
File size: 4,530 Bytes
bde079e e943ee5 1c717e6 7c2176e e943ee5 04b61d2 7c2176e e943ee5 e10a0ad e943ee5 04b61d2 e943ee5 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 |
---
license: apache-2.0
datasets:
- AadityaJain/Fromula_text_classification
language:
- en
base_model:
- google/siglip2-base-patch16-224
pipeline_tag: image-classification
library_name: transformers
tags:
- Formula-Text-Detection
- SigLIP2
- Image-Classification
---

# **Formula-Text-Detection**
> **Formula-Text-Detection** is a vision-language encoder model fine-tuned from **google/siglip2-base-patch16-224** for **binary image classification**. It is built using the **SiglipForImageClassification** architecture to distinguish between **mathematical formulas** and **natural text** in document or image regions.
> [!Note]
> Note: This model works best with plain text or formulas using the same font style
```py
Classification Report:
precision recall f1-score support
formula 0.9983 1.0000 0.9991 6375
text 1.0000 0.9980 0.9990 5457
accuracy 0.9991 11832
macro avg 0.9991 0.9990 0.9991 11832
weighted avg 0.9991 0.9991 0.9991 11832
```

---
> [!note]
*SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features* https://arxiv.org/pdf/2502.14786
---
## **Label Space: 2 Classes**
The model classifies each input image into one of the following categories:
```
Class 0: "formula"
Class 1: "text"
```
---
## **Install Dependencies**
```bash
pip install -q transformers torch pillow gradio
```
---
## **Inference Code**
```python
import gradio as gr
from transformers import AutoImageProcessor, SiglipForImageClassification
from PIL import Image
import torch
# Load model and processor
model_name = "prithivMLmods/Formula-Text-Detection" # Replace with your model path if different
model = SiglipForImageClassification.from_pretrained(model_name)
processor = AutoImageProcessor.from_pretrained(model_name)
# Label mapping
id2label = {
"0": "formula",
"1": "text"
}
def classify_formula_or_text(image):
image = Image.fromarray(image).convert("RGB")
inputs = processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=1).squeeze().tolist()
prediction = {
id2label[str(i)]: round(probs[i], 3) for i in range(len(probs))
}
return prediction
# Gradio Interface
iface = gr.Interface(
fn=classify_formula_or_text,
inputs=gr.Image(type="numpy"),
outputs=gr.Label(num_top_classes=2, label="Formula or Text"),
title="Formula-Text-Detection",
description="Upload an image region to classify whether it contains a mathematical formula or natural text."
)
if __name__ == "__main__":
iface.launch()
```
## **Demo Inference**
> [!Important]
> Text
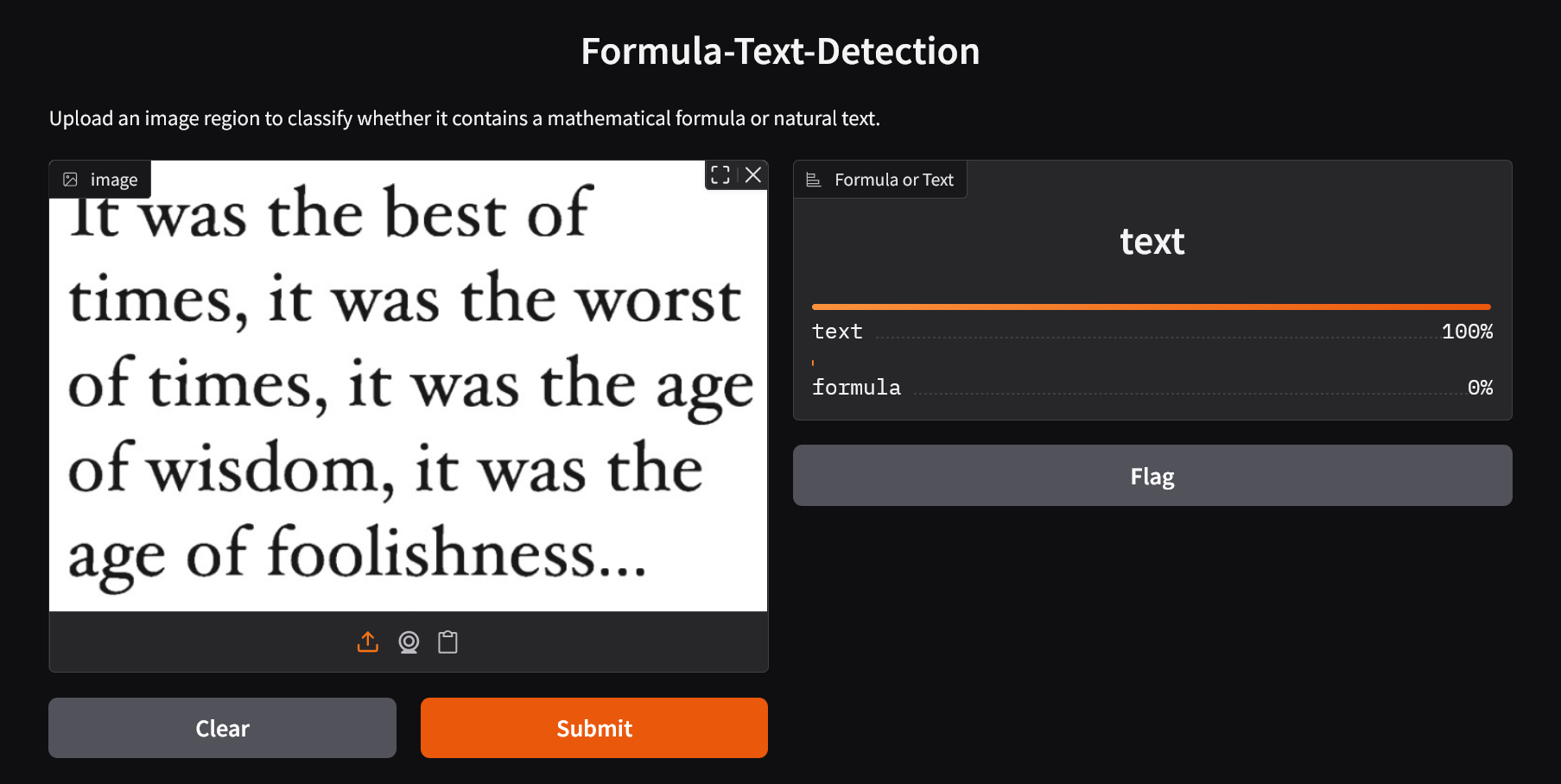


> [!Important]
> Formula



---
## **Intended Use**
**Formula-Text-Detection** can be used in:
- **OCR Preprocessing** – Improve document OCR accuracy by separating formulas from text.
- **Scientific Document Analysis** – Automatically detect mathematical content.
- **Educational Platforms** – Classify and annotate scanned materials.
- **Layout Understanding** – Help AI systems interpret mixed-content documents. |