
Speculator Models
Collection
12 items
•
Updated
•
3
This is a speculator model designed for use with meta-llama/Llama-4-Maverick-17B-128E-Instruct, based on the EAGLE-3 speculative decoding algorithm.
It was converted into the speculators format from the model nvidia/Llama-4-Maverick-17B-128E-Eagle3.
This model should be used with the meta-llama/Llama-4-Maverick-17B-128E-Instruct chat template, specifically through the /chat/completions endpoint.
vllm serve meta-llama/Llama-4-Maverick-17B-128E-Instruct \
-tp 8 \
--speculative-config '{
"model": "RedHatAI/Llama-4-Maverick-17B-128E-Instruct-speculators.eagle3",
"num_speculative_tokens": 3,
"method": "eagle3"
}'
| Use Case | Dataset | Number of Samples |
|---|---|---|
| Coding | HumanEval | 168 |
| Math Reasoning | gsm8k | 80 |
| Text Summarization | CNN/Daily Mail | 80 |
| Use Case | k=1 | k=2 | k=3 | k=4 | k=5 | k=6 | k=7 |
|---|---|---|---|---|---|---|---|
| Coding | 1.83 | 2.45 | 2.94 | 3.26 | 3.47 | 3.57 | 3.62 |
| Math Reasoning | 1.86 | 2.56 | 3.08 | 3.53 | 3.73 | 3.91 | 4.02 |
| Text Summarization | 1.69 | 2.12 | 2.37 | 2.52 | 2.60 | 2.63 | 2.63 |
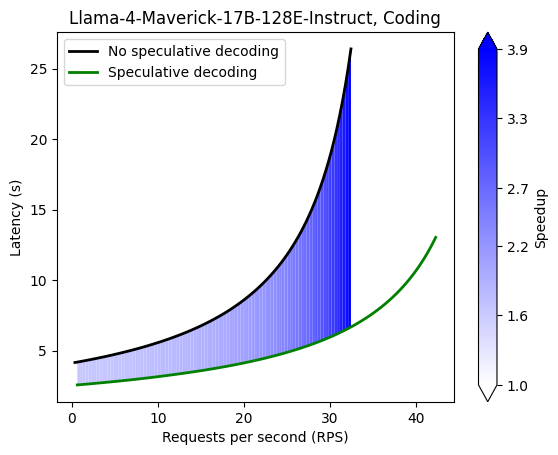
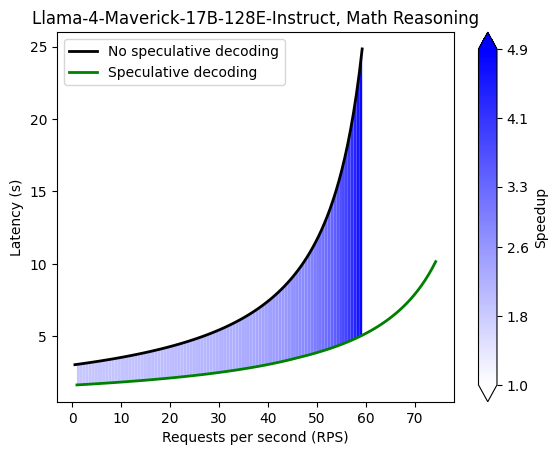
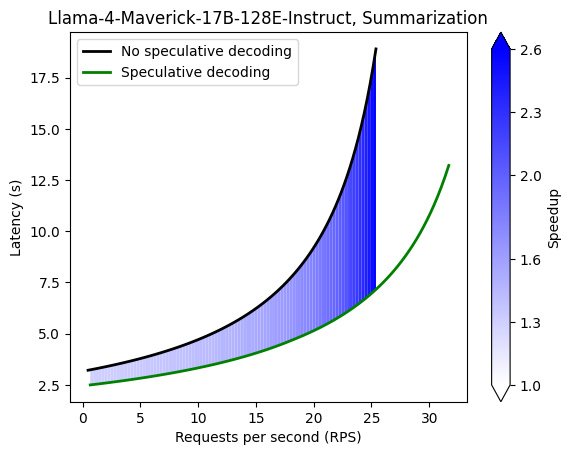
Command
GUIDELLM__PREFERRED_ROUTE="chat_completions" \
guidellm benchmark \
--target "http://localhost:8000/v1" \
--data "RedHatAI/SpeculativeDecoding" \
--rate-type sweep \
--max-seconds 180 \
--output-path "Llama-4-Maverick-HumanEval.json" \
--backend-args '{"extra_body": {"chat_completions": {"temperature":0.6, "top_p":0.9}}}'
If you use this model, please cite both the original NVIDIA model and the Speculators library:
@misc{nvidia2025llama4maverick,
title={Llama 4 Maverick 17B Eagle3},
author={NVIDIA Corporation},
year={2025},
publisher={Hugging Face}
}
@misc{speculators2024,
title={Speculators: A Unified Library for Speculative Decoding},
author={Neural Magic},
year={2024},
url={https://github.com/neuralmagic/speculators}
}
Base model
nvidia/Llama-4-Maverick-17B-128E-Eagle3