
ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration
Description
Orchestrator-8B is a state-of-the-art 8B parameter orchestration model designed to solve complex, multi-turn agentic tasks by coordinating a diverse set of expert models and tools.
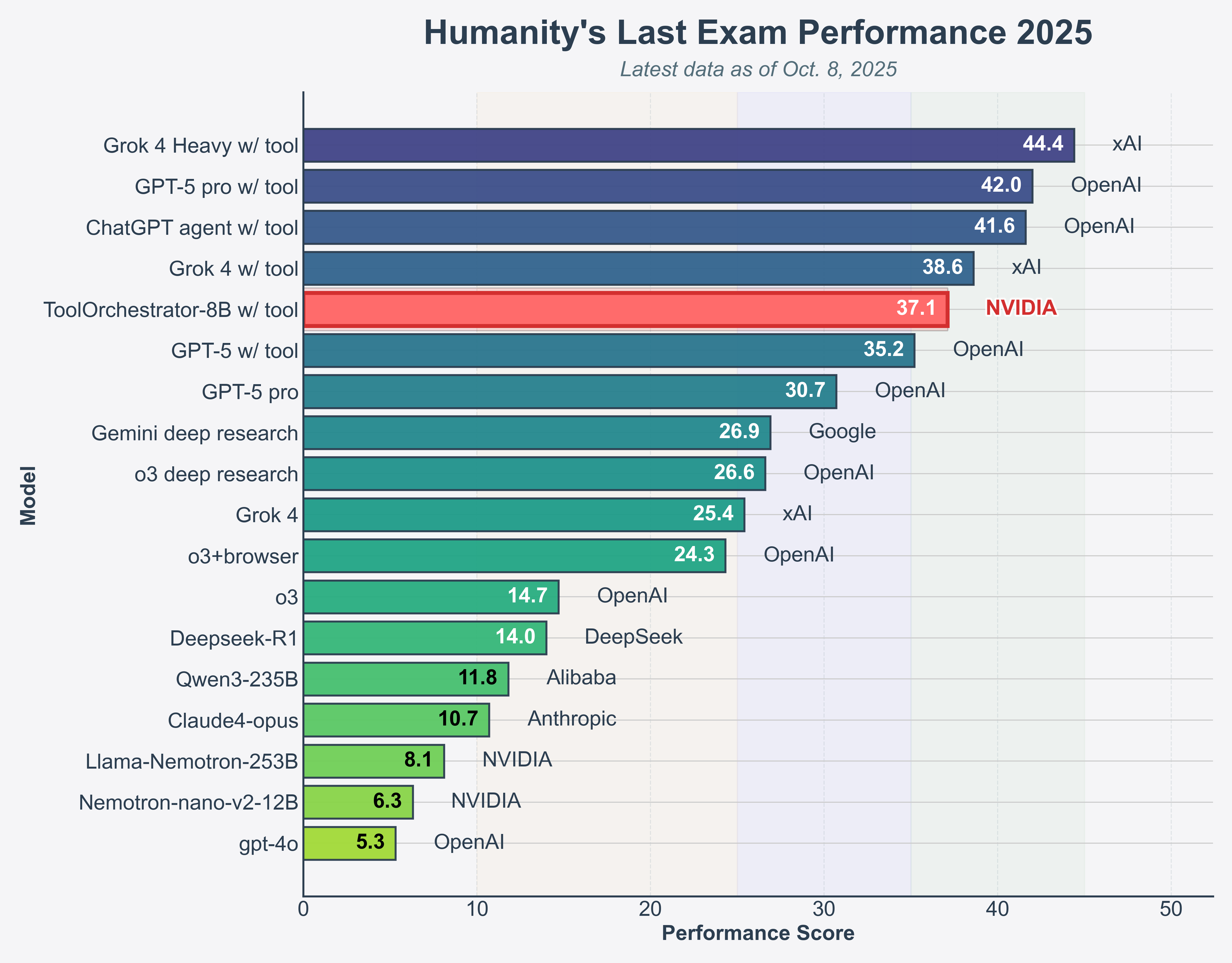
On the Humanity's Last Exam (HLE) benchmark, ToolOrchestrator-8B achieves a score of 37.1%, outperforming GPT-5 (35.1%) while being approximately 2.5x more efficient.
This model is for research and development only.
Key Features
- Intelligent Orchestration: Capable of managing heterogeneous toolsets including basic tools (search, code execution) and other LLMs (specialized and generalist).
- Multi-Objective RL Training: Trained via Group Relative Policy Optimization (GRPO) with a novel reward function that optimizes for accuracy, latency/cost, and adherence to user preferences.
- Efficiency: Delivers higher accuracy at significantly lower computational cost compared to monolithic frontier models.
- Robust Generalization: Demonstrated ability to generalize to unseen tools and pricing configurations.
Benchmark
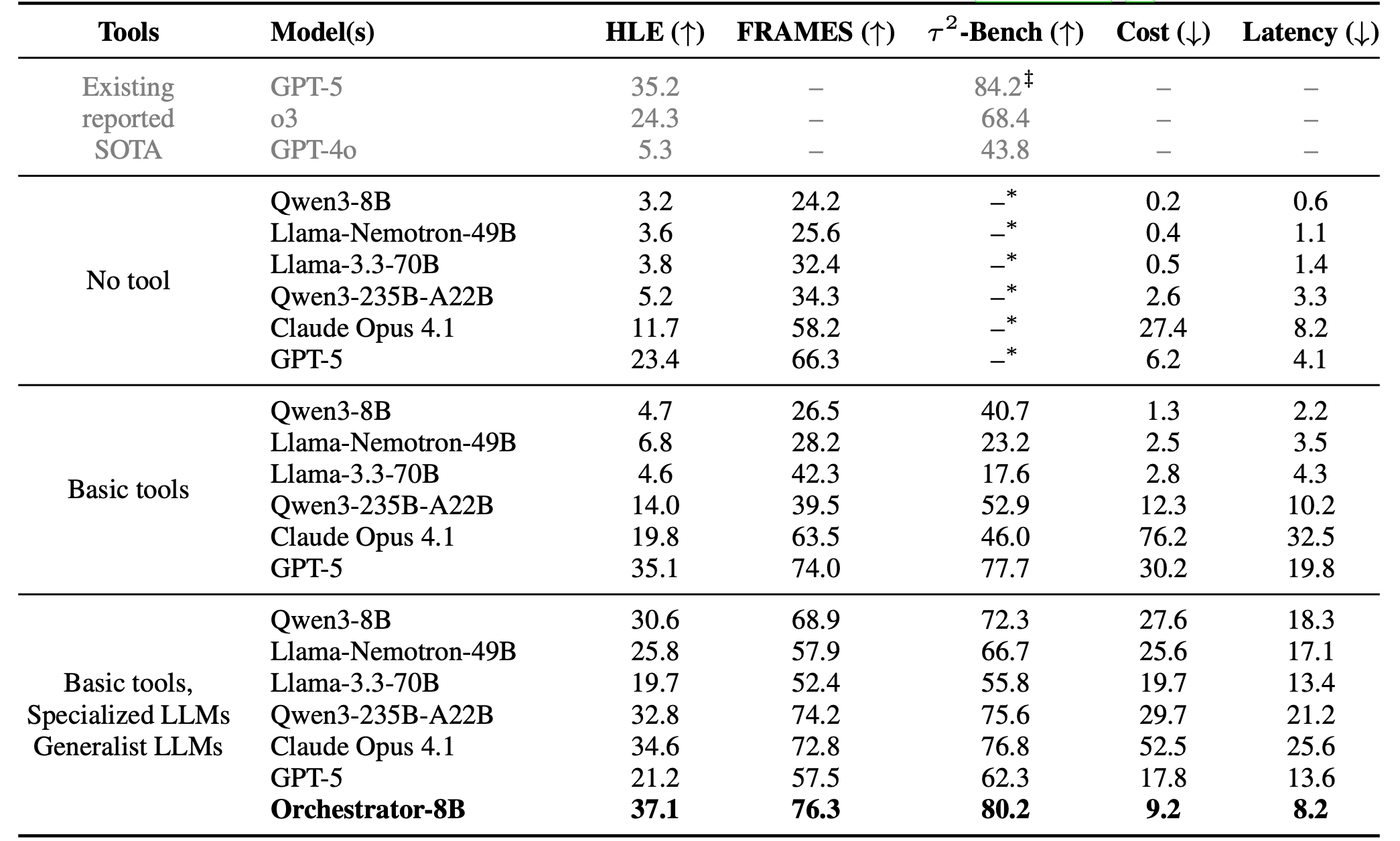
On Humanity’s Last Exam, Orchestrator-8B achieves 37.1%, surpassing GPT-5 (35.1%) with only 30% monetary cost and 2.5x faster. On FRAMES and τ²-Bench, Orchestrator-8B consistently outperforms strong monolithic systems, demonstrating versatile reasoning and robust tool orchestration.
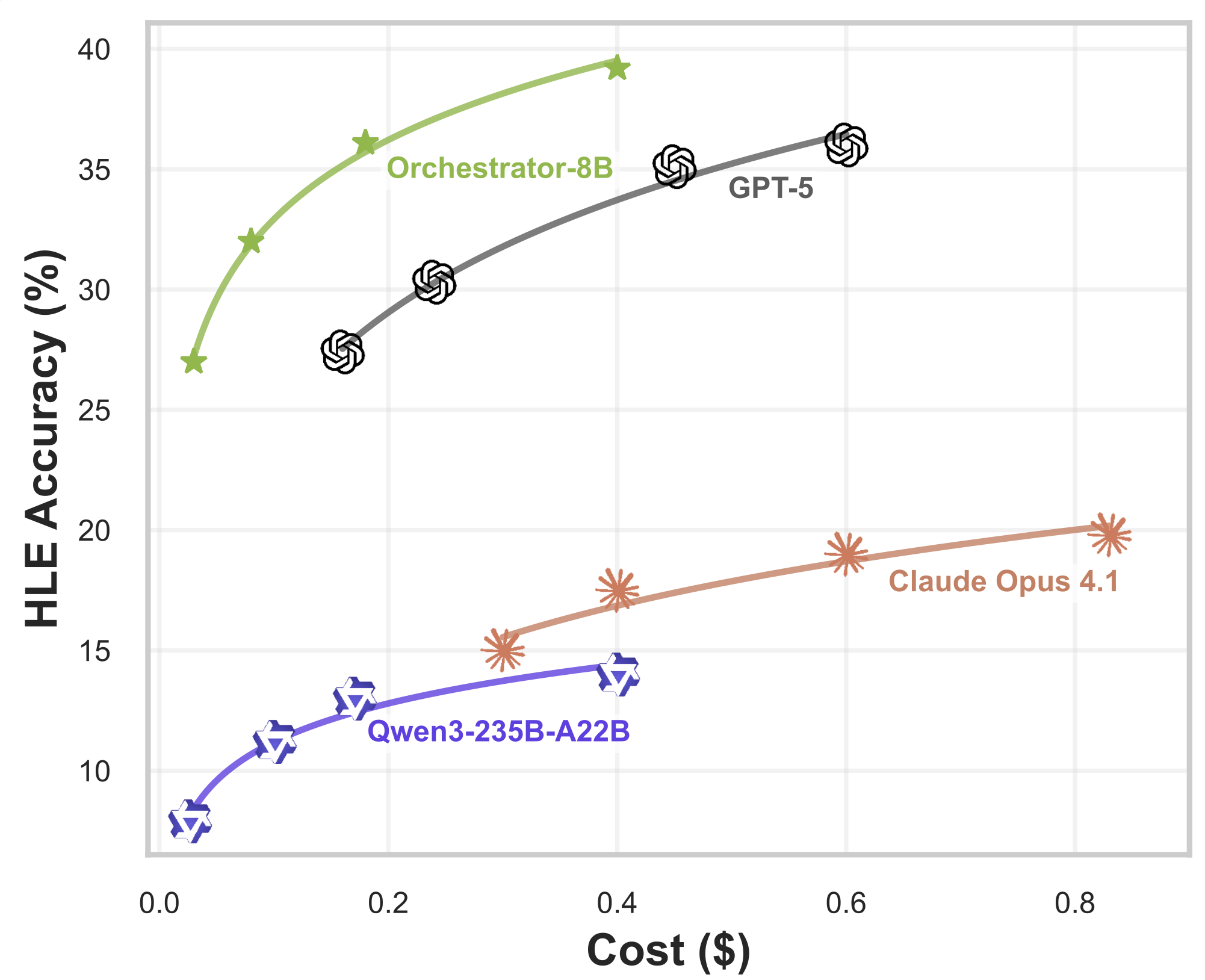
Orchestrator-8B consistently outperforms GPT-5, Claude Opus 4.1 and Qwen3-235B-A22B on HLE with substantially lower cost.
Model Details
- Developed by: NVIDIA & University of Hong Kong
- Model Type: Decoder-only Transformer
- Base Model: Qwen3-8B
- Parameters: 8B
- Language(s): English
- License: NVIDIA License
Model Version(s):
1.0
Training Dataset:
Link:
| Dataset | Link | |------
Orchestrator-8B GGUF Models
Model Generation Details
This model was generated using llama.cpp at commit d82b7a7c1.
Quantization Beyond the IMatrix
I've been experimenting with a new quantization approach that selectively elevates the precision of key layers beyond what the default IMatrix configuration provides.
In my testing, standard IMatrix quantization underperforms at lower bit depths, especially with Mixture of Experts (MoE) models. To address this, I'm using the --tensor-type option in llama.cpp to manually "bump" important layers to higher precision. You can see the implementation here:
👉 Layer bumping with llama.cpp
While this does increase model file size, it significantly improves precision for a given quantization level.
I'd love your feedback—have you tried this? How does it perform for you?
Click here to get info on choosing the right GGUF model format
---------------------|-------------------------------------------------------------------------------------------| | GeneralThought-430K | Link | | ToolScale | Link |
Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Please report model quality, risk, security vulnerabilities or NVIDIA AI Concerns here.
License/Terms of Use
Citation
If you find this model useful, please cite our paper:
@misc{toolorchestra,
title={ToolOrchestra: Elevating Intelligence via Efficient Model and Tool Orchestration},
author={Hongjin Su and Shizhe Diao and Ximing Lu and Mingjie Liu and Jiacheng Xu and Xin Dong and Yonggan Fu and Peter Belcak and Hanrong Ye and Hongxu Yin and Yi Dong and Evelina Bakhturina and Tao Yu and Yejin Choi and Jan Kautz and Pavlo Molchanov},
year={2025},
eprint={2511.21689},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2511.21689},
}
🚀 If you find these models useful
Help me test my AI-Powered Quantum Network Monitor Assistant with quantum-ready security checks:
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : Source Code Quantum Network Monitor. You will also find the code I use to quantize the models if you want to do it yourself GGUFModelBuilder
💬 How to test:
Choose an AI assistant type:
TurboLLM(GPT-4.1-mini)HugLLM(Hugginface Open-source models)TestLLM(Experimental CPU-only)
What I’m Testing
I’m pushing the limits of small open-source models for AI network monitoring, specifically:
- Function calling against live network services
- How small can a model go while still handling:
- Automated Nmap security scans
- Quantum-readiness checks
- Network Monitoring tasks
🟡 TestLLM – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ Zero-configuration setup
- ⏳ 30s load time (slow inference but no API costs) . No token limited as the cost is low.
- 🔧 Help wanted! If you’re into edge-device AI, let’s collaborate!
Other Assistants
🟢 TurboLLM – Uses gpt-4.1-mini :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- Create custom cmd processors to run .net code on Quantum Network Monitor Agents
- Real-time network diagnostics and monitoring
- Security Audits
- Penetration testing (Nmap/Metasploit)
🔵 HugLLM – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
💡 Example commands you could test:
"Give me info on my websites SSL certificate""Check if my server is using quantum safe encyption for communication""Run a comprehensive security audit on my server"- '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code on. This is a very flexible and powerful feature. Use with caution!
Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is open source. Feel free to use whatever you find helpful.
If you appreciate the work, please consider buying me a coffee ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
- Downloads last month
- 2,022