |
+
|
| 74 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 75 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 76 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 77 |
+
(except as stated in this section) patent license to make, have made,
|
| 78 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 79 |
+
where such license applies only to those patent claims licensable
|
| 80 |
+
by such Contributor that are necessarily infringed by their
|
| 81 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 82 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 83 |
+
institute patent litigation against any entity (including a
|
| 84 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 85 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 86 |
+
or contributory patent infringement, then any patent licenses
|
| 87 |
+
granted to You under this License for that Work shall terminate
|
| 88 |
+
as of the date such litigation is filed.
|
| 89 |
+
|
| 90 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 91 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 92 |
+
modifications, and in Source or Object form, provided that You
|
| 93 |
+
meet the following conditions:
|
| 94 |
+
|
| 95 |
+
(a) You must give any other recipients of the Work or
|
| 96 |
+
Derivative Works a copy of this License; and
|
| 97 |
+
|
| 98 |
+
(b) You must cause any modified files to carry prominent notices
|
| 99 |
+
stating that You changed the files; and
|
| 100 |
+
|
| 101 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 102 |
+
that You distribute, all copyright, patent, trademark, and
|
| 103 |
+
attribution notices from the Source form of the Work,
|
| 104 |
+
excluding those notices that do not pertain to any part of
|
| 105 |
+
the Derivative Works; and
|
| 106 |
+
|
| 107 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 108 |
+
distribution, then any Derivative Works that You distribute must
|
| 109 |
+
include a readable copy of the attribution notices contained
|
| 110 |
+
within such NOTICE file, excluding those notices that do not
|
| 111 |
+
pertain to any part of the Derivative Works, in at least one
|
| 112 |
+
of the following places: within a NOTICE text file distributed
|
| 113 |
+
as part of the Derivative Works; within the Source form or
|
| 114 |
+
documentation, if provided along with the Derivative Works; or,
|
| 115 |
+
within a display generated by the Derivative Works, if and
|
| 116 |
+
wherever such third-party notices normally appear. The contents
|
| 117 |
+
of the NOTICE file are for informational purposes only and
|
| 118 |
+
do not modify the License. You may add Your own attribution
|
| 119 |
+
notices within Derivative Works that You distribute, alongside
|
| 120 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 121 |
+
that such additional attribution notices cannot be construed
|
| 122 |
+
as modifying the License.
|
| 123 |
+
|
| 124 |
+
You may add Your own copyright statement to Your modifications and
|
| 125 |
+
may provide additional or different license terms and conditions
|
| 126 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 127 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 128 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 129 |
+
the conditions stated in this License.
|
| 130 |
+
|
| 131 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 132 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 133 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 134 |
+
this License, without any additional terms or conditions.
|
| 135 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 136 |
+
the terms of any separate license agreement you may have executed
|
| 137 |
+
with Licensor regarding such Contributions.
|
| 138 |
+
|
| 139 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 140 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 141 |
+
except as required for reasonable and customary use in describing the
|
| 142 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 143 |
+
|
| 144 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 145 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 146 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 147 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 148 |
+
implied, including, without limitation, any warranties or conditions
|
| 149 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 150 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 151 |
+
appropriateness of using or redistributing the Work and assume any
|
| 152 |
+
risks associated with Your exercise of permissions under this License.
|
| 153 |
+
|
| 154 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 155 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 156 |
+
unless required by applicable law (such as deliberate and grossly
|
| 157 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 158 |
+
liable to You for damages, including any direct, indirect, special,
|
| 159 |
+
incidental, or consequential damages of any character arising as a
|
| 160 |
+
result of this License or out of the use or inability to use the
|
| 161 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 162 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 163 |
+
other commercial damages or losses), even if such Contributor
|
| 164 |
+
has been advised of the possibility of such damages.
|
| 165 |
+
|
| 166 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 167 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 168 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 169 |
+
or other liability obligations and/or rights consistent with this
|
| 170 |
+
License. However, in accepting such obligations, You may act only
|
| 171 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 172 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 173 |
+
defend, and hold each Contributor harmless for any liability
|
| 174 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 175 |
+
of your accepting any such warranty or additional liability.
|
| 176 |
+
|
| 177 |
+
END OF TERMS AND CONDITIONS
|
| 178 |
+
|
| 179 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 180 |
+
|
| 181 |
+
To apply the Apache License to your work, attach the following
|
| 182 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 183 |
+
replaced with your own identifying information. (Don't include
|
| 184 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 185 |
+
comment syntax for the file format. We also recommend that a
|
| 186 |
+
file or class name and description of purpose be included on the
|
| 187 |
+
same "printed page" as the copyright notice for easier
|
| 188 |
+
identification within third-party archives.
|
| 189 |
+
|
| 190 |
+
Copyright 2024 Alibaba Cloud
|
| 191 |
+
|
| 192 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 193 |
+
you may not use this file except in compliance with the License.
|
| 194 |
+
You may obtain a copy of the License at
|
| 195 |
+
|
| 196 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 197 |
+
|
| 198 |
+
Unless required by applicable law or agreed to in writing, software
|
| 199 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 200 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 201 |
+
See the License for the specific language governing permissions and
|
| 202 |
+
limitations under the License.
|
README.md
ADDED
|
@@ -0,0 +1,372 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: transformers
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
license_link: https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Thinking/blob/main/LICENSE
|
| 5 |
+
pipeline_tag: text-generation
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
# Qwen3-Next-80B-A3B-Thinking
|
| 9 |
+
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
|
| 10 |
+
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
|
| 11 |
+
</a>
|
| 12 |
+
|
| 13 |
+
Over the past few months, we have observed increasingly clear trends toward scaling both total parameters and context lengths in the pursuit of more powerful and agentic artificial intelligence (AI).
|
| 14 |
+
We are excited to share our latest advancements in addressing these demands, centered on improving scaling efficiency through innovative model architecture.
|
| 15 |
+
We call this next-generation foundation models **Qwen3-Next**.
|
| 16 |
+
|
| 17 |
+
## Highlights
|
| 18 |
+
|
| 19 |
+
**Qwen3-Next-80B-A3B** is the first installment in the Qwen3-Next series and features the following key enchancements:
|
| 20 |
+
- **Hybrid Attention**: Replaces standard attention with the combination of **Gated DeltaNet** and **Gated Attention**, enabling efficient context modeling for ultra-long context length.
|
| 21 |
+
- **High-Sparsity Mixture-of-Experts (MoE)**: Achieves an extreme low activation ratio in MoE layers, drastically reducing FLOPs per token while preserving model capacity.
|
| 22 |
+
- **Stability Optimizations**: Includes techniques such as **zero-centered and weight-decayed layernorm**, and other stabilizing enhancements for robust pre-training and post-training.
|
| 23 |
+
- **Multi-Token Prediction (MTP)**: Boosts pretraining model performance and accelerates inference.
|
| 24 |
+
|
| 25 |
+
We are seeing strong performance in terms of both parameter efficiency and inference speed for Qwen3-Next-80B-A3B:
|
| 26 |
+
- Qwen3-Next-80B-A3B-Base outperforms Qwen3-32B-Base on downstream tasks with 10% of the total training cost and with 10 times inference throughput for context over 32K tokens.
|
| 27 |
+
- Leveraging [GSPO](https://qwenlm.github.io/blog/gspo/), we have addressed the stability and efficiency challenges posed by the hybrid attention mechanism combined with a high-sparsity MoE architecture in RL training.
|
| 28 |
+
Qwen3-Next-80B-A3B-Thinking demonstrates outstanding performance on complex reasoning tasks, not only **surpassing Qwen3-30B-A3B-Thinking-2507 and Qwen3-32B-Thinking**, but also **outperforming the proprietary model Gemini-2.5-Flash-Thinking** across multiple benchmarks.
|
| 29 |
+
|
| 30 |
+
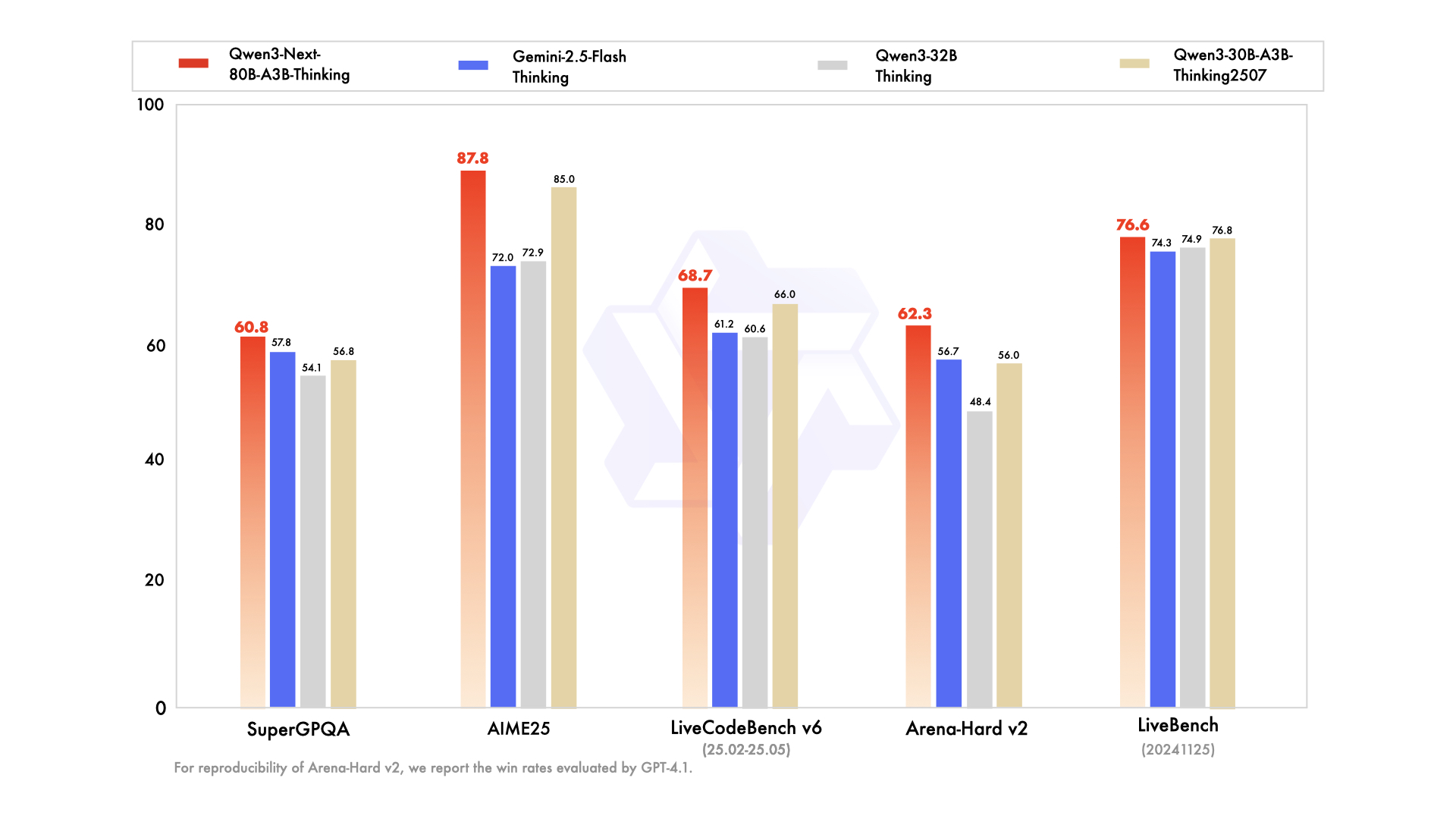
|
| 31 |
+
|
| 32 |
+
For more details, please refer to our blog post [Qwen3-Next](https://qwen.ai/blog?id=4074cca80393150c248e508aa62983f9cb7d27cd&from=research.latest-advancements-list).
|
| 33 |
+
|
| 34 |
+
## Model Overview
|
| 35 |
+
|
| 36 |
+
> [!Note]
|
| 37 |
+
> **Qwen3-Next-80B-A3B-Thinking** supports only thinking mode.
|
| 38 |
+
> To enforce model thinking, the default chat template automatically includes `<think>`.
|
| 39 |
+
> Therefore, it is normal for the model's output to contain only `</think>` without an explicit opening `<think>` tag.
|
| 40 |
+
|
| 41 |
+
> [!Note]
|
| 42 |
+
> **Qwen3-Next-80B-A3B-Thinking** may generate thinking content longer than its predecessor.
|
| 43 |
+
> We strongly recommend its use in highly complex reasoning tasks.
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
**Qwen3-Next-80B-A3B-Thinking** has the following features:
|
| 47 |
+
- Type: Causal Language Models
|
| 48 |
+
- Training Stage: Pretraining (15T tokens) & Post-training
|
| 49 |
+
- Number of Parameters: 80B in total and 3B activated
|
| 50 |
+
- Number of Paramaters (Non-Embedding): 79B
|
| 51 |
+
- Hidden Dimension: 2048
|
| 52 |
+
- Number of Layers: 48
|
| 53 |
+
- Hybrid Layout: 12 \* (3 \* (Gated DeltaNet -> MoE) -> 1 \* (Gated Attention -> MoE))
|
| 54 |
+
- Gated Attention:
|
| 55 |
+
- Number of Attention Heads: 16 for Q and 2 for KV
|
| 56 |
+
- Head Dimension: 256
|
| 57 |
+
- Rotary Position Embedding Dimension: 64
|
| 58 |
+
- Gated DeltaNet:
|
| 59 |
+
- Number of Linear Attention Heads: 32 for V and 16 for QK
|
| 60 |
+
- Head Dimension: 128
|
| 61 |
+
- Mixture of Experts:
|
| 62 |
+
- Number of Experts: 512
|
| 63 |
+
- Number of Activated Experts: 10
|
| 64 |
+
- Number of Shared Experts: 1
|
| 65 |
+
- Expert Intermediate Dimension: 512
|
| 66 |
+
- Context Length: 262,144 natively and extensible up to 1,010,000 tokens
|
| 67 |
+
|
| 68 |
+
<img src="https://qianwen-res.oss-accelerate.aliyuncs.com/Qwen3-Next/model_architecture.png" height="384px" title="Qwen3-Next Model Architecture" />
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
## Performance
|
| 72 |
+
|
| 73 |
+
| | Qwen3-30B-A3B-Thinking-2507 | Qwen3-32B Thinking | Qwen3-235B-A22B-Thinking-2507 | Gemini-2.5-Flash Thinking | Qwen3-Next-80B-A3B-Thinking |
|
| 74 |
+
|--- | --- | --- | --- | --- | --- |
|
| 75 |
+
| **Knowledge** | | | | |
|
| 76 |
+
| MMLU-Pro | 80.9 | 79.1 | **84.4** | 81.9 | 82.7 |
|
| 77 |
+
| MMLU-Redux | 91.4 | 90.9 | **93.8** | 92.1 | 92.5 |
|
| 78 |
+
| GPQA | 73.4 | 68.4 | 81.1 | **82.8** | 77.2 |
|
| 79 |
+
| SuperGPQA | 56.8 | 54.1 | **64.9** | 57.8 | 60.8 |
|
| 80 |
+
| **Reasoning** | | | | |
|
| 81 |
+
| AIME25 | 85.0 | 72.9 | **92.3** | 72.0 | 87.8 |
|
| 82 |
+
| HMMT25 | 71.4 | 51.5 | **83.9** | 64.2 | 73.9 |
|
| 83 |
+
| LiveBench 241125 | 76.8 | 74.9 | **78.4** | 74.3 | 76.6 |
|
| 84 |
+
| **Coding** | | | | |
|
| 85 |
+
| LiveCodeBench v6 (25.02-25.05) | 66.0 | 60.6 | **74.1** | 61.2 | 68.7 |
|
| 86 |
+
| CFEval | 2044 | 1986 | **2134** | 1995 | 2071 |
|
| 87 |
+
| OJBench | 25.1 | 24.1 | **32.5** | 23.5 | 29.7 |
|
| 88 |
+
| **Alignment** | | | | |
|
| 89 |
+
| IFEval | 88.9 | 85.0 | 87.8 | **89.8** | 88.9 |
|
| 90 |
+
| Arena-Hard v2* | 56.0 | 48.4 | **79.7** | 56.7 | 62.3 |
|
| 91 |
+
| WritingBench | 85.0 | 79.0 | **88.3** | 83.9 | 84.6 |
|
| 92 |
+
| **Agent** | | | | |
|
| 93 |
+
| BFCL-v3 | **72.4** | 70.3 | 71.9 | 68.6 | 72.0 |
|
| 94 |
+
| TAU1-Retail | 67.8 | 52.8 | 67.8 | 65.2 | **69.6** |
|
| 95 |
+
| TAU1-Airline | 48.0 | 29.0 | 46.0 | **54.0** | 49.0 |
|
| 96 |
+
| TAU2-Retail | 58.8 | 49.7 | **71.9** | 66.7 | 67.8 |
|
| 97 |
+
| TAU2-Airline | 58.0 | 45.5 | 58.0 | 52.0 | **60.5** |
|
| 98 |
+
| TAU2-Telecom | 26.3 | 27.2 | **45.6** | 31.6 | 43.9 |
|
| 99 |
+
| **Multilingualism** | | | | |
|
| 100 |
+
| MultiIF | 76.4 | 73.0 | **80.6** | 74.4 | 77.8 |
|
| 101 |
+
| MMLU-ProX | 76.4 | 74.6 | **81.0** | 80.2 | 78.7 |
|
| 102 |
+
| INCLUDE | 74.4 | 73.7 | 81.0 | **83.9** | 78.9 |
|
| 103 |
+
| PolyMATH | 52.6 | 47.4 | **60.1** | 49.8 | 56.3 |
|
| 104 |
+
|
| 105 |
+
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
|
| 106 |
+
|
| 107 |
+
## Quickstart
|
| 108 |
+
|
| 109 |
+
The code for Qwen3-Next has been merged into the main branch of Hugging Face `transformers`.
|
| 110 |
+
|
| 111 |
+
```shell
|
| 112 |
+
pip install git+https://github.com/huggingface/transformers.git@main
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
With earlier versions, you will encounter the following error:
|
| 116 |
+
```
|
| 117 |
+
KeyError: 'qwen3_next'
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
|
| 121 |
+
```python
|
| 122 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 123 |
+
|
| 124 |
+
model_name = "Qwen/Qwen3-Next-80B-A3B-Thinking"
|
| 125 |
+
|
| 126 |
+
# load the tokenizer and the model
|
| 127 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 128 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 129 |
+
model_name,
|
| 130 |
+
dtype="auto",
|
| 131 |
+
device_map="auto"
|
| 132 |
+
)
|
| 133 |
+
|
| 134 |
+
# prepare the model input
|
| 135 |
+
prompt = "Give me a short introduction to large language model."
|
| 136 |
+
messages = [
|
| 137 |
+
{"role": "user", "content": prompt},
|
| 138 |
+
]
|
| 139 |
+
text = tokenizer.apply_chat_template(
|
| 140 |
+
messages,
|
| 141 |
+
tokenize=False,
|
| 142 |
+
add_generation_prompt=True,
|
| 143 |
+
)
|
| 144 |
+
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
|
| 145 |
+
|
| 146 |
+
# conduct text completion
|
| 147 |
+
generated_ids = model.generate(
|
| 148 |
+
**model_inputs,
|
| 149 |
+
max_new_tokens=32768,
|
| 150 |
+
)
|
| 151 |
+
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
|
| 152 |
+
|
| 153 |
+
# parsing thinking content
|
| 154 |
+
try:
|
| 155 |
+
# rindex finding 151668 (</think>)
|
| 156 |
+
index = len(output_ids) - output_ids[::-1].index(151668)
|
| 157 |
+
except ValueError:
|
| 158 |
+
index = 0
|
| 159 |
+
|
| 160 |
+
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
|
| 161 |
+
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
|
| 162 |
+
|
| 163 |
+
print("thinking content:", thinking_content) # no opening <think> tag
|
| 164 |
+
print("content:", content)
|
| 165 |
+
```
|
| 166 |
+
|
| 167 |
+
> [!Note]
|
| 168 |
+
> Multi-Token Prediction (MTP) is not generally available in Hugging Face Transformers.
|
| 169 |
+
|
| 170 |
+
> [!Note]
|
| 171 |
+
> The efficiency or throughput improvement depends highly on the implementation.
|
| 172 |
+
> It is recommended to adopt a dedicated inference framework, e.g., SGLang and vLLM, for inference tasks.
|
| 173 |
+
|
| 174 |
+
> [!Tip]
|
| 175 |
+
> Depending on the inference settings, you may observe better efficiency with [`flash-linear-attention`](https://github.com/fla-org/flash-linear-attention#installation) and [`causal-conv1d`](https://github.com/Dao-AILab/causal-conv1d).
|
| 176 |
+
> See the links for detailed instructions and requirements.
|
| 177 |
+
|
| 178 |
+
## Deployment
|
| 179 |
+
|
| 180 |
+
For deployment, you can use the latest `sglang` or `vllm` to create an OpenAI-compatible API endpoint.
|
| 181 |
+
|
| 182 |
+
### SGLang
|
| 183 |
+
|
| 184 |
+
[SGLang](https://github.com/sgl-project/sglang) is a fast serving framework for large language models and vision language models.
|
| 185 |
+
SGLang could be used to launch a server with OpenAI-compatible API service.
|
| 186 |
+
|
| 187 |
+
`sglang>=0.5.2` is required for Qwen3-Next, which can be installed using:
|
| 188 |
+
```shell
|
| 189 |
+
pip install 'sglang[all]>=0.5.2'
|
| 190 |
+
```
|
| 191 |
+
See [its documentation](https://docs.sglang.ai/get_started/install.html) for more details.
|
| 192 |
+
|
| 193 |
+
The following command can be used to create an API endpoint at `http://localhost:30000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
|
| 194 |
+
```shell
|
| 195 |
+
python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Thinking --port 30000 --tp-size 4 --context-length 262144 --reasoning-parser deepseek-r1 --mem-fraction-static 0.8
|
| 196 |
+
```
|
| 197 |
+
|
| 198 |
+
The following command is recommended for MTP with the rest settings the same as above:
|
| 199 |
+
```shell
|
| 200 |
+
python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Thinking --port 30000 --tp-size 4 --context-length 262144 --reasoning-parser deepseek-r1 --mem-fraction-static 0.8 --speculative-algo NEXTN --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4
|
| 201 |
+
```
|
| 202 |
+
|
| 203 |
+
> [!Note]
|
| 204 |
+
> The default context length is 256K.
|
| 205 |
+
> If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value.
|
| 206 |
+
> However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072.
|
| 207 |
+
|
| 208 |
+
Please also refer to SGLang's usage guide on [Qwen3-Next](https://docs.sglang.ai/basic_usage/qwen3.html).
|
| 209 |
+
|
| 210 |
+
### vLLM
|
| 211 |
+
|
| 212 |
+
[vLLM](https://github.com/vllm-project/vllm) is a high-throughput and memory-efficient inference and serving engine for LLMs.
|
| 213 |
+
vLLM could be used to launch a server with OpenAI-compatible API service.
|
| 214 |
+
|
| 215 |
+
`vllm>=0.10.2` is required for Qwen3-Next, which can be installed using:
|
| 216 |
+
```shell
|
| 217 |
+
pip install 'vllm>=0.10.2'
|
| 218 |
+
```
|
| 219 |
+
See [its documentation](https://docs.vllm.ai/en/stable/getting_started/installation/index.html) for more details.
|
| 220 |
+
|
| 221 |
+
The following command can be used to create an API endpoint at `http://localhost:8000/v1` with maximum context length 256K tokens using tensor parallel on 4 GPUs.
|
| 222 |
+
```shell
|
| 223 |
+
vllm serve Qwen/Qwen3-Next-80B-A3B-Thinking --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --reasoning-parser deepseek_r1
|
| 224 |
+
```
|
| 225 |
+
|
| 226 |
+
The following command is recommended for MTP with the rest settings the same as above:
|
| 227 |
+
```shell
|
| 228 |
+
vllm serve Qwen/Qwen3-Next-80B-A3B-Thinking --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --reasoning-parser deepseek_r1 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'
|
| 229 |
+
```
|
| 230 |
+
|
| 231 |
+
> [!Note]
|
| 232 |
+
> The default context length is 256K.
|
| 233 |
+
> If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value.
|
| 234 |
+
> However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.
|
| 235 |
+
|
| 236 |
+
Please also refer to vLLM's usage guide on [Qwen3-Next](https://docs.vllm.ai/projects/recipes/en/latest/Qwen/Qwen3-Next.html).
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
## Agentic Use
|
| 240 |
+
|
| 241 |
+
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
|
| 242 |
+
|
| 243 |
+
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
|
| 244 |
+
```python
|
| 245 |
+
from qwen_agent.agents import Assistant
|
| 246 |
+
|
| 247 |
+
# Define LLM
|
| 248 |
+
# Using Alibaba Cloud Model Studio
|
| 249 |
+
llm_cfg = {
|
| 250 |
+
'model': 'Qwen3-Next-80B-A3B-Thinking',
|
| 251 |
+
'model_type': 'qwen_dashscope',
|
| 252 |
+
}
|
| 253 |
+
|
| 254 |
+
# Using OpenAI-compatible API endpoint. It is recommended to disable the reasoning and the tool call parsing
|
| 255 |
+
# functionality of the deployment frameworks and let Qwen-Agent automate the related operations. For example,
|
| 256 |
+
# `vllm serve Qwen/Qwen3-Next-80B-A3B-Thinking --served-model-name Qwen3-Next-80B-A3B-Thinking --port 8000 --tensor-parallel-size 4 --max-model-len 262144`.
|
| 257 |
+
#
|
| 258 |
+
# llm_cfg = {
|
| 259 |
+
# 'model': 'Qwen3-Next-80B-A3B-Thinking',
|
| 260 |
+
#
|
| 261 |
+
# # Use a custom endpoint compatible with OpenAI API:
|
| 262 |
+
# 'model_server': 'http://localhost:8000/v1', # api_base without reasoning and tool call parsing
|
| 263 |
+
# 'api_key': 'EMPTY',
|
| 264 |
+
# 'generate_cfg': {
|
| 265 |
+
# 'thought_in_content': True,
|
| 266 |
+
# },
|
| 267 |
+
# }
|
| 268 |
+
|
| 269 |
+
# Define Tools
|
| 270 |
+
tools = [
|
| 271 |
+
{'mcpServers': { # You can specify the MCP configuration file
|
| 272 |
+
'time': {
|
| 273 |
+
'command': 'uvx',
|
| 274 |
+
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
|
| 275 |
+
},
|
| 276 |
+
"fetch": {
|
| 277 |
+
"command": "uvx",
|
| 278 |
+
"args": ["mcp-server-fetch"]
|
| 279 |
+
}
|
| 280 |
+
}
|
| 281 |
+
},
|
| 282 |
+
'code_interpreter', # Built-in tools
|
| 283 |
+
]
|
| 284 |
+
|
| 285 |
+
# Define Agent
|
| 286 |
+
bot = Assistant(llm=llm_cfg, function_list=tools)
|
| 287 |
+
|
| 288 |
+
# Streaming generation
|
| 289 |
+
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
|
| 290 |
+
for responses in bot.run(messages=messages):
|
| 291 |
+
pass
|
| 292 |
+
print(responses)
|
| 293 |
+
```
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
## Processing Ultra-Long Texts
|
| 297 |
+
|
| 298 |
+
Qwen3-Next natively supports context lengths of up to 262,144 tokens.
|
| 299 |
+
For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively.
|
| 300 |
+
We have validated the model's performance on context lengths of up to 1 million tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
|
| 301 |
+
|
| 302 |
+
YaRN is currently supported by several inference frameworks, e.g., `transformers`, `vllm` and `sglang`.
|
| 303 |
+
In general, there are two approaches to enabling YaRN for supported frameworks:
|
| 304 |
+
|
| 305 |
+
- Modifying the model files:
|
| 306 |
+
In the `config.json` file, add the `rope_scaling` fields:
|
| 307 |
+
```json
|
| 308 |
+
{
|
| 309 |
+
...,
|
| 310 |
+
"rope_scaling": {
|
| 311 |
+
"rope_type": "yarn",
|
| 312 |
+
"factor": 4.0,
|
| 313 |
+
"original_max_position_embeddings": 262144
|
| 314 |
+
}
|
| 315 |
+
}
|
| 316 |
+
```
|
| 317 |
+
|
| 318 |
+
- Passing command line arguments:
|
| 319 |
+
|
| 320 |
+
For `vllm`, you can use
|
| 321 |
+
```shell
|
| 322 |
+
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}' --max-model-len 1010000
|
| 323 |
+
```
|
| 324 |
+
|
| 325 |
+
For `sglang`, you can use
|
| 326 |
+
```shell
|
| 327 |
+
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":262144}}' --context-length 1010000
|
| 328 |
+
```
|
| 329 |
+
|
| 330 |
+
> [!NOTE]
|
| 331 |
+
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
|
| 332 |
+
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
|
| 333 |
+
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 524,288 tokens, it would be better to set `factor` as 2.0.
|
| 334 |
+
|
| 335 |
+
## Best Practices
|
| 336 |
+
|
| 337 |
+
To achieve optimal performance, we recommend the following settings:
|
| 338 |
+
|
| 339 |
+
1. **Sampling Parameters**:
|
| 340 |
+
- We suggest using `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`.
|
| 341 |
+
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
|
| 342 |
+
|
| 343 |
+
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 81,920 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
|
| 344 |
+
|
| 345 |
+
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
|
| 346 |
+
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
|
| 347 |
+
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
|
| 348 |
+
|
| 349 |
+
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
|
| 350 |
+
|
| 351 |
+
### Citation
|
| 352 |
+
|
| 353 |
+
If you find our work helpful, feel free to give us a cite.
|
| 354 |
+
|
| 355 |
+
```
|
| 356 |
+
@misc{qwen3technicalreport,
|
| 357 |
+
title={Qwen3 Technical Report},
|
| 358 |
+
author={Qwen Team},
|
| 359 |
+
year={2025},
|
| 360 |
+
eprint={2505.09388},
|
| 361 |
+
archivePrefix={arXiv},
|
| 362 |
+
primaryClass={cs.CL},
|
| 363 |
+
url={https://arxiv.org/abs/2505.09388},
|
| 364 |
+
}
|
| 365 |
+
|
| 366 |
+
@article{qwen2.5-1m,
|
| 367 |
+
title={Qwen2.5-1M Technical Report},
|
| 368 |
+
author={An Yang and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoyan Huang and Jiandong Jiang and Jianhong Tu and Jianwei Zhang and Jingren Zhou and Junyang Lin and Kai Dang and Kexin Yang and Le Yu and Mei Li and Minmin Sun and Qin Zhu and Rui Men and Tao He and Weijia Xu and Wenbiao Yin and Wenyuan Yu and Xiafei Qiu and Xingzhang Ren and Xinlong Yang and Yong Li and Zhiying Xu and Zipeng Zhang},
|
| 369 |
+
journal={arXiv preprint arXiv:2501.15383},
|
| 370 |
+
year={2025}
|
| 371 |
+
}
|
| 372 |
+
```
|
config.json
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"Qwen3NextForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_dropout": 0.0,
|
| 6 |
+
"bos_token_id": 151643,
|
| 7 |
+
"decoder_sparse_step": 1,
|
| 8 |
+
"eos_token_id": 151645,
|
| 9 |
+
"full_attention_interval": 4,
|
| 10 |
+
"head_dim": 256,
|
| 11 |
+
"hidden_act": "silu",
|
| 12 |
+
"hidden_size": 2048,
|
| 13 |
+
"initializer_range": 0.02,
|
| 14 |
+
"intermediate_size": 5120,
|
| 15 |
+
"linear_conv_kernel_dim": 4,
|
| 16 |
+
"linear_key_head_dim": 128,
|
| 17 |
+
"linear_num_key_heads": 16,
|
| 18 |
+
"linear_num_value_heads": 32,
|
| 19 |
+
"linear_value_head_dim": 128,
|
| 20 |
+
"max_position_embeddings": 262144,
|
| 21 |
+
"mlp_only_layers": [],
|
| 22 |
+
"model_type": "qwen3_next",
|
| 23 |
+
"moe_intermediate_size": 512,
|
| 24 |
+
"norm_topk_prob": true,
|
| 25 |
+
"num_attention_heads": 16,
|
| 26 |
+
"num_experts": 512,
|
| 27 |
+
"num_experts_per_tok": 10,
|
| 28 |
+
"num_hidden_layers": 48,
|
| 29 |
+
"num_key_value_heads": 2,
|
| 30 |
+
"output_router_logits": false,
|
| 31 |
+
"partial_rotary_factor": 0.25,
|
| 32 |
+
"rms_norm_eps": 1e-06,
|
| 33 |
+
"rope_scaling": null,
|
| 34 |
+
"rope_theta": 10000000,
|
| 35 |
+
"router_aux_loss_coef": 0.001,
|
| 36 |
+
"shared_expert_intermediate_size": 512,
|
| 37 |
+
"tie_word_embeddings": false,
|
| 38 |
+
"torch_dtype": "bfloat16",
|
| 39 |
+
"transformers_version": "4.57.0.dev0",
|
| 40 |
+
"use_cache": true,
|
| 41 |
+
"use_sliding_window": false,
|
| 42 |
+
"vocab_size": 151936
|
| 43 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 151643,
|
| 3 |
+
"do_sample": true,
|
| 4 |
+
"eos_token_id": [
|
| 5 |
+
151645,
|
| 6 |
+
151643
|
| 7 |
+
],
|
| 8 |
+
"pad_token_id": 151643,
|
| 9 |
+
"temperature": 0.6,
|
| 10 |
+
"top_k": 20,
|
| 11 |
+
"top_p": 0.95,
|
| 12 |
+
"transformers_version": "4.57.0.dev0"
|
| 13 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model-00001-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:052530738afe09c9974f47dccc7d9c4b21efb5efc34d8e1a340df9e68430f020
|
| 3 |
+
size 3999619256
|
model-00002-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:93e42c8da1fc2f305a2ff9483b7a81aa3b0a2d8d0443453ea3029eed38dd793e
|
| 3 |
+
size 3999841784
|
model-00003-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ad04951439a586df6261e2398790688863c6e3fc5c38110f2d0e0df36e28afb8
|
| 3 |
+
size 3999515584
|
model-00004-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:91feebaeec4a30451d186c63a939331671f67c7b8f54fdfa443ae1e942e6bb74
|
| 3 |
+
size 3999842000
|
model-00005-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:39106277798c0104e93e4b0b0bb93e37cfc9f8fcbc76f0df0c4efa72e960a8b1
|
| 3 |
+
size 3999842208
|
model-00006-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4240714401dfc448b7d271c21f57d3e37e94fdb4cfe61fc52bc53b7a99157bd7
|
| 3 |
+
size 3999853216
|
model-00007-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3929631b99670794a310c90eb24982d0f469f915825c71bae4f4df46d4ca3530
|
| 3 |
+
size 3999841912
|
model-00008-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c43d1cd32e5c2a10de65e70c9325931798fb6b532aece4d88cb3eaecea92d22d
|
| 3 |
+
size 3999842000
|
model-00009-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fd52002132aaf95122517a36066e182946c7d1c2b169f2065a336f88cbcd95ed
|
| 3 |
+
size 3999843192
|
model-00010-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:993ba16dc87ca863a741e24bc4f323f2f1eca1064bf722635deed5ebd7858615
|
| 3 |
+
size 3999517808
|
model-00011-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0d249961355760972eac6f0affb9637e78a472d636a3d53a265966e57dfa4b4d
|
| 3 |
+
size 4000181296
|
model-00012-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f14839f6e1f3da352b6bd2762f481029e560895d7acf87c1b28f3e6c7c515234
|
| 3 |
+
size 3999843880
|
model-00013-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f2fa09af790cb84885e619c3987be7604f09258e7d9c3ab04f191f98f3acfd29
|
| 3 |
+
size 3999517472
|
model-00014-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e1c75cdd0418b6e69b435c2b5e577e467308e1a23b119eaabdcfc02b8fac8e53
|
| 3 |
+
size 3999843984
|
model-00015-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8690ccb1eb05c2ca89004aca4fcd61166720d9010bf87245fec9779b39964772
|
| 3 |
+
size 4000181736
|
model-00016-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:62c8c923584aa3aef52e09eb602a2157596c6a794bf83fe200eb1d674a6ec1b0
|
| 3 |
+
size 3999517256
|
model-00017-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b7700090ab54d08e938f59401e93febca65f63114891bff0eb6a989722e26910
|
| 3 |
+
size 3999843880
|
model-00018-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3d5647f0ab8c2b7bcfaa9d27c8e38c4bf8ce14e47a7a90c86b7235a94ffe8754
|
| 3 |
+
size 3999843880
|
model-00019-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:80ff91a58854489cc03e63a0aa081aca4f8404680d9e91c1dade97bae2e1f490
|
| 3 |
+
size 3999844096
|
model-00020-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:661e39f30cd12096d19678e33de3c1f87845c1c3516172d2c7f08fb4f11c4c39
|
| 3 |
+
size 3999855040
|
model-00021-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:755584bce3731b23142e1b73633629fcc6adb3b561420b49d792154edd679136
|
| 3 |
+
size 3999843792
|
model-00022-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b3bafdaf9fb67877586bc9def63f1084f629ebb59ea26221c71548671be1ddc0
|
| 3 |
+
size 3999843880
|
model-00023-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:535585842a857806cd1ef6c50e2edc6d125a32ffaa7ab1a59f33a6bddf1b3d52
|
| 3 |
+
size 3999517464
|
model-00024-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:981777db35f69147e78fee76d0ee806270906279f32b6c11897a0c4d370c82fa
|
| 3 |
+
size 3999844264
|
model-00025-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:41c988c731479a5e1ec30108595c1af89153e25e0947044c55f88321c36399f5
|
| 3 |
+
size 4000181296
|
model-00026-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8fcda0f6abe8e3f073a6c4dde1bc62bfc908b2aa3099fa904bdb8fb1bff6fc2b
|
| 3 |
+
size 3999517472
|
model-00027-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1254809103909a3c91055aefc33e1a2e52255f6193f7b4f799f5f4647304ec0f
|
| 3 |
+
size 3999843880
|
model-00028-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:66beb3715380630ae50da9391ca000347087cb108db6d9cbe763a9cbc0e63fea
|
| 3 |
+
size 3999843984
|
model-00029-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5badd3a285bb6c1f232b2c6566ebd54fe8f730d38b0c27f25ecba943e7a5bfcc
|
| 3 |
+
size 3999855320
|
model-00030-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e2c3287b31e36fdb6b77759e540548dc832108cd6835701b872cd3af89104a14
|
| 3 |
+
size 3999843672
|
model-00031-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b479594dd03828de6403fb69f1514ab9cc3e491daf1875a0b6044f5c713dd3b6
|
| 3 |
+
size 3999843880
|
model-00032-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a37b3ed3e66ddd085f3d3e17a8cc2d77cf9d0b728074714f41774e06158547c2
|
| 3 |
+
size 3999843880
|
model-00033-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:131bc0ea8e2ef1847d194842974190c4ddce40341a8c4a04b620fdaec4f2cc21
|
| 3 |
+
size 3999517688
|
model-00034-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5ef895bf4e8d4a5e8dbe58298e016c0549b39bd6a78395a76fe8b430fd0aaf48
|
| 3 |
+
size 4000181496
|
model-00035-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1041213691c66ae0daf6220dce2e88e0f0467b5c64592e90dc84d94a972883f6
|
| 3 |
+
size 3999843792
|
model-00036-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:06b5220816a05a21da3d2b9de862ffeee4fa876e0883097be3f8794447911c8b
|
| 3 |
+
size 3999517472
|
model-00037-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9739e815e66d118bbf21f47ae7d0552cd0b7086d6ada460883edfdea87e90162
|
| 3 |
+
size 3999843872
|
model-00038-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:771b7bd393c518910d14a9d8e747cdcb84bddc4efa29cbed75c5ef3ef623475a
|
| 3 |
+
size 3999844264
|
model-00039-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6ba9c5c5669ae5250d94f0c7e9b59c74da36192f7a3ca6da496fe0fd7d78c37b
|
| 3 |
+
size 3999854888
|
model-00040-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e10c94e3370cf7f4dcd8cf00d310dcec45e9bf64dfce6cb2767463e0bb3646c8
|
| 3 |
+
size 3365572496
|
model-00041-of-00041.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b572d53465890ccedcf18aa2970c2301ddc094ce9a43af9286e7e9dd0f30644a
|
| 3 |
+
size 3301131296
|
model.safetensors.index.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:aeb13307a71acd8fe81861d94ad54ab689df773318809eed3cbe794b4492dae4
|
| 3 |
+
size 11422654
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,239 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"151643": {
|
| 5 |
+
"content": "<|endoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"151644": {
|
| 13 |
+
"content": "<|im_start|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"151645": {
|
| 21 |
+
"content": "<|im_end|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
},
|
| 28 |
+
"151646": {
|
| 29 |
+
"content": "<|object_ref_start|>",
|
| 30 |
+
"lstrip": false,
|
| 31 |
+
"normalized": false,
|
| 32 |
+
"rstrip": false,
|
| 33 |
+
"single_word": false,
|
| 34 |
+
"special": true
|
| 35 |
+
},
|
| 36 |
+
"151647": {
|
| 37 |
+
"content": "<|object_ref_end|>",
|
| 38 |
+
"lstrip": false,
|
| 39 |
+
"normalized": false,
|
| 40 |
+
"rstrip": false,
|
| 41 |
+
"single_word": false,
|
| 42 |
+
"special": true
|
| 43 |
+
},
|
| 44 |
+
"151648": {
|
| 45 |
+
"content": "<|box_start|>",
|
| 46 |
+
"lstrip": false,
|
| 47 |
+
"normalized": false,
|
| 48 |
+
"rstrip": false,
|
| 49 |
+
"single_word": false,
|
| 50 |
+
"special": true
|
| 51 |
+
},
|
| 52 |
+
"151649": {
|
| 53 |
+
"content": "<|box_end|>",
|
| 54 |
+
"lstrip": false,
|
| 55 |
+
"normalized": false,
|
| 56 |
+
"rstrip": false,
|
| 57 |
+
"single_word": false,
|
| 58 |
+
"special": true
|
| 59 |
+
},
|
| 60 |
+
"151650": {
|
| 61 |
+
"content": "<|quad_start|>",
|
| 62 |
+
"lstrip": false,
|
| 63 |
+
"normalized": false,
|
| 64 |
+
"rstrip": false,
|
| 65 |
+
"single_word": false,
|
| 66 |
+
"special": true
|
| 67 |
+
},
|
| 68 |
+
"151651": {
|
| 69 |
+
"content": "<|quad_end|>",
|
| 70 |
+
"lstrip": false,
|
| 71 |
+
"normalized": false,
|
| 72 |
+
"rstrip": false,
|
| 73 |
+
"single_word": false,
|
| 74 |
+
"special": true
|
| 75 |
+
},
|
| 76 |
+
"151652": {
|
| 77 |
+
"content": "<|vision_start|>",
|
| 78 |
+
"lstrip": false,
|
| 79 |
+
"normalized": false,
|
| 80 |
+
"rstrip": false,
|
| 81 |
+
"single_word": false,
|
| 82 |
+
"special": true
|
| 83 |
+
},
|
| 84 |
+
"151653": {
|
| 85 |
+
"content": "<|vision_end|>",
|
| 86 |
+
"lstrip": false,
|
| 87 |
+
"normalized": false,
|
| 88 |
+
"rstrip": false,
|
| 89 |
+
"single_word": false,
|
| 90 |
+
"special": true
|
| 91 |
+
},
|
| 92 |
+
"151654": {
|
| 93 |
+
"content": "<|vision_pad|>",
|
| 94 |
+
"lstrip": false,
|
| 95 |
+
"normalized": false,
|
| 96 |
+
"rstrip": false,
|
| 97 |
+
"single_word": false,
|
| 98 |
+
"special": true
|
| 99 |
+
},
|
| 100 |
+
"151655": {
|
| 101 |
+
"content": "<|image_pad|>",
|
| 102 |
+
"lstrip": false,
|
| 103 |
+
"normalized": false,
|
| 104 |
+
"rstrip": false,
|
| 105 |
+
"single_word": false,
|
| 106 |
+
"special": true
|
| 107 |
+
},
|
| 108 |
+
"151656": {
|
| 109 |
+
"content": "<|video_pad|>",
|
| 110 |
+
"lstrip": false,
|
| 111 |
+
"normalized": false,
|
| 112 |
+
"rstrip": false,
|
| 113 |
+
"single_word": false,
|
| 114 |
+
"special": true
|
| 115 |
+
},
|
| 116 |
+
"151657": {
|
| 117 |
+
"content": "<tool_call>",
|
| 118 |
+
"lstrip": false,
|
| 119 |
+
"normalized": false,
|
| 120 |
+
"rstrip": false,
|
| 121 |
+
"single_word": false,
|
| 122 |
+
"special": false
|
| 123 |
+
},
|
| 124 |
+
"151658": {
|
| 125 |
+
"content": "</tool_call>",
|
| 126 |
+
"lstrip": false,
|
| 127 |
+
"normalized": false,
|
| 128 |
+
"rstrip": false,
|
| 129 |
+
"single_word": false,
|
| 130 |
+
"special": false
|
| 131 |
+
},
|
| 132 |
+
"151659": {
|
| 133 |
+
"content": "<|fim_prefix|>",
|
| 134 |
+
"lstrip": false,
|
| 135 |
+
"normalized": false,
|
| 136 |
+
"rstrip": false,
|
| 137 |
+
"single_word": false,
|
| 138 |
+
"special": false
|
| 139 |
+
},
|
| 140 |
+
"151660": {
|
| 141 |
+
"content": "<|fim_middle|>",
|
| 142 |
+
"lstrip": false,
|
| 143 |
+
"normalized": false,
|
| 144 |
+
"rstrip": false,
|
| 145 |
+
"single_word": false,
|
| 146 |
+
"special": false
|
| 147 |
+
},
|
| 148 |
+
"151661": {
|
| 149 |
+
"content": "<|fim_suffix|>",
|
| 150 |
+
"lstrip": false,
|
| 151 |
+
"normalized": false,
|
| 152 |
+
"rstrip": false,
|
| 153 |
+
"single_word": false,
|
| 154 |
+
"special": false
|
| 155 |
+
},
|
| 156 |
+
"151662": {
|
| 157 |
+
"content": "<|fim_pad|>",
|
| 158 |
+
"lstrip": false,
|
| 159 |
+
"normalized": false,
|
| 160 |
+
"rstrip": false,
|
| 161 |
+
"single_word": false,
|
| 162 |
+
"special": false
|
| 163 |
+
},
|
| 164 |
+
"151663": {
|
| 165 |
+
"content": "<|repo_name|>",
|
| 166 |
+
"lstrip": false,
|
| 167 |
+
"normalized": false,
|
| 168 |
+
"rstrip": false,
|
| 169 |
+
"single_word": false,
|
| 170 |
+
"special": false
|
| 171 |
+
},
|
| 172 |
+
"151664": {
|
| 173 |
+
"content": "<|file_sep|>",
|
| 174 |
+
"lstrip": false,
|
| 175 |
+
"normalized": false,
|
| 176 |
+
"rstrip": false,
|
| 177 |
+
"single_word": false,
|
| 178 |
+
"special": false
|
| 179 |
+
},
|
| 180 |
+
"151665": {
|
| 181 |
+
"content": "<tool_response>",
|
| 182 |
+
"lstrip": false,
|
| 183 |
+
"normalized": false,
|
| 184 |
+
"rstrip": false,
|
| 185 |
+
"single_word": false,
|
| 186 |
+
"special": false
|
| 187 |
+
},
|
| 188 |
+
"151666": {
|
| 189 |
+
"content": "</tool_response>",
|
| 190 |
+
"lstrip": false,
|
| 191 |
+
"normalized": false,
|
| 192 |
+
"rstrip": false,
|
| 193 |
+
"single_word": false,
|
| 194 |
+
"special": false
|
| 195 |
+
},
|
| 196 |
+
"151667": {
|
| 197 |
+
"content": "<think>",
|
| 198 |
+
"lstrip": false,
|
| 199 |
+
"normalized": false,
|
| 200 |
+
"rstrip": false,
|
| 201 |
+
"single_word": false,
|
| 202 |
+
"special": false
|
| 203 |
+
},
|
| 204 |
+
"151668": {
|
| 205 |
+
"content": "</think>",
|
| 206 |
+
"lstrip": false,
|
| 207 |
+
"normalized": false,
|
| 208 |
+
"rstrip": false,
|
| 209 |
+
"single_word": false,
|
| 210 |
+
"special": false
|
| 211 |
+
}
|
| 212 |
+
},
|
| 213 |
+
"additional_special_tokens": [
|
| 214 |
+
"<|im_start|>",
|
| 215 |
+
"<|im_end|>",
|
| 216 |
+
"<|object_ref_start|>",
|
| 217 |
+
"<|object_ref_end|>",
|
| 218 |
+
"<|box_start|>",
|
| 219 |
+
"<|box_end|>",
|
| 220 |
+
"<|quad_start|>",
|
| 221 |
+
"<|quad_end|>",
|
| 222 |
+
"<|vision_start|>",
|
| 223 |
+
"<|vision_end|>",
|
| 224 |
+
"<|vision_pad|>",
|
| 225 |
+
"<|image_pad|>",
|
| 226 |
+
"<|video_pad|>"
|
| 227 |
+
],
|
| 228 |
+
"bos_token": null,
|
| 229 |
+
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0].role == 'system' %}\n {{- messages[0].content + '\\n\\n' }}\n {%- endif %}\n {{- \"# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0].role == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0].content + '<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- set ns = namespace(multi_step_tool=true, last_query_index=messages|length - 1) %}\n{%- for message in messages[::-1] %}\n {%- set index = (messages|length - 1) - loop.index0 %}\n {%- if ns.multi_step_tool and message.role == \"user\" and message.content is string and not(message.content.startswith('<tool_response>') and message.content.endswith('</tool_response>')) %}\n {%- set ns.multi_step_tool = false %}\n {%- set ns.last_query_index = index %}\n {%- endif %}\n{%- endfor %}\n{%- for message in messages %}\n {%- if message.content is string %}\n {%- set content = message.content %}\n {%- else %}\n {%- set content = '' %}\n {%- endif %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) %}\n {{- '<|im_start|>' + message.role + '\\n' + content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {%- set reasoning_content = '' %}\n {%- if message.reasoning_content is string %}\n {%- set reasoning_content = message.reasoning_content %}\n {%- else %}\n {%- if '</think>' in content %}\n {%- set reasoning_content = content.split('</think>')[0].rstrip('\\n').split('<think>')[-1].lstrip('\\n') %}\n {%- set content = content.split('</think>')[-1].lstrip('\\n') %}\n {%- endif %}\n {%- endif %}\n {%- if loop.index0 > ns.last_query_index %}\n {%- if loop.last or (not loop.last and reasoning_content) %}\n {{- '<|im_start|>' + message.role + '\\n<think>\\n' + reasoning_content.strip('\\n') + '\\n</think>\\n\\n' + content.lstrip('\\n') }}\n {%- else %}\n {{- '<|im_start|>' + message.role + '\\n' + content }}\n {%- endif %}\n {%- else %}\n {{- '<|im_start|>' + message.role + '\\n' + content }}\n {%- endif %}\n {%- if message.tool_calls %}\n {%- for tool_call in message.tool_calls %}\n {%- if (loop.first and content) or (not loop.first) %}\n {{- '\\n' }}\n {%- endif %}\n {%- if tool_call.function %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {%- if tool_call.arguments is string %}\n {{- tool_call.arguments }}\n {%- else %}\n {{- tool_call.arguments | tojson }}\n {%- endif %}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {%- endif %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if loop.first or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n<think>\\n' }}\n{%- endif %}",
|
| 230 |
+
"clean_up_tokenization_spaces": false,
|
| 231 |
+
"eos_token": "<|im_end|>",
|
| 232 |
+
"errors": "replace",
|
| 233 |
+
"model_max_length": 1010000,
|
| 234 |
+
"pad_token": "<|endoftext|>",
|
| 235 |
+
"split_special_tokens": false,
|
| 236 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 237 |
+
"unk_token": null,
|
| 238 |
+
"add_bos_token": false
|
| 239 |
+
}
|