
AnyAccomp: Generalizable Accompaniment Generation via Quantized Melodic Bottleneck
Paper • 2509.14052 • Published • 1
This is the official Hugging Face model repository for AnyAccomp, an accompaniment generation framework from the paper AnyAccomp: Generalizable Accompaniment Generation via Quantized Melodic Bottleneck.
AnyAccomp addresses two critical challenges in accompaniment generation: generalization to in-the-wild singing voices and versatility in handling solo instrumental inputs.
The core of our framework is a quantized melodic bottleneck, which extracts robust melodic features. A subsequent flow matching model then generates a matching accompaniment based on these features.
For more details, please visit our GitHub Repository.
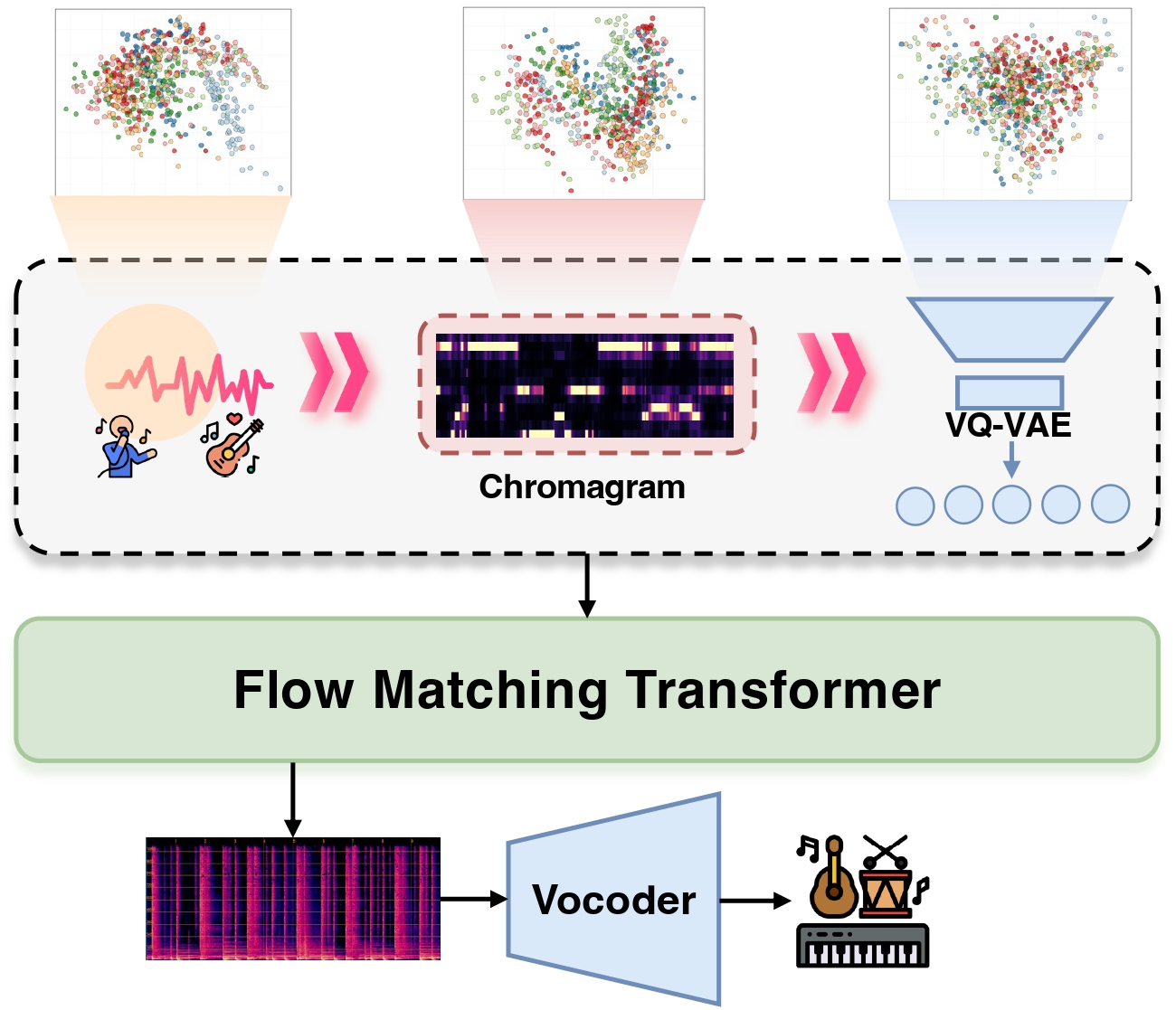
This repository contains the three pretrained components of the AnyAccomp framework:
| Model Name | Directory | Description |
|---|---|---|
| VQ | ./pretrained/vq |
Extracts core melodic features from audio. |
| Flow Matching | ./pretrained/flow_matching |
Generates accompaniments from melodic features. |
| Vocoder | ./pretrained/vocoder |
Converts generated features into audio waveforms. |
To run this model, you need to follow the steps below:
In this section, follow the steps below to clone the repository and install the environment.
git clone https://github.com/AmphionTeam/AnyAccomp.git
# enter the repositry directory
cd AnyAccomp
We provide a simple Python script to download all the necessary pretrained models from Hugging Face into the correct directory.
Before running the script, make sure you are in the AnyAccomp root directory.
Run the following command:
python -c "from huggingface_hub import snapshot_download; snapshot_download(repo_id='amphion/anyaccomp', local_dir='./pretrained', repo_type='model')"
If you have trouble connecting to Hugging Face, you can try switching to a mirror endpoint before running the command:
export HF_ENDPOINT=https://hf-mirror.com
Before start installing, make sure you are under the AnyAccomp directory. If not, use cd to enter.
conda create -n anyaccomp python=3.9
conda activate anyaccomp
conda install -c conda-forge ffmpeg=4.0
pip install -r requirements.txt
Once the setup is complete, you can run the model using either the Gradio demo or the inference script.
You can run the following command to interact with the playground:
python gradio_app.py
If you want to infer several audios, you can use the python inference script from folder.
python infer_from_folder.py
By default, the script loads input audio from ./example/input and saves the results to ./example/output. You can customize these paths in the inference script.
If you use AnyAccomp in your research, please cite our paper:
@article{zhang2025anyaccomp,
title={AnyAccomp: Generalizable Accompaniment Generation via Quantized Melodic Bottleneck},
author={Zhang, Junan and Zhang, Yunjia and Zhang, Xueyao and Wu, Zhizheng},
journal={arXiv preprint arXiv:2509.14052},
year={2025}
}