
language
stringclasses 15
values | src_encoding
stringclasses 34
values | length_bytes
int64 6
7.85M
| score
float64 1.5
5.69
| int_score
int64 2
5
| detected_licenses
listlengths 0
160
| license_type
stringclasses 2
values | text
stringlengths 9
7.85M
|
|---|---|---|---|---|---|---|---|
JavaScript
|
UTF-8
| 677 | 3.328125 | 3 |
[] |
no_license
|
/*
* @lc app=leetcode id=563 lang=javascript
*
* [563] Binary Tree Tilt
*/
/**
* Definition for a binary tree node.
* function TreeNode(val) {
* this.val = val;
* this.left = this.right = null;
* }
*/
/**
* @param {TreeNode} root
* @return {number}
*/
const findSum = node => {
if (!node) return 0;
return node.val + findSum(node.left) + findSum(node.right);
}
var findTilt = function(root) {
if (!root) return 0;
let left = findSum(root.left);
let right = findSum(root.right);
let rootTilt = Math.abs(left - right);
let leftTilt = findTilt(root.left);
let rightTilt = findTilt(root.right);
return rootTilt + leftTilt + rightTilt;
};
|
C
|
UTF-8
| 740 | 3.609375 | 4 |
[] |
no_license
|
#include <stdio.h>
int main(){
int i, j, n=0, tmp, A[7];
for(i=0; i<7; i++){
printf("A[%d] : ", i+1);
scanf("%d", &tmp);
if(tmp == 0) break;
else A[i] = tmp;
n++;
}
if(n==0) printf("\nThe array A has no element!!!");
else{
printf("\nThe array A is : ");
for(i=0; i<n; i++) printf("%d\t", A[i]);
for(i=0; i<n; i++)
for(j=i+1; j<n; j++){
if(A[i] > A[j]){
tmp = A[i];
A[i] = A[j];
A[j] = tmp;
}
}
printf("\nArray after re-arange (increase): ");
for(i=0; i<n; i++) printf("%d\t", A[i]);
}
printf("\n");
return 0;
}
|
Java
|
UTF-8
| 115 | 1.882813 | 2 |
[] |
no_license
|
package org.acouster.data.GraphLogic;
public interface IFsmInputListener {
void handleCommand(String command);
}
|
JavaScript
|
UTF-8
| 2,179 | 2.59375 | 3 |
[
"MIT"
] |
permissive
|
import _ from 'lodash';
import * as firebase from 'firebase';
import events from 'events';
import Heatmap from './heatmap';
class Hotometer extends events.EventEmitter{
constructor(token) {
super();
this.token = token;
this.state = 'home';
this.heatmap = new Heatmap(this.display);
this.display = {
width: window.innerWidth,
height: window.innerHeight
};
this.initFirebase();
this.initHeatmapWatch();
document.addEventListener('mousedown', _.throttle(this::this.addNewClick, 300));
}
calculatePercentage(value, fullPercent) {
return Math.floor((value * 100) / fullPercent);
}
async addNewClick(e) {
let x = e.clientX,
y = e.clientY;
let databaseRef = this.database().ref(`/page/${this.state}/${x}/${y}`);
let databaseData = await databaseRef.once('value'),
data = databaseData.val() || 0;
data++;
databaseRef.set(data);
}
async initFirebase() {
firebase.initializeApp({
apiKey: "AIzaSyDUyAK_YgQ60M9y8FY5Q_lccL-ACkOXlKc",
authDomain: "quentin-b880c.firebaseapp.com",
databaseURL: "https://quentin-b880c.firebaseio.com",
projectId: "quentin-b880c",
storageBucket: "quentin-b880c.appspot.com",
messagingSenderId: "1077925836180"
});
this.database = firebase.database;
try {
await firebase.auth().signInWithCustomToken(this.token);
} catch (e) {
console.log(e);
throw new Error('Invalid token!');
}
}
initHeatmapWatch() {
this.database().ref(`/page`).on('value', (snapshot) => {
this.emit('updateHeatmap', _.get(snapshot.val(), this.state) || null);
} );
}
changeState(state) {
this.state = state;
}
generateHeatmap(data) {
this.heatmap.setData(data);
}
initHeatmap() {
this.on('updateHeatmap', this::this.generateHeatmap);
}
}
const token = 'eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1aWQiOiI1OGRiNWI2M2QyYTQzMGIzZTg4ZWVhNGY0Y2FmMzIxMDIzNTk1MDA1MWE0YTA1OTQ5YTc1OGU0YTUxYjY4YTUwIiwiaWF0IjoxNTEzMzc2NDQ2LCJleHAiOjE1MTMzODAwNDYsImF1ZCI6Imh0dHBzOi8vaWRlbnRpdHl0b29sa2l0Lmdvb2dsZWFwaXMuY29tL2dvb2dsZS5pZGVudGl0eS5pZGVudGl0eXRvb2xraXQudjEuSWRlbnRpdHlUb29sa2l0IiwiaXNzIjoiZmlyZWJhc2UtYWRtaW5zZGstdmd5ZDVAcXVlbnRpbi1iODgwYy5pYW0uZ3NlcnZpY2VhY2NvdW50LmNvbSIsInN1YiI6ImZpcmViYXNlLWFkbWluc2RrLXZneWQ1QHF1ZW50aW4tYjg4MGMuaWFtLmdzZXJ2aWNlYWNjb3VudC5jb20ifQ.FEWp-tn5OpIr_Aa52isMi8via8BaXSpf_LIe5m4JfABYVKBBTSudhYebgFjcrKxUQYbp9u6X7SUEvt6EyUDy874mW-gJPQpjdgARbuWZoiqaJG7-4eZIEMB6Phw7PpuKDv17y5yVoXcv7lEnnibi4DF4kRphJCXaaf3Gnneu7Z_TynJ8QwPkMy4nP4aWxLpPJhh3M9OIaTNTm0J_jpjDSvI1W0Du5XTLtvMeWUSuMQdhMUz-6MkvgulrZaqFR7RPKut7wh--i0qRrNFNoon-sdgQC2EZ2FV_RAiiyF-l2nWAJ3NamFBYkpGABtf3LBfK3lJx5Lw-goINUbFq1GnfsA';
const hotometer = new Hotometer(token);
hotometer.changeState('other-page');
hotometer.initHeatmap();
|
Python
|
UTF-8
| 2,742 | 3.4375 | 3 |
[] |
no_license
|
import numpy as np
import tensorflow as tf
corpus_raw = 'He is the king . The king is royal . She is the royal queen '
# convert to lower case
corpus_raw = corpus_raw.lower()
words = []
for word in corpus_raw.split():
if word != '.': # because we don't want to treat . as a word
words.append(word)
words = set(words) # so that all duplicate words are removed
word2int = {}
int2word = {}
vocab_size = len(words) # gives the total number of unique words
for i,word in enumerate(words):
word2int[word] = i
int2word[i] = word
# raw sentences is a list of sentences.
raw_sentences = corpus_raw.split('.')
sentences = []
for sentence in raw_sentences:
sentences.append(sentence.split())
#print(sentences)
data = []
WINDOW_SIZE = 2
for sentence in sentences:
for word_index, word in enumerate(sentence):
for nb_word in sentence[max(word_index - WINDOW_SIZE, 0) : min(word_index + WINDOW_SIZE, len(sentence)) + 1] :
if nb_word != word:
data.append([word, nb_word])
print(len(data))
#print(data)
# function to convert numbers to one hot vectors
def to_one_hot(data_point_index, vocab_size):
temp = np.zeros(vocab_size)
temp[data_point_index] = 1
return temp
x_train = [] # input word
y_train = [] # output word
for data_word in data:
x_train.append(to_one_hot(word2int[data_word[0]], vocab_size))
y_train.append(to_one_hot(word2int[data_word[1]], vocab_size))
#print(word2int)
# convert them to numpy arrays
x_train = np.asarray(x_train)
y_train = np.asarray(y_train)
#print(x_train)
# making placeholders for x_train and y_train
x = tf.placeholder(tf.float32, shape=(None, vocab_size))
y_label = tf.placeholder(tf.float32, shape=(None, vocab_size))
#print(x)
EMBEDDING_DIM = 5 # you can choose your own number
W1 = tf.Variable(tf.random_normal([vocab_size, EMBEDDING_DIM]))
b1 = tf.Variable(tf.random_normal([EMBEDDING_DIM])) #bias
hidden_representation = tf.add(tf.matmul(x,W1), b1)
W2 = tf.Variable(tf.random_normal([EMBEDDING_DIM, vocab_size]))
b2 = tf.Variable(tf.random_normal([vocab_size]))
prediction = tf.nn.softmax(tf.add( tf.matmul(hidden_representation, W2), b2))
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init) #make sure you do this!
# define the loss function:
cross_entropy_loss = tf.reduce_mean(-tf.reduce_sum(y_label * tf.log(prediction), reduction_indices=[1]))
# define the training step:
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(cross_entropy_loss)
n_iters = 10000
# train for n_iter iterations
for _ in range(n_iters):
sess.run(train_step, feed_dict={x: x_train, y_label: y_train})
print('loss is : ', sess.run(cross_entropy_loss, feed_dict={x: x_train, y_label: y_train}))
|
PHP
|
UTF-8
| 2,867 | 2.875 | 3 |
[] |
no_license
|
<?php
/*
* Githeri.com Copyright 2013. All Rights Reserved.
*/
include_once "./resources/php/functions/sqlconnectandselect.php";
session_start();
$username = dbSanitise($_SESSION["user_name"]);
$getuserid = "SELECT user_id FROM users WHERE user_name = '".$username."'";
$result = selectFromDB($getuserid);
while($row = mysqli_fetch_array($result)){
$userid = $row["user_id"];
}
//PHP below is for image processing and is mostly not mine
$valid_exts = array('jpeg', 'jpg', 'png', 'gif');
$max_file_size = 1024 * 1024; #200kb
$nw = $nh = 250; # image width & height
if ($_SERVER['REQUEST_METHOD'] === 'POST') {
if ( isset($_FILES['image']) ) {
if (! $_FILES['image']['error'] && $_FILES['image']['size'] < $max_file_size) {
# get file extension
$ext = strtolower(pathinfo($_FILES['image']['name'], PATHINFO_EXTENSION));
# file type validity
if (in_array($ext, $valid_exts)) {
$dir = './resources/images/users/' . $userid;
//if dir doesnt exist, make it. If exists, erase current files in dir.
if (!file_exists($dir) && !is_dir($dir)) {
mkdir($dir);
}else{
$files = glob('./resources/images/users/' . $userid . '/*'); // get all file names
foreach($files as $file){ // iterate files
if(is_file($file))
unlink($file); // delete file
}
}
$path = './resources/images/users/' . $userid . '/profilepic.' . $ext;
$size = getimagesize($_FILES['image']['tmp_name']);
# grab data form post request
$x = (int) sanitisedata($_POST['x']);
$y = (int) sanitisedata($_POST['y']);
$w = (int) sanitisedata($_POST['w']) ? sanitisedata($_POST['w']) : $size[0];
$h = (int) sanitisedata($_POST['h']) ? sanitisedata($_POST['h']) : $size[1];
# read image binary data
$data = file_get_contents($_FILES['image']['tmp_name']);
# create v image form binary data
$vImg = imagecreatefromstring($data);
$dstImg = imagecreatetruecolor($nw, $nh);
# copy image
imagecopyresampled($dstImg, $vImg, 0, 0, $x, $y, $nw, $nh, $w, $h);
# save image
imagejpeg($dstImg, $path);
# clean memory
imagedestroy($dstImg);
//echo "<img src='$path' />";
} else {
echo 'unknown problem!';
}
} else {
echo 'file is too small or large';
}
} else {
echo 'file not set';
}
} else {
echo 'bad request!';
}
|
Swift
|
UTF-8
| 2,736 | 2.578125 | 3 |
[
"Apache-2.0"
] |
permissive
|
//
// ChoosePhotoFromAlbumViewController.swift
// Pictureagram
//
// Created by Kymberlee Hill on 3/23/18.
// Copyright © 2018 Kymberlee Hill. All rights reserved.
//
import UIKit
class ChoosePhotoFromAlbumViewController: UIViewController, UIImagePickerControllerDelegate, UINavigationControllerDelegate {
var selectedImage : UIImage?
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view.
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
override func viewDidAppear(_ animated: Bool) {
super.viewDidAppear(true)
let vc = UIImagePickerController()
vc.delegate = self
vc.allowsEditing = true
vc.sourceType = .photoLibrary
present(vc, animated: true, completion: nil)
}
override func viewWillAppear(_ animated: Bool) {
super.viewWillAppear(true)
}
func imagePickerController(_ picker: UIImagePickerController, didFinishPickingMediaWithInfo info: [String : Any]) {
// Get the image captured by the UIImagePickerController
// let originalImage = info[UIImagePickerControllerOriginalImage] as! UIImage
let editedImage = info[UIImagePickerControllerEditedImage] as! UIImage
selectedImage = editedImage
// Do something with the images (based on your use case)
// Dismiss UIImagePickerController to go back to your original view controller
dismiss(animated: true, completion: { () -> Void in
self.dismiss(animated: false, completion: nil)
self.performSegue(withIdentifier: "toCaptionSegue", sender: self)
})
}
func imagePickerControllerDidCancel(_ picker: UIImagePickerController) {
dismiss(animated: true, completion: { () -> Void in
self.dismiss(animated: false, completion: nil)
self.tabBarController?.selectedIndex = 0
})
}
// MARK: - Navigation
// In a storyboard-based application, you will often want to do a little preparation before navigation
override func prepare(for segue: UIStoryboardSegue, sender: Any?) {
// Get the new view controller using segue.destinationViewController.
// Pass the selected object to the new view controller.
if segue.identifier == "toCaptionSegue" {
let controller = segue.destination as! CreatePostViewController
let size = CGSize(width: 300.0, height: 300.0)
controller.postImage = self.selectedImage?.af_imageAspectScaled(toFit: size)
}
}
}
|
Go
|
UTF-8
| 384 | 3.71875 | 4 |
[
"MIT"
] |
permissive
|
package main
import "fmt"
// 定义结构体
type Student struct {
id int
name string
score float64
}
func main() {
students := []Student{
Student{
101,
"张三",
100,
},
Student{
102,
"李四",
96,
},
Student{
103,
"王五",
91,
},
}
fmt.Println(students)
for i := 0; i < len(students); i++ {
fmt.Println(students[i].name)
}
}
|
C
|
UTF-8
| 1,152 | 3.484375 | 3 |
[] |
no_license
|
#include<stdio.h>
#include<stdlib.h>
#defineMAX_SIZE10
typedef struct
{
int key;
}element;
elementheap[MAX_SIZE];
void insert(elementitem,int*n)
{
int i;
if((*n)==MAX_SIZE-1)
{
printf("HeapFull\n");
return;
}
i=++(*n);
while(i!=1&&item.key>heap[i/2].key)
{
heap[i]=heap[i/2];
i/=2;
}
heap[i]=item;
}
elementdeleteHeap(int*n)
{
intparent,child;
elementtemp,item;
if(*n==0)
{
printf("HeapEmpty\n");
item.key=-1;
returnitem;
}
item=heap[1];
temp=heap[(*n)--];
parent=1;
child=2;
while(child<=*n)
{
if(child<*n&&heap[child].key<heap[child+1].key)
child++;
if(temp.key>=heap[child].key)
break;
heap[parent]=heap[child];
parent=child;
child=child*2;
}
heap[parent]=temp;
returnitem;
}
voiddisplay(intn)
{
inti;
for(i=1;i<=n;i++)
{
printf("%d\n",heap[i].key);
}
}
intmain()
{
intchoice,n=0;
elementitem;
while(1)
{
printf("MENU:\n1.Insert\n2.Display\n3.Delete\n");
scanf("%d",&choice);
switch(choice)
{
case1:
printf("Enterelementtoinsert:");
scanf("%d",&item.key);
insert(item,&n);
break;
case2:
display(n);
break;
case3:
item=deleteHeap(&n);
if(item.key!=-1)
printf("ElementDeleted:%d\n",item.key);
break;
default:printf("InvalidChoice\n");
break;
}
}
}
|
C
|
UTF-8
| 574 | 2.921875 | 3 |
[] |
no_license
|
#include<stdio.h>
int main()
{
int n,i,temp,j,a[1000],b[1000],c[1000];
scanf("%d",&n);
for(i=0;i<n;i++)
{
scanf("%d %d",&b[i],&c[i]);
if(i==0)
{
a[i]=c[i];
// printf("%d\n",i);
}
else if(i!=0)
{
a[i]=a[i-1]-b[i]+c[i];
//printf("%d\n",i);
}
}
for(i=0;i<n;i++)
{
for(j=0;j<n-i-1;j++)
if(a[j]>a[j+1])
{
temp=a[j];
a[j]=a[j+1];
a[j+1]=temp;
}
}
printf("%d",a[n-1]);
}
|
C
|
UTF-8
| 1,911 | 4.53125 | 5 |
[] |
no_license
|
/*
Author is : Ibrahim Halil GEZER
5.32 (Guess the Number) Write a C program that plays the game of “guess the number” as follows:
Your program chooses the number to be guessed by selecting an integer at random in the range
1 to 1000. The program then types:
I have a number between 1 and 1000.
Can you guess my number?
Please type your first guess.
The player then types a first guess. The program responds with one of the following:
1. Excellent! You guessed the number!
Would you like to play again (y or n)?
2. Too low. Try again.
3. Too high. Try again.
If the player’s guess is incorrect, your program should loop until the player finally gets the number
right. Your program should keep telling the player Too high or Too low to help the player “zero in”
on the correct answer. [Note: The searching technique employed in this problem is called binary
search. We’ll say more about this in the next problem.]
*/
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void numberguess ( void ) ;
int main ( void ) {
numberguess () ;
return 0 ;
}
void numberguess ( void ) {
srand ( time ( NULL ) ) ;
int number = 1 + rand () % 100 ;
int guess ;
char again ;
printf ( "I have a number between 1 and 1000. \n" ) ;
printf ( "Can you guess my number? \n" ) ;
printf ( "Please type your first guess. \n" ) ;
scanf ( "%d", &guess) ;
while ( guess != number ) {
if ( guess > number ) {
printf ( "Too high. Try again. \n" ) ;
scanf ( "%d", &guess ) ;
}
else if ( guess < number ) {
printf ( "Too low. Try again. \n" ) ;
scanf ( "%d", &guess ) ;
}
}
printf ( "Excellent! You guessed the number! \n" );
printf ( "Would you like to play again (y or n)? ") ;
scanf ("%s", &again) ;
if (again == 'y' || again == 'Y' ) {
printf ("\n");
numberguess () ;
}
}
|
PHP
|
UTF-8
| 1,262 | 2.546875 | 3 |
[
"MIT"
] |
permissive
|
<?php
namespace PhpDesignPatternsCheatsheet\Tests\Behavioral\State;
use PhpDesignPatternsCheatsheet\Behavioral\State\EntityInterface;
use PhpDesignPatternsCheatsheet\Behavioral\State\BreakState;
use PHPUnit\Framework\TestCase;
class BreakStateTest extends TestCase
{
public function testChangeEntity()
{
$entity = $this->createMock(EntityInterface::class);
$entity->expects($this->once())
->method('changeFatigue')
->with(BreakState::FATIGUE_COST);
$entity->expects($this->once())
->method('changeThirst')
->with(BreakState::THIRST_COST);
$entity->expects($this->once())
->method('getFatigue')
->willReturn(1);
$entity->expects($this->never())
->method('revertState');
$state = new BreakState();
$state->execute($entity);
}
public function testRevertStateIfNotFatigued()
{
$entity = $this->createMock(EntityInterface::class);
$entity->expects($this->once())
->method('getFatigue')
->willReturn(0);
$entity->expects($this->once())
->method('revertState');
$state = new BreakState();
$state->execute($entity);
}
}
|
Python
|
UTF-8
| 958 | 3.265625 | 3 |
[
"Apache-2.0"
] |
permissive
|
from typing import Optional
import numpy as np
import pandas as pd
TRANSFORMATION_METHODS = {'log10', 'squareroot', 'cuberoot', 'log2'}
def transform(method: Optional[str], table: pd.DataFrame) -> pd.DataFrame:
table = table.astype(np.float64)
if method is None:
table = table
elif method == 'log10':
table = log10(table)
elif method == 'log2':
table = log2(table)
elif method == 'squareroot':
table = squareroot(table)
elif method == 'cuberoot':
table = cuberoot(table)
else:
raise Exception('Unknown transform method')
return table
def log10(table: pd.DataFrame, min=1e-8):
return np.log10(table.clip(lower=min))
def log2(table: pd.DataFrame, min=1e-8):
return np.log2(table.clip(lower=min))
def squareroot(table: pd.DataFrame):
return np.sqrt(table.clip(lower=0))
def cuberoot(table: pd.DataFrame):
return np.power(table.clip(lower=0), 1.0 / 3.0)
|
Python
|
UTF-8
| 136 | 3.046875 | 3 |
[] |
no_license
|
def reverse_odd(string):
words = string.split(" ");
return " ".join(word[::-1] if len(word) %2 != 0 else word for word in words);
|
Markdown
|
UTF-8
| 879 | 2.96875 | 3 |
[] |
no_license
|
# Como manejar la asincronia
## [Promesas](./Promises.js)
* > Para hacer uso de las promesas debemos crear una funcion la cual retorne una instancia de una promesa, esta va a recibr uns funcion con dos parametros `resolve` y `reject`.
* >`resolve`: se va encargar de ejecutar las funciones que ejecutar las funciones que deseemos anidar con el metodo `.then()`.
* >`reject`: en caso de que la promesa no pueda ser resuelta, reject se va a encargar de retornar el error, este lo podemos manejar por medio de un `catch()` al final del `then()`.
## [Async Await](./Async_await.js)
* > Asyn await es azucar sintactica, esta sintaxia tiene como funcion hacer parecer que nuestro codigo asincrono paresca sincrono.
* > Para poder hacer uso de `await` este debe estar dentro de una funcion `async`.
* >`await`: se emplea cuando hacemos llamados a funciones asyncronas.
|
Python
|
UTF-8
| 259 | 3.515625 | 4 |
[] |
no_license
|
p=int(input("Enter Principal Amount : "))
r=float(input("Enter Rate of Interest p.a. : "))
t=float(input("Enter Number of years : "))
i=(p*r*t)/100
print ("Interest will be :", i)
a=p+i
print ("Amount will be :", a)
input("Press ENTER to Exit....")
|
Go
|
UTF-8
| 10,515 | 2.71875 | 3 |
[
"Apache-2.0"
] |
permissive
|
package main
import "github.com/sybrexsys/RapidKV/datamodel"
import "strconv"
func hdelCommand(db *Database, key string, command datamodel.DataArray) datamodel.CustomDataType {
hkey, err := getKey(command, 0)
if err != nil {
return datamodel.CreateError("ERR Unknown parameter")
}
return db.ProcessValue(key, true, func(elem *Element) (datamodel.CustomDataType, bool) {
if elem.Value == nil {
return datamodel.CreateInt(0), false
}
dict, ok := elem.Value.(datamodel.DataDictionary)
if !ok {
return datamodel.CreateError("WRONGTYPE Operation against a key holding the wrong kind of value"), false
}
processed := 0
idx := 1
for {
cur := dict.Value(hkey)
_, ok = cur.(datamodel.DataNull)
if !ok {
dict.Add(hkey, datamodel.CreateNull())
processed++
}
if idx == command.Count() {
break
}
hkey, err = getKey(command, idx)
if err != nil {
return datamodel.CreateError("ERR Unknown parameter"), false
}
idx++
}
result := datamodel.CreateInt(processed)
return result, true
})
}
func hsetCommand(db *Database, key string, command datamodel.DataArray) datamodel.CustomDataType {
hkey, err := getKey(command, 0)
if err != nil {
return datamodel.CreateError("ERR Unknown parameter")
}
val, err := getKey(command, 1)
if err != nil {
return datamodel.CreateError("ERR Unknown parameter")
}
return db.ProcessValue(key, true, func(elem *Element) (datamodel.CustomDataType, bool) {
var dict datamodel.DataDictionary
if elem.Value == nil {
dict = datamodel.CreateDictionary(10)
elem.Value = dict
} else {
var ok bool
dict, ok = elem.Value.(datamodel.DataDictionary)
if !ok {
return datamodel.CreateError("WRONGTYPE Operation against a key holding the wrong kind of value"), false
}
}
res := 0
cur := dict.Value(hkey)
_, ok := cur.(datamodel.DataNull)
if ok {
res = 1
}
dict.Add(hkey, datamodel.CreateString(val))
result := datamodel.CreateInt(res)
return result, true
})
}
func hexistsCommand(db *Database, key string, command datamodel.DataArray) datamodel.CustomDataType {
hkey, err := getKey(command, 0)
if err != nil {
return datamodel.CreateError("ERR Unknown parameter")
}
return db.GetValueAndProcess(key, func(val datamodel.CustomDataType, isval bool) datamodel.CustomDataType {
if !isval {
return datamodel.CreateInt(0)
}
dict, okstr := val.(datamodel.DataDictionary)
if !okstr {
return datamodel.CreateError("WRONGTYPE Operation against a key holding the wrong kind of value")
}
cur := dict.Value(hkey)
_, ok := cur.(datamodel.DataNull)
if ok {
return datamodel.CreateInt(0)
}
return datamodel.CreateInt(1)
})
}
func hgetCommand(db *Database, key string, command datamodel.DataArray) datamodel.CustomDataType {
hkey, err := getKey(command, 0)
if err != nil {
return datamodel.CreateError("ERR Unknown parameter")
}
return db.GetValueAndProcess(key, func(val datamodel.CustomDataType, isval bool) datamodel.CustomDataType {
if !isval {
return datamodel.CreateNull()
}
dict, okstr := val.(datamodel.DataDictionary)
if !okstr {
return datamodel.CreateError("WRONGTYPE Operation against a key holding the wrong kind of value")
}
cur := dict.Value(hkey)
return cur.Copy()
})
}
func hlenCommand(db *Database, key string, command datamodel.DataArray) datamodel.CustomDataType {
return db.GetValueAndProcess(key, func(val datamodel.CustomDataType, isval bool) datamodel.CustomDataType {
if !isval {
return datamodel.CreateInt(0)
}
dict, okstr := val.(datamodel.DataDictionary)
if !okstr {
return datamodel.CreateError("WRONGTYPE Operation against a key holding the wrong kind of value")
}
return datamodel.CreateInt(dict.Count())
})
}
func hstrlenCommand(db *Database, key string, command datamodel.DataArray) datamodel.CustomDataType {
hkey, err := getKey(command, 0)
if err != nil {
return datamodel.CreateError("ERR Unknown parameter")
}
return db.GetValueAndProcess(key, func(val datamodel.CustomDataType, isval bool) datamodel.CustomDataType {
if !isval {
return datamodel.CreateInt(0)
}
dict, okstr := val.(datamodel.DataDictionary)
if !okstr {
return datamodel.CreateError("WRONGTYPE Operation against a key holding the wrong kind of value")
}
cur := dict.Value(hkey)
str, ok := cur.(datamodel.DataString)
if !ok {
return datamodel.CreateInt(0)
}
strstr := str.Get()
return datamodel.CreateInt(len(strstr))
})
}
func hsetnxCommand(db *Database, key string, command datamodel.DataArray) datamodel.CustomDataType {
hkey, err := getKey(command, 0)
if err != nil {
return datamodel.CreateError("ERR Unknown parameter")
}
val, err := getKey(command, 1)
if err != nil {
return datamodel.CreateError("ERR Unknown parameter")
}
return db.ProcessValue(key, true, func(elem *Element) (datamodel.CustomDataType, bool) {
var dict datamodel.DataDictionary
if elem.Value == nil {
dict = datamodel.CreateDictionary(10)
elem.Value = dict
} else {
var ok bool
dict, ok = elem.Value.(datamodel.DataDictionary)
if !ok {
return datamodel.CreateError("WRONGTYPE Operation against a key holding the wrong kind of value"), false
}
}
cur := dict.Value(hkey)
_, ok := cur.(datamodel.DataNull)
if ok {
dict.Add(hkey, datamodel.CreateString(val))
return datamodel.CreateInt(1), true
}
return datamodel.CreateInt(0), true
})
}
func hgetallCommand(db *Database, key string, command datamodel.DataArray) datamodel.CustomDataType {
return db.GetValueAndProcess(key, func(val datamodel.CustomDataType, isval bool) datamodel.CustomDataType {
if !isval {
return datamodel.CreateArray(0)
}
dict, okstr := val.(datamodel.DataDictionary)
if !okstr {
return datamodel.CreateError("WRONGTYPE Operation against a key holding the wrong kind of value")
}
arr := dict.Keys()
outarr := datamodel.CreateArray(arr.Count() * 2)
for i := 0; i < arr.Count(); i++ {
hkey := arr.Get(i).(datamodel.DataString).Get()
cur := dict.Value(hkey)
str, ok := cur.(datamodel.DataString)
if ok {
outarr.Add(datamodel.CreateString(hkey))
outarr.Add(str.Copy())
}
}
return outarr
})
}
func hkeysCommand(db *Database, key string, command datamodel.DataArray) datamodel.CustomDataType {
return db.GetValueAndProcess(key, func(val datamodel.CustomDataType, isval bool) datamodel.CustomDataType {
if !isval {
return datamodel.CreateArray(0)
}
dict, okstr := val.(datamodel.DataDictionary)
if !okstr {
return datamodel.CreateError("WRONGTYPE Operation against a key holding the wrong kind of value")
}
return dict.Keys()
})
}
func hvalsCommand(db *Database, key string, command datamodel.DataArray) datamodel.CustomDataType {
return db.GetValueAndProcess(key, func(val datamodel.CustomDataType, isval bool) datamodel.CustomDataType {
if !isval {
return datamodel.CreateArray(0)
}
dict, okstr := val.(datamodel.DataDictionary)
if !okstr {
return datamodel.CreateError("WRONGTYPE Operation against a key holding the wrong kind of value")
}
arr := dict.Keys()
outarr := datamodel.CreateArray(arr.Count())
for i := 0; i < arr.Count(); i++ {
hkey := arr.Get(i).(datamodel.DataString).Get()
cur := dict.Value(hkey)
str, ok := cur.(datamodel.DataString)
if ok {
outarr.Add(str.Copy())
}
}
return outarr
})
}
func hincrbyCommand(db *Database, key string, command datamodel.DataArray) datamodel.CustomDataType {
hkey, err := getKey(command, 0)
if err != nil {
return datamodel.CreateError("ERR Unknown parameter")
}
val, err := getInt(command, 1)
if err != nil {
return datamodel.CreateError("ERR Unknown parameter")
}
return db.ProcessValue(key, true, func(elem *Element) (datamodel.CustomDataType, bool) {
var dict datamodel.DataDictionary
if elem.Value == nil {
dict = datamodel.CreateDictionary(10)
elem.Value = dict
} else {
var ok bool
dict, ok = elem.Value.(datamodel.DataDictionary)
if !ok {
return datamodel.CreateError("WRONGTYPE Operation against a key holding the wrong kind of value"), false
}
}
cur := dict.Value(hkey)
_, ok := cur.(datamodel.DataNull)
if ok {
dict.Add(hkey, datamodel.CreateString(strconv.Itoa(val)))
return datamodel.CreateInt(val), true
}
str, ok := cur.(datamodel.DataString)
if ok {
ival, err := strconv.Atoi(str.Get())
if err != nil {
return datamodel.CreateError("ERR value is not an integer or out of range"), false
}
dict.Add(hkey, datamodel.CreateString(strconv.Itoa(val+ival)))
return datamodel.CreateInt(val + ival), true
}
return datamodel.CreateInt(0), true
})
}
func hmgetCommand(db *Database, key string, command datamodel.DataArray) datamodel.CustomDataType {
return db.GetValueAndProcess(key, func(val datamodel.CustomDataType, isval bool) datamodel.CustomDataType {
if !isval {
return datamodel.CreateArray(0)
}
dict, okstr := val.(datamodel.DataDictionary)
if !okstr {
return datamodel.CreateError("WRONGTYPE Operation against a key holding the wrong kind of value")
}
outarr := datamodel.CreateArray(command.Count())
for i := 0; i < command.Count(); i++ {
hkey, err := getKey(command, i)
if err != nil {
return datamodel.CreateError("ERR Unknown parameter")
}
cur := dict.Value(hkey)
switch cur.(type) {
case datamodel.DataString:
outarr.Add(cur.Copy())
case datamodel.DataNull:
outarr.Add(cur.Copy())
}
}
return outarr
})
}
func hmsetCommand(db *Database, key string, command datamodel.DataArray) datamodel.CustomDataType {
return db.ProcessValue(key, true, func(elem *Element) (datamodel.CustomDataType, bool) {
var dict datamodel.DataDictionary
if elem.Value == nil {
dict = datamodel.CreateDictionary(10)
elem.Value = dict
} else {
var ok bool
dict, ok = elem.Value.(datamodel.DataDictionary)
if !ok {
return datamodel.CreateError("WRONGTYPE Operation against a key holding the wrong kind of value"), false
}
}
cnt := command.Count()
if cnt&1 == 1 || cnt == 0 {
return datamodel.CreateError("ERR Invalid syntax"), false
}
for i := 0; i < cnt; i += 2 {
hkey, err := getKey(command, i)
if err != nil {
return datamodel.CreateError("ERR Unknown parameter"), false
}
val, err := getKey(command, i)
if err != nil {
return datamodel.CreateError("ERR Unknown parameter"), false
}
dict.Add(hkey, datamodel.CreateString(val))
}
return datamodel.CreateSimpleString("OK"), true
})
}
|
Markdown
|
UTF-8
| 4,112 | 3.015625 | 3 |
[
"Apache-2.0"
] |
permissive
|
# Advent of Code 2020 :santa: :christmas_tree: :snowman: :sparkles:
[Advent of Code](https://adventofcode.com/) using TypeScript.
There's no need to *build* anything. Source files are transpiled and cached on-the-fly using [esbuild-runner](https://github.com/folke/esbuild-runner/) with pretty much **zero overhead**. Running the code for a certain day, will:
* download the input if needed
* test any examples for each part
* test the answer (if availble) for each part
* measure the performance and update the benchmark section of this readme
## :zap: Benchmark
~~My personal goal for this year is to solve all puzzles within **25ms** total, so an average of **1ms** per puzzle.~~
> **edit:** never mind 😂
<!-- RESULTS:BEGIN -->
### :snowflake: 2020
|[2020](./src/2020) | Part1 | Part2 | Total | Days Total | Stars|
|--- | --- | --- | --- | --- | ---|
|[Day 1](./src/2020/day1.ts) | 12µs | 196µs | ⚡️ 208µs | 208µs | :star: :star: |
|[Day 2](./src/2020/day2.ts) | 320µs | 175µs | ⚡️ 496µs | 703µs | :star: :star: |
|[Day 3](./src/2020/day3.ts) | 3µs | 15µs | ⚡️ 18µs | 721µs | :star: :star: |
|[Day 4](./src/2020/day4.ts) | 302µs | 429µs | ⚡️ 730µs | 1.45ms | :star: :star: |
|[Day 5](./src/2020/day5.ts) | 362µs | 356µs | ⚡️ 718µs | 2.17ms | :star: :star: |
|[Day 6](./src/2020/day6.ts) | 131µs | 143µs | ⚡️ 274µs | 2.44ms | :star: :star: |
|[Day 7](./src/2020/day7.ts) | 573µs | 392µs | ⚡️ 965µs | 3.41ms | :star: :star: |
|[Day 8](./src/2020/day8.ts) | 100µs | 144µs | ⚡️ 244µs | 3.65ms | :star: :star: |
|[Day 9](./src/2020/day9.ts) | 93µs | 47µs | ⚡️ 141µs | 3.79ms | :star: :star: |
|[Day 10](./src/2020/day10.ts) | 14µs | 23µs | ⚡️ 37µs | 3.83ms | :star: :star: |
|[Day 11](./src/2020/day11.ts) | 32.43ms | 55.86ms | ❗️ 88.29ms | 92.12ms | :star: :star: |
|[Day 12](./src/2020/day12.ts) | 23µs | 26µs | ⚡️ 50µs | 92.17ms | :star: :star: |
|[Day 13](./src/2020/day13.ts) | 4µs | 19µs | ⚡️ 23µs | 92.19ms | :star: :star: |
|[Day 14](./src/2020/day14.ts) | 632µs | 6.97ms | ❗️ 7.6ms | 99.79ms | :star: :star: |
|[Day 15](./src/2020/day15.ts) | 10µs | 683.67ms | ❗️ 683.67ms | 783.47ms | :star: :star: |
|[Day 16](./src/2020/day16.ts) | 554µs | 1.26ms | ❗️ 1.81ms | 785.28ms | :star: :star: |
|[Day 17](./src/2020/day17.ts) | 41.86ms | 1359.56ms | ❗️ 1401.42ms | 2186.7ms | :star: :star: |
|[Day 18](./src/2020/day18.ts) | 1.91ms | 1.91ms | ❗️ 3.82ms | 2190.52ms | :star: :star: |
|[Day 19](./src/2020/day19.ts) | 425µs | 667µs | ❗️ 1.09ms | 2191.61ms | :star: :star: |
### :snowflake: 2019
|[2019](./src/2019) | Part1 | Part2 | Total | Days Total | Stars|
|--- | --- | --- | --- | --- | ---|
|[Day 1](./src/2019/day1.ts) | 3µs | 10µs | ⚡️ 13µs | 13µs | :star: :star: |
|[Day 3](./src/2019/day3.ts) | 58.98ms | 114.56ms | ❗️ 173.54ms | 173.55ms | :star: :star: |
|[Day 4](./src/2019/day4.ts) | 6.66ms | 6.29ms | ❗️ 12.95ms | 186.5ms | :star: :star: |
### :snowflake: 2015
|[2015](./src/2015) | Part1 | Part2 | Total | Days Total | Stars|
|--- | --- | --- | --- | --- | ---|
|[Day 1](./src/2015/day1.ts) | 85µs | 9µs | ⚡️ 95µs | 95µs | :star: :star: |
|[Day 2](./src/2015/day2.ts) | 611µs | 785µs | ❗️ 1.4ms | 1.49ms | :star: :star: |
|[Day 3](./src/2015/day3.ts) | 263µs | 282µs | ⚡️ 545µs | 2.04ms | :star: :star: |
|[Day 4](./src/2015/day4.ts) | 592.43ms | 18805.74ms | ❗️ 19398.16ms | 19400.2ms | :star: :star: |
|[Day 5](./src/2015/day5.ts) | 394µs | 703µs | ❗️ 1.1ms | 19401.3ms | :star: :star: |
<!-- RESULTS:END -->
## :rocket: Usage
```shell
$ bin/aoc --help
Usage: aoc [options] [day]
--year [year] Defaults to 2020
--bench Benchmark the solutions for all days
--help|-h Display this help message
```
To run all days:
```shell
$ bin/aoc
```
To run a specific day:
```shell
$ bin/aoc 3
```
To run the benchmarks:
```shell
$ bin/aoc --bench
```
> if a day has not been implemented yet, executing that day will create a new `src/day??.ts` file based on the [template](src/day.template.ts)
|
Python
|
UTF-8
| 527 | 3.28125 | 3 |
[] |
no_license
|
import sys
def counting_sheep(N):
res = set()
if N == 0:
return 'INSOMNIA'
num = N
while True:
[res.add(c) for c in str(num)]
if len(res) == 10:
return num
num += N
def main():
filename = sys.argv[1]
with open(filename, 'r') as f:
count = int(f.readline())
for i in range(count):
N = int(f.readline())
num = counting_sheep(N)
print 'Case #%d: %s' % (i+1, num)
if __name__ == '__main__':
main()
|
Python
|
UTF-8
| 11,148 | 2.65625 | 3 |
[
"MIT"
] |
permissive
|
# coding=utf-8
__author__ = 'kdq'
from gbm import LeastSquaresLoss, LogisticLoss, PairwiseLoss
import numpy as np
# logistic function
from scipy.special import expit
from mla.base import BaseEstimator
from mla.ensemble.base import mse_criterion
from mla.ensemble.tree import Tree
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
import random
from matplotlib import pyplot as plt
import sklearn
import scipy
from NDCG import *
import time
import pandas as pd
from multiprocessing import Pool
random.seed(1234)
class pDARTBase(BaseEstimator):
'''
n_estimators: #trees
learning_rate: eta
max_feature: default:None, all feature
integer:#features
float:fraction of features
max_depth: default:2
min_samples_split: min samples for a node to split
p:drop probability
min_samples_leaf:default:1, min #nodes in a leaf
max_leaf_nodes:default:None, max leaf nodes in a tree
'''
def __init__(self, n_estimators, learning_rate=1., max_features=None, max_depth=2, min_samples_split=10, p=0.1,
min_samples_leaf=1, max_leaf_nodes=None, parallel_gradient=True):
self.min_samples_split = min_samples_split
self.learning_rate = learning_rate
self.max_depth = max_depth
self.max_features = max_features
self.n_estimators = n_estimators
self.min_samples_leaf = min_samples_leaf
self.max_leaf_nodes = max_leaf_nodes
self.parallel_gradient = parallel_gradient
self.p = p
self.trees = []
self.weight = []
self.rank = []
self.raw_y_pred = []
self.loss = None
def fit(self, X, y=None):
self._setup_input(X, y)
self.y_mean= np.mean(y)
self._train()
def plot(self, X):
x = range(len(X))
plt.figure(1)
plt.plot(x, X)
plt.show()
def sample(self):
drop_tree = []
y_pred = np.zeros(self.n_samples, np.float32)
if len(self.trees) == 0:
return y_pred, []
# drop trees from uniform sampling with probability self.p
rank = np.fabs(self.rank).argsort().argsort() + 1
for i, tree in enumerate(self.trees):
rand = np.random.uniform(0, 1)
# p_{i} = 1 / rank
if rand < 1. / rank[i]:
drop_tree.append(i)
else:
y_pred += self.weight[i] * self.raw_y_pred[i]
# if none of trees were droped, random choice 1 tree to drop
if len(drop_tree) == 0:
idx = np.random.choice(range(len(self.trees)))
drop_tree.append(idx)
y_pred += self.weight[idx] * self.raw_y_pred[idx]
return y_pred, drop_tree
def _train(self):
# Initialize model with zeros
# y_pred = np.zeros(self.n_samples, np.float32)
# Or mean
# y_pred = np.full(self.n_samples, self.y_mean)
for n in range(self.n_estimators):
y_pred, drop_tree = self.sample()
residuals = self.loss.grad(self.y, y_pred)
# fk = pd.DataFrame({'fk': residuals})
# print fk.info()
# tree = Tree(regression=True, criterion=mse_criterion)
# Pass multiple target values to the tree learner
# targets = {
# # Residual values
# 'y': residuals,
# # Actual target values
# 'actual': self.y,
# # Predictions from previous step
# 'y_pred': y_pred
# }
# tree.train(self.X, targets, max_features=self.max_features,
# min_samples_split=self.min_samples_split, max_depth=self.max_depth, loss=self.loss)
tree = DecisionTreeRegressor(criterion='friedman_mse', splitter="best", max_depth=self.max_depth,
min_samples_split=self.min_samples_split, max_features=self.max_features,
min_samples_leaf=self.min_samples_leaf, max_leaf_nodes=self.max_leaf_nodes)
tree.fit(self.X, residuals)
predictions = tree.predict(self.X)
error = self.loss.error(self.y, predictions)
# y_pred += self.learning_rate * predictions
self.raw_y_pred.append(predictions)
self.trees.append(tree)
self.rank.append(error)
# rewrite weight
l = len(drop_tree)
self.weight.append(self.learning_rate / (l + 1))
for idx in drop_tree:
self.weight[idx] *= 1.0 * l / (l + 1)
# self.plot(self.rank)
def _predict(self, X=None):
y_pred = np.zeros(X.shape[0], np.float32)
for i, tree in enumerate(self.trees):
y_pred += self.weight[i] * tree.predict(X)
return y_pred
def predict(self, X=None):
return self.loss.transform(self._predict(X))
class pDARTRegressor(pDARTBase):
def fit(self, X, y=None):
self.loss = LeastSquaresLoss()
super(pDARTRegressor, self).fit(X, y)
class pDARTClassifier(pDARTBase):
def fit(self, X, y=None):
# Convert labels from {0, 1} to {-1, 1}
y = (y * 2) - 1
self.loss = LogisticLoss()
super(pDARTClassifier, self).fit(X, y)
class pDARTRanker(pDARTBase):
@classmethod
def _setup_qids(self, qids):
# qid, a, b: qid, start of qid, end of qid
qids_ = {}
pre_qid = qids[0]
pre_idx = 0
for idx, qid in enumerate(qids):
if pre_qid != qid:
qids_[pre_qid] = (pre_qid, pre_idx, idx)
pre_idx = idx
pre_qid = qid
qids_[pre_qid] = (pre_qid, pre_idx, len(qids) + 1)
return qids_
def _update_terminal_regions(self, tree, X, y, lambdas, deltas):
terminal_regions = tree.apply(X)
masked_terminal_regions = terminal_regions.copy()
# no subsample, so no mask
# masked_terminal_regions[~sample_mask] = -1
for leaf in np.where(tree.children_left ==
sklearn.tree._tree.TREE_LEAF)[0]:
terminal_region = np.where(masked_terminal_regions == leaf)
suml = np.sum(lambdas[terminal_region])
sumd = np.sum(deltas[terminal_region])
tree.value[leaf, 0, 0] = 0.0 if sumd == 0.0 else (suml / sumd)
# y_pred += tree.value[terminal_regions, 0, 0] * self.learning_rate
@classmethod
def _calc_lambdas_deltas(self, qid, y, y_pred, idcg, a, b):
ns = y.shape[0]
lambdas = np.zeros(ns)
deltas = np.zeros(ns)
sorted_y_pred = np.argsort(y_pred)[::-1]
# rev_sorted_y_pred = np.argsort(sorted_y_pred)
actual = y[sorted_y_pred]
# pred = y_pred[sorted_y_pred]
dcgs = {}
for i in xrange(ns):
dcgs[(i, i)] = single_dcg(actual, i, i)
for j in xrange(i + 1, ns):
if actual[i] == actual[j]:
continue
dcgs[(i, j)] = single_dcg(actual, i, j)
dcgs[(j, i)] = single_dcg(actual, j, i)
for i in xrange(ns):
for j in xrange(i + 1, ns):
if actual[i] == actual[j]:
continue
deltas_ndcg = np.abs(dcgs[(i, j)] + dcgs[(j, i)] - dcgs[(i, i)] - dcgs[(j, j)]) / idcg
x_i, x_j = sorted_y_pred[i], sorted_y_pred[j]
if actual[i] < actual[j]:
logistic = scipy.special.expit(y_pred[x_i] - y_pred[x_j])
l = logistic * deltas_ndcg
lambdas[x_i] -= l
lambdas[x_j] += l
else:
logistic = scipy.special.expit(y_pred[x_j] - y_pred[x_i])
l = logistic * -deltas_ndcg
lambdas[x_i] += l
lambdas[x_j] -= l
gradient = (1 - logistic) * l
deltas[i] += gradient
deltas[j] += gradient
return lambdas, deltas, a, b
def fit(self, X, y=None, qids=None):
self.loss = PairwiseLoss()
self._setup_input(X, y)
self.qids = self._setup_qids(qids)
self._train()
def _train(self):
self.all_lambdas = np.zeros(self.n_samples, np.float32)
self.all_deltas = np.zeros(self.n_samples, np.float32)
idcgs = {}
for qid, a, b in self.qids.values():
idcgs[qid] = idcg(self.y[a:b])
# if idcgs[qid] == 0.0:
# print a, b, qid, np.mean(self.y[a:b])
# sample_mask = np.zeros(self.n_samples, dtype=np.bool)
for n in range(self.n_estimators):
# calculate lambdas & deltas
print('construct tree :{}, at {}'.format(n + 1, time.ctime()))
print('#qids: {}'.format(len(self.qids)))
y_pred, drop_tree = self.sample()
parameters = []
for idx, (qid, a, b) in enumerate(self.qids.values()):
if idx % 1000 == 0:
print('#iter qids :{}, at {}'.format(idx, time.ctime()))
if self.parallel_gradient:
parameters.append([qid, self.y[a:b], y_pred[a:b], idcgs[qid], a, b])
break
else:
lambdas, deltas, _, _ = self._calc_lambdas_deltas(qid, self.y[a:b], y_pred[a:b], idcgs[qid], a, b)
self.all_lambdas[a:b] = lambdas
self.all_deltas[a:b] = deltas
if self.parallel_gradient:
pool = Pool(8)
res = pool.map(pDARTRanker._calc_lambdas_deltas, parameters)
for l, d, a, b in res:
self.all_lambdas[a:b] = l
self.all_deltas[a:b] = d
print('calculate lambda success, at {}'.format(time.ctime()))
tree = DecisionTreeRegressor(criterion='friedman_mse', splitter="best", max_depth=self.max_depth,
min_samples_split=self.min_samples_split, max_features=self.max_features,
min_samples_leaf=self.min_samples_leaf, max_leaf_nodes=self.max_leaf_nodes)
tree.fit(self.X, self.all_lambdas)
print('construct decision tree success, at {}'.format(time.ctime()))
self._update_terminal_regions(tree.tree_, self.X, self.y, self.all_lambdas, self.all_deltas)
predictions = tree.predict(self.X)
print predictions.shape
print self.y.shape
error = -self.loss.error(self.y, predictions, self.qids)
self.raw_y_pred.append(predictions)
self.trees.append(tree)
self.rank.append(error)
# rewrite weight
l = len(drop_tree)
self.weight.append(self.learning_rate / (l + 1))
for idx in drop_tree:
self.weight[idx] *= 1.0 * l / (l + 1)
print('finish iter {}, at {}'.format(n + 1, time.ctime()))
|
JavaScript
|
UTF-8
| 1,540 | 2.84375 | 3 |
[
"MIT"
] |
permissive
|
import { useState, useEffect } from "react"
import { getPos, calcDistance } from '../utils/location'
const funcs = {
alphabetically: async arr => {
return arr.sort((a, b) => String(a.name).localeCompare(b.name))
},
"delivery price": async arr => {
return arr.sort((a, b) => a.delivery_price - b.delivery_price)
},
nearest: async arr => {
try {
const position = await getPos()
const { latitude, longitude } = position.coords
return arr.sort(
(a, b) =>
calcDistance(latitude, longitude, a.location[0], a.location[1]) -
calcDistance(latitude, longitude, b.location[0], b.location[1])
)
} catch (error) {
alert("Unable to retrieve your location");
return arr;
}
},
}
export const sortNames = Object.keys(funcs)
export default (restaurants, sortBy) => {
const [sorted, setSorted] = useState(restaurants)
const [sorting, setSorting] = useState(false)
useEffect(() => {
const fn = funcs[sortBy]
if (fn) {
setSorting(true)
fn([...restaurants])
.then(async res => {
await fakeAsync(Math.random() * 1000)
setSorted(res)
}).catch(e => { })
.finally(() => setSorting(false))
}
}, [restaurants, sortBy])
return { sorted, sorting }
}
const fakeAsync = delay => new Promise(res => setTimeout(res, delay))
|
Markdown
|
UTF-8
| 1,721 | 3.71875 | 4 |
[
"MIT"
] |
permissive
|
# Chemical-Unscrambler
This python program outputs a list of the possible words that could be made with the symbols of input chemicals.
# How to use
1. Open the IDE: [https://Chemical-Unscrabler.nexussi14.repl.run/](https://Chemical-Unscrabler.nexussi14.repl.run/)
2. Wait for the Prompt
3. Enter a list of element names/symbols.
4. Hit enter.
# How the unscrabler works
It takes words from a text file and uses a lookup function to find words with the same letters (where the order of words does not matter).
## The key to its speed
It converts all the words into integers (which is based on the letters) and groups words with the same integer in a dictionary. Then it converts the typed word into an integer and looks up that integer in the dictionary.
A first function Word2Vect converts a word into a 26 dimensions vector. Each dimension represents the number of occurrences of a letter ('a', 'b', 'c'...).
```
def Word2Vect(word):
l = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
v = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
w = word.lower()
wl = list(w)
for i in range(0, len(wl)):
if wl[i] in l:
ind = l.index(wl[i])
v[ind] += 1
return v
```
Then a second function Vect2Int converts a 26 dimensions vector into an integer. Each dimension is reduced to a 4 bits. All bits of the Integer are used to code the vector.
```
def Vect2Int(vect):
pv = 0
f = 0
for i in range(0, len(vect)):
wip = (vect[i]*(2**pv))
f += wip
pv += 4
return f
```
Using an integer as lookup value in a dictionary makes it run really fast!
|
Python
|
UTF-8
| 4,040 | 2.75 | 3 |
[] |
no_license
|
import getpass
import os
import textwrap
import pandas as pd
from constants import ACTION_PROMPT
from constants import CURRENT_WORKING_DIRECTORY
from constants import DEFAULT_FILEPATH
from constants import FILENAME_PROMPT
from constants import FILENAME_PROMPT_ERROR
from constants import FILENAME_PROMPT_EXPLANATION
from constants import INPUT_PROMPT
from constants import INPUT_PROMPT_ERROR
from constants import INPUT_PROMPT_EXPLANATION
from constants import SALT_PROMPT
from constants import SENSITIVE_COLUMNS_PROMPT
from constants import SENSITIVE_COLUMNS_PROMPT_ERROR
from constants import SENSITIVE_COLUMNS_PROMPT_EXPLANATION
def ask_for_symmetric_key(action):
valid_prompt_result = False
__symmetric_key = ""
while valid_prompt_result is False:
try:
if action == "E":
prompt_explanation = textwrap.dedent(INPUT_PROMPT_EXPLANATION).strip()
print(f"\n{prompt_explanation}")
__symmetric_key = getpass.getpass(prompt=f"\n{INPUT_PROMPT}: ")
valid_prompt_result = True
except Exception:
print(textwrap.dedent(INPUT_PROMPT_ERROR).strip())
return __symmetric_key
def ask_for_sensitive_features():
valid_prompt_result = False
__sensitive_features = []
while valid_prompt_result is False:
try:
prompt_explanation = textwrap.dedent(SENSITIVE_COLUMNS_PROMPT_EXPLANATION).strip()
print(f"\n{prompt_explanation}")
__sensitive_features: list = input(f"\n{SENSITIVE_COLUMNS_PROMPT}: ").split(",")
if len(__sensitive_features) > 0:
valid_prompt_result = True
else:
raise Exception
except Exception:
print(textwrap.dedent(SENSITIVE_COLUMNS_PROMPT_ERROR).strip())
return __sensitive_features
def check_filename(input_filename: str) -> bool:
len_input_filename = len(input_filename)
find_xlsx = input_filename.find(".xlsx")
return len_input_filename > 4 and find_xlsx != -1 and len_input_filename - find_xlsx == 5
def check_filepath(input_filename: str, filepath: str = DEFAULT_FILEPATH) -> bool:
return os.path.isdir(os.path.join(CURRENT_WORKING_DIRECTORY, filepath)) and os.path.exists(
os.path.join(CURRENT_WORKING_DIRECTORY, filepath, input_filename)
)
def ask_for_filename():
valid_prompt_result = False
__filename = ""
while valid_prompt_result is False:
try:
prompt_explanation = textwrap.dedent(FILENAME_PROMPT_EXPLANATION).strip()
print(f"\n{prompt_explanation}")
__filename = input(f"\n{FILENAME_PROMPT}: ")
if check_filename(__filename) and check_filepath(__filename):
valid_prompt_result = True
else:
raise Exception
except Exception:
print(f"\n\n{textwrap.dedent(FILENAME_PROMPT_ERROR).strip()}")
return __filename
def validate_sensitive_features(df_columns: list, features: list) -> bool:
return set(features).issubset(df_columns)
def read_df(filename):
valid_reading_df = False
__df = None
features = []
while valid_reading_df is False:
features = ask_for_sensitive_features()
__df = pd.read_excel(os.path.join(CURRENT_WORKING_DIRECTORY, DEFAULT_FILEPATH, filename))
if validate_sensitive_features(__df.columns, features):
valid_reading_df = True
else:
print(f"\n{SENSITIVE_COLUMNS_PROMPT_ERROR}")
return __df, features
def ask_for_action():
valid_prompt_result = False
__action = ""
while valid_prompt_result is False:
__action = input(f"\n{ACTION_PROMPT}: ")
if __action == "E" or __action == "D":
valid_prompt_result = True
return __action
def ask_for_salt():
valid_prompt_result = False
__salt = ""
while valid_prompt_result is False:
__salt = input(f"\n{SALT_PROMPT}: ")
if len(__salt) != 0:
valid_prompt_result = True
return __salt
|
Java
|
UTF-8
| 535 | 1.875 | 2 |
[
"MIT"
] |
permissive
|
package fr.laposte.sv.project.back.repository;
import fr.laposte.sv.project.back.model.SvSuivi;
import fr.laposte.sv.project.back.model.WebService;
import org.springframework.data.jpa.repository.JpaRepository;
import java.time.LocalDate;
import java.util.Set;
public interface SvSuiviRepository extends JpaRepository<SvSuivi, Integer> {
Set<SvSuivi> findSvSuiviByWebService(WebService webService);
Set<SvSuivi> findByDate(LocalDate date);
// Set<SvSuivi> svSuiviParDate();
// SvSuivi findAll(LocalDate date);
}
|
Java
|
GB18030
| 1,574 | 2.640625 | 3 |
[] |
no_license
|
package util;
import java.io.IOException;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Properties;
import java.util.ResourceBundle;
/**
* @author : yyh
* @date ʱ䣺201876 10:28:50
* @version 1.0
*/
public class DBUtil {
public static Properties properties=new Properties();
public static String driver;
public static String url;
public static String username;
public static String password;
static {
try {
//ļ
properties.load(DBUtil.class.getClassLoader().getResourceAsStream("db.properties"));
driver=properties.getProperty("driver");
url=properties.getProperty("url");
username=properties.getProperty("username");
password=properties.getProperty("password");
Class.forName(driver);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
public static Connection getConnection () throws SQLException {
Connection conn=DriverManager.getConnection(url,username,password);
return conn;
}
public int update(String sql,Object[]...params) {
//sql insert into xxx(ֶ1ֶ2ֶ3) values(?,?,?)
//update xxx set ֶ1=ֶ2= where id=?
PreparedStatement ps;
int result=0;
try {
ps = getConnection().prepareStatement(sql);
for(int i=0;i<params.length;i++) {
ps.setObject((i+1), params[i]);
}
result=ps.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}
return result;
}
}
|
C
|
UTF-8
| 2,989 | 2.765625 | 3 |
[
"MIT"
] |
permissive
|
/*
* Program: Software Renderer
* File: win32_main.c
* Lesson: 1.1
* Description: example of creating a basic window in win32.
*
*/
#include <windows.h>
#include <stdint.h>
#define global_variable static
typedef int8_t int8;
typedef int16_t int16;
typedef int32_t int32;
typedef int64_t int64;
typedef uint8_t uint8;
typedef uint16_t uint16;
typedef uint32_t uint32;
typedef uint64_t uint64;
global_variable uint8 GlobalRunning;
global_variable HWND GlobalWindowHandle;
LRESULT CALLBACK
Win32MainWindowCallback(HWND windowHandle, UINT message, WPARAM wParam, LPARAM lParam)
{
LRESULT result = 0;
switch (message)
{
case WM_CLOSE:
{
GlobalRunning = 0;
} break;
case WM_ACTIVATEAPP:
{
OutputDebugStringA("WM_ACTIVEAPP\n");
} break;
case WM_PAINT:
{
PAINTSTRUCT paintStruct;
HDC deviceContext = BeginPaint(windowHandle, &paintStruct);
EndPaint(windowHandle, &paintStruct);
} break;
default:
{
result = DefWindowProcA(windowHandle, message, wParam, lParam);
} break;
}
return result;
}
int WINAPI
WinMain(HINSTANCE handleInstance, HINSTANCE handlePreviousInstance, LPSTR longPointerCommandLine, int numberCommmandShow)
{
WNDCLASSA windowClass = { 0 };
windowClass.style = (CS_HREDRAW | CS_VREDRAW | CS_OWNDC);
windowClass.lpfnWndProc = Win32MainWindowCallback;
windowClass.hInstance = handleInstance;
windowClass.hCursor = LoadCursor(NULL, IDC_ARROW);
windowClass.lpszClassName = "WindowClass";
if (RegisterClassA(&windowClass))
{
GlobalWindowHandle = CreateWindowExA(0,
windowClass.lpszClassName,
"Software Renderer - Lesson 1.1",
WS_OVERLAPPEDWINDOW | WS_VISIBLE,
CW_USEDEFAULT,
CW_USEDEFAULT,
800,
600,
0,
0,
handleInstance,
0);
if (GlobalWindowHandle)
{
GlobalRunning = 1;
while (GlobalRunning)
{
MSG message;
while (PeekMessage(&message, 0, 0, 0, PM_REMOVE))
{
if (message.message == WM_QUIT)
{
GlobalRunning = 0;
}
TranslateMessage(&message);
DispatchMessage(&message);
}
}
}
}
return 0;
}
|
Python
|
UTF-8
| 1,635 | 2.59375 | 3 |
[] |
no_license
|
import base64
from typing import Any
import lz4
import numpy as np
def dict_to_ndarray(d: dict):
if d is None:
return None
else:
b = base64.b64decode(d["ndarray"])
if d["compression"] == "lz4":
b = lz4.frame.decompress(b)
return np.frombuffer(
b,
dtype=np.dtype(d["dtype"]),
).reshape(d["shape"])
class NDArray(np.ndarray):
@classmethod
def __get_validators__(cls):
yield cls.validate
@classmethod
def __modify_schema__(cls, field_schema):
field_schema.update(
title="NDArray",
oneOf=[
{
"type": "object",
"properties": {
"ndarray": {"type": "string"},
"compression": {"type": "string"},
"dtype": {"type": "string"},
"shape": {"type": "array", "items": {"type": "number"}},
},
},
{"type": "array", "items": {"type": "number"}},
{
"type": "array",
"items": {"type": "array", "items": {"type": "number"}},
},
],
)
@classmethod
def validate(cls, v: Any):
if isinstance(v, np.ndarray):
return v
elif isinstance(v, dict):
return cls.from_dict(v)
elif isinstance(v, list):
return np.array(v)
else:
raise ValueError("invalid type")
@classmethod
def from_dict(cls, d):
return dict_to_ndarray(d)
|
Python
|
UTF-8
| 880 | 3.859375 | 4 |
[] |
no_license
|
class Solution:
def letterCombinations(self, digits: str) -> List[str]:
if len(digits) == 0:
return []
combs = []
letters = {"2": "abc", "3": "def", "4": "ghi", "5": "jkl",
"6": "mno", "7": "pqrs", "8": "tuv", "9": "wxyz"}
def backtrack(index, path):
# If the path is the same length as digits, we have a complete combination
if index == len(digits):
combs.append("".join(path))
return # Backtrack
# Get the letters that the current digit maps to, and loop through them
possible_letters = letters[digits[index]]
for letter in possible_letters:
# Move on to the next digit
backtrack(index + 1, path + [letter])
backtrack(0, [])
return combs
|
Markdown
|
UTF-8
| 1,248 | 2.578125 | 3 |
[] |
no_license
|
## 操作场景
堡垒机系统具备统一管理用户功能,下面将为您详细介绍如何在堡垒机创建用户。
## 操作步骤
1. 登录腾讯云 [堡垒机控制台](https://console.cloud.tencent.com/dsgc/bh),并使用管理员账号登录堡垒机。
2. 单击【用户管理】,进入用户管理页面。
3. 单击【新建】,进入添加添加用户页面,配置如下用户信息。
- 用户 ID:输入用户 ID,即用于登录堡垒机的账号。
- 用户名称:输入用户名称。
- 口令:输入用户的密码。
- 确认口令:确认用户密码。
- 用户类型:默认为其他,并勾选“运维用户”。若您需更换类型,请先创建用户类型,详细配置请查看 [添加用户类型](https://cloud.tencent.com/document/product/1025/32573) 文档。
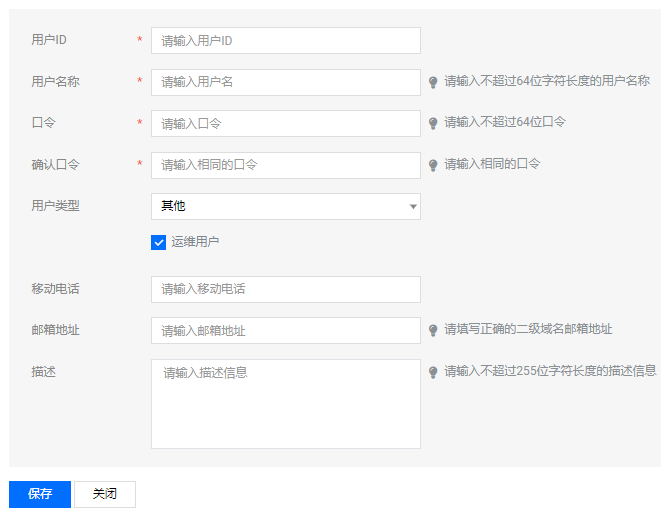
>!
>- 您可以在根节点下添加,也可以在组织结构类型为 “综合组”下添加用户。
>- 页面标`*`的为必填项,输入规则查看页面相应提示,“运维用户”为必选项,否则在没有对用户进行角色授权情况下,运维用户无法登录系统。
4. 单击【保存】,即可创建用户。
|
Markdown
|
UTF-8
| 1,161 | 2.53125 | 3 |
[] |
no_license
|
# Tutorial 13) Grasping objects
## Prerequisites
- Tutorial 6, 7 9, 12
## Tutorial
Combining all previous tutorials allows us to manipulate objects with use of the world model. A motion planner for manipulation, e.g. MoveIt! can create a `trajectory_msgs/JointTrajectory` messages that can be used by the low level to realize a trajectory. These motion planners take an initial configuration, a robot description and an end configuration as input to create their trajectories. The initial configuration and robot description should follow from your robot description parameter and the robot state publisher. The end configuration can be queried from the world model or it can be requested with use of a TFListener when the TFPublisher ED Plugin is used.
The following video shows a grasp where the end configuration is determined with use of the query interface of the world model. The trajectory is calculated with MoveIt! and setpoints to the controller are passed with use of a reference generator that takes kinematic and dynamic constraints into account.
[](https://youtu.be/Zn9XJ5GRmpU)
|
Markdown
|
UTF-8
| 578 | 2.984375 | 3 |
[] |
no_license
|
#Shamir's Secret Sharing Algorithm
I wanted to learn a Haskell without doing any great amount of good, so I
decided to try my hand at a random cryptographic algorithm. [Shamir's Secret
Sharing](https://en.wikipedia.org/wiki/Shamir's_Secret_Sharing) was just what
the doctor ordered. This is one of the first things I ever wrote in Haskell,
and probably the first non-trivial work.
I ended up learning a lot about groups and rings and galois fields (oh my)
through this, but it's been so long since I touched it and it's so lacking in
comments that I'm afraid to dive back in.
|
C
|
UTF-8
| 201 | 3.15625 | 3 |
[] |
no_license
|
#include <stdio.h>
int main(){
int i;
for(i=0;i<=4;i++){
pstar(i*2+1);
}
}
pstar(num)
int num;
{
int i;
for(i=1;i<=num;i++){
printf("*");
}
printf("\n");
}
|
Java
|
UTF-8
| 1,880 | 1.578125 | 2 |
[] |
no_license
|
package net.f;
import java.util.Iterator;
import net.xn;
import net.cp.v;
import net.f.l;
import net.nb.f;
import net.nn.j;
import net.y.p;
import net.y.r;
import net.y.u;
import net.yy.g;
public class o implements l.g {
private final j k;
public o(j var1) {
this.k = var1;
}
public void X(float var1, long var2) {
g var5 = this.k.sf;
v var6 = this.k.s8;
double var7 = var5.hL + (var5.b - var5.hL) * (double)var1;
double var9 = var5.F + (var5.hS - var5.F) * (double)var1;
double var11 = var5.A + (var5.hr - var5.A) * (double)var1;
net.y.d.c();
net.y.d.C();
net.y.d.e(net.y.d.SRC_ALPHA, net.y.d.ONE_MINUS_SRC_ALPHA, net.y.d.ONE, net.y.d.ZERO);
l.K();
net.y.d.w();
net.u.j var13 = new net.u.j(var5.b, 0.0D, var5.hr);
Iterable var14 = net.u.j.e(var13.F(-40, 0, -40), var13.F(40, 0, 40));
r var15 = r.f();
p var16 = var15.k();
var16.m(5, net.y8.x.F);
Iterator var17 = var14.iterator();
if(var17.hasNext()) {
net.u.j var18 = (net.u.j)var17.next();
int var19 = var6.J(var18.t(), var18.y());
if(var6.Z(var18.F(0, var19, 0).b()) == f.ou.p()) {
u.o(var16, (double)((float)var18.t() + 0.25F) - var7, (double)var19 - var9, (double)((float)var18.y() + 0.25F) - var11, (double)((float)var18.t() + 0.75F) - var7, (double)var19 + 0.09375D - var9, (double)((float)var18.y() + 0.75F) - var11, 0.0F, 0.0F, 1.0F, 0.5F);
}
u.o(var16, (double)((float)var18.t() + 0.25F) - var7, (double)var19 - var9, (double)((float)var18.y() + 0.25F) - var11, (double)((float)var18.t() + 0.75F) - var7, (double)var19 + 0.09375D - var9, (double)((float)var18.y() + 0.75F) - var11, 0.0F, 1.0F, 0.0F, 0.5F);
}
var15.p();
net.y.d.S();
net.y.d.Y();
}
private static xn a(xn var0) {
return var0;
}
}
|
Markdown
|
UTF-8
| 43,860 | 2.9375 | 3 |
[] |
no_license
|
---
jupyter:
jupytext:
formats: ipynb,md
text_representation:
extension: .md
format_name: markdown
format_version: '1.2'
jupytext_version: 1.4.0
kernelspec:
display_name: Python 3
language: python
name: python3
---
*by Guillaume Le Fur, Abderrahmane Lazraq and Leonardo Natale*
{guillaume.le-fur , abderrahmane.lazraq , leonardo.natale} @polytechnique.edu
**Important notice:**
Submissions on the platform were made under two user names "guillaume.le-fur & LeonardoNatale" and "Abdou.Lazraq" but the three students worked on this project together and only one report was submitted.
# Introduction: objectives and methodology
The objective of this project is to put the Machine Learning methods that we have been taught during the Machine Learning 2 course into practice, on a real data set, the "Smart meter is coming" challenge.
We will start by introducing our exploratory data analysis and what first conclusions we could draw from it. Then, we will detail the data pre-processing and feature engineering we've done, and justify their interest.
Finally, we will present the results we obtained using two methods : Deep learning (with RNNs and CNNs) and Boosting (with XGboost).
You will be able to find the entirety of the code on the following [GitHub repository](https://github.com/alazraq/AutoML). Not all the code will be detailed here but rather the most important parts.
The data is the following :
```python
# Loading the data and setting the time step as index
X_train = pd.read_csv(
'../provided_data_and_metric/X_train_6GWGSxz.csv',
)
X_train.set_index("time_step", inplace=True)
X_train.index = pd.to_datetime(X_train.index)
Y_train = pd.read_csv(
'../provided_data_and_metric/y_train_2G60rOL.csv',
)
Y_train.set_index("time_step", inplace=True)
Y_train.index = pd.to_datetime(Y_train.index)
```
```python
print(f'Shape of X_train: {X_train.shape}')
print(f'Shape of Y_train: {Y_train.shape}')
```
We initially have 9 predictors and 4 variables to predict. This data is a time series of electric consumption measures in one household, the goal is to find the part of that consumption dedicated to 4 appliances (washing machine, fridge_freezer, TV and kettle)
# Exploratory Data Analysis
## Missing values
Let us have a look at the missing values.
```python
X_train.isna().sum()
```
**Remarks:**
- We notice that the weather data is measured every hour, whereas the consumption data is measured every minute, so we have a lot of **sparsity from the weather data**. Depending on the algorithm, we will either try to impute these missing values (see `DataImputer` classes), or discard the weather data because we think it is not relevant.
- Regarding the consumption data, in order to see if the NaNs could be imputed or not, we tried to see if there were a lot of **consecutive NaNs**. The following table shows the number of NaNs that are consecutive, and that last for more than an hour.
```python
# Detecting consecutive missing data that last more than one hour
consecutive = X_train.consumption.isnull().astype(int) \
.groupby(X_train.consumption.notnull() \
.astype(int).cumsum()).sum()
consecutive[consecutive > 60].sort_values()
```
We can also compute the percentage of missing values that are consecutive.
```python
cons1 = round(consecutive[consecutive > 1].sum()
/X_train.consumption.isna().sum() * 100)
cons10 = round(consecutive[consecutive > 10].sum()
/X_train.consumption.isna().sum() * 100)
cons60 = round(consecutive[consecutive > 60].sum()
/X_train.consumption.isna().sum() * 100)
print(f'Percentage of consecutives (> 1 hour) : {cons60} \
%\nPercentage of consecutive (> 10 min) : {cons10} \
%\nTotal percentage for consecutives : {cons1} %')
```
Given this information, sometimes we have chosen to **discard** all the consecutive missing values that last more than one hour because imputation would have not have produced satisfactory results. Let us look at the missing values in the target Y_train to confirm this decision.
```python
Y_train.isna().sum()
```
Discarding the missing values safely in X_train is also encouraged by the fact that, **when there is a missing consumption in X_train, there is also a missing value in Y_train**. If we choose imputation, we also need to impute Y_train, which is a very risky operation.
## Global vs. per appliance consumption
First of all, if we denote by $\mathcal A$ the ensemble of appliances, $c_a$ the consumption of appliance $a \in \mathcal A$ and $c_{tot}$ the total consumption, it is important to emphasize the fact that, for each timestamp, we have:
$$\sum_{a \in A} c_a \ne c_{tot}$$
We can clearly see this on the following plot:

But this plot is not precise enough. Instead, if we look at the daily moving average over 7 days, we have :

On the graph above, we can clearly see that **the overall consumption trend does not correspond to any per-appliance trend**. Indeed, we can observe two sharp declines (one around 2013-04-15, and another around 2013-08-10) that lead to an opposite effect on the per-appliance trends (on the first one, the per-appliance average drops, and on the second it raises). This makes it even harder to predict the per-appliance consumption as there is no clear link between them and the overall consumption.
The difference between the consumptions can most probably be explained by the **presence of other appliances in the house**.
This means that predicting the consumption of an appliance and its contribution to the total consumption is not the same problem.
Now let us have a look at some specificities of the data.
## Analysis of the predictors
The function add_features performs data augmentation for us to be able to perform a more insightful data exploration. The following features are added:
- **weekday, month and hour:** extracted from the time step
- **is_weekend and is_holidays:** to see if we can observe a different behaviour during weekends and holidays
- **is_breakfast, is_teatime and is_TVtime:** to see if we can spot the parts of the day when people tend to use specific appliances more
We also drop the weather data as it doesn't seem interesting for now.
```python
import holidays
def add_features(x):
'''
Performs data augmentation and drops unuseful features
'''
x = x.drop(
['Unnamed: 9', 'visibility', 'humidity', 'humidex', \
'windchill', 'wind', 'pressure', 'temperature'],
axis=1
)
fr_holidays = holidays.France()
x["weekday"] = x.index.dayofweek
x["month"] = x.index.month
x["hour"] = x.index.hour
x["is_weekend"] = (x["weekday"] > 4) * 1
x["is_holidays"] = (x.index.to_series() \
.apply(lambda t: t in fr_holidays)) * 1
x["is_breakfast"] = ((x.hour > 5) & (x.hour < 9)) * 1
x["is_teatime"] = ((x.hour > 16) & (x.hour < 20)) * 1
x["is_TVtime"] = ((x.hour > 17) & (x.hour < 23)) * 1
x["is_night"] = ((x.hour > 0) & (x.hour < 7)) * 1
return x
X_data_exploration = add_features(X_train)
```
### Weekend influence
```python
X_data_exploration[["consumption", "is_weekend"]].groupby("is_weekend").mean()
```
The overall consumption is **higher during the weekend**, as expected.
### Difference between weekdays

The consumption is also really **high on tuesday**. We could not find any justification for this.
### Difference between months

The consumption is **higher during *cold months*** (October to February). This might be due to the **heating system** which works more in winter than in summer.
### Hourly consumption

The hourly consumption is quite interesting. Indeed, we can see that most of the consumption takes place **after 4 p.m.**, which is after the end of *office hours*, when people are back home, and **before 11 p.m.**, when people go to sleep. There are also two smaller *peaks*, during **breakfast** and **lunch time**.
### Holidays influence
```python
X_data_exploration[["consumption", "is_holidays"]].groupby("is_holidays").mean()
```
The consumption is **lower during the holidays**. Our analysis led us to believe that the data was coming from a **house located in France** because the data was fitting better the holidays in France than the ones in the UK or in the US.
## Analysis of the response variables
### Weekday influence per appliance
Let us look at the mean consumption for each appliance per weekday:
```python
Y_train.groupby(X_data_exploration.weekday).mean()
```
We can see that people tend to use their **washing machine more on Sundays**, which is logical because they have more time on Sundays and **electricity is cheaper**. Based on our assumption that the house is located in France, people most likely trying to take benefit from the *Heures Creuses* electricity rate.
### Month influence per appliance
Looking at the mean consumption for each appliance per month:

We detect a significant increase of the use of the **Kettle in November**, which also makes sense because it is one of the first 'cold' months so people start making tea again to warm themselves.
### Weekend influence per appliance
```python
Y_train.groupby(X_data_exploration.is_weekend).mean()
```
Once again, the use of the **washing machine on the weekend** is confirmed here. People tend to use their **kettle a bit more** as well. **We could have expected the consumption of the TV to be higher** on the weekend but it actually is not.
### Hour influence per appliance

From the plot above, we can extract the following information:
- People use their **TV in the morning**, really early, **and in the evening**, but not much after 11 p.m., after the main movie has finished.
- People use their **kettle around teatime**, which is quite logical, but also a bit in the morning, **for breakfast**.
- The consumption fo the **freezer does not vary much** during the day.
- People tend to turn their **washing machine on when they go to bed**, once again to reduce the **cost of electricity**.
### Holidays influence per appliance
```python
Y_train.groupby(X_data_exploration.is_holidays).mean()
```
**People do not use their washing machine on holidays, nor their kettle**. This makes sense because when people leave the house, the appliances that consume a lot of electricity when used are not used anymore so they stop consuming, while the appliances that consume an almost constant amount of electricity do not vary much because they keep working.
For all these reasons, we thought it would be relevant to **add some features to the data**, to be able to predict the per-appliance consumption with more accuracy. This will be detailed in section 4 of the report.
## Operating time of appliances
The goal here is to know how long each appliance is run on average in order to take this information into consideration when modelling.
### Kettle operating time
Usually, people do not use their Kettle for more than 5 minutes, the time for the water to boil. We want to check this. Below is a table showing for each duration the number of times the kettle was active for that duration.
```python
ket = Y_train.kettle.fillna(0).where(Y_train.kettle.fillna(0) < 2)
ket = ket.isnull().astype(int).groupby(ket.notnull().astype(int).cumsum()).sum()
ket = ket[ket > 0].sort_values(ascending = False)
ket.value_counts()
```
Indeed, most of the time, people use it for **1-3 minutes**. This use will be extremely hard to detect in the time series because it is really short.
### Washing machine operating time
```python
was = Y_train.washing_machine.fillna(0).where(Y_train.washing_machine.fillna(0) < 1)
was = was.isnull().astype(int).groupby(was.notnull().astype(int).cumsum()).sum()
was = was[was > 0].value_counts()
was[was > 5]
```
Here, we can see that the washing machine either works for **1-10 or 100-110 minutes**, which corresponds to a **washing machine cycle**.
### Fridge-freezer operating time
```python
fri = Y_train.fridge_freezer.fillna(0).where(Y_train.fridge_freezer.fillna(0) < 2)
fri = fri.isnull().astype(int).groupby(fri.notnull().astype(int).cumsum()).sum()
fri = fri[fri > 0].sort_values(ascending = False).value_counts()
fri[fri > 200]
```
For the fridge-freezer, we can see that, even though the energy consumption is quite constant, it is most of the time active for a period of around **20 minutes, which corresponds to the duration of a cooling cycle**. It also activates for **1-3 minutes**, which might correspond to the time **when people open the fridge's door**.
```python
tv = Y_train.TV.fillna(0).where(Y_train.TV.fillna(0) < 10)
tv = tv.isnull().astype(int).groupby(tv.notnull().astype(int).cumsum()).sum()
tv = tv[tv > 0].sort_values(ascending = False).value_counts()
tv[tv > 20]
```
Regarding the television, we can see that it is most of the time on for either a very short time (it appears that people like to watch TV during a time which is a multiple of 3), or one which is around 150 minutes, which is approximately **two hours and a half, which is the duration of a movie + the duration of the commercial breaks**.
# Data preprocessing
We define multiple pipelines for the input dataset in order to make the data compatible with the ML approach used:
- one pipeline for RNN
- one pipeline for CNN
- 4 pipelines for XGB, one per appliance
```python
class XPipeline:
"""Pipeline for the features of the input dataset"""
def __init__(self):
self.pipeline = Pipeline([
# Step 1
('DataImputer', DataImputer()),
# Step 2
('MyStandardScaler', MyStandardScaler()),
# Step 3
# FOR XGB
('DataAugmenter', DataAugmenter_TV()), # Different Data Augmenter per appliance
# FOR RNN
('RNNDataAugmenter', RNNDataAugmenter()), # Same Data Augmenter for all 4 appliances
('MyOneHotEncoder', MyOneHotEncoder()),
('RNNDataFormatter', RNNDataFormatter())
# FOR CNN
('CNNDataFormatter', CNNDataFormatter())
])
def fit(self, x):
return self.pipeline.fit(x)
def transform(self, x):
return self.pipeline.transform(x)
class YPipeline:
"""
Pipeline for the target of the input dataset of xgboost model
"""
def __init__(self):
self.pipeline = Pipeline([
('YImputer', YImputer()),
])
def fit(self, x):
return self.pipeline.fit(x)
def transform(self, x):
return self.pipeline.transform(x)
```
The YPipeline is the same for all ML approaches and includes a single step: an imputer that drops days where we have more than one successive hour of missing data as explained above, interpolate missing values linearly for the rest and sets the date as the index.
There are three steps in this pipeline:
- A **DataImputer** and **YImputer** that drops the unuseful columns, drops days where we have more than one successive hour of missing data, interpolates missing values linearly for the rest and sets the date as the index.
```python
class YImputer(BaseEstimator, TransformerMixin):
def __init__(self):
self.X = None
self.days_to_drop = [
"2013-10-27", "2013-10-28", "2013-12-18", "2013-12-19",
"2013-08-01", "2013-08-02", "2013-11-10", "2013-07-07",
"2013-09-07", "2013-03-30", "2013-07-14"
]
def fit(self, x, y=None):
return self
def transform(self, x, y=None):
x.index = pd.to_datetime(x.index)
try:
x.drop(['Unnamed: 9', 'visibility', 'humidity',
'humidex', 'windchill', 'wind', 'pressure'],
axis=1, inplace=True)
for day in self.days_to_drop:
x.drop(x.loc[day].index, inplace=True)
except KeyError as e:
pass
x = x.interpolate(method='linear').fillna(method='bfill')
return x
```
- A **standard scaler** that standardizes features by removing the mean and scaling to unit variance.
```python
class MyStandardScaler(BaseEstimator, TransformerMixin):
def __init__(self):
self.scaler = StandardScaler()
def fit(self, X, y=None):
self.columns = X.columns
self.scaler.fit(X)
return self
def transform(self, X, y=None):
self.index = X.index
X = pd.DataFrame(self.scaler.transform(X),
columns=self.columns,
index=self.index
)
return X
```
The third step is different depending on the ML approach considred:
- **For XGBoost:** A **data augmenter** for feature engineering. We implemented a different data augmenter for each appliance, we inspect those in detail in the following section.
- **For CNN:** A **CNN data formatter** to make the input data compatible with CNN.
- **For RNN:** An **RNN data augmenter** for feature engineering, a **One Hot Encoder** and an **RNN data formatter** to make the imput data compatible with RNN.
These are discussed further in the report.
# Feature engineering by appliance
For each appliance we produced additional features that aim at increasing the predictive power of the machine learning algorithms used by creating features from the raw data that help facilitate the machine learning process for that specific appliance. These follow from the data exploration in section II and include weekday, is_weekend and is_holidays which accounts for French national holidays.
For XGB regression, the most important features that we identified to transform the time series forecasting problem into a supervised learning problem are the lag features and the rolling mean. Here we focus on the different lags and rolling means used for each appliance, as well as other features specific to each appliance.
## Washing machine
```python
class DataAugmenter_Washing_Machine(BaseEstimator, TransformerMixin):
def __init__(self):
pass
def fit(self, x, y=None):
return self
def transform(self, x, y=None):
fr_holidays = holidays.France()
x["weekday"] = x.index.dayofweek
x["month"] = x.index.month
x["hour"] = x.index.hour
x["is_weekend"] = (x["weekday"] > 4) * 1
x["is_holidays"] = (x.index.to_series().apply(lambda t: t in fr_holidays)) * 1
x["is_night"] = ((x.hour > 0) & (x.hour < 7)) * 1
x['lag_1'] = x['consumption'].shift(1)
x['lag_5'] = x['consumption'].shift(5)
x['lag_10'] = x['consumption'].shift(10)
x['lag_20'] = x['consumption'].shift(20)
x['lag_25'] = x['consumption'].shift(25)
x['lag_30'] = x['consumption'].shift(30)
x['lag_35'] = x['consumption'].shift(35)
x['lag_40'] = x['consumption'].shift(40)
x['lag_future_1'] = x['consumption'].shift(-1)
x['lag_future_5'] = x['consumption'].shift(-5)
x['lag_future_10'] = x['consumption'].shift(-10)
x['lag_future_20'] = x['consumption'].shift(-20)
x['lag_future_25'] = x['consumption'].shift(-25)
x['lag_future_30'] = x['consumption'].shift(-30)
x['lag_future_35'] = x['consumption'].shift(-35)
x['lag_future_40'] = x['consumption'].shift(-40)
x['rolling_mean_10'] = x['consumption'].rolling(window=10).mean()
x['rolling_mean_20'] = x['consumption'].rolling(window=20).mean()
x = x.ffill().bfill()
return x
```
For the washing machine, we decided to add the feature **is_night** because people tend to operate the washing machine during the night as we saw in our EDA.
**Lags** of the consumption 40 min in the past and into the future as well as two **rolling means** one over a window of 10 min and the other over 20 min were added to account for a cycle of the washing machine.
## Fridge/ Freezer
```python
class DataAugmenter_Fridge_Freezer(BaseEstimator, TransformerMixin):
def __init__(self):
pass
def fit(self, x, y=None):
return self
def transform(self, x, y=None):
fr_holidays = holidays.France()
x["weekday"] = x.index.dayofweek
x["month"] = x.index.month
x["hour"] = x.index.hour
x["is_weekend"] = (x["weekday"] > 4) * 1
x["is_holidays"] = (x.index.to_series().apply(lambda t: t in fr_holidays)) * 1
x['lag_1'] = x['consumption'].shift(1)
x['lag_5'] = x['consumption'].shift(5)
x['lag_10'] = x['consumption'].shift(10)
x['lag_20'] = x['consumption'].shift(20)
x['lag_future_1'] = x['consumption'].shift(-1)
x['lag_future_5'] = x['consumption'].shift(-5)
x['lag_future_10'] = x['consumption'].shift(-10)
x['lag_future_20'] = x['consumption'].shift(-20)
x['rolling_mean_10'] = x['consumption'].rolling(window=10).mean()
x['rolling_mean_20'] = x['consumption'].rolling(window=20).mean()
x = x.ffill().bfill()
return x
```
In the case of the fridge/ freezer, we decided to keep a **lags** of the consumption 20 min in the past and into the future which corresponds to the duration of a cooling cycle as explained in the EDA.
We also decided to add two **rolling means** one over a window of 10 min and the other over 20 min.
## TV
```python
class DataAugmenter_TV(BaseEstimator, TransformerMixin):
def __init__(self):
pass
def fit(self, x, y=None):
return self
def transform(self, x, y=None):
fr_holidays = holidays.France()
x["weekday"] = x.index.dayofweek
x["month"] = x.index.month
x["hour"] = x.index.hour
x["is_weekend"] = (x["weekday"] > 4) * 1
x["is_holidays"] = (x.index.to_series().apply(lambda t: t in fr_holidays)) * 1
x["is_TVtime"] = ((x.hour > 17) & (x.hour < 23)) * 1
x["is_night"] = ((x.hour > 0) & (x.hour < 7)) * 1
x['lag_1'] = x['consumption'].shift(1)
x['lag_5'] = x['consumption'].shift(5)
x['lag_10'] = x['consumption'].shift(10)
x['lag_20'] = x['consumption'].shift(20)
x['lag_25'] = x['consumption'].shift(25)
x['lag_30'] = x['consumption'].shift(30)
x['lag_35'] = x['consumption'].shift(35)
x['lag_40'] = x['consumption'].shift(40)
x['lag_future_1'] = x['consumption'].shift(-1)
x['lag_future_5'] = x['consumption'].shift(-5)
x['lag_future_10'] = x['consumption'].shift(-10)
x['lag_future_20'] = x['consumption'].shift(-20)
x['lag_future_25'] = x['consumption'].shift(-25)
x['lag_future_30'] = x['consumption'].shift(-30)
x['lag_future_35'] = x['consumption'].shift(-35)
x['lag_future_40'] = x['consumption'].shift(-40)
x['rolling_mean_10'] = x['consumption'].rolling(window=10).mean()
x['rolling_mean_20'] = x['consumption'].rolling(window=20).mean()
x = x.ffill().bfill()
return x
```
For the TV, we add a feature **is_TVtime**, which indicates that the hour is between 5pm and 11pm; supposedly the time most people watch TV as explained in data exploration.
## Kettle
```python
class DataAugmenter_kettle(BaseEstimator, TransformerMixin):
def __init__(self):
pass
def fit(self, x, y=None):
return self
def transform(self, x, y=None):
fr_holidays = holidays.France()
x["weekday"] = x.index.dayofweek
x["month"] = x.index.month
x["hour"] = x.index.hour
x["is_weekend"] = (x["weekday"] > 4) * 1
x["is_holidays"] = (x.index.to_series().apply(lambda t: t in fr_holidays)) * 1
x["is_breakfast"] = ((x.hour > 5) & (x.hour < 9)) * 1
x["is_teatime"] = ((x.hour > 16) & (x.hour < 20)) * 1
x['lag_1'] = x['consumption'].shift(1)
x['lag_2'] = x['consumption'].shift(2)
x['lag_3'] = x['consumption'].shift(3)
x['lag_4'] = x['consumption'].shift(4)
x['lag_5'] = x['consumption'].shift(5)
x['lag_10'] = x['consumption'].shift(10)
x['lag_20'] = x['consumption'].shift(20)
x['lag_future_1'] = x['consumption'].shift(-1)
x['lag_future_2'] = x['consumption'].shift(-2)
x['lag_future_3'] = x['consumption'].shift(-3)
x['lag_future_4'] = x['consumption'].shift(-4)
x['lag_future_5'] = x['consumption'].shift(-5)
x['lag_future_10'] = x['consumption'].shift(-10)
x['lag_future_20'] = x['consumption'].shift(-20)
x['rolling_mean'] = x['consumption'].rolling(window=3).mean()
x = x.ffill().bfill()
return x
```
The kettle is a very special appliance because it only operates for few consecutive minutes as observed above, so we choose to keep a single rolling mean with a window of 3 min.
We also add two features **is_breafast** (5 am to 9 am) and **is_teatime** (4 pm to 8 pm) which indicate the two time periods people use the kettle the most.
# Baseline: MultiOutputRegressor
In order to have an idea of what we could achieve with basic algorithms, our first thought was to try **Linear Regression**.
By default, the LinearRegression of sklearn cannot predict multiple outputs. So, we used the `MultiOutputRegressor` from sklearn in order to wrap the linear regression. It acts as if it was fitting k differents linear regressions, one for each of the k variables to predict.
```python
# Prepare data for regression
di = XPipeline_XGB()
yi = YPipeline_XGB()
X_train = di.transform(X_train)
Y_train = yi.transform(Y_train)
# Split data into train and validation
x_train, x_valid, y_train, y_valid = train_test_split(
X_train, Y_train, test_size=0.33, random_state=42)
# Define and fit Multioutput Linear Regressor
baseline_regressor = MultiOutputRegressor(LinearRegression())
baseline_regressor.fit(x_train, y_train)
```
# First approach: Recurrent Neural Networks
Our first approach, given that the data is time dependent, was to use Recurrent Neural Networks (RNNs), which are famous for their ability to work well on time series.
The hardest part of the work was to format the data correctly so that we could use it efficiently.
## Data formatting
The following code is responsible of the formatting of the data for the RNN. It takes an input of size `(n_obs, n_col)` and produces an output of size `(n_obs / batch_size, batch_size, n_col)`. We simply reformat the data by creating time series of size `batch_size`.
```python
class RNNDataFormatter(BaseEstimator, TransformerMixin):
def __init__(self, batch_size=60):
self.X = None
self.batch_size = batch_size
def fit(self, x, y=None):
return self
def transform(self, x, y=None):
if isinstance(x, pd.DataFrame):
x = x.to_numpy()
print(x.shape)
print(x.__class__.__name__)
while x.shape[0] % self.batch_size != 0:
print("Appending a row")
print([x[-1, :]])
x = np.append(x, [x[-1, :]], axis=0)
print(x.shape)
nb_col = x.shape[1]
return x.reshape((int(x.shape[0] / self.batch_size), self.batch_size, nb_col))
```
## Data augmentation - encoding
As the RNN will be working on all the variables to predict, we only use one `DataAugmenter`, which adds the same features as previously discussed.
```python
class RNNDataAugmenter(BaseEstimator, TransformerMixin):
def __init__(self):
pass
def fit(self, x, y=None):
return self
def transform(self, x, y=None):
fr_holidays = holidays.France()
x["weekday"] = x.index.dayofweek
x["month"] = x.index.month
x["hour"] = x.index.hour
x["is_weekend"] = (x["weekday"] > 4) * 1
x["is_holidays"] = (x.index.to_series().apply(lambda t: t in fr_holidays)) * 1
x["is_breakfast"] = ((x.hour > 5) & (x.hour < 9)) * 1
x["is_teatime"] = ((x.hour > 16) & (x.hour < 20)) * 1
x["is_TVtime"] = ((x.hour > 17) & (x.hour < 23)) * 1
x["is_night"] = ((x.hour > 0) & (x.hour < 7)) * 1
return x
```
We also use a custom One Hot Encoder for the categorical features (hours, weekdays and months). The encoder had to be customized to prevent an error if there are different values between X_train and X_test (if X_test has months that are not present in X_train for instance).
```python
class MyOneHotEncoder(BaseEstimator, TransformerMixin):
def __init__(self):
self.all_possible_hours = np.arange(0, 24)
self.all_possible_weekdays = np.arange(0, 7)
self.all_possible_months = np.arange(1, 13)
self.ohe_hours = OneHotEncoder(drop="first")
self.ohe_weekdays = OneHotEncoder(drop="first")
self.ohe_months = OneHotEncoder(drop="first")
def fit(self, X, y=None):
self.ohe_hours.fit(self.all_possible_hours.reshape(-1,1))
self.ohe_weekdays.fit(self.all_possible_weekdays.reshape(-1,1))
self.ohe_months.fit(self.all_possible_months.reshape(-1,1))
return self
def transform(self, X, y=None):
hours = pd.DataFrame(self.ohe_hours.transform(X.hour.values.reshape(-1,1)).toarray(),
columns=["hour_"+str(i) for i in range(1, 24)],
index=X.index
)
weekdays = pd.DataFrame(self.ohe_weekdays.transform(X.weekday.values.reshape(-1,1)).toarray(),
columns=["weekday_"+str(i) for i in range(1, 7)],
index=X.index
)
months = pd.DataFrame(self.ohe_months.transform(X.month.values.reshape(-1,1)).toarray(),
columns=["month_"+str(i) for i in range(2, 13)],
index=X.index
)
X = pd.concat([X, hours, weekdays, months], axis=1)
X.drop(["month", "weekday", "hour"], axis=1, inplace=True)
return X
```
## Preprocessing Pipeline
```python
class XPipeline_RNN:
"""Pipeline for the features of input dataset of RNN"""
def __init__(self):
self.pipeline = Pipeline([
# Imputing the data
('DataImputer', DataImputer()),
# Scaling it
('MyStandardScaler', MyStandardScaler()),
# Adding features
('RNNDataAugmenter', DataAugmenter()),
# Encoding features
('MyOneHotEncoder', MyOneHotEncoder()),
# Formatting the data correctly
('RNNDataFormatter', RNNDataFormatter())
])
def fit(self, x):
return self.pipeline.fit(x)
def transform(self, x):
return self.pipeline.transform(x)
class YPipeline_RNN:
"""Pipeline for target of input dataset of RNN"""
def __init__(self):
self.pipeline = Pipeline([
# Imputing the data
('YImputer', YImputer()),
# Formatting the data correctly
('RNNDataFormatter', RNNDataFormatter())
])
def fit(self, x):
return self.pipeline.fit(x)
def transform(self, x):
return self.pipeline.transform(x)
```
We apply several transformations to X :
- The missing data is imputed.
- It is scaled.
- Features are added.
- Categorical features are One Hot Encoded.
- Data is formatted to fit the input of the RNN.
Regarding Y, only formatting and imputing missing data are done.
## Architecture
Our architecture is the following :
- One LSTM layer with 20 units.
- One Dense layer with 4 units (corresponding to the 4 variables to predict)
- A ReLU activation function.
- Adam optimizer
- Early stopping, with a patience of 2.
## Custom loss
In the very beginning, we were using the RMSE as a loss to fit our models. But, as the quality of the model is assessed using a metric which is specific to this project, we though it would be interesting to use the custom metric during the training phase. In order to do so, we had to adapt the code of the provided metric to make it compatible with `tensorflow`.
```python
import tensorflow as tf
@tf.function
def metric_nilm(self, y_true, y_pred):
y_pred = tf.reshape(y_pred, [tf.shape(y_pred)[0] * tf.shape(y_pred)[1], tf.shape(y_pred)[2]])
y_true = tf.reshape(y_true, [tf.shape(y_true)[0] * tf.shape(y_true)[1], tf.shape(y_true)[2]])
score = 0.0
test = tf.slice(y_true, [0, 0], [-1, 1])
pred = tf.slice(y_pred, [0, 0], [-1, 1])
score += mt.sqrt(mt.reduce_sum(mt.subtract(pred, test) ** 2) / float(len(test))) * 5.55
test = tf.slice(y_true, [0, 1], [-1, 1])
pred = tf.slice(y_pred, [0, 1], [-1, 1])
score += mt.sqrt(mt.reduce_sum(mt.subtract(pred, test) ** 2) / float(len(test))) * 49.79
test = tf.slice(y_true, [0, 2], [-1, 1])
pred = tf.slice(y_pred, [0, 2], [-1, 1])
score += mt.sqrt(mt.reduce_sum(mt.subtract(pred, test) ** 2) / float(len(test))) * 14.57
test = tf.slice(y_true, [0, 3], [-1, 1])
pred = tf.slice(y_pred, [0, 3], [-1, 1])
score += mt.sqrt(mt.reduce_sum(mt.subtract(pred, test) ** 2) / float(len(test))) * 4.95
score /= 74.86
return score
```
Using this function, we were able to optimize the neural network for our specific problem rather than only minimizing the mean squared error.
# Second approach: Convolutional Neural Networks
The idea to use CNN came up after we asked ourselves the following question:
"*How can we develop a model which takes into account present and future values of consumption, centered around the current time step?*"
## Data Formatting
Our answer, was to structure the data as follows. Let's take a simple example, with just consumption and TV.
The data is originally in this format:
| Cons. | TV |
|-------|--------|
| 10 | 0 |
| 20 | 8 |
| 25 | 10 |
| 18 | 8 |
| 12 | 0 |
| 5 | 0 |
After it goes through our pipeline, it would come out in this format:
| Cons. | TV |
|------------------|--------|
| **15**, 10, 20, | 0 |
| 10, 20, 25 | 8 |
| 20, 25, 18 | 10 |
| 25, 18, 12 | 8 |
| 18, 12, 5 | 0 |
| 12, 5, **15** | 0 |
where the data is left and right padded with the mean value for consumption **15**, in order to center the sequence around the present value.
We have then divided the sequence into multiple input/output patterns, where `batch_size` time steps are used as input and one time step is used as output.
The class `CNNDataFormatter` takes care of this:
```python
class CNNDataFormatter(BaseEstimator, TransformerMixin):
def __init__(self, batch_size=120):
self.X = None
self.batch_size = batch_size
def fit(self, x, y=None):
return self
def transform(self, x, y=None):
xx = np.zeros((x.shape[0], self.batch_size, 1))
x = np.pad(x, ((self.batch_size//2, self.batch_size//2), (0,0)), 'mean')
for i in range(len(xx)):
try:
xx[i, :, :] = x[i:self.batch_size+i, :]
except:
print(i)
return xx
```
The output will be of the size `(401759, 120, 1)`.
## Preprocessing Pipeline
First, the class `DataImputer` takes care of missing values and drops all columns but consumption.
Then the data is passed to a `Standard Scaler`, before being formatted as explained above.
```python
class XPipeline_CNN:
def __init__(self):
self.pipeline = Pipeline([
('DataImputer', DataImputer()),
('StandardScaler', StandardScaler()),
('CNNDataFormatter', RNNDataFormatter())
])
def fit(self, x):
return self.pipeline.fit(x)
def transform(self, x):
return self.pipeline.transform(x)
```
Regarding the target variable, we take care only of the missing values with `YImputer` and do not apply any transformation.
## Architecture
Our architecture is inspired from the one adopted in our deep learning course **MAP545** and is as follows:
- 1D convolution with valid padding, 32 filters, 6 kernel size
- ReLU activation
- 1D convolution with valid padding, 32 filters, 3 kernel size
- ReLU activation
- 1D convolution with valid padding, 48 filters, 3 kernel size
- ReLU activation
- 1D convolution with valid padding, 64 filters, 3 kernel size
- ReLU activation
- 1D convolution with valid padding, 64 filters, 2 kernel size
- ReLU activation
- Flatten
- Dense layer with 1024 nodes, ReLu activation
- Dense layer with 1 nodes, linear activation
Four different models, one per appliance, are fit using the efficient Adam version of stochastic gradient descent and optimized using the mean squared error loss function. Given we train four different models, minimizing the mean squared error is analogous to minimizing the metric nilm per single appliance.
```python
model.compile(loss=keras.losses.mean_squared_error,
optimizer=tf.keras.optimizers.Adam())
history = model.fit(x_train, y_train, epochs=4,
validation_data=(x_valid, y_valid))
```
Promising results were obtained for **TV**, **fridge_freezer** and **washing_machine**.
However, the model fails to predict consumption for **kettle** due to the high sparsity of the data.
**Going further**, more accurate results could be obtained by incorporating other features such as weather data in our model.
All the code is found in the `/CNN` folder in our repository.
# Third approach : ensemble methods - Boosting
For our third attempt, we tried fitting four different regressors - one for each appliance. The goal is to see if we can outperform deep learning methods for some of the appliances, especially kettle for which CNN does not give good results, using classic machine learning methods.
We chose **XGBoost** which has been used to win many data challenges, outperforming several other well-known implementations of gradient tree boosting.
## Preprocessing Pipelines
For each appliance, we preprocess the data using the pipeline defined in section 3. The only difference between the pipelines of each appliance are the data augmenters:
- **Lag features and the rolling means** are used in all augmenters to transform the time series forecasting problem into a supervised learning problem. Different lags and rolling means have been used for each appliance according to its specifities.
- **Other features specific to each appliance** are added like is_TVtime, is_night, is_breakfast and is_teatime
Please refer to the section on feature engineering for more details about this part. We give the pipeline for TV as an example, pipelines for the other appliances are defined in a similar fashion using the corresponding data augmenter defined above
```python
class XPipeline_TV:
def __init__(self):
self.pipeline = Pipeline([
('DataImputer', DataImputer()),
('MyStandardScaler', MyStandardScaler()),
('DataAugmenter_TV', DataAugmenter()),
])
def fit(self, x):
return self.pipeline.fit(x)
def transform(self, x):
return self.pipeline.transform(x)
```
## Custom metric per appliance
In order to be able to fit a different regressor for each appliance, we had to define a custom metric inspired from the metric provided, where we only keep the score corresponding to the specific appliance we are considering.
```python
# Custom nilm metric in case of fridge for example
def nilm_metric(y_true, y_pred):
score = math.sqrt(sum((y_pred.get_label() - y_true) ** 2) / len(y_true)) * 49.79
score /= 74.86
return "nilm", score
```
## Model Definition and Fitting
We fit 4 different regressors, one for each appliance, using the custom nilm_metric defined above.
```python
import xgboost as xgb
# Fitting an XGBoost regressor
xgb_reg = xgb.XGBRegressor(max_depth=10, learning_rate=0.1, n_estimators=100, random_state=42)
xgb_reg.fit(x_train, y_train,
eval_set=[(x_val, y_val)],
eval_metric=nilm_metric,
)
```
<!-- #region -->
### Feature Importance
Let's look at the most important features identifird by XGB for kettle for example:
Feature ranking:
1. is_breakfast (0.144821)
2. lag_10 (0.131271)
3. consumption (0.120324)
4. lag_future_2 (0.100311)
5. lag_future_1 (0.035501)
6. hour_mean (0.035224)
7. lag_3 (0.034047)
8. lag_2 (0.033974)
9. lag_future_5 (0.032470)
10. rolling_mean_-5 (0.030139)
11. lag_future_4 (0.029670)
12. lag_future_3 (0.028952)
13. lag_20 (0.028152)
14. lag_1 (0.027947)
15. lag_5 (0.026906)
<!-- #endregion -->

From the features importance graph, we can clearly see that four features seem to be way more important than the others among which: is_breakfast as expected since it indicates when people use kettle the most, consumption and two lag variables.

We can see on the graph above that the appliance responsible for the **sharpest variations is the kettle**. Indeed, it is turned on for a very short time but consumes a lot of electricity, so these variations are extremely hard to learn and detect with a CNN. This is the main reason why we want to try **Extreme Gradient Boosting** in order to detect more subtle changes in the consumption.
**XGB Result:** We were able to achieve a better prediction for kettle using XGB. But CNN provided better results for the other appliances.
# Results and benchmark - Conclusion
## Results
In this part, the results of all the methods we tried are summarised. At the very beginning, we tried the **Linear Regression** as a baseline. Our score was similar to the benchmark on the website. Afterwards, we started working on **Recurrent Neural Networks**. Setting them up was very time consuming as we lacked some experience in the field. The results were not really satisfactory as we did not manage to make them perform betten than the Linear Regression.
Then, we started working on **XGBoost** and **Convolutional Neural Networks** at the same time. Both were giving good results but some were performing better on some appliances than others. So we tried to **bag** them in order to maximize the accuracy. Once we had used the best tool for every appliance, we started **tuning** the models individually, which led to our best model.


## Conclusion
This project was interesting and challenging on multiple aspects. It was the first time we had to deal with time series, which was a real challenge because it is a whole new paradigm: the data is now linked by its order and not only by the values of the variables.
We have also applied RNNs for the first time. They are complex to understand and require meticulous tuning in order to give satisfactory results. Data formatting and preparation is also a big part of the work on RNNs.
Moreover, we have understood the interest of mixing models when there are multiple variables to predict, so that one can optimize the prediction for every variable.
The sparsity required much attention too, and we would have liked to dedicate more time to its study.
# References
- Kelly, Jack & Knottenbelt, William. (2015). _Neural NILM: Deep Neural Networks Applied to Energy Disaggregation._ 10.1145/2821650.2821672.
- Brownlee, Jason. (2018). _How to Develop Convolutional Neural Network Models for Time Series Forecasting._ http://bit.ly/CNN_TimeSeries [last visited: 22/03/20]
- Géron, Aurélien. (2019). _Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow._ O'Reilly.
|
C
|
UTF-8
| 6,812 | 2.65625 | 3 |
[] |
no_license
|
#include "enemi.h"
#include "../definitions.h"
#include <math.h>
void init_enemi(Enemi enemi[])
{
int i;
for(i=0; i<NBENEMIS; i++)
{
enemi[i].type=INCONU;
enemi[i].active= NULL;
enemi[i].bis=NULL;
enemi[i].bgX=0;
enemi[i].dir=RIGHT;
}
}
void move_enemi(Enemi en[],Helico hl,Background bg)
{
int y;
for(y=0; y<NBENEMIS; y++)
{
if(en[y].active!=NULL)
{
switch(en[y].type)
{
case SOUCOUPE:
if(en[y].position.x<(hl.position.x+hl.active->w/2))
{
en[y].position.x++;
}
else if(en[y].position.x>(hl.position.x+hl.active->w/2))
{
en[y].position.x--;
}
if(en[y].position.y<(hl.position.y+hl.active->h/2))
{
en[y].position.y++;
}
else if(en[y].position.y>(hl.position.y+hl.active->h/2))
{
en[y].position.y--;
}
break;
case TANK:
if( (en[y].position.x+en[y].active->w/2+ DSTTIR ) <= (hl.position.x+hl.active->w/2) )
{
en[y].position.x++;
}
else if( (en[y].position.x+en[y].active->w/2 - DSTTIR) > (hl.position.x+hl.active->w/2) || (en[y].position.x+en[y].active->w > WIDTH) )
{
en[y].position.x--;
}
break;
case AVION:
if(en[y].dir==RIGHT)
{
if(LIMITE_GAUCHE<en[y].position.x)
en[y].position.x--;
else
en[y].dir=LEFT;
}
else
{
if(LIMITE_DROITE>en[y].position.x)
en[y].position.x++;
else
en[y].dir=RIGHT;
}
break;
default:
break;
}
}//fin du if !NULL
}//fin du for
}
void display_enemis(SDL_Surface* screen,Enemi en[],Background bg)
{
int y;
for(y=0; y<NBENEMIS; y++)
{
if(en[y].active!=NULL)
{
en[y].position.x=en[y].position.x-(en[y].bgX- bg.posX);
en[y].bgX=bg.posX;
SDL_BlitSurface((en[y].dir==0) ? en[y].active :en[y].bis, NULL, screen, &en[y].position);
}
}
}
void generate_enemis(int *lastEnemi,int *lastBg,Enemi en[],Background bg)
{
int i=0;
//( abs( (*lastBg) - bg.posX ) >50 )&&
if( (*lastEnemi)+1000<SDL_GetTicks())
{
while(en[i].active!=NULL && i<20)
{
i++;
}
if((rand()%5)==0 && i<20)
{
switch( (rand()%3)+1)
{
case SOUCOUPE:
en[i].active=IMG_Load("assets/enemis/soucoupe.png");
en[i].bis=NULL;
en[i].type=SOUCOUPE;
en[i].bgX=bg.posX;
en[i].position.y=0;
en[i].position.x=WIDTH*(rand()%2);
en[i].dir=0;
break;
case TANK:
en[i].active=IMG_Load("assets/enemis/tank.png");
en[i].bis=NULL;
en[i].type=TANK;
en[i].bgX=bg.posX;
en[i].position.y=HEIGHT-30-(rand()%50);
en[i].position.x=WIDTH;
en[i].dir=0;
break;
case AVION:
en[i].active=IMG_Load("assets/enemis/avion1.png");
en[i].bis=IMG_Load("assets/enemis/avion.png");
en[i].type=AVION;
en[i].bgX=bg.posX;
en[i].position.y=50+(rand()%50);
en[i].position.x=WIDTH;
en[i].dir=1;
break;
}
en[i].lastshot=SDL_GetTicks()-3000;
*lastBg=bg.posX;
*lastEnemi=SDL_GetTicks();
}
}
}
//missile
void init_missile_enemis(MissileEn me[])
{
int i;
for(i=0; i<NBMISSILE; i++)
{
me[i].speedX=0;
me[i].speedY=0;
me[i].image=NULL;
me[i].position.x=0;
me[i].position.y=0;
}
}
void display_missile_enemis(SDL_Surface *screen, MissileEn me[])
{
int i;
for(i=0; i<NBMISSILE; i++)
{
if(me[i].image!=NULL)
SDL_BlitSurface(me[i].image, NULL, screen, &me[i].position);
}
}
void move_missile_enemis(MissileEn me[],Background bg)
{
int i;
for(i=0; i<NBMISSILE; i++)
{
if( (me[i].position.x<=1 || me[i].position.x>=WIDTH || me[i].position.y<=1 || me[i].position.y>=HEIGHT) && me[i].image!=NULL )
{
SDL_FreeSurface(me[i].image);
me[i].image=NULL;
}
if(me[i].image!=NULL)
{
me[i].position.x+=round(me[i].speedX *2) +(bg.posX-me[i].bgX);
me[i].bgX=bg.posX;
me[i].position.y+=round(me[i].speedY *2);
}
}
}
void fire_missile_enemis(Enemi en[], MissileEn me[], Helico hl, Background bg)
{
int i,j=0,dstX,dstY,pX=hl.position.x,pY=hl.position.y;
for(i=0; i<NBENEMIS; i++)
{
if(en[i].active!=NULL && ( en[i].type==TANK || en[i].type==AVION ) && en[i].lastshot+1000 < SDL_GetTicks())
{
if( (rand()%4)==1 )
{
j=0;
while(me[j].image!=NULL && j<NBMISSILE){j++;}
if(NBMISSILE>j)
{
en[i].lastshot=SDL_GetTicks();
me[j].position.x=en[i].position.x+(en[i].active->w/2);
me[j].position.y=en[i].position.y -10 + ( (en[i].type==AVION)? en[i].active->h+11 : 0);
me[j].image= IMG_Load("assets/enemis/missile.png");
me[j].bgX=bg.posX;
dstX=abs(me[j].position.x-pX);
dstY=abs(me[j].position.y-pY);
if(dstX>dstY)
{
me[j].speedX=(pX<me[j].position.x)? -1: 1;
me[j].speedY=(double)(me[j].position.y-pY)/(double)(me[j].position.x-pX);
if(en[i].type==AVION && me[j].speedY<0)
me[j].speedY=0;
}
else
{
me[j].speedY=(pY<me[j].position.y)? -1: 1;
me[j].speedX=- (double)(me[j].position.x-pX)/(double)(me[j].position.y-pY);
if(en[i].type==TANK && me[j].speedY>0)
me[j].speedY=0;
}
}
}
}
}
}
|
Java
|
UTF-8
| 1,154 | 3.828125 | 4 |
[] |
no_license
|
package sorting;
public class HeapSort {
public static void main(String[] args) {
int[] input = {9,5,8,10,4,2,56,87};
DoHeapSort(input);
print(input);
}
static void DoHeapSort(int[] input){
int heapSize = input.length;
for (int i = heapSize/2-1; i >= 0; i--) {
MaxHeapify(input,heapSize, i);
}
for (int i = input.length - 1; i >= 0; i--)
{
//Swap
int temp = input[i];
input[i] = input[0];
input[0] = temp;
heapSize--;
MaxHeapify(input,heapSize, 0);
}
}
private static void MaxHeapify(int[] input, int heapSize, int i) {
int left = 2*i;
int right = 2*i + 1;
int largest = i;
if(left < heapSize && input[left] > input[i]){
largest = left;
}
if(right< heapSize && input[right] > input[largest]){
largest = right;
}
if(largest != i){
int temp = input[i];
input[i] = input[largest];
input[largest] = temp;
MaxHeapify(input, heapSize, largest);
}
}
public static void print(int input[]) {
for (int i = 0; i < input.length; i++) {
System.out.print(input[i] + ",");
}
System.out.println("\n");
}
}
|
Java
|
UTF-8
| 699 | 3 | 3 |
[] |
no_license
|
package formatting.Date;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
/**
* Created by nbkf on 27/12/2559.
*/
public class Date2 {
public static void main(String args[]) {
Date dNow = new Date( );
SimpleDateFormat ft = //EE = วันย่อ EEEE วันเต็ม
//yyyy = พ.ศ
//MM เดือนย่อ MMMM เดือน เต็ม
//dd วันที่
new SimpleDateFormat ("EEEE yyyy.MM.dd 'at' hh:mm:ss a", new Locale("th","TH"));
System.out.println("Current Date: " + ft.format(dNow));
}
}
|
Python
|
UTF-8
| 481 | 3.140625 | 3 |
[] |
no_license
|
# Why scrapping
# Have access to information on the web
#Can be done using a Library called beautiful soup
# If you're looking for an update on the information
import urllib.parse,urllib.request, urllib.error
from bs4 import BeautifulSoup
import ssl
url = input('Enter -->:')
html = urllib.request.urlopen(url).read()
soup = BeautifulSoup(html,'html.parser')
#Retrieve all of the anchor tags
tags = soup('a')
for tag in tags:
print(tag.get('href',None))
|
Java
|
UTF-8
| 767 | 2.015625 | 2 |
[] |
no_license
|
package com.airbnb.p027n2.primitives;
import com.airbnb.p027n2.primitives.TriStateSwitchHalf.OnCheckedChangeListener;
/* renamed from: com.airbnb.n2.primitives.TriStateSwitch$$Lambda$1 */
final /* synthetic */ class TriStateSwitch$$Lambda$1 implements OnCheckedChangeListener {
private final TriStateSwitch arg$1;
private TriStateSwitch$$Lambda$1(TriStateSwitch triStateSwitch) {
this.arg$1 = triStateSwitch;
}
public static OnCheckedChangeListener lambdaFactory$(TriStateSwitch triStateSwitch) {
return new TriStateSwitch$$Lambda$1(triStateSwitch);
}
public void onCheckedChanged(TriStateSwitchHalf triStateSwitchHalf, boolean z) {
TriStateSwitch.lambda$setListeners$0(this.arg$1, triStateSwitchHalf, z);
}
}
|
Markdown
|
UTF-8
| 16,168 | 3.015625 | 3 |
[
"MIT"
] |
permissive
|
---
layout: post
title: Block
subtitle:
date: 2020-07-27
author: LML
header-img: img/post-bg-ios9-web.jpg
catalog: true
tags:
- 内存
---
# 前言
本系列是 iOS Memory 相关内容作为主题的第二篇。本篇主要介绍 Block 内存原理、循环引用的原理。在看本文之前,可以先思考一下一个问题,然后在文中找到答案。
+ 如何定义一个 Block?
+ Blcok 到底是什么?
+ Block 有几种类型,有什么区别
+ __block 修饰符的原理以及作用
+ Block 捕获不同类型的变量的原理
+ Block 为什么会造成循环引用
# block的写法分类
+ 作为属性
```
@property (nonatomic, copy, nullable) dispatch_block_t uploadSuccessedBlock;
@property (nonatomic, copy, nullable) void(^uploadFailedBlock)(NSError *error);
```
+ 直接定义
```
uploadFailedBlock = ^(NSError * _Nonnull error) {
[handler uploadCommandResultFailedWithParams:customDict error:error];
};
__nullable id(^block)(void) = ^() {
return weakObject;
};
```
# block 的本质
block 类型的变量,实质上是一个结构体类型的变量,比如
```
int main() {
void (^blk)(void) = ^{
printf("BLock")
}
}
```
本质上是:
```
struct __block_impl {
void *isa;
int Flags;
int Reserved;
void *Funcptr;
};
struct __main_block_desc_0 {
unsigned long reserved;
unsigned long blocksize;
} __main_block_desc_0_data = {0,sizeof(struct __main__block__impl_0)};
struct __main__block__impl_0 {
struct __block_impl impl;
struct __main_block_desc_0 *Desc;
__main__block__impl_0(void *fp,__main_block_desc_0 *desc,int flags = 0) {
impl.isa = NSStackBlock;
impl.Flags = flags;
impl.Funcptr = fp;
Desc = desc;
}
};
static void __main_block_func_0(__main__block__impl_0 *cself) {
printf("BLock")
}
int main() {
void (^blk)(void) = __main__block__impl_0(__main_block_func_0,&__main_block_desc_0_data);
blk.impl->Funcptr(blk);
return 0;
}
```
+ isa 指针标示了 block 的类型
+ Funcptr 指针指向了函数指针
上面这张是最简单的 block 模型,也是最基本的 block 模型,揭示了 block 的本质是一个结构体。
但是不同类型的block 还会与上面展示的block有些不同,下面会进行详细介绍
# Block 有几种类型,有什么区别
## global block
什么是 global block 即 NSGlobalBlock?
+ 不捕获变量的
+ 捕获global var, Global static var, local static var
这种类型的 block,结构体内部不会增加捕获的变量,与上面示例的代码相同,因为即使捕获变量,全局变量、全局静态变量、局部静态变量存储在全局区域,整个生命周期只存在一份,因此只需要这种类型保存在全局区,不需要在自己的结构体内额外的保存捕获的变量
## stack block
- MRC:
- 没有手动调用 block_copy 的 Block
- 捕获变量,且捕获的变量类型有除去(global var, Global static var, local static var)之外的变量
- ARC
- 没有 strong 指针指向的
```
__weak void (^myBlock1)(void) = ^{
NSLog(@"%d",a);
};
```
## NSMallocBlock
- MRC
- 手动调用了 block_copy 的Block.也需要手动调用 Block_release 释放
- Block作为属性,如果用copy修饰
- 需要在 dealloc 方法中调用 Block__release 对 Block 进行释放
- ARC
- Strong pointer 修饰的 Block
- 捕获了非在全局区存储的变量
- 方法返回的 Block
- 会自动现copy 到堆上,然后加入自动释放池
NSMallocBlock 被 copy,引用计数会加 1;NSStackBlock 被 copy 会由栈上 copy 到堆上,引用计数为1;NSGlobalBlock 被copy,不会发生变化
## blcok 作为 property,用什么修饰?
block使用copy是从MRC遗留下来的“传统”。
在MRC中,方法内部的 block 是在栈区的,由于手动管理引用计数,需要 copy到堆区来防止野指针错误。
在ARC中,写不写都行,对于 block 使用copy还是strong效果是一样的,但写上copy也无伤大雅,还能时刻提醒我们:编译器自动对block进行了copy操作。如果不写 copy,该类的调用者有可能会忘记或者根本不知道“编译器会自动对block进行了copy操作”,他们有可能会在调用之前自行拷贝属性值。这种操作多余而低效。
## 作为参数和返回值的思考
三种Block作为方法的参数和返回值的时候需要注意下:
- NSGlobalBlock:
- 由于存储在全局区,生命周期贯穿整个程序,无论是作为参数还是返回值,无论是ARC还是MRC下都没有变化
- NSMallocBlock——与正常的类实例对象类似
- ARC
- 参数:被赋值给函数参数中的strong poniter,引用计数+1.但是出了函数作用域,计数-1
- 返回值:被加入 autoreleasePool,类似于 strong pointer 修饰的类对象
- MRC
- 参数:引用计数没有变化,没有被隐藏copy,如果是先定义了一个 mallocBlock, 然后异步执行一个方法,这个方法参数可能需要我们手动 copy 下 Block,结束的时候在手动 release,具体情况具体分析(大部分异步执行都是 bloc k实现,block会捕获对象)
- 返回值:如果 init new等开头的方法,返回时候不需要操作;如果不是,则返回的时候我们需要对 BLock 调用auotrelease,承接者如想持有,需要调用 Block_copy
- NSStackBlock
- ARC
- 参数:被自动copy了(因为stack Block被赋值给参数,参数是strong)
- 返回值:先被自动copy,然后自动加入pool
- MRC
- 参数:需要手动进行copy
- 返回值:需要手动进行copy,并加入自动释放池
- Block 作为方法返回值的时候,与普通的 class 对象类似,分为 retain return value 和 no retain return value;前者在 MRC 下不需要做什么直接 return,承接着就会持有该对象 (stackBlock 需要手动 copy 下,因为还没有到堆上);在 ARC 下编译系统不会进行任何操作,承接者也不会;后者 MRC需要手动调用 autorelese(stackBlock需要先copy),ARC下系统会帮忙加入 autorelesepool(stackBlock会先帮忙copy)
- 作为参数时候,也与普通的class对象类似:ARC自动帮忙retain+release;MRC需要自己分析释放要retain,一旦retain需要自己进行release
# __ block 修饰符的原理以及作用
⚠️ __ block 一般只用于修饰非在全局区存储的变量(非 gloabl、local static、glpbal static),下面默认指的是非全局区域的变量。
## 数据结构
```
//__blocks 修饰基础变量对应的数据结构
struct __Block_byref_val_0 {
void *__isa;
__Block_byref_val_0 *forwarding;
int __flags;
int __size;
int val;
};
//__blocks 修饰对象对应的数据结构???
struct __Block_byref_val_0 {
void *__isa;
__Block_byref_val_0 *forwarding;
int __flags;
int __size;
id __ strong val;
};
```
__ block 修饰的变量无论是基础变量还是对象,都变成了一个结构体,结构体内部的 isa 指针标示该结构体是在stack、malloc 还是global 的。
比如一个对象的指针,若被 __ block 修饰,则其本质上会变成一个结构体,结构体内部会有个strong类型的指针指向对象的内存。 至于这个结构体存储在啊哪里,与被谁引用有关系,下面具体介绍。
结构体中比较重要的还有 forwarding 指针,为什么需要 forwarding指针呢?下面也会详细介绍
## 存储域
__block 是存储域类说明符
__block 属性修饰的局部变量,从创建到到被 BLock 使用时,__ block 变量存储在哪个区域呢?
+ 以下两种情况,__block(结构体)存储在栈上:
- 刚初始化时;
- 被栈BLock使用时
+ 下面情况存储在堆上:
- 使用 __block 的 Block 从栈 copy 到堆上, __block 变量也会受影响,会被 copy 到堆上,并被持有
- __block 被多个堆BLock使用,引用计数会增加
- 怎么持有的呢?Block的结构内部持有指向__block变量的strong pointer
- 如果配置在堆上的Block被废弃,那么他持有的__ block变量也会被释放

有一点值得注意,理解的时候需要区分基础类型变量和对象类型的变量
+ 基础类型变量
+ 未被__ block 修饰的时候就是一个栈上的基础变量
+ 被修饰的时候是一个结构体,可能在栈上也可能在堆上,取决于上面说的具体情况
+ 对象类型变量
+ 未被 __ block 修饰的时候,对象的确在堆上,但是定义的指向对象的这个指针在栈上
+ 被 __ block 修饰后,对象仍然在堆上,但是原来的指向对象的指针变成了结构体,结构体内部有个 staong 类型的指针 指向对象内存。结构体存储在哪里,取决于上面说的具体情况。
## 为什么有的变量需要 block 修饰?
什么变量需要 block 修饰呢?
+ 当 Block 想要更改捕获的变量时,这个变量需要用 block 修饰
+ 当期待 Block 捕获的变量(Block 捕获变量即会持有变量)与 Block 外的变量变化统一的时候
为什么需要 block 修饰呢?
简单来说,如果不用 block 修饰,Block 内部捕获的变量与没有被捕获的变量是两份,导致修改的时候内部的更改不能同步到 Block外部,例如:
+ 基础变量
+ 当没有 __block 修饰时,内外基础变量地址不同


+ 被__block 修饰时,内外地址相同


+ 对象类型
+ 当没有 __block 修饰时,内外指向对象的指针的地址不同


+ 有 __block 修饰时,内外指向对象的指针的地址相同


明白了为什么需要 __block 修饰,那么结构体中的 forwarding 指针的作用时什么呢?
为了保证
+ __block变量不管是配置在堆上还是配置在栈上,都能够正确的访问该变量
+ 更通俗的将:保证 __block 变量被 copy 到堆上之后,不通过 Block 访问 __block 变量也能访问到正确的变量
+ forward保证了:
+ 堆上的 __blockde forwarding指针指向自己
+ 栈上的 forwarding 指针指向自己被 copy 到堆上的那个内存;若没有被 copy 到堆上,则指向自己
+ 栈上的 __block 变量结构体实例会在 __block 变量从栈复制到堆上的时候,将自己的成员变量 forwarding 的值替换成复制目标即堆上的 __block 的结构体实例的地址
# Block 捕获变量
上面介绍了什么情况下需要 __block 修饰,为啥需要修饰。这些都涉及到了 Block 对变量的捕获。本小节对 Block 捕获变量的原理进行详细介绍
## 捕获基础变量
### 没有 __block 修饰
- 全局变量,全局 static 变量
- Blocks 结构体与没有捕获变量相比无变化.且可以更改捕获的变量的值,且实际上根本没有捕获变量,因为是全局的保存一份就够了
- 局部static变量
- Blocks 结构体内部会增加一个指向 local static 内存的指针,且可以更改捕获变量的值
- 局部变量
- Blocks 内部会有变量的 copy,与原有的基础变量不是一个,所以编译器做了优化:Blocks内部不能更改捕获的局部变量的值
- 小结
- 能不能更改捕获变量的值,Blocks内部持有变量,都是出于保证:在执行Blocks的时候,捕获的变量仍然存在,能访问,不会因为其释放了而Crash
### 有block修饰。
上面说捕获局部变量不能修改其值,解决办法是用 __block 修饰,为什么这样就解决了呢?
- __block修饰的局部自动变量变为一个结构体,结构体内部有基础类型变量
- Blocks 结构体内部有指向__block结构体的指针
- __block 结构体的存储位置会跟随 Blocks 的存储位置改变而改变
- forward 指针的作用也在此显现:保证 Blocks 内部和外部的访问的结构体是同一个结构体
## 捕获对象
### 普通捕获对象
```
struct __main_block_impl_0 {
struct __block impl impl;
struct __main_block_desc_0 *Desc;
id __strong obj;
__main_block_impl_0(void *fp, __main_block_desc_0 *Desc, id __strong obj1, int flags = 0): obj(obj1) {
impl.isa. = $_NSConCretStackBlock;
impl.Flags=flags;
impl.FuncPtr = fp;
Desc = desc;
}
}
```
Block 结构体内部会有个成员变量:strong 类型的指针,强持有普通对象。当Block 销毁时,也会释放对对象的强引用。Block 结构体对捕获的对象的强引用实质是调用了两个方法
+ ```_block_object_assign``` 方法持有Block截获的对象
+ ```__block_object_dispose ``` 当堆上的Block被废弃的时候,调用此方法解除强引用
但是值得注意的是:Block截获对象需要两个条件
+ 被截获的对象 strong 修饰符修饰
+ 捕获 weak 修饰的对象的时候,Block内部不是 strong 修饰符,是 weak 修饰符,进而不会捕获,不会循环引用。即不会调用```_block_object_assign```
+ Block被copy到堆上
+ BLock 在栈上的时候,也不会调用 ```_block_object_assign```
还有一点需要注意,Blocks 捕获对象,Blocks 结构体内部会新增一个id 类型的指针,指向对象,虽然与Blocks外的指针指向的内存是同一个,但是不是同一个指针,因此不允许改变指针的指向(优化)
### 捕获 __block 修饰的对象
__block修饰对象,被转换为结构体,该结构体也会捕获对象,和 Block 捕获对象很类似.需要满足两个条件,_结构体会持有对象
- strong修饰
- __block 结构体被栈上拷贝到堆上
至于__block 变量什么时候会被拷贝到堆上,与哪个 Block 捕获该 __block 变量有关。
总结下:
Block若捕获__block + strong修饰的对象:
- __block位于堆上的时候强持有对象
- Block强持有结构体
- 二者均通过函数实现持有和释放
如果是 __block 修饰 weak 对象则,
- __block不会强持有对象,weak 持有
- Block强持有__block结构体,依然按照上述规律释放和持有
# 循环引用
## Block 为什么会造成循环引用
Block 会持有捕获的对象,如果捕获的对象还持有Block,就形成了一个引用环,造成循环引用,进而造成内存泄漏。
举个最简单的例子
+ 被捕获的对象本身有strong修饰,引用计数1
+ Block 被捕获对象持有引用计数1
+ Block 持有捕获对象,捕获对象引用计数为2
+ Block 被捕获对象持有,除非不会对象释放,否则不会释放
+ 被捕获对象出作用域,引用计数减1,但仍为1
+ 这时候Block 和被捕获对象引用计数均为1,等待对方释放,内存泄漏
那么如何解决呢?
+ ARC
+ weak 修饰即将被 Block 捕获的变量,然后 Block 内部使用 weak修饰的变量,这样 Block 结构体内生成的是 weak 修饰的指针,没有强持有捕获对象
+ 不过值得注意的是,为了防止 Block 执行的过程中,捕获的变量释放,可以在Block内部最开始的位置用strong修饰捕获的变量,这个strong 修饰的变量作用域只在 Block 的{}中,是个局部变量,出了作用域即释放,不会造成循环引用
+ MRC

## 如何检测循环引用、内存泄漏
+ 工具
+ instrument 的 Leask 和Allocation
+ 库
+ MLeaksFinder + FBRetainCycleDetector 检测引用环
后面会出博客介绍 MLeaksFinder + FBRetainCycleDetector 的原理
# 参考
+ <https://www.jianshu.com/p/d96d27819679>
|
Java
|
UTF-8
| 3,180 | 1.96875 | 2 |
[] |
no_license
|
package annotator.tuke.urbansensing.org.POJO;
import java.util.HashMap;
import java.util.Map;
import javax.annotation.Generated;
import javax.xml.bind.annotation.XmlElement;
import javax.xml.bind.annotation.XmlRootElement;
import org.codehaus.jackson.annotate.JsonAnyGetter;
import org.codehaus.jackson.annotate.JsonAnySetter;
import org.codehaus.jackson.annotate.JsonIgnore;
import org.codehaus.jackson.annotate.JsonProperty;
import org.codehaus.jackson.annotate.JsonPropertyOrder;
@XmlRootElement
public class Resource {
private String URI;
private String Support;
private String Types;
private String SurfaceForm;
private String Offset;
private String SimilarityScore;
private String PercentageOfSecondRank;
/**
*
* @return
* The URI
*/
@XmlElement(name="@@URI")
public String getURI() {
return URI;
}
/**
*
* @param URI
* The @URI
*/
public void setURI(String URI) {
this.URI = URI;
}
/**
*
* @return
* The Support
*/
@XmlElement(name="@@support")
public String getSupport() {
return Support;
}
/**
*
* @param Support
* The @support
*/
public void setSupport(String Support) {
this.Support = Support;
}
/**
*
* @return
* The Types
*/
@XmlElement(name="@@types")
public String getTypes() {
return Types;
}
/**
*
* @param Types
* The @types
*/
public void setTypes(String Types) {
this.Types = Types;
}
/**
*
* @return
* The SurfaceForm
*/
@XmlElement(name="@@surfaceForm")
public String getSurfaceForm() {
return SurfaceForm;
}
/**
*
* @param SurfaceForm
* The @surfaceForm
*/
public void setSurfaceForm(String SurfaceForm) {
this.SurfaceForm = SurfaceForm;
}
/**
*
* @return
* The Offset
*/
@XmlElement(name="@@offset")
public String getOffset() {
return Offset;
}
/**
*
* @param Offset
* The @offset
*/
public void setOffset(String Offset) {
this.Offset = Offset;
}
/**
*
* @return
* The SimilarityScore
*/
@XmlElement(name="@@similarityScore")
public String getSimilarityScore() {
return SimilarityScore;
}
/**
*
* @param SimilarityScore
* The @similarityScore
*/
public void setSimilarityScore(String SimilarityScore) {
this.SimilarityScore = SimilarityScore;
}
/**
*
* @return
* The PercentageOfSecondRank
*/
@XmlElement(name="@@percentageOfSecondRank")
public String getPercentageOfSecondRank() {
return PercentageOfSecondRank;
}
/**
*
* @param PercentageOfSecondRank
* The @percentageOfSecondRank
*/
public void setPercentageOfSecondRank(String PercentageOfSecondRank) {
this.PercentageOfSecondRank = PercentageOfSecondRank;
}
}
|
Markdown
|
UTF-8
| 538 | 2.84375 | 3 |
[] |
no_license
|
# Snake-Game
A small JavaScript game
Title : Snake-Game
Author : Clément Landais (while following apprendre-a-coder.com JavaScript formation)
Used Languages : JavaScript, HTML, CSS
To play : Download all files and open index.html in your Web browser
Rules : A classic snake game. Try to eat as many apples as you can before hitting your own body or a wall. Change direction with the arrow keys. Good luck !
Important : This game was designed to be played on a computer. You will not be able to play it properly on a tablet or mobile phone !
|
Java
|
UTF-8
| 1,203 | 2.1875 | 2 |
[] |
no_license
|
package fr.eisti.gsi2.repositories;
import java.util.List;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import fr.eisti.gsi2.entities.AnnonceEntity;
public interface AnnonceRepository extends JpaRepository<AnnonceEntity,Long> {
// Spécification de la méthode de requête par critères
@Query(value = "SELECT * FROM immobilier.annonce "
+ "WHERE (:codePostal is null or code_postal = :codePostal) "
+ "AND (:typeBien is null or type_bien = :typeBien) "
+ "AND (:typeTransaction is null or type_transaction = :typeTransaction) "
+ "AND (:prixMax is null or (prix_integer BETWEEN :prixMin AND :prixMax)) "
+ "AND (:surfaceMax is null or (surface BETWEEN :surfaceMin AND :surfaceMax))",
nativeQuery = true)
List<AnnonceEntity> findByCriteres(
@Param("codePostal") String codePostal,
@Param("typeBien") String typeBien,
@Param("typeTransaction") String typeTransaction,
@Param("prixMin") Integer prixMin,
@Param("prixMax") Integer prixMax,
@Param("surfaceMin") Integer surfaceMin,
@Param("surfaceMax") Integer surfaceMax);
}
|
Java
|
UTF-8
| 604 | 3.3125 | 3 |
[] |
no_license
|
import java.util.*;
public class derived extends base {
Scanner sc = new Scanner(System.in);
derived() {
System.out.println("Enter the width");
int w = sc.nextInt();
// sc.nextLine();
System.out.println("Enter the height");
int h = sc.nextInt();
width = w;
height = h;
}
void display() {
super.display();
System.out.println("Area of rectangle=" + (width * height));
}
public static void main(String args[]) {
derived obj = new derived();
obj.display();
}
}
|
Swift
|
UTF-8
| 2,938 | 2.59375 | 3 |
[] |
no_license
|
//
// LoginViewController.swift
// OpenWeatherAPI
//
// Created by Mac on 11/21/17.
// Copyright © 2017 Mobile Apps Company. All rights reserved.
//
import UIKit
import CoreData
class LoginPage: PageView, UITextFieldDelegate {
@IBOutlet weak var zipcode:UITextField!
override func viewDidLoad() {
super.viewDidLoad()
zipcode.delegate = self
// Do any additional setup after loading the view.
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
// MARK: - Navigation
override func prepare(for segue: UIStoryboardSegue, sender: Any?) {
// guard let NC = segue.destination as? UINavigationController else {return}
// guard let VC = NC.ViewControllers.first as? RootViewController else {return}
}
func textFieldShouldReturn(_ textField: UITextField) -> Bool {
if(textField.text?.count == 5) {
zipcode.resignFirstResponder()
if let zip = (Int(textField.text ?? "")) {
print("\(zip)")
//self.saveToCoreData(zip)
//performSegue(withIdentifier: "login", sender: self)
}
}
return true
}
private func saveToCoreData(_ zip:Int){
let appDelegate = UIApplication.shared.delegate as! AppDelegate
let managedContext = appDelegate.persistentContainer.viewContext
// let request = NSFetchRequest<NSManagedObject>(entityName:"Location")
// request.predicate = NSPredicate(format: "postal == %@", zip)
//
// do {
// let locations = try managedContext.fetch(request)
// if(locations.count > 0) {return}
// } catch let error {
// print(error.localizedDescription)
// }
guard let entity = NSEntityDescription.entity(forEntityName: "Location", in: managedContext) else {return}
let data = NSManagedObject(entity: entity, insertInto: managedContext)
data.setValue(zip, forKey: "postal")
do {
try managedContext.save()
} catch let error {
print(error.localizedDescription)
}
}
func textField(_ textField: UITextField, shouldChangeCharactersIn range: NSRange, replacementString string: String) -> Bool {
let allowedCharacters = CharacterSet.decimalDigits
let characterSet = CharacterSet(charactersIn: string)
if allowedCharacters.isSuperset(of: characterSet) {
guard let text = textField.text else { return true }
let newLength = text.characters.count + string.characters.count - range.length
return newLength <= 5
}
return false
}
}
|
PHP
|
UTF-8
| 1,302 | 2.625 | 3 |
[] |
no_license
|
<?php
require 'config.php';
?>
<?php
if(isset($_POST['login']))
{
$userName=$_POST['userName'];
$password=$_POST['password'];
$query="select * from fileuploadtable WHERE username='$userName' AND password='$password'";
$query_run = mysqli_query($con,$query);
if(mysqli_num_rows($query_run)>0)
{
$row = mysqli_fetch_assoc($query_run);
// valid
$_SESSION['userName']= $row['userName'];
//$_SESSION['imglink']= $row['imglink'];
header('location:loggedin_layout.php');
}
else
{
// invalid
echo '<script type="text/javascript"> alert("Invalid credentials") </script>';
}
}
?>
<fieldset>
<legend><b>LOGIN</b></legend>
<form action="login.php" method="post">
<table>
<tr>
<td>User Name</td>
<td>:</td>
<td><input name="userName" type="text"></td>
</tr>
<tr>
<td>Password</td>
<td>:</td>
<td><input name="password" type="password"></td>
</tr>
</table>
<hr />
<input name="remember" type="checkbox">Remember Me
<br/><br/>
<input name="login" type="submit" value="Submit">
<a href="forgot_password.html">Forgot Password?</a>
</form>
</fieldset>
|
Java
|
UTF-8
| 293 | 2.5 | 2 |
[] |
no_license
|
package main.java.com.lemsviat.javacore.chapter18;
import org.jetbrains.annotations.NotNull;
import java.util.Comparator;
public class ComparatorFirstName implements Comparator<String> {
public int compare (@NotNull String a, String b){
return a.compareToIgnoreCase(b);
}
}
|
TypeScript
|
UTF-8
| 249 | 2.796875 | 3 |
[] |
no_license
|
export class Recipe{
public name:string;
public description :string;
public imagePath : string;
constructor(name : string,description: string,imagePath:string){
this.imagePath=imagePath;
this.name=name;
this.description=description;
}
}
|
Rust
|
UTF-8
| 2,660 | 2.515625 | 3 |
[
"MIT"
] |
permissive
|
/*
Copyright (C) 2018-2019 de4dot@gmail.com
Permission is hereby granted, free of charge, to any person obtaining
a copy of this software and associated documentation files (the
"Software"), to deal in the Software without restriction, including
without limitation the rights to use, copy, modify, merge, publish,
distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so, subject to
the following conditions:
The above copyright notice and this permission notice shall be
included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
*/
#[cfg(not(feature = "std"))]
#[cfg(any(feature = "gas", feature = "intel", feature = "masm", feature = "nasm", feature = "fast_fmt"))]
use alloc::string::String;
#[cfg(any(feature = "gas", feature = "intel", feature = "masm", feature = "nasm", feature = "fast_fmt"))]
use core::str;
pub(crate) struct DataReader<'a> {
data: &'a [u8],
index: usize,
}
impl<'a> DataReader<'a> {
pub(crate) fn new(data: &'a [u8]) -> Self {
Self { data, index: 0 }
}
#[cfg(any(feature = "gas", feature = "intel", feature = "masm", feature = "nasm", feature = "fast_fmt"))]
pub(crate) fn index(&self) -> usize {
self.index
}
#[cfg(any(feature = "gas", feature = "intel", feature = "masm", feature = "nasm", feature = "fast_fmt"))]
pub(crate) fn set_index(&mut self, index: usize) {
self.index = index
}
pub(crate) fn can_read(&self) -> bool {
self.index < self.data.len()
}
pub(crate) fn read_u8(&mut self) -> usize {
let b = self.data[self.index] as usize;
self.index += 1;
b
}
pub(crate) fn read_compressed_u32(&mut self) -> u32 {
let mut result = 0;
let mut shift = 0;
loop {
debug_assert!(shift < 32);
let b = self.read_u8() as u32;
if (b & 0x80) == 0 {
return result | (b << shift);
}
result |= (b & 0x7F) << shift;
shift += 7;
}
}
#[cfg(any(feature = "gas", feature = "intel", feature = "masm", feature = "nasm", feature = "fast_fmt"))]
pub(crate) fn read_ascii_string(&mut self) -> String {
let len = self.read_u8();
let s = str::from_utf8(&self.data[self.index..self.index + len]).unwrap();
self.index += len;
String::from(s)
}
}
|
TypeScript
|
UTF-8
| 1,326 | 2.6875 | 3 |
[
"MIT"
] |
permissive
|
import { Injectable } from '@angular/core';
import { Subject } from 'rxjs';
import { DateRange } from '../model/DateRange';
const reducer = (map:Map<string, string[]>, currentValue:string) => {
var arr = currentValue.split('.');
var key = arr[0];
var value = arr[1];
if(!map.has(key)) {
map.set(key, [value]);
} else {
map.get(key)?.push(value);
}
return map;
}
@Injectable({
providedIn: 'root'
})
export class SharedService {
// Observable string sources
private selectedTableSource = new Subject<string>();
private selectedColumnSource = new Subject<Map<string, string[]>>();
private dateRangeSource = new Subject<DateRange>();
// Observable string streams
selectedTables$ = this.selectedTableSource.asObservable();
selectedColumns$ = this.selectedColumnSource.asObservable();
dateRange$ =this.dateRangeSource.asObservable();
constructor() { }
// Service message commands
selectTables(tables: string) {
this.selectedTableSource.next(tables);
}
selectColumns(columns: string) {
console.log('columns: ' + columns)
var map = new Map();
var arr = columns.split(',');
var filter = arr.reduce(reducer, map);
this.selectedColumnSource.next(filter);
}
setDateRange(dateRange: DateRange) {
this.dateRangeSource.next(dateRange);
}
}
|
Java
|
UTF-8
| 2,377 | 2.875 | 3 |
[] |
no_license
|
package model;
import java.sql.Date;
public class Product
{
private int product_Id;
private String product_Name;
private Date manufacture_Date;
private char category;
private int price;
private int discount;
private int total_quantity;
private int available_quantity;
public Product()
{
this.product_Id = 1;
this.product_Name = "";
this.manufacture_Date = Date.valueOf("2015-11-20");
this.category = 'E';
this.price = 0;
this.discount = 0;
this.total_quantity = 0;
this.available_quantity = 0;
}
public Product(int id, String product_Name, Date manufacture_Date, char category, int price, int discount, int total_quantity, int available_quantity)
{
this.product_Name = product_Name;
this.manufacture_Date = manufacture_Date;
this.category = category;
this.price = price;
this.discount = discount;
this.total_quantity = total_quantity;
this.available_quantity = available_quantity;
}
public Product(String productName, int price, int discount, int totalQty)
{
this.product_Name = productName;
this.price = price;
this.discount = discount;
this.total_quantity = totalQty;
}
public int getProduct_Id()
{
return this.product_Id;
}
public String getProduct_Name()
{
return this.product_Name;
}
public Date getManufacture_Date()
{
return this.manufacture_Date;
}
public char getCategory()
{
return this.category;
}
public int getPrice()
{
return this.price;
}
public int getDiscount()
{
return this.discount;
}
public int getTotal_quantity()
{
return this.total_quantity;
}
public int getAvailable_quantity()
{
return this.available_quantity;
}
public void setProduct_Id(int product_Id)
{
this.product_Id = product_Id;
}
public void setProduct_Name(String product_Name)
{
this.product_Name = product_Name;
}
public void setManufacture_Date(Date manufacture_Date)
{
this.manufacture_Date = manufacture_Date;
}
public void setCategory(char category)
{
this.category = category;
}
public void setPrice(int price)
{
this.price = price;
}
public void setDiscount(int discount)
{
this.discount = discount;
}
public void setTotal_quantity(int total_quantity)
{
this.total_quantity = total_quantity;
}
public void setAvailable_quantity(int available_quantity)
{
this.available_quantity = available_quantity;
}
}
|
C
|
UTF-8
| 2,013 | 3.15625 | 3 |
[] |
no_license
|
/* 013.c COPYRIGHT FUJITSU LIMITED 2018 */
/* util_indicate_clone use pthread_create */
#include <pthread.h>
#include "test_mck.h"
#include "testsuite.h"
SETUP_EMPTY(TEST_SUITE, TEST_NUMBER)
TEARDOWN_EMPTY(TEST_SUITE, TEST_NUMBER)
static void *child_thread_local(void *arg)
{
int ret;
ret = get_system();
if (ret == 0) {
printf("[OK] this thread running on McKernel.\n");
} else if (ret == -1) {
printf("[NG] this thread running on HOST-Linux.\n");
} else {
printf("[NG] get_system illegal return value(%d)\n", ret);
}
return NULL;
}
static void *child_thread_remote(void *arg)
{
int ret;
ret = get_system();
if (ret == 0) {
printf("[NG] this thread running on McKernel.\n");
} else if (ret == -1) {
printf("[OK] this thread running on HOST-Linux.\n");
} else {
printf("[NG] get_system illegal return value(%d)\n", ret);
}
return NULL;
}
RUN_FUNC(TEST_SUITE, TEST_NUMBER)
{
int ret = 0;
uti_attr_t attr;
pthread_t thread;
/* for remote spawn */
memset(&attr, 0, sizeof(attr));
attr.flags |= UTI_FLAG_SAME_NUMA_DOMAIN;
ret = util_indicate_clone(SPAWN_TO_REMOTE, &attr);
if (ret != 0) {
perror("util_indicate_clone:");
tp_assert(0, "util_indicate_clone error.");
}
memset(&thread, 0, sizeof(thread));
ret = pthread_create(&thread, NULL, child_thread_remote, NULL);
tp_assert(ret == 0, "remote pthread_create error.");
ret = pthread_join(thread, NULL);
tp_assert(ret == 0, "remote pthread_join error.");
/* for local spawn */
memset(&attr, 0, sizeof(attr));
attr.flags |= UTI_FLAG_SAME_NUMA_DOMAIN;
ret = util_indicate_clone(SPAWN_TO_LOCAL, &attr);
if (ret != 0) {
perror("util_indicate_clone:");
tp_assert(0, "util_indicate_clone error.");
}
memset(&thread, 0, sizeof(thread));
ret = pthread_create(&thread, NULL, child_thread_local, NULL);
tp_assert(ret == 0, "local pthread_create error.");
ret = pthread_join(thread, NULL);
tp_assert(ret == 0, "local pthread_join error.");
tp_assert(0, "please check logs. [OK] or [NG]");
return NULL;
}
|
Java
|
UTF-8
| 6,097 | 2.53125 | 3 |
[
"MIT"
] |
permissive
|
package seedu.momentum.model.project.predicates;
import static org.junit.jupiter.api.Assertions.assertFalse;
import static org.junit.jupiter.api.Assertions.assertTrue;
import static seedu.momentum.testutil.TypicalProjects.ALICE;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import org.junit.jupiter.api.Test;
public class NameContainsKeywordsPredicateTest {
private static final List<String> SINGLE_KEYWORD = Collections.singletonList("Alice");
private static final List<String> MULTIPLE_KEYWORDS = Arrays.asList("Alice", "Pauline");
private static final List<String> ONE_MATCHING_KEYWORD = Arrays.asList("Alice", "Bob");
private static final List<String> MIXED_CASE_KEYWORDS = Arrays.asList("AlIcE", "PaUlInE");
private static final List<String> NO_MATCHING_KEYWORDS = Arrays.asList("nothing", "matches");
private static final List<String> ONLY_MATCHES_DESCRIPTION = Arrays.asList("Likes", "Coding");
private static final List<String> ONLY_MATCHES_TAG = Collections.singletonList("friends");
@Test
public void equals() {
List<String> firstPredicateKeywordList = Collections.singletonList("first");
List<String> secondPredicateKeywordList = Arrays.asList("first", "second");
NameContainsKeywordsPredicate firstAnyPredicate =
new NameContainsKeywordsPredicate(FindType.ANY, firstPredicateKeywordList);
NameContainsKeywordsPredicate secondAnyPredicate =
new NameContainsKeywordsPredicate(FindType.ANY, secondPredicateKeywordList);
NameContainsKeywordsPredicate firstAllPredicate =
new NameContainsKeywordsPredicate(FindType.ALL, firstPredicateKeywordList);
NameContainsKeywordsPredicate secondAllPredicate =
new NameContainsKeywordsPredicate(FindType.ALL, secondPredicateKeywordList);
// same object -> returns true
assertTrue(firstAnyPredicate.equals(firstAnyPredicate));
assertTrue(firstAllPredicate.equals(firstAllPredicate));
// same values -> returns true
NameContainsKeywordsPredicate firstAnyPredicateCopy =
new NameContainsKeywordsPredicate(FindType.ANY, firstPredicateKeywordList);
assertTrue(firstAnyPredicate.equals(firstAnyPredicateCopy));
NameContainsKeywordsPredicate firstAllPredicateCopy =
new NameContainsKeywordsPredicate(FindType.ALL, firstPredicateKeywordList);
assertTrue(firstAllPredicate.equals(firstAllPredicateCopy));
// different types -> returns false
assertFalse(firstAnyPredicate.equals(1));
assertFalse(firstAllPredicate.equals(1));
// null -> returns false
assertFalse(firstAnyPredicate.equals(null));
assertFalse(firstAllPredicate.equals(null));
// different keywords -> returns false
assertFalse(firstAnyPredicate.equals(secondAnyPredicate));
assertFalse(firstAllPredicate.equals(secondAllPredicate));
// different findType -> returns false
assertFalse(firstAnyPredicate.equals(firstAllPredicate));
assertFalse(secondAnyPredicate.equals(secondAllPredicate));
}
@Test
public void test_nameContainsKeywords() {
// One keyword (Any)
NameContainsKeywordsPredicate anyPredicate =
new NameContainsKeywordsPredicate(FindType.ANY, SINGLE_KEYWORD);
assertTrue(anyPredicate.test(ALICE));
// Multiple keywords (Any)
anyPredicate = new NameContainsKeywordsPredicate(FindType.ANY, MULTIPLE_KEYWORDS);
assertTrue(anyPredicate.test(ALICE));
// Only one matching keyword (Any)
anyPredicate = new NameContainsKeywordsPredicate(FindType.ANY, ONE_MATCHING_KEYWORD);
assertTrue(anyPredicate.test(ALICE));
// Mixed-case keywords (Any)
anyPredicate = new NameContainsKeywordsPredicate(FindType.ANY, MIXED_CASE_KEYWORDS);
assertTrue(anyPredicate.test(ALICE));
// One keyword (All)
NameContainsKeywordsPredicate allPredicate =
new NameContainsKeywordsPredicate(FindType.ALL, SINGLE_KEYWORD);
assertTrue(allPredicate.test(ALICE));
// Multiple keywords (All)
allPredicate = new NameContainsKeywordsPredicate(FindType.ALL, MULTIPLE_KEYWORDS);
assertTrue(allPredicate.test(ALICE));
// Only one matching keyword (All)
allPredicate = new NameContainsKeywordsPredicate(FindType.ALL, ONE_MATCHING_KEYWORD);
assertFalse(allPredicate.test(ALICE));
// Mixed-case keywords (All)
allPredicate = new NameContainsKeywordsPredicate(FindType.ALL, MIXED_CASE_KEYWORDS);
assertTrue(allPredicate.test(ALICE));
}
@Test
public void test_nameDoesNotContainKeywords_returnsFalse() {
// Non-matching keyword (Any)
NameContainsKeywordsPredicate anyPredicate =
new NameContainsKeywordsPredicate(FindType.ANY, NO_MATCHING_KEYWORDS);
assertFalse(anyPredicate.test(ALICE));
// Keywords match description, but does not match name (Any)
anyPredicate = new NameContainsKeywordsPredicate(FindType.ANY, ONLY_MATCHES_DESCRIPTION);
assertFalse(anyPredicate.test(ALICE));
// Keywords match tag, but does not match name (Any)
anyPredicate = new NameContainsKeywordsPredicate(FindType.ANY, ONLY_MATCHES_DESCRIPTION);
assertFalse(anyPredicate.test(ALICE));
// Non-matching keyword (All)
NameContainsKeywordsPredicate allPredicate =
new NameContainsKeywordsPredicate(FindType.ALL, NO_MATCHING_KEYWORDS);
assertFalse(allPredicate.test(ALICE));
// Keywords match description, but does not match name (All)
allPredicate = new NameContainsKeywordsPredicate(FindType.ALL, ONLY_MATCHES_TAG);
assertFalse(allPredicate.test(ALICE));
// Keywords match tag, but does not match name (All)
allPredicate = new NameContainsKeywordsPredicate(FindType.ALL, ONLY_MATCHES_TAG);
assertFalse(allPredicate.test(ALICE));
}
}
|
Markdown
|
UTF-8
| 2,943 | 3.65625 | 4 |
[] |
no_license
|
## Island Perimeter
> You are given a map in form of a two-dimensional integer grid where 1 represents land and 0 represents water.
>
> Grid cells are connected horizontally/vertically (not diagonally). The grid is completely surrounded by water, and there is exactly one island (i.e., one or more connected land cells).
>
> The island doesn't have "lakes" (water inside that isn't connected to the water around the island). One cell is a square with side length 1. The grid is rectangular, width and height don't exceed 100. Determine the perimeter of the island.
>
>
>
> **Example:**
>
> ```
> Input:
> [[0,1,0,0],
> [1,1,1,0],
> [0,1,0,0],
> [1,1,0,0]]
>
> Output: 16
>
> Explanation: The perimeter is the 16 yellow stripes in the image below:
> ```
* The intuition for me is to calculate the cell of the land , i assume the repeat line number is ```cellNumber-1``` ,the assumption is false !!\
* so we can iterative the land ,and count the right and down neighbor
* or we can calculate the line of the land ,the boundary condition is out of the grid or the neighbor is water ,we should tag the visited``` grid[i] [j]== -1``` ,to avoid dead loop and avoid to miss some repeat line
## Solution DFS to calculate the free line
```java
class Solution {
int n = 0;
int sub = 0;
int row;
int col;
int direction[][]= new int [][]{{0,1},{0,-1},{-1,0},{1,0}};
public int islandPerimeter(int[][] g) {
if(g.length==0||g[0].length==0) return 0;
row = g.length;
col= g[0].length;
for(int i = 0 ;i<row;i++){
for(int j = 0 ;j < col ;j++ ){
if(g[i][j]==1){
dfs(g,i,j);
return n;
}
}
}
return -1 ;
}
private void dfs(int [][] g ,int r ,int c){
//avoid repeat
//important
if(r<0||r>=row||c<0||c>=col||g[r][c]==0){
n++;
return ;
}else if(g[r][c]==1){
g[r][c]=-1;
for(int i = 0 ; i < 4 ;i++){
int newr = r + direction[i][0];
int newc = c + direction[i][1];
dfs(g,newr,newc);
}
}
}
}
```
## Solution Iterative in the grid
```java
public static int islandPerimeter(int[][] grid) {
if (grid == null || grid.length == 0 || grid[0].length == 0) return 0;
int result = 0;
for (int i = 0; i < grid.length; i++) {
for (int j = 0; j < grid[0].length; j++) {
//calculate the right and down cell
//we can also check four directions and minus one every single time
if (grid[i][j] == 1) {
result += 4;
if (i > 0 && grid[i-1][j] == 1) result -= 2;
if (j > 0 && grid[i][j-1] == 1) result -= 2;
}
}
}
return result;
}
```
|
Ruby
|
UTF-8
| 22,424 | 3.25 | 3 |
[] |
no_license
|
#!/usr/bin/env ruby
boardwidth = 54 # board width in millimeters
boardlength = 33 # board length in millimeters
inset = 4 # screw hole distance from edges (also sets corner radii)
horizontal = true # horizontal layout
# XML class that can print itself out with indenting, attributes, and children
class Xml
def initialize(name)
@name = name # node name
@attributes = {} # hash of node attributes
@children = [] # array of node children
@text = nil # optional node text in lieu of child nodes
end
def setText(text)
@text = text
end
def addAttribute(key, value)
@attributes[key] = value
end
def addChild(child)
@children.push(child)
end
def format(level)
# build up indent string for this node
indent = ""
level.times do
indent += " "
end
# all tags begin the same way
tag = "#{indent}<#@name"
# add any attributes this node has
@attributes.each do |key, value|
tag += " #{key} = \"#{value}\""
end
if @children.length != 0
# if this node has children, print them with the indent level bumped
tag += ">\n"
for child in @children
tag += child.format(level + 1)
end
# after printing the child nodes, print this node's close tag
tag += "#{indent}</#@name>"
elsif @text
# if this node has text content, print it out along with the close tag
tag += ">#@text</#@name>"
else
# this node has no text or children, make it a self-closing tag
tag += " />"
end
# in all cases, add a newline when we're done printing this node
tag += "\n"
end
def to_s
# the to-string method simply prints out the node with zero indent
self.format(0)
end
end
# Line class for lines and traces
class Line < Xml
def initialize(layer, width, x1, y1, x2, y2)
super('wire')
self.addAttribute('x1', x1)
self.addAttribute('y1', y1)
self.addAttribute('x2', x2)
self.addAttribute('y2', y2)
self.addAttribute('width', width)
self.addAttribute('layer', layer)
end
end
# arc class for curved lines (inherits from Line and adds "curve" attribute)
class Arc < Line
def initialize(layer, width, x1, y1, x2, y2, angle)
super(layer, width, x1, y1, x2, y2)
self.addAttribute('curve', angle)
end
end
# circle class
class Circle < Xml
def initialize(layer, width, x, y, radius)
super('circle')
self.addAttribute('x', x)
self.addAttribute('y', y)
self.addAttribute('radius', radius)
self.addAttribute('width', width)
self.addAttribute('layer', layer)
end
end
# text class
class Text < Xml
def initialize(layer, size, x, y, string)
super('text')
self.addAttribute('x', x)
self.addAttribute('y', y)
self.addAttribute('size', size)
self.addAttribute('layer', layer)
self.setText(string)
end
end
# via/pad class
class Via < Xml
def initialize(x, y, extent, drill, diameter)
super('via')
self.addAttribute('x', x)
self.addAttribute('y', y)
self.addAttribute('extent', extent)
self.addAttribute('drill', drill)
self.addAttribute('diameter', diameter)
end
end
# subelement class for instantiating library items
class Element < Xml
def initialize(name, library, package, value, x, y)
super('element')
self.addAttribute('name', name)
self.addAttribute('library', library)
self.addAttribute('package', package)
self.addAttribute('value', value)
self.addAttribute('x', x)
self.addAttribute('y', y)
end
end
# vertex class for building polygons
class Vertex < Xml
def initialize(x, y)
super('vertex')
self.addAttribute('x', x)
self.addAttribute('y', y)
end
end
# rectangle class
class Rectangle < Xml
def initialize(layer, x1, y1, x2, y2)
super('rectangle')
self.addAttribute('x1', x1)
self.addAttribute('y1', y1)
self.addAttribute('x2', x2)
self.addAttribute('y2', y2)
self.addAttribute('layer', layer)
end
end
# Eagle layer description class
class Layer < Xml
def initialize(number, name, color, fill, visible, active)
super('layer')
self.addAttribute('number', number)
self.addAttribute('name', name)
self.addAttribute('color', color)
self.addAttribute('fill', fill)
self.addAttribute('visible', visible)
self.addAttribute('active', active)
end
end
# compute half width and length for center offsets
hwidth = boardwidth / 2
hlength = boardlength / 2
# build basic document hierarchy elements
eagle = Xml.new('eagle')
dwg = Xml.new('drawing')
board = Xml.new('board')
libraries = Xml.new('libraries')
elements = Xml.new('elements')
signals = Xml.new('signals')
# assemble elements into basic document hierarchy
eagle.addChild(dwg)
dwg.addChild(board)
board.addChild(libraries)
board.addChild(elements)
board.addChild(signals)
# install measurement grid values
grid = Xml.new('grid')
grid.addAttribute('distance', 0.005)
grid.addAttribute('unitdist', 'inch')
grid.addAttribute('unit', 'inch')
grid.addAttribute('altdistance', 0.001)
grid.addAttribute('altunitdist', 'inch')
grid.addAttribute('altunit', 'inch')
grid.addAttribute('style', 'lines')
grid.addAttribute('multiple', 1)
grid.addAttribute('display', 'no')
dwg.addChild(grid)
# add in drilled holes library
holes = Xml.new('library')
holes.addAttribute('name', 'holes')
libraries.addChild(holes)
packages = Xml.new('packages')
holes.addChild(packages)
# add 3mm hole package to library
package = Xml.new('package')
package.addAttribute('name', '3,0')
description = Xml.new('description')
description.setText('<b>MOUNTING HOLE</b> 3.0 mm with drill center')
package.addChild(description)
layer = 51 # tDocu
width = 2.4892
aoffset = 2.159
arc = Arc.new(layer, width, -aoffset, 0, 0, -aoffset, 90)
arc.addAttribute('cap', 'flat')
package.addChild(arc)
arc = Arc.new(layer, width, 0, aoffset, aoffset, 0, -90)
arc.addAttribute('cap', 'flat')
package.addChild(arc)
width = 0.4572
package.addChild(Circle.new(layer, width, 0, 0, 0.762))
layer = 21 # tPlace
width = 0.1524
package.addChild(Circle.new(layer, width, 0, 0, 3.429))
width = 2.032
package.addChild(Circle.new(layer, width, 0, 0, 1.6))
radius = 3.048
layer = 39 # tKeepout
package.addChild(Circle.new(layer, width, 0, 0, radius))
layer = 40 # bKeepout
package.addChild(Circle.new(layer, width, 0, 0, radius))
layer = 41 # tRestrict
package.addChild(Circle.new(layer, width, 0, 0, radius))
layer = 42 # bRestrict
package.addChild(Circle.new(layer, width, 0, 0, radius))
layer = 43 # vRestrict
package.addChild(Circle.new(layer, width, 0, 0, radius))
layer = 48 # Document
size = 1.27
package.addChild(Text.new(layer, size, -1.27, -3.81, '3,0'))
hole = Xml.new('hole')
hole.addAttribute('x', 0)
hole.addAttribute('y', 0)
hole.addAttribute('drill', 3)
package.addChild(hole)
packages.addChild(package)
# add Eagle layer descriptions
layers = Xml.new('layers')
layers.addChild(Layer.new("1", "Top", "4", "1", "yes", "yes"))
layers.addChild(Layer.new("2", "Route2", "1", "3", "no", "yes"))
layers.addChild(Layer.new("3", "Route3", "4", "3", "no", "yes"))
layers.addChild(Layer.new("4", "Route4", "1", "4", "no", "yes"))
layers.addChild(Layer.new("5", "Route5", "4", "4", "no", "yes"))
layers.addChild(Layer.new("6", "Route6", "1", "8", "no", "yes"))
layers.addChild(Layer.new("7", "Route7", "4", "8", "no", "yes"))
layers.addChild(Layer.new("8", "Route8", "1", "2", "no", "yes"))
layers.addChild(Layer.new("9", "Route9", "4", "2", "no", "yes"))
layers.addChild(Layer.new("10", "Route10", "1", "7", "no", "yes"))
layers.addChild(Layer.new("11", "Route11", "4", "7", "no", "yes"))
layers.addChild(Layer.new("12", "Route12", "1", "5", "no", "yes"))
layers.addChild(Layer.new("13", "Route13", "4", "5", "no", "yes"))
layers.addChild(Layer.new("14", "Route14", "1", "6", "no", "yes"))
layers.addChild(Layer.new("15", "Route15", "4", "6", "no", "yes"))
layers.addChild(Layer.new("16", "Bottom", "1", "1", "yes", "yes"))
layers.addChild(Layer.new("17", "Pads", "2", "1", "yes", "yes"))
layers.addChild(Layer.new("18", "Vias", "2", "1", "yes", "yes"))
layers.addChild(Layer.new("19", "Unrouted", "6", "1", "yes", "yes"))
layers.addChild(Layer.new("20", "Dimension", "15", "1", "yes", "yes"))
layers.addChild(Layer.new("21", "tPlace", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("22", "bPlace", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("23", "tOrigins", "15", "1", "yes", "yes"))
layers.addChild(Layer.new("24", "bOrigins", "15", "1", "yes", "yes"))
layers.addChild(Layer.new("25", "tNames", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("26", "bNames", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("27", "tValues", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("28", "bValues", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("29", "tStop", "7", "3", "no", "yes"))
layers.addChild(Layer.new("30", "bStop", "7", "6", "no", "yes"))
layers.addChild(Layer.new("31", "tCream", "7", "4", "no", "yes"))
layers.addChild(Layer.new("32", "bCream", "7", "5", "no", "yes"))
layers.addChild(Layer.new("33", "tFinish", "6", "3", "no", "yes"))
layers.addChild(Layer.new("34", "bFinish", "6", "6", "no", "yes"))
layers.addChild(Layer.new("35", "tGlue", "7", "4", "no", "yes"))
layers.addChild(Layer.new("36", "bGlue", "7", "5", "no", "yes"))
layers.addChild(Layer.new("37", "tTest", "7", "1", "no", "yes"))
layers.addChild(Layer.new("38", "bTest", "7", "1", "no", "yes"))
layers.addChild(Layer.new("39", "tKeepout", "4", "11", "yes", "yes"))
layers.addChild(Layer.new("40", "bKeepout", "1", "11", "yes", "yes"))
layers.addChild(Layer.new("41", "tRestrict", "4", "10", "yes", "yes"))
layers.addChild(Layer.new("42", "bRestrict", "1", "10", "yes", "yes"))
layers.addChild(Layer.new("43", "vRestrict", "2", "10", "yes", "yes"))
layers.addChild(Layer.new("44", "Drills", "7", "1", "no", "yes"))
layers.addChild(Layer.new("45", "Holes", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("46", "Milling", "3", "1", "no", "yes"))
layers.addChild(Layer.new("47", "Measures", "7", "1", "no", "yes"))
layers.addChild(Layer.new("48", "Document", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("49", "Reference", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("50", "dxf", "7", "1", "no", "yes"))
layers.addChild(Layer.new("51", "tDocu", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("52", "bDocu", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("53", "tGND_GNDA", "7", "9", "no", "no" ))
layers.addChild(Layer.new("54", "bGND_GNDA", "1", "9", "no", "no" ))
layers.addChild(Layer.new("56", "wert", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("91", "Nets", "2", "1", "no", "no" ))
layers.addChild(Layer.new("92", "Busses", "1", "1", "no", "no" ))
layers.addChild(Layer.new("93", "Pins", "2", "1", "no", "no" ))
layers.addChild(Layer.new("94", "Symbols", "4", "1", "no", "no" ))
layers.addChild(Layer.new("95", "Names", "7", "1", "no", "no" ))
layers.addChild(Layer.new("96", "Values", "7", "1", "no", "no" ))
layers.addChild(Layer.new("97", "Info", "7", "1", "no", "no" ))
layers.addChild(Layer.new("98", "Guide", "6", "1", "no", "no" ))
layers.addChild(Layer.new("100", "Muster", "7", "1", "no", "no" ))
layers.addChild(Layer.new("101", "Patch_Top", "12", "4", "yes", "yes"))
layers.addChild(Layer.new("102", "Vscore", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("103", "fp3", "7", "1", "no", "yes"))
layers.addChild(Layer.new("104", "Name", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("105", "Beschreib", "9", "1", "yes", "yes"))
layers.addChild(Layer.new("106", "BGA-Top", "4", "1", "yes", "yes"))
layers.addChild(Layer.new("107", "BD-Top", "5", "1", "yes", "yes"))
layers.addChild(Layer.new("108", "fp8", "7", "1", "no", "yes"))
layers.addChild(Layer.new("109", "fp9", "7", "1", "no", "yes"))
layers.addChild(Layer.new("110", "fp0", "7", "1", "no", "yes"))
layers.addChild(Layer.new("111", "LPC17xx", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("112", "tPlaceRed", "12", "1", "yes", "yes"))
layers.addChild(Layer.new("113", "tPlaceBlue", "9", "1", "yes", "yes"))
layers.addChild(Layer.new("116", "Patch_BOT", "9", "4", "yes", "yes"))
layers.addChild(Layer.new("121", "_tsilk", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("122", "_bsilk", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("123", "tTestmark", "7", "1", "no", "yes"))
layers.addChild(Layer.new("124", "bTestmark", "7", "1", "no", "yes"))
layers.addChild(Layer.new("125", "_tNames", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("126", "_bNames", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("127", "_tValues", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("128", "_bValues", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("131", "tAdjust", "7", "1", "no", "yes"))
layers.addChild(Layer.new("132", "bAdjust", "7", "1", "no", "yes"))
layers.addChild(Layer.new("144", "Drill_legend", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("151", "HeatSink", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("152", "_bDocu", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("199", "Contour", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("200", "200bmp", "1", "10", "yes", "yes"))
layers.addChild(Layer.new("201", "201bmp", "2", "1", "no", "no" ))
layers.addChild(Layer.new("202", "202bmp", "3", "1", "no", "no" ))
layers.addChild(Layer.new("203", "203bmp", "4", "10", "yes", "yes"))
layers.addChild(Layer.new("204", "204bmp", "5", "10", "yes", "yes"))
layers.addChild(Layer.new("205", "205bmp", "6", "10", "yes", "yes"))
layers.addChild(Layer.new("206", "206bmp", "7", "10", "yes", "yes"))
layers.addChild(Layer.new("207", "207bmp", "8", "10", "yes", "yes"))
layers.addChild(Layer.new("208", "208bmp", "9", "10", "yes", "yes"))
layers.addChild(Layer.new("209", "209bmp", "7", "1", "no", "yes"))
layers.addChild(Layer.new("210", "210bmp", "7", "1", "no", "yes"))
layers.addChild(Layer.new("211", "211bmp", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("212", "212bmp", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("213", "213bmp", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("214", "214bmp", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("215", "215bmp", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("216", "216bmp", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("217", "217bmp", "18", "1", "no", "no" ))
layers.addChild(Layer.new("218", "218bmp", "19", "1", "no", "no" ))
layers.addChild(Layer.new("219", "219bmp", "20", "1", "no", "no" ))
layers.addChild(Layer.new("220", "220bmp", "21", "1", "no", "no" ))
layers.addChild(Layer.new("221", "221bmp", "22", "1", "no", "no" ))
layers.addChild(Layer.new("222", "222bmp", "23", "1", "no", "no" ))
layers.addChild(Layer.new("223", "223bmp", "24", "1", "no", "no" ))
layers.addChild(Layer.new("224", "224bmp", "25", "1", "no", "no" ))
layers.addChild(Layer.new("248", "Housing", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("249", "Edge", "7", "1", "yes", "yes"))
layers.addChild(Layer.new("250", "Descript", "7", "1", "no", "no" ))
layers.addChild(Layer.new("251", "SMDround", "7", "1", "no", "no" ))
layers.addChild(Layer.new("254", "cooling", "7", "1", "yes", "yes"))
dwg.addChild(layers)
# add "plain" board element to hold board features
plain = Xml.new('plain')
board.addChild(plain)
# minus signs for negative power buses
layer = 21 # tPlace
width = 0.4064
#plain.addChild(Line.new(layer, width, -33.528, 23.876, -33.528, 22.606))
#plain.addChild(Line.new(layer, width, 33.528, 23.876, 33.528, 22.606))
#plain.addChild(Line.new(layer, width, -33.528, -16.764, -33.528, -18.034))
#plain.addChild(Line.new(layer, width, 33.528, -16.764, 33.528, -18.034))
# plus signs for positive power buses
size = 2.54
#plain.addChild(Text.new(layer, size, -34.544, -24.638, '+'))
#plain.addChild(Text.new(layer, size, 32.512, -24.638, '+'))
#plain.addChild(Text.new(layer, size, 32.512, 16.002, '+'))
#plain.addChild(Text.new(layer, size, -34.798, 16.002, '+'))
# row numbers
x = -37.338
y1 = 15.24
y2 = -16.256
size = 1.016
30.times do |row|
#plain.addChild(Text.new(layer, size, x, y1, row))
#plain.addChild(Text.new(layer, size, x, y2, row))
x += 2.54
end
# no solder mask on back
layer = 30 # bStop
plain.addChild(Rectangle.new(layer, -hwidth, -hlength, hwidth, hlength))
# board outline
layer = 20 # Dimension
width = 0.127
plain.addChild(Arc.new(layer, width, hwidth, hlength - inset, hwidth - inset, hlength, 90))
plain.addChild(Line.new(layer, width, hwidth - inset, hlength, -hwidth + inset, hlength))
plain.addChild(Arc.new(layer, width, hwidth - inset, -hlength, hwidth, -hlength + inset, 90))
plain.addChild(Line.new(layer, width, hwidth, -hlength + inset, hwidth, hlength - inset))
plain.addChild(Arc.new(layer, width, -hwidth + inset, hlength, -hwidth, hlength - inset, 90))
plain.addChild(Line.new(layer, width, hwidth - inset, -hlength, -hwidth + inset, -hlength))
plain.addChild(Arc.new(layer, width, -hwidth, -hlength + inset, -hwidth + inset, -hlength, 90))
plain.addChild(Line.new(layer, width, -hwidth, -hlength + inset, -hwidth, hlength - inset))
# mounting holes
elements.addChild(Element.new('H1', 'holes', '3,0', 'MOUNT-HOLE3.0', hwidth - inset, hlength - inset))
elements.addChild(Element.new('H2', 'holes', '3,0', 'MOUNT-HOLE3.0', -hwidth + inset, hlength - inset))
elements.addChild(Element.new('H3', 'holes', '3,0', 'MOUNT-HOLE3.0', hwidth - inset, -hlength + inset))
elements.addChild(Element.new('H4', 'holes', '3,0', 'MOUNT-HOLE3.0', -hwidth + inset, -hlength + inset))
# draw pads and traces
nholes = 5
npg = 2
gap = 1
if horizontal
prows = 3
extrarows = 0
space = boardwidth - (2 * (inset + 3))
else
prows = 2
extrarows = 1
space = boardlength - (2 * (inset + 1.5))
end
pitch = 0.1 * 25.4
nrows = (space / pitch).to_i
startrow = (nrows - 1) / 2.0 # coerce to floating point to avoid truncation
if horizontal
x = startrow * pitch
ty = (nholes + (gap / 2.0)) * pitch # also coerce to floating point
by = -ty
else
y = startrow * pitch
rx = (nholes + (gap / 2.0)) * pitch # also coerce to floating point
lx = -rx
end
$net = 1
layer = 16 # Bottom
width = 0.4064
# draw a line of pads with traces linking them
def makelink(layer, width, x, y, xincr, yincr, n)
signal = Xml.new('signal')
signal.addAttribute('name', "N$#{$net}")
n.times do |hole|
curx = x + (hole * xincr)
cury = y + (hole * yincr)
signal.addChild(Via.new(curx, cury, '1-16', 1.2, 1.9304))
if hole != 0
signal.addChild(Line.new(layer, width, curx, cury, curx - xincr, cury - yincr))
end
end
$net += 1
return signal
end
# two sets of parallel lines of connected pads
(nrows + extrarows).times do |count|
if horizontal
topskip = 2
bottomskip = 1
signals.addChild(makelink(layer, width, x, ty - (topskip * pitch), 0, -pitch, 3))
signals.addChild(makelink(layer, width, x, by + (bottomskip * pitch), 0, pitch, 4))
x -= pitch
else
signals.addChild(makelink(layer, width, lx, y, pitch, 0, nholes))
signals.addChild(makelink(layer, width, rx, y, -pitch, 0, nholes))
y -= pitch
end
end
# connected pads for power buses
if horizontal
x = startrow * pitch
else
y = (startrow - 1) * pitch
end
npg.times do |count|
if horizontal
# one pair of power buses between the parallel traces
signals.addChild(makelink(layer, width, x, pitch/2 - (pitch * count), -pitch, 0, nrows))
else
# two pairs of power buses outside the parallel traces
signals.addChild(makelink(layer, width, lx + (count - npg) * pitch, y, 0, -pitch, nrows - 2))
signals.addChild(makelink(layer, width, rx - (count - npg) * pitch, y, 0, -pitch, nrows - 2))
end
end
# unconnected pads for further prototyping area
prows.times do |prow|
if horizontal
6.times do |rank|
signals.addChild(makelink(layer, width, x - (prow - 3) * pitch, ty - (rank + 3) * pitch, pitch, pitch, 1))
signals.addChild(makelink(layer, width, -x + (prow - 3) * pitch, ty - (rank + 3) * pitch, pitch, pitch, 1))
end
else
(nrows - 2).times do |row|
signals.addChild(makelink(layer, width, lx - (npg + prow + 1) * pitch, y - row * pitch, pitch, pitch, 1))
signals.addChild(makelink(layer, width, rx + (npg + prow + 1) * pitch, y - row * pitch, pitch, pitch, 1))
end
end
end
# box for badge owner's name
layer = 21 # tDocu
hrwidth = hwidth - (inset + 3)
plain.addChild(Rectangle.new(layer, -hrwidth, hlength - 0.5, hrwidth, hlength - inset - 1.5))
# Brunswick Hackerspace text
label = 'Brunswick Hackerspace'
size = 2
plain.addChild(Text.new(layer, size, -(hrwidth - 2), -hlength + 1, label))
# Brunswick Hackerspace logo (dimensions from Lisa Horne Cook's design)
logosize = 1.4 # scaling factor to fit nicely
logowidth = 26.6 * logosize
logoheight = 10.1 * logosize
logoflex = 6.1 * logosize
logotop = hlength - 6
width = 0.4064
hlogowidth = logowidth / 2.0
polygon = Xml.new('polygon')
polygon.addAttribute('layer', layer)
polygon.addAttribute('width', width)
polygon.addChild(Vertex.new(-hlogowidth, logotop))
polygon.addChild(Vertex.new(0, logotop - logoflex))
polygon.addChild(Vertex.new(hlogowidth, logotop))
polygon.addChild(Vertex.new(hlogowidth, logotop - logoheight))
polygon.addChild(Vertex.new(0, logotop - (logoheight + logoflex)))
polygon.addChild(Vertex.new(-hlogowidth, logotop - logoheight))
plain.addChild(polygon)
# print out finished XML document
print "<?xml version = \"1.0\" encoding = \"UTF-8\" ?>\n"
print "<!DOCTYPE eagle SYSTEM \"eagle.dtd\">\n"
print eagle.to_s
|
Shell
|
UTF-8
| 1,369 | 2.71875 | 3 |
[] |
no_license
|
#!/bin/sh
export subject_dir=nanoxml_v5
export version=3
echo copying to coverage_info
cp -r ${subject_dir}/result/v${version}/componentinfo.txt Coverage_Info
cp -r ${subject_dir}/result/v${version}/covMatrix.txt Coverage_Info
cp -r ${subject_dir}/result/v${version}/error.txt Coverage_Info
echo excuting python CAN.py
python CAN.py dev
echo moving DL_result.txt to result
mv Coverage_Info/DL_result.txt ${subject_dir}/result/v${version}
echo compiling DL.c
gcc -o ${subject_dir}/DL ${subject_dir}/analysePro/DL.c
cd ${subject_dir}
echo excuting DL.c
./DL result/v${version}/componentinfo.txt result/v${version}/DL_result.txt
rm -f DL
echo moving DeepLearning.txt to result
mv DeepLearning.txt result/v${version}/DL_result
echo excuting sliceDL.c
gcc -o sliceDL analysePro/sliceDL.c
./sliceDL result/v${version}/componentinfo.txt result/v${version}/DL_result.txt sliceResult/v${version}/sliceResult.txt
rm -f sliceDL
echo moving SliceDeepLearning.txt to result
mv SliceDeepLearning.txt result/v${version}/DL_result
cd ..
echo get final result
cp -r analysePro/translate translate
chmod u+x translate
./translate ${subject_dir}/result/v${version}/DL_result/DeepLearning.txt ${subject_dir}/result/v${version}/DL_result/SliceDeepLearning.txt
rm -f translate
rm -f Coverage_Info/componentinfo.txt
rm -f Coverage_Info/covMatrix.txt
rm -f Coverage_Info/error.txt
|
Python
|
UTF-8
| 461 | 2.84375 | 3 |
[] |
no_license
|
def binar():
for A in range(8):
if A&4==0: continue
for B in range(8):
if B&2==1: continue
for C in range(8):
if C&1==0: continue
X=(A&4)+((B&4)>>1)+((C&4)>>2)
Y=((A&2)<<1)+(B&2)+((C&2)>>1)
Z=((A&1)<<2)+((B&1)<<1)+(C&1)
if A==~Z&7 and B==X&C and Y==X | Z:
print(A,B,C,X,Y,Z)
print(binar())
|
Java
|
UTF-8
| 5,596 | 2.75 | 3 |
[] |
no_license
|
package com.musala.simple.students.spring.web.helper;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.google.gson.Gson;
import com.musala.simple.students.spring.web.database.AbstractDatabase;
import com.musala.simple.students.spring.web.database.DatabaseFactory;
import com.musala.simple.students.spring.web.database.DatabaseType;
import com.musala.simple.students.spring.web.exception.StudentNotFoundException;
import com.musala.simple.students.spring.web.internal.ErrorMessage;
import com.musala.simple.students.spring.web.student.Student;
import com.musala.simple.students.spring.web.student.StudentDataPrinter;
import com.musala.simple.students.spring.web.student.StudentGroup;
import com.musala.simple.students.spring.web.student.StudentWrapper;
/**
* This is a helper class for performing predefined actions on a database and
* output information on the console for the benefit of the user.
*
* @author yoan.petrushinov
*
*/
public class DbHelper {
private static final String DEFAULT_DB_NAME = "studentsDb";
private static final String DEFAULT_DB_PORT = "27017";
private static final String DEFAULT_DB_HOST = "localhost";
private static final String DEFAULT_DB_USERNAME = "admin";
private static final String DEFAULT_DB_PASSWORD = "admin";
private static final String DB_NAME = "name";
private static final String DB_PORT = "port";
private static final String DB_HOST = "host";
private static final String DB_USER = "username";
private static final String DB_PASSWORD = "password";
private static Logger logger = LoggerFactory.getLogger(DbHelper.class);
private DbHelper() {
}
/**
* Performs predefined actions using a .json file provided as user input
* and returning different outputs to the console for the benefit of the user.
*
* @param args
* arguments array provided by the user as input on the command line
* database
* an implementation of the AbstractDatabase class
*/
public static void performDatabaseActions(String[] args, AbstractDatabase database) {
logger.info("\n\nCurrently working with " + database.getClass().getSimpleName() + "\n\n");
if (ValidationHelper.isInputValid(args)) {
String studentsJsonInfo = FileHelper.readFile(args[0]);
if (!ValidationHelper.isValidJson(studentsJsonInfo)) {
logger.warn(ErrorMessage.NOT_VALID_JSON);
Student[] students = database.getAllStudentsArr();
StudentDataPrinter.printStudents(students);
} else {
StudentWrapper studentWrapper = new Gson().fromJson(studentsJsonInfo, StudentWrapper.class);
StudentGroup studentGroup = new StudentGroup();
studentGroup.fillStudentGroup(studentWrapper.students);
Map<Integer, Student> studentsMap = studentGroup.getStudents();
List<Student> studentsList = new ArrayList<Student>(studentsMap.values());
database.addMultipleStudents(studentsList);
if (ValidationHelper.validUserDetailsRequest(args)) {
int studentId = Integer.parseInt(args[1]);
try {
// Look for the student in the Student Group
Student student = studentGroup.getStudentById(studentId);
StudentDataPrinter.printStudentDetails(student);
} catch (StudentNotFoundException snfe) {
logger.warn(ErrorMessage.STUDENT_NOT_FOUND);
try {
Student student = database.getStudentById(studentId);
StudentDataPrinter.printStudentDetails(student);
} catch (StudentNotFoundException e) {
logger.warn(e.getMessage());
StudentDataPrinter.printStudents(studentsList);
}
}
} else {
StudentDataPrinter.printStudents(studentsList);
}
}
} else {
Student[] students = database.getAllStudentsArr();
if (students.length == 0) {
logger.info(ErrorMessage.DATABASE_EMPTY);
} else {
StudentDataPrinter.printStudents(students);
}
}
}
/**
* Creates a new instance of an implementation of the {@link AbstractDatabase} class.
*
* @param dbType
* The type of database implementation to be initialized (e.g. Mongo, MySql)
* @return database The new instance of the database initialized.
*/
public static AbstractDatabase initializeDatabase(DatabaseType dbType) {
Properties dbProperties = FileHelper.readDbPropertiesFile(dbType);
AbstractDatabase database = DatabaseFactory.createDatabase(dbType)
.withName(dbProperties.getProperty(DB_NAME, DEFAULT_DB_NAME))
.withHost(dbProperties.getProperty(DB_HOST, DEFAULT_DB_HOST))
.withPort(dbProperties.getProperty(DB_PORT, DEFAULT_DB_PORT))
.withUsername(dbProperties.getProperty(DB_USER, DEFAULT_DB_USERNAME))
.withPassword(dbProperties.getProperty(DB_PASSWORD, DEFAULT_DB_PASSWORD)).build();
database.establishConnection();
return database;
}
}
|
Python
|
UTF-8
| 1,118 | 2.640625 | 3 |
[] |
no_license
|
import os #Main Menu
def mainMenu():
os.system("tput setaf 1")
print("""
\t 1 : Basic Operation
\t 2 : Package Management
\t 3 : User Management
\t 4 : Networking
\t 5 : Permissions
\t 6 : Services Management
\t 7 : Use Docker Management
\t 8 : AWS Management
\t 9 : Ansible Management
\t 10 : Hadoop Management
\t 10 : LVM Management
\t 11 : exit
""")
os.system("tput setaf 7")
def selection():
os.system("tput setaf 1")
print("""
1. Your System
2. Remote System
3. Exit
""")
os.system("tput setaf 7")
def per_opt() :
print("""
for read permission press r
for write permission press w
for execute/run permission press x
for both read and write press rw
and so on
""")
|
C
|
UTF-8
| 1,385 | 3.015625 | 3 |
[] |
no_license
|
/*======================================================
> File Name: write.c
> Author: lyh
> E-mail:
> Other :
> Created Time: 2016年03月20日 星期日 19时41分56秒
=======================================================*/
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/ipc.h>
#include<sys/shm.h>
#include<errno.h>
#include<string.h>
#define SHM_SIZE 1024
int main()
{
int shmid;
char *shmaddr;
char write_str[SHM_SIZE];
key_t shmkey;
//获取关键字
if((shmkey = ftok(".",'m'))==-1)
{
perror("ftok error!\n");
return -1;
}
//创建或获取共享内存
if((shmid = shmget(shmkey,SHM_SIZE,IPC_CREAT | 0666))==-1)
{
perror("shmget call failed.\n");
return -1;
}
//将共享内存与进程连接
if((shmaddr = shmat(shmid,(char*)0,0)) == (char*)-1)
{
perror("attach shared memory error!\n");
return -1;
}
//写数据3次
int i=3;
while(i)
{
printf("write: ");
scanf("%s",write_str);
int len = strlen(write_str);
write_str[len] = '\0';
strcpy(shmaddr,write_str);
sleep(10);
i--;
}
//与共享内存断开连接
if(shmdt(shmaddr) == 0)
{
printf("quit\n");
}
return 0;
}
|
Markdown
|
UTF-8
| 7,111 | 2.609375 | 3 |
[] |
no_license
|
# three js
# 1. 添加材质和灯光
* new THERE.SpotLight()创建光源,
* spotLight.position.set()设置光源位置
* scene.add(spotlight) 场景中加入光源
* 添加阴影-阴影效果会浪费较多资源, 一般默认不添加阴影: renderer.shadowMap.enabled = true; 默认false;
* 对平面添加阴影: plane.receiveShadow = true
* 对立方体添加阴影: cube.castShadow = true;
* 打开球体阴影: sphere.castShadow = true;
* 指定阴影可以生成光源spotLight.castShadow = true;
# 2. threejs的动画效果
* requestAnimationFrame进行动画实现
* 可以引入threejs自带开发的辅助库stats.min.js, 进行动画的辅助开发;
* 方块的转动rotation的动画控制 弹跳球position控制Math.sin及Math.cos
# 2. 场景
* 创建场景: 相机 + 光源 + 物体;
* 相机: 决定哪些东西将被显示在屏幕上
* 光源: 生成阴影与改变物体表面显示效果
* 物体: 相机透视图里主要的渲染对象
* 场景的基本功能: scene.add()场景中添加物体; scene.remove()场景中移除物体; scene.children()获取场景中所有子对象的列表; scene.getChildByName()获得场景中所有对象的列表;
* fog通过该属性可以设置场景的雾化效果: scene.fog = new THREE.Fog(颜色, 近距离0.05, 雾化远距离1000);
* overrideMaterial 通过这个属性可以让场景中的所有物体都使用相同材质=> scene.overrideMaterial = new THREE.MeshLambertMaterial({color: 0xff55dd});
# 2. 几何和网格对象
* THREE.Geometry是所有集合对象的基类(简称geom);
* geom.vertices表示几何体的顶点, 是一个数组; geom.faces表示几何体的侧面;
* 网格对象的属性position决定该对象相对于父对象的位置
* 网格对象属性rotation设置对象绕任何一个轴的旋转弧度
* 网格对象属性scale为沿x, y, z缩放对象
* 网格对象属性translateX: x轴平移; translateY: y轴平移; translateZ: z轴平移:
# 3. 相机
* 定义三维空间向二位显示器的投影方式: 透视投影(近大远小-实际场景较多)摄像机, 正交投影(数学理论投影-常用展示效果场景较多)摄像机
* 正交投影照相机THREE.OrthographicCamera(left, rigth, top, bottom, near, far);为了保持显示比例,常见用相机宽高比例与canvas宽高比例应该保持一致。near经常设置很小,far设置很大,以保证图形不会被忽略
* left左边界, right右边界, top上边界, bottom下边界, near近裁面, far远裁面
* camera.lookAt 设置目标点
* 透视投影照相机THREE.PerspectiveCamera(fov张角-视野宽度推荐45°,aspect长宽比-推荐window/innerWidth/widow.innerHeight,near最近距离推荐0.1,far最远距离-应该远大于near推荐1000, 值太大影响性能, 值太小场景显示不全);
*
# 4. 认识光源
* AmbientLight环境光-基础光源, 影响整个场景;
* PointLight点光源-空间中的一个点, 所有方向发射光源;
* SpotLight聚光灯-具有锥形效果的聚光光源;
* DirectionalLight平行光 - 无限光,模拟远处太阳的光源;
* 高级光照效果-半球光(模拟自然), 平面光(指定散发光源的平面), 镜头眩光(为光源添加眩光效果);
* AmbientLight没有明确的光源位置, 在各处形成的亮度一致, 且不会影响阴影的产生; 不能讲环境光作为场景中的唯一光源 => THREE.AmbientLight(hex); add(color); clone();
* PointLight点光源-单点发光照射所有方向, 不会产生阴影, 减少GPU负担, 亮度线性递减; THREEE.PointLight(hex, intensity-光照强度默认1, distance-光源的照射距离默认0); clone(), color光源颜色;
* SpotLight聚光灯光源(锥形光)-是最常用的可以产生阴影的光源, 类似电筒光照效果; THREE.SpotLight(hex, intensity, distance, angle, exponent), castShadow属性设置为true则产生阴影; target决定光照方向, angle光照角度默认为Math.PI / 3;
* DirectionalLight 平行光(方向光~太阳光), 方向光光照强度不变; 常用属性castShadow, target, angle; 不常用属性shadowCameraVisible,shadowCameraFar-阴影近距点, shadowDarkness-阴影, shadowMapWidth-阴影宽高, shadowMapHeight等;
* 高级光照效果-半球光光源: THREE.HemisphereLight(hex, intensity); groundColor从地面发出的光线的颜色, Color从天空中发出的光线的颜色, intensity光线照射的强度;
* 高级光照效果-平面光光源THREE.AreaLight-扩展库提供的效果-效果比较复杂, 性能要求较高: 不能使用THREE.WebGLRenderer()需要使用THREE.WebGLDeferedRenderer() (引入);
* 镜头眩光 THREE.LensFlare(texture, size像素, distance距离, blending融合模式, color)进行添加即可; 在threejs官方demo中, texture文件可以查看部分的眩光位图。
# 5. 认识材质Material
* 材质:决定几何体外表的样式,独立于物体顶点信息之外的与渲染效果相关的属性; 基础材质/深度材质/法向材质/网格面材质/郎伯材质/Phong式材质/着色器材质;
* 理解材质共有属性: THREE.Material基类, 基础属性/融合属性/高级属性;
* 基础属性: id标识符; name赋予材质名称; opacity透明度, transparent是否透明, overdraw过度描绘, visible是否可见, side决定属性在几何体哪个面应用-默认frontside前面; needsUpdate是否刷新;
* 融合属性: blending融合, blenders融合源, blandest融合目标, blending equation融合公式; 指定物体如何与背景进行融合
* 高级属性: depthTest深度测试; depthWrite内部属性, alphaTest决定像素是否展示; ploygonOffset/ploygonOffsetFactor/ploygonOffsetUnits
* MeshBasicMaterial 基础材质-不受光照影响, 被渲染成简单的多边形, 可以显示几何体的线框; 属性color, wireframe-bool显示线框, fog是否受全局雾化效果影响;
* 深度材质: 外观不由光照和材料决定, 由物体到相机的距离决定; 可以与其他材质结合; 属性wireframe是否展示线框, writeframeLinewidth;
* 联合材质: THREE.SceneUtils.createMultiMaterialObject联合多个材质, 产生综合渲染效果
* 法向材质: MeshNormalMaterial通过法向计算颜色, 法向量是与面垂直;属性shading着色方法, wireframe
* 网格面材质: MeshFaceMaterial可以为材质容器的每个面指定材质; 创建一个材质数组mets, 利用new THREE.MeshFaceMaterial(mets)进行材质添加。
* 高级材质: MeshLambertMaterial材质-用于暗淡不光亮表面, MeshPhongMaterial材质用于光亮(金属)表面; MeshLambertMaterial材质(color堆散射光的反射能力, ambient对环境光的反射能力, emissive材质自发光颜色); MeshPhongMaterial材质(ambient对环境光的反射能力, emissive材质自发光颜色, specular材质的光亮程度);
# 6. 几何体-二维/三维/多面
* 二维几何体
********
二维矩形PlaneGeometry; THREE.PlaneGeometry(width宽, height高, widthSegments宽度段数, heightSegments高度段数);
二维圆属性CircleGeometry: THREE.CircleGeometry(radius半径, segments面数量-段数默认8, start圆起始位置, length圆有多大);
********
*
*
*
|
Markdown
|
UTF-8
| 5,836 | 3.140625 | 3 |
[] |
no_license
|
###The Council of Librarians
####Problem:
The Decentralized Library of Alexandria is designed to avoid all central points of failure. The application itself is able to do this by relying on decentralized technology, but there still exists a central point of failure in the entity responsible for its future development.
####Proposed Solution:
An open source, encrypted peer-to-peer communication mechanism and a blockchain token that together allow users all around the world to participate in the management and future development of Alexandria in a decentralized, collaborative manner.
####Summary Overview
A group of ~10 individuals is elected by all holders of the token to serve as the day-to-day managers of the development and marketing efforts for Alexandria. They communicate with each other via a P2P chat room in which only they can participate, but anyone in the world can observe. Normal day to day decision-making power is granted to the Chief Librarian, elected by all holders of the token. If the Chief Librarian or the Council of Librarians deem that a topic should be voted on by all token-holders, a vote will be held.
A second chat room shall also be made available for public discussion - users can pin things said by the management group into the public chat room so that they can comment and discuss decisions made by the management group. If a member of the public feels that a decision made by the management team should be challenged, they can propose a vote on the topic. If enough token holders second the vote, the vote is held by all holders of the token. Votes are made by sending tokens to oneself with their vote included in the transaction as a tx-comment. A “Living Articles of Organization” document will be drafted which contains all of the rules for voting, a description of how day to day decisions are handled, the maximum amounts that financial decisions must be below in order to be made without a vote and the minimum quorum needs for decisions of various types; ie, the decision to award a development bounty to a developer who submits some code may only require a 15% quorum of token holders, but the decision to change the priority of feature development may require a 50% quorum of token holders. Each article of the constitution, and all sections and sub-sections in it can be amended by vote.
The target number of members on the Council of Librarians is determined by popular vote, and from it is extracted a minimum number of tokens that a user must either personally own or have proxied to them by other users (more info on this in the Elections process section below) to be on the Council. For example, to have 10 users on the Council of Librarians, a minimum amount of 9% of the total tokens must be controlled by each user.
####Voting Process
When it has been decided that a vote will be held, the token-holder who requested the vote will publish the question to be voted upon by sending a transaction to themselves with a tx-comment in the following format:
{ "alexandria-proposal" : { "alexandria-vote-name": "[name for topic to be voted on]",
"question": "[question to be decided]", "responses": "[possible response1],[possible response2]",
"quorum": "[# of token-votes req’d to meet quorum]", "polls-open":
"[timestamp when votes will begin to be counted]", "polls-close":
"[deadline for votes to be cast]" } }
Token-holders then submit their votes by sending their tokens to themselves with a tx-comment in the following format:
{ "alexandria-ballot" : { "alexandria-proposal" : "[txid of the TX containing the alexandria-proposal
to be voted on]", "vote": "[chosen response]" } }
####Elections Process
Elections for the Council of Librarians works by users holding some amount of tokens who wish to chose a “representative” or proxy their voting rights to another user sending a tx-comment to themselves in one of the following formats:
{ "alexandria-election" : { "[representative]": "[address of chosen candidate]" } }
Doing this announces the users wish to proxy their day to day decision making ability to another user, but they retain the right to vote for themselves whenever votes are held.
{ "alexandria-election" : { "[vote-proxy]": "[address of chosen candidate]" } }
Doing this announces the users wish to proxy their voting power to the chosen person.
Of particular note, this mechanism should avoid the problems often encountered in “representative democracies” by making it an extremely simple process to un-elect members from the Council if they are making choices that do not reflect the wishes of their constituents (the user base). All they must do is send another message in the same format and either enter their own address or another candidates address.
####Living Articles of Organization
A living AoO will be drafted which contains all of the rules for voting, a description of how day to day decisions are handled, the the maximum amounts that financial decisions must be below in order to be made without a vote and the minimum quorum needs for decisions of various types. Each article of the constitution, and all sections and sub-sections in it can be amended by vote.
####Blockchain Properties
TBD coins, all issued at genesis block.
Considering a mix of NXT assets, XCP assets & Bitshares assets to ensure long term redundancy (if POS turns out to simply be unscalable (or too vulnerable to attack at scale) and NXT goes to 0, BTX and BTS are unaffected, if BTC goes to 0, so does NXT's POW, but NXT & POS are are unaffected, and so on)
Voting tokens should either be free or have a cost payable in another token only. If a user must exhaust their ownership in order to share their voice, that's no good.
Blockchain voting: X% share of tokens = X% of vote
|
Markdown
|
UTF-8
| 2,219 | 2.6875 | 3 |
[] |
no_license
|
---
layout: post
title: "Connect TomTom Runner to Vitality Health"
permalink: "/blog/connect-your-tomtom-runner-to-vitality/"
date: 2018-04-08 13:00:00 +0000
categories: blog
author: Adam Moss
comments: true
body_class: blog
reading-time: 5 mins
photo: "/assets/featured/sync.png"
---

As a precursor I should mention that the solution I'm describing in this post is for an Apple iPhone, however it could easily be done in a similar fashion on an Android with the equivalent of Apple Health.
Choosing a sports/activity watch took a lot of research on my part. As someone who uses Nike+ and Strava to record runs and cycles I was adamant that my watch would send its data to those apps so I didn't lose my historical data. The answer to this conundrum was a TomTom Runner 3 GPS watch, which has been great ever since I started wearing it.
Then, earlier this year my private healthcare was switched to Vitality, a company that has a big emphasis on your day to day fitness via tracking, which all sounds great except that it's long list of integrations doesn't include TomTom! That's right, your Garmin, FitBit, Apple Watch and Polar devices all connect except for TomTom.
I asked TomTom and Vitality via Twitter if they had any intentions of creating a connection in the future and the answer was a resounding "no". In order to get around this I realised that if I can get my data from TomTom Sports into Apple Health then Vitality can in turn get the data from Apple Health.
I signed up to https://www.fitnesssyncer.com which allows you to create a source (TomTom Sports) and a destination (Apple Health) and bingo, the data is now moving across the apps and Vitality no longer thinks I sit on my arse all day (which I suppose I do a lot of anyway).
## How to do it
1. First, make sure you've downloaded the TomTom Sports app to your phone and that your watch is correctly synced up.
2. Second, download the Vitality app (for iPhone & Android), go to Settings > Synce Apple Health Data and choose how much data to sync.
3. Third, create an account on https://www.fitnesssyncer.com, download the app and create a 'Source' from TomTom Sport and a 'Destination' to Apple Health
|
C#
|
UTF-8
| 362 | 2.578125 | 3 |
[
"MIT"
] |
permissive
|
using System;
namespace Tweezers.Schema.Exceptions
{
public sealed class ItemNotFoundException : Exception
{
private string Id { get; set; }
public ItemNotFoundException(string id = null)
{
Id = id ?? string.Empty;
}
public override string Message => $"Could not find item with ID={Id}";
}
}
|
C#
|
UTF-8
| 1,868 | 3.890625 | 4 |
[] |
no_license
|
///Anton Brottare 13/9-2017
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace PetApplication
{
class Pet
{
/// Declaring the variables that will be used
private string name;
private int age;
private bool isFemale;
/// Start method + greeting
public void start()
{
Console.WriteLine();
Console.WriteLine("Greetings from a pet Object!");
Console.WriteLine();
ReadAndSavePetData();
DisplayPetInfo();
}
/// Method for input
public void ReadAndSavePetData()
{
Console.Write("What is the name of your pet? ");
name = Console.ReadLine();
Console.Write("How old is " + name + "? ");
age = int.Parse(Console.ReadLine());
Console.Write("Is " + name + " female (y/n)? ");
char response = char.Parse(Console.ReadLine());
/// The if statement determines the gender of the
/// pet depending on the input from the user.
if ((response == 'y' || response == 'Y'))
isFemale = true;
else
isFemale = false;
}
/// Method for displaying the information back to the user.
public void DisplayPetInfo()
{
Console.WriteLine();
string textOut;
/// The message gets modified with depending on the gender.
if (isFemale == true)
textOut = "Name: " + name + "\nAge: " + age +
"\nGender: Female";
else
textOut = "Name: " + name + "\nAge: " + age +
"\nGender: Male";
Console.WriteLine(textOut);
}
}
}
|
Ruby
|
UTF-8
| 672 | 2.578125 | 3 |
[] |
no_license
|
module AkerPermissionClientConfig
def has_permission?(username_and_groups, role)
permissions.any? do |permission|
username_and_groups.include?(permission.permitted) && permission.attributes["permission-type"].to_s==role.to_s
end
end
def self.included(base)
base.instance_eval do |klass|
def self.authorize!(role, resource_id, username_and_groups)
instance = where(id: resource_id).includes(:permissions).first
unless instance.has_permission?(username_and_groups, role)
raise AkerPermissionGem::NotAuthorized.new("Not authorised to perform #{role} on #{self} #{resource_id}")
end
end
end
end
end
|
PHP
|
UTF-8
| 12,386 | 2.515625 | 3 |
[
"MIT"
] |
permissive
|
<?php
namespace App\Http\Controllers;
use DB;
use App\SatelliteBranch;
use Illuminate\Http\Request;
use App\Http\Controllers\Controller;
class SatelliteBranchController extends Controller
{
/**
* Display a listing of the resource.
*
* @return \Illuminate\Http\Response
*/
public function index()
{
if(!\Auth::user()->checkAccessById(26, "V"))
{
\Session::flash('error', "You don't have permission");
return redirect("/home");
}
//get all items
$satelliteBranches = SatelliteBranch::orderBy('sat_branch', 'DESC')->get();
//get user data
$branches = DB::table('user_area')
->where('user_ID', '=', \Auth::user()->UserID)
->pluck('branch');
$branch = explode(",", $branches[0]);
//dd($branch);
$corporations = DB::table('t_sysdata')
->join('corporation_masters', 't_sysdata.corp_id', '=', 'corporation_masters.corp_id')
->whereIn('t_sysdata.Branch', $branch)
->select('corporation_masters.corp_id', 'corporation_masters.corp_name')
->orderBy('corporation_masters.corp_name', 'ASC')
->distinct()
->get();
return view('satelliteBranches.index')
->with('satelliteBranches', $satelliteBranches)
->with('corporations', $corporations);
}
/**
* Show the form for creating a new resource.
*
* @return \Illuminate\Http\Response
*/
public function create()
{
if(!\Auth::user()->checkAccessById(26, "A"))
{
\Session::flash('error', "You don't have permission");
return redirect("/home");
}
//get user data
$branches = DB::table('user_area')
->where('user_ID', '=', \Auth::user()->UserID)
->pluck('branch');
$branch = explode(",", $branches[0]);
$corporations = DB::table('t_sysdata')
->join('corporation_masters', 't_sysdata.corp_id', '=', 'corporation_masters.corp_id')
->whereIn('t_sysdata.Branch', $branch)
->select('corporation_masters.corp_id', 'corporation_masters.corp_name')
->distinct()
->get();
return view('satelliteBranches.create')
->with('corporations', $corporations);
}
/**
* Store a newly created resource in storage.
*
* @param \Illuminate\Http\Request $request
* @return \Illuminate\Http\Response
*/
public function store(Request $request)
{
if(!\Auth::user()->checkAccessById(26, "A"))
{
\Session::flash('error', "You don't have permission");
return redirect("/home");
}
//get input
$branchName = $request->input('branchName');
$branchDescription = $request->input('branchDescription');
$branchNotes = $request->input('branchNotes');
$active = $request->input('itemActive');
$corporations = $request->input('corporation');
//create new instance
$satelliteBranch = new SatelliteBranch;
$satelliteBranch->short_name = $branchName;
$satelliteBranch->description = $branchDescription;
$satelliteBranch->notes = $branchNotes;
$satelliteBranch->active = $active ? 1 : 0;
$satelliteBranch->corp_id = $corporations != null ? $corporations : "";
$success = $satelliteBranch->save();
if($success) {
\Session::flash('success', "Item added successfully");
return redirect()->route('satellite-branch.index');
}
\Session::flash('error', "Something went wrong!");
return redirect()->route('satellite-branch.index');
}
/**
* Display the specified resource.
*
* @param \App\SatelliteBranch $satelliteBranch
* @return \Illuminate\Http\Response
*/
public function show(SatelliteBranch $satelliteBranch)
{
//
}
/**
* Show the form for editing the specified resource.
*
* @return \Illuminate\Http\Response
*/
public function edit($id) //SatelliteBranch $satelliteBranch
{
if(!\Auth::user()->checkAccessById(26, "E"))
{
\Session::flash('error', "You don't have permission");
return redirect("/home");
}
//get user data
$branches = DB::table('user_area')
->where('user_ID', '=', \Auth::user()->UserID)
->pluck('branch');
$branch = explode(",", $branches[0]);
//dd($branch);
$corporations = DB::table('t_sysdata')
->join('corporation_masters', 't_sysdata.corp_id', '=', 'corporation_masters.corp_id')
->whereIn('t_sysdata.Branch', $branch)
->select('corporation_masters.corp_id', 'corporation_masters.corp_name')
->distinct()
->get();
//find instance
$satelliteBranch = SatelliteBranch::where('sat_branch', $id)->first();
return view('satelliteBranches.edit')
->with('satelliteBranch', $satelliteBranch)
->with('corporations', $corporations);
}
/**
* Update the specified resource in storage.
*
* @param \Illuminate\Http\Request $request
* @param \App\SatelliteBranch $satelliteBranch
* @return \Illuminate\Http\Response
*/
public function update(Request $request, SatelliteBranch $satelliteBranch)
{
if(!\Auth::user()->checkAccessById(26, "E"))
{
\Session::flash('error', "You don't have permission");
return redirect("/home");
}
//get input
$branchName = $request->input('branchName');
$branchDescription = $request->input('branchDescription');
$branchNotes = $request->input('branchNotes');
$active = $request->input('itemActive');
$corporations = $request->input('corporations');
if($corporations){
$corporations = implode(',', $corporations);
}
$satelliteBranch->update([
'short_name' => $branchName,
'description' => $branchDescription,
'notes' => $branchNotes,
'active' => $active ? 1 : 0,
'corp_id' => $corporations != null ? $corporations : ""
]);
\Session::flash('success', "Satellite branch updated successfully");
return redirect()->route('satellite-branch.index');
}
/**
* Remove the specified resource from storage.
*
* @param \App\SatelliteBranch $satelliteBranch
* @return \Illuminate\Http\Response
*/
public function destroy(SatelliteBranch $satelliteBranch)
{
if(!\Auth::user()->checkAccessById(26, "D"))
{
\Session::flash('error', "You don't have permission");
return redirect("/home");
}
$success = $satelliteBranch->delete();
if($success){
\Session::flash('success', "Satellite branch deleted successfully");
return redirect()->route('satellite-branch.index');
}
\Session::flash('error', "Something went wrong!");
return redirect()->route('satellite-branch.index');
}
public function getBranches(Request $request){
$statusData = $request->input('statusData');
$corpId = $request->input('corpId');
$draw = $request->input('draw');
$start = $request->input('start');
$length = $request->input('length');
$columns = $request->input('columns');
$orderable = $request->input('order');
$orderNumColumn = $orderable[0]['column'];
$orderDirection = $orderable[0]['dir'];
$columnName = $columns[$orderNumColumn]['data'];
$search = $request->input('search');
$searchVal = explode(" ", $search['value']);
$recordsTotal = SatelliteBranch::count();
if($searchVal != null && $statusData != "" && $corpId == ""){
$satelliteBranch = SatelliteBranch::where('active', $statusData)
->where(function ($q) use ($search, $columns){
for($i = 0; $i<sizeof($columns)-1; $i++){
$q->orWhere($columns[$i]['data'], 'LIKE', '%'.$search['value'].'%');
}
})
->orderBy($columnName, $orderDirection)
->skip($start)
->take($length)
->get();
$columns = array(
"draw" => $draw,
"recordsTotal" => $recordsTotal,
"recordsFiltered" => ($satelliteBranch != null) ? $satelliteBranch->count() : 0,
"data" => ($satelliteBranch != null) ? $satelliteBranch : 0
);
return response()->json($columns, 200);
}else if($search['value'] != "" && $corpId != "" && $statusData == ""){
$satelliteBranch = SatelliteBranch::where('corp_id', $corpId)
->where(function ($q) use ($search, $columns){
for($i = 0; $i<sizeof($columns)-1; $i++){
$q->orWhere($columns[$i]['data'], 'LIKE', '%'.$search['value'].'%');
}
})
->orderBy($columnName, $orderDirection)
->skip($start)
->take($length)
->get();
$columns = array(
"draw" => $draw,
"recordsTotal" => $recordsTotal,
"recordsFiltered" => ($satelliteBranch != null) ? $satelliteBranch->count() : 0,
"data" => ($satelliteBranch != null) ? $satelliteBranch : 0
);
return response()->json($columns, 200);
}else if($search['value'] != "" && $corpId != "" && $statusData != ""){
$satelliteBranch = SatelliteBranch::where('corp_id', 'LIKE', '%'.$corpId.'%')
->where('active', $statusData)
->where(function ($q) use ($search, $columns){
for($i = 0; $i<sizeof($columns)-1; $i++){
$q->orWhere($columns[$i]['data'], 'LIKE', '%'.$search['value'].'%');
}
})
->orderBy($columnName, $orderDirection)
->skip($start)
->take($length)
->get();
$columns = array(
"draw" => $draw,
"recordsTotal" => $recordsTotal,
"recordsFiltered" => ($satelliteBranch != null) ? $satelliteBranch->count() : 0,
"data" => ($satelliteBranch != null) ? $satelliteBranch : 0
);
return response()->json($columns, 200);
}else if($search['value'] == "" && $statusData != "" && $corpId != ""){
$satelliteBranch = SatelliteBranch::where('corp_id', 'LIKE', '%'.$corpId.'%')
->where('active', $statusData)
->orderBy($columnName, $orderDirection)
->skip($start)
->take($length)
->get();
$columns = array(
"draw" => $draw,
"recordsTotal" => $recordsTotal,
"recordsFiltered" => ($satelliteBranch != null) ? $satelliteBranch->count() : 0,
"data" => ($satelliteBranch != null) ? $satelliteBranch : 0
);
return response()->json($columns, 200);
}
if($statusData != ""){
$satelliteBranch = SatelliteBranch::where('active', $statusData)
->orderBy($columnName, $orderDirection)
->skip($start)
->take($length)
->get();
}else if($corpId != ""){
$satelliteBranch = SatelliteBranch::where('corp_id', 'LIKE', '%'.$corpId.'%')
->orderBy($columnName, $orderDirection)
->skip($start)
->take($length)
->get();
}else{
$satelliteBranch = null;
}
$columns = array(
"draw" => $draw,
"recordsTotal" => $recordsTotal,
"recordsFiltered" => ($satelliteBranch != null) ? $satelliteBranch->count() : 0,
"data" => ($satelliteBranch != null) ? $satelliteBranch : 0
);
return response()->json($columns, 200);
}
}
|
C
|
IBM852
| 3,519 | 3.984375 | 4 |
[] |
no_license
|
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
float Somar (float, float);
float Subtrair (float, float);
float Multiplicar(float, float);
float Dividir(float, float);
float Raiz(float, float);
float Potencia(float, float);
float Seno(float);
float Cosseno(float);
int main () {
int op;
float a, b, r;
do {
system("cls");
Menu();
printf("\n\nDigite a operacao desejada: ");
scanf("%i", &op);
switch (op) {
case 1:
printf("\nSoma");
printf("\nDigite o valor de a: ");
scanf("%f", &a);
printf("\nDigite o valor de b: ");
scanf("%f", &b);
r = Somar(a, b);
printf("%.2f", r);
break;
case 2:
printf("\nSubtrair");
printf("\nDigite o valor de a: ");
scanf("%f", &a);
printf("\nDigite o valor de b: ");
scanf("%f", &b);
r = Subtrair(a, b);
printf("%.2f", r);
break;
case 3:
printf("\nMultiplicacao");
printf("\nDigite o valor de a: ");
scanf("%f", &a);
printf("\nDigite o valor de b: ");
scanf("%f", &b);
r = Multiplicar(a, b);
printf("%.2f", r);
break;
case 4:
printf("\nDivisao");
printf("\nDigite o valor de a: ");
scanf("%f", &a);
printf("\nDigite o valor de b: ");
scanf("%f", &b);
r = Dividir(a, b);
printf("%.2f", r);
break;
case 5:
printf("\nRaiz Ensima");
printf("\nDigite o valor de a: ");
scanf("%f", &a);
printf("\nDigite o valor de b: ");
scanf("%f", &b);
r = Raiz(a, b);
printf("%.2f", r);
break;
case 6:
printf("\nPotencia");
printf("\nDigite o valor de a: ");
scanf("%f", &a);
printf("\nDigite o valor de b: ");
scanf("%f", &b);
r = Potencia(a, b);
printf("%.2f", r);
break;
case 7:
printf("\nSeno");
printf("\nDigite o valor de a: ");
scanf("%f", &a);
r = Seno(a);
printf("%.2f", r);
break;
case 8:
printf("\nCosseno");
printf("\nDigite o valor de a: ");
scanf("%f", &a);
r = Cosseno(a);
printf("%.2f", r);
break;
case -1:
break;
}
system("PAUSE");
}
while(op != (-1));
return op;
return 0;
}
float Somar(float a, float b) {
return (a + b);
}
float Subtrair(float a, float b) {
return (a - b);
}
float Multiplicar(float a, float b) {
return (a * b);
}
float Dividir(float a, float b) {
return (a / b);
}
float Raiz(float a, float b) {
return (pow(a, 1.0 / b));
}
float Potencia(float a, float b) {
return (pow(a, b));
}
float Seno(float a) {
return sin(a);
}
float Cosseno(float a) {
return cos(a);
}
void Menu()
{
printf("\n(1) Soma (a + b)");
printf("\n(2) Subtracao (a - b)");
printf("\n(3) Multiplicacao (a * b)");
printf("\n(4) Divisao (a / b)");
printf("\n(5) Raiz (a^(1 / b))");
printf("\n(6) Potencia (a^b)");
printf("\n(7) Seno (sin(a))");
printf("\n(8) Cosseno (cos(a))");
printf("\n(-1) Sair");
}
|
Java
|
UTF-8
| 186 | 1.585938 | 2 |
[] |
no_license
|
package com.android.salesapp.bean;
public class FollowUpCallBean
{
public int FCID;
public int ProjectID;
public String Date;
public String Time;
public int Reminder;
}
|
PHP
|
UTF-8
| 3,297 | 2.734375 | 3 |
[
"Apache-2.0"
] |
permissive
|
<?php
namespace YBL\Kernel\Traits;
use YBL\Kernel\Crypto\Keccak;
use YBL\Kernel\Crypto\Signature;
use YBL\Kernel\Support\Arr;
use YBL\Kernel\Types\Byte;
/**
* Trait Metadata
* @package YBL\Kernel\Traits
*/
trait MetadataTrait
{
/**
* @var Byte
*/
private $privateKey;
/**
* @var Byte
*/
private $publicKey;
/**
* @param array $data
* @return array
*/
protected function removeFields(array $data): array
{
$removeFields = ['signature', 'dna', 'content'];
foreach ($removeFields as $field) {
if (isset($data[$field])) {
unset($data[$field]);
}
}
return $data;
}
/**
* @param array $array
* @return array
*/
protected function filterEmptyValue(array $array)
{
foreach ($array as $k => $v) {
if ($v === '' || $v === null) {
unset($array[$k]);
} elseif (is_array($v)) {
$array[$k] = self::filterEmptyValue($array[$k]);
}
}
return $array;
}
/**
* @param array $data
* @return array
*/
public function buildMetadata(array $data): array
{
$metadata = $this->removeFields($this->filterEmptyValue($data));
// padding public key
$metadata['pubkey'] = $this->publicKey->getHex();
$metadata = Arr::ksort($metadata);
return $metadata;
}
/**
* @param array $metadata
* @return string
* @throws \Exception
*/
public function sign(array $metadata): string
{
$metadataJson = json_encode($metadata, JSON_UNESCAPED_UNICODE | JSON_UNESCAPED_SLASHES | JSON_HEX_AMP);
// JSON_HEX_TAG will convert "<",">" to "\u003C","\u003E"
// yuanbenlian need "<",">" convert to \u003c","\u003e"
$metadataJson = str_replace(["<", ">"], ["\u003c", "\u003e"], $metadataJson);
$signature = Signature::sign(Byte::initWithHex(Keccak::hash($metadataJson, 256)), $this->privateKey)->getHex();
return $signature;
}
/**
* @param $metadata
* @param string $signature
* @return array
*/
public function setSignature($metadata, string $signature): array
{
$metadata["signature"] = $signature;
return $metadata;
}
/**
* @param $sign
* @return string
*/
public function generateDNA($sign)
{
$msg = Keccak::hash(pack("H*", $sign), 256);
$count = $this->searchHexLeftIsZeroCount($msg);
if ($count > 0) {
$base36 = $this->_base36Encode($msg);
return str_pad($base36, strlen($base36) + $count, "0", STR_PAD_LEFT);
}
return $this->_base36Encode($msg);
}
private function _base36Encode($str)
{
$base36 = gmp_strval(gmp_init($str, 16), 36);
return strtoupper($base36);
}
/**
* @param $str
* @return int
*/
private function searchHexLeftIsZeroCount($str)
{
$count = 0;
for ($i = 0; $i < strlen($str); $i = $i + 2) {
if ($str[$i] == '0' && $str[$i + 1] == '0') {
$count++;
} else {
break;
}
}
return $count;
}
}
|
Python
|
UTF-8
| 388 | 3.484375 | 3 |
[] |
no_license
|
# Teste seu código aos poucos.
# Não teste tudo no final, pois fica mais difícil de identificar erros.
# Use as mensagens de erro para corrigir seu código.
from math import*
r = float(input("raio do tanque: "))
h = float(input("altura da coluna: "))
n = int(input("opcao: "))
if n == 1:
v = (pi*h**2 * (3*r - h))/3
else:
v = (4*pi*r**3)/3 - (pi*h**2 * (3*r - h))/3
print(round(v,4))
|
Markdown
|
UTF-8
| 5,733 | 2.5625 | 3 |
[
"MIT",
"Apache-2.0"
] |
permissive
|
# 분산 및 다중 처리 시스템
## 분산시스템
________
### 네트워크와 분산 시스템의 개념
- 컴퓨터 사용자 간 데이터 교환을 위해 네트워크로 상호 연결
- 분산 시스템과 다중 처리 시스템으로 구분
- 분산 시스템
- 메모리와 클록을 공유X
- 지역 메모리를 유지하는 프로세서로 구성
- 서로 독자적으로 동작
- 다중처리 시스템
- 하나 이상의 프로세스로 구성
- 프로세스들이 메모리와 출력을 공유
### 네트워크의 개념
서로 독립된 시스템 몇 개가 적절한 영역 안에서 속도가 빠른 통신 채널을 이용하여 상호 통신할 수 있도록 지원하는 데이터 통신 시스템
- 강결합 시스템
프로세서들이 메모리 공유
공유 메모리를 점유하려는 프로세서간의 경쟁을 최소화해야 함
=> 경쟁은 결합교환방법으로 해결
- 결합 교환(Combining Switch)
오직 하나의 프로세서만 공유 메모리 액세스 허용
<img class="image image--xl" src="https://user-images.githubusercontent.com/41600558/72244561-e61a4480-3631-11ea-8d80-8ec124ec129e.png"/>
- 약결합 시스템
둘 이상의 독립된 시스템을 **통신선**으로 연결
필요할 때만 통신선을 이용하여 메시지 전달이나 원격 프로시저 호출로 통신
하나의 시스템에서 장애가 발생해도 다른 시스템의 프로세서에 영향X
<img class="image image--xl" src="https://user-images.githubusercontent.com/41600558/72244650-106c0200-3632-11ea-9793-6698bab04e63.png"/>
### 네트워크의 구조
- 망(mesh) 구조
완결 연결(fully connected) 방법
초기 설치비 많음
매우 빠름
신뢰성 높음
<img class="image image--xl" src="https://user-images.githubusercontent.com/41600558/72244683-1feb4b00-3632-11ea-944c-d9bd3c6d43e9.png"/>
- 트리(tree) 구조(계층(hierarchy) 구조)
각 노트가 트리로 구성
인트라넷에서 활용
루트를 제외하고 단일 부모와 자식 몇 개를 가짐
망구조보다 기본비용이 저렴
부모가 고장나면 자식은 서로 통신 불가, 다른 프로세스와도 통신 불가
<img class="image image--xl" src="https://user-images.githubusercontent.com/41600558/72244702-2d083a00-3632-11ea-9fec-9398d0ed8a99.png"/>
- 성형(star) 구조
중앙 노드와만 직접연결
중앙 노드가 메시지 교환 담당
병목현상 발생 가능
중앙 노드 장애는 전체 시스템 마비
기본비용은 노드수에 비례, 통신비용 저렴, 집중 제어로 유지보수 용이
<img class="image image--xl" src="https://user-images.githubusercontent.com/41600558/72244720-385b6580-3632-11ea-9470-3500aae14b79.png"/>
- 링(ring) 구조
각 노드를 정확히 다른 노드 2개와 연결
메시지 전달방향은 단방향/양방향 존재
단방향구조에서는 하나의 노드나 링크가 불능이되면 네트워크 분할
양방향은 2개 고장나면 분할
메시지가 링을 순환하면 통신비용 증가
<img class="image image--xl" src="https://user-images.githubusercontent.com/41600558/72244740-43ae9100-3632-11ea-84f8-6c0914180f3e.png"/>
- 버스(bus) 구조
연결 버스 하나에 모든 노드 연결 방법
버스를 공유하여 경제적
각 노드의 고장은 나머지 노드 간 통신에는 영향X
노드의 추가, 변경, 제거 등이 용이
but, 버스가 고장나면 모든 노드 간 통신 불가능
<img class="image image--xl" src="https://user-images.githubusercontent.com/41600558/72244760-4f01bc80-3632-11ea-82be-cca002174f69.png"/>
### 원격 프로시저 호출(RPC, Remot Procedure Call)
분산 시스템과 단일 시스템의 가장 큰 차이는 프로세스 간 통신.
분산 시스템은 공유 메모리 X
하나의 컴퓨터에서 실행하는 프로세스를 다른 컴퓨터에서 실행하는 프로세스의 프로시저가 호출 가능. 클라이언트/서버 모델.
클라이언트 프로세스가 서버 프로시저를 호출하면 클라이언트 프로세스는 중단되고 서버 프로시저가 실행됨 -> 반환값은 네트워크를 이용해 클라이언트로 전송
- 일반적인 RPC 단계(요청과 응답관계, 1:1)
<img class="image image--xl" src="https://user-images.githubusercontent.com/41600558/72244787-59bc5180-3632-11ea-8939-ff4e54d89ec3.png"/>
##### 스터브(stub)
전송 데이터를 준비하고 수신 데이터를 변환해서 올바르게 해석할 수 있도록 지원하여 처리 결과를 교환하는 모듈
클라이언트 스터브와 서버 스터브로 분류
- RPC 동작 과정
<img class="image image--xl" src="https://user-images.githubusercontent.com/41600558/72244810-63de5000-3632-11ea-8175-515ad0f105a2.png"/>
### 분산 시스템의 구조와 구축 목적
- 분산 시스템의 구조
<img class="image image--xl" src="https://user-images.githubusercontent.com/41600558/72244827-7062a880-3632-11ea-99e6-5cb188b75f3e.png"/>
저렴한 노드 여러개를 운영체제 하나가 제어하여 하나의 프로그램처럼 동작
- 구축 목적
자원 공유 용이
연산속도 향상
신뢰성 향상
통신 기능
- 기본 목표
각종 자원의 투명성 보장
=> 상호연결된 컴퓨터를 사용자가 하나의 컴퓨터 시스템으로 인식할 수 있도록 함
## 네트워크 운영체제
### 네트워크 운영체제(NOS, Network Operating System)의 원리
통신 제어, 분산된 자원을 공유하면서 독립된 시스템들을 서로 연결하기 위해 개발
|
Java
|
UTF-8
| 9,139 | 1.90625 | 2 |
[] |
no_license
|
package com.fiserv.CFCreateUserOrgSpacePermissions.controller;
import static com.fiserv.CFCreateUserOrgSpacePermissions.CfCreateUserOrgSpacePermissionsApplication.getHttpClient;
import static com.fiserv.CFCreateUserOrgSpacePermissions.CfCreateUserOrgSpacePermissionsApplication.localhost;
import com.google.gson.Gson;
import java.io.IOException;
import java.net.Socket;
import java.security.KeyManagementException;
import java.security.KeyStoreException;
import java.security.NoSuchAlgorithmException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.List;
import java.util.Map;
import javax.naming.Context;
import javax.naming.NamingException;
import javax.naming.directory.SearchControls;
import javax.naming.ldap.InitialLdapContext;
import javax.naming.ldap.LdapContext;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
/**
* @author Michael Hug
*/
@RestController("/api/is")
public class isController {
//Methods for tesing connections and permisions to LDAP and CF
@GetMapping("/api/is/LDAPConnectionPresent")
public Map<String, Boolean> isLDAPConnectionPresent() {
Map<String, Boolean> ret = new HashMap<>();
ret.put("isLDAPConnectionPresent", socketTest(System.getenv("LDAP_SERVER_ADDRESS"), Integer.parseInt(System.getenv("LDAP_SERVER_PORT"))));
return ret;
}
@GetMapping("/api/is/LDAPUserPresent/{user}")
public Map<String, Boolean> isLDAPUserPresent(@PathVariable String user) throws NamingException {
Map<String, Boolean> ret = new HashMap<>();
SearchControls constraints = new SearchControls();
constraints.setSearchScope(SearchControls.SUBTREE_SCOPE);
ret.put("isLDAPUserPresent", getLdapContext().search(System.getenv("LDAP_SEARCH_BASE"), "sAMAccountName="+ user, constraints).hasMore());
return ret;
}
@GetMapping("/api/is/CFConnectionPresent")
public Map<String, Boolean> isCFConnectionPresent() {
Map<String, Boolean> ret = new HashMap<>();
ret.put("isCFConnectionPresent", socketTest("api."+System.getenv("CF_SERVER_ADDRESS"), Integer.parseInt(System.getenv("CF_SERVER_PORT"))));
return ret;
}
@GetMapping("/api/is/CFAdminReadWritePermissionsPresent")
public Map<String, Boolean> isAdminCFReadWritePermissionsPresent() throws NoSuchAlgorithmException, KeyStoreException, KeyManagementException, IOException {
Map<String, Boolean> ret = new HashMap<>();
HttpPost httpPost = new HttpPost("https://login."+System.getenv("CF_SERVER_ADDRESS")+"/oauth/token");
httpPost.addHeader("Accept", "application/json");
httpPost.addHeader("Authorization", "Basic Y2Y6");
httpPost.addHeader("Content-Type", "application/x-www-form-urlencoded");
List<NameValuePair> params = new ArrayList<>();
params.add(new BasicNameValuePair("grant_type", "password"));
params.add(new BasicNameValuePair("password", System.getenv("CF_PASS")));
params.add(new BasicNameValuePair("scope", ""));
params.add(new BasicNameValuePair("username", System.getenv("CF_USER")));
httpPost.setEntity(new UrlEncodedFormEntity(params));
System.out.println("DEBUG 0");
try (CloseableHttpClient client = getHttpClient()) {
System.out.println("DEBUG 1");
String responseString = EntityUtils.toString(client.execute(httpPost).getEntity());
System.out.println("DEBUG 2");
Map<String, String> responseGson = new Gson().fromJson(responseString, Map.class);
System.out.println("DEBUG 3");
System.out.println("DEBUG 3.1");
System.out.println(Arrays.toString(responseGson.entrySet().toArray()));
System.out.println("DEBUG 3.2");
String myScope = responseGson.get("scope");
System.out.println("DEBUG 4");
System.out.println("enable debug here(and everywhwre) later---dont forget mh 4 Dec 2017");
System.out.println("DEBUG 5");
if(myScope.contains("cloud_controller.admin") && myScope.contains("cloud_controller.read") && myScope.contains("cloud_controller.write")) {
ret.put("isCFReadWritePermissionsPresent", Boolean.TRUE);
}
else {
ret.put("isCFReadWritePermissionsPresent", Boolean.FALSE);
}
}
return ret;
}
//Methods for validating CF end state
@GetMapping("/api/is/CFUserPresent/{user}")
public Map<String, Boolean> isCFUserPresent(@PathVariable String user) {
Map<String, Boolean> ret = new HashMap<>();
boolean returnType = new RestTemplate().getForObject(localhost+"/api/get/users/", Map.class).containsKey(user);
ret.put("isCFUserPresent", new RestTemplate().getForObject(localhost+"/api/get/users/", Map.class).containsKey(user));
return ret;
}
@GetMapping("/api/is/CfOrgPresent/{org}")
public Map<String,Boolean> isCfOrgPresent(@PathVariable String org) throws NoSuchAlgorithmException, KeyStoreException, KeyManagementException {
Map<String,Boolean> ret = new HashMap<>();
ret.put("isCfOrgPresent", new RestTemplate().getForObject(localhost+"/api/get/orgs/", Map.class).containsKey(org));
return ret;
}
@GetMapping("/api/is/CfSpacePresent/{org}/{space}")
public Map<String, Boolean> isCfSpacePresent(@PathVariable String org, @PathVariable String space) throws NoSuchAlgorithmException, KeyStoreException, KeyManagementException {
Map<String,Boolean> ret = new HashMap<>();
Map<String, String> orgs = new RestTemplate().getForObject(localhost+"/api/get/orgs/", Map.class);
ret.put("isCfSpacePresent", new RestTemplate().getForObject(localhost+"/api/get/spaces/"+orgs.get(org), Map.class).containsKey(space));
return ret;
}
@GetMapping("/api/is/CFPermissionPresent/{org}/{space}/{user}")
public Map<String, Boolean> isCFPermissionPresent(@PathVariable String org, @PathVariable String space, @PathVariable String user) {
boolean orgPresent = false;
boolean spacePresent = false;
Map<String, Object> permissions = new RestTemplate().getForObject(localhost+"/api/get/userpermission/"+user, Map.class);
Map<String, List<Map<String, Map<String, String>>>> crazyMap;
crazyMap = (Map<String, List<Map<String, Map<String, String>>>>) permissions.get("entity");
List<Map<String,Map<String, String>>> usersOrgs = crazyMap.get("organizations");
for( Map<String, Map<String, String>> i : usersOrgs) {
Map<String, String> myEntity = i.get("entity");
String myName = myEntity.get("name");
if(myName.equals(org)) {
orgPresent = true;
}
}
List<Map<String, Map<String, String>>> usersSpaces = crazyMap.get("spaces");
for( Map<String, Map<String, String>> i : usersSpaces) {
Map<String, String> myEntity = i.get("entity");
String myName = myEntity.get("name");
if(myName.equals(space)) {
spacePresent = true;
}
}
Map<String, Boolean> ret = new HashMap<>();
ret.put("isCFUserSpacePermisionPresent", orgPresent && spacePresent);
return ret;
}
//private sector
private LdapContext getLdapContext() {
LdapContext ctx = null;
try{
Hashtable<String, String> env = new Hashtable<>();
env.put(Context.INITIAL_CONTEXT_FACTORY,
"com.sun.jndi.ldap.LdapCtxFactory");
env.put(Context.SECURITY_AUTHENTICATION, "Simple");
env.put(Context.SECURITY_PRINCIPAL, System.getenv("LDAP_USER"));
env.put(Context.SECURITY_CREDENTIALS, System.getenv("LDAP_PASS"));
env.put(Context.PROVIDER_URL, "ldap://"+System.getenv("LDAP_SERVER_ADDRESS")+":"+System.getenv("LDAP_SERVER_PORT"));
ctx = new InitialLdapContext(env, null);
} catch(NamingException nex){
/* returns a null ctx */
}
return ctx;
}
private boolean socketTest(String address, int port) {
boolean ret = false;
try (Socket s = new Socket(address, port)) {
ret = true;
} catch (IOException ex) {
/* ret remains false */
System.out.println("Cannot connect to address on port " + address + port);
}
return ret;
}
}
|
Java
|
UTF-8
| 1,024 | 2.53125 | 3 |
[] |
no_license
|
package models;
import com.fasterxml.jackson.annotation.JsonProperty;
import javax.validation.constraints.NotNull;
/**
* Created by Laufey on 31/10/2016.
*/
public class ChangePasswordModel {
public final static String mediaType = "application/json";
@NotNull
@JsonProperty("oldPassword")
String oldPassword;
@NotNull
@JsonProperty("newPassword")
String newPassword;
public ChangePasswordModel() {
}
public ChangePasswordModel(String oldPassword, String newPassword) {
this.oldPassword = oldPassword;
this.newPassword = newPassword;
}
public static String getMediaType() {
return mediaType;
}
public String getOldPassword() {
return oldPassword;
}
public void setOldPassword(String oldPassword) {
this.oldPassword = oldPassword;
}
public String getNewPassword() {
return newPassword;
}
public void setNewPassword(String newPassword) {
this.newPassword = newPassword;
}
}
|
Python
|
UTF-8
| 149 | 3.546875 | 4 |
[] |
no_license
|
x = 5
y = 3
print(x * y)
x = 10
y = 4
print(x // 4)
x = 5
x /= 3
print(x)
y = 3
y += 3
print(y)
x = 5
y = 3
print(x<y)
x = 10
y = 11
print(x==y)
|
Java
|
UTF-8
| 3,575 | 3.21875 | 3 |
[] |
no_license
|
package ml.vandenheuvel.ti1216.data;
import org.json.JSONObject;
/**
* Instances of this data class represents a chat message.
*/
public class ChatMessage {
/**
* Class-instances/variables.
*/
private int id;
private String sender;
private String message;
private String receiver;
private boolean seen;
/**
* @param id
* the unique identifier of the message
* @param sender
* the username of the person who sends the message
* @param message
* the actual content of the message
* @param receiver
* the username of the person who should receive the message
* @param seen
* whether the message has been seen or not
*/
public ChatMessage(int id, String sender, String message, String receiver, boolean seen) {
this.id = id;
this.sender = sender;
this.message = message;
this.receiver = receiver;
this.seen = seen;
}
/**
* Gets the id of the message.
*
* @return the id
*/
public int getId() {
return id;
}
/**
* Gets the sender of the chat message.
*
* @return the sender of the chat message
*/
public String getSender() {
return sender;
}
/**
* Gets the contents of the chat message.
*
* @return the contents of the chat message
*/
public String getMessage() {
return message;
}
/**
* Gets the receiver of the chat message.
*
* @return the receiver of the chat message
*/
public String getReceiver() {
return receiver;
}
/**
* Gets whether the chat has been seen or not.
*
* @return the seen
*/
public boolean isSeen() {
return seen;
}
/**
* Changes the sender of the chat message.
*
* @param sender
* the sender to change to
*/
public void setSender(String sender) {
this.sender = sender;
}
/**
* Changes the contents of the chat message.
*
* @param message
* the contents to change to
*/
public void setMessage(String message) {
this.message = message;
}
/**
* Changes the receiver of the chat message.
*
* @param receiver
* the receiver to change to
*/
public void setReceiver(String receiver) {
this.receiver = receiver;
}
/**
* Changes whether the chat has been seen or not.
*
* @param seen
* the seen to set
*/
public void setSeen(boolean seen) {
this.seen = seen;
}
/**
* Creates a JSON object out of this ChatMessage object
*
* @return a JSON object out of this ChatMessage object
*/
public JSONObject toJSON() {
JSONObject result = new JSONObject();
result.put("id", this.id);
result.put("sender", this.sender);
result.put("message", this.message);
result.put("receiver", this.receiver);
result.put("seen", this.seen);
return result;
}
/**
* Creates a ChatMessage object out of a JSON object.
*
* @param json
* the JSON object
* @return a chatMessage constructed out of the JSON input
*/
public static ChatMessage fromJSON(JSONObject json) {
return new ChatMessage(json.getInt("id"), json.getString("sender"), json.getString("message"),
json.getString("receiver"), json.getBoolean("seen"));
}
/**
* Checks whether two ChatMessages are equal to each other.
*
* @param other
* the Object to which the ChatMessage is compared
* @return true if the two ChatMessages have the same id, otherwise false
*/
@Override
public boolean equals(Object other) {
if (other instanceof ChatMessage) {
ChatMessage that = (ChatMessage) other;
return this.id == that.id;
}
return false;
}
}
|
Markdown
|
UTF-8
| 1,033 | 2.8125 | 3 |
[] |
no_license
|
---
date: 2005-10-26 17:21:51
layout: post
title: Lesser Evil
---
One of the things I hear pretty often is "sometimes you just have to go with the lesser evil". Now, granted, I probably tend to get myself into situations that would spark that remark more often than is normal. But I'm sure most of you have heard it somewhere along the line. It's not like that really solves anything though. Evil is supposed to be all trixie and insidious. Make you think you're doing good when you're really doing evil. The ol' bait and switch. If I knew which was the lesser evil I wouldn't be pondering in the first place. So instead of pondering I just built an app to help: [Lesser Evil](http://lesserevil.ning.com). So that I can find out what everyone else's take on Lesser Evil is. Should help right around election time. And I threw Cthulhu and Evil Lincoln in there as controls, cause everyone knows nothings really more evil than Evil Lincoln except Cthulhu. So if they end getting voted the lesser evil I know all you people are lying.
|
JavaScript
|
UTF-8
| 1,932 | 2.703125 | 3 |
[] |
no_license
|
const express = require('express');
const bcrypt = require('bcryptjs');
const db = require('./database/dbConfig.js');
const generateToken = require('./functions/generateToken.js');
const protected = require('./functions/protected');
const server = express();
server.use(express.json());
const PORT = 3300;
server.post("/api/register", (req, res) => {
const credentials = req.body;
credentials.password = bcrypt.hashSync(credentials.password, 10);
db("users")
.insert(credentials)
.then(ids => {
const id = ids[0];
db("users")
.where({ id })
.first()
.then(user => {
const token = generateToken(user);
res.status(201).json({ id: user.id, token });
})
.catch(err => {
res.status(500).send(err);
});
})
.catch(err => {
res.status(500).send(err);
});
});
//use credentials in body, create new JWT upon successful login
server.post("/api/login", (req, res) => {
const credentials = req.body;
db("users")
.where({ username: credentials.username })
.first()
.then(user => {
if (user && bcrypt.compareSync(credentials.password, user.password)) {
const token = generateToken(user);
res.status(200).json({ token });
res.send(`Welcome ${user.username}!`);
} else {
res.status(401).json({ message: "You shall not pass!" });
}
})
.catch(err => {
res.status(500).send(err);
});
});
//if logged in, return array of users. verify that password is hashed before save
server.get("/api/users", protected, (req, res) => {
db("users")
.then(users => {
res.json(users);
})
.catch(err => {
res.send(err);
});
});
server.listen(PORT, () => {
console.log(`server listening on port ${PORT}`);
});
|
JavaScript
|
UTF-8
| 1,890 | 3.25 | 3 |
[] |
no_license
|
/**
* Returns the midpoint between two points.
* @param point1 First point.
* @param point2 Second point.
* @returns {[*,*,*,*]} Mid point
*/
function midPoint(point1, point2) {
return [(point1[0] + point2[0]) / 1.5, (point1[1] + point2[1]) / 1.5, (point1[2] + point2[2]) / 1.5, (point1[3] + point2[3]) / 1.5];
}
/*
function midPoint(point1, point2) {
return [(point1[0] + point2[0]) / 2, (point1[1] + point2[1]) / 2, (point1[2] + point2[2]) / 2, (point1[3] + point2[3]) / 2];
}*/
function addPoints(point1, point2) {
return [point1[0] + point2[0], point1[1] + point2[1], point1[2] + point2[2]];
}
function subtractPoints(point1, point2) {
return [point2[0] - point1[0], point2[1] - point1[1], point2[2] - point1[2]];
}
function dividePoint(point, divisor) {
return [point[0]/divisor, point[1]/divisor, point[2] /divisor];
}
function distance(point1, point2) {
return Math.sqrt(Math.pow(point1[0] - point2[0], 2) + Math.pow(point1[1] - point2[1], 2) + Math.pow(point1[2] - point2[2], 2));
}
function vectorNorm(vector) {
var vMag = Math.sqrt(vector[0] * vector[0] + vector[1]* vector[1] + vector[2]* vector[2])
return [vector[0] / vMag, vector[1] / vMag, vector[2] / vMag]
}
function dotProduct(vector1, vector2) {
var v1 = vectorNorm(vector1);
var v2 = vectorNorm(vector2);
return (v1[0] * v2[0] + v1[1] * v2[1] + v1[2] * v2[2]);
}
function angleBetween(vector1, vector2) {
return Math.acos(dotProduct(vector1, vector2));
}
radians = function(degrees) {
return degrees * Math.PI / 180;
};
GAMEMODE = {
HUMAN_VS_HUMAN: 0,
HUMAN_VS_CPU: 1,
CPU_VS_CPU: 2
};
LEVEL = {
EASY: 0,
HARD: 1
};
THEME = {
LEGACY: 0,
NORMAL: 1
};
function sleep(milliseconds) {
var start = new Date().getTime();
for (var i = 0; i < 1e7; i++) {
if ((new Date().getTime() - start) > milliseconds){
break;
}
}
}
|
JavaScript
|
UTF-8
| 2,278 | 3.8125 | 4 |
[] |
no_license
|
var garage = [];
var splitCommand = new Array();
function handleCommand(command) {
splitCommand = command.split(" ");
if (command.includes("create") || command.includes("Create"))
createCar(splitCommand[2], splitCommand[3], splitCommand[4], splitCommand[5]);
else if (command.includes("check in") || command.includes("Check in"))
checkInCar(splitCommand[2]);
else if (command.includes("check out") || command.includes("Check out"))
checkOutCar(splitCommand[2]);
else if (command.includes("calculate") || command.includes("Calculate"))
calculateCar(splitCommand[1]);
else if (command.includes("display") || command.includes("Display"))
displayContent();
else {
document.getElementById("output").innerHTML = "Command not recognised, please try again."
}
}
function createCar(regNo, brand, wheels, faults) {
garage.push({"regNo": regNo, "brand": brand, "wheels": wheels, "faults": faults, "status": "in"});
document.getElementById("output").innerHTML = "A car with reg number " + regNo + " was added to the system.";
}
function checkInCar(regNo) {
for (var car in garage) {
if (garage[car].regNo == regNo) {
garage[car].status = "in";
}
}
document.getElementById("output").innerHTML = "Car with reg number " + regNo + " was checked in.";
}
function checkOutCar(regNo) {
for (var car in garage) {
if (garage[car].regNo == regNo) {
garage[car].status = "out";
}
}
document.getElementById("output").innerHTML = "Car with reg number " + regNo + " was checked out.";
}
function calculateCar(regNo) {
for (var car in garage) {
if (garage[car].regNo == regNo) {
document.getElementById("output").innerHTML = "Repair the car will cost: £" + garage[car].faults*3.55 + ". ";
}
}
}
function displayContent() {
var carInfo = "There are " + garage.length + " cars in the garage: <br>";
for (var car in garage) {
if (garage[car].status == "in") {
carInfo += "Reg number: " + garage[car].regNo + ". ";
carInfo += "Brand: " + garage[car].brand + ". ";
carInfo += "Number of wheels: " + garage[car].wheels + ". ";
carInfo += "Number of faults: " + garage[car].faults + ". <br>";
document.getElementById("output").innerHTML = carInfo;
}
}
}
|
Java
|
UHC
| 927 | 3.828125 | 4 |
[] |
no_license
|
package day9;
import java.util.Scanner;
public class ExamMethod2 {
public static int scan1(int num1, int num2) {
int bigger=0;
if(num1>num2) {
bigger = num1;
}else {
bigger = num2;
}
return bigger;
}
public static int scan2(int num1,int num2) {
int res = num1%num2;
return res;
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println(" Էϼ");
int n1 = sc.nextInt();
int n2 = sc.nextInt();
int result = scan1(n1,n2);
System.out.println(" ū "+result);
System.out.println("\n==========================\n");
int result2 =0, n11=0, n22=0;
while(true) {
System.out.println(" Էϼ");
n11 = sc.nextInt();
n22 = sc.nextInt();
if(n11==0||n22==0) break;
result2 = scan2(n11,n22);
System.out.println(" : "+n11+"%"+n22+" = "+result2);
}
}
}
|
Java
|
UTF-8
| 3,745 | 2.09375 | 2 |
[] |
no_license
|
/*
* Copyright 2013-2016 Emmanuel BRUN (contact@amapj.fr)
*
* This file is part of AmapJ.
*
* AmapJ is free software: you can redistribute it and/or modify
* it under the terms of the GNU Affero General Public License as published by
* the Free Software Foundation, either version 3 of the License, or
* (at your option) any later version.
* AmapJ is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU Affero General Public License for more details.
*
* You should have received a copy of the GNU Affero General Public License
* along with AmapJ. If not, see <http://www.gnu.org/licenses/>.
*
*
*/
package fr.amapj.service.engine.deamons;
import java.util.ArrayList;
import java.util.List;
import org.apache.logging.log4j.LogManager;import org.apache.logging.log4j.Logger;
import fr.amapj.common.StackUtils;
import fr.amapj.model.engine.transaction.DataBaseInfo;
import fr.amapj.model.engine.transaction.DbUtil;
import fr.amapj.model.models.saas.TypLog;
import fr.amapj.service.services.appinstance.AppState;
import fr.amapj.service.services.appinstance.LogAccessDTO;
import fr.amapj.service.services.logview.LogViewService;
import fr.amapj.view.engine.ui.AmapJLogManager;
/**
* Utilitaires pour les demons
*
*/
public class DeamonsUtils
{
private final static Logger logger = LogManager.getLogger();
/**
* Permet d'executer un demon dans toutes les bases
*
*/
static public void executeAsDeamon(Class clazz,DeamonsImpl... deamons)
{
// On fait une copie de la liste des bases : on ne veut pas tenir compte des ajouts enventuels de base
// avant la fin du déroulement complet du démon
List<DataBaseInfo> dataBaseInfos = new ArrayList<DataBaseInfo>(DbUtil.getAllDbs());
internalExecuteAsDeamon(clazz, dataBaseInfos, deamons);
}
/**
* Permet d'executer un demon UNIQUEMENT dans la base MASTER
*
*/
static public void executeAsDeamonInMaster(Class clazz,DeamonsImpl... deamons)
{
// On récupere la base de données MASTER
List<DataBaseInfo> dataBaseInfos = new ArrayList<DataBaseInfo>();
dataBaseInfos.add(DbUtil.getMasterDb());
internalExecuteAsDeamon(clazz, dataBaseInfos, deamons);
}
/**
* Permet l'execution d'un demon dans la liste des bases indiqués
*/
static private void internalExecuteAsDeamon(Class clazz,List<DataBaseInfo> dataBaseInfos,DeamonsImpl... deamons)
{
String deamonName = clazz.getSimpleName();
for (DataBaseInfo dataBaseInfo : dataBaseInfos)
{
if (dataBaseInfo.getState()==AppState.ON)
{
LogAccessDTO dto = new LogViewService().saveAccess(deamonName, null, null, null, null, dataBaseInfo.getDbName(), TypLog.DEAMON,false);
DeamonsContext deamonsContext = new DeamonsContext();
DbUtil.setDbForDeamonThread(dataBaseInfo);
logger.info("Début du démon "+deamonName+" pour la base "+dataBaseInfo.getDbName());
for (int i = 0; i < deamons.length; i++)
{
DeamonsImpl deamonsImpl = deamons[i];
try
{
deamonsImpl.perform(deamonsContext);
}
catch(Throwable t)
{
deamonsContext.nbError++;
logger.info("Erreur sur le démon "+deamonName+" pour la base "+dataBaseInfo.getDbName()+"\n"+StackUtils.asString(t));
}
}
logger.info("Fin du démon "+deamonName+" pour la base "+dataBaseInfo.getDbName());
DbUtil.setDbForDeamonThread(null);
new LogViewService().endAccess(dto.id,deamonsContext.nbError);
AmapJLogManager.endLog(true,dto.logFileName);
}
}
}
}
|
Markdown
|
UTF-8
| 871 | 2.6875 | 3 |
[
"MIT"
] |
permissive
|
---
layout: post
title: "2022年前端大方向"
date: 2022-06-15
tags: [note]
---
简述一下目前前端可能的各个领域方向。
## 前端大方向
* Web体系:融合跨端以及标准化,在债务逐年积累之后,能看到标准化已日趋成为共识。
* 中后台:成熟场景下,对效率的极致追求,包括低代码工具,上下游研发流程,以及框架的融合(跨框架)。
* Serverless:前端向后的延展,NodeJS 的新代名词,处于基建发展阶段。
* 体验系统:与业务最具结合性,前端角色最具优势的用户行为分析,以及切入数据最佳的角度。
* 智能化:最具创新性的领域,但角色优势、业务落地场景待探索。
* 多媒体 & 图形 & 互动:新体验、新交互。前端广度的探索。
* 数据可视化:伪装成前端的专业领域。
|
Markdown
|
UTF-8
| 3,847 | 2.8125 | 3 |
[] |
no_license
|
'''顺阳郡''',[[中国|中国]][[西晋|西晋]]时时设置的[[郡|郡]]。
== 历史 ==
[[太康_(西晋)|太康]]十年(289年)改[[南乡郡|南乡郡]]为顺阳郡,郡治在南乡县(今[[河南省|河南省]][[淅川县|淅川县]][[滔河乡|滔河乡]]老人仓一带)。统领八县,[[酂县|酂县]]、[[顺阳县|顺阳县]]、[[南乡县|南乡县]]、[[丹水县|丹水县]]、[[武当县|武当县]]、[[阴县|阴县]]、[[筑阳县|筑阳县]]、[[析县|析县]],共二万一百户。<ref>晋书/卷015/志第五/地理志下</ref>辖境约当今河南省[[西峡|西峡]]、淅川、[[老河口|老河口]]、[[丹江口|丹江口]]等市县和[[湖北省|湖北省]][[谷城县|谷城县]]以及[[十堰市|十堰市]]、[[郧县|郧县]]以东地。顺阳郡的郡名从289年持续到338年,[[东晋|东晋]][[咸康_(东晋)|咸康]]四年(338年)复名南乡郡。
[[刘宋|刘宋]](420年-479年)时期,又改称顺阳郡。[[元嘉_(刘宋)|元嘉]]二十六年(449年),顺阳郡从[[荆州_(古代)|荆州]]划给[[雍州|雍州]],顺阳郡领八县:[[朝阳县_(南阳郡)|朝阳县]](457年废)、武当县、酂县、阴县、泛阳县、筑阳县、[[析县|析县]]、[[修阳县|修阳县]]。<ref>宋書/卷37/志第二十七/州郡三</ref>[[南齐|南齐]](479年-502年)时,[[梁武帝|梁武帝]]父名“[[蕭順之|蕭順之]]",避帝讳“顺”字,郡名和县名皆改为'''从阳''',属[[南北朝|南北朝]]时期从[[长安|长安]]侨置于[[襄阳|襄阳]]的[[雍州|雍州]],辖顺阳、南乡、丹水、[[槐里县_(刘宋)|槐里]]、[[清水县_(河南)|清水]]、[[郑县_(刘宋)|郑县]],其中槐里、清水和郑县为[[侨置县|侨置县]]。<ref>南齊書/卷15/志第七/州郡下</ref>[[建武_(南齐)|建武]]五年(498年),顺阳被[[北魏|北魏]](386年~534年)攻陷,仍曰顺阳郡,郡治移治顺阳县(今[[河南省|河南省]][[淅川县|淅川县]][[李官桥镇|李官桥镇]]),辖[[顺阳县|顺阳县]]、南乡县、丹水县、[[临洮县_(顺阳郡)|临洮县]]和[[槐里县_(刘宋)|槐里县]]。<ref>魏書/卷106下/地形志二下第七</ref>
[[西魏|西魏]](534年-556年)时又改为南乡郡,辖境缩小。[[隋朝|隋朝]][[开皇|开皇]]初年,南乡郡被废除。
== 顺阳国 ==
{| cellpadding="4" cellspacing="0" style="margin: 0 0 1em 1em; border:1px solid #cccccc; text-align:center; empty-cells:show; border-collapse:collapse;" border="1"
|-
| align ="center" colspan="6" bgcolor="#1E90FF"| <small>晉朝顺阳國(286年—311年)</small>
|- bgcolor="#F2F2F2"
| width="70" align ="center"|傳位 || width="70" align ="center"|稱號 || width="70" align ="center"|姓名 || width="75" align ="center"|在位年數 || width="160" align ="center"|在位時間 || width="100" align ="center"|備註
|-
| align ="center"| <small>第1代</small>||<small>[[顺阳王|顺阳王]]</small>||<small>[[司馬畅|司馬畅]]</small>||<small>26年</small>||<small>286年—311年</small>||<small>[[司馬骏|司馬骏]]子</small>
|-
| align ="center" colspan="6" | <small>國絕</small>
|}
==参看==
*[[顺阳县|顺阳县]]
*[[顺阳川|顺阳川]]
*[[顺阳范氏|顺阳范氏]]
*[[顺阳侯|顺阳侯]]
*[[顺阳王|顺阳王]]
*[[顺阳公主|顺阳公主]]
== 参考资料 ==
{{reflist}}
{{已废的南阳市古代行政区划}}
{{西晋行政区划|nocat}}
{{南朝行政區劃|nocat}}
{{DEFAULTSORT:S}}
[[Category:晋朝的郡|Category:晋朝的郡]]
[[Category:刘宋的郡|Category:刘宋的郡]]
[[Category:南齐的郡|Category:南齐的郡]]
[[Category:北魏的郡|Category:北魏的郡]]
[[Category:西魏的郡|Category:西魏的郡]]
[[Category:河南的郡|Category:河南的郡]]
[[Category:湖北的郡|Category:湖北的郡]]
|
Python
|
UTF-8
| 7,848 | 3.375 | 3 |
[] |
permissive
|
#!/usr/bin/env python2
"""
lazylex/html.py - Low-Level HTML Processing.
See lazylex/README.md for details.
TODO: This should be an Oil library eventually. It's a "lazily-parsed data
structure" like TSV2.
"""
from __future__ import print_function
import re
import sys
def log(msg, *args):
msg = msg % args
print(msg, file=sys.stderr)
class LexError(Exception):
"""For bad lexical elements like <> or && """
def __init__(self, s, pos):
self.s = s
self.pos = pos
def __str__(self):
return '(LexError %r)' % (self.s[self.pos : self.pos + 20])
class ParseError(Exception):
"""For errors in the tag structure."""
def __init__(self, msg, *args):
self.msg = msg
self.args = args
def __str__(self):
return '(ParseError %s)' % (self.msg % self.args)
class Output(object):
"""
Takes an underlying input buffer and an output file. Maintains a position in
the input buffer.
Print FROM the input or print new text to the output.
"""
def __init__(self, s, f):
self.s = s
self.f = f
self.pos = 0
def SkipTo(self, pos):
"""Skip to a position."""
self.pos = pos
def PrintUntil(self, pos):
"""Print until a position."""
piece = self.s[self.pos : pos]
self.f.write(piece)
self.pos = pos
def PrintTheRest(self):
"""Print until the end of the string."""
self.PrintUntil(len(self.s))
def Print(self, s):
"""Print text to the underlying buffer."""
self.f.write(s)
# HTML Tokens
( Decl, Comment, Processing,
StartTag, StartEndTag, EndTag,
DecChar, HexChar, CharEntity,
RawData,
Invalid, EndOfStream ) = range(12)
def _MakeLexer(rules):
return [
# DOTALL is for the comment
(re.compile(pat, re.VERBOSE | re.DOTALL), i) for
(pat, i) in rules
]
#
# Eggex
#
# Tag = / ~['>']+ /
# Is this valid? A single character?
# Tag = / ~'>'* /
# Maybe better: / [NOT '>']+/
# capital letters not allowed there?
#
# But then this is confusing:
# / [NOT ~digit]+/
#
# / [NOT digit] / is [^\d]
# / ~digit / is \D
#
# Or maybe:
#
# / [~ digit]+ /
# / [~ '>']+ /
# / [NOT '>']+ /
# End = / '</' Tag '>' /
# StartEnd = / '<' Tag '/>' /
# Start = / '<' Tag '>' /
#
# EntityRef = / '&' dot{* N} ';' /
LEXER = [
# TODO: instead of nongreedy matches, the loop can just fo .find('-->') and
# .find('?>')
(r'<!-- .*? -->', Comment),
(r'<\? .*? \?>', Processing),
# NOTE: < is allowed in these.
(r'<! [^>]+ >', Decl), # <!DOCTYPE html>
(r'</ [^>]+ >', EndTag), # self-closing <br/> comes FIRST
(r'< [^>]+ />', StartEndTag), # end </a>
(r'< [^>]+ >', StartTag), # start <a>
(r'&\# [0-9]+ ;', DecChar),
(r'&\# x[0-9a-fA-F]+ ;', HexChar),
(r'& [a-zA-Z]+ ;', CharEntity),
# Note: > is allowed in raw data.
# https://stackoverflow.com/questions/10462348/right-angle-bracket-in-html
(r'[^&<]+', RawData),
(r'.', Invalid), # error!
]
LEXER = _MakeLexer(LEXER)
def Tokens(s):
"""
Args:
s: string to parse
"""
pos = 0
n = len(s)
while pos < n:
# Find the FIRST pattern that matches.
for pat, tok_id in LEXER:
m = pat.match(s, pos)
if m:
end_pos = m.end()
yield tok_id, end_pos
pos = end_pos
break
# Zero length sentinel
yield EndOfStream, pos
def ValidTokens(s):
"""
Wrapper around Tokens to prevent callers from having to handle Invalid.
I'm not combining the two functions because I might want to do a 'yield'
transformation on Tokens9)? Exceptions might complicate the issue?
"""
pos = 0
for tok_id, end_pos in Tokens(s):
if tok_id == Invalid:
raise LexError(s, pos)
yield tok_id, end_pos
pos = end_pos
# To match <a or </a
# <h2 but not <2h ?
_TAG_RE = re.compile(r'/? \s* ([a-zA-Z][a-zA-Z0-9]*)', re.VERBOSE)
# To match href="foo"
_ATTR_RE = re.compile(r'''
\s+ # Leading whitespace is required
([a-z]+) # Attribute name
(?: # Optional attribute value
\s* = \s*
(?:
" ([^>"]*) " # double quoted value
| ([a-zA-Z0-9_\-]+) # Just allow unquoted "identifiers"
# TODO: relax this? for href=$foo
)
)?
''', re.VERBOSE)
TagName, AttrName, UnquotedValue, QuotedValue = range(4)
class TagLexer(object):
"""
Given a tag like <a href="..."> or <link type="..." />, the TagLexer
provides a few operations:
- What is the tag?
- Iterate through the attributes, giving (name, value_start_pos, value_end_pos)
"""
def __init__(self, s):
self.s = s
self.start_pos = -1 # Invalid
self.end_pos = -1
def Reset(self, start_pos, end_pos):
self.start_pos = start_pos
self.end_pos = end_pos
def TagString(self):
return self.s[self.start_pos : self.end_pos]
def TagName(self):
# First event
tok_id, start, end = next(self.Tokens())
return self.s[start : end]
def GetSpanForAttrValue(self, attr_name):
# Algorithm: search for QuotedValue or UnquotedValue after AttrName
# TODO: Could also cache these
events = self.Tokens()
val = (-1, -1)
try:
while True:
tok_id, start, end = next(events)
if tok_id == AttrName:
name = self.s[start:end]
if name == attr_name:
# For HasAttr()
#val = True
# Now try to get a real value
tok_id, start, end = next(events)
if tok_id in (QuotedValue, UnquotedValue):
# TODO: Unescape this with htmlentitydefs
# I think we need another lexer!
#
# We could make a single pass?
# Shortcut: 'if '&' in substring'
# Then we need to unescape it
val = start, end
break
except StopIteration:
pass
return val
def GetAttr(self, attr_name):
# Algorithm: search for QuotedValue or UnquotedValue after AttrName
# TODO: Could also cache these
start, end = self.GetSpanForAttrValue(attr_name)
if start == -1:
return None
return self.s[start : end]
def Tokens(self):
"""
Yields a sequence of tokens: Tag (AttrName AttrValue?)*
Where each Token is (Type, start_pos, end_pos)
Note that start and end are NOT redundant! We skip over some unwanted
characters.
"""
m = _TAG_RE.match(self.s, self.start_pos+1)
if not m:
raise RuntimeError('Invalid HTML tag: %r' % self.TagString())
yield TagName, m.start(1), m.end(1)
pos = m.end(0)
while True:
# don't search past the end
m = _ATTR_RE.match(self.s, pos, self.end_pos)
if not m:
# A validating parser would check that > or /> is next -- there's no junk
break
yield AttrName, m.start(1), m.end(1)
# Quoted is group 2, unquoted is group 3.
if m.group(2) is not None:
yield QuotedValue, m.start(2), m.end(2)
elif m.group(3) is not None:
yield UnquotedValue, m.start(3), m.end(3)
# Skip past the "
pos = m.end(0)
def ReadUntilStartTag(it, tag_lexer, tag_name):
"""Find the next <foo>.
tag_lexer is RESET.
"""
pos = 0
while True:
try:
tok_id, end_pos = next(it)
except StopIteration:
break
tag_lexer.Reset(pos, end_pos)
if tok_id == StartTag and tag_lexer.TagName() == tag_name:
return pos, end_pos
pos = end_pos
raise ParseError('No start tag %r', tag_name)
def ReadUntilEndTag(it, tag_lexer, tag_name):
"""Find the next </foo>.
tag_lexer is RESET.
"""
pos = 0
while True:
try:
tok_id, end_pos = next(it)
except StopIteration:
break
tag_lexer.Reset(pos, end_pos)
if tok_id == EndTag and tag_lexer.TagName() == tag_name:
return pos, end_pos
pos = end_pos
raise ParseError('No end tag %r', tag_name)
|
Python
|
UTF-8
| 139 | 4.34375 | 4 |
[] |
no_license
|
# On the next line, use Python's print function to say `Hello World` in the console (this exercise is case-sensitive!)
print("Hello World")
|
Markdown
|
UTF-8
| 581 | 3.15625 | 3 |
[] |
no_license
|
# restapp - spring boot
Movie :
Long id;
Sring tittle;
String director;
int yearOfProduction;
Get:
/movies/{id} ->get film by Id
/movies -> get list of film
Post:
/movies -> add film
Sample request:
curl -i -H "Content-Type: application/json" -X POST -d'{
"tittle": "Potop",
"director": "Hoffman",
"yearOfProduction" : "1974"
}' localhost:8080/movies
Sample response:
{
"id":1,
"tittle":"Potop",
"director":"Hoffman",
"yearOfProduction":1974
}
|
JavaScript
|
UTF-8
| 1,874 | 4.0625 | 4 |
[] |
no_license
|
// A robot is located at the top-left corner of a m x n grid (marked 'Start' in the diagram below).
// The robot can only move either down or right at any point in time. The robot is trying to
// reach the bottom-right corner of the grid (marked 'Finish' in the diagram below).
// How many possible unique paths are there?
// ex 1
// Input: m = 3, n = 2
// Output: 3
// Explanation:
// From the top-left corner, there are a total of 3 ways to reach the bottom-right corner:
// 1. Right -> Right -> Down
// 2. Right -> Down -> Right
// 3. Down -> Right -> Right
// ---------------------
// here | |
// ----------------------
// | | end
// ex 2
// Input: m = 7, n = 3
// Output: 28
// var uniquePaths = function (m, n) {
// function fac(n) {
// return (n < 2) ? 1 : fac(n - 1) * n;
// }
// let total = m - 1 + n - 1;
// return fac(total) / fac(m - 1) / fac(n - 1);
// };
// console.log(uniquePaths(3, 2), 3);
// console.log(uniquePaths(7, 3), 28);
// 000
// 000
// 000
// 0000000
// 0000000
// 0000000
// m - 1 = right times
// n - 1 = down times
const numRoutes = (m, n) => {
for (let i = 1; i < m; i++) {
if (i = m)
for (let k = 1; k < n; k++) {
}
}
}
const uniquePaths = (m, n) => {
let routes = 0;
let current = [1, 1];
const walk = () => {
if (current[0] + 1 <= m) {
current[0]++;
walk();
current[0]--;
}
if (current[1] + 1 <= n) {
current[1]++;
walk();
current[1]--;
}
if (current[0] === m && current[1] === n) routes++;
}
walk();
return routes;
}
// 0, 0, 0, 0
// 0, 0, 0, 0
// 0, 0, 0, 0
console.log(uniquePaths(7, 3))
// if left go left
// if right go right
// 0
// / \
// 0 0
// / \ / \
// 0 0 0 0
// [1,1]
// / \
// [1,2] [2,1]
|
Java
|
UTF-8
| 929 | 2.84375 | 3 |
[] |
no_license
|
package ac.za.cput.cardealership.domain.vehicle;
public class Manufacturer {
private String name;
private String address;
public Manufacturer(String name, String address) {
this.name = name;
this.address = address;
}
public String getName() {
return name;
}
public String getAddress() {
return address;
}
public Manufacturer(Builder builder) {
this.name= builder.name;
this.address = builder.address ;
}
public static class Builder {
private String name;
private String address;
public Builder name(String name) {
this.name = name;
return this;
}
public Builder address(String address) {
this.address = address;
return this;
}
public Manufacturer build() {
return new Manufacturer(this);
}
}
}
|
C#
|
UTF-8
| 6,075 | 2.71875 | 3 |
[] |
no_license
|
using System;
using System.Collections;
using System.Collections.Generic;
using System.Linq;
namespace arookas {
interface sunTerm {
sunExpressionFlags GetExpressionFlags(sunContext context);
}
class sunExpression : sunNode, sunTerm {
public sunExpression(sunSourceLocation location)
: base(location) { }
public override void Compile(sunCompiler compiler) {
var operatorStack = new Stack<sunOperator>(32);
CompileExpression(compiler, this, operatorStack);
}
public sunExpressionFlags Analyze(sunContext context) {
return AnalyzeExpression(context, this);
}
static void CompileExpression(sunCompiler compiler, sunExpression expression, Stack<sunOperator> operatorStack) {
var stackCount = operatorStack.Count;
foreach (var node in expression) {
if (node is sunOperand) {
var operand = node as sunOperand;
// term
var term = operand.Term;
if (term is sunExpression) {
CompileExpression(compiler, term as sunExpression, operatorStack);
}
else {
term.Compile(compiler);
}
var unaryOperators = operand.UnaryOperators;
if (unaryOperators != null) {
unaryOperators.Compile(compiler);
}
}
else if (node is sunOperator) {
var operatorNode = node as sunOperator;
while (operatorStack.Count > stackCount &&
(operatorNode.IsLeftAssociative && operatorNode.Precedence <= operatorStack.Peek().Precedence) ||
(operatorNode.IsRightAssociative && operatorNode.Precedence < operatorStack.Peek().Precedence)) {
operatorStack.Pop().Compile(compiler);
}
operatorStack.Push(operatorNode);
}
}
while (operatorStack.Count > stackCount) {
operatorStack.Pop().Compile(compiler);
}
}
static sunExpressionFlags AnalyzeExpression(sunContext context, sunExpression expression) {
var flags = sunExpressionFlags.None;
foreach (var operand in expression.OfType<sunOperand>()) {
var term = operand.Term as sunTerm;
if (term != null) {
flags |= term.GetExpressionFlags(context);
}
}
return flags;
}
sunExpressionFlags sunTerm.GetExpressionFlags(sunContext context) {
return AnalyzeExpression(context, this);
}
}
[Flags]
enum sunExpressionFlags {
None = 0,
// contents
Literals = 1 << 0,
Variables = 1 << 1,
Augments = 1 << 2,
Calls = 1 << 3,
Constants = 1 << 4,
// description
Dynamic = 1 << 5,
}
class sunOperand : sunNode {
public sunNode UnaryOperators { get { return Count > 1 ? this[0] : null; } }
public sunNode Term { get { return this[Count - 1]; } }
public sunOperand(sunSourceLocation location)
: base(location) { }
// operands are compiled in sunExpression.Compile
}
class sunUnaryOperatorList : sunNode {
public sunUnaryOperatorList(sunSourceLocation location)
: base(location) { }
public override void Compile(sunCompiler compiler) {
foreach (var child in this.Reverse()) {
// compile unary operators in reverse order
child.Compile(compiler);
}
}
}
class sunTernaryOperator : sunNode, sunTerm {
public sunExpression Condition { get { return this[0] as sunExpression; } }
public sunExpression TrueBody { get { return this[1] as sunExpression; } }
public sunExpression FalseBody { get { return this[2] as sunExpression; } }
public sunTernaryOperator(sunSourceLocation location)
: base(location) { }
public override void Compile(sunCompiler compiler) {
Condition.Compile(compiler);
var falsePrologue = new sunJumpNotEqualSite(compiler.Binary);
TrueBody.Compile(compiler);
var trueEpilogue = new sunJumpSite(compiler.Binary);
falsePrologue.Relocate();
FalseBody.Compile(compiler);
trueEpilogue.Relocate();
}
sunExpressionFlags sunTerm.GetExpressionFlags(sunContext context) {
return Condition.Analyze(context) | TrueBody.Analyze(context) | FalseBody.Analyze(context);
}
}
// increment/decrement
class sunPostfixAugment : sunOperand, sunTerm {
public sunIdentifier Variable { get { return this[0] as sunIdentifier; } }
public sunAugment Augment { get { return this[1] as sunAugment; } }
public sunPostfixAugment(sunSourceLocation location)
: base(location) { }
public override void Compile(sunCompiler compiler) {
var symbol = compiler.Context.MustResolveStorable(Variable);
if (symbol is sunConstantSymbol) {
throw new sunAssignConstantException(Variable);
}
if (Parent is sunOperand) {
symbol.CompileGet(compiler);
}
Augment.Compile(compiler, symbol);
}
sunExpressionFlags sunTerm.GetExpressionFlags(sunContext context) {
return sunExpressionFlags.Augments;
}
}
class sunPrefixAugment : sunOperand, sunTerm {
public sunAugment Augment { get { return this[0] as sunAugment; } }
public sunIdentifier Variable { get { return this[1] as sunIdentifier; } }
public sunPrefixAugment(sunSourceLocation location)
: base(location) { }
public override void Compile(sunCompiler compiler) {
var symbol = compiler.Context.MustResolveStorable(Variable);
if (symbol is sunConstantSymbol) {
throw new sunAssignConstantException(Variable);
}
Augment.Compile(compiler, symbol);
if (Parent is sunOperand) {
symbol.CompileGet(compiler);
}
}
sunExpressionFlags sunTerm.GetExpressionFlags(sunContext context) {
return sunExpressionFlags.Augments;
}
}
abstract class sunAugment : sunNode {
protected sunAugment(sunSourceLocation location)
: base(location) { }
public abstract void Compile(sunCompiler compiler, sunStorableSymbol symbol);
}
class sunIncrement : sunAugment {
public sunIncrement(sunSourceLocation location)
: base(location) { }
public override void Compile(sunCompiler compiler, sunStorableSymbol symbol) {
symbol.CompileInc(compiler);
symbol.CompileSet(compiler);
}
}
class sunDecrement : sunAugment {
public sunDecrement(sunSourceLocation location)
: base(location) { }
public override void Compile(sunCompiler compiler, sunStorableSymbol symbol) {
symbol.CompileDec(compiler);
symbol.CompileSet(compiler);
}
}
}
|
JavaScript
|
UTF-8
| 4,798 | 2.59375 | 3 |
[] |
no_license
|
import React, { Component } from "react";
//import { Carousel } from 'react-responsive-carousel';
//require ('react-responsive-carousel/lib/styles/carousel.css');
// import burger from './images/burger.jpg';
// import nachos from './images/nachos.jpg';
// import chinese from './images/chinese.jpg';
import axios from 'axios';
class Category extends Component {
render() {
return (
<div>
<h2>1. Choose a category! -- add as many as you want!</h2>
<div className="foodChoice">
{/* <div className="foodCarousel">
<Carousel showArrows={true} useKeyboardArrows={true} showThumbs={false} infiniteLoop={true} showIndicators={false} dynamicHeight={true} onClickItem={select}>
<div>
<img src={burger} alt="American"/>
<p className="legend">American</p>
</div>
<div>
<img src={chinese} alt="chinese"/>
<p className="legend">Chinese</p>
</div>
<div>
<img src={nachos} alt="nachos"/>
<p className="legend">Mexican</p>
</div>
</Carousel>
</div> */}
<div className="foodChoices" id="foodChoices">
<div className="genre" id="chinese"><span className="imageTitle">Chinese<input type="checkbox" value="chinese" /></span></div>
<div className="genre" id="mexican"><span className="imageTitle">Mexican<input type="checkbox" value="mexican" /></span></div>
<div className="genre" id="italian"><span className="imageTitle">Italian<input type="checkbox" value="italian" /></span></div>
<div className="genre" id="japanese"><span className="imageTitle">Japanese<input type="checkbox" value="japanese" /></span></div>
<div className="genre" id="american"><span className="imageTitle">American<input type="checkbox" value="american" /></span></div>
</div>
<div className="distance-content">
<label>Breakfast<input type="radio" onClick={setTerm} id="breakfast" value="Breakfast" name="mealType"/></label>
<label>Lunch<input type="radio" onClick={setTerm} id="lunch" value="Lunch" name="mealType"/></label>
<label>Dinner<input type="radio" onClick={setTerm} id="dinner" value="Dinner" name="mealType"/></label>
</div>
<form>
<span className="icon"><i className="fa fa-search"></i></span>
<input type="text" id="uiCat" placeholder="Add new item"/>
<button type="button" id="addbutton" onClick={addItem}>Add</button>
{/* <input type="submit" value="submit"/> */}
{/* <NavLink to="/Mealtype">
<input type="submit" id="next" onClick={this.myfunction.bind(this)} value="Submit"/>
</NavLink> */}
</form>
</div>
</div>
);
}
// yelp () {
// var term = document.getElementById("uiCat").value;
// console.log(term);
// // console.log("hello");
// axios.get('http://localhost:8080/yelpInput', {
// headers: {
// 'Access-Control-Allow-Origin': '*',
// 'Content-Type': 'applications/json',
// },
// params: {
// term: term
// }
// })
// .then(function(response) {
// console.log(response.data);
// localStorage.setItem('item', JSON.stringify(response.data));
// console.log("=== " + localStorage.getItem('item'));
// }).catch(function(response) {
// console.log('error:');
// console.log(response);
// });
// }
}
var paramString;
sessionStorage.setItem('paramString', paramString);
paramString = sessionStorage.getItem('paramString');
// Sets user's term parameter
function setTerm(radio) {
console.log(radio.target.id);
sessionStorage.setItem('mealType', radio.target.id);
}
function addItem(button){
// var temp = localStorage.getItem('term');
// console.log(temp+"+"+document.getElementById("uiCat").value);
// temp+"+"+document.getElementById("uiCat").value;
// localStorage.setItem('term', temp);
if(paramString === "undefined"){
console.log('no string');
paramString = document.getElementById("uiCat").value;
}else{
paramString += "+"+document.getElementById("uiCat").value;
}
sessionStorage.setItem('paramString', paramString);
}
// function setCheck(checkbox){
// var genres = document.getElementById("foodChoices");
// console.log(genres.children);
// for(var i = 0; i < genres.children.length; i++){
// // if(genres.children[i].children[1].checked){
// // console.log('checked');
// // }
// console.log(genres.children[i].firstChild.children.checked);
// }
// }
export default Category;
|
C#
|
UTF-8
| 2,136 | 3.21875 | 3 |
[] |
no_license
|
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace Bug
{
class Nodo
{
// Esta clase crea nodos fijos
// Se conectan a otros nodos con la lista de vecinos
// No se utilizan objetos para las aristas
public double x; //coordenadas
public double y;
//public double f; //costo total f = g h
//public double g; //costo para llegar a este nodo
//public double h; //costo heurística
public double dist = -1; //distancia recorrida, por ahora no está calculada
public bool visto = false; //este nodo no ha sido visto (o visitado)
public Circulo c; //se usa para dibujar el nodo
public List<Nodo> vecino; //lista de nodos vecinos, asignados después de la triangulación
Nodo padre; //indica el nodo precedente en la ruta más corta
//------------------------------------------------------------------------------
public Nodo(double x, double y, Circulo c)
{
// constructor
this.x = x; //asignar coordenadas
this.y = y;
this.c = c;
vecino = new List<Nodo>(); //crear lista de vecinos
}
//------------------------------------------------------------------------------
public double Distancia_a_nodo(Nodo nd)
{
// distancia euclidiana
return Math.Sqrt((nd.x - x) * (nd.x - x) + (nd.y - y) * (nd.y - y));
}
//------------------------------------------------------------------------------
public void Agregar_vecino(Nodo nd)
{
if (nd == null) return; //no agregar si es null
if (vecino.Contains(nd) == false) //si todavía no está agregado
{
vecino.Add(nd); //agregar a la lista dinámica
}
if (nd.vecino.Contains(this) == false)
{
nd.vecino.Add(this);
}
}
//------------------------------------------------------------------------------
}
}
|
PHP
|
UTF-8
| 2,506 | 3 | 3 |
[
"MIT"
] |
permissive
|
<?php
if (!function_exists('getSheetHeaderChar')) {
/**
* @param int $index
* @return mixed
*/
function getSheetHeaderChar(int $index)
{
$key = $index;
static $columnHeader = [];
if (!isset($columnHeader[$index])) {
$chars = '';
$asciiNumber = ord('A');
$i = 0;
do {
$index = $i > 0 ? $index - 1 : $index;
$chars = chr($index % 26 + $asciiNumber) . $chars;
$index = intval($index / 26);
$i++;
} while ($index > 0);
$columnHeader[$key] = $chars;
}
return $columnHeader[$key];
}
}
if (!function_exists('getSheetHeaderIndex')) {
/**
* @param string $chars
* @return int
*/
function getSheetHeaderIndex(string $chars)
{
$key = $chars;
static $columnHeader = [];
if (!isset($columnHeader[$key])) {
$chars = str_split(strrev($chars));
$asciiNumber = ord('A');
$number = 0;
foreach ($chars as $index => $char) {
$number += (ord($char) - $asciiNumber) + 26 * $index;
if ($index === 0) {
$number += 1;
}
}
$columnHeader[$key] = $number - 1;
}
return $columnHeader[$key];
}
}
if (!function_exists('createUniqueId')) {
/**
* @param string $suffix
* @param string $prefix
* @return string
*/
function createUniqueId($suffix = '', $prefix = '')
{
return $prefix . uniqid(php_uname('n') . getmypid(), true) . $suffix;
}
}
if (!function_exists('isUTF8Code')) {
/**
* @param $string
* @return bool
*/
function isUTF8Code($string)
{
if (function_exists('mb_check_encoding')) {
return mb_check_encoding($string, 'UTF-8') ? true : false;
}
return preg_match("//u", $string) ? true : false;
}
}
if (!function_exists('download')) {
/**
* @param string $filename
* @param string $filepath
* @param string $contentType
*/
function download(string $filename, string $filepath, $contentType = 'text/csv')
{
header('Content-Type: ' . $contentType);
header('Content-Disposition: attachment; filename="' . $filename . '"');
header('Cache-Control: max-age=0');
header('Pragma: public');
readfile($filepath);
}
}
|
Java
|
UTF-8
| 382 | 1.789063 | 2 |
[] |
no_license
|
package com.huawei.cloud;
import org.ini4j.Config;
import org.ini4j.Configurable;
public class SettingsComponent implements Configurable {
@Override
public Config getConfig() {
Config global = Config.getGlobal();
global.setGlobalSectionName("ServiceStage");
return global;
}
@Override
public void setConfig(Config config) {
}
}
|
C#
|
UTF-8
| 2,417 | 2.515625 | 3 |
[
"MIT"
] |
permissive
|
using System.Collections.Generic;
using System.Linq;
using TravellerTracker.Models;
using TravellerTracker.Support;
using Windows.UI.Xaml;
using Windows.UI.Xaml.Controls;
using Windows.UI.Xaml.Media.Imaging;
// The User Control item template is documented at https://go.microsoft.com/fwlink/?LinkId=234236
namespace TravellerTracker.UserControls
{
public sealed partial class ImageViewer : UserControl
{
public int ShipID
{
get { return (int)GetValue(ShipIDProperty); }
set { SetValue(ShipIDProperty, value); }
}
public int WorldID
{
get { return (int)GetValue(WorldIDProperty); }
set { SetValue(WorldIDProperty, value); }
}
// Using a DependencyProperty as the backing store for WorldID. This enables animation, styling, binding, etc...
public static readonly DependencyProperty WorldIDProperty =
DependencyProperty.Register("WorldID", typeof(int), typeof(ImageViewer), new PropertyMetadata(0));
// Using a DependencyProperty as the backing store for ShipID. This enables animation, styling, binding, etc...
public static readonly DependencyProperty ShipIDProperty =
DependencyProperty.Register("ShipID", typeof(int), typeof(ImageViewer), new PropertyMetadata(0));
public ImageViewer()
{
this.InitializeComponent();
Loaded += ImageViewer_Loaded;
}
private async void ImageViewer_Loaded(object sender, RoutedEventArgs e)
{
List<MyImageList> myImageList = new List<MyImageList>();
List<ImageList> imageList = new List<ImageList>();
if (ShipID > 0) imageList = App.DB.ImageLists.Where(x => x.ShipID == ShipID).ToList();
else if (WorldID > 0) imageList = App.DB.ImageLists.Where(x => x.WorldID == WorldID).ToList();
ImageHandler ih = new ImageHandler();
foreach (ImageList item in imageList)
{
BitmapImage i = await ih.bytesToImage(item.theImage);
myImageList.Add(new MyImageList() { bmp = i, Description = item.Description });
}
ctlCarousel.ItemsSource = myImageList;
}
private class MyImageList
{
public BitmapImage bmp { get; set; }
public string Description { get; set; }
}
}
}
|
JavaScript
|
UTF-8
| 3,674 | 2.53125 | 3 |
[] |
no_license
|
class Protocol{
on_connected(){}
on_disconnected(){}
on_message(message){}
send(message){}
}
class IdentityProtocol extends Protocol
{
constructor(){
super()
this.client_id=null;
}
on_message(message){
if(message.hasOwnProperty('unique_client_id')){
if(this.client_id==null){
this.client_id=message.unique_client_id;
}
return {'client_id':this.client_id};
}
return null;
}
}
class AckProtocol extends IdentityProtocol{
constructor(){
super();
this.queue={};
this.acks=[];
this.msg_id_counter=0;
this.client=null;
this.components=[]
}
add_component(component){
component.setProtocol(this);
this.components.push(component);
}
gen_msg_id(){
if(this.msg_id_counter==Number.MAX_SAFE_INTEGER){
this.msg_id_counter=0;
}
this.msg_id_counter+=1;
return this.msg_id_counter;
}
message_to_remove(msg_ids, key){
msg_ids.forEach(function(id_){
message = this.queue[id_];
msg_keys = Object.keys(message);
if(msg_keys.includes(key))
return id_
});
}
on_disconnected(){
console.log('protocol.js AckProtocol on_disconnected()');
}
on_connected(){
//check if something on queue and return all messages ordered by id
//if next server message is ack, doesn't matter will be sent twice
super.on_connected();
this.acks.forEach(function(ack){
this.send(ack);
});
//must ignore message with dev_id key
var msg_ids = Object.keys(this.queue);
if(msg_ids.length>0){
index = msg_ids.indexOf(this.message_to_remove(msg_ids, 'client_id'));
msg_ids.splice(index,1);
}
msg_ids.forEach(function(id_){
message = this.queue[id_];
message['resend']=1;
self.send(message);
});
}
on_message(message){
console.log('protocol.js AckProtocol on_message(): message='+message);
message = JSON.parse(message);
var on_connect_msg = super.on_message(message);
if(on_connect_msg){
this.send(on_connect_msg);
}
this.acks=[];
//acknowledge message
if(message.hasOwnProperty('ack')){
var msg_id = message['ack'];
if(this.queue[msg_id].hasOwnProperty('client_id')){
console.log('protocol.js AckProtocol on_message(): call onload for each component');
this.components.forEach(function(component){
component.onload();
});
}
delete this.queue[msg_id];
console.log("protocol.js AckProtocol on_message(): got ack for message "+msg_id);
return null;
}else{
// return ack and extract message
// onyl if server signed the message
if(message.hasOwnProperty('id')){
var msg_id = message['id'];
var ack = {'ack':msg_id};
this.acks.push(ack);
console.log("protocol.js AckProtocol on_message: return ack for message "+JSON.stringify(message));
this.send(ack);
}
if(on_connect_msg==null){
this.components.forEach(function(component){
component.on_message(message);
})
}
}
return message;
}
send(message){
console.log("protocol.js AckProtocol send(): send message "+JSON.stringify(message));
super.send(message);
//add message_id to message so it can be acknowledged, only if not ack messag
if(!message.hasOwnProperty('ack') && !message.hasOwnProperty('resend')){
var id_ = this.gen_msg_id();
this.queue[id_]=message;
message['id']=id_
console.log('protocol.js AckProtocol send(): signed message '+JSON.stringify(message));
}
if(message.hasOwnProperty('resend')){
console.log('protocol.js AckProtocol send(): resend message '+JSON.stringify(message));
delete message['resend'];
}
this.client.send(JSON.stringify(message));
}
setClient(client){
this.client=client;
}
}
|
C++
|
UHC
| 1,410 | 2.703125 | 3 |
[] |
no_license
|
#include "ChatServer.h"
#include "LogicProcess.h"
#include "UserManager.h"
#include "RoomManager.h"
#include <string>
#include <iostream>
#include <memory>
void ErrorExit(const char* msg)
{
printf("%s\n", msg);
exit(1);
}
int main()
{
const int SERVER_PORT = 9898;
std::unique_ptr<LogicProcess> logicProcess = std::make_unique<LogicProcess>();
std::unique_ptr<SendServer> sendServer = std::make_unique<SendServer>();
std::unique_ptr<UserManager> userManager = std::make_unique<UserManager>();
std::unique_ptr<RoomManager> roomManager = std::make_unique<RoomManager>();
userManager->SetMgr(roomManager.get(), sendServer.get());
roomManager->SetMgr(userManager.get(), sendServer.get());
logicProcess->SetMgr(roomManager.get(), userManager.get(), sendServer.get());
std::unique_ptr<ChatServer> chatServer = std::make_unique<ChatServer>(logicProcess.get());
if(false == chatServer->Initialize(SERVER_PORT))
{
ErrorExit("[CLOSED] SERVER INITIALIZE FAIL\n");
}
if(false == chatServer->RunServer())
{
ErrorExit("[CLOSED] IOCP SERVER RUN FAIL\n");
}
printf("[INFO] quit Է½ մϴ.\n");
while (true)
{
std::string inputCmd;
std::getline(std::cin, inputCmd);
if (inputCmd == "quit")
{
break;
}
}
chatServer->CloseServer();
logicProcess->Close();
printf("[INFO] SERVER CLOSED. PRESS ENTER TO EXIT.\n");
getchar();
return 0;
}
|
Markdown
|
UTF-8
| 5,873 | 3.25 | 3 |
[
"WTFPL"
] |
permissive
|
---
title: Geek’s Guide to Menstrual Cups
date: 2015-11-29
---
<img src="https://i.imgsafe.org/2380ccd.png" class="scaling left" alt="Geeks Guide to Menstrual Cups"/>
#### What is a Menstrual Cup?
A menstrual cup is a small cup (usually made of silicone) that sits in the vaginal canal to collect menstrual fluid. They can be disposable and generally come in two sizes.
#### Why Use a Menstrual Cup?
There’s a variety reasons to use a menstrual cup over tampons or pads. First reusable menstrual cups cause way less waste. There’s the added benefit of saving money since you don’t need to go out for more supplies every month. They can stay in longer than tampons (generally for up to 12 hours) and so they can be worn overnight. As long as the seal is solid and it doesn’t leak there will be no odor and there’s the added benefit that it’s easy to keep in a bag so you can always have it with you.
#### What are the Different Types and Sizes?
There are many brands of menstrual cup, though as of this writing there’s only one brand of disposable menstrual cup. Some of the more popular brands are DivaCup, Lena, Lunette, Lily Cup, etc. They all advertise different benefits and some are better for certain people.
Most cups come in two sizes. Some brands differentiate the sizes based on whether or not you’ve had children others do this based on the amount of flow you tend to have.
Note that the average volume of menstrual fluid for the entire duration is 35 mL and the normal range is about 10-80 mL. Most cups can hold around 30 mL so unless you have quite a higher than normal flow the ability to hold larger volumes is probably not a concern.
Menstrual cups generally have lines on them for measuring fluid so if you’re interested in data about your body and cycle it’s all right there.
Picking the right cup requires a fair amount of knowledge about yourself and menstrual flow. You should be familiar with the location of your cervix and be aware that this changes during your flow.
You can figure out if you have a high or low cervix by inserting your finger into your vagina and feeling for a small nub (your cervix). Based on how deep you have to insert your finger to reach it will tell you. Anything before the first knuckle of your finger is a low cervix and anything after the second knuckle is high. Between the two is medium.

People with a low cervix should consider shorter cups or those made for people with a low cervix additionally if it’s not super low they can get away with trimming the stem (note: make sure where to trim first and that you aren’t cutting a hole in the cup).
If you have a high cervix there aren’t really any special considerations, but you may want to look for something with a nice long stem.
#### How are Menstrual Cups Inserted?
First things first, before inserting the cup you’ll want to sterilize it by boiling it in water for about 5 minutes (unless it’s disposable).
1. Wash your hands
2. Fold
3. Insert
#### What the Fold?
Okay okay okay. How you fold menstrual cups is one of the biggest discussed things about them. I’ve seen so many different types of folds discussed and created. Some people just like making up their own folds. Whatever works. I’ve even seen one called the clown fold. I don’t even want to think about it.
In general there’s two main folds that are most often used:
C-fold
Just fold the cup in half like the letter C.
Punch-down fold
Take one side and push it down so the top forms a soft point. This is generally easier to insert if you are a bit smaller than the C-fold.

Once you have it folded you can apply some water-based lubricant or just water to give it a little help sliding in. Never use silicone based lubricant on any silicone products, like menstrual cups, because it will cause it to deteriorate. You’ll probably want to get into the ‘hover’ position over a toilet - or Captain Morgan it which ever works for you. Then just relax and ease the cup toward the small of your back.
After you insert it you’ll want to rotate it to make sure it’s fully open. It can be a little shocking to feel it pop open if you don’t do this. I don’t recommend forgetting to make sure it’s open.

Don’t worry - this will all take some getting used to. It can take a bit to figure out the right fold. The right position to to place yourself in. It’s just a process to learn your body and how it works.
#### How are Menstrual Cups Removed?
Wash your hands first. Removal generally requires squeezing the base of the cup to break the seal and you’ll hear a little pop. You’ll want to then slowly rock the cup from side to side to remove. Some kegels can also help push it along. Relaxing is super important here so your muscles won’t hang onto the cup. I’ve also found that folding the cup on the way out helps prevent it from hitting urethra which is super painful and not fun at all.
Empty it out in the toilet and then wash. You’ll want to wash with icy cold water at first to prevent any staining and then you can follow up with hot water and mild soap or menstrual cup wash.
If your period is finally over you can boil the cup and store it in a breathable bag and be ready for next time.
#### What now?
Do some research on what sort of cup you may want. Determine if you are able to have a menstrual cup if you have specific medical concerns. Figure out what your body is like and what your cervix position generally is. When you get your cup remember to be patient with yourself and relax because it does take a bit of practice and can honestly take a number of cycles to master.
|
Markdown
|
UTF-8
| 1,972 | 2.546875 | 3 |
[] |
no_license
|
# CARL
The implementation of “A Context-Aware User-Item Representation Learning for Item Recommendation”, Libing Wu, Cong Quan, Chenliang Li, Qian Wang, Bolong Zheng, Xiangyang Luo, https://dl.acm.org/citation.cfm?id=3298988
## Requirements
Tensorflow 1.2
Python 2.7
Numpy
Scipy
## Data Preparation
To run CARL, 6 files are required:
### Training Rating records:
file_name=TrainInteraction.out
each training sample is a sequence as:
UserId\tItemId\tRating\tDate
Example: 0\t3\t5.0\t1393545600
### Validate Rating records:
file_name=ValInteraction.out
The format is the same as the training data format.
### Testing Rating records:
file_name=TestInteraction.out
The format is the same as the training data format.
### Word2Id diction:
file_name=WordDict.out
Each line follows the format as:
Word\tWord_Id
Example: love\t0
### User Review Document:
file_name=UserReviews.out
each line is the format as:
UserId\tWord1 Word2 Word3 …
Example:0\tI love to eat hamburger …
### Item Review Document:
file_name=ItemReviews.out
The format is the same as the user review doc format.
## Note that:
All files need to be located in the same directory.
Besides, the code also supports to leverage the pretrained word embedding via uncomment the loading function “word2vec_word_embed” in the main file .
Carl.py denotes the model named CARL; Review.py denotes the review-based component while Interaction.py denotes the interaction-based component.
## Configurations
word_latent_dim: the dimension size of word embedding;
latent_dim: the latent dimension of the representation learned from the review documents (entity);
max_len: the maximum doc length;
num_filters: the number of filters of CNN network;
window_size: the length of the sliding window of CNN;
learning_rate: learning rate;
lambda_1: the weight of the regularization part;
drop_out: the keep probability of the drop out strategy;
batch_size: batch size;
epochs: number of training epoch;
|
C#
|
UTF-8
| 1,026 | 2.734375 | 3 |
[
"MIT"
] |
permissive
|
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Xml.Linq;
namespace Datengenerator.Kern
{
class FeldVsTage : Feld
{
public readonly Random Prop;
public FeldVsTage(XElement xml, Random r, Random prop) : base(xml, r)
{
Prop = prop;
}
public override string Generieren(out bool schlecht)
{
if (SchlechtdatenGenerieren && Random.Next(0, SchlechtdatenWahrscheinlichkeit) == 0)
{
schlecht = true;
switch (Random.Next(0, 3))
{
case 0:
return "0";
case 1:
return "94";
default:
return "A";
}
}
else
{
schlecht = false;
return (1 + Prop.Next(90)).ToString();
}
}
}
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.