
language
stringclasses 15
values | src_encoding
stringclasses 34
values | length_bytes
int64 6
7.85M
| score
float64 1.5
5.69
| int_score
int64 2
5
| detected_licenses
listlengths 0
160
| license_type
stringclasses 2
values | text
stringlengths 9
7.85M
|
|---|---|---|---|---|---|---|---|
C++
|
UTF-8
| 3,716 | 3.5625 | 4 |
[] |
no_license
|
#include <iostream>
#include <vector>
#include <functional>
#include <cassert>
#include "BigInt.h"
void test1()
{
std::cout << "TEST CONSTRUCTORS AND OUTPUT." << std::endl;
BigInt a = 1337;
BigInt b("100500100500100500100500");
std::cout << "Init a = " << a << " and " << "b = " << b << std::endl;
BigInt a_copy(a);
BigInt b_moved(std::move(b));
std::cout << "Copied from a = " << a_copy << std::endl;
std::cout << "Moved from b = " << b_moved << std::endl;
assert(b.empty());
}
void test2()
{
std::cout << "TEST ASSIGNMENT OPERATOR AND (UN)EQUALITY OPERATORS" << std::endl;
BigInt a = 1337;
BigInt a_copy = a;
BigInt b = 1337;
std::cout << "Init a = " << a << ", a_copy = a, b = " << b << std::endl;
std::cout << "Check for a == b and a_copy == b" << std::endl;
assert(a == b);
assert(a_copy == b);
std::cout << "Make a = a + 1" << std::endl;
a = a + 1;
std::cout << "Check for a != b and a != a_copy" << std::endl;
assert(a != b);
assert(a != a_copy);
std::cout << "Move b to b_moved." << std::endl;
BigInt b_moved = std::move(b);
assert(b_moved == 1337);
assert(b.empty());
std::cout << "b_moved = " << b_moved << std::endl;
}
void test3()
{
std::cout << "TEST COMPARISION OPERATORS" << std::endl;
BigInt a("12345678901234567890");
BigInt b("-12345678901234567890");
BigInt zero = 0;
BigInt small = 1337;
std::cout << "Init a = " << a << ", b = " << b << ", zero = " << zero << ", small = " << small << std::endl;
std::cout << "Check for a > b." << std::endl;
assert(a > b);
std::cout << "Check for a <= a." << std::endl;
assert(a <= a);
std::cout << "Check for small < a." << std::endl;
assert(small < a);
std::cout << "Check for small >= zero." << std::endl;
assert(small >= zero);
std::cout << "Check for !(zero < zero)." << std::endl;
assert(!(zero < zero));
}
void test4()
{
std::cout << "TEST ARITHMETIC OPERATORS" << std::endl;
BigInt a("12345678901234567890");
BigInt min_a("-12345678901234567890");
BigInt b("987654321123456789");
std::cout << "Init a = " << a << ", min_a = " << min_a << ", b = " << b << std::endl;
BigInt res1 = 0; // a + min_a
std::cout << "Check for a + min_a = min_a + a = 0" << std::endl;
std::cout << min_a + a << std::endl;
assert(min_a + a == 0);
BigInt res2("24691357802469135780"); // a - min_a
std::cout << "Check for a - min_a == " << res2 << " and min_a - a = " << -res2 << std::endl;
assert(a - min_a == res2 && min_a - a == -res2);
BigInt res3("11358024580111111101");
std::cout << "Check for a - b = 11358024580111111101" << std::endl;
assert(a - b == res3);
BigInt res4("13333333222358024679");
std::cout << "Check for a + b = 13333333222358024679" << std::endl;
assert(a + b == res4);
std::cout << "Check for a * b = 12193263114007011086297820577501905210" << std::endl;
BigInt res5("12193263114007011086297820577501905210");
assert(a * b == res5);
std::cout << "Check for b * 0 = 0" << std::endl;
assert(b * 0 == 0);
std::cout << "Check for b * -1 = -b" << std::endl;
assert(b * -1 == -b);
std::cout << "Check for (b + 1) * 2 = b + b + 2" << std::endl;
assert((b + 1) * 2 == b + b + 2);
std::cout << "Check for b + (-b) == a * a * 0" << std::endl;
assert(b + (-b) == a * a * 0);
}
int main()
{
std::vector<std::function<void()>> tests = {test1, test2, test3, test4};
for (const auto& test : tests) {
test();
std::cout << std::endl;
}
}
|
Python
|
UTF-8
| 325 | 2.8125 | 3 |
[] |
no_license
|
def pytha(a,b,c):
if (a*a)+(b*b)==(c*c)
return true
else if (a*a)+(c*c)==(b*b)
return true
else if (c*c)+(b*b)==(a*a)
return true
else
return false
def pytha2(a,b,c):
return (a*a)+(b*b)==(c*c)||(a*a)+(c*c)==(b*b)||(c*c)+(b*b)==(a*a)
# // rundet gegen -unendlich
# -10//3 = -4 = 10//-3
# & rundet gegen 0
#
|
JavaScript
|
UTF-8
| 2,472 | 3.453125 | 3 |
[
"MIT"
] |
permissive
|
/*
* Напиши скрипт создания и очистки коллекции элементов. Пользователь вводит количество элементов в input и нажимает кнопку Создать, после чего рендерится коллекция. При нажатии на кнопку Очистить, коллекция элементов очищается.
* Создай функцию createBoxes(amount), которая принимает 1 параметр amount - число. Функция создает столько div, сколько указано в amount и добавляет их в div#boxes.
* азмеры самого первого <div> - 30px на 30px.
* Каждый элемент после первого, должен быть шире и выше предыдущего на 10px.
* Все элементы должены иметь случайный цвет фона в формате HEX. Используй готовую функцию getRandomHexColor для получения цвета.
* Создай функцию destroyBoxes(), которая очищает содержимое div#boxes, тем самым удаляя все созданные элементы.
*/
const refs = {
input: document.querySelector('#controls > input'),
createBtn: document.querySelector('[data-create]'),
clearBtn: document.querySelector('[data-destroy]'),
boxes: document.querySelector('#boxes'),
};
const { input, createBtn, clearBtn, boxes } = refs;
createBtn.addEventListener('click', createBoxes);
clearBtn.addEventListener('click', destroyBoxes);
let initialSize = 30;
input.value = 0;
function createBoxes() {
let inputValue = input.value;
let markup = '';
for (let i = 0; i < inputValue; i += 1) {
markup += `<div style="width: ${initialSize}px; height: ${initialSize}px; background-color: ${getRandomHexColor()};">
</div>`;
initialSize += 10;
}
boxes.insertAdjacentHTML('beforeend', markup);
input.value = 0;
}
function destroyBoxes() {
boxes.innerHTML = '';
initialSize = 30;
}
function getRandomHexColor() {
const red = Math.floor(Math.random() * 255);
const green = Math.floor(Math.random() * 255);
const blue = Math.floor(Math.random() * 255);
return `rgb(${red}, ${green}, ${blue})`;
}
// function getRandomHexColor() {
// return `#${Math.floor(Math.random() * 16777215).toString(16)}`;
// }
|
C#
|
UTF-8
| 3,609 | 2.8125 | 3 |
[] |
no_license
|
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace ShadowEmu.Common.GameData.D2O
{
public static class ObjectDataManager
{
public static readonly Dictionary<Type, D2oReader> readers = new Dictionary<Type, D2oReader>();
private static string Directory;
public static void Initialize(string directory)
{
Directory = directory;
foreach (var d2iFile in System.IO.Directory.EnumerateFiles(directory).Where(entry => entry.EndsWith(".d2o")))
AddReader(new D2oReader(d2iFile));
}
public static void AddReader(D2oReader d2oFile)
{
var classes = d2oFile.Classes;
foreach (var @class in classes)
{
if (readers.ContainsKey(@class.Value.ClassType))
{
// this classes are not bound to a single file, so we ignore them
readers.Remove(@class.Value.ClassType);
}
else
{
readers.Add(@class.Value.ClassType, d2oFile);
}
}
}
public static List<object> AddSingleReader(string file)
{
var d2oFile = new D2oReader(file);
readers.Clear();
return d2oFile.ReadObjects<object>(true).Values.ToList();
}
public static T Get<T>(uint key)
where T : class
{
return Get<T>((int)key);
}
public static T Get<T>(int key, bool noExceptionThrown = false)
where T : class
{
if (!readers.ContainsKey(typeof(T)))
{
//AddReader(new D2oReader(Directory + @"\" + typeof(T).ToString().Replace("AmaknaProxy.API.Protocol.Data.", "") + "s.d2o"));
throw new Exception("Missing D2O " + typeof(T).ToString().Replace("AmaknaProxy.API.Protocol.Data.", ""));
}
var reader = readers[typeof(T)];
return reader.ReadObject<T>(key, true, noExceptionThrown);
}
public static List<T> GetAll<T>()
where T : class
{
if (!readers.ContainsKey(typeof(T))) // This exception should be called in all cases (serious)
throw new ArgumentException("Cannot find data corresponding to type : " + typeof(T));
var reader = readers[typeof(T)];
return reader.ReadObjects<T>(true).Values.ToList();
}
public static IEnumerable<Type> GetAllTypes()
{
return readers.Keys;
}
private static IEnumerable<object> EnumerateObjects(Type type)
{
if (!readers.ContainsKey(type))
throw new ArgumentException("Cannot find data corresponding to type : " + type);
var reader = readers[type];
return reader.Indexes.Select(index => reader.ReadObject(index.Key, true)).Where(obj => obj.GetType().Name == type.Name);
}
public static IEnumerable<T> EnumerateObjects<T>() where T : class
{
if (!readers.ContainsKey(typeof(T)))
throw new ArgumentException("Cannot find data corresponding to type : " + typeof(T));
var reader = readers[typeof(T)];
return reader.Indexes.Select(index => reader.ReadObject(index.Key, true)).OfType<T>().Select(obj => obj);
}
public static void Dispose()
{
readers.Clear();
}
}
}
|
TypeScript
|
UTF-8
| 329 | 3.140625 | 3 |
[] |
no_license
|
const isStringHexadecimal = (string: string): boolean => {
const lowerCaseString = string.toLowerCase();
const pattern = new RegExp(/([0-9a-f])+$/, "i")
return !isNaN(parseInt(lowerCaseString, 16))
&& lowerCaseString.length % 2 === 0
&& pattern.test(lowerCaseString);
}
export { isStringHexadecimal }
|
Python
|
UTF-8
| 22,924 | 2.8125 | 3 |
[] |
no_license
|
import cv2
import numpy as np
import matplotlib.pyplot as plt
import math
import sys
from skimage import measure,data,color
from PIL import Image
def sliding_window(image, stepSize, windowSize):
# slide a window across the image
for y in range(0, image.shape[0], stepSize[1]):
for x in range(0, image.shape[1], stepSize[0]):
# yield the current window
yield (x, y, image[y:y + windowSize[1], x:x + windowSize[0]])
# 返回滑动窗结果集合,本示例暂时未用到
def get_slice(image, stepSize, windowSize):
slice_sets = []
for (x, y, window) in sliding_window(image, stepSize, windowSize):
# if the window does not meet our desired window size, ignore it
if window.shape[0] != windowSize[1] or window.shape[1] != windowSize[0]:
continue
slice = image[y:y + windowSize[1], x:x + windowSize[0]]
slice_sets.append(slice)
print(slice_sets)
return slice_sets
def handle_img(slice):
l = slice.shape[0]
lx = [] # 储存X坐标
ly = [] # 储存Y坐标
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 灰度
ret, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU) # 二值化
contours, heriachy = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # 获取轮廓
for i, contour in enumerate(contours):
x, y, w, h = cv2.boundingRect(contour) # 外接矩形
mm = cv2.moments(contour) # 几何矩
approxCurve = cv2.approxPolyDP(contour, 4, True) # 多边形逼近
if approxCurve.shape[0] > 2: # 多边形边大于6就显示
cv2.drawContours(image, contours, i, (0, 255, 0), 2)
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2) # 绘制外接矩形
# 重心
if mm['m00'] != 0:
cx = mm['m10'] / mm['m00']
cy = mm['m01'] / mm['m00']
cv2.circle(image, (np.int(cx), np.int(cy)), 3, (0, 0, 255), -1) # 绘制重心
lx.append(np.int(cx)) # 翻转x坐标,图片坐标系原点不在下边
ly.append(l - np.int(cy))
return lx, ly
def duobianxingbijin():
img = cv2.imread('/home/lk/Desktop/项目/裁剪后的/thresh2.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray, 80, 255, cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for i, contour in enumerate(contours):
x, y, w, h = cv2.boundingRect(contour) # 外接矩形
mm = cv2.moments(contour) # 几何矩
approxCurve = cv2.approxPolyDP(contour, 0, True) # 多边形逼近
if approxCurve.shape[0] > 3: # 多边形边大于6就显示
cv2.drawContours(img, contours, i, (0, 255, 0), 2)
# cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 2)
#cv2.imwrite('/home/lk/Desktop/项目/裁剪后的/thresh21.png', img)
#cv2.imshow("img", img)
#cv2.waitKey(0)
#cv2.destroyAllWindows()
return img
def green_points(slice):
#slice=cv2.imread('/home/lk/Desktop/项目/裁剪后的/finaladf (copy).png')
print(slice.shape)
h=slice.shape[0]
w=slice.shape[1]
c=slice.shape[2]
green_pix_ind=[0,255,0]
red_pix_ind=[0,0,255]
print('weight : % s,height : % s'%(w,h))
a = []
b = []
d = []
for row in range(h):
for col in range(w):
for channel in range(c):
if( (slice[(row,col)][:]==green_pix_ind ).all() ):
pv=(row,col)
a.append(row)
b.append(col)
d.append(pv)
#print(a)
#slice[(row, col)][:] = red_pix_ind
#cv2.imshow('sdf',slice)
#cv2.waitKey(0)
#cv2.destroyAllWindows()
#a.reverse(a)
return a,b,d
def bianlislice(slice):
d1=[]
h1 = slice.shape[0]
w1 = slice.shape[1]
for row in range(h1):
for col in range(w1):
pv1=(row,col)
d1.append(pv1)
def jinghua(slice):
print(slice.shape)
a=[]
h=slice.shape[0]
w=slice.shape[1]
channels=slice.shape[2]
print('weight : % s,height : % s'%(w,h))
for row in range(h):
for col in range(w):
for c in range(channels):
pv=slice[row,col,c]
while(pv==255):
a.append(pv)
for slice in slice_sets:
while(a.len<=w):
a[:]=0
return pv
'''def nihe(slice):
a=[]
global lx
global ly
points = zip(x, y) # 获取点
sorted_points = sorted(points)
u = [point[0] for point in sorted_points]
v = [point[1] for point in sorted_points]
return lx,ly'''
def xianshi(lx,ly):
lx = np.array(x)
ly = np.array(y)
fl = np.polyfit(lx, ly, 2)
plot = plt.plot(lx, ly, 'r*')
plt.title('直线拟合')
plt.show()
def handle_point(x, y):
# 排序
ux = []
uy = []
vx = []
vy = []
points = zip(x, y) #获取点
sorted_points = sorted(points)
x = [point[0] for point in sorted_points]
y = [point[1] for point in sorted_points]
# 分割
'''Max = 0
for i in range(len(x) - 1): #找到左右两边点最大间隔
d = np.int(math.hypot(x[i + 1] - x[i], y[i + 1] - y[i]))
if d > Max:
Max = d
k = i
for i in range(len(x)): #区分左右点
if i < k + 1:
lx.append(x[i])
ly.append(y[i])
else:
rx.append(x[i])
ry.append(y[i])
return lx, ly, rx, ry'''
# 拟合,画图
def poly_fitting(lx, ly, rx, ry):
lx = np.array(lx)
ly = np.array(ly)
rx = np.array(rx)
ry = np.array(ry)
fl = np.polyfit(lx, ly, 3) # 用3次多项式拟合
pl = np.poly1d(fl) # 求3次多项式表达式
print("左边:", pl)
lyy = pl(lx) # 拟合y值
fr = np.polyfit(rx, ry, 3) # 用3次多项式拟合
pr = np.poly1d(fr) # 求3次多项式表达式
print("右边:", pr)
ryy = pr(rx) # 拟合y值
# 绘图
plot1 = plt.plot(lx, ly, 'r*')
plot2 = plt.plot(lx, lyy, 'b')
plot3 = plt.plot(rx, ry, 'r*')
plot4 = plt.plot(rx, ryy, 'b')
plt.title('poly_fitting')
plt.show()
def Sobel_gradient(blurred):
# 索比尔算子来计算x、y方向梯度
gradX = cv2.Sobel(blurred, ddepth=cv2.CV_32F, dx=1, dy=0)
gradY = cv2.Sobel(blurred, ddepth=cv2.CV_32F, dx=0, dy=1)
gradient = cv2.subtract(gradX, gradY)
gradient = cv2.convertScaleAbs(gradient)
return gradX, gradY, gradient
#def nihe(point):
def linear_regression(x, y):
N = len(x)
sumx = sum(x)
sumy = sum(y)
sumx2 = sum(x ** 2)
sumxy = sum(x * y)
A = np.mat([[N, sumx], [sumx, sumx2]])
b = np.array([sumy, sumxy])
return np.linalg.solve(A, b)
def Least_squares(x,y):
x_ = sum(x)/len(x)
y_ = sum(y)/len(y)
m = np.zeros(1)
n = np.zeros(1)
k = np.zeros(1)
p = np.zeros(1)
for i in np.arange(50):
k = (x[i]-x_)* (y[i]-y_)
m += k
p = np.square( x[i]-x_ )
n = n + p
a = m/n
b = y_ - a* x_
return a,b
def tichufengxi(slice2): #剔除缝隙像素函数
w,h,c=slice2.shape
heng=[]
zong=[]
zuobiao=[]
for row in range(w):
for col in range(h):
if ( (slice2[(row,col)][:]==[0,0,0] ).all() ):
heng.append(row)
zong.append(col)
pv=(row,col)
zuobiao.append(pv)
return heng,zong,zuobiao
if __name__ == '__main__':
#image = cv2.imread('/home/lk/Desktop/项目/裁剪后的/thresh.png')
img = cv2.imread('/home/lk/Desktop/项目/裁剪后的/thresh2.png')
img1 = cv2.imread('/home/lk/Desktop/项目/dd61ef3905306ad70e8fe659f52c271.jpg')
#img = cv2.imread(sys.argv[1], cv2.CV_LOAD_IMAGE_UNCHANGED)
b = img1[:, :, 0]
g = img1[:, :, 1]
r = img1[:, :, 2]
#cv2.imshow('img', img)
RGB=cv2.cvtColor(img1,cv2.COLOR_BGR2RGB) #由于opencv的问题颜色需要转换
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray, 80, 255, cv2.THRESH_BINARY)
contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for i, contour in enumerate(contours):
x, y, w, h = cv2.boundingRect(contour) # 外接矩形
mm = cv2.moments(contour) # 几何矩
approxCurve = cv2.approxPolyDP(contour, 0, True) # 多边形逼近
if approxCurve.shape[0] > 3: # 显示多边形
cv2.drawContours(img, contours, i, (0, 255, 0), 2) #描边
image=img
# 自定义滑动窗口的大小
w = image.shape[1]
h = image.shape[0]
(winW, winH) = (int(w/6),int(h/22.5)) #窗口大小
stepSize = (int (w/6),int(h/22.5))
cnt = 0
zhixian = []
pianyi=[]
houdu=[]
changdu=[]
c = 1
heng1=[]
zong1=[]
zuobiao1=[]
for (x, y, window) in sliding_window(image, stepSize=stepSize, windowSize=(winW, winH)): #每一个窗口
if window.shape[0] != winH or window.shape[1] != winW: #窗口不符合设定大小就抛弃
continue
clone = image.copy()
cv2.rectangle(clone, (x, y), (x + winW, y + winH), (0, 0, 255), 2)
cv2.imshow("Window", clone)
slice = image[y:y+winH,x:x+winW] #设置不同图片的切片,有描边后的阈值图,还有原图,为了之后效果显示在原图上
slice1=RGB[y:y+winH,x:x+winW]
slice2=img1[y:y+winH,x:x+winW]
cv2.namedWindow('sliding_slice1', 0)
cv2.imshow('sliding_slice1', slice2)
slice_sets1 = []
slice_sets1.append(slice1)
cv2.namedWindow('sliding_slice',0)
cv2.imshow('sliding_slice', slice)
slice_sets = [] #所有切片集合
slice_sets.append(slice)
slice_sets2=[]
slice_sets2.append(slice2)
#zhixian=np.empty(shape=[4,20],dtype=float)
count = 0
diyige = [] #第一个和最后一个的序号集合,为了后面识别窗口位置
zuihouyige = []
a1 = 1
b1 = 6
for count1 in range(20): #因为横向切了四片所以+4
diyige.append(a1)
a1 = a1 + 6
for count2 in range(20):
zuihouyige.append(b1)
b1 = b1 + 6
#print(diyige)
#('this is slice_sets: ', len(slice_sets.))
#cv2.imshow('sdfsd',img1)
for i in range(1):
heng, zong, zuobiao = tichufengxi(slice2)
heng1.append(heng)
zong1.append(zong)
zuobiao1.append(zuobiao)
print(heng1[c - 1])
a,b,d=green_points(slice)
'''q,w,d5=green_points(slice)#获取slice中所有绿色点
a=[row for row in q if row not in heng] #去除木板间缝隙点
b = [col for col in w if col not in zong]
d = [pv for pv in d5 if pv not in zuobiao]'''
d1=bianlislice(slice)
v = a
u = b
p = []
a1, b1, d1 = green_points(slice)
v1 = a1
u1 = b1
'''for i in range(len(d)):
p.append((d[i][1], d1[i][0]))
sorted_point = sorted(p)
u1 = [point[0] for point in sorted_point]
v1 = [point[1] for point in sorted_point]'''
if len(v)!=0: #窗口可能会没有绿色像素点,绿色为描边颜色,有的话才继续
z = max(v) #对绿色点进行预处理,去掉干扰点
q = min(v)
else:
continue
length = z - q
yi = []
er = []
san = []
si = []
wu = []
liu = []
qi = []
ba = []
yi1 = []
er1 = []
san1 = []
si1 = []
wu1 = []
liu1 = []
qi1 = []
ba1 = []
jiu1 = []
shi1 = []
shiyi1 = []
shier1 = []
shisan1 = []
shisi1 = []
shiwu1 = []
e = max(u1)
t = min(u1)
length1 = e - t
for i in range(len(d)): #为了拟合边缘,将窗口中的绿色点按纵坐标分为7组,含坐标最多的组才用来拟合
if 0 < v[i] - q < length / 7:
yi.append(d[i])
elif length / 7 < v[i] - q < length *2/7 :
er.append(d[i])
elif length *2/7 < v[i] - q < length *3/7:
san.append(d[i])
elif length *3/7 < v[i] - q < length *4/7:
si.append(d[i])
elif length *4/ 7 < v[i] - q < length *5/7 :
wu.append(d[i])
elif length *5/ 7 < v[i] - q < length *6/7 :
liu.append(d[i])
elif length *6/ 7 < v[i] - q < length :
qi.append(d[i])
changdu = [len(yi), len(er), len(san), len(si),len(wu),len(liu),len(qi)]
if (max(changdu) == len(yi)):
d=yi
elif (max(changdu) == len(er)):
d=er
elif (max(changdu) == len(san)):
d=san
elif (max(changdu) == len(si)):
d=si
elif (max(changdu) == len(wu)):
d=wu
elif (max(changdu) == len(liu)):
d=liu
elif (max(changdu) == len(qi)):
d=qi
for i in range(len(d)):
if 0 < u1[i] - t < length1 / 8:
yi1.append(d[i])
elif length1 / 8 < u1[i] - t< length1*2 / 8:
er1.append(d[i])
elif length1 *2/ 8 < u1[i] - t < length1 *3/ 8:
san1.append(d[i])
elif length1 *3/ 8 < u1[i] - t < length1 *4/ 8:
si1.append(d[i])
elif length1 *4 / 8 < u1[i] - t < length1 *5/ 8:
wu1.append(d[i])
elif length1*5/ 8<u1[i]-t<length1*6/ 8:
liu1.append(d[i])
elif length1*6/ 8<u1[i]-t<length1*7/8:
qi1.append(d[i])
elif length1*7/8<u1[i]-t<length1:
ba1.append(d[i])
changdu1 = [len(yi1), len(er1), len(san1), len(si1), len(wu1), len(liu1), len(qi1), len(ba1)]
if (max(changdu1) == len(yi1)):
d1 = yi1
elif (max(changdu1) == len(er1)):
d1 = er1
elif (max(changdu1) == len(san1)):
d1 = san1
elif (max(changdu1) == len(si1)):
d1 = si1
elif (max(changdu1) == len(wu1)):
d1 = wu1
elif (max(changdu1) == len(liu1)):
d1 = liu1
elif (max(changdu1) == len(qi1)):
d1 = qi1
elif (max(changdu1) == len(ba1)):
d1 = ba1
changdu2=sorted(changdu1)
#print(changdu2)
if changdu2[1]==len(yi1):
d2 =yi1
elif changdu2[1]==len(er1):
d2=er1
elif changdu2[1]==len(san1):
d2=san1
elif changdu2[1]==len(si1):
d2=si1
elif changdu2[1]==len(wu1):
d2=wu1
elif changdu2[1]==len(liu1):
d2=liu1
elif changdu2[1]==len(qi1):
d2=qi1
elif changdu2[1]==len(ba1):
d2=ba1
'''else :
d=liu'''
#print(d)
p=[]
for i in range(len(d)):
p.append((d[i][1],d[i][0]))
sorted_point = sorted(p)
u = [point[0] for point in sorted_point]
v = [point[1] for point in sorted_point]
p1 = []
for i in range(len(d1)):
p1.append((d1[i][1], d1[i][0]))
sorted_point1 = sorted(p1)
u3 = [point[0] for point in p1]
v3 = [point[1] for point in p1]
p2 = []
for i in range(len(d2)):
p2.append((d2[i][1], d2[i][0]))
# sorted_point1 = sorted(p2)
u4 = [point[0] for point in p2]
v4 = [point[1] for point in p2]
N = len(u) #对获得的绿色像素点进行处理
for i in range(int(len(u) / 2)):
u[i], u[N - i - 1] = u[N - i - 1], u[i]
M = len(v)
for i in range(int(len(v) / 2)):
v[i], v[M - i - 1] = v[M - i - 1], v[i]
#for i in range(len(u)):
#v1=a*u+b
a,b=Least_squares(u,v)#最小二乘法拟合直线,a是斜率.b是偏移
print(a,b)
print(a)
zhixian.append(b)
if a[0]>0.0500000 : #将比较离谱的拟合直线取一个较常见的值
a[0]=0.00200000
elif a[0]<-0.0500000:
a[0]=-0.00200000
v1=a*u+b
dian = []
zhixian.append('%fx+%f'%(a,b))
pianyi.append(b)
#for i in range(slice_sets1):
#plt.figure(figsize=(10, 5), facecolor='w')
plt.figure(figsize=(10, 5))
plt.plot(u, v, 'ro', lw=2, markersize=6)
plt.plot(u, v1, 'b-', lw=2, markersize=6)
#plot2=plt.plot(u)
plt.grid(b=True, ls=':')
plt.xlabel(u'X', fontsize=16)
plt.ylabel(u'Y', fontsize=16)
plt.imshow(slice1)
v11 = [] #在原图上画拟合直线
for i in range(len(u)):
v111 = int(a * u[i] + b)
v11.append(v111)
for l in range(len(u)):
u[l] += x
for k in range(len(v11)):
v11[k] += y
for l in range(len(u3)):
u3[l] += x
for k in range(len(v3)):
v3[k] += y
for l in range(len(u4)):
u4[l] += x
for k in range(len(v4)):
v4[k] += y
diyigedian = [point for point in p if point in p1]
diergedian = [point for point in p if point in p2]
if max(v3)-min(v3)>winH/3: #竖边如果小于长度小于切片的一半就认为不是边缘而是干扰点
cv2.line(img1, (u3[len(u3) - 1], v3[0]), (u3[len(u3) - 1], v3[len(v3) - 1]), (0, 0, 255), thickness=3, lineType=8)
elif max(v3)-min(v3)<winH/3:
v3.clear()
'''if v4 and max(v4)-min(v4)<winH/2:
v4.clear()'''
if v4 and diyigedian:
cv2.line(img1, (u4[len(u4) - 1], v4[0]), (u4[len(u4) - 1], v4[len(v4) - 1]), (0, 0, 255), thickness=3,
lineType=8)
'''if u[0] != x+winW and c not in zuihouyige :
cv2.line(img1, (diyigedian[0]), (x, v11[len(v11) - 1]), (255, 0, 255), thickness=3, lineType=8)'''
if u[len(u)-1] !=x and c not in diyige and c not in zuihouyige and u[0]!=x+winW : #根据切片位置进行优化
cv2.line(img1, (x+winW, v11[0]), (x, v11[len(v11) - 1]), (255, 0, 255), thickness=3, lineType=8)
vector1=np.array([x+winW, v11[0]])
vector2=np.array([x, v11[len(v11) - 1]])
op1 = np.sqrt(np.sum(np.square(vector1 - vector2)))
changdu.append(op1)
elif u[0] != x+winW and c not in zuihouyige :
cv2.line(img1, (x+winW, v11[0]), (u[len(u) - 1], v11[len(v11) - 1]), (255, 255, 0), thickness=3, lineType=8)
vector1 = np.array([x + winW, v11[0]])
vector2 = np.array([u[len(u) - 1], v11[len(v11) - 1]])
op1 = np.sqrt(np.sum(np.square(vector1 - vector2)))
changdu.append(op1)
elif u[len(u)-1] != x and c not in diyige:
cv2.line(img1, (u[0], v11[0]), (x, v11[len(v11) - 1]), (255, 255, 255), thickness=3, lineType=8)
vector1 = np.array([u[0], v11[0]])
vector2 = np.array([x, v11[len(v11) - 1]])
op1 = np.sqrt(np.sum(np.square(vector1 - vector2)))
changdu.append(op1)
else:
cv2.line(img1, (u[0], v11[0]), (u[len(u) - 1], v11[len(v11) - 1]), (0, 0, 255), thickness=3, lineType=8)
vector1 = np.array([u[0], v11[0]])
vector2 = np.array([u[len(u) - 1], v11[len(v11) - 1]])
op1 = np.sqrt(np.sum(np.square(vector1 - vector2)))
changdu.append(op1)
#if u[len(v11) - 1]==x + winW&i%6!=0:
print("第%i块木板的长度:"%c,op1)
cv2.imshow('nihe', img1)
#slice1=plt.plot(u, v1, 'b-', lw=2, markersize=6)
'''sp = slice.shape
w = sp[0] # height(rows) of image
h = sp[1]
color_size = sp[2]
green_pix_ind = [0, 255, 0]
red_pix_ind = [0, 0, 255]
array=np.array(slice)
for x in range(w):
for y in range(h):
#bgr = slice1[x, y]
# m = int(a * x + b)
# if(y == int(a * x + b)) :
array[x, y] = red_pix_ind'''
print('cnt',cnt)
plt.show()
#plt.close()
print('c=',c)
print('zhixian:',zhixian)
print('pianyi:',pianyi)
'''i += 1
plt.savefig('/home/lk/Desktop/项目/效果图/test{}.png'.format(i))
plt.clf()'''
c=c+1
#cv2.imshow('sdfds',img1)
for i in range(len(pianyi) - 4):
gaodu1 = H/22.5 - pianyi[i] + pianyi[i + 4]
houdu.append(gaodu1)
print('木板的厚度:', houdu)
'''u=np.linspace(min(u),max(u),num=50)
u = np.array(u)
v = np.array(v)
fl = np.polyfit(u, v, 2) # 用3次多项式拟合
#a0,a1 = linear_regression(u,v)
pl = np.poly1d(fl)
lv = pl(u) # 拟合u值,不知道为什么画图u和v是反的
print(pl)
plot1 = plt.plot(u,v, 'r*')
#plot2 = plt.plot(u , lv , 'b')
plt.show()'''
#jinghua(slice)
#print(zhixian)
cnt = cnt + 1
cv2.imwrite('/home/lk/Desktop/项目/效果图/zhengfutunihe.jpg',img1)
cv2.waitKey(1000)
cv2.destroyAllWindows()
|
C
|
BIG5
| 1,273 | 3.171875 | 3 |
[] |
no_license
|
# include<stdio.h>
# include<stdlib.h>
# include<time.h>
int main(void){
int cardpoint;
float cppoint;
float sum=0;
int reply;
srand(time(NULL));
printf("ӸqPK10Iba!\nundPI`MWL10IbAåBpqdPI`M\nANĹF!\nJBQBKPCi0.5I\n");
while(sum<=10.5){
printf("Do you want to add another card?\nType 1 for yes or\nType 2 for no\n");
scanf("%d",&reply);
if(reply==1){
cardpoint=1+rand()%13;
sum+=cardpoint;
if(cardpoint<=10){
printf("\nYou get a %d card\n",cardpoint);
}
else if(cardpoint==11){
printf("\nYou get a J card\n");
sum-=10.5;
}
else if(cardpoint==12){
printf("\nYou get a Q card\n");
sum-=11.5;
}
else{
printf("\nYou get a K card\n");
sum-=12.5;
}
printf("You get %.1f points\n\n",sum);
}
else if(reply==2){
break;
}
else{
printf("Please type 1 or 2 again\n\n");
}
}
if(sum<=10.5){
cppoint=0.5+rand()%(21/2);
if(sum>=cppoint){
printf("\nComputer gets %.1f points\n\nYou win!\n",cppoint);
}
else{
printf("\nComputer gets %.1f points\n\nYou lose\n",cppoint);
}
}
else{
printf("\nYou lose\n");
}
}
|
PHP
|
UTF-8
| 5,910 | 2.625 | 3 |
[] |
no_license
|
<?php
/**
* @package GamificationPlatform
* @subpackage GamificationLibrary
* @author Todor Iliev
* @copyright Copyright (C) 2014 Todor Iliev <todor@itprism.com>. All rights reserved.
* @license http://www.gnu.org/copyleft/gpl.html GNU/GPL
*/
defined('JPATH_PLATFORM') or die;
JLoader::register("GamificationTableBadge", JPATH_ADMINISTRATOR . DIRECTORY_SEPARATOR . "components" . DIRECTORY_SEPARATOR . "com_gamification" . DIRECTORY_SEPARATOR . "tables" . DIRECTORY_SEPARATOR . "badge.php");
JLoader::register("GamificationInterfaceTable", JPATH_LIBRARIES . DIRECTORY_SEPARATOR . "gamification" . DIRECTORY_SEPARATOR . "interface" . DIRECTORY_SEPARATOR . "table.php");
/**
* This class contains methods that are used for managing a badge.
*
* @package GamificationPlatform
* @subpackage GamificationLibrary
*/
class GamificationBadge implements GamificationInterfaceTable
{
protected $table;
protected static $instances = array();
/**
* Initialize the object and load data.
*
* <code>
*
* $badgeId = 1;
* $badge = new GamificationBadge($badgeId);
*
* </code>
*
* @param int $id
*/
public function __construct($id = 0)
{
$this->table = new GamificationTableBadge(JFactory::getDbo());
if (!empty($id)) {
$this->table->load($id);
}
}
/**
* Create an instance of the object and load data.
*
* <code>
*
* $badgeId = 1;
* $badge = GamificationBadge::getInstance($badgeId);
*
* </code>
*
* @param int $id
*
* @return GamificationBadge:null
*/
public static function getInstance($id = 0)
{
if (empty(self::$instances[$id])) {
$item = new GamificationBadge($id);
self::$instances[$id] = $item;
}
return self::$instances[$id];
}
/**
* Get badge title.
*
* <code>
*
* $badgeId = 1;
* $badge = GamificationBadge::getInstance($badgeId);
* $title = $badge->getTitle();
*
* </code>
*
* @return string
*/
public function getTitle()
{
return $this->table->title;
}
/**
* Get badge points.
*
* <code>
*
* $badgeId = 1;
* $badge = GamificationBadge::getInstance($badgeId);
* $points = $badge->getPoints();
*
* </code>
*
* @return number
*/
public function getPoints()
{
return $this->table->points;
}
/**
* Get badge image.
*
* <code>
*
* $badgeId = 1;
* $badge = GamificationBadge::getInstance($badgeId);
* $image = $badge->getImage();
*
* </code>
*
* @return string
*/
public function getImage()
{
return $this->table->image;
}
/**
* Get badge note.
*
* <code>
*
* $badgeId = 1;
* $badge = GamificationBadge::getInstance($badgeId);
* $note = $badge->getNote();
*
* </code>
*
* @return string
*/
public function getNote()
{
return $this->table->note;
}
/**
* Check for published badge.
*
* <code>
*
* $badgeId = 1;
* $badge = GamificationBadge::getInstance($badgeId);
*
* if(!$badge->isPublished()) {
* }
*
* </code>
*
* @return boolean
*/
public function isPublished()
{
return (!$this->table->published) ? false : true;
}
/**
* Get the points ID used of the badge.
*
* <code>
*
* $badgeId = 1;
* $badge = GamificationBadge::getInstance($badgeId);
* $pointsId = $badge->getPointsId();
*
* </code>
*
* @return integer
*/
public function getPointsId()
{
return $this->table->points_id;
}
/**
* Get the group ID of the badge.
*
* <code>
*
* $badgeId = 1;
* $badge = GamificationBadge::getInstance($badgeId);
* $groupId = $badge->getGroupId();
*
* </code>
*
* @return integer
*/
public function getGroupId()
{
return $this->table->group_id;
}
/**
* Load badge data using the table object.
*
* <code>
*
* $badgeId = 1;
* $badge = new GamificationBadge();
* $badge->load($badgeId);
*
* </code>
*
*/
public function load($keys, $reset = true)
{
$this->table->load($keys, $reset);
}
/**
* Set the data to the object parameters.
*
* <code>
*
* $data = array(
* "title" => "......",
* "points" => 100,
* "image" => "picture.png",
* "note" => "......",
* "published" => 1,
* "points_id" => 2,
* "group_id" => 3
* );
*
* $badge = new GamificationBadge();
* $badge->bind($data);
*
* </code>
*
* @param array $src
* @param array $ignore
*/
public function bind($src, $ignore = array())
{
$this->table->bind($src, $ignore);
}
/**
* Save the data to the database.
*
* <code>
*
* $data = array(
* "title" => "......",
* "points" => 100,
* "image" => "picture.png",
* "note" => null,
* "published" => 1,
* "points_id" => 2,
* "group_id" => 3
* );
*
* $badge = new GamificationBadge();
* $badge->bind($data);
* $badge->store(true);
*
* </code>
*
* @param $updateNulls
*/
public function store($updateNulls = false)
{
$this->table->store($updateNulls);
}
}
|
Java
|
UTF-8
| 6,885 | 1.835938 | 2 |
[] |
no_license
|
package kr.co.modacom.iot.ltegwdev.sg100;
import android.app.Activity;
import android.app.Fragment;
import android.content.Context;
import android.os.Bundle;
import android.util.Log;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
import android.view.View.OnClickListener;
import android.widget.Button;
import android.widget.TextView;
import kr.co.modacom.iot.ltegwdev.R;
import kr.co.modacom.iot.ltegwdev.control.ZWaveController;
import kr.co.modacom.iot.ltegwdev.model.PropertyVO;
import kr.co.modacom.iot.ltegwdev.model.ZwaveDeviceVO;
import kr.co.modacom.iot.ltegwdev.model.type.DevCat;
import kr.co.modacom.iot.ltegwdev.model.type.DevLabel;
import kr.co.modacom.iot.ltegwdev.model.type.DevModel;
import kr.co.modacom.iot.ltegwdev.model.type.FunctionId;
import kr.co.modacom.iot.ltegwdev.model.type.OnOffStatus;
import kr.co.modacom.iot.ltegwdev.model.type.OpenCloseStatus;
import kr.co.modacom.iot.ltegwdev.model.type.Target;
import kr.co.modacom.iot.ltegwdev.onem2m.M2MManager.OnM2MSendListener;
public class LGZwaveGasValveFragment extends Fragment {
private static final String TAG = LGZwaveGasValveFragment.class.getSimpleName();
private Button btnLgGasValveClose;
private TextView tvInstanceId;
private TextView tvStatus;
private ZWaveController mZWaveCon;
private ZwaveDeviceVO mItem;
private Context mCtx;
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container, Bundle savedInstanceState) {
View view = inflater.inflate(R.layout.lg_fragment_zw_gas_valve, container, false);
if (getActivity() instanceof LGZwaveActivity) {
mCtx = ((LGZwaveActivity) getActivity()).getContext();
}
mZWaveCon = ZWaveController.getInstance(mCtx);
tvInstanceId = (TextView) view.findViewById(R.id.tv_lg_zwave_valve_instance_id);
tvStatus = (TextView) view.findViewById(R.id.tv_lg_zwave_valve_status);
btnLgGasValveClose = (Button) view.findViewById(R.id.btn_lg_zwave_valve_close);
btnLgGasValveClose.setOnClickListener(mOnClickListener);
return view;
}
@Override
public void onStart() {
// TODO Auto-generated method stub
super.onStart();
mItem = getItemFromList(true);
updateZWaveItemStatus(mItem);
}
public ZwaveDeviceVO getItemFromList(boolean flag) {
for (ZwaveDeviceVO item : mZWaveCon.getItems()) {
if (!((LGZwaveActivity)mCtx).isInModelName(item)) {
mItem = item;
if (((LGZwaveActivity) mCtx).getUnpairingFlag() == 1) {
((LGZwaveActivity) mCtx).showUnpairDialog();
}
return item;
} else if (item.getDevCat() == DevCat.ZWAVE.getCode() && item.getModelName().equals(DevModel.GAS_LOCK.getName())
&& item.getPairingFlag() == flag) {
return item;
}
}
return null;
}
public ZwaveDeviceVO getItemFromList(String deviceId) {
for (ZwaveDeviceVO item : mZWaveCon.getItems())
if (item.getDeviceId().equals(deviceId))
return item;
return null;
}
public void requestDeviceInfo() {
mItem = getItemFromList(true);
if (mItem != null)
mZWaveCon.requestDeviceInfo(mOnM2MSendListener, mItem.getDeviceId(), Target.ZWAVE);
}
public ZwaveDeviceVO getItem() {
return mItem;
}
public void setItem(ZwaveDeviceVO mItem) {
this.mItem = mItem;
}
public void updateZWaveItemStatus(ZwaveDeviceVO item) {
if (item != null) {
if (tvInstanceId != null && tvStatus != null) {
int status = -1;
if (item.getModelName().contains("Unknown")) {
return;
}
for (PropertyVO property : item.getProperties()) {
if (property.getLabel().equals(DevLabel.SWITCH.getName())) {
tvInstanceId.setText(Integer.toString(property.getInstanceId()));
status = (Integer) property.getValue();
break;
}
}
tvStatus.setText(status == -1 ? ""
: (status == 0 ? OpenCloseStatus.CLOSE.getName() : OpenCloseStatus.OPEN.getName()));
updateModelInfo();
}
} else {
clearModelInfo();
clearZWaveItemStatus();
}
}
public void clearZWaveItemStatus() {
// TODO Auto-generated method stub
mItem = null;
if (tvInstanceId != null)
tvInstanceId.setText("");
if (tvStatus != null)
tvStatus.setText("");
}
public void requestStateUpdate(OpenCloseStatus value) {
if (mItem != null) {
for (PropertyVO property : mItem.getProperties()) {
if (property.getLabel().equals(DevLabel.SWITCH.getName())) {
property.setValue(value.getCode());
break;
}
}
mZWaveCon.requestStateUpdate(mOnM2MSendListener, Target.ZWAVE, mItem);
}
}
public void showProgressDialog(String msg) {
Activity activity = getActivity();
if (activity instanceof LGZwaveActivity) {
((LGZwaveActivity) activity).showProgressDialog(msg);
}
}
public void hideProgressDialog() {
Activity activity = getActivity();
if (activity instanceof LGZwaveActivity) {
((LGZwaveActivity) activity).hideProgressDialog();
}
}
public void updateModelInfo() {
Activity activity = getActivity();
if (activity instanceof LGZwaveActivity) {
((LGZwaveActivity) activity).updateModelInfo(mItem.getModelInfo().substring(0, 4),
mItem.getModelInfo().substring(4, 8), mItem.getModelInfo().substring(8, 12));
}
}
public void clearModelInfo() {
Activity activity = getActivity();
if (activity instanceof LGZwaveActivity) {
((LGZwaveActivity) activity).clearModelInfo();
}
}
public void updateZWaveState(FunctionId funcId) {
if (mZWaveCon == null) {
return;
}
switch (funcId) {
case DEVICE_INFO:
hideProgressDialog();
mItem = getItemFromList(true);
updateZWaveItemStatus(mItem);
case DEVICE_PAIRING:
hideProgressDialog();
mItem = getItemFromList(true);
updateZWaveItemStatus(mItem);
break;
case DEVICE_UNPAIRING:
hideProgressDialog();
mItem = getItemFromList(mItem.getDeviceId());
updateZWaveItemStatus(null);
break;
case DEVICE_CONTROL:
case UPDATED_DEVICE:
mItem = getItemFromList(mItem.getDeviceId());
updateZWaveItemStatus(mItem);
break;
default:
break;
}
}
OnClickListener mOnClickListener = new OnClickListener() {
@Override
public void onClick(View v) {
// TODO Auto-generated method stub
switch (v.getId()) {
case R.id.btn_lg_zwave_valve_close:
if (!tvStatus.getText().equals(OpenCloseStatus.CLOSE.getName()))
requestStateUpdate(OpenCloseStatus.CLOSE);
break;
}
}
};
protected OnM2MSendListener mOnM2MSendListener = new OnM2MSendListener() {
@Override
public void onPreSend() {
showProgressDialog("메시지 전송 요청 중...");
}
@Override
public void onPostSend() {
}
@Override
public void onCancelled() {
hideProgressDialog();
}
};
}
|
Python
|
UTF-8
| 249 | 4.09375 | 4 |
[] |
no_license
|
n = int(input("How many bills you wish to process : "))
for i in range(1,n+1):
billamount = int(input("Enter the amount : "))
tax = billamount*(18/100)
print("For {} amount taxes are {}".format(billamount,tax))
print("Thank You !!")
|
Python
|
UTF-8
| 2,433 | 2.546875 | 3 |
[
"MIT"
] |
permissive
|
import socket
import struct
import binascii
import pprint as pp
import network
import time
import uuid
import stringify
import unpack
import time
import modify
def main(write_file=False):
# Timing
run_sniffer_for = int(input('For how many second should sniffer run?: ')) * 1000
run_start = int(round(time.time() * 1000))
# Init network socket
local_ip = socket.gethostbyname(socket.gethostname())
net = network.Network(local_ip, 0)
# f
if write_file:
f = create_write_file()
all_packets = []
while True:
# Get data
try:
raw_data = net.get_raw_data()
except OSError:
print('Could not get packet!')
continue
# Unpack data
unpacked_ip_header = unpack.ip_header(raw_data)
unpacked_tcp_header = unpack.tcp_fragment(raw_data)
# Merge unpacked data to one dict
merged_tcp_ip = {**unpacked_ip_header, **unpacked_tcp_header}
# Move to paccket
all_packets.append(merged_tcp_ip)
# Create readable Format data
readable_result = stringify.tcp_ip(unpacked_ip_header, unpacked_tcp_header, stringify.MODE_HEX_PAIR)
# f
if write_file:
f.write(readable_result + "\n\n")
# Timing
elapsed_time = int(round(time.time() * 1000))
print((elapsed_time - run_start) / 1000)
if elapsed_time - run_start > run_sniffer_for:
break
#print(readable_result)
sorted_packets = modify.sort_by_tuple(all_packets)
grouped_payload = modify.group_tuple_payload(sorted_packets)
print(stringify.grouped_tuple_payload(grouped_payload))
pp.pprint(modify.packet_strip(all_packets, [], [40]))
net.close()
# f
if write_file:
f.close()
# Create txt file with random name and timestamp
def create_write_file():
return open(generate_filename(), 'w')
# Generate name
def generate_filename():
timestamp = time.strftime('D%y-%m-%d_T%H-%M-%S')
filename = ('{}_{}.txt').format(timestamp, str(uuid.uuid4()))
return filename
# Get encodings from list supported by python
def get_standard_encodings():
f = open('standard_encodings.txt', 'r')
encodings = map(lambda line: line.split('\t')[0], f)
f.close
return encodings
main()
|
Java
|
UTF-8
| 11,990 | 2.09375 | 2 |
[] |
no_license
|
package embedded.com.android.dx.cf.direct;
import embedded.com.android.dx.cf.code.*;
import embedded.com.android.dx.rop.cst.*;
import embedded.com.android.dx.cf.attrib.*;
import embedded.com.android.dx.cf.iface.*;
import embedded.com.android.dx.util.*;
import embedded.com.android.dx.cf.cst.*;
import embedded.com.android.dx.rop.code.*;
import embedded.com.android.dx.rop.type.*;
public class DirectClassFile implements ClassFile
{
private static final int CLASS_FILE_MAGIC = -889275714;
private static final int CLASS_FILE_MIN_MAJOR_VERSION = 45;
private static final int CLASS_FILE_MAX_MAJOR_VERSION = 52;
private static final int CLASS_FILE_MAX_MINOR_VERSION = 0;
private final String filePath;
private final ByteArray bytes;
private final boolean strictParse;
private StdConstantPool pool;
private int accessFlags;
private CstType thisClass;
private CstType superClass;
private TypeList interfaces;
private FieldList fields;
private MethodList methods;
private StdAttributeList attributes;
private AttributeFactory attributeFactory;
private ParseObserver observer;
public static String stringOrNone(final Object obj) {
if (obj == null) {
return "(none)";
}
return obj.toString();
}
public DirectClassFile(final ByteArray bytes, final String filePath, final boolean strictParse) {
if (bytes == null) {
throw new NullPointerException("bytes == null");
}
if (filePath == null) {
throw new NullPointerException("filePath == null");
}
this.filePath = filePath;
this.bytes = bytes;
this.strictParse = strictParse;
this.accessFlags = -1;
}
public DirectClassFile(final byte[] bytes, final String filePath, final boolean strictParse) {
this(new ByteArray(bytes), filePath, strictParse);
}
public void setObserver(final ParseObserver observer) {
this.observer = observer;
}
public void setAttributeFactory(final AttributeFactory attributeFactory) {
if (attributeFactory == null) {
throw new NullPointerException("attributeFactory == null");
}
this.attributeFactory = attributeFactory;
}
public String getFilePath() {
return this.filePath;
}
public ByteArray getBytes() {
return this.bytes;
}
@Override
public int getMagic() {
this.parseToInterfacesIfNecessary();
return this.getMagic0();
}
@Override
public int getMinorVersion() {
this.parseToInterfacesIfNecessary();
return this.getMinorVersion0();
}
@Override
public int getMajorVersion() {
this.parseToInterfacesIfNecessary();
return this.getMajorVersion0();
}
@Override
public int getAccessFlags() {
this.parseToInterfacesIfNecessary();
return this.accessFlags;
}
@Override
public CstType getThisClass() {
this.parseToInterfacesIfNecessary();
return this.thisClass;
}
@Override
public CstType getSuperclass() {
this.parseToInterfacesIfNecessary();
return this.superClass;
}
@Override
public ConstantPool getConstantPool() {
this.parseToInterfacesIfNecessary();
return this.pool;
}
@Override
public TypeList getInterfaces() {
this.parseToInterfacesIfNecessary();
return this.interfaces;
}
@Override
public FieldList getFields() {
this.parseToEndIfNecessary();
return this.fields;
}
@Override
public MethodList getMethods() {
this.parseToEndIfNecessary();
return this.methods;
}
@Override
public AttributeList getAttributes() {
this.parseToEndIfNecessary();
return this.attributes;
}
@Override
public BootstrapMethodsList getBootstrapMethods() {
final AttBootstrapMethods bootstrapMethodsAttribute = (AttBootstrapMethods)this.getAttributes().findFirst("BootstrapMethods");
if (bootstrapMethodsAttribute != null) {
return bootstrapMethodsAttribute.getBootstrapMethods();
}
return BootstrapMethodsList.EMPTY;
}
@Override
public CstString getSourceFile() {
final AttributeList attribs = this.getAttributes();
final Attribute attSf = attribs.findFirst("SourceFile");
if (attSf instanceof AttSourceFile) {
return ((AttSourceFile)attSf).getSourceFile();
}
return null;
}
public TypeList makeTypeList(final int offset, final int size) {
if (size == 0) {
return StdTypeList.EMPTY;
}
if (this.pool == null) {
throw new IllegalStateException("pool not yet initialized");
}
return new DcfTypeList(this.bytes, offset, size, this.pool, this.observer);
}
public int getMagic0() {
return this.bytes.getInt(0);
}
public int getMinorVersion0() {
return this.bytes.getUnsignedShort(4);
}
public int getMajorVersion0() {
return this.bytes.getUnsignedShort(6);
}
private void parseToInterfacesIfNecessary() {
if (this.accessFlags == -1) {
this.parse();
}
}
private void parseToEndIfNecessary() {
if (this.attributes == null) {
this.parse();
}
}
private void parse() {
try {
this.parse0();
}
catch (ParseException ex) {
ex.addContext("...while parsing " + this.filePath);
throw ex;
}
catch (RuntimeException ex2) {
final ParseException pe = new ParseException(ex2);
pe.addContext("...while parsing " + this.filePath);
throw pe;
}
}
private boolean isGoodMagic(final int magic) {
return magic == -889275714;
}
private boolean isGoodVersion(final int minorVersion, final int majorVersion) {
if (minorVersion >= 0) {
if (majorVersion == 52) {
if (minorVersion <= 0) {
return true;
}
}
else if (majorVersion < 52 && majorVersion >= 45) {
return true;
}
}
return false;
}
private void parse0() {
if (this.bytes.size() < 10) {
throw new ParseException("severely truncated class file");
}
if (this.observer != null) {
this.observer.parsed(this.bytes, 0, 0, "begin classfile");
this.observer.parsed(this.bytes, 0, 4, "magic: " + Hex.u4(this.getMagic0()));
this.observer.parsed(this.bytes, 4, 2, "minor_version: " + Hex.u2(this.getMinorVersion0()));
this.observer.parsed(this.bytes, 6, 2, "major_version: " + Hex.u2(this.getMajorVersion0()));
}
if (this.strictParse) {
if (!this.isGoodMagic(this.getMagic0())) {
throw new ParseException("bad class file magic (" + Hex.u4(this.getMagic0()) + ")");
}
if (!this.isGoodVersion(this.getMinorVersion0(), this.getMajorVersion0())) {
throw new ParseException("unsupported class file version " + this.getMajorVersion0() + "." + this.getMinorVersion0());
}
}
final ConstantPoolParser cpParser = new ConstantPoolParser(this.bytes);
cpParser.setObserver(this.observer);
(this.pool = cpParser.getPool()).setImmutable();
int at = cpParser.getEndOffset();
final int accessFlags = this.bytes.getUnsignedShort(at);
int cpi = this.bytes.getUnsignedShort(at + 2);
this.thisClass = (CstType)this.pool.get(cpi);
cpi = this.bytes.getUnsignedShort(at + 4);
this.superClass = (CstType)this.pool.get0Ok(cpi);
final int count = this.bytes.getUnsignedShort(at + 6);
if (this.observer != null) {
this.observer.parsed(this.bytes, at, 2, "access_flags: " + AccessFlags.classString(accessFlags));
this.observer.parsed(this.bytes, at + 2, 2, "this_class: " + this.thisClass);
this.observer.parsed(this.bytes, at + 4, 2, "super_class: " + stringOrNone(this.superClass));
this.observer.parsed(this.bytes, at + 6, 2, "interfaces_count: " + Hex.u2(count));
if (count != 0) {
this.observer.parsed(this.bytes, at + 8, 0, "interfaces:");
}
}
at += 8;
this.interfaces = this.makeTypeList(at, count);
at += count * 2;
if (this.strictParse) {
final String thisClassName = this.thisClass.getClassType().getClassName();
if (!this.filePath.endsWith(".class") || !this.filePath.startsWith(thisClassName) || this.filePath.length() != thisClassName.length() + 6) {
throw new ParseException("class name (" + thisClassName + ") does not match path (" + this.filePath + ")");
}
}
this.accessFlags = accessFlags;
final FieldListParser flParser = new FieldListParser(this, this.thisClass, at, this.attributeFactory);
flParser.setObserver(this.observer);
this.fields = flParser.getList();
at = flParser.getEndOffset();
final MethodListParser mlParser = new MethodListParser(this, this.thisClass, at, this.attributeFactory);
mlParser.setObserver(this.observer);
this.methods = mlParser.getList();
at = mlParser.getEndOffset();
final AttributeListParser alParser = new AttributeListParser(this, 0, at, this.attributeFactory);
alParser.setObserver(this.observer);
(this.attributes = alParser.getList()).setImmutable();
at = alParser.getEndOffset();
if (at != this.bytes.size()) {
throw new ParseException("extra bytes at end of class file, at offset " + Hex.u4(at));
}
if (this.observer != null) {
this.observer.parsed(this.bytes, at, 0, "end classfile");
}
}
private static class DcfTypeList implements TypeList
{
private final ByteArray bytes;
private final int size;
private final StdConstantPool pool;
public DcfTypeList(ByteArray bytes, int offset, final int size, final StdConstantPool pool, final ParseObserver observer) {
if (size < 0) {
throw new IllegalArgumentException("size < 0");
}
bytes = bytes.slice(offset, offset + size * 2);
this.bytes = bytes;
this.size = size;
this.pool = pool;
for (int i = 0; i < size; ++i) {
offset = i * 2;
final int idx = bytes.getUnsignedShort(offset);
CstType type;
try {
type = (CstType)pool.get(idx);
}
catch (ClassCastException ex) {
throw new RuntimeException("bogus class cpi", ex);
}
if (observer != null) {
observer.parsed(bytes, offset, 2, " " + type);
}
}
}
@Override
public boolean isMutable() {
return false;
}
@Override
public int size() {
return this.size;
}
@Override
public int getWordCount() {
return this.size;
}
@Override
public Type getType(final int n) {
final int idx = this.bytes.getUnsignedShort(n * 2);
return ((CstType)this.pool.get(idx)).getClassType();
}
@Override
public TypeList withAddedType(final Type type) {
throw new UnsupportedOperationException("unsupported");
}
}
}
|
Java
|
UTF-8
| 766 | 1.867188 | 2 |
[] |
no_license
|
package com.iw.cf.core.dao;
import com.iw.cf.core.dto.Era;
import org.apache.ibatis.session.SqlSession;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
public class EraDao {
@Autowired
private SqlSession sqlSession;
public void insert(Era era) {
sqlSession.insert("com.iw.cf.mybatis.Era.insert", era);
}
public void deleteAll() {
sqlSession.delete("com.iw.cf.mybatis.Era.deleteAll");
}
public List<Era> getAll() {
return sqlSession.selectList("com.iw.cf.mybatis.Era.getAll");
}
public List<Era> getWithVideos() {
return sqlSession.selectList("com.iw.cf.mybatis.Era.getWithVideos");
}
}
|
Python
|
UTF-8
| 865 | 3.859375 | 4 |
[] |
no_license
|
"""The program will prompt for a URL, read the XML data from that URL using urllib
and then parse and extract the comment counts from the XML data,
compute the sum of the numbers in the file.
Data:
<comment>
<name>Matthias</name>
<count>97</count>
</comment>
"""
import urllib.request, urllib.parse, urllib.error
import xml.etree.ElementTree as ET
import ssl
# Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = input('Enter url: ')
try:
f = urllib.request.urlopen(url, context=ctx).read()
except:
print('Verify your url')
quit()
print(f'Retrieving {url}')
data = f.decode()
print(f'Retrieved {len(data)} characters')
root = ET.fromstring(data)
nums = list()
for count in root.findall('.//count'):
nums.append(int(count.text))
print(f'Sum: {sum(nums)}')
|
Java
|
UTF-8
| 564 | 2.96875 | 3 |
[] |
no_license
|
package com.pzy.study.C21备忘录模式;
import java.util.HashMap;
/**
* Destription:
* Author: pengzuyao
* Time: 2019-07-14
*/
public class MementCaretaker {
private HashMap<String ,MementoIF> mementoMap;
public MementCaretaker(){
mementoMap = new HashMap<String ,MementoIF>();
}
public MementoIF retrieveMemento(String name){
return mementoMap.get(name);
}
/**
* 保存备忘录
*/
public void saveMemento(String name , MementoIF mementoIF){
this.mementoMap.put(name , mementoIF);
}
}
|
Python
|
UTF-8
| 1,843 | 2.75 | 3 |
[] |
no_license
|
import requests
import time
from datetime import datetime
import json
from trading.utils.validation import isFloat, isValidDate
from trading.events.event import Tick
from trading.utils.time import to_utc_timestamp
from trading.DataSource.DataSource import DataSource
from trading.utils.logger import Logger
class OANDATicker(DataSource, Logger):
def __init__(self, instruments):
super(OANDATicker, self).__init__()
self.domain = 'api-fxpractice.oanda.com'
self.access_token = '4e8c5da75cbc23c5499ed9911f713699-78a54194e5457e0a3f7b05e0d10e06d0'
self.instruments = instruments
self.last_tick = None
def connect(self):
while True:
try:
url = "https://" + self.domain + "/v1/prices"
headers = {'Authorization' : 'Bearer ' + self.access_token}
params = {'instruments' : self.instruments}
r = requests.get(url, headers=headers, params=params).json()
tick = self.forge_tick(r)
if tick != self.last_tick:
self.emit(Tick(**tick))
self.last_tick = tick
time.sleep(1)
except Exception as e:
print("Caught exception when connecting to stream\n" + str(e))
def forge_tick(self, response):
price = response['prices'][0]
tick = {}
tick['ask'] = price['ask']
tick['bid'] = price['bid']
tick['ask_volume'] = -1
tick['bid_volume'] = -1
tick['symbol'] = price['instrument']
t = time.mktime(datetime.strptime(price['time'], '%Y-%m-%dT%H:%M:%S.%fZ' ).timetuple())
tick['timestamp'] = int(t)
return tick
if __name__ == "__main__":
instruments = ['EUR_USD']
s = StreamingForexPrices(instruments)
s.connect_to_stream()
|
Java
|
UTF-8
| 3,998 | 2.390625 | 2 |
[] |
no_license
|
/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
import java.io.IOException;
import java.io.PrintWriter;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.Scanner;
import java.util.logging.Level;
import java.util.logging.Logger;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.sql.*;
import javax.servlet.ServletContext;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpSession;
/**
*
* @author Yushant Tyagi
*/
@WebServlet(urlPatterns = {"/user_register"})
public class user_register extends HttpServlet {
static int check(Connection con,String email){
int count=0;
try{
Statement stmt=con.createStatement();
ResultSet rs=stmt.executeQuery("select count(*) from users where email='"+email+"'");
rs.next();
count = rs.getInt(1);
} catch (SQLException ex) {
Logger.getLogger(user_login.class.getName()).log(Level.SEVERE, null, ex);
}
if(count>0){return 1;}
return 0;
}
static void insert(Connection con,String a,String b,String c,String d,String e){
try{
Scanner sc=new Scanner(System.in);
String query = " insert into users (password, fullname, email, phone,location,userid)"
+ " values (?, ?, ?, ?, ?,0)";
PreparedStatement preparedStmt = con.prepareStatement(query);
preparedStmt.setString (1, a);
preparedStmt.setString (2, b);
preparedStmt.setString (3, c);
preparedStmt.setString (4,d);
preparedStmt.setString(5,e);
preparedStmt.execute();
System.out.println("\ninserted successfully\n\n");
} catch (SQLException ex) {
Logger.getLogger(user_register.class.getName()).log(Level.SEVERE, null, ex);
}
}
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
HttpSession session=request.getSession(false);
PrintWriter out=response.getWriter();
response.setContentType("text/html;charset=UTF-8");
String name=request.getParameter("fullname");
String phone=request.getParameter("phone");
String email=request.getParameter("email");
String location=request.getParameter("location");
String password=request.getParameter("password");
int id;
session.setAttribute("email", email);
out.println(name+phone+email+location+password);
try{
Class.forName("com.mysql.jdbc.Driver");
System.out.println("driver loaded");
Connection con=DriverManager.getConnection("jdbc:mysql://localhost:3306/foodshala?zeroDateTimeBehavior=convertToNull&useSSL=false","root","root");
System.out.println("connection established");
Scanner sc=new Scanner(System.in);
if(check(con,email)==1){
out.println("email already exists");
}
else{
insert(con,password,name,email,phone,location);
}
} catch (ClassNotFoundException ex) {
Logger.getLogger(user_register.class.getName()).log(Level.SEVERE, null, ex);
} catch (SQLException ex) {
Logger.getLogger(user_register.class.getName()).log(Level.SEVERE, null, ex);
}
request.setAttribute("email", email);
ServletContext sc = getServletContext();
sc.getRequestDispatcher("/shop.jsp").forward(request, response);
}
}
|
Python
|
UTF-8
| 454 | 4.21875 | 4 |
[] |
no_license
|
print(abs(-5)) # 절대값 구하기
print(pow(4, 2)) # 4^2 = 16
print(max(5, 12)) # 12
print(min(5, 12)) # 12
print(round(3.14)) # 3
print("-" * 15)
from math import *
print(floor(4.99)) # 내림
print(ceil(3.14)) # 올림
print(sqrt(16)) # 제곱근
print("-" * 15)
from random import *
print(random()) # 0~1사이의 랜덤값 생성
print(random() * 10)
print(randint(0, 100))
print(int(random() * 10 + 1)) # 1~10사이의 값을 출력
|
Java
|
UTF-8
| 2,944 | 2.234375 | 2 |
[
"Apache-2.0"
] |
permissive
|
package org.ripple.power.command;
import org.json.JSONObject;
import org.ripple.power.txns.CurrencyUtils;
public abstract class AMacros implements IMacros {
protected String clazz;
protected final String[] commands;
protected boolean syncing;
protected DMacros macros;
protected IScriptLog log;
protected int line;
protected void error(Exception ex) {
if (log != null) {
log.err("line: %s\nexception: %s\n", line, ex.getMessage());
}
}
protected void setMacros(DMacros m) {
this.macros = m;
}
protected void setScriptLog(IScriptLog l) {
this.log = l;
}
protected void setLine(int l) {
this.line = l;
}
protected void setConfig(IScriptLog l, DMacros m, int line) {
setMacros(m);
setScriptLog(l);
setLine(line);
}
public AMacros(String clazz, String[] cmdtables) {
this.clazz = clazz;
this.commands = cmdtables;
}
protected void log(int type, JSONObject res) {
if (res != null) {
log(type, res.toString());
}
}
protected void log(int type, String message) {
if (log != null && message != null) {
log.info(clazz + getCommandName(type));
log.info(message);
log.newline();
}
}
public boolean isSyncing() {
return syncing;
}
protected void setSyncing(int type, boolean sy) {
syncing = sy;
macros.setVariable(clazz + getCommandName(type) + ".syncing", syncing);
}
protected void setJsonArrayVar(int type, JSONObject obj, String name, int idx, String key) {
setJsonArrayVar(type, obj, name, idx, key, false);
}
protected void setJsonArrayVar(int type, JSONObject obj, String name, int idx, String key, boolean useCur) {
String result = name + "[" + idx + "]" + "." + key;
if (obj.has(key)) {
if (useCur) {
setVar(type, result, CurrencyUtils.getIssuedCurrency(obj.get(key)));
} else {
setVar(type, result, obj.get(key));
}
} else {
setVar(type, result, null);
}
}
protected void setJsonVar(int type, JSONObject obj, String key) {
if (obj.has(key)) {
setVar(type, key, obj.get(key));
} else {
setVar(type, key, null);
}
}
protected void setVar(int type, String key, Object value) {
setVar(type, key, value, false);
}
protected void setVar(int type, Object value) {
setVar(type, null, value, true);
}
protected void setVar(int type, String key, Object value, boolean useThis) {
if (macros != null) {
if (useThis) {
macros.setVariable(clazz + getCommandName(type), value);
} else {
macros.setVariable(clazz + getCommandName(type) + "." + key, value);
}
}
}
protected String getCommandName(int id) {
if (commands == null) {
return null;
}
if (id > -1 && id < commands.length) {
return commands[id];
}
return null;
}
protected int lookupCommand(String str) {
if (commands == null) {
return -1;
}
str = str.toLowerCase().trim();
for (int i = 0; i < commands.length; i++) {
if (str.equals(commands[i])) {
return i;
}
}
return -1;
}
}
|
Markdown
|
UTF-8
| 12,488 | 2.5625 | 3 |
[
"LicenseRef-scancode-public-domain"
] |
permissive
|
> *The following text is extracted and transformed from the itk.org privacy policy that was archived on 2019-12-31. Please check the [original snapshot on the Wayback Machine](https://web.archive.org/web/20191231233142id_/https%3A//www.kitware.com/privacy) for the most accurate reproduction.*
# Privacy - Kitware, Inc.
#### We created this Privacy Statement to demonstrate our firm commitment to the individual’s right to data protection and privacy. This Privacy Statement outlines how we handle information that can be used to directly or indirectly identify an individual (“Personal Data”).
## A. General Information
**When does this Privacy Statement apply?** This Privacy Statement applies to Personal Data that you provide to KITWARE or which is derived from the Personal Data as outlined below. The use of any information that is gathered by cookies or other web tracking technologies is subject to the terms of our Cookies Policy.
**Data Controller**. The data controller of Kitware, Inc. is Kitware, Inc., 1712 Route 9, Suite 300, Clifton Park, NY 12065 (“KITWARE”).
**What does KITWARE do with my Personal Data?** KITWARE will process the Personal Data provided hereunder only as set out in this Privacy Statement. Where the processing of your Personal Data is based on a statutory permission, you can find information on which Personal Data KITWARE is processing or using for which purposes in Section B below. Where consent for the processing of your Personal Data is required you can find further information in Section C. below.
**Duration of processing of Personal Data**. Where KITWARE is processing and using your Personal Data as permitted by law or under your consent, KITWARE will store your Personal Data (i) only for as long as is required to fulfil the purposes set out below or (ii) until you object to KITWARE’s use of your Personal Data (where KITWARE has a legitimate interest in using your Personal Data), or (iii) until you withdraw your consent (where you consented to KITWARE using your Personal Data). However, where KITWARE is required to retain your Personal Data longer or where your Personal Data is required for KITWARE to assert or defend against legal claims, KITWARE will retain your Personal Data until the end of the relevant retention period or until the claims in question have been settled.
**Why am I required to provide Personal Data?** As a general principle, your granting of any consent and your provision of any Personal Data hereunder is entirely voluntary; there are generally no detrimental effects on you if you choose not to consent or to provide Personal Data. However, there are circumstances in which KITWARE cannot take action without certain Personal Data, for example because this Personal Data is required to provide you with requested information, enter into a contract, make comments on our blog or participate in our mailing list. In these cases, it will, unfortunately, not be possible for KITWARE to provide you with what you request without the relevant Personal Data.
**Where will my Personal Data be processed?** KITWARE has affiliates and third-party service providers within, as well as outside of the European Economic Area (the “EEA”). As a consequence, whenever KITWARE is using or otherwise processing your Personal Data for the purposes set out in this Privacy Statement, KITWARE may transfer your Personal Data to countries outside of the EEA, including to such countries in which a statutory level of data protection applies that is not comparable to the level of data protection within the EEA.
**Data subjects’ rights**. You can request from KITWARE at any time information about which Personal Data KITWARE processes about you and the correction or deletion of such Personal Data. Please note, however, that KITWARE can delete your Personal Data only if there is no statutory obligation or prevailing right of KITWARE to retain it. Kindly note that if you request that KITWARE delete your Personal Data, you will not be able to continue to use any KITWARE service that requires KITWARE’s use of your Personal Data.
If KITWARE uses your Personal Data based on your consent or to perform a contract with you, you may further request from KITWARE a copy of the Personal Data that you have provided to KITWARE. In this case, please send an email to compliance@kitware.com and specify the information or processing activities to which your request relates and the format in which you would like this information. KITWARE will carefully consider your request and discuss with you how it can best fulfill it.
**Right to lodge a complaint**. If you believe that KITWARE is not processing your Personal Data in accordance with the requirements set out herein or applicable EEA data protection laws, you can at any time lodge a complaint with the data protection authority of the EEA country in which you live.
**Use of this website by children**. This website is not intended for anyone under the age of 16 years. If you are younger than 16, you may not register with or use this website.
**Links to other websites**. This website may contain links to foreign (meaning non-KITWARE Entities) websites. KITWARE is not responsible for the privacy practices or the content of websites outside of KITWARE. Therefore, we recommend that you carefully read the privacy statements of such foreign sites.
## B. Where KITWARE uses My Personal Data based on the Law
In the following cases, KITWARE is permitted to process your Personal Data under the applicable data protection law.
**Providing the requested goods or services.** If you order goods or services from KITWARE, KITWARE will use the Personal Data that you enter into the contract, Purchase Order or Purchase Form only to process your order or to provide the requested goods or service. This may include taking the necessary steps prior to entering into the contract, responding to your related inquiries, and providing you with shipping and billing information and to process or provide customer feedback and support. This may also include conversation data that you may trigger via contact forms, emails, or telephone. In this Privacy Statement, “goods and services” includes access to KITWARE’s web services, offerings, other content, non-marketing related newsletters, trainings and events.
We communicate on a regular basis by email and telephone with customers. We may use your email address to discuss contract related matters, to send you notice of payments, to send you information about changes to our products and services, and to send notices and other disclosures as required by law. Generally, users cannot opt out of these communications, which are not marketing-related but merely required for the relevant business relationship. With regard to marketing-related types of communication (i.e. emails and phone calls), KITWARE will (i) where legally required only provide you with such information after you have opted in and (ii) provide you the opportunity to opt out if you do not want to receive further marketing-related types of communication from us. You can opt out of these at any time by e-mailing [compliance@kitware.com](mailto:compliance@kitware.com).
**Ensuring compliance**. KITWARE and its products, technologies, and services are subject to the export laws of various countries including, without limitation, those of the European Union and its member states, and of the United States of America. You acknowledge that, pursuant to the applicable export laws, trade sanctions, and embargoes issued by these countries, KITWARE is required to take measures to prevent entities, organizations, and parties listed on government-issued sanctioned-party lists from accessing certain KITWARE products, technologies, and services. This may include (i) automated checks of any user registration data as set out herein and other information a user provides about his or her identity against applicable sanctioned-party lists; (ii) regular repetition of such checks; (iii) blocking of access to KITWARE’s services and systems in case of a potential match; and (iv) contacting a user to confirm his or her identity in case of a potential match.
**KITWARE’s legitimate interest**. Each of the use cases below constitutes a legitimate interest of KITWARE to process or use your Personal Data. If you do not agree with this approach, you may object to Kitware’s processing or use of your Personal Data as set out below.
Questionnaires and surveys. KITWARE may invite you to participate in questionnaires and surveys. These questionnaires and surveys will be generally designed in a way that they can be answered without any Personal Data. If you nonetheless enter Personal Data in a questionnaire or survey, KITWARE may use such Personal Data to improve its products and services.
Creation of anonymized data sets. KITWARE may anonymize Personal Data provided under this Privacy Statement to create anonymized datasets, which will then be used to improve its and its affiliates’ products and services.
In order to keep you up-to-date/request feedback. Within an existing business relationship between you and KITWARE, KITWARE may inform you, where permitted in accordance with local laws, about its products or services (including trainings or events) which are similar or relate to such products and services you have already purchased or used from KITWARE. Furthermore, where you have attended a training or event of KITWARE or purchased products or services from KITWARE, KITWARE may contact you for feedback regarding the improvement of the relevant training or event.
**Right to object.** You may object to KITWARE using Personal Data for the above purposes at any time by emailing [compliance@kitware.com](mailto:compliance@kitware.com). If you do so, KITWARE will cease using your Personal Data for the above purposes and remove it from its systems unless KITWARE is permitted to use such Personal Data for another purpose set out in this Privacy Statement or KITWARE determines and demonstrates a compelling legitimate interest to continue processing your Personal Data.
## C. Where KITWARE uses My Personal Data based on My Consent
In the following cases KITWARE will only use your Personal Data as further detailed below after you have granted your prior consent into the relevant processing operations.
**News about KITWARE’s Products and Services.** Subject to your consent, KITWARE may use your name, email and postal address, telephone number, job title and basic information about your employer (name, address, and industry) as well as an interaction profile based on prior interactions with KITWARE – in order to keep you up to date on the latest product announcements and other information about KITWARE’s software and services (including marketing-related newsletters), as well as events of KITWARE and in order to display relevant content on KITWARE’s websites.
**Creating user profiles.** KITWARE offers you the option to use its web offerings including forums, blogs, and networks. User profiles provide the option to display personal information about you to other users, including but not limited to your name, photo, social media accounts, postal or email address, or both, telephone number, personal interests, skills, and basic information about your company. Kindly note that without your consent for KITWARE to create such user profiles KITWARE will not be in a position to offer such services to you.
**Event profiling.** If you register for an event or training, KITWARE may share basic participant information (your name, company, and email address) with other participants of the same event, seminar, or webinar for the purpose of communication and the exchange of ideas.
**Revocation of a consent granted hereunder.** You may at any time withdraw a consent granted hereunder by emailing [compliance@kitware.com](mailto:compliance@kitware.com). In case of withdrawal, KITWARE will not process Personal Data subject to this consent any longer unless legally required to do so. In case KITWARE is required to retain your Personal Data for legal reasons your Personal Data will be restricted from further processing and only retained for the term required by law. However, any withdrawal has no effect on past processing of personal data by KITWARE up to the point in time of your withdrawal. Furthermore, if your use of an KITWARE offering requires your prior consent, KITWARE will no longer be able to provide the relevant service.
|
Java
|
UTF-8
| 4,370 | 2.296875 | 2 |
[] |
no_license
|
package com.fortune_user;
import android.content.ContentValues;
import android.content.Context;
import android.database.Cursor;
import android.database.sqlite.SQLiteDatabase;
import android.database.sqlite.SQLiteOpenHelper;
public class UserDatabaseHandler extends SQLiteOpenHelper {
private static final String DATABASE_NAME = "udbfortuneuser";
private static final int DATABASE_VERSION = 1;
private static final String TABLE_name1 = "user";
private static final String TABLE_name2 = "fcmid";
private static final String TABLE_name3 = "screenwidth";
private static final String fcmid = "fcmid";
private static final String pkey = "pkey";
private static final String userid = "userid";
private static final String screenwidth = "screenwidth";
private static String CREATE_TABLE1 = "CREATE TABLE " + TABLE_name1 + "("+pkey +" INTEGER PRIMARY KEY AUTOINCREMENT,"+userid+" TEXT"+")";
private static String CREATE_TABLE2= "CREATE TABLE " + TABLE_name2 + "("+pkey +" INTEGER PRIMARY KEY AUTOINCREMENT,"+fcmid+" TEXT"+")";
private static String CREATE_TABLE3= "CREATE TABLE " + TABLE_name3 + "("+pkey +" INTEGER PRIMARY KEY AUTOINCREMENT,"+screenwidth+" TEXT"+")";
public UserDatabaseHandler(Context context) {
super(context, DATABASE_NAME, null, DATABASE_VERSION);
}
public void onCreate(SQLiteDatabase db) {
db.execSQL(CREATE_TABLE1);
db.execSQL(CREATE_TABLE2);
db.execSQL(CREATE_TABLE3);
}
public void onUpgrade(SQLiteDatabase db, int oldVersion, int newVersion) {
db.execSQL("DROP TABLE IF EXISTS "+TABLE_name1);
db.execSQL("DROP TABLE IF EXISTS "+TABLE_name2);
db.execSQL("DROP TABLE IF EXISTS "+TABLE_name3);
onCreate(db);
}
public void onDowngrade(SQLiteDatabase db, int oldVersion, int newVersion) {
db.execSQL("DROP TABLE IF EXISTS "+TABLE_name1);
db.execSQL("DROP TABLE IF EXISTS "+TABLE_name2);
db.execSQL("DROP TABLE IF EXISTS "+TABLE_name3);
onCreate(db);
}
public void addfcmid(String fcmid1) {
deletefcmid();
SQLiteDatabase db = getWritableDatabase();
ContentValues values = new ContentValues();
values.put(fcmid, fcmid1);
db.insert(TABLE_name2, null, values);
db.close();
}
public String getfcmid() {
String link = "";
Cursor c = getReadableDatabase().rawQuery("SELECT * FROM "+TABLE_name2, null);
while (c.moveToNext()) {
link = c.getString(1);
}
c.close();
return link;
}
public void deletefcmid() {
getWritableDatabase().execSQL("delete from "+TABLE_name2);
}
public String get_userid() {
String link = "";
SQLiteDatabase sql = getReadableDatabase();
Cursor c = sql.rawQuery("SELECT * FROM "+TABLE_name1, null);
while (c.moveToNext()) {
link = c.getString(1);
}
c.close();
sql.close();
return link;
}
public void adduser(String userid1) {
deleteuser();
SQLiteDatabase db = getWritableDatabase();
ContentValues values = new ContentValues();
values.put(userid, userid1);
db.insert(TABLE_name1, null, values);
db.close();
}
public void deleteuser() {
SQLiteDatabase db = getWritableDatabase();
db.execSQL("delete from "+TABLE_name1);
db.close();
}
public String get_screenwidth() {
String link = "";
SQLiteDatabase sql = getReadableDatabase();
Cursor c = sql.rawQuery("SELECT * FROM "+TABLE_name3, null);
while (c.moveToNext()) {
link = c.getString(1);
}
c.close();
sql.close();
return link;
}
public void addscreenwidth(String userid1) {
deletescreenwidth();
SQLiteDatabase db = getWritableDatabase();
ContentValues values = new ContentValues();
values.put(userid, userid1);
db.insert(TABLE_name3, null, values);
db.close();
}
public void deletescreenwidth() {
SQLiteDatabase db = getWritableDatabase();
db.execSQL("delete from "+TABLE_name3);
db.close();
}
}
|
Python
|
UTF-8
| 946 | 2.765625 | 3 |
[] |
no_license
|
#!/scisoft/bin/python
"""
Make a list of files for use in WIRCSOFT
Options:
-n : Name -- The name of the region
-l : Lower -- Starting index
-u : Upper -- Ending index
-h : Help -- Display this help
"""
import os,sys
import getopt
def main():
try:
opts,args = getopt.getopt(sys.argv[1:],"n:l:u:h")
except getopt.GetoptError,err:
print(str(err))
print(__doc__)
sys.exit(2)
for o,a in opts:
if o == "-n":
name = a
elif o == "-l":
lower = a
elif o == "-u":
upper = a
elif o == "-h":
print(__doc__)
sys.exit(1)
else:
assert False, "unhandled option"
print(__doc__)
sys.exit(2)
ff = open(name+".list",'w')
for i in range(int(lower),int(upper)+1):
ff.write("wirc"+str(i).zfill(4)+".fits\n")
ff.close()
if __name__ == '__main__':
main()
|
Java
|
UTF-8
| 5,529 | 3.84375 | 4 |
[] |
no_license
|
package trees;
import java.util.ArrayList;
import java.util.Stack;
import reusableobjects.TreeNode;
public class TreePaths {
/**
* Longest path between two nodes
* @param root
* @return
*/
public int longestPath(TreeNode root) {
Stack<TreeNode> s = new Stack<TreeNode>();
HeightOfTree h = new HeightOfTree();
//Add all the left children
//to stack until null
while(root != null) {
s.push(root);
root = root.left;
}
//Pop each node, from bottom up,
//calculate path cost left + right + node
//Update max path accordingly
int depth = 0;
int maxPath = 0;
while(!s.isEmpty()) {
TreeNode current = s.pop();
depth++;
int path = depth + h.getHeight(current.right);
maxPath = (path > maxPath) ? path : maxPath;
}
return maxPath;
}
/*Given a binary tree and a sum, determine if the tree has a root-to-leaf path such that adding up all the values along the path equals the given sum.
For example:
Given the below binary tree and sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ \
7 2 1
return true, as there exist a root-to-leaf path 5->4->11->2 which sum is 22.*/
public boolean hasPathSum(TreeNode root, int sum) {
if(root == null)
return false;
if(root.val == sum && root.left == null && root.right == null)
return true;
return hasPathSum(root, sum, root.val, 0);
}
private boolean hasPathSum(TreeNode root, int sum, int curSum, int depth) {
if(root.left == null && root.right == null)
return (sum == curSum && depth > 0);
boolean hasPath = false;
if(root.left != null)
hasPath = hasPathSum(root.left, sum, curSum + root.left.val, depth + 1);
if(!hasPath && root.right != null)
hasPath = hasPathSum(root.right, sum, curSum + root.right.val, depth + 1);
return hasPath;
}
/*Given a binary tree and a sum, find all root-to-leaf paths where each path's sum equals the given sum.
For example:
Given the below binary tree and sum = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ / \
7 2 5 1
return
[
[5,4,11,2],
[5,8,4,5]
]*/
public ArrayList<ArrayList<Integer>> pathSum(TreeNode root, int sum) {
ArrayList<ArrayList<Integer>> paths = new ArrayList<ArrayList<Integer>>();
ArrayList<Integer> path = new ArrayList<Integer>();
if(root == null)
return paths;
path.add(root.val);
if(root.val == sum && root.left == null && root.right == null) {
paths.add(path);
return paths;
}
paths = hasPathSum(root, sum, root.val, 0, paths, path);
return paths;
}
private ArrayList<ArrayList<Integer>> hasPathSum(TreeNode root, int sum, int curSum, int depth, ArrayList<ArrayList<Integer>> paths, ArrayList<Integer> path) {
if(root.left == null && root.right == null) {
if (sum == curSum && depth > 0) {
paths.add(path);
}
return paths;
}
if(root.left != null) {
path.add(root.left.val);
paths = hasPathSum(root.left, sum, curSum + root.left.val, depth + 1, paths, new ArrayList<Integer>(path));
path.remove(path.size() - 1);
}
if(root.right != null) {
path.add(root.right.val);
paths = hasPathSum(root.right, sum, curSum + root.right.val, depth + 1, paths, new ArrayList<Integer>(path));
path.remove(path.size() - 1);
}
return paths;
}
/*
Given a binary tree containing digits from 0-9 only, each root-to-leaf path could represent a number.
An example is the root-to-leaf path 1->2->3 which represents the number 123.
Find the total sum of all root-to-leaf numbers.
For example,
1
/ \
2 3
The root-to-leaf path 1->2 represents the number 12.
The root-to-leaf path 1->3 represents the number 13.
Return the sum = 12 + 13 = 25.
*/
public int sumNumbers(TreeNode root) {
//When root is null
if(root == null)
return 0;
//When root has no children
if(root.left == null && root.right == null)
return root.val;
//To keep track of each path
StringBuilder sb = new StringBuilder();
//To keep track of all paths
ArrayList<String> paths = new ArrayList<String>();
//DFS
paths = dfs(root, sb, paths);
//Generate sum
int sum = 0;
for(int i = 0; i < paths.size(); i++) {
sum += Integer.parseInt(paths.get(i));
}
return sum;
}
private ArrayList<String> dfs(TreeNode root, StringBuilder sb, ArrayList<String> paths) {
if(root == null)
return paths;
if(root.left == null && root.right == null) {
sb.append(root.val);
paths.add(sb.toString());
sb.delete(sb.length() - 1, sb.length());
return paths;
}
sb.append(root.val);
paths = dfs(root.left, sb, paths);
paths = dfs(root.right, sb, paths);
sb.delete(sb.length() - 1, sb.length());
return paths;
}
}
|
C
|
UTF-8
| 325 | 2.65625 | 3 |
[
"MIT"
] |
permissive
|
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#include <inttypes.h>
#include "aterm.h"
int main(void) {
// setvbuf(stdout, NULL, _IONBF, 0);
aterm* at = at_parse(stdin);
printf("Getting ready to to_string\n");
char* sterm = aterm_to_string(*at);
printf("Back from to_string\n");
printf("%s\n", sterm);
}
|
C++
|
UTF-8
| 977 | 2.953125 | 3 |
[
"Apache-2.0"
] |
permissive
|
/**
Copyright 2017 Udey Rishi
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
#include <catch.hpp>
#include <dumb_cpp_math.hpp>
SCENARIO("Test Adder", "[Adder]") {
GIVEN("An Adder object") {
dumb_math::Adder adder(10, 20);
REQUIRE(adder.getFirst() == 10);
REQUIRE(adder.getSecond() == 20);
WHEN("first and second are set") {
THEN("getSum returns the sum") {
REQUIRE(adder.getSum() == 30);
}
}
}
}
|
C#
|
UTF-8
| 3,145 | 3.3125 | 3 |
[] |
no_license
|
using RepositoryPatterns;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace StreamingContent_Inheritance
{
public class StreamingRepository : StreamingContentRepository
{
// using this _contentDirectory from streamingcontentrepo.cs - protected readonly List<StreamingContent> _contentDirectory = new List<StreamingContent>();
//Read - shows
public Show GetShowByTitle(string title)
{
//to find a specific show
foreach (StreamingContent content in _contentDirectory)
{
if (content.Title.ToLower() == title.ToLower() && content.GetType() == typeof(Show))
{
return (Show)content;
}
}
return null;
}
//Read - Movies
public Movie GetMovieByTitle(string title)
{
foreach (StreamingContent content in _contentDirectory)
{
if (content.Title.ToLower() == title.ToLower() && content is Movie)
{
return (Movie)content;
}
}
return null;
}
//Read get all
public List<Show> GetAllShows()
{
//use to add our shows - starts empty - this is a "newed-up" version of the list
List<Show> allshows = new List<Show>();
foreach (StreamingContent content in _contentDirectory)
{
//if the content we find is of type SHOW...
if (content is Show)
{
//add the show to the allshows list
allshows.Add((Show)content);
}
}
return allshows;
}
public List<Movie> GetAllMovies()
{
List<Movie> allMovies = new List<Movie>();
foreach (StreamingContent content in _contentDirectory)
{
if (content is Movie)
{
allMovies.Add(content as Movie);
}
}
return allMovies;
}
public List<Movie> GetMovieByRuntime(double runTime)
{
List<Movie> moviesByRunTime = new List<Movie>();
foreach (Movie content in _contentDirectory)
{
if (runTime == content.RunTime && content is Movie)
{
return moviesByRunTime;
}
}
return null;
}
public List<Show> GetShowByEpisodes(int episodeCount)
{
List<Show> showByEpisodes = new List<Show>();
foreach (Show content in _contentDirectory)
{
if (episodeCount == content.EpisodeCount && content is Show)
{
return showByEpisodes;
}
}
return null;
}
//get by other parameters, such as runtime/avg runtime,shows with over x episodes, get shows or movie by rating
}
}
|
C#
|
UTF-8
| 1,912 | 2.71875 | 3 |
[] |
no_license
|
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.IO.Ports;
namespace Reader
{
public partial class ComSettings : Form
{
private SerialPort _Port;
public SerialPort Port
{
get { return _Port; }
set
{
_Port = value;
Init();
}
}
public ComSettings()
{
InitializeComponent();
comboBoxPorts.Items.Clear();
comboBoxPorts.Items.AddRange(SerialPort.GetPortNames());
}
private void Init()
{
comboBoxPorts.Text = _Port.PortName;
comboBoxStopbits.SelectedIndex = (int)_Port.StopBits;
comboBoxBaudrate.Text = _Port.BaudRate.ToString();
comboBoxParity.SelectedIndex = (int)_Port.Parity;
comboBoxHandshake.SelectedIndex = (int)_Port.Handshake;
}
private void button1_Click(object sender, EventArgs e)
{
try
{
if (_Port.IsOpen)
{
_Port.Close();
}
_Port.PortName = comboBoxPorts.Text;
_Port.StopBits = (StopBits)comboBoxStopbits.SelectedIndex;
_Port.BaudRate = int.Parse(comboBoxBaudrate.Text);
_Port.Parity = (Parity)comboBoxParity.SelectedIndex;
_Port.Handshake = (Handshake)comboBoxHandshake.SelectedIndex;
_Port.Open();
}
catch (Exception ex)
{
MessageBox.Show("Fail to update the setting to the port. The message:\n\n" + ex.Message,
"Error", MessageBoxButtons.OK, MessageBoxIcon.Error);
}
}
}
}
|
Python
|
UTF-8
| 1,660 | 3.0625 | 3 |
[] |
no_license
|
#(a) Si tu aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa está en primero (valor 1) de videojuegos (valor 'videojuegos')
curso_aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa==1 and g_comp_2=='Diseño y desarrollo de videojuegos'
#(b) Si tu aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa no está en primero de videojuegos. Escribe dos expresiones distintas
curso_aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa!=1 or g_comp_2!='Diseño y desarrollo de videojuegos'
not(curso_aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa==1 and g_comp_2=='Diseño y desarrollo de videojuegos')
#(c) Si tu aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa está en enfermeria, medicina o psicologia
g_comp_2=='enfermeria' or g_comp_2=='medicina' or g_comp_2=='psicologia'
#(d) Si tu aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa no está en enfermeriaa, medicina ni psicologia. Escribe dos expresiones distintas
not(g_comp_2=='enfermeria' and g_comp_2=='medicina' and g_comp_2=='psicologia')
g_comp_2!='enfermeria' or g_comp_2!='medicina' or g_comp_2!='psicologia'
#(e) Si tu aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa y tú estáis en el mismo curso del mismo grado
curso_aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa==mi_curso and g_comp_2==mi_grado
#(f) Si tu aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa y tú no estáis en el mismo curso del mismo grado.Escribe dos expresiones distintas
curso_aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa!=mi_curso and g_comp_2==mi_grado
not(curso_aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa==mi_curso or g_comp_2!=mi_grado)
#(g) Si tu aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa y tú estais en el mismo curso pero no del mismo grado
curso_aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa==mi_curso and g_comp_2!=mi_grado
|
Java
|
UTF-8
| 35,704 | 2.09375 | 2 |
[] |
no_license
|
package edu.ku.cete.domain.professionaldevelopment;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class BatchStudentTrackerExample {
/**
* This field was generated by MyBatis Generator. This field corresponds to the database table batchstudenttracker
* @mbggenerated Mon Nov 24 00:50:03 CST 2014
*/
protected String orderByClause;
/**
* This field was generated by MyBatis Generator. This field corresponds to the database table batchstudenttracker
* @mbggenerated Mon Nov 24 00:50:03 CST 2014
*/
protected boolean distinct;
/**
* This field was generated by MyBatis Generator. This field corresponds to the database table batchstudenttracker
* @mbggenerated Mon Nov 24 00:50:03 CST 2014
*/
protected List<Criteria> oredCriteria;
/**
* This method was generated by MyBatis Generator. This method corresponds to the database table batchstudenttracker
* @mbggenerated Mon Nov 24 00:50:03 CST 2014
*/
public BatchStudentTrackerExample() {
oredCriteria = new ArrayList<Criteria>();
}
/**
* This method was generated by MyBatis Generator. This method corresponds to the database table batchstudenttracker
* @mbggenerated Mon Nov 24 00:50:03 CST 2014
*/
public void setOrderByClause(String orderByClause) {
this.orderByClause = orderByClause;
}
/**
* This method was generated by MyBatis Generator. This method corresponds to the database table batchstudenttracker
* @mbggenerated Mon Nov 24 00:50:03 CST 2014
*/
public String getOrderByClause() {
return orderByClause;
}
/**
* This method was generated by MyBatis Generator. This method corresponds to the database table batchstudenttracker
* @mbggenerated Mon Nov 24 00:50:03 CST 2014
*/
public void setDistinct(boolean distinct) {
this.distinct = distinct;
}
/**
* This method was generated by MyBatis Generator. This method corresponds to the database table batchstudenttracker
* @mbggenerated Mon Nov 24 00:50:03 CST 2014
*/
public boolean isDistinct() {
return distinct;
}
/**
* This method was generated by MyBatis Generator. This method corresponds to the database table batchstudenttracker
* @mbggenerated Mon Nov 24 00:50:03 CST 2014
*/
public List<Criteria> getOredCriteria() {
return oredCriteria;
}
/**
* This method was generated by MyBatis Generator. This method corresponds to the database table batchstudenttracker
* @mbggenerated Mon Nov 24 00:50:03 CST 2014
*/
public void or(Criteria criteria) {
oredCriteria.add(criteria);
}
/**
* This method was generated by MyBatis Generator. This method corresponds to the database table batchstudenttracker
* @mbggenerated Mon Nov 24 00:50:03 CST 2014
*/
public Criteria or() {
Criteria criteria = createCriteriaInternal();
oredCriteria.add(criteria);
return criteria;
}
/**
* This method was generated by MyBatis Generator. This method corresponds to the database table batchstudenttracker
* @mbggenerated Mon Nov 24 00:50:03 CST 2014
*/
public Criteria createCriteria() {
Criteria criteria = createCriteriaInternal();
if (oredCriteria.size() == 0) {
oredCriteria.add(criteria);
}
return criteria;
}
/**
* This method was generated by MyBatis Generator. This method corresponds to the database table batchstudenttracker
* @mbggenerated Mon Nov 24 00:50:03 CST 2014
*/
protected Criteria createCriteriaInternal() {
Criteria criteria = new Criteria();
return criteria;
}
/**
* This method was generated by MyBatis Generator. This method corresponds to the database table batchstudenttracker
* @mbggenerated Mon Nov 24 00:50:03 CST 2014
*/
public void clear() {
oredCriteria.clear();
orderByClause = null;
distinct = false;
}
/**
* This class was generated by MyBatis Generator. This class corresponds to the database table batchstudenttracker
* @mbggenerated Mon Nov 24 00:50:03 CST 2014
*/
protected abstract static class GeneratedCriteria {
protected List<Criterion> criteria;
protected GeneratedCriteria() {
super();
criteria = new ArrayList<Criterion>();
}
public boolean isValid() {
return criteria.size() > 0;
}
public List<Criterion> getAllCriteria() {
return criteria;
}
public List<Criterion> getCriteria() {
return criteria;
}
protected void addCriterion(String condition) {
if (condition == null) {
throw new RuntimeException("Value for condition cannot be null");
}
criteria.add(new Criterion(condition));
}
protected void addCriterion(String condition, Object value,
String property) {
if (value == null) {
throw new RuntimeException("Value for " + property
+ " cannot be null");
}
criteria.add(new Criterion(condition, value));
}
protected void addCriterion(String condition, Object value1,
Object value2, String property) {
if (value1 == null || value2 == null) {
throw new RuntimeException("Between values for " + property
+ " cannot be null");
}
criteria.add(new Criterion(condition, value1, value2));
}
public Criteria andIdIsNull() {
addCriterion("id is null");
return (Criteria) this;
}
public Criteria andIdIsNotNull() {
addCriterion("id is not null");
return (Criteria) this;
}
public Criteria andIdEqualTo(Long value) {
addCriterion("id =", value, "id");
return (Criteria) this;
}
public Criteria andIdNotEqualTo(Long value) {
addCriterion("id <>", value, "id");
return (Criteria) this;
}
public Criteria andIdGreaterThan(Long value) {
addCriterion("id >", value, "id");
return (Criteria) this;
}
public Criteria andIdGreaterThanOrEqualTo(Long value) {
addCriterion("id >=", value, "id");
return (Criteria) this;
}
public Criteria andIdLessThan(Long value) {
addCriterion("id <", value, "id");
return (Criteria) this;
}
public Criteria andIdLessThanOrEqualTo(Long value) {
addCriterion("id <=", value, "id");
return (Criteria) this;
}
public Criteria andIdIn(List<Long> values) {
addCriterion("id in", values, "id");
return (Criteria) this;
}
public Criteria andIdNotIn(List<Long> values) {
addCriterion("id not in", values, "id");
return (Criteria) this;
}
public Criteria andIdBetween(Long value1, Long value2) {
addCriterion("id between", value1, value2, "id");
return (Criteria) this;
}
public Criteria andIdNotBetween(Long value1, Long value2) {
addCriterion("id not between", value1, value2, "id");
return (Criteria) this;
}
public Criteria andSubmissionDateIsNull() {
addCriterion("submissiondate is null");
return (Criteria) this;
}
public Criteria andSubmissionDateIsNotNull() {
addCriterion("submissiondate is not null");
return (Criteria) this;
}
public Criteria andSubmissionDateEqualTo(Date value) {
addCriterion("submissiondate =", value, "submissionDate");
return (Criteria) this;
}
public Criteria andSubmissionDateNotEqualTo(Date value) {
addCriterion("submissiondate <>", value, "submissionDate");
return (Criteria) this;
}
public Criteria andSubmissionDateGreaterThan(Date value) {
addCriterion("submissiondate >", value, "submissionDate");
return (Criteria) this;
}
public Criteria andSubmissionDateGreaterThanOrEqualTo(Date value) {
addCriterion("submissiondate >=", value, "submissionDate");
return (Criteria) this;
}
public Criteria andSubmissionDateLessThan(Date value) {
addCriterion("submissiondate <", value, "submissionDate");
return (Criteria) this;
}
public Criteria andSubmissionDateLessThanOrEqualTo(Date value) {
addCriterion("submissiondate <=", value, "submissionDate");
return (Criteria) this;
}
public Criteria andSubmissionDateIn(List<Date> values) {
addCriterion("submissiondate in", values, "submissionDate");
return (Criteria) this;
}
public Criteria andSubmissionDateNotIn(List<Date> values) {
addCriterion("submissiondate not in", values, "submissionDate");
return (Criteria) this;
}
public Criteria andSubmissionDateBetween(Date value1, Date value2) {
addCriterion("submissiondate between", value1, value2,
"submissionDate");
return (Criteria) this;
}
public Criteria andSubmissionDateNotBetween(Date value1, Date value2) {
addCriterion("submissiondate not between", value1, value2,
"submissionDate");
return (Criteria) this;
}
public Criteria andStatusIsNull() {
addCriterion("status is null");
return (Criteria) this;
}
public Criteria andStatusIsNotNull() {
addCriterion("status is not null");
return (Criteria) this;
}
public Criteria andStatusEqualTo(String value) {
addCriterion("status =", value, "status");
return (Criteria) this;
}
public Criteria andStatusNotEqualTo(String value) {
addCriterion("status <>", value, "status");
return (Criteria) this;
}
public Criteria andStatusGreaterThan(String value) {
addCriterion("status >", value, "status");
return (Criteria) this;
}
public Criteria andStatusGreaterThanOrEqualTo(String value) {
addCriterion("status >=", value, "status");
return (Criteria) this;
}
public Criteria andStatusLessThan(String value) {
addCriterion("status <", value, "status");
return (Criteria) this;
}
public Criteria andStatusLessThanOrEqualTo(String value) {
addCriterion("status <=", value, "status");
return (Criteria) this;
}
public Criteria andStatusLike(String value) {
addCriterion("status like", value, "status");
return (Criteria) this;
}
public Criteria andStatusNotLike(String value) {
addCriterion("status not like", value, "status");
return (Criteria) this;
}
public Criteria andStatusIn(List<String> values) {
addCriterion("status in", values, "status");
return (Criteria) this;
}
public Criteria andStatusNotIn(List<String> values) {
addCriterion("status not in", values, "status");
return (Criteria) this;
}
public Criteria andStatusBetween(String value1, String value2) {
addCriterion("status between", value1, value2, "status");
return (Criteria) this;
}
public Criteria andStatusNotBetween(String value1, String value2) {
addCriterion("status not between", value1, value2, "status");
return (Criteria) this;
}
public Criteria andAssessmentProgramIsNull() {
addCriterion("assessmentprogram is null");
return (Criteria) this;
}
public Criteria andAssessmentProgramIsNotNull() {
addCriterion("assessmentprogram is not null");
return (Criteria) this;
}
public Criteria andAssessmentProgramEqualTo(Long value) {
addCriterion("assessmentprogram =", value, "assessmentProgram");
return (Criteria) this;
}
public Criteria andAssessmentProgramNotEqualTo(Long value) {
addCriterion("assessmentprogram <>", value, "assessmentProgram");
return (Criteria) this;
}
public Criteria andAssessmentProgramGreaterThan(Long value) {
addCriterion("assessmentprogram >", value, "assessmentProgram");
return (Criteria) this;
}
public Criteria andAssessmentProgramGreaterThanOrEqualTo(Long value) {
addCriterion("assessmentprogram >=", value, "assessmentProgram");
return (Criteria) this;
}
public Criteria andAssessmentProgramLessThan(Long value) {
addCriterion("assessmentprogram <", value, "assessmentProgram");
return (Criteria) this;
}
public Criteria andAssessmentProgramLessThanOrEqualTo(Long value) {
addCriterion("assessmentprogram <=", value, "assessmentProgram");
return (Criteria) this;
}
public Criteria andAssessmentProgramIn(List<Long> values) {
addCriterion("assessmentprogram in", values, "assessmentProgram");
return (Criteria) this;
}
public Criteria andAssessmentProgramNotIn(List<Long> values) {
addCriterion("assessmentprogram not in", values,
"assessmentProgram");
return (Criteria) this;
}
public Criteria andAssessmentProgramBetween(Long value1, Long value2) {
addCriterion("assessmentprogram between", value1, value2,
"assessmentProgram");
return (Criteria) this;
}
public Criteria andAssessmentProgramNotBetween(Long value1, Long value2) {
addCriterion("assessmentprogram not between", value1, value2,
"assessmentProgram");
return (Criteria) this;
}
public Criteria andOrgIdIsNull() {
addCriterion("orgid is null");
return (Criteria) this;
}
public Criteria andOrgIdIsNotNull() {
addCriterion("orgid is not null");
return (Criteria) this;
}
public Criteria andOrgIdEqualTo(Long value) {
addCriterion("orgid =", value, "orgId");
return (Criteria) this;
}
public Criteria andOrgIdNotEqualTo(Long value) {
addCriterion("orgid <>", value, "orgId");
return (Criteria) this;
}
public Criteria andOrgIdGreaterThan(Long value) {
addCriterion("orgid >", value, "orgId");
return (Criteria) this;
}
public Criteria andOrgIdGreaterThanOrEqualTo(Long value) {
addCriterion("orgid >=", value, "orgId");
return (Criteria) this;
}
public Criteria andOrgIdLessThan(Long value) {
addCriterion("orgid <", value, "orgId");
return (Criteria) this;
}
public Criteria andOrgIdLessThanOrEqualTo(Long value) {
addCriterion("orgid <=", value, "orgId");
return (Criteria) this;
}
public Criteria andOrgIdIn(List<Long> values) {
addCriterion("orgid in", values, "orgId");
return (Criteria) this;
}
public Criteria andOrgIdNotIn(List<Long> values) {
addCriterion("orgid not in", values, "orgId");
return (Criteria) this;
}
public Criteria andOrgIdBetween(Long value1, Long value2) {
addCriterion("orgid between", value1, value2, "orgId");
return (Criteria) this;
}
public Criteria andOrgIdNotBetween(Long value1, Long value2) {
addCriterion("orgid not between", value1, value2, "orgId");
return (Criteria) this;
}
public Criteria andOrgDisplayIdentifierIsNull() {
addCriterion("orgdisplayidentifier is null");
return (Criteria) this;
}
public Criteria andOrgDisplayIdentifierIsNotNull() {
addCriterion("orgdisplayidentifier is not null");
return (Criteria) this;
}
public Criteria andOrgDisplayIdentifierEqualTo(String value) {
addCriterion("orgdisplayidentifier =", value,
"orgDisplayIdentifier");
return (Criteria) this;
}
public Criteria andOrgDisplayIdentifierNotEqualTo(String value) {
addCriterion("orgdisplayidentifier <>", value,
"orgDisplayIdentifier");
return (Criteria) this;
}
public Criteria andOrgDisplayIdentifierGreaterThan(String value) {
addCriterion("orgdisplayidentifier >", value,
"orgDisplayIdentifier");
return (Criteria) this;
}
public Criteria andOrgDisplayIdentifierGreaterThanOrEqualTo(String value) {
addCriterion("orgdisplayidentifier >=", value,
"orgDisplayIdentifier");
return (Criteria) this;
}
public Criteria andOrgDisplayIdentifierLessThan(String value) {
addCriterion("orgdisplayidentifier <", value,
"orgDisplayIdentifier");
return (Criteria) this;
}
public Criteria andOrgDisplayIdentifierLessThanOrEqualTo(String value) {
addCriterion("orgdisplayidentifier <=", value,
"orgDisplayIdentifier");
return (Criteria) this;
}
public Criteria andOrgDisplayIdentifierLike(String value) {
addCriterion("orgdisplayidentifier like", value,
"orgDisplayIdentifier");
return (Criteria) this;
}
public Criteria andOrgDisplayIdentifierNotLike(String value) {
addCriterion("orgdisplayidentifier not like", value,
"orgDisplayIdentifier");
return (Criteria) this;
}
public Criteria andOrgDisplayIdentifierIn(List<String> values) {
addCriterion("orgdisplayidentifier in", values,
"orgDisplayIdentifier");
return (Criteria) this;
}
public Criteria andOrgDisplayIdentifierNotIn(List<String> values) {
addCriterion("orgdisplayidentifier not in", values,
"orgDisplayIdentifier");
return (Criteria) this;
}
public Criteria andOrgDisplayIdentifierBetween(String value1,
String value2) {
addCriterion("orgdisplayidentifier between", value1, value2,
"orgDisplayIdentifier");
return (Criteria) this;
}
public Criteria andOrgDisplayIdentifierNotBetween(String value1,
String value2) {
addCriterion("orgdisplayidentifier not between", value1, value2,
"orgDisplayIdentifier");
return (Criteria) this;
}
public Criteria andOrgSchoolYearIsNull() {
addCriterion("orgschoolyear is null");
return (Criteria) this;
}
public Criteria andOrgSchoolYearIsNotNull() {
addCriterion("orgschoolyear is not null");
return (Criteria) this;
}
public Criteria andOrgSchoolYearEqualTo(Integer value) {
addCriterion("orgschoolyear =", value, "orgSchoolYear");
return (Criteria) this;
}
public Criteria andOrgSchoolYearNotEqualTo(Integer value) {
addCriterion("orgschoolyear <>", value, "orgSchoolYear");
return (Criteria) this;
}
public Criteria andOrgSchoolYearGreaterThan(Integer value) {
addCriterion("orgschoolyear >", value, "orgSchoolYear");
return (Criteria) this;
}
public Criteria andOrgSchoolYearGreaterThanOrEqualTo(Integer value) {
addCriterion("orgschoolyear >=", value, "orgSchoolYear");
return (Criteria) this;
}
public Criteria andOrgSchoolYearLessThan(Integer value) {
addCriterion("orgschoolyear <", value, "orgSchoolYear");
return (Criteria) this;
}
public Criteria andOrgSchoolYearLessThanOrEqualTo(Integer value) {
addCriterion("orgschoolyear <=", value, "orgSchoolYear");
return (Criteria) this;
}
public Criteria andOrgSchoolYearIn(List<Integer> values) {
addCriterion("orgschoolyear in", values, "orgSchoolYear");
return (Criteria) this;
}
public Criteria andOrgSchoolYearNotIn(List<Integer> values) {
addCriterion("orgschoolyear not in", values, "orgSchoolYear");
return (Criteria) this;
}
public Criteria andOrgSchoolYearBetween(Integer value1, Integer value2) {
addCriterion("orgschoolyear between", value1, value2,
"orgSchoolYear");
return (Criteria) this;
}
public Criteria andOrgSchoolYearNotBetween(Integer value1,
Integer value2) {
addCriterion("orgschoolyear not between", value1, value2,
"orgSchoolYear");
return (Criteria) this;
}
public Criteria andOrgPoolTypeIsNull() {
addCriterion("orgpooltype is null");
return (Criteria) this;
}
public Criteria andOrgPoolTypeIsNotNull() {
addCriterion("orgpooltype is not null");
return (Criteria) this;
}
public Criteria andOrgPoolTypeEqualTo(String value) {
addCriterion("orgpooltype =", value, "orgPoolType");
return (Criteria) this;
}
public Criteria andOrgPoolTypeNotEqualTo(String value) {
addCriterion("orgpooltype <>", value, "orgPoolType");
return (Criteria) this;
}
public Criteria andOrgPoolTypeGreaterThan(String value) {
addCriterion("orgpooltype >", value, "orgPoolType");
return (Criteria) this;
}
public Criteria andOrgPoolTypeGreaterThanOrEqualTo(String value) {
addCriterion("orgpooltype >=", value, "orgPoolType");
return (Criteria) this;
}
public Criteria andOrgPoolTypeLessThan(String value) {
addCriterion("orgpooltype <", value, "orgPoolType");
return (Criteria) this;
}
public Criteria andOrgPoolTypeLessThanOrEqualTo(String value) {
addCriterion("orgpooltype <=", value, "orgPoolType");
return (Criteria) this;
}
public Criteria andOrgPoolTypeLike(String value) {
addCriterion("orgpooltype like", value, "orgPoolType");
return (Criteria) this;
}
public Criteria andOrgPoolTypeNotLike(String value) {
addCriterion("orgpooltype not like", value, "orgPoolType");
return (Criteria) this;
}
public Criteria andOrgPoolTypeIn(List<String> values) {
addCriterion("orgpooltype in", values, "orgPoolType");
return (Criteria) this;
}
public Criteria andOrgPoolTypeNotIn(List<String> values) {
addCriterion("orgpooltype not in", values, "orgPoolType");
return (Criteria) this;
}
public Criteria andOrgPoolTypeBetween(String value1, String value2) {
addCriterion("orgpooltype between", value1, value2, "orgPoolType");
return (Criteria) this;
}
public Criteria andOrgPoolTypeNotBetween(String value1, String value2) {
addCriterion("orgpooltype not between", value1, value2,
"orgPoolType");
return (Criteria) this;
}
public Criteria andContentAreaIdIsNull() {
addCriterion("contentareaid is null");
return (Criteria) this;
}
public Criteria andContentAreaIdIsNotNull() {
addCriterion("contentareaid is not null");
return (Criteria) this;
}
public Criteria andContentAreaIdEqualTo(Long value) {
addCriterion("contentareaid =", value, "contentAreaId");
return (Criteria) this;
}
public Criteria andContentAreaIdNotEqualTo(Long value) {
addCriterion("contentareaid <>", value, "contentAreaId");
return (Criteria) this;
}
public Criteria andContentAreaIdGreaterThan(Long value) {
addCriterion("contentareaid >", value, "contentAreaId");
return (Criteria) this;
}
public Criteria andContentAreaIdGreaterThanOrEqualTo(Long value) {
addCriterion("contentareaid >=", value, "contentAreaId");
return (Criteria) this;
}
public Criteria andContentAreaIdLessThan(Long value) {
addCriterion("contentareaid <", value, "contentAreaId");
return (Criteria) this;
}
public Criteria andContentAreaIdLessThanOrEqualTo(Long value) {
addCriterion("contentareaid <=", value, "contentAreaId");
return (Criteria) this;
}
public Criteria andContentAreaIdIn(List<Long> values) {
addCriterion("contentareaid in", values, "contentAreaId");
return (Criteria) this;
}
public Criteria andContentAreaIdNotIn(List<Long> values) {
addCriterion("contentareaid not in", values, "contentAreaId");
return (Criteria) this;
}
public Criteria andContentAreaIdBetween(Long value1, Long value2) {
addCriterion("contentareaid between", value1, value2,
"contentAreaId");
return (Criteria) this;
}
public Criteria andContentAreaIdNotBetween(Long value1, Long value2) {
addCriterion("contentareaid not between", value1, value2,
"contentAreaId");
return (Criteria) this;
}
public Criteria andContentAreaNameIsNull() {
addCriterion("contentareaname is null");
return (Criteria) this;
}
public Criteria andContentAreaNameIsNotNull() {
addCriterion("contentareaname is not null");
return (Criteria) this;
}
public Criteria andContentAreaNameEqualTo(String value) {
addCriterion("contentareaname =", value, "contentAreaName");
return (Criteria) this;
}
public Criteria andContentAreaNameNotEqualTo(String value) {
addCriterion("contentareaname <>", value, "contentAreaName");
return (Criteria) this;
}
public Criteria andContentAreaNameGreaterThan(String value) {
addCriterion("contentareaname >", value, "contentAreaName");
return (Criteria) this;
}
public Criteria andContentAreaNameGreaterThanOrEqualTo(String value) {
addCriterion("contentareaname >=", value, "contentAreaName");
return (Criteria) this;
}
public Criteria andContentAreaNameLessThan(String value) {
addCriterion("contentareaname <", value, "contentAreaName");
return (Criteria) this;
}
public Criteria andContentAreaNameLessThanOrEqualTo(String value) {
addCriterion("contentareaname <=", value, "contentAreaName");
return (Criteria) this;
}
public Criteria andContentAreaNameLike(String value) {
addCriterion("contentareaname like", value, "contentAreaName");
return (Criteria) this;
}
public Criteria andContentAreaNameNotLike(String value) {
addCriterion("contentareaname not like", value, "contentAreaName");
return (Criteria) this;
}
public Criteria andContentAreaNameIn(List<String> values) {
addCriterion("contentareaname in", values, "contentAreaName");
return (Criteria) this;
}
public Criteria andContentAreaNameNotIn(List<String> values) {
addCriterion("contentareaname not in", values, "contentAreaName");
return (Criteria) this;
}
public Criteria andContentAreaNameBetween(String value1, String value2) {
addCriterion("contentareaname between", value1, value2,
"contentAreaName");
return (Criteria) this;
}
public Criteria andContentAreaNameNotBetween(String value1,
String value2) {
addCriterion("contentareaname not between", value1, value2,
"contentAreaName");
return (Criteria) this;
}
public Criteria andSuccessCountIsNull() {
addCriterion("successcount is null");
return (Criteria) this;
}
public Criteria andSuccessCountIsNotNull() {
addCriterion("successcount is not null");
return (Criteria) this;
}
public Criteria andSuccessCountEqualTo(Integer value) {
addCriterion("successcount =", value, "successCount");
return (Criteria) this;
}
public Criteria andSuccessCountNotEqualTo(Integer value) {
addCriterion("successcount <>", value, "successCount");
return (Criteria) this;
}
public Criteria andSuccessCountGreaterThan(Integer value) {
addCriterion("successcount >", value, "successCount");
return (Criteria) this;
}
public Criteria andSuccessCountGreaterThanOrEqualTo(Integer value) {
addCriterion("successcount >=", value, "successCount");
return (Criteria) this;
}
public Criteria andSuccessCountLessThan(Integer value) {
addCriterion("successcount <", value, "successCount");
return (Criteria) this;
}
public Criteria andSuccessCountLessThanOrEqualTo(Integer value) {
addCriterion("successcount <=", value, "successCount");
return (Criteria) this;
}
public Criteria andSuccessCountIn(List<Integer> values) {
addCriterion("successcount in", values, "successCount");
return (Criteria) this;
}
public Criteria andSuccessCountNotIn(List<Integer> values) {
addCriterion("successcount not in", values, "successCount");
return (Criteria) this;
}
public Criteria andSuccessCountBetween(Integer value1, Integer value2) {
addCriterion("successcount between", value1, value2, "successCount");
return (Criteria) this;
}
public Criteria andSuccessCountNotBetween(Integer value1, Integer value2) {
addCriterion("successcount not between", value1, value2,
"successCount");
return (Criteria) this;
}
public Criteria andFailedCountIsNull() {
addCriterion("failedcount is null");
return (Criteria) this;
}
public Criteria andFailedCountIsNotNull() {
addCriterion("failedcount is not null");
return (Criteria) this;
}
public Criteria andFailedCountEqualTo(Integer value) {
addCriterion("failedcount =", value, "failedCount");
return (Criteria) this;
}
public Criteria andFailedCountNotEqualTo(Integer value) {
addCriterion("failedcount <>", value, "failedCount");
return (Criteria) this;
}
public Criteria andFailedCountGreaterThan(Integer value) {
addCriterion("failedcount >", value, "failedCount");
return (Criteria) this;
}
public Criteria andFailedCountGreaterThanOrEqualTo(Integer value) {
addCriterion("failedcount >=", value, "failedCount");
return (Criteria) this;
}
public Criteria andFailedCountLessThan(Integer value) {
addCriterion("failedcount <", value, "failedCount");
return (Criteria) this;
}
public Criteria andFailedCountLessThanOrEqualTo(Integer value) {
addCriterion("failedcount <=", value, "failedCount");
return (Criteria) this;
}
public Criteria andFailedCountIn(List<Integer> values) {
addCriterion("failedcount in", values, "failedCount");
return (Criteria) this;
}
public Criteria andFailedCountNotIn(List<Integer> values) {
addCriterion("failedcount not in", values, "failedCount");
return (Criteria) this;
}
public Criteria andFailedCountBetween(Integer value1, Integer value2) {
addCriterion("failedcount between", value1, value2, "failedCount");
return (Criteria) this;
}
public Criteria andFailedCountNotBetween(Integer value1, Integer value2) {
addCriterion("failedcount not between", value1, value2,
"failedCount");
return (Criteria) this;
}
public Criteria andCreatedDateIsNull() {
addCriterion("createddate is null");
return (Criteria) this;
}
public Criteria andCreatedDateIsNotNull() {
addCriterion("createddate is not null");
return (Criteria) this;
}
public Criteria andCreatedDateEqualTo(Date value) {
addCriterion("createddate =", value, "createdDate");
return (Criteria) this;
}
public Criteria andCreatedDateNotEqualTo(Date value) {
addCriterion("createddate <>", value, "createdDate");
return (Criteria) this;
}
public Criteria andCreatedDateGreaterThan(Date value) {
addCriterion("createddate >", value, "createdDate");
return (Criteria) this;
}
public Criteria andCreatedDateGreaterThanOrEqualTo(Date value) {
addCriterion("createddate >=", value, "createdDate");
return (Criteria) this;
}
public Criteria andCreatedDateLessThan(Date value) {
addCriterion("createddate <", value, "createdDate");
return (Criteria) this;
}
public Criteria andCreatedDateLessThanOrEqualTo(Date value) {
addCriterion("createddate <=", value, "createdDate");
return (Criteria) this;
}
public Criteria andCreatedDateIn(List<Date> values) {
addCriterion("createddate in", values, "createdDate");
return (Criteria) this;
}
public Criteria andCreatedDateNotIn(List<Date> values) {
addCriterion("createddate not in", values, "createdDate");
return (Criteria) this;
}
public Criteria andCreatedDateBetween(Date value1, Date value2) {
addCriterion("createddate between", value1, value2, "createdDate");
return (Criteria) this;
}
public Criteria andCreatedDateNotBetween(Date value1, Date value2) {
addCriterion("createddate not between", value1, value2,
"createdDate");
return (Criteria) this;
}
public Criteria andModifiedDateIsNull() {
addCriterion("modifieddate is null");
return (Criteria) this;
}
public Criteria andModifiedDateIsNotNull() {
addCriterion("modifieddate is not null");
return (Criteria) this;
}
public Criteria andModifiedDateEqualTo(Date value) {
addCriterion("modifieddate =", value, "modifiedDate");
return (Criteria) this;
}
public Criteria andModifiedDateNotEqualTo(Date value) {
addCriterion("modifieddate <>", value, "modifiedDate");
return (Criteria) this;
}
public Criteria andModifiedDateGreaterThan(Date value) {
addCriterion("modifieddate >", value, "modifiedDate");
return (Criteria) this;
}
public Criteria andModifiedDateGreaterThanOrEqualTo(Date value) {
addCriterion("modifieddate >=", value, "modifiedDate");
return (Criteria) this;
}
public Criteria andModifiedDateLessThan(Date value) {
addCriterion("modifieddate <", value, "modifiedDate");
return (Criteria) this;
}
public Criteria andModifiedDateLessThanOrEqualTo(Date value) {
addCriterion("modifieddate <=", value, "modifiedDate");
return (Criteria) this;
}
public Criteria andModifiedDateIn(List<Date> values) {
addCriterion("modifieddate in", values, "modifiedDate");
return (Criteria) this;
}
public Criteria andModifiedDateNotIn(List<Date> values) {
addCriterion("modifieddate not in", values, "modifiedDate");
return (Criteria) this;
}
public Criteria andModifiedDateBetween(Date value1, Date value2) {
addCriterion("modifieddate between", value1, value2, "modifiedDate");
return (Criteria) this;
}
public Criteria andModifiedDateNotBetween(Date value1, Date value2) {
addCriterion("modifieddate not between", value1, value2,
"modifiedDate");
return (Criteria) this;
}
public Criteria andCreatedUserIsNull() {
addCriterion("createduser is null");
return (Criteria) this;
}
public Criteria andCreatedUserIsNotNull() {
addCriterion("createduser is not null");
return (Criteria) this;
}
public Criteria andCreatedUserEqualTo(Long value) {
addCriterion("createduser =", value, "createdUser");
return (Criteria) this;
}
public Criteria andCreatedUserNotEqualTo(Long value) {
addCriterion("createduser <>", value, "createdUser");
return (Criteria) this;
}
public Criteria andCreatedUserGreaterThan(Long value) {
addCriterion("createduser >", value, "createdUser");
return (Criteria) this;
}
public Criteria andCreatedUserGreaterThanOrEqualTo(Long value) {
addCriterion("createduser >=", value, "createdUser");
return (Criteria) this;
}
public Criteria andCreatedUserLessThan(Long value) {
addCriterion("createduser <", value, "createdUser");
return (Criteria) this;
}
public Criteria andCreatedUserLessThanOrEqualTo(Long value) {
addCriterion("createduser <=", value, "createdUser");
return (Criteria) this;
}
public Criteria andCreatedUserIn(List<Long> values) {
addCriterion("createduser in", values, "createdUser");
return (Criteria) this;
}
public Criteria andCreatedUserNotIn(List<Long> values) {
addCriterion("createduser not in", values, "createdUser");
return (Criteria) this;
}
public Criteria andCreatedUserBetween(Long value1, Long value2) {
addCriterion("createduser between", value1, value2, "createdUser");
return (Criteria) this;
}
public Criteria andCreatedUserNotBetween(Long value1, Long value2) {
addCriterion("createduser not between", value1, value2,
"createdUser");
return (Criteria) this;
}
}
/**
* This class was generated by MyBatis Generator. This class corresponds to the database table batchstudenttracker
* @mbggenerated Mon Nov 24 00:50:03 CST 2014
*/
public static class Criterion {
private String condition;
private Object value;
private Object secondValue;
private boolean noValue;
private boolean singleValue;
private boolean betweenValue;
private boolean listValue;
private String typeHandler;
public String getCondition() {
return condition;
}
public Object getValue() {
return value;
}
public Object getSecondValue() {
return secondValue;
}
public boolean isNoValue() {
return noValue;
}
public boolean isSingleValue() {
return singleValue;
}
public boolean isBetweenValue() {
return betweenValue;
}
public boolean isListValue() {
return listValue;
}
public String getTypeHandler() {
return typeHandler;
}
protected Criterion(String condition) {
super();
this.condition = condition;
this.typeHandler = null;
this.noValue = true;
}
protected Criterion(String condition, Object value, String typeHandler) {
super();
this.condition = condition;
this.value = value;
this.typeHandler = typeHandler;
if (value instanceof List<?>) {
this.listValue = true;
} else {
this.singleValue = true;
}
}
protected Criterion(String condition, Object value) {
this(condition, value, null);
}
protected Criterion(String condition, Object value, Object secondValue,
String typeHandler) {
super();
this.condition = condition;
this.value = value;
this.secondValue = secondValue;
this.typeHandler = typeHandler;
this.betweenValue = true;
}
protected Criterion(String condition, Object value, Object secondValue) {
this(condition, value, secondValue, null);
}
}
/**
* This class was generated by MyBatis Generator.
* This class corresponds to the database table batchstudenttracker
*
* @mbggenerated do_not_delete_during_merge Sun Nov 23 23:46:17 CST 2014
*/
public static class Criteria extends GeneratedCriteria {
protected Criteria() {
super();
}
}
}
|
C++
|
UTF-8
| 3,641 | 2.9375 | 3 |
[] |
no_license
|
/*******************************************************************************
All content (c)2015, DigiPen (USA) Corporation, all rights reserved.
Primary Author: <yongmin.cho>
Coproducers:
<name> : <Sukjun Park>
File Description:
Header of math.cpp
*******************************************************************************/
#ifndef MATH_H
#define MATH_H
#include <cmath>
#include <type_traits>
#include <cstdlib>
const float SPRING = 75.f;
const float EDGE_SPRING = 1500;
namespace
{
const float EPSILON = 0.0001f;
const float PI = 3.14159265359f;
}
class Vector
{
public:
float x;
float y;
Vector();
template <typename T>
Vector(T v)
{
static_assert(std::is_arithmetic<T>::value, "Template Type must be arithmentic type");
x = static_cast<float>(v);
y = static_cast<float>(v);
}
template <typename T, typename U>
Vector(T vX, U vY)
{
static_assert(std::is_arithmetic<T>::value, "Template Type must be arithmentic type");
static_assert(std::is_arithmetic<U>::value, "Template Type must be arithmentic type");
x = static_cast<float>(vX);
y = static_cast<float>(vY);
}
void Set(float vX, float vY);
Vector operator+(const Vector& rhs) const;
Vector operator+(float s) const;
Vector operator-(const Vector& rhs) const;
Vector operator-(float s) const;
Vector operator-(void) const;
Vector operator*(const Vector& rhs) const;
Vector operator*(float s) const;
Vector operator/(const Vector& rhs) const;
Vector operator/(float s) const;
void operator+=(const Vector& rhs);
const bool operator==(const Vector& rhs);
const bool operator!=(const Vector& rhs);
void operator-=(const Vector& rhs);
void operator*=(const Vector& rhs);
void operator/=(const Vector& rhs);
float LengthSqr(void) const;
float Length(void) const;
void Rotate(float radians);
void Normalize(void);
};
const Vector gravity(0, -100.f);
class Mat2
{
public:
float m00, m01;
float m10, m11;
float m[2][2];
Mat2();// : m00(0), m01(0), m10(0), m11(0) { }
Mat2(float radians);
Mat2(float a, float b, float c, float d);
void Set(float radians);
Mat2 Abs(void) const;
Vector AxisX(void) const;
Vector AxisY(void) const;
Mat2 Transpose(void) const;
const Vector operator*(const Vector& rhs) const;
const Mat2 operator*(const Mat2& rhs) const;
};
inline float Dot(const Vector& a, const Vector& b)
{
return (a.x * b.x + a.y * b.y);
}
inline float DistanceSquared(const Vector& a, const Vector& b)
{
Vector c = a - b;
return Dot(c, c);
}
inline Vector Cross(const Vector& v, float a)
{
return Vector(a * v.y, -a * v.x);
}
inline Vector Cross(float a, const Vector& v)
{
return Vector(-a * v.y, a * v.x);
}
inline float Cross(const Vector& a, const Vector& b)
{
return a.x * b.y - a.y * b.x;
}
// Comparison with tolerance of EPSILON
inline bool Equal(float a, float b)
{
// <= instead of < for NaN comparison safety
return std::abs(a - b) <= EPSILON;
}
inline float Squared(float a)
{
return a * a;
}
inline float ABS(float X)
{
if (X < 0)
return -X;
return X;
}
inline int PowerOf2(int x)
{
return ((x > 0) && !(x & (x - 1)));
}
inline float RandMinMax(const float Min, const float Max)
{
if (Min == Max) return Min;
return Min + static_cast <float> (rand()) / (static_cast <float> (RAND_MAX / (Max - Min)));
}
inline int RandMinMax(const int Min, const int Max)
{
if (Min == Max) return Min;
return Min + rand() / (RAND_MAX / (Max - Min));
}
inline float Degree2Rad(const float degree)
{
//degree * PI / 180;
return degree * 0.01745329251f;
}
inline float Rad2Degree(const float rad)
{
//rad * 180 / PI;
return rad * 57.2957795131f;
}
#endif
|
Java
|
UTF-8
| 8,603 | 2.25 | 2 |
[
"Apache-2.0"
] |
permissive
|
/*
* The University of Wales, Cardiff Triana Project Software License (Based
* on the Apache Software License Version 1.1)
*
* Copyright (c) 2007 University of Wales, Cardiff. All rights reserved.
*
* Redistribution and use of the software in source and binary forms, with
* or without modification, are permitted provided that the following
* conditions are met:
*
* 1. Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
*
* 2. Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
*
* 3. The end-user documentation included with the redistribution, if any,
* must include the following acknowledgment: "This product includes
* software developed by the University of Wales, Cardiff for the Triana
* Project (http://www.trianacode.org)." Alternately, this
* acknowledgment may appear in the software itself, if and wherever
* such third-party acknowledgments normally appear.
*
* 4. The names "Triana" and "University of Wales, Cardiff" must not be
* used to endorse or promote products derived from this software
* without prior written permission. For written permission, please
* contact triana@trianacode.org.
*
* 5. Products derived from this software may not be called "Triana," nor
* may Triana appear in their name, without prior written permission of
* the University of Wales, Cardiff.
*
* 6. This software may not be sold, used or incorporated into any product
* for sale to third parties.
*
* THIS SOFTWARE IS PROVIDED ``AS IS'' AND ANY EXPRESSED OR IMPLIED
* WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF
* MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN
* NO EVENT SHALL UNIVERSITY OF WALES, CARDIFF OR ITS CONTRIBUTORS BE
* LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
* CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
* SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
* INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
* CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
* ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF
* THE POSSIBILITY OF SUCH DAMAGE.
*
* ------------------------------------------------------------------------
*
* This software consists of voluntary contributions made by many
* individuals on behalf of the Triana Project. For more information on the
* Triana Project, please see. http://www.trianacode.org.
*
* This license is based on the BSD license as adopted by the Apache
* Foundation and is governed by the laws of England and Wales.
*
*/
package triana.types.util;
import java.io.Serializable;
/**
* Triplet is an Object containing three numbers that can generate a uniform sequence of numbers, which can be used to
* represent an array index or an independent variable in, say, graphical applications. The elements of Triplet are
* numbers giving the integer length of the sequence and the doubles start and step of the sequence. Various methods are
* provided for creating and reading Triplets and converting them to equivalent arrays of numbers.
*
* @author Bernard Schutz
* @version $Revision: 4048 $
*/
public class Triplet extends Object implements Serializable {
private int length;
private double start;
private double step;
/**
* Constructs an empty Triplet. capacity and the specified capacityIncrement.
*/
public Triplet() {
}
/**
* Constructs a Triplet with the specified <i>length</i>, <i>start</i>, and <i>step</i>.
*
* @param l The number of elements in the uniformly spaced set.
* @param st The first value of the set.
* @param sp The interval (uniform) between values in the set.
*/
public Triplet(int l, double st, double sp) {
length = l;
start = st;
step = sp;
}
/**
* Constructs a Triplet with the specified <i>length</i> and default values of <i>start</i> (0) and <i>step</i>
* (1).
*
* @param l The number of elements in the uniformly spaced set.
*/
public Triplet(int l) {
length = l;
start = 0.0;
step = 1.0;
}
/**
* Constructs a Triplet with the specified <i>length</i> and starting value, and with a default value of the
* <i>step</i> (1).
*
* @param l The number of elements in the uniformly spaced set.
* @param st The first value of the set.
*/
public Triplet(int l, double st) {
length = l;
start = st;
step = 1.0;
}
/**
* Constructs a Triplet from an array of doubles that should contain a uniformly spaced set of values. Users are
* responsible for testing the array using method <i>testUniform</i>, below.
*/
public Triplet(double[] array) {
length = array.length;
start = array[0];
step = array[1] - array[0];
}
/**
* Returns the <i>length</i> element of the Triplet.
*/
public int getLength() {
return length;
}
/**
* Returns the <i>start</i> element of the Triplet.
*/
public double getStart() {
return start;
}
/**
* Returns the <i>step</i> element of the Triplet.
*/
public double getStep() {
return step;
}
/**
* Returns the last element of the sequence generated by the Triplet.
*/
public double getLast() {
return start + step * (length - 1);
}
/**
* Sets the <i>length</i> element of the Triplet.
*/
public void setLength(int l) {
length = l;
}
/**
* Sets the <i>start</i> element of the Triplet.
*/
public void setStart(double st) {
start = st;
}
/**
* Sets the <i>step</i> element of the Triplet.
*/
public void setStep(double sp) {
step = sp;
}
/**
* Returns an array of doubles generated by the Triplet.
*/
public double[] convertToArray() {
double[] values = new double[length];
if (length > 0) {
values[0] = start;
if (length > 1) {
for (int k = 1; k < length; k++) {
values[k] = values[k - 1] + step;
}
}
}
return values;
}
/**
* Class method that tests a one-dimensional array to see if it is uniform and can therefore be converted to a
* Triplet. TODO - ADDED BY ANDREW 12.08.10 - have I broken this?
*/
public static boolean testUniform(double[] values) {
if (values == null) {
return false;
}
int length = values.length;
if (length > 0 && length < 3) {
return true;
}
double step = values[1] - values[0];
double newStep = step;
for (int k = 2; k < length; k++) {
newStep = values[k] - values[k - 1];
if (newStep != step) {
return false;
}
}
return true;
}
/**
* Class method that converts a uniformly spaced one-dimensional array of doubles to a Triplet. This does not test
* whether the array is uniform: use method <i>testUniform</i> to do that. It just uses the first values and length
* of the array to generate the Triplet.
*/
public static Triplet convertToTriplet(double[] values) {
int length = values.length;
if (length == 1) {
return new Triplet(1, values[0], 0);
}
return new Triplet(length, values[0], values[1] - values[0]);
}
/**
* @return a string representation of this Triplet in the form :- <br> el0 el1 el2 \n </p>
*/
public final String toAString() {
String s = String.valueOf(length) + " " + String.valueOf(start) + " " + String.valueOf(step) + "\n";
return s;
}
/**
* @return a string representation of this Triplet in the form :- <br> el0 \n el1 \n el2 \n </p>
*/
public final String toAColumn() {
String s = String.valueOf(length) + "\n" + String.valueOf(start) + "\n" + String.valueOf(step) + "\n";
return s;
}
/**
* Copy by value not by reference
*/
public Triplet copy() {
Triplet tr = new Triplet(length, start, step);
return tr;
}
}
|
Java
|
UTF-8
| 2,465 | 2.859375 | 3 |
[] |
no_license
|
import java.util.*;
class Waste
{
private GregorianCalendar wasteDate;
private int wastePrice;
private FoodReserve foodReserve;
private String tag;
public Waste()
{
this(new GregorianCalendar(),0,new FoodReserve(),"");
}
public Waste(FoodReserve foodReserve)
{
this.foodReserve=foodReserve;
}
public Waste(int wastePrice)
{
this.wastePrice=wastePrice;
}
public Waste(GregorianCalendar wasteDate)
{
this.wasteDate=wasteDate;
}
public Waste(String tag)
{
this.tag=tag;
}
public Waste(FoodReserve foodReserve,int wastePrice)
{
this.foodReserve=foodReserve;
this.wastePrice=wastePrice;
}
public Waste(FoodReserve foodReserve,String tag)
{
this.foodReserve=foodReserve;
this.tag=tag;
}
public Waste(int wastePrice,GregorianCalendar wasteDate)
{
this.wastePrice=wastePrice;
this.wasteDate=wasteDate;
}
public Waste(int wastePrice, String tag)
{
this.wastePrice=wastePrice;
this.tag=tag;
}
public Waste(GregorianCalendar wasteDate,String tag)
{
this.wasteDate=wasteDate;
this.tag=tag;
}
public Waste(FoodReserve foodReserve, int wastePrice, GregorianCalendar wasteDate)
{
this.foodReserve = foodReserve;
this.wastePrice=wastePrice;
this.wasteDate=wasteDate;
}
public Waste(FoodReserve foodReserve, int wastePrice, String tag)
{
this.foodReserve=foodReserve;
this.wastePrice=wastePrice;
this.tag=tag;
}
public Waste(FoodReserve foodReserve,GregorianCalendar wasteDate,String tag)
{
this.foodReserve=foodReserve;
this.wasteDate=wasteDate;
this.tag=tag;
}
public Waste(int wastePrice,GregorianCalendar wasteDate,String tag)
{
this.wastePrice=wastePrice;
this.wasteDate=wasteDate;
this.tag=tag;
}
public Waste(GregorianCalendar wasteDate,int wastePrice,FoodReserve foodReserve, String tag)
{
this.wasteDate=wasteDate;
this.wastePrice=wastePrice;
this.foodReserve=foodReserve;
this.tag=tag;
}
public void setFoodReserve(FoodReserve foodReserve)
{
this.foodReserve=foodReserve;
}
public FoodReserve getFoodReserve()
{
return this.foodReserve;
}
public void setWastePrice(int wastePrice)
{
this.wastePrice=wastePrice;
}
public int getWastePrice()
{
return this.wastePrice;
}
public void setWasteDate(GregorianCalendar wasteDate)
{
this.wasteDate=wasteDate;
}
public GregorianCalendar getWasteDate()
{
return this.wasteDate;
}
public void setTag(String tag)
{
this.tag=tag;
}
public String getTag()
{
return this.tag;
}
}
|
Python
|
UTF-8
| 118 | 3.234375 | 3 |
[] |
no_license
|
#!/usr/bin/python3
par = []
for n in range(20):
if n % 2 != 0:
continue
par.append(n)
print(par)
|
JavaScript
|
UTF-8
| 7,211 | 2.75 | 3 |
[] |
no_license
|
// import TraceData from './traceData'
// import SingleTrace from './singleTrace'
import TraceData from './traceData'
import SingleTrace from './singleTrace'
function byte2binary (n) {
if (n < 0 || n > 255 || n % 1 !== 0) {
throw new Error(n + ' does not fit in a byte')
}
return ('000000000' + n.toString(2)).substr(-8)
}
/**
* Created by pj on 17-4-9.
*/
const fs = require('fs')
/**
* 读取头文件
* @param path
*/
export function readHeader (path) {
// 检测文件是否有问题
fs.stat(path, function (err, stat) {
if (err === null) {
if (!stat.isFile()) {
throw new MediaError('file do not exists')
}
} else {
throw new MediaError('file do not exists')
}
})
let fd = fs.openSync(path, 'r')
let traceData = new TraceData()
traceData.filename = path
let stopFlag = false
let stepSize = 2
/*
* state 在这里表明处理字符时的状态。
* =0 正在处理tag and length
* =1 正在处理内容
*/
let stepStatus = 0
let stepTag = 0
function opTagAndLength () {
let buffer = Buffer.alloc(stepSize)
fs.readSync(fd, buffer, 0, stepSize, traceData.fHeaderLen)
traceData.fHeaderLen += stepSize
stepTag = buffer.readInt8(0)
stepSize = buffer.readInt8(1)
if (stepTag === 95 && stepSize === 0) {
stopFlag = true
}
stepStatus = 1
}
function opInfo () {
let buffer = Buffer.alloc(stepSize)
fs.readSync(fd, buffer, 0, stepSize, traceData.fHeaderLen)
traceData.fHeaderLen += stepSize
// assert(bytesLen === stepSize)
if (stepTag === 65 ||
stepTag === 66 ||
stepTag === 68 ||
stepTag === 69 ||
stepTag === 72) {
/*
* convert to int;
*/
let result = 0
if (stepTag === 68) {
result = buffer.readInt16LE(0)
} else if (stepTag === 69) {
result = buffer.readInt8(0)
} else {
result = buffer.readInt32LE(0)
}
switch (stepTag) {
case 65:
traceData.traceNum = result
break
case 66:
traceData.sampleNum = result
break
case 68:
traceData.cryDataLen = result
break
case 69:
traceData.titleSpaceLen = result
break
case 72:
traceData.xOffset = result
break
default:
break
}
} else if (stepTag === 70 ||
stepTag === 71 ||
stepTag === 73 ||
stepTag === 74) {
/*
* convert to string
*/
let result = buffer.toString()
switch (stepTag) {
case 70:
traceData.globalTitle = result
break
case 71:
traceData.description = result
break
case 73:
traceData.labelX = result
break
case 74:
traceData.labelY = result
break
default:
break
}
} else if (stepTag === 67) {
/*
* convert to binary string
*/
let result = byte2binary(buffer.readInt8(0))
traceData.sampleType = result[3] !== '1'
if (result[7] === '1') {
traceData.sampleDataLen = 1
} else if (result[6] === '1') {
traceData.sampleDataLen = 2
} else if (result[5] === '1') {
traceData.sampleDataLen = 4
}
} else if (stepTag === 75 || stepTag === 76) {
/*
* convert to float
*/
let result = buffer.readFloatLE(0)
switch (stepTag) {
case 75:
traceData.scaleX = result
break
case 76:
traceData.scaleY = result
break
default:
break
}
} else if (stepTag === 68) {
}
stepStatus = 0
stepSize = 2
}
while (true) {
switch (stepStatus) {
case 0:
opTagAndLength()
break
case 1:
opInfo()
break
}
if (stopFlag) {
// traceData.fHeaderLen += 2
break
}
// traceData.fHeaderLen += stepSize
}
return traceData
}
/**
* 解析读取出来的原始曲线(不包括头文件)
* @param rawSingleTraceData
* @param titleSpaceLen
* @param cryDataLen
* @param sampleType
* @param begSampleIndex
* @param endSampleIndex
* @param sampleDataLen
* @returns {SingleTrace}
*/
function readSingleTraceData (rawSingleTraceData,
titleSpaceLen, cryDataLen,
sampleType, sampleDataLen,
begSampleIndex, endSampleIndex) {
let singleTrace = new SingleTrace()
singleTrace.traceTitle = rawSingleTraceData.slice(0, titleSpaceLen).toString()
singleTrace.cryData = []
for (let i = 0; i < cryDataLen; i++) {
singleTrace.cryData.push(
rawSingleTraceData.slice(titleSpaceLen + i, titleSpaceLen + i + 1).readInt8(0))
}
let index = titleSpaceLen + cryDataLen + sampleDataLen * begSampleIndex
while (true) {
/**
* if is integer
*/
let out = null
if (sampleType) {
switch (sampleDataLen) {
case 1:
out = rawSingleTraceData.readInt8(index)
break
case 2:
out = rawSingleTraceData.readInt16LE(index)
break
case 4:
out = rawSingleTraceData.readInt32LE(index)
break
default:
console.log('error')
break
}
} else {
switch (cryDataLen) {
case 1:
console.log('can not do this')
break
case 2:
console.log('can not do this')
break
case 4:
out = rawSingleTraceData.readFloatLE(index)
break
default:
console.log('error')
break
}
}
singleTrace.samples.push(out)
index += sampleDataLen
if (index === titleSpaceLen + cryDataLen + sampleDataLen * endSampleIndex) {
break
}
}
return singleTrace
}
/**
* 读取多条traces
* @param traceData
* @param begIndex
* @param endIndex
* @param begSampleIndex
* @param endSampleIndex
* @returns {*}
*/
export function readMultiTrace (traceData, begIndex, endIndex,
begSampleIndex, endSampleIndex) {
if (!(traceData instanceof TraceData)) {
throw new TypeError('params header should be TraceData instanceof')
}
if (begIndex > endIndex) {
throw new EvalError('begIndex should smaller than endIndex')
}
if (begIndex === endIndex) {
return traceData
}
let fd = fs.openSync(traceData.filename, 'r')
let singleTraceLen = traceData.SingleTraceLen()
let position = begIndex * singleTraceLen + traceData.fHeaderLen
let buffer = Buffer.alloc(singleTraceLen)
for (let i = begIndex; i < endIndex; i++) {
fs.readSync(fd, buffer, 0, singleTraceLen, position)
position += singleTraceLen
let singleTrace = readSingleTraceData(buffer,
traceData.titleSpaceLen,
traceData.cryDataLen,
traceData.sampleType,
traceData.sampleDataLen,
begSampleIndex,
endSampleIndex)
singleTrace.traceIndex = i
traceData.traces.push(singleTrace)
}
return traceData
}
//
// module.exports.readMultiTrace = readMultiTrace
// module.exports.readHeader = readHeader
|
Rust
|
UTF-8
| 3,195 | 2.84375 | 3 |
[
"MIT"
] |
permissive
|
//! FS utils for creating temporary files folder and doing FS work.
use crate::error::{Error, IOError};
use async_stream::try_stream;
use futures::stream::Stream;
use grpc_api::{Script, TargetOs};
use std::io;
use std::io::Write;
use std::path::{Path, PathBuf};
use tempfile::{Builder, NamedTempFile, TempDir};
use tokio::fs;
const TEMP_DIR: &str = "/tmp/scripts";
pub async fn new_tmp_dir() -> Result<TempDir, std::io::Error> {
if cfg!(target_family = "unix") {
let p = Path::new(TEMP_DIR);
if !p.exists() {
tokio::fs::create_dir(p).await?
}
Builder::new().tempdir_in(TEMP_DIR)
} else {
tempfile::tempdir()
}
}
pub async fn extract_files_include(zip: &[u8]) -> Result<TempDir, Error> {
let dir = new_tmp_dir().await.map_err(|e| IOError::CreateFile(e))?;
let c_dir = dir.path().clone();
tokio::task::block_in_place(move || unzip_into_dir(c_dir, &zip))?;
Ok(dir)
}
pub fn new_tmp_script_file(
script_type: Script,
content: &str,
) -> Result<NamedTempFile, std::io::Error> {
let mut file = if cfg!(target_family = "unix") {
Builder::new()
.suffix(script_type.file_extension())
.tempfile_in(TEMP_DIR)?
} else {
Builder::new()
.suffix(script_type.file_extension())
.tempfile()?
};
let content = if script_type.target_os() == TargetOs::Unix && content.contains("\r\n") {
content.replace("\r\n", "\n")
} else {
content.to_string()
};
file.write(content.as_bytes())?;
Ok(file)
}
pub fn ls_dir_content(root: PathBuf) -> impl Stream<Item = Result<PathBuf, IOError>> {
try_stream! {
if !root.is_file() {
let mut stack = vec![root.to_path_buf()];
while let Some(dir) = stack.pop() {
let mut dir_entry = fs::read_dir(&dir).await.map_err(|_e| IOError::ListDir(dir.clone()))?;
while let Ok(Some(entry)) = dir_entry.next_entry().await {
if entry.file_type().await.map_err(|_e| IOError::ListDir(dir.clone()))?.is_dir() {
stack.push(entry.path());
}
yield entry.path();
}
}
}
}
}
fn unzip_into_dir(outdir: &Path, zip_buf: &[u8]) -> Result<(), IOError> {
if !zip_buf.is_empty() {
let reader = std::io::Cursor::new(zip_buf);
let mut zip = zip::ZipArchive::new(reader)?;
use std::fs;
for i in 0..zip.len() {
let mut file = zip.by_index(i)?;
let outpath = outdir.join(file.sanitized_name());
if file.is_dir() {
fs::create_dir_all(&outpath).map_err(|e| IOError::CreateFile(e))?;
} else {
if let Some(p) = outpath.parent() {
if !p.exists() {
fs::create_dir_all(&p).map_err(|e| IOError::Copy(e))?;
}
}
let mut outfile = fs::File::create(&outpath).map_err(|e| IOError::CreateFile(e))?;
io::copy(&mut file, &mut outfile).map_err(|e| IOError::Copy(e))?;
}
}
}
Ok(())
}
|
Python
|
UTF-8
| 956 | 2.96875 | 3 |
[] |
no_license
|
from unittest import TestCase
from yahtzee import get_score_three_of_a_kind
class Test(TestCase):
def test_get_score_three_kind_no_matches(self):
players_dice = [1, 6, 3, 4, 5]
actual = get_score_three_of_a_kind(players_dice)
expected = 0
self.assertEqual(expected, actual)
def test_get_score_three_kind_1_match(self):
players_dice = [2, 3, 4, 5, 5]
actual = get_score_three_of_a_kind(players_dice)
expected = 0
self.assertEqual(expected, actual)
def test_get_score_three_kind_three_matches(self):
players_dice = [2, 2, 2, 4, 5]
actual = get_score_three_of_a_kind(players_dice)
expected = 15
self.assertEqual(expected, actual)
def test_get_score_three_kind_four_matches(self):
players_dice = [2, 2, 2, 2, 5]
actual = get_score_three_of_a_kind(players_dice)
expected = 13
self.assertEqual(expected, actual)
|
SQL
|
UTF-8
| 7,158 | 3.765625 | 4 |
[
"MIT"
] |
permissive
|
DROP SCHEMA IF EXISTS c9;
CREATE SCHEMA IF NOT EXISTS c9;
use c9;
CREATE TABLE IF NOT EXISTS `students` (
`id_student` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`n_identification` varchar(25),
`name` varchar(25),
`hometown` varchar(50) NOT NULL,
`date_birth` date NOT NULL,
`current_course` varchar(25) NOT NULL,
`repet_course` tinyint(1) NOT NULL,
`email` varchar(100),
PRIMARY KEY (`id_student`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
CREATE TABLE IF NOT EXISTS `relatives` (
`id_relative` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`id_student` smallint(5) unsigned NOT NULL,
`type` varchar(25),
`name` varchar(25),
`date_birth` date NOT NULL,
`grade` varchar(25) NOT NULL,
`profession` varchar(25),
`adress` varchar(25),
`phone` varchar(25),
`email` varchar(50),
PRIMARY KEY (`id_relative`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
CREATE TABLE IF NOT EXISTS `students_relatives` (
`id_stu_rel` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`id_student` smallint(5) unsigned NOT NULL,
`id_relative` smallint(5) unsigned NOT NULL,
PRIMARY KEY (`id_stu_rel`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
ALTER TABLE `students_relatives`
ADD FOREIGN KEY (`id_student`)
REFERENCES `students`(`id_student`);
ALTER TABLE `students_relatives`
ADD FOREIGN KEY (`id_relative`)
REFERENCES `relatives`(`id_relative`);
CREATE TRIGGER add_relative_to_student AFTER INSERT ON `relatives`
FOR EACH ROW
BEGIN
INSERT INTO `students_relatives` SET
students_relatives.id_student = new.id_alum,
students_relatives.id_relative = new.id_relative;
END;
CREATE TABLE IF NOT EXISTS `family_relationship` (
`id_relationship` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`id_student` smallint(5) unsigned NOT NULL,
`with_father` varchar(50),
`with_mother` varchar(50),
`with_brothers` varchar(50),
`with_step_parents` varchar(50),
`observations` varchar(1000),
`date`timestamp DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id_relationship`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
CREATE TABLE IF NOT EXISTS `school_histories` (
`id_school_histories` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`id_student` smallint(5) unsigned NOT NULL,
`histori_school` varchar(255),
`skills_dificulties` varchar(255),
`date`timestamp DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id_school_histories`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
/*
CREATE TABLE IF NOT EXISTS `psychological_histories` (
`id_psychological` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`id_student` smallint(5) unsigned NOT NULL,
`id_school_histories`smallint(5) unsigned NOT NULL,
`id_relationship`smallint(5) unsigned NOT NULL,
`date`timestamp DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id_psychological`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
ALTER TABLE `psychological_histories`
ADD FOREIGN KEY (`id_student`)
REFERENCES `students`(`id_student`);
ALTER TABLE `psychological_histories`
ADD FOREIGN KEY (`id_ant_family`)
REFERENCES `family_histories`(`id_ant_family`);
ALTER TABLE `psychological_histories`
ADD FOREIGN KEY (`id_school_histories`)
REFERENCES `school_histories`(`id_school_histories`);
ALTER TABLE `psychological_histories`
ADD FOREIGN KEY (`id_relationship`)
REFERENCES `family_relationship`(`id_relationship`);
*/
ALTER TABLE `school_histories`
ADD FOREIGN KEY (`id_student`)
REFERENCES `students`(`id_student`);
ALTER TABLE `family_relationship`
ADD FOREIGN KEY (`id_student`)
REFERENCES `students`(`id_student`);
/*
CREATE TABLE IF NOT EXISTS `psychological_histories` (
`id_psychological` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`id_student` smallint(5) unsigned NOT NULL,
`date`timestamp DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id_remition`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
*/
CREATE TABLE IF NOT EXISTS `remtion_teacher` (
`id_remition` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`id_student` smallint(5) unsigned NOT NULL,
`reason` varchar(500) NOT NULL,
`description` varchar(500)NOT NULL,
`commtens` varchar(500),
`comp_teacher` varchar(500),
`comp_parents` varchar(500),
`conclutions` varchar(500),
`date`timestamp DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id_remition`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
ALTER TABLE `remtion_teacher`
ADD FOREIGN KEY (`id_student`)
REFERENCES `students`(`id_student`);
CREATE TABLE IF NOT EXISTS `psicology_asistan_register` (
`id_register` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`id_student` smallint(5) unsigned NOT NULL,
`reason`varchar(500)NOT NULL,
`funcionary`varchar(500)NOT NULL,
`date` timestamp DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id_register`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
ALTER TABLE `psicology_asistan_register`
ADD FOREIGN KEY (`id_student`)
REFERENCES `students`(`id_student`);
CREATE TABLE IF NOT EXISTS `register_histories` (
`id_social_economic` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`id_student` smallint(5) unsigned NOT NULL,
`free_time`varchar(1000),
`inter_persons`varchar(50),
`behavior_encouragement` varchar(50),
`life_proyect` varchar(1000),
`ant_health` varchar(500),
`ant_psicology` varchar(500),
`date` timestamp DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id_social_economic`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
ALTER TABLE `social_economic_histories`
ADD FOREIGN KEY (`id_student`)
REFERENCES `students`(`id_student`);
CREATE TABLE IF NOT EXISTS `appointmets` (
`id_appointmet` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`id_student` smallint(5) unsigned NOT NULL,
`description`varchar(255),
`asing_appo`varchar(50),
`state_appo` varchar(50),
`request_date`varchar(50),
`date`timestamp DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id_appointmet`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
ALTER TABLE `appointmets`
ADD FOREIGN KEY (`id_student`)
REFERENCES `students`(`id_student`);
CREATE TABLE IF NOT EXISTS `asing_date` (
`id_asing_date` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`asing_appo`varchar(50),
`state_appo` smallint(5) unsigned,
PRIMARY KEY (`id_asing_date`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO asing_date (asing_appo,state_appo)
VALUES ('lunes 8:15 am',0);
INSERT INTO asing_date (asing_appo,state_appo)
VALUES ('martes 8:15 am',0);
INSERT INTO asing_date (asing_appo,state_appo)
VALUES ('miercoles 8:15 am',0);
INSERT INTO asing_date (asing_appo,state_appo)
VALUES ('jueves 8:15 am',0);
INSERT INTO asing_date (asing_appo,state_appo)
VALUES ('viernes 8:15 am',0);
CREATE TABLE IF NOT EXISTS `users` (
`id_user` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`name`varchar(50),
`last_name`varchar(50),
`email`varchar(50),
`username`varchar(50),
`password`varchar(50),
`role`varchar(50),
PRIMARY KEY (`id_user`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*
INSERT INTO users (name,last_name,email,username,password,role)
VALUES ('root','root','root@email.com','root',81dc9bdb52d04dc20036dbd8313ed055,'admin');
*/
|
Java
|
UTF-8
| 604 | 1.890625 | 2 |
[] |
no_license
|
package com.trkj.tsm.dao;
import com.trkj.tsm.entity.Classroom;
import com.trkj.tsm.vo.ClassroomVo;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
@Mapper
public interface ClassroomDao {
int deleteByPrimaryKey(Integer classroomId);
int insert(Classroom record);
int insertSelective(Classroom record);
Classroom selectByPrimaryKey(Integer classroomId);
int updateByPrimaryKeySelective(Classroom record);
int updateByPrimaryKey(Classroom record);
List<ClassroomVo> selectfinds();
List<ClassroomVo> selectAllClassRoomsByState(int TimeLiness);
}
|
Java
|
UTF-8
| 4,519 | 2.328125 | 2 |
[
"Apache-2.0"
] |
permissive
|
package so.droidman;
import java.io.InputStream;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.CookieStore;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.protocol.ClientContext;
import org.apache.http.entity.BufferedHttpEntity;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.params.BasicHttpParams;
import org.apache.http.params.HttpConnectionParams;
import org.apache.http.params.HttpParams;
import org.apache.http.protocol.BasicHttpContext;
import org.apache.http.protocol.HttpContext;
import android.graphics.Bitmap;
import android.graphics.BitmapFactory;
import android.os.AsyncTask;
import android.os.SystemClock;
public class AsyncImageLoader extends AsyncTask<String, Integer, Bitmap> {
private static String network_response;
private static boolean doAcceptAllSSL = false, doUseCookie = false;
private onImageLoaderListener mOnImageLoaderListener;
private int progress;
private onProgressUpdateListener mOnProgressUpdateListener;
private Bitmap bmpResult;
public AsyncImageLoader(onImageLoaderListener mOnImageLoaderListener,
boolean doAcceptAllSSL, boolean doUseCookie,
onProgressUpdateListener mOnProgressUpdateListener) {
this.mOnImageLoaderListener = mOnImageLoaderListener;
AsyncImageLoader.doAcceptAllSSL = doAcceptAllSSL;
AsyncImageLoader.doUseCookie = doUseCookie;
this.mOnProgressUpdateListener = mOnProgressUpdateListener;
}
/**
* This is our interface that listens for image download completion.
*/
public interface onImageLoaderListener {
/**
* This callback will be invoked when the image has finished
* downloading.
*
* @param image
* the image as Bitmap object or null in case of an error
* @param response
* the network response
*/
void onImageLoaded(Bitmap image, String response);
}
/**
* That interface will allow us to update MainActivity's Views
*/
public interface onProgressUpdateListener {
/**
* Invoked when AsyncTask.onProgressUpdate() is called.
*
* @param progress
* the current download progress
*/
void doUpdateProgress(int progress);
}
@Override
protected Bitmap doInBackground(String... params) {
bmpResult = downloadImage(params[0]);
/**
* This is just an example of a correct way to show the progress on UI
* thread. To show a <i>real</i> progress, you will need to know the
* length of the file being downloaded
*/
while (progress < 100) {
progress += 1;
publishProgress(progress);
SystemClock.sleep(100);
}
return bmpResult;
}
@Override
protected void onPostExecute(Bitmap result) {
super.onPostExecute(result);
/**
* called on the UI thread
*/
if (mOnImageLoaderListener != null) {
mOnImageLoaderListener.onImageLoaded(result, network_response);
}
}
@Override
protected void onProgressUpdate(Integer... values) {
super.onProgressUpdate(values);
/**
* publish the progress on UI thread
*/
mOnProgressUpdateListener.doUpdateProgress(values[0]);
}
public static Bitmap downloadImage(String url) {
HttpParams hparams = new BasicHttpParams();
/**
* You can also add timeouts to the settings menu in a real project
*/
HttpConnectionParams.setConnectionTimeout(hparams, 10000);
HttpConnectionParams.setSoTimeout(hparams, 10000);
HttpGet get = new HttpGet(url);
DefaultHttpClient client;
try {
if (doAcceptAllSSL)
client = (DefaultHttpClient) SSLErrorPreventer
.setAcceptAllSSL(new DefaultHttpClient(hparams));
else
client = new DefaultHttpClient(hparams);
HttpResponse response = null;
if (doUseCookie) {
CookieStore store = client.getCookieStore();
HttpContext ctx = new BasicHttpContext();
store.addCookie(Utils.sessionCookie);
ctx.setAttribute(ClientContext.COOKIE_STORE, store);
}
response = client.execute(get);
network_response = response.getStatusLine().toString();
MainActivity.tmpResponseForUIDownload = network_response;
HttpEntity responseEntity = response.getEntity();
BufferedHttpEntity httpEntity = new BufferedHttpEntity(
responseEntity);
InputStream imageStream = httpEntity.getContent();
return BitmapFactory.decodeStream(imageStream);
} catch (Exception ex) {
ex.printStackTrace();
return null;
}
}
}
|
Markdown
|
UTF-8
| 3,941 | 3.03125 | 3 |
[] |
no_license
|
# slack-psn-activity
This is a [Tampermonkey](https://tampermonkey.net) [userscript](https://en.wikipedia.org/wiki/Userscript) that runs in [Chrome](https://www.google.com/chrome/) to post notifications to [Slack](https://www.slack.com) about [PSN](https://www.playstation.com) activity of friends.
If you are using Slack for a community of PSN gamers, this script can help. Since Sony is ~~too stupid~~ ~~too lazy~~ unable to make a real API for communities to use to get basic information like the online status of their friends, the only option is to pull the information from the Playstation web site. This script does just that.
Because this is a userscript that is injected into the context of the Playstation site, you won't run into painful issues dealing with [Captchas](https://axesslab.com/captchas-suck/) like I did on my first attempts when I used Selenium to scrape the page.
The suggested way for communities to use this script is to create a new, free PSN ID and have your community members friend that account on PSN. Not only does this make everything "opt-in" for the community, it also gets around the problem that the web page doesn't show the online status of the account current being used to log into the web site.
Of course, you'll also need to set up an incoming Slack web hook for your Slack. You can do that at the [Slack API](https://api.slack.com) page. Make an application (I called mine PSNBot) and use the "Add features and functionality" link to create an incoming web hook to a channel. It's suggested to make a specific channel (I called ours "#psn-activity").
Once you've got that all setup, you'll need this script in Chrome which has [Tampermonkey already installed](https://chrome.google.com/webstore/detail/tampermonkey/dhdgffkkebhmkfjojejmpbldmpobfkfo). The script is installed by visiting the [source for the script in this repo](https://github.com/cleverkraft/slack-psn-activity/blob/master/slack-psn-activity.user.js) and then click the "Raw" button. Tampermonkey will pop up an installation page. Click install.
With the script in place, you can now go to the [PSN What's New](https://my.playstation.com/whatsnew) page. You'll need to log into the PSN ID that you want to monitor, of course. The first time the script launches, it will ask for the Slack incoming web hook URL to use to post messages. It will now poll the page every 30 seconds and post to Slack when there are changes. It will also reload the page every eight hours, since I've seen the page stall out after a long time being open.
In my experience, the web page has a very long time before it needs to re-authenticate. So long, in fact, that I'm not even sure when it happens. When I have more experience with this issue, the script will be updated so it will notify (via Slack) when it needs help.
The script has four menu options, available under the Tampermonkey icon when you are on the PSN What's New page:
* Setup Slack Webhook: allows you to set the web hook URL, done automatically when the script starts for the first time.
* Set Friends Name: by default, the script will use the PSN ID to identify people. You can opt to use a specified name instead. This will loop through all the PSN IDs and ask for each one what name to use. Cancel will stop.
* Force Slack Notification: this will post an update to Slack based on what is currently going on. This is in case some weird sequence of events causes the information on Slack to be vast different from what's on the web page. Shouldn't be needed, but the script is still an early beta, so there you go.
* Send message to Slack: allows you to post an arbitrary message to Slack as your bot user. Useful to inform your community when there's been (ahem) issues with the script.
This script has been tested on Chrome for OS X. It should work on other platforms as well, though on the Raspberry Pi I've had it lock up the whole computer after awhile.
|
Markdown
|
UTF-8
| 5,073 | 3.171875 | 3 |
[
"MIT"
] |
permissive
|
# Manual guide
This guide uses example data wrapped around double curly brackets - `{{example_data}}`. You should replace it with valid values of your own choice.
## NAS setup
1. Connect to Raspberry Pi through SSH (using `ssh`, `putty` or some other SSH client of choice).
2. Create new users - `{{admin}}` (an administrator) and `{{user}}` (a shared user) with passwords of choice:
```
$ sudo useradd -m {{admin}} -p {{admin_password}}
$ sudo useradd -m {{user}} -p {{user_password}}
```
3. Create a new group `{{group}}` for both adminisitrator and shared user:
```
$ sudo groupadd {{group}}
```
4. Add `{{admin}}` and `{{user}}` to the newly created group `{{group}}`:
```
$ sudo usermod -a -G {{group}} {{admin}}
$ sudo usermod -a -G {{group}} {{user}}
```
5. Make sure everything went fine with:
```
$ grep {{group}} /etc/group
{{group}}:x:1003:{{admin}},{{user}}
```
6. Locate plugged USB flash drive(s) paritions with:
```
$ sudo fdisk -l
```
7. There will likely be many disks and partitions shown but the ones relevant can be labeled somewhat similarly to `Disk model: Flash Drive` or simply matched by their storage size.
> In my case the partitions were `/dev/sda1` and `/dev/sdb1` because I was using two USB flash drives.
8. Format the disk(s) to `vfat` format:
> In case you're using more than one USB flash drive you should run this command for all of them.
```
$ sudo mkfs -t vfat {{partition}}
```
9. Create a `{{mount_point}}` directory for USB flash drive(s) at any fitting location. It's a good practice to place them in `/mnt`:
> For multiple flash drives make sure to create a unique mount point for each of them - In my case `/mnt/usb-flash-drive-01` and `/mnt/usb-flash-drive-02`.
```
$ sudo mkdir {{mount_point}}
```
10. Mount the drives at newly created mount points, it's very important to set group and user permissions at mount with `uid`, `gid`, `dmask` and `fmask`:
> For more than one USB flash drive you should run this command for all the drives.
```
sudo mount -t vfat -o rw,uid={{admin}},gid={{group}},dmask=0007,fmask=0007 {{partition}} {{mount_point}}
```
11. Login as `{{admin}}` user:
```
$ sudo su {{admin}}
```
12. Create a `{{nas_directory}}` directory on the USB flash drive(s):
> If using more than one drive, create a `{{nas_directory}}` directory on each of them.
```
mkdir {{mount_point}}/{{nas_directory}}
```
13. Go back to the root user.
```
exit
```
14. Install `samba`:
```
sudo apt-get install samba
```
15. Add `{{user}}` to `samba`:
```
sudo smbpasswd -a {{user}}
```
16. Make a backup of `smb.config` in home directory:
```
cp /etc/samba/smb.conf ~
```
17. Set up file sharing through `samba` - use text editor of choice to edit `/etc/samba/smb.config`:
```
sudo nano /etc/samba/smb.config
```
And add necessary config section at the end of file:
```
# NAS
[nas]
comment = NAS (Network Attached Storage)
path = {{mount_point}}/{{nas_directory}}
valid users = {{admin}}, {{user}}
read only = no
```
18. Restart `samba`:
```
sudo service smbd restart
```
19. You can now connect to your network drive at `//{{raspberry_pi_ip_address}}/{{nas_directory}}` with `{{user}}` credentials.
> On Windows use backslashes instead of slashes in the address - `\\{{raspberry_pi_ip_address}}\{{nas_directory}}`.
## Backup setup
This part of the guide is fully **optional** and it **requires more than one USB flash drive**.
20. Login as `{{admin}}` again:
```
$ sudo su {{admin}}
```
21. Go to `{{admin}}` home directory:
```
$ cd ~
$ pwd
/home/{{admin}}
```
22. Create a new `cron` directory:
```
mkdir cron
```
23. Go to the newly created `cron` directory:
```
$ cd cron
```
24. Create a `backup.sh` file and edit it with a preferred text editor:
```
$ nano backup.sh
```
25. Enter the following content into the `backup.sh` file:
> If using more than two USB flash drives repeat this line for all of them.
```
rsync -a {{mount_point_01}}/{{nas_directory}}/* {{mount_point_02}}/{{nas_directory}}
```
26. Create a `crontab.txt` file and edit it with a preferred text editor:
```
$ nano crontab.txt
```
27. Enter the following content into the `crontab.txt` file:
> You can use any cron expression of choice. This default `0 0 * * *` will make sure the backups run every day at midnight (00:00 a.m.).
```
0 0 * * * /home/{{admin}}/cron/backup.sh > /dev/null
```
28. Register a new cron job to backup files from the main USB flash drive to the rest of them:
```
$ crontab crontab.txt
```
29. Make sure the crontab was registered correctly:
```
$ crontab -l
0 0 * * * /home/{{admin}}/cron/backup.sh > /dev/null
```
30. Now the backups should run periodically at chosen time.
|
Markdown
|
UTF-8
| 3,346 | 2.75 | 3 |
[] |
no_license
|
## Restaurant App
A app designed for restaurant staff to manage incoming orders. Works on mobile.
---
### Screenshots
<img src="https://raw.githubusercontent.com/Yurtledaturtle/RESTaurant/master/public/images/Screenshot.png">
### ERD
<img src="https://raw.githubusercontent.com/Yurtledaturtle/RESTaurant/master/public/images/RESTaurant_ERD.png">
---
### Languages & Frameworks Included
Ruby, Ruby on Rails, Sinatra, JavaScript, jQuery, HTML, CSS, Skeleton.
---
```
____ _____ ____ _____ _
| _ \| ____/ ___|_ _|_ _ _ _ _ __ __ _ _ __ | |_
| |_) | _| \___ \ | |/ _` | | | | '__/ _` | '_ \| __|
| _ <| |___ ___) || | (_| | |_| | | | (_| | | | | |_
|_| \_\_____|____/ |_|\__,_|\__,_|_| \__,_|_| |_|\__|
```
---
- It's the future! In the olden days... waitstaff needed to keep track of a party's order by hand!
- A client has requested an application to help!
- Here is what they wrote:
```
Dear Developer,
I want an application so our waitstaff can manage our food orders...
Overall... an employee should be able to...
a: select a party of customers
b: select food items the customers have ordered
c: see a receipt
We'll keep thinking about it over the next few days and send more details when they come up.
Best,
Gadoe
```
##It's up to you! What does this entail?
- Some starting ideas:
####Food Item: An item of food on the menu (aka menu item)
- name?
- cuisine type?
- what is the price?
- any allergens?
- more info?
####Party: A single group of people
- table number?
- number of guests?
- did they pay yet?
- more info?
####Responsive:
- This almost seems... like the mobile version is more important than the full-screen. Of course the full-screen needs to look good but... if waitstaff will be using this larger on their phones... that mobile version is hugely important. Consider designing for "mobile first".
---
###Technologies:
- Sinatra Web Application
- Postgresql Database
---
```
Hello Developer,
Andrew sent me some questions. I answered them below
Best,
Gadoe
Q: What kind of RESTaurant?
A: “I have a Taco styles AND a BBQ style! Don’t worry about it! I’ll add my own foods!”
Q: Copy of menu?
A: “Changes too much! Just through any food in there of now?”
Q: Layout of Tables?
A: “Again… since I have a couple restaurants… I’ll need to move things around in practice. Feel free to make it feel right to you.”
Q: Can we just ‘pick’ what kind of RESTaurant it is?
A: “Yes… if it’s delicious!!!”
Q: Full list of waitstaff?
A: “I need to hire new people ALL the time! Let’s not worry about this for now. No need to worry about who is placing the orders and such. Let’s just assume I’ll assign waitstaff to tables so we don’t need to build that into the system.”
Q: How can we be in contact?
A: “I am SUPER busy… so most contact will happen through Andrew. You can email me at specificassembly@gmail.com But… don’t count on it. Feel free to send a message but Andrew will probably be a faster source of information.”
```
---
#### 08/26/15
```
Dear Developer,
Almost forgot! I need a way to manage my menu!
Maybe... when I go `/admin` I can have a display where I could...
- add a new menu item
- remove an existing menu item
- edit an existing menu item
Sound good? Thanks!
Best,
Gadoe
```
|
Python
|
UTF-8
| 769 | 3.65625 | 4 |
[] |
no_license
|
#题目:https://leetcode.com/problems/letter-combinations-of-a-phone-number/
class Solution(object):
def letterCombinations(self, digits):
"""
:type digits: str
:rtype: List[str]
"""
d = {'2':'abc', '3':'def', '4':'ghi', '5':'jkl',
'6':'mno', '7':'pqrs', '8':'tuv', '9':'wxyz'}
if len(digits) == 0:
return ''
def helper(index, path):
if len(path) == len(digits):
com.append(''.join(path))
return
for i in d[digits[index]]:
path.append(i)
helper(index + 1, path)
path.pop()
com = []
helper(0, [])
return com
|
Python
|
UTF-8
| 3,040 | 2.6875 | 3 |
[] |
no_license
|
# coding:utf-8
import urllib2
import re
import Tool
class BDTB:
def __init__(self,baseUrl,seelz):
self.baseUrl=baseUrl
self.seeLZ='?see_lz='+str(seelz)
self.user_agnt = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
self.headers = {'User-Agent': self.user_agnt}
self.tool=Tool.Tool()
self.file=None
self.defaultTitle=u'百度贴吧'
def getPage(self,pageNum):
try:
url=self.baseUrl+self.seeLZ+'&pn='+str(pageNum)
request=urllib2.Request(url,headers=self.headers)
response=urllib2.urlopen(request)
#print response.read()
return response.read()
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"链接百度贴吧失败,错误原因",e.reason
return None
def getContent(self,page):
pattern=re.compile('<div id="post_content_.*?>(.*?)</div>',re.S)
items=re.findall(pattern,page)
content=[]
for item in items:
content.append(("\n"+self.tool.repalce(item)+"\n"))
return content
def getTitle(self,pagecode):
#pagecode=self.getPage(1)
pattern=re.compile('<h3 class="core_title_txt.*?>(.*?)</h3>',re.S)
result=re.search(pattern,pagecode)
if result:
print result.group(1).strip()
return result.group(1).strip().decode("utf-8")
else:
print "没有结果"
def getPageNum(self,pagecode):
#pagecode=self.getPage(1)
pattern=re.compile('<ul class="l_posts_num".*?<span class="red">(.*?)</span>',re.S)
result=re.search(pattern,pagecode)
if result:
print result.group(1)
return result.group(1)
else:
print "没有搜索到页数"
def setFileTitle(self,title):
if title is not None:
self.file=open(title+".txt","w+")
else:
self.file=open(self.defaultTitle+".txt","w+")
def writerData(self,content):
for i in content:
self.file.write(i)
def start(self):
indexPage=self.getPage(1)
pageNum=self.getPageNum(indexPage)
title=self.getTitle(indexPage)
self.setFileTitle(title)
if pageNum==None:
print "URL已经失效,请重试"
return
else:
try:
print "该帖子共有"+str(pageNum)+"页"
for i in range(1,int(pageNum)+1):
print "正在写入第"+str(i)+"页"
page=self.getPage(i)
content=self.getContent(page)
self.writerData(content)
except IOError,e:
print "写入异常,原因:"+e.message
finally:
self.file.close()
print "写入完成"
baseUrl='https://tieba.baidu.com/p/3138733512'
bdtb=BDTB(baseUrl,1)
bdtb.start()
|
C++
|
UTF-8
| 2,716 | 3.625 | 4 |
[] |
no_license
|
// File Name: drama.h
// Programmer: Tabitha Roemish & Prathyusha Pillari
// Date: February 23, 2018
// File contains: drama class declaration [D]
// Inherits from the Movie class.
// Holds a single Drama movie type’s attributes.
#include "drama.h"
#include <iostream>
// initializes the variables
Drama::Drama(int stock, std::string director, std::string title, int year)
{
this->stock = stock;
this->director = director;
this->title = title;
this->releaseYear = year;
this->key = director + title;
this->genre = "Drama";
}
// prints the drama string
void Drama::print()
{
// D, 10, Steven Spielberg, Schindler's List, 1993
// print out the movie type, stock, director, title, and
// release year
std::cout << "D, " << this->stock << ", " << this->director << ", " <<
this->title << ", " << this->releaseYear << std::endl;
}
// returns true if the this director is > than the object
// if director is same, retuns true if the this title is > than the object
bool Drama::operator>(Drama & dm)
{
// comapres the directors
if (this->director > dm.director)
return true;
else if (this->director == dm.director)
// comapres the titles if directors are equal
if (this->title > dm.title)
return true;
return false;
}
// returns true if the director and teh title are same
bool Drama::operator==(Drama & dm)
{
// comapres the directors and titles
if (this->director == dm.director && this->title == dm.title)
return true;
else
return false;
}
// uses dynamic cast to comapre movie object and drama object
bool Drama::operator>(Movie & mv)
{
// returns true if this is > movie object
Drama * ptr = dynamic_cast<Drama*>(&mv);
return *this > *ptr;
}
// uses dynamic cast to comapre movie object and drama object
bool Drama::operator<(Movie & mv)
{
// returns true if this is < movie object
Drama * ptr = dynamic_cast<Drama*>(&mv);
return *ptr > *this;
}
// uses dynamic cast to comapre movie object and drama object
bool Drama::operator==(Movie & mv)
{
// returns true if this is = movie object
Drama * ptr = dynamic_cast<Drama*>(&mv);
return *this == *ptr;
}
//subtracts one from current stock
void Drama::brwMovie()
{
if (stock > 0)
stock--;
}
//adds one to current stock
void Drama::rtnMovie()
{
stock++;
}
//accessors for private variables
std::string Drama::getTitle() const
{
return title;
}
std::string Drama::getGenre() const
{
return genre;
}
std::string Drama::getDirector() const
{
return director;
}
int Drama::getReleaseYear() const
{
return releaseYear;
}
std::string Drama::getKey() const
{
return key;
}
//returns current stock of movie
int Drama::getStock() const
{
return stock;
}
|
Shell
|
UTF-8
| 1,055 | 3.328125 | 3 |
[
"MIT"
] |
permissive
|
#!/usr/bin/env bash
# Usage:
# 1. npm install
# 1. ./update_assets.sh
# 1. review any changes manually, ignoring where where the engine adds configurations
DIST_PATH="node_modules/redoc/dist"
ASSETS_PATH="app/assets"
npm install
command -v beautify >/dev/null || npm install -g beautify
strip_trailing_whitespace() {
git ls-files app/assets/**/*{erb,css,html,js} | while read -r file ; do sed -i '' -e's/[[:space:]]*$//' "$file"; done
}
# node_modules/redoc/dist/
# ├── redoc.min.js
# └── redoc.min.map
# javascript
mkdir -p "${ASSETS_PATH}/javascripts/api_doc_server/"
cp "${DIST_PATH}/redoc.min.map" "${ASSETS_PATH}/javascripts/api_doc_server/"
cp "${DIST_PATH}/redoc.min.js" "${ASSETS_PATH}/javascripts/api_doc_server/redoc.min.js"
cp "${DIST_PATH}/redoc.min.js" "${ASSETS_PATH}/javascripts/api_doc_server/redoc.js"
# beautify to more easily see diff
beautify -o "${ASSETS_PATH}/javascripts/api_doc_server/redoc.js" -f js "${ASSETS_PATH}/javascripts/api_doc_server/redoc.js"
# Strip trailing whitespace
strip_trailing_whitespace
|
Java
|
UTF-8
| 15,359 | 1.890625 | 2 |
[] |
no_license
|
package com.example.psato.paulosato_sample;
import android.app.AlertDialog;
import android.app.ProgressDialog;
import android.content.DialogInterface;
import android.graphics.Bitmap;
import android.graphics.Color;
import android.os.Bundle;
import android.support.design.widget.AppBarLayout;
import android.support.design.widget.CollapsingToolbarLayout;
import android.support.v4.app.LoaderManager;
import android.support.v4.content.Loader;
import android.support.v4.view.ViewCompat;
import android.support.v7.app.AppCompatActivity;
import android.support.v7.widget.Toolbar;
import android.util.Log;
import android.view.LayoutInflater;
import android.view.MenuItem;
import android.view.View;
import android.view.Menu;
import android.widget.ImageView;
import android.widget.LinearLayout;
import android.widget.TextView;
import java.lang.ref.WeakReference;
import java.util.List;
public class EpisodeListActivity extends AppCompatActivity {
private final static double TOOLBAR_STARTING_ALPHA = 0x6c;
private final static double TOOLBAR_TRASHHOLD_FACTOR = 2.44;
private LinearLayout mListLayout = null;
private AppBarLayout mAppBarLayout;
private AppBarLayout.OnOffsetChangedListener mListener;
private CollapsingToolbarLayout mCollapsingToolbar;
private Toolbar mToolbar;
private TextView mSeasonTitle;
private TextView mSeasonRating;
private ProgressDialog mProgress;
private EpisodeLoaderManager mEpisodeLoaderManager;
private RatingLoaderManager mRatingLoaderManager;
private ShowCoverLoaderManager mShowCoverLoaderManager;
private SeasonCoverLoaderManager mSeasonCoverLoaderManager;
private ImageView mShowCoverImage;
private ImageView mSeasonCoverImage;
private boolean isLoadingEpisodes = false;
private boolean isLoadingRating = false;
private boolean isLoadingShowCover = false;
private boolean isLoadingSeasonCover = false;
private boolean isEpisodesLoaded = false;
private boolean isRatingLoaded = false;
private boolean isShowCoverLoaded = false;
private boolean isSeasonCoverLoaded = false;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setTitle("");
setContentView(R.layout.activity_episode_list);
mToolbar = (Toolbar) findViewById(R.id.toolbar);
mAppBarLayout = (AppBarLayout) findViewById(R.id.app_bar);
mCollapsingToolbar = (CollapsingToolbarLayout) findViewById(R.id.toolbar_layout);
mListLayout = (LinearLayout) findViewById(R.id.episode_list);
mSeasonTitle = (TextView) findViewById(R.id.season_title_toolbar);
mSeasonTitle.setText("Season " + Constants.SEASONS);
mSeasonRating = (TextView) findViewById(R.id.season_rating_text);
mShowCoverImage = (ImageView) findViewById(R.id.show_cover_image);
mSeasonCoverImage = (ImageView) findViewById(R.id.serie_cover_image);
setSupportActionBar(mToolbar);
mEpisodeLoaderManager = new EpisodeLoaderManager(this);
mRatingLoaderManager = new RatingLoaderManager(this);
mShowCoverLoaderManager = new ShowCoverLoaderManager(this);
mSeasonCoverLoaderManager = new SeasonCoverLoaderManager(this);
getSupportActionBar().setDisplayHomeAsUpEnabled(true);
mProgress = new ProgressDialog(this);
mProgress.setCanceledOnTouchOutside(false);
mProgress.setTitle("Loading");
mProgress.setMessage("Wait while loading season information");
mProgress.setOnCancelListener(new LoadingCancelListener(this));
mListener = new ToolbarColorOffsetChangeListener(this);
mAppBarLayout.addOnOffsetChangedListener(mListener);
loadData();
}
private static class LoadingCancelListener implements DialogInterface.OnCancelListener{
private WeakReference<EpisodeListActivity> mEpisodeListActivityReference;
public LoadingCancelListener(EpisodeListActivity activity) {
mEpisodeListActivityReference = new WeakReference<EpisodeListActivity>(activity);
}
@Override
public void onCancel(DialogInterface dialog) {
EpisodeListActivity reference = mEpisodeListActivityReference.get();
if (reference != null) {
reference.onBackPressed();
}
}
}
private static class ToolbarColorOffsetChangeListener implements AppBarLayout.OnOffsetChangedListener {
private WeakReference<EpisodeListActivity> mEpisodeListActivityReference;
public ToolbarColorOffsetChangeListener(EpisodeListActivity activity) {
mEpisodeListActivityReference = new WeakReference<EpisodeListActivity>(activity);
}
@Override
public void onOffsetChanged(AppBarLayout appBarLayout, int verticalOffset) {
EpisodeListActivity reference = mEpisodeListActivityReference.get();
if (reference != null) {
double originalAlpha = TOOLBAR_STARTING_ALPHA;
double minHeight = TOOLBAR_TRASHHOLD_FACTOR * ViewCompat.getMinimumHeight(reference.mCollapsingToolbar);
if (reference.mCollapsingToolbar.getHeight() + verticalOffset < minHeight) {
reference.mToolbar.setBackgroundColor(Color.TRANSPARENT);
} else {
double percentage = reference.mCollapsingToolbar.getHeight() + verticalOffset - minHeight;
percentage = percentage / (reference.mCollapsingToolbar.getHeight() - minHeight);
Double alpha = originalAlpha * percentage;
reference.mToolbar.setBackgroundColor(Color.argb(alpha.intValue(), 0, 0, 0));
}
}
}
}
private void loadData() {
isLoadingEpisodes = true;
isLoadingRating = true;
isLoadingShowCover = true;
isLoadingSeasonCover = true;
isEpisodesLoaded = false;
isRatingLoaded = false;
isShowCoverLoaded = false;
isSeasonCoverLoaded = false;
mProgress.show();
getSupportLoaderManager().initLoader(0, null, mEpisodeLoaderManager);
getSupportLoaderManager().initLoader(1, null, mRatingLoaderManager);
getSupportLoaderManager().initLoader(2, null, mShowCoverLoaderManager);
getSupportLoaderManager().initLoader(3, null, mSeasonCoverLoaderManager);
}
private void resetLoaders() {
getSupportLoaderManager().restartLoader(0, null, mEpisodeLoaderManager);
getSupportLoaderManager().restartLoader(1, null, mRatingLoaderManager);
getSupportLoaderManager().restartLoader(2, null, mShowCoverLoaderManager);
getSupportLoaderManager().restartLoader(3, null, mSeasonCoverLoaderManager);
}
private void finishedLoadingAllData() {
mProgress.dismiss();
if (!isEpisodesLoaded && !isRatingLoaded
&& !isRatingLoaded && !isSeasonCoverLoaded) {
AlertDialog.Builder builder = new AlertDialog.Builder(this);
builder.setTitle("Error");
builder.setMessage("Problem when downloading data.");
builder.setPositiveButton("Retry",new ErrorDialogRetryListener(this));
builder.setNegativeButton("Cancel", null);
builder.show();
}
}
private static class ErrorDialogRetryListener implements DialogInterface.OnClickListener{
private WeakReference<EpisodeListActivity> mEpisodeListActivityReference;
public ErrorDialogRetryListener(EpisodeListActivity activity) {
mEpisodeListActivityReference = new WeakReference<EpisodeListActivity>(activity);
}
@Override
public void onClick(DialogInterface dialog, int which) {
EpisodeListActivity reference = mEpisodeListActivityReference.get();
if (reference != null) {
reference.resetLoaders();
reference.loadData();
}
dialog.dismiss();
}
}
@Override
public boolean onCreateOptionsMenu(Menu menu) {
return true;
}
@Override
public boolean onOptionsItemSelected(MenuItem item) {
switch (item.getItemId()) {
// Respond to the action bar's Up/Home button
case android.R.id.home:
onBackPressed();
return true;
}
return super.onOptionsItemSelected(item);
}
private void populateScrollview(List<String> episodes) {
mListLayout.removeAllViews();
for (int i = 0; i < episodes.size(); i++) {
LayoutInflater inflater = LayoutInflater.from(this);
View listItem = inflater.inflate(R.layout.list_item_layout, null);
TextView title = (TextView) listItem.findViewById(R.id.episode_title_text);
TextView number = (TextView) listItem.findViewById(R.id.episode_number_text);
title.setText(episodes.get(i));
number.setText("E" + (i + 1));
mListLayout.addView(listItem);
}
}
@Override
protected void onDestroy() {
mAppBarLayout.removeOnOffsetChangedListener(mListener);
mListener = null;
mProgress.dismiss();
mListLayout.removeAllViews();
super.onDestroy();
}
private static class EpisodeLoaderManager implements LoaderManager.LoaderCallbacks<List<String>> {
private WeakReference<EpisodeListActivity> mEpisodeListActivityReference;
public EpisodeLoaderManager(EpisodeListActivity activity) {
mEpisodeListActivityReference = new WeakReference<EpisodeListActivity>(activity);
}
@Override
public Loader<List<String>> onCreateLoader(int id, Bundle args) {
EpisodeListActivity reference = mEpisodeListActivityReference.get();
if (reference != null) {
return new EpisodeListLoader(reference);
} else {
return null;
}
}
@Override
public void onLoadFinished(Loader<List<String>> loader, List<String> data) {
EpisodeListActivity reference = mEpisodeListActivityReference.get();
if (reference != null) {
if (data != null) {
reference.populateScrollview(data);
reference.isEpisodesLoaded = true;
}
reference.isLoadingEpisodes = false;
if (!reference.isLoadingEpisodes && !reference.isLoadingRating &&
!reference.isLoadingShowCover && !reference.isLoadingSeasonCover) {
reference.finishedLoadingAllData();
}
}
// To dismiss the dialog
}
@Override
public void onLoaderReset(Loader<List<String>> loader) {
}
}
private static class RatingLoaderManager implements LoaderManager.LoaderCallbacks<String> {
private WeakReference<EpisodeListActivity> mEpisodeListActivityReference;
public RatingLoaderManager(EpisodeListActivity activity) {
mEpisodeListActivityReference = new WeakReference<EpisodeListActivity>(activity);
}
@Override
public Loader<String> onCreateLoader(int id, Bundle args) {
EpisodeListActivity reference = mEpisodeListActivityReference.get();
if (reference != null) {
return new SeasonRatingLoader(reference);
} else {
return null;
}
}
@Override
public void onLoadFinished(Loader<String> loader, String data) {
EpisodeListActivity reference = mEpisodeListActivityReference.get();
if (reference != null) {
if (data != null) {
reference.mSeasonRating.setText(data);
reference.isRatingLoaded = true;
}
reference.isLoadingRating = false;
if (!reference.isLoadingEpisodes && !reference.isLoadingRating &&
!reference.isLoadingShowCover && !reference.isLoadingSeasonCover) {
reference.finishedLoadingAllData();
}
}
}
@Override
public void onLoaderReset(Loader<String> loader) {
}
}
private static class ShowCoverLoaderManager implements LoaderManager.LoaderCallbacks<Bitmap> {
private WeakReference<EpisodeListActivity> mEpisodeListActivityReference;
public ShowCoverLoaderManager(EpisodeListActivity activity) {
mEpisodeListActivityReference = new WeakReference<EpisodeListActivity>(activity);
}
@Override
public Loader<Bitmap> onCreateLoader(int id, Bundle args) {
EpisodeListActivity reference = mEpisodeListActivityReference.get();
if (reference != null) {
return new ShowCoverLoader(reference);
} else {
return null;
}
}
@Override
public void onLoadFinished(Loader<Bitmap> loader, Bitmap data) {
EpisodeListActivity reference = mEpisodeListActivityReference.get();
if (reference != null) {
if (data != null) {
reference.mShowCoverImage.setImageBitmap(data);
reference.isShowCoverLoaded = true;
}
reference.isLoadingShowCover = false;
if (!reference.isLoadingEpisodes && !reference.isLoadingRating &&
!reference.isLoadingShowCover && !reference.isLoadingSeasonCover) {
reference.finishedLoadingAllData();
}
}
}
@Override
public void onLoaderReset(Loader<Bitmap> loader) {
}
}
private static class SeasonCoverLoaderManager implements LoaderManager.LoaderCallbacks<Bitmap> {
private WeakReference<EpisodeListActivity> mEpisodeListActivityReference;
public SeasonCoverLoaderManager(EpisodeListActivity activity) {
mEpisodeListActivityReference = new WeakReference<EpisodeListActivity>(activity);
}
@Override
public Loader<Bitmap> onCreateLoader(int id, Bundle args) {
EpisodeListActivity reference = mEpisodeListActivityReference.get();
if (reference != null) {
return new SeasonCoverLoader(reference);
} else {
return null;
}
}
@Override
public void onLoadFinished(Loader<Bitmap> loader, Bitmap data) {
EpisodeListActivity reference = mEpisodeListActivityReference.get();
if (reference != null) {
if (data != null) {
reference.mSeasonCoverImage.setImageBitmap(data);
reference.isSeasonCoverLoaded = true;
}
reference.isLoadingSeasonCover = false;
if (!reference.isLoadingEpisodes && !reference.isLoadingRating &&
!reference.isLoadingShowCover && !reference.isLoadingSeasonCover) {
reference.finishedLoadingAllData();
}
}
}
@Override
public void onLoaderReset(Loader<Bitmap> loader) {
}
}
}
|
Java
|
UTF-8
| 3,130 | 3.125 | 3 |
[] |
no_license
|
package com.company.jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ResourceBundle;
/**
* @author 苏东坡
* @version 1.0
* @ClassName JdbcTest3
* @company 公司
* @Description 从属性文件中读取数据库连接信息1
* 第一步: 注册驱动 (作用:告诉Java程序,即将要连接的是哪个品牌的数据库)
* 第二步: 获取连接 (表示JVM的进程和数据库的进程之间通道打开了,这属于进程之间通信,重要级的,使用完后一定要关闭)
* 第三步: 获取数据库连接对象(专门执行sql语句的对象)
* 第四步: 执行sql语句(DQL DML)
* 第五步: 处理查询结果集(只有当第四执行的是select语句的时候,才能有这第五步处理查询结果集)
* 第六步: 释放资源(使用完资源后之后一定要关闭资源。Java和数据库属于进程间的通信,开启之后一定要关闭)
*
*
*
* 注册驱动两种方式
* 第一种注册驱动 Class.forName("com.mysql.jdbc.Driver");
* 第二种注册驱动 DriverManager.registerDriver(com.mysql.jdbc.Driver);
*
* 说明: localhost和127.0.0.1都是本机IP地址
*
* idea
* Project Structure->Moudles->Dependencies->JARs or directories找到
* mysql-connector-java-8.0.26.jar 点击ok,然后勾上mysql-connector-java-8.0.26.jar就可以了
* 这里是为了不报没有这个驱动的错误
*
*
* jdbc2这里指的是jdbc2.properties
*
* @createTime 2021年09月19日 13:28:28
*/
public class JdbcTest3 {
public static void main(String[] args) {
//使用资源绑定器绑定属性配置文件中
ResourceBundle resourceBundle = ResourceBundle.getBundle("jdbc2");
String driver = resourceBundle.getString("driver");
String url =resourceBundle.getString("url");
String user =resourceBundle.getString("user");
String password =resourceBundle.getString("password");
Statement stmt = null;
Connection con = null;
try{
//注册驱动
Class.forName(driver);
//获取连接
con = DriverManager.getConnection(url,user,password);
if (con!=null){
System.out.println("数据库连接对象"+con);
}
//获取数据库连接对象
stmt = con.createStatement();
//执行sql语句
String sql = "INSERT INTO student(name,age,email) VALUES('菊花',31,'112@qq.com')";
//获取查询结果集
int count = stmt.executeUpdate(sql);
System.out.println("新增:"+((count == 1)?1:0)+"数据成功");
}catch (Exception e){
e.printStackTrace();
}finally {
try {
if (stmt != null){
stmt.close();
}
}catch (SQLException e){
e.printStackTrace();
}
try {
if (con != null){
con.close();
}
}catch (SQLException e){
e.printStackTrace();
}
}
}
}
|
PHP
|
UTF-8
| 756 | 2.5625 | 3 |
[] |
no_license
|
<?php
$entryDataFound = isset($entryData);
if(isset($_POST) && !empty($_FILES['image']['name'])){
$name = $_FILES['image']['name'];
list($txt, $ext) = explode(".", $name);
$image_name = time().".".$ext;
$tmp = $_FILES['image']['tmp_name'];
if(move_uploaded_file($tmp, '../../img/cars/'.$image_name)){
echo "<img width='100%' height='100%' src='../../img/cars/".$image_name."'>";
echo "<input type='hidden' id='GetImage' value='img/cars/".$image_name."'>";
?><script type='text/javascript'>
//var img = $("#GetImage").val;
parent.incomingValue("<?php echo "img/cars/".$image_name; ?> ");
//parent.document.getElementById('img1').value = img;
</script>
<?php
}else{
echo "image uploading failed";
}
}
?>
|
TypeScript
|
UTF-8
| 1,233 | 2.5625 | 3 |
[] |
no_license
|
import { Component, OnInit } from '@angular/core';
import {ProductService} from 'src/app/services/product.service';// is global singletton
//so we need to refer this by using depency injection
//better way to call the src folder to import is to start at scr/app
import {Product} from 'src/app/models/product'
import { WishlistService } from 'src/app/services/wishlist.service';
@Component({
selector: 'app-product-list',
templateUrl: './product-list.component.html',
styleUrls: ['./product-list.component.css']
})
export class ProductListComponent implements OnInit {
productList: Product[]=[]
wishlist:number[]=[]
// calling in the constructor is dependencies injection
constructor( private productService:ProductService,
private wishlistService:WishlistService) { }
ngOnInit(): void {
//this.productList= this.productService.getProduct() // use wen getting data from produts array in product.service
this.loadProduct()
this.loadWishlist()
}
loadProduct(){
this.productService.getProducts().subscribe((products)=>{
this.productList=products
})
}
loadWishlist(){
this.wishlistService.getWishlist().subscribe(productIds =>{
this.wishlist=productIds
})
}
}
|
Shell
|
UTF-8
| 380 | 2.828125 | 3 |
[
"BSD-3-Clause"
] |
permissive
|
#!/bin/bash
# Usage: bash eradicate_setup.sh
SCRIPT_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )"
source $SCRIPT_DIR/../../config.sh
download_infer $SCRIPT_DIR
# Create sandbox
mkdir $ERAD_PROJ_FILES
mkdir $ERAD_PROJ_REPORTS
# Checkout d4j files
export PATH=$PATH:$D4J_DIR/framework/bin
download_d4j_repos $ERAD_PROJ_FILES $CONFIG_SCRIPT_DIR/d4j.input
|
Java
|
UTF-8
| 1,708 | 2.703125 | 3 |
[] |
no_license
|
package com.sougat818.p3;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Test;
public class Problem3Test {
private Problem3 problem3;
@Before
public void setUp() {
problem3 = new Problem3();
}
@Test
public void testSolution1() {
ListNode listNode1 = new ListNode(new int[]{2, 4, 3});
ListNode listNode2 = new ListNode(new int[]{5, 6, 4});
Assert.assertEquals("708", problem3.addTwoNumbers(listNode1, listNode2).toString());
}
@Test
public void testSolution2() {
ListNode listNode1 = new ListNode(new int[]{});
ListNode listNode2 = new ListNode(new int[]{});
Assert.assertEquals("0", problem3.addTwoNumbers(listNode1, listNode2).toString());
}
@Test
public void testSolution3() {
ListNode listNode = new ListNode(
new int[]{9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9,
9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9,
9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9,
9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9});
Assert.assertEquals(
"8999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999991",
problem3.addTwoNumbers(listNode, listNode).toString());
}
@Test
public void testSolution4() {
ListNode listNode1 = new ListNode(new int[]{1, 2, 3, 4, 5});
ListNode listNode2 = new ListNode(new int[]{9, 8, 1, 6});
Assert.assertEquals("01506", problem3.addTwoNumbers(listNode1, listNode2).toString());
Assert.assertEquals("01506", problem3.addTwoNumbers(listNode2, listNode1).toString());
}
}
|
C++
|
UTF-8
| 1,055 | 2.71875 | 3 |
[] |
no_license
|
#include <iostream>
#include <algorithm>
#include <string>
using namespace std;
int main()
{
ios_base::sync_with_stdio(false);
string num;
int i,y,x,t=1024;
while(t--)
{
cin>>num;
y=0;
x = num.length();
reverse(num.begin(),num.end());
if(num=="0")
{
cout<<-2<<endl;
continue;
}
if(num=="1")
{
cout<<1<<endl;
continue;
}
num = num + "0";
for( i=0; i<x && num[i]=='0'; i++ )
{
num[i]='9';
}
num[i] = num[i] - 1;
for( i=0; i<=x; i++ )
{
y = y + num[i]-'0' + num[i] - '0' ;
num[i] = y%10 + '0';
y = y/10;
}
reverse(num.begin(),num.end());
for(i=0;i<=x;i++)
{
if(i==0&&num[i]=='0')
continue;
else
cout<<num[i];
}
cout<<endl;
}
return 0;
}
|
Java
|
UTF-8
| 2,675 | 1.8125 | 2 |
[] |
no_license
|
package com.dbg.model.test;
import java.io.Serializable;
import javax.persistence.*;
import java.util.List;
/**
* The persistent class for the tm_pers database table.
*
*/
@Entity
@Table(name="TM_PERS")
@NamedQuery(name="TmPer.findAll", query="SELECT t FROM TmPer t")
public class TmPer implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@Column(name="ID_PERS")
private int idPers;
@Column(name="DIRE_PERS")
private String direPers;
@Column(name="DNI_PERS")
private String dniPers;
@Column(name="EMAIL_PERS")
private String emailPers;
@Column(name="ID_USUA")
private String idUsua;
@Column(name="NB_PERS")
private String nbPers;
@Column(name="TELF_PERS")
private String telfPers;
//bi-directional many-to-one association to TcInci
@OneToMany(mappedBy="tmPer")
private List<TcInci> tcIncis;
//bi-directional many-to-one association to TmUsua
//@OneToMany(mappedBy="tmPer")
//private List<TmUsua> tmUsuas;
public TmPer() {
}
public int getIdPers() {
return this.idPers;
}
public void setIdPers(int idPers) {
this.idPers = idPers;
}
public String getDirePers() {
return this.direPers;
}
public void setDirePers(String direPers) {
this.direPers = direPers;
}
public String getDniPers() {
return this.dniPers;
}
public void setDniPers(String dniPers) {
this.dniPers = dniPers;
}
public String getEmailPers() {
return this.emailPers;
}
public void setEmailPers(String emailPers) {
this.emailPers = emailPers;
}
public String getIdUsua() {
return this.idUsua;
}
public void setIdUsua(String idUsua) {
this.idUsua = idUsua;
}
public String getNbPers() {
return this.nbPers;
}
public void setNbPers(String nbPers) {
this.nbPers = nbPers;
}
public String getTelfPers() {
return this.telfPers;
}
public void setTelfPers(String telfPers) {
this.telfPers = telfPers;
}
public List<TcInci> getTcIncis() {
return this.tcIncis;
}
public void setTcIncis(List<TcInci> tcIncis) {
this.tcIncis = tcIncis;
}
public TcInci addTcInci(TcInci tcInci) {
getTcIncis().add(tcInci);
tcInci.setTmPer(this);
return tcInci;
}
public TcInci removeTcInci(TcInci tcInci) {
getTcIncis().remove(tcInci);
tcInci.setTmPer(null);
return tcInci;
}
//public List<TmUsua> getTmUsuas() {
// return this.tmUsuas;
//}
//public void setTmUsuas(List<TmUsua> tmUsuas) {
// this.tmUsuas = tmUsuas;
//}
/*public TmUsua addTmUsua(TmUsua tmUsua) {
getTmUsuas().add(tmUsua);
tmUsua.setTmPer(this);
return tmUsua;
}
public TmUsua removeTmUsua(TmUsua tmUsua) {
getTmUsuas().remove(tmUsua);
tmUsua.setTmPer(null);
return tmUsua;
}*/
}
|
Markdown
|
UTF-8
| 16,144 | 2.703125 | 3 |
[] |
no_license
|
---
title: Digital Pedagogy in the Humanities
subtitle: Concepts, Models, and Experiments
chapter: Project Management
URL: keywords/projectManagement.md
author:
- family: Siemens
given: Lynne
editor:
- family: Sayers
given: Jentery
publisher: Modern Language Association
type: book
---
# PROJECT MANAGEMENT (Draft)
## Lynne Siemens
University of Victoria | [Website](https://lynnesiemens.wordpress.com)
---
##### Publication Status:
* **unreviewed draft**
* draft version undergoing editorial review
* draft version undergoing peer-to-peer review
* published
---
## CURATORIAL STATEMENT
Along with those in the social sciences, humanities researchers, librarians, content experts, students and others are turning to collaborations to explore increasingly complex questions and implement new types of methodologies and tools, such as those in the Digital Humanities (DH). Further, granting agencies are encouraging this trend with targeted programs such as Digging into Data and Partnership Grants, among others. As a result, teams need to understand ways to coordinate efforts among tasks and members in order to accomplish project objectives and satisfy stakeholders (Siemens and INKE Research Group 2014; Siemens 2009). Project Management with its associated methods, tools and techniques provide a way to do this (Siemens 2012).
While most individuals would not (hopefully) deny the need for the effective planning and managing of projects, knowledge and skills about the topic are typically not a formal part of training in the field (Leon 2011; Siemens 2013). Instead, the gap tends to be filled as part of DH-oriented courses, such as Bailar and Spiro’s Introduction to Digital Humanities (Bailar and Spiro 2013), training programs such as the Praxis Program at the Scholar’s Lab (2011), project management workshops at Humanities Intensive Teaching and Learning (HILT 2015), Digital Humanities Summer Institute (DHSI 2015), and the European Summer University in Digital Humanities (2015), and/or the school of hard learned experience, often very effective but not necessarily efficient (Guiliano 2012; Simeone et al. 2011; Causer, Tonra and Wallace 2012; Siemens and INKE Research Group 2012; 2013; National Endowment for the Humanities Office of Digital Humanities 2010).
Hence, the need for a resource such as this one which pulls together repositories, websites, articles and reflections on project management and its many component parts. What follows below is a variety of materials that could be used within an undergraduate and graduate courses on project management specifically and DH more generally or as foundations for workshops on the topic. Those who are ready part of a project will find these resources useful for undertaking initial planning and/or managing ongoing work.
## CURATED ARTIFACTS
### DevDH

* Source URL: http://devdh.org
* Creator: Jennifer Guiliano (Indiana University-Purdue University Indianapolis) and Simon Appleford (Creighton University)
Jennifer Guiliano and Simon Appleford created this site, drawing on their experience as project managers and team members. It is a repository of training materials, recorded lectures, exemplars and links about project management within the Digital Humanities. It covers topics such as team development, budgeting, publicity campaigns, data management and others. This resource would be useful in project management workshops and courses and individuals planning their first (or subsequent) project. It should be noted that the budget section is oriented towards American funding agencies.
### Digital Project Planning and Management Basics, Instructor Manual

* Source URL: http://www.loc.gov/catworkshop/courses/digitalprojplan/pdf/Instructor-Final.pdf
* Creator: Mary S. Woodley (California State University, Northridge)
This is a workshop manual for a 2-day workshop on digital project management, developed on behalf of the Library of Congress and the Association for Library Collections and Technical Services. Topics include team building and planning, business plan development, planning and grant writing, project management, and outcome evaluation and assessment. It includes slides, instructor notes and classroom activities and exercises. The accompanying trainee manual is available at http://www.loc.gov/catworkshop/courses/digitalprojplan/pdf/Trainee-Final.pdf. These guides would be useful as a resource within courses and workshop and individuals planning and managing their projects.
### Project Management for Humanists: Preparing Future Primary Investigators

* Source URL: http://mediacommons.futureofthebook.org/alt-ac/pieces/project-management-humanists
* Creator: Sharon M. Leon (George Mason University)
Drawing upon her perhaps hard learned experiences, Sharon Leon presents a guide to project management, geared to the humanist undertaking their first project. She covers topics such as managing the project, running efficient meeting and managing the project manager. She also offers some thoughts on models for changing graduate education to better prepare huamanists for life as project work and collaborations. Anyone who is looking for a “getting started” guide to project management will find this a useful article.
### Comparison of Project Management Software

* Source URL: http://en.wikipedia.org/wiki/Comparison_of_project_management_software
* Creator: The Crowd
People often ask which software is best to use for project management to which no easy answer exists. This Wikipedia page provides a comparison of the plethora of project management software across criteria such as whether web-based, hosted on premises, proprietary and/or open source, and the programming language. It should be noted that this list does not include apps and “low tech” methods such as white boards, flip charts, post-it notes and markers.
### Office of NEH Progress Reports on Grants (Summary Findings of NEH Digital Humanities Start-Up Grants, 2007–2010)

* Source URL: http://www.neh.gov/files/divisions/odh/odh-resource-summary.report.odh_.sug_.pdf
* Creator: National Endowments for the Humanities
While this may seem like a surprising choice for a list such as this, this resource provides a summary of outcomes from the first round of National Endowment of the Humanities Digital Humanities Start-up Grants, including a survey of project directors and a summary of end-of-grant “white papers” which distilled the lessons learned from the projects. Among other things, respondents reflected on the importance of goal setting, team work, and contingencies planning. Anyone planning their first project and applying for funding would find this report an interesting read.
### The Praxis Program at the Scholar’s Lab

* Source URL: http://praxis.scholarslab.org
* Creator: The Scholars’ Lab (University of Virginia)
The Praxis Program at the Scholar’s Lab is a training program in which graduate students at University of Virginia are funded to work as a team to develop a digital humanities project or tool. To prepare them for this work, the program has developed a series of modules, including “toward a project charter”, “intro to project management” and “grants, budgets and sustainability.” The participants regularly blog about their experiences. The blog and associated resources would be appropriate for project management workshops and courses.
### Collaborators’ Bill of Rights

* Source URL: http://mcpress.media-commons.org/offthetracks/part-one-models-for-collaboration-career-paths-acquiring-institutional-support-and-transformation-in-the-field/a-collaboration/collaborators’-bill-of-rights/
* Creator: Participants in the “Off the Tracks: Laying New Lines for Digital Humanities Scholars” Workshop
Teamwork and collaboration is a key component of any project, particularly within the Digital Humanities. However, clear models for recognizing team member contributions to digital projects are not present within the Humanities with its historical emphasis on the single author. As a result, the participants of the “Off the Tracks – Laying New Lines for Digital Humanities Scholars” workshop developed the collaborators’ bill of rights with the fundamental principle that “all kinds of work on a project are equally deserving of credit…” Anyone starting a digital project with other individuals will want to refer to this document to guide discussions about ways to recognize effort within the project.
### The iterative design of a project charter for interdisciplinary research

* Source URL: http://dl.acm.org/citation.cfm?id=1394476
* Creator: Stan Ruecker (Illinois Institute of Technology) and Milena Radzikowska (Mount Royal University)
This paper outlines Stan Ruecker and Milena Radzikowska’s experience using a project charter within their collaborations as a way to reduce misunderstandings. This charter makes explicit several principles that guide the working relationship between researchers from different disciplines. This article will be of interest to anyone who is looking for a project charter template for their digital project.
### The Dynamics of Intense Work Groups: A Study of British String Quartets

* Source URL: http://www.jstor.org/stable/2393352?seq=1#page_scan_tab_contents
* Creators: J. Keith Murnighan (University of Illinois at Urbana-Champaign) and Donald E. Conlon (University of Delware)
This article provides an interesting comparison between work groups and string quartets, between the balance of the individual and team. A successful string quartets are by definition both individualistic with different instruments playing a variety of parts, and yet highly interdependent as they play a coordinated sound. Like productive research collaborations, there is little room for individually focused musicians in successful string quarters. This article would be a good ready for anyone trying to determine if they are ready to work within a team.
### Transcription Maximized; Expense Minimized? Crowdsourcing and Editing the Collected Works of Jeremy Bentham

* Source URL: http://llc.oxfordjournals.org/content/early/2012/03/28/llc.fqs004.full.pdf
* Creator: Tim Causer (University College London), Justin Tonra (University of Virginia), and Valerie Wallace (University College London/Harvard University)
An important part of project management is reflection at a project’s completion to determine lessons learned a step not often taken by teams. This article is an exception with an excellent review of the Transcribe Bentham project touching on evaluation of project success against cost-effectiveness and public engagement and access, quality control, volunteer management, and other topics. These lessons are relevant to anyone considering a crowdsourcing project and other forms of digital projects.
## RELATED MATERIALS
Duarte, Deborah L., and Nancy Tennant Snyder. Mastering Virtual Teams. 3rd ed. New York, New York: John Wiley & Sons, Inc., 2006.
Howard Hughes Medical Institute, and Burroughs Wellcome Fund. Making the Right Moves: A Practical Guide to Scientific Management for Postdocs and New Faculty. 2nd ed. Research Triangle Park, North Carolina: Howard Hughes Medical Institute, Burroughs Wellcome Fund, 2006.
Knutson, Joan, and Ira Bitz. Project Management: How to Plan and Manage Successful Projects. New York, New York: AMACOM, 1991.
Olson, Gary M., and Judith S. Olson. "Distance Matters." Human-Computer Interaction 15.2/3 (2000): 139-78.
Siemens, Lynne, and INKE Research Group. "INKE Administrative Structure: Omnibus Document." Scholarly and Research Communication 3.1 (2012). http://src-online.ca/index.php/src/article/view/50
## WORKS CITED
Appleford, Simon, and Jennifer Guiliano. "Devdh: Development for the Digital Humanities". 2013. March 5, 2015. <http://devdh.org>.
Bailar, Melissa, and Lisa Spiro. "Introduction to Digital Humanities". 2013. March 5, 2015. <http://digitalhumanities.rice.edu/fall-2013-syllabus/%3E.
Causer, Tim, Justin Tonra, and Valerie Wallace. "Transcription Maximized; Expense Minimized? Crowdsourcing and Editing the Collected Works of Jeremy Bentham." Literary & Linguistic Computing 27.2 (2012): 119-37.
"Comparison of Project Management Software". 2015. The Free Encyclopedia. Wikimedia Foundation Wikipedia, Inc.: March 5, 2015. <http://en.wikipedia.org/wiki/Comparison_of_project_management_software>.
DHSI. "Digital Humanitites Summer Institute". 2015. March 5, 2015. <http://dhsi.org/%3E.
Guiliano, J. "NEH Project Director’s Meeting: Lessons for Promoting Your Project." MITH Blog 2012. Vol. October 3, 2012.
HILT. "Courses". 2015. March 5, 2015. <http://www.dhtraining.org/hilt2015/%3E.
Howard Hughes Medical Institute, and Burroughs Wellcome Fund. Making the Right Moves: A Practical Guide to Scientific Management for Postdocs and New Faculty. 2nd ed. Research Triangle Park, North Carolina: Howard Hughes Medical Institute, Burroughs Wellcome Fund, 2006.
Knutson, Joan, and Ira Bitz. Project Management: How to Plan and Manage Successful Projects. New York, New York: AMACOM, 1991.
Leon, Sharon M. "Project Management for Humanists: Preparing Future Primary Investigators". 2011. June 24, 2011. <http://mediacommons.futureofthebook.org/alt-ac/pieces/project-management-humanists%3E.
Murnighan, J. Keith, and Donald E. Conlon. "The Dynamics of Intense Work Groups: A Study of British String Quartets." Administrative Science Quarterly 36.2 (1991): 165-86.
National Endowment for the Humanities Office of Digital Humanities. Summary Findings of NEH Digital Humanities Start-up Grants (2007-2010). Washington, D.C.: National Endowment for the Humanities, 2010.
Off the Tracks. "Collaborators’ Bill of Rights". 2011. March 5, 2015. <http://mcpress.media-commons.org/offthetracks/part-one-models-for-collaboration-career-paths-acquiring-institutional-support-and-transformation-in-the-field/a-collaboration/collaborators’-bill-of-rights/>.
Olson, Gary M., and Judith S. Olson. "Distance Matters." Human-Computer Interaction 15.2/3 (2000): 139-78.
Ruecker, Stan, and Milena Radzikowska. "The Iterative Design of a Project Charter for Interdisciplinary Research." DIS 2007. 2007.
Scholars' Lab. "The Praxis Program at the Scholars' Lab". 2011. September 12, 2011. <http://praxis.scholarslab.org/%3E.
Siemens, Lynne. "DHSI Project Planning Course Pack". 2012. March 5, 2015. <http://dhsi.org/content/2012Curriculum/12.ProjectPlanning.pdf%3E.
Siemens, Lynne. "'It's a Team If You Use "Reply All": An Exploration of Research Teams in Digital Humanities Environments." Literary & Linguistic Computing 24.2 (2009): 225-33.
Siemens, Lynne. "Meta-Methodologies and the DH Methodological Commons: Potential Contribution of Management and Entrepreneurship to Dh Skill Development." DH 2013. 2013.
Siemens, Lynne, and INKE Research Group. "Firing on All Cylinders: Progress and Transition in INKE's Year 2." Scholarly and Research Communication 3.4 (2012): 1-16.
Siemens, Lynne, and INKE Research Group. "INKE Administrative Structure: Omnibus Document." Scholarly and Research Communication 3.1 (2012).
Siemens, Lynne, and INKE Research Group. "Research Collaboration as “Layers of Engagement”: INKE in Year Four." Scholarly and Research Communication 5.4 (2014): 1-12.
Siemens, Lynne, and INKE Research Group. "Responding to Change and Transition in INKE’s Year Three." Scholarly and Research Communication 4.3 (2013): 12 pp.
Simeone, M., et al. "Digging into Data Using New Collaborative Infrastructures Supporting Humanities-Based Computer Science Research." First Monday 16.5 (2011).
The European Summer University in Digital Humanities. ""Culture & Technology" - the European Summer University in Digital Humanities". 2015. March 5, 2015. <http://www.culingtec.uni-leipzig.de/ESU_C_T/node/97%3E.
Woodley, Mary S. Digital Project Planning & Management Basics: Instructor Manual, 2008.
|
Java
|
UTF-8
| 2,178 | 2.375 | 2 |
[] |
no_license
|
package com.example.ancacret.rssfeed.pojo;
import android.graphics.drawable.GradientDrawable;
import android.os.Parcel;
import android.view.LayoutInflater;
import android.view.View;
import android.widget.TextView;
import com.example.ancacret.rssfeed.R;
import com.example.ancacret.rssfeed.adapters.DrawerCategoriesAdapter;
import com.example.ancacret.rssfeed.interfaces.DrawerListItem;
public class DrawerCategoryListItem extends ListViewItem implements DrawerListItem {
private String mCategoryLink;
private HeaderItem mItem;
public DrawerCategoryListItem(String categoryLink, HeaderItem item) {
mCategoryLink = categoryLink;
mItem = item;
}
public String getCategoryLink() {
return mCategoryLink;
}
public HeaderItem getItem() {
return mItem;
}
public void setItem(HeaderItem item) {
mItem = item;
}
@Override
public View getView(LayoutInflater inflater, View convertView) {
DrawerViewHolder2 holder;
if(convertView == null || convertView.getTag() instanceof DrawerViewHolder2){
holder = new DrawerViewHolder2();
convertView = inflater.inflate(R.layout.drawer_list_item, null);
holder.icon = convertView.findViewById(R.id.item_icon);
holder.name = (TextView) convertView.findViewById(R.id.itemText);
convertView.setTag(holder);
} else {
holder = (DrawerViewHolder2) convertView.getTag();
}
holder.name.setText(mItem.getCategory());
GradientDrawable drawable = new GradientDrawable();
drawable.setCornerRadius(100);
drawable.setColor(mItem.getColor());
holder.icon.setBackground(drawable);
return convertView;
}
private class DrawerViewHolder2{
TextView name;
View icon;
private DrawerViewHolder2() {
}
}
@Override
public int getViewType() {
return DrawerCategoriesAdapter.ROW_TYPE.LIST_ITEM.ordinal();
}
@Override
public int describeContents() {
return 0;
}
@Override
public void writeToParcel(Parcel dest, int flags) {
}
}
|
C++
|
UTF-8
| 1,447 | 2.890625 | 3 |
[] |
no_license
|
#ifndef CAMERA_CPP
#define CAMERA_CPP
#include <glm/gtc/matrix_transform.hpp>
#include "camera.hpp"
#include <cmath>
#include <glm/gtx/rotate_vector.hpp>
void Camera::set_position(const glm::vec3 &position)
{
this->m_position[0] = position[0];
this->m_position[1] = position[1];
this->m_position[2] = position[2];
}
void Camera::rotate(float amount, const glm::vec3 &axis)
{
this->m_direction = glm::rotate(this->m_direction, amount, axis);
}
// Teste
void Camera::rotate_up(float amount)
{
glm::vec3 normal_vector = glm::cross(this->m_direction, this->m_up);
glm::vec3 normal_up = glm::cross(this->m_direction, -normal_vector);
this->m_up = glm::rotate(normal_up, amount, this->m_direction);
}
void Camera::translate(float amount)
{
this->m_position = this->m_position + amount * this->m_direction;
}
void Camera::translate(float amount, const glm::vec3 &direction)
{
this->m_position = this->m_position + amount * direction;
}
void Camera::translate(const glm::vec3 &direction)
{
this->m_position = this->m_position + direction;
}
void Camera::update_view_matrix()
{
this->view_matrix = glm::lookAt(this->m_position, this->m_position + this->m_direction, this->m_up);
}
void Camera::point_to(ScenarioItem *item)
{
glm::vec3 item_position = item->get_position();
this->m_direction = item_position - this->m_position;
this->m_direction = glm::normalize(this->m_direction);
}
#endif
|
Python
|
UTF-8
| 4,172 | 2.859375 | 3 |
[] |
no_license
|
import numpy as np
import random
class Dataset(object):
def __init__(self, data, batch_size, num_vocab, pad_idx, shuffle=True):
self.que = data[0]
self.ans = data[1]
self.batch_size = batch_size
self.length = len(self.que)
self.batch_idx = 0
self.shuffle = True
self.current_batch_que = None
self.current_batch_ans = None
self.pad_idx = pad_idx
self.num_vocab = num_vocab
self.__random_shuffle()
def __random_shuffle(self):
idx = np.random.permutation(self.length)
self.que = self.que[idx]
self.ans = self.ans[idx]
def __dense_to_onehot_batch(self, batch):
return (np.arange(self.num_vocab) == batch[:, :, None]).astype(int)
def set_next_batch(self):
under = self.batch_idx
upper = under + self.batch_size
max_ = self.length
if upper <= max_:
batch_que = self.que[under:upper]
batch_ans = self.ans[under:upper]
under = upper
else:
rest = upper - max_
if self.shuffle is True:
self.__random_shuffle()
batch_que = np.concatenate(
(self.que[under:max_], self.que[0:rest]))
batch_ans = np.concatenate(
(self.ans[under:max_], self.ans[0:rest]))
under = rest
self.current_batch_que = self.__dense_to_onehot_batch(batch_que)
self.current_batch_ans = batch_ans
self.batch_idx = under
class BatchGenerator(object):
def __init__(self, dataset):
self.dataset = dataset
def swap_random_words(self, batch, pad_idx):
import copy
batch_clone = copy.deepcopy(batch) # for preserving raw data
for sent in batch_clone:
if pad_idx in sent:
len_sent = sent.tolist().index(pad_idx)
else: # if there's no PAD at all
len_sent = len(sent)
if len_sent < 2: # if sent is consist of less than 2 words
continue # skip over to the next batch
else: # prevent duplication
i, j = random.sample(range(0, len_sent), 2)
sent[i], sent[j] = sent[j], sent[i]
return batch_clone
def dense_to_onehot(self, labels, num_classes):
return np.eye(num_classes)[labels]
def get_d_batch(self):
""" for discriminator pre-training.
divide data batch(2n) in half : real data(n) + fake data(n) """
if not self.dataset.batch_size % 2 == 0:
raise Exception("[!] batch size must be even.")
half_size = self.dataset.batch_size//2
self.dataset.set_next_batch()
# questions
batch_que = self.dataset.current_batch_que
que_real = batch_que[0:half_size]
que_fake_raw = batch_que[half_size:]
que_fake = self.swap_random_words(que_fake_raw, self.dataset.pad_idx)
batch_que = np.concatenate((que_real, que_fake))
# answers
batch_ans = self.dataset.current_batch_ans
# labels
label_real = self.dense_to_onehot(np.ones(half_size, dtype=np.int), 2)
label_fake = self.dense_to_onehot(np.zeros(half_size, dtype=np.int), 2)
batch_label = np.concatenate((label_real, label_fake))
return batch_que, batch_ans, batch_label
def get_gan_data_batch(self):
self.dataset.set_next_batch()
return self.dataset.current_batch_que, self.dataset.current_batch_ans
def get_gan_label_batch(self):
batch_size = self.dataset.batch_size
label_real = self.dense_to_onehot(np.ones(batch_size, dtype=np.int), 2)
label_fake = self.dense_to_onehot(
np.zeros(batch_size, dtype=np.int), 2)
return np.concatenate((label_real, label_fake))
def get_binary_label_batch(self, is_true):
batch_size = self.dataset.batch_size
if is_true:
label = self.dense_to_onehot(np.ones(batch_size, dtype=np.int), 2)
else:
label = self.dense_to_onehot(np.zeros(batch_size, dtype=np.int), 2)
return label
|
Ruby
|
UTF-8
| 589 | 3.90625 | 4 |
[] |
no_license
|
# @param {Integer} n
# @param {Integer[]} primes
# @return {Integer}
def nth_super_ugly_number(n, primes)
count = Array.new(primes.count, 0)
res = Array.new(n)
res[0] = 1
1.upto(n - 1) do |t|
min = 1000000000000
count.each_with_index do |c, i|
min = [primes[i] * res[c], min].min
end
res[t] = min
count.each_with_index do |c, i|
if min == primes[i] * res[c]
count[i] += 1
end
end
end
res
end
p nth_super_ugly_number(12, [2, 7, 13, 19])
|
Markdown
|
UTF-8
| 518 | 2.765625 | 3 |
[
"MIT"
] |
permissive
|
## EXERCISE 5
At times, one would like to ssh between servers without typing a password or the need to approve new servers.
Please add the commands required to ssh password-less from server1 to sever2 and without host key checking.
Script to update configuration should be put in the following files.
* for server1 update this file: `exercise5-fix_server1.sh`
* for server2 update this file: `exercise5-fix_server2.sh`
> Once you're done continue to the next exercise
[Next: **Exercise 6 ** ➡️](exercise-6.md)
|
C#
|
UTF-8
| 6,394 | 2.703125 | 3 |
[
"MIT"
] |
permissive
|
using System;
using UnityEngine;
using System.Collections.Generic;
[Serializable]
public class KingsCallToArms : Events {
public static int frequency = 1;
private List<Player> highestRankPlayers;
public Player currentPlayer;
public Player firstPlayer;
private BoardManagerMediator board;
public KingsCallToArms () : base ("King's Call to Arms") { }
//Event description: The highest ranked player(s) must place 1 weapon in the discard pile. If unable to do so, 2 Foe Cards must be discarded.
public override void startBehaviour() {
Logger.getInstance ().info ("Started the Kings Call To Arms behaviour");
Debug.Log("Started the Kings Call To Arms behaviour");
board = BoardManagerMediator.getInstance();
List<Player> allPlayers = board.getPlayers();
//Find highest ranked player(s)
highestRankPlayers = new List<Player>();
//populate a list of players with the lowest rank
foreach (Player player in allPlayers) {
if (highestRankPlayers.Count == 0) {
highestRankPlayers.Add (player);
} else if (player.getRank ().getBattlePoints() > highestRankPlayers [0].getRank ().getBattlePoints()) {
highestRankPlayers.Clear ();
highestRankPlayers.Add (player);
} else if (player.getRank ().getBattlePoints() == highestRankPlayers [0].getRank ().getBattlePoints()) {
highestRankPlayers.Add (player);
}
}
Logger.getInstance ().debug ("Populated a list of players with the highest rank");
Debug.Log("Populated a list of players with the highest rank");
if (highestRankPlayers.Count != 0) { // For safety
currentPlayer = highestRankPlayers [0];
firstPlayer = currentPlayer;
Logger.getInstance ().debug ("Prompting event action for player " + currentPlayer.getName());
Debug.Log("Prompting event action for player " + currentPlayer.getName());
PromptEventAction ();
}
}
public void PromptEventAction() {
int numFoeCards = getNumFoeCards ();
Logger.getInstance ().trace ("numFoeCards for the current player is " + numFoeCards);
Debug.Log("numFoeCards for the current player is " + numFoeCards);
if (hasWeapons ()) {
Logger.getInstance ().debug ("Player to discard weapon");
Debug.Log("Player to discard weapon");
currentPlayer.PromptDiscardWeaponKingsCallToArms (this);
}
else if (numFoeCards > 1) {
Logger.getInstance ().debug ("Player to discard foes.");
Debug.Log("Player to discard foes");
currentPlayer.PromptDiscardFoesKingsCallToArms (this, numFoeCards);
}
else {
//call same function on next player
Logger.getInstance ().debug ("Player is unable to discard weapons/foes, moving onto next player");
Debug.Log("Player is unable to discard weapons/foes, moving onto next player");
if (board.IsOnlineGame())
{
board.getPhotonView().RPC("CallToArmsPromptNextPlayer", PhotonTargets.Others);
}
PromptNextPlayer();
}
Debug.Log ("Finished King's Call To Arms.");
}
public void PromptNextPlayer()
{
currentPlayer = board.getNextPlayer(currentPlayer);
if (currentPlayer != firstPlayer)
{
Debug.Log("Got finished response from last player, moving onto next player...");
Logger.getInstance().debug("Got finished response from last player, moving onto next player...");
PromptEventAction();
}
else
{
board.nextTurn();
}
}
public void PlayerDiscardedWeapon()
{
Debug.Log("Entered 'PlayerDiscardedWeapon");
Debug.Log("PLAYER WHOSE CARD WE ARE ABOUT TO REMOVE: " + currentPlayer.getName());
List<Adventure> dicardedCards = board.GetDiscardedCards(currentPlayer);
Debug.Log("Number of cards discarded: " + dicardedCards.Count);
if (dicardedCards.Count == 1){
if (dicardedCards[0].IsWeapon()) {
currentPlayer.GetAndRemoveCards ();
if (board.IsOnlineGame())
{
board.getPhotonView().RPC("CallToArmsPromptNextPlayer", PhotonTargets.Others);
}
PromptNextPlayer();
}
else{
Debug.Log("Player played incorrect card...");
Logger.getInstance().debug("Player played incorrect card...");
currentPlayer.PromptDiscardWeaponKingsCallToArms (this);
}
}
else{
Debug.Log("Player discarded incorrect number of cards...");
Logger.getInstance().debug("Player discarded incorrect number of cards...");
currentPlayer.PromptDiscardWeaponKingsCallToArms (this);
}
}
public void PlayerDiscardedFoes()
{
bool valid = true;
Debug.Log("Entered 'PLayerDiscardedFoes");
List<Adventure> dicardedCards = board.GetDiscardedCards(currentPlayer);
Debug.Log("Number of cards discarded: " + dicardedCards.Count);
if (dicardedCards.Count == getNumFoeCards()) {
foreach (Card card in dicardedCards) {
if (!card.IsFoe()) {
valid = false;
}
}
if (valid) {
currentPlayer.GetAndRemoveCards ();
if (board.IsOnlineGame())
{
board.getPhotonView().RPC("CallToArmsPromptNextPlayer", PhotonTargets.Others);
}
PromptNextPlayer();
}
else {
Debug.Log("Player played incorrect card...");
Logger.getInstance().debug("Player played incorrect card...");
currentPlayer.PromptDiscardFoesKingsCallToArms (this, getNumFoeCards ());
}
}
else{
Debug.Log("Player discarded incorrect number of cards...");
Logger.getInstance().debug("Player discarded incorrect number of cards...");
currentPlayer.PromptDiscardFoesKingsCallToArms (this, getNumFoeCards ());
}
}
private int getNumFoeCards() {
int numFoeCards = 0;
foreach (Card card in currentPlayer.GetHand()) {
if (card.IsFoe()) {
numFoeCards++;
if (numFoeCards == 2) {
return numFoeCards;
}
}
}
return numFoeCards;
}
public bool hasWeapons() {
foreach (Card card in currentPlayer.GetHand()) {
if (card.IsWeapon()) {
return true;
}
}
return false;
}
}
|
C
|
UTF-8
| 2,043 | 2.671875 | 3 |
[] |
no_license
|
//!
//! \file ostime.c
//! \brief <i><b>OSAL Timers Handling Functions</b></i>
//! \details This is the implementation file for the OSAL
//! (Operating System Abstraction Layer) timer Functions.
//! \author Raffaele Belardi
//! \author (original version) Luca Pesenti
//! \version 1.0
//! \date 07 Sept 2010
//! \bug Unknown
//! \warning None
//!
#ifdef __cplusplus
extern "C" {
#endif
/************************************************************************
| includes of component-internal interfaces
| (scope: component-local)
|-----------------------------------------------------------------------*/
#include "target_config.h"
#include "osal.h"
#include <sys/time.h> /* for gettimeofday */
/************************************************************************
|defines and macros (scope: module-local)
|-----------------------------------------------------------------------*/
#define USEC_MAX 1000000
/************************************************************************
| variable definition (scope: module-local)
|-----------------------------------------------------------------------*/
static struct timeval startup_tv;
/************************************************************************
|function implementation (scope: global)
|-----------------------------------------------------------------------*/
/**
*
* @brief OSAL_ClockGetElapsedTime;
*
* @details This Function returns the elapsed time since the start of the
* system through OSAL_Boot() in milliseconds.
*
* @return Time in milliseconds
*
*/
OSAL_tMSecond OSAL_ClockGetElapsedTime(void)
{
struct timeval tv;
int sec, usec;
gettimeofday(&tv, NULL);
if (startup_tv.tv_usec > tv.tv_usec)
{
tv.tv_sec--;
tv.tv_usec += USEC_MAX;
}
sec = tv.tv_sec - startup_tv.tv_sec;
usec = tv.tv_usec - startup_tv.tv_usec;
return (OSAL_tMSecond)((sec * 1000) + (usec / 1000));
}
void OSAL_ClockResetTime(void)
{
gettimeofday(&startup_tv, NULL);
}
#ifdef __cplusplus
}
#endif
/** @} */
/* End of File */
|
C++
|
UTF-8
| 17,765 | 3.125 | 3 |
[
"BSD-2-Clause"
] |
permissive
|
/**
* @file scalar_math.h
* Expression template functors to create new math algorithms for scientific
* applications.
*/
#pragma once
#include <usml/ublas/math_traits.h>
namespace usml {
namespace ublas {
/**
* @internal
* Expression template functors to create new math algorithms for scientific
* applications. These routines use math_traits<> to invoke a generalized
* version of transcendental functions of real and complex numbers.
* These include:
*
* - limiting functions: max(), min(), floor(), ceil()
* - algebraic functions: abs(), abs2(), arg(), sqrt(), copysign()
* - trigonometric functions: cos(), cosh(), sin(), sinh(), tan(), tanh()
* - inverse trig functions: acos(), acosh(), asin(), asinh(),
* atan(), atan2(), atanh()
* - exponential functions: exp(), log(), log10(), pow()
* - signal processing functions: signal(), asignal()
*
* Based on the design of the uBLAS scalar functor classes.
*
* Developers will not usually use these classes directly.
* They are designed to evaluate the expression templates
* in the vector_math.h and matrix_math.h headers.
*/
//**********************************************************
// limiting functions
/**
* @internal
* Maximum value of two arguments.
*/
template<class T1, class T2>
struct scalar_max:
public scalar_binary_functor<T1, T2> {
typedef typename scalar_binary_functor<T1, T2>::argument1_type
argument1_type;
typedef typename scalar_binary_functor<T1, T2>::argument2_type
argument2_type;
typedef typename scalar_binary_functor<T1, T2>::result_type
result_type;
static inline result_type apply(argument1_type t1, argument2_type t2) {
return math_traits<result_type>::max(t1,t2) ;
}
};
/**
* @internal
* Minimum value of two arguments.
*/
template<class T1, class T2>
struct scalar_min:
public scalar_binary_functor<T1, T2> {
typedef typename scalar_binary_functor<T1, T2>::argument1_type
argument1_type;
typedef typename scalar_binary_functor<T1, T2>::argument2_type
argument2_type;
typedef typename scalar_binary_functor<T1, T2>::result_type
result_type;
static inline result_type apply(argument1_type t1, argument2_type t2) {
return math_traits<result_type>::min(t1,t2) ;
}
};
/**
* @internal
* Rounding a scalar down to the nearest integer.
*/
template<class T>
struct scalar_floor:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::floor(t) ;
}
};
/**
* @internal
* Rounding a scalar up to the nearest integer.
*/
template<class T>
struct scalar_ceil:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::ceil(t) ;
}
};
//**********************************************************
// conversion functions
/**
* @internal
* Convert angle value in radians to degrees.
*/
template<class T>
struct scalar_to_degrees:
public scalar_real_unary_functor<T> {
typedef typename scalar_real_unary_functor<T>::argument_type
argument_type;
typedef typename scalar_real_unary_functor<T>::result_type
result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::to_degrees(t);
}
};
/**
* @internal
* Convert angle value in degrees to radians.
*/
template<class T>
struct scalar_to_radians:
public scalar_real_unary_functor<T> {
typedef typename scalar_real_unary_functor<T>::argument_type
argument_type;
typedef typename scalar_real_unary_functor<T>::result_type
result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::to_radians(t);
}
};
/**
* @internal
* Convert colatitude (radians from north) value to
* latitude (degrees from equator).
*/
template<class T>
struct scalar_to_latitude:
public scalar_real_unary_functor<T> {
typedef typename scalar_real_unary_functor<T>::argument_type
argument_type;
typedef typename scalar_real_unary_functor<T>::result_type
result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::to_latitude(t);
}
};
/**
* @internal
* Convert latitude (degrees from equator) value to
* colatitude (radians from north).
*/
template<class T>
struct scalar_to_colatitude:
public scalar_real_unary_functor<T> {
typedef typename scalar_real_unary_functor<T>::argument_type
argument_type;
typedef typename scalar_real_unary_functor<T>::result_type
result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::to_colatitude(t);
}
};
//**********************************************************
// algebraic functions
/**
* @internal
* Magnitude of a complex scalar.
*/
template<class T>
struct scalar_abs:
public scalar_real_unary_functor<T> {
typedef typename scalar_real_unary_functor<T>::argument_type
argument_type;
typedef typename scalar_real_unary_functor<T>::result_type
result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::abs(t);
}
};
/**
* @internal
* Magnitude squared of a complex scalar.
*/
template<class T>
struct scalar_abs2:
public scalar_real_unary_functor<T> {
typedef typename scalar_real_unary_functor<T>::argument_type
argument_type;
typedef typename scalar_real_unary_functor<T>::result_type
result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::abs2(t);
}
};
/**
* @internal
* Phase of a complex scalar.
*/
template<class T>
struct scalar_arg:
public scalar_real_unary_functor<T> {
typedef typename scalar_real_unary_functor<T>::argument_type
argument_type;
typedef typename scalar_real_unary_functor<T>::result_type
result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::arg(t);
}
};
/**
* @internal
* Square root of a scalar.
*/
template<class T>
struct scalar_sqrt:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::sqrt(t);
}
};
/**
* @internal
* Copy sign of a number.
*/
template<class T1, class T2>
struct scalar_copysign:
public scalar_binary_functor<T1, T2> {
typedef typename scalar_binary_functor<T1, T2>::argument1_type
argument1_type;
typedef typename scalar_binary_functor<T1, T2>::argument2_type
argument2_type;
typedef typename scalar_binary_functor<T1, T2>::result_type
result_type;
static inline result_type apply(argument1_type t1, argument2_type t2) {
return math_traits<result_type>::copysign(t1,t2) ;
}
};
//**********************************************************
// trigonometric functions
/**
* @internal
* Cosine of a scalar.
*/
template<class T>
struct scalar_cos:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::cos(t);
}
};
/**
* @internal
* Hyperbolic cosine of a scalar.
*/
template<class T>
struct scalar_cosh:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::cosh(t);
}
};
/**
* @internal
* Sine of a scalar.
*/
template<class T>
struct scalar_sin:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::sin(t);
}
};
/**
* @internal
* Hyperbolic sine of a scalar.
*/
template<class T>
struct scalar_sinh:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::sinh(t);
}
};
/**
* @internal
* Tangent of a scalar.
*/
template<class T>
struct scalar_tan:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::tan(t);
}
};
/**
* @internal
* Hyperbolic tangent of a scalar.
*/
template<class T>
struct scalar_tanh:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::tanh(t);
}
};
//**********************************************************
// inverse trigonometric functions
/**
* @internal
* Inverse cosine of a scalar.
*/
template<class T>
struct scalar_acos:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::acos(t);
}
};
/**
* @internal
* Inverse hyperbolic cosine of a scalar.
*/
template<class T>
struct scalar_acosh:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::acosh(t);
}
};
/**
* @internal
* Inverse sine of a scalar.
*/
template<class T>
struct scalar_asin:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::asin(t);
}
};
/**
* @internal
* Inverse hyperbolic sine of a scalar.
*/
template<class T>
struct scalar_asinh:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::asinh(t);
}
};
/**
* @internal
* Inverse tangent of a scalar.
*/
template<class T>
struct scalar_atan:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::atan(t);
}
};
/**
* @internal
* Inverse tangent of scalars y / x.
*/
template<class T1, class T2>
struct scalar_atan2:
public scalar_binary_functor<T1, T2> {
typedef typename scalar_binary_functor<T1, T2>::argument1_type
argument1_type;
typedef typename scalar_binary_functor<T1, T2>::argument2_type
argument2_type;
typedef typename scalar_binary_functor<T1, T2>::result_type
result_type;
static inline result_type apply(argument1_type y, argument2_type x) {
return math_traits<result_type>::atan2(y,x) ;
}
};
/**
* @internal
* Inverse hyperbolic tangent of a scalar.
*/
template<class T>
struct scalar_atanh:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::atanh(t);
}
};
//**********************************************************
// exponential functions
/**
* @internal
* Exponential of a scalar.
*/
template<class T>
struct scalar_exp:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::exp(t);
}
};
/**
* @internal
* Natural logarithm of a scalar.
*/
template<class T>
struct scalar_log:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::log(t);
}
};
/**
* @internal
* Base 10 logarithm of a scalar.
*/
template<class T>
struct scalar_log10:
public scalar_unary_functor<T> {
typedef typename scalar_unary_functor<T>::argument_type argument_type;
typedef typename scalar_unary_functor<T>::result_type result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::log10(t);
}
};
/**
* @internal
* Real or complex value raised to a power.
*/
template<class T1, class T2>
struct scalar_pow:
public scalar_binary_functor<T1, T2> {
typedef typename scalar_binary_functor<T1, T2>::argument1_type
argument1_type;
typedef typename scalar_binary_functor<T1, T2>::argument2_type
argument2_type;
typedef typename scalar_binary_functor<T1, T2>::result_type
result_type;
static inline result_type apply(argument1_type t1, argument2_type t2) {
return math_traits<result_type>::pow(t1,t2) ;
}
};
//**********************************************************
// signal processing functions
/**
* @internal
* Converts a real phase angle into a real valued signal.
* The sin(t) form is used to make the phase zero at t=0.
*/
template<class T>
struct scalar_signal:
public scalar_real_unary_functor<T> {
typedef typename scalar_real_unary_functor<T>::argument_type
argument_type;
typedef typename scalar_real_unary_functor<T>::result_type
result_type;
static inline result_type apply(argument_type t) {
return math_traits<result_type>::sin(t);
}
};
/**
* @internal
* Converts a real phase angle into a complex analytic signal.
* The real part of this result is equivalent to scalar_signal(t).
*/
template<class T>
struct scalar_asignal {
typedef T argument_type;
typedef complex<T> result_type ;
static inline result_type apply(argument_type t) {
return result_type( math_traits<T>::sin(t),
math_traits<T>::cos(t) ) ;
}
};
} // end of ublas namespace
} // end of usml namespace
|
PHP
|
UTF-8
| 922 | 2.796875 | 3 |
[] |
no_license
|
<?php
session_start();
function showForm() {
echo file_get_contents("login.html");
exit();
}
require_once "../../lib/autoload.php";
if (!isset($_SESSION['logedin'])) {
// Look if Login Process ongoing
if (!isset($_POST['username']) and !isset($_POST['password'])) {
// Send User login form
showForm();
} else {
// Check if user exists
$statement = Database::execute("SELECT password, rank FROM team WHERE name = ?", array($_POST['username']));
if ($statement->rowCount() != 1) {
showForm();
}
$data = $statement->fetch();
// Check if password is right
if (!password_verify($_POST['password'], $data['password'])) {
showForm();
}
// Set Session
$_SESSION['logedin'] = 1;
$_SESSION['name'] = $_POST['username'];
$_SESSION['rank'] = $data['rank'];
}
}
?>
|
Markdown
|
UTF-8
| 1,675 | 3.796875 | 4 |
[] |
no_license
|
1. Write a python program to print all characters in a string 'www.google.com'.
Example: 'Hello' should be printed as:
H
e
l
l
o
2. WAPP to make the a string 'Don't Stop Me Now' to all UPPERCASE
3. WAPP to make the a string 'Don't Stop Me Now' to all lowercase
4. Write a python program to count the character frequency for each character in a string 'www.google.com'
Example: 'Hello' should be printed as:
H - 1
e - 1
l - 2
o - 1
Hint: use the find function
5. Write a python program to split a string 'www.google.com' into a list of characters
Example: 'Hello' should be converted to ['H', 'e', 'l', 'l', 'o']
6. Write a python program to print the following pattern
1, 3, 5, 7, 9
7. WAPP to convert a list of characters to a string.
Example: ['H', 'e', 'l', 'l', 'o'] should be converted to 'Hello'
Hint: traverse the list
8. WAPP to collect all pair combinations of two tuples.
Input : test_tuple1 = (1, 2), test_tuple2 = (10, 20)
Output : [(1, 10), (1, 20), (2, 10), (2, 20), (10, 1), (10, 2), (20, 1), (20, 2)]
9. WAPP to remove negative elements in a list
Input : test_list = [1, 4, 3, -8, -1]
Output : [1, 4, 3]
10. WAPP that accepts an integer (n) and computes the value of n+nn+nnn.
Example: if the input in 3, you have to calculate 3 + 33 + 333 = 369
11. Write a Python Function to collect alternate items from input list.
Input: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Output: [0, 2, 4, 6, 8]
|
C#
|
UTF-8
| 5,283 | 2.609375 | 3 |
[] |
no_license
|
using System;
using System.Collections.Generic;
using Estudos.IdempotentConsumer.Enums;
using Estudos.IdempotentConsumer.Repositories.Base;
using FluentAssertions;
using Xunit;
namespace Estudos.IdempotentConsumer.Tests.Unitary.Repositories.Base;
public class EntryTest
{
private static readonly Entry DefaultEntry = new("InstanceId", "IdempotencyKey", RepositoryEntryState.None, DateTime.Now);
[Fact(DisplayName = "Deve criar objeto Entry")]
public void ShouldCreateEntryObject()
{
// arrange - act
var result = new Entry("InstanceId", "IdempotencyKey", RepositoryEntryState.Reserved, DateTime.Now);
// assert
ValidateObjectProperties(result, DateTime.Now.Date, "InstanceId", "IdempotencyKey", RepositoryEntryState.Reserved);
}
[Theory(DisplayName = "Deve validar se objeto existe")]
[InlineData("InstanceId", "IdempotencyKey", true)]
[InlineData("", "IdempotencyKey", false)]
[InlineData("InstanceId", "", false)]
[InlineData("", "", false)]
public void ShouldValidateExistEntryObject(string instanceId, string idempotencyKey, bool expectedResult)
{
// arrange
var entry = new Entry(instanceId, idempotencyKey, RepositoryEntryState.Processing, DateTime.Now);
// act - assert
entry.Exist().Should().Be(expectedResult);
}
[Theory(DisplayName = "Deve validar comparação do objeto")]
[MemberData(nameof(ScenariosEntryEquals))]
public void ShouldValidateEqualsEntryObject(Entry entry, object equalsObjectToCompare, bool expectedResult)
{
// arrange - act - assert
entry.Equals(equalsObjectToCompare).Should().Be(expectedResult);
}
[Fact(DisplayName = "Deve validar obtenção do hash code")]
public void ShouldValidateGetHashCode()
{
// assert
var entry = new Entry("InstanceId", "IdempotencyKey", RepositoryEntryState.Processing, DateTime.Now);
// act
var result = entry.GetHashCode();
// assert
result.Should().NotBe(0);
}
[Fact(DisplayName = "Deve criar objeto Entry empty")]
public void ShouldCreateEmptyEntry()
{
// arrange - act
var result = Entry.Empty;
// assert
ValidateObjectProperties(result, default, string.Empty, string.Empty, RepositoryEntryState.None);
}
[Theory(DisplayName = "Deve validar predicate")]
[InlineData("InstanceId", "IdempotencyKey", true)]
[InlineData("", "IdempotencyKey", false)]
[InlineData("InstanceId", "", false)]
[InlineData("false", "", false)]
public void ShouldValidatePredicate(string instanceId, string idempotencyKey, bool expectedResult)
{
// arrange
var entry = new Entry(instanceId, idempotencyKey, RepositoryEntryState.Processing, DateTime.Now);
// act
var predicate = Entry.Predicate("InstanceId", "IdempotencyKey");
// assert
predicate.Invoke(entry).Should().Be(expectedResult);
}
[Fact(DisplayName = "Deve validar predicate com entry nullo")]
public void ShouldValidatePredicateWitNullPredicate()
{
// arrange - act
var predicate = Entry.Predicate("InstanceId", "IdempotencyKey");
// assert
predicate.Invoke(null!).Should().BeFalse();
}
private static void ValidateObjectProperties(Entry entry, DateTime timestamp, string instanceId, string idempotencyKey, RepositoryEntryState state)
{
entry.Timestamp.Date.Should().Be(timestamp);
entry.InstanceId.Should().BeEquivalentTo(instanceId);
entry.IdempotencyKey.Should().BeEquivalentTo(idempotencyKey);
entry.State.Should().Be(state);
}
public static IEnumerable<object[]> ScenariosEntryEquals => new List<object[]>
{
new object[] {DefaultEntry, DefaultEntry, true},
new object[] {Entry.Empty, null!, false},
new object[] {Entry.Empty, null!, false},
new object[] {Entry.Empty, new(), false},
new object[] {new Entry("InstanceId", "IdempotencyKey", RepositoryEntryState.None, DateTime.Now), new Entry("InstanceId", "IdempotencyKey", RepositoryEntryState.None, DateTime.Now), true},
new object[] {new Entry("InstanceId", "IdempotencyKey", RepositoryEntryState.None, DateTime.Now), new Entry("", "IdempotencyKey", RepositoryEntryState.None, DateTime.Now), false},
new object[] {new Entry("InstanceId", "IdempotencyKey", RepositoryEntryState.None, DateTime.Now), new Entry("InstanceId", "", RepositoryEntryState.None, DateTime.Now), false},
new object[] {new Entry("InstanceId", "IdempotencyKey", RepositoryEntryState.None, DateTime.Now), new Entry("", "", RepositoryEntryState.None, DateTime.Now), false},
new object[] {new Entry("", "IdempotencyKey", RepositoryEntryState.None, DateTime.Now), new Entry("InstanceId", "IdempotencyKey", RepositoryEntryState.None, DateTime.Now), false},
new object[] {new Entry("InstanceId", "", RepositoryEntryState.None, DateTime.Now), new Entry("InstanceId", "IdempotencyKey", RepositoryEntryState.None, DateTime.Now), false},
new object[] {new Entry("", "", RepositoryEntryState.None, DateTime.Now), new Entry("InstanceId", "IdempotencyKey", RepositoryEntryState.None, DateTime.Now), false}
};
}
|
Java
|
UTF-8
| 209 | 1.851563 | 2 |
[
"OGL-UK-3.0"
] |
permissive
|
package uk.gov.caz.psr.controller.exception;
public class PaymentInfoVrnValidationException extends RuntimeException {
public PaymentInfoVrnValidationException(String message) {
super(message);
}
}
|
Markdown
|
UTF-8
| 1,298 | 3.140625 | 3 |
[] |
no_license
|
## mandelbrot
A simple Mandelbrot set visualization with matplotlib
### Dependencies
- python 3
- numpy
- matplotlib
- numba
NOTE: I have only used this with python 3.7, numpy 1.16.2, matplotlib 3.0.3 and numba 0.43.1.
### Documentation
#### Class constructor
```python
Mandelbrot.__init__(width=9, height=6, dpi=72, extent=[-2,1,-1,1], maxIter=128, cmap="cubehelix", zoom=2):
```
Parameters:
- **width** - width of figure in inches
- **height** - height of figure in inches
- **dpi** - dot per inch i.e. a measurement for resolution
- **extent** - an array of the boundary coordinates: [real_min, real_max, imaginary_min, imaginary_max]
- **maxIter** - maximum iteration used in calculation, a larger value will render more detail
- **cmap** - the colormap, used for customizing the color of the image, see [matplotlib.org/users/colormaps](https://matplotlib.org/users/colormaps.html) to find one that you prefer
- **zoom** - zoom parameter
#### Basic example
```python
import Mandelbrot as mb
extent = [-0.40, 0.15, 0.63, 1]
mandel = mb.Mandelbrot(extent=extent, cmap="magma")
mandel.plot()
```
This will create a matplotlib figure like this:

Clicking on the hyperbolic component in the middle updates the figure:

|
Python
|
UTF-8
| 296 | 3.4375 | 3 |
[] |
no_license
|
m=int(input())
n=int(input())
maiorMultiplo=0
cont=m
while(cont<=n):
if(cont%m == 0):
if(cont>=maiorMultiplo):
maiorMultiplo=cont
cont+=1
if(maiorMultiplo==0):
print("sem multiplos menores que",n,)
else:
print(maiorMultiplo)
|
JavaScript
|
UTF-8
| 2,624 | 2.59375 | 3 |
[
"MIT"
] |
permissive
|
/* eslint-disable react/prop-types */
import React from 'react';
import { mount, byId, text, simulate, runAllTimers } from 'react-test-render-fns';
import TrafficLights from './components/TrafficLights';
import TrafficLightsWithWalk from './components/TrafficLightsWithWalk';
jest.useFakeTimers();
const clickBtn = ($root, buttonType) => {
const $btn = $root.find(byId(buttonType));
simulate(new Event('click'), $btn);
};
describe('useStateMachine single state', () => {
const checkState = (state, $root) => {
expect(text($root.find(byId('state')))).toBe(state);
expect(text($root.find(byId('cata')))).toBe(`${state} color`);
};
it('should be green', () => {
const $root = mount(<TrafficLights />);
checkState('green', $root);
});
it('should be red after click', () => {
const $root = mount(<TrafficLights />);
clickBtn($root, 'next');
checkState('red', $root);
});
it('should be orange after 2 clicks', () => {
const $root = mount(<TrafficLights />);
clickBtn($root, 'next');
clickBtn($root, 'next');
checkState('orange', $root);
});
it('should be green after 2 clicks', () => {
const $root = mount(<TrafficLights />);
clickBtn($root, 'next');
clickBtn($root, 'next');
clickBtn($root, 'next');
checkState('green', $root);
});
it('should call action on the specific transitions', () => {
const onNext = jest.fn();
const $root = mount(<TrafficLights onNext={onNext} />);
expect(onNext).not.toHaveBeenCalled();
clickBtn($root, 'next');
expect(onNext).toHaveBeenCalledTimes(1);
expect(onNext.mock.calls[0][0]).toBe('green');
expect(onNext.mock.calls[0][2]).toBe(1);
expect(onNext.mock.calls[0][3]).toBe(2);
clickBtn($root, 'next');
expect(onNext).toHaveBeenCalledTimes(2);
expect(onNext.mock.calls[1][0]).toBe('red');
expect(onNext.mock.calls[1][2]).toBe(1);
expect(onNext.mock.calls[1][3]).toBe(2);
clickBtn($root, 'next');
expect(onNext).toHaveBeenCalledTimes(3);
expect(onNext.mock.calls[2][0]).toBe('orange');
expect(onNext.mock.calls[1][2]).toBe(1);
expect(onNext.mock.calls[1][3]).toBe(2);
clickBtn($root, 'next');
expect(onNext).toHaveBeenCalledTimes(4);
expect(onNext.mock.calls[3][0]).toBe('green');
expect(onNext.mock.calls[1][2]).toBe(1);
expect(onNext.mock.calls[1][3]).toBe(2);
});
it('should throw error on invalid transitions and state should remain unchanged', () => {
const $root = mount(<TrafficLights />);
expect(() => clickBtn($root, 'prev')).toThrowError();
checkState('green', $root);
});
});
|
Markdown
|
UTF-8
| 19,259 | 3 | 3 |
[] |
no_license
|
##CPU100%,频繁FullGC排查
jstack 和内存信息,然后重启系统,尽快保证系统的可用性。
这种情况可能的原因主要有两种:
* 代码中某个位置读取数据量较大,导致系统内存耗尽,从而导致 Full GC 次数过多,系统缓慢。
* 代码中有比较耗 CPU 的操作,导致 CPU 过高,系统运行缓慢。
相对来说,这是出现频率\*\*\*的两种线上问题,而且它们会直接导致系统不可用。
另外有几种情况也会导致某个功能运行缓慢,但是不至于导致系统不可用:
* 代码某个位置有阻塞性的操作,导致该功能调用整体比较耗时,但出现是比较随机的。
* 某个线程由于某种原因而进入 WAITING 状态,此时该功能整体不可用,但是无法复现。
* 由于锁使用不当,导致多个线程进入死锁状态,从而导致系统整体比较缓慢。
对于这三种情况,通过查看 CPU 和系统内存情况是无法查看出具体问题的,因为它们相对来说都是具有一定阻塞性操作,CPU 和系统内存使用情况都不高,但是功能却很慢。
下面我们就通过查看系统日志来一步一步甄别上述几种问题。
**Full GC 次数过多**
相对来说,这种情况是最容易出现的,尤其是新功能上线时。
对于 Full GC 较多的情况,其主要有如下两个特征:
* 线上多个线程的 CPU 都超过了 \*\*\* jstack 命令可以看到这些线程主要是垃圾回收线程。
* 通过 jstat 命令监控 GC 情况,可以看到 Full GC 次数非常多,并且次数在不断增加。
首先我们可以使用 top 命令查看系统 CPU 的占用情况,如下是系统 CPU 较高的一个示例:
1. top \- 08:31:10 up 30 min, 0 users, load average: 0.73, 0.58, 0.34
2. KiB Mem: 2046460 total, 1923864 used, 122596 free, 14388 buffers
3. KiB Swap: 1048572 total, 0 used, 1048572 free. 1192352 cached Mem
5. PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
6. 9 root 20 0 2557160 288976 15812 S 98.0 14.1 0:42.60 java
可以看到,有一个 Java 程序此时 CPU 占用量达到了 98.8%,此时我们可以复制该进程 id9,并且使用如下命令查看该进程的各个线程运行情况:
1. top \-Hp 9
该进程下的各个线程运行情况如下:
1. top \- 08:31:16 up 30 min, 0 users, load average: 0.75, 0.59, 0.35
2. Threads: 11 total, 1 running, 10 sleeping, 0 stopped, 0 zombie
3. %Cpu(s): 3.5 us, 0.6 sy, 0.0 ni, 95.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
4. KiB Mem: 2046460 total, 1924856 used, 121604 free, 14396 buffers
5. KiB Swap: 1048572 total, 0 used, 1048572 free. 1192532 cached Mem
7. PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8. 10 root 20 0 2557160 289824 15872 R 79.3 14.2 0:41.49 java
9. 11 root 20 0 2557160 289824 15872 S 13.2 14.2 0:06.78 java
可以看到,在进程为 9 的 Java 程序中各个线程的 CPU 占用情况,接下来我们可以通过 jstack 命令查看线程 id 为 10 的线程为什么耗费 CPU \*\*\*。
需要注意的是,在 jsatck 命令展示的结果中,线程 id 都转换成了十六进制形式。
可以用如下命令查看转换结果,也可以找一个科学计算器进行转换:
1. root@a39de7e7934b:/# printf "%x\\n" 10
2. a
这里打印结果说明该线程在 jstack 中的展现形式为 0xa,通过 jstack 命令我们可以看到如下信息:
1. "main" #1 prio=5 os\_prio=0 tid=0x00007f8718009800 nid=0xb runnable \[0x00007f871fe41000\]
2. java.lang.Thread.State: RUNNABLE
3. at com.aibaobei.chapter2.eg2.UserDemo.main(UserDemo.java:9)
5. "VM Thread" os\_prio=0 tid=0x00007f871806e000 nid=0xa runnable
这里的 VM Thread 一行的\*\*\*显示 nid=0xa,这里 nid 的意思就是操作系统线程 id 的意思,而 VM Thread 指的就是垃圾回收的线程。
这里我们基本上可以确定,当前系统缓慢的原因主要是垃圾回收过于频繁,导致 GC 停顿时间较长。
我们通过如下命令可以查看 GC 的情况:
1. root@8d36124607a0:/# jstat \-gcutil 9 1000 10
2. S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
3. 0.00 0.00 0.00 75.07 59.09 59.60 3259 0.919 6517 7.715 8.635
4. 0.00 0.00 0.00 0.08 59.09 59.60 3306 0.930 6611 7.822 8.752
5. 0.00 0.00 0.00 0.08 59.09 59.60 3351 0.943 6701 7.924 8.867
6. 0.00 0.00 0.00 0.08 59.09 59.60 3397 0.955 6793 8.029 8.984
可以看到,这里 FGC 指的是 Full GC 数量,这里高达 6793,而且还在不断增长。从而进一步证实了是由于内存溢出导致的系统缓慢。
那么这里确认了内存溢出,但是如何查看你是哪些对象导致的内存溢出呢,这个可以 Dump 出内存日志,然后通过 Eclipse 的 Mat 工具进行查看。
如下图是其展示的一个对象树结构:
[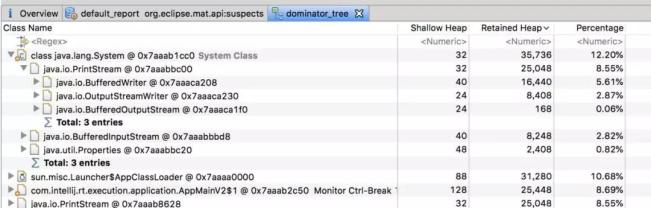](https://s4.51cto.com/oss/201906/24/8ceab85cce23c50da8ab35f7c3d51e99.jpg-wh_651x-s_3890170836.jpg)
经过 Mat 工具分析之后,我们基本上就能确定内存中主要是哪个对象比较消耗内存,然后找到该对象的创建位置,进行处理即可。
这里主要是 PrintStream 最多,但是我们也可以看到,其内存消耗量只有 12.2%。
也就是说,其还不足以导致大量的 Full GC,此时我们需要考虑另外一种情况,就是代码或者第三方依赖的包中有显示的 System.gc() 调用。
这种情况我们查看 Dump 内存得到的文件即可判断,因为其会打印 GC 原因:
1. \[Full GC (System.gc()) \[Tenured: 262546K\->262546K(349568K), 0.0014879 secs\] 262546K\->262546K(506816K), \[Metaspace: 3109K\->3109K(1056768K)\], 0.0015151 secs\] \[Times: user\=0.00 sys=0.00, real\=0.01 secs\]
2. \[GC (Allocation Failure) \[DefNew: 2795K\->0K(157248K), 0.0001504 secs\]\[Tenured: 262546K\->402K(349568K), 0.0012949 secs\] 265342K\->402K(506816K), \[Metaspace: 3109K\->3109K(1056768K)\], 0.0014699 secs\] \[Times: user\=0.00
比如这里\*\*\*次 GC 是由于 System.gc() 的显示调用导致的,而第二次 GC 则是 JVM 主动发起的。
总结来说,对于 Full GC 次数过多,主要有以下两种原因:
* 代码中一次获取了大量的对象,导致内存溢出,此时可以通过 Eclipse 的 Mat 工具查看内存中有哪些对象比较多。
* 内存占用不高,但是 Full GC 次数还是比较多,此时可能是显示的 System.gc() 调用导致 GC 次数过多,这可以通过添加 \-XX:+DisableExplicitGC 来禁用 JVM 对显示 GC 的响应。
**CPU 过高**
在前面\*\*\*点中,我们讲到,CPU 过高可能是系统频繁的进行 Full GC,导致系统缓慢。
而我们平常也肯定能遇到比较耗时的计算,导致 CPU 过高的情况,此时查看方式其实与上面的非常类似。
首先我们通过 top 命令查看当前 CPU 消耗过高的进程是哪个,从而得到进程 id;然后通过 top \-Hp 来查看该进程中有哪些线程 CPU 过高,一般超过 80% 就是比较高的,80% 左右是合理情况。
这样我们就能得到 CPU 消耗比较高的线程 id。接着通过该线程 id 的十六进制表示在 jstack 日志中查看当前线程具体的堆栈信息。
在这里我们就可以区分导致 CPU 过高的原因具体是 Full GC 次数过多还是代码中有比较耗时的计算了。
如果是 Full GC 次数过多,那么通过 jstack 得到的线程信息会是类似于 VM Thread 之类的线程。
而如果是代码中有比较耗时的计算,那么我们得到的就是一个线程的具体堆栈信息。
如下是一个代码中有比较耗时的计算,导致 CPU 过高的线程信息:
[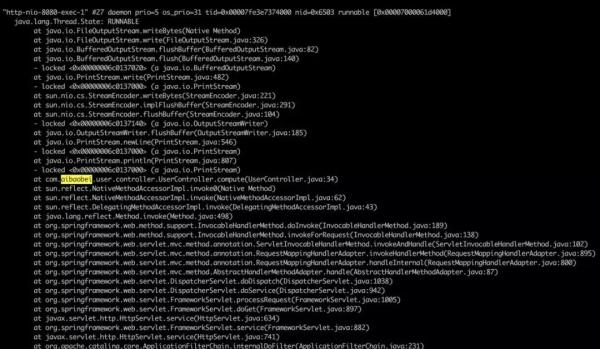](https://s4.51cto.com/oss/201906/24/ee7dc99c6fc6809bdf1ce1c755de9a50.jpg-wh_600x-s_1977037863.jpg)
这里可以看到,在请求 UserController 的时候,由于该 Controller 进行了一个比较耗时的调用,导致该线程的 CPU 一直处于 100%。
我们可以根据堆栈信息,直接定位到 UserController 的 34 行,查看代码中具体是什么原因导致计算量如此之高。
**不定期出现的接口耗时现象**
对于这种情况,比较典型的例子就是,我们某个接口访问经常需要 2~3s 才能返回。
这是比较麻烦的一种情况,因为一般来说,其消耗的 CPU 不多,而且占用的内存也不高,也就是说,我们通过上述两种方式进行排查是无法解决这种问题的。
而且由于这样的接口耗时比较大的问题是不定时出现的,这就导致了我们在通过 jstack 命令即使得到了线程访问的堆栈信息,我们也没法判断具体哪个线程是正在执行比较耗时操作的线程。
对于不定时出现的接口耗时比较严重的问题,我们的定位思路基本如下:首先找到该接口,通过压测工具不断加大访问力度。
如果说该接口中有某个位置是比较耗时的,由于我们的访问的频率非常高,那么大多数的线程最终都将阻塞于该阻塞点。
这样通过多个线程具有相同的堆栈日志,我们基本上就可以定位到该接口中比较耗时的代码的位置。
如下是一个代码中有比较耗时的阻塞操作通过压测工具得到的线程堆栈日志:
1. "http\-nio\-8080\-exec\-2" #29 daemon prio=5 os\_prio=31 tid=0x00007fd08cb26000 nid=0x9603 waiting on condition \[0x00007000031d5000\]
2. java.lang.Thread.State: TIMED\_WAITING (sleeping)
3. at java.lang.Thread.sleep(Native Method)
4. at java.lang.Thread.sleep(Thread.java:340)
5. at java.util.concurrent.TimeUnit.sleep(TimeUnit.java:386)
6. at com.aibaobei.user.controller.UserController.detail(UserController.java:18)
8. "http\-nio\-8080\-exec\-3" #30 daemon prio=5 os\_prio=31 tid=0x00007fd08cb27000 nid=0x6203 waiting on condition \[0x00007000032d8000\]
9. java.lang.Thread.State: TIMED\_WAITING (sleeping)
10. at java.lang.Thread.sleep(Native Method)
11. at java.lang.Thread.sleep(Thread.java:340)
12. at java.util.concurrent.TimeUnit.sleep(TimeUnit.java:386)
13. at com.aibaobei.user.controller.UserController.detail(UserController.java:18)
15. "http\-nio\-8080\-exec\-4" #31 daemon prio=5 os\_prio=31 tid=0x00007fd08d0fa000 nid=0x6403 waiting on condition \[0x00007000033db000\]
16. java.lang.Thread.State: TIMED\_WAITING (sleeping)
17. at java.lang.Thread.sleep(Native Method)
18. at java.lang.Thread.sleep(Thread.java:340)
19. at java.util.concurrent.TimeUnit.sleep(TimeUnit.java:386)
20. at com.aibaobei.user.controller.UserController.detail(UserController.java:18)
从上面的日志你可以看出,这里有多个线程都阻塞在了 UserController 的第 18 行,说明这是一个阻塞点,也就是导致该接口比较缓慢的原因。
**某个线程进入 WAITING 状态**
对于这种情况,这是比较罕见的一种情况,但是也是有可能出现的,而且由于其具有一定的“不可复现性”,因而我们在排查的时候是非常难以发现的。
笔者曾经就遇到过类似的这种情况,具体的场景是,在使用 CountDownLatch 时,由于需要每一个并行的任务都执行完成之后才会唤醒主线程往下执行。
而当时我们是通过 CountDownLatch 控制多个线程连接并导出用户的 Gmail 邮箱数据,这其中有一个线程连接上了用户邮箱,但是连接被服务器挂起了,导致该线程一直在等待服务器的响应。
最终导致我们的主线程和其余几个线程都处于 WAITING 状态。
对于这样的问题,查看过 jstack 日志的读者应该都知道,正常情况下,线上大多数线程都是处于 TIMED\_WAITING 状态。
而我们这里出问题的线程所处的状态与其是一模一样的,这就非常容易混淆我们的判断。
解决这个问题的思路主要如下:
①通过 grep 在 jstack 日志中找出所有的处于 TIMED\_WAITING 状态的线程,将其导出到某个文件中,如 a1.log,如下是一个导出的日志文件示例:
1. "Attach Listener" #13 daemon prio=9 os\_prio=31 tid=0x00007fe690064000 nid=0xd07 waiting on condition \[0x0000000000000000\]
2. "DestroyJavaVM" #12 prio=5 os\_prio=31 tid=0x00007fe690066000 nid=0x2603 waiting on condition \[0x0000000000000000\]
3. "Thread\-0" #11 prio=5 os\_prio=31 tid=0x00007fe690065000 nid=0x5a03 waiting on condition \[0x0000700003ad4000\]
4. "C1 CompilerThread3" #9 daemon prio=9 os\_prio=31 tid=0x00007fe68c00a000 nid=0xa903 waiting on condition \[0x0000000000000000\]
②等待一段时间之后,比如 10s,再次对 jstack 日志进行 grep,将其导出到另一个文件,如 a2.log,结果如下所示:
1. "DestroyJavaVM" #12 prio=5 os\_prio=31 tid=0x00007fe690066000 nid=0x2603 waiting on condition \[0x0000000000000000\]
2. "Thread\-0" #11 prio=5 os\_prio=31 tid=0x00007fe690065000 nid=0x5a03 waiting on condition \[0x0000700003ad4000\]
3. "VM Periodic Task Thread" os\_prio=31 tid=0x00007fe68d114000 nid=0xa803 waiting on condition
③重复步骤 2,待导出 3~4 个文件之后,我们对导出的文件进行对比,找出其中在这几个文件中一直都存在的用户线程。
这个线程基本上就可以确认是包含了处于等待状态有问题的线程。因为正常的请求线程是不会在 20~30s 之后还是处于等待状态的。
④经过排查得到这些线程之后,我们可以继续对其堆栈信息进行排查,如果该线程本身就应该处于等待状态,比如用户创建的线程池中处于空闲状态的线程,那么这种线程的堆栈信息中是不会包含用户自定义的类的。
这些都可以排除掉,而剩下的线程基本上就可以确认是我们要找的有问题的线程。
通过其堆栈信息,我们就可以得出具体是在哪个位置的代码导致该线程处于等待状态了。
这里需要说明的是,我们在判断是否为用户线程时,可以通过线程最前面的线程名来判断,因为一般的框架的线程命名都是非常规范的。
我们通过线程名就可以直接判断得出该线程是某些框架中的线程,这种线程基本上可以排除掉。
而剩余的,比如上面的 Thread\-0,以及我们可以辨别的自定义线程名,这些都是我们需要排查的对象。
经过上面的方式进行排查之后,我们基本上就可以得出这里的 Thread\-0 就是我们要找的线程,通过查看其堆栈信息,我们就可以得到具体是在哪个位置导致其处于等待状态了。
如下示例中则是在 SyncTask 的第 8 行导致该线程进入等待了:
1. "Thread\-0" #11 prio=5 os\_prio=31 tid=0x00007f9de08c7000 nid=0x5603 waiting on condition \[0x0000700001f89000\]
2. java.lang.Thread.State: WAITING (parking)
3. at sun.misc.Unsafe.park(Native Method)
4. at java.util.concurrent.locks.LockSupport.park(LockSupport.java:304)
5. at com.aibaobei.chapter2.eg4.SyncTask.lambda$main$0(SyncTask.java:8)
6. at com.aibaobei.chapter2.eg4.SyncTask$$Lambda$1/1791741888.run(Unknown Source)
7. at java.lang.Thread.run(Thread.java:748)
**死锁**
对于死锁,这种情况基本上很容易发现,因为 jstack 可以帮助我们检查死锁,并且在日志中打印具体的死锁线程信息。
如下是一个产生死锁的一个 jstack 日志示例:
[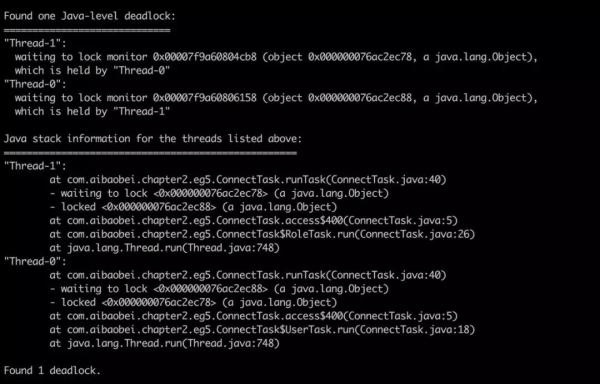](https://s3.51cto.com/oss/201906/24/286bf59f42a4c4f10ec4383ed40f427a.jpg-wh_600x-s_425765430.jpg)
可以看到,在 jstack 日志的底部,其直接帮我们分析了日志中存在哪些死锁,以及每个死锁的线程堆栈信息。
这里我们有两个用户线程分别在等待对方释放锁,而被阻塞的位置都是在 ConnectTask 的第 5 行,此时我们就可以直接定位到该位置,并且进行代码分析,从而找到产生死锁的原因。
**小结**
本文主要讲解了线上可能出现的五种导致系统缓慢的情况,详细分析了每种情况产生时的现象,已经根据现象我们可以通过哪些方式定位得到是这种原因导致的系统缓慢。
简要的说,我们进行线上日志分析时,主要可以分为如下步骤:
①通过 top 命令查看 CPU 情况,如果 CPU 比较高,则通过 top \-Hp 命令查看当前进程的各个线程运行情况。
找出 CPU 过高的线程之后,将其线程 id 转换为十六进制的表现形式,然后在 jstack 日志中查看该线程主要在进行的工作。
这里又分为两种情况:
* 如果是正常的用户线程,则通过该线程的堆栈信息查看其具体是在哪处用户代码处运行比较消耗 CPU。
* 如果该线程是 VM Thread,则通过 jstat \-gcutil 命令监控当前系统的 GC 状况。
然后通过 jmap dump:format=b,file= 导出系统当前的内存数据。
导出之后将内存情况放到 Eclipse 的 Mat 工具中进行分析即可得出内存中主要是什么对象比较消耗内存,进而可以处理相关代码。
②如果通过 top 命令看到 CPU 并不高,并且系统内存占用率也比较低。此时就可以考虑是否是由于另外三种情况导致的问题。
具体的可以根据具体情况分析:
* 如果是接口调用比较耗时,并且是不定时出现,则可以通过压测的方式加大阻塞点出现的频率,从而通过 jstack 查看堆栈信息,找到阻塞点。
* 如果是某个功能突然出现停滞的状况,这种情况也无法复现,此时可以通过多次导出 jstack 日志的方式对比哪些用户线程是一直都处于等待状态,这些线程就是可能存在问题的线程。
* 如果通过 jstack 可以查看到死锁状态,则可以检查产生死锁的两个线程的具体阻塞点,从而处理相应的问题。
本文主要是提出了五种常见的导致线上功能缓慢的问题,以及排查思路。当然,线上的问题出现的形式是多种多样的,也不一定局限于这几种情况。
|
Java
|
UTF-8
| 2,276 | 3.21875 | 3 |
[] |
no_license
|
/**
* A Character that can be controlled by the interface.
*/
package yuuki.entity;
import java.util.ArrayList;
import yuuki.action.Action;
import yuuki.ui.Interactable;
public class PlayerCharacter extends Character {
/**
* A reference to the user interface for this PC to get its moves from.
*/
private Interactable ui;
/**
* Allocates a new Character. Most stats are set manually, but experience
* is automatically calculated from the starting level. All stats are the
* base stats; all actual stats are calculated by multiplying the stat gain
* by the level and adding the base stat.
*
* @param name The name of the Character.
* @param level The level of the new Character. XP is set to match this.
* @param moves The moves that this Character knows.
* @param hp The health stat of the new Character.
* @param mp The mana stat of the new Character.
* @param strength The physical strength of the Character.
* @param defense The Character's resistance to damage.
* @param agility The Character's avoidance of hits.
* @param accuracy The Character's ability to hit.
* @param magic The magical ability of the Character.
* @param luck The ability of the Character to get a critical hit.
* @param ui The interface that this Character should get input from.
*/
public PlayerCharacter(String name, int level, Action[] moves,
VariableStat hp, VariableStat mp, Stat strength,
Stat defense, Stat agility, Stat accuracy, Stat magic,
Stat luck, Interactable ui) {
super(name, level, moves, hp, mp, strength, defense, agility, accuracy,
magic, luck);
this.ui = ui;
}
/**
* Decides what move to do next based on input from the interface.
*
* @param fighters The states of the players, including this one.
*
* @return The move that was selected by the player.
*/
protected Action selectAction(ArrayList<ArrayList<Character>> fighters) {
int index = ui.selectAction(moves);
return moves[index].clone();
}
/**
* Selects the target of an action based on the other players.
*
* @param fighters The states of the other players.
*
* @return The target.
*/
protected Character selectTarget(
ArrayList<ArrayList<Character>> fighters) {
return ui.selectTarget(fighters);
}
}
|
C
|
UTF-8
| 13,830 | 2.71875 | 3 |
[
"MIT"
] |
permissive
|
//==============================================================================
// UTILITY
//==============================================================================
ProteoColor brightness(ProteoColor color,float bright)
{
ProteoColor col={255,
MIN(255,color.r*bright),
MIN(255,color.g*bright),
MIN(255,color.b*bright)};
return col;
}
ProteoColor saturation(ProteoColor color, float sat)
{
const float Pr=0.299;
const float Pg=0.587;
const float Pb=0.114;
float P=sqrt(color.r*color.r*Pr+color.g*color.g*Pg+color.b*color.b*Pb);
ProteoColor col={255,
P+(color.r-P)*sat,
P+(color.g-P)*sat,
P+(color.b-P)*sat};
return col;
}
ProteoColor ColorInterpolation(ProteoColor startColor, float t, ProteoColor endColor)
{
//printf("ColorInterpolation: %f\n",t);
ProteoColor finalColor;
finalColor.r = startColor.r + (endColor.r - startColor.r) * t;
finalColor.g = startColor.g + (endColor.g - startColor.g) * t;
finalColor.b = startColor.b + (endColor.b - startColor.b) * t;
finalColor.a = startColor.a + (endColor.a - startColor.a) * t;
return finalColor;
}
float interpolation(float start, float t, float end)
{
return start + (end - start) * t;
}
char font_path[256];
char* font2path(const char* font)
{
//#ifdef __EMSCRIPTEN__
//strcpy(font_path,"");
//#else
//#endif
size_t n = sizeof(nfonts)/sizeof(nfonts[0]);
for(int i=0;i<n;i++)
{
if(strcasecmp(font,nfonts[i].name)==0)
{
if(nfonts[i].base==TRUE)
strcpy(font_path,config.basedir);
else
{
#if TARGET_OS_MAC
wordexp_t exp_result;
wordexp("~/Library/Preferences/Proteo/", &exp_result, 0);
strcpy(font_path,exp_result.we_wordv[0]);
wordfree(&exp_result);
#else
strcpy(font_path,config.basedir);
#endif
}
return strcat(font_path,nfonts[i].path);
}
}
return NULL;
}
char icon_path[256];
char* icon2path(const char* icon)
{
strcpy(icon_path,config.basedir);
//#endif
size_t n = sizeof(nicons)/sizeof(nicons[0]);
for(int i=0;i<n;i++)
{
if(strcasecmp(icon,nicons[i].name)==0)
{
return strcat(icon_path,nicons[i].path);
}
}
return NULL;
}
ProteoColor hex2color(const char* input) {
size_t n = sizeof(colors)/sizeof(colors[0]);
for(int i=0;i<n;i++)
{
if(strcasecmp(input,colors[i].name)==0) return colors[i].color;
}
ProteoColor col;
char color[10];
if(verbose) printf("hex2color: %s\n",input);
if (input[0] == '#')
{
if(strlen(input)==7)
{
strcpy(color+1,input);
color[0]='f';
color[1]='f';
}
else
{
strcpy(color,input);
color[0]='0';
}
}
else
{
return col;
}
unsigned long value = strtoul(color, NULL, 16);
col.a = (value >> 24) & 0xff;
col.r = (value >> 16) & 0xff;
col.g = (value >> 8) & 0xff;
col.b = (value >> 0) & 0xff;
//return color;
return col;
}
void mkpath(const char* dir) {
char tmp[256];
char *p = NULL;
size_t len;
snprintf(tmp, sizeof(tmp),"%s",dir);
dirname(tmp);
len = strlen(tmp);
if(tmp[len - 1] == '/')
tmp[len - 1] = 0;
for(p = tmp + 1; *p; p++)
if(*p == '/') {
*p = 0;
#if TARGET_OS_WINDOWS //defined(WIN32) || defined(_WIN32) || defined(__WIN32__) || defined(__NT__) || defined(__MINGW64__)
_mkdir(tmp);
#else
int ret=mkdir(tmp, S_IRWXU);
#endif
*p = '/';
}
#if TARGET_OS_WINDOWS //defined(WIN32) || defined(_WIN32) || defined(__WIN32__) || defined(__NT__) || defined(__MINGW64__)
_mkdir(tmp);
#else
int ret=mkdir(tmp, S_IRWXU);
#endif
}
int writefile(char* filename,char* data)
{
FILE *handler=fopen(filename,"w");
if (handler)
{
fprintf(handler,"%s",data);
fclose(handler);
return 0;
}
else printf("Write file %s error: %s\n",filename,strerror(errno));
return 1;
}
int writedatafile(char* filename,char* data,int data_size)
{
int write_size;
FILE *handler=fopen(filename,"wb");
if (handler)
{
write_size = fwrite(data, sizeof(char), data_size, handler);
fclose(handler);
if(debug) printf("Write data file: %s,%d,%d\n",filename,data_size,write_size);
return write_size;
}
else printf("Write data %s error: %s\n",filename,strerror(errno));
return 0;
}
char* loadfile(char *filename)
{
char *buffer = NULL;
int string_size, read_size;
FILE *handler = fopen(filename, "r");
if (handler)
{
fseek(handler, 0, SEEK_END);
string_size = ftell(handler);
rewind(handler);
buffer = (char*) malloc(sizeof(char) * (string_size + 1) );
if(buffer!=NULL)
{
read_size = fread(buffer, sizeof(char), string_size, handler);
buffer[string_size] = '\0';
if (string_size != read_size)
{
free(buffer);
buffer = NULL;
}
}
fclose(handler);
}
else printf("Load file %s error: %s\n",filename,strerror(errno));
return buffer;
}
int loaddatafile(char *filename,char **buffer)
{
int data_size, read_size;
FILE *handler = fopen(filename, "r");
if (handler)
{
fseek(handler, 0, SEEK_END);
data_size = ftell(handler);
rewind(handler);
*buffer = (char*) malloc(sizeof(char) * (data_size) );
if(buffer!=NULL)
{
read_size = fread(*buffer, sizeof(char), data_size, handler);
if (data_size != read_size)
{
free(*buffer);
*buffer = NULL;
return 0;
}
//if(debug) printf("Load data file: %s,%d,%d\n",filename,data_size,read_size);
if(debug) printf("Load data file: %s\n",filename);
}
fclose(handler);
}
else printf("Load data %s error: %s\n",filename,strerror(errno));
return read_size;
}
void hexDump (const char * desc, const void * addr, const int len) {
int i;
unsigned char buff[17];
const unsigned char * pc = (const unsigned char *)addr;
// Output description if given.
if (desc != NULL)
printf ("%s:\n", desc);
// Length checks.
if (len == 0) {
printf(" ZERO LENGTH\n");
return;
}
else if (len < 0) {
printf(" NEGATIVE LENGTH: %d\n", len);
return;
}
// Process every byte in the data.
for (i = 0; i < len; i++) {
// Multiple of 16 means new line (with line offset).
if ((i % 16) == 0) {
// Don't print ASCII buffer for the "zeroth" line.
if (i != 0)
printf (" %s\n", buff);
// Output the offset.
printf (" %04x ", i);
}
// Now the hex code for the specific character.
printf (" %02x", pc[i]);
// And buffer a printable ASCII character for later.
if ((pc[i] < 0x20) || (pc[i] > 0x7e)) // isprint() may be better.
buff[i % 16] = '.';
else
buff[i % 16] = pc[i];
buff[(i % 16) + 1] = '\0';
}
// Pad out last line if not exactly 16 characters.
while ((i % 16) != 0) {
printf (" ");
i++;
}
// And print the final ASCII buffer.
printf (" %s\n", buff);
}
char* concat(const char *s1, const char *s2)
{
const size_t len1 = strlen(s1);
const size_t len2 = strlen(s2);
char *result = malloc(len1 + len2 + 1);
if(result!=NULL)
{
memcpy(result, s1, len1);
memcpy(result + len1, s2, len2 + 1);
}
result[len1 + len2]=0;
return result;
}
char* concat3(const char *s1, const char *s2, const char *s3)
{
const size_t len1 = strlen(s1);
const size_t len2 = strlen(s2);
const size_t len3 = strlen(s3);
char *result = malloc(len1 + len2 + len3 + 1);
if(result!=NULL)
{
memcpy(result, s1, len1);
memcpy(result + len1, s2, len2);
memcpy(result + len1 + len2, s3, len3 + 1); // +1 to copy the null-terminator
}
result[len1 + len2 + len3]=0;
return result;
}
int c_quote(const char* src, char* dest, int maxlen) {
int count = 0;
if(maxlen < 0) {
maxlen = strlen(src)+1; /* add 1 for NULL-terminator */
}
while(src && maxlen > 0) {
switch(*src) {
/* these normal, printable chars just need a slash appended */
case '\\':
case '\"':
case '\'':
if(dest) {
*dest++ = '\\';
*dest++ = *src;
}
count += 2;
break;
/* newlines/tabs and unprintable characters need a special code.
* Use the macro CASE_CHAR defined below.
* The first arg for the macro is the char to compare to,
* the 2nd arg is the char to put in the result string, after the '\' */
#define CASE_CHAR(c, d) case c:\
if(dest) {\
*dest++ = '\\'; *dest++ = (d);\
}\
count += 2;\
break;
/* -------------- */
CASE_CHAR('\n', 'n');
CASE_CHAR('\t', 't');
CASE_CHAR('\b', 'b');
/* ------------- */
#undef CASE_CHAR
/* by default, just copy the char over */
default:
if(dest) {
*dest++ = *src;
}
count++;
}
++src;
--maxlen;
}
return count;
}
//simple encrypt-decrypt function
void encryptDecrypt(char inpString[])
{
char xorKey[] = "Key";
int len = strlen(inpString);
for (int i = 0; i < len; i++)
{
inpString[i] = inpString[i] ^ xorKey[i%strlen(xorKey)];
printf("%c",inpString[i]);
}
}
#ifdef AFFINE
SDL_Point affineTrasformation(SDL_Point point,float affine[3][3])
{
SDL_Point ret;
ret.x=point.x*affine[0][0]+point.y*affine[1][0]+affine[2][0];
ret.y=point.x*affine[0][1]+point.y*affine[1][1]+affine[2][1];
return ret;
}
#endif
void mult_matrices(float a[3][3], float b[3][3], float result[3][3])
{
int i, j, k;
for(i = 0; i < 3; i++)
{
for(j = 0; j < 3; j++)
{
for(k = 0; k < 3; k++)
{
result[i][j] += a[i][k] * b[k][j];
}
}
}
}
void laderman_mul(const float a[3][3],const float b[3][3],float c[3][3]) {
float m[24]; // not off by one, just wanted to match the index from the paper
m[1 ]= (a[0][0]+a[0][1]+a[0][2]-a[1][0]-a[1][1]-a[2][1]-a[2][2])*b[1][1];
m[2 ]= (a[0][0]-a[1][0])*(-b[0][1]+b[1][1]);
m[3 ]= a[1][1]*(-b[0][0]+b[0][1]+b[1][0]-b[1][1]-b[1][2]-b[2][0]+b[2][2]);
m[4 ]= (-a[0][0]+a[1][0]+a[1][1])*(b[0][0]-b[0][1]+b[1][1]);
m[5 ]= (a[1][0]+a[1][1])*(-b[0][0]+b[0][1]);
m[6 ]= a[0][0]*b[0][0];
m[7 ]= (-a[0][0]+a[2][0]+a[2][1])*(b[0][0]-b[0][2]+b[1][2]);
m[8 ]= (-a[0][0]+a[2][0])*(b[0][2]-b[1][2]);
m[9 ]= (a[2][0]+a[2][1])*(-b[0][0]+b[0][2]);
m[10]= (a[0][0]+a[0][1]+a[0][2]-a[1][1]-a[1][2]-a[2][0]-a[2][1])*b[1][2];
m[11]= a[2][1]*(-b[0][0]+b[0][2]+b[1][0]-b[1][1]-b[1][2]-b[2][0]+b[2][1]);
m[12]= (-a[0][2]+a[2][1]+a[2][2])*(b[1][1]+b[2][0]-b[2][1]);
m[13]= (a[0][2]-a[2][2])*(b[1][1]-b[2][1]);
m[14]= a[0][2]*b[2][0];
m[15]= (a[2][1]+a[2][2])*(-b[2][0]+b[2][1]);
m[16]= (-a[0][2]+a[1][1]+a[1][2])*(b[1][2]+b[2][0]-b[2][2]);
m[17]= (a[0][2]-a[1][2])*(b[1][2]-b[2][2]);
m[18]= (a[1][1]+a[1][2])*(-b[2][0]+b[2][2]);
m[19]= a[0][1]*b[1][0];
m[20]= a[1][2]*b[2][1];
m[21]= a[1][0]*b[0][2];
m[22]= a[2][0]*b[0][1];
m[23]= a[2][2]*b[2][2];
c[0][0] = m[6]+m[14]+m[19];
c[0][1] = m[1]+m[4]+m[5]+m[6]+m[12]+m[14]+m[15];
c[0][2] = m[6]+m[7]+m[9]+m[10]+m[14]+m[16]+m[18];
c[1][0] = m[2]+m[3]+m[4]+m[6]+m[14]+m[16]+m[17];
c[1][1] = m[2]+m[4]+m[5]+m[6]+m[20];
c[1][2] = m[14]+m[16]+m[17]+m[18]+m[21];
c[2][0] = m[6]+m[7]+m[8]+m[11]+m[12]+m[13]+m[14];
c[2][1] = m[12]+m[13]+m[14]+m[15]+m[22];
c[2][2] = m[6]+m[7]+m[8]+m[9]+m[23];
}
SDL_FPoint I2FPoint(SDL_Point p)
{
SDL_FPoint ret={p.x,p.y};
return ret;
}
SDL_Point F2IPoint(SDL_FPoint p)
{
SDL_Point ret={p.x,p.y};
return ret;
}
SDL_FPoint subtract(SDL_FPoint p0, SDL_FPoint p1)
{
SDL_FPoint ret={p0.x-p1.x,p0.y-p1.y};
return ret;
}
SDL_FPoint sum(SDL_FPoint p0, SDL_FPoint p1)
{
SDL_FPoint ret={p0.x+p1.x,p0.y+p1.y};
return ret;
}
SDL_FPoint multiply(SDL_FPoint p, float f)
{
SDL_FPoint ret={p.x*f,p.y*f};
return ret;
}
float dot(SDL_FPoint p0, SDL_FPoint p1)
{
float ret=(p0.x*p1.x)+(p0.y*p1.y);
return ret;
}
float distance(SDL_FPoint p0,SDL_FPoint p1)
{
return hypotf(p0.x-p1.x,p0.y-p1.y);
}
SDL_FPoint normalize(SDL_FPoint p)
{
float mag=hypotf(p.x,p.y);
SDL_FPoint ret={p.x/mag,p.y/mag};
//problema di normalizzazione? vettore spesso 0
return ret;
}
float magnitude(SDL_FPoint p)
{
float len=hypotf(p.x,p.y);
return len;
}
SDL_FPoint getClosestPointOnSegment(SDL_FPoint p0, SDL_FPoint p1, SDL_FPoint p)
{
SDL_FPoint d=subtract(p1,p0);
float c=dot(subtract(p,p0),d)/dot(d,d);
if(c>=1) return p1;
else if(c<=0) return p0;
else return sum(p0,multiply(d,c));
}
/*static getClosestPointOnSegment(p0, p1, p) {
let d = p1.subtract(p0);
let c = p.subtract(p0).dot(d) / (d.dot(d));
if (c >= 1) {
return p1.clone();
} else if (c <= 0) {
return p0.clone();
} else {
return p0.add(d.multiply(c));
}
}
*/
|
C#
|
UTF-8
| 5,482 | 2.5625 | 3 |
[
"MIT"
] |
permissive
|
/****************************************************************************
* Copyright (c) 2021.4 liangxie
*
* http://qframework.io
* https://github.com/liangxiegame/QFramework
*
* Permission is hereby granted, free of charge, to any person obtaining a copy
* of this software and associated documentation files (the "Software"), to deal
* in the Software without restriction, including without limitation the rights
* to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
* copies of the Software, and to permit persons to whom the Software is
* furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in
* all copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
* THE SOFTWARE.
****************************************************************************/
using UnityEngine;
namespace QFramework
{
[System.Serializable]
public class AIActionsList : ReorderableArray<AIAction>
{
}
[System.Serializable]
public class AITransitionsList : ReorderableArray<AITransition>
{
}
/// <summary>
/// A State is a combination of one or more actions, and one or more transitions. An example of a state could be "_patrolling until an enemy gets in range_".
/// </summary>
[System.Serializable]
public class AIState
{
/// the name of the state (will be used as a reference in Transitions
public string StateName;
[Reorderable(null, "Action", null)]
public AIActionsList Actions;
[Reorderable(null, "Transition", null)]
public AITransitionsList Transitions;/*
/// a list of actions to perform in this state
public List<AIAction> Actions;
/// a list of transitions to evaluate to exit this state
public List<AITransition> Transitions;*/
protected AIBrain mBrain;
/// <summary>
/// Sets this state's brain to the one specified in parameters
/// </summary>
/// <param name="brain"></param>
public virtual void SetBrain(AIBrain brain)
{
mBrain = brain;
}
/// <summary>
/// Updates the state, performing actions and testing transitions
/// </summary>
public virtual void UpdateState()
{
PerformActions();
EvaluateTransitions();
}
/// <summary>
/// On enter state we pass that info to our actions and decisions
/// </summary>
public virtual void EnterState()
{
foreach (AIAction action in Actions)
{
action.OnEnterState();
}
foreach (AITransition transition in Transitions)
{
if (transition.Decision != null)
{
transition.Decision.OnEnterState();
}
}
}
/// <summary>
/// On exit state we pass that info to our actions and decisions
/// </summary>
public virtual void ExitState()
{
foreach (AIAction action in Actions)
{
action.OnExitState();
}
foreach (AITransition transition in Transitions)
{
if (transition.Decision != null)
{
transition.Decision.OnExitState();
}
}
}
/// <summary>
/// Performs this state's actions
/// </summary>
protected virtual void PerformActions()
{
if (Actions.Count == 0) { return; }
for (int i=0; i<Actions.Count; i++)
{
if (Actions[i] != null)
{
Actions[i].PerformAction();
}
else
{
Log.E("An action in " + mBrain.gameObject.name + " is null.");
}
}
}
/// <summary>
/// Tests this state's transitions
/// </summary>
protected virtual void EvaluateTransitions()
{
if (Transitions.Count == 0) { return; }
for (int i = 0; i < Transitions.Count; i++)
{
if (Transitions[i].Decision != null)
{
if (Transitions[i].Decision.Decide())
{
if (Transitions[i].TrueState != "")
{
mBrain.TransitionToState(Transitions[i].TrueState);
}
}
else
{
if (Transitions[i].FalseState != "")
{
mBrain.TransitionToState(Transitions[i].FalseState);
}
}
}
}
}
}
}
|
TypeScript
|
UTF-8
| 5,283 | 2.703125 | 3 |
[] |
no_license
|
import { Component, OnInit } from '@angular/core';
import { Heros } from "app/heros";
import { PrenomInsee } from "app/prenominsee";
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent implements OnInit {
title = 'app works!';
data: any;
options: any;
heros1:Heros = {id: 11, power: 45};
heros2:Heros = {id: 2, power: 25};
heros3:Heros = {id: 15, power: 35};
listeHeros:Heros[];
listeNombres:Number[];
prenomStats:PrenomInsee[];
tableauAnnees: string[];
tableauNaissances : Number[];
anneesRef:Number[];
motAnime: string;
toggle : boolean;
// ************CONSTRUCTEUR*************
constructor() {
this.listeNombres = new Array<Number>();
this.listeNombres = [1,2,3,4,5,6,7,8,9,10 ];
this.listeHeros = new Array<Heros>();
this.tableauAnnees = new Array<string>();
this.tableauNaissances = [];
this.anneesRef = [2000,2001,2002,2003,2004,2005,2006,2007,2008,2009,2010,2011,2012,2013,2014,2015];
this.listeHeros = [
{id: 11, power: 25},
{id: 12, power: 18},
{id: 13, power: 44},
{id: 14, power: 77},
{id: 15, power: 33},
{id: 16, power: 25},
{id: 17, power: 74},
{id: 18, power: 44},
{id: 19, power: 66},
{id: 20,power: 12}
];
this.prenomStats = new Array<PrenomInsee>();
this.prenomStats = [
{annee: 2000, nombreNaissance: 25},
{annee: 2002, nombreNaissance: 105},
{annee: 2003, nombreNaissance: 50},
{annee: 2004, nombreNaissance: 76},
{annee: 2007, nombreNaissance: 10},
{annee: 2009, nombreNaissance: 150}
];
this.toggle = false;
this.motAnime = "Robert";
}
// ************FIN CONSTRUCTEUR*************
ngOnInit() {
/*
this.listeHeros.push(this.heros1);
this.listeHeros.push(this.heros2);
this.listeHeros.push(this.heros3);
console.log(this.listeHeros.length);
this.listeHeros.forEach(function(heros) {
console.log(heros.id + " " + heros.power)
});
*/
for(var i = 1900; i <= 2015; i++){
this.tableauAnnees.push(i.toString());
}
/*
this.prenomStats.forEach(function(prenominsee) {
console.log(prenominsee.annee + " " + prenominsee.nombreNaissance)
});
*/
this.data = {
labels: this.tableauAnnees,
datasets: [
{
label: 'My First dataset',
backgroundColor: '#42A5F5',
borderColor: '#1E88E5',
data: [0,1,2,3,4,5]
//this.tableauNaissances
//this.listeHeros.entries()
//this.listeNombres
//this.heros1.id
//this.listeHeros.forEach(function(heros) { heros.power })
},
]
},
this.options = {
title: {
display: true,
text: 'My Title',
fontSize: 16
},
legend: { position: 'bottom'},
scales: {
xAxes: [{
ticks: {
autoSkip: true,
maxTicksLimit: 55
}
}]
}
};
} // FIN ONINIT ****
/* EXEMPLE
var arr = [
{"name":"apple", "count": 2},
{"name":"orange", "count": 5},
{"name":"pear", "count": 3},
{"name":"orange", "count": 16},
];
var newArr = [];
for(var i= 0, l = arr.length; i< l; i++){
if(arr[i].name === "orange" ){
newArr.push(arr[i]);
}
}
*/
creerTableauNaissances(){
//var items: number[] = [];
for(var i = 2000; i <= 2015; i++){
this.prenomStats.forEach(function(prenominsee) {
if (i == prenominsee.annee) {
this.tableauNaissances.push(prenominsee.nombreNaissance);
console.log(this.prenominsee.nombreNaissance);
}
else {
this.tableauNaissances.push(0);
console.log("0");
}
});
}
}
creerTableauNaissances2():Number[] {
this.prenomStats.forEach(function(prenominsee) {
this.tableauNaissances.push(prenominsee.nombreNaissance)
});
return this.tableauNaissances;
}
creerTableauNaissance3():void {
for(var i= 0; i <= 15; i++){
var iterateur = this.anneesRef.entries();
console.log(this.prenomStats[i].annee);
}
}
public changerMotAnime() {
if(this.toggle) {
this.motAnime = "Robert";
this.toggle = false;
}
else {
this.motAnime = "Micheline";
this.toggle = true;
}
}
}
|
Markdown
|
UTF-8
| 102,675 | 2.84375 | 3 |
[] |
no_license
|
### Note:
This is **the third version** of the final project. Below is the list of modifications I made from the second version.
- Included graphs showing the scores of each K value for **SelectKBest**.
- In **the second version**, due to the randomness, I decided not to use the **feature importances** in **Decision Tree** when selecting the best features. In this version, I used this method to remove lowest one at a time iteratively.
- Enhanced the performance by using **cv** parameter in **GridSearchCV**.
- Used **Pipeline** to rescale the data set more easily.
- Used **KNeighborClassifier** instead of **KNeighborRegressor**.
- Only used **Decision Tree** and **KNN** for the classifiers. Excluded **GaussianNB**, **SVM** and **Logistic Regression**.
- Included the importance of **parameter tuning** in the **Final Thoughts**.
# Identifying POI from Enron Dataset
### Final Project - Machine Learning Course
### Udacity Data Analyst Nanodegree
This is the final project for the machine learning course. Enron financial data and email data will be investigated to find the list of person of interest (POI) who were involved in the fraud activities.
Below is the order of the investigation process I will employ for this final project.
- Univariate analysis
- Process the dataset (taking care of missing values and outliers)
- Select good features that don't have too many zeros or missing values
- Calculate accuracy, precision and recall for each feature I selected using classifiers with default parameters.
- Bivariate analysis
- Use features that show the high scores from the univariate analysis
- Calculate accuracy, precision and recall from a pair of features using more classifiers and various parameters.
- Multivariate analysis
- Calculate accuracy, precision and recall from features with the best scores from univariate and bivariate analysis.
In the end, I will choose the combination of features and classifier that shows the best scores.
First, necessary Libraries will be loaded.
```python
#!/usr/bin/python
import sys
import pickle
import pprint
import matplotlib.pyplot as plt
import numpy as np
### Setting the path
sys.path.append("../tools/")
### These are the scripts given in the class
from feature_format import featureFormat, targetFeatureSplit
from tester import dump_classifier_and_data
```
Load the dictionary containing the dataset.
```python
### Load the dictionary containing the dataset
with open("final_project_dataset.pkl", "r") as data_file:
data_dict = pickle.load(data_file)
```
```python
len(data_dict)
```
146
There are total 146 number of data in data_dict. I am going to print out the first two of the data from data_dict to see how the dictionary looks like.
```python
stop = 0
for k, v in data_dict.iteritems():
print k
pprint.pprint(v)
if stop == 1:
break
stop += 1
```
METTS MARK
{'bonus': 600000,
'deferral_payments': 'NaN',
'deferred_income': 'NaN',
'director_fees': 'NaN',
'email_address': 'mark.metts@enron.com',
'exercised_stock_options': 'NaN',
'expenses': 94299,
'from_messages': 29,
'from_poi_to_this_person': 38,
'from_this_person_to_poi': 1,
'loan_advances': 'NaN',
'long_term_incentive': 'NaN',
'other': 1740,
'poi': False,
'restricted_stock': 585062,
'restricted_stock_deferred': 'NaN',
'salary': 365788,
'shared_receipt_with_poi': 702,
'to_messages': 807,
'total_payments': 1061827,
'total_stock_value': 585062}
BAXTER JOHN C
{'bonus': 1200000,
'deferral_payments': 1295738,
'deferred_income': -1386055,
'director_fees': 'NaN',
'email_address': 'NaN',
'exercised_stock_options': 6680544,
'expenses': 11200,
'from_messages': 'NaN',
'from_poi_to_this_person': 'NaN',
'from_this_person_to_poi': 'NaN',
'loan_advances': 'NaN',
'long_term_incentive': 1586055,
'other': 2660303,
'poi': False,
'restricted_stock': 3942714,
'restricted_stock_deferred': 'NaN',
'salary': 267102,
'shared_receipt_with_poi': 'NaN',
'to_messages': 'NaN',
'total_payments': 5634343,
'total_stock_value': 10623258}
The keys of data_dict are the names of people and the values are various features. Every feature except poi and email_address are numerical values. It looks like it is either a number of 'NaN' when the data is missing. And poi is a boolean value that I can use to find POI's.
```python
### Finding the number of features
for k,v in data_dict.iteritems():
print "The number of features:", len(v)
features_list = v.keys() # features are saved separately for later use
### Save the raw features
total_features_list = v.keys()
break
```
The number of features: 21
There are total 21 features in the dataset. I will ignore "email_address" because they are not numerical values. And I will ingore 'other' as well because I don't know what this is.
```python
### Removing poi and email_address
try:
features_list.remove("email_address")
features_list.remove("other")
except:
pass
try:
total_features_list.remove("email_address")
total_features_list.remove("other")
except:
pass
### Convert data_dict into numpy array
data = featureFormat(data_dict, features_list)
print "The type of data:", type(data)
print "The total number of data", data.shape
```
The type of data: <type 'numpy.ndarray'>
The total number of data (145, 19)
Now the data_dict is converted to numpy array. And it contains 145 rows and 19 columns.
featureFormat ignores the "NaN" values and creates numpy array that I can use it for the analysis more easily.
Using data numpy array I will check the number of poi's and non-poi's.
```python
### Finding the index of poi
poi_ind = features_list.index("poi")
### Print out the number of poi and non-poi
print "The total number of poi:", np.sum(data[:,poi_ind])
print "The total number of non-poi:", np.size(data[:,poi_ind]) - np.sum(data[:,poi_ind])
```
The total number of poi: 18.0
The total number of non-poi: 127.0
There are total **18 POI** and **127 non-POI**.
```python
### Move poi column to the end
### data
tmp_data = data
tmp_data[:,-1] = data[:,poi_ind]
tmp_data[:,poi_ind] = data[:,-1]
data = tmp_data
### features_list
tmp = features_list[-1]
features_list[poi_ind] = tmp
features_list[-1] = "poi"
### Reassign poi index
poi_ind = features_list.index("poi")
```
I moved poi column to the end to use the data more easily.
## Plotting
From now on, I will start drawing various plots for univariate analysis and bivariate analysis.
I will draw histograms for each feature first.
```python
### Create new features list without poi
features_list_new = [ii for ii in features_list if ii != "poi"]
%matplotlib inline
### 20 histograms for features
plt.rcParams["figure.figsize"] = (20,20)
f, axarr = plt.subplots(6, 3)
### the histogram of the data
### x: x coordinate values, y: y coordinate values
### r: row index, c: column index
### title: title of a subplot
def subplot_histogram(x, bins, r, c, title):
axarr[r, c].hist(x, bins = bins)
axarr[r, c].set_title(title)
axarr[r, c].set_ylabel("count")
for i in range(len(features_list_new)):
subplot_histogram(data[:,i],50,i/3,i%3,features_list_new[i])
plt.show()
```

Above diagrams show 19 histograms. I first created new list of features excluding poi because array of poi consists of only true or false so it won't provide an insightful histogram.
Looking at these histograms, I can see there are outliers for every feature.
I will look into salary more deeply and see if there is any interesting thing going on.
```python
%matplotlib inline
### Find indices for salary
salary_ind = features_list.index("salary")
### Set the size of the plot
plt.rcParams["figure.figsize"] = (20,5)
### Draw Salary histogram
plt.hist(data[:,salary_ind], bins=100)
plt.xlabel("salary")
plt.ylabel("count")
plt.title("Salary Histogram")
plt.show()
```

Now I will get rid of the outlier above 2.5e7 and replot the histogram
```python
### Total sum of salaries
import numpy as np
print np.sum(data[:,salary_ind]), "is the total sum of salaries"
### Create new array that contains salar values without outliers
salary_no_outliers = []
for i in data[:,salary_ind]:
if i < 2.5e7:
salary_no_outliers.append(i)
else:
print i, "is removed"
### Draw Salary histogram
plt.hist(salary_no_outliers, bins=100)
plt.xlabel("salary without outliers")
plt.ylabel("count")
plt.title("Salary Histogram")
plt.show()
```
53408458.0 is the total sum of salaries
26704229.0 is removed

The outlier removed is half of the total sum of salary array, which means someone added a total sum of salaries into the data. I believe that in data_dict there is a key that contains the sum of every feature.
```python
for k,v in data_dict.iteritems():
if v["salary"] == 26704229.0:
print k,v
```
TOTAL {'salary': 26704229, 'to_messages': 'NaN', 'deferral_payments': 32083396, 'total_payments': 309886585, 'exercised_stock_options': 311764000, 'bonus': 97343619, 'restricted_stock': 130322299, 'shared_receipt_with_poi': 'NaN', 'restricted_stock_deferred': -7576788, 'total_stock_value': 434509511, 'expenses': 5235198, 'loan_advances': 83925000, 'from_messages': 'NaN', 'other': 42667589, 'from_this_person_to_poi': 'NaN', 'poi': False, 'director_fees': 1398517, 'deferred_income': -27992891, 'long_term_incentive': 48521928, 'email_address': 'NaN', 'from_poi_to_this_person': 'NaN'}
As I expected one of the keys in data_dict is TOTAL. I will create a new dictionary that excludes this key.
```python
### New data_dict excluding TOTAL key
data_dict_new = {}
for k, v in data_dict.iteritems():
if k != "TOTAL":
data_dict_new[k] = v
### Print out the new data_dict length
print "The length of the new data_dict:", len(data_dict_new)
```
The length of the new data_dict: 145
Now there are 145 data in the data_dict_new. I will graph the histograms again.
```python
### Convert data_dict_new into numpy array
data = featureFormat(data_dict_new, features_list)
%matplotlib inline
### 20 histograms for features
plt.rcParams["figure.figsize"] = (20,20)
f, axarr = plt.subplots(6, 3)
### the histogram of the data
### x: x coordinate values, y: y coordinate values
### r: row index, c: column index
### title: title of a subplot
def subplot_histogram(x, bins, r, c, title):
axarr[r, c].hist(x, bins = bins)
axarr[r, c].set_title(title)
axarr[r, c].set_ylabel("count")
for i in range(len(features_list_new)):
subplot_histogram(data[:,i],50,i/3,i%3,features_list_new[i])
plt.show()
```

The histograms are better than before. Although there are still outliers in histograms, getting rid of them might not be a good idea because those values may be helpful identifying POI's.
I suspect that some of these features will have too many zeros because featureFormat function convert NaN to zero in some cases. I will print out the number of zeros for each feature.
```python
### defining function that counts zeros
def counting_zeros(data, features_list, feature):
total_count = 0
count = 0
feature_data = data[:,features_list.index(feature)]
for i in feature_data:
total_count += 1
if i == 0:
count += 1
print "{}: {}, {}%".format(feature,count, int(float(count)*100/float(total_count)))
### Printing out the number of zeros for each feature
for i in features_list[:-1]:
counting_zeros(data, features_list, i)
```
salary: 50, 34%
to_messages: 58, 40%
deferral_payments: 106, 73%
total_payments: 20, 13%
exercised_stock_options: 43, 29%
bonus: 63, 43%
restricted_stock: 35, 24%
shared_receipt_with_poi: 58, 40%
restricted_stock_deferred: 127, 88%
total_stock_value: 19, 13%
expenses: 50, 34%
loan_advances: 141, 97%
from_messages: 58, 40%
from_this_person_to_poi: 78, 54%
from_poi_to_this_person: 70, 48%
director_fees: 128, 88%
deferred_income: 96, 66%
long_term_incentive: 79, 54%
I will ignore features with more than 60% of zeros from now on.
### Features that will be ignored:
- deferral_payments
- restricted_stock_deferred
- loan_advances
- director_fees
- deferred_income
I will recreate data numpy array and features_list array that exclude the features above.
```python
### Save the original features_list before change
features_list_original = features_list
### list of features with too many zeros
too_many_zeros = ["deferral_payments",
"restricted_stock_deferred",
"loan_advances",
"director_fees",
"deferred_income"]
### remove the above features from features_list
for i in too_many_zeros:
if i in features_list:
features_list.remove(i)
### Convert data_dict_new into numpy array
data = featureFormat(data_dict_new, features_list)
print data.shape
```
(144, 14)
Now the number of columns of data is reduced to 14.
### Checking Scores
Now I am going to test each feature using GaussianNB and check the accuracy, precision and recall. Then I will use features with high values for later use.
I will employ tester functions from tester.
```python
### Import functions from tester_edited.py
from tester_edited import load_classifier_and_data, test_classifier
from sklearn.cross_validation import StratifiedShuffleSplit
```
This will be a repetitive process so I will create a function to do this. The code is from **tester.py**.
```python
### the code is from "poi_id.py" from final_project folder.
### this function will split the data into test and train
### apply classifier and calculate the accuracy, precision and recall
def test(features_list, clf, print_result=False, draw_graph=False, rescale=False):
### Store to my_dataset for easy export below.
my_dataset = data_dict
### Extract features and labels from dataset for local testing
data = featureFormat(my_dataset, features_list, sort_keys = True)
labels, features = targetFeatureSplit(data)
# ### Split train and test by 30 %
# from sklearn.cross_validation import train_test_split
# features_train, features_test, labels_train, labels_test = \
# train_test_split(features, labels, test_size=0.3, random_state=42)
### Dump the data to the local files
dump_classifier_and_data(clf, my_dataset, features_list)
### Load the data from the local files
clf, dataset, feature_list = load_classifier_and_data()
### Print out the result
scores = test_classifier(
clf, dataset, feature_list,
print_result=print_result, draw_graph=draw_graph, rescale=rescale)
return scores
### import GaussianNB
from sklearn.naive_bayes import GaussianNB
### import Decision Tree
from sklearn import tree
### This function only test the data using
### GaussianNB and Decision Tree
def classify_simple(features_list, print_result=False):
print "Features list:", features_list[1:]
### Set GaussianNB
clf_NB = GaussianNB()
### Set Decision Tree
clf_tree = tree.DecisionTreeClassifier()
### Call test function and print out test
scores_NB = test(features_list,clf_NB, print_result=print_result)
tree_NB = test(features_list,clf_tree, print_result=print_result)
return [ scores_NB, tree_NB ]
```
I created a function that can show the accuracy, precision and recall values from features list input. The test function is mainly from the "poi-id.py" file from the final project folder. I creates clf for classifier, features list and dataset so that it can be loaded in test_classifier function in "tester.py" file. Note that the validation used in this code is Train/Test split. The purpose is not to get the largest scores but to select features that show the high scores compared to the others. So I don't use other cross validation for now. For the same reason, I don't specify any parameter for classifiers. The parameters will be adjusted at a later section.
```python
### Always put poi at the zeroth index
classify_simple(["poi", "salary"],print_result=True)
```
Features list: ['salary']
GaussianNB()
Best parameters:
No GridSearch
Accuracy: 0.25560 Precision: 0.18481 Recall: 0.79800 F1: 0.30011 F2: 0.47968
Total predictions: 20000 True positives: 3192 False positives: 14080 False negatives: 808 True negatives: 1920
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')
Best parameters:
No GridSearch
Accuracy: 0.69210 Precision: 0.23619 Recall: 0.24150 F1: 0.23881 F2: 0.24042
Total predictions: 20000 True positives: 966 False positives: 3124 False negatives: 3034 True negatives: 12876
[[0.2556, 0.18480778138026865, 0.798, {}],
[0.6921, 0.23618581907090463, 0.2415, {}]]
I ran the function using poi and salary. Fortunately the function works.
I will use this function for all the other features.
```python
### Iterate over the features_list
scores_list = {}
for i in features_list[:-1]:
scores_list[i] = classify_simple(["poi", i])
```
Features list: ['salary']
Features list: ['to_messages']
Got a divide by zero when trying out: GaussianNB()
Precision or recall may be undefined due to a lack of true positive predicitons.
Features list: ['total_payments']
Features list: ['exercised_stock_options']
Features list: ['bonus']
Features list: ['restricted_stock']
Features list: ['shared_receipt_with_poi']
Got a divide by zero when trying out: GaussianNB()
Precision or recall may be undefined due to a lack of true positive predicitons.
Features list: ['total_stock_value']
Features list: ['expenses']
Features list: ['from_messages']
Got a divide by zero when trying out: GaussianNB()
Precision or recall may be undefined due to a lack of true positive predicitons.
Features list: ['from_this_person_to_poi']
Got a divide by zero when trying out: GaussianNB()
Precision or recall may be undefined due to a lack of true positive predicitons.
Features list: ['from_poi_to_this_person']
Features list: ['long_term_incentive']
```python
### Print out scores of each feature
print " Accuarcy Precision Recall"
for k,v in scores_list.iteritems():
print k
if v[0] == None:
print "NB ---------None---------"
else:
print "NB {0:.4f} {1:.4f} {2:.4f}".format(v[0][0], v[0][1], v[0][2])
print "tree {0:.4f} {1:.4f} {2:.4f}".format(v[1][0], v[1][1], v[1][2])
```
Accuarcy Precision Recall
salary
NB 0.2556 0.1848 0.7980
tree 0.6921 0.2362 0.2415
to_messages
NB ---------None---------
tree 0.7371 0.0856 0.1410
total_payments
NB 0.7631 0.0694 0.0435
tree 0.7393 0.0804 0.0665
bonus
NB 0.3780 0.2223 0.7200
tree 0.7623 0.4427 0.2685
total_stock_value
NB 0.8406 0.3200 0.0320
tree 0.7584 0.2300 0.2430
shared_receipt_with_poi
NB ---------None---------
tree 0.8421 0.3020 0.3210
exercised_stock_options
NB 0.8994 0.2108 0.0390
tree 0.8571 0.2686 0.3320
from_messages
NB ---------None---------
tree 0.7259 0.0067 0.0100
from_this_person_to_poi
NB ---------None---------
tree 0.7444 0.0218 0.0180
long_term_incentive
NB 0.3980 0.1471 0.6700
tree 0.6943 0.0250 0.0300
expenses
NB 0.3068 0.1885 0.7460
tree 0.6466 0.1295 0.1340
restricted_stock
NB 0.7380 0.1013 0.0560
tree 0.7297 0.1196 0.0765
from_poi_to_this_person
NB 0.7365 0.0263 0.0015
tree 0.6425 0.1312 0.0765
Notice that those features where NB score is zero have zeros more than 50%. Initially I thought removing features with zeros more than 60% might be sufficient but apparently I should have set my threshold to be 60% instead of 50%.
And I will remove total_payments from my list because this feature has precision and recall values less than 1%.
```python
### list of features with too many zeros above 50%
too_many_zeros = ["to_messages",
"shared_receipt_with_poi",
"from_messages",
"from_this_person_to_poi",
"total_payments"]
### remove the above features from features_list
for i in too_many_zeros:
if i in features_list:
features_list.remove(i)
### Convert data_dict_new into numpy array
data = featureFormat(data_dict_new, features_list)
print "Shape of data:", data.shape
pprint.pprint(features_list)
```
Shape of data: (139, 9)
['salary',
'exercised_stock_options',
'bonus',
'restricted_stock',
'total_stock_value',
'expenses',
'from_poi_to_this_person',
'long_term_incentive',
'poi']
The number of columns are reduced to 9 including poi. Let's print the result again only from these features.
```python
### Print out scores of each feature
print " Accuarcy Precision Recall"
for k,v in scores_list.iteritems():
if k in features_list:
print k
if v[0] == None:
print "NB ---------None---------"
else:
print "NB {0:.4f} {1:.4f} {2:.4f}".format(v[0][0], v[0][1], v[0][2])
print "tree {0:.4f} {1:.4f} {2:.4f}".format(v[1][0], v[1][1], v[1][2])
```
Accuarcy Precision Recall
salary
NB 0.2556 0.1848 0.7980
tree 0.6921 0.2362 0.2415
bonus
NB 0.3780 0.2223 0.7200
tree 0.7623 0.4427 0.2685
total_stock_value
NB 0.8406 0.3200 0.0320
tree 0.7584 0.2300 0.2430
exercised_stock_options
NB 0.8994 0.2108 0.0390
tree 0.8571 0.2686 0.3320
long_term_incentive
NB 0.3980 0.1471 0.6700
tree 0.6943 0.0250 0.0300
expenses
NB 0.3068 0.1885 0.7460
tree 0.6466 0.1295 0.1340
restricted_stock
NB 0.7380 0.1013 0.0560
tree 0.7297 0.1196 0.0765
from_poi_to_this_person
NB 0.7365 0.0263 0.0015
tree 0.6425 0.1312 0.0765
From the result above, the features with the best scores are **bonus**, **exercised_stock_options** and **total_stock_value**.
I will use these features as my main dependent variables for the bivariate analysis.
## Selecting features using SelectKBest and Decision Tree Features Importance
The above selection is choosing the features with few zeros. However, having many zeros not necessarily means the data is bad.
In the previous version, I found **14** features with the best scores using **SelectKBest**. And **14** is a number I chose randomly so it doesn't have any significance. In this version, I will find the number that maximize the performance using **SelectKBest**.
```python
total_features_list
```
['salary',
'to_messages',
'deferral_payments',
'total_payments',
'exercised_stock_options',
'bonus',
'restricted_stock',
'shared_receipt_with_poi',
'restricted_stock_deferred',
'total_stock_value',
'expenses',
'loan_advances',
'from_messages',
'from_this_person_to_poi',
'poi',
'director_fees',
'deferred_income',
'long_term_incentive',
'from_poi_to_this_person']
```python
### Convert data_dict_new into numpy array
total_data = featureFormat(data_dict_new, total_features_list)
print total_data.shape
### Extract features from the data
features = total_data
features = np.delete(features, total_features_list.index("poi"), 1)
### Extract a label from the data
label = total_data[:,total_features_list.index("poi")]
### Rescale features
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
features = min_max_scaler.fit_transform(features)
### Import SelectKBest
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_classif
pre_selected_list = []
features_by_importance = []
for k in range(1,19):
selector = SelectKBest(f_classif, k=k)
selector = selector.fit(features,label)
features_list_wo_poi = [i for i in total_features_list if i!="poi"] ### features list without poi
### Print features chosen by SelectKBest
selected_list = [features_list_wo_poi[i] for i in range(len(features_list_wo_poi)) if selector.get_support()[i]]
print "K:", k
for i in selected_list:
if i not in pre_selected_list:
print "\t", i
features_by_importance.append(i)
pre_selected_list = selected_list
```
(144, 19)
K: 1
exercised_stock_options
K: 2
total_stock_value
K: 3
bonus
K: 4
salary
K: 5
deferred_income
K: 6
long_term_incentive
K: 7
restricted_stock
K: 8
total_payments
K: 9
shared_receipt_with_poi
K: 10
loan_advances
K: 11
expenses
K: 12
from_poi_to_this_person
K: 13
from_this_person_to_poi
K: 14
director_fees
K: 15
to_messages
K: 16
deferral_payments
K: 17
from_messages
K: 18
restricted_stock_deferred
The above shows the features that are selected by its importance. The best feature is **exercised_stock_option** and the next best feature is **total_stock_value** and so on. Now I will calculate the scores for each **k** value using **Decision Tree**.
```python
### Import Cross Validation
from sklearn.cross_validation import StratifiedShuffleSplit
### Import MinMaxScaler
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
### Import DecisionTree Classifier
clf = tree.DecisionTreeClassifier(criterion='gini', splitter='random', min_samples_split=5)
### Use pipeline
from sklearn.pipeline import Pipeline
pipe = Pipeline(steps=[('minmaxer', min_max_scaler), ('clf', clf)])
### Set up the print format
PERF_FORMAT_STRING = "\
\tAccuracy: {:>0.{display_precision}f}\tPrecision: {:>0.{display_precision}f}\t\
Recall: {:>0.{display_precision}f}\tF1: {:>0.{display_precision}f}\tF2: {:>0.{display_precision}f}"
RESULTS_FORMAT_STRING = "\tTotal predictions: {:4d}\tTrue positives: {:4d}\tFalse positives: {:4d}\
\tFalse negatives: {:4d}\tTrue negatives: {:4d}"
### Set up the arrays for precision, recall and F1
precision_list = []
recall_list = []
f1_list = []
### Calculate scores for each K value
for i in range(len(features_by_importance)):
selected_features_list = features_by_importance[:(i+1)]
selected_features_list.insert(0,'poi')
selected_data = featureFormat(data_dict_new, selected_features_list)
### Split the data into labels and features
labels, features = targetFeatureSplit(selected_data)
cv = StratifiedShuffleSplit(labels, 1000, random_state = 42)
true_negatives = 0
false_negatives = 0
true_positives = 0
false_positives = 0
for train_idx, test_idx in cv:
features_train = []
features_test = []
labels_train = []
labels_test = []
for ii in train_idx:
features_train.append( features[ii] )
labels_train.append( labels[ii] )
for jj in test_idx:
features_test.append( features[jj] )
labels_test.append( labels[jj] )
features_test.append( features[jj])
labels_test.append( labels[jj] )
### fit the classifier using training set, and test on test set
pipe.fit(features_train, labels_train)
try:
print clf.best_params_
for k,v in clf.best_params_.iteritems():
if k in best_params_collector:
best_params_collector[k].append(v)
else:
best_params_collector[k] = [v]
except:
pass
predictions = pipe.predict(features_test)
for prediction, truth in zip(predictions, labels_test):
### Assign prediction either 0 or 1
if prediction < .5:
prediction = 0
else:
prediction = 1
if prediction == 0 and truth == 0:
true_negatives += 1
elif prediction == 0 and truth == 1:
false_negatives += 1
elif prediction == 1 and truth == 0:
false_positives += 1
elif prediction == 1 and truth == 1:
true_positives += 1
try:
total_predictions = true_negatives + false_negatives + false_positives + true_positives
accuracy = 1.0*(true_positives + true_negatives)/total_predictions
precision = 1.0*true_positives/(true_positives+false_positives)
recall = 1.0*true_positives/(true_positives+false_negatives)
f1 = 2.0 * true_positives/(2*true_positives + false_positives+false_negatives)
f2 = (1+2.0*2.0) * precision*recall/(4*precision + recall)
print selected_features_list[-1]
print PERF_FORMAT_STRING.format(accuracy, precision, recall, f1, f2, display_precision = 5)
precision_list.append(precision)
recall_list.append(recall)
f1_list.append(f1)
except:
print "Precision or recall may be undefined due to a lack of true positive predicitons.\n"
```
exercised_stock_options
Accuracy: 0.91600 Precision: 0.58676 Recall: 0.25700 F1: 0.35744 F2: 0.28954
total_stock_value
Accuracy: 0.83269 Precision: 0.41117 Recall: 0.20250 F1: 0.27136 F2: 0.22538
bonus
Accuracy: 0.84115 Precision: 0.47486 Recall: 0.30700 F1: 0.37291 F2: 0.33036
salary
Accuracy: 0.82315 Precision: 0.39252 Recall: 0.27300 F1: 0.32203 F2: 0.29070
deferred_income
Accuracy: 0.82700 Precision: 0.35568 Recall: 0.26000 F1: 0.30040 F2: 0.27478
long_term_incentive
Accuracy: 0.82164 Precision: 0.33554 Recall: 0.25350 F1: 0.28881 F2: 0.26653
restricted_stock
Accuracy: 0.82064 Precision: 0.33505 Recall: 0.25950 F1: 0.29248 F2: 0.27176
total_payments
Accuracy: 0.82747 Precision: 0.32029 Recall: 0.26200 F1: 0.28823 F2: 0.27190
shared_receipt_with_poi
Accuracy: 0.82160 Precision: 0.30507 Recall: 0.26450 F1: 0.28334 F2: 0.27173
loan_advances
Accuracy: 0.82313 Precision: 0.31268 Recall: 0.27250 F1: 0.29121 F2: 0.27969
expenses
Accuracy: 0.82460 Precision: 0.32185 Recall: 0.28500 F1: 0.30231 F2: 0.29168
from_poi_to_this_person
Accuracy: 0.81860 Precision: 0.30691 Recall: 0.28650 F1: 0.29635 F2: 0.29036
from_this_person_to_poi
Accuracy: 0.81920 Precision: 0.29841 Recall: 0.26350 F1: 0.27987 F2: 0.26981
director_fees
Accuracy: 0.82040 Precision: 0.30913 Recall: 0.28100 F1: 0.29439 F2: 0.28621
to_messages
Accuracy: 0.81613 Precision: 0.29084 Recall: 0.26350 F1: 0.27650 F2: 0.26855
deferral_payments
Accuracy: 0.82100 Precision: 0.30529 Recall: 0.26850 F1: 0.28571 F2: 0.27513
from_messages
Accuracy: 0.82127 Precision: 0.31094 Recall: 0.28000 F1: 0.29466 F2: 0.28569
restricted_stock_deferred
Accuracy: 0.82173 Precision: 0.31194 Recall: 0.27950 F1: 0.29483 F2: 0.28544
Scores for each **K** value are calculated above. The feature is appended to the list and the scores are calculated one at a time. According to the result, **Recall** is the highest when **K** is 3.
Let's graph the result.
```python
%matplotlib inline
### Set the size of the plot
plt.rcParams["figure.figsize"] = (10,6)
### Set up the x-axis
k_values = range(1,len(recall_list)+1)
### Draw Salary histogram
plt.plot(k_values, precision_list, k_values, recall_list, k_values, f1_list)
x = [1,18]
y = [.3,.3]
plt.plot(x,y)
plt.xlim([1,18])
plt.legend(['precision','recall','f1'])
plt.xlabel("K")
plt.ylabel("Scores")
plt.title("Scores for each K value")
plt.show()
```

The graph above shows the result more visually. First of all the **Precision** is exceptionally high when **K** is 1. However, the **Recall** is the lowest at this point. This means that the model is good picking up the true POIs but it is not good at choosing all of the POIs. For example, if there are 10 POIs then the model chooses 2 or 3 of them correctly but misses other POIs. So it is important to consider **Recall** value as well when evaluating the performance.
I drew a horizontal line at **0.3** because it is the threshold given from the rubric. There is only 1 value of **K** when all of these scores are above **0.3** and that is when **K** is 3.
These are the features selected by **SelectKBest**.
- exercised_stock_options
- total_stock_value
- bonus
Now I will choose the best features using **Feature Importance** in **Decision Tree** algorithm.
Below is the process I will employ to find the best features using **Feature Importance**.
1. Start from the list containing all of the features.
2. Calculate the scores with the list using **Decision Tree**.
3. Calculate **Feature Importance** for each feature in the list.
4. Drop the feature with the lowest **Importance**.
5. Go back to **step 2** and repeat the process.
```python
### Use GridSearchCV to find the best parameters
from sklearn.grid_search import GridSearchCV
### Import DecisionTree Classifier
clf = tree.DecisionTreeClassifier()
param_grid = {
'criterion': ['gini', 'entropy'],
'splitter' : ['best', 'random'],
'min_samples_split': range(2,9)
}
### Set up the arrays for precision, recall and F1
precision_list = []
recall_list = []
f1_list = []
if 'poi' not in total_features_list:
total_features_list.append('poi')
selected_features_list = [i for i in total_features_list if i != 'poi']
features_by_importance = []
### Calculate scores for each K value
for i in range(len(total_features_list)-1):
print
try:
print "Dropped Feature:", features_by_importance[-1]
except:
pass
selected_features_list_with_poi = ['poi']
selected_features_list_with_poi.extend(selected_features_list)
selected_data = featureFormat(data_dict_new, selected_features_list_with_poi)
### Split the data into labels and features
labels, features = targetFeatureSplit(selected_data)
### Recale the features
features = min_max_scaler.fit_transform(features)
cv = StratifiedShuffleSplit(labels, 100, random_state = 42)
clf_grid = GridSearchCV(clf, param_grid, cv = cv, scoring = 'recall')
clf_grid.fit(features, labels)
print clf_grid.best_params_
clf.set_params(criterion=clf_grid.best_params_["criterion"],
splitter=clf_grid.best_params_["splitter"],
min_samples_split=clf_grid.best_params_["min_samples_split"])
true_negatives = 0
false_negatives = 0
true_positives = 0
false_positives = 0
for train_idx, test_idx in cv:
features_train = []
features_test = []
labels_train = []
labels_test = []
for ii in train_idx:
features_train.append( features[ii] )
labels_train.append( labels[ii] )
for jj in test_idx:
features_test.append( features[jj] )
labels_test.append( labels[jj] )
features_test.append( features[jj])
labels_test.append( labels[jj] )
### fit the classifier using training set, and test on test set
clf.fit(features_train, labels_train)
predictions = clf.predict(features_test)
for prediction, truth in zip(predictions, labels_test):
### Assign prediction either 0 or 1
if prediction < .5:
prediction = 0
else:
prediction = 1
if prediction == 0 and truth == 0:
true_negatives += 1
elif prediction == 0 and truth == 1:
false_negatives += 1
elif prediction == 1 and truth == 0:
false_positives += 1
elif prediction == 1 and truth == 1:
true_positives += 1
total_predictions = true_negatives + false_negatives + false_positives + true_positives
accuracy = 1.0*(true_positives + true_negatives)/total_predictions
precision = 1.0*true_positives/(true_positives+false_positives)
recall = 1.0*true_positives/(true_positives+false_negatives)
f1 = 2.0 * true_positives/(2*true_positives + false_positives+false_negatives)
f2 = (1+2.0*2.0) * precision*recall/(4*precision + recall)
print PERF_FORMAT_STRING.format(accuracy, precision, recall, f1, f2, display_precision = 5)
importances = clf.feature_importances_
precision_list.append(precision)
recall_list.append(recall)
f1_list.append(f1)
### Find the index of the feature with the lowest importance
min_importance = min(importances)
features_by_importance.append(selected_features_list[np.argmin(importances)])
selected_features_list.remove(selected_features_list[np.argmin(importances)])
```
Dropped Feature: {'min_samples_split': 2, 'splitter': 'random', 'criterion': 'gini'}
Accuracy: 0.80067 Precision: 0.26977 Recall: 0.29000 F1: 0.27952 F2: 0.28571
Dropped Feature: to_messages
{'min_samples_split': 2, 'splitter': 'random', 'criterion': 'gini'}
Accuracy: 0.80400 Precision: 0.25521 Recall: 0.24500 F1: 0.25000 F2: 0.24698
Dropped Feature: deferral_payments
{'min_samples_split': 5, 'splitter': 'random', 'criterion': 'gini'}
Accuracy: 0.81600 Precision: 0.26829 Recall: 0.22000 F1: 0.24176 F2: 0.22822
Dropped Feature: bonus
{'min_samples_split': 7, 'splitter': 'best', 'criterion': 'entropy'}
Accuracy: 0.82533 Precision: 0.32386 Recall: 0.28500 F1: 0.30319 F2: 0.29201
Dropped Feature: salary
{'min_samples_split': 4, 'splitter': 'random', 'criterion': 'gini'}
Accuracy: 0.83000 Precision: 0.33333 Recall: 0.27500 F1: 0.30137 F2: 0.28497
Dropped Feature: restricted_stock_deferred
{'min_samples_split': 2, 'splitter': 'random', 'criterion': 'gini'}
Accuracy: 0.82000 Precision: 0.32143 Recall: 0.31500 F1: 0.31818 F2: 0.31627
Dropped Feature: loan_advances
{'min_samples_split': 2, 'splitter': 'random', 'criterion': 'entropy'}
Accuracy: 0.80400 Precision: 0.26500 Recall: 0.26500 F1: 0.26500 F2: 0.26500
Dropped Feature: from_messages
{'min_samples_split': 3, 'splitter': 'best', 'criterion': 'entropy'}
Accuracy: 0.82867 Precision: 0.34426 Recall: 0.31500 F1: 0.32898 F2: 0.32045
Dropped Feature: total_payments
{'min_samples_split': 3, 'splitter': 'random', 'criterion': 'gini'}
Accuracy: 0.80267 Precision: 0.24194 Recall: 0.22500 F1: 0.23316 F2: 0.22819
Dropped Feature: from_this_person_to_poi
{'min_samples_split': 6, 'splitter': 'random', 'criterion': 'gini'}
Accuracy: 0.82200 Precision: 0.28387 Recall: 0.22000 F1: 0.24789 F2: 0.23037
Dropped Feature: restricted_stock
{'min_samples_split': 2, 'splitter': 'random', 'criterion': 'gini'}
Accuracy: 0.81200 Precision: 0.29293 Recall: 0.29000 F1: 0.29146 F2: 0.29058
Dropped Feature: director_fees
{'min_samples_split': 4, 'splitter': 'best', 'criterion': 'entropy'}
Accuracy: 0.83800 Precision: 0.39512 Recall: 0.40500 F1: 0.40000 F2: 0.40299
Dropped Feature: deferred_income
{'min_samples_split': 4, 'splitter': 'best', 'criterion': 'entropy'}
Accuracy: 0.84571 Precision: 0.45455 Recall: 0.40000 F1: 0.42553 F2: 0.40984
Dropped Feature: exercised_stock_options
{'min_samples_split': 2, 'splitter': 'best', 'criterion': 'gini'}
Accuracy: 0.81929 Precision: 0.36683 Recall: 0.36500 F1: 0.36591 F2: 0.36537
Dropped Feature: from_poi_to_this_person
{'min_samples_split': 2, 'splitter': 'best', 'criterion': 'entropy'}
Accuracy: 0.81429 Precision: 0.35577 Recall: 0.37000 F1: 0.36275 F2: 0.36706
Dropped Feature: long_term_incentive
{'min_samples_split': 3, 'splitter': 'best', 'criterion': 'entropy'}
Accuracy: 0.82714 Precision: 0.39175 Recall: 0.38000 F1: 0.38579 F2: 0.38229
Dropped Feature: total_stock_value
{'min_samples_split': 2, 'splitter': 'best', 'criterion': 'gini'}
Accuracy: 0.75167 Precision: 0.29237 Recall: 0.34500 F1: 0.31651 F2: 0.33301
Dropped Feature: shared_receipt_with_poi
{'min_samples_split': 2, 'splitter': 'random', 'criterion': 'entropy'}
Accuracy: 0.65300 Precision: 0.14833 Recall: 0.15500 F1: 0.15159 F2: 0.15362
Let's graph the scores to look at the result more visually.
```python
%matplotlib inline
### Set the size of the plot
plt.rcParams["figure.figsize"] = (10,6)
### Set up the x-axis
k_values = range(1,len(recall_list)+1)
### Draw Salary histogram
plt.plot(k_values, precision_list, k_values, recall_list, k_values, f1_list)
x = [1,18]
y = [.3,.3]
plt.plot(x,y)
plt.xlim([1,18])
plt.legend(['precision','recall','f1'],loc='center left', bbox_to_anchor=(1, 0.5))
plt.xticks(k_values,['18','17','16','15','14','13','12','11','10','9','8','7','6','5','4','3','2','1'], size='small')
plt.xlabel("K")
plt.ylabel("Scores")
plt.title("Scores for each K value")
plt.show()
```

Note that I used **GridSearchCV** to achieve the best estimate of importances of each feature. In order to speed up the result, I set the *folds* to 100. And the result will be different everytime I run the code above. Regardless of the randomness, I found that the general pattern of the scores are similar. As **K** decreases, the results get better.
- The best **Precision** is attained when **K** is 3.
- The best **Recall** is attained when **K** is 3.
- The best **F1** is attained when **K** is 3.
In this particular result, 3 seems to be the most optimized value for **K**.
Let's look at the list of these 3 features.
```python
features_by_importance[-3:]
```
['total_stock_value', 'shared_receipt_with_poi', 'expenses']
As I mentioned above, the result will be changed if I run this code again.
# Bivariate Analysis
In the **3rd** version of the final project, I removed most of the analysis I made in the 2nd version because we found that the number of features with the most optimized results are greater or equal to 3.
The purpose of the bivariate analysis in this version is to create a new feature by looking at the pairs of features from the list.
```python
### Set the poi_ind
poi_ind = features_list.index("poi")
%matplotlib inline
### Set the size of the plot
plt.rcParams["figure.figsize"] = (6,6)
### function for scatter plots
def scatter_plotting(x,y):
### Find index of x and y
x_ind = features_list.index(x)
y_ind = features_list.index(y)
### Create arrays for salary and bonus for poi and non-poi
x_poi = [data[:,x_ind][ii] for ii in range(0, len(data[:,0])) if data[:,poi_ind][ii]]
y_poi = [data[:,y_ind][ii] for ii in range(0, len(data[:,0])) if data[:,poi_ind][ii]]
x_nonpoi = [data[:,x_ind][ii] for ii in range(0, len(data[:,0])) if not data[:,poi_ind][ii]]
y_nonpoi = [data[:,y_ind][ii] for ii in range(0, len(data[:,0])) if not data[:,poi_ind][ii]]
### Draw Salary histogram
plt.scatter(x_poi, y_poi, color="r",label="poi")
plt.scatter(x_nonpoi,y_nonpoi,color="b",label="non-poi")
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.xlabel(x)
plt.ylabel(y)
plt.title("{} and {}".format(x, y))
plt.show()
```
I will draw 3 by 3 subplots showing the scatter plots between either bonus, exercised_option_prices or total_stock_value and anything else in the features_list.
```python
%matplotlib inline
### 15 histograms for features
plt.rcParams["figure.figsize"] = (20,20)
f, axarr = plt.subplots(3, 3)
### Set up the data
data = featureFormat(data_dict_new, total_features_list)
### Set the poi index
poi_ind = total_features_list.index('poi')
### the scatter plots of the data
### x: x coordinate values, y: y coordinate values
### r: row index, c: column index
### title: title of a subplot
def subplot_scatter_plot(x, y, r, c):
### Find index of x and y
x_ind = total_features_list.index(x)
y_ind = total_features_list.index(y)
### Create arrays for salary and bonus for poi and non-poi
x_poi = [data[:,x_ind][ii] for ii in range(0, len(data[:,0])) if data[:,poi_ind][ii]]
y_poi = [data[:,y_ind][ii] for ii in range(0, len(data[:,0])) if data[:,poi_ind][ii]]
x_nonpoi = [data[:,x_ind][ii] for ii in range(0, len(data[:,0])) if not data[:,poi_ind][ii]]
y_nonpoi = [data[:,y_ind][ii] for ii in range(0, len(data[:,0])) if not data[:,poi_ind][ii]]
### Draw Salary histogram
axarr[r,c].scatter(x_poi, y_poi, color="r",label="poi")
axarr[r,c].scatter(x_nonpoi,y_nonpoi,color="b",label="non-poi")
axarr[r,c].set_title("{}\nvs {}".format(x,y))
### Setting x coordinate values and y coordinate values
x_values = ["bonus", "exercised_stock_options", "total_stock_value"]
y_values = ["salary", "long_term_incentive", "deferred_income"]
r = 0
c = 0
for y in y_values:
for x in x_values:
subplot_scatter_plot(x,y,r,c)
c = (c+1) % 3
r += 1
plt.show()
```

Red dots are POIs and blue dots are non-POIs. I am not interested in identifying 4 POIs outside of the cluster at the left bottom corner because that can be identified very easily when I set a boundary between the cluster and outliners. What I am interested in is identifying POIs within the cluster. So I need to look for the scatter plot where red dots are close together within the cluster. A good example is a scatter plot between bonus and expense. POIs are close together and the cluster is more dispersed than other scatter plots. Another good example is scatter plot between bonus and long_term_incentive. 6 red dots are very close within the cluster.
### Creating a new feature
Based on the above plots, the blue dots have greater slopes than the red dots in the scatter plot of **exercised_stock_options** and **deferred_income**. I decided to create a new feature by dividing **deferred_income** from **exercised_stock_options** weighted by the sum of the squares of these features to the power of 0.2. I used *log* to get a better distribution.
```python
### Rescale each feature
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
### Insert new key to the dictionary for each person
for k,v in data_dict_new.iteritems():
di = (v["deferred_income"])
es = (v["exercised_stock_options"])
if di == "NaN" or es == "NaN":
v["eso_deferred_income"] = 0.0
elif di*es == 0:
v["eso_deferred_income"] = 0.0
else:
es = float(es)
di = float(di)
v["eso_deferred_income"] = np.log(np.abs(es/di) * np.power(di*di + es*es, .2))
### Add the new feature to the features_list
if "eso_deferred_income" not in features_list:
features_list.append("eso_deferred_income")
features_list_tmp = ["poi","eso_deferred_income"]
data_new_feature = featureFormat(data_dict_new, features_list_tmp)
### Split the data into labels and features
labels, features = targetFeatureSplit(data_new_feature)
### Rescale the new feature
features = min_max_scaler.fit_transform(features)
```
The code above appends the new feature to the existing data numpy array. In the code I set the new feature's value equal to 0 when the denominator is zero or the numerator is zero to avoid having *inf* values.
Then I scaled the new feature to 0 to 1.
### Plotting a new feature
```python
### Draw eso_expenses histogram
plt.rcParams["figure.figsize"] = (10,5)
plt.hist(data_new_feature, bins=50)
plt.xlabel("eso_deferred_income")
plt.ylabel("count")
plt.title("eso_deferred_income Histogram")
plt.show()
```

```python
### Create arrays for salary and bonus for poi and non-poi
x_poi = [features[ii] for ii in range(0, len(features)) if labels[ii]]
x_nonpoi = [features[ii] for ii in range(0, len(features)) if not labels[ii]]
### Draw Salary histogram
plt.scatter(x_poi, x_poi, color="r",label="poi")
plt.scatter(x_nonpoi,x_nonpoi,color="b",label="non-poi")
plt.title("eso_deferred_income")
plt.show()
```

The histogram shows that the majority of values of the new features are zeros. The second scatter plot is showing the distribution of the new feature colored by poi and non-poi.
## Testing the new feature - Decision Tree
I will run Decision Tree with this new feature and other features.
```python
total_features_list
```
['salary',
'to_messages',
'deferral_payments',
'total_payments',
'exercised_stock_options',
'bonus',
'restricted_stock',
'shared_receipt_with_poi',
'restricted_stock_deferred',
'total_stock_value',
'expenses',
'loan_advances',
'from_messages',
'from_this_person_to_poi',
'poi',
'director_fees',
'deferred_income',
'long_term_incentive',
'from_poi_to_this_person']
```python
### Import a classifier library
from sklearn.neighbors import KNeighborsClassifier
### Setting features array and label array
data_features_only = np.delete(data, total_features_list.index("poi"), 1)
labels = data[:, total_features_list.index("poi")]
### Take out poi from the features list
features_list_wo_poi = [i for i in total_features_list if i != "poi"]
### Rescale features
min_max_scaler = MinMaxScaler()
data_features_only = min_max_scaler.fit_transform(data_features_only)
### Format the result
PERF_FORMAT_STRING = "\
\tAccuracy: {:>0.{display_precision}f}\tPrecision: {:>0.{display_precision}f}\t\
Recall: {:>0.{display_precision}f}\tF1: {:>0.{display_precision}f}\tF2: {:>0.{display_precision}f}"
RESULTS_FORMAT_STRING = "\tTotal predictions: {:4d}\tTrue positives: {:4d}\tFalse positives: {:4d}\
\tFalse negatives: {:4d}\tTrue negatives: {:4d}"
```
Above codes are setting up what's necessary to run Decision Tree. Major of them are identical to the codes in **tester.py** file.
First of all, features and labels arrays are created and rescaled with **MinMaxScaler**.
Decision Tree with the best parameters are set up and for the cross validation, I am going to use **StratifiedShuffleSplit**. Since there are only 18 POIs, when using test and train split, the test data most likely would end up having no POIs. So folding the number of data will fix such problem.
```python
features_list_wo_poi
```
['salary',
'to_messages',
'deferral_payments',
'total_payments',
'exercised_stock_options',
'bonus',
'restricted_stock',
'shared_receipt_with_poi',
'restricted_stock_deferred',
'total_stock_value',
'expenses',
'loan_advances',
'from_messages',
'from_this_person_to_poi',
'director_fees',
'deferred_income',
'long_term_incentive',
'from_poi_to_this_person']
```python
### Calculate scores
### if classi is Decision Tree then calculate scores of the pairs of the new feature with other features using Decision Tree
### if classi is KNN then scores using KNN
def calculate_with_clf(classi):
precision_list = []
recall_list = []
f1_list = []
other_feature = [i for i in features_list_wo_poi if i != "eso_deferred_income"]
for fe in other_feature:
selected_features_list_with_poi = ['poi', 'eso_deferred_income']
selected_features_list_with_poi.append(fe)
selected_data = featureFormat(data_dict_new, selected_features_list_with_poi)
### Split the data into labels and features
labels, features = targetFeatureSplit(selected_data)
### Recale the features
features = min_max_scaler.fit_transform(features)
### Set up the validation
cv = StratifiedShuffleSplit(labels, 100, random_state = 42)
### Set up the classifier
if classi == "DecisionTree":
clf = tree.DecisionTreeClassifier()
param_grid = {
'criterion': ['gini', 'entropy'],
'splitter' : ['best', 'random'],
'min_samples_split': range(2,10)
}
elif classi == "KNN":
clf = KNeighborsClassifier()
param_grid = {
'n_neighbors': [1,2,3,4,5,6,7,8,9,10],
'weights': ['uniform', 'distance'],
'algorithm': ['auto','ball_tree','kd_tree','brute']
}
cv = StratifiedShuffleSplit(labels, 100, random_state = 42)
clf_grid = GridSearchCV(clf, param_grid, cv = cv, scoring = 'recall')
clf_grid.fit(features, labels)
if classi == "DecisionTree":
clf.set_params(criterion=clf_grid.best_params_["criterion"],
splitter=clf_grid.best_params_["splitter"],
min_samples_split=clf_grid.best_params_["min_samples_split"])
elif classi == "KNN":
clf.set_params(n_neighbors=clf_grid.best_params_["n_neighbors"],
weights=clf_grid.best_params_["weights"],
algorithm=clf_grid.best_params_["algorithm"])
print clf.get_params
true_negatives = 0
false_negatives = 0
true_positives = 0
false_positives = 0
### Getting train and test data sets
for train_idx, test_idx in cv:
features_train = []
features_test = []
labels_train = []
labels_test = []
for ii in train_idx:
features_train.append( features[ii] )
labels_train.append( labels[ii] )
for jj in test_idx:
features_test.append( features[jj] )
labels_test.append( labels[jj] )
features_test.append( features[jj])
labels_test.append( labels[jj] )
### fit the classifier using training set, and test on test set
clf.fit(features_train, labels_train)
predictions = clf.predict(features_test)
for prediction, truth in zip(predictions, labels_test):
### Assign prediction either 0 or 1
if prediction < .5:
prediction = 0
else:
prediction = 1
if prediction == 0 and truth == 0:
true_negatives += 1
elif prediction == 0 and truth == 1:
false_negatives += 1
elif prediction == 1 and truth == 0:
false_positives += 1
elif prediction == 1 and truth == 1:
true_positives += 1
try:
total_predictions = true_negatives + false_negatives + false_positives + true_positives
accuracy = 1.0*(true_positives + true_negatives)/total_predictions
precision = 1.0*true_positives/(true_positives+false_positives)
recall = 1.0*true_positives/(true_positives+false_negatives)
f1 = 2.0 * true_positives/(2*true_positives + false_positives+false_negatives)
f2 = (1+2.0*2.0) * precision*recall/(4*precision + recall)
print "eso_deferred_income and", fe
print PERF_FORMAT_STRING.format(accuracy, precision, recall, f1, f2, display_precision = 5)
print RESULTS_FORMAT_STRING.format(total_predictions, true_positives, false_positives, false_negatives, true_negatives)
print ""
precision_list.append(precision)
recall_list.append(recall)
f1_list.append(f1)
except:
print "Got a divide by zero when trying out:", clf
print "Precision or recall may be undefined due to a lack of true positive predicitons.\n"
return (precision_list, recall_list, f1_list, other_feature)
```
```python
precision_list_1, recall_list_1, f1_list_1, other_feature = calculate_with_clf("DecisionTree")
```
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')>
eso_deferred_income and salary
Accuracy: 0.69200 Precision: 0.19318 Recall: 0.17000 F1: 0.18085 F2: 0.17418
Total predictions: 2000 True positives: 68 False positives: 284 False negatives: 332 True negatives: 1316
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=4, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')>
eso_deferred_income and to_messages
Accuracy: 0.82100 Precision: 0.21583 Recall: 0.30000 F1: 0.25105 F2: 0.27829
Total predictions: 2000 True positives: 60 False positives: 218 False negatives: 140 True negatives: 1582
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='random')>
eso_deferred_income and deferral_payments
Accuracy: 0.72500 Precision: 0.19048 Recall: 0.20000 F1: 0.19512 F2: 0.19802
Total predictions: 1200 True positives: 40 False positives: 170 False negatives: 160 True negatives: 830
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=4, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')>
eso_deferred_income and total_payments
Accuracy: 0.78462 Precision: 0.24684 Recall: 0.19500 F1: 0.21788 F2: 0.20355
Total predictions: 2600 True positives: 78 False positives: 238 False negatives: 322 True negatives: 1962
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')>
eso_deferred_income and exercised_stock_options
Accuracy: 0.85909 Precision: 0.29323 Recall: 0.39000 F1: 0.33476 F2: 0.36585
Total predictions: 2200 True positives: 78 False positives: 188 False negatives: 122 True negatives: 1812
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='random')>
eso_deferred_income and bonus
Accuracy: 0.77000 Precision: 0.47407 Recall: 0.32000 F1: 0.38209 F2: 0.34225
Total predictions: 1800 True positives: 128 False positives: 142 False negatives: 272 True negatives: 1258
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='random')>
eso_deferred_income and restricted_stock
Accuracy: 0.73500 Precision: 0.05303 Recall: 0.03500 F1: 0.04217 F2: 0.03755
Total predictions: 2400 True positives: 14 False positives: 250 False negatives: 386 True negatives: 1750
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='random')>
eso_deferred_income and shared_receipt_with_poi
Accuracy: 0.80600 Precision: 0.19481 Recall: 0.30000 F1: 0.23622 F2: 0.27076
Total predictions: 2000 True positives: 60 False positives: 248 False negatives: 140 True negatives: 1552
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')>
eso_deferred_income and restricted_stock_deferred
Accuracy: 0.81500 Precision: 0.60833 Recall: 0.73000 F1: 0.66364 F2: 0.70192
Total predictions: 800 True positives: 146 False positives: 94 False negatives: 54 True negatives: 506
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=4, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='random')>
eso_deferred_income and total_stock_value
Accuracy: 0.83231 Precision: 0.40000 Recall: 0.18000 F1: 0.24828 F2: 0.20225
Total predictions: 2600 True positives: 72 False positives: 108 False negatives: 328 True negatives: 2092
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='random')>
eso_deferred_income and expenses
Accuracy: 0.75364 Precision: 0.30168 Recall: 0.27000 F1: 0.28496 F2: 0.27579
Total predictions: 2200 True positives: 108 False positives: 250 False negatives: 292 True negatives: 1550
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')>
eso_deferred_income and loan_advances
Accuracy: 0.71333 Precision: 0.57000 Recall: 0.57000 F1: 0.57000 F2: 0.57000
Total predictions: 600 True positives: 114 False positives: 86 False negatives: 86 True negatives: 314
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')>
eso_deferred_income and from_messages
Accuracy: 0.77700 Precision: 0.14451 Recall: 0.25000 F1: 0.18315 F2: 0.21815
Total predictions: 2000 True positives: 50 False positives: 296 False negatives: 150 True negatives: 1504
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')>
eso_deferred_income and from_this_person_to_poi
Accuracy: 0.82750 Precision: 0.27381 Recall: 0.23000 F1: 0.25000 F2: 0.23760
Total predictions: 1600 True positives: 46 False positives: 122 False negatives: 154 True negatives: 1278
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')>
eso_deferred_income and director_fees
Accuracy: 0.85600 Precision: 0.62500 Recall: 0.70000 F1: 0.66038 F2: 0.68359
Total predictions: 1000 True positives: 140 False positives: 84 False negatives: 60 True negatives: 716
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='random')>
eso_deferred_income and deferred_income
Accuracy: 0.65800 Precision: 0.19658 Recall: 0.23000 F1: 0.21198 F2: 0.22244
Total predictions: 1000 True positives: 46 False positives: 188 False negatives: 154 True negatives: 612
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='random')>
eso_deferred_income and long_term_incentive
Accuracy: 0.63125 Precision: 0.18543 Recall: 0.14000 F1: 0.15954 F2: 0.14721
Total predictions: 1600 True positives: 56 False positives: 246 False negatives: 344 True negatives: 954
<bound method DecisionTreeClassifier.get_params of DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='random')>
eso_deferred_income and from_poi_to_this_person
Accuracy: 0.72700 Precision: 0.27607 Recall: 0.22500 F1: 0.24793 F2: 0.23364
Total predictions: 2000 True positives: 90 False positives: 236 False negatives: 310 True negatives: 1364
```python
%matplotlib inline
### Set the size of the plot
plt.rcParams["figure.figsize"] = (18,6)
### Set up the x-axis
k_values = range(len(precision_list_1))
print len(k_values)
print len(other_feature)
### Draw Salary histogram
plt.plot(k_values, precision_list_1, k_values, recall_list_1, k_values, f1_list_1)
x = [0,18]
y = [.3,.3]
plt.plot(x,y)
plt.xlim([0,len(precision_list_1)-1])
plt.legend(['precision','recall','f1'],loc='center left', bbox_to_anchor=(1, 0.5))
plt.xticks(k_values, other_feature, rotation='vertical')
plt.xlabel("K")
plt.ylabel("Scores")
plt.title("Scores with the new feature using Decision Tree")
plt.show()
```
18
18

One noticiable result is that there are three highest peaks at **restricted_stock_deferred**, **loan_advances** and **director_fees**.
Below is the summary of those top results.
```python
top_3_results = ["restricted_stock_deferred", "loan_advances", "director_fees"]
print " Precision Recall F1"
for i in top_3_results:
print i
ind = other_feature.index(i)
print " {:.4f} {:.4f} {:.4f}".format(precision_list_1[ind], recall_list_1[ind], f1_list_1[ind])
```
Precision Recall F1
restricted_stock_deferred
0.6083 0.7300 0.6636
loan_advances
0.5700 0.5700 0.5700
director_fees
0.6250 0.7000 0.6604
## Testing the new feature - KNN
This time I will calculate the new feature using **KNN** classifier.
```python
precision_list, recall_list, f1_list, other_feature = calculate_with_clf("KNN")
```
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and salary
Accuracy: 0.64700 Precision: 0.03067 Recall: 0.02500 F1: 0.02755 F2: 0.02596
Total predictions: 2000 True positives: 10 False positives: 316 False negatives: 390 True negatives: 1284
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and to_messages
Accuracy: 0.82900 Precision: 0.16190 Recall: 0.17000 F1: 0.16585 F2: 0.16832
Total predictions: 2000 True positives: 34 False positives: 176 False negatives: 166 True negatives: 1624
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and deferral_payments
Accuracy: 0.78500 Precision: 0.37391 Recall: 0.43000 F1: 0.40000 F2: 0.41748
Total predictions: 1200 True positives: 86 False positives: 144 False negatives: 114 True negatives: 856
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and total_payments
Accuracy: 0.75462 Precision: 0.18182 Recall: 0.17000 F1: 0.17571 F2: 0.17224
Total predictions: 2600 True positives: 68 False positives: 306 False negatives: 332 True negatives: 1894
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and exercised_stock_options
Accuracy: 0.84909 Precision: 0.15625 Recall: 0.15000 F1: 0.15306 F2: 0.15121
Total predictions: 2200 True positives: 30 False positives: 162 False negatives: 170 True negatives: 1838
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and bonus
Accuracy: 0.72889 Precision: 0.34722 Recall: 0.25000 F1: 0.29070 F2: 0.26483
Total predictions: 1800 True positives: 100 False positives: 188 False negatives: 300 True negatives: 1212
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
Got a divide by zero when trying out: KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')
Precision or recall may be undefined due to a lack of true positive predicitons.
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and shared_receipt_with_poi
Accuracy: 0.79000 Precision: 0.15625 Recall: 0.25000 F1: 0.19231 F2: 0.22321
Total predictions: 2000 True positives: 50 False positives: 270 False negatives: 150 True negatives: 1530
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and restricted_stock_deferred
Accuracy: 0.80250 Precision: 0.58400 Recall: 0.73000 F1: 0.64889 F2: 0.69524
Total predictions: 800 True positives: 146 False positives: 104 False negatives: 54 True negatives: 496
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and total_stock_value
Accuracy: 0.75692 Precision: 0.13291 Recall: 0.10500 F1: 0.11732 F2: 0.10960
Total predictions: 2600 True positives: 42 False positives: 274 False negatives: 358 True negatives: 1926
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and expenses
Accuracy: 0.71091 Precision: 0.17582 Recall: 0.16000 F1: 0.16754 F2: 0.16293
Total predictions: 2200 True positives: 64 False positives: 300 False negatives: 336 True negatives: 1500
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and loan_advances
Accuracy: 0.71333 Precision: 0.57292 Recall: 0.55000 F1: 0.56122 F2: 0.55444
Total predictions: 600 True positives: 110 False positives: 82 False negatives: 90 True negatives: 318
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and from_messages
Accuracy: 0.77200 Precision: 0.14045 Recall: 0.25000 F1: 0.17986 F2: 0.21626
Total predictions: 2000 True positives: 50 False positives: 306 False negatives: 150 True negatives: 1494
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and from_this_person_to_poi
Accuracy: 0.75750 Precision: 0.17361 Recall: 0.25000 F1: 0.20492 F2: 0.22978
Total predictions: 1600 True positives: 50 False positives: 238 False negatives: 150 True negatives: 1162
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and director_fees
Accuracy: 0.86000 Precision: 0.63636 Recall: 0.70000 F1: 0.66667 F2: 0.68627
Total predictions: 1000 True positives: 140 False positives: 80 False negatives: 60 True negatives: 720
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and deferred_income
Accuracy: 0.70000 Precision: 0.26852 Recall: 0.29000 F1: 0.27885 F2: 0.28543
Total predictions: 1000 True positives: 58 False positives: 158 False negatives: 142 True negatives: 642
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and long_term_incentive
Accuracy: 0.64250 Precision: 0.21333 Recall: 0.16000 F1: 0.18286 F2: 0.16842
Total predictions: 1600 True positives: 64 False positives: 236 False negatives: 336 True negatives: 964
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=3, p=2,
weights='distance')>
eso_deferred_income and from_poi_to_this_person
Accuracy: 0.73400 Precision: 0.30814 Recall: 0.26500 F1: 0.28495 F2: 0.27263
Total predictions: 2000 True positives: 106 False positives: 238 False negatives: 294 True negatives: 1362
```python
%matplotlib inline
### Set the size of the plot
plt.rcParams["figure.figsize"] = (18,6)
### Set up the x-axis
k_values = range(len(precision_list))
other_features_no_restricted_stock = [i for i in other_feature if i!="restricted_stock"]
### Draw Salary histogram
plt.plot(k_values, precision_list, k_values, recall_list, k_values, f1_list)
x = [0,18]
y = [.3,.3]
plt.plot(x,y)
plt.xlim([0,len(precision_list)-1])
plt.legend(['precision','recall','f1'],loc='center left', bbox_to_anchor=(1, 0.5))
plt.xticks(k_values,other_features_no_restricted_stock, rotation='vertical')
plt.xlabel("K")
plt.ylabel("Scores")
plt.title("Scores from KNN")
plt.show()
```

Similar to the previous result there are 3 peaks at the exactly same features. I will print out the summary of these 3 peaks
```python
top_3_results = ["restricted_stock_deferred", "loan_advances", "director_fees"]
print " Precision Recall F1"
for i in top_3_results:
print i
ind = other_features_no_restricted_stock.index(i)
print " {:.4f} {:.4f} {:.4f}".format(precision_list[ind], recall_list[ind], f1_list[ind])
```
Precision Recall F1
restricted_stock_deferred
0.5840 0.7300 0.6489
loan_advances
0.5729 0.5500 0.5612
director_fees
0.6364 0.7000 0.6667
# Multivariate Analysis
This will be the final round of achieving the highest scores from the data set. So far I conducted a univariate analysis to find the single features having the highest scores and then I calculated the number of features that optimized the scores the most. It turns out that **3** features are the best number of features to use and the scores get lower if I use more than this.
I created a new feature based on my observations from the analysis and the new feature showed good scores. So I need to recalculate the number of features that optimize the model the most using **SelectKBest** including this new feature.
## Selecting Features
```python
### Convert data_dict_new into numpy array
total_data = featureFormat(data_dict_new, total_features_list)
print total_data.shape
print len(total_features_list)
### Extract features from the data
features = total_data
features = np.delete(features, total_features_list.index("poi"), 1)
print features.shape
### Extract a label from the data
label = total_data[:,total_features_list.index("poi")]
### Rescale features
min_max_scaler = MinMaxScaler()
features = min_max_scaler.fit_transform(features)
### Import SelectKBest
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_classif
pre_selected_list = []
features_by_importance = []
for k in range(1,19):
selector = SelectKBest(f_classif, k=k)
selector = selector.fit(features,label)
features_list_wo_poi = [i for i in total_features_list if i!="poi"] ### features list without poi
### Print features chosen by SelectKBest
selected_list = [features_list_wo_poi[i] for i in range(len(features_list_wo_poi)) if selector.get_support()[i]]
print "K:", k
for i in selected_list:
if i not in pre_selected_list:
print "\t", i
features_by_importance.append(i)
pre_selected_list = selected_list
```
(144, 19)
19
(144, 18)
K: 1
exercised_stock_options
K: 2
total_stock_value
K: 3
bonus
K: 4
salary
K: 5
deferred_income
K: 6
long_term_incentive
K: 7
restricted_stock
K: 8
total_payments
K: 9
shared_receipt_with_poi
K: 10
loan_advances
K: 11
expenses
K: 12
from_poi_to_this_person
K: 13
from_this_person_to_poi
K: 14
director_fees
K: 15
to_messages
K: 16
deferral_payments
K: 17
from_messages
K: 18
restricted_stock_deferred
So our new feature is chosen at the 13th position.
Note that in this code, the amount of the data has not been increased when using **SelectKBest** method. So the result is somewhat unreliable due to the fact that some of the features contain maybe less than 30 points while others contain more than 50. So next, I will use Decision Tree method to select features and in this time I will increase the amount of the data using **folds** parameter in the cross validation.
## Decision Tree
```python
### Use GridSearchCV to find the best parameters
from sklearn.grid_search import GridSearchCV
### Import DecisionTree Classifier
clf = tree.DecisionTreeClassifier()
param_grid = {
'criterion': ['gini', 'entropy'],
'splitter' : ['best', 'random'],
'min_samples_split': range(2,9)
}
### Set up the arrays for precision, recall and F1
precision_list = []
recall_list = []
f1_list = []
if 'poi' not in total_features_list:
total_features_list.append('poi')
selected_features_list = [i for i in total_features_list if i != 'poi']
features_by_importance = []
### Calculate scores for each K value
for i in range(len(total_features_list)-1):
print
try:
print "Dropped Feature:", features_by_importance[-1]
except:
pass
selected_features_list_with_poi = ['poi']
selected_features_list_with_poi.extend(selected_features_list)
selected_data = featureFormat(data_dict_new, selected_features_list_with_poi)
### Split the data into labels and features
labels, features = targetFeatureSplit(selected_data)
### Recale the features
features = min_max_scaler.fit_transform(features)
cv = StratifiedShuffleSplit(labels, 100, random_state = 42)
clf_grid = GridSearchCV(clf, param_grid, cv = cv, scoring = 'recall')
clf_grid.fit(features, labels)
print clf_grid.best_params_
clf.set_params(criterion=clf_grid.best_params_["criterion"],
splitter=clf_grid.best_params_["splitter"],
min_samples_split=clf_grid.best_params_["min_samples_split"])
true_negatives = 0
false_negatives = 0
true_positives = 0
false_positives = 0
for train_idx, test_idx in cv:
features_train = []
features_test = []
labels_train = []
labels_test = []
for ii in train_idx:
features_train.append( features[ii] )
labels_train.append( labels[ii] )
for jj in test_idx:
features_test.append( features[jj] )
labels_test.append( labels[jj] )
features_test.append( features[jj])
labels_test.append( labels[jj] )
### fit the classifier using training set, and test on test set
clf.fit(features_train, labels_train)
predictions = clf.predict(features_test)
for prediction, truth in zip(predictions, labels_test):
### Assign prediction either 0 or 1
if prediction < .5:
prediction = 0
else:
prediction = 1
if prediction == 0 and truth == 0:
true_negatives += 1
elif prediction == 0 and truth == 1:
false_negatives += 1
elif prediction == 1 and truth == 0:
false_positives += 1
elif prediction == 1 and truth == 1:
true_positives += 1
total_predictions = true_negatives + false_negatives + false_positives + true_positives
accuracy = 1.0*(true_positives + true_negatives)/total_predictions
precision = 1.0*true_positives/(true_positives+false_positives)
recall = 1.0*true_positives/(true_positives+false_negatives)
f1 = 2.0 * true_positives/(2*true_positives + false_positives+false_negatives)
f2 = (1+2.0*2.0) * precision*recall/(4*precision + recall)
print PERF_FORMAT_STRING.format(accuracy, precision, recall, f1, f2, display_precision = 5)
importances = clf.feature_importances_
precision_list.append(precision)
recall_list.append(recall)
f1_list.append(f1)
### Find the index of the feature with the lowest importance
min_importance = min(importances)
features_by_importance.append(selected_features_list[np.argmin(importances)])
selected_features_list.remove(selected_features_list[np.argmin(importances)])
```
Dropped Feature: {'min_samples_split': 2, 'splitter': 'random', 'criterion': 'entropy'}
Accuracy: 0.81067 Precision: 0.27895 Recall: 0.26500 F1: 0.27179 F2: 0.26768
Dropped Feature: restricted_stock_deferred
{'min_samples_split': 2, 'splitter': 'random', 'criterion': 'entropy'}
Accuracy: 0.81200 Precision: 0.29082 Recall: 0.28500 F1: 0.28788 F2: 0.28614
Dropped Feature: salary
{'min_samples_split': 2, 'splitter': 'random', 'criterion': 'gini'}
Accuracy: 0.81200 Precision: 0.29902 Recall: 0.30500 F1: 0.30198 F2: 0.30378
Dropped Feature: deferral_payments
{'min_samples_split': 2, 'splitter': 'random', 'criterion': 'entropy'}
Accuracy: 0.81533 Precision: 0.30457 Recall: 0.30000 F1: 0.30227 F2: 0.30090
Dropped Feature: loan_advances
{'min_samples_split': 2, 'splitter': 'random', 'criterion': 'entropy'}
Accuracy: 0.81400 Precision: 0.31280 Recall: 0.33000 F1: 0.32117 F2: 0.32641
Dropped Feature: total_payments
{'min_samples_split': 2, 'splitter': 'random', 'criterion': 'gini'}
Accuracy: 0.81133 Precision: 0.29756 Recall: 0.30500 F1: 0.30123 F2: 0.30348
Dropped Feature: to_messages
{'min_samples_split': 4, 'splitter': 'random', 'criterion': 'gini'}
Accuracy: 0.82200 Precision: 0.31285 Recall: 0.28000 F1: 0.29551 F2: 0.28601
Dropped Feature: bonus
{'min_samples_split': 3, 'splitter': 'random', 'criterion': 'gini'}
Accuracy: 0.81733 Precision: 0.29670 Recall: 0.27000 F1: 0.28272 F2: 0.27495
Dropped Feature: restricted_stock
{'min_samples_split': 2, 'splitter': 'random', 'criterion': 'gini'}
Accuracy: 0.81333 Precision: 0.29592 Recall: 0.29000 F1: 0.29293 F2: 0.29116
Dropped Feature: from_messages
{'min_samples_split': 2, 'splitter': 'best', 'criterion': 'gini'}
Accuracy: 0.81467 Precision: 0.29897 Recall: 0.29000 F1: 0.29442 F2: 0.29175
Dropped Feature: director_fees
{'min_samples_split': 2, 'splitter': 'best', 'criterion': 'entropy'}
Accuracy: 0.83467 Precision: 0.38000 Recall: 0.38000 F1: 0.38000 F2: 0.38000
Dropped Feature: shared_receipt_with_poi
{'min_samples_split': 3, 'splitter': 'best', 'criterion': 'gini'}
Accuracy: 0.84133 Precision: 0.40686 Recall: 0.41500 F1: 0.41089 F2: 0.41335
Dropped Feature: long_term_incentive
{'min_samples_split': 2, 'splitter': 'best', 'criterion': 'gini'}
Accuracy: 0.83429 Precision: 0.41667 Recall: 0.40000 F1: 0.40816 F2: 0.40323
Dropped Feature: from_poi_to_this_person
{'min_samples_split': 2, 'splitter': 'best', 'criterion': 'gini'}
Accuracy: 0.84929 Precision: 0.46927 Recall: 0.42000 F1: 0.44327 F2: 0.42901
Dropped Feature: total_stock_value
{'min_samples_split': 2, 'splitter': 'best', 'criterion': 'gini'}
Accuracy: 0.84857 Precision: 0.47143 Recall: 0.49500 F1: 0.48293 F2: 0.49010
Dropped Feature: deferred_income
{'min_samples_split': 2, 'splitter': 'best', 'criterion': 'gini'}
Accuracy: 0.84786 Precision: 0.46701 Recall: 0.46000 F1: 0.46348 F2: 0.46138
Dropped Feature: from_this_person_to_poi
{'min_samples_split': 4, 'splitter': 'best', 'criterion': 'entropy'}
Accuracy: 0.79231 Precision: 0.32143 Recall: 0.31500 F1: 0.31818 F2: 0.31627
Dropped Feature: exercised_stock_options
{'min_samples_split': 2, 'splitter': 'random', 'criterion': 'gini'}
Accuracy: 0.68000 Precision: 0.20297 Recall: 0.20500 F1: 0.20398 F2: 0.20459
```python
%matplotlib inline
### Set the size of the plot
plt.rcParams["figure.figsize"] = (10,6)
### Set up the x-axis
k_values = range(1,len(recall_list)+1)
### Draw Salary histogram
plt.plot(k_values, precision_list, k_values, recall_list, k_values, f1_list)
x = [1,19]
y = [.3,.3]
plt.plot(x,y)
plt.xlim([1,19])
plt.legend(['precision','recall','f1'],loc='center left', bbox_to_anchor=(1, 0.5))
plt.xticks(k_values,['19','18','17','16','15','14','13','12','11','10','9','8','7','6','5','4','3','2','1'], size='small')
plt.xlabel("K")
plt.ylabel("Scores")
plt.title("Scores for each K value")
plt.show()
```

The highest **precision** is acheived when **K=3** and the highest **recall** is achieved when **K=5**. I will choose **K=3** as the most optimized number because when **K=5**, **precision** and **f1** are very low.
When **K=3**
- Chosen features: **exercised_stock_options**, **deferred_income** and **expenses**
- Accuracy: ~ 86.8%
- Precision: ~ 54.1%
- Recall: ~ 49.5 %
**Note:** Again, the result will vary everytime I run the code.
## KNN
I will calculate the scores using the features selected above: **exercised_stock_options**, **deferred_income** and **expenses**
```python
### Calculate scores
### if classi is Decision Tree then calculate scores of the pairs of the new feature with other features using Decision Tree
### if classi is KNN then scores using KNN
precision_list = []
recall_list = []
f1_list = []
selected_features_list_with_poi = ['poi', 'exercised_stock_options', 'deferred_income', 'expenses']
selected_data = featureFormat(data_dict_new, selected_features_list_with_poi)
### Split the data into labels and features
labels, features = targetFeatureSplit(selected_data)
### Recale the features
features = min_max_scaler.fit_transform(features)
### Set up the validation
cv = StratifiedShuffleSplit(labels, 100, random_state = 42)
### Set up the classifier
clf = KNeighborsClassifier()
param_grid = {
'n_neighbors': [1,2,3,4,5,6,7,8,9,10],
'weights': ['uniform', 'distance'],
'algorithm': ['auto','ball_tree','kd_tree','brute']
}
cv = StratifiedShuffleSplit(labels, 100, random_state = 42)
clf_grid = GridSearchCV(clf, param_grid, cv = cv, scoring = 'recall')
clf_grid.fit(features, labels)
clf.set_params(n_neighbors=clf_grid.best_params_["n_neighbors"],
weights=clf_grid.best_params_["weights"],
algorithm=clf_grid.best_params_["algorithm"])
print clf.get_params
true_negatives = 0
false_negatives = 0
true_positives = 0
false_positives = 0
### Getting train and test data sets
for train_idx, test_idx in cv:
features_train = []
features_test = []
labels_train = []
labels_test = []
for ii in train_idx:
features_train.append( features[ii] )
labels_train.append( labels[ii] )
for jj in test_idx:
features_test.append( features[jj] )
labels_test.append( labels[jj] )
features_test.append( features[jj])
labels_test.append( labels[jj] )
### fit the classifier using training set, and test on test set
clf.fit(features_train, labels_train)
predictions = clf.predict(features_test)
for prediction, truth in zip(predictions, labels_test):
### Assign prediction either 0 or 1
if prediction < .5:
prediction = 0
else:
prediction = 1
if prediction == 0 and truth == 0:
true_negatives += 1
elif prediction == 0 and truth == 1:
false_negatives += 1
elif prediction == 1 and truth == 0:
false_positives += 1
elif prediction == 1 and truth == 1:
true_positives += 1
try:
total_predictions = true_negatives + false_negatives + false_positives + true_positives
accuracy = 1.0*(true_positives + true_negatives)/total_predictions
precision = 1.0*true_positives/(true_positives+false_positives)
recall = 1.0*true_positives/(true_positives+false_negatives)
f1 = 2.0 * true_positives/(2*true_positives + false_positives+false_negatives)
f2 = (1+2.0*2.0) * precision*recall/(4*precision + recall)
print "eso_deferred_income and", fe
print PERF_FORMAT_STRING.format(accuracy, precision, recall, f1, f2, display_precision = 5)
print RESULTS_FORMAT_STRING.format(total_predictions, true_positives, false_positives, false_negatives, true_negatives)
print ""
precision_list.append(precision)
recall_list.append(recall)
f1_list.append(f1)
except:
print "Got a divide by zero when trying out:", clf
print "Precision or recall may be undefined due to a lack of true positive predicitons.\n"
```
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and Got a divide by zero when trying out: KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')
Precision or recall may be undefined due to a lack of true positive predicitons.
When using the 3 best features from the **Decision Tree Feature Importances** method, an error occurs due to a lack of non-zero values. It seems **KNN** requires more non-zero values.
Let's use the top 3 features selected from **SelectKBest**.
```python
### Calculate scores
### if classi is Decision Tree then calculate scores of the pairs of the new feature with other features using Decision Tree
### if classi is KNN then scores using KNN
precision_list = []
recall_list = []
f1_list = []
selected_features_list_with_poi = ['poi', 'exercised_stock_options', 'total_stock_value', 'bonus']
selected_data = featureFormat(data_dict_new, selected_features_list_with_poi)
### Split the data into labels and features
labels, features = targetFeatureSplit(selected_data)
### Recale the features
features = min_max_scaler.fit_transform(features)
### Set up the validation
cv = StratifiedShuffleSplit(labels, 100, random_state = 42)
### Set up the classifier
clf = KNeighborsClassifier()
param_grid = {
'n_neighbors': [1,2,3,4,5,6,7,8,9,10],
'weights': ['uniform', 'distance'],
'algorithm': ['auto','ball_tree','kd_tree','brute']
}
cv = StratifiedShuffleSplit(labels, 100, random_state = 42)
clf_grid = GridSearchCV(clf, param_grid, cv = cv, scoring = 'recall')
clf_grid.fit(features, labels)
clf.set_params(n_neighbors=clf_grid.best_params_["n_neighbors"],
weights=clf_grid.best_params_["weights"],
algorithm=clf_grid.best_params_["algorithm"])
print clf.get_params
true_negatives = 0
false_negatives = 0
true_positives = 0
false_positives = 0
### Getting train and test data sets
for train_idx, test_idx in cv:
features_train = []
features_test = []
labels_train = []
labels_test = []
for ii in train_idx:
features_train.append( features[ii] )
labels_train.append( labels[ii] )
for jj in test_idx:
features_test.append( features[jj] )
labels_test.append( labels[jj] )
features_test.append( features[jj])
labels_test.append( labels[jj] )
### fit the classifier using training set, and test on test set
clf.fit(features_train, labels_train)
predictions = clf.predict(features_test)
for prediction, truth in zip(predictions, labels_test):
### Assign prediction either 0 or 1
if prediction < .5:
prediction = 0
else:
prediction = 1
if prediction == 0 and truth == 0:
true_negatives += 1
elif prediction == 0 and truth == 1:
false_negatives += 1
elif prediction == 1 and truth == 0:
false_positives += 1
elif prediction == 1 and truth == 1:
true_positives += 1
try:
total_predictions = true_negatives + false_negatives + false_positives + true_positives
accuracy = 1.0*(true_positives + true_negatives)/total_predictions
precision = 1.0*true_positives/(true_positives+false_positives)
recall = 1.0*true_positives/(true_positives+false_negatives)
f1 = 2.0 * true_positives/(2*true_positives + false_positives+false_negatives)
f2 = (1+2.0*2.0) * precision*recall/(4*precision + recall)
print "eso_deferred_income and", fe
print PERF_FORMAT_STRING.format(accuracy, precision, recall, f1, f2, display_precision = 5)
print RESULTS_FORMAT_STRING.format(total_predictions, true_positives, false_positives, false_negatives, true_negatives)
print ""
precision_list.append(precision)
recall_list.append(recall)
f1_list.append(f1)
except:
print "Got a divide by zero when trying out:", clf
print "Precision or recall may be undefined due to a lack of true positive predicitons.\n"
```
<bound method KNeighborsClassifier.get_params of KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')>
eso_deferred_income and Got a divide by zero when trying out: KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')
Precision or recall may be undefined due to a lack of true positive predicitons.
Unfortunately, an error occured again for the same reason.
# Final Thought
#### Usage of Parameter Tuning
I used parameter tuning a lot of times for this project using **GridSearchCV**. Depending on the data we have, parameters of the model have to be adjusted to achieve the best solution. Thanks to the **sklearn** library, finding such parameters is not very difficult.
#### Usage of Evaluation Metrics
When evaluating the results, I calculated **Accuracy**, **Precision**, and **Recall**. I didn't put much emphasis on **Accuracy**. **Accuracy** is calculated by summing true positives and true negatives and dividing it by total predictions. Most of the time this value is above **70%**. Due to very small amount of POIs, assuming everything to be non-POI can give us a good **Accuracy**. So this score is not very reliable in deciding the best algorithm.
So I focus on using **Precision** and **Recall**. A good **Precision** tells you that when the algorithm identify POI groups from the test set, then most of them will be true POIs. A good **Recall** values tells you that most of the true POIs in the test set will be identified as POIs by the algorithm. I thought that both of these scores are equally important when choosing the best algorithm.
#### Discuss validation and its importance.
Validation is important when evaluating the algorithms. The most basic validation is Test and Train split with certain percentage. For example, if I use 70% then I take 70% of the data as a train set and 30% of the data as a test set. The algorithm is trained by the 70% of the data and it will be applied to the 30% and the result will be analyzed.
Test and Train is just one of many validations. Analyzing the algorithms using validations is very important because if we create an algorithm then we need to know if the algorithm really works before we apply this algorithm to the real world. Using the existing data set we have, we can estimate and predict what would happend if the algorithm is used in the real world.
We need to choose the validation properly because sometimes depending on the data set we have, certain types of validations won't work very well. For example, in this project, using Train and Test validation won't provide us a reliable result because when dividing the data set into train and test, with a high probability, the test set won't contain any POIs, due to a small number of POI in the data set.
#### Validation Strategy
I used **StratifiedShuffleSplit** as a cross validation for this project. I thought this is the best cross validation to be used because it increases the size of the data points randomly and provides the better calculation. Due to small number of POIs in the data set, Test and Train split can cause zero POI in test set very frequently, so it won’t give very good calculation.
#### Further Note
For this final project, I first investigated the overall data set first. I checked the number features in the data set, the number of POIs, and see if there are any features with too many zeros or missing values. Then, I found an outlier and realized that there was “Total” summing all the features in the data set. I got rid of this “Total” and the data showed better plots.
** Note: **
*poi_id.py* includes the result with the best scores from my investigation and it can be tested by running *tester.py*.
|
Java
|
UTF-8
| 933 | 3.484375 | 3 |
[
"Apache-2.0"
] |
permissive
|
import java.util.Random;
public class CuriousBunny extends Animal implements Teleporter
{
private Random rand = new Random();
private int x = 0;
private int y = 0;
public CuriousBunny()
{
}
public CuriousBunny(String name, String color)
{
super(name,color);
}
public void hop()
{
if(health>0)
{
System.out.println("I am "+this.name+" and I am hopping.");
}
else
System.out.println(this.name+ " died.");
}
public void teleport()
{
this.x = rand.nextInt(1000) + 1;
this.y = rand.nextInt(500) + 1;
System.out.println(this.name + " Teleported");
}
public String getPosition()
{
return("(" + this.x + ", " + this.y + " )");
}
}
|
TypeScript
|
UTF-8
| 2,044 | 2.78125 | 3 |
[] |
no_license
|
import {
all,
call,
fork,
put,
takeEvery,
takeLatest
} from "redux-saga/effects";
import callApi from "../../utils/callApi";
import { fetchError, fetchSuccess, selectRepo, repoSelected } from "./actions";
import { ReposActionTypes } from "./types";
const API_ENDPOINT = "https://api.github.com/repos/facebook";
function* handleFetch() {
try {
// To call async functions, use redux-saga's `call()`.
const res = yield call(callApi, "get", API_ENDPOINT, "/create-react-app");
console.log(API_ENDPOINT);
if (res.error) {
yield put(fetchError(res.error));
} else {
yield put(fetchSuccess(res));
}
} catch (err) {
if (err instanceof Error) {
yield put(fetchError(err.stack!));
} else {
yield put(fetchError("An unknown error occured."));
}
}
}
function* handleSelect(action: ReturnType<typeof selectRepo>) {
try {
const detail = yield call(
callApi,
"get",
API_ENDPOINT,
`/repos/${action.payload}`
);
const players = yield call(
callApi,
"get",
API_ENDPOINT,
`/repos/${action.payload}/players`
);
if (detail.error || players.error) {
yield put(fetchError(detail.error || players.error));
} else {
yield put(repoSelected({ detail, players }));
}
} catch (err) {
if (err instanceof Error) {
yield put(fetchError(err.stack!));
} else {
yield put(fetchError("An unknown error occured."));
}
}
}
// This is our watcher function. We use `take*()` functions to watch Redux for a specific action
// type, and run our saga, for example the `handleFetch()` saga above.
function* watchFetchRequest() {
yield takeEvery(ReposActionTypes.FETCH_REQUEST, handleFetch);
}
function* watchSelectRepo() {
yield takeLatest(ReposActionTypes.SELECT_TEAM, handleSelect);
}
// We can also use `fork()` here to split our saga into multiple watchers.
function* heroesSaga() {
yield all([fork(watchFetchRequest), fork(watchSelectRepo)]);
}
export default heroesSaga;
|
Java
|
UTF-8
| 829 | 1.742188 | 2 |
[] |
no_license
|
package com.gautams.pos.view.splash;
import android.databinding.DataBindingUtil;
import android.os.Bundle;
import com.gautams.pos.R;
import com.gautams.pos.databinding.ActivitySplashBinding;
import com.gautams.pos.view.base.BaseActivity;
import com.gautams.pos.view.splash.vm.SplashActivityViewModel;
import javax.inject.Inject;
public class SplashActivity extends BaseActivity {
@Inject
SplashActivityViewModel splashActivityViewModel;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
ActivitySplashBinding activitySplashBinding = DataBindingUtil.setContentView(this, R.layout.activity_splash);
activitySplashBinding.setViewModel(splashActivityViewModel);
splashActivityViewModel.startIssueListActivity(this);
}
}
|
Java
|
UTF-8
| 2,379 | 2.640625 | 3 |
[
"Unlicense"
] |
permissive
|
package com.webserver.Http;
import java.io.File;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class HttpContext {
public static final int CR=13;
public static final int LF=10;
private static Map<Integer,String> statusCode_Reason_Mapping=new HashMap<Integer,String>();
private static Map<String,String> mimeMapping=new HashMap<String,String>();
static {
initStatusCodeReasonMapping();
initMimeMapping();
}
private static void initStatusCodeReasonMapping() {
statusCode_Reason_Mapping.put(200,"OK");
statusCode_Reason_Mapping.put(201,"Created");
statusCode_Reason_Mapping.put(202,"Accepted");
statusCode_Reason_Mapping.put(204,"No Content" );
statusCode_Reason_Mapping.put(301,"Moved Permanently");
statusCode_Reason_Mapping.put(302,"Moved Temporarily" );
statusCode_Reason_Mapping.put(304,"Not Modified" );
statusCode_Reason_Mapping.put(400,"Bad Request" );
statusCode_Reason_Mapping.put(401,"Unauthorized" );
statusCode_Reason_Mapping.put(403,"Unauthorized" );
statusCode_Reason_Mapping.put(404,"Not Found" );
statusCode_Reason_Mapping.put(500,"Internal Server Error" );
statusCode_Reason_Mapping.put(501,"Not Implemented" );
statusCode_Reason_Mapping.put(502,"Bad Gateway" );
statusCode_Reason_Mapping.put(503,"Service Unavailable" );
}
private static void initMimeMapping(){
try {
SAXReader reader=new SAXReader();
Document doc=reader.read(new File("./conf/web.xml"));
Element root=doc.getRootElement();
List<Element> element=root.elements("mime-mapping");
for(Element ele:element){
String key=ele.elementTextTrim("extension");
String value=ele.elementTextTrim("mime-type");
mimeMapping.put(key, value);
}
System.out.println("输出mimeMapping集合 :"+mimeMapping);
System.out.println("mimeMapping集合元素个数为 :"+mimeMapping.size());
} catch (DocumentException e) {
e.printStackTrace();
}
}
public static String getStatusReason(int statusCode) {
return statusCode_Reason_Mapping.get(statusCode);
}
public static String getContentType(String exe){
return mimeMapping.get(exe);
}
public static void main(String[] args) {
System.out.println(getContentType("jpg"));
}
}
|
Java
|
UTF-8
| 916 | 1.96875 | 2 |
[] |
no_license
|
package com.workout.fitness.womenfitness.activities;
import androidx.appcompat.app.AppCompatActivity;
import android.content.Intent;
import android.net.Uri;
import android.os.Bundle;
import android.view.View;
import android.widget.Button;
import com.workout.fitness.womenfitness.R;
public class UpdateActivity extends AppCompatActivity {
private Button updateButton;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_update);
updateButton = findViewById(R.id.update_btn);
updateButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
startActivity(new Intent(Intent.ACTION_VIEW, Uri.parse
("market://details?id=com.workout.fitness.womenfitness")));
}
});
}
}
|
Java
|
UTF-8
| 1,071 | 3.53125 | 4 |
[] |
no_license
|
package dynamicProgramming.lisPattern;
//https://www.interviewbit.com/problems/length-of-longest-subsequence/
public class LongestBitonicSubsequence {
public static int longestSubsequenceLength(final int[] A) {
if(A.length <2){
return A.length;
}
int leftInc[] = new int[A.length];
int rightDec[] = new int[A.length];
int max = 0, temp;
leftInc[0] = 0;
rightDec[A.length-1] = 0;
for(int i = 1; i< A.length; i++){
for(int j = 0; j<i; j++){
if(A[j]< A[i] && leftInc[j] + 1 > leftInc[i])
leftInc[i] = leftInc[j] + 1;
}
}
for(int i = A.length-2; i>=0; i--){
for(int j = A.length-1; j>i; j--){
if(A[j]< A[i] && rightDec[j] + 1 > rightDec[i])
rightDec[i] = rightDec[j] + 1;
}
}
for(int i = 1; i< A.length; i++){
temp = 1 + leftInc[i] + rightDec[i];
max = Math.max(max, temp);
}
return max;
}
public static void main(String[] args) {
System.out.println(longestSubsequenceLength(new int[]{1, 11, 2, 10, 4, 5, 2, 1}));
}
}
|
Markdown
|
UTF-8
| 1,357 | 3.09375 | 3 |
[] |
no_license
|
#Talk in js代理模式
·将js的面对对象通过送花的情景讲出来
1、对象JSON Object,描述性,对象字面量,js是动态灵活的语言
{}Object;
2、将现实世界跟代码结合,属性和方法组成复杂数据结构
key:value,value值为function方法,对象有行为或动作时用方法;
3、接口,两个对象实现同样的方法,可以在执行中互换使用,这是代理模式的核心:
-代理模式proxyable:
使用代理模式可以实现更复杂有用的功能,更好的控制对象;
不同对象间实现相同的接口,用于实现相同的动作,使用代理对象可以更好地了解目标对象,数据传送发起者只须负责将数据发送出去,而不再需要了解数据接收方的复杂细节;对于细节的了解监听通过代理对象实现;
-js语法
1、JSON Object literal;
2、this关键字,在对象内部使用this引用对象本身;
3、setTimeout定时器,以毫秒即时,调用指定函数;
-了解前端工作流管理工具
1、安装 npm install stylus -g
-编程素养:
1、函数封装
2、设计需求-->基本能力,将需求细化-函数是解决问题的每一步,而非一行行代码;
3、注释代码:功能、参数、返回值、作者时间;
|
Java
|
UTF-8
| 1,063 | 2.21875 | 2 |
[] |
no_license
|
package com.controller;/********************************************************************
/**
* @Project: spring_web
* @Package com.controller
* @author wangzhenxin
* @date 2017-11-01 9:42
* @Copyright: 2017 www.zyht.com Inc. All rights reserved.
* @version V1.0
*/
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.util.Date;
/**
* @author wangzhenxin
* @ClassName FileUploadController
* @Description 类描述
* @date 2017-11-01
*/
@Controller
@RequestMapping("/file")
public class FileUploadController {
@RequestMapping("/upload")
public String upload(@RequestParam("file") MultipartFile file) throws IOException {
String path="E:/"+new Date().getTime()+ file.getOriginalFilename();
java.io.File newFile= new java.io.File(path);
file.transferTo(newFile);
return "index";
}
}
|
Python
|
UTF-8
| 6,351 | 2.609375 | 3 |
[] |
no_license
|
import os
import shutil
import sass
from jsmin import jsmin
from django.conf import settings
from django.core.management import call_command
from journal import models as journal_models
def process_scss():
"""Compiles SCSS into CSS in the Static Assets folder"""
paths = [
os.path.join(settings.BASE_DIR, 'themes/CMESH/assets/foundation-sites/scss/'),
os.path.join(settings.BASE_DIR, 'themes/CMESH/assets/motion-ui/src/')
]
# File dirs
app_scss_file = os.path.join(settings.BASE_DIR, 'themes/CMESH/assets/scss/app.scss')
app_css_file = os.path.join(settings.BASE_DIR, 'static/CMESH/css/app.css')
compiled_css_from_file = sass.compile(filename=app_scss_file, include_paths=paths)
# Open the CSS file and write into it
write_file = open(app_css_file, 'w')
write_file.write(compiled_css_from_file)
def minify_js_proc(src_text):
"""
:param src_text: Source text to be minified
:return: Minified text
"""
return jsmin(src_text)
def process_js_files(source_paths, dest_path, min_path):
f = open(dest_path, 'w')
js_file = None
try:
js_file = open(min_path, 'w')
for src_file in source_paths:
with open(src_file) as inputFile:
src_text = inputFile.read()
min_text = src_text # minify_js_proc(src_text)
f.write(src_text)
js_file.write(min_text)
finally:
f.close()
if js_file and not js_file.closed:
js_file.close()
def process_js():
"""Copies JS from compile into static assets
"""
source_paths = [
os.path.join(settings.BASE_DIR, 'themes/CMESH/assets/js/admin.js'),
os.path.join(settings.BASE_DIR, 'themes/CMESH/assets/js/app.js'),
os.path.join(settings.BASE_DIR, 'themes/CMESH/assets/js/footnotes.js'),
os.path.join(settings.BASE_DIR, 'themes/CMESH/assets/js/table_of_contents.js'),
os.path.join(settings.BASE_DIR, 'themes/CMESH/assets/js/text_resize.js'),
os.path.join(settings.BASE_DIR, 'themes/CMESH/assets/js/toastr.js'),
]
dest_path = os.path.join(settings.BASE_DIR, 'static/CMESH/js/app.js')
min_path = os.path.join(settings.BASE_DIR, 'static/CMESH/js/app.min.js')
process_js_files(source_paths, dest_path, min_path)
def copy_files(src_path, dest_path):
"""
:param src_path: The source folder for copying
:param dest_path: The destination these files/folders should be copied to
:return: None
"""
if not os.path.exists(src_path):
os.makedirs(src_path)
files = os.listdir(src_path)
for file_name in files:
full_file_name = os.path.join(src_path, file_name)
if os.path.isfile(full_file_name):
shutil.copy(full_file_name, dest_path)
else:
dir_dest = os.path.join(dest_path, file_name)
if os.path.exists(dir_dest):
shutil.rmtree(os.path.join(dir_dest))
shutil.copytree(full_file_name, dir_dest)
def copy_file(source, destination):
"""
:param source: The source of the folder for copying
:param destination: The destination folder for the file
:return:
"""
destination_folder = os.path.join(settings.BASE_DIR, os.path.dirname(destination))
if not os.path.exists(destination_folder):
os.mkdir(destination_folder)
shutil.copy(os.path.join(settings.BASE_DIR, source),
os.path.join(settings.BASE_DIR, destination))
def process_fonts():
"""Processes fonts from the compile folder into Static Assets"""
fonts_path = os.path.join(settings.BASE_DIR, 'themes/CMESH/assets/fonts/')
static_fonts = os.path.join(settings.BASE_DIR, 'static/CMESH/fonts/')
copy_files(fonts_path, static_fonts)
def process_images():
"""Processes images from the compile folder into Static Assets"""
image_path = os.path.join(settings.BASE_DIR, 'themes/CMESH/assets/img/')
static_images = os.path.join(settings.BASE_DIR, 'static/CMESH/img/')
copy_files(image_path, static_images)
def process_journals():
journals = journal_models.Journal.objects.all()
paths = [
os.path.join(settings.BASE_DIR, 'themes/CMESH/assets/foundation-sites/scss/'),
os.path.join(settings.BASE_DIR, 'themes/CMESH/assets/motion-ui/src/')
]
for journal in journals:
# look for SCSS folder and files
scss_files = journal.scss_files
if len(scss_files) == 0:
print('Journal with ID {0} [{1}] has no SCSS to compile'.format(journal.id, journal.name))
else:
print('Journal with ID {0} [{1}]: processing overrides'.format(journal.id, journal.name))
override_css_dir = os.path.join(settings.BASE_DIR, 'static', 'CMESH', 'css')
override_css_file = os.path.join(override_css_dir, 'journal{0}_override.css'.format(str(journal.id)))
# we will only process one single SCSS override file for a journal
compiled_css_from_file = sass.compile(filename=scss_files[0], include_paths=paths)
# test if the journal CSS directory exists and create it if not
os.makedirs(override_css_dir, exist_ok=True)
# open the journal CSS override file and write into it
write_file = open(override_css_file, 'w')
write_file.write(compiled_css_from_file)
journal_dir = os.path.join(settings.BASE_DIR, 'files', 'journals', str(journal.id))
journal_header_image = os.path.join(journal_dir, 'header.png')
if os.path.isfile(journal_header_image):
print('Journal with ID {0} [{1}]: processing header image'.format(journal.id, journal.name))
dest_path = os.path.join(settings.BASE_DIR, 'static', 'CMESH', 'img', 'journal_header{0}.png'.format(journal.id))
copy_file(journal_header_image, dest_path)
def create_paths():
base_path = os.path.join(settings.BASE_DIR, 'static', 'CMESH')
folders = ['css', 'js', 'fonts', 'img']
for folder in folders:
os.makedirs(os.path.join(base_path, folder), exist_ok=True)
def build():
create_paths()
print("Processing SCSS")
process_scss()
print("Processing JS")
process_js()
print("Processing journal overrides")
process_journals()
call_command('collectstatic', '--noinput')
|
Java
|
UTF-8
| 2,562 | 2.875 | 3 |
[] |
no_license
|
package db;
import models.calander.Day;
import models.food.Food;
import models.food.Meal;
import models.person.Person;
import org.hibernate.Criteria;
import org.hibernate.HibernateException;
import org.hibernate.Session;
import org.hibernate.criterion.Restrictions;
import java.util.ArrayList;
import java.util.List;
public class DBDay {
private static Session session;
public static List<Meal> AllMealsForADay(Person person){
List<Meal> results = new ArrayList<Meal>();
List<Day> daysResults = AllDaysBelongingToAPerson(person);
for(Day day : daysResults){
results.addAll(allMealsForADay(day));
} return results;
}
public static List<Food> foodsForADayFromAPerson(Person person){
List<Food> foodResult = new ArrayList<Food>();
List<Meal> result = AllMealsForADay(person);
for(Meal meal: result){
foodResult.addAll(allFoodsForADay(meal));
} return foodResult;
}
public static List<Day> AllDaysBelongingToAPerson(Person person) {
session = HibernateUtil.getSessionFactory().openSession();
List<Day> result = null;
try {
Criteria cr = session.createCriteria(Day.class);
cr.add(Restrictions.eq("person", person));
result = cr.list();
} catch (HibernateException e) {
e.printStackTrace();
} finally {
session.close();
}
return result;
}
public static List<Meal> allMealsForADay(Day day) {
session = HibernateUtil.getSessionFactory().openSession();
List<Meal> result = null;
try {
Criteria cr = session.createCriteria(Meal.class);
cr.add(Restrictions.eq("day", day));
cr.add(Restrictions.eq("day.id", day.getId()));
result = cr.list();
} catch (HibernateException e) {
e.printStackTrace();
} finally {
session.close();
}
return result;
}
public static List<Food> allFoodsForADay(Meal meal) {
session = HibernateUtil.getSessionFactory().openSession();
List<Food> result = null;
try {
Criteria cr = session.createCriteria(Food.class);
cr.add(Restrictions.eq("meal", meal));
cr.add(Restrictions.eq("meal.id", meal.getId()));
result = cr.list();
} catch (HibernateException e) {
e.printStackTrace();
} finally {
session.close();
}
return result;
}
}
|
Python
|
UTF-8
| 107 | 3.859375 | 4 |
[] |
no_license
|
number = input("Enter a number: ")
product = 1
for i in number:
product = product * int(i)
print (product)
|
Rust
|
UTF-8
| 1,573 | 3.78125 | 4 |
[
"MIT"
] |
permissive
|
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
#[derive(Debug)]
pub struct Button {
pub width: u32,
pub height: u32,
pub label: String,
}
impl Draw for Button {
fn draw(&self) {
println!("[{}]", self.label);
}
}
#[derive(Debug)]
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
let last = self.options.len() - 1;
for (index, option) in self.options.iter().enumerate() {
let margin = match index {
0 => "┏",
l if l == last => "┗",
_ => "┣"
};
println!("{}{}", margin, option);
}
}
}
fn main() {
let s = Screen {
components: vec![
Box::new(SelectBox {
width: 100,
height: 20,
options: vec![
String::from("Bleh"),
String::from("Bleu"),
String::from("Blih"),
],
}),
Box::new(Button {
width: 32,
height: 10,
label: String::from("OK"),
}),
// Box::new(String::from("Hi!")),
// ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Draw` is not implemented for `std::string::String`
]
};
s.run();
}
|
Python
|
UTF-8
| 1,412 | 2.96875 | 3 |
[
"MIT"
] |
permissive
|
# -*- coding: utf-8 -*-
"""
实用函数
"""
import time
from itertools import chain, zip_longest
from flask_login import login_required as login_required_
from flask_smorest.utils import deepupdate
from operator import truth
def login_required(func):
"""包装 flask-login 的 login_required 装饰器
给该函数的 401 响应添加 api doc
"""
doc = {'responses': {"401": {'description': "未登录,或者 token 已过期"}}}
func._api_manual_doc = deepupdate(getattr(func, '_api_manual_doc', {}), doc)
return login_required_(func)
def timestamp():
"""Return the current timestamp as an integer."""
return int(time.time())
def group_each(a, size: int, allow_none=False):
"""
将一个可迭代对象 a 内的元素, 每 size 个分为一组
group_each([1,2,3,4], 2) -> [(1,2), (3,4)]
"""
func = zip_longest if allow_none else zip
iterators = [iter(a)] * size # 将新构造的 iterator 复制 size 次(浅复制)
return func(*iterators) # 然后 zip
def iter_one_by_one(items, allow_none=False):
func = zip_longest if allow_none else zip
return chain.from_iterable(func(*items))
def filter_truth(items):
return filter(truth, items) # 过滤掉判断为 False 的 items
def equal(a, b):
"""判断两个 object 的内容是否一致(只判断浅层数据)"""
return a.__dict__ == b.__dict__
|
Java
|
WINDOWS-1252
| 35,263 | 1.71875 | 2 |
[] |
no_license
|
package hr.ante.test.asktable;
import hr.ante.test.asktable.comparator.ASKTableSortOnClick2;
import hr.ante.test.asktable.comparator.ASSortComparatorExample2;
import java.util.Arrays;
import java.util.Comparator;
import java.util.Vector;
import org.eclipse.jface.action.Action;
import org.eclipse.jface.action.IMenuManager;
import org.eclipse.jface.action.MenuManager;
import org.eclipse.swt.SWT;
import org.eclipse.swt.SWTError;
import org.eclipse.swt.dnd.Clipboard;
import org.eclipse.swt.dnd.DND;
import org.eclipse.swt.dnd.TextTransfer;
import org.eclipse.swt.dnd.Transfer;
import org.eclipse.swt.events.SelectionAdapter;
import org.eclipse.swt.events.SelectionEvent;
import org.eclipse.swt.graphics.Image;
import org.eclipse.swt.graphics.Point;
import org.eclipse.swt.widgets.Display;
import org.eclipse.swt.widgets.Menu;
import org.eclipse.swt.widgets.MenuItem;
import org.eclipse.ui.IActionBars;
import org.eclipse.ui.actions.ActionFactory;
import org.mihalis.opal.opalDialog.Dialog;
import de.kupzog.ktable.KTable;
import de.kupzog.ktable.KTableCellSelectionListener;
import de.kupzog.ktable.KTableModel;
import de.kupzog.ktable.KTableSortComparator;
import de.kupzog.ktable.KTableSortedModel;
public class ASKTableContextMenu{
static final char TAB = '\t';
static final String PlatformLineDelimiter = System.getProperty("line.separator");
//public KTableCutAction m_CutAction;
//public KTablePasteAction m_PasteAction;
public KTableSelectAllAction m_SelectAllAction;
public ASKTableSelectAllColumnRowsAction m_SelectAllColumnRowsAction;
public ASKTableSelectAllRowColumnsAction m_SelectAllRowColumnsAction;
public KTableCopyAction m_CopyAction;
public KTableCopyAllAction m_CopyAllAction;
public ASKTableSortAction m_SortAction;
public ASKTableFilterAction m_FilterAction;
protected int m_Col;
protected int m_Row;
protected Vector<Integer> rowsWithText = null;
protected KTableSortedModel m_Model;
protected Menu m_Menu;
protected Menu m_FixedMenu;
protected MenuItem fixedItemSort;
protected MenuItem fixedItemSelectAllColRows;
protected MenuItem fixedItemFilter;
protected MenuItem fixedItemSelectAllRowCols;
protected MenuItem fixedItemSeparator;
protected MenuItem fixedItemSelectAll;
protected MenuItem fixedItemCopyAll;
protected Menu fixedItemSubMenu;
protected MenuItem fixedItemSubItem1;
protected MenuItem fixedItemSubItem2;
protected MenuItem fixedItemSubItem3;
protected Menu m_CellMenu;
protected MenuItem cellItemCopy;
protected KTable m_table;
protected MenuManager m_fixedContextMenuManager;
MenuManager m_SubitemSort;
public ASKTableContextMenu(KTable table,KTableSortedModel model/*,boolean isFixedCell, String doSomething, int clickedColumn*/) {
m_Model = model;
m_table = table;
createActions();
registerActionUpdater();
// add actions to context menu:
//m_fixedContextMenuManager = new MenuManager("#PopupMenu");
//m_fixedContextMenuManager.setRemoveAllWhenShown(true);
//m_Menu = new Menu(m_table.getShell(), SWT.POP_UP);
//m_Menu = m_fixedContextMenuManager.createContextMenu(m_table);
//m_table.setMenu(m_Menu);
}
public void createContextMenu(boolean isFixedCell,boolean isColumnSelected)
{
m_FixedMenu = new Menu(m_table.getShell(), SWT.POP_UP);
if(isFixedCell){
if(!isColumnSelected)
{
fixedItemSelectAllRowCols = new MenuItem(m_FixedMenu, SWT.PUSH);
fixedItemSelectAllRowCols.setText("Select All Row Columns");
fixedItemSelectAllRowCols.addSelectionListener(new SelectionAdapter() {
@Override
public void widgetSelected(SelectionEvent e) {
// TODO Auto-generated method stub
m_SelectAllRowColumnsAction.run();
}
});
//3. item in FixedMenu - separator
fixedItemSeparator = new MenuItem(m_FixedMenu, SWT.SEPARATOR);
//4. item in FixedMenu
fixedItemSelectAll = new MenuItem(m_FixedMenu, SWT.PUSH);
fixedItemSelectAll.setText("Select All");
fixedItemSelectAll.addSelectionListener(new SelectionAdapter() {
@Override
public void widgetSelected(SelectionEvent e) {
// TODO Auto-generated method stub
m_SelectAllAction.run();
}
});
fixedItemCopyAll = new MenuItem(m_FixedMenu, SWT.PUSH);
fixedItemCopyAll.setEnabled(true);
fixedItemCopyAll.setText("Copy All");
fixedItemCopyAll.addSelectionListener(new SelectionAdapter() {
@Override
public void widgetSelected(SelectionEvent e) {
// TODO Auto-generated method stub
m_CopyAllAction.run();
}
});
}
else{
Image ascending = null;
Image descending = null;
Image sort = null;
try {
ascending = new Image(Display.getCurrent(), "C:\\IT\\astrikom\\workspace4\\hr.ante.test\\src\\icons\\sort_up_green.png");
descending = new Image(Display.getCurrent(), "C:\\IT\\astrikom\\workspace4\\hr.ante.test\\src\\icons\\sort_down_green.png");
sort = new Image(Display.getCurrent(), "C:\\IT\\astrikom\\workspace4\\hr.ante.test\\src\\icons\\sort_neutral_green.png");
} catch (Exception e) {
System.out.println("Cannot load images");
System.out.println(e.getMessage());
System.exit(1);
}
//1. item in FixedMenu
fixedItemSort = new MenuItem(m_FixedMenu, SWT.CASCADE);
fixedItemSort.setText("Sort");
fixedItemSort.setImage(sort);
//Sub menu in 1. item in FixedMenu
fixedItemSubMenu = new Menu(m_FixedMenu);
fixedItemSort.setMenu(fixedItemSubMenu);
//1. sub item in 1. in FixedMenu
fixedItemSubItem1 = new MenuItem(fixedItemSubMenu, SWT.PUSH);
fixedItemSubItem1.setText("Ascending");
fixedItemSubItem1.setImage(ascending/*ResourceManager.getPluginImage("hr.ante.test.icons", "sort_up.png")*/);
fixedItemSubItem1.addSelectionListener(new SelectionAdapter() {
@Override
public void widgetSelected(SelectionEvent e) {
// TODO Auto-generated method stub
//m_table.setSelection(null, false);
m_SortAction.run(ASSortComparatorExample2.SORT_DOWN);
}
});
//2. sub item in 1. item in FixedMenu
fixedItemSubItem2 = new MenuItem(fixedItemSubMenu, SWT.PUSH);
fixedItemSubItem2.setText("Descending");
fixedItemSubItem2.setImage(descending);
fixedItemSubItem2.addSelectionListener(new SelectionAdapter() {
@Override
public void widgetSelected(SelectionEvent e) {
// TODO Auto-generated method stub
// implement the sorting when clicking on the header.
//m_table.setSelection(null, false);
m_SortAction.run(ASSortComparatorExample2.SORT_UP);
//sortOnClick(col, row, new ASSortComparatorExample2(model,col, ASSortComparatorExample2.SORT_UP),ASSortComparatorExample2.SORT_UP, 3);
}
});
//3. sub item in 1. item in FixedMenu
fixedItemSubItem3 = new MenuItem(fixedItemSubMenu, SWT.PUSH);
fixedItemSubItem3.setText("Clean Sort");
fixedItemSubItem3.addSelectionListener(new SelectionAdapter() {
@Override
public void widgetSelected(SelectionEvent e) {
// TODO Auto-generated method stub
// implement the sorting when clicking on the header.
//m_table.setSelection(null, false);
m_SortAction.run(ASSortComparatorExample2.SORT_NONE);
// sortOnClick(col, row, new ASSortComparatorExample2(model,col, ASSortComparatorExample2.SORT_NONE),ASSortComparatorExample2.SORT_NONE, 3);
}
});
fixedItemFilter = new MenuItem(m_FixedMenu, SWT.PUSH);
fixedItemFilter.setText("Filter");
fixedItemFilter.addSelectionListener(new SelectionAdapter() {
@Override
public void widgetSelected(SelectionEvent e) {
// TODO Auto-generated method stub
final String input = Dialog.ask("Enter Filter", "Enter Filter text", "");
if(input!=""){
System.out.println("Choice is..." + input);
m_FilterAction.run(input);
}
}
});
//2. item in FixedMenu
fixedItemSelectAllColRows = new MenuItem(m_FixedMenu, SWT.PUSH);
fixedItemSelectAllColRows.setText("Select All Column Rows");
fixedItemSelectAllColRows.addSelectionListener(new SelectionAdapter() {
@Override
public void widgetSelected(SelectionEvent e) {
// TODO Auto-generated method stub
m_SelectAllColumnRowsAction.run();
}
});
//3. item in FixedMenu - separator
fixedItemSeparator = new MenuItem(m_FixedMenu, SWT.SEPARATOR);
//4. item in FixedMenu
fixedItemSelectAll = new MenuItem(m_FixedMenu, SWT.PUSH);
fixedItemSelectAll.setText("Select All");
fixedItemSelectAll.addSelectionListener(new SelectionAdapter() {
@Override
public void widgetSelected(SelectionEvent e) {
// TODO Auto-generated method stub
m_SelectAllAction.run();
}
});
fixedItemCopyAll = new MenuItem(m_FixedMenu, SWT.PUSH);
fixedItemCopyAll.setEnabled(true);
fixedItemCopyAll.setText("Copy All");
fixedItemCopyAll.addSelectionListener(new SelectionAdapter() {
@Override
public void widgetSelected(SelectionEvent e) {
// TODO Auto-generated method stub
m_CopyAllAction.run();
}
});
}
m_table.setMenu(m_FixedMenu);
}
else{
m_CellMenu = new Menu(m_table.getShell(), SWT.POP_UP);
cellItemCopy = new MenuItem(m_CellMenu, SWT.CASCADE);
cellItemCopy.setText("Copy");
cellItemCopy.addSelectionListener(new SelectionAdapter() {
@Override
public void widgetSelected(SelectionEvent e) {
// TODO Auto-generated method stub
m_CopyAction.run();
}
});
m_table.setMenu(m_CellMenu);
}
m_table.redraw();
//
// m_fixedContextMenuManager.addMenuListener(new IMenuListener() {
// public void menuAboutToShow(IMenuManager manager) {
// fillFixedContextMenu(manager);
// }
// });
}
protected void fillFixedContextMenu(IMenuManager menumanager) {
// menumanager.add(m_CopyAction);
// menumanager.add(m_CutAction);
// menumanager.add(m_PasteAction);
// menumanager.add(new Separator());
// menumanager.add(m_CopyAllAction);
// menumanager.add(m_SortAction);
// createFixedSortMenu();
// menumanager.add(m_SubitemSort);
// menumanager.add(m_SelectAllAction);
// menumanager.add(new Separator());
// // Other plug-ins can contribute their actions here
// menumanager.add(new Separator(IWorkbenchActionConstants.MB_ADDITIONS));
}
/**
* Registers the cut, copy, paste and select_all actions for global use at the IActionBar given.<p>
* Currently does not set up the UNDO and REDO actions because they will be implemented in another way.
* @param actionBar The IActionBars that allows global action registration. Normally
* you can get that with getViewerSite().getActionBars() or getEditorSite().getActionBars().
*/
public void registerGlobalActions(IActionBars actionBar) {
// actionBar.setGlobalActionHandler(ActionFactory.CUT.getId(), this.m_CutAction);
actionBar.setGlobalActionHandler(ActionFactory.COPY.getId(), this.m_CopyAction);
// actionBar.setGlobalActionHandler(ActionFactory.PASTE.getId(),this.m_PasteAction);
actionBar.setGlobalActionHandler(ActionFactory.SELECT_ALL.getId(), this.m_SelectAllAction);
actionBar.updateActionBars();
}
public void sortOnClick(int col, int row, KTableSortComparator comparator, int direction, int button) {
if (m_table.getModel() instanceof KTableSortedModel) {
//KTableSortedModel model = (KTableSortedModel) m_table.getModel();
if (row<m_Model.getFixedHeaderRowCount() &&
col>=m_Model.getFixedHeaderColumnCount()) {
if (button == 1) {
// implement the sorting when clicking on the header.
// int type = direction;
// if (model.getSortColumn() == col) {
if (m_Model.getSortState() == KTableSortComparator.SORT_UP) {
direction = KTableSortComparator.SORT_DOWN;
} if (m_Model.getSortState() == KTableSortComparator.SORT_UP) {
direction = KTableSortComparator.SORT_DOWN;
} else if (m_Model.getSortState() == KTableSortComparator.SORT_NONE) {
direction = KTableSortComparator.SORT_UP;
}
// }
}
// update the comparator properly:
comparator.setColumnToCompare(col);
comparator.setSortDirection(direction);
// perform the sorting
m_Model.sort(comparator);
// needed to make the resorting visible!
m_table.redraw();
}
}
}
protected void createActions() {
m_CopyAction = new KTableCopyAction();
m_CopyAllAction = new KTableCopyAllAction();
// m_PasteAction = new KTablePasteAction();
m_FilterAction = new ASKTableFilterAction();
m_SortAction = new ASKTableSortAction();
m_SelectAllAction = new KTableSelectAllAction();
m_SelectAllColumnRowsAction = new ASKTableSelectAllColumnRowsAction();
m_SelectAllRowColumnsAction = new ASKTableSelectAllRowColumnsAction();
// m_CutAction = new KTableCutAction();
}
protected void registerActionUpdater() {
m_table.addCellSelectionListener(new KTableCellSelectionListener() {
public void cellSelected(int col, int row, int statemask) {
m_table.setMenu(null);
m_table.redraw();
m_Col=col;
m_Row=row;
createContextMenu(false,false);
}
public void fixedCellSelected(int col, int row, int statemask) {
m_table.setMenu(null);
m_table.redraw();
m_table.setSelection(null, false);
if(col==0 && row==0){
m_table.setMenu(null);
m_table.redraw();
m_SelectAllAction.run();
}
else if(col==0 && row!=0){
m_Col=col;
m_Row=row;
m_SelectAllRowColumnsAction.run();
createContextMenu(true,false);
}
else if(col!=0){
m_Col=col;
m_Row=row;;
m_SelectAllColumnRowsAction.run();
createContextMenu(true,true);
}
}
});
}
/*protected void updateActions() {
m_CopyAction.updateEnabledState();
m_CutAction.updateEnabledState();
m_PasteAction.updateEnabledState();
}*/
/*protected void updateFixedActions() {
m_CopyAction.updateEnabledState();
m_CopyAllAction.updateEnabledState();
m_CutAction.updateEnabledState();
m_PasteAction.updateEnabledState();
m_SortAction.updateEnabledState();
m_SelectAllAction.updateEnabledState();
}*/
/**
* SELECT ALL
*
*/
protected class KTableSelectAllAction extends Action {
protected KTableSelectAllAction() {
setId("KTableSelectAllActionHandler");//$NON-NLS-1$
//setEnabled(false);
setText("Select All");
}
public void run() {
if (m_table != null && !m_table.isDisposed()) {
if (m_Model != null) {
selectAll(m_Model);
}
}
}
// //public void updateEnabledState() {
// // if (m_table != null && !m_table.isDisposed() &&
// m_table.isMultiSelectMode()) {
// // setEnabled(true);
// // } else setEnabled(false);
// //}
protected void selectAll(KTableModel model) {
Vector<Point> sel = new Vector<Point>();
for (int row=model.getFixedHeaderRowCount(); row<model.getRowCount(); row++)
for (int col=model.getFixedHeaderColumnCount(); col<model.getColumnCount(); col++) {
if (model.belongsToCell(col, row)!=null){
Point cell = model.belongsToCell(col, row);
if (cell.x==col && cell.y==row)
sel.add(cell);
}
else
sel.add(new Point(col, row));
}
try {
m_table.setRedraw(false);
m_table.setSelection(new Point[]{}, false);
m_table.setSelection((Point[])sel.toArray(new Point[]{}), false);
} finally {
m_table.setRedraw(true);
}
}
}
/**
* SELECT ALL COLUMN ROWS
*
*/
protected class ASKTableSelectAllColumnRowsAction extends Action {
protected ASKTableSelectAllColumnRowsAction() {
setId("ASKTableSelectAllColumnRowsActionHandler");//$NON-NLS-1$
setText("Select Column");
}
public void run() {
if (m_table != null && !m_table.isDisposed()) {
if (m_Model!=null){
if (!m_table.isRowSelectMode() && m_table.isMultiSelectMode()) {
selectAllRows(m_Model);
}
}
}
}
public void updateEnabledState(boolean setTrue) {
if (m_table != null && !m_table.isDisposed() && m_table.isMultiSelectMode() && setTrue) {
fixedItemSelectAllColRows.setEnabled(true);
} else fixedItemSelectAllColRows.setEnabled(false);
}
protected void selectAllRows(KTableModel model) {
Vector<Point> sel = new Vector<Point>();
for (int row=model.getFixedHeaderRowCount(); row<model.getRowCount(); row++)
{
if (model.belongsToCell(m_Col, row)!=null){
Point currentCell = model.belongsToCell(m_Col, row);
if (currentCell.x==m_Col && currentCell.y==row)
sel.add(currentCell);
}
else
sel.add(new Point(m_Col,row));
}
try {
m_table.setRedraw(false);
m_table.setSelection(new Point[]{}, false);
m_table.setSelection((Point[])sel.toArray(new Point[]{}), false);
} finally {
m_table.setRedraw(true);
}
}
}
/**
* SELECT ALL ROW COLUMNS
*
*/
protected class ASKTableSelectAllRowColumnsAction extends Action {
protected ASKTableSelectAllRowColumnsAction() {
setId("ASKTableSelectAllRowColumnsActionHandler");//$NON-NLS-1$
setText("Select Row");
}
public void run() {
if (m_table != null && !m_table.isDisposed()) {
if (m_Model!=null){
if (!m_table.isRowSelectMode() && m_table.isMultiSelectMode()) {
selectAllColumns(m_Model);
}
}
}
}
public void updateEnabledState(boolean setTrue) {
if (m_table != null && !m_table.isDisposed() && m_table.isMultiSelectMode() && setTrue) {
fixedItemSelectAllRowCols.setEnabled(true);
} else fixedItemSelectAllRowCols.setEnabled(false);
}
protected void selectAllColumns(KTableModel model) {
Vector<Point> sel = new Vector<Point>();
for (int col=model.getFixedHeaderColumnCount(); col<model.getColumnCount(); col++)
{
if (model.belongsToCell(col, m_Row)!=null){
Point currentCell = model.belongsToCell(col, m_Row);
if (currentCell.x==col && currentCell.y==m_Row)
sel.add(currentCell);
}
else
sel.add(new Point(col,m_Row));
}
try {
m_table.setRedraw(false);
m_table.setSelection(new Point[]{}, false);
m_table.setSelection((Point[])sel.toArray(new Point[]{}), false);
} finally {
m_table.setRedraw(true);
}
}
}
/**
* COPY
*
*/
protected class KTableCopyAction extends Action {
protected KTableCopyAction() {
setId("KTableCopyActionHandler");//$NON-NLS-1$
setText("Copy");
}
public void run() {
if (m_table != null && !m_table.isDisposed()) {
setClipboardContent(m_table.getCellSelection());
}
}
//public void updateEnabledState() {
// if (m_table != null && !m_table.isDisposed()) {
// Point[] selection = m_table.getCellSelection();
// setEnabled(selection!=null && selection.length>0);
// } else setEnabled(false);
//}
}
/**
* COPY ALL
*
*/
protected class KTableCopyAllAction extends Action {
protected KTableCopyAllAction() {
setId("KTableCopyAllActionHandler");//$NON-NLS-1$
setText("Copy All");
}
public void run() {
if (m_table != null && !m_table.isDisposed()) {
if(getAllTableCells()!=null)
setClipboardContent(getAllTableCells());
}
}
//public void updateEnabledState() {
// if (m_table != null && !m_table.isDisposed()) {
// setEnabled(true);
// } else setEnabled(false);
//}
private Point[] getAllTableCells() {
if (m_Model==null) return new Point[]{};
Vector<Point> cells = new Vector<Point>(m_Model.getColumnCount()*m_Model.getRowCount());
for (int row=0; row<m_Model.getRowCount(); row++) {
for (int col=0; col<m_Model.getColumnCount(); col++) {
if (m_Model.belongsToCell(col, row)!=null){
Point valid = m_Model.belongsToCell(col, row);
if (valid.y==row && valid.x==col)
cells.add(valid);
}
else
cells.add(new Point(col, row));
}
}
return (Point[])cells.toArray(new Point[]{});
}
}
/* protected class KTablePasteAction extends Action {
protected KTablePasteAction() {
setId("KTablePasteActionHandler");//$NON-NLS-1$
setText("Paste");
}
public void run() {
if (m_table != null && !m_table.isDisposed()) {
pasteToSelection(getTextFromClipboard(), m_table.getCellSelection());
}
}
protected String getTextFromClipboard() {
Clipboard clipboard = new Clipboard(m_table.getDisplay());
try {
return clipboard.getContents(TextTransfer.getInstance()).toString();
} catch (Exception ex) {
return " ";
} finally {
clipboard.dispose();
}
}
protected void pasteToSelection(String text, Point[] selection) {
if (selection==null || selection.length==0) return;
if (m_Model==null) return;
try {
m_table.setRedraw(false);
m_table.setSelection(new Point[]{}, false);
Vector<Point> sel = new Vector<Point>();
String[][] cellTexts = parseCellTexts(text);
for (int row=0; row<cellTexts.length; row++)
for (int col=0; col<cellTexts[row].length; col++) {
m_Model.setContentAt(col+selection[0].x, row+selection[0].y, cellTexts[row][col]);
sel.add(new Point(col+selection[0].x, row+selection[0].y));
}
m_table.setSelection((Point[])sel.toArray(new Point[]{}), false);
} finally {
m_table.setRedraw(true);
}
}
protected String[][] parseCellTexts(String text) {
if (!m_table.isMultiSelectMode()) {
return new String[][]{{text}};
} else {
String[] lines = text.split(PlatformLineDelimiter);
String[][] cellText = new String[lines.length][];
for (int line=0; line<lines.length; line++)
cellText[line] = lines[line].split(TAB+"");
return cellText;
}
}
//public void updateEnabledState() {
// if (m_table != null && !m_table.isDisposed()) {
// Point[] selection = m_table.getCellSelection();
// if (selection==null)
// setEnabled(false);
// else if (selection.length>1) // && !m_table.isMultiSelectMode())
// setEnabled(false);
// else setEnabled(true);
// } else setEnabled(false);
}
}*/
/**
* SORT
*
*/
protected class ASKTableSortAction extends Action {
protected ASKTableSortAction() {
setId("KTableSortActionHandler");//$NON-NLS-1$
setText("Sort");
}
public void run(int direction) {
if (m_table != null && !m_table.isDisposed()) {
//sortOnClick(m_Col, m_Row, new ASSortComparatorExample2(m_Model,m_Col, ASSortComparatorExample2.SORT_DOWN),ASSortComparatorExample2.SORT_DOWN, 3);
//sortOnClick(m_Col, m_Row, new ASSortComparatorExample2(m_Model,m_Col, direction),direction, buttonClicked);
new ASKTableSortOnClick2(m_table,m_Col, 0, new ASSortComparatorExample2(m_Model,m_Col, direction),direction, 3);
}
}
//public void updateEnabledState() {
// if (m_table != null && !m_table.isDisposed()) {
// setEnabled(true);
// } else setEnabled(false);
//}
}
/**
* FILTER
*
*/
protected class ASKTableFilterAction extends Action {
protected ASKTableFilterAction() {
setId("KTableFilterActionHandler");//$NON-NLS-1$
setText("Filter");
}
public void run(String filterText) {
if (m_table != null && !m_table.isDisposed()) {
Vector<Point> sel = new Vector<Point>();
//Object content;
searchText(filterText);
for (int row=m_Model.getFixedHeaderRowCount(); row<m_Model.getRowCount(); row++){
for (int col=m_Model.getFixedHeaderColumnCount(); col<m_Model.getColumnCount(); col++) {
if (m_Model.belongsToCell(col, row)!=null){
Point cell = m_Model.belongsToCell(col, row);
if (cell.x==col && cell.y==row)
sel.add(cell);
else
sel.add(new Point(col, row));
// if(col==m_Col){
// content = m_Model.getContentAt(col, row);
// if(content.toString().contains(filterText)){
// m_Model.setContentAt(m_Col, rowCounter, content);
// filterSuccesful=true;
//
// rowCounter++;
// if(content instanceof Boolean)
// m_Model.setContentAt(col,row,false);
// m_Model.setContentAt(col,row,"");
// }
//
// }
// sel.add(cell);
}
//else
// sel.add(new Point(col, row));
}
}
try {
m_table.setRedraw(false);
m_table.setSelection(new Point[]{}, false);
m_table.setSelection((Point[])sel.toArray(new Point[]{}), false);
} finally {
m_table.setRedraw(true);
}
}
}
//public void updateEnabledState() {
// if (m_table != null && !m_table.isDisposed()) {
// setEnabled(true);
// } else setEnabled(false);
//}
protected void searchText(String filterText)
{
Object content;
rowsWithText = new Vector<Integer>();
int ctr=1;
boolean filterSuccesful=false;
// int rowCounter=1;
// int rowBefore=1;
for (int row = m_Model.getFixedHeaderRowCount(); row < m_Model
.getRowCount(); row++) {
content = m_Model.getContentAt(m_Col, row);
if (content.toString().contains(filterText)) {
rowsWithText.add(row);
filterSuccesful = true;
// rowCounter++;
// if(content instanceof Boolean)
// m_Model.setContentAt(col,row,false);
// m_Model.setContentAt(col,row,"");
}
}
if (!filterSuccesful) {
Dialog.inform("Filter failed", ".........");
return;
}
int rowCounter=1;
int elementCounter=0;
if(rowsWithText!=null){
for (int row=m_Model.getFixedHeaderRowCount(); row<rowsWithText.size(); row++){
for (int col=m_Model.getFixedHeaderColumnCount(); col<m_Model.getColumnCount(); col++) {
if(!rowsWithText.isEmpty()){
m_Model.setContentAt(col, row, m_Model.getContentAt(col, rowsWithText.get(elementCounter)));
elementCounter++;
}
else
if(m_Model.getContentAt(col, row) instanceof Boolean)
m_Model.setContentAt(col, row,false);
m_Model.setContentAt(col, row,"");
}
}
}
}
}
/**
* Copies the specified text range to the clipboard. The table will be placed
* in the clipboard in plain text format and RTF format.
* @param selection The list of cell indices thats content should be set
* to the clipboard.
*
* @exception SWTError, see Clipboard.setContents
* @see org.eclipse.swt.dnd.Clipboard.setContents
*/
protected void setClipboardContent(Point[] selection) throws SWTError {
//RTFTransfer rtfTransfer = RTFTransfer.getInstance();
TextTransfer plainTextTransfer = TextTransfer.getInstance();
//HTMLTransfer htmlTransfer = HTMLTransfer.getInstance();
//String rtfText = getRTFForSelection(selection);
String plainText = getTextForSelection(selection);
//String htmlText = getHTMLForSelection(selection);
Clipboard clipboard = new Clipboard(m_table.getDisplay());
try {
//clipboard.setContents(new String[] {plainText,rtfText}, new Transfer[] {plainTextTransfer,rtfTransfer});//RTF Transfer
clipboard.setContents(new String[] {plainText}, new Transfer[] {plainTextTransfer});//Plain Text Transfer
//clipboard.setContents(new String[] { plainText, htmlText }, new Transfer[] { plainTextTransfer, htmlTransfer }); // HTmlTransfer
} catch (SWTError error) {
// Copy to clipboard failed. This happens when another application
// is accessing the clipboard while we copy. Ignore the error.
// Rethrow all other errors.
if (error.code != DND.ERROR_CANNOT_SET_CLIPBOARD) {
throw error;
}
} finally {
clipboard.dispose();
}
}
private Point[] findTableDimensions(Point[] selection) {
Point topLeft = new Point(-1,-1);
Point bottomRight = new Point(-1, -1);
for (int i=0; i<selection.length; i++) {
Point cell = selection[i];
if (topLeft.x<0) topLeft.x = cell.x;
else if (topLeft.x>cell.x) topLeft.x = cell.x;
if (bottomRight.x<0) bottomRight.x = cell.x;
else if (bottomRight.x<cell.x) bottomRight.x = cell.x;
if (topLeft.y<0) topLeft.y = cell.y;
else if (topLeft.y>cell.y) topLeft.y = cell.y;
if (bottomRight.y<0) bottomRight.y = cell.y;
else if (bottomRight.y<cell.y) bottomRight.y = cell.y;
}
return new Point[]{topLeft, bottomRight};
}
private Point findCellSpanning(int col, int row, KTableModel model) {
Point spanning = new Point(1,1);
Point cell = new Point(col, row);
while (model.belongsToCell(col+spanning.x, row).equals(cell))
spanning.x++;
while (model.belongsToCell(col, row+spanning.y).equals(cell))
spanning.y++;
return spanning;
}
protected String getHTMLForSelection(Point[] selection) {
StringBuffer html = new StringBuffer();
sortSelectedCells(selection);
Point[] dimensions = findTableDimensions(selection);
Point topLeft = dimensions[0];
Point bottomRight = dimensions[1];
KTableModel model = m_table.getModel();
if (model==null) return "";
// add header:
html.append("Version:1.0\n");
html.append("StartHTML:0000000000\n");
html.append("EndHTML:0000000000\n");
html.append("StartFragment:0000000000\n");
html.append("EndFragment:0000000000\n");
html.append("<html><body><table>");
Point nextValidCell = selection[0];
int selCounter = 1;
for (int row = topLeft.y; row<=bottomRight.y; row++) {
html.append("<tr>");
for (int col = topLeft.x; col<=bottomRight.x; col++) {
if (model.belongsToCell(col, row)!=null){
// may skip the cell when it is spanned by another one.
if(model.belongsToCell(col, row).equals(new Point(col, row))) {
if (nextValidCell.x == col && nextValidCell.y == row) {
html.append("<td");
Point spanning = findCellSpanning(col, row, model);
if (spanning.x>1)
html.append(" colspan=\""+spanning.x+"\"");
if (spanning.y>1)
html.append(" rowspan=\""+spanning.y+"\"");
html.append(">");
Object content = model.getContentAt(col, row);
html.append(maskHtmlChars(content.toString()));
if (selCounter<selection.length) {
nextValidCell = selection[selCounter];
selCounter++;
}
}
else
html.append("<td>");
html.append("</td>");
}
}
}
html.append("</tr>");
}
html.append("</table></body></html>");
return html.toString();
}
private String maskHtmlChars(String text) {
text = text.replaceAll("&", "&");
text = text.replaceAll("","ä");
text = text.replaceAll("", "Ä");
text = text.replaceAll("", "ö");
text = text.replaceAll("", "Ö");
text = text.replaceAll("", "ü");
text = text.replaceAll("", "Ü");
text = text.replaceAll("", "ß");
text = text.replaceAll("\"", """);
text = text.replaceAll("<", "<");
text = text.replaceAll(">", ">");
text = text.replaceAll("", "€");
return text;
}
protected String getTextForSelection(Point[] selection) {
StringBuffer text = new StringBuffer();
Point topLeft = sortSelectedCells(selection);
KTableModel model = m_table.getModel();
if (model==null) return "";
int currentCol = topLeft.x;
for (int i=0; i<selection.length; i++) {
for (; currentCol<selection[i].x; currentCol++)
text.append(TAB);
Object content = model.getContentAt(selection[i].x, selection[i].y);
text.append(content.toString());
if (i+1<selection.length) {
for (int row = selection[i].y; row<selection[i+1].y; row++)
text.append(PlatformLineDelimiter);
if (selection[i].y!=selection[i+1].y)
currentCol=topLeft.x;
}
}
if(text.toString().length()==0)
return " ";
return text.toString();
}
protected String getRTFForSelection(Point[] selection) {
return getTextForSelection(selection);
}
protected Point sortSelectedCells(Point[] selection) {
Arrays.sort(selection, new Comparator<Object>() {
public int compare(Object o1, Object o2) {
Point p1 = (Point)o1;
Point p2 = (Point)o2;
if (p1.y<p2.y) return -1;
if (p1.y>p2.y) return +1;
if (p1.x<p2.x) return -1;
if (p1.x>p2.x) return +1;
return 0;
}
});
int minCol = selection[0].x;
for (int i=1; i<selection.length; i++)
if (selection[i].x<minCol) minCol=selection[i].x;
return new Point(minCol, selection[0].y);
}
}
|
Java
|
UTF-8
| 5,788 | 2.234375 | 2 |
[
"MIT"
] |
permissive
|
package com.xqoo.email.vo;
import com.fasterxml.jackson.annotation.JsonFormat;
import io.swagger.annotations.ApiModelProperty;
import javax.validation.constraints.NotNull;
import java.util.Date;
import java.util.Objects;
/**
* @author: zhangdong
* @date 2021/1/20
* @description TODO
*/
public class EmailTemplateVO {
@ApiModelProperty("自增长id")
private Integer id;
@ApiModelProperty("模板名称")
@NotNull(message = "模板名称不能为空")
private String templateName;
@ApiModelProperty("邮件标题")
@NotNull(message = "邮件标题不能为空")
private String emailSubject;
@ApiModelProperty("邮件内容")
@NotNull(message = "邮件内容不能为空")
private String emailText;
@ApiModelProperty("模板类型")
private Integer templateType;
@ApiModelProperty("删除标识")
private Integer delFlag;
@ApiModelProperty("邮件文件路径")
private String emailFilePath;
@ApiModelProperty("邮件文件名称")
private String emailFileName;
@ApiModelProperty("创建人")
private String createBy;
@ApiModelProperty("创建时间")
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss" ,timezone = "GMT+8")
private Date createDate;
@ApiModelProperty("最近修改人")
private String updateBy;
@ApiModelProperty("最近修改时间")
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss" ,timezone = "GMT+8")
private Date updateDate;
@ApiModelProperty("备注信息")
private String remarkTips;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof EmailTemplateVO)) return false;
EmailTemplateVO that = (EmailTemplateVO) o;
return Objects.equals(getTemplateName(), that.getTemplateName()) &&
Objects.equals(getEmailSubject(), that.getEmailSubject()) &&
Objects.equals(getEmailText(), that.getEmailText()) &&
Objects.equals(getTemplateType(), that.getTemplateType()) &&
Objects.equals(getDelFlag(), that.getDelFlag()) &&
Objects.equals(getEmailFilePath(), that.getEmailFilePath()) &&
Objects.equals(getEmailFileName(), that.getEmailFileName()) &&
Objects.equals(getCreateBy(), that.getCreateBy()) &&
Objects.equals(getCreateDate(), that.getCreateDate()) &&
Objects.equals(getUpdateBy(), that.getUpdateBy()) &&
Objects.equals(getUpdateDate(), that.getUpdateDate()) &&
Objects.equals(getRemarkTips(), that.getRemarkTips());
}
@Override
public int hashCode() {
return Objects.hash(getTemplateName(), getEmailSubject(), getEmailText(), getTemplateType(), getDelFlag(), getEmailFilePath(), getEmailFileName(), getCreateBy(), getCreateDate(), getUpdateBy(), getUpdateDate(), getRemarkTips());
}
@Override
public String toString() {
return "EmailTemplateVO{" +
"templateName='" + templateName + '\'' +
", emailSubject='" + emailSubject + '\'' +
", emailText='" + emailText + '\'' +
", templateType=" + templateType +
", delFlag=" + delFlag +
", emailFilePath='" + emailFilePath + '\'' +
", emailFileName='" + emailFileName + '\'' +
", createBy='" + createBy + '\'' +
", createDate=" + createDate +
", updateBy='" + updateBy + '\'' +
", updateDate=" + updateDate +
", remarkTips='" + remarkTips + '\'' +
'}';
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getTemplateName() {
return templateName;
}
public void setTemplateName(String templateName) {
this.templateName = templateName;
}
public String getEmailSubject() {
return emailSubject;
}
public void setEmailSubject(String emailSubject) {
this.emailSubject = emailSubject;
}
public String getEmailText() {
return emailText;
}
public void setEmailText(String emailText) {
this.emailText = emailText;
}
public Integer getTemplateType() {
return templateType;
}
public void setTemplateType(Integer templateType) {
this.templateType = templateType;
}
public Integer getDelFlag() {
return delFlag;
}
public void setDelFlag(Integer delFlag) {
this.delFlag = delFlag;
}
public String getEmailFilePath() {
return emailFilePath;
}
public void setEmailFilePath(String emailFilePath) {
this.emailFilePath = emailFilePath;
}
public String getEmailFileName() {
return emailFileName;
}
public void setEmailFileName(String emailFileName) {
this.emailFileName = emailFileName;
}
public String getCreateBy() {
return createBy;
}
public void setCreateBy(String createBy) {
this.createBy = createBy;
}
public Date getCreateDate() {
return createDate;
}
public void setCreateDate(Date createDate) {
this.createDate = createDate;
}
public String getUpdateBy() {
return updateBy;
}
public void setUpdateBy(String updateBy) {
this.updateBy = updateBy;
}
public Date getUpdateDate() {
return updateDate;
}
public void setUpdateDate(Date updateDate) {
this.updateDate = updateDate;
}
public String getRemarkTips() {
return remarkTips;
}
public void setRemarkTips(String remarkTips) {
this.remarkTips = remarkTips;
}
}
|
JavaScript
|
UTF-8
| 283 | 4.21875 | 4 |
[] |
no_license
|
// ejemplo de hoisting var
var miNombre = undefined;
console.log(miNombre + " Soy ese hoisting");
miNombre = "Jimmy";
// ejecuta en consola para ver el resultado
// ejemplo de hoisting function
hey();
function hey( ){
console.log("hola " + miNombre);
}
var miNombre = "Jimmy";
|
JavaScript
|
UTF-8
| 2,023 | 3.015625 | 3 |
[] |
no_license
|
function TodoViewModel(todo) {
var self = this;
this.todo = todo;
self.date = '';
self.newNoteText = ko.observable('');
self.notes = ko.observableArray();
// this.availableColors = ko.observableArray(["red", "slateblue", "lightseagreen", "khaki", "slategray", "deeppink", "coral"]);
// this.availableColors = ko.observableArray([["red", "1"], ["slateblue", "2"]]);
this.availableColors = ko.observableArray([{color:"rgb(56,212,208)", colorName: "aquamarine"}, {color:"rgb(209,131,219)", colorName:"purple"}, {color:"rgb(156,219,131)", colorName:"green"}, {color:"rgb(242,105,105)", colorName:"red"}, {color:"rgb(55,170,225)", colorName:"blue"}, {color:"rgb(255,154,127)", colorName:"orange"}]);
self.chosenColor = ko.observable();
// self.colorName = ko.observable();
this.addNote = function() {
console.log(self.chosenColor().color);
console.log(self.chosenColor().colorName);
self.date = moment().format('MMMM MM, LT');
this.todo.addNote(this.newNoteText(), this.chosenColor().color);
this.newNoteText('');
this.notes(this.todo.notesArr);
// this.notee = document.querySelector(".note");
// console.log('this.notee', this.notee);
// document.querySelector(".note").style.opacity = '1';
}
self.removeNotes = function(note) {
self.notes.remove(note);
}
this.onEditMode = function() {
this.isEditMode(true);
this.turnOnBtn(true);
}
}
function TodoView() {
this.notesArr = [];
var counter = 1;
this.addNote = function(todoTitle, color) {
this.notesArr.unshift({
id: 'Note ' + counter++,
title: ko.observable(todoTitle),
color: color,
isEditMode: ko.observable(false),
turnOnBtn: ko.observable(false)
})
console.log(this.notesArr);
}
}
var todo = new TodoView();
ko.applyBindings(new TodoViewModel(todo), document.getElementById('wrapperr'));
|
TypeScript
|
UTF-8
| 128 | 2.578125 | 3 |
[] |
no_license
|
/**
* Interface for the 'User' data
*/
export interface UserEntity {
id: string;
firstName: string;
lastName: string;
}
|
Python
|
UTF-8
| 684 | 2.90625 | 3 |
[
"MIT"
] |
permissive
|
from .base import JiraBase
from .utils import render
class Row(JiraBase):
def __init__(self, *columns):
self.columns = list(columns)
def render(self) -> str:
inner = "|".join([render(c) for c in self.columns])
return f"|{inner}|"
class HeadRow(Row):
def render(self) -> str:
inner = "||".join([render(c) for c in self.columns])
return f"||{inner}||"
class Table(JiraBase):
def __init__(self, *rows):
self.rows = list(rows)
def append(self, *columns):
self.rows.append(Row(*columns))
def render(self) -> str:
inner = "\n".join([render(r) for r in self.rows])
return f"\n{inner}\n"
|
Swift
|
UTF-8
| 3,524 | 2.65625 | 3 |
[] |
no_license
|
//
// AddPasswordViewController.swift
// PasswordKeeper
//
// Created by Herman Kwan on 6/12/18.
// Copyright © 2018 Herman Kwan. All rights reserved.
//
import UIKit
import AudioToolbox
class AddPasswordViewController: UIViewController {
@IBOutlet weak var titleTextField: UITextField!
@IBOutlet weak var usernameTextField: UITextField!
@IBOutlet weak var passwordTextField: UITextField!
@IBOutlet weak var notesTextView: UITextView!
override func viewDidLoad() {
super.viewDidLoad()
navigationItem.title = "New"
navigationController?.navigationBar.tintColor = UIColor.white
tabBarController?.tabBar.isHidden = true
titleTextField.delegate = self
usernameTextField.delegate = self
passwordTextField.delegate = self
notesTextView.delegate = self
notesTextView.inputAccessoryView = toolBar
titleTextField.textContentType = UITextContentType("")
usernameTextField.textContentType = UITextContentType("")
passwordTextField.textContentType = UITextContentType("")
notesTextView.textContentType = UITextContentType("")
}
let toolBar: UIToolbar = {
let tb = UIToolbar()
tb.sizeToFit()
let flex = UIBarButtonItem(barButtonSystemItem: .flexibleSpace, target: self, action: nil)
let done = UIBarButtonItem(barButtonSystemItem: .done, target: self, action: #selector(doneToolBarTapped))
tb.items = [flex, done]
return tb
}()
@objc func doneToolBarTapped() {
UIView.animate(withDuration: 0.4) {
self.view.transform = CGAffineTransform(translationX: 0, y: 0)
self.notesTextView.resignFirstResponder()
}
}
@IBAction func addButtonTapped(_ sender: UIBarButtonItem) {
guard let title = titleTextField.text, !title.isEmpty, let username = usernameTextField.text, !username.isEmpty, let passcode = passwordTextField.text, !passcode.isEmpty, let notes = notesTextView.text else {
AudioServicesPlaySystemSound(kSystemSoundID_Vibrate)
let alert = UIAlertController(title: "Missing Information", message: "Please make sure to at least fill out title, username, and password", preferredStyle: .alert)
let okay = UIAlertAction(title: "Okay", style: .default, handler: nil)
alert.addAction(okay)
present(alert, animated: true, completion: nil)
return
}
PasswordController.shared.createNewPassword(title: title, username: username, passcode: passcode, notes: notes)
navigationController?.popViewController(animated: true)
}
}
extension AddPasswordViewController: UITextFieldDelegate {
func textFieldShouldReturn(_ textField: UITextField) -> Bool {
titleTextField.resignFirstResponder()
usernameTextField.resignFirstResponder()
passwordTextField.resignFirstResponder()
return true
}
}
extension AddPasswordViewController: UITextViewDelegate {
func textViewDidBeginEditing(_ textView: UITextView) {
UIView.animate(withDuration: 0.4) {
self.view.transform = CGAffineTransform(translationX: 0, y: -(self.view.frame.height / 3))
}
}
func textViewDidEndEditing(_ textView: UITextView) {
UIView.animate(withDuration: 0.4) {
self.view.transform = CGAffineTransform(translationX: 0, y: 0)
}
}
}
|
C++
|
UTF-8
| 1,319 | 3 | 3 |
[] |
no_license
|
#include "Delegate.h"
#include "Utils.h"
class B
{
public:
bool Func(int i)
{
LOG("Test Member Function (%d)\n", i);
return true;
}
void FuncMulticast(int i, int j)
{
LOG("Test Multicast Member Function (%d, %d)\n", i, j);
}
};
bool TestRawFunc()
{
LOG("Test Raw Function\n");
return true;
}
void TestMulticastRawFunc(int i, int j)
{
LOG("Test Multicast Raw Function (%d, %d)\n", i, j);
}
void TestDelegate()
{
const char* Toto = "Lambda";
B b;
bool res = false;
Delegate<> TestVoidVoidLambda;
TestVoidVoidLambda.BindLambda([Toto]() { LOG("Test Void Void %s\n", Toto); });
TestVoidVoidLambda.Execute();
Delegate<bool> TestBoolVoidRaw;
TestBoolVoidRaw.BindRaw(&TestRawFunc);
res = TestBoolVoidRaw.Execute();
Delegate<bool, int> TestBoolIntMember;
TestBoolIntMember.BindMember(&b, &B::Func);
res = TestBoolIntMember.Execute(42);
MulticastDelegate<int, int> TestMulticast;
TestMulticast.AddMember(&b, &B::FuncMulticast);
TestMulticast.AddMemberUnique(&b, &B::FuncMulticast);
TestMulticast.RemoveMember(&b, &B::FuncMulticast);
TestMulticast.AddMember(&b, &B::FuncMulticast);
TestMulticast.AddLambda([Toto](int i, int j) { LOG("Test Multicast %s (%d, %d)\n", Toto, i, j); });
TestMulticast.AddRaw(TestMulticastRawFunc);
TestMulticast.Broadcast(4, 8);
TestMulticast.Clear();
}
|
Java
|
UTF-8
| 1,567 | 2.703125 | 3 |
[
"BSD-3-Clause"
] |
permissive
|
package edu.ksu.cs.benign;
import android.app.IntentService;
import android.content.Intent;
import android.util.Log;
import java.io.File;
/**
* An {@link IntentService} subclass for handling asynchronous task requests in
* a service on a separate handler thread.
* <p>
* TODO: Customize class - update intent actions and extra parameters.
*/
public class DeleteFilesIntentService extends IntentService {
public DeleteFilesIntentService() {
super("DeleteFilesIntentService");
}
@Override
protected void onHandleIntent(Intent intent) {
boolean delete = intent.getBooleanExtra("Delete", false);
if (delete) {
File dir = getFilesDir();
File file = new File(dir, "myfile");
if (file.exists()) {
Log.d("DeleteFilesService", file.getName() + " exists");
if (file.delete()) {
startActivity(new Intent(getApplicationContext(), DeleteStatusActivity.class)
.addFlags(Intent.FLAG_ACTIVITY_NEW_TASK)
.putExtra("status", "success"));
Log.d("DeleteFilesService", file.getName() + " deleted");
} else {
Log.d("DeleteFilesService", file.getName() + " could not be deleted");
}
}
} else
startActivity(new Intent(getApplicationContext(), DeleteStatusActivity.class)
.addFlags(Intent.FLAG_ACTIVITY_NEW_TASK)
.putExtra("status", "fail"));
}
}
|
Python
|
UTF-8
| 708 | 2.546875 | 3 |
[
"MIT"
] |
permissive
|
import sys
import json
def main(args):
vcf_filename = args[1]
gt_map = {}
with open(vcf_filename) as f:
for line in f:
line = line.strip()
if line.startswith('#'):
continue
terms = line.split('\t')
assert(len(terms) > 9)
for sample_idx in range(9, len(terms)):
if terms[sample_idx] not in gt_map:
gt_map[terms[sample_idx]] = 0
gt_map[terms[sample_idx]] += 1
print(json.dumps(gt_map, indent=2))
with open(vcf_filename + '.gt_freqs.json', 'w') as fout:
json.dump(gt_map, fout)
if __name__ == '__main__':
print(sys.argv)
main(sys.argv)
|
Go
|
UTF-8
| 3,459 | 2.625 | 3 |
[
"MIT"
] |
permissive
|
package generator
import (
"fmt"
"io/ioutil"
"path/filepath"
"strings"
"testing"
"context"
strings2 "github.com/recolabs/microgen/generator/strings"
"github.com/recolabs/microgen/generator/template"
"github.com/stretchr/testify/assert"
"github.com/vetcher/go-astra"
"github.com/vetcher/go-astra/types"
)
func findInterface(file *types.File, ifaceName string) *types.Interface {
for i := range file.Interfaces {
if file.Interfaces[i].Name == ifaceName {
return &file.Interfaces[i]
}
}
return nil
}
func loadInterface(sourceFile, ifaceName string) (*types.Interface, error) {
info, err := astra.ParseFile(sourceFile)
if err != nil {
return nil, err
}
i := findInterface(info, ifaceName)
if i == nil {
return nil, fmt.Errorf("could not find %s interface", ifaceName)
}
return i, nil
}
func TestTemplates(t *testing.T) {
outPath := "./test_out/"
sourcePath := "./test_assets/service.go.txt"
absSourcePath, err := filepath.Abs(sourcePath)
importPackagePath, err := resolvePackagePath(outPath)
iface, err := loadInterface(sourcePath, "StringService")
if err != nil {
t.Fatal(err)
}
genInfo := &template.GenerationInfo{
SourcePackageImport: importPackagePath,
Iface: iface,
OutputFilePath: outPath,
SourceFilePath: absSourcePath,
ProtobufPackageImport: strings2.FetchMetaInfo(TagMark+ProtobufTag, iface.Docs),
}
t.Log("protobuf pkg", genInfo.ProtobufPackageImport)
allTemplateTests := []struct {
TestName string
Template template.Template
OutFilePath string
}{
{
TestName: "Endpoints",
Template: template.NewEndpointsTemplate(genInfo),
OutFilePath: "transport_endpoints.go.txt",
},
{
TestName: "Exchange",
Template: template.NewExchangeTemplate(genInfo),
OutFilePath: "transport_exchanges.go.txt",
},
{
TestName: "Middleware",
Template: template.NewMiddlewareTemplate(genInfo),
OutFilePath: "middleware.go.txt",
},
{
TestName: "Logging",
Template: template.NewLoggingTemplate(genInfo),
OutFilePath: "logging.go.txt",
},
{
TestName: "GRPC Server",
Template: template.NewGRPCServerTemplate(genInfo),
OutFilePath: "grpc_server.go.txt",
},
{
TestName: "GRPC Client",
Template: template.NewGRPCClientTemplate(genInfo),
OutFilePath: "grpc_client.go.txt",
},
{
TestName: "GRPC Converter",
Template: template.NewGRPCEndpointConverterTemplate(genInfo),
OutFilePath: "grpc_converters.go.txt",
},
{
TestName: "GRPC Type Converter",
Template: template.NewStubGRPCTypeConverterTemplate(genInfo),
OutFilePath: "grpc_type.go.txt",
},
}
for _, test := range allTemplateTests {
t.Run(test.TestName, func(t *testing.T) {
expected, err := ioutil.ReadFile("test_assets/" + test.OutFilePath)
if err != nil {
t.Fatalf("read expected file error: %v", err)
}
absOutPath := "./test_out/"
gen, err := NewGenUnit(context.Background(), test.Template, absOutPath)
if err != nil {
t.Fatalf("NewGenUnit: %v", err)
}
err = gen.Generate(context.Background())
if err != nil {
t.Fatalf("unable to generate: %v", err)
}
actual, err := ioutil.ReadFile("./test_out/" + test.Template.DefaultPath())
if err != nil {
t.Fatalf("read actual file error: %v", err)
}
assert.Equal(t,
strings.Split(string(expected[:]), "\n"),
strings.Split(string(actual[:]), "\n"),
)
})
}
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.