
🚀 Best Practices for Evaluating the Qwen3-Next Model

Qwen3-Next is the next-generation foundational model in the Qwen series, achieving groundbreaking advancements in inference, instruction following, agent capabilities, and multilingual support. In this best practices guide, we will conduct a comprehensive evaluation using the EvalScope framework, taking the Qwen3-Next-80B-A3B-Instruct model as an example. This will cover both model service inference performance evaluation and model capability assessment.
Installing Dependencies
First, install the EvalScope model evaluation framework:
pip install 'evalscope[app,perf]' -U
pip install git+https://github.com/huggingface/transformers.git@main
Model Service Inference Performance Evaluation
To begin, we need to access the model's capabilities through an OpenAI API-compatible inference service for evaluation. Notably, EvalScope also supports model inference evaluation using transformers. For more details, refer to the documentation.
In addition to deploying the model to cloud services supporting the OpenAI interface, you can choose to launch the model locally using frameworks like vLLM or ollama. These inference frameworks can efficiently handle multiple concurrent requests, accelerating the evaluation process.
Below, we demonstrate how to launch the Qwen3-Next-80B-A3B-Instruct model service locally using vLLM and conduct performance evaluation.
Installing Dependencies
Using the vLLM framework (requires the nightly version of vLLM and the latest version of transformers), install the following dependencies:
pip install vllm --pre --extra-index-url https://wheels.vllm.ai/nightly
Launching the Model Service
The following command can be used to create an API endpoint at http://localhost:8801/v1 with a maximum context length of 8K tokens, utilizing tensor parallelism across 4 GPUs:
VLLM_USE_MODELSCOPE=true VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --served-model-name Qwen3-Next-80B-A3B-Instruct --port 8801 --tensor-parallel-size 4 --max-model-len 8000 --gpu-memory-utilization 0.9 --max-num-seqs 32
- Currently, the environment variable VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 is required.
- The default context length is 256K. If the server fails to start, consider reducing the context length to a smaller value, such as 8000, and the maximum number of sequences to 32.
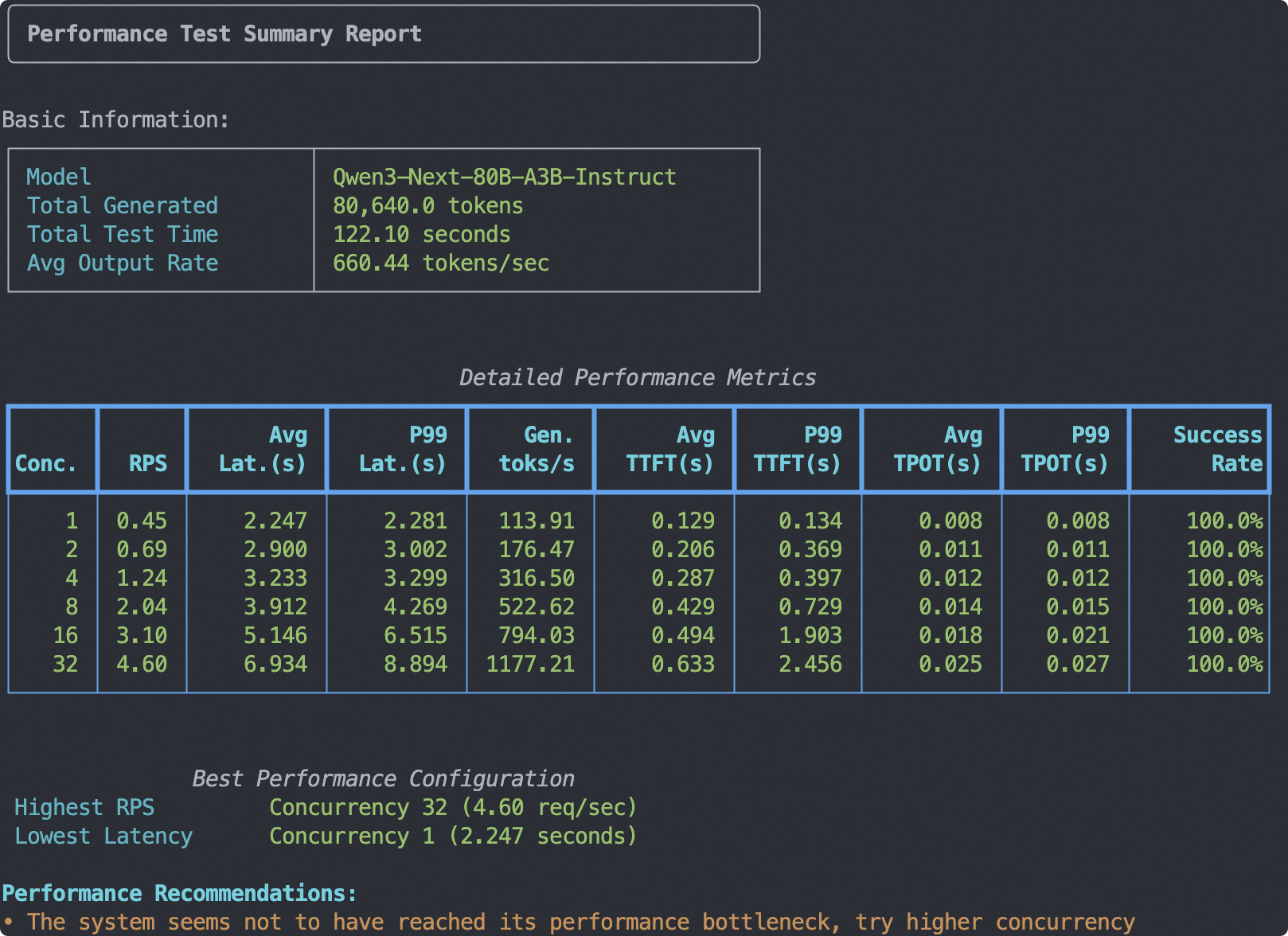
Conducting Stress Testing
- Test environment: 4 * A100 80G
- Test model: Qwen3-Next-80B-A3B-Instruct
- Test data: Randomly generated tokens of length 1024
- Test output length: 256 tokens
- Test concurrency: 1, 2, 4, 8, 16, 32
Run the following command:
evalscope perf \
--url "http://127.0.0.1:8801/v1/chat/completions" \
--parallel 1 2 4 8 16 32 \
--number 5 10 20 40 80 160 \
--model Qwen3-Next-80B-A3B-Instruct \
--api openai \
--dataset random \
--min-prompt-length 1024 \
--max-prompt-length 1024 \
--min-tokens 256 \
--max-tokens 256 \
--tokenizer-path Qwen/Qwen3-Next-80B-A3B-Instruct \
--extra-args '{"ignore_eos": true}'
For detailed parameter explanations, refer to Performance Evaluation.
Sample output:
Model Capability Evaluation
Next, we proceed with the model capability evaluation process.
Note: The subsequent evaluation process is based on the model service launched via vLLM. You can follow the steps in the previous model service performance evaluation to launch the model service or use a local model service. The model defaults to using the thinking mode.
Constructing an Evaluation Collection (Optional)
To comprehensively evaluate the model's capabilities, we can mix benchmarks supported by EvalScope to construct a comprehensive evaluation collection. Below is an example of an evaluation collection covering mainstream benchmarks, assessing the model's coding ability (LiveCodeBench), mathematical ability (AIME2024, AIME2025), knowledge ability (MMLU-Pro, CEVAL), and instruction following (IFEval).
Run the following code to automatically download and mix datasets based on the defined Schema, and save the constructed evaluation collection in a local jsonl file. You can also skip this step and directly use the processed data collection available in the ModelScope repository.
from evalscope.collections import CollectionSchema, DatasetInfo, WeightedSampler
from evalscope.utils.io_utils import dump_jsonl_data
schema = CollectionSchema(name='Qwen3', datasets=[
CollectionSchema(name='English', datasets=[
DatasetInfo(name='mmlu_pro', weight=1, task_type='exam', tags=['en'], args={'few_shot_num': 0}),
DatasetInfo(name='mmlu_redux', weight=1, task_type='exam', tags=['en'], args={'few_shot_num': 0}),
DatasetInfo(name='ifeval', weight=1, task_type='instruction', tags=['en'], args={'few_shot_num': 0}),
]),
CollectionSchema(name='Chinese', datasets=[
DatasetInfo(name='ceval', weight=1, task_type='exam', tags=['zh'], args={'few_shot_num': 0}),
DatasetInfo(name='iquiz', weight=1, task_type='exam', tags=['zh'], args={'few_shot_num': 0}),
]),
CollectionSchema(name='Code', datasets=[
DatasetInfo(name='live_code_bench', weight=1, task_type='code', tags=['en'], args={'few_shot_num': 0, 'subset_list': ['v5_v6'], 'extra_params': {'start_date': '2025-01-01', 'end_date': '2025-04-30'}}),
]),
CollectionSchema(name='Math&Science', datasets=[
DatasetInfo(name='math_500', weight=1, task_type='math', tags=['en'], args={'few_shot_num': 0}),
DatasetInfo(name='aime24', weight=1, task_type='math', tags=['en'], args={'few_shot_num': 0}),
DatasetInfo(name='aime25', weight=1, task_type='math', tags=['en'], args={'few_shot_num': 0}),
DatasetInfo(name='gpqa_diamond', weight=1, task_type='knowledge', tags=['en'], args={'few_shot_num': 0})
])
])
# get the mixed data
mixed_data = WeightedSampler(schema).sample(100000000) # set a large number to ensure all datasets are sampled
# dump the mixed data to a jsonl file
dump_jsonl_data(mixed_data, 'outputs/qwen3_test.jsonl')
Running the Evaluation Task
Run the following code to evaluate the performance of the Qwen3-Next model:
from evalscope import TaskConfig, run_task
task_cfg = TaskConfig(
model='Qwen3-Next-80B-A3B-Instruct',
api_url='http://127.0.0.1:8801/v1/chat/completions',
eval_type='openai_api',
datasets=[
'data_collection',
],
dataset_args={
'data_collection': {
'dataset_id': 'evalscope/Qwen3-Test-Collection',
'shuffle': True,
}
},
eval_batch_size=32,
generation_config={
'max_tokens': 6000, # Maximum number of tokens to generate, recommended to set a large value to avoid output truncation
'temperature': 0.7, # Sampling temperature (recommended value from Qwen report)
'top_p': 0.8, # Top-p sampling (recommended value from Qwen report)
'top_k': 20, # Top-k sampling (recommended value from Qwen report)
},
timeout=60000, # Timeout
stream=True, # Whether to use streaming output
limit=100, # Set to 100 data points for testing
)
run_task(task_cfg=task_cfg)
Sample output:
Note ⚠️: The results below are based on 100 data points and are only for testing the evaluation process. For formal evaluation, remove this limitation.
+-------------+---------------------+--------------+---------------+-------+
| task_type | metric | dataset_name | average_score | count |
+-------------+---------------------+--------------+---------------+-------+
| exam | acc | mmlu_pro | 0.7869 | 61 |
| exam | acc | mmlu_redux | 0.913 | 23 |
| exam | acc | ceval | 0.8333 | 6 |
| instruction | prompt_level_strict | ifeval | 0.6 | 5 |
| math | acc | math_500 | 1.0 | 4 |
| knowledge | acc | gpqa_diamond | 0.0 | 1 |
+-------------+---------------------+--------------+---------------+-------+
For more available evaluation datasets, refer to the Dataset List.
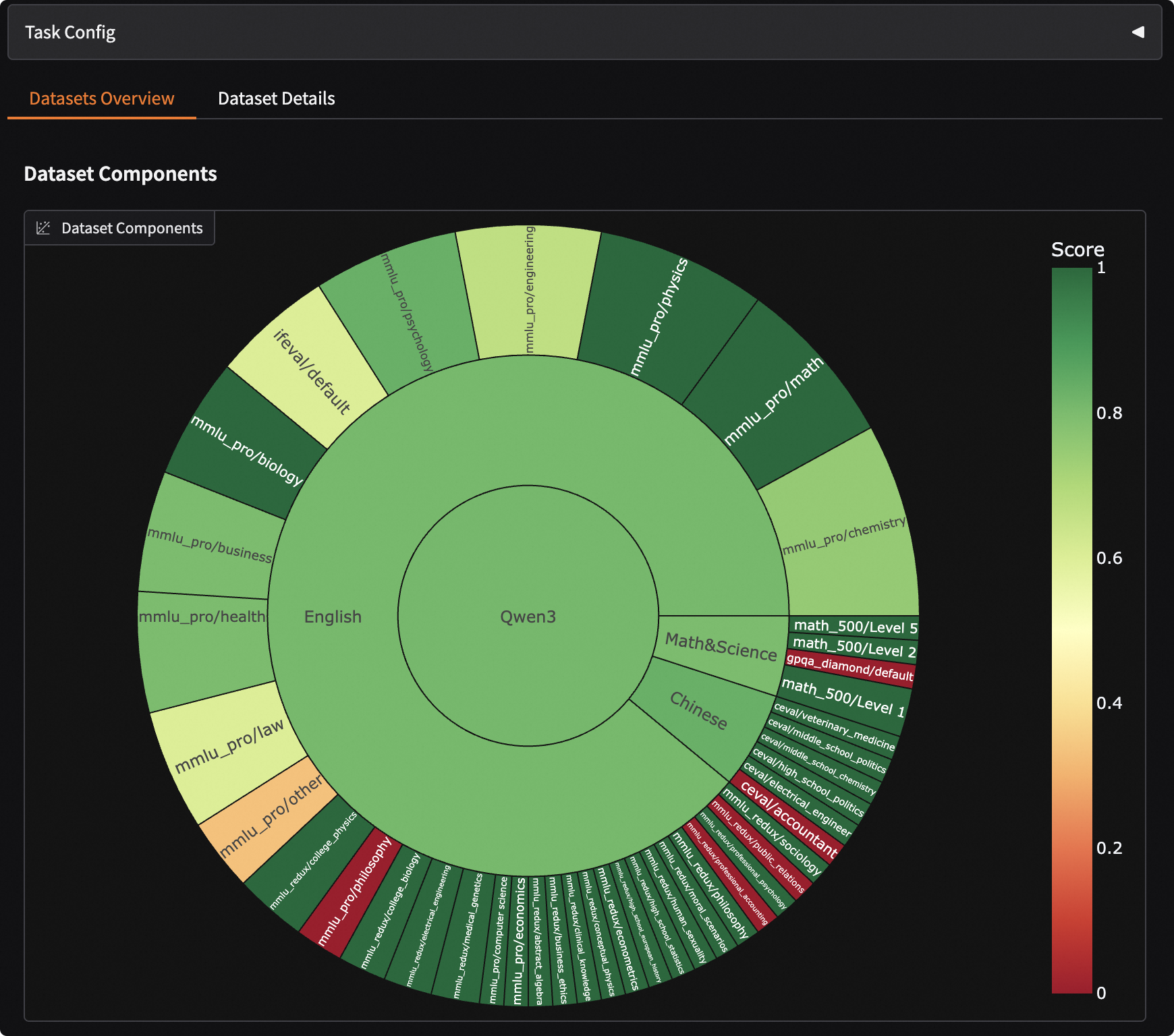
Visualizing Evaluation Results
EvalScope supports result visualization, allowing you to view the model's specific outputs.
Run the following command to launch a Gradio-based visualization interface:
evalscope app
Select the evaluation report and click load to see the model's output for each question and the overall accuracy:

Thanks. I'm getting an error like this one
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/model_executor/layers/fla/ops/op.py", line 26, in
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] exp = tl.exp
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] ^^^^^^
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] AttributeError: module 'triton.language' has no attribute 'exp'
on running this command
(torch313) ljubomir@macbook2(:):~/llama.cpp$ VLLM_USE_MODELSCOPE=true VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve models/Qwen3-Next-80B-A3B-Instruct-4bit --served-model-name Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 8000 --gpu-memory-utilization 0.9 --max-num-seqs 32
The model files downaloded off HF are
(torch313) ljubomir@macbook2(:):~/llama.cpp$ l models/Qwen3-Next-80B-A3B-Instruct-4bit
lrwx------@ 1 ljubomir staff 79B 14 Sep 12:29 models/Qwen3-Next-80B-A3B-Instruct-4bit -> /Users/ljubomir/.lmstudio/models/mlx-community/Qwen3-Next-80B-A3B-Instruct-4bit
(torch313) ljubomir@macbook2(:):~/llama.cpp$ l models/Qwen3-Next-80B-A3B-Instruct-4bit/
total 87631824
-rw-r--r--@ 1 ljubomir staff 707B 14 Sep 11:11 added_tokens.json
-rw-r--r--@ 1 ljubomir staff 3.9K 14 Sep 11:11 chat_template.jinja
-rw-r--r--@ 1 ljubomir staff 22K 14 Sep 11:11 config.json
-rw-r--r--@ 1 ljubomir staff 221B 14 Sep 11:11 generation_config.json
-rw-r--r--@ 1 ljubomir staff 1.6M 14 Sep 11:11 merges.txt
-rw-r--r--@ 1 ljubomir staff 4.8G 14 Sep 11:36 model-00001-of-00009.safetensors
-rw-r--r--@ 1 ljubomir staff 4.9G 14 Sep 11:29 model-00002-of-00009.safetensors
-rw-r--r--@ 1 ljubomir staff 4.9G 14 Sep 11:35 model-00003-of-00009.safetensors
-rw-r--r--@ 1 ljubomir staff 4.9G 14 Sep 11:48 model-00004-of-00009.safetensors
-rw-r--r--@ 1 ljubomir staff 4.9G 14 Sep 11:59 model-00005-of-00009.safetensors
-rw-r--r--@ 1 ljubomir staff 4.9G 14 Sep 11:58 model-00006-of-00009.safetensors
-rw-r--r--@ 1 ljubomir staff 4.9G 14 Sep 12:05 model-00007-of-00009.safetensors
-rw-r--r--@ 1 ljubomir staff 4.9G 14 Sep 12:13 model-00008-of-00009.safetensors
-rw-r--r--@ 1 ljubomir staff 2.7G 14 Sep 12:11 model-00009-of-00009.safetensors
-rw-r--r--@ 1 ljubomir staff 169K 14 Sep 12:06 model.safetensors.index.json
-rw-r--r--@ 1 ljubomir staff 613B 14 Sep 12:06 special_tokens_map.json
-rw-r--r--@ 1 ljubomir staff 5.3K 14 Sep 12:06 tokenizer_config.json
-rw-r--r--@ 1 ljubomir staff 11M 14 Sep 12:06 tokenizer.json
-rw-r--r--@ 1 ljubomir staff 2.6M 14 Sep 12:06 vocab.json
Full error log
(torch313) ljubomir@macbook2(:):~/llama.cpp$ VLLM_USE_MODELSCOPE=true VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve models/Qwen3-Next-80B-A3B-Instruct-4bit --served-model-name Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 8000 --gpu-memory-utilization 0.9 --max-num-seqs 32
/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/modelscope/hub/constants.py:62: SyntaxWarning: invalid escape sequence '\ '
,--. ,--.).-'),-----. \ .'_ (,------.,--. (_)---_) .-----. .-'),-----. _. \(,------. 🚨high_res_pixel_values` is part of DeepseekVLHybridForConditionalGeneration.forward's signature, but not documented. Make sure to add it to the docstring of the function in /Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/transformers/models/deepseek_vl_hybrid/modeling_deepseek_vl_hybrid.py.
INFO 09-16 06:53:52 [init.py:216] Automatically detected platform cpu.
WARNING 09-16 06:53:53 [_custom_ops.py:20] Failed to import from vllm._C with ImportError("dlopen(/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/_C.abi3.so, 0x0002): symbol not found in flat namespace '__ZN3c1010TensorImpl17set_autograd_metaESt10unique_ptrINS_21AutogradMetaInterfaceESt14default_deleteIS2_EE'")
(APIServer pid=95090) INFO 09-16 06:53:54 [api_server.py:1896] vLLM API server version 0.10.2
(APIServer pid=95090) INFO 09-16 06:53:54 [utils.py:328] non-default args: {'model_tag': 'models/Qwen3-Next-80B-A3B-Instruct-4bit', 'model': 'models/Qwen3-Next-80B-A3B-Instruct-4bit', 'max_model_len': 8000, 'served_model_name': ['Qwen3-Next-80B-A3B-Instruct'], 'tensor_parallel_size': 4, 'max_num_seqs': 32}
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] Error in inspecting model architecture 'Qwen3NextForCausalLM'
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] Traceback (most recent call last):
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/model_executor/models/registry.py", line 867, in _run_in_subprocess
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] returned.check_returncode()
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] ~~~~~~~~~~~~~~~~~~~~~~~~~^^
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "/opt/homebrew/Cellar/python@3.13/3.13.7/Frameworks/Python.framework/Versions/3.13/lib/python3.13/subprocess.py", line 508, in check_returncode
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] raise CalledProcessError(self.returncode, self.args, self.stdout,
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] self.stderr)
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] subprocess.CalledProcessError: Command '['/Users/ljubomir/python3-venv/torch313/bin/python3', '-m', 'vllm.model_executor.models.registry']' returned non-zero exit status 1.
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449]
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] The above exception was the direct cause of the following exception:
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449]
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] Traceback (most recent call last):
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/model_executor/models/registry.py", line 447, in _try_inspect_model_cls
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] return model.inspect_model_cls()
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] ~~~~~~~~~~~~~~~~~~~~~~~^^
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/model_executor/models/registry.py", line 418, in inspect_model_cls
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] return _run_in_subprocess(
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] lambda: _ModelInfo.from_model_cls(self.load_model_cls()))
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/model_executor/models/registry.py", line 870, in _run_in_subprocess
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] raise RuntimeError(f"Error raised in subprocess:\n"
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] f"{returned.stderr.decode()}") from e
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] RuntimeError: Error raised in subprocess:
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] :128: RuntimeWarning: 'vllm.model_executor.models.registry' found in sys.modules after import of package 'vllm.model_executor.models', but prior to execution of 'vllm.model_executor.models.registry'; this may result in unpredictable behaviour
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] Traceback (most recent call last):
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "", line 198, in _run_module_as_main
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "", line 88, in _run_code
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/model_executor/models/registry.py", line 891, in
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] _run()
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] ~~~~^^
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/model_executor/models/registry.py", line 884, in _run
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] result = fn()
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/model_executor/models/registry.py", line 419, in
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] lambda: _ModelInfo.from_model_cls(self.load_model_cls()))
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] ~~~~~~~~~~~~~~~~~~~^^
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/model_executor/models/registry.py", line 422, in load_model_cls
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] mod = importlib.import_module(self.module_name)
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "/opt/homebrew/Cellar/python@3.13/3.13.7/Frameworks/Python.framework/Versions/3.13/lib/python3.13/importlib/init.py", line 88, in import_module
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] return _bootstrap._gcd_import(name[level:], package, level)
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] ~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "", line 1387, in _gcd_import
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "", line 1360, in _find_and_load
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "", line 1331, in _find_and_load_unlocked
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "", line 935, in _load_unlocked
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "", line 1026, in exec_module
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "", line 488, in _call_with_frames_removed
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/model_executor/models/qwen3_next.py", line 24, in
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] from vllm.model_executor.layers.fla.ops import (
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] RMSNormGated, chunk_gated_delta_rule, fused_recurrent_gated_delta_rule)
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/model_executor/layers/fla/ops/init.py", line 9, in
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] from .chunk import chunk_gated_delta_rule
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/model_executor/layers/fla/ops/chunk.py", line 16, in
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] from .chunk_delta_h import chunk_gated_delta_rule_fwd_h
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/model_executor/layers/fla/ops/chunk_delta_h.py", line 17, in
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] from .op import exp
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/model_executor/layers/fla/ops/op.py", line 26, in
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] exp = tl.exp
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] ^^^^^^
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449] AttributeError: module 'triton.language' has no attribute 'exp'
(APIServer pid=95090) ERROR 09-16 06:53:58 [registry.py:449]
(APIServer pid=95090) Traceback (most recent call last):
(APIServer pid=95090) File "/Users/ljubomir/python3-venv/torch313/bin/vllm", line 10, in
(APIServer pid=95090) sys.exit(main())
(APIServer pid=95090) ~~~~^^
(APIServer pid=95090) File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/entrypoints/cli/main.py", line 54, in main
(APIServer pid=95090) args.dispatch_function(args)
(APIServer pid=95090) ~~~~~~~~~~~~~~~~~~~~~~^^^^^^
(APIServer pid=95090) File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/entrypoints/cli/serve.py", line 50, in cmd
(APIServer pid=95090) uvloop.run(run_server(args))
(APIServer pid=95090) ~~~~~~~~~~^^^^^^^^^^^^^^^^^^
(APIServer pid=95090) File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/uvloop/init.py", line 109, in run
(APIServer pid=95090) return __asyncio.run(
(APIServer pid=95090) ~~~~~~~~~~~~~^
(APIServer pid=95090) wrapper(),
(APIServer pid=95090) ^^^^^^^^^^
(APIServer pid=95090) ...<2 lines>...
(APIServer pid=95090) **run_kwargs
(APIServer pid=95090) ^^^^^^^^^^^^
(APIServer pid=95090) )
(APIServer pid=95090) ^
(APIServer pid=95090) File "/opt/homebrew/Cellar/python@3.13/3.13.7/Frameworks/Python.framework/Versions/3.13/lib/python3.13/asyncio/runners.py", line 195, in run
(APIServer pid=95090) return runner.run(main)
(APIServer pid=95090) ~~~~~~~~~~^^^^^^
(APIServer pid=95090) File "/opt/homebrew/Cellar/python@3.13/3.13.7/Frameworks/Python.framework/Versions/3.13/lib/python3.13/asyncio/runners.py", line 118, in run
(APIServer pid=95090) return self._loop.run_until_complete(task)
(APIServer pid=95090) ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^^^^^^
(APIServer pid=95090) File "uvloop/loop.pyx", line 1518, in uvloop.loop.Loop.run_until_complete
(APIServer pid=95090) File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/uvloop/init.py", line 61, in wrapper
(APIServer pid=95090) return await main
(APIServer pid=95090) ^^^^^^^^^^
(APIServer pid=95090) File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/entrypoints/openai/api_server.py", line 1941, in run_server
(APIServer pid=95090) await run_server_worker(listen_address, sock, args, **uvicorn_kwargs)
(APIServer pid=95090) File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/entrypoints/openai/api_server.py", line 1961, in run_server_worker
(APIServer pid=95090) async with build_async_engine_client(
(APIServer pid=95090) ~~~~~~~~~~~~~~~~~~~~~~~~~^
(APIServer pid=95090) args,
(APIServer pid=95090) ^^^^^
(APIServer pid=95090) client_config=client_config,
(APIServer pid=95090) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^
(APIServer pid=95090) ) as engine_client:
(APIServer pid=95090) ^
(APIServer pid=95090) File "/opt/homebrew/Cellar/python@3.13/3.13.7/Frameworks/Python.framework/Versions/3.13/lib/python3.13/contextlib.py", line 214, in aenter
(APIServer pid=95090) return await anext(self.gen)
(APIServer pid=95090) ^^^^^^^^^^^^^^^^^^^^^
(APIServer pid=95090) File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/entrypoints/openai/api_server.py", line 179, in build_async_engine_client
(APIServer pid=95090) async with build_async_engine_client_from_engine_args(
(APIServer pid=95090) ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^
(APIServer pid=95090) engine_args,
(APIServer pid=95090) ^^^^^^^^^^^^
(APIServer pid=95090) ...<2 lines>...
(APIServer pid=95090) client_config=client_config,
(APIServer pid=95090) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^
(APIServer pid=95090) ) as engine:
(APIServer pid=95090) ^
(APIServer pid=95090) File "/opt/homebrew/Cellar/python@3.13/3.13.7/Frameworks/Python.framework/Versions/3.13/lib/python3.13/contextlib.py", line 214, in aenter
(APIServer pid=95090) return await anext(self.gen)
(APIServer pid=95090) ^^^^^^^^^^^^^^^^^^^^^
(APIServer pid=95090) File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/entrypoints/openai/api_server.py", line 205, in build_async_engine_client_from_engine_args
(APIServer pid=95090) vllm_config = engine_args.create_engine_config(usage_context=usage_context)
(APIServer pid=95090) File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/engine/arg_utils.py", line 1119, in create_engine_config
(APIServer pid=95090) model_config = self.create_model_config()
(APIServer pid=95090) File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/vllm/engine/arg_utils.py", line 963, in create_model_config
(APIServer pid=95090) return ModelConfig(
(APIServer pid=95090) model=self.model,
(APIServer pid=95090) ...<45 lines>...
(APIServer pid=95090) io_processor_plugin=self.io_processor_plugin,
(APIServer pid=95090) )
(APIServer pid=95090) File "/Users/ljubomir/python3-venv/torch313/lib/python3.13/site-packages/pydantic/_internal/_dataclasses.py", line 123, in init
(APIServer pid=95090) s.pydantic_validator.validate_python(ArgsKwargs(args, kwargs), self_instance=s)
(APIServer pid=95090) ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
(APIServer pid=95090) pydantic_core._pydantic_core.ValidationError: 1 validation error for ModelConfig
(APIServer pid=95090) Value error, Model architectures ['Qwen3NextForCausalLM'] failed to be inspected. Please check the logs for more details. [type=value_error, input_value=ArgsKwargs((), {'model': ...rocessor_plugin': None}), input_type=ArgsKwargs]
(APIServer pid=95090) For further information visit https://errors.pydantic.dev/2.11/v/value_error
The python env the packages installed are
(torch313) ljubomir@macbook2(:):~/llama.cpp$ uv pip freeze
Using Python 3.13.7 environment at: /Users/ljubomir/python3-venv/torch313
absl-py==2.3.1
accelerate==1.10.0
adam-atan2==0.0.3
addict==2.4.0
aenum==3.1.16
aider-install==0.2.0
aiofiles==23.2.1
aiohappyeyeballs==2.6.1
aiohttp==3.12.15
aioice==0.10.1
aiortc==1.13.0
aiosignal==1.4.0
alabaster==1.0.0
alembic==1.16.4
altair==5.5.0
annotated-types==0.7.0
antlr4-python3-runtime==4.13.2
anyio==4.10.0
applaunchservices==0.3.0
appnope==0.1.4
argdantic==1.3.3
argon2-cffi==25.1.0
argon2-cffi-bindings==25.1.0
arrow==1.3.0
astor==0.8.1
astroid==3.3.11
asttokens==3.0.0
async-lru==2.0.5
asyncer==0.0.8
asyncssh==2.21.0
atomicwrites==1.4.1
attrs==25.3.0
audioop-lts==0.2.2
audioread==3.0.1
autopep8==2.0.4
av==14.4.0
babel==2.17.0
backoff==2.2.1
backports-tarfile==1.2.0
bcrypt==4.3.0
beautifulsoup4==4.13.4
binaryornot==0.4.4
black==25.1.0
blake3==1.0.5
bleach==6.2.0
blendmodes==2025
blis==1.3.0
brotli==1.1.0
build==1.3.0
cachetools==6.1.0
catalogue==2.0.10
cbor2==5.7.0
certifi==2025.8.3
cffi==1.17.1
chardet==5.2.0
charset-normalizer==3.4.3
chz==0.3.0
clean-fid==0.1.35
click==8.2.1
click-default-group==1.2.4
clip @ https://github.com/openai/CLIP/archive/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1.zip
cloudpathlib==0.21.1
cloudpickle==3.1.1
colorama==0.4.6
coloredlogs==15.0.1
colorlog==6.9.0
comfyui-embedded-docs==0.2.5
comfyui-frontend-package==1.26.0
comfyui-workflow-templates==0.1.52
comm==0.2.3
compressed-tensors==0.11.0
condense-json==0.1.3
confection==0.1.5
contourpy==1.3.3
cookiecutter==2.6.0
coolname==2.2.0
cryptography==45.0.6
csvw==3.5.1
curated-tokenizers==0.0.9
curated-transformers==0.1.1
cycler==0.12.1
cymem==2.0.11
cython==3.1.2
dacite==1.9.2
dataproperty==1.1.0
datasets==3.6.0
debugpy==1.8.16
decorator==5.2.1
defusedxml==0.7.1
deprecated==1.2.18
deprecation==2.1.0
depyf==0.19.0
diff-match-patch==20241021
dill==0.3.8
diskcache==5.6.3
distro==1.9.0
dlinfo==2.0.0
dnspython==2.7.0
docker==7.1.0
docopt==0.6.2
docstring-parser==0.17.0
docstring-to-markdown==0.17
docutils==0.21.2
dol==0.3.19
dotenv==0.9.9
dspy==2.6.27
einops==0.8.1
einx==0.3.0
email-validator==2.3.0
en-core-web-sm @ https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.8.0/en_core_web_sm-3.8.0-py3-none-any.whl
encodec==0.1.1
espeakng-loader==0.2.4
evalscope==1.0.1
evaluate==0.4.5
executing==2.2.0
facexlib==0.3.0
fastapi==0.116.1
fastapi-cli==0.0.11
fastapi-cloud-cli==0.1.5
fastjsonschema==2.21.1
fastrtc==0.0.29
fastrtc-moonshine-onnx==20241016
ffmpy==0.6.1
filelock==3.19.1
files-to-prompt==0.6
filterpy==1.4.5
flake8==7.1.2
flatbuffers==25.2.10
fonttools==4.59.2
fqdn==1.5.1
frozendict==2.4.6
frozenlist==1.7.0
fsspec==2025.3.0
ftfy==6.3.1
future==1.0.0
gguf==0.17.1
gitdb==4.0.12
gitpython==3.1.45
google-crc32c==1.7.1
gpt-oss==0.0.1
gpt4all==2.8.2
gradio==5.4.0
gradio-client==1.4.2
groovy==0.1.2
grpcio==1.74.0
h11==0.16.0
hf==0.0.8
hf-xet==1.1.10
html2text==2025.4.15
html5lib==1.1
httpcore==1.0.9
httptools==0.6.4
httpx==0.28.1
huggingface-hub==0.34.5
humanfriendly==10.0
hydra-core==1.3.2
idna==3.10
ifaddr==0.2.0
imageio==2.37.0
imagesize==1.4.1
importlib-metadata==8.7.0
importlib-resources==6.5.2
inflection==0.5.1
iniconfig==2.1.0
interegular==0.3.3
intervaltree==3.1.0
ipdb==0.13.13
ipykernel==6.30.1
ipython==8.37.0
ipython-genutils==0.2.0
ipython-pygments-lexers==1.1.1
ipywidgets==8.1.7
isodate==0.7.2
isoduration==20.11.0
isort==6.0.1
jaraco-classes==3.4.0
jaraco-context==6.0.1
jaraco-functools==4.2.1
jedi==0.19.2
jellyfish==1.2.0
jieba==0.42.1
jinja2==3.1.6
jiter==0.11.0
joblib==1.5.2
json-repair==0.48.0
json5==0.12.0
jsonlines==4.0.0
jsonmerge==1.9.2
jsonpointer==3.0.0
jsonschema==4.25.0
jsonschema-specifications==2025.4.1
jupyter==1.1.1
jupyter-client==8.6.3
jupyter-console==6.6.3
jupyter-contrib-core==0.4.2
jupyter-contrib-nbextensions==0.7.0
jupyter-core==5.8.1
jupyter-events==0.12.0
jupyter-highlight-selected-word==0.2.0
jupyter-lsp==2.2.6
jupyter-nbextensions-configurator==0.6.4
jupyter-server==2.16.0
jupyter-server-terminals==0.5.3
jupyterlab==4.4.5
jupyterlab-extensions==0.0.1
jupyterlab-pygments==0.3.0
jupyterlab-server==2.27.3
jupyterlab-widgets==3.0.15
keyring==25.6.0
kiwisolver==1.4.9
kokoro==0.9.4
kornia==0.8.1
kornia-rs==0.1.9
langcodes==3.5.0
langdetect==1.0.9
language-data==1.3.0
language-tags==1.2.0
lark==1.2.2
latex2sympy2-extended==1.10.2
lazy-loader==0.4
lckr-jupyterlab-variableinspector==3.2.4
librosa==0.11.0
lightning-utilities==0.15.2
litellm==1.75.2
llguidance==0.7.30
llm==0.26
llm-fragments-github==0.4
llm-gpt4all==0.4
llvmlite==0.44.0
lm-eval==0.4.9
lm-format-enforcer==0.11.3
loguru==0.7.3
lxml==6.0.1
magicattr==0.1.6
mako==1.3.10
marisa-trie==1.2.1
markdown==3.9
markdown-it-py==4.0.0
markupsafe==2.1.5
matplotlib==3.10.6
matplotlib-inline==0.1.7
mbstrdecoder==1.1.4
mccabe==0.7.0
mdurl==0.1.2
misaki==0.9.4
mistral-common==1.8.5
mistune==3.1.3
mlx==0.29.1
mlx-audio==0.2.3
mlx-lm @ git+https://github.com/ml-explore/mlx-lm.git@06a9fdc5ad79f500ff1c5f1aae829b041c9785f9
mlx-metal==0.29.1
mlx-optimizers==0.4.1
mlx-vlm==0.3.2
mlx-whisper==0.4.2
modelscope==1.30.0
more-itertools==10.7.0
moshi==0.0.0
mpmath==1.3.0
msgpack==1.1.1
msgspec==0.19.0
multidict==6.6.4
multiprocess==0.70.16
murmurhash==1.0.13
mypy-extensions==1.1.0
narwhals==2.0.1
nbclient==0.10.2
nbconvert==7.16.6
nbformat==5.10.4
nest-asyncio==1.6.0
networkx==3.5
ninja==1.13.0
nltk==3.9.1
nodeenv==1.9.1
notebook==7.4.5
notebook-shim==0.2.4
num2words==0.5.14
numba==0.61.2
numexpr==2.11.0
numpy==2.2.6
numpydoc==1.9.0
omegaconf==2.3.0
onnxruntime==1.22.1
open-clip-torch==3.1.0
openai==1.107.3
openai-harmony==0.0.3
opencv-python==4.12.0.88
opencv-python-headless==4.12.0.88
optuna==4.4.0
orjson==3.11.3
outlines-core==0.2.11
overrides==7.7.0
packaging==25.0
pandas==2.3.2
pandocfilters==1.5.1
parso==0.8.4
partial-json-parser==0.2.1.1.post6
pathspec==0.12.1
pathvalidate==3.3.1
peft==0.17.0
pexpect==4.9.0
phonemizer==3.3.0
phonemizer-fork==3.3.2
pickleshare==0.7.5
piexif==1.1.3
pillow==11.3.0
pillow-avif-plugin==1.5.2
pip==25.2
pip-tools==7.5.0
platformdirs==4.3.8
plotly==5.24.1
pluggy==1.6.0
pooch==1.8.2
portalocker==3.2.0
preshed==3.0.10
prometheus-client==0.22.1
prometheus-fastapi-instrumentator==7.1.0
prompt-toolkit==3.0.51
propcache==0.3.2
protobuf==6.31.1
psutil==7.0.0
ptyprocess==0.7.0
pure-eval==0.2.3
puremagic==1.30
py-cpuinfo==9.0.0
py4j==0.10.9.9
pyarrow==21.0.0
pybase64==1.4.2
pybind11==3.0.0
pycodestyle==2.12.1
pycountry==24.6.1
pycparser==2.22
pydantic==2.11.9
pydantic-core==2.33.2
pydantic-extra-types==2.10.5
pydantic-settings==2.10.1
pydocstyle==6.3.0
pydub==0.25.1
pyee==13.0.0
pyflakes==3.2.0
pygithub==2.7.0
pygments==2.19.2
pyjwt==2.10.1
pylibsrtp==0.12.0
pylint==3.3.7
pylint-venv==3.0.4
pyloudnorm==0.1.1
pyls-spyder==0.4.0
pynacl==1.5.0
pyobjc-core==11.1
pyobjc-framework-cocoa==11.1
pyobjc-framework-coreservices==11.1
pyobjc-framework-fsevents==11.1
pyopenssl==25.1.0
pyparsing==3.2.4
pyproject-hooks==1.2.0
pyqt5==5.15.11
pyqt5-qt5==5.15.17
pyqt5-sip==12.17.0
pyqtwebengine==5.15.7
pyqtwebengine-qt5==5.15.17
pyspark==4.0.0
pytablewriter==1.2.1
pytesseract==0.3.13
pytest==8.4.1
python-dateutil==2.9.0.post0
python-dotenv==1.1.1
python-json-logger==3.3.0
python-lsp-black==2.0.0
python-lsp-jsonrpc==1.1.2
python-lsp-server==1.12.2
python-multipart==0.0.20
python-slugify==8.0.4
python-ulid==3.0.0
pytoolconfig==1.3.1
pytorch-lightning==2.5.2
pytz==2025.2
pyuca==1.2
pywavelets==1.9.0
pyyaml==6.0.2
pyzmq==27.0.1
qdarkstyle==3.2.3
qstylizer==0.2.4
qtawesome==1.4.0
qtconsole==5.6.1
qtpy==2.4.3
ray==2.49.1
rdflib==7.1.4
referencing==0.36.2
regex==2025.9.1
requests==2.32.5
resize-right==0.0.2
rfc3339-validator==0.1.4
rfc3986==1.5.0
rfc3986-validator==0.1.1
rfc3987-syntax==1.1.0
rich==14.1.0
rich-toolkit==0.15.1
rignore==0.6.4
roman-numerals-py==3.1.0
rope==1.14.0
rouge-chinese==1.0.3
rouge-score==0.1.2
rpds-py==0.27.0
rtree==1.4.0
ruff==0.13.0
sacrebleu==2.5.1
safehttpx==0.1.6
safetensors==0.6.2
scikit-image==0.25.2
scikit-learn==1.7.2
scipy==1.16.2
seaborn==0.13.2
segments==2.3.0
semantic-version==2.10.0
send2trash==1.8.3
sentencepiece==0.2.0
sentry-sdk==2.34.1
setproctitle==1.3.6
setuptools==79.0.1
shellingham==1.5.4
simplejson==3.20.1
six==1.17.0
smart-open==7.3.0.post1
smmap==5.0.2
sniffio==1.3.1
snowballstemmer==3.0.1
sortedcontainers==2.4.0
sounddevice==0.5.2
soundfile==0.13.1
soupsieve==2.7
soxr==0.5.0.post1
spacy==3.8.7
spacy-curated-transformers==0.3.1
spacy-legacy==3.0.12
spacy-loggers==1.0.5
spandrel==0.4.1
spandrel-extra-arches==0.2.0
spark-nlp==6.1.1
sphinx==8.2.3
sphinxcontrib-applehelp==2.0.0
sphinxcontrib-devhelp==2.0.0
sphinxcontrib-htmlhelp==2.1.0
sphinxcontrib-jsmath==1.0.1
sphinxcontrib-qthelp==2.0.0
sphinxcontrib-serializinghtml==2.0.0
sphn==0.2.0
spyder==6.0.7
spyder-kernels==3.0.5
sqlalchemy==2.0.42
sqlite-fts4==1.0.3
sqlite-migrate==0.1b0
sqlite-utils==3.38
sqlitedict==2.1.0
srsly==2.5.1
sse-starlette==3.0.2
stack-data==0.6.3
standard-aifc==3.13.0
standard-chunk==3.13.0
standard-sunau==3.13.0
starlette==0.47.3
strip-tags==0.6
structlog==25.4.0
superqt==0.7.5
sympy==1.14.0
tabledata==1.3.4
tabulate==0.9.0
tcolorpy==0.1.7
tenacity==9.1.2
tensorboard==2.20.0
tensorboard-data-server==0.7.2
tensorboardx==2.6.4
termcolor==3.1.0
terminado==0.18.1
text-unidecode==1.3
textdistance==4.6.3
thinc==8.3.6
threadpoolctl==3.6.0
three-merge==0.1.1
tifffile==2025.6.11
tiktoken==0.10.0
timm==1.0.19
tinycss2==1.4.0
tokenizers==0.22.0
tomesd==0.1.3
tomlkit==0.12.0
torch==2.8.0
torchaudio==2.8.0
torchdiffeq==0.2.5
torchmetrics==1.8.1
torchsde==0.2.6
torchvision==0.23.0
tornado==6.5.1
tqdm==4.67.1
tqdm-multiprocess==0.0.11
traitlets==5.14.3
trampoline==0.1.2
transformers @ git+https://github.com/huggingface/transformers.git@5af248b3e3bf854e884c53f05b17ed1e0ca2ed24
ttok==0.3
typepy==1.3.4
typer==0.17.4
types-python-dateutil==2.9.0.20250708
typing-extensions==4.15.0
typing-inspection==0.4.1
tzdata==2025.2
ujson==5.10.0
uri-template==1.3.0
uritemplate==4.2.0
urllib3==2.5.0
uv==0.8.6
uvicorn==0.35.0
uvloop==0.21.0
vllm==0.10.2
wandb==0.21.1
wasabi==1.1.3
watchdog==6.0.0
watchfiles==1.1.0
wcwidth==0.2.13
weasel==0.4.1
webcolors==24.11.1
webencodings==0.5.1
webrtcvad==2.0.10
websocket-client==1.8.0
websockets==12.0
werkzeug==3.1.3
whatthepatch==1.0.7
wheel==0.45.1
widgetsnbextension==4.0.14
word2number==1.1
wrapt==1.17.2
wurlitzer==3.1.1
xgrammar==0.1.23
xxhash==3.5.0
yapf==0.43.0
yarl==1.20.1
zipp==3.23.0
zstandard==0.23.0
Thank you for any help! If you see anything wrong with the above, please shout my way - thanks!
Ljubomir