
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
list | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/26230
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26230/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26230/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26230/events
|
https://github.com/huggingface/transformers/issues/26230
| 1,901,481,216 |
I_kwDOCUB6oc5xVk0A
| 26,230 |
git-base-vatex: input pixel_value dimension mismatch (blocking issue)
|
{
"login": "shreyaskar123",
"id": 47864384,
"node_id": "MDQ6VXNlcjQ3ODY0Mzg0",
"avatar_url": "https://avatars.githubusercontent.com/u/47864384?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shreyaskar123",
"html_url": "https://github.com/shreyaskar123",
"followers_url": "https://api.github.com/users/shreyaskar123/followers",
"following_url": "https://api.github.com/users/shreyaskar123/following{/other_user}",
"gists_url": "https://api.github.com/users/shreyaskar123/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shreyaskar123/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shreyaskar123/subscriptions",
"organizations_url": "https://api.github.com/users/shreyaskar123/orgs",
"repos_url": "https://api.github.com/users/shreyaskar123/repos",
"events_url": "https://api.github.com/users/shreyaskar123/events{/privacy}",
"received_events_url": "https://api.github.com/users/shreyaskar123/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! I would suggest you to try to isolate the bug as we have limited timeframe to debug your custom code. If this is indeed a bug we can help you, otherwise the [community forum](https://discuss.huggingface.co/) is a good place to ask this! ",
"@ArthurZucker: I believe this is a bug because most of the code in` _get_item_` is from the provided example. Could you please look into this? I believe this has something to do with the git-base-vatex processor. Specifically, inside ` _get_item_` pixel_values is of shape torch.Size([1, 6, 3, 224, 224]) (dim = 5) and then `torch_default_data_collator` is increasing the dimension to 6 via `batch[k] = torch.stack([f[k] for f in features])`, causing the error. I tried to combat this by squeezing the first dimension in `_get_item` and make the tensor of size torch.Size([6, 3, 224, 224]) but then for some reason inside `_call_impl` in `module.py` pixel_values isn't even a part of `kwargs `when doing the `forward_call`, causing an error. I get the exact same error when trying to squeeze the extra dimension inside the `torch_default_data_collator` in `data_collator.py` via the following code. \r\n\r\n```\r\n for k, v in first.items():\r\n if k not in (\"label\", \"label_ids\") and v is not None and not isinstance(v, str):\r\n if isinstance(v, torch.Tensor):\r\n if k == 'pixel_values' and v.shape[0] == 1: # Add this condition\r\n batch[k] = torch.stack([f[k].squeeze(0) for f in features])\r\n else:\r\n batch[k] = torch.stack([f[k] for f in features])\r\n```\r\n\r\n Any help would be greatly appreciated Thanks! ",
"Hi @shreyaskar123 this is not a bug on our side, it's a bug on the data preparation side. You can fix it by removing the batch dimension which the processor creates by default.",
"@NielsRogge: I did try to remove the batch dimension (see https://github.com/huggingface/transformers/issues/26230#issuecomment-1724807694), but I get a error that pixel_values isn't part of kwargs anymore. Could you please take a look? ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,695 | 1,698 | 1,698 |
NONE
| null |
### System Info
- `transformers` version: 4.30.2
- Platform: Linux-4.19.0-25-cloud-amd64-x86_64-with-debian-10.13
- Python version: 3.7.12
- Huggingface_hub version: 0.15.1
- Safetensors version: 0.3.1 but is ignored because of PyTorch version too old.
- PyTorch version (GPU?): 1.9.0+cu111 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help?
@NielsRogge
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```
from torch.utils.data import Dataset
import av
import numpy as np
import torch
from PIL import Image
from huggingface_hub import hf_hub_download
from transformers import AutoProcessor, AutoModelForCausalLM
from generativeimage2text.make_dataset import create_video_captions
from transformers import AutoProcessor, AutoModelForCausalLM, TrainingArguments, Trainer
from typing import Union, List
import json
import glob
import os
import math
from datasets import load_dataset
import shutil
from tqdm import tqdm
from moviepy.editor import VideoFileClip
from evaluate import load
processor = AutoProcessor.from_pretrained("microsoft/git-base-vatex")
model = AutoModelForCausalLM.from_pretrained("microsoft/git-base-vatex")
np.random.seed(45)
def read_video_pyav(container, indices):
'''
Decode the video with PyAV decoder.
Args:
container (`av.container.input.InputContainer`): PyAV container.
indices (`List[int]`): List of frame indices to decode.
Returns:
result (np.ndarray): np array of decoded frames of shape (num_frames, height, width, 3).
'''
frames = []
container.seek(0)
start_index = indices[0]
end_index = indices[-1]
for i, frame in enumerate(container.decode(video=0)):
if i > end_index:
break
if i >= start_index and i in indices:
frames.append(frame)
return np.stack([x.to_ndarray(format="rgb24") for x in frames])
def sample_frame_indices(clip_len, seg_len):
'''
Sample a given number of frame indices from the video.
Args:
clip_len (`int`): Total number of frames to sample.
seg_len (`int`): Maximum allowed index of sample's last frame.
Returns:
indices (`List[int]`): List of sampled frame indices
'''
frame_sample_rate = (seg_len / clip_len) - 1
converted_len = int(clip_len * frame_sample_rate)
end_idx = np.random.randint(converted_len, seg_len)
start_idx = end_idx - converted_len
indices = np.linspace(start_idx, end_idx, num=clip_len)
indices = np.clip(indices, start_idx, end_idx - 1).astype(np.int64)
return indices
class VideoCaptioningDataset(Dataset):
def __init__(self, videos, captions, processor, num_frames):
self.videos = videos
self.captions = captions
self.processor = processor
self.num_frames = num_frames
self.cache = {} # to store processed samples
def __len__(self):
return len(self.videos)
def __getitem__(self, idx):
if idx in self.cache:
return self.cache[idx]
video_file = list(self.videos)[idx]
caption = self.captions[idx]
container = av.open(video_file)
indices = sample_frame_indices(
clip_len=self.num_frames, seg_len=container.streams.video[0].frames
)
frames = read_video_pyav(container, indices)
# process the pixel values and caption with the processor
pixel_values = self.processor(images=list(frames), return_tensors="pt").pixel_values
# pixel_values = pixel_values.squeeze(0)
inputs = self.processor(text=caption, return_tensors="pt", padding="max_length", max_length=50)
sample = {
"pixel_values": pixel_values,
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"],
"labels": inputs["input_ids"],
}
return sample
from sklearn.model_selection import train_test_split
videos = ['/home/name/GenerativeImage2Text/generativeimage2text/output_videos/clip_03_segment_0.mp4',
'/home/name/GenerativeImage2Text/generativeimage2text/output_videos/clip_07_segment_0.mp4',
'/home/name/GenerativeImage2Text/generativeimage2text/output_videos/clip_07_segment_1.mp4',
'/home/name/GenerativeImage2Text/generativeimage2text/output_videos/clip_07_segment_2.mp4',
'/home/name/GenerativeImage2Text/generativeimage2text/output_videos/clip_07_segment_3.mp4',
'/home/name/GenerativeImage2Text/generativeimage2text/output_videos/clip_07_segment_4.mp4',
'/home/name/GenerativeImage2Text/generativeimage2text/output_videos/clip_07_segment_5.mp4',
'/home/name/GenerativeImage2Text/generativeimage2text/output_videos/clip_07_segment_6.mp4',
'/home/name/GenerativeImage2Text/generativeimage2text/output_videos/clip_07_segment_7.mp4',
'/home/name/GenerativeImage2Text/generativeimage2text/output_videos/clip_07_segment_8.mp4']
captions = ['hi', 'hi', 'hi', 'hi', 'hi', 'hi', 'hi', 'hi', 'hi', 'hi'] # for demo -- the real data is PHI but I can confirm that the video files exist and is in the same format so that isn't the issue.
dataset = VideoCaptioningDataset(videos, captions, processor, 6)
train_dataset, val_dataset = train_test_split(dataset, test_size=0.1)
training_args = TrainingArguments(
output_dir=f"video_finetune_1",
learning_rate=5e-5,
num_train_epochs=50,
fp16=True,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
gradient_accumulation_steps=16,
save_total_limit=3,
evaluation_strategy="steps",
eval_steps=50,
save_strategy="steps",
save_steps=50,
logging_steps=50,
remove_unused_columns=False,
push_to_hub=False,
label_names=["labels"],
load_best_model_at_end=True
)
def compute_metrics(eval_pred):
logits, labels = eval_pred
predicted = logits.argmax(-1)
decoded_labels = processor.batch_decode(labels, skip_special_tokens=True)
decoded_predictions = processor.batch_decode(predicted, skip_special_tokens=True)
wer_score = wer.compute(predictions=decoded_predictions, references=decoded_labels)
bleu_score = bleu.compute(predictions=decoded_predictions, references=decoded_labels)
return {"wer_score": wer_score, "bleu_score": bleu_score}
wer = load("wer")
bleu = load("bleu")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=compute_metrics,
)
val = train_dataset[0]["pixel_values"].ndim
print(f"the dim is {val}")
trainer.train()
```
At this point when I do the print the dimension is 5 (as expected). But when I print the dimension of ```pixel_values``` in the first line in ``` forward ``` in file ``` modeling_git.py" ``` the dimension is 6. Because of this I get error
``` raise ValueError("pixel_values must be of rank 4 or 5") ValueError: pixel_values must be of rank 4 or 5 ```
This is the full stack trace for reference:
```
File "generativeimage2text/video_finetune.py", line 231, in <module>
trainer.train()
File "/home/name/GenerativeImage2Text/git2/lib/python3.7/site-packages/transformers/trainer.py", line 1649, in train
ignore_keys_for_eval=ignore_keys_for_eval,
File "/home/name/GenerativeImage2Text/git2/lib/python3.7/site-packages/transformers/trainer.py", line 1938, in _inner_training_loop
tr_loss_step = self.training_step(model, inputs)
File "/home/name/GenerativeImage2Text/git2/lib/python3.7/site-packages/transformers/trainer.py", line 2759, in training_step
loss = self.compute_loss(model, inputs)
File "/home/name/GenerativeImage2Text/git2/lib/python3.7/site-packages/transformers/trainer.py", line 2784, in compute_loss
outputs = model(**inputs)
File "/home/name/GenerativeImage2Text/git2/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/name/GenerativeImage2Text/git2/lib/python3.7/site-packages/accelerate/utils/operations.py", line 553, in forward
return model_forward(*args, **kwargs)
File "/home/name/GenerativeImage2Text/git2/lib/python3.7/site-packages/accelerate/utils/operations.py", line 541, in __call__
return convert_to_fp32(self.model_forward(*args, **kwargs))
File "/home/name/GenerativeImage2Text/git2/lib/python3.7/site-packages/torch/cuda/amp/autocast_mode.py", line 141, in decorate_autocast
return func(*args, **kwargs)
File "/home/name/GenerativeImage2Text/git2/lib/python3.7/site-packages/transformers/models/git/modeling_git.py", line 1507, in forward
return_dict=return_dict,
File "/home/name/GenerativeImage2Text/git2/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/name/GenerativeImage2Text/git2/lib/python3.7/site-packages/transformers/models/git/modeling_git.py", line 1250, in forward
raise ValueError("pixel_values must be of rank 4 or 5")
ValueError: pixel_values must be of rank 4 or 5
```
### Expected behavior
Ideally the dimension of ```pixel_values``` inside ```forward``` would also be 5 and the finetuning of git-base-vatex on video would work This is a blocking issue and any help would be really appreciated!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26230/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26230/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26229
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26229/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26229/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26229/events
|
https://github.com/huggingface/transformers/pull/26229
| 1,901,444,669 |
PR_kwDOCUB6oc5amL20
| 26,229 |
refactor: change default block_size
|
{
"login": "pphuc25",
"id": 81808312,
"node_id": "MDQ6VXNlcjgxODA4MzEy",
"avatar_url": "https://avatars.githubusercontent.com/u/81808312?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pphuc25",
"html_url": "https://github.com/pphuc25",
"followers_url": "https://api.github.com/users/pphuc25/followers",
"following_url": "https://api.github.com/users/pphuc25/following{/other_user}",
"gists_url": "https://api.github.com/users/pphuc25/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pphuc25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pphuc25/subscriptions",
"organizations_url": "https://api.github.com/users/pphuc25/orgs",
"repos_url": "https://api.github.com/users/pphuc25/repos",
"events_url": "https://api.github.com/users/pphuc25/events{/privacy}",
"received_events_url": "https://api.github.com/users/pphuc25/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"however, I have some confuse because why I can not pass the test case",
"thank you @ArthurZucker, but I have some confuse why I just change 1024 to min(1024, config.max_position_embeddings) and docs and then I can not pass the test case, still stuck, can you help me",
"Hey @pphuc25 - don't worry, your PR is perfect! All you need to do is rebase onto `main`:\r\n\r\n```\r\ngit fetch upstream\r\ngit rebase upstream main\r\n```\r\n\r\nAnd then force push:\r\n```\r\ngit commit -m \"rebase\" --allow-empty\r\ngit push -f origin flax_min_block_size\r\n```\r\n\r\nThis should fix your CI issues! The test that's failing isn't related to your PR and was fixed yesterday on `main`.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26229). All of your documentation changes will be reflected on that endpoint.",
"thanks @sanchit-gandhi so much on very helpful information, but this seem to still bug.",
"Hmm could you try running: `make fix-copies` and pushing? Does this change the code for you at all?",
"Thank you for really helpful support @sanchit-gandhi, this help me so much and gain me more knowledge, thank you really much.",
"but @sanchit-gandhi, I think you should review the code to merge PR",
"Shall we merge this one @ArthurZucker since it protects against an edge case, and then add follow-up features to your own codebase / the HF Hub @pphuc25?",
"Sure! "
] | 1,695 | 1,696 | 1,696 |
CONTRIBUTOR
| null |
Hi,
As mentioned in issue #26069, I have created a new PR with the aim of modifying the block_size for all files. The goal is to set the block size = min(1024, config.max_position_embeddings). This change is intended to ensure synchronization and prevent errors that can occur when the block size exceeds the maximum position embeddings value.
I would like to cc @sanchit-gandhi to review my PR, thank you so much
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26229/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26229/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26229",
"html_url": "https://github.com/huggingface/transformers/pull/26229",
"diff_url": "https://github.com/huggingface/transformers/pull/26229.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26229.patch",
"merged_at": 1696429898000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26228
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26228/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26228/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26228/events
|
https://github.com/huggingface/transformers/pull/26228
| 1,901,406,750 |
PR_kwDOCUB6oc5amDqi
| 26,228 |
[Permisson] Style fix
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Merging as you are probably out! ",
"Thanks! Beat me to it 😉"
] | 1,695 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
# What does this PR do?
Rebases and runs `make fix-copies` to fix the red CI on `main`
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26228/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26228/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26228",
"html_url": "https://github.com/huggingface/transformers/pull/26228",
"diff_url": "https://github.com/huggingface/transformers/pull/26228.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26228.patch",
"merged_at": 1695059391000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26227
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26227/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26227/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26227/events
|
https://github.com/huggingface/transformers/pull/26227
| 1,901,374,445 |
PR_kwDOCUB6oc5al8q6
| 26,227 |
add custom RMSNorm to `ALL_LAYERNORM_LAYERS`
|
{
"login": "shijie-wu",
"id": 2987758,
"node_id": "MDQ6VXNlcjI5ODc3NTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2987758?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shijie-wu",
"html_url": "https://github.com/shijie-wu",
"followers_url": "https://api.github.com/users/shijie-wu/followers",
"following_url": "https://api.github.com/users/shijie-wu/following{/other_user}",
"gists_url": "https://api.github.com/users/shijie-wu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shijie-wu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shijie-wu/subscriptions",
"organizations_url": "https://api.github.com/users/shijie-wu/orgs",
"repos_url": "https://api.github.com/users/shijie-wu/repos",
"events_url": "https://api.github.com/users/shijie-wu/events{/privacy}",
"received_events_url": "https://api.github.com/users/shijie-wu/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@ArthurZucker done! `MegaRMSNorm` - a part of `MegaSequenceNorm` - is already in `ALL_LAYERNORM_LAYERS` https://github.com/huggingface/transformers/blob/493b24ba109ed680f40ec81ef73e4cc303e810ee/src/transformers/models/mega/modeling_mega.py#L317\r\n\r\ndo we want to add all these to `ALL_LAYERNORM_LAYERS`?\r\n\r\nhttps://github.com/huggingface/transformers/blob/493b24ba109ed680f40ec81ef73e4cc303e810ee/src/transformers/models/mega/modeling_mega.py#L294-L301",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26227). All of your documentation changes will be reflected on that endpoint.",
"after discussion with @ArthurZucker, it seems best to limit to scope of this PR to adding custom RMSNorm to `ALL_LAYERNORM_LAYERS`. Adding nn.BatchNorm1d might create unintentional impact."
] | 1,695 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
# What does this PR do?
It fixed a issue discovered during discussion of PR https://github.com/huggingface/transformers/pull/26152.
> @ArthurZucker: the `ALL_LAYERNORM_LAYERS` should contain all the custom layer norm classes (from `transformers` modeling files) and should be updated if that is not the case
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@ArthurZucker
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26227/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26227/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26227",
"html_url": "https://github.com/huggingface/transformers/pull/26227",
"diff_url": "https://github.com/huggingface/transformers/pull/26227.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26227.patch",
"merged_at": 1695228717000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26226
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26226/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26226/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26226/events
|
https://github.com/huggingface/transformers/pull/26226
| 1,901,326,695 |
PR_kwDOCUB6oc5alx_5
| 26,226 |
APEX: use MixedFusedRMSNorm instead of FusedRMSNorm for numerical consistency
|
{
"login": "fxmarty",
"id": 9808326,
"node_id": "MDQ6VXNlcjk4MDgzMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9808326?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fxmarty",
"html_url": "https://github.com/fxmarty",
"followers_url": "https://api.github.com/users/fxmarty/followers",
"following_url": "https://api.github.com/users/fxmarty/following{/other_user}",
"gists_url": "https://api.github.com/users/fxmarty/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fxmarty/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fxmarty/subscriptions",
"organizations_url": "https://api.github.com/users/fxmarty/orgs",
"repos_url": "https://api.github.com/users/fxmarty/repos",
"events_url": "https://api.github.com/users/fxmarty/events{/privacy}",
"received_events_url": "https://api.github.com/users/fxmarty/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26226). All of your documentation changes will be reflected on that endpoint.",
"Good for me, but let's wait for @mfuntowicz 's response.\r\n\r\nBut why we can't just uninstall apex on the AMD docker image? The goal here is not to test the functionality of APEX.",
"> why we can't just uninstall apex on the AMD docker image\r\n\r\nIMO it makes sense to test both paths, the APEX path is broken as well on NVIDIA GPUs. APEX is installed by default in the PyTorch docker image provided by AMD, and it makes sense to expect Transformers to work with the image.",
"Those 3rd party libraries cause problems quite frequently especially when they change versions or torch get a new version.\r\n\r\nThere is `docker/transformers-pytorch-deepspeed-latest-gpu/Dockerfile` used by the job `run_all_tests_torch_cuda_extensions_gpu` - this has apex installed, but this is a separate job, in particular for DeepSpeed.\r\n\r\nLet's not spend too much time but just make the **usual** model and common tests run on AMD CI for now.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,695 | 1,701 | 1,701 |
COLLABORATOR
| null |
As per title.
APEX `FusedRMSNorm` initialize the returned tensor to the `input` dtype, which raises an error in case the model is set on fp16, where we may have `fp32` input to the layer norm layer:
```
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/apex-0.1-py3.8-linux-x86_64.egg/apex/normalization/fused_layer_norm.py", line 189, in fused_rms_norm_affine
return FusedRMSNormAffineFunction.apply(*args)
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/autograd/function.py", line 506, in apply
return super().apply(*args, **kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/apex-0.1-py3.8-linux-x86_64.egg/apex/normalization/fused_layer_norm.py", line 69, in forward
output, invvar = fused_layer_norm_cuda.rms_forward_affine(
```
Comparing to [T5LayerNorm](https://github.com/huggingface/transformers/blob/820c46a707ddd033975bc3b0549eea200e64c7da/src/transformers/models/t5/modeling_t5.py#L247-L261) where the output is on the weight dtype. That is exactly what `MixedFusedRMSNorm` is for, see https://github.com/NVIDIA/apex/blob/52e18c894223800cb611682dce27d88050edf1de/apex/normalization/fused_layer_norm.py#L420 and https://github.com/NVIDIA/apex/blob/52e18c894223800cb611682dce27d88050edf1de/csrc/layer_norm_cuda.cpp#L205
For example, the test `pytest tests/test_pipeline_mixin.py::VisualQuestionAnsweringPipelineTests::test_small_model_pt_blip2 -s -vvvvv` fails when `apex` is available (and accelerate is installed). This error was never detected because the docker images used for testing do not have APEX installed (e.g. `nvidia/cuda:11.8.0-cudnn8-devel-ubuntu20.04`)
This is an issue for the AMD CI as the image used `rocm/pytorch:rocm5.6_ubuntu20.04_py3.8_pytorch_2.0.1` has RoCm APEX installed by default.
---
Slightly out of topic: something I don't get is why [neither t5x](https://github.com/google-research/t5x/blob/ea66ec835a5b413ca9d211de96aa899900a84c13/t5x/examples/t5/layers.py#L445) nor transformers seem to recast to fp16 after the FFN. Due to the `keep_in_fp32` attribute, [this weight](https://github.com/huggingface/transformers/blob/820c46a707ddd033975bc3b0549eea200e64c7da/src/transformers/models/t5/modeling_t5.py#L284C14-L284C14) is always in fp32 and then fp32 is propagated in the model. t5x seem to do the same.
Related: https://github.com/huggingface/transformers/pull/26225
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26226/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26226/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26226",
"html_url": "https://github.com/huggingface/transformers/pull/26226",
"diff_url": "https://github.com/huggingface/transformers/pull/26226.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26226.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/26225
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26225/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26225/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26225/events
|
https://github.com/huggingface/transformers/pull/26225
| 1,901,317,071 |
PR_kwDOCUB6oc5alv42
| 26,225 |
Keep relevant weights in fp32 when `model._keep_in_fp32_modules` is set even when `accelerate` is not installed
|
{
"login": "fxmarty",
"id": 9808326,
"node_id": "MDQ6VXNlcjk4MDgzMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9808326?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fxmarty",
"html_url": "https://github.com/fxmarty",
"followers_url": "https://api.github.com/users/fxmarty/followers",
"following_url": "https://api.github.com/users/fxmarty/following{/other_user}",
"gists_url": "https://api.github.com/users/fxmarty/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fxmarty/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fxmarty/subscriptions",
"organizations_url": "https://api.github.com/users/fxmarty/orgs",
"repos_url": "https://api.github.com/users/fxmarty/repos",
"events_url": "https://api.github.com/users/fxmarty/events{/privacy}",
"received_events_url": "https://api.github.com/users/fxmarty/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"sounds good",
"I fixed the original test that was not actually testing the case where `accelerate` is not available.",
"nice! \r\n"
] | 1,695 | 1,706 | 1,695 |
COLLABORATOR
| null |
As per title, aligns the behavior of `PreTrainedModel.from_pretrained(..., torch_dtype=torch.float16)` when accelerate is installed and when it is not.
Previously,
```python
import torch
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained("t5-small", torch_dtype=torch.float16)
print(model.encoder.block[0].layer[1].DenseReluDense.wo.weight.dtype)
```
would print `torch.float16` when accelerate was not installed, and `torch.float32` when installed. Having different dtype depending on an external package being installed or not is bug prone. [As `accelerate` is a hard requirement](https://github.com/huggingface/transformers/blob/e4e55af79c9b3dfd15cc2224f8f5b80680d83f03/setup.py#L260), it could be also reasonable to simply raise an error in `from_pretrained` if using pytorch & accelerate is not installed.
Note:
```python
for name, param in model.named_parameters():
param = param.to(torch.float32)
```
does nothing out of the loop scope.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26225/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26225/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26225",
"html_url": "https://github.com/huggingface/transformers/pull/26225",
"diff_url": "https://github.com/huggingface/transformers/pull/26225.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26225.patch",
"merged_at": 1695290403000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26224
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26224/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26224/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26224/events
|
https://github.com/huggingface/transformers/pull/26224
| 1,901,292,887 |
PR_kwDOCUB6oc5alqkR
| 26,224 |
Add Keras Core (Keras 3.0) support
|
{
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26224). All of your documentation changes will be reflected on that endpoint.",
"Don't stale yet!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,695 | 1,706 | 1,706 |
MEMBER
| null |
This PR is a very-very-very work in progress effort to add Keras Core support, and to prepare for the transition to Keras 3.0. Because Keras Core is still a beta/preview, this PR is likely to be fairly slow and cautious, we don't want to lock ourselves into an API that may change under our feet!
The goal of this PR is to create a "minimum viable port(duct)" of our `tf.keras` code to `keras-core` to assess how difficult it will be to support Keras Core. Therefore, this port has the following properties:
- Only loading from `safetensors` will be supported for now, so I don't have to support every possible combination of (weights_format, model_framework)
- All mixins like `GenerationMixin` will be inherited directly from the framework that corresponds to the active `keras-core` framework. This means that `keras-core` classes will change their inheritance depending on which framework is live, which is risky but greatly reduces the amount of code I need to write.
- We will mainly be supporting TF and JAX as Keras Core frameworks. All of our models have PyTorch code already, which will probably be more stable and better-tested than using Keras Core + PyTorch, so I doubt we'd see much usage there. In addition, TF and JAX fit Keras Core's assumptions much more naturally than PyTorch does.
The plan for this PR is:
- [x] Create `modeling_keras_outputs.py` (ported from `modeling_tf_outputs.py`)
- [ ] Create `modeling_keras_utils.py` (ported from `modeling_tf_utils.py`)
- [ ] Port a single model to keras-core (probably BERT or DistilBERT)
- [ ] Add model tests to ensure that outputs match
- [ ] Improve support for our data classes, like supporting BatchEncoding in `fit()` or auto-wrapping HF datasets in a Keras `PyDataset`
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26224/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26224/timeline
| null | true |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26224",
"html_url": "https://github.com/huggingface/transformers/pull/26224",
"diff_url": "https://github.com/huggingface/transformers/pull/26224.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26224.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/26223
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26223/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26223/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26223/events
|
https://github.com/huggingface/transformers/pull/26223
| 1,901,281,211 |
PR_kwDOCUB6oc5aloAS
| 26,223 |
Use CircleCI `store_test_results`
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Very cool! Thanks @ydshieh and @ArthurZucker, this looks cool!",
"> More than me loving it, it gives us [access to the slow tests, the flaky tests, the tests that usually fail](https://app.circleci.com/insights/github/huggingface/transformers/workflows/run_tests/tests?branch=make_arthur_eye_happy) etc. Let's add this to all CI jobs!\r\n\r\nOK!",
"@ArthurZucker I think all pytest jobs have this feature enabled. `.circleci/config.yml` doesn't have pytest but just some usual python scripts. Could you elaborate a bit more what you suggest? Thanks!",
"I mean `check_repository_consistency`, `check_code_quality`, `pr_documentation_test` if possible! ",
"Hi,\r\n\r\n`pr_documentation_test` is already included in the current change.\r\n\r\nThe other 2 jobs are not `pytest`, and I am not sure if there is anything we can do similar to `pytest --junitxml=test-results/junit.xml`",
"We could make them use pytest, but only if you think it’s relevant! ",
"IMO, those are not really tests but checks of formatting :-). They won't be flaky, and those could not be splitted into individual test **methods** but each script as a whole.\r\n\r\nI would rather move forward and take the new feature already available (with this PR) for us even only for the pytest jobs.\r\n\r\nThank you for asking to add this, Sir!"
] | 1,695 | 1,695 | 1,695 |
COLLABORATOR
| null |
# What does this PR do?
@ArthurZucker loves it.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26223/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26223/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26223",
"html_url": "https://github.com/huggingface/transformers/pull/26223",
"diff_url": "https://github.com/huggingface/transformers/pull/26223.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26223.patch",
"merged_at": 1695365814000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26222
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26222/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26222/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26222/events
|
https://github.com/huggingface/transformers/pull/26222
| 1,901,252,313 |
PR_kwDOCUB6oc5alhsB
| 26,222 |
[Check] Fix config docstring
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,695 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
# What does this PR do?
Fixes https://github.com/huggingface/transformers/pull/26183/files#r1328944428 by removing the debugging statements in the config docstring checker.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26222/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26222/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26222",
"html_url": "https://github.com/huggingface/transformers/pull/26222",
"diff_url": "https://github.com/huggingface/transformers/pull/26222.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26222.patch",
"merged_at": 1695059882000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26221
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26221/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26221/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26221/events
|
https://github.com/huggingface/transformers/issues/26221
| 1,901,183,746 |
I_kwDOCUB6oc5xUcMC
| 26,221 |
Gradient checkpointing should have no functional impact
|
{
"login": "marianokamp",
"id": 3245189,
"node_id": "MDQ6VXNlcjMyNDUxODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3245189?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/marianokamp",
"html_url": "https://github.com/marianokamp",
"followers_url": "https://api.github.com/users/marianokamp/followers",
"following_url": "https://api.github.com/users/marianokamp/following{/other_user}",
"gists_url": "https://api.github.com/users/marianokamp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/marianokamp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/marianokamp/subscriptions",
"organizations_url": "https://api.github.com/users/marianokamp/orgs",
"repos_url": "https://api.github.com/users/marianokamp/repos",
"events_url": "https://api.github.com/users/marianokamp/events{/privacy}",
"received_events_url": "https://api.github.com/users/marianokamp/received_events",
"type": "User",
"site_admin": false
}
|
[] |
open
| false | null |
[] |
[
"No answer or re-action yet, but not stale either.",
"Gentle ping @muellerzr @pacman100 ",
"@pacman100, @muellerz \r\nJust re-ran with transformers 4.36.0, same result: \r\n\r\n\r\n",
"@pacman100, @muellerzr, @younesbelkada. Anything I can do here to help you acknowledge the ticket? If I am hearing nothing I will let it auto-close. ",
"Hello @marianokamp, Thank you for your patience. As I don't have a clear minimal reproducer here, I ran the below experiments and don't see a diff in performance with and without gradient checkpointing.\r\n\r\n1. Code: https://github.com/huggingface/peft/blob/main/examples/sequence_classification/LoRA.ipynb\r\n2. Use the `set_seed` for deterministic runs:\r\n```diff\r\nimport argparse\r\nimport os\r\n\r\nimport torch\r\nfrom torch.optim import AdamW\r\nfrom torch.utils.data import DataLoader\r\nfrom peft import (\r\n get_peft_config,\r\n get_peft_model,\r\n get_peft_model_state_dict,\r\n set_peft_model_state_dict,\r\n LoraConfig,\r\n PeftType,\r\n PrefixTuningConfig,\r\n PromptEncoderConfig,\r\n)\r\n\r\nimport evaluate\r\nfrom datasets import load_dataset\r\nfrom transformers import AutoModelForSequenceClassification, AutoTokenizer, get_linear_schedule_with_warmup, set_seed\r\nfrom tqdm import tqdm\r\n\r\n+ set_seed(100)\r\n```\r\n3. In gradient ckpt run, add the `model.gradient_checkpointing_enable` command:\r\n```diff\r\nmodel = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)\r\nmodel = get_peft_model(model, peft_config)\r\nmodel.print_trainable_parameters()\r\nmodel\r\n+ model.gradient_checkpointing_enable(gradient_checkpointing_kwargs={\"use_reentrant\":False})\r\n```\r\n4. Run the notebooks with and without gradient ckpt.\r\n5. mem usage:\r\n\r\n6. Without gradient ckpt output logs:\r\n```\r\n0%| | 0/115 [00:00<?, ?it/s]You're using a RobertaTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:27<00:00, 4.18it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.53it/s]\r\nepoch 0: {'accuracy': 0.7083333333333334, 'f1': 0.8210526315789474}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.30it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.52it/s]\r\nepoch 1: {'accuracy': 0.6838235294117647, 'f1': 0.8122270742358079}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.31it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.53it/s]\r\nepoch 2: {'accuracy': 0.6838235294117647, 'f1': 0.8122270742358079}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.29it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.52it/s]\r\nepoch 3: {'accuracy': 0.6838235294117647, 'f1': 0.8122270742358079}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.27it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.52it/s]\r\nepoch 4: {'accuracy': 0.6838235294117647, 'f1': 0.8122270742358079}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.30it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.54it/s]\r\nepoch 5: {'accuracy': 0.8186274509803921, 'f1': 0.8766666666666666}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.26it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.54it/s]\r\nepoch 6: {'accuracy': 0.8333333333333334, 'f1': 0.8885245901639344}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.26it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.50it/s]\r\nepoch 7: {'accuracy': 0.875, 'f1': 0.9109947643979057}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.30it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.52it/s]\r\nepoch 8: {'accuracy': 0.8872549019607843, 'f1': 0.9184397163120569}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.30it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.51it/s]\r\nepoch 9: {'accuracy': 0.8872549019607843, 'f1': 0.9201388888888888}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.29it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.49it/s]\r\nepoch 10: {'accuracy': 0.8921568627450981, 'f1': 0.9225352112676057}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.29it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.49it/s]\r\nepoch 11: {'accuracy': 0.8897058823529411, 'f1': 0.9220103986135182}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.28it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.49it/s]\r\nepoch 12: {'accuracy': 0.8946078431372549, 'f1': 0.9241622574955909}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.27it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.46it/s]\r\nepoch 13: {'accuracy': 0.8970588235294118, 'f1': 0.926056338028169}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.27it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.43it/s]\r\nepoch 14: {'accuracy': 0.8921568627450981, 'f1': 0.9225352112676057}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.28it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.43it/s]\r\nepoch 15: {'accuracy': 0.8872549019607843, 'f1': 0.9181494661921709}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.28it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.49it/s]\r\nepoch 16: {'accuracy': 0.8897058823529411, 'f1': 0.9211908931698775}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.27it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.48it/s]\r\nepoch 17: {'accuracy': 0.8897058823529411, 'f1': 0.9203539823008849}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.26it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.44it/s]\r\nepoch 18: {'accuracy': 0.8872549019607843, 'f1': 0.9195804195804195}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:26<00:00, 4.26it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.43it/s]\r\nepoch 19: {'accuracy': 0.8921568627450981, 'f1': 0.923076923076923}\r\n```\r\n7. with gradient checkpointing output logs:\r\n```\r\n0%| | 0/115 [00:00<?, ?it/s]You're using a RobertaTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:41<00:00, 2.77it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.37it/s]\r\nepoch 0: {'accuracy': 0.7083333333333334, 'f1': 0.8210526315789474}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.82it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.37it/s]\r\nepoch 1: {'accuracy': 0.6838235294117647, 'f1': 0.8122270742358079}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.82it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.39it/s]\r\nepoch 2: {'accuracy': 0.6838235294117647, 'f1': 0.8122270742358079}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.82it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.41it/s]\r\nepoch 3: {'accuracy': 0.6838235294117647, 'f1': 0.8122270742358079}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.81it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.40it/s]\r\nepoch 4: {'accuracy': 0.6838235294117647, 'f1': 0.8122270742358079}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.83it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.40it/s]\r\nepoch 5: {'accuracy': 0.8186274509803921, 'f1': 0.8766666666666666}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:41<00:00, 2.79it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.44it/s]\r\nepoch 6: {'accuracy': 0.8333333333333334, 'f1': 0.8885245901639344}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.81it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.42it/s]\r\nepoch 7: {'accuracy': 0.875, 'f1': 0.9109947643979057}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.83it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.40it/s]\r\nepoch 8: {'accuracy': 0.8872549019607843, 'f1': 0.9184397163120569}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.84it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.39it/s]\r\nepoch 9: {'accuracy': 0.8872549019607843, 'f1': 0.9201388888888888}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.82it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.40it/s]\r\nepoch 10: {'accuracy': 0.8921568627450981, 'f1': 0.9225352112676057}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.83it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.39it/s]\r\nepoch 11: {'accuracy': 0.8897058823529411, 'f1': 0.9220103986135182}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.81it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.40it/s]\r\nepoch 12: {'accuracy': 0.8946078431372549, 'f1': 0.9241622574955909}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.82it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.39it/s]\r\nepoch 13: {'accuracy': 0.8970588235294118, 'f1': 0.926056338028169}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.82it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.34it/s]\r\nepoch 14: {'accuracy': 0.8921568627450981, 'f1': 0.9225352112676057}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.83it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.33it/s]\r\nepoch 15: {'accuracy': 0.8872549019607843, 'f1': 0.9181494661921709}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.81it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.41it/s]\r\nepoch 16: {'accuracy': 0.8897058823529411, 'f1': 0.9211908931698775}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.82it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.42it/s]\r\nepoch 17: {'accuracy': 0.8897058823529411, 'f1': 0.9203539823008849}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.81it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.35it/s]\r\nepoch 18: {'accuracy': 0.8872549019607843, 'f1': 0.9195804195804195}\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 115/115 [00:40<00:00, 2.83it/s]\r\n100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 8.39it/s]\r\nepoch 19: {'accuracy': 0.8921568627450981, 'f1': 0.923076923076923}\r\n```\r\n\r\nObservations: No performance gap between runs with gradient checkpointing and without gradient checkpointing.",
"Thanks @pacman100. I got it now - a minimalist example is needed. I will try to create one over the weekend. \r\n",
"@pacman100. Hi Sourab, thanks for investing the time!\r\n\r\nYou didn't say otherwise, so it's confirmed that using gradient checkpointing should not change the functional impact of the model, correct?\r\n\r\nI now have a minimal implementation [sample notebook](https://github.com/marianokamp/export/blob/main/hf2/gradient_checkpointing.ipynb) that shows the issue.\r\n\r\nBackground: The [original code](https://github.com/marianokamp/peft_lora/blob/main/src/lora.py) is from an [article](https://towardsdatascience.com/dive-into-lora-adapters-38f4da488ede) that illustrates for educational purposes how a simple LoRA implementation looks like. It's just Python code and worked fine, until I tried gradient checkpointing in the [2nd article](https://towardsdatascience.com/a-winding-road-to-parameter-efficiency-12448e64524d). \r\n\r\nI am not aware of specific expectations that the transformers lib has on code. But there are two things I do in my example that may be worth pointing out as not being in the middle of the road. (a) Freezing modules and (b) overwriting the forward function in the module to be adapted to point it to the adapter implementation in the forward pass. Both work fine without gradient checkpointing, but maybe they are problematic with gradient checkpointing? The code is in the example I linked above, but for easier consumption I reproduce this method here:\r\n\r\n```Python\r\ndef adapt_model(model):\r\n\r\n class MinimalLoRAAdapter(nn.Module): \r\n def __init__(self, \r\n adaptee):\r\n super().__init__()\r\n\r\n self.adaptee = adaptee\r\n\r\n self.orig_forward = adaptee.forward\r\n adaptee.forward = self.forward # <-----------------\r\n \r\n r = 1\r\n adaptee.lora_A = nn.Parameter(\r\n torch.randn(adaptee.in_features, r) / math.sqrt(adaptee.in_features)\r\n )\r\n adaptee.lora_B = nn.Parameter(torch.zeros(r, adaptee.out_features))\r\n\r\n def forward(self, x, *args, **kwargs):\r\n return (\r\n self.orig_forward(x, *args, **kwargs) # <-----------------\r\n + F.dropout(x, 0.1) @ self.adaptee.lora_A @ self.adaptee.lora_B\r\n )\r\n \r\n # freeze all layers, incl. embeddings, except for the classifier\r\n for m in model.roberta.modules(): \r\n m.requires_grad_(False) # <-----------------\r\n\r\n # Adapt linear modules in transformer layers\r\n for m in model.roberta.encoder.modules(): \r\n if isinstance(m, nn.Linear):\r\n MinimalLoRAAdapter(m)\r\n```\r\n\r\nHere is an excerpt from the output. Full output in the linked notebook (check eval_accuracy):\r\n\r\n```\r\n---- without gradient checkpointing ----\r\n\r\n[..]\r\nmodel.is_gradient_checkpointing=False\r\n[..]\r\n{'train_runtime': 457.1886, 'train_samples_per_second': 489.951, 'train_steps_per_second': 2.187, 'train_loss': 0.38296363830566404, 'epoch': 3.32}\r\n{'eval_loss': 0.23593959212303162, 'eval_accuracy': 0.908256880733945, 'eval_runtime': 1.6902, 'eval_samples_per_second': 515.919, 'eval_steps_per_second': 64.49, 'epoch': 3.32}\r\n\r\n---- with gradient checkpointing ----\r\n\r\n[..]\r\nmodel.is_gradient_checkpointing=True\r\n[..]\r\n{'train_runtime': 227.8506, 'train_samples_per_second': 983.101, 'train_steps_per_second': 4.389, 'train_loss': 0.6675097045898437, 'epoch': 3.32}\r\n{'eval_loss': 0.6635248064994812, 'eval_accuracy': 0.5194954128440367, 'eval_runtime': 1.6397, 'eval_samples_per_second': 531.808, 'eval_steps_per_second': 66.476, 'epoch': 3.32}\r\n[..]\r\n```\r\nI tried the above with both GPU and CPU and I can observe the same behavior. Hope that helps to narrow it down. "
] | 1,695 | 1,707 | null |
NONE
| null |
### System Info
Latest released and py3.10.
accelerate-0.21.0 aiohttp-3.8.5 aiosignal-1.3.1 async-timeout-4.0.3 bitsandbytes-0.41.0 datasets-2.14.5 evaluate-0.4.0 frozenlist-1.4.0 huggingface-hub-0.17.1 multidict-6.0.4 peft-0.4.0 pynvml-11.5.0 regex-2023.8.8 responses-0.18.0 safetensors-0.3.3 sagemaker-inference-1.10.0 tensorboardX-2.6.2.2 tokenizers-0.13.3 transformers-4.33.2 xxhash-3.3.0 yarl-1.9.2
### Who can help?
@pacman100, @muellerzr
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Hi @pacman100, @muellerzr.
I was wondering about the memory use of LoRA. Specifically what happens if I adapt modules that are
- (top) closer to the head of the network than to the inputs, as opposed to
- (bottom) the other way around.
Given that the number of parameters to train remains the same in both cases, the memory usage should be the same, except that to calculate the gradients for (bottom) we would need to keep more activations around from the forward pass. If that were the case, then turning on gradient checkpointing should make (top) and (bottom) use the same memory, as we are discarding the activations and recalculating them on the backward pass. That is correct, no (@younesbelkada)?
Trying this out, I can see that behavior as expected. However, the accuracy also changed.
My understanding would be that with gradient checkpointing we would now need less memory, more time, but the functional aspects, here model performance, should be unchanged. Hence the issue.
### Details
Below you can see on the x-axis on which layer of a 12 layer RoBERTa Base the adapters were applied. As you can see the memory for (bottom - lower layer numbers, closer to the embeddings) are higher than for (top - higher layer numbers, closer to the head), when not using gradient checkpointing, and they are same when using gradient checkpointing.

However, when looking at the model performance we can see that we have a difference of 0.1 between using and not using checkpointing.

Not that it matters, but this is using the glue/sst-2 dataset. I am not changing anything, but passing 0 or 1 as an argument to Trainer's gradient_checkpointing attribute (and 0 and 1 to empty-cuda-cache every 30 seconds).
### Expected behavior
No functional change when using gradient_checkpointing.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26221/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26221/timeline
| null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/26220
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26220/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26220/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26220/events
|
https://github.com/huggingface/transformers/issues/26220
| 1,901,080,392 |
I_kwDOCUB6oc5xUC9I
| 26,220 |
How does one preprocess a pdf file before passing it into pipeline for summarization?
|
{
"login": "pythonvijay",
"id": 144582559,
"node_id": "U_kgDOCJ4nnw",
"avatar_url": "https://avatars.githubusercontent.com/u/144582559?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pythonvijay",
"html_url": "https://github.com/pythonvijay",
"followers_url": "https://api.github.com/users/pythonvijay/followers",
"following_url": "https://api.github.com/users/pythonvijay/following{/other_user}",
"gists_url": "https://api.github.com/users/pythonvijay/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pythonvijay/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pythonvijay/subscriptions",
"organizations_url": "https://api.github.com/users/pythonvijay/orgs",
"repos_url": "https://api.github.com/users/pythonvijay/repos",
"events_url": "https://api.github.com/users/pythonvijay/events{/privacy}",
"received_events_url": "https://api.github.com/users/pythonvijay/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey 🤗 thanks for opening an issue! We try to keep the github issues for bugs/feature requests, and less for custom code decoding. Seems like you are not even using transformers here. \r\nCould you ask your question on the [forum](https://discuss.huggingface.co/) instead? I'm sure the community will be of help!\r\n\r\nThanks!",
"This is a pre step to feed the PDF file into a huggingface hosted transformer **T5-base** for text summarization"
] | 1,695 | 1,695 | 1,695 |
NONE
| null |
Hi,
I think I am unable to read the pdf file in the required format as it runs into an error when I try to read it through PdfReader
here is my code:
```
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
# Authenticate and create the PyDrive client.
# This only needs to be done once per notebook.
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
# Download a file based on its file ID.
#
# A file ID looks like: laggVyWshwcyP6kEI-y_W3P8D26sz
file_id = "1RjF9CRj8xTQakH5jex1ppBrTw1heHwPS"
downloaded = drive.CreateFile({'id': file_id})
```
it works upto this point...
next, I pass this -
`print('Downloaded content "{}"'.format(downloaded.GetContentString()))`
and I get this error:
`UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb5 in position 11: invalid start byte`
and when I try to read the variable 'downloaded' into PdfReader, I again get an error:
`reader = PdfReader(downloaded)`
`AttributeError: 'GoogleDriveFile' object has no attribute 'seek'`
Please advise what I need to correct to make this work!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26220/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26220/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26219
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26219/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26219/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26219/events
|
https://github.com/huggingface/transformers/issues/26219
| 1,901,056,262 |
I_kwDOCUB6oc5xT9EG
| 26,219 |
Converting TIMM to HF Vision transformers
|
{
"login": "prabhuteja12",
"id": 11191577,
"node_id": "MDQ6VXNlcjExMTkxNTc3",
"avatar_url": "https://avatars.githubusercontent.com/u/11191577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/prabhuteja12",
"html_url": "https://github.com/prabhuteja12",
"followers_url": "https://api.github.com/users/prabhuteja12/followers",
"following_url": "https://api.github.com/users/prabhuteja12/following{/other_user}",
"gists_url": "https://api.github.com/users/prabhuteja12/gists{/gist_id}",
"starred_url": "https://api.github.com/users/prabhuteja12/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/prabhuteja12/subscriptions",
"organizations_url": "https://api.github.com/users/prabhuteja12/orgs",
"repos_url": "https://api.github.com/users/prabhuteja12/repos",
"events_url": "https://api.github.com/users/prabhuteja12/events{/privacy}",
"received_events_url": "https://api.github.com/users/prabhuteja12/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1990918270,
"node_id": "MDU6TGFiZWwxOTkwOTE4Mjcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20First%20Issue",
"name": "Good First Issue",
"color": "bbf794",
"default": false,
"description": ""
}
] |
closed
| false | null |
[] |
[
"Hey! Would you like to open a pr for this? 🤗 ",
"I might take some time before I can work on this, so if that is ok I can take a stab at this.",
"Sure! in the mean time anyone in the community can feel free to do this, tagging as a good first issue ",
"Hi,\r\n\r\nThat's because the script assumes that the patch size can be inferred from the model name:\r\n```\r\nconfig.patch_size = int(vit_name[-6:-4])\r\n```\r\nhowever for `vit_base_patch16_224.augreg_in21k_ft_in1k`, the patch size is not at the characters [-6:-4].\r\n\r\nHence it could make sense to make the conversion script more general, by having a more clever way to get the patch size based on the name, for instance using `model_name.find(\"patch\")`",
"Hi is anyone assigned to this issue I would like to contribute to it\r\n",
"@prabhuteja12 I want to work on this issue , can you give me some more description about the issue.",
"Yes, a fix has been proposed in #26353 and is under review. ",
"Given that the proposed fix is not accepted (in the PR). Can I work on this?",
"Sure! if you take into account the comment from the other PR would be great 🤗 ",
"hi @ArthurZucker since #26908 has been merged do you think we can close this also #26353 while at it",
"Yes! Closing 🤗 "
] | 1,695 | 1,704 | 1,704 |
NONE
| null |
### System Info
- `transformers` version: 4.31.0
- Platform: Linux-5.15.0-1040-aws-x86_64-with-glibc2.31
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.2
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 1.13.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help?
@amyeroberts
Thank you for the tool to convert timm weights to HF ViT implementation compatible ones! I'm, however, facing issues with converting the `augreg` weights. Running
`python -m transformers.models.vit.convert_vit_timm_to_pytorch --vit_name vit_base_patch16_224.augreg_in21k_ft_in1k --pytorch_dump_folder_path $MY_MODEL_PATH`
results in an error
```
line 156, in convert_vit_checkpoint
config.patch_size = int(vit_name[-6:-4])
ValueError: invalid literal for int() with base 10: 't_'
```
The issue stems from the code to infer the input image size and patch size configs which are currently hard coded to exist at specific indices (which doesn't always happen). Can this be fixed? I have right now patched hacked a version locally that works for this specific `vit_name` example, but a more general fix would be great!
### Information
- [ ] The official example scripts
- [x] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Steps to reproduce the behaviour
1. `python -m transformers.models.vit.convert_vit_timm_to_pytorch --vit_name vit_base_patch16_224.augreg_in21k_ft_in1k --pytorch_dump_folder_path local_dump_folder`
### Expected behavior
A converted `pytorch_model.bin` and corresponding `config` in `local_dump_folder`.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26219/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26219/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26218
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26218/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26218/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26218/events
|
https://github.com/huggingface/transformers/issues/26218
| 1,901,053,044 |
I_kwDOCUB6oc5xT8R0
| 26,218 |
How to manually set the seed of randomsampler generator when training using transformers trainer
|
{
"login": "young-chao",
"id": 34190033,
"node_id": "MDQ6VXNlcjM0MTkwMDMz",
"avatar_url": "https://avatars.githubusercontent.com/u/34190033?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/young-chao",
"html_url": "https://github.com/young-chao",
"followers_url": "https://api.github.com/users/young-chao/followers",
"following_url": "https://api.github.com/users/young-chao/following{/other_user}",
"gists_url": "https://api.github.com/users/young-chao/gists{/gist_id}",
"starred_url": "https://api.github.com/users/young-chao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/young-chao/subscriptions",
"organizations_url": "https://api.github.com/users/young-chao/orgs",
"repos_url": "https://api.github.com/users/young-chao/repos",
"events_url": "https://api.github.com/users/young-chao/events{/privacy}",
"received_events_url": "https://api.github.com/users/young-chao/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"\r\nI found that the default initialized state of the generator is always this tensor, regardless of the cuda version, pytorch version, etc.",
"Two things you can try: \r\n- pass a generator \r\n- use `set_seed(X)` which is a utility trainer. \r\n",
"> Two things you can try:\r\n> \r\n> * pass a generator\r\n> * use `set_seed(X)` which is a utility trainer.\r\n\r\nThank you for your reply, I will try your solution. ",
"@ArthurZucker I am going to try your solution, but I found that the trainer does not receive dataloader or sampler as a parameter, so where should I pass the generator to the sampler. Moreover, the trainer does not have this set_seed method. Do you mean the set_seed method of transformers? The script I use uses this method, however it only affects the default generator.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"你好,你的邮件已收到,谢谢!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,695 | 1,700 | 1,700 |
NONE
| null |
### System Info
I used a [script](https://github.com/huggingface/transformers/blob/v4.33.0/examples/pytorch/language-modeling/run_clm.py) to continue pre-training the llama2 model. In the second epoch, the loss began to explode, so I chose to reload the checkpoint to continue training, but the loss changes were completely consistent with before, which made me doubt the iteration of the dataset is always consistent. So I tried modifying the [seed.](https://github.com/huggingface/transformers/blob/v4.33.0/examples/pytorch/language-modeling/run_clm.py#L309C33-L309C33) But in the end, my training loss is always consistent, and the state I print randomsampler is always the same.
I hope someone can tell me how to solve this problem, including where the seed of this generator is specified.
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
transformers==4.33.0
pytorch==1.13.1
accelerate==0.21.0
deepspeed==0.10.0
### Expected behavior
I hope that the sampling of training data set should be different every time.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26218/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26218/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26217
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26217/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26217/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26217/events
|
https://github.com/huggingface/transformers/pull/26217
| 1,900,975,656 |
PR_kwDOCUB6oc5aklAn
| 26,217 |
Fix ConversationalPipeline tests
|
{
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,695 | 1,695 | 1,695 |
MEMBER
| null |
This PR fixes the failing conversation pipeline tests in the CI. The causes were:
1) `BlenderBotSmall` was missing a `default_chat_template`
2) The old `Conversation` object distinguished between processed and unprocessed user inputs. The new object doesn't! This caused a couple of tests that were expecting the old behaviour to fail. `ConversationalPipeline` has already been updated to handle the new behaviour, so only a few test values needed to be changed.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26217/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26217/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26217",
"html_url": "https://github.com/huggingface/transformers/pull/26217",
"diff_url": "https://github.com/huggingface/transformers/pull/26217.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26217.patch",
"merged_at": 1695046137000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26216
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26216/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26216/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26216/events
|
https://github.com/huggingface/transformers/issues/26216
| 1,900,669,543 |
I_kwDOCUB6oc5xSepn
| 26,216 |
Some MarianMT models broken and output garbage
|
{
"login": "fergusq",
"id": 3512480,
"node_id": "MDQ6VXNlcjM1MTI0ODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3512480?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fergusq",
"html_url": "https://github.com/fergusq",
"followers_url": "https://api.github.com/users/fergusq/followers",
"following_url": "https://api.github.com/users/fergusq/following{/other_user}",
"gists_url": "https://api.github.com/users/fergusq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fergusq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fergusq/subscriptions",
"organizations_url": "https://api.github.com/users/fergusq/orgs",
"repos_url": "https://api.github.com/users/fergusq/repos",
"events_url": "https://api.github.com/users/fergusq/events{/privacy}",
"received_events_url": "https://api.github.com/users/fergusq/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3081136536,
"node_id": "MDU6TGFiZWwzMDgxMTM2NTM2",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20Difficult%20Issue",
"name": "Good Difficult Issue",
"color": "684CC7",
"default": false,
"description": ""
}
] |
open
| false | null |
[] |
[
"I can confirm that the bug exists even after reinstalling the models and updating transformers to 4.33.2.",
"Hey! As I answered on the issue that was opened [here](https://github.com/Helsinki-NLP/Tatoeba-Challenge/issues/35), the Helsinki team should merge the PR we opened to fix the models on the hub! ",
"In the mean time use `model = AutoModelForSeq2SeqLM.from_pretrained(\"Helsinki-NLP/opus-tatoeba-en-ja\", revision = \"refs/pr/3\"` 😉 ",
"The Finnish–English model doesn't seem to have a similar PR as in the English–Japanese model. Could you share the script used to create the fixed version?",
"I'll upload PRs to all models, working on it! ",
"Hi. Is the updated script available somewhere? We are using some models that have not been published to huggingface and would need to convert them ourselves.",
"I think that the conversion script works as expected, but some models have to be converted again! Really sorry I could not go through this yet. Will update here soon! ",
"I attempted to convert a model per the master branch of the transformers library with the following steps, but the result was broken:\r\n\r\n* Cloned transformers and the tatoeba challenge repo\r\n* Installed transformers via `pip install .` and then the packages that it was missing with `torch wget sentencepiece gitpython`.\r\n* Ran the conversion with `python src/transformers/models/marian/convert_marian_tatoeba_to_pytorch.py --models fin-eng --save_dir converted`, resulting in `converted/opus-mt-fin-eng` was created without issue.\r\n* Loaded the model into a pipeline and ran it with:\r\n\r\n```\r\nfrom transformers import pipeline\r\np = pipeline(\"translation\", model=\"/path/to/converted/opus-mt-fin-eng\", max_new_tokens=50)\r\np(\"Mitähän tein väärin?\")\r\n```\r\n\r\nThe result it gave was `[{'translation_text': ',,,,,,, W W W W W W W W,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,'}]`. It also gave the warning\r\n\r\n> spaces_between_special_tokens is deprecated and will be removed in transformers v5. It was adding spaces between `added_tokens`, not special tokens, and does not exist in our fast implementation. Future tokenizers will handle the decoding process on a per-model rule.\r\n\r\nAm I doing something wrong, or is there something broken in the conversion script itself? (Am I perhaps using a wrong version?)",
"No I think the warning can be safely ignored in that case. Mostprobably an issue in the conversion. If you can push the raw model to thehub it will help me in debugging! ",
"The model is the one downloaded by the comand above. Do you want the converted result or for me to fish out whatever the command downloaded (it is mt-tc-big-fi-en that is publicly available)?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Thank you @artzucker for uploading the fixed version of the Finnish-English model.\r\n\r\nConverting the as of yet not on the Huggingface hub Finnish-Swedish model still gives garbage results, but so does (for me) converting the Finnish-English model. However, using the revision of the Finnish-English model from the pr like so gives correct results:\r\n\r\n```python\r\np = pipeline(\"translation\", model=\"Helsinki-NLP/opus-mt-tc-big-fi-en\", revision = \"refs/pr/6\", max_new_tokens=50)\r\n```\r\n\r\nThis leads me to believe that there's something wrong (at least different) with the steps I am taking to convert it. Is the correct way to convert the models documented somewhere? I know of this: https://github.com/huggingface/transformers/blob/main/scripts/tatoeba/README.md and followed it (plus also installing `torch` and `SentencePiece` which is not mentioned there) Before this breaking change, I used these steps to successfully convert the Swedish model once.\r\n\r\nI will contact the Helsinki people and ask, why the Finnish-Swedish model hasn't been uploaded to the Huggingface hub (or if it has been and I missed it, where). If it can be put there and you could take a look at it, that'd be great.\r\n\r\nIn the meantime, if you want to check if there is something surprising about the Finnish-Swedish model itself after all, it is this one: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/fin-swe#opustcv20210807bt-2021-12-08zip",
"Hey! I think I need to update the conversion script : readmes etc. Might not have time next week (will be off) but will definitely work on fixing this once and forall! \r\nFeel free to share whatever you can (repo with both weights for example) that would help!",
"I think that the last I'll keep open to track the conversion script update 😉 ",
"No time to tackle this yet sorry, adding the good difficult issue tag! "
] | 1,695 | 1,702 | null |
NONE
| null |
### System Info
- `transformers` version: 4.30.2
- Platform: macOS-13.4.1-arm64-arm-64bit
- Python version: 3.11.4
- Huggingface_hub version: 0.16.3
- Safetensors version: 0.3.1
- PyTorch version (GPU?): 2.1.0.dev20230413 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help?
@ArthurZucker @younesbelkada @gante
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Some of the MarianMT models I use like `Helsinki-NLP/opus-mt-tc-big-fi-en` are currently broken. This bug is reproduced in the Huggingface Hub inference widget: https://huggingface.co/Helsinki-NLP/opus-mt-tc-big-fi-en?text=Kissa+k%C3%A4velee+kadulla You can see that it gives a garbage translation.
This model worked just last week! I also see that the model hasn't been updated in the Hub for over a month, so the bug must be in the transformers library.
Simple code to reproduce locally:
```
>>> tokenizer = transformers.AutoTokenizer.from_pretrained("Helsinki-NLP/opus-mt-tc-big-fi-en")
>>> model = transformers.AutoModelForSeq2SeqLM.from_pretrained("Helsinki-NLP/opus-mt-tc-big-fi-en")
>>> model.generate(**tokenizer("kissa kävelee kadulla", return_tensors="pt"))
tensor([[57829, 16542, 16542, 16542, 16542, 16542, 16542, 16542, 16542, 16542,
16542, 16542, 16542, 16542, 16542, 16542, 16542, 16542, 16542, 16542,
16542, 16542, 16542, 16542, 16542, 16542, 16542, 16542, 16542, 16542,
16542, 16542, 16542, 16542, 16542, 16542, 16542, 16542, 16542, 16542,
16542, 16542, 16542, 16542, 16542, 16542, 16542, 19074, 19074, 19074,
19074, 19074, 19074, 19074, 19074, 19074, 19074, 19074, 19074, 19074,
19074, 19074, 19074, 19074, 19074, 19074, 19074, 19074, 19074, 19074,
19074, 19074, 19074, 19074, 19074, 19074, 19074, 19074, 19074, 19074,
19074, 19074, 19074, 19074, 19074, 19074, 19074, 19074, 19074, 19074,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825, 11825,
11825, 41756]])
```
### Expected behavior
The model should give a proper translation.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26216/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26216/timeline
| null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/26215
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26215/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26215/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26215/events
|
https://github.com/huggingface/transformers/pull/26215
| 1,900,537,603 |
PR_kwDOCUB6oc5ajE40
| 26,215 |
Fix Error not captured in PR doctesting
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Error should have been reported in the console of https://app.circleci.com/pipelines/github/huggingface/transformers/72920/workflows/33795bcf-6b08-4c2f-b040-aa54bb44b12f/jobs/921247/steps, but it is not.\r\n\r\n(The artifact has `errors.txt` file)"
] | 1,695 | 1,695 | 1,695 |
COLLABORATOR
| null |
# What does this PR do?
In https://app.circleci.com/pipelines/github/huggingface/transformers/72920/workflows/33795bcf-6b08-4c2f-b040-aa54bb44b12f/jobs/921247/artifacts,
we have `errors.txt` but not `failures_short.txt`. But we only checked the file `failures_short.txt`, therefore the error is not detected, and showing all test passed.
This PR fixes this.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26215/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26215/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26215",
"html_url": "https://github.com/huggingface/transformers/pull/26215",
"diff_url": "https://github.com/huggingface/transformers/pull/26215.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26215.patch",
"merged_at": 1695137271000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26214
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26214/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26214/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26214/events
|
https://github.com/huggingface/transformers/issues/26214
| 1,900,526,619 |
I_kwDOCUB6oc5xR7wb
| 26,214 |
Custom positional embeddings for whisper
|
{
"login": "bcl213124314",
"id": 145325557,
"node_id": "U_kgDOCKl99Q",
"avatar_url": "https://avatars.githubusercontent.com/u/145325557?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bcl213124314",
"html_url": "https://github.com/bcl213124314",
"followers_url": "https://api.github.com/users/bcl213124314/followers",
"following_url": "https://api.github.com/users/bcl213124314/following{/other_user}",
"gists_url": "https://api.github.com/users/bcl213124314/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bcl213124314/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bcl213124314/subscriptions",
"organizations_url": "https://api.github.com/users/bcl213124314/orgs",
"repos_url": "https://api.github.com/users/bcl213124314/repos",
"events_url": "https://api.github.com/users/bcl213124314/events{/privacy}",
"received_events_url": "https://api.github.com/users/bcl213124314/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1314768611,
"node_id": "MDU6TGFiZWwxMzE0NzY4NjEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": null
}
] |
closed
| false | null |
[] |
[
"You should have a look at #25744 😉 This is not planned ",
"Thanks for the link. Sorry for not searching enough.",
"No worries 🤗 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,695 | 1,698 | 1,698 |
NONE
| null |
### Feature request
Add the ability to pass custom positional encodings from the generate() call of the ConditionalGeneration model down to the forward() of the WhisperEncoder.
### Motivation
Currently the processor pads the audio input to 3000 mel frames (30 s). Encoding all 3000 frames is the main computational cost of transcribing short audio segments which are a lot shorter than 30 s. The only place where this fixed number of 3000 frames is currently hard coded into the model is:
```
embed_pos = self.embed_positions.weight
hidden_states = inputs_embeds + embed_pos
```
in the forward method of the whisper encoder, since embed_position.weight has a fixed shape.
Custom positional embeddings would allow the inference of shorter inputs, decreasing the computational cost of the encoding.
Of course that is not what the model was originally trained with and, depending on the custom positional encodings one might use, this changes the output of the model dramatically.
Short tests have shown that just setting
`embed_pos = self.embed_positions.weight[0:inputs_embeds.shape[1]]`
leads to reasonable predictions.
Better engineered schemes to generate embeddings for shorter inputs might lead to even better results.
### Your contribution
This is a pretty small change and I have implemented it [here](https://github.com/bcl213124314/transformers/tree/encoder_pos_embeddings)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26214/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26214/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26213
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26213/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26213/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26213/events
|
https://github.com/huggingface/transformers/pull/26213
| 1,900,472,939 |
PR_kwDOCUB6oc5ai26T
| 26,213 |
Remove `utils/documentation_tests.txt`
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,695 | 1,695 | 1,695 |
COLLABORATOR
| null |
# What does this PR do?
This file is already removed in #25680 (we decided to use `no_doctested.txt` to explicitly exclude some files - all others should be doctested).
However, #24085 added it back (which was a mistake of not having on top of the latest main at that time). This PR just removes this file again.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26213/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26213/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26213",
"html_url": "https://github.com/huggingface/transformers/pull/26213",
"diff_url": "https://github.com/huggingface/transformers/pull/26213.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26213.patch",
"merged_at": 1695036781000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26212
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26212/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26212/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26212/events
|
https://github.com/huggingface/transformers/pull/26212
| 1,900,434,938 |
PR_kwDOCUB6oc5aiurq
| 26,212 |
No doctest for `convert_bros_to_pytorch.py`
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,695 | 1,695 | 1,695 |
COLLABORATOR
| null |
# What does this PR do?
No need to doctest this file.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26212/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26212/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26212",
"html_url": "https://github.com/huggingface/transformers/pull/26212",
"diff_url": "https://github.com/huggingface/transformers/pull/26212.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26212.patch",
"merged_at": 1695036719000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26211
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26211/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26211/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26211/events
|
https://github.com/huggingface/transformers/pull/26211
| 1,900,415,873 |
PR_kwDOCUB6oc5aiqhl
| 26,211 |
Do not warn about unexpected decoder weights when loading T5EncoderModel and LongT5EncoderModel
|
{
"login": "fleonce",
"id": 8986525,
"node_id": "MDQ6VXNlcjg5ODY1MjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/8986525?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fleonce",
"html_url": "https://github.com/fleonce",
"followers_url": "https://api.github.com/users/fleonce/followers",
"following_url": "https://api.github.com/users/fleonce/following{/other_user}",
"gists_url": "https://api.github.com/users/fleonce/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fleonce/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fleonce/subscriptions",
"organizations_url": "https://api.github.com/users/fleonce/orgs",
"repos_url": "https://api.github.com/users/fleonce/repos",
"events_url": "https://api.github.com/users/fleonce/events{/privacy}",
"received_events_url": "https://api.github.com/users/fleonce/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26211). All of your documentation changes will be reflected on that endpoint.",
"Thank you for the follow-up question!\r\nThe problem can be reproduced when the log level for the whole library has been set to INFO:\r\n```python3\r\nimport transformers\r\ntransformers.logging.set_verbosity_info()\r\nm = transformers.T5EncoderModel.from_pretrained('t5-small')\r\n```\r\n\r\nI was not using the latest version of `transformers` when I was encountering this issue initially, now it is hidden by default because verbosity info is required to show those kinds of warnings, unless `T5EncoderModel` is contained in `model.config.architectures`, but only `T5ForConditionalGeneration` is in there. This seems to be caused by commit 096f2cf12664bb7da41f89897d3a22966baee9b4 (https://github.com/huggingface/transformers/blob/bc7ce1808f6c30df87fd9dff871a53ef510ccf77/src/transformers/modeling_utils.py#L3674)\r\n\r\nThe problem persists however, but we wont see the warning by default"
] | 1,695 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
# What does this PR do?
Adds `[r"decoder"]` to both `T5EncoderModel` and `LongT5EncoderModel`, as both models do not have any decoder layers and loading pretrained model checkpoints like `t5-small` will give warnings about keys found in the checkpoint but not in the model itself. To prevent this issue, `r"decoder"` has been added to `_keys_to_ignore_on_load_unexpected` for both model classes.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@ArthurZucker @younesbelkada
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26211/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26211/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26211",
"html_url": "https://github.com/huggingface/transformers/pull/26211",
"diff_url": "https://github.com/huggingface/transformers/pull/26211.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26211.patch",
"merged_at": 1695893263000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26210
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26210/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26210/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26210/events
|
https://github.com/huggingface/transformers/issues/26210
| 1,900,374,303 |
I_kwDOCUB6oc5xRWkf
| 26,210 |
❓ Questions to google/reformer-enwik8, hidden_state is independent to the context?
|
{
"login": "shipengAlan",
"id": 9625832,
"node_id": "MDQ6VXNlcjk2MjU4MzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/9625832?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shipengAlan",
"html_url": "https://github.com/shipengAlan",
"followers_url": "https://api.github.com/users/shipengAlan/followers",
"following_url": "https://api.github.com/users/shipengAlan/following{/other_user}",
"gists_url": "https://api.github.com/users/shipengAlan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shipengAlan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shipengAlan/subscriptions",
"organizations_url": "https://api.github.com/users/shipengAlan/orgs",
"repos_url": "https://api.github.com/users/shipengAlan/repos",
"events_url": "https://api.github.com/users/shipengAlan/events{/privacy}",
"received_events_url": "https://api.github.com/users/shipengAlan/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"This depends on whether or not the model uses `bidirectional attention` or `causal` attention. \r\nThis is not general and rather model specific. Usually decoders use `causal` attention while encoder `bidirectional`. Try setting `is_decoder = False` 😉 ",
"Thank you so much, Arthur @ArthurZucker\r\nAs your suggestion, the hidden_state of char become different under different context. 👍\r\n\r\n```\r\nimport torch\r\nfrom transformers import ReformerModelWithLMHead,AutoTokenizer,ReformerForSequenceClassification,ReformerModel\r\nfrom transformers import ReformerConfig, ReformerModel\r\nconf = ReformerConfig.from_pretrained('google/reformer-enwik8')\r\nconf.is_decoder=False\r\nmodel = ReformerModel.from_pretrained(\"google/reformer-enwik8\", config=conf)\r\nmodel.eval()\r\n\r\nencoded, attention_masks = encode([\"Hi\", \"Hello\"])\r\nout = model.forward(encoded, attention_mask=attention_masks, output_hidden_states=True)\r\n\r\nout.hidden_states[-1][1, 0, :] == out.hidden_states[-1][0, 0, :]\r\n\r\n...tensor([False, False, False, ..., False, False, False])\r\n\r\nencoded\r\n...tensor([[ 74, 107, 0, 0, 0],\r\n [ 74, 103, 110, 110, 113]])\r\n\r\nout.hidden_states[-1]\r\n...tensor([[[ -0.4034, 3.6106, -8.6159, ..., -1.6709, -13.2370, 3.6557],\r\n [ -3.0774, 15.5188, -6.5163, ..., 2.5811, -11.8358, 5.5339],\r\n [ 2.9285, -7.2961, -17.6565, ..., 1.8124, -8.6599, 0.6633],\r\n [ -5.1294, 1.7743, -18.9366, ..., 1.2802, -8.8503, 3.6187],\r\n [ -4.7954, -5.2946, -16.2219, ..., 3.6296, -8.2144, 4.6336]],\r\n\r\n [[-24.0092, 17.1780, -19.1030, ..., 18.7862, 17.9711, 6.1703],\r\n [-16.9048, 13.5032, -18.7212, ..., 3.4969, 19.2100, 1.7013],\r\n [ -5.7089, 13.5217, 2.0973, ..., 1.9111, 12.5311, -18.0838],\r\n [ 7.1809, 25.9611, -15.1986, ..., -8.1871, -4.8213, -0.1738],\r\n [ 5.5061, -15.3236, -7.9121, ..., 11.0452, 11.3647, -12.2207]]])\r\n```",
"For BERT, we use the first special token [CLS] hidden_state to represent the sentence.\r\nBut for this char-level reformer, we don't have a \"token\" during pre-training and use it to embed the sentence. \r\nI have no idea that I can use the hidden_state of first char to embedding the sentence or use avg. hidden_state of all chars.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,695 | 1,698 | 1,698 |
NONE
| null |
### Background
Based on char-level model reformer, I want to embed a text into embedding as one of downstream feature.
Like Bert, we usually use the hidden state at text embedding at [CLS] position.
So a natural idea is to use the first/last position's hidden_state as the embedding of the sentence.
But I found the hidden_state of each char is independent to the context.
For example, in the two sentence"Hi! ET" and "Hello", the last hidden_state of "H" is same.
```
def encode(list_of_strings, pad_token_id=0):
max_length = max([len(string) for string in list_of_strings])
# create emtpy tensors
attention_masks = torch.zeros((len(list_of_strings), max_length), dtype=torch.long)
input_ids = torch.full((len(list_of_strings), max_length), pad_token_id, dtype=torch.long)
for idx, string in enumerate(list_of_strings):
# make sure string is in byte format
if not isinstance(string, bytes):
string = str.encode(string)
input_ids[idx, :len(string)] = torch.tensor([x + 2 for x in string])
attention_masks[idx, :len(string)] = 1
return input_ids, attention_masks
import torch
from transformers import ReformerModelWithLMHead
model = ReformerModelWithLMHead.from_pretrained("google/reformer-enwik8")
encoded, attention_masks = encode(["Hi! ET", "Hello world"])
out = model.forward(encoded, attention_mask=attention_masks, output_hidden_states=True)
out.hidden_states[-1][1, 0, :] == out.hidden_states[-1][0, 0, :]
... tensor([True, True, True, ..., True, True, True])
# "H"'s hidden_state is all same under different sentences.
```
### Who can help?
@patrickvonplaten, @ArthurZucker and @younesbelkada
### Information
- [x] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Coder as above
### Expected behavior
Same char's hidden_state under different sentences is different according to attention layer concept.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26210/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26210/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26209
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26209/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26209/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26209/events
|
https://github.com/huggingface/transformers/issues/26209
| 1,900,326,185 |
I_kwDOCUB6oc5xRK0p
| 26,209 |
minimum learning rate should be allowed to set in lr schedulers
|
{
"login": "annahung31",
"id": 39179888,
"node_id": "MDQ6VXNlcjM5MTc5ODg4",
"avatar_url": "https://avatars.githubusercontent.com/u/39179888?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/annahung31",
"html_url": "https://github.com/annahung31",
"followers_url": "https://api.github.com/users/annahung31/followers",
"following_url": "https://api.github.com/users/annahung31/following{/other_user}",
"gists_url": "https://api.github.com/users/annahung31/gists{/gist_id}",
"starred_url": "https://api.github.com/users/annahung31/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/annahung31/subscriptions",
"organizations_url": "https://api.github.com/users/annahung31/orgs",
"repos_url": "https://api.github.com/users/annahung31/repos",
"events_url": "https://api.github.com/users/annahung31/events{/privacy}",
"received_events_url": "https://api.github.com/users/annahung31/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2648621985,
"node_id": "MDU6TGFiZWwyNjQ4NjIxOTg1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Feature%20request",
"name": "Feature request",
"color": "FBCA04",
"default": false,
"description": "Request for a new feature"
}
] |
open
| false | null |
[] |
[
"Is the following not pretty much what you are looking for:\r\n```python \r\n min_lr_ratio (`float`, *optional*, defaults to 0):\r\n The final learning rate at the end of the linear decay will be `init_lr * min_lr_ratio`.\r\n```\r\n",
"Yes, it can work for me. This argument is in `optimization_tf.py`, can we have it in `optimization.py`?",
"I ran into the same kind of problem today. I think adding that option is a good idea.",
"Would one of you like to open a PR for this? 🤗 ",
"Yeah, let me do that!",
"Wait I face the same problem, but simply changing 0.0 to min_lr_ratio will not work.\r\nAccording to the papers, the lr must be reduced slowly considering all the learning steps.\r\nIf we only change the ratio, the the model will reduce lr until it reach min learning rate after x numbers of steps then will keeps training with that lr until it finishes. \r\n\r\nThis is my custom trainer, I dont know how to replicates the behaviors in papers yet, please correct me if I am wrong or if I misunderstanding your implementation.\r\n`class CustomTrainer(Trainer):\r\n def __init__(self, *args, **kwargs):\r\n super().__init__(*args, **kwargs)\r\n\r\n\r\n def create_optimizer_and_scheduler(self, num_training_steps):\r\n self.optimizer = AdamW(self.model.parameters(),\r\n lr=self.args.learning_rate,\r\n weight_decay=self.args.weight_decay,\r\n eps=self.args.adam_epsilon)\r\n \r\n def CUSTOM_get_cosine_schedule_with_warmup_lr_lambda(\r\n current_step: int, *, num_warmup_steps: int, num_training_steps: int, num_cycles: float\r\n ):\r\n if current_step < num_warmup_steps:\r\n return float(current_step) / float(max(1, num_warmup_steps))\r\n progress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))\r\n return max(0.1, 0.5 * (1.0 + math.cos(math.pi * float(num_cycles) * 2.0 * progress)))\r\n \r\n def CUSTOM_get_cosine_schedule_with_warmup(\r\n optimizer: Optimizer, num_warmup_steps: int, num_training_steps: int, num_cycles: float = 0.5, last_epoch: int = -1\r\n ):\r\n\r\n lr_lambda = partial(\r\n CUSTOM_get_cosine_schedule_with_warmup_lr_lambda,\r\n num_warmup_steps=num_warmup_steps,\r\n num_training_steps=num_training_steps,\r\n num_cycles=num_cycles,\r\n )\r\n return LambdaLR(optimizer, lr_lambda, last_epoch)\r\n\r\n self.lr_scheduler = CUSTOM_get_cosine_schedule_with_warmup(\r\n self.optimizer, self.args.warmup_steps, num_training_steps)`",
"Yes, you are right. \r\nAfter I encountered this issue, my strategy is to add one more argument called `milestone` (I'm still thinking about a better naming), it represents the training step that where mininum learning rate locates. Then keeps training with that lr until it finishes.\r\nSo my implementation for linear scheduler is like: \r\n```\r\ndef _get_linear_schedule_with_warmup_lr_lambda(\r\n current_step: int,\r\n *,\r\n num_warmup_steps: int,\r\n num_training_steps: int,\r\n min_lr_ratio: float,\r\n milestone: int,\r\n):\r\n\r\n if current_step < num_warmup_steps:\r\n return float(current_step) / float(max(1, num_warmup_steps))\r\n if current_step <= milestone:\r\n return 1 - (current_step / milestone) * (1 - min_lr_ratio)\r\n else:\r\n return min_lr_ratio\r\n\r\ndef get_linear_schedule_with_warmup(\r\n optimizer: Any,\r\n num_warmup_steps: int,\r\n num_training_steps: int,\r\n milestone: Optional[int],\r\n min_lr_ratio: float = 0.0,\r\n last_epoch: int = -1,\r\n):\r\n \"\"\"\r\n Create a schedule with a learning rate that decreases linearly from the initial lr set in the optimizer to initial learning * min_lr_ratio, after\r\n a warmup period during which it increases linearly from 0 to the initial lr set in the optimizer.\r\n\r\n Args:\r\n last_epoch (`int`, *optional*, defaults to -1):\r\n The index of the last epoch when resuming training.\r\n\r\n Return:\r\n `torch.optim.lr_scheduler.LambdaLR` with the appropriate schedule.\r\n \"\"\"\r\n\r\n milestone = (\r\n milestone if milestone is not None else num_training_steps - 1\r\n ) # to make the last learning rate become 0.\r\n\r\n lr_lambda = partial(\r\n _get_linear_schedule_with_warmup_lr_lambda,\r\n num_warmup_steps=num_warmup_steps,\r\n num_training_steps=num_training_steps,\r\n min_lr_ratio=min_lr_ratio,\r\n milestone=milestone,\r\n )\r\n\r\n return LambdaLR(optimizer, lr_lambda, last_epoch)\r\n\r\n```\r\n\r\nIf we want the lr be reduced slowly considering all the learning steps, we can set milestone = num_training_steps - 1. This is set to default so that the behavior align with the original code.\r\n\r\nAs for the cosine scheduler, I found that I can change the parameter `num_cycles` to control the curve, \r\nThe default is `num_cycles=0.5`, so the lr will reach the end of 0.0 at the end of training process. We can change it to 0.25, then the lr will reach to half of the initial learning rate at the end.\r\n\r\nHowever, this parameter cannot be reached from Trainer setting. For me, currently the workaround is to add this parameter like:\r\n\r\n```\r\ntrain_args = TrainingArguments(....)\r\ntrain_args.num_cycles = 0.25\r\n\r\n#in custom trainer:\r\nclass MyTrainer(Trainer):\r\n ....\r\n\r\n def create_trainer(self, num_training_steps):\r\n self.lr_scheduler = get_scheduler(\r\n ....\r\n num_cycles = self.args.num_cycles\r\n )\r\n```\r\n\r\nI'm thinking about add it into TrainingArguments directly.\r\n\r\nDoes this implementation makes sense to you? Any suggestion is welcome.",
"\r\nYou implementation is almost perfect. But the line is crack at your milestone.\r\nI came up with this for linear scheduler. I think there must be better way, but we have all variables needed to calculate the desired LR smoothly.\r\n\r\n\r\n\r\n",
"Just replace `max(0.0, float(num_training_steps - current_step) / float(max(1, num_training_steps - num_warmup_steps)))` to \r\n\r\n`max(\r\n min_lr_ratio,\r\n min_lr_ratio + (1-min_lr_ratio) * float(num_training_steps - current_step) / float(max(1, num_training_steps - num_warmup_steps))`",
"Any update?",
"你好,你的邮件已收到,谢谢!"
] | 1,695 | 1,707 | null |
NONE
| null |
### Feature request
In current lr schedulers provided in `optimization.py`, the minimum learning rate is always `0.0`.
We could add one more input parameter like "min_lr" to let user defind the minimum learning rate.
Take `_get_linear_schedule_with_warmup_lr_lambda` as an example:
Original:
```
def _get_linear_schedule_with_warmup_lr_lambda(current_step: int, *, num_warmup_steps: int, num_training_steps: int):
if current_step < num_warmup_steps:
return float(current_step) / float(max(1, num_warmup_steps))
return max(0.0, float(num_training_steps - current_step) / float(max(1, num_training_steps - num_warmup_steps)))
```
We can change it into:
```
def _get_linear_schedule_with_warmup_lr_lambda(current_step: int, *, num_warmup_steps: int, num_training_steps: int, min_lr: float = 0.0):
if current_step < num_warmup_steps:
return float(current_step) / float(max(1, num_warmup_steps))
return max(min_lr, float(num_training_steps - current_step) / float(max(1, num_training_steps - num_warmup_steps)))
```
### Motivation
In some papers, they mentioned about their lr scheduling. Take [LIMA](http://arxiv.org/abs/2305.11206) as an example:
```
Without warmup steps, we set the initial learning rate to 1e − 5 and linearly decaying to 1e − 6 by the end of training.
```
To reproduce the experiment using their recipe, I need to rewrite the scheduler (and the all related functions like get_scheduler/create_scheduler) in the trainer, that makes the code really ugly.
So I think it might be good to have this kind of feature to make trainer more flexible.
### Your contribution
I can submit a PR for this feature.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26209/reactions",
"total_count": 7,
"+1": 7,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26209/timeline
| null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/26208
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26208/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26208/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26208/events
|
https://github.com/huggingface/transformers/pull/26208
| 1,899,985,886 |
PR_kwDOCUB6oc5ahMyV
| 26,208 |
Add Russian localization for README
|
{
"login": "qweme32",
"id": 99718350,
"node_id": "U_kgDOBfGUzg",
"avatar_url": "https://avatars.githubusercontent.com/u/99718350?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/qweme32",
"html_url": "https://github.com/qweme32",
"followers_url": "https://api.github.com/users/qweme32/followers",
"following_url": "https://api.github.com/users/qweme32/following{/other_user}",
"gists_url": "https://api.github.com/users/qweme32/gists{/gist_id}",
"starred_url": "https://api.github.com/users/qweme32/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/qweme32/subscriptions",
"organizations_url": "https://api.github.com/users/qweme32/orgs",
"repos_url": "https://api.github.com/users/qweme32/repos",
"events_url": "https://api.github.com/users/qweme32/events{/privacy}",
"received_events_url": "https://api.github.com/users/qweme32/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @stevhliu ",
"awesome ",
"any comments?",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26208). All of your documentation changes will be reflected on that endpoint.",
"thx, added @stevhliu "
] | 1,694 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
# What does this PR do?
Add Russian localization for README.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26208/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26208/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26208",
"html_url": "https://github.com/huggingface/transformers/pull/26208",
"diff_url": "https://github.com/huggingface/transformers/pull/26208.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26208.patch",
"merged_at": 1695660144000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26207
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26207/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26207/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26207/events
|
https://github.com/huggingface/transformers/issues/26207
| 1,899,975,518 |
I_kwDOCUB6oc5xP1Ne
| 26,207 |
From the first step, loss is always 0.0 and evel_loss becomes NaN.
|
{
"login": "50516017",
"id": 23068536,
"node_id": "MDQ6VXNlcjIzMDY4NTM2",
"avatar_url": "https://avatars.githubusercontent.com/u/23068536?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/50516017",
"html_url": "https://github.com/50516017",
"followers_url": "https://api.github.com/users/50516017/followers",
"following_url": "https://api.github.com/users/50516017/following{/other_user}",
"gists_url": "https://api.github.com/users/50516017/gists{/gist_id}",
"starred_url": "https://api.github.com/users/50516017/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/50516017/subscriptions",
"organizations_url": "https://api.github.com/users/50516017/orgs",
"repos_url": "https://api.github.com/users/50516017/repos",
"events_url": "https://api.github.com/users/50516017/events{/privacy}",
"received_events_url": "https://api.github.com/users/50516017/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @50516017 \r\nThanks for the issue! \r\nYou can't perform pure fine-tuning on 8bit/4bit models, please use LoRA adapters that you can easily attach to the model before passing it to `Trainer`:\r\n\r\n```python\r\nfrom peft import LoraConfig\r\n\r\n\r\nmodel_name = \"rinna/japanese-gpt-neox-3.6b-instruction-ppo\"\r\ntokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)\r\nconfig = AutoConfig.from_pretrained(model_name,use_fast=False)\r\nmodel = AutoModelForCausalLM.from_pretrained(\r\n model_name,\r\n config=config,\r\n device_map=\"auto\",\r\n load_in_8bit=True\r\n)\r\n\r\nlora_config = LoraConfig(\r\n r=8\r\n)\r\n\r\nmodel.add_adapter(lora_config)\r\n\r\nnew_dataset = transform_dialogues(dataset)\r\nVAL_SET_SIZE = int(len(new_dataset) * 0.05)\r\ncollator = InstructCollator(tokenizer)\r\n\r\ntrainer = transformers.Trainer(\r\n model = model,\r\n data_collator=collator,\r\n train_dataset=tokenized_train,\r\n eval_dataset=tokenized_val,\r\n args=transformers.TrainingArguments(\r\n num_train_epochs=10,\r\n learning_rate=3e-5,\r\n evaluation_strategy=\"steps\",\r\n save_strategy=\"steps\",\r\n eval_steps=eval_steps,\r\n save_steps=save_steps,\r\n per_device_train_batch_size=MICRO_BATCH_SIZE,\r\n per_device_eval_batch_size=MICRO_BATCH_SIZE,\r\n gradient_accumulation_steps=BATCH_SIZE // MICRO_BATCH_SIZE,\r\n dataloader_num_workers=12,\r\n logging_steps=logging_steps,\r\n output_dir=f\"{output_dir}/{learn_start_time}\",\r\n report_to=\"wandb\",\r\n save_total_limit=1,\r\n load_best_model_at_end=True,\r\n greater_is_better=False,\r\n metric_for_best_model=\"eval_loss\",\r\n auto_find_batch_size=True\r\n )\r\n)\r\nmodel.config.use_cache = False\r\ntrainer.train()\r\n```",
"@ArthurZucker we actually do pass a logger.info here: https://github.com/huggingface/transformers/blob/main/src/transformers/trainer.py#L408 maybe we should set a stronger check and raise a value error instead as it is very confusing for some users, what do you think also @SunMarc ?",
"Yes, I think that it is reasonable to use a value error in that case. ",
"Awesome, I'll work on it asap!",
"Given how many issues we have had on this, yes, let's raise an error! ",
"Sorry, I misunderstood. Thank you for your reply!"
] | 1,694 | 1,695 | 1,695 |
NONE
| null |
### System Info
- `transformers` version: 4.34.0.dev0
- Platform: Linux-5.15.90.1-microsoft-standard-WSL2-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.20.3
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@pacman100,@muellerz,@younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I want to create a chatbot with a certain character using transformer. I prepared a simple dataset for teaching tone and started training a model with the code below. However, loss became 0 and eval_loss became NaN. What approach should I take?
```
model_name = "rinna/japanese-gpt-neox-3.6b-instruction-ppo"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
config = AutoConfig.from_pretrained(model_name,use_fast=False)
model = AutoModelForCausalLM.from_pretrained(
model_name,
config=config,
device_map="auto",
load_in_8bit=True
)
new_dataset = transform_dialogues(dataset)
VAL_SET_SIZE = int(len(new_dataset) * 0.05)
collator = InstructCollator(tokenizer)
trainer = transformers.Trainer(
model = model,
data_collator=collator,
train_dataset=tokenized_train,
eval_dataset=tokenized_val,
args=transformers.TrainingArguments(
num_train_epochs=10,
learning_rate=3e-5,
evaluation_strategy="steps",
save_strategy="steps",
eval_steps=eval_steps,
save_steps=save_steps,
per_device_train_batch_size=MICRO_BATCH_SIZE,
per_device_eval_batch_size=MICRO_BATCH_SIZE,
gradient_accumulation_steps=BATCH_SIZE // MICRO_BATCH_SIZE,
dataloader_num_workers=12,
logging_steps=logging_steps,
output_dir=f"{output_dir}/{learn_start_time}",
report_to="wandb",
save_total_limit=1,
load_best_model_at_end=True,
greater_is_better=False,
metric_for_best_model="eval_loss",
auto_find_batch_size=True
)
)
model.config.use_cache = False
trainer.train()
```
My own collator is below. Could this be causing the problem?
```
class InstructCollator():
def __init__(self, tokenizer, ignore_index=-100):
self.tokenizer = tokenizer
self.ignore_index = -100
def __call__(self, examples):
input_batch = []
label_batch = []
for example in examples:
input_batch.append(example['input_ids'])
label_batch.append(example['labels'])
input_ids = pad_sequence(
input_batch, batch_first=True, padding_value=self.tokenizer.pad_token_id
)
labels = pad_sequence(
label_batch, batch_first=True, padding_value=self.ignore_index
)
attention_mask = input_ids.ne(self.tokenizer.pad_token_id)
return {
'input_ids': input_ids,
'labels': labels,
'attention_mask': attention_mask
}
```
### Expected behavior
A large loss is recorded in the first step, and after that, loss = 0, evel_loss = Nan.
```
train start
0%| | 0/600 [01:01<?, ?it/s]{'loss': 76656.0521, 'learning_rate': 2.9925619834710744e-05, 'epoch': 0.02} | 0/1210 [00:00<?, ?it/s]{'loss': 0.0, 'learning_rate': 2.9851239669421488e-05, 'epoch': 0.05}
{'loss': 0.0, 'learning_rate': 2.9776859504132232e-05, 'epoch': 0.07}
{'eval_loss': nan, 'eval_runtime': 14.0042, 'eval_samples_per_second': 7.284, 'eval_steps_per_second': 3.642, 'epoch': 0.08}
{'loss': 0.0, 'learning_rate': 2.9702479338842976e-05, 'epoch': 0.1}
{'loss': 0.0, 'learning_rate': 2.962809917355372e-05, 'epoch': 0.12}
{'loss': 0.0, 'learning_rate': 2.9553719008264463e-05, 'epoch': 0.15}
...
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26207/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26207/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26206
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26206/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26206/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26206/events
|
https://github.com/huggingface/transformers/pull/26206
| 1,899,900,152 |
PR_kwDOCUB6oc5ag7tj
| 26,206 |
[docs] Fix model reference in zero shot image classification example
|
{
"login": "Aleksandar1932",
"id": 29300910,
"node_id": "MDQ6VXNlcjI5MzAwOTEw",
"avatar_url": "https://avatars.githubusercontent.com/u/29300910?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Aleksandar1932",
"html_url": "https://github.com/Aleksandar1932",
"followers_url": "https://api.github.com/users/Aleksandar1932/followers",
"following_url": "https://api.github.com/users/Aleksandar1932/following{/other_user}",
"gists_url": "https://api.github.com/users/Aleksandar1932/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Aleksandar1932/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Aleksandar1932/subscriptions",
"organizations_url": "https://api.github.com/users/Aleksandar1932/orgs",
"repos_url": "https://api.github.com/users/Aleksandar1932/repos",
"events_url": "https://api.github.com/users/Aleksandar1932/events{/privacy}",
"received_events_url": "https://api.github.com/users/Aleksandar1932/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26206). All of your documentation changes will be reflected on that endpoint."
] | 1,694 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
# What does this PR do?
This PR fixes a typo in the docs, more specifically the model reference, since it it defined as `detector` and later referenced as predictor which is not defined. Settled on `detector`, since on example in other locale (`docs/source/ko/tasks/zero_shot_object_detection.md`) is `detector`.
## Before submitting
- [X] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26206/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26206/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26206",
"html_url": "https://github.com/huggingface/transformers/pull/26206",
"diff_url": "https://github.com/huggingface/transformers/pull/26206.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26206.patch",
"merged_at": 1695077112000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26205
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26205/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26205/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26205/events
|
https://github.com/huggingface/transformers/issues/26205
| 1,899,855,350 |
I_kwDOCUB6oc5xPX32
| 26,205 |
Custom training for LayoutLMv3 for document answering task
|
{
"login": "NevilleMthw",
"id": 18580821,
"node_id": "MDQ6VXNlcjE4NTgwODIx",
"avatar_url": "https://avatars.githubusercontent.com/u/18580821?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NevilleMthw",
"html_url": "https://github.com/NevilleMthw",
"followers_url": "https://api.github.com/users/NevilleMthw/followers",
"following_url": "https://api.github.com/users/NevilleMthw/following{/other_user}",
"gists_url": "https://api.github.com/users/NevilleMthw/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NevilleMthw/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NevilleMthw/subscriptions",
"organizations_url": "https://api.github.com/users/NevilleMthw/orgs",
"repos_url": "https://api.github.com/users/NevilleMthw/repos",
"events_url": "https://api.github.com/users/NevilleMthw/events{/privacy}",
"received_events_url": "https://api.github.com/users/NevilleMthw/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"See my demo notebook here: https://github.com/NielsRogge/Transformers-Tutorials/blob/master/LayoutLMv2/DocVQA/Fine_tuning_LayoutLMv2ForQuestionAnswering_on_DocVQA.ipynb.\r\n\r\nIt's equivalent for LayoutLMv3, just make sure to prepare the data in the right format",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,694 | 1,698 | 1,698 |
NONE
| null |
### System Info
- `transformers` version: 4.32.0
- Platform: Linux-6.2.0-32-generic-x86_64-with-glibc2.35
- Python version: 3.11.4
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: N/A
- Using distributed or parallel set-up in script?: N/A
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Hello,
I am not having a specific type of bug but I would like to know if there is any sort of guide towards a custom dataset training for LayoutLMv3, I am following through this link but I don't see how someone with another dataset can follow: https://huggingface.co/docs/transformers/tasks/document_question_answering#evaluation
Is there any standard for the JSON structure? Is there a specific way to import the data so that we can use the existing functions?
Thanks.
### Expected behavior
Ability to fine tune with custom dataset instead of Docvqa dataset.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26205/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26205/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26204
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26204/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26204/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26204/events
|
https://github.com/huggingface/transformers/issues/26204
| 1,899,849,869 |
I_kwDOCUB6oc5xPWiN
| 26,204 |
Running Phi1.0 on a Mac M2
|
{
"login": "erlebach",
"id": 324708,
"node_id": "MDQ6VXNlcjMyNDcwOA==",
"avatar_url": "https://avatars.githubusercontent.com/u/324708?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/erlebach",
"html_url": "https://github.com/erlebach",
"followers_url": "https://api.github.com/users/erlebach/followers",
"following_url": "https://api.github.com/users/erlebach/following{/other_user}",
"gists_url": "https://api.github.com/users/erlebach/gists{/gist_id}",
"starred_url": "https://api.github.com/users/erlebach/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/erlebach/subscriptions",
"organizations_url": "https://api.github.com/users/erlebach/orgs",
"repos_url": "https://api.github.com/users/erlebach/repos",
"events_url": "https://api.github.com/users/erlebach/events{/privacy}",
"received_events_url": "https://api.github.com/users/erlebach/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! The error suggest that you are running the model in half precision (torch.float16) but layer norm is not supported. You should either try in `bfloat16` or just float32`",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Thank you, Arthur. I'll check it out. Just saw your reply.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,694 | 1,700 | 1,700 |
NONE
| null |
### System Info
transformers-cli env
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 4.33.2
- Platform: macOS-13.5.2-arm64-arm-64bit
- Python version: 3.10.10
- Huggingface_hub version: 0.17.1
- Safetensors version: 0.3.3
- Accelerate version: 0.23.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No.
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@ArthurZucker @younesbelkada
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I am running the Phi1.0 model with the following Poetry setup on a mac (without CUDA):
```
[tool.poetry]
name = "my_phi-1"
version = "0.1.0"
description = ""
authors = ["erlebach <gordon.erlebach@gmail.com>"]
readme = "README.md"
[tool.poetry.dependencies]
python = "^3.10"
torch = "^2.0.1"
numpy = "^1.25.2"
transformers = "^4.33.1"
datasets = "^2.14.5"
tiktoken = "^0.4.0"
wandb = "^0.15.10"
tqdm = "^4.66.1"
einops = "^0.6.1"
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
```
and get a stacktrace when running with Python 10.x:
```
Traceback (most recent call last):
File "/Users/erlebach/src/2023/poetry/my_phi-1/phi-1/sample.py", line 12, in <module>
outputs = model.generate(**inputs, max_length=200)
File "/Users/erlebach/src/2023/poetry/my_phi-1/.venv/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/Users/erlebach/src/2023/poetry/my_phi-1/.venv/lib/python3.10/site-packages/transformers/generation/utils.py", line 1602, in generate
return self.greedy_search(
File "/Users/erlebach/src/2023/poetry/my_phi-1/.venv/lib/python3.10/site-packages/transformers/generation/utils.py", line 2450, in greedy_search
outputs = self(
File "/Users/erlebach/src/2023/poetry/my_phi-1/.venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/Users/erlebach/.cache/huggingface/modules/transformers_modules/microsoft/phi-1/621f8448067757fafc89009d08bd7d71ad0239e1/modeling_mixformer_sequential.py", line 771, in forward
hidden_layer = module(hidden_layer, past_cache=past_key_values)
File "/Users/erlebach/src/2023/poetry/my_phi-1/.venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/Users/erlebach/.cache/huggingface/modules/transformers_modules/microsoft/phi-1/621f8448067757fafc89009d08bd7d71ad0239e1/modeling_mixformer_sequential.py", line 625, in forward
hidden_states = self.ln(hidden_states)
File "/Users/erlebach/src/2023/poetry/my_phi-1/.venv/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/Users/erlebach/src/2023/poetry/my_phi-1/.venv/lib/python3.10/site-packages/torch/nn/modules/normalization.py", line 190, in forward
return F.layer_norm(
File "/Users/erlebach/src/2023/poetry/my_phi-1/.venv/lib/python3.10/site-packages/torch/nn/functional.py", line 2512, in layer_norm
return handle_torch_function(
File "/Users/erlebach/src/2023/poetry/my_phi-1/.venv/lib/python3.10/site-packages/torch/overrides.py", line 1534, in handle_torch_function
result = mode.__torch_function__(public_api, types, args, kwargs)
File "/Users/erlebach/src/2023/poetry/my_phi-1/.venv/lib/python3.10/site-packages/torch/utils/_device.py", line 62, in __torch_function__
return func(*args, **kwargs)
File "/Users/erlebach/src/2023/poetry/my_phi-1/.venv/lib/python3.10/site-packages/torch/nn/functional.py", line 2515, in layer_norm
return torch.layer_norm(input, normalized_shape, weight, bias, eps, torch.backends.cudnn.enabled)
RuntimeError: "LayerNormKernelImpl" not implemented for 'Half'
```
I am not using Cuda. I probably must load a different library? Thank you for any insight!
Gordon
### Expected behavior
I would expect no stacktrace.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26204/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26204/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26203
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26203/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26203/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26203/events
|
https://github.com/huggingface/transformers/issues/26203
| 1,899,839,567 |
I_kwDOCUB6oc5xPUBP
| 26,203 |
RuntimeError: Caught RuntimeError in replica 0 on device 0
|
{
"login": "ArnaudHureaux",
"id": 51860563,
"node_id": "MDQ6VXNlcjUxODYwNTYz",
"avatar_url": "https://avatars.githubusercontent.com/u/51860563?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArnaudHureaux",
"html_url": "https://github.com/ArnaudHureaux",
"followers_url": "https://api.github.com/users/ArnaudHureaux/followers",
"following_url": "https://api.github.com/users/ArnaudHureaux/following{/other_user}",
"gists_url": "https://api.github.com/users/ArnaudHureaux/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArnaudHureaux/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArnaudHureaux/subscriptions",
"organizations_url": "https://api.github.com/users/ArnaudHureaux/orgs",
"repos_url": "https://api.github.com/users/ArnaudHureaux/repos",
"events_url": "https://api.github.com/users/ArnaudHureaux/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArnaudHureaux/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey, could you provide the full traceback? 🤗 next time would be great if you can format the code to make it easier to read! \r\ncc @younesbelkada if you know what is going on here.",
"Hi @ArnaudHureaux \r\nThanks for the issue, in order to help you, can you share the full traceback please? ",
"> Hey, could you provide the full traceback? 🤗 next time would be great if you can format the code to make it easier to read! cc @younesbelkada if you know what is going on here.\r\n\r\nOh yeah my bad, i edited my comment sorry, i forgotten the presence of \"#####\" in my code 🤗\r\n\r\n@younesbelkada thanks a lot for your help, please find below the full traceback :\r\n\r\n```python\r\n\r\nYou're using a LlamaTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.\r\n---------------------------------------------------------------------------\r\nRuntimeError Traceback (most recent call last)\r\nCell In[10], line 44\r\n 13 training_arguments = TrainingArguments(\r\n 14 output_dir=output_dir,\r\n 15 num_train_epochs=num_train_epochs,\r\n (...)\r\n 30 report_to=\"tensorboard\"\r\n 31 )\r\n 33 trainer = SFTTrainer(\r\n 34 model=model,\r\n 35 train_dataset=dataset,\r\n (...)\r\n 41 packing=packing,\r\n 42 )\r\n---> 44 trainer.train()\r\n 45 trainer.model.save_pretrained(new_model)\r\n\r\nFile /usr/local/lib/python3.10/dist-packages/transformers/trainer.py:1539, in Trainer.train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)\r\n 1534 self.model_wrapped = self.model\r\n 1536 inner_training_loop = find_executable_batch_size(\r\n 1537 self._inner_training_loop, self._train_batch_size, args.auto_find_batch_size\r\n 1538 )\r\n-> 1539 return inner_training_loop(\r\n 1540 args=args,\r\n 1541 resume_from_checkpoint=resume_from_checkpoint,\r\n 1542 trial=trial,\r\n 1543 ignore_keys_for_eval=ignore_keys_for_eval,\r\n 1544 )\r\n\r\nFile /usr/local/lib/python3.10/dist-packages/transformers/trainer.py:1809, in Trainer._inner_training_loop(self, batch_size, args, resume_from_checkpoint, trial, ignore_keys_for_eval)\r\n 1806 self.control = self.callback_handler.on_step_begin(args, self.state, self.control)\r\n 1808 with self.accelerator.accumulate(model):\r\n-> 1809 tr_loss_step = self.training_step(model, inputs)\r\n 1811 if (\r\n 1812 args.logging_nan_inf_filter\r\n 1813 and not is_torch_tpu_available()\r\n 1814 and (torch.isnan(tr_loss_step) or torch.isinf(tr_loss_step))\r\n 1815 ):\r\n 1816 # if loss is nan or inf simply add the average of previous logged losses\r\n 1817 tr_loss += tr_loss / (1 + self.state.global_step - self._globalstep_last_logged)\r\n\r\nFile /usr/local/lib/python3.10/dist-packages/transformers/trainer.py:2654, in Trainer.training_step(self, model, inputs)\r\n 2651 return loss_mb.reduce_mean().detach().to(self.args.device)\r\n 2653 with self.compute_loss_context_manager():\r\n-> 2654 loss = self.compute_loss(model, inputs)\r\n 2656 if self.args.n_gpu > 1:\r\n 2657 loss = loss.mean() # mean() to average on multi-gpu parallel training\r\n\r\nFile /usr/local/lib/python3.10/dist-packages/transformers/trainer.py:2679, in Trainer.compute_loss(self, model, inputs, return_outputs)\r\n 2677 else:\r\n 2678 labels = None\r\n-> 2679 outputs = model(**inputs)\r\n 2680 # Save past state if it exists\r\n 2681 # TODO: this needs to be fixed and made cleaner later.\r\n 2682 if self.args.past_index >= 0:\r\n\r\nFile /usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)\r\n 1496 # If we don't have any hooks, we want to skip the rest of the logic in\r\n 1497 # this function, and just call forward.\r\n 1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks\r\n 1499 or _global_backward_pre_hooks or _global_backward_hooks\r\n 1500 or _global_forward_hooks or _global_forward_pre_hooks):\r\n-> 1501 return forward_call(*args, **kwargs)\r\n 1502 # Do not call functions when jit is used\r\n 1503 full_backward_hooks, non_full_backward_hooks = [], []\r\n\r\nFile /usr/local/lib/python3.10/dist-packages/torch/nn/parallel/data_parallel.py:171, in DataParallel.forward(self, *inputs, **kwargs)\r\n 169 return self.module(*inputs[0], **kwargs[0])\r\n 170 replicas = self.replicate(self.module, self.device_ids[:len(inputs)])\r\n--> 171 outputs = self.parallel_apply(replicas, inputs, kwargs)\r\n 172 return self.gather(outputs, self.output_device)\r\n\r\nFile /usr/local/lib/python3.10/dist-packages/torch/nn/parallel/data_parallel.py:181, in DataParallel.parallel_apply(self, replicas, inputs, kwargs)\r\n 180 def parallel_apply(self, replicas, inputs, kwargs):\r\n--> 181 return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])\r\n\r\nFile /usr/local/lib/python3.10/dist-packages/torch/nn/parallel/parallel_apply.py:89, in parallel_apply(modules, inputs, kwargs_tup, devices)\r\n 87 output = results[i]\r\n 88 if isinstance(output, ExceptionWrapper):\r\n---> 89 output.reraise()\r\n 90 outputs.append(output)\r\n 91 return outputs\r\n\r\nFile /usr/local/lib/python3.10/dist-packages/torch/_utils.py:644, in ExceptionWrapper.reraise(self)\r\n 640 except TypeError:\r\n 641 # If the exception takes multiple arguments, don't try to\r\n 642 # instantiate since we don't know how to\r\n 643 raise RuntimeError(msg) from None\r\n--> 644 raise exception\r\n\r\nRuntimeError: Caught RuntimeError in replica 0 on device 0.\r\nOriginal Traceback (most recent call last):\r\n File \"/usr/local/lib/python3.10/dist-packages/torch/nn/parallel/parallel_apply.py\", line 64, in _worker\r\n output = module(*input, **kwargs)\r\n File \"/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"/usr/local/lib/python3.10/dist-packages/peft/peft_model.py\", line 922, in forward\r\n return self.base_model(\r\n File \"/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"/usr/local/lib/python3.10/dist-packages/accelerate/hooks.py\", line 165, in new_forward\r\n output = old_forward(*args, **kwargs)\r\n File \"/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py\", line 806, in forward\r\n outputs = self.model(\r\n File \"/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"/usr/local/lib/python3.10/dist-packages/accelerate/hooks.py\", line 165, in new_forward\r\n output = old_forward(*args, **kwargs)\r\n File \"/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py\", line 685, in forward\r\n layer_outputs = torch.utils.checkpoint.checkpoint(\r\n File \"/usr/local/lib/python3.10/dist-packages/torch/utils/checkpoint.py\", line 249, in checkpoint\r\n return CheckpointFunction.apply(function, preserve, *args)\r\n File \"/usr/local/lib/python3.10/dist-packages/torch/autograd/function.py\", line 506, in apply\r\n return super().apply(*args, **kwargs) # type: ignore[misc]\r\n File \"/usr/local/lib/python3.10/dist-packages/torch/utils/checkpoint.py\", line 107, in forward\r\n outputs = run_function(*args)\r\n File \"/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py\", line 681, in custom_forward\r\n return module(*inputs, output_attentions, None)\r\n File \"/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"/usr/local/lib/python3.10/dist-packages/accelerate/hooks.py\", line 165, in new_forward\r\n output = old_forward(*args, **kwargs)\r\n File \"/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py\", line 408, in forward\r\n hidden_states, self_attn_weights, present_key_value = self.self_attn(\r\n File \"/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py\", line 1501, in _call_impl\r\n return forward_call(*args, **kwargs)\r\n File \"/usr/local/lib/python3.10/dist-packages/accelerate/hooks.py\", line 165, in new_forward\r\n output = old_forward(*args, **kwargs)\r\n File \"/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py\", line 295, in forward\r\n query_states = [F.linear(hidden_states, query_slices[i]) for i in range(self.pretraining_tp)]\r\n File \"/usr/local/lib/python3.10/dist-packages/transformers/models/llama/modeling_llama.py\", line 295, in <listcomp>\r\n query_states = [F.linear(hidden_states, query_slices[i]) for i in range(self.pretraining_tp)]\r\nRuntimeError: mat1 and mat2 shapes cannot be multiplied (1024x8192 and 1x1024)```",
"Hmm it seems it uses `pretraining_tp=1` despite you are forcing it on the script, and this is the culprit as it is not supported in PEFT - @ArthurZucker I thought the pretraining_tp was always forced to be 1.\r\nCan you add `revision=\"refs/pr/1` on `from_pretrained` ?",
"Thanks @younesbelkada but which \"from_pretrained\" ? \r\n\r\n```\r\npython\r\nmodel = AutoModelForCausalLM.from_pretrained(\r\n```\r\n\r\nor \r\n\r\n```\r\npython\r\ntokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)\r\n```",
"?",
"Hey, I invite you to read the documentation about the model you are using: [Llama](https://huggingface.co/docs/transformers/v4.32.0/model_doc/llama). \r\n[Here](https://huggingface.co/docs/transformers/v4.32.0/model_doc/llama#transformers.LlamaConfig.pretraining_tp), the `pertaining_tp` argument is explained. 🤗 \\\r\nAs this is an argument for the modelling code, it should be added to the `from_pretrained` used to initialise the model. ",
"hi @ArnaudHureaux can you try this snippet:\r\n\r\n```python\r\nimport os\r\nimport torch\r\nfrom datasets import load_dataset\r\nfrom transformers import (\r\n AutoModelForCausalLM,\r\n AutoTokenizer,\r\n BitsAndBytesConfig,\r\n HfArgumentParser,\r\n TrainingArguments,\r\n pipeline,\r\n logging,\r\n)\r\nfrom peft import LoraConfig, PeftModel\r\nfrom trl import SFTTrainer\r\n\r\nmodel_name = \"NousResearch/Llama-2-70b-chat-hf\"\r\ndataset_name = \"mlabonne/guanaco-llama2-1k\"\r\nnew_model = \"Llama-2-70b-chat-hf-miniguanaco\"\r\nlora_r = 64\r\nlora_alpha = 16\r\nlora_dropout = 0.1\r\nuse_4bit = True\r\nbnb_4bit_compute_dtype = \"float16\"\r\nbnb_4bit_quant_type = \"nf4\"\r\nuse_nested_quant = False\r\noutput_dir = \"./results\"\r\nnum_train_epochs = 1\r\nfp16 = False\r\nbf16 = True\r\nper_device_train_batch_size = 1\r\nper_device_eval_batch_size = 2\r\ngradient_accumulation_steps = 1\r\ngradient_checkpointing = True\r\nmax_grad_norm = 0.3\r\nlearning_rate = 2e-4\r\nweight_decay = 0.001\r\noptim = \"paged_adamw_32bit\"\r\nlr_scheduler_type = \"constant\"\r\nmax_steps = -1\r\nwarmup_ratio = 0.03\r\ngroup_by_length = True\r\nsave_steps = 25\r\nlogging_steps = 25\r\nmax_seq_length = None\r\npacking = False\r\ndevice_map = {\"\": 0}\r\n\r\ndataset = load_dataset(dataset_name, split=\"train\")\r\n\r\ncompute_dtype = getattr(torch, bnb_4bit_compute_dtype)\r\n\r\nbnb_config = BitsAndBytesConfig(\r\n load_in_4bit=use_4bit,\r\n bnb_4bit_quant_type=bnb_4bit_quant_type,\r\n bnb_4bit_compute_dtype=compute_dtype,\r\n bnb_4bit_use_double_quant=use_nested_quant,\r\n)\r\n\r\nif compute_dtype == torch.float16 and use_4bit:\r\n major, _ = torch.cuda.get_device_capability()\r\n if major >= 8:\r\n print(\"=\" * 80)\r\n print(\"Your GPU supports bfloat16: accelerate training with bf16=True\")\r\n print(\"=\" * 80)\r\n\r\n# Load base model\r\nmodel = AutoModelForCausalLM.from_pretrained(\r\n model_name,\r\n quantization_config=bnb_config,\r\n device_map=device_map # Pass in the device map,\r\n revision=\"refs/pr/1\"\r\n)\r\n\r\nmodel.config.use_cache = False\r\nmodel.config.pretraining_tp = 1\r\n\r\ntokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)\r\ntokenizer.pad_token = tokenizer.eos_token\r\ntokenizer.padding_side = \"right\" # Fix weird overflow issue with fp16 training\r\n\r\npeft_config = LoraConfig(\r\n lora_alpha=lora_alpha,\r\n lora_dropout=lora_dropout,\r\n r=lora_r,\r\n bias=\"none\",\r\n task_type=\"CAUSAL_LM\",\r\n)\r\n\r\ntraining_arguments = TrainingArguments(\r\n output_dir=output_dir,\r\n num_train_epochs=num_train_epochs,\r\n per_device_train_batch_size=per_device_train_batch_size,\r\n gradient_accumulation_steps=gradient_accumulation_steps,\r\n optim=optim,\r\n save_steps=save_steps,\r\n logging_steps=logging_steps,\r\n learning_rate=learning_rate,\r\n weight_decay=weight_decay,\r\n fp16=fp16,\r\n bf16=bf16,\r\n max_grad_norm=max_grad_norm,\r\n max_steps=max_steps,\r\n warmup_ratio=warmup_ratio,\r\n group_by_length=group_by_length,\r\n lr_scheduler_type=lr_scheduler_type,\r\n report_to=\"tensorboard\"\r\n)\r\n\r\ntrainer = SFTTrainer(\r\n model=model,\r\n train_dataset=dataset,\r\n peft_config=peft_config,\r\n dataset_text_field=\"text\",\r\n max_seq_length=max_seq_length,\r\n tokenizer=tokenizer,\r\n args=training_arguments,\r\n packing=packing,\r\n)\r\n\r\ntrainer.train()\r\ntrainer.model.save_pretrained(new_model)\r\n```\r\n\r\nHowever this is very surprising as you have correctly set: `model.config.pretraining_tp = 1` , can you try with the latest transformers: `pip install -U transformers` ?",
"Hi @younesbelkada,\r\n\r\nThanks a lot for your answer, the training worked perfectly with your code !\r\n\r\nBut now i want to push the model on the hugging face hub,,so i stopped and reset my kernel & server and i ran this code (which worked for the llama-7B example) :\r\n\r\n```python\r\n# Reload model in FP16 and merge it with LoRA weights\r\nbase_model = AutoModelForCausalLM.from_pretrained(\r\n model_name,\r\n low_cpu_mem_usage=True,\r\n return_dict=True,\r\n torch_dtype=torch.float16,\r\n device_map=device_map,\r\n)\r\nmodel = PeftModel.from_pretrained(base_model, new_model)\r\nmodel = model.merge_and_unload()\r\n\r\n# Reload tokenizer to save it\r\ntokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)\r\ntokenizer.pad_token = tokenizer.eos_token\r\ntokenizer.padding_side = \"right\"\r\n\r\nmodel.push_to_hub(new_model, use_temp_dir=False)\r\ntokenizer.push_to_hub(new_model, use_temp_dir=False)\r\n```\r\n\r\nBut i don't know why i have a cuda memory error with my 2 GPUs A80: \r\n\r\n```python\r\n---------------------------------------------------------------------------\r\nOutOfMemoryError Traceback (most recent call last)\r\nCell In[8], line 2\r\n 1 # Reload model in FP16 and merge it with LoRA weights\r\n----> 2 base_model = AutoModelForCausalLM.from_pretrained(\r\n 3 model_name,\r\n 4 low_cpu_mem_usage=True,\r\n 5 return_dict=True,\r\n 6 torch_dtype=torch.float16,\r\n 7 device_map=device_map,\r\n 8 )\r\n 9 model = PeftModel.from_pretrained(base_model, new_model)\r\n 10 model = model.merge_and_unload()\r\n\r\nFile /usr/local/lib/python3.10/dist-packages/transformers/models/auto/auto_factory.py:493, in _BaseAutoModelClass.from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)\r\n 491 elif type(config) in cls._model_mapping.keys():\r\n 492 model_class = _get_model_class(config, cls._model_mapping)\r\n--> 493 return model_class.from_pretrained(\r\n 494 pretrained_model_name_or_path, *model_args, config=config, **hub_kwargs, **kwargs\r\n 495 )\r\n 496 raise ValueError(\r\n 497 f\"Unrecognized configuration class {config.__class__} for this kind of AutoModel: {cls.__name__}.\\n\"\r\n 498 f\"Model type should be one of {', '.join(c.__name__ for c in cls._model_mapping.keys())}.\"\r\n 499 )\r\n\r\nFile /usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py:2903, in PreTrainedModel.from_pretrained(cls, pretrained_model_name_or_path, config, cache_dir, ignore_mismatched_sizes, force_download, local_files_only, token, revision, use_safetensors, *model_args, **kwargs)\r\n 2893 if dtype_orig is not None:\r\n 2894 torch.set_default_dtype(dtype_orig)\r\n 2896 (\r\n 2897 model,\r\n 2898 missing_keys,\r\n 2899 unexpected_keys,\r\n 2900 mismatched_keys,\r\n 2901 offload_index,\r\n 2902 error_msgs,\r\n-> 2903 ) = cls._load_pretrained_model(\r\n 2904 model,\r\n 2905 state_dict,\r\n 2906 loaded_state_dict_keys, # XXX: rename?\r\n 2907 resolved_archive_file,\r\n 2908 pretrained_model_name_or_path,\r\n 2909 ignore_mismatched_sizes=ignore_mismatched_sizes,\r\n 2910 sharded_metadata=sharded_metadata,\r\n 2911 _fast_init=_fast_init,\r\n 2912 low_cpu_mem_usage=low_cpu_mem_usage,\r\n 2913 device_map=device_map,\r\n 2914 offload_folder=offload_folder,\r\n 2915 offload_state_dict=offload_state_dict,\r\n 2916 dtype=torch_dtype,\r\n 2917 is_quantized=(load_in_8bit or load_in_4bit),\r\n 2918 keep_in_fp32_modules=keep_in_fp32_modules,\r\n 2919 )\r\n 2921 model.is_loaded_in_4bit = load_in_4bit\r\n 2922 model.is_loaded_in_8bit = load_in_8bit\r\n\r\nFile /usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py:3260, in PreTrainedModel._load_pretrained_model(cls, model, state_dict, loaded_keys, resolved_archive_file, pretrained_model_name_or_path, ignore_mismatched_sizes, sharded_metadata, _fast_init, low_cpu_mem_usage, device_map, offload_folder, offload_state_dict, dtype, is_quantized, keep_in_fp32_modules)\r\n 3250 mismatched_keys += _find_mismatched_keys(\r\n 3251 state_dict,\r\n 3252 model_state_dict,\r\n (...)\r\n 3256 ignore_mismatched_sizes,\r\n 3257 )\r\n 3259 if low_cpu_mem_usage:\r\n-> 3260 new_error_msgs, offload_index, state_dict_index = _load_state_dict_into_meta_model(\r\n 3261 model_to_load,\r\n 3262 state_dict,\r\n 3263 loaded_keys,\r\n 3264 start_prefix,\r\n 3265 expected_keys,\r\n 3266 device_map=device_map,\r\n 3267 offload_folder=offload_folder,\r\n 3268 offload_index=offload_index,\r\n 3269 state_dict_folder=state_dict_folder,\r\n 3270 state_dict_index=state_dict_index,\r\n 3271 dtype=dtype,\r\n 3272 is_quantized=is_quantized,\r\n 3273 is_safetensors=is_safetensors,\r\n 3274 keep_in_fp32_modules=keep_in_fp32_modules,\r\n 3275 )\r\n 3276 error_msgs += new_error_msgs\r\n 3277 else:\r\n\r\nFile /usr/local/lib/python3.10/dist-packages/transformers/modeling_utils.py:717, in _load_state_dict_into_meta_model(model, state_dict, loaded_state_dict_keys, start_prefix, expected_keys, device_map, offload_folder, offload_index, state_dict_folder, state_dict_index, dtype, is_quantized, is_safetensors, keep_in_fp32_modules)\r\n 714 state_dict_index = offload_weight(param, param_name, state_dict_folder, state_dict_index)\r\n 715 elif not is_quantized:\r\n 716 # For backward compatibility with older versions of `accelerate`\r\n--> 717 set_module_tensor_to_device(model, param_name, param_device, **set_module_kwargs)\r\n 718 else:\r\n 719 if param.dtype == torch.int8 and param_name.replace(\"weight\", \"SCB\") in state_dict.keys():\r\n\r\nFile /usr/local/lib/python3.10/dist-packages/accelerate/utils/modeling.py:298, in set_module_tensor_to_device(module, tensor_name, device, value, dtype, fp16_statistics)\r\n 296 module._parameters[tensor_name] = param_cls(new_value, requires_grad=old_value.requires_grad)\r\n 297 elif isinstance(value, torch.Tensor):\r\n--> 298 new_value = value.to(device)\r\n 299 else:\r\n 300 new_value = torch.tensor(value, device=device)\r\n\r\nOutOfMemoryError: CUDA out of memory. Tried to allocate 448.00 MiB (GPU 0; 79.15 GiB total capacity; 78.58 GiB already allocated; 153.25 MiB free; 78.58 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF\r\n```\r\n\r\n\r\nI ran \r\n\r\n```python\r\ntorch.cuda.memory_summary(device=None, abbreviated=False)\r\n```\r\nAnd i get this output :\r\n```\r\n|===========================================================================|\r\n| PyTorch CUDA memory summary, device ID 0 |\r\n|---------------------------------------------------------------------------|\r\n| CUDA OOMs: 1 | cudaMalloc retries: 1 |\r\n|===========================================================================|\r\n| Metric | Cur Usage | Peak Usage | Tot Alloc | Tot Freed |\r\n|---------------------------------------------------------------------------|\r\n| Allocated memory | 80469 MiB | 80469 MiB | 80469 MiB | 0 B |\r\n| from large pool | 80468 MiB | 80468 MiB | 80468 MiB | 0 B |\r\n| from small pool | 1 MiB | 1 MiB | 1 MiB | 0 B |\r\n|---------------------------------------------------------------------------|\r\n| Active memory | 80469 MiB | 80469 MiB | 80469 MiB | 0 B |\r\n| from large pool | 80468 MiB | 80468 MiB | 80468 MiB | 0 B |\r\n| from small pool | 1 MiB | 1 MiB | 1 MiB | 0 B |\r\n|---------------------------------------------------------------------------|\r\n| Requested memory | 80469 MiB | 80469 MiB | 80469 MiB | 0 B |\r\n| from large pool | 80468 MiB | 80468 MiB | 80468 MiB | 0 B |\r\n| from small pool | 1 MiB | 1 MiB | 1 MiB | 0 B |\r\n|---------------------------------------------------------------------------|\r\n| GPU reserved memory | 80470 MiB | 80470 MiB | 80470 MiB | 0 B |\r\n| from large pool | 80468 MiB | 80468 MiB | 80468 MiB | 0 B |\r\n| from small pool | 2 MiB | 2 MiB | 2 MiB | 0 B |\r\n|---------------------------------------------------------------------------|\r\n| Non-releasable memory | 450048 B | 2032 KiB | 2032 KiB | 1592 KiB |\r\n| from large pool | 0 B | 0 KiB | 0 KiB | 0 KiB |\r\n| from small pool | 450048 B | 2032 KiB | 2032 KiB | 1592 KiB |\r\n|---------------------------------------------------------------------------|\r\n| Allocations | 492 | 492 | 492 | 0 |\r\n| from large pool | 344 | 344 | 344 | 0 |\r\n| from small pool | 148 | 148 | 148 | 0 |\r\n|---------------------------------------------------------------------------|\r\n| Active allocs | 492 | 492 | 492 | 0 |\r\n| from large pool | 344 | 344 | 344 | 0 |\r\n| from small pool | 148 | 148 | 148 | 0 |\r\n|---------------------------------------------------------------------------|\r\n| GPU reserved segments | 345 | 345 | 345 | 0 |\r\n| from large pool | 344 | 344 | 344 | 0 |\r\n| from small pool | 1 | 1 | 1 | 0 |\r\n|---------------------------------------------------------------------------|\r\n| Non-releasable allocs | 1 | 1 | 1 | 0 |\r\n| from large pool | 0 | 0 | 0 | 0 |\r\n| from small pool | 1 | 1 | 1 | 0 |\r\n|---------------------------------------------------------------------------|\r\n| Oversize allocations | 0 | 0 | 0 | 0 |\r\n|---------------------------------------------------------------------------|\r\n| Oversize GPU segments | 0 | 0 | 0 | 0 |\r\n|===========================================================================|\r\n\r\n```\r\n\r\n\r\n\r\nI think the problem is that i'am using only 1 GPU whereas i have 2 GPUs on my server\r\nAny idea of what i should do ? How can i use my 2 GPUs in this code ?",
"Ok my bad, i just replaced device_map=device_map by device_map='auto' and it worked !\r\n\r\n\r\n```python\r\nbase_model = AutoModelForCausalLM.from_pretrained(\r\n model_name,\r\n low_cpu_mem_usage=True,\r\n return_dict=True,\r\n torch_dtype=torch.float16,\r\n device_map = 'auto'\r\n #device_map=device_map\r\n)\r\n```",
"Awesome ! Great that the training worked now ! \r\nFeel free to close the issue if you thinks your concerns have been solved ! Thanks again !",
"Yeah it's 100% solved ! I have my own model on the huggingfacehub, i will now try to API-se this model with text-generation-inference\r\n\r\n\r\n\r\nThanks again @younesbelkada \r\n",
"Very nice @ArnaudHureaux ! 🚀 ",
"Oh, last question @younesbelkada \r\n\r\nWith this code I sucessfully created a finetuned model : https://huggingface.co/ArnaudHureaux/Llama-2-70b-chat-hf-miniguanaco/tree/main\r\n\r\nBut there is no .safetensors files in this model instead of the original model https://huggingface.co/meta-llama/Llama-2-70b-chat-hf/tree/main and i need them to deploy this model on text-generation-inference API\r\n\r\nHow can i convert the .bin into .safetensors ?\r\n\r\n(i know that the question is not related to my issue so i didn't reopen it and i created a topic on the generalist forum https://discuss.huggingface.co/t/how-convert-the-bin-files-into-safetensors-files/56721\r\n\r\nThanks by advance for your answer ;)",
"Oh forget about, i was finally able to deploy the model without the safetensors ;)",
"Perfect! Could you share the fix so that the community could also take some inspiration from it in case they face the same issue ? 🙏 ",
"Yeah, it was just an error from my side, the \"there is no .safetensors\" was just a warning, and the error was indeed only related to a bad settings of my docker run command (with no links with the current issue)"
] | 1,694 | 1,695 | 1,695 |
NONE
| null |
### System Info
transformers version -> 4.33
python version -> 3.10.6
I try to finetune this huggingface model : NousResearch/Llama-2-70b-chat-hf
With this huggingface dataset : mlabonne/guanaco-llama2-1k
None of those previous answers helped me :
https://github.com/huggingface/transformers/issues/23754 -> i didn't understood the error
https://github.com/huggingface/transformers/issues/6855 -> I reduce the batch size by 1 and i used 4 A100 GPU, no result
### Who can help?
Who can help -> text models: @ArthurZucker and @younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
1.Deploy a server RunPod with 4 A100 GPU (7.96$ per hour) with the pytorch image "RunPod Pytorch 2.0.1"
2. Install those libraries :
```bash
!pip install transformers[sentencepiece]
!pip install yolk3k
!yolk -V trl
!pip install -q accelerate==0.21.0 peft==0.4.0 bitsandbytes==0.40.2 transformers==4.31.0 trl==0.7.1
!pip install scipy tensorboardX
!pip install sentencepiece
```
3. Run this code :
```python
import os
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
TrainingArguments,
pipeline,
logging,
)
from peft import LoraConfig, PeftModel
from trl import SFTTrainer
model_name = "NousResearch/Llama-2-70b-chat-hf"
dataset_name = "mlabonne/guanaco-llama2-1k"
new_model = "Llama-2-70b-chat-hf-miniguanaco"
lora_r = 64
lora_alpha = 16
lora_dropout = 0.1
use_4bit = True
bnb_4bit_compute_dtype = "float16"
bnb_4bit_quant_type = "nf4"
use_nested_quant = False
output_dir = "./results"
num_train_epochs = 1
fp16 = False
bf16 = True
per_device_train_batch_size = 1
per_device_eval_batch_size = 2
gradient_accumulation_steps = 1
gradient_checkpointing = True
max_grad_norm = 0.3
learning_rate = 2e-4
weight_decay = 0.001
optim = "paged_adamw_32bit"
lr_scheduler_type = "constant"
max_steps = -1
warmup_ratio = 0.03
group_by_length = True
save_steps = 25
logging_steps = 25
max_seq_length = None
packing = False
device_map = {"": 0}
dataset = load_dataset(dataset_name, split="train")
compute_dtype = getattr(torch, bnb_4bit_compute_dtype)
bnb_config = BitsAndBytesConfig(
load_in_4bit=use_4bit,
bnb_4bit_quant_type=bnb_4bit_quant_type,
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=use_nested_quant,
)
if compute_dtype == torch.float16 and use_4bit:
major, _ = torch.cuda.get_device_capability()
if major >= 8:
print("=" * 80)
print("Your GPU supports bfloat16: accelerate training with bf16=True")
print("=" * 80)
# Load base model
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map=device_map # Pass in the device map
)
model.config.use_cache = False
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right" # Fix weird overflow issue with fp16 training
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_r,
bias="none",
task_type="CAUSAL_LM",
)
training_arguments = TrainingArguments(
output_dir=output_dir,
num_train_epochs=num_train_epochs,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
weight_decay=weight_decay,
fp16=fp16,
bf16=bf16,
max_grad_norm=max_grad_norm,
max_steps=max_steps,
warmup_ratio=warmup_ratio,
group_by_length=group_by_length,
lr_scheduler_type=lr_scheduler_type,
report_to="tensorboard"
)
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
packing=packing,
)
trainer.train()
trainer.model.save_pretrained(new_model)`
```
### Expected behavior
To get a finetunned model, this code worked with the 7B version model
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26203/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26203/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26202
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26202/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26202/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26202/events
|
https://github.com/huggingface/transformers/issues/26202
| 1,899,730,235 |
I_kwDOCUB6oc5xO5U7
| 26,202 |
Large Language Models as Optimizers
|
{
"login": "rajveer43",
"id": 64583161,
"node_id": "MDQ6VXNlcjY0NTgzMTYx",
"avatar_url": "https://avatars.githubusercontent.com/u/64583161?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rajveer43",
"html_url": "https://github.com/rajveer43",
"followers_url": "https://api.github.com/users/rajveer43/followers",
"following_url": "https://api.github.com/users/rajveer43/following{/other_user}",
"gists_url": "https://api.github.com/users/rajveer43/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rajveer43/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rajveer43/subscriptions",
"organizations_url": "https://api.github.com/users/rajveer43/orgs",
"repos_url": "https://api.github.com/users/rajveer43/repos",
"events_url": "https://api.github.com/users/rajveer43/events{/privacy}",
"received_events_url": "https://api.github.com/users/rajveer43/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"what do you think of this one @ArthurZucker ",
"As it is a feature request, unless someone form the community tackles it I would recommend trying to put the code on the hub first and share this here! ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Okay will do that",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,694 | 1,702 | 1,702 |
CONTRIBUTOR
| null |
### Feature request
Optimization is ubiquitous. While derivative-based algorithms have been powerful tools for various problems, the absence of gradient imposes challenges on many real-world applications. In this work, we propose Optimization by PROmpting (OPRO), a simple and effective approach to leverage large language models (LLMs) as optimizers, where the optimization task is described in natural language. In each optimization step, the LLM generates new solutions from the prompt that contains previously generated solutions with their values, then the new solutions are evaluated and added to the prompt for the next optimization step. We first showcase OPRO on linear regression and traveling salesman problems, then move on to prompt optimization where the goal is to find instructions that maximize the task accuracy. With a variety of LLMs, we demonstrate that the best prompts optimized by OPRO outperform human-designed prompts by up to 8% on GSM8K, and by up to 50% on Big-Bench Hard tasks.
### Motivation
-
### Your contribution
https://github.com/Moocember/Optimization-by-PROmpting
https://arxiv.org/abs/2309.03409
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26202/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/26202/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26201
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26201/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26201/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26201/events
|
https://github.com/huggingface/transformers/pull/26201
| 1,899,660,607 |
PR_kwDOCUB6oc5agOTA
| 26,201 |
Fix tokenizer truncation
|
{
"login": "ranchlai",
"id": 5043767,
"node_id": "MDQ6VXNlcjUwNDM3Njc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5043767?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ranchlai",
"html_url": "https://github.com/ranchlai",
"followers_url": "https://api.github.com/users/ranchlai/followers",
"following_url": "https://api.github.com/users/ranchlai/following{/other_user}",
"gists_url": "https://api.github.com/users/ranchlai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ranchlai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ranchlai/subscriptions",
"organizations_url": "https://api.github.com/users/ranchlai/orgs",
"repos_url": "https://api.github.com/users/ranchlai/repos",
"events_url": "https://api.github.com/users/ranchlai/events{/privacy}",
"received_events_url": "https://api.github.com/users/ranchlai/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi, @ArthurZucker Sorry for late reply. \r\n\r\nPlease check the following code if you could. For`\"meta-llama/Llama-2-7b-chat-hf\"` , this PR makes slow tokenizer the same as fast version. The fast version is \"more correct\" as it truncates to 1 as requested.\r\n\r\nBut for `bert-base-cased`, fast and slow are the same, failing to do the truncation. If I make the slow version do the truncation, it will be different from the fast version.\r\n\r\nMaybe `max_lenght`<=2 is not a very interesting case. \r\n\r\n```python\r\n\r\nfrom transformers import AutoTokenizer\r\n\r\nname = \"meta-llama/Llama-2-7b-chat-hf\"\r\ntext = \"Example to test truncation\"\r\ntokenizer = AutoTokenizer.from_pretrained(name, use_fast=False)\r\ntokenizer_fast = AutoTokenizer.from_pretrained(name, use_fast=True)\r\n\r\np = tokenizer(text, max_length=1, truncation=True, add_special_tokens=True)\r\nprint(p)\r\n# {'input_ids': [1, 8741, 304, 1243, 21022, 362], 'attention_mask': [1, 1, 1, 1, 1, 1]}\r\n\r\nt = tokenizer_fast(text, max_length=1, truncation=True, add_special_tokens=True)\r\nprint(t)\r\n# {'input_ids': [1], 'attention_mask': [1]}\r\n\r\nname = \"bert-base-cased\"\r\ntokenizer = AutoTokenizer.from_pretrained(name, use_fast=False)\r\ntokenizer_fast = AutoTokenizer.from_pretrained(name, use_fast=True)\r\n\r\np = tokenizer(text, max_length=1, truncation=True, add_special_tokens=True)\r\nprint(p)\r\n# {'input_ids': [101, 16409, 26671, 1106, 2774, 189, 10607, 14520, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}\r\nt = tokenizer_fast(text, max_length=1, truncation=True, add_special_tokens=True)\r\nprint(t)\r\n# {'input_ids': [101, 16409, 26671, 1106, 2774, 189, 10607, 14520, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}\r\n```\r\n\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,694 | 1,699 | 1,699 |
CONTRIBUTOR
| null |
# This PR fixes a tokenizer truncation bug.
Setting max_length=0 or 1 leads to the following problem that should be fixed:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf", use_fast=False)
text = "hello world hello world"
tokens = tokenizer(text, max_length=1, truncation=True, add_special_tokens=True)
print("tokens: ", tokens)
>>> [ERROR|/root/data/code/transformers/src/transformers/tokenization_utils_base.py:3468] 2023-09-17 13:08:29,020 >> >>> We need to remove 4 to truncate the input but the first sequence has a length 4.
>>> tokens: {'input_ids': [1, 22172, 3186, 22172, 3186], 'attention_mask': [1, 1, 1, 1, 1]}
```
This PR also make the length of tokens in consistent with fast-tokenizer.
Also added unit-test for this fix.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26201/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26201/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26201",
"html_url": "https://github.com/huggingface/transformers/pull/26201",
"diff_url": "https://github.com/huggingface/transformers/pull/26201.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26201.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/26200
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26200/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26200/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26200/events
|
https://github.com/huggingface/transformers/pull/26200
| 1,899,435,812 |
PR_kwDOCUB6oc5afjnH
| 26,200 |
🌐 [i18n-KO] Translated `audio_classification.mdx` to Korean
|
{
"login": "gabrielwithappy",
"id": 102908949,
"node_id": "U_kgDOBiJEFQ",
"avatar_url": "https://avatars.githubusercontent.com/u/102908949?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gabrielwithappy",
"html_url": "https://github.com/gabrielwithappy",
"followers_url": "https://api.github.com/users/gabrielwithappy/followers",
"following_url": "https://api.github.com/users/gabrielwithappy/following{/other_user}",
"gists_url": "https://api.github.com/users/gabrielwithappy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gabrielwithappy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gabrielwithappy/subscriptions",
"organizations_url": "https://api.github.com/users/gabrielwithappy/orgs",
"repos_url": "https://api.github.com/users/gabrielwithappy/repos",
"events_url": "https://api.github.com/users/gabrielwithappy/events{/privacy}",
"received_events_url": "https://api.github.com/users/gabrielwithappy/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Team PseudoLab, may you please review this PR? @0525hhgus, @kihoon71, @sim-so, @gabrielwithappy, @HanNayeoniee, @wonhyeongseo, @jungnerd",
"@wonhyeongseo \r\nI updated your suggestion!\r\nThank you for your feedback. :-)",
"> 좋은 번역 감사합니다 😀\n> 오디오 관련 용어를 꼼꼼하게 번역해주셔서 수월하게 이해했습니다 👍\n> 아래 리뷰를 남기니, 참고 부탁드립니다!\n\n꼼꼼한 리뷰 너무감사 드립니다!!🤗",
"@sgugger, @ArthurZucker, @eunseojo \r\nMay you please review this PR? ",
"cc @stevhliu for review :)",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26200). All of your documentation changes will be reflected on that endpoint."
] | 1,694 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
<!-- PR의 제목은 "🌐 [i18n-KO] Translated `<your_file>.mdx` to Korean" 으로 부탁드립니다 -->
# What does this PR do?
Translated the `audio_classification.mdx` file of the documentation to Korean.
Thank you in advance for your review.
Part of https://github.com/huggingface/transformers/issues/20179
<!-- 메인 이슈에 기록이 남아요! 가짜연구소 리포를 사용해 연습하실때는 제거해주시면 감사하겠습니다! :smile: -->
## Before reviewing
- [x] Check for missing / redundant translations (번역 누락/중복 검사)
- [x] Grammar Check (맞춤법 검사)
- [x] Review or Add new terms to glossary (용어 확인 및 추가)
- [x] Check Inline TOC (e.g. `[[lowercased-header]]`)
- [ ] Check live-preview for gotchas (live-preview로 정상작동 확인)
## Who can review? (Initial)
<!-- 1. 위 체크가 모두 완료된 뒤에만 가짜연구소 팀원들에게 리뷰 요청하는 아래 주석을 노출해주세요! -->
Team PseudoLab, may you please review this PR? @0525hhgus, @KIHOON71, @sim-so, @gabrielwithappy, @HanNayeoniee, @wonhyeongseo, @jungnerd
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review? (Final)
<!-- 2. 가짜연구소 팀원들과 리뷰가 끝난 후에만 허깅페이스 직원들에게 리뷰 요청하는 아래 주석을 노출해주세요! -->
<!-- @sgugger, @ArthurZucker, @eunseojo May you please review this PR? -->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26200/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26200/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26200",
"html_url": "https://github.com/huggingface/transformers/pull/26200",
"diff_url": "https://github.com/huggingface/transformers/pull/26200.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26200.patch",
"merged_at": 1695662685000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26199
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26199/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26199/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26199/events
|
https://github.com/huggingface/transformers/pull/26199
| 1,899,415,940 |
PR_kwDOCUB6oc5affxS
| 26,199 |
Falcon: remove cache reformatting in the modeling code
|
{
"login": "fxmarty",
"id": 9808326,
"node_id": "MDQ6VXNlcjk4MDgzMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9808326?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fxmarty",
"html_url": "https://github.com/fxmarty",
"followers_url": "https://api.github.com/users/fxmarty/followers",
"following_url": "https://api.github.com/users/fxmarty/following{/other_user}",
"gists_url": "https://api.github.com/users/fxmarty/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fxmarty/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fxmarty/subscriptions",
"organizations_url": "https://api.github.com/users/fxmarty/orgs",
"repos_url": "https://api.github.com/users/fxmarty/repos",
"events_url": "https://api.github.com/users/fxmarty/events{/privacy}",
"received_events_url": "https://api.github.com/users/fxmarty/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26199). All of your documentation changes will be reflected on that endpoint.",
"Hi @fxmarty, I think refactoring this out of the model code to put it in `prepare_inputs_for_generation` is fine!\r\n\r\nI don't think that should break anything (cc @Narsil in case it affects TGI, but I don't think it should)",
"If you don't break `transformers`, you don't break `tgi` :).\r\n\r\nModifying repos themselves might break TGI though (because there's some running code relying on config.model_type at least).\r\n",
"This shouldn't need any modifications to repos/weights, thankfully!",
"Thank you @Rocketknight1, let me know if I should run any slow tests!",
"Left a couple of comments - I can run the slow tests afterwards, once they're resolved!",
"Slow tests look good to me, other test failures look like they're unrelated. Pinging @arthurzucker for core maintainer review, though - especially since there's some special-casing added to core code here!",
"WDYT @LysandreJik @ArthurZucker ?",
"@ArthurZucker well it is more the PR adding Falcon that was breaking in that regard with the common practice set by bloom. No other models than Falcon reformat the KV cache in the modeling itself. Why is that?",
"@LysandreJik @ArthurZucker Let me know if I should close this PR.",
"Yeah I don't think we should break this at this point and would rather way for the cache refactoring WDYT? "
] | 1,694 | 1,697 | 1,697 |
COLLABORATOR
| null |
When Falcon has been ported to transformers, it appears that methods `_convert_to_rw_cache` and `_convert_cache_to_standard_format` were directly called in the model, which is NOT what is traditionally done in Transformers, with the precedent of Bloom: https://github.com/huggingface/transformers/blob/0a55d9f7376f72ad3ff296d4249840021b03bcc4/src/transformers/models/bloom/modeling_bloom.py#L853 & https://github.com/huggingface/transformers/blob/0a55d9f7376f72ad3ff296d4249840021b03bcc4/src/transformers/models/bloom/modeling_bloom.py#L949
@Rocketknight1 I am wondering if it is fine to put back the cache reordering in `prepare_inputs_for_generation` & `_reorder_cache`? Having it in the modeling is a bit bad for people who want to rewrite their own generation, export the model, etc. It is also inconsistent with the information in `FALCON_INPUTS_DOCSTRING`.
I noticed this working on the ONNX export, where it is not really meaningful to have those ops in the model itself. Another solution is to monkey patch transformers, but I believe this should be upstream.
Related: https://github.com/huggingface/transformers/issues/26097
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26199/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26199/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26199",
"html_url": "https://github.com/huggingface/transformers/pull/26199",
"diff_url": "https://github.com/huggingface/transformers/pull/26199.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26199.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/26198
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26198/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26198/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26198/events
|
https://github.com/huggingface/transformers/pull/26198
| 1,899,407,115 |
PR_kwDOCUB6oc5afeDK
| 26,198 |
Update README.md
|
{
"login": "NinoRisteski",
"id": 95188570,
"node_id": "U_kgDOBax2Wg",
"avatar_url": "https://avatars.githubusercontent.com/u/95188570?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NinoRisteski",
"html_url": "https://github.com/NinoRisteski",
"followers_url": "https://api.github.com/users/NinoRisteski/followers",
"following_url": "https://api.github.com/users/NinoRisteski/following{/other_user}",
"gists_url": "https://api.github.com/users/NinoRisteski/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NinoRisteski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NinoRisteski/subscriptions",
"organizations_url": "https://api.github.com/users/NinoRisteski/orgs",
"repos_url": "https://api.github.com/users/NinoRisteski/repos",
"events_url": "https://api.github.com/users/NinoRisteski/events{/privacy}",
"received_events_url": "https://api.github.com/users/NinoRisteski/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26198). All of your documentation changes will be reflected on that endpoint."
] | 1,694 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
Fixed a few typos
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26198/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26198/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26198",
"html_url": "https://github.com/huggingface/transformers/pull/26198",
"diff_url": "https://github.com/huggingface/transformers/pull/26198.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26198.patch",
"merged_at": 1695074573000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26197
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26197/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26197/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26197/events
|
https://github.com/huggingface/transformers/pull/26197
| 1,899,402,263 |
PR_kwDOCUB6oc5afdF8
| 26,197 |
Update add_new_pipeline.md
|
{
"login": "NinoRisteski",
"id": 95188570,
"node_id": "U_kgDOBax2Wg",
"avatar_url": "https://avatars.githubusercontent.com/u/95188570?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NinoRisteski",
"html_url": "https://github.com/NinoRisteski",
"followers_url": "https://api.github.com/users/NinoRisteski/followers",
"following_url": "https://api.github.com/users/NinoRisteski/following{/other_user}",
"gists_url": "https://api.github.com/users/NinoRisteski/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NinoRisteski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NinoRisteski/subscriptions",
"organizations_url": "https://api.github.com/users/NinoRisteski/orgs",
"repos_url": "https://api.github.com/users/NinoRisteski/repos",
"events_url": "https://api.github.com/users/NinoRisteski/events{/privacy}",
"received_events_url": "https://api.github.com/users/NinoRisteski/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26197). All of your documentation changes will be reflected on that endpoint."
] | 1,694 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
fixed a few typos
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26197/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26197/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26197",
"html_url": "https://github.com/huggingface/transformers/pull/26197",
"diff_url": "https://github.com/huggingface/transformers/pull/26197.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26197.patch",
"merged_at": 1695076876000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26196
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26196/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26196/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26196/events
|
https://github.com/huggingface/transformers/issues/26196
| 1,899,374,090 |
I_kwDOCUB6oc5xNiYK
| 26,196 |
Unable to process image in pipeline for document question-answering
|
{
"login": "pythonvijay",
"id": 144582559,
"node_id": "U_kgDOCJ4nnw",
"avatar_url": "https://avatars.githubusercontent.com/u/144582559?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pythonvijay",
"html_url": "https://github.com/pythonvijay",
"followers_url": "https://api.github.com/users/pythonvijay/followers",
"following_url": "https://api.github.com/users/pythonvijay/following{/other_user}",
"gists_url": "https://api.github.com/users/pythonvijay/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pythonvijay/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pythonvijay/subscriptions",
"organizations_url": "https://api.github.com/users/pythonvijay/orgs",
"repos_url": "https://api.github.com/users/pythonvijay/repos",
"events_url": "https://api.github.com/users/pythonvijay/events{/privacy}",
"received_events_url": "https://api.github.com/users/pythonvijay/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Not an expert but seems to me that open cv imread() is returning a numpy array (it is if you check the c++ code) and your pipeline expects a file. Have you tried instead to send `Image.open('testing.png')` or just `open('testing.png')` to pipe? something like:\r\n\r\n```\r\nwith open('testimg.png', 'r') as fin:\r\n pipe(image=fin, question=question)\r\n```\r\n",
"\r\nIf I pass open () as below in pipe, I get the error as below the code:\r\n\r\n```\r\nwith open('testimg.png', 'r') as fin:\r\n pipe(image=fin, question=question)\r\n```\r\nerror:\r\n\r\n```\r\n----> 5 pipe(image=fin, question=question)\r\n\r\n9 frames\r\n[/usr/local/lib/python3.10/dist-packages/transformers/image_utils.py](https://localhost:8080/#) in load_image(image, timeout)\r\n 315 image = image\r\n 316 else:\r\n--> 317 raise ValueError(\r\n 318 \"Incorrect format used for image. Should be an url linking to an image, a base64 string, a local path, or a PIL image.\"\r\n 319 )\r\n\r\nValueError: Incorrect format used for image. Should be an url linking to an image, a base64 string, a local path, or a PIL image.\r\n```\r\nIf I use Image.open() as here, I get the error as below this code:\r\n```\r\nwith Image.open('testimg.png', 'r') as fin:\r\n pipe(image=fin, question=question)\r\n```\r\n```\r\n----> 5 pipe(image=fin, question=question)\r\n\r\n4 frames\r\n[/usr/local/lib/python3.10/dist-packages/transformers/utils/generic.py](https://localhost:8080/#) in pop(self, *args, **kwargs)\r\n 374 \r\n 375 def pop(self, *args, **kwargs):\r\n--> 376 raise Exception(f\"You cannot use ``pop`` on a {self.__class__.__name__} instance.\")\r\n 377 \r\n 378 def update(self, *args, **kwargs):\r\n\r\nException: You cannot use ``pop`` on a ModelOutput instance.\r\n```",
"have you tried `pipe(image='testimg.png', question=question)`? That's what `ValueError: Incorrect format used for image. Should be an url linking to an image, a base64 string, a local path, or a PIL image.` seems to be asking for",
"Could share the output of `transformers-cli env` ? You should try one the latest release of transformers! ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,694 | 1,698 | 1,698 |
NONE
| null |
Hi,
I am trying to read an image into google colab and then process it through pipeline() for document Q&A but it seems that my image is not read by pipeline or maybe not in a supported format;
Here is my code
```
from docquery import document, pipeline
from transformers import pipeline
from PIL import Image
pipe = pipeline("document-question-answering",model="impira/layoutlm-document-qa")
from google.colab import files
import cv2
import matplotlib.pyplot as plt
uploaded = files.upload()
```
```
img = cv2.imread ('testimg.png')
plt.imshow (img)
```
```
question = "What is IndexError?"
#image = Image.open(img)
pipe(image=img, question=question)
```
error message below - please advise what am I doing wrong here!
```
AttributeError Traceback (most recent call last)
[/usr/local/lib/python3.10/dist-packages/PIL/Image.py](https://localhost:8080/#) in open(fp, mode, formats)
3230 try:
-> 3231 fp.seek(0)
3232 except (AttributeError, io.UnsupportedOperation):
AttributeError: 'numpy.ndarray' object has no attribute 'seek'
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26196/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26196/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26195
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26195/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26195/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26195/events
|
https://github.com/huggingface/transformers/issues/26195
| 1,899,328,198 |
I_kwDOCUB6oc5xNXLG
| 26,195 |
Transformers LocalAgent - Error with GPT model, are there any specific limitations for LocalAgent?
|
{
"login": "gidzr",
"id": 83053994,
"node_id": "MDQ6VXNlcjgzMDUzOTk0",
"avatar_url": "https://avatars.githubusercontent.com/u/83053994?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gidzr",
"html_url": "https://github.com/gidzr",
"followers_url": "https://api.github.com/users/gidzr/followers",
"following_url": "https://api.github.com/users/gidzr/following{/other_user}",
"gists_url": "https://api.github.com/users/gidzr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gidzr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gidzr/subscriptions",
"organizations_url": "https://api.github.com/users/gidzr/orgs",
"repos_url": "https://api.github.com/users/gidzr/repos",
"events_url": "https://api.github.com/users/gidzr/events{/privacy}",
"received_events_url": "https://api.github.com/users/gidzr/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! as the issue mentions, there seems to be an issue with the tokenized inputs. I'll ping @Rocketknight1 here as I won't have time to look into this",
"Hi @gidzr, the cause here is that GPT-2 simply doesn't have the required sequence length to handle the very long default prompt used by transformers agents. The default prompt describes multiple tools and their arguments, and tokenizes to ~1590 tokens in GPT-2, whereas GPT-2 only has a maximum sequence length of 1024.\r\n\r\nIn general, agent prompts like these will only work well with models that have a long maximum sequence length and have been fine-tuned with instruction training.",
"@Rocketknight1 Ahh I see.. Re-reading the error, I can see the issue re token size, but my prompt was simply \"Tell me what a black hole is made of?\" was only ~15 tokens which really confused me.\r\n\r\nYou refer to the \"default prompt\" which describes tools and arguments and behind the scenes. Is there any way for me to 'hack' this in a LocalAgent config? eg. if I add my info for these?\r\n- chat_prompt_template (str, optional\r\n- run_prompt_template (str, optional)\r\n- additional_tools ([Tool] list of tools or dictionary with tool values, optional)\r\n\r\nI'm assuming if I enter null or custom values for these params it can reduce the token size for input? However, I'm not sure what I'm overriding and how this would affect the Agent's operation. \r\n\r\n**Is there a view of what the defaults for these look like so I can override with a shorter version of each**?",
"Hi @gidzr, take a look at the [Custom Tools and Prompts](https://huggingface.co/docs/transformers/custom_tools) guide!",
"Again though, note that GPT-2 is a pure text-completion model, and has not been trained to follow instructions or use external tools. I expect even if you can make the prompt short enough to work with it, the results will probably not be very good!",
"Hey @Rocketknight1 - noted. \r\n\r\nJust playing around with the features etc. There's a learning curve so wanted to be cheeky and pick your brains if possible in this forum.\r\n\r\nAm I correct in understanding that:\r\n- Tools: just like pipelines, but whereas Pipelines use task as a shorthand to optimise parameters (num_beams, temperature, etc) with a flexible prompt for a given LLM, Tools are locked down on a specific predetermined LLM, prompt, and parameters. Is that right?\r\n- Agents: an LLM tuned to accept a specific type of prompt format, which guides the LLM to generate code to execute tools for a desired outcome? **Or** are Agents emergent from any reasonably sized LLM with the correct type of prompt? (ie. could I copy/paste your prompt into Llama/Phi1_5/GPT4 and get the same results?)\r\n\r\nThere's a lot in huggingface, it's like drinking from a firehose.. My only remaining confusion for tools and agents is how much is clever prompting vs customised LLM models running in the background vs coding shorthands (like JQuery is to Javascript).\r\n\r\nReferences\r\nhttps://huggingface.co/docs/transformers/custom_tools\r\nhttps://huggingface.co/docs/transformers/transformers_agents\r\nhttps://huggingface.co/docs/transformers/main_classes/agent",
"Ha, I'll allow it. Tools can be anything - they're often not even ML at all, just some code that exposes an API. A calculator app is a common 'tool' for LLMs. However, they can also be a full model/pipeline that does a specific task (like image recognition).\r\n\r\nAn agent is an LLM that has been trained in the presence of tools. I suspect some smarter LLMs that have been trained to follow instructions can use tools if they're well-described in the prompt, even if they haven't seen tools during training, but you'll probably get the best results if the model has been specifically trained with them.\r\n\r\nThe 'agent' LLM is given a description of the tools it has available, as well as the task and input data, and then it tries to solve the task by either writing answers itself, or by making an API call to one of the tools it has available. This process can be iterative - the agent can call multiple tools before emitting a final answer.\r\n\r\nIn general, agents are quite an advanced and experimental topic, even at the cutting edge. If what you're trying to do can be accomplished with a single pipeline, you'll often get better results than trying to do it with a fully general agent!",
"EPICNESS! ..thanks for that.. totally makes sense. Agent-tools are a very cool experimentation. \r\n\r\nI was thinking along the same lines re pipelines. My impression is that agents are best suited for multi-modal uses that bring audio+visual+text together when a task is very open-ended, with pipes best suited for a single LLM and targeted use case, whereas multi-LLM (translation+completion) within a mode (text) will need a bit of trial and error to see which works best. Also, as I'm running CPU and agents use specific LLMs for tools, performance will influence the solution.\r\n\r\nYour comments re Langchain surprised me a little. I was initially 100% Langchain and loved it, but the outdated API documentation, blackbox approach, and unclear multiple approaches (eg. chain.run() vs chain.generate() vs chain()) moved me towards a full HF eco-system. Langchain feels like it wants to be an umbrella or integration layer, but doesn't simplify or accelerate the base technology it's drawing on - and ends up becoming bloat (eg. the qa_chain-chroma implementation). Some elements are awesome, but HF/onnx/accelerate/pipelines, etc .. provide better performance and usage for me.\r\n\r\nThanks again!\r\n\r\nRefs\r\nhttps://huggingface.co/docs/transformers/transformers_agents#a-curated-set-of-tools\r\nhttps://huggingface.co/docs/transformers/custom_tools#future-compatibility-with-langchain"
] | 1,694 | 1,696 | 1,696 |
NONE
| null |
### System Info
cpu, latest version transformers, python 3.10
### Who can help?
@ArthurZucker, @younesbelkada and @Narsil
Hey there
I am using the example you provide for LocalAgent at: https://huggingface.co/docs/transformers/main_classes/agent#transformers.LocalAgent
Except I've replaced the example repo with GPT, and asked a general question to see how the model responds.
I get the following warnings and error in CLI
```bash
Token indices sequence length is longer than the specified maximum sequence length for this model (1592 > 1024). Running this sequence through the model will result in indexing errors
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Traceback (most recent call last):
File "/root/test.py", line 1838, in <module>
runInferenceCausalLM1(context)
File "/root/test.py", line 1662, in runInferenceCausalLM1
agent.run("Tell me what a black hole is made of?.")
File "/root/projectName11/lib/python3.10/site-packages/transformers/tools/agents.py", line 341, in run
result = self.generate_one(prompt, stop=["Task:"])
File "/root/projectName11/lib/python3.10/site-packages/transformers/tools/agents.py", line 740, in generate_one
outputs = self.model.generate(
File "/root/projectName11/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/root/projectName11/lib/python3.10/site-packages/transformers/generation/utils.py", line 1602, in generate
return self.greedy_search(
File "/root/projectName11/lib/python3.10/site-packages/transformers/generation/utils.py", line 2450, in greedy_search
outputs = self(
File "/root/projectName11/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/root/projectName11/lib/python3.10/site-packages/transformers/models/gpt2/modeling_gpt2.py", line 1076, in forward
transformer_outputs = self.transformer(
File "/root/projectName11/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/root/projectName11/lib/python3.10/site-packages/transformers/models/gpt2/modeling_gpt2.py", line 844, in forward
position_embeds = self.wpe(position_ids)
File "/root/projectName11/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/root/projectName11/lib/python3.10/site-packages/torch/nn/modules/sparse.py", line 162, in forward
return F.embedding(
File "/root/projectName11/lib/python3.10/site-packages/torch/nn/functional.py", line 2210, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
IndexError: index out of range in self
```
The code I'm using is shown below, and is a straight copy from the online quickstart - except - modified for a different task and model. However, should still work.
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LocalAgent
model = AutoModelForCausalLM.from_pretrained('gpt2', device_map="auto")
tokenizer = AutoTokenizer.from_pretrained('gpt2')
agent = LocalAgent(model, tokenizer)
agent.run("Tell me what a black hole is made of?.")
```
I've tried with and without torch_dtype=torch.bfloat16 - I don't think this is the cause.
### Expected behavior
I thought an agent would return the same result as if I'd run the inference with pipeline or transformer approach. I am testing the agent because I was keen on seeing how the prompting helper works.
Thanks
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26195/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26195/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26194
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26194/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26194/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26194/events
|
https://github.com/huggingface/transformers/pull/26194
| 1,899,265,363 |
PR_kwDOCUB6oc5afC4W
| 26,194 |
Extend Trainer to enable Ascend NPU to use the fused Adamw optimizer when training
|
{
"login": "statelesshz",
"id": 28150734,
"node_id": "MDQ6VXNlcjI4MTUwNzM0",
"avatar_url": "https://avatars.githubusercontent.com/u/28150734?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/statelesshz",
"html_url": "https://github.com/statelesshz",
"followers_url": "https://api.github.com/users/statelesshz/followers",
"following_url": "https://api.github.com/users/statelesshz/following{/other_user}",
"gists_url": "https://api.github.com/users/statelesshz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/statelesshz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/statelesshz/subscriptions",
"organizations_url": "https://api.github.com/users/statelesshz/orgs",
"repos_url": "https://api.github.com/users/statelesshz/repos",
"events_url": "https://api.github.com/users/statelesshz/events{/privacy}",
"received_events_url": "https://api.github.com/users/statelesshz/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Rebase my commits to master HEAD to avoid too many merges back from the master.",
"BTW, Is this PR still under review? Any review suggestions? Please let me know if there is anything else that needs to be done.\r\ncc @muellerzr",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26194). All of your documentation changes will be reflected on that endpoint."
] | 1,694 | 1,696 | 1,696 |
CONTRIBUTOR
| null |
# What does this PR do?
This PR intends to extend Transformers Trainer Class with NpuFusedAdamw optimizer for model training when using Ascend NPU.
Verified with text-classification task:
```bash
export TASK_NAME=sst2
python run_glue.py \
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--optim adamw_torch_npu_fused \
--output_dir ./output
```
The result of `train_samples_per_second` is as follows
| Device | `adamw_torch`(default) | `adamw_torch_npu_fused` |
| ----------------- | --------------------------------- | ------------------------ |
| Ascend 910B | 96.586 | 149.876 |
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
cc @pacman100 and @muellerzr
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26194/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26194/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26194",
"html_url": "https://github.com/huggingface/transformers/pull/26194",
"diff_url": "https://github.com/huggingface/transformers/pull/26194.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26194.patch",
"merged_at": 1696424231000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26193
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26193/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26193/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26193/events
|
https://github.com/huggingface/transformers/pull/26193
| 1,899,108,738 |
PR_kwDOCUB6oc5aeiYh
| 26,193 |
Correctly update vocab size in resize_token_embeddings with pad_to_multiple_of!=0
|
{
"login": "zrqiao",
"id": 22074748,
"node_id": "MDQ6VXNlcjIyMDc0NzQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/22074748?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zrqiao",
"html_url": "https://github.com/zrqiao",
"followers_url": "https://api.github.com/users/zrqiao/followers",
"following_url": "https://api.github.com/users/zrqiao/following{/other_user}",
"gists_url": "https://api.github.com/users/zrqiao/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zrqiao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zrqiao/subscriptions",
"organizations_url": "https://api.github.com/users/zrqiao/orgs",
"repos_url": "https://api.github.com/users/zrqiao/repos",
"events_url": "https://api.github.com/users/zrqiao/events{/privacy}",
"received_events_url": "https://api.github.com/users/zrqiao/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey ! I think the patch release should have brought the fix! ",
"> Hey ! I think the patch release should have bought the fix!\r\n\r\nThanks!! \r\n"
] | 1,694 | 1,695 | 1,694 |
NONE
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
In [PreTrainedModel.resize_token_embeddings](https://github.com/huggingface/transformers/blob/0a55d9f7376f72ad3ff296d4249840021b03bcc4/src/transformers/modeling_utils.py#L1068), the vocabulary size attributes are not correctly updated if `pad_to_multiple_of!=None`. This led to tensor size mismatches in CausalLM loss calculation.
This PR implements a hotfix for this issue.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26193/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26193/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26193",
"html_url": "https://github.com/huggingface/transformers/pull/26193",
"diff_url": "https://github.com/huggingface/transformers/pull/26193.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26193.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/26192
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26192/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26192/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26192/events
|
https://github.com/huggingface/transformers/pull/26192
| 1,899,069,690 |
PR_kwDOCUB6oc5aeZy4
| 26,192 |
custom checkpoint in trainer.py
|
{
"login": "mzamini92",
"id": 32536264,
"node_id": "MDQ6VXNlcjMyNTM2MjY0",
"avatar_url": "https://avatars.githubusercontent.com/u/32536264?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mzamini92",
"html_url": "https://github.com/mzamini92",
"followers_url": "https://api.github.com/users/mzamini92/followers",
"following_url": "https://api.github.com/users/mzamini92/following{/other_user}",
"gists_url": "https://api.github.com/users/mzamini92/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mzamini92/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mzamini92/subscriptions",
"organizations_url": "https://api.github.com/users/mzamini92/orgs",
"repos_url": "https://api.github.com/users/mzamini92/repos",
"events_url": "https://api.github.com/users/mzamini92/events{/privacy}",
"received_events_url": "https://api.github.com/users/mzamini92/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @muellerzr and @pacman100 ",
"I'm pretty sure the naming conventions we are are standardized and immutable for the filenames, so I'm not sure this is a venture we want to go down unless I'm mistaken (cc @ArthurZucker trainer doesn't support custom model names due to integrating with everything else, right?) ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,694 | 1,707 | 1,707 |
NONE
| null |
I was wondering can we do like this? `_custom_save_checkpoint` is that it provides more control and flexibility for customizing how checkpoints are saved. You can define your own naming conventions and include or exclude specific information in the checkpoint. This can be useful if you have specific requirements or want to integrate with external systems or tools that expect a certain checkpoint format. In contrast, `_tune_save_checkpoint` is designed specifically for use with Ray Tune and follows Ray Tune's conventions for managing checkpoints. It may be more convenient when we are using Ray Tune for hyperparameter tuning and need to manage checkpoints in a standardized way.
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26192/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26192/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26192",
"html_url": "https://github.com/huggingface/transformers/pull/26192",
"diff_url": "https://github.com/huggingface/transformers/pull/26192.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26192.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/26191
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26191/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26191/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26191/events
|
https://github.com/huggingface/transformers/issues/26191
| 1,899,052,114 |
I_kwDOCUB6oc5xMTxS
| 26,191 |
Allow custom logit warpers
|
{
"login": "lshamis",
"id": 3943815,
"node_id": "MDQ6VXNlcjM5NDM4MTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/3943815?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lshamis",
"html_url": "https://github.com/lshamis",
"followers_url": "https://api.github.com/users/lshamis/followers",
"following_url": "https://api.github.com/users/lshamis/following{/other_user}",
"gists_url": "https://api.github.com/users/lshamis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lshamis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lshamis/subscriptions",
"organizations_url": "https://api.github.com/users/lshamis/orgs",
"repos_url": "https://api.github.com/users/lshamis/repos",
"events_url": "https://api.github.com/users/lshamis/events{/privacy}",
"received_events_url": "https://api.github.com/users/lshamis/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I see the same call in beam sampling and assisted generation. Maybe custom logit warpers can be handled in `generate()` the same way `logits_processor` is used i.e., the caller can pass in a list of custom warpers as an arg `logits_warper` but has to be sure this doesn't collide with any from the config or raise? I can take a shot at a PR if that seems like the right direction. ",
"Hey @lshamis, you can probably overload `_get_logits_warper` in the mean time? The goal of transformers is to be easy to develop on top of it, but not necessarly fit your particular use case! If more people from the community require it, we might consider adding this. \r\nFYI @gante ",
"Hey @lshamis @hedeershowk 👋 \r\n\r\nAs @ArthurZucker wrote, we'd like to avoid adding more custom code if possible :) \r\n\r\nLet me attempt to present a solution that doesn't require new code: `logits_processor` and `logits_warper` behave the same way, the only difference being that the latter are only fetched on sampling-based decoding methods. However, nothing prevents you from adding a custom `logits_processor` for sampling purposes, e.g. the `top_k` operation. The only thing you won't have control over is the order of operations (if that's relevant for your use case), in which case I'd suggest overwriting our functions as @ArthurZucker suggested!\r\n\r\nI hope this helps 🤗 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,694 | 1,700 | 1,700 |
NONE
| null |
### Feature request
Currently, when generation sampling, logit warpers are automatically generated from the generation_config.
https://github.com/huggingface/transformers/blob/0a55d9f7376f72ad3ff296d4249840021b03bcc4/src/transformers/generation/utils.py#L1641
which does not support any custom logit warpers
https://github.com/huggingface/transformers/blob/0a55d9f7376f72ad3ff296d4249840021b03bcc4/src/transformers/generation/utils.py#L811
Custom logits processor are allowed and follow a nearly identical code path.
### Motivation
I am unable to experiment with changes to sampling without also changing the logits via a LogitsProcessor.
### Your contribution
I can submit a PR, but am not necessarily the best person to do so.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26191/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26191/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26190
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26190/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26190/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26190/events
|
https://github.com/huggingface/transformers/pull/26190
| 1,899,000,534 |
PR_kwDOCUB6oc5aeKzh
| 26,190 |
Improve padding behaviour of `ClapFeatureExtractor`
|
{
"login": "anmolojha",
"id": 35429956,
"node_id": "MDQ6VXNlcjM1NDI5OTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/35429956?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/anmolojha",
"html_url": "https://github.com/anmolojha",
"followers_url": "https://api.github.com/users/anmolojha/followers",
"following_url": "https://api.github.com/users/anmolojha/following{/other_user}",
"gists_url": "https://api.github.com/users/anmolojha/gists{/gist_id}",
"starred_url": "https://api.github.com/users/anmolojha/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/anmolojha/subscriptions",
"organizations_url": "https://api.github.com/users/anmolojha/orgs",
"repos_url": "https://api.github.com/users/anmolojha/repos",
"events_url": "https://api.github.com/users/anmolojha/events{/privacy}",
"received_events_url": "https://api.github.com/users/anmolojha/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @sanchit-gandhi! I need your advice on how can we create this PR without breaking anything. I have implemented what seems like the best way to me. Looking forward to hearing from you. Thanks!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Hey @anmolojha do you still want to work on this or should we close it? 🤗 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,694 | 1,707 | 1,707 |
NONE
| null |
# What does this PR do?
Currently, `ClapFeatureExtractor`'s padding behaviour is unintuitive. Specifically,
* It works with any value of argument `padding` without any check.
* It uses non default padding strategy if `padding=True`.
This was discussed in more detail around [this](https://github.com/huggingface/transformers/issues/23648#issuecomment-1558586027) comment of issue #23648.
This PR closes #23648.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@sanchit-gandhi
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26190/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26190/timeline
| null | true |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26190",
"html_url": "https://github.com/huggingface/transformers/pull/26190",
"diff_url": "https://github.com/huggingface/transformers/pull/26190.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26190.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/26189
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26189/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26189/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26189/events
|
https://github.com/huggingface/transformers/issues/26189
| 1,898,896,044 |
I_kwDOCUB6oc5xLtqs
| 26,189 |
Problem with c10d pickle in distributed run
|
{
"login": "jmzeng",
"id": 5641698,
"node_id": "MDQ6VXNlcjU2NDE2OTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/5641698?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jmzeng",
"html_url": "https://github.com/jmzeng",
"followers_url": "https://api.github.com/users/jmzeng/followers",
"following_url": "https://api.github.com/users/jmzeng/following{/other_user}",
"gists_url": "https://api.github.com/users/jmzeng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jmzeng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jmzeng/subscriptions",
"organizations_url": "https://api.github.com/users/jmzeng/orgs",
"repos_url": "https://api.github.com/users/jmzeng/repos",
"events_url": "https://api.github.com/users/jmzeng/events{/privacy}",
"received_events_url": "https://api.github.com/users/jmzeng/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "muellerzr",
"id": 7831895,
"node_id": "MDQ6VXNlcjc4MzE4OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7831895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/muellerzr",
"html_url": "https://github.com/muellerzr",
"followers_url": "https://api.github.com/users/muellerzr/followers",
"following_url": "https://api.github.com/users/muellerzr/following{/other_user}",
"gists_url": "https://api.github.com/users/muellerzr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/muellerzr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muellerzr/subscriptions",
"organizations_url": "https://api.github.com/users/muellerzr/orgs",
"repos_url": "https://api.github.com/users/muellerzr/repos",
"events_url": "https://api.github.com/users/muellerzr/events{/privacy}",
"received_events_url": "https://api.github.com/users/muellerzr/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "muellerzr",
"id": 7831895,
"node_id": "MDQ6VXNlcjc4MzE4OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7831895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/muellerzr",
"html_url": "https://github.com/muellerzr",
"followers_url": "https://api.github.com/users/muellerzr/followers",
"following_url": "https://api.github.com/users/muellerzr/following{/other_user}",
"gists_url": "https://api.github.com/users/muellerzr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/muellerzr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muellerzr/subscriptions",
"organizations_url": "https://api.github.com/users/muellerzr/orgs",
"repos_url": "https://api.github.com/users/muellerzr/repos",
"events_url": "https://api.github.com/users/muellerzr/events{/privacy}",
"received_events_url": "https://api.github.com/users/muellerzr/received_events",
"type": "User",
"site_admin": false
}
] |
[
"cc @muellerzr as it is related to dataloaders.",
"Same comment as here: https://github.com/huggingface/trl/issues/796#issuecomment-1735049375\r\n\r\nCan you give us some details about your dataset? ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,694 | 1,702 | 1,702 |
NONE
| null |
### System Info
- `transformers` version: 4.32.1
- Platform: Linux-5.15.0-83-generic-x86_64-with-glibc2.31
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: yes
### Who can help?
@pacman100 @muellerzr I'm experiencing an issue where there is a pickle error with multi-node distributed training. The error would happen about 190 steps into training and I've previously trained the same data for over 300 steps on a single node. I actually also hit this bug when using the latest transformers version from the main branch.
See error below:
```python
54 Traceback (most recent call last):
[...]
train_llm.py", line 213, in pretrain
60 trainer.train()
61 File "/usr/lib/python3/dist-packages/transformers/trainer.py", line 1555, in train
62 return inner_training_loop(
63 File "/usr/lib/python3/dist-packages/transformers/trainer.py", line 1815, in _inner_training_loop
64 for step, inputs in enumerate(epoch_iterator):
65 File "/usr/lib/python3/dist-packages/accelerate/data_loader.py", line 593, in __iter__
66 next_batch, next_batch_info = self._fetch_batches(main_iterator)
67 File "/usr/lib/python3/dist-packages/accelerate/data_loader.py", line 534, in _fetch_batches
68 broadcast_object_list(batch_info)
69 File "/usr/lib/python3/dist-packages/accelerate/utils/operations.py", line 456, in broadcast_object_list
70 torch.distributed.broadcast_object_list(object_list, src=from_process)
71 File "/usr/lib/python3/dist-packages/torch/distributed/distributed_c10d.py", line 1451, in wrapper
72 return func(*args, **kwargs)
73 File "/usr/lib/python3/dist-packages/torch/distributed/distributed_c10d.py", line 2277, in broadcast_object_list
74 object_list[i] = _tensor_to_object(obj_view, obj_size)
75 File "/usr/lib/python3/dist-packages/torch/distributed/distributed_c10d.py", line 1970, in _tensor_to_object
76 return _unpickler(io.BytesIO(buf)).load()
77 _pickle.UnpicklingError: invalid load key, '\x01'.
```
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
The run is launched using
`torchrun --nnodes=2 --node_rank=1 --nproc-per-node=8 --rdzv-id=428 --rdzv-backend=c10d --rdzv-endpoint=IP1:1234 train_llm.py`
I am using the SFTTrainer with the ConstantLengthDataset and `packing=True`.
### Expected behavior
I expect this should continue to train.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26189/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26189/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26188
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26188/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26188/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26188/events
|
https://github.com/huggingface/transformers/pull/26188
| 1,898,799,768 |
PR_kwDOCUB6oc5adfkb
| 26,188 |
[Wav2Vec2-Conf / LLaMA] Style fix
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"CI went red on `main`: the permisson model wasn't checked as part of the PR. Needed to rebase to include it: #26228"
] | 1,694 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
# What does this PR do?
Small style fix to stay consistent with the rest of the modelling code: `torch.nn -> nn`
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26188/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26188/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26188",
"html_url": "https://github.com/huggingface/transformers/pull/26188",
"diff_url": "https://github.com/huggingface/transformers/pull/26188.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26188.patch",
"merged_at": 1695054276000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26187
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26187/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26187/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26187/events
|
https://github.com/huggingface/transformers/pull/26187
| 1,898,650,708 |
PR_kwDOCUB6oc5ac_Bt
| 26,187 |
[FSMT] Fix non-shared weights
|
{
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,694 | 1,695 | 1,695 |
MEMBER
| null |
FSMT shares weights across three layers.
The `tie_weights` method wasn't having the intended effect on all three (only on the input and output embeddings), leading to errors when converting the model to safetensors.
See https://huggingface.co/facebook/wmt19-en-de/discussions/7
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26187/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26187/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26187",
"html_url": "https://github.com/huggingface/transformers/pull/26187",
"diff_url": "https://github.com/huggingface/transformers/pull/26187.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26187.patch",
"merged_at": 1695049119000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26186
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26186/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26186/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26186/events
|
https://github.com/huggingface/transformers/issues/26186
| 1,898,563,666 |
I_kwDOCUB6oc5xKchS
| 26,186 |
FSDP/Accelerate: Training can't be continued from checkpoint with SHARDED_STATE_DICT
|
{
"login": "jphme",
"id": 2862336,
"node_id": "MDQ6VXNlcjI4NjIzMzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/2862336?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jphme",
"html_url": "https://github.com/jphme",
"followers_url": "https://api.github.com/users/jphme/followers",
"following_url": "https://api.github.com/users/jphme/following{/other_user}",
"gists_url": "https://api.github.com/users/jphme/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jphme/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jphme/subscriptions",
"organizations_url": "https://api.github.com/users/jphme/orgs",
"repos_url": "https://api.github.com/users/jphme/repos",
"events_url": "https://api.github.com/users/jphme/events{/privacy}",
"received_events_url": "https://api.github.com/users/jphme/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @pacman100 ",
"I believe this will be fixed by #26180 will review",
"> I believe this will be fixed by #26180 will review\r\n\r\nmany thanks, very timely and it does indeed solve the issue! Commented on the PR with a follow-up issue but will close this as the specific issue is solved by the PR.",
"I am facing this exact issue. What is the script that will consolidate the fsdp model shards as a single file? I have the checkpoint but no way to save the model.",
"> I am facing this exact issue. What is the script that will consolidate the fsdp model shards as a single file? I have the checkpoint but no way to save the model.\r\n\r\nTry out https://github.com/huggingface/transformers/pull/26180 (there @pacman100 also linked to the torch methods to directly load sharded state dicts). \r\n\r\nUnfortunately, as it currently stands, you can start training, create checkpoints, finish training and save the model but still run OOM when trying to continue from a checkpoint, so if you max out VRAM during your training runs, checkpoints are currently useless with SHARDED_STATE_DICT :/.",
"> > I am facing this exact issue. What is the script that will consolidate the fsdp model shards as a single file? I have the checkpoint but no way to save the model.\r\n> \r\n> Try out #26180 (there @pacman100 also linked to the torch methods to directly load sharded state dicts).\r\n> \r\n> Unfortunately, as it currently stands, you can start training, create checkpoints, finish training and save the model but still run OOM when trying to continue from a checkpoint, so if you max out VRAM during your training runs, checkpoints are currently useless with SHARDED_STATE_DICT :/.\r\n\r\n @jphme\r\nDoes your statement mean that if a model is trained using FSDP, it cannot be restarted from a saved checkpoint in the middle of training, and must be retrained from iteration 0?"
] | 1,694 | 1,706 | 1,694 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.34.0.dev0
- Platform: Linux-5.4.0-156-generic-x86_64-with-glibc2.35
- Python version: 3.9.18
- Huggingface_hub version: 0.17.1
- Safetensors version: 0.3.3
- Accelerate version: 0.23.0.dev0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: 4 * V100
- Using distributed or parallel set-up in script?: FSDP via accelerate
### Who can help?
cc @pacman100
I can´t continue Training from Checkpoints that were created with `fsdp_state_dict_type: SHARDED_STATE_DICT` via FSDP/ Accelerate. The rest of the training (and also model saving after calling `trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")` when the training has finished) works fine.
This is the error:
```python
File "/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/transformers/trainer.py", line 2093, in _load_from_checkpoint
raise ValueError(f"Can't find a valid checkpoint at {resume_from_checkpoint}")
ValueError: Can't find a valid checkpoint at /workspace/models/fsdp_debug/checkpoint-5
```
My FSDP config:
```
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_forward_prefetch: true
fsdp_offload_params: false
fsdp_sharding_strategy: 1
fsdp_state_dict_type: SHARDED_STATE_DICT
fsdp_sync_module_states: true
fsdp_use_orig_params: true
limit_all_gathers: true
```
Checkpoint contents:
```
-rw-r--r-- 1 root root 635 Sep 15 12:00 config.json
-rw-r--r-- 1 root root 188 Sep 15 12:00 generation_config.json
drwxr-xr-x 2 root root 4.0K Sep 15 12:00 optimizer_0
drwxr-xr-x 2 root root 4.0K Sep 15 12:00 pytorch_model_0
-rw-r--r-- 1 root root 18K Sep 15 12:00 rng_state_0.pth
-rw-r--r-- 1 root root 18K Sep 15 12:00 rng_state_1.pth
-rw-r--r-- 1 root root 18K Sep 15 12:00 rng_state_2.pth
-rw-r--r-- 1 root root 18K Sep 15 12:00 rng_state_3.pth
-rw-r--r-- 1 root root 627 Sep 15 12:00 scheduler.pt
-rw-r--r-- 1 root root 946 Sep 15 12:00 trainer_state.json
-rw-r--r-- 1 root root 4.8K Sep 15 12:00 training_args.bin
#pytorch_model_0
total 13G
-rw-r--r-- 1 root root 3.2G Sep 15 12:00 __0_0.distcp
-rw-r--r-- 1 root root 3.2G Sep 15 12:00 __1_0.distcp
-rw-r--r-- 1 root root 3.2G Sep 15 12:00 __2_0.distcp
-rw-r--r-- 1 root root 3.2G Sep 15 12:00 __3_0.distcp
```
At first I thought this is just an error because the trainer expects a `pytorch_model.bin` which isn't available in the directory (see https://github.com/huggingface/transformers/blob/2518e368105a78f6cdc50ded6971712f2c1e7ac4/src/transformers/trainer.py#L2085 ).
However when trying to call `load_fsdp_model(self.accelerator.state.fsdp_plugin, self.accelerator, model, resume_from_checkpoint)` directly in `_load_from_checkpoint`, i get the following error:
```python
File "/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/transformers/trainer.py", line 1694, in _inner_training_loop
FullyShardedDataParallel.set_state_dict_type(
File "/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/distributed/fsdp/fully_sharded_data_parallel.py", line 608, in set_state_dict_type
load_fsdp_model(self.accelerator.state.fsdp_plugin, self.accelerator, model, resume_from_checkpoint)
File "/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/accelerate/utils/fsdp_utils.py", line 129, in load_fsdp_model
load_result = model.load_state_dict(state_dict)
File "/root/miniconda3/envs/py3.9/lib/python3.9/contextlib.py", line 126, in __exit__
self._load_from_checkpoint(resume_from_checkpoint, model)state_dict_config_type = _state_dict_type_to_config[state_dict_type]
File "/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/transformers/trainer.py", line 2076, in _load_from_checkpoint
next(self.gen)
KeyError File "/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/distributed/fsdp/fully_sharded_data_parallel.py", line 720, in state_dict_type
: None
FullyShardedDataParallel.set_state_dict_type(
File "/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/distributed/fsdp/fully_sharded_data_parallel.py", line 608, in set_state_dict_type
state_dict_config_type = _state_dict_type_to_config[state_dict_type]
KeyError: None
```
Content of `self.accelerator.state.fsdp_plugin`:
> FullyShardedDataParallelPlugin(sharding_strategy=<ShardingStrategy.FULL_SHARD: 1>, backward_prefetch=None, mixed_precision_policy=MixedPrecision(param_dtype=torch.float16, reduce_dtype=torch.float16, buffer_dtype=torch.float16, keep_low_precision_grads=False, cast_forward_inputs=False, cast_root_forward_inputs=True), auto_wrap_policy=None, cpu_offload=CPUOffload(offload_params=False), ignored_modules=None, state_dict_type=<StateDictType.SHARDED_STATE_DICT: 3>, state_dict_config=None, optim_state_dict_config=None, limit_all_gathers=True, use_orig_params=False, param_init_fn=<function FullyShardedDataParallelPlugin.__post_init__.<locals>.<lambda> at 0x7f66aabbb160>, sync_module_states=True, forward_prefetch=False, activation_checkpointing=False)
Any idea on how to fix this? Many thanks!
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
see above
### Expected behavior
Training can be resumed from checkpoints.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26186/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26186/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26185
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26185/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26185/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26185/events
|
https://github.com/huggingface/transformers/pull/26185
| 1,898,490,825 |
PR_kwDOCUB6oc5acb8L
| 26,185 |
Chat Template kwargs
|
{
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26185). All of your documentation changes will be reflected on that endpoint.",
"That's a fair point! I noticed when I was browsing the Hub that several models had chat templates that needed variable substitutions that don't work cleanly with the current template. [Here's](https://huggingface.co/PygmalionAI/pygmalion-6b) a good example - the `<CHARACTER>` variable needs to be filled in somehow, which would force the user to rewrite the template for every character.\r\n\r\nThinking about it more, though, maybe for a model like that extra information would need to be supplied e.g. as extra keys in the conversation inputs instead?",
"~I'm going to resurrect this PR - I think template kwargs are the right way to handle another thing I want to add: The ability to include a 'generation prompt' in the template.~\r\n\r\nScratch that, I think it makes more sense as a separate argument to `apply_chat_template` - I'll make a new PR!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,694 | 1,699 | 1,699 |
MEMBER
| null |
This PR adds an extra `chat_template_kwargs` attribute, so that the behaviour of templates can be modified without rewriting the whole thing. I factored out the messy LLaMA default system message stuff in a cleaner way using these, and I'm going to need it for the templates of some other checkpoints on the Hub as well!
This is implemented in a backward-compatible way, so no existing code should break because of it.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26185/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26185/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26185",
"html_url": "https://github.com/huggingface/transformers/pull/26185",
"diff_url": "https://github.com/huggingface/transformers/pull/26185.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26185.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/26184
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26184/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26184/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26184/events
|
https://github.com/huggingface/transformers/issues/26184
| 1,898,464,010 |
I_kwDOCUB6oc5xKEMK
| 26,184 |
WhisperTokenizerFast omits language and task tokens
|
{
"login": "tsobolev",
"id": 28811005,
"node_id": "MDQ6VXNlcjI4ODExMDA1",
"avatar_url": "https://avatars.githubusercontent.com/u/28811005?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tsobolev",
"html_url": "https://github.com/tsobolev",
"followers_url": "https://api.github.com/users/tsobolev/followers",
"following_url": "https://api.github.com/users/tsobolev/following{/other_user}",
"gists_url": "https://api.github.com/users/tsobolev/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tsobolev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tsobolev/subscriptions",
"organizations_url": "https://api.github.com/users/tsobolev/orgs",
"repos_url": "https://api.github.com/users/tsobolev/repos",
"events_url": "https://api.github.com/users/tsobolev/events{/privacy}",
"received_events_url": "https://api.github.com/users/tsobolev/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Hey! Thanks for reporting. You need to call the `tokenizer_fast.set_prefix_tokens()` function to make sure the changes are applied. \r\nA fix would be to call this function in the `__init__`, would you like to open a PR for the fix? ",
"cc @sanchit-gandhi if there was a reason not to call this at init time? ",
"When I call this function in the `__init__`, it causes error:\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/user/transformers/my-test.py\", line 6, in <module>\r\n tokenizer_fast = WhisperTokenizerFast.from_pretrained(model_ckpt, language=\"ka\", task=\"transcribe\")\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/home/user/transformers/src/transformers/tokenization_utils_base.py\", line 1967, in from_pretrained\r\n return cls._from_pretrained(\r\n ^^^^^^^^^^^^^^^^^^^^^\r\n File \"/home/user/transformers/src/transformers/tokenization_utils_base.py\", line 2130, in _from_pretrained\r\n tokenizer = cls(*init_inputs, **init_kwargs)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/home/user/transformers/src/transformers/models/whisper/tokenization_whisper_fast.py\", line 182, in __init__\r\n self.set_prefix_tokens()\r\n File \"/home/user/transformers/src/transformers/models/whisper/tokenization_whisper_fast.py\", line 432, in set_prefix_tokens\r\n prefix_token_ids = self.prefix_tokens\r\n ^^^^^^^^^^^^^^^^^^\r\n File \"/home/user/transformers/src/transformers/models/whisper/tokenization_whisper_fast.py\", line 450, in prefix_tokens\r\n bos_token_id = all_special_ids[-106]\r\n ~~~~~~~~~~~~~~~^^^^^^\r\nIndexError: list index out of range\r\n```\r\nI can insert `self.set_prefix_tokens()` in beginning of `_batch_encode_plus` and `_encode_plus` and it works, but this doesn't seem to be the right solution.",
"That is not what I meant. Once the tokenizer is initialized, just call `tokenizer.set_prefix_tokens()`. This should only be set once. Touching the processor on the fly is not completely recommended 😉 ",
"If I instantiate `tokenizer_fast` in my script and then call `tokenizer_fast.set_prefix_tokens()` everything works fine.\r\n\r\n> A fix would be to call this function in the `__init__`\r\n\r\nAs i understand, the fix is to eliminating the need to extra call the function `set_prefox_tokens()` after instantiating `tokenizer_fast`?\r\n\r\nI'm trying to figure out if it's possible to make `WhisperTokenizerFast` and `WhisperTokenizer` behave the same way,\r\nbecause `WhisperTokenizer` does not require an additional `set_prefix_tokens()` call. \r\nThis inconsistency is a bit confusing.\r\n",
"The confusion here comes from the difference between a fast and a slow tokenizer. In a fast tokenizer, the inputs is processed not using `build_inputs_with_special_tokens` but using the `processor`. Fast tokenizers are based on rust, and are supposed to be initialized once and not modified much. Adding the `set_prefox_tokens()` is the fix for this as it allows initializing with different parameters. \r\n\r\nThe slow tokenizer uses a property that is always re_computed on the fly. This can add (probably small) overhead, but is also not very clear it seems. ",
"Still unclear.\r\nIs it possible to make WhisperTokenizerFast produce same output as WhisperTokenizer instansiated with same code, without extra set_prefix_tokens() (make it under the hood), or it feature and i should close this issue?\r\nOr in should by done in rust library not in transformers python code? \r\nAnyway, with extra call set_prefix_tokens() after instantiating tokenizer everything works fine.",
"I didn't add the Whisper fast tokenizer, but for equivalent behaviour with the slow one, the prefix tokens should be set at `__init__`. It looks like they're only registered in the processor when we call `set_prefix_tokens`: https://github.com/huggingface/transformers/blob/e4e55af79c9b3dfd15cc2224f8f5b80680d83f03/src/transformers/models/whisper/tokenization_whisper_fast.py#L435\r\n\r\nI guess it's not possible to do this in the `__init__` because we need access to `all_special_ids` (property) and the encoding method `convert_ids_to_tokens`. Unless you know of a workaround @ArthurZucker like a post init?",
"We will be able to do this once #23909 is merged 😉 I'll take care of it. \r\n@tsobolev sorry for being unclear: we will fix this to have the same behaviour at init time. You can in the mean time use the fix I proposed.\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"I think this was fixed by updating the tokenizer so closing 😉 "
] | 1,694 | 1,697 | 1,697 |
NONE
| null |
### System Info
- `transformers` version: 4.34.0.dev0
- Platform: Linux-5.15.120+-x86_64-with-glibc2.31
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.0+cpu (False)
- Tensorflow version (GPU?): 2.12.0 (False)
- Flax version (CPU?/GPU?/TPU?): 0.7.2 (cpu)
- Jax version: 0.4.13
- JaxLib version: 0.4.13
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@ArthurZucker
Hello.
WhisperTokenizerFast omits language and task tokens: <|ka|><|transcribe|>
Is it bug or feature?
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
from transformers import WhisperTokenizer, AutoFeatureExtractor, WhisperTokenizerFast
model_ckpt = "openai/whisper-tiny"
tokenizer = WhisperTokenizer.from_pretrained(model_ckpt, language="ka", task="transcribe")
tokenizer_fast = WhisperTokenizerFast.from_pretrained(model_ckpt, language="ka", task="transcribe")
feature_extractor = AutoFeatureExtractor.from_pretrained(model_ckpt)
input_ids = tokenizer('ქართული სახელმწიფოებრიობისა და კულტურის მდგრადობა უშუალოდ დაკავშირებული იყო საქართველოს დედაქალაქის ბედთან.')['input_ids']
print('tokenizer_slow:',tokenizer.decode(input_ids, skip_special_tokens=False))
input_ids = tokenizer_fast('ქართული სახელმწიფოებრიობისა და კულტურის მდგრადობა უშუალოდ დაკავშირებული იყო საქართველოს დედაქალაქის ბედთან.')['input_ids']
print('tokenizer_fast:',tokenizer.decode(input_ids, skip_special_tokens=False))
```
tokenizer_slow: <|startoftranscript|><|ka|><|transcribe|><|notimestamps|>ქართული სახელმწიფოებრიობისა და კულტურის მდგრადობა უშუალოდ დაკავშირებული იყო საქართველოს დედაქალაქის ბედთან.<|endoftext|>
tokenizer_fast: <|startoftranscript|><|notimestamps|>ქართული სახელმწიფოებრიობისა და კულტურის მდგრადობა უშუალოდ დაკავშირებული იყო საქართველოს დედაქალაქის ბედთან.<|endoftext|>
### Expected behavior
tokenizer_fast: <|startoftranscript|><|ka|><|transcribe|><|notimestamps|>ქართული სახელმწიფოებრიობისა და კულტურის მდგრადობა უშუალოდ დაკავშირებული იყო საქართველოს დედაქალაქის ბედთან.<|endoftext|>
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26184/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26184/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26183
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26183/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26183/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26183/events
|
https://github.com/huggingface/transformers/pull/26183
| 1,898,285,597 |
PR_kwDOCUB6oc5abu0-
| 26,183 |
moved `ctrl` to `Salesforce/ctrl`
|
{
"login": "julien-c",
"id": 326577,
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/julien-c",
"html_url": "https://github.com/julien-c",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"repos_url": "https://api.github.com/users/julien-c/repos",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Taking a look at and fixing the failures"
] | 1,694 | 1,695 | 1,695 |
MEMBER
| null |
redirects should theoretically work, but still updating those repo references for clarity
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26183/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26183/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26183",
"html_url": "https://github.com/huggingface/transformers/pull/26183",
"diff_url": "https://github.com/huggingface/transformers/pull/26183.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26183.patch",
"merged_at": 1695037963000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26182
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26182/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26182/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26182/events
|
https://github.com/huggingface/transformers/pull/26182
| 1,898,250,150 |
PR_kwDOCUB6oc5abnMs
| 26,182 |
Porting the torchaudio kaldi fbank implementation to audio_utils
|
{
"login": "ylacombe",
"id": 52246514,
"node_id": "MDQ6VXNlcjUyMjQ2NTE0",
"avatar_url": "https://avatars.githubusercontent.com/u/52246514?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ylacombe",
"html_url": "https://github.com/ylacombe",
"followers_url": "https://api.github.com/users/ylacombe/followers",
"following_url": "https://api.github.com/users/ylacombe/following{/other_user}",
"gists_url": "https://api.github.com/users/ylacombe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ylacombe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ylacombe/subscriptions",
"organizations_url": "https://api.github.com/users/ylacombe/orgs",
"repos_url": "https://api.github.com/users/ylacombe/repos",
"events_url": "https://api.github.com/users/ylacombe/events{/privacy}",
"received_events_url": "https://api.github.com/users/ylacombe/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"I've applied your suggestions @sanchit-gandhi and corrected the `use_torchaudio_version` naming to `triangularize_in_mel_space` with a more appropriate description, thanks for the review!\r\n\r\n@ArthurZucker, would it be possible to review this PR when you have time ? thanks!",
"Thanks for your review @ArthurZucker ! I'm gonna merge as soon as tests pass.\r\n\r\nBTW, `np.exp(...,base=10)` doesn't work. I used `np.power(10,...)` instead :hugs: "
] | 1,694 | 1,695 | 1,695 |
COLLABORATOR
| null |
# What does this PR do?
> [Kaldi](https://kaldi-asr.org/doc/) is a toolkit for speech recognition, intended for use by speech recognition researchers and professionals.
Its [torchaudio `fbank` implementation](https://pytorch.org/audio/stable/compliance.kaldi.html) is sometimes used in the library, notably in the [Audio Spectrogram Transformer](https://github.com/huggingface/transformers/blob/d70fab8b2062526e9c2c60196421a8bc96c7df03/src/transformers/models/audio_spectrogram_transformer/feature_extraction_audio_spectrogram_transformer.py#L97) and [SpeechToText](https://github.com/huggingface/transformers/blob/d70fab8b2062526e9c2c60196421a8bc96c7df03/src/transformers/models/speech_to_text/feature_extraction_speech_to_text.py#L90) models.
It will also be used in the future [SeamlessM4T model](https://github.com/huggingface/transformers/pull/25693#pullrequestreview-1624417597).
This PR aims to port [the implementation](https://pytorch.org/audio/stable/_modules/torchaudio/compliance/kaldi.html#fbank) to `numpy`, directly in `audio_utils.py`.
Why is this important? It will reduce `transformers` dependence on `torchaudio` for some models.
Atm, I enriched some of `audio_utils` methods and added tests to make sure it has the same results as `torchaudio`.
## Before submitting
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
cc @ArthurZucker and @sanchit-gandhi , what do you think of this feature ?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26182/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26182/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26182",
"html_url": "https://github.com/huggingface/transformers/pull/26182",
"diff_url": "https://github.com/huggingface/transformers/pull/26182.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26182.patch",
"merged_at": 1695311568000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26181
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26181/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26181/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26181/events
|
https://github.com/huggingface/transformers/issues/26181
| 1,898,058,044 |
I_kwDOCUB6oc5xIhE8
| 26,181 |
Bug report of quantizing Falcon40b using GPTQConfig
|
{
"login": "SantiDianaClibrain",
"id": 138574271,
"node_id": "U_kgDOCEJ5vw",
"avatar_url": "https://avatars.githubusercontent.com/u/138574271?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SantiDianaClibrain",
"html_url": "https://github.com/SantiDianaClibrain",
"followers_url": "https://api.github.com/users/SantiDianaClibrain/followers",
"following_url": "https://api.github.com/users/SantiDianaClibrain/following{/other_user}",
"gists_url": "https://api.github.com/users/SantiDianaClibrain/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SantiDianaClibrain/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SantiDianaClibrain/subscriptions",
"organizations_url": "https://api.github.com/users/SantiDianaClibrain/orgs",
"repos_url": "https://api.github.com/users/SantiDianaClibrain/repos",
"events_url": "https://api.github.com/users/SantiDianaClibrain/events{/privacy}",
"received_events_url": "https://api.github.com/users/SantiDianaClibrain/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @SantiDianaClibrain , thanks for reporting. I am unable to reproduce the error on my side. Which version of optimum and transformers are you using ? Does the script work by just changing the model to a llama model ? Make sure to not name your file to gptq.py. It will lead to import error. ",
"Hey @SunMarc. Thanks for your quick reply. I am using:\r\n`transformers` == 4.33.1\r\n`optimum` == 1.13.1\r\n\r\nBy the way, I rerunned the code and found another issue, Let's see if that sounds familiar to you.\r\n\r\n```\r\nTraceback (most recent call last): \r\n File \"/home/santi/quantizer.py\", line 27, in <module>\r\n quant_model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config, device_map='auto',trust_remote_code=True)\r\n File \"/opt/conda/lib/python3.10/site-packages/transformers/models/auto/auto_factory.py\", line 558, in from_pretrained\r\n return model_class.from_pretrained(\r\n File \"/opt/conda/lib/python3.10/site-packages/transformers/modeling_utils.py\", line 3241, in from_pretrained\r\n quantizer.quantize_model(model, quantization_config.tokenizer)\r\n File \"/opt/conda/lib/python3.10/site-packages/torch/utils/_contextlib.py\", line 115, in decorate_context\r\n return func(*args, **kwargs)\r\n File \"/opt/conda/lib/python3.10/site-packages/optimum/gptq/quantizer.py\", line 419, in quantize_model\r\n scale, zero, g_idx = gptq[name].fasterquant(\r\n File \"/opt/conda/lib/python3.10/site-packages/auto_gptq/quantization/gptq.py\", line 112, in fasterquant\r\n H = torch.linalg.cholesky(H, upper=True)\r\ntorch._C._LinAlgError: linalg.cholesky: The factorization could not be completed because the input is not positive-definite (the leading minor of order 32410 is not positive-definite).\r\n```\r\n\r\nThat happens when loading `model_id = tiiuae/falcon-40b`, which is the standard falcon 40b of HuggingFace. Don't know what can be happening. ",
"I used exactly the same code with a` llama-7b` and I was capable of quantizing it. ",
"Are you using a custom dataset to calibrate the quantization? It's computing some matrix using the dataset and it seems to run into an issue. You should probably ask in auto_gptq library as we use that as the backend. ",
"Yes I am! Okay, thanks for the reply."
] | 1,694 | 1,694 | 1,694 |
NONE
| null |
### System Info
I am receiving an error while trying to quantize a falcon-type model using GPTQConfig.
**System information**
- `transformers` version: 4.31.1
- Python version: 3.11.5
- Huggingface_hub version: 0.15.1
- Accelerate version: 0.21.0
**Who can help?**
@SunMarc and @younesbelkada
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```
model_id = "tiiuae/falcon-40b"
quantization_config = GPTQConfig(
bits=4,
group_size=128,
dataset=quant_ds,
desc_act=False,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
quant_model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config, device_map='auto')
```
The error reported is:
```
from optimum.gptq import GPTQQuantizer
ImportError: cannot import name 'GPTQQuantizer' from partially initialized module 'optimum.gptq' (most likely due to a circular import) (/mnt/data/wangjiancheng/miniconda3/envs/autogptq/lib/python3.9/site-packages/optimum/gptq/__init__.py)
```
The same code worked for me with a llama-like model.
### Expected behavior
Code with no error
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26181/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26181/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26180
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26180/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26180/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26180/events
|
https://github.com/huggingface/transformers/pull/26180
| 1,897,926,597 |
PR_kwDOCUB6oc5aag9G
| 26,180 |
FSDP tests and checkpointing fixes
|
{
"login": "pacman100",
"id": 13534540,
"node_id": "MDQ6VXNlcjEzNTM0NTQw",
"avatar_url": "https://avatars.githubusercontent.com/u/13534540?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pacman100",
"html_url": "https://github.com/pacman100",
"followers_url": "https://api.github.com/users/pacman100/followers",
"following_url": "https://api.github.com/users/pacman100/following{/other_user}",
"gists_url": "https://api.github.com/users/pacman100/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pacman100/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pacman100/subscriptions",
"organizations_url": "https://api.github.com/users/pacman100/orgs",
"repos_url": "https://api.github.com/users/pacman100/repos",
"events_url": "https://api.github.com/users/pacman100/events{/privacy}",
"received_events_url": "https://api.github.com/users/pacman100/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Just a short feedback, when trying to resume from a checkpoint with SHARDED_STATE_DICT (see #26186 for setup/details) with this PR, i get a Cuda OOM error, full stacktrace below. \r\n\r\n<details>\r\n<summary>Full Stacktrace</summary>\r\n\r\n```bash\r\n File \"/workspace/axolotl/scripts/finetune.py\", line 287, in <module>\r\nTraceback (most recent call last):\r\n File \"/workspace/axolotl/scripts/finetune.py\", line 287, in <module>\r\nTraceback (most recent call last):\r\n fire.Fire(do_cli)\r\n File \"/workspace/axolotl/scripts/finetune.py\", line 287, in <module>\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/fire/core.py\", line 141, in Fire\r\n fire.Fire(do_cli)\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/fire/core.py\", line 141, in Fire\r\nfire.Fire(do_cli)\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/fire/core.py\", line 141, in Fire\r\n component_trace = _Fire(component, args, parsed_flag_args, context, name)\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/fire/core.py\", line 475, in _Fire\r\n component_trace = _Fire(component, args, parsed_flag_args, context, name)\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/fire/core.py\", line 475, in _Fire\r\ncomponent, remaining_args = _CallAndUpdateTrace(\r\ncomponent_trace = _Fire(component, args, parsed_flag_args, context, name) File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/fire/core.py\", line 691, in _CallAndUpdateTrace\r\n\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/fire/core.py\", line 475, in _Fire\r\n component = fn(*varargs, **kwargs)\r\n File \"/workspace/axolotl/scripts/finetune.py\", line 283, in do_cli\r\ncomponent, remaining_args = _CallAndUpdateTrace(\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/fire/core.py\", line 691, in _CallAndUpdateTrace\r\n component, remaining_args = _CallAndUpdateTrace(train(cfg=parsed_cfg, cli_args=parsed_cli_args, dataset_meta=dataset_meta)\r\n\r\n File \"/workspace/axolotl/src/axolotl/train.py\", line 116, in train\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/fire/core.py\", line 691, in _CallAndUpdateTrace\r\n component = fn(*varargs, **kwargs)\r\n File \"/workspace/axolotl/scripts/finetune.py\", line 283, in do_cli\r\n trainer.train(resume_from_checkpoint=resume_from_checkpoint)component = fn(*varargs, **kwargs)\r\n\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/transformers/trainer.py\", line 1575, in train\r\n File \"/workspace/axolotl/scripts/finetune.py\", line 283, in do_cli\r\n train(cfg=parsed_cfg, cli_args=parsed_cli_args, dataset_meta=dataset_meta)\r\n File \"/workspace/axolotl/src/axolotl/train.py\", line 116, in train\r\ntrain(cfg=parsed_cfg, cli_args=parsed_cli_args, dataset_meta=dataset_meta)\r\n File \"/workspace/axolotl/src/axolotl/train.py\", line 116, in train\r\n trainer.train(resume_from_checkpoint=resume_from_checkpoint)\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/transformers/trainer.py\", line 1575, in train\r\ntrainer.train(resume_from_checkpoint=resume_from_checkpoint)\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/transformers/trainer.py\", line 1575, in train\r\n return inner_training_loop(\r\n return inner_training_loop( File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/transformers/trainer.py\", line 1876, in _inner_training_loop\r\nreturn inner_training_loop(\r\n\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/transformers/trainer.py\", line 1876, in _inner_training_loop\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/transformers/trainer.py\", line 1876, in _inner_training_loop\r\n tr_loss_step = self.training_step(model, inputs)\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/transformers/trainer.py\", line 2768, in training_step\r\n tr_loss_step = self.training_step(model, inputs)\r\ntr_loss_step = self.training_step(model, inputs)\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/transformers/trainer.py\", line 2768, in training_step\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/transformers/trainer.py\", line 2768, in training_step\r\n self.accelerator.backward(loss)\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/accelerate/accelerator.py\", line 1963, in backward\r\n self.scaler.scale(loss).backward(**kwargs)\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/_tensor.py\", line 487, in backward\r\n self.accelerator.backward(loss)\r\nself.accelerator.backward(loss)\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/accelerate/accelerator.py\", line 1963, in backward\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/accelerate/accelerator.py\", line 1963, in backward\r\n torch.autograd.backward(\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/autograd/__init__.py\", line 200, in backward\r\n self.scaler.scale(loss).backward(**kwargs)self.scaler.scale(loss).backward(**kwargs)\r\n\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/_tensor.py\", line 487, in backward\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/_tensor.py\", line 487, in backward\r\n Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/autograd/function.py\", line 274, in apply\r\n torch.autograd.backward(torch.autograd.backward(\r\n\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/autograd/__init__.py\", line 200, in backward\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/autograd/__init__.py\", line 200, in backward\r\n return user_fn(self, *args)Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward passVariable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass\r\n\r\n\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/utils/checkpoint.py\", line 157, in backward\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/autograd/function.py\", line 274, in apply\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/autograd/function.py\", line 274, in apply\r\n return user_fn(self, *args)return user_fn(self, *args)\r\n\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/utils/checkpoint.py\", line 157, in backward\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/utils/checkpoint.py\", line 157, in backward\r\n torch.autograd.backward(outputs_with_grad, args_with_grad)\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/autograd/__init__.py\", line 200, in backward\r\n torch.autograd.backward(outputs_with_grad, args_with_grad)torch.autograd.backward(outputs_with_grad, args_with_grad)\r\n\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/autograd/__init__.py\", line 200, in backward\r\n File \"/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/torch/autograd/__init__.py\", line 200, in backward\r\n Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass\r\ntorch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 172.00 MiB (GPU 3; 31.74 GiB total capacity; 30.59 GiB already allocated; 168.38 MiB free; 31.12 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONFVariable._execution_engine.run_backward( # Calls into the C++ engine to run the backward passVariable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass\r\n```\r\n\r\n</details>",
"Hello @jphme, I do notice an increase in GPU memory consumption of about 600MB for above tests when resuming from checkpoint saved via `SHARDED_STATE_DICT`. However, that needs to be resolved by PyTorch team as it does not pertain to the integration. Could you raise an issue with PyTorch repo: https://github.com/pytorch/pytorch/issues regarding this?",
"> Hello @jphme, I do notice an increase in GPU memory consumption of about 600MB for above tests when using `SHARDED_STATE_DICT`. However, that needs to be resolved by PyTorch team as it does not pertain to the integration. Could you raise an issue with PyTorch repo: https://github.com/pytorch/pytorch/issues regarding this?\r\n\r\nHi @pacman100 sure - but just to clarify: The training started (and ran until the checkpoint) without problems and its also possible to extract the model after the training with `trainer.accelerator.state.fsdp_plugin.set_state_dict_type(\"FULL_STATE_DICT\")` on the same instance/setup. \r\n\r\nSo you mean that specifically for restarting from a `SHARDED_STATE_DICT` checkpoint more VRAM is needed and we can do nothing about it?\r\n\r\nThis is quite dangerous as everyone tunes their runs so VRAM is maxed and that would mean that many runs can't be restarted from checkpoints...\r\n\r\nEDIT: Ok I re-read your post - in my case the checkpoint was indeed created with the main branch and I only tried to restart with this PR; if the PR generally increases VRAM consumption that would explain it. \r\n\r\nBut then I don't understand whats exactly the Pytorch issue. And is there no way (with offloading) to avoid the increased VRAM consumption as everything besides checkpointing (training, model extraction) worked fine for me? (Sorry if i am a bit slow understanding, still new to FSDP/Torch - many thanks for your work on this!) ",
"> if the PR generally increases VRAM consumption that would explain it.\r\n\r\nThis PR doesn't increase VRAM consumption. Internally, it is calling the Torch utility here: \r\n\r\nhttps://github.com/huggingface/accelerate/blob/a87c95da9e3b416fb10a0e7dac7d397c015c3ed5/src/accelerate/utils/fsdp_utils.py#L114-L130\r\n\r\nand here:\r\n\r\nhttps://github.com/huggingface/accelerate/blob/a87c95da9e3b416fb10a0e7dac7d397c015c3ed5/src/accelerate/utils/fsdp_utils.py#L178-L192\r\n\r\nThese are probably leading to the increased VRAM consumption. ",
"So just for further reference (because other people are starting to have the same issue and commented on my closed issue): Checkpoints are currently of no use with `SHARDED_STATE_DICT` if maxing out Vram during training, because you will run OOM when trying to continue, even if everything else (starting training, creating checkpoint, saving model at the end after converting to FULL_STATE_DICT) works fine.\r\n\r\nWill try with torch nightly if I have the opportunity (there seems to be a new env that could help), unfortunately very busy currently. ",
"Hi, has this fix been merged into the new the new transformers v4.33.3? ",
"Hey @jmzeng, it is not part of v4.33.3 but will be part of v4.34.0 which will be released early next week.\r\n\r\nIn the meantime, you can install from source:\r\n```\r\npip install git+https://github.com/huggingface/transformers\r\n```"
] | 1,694 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
# What does this PR do?
1. Fixes certain bugs with checkpointing when using FSDP
2. Adds tests for FSDP integration in Trainer.
3. Different combination runs to check resuming from checkpoints work as expected.
Below we will run the different combinations of FSDP `SHARDING_STRATEGY` and `STATE_DICT_TYPE` for the `run_glue.py` transformers example
Initial setup:
```
cd transformers
export CUDA_VISISBLE_DEVICES=0,1
export TASK_NAME=mrpc
```
a. **FULL_SHARD + FULL_STATE_DICT**
i. command to run:
```
torchrun --nnodes 1 --nproc-per-node 2 ./examples/pytorch/text-classification/run_glue.py --model_name_or_path bert-base-cased --task_name $TASK_NAME --do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 16 --learning_rate 5e-5 --num_train_epochs 3 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --lr_scheduler_type cosine --save_strategy "epoch" --evaluation_strategy "epoch" --logging_steps 1 --fsdp "full_shard auto_wrap" --fsdp_transformer_layer_cls_to_wrap BertLayer --bf16
```
Kill the process after epoch 1. Run the above command with --resume_from_checkpoint as below:
```
torchrun --nnodes 1 --nproc-per-node 2 ./examples/pytorch/text-classification/run_glue.py --model_name_or_path bert-base-cased --task_name $TASK_NAME --do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 16 --learning_rate 5e-5 --num_train_epochs 3 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --lr_scheduler_type cosine --save_strategy "epoch" --evaluation_strategy "epoch" --logging_steps 1 --fsdp "full_shard auto_wrap" --fsdp_transformer_layer_cls_to_wrap BertLayer --bf16 --resume_from_checkpoint /tmp/$TASK_NAME/checkpoint-115/
```
iii. Plots of loss and learning rate:

b. **SHARD_GRAD_OP + FULL_STATE_DICT**
Same as above but with the following cmd arg `--fsdp "shard_grad_op auto_wrap"`
Plots:

c. **FULL_SHARD + SHARDED_STATE_DICT**
i. Here, we will need to use the accelerate launcher as the option to choose `SHARDED_STATE_DICT` is currently available via `accelerate config`. Below is the config file `fsdp_config.yaml`:
```yaml
compute_environment: LOCAL_MACHINE
debug: false
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_forward_prefetch: false
fsdp_offload_params: false
fsdp_sharding_strategy: 1
fsdp_state_dict_type: SHARDED_STATE_DICT
fsdp_sync_module_states: true
fsdp_transformer_layer_cls_to_wrap: BertLayer
fsdp_use_orig_params: true
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
```
ii. command to run:
```
accelerate launch --config_file "fsdp_config.yaml" ./examples/pytorch/text-classification/run_glue.py --model_name_or_path bert-base-cased --task_name $TASK_NAME --do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 16 --learning_rate 5e-5 --num_train_epochs 3 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --lr_scheduler_type cosine --save_strategy "epoch" --evaluation_strategy "epoch" --logging_steps 1
```
Kill the process after epoch 1. Run the above command with --resume_from_checkpoint as below:
```
accelerate launch --config_file "fsdp_config.yaml" ./examples/pytorch/text-classification/run_glue.py --model_name_or_path bert-base-cased --task_name $TASK_NAME --do_eval --max_seq_length 128 --per_device_train_batch_size 16 --learning_rate 5e-5 --num_train_epochs 5 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --lr_scheduler_type cosine --save_strategy "epoch" --evaluation_strategy "epoch" --logging_steps 1 --resume_from_checkpoint /tmp/$TASK_NAME/checkpoint-115/
```
iii. Plots:

d. **SHARD_GRAD_OP + SHARDED_STATE_DICT**
Just run the `accelerate config` command and choose `SHARD_GRAD_OP` Sharding strategy and get `fsdp_config.yaml` similar to the above case. The rest is the same.
Plots:

|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26180/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26180/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26180",
"html_url": "https://github.com/huggingface/transformers/pull/26180",
"diff_url": "https://github.com/huggingface/transformers/pull/26180.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26180.patch",
"merged_at": 1695185776000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26179
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26179/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26179/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26179/events
|
https://github.com/huggingface/transformers/issues/26179
| 1,897,870,583 |
I_kwDOCUB6oc5xHzT3
| 26,179 |
KeyError: <class 'transformers.models.falcon.configuration_falcon.FalconConfig'>`
|
{
"login": "ishaansharma",
"id": 8963395,
"node_id": "MDQ6VXNlcjg5NjMzOTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/8963395?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ishaansharma",
"html_url": "https://github.com/ishaansharma",
"followers_url": "https://api.github.com/users/ishaansharma/followers",
"following_url": "https://api.github.com/users/ishaansharma/following{/other_user}",
"gists_url": "https://api.github.com/users/ishaansharma/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ishaansharma/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ishaansharma/subscriptions",
"organizations_url": "https://api.github.com/users/ishaansharma/orgs",
"repos_url": "https://api.github.com/users/ishaansharma/repos",
"events_url": "https://api.github.com/users/ishaansharma/events{/privacy}",
"received_events_url": "https://api.github.com/users/ishaansharma/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! Could you share the ` tokenizer_config.json` or ` tokenizer.json` files? ",
"This is the tokenizer_config.json content : \r\n\r\n```\r\n{\r\n \"add_prefix_space\": false,\r\n \"additional_special_tokens\": [\r\n \">>TITLE<<\",\r\n \">>ABSTRACT<<\",\r\n \">>INTRODUCTION<<\",\r\n \">>SUMMARY<<\",\r\n \">>COMMENT<<\",\r\n \">>ANSWER<<\",\r\n \">>QUESTION<<\",\r\n \">>DOMAIN<<\",\r\n \">>PREFIX<<\",\r\n \">>SUFFIX<<\",\r\n \">>MIDDLE<<\"\r\n ],\r\n \"clean_up_tokenization_spaces\": true,\r\n \"eos_token\": \"<|endoftext|>\",\r\n \"model_input_names\": [\r\n \"input_ids\",\r\n \"attention_mask\"\r\n ],\r\n \"model_max_length\": 2048,\r\n \"tokenizer_class\": \"PreTrainedTokenizerFast\"\r\n}\r\n```",
"You are trying to use the `PreTrainedTokenizerFast` without any `tokenizer.json` file. Since there is no mapping for falcon, it's gonna be a bit hard. Need to have a `tokenizer.json` file. Otherwise it should try to initialised a slow tokenizer and then convert it, which should work even if there is no mapping. "
] | 1,694 | 1,695 | 1,695 |
NONE
| null |
### System Info
- `transformers` version: 4.34.0.dev0
- Platform: Linux-6.2.0-31-generic-x86_64-with-glibc2.17
- Python version: 3.8.16
- Huggingface_hub version: 0.17.1
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: - compute_environment: LOCAL_MACHINE
- distributed_type: NO
- mixed_precision: fp16
- use_cpu: False
- debug: False
- num_processes: 1
- machine_rank: 0
- num_machines: 1
- gpu_ids: all
- rdzv_backend: static
- same_network: True
- main_training_function: main
- downcast_bf16: no
- tpu_use_cluster: False
- tpu_use_sudo: False
- tpu_env: []
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): 2.10.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@Narsil, @younesbelkada, @ArthurZucker
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
[Code from this post used for inference ](https://huggingface.co/blog/falcon#inference)
The when loading the tokenizer from_pretrained function using AutoTokenizer class, I am getting an error that is restricting me to run the following code .
```
from transformers import AutoTokenizer
import transformers
import torch
model = "my_finetuned_classification_model_folder_path"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-classification",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
```
The config file of the finetuned model is :
```
{
"_name_or_path": "../model/hf_pretrain_tiny-random-falcon-7b_G5CST_15T_v1",
"alibi": false,
"apply_residual_connection_post_layernorm": false,
"architectures": [
"FalconForSequenceClassification"
],
"attention_dropout": 0.0,
"bias": false,
"bos_token_id": 11,
"eos_token_id": 11,
"gradient_checkpointing": true,
"hidden_dropout": 0.0,
"hidden_size": 1136,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1",
"2": "LABEL_2",
"3": "LABEL_3",
"4": "LABEL_4",
"5": "LABEL_5",
"6": "LABEL_6",
"7": "LABEL_7",
"8": "LABEL_8",
"9": "LABEL_9",
"10": "LABEL_10",
"11": "LABEL_11",
"12": "LABEL_12",
"13": "LABEL_13",
"14": "LABEL_14"
},
"initializer_range": 0.02,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1,
"LABEL_10": 10,
"LABEL_11": 11,
"LABEL_12": 12,
"LABEL_13": 13,
"LABEL_14": 14,
"LABEL_2": 2,
"LABEL_3": 3,
"LABEL_4": 4,
"LABEL_5": 5,
"LABEL_6": 6,
"LABEL_7": 7,
"LABEL_8": 8,
"LABEL_9": 9
},
"layer_norm_epsilon": 1e-05,
"max_position_embeddings": 2048,
"model_type": "falcon",
"multi_query": true,
"new_decoder_architecture": false,
"num_attention_heads": 71,
"num_hidden_layers": 2,
"num_kv_heads": 71,
"pad_token_id": 11,
"parallel_attn": true,
"problem_type": "single_label_classification",
"rope_scaling": null,
"rope_theta": 10000.0,
"torch_dtype": "float32",
"transformers_version": "4.34.0.dev0",
"use_cache": false,
"vocab_size": 65024
}
```
### Expected behavior
The error that i got after running the code is as follows:
````
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Input In [6], in <cell line: 1>()
----> 1 tokenizer = AutoTokenizer.from_pretrained(model_path)
3 pipeline = transformers.pipeline(
4 "text-classification",
5 model=model,
(...)
9 device_map="auto",
10 )
File ~/miniconda3/envs/ailab/lib/python3.8/site-packages/transformers/models/auto/tokenization_auto.py:759, in AutoTokenizer.from_pretrained(cls, pretrained_model_name_or_path, *inputs, **kwargs)
757 model_type = config_class_to_model_type(type(config).name)
758 if model_type is not None:
--> 759 tokenizer_class_py, tokenizer_class_fast = TOKENIZER_MAPPING[type(config)]
760 if tokenizer_class_fast and (use_fast or tokenizer_class_py is None):
761 return tokenizer_class_fast.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
File ~/miniconda3/envs/ailab/lib/python3.8/site-packages/transformers/models/auto/auto_factory.py:745, in _LazyAutoMapping.getitem(self, key)
743 model_name = self._model_mapping[mtype]
744 return self._load_attr_from_module(mtype, model_name)
--> 745 raise KeyError(key)
KeyError: <class 'transformers.models.falcon.configuration_falcon.FalconConfig'>
````
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26179/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26179/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26178
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26178/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26178/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26178/events
|
https://github.com/huggingface/transformers/pull/26178
| 1,897,812,853 |
PR_kwDOCUB6oc5aaI20
| 26,178 |
support megatron-lm plugin in training
|
{
"login": "xiaojunjie",
"id": 9473836,
"node_id": "MDQ6VXNlcjk0NzM4MzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9473836?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/xiaojunjie",
"html_url": "https://github.com/xiaojunjie",
"followers_url": "https://api.github.com/users/xiaojunjie/followers",
"following_url": "https://api.github.com/users/xiaojunjie/following{/other_user}",
"gists_url": "https://api.github.com/users/xiaojunjie/gists{/gist_id}",
"starred_url": "https://api.github.com/users/xiaojunjie/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/xiaojunjie/subscriptions",
"organizations_url": "https://api.github.com/users/xiaojunjie/orgs",
"repos_url": "https://api.github.com/users/xiaojunjie/repos",
"events_url": "https://api.github.com/users/xiaojunjie/events{/privacy}",
"received_events_url": "https://api.github.com/users/xiaojunjie/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Hello, yes, this is not planned."
] | 1,694 | 1,702 | 1,698 |
NONE
| null |
# What does this PR do?
Q: How to train models in trainer.py with megatron_lm_plugin?
I think there are 3 main steps that need to be done:
- support megatron-lm plugin in trainer of transformers.
- give compatible api for transformers in accelerate.
- deveplot a tool to convert checkpoint in Megatron
this pr is for the first step.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] discussed via the forum [50804](https://discuss.huggingface.co/t/how-to-run-trainer-py-with-megatron-lm-plugin/50804)
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@pacman100
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26178/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26178/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26178",
"html_url": "https://github.com/huggingface/transformers/pull/26178",
"diff_url": "https://github.com/huggingface/transformers/pull/26178.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26178.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/26177
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26177/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26177/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26177/events
|
https://github.com/huggingface/transformers/pull/26177
| 1,897,775,996 |
PR_kwDOCUB6oc5aaA0Z
| 26,177 |
[DINOv2] Convert more checkpoints
|
{
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks !"
] | 1,694 | 1,696 | 1,696 |
CONTRIBUTOR
| null |
# What does this PR do?
This PR converts the DINOv2 checkpoints of image classification on ImageNet-1k ([source](https://github.com/facebookresearch/dinov2#pretrained-heads---image-classification)).
It also improves the doc test for `Dinov2ForImageClassification`.
Fixes #26167
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26177/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26177/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26177",
"html_url": "https://github.com/huggingface/transformers/pull/26177",
"diff_url": "https://github.com/huggingface/transformers/pull/26177.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26177.patch",
"merged_at": 1696838284000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26176
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26176/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26176/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26176/events
|
https://github.com/huggingface/transformers/pull/26176
| 1,897,673,607 |
PR_kwDOCUB6oc5aZq7h
| 26,176 |
Add Auto Device Map option for BERT Models
|
{
"login": "tanaymeh",
"id": 26519539,
"node_id": "MDQ6VXNlcjI2NTE5NTM5",
"avatar_url": "https://avatars.githubusercontent.com/u/26519539?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tanaymeh",
"html_url": "https://github.com/tanaymeh",
"followers_url": "https://api.github.com/users/tanaymeh/followers",
"following_url": "https://api.github.com/users/tanaymeh/following{/other_user}",
"gists_url": "https://api.github.com/users/tanaymeh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tanaymeh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tanaymeh/subscriptions",
"organizations_url": "https://api.github.com/users/tanaymeh/orgs",
"repos_url": "https://api.github.com/users/tanaymeh/repos",
"events_url": "https://api.github.com/users/tanaymeh/events{/privacy}",
"received_events_url": "https://api.github.com/users/tanaymeh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@younesbelkada, Sure! I am travelling to London this weekend and early next week so after that I will be able to push other changes and fix this.\r\n\r\nThanks for taking time and reviewing this, I will mark the PR to be \"Ready\" once I am done making changes. Cheers!",
"Hi @younesbelkada, I am facing a rather peculiar issue. While testing my `_no_split_modules` changes to the BERT code (bert-large-cased model), I encountered an error that only seems to arise when I have the `_no_split_modules` code present (and not when it is commented out).\r\n\r\nBelow is the error:\r\n```Downloading model.safetensors: 2%|█▉ | 31.5M/1.34G [00:00<00:15, 84.1MB/s] 'classTraceback (most recent call last):\r\n File \"/root/transformers/src/test.py\", line 5, in <module>\r\n model = AutoModelForSequenceClassification.from_pretrained('bert-large-uncased', device_map='auto')\r\n File \"/root/transformers/src/transformers/models/auto/auto_factory.py\", line 563, in from_pretrained\r\n return model_class.from_pretrained(\r\n File \"/root/transformers/src/transformers/modeling_utils.py\", line 2813, in from_pretrained\r\n resolved_archive_file = cached_file(pretrained_model_name_or_path, filename, **cached_file_kwargs)\r\n File \"/root/transformers/src/transformers/utils/hub.py\", line 429, in cached_file\r\n resolved_file = hf_hub_download(\r\n File \"/opt/conda/lib/python3.10/site-packages/huggingface_hub/utils/_validators.py\", line 118, in _inner_fn\r\n return fn(*args, **kwargs)\r\n File \"/opt/conda/lib/python3.10/site-packages/huggingface_hub/file_download.py\", line 1431, in hf_hub_download\r\n http_get(\r\n File \"/opt/conda/lib/python3.10/site-packages/huggingface_hub/file_download.py\", line 557, in http_get\r\n raise EnvironmentError(\r\nOSError: Consistency check failed: file should be of size 1344951957 but has size 36775558 (model.safetensors).\r\nWe are sorry for the inconvenience. Please retry download and pass `force_download=True, resume_download=False` as argument.\r\nIf the issue persists, please let us know by opening an issue on https://github.com/huggingface/huggingface_hub.\r\n```\r\n\r\nWhat's peculiar is that, as soon as I comment out the `_no_split_modules = [\"BertEmbeddings\", \"BertSelfAttention\"]` code, the error goes away and the model downloads all fine.\r\n\r\nWhat I don't understand is the nature of this error, since it is caused when trying to download the model (and not loading it, which would've been a plausible place for the error to occur).\r\n\r\nAlso, If I download the model with `_no_split_modules` commented out and then load the model with it uncommented, the code runs perfectly fine.\r\n\r\nBelow is the test code script that I am running to test.\r\n\r\n```python\r\nimport torch\r\nimport random\r\nfrom transformers import AutoModelForSequenceClassification\r\nmodel = AutoModelForSequenceClassification.from_pretrained('bert-large-uncased', device_map='auto')\r\nprint(model(torch.tensor([[random.randint(0, 300) for x in range(512)]])))\r\n```",
"Hi @tanaymeh \r\nThanks for getting back to me, I ran \r\n\r\n```python\r\nimport torch\r\nimport random\r\nfrom transformers import AutoModelForSequenceClassification\r\nmodel = AutoModelForSequenceClassification.from_pretrained('bert-large-uncased', device_map='auto')\r\nprint(model(torch.tensor([[random.randint(0, 300) for x in range(512)]])))\r\n```\r\nwith the changes proposed in the PR and the script worked fine on my end - not sure what is happening \r\n\r\nI have also tried to run the accelerate tests and they seem to fail :/ Let me know if you need any help!",
"Hi @younesbelkada, I checked line by line and Bert and RoBERTa have almost the same exact implementations.\r\nYet, when I use the same `_no_split_modules = [\"BertEmbeddings\", \"BertSelfAttention\"]` (as used in RoBERTa), it throws multiple accelerate errors.\r\n\r\nI tried debugging but to no avail, do you suspect any potential causes?",
"Hmmm I see, what are the errors you get? Can you share the full traceback ?",
"@younesbelkada Here's the entire error log:\r\n\r\n```python\r\n============================= test session starts ==============================\r\nplatform linux -- Python 3.10.13, pytest-7.4.2, pluggy-1.0.0\r\nrootdir: /root/new/transformers\r\nconfigfile: setup.cfg\r\nplugins: hypothesis-6.87.2, anyio-4.0.0\r\ncollected 364 items / 361 deselected / 3 selected\r\n\r\ntests/models/bert/test_modeling_bert.py FFF [100%]\r\n\r\n=================================== FAILURES ===================================\r\n________________________ BertModelTest.test_cpu_offload ________________________\r\n\r\nself = <tests.models.bert.test_modeling_bert.BertModelTest testMethod=test_cpu_offload>\r\n\r\n @require_accelerate\r\n @mark.accelerate_tests\r\n @require_torch_gpu\r\n def test_cpu_offload(self):\r\n config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()\r\n \r\n for model_class in self.all_model_classes:\r\n if model_class._no_split_modules is None:\r\n continue\r\n \r\n inputs_dict_class = self._prepare_for_class(inputs_dict, model_class)\r\n model = model_class(config).eval()\r\n model = model.to(torch_device)\r\n \r\n torch.manual_seed(0)\r\n base_output = model(**inputs_dict_class)\r\n \r\n model_size = compute_module_sizes(model)[\"\"]\r\n # We test several splits of sizes to make sure it works.\r\n max_gpu_sizes = [int(p * model_size) for p in self.model_split_percents[1:]]\r\n with tempfile.TemporaryDirectory() as tmp_dir:\r\n model.cpu().save_pretrained(tmp_dir)\r\n \r\n for max_size in max_gpu_sizes:\r\n max_memory = {0: max_size, \"cpu\": model_size * 2}\r\n new_model = model_class.from_pretrained(tmp_dir, device_map=\"auto\", max_memory=max_memory)\r\n # Making sure part of the model will actually end up offloaded\r\n self.assertSetEqual(set(new_model.hf_device_map.values()), {0, \"cpu\"})\r\n \r\n> self.check_device_map_is_respected(new_model, new_model.hf_device_map)\r\n\r\ntests/test_modeling_common.py:2600: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_modeling_common.py:2529: in check_device_map_is_respected\r\n self.assertEqual(param.device, torch.device(\"meta\"))\r\nE AssertionError: device(type='cpu') != device(type='meta')\r\n----------------------------- Captured stderr call -----------------------------\r\nIf you want to use `BertLMHeadModel` as a standalone, add `is_decoder=True.`\r\nIf you want to use `BertLMHeadModel` as a standalone, add `is_decoder=True.`\r\n_______________________ BertModelTest.test_disk_offload ________________________\r\n\r\nself = <tests.models.bert.test_modeling_bert.BertModelTest testMethod=test_disk_offload>\r\n\r\n @require_accelerate\r\n @mark.accelerate_tests\r\n @require_torch_gpu\r\n def test_disk_offload(self):\r\n config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()\r\n \r\n for model_class in self.all_model_classes:\r\n if model_class._no_split_modules is None:\r\n continue\r\n \r\n inputs_dict_class = self._prepare_for_class(inputs_dict, model_class)\r\n model = model_class(config).eval()\r\n model = model.to(torch_device)\r\n torch.manual_seed(0)\r\n base_output = model(**inputs_dict_class)\r\n \r\n model_size = compute_module_sizes(model)[\"\"]\r\n with tempfile.TemporaryDirectory() as tmp_dir:\r\n model.cpu().save_pretrained(tmp_dir)\r\n \r\n with self.assertRaises(ValueError):\r\n max_size = int(self.model_split_percents[0] * model_size)\r\n max_memory = {0: max_size, \"cpu\": max_size}\r\n # This errors out cause it's missing an offload folder\r\n new_model = model_class.from_pretrained(tmp_dir, device_map=\"auto\", max_memory=max_memory)\r\n \r\n max_size = int(self.model_split_percents[1] * model_size)\r\n max_memory = {0: max_size, \"cpu\": max_size}\r\n new_model = model_class.from_pretrained(\r\n tmp_dir, device_map=\"auto\", max_memory=max_memory, offload_folder=tmp_dir\r\n )\r\n \r\n> self.check_device_map_is_respected(new_model, new_model.hf_device_map)\r\n\r\ntests/test_modeling_common.py:2565: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_modeling_common.py:2529: in check_device_map_is_respected\r\n self.assertEqual(param.device, torch.device(\"meta\"))\r\nE AssertionError: device(type='cpu') != device(type='meta')\r\n----------------------------- Captured stderr call -----------------------------\r\nIf you want to use `BertLMHeadModel` as a standalone, add `is_decoder=True.`\r\nIf you want to use `BertLMHeadModel` as a standalone, add `is_decoder=True.`\r\nIf you want to use `BertLMHeadModel` as a standalone, add `is_decoder=True.`\r\n_____________________ BertModelTest.test_model_parallelism _____________________\r\n\r\nself = <tests.models.bert.test_modeling_bert.BertModelTest testMethod=test_model_parallelism>\r\n\r\n @require_accelerate\r\n @mark.accelerate_tests\r\n @require_torch_multi_gpu\r\n def test_model_parallelism(self):\r\n config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()\r\n \r\n for model_class in self.all_model_classes:\r\n if model_class._no_split_modules is None:\r\n continue\r\n \r\n inputs_dict_class = self._prepare_for_class(inputs_dict, model_class)\r\n model = model_class(config).eval()\r\n model = model.to(torch_device)\r\n \r\n torch.manual_seed(0)\r\n base_output = model(**inputs_dict_class)\r\n \r\n model_size = compute_module_sizes(model)[\"\"]\r\n # We test several splits of sizes to make sure it works.\r\n max_gpu_sizes = [int(p * model_size) for p in self.model_split_percents[1:]]\r\n with tempfile.TemporaryDirectory() as tmp_dir:\r\n model.cpu().save_pretrained(tmp_dir)\r\n \r\n for max_size in max_gpu_sizes:\r\n max_memory = {0: max_size, 1: model_size * 2, \"cpu\": model_size * 2}\r\n new_model = model_class.from_pretrained(tmp_dir, device_map=\"auto\", max_memory=max_memory)\r\n # Making sure part of the model will actually end up offloaded\r\n> self.assertSetEqual(set(new_model.hf_device_map.values()), {0, 1})\r\nE AssertionError: Items in the second set but not the first:\r\nE 0\r\n\r\ntests/test_modeling_common.py:2634: AssertionError\r\n----------------------------- Captured stderr call -----------------------------\r\nIf you want to use `BertLMHeadModel` as a standalone, add `is_decoder=True.`\r\nIf you want to use `BertLMHeadModel` as a standalone, add `is_decoder=True.`\r\nIf you want to use `BertLMHeadModel` as a standalone, add `is_decoder=True.`\r\n=============================== warnings summary ===============================\r\n../../../opt/conda/lib/python3.10/site-packages/_pytest/config/__init__.py:1373\r\n /opt/conda/lib/python3.10/site-packages/_pytest/config/__init__.py:1373: PytestConfigWarning: Unknown config option: doctest_glob\r\n \r\n self._warn_or_fail_if_strict(f\"Unknown config option: {key}\\n\")\r\n\r\ntests/test_modeling_common.py:2746\r\n /root/new/transformers/tests/test_modeling_common.py:2746: PytestUnknownMarkWarning: Unknown pytest.mark.flash_attn_test - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/stable/how-to/mark.html\r\n @mark.flash_attn_test\r\n\r\ntests/test_modeling_common.py:2773\r\n /root/new/transformers/tests/test_modeling_common.py:2773: PytestUnknownMarkWarning: Unknown pytest.mark.flash_attn_test - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/stable/how-to/mark.html\r\n @mark.flash_attn_test\r\n\r\ntests/test_modeling_common.py:2815\r\n /root/new/transformers/tests/test_modeling_common.py:2815: PytestUnknownMarkWarning: Unknown pytest.mark.flash_attn_test - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/stable/how-to/mark.html\r\n @mark.flash_attn_test\r\n\r\ntests/test_modeling_common.py:2857\r\n /root/new/transformers/tests/test_modeling_common.py:2857: PytestUnknownMarkWarning: Unknown pytest.mark.flash_attn_test - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/stable/how-to/mark.html\r\n @mark.flash_attn_test\r\n\r\ntests/test_modeling_common.py:2894\r\n /root/new/transformers/tests/test_modeling_common.py:2894: PytestUnknownMarkWarning: Unknown pytest.mark.flash_attn_test - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/stable/how-to/mark.html\r\n @mark.flash_attn_test\r\n\r\ntests/test_modeling_common.py:2931\r\n /root/new/transformers/tests/test_modeling_common.py:2931: PytestUnknownMarkWarning: Unknown pytest.mark.flash_attn_test - is this a typo? You can register custom marks to avoid this warning - for details, see https://docs.pytest.org/en/stable/how-to/mark.html\r\n @mark.flash_attn_test\r\n\r\n../../../opt/conda/lib/python3.10/site-packages/torch/utils/cpp_extension.py:28\r\n /opt/conda/lib/python3.10/site-packages/torch/utils/cpp_extension.py:28: DeprecationWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html\r\n from pkg_resources import packaging # type: ignore[attr-defined]\r\n\r\n../../../opt/conda/lib/python3.10/site-packages/pkg_resources/__init__.py:2871\r\n../../../opt/conda/lib/python3.10/site-packages/pkg_resources/__init__.py:2871\r\n /opt/conda/lib/python3.10/site-packages/pkg_resources/__init__.py:2871: DeprecationWarning: Deprecated call to `pkg_resources.declare_namespace('ruamel')`.\r\n Implementing implicit namespace packages (as specified in PEP 420) is preferred to `pkg_resources.declare_namespace`. See https://setuptools.pypa.io/en/latest/references/keywords.html#keyword-namespace-packages\r\n declare_namespace(pkg)\r\n\r\n-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html\r\n=========================== short test summary info ============================\r\nFAILED tests/models/bert/test_modeling_bert.py::BertModelTest::test_cpu_offload\r\nFAILED tests/models/bert/test_modeling_bert.py::BertModelTest::test_disk_offload\r\nFAILED tests/models/bert/test_modeling_bert.py::BertModelTest::test_model_parallelism\r\n================ 3 failed, 361 deselected, 10 warnings in 5.16s ================\r\n```",
"Hi @younesbelkada, have you found any updates on the issue?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Hi @amyeroberts!\r\nPerhaps you may have some update or possible direction to proceed with this?\r\n\r\nThanks!",
"@tanaymeh The failures of these tests indicate that the model weights aren't being distributed across devices as expected e.g. for `tests/models/bert/test_modeling_bert.py::BertModelTest::test_model_parallelism` it's expected that the model will be across two devices. To resolve it's a case of dropping into the test to inspect where there differences are and modifying `_no_split_modules` to see how to get the tests to pass e.g. for `test_cpu_offload` - which `param` is raising the assertion?\r\n\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"seeing error. Please help here\r\n\r\nValueError: BertLMHeadModel does not support `device_map='auto'`. To implement support, the model class needs to implement the `_no_split_modules` attribute.",
"Hi @bp020108, you're seeing this error as `device_map=\"auto\"` isn't supported for bert yet. This PR was closed and not merged in. If you'd like to add this support for BERT, you or anyone else in the community is welcome to open a PR to add this. "
] | 1,694 | 1,708 | 1,702 |
CONTRIBUTOR
| null |
# What does this PR do?
This PR adds the `'device_map': "auto"` functionality for BERT Models for ease in multi-GPU training.
Fixes #25296
## Who can review?
@younesbelkada
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26176/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26176/timeline
| null | true |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26176",
"html_url": "https://github.com/huggingface/transformers/pull/26176",
"diff_url": "https://github.com/huggingface/transformers/pull/26176.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26176.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/26175
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26175/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26175/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26175/events
|
https://github.com/huggingface/transformers/pull/26175
| 1,897,623,648 |
PR_kwDOCUB6oc5aZhJZ
| 26,175 |
Fix no_grad when using AdaFactor out of transformers.
|
{
"login": "richarddwang",
"id": 17963619,
"node_id": "MDQ6VXNlcjE3OTYzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/17963619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/richarddwang",
"html_url": "https://github.com/richarddwang",
"followers_url": "https://api.github.com/users/richarddwang/followers",
"following_url": "https://api.github.com/users/richarddwang/following{/other_user}",
"gists_url": "https://api.github.com/users/richarddwang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/richarddwang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/richarddwang/subscriptions",
"organizations_url": "https://api.github.com/users/richarddwang/orgs",
"repos_url": "https://api.github.com/users/richarddwang/repos",
"events_url": "https://api.github.com/users/richarddwang/events{/privacy}",
"received_events_url": "https://api.github.com/users/richarddwang/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,694 | 1,698 | 1,698 |
NONE
| null |
When using `transformers.optimization.AdaFactor` with my own code not using `Trainer`, autograd will say there is no grad to backprop.
I believe it might work well with `Trainer`, but this simple and small fix makes it more useful.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26175/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26175/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26175",
"html_url": "https://github.com/huggingface/transformers/pull/26175",
"diff_url": "https://github.com/huggingface/transformers/pull/26175.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26175.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/26174
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26174/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26174/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26174/events
|
https://github.com/huggingface/transformers/issues/26174
| 1,897,559,482 |
I_kwDOCUB6oc5xGnW6
| 26,174 |
Wrong shape of hidden_states and attentions when generating
|
{
"login": "wywyWang",
"id": 37433002,
"node_id": "MDQ6VXNlcjM3NDMzMDAy",
"avatar_url": "https://avatars.githubusercontent.com/u/37433002?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wywyWang",
"html_url": "https://github.com/wywyWang",
"followers_url": "https://api.github.com/users/wywyWang/followers",
"following_url": "https://api.github.com/users/wywyWang/following{/other_user}",
"gists_url": "https://api.github.com/users/wywyWang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wywyWang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wywyWang/subscriptions",
"organizations_url": "https://api.github.com/users/wywyWang/orgs",
"repos_url": "https://api.github.com/users/wywyWang/repos",
"events_url": "https://api.github.com/users/wywyWang/events{/privacy}",
"received_events_url": "https://api.github.com/users/wywyWang/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey @wywyWang, I'm not sure the implementation is wrong. The documentation says the following for `attentions`: \r\n\r\n> Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of torch.FloatTensor of shape (batch_size, num_heads, generated_length, sequence_length).\r\n\r\nIf we print the intermediary values, this is what we get:\r\n\r\n```py\r\nfrom transformers import AutoModelForCausalLM, AutoTokenizer\r\npath = \"gpt2\"\r\ntokenizer = AutoTokenizer.from_pretrained(path)\r\nmodel = AutoModelForCausalLM.from_pretrained(path)\r\nprompt = \"Hey, are you conscious?\"\r\ninputs = tokenizer.encode(prompt, return_tensors=\"pt\")\r\n\r\noutput_sequences = model.generate(input_ids=inputs, max_length=30, output_attentions=True, output_hidden_states=True, return_dict_in_generate=True)\r\n\r\nfor generated_token_index, attention in enumerate(output_sequences.attentions):\r\n for i, decoder_element in enumerate(attention):\r\n print(f\"Generated token index: {generated_token_index}, decoder element {i} shape: {decoder_element.shape}\")\r\n```\r\n\r\n```\r\nGenerated token index: 0, shape: torch.Size([1, 12, 6, 6])\r\nGenerated token index: 1, shape: torch.Size([1, 12, 1, 7])\r\nGenerated token index: 2, shape: torch.Size([1, 12, 1, 8])\r\nGenerated token index: 3, shape: torch.Size([1, 12, 1, 9])\r\nGenerated token index: 4, shape: torch.Size([1, 12, 1, 10])\r\nGenerated token index: 5, shape: torch.Size([1, 12, 1, 11])\r\nGenerated token index: 6, shape: torch.Size([1, 12, 1, 12])\r\nGenerated token index: 7, shape: torch.Size([1, 12, 1, 13])\r\nGenerated token index: 8, shape: torch.Size([1, 12, 1, 14])\r\nGenerated token index: 9, shape: torch.Size([1, 12, 1, 15])\r\nGenerated token index: 10, shape: torch.Size([1, 12, 1, 16])\r\nGenerated token index: 11, shape: torch.Size([1, 12, 1, 17])\r\nGenerated token index: 12, shape: torch.Size([1, 12, 1, 18])\r\nGenerated token index: 13, shape: torch.Size([1, 12, 1, 19])\r\nGenerated token index: 14, shape: torch.Size([1, 12, 1, 20])\r\nGenerated token index: 15, shape: torch.Size([1, 12, 1, 21])\r\nGenerated token index: 16, shape: torch.Size([1, 12, 1, 22])\r\nGenerated token index: 17, shape: torch.Size([1, 12, 1, 23])\r\nGenerated token index: 18, shape: torch.Size([1, 12, 1, 24])\r\nGenerated token index: 19, shape: torch.Size([1, 12, 1, 25])\r\nGenerated token index: 20, shape: torch.Size([1, 12, 1, 26])\r\nGenerated token index: 21, shape: torch.Size([1, 12, 1, 27])\r\nGenerated token index: 22, shape: torch.Size([1, 12, 1, 28])\r\nGenerated token index: 23, shape: torch.Size([1, 12, 1, 29])\r\n```\r\n\r\nHere we see that:\r\n- `batch_size` is equal to 1 all the time, which seems good\r\n- `num_heads` is equal to 12 all the time, which also seems good\r\n- `generated_length` starts with 6 because that is the initial sequence passed through. It then drops to 1 as the model generates one token at a time, re-using past key values for the previous tokens.\r\n- `sequence_length` starts with 6, and then continues to update itself up until when it reaches the end of the generation.\r\n\r\nOut of curiosity I passed an explicit `use_cache=False` value to the `generate` method so that it does not leverage past key-values caching, therefore having the attention attend to all tokens at each forward pass:\r\n\r\n```py\r\nfrom transformers import AutoModelForCausalLM, AutoTokenizer\r\npath = \"gpt2\"\r\ntokenizer = AutoTokenizer.from_pretrained(path)\r\nmodel = AutoModelForCausalLM.from_pretrained(path)\r\nprompt = \"Hey, are you conscious?\"\r\ninputs = tokenizer.encode(prompt, return_tensors=\"pt\")\r\n\r\noutput_sequences = model.generate(input_ids=inputs, max_length=30, output_attentions=True, output_hidden_states=True, return_dict_in_generate=True, use_cache=False)\r\n\r\nfor generated_token_index, attention in enumerate(output_sequences.attentions):\r\n decoder_element = attention[0]\r\n print(f\"Generated token index: {generated_token_index}, shape: {decoder_element.shape}\")\r\n```\r\n\r\n```\r\nGenerated token index: 0, shape: torch.Size([1, 12, 6, 6])\r\nGenerated token index: 1, shape: torch.Size([1, 12, 7, 7])\r\nGenerated token index: 2, shape: torch.Size([1, 12, 8, 8])\r\nGenerated token index: 3, shape: torch.Size([1, 12, 9, 9])\r\nGenerated token index: 4, shape: torch.Size([1, 12, 10, 10])\r\nGenerated token index: 5, shape: torch.Size([1, 12, 11, 11])\r\nGenerated token index: 6, shape: torch.Size([1, 12, 12, 12])\r\nGenerated token index: 7, shape: torch.Size([1, 12, 13, 13])\r\nGenerated token index: 8, shape: torch.Size([1, 12, 14, 14])\r\nGenerated token index: 9, shape: torch.Size([1, 12, 15, 15])\r\nGenerated token index: 10, shape: torch.Size([1, 12, 16, 16])\r\nGenerated token index: 11, shape: torch.Size([1, 12, 17, 17])\r\nGenerated token index: 12, shape: torch.Size([1, 12, 18, 18])\r\nGenerated token index: 13, shape: torch.Size([1, 12, 19, 19])\r\nGenerated token index: 14, shape: torch.Size([1, 12, 20, 20])\r\nGenerated token index: 15, shape: torch.Size([1, 12, 21, 21])\r\nGenerated token index: 16, shape: torch.Size([1, 12, 22, 22])\r\nGenerated token index: 17, shape: torch.Size([1, 12, 23, 23])\r\nGenerated token index: 18, shape: torch.Size([1, 12, 24, 24])\r\nGenerated token index: 19, shape: torch.Size([1, 12, 25, 25])\r\nGenerated token index: 20, shape: torch.Size([1, 12, 26, 26])\r\nGenerated token index: 21, shape: torch.Size([1, 12, 27, 27])\r\nGenerated token index: 22, shape: torch.Size([1, 12, 28, 28])\r\nGenerated token index: 23, shape: torch.Size([1, 12, 29, 29])\r\n```\r\n\r\nWe do verify that it does indeed return have a `generated_length` corresponding to all tokens generated without past leveraging of the past key values.\r\n\r\nI'll let @gante comment on whether this is correct or not when back from leave, but the implementation does not seem to be wrong to me.",
"Hey @wywyWang 👋 \r\n\r\nI confirm everything written in the comment above :)",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,694 | 1,700 | 1,700 |
NONE
| null |
### System Info
- `transformers` version: 4.33.0
- Platform: Windows-10-10.0.22621-SP0
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1 (False)
### Who can help?
@stevhliu, @MKhalusova, @gante
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I would like to get the attentions of the generated tokens using llama. The document of [[GreedySearchDecoderOnlyOutput](https://huggingface.co/docs/transformers/v4.33.0/en/internal/generation_utils#transformers.generation.GreedySearchDecoderOnlyOutput)](https://huggingface.co/docs/transformers/internal/generation_utils#transformers.generation.SampleDecoderOnlyOutput) says that the size of attentions is (num_return_sequences, batch_size, num_heads, **generated_length**, sequence_length) and the size of hidden states is (num_return_sequences, batch_size, **generated_length**, hidden_size) (ignore the tuples for simplicity). Here the `sequence_length` is the input length of prompt. I thought it might be input_len + generated_len, but the size I printed only contained input_len.
I used the provided example of llama but the size of attention is (num_return_sequences, batch_size, num_heads, **sequence_length**, sequence_length) and the size of hidden states is (num_return_sequences, batch_size, **sequence_length**, hidden_size). I also tried GPT-2 but also got the same behaviors. I am not sure if I missed anything to get the expected results. Thank you.
```python
from transformers import LlamaForCausalLM, LlamaTokenizer
path = "src/llama-2-7b-chat-hf"
tokenizer = LlamaTokenizer.from_pretrained(path)
model = LlamaForCausalLM.from_pretrained(path)
prompt = "Hey, are you conscious? Can you talk to me?"
inputs = tokenizer.encode(prompt, return_tensors="pt")
output_sequences = model.generate(input_ids=inputs, max_length=30, output_attentions=True, output_hidden_states=True, return_dict_in_generate=True)
print(output_sequences.attentions)
print(output_sequences.hidden_states)
```
### Expected behavior
Attention: (num_return_sequences, batch_size, num_heads, **generated_length**, sequence_length)
Hidden states: (num_return_sequences, batch_size, **generated_length**, hidden_size)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26174/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26174/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26173
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26173/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26173/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26173/events
|
https://github.com/huggingface/transformers/issues/26173
| 1,897,556,205 |
I_kwDOCUB6oc5xGmjt
| 26,173 |
`Some weights of GPT2LMHeadModel were not initialized` when specifying `device_map=torch.device("cpu")`
|
{
"login": "samuela",
"id": 226872,
"node_id": "MDQ6VXNlcjIyNjg3Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/226872?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/samuela",
"html_url": "https://github.com/samuela",
"followers_url": "https://api.github.com/users/samuela/followers",
"following_url": "https://api.github.com/users/samuela/following{/other_user}",
"gists_url": "https://api.github.com/users/samuela/gists{/gist_id}",
"starred_url": "https://api.github.com/users/samuela/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/samuela/subscriptions",
"organizations_url": "https://api.github.com/users/samuela/orgs",
"repos_url": "https://api.github.com/users/samuela/repos",
"events_url": "https://api.github.com/users/samuela/events{/privacy}",
"received_events_url": "https://api.github.com/users/samuela/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"When we look at how GPT-2 is pretrained, we find it consists of a stack of decoders and an LM head (a linear layer and softmax) on top of this stack. When GPT-2 is saved as a pretrained model, typically only the weights for the decoders are saved.\r\n\r\nSo, when we initialize a model like `GPT2LMHeadModel`, which includes both the decoders and the LM head, the decoders get initialized with their pretrained weights, but the LM head is initialized with brand new, randomly initialized weights. This is why you might see a warning message at times during this initialization process.\r\n\r\nHope it helps. ",
"Hi @shahad-mahmud, thanks for your response. Perhaps I'm revealing my ignorance of gpt2's internals here, but isn't the \"LM head\" -- with linear layer and softmax -- necessary for using gpt2 as a causal language model, and in particular doing text generation?",
"Yes you indeed need the weights for the LM head for text generation and for this you have to fine-tune the `GPT2LMHeadModel` at first. Then using this fine-tuned model you can accomplish the text generation task.\r\n\r\nLet's investigate this a bit more.\r\n\r\n## The raw weights\r\n\r\nAt first we will download the GPT-2 pretrained weights and investigate which parameters it contain utilizing the following code:\r\n\r\n1. Download the weights.\r\n\r\n```bash\r\nwget https://huggingface.co/gpt2/resolve/main/pytorch_model.bin\r\n```\r\n\r\n2. Load the weights and look at the keys.\r\n\r\n```python\r\nimport torch\r\n\r\ngpt2_weights = torch.load('pytorch_model.bin')\r\nprint(gpt2_weights.keys())\r\n```\r\n\r\nIt will print the following keys:\r\n\r\n```bash\r\nodict_keys(['wte.weight', 'wpe.weight', 'h.0.ln_1.weight', 'h.0.ln_1.bias', 'h.0.attn.bias', 'h.0.attn.c_attn.weight', 'h.0.attn.c_attn.bias', 'h.0.attn.c_proj.weight', 'h.0.attn.c_proj.bias', 'h.0.ln_2.weight', 'h.0.ln_2.bias', 'h.0.mlp.c_fc.weight', 'h.0.mlp.c_fc.bias', 'h.0.mlp.c_proj.weight', 'h.0.mlp.c_proj.bias', 'h.1.ln_1.weight', 'h.1.ln_1.bias', 'h.1.attn.bias', 'h.1.attn.c_attn.weight', 'h.1.attn.c_attn.bias', 'h.1.attn.c_proj.weight', 'h.1.attn.c_proj.bias', 'h.1.ln_2.weight', 'h.1.ln_2.bias', 'h.1.mlp.c_fc.weight', 'h.1.mlp.c_fc.bias', 'h.1.mlp.c_proj.weight', 'h.1.mlp.c_proj.bias', 'h.2.ln_1.weight', 'h.2.ln_1.bias', 'h.2.attn.bias', 'h.2.attn.c_attn.weight', 'h.2.attn.c_attn.bias', 'h.2.attn.c_proj.weight', 'h.2.attn.c_proj.bias', 'h.2.ln_2.weight', 'h.2.ln_2.bias', 'h.2.mlp.c_fc.weight', 'h.2.mlp.c_fc.bias', 'h.2.mlp.c_proj.weight', 'h.2.mlp.c_proj.bias', 'h.3.ln_1.weight', 'h.3.ln_1.bias', 'h.3.attn.bias', 'h.3.attn.c_attn.weight', 'h.3.attn.c_attn.bias', 'h.3.attn.c_proj.weight', 'h.3.attn.c_proj.bias', 'h.3.ln_2.weight', 'h.3.ln_2.bias', 'h.3.mlp.c_fc.weight', 'h.3.mlp.c_fc.bias', 'h.3.mlp.c_proj.weight', 'h.3.mlp.c_proj.bias', 'h.4.ln_1.weight', 'h.4.ln_1.bias', 'h.4.attn.bias', 'h.4.attn.c_attn.weight', 'h.4.attn.c_attn.bias', 'h.4.attn.c_proj.weight', 'h.4.attn.c_proj.bias', 'h.4.ln_2.weight', 'h.4.ln_2.bias', 'h.4.mlp.c_fc.weight', 'h.4.mlp.c_fc.bias', 'h.4.mlp.c_proj.weight', 'h.4.mlp.c_proj.bias', 'h.5.ln_1.weight', 'h.5.ln_1.bias', 'h.5.attn.bias', 'h.5.attn.c_attn.weight', 'h.5.attn.c_attn.bias', 'h.5.attn.c_proj.weight', 'h.5.attn.c_proj.bias', 'h.5.ln_2.weight', 'h.5.ln_2.bias', 'h.5.mlp.c_fc.weight', 'h.5.mlp.c_fc.bias', 'h.5.mlp.c_proj.weight', 'h.5.mlp.c_proj.bias', 'h.6.ln_1.weight', 'h.6.ln_1.bias', 'h.6.attn.bias', 'h.6.attn.c_attn.weight', 'h.6.attn.c_attn.bias', 'h.6.attn.c_proj.weight', 'h.6.attn.c_proj.bias', 'h.6.ln_2.weight', 'h.6.ln_2.bias', 'h.6.mlp.c_fc.weight', 'h.6.mlp.c_fc.bias', 'h.6.mlp.c_proj.weight', 'h.6.mlp.c_proj.bias', 'h.7.ln_1.weight', 'h.7.ln_1.bias', 'h.7.attn.bias', 'h.7.attn.c_attn.weight', 'h.7.attn.c_attn.bias', 'h.7.attn.c_proj.weight', 'h.7.attn.c_proj.bias', 'h.7.ln_2.weight', 'h.7.ln_2.bias', 'h.7.mlp.c_fc.weight', 'h.7.mlp.c_fc.bias', 'h.7.mlp.c_proj.weight', 'h.7.mlp.c_proj.bias', 'h.8.ln_1.weight', 'h.8.ln_1.bias', 'h.8.attn.bias', 'h.8.attn.c_attn.weight', 'h.8.attn.c_attn.bias', 'h.8.attn.c_proj.weight', 'h.8.attn.c_proj.bias', 'h.8.ln_2.weight', 'h.8.ln_2.bias', 'h.8.mlp.c_fc.weight', 'h.8.mlp.c_fc.bias', 'h.8.mlp.c_proj.weight', 'h.8.mlp.c_proj.bias', 'h.9.ln_1.weight', 'h.9.ln_1.bias', 'h.9.attn.bias', 'h.9.attn.c_attn.weight', 'h.9.attn.c_attn.bias', 'h.9.attn.c_proj.weight', 'h.9.attn.c_proj.bias', 'h.9.ln_2.weight', 'h.9.ln_2.bias', 'h.9.mlp.c_fc.weight', 'h.9.mlp.c_fc.bias', 'h.9.mlp.c_proj.weight', 'h.9.mlp.c_proj.bias', 'h.10.ln_1.weight', 'h.10.ln_1.bias', 'h.10.attn.bias', 'h.10.attn.c_attn.weight', 'h.10.attn.c_attn.bias', 'h.10.attn.c_proj.weight', 'h.10.attn.c_proj.bias', 'h.10.ln_2.weight', 'h.10.ln_2.bias', 'h.10.mlp.c_fc.weight', 'h.10.mlp.c_fc.bias', 'h.10.mlp.c_proj.weight', 'h.10.mlp.c_proj.bias', 'h.11.ln_1.weight', 'h.11.ln_1.bias', 'h.11.attn.bias', 'h.11.attn.c_attn.weight', 'h.11.attn.c_attn.bias', 'h.11.attn.c_proj.weight', 'h.11.attn.c_proj.bias', 'h.11.ln_2.weight', 'h.11.ln_2.bias', 'h.11.mlp.c_fc.weight', 'h.11.mlp.c_fc.bias', 'h.11.mlp.c_proj.weight', 'h.11.mlp.c_proj.bias', 'ln_f.weight', 'ln_f.bias'])\r\n```\r\n\r\nHere `wte` and `wpe` are weights for word embeddings and positional embeddings respectively. All weights starting with `h` are the decoder blocks. There are 12 of them (0 to 11). Finally `ln_f` is the weights for the linear layer after the decoders.\r\n\r\n## Model Modules\r\n\r\nNow let's look which modules the `GPT2Model` and `GPT2LMHeadModel` contains.\r\n\r\n### `GPT2Model` modules\r\n\r\n```python\r\nimport transformers\r\n\r\ngpt2_configs = transformers.AutoConfig.from_pretrained('gpt2')\r\ngpt2 = transformers.GPT2Model(gpt2_configs)\r\n\r\nprint(vars(gpt2)['_modules'])\r\n```\r\n\r\nExecuting it, you will get the following modules.\r\n\r\n```bash\r\nOrderedDict([('wte', Embedding(50257, 768)), ('wpe', Embedding(1024, 768)), ('drop', Dropout(p=0.1, inplace=False)), ('h', ModuleList(\r\n (0-11): 12 x GPT2Block(\r\n (ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)\r\n (attn): GPT2Attention(\r\n (c_attn): Conv1D()\r\n (c_proj): Conv1D()\r\n (attn_dropout): Dropout(p=0.1, inplace=False)\r\n (resid_dropout): Dropout(p=0.1, inplace=False)\r\n )\r\n (ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)\r\n (mlp): GPT2MLP(\r\n (c_fc): Conv1D()\r\n (c_proj): Conv1D()\r\n (act): NewGELUActivation()\r\n (dropout): Dropout(p=0.1, inplace=False)\r\n )\r\n )\r\n)), ('ln_f', LayerNorm((768,), eps=1e-05, elementwise_affine=True))])\r\n```\r\n\r\nThese modules are exactly same as the saved weights in the `pytorch_model.bin` file.\r\n\r\n### `GPT2LMHeadModel` modules\r\n\r\n```python\r\nimport transformers\r\n\r\ngpt2_configs = transformers.AutoConfig.from_pretrained('gpt2')\r\ngpt2_lm = transformers.GPT2LMHeadModel(gpt2_configs)\r\n\r\nprint(vars(gpt2_lm)['_modules'])\r\n```\r\n\r\n```bash\r\nOrderedDict([('transformer', GPT2Model(\r\n (wte): Embedding(50257, 768)\r\n (wpe): Embedding(1024, 768)\r\n (drop): Dropout(p=0.1, inplace=False)\r\n (h): ModuleList(\r\n (0-11): 12 x GPT2Block(\r\n (ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)\r\n (attn): GPT2Attention(\r\n (c_attn): Conv1D()\r\n (c_proj): Conv1D()\r\n (attn_dropout): Dropout(p=0.1, inplace=False)\r\n (resid_dropout): Dropout(p=0.1, inplace=False)\r\n )\r\n (ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)\r\n (mlp): GPT2MLP(\r\n (c_fc): Conv1D()\r\n (c_proj): Conv1D()\r\n (act): NewGELUActivation()\r\n (dropout): Dropout(p=0.1, inplace=False)\r\n )\r\n )\r\n )\r\n (ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True)\r\n)), ('lm_head', Linear(in_features=768, out_features=50257, bias=False))])\r\n```\r\n\r\nSo, it has the same modules like `GPT2Model` plus the modules for `lm_head`. But there is no saved weights for this `lm_head` in the `pytorch_model.bin` file. So, you have to fine-tune your `GPT2LMHeadModel` for the text generation. Here is a tutorial from Hugging Face on text generation fine-tuning using GPT-2: https://huggingface.co/learn/nlp-course/chapter7/6\r\n\r\nHope it helps. Thank you @samuela. \r\n",
"Hey both! Thanks for opening the issue. It seems to me that you are just not using the latest release as I can' t reproduce this. \r\nThe model on the hub includes no `lm_head` weights as they are most probably tied ( meaning that the lm_head weights are the transposed version of the embedding tokens",
"Roger that, I'll try updating to latest and see if I can repro.",
"Just tried on 4.33.2 and the issue is gone, thanks @ArthurZucker !"
] | 1,694 | 1,694 | 1,694 |
NONE
| null |
### System Info
Running
```py
AutoModelForCausalLM.from_pretrained("gpt2")
```
works for me without issue.
Running
```py
AutoModelForCausalLM.from_pretrained("gpt2", device_map=torch.device("cpu"))
```
which to should presumably do the exact same thing, gives me a warning:
```
Some weights of GPT2LMHeadModel were not initialized from the model checkpoint at gpt2 and are newly initialized: ['lm_head.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
Why does specifying `device_map=` result in this warning/error? I'm seeing the same thing with `device_map=torch.device("cuda")` as well.
I'm using torch 2.0.1 and transformers 4.31.0.
### Who can help?
@ArthurZucker and @younesbelkada
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Create a shell.nix file with the following contents:
```nix
let
# Last updated: 2023-09-14. Check for new commits at https://status.nixos.org.
pkgs = import (fetchTarball "https://github.com/NixOS/nixpkgs/archive/1697b7d480449b01111e352021f46e5879e47643.tar.gz") {
config.allowUnfree = true;
config.cudaSupport = true;
};
in
pkgs.mkShell {
buildInputs = with pkgs; [
python3
python3Packages.accelerate
python3Packages.torch-bin
python3Packages.transformers
];
}
```
Then run `nix-shell` followed by `python3 -c "import torch; from transformers import AutoModelForCausalLM; AutoModelForCausalLM.from_pretrained('gpt2', device_map=torch.device('cpu'))"`.
### Expected behavior
`device_map` to not result in missing weights warnings. `device_map=torch.device("cpu")` should behave the same as the default behavior.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26173/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26173/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26172
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26172/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26172/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26172/events
|
https://github.com/huggingface/transformers/pull/26172
| 1,897,454,004 |
PR_kwDOCUB6oc5aY9fI
| 26,172 |
Add FastViT model
|
{
"login": "JorgeAV-ai",
"id": 32791438,
"node_id": "MDQ6VXNlcjMyNzkxNDM4",
"avatar_url": "https://avatars.githubusercontent.com/u/32791438?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JorgeAV-ai",
"html_url": "https://github.com/JorgeAV-ai",
"followers_url": "https://api.github.com/users/JorgeAV-ai/followers",
"following_url": "https://api.github.com/users/JorgeAV-ai/following{/other_user}",
"gists_url": "https://api.github.com/users/JorgeAV-ai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JorgeAV-ai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JorgeAV-ai/subscriptions",
"organizations_url": "https://api.github.com/users/JorgeAV-ai/orgs",
"repos_url": "https://api.github.com/users/JorgeAV-ai/repos",
"events_url": "https://api.github.com/users/JorgeAV-ai/events{/privacy}",
"received_events_url": "https://api.github.com/users/JorgeAV-ai/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @rafaelpadilla 😉 to keep your eyes on this! ",
"Small ping here, sorry if this is a bad time for pinging you, i am going to collect some of the doubts that have arisen during this days applying the model structure:\r\n\r\n1. This model is characterized by having a different training-test infrastructure, are any other model applied inside of huggingface with this 'feature'? I would like to have a reference but i did not find any model with this 'special feature' (As a quick explanation, basically they train with all the batchnorms + residual connections, once is trained, for inference they restructure the weights, deleting norms + residual connections and some convolutions)\r\n2. The question about the ImageProcessor has not been solved yet, i am going to formulate it again. I am using ViTImageProcessor to avoid repeat the same code, the unique difference is the image size, by default in ViTImageProcessor is 224 and for FastViT is 256, Should I add a \"FastViTImageProcessor\"? The idea is to keep the code as clear as possible and at the same time as readable as possible, in my opinion is not worth it but i will let you guys decide 👍 .\r\n\r\nThank you so much for your time \r\nPing @ArthurZucker @rafaelpadilla\r\nAnd I am going to ping @NielsRogge , I am pretty sure he can clarify some of the doubts 😊 ",
"Hey! \r\n1. I am not really sure, but I think the most important is to add support for inference rather than training, especially if they have a very complicated training pipeline, let's just go with inference. \r\n2. No, you should be able to change the image size when pushing a ` ViTImageProcessor` to the hub! No need for a new model if something can be controlled from a configuration/init argument. ",
"Hi @JorgeAV-ai regarding creating an image processor: it's pretty important to make sure that the image processor in HF Transformers creates the exact same pixel values as the ones created in the original implementation. Just using ViTImageProcessor will probably result in slightly different pixel_values. Things to be taken into account are the image mean/std when normalizing, whether padding/resizing/center cropping is applied, etc. \r\n\r\nSee [here](https://github.com/huggingface/transformers/blob/408b2b3c5057b275855ae4c43c452a7f0b37aa45/src/transformers/models/nougat/convert_nougat_to_hf.py#L179-L183) for an example how we check that both match.",
"Thanks for the help, the PR is now ready for review. I noticed the reviewer for this PR is @rafaelpadilla , so any feedback would be greatly appreciated 😁",
"I added some questions above. I also noticed that some of your comments might be related to an outdated code. Would you mind taking a look again? Thanks 😊",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Hi @JorgeAV-ai are you planning to work further on this PR?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,694 | 1,702 | 1,702 |
NONE
| null |
# What does this PR do?
Fixes #25526
I have seen that the PR is still open and still no PR has been submitted during these weeks so I have decided to open mine once I finish the model structure + testing
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
cc: @amyeroberts
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26172/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26172/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26172",
"html_url": "https://github.com/huggingface/transformers/pull/26172",
"diff_url": "https://github.com/huggingface/transformers/pull/26172.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26172.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/26171
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26171/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26171/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26171/events
|
https://github.com/huggingface/transformers/issues/26171
| 1,897,323,604 |
I_kwDOCUB6oc5xFtxU
| 26,171 |
Training model from checkpoint with adamw_torch_fused
|
{
"login": "bhperry",
"id": 11621797,
"node_id": "MDQ6VXNlcjExNjIxNzk3",
"avatar_url": "https://avatars.githubusercontent.com/u/11621797?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bhperry",
"html_url": "https://github.com/bhperry",
"followers_url": "https://api.github.com/users/bhperry/followers",
"following_url": "https://api.github.com/users/bhperry/following{/other_user}",
"gists_url": "https://api.github.com/users/bhperry/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bhperry/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bhperry/subscriptions",
"organizations_url": "https://api.github.com/users/bhperry/orgs",
"repos_url": "https://api.github.com/users/bhperry/repos",
"events_url": "https://api.github.com/users/bhperry/events{/privacy}",
"received_events_url": "https://api.github.com/users/bhperry/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"This thread seems potentially relevant https://discuss.pytorch.org/t/loading-a-model-runtimeerror-expected-all-tensors-to-be-on-the-same-device-but-found-at-least-two-devices-cuda-0-and-cpu/143897\r\n\r\nGuessing there's just something missing when re-loading the fused optimizer.",
"I'm pretty sure this is expected, but will ping @pacman100 for his insight! ",
"> This thread seems potentially relevant https://discuss.pytorch.org/t/loading-a-model-runtimeerror-expected-all-tensors-to-be-on-the-same-device-but-found-at-least-two-devices-cuda-0-and-cpu/143897\r\n\r\n> Guessing there's just something missing when re-loading the fused optimizer.\r\n\r\nHello, yes, that seems to be the case. Maybe, try passing the model loaded on the correct device to the Trainer as per the discussion in the above link you shared.",
"Model is loaded to the correct device, my understanding from the thread is that the optimizer is not loaded correctly. Thought the trainer would be able to figure that out based on the TrainingArguments, but I guess the answer is to load the optimizer manually when using fused.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,694 | 1,699 | 1,699 |
NONE
| null |
### System Info
- `transformers` version: 4.33.1
- Platform: Linux-5.4.253-167.359.amzn2.x86_64-x86_64-with-glibc2.35
- Python version: 3.9.18
- Huggingface_hub version: 0.17.1
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
1. Create a transformers Trainer and TrainingArguments with ` optim="adamw_torch_fused"`
2. To quickly reproduce, set `save_strategy="steps"` and `save_steps=1`
3. Run training script until at least the first step is completed, then cancel
4. Run training again with `trainer.train(resume_from_checkpoint=True)`
```Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:48<00:00, 24.08s/it]
trainable params: 4,194,304 || all params: 6,742,609,920 || trainable%: 0.06220594176090199
0%| | 0/38523 [00:32<?, ?it/s]
Traceback (most recent call last): | 0/77049 [00:00<?, ?it/s]
File "/home/jovyan/workspace/llm/llm/training/training.py", line 150, in <module>
tune()
File "/home/jovyan/workspace/llm/llm/training/training.py", line 136, in tune
trainer.train(resume_from_checkpoint=RESUME_FROM_CHECKPOINT and has_checkpoint(output_dir))
File "/opt/saturncloud/envs/saturn/lib/python3.9/site-packages/transformers/trainer.py", line 1553, in train
return inner_training_loop(
File "/opt/saturncloud/envs/saturn/lib/python3.9/site-packages/accelerate/utils/memory.py", line 136, in decorator
return function(batch_size, *args, **kwargs)
File "/opt/saturncloud/envs/saturn/lib/python3.9/site-packages/transformers/trainer.py", line 1914, in _inner_training_loop
self.optimizer.step()
File "/opt/saturncloud/envs/saturn/lib/python3.9/site-packages/torch/optim/lr_scheduler.py", line 69, in wrapper
return wrapped(*args, **kwargs)
File "/opt/saturncloud/envs/saturn/lib/python3.9/site-packages/accelerate/optimizer.py", line 145, in step
self.optimizer.step(closure)
File "/opt/saturncloud/envs/saturn/lib/python3.9/site-packages/torch/optim/lr_scheduler.py", line 69, in wrapper
return wrapped(*args, **kwargs)
File "/opt/saturncloud/envs/saturn/lib/python3.9/site-packages/torch/optim/optimizer.py", line 280, in wrapper
out = func(*args, **kwargs)
File "/opt/saturncloud/envs/saturn/lib/python3.9/site-packages/torch/optim/optimizer.py", line 33, in _use_grad
ret = func(self, *args, **kwargs)
File "/opt/saturncloud/envs/saturn/lib/python3.9/site-packages/torch/optim/adamw.py", line 171, in step
adamw(
File "/opt/saturncloud/envs/saturn/lib/python3.9/site-packages/torch/optim/adamw.py", line 321, in adamw
func(
File "/opt/saturncloud/envs/saturn/lib/python3.9/site-packages/torch/optim/adamw.py", line 615, in _fused_adamw
torch._fused_adamw_(
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument state_steps in method wrapper_CUDA___fused_adamw_)
```
### Expected behavior
Expected to be able to resume training when using adamw_torch_fused optimizer. This works fine with adamw_torch optimizer.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26171/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/26171/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26170
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26170/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26170/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26170/events
|
https://github.com/huggingface/transformers/pull/26170
| 1,897,283,373 |
PR_kwDOCUB6oc5aYXtW
| 26,170 |
Add Phi-1 and Phi-1_5
|
{
"login": "susnato",
"id": 56069179,
"node_id": "MDQ6VXNlcjU2MDY5MTc5",
"avatar_url": "https://avatars.githubusercontent.com/u/56069179?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/susnato",
"html_url": "https://github.com/susnato",
"followers_url": "https://api.github.com/users/susnato/followers",
"following_url": "https://api.github.com/users/susnato/following{/other_user}",
"gists_url": "https://api.github.com/users/susnato/gists{/gist_id}",
"starred_url": "https://api.github.com/users/susnato/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/susnato/subscriptions",
"organizations_url": "https://api.github.com/users/susnato/orgs",
"repos_url": "https://api.github.com/users/susnato/repos",
"events_url": "https://api.github.com/users/susnato/events{/privacy}",
"received_events_url": "https://api.github.com/users/susnato/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey @susnato, thanks for opening your PR! Let us know if we can help in any way.\r\n\r\nAlso cc @gugarosa and @sgunasekar as you've been doing impressive maintenance work on your models :hugs: ",
"Hi @LysandreJik, this PR is ready for review.\r\nPlease refer to this [colab notebook](https://colab.research.google.com/drive/1rY-T36vqG9b-0IM3IJq741zBlcSxSit1?usp=sharing) to check the logits matching for `Phi-1` and `Phi-1.5`.\r\n\r\nBTW the test - `test_left_padding_compatibility` seems to be failing here, but it is passing on my local machine. Do you know what could be causing this discrepancy?",
" Nice, thanks a lot! Pinging @ArthurZucker and @Rocketknight1 to take a look :)",
"Will this PR support the training for phi models?",
"Hi @SinclairCoder, yes it will.",
"Hello @ArthurZucker, thanks for the suggestions and apologies for the delay. \r\n\r\nI have changed the code quite a bit according to the `persimmon`. For the `PhiAttention`, there is slight difference between the `_split_heads` methods of phi and persimmon so I could not just add `# Copied from` across the whole class, instead I have added that statement to the relevant methods seperately.\r\nIn addition to that please note that there are subtle differences in the `PhiDecoderLayer` and `PhiModel` too.\r\n\r\nPlease review it and let me know if you are ok with the changes or not. ",
"Hi @ArthurZucker , I have worked on the comments and now `PhiAttention` and `PhiModel` are same as their Persimmon counterparts. \r\n\r\nPlease review it and let me know if this works with you. ",
"(also make sure the CI are green 🤗 )",
"Hello @ArthurZucker, I have pushed the changes and The CI is green now!\r\n\r\nRegarding the BC compatibility issue - \r\nIf it's ok with you, I would like to tackle that step by step after the PR is merged :smiley: .\r\n\r\n1. Let's work together to make this PR merged.\r\n2. After it is merged I will create a PR on the huggingface hub to upload both of the weights.\r\n3. After that I will update the checkpoints, demo etc with separate PR just like we did for pop2piano. We can then tackle the compatibility issue in this step and update the config if needed.\r\n\r\nPlease let me know if this works with you :).\r\n\r\n ",
"For sure, then we should use the same model_type as them, this way we won't have any problems and should not affect anyone! ",
"(The issue is taht other libraries like TGI use the model_type and otherwise we need to wait for them) ",
"Hi @ArthurZucker, I have updated the model_type as theirs(`\"mixformer-sequential\"`) and mentioned the error I am getting(after the updation) and temporary fix [here](https://github.com/huggingface/transformers/pull/26170#discussion_r1370124238).",
"I am also super down to have the correct model type but we know that's gonna have issue. Last time we had to revert the falcon PR 😓 We don't have the perfect solution yet, I can work on this before we actually push the checkpoints and the config if you are okay to wait? Otherwise we can use their model type for now and later on once I find the correct way to approach this we'll update! 😉 ",
"> I am also super down to have the correct model type but we know that's gonna have issue. Last time we had to revert the falcon PR 😓 We don't have the perfect solution yet, I can work on this before we actually push the checkpoints and the config if you are okay to wait?\r\n\r\nIf you think that's relatively better solution, then I will wait. \r\n\r\nBut then could you please explain me the whole process a little bit? I mean, will you first work towards changing the `model_type` to \"phi\" on the Hub then this PR and then actually push the checkpoints and the config?\r\n\r\nAlso I have a question - after the PR is merged, we will need to delete the modelling files on the HuggingFace Hub right? So that everyone loads the model from the library only?",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26170). All of your documentation changes will be reflected on that endpoint.",
"when importing phi with transformers == 4.34.1 `from transformers import PhiModel`\r\n[](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26170/en/model_doc/phi)\r\n\r\nI get an error: ImportError: cannot import name 'PhiForCausalLM'\r\n\r\nHas the updates been made yet? Just seeing if this is expected. \r\n",
"Hey @susnato, we'll probably merge this PR, then open a PR to the repo on the hub with the new checkpoints and a deletion of the code, making sure checking out this revision works, then merging once the release happens (next week). I'll let @Rocketknight1 help you with this as he went thought that for Falcon! \r\n\r\nRegarding this PR, let's merge it but with the correct model_type (so the one they have in their config) for now. I didn't have time to dive into fixing and will be off for a week so will tackle after that! ",
"Hey @ArthurZucker, I tried to change to `mixformer-sequential` for `MODEL_NAMES_MAPPING` and `CONFIG_MAPPING_NAMES` but it seems that I need to change the whole directory from `phi` to `mixformer-sequential` in order to make it work.\r\n \r\n\r\nOtherwise I believe that we can also add `(\"mixformer-sequential\", \"phi\")` to `SPECIAL_MODEL_TYPE_TO_MODULE_NAME` so that every `mixformer-sequential` will get converted to `phi`.\r\n\r\nWDYT?\r\n ",
"Mmm yeah something like `HUB_MODEL_TYPE_TO_TRANSFORMERS_MODEL_TYPE` will have to be created, but it's a bit more involved we need to test and make sure we handle edge case",
"I'll try to do this today 👍🏻 ",
"Okk thanks!",
"Just replying here to say that yes, I'm available to help when you're ready to start porting checkpoints!",
"Hello @Rocketknight1, thanks for the reply!\r\n\r\nI have already ported the checkpoints and saved here - [phi-1](https://huggingface.co/susnato/phi-1_dev) and [phi-1.5](https://huggingface.co/susnato/phi-1_5_dev)\r\n\r\nThe main [issue](https://github.com/huggingface/transformers/pull/26170#pullrequestreview-1692913227) that @ArthurZucker was talking about was the difference between the `model_type`, the [online config file, on the hub](https://huggingface.co/microsoft/phi-1/blob/371fd519ab41b5bc2e96838936c2349dc49656db/config.json#L14) has model_type as `mixformer-sequential` but here we have it as `phi`. This won't matter if we change the model_type to phi on the Hub.\r\nAlso I believe that we will need to delete the modelling files on the HuggingFace Hub right?\r\n\r\nSo, how should I approach this? should I first open a PR to transfer the weights and config to the original repo on Hub or this PR needs to be merged first then the weights transfer? WDYT? \r\n",
"@susnato This PR will need to be merged first, because otherwise the updated repos won't work for anyone else.\r\n\r\nAfter that, the way we did it was to make a PR to each checkpoint repo, and do the following:\r\n\r\n1) Copy the `configuration_phi.py` and `modeling_phi.py` files from this PR into the repo, overwriting the old ones.\r\n2) Ensure the files don't use relative imports (e.g. replace `from ..modeling_utils import` with `from transformers.modeling_utils import`\r\n3) Set the `architectures` and `auto_map` keys in `config.json` to point to the new classes.\r\n4) Set the `model_type` to the new type (e.g. `phi` in this case)\r\n\r\nThis way, users who have updated to the latest version of `transformers` can use `trust_remote_code=False` and get the library code, but users who haven't can continue with their old workflows.",
"Hi @Rocketknight1, thanks a lot for the explanation!\r\n\r\nSo just to be clear - we will merge this PR with `model_type = \"phi\"` right? Or we need to use `mixformer-sequential`?",
"@susnato we should use \"phi\"",
"@Rocketknight1, Okk. Then lets try to work towards merging this first.\r\n\r\nIf you don't mind could you please review this? :sweat_smile: ",
"@susnato will do! Please do the rebase anyway though, lol. I think we'll get lucky, and if we don't then it's better to find out here then after we merge!",
"Hello @Rocketknight1, I have rebased and did necessary changes.\r\n\r\nPlease note that I have also added an [dropout layer](https://github.com/susnato/transformers/blob/26cceddd5504d5f58d899469483a0245f082f0ee/src/transformers/models/phi/modeling_phi.py#L610) after the `input_embeds` which was missing in the previous commits. ",
"Got it! Pinging either @arthurzucker or @amyeroberts for core maintainer final review. I checked with the TGI team and they said it would be fine to do the port and change the model type to `phi`."
] | 1,694 | 1,703 | 1,699 |
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #26110
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
[Colab Link](https://colab.research.google.com/drive/1rY-T36vqG9b-0IM3IJq741zBlcSxSit1?usp=sharing) to verify logits.
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
cc : @xenova
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26170/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 3,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26170/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26170",
"html_url": "https://github.com/huggingface/transformers/pull/26170",
"diff_url": "https://github.com/huggingface/transformers/pull/26170.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26170.patch",
"merged_at": 1699630110000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26169
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26169/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26169/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26169/events
|
https://github.com/huggingface/transformers/issues/26169
| 1,897,196,488 |
I_kwDOCUB6oc5xFOvI
| 26,169 |
Segmentation Fault when trying to load HuggingFace Model
|
{
"login": "y12uc231",
"id": 5621640,
"node_id": "MDQ6VXNlcjU2MjE2NDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/5621640?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/y12uc231",
"html_url": "https://github.com/y12uc231",
"followers_url": "https://api.github.com/users/y12uc231/followers",
"following_url": "https://api.github.com/users/y12uc231/following{/other_user}",
"gists_url": "https://api.github.com/users/y12uc231/gists{/gist_id}",
"starred_url": "https://api.github.com/users/y12uc231/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/y12uc231/subscriptions",
"organizations_url": "https://api.github.com/users/y12uc231/orgs",
"repos_url": "https://api.github.com/users/y12uc231/repos",
"events_url": "https://api.github.com/users/y12uc231/events{/privacy}",
"received_events_url": "https://api.github.com/users/y12uc231/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! I cant reproduce this, you should try to re-install python this does not seem to have anything to do with transformers",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,694 | 1,698 | 1,698 |
NONE
| null |
### System Info
```
Python 3.9.12 (main, Apr 5 2022, 01:53:17)
[Clang 12.0.0 ] :: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained("gpt2")
zsh: segmentation fault python
```
I am using transformers version = '4.33.1'
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
In the python terminal.
```
Python 3.9.12 (main, Apr 5 2022, 01:53:17)
[Clang 12.0.0 ] :: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained("gpt2")
zsh: segmentation fault python
```
### Expected behavior
The model should load instead of throwing a segmentation fault.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26169/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26169/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26168
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26168/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26168/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26168/events
|
https://github.com/huggingface/transformers/pull/26168
| 1,896,932,172 |
PR_kwDOCUB6oc5aXMmD
| 26,168 |
Tweaks to Chat Templates docs
|
{
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,694 | 1,694 | 1,694 |
MEMBER
| null |
A few small fixes for the Chat Templates docs that I noticed after merging the PR!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26168/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26168/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26168",
"html_url": "https://github.com/huggingface/transformers/pull/26168",
"diff_url": "https://github.com/huggingface/transformers/pull/26168.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26168.patch",
"merged_at": 1694778658000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26167
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26167/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26167/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26167/events
|
https://github.com/huggingface/transformers/issues/26167
| 1,896,906,733 |
I_kwDOCUB6oc5xEH_t
| 26,167 |
Fail loading pretrained weights for Dinov2ForImageClassification model
|
{
"login": "ofirshifman",
"id": 39139239,
"node_id": "MDQ6VXNlcjM5MTM5MjM5",
"avatar_url": "https://avatars.githubusercontent.com/u/39139239?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ofirshifman",
"html_url": "https://github.com/ofirshifman",
"followers_url": "https://api.github.com/users/ofirshifman/followers",
"following_url": "https://api.github.com/users/ofirshifman/following{/other_user}",
"gists_url": "https://api.github.com/users/ofirshifman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ofirshifman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ofirshifman/subscriptions",
"organizations_url": "https://api.github.com/users/ofirshifman/orgs",
"repos_url": "https://api.github.com/users/ofirshifman/repos",
"events_url": "https://api.github.com/users/ofirshifman/events{/privacy}",
"received_events_url": "https://api.github.com/users/ofirshifman/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @NielsRogge and @amyeroberts ",
"Hi @ofirshifman,\r\n\r\nThanks for your interest in DINOv2. Note that the error is expected, given that [facebook/dinov2-base](https://huggingface.co/facebook/dinov2-base) is only the base Transformer without any head on top, useful for feature extraction. However Meta just released the linear heads on top, hence I'm adding support for them in the PR above (you can load them using `Dinov2ForImageClassification`). \r\n\r\nThey are on the hub:\r\n- https://huggingface.co/facebook/dinov2-small-imagenet1k-1-layer\r\n- https://huggingface.co/facebook/dinov2-base-imagenet1k-1-layer\r\n- https://huggingface.co/facebook/dinov2-large-imagenet1k-1-layer\r\n- https://huggingface.co/facebook/dinov2-giant-imagenet1k-1-layer.",
"Thanks for uploading it to the hub @NielsRogge! That's great!",
"I was playing a Little with the code and wondered what is the best practice according to the hub's API to get both the CLS output and the base model output, I can edit my own code to get it, but maybe it worth adding ImageClassifierOutputWithPooling or something similar. \r\nwhat do you thing?",
"You can always get the CLS tokens of whatever layers you want by specifying `output_hidden_states=True`:\r\n\r\n```\r\nfrom transformers import Dinov2ForImageClassification\r\nimport torch\r\n\r\nmodel = Dinov2ForImageClassification.from_pretrained(\"facebook/dinov2-small-imagenet1k-1-layer\")\r\n\r\npixel_values = torch.randn(1, 3, 224, 224)\r\n\r\nwith torch.no_grad():\r\n outputs = model(pixel_values, output_hidden_states=True)\r\n\r\n# get the intermediate hidden states, let's use the last one\r\nhidden_states = outputs.hidden_states\r\nlast_hidden_state = hidden_states[-1]\r\n\r\n# get the CLS token feature, or the patch features\r\ncls_token_feature = last_hidden_state[:,0,:]\r\npatch_features = last_hidden_state[:,1:,:]\r\n```",
"Just a small note: `pooler_output` is not exactly `cls_token_feature`, since the model also applies LayerNorm on it.\r\nIn order to get exactly the `pooler_output` one should add this to your code:\r\n```\r\n sequence_output = model.base_model.layernorm(last_hidden_state)\r\n pooled_output = sequence_output[:, 0, :]\r\n```\r\n\r\nThanks again for the help."
] | 1,694 | 1,696 | 1,696 |
NONE
| null |
### System Info
both on:
transformers 4.32.0
transformers 4.34.0.dev0
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I've encountered a bug with the Dinov2ForImageClassification model from Hugging Face Transformers. As per the provided documentation [here](https://huggingface.co/docs/transformers/main/model_doc/dinov2#transformers.Dinov2ForImageClassification), I've followed the code example using the latest Transformers version. However, when running the code, I encounter an error indicating that the model is performing binary classification instead of the expected ImageNet 1000-way classification.
Here's my code:
```
from transformers import AutoImageProcessor, Dinov2ForImageClassification
import torch
from datasets import load_dataset
# Load a sample image dataset (in this case, 'huggingface/cats-image')
dataset = load_dataset('huggingface/cats-image')
image = dataset['test']['image'][0]
# Load the image processor and the Dinov2ForImageClassification model
image_processor = AutoImageProcessor.from_pretrained('facebook/dinov2-base')
model = Dinov2ForImageClassification.from_pretrained('facebook/dinov2-base')
# Prepare the input and obtain logits
inputs = image_processor(image, return_tensors='pt')
with torch.no_grad():
logits = model(**inputs).logits
# The expected number of labels for ImageNet classification should be 1000
predicted_label = logits.argmax(-1).item()
```
Regardless of whether I specify num_labels=1000 during model initialization to correct the label dimensions, the following error persists:
```
Some weights of Dinov2ForImageClassification were not initialized from the model checkpoint at facebook/dinov2-base and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
The issue persists, and I'm unable to utilize the pretrained Dinov2ForImageClassification model for ImageNet 1000-way classification as intended.
### Expected behavior
loading without warning, having 1000-way long output vector, that is representing the correct classification labels of ImageNet.
see more here:
https://discuss.huggingface.co/t/dino2-for-classification-has-wrong-number-of-labels/55027
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26167/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26167/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26166
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26166/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26166/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26166/events
|
https://github.com/huggingface/transformers/pull/26166
| 1,896,868,216 |
PR_kwDOCUB6oc5aW-s_
| 26,166 |
refactor: add min to block size
|
{
"login": "pphuc25",
"id": 81808312,
"node_id": "MDQ6VXNlcjgxODA4MzEy",
"avatar_url": "https://avatars.githubusercontent.com/u/81808312?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pphuc25",
"html_url": "https://github.com/pphuc25",
"followers_url": "https://api.github.com/users/pphuc25/followers",
"following_url": "https://api.github.com/users/pphuc25/following{/other_user}",
"gists_url": "https://api.github.com/users/pphuc25/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pphuc25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pphuc25/subscriptions",
"organizations_url": "https://api.github.com/users/pphuc25/orgs",
"repos_url": "https://api.github.com/users/pphuc25/repos",
"events_url": "https://api.github.com/users/pphuc25/events{/privacy}",
"received_events_url": "https://api.github.com/users/pphuc25/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"This is just a mistake when I make a pull request, the main pull request of this is in #26069 ",
"Reviewed directly on the PR linked!"
] | 1,694 | 1,695 | 1,694 |
CONTRIBUTOR
| null |
Hi,
Referring to #26069 and incorporating the recommendation of @sanchit-gandhi, I am submitting this pull request (PR) to include a minimum value constraint on the block_size parameter. This change aims to prevent potential errors from occurring.
I would like to cc @sanchit-gandhi to review my PR, and thank you so much for your suggestion.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26166/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26166/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26166",
"html_url": "https://github.com/huggingface/transformers/pull/26166",
"diff_url": "https://github.com/huggingface/transformers/pull/26166.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26166.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/26165
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26165/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26165/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26165/events
|
https://github.com/huggingface/transformers/issues/26165
| 1,896,803,452 |
I_kwDOCUB6oc5xDux8
| 26,165 |
Error with load_in_4bit argument when loading model
|
{
"login": "matsuobasho",
"id": 13874772,
"node_id": "MDQ6VXNlcjEzODc0Nzcy",
"avatar_url": "https://avatars.githubusercontent.com/u/13874772?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/matsuobasho",
"html_url": "https://github.com/matsuobasho",
"followers_url": "https://api.github.com/users/matsuobasho/followers",
"following_url": "https://api.github.com/users/matsuobasho/following{/other_user}",
"gists_url": "https://api.github.com/users/matsuobasho/gists{/gist_id}",
"starred_url": "https://api.github.com/users/matsuobasho/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/matsuobasho/subscriptions",
"organizations_url": "https://api.github.com/users/matsuobasho/orgs",
"repos_url": "https://api.github.com/users/matsuobasho/repos",
"events_url": "https://api.github.com/users/matsuobasho/events{/privacy}",
"received_events_url": "https://api.github.com/users/matsuobasho/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @matsuobasho , I can't reproduce the error after switching to your setup. Please check which one of these conditions fails: `is_accelerate_available()` and `is_bitsandbytes_available()`. You can import them with \r\n```py\r\nfrom transformers.utils import is_accelerate_available, is_bitsandbytes_available\r\n```",
"@SunMarc, thanks for the response.\r\n\r\n`is_bitsandbytes_available()` returns False",
"Then check inside the code where it returns false. It is either torch or bitsandbytes the problem. After you find it, reinstall the library. ",
"I'm able to import torch.\r\nWhen I import bitsandbytes I see this warning:\r\n`UserWarning: The installed version of bitsandbytes was compiled without GPU support. 8-bit optimizers, 8-bit multiplication, and GPU quantization are unavailable.\r\n warn(\"The installed version of bitsandbytes was compiled without GPU support. \"\r\n'NoneType' object has no attribute 'cadam32bit_grad_fp32'`\r\n\r\nSo that seems to be the problem but not sure how to resolve. Also, do I need CUDA in order for bitsandbytes to work? I'm just running this locally on a CPU.",
"Hi @matsuobasho \r\n\r\n> So that seems to be the problem but not sure how to resolve. Also, do I need CUDA in order for bitsandbytes to work? I'm just running this locally on a CPU.\r\n\r\nNote that bitsandbytes features we have integrated only works on GPU, so your behaviour is expected unfortunately. To use these feature, you can use for instance free-tier GPU instances such as google colab or kaggle notebooks",
"Ok, thank you."
] | 1,694 | 1,694 | 1,694 |
NONE
| null |
### System Info
OS: Windows 10 64-bit
Python version: 3.9.6
Transformers: 4.33.1 (imported with `pipenv install transformers[torch]`)
Accelerate: 0.22.0
BitsandBytes: 0.41.1
Environment manager: pipenv
### Who can help?
@SunMarc @younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I get an error saying that I need Accelerate when using the `load_in_4bit` argument in the `from_pretrained` method.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "Salesforce/codegen-350M-mono"
device = "cpu"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(checkpoint, trust_remote_code=True, load_in_4bit = True).to(device)
```
Error:
```ImportError:` Using `load_in_8bit=True` requires Accelerate: `pip install accelerate` and the latest version of bitsandbytes `pip install -i https://test.pypi.org/simple/ bitsandbytes` or pip install bitsandbytes` ```
Same issue expressed by many people in [this](https://huggingface.co/anon8231489123/vicuna-13b-GPTQ-4bit-128g/discussions/11) post.
### Expected behavior
Model loads without errors.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26165/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26165/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26164
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26164/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26164/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26164/events
|
https://github.com/huggingface/transformers/pull/26164
| 1,896,647,285 |
PR_kwDOCUB6oc5aWOym
| 26,164 |
[Whisper] Check length of prompt + max new tokens
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,694 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
# What does this PR do?
Fixes #25422: adds a check for the combined length of prompt + max new tokens. If this total exceeds the model's max length (`max_target_positions`), we throw an error.
cc @connor-henderson @Helene-Maxcici
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26164/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26164/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26164",
"html_url": "https://github.com/huggingface/transformers/pull/26164",
"diff_url": "https://github.com/huggingface/transformers/pull/26164.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26164.patch",
"merged_at": 1694789191000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26163
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26163/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26163/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26163/events
|
https://github.com/huggingface/transformers/pull/26163
| 1,896,608,762 |
PR_kwDOCUB6oc5aWGav
| 26,163 |
add bf16 mixed precision support for NPU
|
{
"login": "statelesshz",
"id": 28150734,
"node_id": "MDQ6VXNlcjI4MTUwNzM0",
"avatar_url": "https://avatars.githubusercontent.com/u/28150734?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/statelesshz",
"html_url": "https://github.com/statelesshz",
"followers_url": "https://api.github.com/users/statelesshz/followers",
"following_url": "https://api.github.com/users/statelesshz/following{/other_user}",
"gists_url": "https://api.github.com/users/statelesshz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/statelesshz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/statelesshz/subscriptions",
"organizations_url": "https://api.github.com/users/statelesshz/orgs",
"repos_url": "https://api.github.com/users/statelesshz/repos",
"events_url": "https://api.github.com/users/statelesshz/events{/privacy}",
"received_events_url": "https://api.github.com/users/statelesshz/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26163). All of your documentation changes will be reflected on that endpoint.",
"@muellerzr sorry for bothering you. This PR is ready to be merged :D."
] | 1,694 | 1,696 | 1,695 |
CONTRIBUTOR
| null |
# What does this PR do?
Accelerate already provides NPU support for mixed precision training using bf16. See https://github.com/huggingface/accelerate/pull/1949. This PR makes it available on Transformers 🤗
Verified on text classification example using the following script:
```
export TASK_NAME=mrpc
python run_glue.py \
--model_name_or_path bert-base-cased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--bf16 \
--output_dir ./output
```
## Who can review?
Anyone in the community is free to review the PR once the tests have passed.
@pacman100 and @muellerzr Good day:-). Could you please take a look at this PR for me? Thanks.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26163/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26163/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26163",
"html_url": "https://github.com/huggingface/transformers/pull/26163",
"diff_url": "https://github.com/huggingface/transformers/pull/26163.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26163.patch",
"merged_at": 1695810520000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26162
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26162/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26162/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26162/events
|
https://github.com/huggingface/transformers/pull/26162
| 1,896,556,334 |
PR_kwDOCUB6oc5aV7Sp
| 26,162 |
Remove unnecessary unsqueeze - squeeze in rotary positional embedding
|
{
"login": "fxmarty",
"id": 9808326,
"node_id": "MDQ6VXNlcjk4MDgzMjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9808326?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fxmarty",
"html_url": "https://github.com/fxmarty",
"followers_url": "https://api.github.com/users/fxmarty/followers",
"following_url": "https://api.github.com/users/fxmarty/following{/other_user}",
"gists_url": "https://api.github.com/users/fxmarty/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fxmarty/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fxmarty/subscriptions",
"organizations_url": "https://api.github.com/users/fxmarty/orgs",
"repos_url": "https://api.github.com/users/fxmarty/repos",
"events_url": "https://api.github.com/users/fxmarty/events{/privacy}",
"received_events_url": "https://api.github.com/users/fxmarty/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"FYI @gante if there is anything we are missing here? ",
"There's the same unsqueeze - squeeze in falcon. Maybe I am misunderstanding something in rotary positional embedding.\r\n\r\n---\r\nEdit:\r\n\r\nThis test fails on this branch:\r\n```\r\nFAILED tests/models/llama/test_modeling_llama.py::CodeLlamaIntegrationTest::test_model_7b_logits - AssertionError: Lists differ: ['<s>▁<PRE> def remove_non_ascii(s: str) -> st[893 chars]ID>'] != ['<s> <PRE> def remove_non_ascii(s: str) -> st[893 chars...\r\n```\r\n\r\nhowever it seems unrelated (also fails on 866df66fe4a3b3b948b926d849ef291675b8a24c & tokenizers==0.13.3)\r\n\r\n",
"Yep it's unrelated, seen this failing, the `fast` tokenizer is not properly splitting ",
"Updated other affected archs.\r\n\r\nThis PR https://github.com/huggingface/transformers/pull/22785 was great, but incomplete. cc @fpgaminer\r\n\r\nRunning slow tests (`RUN_SLOW=1 pytest tests/models/gpt_neox/test_modeling_gpt_neox.py -s -vvvvv`, `RUN_SLOW=1 pytest tests/models/idefics/ -s -vvvvv`, `RUN_SLOW=1 pytest tests/models/falcon/ -s -vvvvv`), no more tests fail than on main.\r\n\r\nRelated PR: https://github.com/huggingface/transformers/pull/25830, maybe @ArthurZucker you want to merge that first?\r\n\r\n---\r\n\r\nNote: some slow tests do not pass, but they don't pass on main 0a55d9f7376f72ad3ff296d4249840021b03bcc4 either:\r\n\r\n```\r\nFAILED tests/models/falcon/test_modeling_falcon.py::FalconModelTest::test_cpu_offload - AssertionError: False is not true\r\nFAILED tests/models/falcon/test_modeling_falcon.py::FalconModelTest::test_disk_offload - AssertionError: False is not true\r\nFAILED tests/models/falcon/test_modeling_falcon.py::FalconModelTest::test_feed_forward_chunking - AssertionError: False is not true\r\nFAILED tests/models/falcon/test_modeling_falcon.py::FalconModelTest::test_left_padding_compatibility - AssertionError: False is not true\r\n\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsModelTest::test_cpu_offload - AssertionError: False is not true\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsModelTest::test_determinism - ValueError: zero-size array to reduction operation maximum which has no identity\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsModelTest::test_disk_offload - AssertionError: False is not true\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsModelTest::test_feed_forward_chunking - AssertionError: False is not true\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsModelTest::test_model_parallelism - AssertionError: False is not true\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsForVisionText2TextTest::test_cpu_offload - AssertionError: False is not true\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsForVisionText2TextTest::test_determinism - ValueError: zero-size array to reduction operation maximum which has no identity\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsForVisionText2TextTest::test_disk_offload - AssertionError: False is not true\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsForVisionText2TextTest::test_feed_forward_chunking - AssertionError: False is not true\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsForVisionText2TextTest::test_model_parallelism - AssertionError: False is not true\r\n```",
"Do you think this can make it in the release?",
"Actually let's wait a bit in case this breaks things! \r\n",
"sure",
"Should be in a good state now.\r\n\r\nSummary of slow tests:\r\n\r\n`RUN_SLOW=1 CUDA_VISIBLE_DEVICES=0 pytest tests/models/llama/ -s -vvvvv` errors on (same as main)\r\n\r\n```\r\nFAILED tests/models/llama/test_modeling_llama.py::CodeLlamaIntegrationTest::test_model_7b_logits\r\nE AssertionError: Lists differ: ['<s>▁<PRE> def remove_non_ascii(s: str) -> st[893 chars]ID>'] != ['<s> <PRE> def remove_non_ascii(s: str) -> st[893 chars]ID>']\r\n```\r\n\r\n`RUN_SLOW=1 CUDA_VISIBLE_DEVICES=0 pytest tests/models/idefics/ -s -vvvvv` errors on (same as main)\r\n\r\n```\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsModelTest::test_cpu_offload - AssertionError: False is not true\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsModelTest::test_determinism - ValueError: zero-size array to reduction operation maximum which has no identity\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsModelTest::test_disk_offload - AssertionError: False is not true\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsModelTest::test_feed_forward_chunking - AssertionError: False is not true\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsForVisionText2TextTest::test_cpu_offload - AssertionError: False is not true\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsForVisionText2TextTest::test_determinism - ValueError: zero-size array to reduction operation maximum which has no identity\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsForVisionText2TextTest::test_disk_offload - AssertionError: False is not true\r\nFAILED tests/models/idefics/test_modeling_idefics.py::IdeficsForVisionText2TextTest::test_feed_forward_chunking - AssertionError: False is not true\r\n```\r\n\r\n`RUN_SLOW=1 CUDA_VISIBLE_DEVICES=0 pytest tests/models/mistral/ -s -vvvvv` errors on (same as main)\r\n\r\n```\r\nFAILED tests/models/mistral/test_modeling_mistral.py::MistralIntegrationTest::test_model_7b_generation - AssertionError: 'My f[17 chars]t is mayonnaise. I love it on sandwiches, in s[13 chars]gers' != 'My f[17 chars]t is 100% ketchup. I love it on everythin...\r\nFAILED tests/models/mistral/test_modeling_mistral.py::MistralIntegrationTest::test_model_7b_logits - RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument index ...\r\n```\r\n\r\n`RUN_SLOW=1 CUDA_VISIBLE_DEVICES=0 pytest tests/models/falcon/ -s -vvvvv` errors on (same as main)\r\n\r\n```\r\nFAILED tests/models/falcon/test_modeling_falcon.py::FalconModelTest::test_left_padding_compatibility - AssertionError: False is not true\r\n```\r\n\r\n`RUN_SLOW=1 CUDA_VISIBLE_DEVICES=0 pytest tests/models/gpt_neox/ -s -vvvvv` pass.",
"This PR fixes `tests/models/mistral/test_modeling_mistral.py::MistralIntegrationTest::test_model_7b_logits` as well. \r\n\r\nThe test `tests/models/mistral/test_modeling_mistral.py::MistralIntegrationTest::test_model_7b_generation` (that uses using slow tokenizers) seem to have never worked (on 72958fcd3c98a7afdc61f953aa58c544ebda2f79) cc @Bam4d, so I will ignore it for now.",
"@fxmarty thank you for the fix! \r\n\r\nI suppose this redundant pattern got in `gpt_neox`, and we were copying it over to other new models with RoPE :)"
] | 1,694 | 1,697 | 1,696 |
COLLABORATOR
| null |
As per title, removes unnecessary operations in the model initialization and forward.
Fixes https://github.com/pytorch/pytorch/issues/109292
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26162/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26162/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26162",
"html_url": "https://github.com/huggingface/transformers/pull/26162",
"diff_url": "https://github.com/huggingface/transformers/pull/26162.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26162.patch",
"merged_at": 1696584315000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26161
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26161/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26161/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26161/events
|
https://github.com/huggingface/transformers/pull/26161
| 1,896,326,153 |
PR_kwDOCUB6oc5aVI_S
| 26,161 |
Translated the accelerate.md file of the documentation to Chinese
|
{
"login": "liteli1987gmail",
"id": 59245973,
"node_id": "MDQ6VXNlcjU5MjQ1OTcz",
"avatar_url": "https://avatars.githubusercontent.com/u/59245973?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/liteli1987gmail",
"html_url": "https://github.com/liteli1987gmail",
"followers_url": "https://api.github.com/users/liteli1987gmail/followers",
"following_url": "https://api.github.com/users/liteli1987gmail/following{/other_user}",
"gists_url": "https://api.github.com/users/liteli1987gmail/gists{/gist_id}",
"starred_url": "https://api.github.com/users/liteli1987gmail/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/liteli1987gmail/subscriptions",
"organizations_url": "https://api.github.com/users/liteli1987gmail/orgs",
"repos_url": "https://api.github.com/users/liteli1987gmail/repos",
"events_url": "https://api.github.com/users/liteli1987gmail/events{/privacy}",
"received_events_url": "https://api.github.com/users/liteli1987gmail/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26161). All of your documentation changes will be reflected on that endpoint.",
"Hi @liteli1987gmail, hope you don't mind me committing Arthur's suggestion for you so we can merge this PR! Thanks again for the translation :)"
] | 1,694 | 1,697 | 1,697 |
CONTRIBUTOR
| null |
What does this PR do?
🍅Add zh (Chinese) translation accelerate.md
😊Add accelerate to _toctree.yml
- issue Transformers documentation translation to Chinese (Simplified) #20095
Who can review?
Documentation: @stevhliu and @MKhalusova
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26161/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26161/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26161",
"html_url": "https://github.com/huggingface/transformers/pull/26161",
"diff_url": "https://github.com/huggingface/transformers/pull/26161.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26161.patch",
"merged_at": 1697046862000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26160
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26160/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26160/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26160/events
|
https://github.com/huggingface/transformers/issues/26160
| 1,896,267,196 |
I_kwDOCUB6oc5xBr28
| 26,160 |
Trainer of AutoModelForSequenceClassification is saving the wrong score module (or trained parameters are in the wrong module)
|
{
"login": "koen-dejonghe",
"id": 2901242,
"node_id": "MDQ6VXNlcjI5MDEyNDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/2901242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/koen-dejonghe",
"html_url": "https://github.com/koen-dejonghe",
"followers_url": "https://api.github.com/users/koen-dejonghe/followers",
"following_url": "https://api.github.com/users/koen-dejonghe/following{/other_user}",
"gists_url": "https://api.github.com/users/koen-dejonghe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/koen-dejonghe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/koen-dejonghe/subscriptions",
"organizations_url": "https://api.github.com/users/koen-dejonghe/orgs",
"repos_url": "https://api.github.com/users/koen-dejonghe/repos",
"events_url": "https://api.github.com/users/koen-dejonghe/events{/privacy}",
"received_events_url": "https://api.github.com/users/koen-dejonghe/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 5616426447,
"node_id": "LA_kwDOCUB6oc8AAAABTsPdzw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/solved",
"name": "solved",
"color": "B1D6DC",
"default": false,
"description": ""
}
] |
open
| false | null |
[] |
[
"Looks interesting, I am doing something similar with 0.17.2 , I noticed that the linear layers doesn't change, did you suffer from something like that",
"I have the same issues. `Peft` splits `score` into `original_module (no grad)` and `default (grad=true)`. Every checkpoint only `default` adapter layer is saved and without the `original_module` the evaluation metrics are off. I got better insights by going through #602 and #876. \r\n\r\n@natank1 your issue might be fixed with this [pull request](https://github.com/huggingface/peft/pull/755). ",
"Thanks\r\n\r\nבתאריך יום ג׳, 17 באוק׳ 2023 ב-3:55 מאת Thein Oo ***@***.***>:\r\n\r\n> I have the same issues. Peft splits score into original_module (no grad)\r\n> and default (grad=true). Every checkpoint only default adapter layer is\r\n> saved and without the original_module the evaluation metrics are off. I\r\n> got better insights by going through #602\r\n> <https://github.com/huggingface/transformers/issues/602> and #876\r\n> <https://github.com/huggingface/transformers/issues/876>.\r\n>\r\n> @natank1 <https://github.com/natank1> your issue might be fixed with this pull\r\n> request <https://github.com/huggingface/peft/pull/755>.\r\n>\r\n> —\r\n> Reply to this email directly, view it on GitHub\r\n> <https://github.com/huggingface/transformers/issues/26160#issuecomment-1765488409>,\r\n> or unsubscribe\r\n> <https://github.com/notifications/unsubscribe-auth/AB7W2Z7FZOV5ZVSC35ERNNTX7XJRZAVCNFSM6AAAAAA4X34AFKVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMYTONRVGQ4DQNBQHE>\r\n> .\r\n> You are receiving this because you were mentioned.Message ID:\r\n> ***@***.***>\r\n>\r\n",
"Sorry for re--discussing: in the version I work score(under the peftmodel..basemodel.model) is a linear and simply doesn't update : I work on 0.17.2 (HF) and 4.34.dev (trnaformers)",
"Note: the bug does not occur when you don’t specify `target_modules` in LoraConfig, so effectively only use default q & v of the attention blocks.",
"in my case I dont define target . Notsure whether it is due to different versions",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Hi,\r\n\r\nI confirm this is severe a bug (probably only for 'multi-label-task') and the [workaround](https://discuss.huggingface.co/t/llama-2-sequence-classification-much-lower-accuracy-on-inference-from-checkpoint-compared-to-model/54910) does solve this issue.\r\n\r\nI have fine-tuned LLAMA-2-7b using QLora for multi-label classification on 6k context using RoPE scaling. After training the model for 2 epochs I get F1 macro 0.51 and micro 0.65 on the evaluation dataset. However, When I tried to reproduce these scores in the inference pipeline on the same evaluation dataset I failed with F1 scores of 0.13 and 0.18, where all the predictions are random.\r\n\r\nI tried training with and without flash_attention, and RoPE scaling but couldn't reproduce the\r\nevaluation metrics. I also confirmed that the 'score' head is saved by setting 'module_to_save=[score]' but nothing worked. \r\n",
"pinging @muellerzr and @pacman100 as it seems this issue still exists ",
"Hello @koen-dejonghe,\r\n\r\nwith the latest versions of Transformers, Accelerate and PEFT, when you call `trainer.save_model()`, only the adapter weights get saved and for inference you would need to do use `PeftModel.from_pretrained`. Please refer https://huggingface.co/docs/peft/quicktour#save-model for the details wrt saving and loading the adapter weights.\r\n\r\nIf you want to save the base model with the adapter weights merged in, please do the following:\r\n```\r\nmodel = trainer.model.merge_and_unload()\r\nmodel.save_pretrained(\"final-checkpoint-transformers\")\r\n```\r\n\r\nThen you can load the ckpt as usual using `AutoModelForSequenceClassification.from_pretrained `",
"Here is the minimal notebook example wherein I finetune tinyllama on mrpc seq cls task using qlora and targeting all linear layers. When I load the model for inference via `AutoPeftModelForSequenceClassification`, everything is working as expected. Please let us know if the recent releases have fixed this issue.\r\n\r\n[tinyllama_qlora_seqcls.ipynb.zip](https://github.com/huggingface/transformers/files/14175992/tinyllama_qlora_seqcls.ipynb.zip)\r\n",
"@pacman100 this still seems to be an issue when doing multi-label classification. I just tried now with the latest updates for transformers, peft, and accelerate. I notice your notebook is binary classification not multi-label, which could account for the discrepancy?",
"Hello, could you please share the minimal example that we can run end-to-end to further deep dive?",
"I will try and write something appropriate asap. Your original notebook you posted could illustrate the problem if you use a multilabel problem instead of a binary classification problem. This huggingface dataset \"victoriadreis/TuPY_dataset_multilabel\" might be a good publicly available test.\r\n\r\nWhen you reload the model it uses a random linear layer at the end instead of the one you have finetuned, giving random results. Other people have reported it doesn't properly save the final classification layer.\r\n",
"It seems this issue is solved now. I instruction fine-tuned the llama2 model with QLoRA and everything during training/validation and even inference was ok. \r\n\r\n```\r\n# training args and trainer\r\ntraining_args = TrainingArguments(output_dir=output_dir, ...)\r\ntrainer = Trainer(args=training_args, ...)\r\ntrainer.train()\r\n\r\ntrainer.save_model()\r\n# load model and tokenizer\r\npeft_model = AutoPeftModelForCausalLM.from_pretrained(output_dir, device_map=\"auto\", torch_dtype=torch.bfloat16)\r\ntokenizer = AutoTokenizer.from_pretrained(output_dir)\r\n```\r\n",
"@shakibyzn have you tried it with AutoPeftModelForSequenceClassification head?\r\n\r\nI've had no issues with CausalLM and Seq2Seq models.\r\n\r\nI think the problems are relating to the linear classification head at the end not being saved properly and initialising a random classification head when reloading.\r\n\r\nMy personal problem is related to a multi-label classification problem using GatorTron medium, so I also don't know if that makes a difference. I want to write a script to demonstrate, but due to time pressures, and using confidential data in my project, I need to find the time to do it.",
"@stephenhbarlow My next task is to use the Llama2 model together with QLoRA for multi-class sequence classification. I'll let you know about the result by tomorrow.",
"@stephenhbarlow I did a single run and the result was what I expected. Here is a simplified version of my code:\r\nI fine-tuned meta-llama/Llama-2-7b-hf as a sequence classification task.\r\n```\r\n# load your dataset\r\ndataset = load_data(...)\r\n\r\n# bnb config\r\nbnb_config = BitsAndBytesConfig(...)\r\n\r\nmodel = AutoModelForSequenceClassification.from_pretrained(model_name, quantization_config=bnb_config, num_labels=YOUR_NUM_LABELS)\r\n\r\ntokenizer = AutoTokenizer.from_pretrained(tokenizer_name)\r\ntokenizer.pad_token = tokenizer.eos_token\r\n\r\ntokenized_datasets = dataset.map(YOUR_PREPROCESS_FUNC)\r\n\r\npeft_config = LoraConfig(r=r, lora_alpha=lora_alpha, bias=\"none\", task_type=\"SEQ_CLS\")\r\nmodel = prepare_model_for_kbit_training(model)\r\nmodel = get_peft_model(model, peft_config)\r\n\r\ntraining_args = TrainingArguments(output_dir=output_dir, ...)\r\ntrainer = Trainer(...)\r\n\r\ntrainer.train()\r\ntrainer.save_model()\r\n\r\n# load model and tokenizer\r\npeft_model = AutoPeftModelForSequenceClassification.from_pretrained(output_dir, id2label=id_to_label)\r\ntokenizer = AutoTokenizer.from_pretrained(output_dir)\r\n\r\n# evaluate \r\nevaluate_fn(peft_model, dataset['test'])\r\n```",
"@shakibyzn interesting - must be related to multi-label classification for some reason. Still planning on making a notebook to demonstrate when I can.",
"@stephenhbarlow I wouldn't say it's related to that. Take a look at this [medium blog post](https://medium.com/@lukas.hauzenberger/multilabel-classification-using-mistral-7b-on-a-single-gpu-with-quantization-and-lora-8f848b5237f3\r\n). It might be helpful. Does your model perform as expected on the validation set (output of trainer I mean)? Or is it only a problem with inference?",
"@shakibyzn It's either that or related to the base model I'm using (Gatortron Medium). Basically it all works fine through training and as long as the trained model is still in memory it works great. The problem is with saving/reloading. The reloaded model initializes a new classification head so you get random results. I've tried the various things in the documentation like saving specific module and whatnot, but no success so far.\r\n\r\nI've implemented it very similarly to the blogpost and results completely change when reloading (random basically cos the final layer is random).",
"Here's another person having a problem that linked me to this issue:\r\n\r\nhttps://discuss.huggingface.co/t/llama-2-sequence-classification-much-lower-accuracy-on-inference-from-checkpoint-compared-to-model/54910\r\n",
"Perhaps this post can be beneficial \r\n\r\n(https://natan-katz.medium.com/codellama-classification-finetuning-28fa5546f64f\r\n\r\n\r\n",
"@stephenhbarlow I saw his post. Have you tried a newer version of transformers? e.g. 4.35?",
"I'm having the same issue, with esm (sequence classification + peft). Saving with merge+unload results in a garbage model upon reloading. ",
"@shakibyzn I'm using latest versions of Transformers, PEFT and Accelerate"
] | 1,694 | 1,708 | null |
NONE
| null |
### System Info
- `transformers` version: 4.33.1
- Platform: Linux-3.10.0-1160.71.1.el7.x86_64-x86_64-with-glibc2.35
- Python version: 3.10.13
- Huggingface_hub version: 0.17.1
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: - compute_environment: LOCAL_MACHINE
- distributed_type: MULTI_GPU
- mixed_precision: bf16
- use_cpu: False
- debug: False
- num_processes: 2
- machine_rank: 0
- num_machines: 1
- gpu_ids: 1,2
- rdzv_backend: static
- same_network: True
- main_training_function: main
- downcast_bf16: no
- tpu_use_cluster: False
- tpu_use_sudo: False
- tpu_env: []
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help?
@younesbelkada
@muellerzr
@pacman100
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
The trainer setup is like this.
The trainer saves checkpoints every 100 steps and does an evaluation of accuracy and F1.
```
q_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForSequenceClassification.from_pretrained(
"meta-llama/Llama-2-13b-hf",
quantization_config=q_config,
device_map="auto",
num_labels=n_labels,
)
model.config.pad_token_id = tokenizer.pad_token_id
model.config.use_cache = False
peft_config = LoraConfig(
r=16,
lora_alpha=64,
lora_dropout=0.1,
bias="none",
task_type=TaskType.SEQ_CLS,
target_modules=['v_proj', 'down_proj', 'up_proj', 'q_proj', 'gate_proj', 'k_proj', 'o_proj']
)
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, peft_config)
training_args = TrainingArguments(...)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=ds_train,
eval_dataset=ds_test,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
)
trainer.train()
trainer.save_model("final-checkpoint")
```
I load the final checkpoint as follows. Note I've tried all the other possible ways to load the model as well. The problem is not in the loading.
```
model = AutoModelForSequenceClassification.from_pretrained(
"final-checkpoint",
device_map="auto",
num_labels=n_labels,
quantization_config=q_config
)
```
When I do inference with this model on the same test dataset used during training, the loss, F1 and accuracy are really bad compared to the output of the training evaluator.
The modules in the trained model look like this:
```
(score): ModulesToSaveWrapper(
(original_module): Linear(in_features=5120, out_features=647, bias=False)
(modules_to_save): ModuleDict(
(default): Linear(in_features=5120, out_features=647, bias=False)
)
)
```
What is being saved to the checkpoints is `score.modules_to_save.default`.
If I dump `score.original_module.weight` to a file and load it in a model instantiated from a checkpoint, I get the original loss and metrics.
For example (skipped some steps):
```
# on trained model
orig_weights = trained_model.model.score.original_module.weight.cpu().detach()
# on checkpoint model:
checkpoint_model.score.load_state_dict({"weight": orig_weights})
```
See also https://discuss.huggingface.co/t/llama-2-sequence-classification-much-lower-accuracy-on-inference-from-checkpoint-compared-to-model/54910/2
### Expected behavior
Metrics and loss during inference based off a checkpoint should be comparable to the evaluation during training with the same test dataset.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26160/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26160/timeline
|
reopened
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26159
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26159/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26159/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26159/events
|
https://github.com/huggingface/transformers/issues/26159
| 1,895,788,365 |
I_kwDOCUB6oc5w_29N
| 26,159 |
Bug report in resume training using Trainer and FSDP
|
{
"login": "Yuanhy1997",
"id": 43648608,
"node_id": "MDQ6VXNlcjQzNjQ4NjA4",
"avatar_url": "https://avatars.githubusercontent.com/u/43648608?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Yuanhy1997",
"html_url": "https://github.com/Yuanhy1997",
"followers_url": "https://api.github.com/users/Yuanhy1997/followers",
"following_url": "https://api.github.com/users/Yuanhy1997/following{/other_user}",
"gists_url": "https://api.github.com/users/Yuanhy1997/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Yuanhy1997/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Yuanhy1997/subscriptions",
"organizations_url": "https://api.github.com/users/Yuanhy1997/orgs",
"repos_url": "https://api.github.com/users/Yuanhy1997/repos",
"events_url": "https://api.github.com/users/Yuanhy1997/events{/privacy}",
"received_events_url": "https://api.github.com/users/Yuanhy1997/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! Could you share a reproducer here? (even if it is the same) \r\n",
"Sorry, I cannot share the log because I am using the machines in a company. But I am using the 4.33.0 version transformers and the up-to-date accelerator. The training is a distributed training on 4 nodes with 8 gpus on each. I am using the FSDP in a full shard and auto wrap manner. The saved checkpoint is saved by the Trainer setting the saving strategy as 'steps'.\r\n\r\nThen when I am using the Trainer to resume training, which is setting the args True in the train() function, I will encounter the error. I think this can be easily reproduced. I figure this out according the mentioned modification. \r\n\r\nThe reason there would be a Type error of None is that the FSDP function of load parameter will check is the sharding strategy of the saved weights is the same as the current model to load to. In Trainer, this all happens before prepare the model with accelerate. ",
"also ccing @muellerzr for trainer 😉 ",
"Hi, I'm also running into the exact same error. Would be great if there is a permanent fix. I did check the `fsdp_plugin.state_dict_type` that is passed in through https://github.com/huggingface/accelerate/blob/main/src/accelerate/utils/fsdp_utils.py and then into https://pytorch.org/docs/stable/fsdp.html#torch.distributed.fsdp.FullyShardedDataParallel.set_state_dict_type. It was passed in correctly at first but after a few iterations it becomes None, which may be causing the issue. \r\n\r\nI temporarily implemented this fix by @winglian (https://github.com/OpenAccess-AI-Collective/axolotl/pull/400/files#diff-0b142e48f0c0b4bdf2677ce86ee6352c3a5e5a3a9ddf22020a2920f496f74d2eR29). It gets past the error, but hangs on actually resuming the run. \r\n\r\nMoreover, I'm also wondering if it's possible to resume training on a different machine. For example, if I saved the previous FSDP using distributed on 2 nodes, can I resume the checkpoint on 3 nodes? \r\n\r\nThanks. ",
"Yes, at first it checks the fsdp strategy of your program about to use (ie, fsdp_plugin.state_dict_type). Then the type becomes none because the program starts to check the model's FSDP strategy and the accelerator hasn't prepared it with FSDP. \r\n\r\nI think It would be an issue if you save with 2 nodes and resume with 3 nodes, since the rng_state would have a mismatching issue of partitions.",
"Got it. Is it possible to reset the rng_states to resume on the 3 nodes? ",
"I have never tried it. But I think there would be a way......",
"cc @pacman100 for fsdp",
"Might be relevant to check #26180 as well ",
"Fixed in PR https://github.com/huggingface/transformers/pull/26180"
] | 1,694 | 1,695 | 1,695 |
NONE
| null |
@pacman100 I'm also running into a similar error with the latest main branch:
```
File "/home/hyen/.conda/envs/cross/lib/python3.10/site-packages/torch/distributed/fsdp/fully_sharded_data_parallel.py", line 608, in set_state_dict_type
state_dict_config_type = _state_dict_type_to_config[state_dict_type]
KeyError: None
```
_Originally posted by @howard-yen in https://github.com/huggingface/transformers/issues/25100#issuecomment-1696602953_
I met the exact same error when resuming checkpoint for continuous training when using FSDP. This happens because in the pytorch FSDP load checkpoint function. The function has to check the model to load weights to is using the same FSDP strategy. But in the below lines in src/transformers/trainer.py (in the _inner_training_loop() func line 1963-1964)
```
if (is_sagemaker_mp_enabled() or self.is_fsdp_enabled) and resume_from_checkpoint is not None:
self._load_from_checkpoint(resume_from_checkpoint, model)
```
these lines happen before the accelerator prepares the models. After I move the lines after the accelerator.prepare(model), the resuming works fine for me.
Hope this can be fixed properly, because I don't know naively moving these lines below accelerator.prepare would cause any troubles for sagmakes_mp.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26159/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26159/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26158
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26158/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26158/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26158/events
|
https://github.com/huggingface/transformers/pull/26158
| 1,895,410,419 |
PR_kwDOCUB6oc5aSEKk
| 26,158 |
Llama128k support
|
{
"login": "AndreSlavescu",
"id": 51034490,
"node_id": "MDQ6VXNlcjUxMDM0NDkw",
"avatar_url": "https://avatars.githubusercontent.com/u/51034490?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AndreSlavescu",
"html_url": "https://github.com/AndreSlavescu",
"followers_url": "https://api.github.com/users/AndreSlavescu/followers",
"following_url": "https://api.github.com/users/AndreSlavescu/following{/other_user}",
"gists_url": "https://api.github.com/users/AndreSlavescu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AndreSlavescu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AndreSlavescu/subscriptions",
"organizations_url": "https://api.github.com/users/AndreSlavescu/orgs",
"repos_url": "https://api.github.com/users/AndreSlavescu/repos",
"events_url": "https://api.github.com/users/AndreSlavescu/events{/privacy}",
"received_events_url": "https://api.github.com/users/AndreSlavescu/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,694 | 1,694 | 1,694 |
NONE
| null | null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26158/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26158/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26158",
"html_url": "https://github.com/huggingface/transformers/pull/26158",
"diff_url": "https://github.com/huggingface/transformers/pull/26158.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26158.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/26157
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26157/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26157/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26157/events
|
https://github.com/huggingface/transformers/issues/26157
| 1,895,401,540 |
I_kwDOCUB6oc5w-YhE
| 26,157 |
FSDP Model loading with accelerate results in crash (OOM)
|
{
"login": "jphme",
"id": 2862336,
"node_id": "MDQ6VXNlcjI4NjIzMzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/2862336?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jphme",
"html_url": "https://github.com/jphme",
"followers_url": "https://api.github.com/users/jphme/followers",
"following_url": "https://api.github.com/users/jphme/following{/other_user}",
"gists_url": "https://api.github.com/users/jphme/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jphme/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jphme/subscriptions",
"organizations_url": "https://api.github.com/users/jphme/orgs",
"repos_url": "https://api.github.com/users/jphme/repos",
"events_url": "https://api.github.com/users/jphme/events{/privacy}",
"received_events_url": "https://api.github.com/users/jphme/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hello, can you share the training code? Please make sure that torch distributed process group is already initialized before loading the pretrained model. When using Trainer, make sure the object of `TrainingArguments` is created before loading the pretrained model as it initializes the torch-distributed process group. \r\n\r\n```\r\ntraining_arguments = TrainingArguments(\r\n ...\r\n )\r\n\r\nmodel = AutoModelForCausalLM.from_pretrained()\r\n...\r\n```\r\n\r\nThis is because we want only the main process to have the pretrained model loaded and all other processes to have empty weights. For this to happen, the process group needs to be initialized via `torch.distributed.init_process_group` which happens when creating an object of `TrainingArguments`. See the check here needed for RAM efficient FSDP loading \r\n\r\nhttps://github.com/huggingface/transformers/blob/05de038f3d249ce96740885f85fd8d0aa00c29bc/src/transformers/modeling_utils.py#L122-L127\r\n",
"Many thanks, this solved my issue (and had a small configuration issue which overwrote some config flags) - FSDP is now finally working!"
] | 1,694 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.34.0.dev0
- Platform: Linux-5.4.0-156-generic-x86_64-with-glibc2.35
- Python version: 3.9.18
- Huggingface_hub version: 0.17.1
- Safetensors version: 0.3.3
- Accelerate version: 0.23.0.dev0
- Accelerate config: https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/configs/fsdp_config.yaml
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: y
- Using distributed or parallel set-up in script?: FSDP
### Who can help?
@pacman100
When trying to start a full FT of Llama 7b on an 4*V100s instance (using [this](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/configs/fsdp_config.yaml) config without bf16, also tried other variations e.g. with `fsdp_transformer_layer_cls_to_wrap: LlamaDecoderLayer` ) with accelerate, CPU ram fills until process termination.
I though that https://github.com/huggingface/transformers/pull/25107 should have solved this, but whatever I do, can't get it to work. Could the Volta arch be a reason for this?
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
accelerate config:
```
compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: FSDP
downcast_bf16: 'no'
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch_policy: BACKWARD_PRE
fsdp_forward_prefetch: true
fsdp_offload_params: true
fsdp_sharding_strategy: 1
fsdp_state_dict_type: SHARDED_STATE_DICT
fsdp_sync_module_states: true
fsdp_use_orig_params: true
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: 'no'
num_machines: 1
num_processes: 4
use_cpu: false
```
seq_len 2048, llama2-7b, happens with different datasets, 4* V100s, 173GB ram
### Expected behavior
Model loads and finetuning works with FSDP
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26157/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26157/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26156
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26156/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26156/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26156/events
|
https://github.com/huggingface/transformers/issues/26156
| 1,895,397,834 |
I_kwDOCUB6oc5w-XnK
| 26,156 |
Number of tokens mismatch for CodeLlama-34b-hf
|
{
"login": "irenedea",
"id": 14367635,
"node_id": "MDQ6VXNlcjE0MzY3NjM1",
"avatar_url": "https://avatars.githubusercontent.com/u/14367635?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/irenedea",
"html_url": "https://github.com/irenedea",
"followers_url": "https://api.github.com/users/irenedea/followers",
"following_url": "https://api.github.com/users/irenedea/following{/other_user}",
"gists_url": "https://api.github.com/users/irenedea/gists{/gist_id}",
"starred_url": "https://api.github.com/users/irenedea/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/irenedea/subscriptions",
"organizations_url": "https://api.github.com/users/irenedea/orgs",
"repos_url": "https://api.github.com/users/irenedea/repos",
"events_url": "https://api.github.com/users/irenedea/events{/privacy}",
"received_events_url": "https://api.github.com/users/irenedea/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @ArthurZucker maybe you know what is going on here?",
"Hey! This model does not support `infilling`, but the correct tokenizer was not pushed to the hub. I'll do that asap.\r\nAlso your expectation that `len(tokenizer)` == `config.vocab_size` is not necessarily correct. Some models have unused embedding (if they padded the embedding for performances for example) while some tokenizers have holes and thus don't account for the full range of the embedding dimension. ",
"Ah yeah, equality is not correct but `config.vocab_size` should be greater than or equal to `len(tokenizer)`, yeah?",
"yep, in this specific case the 4 special tokens should not be added! ",
"Great, thanks!",
"Thanks @ArthurZucker!",
"Hey @ArthurZucker, I wanted to flag another issue, reproduced with the following:\r\n```\r\nfrom transformers import AutoTokenizer, CodeLlamaTokenizerFast\r\nmodel = 'codellama/CodeLlama-34b-hf'\r\ntokenizer = AutoTokenizer.from_pretrained(model, revision='81acc49ea9e2e851b1d1f33dacd763816ce7fbe4')\r\n\r\nassert isinstance(tokenizer, CodeLlamaTokenizerFast)\r\nprint(tokenizer.encode_plus('hello')) # Errors\r\n```\r\nThe following error occurs in CodeLlamaTokenizerFast.encode_plus (L298) because tokenizer.fill_token is None.\r\n`TypeError: 'in <string>' requires string as left operand, not NoneType`",
"Yep, this needs changes in the tokenizer, will open a PR ! \r\n"
] | 1,694 | 1,696 | 1,696 |
NONE
| null |
### System Info
- huggingface_hub version: 0.16.4
- Platform: macOS-13.5-arm64-arm-64bit
- Python version: 3.11.5
- Running in iPython ?: No
- Running in notebook ?: No
- Running in Google Colab ?: No
- Token path ?: /Users/irene.dea/.cache/huggingface/token
- Has saved token ?: False
- Configured git credential helpers: osxkeychain
- FastAI: N/A
- Tensorflow: N/A
- Torch: 2.0.1
- Jinja2: 3.1.2
- Graphviz: N/A
- Pydot: N/A
- Pillow: 10.0.0
- hf_transfer: N/A
- gradio: N/A
- tensorboard: N/A
- numpy: 1.25.2
- pydantic: N/A
- aiohttp: 3.8.5
- ENDPOINT: https://huggingface.co
- HUGGINGFACE_HUB_CACHE: /Users/irene.dea/.cache/huggingface/hub
- HUGGINGFACE_ASSETS_CACHE: /Users/irene.dea/.cache/huggingface/assets
- HF_TOKEN_PATH: /Users/irene.dea/.cache/huggingface/token
- HF_HUB_OFFLINE: False
- HF_HUB_DISABLE_TELEMETRY: False
- HF_HUB_DISABLE_PROGRESS_BARS: None
- HF_HUB_DISABLE_SYMLINKS_WARNING: False
- HF_HUB_DISABLE_EXPERIMENTAL_WARNING: False
- HF_HUB_DISABLE_IMPLICIT_TOKEN: False
- HF_HUB_ENABLE_HF_TRANSFER: False
git-commit: 05de038
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
The number of tokens in the CodeLlama-34b-hf tokenizer is greater than vocab_size specified by the model config.
Additionally, when instantiating the tokenizer, the following message is output: `Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.`
To reproduce:
```
from transformers import AutoTokenizer, PretrainedConfig
model = 'codellama/CodeLlama-34b-hf'
tokenizer = AutoTokenizer.from_pretrained(model)
config = PretrainedConfig.from_pretrained(model)
assert len(tokenizer) == config.vocab_size
```
Ran with 05de038
### Expected behavior
I expect the number of tokens in my tokenizer and the vocab_size to be the same. In other words the assert in the reproduction example should pass.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26156/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26156/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26155
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26155/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26155/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26155/events
|
https://github.com/huggingface/transformers/pull/26155
| 1,895,362,188 |
PR_kwDOCUB6oc5aR599
| 26,155 |
Update docs to explain disabling callbacks using report_to
|
{
"login": "nebrelbug",
"id": 25597854,
"node_id": "MDQ6VXNlcjI1NTk3ODU0",
"avatar_url": "https://avatars.githubusercontent.com/u/25597854?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nebrelbug",
"html_url": "https://github.com/nebrelbug",
"followers_url": "https://api.github.com/users/nebrelbug/followers",
"following_url": "https://api.github.com/users/nebrelbug/following{/other_user}",
"gists_url": "https://api.github.com/users/nebrelbug/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nebrelbug/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nebrelbug/subscriptions",
"organizations_url": "https://api.github.com/users/nebrelbug/orgs",
"repos_url": "https://api.github.com/users/nebrelbug/repos",
"events_url": "https://api.github.com/users/nebrelbug/events{/privacy}",
"received_events_url": "https://api.github.com/users/nebrelbug/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26155). All of your documentation changes will be reflected on that endpoint.",
"@muellerzr sure! Just pushed that change."
] | 1,694 | 1,697 | 1,697 |
CONTRIBUTOR
| null |
# What does this PR do?
Fixes #26036. I added clarification to the Callback documentation page explaining how to "turn off" default callbacks using `TrainerArguments.report_to`.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- https://github.com/huggingface/transformers/issues/26036#issuecomment-1717603016
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@muellerzr @pacman100
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26155/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26155/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26155",
"html_url": "https://github.com/huggingface/transformers/pull/26155",
"diff_url": "https://github.com/huggingface/transformers/pull/26155.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26155.patch",
"merged_at": 1697025023000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26154
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26154/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26154/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26154/events
|
https://github.com/huggingface/transformers/issues/26154
| 1,895,352,367 |
I_kwDOCUB6oc5w-Mgv
| 26,154 |
IdeficsProcessor: Changing `image_size` will result in `RuntimeError`
|
{
"login": "xhluca",
"id": 21180505,
"node_id": "MDQ6VXNlcjIxMTgwNTA1",
"avatar_url": "https://avatars.githubusercontent.com/u/21180505?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/xhluca",
"html_url": "https://github.com/xhluca",
"followers_url": "https://api.github.com/users/xhluca/followers",
"following_url": "https://api.github.com/users/xhluca/following{/other_user}",
"gists_url": "https://api.github.com/users/xhluca/gists{/gist_id}",
"starred_url": "https://api.github.com/users/xhluca/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/xhluca/subscriptions",
"organizations_url": "https://api.github.com/users/xhluca/orgs",
"repos_url": "https://api.github.com/users/xhluca/repos",
"events_url": "https://api.github.com/users/xhluca/events{/privacy}",
"received_events_url": "https://api.github.com/users/xhluca/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Could you have a look into this @leot13 ? related to what you've been working on",
"Yes this is being solved in this [PR](https://github.com/huggingface/transformers/pull/26029). \r\nYou should be allowed to interpolate the embeddings. However the model was trained with a fixed image size of 224x224, so it's not guaranteed you'll have improvements in performance",
"Thanks. @leot13 what version should I upgrade to? If it's not released yet, let me know which version you plan to release it with.",
"You should install from source if you want to have this. It will be in the next release 😉 "
] | 1,694 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.33.0
- Platform: Linux-5.15.120+-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.0 (True)
- Tensorflow version (GPU?): 2.12.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.7.2 (gpu)
- Jax version: 0.4.13
- JaxLib version: 0.4.13
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@VictorSanh
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
If we change the `image_size` in the official example:
```python
import torch
from transformers import IdeficsForVisionText2Text, AutoProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
checkpoint = "HuggingFaceM4/tiny-random-idefics"
model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).to(device)
processor = AutoProcessor.from_pretrained(checkpoint, image_size=224*2)
# We feed to the model an arbitrary sequence of text strings and images. Images can be either URLs or PIL Images.
prompts = [
[
"User: What is in this image?",
"https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG",
"<end_of_utterance>",
"\nAssistant: This picture depicts Idefix, the dog of Obelix in Asterix and Obelix. Idefix is running on the ground.<end_of_utterance>",
"\nUser:",
"https://static.wikia.nocookie.net/asterix/images/2/25/R22b.gif/revision/latest?cb=20110815073052",
"And who is that?<end_of_utterance>",
"\nAssistant:",
],
]
# --batched mode
inputs = processor(prompts, add_end_of_utterance_token=False, return_tensors="pt").to(device)
# --single sample mode
# inputs = processor(prompts[0], return_tensors="pt").to(device)
# Generation args
exit_condition = processor.tokenizer("<end_of_utterance>", add_special_tokens=False).input_ids
bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
generated_ids = model.generate(**inputs, eos_token_id=exit_condition, bad_words_ids=bad_words_ids, max_length=100)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
for i, t in enumerate(generated_text):
print(f"{i}:\n{t}\n")
```
We get the following error:
```
RuntimeError: The size of tensor a (50177) must match the size of tensor b (226) at non-singleton dimension 1
```
Here's the full output:
```
[4]:
!transformers-cli env
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
/opt/conda/lib/python3.10/site-packages/scipy/__init__.py:146: UserWarning: A NumPy version >=1.16.5 and <1.23.0 is required for this version of SciPy (detected version 1.23.5
warnings.warn(f"A NumPy version >={np_minversion} and <{np_maxversion}"
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 4.33.0
- Platform: Linux-5.15.120+-x86_64-with-glibc2.35
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.0 (True)
- Tensorflow version (GPU?): 2.12.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.7.2 (gpu)
- Jax version: 0.4.13
- JaxLib version: 0.4.13
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
[3]:
import torch
from transformers import IdeficsForVisionText2Text, AutoProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
checkpoint = "HuggingFaceM4/tiny-random-idefics"
model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).to(device)
processor = AutoProcessor.from_pretrained(checkpoint, image_size=224*2)
[3]:
# We feed to the model an arbitrary sequence of text strings and images. Images can be either URLs or PIL Images.
prompts = [
[
"User: What is in this image?",
"https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG",
"<end_of_utterance>",
"\nAssistant: This picture depicts Idefix, the dog of Obelix in Asterix and Obelix. Idefix is running on the ground.<end_of_utterance>",
"\nUser:",
"https://static.wikia.nocookie.net/asterix/images/2/25/R22b.gif/revision/latest?cb=20110815073052",
"And who is that?<end_of_utterance>",
"\nAssistant:",
],
]
# --batched mode
inputs = processor(prompts, add_end_of_utterance_token=False, return_tensors="pt").to(device)
# --single sample mode
# inputs = processor(prompts[0], return_tensors="pt").to(device)
# Generation args
exit_condition = processor.tokenizer("<end_of_utterance>", add_special_tokens=False).input_ids
bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
generated_ids = model.generate(**inputs, eos_token_id=exit_condition, bad_words_ids=bad_words_ids, max_length=100)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
for i, t in enumerate(generated_text):
print(f"{i}:\n{t}\n")
Both `max_new_tokens` (=128) and `max_length`(=100) seem to have been set. `max_new_tokens` will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[3], line 37
34 exit_condition = processor.tokenizer("<end_of_utterance>", add_special_tokens=False).input_ids
35 bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
---> 37 generated_ids = model.generate(**inputs, eos_token_id=exit_condition, bad_words_ids=bad_words_ids, max_length=100)
38 generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
39 for i, t in enumerate(generated_text):
File /opt/conda/lib/python3.10/site-packages/torch/utils/_contextlib.py:115, in context_decorator.<locals>.decorate_context(*args, **kwargs)
112 @functools.wraps(func)
113 def decorate_context(*args, **kwargs):
114 with ctx_factory():
--> 115 return func(*args, **kwargs)
File /opt/conda/lib/python3.10/site-packages/transformers/generation/utils.py:1602, in GenerationMixin.generate(self, inputs, generation_config, logits_processor, stopping_criteria, prefix_allowed_tokens_fn, synced_gpus, assistant_model, streamer, negative_prompt_ids, negative_prompt_attention_mask, **kwargs)
1585 return self.assisted_decoding(
1586 input_ids,
1587 assistant_model=assistant_model,
(...)
1598 **model_kwargs,
1599 )
1600 if generation_mode == GenerationMode.GREEDY_SEARCH:
1601 # 11. run greedy search
-> 1602 return self.greedy_search(
1603 input_ids,
1604 logits_processor=logits_processor,
1605 stopping_criteria=stopping_criteria,
1606 pad_token_id=generation_config.pad_token_id,
1607 eos_token_id=generation_config.eos_token_id,
1608 output_scores=generation_config.output_scores,
1609 return_dict_in_generate=generation_config.return_dict_in_generate,
1610 synced_gpus=synced_gpus,
1611 streamer=streamer,
1612 **model_kwargs,
1613 )
1615 elif generation_mode == GenerationMode.CONTRASTIVE_SEARCH:
1616 if not model_kwargs["use_cache"]:
File /opt/conda/lib/python3.10/site-packages/transformers/generation/utils.py:2450, in GenerationMixin.greedy_search(self, input_ids, logits_processor, stopping_criteria, max_length, pad_token_id, eos_token_id, output_attentions, output_hidden_states, output_scores, return_dict_in_generate, synced_gpus, streamer, **model_kwargs)
2447 model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
2449 # forward pass to get next token
-> 2450 outputs = self(
2451 **model_inputs,
2452 return_dict=True,
2453 output_attentions=output_attentions,
2454 output_hidden_states=output_hidden_states,
2455 )
2457 if synced_gpus and this_peer_finished:
2458 continue # don't waste resources running the code we don't need
File /opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/conda/lib/python3.10/site-packages/transformers/models/idefics/modeling_idefics.py:1506, in IdeficsForVisionText2Text.forward(self, input_ids, attention_mask, position_ids, past_key_values, inputs_embeds, pixel_values, image_encoder_embeddings, perceiver_embeddings, image_attention_mask, labels, use_cache, output_attentions, output_hidden_states, return_dict)
1503 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
1505 # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
-> 1506 outputs = self.model(
1507 input_ids=input_ids,
1508 attention_mask=attention_mask,
1509 position_ids=position_ids,
1510 past_key_values=past_key_values,
1511 inputs_embeds=inputs_embeds,
1512 pixel_values=pixel_values,
1513 image_encoder_embeddings=image_encoder_embeddings,
1514 perceiver_embeddings=perceiver_embeddings,
1515 image_attention_mask=image_attention_mask,
1516 use_cache=use_cache,
1517 output_attentions=output_attentions,
1518 output_hidden_states=output_hidden_states,
1519 return_dict=return_dict,
1520 )
1522 hidden_states = outputs[0]
1523 logits = self.lm_head(hidden_states)
File /opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/conda/lib/python3.10/site-packages/transformers/models/idefics/modeling_idefics.py:1215, in IdeficsModel.forward(self, input_ids, attention_mask, position_ids, past_key_values, inputs_embeds, pixel_values, image_encoder_embeddings, perceiver_embeddings, image_attention_mask, use_cache, output_attentions, output_hidden_states, return_dict)
1212 pixel_values = pixel_values.contiguous().view(batch_size * num_images, *pixel_values.shape[2:])
1214 # Get sequence from the vision encoder
-> 1215 image_hidden_states = self.vision_model(pixel_values=pixel_values).last_hidden_state
1217 elif image_encoder_embeddings is not None:
1218 batch_size, num_images, image_seq_len, image_hidden_size = image_encoder_embeddings.size()
File /opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/conda/lib/python3.10/site-packages/transformers/models/idefics/vision.py:411, in IdeficsVisionTransformer.forward(self, pixel_values, output_attentions, output_hidden_states, return_dict)
408 if pixel_values is None:
409 raise ValueError("You have to specify pixel_values")
--> 411 hidden_states = self.embeddings(pixel_values)
412 hidden_states = self.pre_layrnorm(hidden_states)
414 encoder_outputs = self.encoder(
415 inputs_embeds=hidden_states,
416 output_attentions=output_attentions,
417 output_hidden_states=output_hidden_states,
418 return_dict=return_dict,
419 )
File /opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py:1501, in Module._call_impl(self, *args, **kwargs)
1496 # If we don't have any hooks, we want to skip the rest of the logic in
1497 # this function, and just call forward.
1498 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/conda/lib/python3.10/site-packages/transformers/models/idefics/vision.py:98, in IdeficsVisionEmbeddings.forward(self, pixel_values)
96 class_embeds = self.class_embedding.expand(batch_size, 1, -1)
97 embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
---> 98 embeddings = embeddings + self.position_embedding(self.position_ids)
99 return embeddings
RuntimeError: The size of tensor a (50177) must match the size of tensor b (226) at non-singleton dimension 1
```
### Expected behavior
224px is very low for images with finegrained details. We should be able to use bigger images (with more image patches).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26154/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26154/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26153
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26153/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26153/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26153/events
|
https://github.com/huggingface/transformers/issues/26153
| 1,895,308,925 |
I_kwDOCUB6oc5w-B59
| 26,153 |
BitsAndBytes
|
{
"login": "Shikamaru5",
"id": 86502093,
"node_id": "MDQ6VXNlcjg2NTAyMDkz",
"avatar_url": "https://avatars.githubusercontent.com/u/86502093?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Shikamaru5",
"html_url": "https://github.com/Shikamaru5",
"followers_url": "https://api.github.com/users/Shikamaru5/followers",
"following_url": "https://api.github.com/users/Shikamaru5/following{/other_user}",
"gists_url": "https://api.github.com/users/Shikamaru5/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Shikamaru5/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Shikamaru5/subscriptions",
"organizations_url": "https://api.github.com/users/Shikamaru5/orgs",
"repos_url": "https://api.github.com/users/Shikamaru5/repos",
"events_url": "https://api.github.com/users/Shikamaru5/events{/privacy}",
"received_events_url": "https://api.github.com/users/Shikamaru5/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey 🤗 thanks for opening an issue! We try to keep the github issues for bugs/feature requests.\r\nCould you ask your question on the [forum](https://discuss.huggingface.co/) instead? I'm sure the community will be of help!\r\nYou can also ping @younesbelkada there. \r\nThanks!",
"Ok sounds good thanks, I just added the question on the forum.",
"+1 I amended the forum discussion but to me looks more like a bug.",
"cc @younesbelkada maybe just update the warning to include `4bits` ",
"I'm not too sure but I added this to bnb_config: load_in_8bit_fp32_cpu_offload=True and then I created a custom device_map with every single layer of the model to the gpu which ended up being around 456 layers, but it seems to have loaded now, yay me!",
"well if we specifically don't want any kind of offload (hence leave this flag to False) then I think there is no reason why this warning should pop up, but maybe I am missing something.",
"Hey there! \r\nI think passing `load_in_8bit_fp32_cpu_offload` also works for 4bit models, if that's the case I agree it is confusing, we should add a new arg `load_in_4bit_fp32_cpu_offload` that would behave exactly as the 8-bit arg. I can work on that and propose a fix. I will keep you posted"
] | 1,694 | 1,694 | 1,694 |
NONE
| null |
I'm trying to run my model with:
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
Trouble is when I run it I get an error about some modules are dispatched on the CPU or the disk. If you want to dispatch the model on the CPU or the disk while keeping these modules in 32-bit, you need to set `load_in_8bit_fp32_cpu_offload=True` and pass a custom `device_map` to `from_pretrained`
Looking into it on hugging_face and goodle, and some of the code in modeling_utils.py. I didn't see anything that suggested you could do something like 'load_in_4bit_fp32_cpu_offload=True' or something along those lines. I'm guessing it isn't a feature yet, or maybe coming? If anyone has any ideas about that I'd be really grateful. I'm going to test the 8bit thing and see if that's enough but I'm not totally certain that 8bits will be low enough to load the model unfortunately.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26153/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26153/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26152
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26152/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26152/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26152/events
|
https://github.com/huggingface/transformers/pull/26152
| 1,895,222,521 |
PR_kwDOCUB6oc5aRbm7
| 26,152 |
refactor decay_parameters production into its own function
|
{
"login": "shijie-wu",
"id": 2987758,
"node_id": "MDQ6VXNlcjI5ODc3NTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2987758?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shijie-wu",
"html_url": "https://github.com/shijie-wu",
"followers_url": "https://api.github.com/users/shijie-wu/followers",
"following_url": "https://api.github.com/users/shijie-wu/following{/other_user}",
"gists_url": "https://api.github.com/users/shijie-wu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shijie-wu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shijie-wu/subscriptions",
"organizations_url": "https://api.github.com/users/shijie-wu/orgs",
"repos_url": "https://api.github.com/users/shijie-wu/repos",
"events_url": "https://api.github.com/users/shijie-wu/events{/privacy}",
"received_events_url": "https://api.github.com/users/shijie-wu/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26152). All of your documentation changes will be reflected on that endpoint.",
"Hey sorry for the late reply, I'll have look"
] | 1,694 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
# What does this PR do?
Fixes #26145
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? https://github.com/huggingface/transformers/issues/26145
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@muellerzr @ArthurZucker
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26152/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26152/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26152",
"html_url": "https://github.com/huggingface/transformers/pull/26152",
"diff_url": "https://github.com/huggingface/transformers/pull/26152.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26152.patch",
"merged_at": 1695051611000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26151
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26151/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26151/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26151/events
|
https://github.com/huggingface/transformers/pull/26151
| 1,895,197,203 |
PR_kwDOCUB6oc5aRWGi
| 26,151 |
Create the return value on device to avoid unnecessary copying from CPU
|
{
"login": "mksit",
"id": 25057334,
"node_id": "MDQ6VXNlcjI1MDU3MzM0",
"avatar_url": "https://avatars.githubusercontent.com/u/25057334?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mksit",
"html_url": "https://github.com/mksit",
"followers_url": "https://api.github.com/users/mksit/followers",
"following_url": "https://api.github.com/users/mksit/following{/other_user}",
"gists_url": "https://api.github.com/users/mksit/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mksit/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mksit/subscriptions",
"organizations_url": "https://api.github.com/users/mksit/orgs",
"repos_url": "https://api.github.com/users/mksit/repos",
"events_url": "https://api.github.com/users/mksit/events{/privacy}",
"received_events_url": "https://api.github.com/users/mksit/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I am sorry that I did not explain clearly. The tensor is created on `device=hidden_states.device`, but the current creation method has caused non-negligible overheads due to the data copying in my program, which can be seen in the following trace.\r\n\r\n\r\n\r\nThis overhead seems unnecessary, so I have suggested this change in this commit.\r\n\r\n\r\n",
"@mksit Are you sure the `aten::to` op is not there anymore when replacing `torch.Tensor` by `torch.zeros`? I generally don't trust pytorch profiler for the timing of `aten::to`. @NouamaneTazi may have more insights",
"@fxmarty The `aten::to` operation disappeared after the replacement in my case. What do you suggest for the profiling of `aten::to`?",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26151). All of your documentation changes will be reflected on that endpoint."
] | 1,694 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
# What does this PR do?
`router_tuple = (torch.tensor([0], device=hidden_states.device),)` introduces an unnecessary data copy from the CPU. I have changed it to create the return tensor on the device to avoid potential performance issues.
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26151/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26151/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26151",
"html_url": "https://github.com/huggingface/transformers/pull/26151",
"diff_url": "https://github.com/huggingface/transformers/pull/26151.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26151.patch",
"merged_at": 1695073573000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26150
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26150/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26150/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26150/events
|
https://github.com/huggingface/transformers/pull/26150
| 1,894,936,278 |
PR_kwDOCUB6oc5aQctX
| 26,150 |
cache umt5 bias computation
|
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] |
open
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26150). All of your documentation changes will be reflected on that endpoint.",
"This is great @ArthurZucker! My new results are:\r\n\r\n```\r\nComparing to facebook/mbart-large-50-many-to-one-mmt: (for pseed, higher is slower)\r\n\r\ngoogle/umt5-small: 22.08% (relative speed); 50.19% (relative size) -- speed used to be 975.10%!\r\ngoogle/mt5-small: 12.57% (relative speed); 49.14% (relative size)\r\nt5-small: 32.21% (relative speed); 9.90% (relative size)\r\n```\r\n\r\nThat's like a 45x improvement?! :o\r\n\r\nI know I'm probably _too_ excited but any idea when this can be merged? Or is https://github.com/huggingface/transformers/issues/23145 blocking this?",
"The linked issue is blocking + for now the output is garbage, working on this 😉 ",
"Ah great, I'll have some patience and keep an eye out to the progress here. ",
"Bump to keep active",
"Thanks! Did not have time to improve this yet :( ",
"> Thanks! Did not have time to improve this yet :(\r\n\r\nNo worries! I'll just keep bumping this when it becomes marked as stale until you find some time! (Or if you want to just close this that's only fine ofc) "
] | 1,694 | 1,704 | null |
COLLABORATOR
| null |
# What does this PR do?
Should fix #26144, by caching the relative bias and only returning the one that is required for the current computation.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26150/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26150/timeline
| null | true |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26150",
"html_url": "https://github.com/huggingface/transformers/pull/26150",
"diff_url": "https://github.com/huggingface/transformers/pull/26150.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26150.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/26149
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26149/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26149/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26149/events
|
https://github.com/huggingface/transformers/pull/26149
| 1,894,810,529 |
PR_kwDOCUB6oc5aQBbd
| 26,149 |
[Whisper] Allow basic text normalization
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Gently pinging @ArthurZucker since this one might have slipped through the net!",
"I don't agree with using one argument! See the original comment for the rationales for using two arguments: https://github.com/huggingface/transformers/pull/26149#issue-1894810529"
] | 1,694 | 1,696 | 1,696 |
CONTRIBUTOR
| null |
# What does this PR do?
Supersedes #20707. This PR adds the option of performing **basic** text normalisation, which is used for multilingual decoding. Rather than replacing English text normalisation altogether, we add it as an alternative option. The rationale for this is:
1. Users running a multilingual checkpoint (e.g. large-v2) might still want to apply the English normaliser if they are using it for English ASR
2. Prevent a breaking change in the API, where passing `normalize=True` switches from using the English normaliser to the basic normalizer silently
=> instead, we add a new argument `basic_normalizer`, which can be toggled to enable/disable basic text normalisation
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26149/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26149/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26149",
"html_url": "https://github.com/huggingface/transformers/pull/26149",
"diff_url": "https://github.com/huggingface/transformers/pull/26149.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26149.patch",
"merged_at": 1696352237000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26148
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26148/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26148/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26148/events
|
https://github.com/huggingface/transformers/issues/26148
| 1,894,785,281 |
I_kwDOCUB6oc5w8CEB
| 26,148 |
Deepspeed optimizer initalization fails (AttributeError: 'DummyOptim' object has no attribute 'step')
|
{
"login": "jphme",
"id": 2862336,
"node_id": "MDQ6VXNlcjI4NjIzMzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/2862336?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jphme",
"html_url": "https://github.com/jphme",
"followers_url": "https://api.github.com/users/jphme/followers",
"following_url": "https://api.github.com/users/jphme/following{/other_user}",
"gists_url": "https://api.github.com/users/jphme/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jphme/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jphme/subscriptions",
"organizations_url": "https://api.github.com/users/jphme/orgs",
"repos_url": "https://api.github.com/users/jphme/repos",
"events_url": "https://api.github.com/users/jphme/events{/privacy}",
"received_events_url": "https://api.github.com/users/jphme/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"so how to solve it\r\n",
"Hello, I did the following and things work as expected:\r\n\r\n1. vim ds_config_issue_26148.json\r\n```\r\n{\r\n \"zero_optimization\": {\r\n \"stage\": 2,\r\n \"contiguous_gradients\": true,\r\n \"offload_optimizer\": {\r\n \"device\": \"cpu\",\r\n \"pin_memory\": true\r\n },\r\n \"overlap_comm\": true,\r\n \"allgather_partitions\": true,\r\n \"allgather_bucket_size\": 5e8,\r\n \"reduce_scatter\": true,\r\n \"reduce_bucket_size\": 5e8\r\n },\r\n \"bf16\": {\r\n \"enabled\": \"auto\"\r\n },\r\n \"fp16\": {\r\n \"enabled\": \"auto\",\r\n \"loss_scale\": 0,\r\n \"initial_scale_power\": 32,\r\n \"loss_scale_window\": 1000,\r\n \"hysteresis\": 2,\r\n \"min_loss_scale\": 1\r\n },\r\n \"optimizer\": {\r\n \"type\": \"Adam\",\r\n \"params\": {\r\n \"lr\": 0.00001,\r\n \"betas\": [\r\n 0.9,\r\n 0.999\r\n ],\r\n \"eps\": 1e-8,\r\n \"weight_decay\": 0.1\r\n }\r\n },\r\n \"scheduler\": {\r\n \"type\": \"WarmupDecayLR\",\r\n \"params\": {\r\n \"warmup_min_lr\": \"auto\",\r\n \"warmup_max_lr\": \"auto\",\r\n \"warmup_num_steps\": \"auto\",\r\n \"total_num_steps\": \"auto\"\r\n }\r\n },\r\n \"gradient_accumulation_steps\": \"auto\",\r\n \"gradient_clipping\": \"auto\",\r\n \"train_batch_size\": \"auto\",\r\n \"train_micro_batch_size_per_gpu\": \"auto\",\r\n \"wall_clock_breakdown\": false,\r\n \"flops_profiler\": {\r\n \"enabled\": false,\r\n \"detailed\": false\r\n } \r\n}\r\n```\r\n\r\n2. `accelerate config --config_file config.yaml`:\r\n```\r\ncompute_environment: LOCAL_MACHINE\r\ndebug: false\r\ndeepspeed_config:\r\n deepspeed_config_file: ds_config_issue_26148.json\r\n zero3_init_flag: true\r\ndistributed_type: DEEPSPEED\r\ndowncast_bf16: 'no'\r\nmachine_rank: 0\r\nmain_training_function: main\r\nnum_machines: 1\r\nnum_processes: 2\r\nrdzv_backend: static\r\nsame_network: true\r\ntpu_env: []\r\ntpu_use_cluster: false\r\ntpu_use_sudo: false\r\nuse_cpu: false\r\n```\r\n\r\n3. running below commands:\r\n```\r\nexport TASK_NAME=mrpc\r\nexport WANDB_DISABLED=\"true\"\r\n\r\n accelerate launch --config_file ds_config.yaml ./examples/pytorch/text-classification/run_glue.py --model_name_or_path bert-base-cased --task_name $TASK_NAME --do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 16 --learning_rate 1e-05 --weight_decay 0.1 --num_train_epochs 3 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --bf16\r\n```\r\n\r\noutput logs:\r\n```\r\n[2023-10-02 08:36:56,659] [INFO] [config.py:957:print_user_config] json = {\r\n \"zero_optimization\": {\r\n \"stage\": 2, \r\n \"contiguous_gradients\": true, \r\n \"offload_optimizer\": {\r\n \"device\": \"cpu\", \r\n \"pin_memory\": true\r\n }, \r\n \"overlap_comm\": true, \r\n \"allgather_partitions\": true, \r\n \"allgather_bucket_size\": 5.000000e+08, \r\n \"reduce_scatter\": true, \r\n \"reduce_bucket_size\": 5.000000e+08\r\n }, \r\n \"bf16\": {\r\n \"enabled\": true\r\n }, \r\n \"fp16\": {\r\n \"enabled\": false, \r\n \"loss_scale\": 0, \r\n \"initial_scale_power\": 32, \r\n \"loss_scale_window\": 1000, \r\n \"hysteresis\": 2, \r\n \"min_loss_scale\": 1\r\n }, \r\n \"optimizer\": {\r\n \"type\": \"Adam\", \r\n \"params\": {\r\n \"lr\": 1e-05, \r\n \"betas\": [0.9, 0.999], \r\n \"eps\": 1e-08, \r\n \"weight_decay\": 0.1\r\n }\r\n }, \r\n \"scheduler\": {\r\n \"type\": \"WarmupDecayLR\", \r\n \"params\": {\r\n \"warmup_min_lr\": 0, \r\n \"warmup_max_lr\": 1e-05, \r\n \"warmup_num_steps\": 0, \r\n \"total_num_steps\": 345\r\n }\r\n }, \r\n \"gradient_accumulation_steps\": 1, \r\n \"gradient_clipping\": 1.0, \r\n \"train_batch_size\": 32, \r\n \"train_micro_batch_size_per_gpu\": 16, \r\n \"wall_clock_breakdown\": false, \r\n \"flops_profiler\": {\r\n \"enabled\": false, \r\n \"detailed\": false\r\n }, \r\n \"steps_per_print\": inf\r\n}\r\n[INFO|trainer.py:1760] 2023-10-02 08:36:56,659 >> ***** Running training *****\r\n[INFO|trainer.py:1761] 2023-10-02 08:36:56,659 >> Num examples = 3,668\r\n[INFO|trainer.py:1762] 2023-10-02 08:36:56,659 >> Num Epochs = 3\r\n[INFO|trainer.py:1763] 2023-10-02 08:36:56,659 >> Instantaneous batch size per device = 16\r\n[INFO|trainer.py:1766] 2023-10-02 08:36:56,659 >> Total train batch size (w. parallel, distributed & accumulation) = 32\r\n[INFO|trainer.py:1767] 2023-10-02 08:36:56,659 >> Gradient Accumulation steps = 1\r\n[INFO|trainer.py:1768] 2023-10-02 08:36:56,659 >> Total optimization steps = 345\r\n[INFO|trainer.py:1769] 2023-10-02 08:36:56,660 >> Number of trainable parameters = 108,311,810\r\n 0%| | 0/345 [00:00<?, ?it/s]/home/sourab/miniconda3/envs/hf/lib/python3.10/site-packages/deepspeed/runtime/zero/stage_1_and_2.py:1886: UserWarning: The torch.cuda.*DtypeTensor constructors are no longer recommended. It's best to use methods such as torch.tensor(data, dtype=*, device='cuda') to create tensors. (Triggered internally at ../torch/csrc/tensor/python_tensor.cpp:83.)\r\n overflow_gpu = get_accelerator().ByteTensor([overflow])\r\n/home/sourab/miniconda3/envs/hf/lib/python3.10/site-packages/deepspeed/runtime/zero/stage_1_and_2.py:1886: UserWarning: The torch.cuda.*DtypeTensor constructors are no longer recommended. It's best to use methods such as torch.tensor(data, dtype=*, device='cuda') to create tensors. (Triggered internally at ../torch/csrc/tensor/python_tensor.cpp:83.)\r\n overflow_gpu = get_accelerator().ByteTensor([overflow])\r\n100%|████████████████████████████████████████████████████████████████████████████████████████| 345/345 [01:15<00:00, 4.62it/s][INFO|trainer.py:2017] 2023-10-02 08:38:12,075 >> \r\n\r\nTraining completed. Do not forget to share your model on huggingface.co/models =)\r\n\r\n\r\n{'train_runtime': 75.4148, 'train_samples_per_second': 145.913, 'train_steps_per_second': 4.575, 'train_loss': 0.5232365262681159, 'epoch': 3.0}\r\n100%|████████████████████████████████████████████████████████████████████████████████████████| 345/345 [01:15<00:00, 4.57it/s]\r\n[INFO|trainer.py:2939] 2023-10-02 08:38:12,155 >> Saving model checkpoint to /tmp/mrpc/\r\n[INFO|configuration_utils.py:460] 2023-10-02 08:38:12,156 >> Configuration saved in /tmp/mrpc/config.json\r\n[INFO|modeling_utils.py:2114] 2023-10-02 08:38:12,454 >> Model weights saved in /tmp/mrpc/pytorch_model.bin\r\n[INFO|tokenization_utils_base.py:2445] 2023-10-02 08:38:12,455 >> tokenizer config file saved in /tmp/mrpc/tokenizer_config.json\r\n[INFO|tokenization_utils_base.py:2454] 2023-10-02 08:38:12,455 >> Special tokens file saved in /tmp/mrpc/special_tokens_map.json\r\n***** train metrics *****\r\n epoch = 3.0\r\n train_loss = 0.5232\r\n train_runtime = 0:01:15.41\r\n train_samples = 3668\r\n train_samples_per_second = 145.913\r\n train_steps_per_second = 4.575\r\n10/02/2023 08:38:12 - INFO - __main__ - *** Evaluate ***\r\n[INFO|trainer.py:761] 2023-10-02 08:38:12,491 >> The following columns in the evaluation set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: idx, sentence1, sentence2. If idx, sentence1, sentence2 are not expected by `BertForSequenceClassification.forward`, you can safely ignore this message.\r\n[INFO|trainer.py:3213] 2023-10-02 08:38:12,493 >> ***** Running Evaluation *****\r\n[INFO|trainer.py:3215] 2023-10-02 08:38:12,493 >> Num examples = 408\r\n[INFO|trainer.py:3218] 2023-10-02 08:38:12,493 >> Batch size = 8\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████| 26/26 [00:00<00:00, 85.34it/s]\r\n***** eval metrics *****\r\n epoch = 3.0\r\n eval_accuracy = 0.7966\r\n eval_combined_score = 0.8256\r\n eval_f1 = 0.8546\r\n eval_loss = 0.4453\r\n eval_runtime = 0:00:00.31\r\n eval_samples = 408\r\n eval_samples_per_second = 1281.051\r\n eval_steps_per_second = 81.636\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"The issue went away with newer library versions, many thanks.",
"> The issue went away with newer library versions, many thanks.\r\n\r\n\r\nHave you discovered any answers to the issue you mentioned? It appears I've run into the same problem : \"tried to get the lr value before the scheduler/optimizer began stepping, resulting in lr=0.\""
] | 1,694 | 1,703 | 1,698 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.34.0.dev0
- Platform: Linux-5.4.0-156-generic-x86_64-with-glibc2.35
- Python version: 3.9.18
- Huggingface_hub version: 0.17.1
- Safetensors version: 0.3.3
- Accelerate version: 0.23.0.dev0
- Accelerate config: yes
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?:4*V100
- Using distributed or parallel set-up in script?: deepspeed
### Who can help?
cc @pacman100
When trying to start a training with Deepspeed zero 2 and CPU offloading, optimizer initalization fails.
I get weird errors ("AttributeError: 'DummyOptim' object has no attribute 'step'" for single GPU, "tried to get lr value before scheduler/optimizer started stepping, returning lr=0 "for multi GPU) that I didn't get yesterday with the exact same config (but on a different server and I rebuilt the docker image with transformers from main).
I tried different configs ("standard" config, setting everything to "auto", setting everything to fixed values, Adam + AdamW) but the error persists.
Any idea what could be the reason for this?
EDIT: I am launching with `accelerate launch` . #24640 could be related.
Stacktrace
```
File "/workspace/axolotl/src/axolotl/train.py", line 120, in train
trainer.train(resume_from_checkpoint=resume_from_checkpoint)
File "/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/transformers/trainer.py", line 1575, in train
return inner_training_loop(
File "/root/miniconda3/envs/py3.9/lib/python3.9/site-packages/transformers/trainer.py", line 1954, in _inner_training_loop
self.optimizer.step()
AttributeError: 'DummyOptim' object has no attribute 'step'
```
Example config (as described above happens with different setups):
zero2.json
```
{
"zero_optimization": {
"stage": 2,
"contiguous_gradients": true,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"reduce_scatter": true,
"reduce_bucket_size": 5e8
},
"bf16": {
"enabled": "auto"
},
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"initial_scale_power": 32,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "Adam",
"params": {
"lr": 0.00001,
"betas": [
0.9,
0.999
],
"eps": 1e-8,
"weight_decay": 0.1
}
},
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto",
"total_num_steps": "auto"
}
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false,
"flops_profiler": {
"enabled": false,
"detailed": false
}
}
```
Trainer
```
gradient_accumulation_steps: 1
micro_batch_size: 1
num_epochs: 1
optimizer: paged_adamw_32bit
#adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.00001
```
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
see above
### Expected behavior
Deepspeed optimizer initalizes, as it did yesterday with the same params.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26148/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/26148/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26147
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26147/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26147/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26147/events
|
https://github.com/huggingface/transformers/pull/26147
| 1,894,720,271 |
PR_kwDOCUB6oc5aPtw1
| 26,147 |
Generate: ignore warning when `generation_config.max_length` is set to `None`
|
{
"login": "gante",
"id": 12240844,
"node_id": "MDQ6VXNlcjEyMjQwODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12240844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gante",
"html_url": "https://github.com/gante",
"followers_url": "https://api.github.com/users/gante/followers",
"following_url": "https://api.github.com/users/gante/following{/other_user}",
"gists_url": "https://api.github.com/users/gante/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gante/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gante/subscriptions",
"organizations_url": "https://api.github.com/users/gante/orgs",
"repos_url": "https://api.github.com/users/gante/repos",
"events_url": "https://api.github.com/users/gante/events{/privacy}",
"received_events_url": "https://api.github.com/users/gante/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,694 | 1,694 | 1,694 |
MEMBER
| null |
# What does this PR do?
As raised and suggested by our fellow @BramVanroy, ignores the warning complaining about both `max_new_tokens` and `max_length` being set when `generation_config.max_length is None`
This tackles needless warnings when users set the generation config like (e.g.):
```
gen_config = GenerationConfig.from_pretrained(
model_name,
max_new_tokens=200,
max_length=None, # because the model has some `max_length` defined and we don't want it
num_beams=1,
)
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26147/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26147/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26147",
"html_url": "https://github.com/huggingface/transformers/pull/26147",
"diff_url": "https://github.com/huggingface/transformers/pull/26147.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26147.patch",
"merged_at": 1694620258000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26146
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26146/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26146/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26146/events
|
https://github.com/huggingface/transformers/pull/26146
| 1,894,710,011 |
PR_kwDOCUB6oc5aPrfA
| 26,146 |
[TTA Pipeline] Test MusicGen and VITS
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"In order to make pipeline tests (those with tiny models) work, the tiny model should be in the file `tests/utils/tiny_model_summary.json`.\r\n\r\nSo far `MusicgenForConditionalGeneration` is on the Hub but not in this file. Same for `hf-internal-testing/tiny-random-VitsModel`.\r\n\r\nI will update this file later. ",
"Thanks @ydshieh! Is there a place where the tiny pipeline tests are documented? Or a way we can run this check automatically? I wasn't aware we needed to add them to `tiny_model_summary.json` too!",
"Hi @sanchit-gandhi \r\n\r\nIt is mentioned in [our internal notion doc](https://www.notion.so/huggingface2/Pipeline-Testing-in-transformers-87c5f26a2c3847ada94935878b77cc34#e2be051c13784bf8a459fd95674b1724)\r\n\r\n> - The file [[**tests/utils/tiny_model_summary.json](https://github.com/huggingface/transformers/blob/main/tests/utils/tiny_model_summary.json)](https://github.com/huggingface/transformers/blob/main/tests/utils/tiny_model_summary.json)** needs to be updated with the information about the new tiny models created/uploaded in the previous step.\r\n\r\n~ 1 year ago, we decided to make pipeline testing to use tiny models on `hf-internal-testing` (rather than creating them on the fly during testing). For some technical reasons, CI needs to access to `tiny_model_summary.json` which should be updated whenever some new architectures are available. Currently I check the results on a GitHub Action workflow once every 1 or 2 months and update this file.",
"Amazing! Thank you for the information 🤗"
] | 1,694 | 1,695 | 1,694 |
CONTRIBUTOR
| null |
# What does this PR do?
Add tiny-random pipeline tests for MusicGen and VITS
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26146/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26146/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26146",
"html_url": "https://github.com/huggingface/transformers/pull/26146",
"diff_url": "https://github.com/huggingface/transformers/pull/26146.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26146.patch",
"merged_at": 1694768436000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26145
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26145/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26145/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26145/events
|
https://github.com/huggingface/transformers/issues/26145
| 1,894,642,468 |
I_kwDOCUB6oc5w7fMk
| 26,145 |
allow easier user customizable `decay_parameters` in trainer
|
{
"login": "shijie-wu",
"id": 2987758,
"node_id": "MDQ6VXNlcjI5ODc3NTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2987758?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shijie-wu",
"html_url": "https://github.com/shijie-wu",
"followers_url": "https://api.github.com/users/shijie-wu/followers",
"following_url": "https://api.github.com/users/shijie-wu/following{/other_user}",
"gists_url": "https://api.github.com/users/shijie-wu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shijie-wu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shijie-wu/subscriptions",
"organizations_url": "https://api.github.com/users/shijie-wu/orgs",
"repos_url": "https://api.github.com/users/shijie-wu/repos",
"events_url": "https://api.github.com/users/shijie-wu/events{/privacy}",
"received_events_url": "https://api.github.com/users/shijie-wu/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2648621985,
"node_id": "MDU6TGFiZWwyNjQ4NjIxOTg1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Feature%20request",
"name": "Feature request",
"color": "FBCA04",
"default": false,
"description": "Request for a new feature"
}
] |
closed
| false | null |
[] |
[
"cc @muellerzr if you think this should be done? ",
"This *feels* like it's okay to me, but I'd need to see what the full implementation will look like @shijie-wu if you want to take a stab at it :) "
] | 1,694 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
### Feature request
allow easier user customizable `decay_parameters` in trainer
### Motivation
https://github.com/huggingface/transformers/blob/32ec7345f2d752c294ddf5aff495b657c9cd9d3b/src/transformers/trainer.py#L964-L965
Currently to modify `decay_parameters` for weight decay, user need to inherit and implement the entire `create_optimizer`. By refactor this two line into a function, user can modify `decay_parameters` much easier.
### Your contribution
if this sounds good, i am happy to submit a PR
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26145/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26145/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26144
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26144/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26144/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26144/events
|
https://github.com/huggingface/transformers/issues/26144
| 1,894,550,415 |
I_kwDOCUB6oc5w7IuP
| 26,144 |
UMT5 incredibly slow in generating
|
{
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] |
open
| false | null |
[] |
[
"Hey Thanks for reporting I'll investigate! \r\nNot sure why you would need to run 100 iterations of the `generate` method this way, but for one generation:\r\n- umt5: \r\n```python\r\n>>> start_time = time.time();model.generate(**encoded, generation_config=gen_config);print(time.time()-start_time)\r\n1.5145587921142578\r\n```\r\n\r\n- mbart: \r\n```python\r\n>>> start_time = time.time();model.generate(**encoded, generation_config=gen_config);print(time.time()-start_time)\r\n1.5777842998504639\r\n```\r\n\r\nFor 10 iterations:\r\n- umt5: `16.204639673233032`\r\n- mbart: 16.71877956390381\r\n\r\nso not sure if this is simply a bug in the time logging?",
"The same difference (around 9-10x) can be observed when leaving out the prefix for umT5.",
"also you can do `encoded = tokenizer(text, return_tensors=\"pt\").to(model.device)` 😉 ",
"I was not using device map = auto, might be the `_no_split_module` difference",
"I can't reproduce your results. Do you have accelerate installed? Can you share your `transformers-cli env`? @ArthurZucker ",
"I can reproduce your results using you exact script so will investigate anyway ! \r\n\r\n",
"Even without device_map and your other suggested changes, I still see a noticeable difference. A 4x difference for one generation. Attaching for reproducibility.\r\n\r\n```python\r\nimport gc\r\nimport time\r\nfrom tqdm import trange\r\nfrom transformers import AutoTokenizer, AutoModelForSeq2SeqLM, GenerationConfig\r\n\r\n\r\nif __name__ == \"__main__\":\r\n timings = {}\r\n\r\n for model_name in (\"facebook/mbart-large-50-many-to-one-mmt\", \"google/umt5-small\"):\r\n model = AutoModelForSeq2SeqLM.from_pretrained(model_name)\r\n model = model.to(\"cuda\")\r\n print(model_name, model.num_parameters())\r\n # google/umt5-small 306601984\r\n # facebook/mbart-large-50-many-to-one-mmt 1122990080\r\n tokenizer = AutoTokenizer.from_pretrained(model_name)\r\n gen_config = GenerationConfig.from_pretrained(\r\n model_name,\r\n max_new_tokens=200,\r\n max_length=None,\r\n num_beams=1,\r\n )\r\n text = \"I would really like to eat some cookies now.\"\r\n\r\n encoded = tokenizer(text, return_tensors=\"pt\").to(model.device)\r\n start_time = time.time()\r\n model.generate(**encoded, generation_config=gen_config)\r\n timings[model_name] = time.time() - start_time\r\n\r\n for model_name, timings in timings.items():\r\n print(f\"Generation duration for {model_name.split('/')[1]}:\\t{timings}\")\r\n # Generation duration for mbart-large-50-many-to-one-mmt: 0.4059898853302002\r\n # Generation duration for umt5-small: 1.7038893699645996\r\n\r\n```",
"Yep, the faulty function is `compute_bias` which if you remove it (so use a default positional bias) you have the same performances. This is kind of expected, but we should definitely try to use a caching mechanism for this",
"You should compare with `mt5` or `t5` which have similar architecture, bias etc 😉 ",
"New snippet! @ArthurZucker It compares umt5, t5, and mt5. It seems umt5 is definitely the outlier here\r\n\r\n```python\r\nimport gc\r\nimport time\r\nfrom statistics import mean\r\n\r\nfrom tqdm import trange\r\nfrom transformers import AutoTokenizer, AutoModelForSeq2SeqLM, GenerationConfig\r\n\r\n\r\nif __name__ == \"__main__\":\r\n timings = {}\r\n sizes = {}\r\n for model_name in (\"facebook/mbart-large-50-many-to-one-mmt\", \"google/umt5-small\", \"google/mt5-small\", \"t5-small\"):\r\n model = AutoModelForSeq2SeqLM.from_pretrained(model_name)\r\n sizes[model_name] = model.num_parameters()\r\n model = model.to(\"cuda\")\r\n tokenizer = AutoTokenizer.from_pretrained(model_name)\r\n gen_config = GenerationConfig.from_pretrained(\r\n model_name,\r\n max_new_tokens=200,\r\n max_length=None,\r\n num_beams=1,\r\n )\r\n text = \"I would really like to eat some cookies now.\"\r\n\r\n encoded = tokenizer(text, return_tensors=\"pt\").to(model.device)\r\n timings[model_name] = []\r\n for _ in trange(10):\r\n start_time = time.time()\r\n model.generate(**encoded, generation_config=gen_config)\r\n timings[model_name].append(time.time() - start_time)\r\n\r\n timings[model_name] = mean(timings[model_name])\r\n\r\n baseline_time = timings.pop(\"facebook/mbart-large-50-many-to-one-mmt\")\r\n baseline_size = sizes.pop(\"facebook/mbart-large-50-many-to-one-mmt\")\r\n\r\n print(\"Comparing to facebook/mbart-large-50-many-to-one-mmt:\")\r\n for model_name, timing in timings.items():\r\n size = sizes[model_name]\r\n print(f\"{model_name}:\\t {(timing*100/baseline_time):.2f}% (relative speed); {(size*100/baseline_size):.2f}% (relative size)\")\r\n\r\n```\r\n\r\nOutput (relative to `facebook/mbart-large-50-many-to-one-mmt`):\r\n\r\n```\r\ngoogle/umt5-small: 975.10% (relative gen. time); 50.19% (relative size)\r\ngoogle/mt5-small: 12.80% (relative gen. time); 49.14% (relative size)\r\nt5-small: 33.08% (relative gen. time); 9.90% (relative size)\r\n```\r\n\r\nInteresting to me that mt5 is so fast given it's size.",
"For ease-of-access:\r\n- t5: https://github.com/huggingface/transformers/blob/7ccac73f749ce535851b9188f3867d5ed87c318c/src/transformers/models/t5/modeling_t5.py#L437\r\n- mt5: https://github.com/huggingface/transformers/blob/7ccac73f749ce535851b9188f3867d5ed87c318c/src/transformers/models/mt5/modeling_mt5.py#L298\r\n- umt5: https://github.com/huggingface/transformers/blob/7ccac73f749ce535851b9188f3867d5ed87c318c/src/transformers/models/umt5/modeling_umt5.py#L232\r\n\r\nAll of these look the same to me, however. (umT5 simplifies it a little bit by getting attributes directly from `self` but apart from that they seem the same. So I am not sure if that is the cause? @ArthurZucker \r\n",
"UMT5 uses a bias for each layer that is not shared vs shared in other models. ",
"We should pre-compute all the positional bias wrt to the max sequence length of the model, cache it and only fetch the ones we need! Same for T5 but it's already pretty fast. Will open a PR ! ",
"(sorry)\r\n",
"Ah, sorry yes you are absolutely right! \r\n\r\nhttps://github.com/huggingface/transformers/blob/7ccac73f749ce535851b9188f3867d5ed87c318c/src/transformers/models/umt5/modeling_umt5.py#L322\r\n\r\nWould be great if this could be cached indeed. That would make my current research a lot more feasible!",
"Oups, sorry did not have time to work more on the fix! ",
"It's not on my priority list so if anyone wants to take over the PR feel free to do so! "
] | 1,694 | 1,704 | null |
COLLABORATOR
| null |
### System Info
- `transformers` version: 4.33.1
- Platform: Linux-5.14.0-284.25.1.el9_2.x86_64-x86_64-with-glibc2.34
- Python version: 3.11.4
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
### Who can help?
@ArthurZucker and @younesbelkada and @gante
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```python
import time
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, GenerationConfig
if __name__ == "__main__":
timings = {}
for model_name in ("facebook/mbart-large-50-many-to-one-mmt", "google/umt5-small"):
model = AutoModelForSeq2SeqLM.from_pretrained(model_name, device_map={"": "cuda"})
print(model_name, model.num_parameters())
# google/umt5-small 306601984
# facebook/mbart-large-50-many-to-one-mmt 1122990080
tokenizer = AutoTokenizer.from_pretrained(model_name)
gen_config = GenerationConfig.from_pretrained(
model_name,
max_new_tokens=200,
max_length=None,
num_beams=1,
)
text = "I would really like to eat some cookies now."
if "t5" in model_name:
text = f"translate English to Dutch: {text}"
encoded = tokenizer(text, return_tensors="pt")
encoded = {k: v.to(model.device) for k, v in encoded.items()}
start_time = time.perf_counter_ns()
for _ in range(100):
_ = model.generate(**encoded, generation_config=gen_config)
timings[model_name] = time.perf_counter_ns() - start_time
for model_name, timings in timings.items():
print(f"Generation duration for {model_name.split('/')[1]}:\t{timings}")
# Generation duration for mbart-large-50-many-to-one-mmt: 22413427363
# Generation duration for umt5-small: 207906791077
```
So despite UMT5-small having only about **27%** the number of parameters of the MBART-large model it is **9-10x** slower!
(I also tried with a gc.collect() after each generation.)
### Expected behavior
Faster inference/generation speed. Training is fine so I assume caching of past states is not (correctly) implemented but I might be wrong. This PR on adding caching to T5 by @patrickvonplaten might be related: https://github.com/huggingface/transformers/pull/3682
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26144/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26144/timeline
|
reopened
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26143
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26143/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26143/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26143/events
|
https://github.com/huggingface/transformers/issues/26143
| 1,894,546,554 |
I_kwDOCUB6oc5w7Hx6
| 26,143 |
storing & logging gradient norm in trainer
|
{
"login": "shijie-wu",
"id": 2987758,
"node_id": "MDQ6VXNlcjI5ODc3NTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2987758?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shijie-wu",
"html_url": "https://github.com/shijie-wu",
"followers_url": "https://api.github.com/users/shijie-wu/followers",
"following_url": "https://api.github.com/users/shijie-wu/following{/other_user}",
"gists_url": "https://api.github.com/users/shijie-wu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shijie-wu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shijie-wu/subscriptions",
"organizations_url": "https://api.github.com/users/shijie-wu/orgs",
"repos_url": "https://api.github.com/users/shijie-wu/repos",
"events_url": "https://api.github.com/users/shijie-wu/events{/privacy}",
"received_events_url": "https://api.github.com/users/shijie-wu/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2648621985,
"node_id": "MDU6TGFiZWwyNjQ4NjIxOTg1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Feature%20request",
"name": "Feature request",
"color": "FBCA04",
"default": false,
"description": "Request for a new feature"
}
] |
closed
| false | null |
[] |
[] | 1,694 | 1,708 | 1,708 |
CONTRIBUTOR
| null |
### Feature request
store and log gradient norm in trainer
### Motivation
Gradient norm is an important metric but currently the gradient norm is discarded during clipping.
### Your contribution
I checked and all of the following grad_norm_clip functions return the gradient norm. We can get gradient norm without extra compute by storing the return value, and we can then log it. If this sounds good i am happy to prepare a PR.
https://github.com/huggingface/transformers/blob/32ec7345f2d752c294ddf5aff495b657c9cd9d3b/src/transformers/trainer.py#L1918-L1936
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26143/reactions",
"total_count": 10,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 10,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26143/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26142
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26142/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26142/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26142/events
|
https://github.com/huggingface/transformers/pull/26142
| 1,894,538,248 |
PR_kwDOCUB6oc5aPF1N
| 26,142 |
[docs] last hidden state vs hidden_states[-1]
|
{
"login": "MKhalusova",
"id": 1065417,
"node_id": "MDQ6VXNlcjEwNjU0MTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1065417?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MKhalusova",
"html_url": "https://github.com/MKhalusova",
"followers_url": "https://api.github.com/users/MKhalusova/followers",
"following_url": "https://api.github.com/users/MKhalusova/following{/other_user}",
"gists_url": "https://api.github.com/users/MKhalusova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MKhalusova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MKhalusova/subscriptions",
"organizations_url": "https://api.github.com/users/MKhalusova/orgs",
"repos_url": "https://api.github.com/users/MKhalusova/repos",
"events_url": "https://api.github.com/users/MKhalusova/events{/privacy}",
"received_events_url": "https://api.github.com/users/MKhalusova/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,694 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
Intuitively one may think that `output.hidden_states[-1]` (returned when `output_hidden_states` is set to `True`) should match the `output.last_hidden_states` exactly. However, this is not always the case. Models like CLIP, ClipSeg, GroupVit, OWLViT, and X-CLIP apply `layernorm` before returning the `last_hidden_states`. Some other models apply `post_layernorm` or `norm`.
This PR adds a small note in the docs to address possible confusion.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26142/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26142/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26142",
"html_url": "https://github.com/huggingface/transformers/pull/26142",
"diff_url": "https://github.com/huggingface/transformers/pull/26142.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26142.patch",
"merged_at": 1694630143000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26141
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26141/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26141/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26141/events
|
https://github.com/huggingface/transformers/issues/26141
| 1,894,521,838 |
I_kwDOCUB6oc5w7Bvu
| 26,141 |
Training Loss Sudden Spike After 8 Hours of pre-training a BERT Model
|
{
"login": "M98M",
"id": 29666386,
"node_id": "MDQ6VXNlcjI5NjY2Mzg2",
"avatar_url": "https://avatars.githubusercontent.com/u/29666386?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/M98M",
"html_url": "https://github.com/M98M",
"followers_url": "https://api.github.com/users/M98M/followers",
"following_url": "https://api.github.com/users/M98M/following{/other_user}",
"gists_url": "https://api.github.com/users/M98M/gists{/gist_id}",
"starred_url": "https://api.github.com/users/M98M/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/M98M/subscriptions",
"organizations_url": "https://api.github.com/users/M98M/orgs",
"repos_url": "https://api.github.com/users/M98M/repos",
"events_url": "https://api.github.com/users/M98M/events{/privacy}",
"received_events_url": "https://api.github.com/users/M98M/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey 🤗 thanks for opening an issue! We try to keep the github issues for bugs/feature requests.\r\nCould you ask your question on the [forum](https://discuss.huggingface.co/) instead? I'm sure the community will be of help!\r\n\r\nThanks!",
"Hello, could you try a lower learning rate as you have decreased the batch size, along with warmup and linear delay for learning rate?",
"> Hello, could you try a lower learning rate as you have decreased the batch size, along with warmup and linear delay for learning rate?\r\nafter some investigation, it seems that it's vanishing gradient problem. (plot of min/avg gradients for each layer after loss jumps)\r\n\r\n\r\nwhile before the model collapses it looks like this:\r\n\r\n\r\nSo I have tried increasing warmup to a much higher steps (10%) and lowered LR to 4e-5. the model is working fine for last couple days, but it's still early to conclude.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"@M98M \r\n\r\n> > Hello, could you try a lower learning rate as you have decreased the batch size, along with warmup and linear delay for learning rate?\r\n> > after some investigation, it seems that it's vanishing gradient problem. (plot of min/avg gradients for each layer after loss jumps)\r\n> > 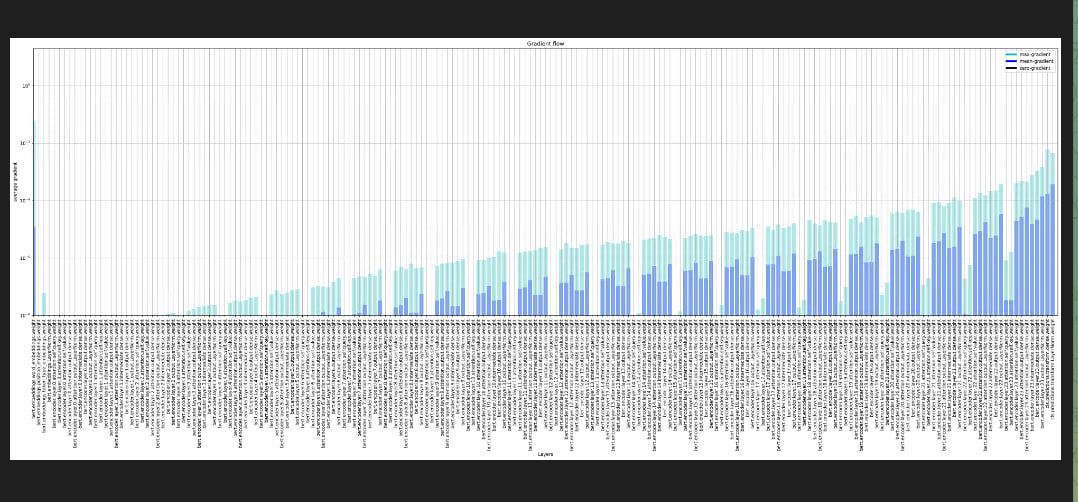\r\n> \r\n> while before the model collapses it looks like this: 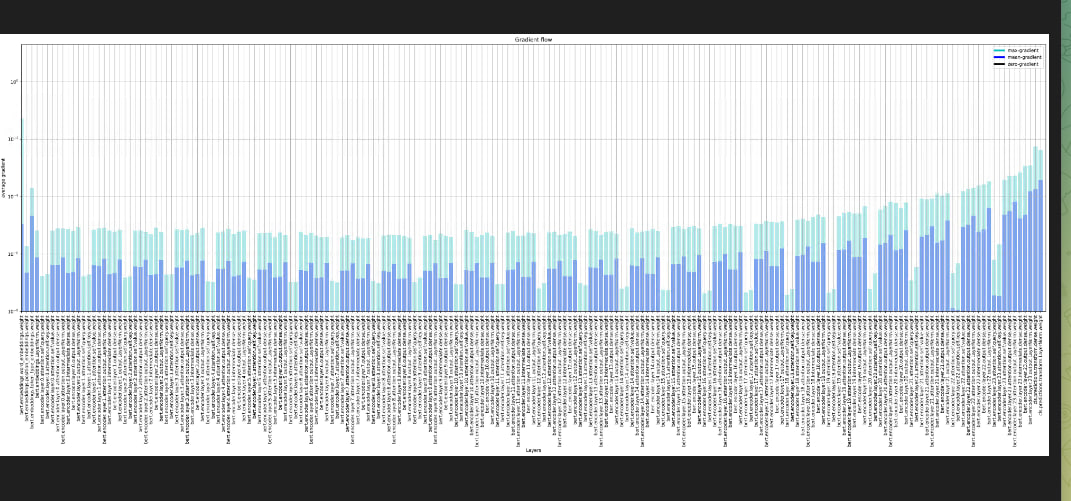\r\n> \r\n> So I have tried increasing warmup to a much higher steps (10%) and lowered LR to 4e-5. the model is working fine for last couple days, but it's still early to conclude.\r\n\r\nhi @M98M, have u solved the problem after longered the warmup phase and lowered the LR?",
"Hi @keyu-tian. Yes, the longer warmup seems to have fixed it. The training was completed without further issues.",
"@M98M many thanks for your quick reply and helpful experiences!"
] | 1,694 | 1,700 | 1,698 |
NONE
| null |
### System Info
os: windows server 2019
gpu: A100 40Gb
RAM: 128 GB
python 3.10.11
transformers 4.31.0
pytorch 2.0.1+cu118
### Who can help?
@muellerz
@pacman100
### Information
- [x] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
config_large = BertConfig(vocab_size=50_000,hidden_size= 1024, intermediate_size= 4096,
num_attention_heads= 16, num_hidden_layers= 20,)
model_large = BertForMaskedLM(config=config_large)
training_args = TrainingArguments(
output_dir="./mymodel",
overwrite_output_dir=False, # changed
num_train_epochs=20,
per_gpu_train_batch_size=16,
#
logging_steps = 0.00001,
save_strategy = 'steps',
save_steps= 0.008,
save_total_limit=20,
evaluation_strategy='steps',
eval_steps = 0.008,
#
learning_rate=5e-5,
warmup_steps= 20000,
#
tf32 = True,
optim = "adamw_torch_fused",
group_by_length = True,
#
prediction_loss_only=True,
#
hub_model_id = 'mymodel',
push_to_hub = True,
hub_strategy = 'every_save',
hub_private_repo = True,
)
trainer = Trainer(
model=model_large,
args=training_args,
data_collator=data_collator_wwm,
train_dataset=data['train'],
eval_dataset=data['test']
)
```
### Expected behavior
I am pretraining a bert model. I did it for bert base and results were **very good** and train loss got to less that 2.8 for my dataset (after 5 epochs in 10 days):

but when I tried for bert Large the loss gets stuck around 8.0 in less than an hour and didnt change even after 10 hours. (same train args as bert base but batch size is halved to fit)
I tried different things like warmup and different Learning Rates to no avail. The GPU memory usage for bert large was around 39GB (compared to 33GB for bert base with 32 batch size)

So I thought maybe if I make the model a bit smaller it would work. I changed the number of layers to 20 (from 24) and it worked fine for a while but not even midway through the first epoch it spiked back to the loss of 8.0. I have never seen such behavior in transformer models.

the learning rate graph looks completely normal. this just looks like an infamous case of exploding gradient i suppose, but I haven't heard of them happening in transformer models.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26141/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26141/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26140
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26140/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26140/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26140/events
|
https://github.com/huggingface/transformers/issues/26140
| 1,894,439,872 |
I_kwDOCUB6oc5w6tvA
| 26,140 |
Sharded Weight Files Not Uploaded by `_push_from_checkpoint` function in DeepSpeed ZeRO Stage 3 Training
|
{
"login": "e-mon",
"id": 2805136,
"node_id": "MDQ6VXNlcjI4MDUxMzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/2805136?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/e-mon",
"html_url": "https://github.com/e-mon",
"followers_url": "https://api.github.com/users/e-mon/followers",
"following_url": "https://api.github.com/users/e-mon/following{/other_user}",
"gists_url": "https://api.github.com/users/e-mon/gists{/gist_id}",
"starred_url": "https://api.github.com/users/e-mon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/e-mon/subscriptions",
"organizations_url": "https://api.github.com/users/e-mon/orgs",
"repos_url": "https://api.github.com/users/e-mon/repos",
"events_url": "https://api.github.com/users/e-mon/events{/privacy}",
"received_events_url": "https://api.github.com/users/e-mon/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2659267025,
"node_id": "MDU6TGFiZWwyNjU5MjY3MDI1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/DeepSpeed",
"name": "DeepSpeed",
"color": "4D34F7",
"default": false,
"description": ""
}
] |
closed
| false | null |
[] |
[
"Yes, you are correct. Currently, the sharded weights aren't being copied to the main output directory and as such not being uploaded to the Hub. It would be great if you could submit a PR resolving it.",
"Hello @ArthurZucker, this is not limited to DeepSpeed, even when doing normal training with say DDP, if the model gets sharded, it won't be uploaded to the hub at present.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,694 | 1,705 | 1,705 |
NONE
| null |
### System Info
- `transformers` version: 4.33.1
- Platform: Linux-4.18.0-372.9.1.el8.x86_64-x86_64-with-glibc2.28
- Python version: 3.10.10
- Huggingface_hub version: 0.17.1
- Safetensors version: 0.3.3
- Accelerate version: 0.22.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: yes, deepspeed
### Who can help?
@muellerz and @pacman100
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I attempted to train "https://huggingface.co/codellama/CodeLlama-7b-hf" using DeepSpeed ZeRO Stage 3, but found that the `_push_from_checkpoint` function was not working properly, and the weights file was not being uploaded. I was able to confirm that the sharded weights file, named like `pytorch_model-00001-of-00002.bin`, was being saved in the checkpoint directory.
From what I can tell after looking at the code below, it does not seem that such divided files are included in the upload target. Is this the expected behavior? If the divided files should be included in the target, I am considering creating a Pull Request.
https://github.com/huggingface/transformers/blob/main/src/transformers/trainer.py#L3624
### Expected behavior
all checkpoints to be uploaded to the Hugging Face Hub.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26140/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26140/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26139
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26139/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26139/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26139/events
|
https://github.com/huggingface/transformers/pull/26139
| 1,894,274,652 |
PR_kwDOCUB6oc5aOMCT
| 26,139 |
optimize VRAM for calculating pos_bias in LayoutLM v2, v3
|
{
"login": "NormXU",
"id": 33339685,
"node_id": "MDQ6VXNlcjMzMzM5Njg1",
"avatar_url": "https://avatars.githubusercontent.com/u/33339685?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NormXU",
"html_url": "https://github.com/NormXU",
"followers_url": "https://api.github.com/users/NormXU/followers",
"following_url": "https://api.github.com/users/NormXU/following{/other_user}",
"gists_url": "https://api.github.com/users/NormXU/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NormXU/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NormXU/subscriptions",
"organizations_url": "https://api.github.com/users/NormXU/orgs",
"repos_url": "https://api.github.com/users/NormXU/repos",
"events_url": "https://api.github.com/users/NormXU/events{/privacy}",
"received_events_url": "https://api.github.com/users/NormXU/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! Thanks for opening a PR, pinging @rafaelpadilla for a review here 😉 ",
"@rafaelpadilla I've reformatted the codes. It's ready to be merged.",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26139). All of your documentation changes will be reflected on that endpoint."
] | 1,694 | 1,695 | 1,695 |
CONTRIBUTOR
| null |
# What does this PR do?
The current implementation of calculating 1d_pos_bias/2d_pos_bias in LayoutLMv2, v3 is VRAM-consuming due to the large one-hot matrix.
Considering the idea of 1d_pos_bias/2d_pos_bias is to categorize all relative positions into several buckets, assign each position id to a specific bucket based on its relative distance to another token, and embed the position id into a feature, we can drop the large one-hot matrix and directly use the Linear weight features like an nn.Embedding.
In my tests, as for an input sequence of $[10, 1024]$ (bz, nseq), this can save 3 Gb VRAM for 2d_pos_bias calculations
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests? # This PR can reuse previous tests
## Who can review?
@ArthurZucker and @younesbelkada
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26139/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26139/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26139",
"html_url": "https://github.com/huggingface/transformers/pull/26139",
"diff_url": "https://github.com/huggingface/transformers/pull/26139.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26139.patch",
"merged_at": 1695887758000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26138
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26138/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26138/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26138/events
|
https://github.com/huggingface/transformers/pull/26138
| 1,894,233,570 |
PR_kwDOCUB6oc5aODBy
| 26,138 |
add japanese documentation
|
{
"login": "rajveer43",
"id": 64583161,
"node_id": "MDQ6VXNlcjY0NTgzMTYx",
"avatar_url": "https://avatars.githubusercontent.com/u/64583161?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rajveer43",
"html_url": "https://github.com/rajveer43",
"followers_url": "https://api.github.com/users/rajveer43/followers",
"following_url": "https://api.github.com/users/rajveer43/following{/other_user}",
"gists_url": "https://api.github.com/users/rajveer43/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rajveer43/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rajveer43/subscriptions",
"organizations_url": "https://api.github.com/users/rajveer43/orgs",
"repos_url": "https://api.github.com/users/rajveer43/repos",
"events_url": "https://api.github.com/users/rajveer43/events{/privacy}",
"received_events_url": "https://api.github.com/users/rajveer43/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @younesbelkada @stevhliu ",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26138). All of your documentation changes will be reflected on that endpoint.",
"@stevhliu I have added documentation for preprocessing.md as well kindly review it and added language code for it as well in the worflows.",
"also will add for most of the files ",
"will add for all!",
"@stevhliu \r\n\r\nin `peft.md`, these things are remaining\r\n- Link to PEFT docs for further details\r\n- Trainer \r\n- 8-bit / 4-bit examples ?\r\n",
"@stevhliu There are still few docs remaining. ",
"@younesbelkada @stevhliu review the PR once and merge. there are still few documents left. which can me translated later on! ",
"> Great job! Can you add the missing files [here](https://github.com/huggingface/transformers/actions/runs/6348047242/job/17261143258?pr=26138#step:11:839) to the `toctree`?\r\n\r\nSure I will. I just saw the Build PR Doc has failed. will add it today!",
"@stevhliu Kindly approve the workflow!",
"> Hey, it looks like you're still missing some entries in the `toctree` and or the file name is incorrect. For example, your filename is `glosaary` instead of `glossary`. Finally, can you also follow the same order as it is [here](https://github.com/huggingface/transformers/blob/main/docs/source/en/_toctree.yml)?\r\n\r\nsure!",
"@stevhliu Can you give me some insight about `toctree.yml`, I mean, How I should name and give title names, a bit of explanation would help me to add contents in toctree.yml for Japanese documentation",
"I studied the toctree.yml file for English document and I found it contains the documentation for other folder related files. I will be translating those too within this PR!",
"> I will be translating those too within this PR!\r\n\r\nActually, would it be ok with you to translate those in a separate PR? This one is getting quite big already and it'd be easier to merge this one first. \r\n\r\nThe `toctree` order/structure should be the same for both the English and Japanese translations. For example, the Tutorial section should be:\r\n\r\n```yml\r\n- sections:\r\n - local: pipeline_tutorial\r\n title: Run inference with pipelines\r\n - local: autoclass_tutorial\r\n title: Write portable code with AutoClass\r\n - local: preprocessing\r\n title: Preprocess data\r\n - local: training\r\n title: Fine-tune a pretrained model\r\n...\r\n...\r\n```\r\n\r\nYou can translate the title names to their equivalent in Japanese, but I was more referring to the local filenames should match the name in the `toctree`.",
"> > I will be translating those too within this PR!\r\n> \r\n> Actually, would it be ok with you to translate those in a separate PR? This one is getting quite big already and it'd be easier to merge this one first.\r\n> \r\n> The `toctree` order/structure should be the same for both the English and Japanese translations. For example, the Tutorial section should be:\r\n> \r\n> ```yaml\r\n> - sections:\r\n> - local: pipeline_tutorial\r\n> title: Run inference with pipelines\r\n> - local: autoclass_tutorial\r\n> title: Write portable code with AutoClass\r\n> - local: preprocessing\r\n> title: Preprocess data\r\n> - local: training\r\n> title: Fine-tune a pretrained model\r\n> ...\r\n> ...\r\n> ```\r\n> \r\n> You can translate the title names to their equivalent in Japanese, but I was more referring to the local filenames should match the name in the `toctree`.\r\nYup. I will be taking care of that!",
"Can you add these files to the `toctree` as well:\r\n\r\n```\r\nRuntimeError: The following files are not present in the table of contents:\r\n- data_collator\r\n- custom_model\r\n- transformer_agents\r\n```",
"@stevhliu Data collator.md is a part of main_classes so will add that in next PR.",
"I will make sure I do not take this many iteration of reviews in the next PR. And Making Module wise PR",
"Locally It is not passing I got the following error while building doc locally\r\n\r\n```bash\r\ndoc-builder build transformers docs/source/ja/ --build_dir ~/tmp/test-build\r\n```\r\nI am running above command and the logs are. do I need to add that files to `_toctree.yml`, Its contradicts to `PR_doc_build` workflow\r\n\r\n```bash\r\nBuilding docs for transformers docs/source/ja/ /home/codespace/tmp/test-build/transformers/main/en\r\nBuilding the MDX files: 100%|████████████████████████████████████████████████████████████████████████████████████████████████| 60/60 [00:00<00:00, 210.89it/s]\r\nTraceback (most recent call last):\r\n File \"/home/codespace/.python/current/bin/doc-builder\", line 8, in <module>\r\n sys.exit(main())\r\n File \"/usr/local/python/3.10.8/lib/python3.10/site-packages/doc_builder/commands/doc_builder_cli.py\", line 47, in main\r\n args.func(args)\r\n File \"/usr/local/python/3.10.8/lib/python3.10/site-packages/doc_builder/commands/build.py\", line 102, in build_command\r\n build_doc(\r\n File \"/usr/local/python/3.10.8/lib/python3.10/site-packages/doc_builder/build_doc.py\", line 369, in build_doc\r\n sphinx_refs = check_toc_integrity(doc_folder, output_dir)\r\n File \"/usr/local/python/3.10.8/lib/python3.10/site-packages/doc_builder/build_doc.py\", line 427, in check_toc_integrity\r\n raise RuntimeError(\r\nRuntimeError: The following files are not present in the table of contents:\r\n- debugging\r\n- notebooks\r\n- add_new_pipeline\r\n- sagemaker\r\n- contributing\r\n- tasks/visual_question_answering\r\n- tasks/audio_classification\r\n- tasks/summarization\r\n- tasks/document_question_answering\r\n- tasks/image_classification\r\n- tasks/sequence_classification\r\n- tasks/masked_language_modeling\r\n- tasks/video_classification\r\n- tasks/question_answering\r\n- tasks/semantic_segmentation\r\n- tasks/idefics\r\n- tasks/zero_shot_image_classification\r\n- tasks/language_modeling\r\n- tasks/asr\r\n- tasks/image_captioning\r\n- tasks/monocular_depth_estimation\r\n- tasks/multiple_choice\r\n- tasks/translation\r\n- tasks/text-to-speech\r\n- tasks/object_detection\r\n- tasks/token_classification\r\n- tasks/zero_shot_object_detection\r\n- main_classes/output\r\n- main_classes/configuration\r\n- main_classes/deepspeed\r\n- main_classes/keras_callbacks\r\n- main_classes/onnx\r\n- main_classes/feature_extractor\r\n- main_classes/pipelines\r\n- main_classes/image_processor\r\n- main_classes/trainer\r\n- main_classes/callback\r\n- main_classes/agent\r\n- main_classes/logging\r\n- main_classes/quantization\r\n- main_classes/text_generation\r\n- main_classes/optimizer_schedules\r\n- main_classes/model\r\n- main_classes/tokenizer\r\n- main_classes/data_collator\r\n- main_classes/processors\r\n- internal/file_utils\r\n- internal/modeling_utils\r\n- internal/pipelines_utils\r\n- internal/image_processing_utils\r\n- internal/tokenization_utils\r\n- internal/time_series_utils\r\n- internal/audio_utils\r\n- internal/generation_utils\r\n- internal/trainer_utils\r\n- model_doc/swiftformer\r\n- model_doc/mpnet\r\n- model_doc/auto\r\n- model_doc/cpm\r\n- model_doc/persimmon\r\n- model_doc/mobilevitv2\r\n- model_doc/switch_transformers\r\n- model_doc/roc_bert\r\n- model_doc/flan-ul2\r\n- model_doc/owlvit\r\n- model_doc/barthez\r\n- model_doc/vision-text-dual-encoder\r\n- model_doc/ul2\r\n- model_doc/phobert\r\n- model_doc/xlm-roberta\r\n- model_doc/realm\r\n- model_doc/convnextv2\r\n- model_doc/gptj\r\n- model_doc/git\r\n- model_doc/xlm-prophetnet\r\n- model_doc/xclip\r\n- model_doc/segformer\r\n- model_doc/vilt\r\n- model_doc/pix2struct\r\n- model_doc/clap\r\n- model_doc/speech-encoder-decoder\r\n- model_doc/dpr\r\n- model_doc/canine\r\n- model_doc/herbert\r\n- model_doc/tapas\r\n- model_doc/bigbird_pegasus\r\n- model_doc/deformable_detr\r\n- model_doc/roberta-prelayernorm\r\n- model_doc/marian\r\n- model_doc/pegasus_x\r\n- model_doc/bridgetower\r\n- model_doc/vision-encoder-decoder\r\n- model_doc/bark\r\n- model_doc/encoder-decoder\r\n- model_doc/rembert\r\n- model_doc/oneformer\r\n- model_doc/esm\r\n- model_doc/bert-generation\r\n- model_doc/llama2\r\n- model_doc/dinov2\r\n- model_doc/wav2vec2-conformer\r\n- model_doc/convbert\r\n- model_doc/layoutlmv2\r\n- model_doc/instructblip\r\n- model_doc/trocr\r\n- model_doc/lxmert\r\n- model_doc/vits\r\n- model_doc/vivit\r\n- model_doc/matcha\r\n- model_doc/deta\r\n- model_doc/dinat\r\n- model_doc/cvt\r\n- model_doc/mra\r\n- model_doc/retribert\r\n- model_doc/mobilevit\r\n- model_doc/van\r\n- model_doc/conditional_detr\r\n- model_doc/gpt_neox\r\n- model_doc/squeezebert\r\n- model_doc/data2vec\r\n- model_doc/ernie_m\r\n- model_doc/sam\r\n- model_doc/vit_mae\r\n- model_doc/mbart\r\n- model_doc/opt\r\n- model_doc/informer\r\n- model_doc/visual_bert\r\n- model_doc/mpt\r\n- model_doc/jukebox\r\n- model_doc/convnext\r\n- model_doc/xlnet\r\n- model_doc/gpt_bigcode\r\n- model_doc/code_llama\r\n- model_doc/umt5\r\n- model_doc/transfo-xl\r\n- model_doc/bert-japanese\r\n- model_doc/nystromformer\r\n- model_doc/roformer\r\n- model_doc/fnet\r\n- model_doc/sew-d\r\n- model_doc/musicgen\r\n- model_doc/mobilenet_v1\r\n- model_doc/videomae\r\n- model_doc/rwkv\r\n- model_doc/flan-t5\r\n- model_doc/timesformer\r\n- model_doc/swin\r\n- model_doc/roberta\r\n- model_doc/whisper\r\n- model_doc/camembert\r\n- model_doc/plbart\r\n- model_doc/vit_msn\r\n- model_doc/megatron_gpt2\r\n- model_doc/bort\r\n- model_doc/m2m_100\r\n- model_doc/bloom\r\n- model_doc/codegen\r\n- model_doc/deplot\r\n- model_doc/gpt_neox_japanese\r\n- model_doc/nat\r\n- model_doc/speech_to_text_2\r\n- model_doc/mega\r\n- model_doc/mobilebert\r\n- model_doc/wav2vec2\r\n- model_doc/blip-2\r\n- model_doc/beit\r\n- model_doc/t5v1.1\r\n- model_doc/gpt-sw3\r\n- model_doc/reformer\r\n- model_doc/clip\r\n- model_doc/funnel\r\n- model_doc/resnet\r\n- model_doc/poolformer\r\n- model_doc/regnet\r\n- model_doc/bertweet\r\n- model_doc/fsmt\r\n- model_doc/mask2former\r\n- model_doc/flava\r\n- model_doc/tapex\r\n- model_doc/dialogpt\r\n- model_doc/mvp\r\n- model_doc/longformer\r\n- model_doc/xmod\r\n- model_doc/ernie\r\n- model_doc/idefics\r\n- model_doc/focalnet\r\n- model_doc/rag\r\n- model_doc/pop2piano\r\n- model_doc/layoutlmv3\r\n- model_doc/chinese_clip\r\n- model_doc/xlsr_wav2vec2\r\n- model_doc/trajectory_transformer\r\n- model_doc/layoutxlm\r\n- model_doc/bros\r\n- model_doc/xlm-v\r\n- model_doc/speecht5\r\n- model_doc/unispeech-sat\r\n- model_doc/prophetnet\r\n- model_doc/mgp-str\r\n- model_doc/bart\r\n- model_doc/nezha\r\n- model_doc/table-transformer\r\n- model_doc/upernet\r\n- model_doc/bit\r\n- model_doc/mctct\r\n- model_doc/hubert\r\n- model_doc/graphormer\r\n- model_doc/vit_hybrid\r\n- model_doc/mluke\r\n- model_doc/t5\r\n- model_doc/swin2sr\r\n- model_doc/ctrl\r\n- model_doc/perceiver\r\n- model_doc/led\r\n- model_doc/vitdet\r\n- model_doc/llama\r\n- model_doc/mobilenet_v2\r\n- model_doc/unispeech\r\n- model_doc/dpt\r\n- model_doc/luke\r\n- model_doc/splinter\r\n- model_doc/clipseg\r\n- model_doc/efficientnet\r\n- model_doc/yoso\r\n- model_doc/decision_transformer\r\n- model_doc/donut\r\n- model_doc/nllb\r\n- model_doc/lilt\r\n- model_doc/wav2vec2_phoneme\r\n- model_doc/falcon\r\n- model_doc/blenderbot\r\n- model_doc/bert\r\n- model_doc/gpt_neo\r\n- model_doc/efficientformer\r\n- model_doc/groupvit\r\n- model_doc/imagegpt\r\n- model_doc/nougat\r\n- model_doc/openai-gpt\r\n- model_doc/electra\r\n- model_doc/longt5\r\n- model_doc/megatron-bert\r\n- model_doc/deit\r\n- model_doc/encodec\r\n- model_doc/biogpt\r\n- model_doc/time_series_transformer\r\n- model_doc/mt5\r\n- model_doc/xglm\r\n- model_doc/flaubert\r\n- model_doc/distilbert\r\n- model_doc/pvt\r\n- model_doc/audio-spectrogram-transformer\r\n- model_doc/qdqbert\r\n- model_doc/deberta\r\n- model_doc/wavlm\r\n- model_doc/xlm\r\n- model_doc/glpn\r\n- model_doc/swinv2\r\n- model_doc/gptsan-japanese\r\n- model_doc/blenderbot-small\r\n- model_doc/markuplm\r\n- model_doc/tvlt\r\n- model_doc/speech_to_text\r\n- model_doc/yolos\r\n- model_doc/align\r\n- model_doc/gpt2\r\n- model_doc/xlm-roberta-xl\r\n- model_doc/levit\r\n- model_doc/pegasus\r\n- model_doc/bartpho\r\n- model_doc/autoformer\r\n- model_doc/open-llama\r\n- model_doc/layoutlm\r\n- model_doc/albert\r\n- model_doc/big_bird\r\n- model_doc/detr\r\n- model_doc/ibert\r\n- model_doc/vit\r\n- model_doc/vitmatte\r\n- model_doc/altclip\r\n- model_doc/dit\r\n- model_doc/nllb-moe\r\n- model_doc/maskformer\r\n- model_doc/blip\r\n- model_doc/deberta-v2\r\n- model_doc/mistral\r\n- model_doc/cpmant\r\n- model_doc/sew\r\n- model_doc/mms\r\n- model_doc/xls_r\r\n- model_doc/byt5\r\nAdd them to docs/source/ja/_toctree.yml.\r\n```",
"> Locally It is not passing I got the following error while building doc locally\r\n\r\nIt's probably because all those files are in the directory, so you can just remove them, and it should be built locally. But it's ok since the CI tests are passing now. There are still some changes (like this [one](https://github.com/huggingface/transformers/pull/26138#discussion_r1349216856)) that need to be addressed.",
"things I learned:\r\n- Work module wise\r\n- documentation is as much as important as coding.\r\n",
"@stevhliu approve the workflow.",
"Thanks again for translating and contributing such a significant amount of the docs to Japanese! 🇯🇵🥳 Hope you had fun!\r\n\r\nOne last thing before we merge, let's revert the changes to the English `md` files. The date should reflect when the doc was written so there's no need to update them to 2023.",
"> Thanks again for translating and contributing such a significant amount of the docs to Japanese! 🇯🇵🥳 Hope you had fun!\r\n> \r\n> One last thing before we merge, let's revert the changes to the English `md` files. The date should reflect when the doc was written so there's no need to update them to 2023.\r\n\r\nsure",
"@stevhliu I reverted the changes you told!"
] | 1,694 | 1,697 | 1,697 |
CONTRIBUTOR
| null |
part of #18413
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #18413
Fixes #26355
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @muellerz and @pacman100
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
- Big Model Inference: @SunMarc
- quantization (bitsandbytes, autogpt): @SunMarc and @younesbelkada
Documentation: @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: See Models above and tag the person corresponding to the modality of the example.
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26138/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26138/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26138",
"html_url": "https://github.com/huggingface/transformers/pull/26138",
"diff_url": "https://github.com/huggingface/transformers/pull/26138.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26138.patch",
"merged_at": 1697045197000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26137
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26137/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26137/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26137/events
|
https://github.com/huggingface/transformers/pull/26137
| 1,894,194,211 |
PR_kwDOCUB6oc5aN6Vt
| 26,137 |
Falcon: batched generation
|
{
"login": "gante",
"id": 12240844,
"node_id": "MDQ6VXNlcjEyMjQwODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12240844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gante",
"html_url": "https://github.com/gante",
"followers_url": "https://api.github.com/users/gante/followers",
"following_url": "https://api.github.com/users/gante/following{/other_user}",
"gists_url": "https://api.github.com/users/gante/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gante/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gante/subscriptions",
"organizations_url": "https://api.github.com/users/gante/orgs",
"repos_url": "https://api.github.com/users/gante/repos",
"events_url": "https://api.github.com/users/gante/events{/privacy}",
"received_events_url": "https://api.github.com/users/gante/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"@ArthurZucker woops, sorry, there are still tests to fix, I will ping you again when they are fixed!",
"@ArthurZucker ready now",
"> Let's be careful with padding as we have been getting a lot of issues regarding this!\r\n\r\n@ArthurZucker 100% agreed! If you come across a new model, plz make sure there is a test for this 🙏 ",
"@ArthurZucker suggestions applied 💪 "
] | 1,694 | 1,694 | 1,694 |
MEMBER
| null |
# What does this PR do?
This PR does three things:
1. Fixes the minimum float number added to the attention mask, in the positions the attention mask is `0`. In some numerical precisions, the numerical attention mask was getting `-inf`, which wrecked downstream computations.
2. Adds the `position_ids` input to Falcon, which is needed for proper batched generation. When it is not passed, the forward pass builds the position ids from the sequence length, which does not account for the left-padding in batched generation -- the model could still generate, but the results should be slightly better after the fix.
3. Add tests for batched generation with left padding
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26137/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26137/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26137",
"html_url": "https://github.com/huggingface/transformers/pull/26137",
"diff_url": "https://github.com/huggingface/transformers/pull/26137.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26137.patch",
"merged_at": 1694620852000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26136
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26136/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26136/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26136/events
|
https://github.com/huggingface/transformers/pull/26136
| 1,894,142,293 |
PR_kwDOCUB6oc5aNu71
| 26,136 |
[MusicGen] Add sampling rate to config
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,694 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
# What does this PR do?
Adds sampling rate attribute to the parent model config. We get the sampling rate from the EnCodec sub-model config. Adding this attribute brings consistency with the other TTA models in the lib, where the output sampling rate is accessible directly through the top-level config (https://github.com/huggingface/audio-transformers-course/pull/140#discussion_r1324226366)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26136/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26136/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26136",
"html_url": "https://github.com/huggingface/transformers/pull/26136",
"diff_url": "https://github.com/huggingface/transformers/pull/26136.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26136.patch",
"merged_at": 1694707027000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26135
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26135/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26135/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26135/events
|
https://github.com/huggingface/transformers/pull/26135
| 1,894,080,284 |
PR_kwDOCUB6oc5aNhVI
| 26,135 |
Flex xpu bug fix
|
{
"login": "abhilash1910",
"id": 30946547,
"node_id": "MDQ6VXNlcjMwOTQ2NTQ3",
"avatar_url": "https://avatars.githubusercontent.com/u/30946547?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abhilash1910",
"html_url": "https://github.com/abhilash1910",
"followers_url": "https://api.github.com/users/abhilash1910/followers",
"following_url": "https://api.github.com/users/abhilash1910/following{/other_user}",
"gists_url": "https://api.github.com/users/abhilash1910/gists{/gist_id}",
"starred_url": "https://api.github.com/users/abhilash1910/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhilash1910/subscriptions",
"organizations_url": "https://api.github.com/users/abhilash1910/orgs",
"repos_url": "https://api.github.com/users/abhilash1910/repos",
"events_url": "https://api.github.com/users/abhilash1910/events{/privacy}",
"received_events_url": "https://api.github.com/users/abhilash1910/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_26135). All of your documentation changes will be reflected on that endpoint.",
"@muellerzr Could you confirm if this fix is OK and if there's anywhere else that needs to be updated?"
] | 1,694 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
# What does this PR do?
For some Flex Intel XPUs there is support for fp16 mp ; hence this exception should not be raise if fp16 is provided as mp dtype .
cc @muellerzr @amyeroberts
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26135/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26135/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26135",
"html_url": "https://github.com/huggingface/transformers/pull/26135",
"diff_url": "https://github.com/huggingface/transformers/pull/26135.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26135.patch",
"merged_at": 1694635432000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26134
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26134/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26134/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26134/events
|
https://github.com/huggingface/transformers/pull/26134
| 1,894,016,772 |
PR_kwDOCUB6oc5aNTt5
| 26,134 |
[`RWKV`] Final fix RWMV 4bit
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks for the review, I added a test that should be applicable to other checkpoints as well, as they use the same arch"
] | 1,694 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
# What does this PR do?
Fixes https://github.com/huggingface/transformers/issues/23848
Double quantization was not working properly for RWKV models as stated in the PR above - leading to an error. This PR proposed a global fix for RWKV models so that they can be ran in 4bit bitsandbytes without any problem.
The followed approach here is the following:
- For each target layer, de-quantize the 4bit weights using `bnb.nn.functional.dequantize_4bit`
- Perform the weights scaling
- Requantize the weights again.
That way it is possible to make sure to cover both the double quantization and classic 4bit quantization and match the results together
```python
import torch
from transformers import RwkvForCausalLM, AutoTokenizer, BitsAndBytesConfig
model_id = "RWKV/rwkv-4-169m-pile"
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True
)
model = RwkvForCausalLM.from_pretrained(model_id, quantization_config=quantization_config)
tok = AutoTokenizer.from_pretrained(model_id)
text = "Hello my name is"
input_ids = tok.encode(text, return_tensors="pt").to(0)
out = model.generate(input_ids, max_new_tokens=30)
print(tok.decode(out[0], skip_special_tokens=True))
model_non_dequant = RwkvForCausalLM.from_pretrained(model_id, load_in_4bit=True)
text = "Hello my name is"
input_ids = tok.encode(text, return_tensors="pt").to(0)
out = model.generate(input_ids, max_new_tokens=30)
print(tok.decode(out[0], skip_special_tokens=True))
```
cc @amyeroberts and @SunMarc for your information!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26134/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/26134/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26134",
"html_url": "https://github.com/huggingface/transformers/pull/26134",
"diff_url": "https://github.com/huggingface/transformers/pull/26134.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26134.patch",
"merged_at": 1694615420000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26133
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26133/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26133/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26133/events
|
https://github.com/huggingface/transformers/issues/26133
| 1,894,015,256 |
I_kwDOCUB6oc5w5GEY
| 26,133 |
Getting equivalence between torchvision and image transforms when normalizing without rescaling
|
{
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@NielsRogge This is happening because the dtype of the images when calling the torch and image_transforms `normalize` aren't the same. If you cast the dtype to float32, then you'll get the equivalent behaviour: \r\n\r\n```py\r\npixel_values = normalize(np.array(image).astype(np.float32), mean=(123.675, 116.28, 103.53), std=(58.395, 57.12, 57.375))\r\n```\r\n\r\nThis is because `ToTensor()` is doing three things: casting to float32, rescaling, converting to a torch tensor. \r\n",
"Thanks a lot, this was what I needed!"
] | 1,694 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
### System Info
Torchvision version 0.14.0
Transformers version 4.27.0.dev0
### Reproduction
Trying to have equivalent performance for the following (relevant for #26092):
```
from transformers.image_transforms import normalize
from PIL import Image
import requests
import numpy as np
import torch
from torchvision import transforms
url = "https://dl.fbaipublicfiles.com/dinov2/images/example.jpg"
image = Image.open(requests.get(url, stream=True).raw)
def make_depth_transform() -> transforms.Compose:
return transforms.Compose([
transforms.ToTensor(),
lambda x: 255.0 * x[:3], # Discard alpha component and scale by 255
transforms.Normalize(
mean=(123.675, 116.28, 103.53),
std=(58.395, 57.12, 57.375),
),
])
# prepare image using torchvision
transform = make_depth_transform()
original_pixel_values = transform(image)
# prepare image using Transformers' image transforms
pixel_values = normalize(np.array(image), mean=(123.675, 116.28, 103.53), std=(58.395, 57.12, 57.375))
pixel_values = np.moveaxis(pixel_values, -1, 0)
pixel_values = torch.from_numpy(pixel_values).float()
assert original_pixel_values.shape == pixel_values.shape
assert torch.allclose(original_pixel_values, pixel_values)
```
The assertion above currently fails.
### Expected behavior
I would like to have equivalent behaviour between torchvision and our image transforms when normalizing without rescaling.
cc @amyeroberts
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26133/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26133/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/26132
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26132/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26132/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26132/events
|
https://github.com/huggingface/transformers/pull/26132
| 1,893,977,604 |
PR_kwDOCUB6oc5aNLQr
| 26,132 |
[`core`] fix 4bit `num_parameters`
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,694 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
# What does this PR do?
Fixes https://github.com/huggingface/transformers/issues/25978
For 4bit models, the parameters are stored under `bnb.Param4bit` class, that uses `torch.uint8` tensors to store the 4bit weights. However, since the uint8 precision is in 8bit, half of its storage is used. To give a more concrete example, if we want to store a 100x100 matrix in 4bit using `Param4bit`, it will be stored under a 100x50 Parameters in uint8. This is what I know per my understanding, therefore when computing the number of parameters it is crucial to multiply the number of elements `numel()` by two, to retrieve the correct number of elements.
With this PR, we compute the correct number of parameters for 4bit models, and a nice test has been added.
cc @amyeroberts and @SunMarc just for your information in case you were not aware of this
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26132/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/26132/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/26132",
"html_url": "https://github.com/huggingface/transformers/pull/26132",
"diff_url": "https://github.com/huggingface/transformers/pull/26132.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/26132.patch",
"merged_at": 1694607155000
}
|
https://api.github.com/repos/huggingface/transformers/issues/26131
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/26131/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/26131/comments
|
https://api.github.com/repos/huggingface/transformers/issues/26131/events
|
https://github.com/huggingface/transformers/issues/26131
| 1,893,965,086 |
I_kwDOCUB6oc5w450e
| 26,131 |
The "padding" parameter of tokenizer doesn't seem to work
|
{
"login": "a815063199",
"id": 37767445,
"node_id": "MDQ6VXNlcjM3NzY3NDQ1",
"avatar_url": "https://avatars.githubusercontent.com/u/37767445?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/a815063199",
"html_url": "https://github.com/a815063199",
"followers_url": "https://api.github.com/users/a815063199/followers",
"following_url": "https://api.github.com/users/a815063199/following{/other_user}",
"gists_url": "https://api.github.com/users/a815063199/gists{/gist_id}",
"starred_url": "https://api.github.com/users/a815063199/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/a815063199/subscriptions",
"organizations_url": "https://api.github.com/users/a815063199/orgs",
"repos_url": "https://api.github.com/users/a815063199/repos",
"events_url": "https://api.github.com/users/a815063199/events{/privacy}",
"received_events_url": "https://api.github.com/users/a815063199/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @a815063199, thanks for raising this issue! \r\n\r\nYou need to pass `padding=\"max_length\"` to pad to the max length specified. With `padding=True` the tokenizer pads to the max sequence length in the batch. There's more information in the docs here: https://huggingface.co/docs/transformers/pad_truncation",
"ok~ i misunderstood the meaning of `padding=true`. thanks`"
] | 1,694 | 1,694 | 1,694 |
NONE
| null |
### System Info
- `transformers` version: 4.33.0
- Platform: Linux-4.15.0-206-generic-x86_64-with-glibc2.35
- Python version: 3.10.6
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.3
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@ArthurZucker
The padding parameter of the tokenizer seems to have no effect, and the tensor shape returned by the tokenizer using padding is not being padded. Use pad_to_max_length parameter can be correctly padding
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```python
from transformers import BertModel, BertTokenizer, BertTokenizerFast
model_name = 'moka-ai/m3e-base'
tokenizer = BertTokenizerFast.from_pretrained(model_name)
sentences = "我今天中午吃的拉面,你吃的啥"
inputs = tokenizer.encode_plus(
sentences, # 输入文本
add_special_tokens=True, # 添加特殊标记
max_length=512, # 最大长度
#pad_to_max_length=True, # 使用padding填充
padding=True, # 使用padding填充
truncation=True,
return_attention_mask=True, # 返回attention mask
return_tensors='pt' # 返回pt类型的张量
)
for k, v in inputs.items():
print(v.shape) # except shape is (1, 512), but get (1, 16) when using "padding=True"
```
### Expected behavior
the padding parameter of tokenizer should work same as the pad_to_max_length
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/26131/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/26131/timeline
|
completed
| null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.