Spaces:
Paused

Paused
bitbotcoder
commited on
Commit
·
7f45a59
1
Parent(s):
742dd70
alpha1
Browse files- .gitignore +8 -0
- README.md +101 -2
- app.py +83 -0
- images/MLWiz.jpg +0 -0
- images/mlwiz1.jpeg +0 -0
- images/mlwiz2.jpeg +0 -0
- images/mlwiz3.jpeg +0 -0
- images/mlwiz4.jpeg +0 -0
- images/mlwiz5.jpeg +0 -0
- images/mlwiz6.jpeg +0 -0
- license +7 -0
- logo.png +0 -0
- ml_pipeline.py +305 -0
- requirements.txt +6 -0
.gitignore
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.pkl
|
| 2 |
+
sweet*.html
|
| 3 |
+
profile*.html
|
| 4 |
+
t-SNE*png
|
| 5 |
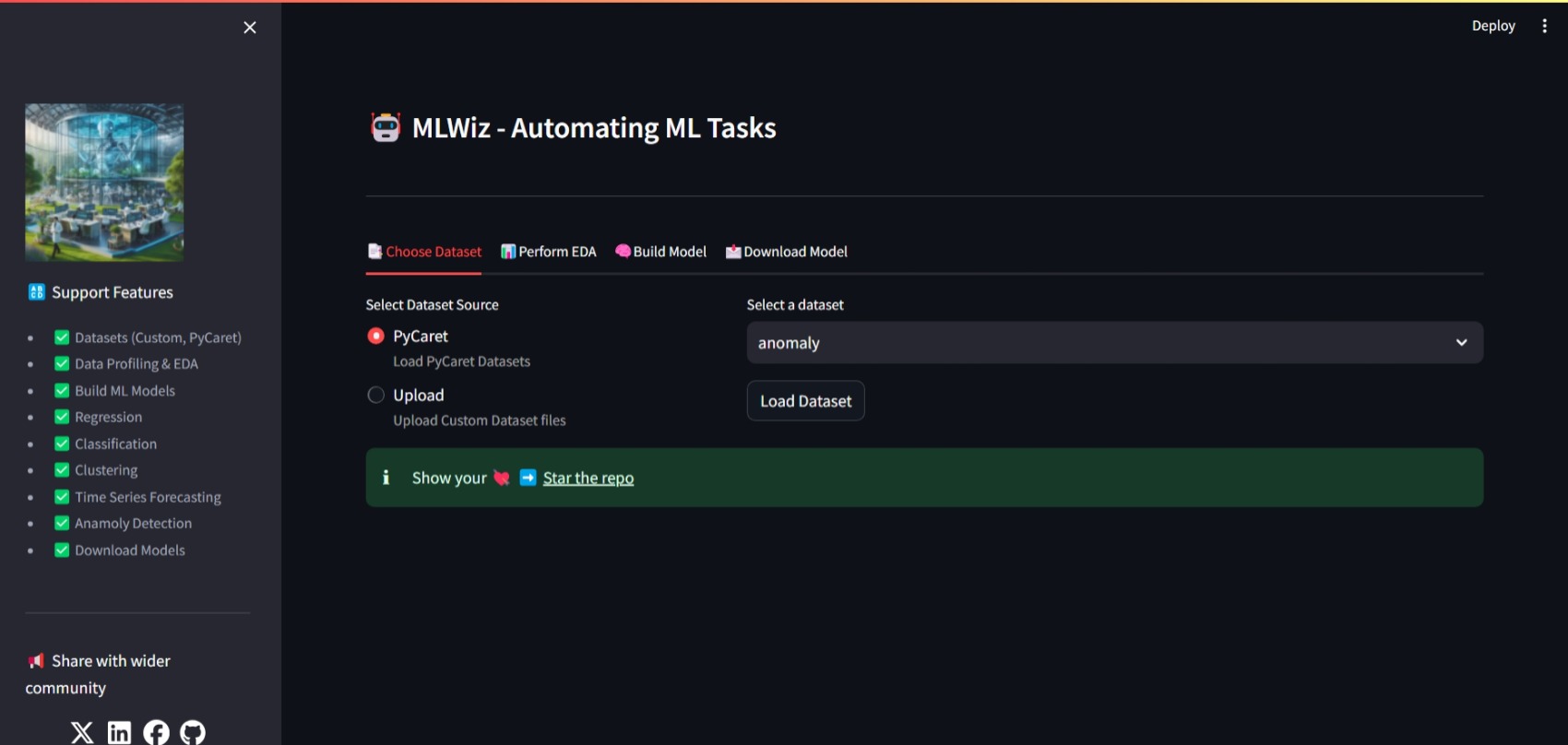
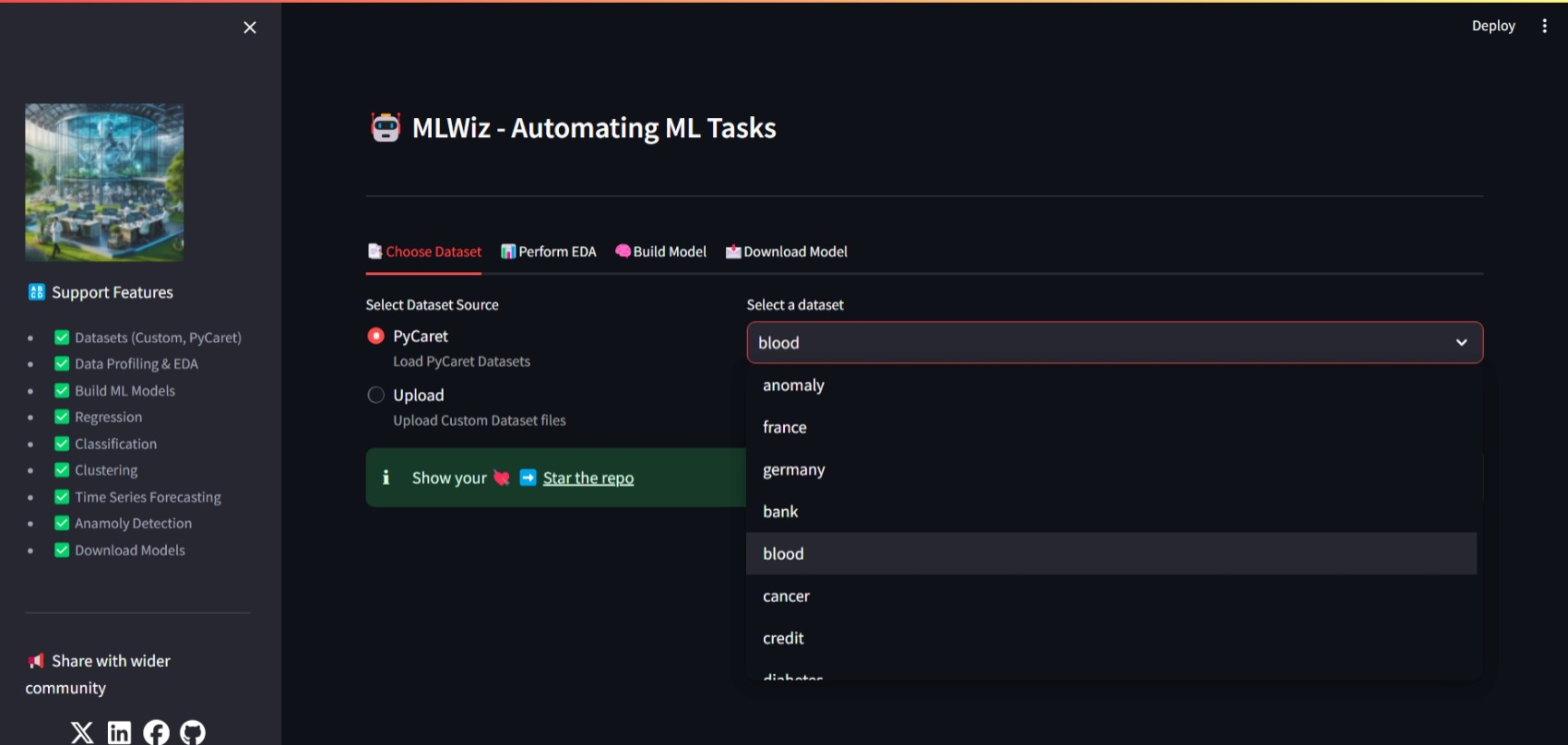
+
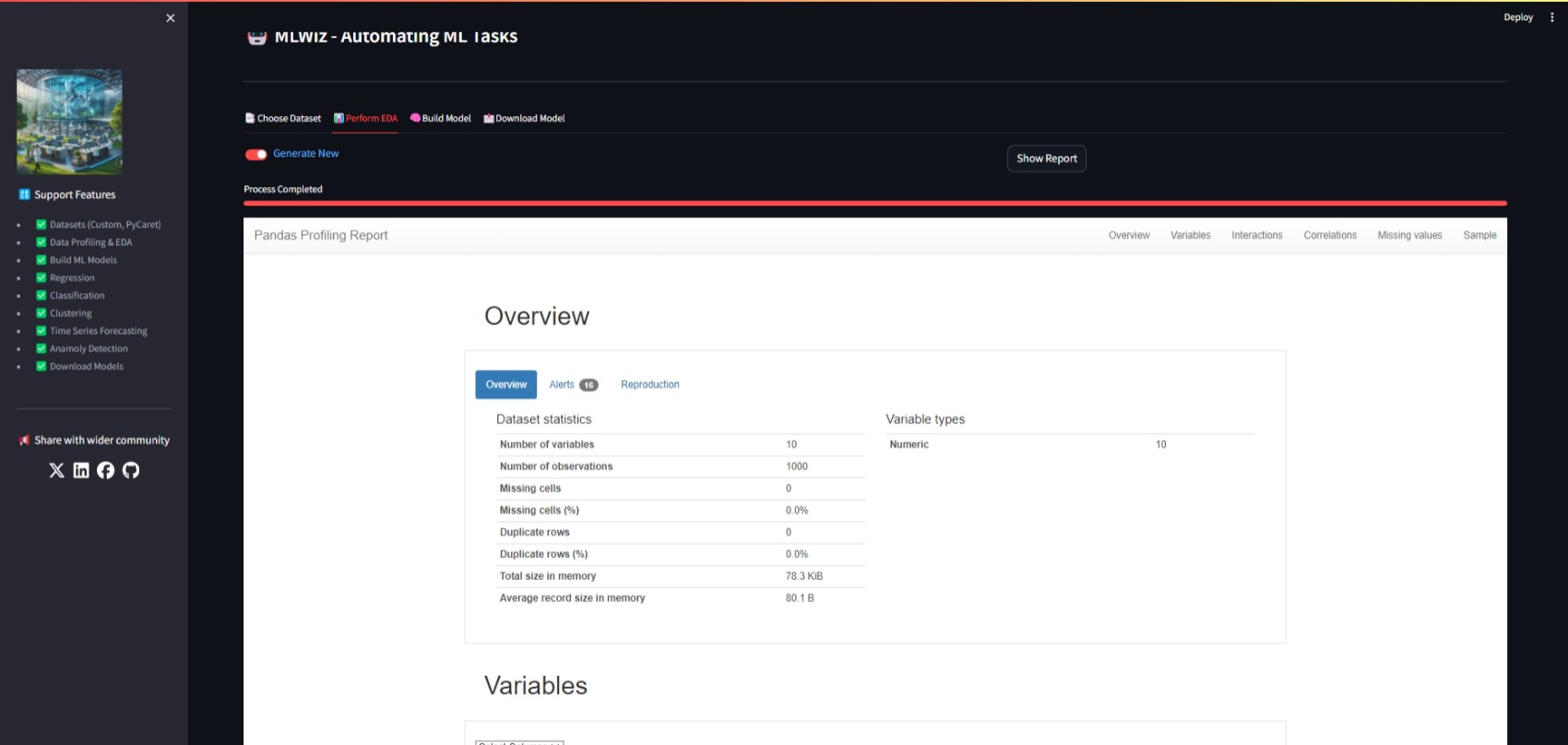
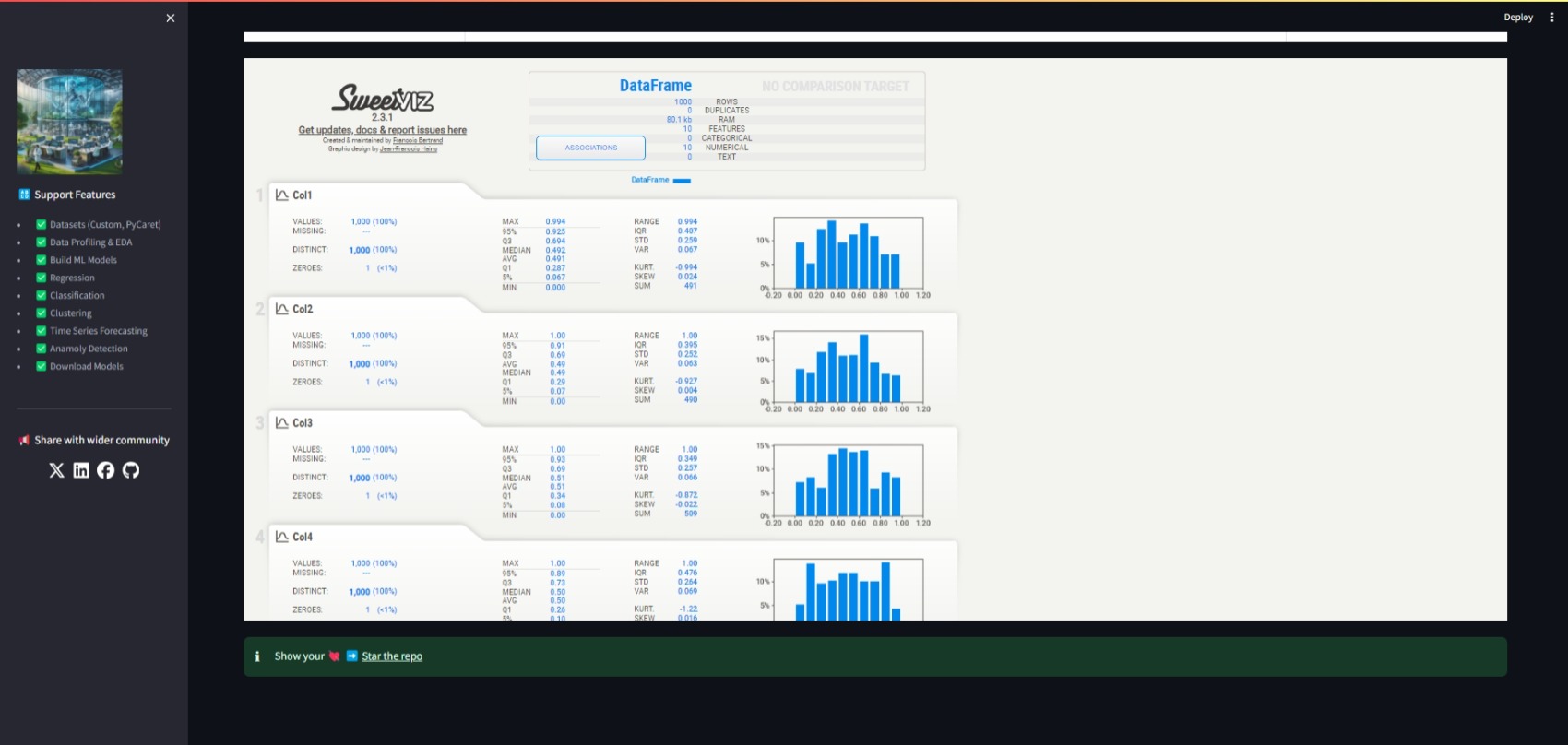
Precision*.png
|
| 6 |
+
*.log
|
| 7 |
+
__pycache__/*
|
| 8 |
+
*Zone.Identifier
|
README.md
CHANGED
|
@@ -1,6 +1,6 @@
|
|
| 1 |
---
|
| 2 |
title: Automl
|
| 3 |
-
emoji:
|
| 4 |
colorFrom: indigo
|
| 5 |
colorTo: blue
|
| 6 |
sdk: streamlit
|
|
@@ -9,5 +9,104 @@ app_file: app.py
|
|
| 9 |
pinned: false
|
| 10 |
license: mit
|
| 11 |
---
|
|
|
|
| 12 |
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
title: Automl
|
| 3 |
+
emoji: 🤖
|
| 4 |
colorFrom: indigo
|
| 5 |
colorTo: blue
|
| 6 |
sdk: streamlit
|
|
|
|
| 9 |
pinned: false
|
| 10 |
license: mit
|
| 11 |
---
|
| 12 |
+
# MLWiz
|
| 13 |
|
| 14 |
+
MLWiz is a user-friendly web application for performing automated machine learning (AutoML) tasks using PyCaret. The app allows you to upload datasets, perform exploratory data analysis (EDA), build various types of machine learning models, and download the trained models. It supports classification, regression, clustering, anomaly detection, and time series forecasting tasks.
|
| 15 |
+
|
| 16 |
+
## Features
|
| 17 |
+
|
| 18 |
+
- **Upload Datasets**: Upload your datasets in CSV or XLSX format.
|
| 19 |
+
|
| 20 |
+

|
| 21 |
+
|
| 22 |
+
- **Exploratory Data Analysis (EDA)**: Generate comprehensive EDA reports using Sweetviz, Pandas Profiling.
|
| 23 |
+
|
| 24 |
+

|
| 25 |
+
|
| 26 |
+

|
| 27 |
+
|
| 28 |
+
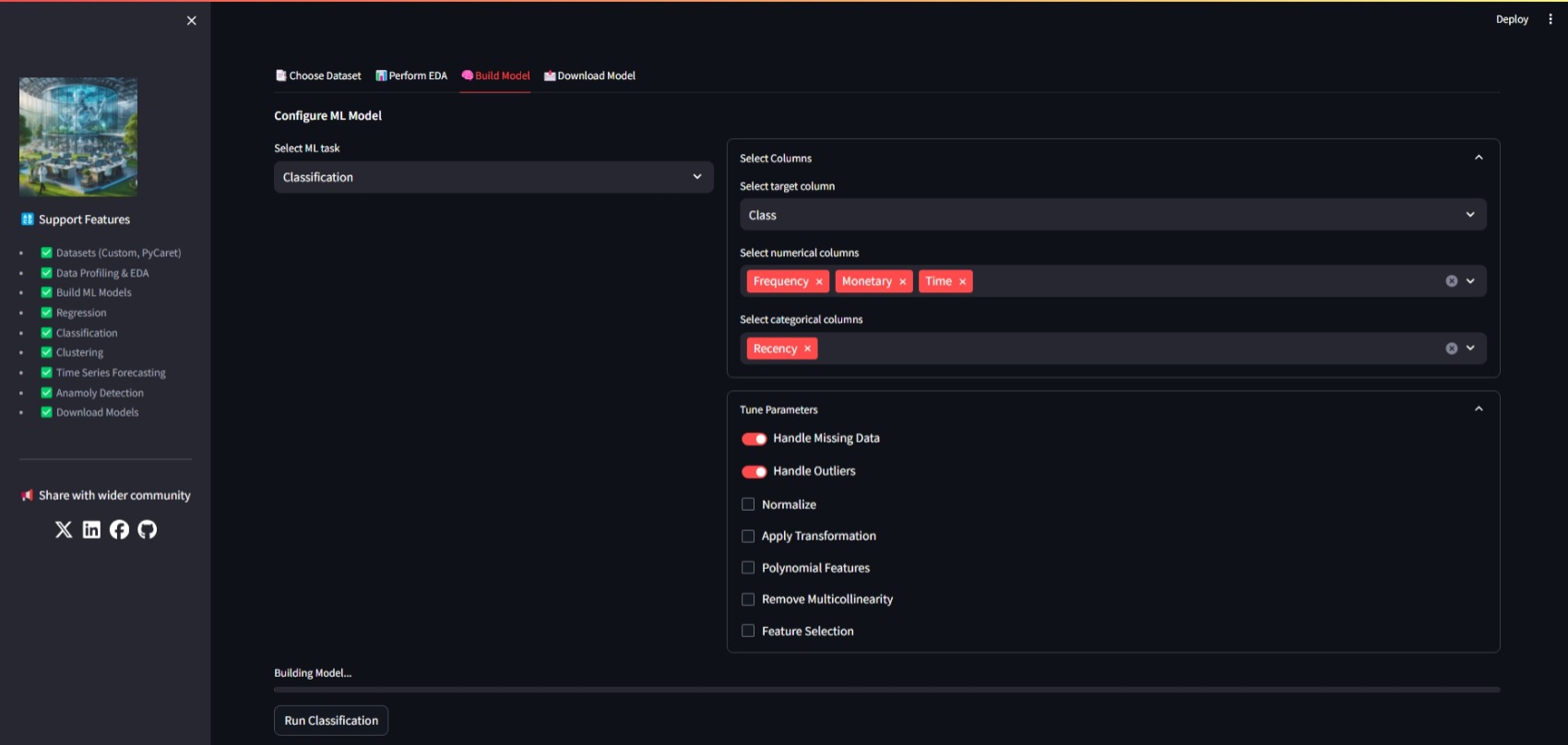
- **Build ML Models**:
|
| 29 |
+
Configure preprocessing and model parameters supports
|
| 30 |
+
- Feature Selection
|
| 31 |
+
- Feature Transformation
|
| 32 |
+
- One Hot Encoding
|
| 33 |
+
- Normalization
|
| 34 |
+
- Missing Data Imputation
|
| 35 |
+
- Outlier Handling
|
| 36 |
+
|
| 37 |
+
Build Machine Learning models for :
|
| 38 |
+
|
| 39 |
+
- Classification
|
| 40 |
+
- Regression
|
| 41 |
+
- Clustering
|
| 42 |
+
- Anomaly Detection
|
| 43 |
+
- Time Series Forecasting
|
| 44 |
+
|
| 45 |
+

|
| 46 |
+
|
| 47 |
+

|
| 48 |
+
|
| 49 |
+
- **Download Models**: Download the trained models for further use.
|
| 50 |
+
|
| 51 |
+

|
| 52 |
+
|
| 53 |
+
## Installation
|
| 54 |
+
|
| 55 |
+
1. **Clone the repository:**
|
| 56 |
+
```bash
|
| 57 |
+
git clone https://github.com/bitbotcoder/mlwiz.git
|
| 58 |
+
cd ai-insight-hub
|
| 59 |
+
|
| 60 |
+
2. **Create and activate a virtual environment (optional but recommended):**
|
| 61 |
+
```bash
|
| 62 |
+
python -m venv venv
|
| 63 |
+
source venv/bin/activate # On Windows, use `venv\Scripts\activate`
|
| 64 |
+
|
| 65 |
+
3. **Install the required dependencies:**
|
| 66 |
+
```bash
|
| 67 |
+
pip install -r requirements.txt
|
| 68 |
+
|
| 69 |
+
4. **Running the App**
|
| 70 |
+
To run the Streamlit app, execute the following command in your terminal:
|
| 71 |
+
```bash
|
| 72 |
+
streamlit run app.py
|
| 73 |
+
|
| 74 |
+
### Usage
|
| 75 |
+
1. Choose Dataset: Select a dataset source (Upload or PyCaret) and load the dataset.
|
| 76 |
+
2. Perform EDA: Navigate to the "Perform EDA" section to generate an EDA report.
|
| 77 |
+
3. Build Model: Navigate to the "Build Model" section to configure and train a machine learning model.
|
| 78 |
+
4. Download Model: Navigate to the "Download Model" section to download the trained model.
|
| 79 |
+
|
| 80 |
+
### File Structure
|
| 81 |
+
- `app.py`: The main entry point for the Streamlit app.
|
| 82 |
+
- `ml_pipeline.py`: Contains the functions for data loading, EDA, model building, and model downloading.
|
| 83 |
+
- `requirements.txt`: Lists the Python packages required to run the app.
|
| 84 |
+
|
| 85 |
+
### Dependencies
|
| 86 |
+
- streamlit
|
| 87 |
+
- pandas
|
| 88 |
+
- sweetviz
|
| 89 |
+
- pycaret
|
| 90 |
+
|
| 91 |
+
6. Install the dependencies using the command:
|
| 92 |
+
```bash
|
| 93 |
+
pip install -r requirements.txt
|
| 94 |
+
|
| 95 |
+
Contributing
|
| 96 |
+
Contributions are welcome!
|
| 97 |
+
|
| 98 |
+
License
|
| 99 |
+
This project is licensed under the MIT License. See the LICENSE file for more details.
|
| 100 |
+
|
| 101 |
+
Acknowledgements
|
| 102 |
+
- [Streamlit](https://github.com/streamlit/streamlit)
|
| 103 |
+
- [PyCaret](https://github.com/pycaret/pycaret)
|
| 104 |
+
- [Sweetviz](https://github.com/fbdesignpro/sweetviz)
|
| 105 |
+
- [Ydata profiling](https://github.com/ydataai/ydata-profiling)
|
| 106 |
+
|
| 107 |
+
📢 Share with wider community:
|
| 108 |
+
- [X](https://x.com/intent/tweet?hashtags=streamlit%2Cpython&text=Check%20out%20this%20awesome%20Streamlit%20app%20I%20built%0A&url=https%3A%2F%2Fautoml-wiz.streamlit.app)
|
| 109 |
+
- [LinkedIn](https://www.linkedin.com/sharing/share-offsite/?summary=https%3A%2F%2Fautoml-wiz.streamlit.app%20%23streamlit%20%23python&title=Check%20out%20this%20awesome%20Streamlit%20app%20I%20built%0A&url=https%3A%2F%2Fautoml-wiz.streamlit.app")
|
| 110 |
+
- [Facebook](https://www.facebook.com/sharer/sharer.php?kid_directed_site=0&u=https%3A%2F%2Fautoml-wiz.streamlit.app)
|
| 111 |
+
|
| 112 |
+
---
|
app.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
try:
|
| 2 |
+
import streamlit as st
|
| 3 |
+
from ml_pipeline import load_data, eda_report, build_model, download_model,load_pycaret_dataset, get_all_datasets, handle_exception
|
| 4 |
+
from st_social_media_links import SocialMediaIcons
|
| 5 |
+
import streamlit.components.v1 as components
|
| 6 |
+
import traceback
|
| 7 |
+
|
| 8 |
+
VERSION = "0.5.4"
|
| 9 |
+
|
| 10 |
+
# Title and description
|
| 11 |
+
st.set_page_config(
|
| 12 |
+
page_title="MLWiz - AutoML WorkBench",
|
| 13 |
+
page_icon="🤖",
|
| 14 |
+
menu_items={
|
| 15 |
+
"About": f"MLWize v{VERSION}"
|
| 16 |
+
f"\nApp contact: [Sumit Khanna](https://github.com/bitbotcoder/)",
|
| 17 |
+
"Report a Bug": "https://github.com/bitbotcoder/mlwiz/issues/new",
|
| 18 |
+
"Get help": None,
|
| 19 |
+
},
|
| 20 |
+
layout="wide",
|
| 21 |
+
)
|
| 22 |
+
st.subheader("🤖 MLWiz - Automating ML Tasks")
|
| 23 |
+
st.divider()
|
| 24 |
+
with st.sidebar:
|
| 25 |
+
st.image('logo.png', width=150)
|
| 26 |
+
st.write("🔠 Supported Features")
|
| 27 |
+
st.caption("""
|
| 28 |
+
- ✅ Datasets (Custom, PyCaret(disabled))
|
| 29 |
+
- ✅ Data Profiling & EDA
|
| 30 |
+
- ✅ Build ML Models
|
| 31 |
+
- ✅ Regression
|
| 32 |
+
- ✅ Classification
|
| 33 |
+
- ✅ Clustering
|
| 34 |
+
- ✅ Time Series Forecasting
|
| 35 |
+
- ✅ Anamoly Detection
|
| 36 |
+
- ✅ Download Models
|
| 37 |
+
""")
|
| 38 |
+
st.divider()
|
| 39 |
+
st.write("📢 Share with wider community")
|
| 40 |
+
social_media_links = [
|
| 41 |
+
"https://x.com/intent/tweet?hashtags=streamlit%2Cpython&text=Check%20out%20this%20awesome%20Streamlit%20app%20I%20built%0A&url=https%3A%2F%2Fautoml-wiz.streamlit.app",
|
| 42 |
+
"https://www.linkedin.com/sharing/share-offsite/?summary=https%3A%2F%2Fautoml-wiz.streamlit.app%20%23streamlit%20%23python&title=Check%20out%20this%20awesome%20Streamlit%20app%20I%20built%0A&url=https%3A%2F%2Fautoml-wiz.streamlit.app",
|
| 43 |
+
"https://www.facebook.com/sharer/sharer.php?kid_directed_site=0&u=https%3A%2F%2Fautoml-wiz.streamlit.app",
|
| 44 |
+
"https://github.com/bitbotcoder/mlwiz"
|
| 45 |
+
]
|
| 46 |
+
|
| 47 |
+
social_media_icons = SocialMediaIcons(social_media_links, colors=["white"] * len(social_media_links))
|
| 48 |
+
|
| 49 |
+
social_media_icons.render(sidebar=True)
|
| 50 |
+
|
| 51 |
+
#Tasks based on user selection
|
| 52 |
+
tab1, tab2, tab3, tab4, = st.tabs(["📑Choose Dataset", "📊Perform EDA", "🧠Build Model", "📩Download Model"])
|
| 53 |
+
|
| 54 |
+
with tab1:
|
| 55 |
+
c1, c2 = st.columns([1,2])
|
| 56 |
+
c1.write("Upload Custom Dataset files")
|
| 57 |
+
#dataset_source = c1.radio("Select Dataset Source", options=["PyCaret", "Upload"], captions=["Load PyCaret Datasets", "Upload Custom Dataset files"])
|
| 58 |
+
#if dataset_source == "PyCaret":
|
| 59 |
+
# pycaret_datasets = get_all_datasets()
|
| 60 |
+
# selected_dataset = c2.selectbox("Select a dataset", pycaret_datasets)
|
| 61 |
+
# if c2.button("Load Dataset"):
|
| 62 |
+
# load_pycaret_dataset(selected_dataset)
|
| 63 |
+
#elif dataset_source == "Upload":
|
| 64 |
+
uploaded_file = c2.file_uploader("Choose a file", type=["csv", "xlsx"])
|
| 65 |
+
if uploaded_file is not None:
|
| 66 |
+
load_data(uploaded_file)
|
| 67 |
+
|
| 68 |
+
with tab2:
|
| 69 |
+
eda_report()
|
| 70 |
+
with tab3:
|
| 71 |
+
st.write("**Configure ML Model**")
|
| 72 |
+
col1,col2 = st.columns([0.4,0.7])
|
| 73 |
+
task = col1.selectbox("Select ML task", ["Classification", "Regression", "Clustering", "Anomaly Detection", "Time Series Forecasting"])
|
| 74 |
+
build_model(task,col2)
|
| 75 |
+
with tab4:
|
| 76 |
+
download_model(task)
|
| 77 |
+
except Exception as e:
|
| 78 |
+
handle_exception(e)
|
| 79 |
+
|
| 80 |
+
st.success(
|
| 81 |
+
"Show your 💘 ➡️ [Star the repo](https://github.com/bitbotcoder/mlwiz/)",
|
| 82 |
+
icon="ℹ️",
|
| 83 |
+
)
|
images/MLWiz.jpg
ADDED
|
images/mlwiz1.jpeg
ADDED
|
images/mlwiz2.jpeg
ADDED
|
images/mlwiz3.jpeg
ADDED
|
images/mlwiz4.jpeg
ADDED
|
images/mlwiz5.jpeg
ADDED
|
images/mlwiz6.jpeg
ADDED

|
license
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright <2024> <COPYRIGHT bitbotcoder>
|
| 2 |
+
|
| 3 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
|
| 4 |
+
|
| 5 |
+
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
| 6 |
+
|
| 7 |
+
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
logo.png
ADDED
|
|
ml_pipeline.py
ADDED
|
@@ -0,0 +1,305 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import sweetviz as sv
|
| 4 |
+
from pycaret.classification import setup as cls_setup, compare_models as cls_compare, save_model as cls_save, pull as cls_pull, plot_model as cls_plot
|
| 5 |
+
from pycaret.regression import setup as reg_setup, compare_models as reg_compare, save_model as reg_save, pull as reg_pull, plot_model as reg_plot
|
| 6 |
+
from pycaret.clustering import setup as clu_setup, create_model as clu_create, plot_model as clu_plot, save_model as clu_save, pull as clu_pull
|
| 7 |
+
from pycaret.anomaly import setup as ano_setup, create_model as ano_create, plot_model as ano_plot, save_model as ano_save, pull as ano_pull
|
| 8 |
+
from pycaret.time_series import setup as ts_setup, compare_models as ts_compare, save_model as ts_save, pull as ts_pull, plot_model as ts_plot
|
| 9 |
+
from pycaret.datasets import get_data
|
| 10 |
+
import streamlit.components.v1 as components
|
| 11 |
+
import traceback
|
| 12 |
+
from ydata_profiling import ProfileReport
|
| 13 |
+
import os
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def get_all_datasets():
|
| 18 |
+
df = get_data('index')
|
| 19 |
+
return df['Dataset'].to_list()
|
| 20 |
+
|
| 21 |
+
def show_profile_reports(container):
|
| 22 |
+
if os.path.exists("profile_report.html"):
|
| 23 |
+
with open('profile_report.html', 'r') as f:
|
| 24 |
+
html_content = f.read()
|
| 25 |
+
with container:
|
| 26 |
+
components.html(html_content, height=800, scrolling=True)
|
| 27 |
+
if os.path.exists("sweetviz_report.html"):
|
| 28 |
+
with open('sweetviz_report.html', 'r') as f:
|
| 29 |
+
html_content = f.read()
|
| 30 |
+
with container:
|
| 31 |
+
components.html(html_content, height=800, scrolling=True)
|
| 32 |
+
|
| 33 |
+
def data_profile(df,container):
|
| 34 |
+
profile = ProfileReport(df)
|
| 35 |
+
profile.to_file("profile_report.html")
|
| 36 |
+
with open('profile_report.html', 'r') as f:
|
| 37 |
+
html_content = f.read()
|
| 38 |
+
with container:
|
| 39 |
+
components.html(html_content, height=800, scrolling=True)
|
| 40 |
+
|
| 41 |
+
def update_progress(progress_bar, step, max_steps):
|
| 42 |
+
progress = int((step / max_steps) * 100)
|
| 43 |
+
t = f"Processing....Step {step}/{max_steps}"
|
| 44 |
+
if step == max_steps:
|
| 45 |
+
t="Process Completed"
|
| 46 |
+
progress_bar.progress(progress, text=t)
|
| 47 |
+
|
| 48 |
+
def display_sweetviz_report(dataframe,container):
|
| 49 |
+
report = sv.analyze(dataframe)
|
| 50 |
+
report.show_html('sweetviz_report.html', open_browser=False)
|
| 51 |
+
with open('sweetviz_report.html', 'r') as f:
|
| 52 |
+
html_content = f.read()
|
| 53 |
+
with container:
|
| 54 |
+
components.html(html_content, height=800, scrolling=True)
|
| 55 |
+
|
| 56 |
+
def handle_exception(e):
|
| 57 |
+
st.error(
|
| 58 |
+
f"""The app has encountered an error:
|
| 59 |
+
**{e}**
|
| 60 |
+
Please check settings - columns selections and model parameters
|
| 61 |
+
Or
|
| 62 |
+
Create an issue [here](https://github.com/bitbotcoder/mlwiz/issues/new) with the below error details
|
| 63 |
+
""",
|
| 64 |
+
icon="🥺",
|
| 65 |
+
)
|
| 66 |
+
with st.expander("See Error details"):
|
| 67 |
+
st.error(traceback.format_exc())
|
| 68 |
+
|
| 69 |
+
def load_data(uploaded_file):
|
| 70 |
+
try:
|
| 71 |
+
if uploaded_file.name.endswith('.csv'):
|
| 72 |
+
df = pd.read_csv(uploaded_file)
|
| 73 |
+
elif uploaded_file.name.endswith('.xlsx'):
|
| 74 |
+
df = pd.read_excel(uploaded_file)
|
| 75 |
+
st.write("## Dataset")
|
| 76 |
+
st.write(df.head())
|
| 77 |
+
st.session_state['dataframe'] = df
|
| 78 |
+
except Exception as e:
|
| 79 |
+
handle_exception(e)
|
| 80 |
+
|
| 81 |
+
def load_pycaret_dataset(dataset_name):
|
| 82 |
+
try:
|
| 83 |
+
df = get_data(dataset_name)
|
| 84 |
+
st.write("## Dataset")
|
| 85 |
+
st.write(df.head())
|
| 86 |
+
st.session_state['dataframe'] = df
|
| 87 |
+
except Exception as e:
|
| 88 |
+
handle_exception(e)
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def eda_report():
|
| 92 |
+
if 'dataframe' in st.session_state:
|
| 93 |
+
df = st.session_state['dataframe']
|
| 94 |
+
col1,col2 = st.columns([0.6,0.4])
|
| 95 |
+
new_report = col1.toggle(":blue[Generate New]", value=True)
|
| 96 |
+
show_button = col2.button("Show Report")
|
| 97 |
+
pb = st.progress(0, text="Generating Report")
|
| 98 |
+
cont = st.container(border=False)
|
| 99 |
+
try:
|
| 100 |
+
if show_button:
|
| 101 |
+
if new_report:
|
| 102 |
+
update_progress(pb,1,4)
|
| 103 |
+
data_profile(df, cont)
|
| 104 |
+
update_progress(pb,2,4)
|
| 105 |
+
display_sweetviz_report(df, cont)
|
| 106 |
+
update_progress(pb,4,4)
|
| 107 |
+
else:
|
| 108 |
+
show_profile_reports(cont)
|
| 109 |
+
|
| 110 |
+
except Exception as e:
|
| 111 |
+
handle_exception(e)
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def build_model(task, container):
|
| 115 |
+
|
| 116 |
+
if 'dataframe' in st.session_state:
|
| 117 |
+
df = st.session_state['dataframe']
|
| 118 |
+
feature_expander = container.expander("Select Columns")
|
| 119 |
+
target_column = feature_expander.selectbox("Select target column", df.columns) if task in ["Classification", "Regression", "Time Series Forecasting"] else None
|
| 120 |
+
numerical_columns = feature_expander.multiselect("Select numerical columns", df.columns)
|
| 121 |
+
categorical_columns = feature_expander.multiselect("Select categorical columns", df.columns)
|
| 122 |
+
|
| 123 |
+
params_expander = container.expander("Tune Parameters")
|
| 124 |
+
# Data Preparation
|
| 125 |
+
handle_missing_data = params_expander.toggle("Handle Missing Data", value=True)
|
| 126 |
+
handle_outliers = params_expander.toggle("Handle Outliers", value=True)
|
| 127 |
+
|
| 128 |
+
# Scale and Transform
|
| 129 |
+
normalize = params_expander.checkbox("Normalize", value=False)
|
| 130 |
+
normalize_method = params_expander.selectbox("Normalize Method", ["zscore", "minmax", "maxabs", "robust"], index=0 if normalize else -1) if normalize else None
|
| 131 |
+
transformation = params_expander.checkbox("Apply Transformation", value=False)
|
| 132 |
+
transformation_method = params_expander.selectbox("Transformation Method", ["yeo-johnson", "quantile"], index=0 if transformation else -1) if transformation else None
|
| 133 |
+
|
| 134 |
+
# Feature Engineering
|
| 135 |
+
polynomial_features = params_expander.checkbox("Polynomial Features", value=False)
|
| 136 |
+
polynomial_degree = params_expander.slider("Polynomial Degree", 2, 5, 2) if polynomial_features else None
|
| 137 |
+
|
| 138 |
+
# Feature Selection
|
| 139 |
+
remove_multicollinearity = params_expander.checkbox("Remove Multicollinearity", value=False)
|
| 140 |
+
multicollinearity_threshold = params_expander.slider("Multicollinearity Threshold", 0.5, 1.0, 0.9) if remove_multicollinearity else None
|
| 141 |
+
|
| 142 |
+
if not (task == "Anomaly Detection" or task == "Clustering") :
|
| 143 |
+
feature_selection = params_expander.checkbox("Feature Selection", value=False)
|
| 144 |
+
feature_selection_method = params_expander.selectbox("Feature Selection Method", ["classic", "exhaustive"], index=0 if feature_selection else -1) if feature_selection else None
|
| 145 |
+
else:
|
| 146 |
+
feature_selection = None
|
| 147 |
+
feature_selection_method = None
|
| 148 |
+
|
| 149 |
+
try:
|
| 150 |
+
# Setup arguments for PyCaret
|
| 151 |
+
setup_kwargs = {
|
| 152 |
+
'data': df[numerical_columns + categorical_columns + ([target_column] if target_column else [])],
|
| 153 |
+
'categorical_features': categorical_columns,
|
| 154 |
+
'numeric_features': numerical_columns,
|
| 155 |
+
'target': target_column,
|
| 156 |
+
'preprocess': handle_missing_data,
|
| 157 |
+
'remove_outliers': handle_outliers,
|
| 158 |
+
'normalize': normalize,
|
| 159 |
+
'normalize_method': normalize_method,
|
| 160 |
+
'transformation': transformation,
|
| 161 |
+
'transformation_method': transformation_method,
|
| 162 |
+
'polynomial_features': polynomial_features,
|
| 163 |
+
'polynomial_degree': polynomial_degree,
|
| 164 |
+
'remove_multicollinearity': remove_multicollinearity,
|
| 165 |
+
'multicollinearity_threshold': multicollinearity_threshold,
|
| 166 |
+
'feature_selection': feature_selection,
|
| 167 |
+
'feature_selection_method': feature_selection_method
|
| 168 |
+
}
|
| 169 |
+
pb = st.progress(0, text="Building Model...")
|
| 170 |
+
|
| 171 |
+
if task == "Classification" and st.button("Run Classification"):
|
| 172 |
+
|
| 173 |
+
df[target_column] = df[target_column].astype('category')
|
| 174 |
+
|
| 175 |
+
df.dropna(subset=[target_column] + numerical_columns + categorical_columns, inplace=True)
|
| 176 |
+
|
| 177 |
+
if len(df) < 2:
|
| 178 |
+
st.error("Not enough data to split into train and test sets.")
|
| 179 |
+
return
|
| 180 |
+
update_progress(pb,1,7)
|
| 181 |
+
exp = cls_setup(**setup_kwargs)
|
| 182 |
+
update_progress(pb,2,7)
|
| 183 |
+
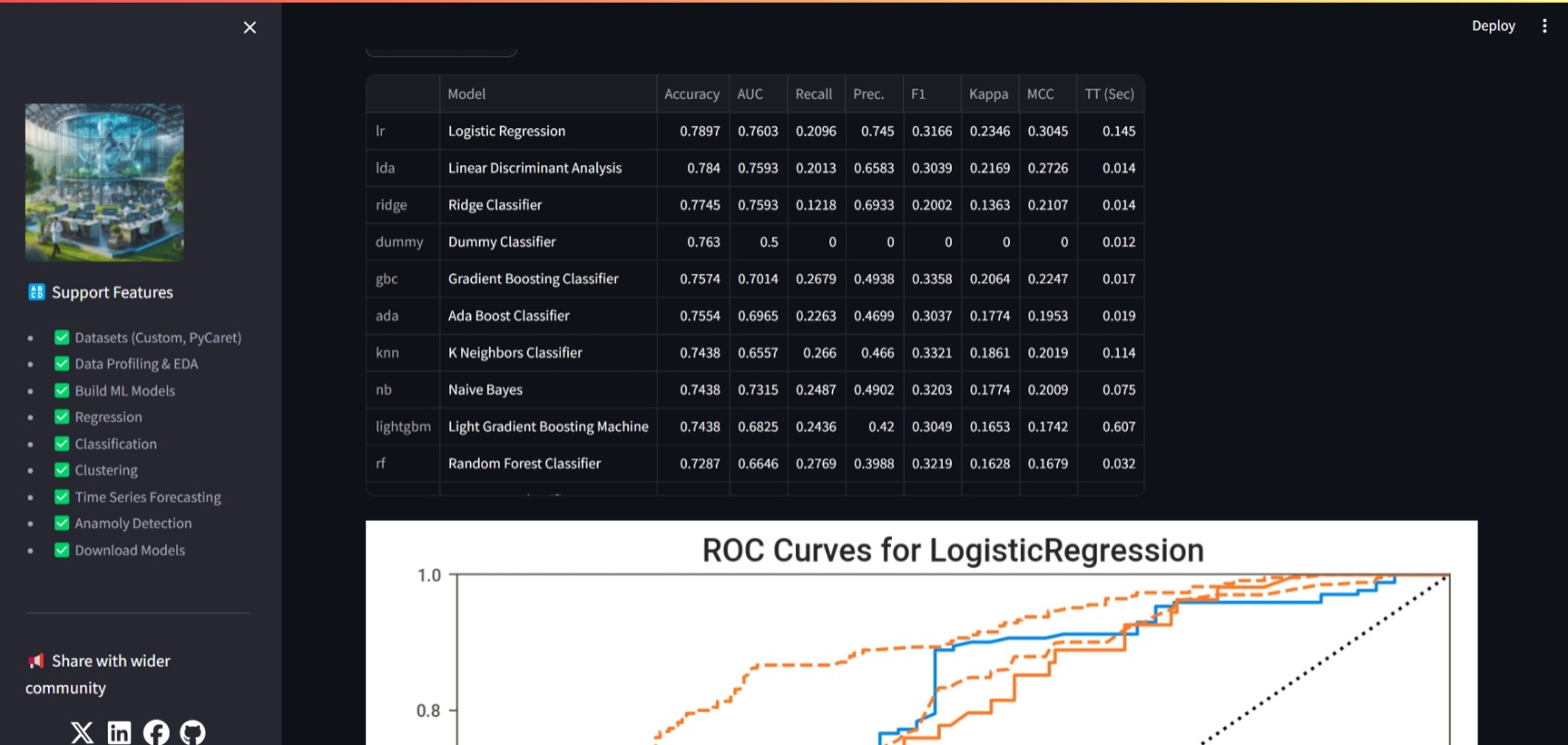
best_model = cls_compare()
|
| 184 |
+
update_progress(pb,3,7)
|
| 185 |
+
st.dataframe(cls_pull())
|
| 186 |
+
update_progress(pb,4,7)
|
| 187 |
+
cls_plot(best_model, plot='auc',display_format="streamlit")
|
| 188 |
+
cls_plot(best_model, plot='confusion_matrix',display_format="streamlit")
|
| 189 |
+
update_progress(pb,5,7)
|
| 190 |
+
st.image(cls_plot(best_model, plot='pr',save=True))
|
| 191 |
+
update_progress(pb,6,7)
|
| 192 |
+
cls_save(best_model, 'best_classification_model')
|
| 193 |
+
st.write('Best Model based on metrics - ')
|
| 194 |
+
st.write(best_model)
|
| 195 |
+
update_progress(pb,7,7)
|
| 196 |
+
|
| 197 |
+
elif task == "Regression" and st.button("Run Regression"):
|
| 198 |
+
update_progress(pb,1,7)
|
| 199 |
+
df[target_column] = pd.to_numeric(df[target_column], errors='coerce')
|
| 200 |
+
update_progress(pb,2,7)
|
| 201 |
+
df.dropna(subset=[target_column] + numerical_columns + categorical_columns, inplace=True)
|
| 202 |
+
update_progress(pb,3,7)
|
| 203 |
+
if len(df) < 2:
|
| 204 |
+
st.error("Not enough data to split into train and test sets.")
|
| 205 |
+
return
|
| 206 |
+
|
| 207 |
+
exp = reg_setup(**setup_kwargs)
|
| 208 |
+
best_model = reg_compare()
|
| 209 |
+
update_progress(pb,4,7)
|
| 210 |
+
st.dataframe(reg_pull())
|
| 211 |
+
update_progress(pb,5,7)
|
| 212 |
+
st.image(reg_plot(best_model, plot='residuals', save=True))
|
| 213 |
+
st.image(reg_plot(best_model, plot='error', save=True))
|
| 214 |
+
st.image(reg_plot(best_model, plot='error', save=True))
|
| 215 |
+
update_progress(pb,6,7)
|
| 216 |
+
reg_save(best_model, 'best_regression_model')
|
| 217 |
+
st.write('Best Model based on metrics - ')
|
| 218 |
+
st.write(best_model)
|
| 219 |
+
update_progress(pb,7,7)
|
| 220 |
+
elif task == "Clustering" and st.button("Run Clustering"):
|
| 221 |
+
update_progress(pb,1,7)
|
| 222 |
+
df.dropna(subset=numerical_columns + categorical_columns, inplace=True)
|
| 223 |
+
update_progress(pb,2,7)
|
| 224 |
+
setup_kwargs.pop('target')
|
| 225 |
+
setup_kwargs.pop('feature_selection')
|
| 226 |
+
setup_kwargs.pop('feature_selection_method')
|
| 227 |
+
update_progress(pb,3,7)
|
| 228 |
+
exp = clu_setup(**setup_kwargs)
|
| 229 |
+
best_model = clu_create('kmeans')
|
| 230 |
+
update_progress(pb,4,7)
|
| 231 |
+
clu_plot(best_model, plot='cluster', display_format='streamlit')
|
| 232 |
+
clu_plot(best_model, plot='elbow', display_format='streamlit')
|
| 233 |
+
update_progress(pb,5,7)
|
| 234 |
+
st.write(best_model)
|
| 235 |
+
st.dataframe(clu_pull())
|
| 236 |
+
update_progress(pb,6,7)
|
| 237 |
+
clu_save(best_model, 'best_clustering_model')
|
| 238 |
+
st.write('Best Model based on metrics - ')
|
| 239 |
+
st.write(best_model)
|
| 240 |
+
update_progress(pb,7,7)
|
| 241 |
+
|
| 242 |
+
elif task == "Anomaly Detection" and st.button("Run Anomaly Detection"):
|
| 243 |
+
update_progress(pb,1,7)
|
| 244 |
+
df.dropna(subset=numerical_columns + categorical_columns, inplace=True)
|
| 245 |
+
update_progress(pb,2,7)
|
| 246 |
+
setup_kwargs.pop('target')
|
| 247 |
+
setup_kwargs.pop('feature_selection')
|
| 248 |
+
setup_kwargs.pop('feature_selection_method')
|
| 249 |
+
update_progress(pb,3,7)
|
| 250 |
+
exp = ano_setup(**setup_kwargs)
|
| 251 |
+
best_model = ano_create('iforest')
|
| 252 |
+
update_progress(pb,4,7)
|
| 253 |
+
ano_plot(best_model, plot='tsne', display_format='streamlit')
|
| 254 |
+
update_progress(pb,5,7)
|
| 255 |
+
st.write(best_model)
|
| 256 |
+
st.dataframe(ano_pull())
|
| 257 |
+
update_progress(pb,6,7)
|
| 258 |
+
ano_save(best_model, 'best_anomaly_model')
|
| 259 |
+
st.write('Best Model based on metrics - ')
|
| 260 |
+
st.write(best_model)
|
| 261 |
+
update_progress(pb,7,7)
|
| 262 |
+
elif task == "Time Series Forecasting" :
|
| 263 |
+
date_column = feature_expander.selectbox("Select date column", df.columns)
|
| 264 |
+
if st.button("Run Time Series Forecasting"):
|
| 265 |
+
update_progress(pb,1,5)
|
| 266 |
+
df[date_column] = pd.to_datetime(df[date_column])
|
| 267 |
+
df[target_column] = pd.to_numeric(df[target_column], errors='coerce')
|
| 268 |
+
df.dropna(subset=[target_column], inplace=True)
|
| 269 |
+
update_progress(pb,2,5)
|
| 270 |
+
df = df.set_index(date_column).asfreq('D')
|
| 271 |
+
exp = ts_setup(df, target=target_column, numeric_imputation_target='mean', numeric_imputation_exogenous='mean')
|
| 272 |
+
best_model = ts_compare()
|
| 273 |
+
update_progress(pb,3,5)
|
| 274 |
+
st.dataframe(ts_pull())
|
| 275 |
+
ts_plot(best_model, plot='forecast', display_format="streamlit")
|
| 276 |
+
ts_save(best_model, 'best_timeseries_model')
|
| 277 |
+
update_progress(pb,4,5)
|
| 278 |
+
st.write('Best Model based on metrics - ')
|
| 279 |
+
st.write(best_model)
|
| 280 |
+
update_progress(pb,5,5)
|
| 281 |
+
except Exception as e:
|
| 282 |
+
handle_exception(e)
|
| 283 |
+
|
| 284 |
+
def download_model(task):
|
| 285 |
+
model_file = None
|
| 286 |
+
if task == "Classification":
|
| 287 |
+
model_file = 'best_classification_model.pkl'
|
| 288 |
+
elif task == "Regression":
|
| 289 |
+
model_file = 'best_regression_model.pkl'
|
| 290 |
+
elif task == "Clustering":
|
| 291 |
+
model_file = 'best_clustering_model.pkl'
|
| 292 |
+
elif task == "Anomaly Detection":
|
| 293 |
+
model_file = 'best_anomaly_model.pkl'
|
| 294 |
+
elif task == "Time Series Forecasting":
|
| 295 |
+
model_file = 'best_timeseries_model.pkl'
|
| 296 |
+
|
| 297 |
+
if model_file:
|
| 298 |
+
if os.path.exists(model_file):
|
| 299 |
+
try:
|
| 300 |
+
with open(model_file, 'rb') as f:
|
| 301 |
+
st.download_button('Download Model', f, file_name=model_file)
|
| 302 |
+
except Exception as e:
|
| 303 |
+
handle_exception(e)
|
| 304 |
+
else:
|
| 305 |
+
st.error("❗No File Found | First Build A ML Model ")
|
requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
streamlit
|
| 2 |
+
pandas
|
| 3 |
+
sweetviz
|
| 4 |
+
pycaret
|
| 5 |
+
ydata_profiling
|
| 6 |
+
st_social_media_links
|