 +
+## Results
+
+
+## Results
+ +
+## Setup:
+### Environment Setup:
+```
+# 1. Create environment
+sudo apt-get install libsndfile1-dev ffmpeg enchant
+conda create -n tts-env
+conda activate tts-env
+
+# 2. Setup PyTorch
+pip3 install -U torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
+
+# 3. Setup Trainer
+git clone https://github.com/gokulkarthik/Trainer
+
+cd Trainer
+pip3 install -e .[all]
+cd ..
+[or]
+cp Trainer/trainer/logging/wandb_logger.py to the local Trainer installation # fixed wandb logger
+cp Trainer/trainer/trainer.py to the local Trainer installation # fixed model.module.test_log and added code to log epoch
+add `gpus = [str(gpu) for gpu in gpus]` in line 53 of trainer/distribute.py
+
+# 4. Setup TTS
+git clone https://github.com/gokulkarthik/TTS
+
+cd TTS
+pip3 install -e .[all]
+cd ..
+[or]
+cp TTS/TTS/bin/synthesize.py to the local TTS installation # added multiple output support for TTS.bin.synthesis
+
+# 5. Install other requirements
+> pip3 install -r requirements.txt
+```
+
+
+### Data Setup:
+1. Format IndicTTS dataset in LJSpeech format using [preprocessing/FormatDatasets.ipynb](./preprocessing/FormatDatasets.ipynb)
+2. Analyze IndicTTS dataset to check TTS suitability using [preprocessing/AnalyzeDataset.ipynb](./preprocessing/AnalyzeDataset.ipynb)
+
+### Training Steps:
+1. Set the configuration with [main.py](./main.py), [vocoder.py](./vocoder.py), [configs](./configs) and [run.sh](./run.sh). Make sure to update the CUDA_VISIBLE_DEVICES in all these files.
+2. Train and test by executing `sh run.sh`
+
+### Inference:
+Trained model weight and config files can be downloaded at [this link.](https://github.com/AI4Bharat/Indic-TTS/releases/tag/v1-checkpoints-release)
+
+```
+python3 -m TTS.bin.synthesize --text
+
+## Setup:
+### Environment Setup:
+```
+# 1. Create environment
+sudo apt-get install libsndfile1-dev ffmpeg enchant
+conda create -n tts-env
+conda activate tts-env
+
+# 2. Setup PyTorch
+pip3 install -U torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
+
+# 3. Setup Trainer
+git clone https://github.com/gokulkarthik/Trainer
+
+cd Trainer
+pip3 install -e .[all]
+cd ..
+[or]
+cp Trainer/trainer/logging/wandb_logger.py to the local Trainer installation # fixed wandb logger
+cp Trainer/trainer/trainer.py to the local Trainer installation # fixed model.module.test_log and added code to log epoch
+add `gpus = [str(gpu) for gpu in gpus]` in line 53 of trainer/distribute.py
+
+# 4. Setup TTS
+git clone https://github.com/gokulkarthik/TTS
+
+cd TTS
+pip3 install -e .[all]
+cd ..
+[or]
+cp TTS/TTS/bin/synthesize.py to the local TTS installation # added multiple output support for TTS.bin.synthesis
+
+# 5. Install other requirements
+> pip3 install -r requirements.txt
+```
+
+
+### Data Setup:
+1. Format IndicTTS dataset in LJSpeech format using [preprocessing/FormatDatasets.ipynb](./preprocessing/FormatDatasets.ipynb)
+2. Analyze IndicTTS dataset to check TTS suitability using [preprocessing/AnalyzeDataset.ipynb](./preprocessing/AnalyzeDataset.ipynb)
+
+### Training Steps:
+1. Set the configuration with [main.py](./main.py), [vocoder.py](./vocoder.py), [configs](./configs) and [run.sh](./run.sh). Make sure to update the CUDA_VISIBLE_DEVICES in all these files.
+2. Train and test by executing `sh run.sh`
+
+### Inference:
+Trained model weight and config files can be downloaded at [this link.](https://github.com/AI4Bharat/Indic-TTS/releases/tag/v1-checkpoints-release)
+
+```
+python3 -m TTS.bin.synthesize --text  +
+🐸TTS is a library for advanced Text-to-Speech generation. It's built on the latest research, was designed to achieve the best trade-off among ease-of-training, speed and quality.
+🐸TTS comes with pretrained models, tools for measuring dataset quality and already used in **20+ languages** for products and research projects.
+
+[](https://gitter.im/coqui-ai/TTS?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge)
+[](https://gitter.im/coqui-ai/TTS?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge)
+[ +
+## 💬 Where to ask questions
+Please use our dedicated channels for questions and discussion. Help is much more valuable if it's shared publicly so that more people can benefit from it.
+
+| Type | Platforms |
+| ------------------------------- | --------------------------------------- |
+| 🚨 **Bug Reports** | [GitHub Issue Tracker] |
+| 🎁 **Feature Requests & Ideas** | [GitHub Issue Tracker] |
+| 👩💻 **Usage Questions** | [Github Discussions] |
+| 🗯 **General Discussion** | [Github Discussions] or [Gitter Room] |
+
+[github issue tracker]: https://github.com/coqui-ai/tts/issues
+[github discussions]: https://github.com/coqui-ai/TTS/discussions
+[gitter room]: https://gitter.im/coqui-ai/TTS?utm_source=share-link&utm_medium=link&utm_campaign=share-link
+[Tutorials and Examples]: https://github.com/coqui-ai/TTS/wiki/TTS-Notebooks-and-Tutorials
+
+
+## 🔗 Links and Resources
+| Type | Links |
+| ------------------------------- | --------------------------------------- |
+| 💼 **Documentation** | [ReadTheDocs](https://tts.readthedocs.io/en/latest/)
+| 💾 **Installation** | [TTS/README.md](https://github.com/coqui-ai/TTS/tree/dev#install-tts)|
+| 👩💻 **Contributing** | [CONTRIBUTING.md](https://github.com/coqui-ai/TTS/blob/main/CONTRIBUTING.md)|
+| 📌 **Road Map** | [Main Development Plans](https://github.com/coqui-ai/TTS/issues/378)
+| 🚀 **Released Models** | [TTS Releases](https://github.com/coqui-ai/TTS/releases) and [Experimental Models](https://github.com/coqui-ai/TTS/wiki/Experimental-Released-Models)|
+
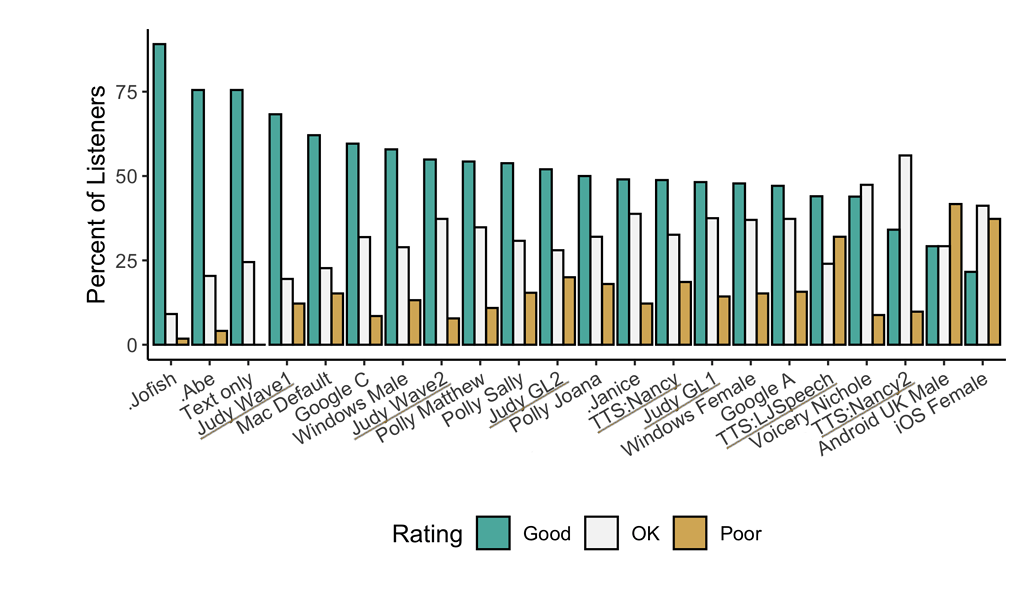
+## 🥇 TTS Performance
+
+
+## 💬 Where to ask questions
+Please use our dedicated channels for questions and discussion. Help is much more valuable if it's shared publicly so that more people can benefit from it.
+
+| Type | Platforms |
+| ------------------------------- | --------------------------------------- |
+| 🚨 **Bug Reports** | [GitHub Issue Tracker] |
+| 🎁 **Feature Requests & Ideas** | [GitHub Issue Tracker] |
+| 👩💻 **Usage Questions** | [Github Discussions] |
+| 🗯 **General Discussion** | [Github Discussions] or [Gitter Room] |
+
+[github issue tracker]: https://github.com/coqui-ai/tts/issues
+[github discussions]: https://github.com/coqui-ai/TTS/discussions
+[gitter room]: https://gitter.im/coqui-ai/TTS?utm_source=share-link&utm_medium=link&utm_campaign=share-link
+[Tutorials and Examples]: https://github.com/coqui-ai/TTS/wiki/TTS-Notebooks-and-Tutorials
+
+
+## 🔗 Links and Resources
+| Type | Links |
+| ------------------------------- | --------------------------------------- |
+| 💼 **Documentation** | [ReadTheDocs](https://tts.readthedocs.io/en/latest/)
+| 💾 **Installation** | [TTS/README.md](https://github.com/coqui-ai/TTS/tree/dev#install-tts)|
+| 👩💻 **Contributing** | [CONTRIBUTING.md](https://github.com/coqui-ai/TTS/blob/main/CONTRIBUTING.md)|
+| 📌 **Road Map** | [Main Development Plans](https://github.com/coqui-ai/TTS/issues/378)
+| 🚀 **Released Models** | [TTS Releases](https://github.com/coqui-ai/TTS/releases) and [Experimental Models](https://github.com/coqui-ai/TTS/wiki/Experimental-Released-Models)|
+
+## 🥇 TTS Performance
+
+
+🐸TTS is a library for advanced Text-to-Speech generation. It's built on the latest research, was designed to achieve the best trade-off among ease-of-training, speed and quality.
+🐸TTS comes with pretrained models, tools for measuring dataset quality and already used in **20+ languages** for products and research projects.
+
+[](https://gitter.im/coqui-ai/TTS?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge)
+[
+| 💾 **Installation** | [TTS/README.md](https://github.com/coqui-ai/TTS/tree/dev#install-tts)|
+| 👩💻 **Contributing** | [CONTRIBUTING.md](https://github.com/coqui-ai/TTS/blob/main/CONTRIBUTING.md)|
+| 📌 **Road Map** | [Main Development Plans](https://github.com/coqui-ai/TTS/issues/378)
+| 🚀 **Released Models** | [TTS Releases](https://github.com/coqui-ai/TTS/releases) and [Experimental Models](https://github.com/coqui-ai/TTS/wiki/Experimental-Released-Models)|
+
+## 🥇 TTS Performance
+
 +
+ {% if show_details == true %}
+
+
+
+ {% if show_details == true %}
+
+
+ Model details
+
+
+
+
+
+
+
+
+
+ CLI arguments:
+| CLI key | +Value | +
| {{ key }} | +{{ value }} | +
+
+ {% if model_config != None %}
+
+
+
+
+
+
+
+
+
+
+ {% endif %}
+
+ Model config:
+ +| Key | +Value | +
| {{ key }} | +{{ value }} | +
+ {% if vocoder_config != None %}
+
+
+ {% else %}
+
+
+
+
+ {% endif %}
+ Vocoder model config:
+ +| Key | +Value | +
| {{ key }} | +{{ value }} | +
+ Please start server with --show_details=true to see details.
+
+
+ {% endif %}
+
+
+
+
\ No newline at end of file
diff --git a/Indic-TTS/TTS/TTS/server/templates/index.html b/Indic-TTS/TTS/TTS/server/templates/index.html
new file mode 100644
index 0000000000000000000000000000000000000000..b0eab291a2c78e678709aba7dddb2b97b8e94b0f
--- /dev/null
+++ b/Indic-TTS/TTS/TTS/server/templates/index.html
@@ -0,0 +1,143 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/Indic-TTS/TTS/TTS/tts/__init__.py b/Indic-TTS/TTS/TTS/tts/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/Indic-TTS/TTS/TTS/tts/__pycache__/__init__.cpython-37.pyc b/Indic-TTS/TTS/TTS/tts/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a8eeabe3dc13f757056639de5f79c9ed06508b3e
Binary files /dev/null and b/Indic-TTS/TTS/TTS/tts/__pycache__/__init__.cpython-37.pyc differ
diff --git a/Indic-TTS/TTS/TTS/tts/configs/__init__.py b/Indic-TTS/TTS/TTS/tts/configs/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3146ac1c116cb807a81889b7a9ab223b9a051036
--- /dev/null
+++ b/Indic-TTS/TTS/TTS/tts/configs/__init__.py
@@ -0,0 +1,17 @@
+import importlib
+import os
+from inspect import isclass
+
+# import all files under configs/
+# configs_dir = os.path.dirname(__file__)
+# for file in os.listdir(configs_dir):
+# path = os.path.join(configs_dir, file)
+# if not file.startswith("_") and not file.startswith(".") and (file.endswith(".py") or os.path.isdir(path)):
+# config_name = file[: file.find(".py")] if file.endswith(".py") else file
+# module = importlib.import_module("TTS.tts.configs." + config_name)
+# for attribute_name in dir(module):
+# attribute = getattr(module, attribute_name)
+
+# if isclass(attribute):
+# # Add the class to this package's variables
+# globals()[attribute_name] = attribute
diff --git a/Indic-TTS/TTS/TTS/tts/configs/__pycache__/__init__.cpython-37.pyc b/Indic-TTS/TTS/TTS/tts/configs/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..a667a9aef2594250788e230cebb267264cfed7a2
Binary files /dev/null and b/Indic-TTS/TTS/TTS/tts/configs/__pycache__/__init__.cpython-37.pyc differ
diff --git a/Indic-TTS/TTS/TTS/tts/configs/__pycache__/fast_pitch_config.cpython-37.pyc b/Indic-TTS/TTS/TTS/tts/configs/__pycache__/fast_pitch_config.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..d89fa20499dddde1fa7b1db19ce52a1e9225f062
Binary files /dev/null and b/Indic-TTS/TTS/TTS/tts/configs/__pycache__/fast_pitch_config.cpython-37.pyc differ
diff --git a/Indic-TTS/TTS/TTS/tts/configs/__pycache__/shared_configs.cpython-37.pyc b/Indic-TTS/TTS/TTS/tts/configs/__pycache__/shared_configs.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..39c35d5d335e2dcbf15a0a8505cc4b2ee7efdfce
Binary files /dev/null and b/Indic-TTS/TTS/TTS/tts/configs/__pycache__/shared_configs.cpython-37.pyc differ
diff --git a/Indic-TTS/TTS/TTS/tts/configs/align_tts_config.py b/Indic-TTS/TTS/TTS/tts/configs/align_tts_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..317a01af53ce26914d83610a913eb44b5836dac2
--- /dev/null
+++ b/Indic-TTS/TTS/TTS/tts/configs/align_tts_config.py
@@ -0,0 +1,107 @@
+from dataclasses import dataclass, field
+from typing import List
+
+from TTS.tts.configs.shared_configs import BaseTTSConfig
+from TTS.tts.models.align_tts import AlignTTSArgs
+
+
+@dataclass
+class AlignTTSConfig(BaseTTSConfig):
+ """Defines parameters for AlignTTS model.
+ Example:
+
+ >>> from TTS.tts.configs.align_tts_config import AlignTTSConfig
+ >>> config = AlignTTSConfig()
+
+ Args:
+ model(str):
+ Model name used for selecting the right model at initialization. Defaults to `align_tts`.
+ positional_encoding (bool):
+ enable / disable positional encoding applied to the encoder output. Defaults to True.
+ hidden_channels (int):
+ Base number of hidden channels. Defines all the layers expect ones defined by the specific encoder or decoder
+ parameters. Defaults to 256.
+ hidden_channels_dp (int):
+ Number of hidden channels of the duration predictor's layers. Defaults to 256.
+ encoder_type (str):
+ Type of the encoder used by the model. Look at `TTS.tts.layers.feed_forward.encoder` for more details.
+ Defaults to `fftransformer`.
+ encoder_params (dict):
+ Parameters used to define the encoder network. Look at `TTS.tts.layers.feed_forward.encoder` for more details.
+ Defaults to `{"hidden_channels_ffn": 1024, "num_heads": 2, "num_layers": 6, "dropout_p": 0.1}`.
+ decoder_type (str):
+ Type of the decoder used by the model. Look at `TTS.tts.layers.feed_forward.decoder` for more details.
+ Defaults to `fftransformer`.
+ decoder_params (dict):
+ Parameters used to define the decoder network. Look at `TTS.tts.layers.feed_forward.decoder` for more details.
+ Defaults to `{"hidden_channels_ffn": 1024, "num_heads": 2, "num_layers": 6, "dropout_p": 0.1}`.
+ phase_start_steps (List[int]):
+ A list of number of steps required to start the next training phase. AlignTTS has 4 different training
+ phases. Thus you need to define 4 different values to enable phase based training. If None, it
+ trains the whole model together. Defaults to None.
+ ssim_alpha (float):
+ Weight for the SSIM loss. If set <= 0, disables the SSIM loss. Defaults to 1.0.
+ duration_loss_alpha (float):
+ Weight for the duration predictor's loss. Defaults to 1.0.
+ mdn_alpha (float):
+ Weight for the MDN loss. Defaults to 1.0.
+ spec_loss_alpha (float):
+ Weight for the MSE spectrogram loss. If set <= 0, disables the L1 loss. Defaults to 1.0.
+ use_speaker_embedding (bool):
+ enable / disable using speaker embeddings for multi-speaker models. If set True, the model is
+ in the multi-speaker mode. Defaults to False.
+ use_d_vector_file (bool):
+ enable /disable using external speaker embeddings in place of the learned embeddings. Defaults to False.
+ d_vector_file (str):
+ Path to the file including pre-computed speaker embeddings. Defaults to None.
+ noam_schedule (bool):
+ enable / disable the use of Noam LR scheduler. Defaults to False.
+ warmup_steps (int):
+ Number of warm-up steps for the Noam scheduler. Defaults 4000.
+ lr (float):
+ Initial learning rate. Defaults to `1e-3`.
+ wd (float):
+ Weight decay coefficient. Defaults to `1e-7`.
+ min_seq_len (int):
+ Minimum input sequence length to be used at training.
+ max_seq_len (int):
+ Maximum input sequence length to be used at training. Larger values result in more VRAM usage."""
+
+ model: str = "align_tts"
+ # model specific params
+ model_args: AlignTTSArgs = field(default_factory=AlignTTSArgs)
+ phase_start_steps: List[int] = None
+
+ ssim_alpha: float = 1.0
+ spec_loss_alpha: float = 1.0
+ dur_loss_alpha: float = 1.0
+ mdn_alpha: float = 1.0
+
+ # multi-speaker settings
+ use_speaker_embedding: bool = False
+ use_d_vector_file: bool = False
+ d_vector_file: str = False
+
+ # optimizer parameters
+ optimizer: str = "Adam"
+ optimizer_params: dict = field(default_factory=lambda: {"betas": [0.9, 0.998], "weight_decay": 1e-6})
+ lr_scheduler: str = None
+ lr_scheduler_params: dict = None
+ lr: float = 1e-4
+ grad_clip: float = 5.0
+
+ # overrides
+ min_seq_len: int = 13
+ max_seq_len: int = 200
+ r: int = 1
+
+ # testing
+ test_sentences: List[str] = field(
+ default_factory=lambda: [
+ "It took me quite a long time to develop a voice, and now that I have it I'm not going to be silent.",
+ "Be a voice, not an echo.",
+ "I'm sorry Dave. I'm afraid I can't do that.",
+ "This cake is great. It's so delicious and moist.",
+ "Prior to November 22, 1963.",
+ ]
+ )
diff --git a/Indic-TTS/TTS/TTS/tts/configs/fast_pitch_config.py b/Indic-TTS/TTS/TTS/tts/configs/fast_pitch_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..26ccfdd54037a63c4d5d638109cd30524f8f22ca
--- /dev/null
+++ b/Indic-TTS/TTS/TTS/tts/configs/fast_pitch_config.py
@@ -0,0 +1,182 @@
+from dataclasses import dataclass, field
+from typing import List
+
+from TTS.tts.configs.shared_configs import BaseTTSConfig
+from TTS.tts.models.forward_tts import ForwardTTSArgs
+
+
+@dataclass
+class FastPitchConfig(BaseTTSConfig):
+ """Configure `ForwardTTS` as FastPitch model.
+
+ Example:
+
+ >>> from TTS.tts.configs.fast_pitch_config import FastPitchConfig
+ >>> config = FastPitchConfig()
+
+ Args:
+ model (str):
+ Model name used for selecting the right model at initialization. Defaults to `fast_pitch`.
+
+ base_model (str):
+ Name of the base model being configured as this model so that 🐸 TTS knows it needs to initiate
+ the base model rather than searching for the `model` implementation. Defaults to `forward_tts`.
+
+ model_args (Coqpit):
+ Model class arguments. Check `FastPitchArgs` for more details. Defaults to `FastPitchArgs()`.
+
+ data_dep_init_steps (int):
+ Number of steps used for computing normalization parameters at the beginning of the training. GlowTTS uses
+ Activation Normalization that pre-computes normalization stats at the beginning and use the same values
+ for the rest. Defaults to 10.
+
+ speakers_file (str):
+ Path to the file containing the list of speakers. Needed at inference for loading matching speaker ids to
+ speaker names. Defaults to `None`.
+
+ use_speaker_embedding (bool):
+ enable / disable using speaker embeddings for multi-speaker models. If set True, the model is
+ in the multi-speaker mode. Defaults to False.
+
+ use_d_vector_file (bool):
+ enable /disable using external speaker embeddings in place of the learned embeddings. Defaults to False.
+
+ d_vector_file (str):
+ Path to the file including pre-computed speaker embeddings. Defaults to None.
+
+ d_vector_dim (int):
+ Dimension of the external speaker embeddings. Defaults to 0.
+
+ optimizer (str):
+ Name of the model optimizer. Defaults to `Adam`.
+
+ optimizer_params (dict):
+ Arguments of the model optimizer. Defaults to `{"betas": [0.9, 0.998], "weight_decay": 1e-6}`.
+
+ lr_scheduler (str):
+ Name of the learning rate scheduler. Defaults to `Noam`.
+
+ lr_scheduler_params (dict):
+ Arguments of the learning rate scheduler. Defaults to `{"warmup_steps": 4000}`.
+
+ lr (float):
+ Initial learning rate. Defaults to `1e-3`.
+
+ grad_clip (float):
+ Gradient norm clipping value. Defaults to `5.0`.
+
+ spec_loss_type (str):
+ Type of the spectrogram loss. Check `ForwardTTSLoss` for possible values. Defaults to `mse`.
+
+ duration_loss_type (str):
+ Type of the duration loss. Check `ForwardTTSLoss` for possible values. Defaults to `mse`.
+
+ use_ssim_loss (bool):
+ Enable/disable the use of SSIM (Structural Similarity) loss. Defaults to True.
+
+ wd (float):
+ Weight decay coefficient. Defaults to `1e-7`.
+
+ ssim_loss_alpha (float):
+ Weight for the SSIM loss. If set 0, disables the SSIM loss. Defaults to 1.0.
+
+ dur_loss_alpha (float):
+ Weight for the duration predictor's loss. If set 0, disables the huber loss. Defaults to 1.0.
+
+ spec_loss_alpha (float):
+ Weight for the L1 spectrogram loss. If set 0, disables the L1 loss. Defaults to 1.0.
+
+ pitch_loss_alpha (float):
+ Weight for the pitch predictor's loss. If set 0, disables the pitch predictor. Defaults to 1.0.
+
+ binary_align_loss_alpha (float):
+ Weight for the binary loss. If set 0, disables the binary loss. Defaults to 1.0.
+
+ binary_loss_warmup_epochs (float):
+ Number of epochs to gradually increase the binary loss impact. Defaults to 150.
+
+ min_seq_len (int):
+ Minimum input sequence length to be used at training.
+
+ max_seq_len (int):
+ Maximum input sequence length to be used at training. Larger values result in more VRAM usage.
+ """
+
+ model: str = "fast_pitch"
+ base_model: str = "forward_tts"
+
+ # model specific params
+ model_args: ForwardTTSArgs = ForwardTTSArgs()
+
+ # data loader params
+ return_wav: bool = False
+ compute_linear_spec: bool = False
+
+ # multi-speaker settings
+ num_speakers: int = 0
+ speakers_file: str = None
+ use_speaker_embedding: bool = False
+ use_d_vector_file: bool = False
+ d_vector_file: str = False
+ d_vector_dim: int = 0
+
+ # optimizer parameters
+ optimizer: str = "Adam"
+ optimizer_params: dict = field(default_factory=lambda: {"betas": [0.9, 0.998], "weight_decay": 1e-6})
+ lr_scheduler: str = "NoamLR"
+ lr_scheduler_params: dict = field(default_factory=lambda: {"warmup_steps": 4000})
+ lr: float = 1e-4
+ grad_clip: float = 5.0
+
+ # loss params
+ spec_loss_type: str = "mse"
+ duration_loss_type: str = "mse"
+ use_ssim_loss: bool = True
+ ssim_loss_alpha: float = 1.0
+ spec_loss_alpha: float = 1.0
+ aligner_loss_alpha: float = 1.0
+ pitch_loss_alpha: float = 0.1
+ dur_loss_alpha: float = 0.1
+ binary_align_loss_alpha: float = 0.1
+ spk_encoder_loss_alpha: float = 0.1
+ binary_loss_warmup_epochs: int = 150
+ aligner_epochs: int = 1000
+
+ # overrides
+ min_seq_len: int = 13
+ max_seq_len: int = 200
+ r: int = 1 # DO NOT CHANGE
+
+ # dataset configs
+ compute_f0: bool = True
+ f0_cache_path: str = None
+
+ # testing
+ test_sentences: List[str] = field(
+ default_factory=lambda: [
+ "It took me quite a long time to develop a voice, and now that I have it I'm not going to be silent.",
+ "Be a voice, not an echo.",
+ "I'm sorry Dave. I'm afraid I can't do that.",
+ "This cake is great. It's so delicious and moist.",
+ "Prior to November 22, 1963.",
+ ]
+ )
+
+ def __post_init__(self):
+ # Pass multi-speaker parameters to the model args as `model.init_multispeaker()` looks for it there.
+ if self.num_speakers > 0:
+ self.model_args.num_speakers = self.num_speakers
+
+ # speaker embedding settings
+ if self.use_speaker_embedding:
+ self.model_args.use_speaker_embedding = True
+ if self.speakers_file:
+ self.model_args.speakers_file = self.speakers_file
+
+ # d-vector settings
+ if self.use_d_vector_file:
+ self.model_args.use_d_vector_file = True
+ if self.d_vector_dim is not None and self.d_vector_dim > 0:
+ self.model_args.d_vector_dim = self.d_vector_dim
+ if self.d_vector_file:
+ self.model_args.d_vector_file = self.d_vector_file
diff --git a/Indic-TTS/TTS/TTS/tts/configs/fast_speech_config.py b/Indic-TTS/TTS/TTS/tts/configs/fast_speech_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..16a76e215f4d47d086bea827d2b6ccc61524e5c1
--- /dev/null
+++ b/Indic-TTS/TTS/TTS/tts/configs/fast_speech_config.py
@@ -0,0 +1,177 @@
+from dataclasses import dataclass, field
+from typing import List
+
+from TTS.tts.configs.shared_configs import BaseTTSConfig
+from TTS.tts.models.forward_tts import ForwardTTSArgs
+
+
+@dataclass
+class FastSpeechConfig(BaseTTSConfig):
+ """Configure `ForwardTTS` as FastSpeech model.
+
+ Example:
+
+ >>> from TTS.tts.configs.fast_speech_config import FastSpeechConfig
+ >>> config = FastSpeechConfig()
+
+ Args:
+ model (str):
+ Model name used for selecting the right model at initialization. Defaults to `fast_pitch`.
+
+ base_model (str):
+ Name of the base model being configured as this model so that 🐸 TTS knows it needs to initiate
+ the base model rather than searching for the `model` implementation. Defaults to `forward_tts`.
+
+ model_args (Coqpit):
+ Model class arguments. Check `FastSpeechArgs` for more details. Defaults to `FastSpeechArgs()`.
+
+ data_dep_init_steps (int):
+ Number of steps used for computing normalization parameters at the beginning of the training. GlowTTS uses
+ Activation Normalization that pre-computes normalization stats at the beginning and use the same values
+ for the rest. Defaults to 10.
+
+ speakers_file (str):
+ Path to the file containing the list of speakers. Needed at inference for loading matching speaker ids to
+ speaker names. Defaults to `None`.
+
+
+ use_speaker_embedding (bool):
+ enable / disable using speaker embeddings for multi-speaker models. If set True, the model is
+ in the multi-speaker mode. Defaults to False.
+
+ use_d_vector_file (bool):
+ enable /disable using external speaker embeddings in place of the learned embeddings. Defaults to False.
+
+ d_vector_file (str):
+ Path to the file including pre-computed speaker embeddings. Defaults to None.
+
+ d_vector_dim (int):
+ Dimension of the external speaker embeddings. Defaults to 0.
+
+ optimizer (str):
+ Name of the model optimizer. Defaults to `Adam`.
+
+ optimizer_params (dict):
+ Arguments of the model optimizer. Defaults to `{"betas": [0.9, 0.998], "weight_decay": 1e-6}`.
+
+ lr_scheduler (str):
+ Name of the learning rate scheduler. Defaults to `Noam`.
+
+ lr_scheduler_params (dict):
+ Arguments of the learning rate scheduler. Defaults to `{"warmup_steps": 4000}`.
+
+ lr (float):
+ Initial learning rate. Defaults to `1e-3`.
+
+ grad_clip (float):
+ Gradient norm clipping value. Defaults to `5.0`.
+
+ spec_loss_type (str):
+ Type of the spectrogram loss. Check `ForwardTTSLoss` for possible values. Defaults to `mse`.
+
+ duration_loss_type (str):
+ Type of the duration loss. Check `ForwardTTSLoss` for possible values. Defaults to `mse`.
+
+ use_ssim_loss (bool):
+ Enable/disable the use of SSIM (Structural Similarity) loss. Defaults to True.
+
+ wd (float):
+ Weight decay coefficient. Defaults to `1e-7`.
+
+ ssim_loss_alpha (float):
+ Weight for the SSIM loss. If set 0, disables the SSIM loss. Defaults to 1.0.
+
+ dur_loss_alpha (float):
+ Weight for the duration predictor's loss. If set 0, disables the huber loss. Defaults to 1.0.
+
+ spec_loss_alpha (float):
+ Weight for the L1 spectrogram loss. If set 0, disables the L1 loss. Defaults to 1.0.
+
+ pitch_loss_alpha (float):
+ Weight for the pitch predictor's loss. If set 0, disables the pitch predictor. Defaults to 1.0.
+
+ binary_loss_alpha (float):
+ Weight for the binary loss. If set 0, disables the binary loss. Defaults to 1.0.
+
+ binary_loss_warmup_epochs (float):
+ Number of epochs to gradually increase the binary loss impact. Defaults to 150.
+
+ min_seq_len (int):
+ Minimum input sequence length to be used at training.
+
+ max_seq_len (int):
+ Maximum input sequence length to be used at training. Larger values result in more VRAM usage.
+ """
+
+ model: str = "fast_speech"
+ base_model: str = "forward_tts"
+
+ # model specific params
+ model_args: ForwardTTSArgs = ForwardTTSArgs(use_pitch=False)
+
+ # multi-speaker settings
+ num_speakers: int = 0
+ speakers_file: str = None
+ use_speaker_embedding: bool = False
+ use_d_vector_file: bool = False
+ d_vector_file: str = False
+ d_vector_dim: int = 0
+
+ # optimizer parameters
+ optimizer: str = "Adam"
+ optimizer_params: dict = field(default_factory=lambda: {"betas": [0.9, 0.998], "weight_decay": 1e-6})
+ lr_scheduler: str = "NoamLR"
+ lr_scheduler_params: dict = field(default_factory=lambda: {"warmup_steps": 4000})
+ lr: float = 1e-4
+ grad_clip: float = 5.0
+
+ # loss params
+ spec_loss_type: str = "mse"
+ duration_loss_type: str = "mse"
+ use_ssim_loss: bool = True
+ ssim_loss_alpha: float = 1.0
+ dur_loss_alpha: float = 1.0
+ spec_loss_alpha: float = 1.0
+ pitch_loss_alpha: float = 0.0
+ aligner_loss_alpha: float = 1.0
+ binary_align_loss_alpha: float = 1.0
+ binary_loss_warmup_epochs: int = 150
+
+ # overrides
+ min_seq_len: int = 13
+ max_seq_len: int = 200
+ r: int = 1 # DO NOT CHANGE
+
+ # dataset configs
+ compute_f0: bool = False
+ f0_cache_path: str = None
+
+ # testing
+ test_sentences: List[str] = field(
+ default_factory=lambda: [
+ "It took me quite a long time to develop a voice, and now that I have it I'm not going to be silent.",
+ "Be a voice, not an echo.",
+ "I'm sorry Dave. I'm afraid I can't do that.",
+ "This cake is great. It's so delicious and moist.",
+ "Prior to November 22, 1963.",
+ ]
+ )
+
+ def __post_init__(self):
+ # Pass multi-speaker parameters to the model args as `model.init_multispeaker()` looks for it there.
+ if self.num_speakers > 0:
+ self.model_args.num_speakers = self.num_speakers
+
+ # speaker embedding settings
+ if self.use_speaker_embedding:
+ self.model_args.use_speaker_embedding = True
+ if self.speakers_file:
+ self.model_args.speakers_file = self.speakers_file
+
+ # d-vector settings
+ if self.use_d_vector_file:
+ self.model_args.use_d_vector_file = True
+ if self.d_vector_dim is not None and self.d_vector_dim > 0:
+ self.model_args.d_vector_dim = self.d_vector_dim
+ if self.d_vector_file:
+ self.model_args.d_vector_file = self.d_vector_file
diff --git a/Indic-TTS/TTS/TTS/tts/configs/glow_tts_config.py b/Indic-TTS/TTS/TTS/tts/configs/glow_tts_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..f42f3e5a510bacf1b2312ccea7d46201bbcb774f
--- /dev/null
+++ b/Indic-TTS/TTS/TTS/tts/configs/glow_tts_config.py
@@ -0,0 +1,182 @@
+from dataclasses import dataclass, field
+from typing import List
+
+from TTS.tts.configs.shared_configs import BaseTTSConfig
+
+
+@dataclass
+class GlowTTSConfig(BaseTTSConfig):
+ """Defines parameters for GlowTTS model.
+
+ Example:
+
+ >>> from TTS.tts.configs.glow_tts_config import GlowTTSConfig
+ >>> config = GlowTTSConfig()
+
+ Args:
+ model(str):
+ Model name used for selecting the right model at initialization. Defaults to `glow_tts`.
+ encoder_type (str):
+ Type of the encoder used by the model. Look at `TTS.tts.layers.glow_tts.encoder` for more details.
+ Defaults to `rel_pos_transformers`.
+ encoder_params (dict):
+ Parameters used to define the encoder network. Look at `TTS.tts.layers.glow_tts.encoder` for more details.
+ Defaults to `{"kernel_size": 3, "dropout_p": 0.1, "num_layers": 6, "num_heads": 2, "hidden_channels_ffn": 768}`
+ use_encoder_prenet (bool):
+ enable / disable the use of a prenet for the encoder. Defaults to True.
+ hidden_channels_enc (int):
+ Number of base hidden channels used by the encoder network. It defines the input and the output channel sizes,
+ and for some encoder types internal hidden channels sizes too. Defaults to 192.
+ hidden_channels_dec (int):
+ Number of base hidden channels used by the decoder WaveNet network. Defaults to 192 as in the original work.
+ hidden_channels_dp (int):
+ Number of layer channels of the duration predictor network. Defaults to 256 as in the original work.
+ mean_only (bool):
+ If true predict only the mean values by the decoder flow. Defaults to True.
+ out_channels (int):
+ Number of channels of the model output tensor. Defaults to 80.
+ num_flow_blocks_dec (int):
+ Number of decoder blocks. Defaults to 12.
+ inference_noise_scale (float):
+ Noise scale used at inference. Defaults to 0.33.
+ kernel_size_dec (int):
+ Decoder kernel size. Defaults to 5
+ dilation_rate (int):
+ Rate to increase dilation by each layer in a decoder block. Defaults to 1.
+ num_block_layers (int):
+ Number of decoder layers in each decoder block. Defaults to 4.
+ dropout_p_dec (float):
+ Dropout rate for decoder. Defaults to 0.1.
+ num_speaker (int):
+ Number of speaker to define the size of speaker embedding layer. Defaults to 0.
+ c_in_channels (int):
+ Number of speaker embedding channels. It is set to 512 if embeddings are learned. Defaults to 0.
+ num_splits (int):
+ Number of split levels in inversible conv1x1 operation. Defaults to 4.
+ num_squeeze (int):
+ Number of squeeze levels. When squeezing channels increases and time steps reduces by the factor
+ 'num_squeeze'. Defaults to 2.
+ sigmoid_scale (bool):
+ enable/disable sigmoid scaling in decoder. Defaults to False.
+ mean_only (bool):
+ If True, encoder only computes mean value and uses constant variance for each time step. Defaults to true.
+ encoder_type (str):
+ Encoder module type. Possible values are`["rel_pos_transformer", "gated_conv", "residual_conv_bn", "time_depth_separable"]`
+ Check `TTS.tts.layers.glow_tts.encoder` for more details. Defaults to `rel_pos_transformers` as in the original paper.
+ encoder_params (dict):
+ Encoder module parameters. Defaults to None.
+ d_vector_dim (int):
+ Channels of external speaker embedding vectors. Defaults to 0.
+ data_dep_init_steps (int):
+ Number of steps used for computing normalization parameters at the beginning of the training. GlowTTS uses
+ Activation Normalization that pre-computes normalization stats at the beginning and use the same values
+ for the rest. Defaults to 10.
+ style_wav_for_test (str):
+ Path to the wav file used for changing the style of the speech. Defaults to None.
+ inference_noise_scale (float):
+ Variance used for sampling the random noise added to the decoder's input at inference. Defaults to 0.0.
+ length_scale (float):
+ Multiply the predicted durations with this value to change the speech speed. Defaults to 1.
+ use_speaker_embedding (bool):
+ enable / disable using speaker embeddings for multi-speaker models. If set True, the model is
+ in the multi-speaker mode. Defaults to False.
+ use_d_vector_file (bool):
+ enable /disable using external speaker embeddings in place of the learned embeddings. Defaults to False.
+ d_vector_file (str):
+ Path to the file including pre-computed speaker embeddings. Defaults to None.
+ noam_schedule (bool):
+ enable / disable the use of Noam LR scheduler. Defaults to False.
+ warmup_steps (int):
+ Number of warm-up steps for the Noam scheduler. Defaults 4000.
+ lr (float):
+ Initial learning rate. Defaults to `1e-3`.
+ wd (float):
+ Weight decay coefficient. Defaults to `1e-7`.
+ min_seq_len (int):
+ Minimum input sequence length to be used at training.
+ max_seq_len (int):
+ Maximum input sequence length to be used at training. Larger values result in more VRAM usage.
+ """
+
+ model: str = "glow_tts"
+
+ # model params
+ num_chars: int = None
+ encoder_type: str = "rel_pos_transformer"
+ encoder_params: dict = field(
+ default_factory=lambda: {
+ "kernel_size": 3,
+ "dropout_p": 0.1,
+ "num_layers": 6,
+ "num_heads": 2,
+ "hidden_channels_ffn": 768,
+ }
+ )
+ use_encoder_prenet: bool = True
+ hidden_channels_enc: int = 192
+ hidden_channels_dec: int = 192
+ hidden_channels_dp: int = 256
+ dropout_p_dp: float = 0.1
+ dropout_p_dec: float = 0.05
+ mean_only: bool = True
+ out_channels: int = 80
+ num_flow_blocks_dec: int = 12
+ inference_noise_scale: float = 0.33
+ kernel_size_dec: int = 5
+ dilation_rate: int = 1
+ num_block_layers: int = 4
+ num_speakers: int = 0
+ c_in_channels: int = 0
+ num_splits: int = 4
+ num_squeeze: int = 2
+ sigmoid_scale: bool = False
+ encoder_type: str = "rel_pos_transformer"
+ encoder_params: dict = field(
+ default_factory=lambda: {
+ "kernel_size": 3,
+ "dropout_p": 0.1,
+ "num_layers": 6,
+ "num_heads": 2,
+ "hidden_channels_ffn": 768,
+ "input_length": None,
+ }
+ )
+ d_vector_dim: int = 0
+
+ # training params
+ data_dep_init_steps: int = 10
+
+ # inference params
+ style_wav_for_test: str = None
+ inference_noise_scale: float = 0.0
+ length_scale: float = 1.0
+
+ # multi-speaker settings
+ use_speaker_embedding: bool = False
+ speakers_file: str = None
+ use_d_vector_file: bool = False
+ d_vector_file: str = False
+
+ # optimizer parameters
+ optimizer: str = "RAdam"
+ optimizer_params: dict = field(default_factory=lambda: {"betas": [0.9, 0.998], "weight_decay": 1e-6})
+ lr_scheduler: str = "NoamLR"
+ lr_scheduler_params: dict = field(default_factory=lambda: {"warmup_steps": 4000})
+ grad_clip: float = 5.0
+ lr: float = 1e-3
+
+ # overrides
+ min_seq_len: int = 3
+ max_seq_len: int = 500
+ r: int = 1 # DO NOT CHANGE - TODO: make this immutable once coqpit implements it.
+
+ # testing
+ test_sentences: List[str] = field(
+ default_factory=lambda: [
+ "It took me quite a long time to develop a voice, and now that I have it I'm not going to be silent.",
+ "Be a voice, not an echo.",
+ "I'm sorry Dave. I'm afraid I can't do that.",
+ "This cake is great. It's so delicious and moist.",
+ "Prior to November 22, 1963.",
+ ]
+ )
diff --git a/Indic-TTS/TTS/TTS/tts/configs/shared_configs.py b/Indic-TTS/TTS/TTS/tts/configs/shared_configs.py
new file mode 100644
index 0000000000000000000000000000000000000000..4704687c268780ed518f8c6a4ca64808dbab8e65
--- /dev/null
+++ b/Indic-TTS/TTS/TTS/tts/configs/shared_configs.py
@@ -0,0 +1,335 @@
+from dataclasses import asdict, dataclass, field
+from typing import Dict, List
+
+from coqpit import Coqpit, check_argument
+
+from TTS.config import BaseAudioConfig, BaseDatasetConfig, BaseTrainingConfig
+
+
+@dataclass
+class GSTConfig(Coqpit):
+ """Defines the Global Style Token Module
+
+ Args:
+ gst_style_input_wav (str):
+ Path to the wav file used to define the style of the output speech at inference. Defaults to None.
+
+ gst_style_input_weights (dict):
+ Defines the weights for each style token used at inference. Defaults to None.
+
+ gst_embedding_dim (int):
+ Defines the size of the GST embedding vector dimensions. Defaults to 256.
+
+ gst_num_heads (int):
+ Number of attention heads used by the multi-head attention. Defaults to 4.
+
+ gst_num_style_tokens (int):
+ Number of style token vectors. Defaults to 10.
+ """
+
+ gst_style_input_wav: str = None
+ gst_style_input_weights: dict = None
+ gst_embedding_dim: int = 256
+ gst_use_speaker_embedding: bool = False
+ gst_num_heads: int = 4
+ gst_num_style_tokens: int = 10
+
+ def check_values(
+ self,
+ ):
+ """Check config fields"""
+ c = asdict(self)
+ super().check_values()
+ check_argument("gst_style_input_weights", c, restricted=False)
+ check_argument("gst_style_input_wav", c, restricted=False)
+ check_argument("gst_embedding_dim", c, restricted=True, min_val=0, max_val=1000)
+ check_argument("gst_use_speaker_embedding", c, restricted=False)
+ check_argument("gst_num_heads", c, restricted=True, min_val=2, max_val=10)
+ check_argument("gst_num_style_tokens", c, restricted=True, min_val=1, max_val=1000)
+
+
+@dataclass
+class CapacitronVAEConfig(Coqpit):
+ """Defines the capacitron VAE Module
+ Args:
+ capacitron_capacity (int):
+ Defines the variational capacity limit of the prosody embeddings. Defaults to 150.
+ capacitron_VAE_embedding_dim (int):
+ Defines the size of the Capacitron embedding vector dimension. Defaults to 128.
+ capacitron_use_text_summary_embeddings (bool):
+ If True, use a text summary embedding in Capacitron. Defaults to True.
+ capacitron_text_summary_embedding_dim (int):
+ Defines the size of the capacitron text embedding vector dimension. Defaults to 128.
+ capacitron_use_speaker_embedding (bool):
+ if True use speaker embeddings in Capacitron. Defaults to False.
+ capacitron_VAE_loss_alpha (float):
+ Weight for the VAE loss of the Tacotron model. If set less than or equal to zero, it disables the
+ corresponding loss function. Defaults to 0.25
+ capacitron_grad_clip (float):
+ Gradient clipping value for all gradients except beta. Defaults to 5.0
+ """
+
+ capacitron_loss_alpha: int = 1
+ capacitron_capacity: int = 150
+ capacitron_VAE_embedding_dim: int = 128
+ capacitron_use_text_summary_embeddings: bool = True
+ capacitron_text_summary_embedding_dim: int = 128
+ capacitron_use_speaker_embedding: bool = False
+ capacitron_VAE_loss_alpha: float = 0.25
+ capacitron_grad_clip: float = 5.0
+
+ def check_values(
+ self,
+ ):
+ """Check config fields"""
+ c = asdict(self)
+ super().check_values()
+ check_argument("capacitron_capacity", c, restricted=True, min_val=10, max_val=500)
+ check_argument("capacitron_VAE_embedding_dim", c, restricted=True, min_val=16, max_val=1024)
+ check_argument("capacitron_use_speaker_embedding", c, restricted=False)
+ check_argument("capacitron_text_summary_embedding_dim", c, restricted=False, min_val=16, max_val=512)
+ check_argument("capacitron_VAE_loss_alpha", c, restricted=False)
+ check_argument("capacitron_grad_clip", c, restricted=False)
+
+
+@dataclass
+class CharactersConfig(Coqpit):
+ """Defines arguments for the `BaseCharacters` or `BaseVocabulary` and their subclasses.
+
+ Args:
+ characters_class (str):
+ Defines the class of the characters used. If None, we pick ```Phonemes``` or ```Graphemes``` based on
+ the configuration. Defaults to None.
+
+ vocab_dict (dict):
+ Defines the vocabulary dictionary used to encode the characters. Defaults to None.
+
+ pad (str):
+ characters in place of empty padding. Defaults to None.
+
+ eos (str):
+ characters showing the end of a sentence. Defaults to None.
+
+ bos (str):
+ characters showing the beginning of a sentence. Defaults to None.
+
+ blank (str):
+ Optional character used between characters by some models for better prosody. Defaults to `_blank`.
+
+ characters (str):
+ character set used by the model. Characters not in this list are ignored when converting input text to
+ a list of sequence IDs. Defaults to None.
+
+ punctuations (str):
+ characters considered as punctuation as parsing the input sentence. Defaults to None.
+
+ phonemes (str):
+ characters considered as parsing phonemes. This is only for backwards compat. Use `characters` for new
+ models. Defaults to None.
+
+ is_unique (bool):
+ remove any duplicate characters in the character lists. It is a bandaid for compatibility with the old
+ models trained with character lists with duplicates. Defaults to True.
+
+ is_sorted (bool):
+ Sort the characters in alphabetical order. Defaults to True.
+ """
+
+ characters_class: str = None
+
+ # using BaseVocabulary
+ vocab_dict: Dict = None
+
+ # using on BaseCharacters
+ pad: str = None
+ eos: str = None
+ bos: str = None
+ blank: str = None
+ characters: str = None
+ punctuations: str = None
+ phonemes: str = None
+ is_unique: bool = True # for backwards compatibility of models trained with char sets with duplicates
+ is_sorted: bool = True
+
+
+@dataclass
+class BaseTTSConfig(BaseTrainingConfig):
+ """Shared parameters among all the tts models.
+
+ Args:
+
+ audio (BaseAudioConfig):
+ Audio processor config object instance.
+
+ use_phonemes (bool):
+ enable / disable phoneme use.
+
+ phonemizer (str):
+ Name of the phonemizer to use. If set None, the phonemizer will be selected by `phoneme_language`.
+ Defaults to None.
+
+ phoneme_language (str):
+ Language code for the phonemizer. You can check the list of supported languages by running
+ `python TTS/tts/utils/text/phonemizers/__init__.py`. Defaults to None.
+
+ compute_input_seq_cache (bool):
+ enable / disable precomputation of the phoneme sequences. At the expense of some delay at the beginning of
+ the training, It allows faster data loader time and precise limitation with `max_seq_len` and
+ `min_seq_len`.
+
+ text_cleaner (str):
+ Name of the text cleaner used for cleaning and formatting transcripts.
+
+ enable_eos_bos_chars (bool):
+ enable / disable the use of eos and bos characters.
+
+ test_senteces_file (str):
+ Path to a txt file that has sentences used at test time. The file must have a sentence per line.
+
+ phoneme_cache_path (str):
+ Path to the output folder caching the computed phonemes for each sample.
+
+ characters (CharactersConfig):
+ Instance of a CharactersConfig class.
+
+ batch_group_size (int):
+ Size of the batch groups used for bucketing. By default, the dataloader orders samples by the sequence
+ length for a more efficient and stable training. If `batch_group_size > 1` then it performs bucketing to
+ prevent using the same batches for each epoch.
+
+ loss_masking (bool):
+ enable / disable masking loss values against padded segments of samples in a batch.
+
+ sort_by_audio_len (bool):
+ If true, dataloder sorts the data by audio length else sorts by the input text length. Defaults to `False`.
+
+ min_text_len (int):
+ Minimum length of input text to be used. All shorter samples will be ignored. Defaults to 0.
+
+ max_text_len (int):
+ Maximum length of input text to be used. All longer samples will be ignored. Defaults to float("inf").
+
+ min_audio_len (int):
+ Minimum length of input audio to be used. All shorter samples will be ignored. Defaults to 0.
+
+ max_audio_len (int):
+ Maximum length of input audio to be used. All longer samples will be ignored. The maximum length in the
+ dataset defines the VRAM used in the training. Hence, pay attention to this value if you encounter an
+ OOM error in training. Defaults to float("inf").
+
+ compute_f0 (int):
+ (Not in use yet).
+
+ compute_linear_spec (bool):
+ If True data loader computes and returns linear spectrograms alongside the other data.
+
+ precompute_num_workers (int):
+ Number of workers to precompute features. Defaults to 0.
+
+ use_noise_augment (bool):
+ Augment the input audio with random noise.
+
+ start_by_longest (bool):
+ If True, the data loader will start loading the longest batch first. It is useful for checking OOM issues.
+ Defaults to False.
+
+ add_blank (bool):
+ Add blank characters between each other two characters. It improves performance for some models at expense
+ of slower run-time due to the longer input sequence.
+
+ datasets (List[BaseDatasetConfig]):
+ List of datasets used for training. If multiple datasets are provided, they are merged and used together
+ for training.
+
+ optimizer (str):
+ Optimizer used for the training. Set one from `torch.optim.Optimizer` or `TTS.utils.training`.
+ Defaults to ``.
+
+ optimizer_params (dict):
+ Optimizer kwargs. Defaults to `{"betas": [0.8, 0.99], "weight_decay": 0.0}`
+
+ lr_scheduler (str):
+ Learning rate scheduler for the training. Use one from `torch.optim.Scheduler` schedulers or
+ `TTS.utils.training`. Defaults to ``.
+
+ lr_scheduler_params (dict):
+ Parameters for the generator learning rate scheduler. Defaults to `{"warmup": 4000}`.
+
+ test_sentences (List[str]):
+ List of sentences to be used at testing. Defaults to '[]'
+
+ eval_split_max_size (int):
+ Number maximum of samples to be used for evaluation in proportion split. Defaults to None (Disabled).
+
+ eval_split_size (float):
+ If between 0.0 and 1.0 represents the proportion of the dataset to include in the evaluation set.
+ If > 1, represents the absolute number of evaluation samples. Defaults to 0.01 (1%).
+
+ use_speaker_weighted_sampler (bool):
+ Enable / Disable the batch balancer by speaker. Defaults to ```False```.
+
+ speaker_weighted_sampler_alpha (float):
+ Number that control the influence of the speaker sampler weights. Defaults to ```1.0```.
+
+ use_language_weighted_sampler (bool):
+ Enable / Disable the batch balancer by language. Defaults to ```False```.
+
+ language_weighted_sampler_alpha (float):
+ Number that control the influence of the language sampler weights. Defaults to ```1.0```.
+
+ use_length_weighted_sampler (bool):
+ Enable / Disable the batch balancer by audio length. If enabled the dataset will be divided
+ into 10 buckets considering the min and max audio of the dataset. The sampler weights will be
+ computed forcing to have the same quantity of data for each bucket in each training batch. Defaults to ```False```.
+
+ length_weighted_sampler_alpha (float):
+ Number that control the influence of the length sampler weights. Defaults to ```1.0```.
+ """
+
+ audio: BaseAudioConfig = field(default_factory=BaseAudioConfig)
+ # phoneme settings
+ use_phonemes: bool = False
+ phonemizer: str = None
+ phoneme_language: str = None
+ compute_input_seq_cache: bool = False
+ text_cleaner: str = None
+ enable_eos_bos_chars: bool = False
+ test_sentences_file: str = ""
+ phoneme_cache_path: str = None
+ # vocabulary parameters
+ characters: CharactersConfig = None
+ add_blank: bool = False
+ # training params
+ batch_group_size: int = 0
+ loss_masking: bool = None
+ # dataloading
+ sort_by_audio_len: bool = False
+ min_audio_len: int = 1
+ max_audio_len: int = float("inf")
+ min_text_len: int = 1
+ max_text_len: int = float("inf")
+ compute_f0: bool = False
+ compute_linear_spec: bool = False
+ precompute_num_workers: int = 0
+ use_noise_augment: bool = False
+ start_by_longest: bool = False
+ # dataset
+ datasets: List[BaseDatasetConfig] = field(default_factory=lambda: [BaseDatasetConfig()])
+ # optimizer
+ optimizer: str = "radam"
+ optimizer_params: dict = None
+ # scheduler
+ lr_scheduler: str = ""
+ lr_scheduler_params: dict = field(default_factory=lambda: {})
+ # testing
+ test_sentences: List[str] = field(default_factory=lambda: [])
+ # evaluation
+ eval_split_max_size: int = None
+ eval_split_size: float = 0.01
+ # weighted samplers
+ use_speaker_weighted_sampler: bool = False
+ speaker_weighted_sampler_alpha: float = 1.0
+ use_language_weighted_sampler: bool = False
+ language_weighted_sampler_alpha: float = 1.0
+ use_length_weighted_sampler: bool = False
+ length_weighted_sampler_alpha: float = 1.0
diff --git a/Indic-TTS/TTS/TTS/tts/configs/speedy_speech_config.py b/Indic-TTS/TTS/TTS/tts/configs/speedy_speech_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..4bf5101fcad2479e87836c827658c88addfd7cc6
--- /dev/null
+++ b/Indic-TTS/TTS/TTS/tts/configs/speedy_speech_config.py
@@ -0,0 +1,192 @@
+from dataclasses import dataclass, field
+from typing import List
+
+from TTS.tts.configs.shared_configs import BaseTTSConfig
+from TTS.tts.models.forward_tts import ForwardTTSArgs
+
+
+@dataclass
+class SpeedySpeechConfig(BaseTTSConfig):
+ """Configure `ForwardTTS` as SpeedySpeech model.
+
+ Example:
+
+ >>> from TTS.tts.configs.speedy_speech_config import SpeedySpeechConfig
+ >>> config = SpeedySpeechConfig()
+
+ Args:
+ model (str):
+ Model name used for selecting the right model at initialization. Defaults to `speedy_speech`.
+
+ base_model (str):
+ Name of the base model being configured as this model so that 🐸 TTS knows it needs to initiate
+ the base model rather than searching for the `model` implementation. Defaults to `forward_tts`.
+
+ model_args (Coqpit):
+ Model class arguments. Check `FastPitchArgs` for more details. Defaults to `FastPitchArgs()`.
+
+ data_dep_init_steps (int):
+ Number of steps used for computing normalization parameters at the beginning of the training. GlowTTS uses
+ Activation Normalization that pre-computes normalization stats at the beginning and use the same values
+ for the rest. Defaults to 10.
+
+ speakers_file (str):
+ Path to the file containing the list of speakers. Needed at inference for loading matching speaker ids to
+ speaker names. Defaults to `None`.
+
+ use_speaker_embedding (bool):
+ enable / disable using speaker embeddings for multi-speaker models. If set True, the model is
+ in the multi-speaker mode. Defaults to False.
+
+ use_d_vector_file (bool):
+ enable /disable using external speaker embeddings in place of the learned embeddings. Defaults to False.
+
+ d_vector_file (str):
+ Path to the file including pre-computed speaker embeddings. Defaults to None.
+
+ d_vector_dim (int):
+ Dimension of the external speaker embeddings. Defaults to 0.
+
+ optimizer (str):
+ Name of the model optimizer. Defaults to `RAdam`.
+
+ optimizer_params (dict):
+ Arguments of the model optimizer. Defaults to `{"betas": [0.9, 0.998], "weight_decay": 1e-6}`.
+
+ lr_scheduler (str):
+ Name of the learning rate scheduler. Defaults to `Noam`.
+
+ lr_scheduler_params (dict):
+ Arguments of the learning rate scheduler. Defaults to `{"warmup_steps": 4000}`.
+
+ lr (float):
+ Initial learning rate. Defaults to `1e-3`.
+
+ grad_clip (float):
+ Gradient norm clipping value. Defaults to `5.0`.
+
+ spec_loss_type (str):
+ Type of the spectrogram loss. Check `ForwardTTSLoss` for possible values. Defaults to `l1`.
+
+ duration_loss_type (str):
+ Type of the duration loss. Check `ForwardTTSLoss` for possible values. Defaults to `huber`.
+
+ use_ssim_loss (bool):
+ Enable/disable the use of SSIM (Structural Similarity) loss. Defaults to True.
+
+ wd (float):
+ Weight decay coefficient. Defaults to `1e-7`.
+
+ ssim_loss_alpha (float):
+ Weight for the SSIM loss. If set 0, disables the SSIM loss. Defaults to 1.0.
+
+ dur_loss_alpha (float):
+ Weight for the duration predictor's loss. If set 0, disables the huber loss. Defaults to 1.0.
+
+ spec_loss_alpha (float):
+ Weight for the L1 spectrogram loss. If set 0, disables the L1 loss. Defaults to 1.0.
+
+ binary_loss_alpha (float):
+ Weight for the binary loss. If set 0, disables the binary loss. Defaults to 1.0.
+
+ binary_loss_warmup_epochs (float):
+ Number of epochs to gradually increase the binary loss impact. Defaults to 150.
+
+ min_seq_len (int):
+ Minimum input sequence length to be used at training.
+
+ max_seq_len (int):
+ Maximum input sequence length to be used at training. Larger values result in more VRAM usage.
+ """
+
+ model: str = "speedy_speech"
+ base_model: str = "forward_tts"
+
+ # set model args as SpeedySpeech
+ model_args: ForwardTTSArgs = ForwardTTSArgs(
+ use_pitch=False,
+ encoder_type="residual_conv_bn",
+ encoder_params={
+ "kernel_size": 4,
+ "dilations": 4 * [1, 2, 4] + [1],
+ "num_conv_blocks": 2,
+ "num_res_blocks": 13,
+ },
+ decoder_type="residual_conv_bn",
+ decoder_params={
+ "kernel_size": 4,
+ "dilations": 4 * [1, 2, 4, 8] + [1],
+ "num_conv_blocks": 2,
+ "num_res_blocks": 17,
+ },
+ out_channels=80,
+ hidden_channels=128,
+ positional_encoding=True,
+ detach_duration_predictor=True,
+ )
+
+ # multi-speaker settings
+ num_speakers: int = 0
+ speakers_file: str = None
+ use_speaker_embedding: bool = False
+ use_d_vector_file: bool = False
+ d_vector_file: str = False
+ d_vector_dim: int = 0
+
+ # optimizer parameters
+ optimizer: str = "Adam"
+ optimizer_params: dict = field(default_factory=lambda: {"betas": [0.9, 0.998], "weight_decay": 1e-6})
+ lr_scheduler: str = "NoamLR"
+ lr_scheduler_params: dict = field(default_factory=lambda: {"warmup_steps": 4000})
+ lr: float = 1e-4
+ grad_clip: float = 5.0
+
+ # loss params
+ spec_loss_type: str = "l1"
+ duration_loss_type: str = "huber"
+ use_ssim_loss: bool = False
+ ssim_loss_alpha: float = 1.0
+ dur_loss_alpha: float = 1.0
+ spec_loss_alpha: float = 1.0
+ aligner_loss_alpha: float = 1.0
+ binary_align_loss_alpha: float = 0.3
+ binary_loss_warmup_epochs: int = 150
+
+ # overrides
+ min_seq_len: int = 13
+ max_seq_len: int = 200
+ r: int = 1 # DO NOT CHANGE
+
+ # dataset configs
+ compute_f0: bool = False
+ f0_cache_path: str = None
+
+ # testing
+ test_sentences: List[str] = field(
+ default_factory=lambda: [
+ "It took me quite a long time to develop a voice, and now that I have it I'm not going to be silent.",
+ "Be a voice, not an echo.",
+ "I'm sorry Dave. I'm afraid I can't do that.",
+ "This cake is great. It's so delicious and moist.",
+ "Prior to November 22, 1963.",
+ ]
+ )
+
+ def __post_init__(self):
+ # Pass multi-speaker parameters to the model args as `model.init_multispeaker()` looks for it there.
+ if self.num_speakers > 0:
+ self.model_args.num_speakers = self.num_speakers
+
+ # speaker embedding settings
+ if self.use_speaker_embedding:
+ self.model_args.use_speaker_embedding = True
+ if self.speakers_file:
+ self.model_args.speakers_file = self.speakers_file
+
+ # d-vector settings
+ if self.use_d_vector_file:
+ self.model_args.use_d_vector_file = True
+ if self.d_vector_dim is not None and self.d_vector_dim > 0:
+ self.model_args.d_vector_dim = self.d_vector_dim
+ if self.d_vector_file:
+ self.model_args.d_vector_file = self.d_vector_file
diff --git a/Indic-TTS/TTS/TTS/tts/configs/tacotron2_config.py b/Indic-TTS/TTS/TTS/tts/configs/tacotron2_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..95b65202218cf3aa0dd70c8d8cd55a3f913ed308
--- /dev/null
+++ b/Indic-TTS/TTS/TTS/tts/configs/tacotron2_config.py
@@ -0,0 +1,21 @@
+from dataclasses import dataclass
+
+from TTS.tts.configs.tacotron_config import TacotronConfig
+
+
+@dataclass
+class Tacotron2Config(TacotronConfig):
+ """Defines parameters for Tacotron2 based models.
+
+ Example:
+
+ >>> from TTS.tts.configs.tacotron2_config import Tacotron2Config
+ >>> config = Tacotron2Config()
+
+ Check `TacotronConfig` for argument descriptions.
+ """
+
+ model: str = "tacotron2"
+ out_channels: int = 80
+ encoder_in_features: int = 512
+ decoder_in_features: int = 512
diff --git a/Indic-TTS/TTS/TTS/tts/configs/tacotron_config.py b/Indic-TTS/TTS/TTS/tts/configs/tacotron_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..e25609ffcf685fae91fc40eaa2201e728ebc73c4
--- /dev/null
+++ b/Indic-TTS/TTS/TTS/tts/configs/tacotron_config.py
@@ -0,0 +1,235 @@
+from dataclasses import dataclass, field
+from typing import List
+
+from TTS.tts.configs.shared_configs import BaseTTSConfig, CapacitronVAEConfig, GSTConfig
+
+
+@dataclass
+class TacotronConfig(BaseTTSConfig):
+ """Defines parameters for Tacotron based models.
+
+ Example:
+
+ >>> from TTS.tts.configs.tacotron_config import TacotronConfig
+ >>> config = TacotronConfig()
+
+ Args:
+ model (str):
+ Model name used to select the right model class to initilize. Defaults to `Tacotron`.
+ use_gst (bool):
+ enable / disable the use of Global Style Token modules. Defaults to False.
+ gst (GSTConfig):
+ Instance of `GSTConfig` class.
+ gst_style_input (str):
+ Path to the wav file used at inference to set the speech style through GST. If `GST` is enabled and
+ this is not defined, the model uses a zero vector as an input. Defaults to None.
+ use_capacitron_vae (bool):
+ enable / disable the use of Capacitron modules. Defaults to False.
+ capacitron_vae (CapacitronConfig):
+ Instance of `CapacitronConfig` class.
+ num_chars (int):
+ Number of characters used by the model. It must be defined before initializing the model. Defaults to None.
+ num_speakers (int):
+ Number of speakers for multi-speaker models. Defaults to 1.
+ r (int):
+ Initial number of output frames that the decoder computed per iteration. Larger values makes training and inference
+ faster but reduces the quality of the output frames. This must be equal to the largest `r` value used in
+ `gradual_training` schedule. Defaults to 1.
+ gradual_training (List[List]):
+ Parameters for the gradual training schedule. It is in the form `[[a, b, c], [d ,e ,f] ..]` where `a` is
+ the step number to start using the rest of the values, `b` is the `r` value and `c` is the batch size.
+ If sets None, no gradual training is used. Defaults to None.
+ memory_size (int):
+ Defines the number of previous frames used by the Prenet. If set to < 0, then it uses only the last frame.
+ Defaults to -1.
+ prenet_type (str):
+ `original` or `bn`. `original` sets the default Prenet and `bn` uses Batch Normalization version of the
+ Prenet. Defaults to `original`.
+ prenet_dropout (bool):
+ enables / disables the use of dropout in the Prenet. Defaults to True.
+ prenet_dropout_at_inference (bool):
+ enable / disable the use of dropout in the Prenet at the inference time. Defaults to False.
+ stopnet (bool):
+ enable /disable the Stopnet that predicts the end of the decoder sequence. Defaults to True.
+ stopnet_pos_weight (float):
+ Weight that is applied to over-weight positive instances in the Stopnet loss. Use larger values with
+ datasets with longer sentences. Defaults to 10.
+ max_decoder_steps (int):
+ Max number of steps allowed for the decoder. Defaults to 50.
+ encoder_in_features (int):
+ Channels of encoder input and character embedding tensors. Defaults to 256.
+ decoder_in_features (int):
+ Channels of decoder input and encoder output tensors. Defaults to 256.
+ out_channels (int):
+ Channels of the final model output. It must match the spectragram size. Defaults to 80.
+ separate_stopnet (bool):
+ Use a distinct Stopnet which is trained separately from the rest of the model. Defaults to True.
+ attention_type (str):
+ attention type. Check ```TTS.tts.layers.attentions.init_attn```. Defaults to 'original'.
+ attention_heads (int):
+ Number of attention heads for GMM attention. Defaults to 5.
+ windowing (bool):
+ It especially useful at inference to keep attention alignment diagonal. Defaults to False.
+ use_forward_attn (bool):
+ It is only valid if ```attn_type``` is ```original```. Defaults to False.
+ forward_attn_mask (bool):
+ enable/disable extra masking over forward attention. It is useful at inference to prevent
+ possible attention failures. Defaults to False.
+ transition_agent (bool):
+ enable/disable transition agent in forward attention. Defaults to False.
+ location_attn (bool):
+ enable/disable location sensitive attention as in the original Tacotron2 paper.
+ It is only valid if ```attn_type``` is ```original```. Defaults to True.
+ bidirectional_decoder (bool):
+ enable/disable bidirectional decoding. Defaults to False.
+ double_decoder_consistency (bool):
+ enable/disable double decoder consistency. Defaults to False.
+ ddc_r (int):
+ reduction rate used by the coarse decoder when `double_decoder_consistency` is in use. Set this
+ as a multiple of the `r` value. Defaults to 6.
+ speakers_file (str):
+ Path to the speaker mapping file for the Speaker Manager. Defaults to None.
+ use_speaker_embedding (bool):
+ enable / disable using speaker embeddings for multi-speaker models. If set True, the model is
+ in the multi-speaker mode. Defaults to False.
+ use_d_vector_file (bool):
+ enable /disable using external speaker embeddings in place of the learned embeddings. Defaults to False.
+ d_vector_file (str):
+ Path to the file including pre-computed speaker embeddings. Defaults to None.
+ optimizer (str):
+ Optimizer used for the training. Set one from `torch.optim.Optimizer` or `TTS.utils.training`.
+ Defaults to `RAdam`.
+ optimizer_params (dict):
+ Optimizer kwargs. Defaults to `{"betas": [0.8, 0.99], "weight_decay": 0.0}`
+ lr_scheduler (str):
+ Learning rate scheduler for the training. Use one from `torch.optim.Scheduler` schedulers or
+ `TTS.utils.training`. Defaults to `NoamLR`.
+ lr_scheduler_params (dict):
+ Parameters for the generator learning rate scheduler. Defaults to `{"warmup": 4000}`.
+ lr (float):
+ Initial learning rate. Defaults to `1e-4`.
+ wd (float):
+ Weight decay coefficient. Defaults to `1e-6`.
+ grad_clip (float):
+ Gradient clipping threshold. Defaults to `5`.
+ seq_len_norm (bool):
+ enable / disable the sequnce length normalization in the loss functions. If set True, loss of a sample
+ is divided by the sequence length. Defaults to False.
+ loss_masking (bool):
+ enable / disable masking the paddings of the samples in loss computation. Defaults to True.
+ decoder_loss_alpha (float):
+ Weight for the decoder loss of the Tacotron model. If set less than or equal to zero, it disables the
+ corresponding loss function. Defaults to 0.25
+ postnet_loss_alpha (float):
+ Weight for the postnet loss of the Tacotron model. If set less than or equal to zero, it disables the
+ corresponding loss function. Defaults to 0.25
+ postnet_diff_spec_alpha (float):
+ Weight for the postnet differential loss of the Tacotron model. If set less than or equal to zero, it disables the
+ corresponding loss function. Defaults to 0.25
+ decoder_diff_spec_alpha (float):
+
+ Weight for the decoder differential loss of the Tacotron model. If set less than or equal to zero, it disables the
+ corresponding loss function. Defaults to 0.25
+ decoder_ssim_alpha (float):
+ Weight for the decoder SSIM loss of the Tacotron model. If set less than or equal to zero, it disables the
+ corresponding loss function. Defaults to 0.25
+ postnet_ssim_alpha (float):
+ Weight for the postnet SSIM loss of the Tacotron model. If set less than or equal to zero, it disables the
+ corresponding loss function. Defaults to 0.25
+ ga_alpha (float):
+ Weight for the guided attention loss. If set less than or equal to zero, it disables the corresponding loss
+ function. Defaults to 5.
+ """
+
+ model: str = "tacotron"
+ # model_params: TacotronArgs = field(default_factory=lambda: TacotronArgs())
+ use_gst: bool = False
+ gst: GSTConfig = None
+ gst_style_input: str = None
+
+ use_capacitron_vae: bool = False
+ capacitron_vae: CapacitronVAEConfig = None
+
+ # model specific params
+ num_speakers: int = 1
+ num_chars: int = 0
+ r: int = 2
+ gradual_training: List[List[int]] = None
+ memory_size: int = -1
+ prenet_type: str = "original"
+ prenet_dropout: bool = True
+ prenet_dropout_at_inference: bool = False
+ stopnet: bool = True
+ separate_stopnet: bool = True
+ stopnet_pos_weight: float = 10.0
+ max_decoder_steps: int = 500
+ encoder_in_features: int = 256
+ decoder_in_features: int = 256
+ decoder_output_dim: int = 80
+ out_channels: int = 513
+
+ # attention layers
+ attention_type: str = "original"
+ attention_heads: int = None
+ attention_norm: str = "sigmoid"
+ attention_win: bool = False
+ windowing: bool = False
+ use_forward_attn: bool = False
+ forward_attn_mask: bool = False
+ transition_agent: bool = False
+ location_attn: bool = True
+
+ # advance methods
+ bidirectional_decoder: bool = False
+ double_decoder_consistency: bool = False
+ ddc_r: int = 6
+
+ # multi-speaker settings
+ speakers_file: str = None
+ use_speaker_embedding: bool = False
+ speaker_embedding_dim: int = 512
+ use_d_vector_file: bool = False
+ d_vector_file: str = False
+ d_vector_dim: int = None
+
+ # optimizer parameters
+ optimizer: str = "RAdam"
+ optimizer_params: dict = field(default_factory=lambda: {"betas": [0.9, 0.998], "weight_decay": 1e-6})
+ lr_scheduler: str = "NoamLR"
+ lr_scheduler_params: dict = field(default_factory=lambda: {"warmup_steps": 4000})
+ lr: float = 1e-4
+ grad_clip: float = 5.0
+ seq_len_norm: bool = False
+ loss_masking: bool = True
+
+ # loss params
+ decoder_loss_alpha: float = 0.25
+ postnet_loss_alpha: float = 0.25
+ postnet_diff_spec_alpha: float = 0.25
+ decoder_diff_spec_alpha: float = 0.25
+ decoder_ssim_alpha: float = 0.25
+ postnet_ssim_alpha: float = 0.25
+ ga_alpha: float = 5.0
+
+ # testing
+ test_sentences: List[str] = field(
+ default_factory=lambda: [
+ "It took me quite a long time to develop a voice, and now that I have it I'm not going to be silent.",
+ "Be a voice, not an echo.",
+ "I'm sorry Dave. I'm afraid I can't do that.",
+ "This cake is great. It's so delicious and moist.",
+ "Prior to November 22, 1963.",
+ ]
+ )
+
+ def check_values(self):
+ if self.gradual_training:
+ assert (
+ self.gradual_training[0][1] == self.r
+ ), f"[!] the first scheduled gradual training `r` must be equal to the model's `r` value. {self.gradual_training[0][1]} vs {self.r}"
+ if self.model == "tacotron" and self.audio is not None:
+ assert self.out_channels == (
+ self.audio.fft_size // 2 + 1
+ ), f"{self.out_channels} vs {self.audio.fft_size // 2 + 1}"
+ if self.model == "tacotron2" and self.audio is not None:
+ assert self.out_channels == self.audio.num_mels
diff --git a/Indic-TTS/TTS/TTS/tts/configs/vits_config.py b/Indic-TTS/TTS/TTS/tts/configs/vits_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8c7f91dcd965e0d1f1e3f2b78de321e27af3b95
--- /dev/null
+++ b/Indic-TTS/TTS/TTS/tts/configs/vits_config.py
@@ -0,0 +1,155 @@
+from dataclasses import dataclass, field
+from typing import List
+
+from TTS.tts.configs.shared_configs import BaseTTSConfig
+from TTS.tts.models.vits import VitsArgs
+
+
+@dataclass
+class VitsConfig(BaseTTSConfig):
+ """Defines parameters for VITS End2End TTS model.
+
+ Args:
+ model (str):
+ Model name. Do not change unless you know what you are doing.
+
+ model_args (VitsArgs):
+ Model architecture arguments. Defaults to `VitsArgs()`.
+
+ grad_clip (List):
+ Gradient clipping thresholds for each optimizer. Defaults to `[1000.0, 1000.0]`.
+
+ lr_gen (float):
+ Initial learning rate for the generator. Defaults to 0.0002.
+
+ lr_disc (float):
+ Initial learning rate for the discriminator. Defaults to 0.0002.
+
+ lr_scheduler_gen (str):
+ Name of the learning rate scheduler for the generator. One of the `torch.optim.lr_scheduler.*`. Defaults to
+ `ExponentialLR`.
+
+ lr_scheduler_gen_params (dict):
+ Parameters for the learning rate scheduler of the generator. Defaults to `{'gamma': 0.999875, "last_epoch":-1}`.
+
+ lr_scheduler_disc (str):
+ Name of the learning rate scheduler for the discriminator. One of the `torch.optim.lr_scheduler.*`. Defaults to
+ `ExponentialLR`.
+
+ lr_scheduler_disc_params (dict):
+ Parameters for the learning rate scheduler of the discriminator. Defaults to `{'gamma': 0.999875, "last_epoch":-1}`.
+
+ scheduler_after_epoch (bool):
+ If true, step the schedulers after each epoch else after each step. Defaults to `False`.
+
+ optimizer (str):
+ Name of the optimizer to use with both the generator and the discriminator networks. One of the
+ `torch.optim.*`. Defaults to `AdamW`.
+
+ kl_loss_alpha (float):
+ Loss weight for KL loss. Defaults to 1.0.
+
+ disc_loss_alpha (float):
+ Loss weight for the discriminator loss. Defaults to 1.0.
+
+ gen_loss_alpha (float):
+ Loss weight for the generator loss. Defaults to 1.0.
+
+ feat_loss_alpha (float):
+ Loss weight for the feature matching loss. Defaults to 1.0.
+
+ mel_loss_alpha (float):
+ Loss weight for the mel loss. Defaults to 45.0.
+
+ return_wav (bool):
+ If true, data loader returns the waveform as well as the other outputs. Do not change. Defaults to `True`.
+
+ compute_linear_spec (bool):
+ If true, the linear spectrogram is computed and returned alongside the mel output. Do not change. Defaults to `True`.
+
+ r (int):
+ Number of spectrogram frames to be generated at a time. Do not change. Defaults to `1`.
+
+ add_blank (bool):
+ If true, a blank token is added in between every character. Defaults to `True`.
+
+ test_sentences (List[List]):
+ List of sentences with speaker and language information to be used for testing.
+
+ language_ids_file (str):
+ Path to the language ids file.
+
+ use_language_embedding (bool):
+ If true, language embedding is used. Defaults to `False`.
+
+ Note:
+ Check :class:`TTS.tts.configs.shared_configs.BaseTTSConfig` for the inherited parameters.
+
+ Example:
+
+ >>> from TTS.tts.configs.vits_config import VitsConfig
+ >>> config = VitsConfig()
+ """
+
+ model: str = "vits"
+ # model specific params
+ model_args: VitsArgs = field(default_factory=VitsArgs)
+
+ # optimizer
+ grad_clip: List[float] = field(default_factory=lambda: [1000, 1000])
+ lr_gen: float = 0.0002
+ lr_disc: float = 0.0002
+ lr_scheduler_gen: str = "ExponentialLR"
+ lr_scheduler_gen_params: dict = field(default_factory=lambda: {"gamma": 0.999875, "last_epoch": -1})
+ lr_scheduler_disc: str = "ExponentialLR"
+ lr_scheduler_disc_params: dict = field(default_factory=lambda: {"gamma": 0.999875, "last_epoch": -1})
+ scheduler_after_epoch: bool = True
+ optimizer: str = "AdamW"
+ optimizer_params: dict = field(default_factory=lambda: {"betas": [0.8, 0.99], "eps": 1e-9, "weight_decay": 0.01})
+
+ # loss params
+ kl_loss_alpha: float = 1.0
+ disc_loss_alpha: float = 1.0
+ gen_loss_alpha: float = 1.0
+ feat_loss_alpha: float = 1.0
+ mel_loss_alpha: float = 45.0
+ dur_loss_alpha: float = 1.0
+ speaker_encoder_loss_alpha: float = 1.0
+
+ # data loader params
+ return_wav: bool = True
+ compute_linear_spec: bool = True
+
+ # overrides
+ r: int = 1 # DO NOT CHANGE
+ add_blank: bool = True
+
+ # testing
+ test_sentences: List[List] = field(
+ default_factory=lambda: [
+ ["It took me quite a long time to develop a voice, and now that I have it I'm not going to be silent."],
+ ["Be a voice, not an echo."],
+ ["I'm sorry Dave. I'm afraid I can't do that."],
+ ["This cake is great. It's so delicious and moist."],
+ ["Prior to November 22, 1963."],
+ ]
+ )
+
+ # multi-speaker settings
+ # use speaker embedding layer
+ num_speakers: int = 0
+ use_speaker_embedding: bool = False
+ speakers_file: str = None
+ speaker_embedding_channels: int = 256
+ language_ids_file: str = None
+ use_language_embedding: bool = False
+
+ # use d-vectors
+ use_d_vector_file: bool = False
+ d_vector_file: str = None
+ d_vector_dim: int = None
+
+ def __post_init__(self):
+ for key, val in self.model_args.items():
+ if hasattr(self, key):
+ self[key] = val
diff --git a/Indic-TTS/TTS/TTS/tts/datasets/__init__.py b/Indic-TTS/TTS/TTS/tts/datasets/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..6c7c9eddeae7dd68cd8e73feab9e6f7ec7f002b0
--- /dev/null
+++ b/Indic-TTS/TTS/TTS/tts/datasets/__init__.py
@@ -0,0 +1,169 @@
+import sys
+from collections import Counter
+from pathlib import Path
+from typing import Callable, Dict, List, Tuple, Union
+
+import numpy as np
+
+from TTS.tts.datasets.dataset import *
+from TTS.tts.datasets.formatters import *
+
+
+def split_dataset(items, eval_split_max_size=None, eval_split_size=0.01):
+ """Split a dataset into train and eval. Consider speaker distribution in multi-speaker training.
+
+ Args:
+ <<<<<<< HEAD
+ items (List[List]):
+ A list of samples. Each sample is a list of `[audio_path, text, speaker_id]`.
+
+ eval_split_max_size (int):
+ Number maximum of samples to be used for evaluation in proportion split. Defaults to None (Disabled).
+
+ eval_split_size (float):
+ If between 0.0 and 1.0 represents the proportion of the dataset to include in the evaluation set.
+ If > 1, represents the absolute number of evaluation samples. Defaults to 0.01 (1%).
+ =======
+ items (List[List]): A list of samples. Each sample is a list of `[text, audio_path, speaker_id]`.
+ >>>>>>> Fix docstring
+ """
+ speakers = [item["speaker_name"] for item in items]
+ is_multi_speaker = len(set(speakers)) > 1
+ if eval_split_size > 1:
+ eval_split_size = int(eval_split_size)
+ else:
+ if eval_split_max_size:
+ eval_split_size = min(eval_split_max_size, int(len(items) * eval_split_size))
+ else:
+ eval_split_size = int(len(items) * eval_split_size)
+
+ assert (
+ eval_split_size > 0
+ ), " [!] You do not have enough samples for the evaluation set. You can work around this setting the 'eval_split_size' parameter to a minimum of {}".format(
+ 1 / len(items)
+ )
+ np.random.seed(0)
+ np.random.shuffle(items)
+ if is_multi_speaker:
+ items_eval = []
+ speakers = [item["speaker_name"] for item in items]
+ speaker_counter = Counter(speakers)
+ while len(items_eval) < eval_split_size:
+ item_idx = np.random.randint(0, len(items))
+ speaker_to_be_removed = items[item_idx]["speaker_name"]
+ if speaker_counter[speaker_to_be_removed] > 1:
+ items_eval.append(items[item_idx])
+ speaker_counter[speaker_to_be_removed] -= 1
+ del items[item_idx]
+ return items_eval, items
+ return items[:eval_split_size], items[eval_split_size:]
+
+
+def load_tts_samples(
+ datasets: Union[List[Dict], Dict],
+ eval_split=True,
+ formatter: Callable = None,
+ eval_split_max_size=None,
+ eval_split_size=0.01,
+) -> Tuple[List[List], List[List]]:
+ """Parse the dataset from the datasets config, load the samples as a List and load the attention alignments if provided.
+ If `formatter` is not None, apply the formatter to the samples else pick the formatter from the available ones based
+ on the dataset name.
+
+ Args:
+ datasets (List[Dict], Dict): A list of datasets or a single dataset dictionary. If multiple datasets are
+ in the list, they are all merged.
+
+ eval_split (bool, optional): If true, create a evaluation split. If an eval split provided explicitly, generate
+ an eval split automatically. Defaults to True.
+
+ formatter (Callable, optional): The preprocessing function to be applied to create the list of samples. It
+ must take the root_path and the meta_file name and return a list of samples in the format of
+ `[[text, audio_path, speaker_id], ...]]`. See the available formatters in `TTS.tts.dataset.formatter` as
+ example. Defaults to None.
+
+ eval_split_max_size (int):
+ Number maximum of samples to be used for evaluation in proportion split. Defaults to None (Disabled).
+
+ eval_split_size (float):
+ If between 0.0 and 1.0 represents the proportion of the dataset to include in the evaluation set.
+ If > 1, represents the absolute number of evaluation samples. Defaults to 0.01 (1%).
+
+ Returns:
+ Tuple[List[List], List[List]: training and evaluation splits of the dataset.
+ """
+ meta_data_train_all = []
+ meta_data_eval_all = [] if eval_split else None
+ if not isinstance(datasets, list):
+ datasets = [datasets]
+ for dataset in datasets:
+ name = dataset["name"]
+ root_path = dataset["path"]
+ meta_file_train = dataset["meta_file_train"]
+ meta_file_val = dataset["meta_file_val"]
+ ignored_speakers = dataset["ignored_speakers"]
+ language = dataset["language"]
+
+ # setup the right data processor
+ if formatter is None:
+ formatter = _get_formatter_by_name(name)
+ # load train set
+ meta_data_train = formatter(root_path, meta_file_train, ignored_speakers=ignored_speakers)
+ meta_data_train = [{**item, **{"language": language}} for item in meta_data_train]
+
+ print(f" | > Found {len(meta_data_train)} files in {Path(root_path).resolve()}")
+ # load evaluation split if set
+ if eval_split:
+ if meta_file_val:
+ meta_data_eval = formatter(root_path, meta_file_val, ignored_speakers=ignored_speakers)
+ meta_data_eval = [{**item, **{"language": language}} for item in meta_data_eval]
+ else:
+ meta_data_eval, meta_data_train = split_dataset(meta_data_train, eval_split_max_size, eval_split_size)
+ meta_data_eval_all += meta_data_eval
+ meta_data_train_all += meta_data_train
+ # load attention masks for the duration predictor training
+ if dataset.meta_file_attn_mask:
+ meta_data = dict(load_attention_mask_meta_data(dataset["meta_file_attn_mask"]))
+ for idx, ins in enumerate(meta_data_train_all):
+ attn_file = meta_data[ins["audio_file"]].strip()
+ meta_data_train_all[idx].update({"alignment_file": attn_file})
+ if meta_data_eval_all:
+ for idx, ins in enumerate(meta_data_eval_all):
+ attn_file = meta_data[ins["audio_file"]].strip()
+ meta_data_eval_all[idx].update({"alignment_file": attn_file})
+ # set none for the next iter
+ formatter = None
+ return meta_data_train_all, meta_data_eval_all
+
+
+def load_attention_mask_meta_data(metafile_path):
+ """Load meta data file created by compute_attention_masks.py"""
+ with open(metafile_path, "r", encoding="utf-8") as f:
+ lines = f.readlines()
+
+ meta_data = []
+ for line in lines:
+ wav_file, attn_file = line.split("|")
+ meta_data.append([wav_file, attn_file])
+ return meta_data
+
+
+def _get_formatter_by_name(name):
+ """Returns the respective preprocessing function."""
+ thismodule = sys.modules[__name__]
+ return getattr(thismodule, name.lower())
+
+
+def find_unique_chars(data_samples, verbose=True):
+ texts = "".join(item[0] for item in data_samples)
+ chars = set(texts)
+ lower_chars = filter(lambda c: c.islower(), chars)
+ chars_force_lower = [c.lower() for c in chars]
+ chars_force_lower = set(chars_force_lower)
+
+ if verbose:
+ print(f" > Number of unique characters: {len(chars)}")
+ print(f" > Unique characters: {''.join(sorted(chars))}")
+ print(f" > Unique lower characters: {''.join(sorted(lower_chars))}")
+ print(f" > Unique all forced to lower characters: {''.join(sorted(chars_force_lower))}")
+ return chars_force_lower
diff --git a/Indic-TTS/TTS/TTS/tts/datasets/__pycache__/__init__.cpython-37.pyc b/Indic-TTS/TTS/TTS/tts/datasets/__pycache__/__init__.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7fc2a0b8c96c12b96d7effa0aba9df664526bbd5
Binary files /dev/null and b/Indic-TTS/TTS/TTS/tts/datasets/__pycache__/__init__.cpython-37.pyc differ
diff --git a/Indic-TTS/TTS/TTS/tts/datasets/__pycache__/dataset.cpython-37.pyc b/Indic-TTS/TTS/TTS/tts/datasets/__pycache__/dataset.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c023ebfae676f746145afc1511ec29ac293b6b34
Binary files /dev/null and b/Indic-TTS/TTS/TTS/tts/datasets/__pycache__/dataset.cpython-37.pyc differ
diff --git a/Indic-TTS/TTS/TTS/tts/datasets/__pycache__/formatters.cpython-37.pyc b/Indic-TTS/TTS/TTS/tts/datasets/__pycache__/formatters.cpython-37.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..53a6b553a66627f55a9ae18a52cca5bba60d7825
Binary files /dev/null and b/Indic-TTS/TTS/TTS/tts/datasets/__pycache__/formatters.cpython-37.pyc differ
diff --git a/Indic-TTS/TTS/TTS/tts/datasets/dataset.py b/Indic-TTS/TTS/TTS/tts/datasets/dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..d8f16e4efe390d8ebaf63eb681ec3d5646e6be3e
--- /dev/null
+++ b/Indic-TTS/TTS/TTS/tts/datasets/dataset.py
@@ -0,0 +1,772 @@
+import collections
+import os
+import random
+from typing import Dict, List, Union
+
+import numpy as np
+import torch
+import tqdm
+from torch.utils.data import Dataset
+
+from TTS.tts.utils.data import prepare_data, prepare_stop_target, prepare_tensor
+from TTS.utils.audio import AudioProcessor
+
+# to prevent too many open files error as suggested here
+# https://github.com/pytorch/pytorch/issues/11201#issuecomment-421146936
+torch.multiprocessing.set_sharing_strategy("file_system")
+
+
+def _parse_sample(item):
+ language_name = None
+ attn_file = None
+ if len(item) == 5:
+ text, wav_file, speaker_name, language_name, attn_file = item
+ elif len(item) == 4:
+ text, wav_file, speaker_name, language_name = item
+ elif len(item) == 3:
+ text, wav_file, speaker_name = item
+ else:
+ raise ValueError(" [!] Dataset cannot parse the sample.")
+ return text, wav_file, speaker_name, language_name, attn_file
+
+
+def noise_augment_audio(wav):
+ return wav + (1.0 / 32768.0) * np.random.rand(*wav.shape)
+
+
+class TTSDataset(Dataset):
+ def __init__(
+ self,
+ outputs_per_step: int = 1,
+ compute_linear_spec: bool = False,
+ ap: AudioProcessor = None,
+ samples: List[Dict] = None,
+ tokenizer: "TTSTokenizer" = None,
+ compute_f0: bool = False,
+ f0_cache_path: str = None,
+ return_wav: bool = False,
+ batch_group_size: int = 0,
+ min_text_len: int = 0,
+ max_text_len: int = float("inf"),
+ min_audio_len: int = 0,
+ max_audio_len: int = float("inf"),
+ phoneme_cache_path: str = None,
+ precompute_num_workers: int = 0,
+ speaker_id_mapping: Dict = None,
+ d_vector_mapping: Dict = None,
+ language_id_mapping: Dict = None,
+ use_noise_augment: bool = False,
+ start_by_longest: bool = False,
+ verbose: bool = False,
+ ):
+ """Generic 📂 data loader for `tts` models. It is configurable for different outputs and needs.
+
+ If you need something different, you can subclass and override.
+
+ Args:
+ outputs_per_step (int): Number of time frames predicted per step.
+
+ compute_linear_spec (bool): compute linear spectrogram if True.
+
+ ap (TTS.tts.utils.AudioProcessor): Audio processor object.
+
+ samples (list): List of dataset samples.
+
+ tokenizer (TTSTokenizer): tokenizer to convert text to sequence IDs. If None init internally else
+ use the given. Defaults to None.
+
+ compute_f0 (bool): compute f0 if True. Defaults to False.
+
+ f0_cache_path (str): Path to store f0 cache. Defaults to None.
+
+ return_wav (bool): Return the waveform of the sample. Defaults to False.
+
+ batch_group_size (int): Range of batch randomization after sorting
+ sequences by length. It shuffles each batch with bucketing to gather similar lenght sequences in a
+ batch. Set 0 to disable. Defaults to 0.
+
+ min_text_len (int): Minimum length of input text to be used. All shorter samples will be ignored.
+ Defaults to 0.
+
+ max_text_len (int): Maximum length of input text to be used. All longer samples will be ignored.
+ Defaults to float("inf").
+
+ min_audio_len (int): Minimum length of input audio to be used. All shorter samples will be ignored.
+ Defaults to 0.
+
+ max_audio_len (int): Maximum length of input audio to be used. All longer samples will be ignored.
+ The maximum length in the dataset defines the VRAM used in the training. Hence, pay attention to
+ this value if you encounter an OOM error in training. Defaults to float("inf").
+
+ phoneme_cache_path (str): Path to cache computed phonemes. It writes phonemes of each sample to a
+ separate file. Defaults to None.
+
+ precompute_num_workers (int): Number of workers to precompute features. Defaults to 0.
+
+ speaker_id_mapping (dict): Mapping of speaker names to IDs used to compute embedding vectors by the
+ embedding layer. Defaults to None.
+
+ d_vector_mapping (dict): Mapping of wav files to computed d-vectors. Defaults to None.
+
+ use_noise_augment (bool): Enable adding random noise to wav for augmentation. Defaults to False.
+
+ start_by_longest (bool): Start by longest sequence. It is especially useful to check OOM. Defaults to False.
+
+ verbose (bool): Print diagnostic information. Defaults to false.
+ """
+ super().__init__()
+ self.batch_group_size = batch_group_size
+ self._samples = samples
+ self.outputs_per_step = outputs_per_step
+ self.compute_linear_spec = compute_linear_spec
+ self.return_wav = return_wav
+ self.compute_f0 = compute_f0
+ self.f0_cache_path = f0_cache_path
+ self.min_audio_len = min_audio_len
+ self.max_audio_len = max_audio_len
+ self.min_text_len = min_text_len
+ self.max_text_len = max_text_len
+ self.ap = ap
+ self.phoneme_cache_path = phoneme_cache_path
+ self.speaker_id_mapping = speaker_id_mapping
+ self.d_vector_mapping = d_vector_mapping
+ self.language_id_mapping = language_id_mapping
+ self.use_noise_augment = use_noise_augment
+ self.start_by_longest = start_by_longest
+
+ self.verbose = verbose
+ self.rescue_item_idx = 1
+ self.pitch_computed = False
+ self.tokenizer = tokenizer
+
+ if self.tokenizer.use_phonemes:
+ self.phoneme_dataset = PhonemeDataset(
+ self.samples, self.tokenizer, phoneme_cache_path, precompute_num_workers=precompute_num_workers
+ )
+
+ if compute_f0:
+ self.f0_dataset = F0Dataset(
+ self.samples, self.ap, cache_path=f0_cache_path, precompute_num_workers=precompute_num_workers
+ )
+
+ if self.verbose:
+ self.print_logs()
+
+ @property
+ def lengths(self):
+ lens = []
+ for item in self.samples:
+ _, wav_file, *_ = _parse_sample(item)
+ audio_len = os.path.getsize(wav_file) / 16 * 8 # assuming 16bit audio
+ lens.append(audio_len)
+ return lens
+
+ @property
+ def samples(self):
+ return self._samples
+
+ @samples.setter
+ def samples(self, new_samples):
+ self._samples = new_samples
+ if hasattr(self, "f0_dataset"):
+ self.f0_dataset.samples = new_samples
+ if hasattr(self, "phoneme_dataset"):
+ self.phoneme_dataset.samples = new_samples
+
+ def __len__(self):
+ return len(self.samples)
+
+ def __getitem__(self, idx):
+ return self.load_data(idx)
+
+ def print_logs(self, level: int = 0) -> None:
+ indent = "\t" * level
+ print("\n")
+ print(f"{indent}> DataLoader initialization")
+ print(f"{indent}| > Tokenizer:")
+ self.tokenizer.print_logs(level + 1)
+ print(f"{indent}| > Number of instances : {len(self.samples)}")
+
+ def load_wav(self, filename):
+ waveform = self.ap.load_wav(filename)
+ assert waveform.size > 0
+ return waveform
+
+ def get_phonemes(self, idx, text):
+ out_dict = self.phoneme_dataset[idx]
+ assert text == out_dict["text"], f"{text} != {out_dict['text']}"
+ assert len(out_dict["token_ids"]) > 0
+ return out_dict
+
+ def get_f0(self, idx):
+ out_dict = self.f0_dataset[idx]
+ item = self.samples[idx]
+ assert item["audio_file"] == out_dict["audio_file"]
+ return out_dict
+
+ @staticmethod
+ def get_attn_mask(attn_file):
+ return np.load(attn_file)
+
+ def get_token_ids(self, idx, text):
+ if self.tokenizer.use_phonemes:
+ token_ids = self.get_phonemes(idx, text)["token_ids"]
+ else:
+ token_ids = self.tokenizer.text_to_ids(text)
+ return np.array(token_ids, dtype=np.int32)
+
+ def load_data(self, idx):
+ item = self.samples[idx]
+
+ raw_text = item["text"]
+
+ wav = np.asarray(self.load_wav(item["audio_file"]), dtype=np.float32)
+
+ # apply noise for augmentation
+ if self.use_noise_augment:
+ wav = noise_augment_audio(wav)
+
+ # get token ids
+ token_ids = self.get_token_ids(idx, item["text"])
+
+ # get pre-computed attention maps
+ attn = None
+ if "alignment_file" in item:
+ attn = self.get_attn_mask(item["alignment_file"])
+
+ # after phonemization the text length may change
+ # this is a shareful 🤭 hack to prevent longer phonemes
+ # TODO: find a better fix
+ if len(token_ids) > self.max_text_len or len(wav) < self.min_audio_len:
+ self.rescue_item_idx += 1
+ return self.load_data(self.rescue_item_idx)
+
+ # get f0 values
+ f0 = None
+ if self.compute_f0:
+ f0 = self.get_f0(idx)["f0"]
+
+ sample = {
+ "raw_text": raw_text,
+ "token_ids": token_ids,
+ "wav": wav,
+ "pitch": f0,
+ "attn": attn,
+ "item_idx": item["audio_file"],
+ "speaker_name": item["speaker_name"],
+ "language_name": item["language"],
+ "wav_file_name": os.path.basename(item["audio_file"]),
+ }
+ return sample
+
+ @staticmethod
+ def _compute_lengths(samples):
+ new_samples = []
+ for item in samples:
+ audio_length = os.path.getsize(item["audio_file"]) / 16 * 8 # assuming 16bit audio
+ text_lenght = len(item["text"])
+ item["audio_length"] = audio_length
+ item["text_length"] = text_lenght
+ new_samples += [item]
+ return new_samples
+
+ @staticmethod
+ def filter_by_length(lengths: List[int], min_len: int, max_len: int):
+ idxs = np.argsort(lengths) # ascending order
+ ignore_idx = []
+ keep_idx = []
+ for idx in idxs:
+ length = lengths[idx]
+ if length < min_len or length > max_len:
+ ignore_idx.append(idx)
+ else:
+ keep_idx.append(idx)
+ return ignore_idx, keep_idx
+
+ @staticmethod
+ def sort_by_length(samples: List[List]):
+ audio_lengths = [s["audio_length"] for s in samples]
+ idxs = np.argsort(audio_lengths) # ascending order
+ return idxs
+
+ @staticmethod
+ def create_buckets(samples, batch_group_size: int):
+ assert batch_group_size > 0
+ for i in range(len(samples) // batch_group_size):
+ offset = i * batch_group_size
+ end_offset = offset + batch_group_size
+ temp_items = samples[offset:end_offset]
+ random.shuffle(temp_items)
+ samples[offset:end_offset] = temp_items
+ return samples
+
+ @staticmethod
+ def _select_samples_by_idx(idxs, samples):
+ samples_new = []
+ for idx in idxs:
+ samples_new.append(samples[idx])
+ return samples_new
+
+ def preprocess_samples(self):
+ r"""Sort `items` based on text length or audio length in ascending order. Filter out samples out or the length
+ range.
+ """
+ samples = self._compute_lengths(self.samples)
+
+ # sort items based on the sequence length in ascending order
+ text_lengths = [i["text_length"] for i in samples]
+ audio_lengths = [i["audio_length"] for i in samples]
+ text_ignore_idx, text_keep_idx = self.filter_by_length(text_lengths, self.min_text_len, self.max_text_len)
+ audio_ignore_idx, audio_keep_idx = self.filter_by_length(audio_lengths, self.min_audio_len, self.max_audio_len)
+ keep_idx = list(set(audio_keep_idx) & set(text_keep_idx))
+ ignore_idx = list(set(audio_ignore_idx) | set(text_ignore_idx))
+
+ samples = self._select_samples_by_idx(keep_idx, samples)
+
+ sorted_idxs = self.sort_by_length(samples)
+
+ if self.start_by_longest:
+ longest_idxs = sorted_idxs[-1]
+ sorted_idxs[-1] = sorted_idxs[0]
+ sorted_idxs[0] = longest_idxs
+
+ samples = self._select_samples_by_idx(sorted_idxs, samples)
+
+ if len(samples) == 0:
+ raise RuntimeError(" [!] No samples left")
+
+ # shuffle batch groups
+ # create batches with similar length items
+ # the larger the `batch_group_size`, the higher the length variety in a batch.
+ if self.batch_group_size > 0:
+ samples = self.create_buckets(samples, self.batch_group_size)
+
+ # update items to the new sorted items
+ audio_lengths = [s["audio_length"] for s in samples]
+ text_lengths = [s["text_length"] for s in samples]
+ self.samples = samples
+
+ if self.verbose:
+ print(" | > Preprocessing samples")
+ print(" | > Max text length: {}".format(np.max(text_lengths)))
+ print(" | > Min text length: {}".format(np.min(text_lengths)))
+ print(" | > Avg text length: {}".format(np.mean(text_lengths)))
+ print(" | ")
+ print(" | > Max audio length: {}".format(np.max(audio_lengths)))
+ print(" | > Min audio length: {}".format(np.min(audio_lengths)))
+ print(" | > Avg audio length: {}".format(np.mean(audio_lengths)))
+ print(f" | > Num. instances discarded samples: {len(ignore_idx)}")
+ print(" | > Batch group size: {}.".format(self.batch_group_size))
+
+ @staticmethod
+ def _sort_batch(batch, text_lengths):
+ """Sort the batch by the input text length for RNN efficiency.
+
+ Args:
+ batch (Dict): Batch returned by `__getitem__`.
+ text_lengths (List[int]): Lengths of the input character sequences.
+ """
+ text_lengths, ids_sorted_decreasing = torch.sort(torch.LongTensor(text_lengths), dim=0, descending=True)
+ batch = [batch[idx] for idx in ids_sorted_decreasing]
+ return batch, text_lengths, ids_sorted_decreasing
+
+ def collate_fn(self, batch):
+ r"""
+ Perform preprocessing and create a final data batch:
+ 1. Sort batch instances by text-length
+ 2. Convert Audio signal to features.
+ 3. PAD sequences wrt r.
+ 4. Load to Torch.
+ """
+
+ # Puts each data field into a tensor with outer dimension batch size
+ if isinstance(batch[0], collections.abc.Mapping):
+
+ token_ids_lengths = np.array([len(d["token_ids"]) for d in batch])
+
+ # sort items with text input length for RNN efficiency
+ batch, token_ids_lengths, ids_sorted_decreasing = self._sort_batch(batch, token_ids_lengths)
+
+ # convert list of dicts to dict of lists
+ batch = {k: [dic[k] for dic in batch] for k in batch[0]}
+
+ # get language ids from language names
+ if self.language_id_mapping is not None:
+ language_ids = [self.language_id_mapping[ln] for ln in batch["language_name"]]
+ else:
+ language_ids = None
+ # get pre-computed d-vectors
+ if self.d_vector_mapping is not None:
+ wav_files_names = list(batch["wav_file_name"])
+ d_vectors = [self.d_vector_mapping[w]["embedding"] for w in wav_files_names]
+ else:
+ d_vectors = None
+
+ # get numerical speaker ids from speaker names
+ if self.speaker_id_mapping:
+ speaker_ids = [self.speaker_id_mapping[sn] for sn in batch["speaker_name"]]
+ else:
+ speaker_ids = None
+ # compute features
+ mel = [self.ap.melspectrogram(w).astype("float32") for w in batch["wav"]]
+
+ mel_lengths = [m.shape[1] for m in mel]
+
+ # lengths adjusted by the reduction factor
+ mel_lengths_adjusted = [
+ m.shape[1] + (self.outputs_per_step - (m.shape[1] % self.outputs_per_step))
+ if m.shape[1] % self.outputs_per_step
+ else m.shape[1]
+ for m in mel
+ ]
+
+ # compute 'stop token' targets
+ stop_targets = [np.array([0.0] * (mel_len - 1) + [1.0]) for mel_len in mel_lengths]
+
+ # PAD stop targets
+ stop_targets = prepare_stop_target(stop_targets, self.outputs_per_step)
+
+ # PAD sequences with longest instance in the batch
+ token_ids = prepare_data(batch["token_ids"]).astype(np.int32)
+
+ # PAD features with longest instance
+ mel = prepare_tensor(mel, self.outputs_per_step)
+
+ # B x D x T --> B x T x D
+ mel = mel.transpose(0, 2, 1)
+
+ # convert things to pytorch
+ token_ids_lengths = torch.LongTensor(token_ids_lengths)
+ token_ids = torch.LongTensor(token_ids)
+ mel = torch.FloatTensor(mel).contiguous()
+ mel_lengths = torch.LongTensor(mel_lengths)
+ stop_targets = torch.FloatTensor(stop_targets)
+
+ # speaker vectors
+ if d_vectors is not None:
+ d_vectors = torch.FloatTensor(d_vectors)
+
+ if speaker_ids is not None:
+ speaker_ids = torch.LongTensor(speaker_ids)
+
+ if language_ids is not None:
+ language_ids = torch.LongTensor(language_ids)
+
+ # compute linear spectrogram
+ linear = None
+ if self.compute_linear_spec:
+ linear = [self.ap.spectrogram(w).astype("float32") for w in batch["wav"]]
+ linear = prepare_tensor(linear, self.outputs_per_step)
+ linear = linear.transpose(0, 2, 1)
+ assert mel.shape[1] == linear.shape[1]
+ linear = torch.FloatTensor(linear).contiguous()
+
+ # format waveforms
+ wav_padded = None
+ if self.return_wav:
+ wav_lengths = [w.shape[0] for w in batch["wav"]]
+ max_wav_len = max(mel_lengths_adjusted) * self.ap.hop_length
+ wav_lengths = torch.LongTensor(wav_lengths)
+ wav_padded = torch.zeros(len(batch["wav"]), 1, max_wav_len)
+ for i, w in enumerate(batch["wav"]):
+ mel_length = mel_lengths_adjusted[i]
+ w = np.pad(w, (0, self.ap.hop_length * self.outputs_per_step), mode="edge")
+ w = w[: mel_length * self.ap.hop_length]
+ wav_padded[i, :, : w.shape[0]] = torch.from_numpy(w)
+ wav_padded.transpose_(1, 2)
+
+ # format F0
+ if self.compute_f0:
+ pitch = prepare_data(batch["pitch"])
+ assert mel.shape[1] == pitch.shape[1], f"[!] {mel.shape} vs {pitch.shape}"
+ pitch = torch.FloatTensor(pitch)[:, None, :].contiguous() # B x 1 xT
+ else:
+ pitch = None
+
+ # format attention masks
+ attns = None
+ if batch["attn"][0] is not None:
+ attns = [batch["attn"][idx].T for idx in ids_sorted_decreasing]
+ for idx, attn in enumerate(attns):
+ pad2 = mel.shape[1] - attn.shape[1]
+ pad1 = token_ids.shape[1] - attn.shape[0]
+ assert pad1 >= 0 and pad2 >= 0, f"[!] Negative padding - {pad1} and {pad2}"
+ attn = np.pad(attn, [[0, pad1], [0, pad2]])
+ attns[idx] = attn
+ attns = prepare_tensor(attns, self.outputs_per_step)
+ attns = torch.FloatTensor(attns).unsqueeze(1)
+
+ return {
+ "token_id": token_ids,
+ "token_id_lengths": token_ids_lengths,
+ "speaker_names": batch["speaker_name"],
+ "linear": linear,
+ "mel": mel,
+ "mel_lengths": mel_lengths,
+ "stop_targets": stop_targets,
+ "item_idxs": batch["item_idx"],
+ "d_vectors": d_vectors,
+ "speaker_ids": speaker_ids,
+ "attns": attns,
+ "waveform": wav_padded,
+ "raw_text": batch["raw_text"],
+ "pitch": pitch,
+ "language_ids": language_ids,
+ }
+
+ raise TypeError(
+ (
+ "batch must contain tensors, numbers, dicts or lists;\
+ found {}".format(
+ type(batch[0])
+ )
+ )
+ )
+
+
+class PhonemeDataset(Dataset):
+ """Phoneme Dataset for converting input text to phonemes and then token IDs
+
+ At initialization, it pre-computes the phonemes under `cache_path` and loads them in training to reduce data
+ loading latency. If `cache_path` is already present, it skips the pre-computation.
+
+ Args:
+ samples (Union[List[List], List[Dict]]):
+ List of samples. Each sample is a list or a dict.
+
+ tokenizer (TTSTokenizer):
+ Tokenizer to convert input text to phonemes.
+
+ cache_path (str):
+ Path to cache phonemes. If `cache_path` is already present or None, it skips the pre-computation.
+
+ precompute_num_workers (int):
+ Number of workers used for pre-computing the phonemes. Defaults to 0.
+ """
+
+ def __init__(
+ self,
+ samples: Union[List[Dict], List[List]],
+ tokenizer: "TTSTokenizer",
+ cache_path: str,
+ precompute_num_workers=0,
+ ):
+ self.samples = samples
+ self.tokenizer = tokenizer
+ self.cache_path = cache_path
+ if cache_path is not None and not os.path.exists(cache_path):
+ os.makedirs(cache_path)
+ self.precompute(precompute_num_workers)
+
+ def __getitem__(self, index):
+ item = self.samples[index]
+ ids = self.compute_or_load(item["audio_file"], item["text"])
+ ph_hat = self.tokenizer.ids_to_text(ids)
+ return {"text": item["text"], "ph_hat": ph_hat, "token_ids": ids, "token_ids_len": len(ids)}
+
+ def __len__(self):
+ return len(self.samples)
+
+ def compute_or_load(self, wav_file, text):
+ """Compute phonemes for the given text.
+
+ If the phonemes are already cached, load them from cache.
+ """
+ file_name = os.path.splitext(os.path.basename(wav_file))[0]
+ file_ext = "_phoneme.npy"
+ cache_path = os.path.join(self.cache_path, file_name + file_ext)
+ try:
+ ids = np.load(cache_path)
+ except FileNotFoundError:
+ ids = self.tokenizer.text_to_ids(text)
+ np.save(cache_path, ids)
+ return ids
+
+ def get_pad_id(self):
+ """Get pad token ID for sequence padding"""
+ return self.tokenizer.pad_id
+
+ def precompute(self, num_workers=1):
+ """Precompute phonemes for all samples.
+
+ We use pytorch dataloader because we are lazy.
+ """
+ print("[*] Pre-computing phonemes...")
+ with tqdm.tqdm(total=len(self)) as pbar:
+ batch_size = num_workers if num_workers > 0 else 1
+ dataloder = torch.utils.data.DataLoader(
+ batch_size=batch_size, dataset=self, shuffle=False, num_workers=num_workers, collate_fn=self.collate_fn
+ )
+ for _ in dataloder:
+ pbar.update(batch_size)
+
+ def collate_fn(self, batch):
+ ids = [item["token_ids"] for item in batch]
+ ids_lens = [item["token_ids_len"] for item in batch]
+ texts = [item["text"] for item in batch]
+ texts_hat = [item["ph_hat"] for item in batch]
+ ids_lens_max = max(ids_lens)
+ ids_torch = torch.LongTensor(len(ids), ids_lens_max).fill_(self.get_pad_id())
+ for i, ids_len in enumerate(ids_lens):
+ ids_torch[i, :ids_len] = torch.LongTensor(ids[i])
+ return {"text": texts, "ph_hat": texts_hat, "token_ids": ids_torch}
+
+ def print_logs(self, level: int = 0) -> None:
+ indent = "\t" * level
+ print("\n")
+ print(f"{indent}> PhonemeDataset ")
+ print(f"{indent}| > Tokenizer:")
+ self.tokenizer.print_logs(level + 1)
+ print(f"{indent}| > Number of instances : {len(self.samples)}")
+
+
+class F0Dataset:
+ """F0 Dataset for computing F0 from wav files in CPU
+
+ Pre-compute F0 values for all the samples at initialization if `cache_path` is not None or already present. It
+ also computes the mean and std of F0 values if `normalize_f0` is True.
+
+ Args:
+ samples (Union[List[List], List[Dict]]):
+ List of samples. Each sample is a list or a dict.
+
+ ap (AudioProcessor):
+ AudioProcessor to compute F0 from wav files.
+
+ cache_path (str):
+ Path to cache F0 values. If `cache_path` is already present or None, it skips the pre-computation.
+ Defaults to None.
+
+ precompute_num_workers (int):
+ Number of workers used for pre-computing the F0 values. Defaults to 0.
+
+ normalize_f0 (bool):
+ Whether to normalize F0 values by mean and std. Defaults to True.
+ """
+
+ def __init__(
+ self,
+ samples: Union[List[List], List[Dict]],
+ ap: "AudioProcessor",
+ verbose=False,
+ cache_path: str = None,
+ precompute_num_workers=0,
+ normalize_f0=True,
+ ):
+ self.samples = samples
+ self.ap = ap
+ self.verbose = verbose
+ self.cache_path = cache_path
+ self.normalize_f0 = normalize_f0
+ self.pad_id = 0.0
+ self.mean = None
+ self.std = None
+ if cache_path is not None and not os.path.exists(cache_path):
+ os.makedirs(cache_path)
+ self.precompute(precompute_num_workers)
+ if normalize_f0:
+ self.load_stats(cache_path)
+
+ def __getitem__(self, idx):
+ item = self.samples[idx]
+ f0 = self.compute_or_load(item["audio_file"])
+ if self.normalize_f0:
+ assert self.mean is not None and self.std is not None, " [!] Mean and STD is not available"
+ f0 = self.normalize(f0)
+ return {"audio_file": item["audio_file"], "f0": f0}
+
+ def __len__(self):
+ return len(self.samples)
+
+ def precompute(self, num_workers=0):
+ print("[*] Pre-computing F0s...")
+ with tqdm.tqdm(total=len(self)) as pbar:
+ batch_size = num_workers if num_workers > 0 else 1
+ # we do not normalize at preproessing
+ normalize_f0 = self.normalize_f0
+ self.normalize_f0 = False
+ dataloder = torch.utils.data.DataLoader(
+ batch_size=batch_size, dataset=self, shuffle=False, num_workers=num_workers, collate_fn=self.collate_fn
+ )
+ computed_data = []
+ for batch in dataloder:
+ f0 = batch["f0"]
+ computed_data.append(f for f in f0)
+ pbar.update(batch_size)
+ self.normalize_f0 = normalize_f0
+
+ if self.normalize_f0:
+ computed_data = [tensor for batch in computed_data for tensor in batch] # flatten
+ pitch_mean, pitch_std = self.compute_pitch_stats(computed_data)
+ pitch_stats = {"mean": pitch_mean, "std": pitch_std}
+ np.save(os.path.join(self.cache_path, "pitch_stats"), pitch_stats, allow_pickle=True)
+
+ def get_pad_id(self):
+ return self.pad_id
+
+ @staticmethod
+ def create_pitch_file_path(wav_file, cache_path):
+ file_name = os.path.splitext(os.path.basename(wav_file))[0]
+ pitch_file = os.path.join(cache_path, file_name + "_pitch.npy")
+ return pitch_file
+
+ @staticmethod
+ def _compute_and_save_pitch(ap, wav_file, pitch_file=None):
+ wav = ap.load_wav(wav_file)
+ pitch = ap.compute_f0(wav)
+ if pitch_file:
+ np.save(pitch_file, pitch)
+ return pitch
+
+ @staticmethod
+ def compute_pitch_stats(pitch_vecs):
+ nonzeros = np.concatenate([v[np.where(v != 0.0)[0]] for v in pitch_vecs])
+ mean, std = np.mean(nonzeros), np.std(nonzeros)
+ return mean, std
+
+ def load_stats(self, cache_path):
+ stats_path = os.path.join(cache_path, "pitch_stats.npy")
+ stats = np.load(stats_path, allow_pickle=True).item()
+ self.mean = stats["mean"].astype(np.float32)
+ self.std = stats["std"].astype(np.float32)
+
+ def normalize(self, pitch):
+ zero_idxs = np.where(pitch == 0.0)[0]
+ pitch = pitch - self.mean
+ pitch = pitch / self.std
+ pitch[zero_idxs] = 0.0
+ return pitch
+
+ def denormalize(self, pitch):
+ zero_idxs = np.where(pitch == 0.0)[0]
+ pitch *= self.std
+ pitch += self.mean
+ pitch[zero_idxs] = 0.0
+ return pitch
+
+ def compute_or_load(self, wav_file):
+ """
+ compute pitch and return a numpy array of pitch values
+ """
+ pitch_file = self.create_pitch_file_path(wav_file, self.cache_path)
+ if not os.path.exists(pitch_file):
+ pitch = self._compute_and_save_pitch(self.ap, wav_file, pitch_file)
+ else:
+ pitch = np.load(pitch_file)
+ return pitch.astype(np.float32)
+
+ def collate_fn(self, batch):
+ audio_file = [item["audio_file"] for item in batch]
+ f0s = [item["f0"] for item in batch]
+ f0_lens = [len(item["f0"]) for item in batch]
+ f0_lens_max = max(f0_lens)
+ f0s_torch = torch.LongTensor(len(f0s), f0_lens_max).fill_(self.get_pad_id())
+ for i, f0_len in enumerate(f0_lens):
+ f0s_torch[i, :f0_len] = torch.LongTensor(f0s[i])
+ return {"audio_file": audio_file, "f0": f0s_torch, "f0_lens": f0_lens}
+
+ def print_logs(self, level: int = 0) -> None:
+ indent = "\t" * level
+ print("\n")
+ print(f"{indent}> F0Dataset ")
+ print(f"{indent}| > Number of instances : {len(self.samples)}")
diff --git a/Indic-TTS/TTS/TTS/tts/datasets/formatters.py b/Indic-TTS/TTS/TTS/tts/datasets/formatters.py
new file mode 100644
index 0000000000000000000000000000000000000000..ef05ea7c7ada5b614240bd0733529e530c137d10
--- /dev/null
+++ b/Indic-TTS/TTS/TTS/tts/datasets/formatters.py
@@ -0,0 +1,558 @@
+import os
+import re
+import xml.etree.ElementTree as ET
+from glob import glob
+from pathlib import Path
+from typing import List
+
+import pandas as pd
+from tqdm import tqdm
+
+########################
+# DATASETS
+########################
+
+
+def coqui(root_path, meta_file, ignored_speakers=None):
+ """Interal dataset formatter."""
+ metadata = pd.read_csv(os.path.join(root_path, meta_file), sep="|")
+ assert all(x in metadata.columns for x in ["audio_file", "text"])
+ speaker_name = None if "speaker_name" in metadata.columns else "coqui"
+ emotion_name = None if "emotion_name" in metadata.columns else "neutral"
+ items = []
+ not_found_counter = 0
+ for row in metadata.itertuples():
+ if speaker_name is None and ignored_speakers is not None and row.speaker_name in ignored_speakers:
+ continue
+ audio_path = os.path.join(root_path, row.audio_file)
+ if not os.path.exists(audio_path):
+ not_found_counter += 1
+ continue
+ items.append(
+ {
+ "text": row.text,
+ "audio_file": audio_path,
+ "speaker_name": speaker_name if speaker_name is not None else row.speaker_name,
+ "emotion_name": emotion_name if emotion_name is not None else row.emotion_name,
+ }
+ )
+ if not_found_counter > 0:
+ print(f" | > [!] {not_found_counter} files not found")
+ return items
+
+
+def tweb(root_path, meta_file, **kwargs): # pylint: disable=unused-argument
+ """Normalize TWEB dataset.
+ https://www.kaggle.com/bryanpark/the-world-english-bible-speech-dataset
+ """
+ txt_file = os.path.join(root_path, meta_file)
+ items = []
+ speaker_name = "tweb"
+ with open(txt_file, "r", encoding="utf-8") as ttf:
+ for line in ttf:
+ cols = line.split("\t")
+ wav_file = os.path.join(root_path, cols[0] + ".wav")
+ text = cols[1]
+ items.append({"text": text, "audio_file": wav_file, "speaker_name": speaker_name})
+ return items
+
+
+def mozilla(root_path, meta_file, **kwargs): # pylint: disable=unused-argument
+ """Normalizes Mozilla meta data files to TTS format"""
+ txt_file = os.path.join(root_path, meta_file)
+ items = []
+ speaker_name = "mozilla"
+ with open(txt_file, "r", encoding="utf-8") as ttf:
+ for line in ttf:
+ cols = line.split("|")
+ wav_file = cols[1].strip()
+ text = cols[0].strip()
+ wav_file = os.path.join(root_path, "wavs", wav_file)
+ items.append({"text": text, "audio_file": wav_file, "speaker_name": speaker_name})
+ return items
+
+
+def mozilla_de(root_path, meta_file, **kwargs): # pylint: disable=unused-argument
+ """Normalizes Mozilla meta data files to TTS format"""
+ txt_file = os.path.join(root_path, meta_file)
+ items = []
+ speaker_name = "mozilla"
+ with open(txt_file, "r", encoding="ISO 8859-1") as ttf:
+ for line in ttf:
+ cols = line.strip().split("|")
+ wav_file = cols[0].strip()
+ text = cols[1].strip()
+ folder_name = f"BATCH_{wav_file.split('_')[0]}_FINAL"
+ wav_file = os.path.join(root_path, folder_name, wav_file)
+ items.append({"text": text, "audio_file": wav_file, "speaker_name": speaker_name})
+ return items
+
+
+def mailabs(root_path, meta_files=None, ignored_speakers=None):
+ """Normalizes M-AI-Labs meta data files to TTS format
+
+ Args:
+ root_path (str): root folder of the MAILAB language folder.
+ meta_files (str): list of meta files to be used in the training. If None, finds all the csv files
+ recursively. Defaults to None
+ """
+ speaker_regex = re.compile("by_book/(male|female)/(?P
+
+
+ }}) +
+
+
+
+ + {%if use_multi_speaker%} + Choose a speaker: +
+ {%endif%} + + {%if show_details%} +
+ {%endif%} + + +
+
+
+ -
+
+ + {%if use_multi_speaker%} + Choose a speaker: +
+ {%endif%} + + {%if show_details%} +
+ {%endif%} + + +