
language
stringclasses 15
values | src_encoding
stringclasses 34
values | length_bytes
int64 6
7.85M
| score
float64 1.5
5.69
| int_score
int64 2
5
| detected_licenses
listlengths 0
160
| license_type
stringclasses 2
values | text
stringlengths 9
7.85M
|
|---|---|---|---|---|---|---|---|
JavaScript
|
UTF-8
| 354 | 3.265625 | 3 |
[] |
no_license
|
function Person(firstName, lastName) {
this.firstName = firstName;
this.lastName = lastName;
this.getFullName = function() {
return this.firstName + " " + this.lastName;
}
}
var MyJavaClass = Java.type("com.lianjia.jsengine.TestJS");
var person1 = new Person("Peter", "Parker");
MyJavaClass.fun4(person1);
// Full Name is: Peter Parker
|
JavaScript
|
UTF-8
| 1,690 | 2.90625 | 3 |
[] |
no_license
|
"use strict";
$(document).ready( () => {
deleteAllCookies();
const path = `http://${$(location).attr('host')}`;
$("#login-public").click( () => {
let username = $("#username").val();
// var password = $("#password").val();
if(verifyUsername(username)) {
$.ajax({
type: 'POST',
url: `${path}/login`,
data: {name: username},
success(content) {
window.location.href = `${path}/chat`;
}
});
} else {
return false; // to stop link
}
});
$("#create-accessCode").click( () => {
const username = $("#username").val();
// var password = $("#password").val();
verifyUsername();
$.ajax({
type: 'POST',
url: `${path}/login/generateAccessCode`,
data: {name: username},
success(data) {
$("#username").val(username);
$("#accessCode").val(data.accessCode);
}
});
return false; // to stop link
});
});
function deleteAllCookies() {
const cookies = document.cookie.split(";");
for (let i = 0; i < cookies.length; i++) {
const cookie = cookies[i];
const eqPos = cookie.indexOf("=");
const name = eqPos > -1 ? cookie.substr(0, eqPos) : cookie;
document.cookie = `${name}=;expires=Thu, 01 Jan 1970 00:00:00 GMT`;
}
}
function verifyUsername(username){
const regex = /[!@#\$%\^\&*\)\(+=.-]{1,}/g;
if (regex.test(username) || username.trim() == ''){
alert('Please Enter a Valid Username');
return false;
} else {
return true;
}
}
|
PHP
|
UTF-8
| 864 | 2.859375 | 3 |
[] |
no_license
|
<!DOCTYPE html>
<html>
<head>
<title>formulaire</title>
<meta charset="utf-8"/>
</head>
<body>
<P>BONJOUR </P>
<?php
function securisation($donnees){
$donnees=trim($donnees);
$donnees=stripcslashes($donnees);
$donnees=strip_tags($donnees);
return $donnees;
}
echo securisation($_POST['prenom']) .'<br/>'. securisation($_POST['nom']);
?>
<p>Clique <a href="index.php">ici</a> pour reveneir au formualire</p>
<p><a href="mysql.php">mysql</a></p>
<?php
try {
$connection = new PDO("mysql:host=127.0.0.1;dbname=test2", "root", "root");
$connection->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$requet=$connection->prepare("SELECT prenom FROM visiteur WHERE sexe='H'");
$requet->execute();
$resul=$requet->fetchAll();
echo '<pre>';
print_r($resul);
echo'</pre>';
}
catch(PDOException $e){
echo 'echec ';
}
?>
</body>
</html>
|
JavaScript
|
UTF-8
| 824 | 4.75 | 5 |
[] |
no_license
|
// The boolean has only two values: true and flase
// This type is commonly used to store yes/no values: true means “yes, correct”, and false means “no, incorrect”.
let nameFieldChecked = true;
let ageFieldChecked = false;
console.log(nameFieldChecked)
console.log(ageFieldChecked)
let isGreat = 4 > 1;
console.log(isGreat);
let age = null;
console.log(age)
/*
In JavaScript, null is not a “reference to a non-existing object” or a “null pointer” like in some other languages.
It’s just a special value which represents “nothing”, “empty” or “value unknown”.
The code above states that age is unknown.
*/
let age2;
console.log(age2)
/*
The meaning of undefined is “value is not assigned”.
If a variable is declared, but not assigned, then its value is undefined
*/
typeof undefined
|
Java
|
UTF-8
| 311 | 1.585938 | 2 |
[] |
no_license
|
package top.zhacker.sample.retail.online.item.domain.item.param;
import lombok.Data;
import lombok.experimental.Accessors;
/**
* Created by zhacker.
* Time 2018/2/12 下午9:09
*/
@Data
@Accessors(chain = true)
public class ItemUpdateStatusParam {
private Long itemId;
private Integer status;
}
|
C#
|
UTF-8
| 2,021 | 2.671875 | 3 |
[] |
no_license
|
using Newtonsoft.Json;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Windows.Media.Streaming.Adaptive;
using Windows.Storage;
namespace DataAccess.Data
{
public static class SettingsContext
{
private static string fileName = "settings.json";
private static Settings _settings { get; set; }
public static async Task CreateSettingsFile()
{
FileInfo fInfo = new FileInfo(fileName);
if (fInfo.Exists)
{
StorageFile storageFile = await ApplicationData.Current.LocalFolder.CreateFileAsync(fileName);
}
}
//public static void GetSettingsInformation()
//{
// //StorageFile settingsFile = await ApplicationData.Current.LocalFolder.GetFileAsync("settings.json");
// //var settings = JsonConvert.DeserializeObject<Settings>(await FileIO.ReadTextAsync(settingsFile));
// var settingsFile = "{\"status\": [\"Open\", \"Waiting\", \"Closed\"], \"maxItemsCount\": 4}";
// _settings = JsonConvert.DeserializeObject<Settings>(settingsFile);
//}
public static async Task GetSettingsInfo()
{
StorageFile settingsFile = await ApplicationData.Current.LocalFolder.GetFileAsync(fileName);
_settings = JsonConvert.DeserializeObject<Settings>(await FileIO.ReadTextAsync(settingsFile));
}
public static IEnumerable<string> GetStatus()
{
List<string> list = new List<string>();
foreach (var status in _settings.status)
{
list.Add(status);
}
return list;
}
public static int GetMaxItemsCount()
{
return _settings.maxItemsCount;
}
}
public class Settings
{
public string[] status { get; set; }
public int maxItemsCount { get; set; }
}
}
|
Java
|
UTF-8
| 944 | 2.484375 | 2 |
[
"Apache-2.0"
] |
permissive
|
package data.cleaning.core.service.repair.impl;
import data.cleaning.core.service.dataset.impl.Record;
public class Violation {
private Record record;
public Record getRecord() {
return record;
}
public void setRecord(Record record) {
this.record = record;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((record == null) ? 0 : record.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Violation other = (Violation) obj;
if (record == null) {
if (other.record != null)
return false;
} else if (!record.equals(other.record))
return false;
return true;
}
@Override
public String toString() {
// return "(" + record.getId() + ", " + getMembership() + ")";
return record.getId() + " ";
}
}
|
Java
|
GB18030
| 467 | 2.140625 | 2 |
[] |
no_license
|
package ccc_ui.ui;
import java.awt.Color;
public class UiStyle
{
public String bkImage = null;
public int imageStyle = IMAGE_STYLE_STRETCH;
public Color colorForeground = null;
public Color colorBackground = null;
public static final int IMAGE_STYLE_STRETCH = 0; //
public static final int IMAGE_STYLE_PINGPU = 1; // ƽ
public static final int IMAGE_STYLE_SUOFANG = 2; //
}
|
C++
|
UTF-8
| 673 | 3.265625 | 3 |
[] |
no_license
|
// Question https://leetcode.com/problems/find-peak-element
class Solution {
public:
int findPeakElement(vector<int>& nums) {
int len = nums.size(), l = 0, r = len - 1;
int mid, mL, mR;
while (l <= r) {
mid = l + (r - l) / 2;
mL = (mid - 1 < 0) ? INT_MIN : nums[mid - 1];
mR = (mid + 1 >= len) ? INT_MAX : nums[mid + 1];
if (nums[mid] > mL && nums[mid] > mR) {
return mid;
}
if (mL > mR) {
r = mid - 1;
}
else {
l = mid + 1;
}
}
return mid;
}
};
|
C#
|
UTF-8
| 4,502 | 2.609375 | 3 |
[] |
no_license
|
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using GitTask.Domain.Attributes;
using GitTask.Domain.Services.Interface;
using GitTask.Storage.Exception;
namespace GitTask.Storage
{
public class QueryService<TModel> : IQueryService<TModel>
{
private readonly IStorageService<TModel> _storageService;
private readonly HashSet<object> _recentlyChanged;
private readonly HashSet<object> _recentlyDeleted;
private Dictionary<object, TModel> _data;
public event Action<TModel> ElementAdded;
public event Action<TModel> ElementUpdated;
public event Action<TModel> ElementDeleted;
public event Action ElementsReloaded;
public QueryService(IStorageService<TModel> storageService, IMergingService mergingService)
{
_storageService = storageService;
_recentlyChanged = new HashSet<object>();
_recentlyDeleted = new HashSet<object>();
mergingService.MergingCompleted += InitializeDataFromStorage;
_data = new Dictionary<object, TModel>();
InitializeDataFromStorage();
}
private async void InitializeDataFromStorage()
{
_recentlyChanged.Clear();
_recentlyDeleted.Clear();
_data = GetKeySortedData(await _storageService.GetAll());
ElementsReloaded?.Invoke();
}
public IEnumerable<TModel> GetByProperty(string propertyName, object propertyValue)
{
var property = typeof(TModel).GetProperty(propertyName);
if (property == null)
{
throw new PropertyNotFoundException(propertyName, typeof(TModel));
}
return _data.Values.Where(modelObject => property.GetValue(modelObject) == propertyValue);
}
public IEnumerable<TModel> GetAll()
{
return _data.Values;
}
public void Delete(object keyValue)
{
AssertKeyExists(keyValue);
var removed = GetByKey(keyValue);
RemoveFromCollection(keyValue);
ElementDeleted?.Invoke(removed);
}
public TModel GetByKey(object keyValue)
{
AssertKeyExists(keyValue);
return _data[keyValue];
}
public void AddNew(TModel modelObject)
{
var modelObjectKeyValue = KeyAttribute.GetKeyValue(modelObject);
AssertKeyNotExists(modelObjectKeyValue);
UpdateCollection(modelObjectKeyValue, modelObject);
ElementAdded?.Invoke(modelObject);
}
public void Update(TModel modelObject)
{
var modelObjectKeyValue = KeyAttribute.GetKeyValue(modelObject);
AssertKeyExists(modelObjectKeyValue);
UpdateCollection(modelObjectKeyValue, modelObject);
ElementUpdated?.Invoke(modelObject);
}
public async Task SaveChanges()
{
foreach (var modelObjectKeyValue in _recentlyChanged)
{
await _storageService.Save(_data[modelObjectKeyValue]);
}
foreach (var modelObjectKeyValue in _recentlyDeleted)
{
await _storageService.Delete(modelObjectKeyValue);
}
_recentlyChanged.Clear();
_recentlyDeleted.Clear();
}
private void AssertKeyExists(object keyValue)
{
if (!_data.ContainsKey(keyValue))
{
throw new KeyNotExistsException(keyValue);
}
}
private void AssertKeyNotExists(object keyValue)
{
if (_data.ContainsKey(keyValue))
{
throw new KeyAlreadyExistsException(keyValue);
}
}
private void UpdateCollection(object keyValue, TModel modelObject)
{
_data[keyValue] = modelObject;
_recentlyChanged.Add(keyValue);
}
private void RemoveFromCollection(object keyValue)
{
_data.Remove(keyValue);
_recentlyDeleted.Add(keyValue);
}
private static Dictionary<object, TModel> GetKeySortedData(IEnumerable<TModel> data)
{
var modelKeyProperty = KeyAttribute.GetKeyProperty(typeof(TModel));
return data.ToDictionary(modelObject => modelKeyProperty.GetValue(modelObject));
}
}
}
|
Swift
|
UTF-8
| 670 | 2.515625 | 3 |
[] |
no_license
|
import Foundation
import CoreData
import WalletPresentationData
public class TextureEntity: NSManagedObject, CDHelperEntity {
public static var entityName: String! { return "TextureEntity" }
@NSManaged public var front: String
@NSManaged public var back: String
}
extension TextureEntity {
public func convertEntityInPresentationData() -> Texture {
return Texture(front: front, back: back)
}
}
extension Texture {
public func convertResponseInEntity() -> TextureEntity {
let entity = TextureEntity.newInBackgroundQueue()
entity.front = front
entity.back = back
return entity
}
}
|
Ruby
|
UTF-8
| 575 | 2.59375 | 3 |
[] |
no_license
|
require 'Munging'
describe Munging do
describe 'min' do
it "should return day 3" do
data = [{:day => 1, :max =>88, :min => 59}, {:day => 2, :max =>88, :min => 40}, {:day => 3, :max =>88, :min => 70}]
dataMunging = Munging.new(data)
dataMunging.findSmallestRange()[:day].should eq 3
end
it "should return day 2" do
data = [{:day => 1, :max =>88, :min => 59}, {:day => 2, :max =>50, :min => 60}, {:day => 3, :max =>88, :min => 70}]
dataMunging = Munging.new(data)
dataMunging.findSmallestRange()[:day].should eq 2
end
end
end
|
C#
|
UTF-8
| 23,851 | 2.859375 | 3 |
[] |
no_license
|
/*
* Author: Kishore Reddy
* Url: http://commonlibrarynet.codeplex.com/
* Title: CommonLibrary.NET
* Copyright: � 2009 Kishore Reddy
* License: LGPL License
* LicenseUrl: http://commonlibrarynet.codeplex.com/license
* Description: A C# based .NET 3.5 Open-Source collection of reusable components.
* Usage: Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Linq.Expressions;
namespace ComLib.Data
{
/// <summary>
/// This class implements a method to create queries.
/// </summary>
/// <typeparam name="T"></typeparam>
public class Query<T> : Query, IQuery<T>
{
/// <summary>
/// Creates a new instance.
/// </summary>
/// <returns>An empty string.</returns>
public static new IQuery<T> New()
{
return New(string.Empty);
}
// Static factory
/// <summary>
/// Creates new Query object for the specified db provider name.
/// </summary>
/// <param name="dbProviderName">Name of the db provider.</param>
/// <returns>A new instance of Query.</returns>
public static IQuery<T> New(string dbProviderName)
{
if (string.IsNullOrEmpty(dbProviderName)) return new Query<T>();
// No support for other databases yet.
// Not sure it's necessay but just in case.
return new Query<T>();
}
/// <summary>
/// Initializes a new instance of the <see cref="Query<T>"/> class.
/// </summary>
public Query()
{
_builder = new QueryBuilderSql(this);
}
/// <summary>
/// Adds a condition to the query.
/// </summary>
/// <param name="exp">Expression to extract field name.</param>
/// <param name="comparison">Comparison expression.</param>
/// <param name="val">Value to compare against.</param>
/// <returns>This instance.</returns>
public IQuery<T> AddCondition(Expression<Func<T, object>> exp, ExpressionType comparison, object val)
{
string field = ExpressionHelper.GetPropertyName<T>(exp);
AddCondition(field, comparison, val);
return this;
}
/// <summary>
/// Adds columns to a select statement.
/// </summary>
/// <param name="colExpressions">Expressions to retrieve column names.</param>
/// <returns>This instance.</returns>
public IQuery<T> Select(params Expression<Func<T, object>>[] colExpressions)
{
if (colExpressions == null || colExpressions.Length == 0)
return this;
string[] cols = new string[colExpressions.Length];
for (int ndx = 0; ndx < colExpressions.Length; ndx++)
cols[ndx] = ExpressionHelper.GetPropertyName<T>(colExpressions[ndx]);
return Select(cols);
}
/// <summary>
/// Adds a WHERE clause to the query.
/// </summary>
/// <param name="exp">Expression to retrieve property name.</param>
/// <returns>This instance.</returns>
public IQuery<T> Where(Expression<Func<T, object>> exp)
{
string field = ExpressionHelper.GetPropertyName<T>(exp);
return StartNewCondition(ConditionType.None, field) as IQuery<T>;
}
/// <summary>
/// Adds an AND condition to the query.
/// </summary>
/// <param name="exp">Expression to retrieve property name.</param>
/// <returns>This instance.</returns>
public IQuery<T> And(Expression<Func<T, object>> exp)
{
string field = ExpressionHelper.GetPropertyName<T>(exp);
return StartNewCondition(ConditionType.And, field) as IQuery<T>;
}
/// <summary>
/// Adds an OR condition to the query.
/// </summary>
/// <param name="exp">Expression to retrieve property name.</param>
/// <returns>This instance.</returns>
public IQuery<T> Or(Expression<Func<T, object>> exp)
{
string field = ExpressionHelper.GetPropertyName<T>(exp);
return StartNewCondition(ConditionType.Or, field) as IQuery<T>;
}
/// <summary>
/// Adds an Order-By clause to the query.
/// </summary>
/// <param name="exp">Expression to retrieve property name.</param>
/// <returns>This instance.</returns>
public IQuery<T> OrderBy(Expression<Func<T, object>> exp)
{
string field = ExpressionHelper.GetPropertyName<T>(exp);
return OrderByInternal(field, OrderByType.Asc);
}
/// <summary>
/// Adds a descending order clause to the query.
/// </summary>
/// <param name="exp">Expression to retrieve property name.</param>
/// <returns>This instance.</returns>
public IQuery<T> OrderByDescending(Expression<Func<T, object>> exp)
{
string field = ExpressionHelper.GetPropertyName<T>(exp);
return OrderByInternal(field, OrderByType.Desc);
}
/// <summary>
/// Adds columns to a select statement.
/// </summary>
/// <param name="cols">Array with columns to add.</param>
/// <returns>This instance.</returns>
public IQuery<T> Select(params string[] cols)
{
if( cols == null || cols.Length == 0)
return this;
foreach (string col in cols)
_data.SelectFields.Add(new SelectField() { Field = col });
return this;
}
/// <summary>
/// Adds a column to a select statement.
/// </summary>
/// <param name="col">Name of column to add.</param>
/// <returns>This instance.</returns>
public IQuery<T> Select(string col)
{
_data.SelectFields.Add(new SelectField() { Field = col });
return this;
}
/// <summary>
/// Adds an AS clause to the query.
/// </summary>
/// <param name="columnAlias">Column alias to use.</param>
/// <returns>This instance.</returns>
public IQuery<T> As(string columnAlias)
{
if (_data.SelectFields == null || _data.SelectFields.Count == 0)
return this;
_data.SelectFields[_data.SelectFields.Count - 1].Alias = columnAlias;
return this;
}
/// <summary>
/// Designates the table to operate on.
/// </summary>
/// <param name="tableName">Name of table.</param>
/// <returns>This instance.</returns>
public IQuery<T> From(string tableName)
{
_data.From = tableName;
return this;
}
/// <summary>
/// Adds a WHERE condition to the query.
/// </summary>
/// <param name="field">Name of field to use.</param>
/// <returns>This instance.</returns>
public IQuery<T> Where(string field)
{
return StartNewCondition(ConditionType.None, field) as IQuery<T>;
}
/// <summary>
/// Adds an AND operation to the query.
/// </summary>
/// <param name="field">Name of field to use.</param>
/// <returns>This instance.</returns>
public IQuery<T> And(string field)
{
return StartNewCondition(ConditionType.And, field) as IQuery<T>;
}
/// <summary>
/// Adds an OR operation to the query.
/// </summary>
/// <param name="field">Name of field to use.</param>
/// <returns>This instance.</returns>
public IQuery<T> Or(string field)
{
return StartNewCondition(ConditionType.Or, field) as IQuery<T>;
}
/// <summary>
/// Adds an equality condition to the query.
/// </summary>
/// <param name="val">Value to check for.</param>
/// <returns>This instance.</returns>
public IQuery<T> Is(object val)
{
return BuildCondition("=", val);
}
/// <summary>
/// Adds an inequality condition to the query.
/// </summary>
/// <param name="val">Value to check for.</param>
/// <returns>This instance.</returns>
public IQuery<T> Not(object val)
{
return BuildCondition("<>", val);
}
/// <summary>
/// Adds a null comparison condition to the query.
/// </summary>
/// <returns>This instance.</returns>
public IQuery<T> Null()
{
_lastCondition.Comparison = "is";
_lastCondition.Value = "null";
return this;
}
/// <summary>
/// Adds a not-null comparison condition to the query.
/// </summary>
/// <returns>This instance.</returns>
public IQuery<T> NotNull()
{
_lastCondition.Comparison = "is not";
_lastCondition.Value = "null";
return this;
}
/// <summary>
/// Adds an IN condition to the query.
/// </summary>
/// <typeparam name="TParam">Type of parameter.</typeparam>
/// <param name="vals">Array with values to check for.</param>
/// <returns>This instance.</returns>
public IQuery<T> In<TParam>(params object[] vals)
{
return BuildCondition<TParam>("in", vals);
}
/// <summary>
/// Adds a NOT-IN condition to the query.
/// </summary>
/// <typeparam name="TParam">Type of parameter.</typeparam>
/// <param name="vals">Array with values to check for.</param>
/// <returns>This instance.</returns>
public IQuery<T> NotIn<TParam>(params object[] vals)
{
return BuildCondition<TParam>("not in", vals);
}
/// <summary>
/// Adds a LIKE condition to the query.
/// </summary>
/// <param name="val">Value to check for.</param>
/// <returns>This instance.</returns>
public IQuery<T> Like(string val)
{
return BuildCondition("like", val);
}
/// <summary>
/// Adds a LIKE condition to the query.
/// </summary>
/// <param name="val">Value to check for.</param>
/// <param name="addWildcardPrefix">True to add a wildcard prefix.</param>
/// <param name="addWildcardSuffix">True to add a wildcard suffix.</param>
/// <returns>This instance.</returns>
public IQuery<T> Like(string val, bool addWildcardPrefix, bool addWildcardSuffix)
{
if (addWildcardPrefix) val = "%" + val;
if (addWildcardSuffix) val = val + "%";
return BuildCondition("like", val);
}
/// <summary>
/// Adds a greater-than comparison to the query.
/// </summary>
/// <param name="val">Value to check against.</param>
/// <returns>This instance.</returns>
public IQuery<T> MoreThan(object val)
{
return BuildCondition(">", val);
}
/// <summary>
/// Adds a greater-or-equal comparison to the query.
/// </summary>
/// <param name="val">Value to check against.</param>
/// <returns>This instance.</returns>
public IQuery<T> MoreEqual(object val)
{
return BuildCondition(">=", val);
}
/// <summary>
/// Adds a less-than comparison to the query.
/// </summary>
/// <param name="val">Value to check against.</param>
/// <returns>This instance.</returns>
public IQuery<T> LessThan(object val)
{
return BuildCondition("<", val);
}
/// <summary>
/// Adds a less-or-equal-than comparison to the query.
/// </summary>
/// <param name="val">Value to check against.</param>
/// <returns>This instance.</returns>
public IQuery<T> LessEqual(object val)
{
return BuildCondition("<=", val);
}
/// <summary>
/// Adds an ascending order-by clause to the query.
/// </summary>
/// <param name="field">Name of field to use.</param>
/// <returns>this instance.</returns>
public IQuery<T> OrderBy(string field)
{
return OrderByInternal(field, OrderByType.Asc);
}
/// <summary>
/// Adds a descending order-by clause to the query.
/// </summary>
/// <param name="field">Name of field to use.</param>
/// <returns>This instance.</returns>
public IQuery<T> OrderByDescending(string field)
{
return OrderByInternal(field, OrderByType.Desc);
}
/// <summary>
/// Limits the query result to a number of records.
/// </summary>
/// <param name="maxRecords">Number of records to limit.</param>
/// <returns>This instance.</returns>
public IQuery<T> Limit(int maxRecords)
{
_data.RecordLimit = maxRecords;
_data.IsRecordLimitEnabled = true;
return this;
}
/// <summary>
/// Completes the query.
/// </summary>
/// <returns>This instance.</returns>
public IQuery<T> End()
{
Complete();
return this;
}
#region Private Helper methods
/// <summary>
/// Adds a condition to the query.
/// </summary>
/// <typeparam name="TParam">Type of parameter.</typeparam>
/// <param name="comparison">Comparison operator.</param>
/// <param name="vals">Values to use.</param>
/// <returns>This instance.</returns>
protected new IQuery<T> BuildCondition<TParam>(string comparison, params object[] vals)
{
var buffer = new StringBuilder();
// String
if (typeof(TParam) == typeof(string))
{
buffer.Append("'" + Encode((string)vals[0]) + "'");
for (int ndx = 1; ndx < vals.Length; ndx++)
buffer.Append(", '" + Encode((string)vals[ndx]) + "'");
}
// DateTime
else if (typeof(TParam) == typeof(DateTime))
{
buffer.Append("'" + Encode(((DateTime)vals[0]).ToShortDateString()) + "'");
for (int ndx = 1; ndx < vals.Length; ndx++)
buffer.Append(", '" + Encode(((DateTime)vals[ndx]).ToShortDateString()) + "'");
}
// int, long, float, double.
else if (TypeHelper.IsNumeric(typeof(TParam)))
{
buffer.Append(TypeHelper.Join(vals));
}
_lastCondition.Comparison = comparison;
_lastCondition.Value = "( " + buffer.ToString() + " )";
return this;
}
/// <summary>
/// Adds a condition to the query.
/// </summary>
/// <param name="comparison">Comparison operator.</param>
/// <param name="val">Value to use.</param>
/// <returns>This instance.</returns>
protected new IQuery<T> BuildCondition(string comparison, object val)
{
var valToUse = ConvertVal(val);
_lastCondition.Comparison = comparison;
_lastCondition.Value = valToUse;
return this;
}
/// <summary>
/// Adds an order-by to the query.
/// </summary>
/// <param name="field">Name of field.</param>
/// <param name="order">Type of ordering.</param>
/// <returns>This instance.</returns>
protected IQuery<T> OrderByInternal(string field, OrderByType order)
{
if (_data.LastOrderBy != null)
{
_data.Orderings.Add(_data.LastOrderBy);
}
_data.LastOrderBy = new OrderByClause() { Field = field, Ordering = order };
return this;
}
#endregion
}
/// <summary>
/// Base class for Query.
/// </summary>
public class Query : IQuery
{
/// <summary>
/// Query information.
/// </summary>
protected QueryData _data = new QueryData();
/// <summary>
/// Instance of query builder.
/// </summary>
protected IQueryBuilder _builder;
/// <summary>
/// Last condition used when creating the query.
/// </summary>
protected Condition _lastCondition;
/// <summary>
///
/// </summary>
/// <returns></returns>
public static IQuery<object> New()
{
return Query<object>.New();
}
/// <summary>
/// The data for the criteria, including select field, conditions, orderby etc.
/// </summary>
public QueryData Data
{
get { return _data; }
set { _data = value; }
}
/// <summary>
/// The data for the criteria, including select field, conditions, orderby etc.
/// </summary>
public IQueryBuilder Builder
{
get { return _builder; }
set { _builder = value; }
}
/// <summary>
/// Adds a new AND condition to the query.
/// </summary>
/// <param name="field">Conditional field.</param>
/// <param name="comparison">Comparison expression.</param>
/// <param name="val">Value to check against.</param>
public void AddCondition(string field, ExpressionType comparison, object val)
{
StartNewCondition(ConditionType.And, field);
string sign = RepositoryExpressionTypeHelper.GetText(comparison);
BuildCondition(sign, val);
}
/// <summary>
/// Completes this condition construction.
/// </summary>
public void Complete()
{
if (_lastCondition != null)
{
_data.Conditions.Add(_lastCondition);
_lastCondition = null;
}
if (_data.LastOrderBy != null)
{
_data.Orderings.Add(_data.LastOrderBy);
_data.LastOrderBy = null;
}
}
/// <summary>
/// Builds a comparison condition.
/// </summary>
/// <typeparam name="TParam">Type of parameter.</typeparam>
/// <param name="comparison">Comparison operator.</param>
/// <param name="vals">Values to compare against.</param>
/// <returns>This instance.</returns>
protected virtual IQuery BuildCondition<TParam>(string comparison, params object[] vals)
{
var buffer = new StringBuilder();
// String
if (typeof(TParam) == typeof(string))
{
buffer.Append("'" + Encode((string)vals[0]) + "'");
for (int ndx = 1; ndx < vals.Length; ndx++)
buffer.Append(", '" + Encode((string)vals[ndx]) + "'");
}
// DateTime
else if (typeof(TParam) == typeof(DateTime))
{
buffer.Append("'" + Encode(((DateTime)vals[0]).ToShortDateString()) + "'");
for (int ndx = 1; ndx < vals.Length; ndx++)
buffer.Append(", '" + Encode(((DateTime)vals[ndx]).ToShortDateString()) + "'");
}
// int, long, float, double.
else if (TypeHelper.IsNumeric(typeof(TParam)))
{
buffer.Append(TypeHelper.Join(vals));
}
_lastCondition.Comparison = comparison;
_lastCondition.Value = "( " + buffer.ToString() + " )";
return this;
}
/// <summary>
/// Builds a comparison condition using a string.
/// </summary>
/// <param name="comparison">Comparison operator.</param>
/// <param name="val">String value to compare against.</param>
/// <returns>This instance.</returns>
protected virtual IQuery BuildCondition(string comparison, object val)
{
var valToUse = ConvertVal(val);
_lastCondition.Comparison = comparison;
_lastCondition.Value = valToUse;
return this;
}
/// <summary>
/// Converts an object to an equivalent string value.
/// </summary>
/// <param name="val">Object to convert to string.</param>
/// <returns>String equivalent of object.</returns>
protected string ConvertVal(object val)
{
string valToUse = "";
// String
if (val == null || (val.GetType() == typeof(string) && string.IsNullOrEmpty((string)val)))
return "''";
if (val.GetType() == typeof(string))
valToUse = "'" + Encode((string)val) + "'";
// Bool
else if (val.GetType() == typeof(bool))
{
bool bval = (bool)val;
valToUse = bval ? "1" : "0";
}
// DateTime
else if (val.GetType() == typeof(DateTime))
{
DateTime date = (DateTime)val;
valToUse = "'" + date.ToShortDateString() + "'";
}
// Int / Long / float / double
else if (TypeHelper.IsNumeric(val))
valToUse = val.ToString();
return valToUse;
}
/// <summary>
/// Starts a new query condition after
/// saving any previous one.
/// </summary>
/// <param name="condition">Condition to start.</param>
/// <param name="fieldName">Name of field to operate on.</param>
/// <returns>This instance.</returns>
protected IQuery StartNewCondition(ConditionType condition, string fieldName)
{
if (_lastCondition != null)
{
_data.Conditions.Add(_lastCondition);
}
_lastCondition = new Condition(condition);
_lastCondition.Field = fieldName;
return this;
}
/// <summary>
/// Encode the text for single quotes.
/// </summary>
/// <param name="text">Text to encode.</param>
/// <returns>Encoded text.</returns>
public static string Encode(string text)
{
if (string.IsNullOrEmpty(text)) return text;
return text.Replace("'", "''");
}
}
}
|
Python
|
UTF-8
| 2,587 | 4.59375 | 5 |
[] |
no_license
|
# --- DAY THREE ------
'''
1. Write a short Python function that takes a sequence of integer values and
determines if there is a distinct pair of numbers in the sequence whose
product is odd.
'''
def product_is_odd(values):
'''
Checks if there is distinct pairs whose product is odd
and None when is no distinct pairs whose product is odd
param values: Sequence of integers
return: True or None
'''
for i in range(len(values)):
for j in range(len(values)):
if i!=j:
product = values[i]*values[j]
if product%2 != 0:
return True
v1 = [1,2,4,6,]
v2 = [1,2,3,4,5,6,7]
print(v1, product_is_odd(v1))
print(v2,product_is_odd(v2))
'''
2. Write a Python function that takes a sequence of numbers and determines
if all the numbers are different from each other (that is, they are distinct).
'''
def is_distinct(nums):
'''
Checks if there is distinct numbers in the sequence
param nums: a list of numbers
return: returns True if there is distinct numbers , else None
'''
s = set(nums) # create a set from the sequence of numbers, nums
if len(s) == len(nums): # evaluate if the sequence of numbers is equivalent to the set of the numbers
return True
else:
return False
n1 = [1,2,3,6,5,4,8,7,10,8,9]
n2 = [2,4,85,96,144,12,34]
print(n1,is_distinct(n1))
print(n2, is_distinct(n2))
'''
3. Demonstrate how to use Python’s list comprehension syntax to produce
the list [0, 2, 6, 12, 20, 30, 42, 56, 72, 90].
'''
# -- using list comprehension
sequence = [k*(k+1) for k in range(10)]
print(sequence)
# --- Work it out without list conprehension. This is my additional exploration
def new_sequence(k):
seq = []
for i in range(k):
seq.append(i*(i+1))
print(seq)
new_sequence(10)
'''
4. Python’s random module includes a function shuffle(data) that accepts a
list of elements and randomly reorders the elements so that each possible
order occurs with equal probability. The random module includes a
more basic function randint(a, b) that returns a uniformly random integer
from a to b (including both endpoints). Using only the randint function,
implement your own version of the shuffle function.
'''
# import random module
import random
def shuffle_int(x,y):
'''
Return a random integer using random module
param (x,y): a sequence of number from x to y
return : a random number form x to y including both endpoints
'''
z = random.randint(x,y)
print(z)
shuffle_int(1,5)
|
Java
|
UTF-8
| 2,204 | 3.203125 | 3 |
[] |
no_license
|
package ca.carleton.comp.game;
import ca.carleton.comp.util.RandomUtil;
import java.util.ArrayList;
import java.util.List;
public class Dice {
private int index;
private int status;
private List<DiceSide> diceSideList;
public Dice(int index) {
this.index = index;
this.status = 1;
diceSideList = new ArrayList<>();
diceSideList.add(DiceSide.skull);
diceSideList.add(DiceSide.monkey);
diceSideList.add(DiceSide.parrot);
diceSideList.add(DiceSide.sword);
diceSideList.add(DiceSide.coin);
diceSideList.add(DiceSide.diamond);
}
public DiceSide roll() {
int i = RandomUtil.randInt(0, 5);
return DiceSide.getByIndex(i);
}
public List<DiceSide> getDiceSideList() {
return diceSideList;
}
public int getIndex() {
return index;
}
public int getStatus() {
return status;
}
public void setStatus(int status) {
this.status = status;
}
public enum DiceSide {
skull(0, "skull"),
monkey(1, "monkey"),
parrot(2, "parrot"),
sword(3, "sword"),
coin(4, "coin"),
diamond(5, "diamond"),
unknown(6, "unknown");
private int index;
private String name;
DiceSide(int index, String name) {
this.index = index;
this.name = name;
}
public static DiceSide getByIndex(int index) {
for (DiceSide diceSide : DiceSide.values()) {
if (diceSide.index == index) {
return diceSide;
}
}
return unknown;
}
public static DiceSide getByName(String name) {
for (DiceSide diceSide : DiceSide.values()) {
if (diceSide.name.equals(name)) {
return diceSide;
}
}
return unknown;
}
public int getIndex() {
return index;
}
public String getName() {
return name;
}
@Override
public String toString() {
return "\'" + name + '\'';
}
}
}
|
Markdown
|
UTF-8
| 2,265 | 2.515625 | 3 |
[
"MIT"
] |
permissive
|
# ios-sdk <a href="https://cocoapods.org/pods/IngresseSDK"><img src="https://img.shields.io/cocoapods/v/IngresseSDK.svg?style=flat"></a>
Ingresse iOS SDK
## Installation guide
Add this to your Podfile:
```ruby
pod 'IngresseSDK'
```
Import SDK on your Swift class
```swift
import IngresseSDK
```
## IngresseClient
### Passing device info to SDK:
This info is used to identify your app and user device for better and faster problem solving
```swift
import Foundation
import UIKit
class UserAgent {
static func getUserAgent() -> String {
let currentDevice = UIDevice.current
let osDescriptor = "iOS/ \(currentDevice.systemVersion)"
let deviceModel = currentDevice.name
let deviceDescriptor = "\(osDescriptor) [\(deviceModel)]"
guard let bundleDict = Bundle(for: UserAgent.self).infoDictionary,
let appName = bundleDict["CFBundleName"] as? String,
let appVersion = bundleDict["CFBundleShortVersionString"] as? String
else { return deviceDescriptor }
let appDescriptor = "\(appName)/\(appVersion)"
return "\(appDescriptor) \(deviceDescriptor)"
}
}
```
### Create a SDK Manager to your app
```swift
import IngresseSDK
class MySDKManager {
static let shared = MySDKManager()
var service: IngresseService!
init() {
let client = IngresseClient(
apiKey: "<API_KEY>",
userAgent: UserAgent.getUserAgent(),
urlHost: "<YOUR_HOST>")
self.service = IngresseService(client: client)
}
}
```
## IngresseService
After creating your SDK Manager you can use it to access your IngresseService
```swift
let service = MySDKManager.shared.service
```
You can use different types of service from IngresseService
### AuthService
Used to login and get user data
```swift
let authService = service.auth
authService.loginWithEmail("example@email.com", andPassword: "******", onSuccess: (Callback block), onError: (Callback block))
```
### EntranceService
Used to make entrance related operations such as guest-list download and checkin
```swift
let entranceService = service.entrance
entranceService.getGuestListOfEvent("EVENT_ID", sessionId: "SESSION_ID", userToken: "REQUIRED_USER_TOKEN", page: 1, delegate: MyClass)
```
|
Markdown
|
UTF-8
| 2,231 | 2.609375 | 3 |
[] |
no_license
|
# Overview
[Azure Policy extension](https://learn.microsoft.com/en-us/azure/governance/policy/concepts/policy-for-kubernetes) for Azure Arc enabled Kubernetes lets you centrally manage compliance of your Kubernetes clusters. In this example, we walk through how to ensure our cluster only uses docker images from approved container registry.
## How it works
Here are the main steps to enable policy on Arc managed Kubernetes clusters. You can find the complete tutorial [here](https://learn.microsoft.com/en-us/azure/governance/policy/concepts/policy-for-kubernetes).
1. Install Azure Policy Extension:
```bash
az k8s-extension create --cluster-type connectedClusters --cluster-name <CLUSTER_NAME> --resource-group <RESOURCE_GROUP> --extension-type Microsoft.PolicyInsights --name <EXTENSION_INSTANCE_NAME>
```
2. Assign a policy definition as documented [here](https://learn.microsoft.com/en-us/azure/governance/policy/concepts/policy-for-kubernetes#assign-a-policy-definition). In this case we select a policy called `Kubernetes cluster containers should only use allowed images`. When configuring the policy assignment, you can specify which namespaces to apply the policy as well as exceptions as shown below:
<img src="media/policyEdit.png" />
3. Check the policy status in the cluster.
It takes 15 minutes or so for the policy to be synced to the cluster and evaluated. Run the following commands to show the policy violations.
```bash
kubectl get constrainttemplates
kubectl get k8sazurev2containerallowedimages
kubectl get k8sazurev2containerallowedimages azurepolicy-k8sazurev2containerallowedimag-<id> -o yaml
```
You can also go to the Azure Portal to see all the [policy compliance status](https://ms.portal.azure.com/#view/Microsoft_Azure_Policy/PolicyMenuBlade/~/Compliance).
4. Try deploy a pod using an image from an un-approved container registry, and you will see it's blocked.
```bash
> kubectl run busybox -it --rm --restart=Never --image=busybox --namespace demo -- /bin/bash
Error from server (Forbidden): admission webhook "validation.gatekeeper.sh" denied the request: [azurepolicy-k8sazurev2containerallowedimag-<id>] Container image busybox for container busybox has not been allowed.
```
|
C++
|
UTF-8
| 3,785 | 2.984375 | 3 |
[] |
no_license
|
#include "BackgroundController.h"
BackgroundController::BackgroundController(void)
{
tree = NULL;
listObjects = NULL; // => list object, tất cả tile
nodes = NULL; // số node
currentTiles = NULL;
}
BackgroundController::BackgroundController(int level)
{
string fileName;
switch (level)
{
case 1:
fileName = "Resources\\Maps\\Level1.txt";
break;
case 2:
fileName = "Resources\\Maps\\Level2.txt";
break;
default:
break;
}
ifstream map(fileName);
currentTiles = new list<int>();
if (map.is_open())
{
float posX, posY; int value;
int count;
map >> count;
switch (level )
{
case 1:
bgSprite = new GSprite(new GTexture("Resources\\Maps\\Level1.png", count, 1, count), 1000);
break;
case 2:
bgSprite = new GSprite(new GTexture("Resources\\Maps\\Level2.png", count, 1, count), 1000);
break;
default:
break;
}
map >> count >> G_MapWidth >> G_MapHeight;
int id;
listObjects = new std::map<int, Tile*>();
Tile* _obj;
for (int i = 0; i < count; i++)
{
//so thu tu dong - idObj -...
map >> id >> value >> posX >> posY;
listObjects->insert(pair<int, Tile*>(id, new Tile(value, posX, posY)));
}
//Doc quadtree
string line;
nodes = new std::map<int, QNode*>();
int size;
while (!map.eof())
{
//posX == left; posY == top; size == size q
map >> id >> posX >> posY >> size;
//Doc id Object trong node
getline(map, line);
istringstream str_line(line);
list<int> *_objOfNode = new list<int>();
while (str_line >> value)
{
_objOfNode->push_back(value);
}
QNode* _nodeTree = new QNode(posX, posY, size, *_objOfNode);
//Dua node vao _myMap
nodes->insert(pair<int, QNode*>(id, _nodeTree));
}
map.close();
}
}
void BackgroundController::GetAvailableTiles(int viewportX, int viewportY)
{
currentTiles->clear();
GetObjectsIn(viewportX, viewportY, tree);
}
void BackgroundController::GetObjectsIn(int viewportX, int viewportY, QNode* _node)
{
if (_node->leftTop != NULL)
{
if (viewportX < _node->rightTop->left && viewportY > _node->leftBottom->top)
GetObjectsIn(viewportX, viewportY, _node->leftTop);
if (viewportX + G_ScreenWidth > _node->rightTop->left && viewportY > _node->rightBottom->top)
GetObjectsIn(viewportX, viewportY, _node->rightTop);
if (viewportX < _node->rightBottom->left && viewportY - G_ScreenHeight < _node->leftBottom->top)
GetObjectsIn(viewportX, viewportY, _node->leftBottom);
if (viewportX + G_ScreenWidth > _node->rightBottom->left && viewportY - G_ScreenHeight < _node->rightBottom->top)
GetObjectsIn(viewportX, viewportY, _node->rightBottom);
}
else
{
for (list<int>::iterator _itBegin = _node->listObject.begin(); _itBegin != _node->listObject.end(); _itBegin++)
{
currentTiles->push_back(*_itBegin);
}
}
}
void BackgroundController::LoadQuadTreeFromFile()
{
Load(0, tree);
// Sau hàm này, tree sẽ = với file levelX.txt
}
void BackgroundController::Load(int id, QNode *& _nodeTree)
{
map<int, QNode*>::iterator _node = nodes->find(id);
if (_node != nodes->end())
{
_nodeTree = new QNode(_node->second->left, _node->second->top, _node->second->size, _node->second->listObject);
Load(_node->first * 8 + 1, _nodeTree->leftTop);
Load(_node->first * 8 + 2, _nodeTree->rightTop);
Load(_node->first * 8 + 3, _nodeTree->leftBottom);
Load(_node->first * 8 + 4, _nodeTree->rightBottom);
}
}
void BackgroundController::Draw(GCamera *camera)
{
for (list<int>::iterator _itBegin = currentTiles->begin(); _itBegin != currentTiles->end(); _itBegin++)
{
Tile* obj = listObjects->find(*_itBegin)->second;
D3DXVECTOR2 t = camera->Transform(obj->posX, obj->posY);
bgSprite->DrawIndex(obj->idTile, t.x, t.y);
}
}
BackgroundController::~BackgroundController(void)
{
}
|
C++
|
UTF-8
| 804 | 2.59375 | 3 |
[] |
no_license
|
#include "Operario.h"
float Operario::calculaSalOP(float comissao, float valorProducao,float salBase)
{
float comitemp, acc, somado;
comitemp = comissao / 100;
acc = comitemp * valorProducao;
salTotal = acc + salBase;
return salTotal;
}
float Operario::salAleatorio()
{
float salBase;
float salt;
salt = rand() % 5000 + 1000;
salBase = salt;
return salBase;
}
float Operario::comiAleatorio()
{
float com;
com = rand() % 15 + 2;
return com;
}
float Operario::prodAleatorio()
{
float producao;
producao = rand() % 50000;
return producao;
}
void Operario::setValorProd(float prod)
{
valorProducao = prod;
}
void Operario::setValorComissao(float comi)
{
comissao = comi;
}
float Operario::getValorProd()
{
return valorProducao;
}
float Operario::getComissao()
{
return comissao;
}
|
Go
|
UTF-8
| 1,028 | 2.609375 | 3 |
[
"Apache-2.0"
] |
permissive
|
package webhook
import (
"context"
"github.com/stretchr/testify/assert"
admissionv1 "k8s.io/api/admission/v1"
"sigs.k8s.io/controller-runtime/pkg/webhook/admission"
"testing"
)
func TestContextGetAdmissionRequestAndContextWithAdmissionRequest(t *testing.T) {
type args struct {
req *admission.Request
}
tests := []struct {
name string
args args
want *admission.Request
}{
{
name: "with request",
args: args{
req: &admission.Request{
AdmissionRequest: admissionv1.AdmissionRequest{
UID: "1",
},
},
},
want: &admission.Request{
AdmissionRequest: admissionv1.AdmissionRequest{
UID: "1",
},
},
},
{
name: "without request",
args: args{
req: nil,
},
want: nil,
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
ctx := context.Background()
if tt.args.req != nil {
ctx = ContextWithAdmissionRequest(ctx, *tt.args.req)
}
got := ContextGetAdmissionRequest(ctx)
assert.Equal(t, tt.want, got)
})
}
}
|
Python
|
UTF-8
| 743 | 2.6875 | 3 |
[] |
no_license
|
import os
import shutil
import git
def download_repository(repository, update_repository, checkout_target='master'):
name = get_name(repository)
path = "tmp/{}".format(name)
if os.path.exists(path):
if update_repository == 'true':
shutil.rmtree(path)
else:
checkout(path, checkout_target)
return path
git.Git().clone(repository, path)
checkout(path, checkout_target)
return path
def checkout(path, target):
g = git.Git(path)
# If target is a tag, fetch will throw exception
try:
g.fetch("origin", target)
except:
pass
g.checkout(target)
return g
def get_name(rep):
splt = rep.split("/")
return splt[-1]
|
Rust
|
UTF-8
| 2,680 | 3.46875 | 3 |
[
"MIT"
] |
permissive
|
// this module adds some functionality based on the required implementations
// here like: `LinkedList::pop_back` or `Clone for LinkedList<T>`
// You are free to use anything in it, but it's mainly for the test framework.
mod pre_implemented;
pub struct LinkedList<T>(std::marker::PhantomData<T>);
pub struct Cursor<'a, T>(std::marker::PhantomData<&'a mut T>);
pub struct Iter<'a, T>(std::marker::PhantomData<&'a T>);
impl<T> LinkedList<T> {
pub fn new() -> Self {
unimplemented!()
}
// You may be wondering why it's necessary to have is_empty()
// when it can easily be determined from len().
// It's good custom to have both because len() can be expensive for some types,
// whereas is_empty() is almost always cheap.
// (Also ask yourself whether len() is expensive for LinkedList)
pub fn is_empty(&self) -> bool {
unimplemented!()
}
pub fn len(&self) -> usize {
unimplemented!()
}
/// Return a cursor positioned on the front element
pub fn cursor_front(&mut self) -> Cursor<'_, T> {
unimplemented!()
}
/// Return a cursor positioned on the back element
pub fn cursor_back(&mut self) -> Cursor<'_, T> {
unimplemented!()
}
/// Return an iterator that moves from front to back
pub fn iter(&self) -> Iter<'_, T> {
unimplemented!()
}
}
// the cursor is expected to act as if it is at the position of an element
// and it also has to work with and be able to insert into an empty list.
impl<T> Cursor<'_, T> {
/// Take a mutable reference to the current element
pub fn peek_mut(&mut self) -> Option<&mut T> {
unimplemented!()
}
/// Move one position forward (towards the back) and
/// return a reference to the new position
#[allow(clippy::should_implement_trait)]
pub fn next(&mut self) -> Option<&mut T> {
unimplemented!()
}
/// Move one position backward (towards the front) and
/// return a reference to the new position
pub fn prev(&mut self) -> Option<&mut T> {
unimplemented!()
}
/// Remove and return the element at the current position and move the cursor
/// to the neighboring element that's closest to the back. This can be
/// either the next or previous position.
pub fn take(&mut self) -> Option<T> {
unimplemented!()
}
pub fn insert_after(&mut self, _element: T) {
unimplemented!()
}
pub fn insert_before(&mut self, _element: T) {
unimplemented!()
}
}
impl<'a, T> Iterator for Iter<'a, T> {
type Item = &'a T;
fn next(&mut self) -> Option<&'a T> {
unimplemented!()
}
}
|
C++
|
UTF-8
| 400 | 2.84375 | 3 |
[] |
no_license
|
#include "Actor.h"
/*#TODO 3: Implement Actor*/
Actor::Actor() {
name = "unknown";
}
Actor::Actor(const string &aName) {
name = aName;
}
Actor::~Actor() {
}
const string &Actor::getName() const {
return name;
}
void Actor::setName(const string &aName) {
name = aName;
}
ostream &operator<<(ostream &out, const Actor &anActor) {
out << anActor.getName();
return out;
}
|
TypeScript
|
UTF-8
| 815 | 2.609375 | 3 |
[
"MIT"
] |
permissive
|
/* eslint-disable no-nested-ternary */
import {ConditionalProperty, CurrentUser} from '@sanity/types'
export interface ConditionalPropertyCallbackContext {
parent?: unknown
document?: Record<string, unknown>
currentUser: Omit<CurrentUser, 'role'> | null
value: unknown
}
export function resolveConditionalProperty(
property: ConditionalProperty,
context: ConditionalPropertyCallbackContext,
) {
const {currentUser, document, parent, value} = context
if (typeof property === 'boolean' || property === undefined) {
return Boolean(property)
}
return (
property({
document: document as any,
parent,
value,
currentUser,
}) === true // note: we can't strictly "trust" the return value here, so the conditional property should probably be typed as unknown
)
}
|
Python
|
UTF-8
| 883 | 2.71875 | 3 |
[] |
no_license
|
#!/usr/bin/env python
__author__ = "Razin Shaikh and Minjie Lyu"
__credits__ = ["Razin Shaikh", "Minjie Lyu", "Vladimir Brusic"]
__version__ = "1.0"
__status__ = "Prototype"
def save_row_head(file):
'''Saves the row head(gene names / ENSG) from CSV file'''
with open(file) as f:
data = f.readlines()
data = data[1:]
row_head = []
for line in data:
row_head.append(line[:line.index(',')])
with open(file.split('.')[0] + '_row.txt', 'w') as f:
for i in row_head:
f.write(i + '\n')
return file.split('.')[0] + '_row.txt'
def return_row_head(file):
'''Returns the row head(gene names / ENSG) from CSV file'''
with open(file) as f:
data = f.readlines()
data = data[1:]
row_head = []
for line in data:
row_head.append(line[:line.index(',')])
return row_head
|
Java
|
UTF-8
| 630 | 2.734375 | 3 |
[
"MIT"
] |
permissive
|
package hr.fer.zemris.ml.training.decision_tree;
import java.util.List;
import hr.fer.zemris.ml.model.data.Sample;
import hr.fer.zemris.ml.model.decision_tree.DecisionTree;
/**
* Interface for decision tree generators.
*
* @author Dan
* @param <T> Type of the target value, usually {@code String} for
* classification and {@code Double} for function approximation tasks.
*/
public interface ITreeGenerator<T> {
/**
* Trains a decision tree on given samples.
*
* @param samples training samples
* @return a trained tree
*/
DecisionTree<T> buildTree(List<Sample<T>> samples);
}
|
Java
|
UTF-8
| 767 | 3.09375 | 3 |
[] |
no_license
|
package sourcecode.spring.aop.javaproxy.staticproxy;
import sourcecode.spring.aop.javaproxy.staticproxy.model.Boy;
import sourcecode.spring.aop.javaproxy.staticproxy.model.Child;
import sourcecode.spring.aop.javaproxy.staticproxy.model.Girl;
import sourcecode.spring.aop.javaproxy.staticproxy.proxy.ChildProxy;
import java.util.ArrayList;
import java.util.List;
/**
* Author: blueaken
* Date: 2/1/16 2:00 PM
*/
public class Test {
public static void main(String[] args){
List<Child> children= new ArrayList<>();
//把Boy和Girl的对象,交给ProxyChild对象代理
children.add(new ChildProxy(new Boy()));
children.add(new ChildProxy(new Girl()));
for(Child c : children){
c.say();
}
}
}
|
Java
|
UTF-8
| 2,145 | 1.9375 | 2 |
[
"LicenseRef-scancode-warranty-disclaimer",
"Apache-2.0"
] |
permissive
|
/*
* Copyright 2019-2020 the Joy Authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.leadpony.joy.core;
import static org.leadpony.joy.core.Preconditions.requireNonNull;
import java.util.Collection;
import java.util.Map;
import jakarta.json.JsonArray;
import jakarta.json.JsonArrayBuilder;
import jakarta.json.JsonBuilderFactory;
import jakarta.json.JsonObject;
import jakarta.json.JsonObjectBuilder;
/**
* @author leadpony
*/
class JsonBuilderFactoryImpl extends ConfigurableFactory implements JsonBuilderFactory {
JsonBuilderFactoryImpl(Map<String, ?> config) {
super(config, NO_SUPPORTED_PROPERTIES);
}
@Override
public JsonObjectBuilder createObjectBuilder() {
return new JsonObjectBuilderImpl();
}
@Override
public JsonObjectBuilder createObjectBuilder(JsonObject object) {
requireNonNull(object, "object");
return new JsonObjectBuilderImpl(object);
}
@Override
public JsonObjectBuilder createObjectBuilder(Map<String, Object> object) {
requireNonNull(object, "object");
return new JsonObjectBuilderImpl(object);
}
@Override
public JsonArrayBuilder createArrayBuilder() {
return new JsonArrayBuilderImpl();
}
@Override
public JsonArrayBuilder createArrayBuilder(JsonArray array) {
requireNonNull(array, "array");
return new JsonArrayBuilderImpl(array);
}
@Override
public JsonArrayBuilder createArrayBuilder(Collection<?> collection) {
requireNonNull(collection, "collection");
return new JsonArrayBuilderImpl(collection);
}
}
|
JavaScript
|
UTF-8
| 315 | 3.171875 | 3 |
[] |
no_license
|
var hotel = {
name: 'Park',
rooms: 120,
booked: 77,
checkAvailability: function() {
return this.rooms - this.booked;
}
};
var eleName = document.getElementById('hotelName');
eleName.textContent = hotel.name;
var eleRooms = document.getElementById('rooms');
eleRooms.textContent = hotel.checkAvailability();
|
C
|
UTF-8
| 15,057 | 2.921875 | 3 |
[] |
no_license
|
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
#include <readline/readline.h>
#include <readline/history.h>
#include <string.h>
#include <fcntl.h>
#include <sys/wait.h>
#include "log_debug.h"
//#include "list.h"
#include "shortcut_signal.h"
#include "custom_command.h"
#define STRLEN 255
// A static variable for holding the line.
char *line_read = (char *)NULL;
//struct list_head* pid_list;
struct node_cmd
{
char** arg; // the arguments list of the command
int ntokens;
char out[255]; // the output : "stdout" "next" "filename"
char in[255]; // the input : "stdin" "prev" "filename"
struct list_head list;
int background; // run in background (1) or not (0)
};
// Read a string, and return a pointer to it.
// Returns NULL on EOF.
char* rl_gets ()
{
char promptstr[255];
char buf[255];
// If the buffer has already been allocated,
// return the memory to the freze pool.
if (line_read)
{
free (line_read);
line_read = (char *)NULL;
}
sprintf(promptstr, "%s:%s >> ", getenv("USER"), getcwd(buf, sizeof(buf)));
// Get a line from the user.
line_read = readline (promptstr);
// If the line has any text in it,
// save it on the history.
if (line_read && *line_read)
add_history (line_read);
return (line_read);
}
/* lexer()
@params: line_read -- the string to be parsed
_ntokens -- (address) the number of tokens, note that may be some tokens would be NULL
@return: arg -- store the tokens, arg[i] respents the ith token
*/
char** lexer(char* line_read, int* _ntokens)
{
char delim = ' ';
int nspace = 0;
int i;
// count the number of 'space'
for (i = 0; i < strlen(line_read); i++)
{
//log_debug("%d%c" ,strlen(line_read), line_read[i]);
if (line_read[i] == delim)
{
if (i > 0 && line_read[i-1] == '\\')
continue;
nspace++;
}
}
//log_debug("%s %d\n", line_read, nspace);
// tokens = #space + 1; and the additional one is set as NULL to label the end
int ntokens = nspace + 2;
char **arg = (char**)malloc(ntokens*sizeof(char*));
//log_debug("arg : %p\n", arg);
for (i = 0; i < ntokens; i++)
{
arg[i] = (char*)malloc(STRLEN*sizeof(char));
strcpy(arg[i], "\0");
}
char *pstr;
int offset = 0;
int pos = 0;
// seperate the string using 'space' to get tokens
//for (i = 0; i < ntokens; i++)
int count = 0;
while (offset < strlen(line_read))
{
if (offset == 0 && pos == 0)
pstr = strchr(line_read + offset, delim);
else
pstr = strchr(line_read + pos + 1, delim);
if (pstr == NULL)
pos = strlen(line_read);
else
{
pos = strlen(line_read) - strlen(pstr);
//log_debug("%s\n", pstr);
}
// "\ " means a whitespace in the filename
if (pos > 0 && line_read[pos-1] == '\\')
{
//offset = pos+1;
continue;
}
//log_debug("%d %d\n", offset, pos);
if (pos > offset)
{
strncpy(arg[count], line_read + offset, pos - offset);
arg[count][pos-offset] = '\0';
// elimate the "\"
char* ptmp = strchr(arg[count], '\\');
if (ptmp != NULL)
{
int postmp = strlen(arg[count]) - strlen(ptmp);
int i;
for(i = postmp; i < strlen(arg[count]); i++)
arg[count][i] = arg[count][i+1];
}
}
else // this is a 'space', so skip this string
{
offset = pos+1;
continue;
}
offset = pos+1;
log_debug("%s\n", arg[count]);
count++;
}
//log_debug("token count:%d\n", count);
for (i = count; i < ntokens; i++)
{
free(arg[i]);
arg[i] = NULL;
}
*_ntokens = ntokens;
//log_debug("The end of lexer\n");
return arg;
}
/* free_string()
* @params: arg -- the pointer of the string list
ntokens -- the number of string in the list
@return: void
*/
void free_string(char** arg, int ntokens)
{
int i;
for (i = 0; i < ntokens; i++)
{
if (arg[i] != NULL);
{
free(arg[i]);
arg[i] = NULL;
}
}
free(arg);
arg = NULL;
}
/* free_list()
* @params: head -- the pointer of the list
* @return: void
*/
void free_list(struct list_head *head)
{
struct list_head *plist, *n;
list_for_each_safe(plist, n, head)
{
struct node_cmd *node = list_entry(plist, struct node_cmd, list);
free_string(node->arg,node->ntokens);
list_del(&node->list);
node = NULL;
}
head = NULL;
}
/* parser()
* @params: arg -- arguments list
ntokens -- the ntokens of the list
@return: the head of the list, every node of the list represents one command
*/
struct list_head* parser(char** arg, int ntokens)
{
int i;
int pos = 0;
int prevpos = 0;
struct list_head *head = (struct list_head*)malloc(sizeof(struct list_head));
int count = 0;
INIT_LIST_HEAD(head);
while (pos < ntokens)
{
// skip the null token
//if (arg[pos] == NULL && pos < ntokens - 1)
//{
// pos++;
// continue;
//}
log_debug("%s\n", arg[pos]);
// find the position of pipes - '|'
if (arg[pos] == NULL || strcmp(arg[pos], "|") == 0 || strcmp(arg[pos], "&") == 0)
{
// if this is the last token
//if (pos == ntokens - 1)
// pos += 1;
// malloc for node
struct node_cmd *node = (struct node_cmd*)malloc(sizeof(struct node_cmd));
node->background = 0;
// output redirection
strcpy(node->out, "next");
if (arg[pos] == NULL)
strcpy(node->out, "stdout");
else if (pos+1 < ntokens && strcmp(arg[pos], "&") == 0 && arg[pos+1] == NULL)
strcpy(node->out, "stdout");
// input redirection
if (prevpos == 0)
strcpy(node->in , "stdin");
else
strcpy(node->in, "prev");
// malloc
char **cmdarg = (char**)malloc((pos-prevpos+1)*sizeof(char*));
node->arg = cmdarg;
for (i = 0; i < pos - prevpos + 1; i++)
{
cmdarg[i] = (char*)malloc(STRLEN*sizeof(char));
strcpy(cmdarg[i], "\0");
}
node->ntokens = pos - prevpos + 1;
//log_debug("%d-%d\n", prevpos, pos);
// prevpos ~ pos : one command
i = prevpos;
count = 0;
while (i < pos)
{
//log_debug("%s\n", arg[i]);
// output redirection
if (strcmp(arg[i], ">") == 0)
{
if (i+1 < pos)
strcpy(node->out, arg[++i]);
}
// input redirection
else if (strcmp(arg[i], "<") == 0)
{
if (i+1 < pos)
strcpy(node->in, arg[++i]);
}
else
{
strcpy(cmdarg[count], arg[i]);
log_debug("cmdarg[%d] = %s\n", count, cmdarg[count]);
count++;
}
i++;
}
//log_debug("count:%d tokens:%d\n", count, node->ntokens);
// set the remaining tokens to NULL
for (i = count; i < node->ntokens; i++)
{
free(cmdarg[i]);
cmdarg[i] = NULL;
}
prevpos = pos+1;
// are these commands running in background or not
// only if the '&' appear in the end of the command, it takes effect.
if (pos+1 < ntokens && arg[pos] != NULL && strcmp(arg[pos], "&") == 0 )// )// )// )// )// )// )// && arg[pos+1] == NULL)
node->background = 1;
// add this node to the list
list_add(&node->list, head);
if (arg[pos] == NULL)
break;
if (pos+1 < ntokens && arg[pos] != NULL && strcmp(arg[pos], "&") == 0 && arg[pos+1] == NULL)
break;
}
pos++;
}
free_string(arg, ntokens);
return head;
}
/* exec_singlecmd()
@params: path -- the path of the command
arg -- the arguments of the command
ntokens -- the number of the tokens in arg (actually length(arg) == ntokens+1,
because the last token is always set to NULL)
@return: void
*/
void exec_singlecmd(char** arg, int ntokens)
{
/*int i;
for (i = 0 ; i < ntokens; i++)
{
log_debug("%s\n", arg[i]);
}*/
// fork to execute the command
if (fork() == 0)
{
// execvp() search $PATH to locate the bin file
int ret = execvp(arg[0], arg);
// print the error message
if (ret < 0)
//printf("error:%s\n", strerror(errno));
perror("error");
// free
free_string(arg, ntokens);
exit(0);
}
// wait until the child process return
wait(NULL);
}
/* exec_multicmd()
@params: head -- the head of the list, every node in the list represent a command
@return: void
*/
void exec_multicmd(struct list_head *head)
{
int forkstatus = 1;
int i;
int pnum = 0;
int background = 0;
struct list_head *plist;
// count the number of the command
list_for_each(plist, head)
{
struct node_cmd *node = list_entry(plist, struct node_cmd, list);
if (pnum == 0 && node->background == 1)
{
background = 1;
}
pnum++;
}
log_debug("background:%d\n", background);
// pipe descriptor
int **fd = NULL;
if (pnum > 1)
{
fd = (int**)malloc((pnum-1)*sizeof(int*));
for (i = 0; i < pnum-1; i++)
{
fd[i] = (int*)malloc(2*sizeof(int));
int flag= pipe(fd[i]);
log_debug("pipe return:%d\n",flag);
log_debug("fd[%d]:%d %d\n", i, fd[i][0], fd[i][1]);
}
}
int idx = 0;
int cust = 0;
int ret;
// loop for every command
list_for_each(plist, head)
{
struct node_cmd *node = list_entry(plist, struct node_cmd, list);
//log_debug("tokens:%d\n", node->ntokens);
for (i = 0 ; i < node->ntokens; i++)
{
log_debug("%p %s %s %s %d\n", node, node->arg[i], node->in, node->out, node->background);
}
cust = execute_cust_cmd(node->arg[0], node->arg);
log_debug("execute_cust_cmd return %d\n", cust);
if (cust == 0)
continue;
else if (cust > 0)
{
// fg
if (strcmp(node->arg[0],"fg") == 0)
{
// add it to the pid_list
struct node_process *node = (struct node_process*)malloc(sizeof(struct node_process));
node->pid = cust;
list_add(&node->list, pid_list);
// and remove from the jobs_list;
struct list_head *plist, *n;
list_for_each_safe(plist, n, jobs_list)
{
struct node_process *node = list_entry(plist, struct node_process, list);
if (node->pid == cust)
{
list_del(&node->list);
break;
}
}
break;
}
// bg
else
{
struct list_head *plist, *n;
list_for_each_safe(plist, n, jobs_list)
{
struct node_process *node = list_entry(plist, struct node_process, list);
if (node->pid == cust)
{
node->pstatus = Running;
kill(node->pid, SIGCONT);
break;
}
}
background = 1;
break;
}
}
// fork to execute the command
forkstatus = fork();
if (forkstatus == 0)
{
// input
if (strcmp(node->in, "prev") == 0)
{
close(STDIN_FILENO);
dup2(fd[idx][0], STDIN_FILENO);
}
else if(strcmp(node->in, "stdin") != 0)
{
int fp = open(node->in, O_RDONLY);
dup2(fp, STDIN_FILENO);
}
//log_debug("%p input:%d\n", node, STDIN_FILENO);
// output
if (strcmp(node->out, "next") == 0)
{
close(STDOUT_FILENO);
dup2(fd[idx-1][1], STDOUT_FILENO);
}
else if(strcmp(node->out, "stdout") != 0)
{
int fp = open(node->out, O_WRONLY | O_CREAT | O_TRUNC, 0600);
dup2(fp, STDOUT_FILENO);
}
for (i = 0; i < pnum-1; i++)
{
close(fd[i][1]);
close(fd[i][0]);
}
log_debug("%s pid: %d\n", node->arg[0], getpid());
//execvp() search $PATH to locate the bin file
ret = execvp(node->arg[0], node->arg);
// print the error message
if (ret < 0)
{
//printf("error:%s\n", strerror(errno));
fprintf(stderr, "%s:%s\n", node->arg[0], strerror(errno));
exit(-1);
}
}
// in parent process: put every pid of non-background process into the list
else if (background == 0)
{
struct node_process *node = (struct node_process*)malloc(sizeof(struct node_process));
node->pid = forkstatus;
node->pstatus = Running;
log_debug("pid %d inqueue\n", forkstatus);
list_add(&node->list, pid_list);
}
// in parent process: add background process into the jobs list
else
{
struct node_process *node = (struct node_process*)malloc(sizeof(struct node_process));
node->pid = forkstatus;
node->pstatus = Running;
list_add(&node->list, jobs_list);
}
idx++;
}
// wait until the child process return
if (forkstatus > 0 && cust != 0)
{
// close the pipe in the parent process
for (i = 0; i < pnum-1; i++)
{
close(fd[i][0]);
close(fd[i][1]);
}
// wait until all the process return
if (background == 0)
{
// wait the process in the pid_list
while (!list_empty(pid_list))
{
int ret = wait(NULL);
struct list_head *plist, *n;
// search the pid:ret
list_for_each_safe(plist, n, pid_list)
{
struct node_process *node = list_entry(plist, struct node_process, list);
if (node->pid == ret)
{
log_debug("wait %d return %d %d\n", i, ret, node->pid);
// delete this node
list_del(&node->list);
break;
}
}
// update the jobs_list
list_for_each(plist, jobs_list)
{
struct node_process *node = list_entry(plist, struct node_process, list);
if (node->pid == ret)
{
node->pstatus = Done;
break;
}
}
}
}
}
}
int main(int argc, char** argv)
{
char** arg = NULL;
int ntokens = 0;
struct list_head *head;
struct list_head *plist, *n;
// init list head for jobs_list
jobs_list = (struct list_head*)malloc(sizeof(struct list_head));
INIT_LIST_HEAD(jobs_list);
// init list head for pid_list
pid_list = (struct list_head*)malloc(sizeof(struct list_head));
INIT_LIST_HEAD(pid_list);
// signal - Ctrl-C
struct sigaction act;
sigfillset(&(act.sa_mask));
act.sa_flags = SA_SIGINFO;
act.sa_handler = handle_signals_ctrl_c;
if (sigaction(SIGINT, &act, NULL) < 0)
{
printf("failed to register interrupts with kernel\n");
}
// signal - Ctrl-Z
struct sigaction act_z;
sigfillset(&(act_z.sa_mask));
act_z.sa_flags = SA_SIGINFO;
act_z.sa_handler = handle_signals_ctrl_z;
if (sigaction(SIGTSTP, &act_z, NULL) < 0)
{
printf("failed to register interrupts with kernel\n");
}
// sigsetjmp
if ( sigsetjmp( ctrlc_buf, 1 ) != 0 )
{
;
}
if ( sigsetjmp( ctrlz_buf, 1 ) != 0 )
{
log_debug("ctrlz sigsetjmp\n");
struct list_head *plist, *n;
// move the list in pid_list to jobs_list
list_for_each_safe(plist, n, pid_list)
{
struct node_process *node = list_entry(plist, struct node_process, list);
log_debug("pid:%d pstatus:%d\n", node->pid, node->pstatus);
struct node_process *newnode = (struct node_process*)malloc(sizeof(struct node_process));
newnode->pstatus = Stopped;
newnode->pid = node->pid;
list_add(&newnode->list, jobs_list);
list_del(&node->list);
}
log_debug("jobs_list empty:%d\n", list_empty(jobs_list));
}
// loop
while(1)
{
arg = NULL;
ntokens = 0;
// readline
line_read = rl_gets();
// print the jobs that were done
int i = 0;
int ret;
list_for_each_safe(plist, n, jobs_list)
{
struct node_process *node = list_entry(plist, struct node_process, list);
ret = waitpid(node->pid, NULL, WNOHANG);
if (ret == -1)
node->pstatus = Done;
if (node->pstatus == Done)
{
printf("[%d]\tpid:%d\t%s\n", i, node->pid, process_status_str[node->pstatus]);
// delete this node
list_del(&node->list);
}
i++;
}
// handle the input
if (line_read && *line_read)
{
arg = lexer(line_read, &ntokens);
//exec_singlecmd(arg, ntokens);
//log_debug("arg : %p\n", arg);
head = parser(arg, ntokens);
exec_multicmd(head);
free_list(head);
}
}
//free(pid_list);
//pid_list = NULL;
return 0;
}
|
Java
|
UTF-8
| 471 | 2.09375 | 2 |
[] |
no_license
|
package org.sagebionetworks.bridge.models.accounts;
import org.sagebionetworks.bridge.models.BridgeEntity;
import com.fasterxml.jackson.annotation.JsonProperty;
public final class ExternalIdentifier implements BridgeEntity {
private final String identifier;
public ExternalIdentifier(@JsonProperty("identifier") String identifier) {
this.identifier = identifier;
}
public String getIdentifier() {
return identifier;
}
}
|
Markdown
|
UTF-8
| 1,026 | 3.5 | 4 |
[] |
no_license
|
# my algorithms
When I am doing projects, I am faced with problems that require me to write some algorithms to solve them. In this repository are these algorithms, please help make them optimal or leave a thank you if the are helpful to you.
# INSERT INTO BINARY TREE ALG1
This algorithm inserts a sorted list of elements into a binary tree in N steps where N is the size of the array to be inserted. The elements are inserted to produce a balanced binary tree hence giving a total insertion cost of nlogn instead of n2. Additionally, it maintains a space complexity of O(n).
The array dealt with should be a integer index based array, not an associative one.
The associative version will be released soon. If you need it, you can make a request using the issure tab.
# ->WHY IS THIS ALGORITHM USEFUL (ALG1)<-
Assuming you get the elements from, say a range function, or a Database with order by (ASC or DESC) and you want to store the results in a binary tree for quick modification. This algorithm helps you achieve that.
|
Java
|
UTF-8
| 2,287 | 2.71875 | 3 |
[
"Apache-2.0"
] |
permissive
|
package ru.yandex.qatools.ashot.screentaker;
import org.openqa.selenium.JavascriptExecutor;
import org.openqa.selenium.WebDriver;
import java.awt.*;
import java.awt.image.BufferedImage;
/**
* @author <a href="pazone@yandex-team.ru">Pavel Zorin</a>
* <p/>
* Pastes together parts of screenshots
* Used when driver shoots viewport only
*/
public abstract class VerticalPastingShootingStrategy extends HeadCuttingShootingStrategy {
protected int scrollTimeout = 0;
public void setScrollTimeout(int scrollTimeout) {
this.scrollTimeout = scrollTimeout;
}
protected VerticalPastingShootingStrategy(int scrollTimeout, int headerToCut) {
super(headerToCut);
this.scrollTimeout = scrollTimeout;
}
@Override
public BufferedImage getScreenshot(WebDriver wd) {
JavascriptExecutor js = (JavascriptExecutor) wd;
int allH = getFullHeight(wd);
int allW = getFullWidth(wd);
int winH = getWindowHeight(wd);
int scrollTimes = allH / winH;
int tail = allH - winH * scrollTimes;
BufferedImage finalImage = new BufferedImage(allW, allH, BufferedImage.TYPE_4BYTE_ABGR);
Graphics2D graphics = finalImage.createGraphics();
for (int n = 0; n < scrollTimes; n++) {
js.executeScript("scrollTo(0, arguments[0])", winH * n);
waitForScrolling();
BufferedImage part = super.getScreenshot(wd);
graphics.drawImage(part, 0, n * winH, null);
}
if (tail > 0) {
js.executeScript("scrollTo(0, document.body.scrollHeight)");
waitForScrolling();
BufferedImage last = super.getScreenshot(wd);
BufferedImage tailImage = last.getSubimage(0, last.getHeight() - tail, last.getWidth(), tail);
graphics.drawImage(tailImage, 0, scrollTimes * winH, null);
}
graphics.dispose();
return finalImage;
}
private void waitForScrolling() {
try {
Thread.sleep(scrollTimeout);
} catch (InterruptedException ignored) {
}
}
public abstract int getFullHeight(WebDriver driver);
public abstract int getFullWidth(WebDriver driver);
public abstract int getWindowHeight(WebDriver driver);
}
|
C#
|
UTF-8
| 3,138 | 2.8125 | 3 |
[
"MIT",
"MS-PL",
"BSL-1.0",
"LicenseRef-scancode-unknown-license-reference"
] |
permissive
|
using System;
using System.Collections.Generic;
using System.Text;
using GameUtils.Math;
namespace GameUtils.Graphics
{
/// <summary>
/// Formats a given text and saves the resulting layout.
/// </summary>
public class TextLayout : IResource
{
internal struct PositionedGlyph
{
public Font.Glyph Glyph;
public Vector2 Location;
}
readonly ISurface surface;
readonly string text;
readonly Vector2 bounds;
readonly Font font;
readonly float fontSize;
readonly TextFormat format;
bool dpiChanged;
internal List<PositionedGlyph> Glyphs;
public object Tag { get; set; }
public bool IsReady { get; set; }
void Layout()
{
float scale = (fontSize * surface.Dpi) / (72 * font.UnitsPerEm);
int currentLineStart = 0;
int currentLineEnd = 0;
float currentLineLength = 0;
int currentWordStart = 0;
int currentWordEnd = 0;
float currentWordLength = 0;
var lines = new List<string>();
var currentLine = new StringBuilder();
for (int i = 0; i < text.Length; i++)
{
if (char.IsControl(text[i]))
{
}
else
{
Font.Glyph glyph = font.GetGlyph(text[i]);
currentWordLength += glyph.AdvanceWidth * scale;
}
}
}
void OnSurfaceDpiChanged(object obj, EventArgs e)
{
dpiChanged = true;
}
public TextLayout(string text, Vector2 bounds, Font font, float fontSize, TextFormat format)
{
surface = GameEngine.TryQueryComponent<ISurface>();
if (surface == null) throw new InvalidOperationException("A surface must be registered before a text layout can be created.");
surface.DpiChanged += OnSurfaceDpiChanged;
this.text = text;
this.bounds = bounds;
this.font = font;
this.fontSize = fontSize;
this.format = format;
dpiChanged = false;
Glyphs = new List<PositionedGlyph>();
Layout();
}
private bool disposed;
public void Dispose()
{
if (!disposed)
{
Dispose(true);
GC.SuppressFinalize(this);
disposed = true;
}
}
private void Dispose(bool disposing)
{
if (disposing)
{
Glyphs.Clear();
Glyphs = null;
}
surface.DpiChanged -= OnSurfaceDpiChanged;
}
~TextLayout()
{
Dispose(false);
}
public UpdateMode UpdateMode => UpdateMode.InitUpdateAsynchronous;
public void ApplyChanges()
{
if (dpiChanged)
{
Layout();
dpiChanged = false;
}
}
}
}
|
Python
|
UTF-8
| 1,058 | 3.53125 | 4 |
[] |
no_license
|
import pandas as pd
soccer = pd.read_csv("mls-salaries-2017.csv.csv")
print(soccer.head(10))
print(len(soccer.index))
avg_sal = soccer["base_salary"].mean()
print(avg_sal)
max_sal = soccer["base_salary"].max()
print(max_sal)
max_gcompen = soccer["guaranteed_compensation"].max()
print(max_gcompen)
player = soccer[soccer["guaranteed_compensation"] == soccer["guaranteed_compensation"].max()]["last_name"].iloc[0]
print(player)
# Gonzalez Pirez position
gonzalo = soccer[soccer["last_name"] == "Gonzalez Pirez"]["position"].iloc[0]
print(gonzalo)
# Avg sals for positions
avgp = soccer.groupby("position").mean()
print(avgp)
# How many positions are there?
pss = soccer["position"].nunique()
print(pss)
# Hangi mevkide kaç kişi?
pssv = soccer["position"].value_counts()
print(pssv)
print(soccer["club"].value_counts())
def son_find(last_name):
if "son" in last_name.lower():
return True
return False
# Name ends with "son"
son_player = soccer[soccer["last_name"].apply(son_find)]
print(son_player)
|
Shell
|
UTF-8
| 197 | 2.8125 | 3 |
[] |
no_license
|
# where to keep passphrase files
PASSDIR=~/lib/secrets
# ensure the shell function is loaded when referenced
autoload gp
# do filename completion for the command 'gp'
compctl -f -W ${PASSDIR} gp
|
Markdown
|
UTF-8
| 1,195 | 2.71875 | 3 |
[] |
no_license
|
# 一些路径
如果 URL 是一个绝对路径 (例如 /images/foo.png ),它将会被保留不变。
<img alt="Vue logo" src="/assets/logo.png">
<img alt="Vue logo" src="http://image.xx.com/logo.png">
如果 URL 以 . 开头会作为一个相对模块请求被解释并基于文件系统相对路径。
<img alt="Vue logo" src="./assets/logo.png">
如果 URL 以 ~ 开头会作为一个模块请求被解析。这意味着你甚至可以引用 Node 模块中的资源
<img src="~some-npm-package/foo.png">
如果 URL 以 @ 开头会作为一个模块请求被解析。Vue CLI 默认会设置一个指向 src 的别名 @ 。
import Hello from '@/components/Hello.vue'
在 public/index.html 等通过 html-webpack-plugin 用作模板的 HTML 文件中,你需要通过 <%= BASE_URL %> 设置链接前缀
<link rel="icon" href="<%= BASE_URL %>favicon.ico">
在模板中,先向组件传入 BASE_URL:
<img :src="`${publicPath}my-image.png`">
```js
data () {
return {
publicPath: process.env.BASE_URL
}
}
let a = 2;
```
## 部署的 基本路径
```js
// vue.config.js
module.exports = {
publicPath: process.env.NODE_ENV === "production" ? "/cart/" : "/",
};
```
|
Python
|
UTF-8
| 989 | 3.078125 | 3 |
[] |
no_license
|
# get link
from bs4 import BeautifulSoup
from urllib.request import Request, urlopen
req = Request("https://warstek.com/category/sains-alam")
html_page = urlopen(req)
soup = BeautifulSoup(html_page, "lxml")
links = []
for result in soup.findAll('a'):
links.append(result.get('href'))
print(links)
# get web content & write to text file
import requests
f = open('datamentah.txt','w', encoding="utf-8")
for item in links:
f = open('datamentah.txt','a', encoding="utf-8")
if 'http' in str(item):
page = requests.get(item)
soup = BeautifulSoup(page.content, 'html.parser')
for contentData in soup.find_all('p'):
f.write(contentData.get_text())
f.write('\n')
f.write("\n\n")
f.close()
count=0
file = open("datamentah.txt","r", encoding="utf-8")
for word in file.read().split():
count +=1
file.close();
if count > 100000:
break
print('total word is', count)
|
Markdown
|
UTF-8
| 11,274 | 2.78125 | 3 |
[] |
no_license
|
# Trabajo Práctico Final Foundations
### ITBA - Cloud Data Engineering
Bienvenido al TP Final de la sección Foundations del Módulo 1 de la Diplomatura en Cloud Data Engineering del ITBA.
En este trabajo práctico vas a poner en práctica los conocimientos adquiridos en:
1. Bases de Datos Relacionales (PostgreSQL específicamente).
2. BASH y Linux Commandline.
3. Python 3.7+.
4. Docker.
Para realizar este TP vamos a utlizar la plataforma Github Classrooms donde cada alumno tendrá acceso a un repositorio de Git privado hosteado en la plataforma Github.
En cada repositorio, en la sección de [Issues](https://guides.github.com/features/issues/) (tab a la derecha de Code en las tabs de navegación en la parte superior de la pantalla) podrás ver que hay creado un issue por cada ejercicio.
El objetivo es resolver ejercicio/issue creando un branch y un pull request asociado.
Debido a que cada ejercico utiliza el avance realizado en el issue anterior, cada nuevo branch debe partir del branch del ejercicio anterior.
Para poder realizar llevar a cabo esto puede realizarlo desde la web de Github pero recomendamos hacerlo con la aplicación de línea de comando de git o con la aplicación de [Github Desktop](https://desktop.github.com/) (interfaz visual) o [Github CLI](https://cli.github.com/) (interfaz de línea de comando).
La idea de utilizar Github es replicar el ambiente de un proyecto real donde las tareas se deberían definir como issues y cada nuevo feature se debería crear con un Pull Request correspondiente que lo resuelve.
https://guides.github.com/introduction/flow/
https://docs.github.com/en/github/getting-started-with-github/quickstart/github-flow
**MUY IMPORTANTE: parte importante del Trabajo Práctico es aprender a buscar en Google para poder resolver de manera exitosa el trabajo práctico**
## Ejercicios
### Ejercicio 1: Elección de dataset y preguntas
Elegir un dataset de la [wiki de PostgreSQL ](https://wiki.postgresql.org/wiki/Sample_Databases) u otra fuente que sea de interés para el alumno.
Crear un Pull Request con un archivo en [formato markdown](https://guides.github.com/features/mastering-markdown/) expliando el dataset elegido y una breve descripción de al menos 4 preguntas de negocio que se podrían responder teniendo esos datos en una base de datos relacional de manera que sean consultables con lenguaje SQL.
Otras fuentes de datos abiertos sugeridas:
https://catalog.data.gov/dataset
https://datasetsearch.research.google.com/
https://www.kaggle.com/datasets
## Ejercicio 2: Crear container de la DB
Crear un archivo de [docker-compose](https://docs.docker.com/compose/gettingstarted/) que cree un container de [Docker](https://docs.docker.com/get-started/) con una base de datos PostgreSQL con la versión 12.7.
Recomendamos usar la [imagen oficial de PostgreSQL](https://hub.docker.com/_/postgres) disponible en Docker Hub.
Se debe exponer el puerto estándar de esa base de datos para que pueda recibir conexiones desde la máquina donde se levante el container.
## Ejercicio 3: Script para creación de tablas
Crear un script de bash que ejecute uno o varios scripts SQL que creen las tablas de la base de datos en la base PostgreSQL creada en el container del ejercicio anterior.
Se deben solamente crear las tablas, primary keys, foreign keys y otras operaciones de [DDL](https://en.wikipedia.org/wiki/Data_definition_language) sin crear o insertar los datos.
## Ejercicio 4: Popular la base de datos
Crear un script de Python que una vez que el container se encuentre funcionando y se hayan ejecutado todas las operaciones de DDL necesarias, popule la base de datos con el dataset elegido.
La base de datos debe quedar lista para recibir consultas. Durante la carga de información puede momentareamente remover cualquier constraint que no le permita insertar la información pero luego debe volverla a crear.
Este script debe ejecutarse dentro de un nuevo container de Docker mediante el comando `docker run`.
El container de Docker generado para no debe contener los datos crudos que se utilizarían para cargar la base.
Para pasar los archivos con los datos, se puede montar un volumen (argumento `-v` de `docker run`) o bien bajarlos directamente desde Internet usando alguna librería de Python (como `requests`).
## Ejercicio 5: Consultas a la base de datos
Escribir un script de Python que realice al menos 5 consultas SQL que puedan agregar valor al negocio y muestre por pantalla un reporte con los resultados.
Este script de reporting debe correrse mediante una imagen de Docker con `docker run` del mismo modo que el script del ejercicio 4.
## Ejercicio 6: Documentación y ejecución end2end
Agregue una sección al README.md comentando como resolvió los ejercicios, linkeando al archivo con la descripción del dataset y explicando como ejecutar un script de BASH para ejecutar todo el proceso end2end desde la creación del container, operaciones de DDL, carga de datos y consultas. Para esto crear el archivo de BASH correspondiente.
## Resolución de ejercicios
### Elección del dataset y preguntas
En el siguiente [link](https://github.com/flanfranco/tpf-foundations-flanfranco/blob/main/documentation/dataset_info.md) se detalla el dataset seleccionado, junto con su modelo de datos y las preguntas de análisis a responder.
### Acerca de la solución
Las tecnologías utilizadas para resolver los distintos apartados fueron:
1. Sistema operativo Linux Ubuntu 20.04
2. Docker y Docker-Compose
3. DBeaver
4. Github
**¿Por qué Docker-Compose?**
Se optó por Docker-Compose como orquestador sobre scripts de Bash principalmente porque ofrece un importante dinamismo a la hora de desplegar rápidamente una solución productiva. A su vez Docker-Compose mantiene el tracking de manera nativa de todo lo que ocurre con los containers ejecutados, y como características fundamentales ofrece estandarización, legilibilidad, y portabilidad a la hora de definir la orquestación, facilitando el mantenimiento de la misma.
Es importante remarcar que la resolución de los ejercicios podría llevarse a cabo completamente con scripts de Bash logrando los mismos resultados, utilizando piping (por ejemplo: `echo "SQL Query;" | docker exec -i docker_postgres_db_1 psql -U username database`), variables (ejemplo: `docker run -v $(pwd)/csv_volume:/csv_volume my-app-image`) y estructuras lógicas de comparación e iteración para gestionar la ejecución de toda la orquestación. Es en base a este último punto donde se optó por una solución mas robusta como Docker-Compose para poder orquestar toda la ejecución, y a su vez que esta solución pueda servir como base para futuros trabajos prácticos correspondientes a los próximos módulos.
### Guía de ejecución
Para poder ejecutar la solución es requisito tener instalado Docker y Docker-Compose en el sistema operativo.
A continuación se listan los pasos para desplegar la solución:
1. Descargar el contenido del [repositorio](https://github.com/flanfranco/tpf-foundations-flanfranco.git)
2. Posicionados sobre la carpeta donde descargamos el contenido del repositorio ("tpf-foundations-flanfranco") se debería encontrar el archivo `docker-compose.yml` que contiene todas las especificaciones correspondientes al proceso de orquestación. Allí ejecutamos: `docker-compose up` para que se empiece a desplegar la solución.
3. Una vez que la solución terminó de desplegarse deberíamos ver algo similar a la siguiente captura:

4. Ya teniendo desplegada la solución, para poder acceder a la Jupyter Notebook (que contiene el análisis) solo haría falta ingresar al siguiente [link](http://127.0.0.1:8888/?token=itba_jupyter_notebook_token): `http://127.0.0.1:8888/?token=itba_jupyter_notebook_token`
5. Una vez en el repositorio de Jupyter, deberíamos seleccionar la siguiente notebook `ITBA CDE TP Foundations Flavio Lanfranco.ipynb` como se muestra en la captura a continuación:

Logrando acceder, finalmente, a la notebook que contiene todo el análisis interactivo para responder los [requerimientos planteados](https://github.com/flanfranco/tpf-foundations-flanfranco/blob/main/documentation/dataset_info.md).

### Comentarios acerca del desarrollo
En los siguientes apartados se comenta en detalle las principales consideraciones tenidas en cuenta en el desarrollo de la solución:
1. En la siguiente captura se muestra y comenta el contenido del `docker-compose.yml` detallando las características principales definidas para la orquestación:

2. Con respecto a la creación del container de la DB requerida en el Ejercicio 2, se comparte una captura del dockerfile donde además se muestra como se ejecuta la creación del schema y tablas necesarias para el Ejercicio 3:

3. En las siguientes capturas se muestra cómo se llevó adelante la resolución del Ejercicio 4 definiendo el siguiente dockerfile y script de python:


5. Finalmente se comparte captura del dockerfile utilizado para resolver el Ejercicio 5:

### Notas finales
Es importante remarcar que se podría mejorar mucho mas la solución presentada, por ejemplo, en lo referido al script de python para que considere control de excepciones, reintentos, logueo, etc... Todo esto podría desarrollarse como un framework para luego reutilizarse en otros proyectos.
También, respecto a la parametrización de la solución, los schemas, nombres de tablas/csv, y credenciales podrían haberse definido en un archivo externo (json) evitando el harcodeo en el desarrollo y mejorando aspectos referidos a la seguridad.
A su vez se podrían haber utilizado imágenes de docker mucho mas pequeñas y básicas que las presentadas, reduciendo considerablemente el espacio de almacenamiento necesario para desplegar la solución.
La idea es que esta solución sea el punto de partida (y de mejoras) para la realización de los futuros trabajos prácticos correspondientes a los próximos módulos de la diplomatura.
Gracias por el tiempo brindado!!!
👨🏽💻 Flavio Lanfranco
|
Python
|
UTF-8
| 4,060 | 2.625 | 3 |
[] |
no_license
|
import cv2
import numpy as np
# These 4 are too slow
# BIG anime eyes
def apBigErode(frame):
return cv2.erode(frame, kernBigEllipse)
# Makes thin things disappear
def apOpen(frame):
return cv2.morphologyEx(frame, cv2.MORPH_OPEN, kernBigEllipse)
# Very funky looking - blackens and makes edges emphasized
def apGradient(frame):
return cv2.morphologyEx(frame, cv2.MORPH_GRADIENT, kernBigEllipse)
# keeps White things only, very unsettling to look at eyes
def apHatFilter(frame):
return cv2.morphologyEx(frame, cv2.MORPH_BLACKHAT, kernBigEllipse)
# return cv2.morphologyEx(frame, cv2.MORPH_TOPHAT, kernBigEllipse):wq
# failed laplacian, too slow
kern = np.ones((3, 3)) * -1
kern[1][1] = 8
#return cv2.filter2D(frame, -1, kern)
# Both blurs are too boring
# Median blur
def apMedian(frame, ksize=5):
frame = cv2.medianBlur(frame, ksize)
return cv2.medianBlur(frame, ksize)
# standard Gaussian blur
def apGaussian(frame, kSize=5):
return cv2.GaussianBlur(frame, (kSize,kSize), -1)
# Less optimal background subtractions
# backSub = cv2.createBackgroundSubtractorKNN() # Default is good, but edited is faster
# backSub = cv2.createBackgroundSubtractorKNN(history=3, detectShadows=False)
# janky shit, ugly and boring.
def apSharpenLaplacian(frame):
frame = apGrayscale(frame)
#frame = cv2.boxFilter(frame,-1,ksize=(5,5))
return frame-apGaussian(apLaplacian(frame)*apCanny(frame))
# Not cool enough, but might be included anyway
def apCanny(frame, th1 = 80, th2 = 200):
frame = cv2.Canny(frame, th1, th2)
return frame
#Not cool enough compared to colorededges
# Similar to previous, but makes the space bigger first
def apNovelInfo(frame):
mask = apCanny(frame)
mask = apGaussian(mask)
mask = apGaussian(mask)
return cv2.bitwise_and(frame, frame, mask=mask)
def apScharrX(frame):
return cv2.Scharr(frame, -1, 1,0)
def apScharrY(frame):
return cv2.Scharr(frame, -1, 0,1)
# Too noisy to use
# you tried to do it yourself but it was too slow
def apLaplacian(frame, surroundings=-1):
return cv2.Laplacian(frame,-1,ksize=5)
# Too strong of a ghostly lag to use, but hana said it most resembles drugs
def apGhostly(frame):
return ghostFilter.apply(frame)
# Not cool enough
# Select only one channel to see - preserves color so everything is red tinted
def apOneChanCol(frame, ch1 = 2, minimum = .5):
if len(channels) == 3:
channels.remove(ch1)
for thing in channels:
frame[:,:,thing] = frame[:,:,thing]*minimum
return frame
channels = [0,1,2]
# Not cool enough
# Take a color channel as the greyscale values. Could do something interesting by adding/subtracting different channels after thresholding?
def apOneChannelAsGreyscale(frame, ch1 = 1):
return frame[:,:,2]
# Interesting movement effects, but too noisy to use. Get rid of high frequency noise and we can talk
def apSubtract(frame):
# frame = ghostForSubtraction.apply(frame)
# return frame
try:
tmp = frame.copy() - prev[0].copy()
except:
tmp = frame
prev[0] = frame
return tmp
# Gross looking but cool
def apScaleDown(frame):
frame = frame-50
return frame
# Tried to make a filter that made everything move slowly, by resizing bigger and smaller. Worked to make an aliased variable in the function, and did some slow stuff with the world. Should target a breathing frequency with sine wave.
#def apResize(frame, x=.15,y=.15,cycNum = [0.3,.5],inter = cv2.INTER_NEAREST):
def apResize(frame, x=.08,y=.08,cycNum = [0,.05],inter = cv2.INTER_AREA):
#frame = apMedian(frame)
if cycNum[0] >= 4 or cycNum[0] < .3:
cycNum[1] = -cycNum[1]
#quant = 10
#cyc=[(0,0),(quant,0),(quant,quant),(0,quant)]
#sel = cyc[cycNum[0]+1]
cycNum[0] = (cycNum[0] + cycNum[1])
numer = cycNum[0]
#print(cycNum,numer)
divider = 10
frame = cv2.resize(frame,(0,0),fx= (1+numer/divider), fy=(1+numer/divider))
def aCUBIC(frame):
return apResize(frame, inter = cv2.INTER_CUBIC)
|
Java
|
UTF-8
| 764 | 2.390625 | 2 |
[] |
no_license
|
package org.hibernate.bugs.models;
import javax.persistence.*;
@Entity
public class OrganizationProduct {
@EmbeddedId
private OrganizationProductKey org_product_id;
@ManyToOne
private Product product;
public OrganizationProduct(OrganizationProductKey org_product_id, Product product) {
this.org_product_id = org_product_id;
this.product = product;
}
public OrganizationProduct() {
}
public OrganizationProductKey getId() {
return org_product_id;
}
public void setId(OrganizationProductKey id) {
this.org_product_id = id;
}
public Product getProduct() {
return product;
}
public void setProduct(Product product) {
this.product = product;
}
}
|
PHP
|
UTF-8
| 185 | 2.796875 | 3 |
[] |
no_license
|
<?php
class Bracket {
protected $organizers = array();
protected function addOrganizers( $user_id ) {
}
protected function getOrganizers() {
return $this->organizers;
}
}
?>
|
Markdown
|
UTF-8
| 10,327 | 2.734375 | 3 |
[
"BSD-3-Clause",
"MIT",
"Apache-2.0",
"BSD-2-Clause"
] |
permissive
|
# graphql-gw
This is a GraphQL gateway that lets you easily compose or federate other
GraphQL upstream servers.
<img src="https://raw.githubusercontent.com/chirino/graphql-gw/master/docs/images/graphql-gw-overview.jpg" alt="diagram of graphql-gw" width="488">
## Features
* Consolidate access to multiple upstream GraphQL servers via a single GraphQL gateway server.
* Introspection of the upstream server to discover their GraphQL schemas.
* The configuration uses GraphQL queries to define which upstream fields and types can be accessed.
* Upstream types, that are accessible, are automatically merged into the gateway schema.
* Type conflict due to the same type name existing in multiple upstream servers can be avoided by renaming types in the gateway.
* Supports GraphQL Queries, Mutations, and Subscriptions
* Production mode settings to avoid the gateway's schema from dynamically changing due to changes in the upstream schemas.
* Uses the dataloader pattern to batch multiple query requests to the upstream servers.
* Link the graphs of different upstream servers by defining additional link fields.
* Web based configuration UI
* OpenAPI based upstream servers (get automatically converted to GraphQL Schema)
### Installing
Please download [latest github release](https://github.com/chirino/graphql-gw/releases) for your platform
### Building from source
`go get -u github.com/chirino/graphql-gw`
## Getting started
Running
```
graphql-gw config init
graphql-gw serve
```
### Demos
* https://www.youtube.com/watch?v=I5AStj2csD0
## Build from source
```bash
go build -o=graphql-gw main.go
```
### Usage
`$ graphql-gw --help`
```
A GraphQL composition gateway
Usage:
graphql-gw [command]
Available Commands:
help Help about any command
new creates a graphql-gw project with default config
serve Runs the gateway service
Flags:
-h, --help help for graphql-gw
--verbose enables increased verbosity
Use "graphql-gw [command] --help" for more information about a command.
```
### Development and Production Mode
The `graphql-gw serve` command will run the gateway in development mode. Development mode will cause the gateway to download upstream schemas on start up. The schema files will be stored in the `upstreams` directory (located in the same directory as the gateway configuration file). If any of the schemas cannot be downloaded the gateway will fail to startup.
You can use `graphql-gw serve --production` to enabled production mode. In this mode, the schema for the upstream severs will be loaded from the `upstreams` directory that they were stored when you used development mode. This ensures that your gateway will have a consistent schema presented, and that it's start up will not be impacted by the availability of the upstream
servers.
## Configuration Guide
### `listen:`
Set the `listen:` to the host and port you want the graphql server to listen on.
Example:
```yaml
listen: localhost:8080
```
### `upstreams:`
The upstreams section holds a map of all the upstream severs that you will be
accessing with the gateway. The example below defines two upstream servers: `anilist` and `users`. Keep in mind that the URL configured must be a graphql server that is accessible from the gateway's network.
```yaml
upstreams:
anilist:
url: https://graphql.anilist.co/
users:
url: https://users.acme.io/graphql
```
If there are duplicate types across the upstream severs you can configure either type name prefixes or suffixes on the upstream severs so that conflicts can be avoided when imported into the gateway. Example:
```yaml
upstreams:
anilist:
url: https://graphql.anilist.co/
prefix: Ani
suffix: Type
users:
url: https://users.acme.io/graphql
```
### `schema:`
The optional schema section allows you configure the root query type names. The default values of those fields are shown in the folllowing table.
| Field | Default |
| ----------- | -------------- |
| `query:` | `Query` |
| `mutation:` | `Mutation` |
| `schema:` | `Subscription` |
The example below only the root mutaiton type name is changed from it's default value to `GatewayMutation`. Doing something like this can be useful if you do not want to rename type name from an upstream it contains a type name for one of these root query type names.
```yaml
schema:
mutation: GatewayMutation
```
### `types:`
Use the `types:` section of the configuration to define the fields that can be
accessed by clients of the `graphql-gw`. You typicaly start by configuring the root query type names
The following example will add a field `myfield` to the `Query` type where the type is the root query of the `anilist` upstream server.
```yaml
types:
- name: Query
actions:
- type: mount
field: myfield
upstream: anilist
query: query {}
```
### `actions:`
`actions:` is a list configuration actions to take against on the named type. The actions are processed in order. You can select from the following actions types:
| type | Description |
| ------------------------------- | ------------------------------------------------------------------------- |
| [`mount`](#action-type-mount) | mounts an upstream field onto a gateway schema type using a graphql query |
| [`rename`](#action-type-rename) | renames either a type or field in the gateway schema. |
### Action `type: mount`
The `mount` action can be used to mount an upstream field onto a gateway schema type using a graphql query
| Field | Required | Description |
| ----------- | -------- | --------------------------------------------------------------------------------------------------------------------------------------- |
| `upstream:` | yes | a reference to an upstream server defined in the `upstreams:` section. |
| `query:` | yes | partial graphql query document to one node in the upstream server graph. |
| `field:` | no | field name to mount the resulting node on to. not not specified, then all the field of the node are mounted on to the the parent type. |
### Action `type: link`
The `link` action is a more advanced version of mount. It is typically used to create new fields that link to data from a different upstream server.
| Field | Required | Description |
| ----------- | -------- | ------------------------------------------------------------------------------------------------------------------------------------------------ |
| `upstream:` | yes | a reference to an upstream server defined in the `upstreams:` section. |
| `query:` | yes | partial graphql query document to one node in the upstream server graph. |
| `field:` | yes | field name to mount the resulting node on to. |
| `vars:` | no | a map of variable names to query selection paths to single leaf node. The selections defined here will be the values passed to the the `query:` |
### Action `type: rename`
The `rename` action can be used to rename either a type or field in the gateway schema.
| Field | Required | Description |
| -------- | -------- | -------------------------------------------------------------------------------------------- |
| `field:` | no | if not set, you will be renaming the type, if set, you will be renaming a field of the type. |
| `to:` | yes | the new name |
### Action `type: remove`
The `remove` action can be used to remove a field from a type.
| Field | Required | Description |
| -------- | -------- | -------------------------------------- |
| `field:` | yes | The field name to remove from the type |
## Common Use Cases
### Importing all the fields of an upstream graphql server
If you want to import all the fields of an upstream server type, simply don't specify the name for the field to mount the query on to. The following example will import all the query fields onto the `Query` type and all the mutation fields on the `Mutation` type.
```yaml
types:
- name: Query
actions:
- type: mount
upstream: anilist
query: query {}
- name: Mutation
actions:
- type: mount
upstream: anilist
query: mutation {}
```
### Importing a nested field of upstream graphql server
Use a full graphql query to access nested child graph elements of the upstream
graphql server. Feel free to use argument variables or literals in the query.
variables used in the query will be translated into arguments for the newly defined
field.
```yaml
types:
- name: Query
actions:
- type: mount
field: pagedCharacterSearch
upstream: anilist
query: |
query ($search:String, $page:Int) {
Page(page:$page, perPage:10) {
characters(search:$search)
}
}
```
In the example above a `pagedCharacterSearch(search:String, page:Int)` field would be defined on the Query type and it would return the type returned by the `characters`field of the anilist upstream.
## License
[BSD](./LICENSE)
## Development
- We love [pull requests](https://github.com/chirino/graphql-gw/pulls)
- [Open Issues](https://github.com/chirino/graphql-gw/issues)
- graphql-gw is written in [Go](https://golang.org/). It should work on any platform where go is supported.
- Built on this [GraphQL](https://github.com/chirino/graphql) framework
|
C++
|
UTF-8
| 831 | 3.5 | 4 |
[] |
no_license
|
/*#include<iostream>
#include<string>
#include<vector>
using namespace std;
class DrawYellow
{
public:
void draw()
{
cout << "yellow" << endl;
}
};
class DrawRed
{
public:
void draw()
{
cout << "red" << endl;
}
};
class geometricobject
{
public:
virtual void draw() = 0;
};
template<class Color>
class geometric :public geometricobject
{
public:
void draw()
{
Color color;
color.draw();
}
};
void main()
{
vector<geometricobject*>drawincolor;
drawincolor.push_back(new geometric<DrawRed>);
drawincolor.push_back(new geometric < DrawYellow>);
for (auto x : drawincolor)
x->draw();
}*/
#include<iostream>
#include<string>
using namespace std;
template <class T_type>
void print(const T_type &i) {
cout << i << endl;
}
int main() {
print(1);
print(2.345f);
print("Hello World");
return 0;
}
|
PHP
|
UTF-8
| 1,265 | 2.515625 | 3 |
[] |
no_license
|
<!DOCTYPE html>
<html lang="es">
<head>
<link rel="stylesheet" href="css/estilo.css">
<link href='http://fonts.googleapis.com/css?family=Nunito:400,300' rel='stylesheet' type='text/css'>
<title>Mostrar Clientes</title>
</head>
<body background="imagenes/imagen3.jpg">
<?php
include('conexion.php');
$sql="Select * from cliente";
$consulta=mysqli_query($conn,$sql);
$nf=mysqli_num_rows($consulta);
?>
<center><table border="1">
<tr >
<br><center><image src="imagenes/logo2.png">
<br>
<th>Id</th>
<th>Nombre</th>
<th>Eliminar</th>
<th>Imprimir</th>
</tr>
<?php for ($i=0;$i<$nf;$i++)
{
$cliente=mysqli_fetch_array($consulta);
?>
<tr>
<td><?php echo $cliente['id_cliente'];?></td>
<td><?php echo $cliente['nombre'];?> <?php echo $cliente['apellidos'];?></td>
<td><a href="eliminar_cliente.php?id_cliente=<?php echo $cliente['id_cliente']?>">Eliminar</a></td>
<td><a href="reporte_clientes.php?id_cliente=<?php echo $cliente['id_cliente']?>">Imprimir</a></td>
</tr>
<?php
} // for de consulta general
mysqli_close($conn)?>
</table>
<br>
<a href="lista_clientes.php" target="_blank">Regresar</a>
</body>
</html>
|
Java
|
UTF-8
| 712 | 2.328125 | 2 |
[] |
no_license
|
package ru.masterdm.spo.utils;
import java.util.HashSet;
import java.util.concurrent.ConcurrentHashMap;
public class CollectStages {
private static volatile CollectStages instance;
public final ConcurrentHashMap<Long,HashSet<Long>> cache;
public static CollectStages singleton() {
CollectStages localInstance = instance;
if (localInstance == null) {
synchronized (CollectStages.class) {
localInstance = instance;
if (localInstance == null) {
instance = localInstance = new CollectStages();
}
}
}
return localInstance;
}
private CollectStages() {
super();
cache = new ConcurrentHashMap<Long, HashSet<Long>>();
}
public void reset(){
cache.clear();
}
}
|
Python
|
UTF-8
| 353 | 3.828125 | 4 |
[] |
no_license
|
t = int(input())
for i in range(t):
s = input().split(" ")
d = int(s[0])
n = int(s[1])
current = 0.0
for _ in range(n):
s = input().split(" ")
remaining = d - int(s[0])
speed = int(s[1])
time = remaining/speed
current = max(time, current)
print("Case #{}: {}".format(i+1, d/current))
|
Markdown
|
UTF-8
| 16,272 | 3.078125 | 3 |
[] |
no_license
|
# 理解 Golang 的 GC
## GC
GC 的实现方式主要分为三大类
- 引用计数
- 标记清除
- 复制
具体的定义不是本文要说的,网上很多介绍,也可以看松本行弘的《代码的未来》这本书。
GC 还有很多优化技巧,最重要的两个是**压缩(compact)**和**分代(generational)**
一句话概括 Go 实现的 GC 是采用**不压缩、不分代的并发标记清除**的实现方式。
## SLO
**99%的 SLI 和 99%的 SLO 完全不同**
如果把一次请求视为一项 SLI,用户会话视为 SLO。具体定义可见《SRE:Google 运维解密》。如果一次会话需要 100 次请求来完成,每次请求有 99%的概率正常响应,那一次会话正常响应的概率只有不到 37%。如果想要达到会话级别的 99%的话,那单次请求就需要达到 99.99%。
2014 年,Go 必须要解决 GC 延迟这个命运攸关的问题,所以定下一个 SLO:**GC 停顿小于 10ms**,最终花了将近两年的时间完成它。
**Go GC 的成果**
| 年份 | Go 版本迭代 | GC 停顿 | 改进 |
| ------ | ----------- | ------------------------- | ------------------------------ |
| 201508 | 1.4->1.5 | 400ms -> 40ms | 采用并发标记清除实现 |
| 201605 | 1.5->1.6 | 40ms -> 5ms | 消除 STW 中 O(heap) 的处理 |
| 201605 | 1.6->1.6.3 | <5ms | fix bugs,达成小于 10ms 的 SLO |
| 201608 | 1.6.3->1.7 | <2ms | 消除 STW 中 O(heap) 的处理 |
| 201705 | 1.7->1.8 | <1ms per goroutine <100us | 避免 STW 中的栈扫描 |
| 201708 | 1.8->1.9 | 提升微小 | 细节优化 |
在 1.9 以后,Go 的 GC 停顿已经控制在微秒级别,已知的可提升空间大概只有 100-200us,Go 需要探索提升更大优化方案,后面再说这部分,我们先总结下 Go 解决 GC 痛点的关键:并发标记清除论文。
## Dijkstra
想了解 GC 的实现如果直接看代码的话是很难的,因为 GC 有太多太多的优化细节散布在代码中,很难把主要逻辑抽离出来,并且代码和注释中会存在很多 paper、design、proposal 中定义的术语,所以要了解 GC 的逻辑需需要找到它最原始的面貌。所以我先从 paper 开始着手。
虽然 Dijkstra 最出名的作品的是他寻径算法,但是他对并发领域贡献是非常大的,他发过的 paper 比如 [Dijkstra 互斥算法](https://www.di.ens.fr/~pouzet/cours/systeme/bib/dijkstra.pdf) 被称为分布式互斥的鼻祖算法,我之前用 C++ 实现了一版简单验证一下[dijkstra-mutex](https://github.com/snowcrumble/dijkstra-mutex),在团队内做过一次分享。
话说回来,Go 在 1.5 版本引入的并发标记清除垃圾回收就是基于 Dijkstra 在 1978 年发布的 paper [On-the-fly Garbage Collection](https://lamport.azurewebsites.net/pubs/garbage.pdf) 实现的。在这篇论文之前,标记清除 GC 的理论是:标记阶段将堆上所有可达的节点标记,清除时将未标记的节点加入空闲节点列表,具体可见`CSAPP`书中的介绍。标记清除 GC 的痛点是 STW 时间,而论文通过新增一种标记状态来实现并行标记清除,避免了 STW。
### 核心
我总结下论文的核心概念:堆模型和五种操作、三种颜色、两个阶段、并发和摊销。
### 论文介绍
下面介绍下这篇论文的主要内容,不感兴趣可以直接略过看下一节。
**术语**
- mutator:用户代码所在的线程
- collector:GC 线程
- freelist:可回收的对象表
- STW:Stop The World,GC 停顿
**五种操作**
堆模型的定义,用有向图来表示多个数据结构,固定数量的节点,每个图有固定数量的根,每个节点只有两条边,从一个根出发有向可达的节点的集合为一个“数据结构”,孤立的节点为“垃圾”。

基于这个模型,mutator 只有 5 种操作:
1. 将一个可达节点的一条边指向另一个可达节点
2. 将一个可达节点的一条边指向一个不可达节点
3. 给一个无边节点添加一条边指向可达节点
4. 给一个无边节点添加一条边指向一个无边的不可达节点
5. 删除一个可达节点的一条边
其中操作 1、2、5 会创建“垃圾”,操作 2、4 会回收“垃圾”,而 GC 的任务就是找到“垃圾”并清理。Lisp 的 GC 实现是采用原始的同步标记清除方法,它在 STW 期间从根开始遍历,找到“垃圾”并将它们添加到 freelist ,在 freelist 快满的时候清理。这个方法的问题是 STW 时间长,无法预测图中节点的交叉程度。
所以论文中并发标记清除的三个目标是:
1. 尽量的减少线程间的互斥和同步操作,只存在对一个变量的互斥读写操作
2. 尽量减少 GC 与工作线程协调的开销
3. 尽量减少工作线程对 GC 的影响,gc 分为标记阶段和回收阶段,这期间可能会有新的垃圾,这是无法避免的,会交给下个 GC 周期来处理。在标记阶段新增的垃圾也一定会在下一次追加阶段被处理。
关键的地方来了,paper 中用两个特殊节点将 5 种操作简化为 1 种操作,这是一个很神的 trick,完成了相当于“剪枝”的效果。
1. 特殊的 NIL 根,他的左右两边都指向自己,用来表示上面 5 种操作的一些特殊情况,以此来减少需要处理的情况,它可以把操作 3 和 5 作为 操作 1 的一个特例,然后把操作 4 当成操作 2 的特例。
2. 特殊的 freelist 根,不把 freelist 中的当做垃圾,连接 NIL 和所有 freelist 中的节点,并且不连接其他任何节点。这样可以将操作 2 归到操作 1
简化后,mutator 就只剩下一个逻辑:将一个可达节点的一条边指向另一个可达节点。这样一来,需要实现的原子操作就大量减少了。
**三种颜色**
黑、白、灰。颜色迁移的限制:
- 节点颜色不能从深变浅,包括 黑->白,黑->灰,灰->白
- 深色节点不能引用浅色节点
**两个阶段**
在 GC 的两个阶段,mutator 和 collector 会有不同的操作。
标记阶段
- mutator:将一个可达节点的一条边指向另一个可达节点
- collector:标记所有可达的节点,即将所有可达节点变黑,白->黑,灰->黑,灰变黑时要连同其子节点一起。
回收阶段
- mutator:将一个可达节点的一条边指向另一个可达节点,此时将白色节点变灰
- collector:将未标记的节点添加到 freelist,取消其他标记,即将白色垃圾添加到 freelist,把黑色节点变白
**并发和摊销**
论文提出的方法理论上是不需要 STW 的,mutator 和 collector 可以完全并发运行,这样可以利用多核 CPU,并发标记、并发回收,只是每次 mutator 修改对象时都需要做额外的判断,以此来摊销老的标记清除方法的停顿时间。不过实现上没有 STW 不一定是最合理的,反而会影响性能,乍一听有点反直觉,但这是因为全局**写屏障**的存在,比如 Go 会用 STW 来开关写屏障来减少对 GC 期之外工作任务的影响。
## 实现
Go 基于 Dijkstra 的实现引入了一些附加物
**写屏障(write barrier)**
Go 的写屏障将当前可访问的对象从白色变为灰色,具体实现跟 CPU 架构相关。比如,go 用汇编来实现的 X86 架构的写屏障 [runtime·gcWriteBarrier](https://github.com/golang/go/blob/go1.15.2/src/runtime/asm_amd64.s#L1395)。Go 会在编译时将写屏障注入到代码中。写屏障仅在标记阶段和标记中止阶段开启,或是 cgo 检查时。另外,Go 对 write barrier 还做了一些优化,混合使用 `Yuasa-style deletion` 和 `Dijkstra insertion`,引入**write barrier buffer**来优化 per-P 的单独指针的写屏障,对一些涉及到内存排序的场景,用幂等的覆盖写操作代替使用写屏障来保证执行顺序等。
**计步器(pacing)**
用于调控 GC 触发时机,主要从两个方面进行调控下次 GC 的时机:内存增长情况和 CPU 使用情况。GC 标记阶段后台会占用最多 25% 的 CPU,比如程序使用四个 P 运行的话,GC 会占用其中一个 P,并且会固定在这个 P 上运行标记的 goroutine。这是正常的情况,但是如果新分配的速度大于标记的速度,那就需要一些额外的 标记辅助(Mark assist) goroutine 占用其他的 P 去辅助标记,Mark assist 做的工作跟 GC 的标记工作一样,不过会分块处理,每次最多处理 64k 内存,因此两次处理的间隙可以让用户的 goroutine 被调度。而需要的 assist 数量会根据内存增长情况和 CPU 负载情况进行动态调整,这就是 pacing 的工作,它是基于一种反馈控制算法,具体实现在 [runtime/mgc.go](https://github.com/golang/go/blob/go1.15.2/src/runtime/mgc.go#L336)中。
## 开发者
在理解了 Go GC 的实现理论后,开发者可以让自己的代码与 GC 更好的配合,有写需要注意的地方,在 GC 阶段,有短暂的 STW 用以开启、关闭写屏障,这需要停止所有 goroutine,通常只需要几十微秒,但需要开发者:
- 尽量减少分配到堆的代码,这样可以直接减少 GC 的压力,因为需要标记清除的对象减少了,可以利用逃逸分析工具观察哪些变量逃逸到堆中,其中哪些是可以避免的。
- 尽量不要写循环分配堆内存的代码,尽量将循环中分配内存的操作移提出到循环外。
## 质疑
有很多人对 Go GC 的质疑是因为 Go 1.5 之前的 GC 真的很慢,那是直接影响在是否生产环境中使用 Go 的因素,但这已经是过去式了。其他的一些质疑是为什么 Go 不采用压缩、也不采用分代的优化方案,Go 团队对此也有所回应:
**分代(Generational)**
分代 GC 基于一个假设,大多数对象都是临时用一下马上就释放了,分代可以帮助 GC 更快的找到这些对象,这可以减少 STW 时间,但是 Go 编译器会做逃逸分析,它会将大部分临时变量在栈中分配。同时 Go 还采用并行 GC 的算法,STW 时间非常短,清理会在程序运行时后台进行。不过分代 GC 依然可能减少后台清理的时间。
**压缩(Compact)**
压缩是为了避免内存碎片,这可以让你使用最简单的内存分配器来提高性能,简单的 bump allocator 在单线程下很快,但是多线程需要加锁。但是现代的内存分配器已经避免了内存碎片,ptmalloc、tcmalloc、jemalloc,go 的内存分配器在 tcmalloc 的基础上开发的。另外,Go 采用的是 per-P caches(mheap),小于 32kb 的对象会在 mheap 上分配,大对象才会在 heap 上。
在众多的质疑声音中,有一篇比较专业的来自 2016 年 12 月的 [文章](https://blog.plan99.net/modern-garbage-collection-911ef4f8bd8e#.3dan5aqgm),作者对 GC 的理论的了解很全面,但是对 Go 团队的 GC 设计理念没有充分的理解,他认为 Go 太过在意 GC 停顿而对 GC 的其他功能做出了取舍了,比如内存碎片导致的浪费。但是 Go 团队深刻分析了摩尔定律对硬件的影响,比如他们总结发现摩尔定律对 CPU 的影响虽然明显变弱,但是对内存来说还是有一定参考价值,所以他们认为未来五年甚至十年内存的成本相比 CPU 会降幅更大,所以 Go 设计 GC 的目标是基于这个预测,那么内存的浪费当然就被“取舍”了,并且像 tcmalloc、jemalloc 这种现代内存分配器已经对内存碎片进行了很大程度的控制,所谓的内存浪费并不明显,除非是在特定领域,比如内存特别小的嵌入式设备。
作者还认为 Go 的非抢占式调度的设计会让紧循环计算直接影响 STW 时间,比如解码大块的 base64 数据,这在文章发布日期确实是个问题,不过在 2015 年就已经有关于抢占紧循环的相关 [issue](https://github.com/golang/go/issues/10958),并在 2020 年 Go1.14 版本解决了这个问题。不过文章提出的另一个问题——吞吐量——确实是 Go 的 GC 目前的弱点,堆内存分配速度越快,GC 占用的 CPU 时间就越多,Go 会动态调节以达到分配速度与标记速度的平衡,这就会影响到应用程序的吞吐量。但是 Go 的逃逸分析也会尽可能避免这种情况的发生,其他的就要交给开发者对 Go GC 的同理心了,尽量写出值传递的代码,而且分代 GC 也不能解决吞吐量的难题。而关于 Go 采用“双倍堆”的问题,在 Go 看来这属于“设计如此”,Go 提供的数据分析表明,堆开销的增长与写屏障的影响是成反比的,所以双倍堆可以提高性能,这也是 Go 的取舍。
## 未来
很多人都会对标记清除的 GC 方案会有先入为主的看法,认为它是十分老旧的,问题很多的方法,觉得它只适合在大学课程中以此作为 GC 章节的讲解。采用标记清除的古董语言 Lisp 就被人诟病 GC 很慢,Objective-C 引入标记清除 GC 后发现很多问题,很快就用引用计数的版本替换掉了,不过引用计数方案也有它的问题,比如循环引用需要额外解决,性能问题,它采用的意外摊销(accidentally amortized)策略不能保证响应时间。
虽然 Go 的 GC 已经十分出色了,但是 Go 团队依然没有放弃持续寻找优化空间,分代 GC 是一个实现简单,又节约内存的方案,没有明显缺点,Go 在 2018 年制定新的 SLO 之后,尝试了一个**ROC (Request Oriented Collector)** 的方案,但是效果并不理想,最后还是把目光挪到了分代 GC,但是 Go 需要保持面向值的属性,所以需要实现非移动、非复制的分代 GC,通过 bitset 来标记上次 gc 保留下来的指针,但 benchmark 表现不行,这是由于分代 GC 需要全局开启写屏障,虽然可以优化但开销不可避免,另外值传递和逃逸分析大幅降低了“年轻指针”,这让分代 GC 的优势发挥不出来。Go 又尝试用哈希表来维护老指针的标记,这可以去掉 GC 期之外写屏障,以哈希计算的开销来替换写屏障的开销,同时用加密级别的哈希来避免处理哈希碰撞,不过结果依然几乎没有提升。所以 Go 接下来要做的只能是继续优化写屏障,完善逃逸分析的一些[缺陷](https://docs.google.com/document/d/1CxgUBPlx9iJzkz9JWkb6tIpTe5q32QDmz8l0BouG0Cw/edit#heading=h.n6xah83txgl1)。
## 引用
[On-the-fly Garbage Collection](https://lamport.azurewebsites.net/pubs/garbage.pdf)
[Getting to Go: The Journey of Go's Garbage Collector - The Go Blog](https://blog.golang.org/ismmkeynote)
[Go GC: Prioritizing low latency and simplicity](https://blog.golang.org/go15gc)
[go1.15.2 source code](https://github.com/golang/go/tree/go1.15.2)
[Garbage Collection In Go : Part I - Semantics](https://www.ardanlabs.com/blog/2018/12/garbage-collection-in-go-part1-semantics.html)
[Garbage Collection In Go : Part II - GC Traces](https://www.ardanlabs.com/blog/2019/05/garbage-collection-in-go-part2-gctraces.html)
[Garbage Collection In Go : Part III - GC Pacing](https://www.ardanlabs.com/blog/2019/07/garbage-collection-in-go-part3-gcpacing.html)
[Visualizing Garbage Collection Algorithms](https://spin.atomicobject.com/2014/09/03/visualizing-garbage-collection-algorithms/)
[runtime: clean up async preemption loose ends · Issue #36365 · golang/go · GitHub](https://github.com/golang/go/issues/36365)
[Go 1.5 concurrent garbage collector pacing](https://docs.google.com/document/d/1wmjrocXIWTr1JxU-3EQBI6BK6KgtiFArkG47XK73xIQ/edit#)
[Request Oriented Collector (ROC) Algorithm - Google 文档](https://docs.google.com/document/d/1gCsFxXamW8RRvOe5hECz98Ftk-tcRRJcDFANj2VwCB0/view)
[Why golang garbage-collector not implement Generational and Compact gc?](https://groups.google.com/g/golang-nuts/c/KJiyv2mV2pU)
|
PHP
|
UTF-8
| 1,850 | 2.65625 | 3 |
[] |
no_license
|
<?php
require 'e.php';
use \Event as Event;
use \EventBase as EventBase;
$socketAddress = "tcp://0.0.0.0:9000";
echo $socketAddress;
$server = stream_socket_server($socketAddress);
$eventBase = new EventBase();
//记录我们所创建的这样时间,让$eventBase可以找到这个事件
$count = [];
$event = new Event($eventBase,$server,Event::PERSIST | Event::READ | Event::WRITE,function($socket) use ($eventBase,&$count){
echo "链接开始\n";
//建立与用户链接
//在闭包中的function($socket)中的$socket就是在构造函数中传递的$server这个属性,即$socket=$server
$client = stream_socket_accept($socket);
//加上这一句,然后两个终端同时请求,则可以看到这里是阻塞的
// sleep(10);
//第一次代码,不能处理多个事件
// var_dump(fread($client,65535));
// fwrite($client, "提前祝大家平安夜快乐 \n");
// fclose($client);
//第二次代码,嵌套处理多个事件
//这个发现没有正常触发
// $event2 = new Event($eventBase,$client,Event::PERSIST | Event::READ | Event::WRITE ,function($socket){
// //对建立链接处理事件
// var_dump(fread($socket,65535));
// fwrite($socket, "提前祝大家平安夜快乐 \n");
// fclose($socket);
// });
// $event2->add();
//以上代码会出现一个问题,在嵌套里面的代码没有执行
//第三次代码,要加上$count这个变量才能正常运行
//因为Event 在同一个文件不能嵌套定义,而转为引用式的嵌套
//event:因为在同一个作用域中,如果嵌套可能会存在覆盖问题;因此不支持
(new E($eventBase,$client,$count))->handler();
echo "链接结束 \n";
});
$event->add();
$count[(int)$server][Event::PERSIST | Event::READ | Event::WRITE] = $event;
$eventBase->loop();
|
Java
|
UTF-8
| 4,972 | 3.1875 | 3 |
[] |
no_license
|
package com.utrasarvikingar.tictactoe;
import static org.junit.Assert.assertEquals;
import org.junit.Test;
public class TicTacServiceTest{
public static void main(String args[]){
org.junit.runner.JUnitCore.main("com.utrasarvikingar.TicTacServiceTest");
}
private TicTacService s = new TicTacService();
private char[][] grid = s.getGrid();
private final int GRID_SIZE = 3;
private final char PLAYER_X = 'X';
private final char PLAYER_O = 'O';
// 1
@Test
public void testGridSize(){
assertEquals(9, s.getSize());
}
// 2
@Test
public void testEmptyGrid(){
boolean isEmpty = true;
int counter = 1;
for (int x = 0; x < GRID_SIZE; x++){
for (int y = 0; y < GRID_SIZE; y++){
if ((int)grid[x][y] != (counter + 48)){ //<-- Converting char to ASCII and comparing with counter
isEmpty = false;
}
counter ++;
}
}
assertEquals(true, isEmpty);
}
// 3
@Test
public void testGetCell(){
assertEquals('5', s.getCell(1,1));
}
// 4
@Test
public void testSetCell(){
s.setCell(0,1,PLAYER_X);
assertEquals('X', grid[0][1]);
}
// 5
@Test
public void testIsItEmpty(){
s.setCell(0,1,PLAYER_X);
assertEquals(false, s.isItEmpty(0,1));
}
// 6
@Test
public void testIsItEmpty2(){
s.setCell(0,1,PLAYER_X);
assertEquals(true, s.isItEmpty(0,0));
}
// 7
@Test
public void testIsItAValidNumber(){
assertEquals(false, s.isItAValidNumber("Ex"));
}
// 8
@Test
public void testIsItAValidNumber2(){
assertEquals(true, s.isItAValidNumber("3"));
}
// 9
@Test
public void testIsItAValidNumber3(){
assertEquals(false, s.isItAValidNumber("15"));
}
// 10
@Test
public void testGetCurrentPlayer(){
assertEquals(PLAYER_X, s.getCurrentPlayer());
}
// 11
@Test
public void testSwitchPlayer(){
s.switchPlayer();
assertEquals(PLAYER_O, s.getCurrentPlayer());
}
// 12
@Test
public void testSwitchPlayerBack(){
s.switchPlayer();
s.switchPlayer();
assertEquals(PLAYER_X, s.getCurrentPlayer());
}
// 13
@Test
public void testHorizontalWin(){
for(int i = 0; i < GRID_SIZE; i++){
grid[0][i] = PLAYER_X;
}
assertEquals(PLAYER_X, s.checkHorizontal());
}
// 14
@Test
public void testHorizontalNotWin(){
grid[0][0] = PLAYER_X;
grid[0][1] = PLAYER_X;
assertEquals('F', s.checkHorizontal());
}
// 15
@Test
public void testVerticalWin(){
for(int j = 0; j < GRID_SIZE; j++){
grid[j][0] = PLAYER_O;
}
assertEquals(PLAYER_O, s.checkVertical());
}
// 16
@Test
public void testVerticalNotWin(){
grid[0][0] = PLAYER_O;
grid[1][0] = PLAYER_O;
grid[2][0] = PLAYER_X;
assertEquals('F', s.checkVertical());
}
// 17
@Test
public void testDiagonalWin(){
for(int i = 0; i < GRID_SIZE; i++){
grid[i][i] = PLAYER_X;
}
assertEquals(PLAYER_X, s.checkDiagonal());
}
// 18
@Test
public void testDiagonalNotWin(){
grid[0][0] = PLAYER_O;
grid[2][2] = PLAYER_O;
assertEquals('F', s.checkDiagonal());
}
// 19
@Test
public void testCheckIfSomeoneWon(){
for(int i = 0; i < GRID_SIZE; i++){
grid[0][i] = PLAYER_X;
}
assertEquals(true, s.checkIfSomeoneWon());
}
// 20
@Test
public void testCheckIfSomeoneDidNotWin(){
grid[0][0] = PLAYER_X;
grid[0][1] = PLAYER_X;
assertEquals(false, s.checkIfSomeoneWon());
}
// 21
@Test
public void testCheckIfGridIsNotFull(){
grid[1][2] = PLAYER_X;
grid[1][1] = PLAYER_O;
assertEquals(false, s.checkIfGridIsFull());
}
// 22
@Test
public void testCheckIfGridIsFull(){
grid[0][0] = PLAYER_X;
grid[1][0] = PLAYER_O;
grid[2][0] = PLAYER_X;
grid[0][1] = PLAYER_O;
grid[1][1] = PLAYER_X;
grid[2][1] = PLAYER_O;
grid[0][2] = PLAYER_X;
grid[1][2] = PLAYER_O;
grid[2][2] = PLAYER_X;
assertEquals(true, s.checkIfGridIsFull());
}
// 23
@Test
public void testCheckIfSomeoneWon2(){
grid[0][0] = PLAYER_O;
grid[0][1] = PLAYER_O;
grid[0][2] = PLAYER_O;
assertEquals(true, s.checkIfSomeoneWon());
}
// 24
@Test
public void testCheckIfSomeoneDidNotWon2(){
grid[0][0] = PLAYER_O;
grid[0][1] = PLAYER_X;
grid[0][2] = PLAYER_O;
assertEquals(false, s.checkIfSomeoneWon());
}
// 25
@Test
public void testCheckIfSomeoneWon3(){
grid[0][0] = PLAYER_X;
grid[1][1] = PLAYER_X;
grid[2][2] = PLAYER_X;
assertEquals(true, s.checkIfSomeoneWon());
}
// 26
@Test
public void testGetCellRow(){
assertEquals(2, s.getCellRow('9'));
}
// 27
@Test
public void testGetCellRow2(){
assertEquals(0, s.getCellRow('2'));
}
// 28
@Test
public void testGetCellCol(){
assertEquals(1, s.getCellCol('8'));
}
// 29
@Test
public void testGetCellCol2(){
assertEquals(0, s.getCellCol('4'));
}
}
|
Java
|
UTF-8
| 296 | 1.554688 | 2 |
[] |
no_license
|
package bedemo.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
import bedemo.service.domain.Regeling;
@SuppressWarnings("unused")
@Repository
public interface RegelingRepo extends JpaRepository<Regeling, Long> {
}
|
Markdown
|
UTF-8
| 1,032 | 2.609375 | 3 |
[
"MIT"
] |
permissive
|
# Film app ( test )
## Two apps CLI-client and server with express.js
# About
## Installation
1. Clone this repository
```bash
git clone https://github.com/JohnyKovalenko1337/.git
```
2. Use the package manager [npm](http://www.npmjs.com/) to install dependencies.
```bash
npm install
```
## How to start?
1. node ./cli/app to start CLI
2. node ./server/server in another terminal to start the server
## ScreenShots
### menu

### Get film by id
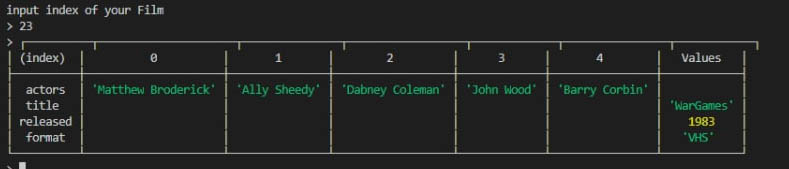
### add film
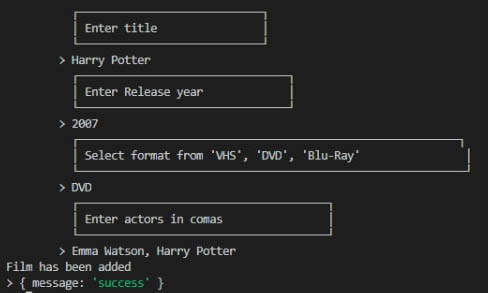
### Get films

### Get after import
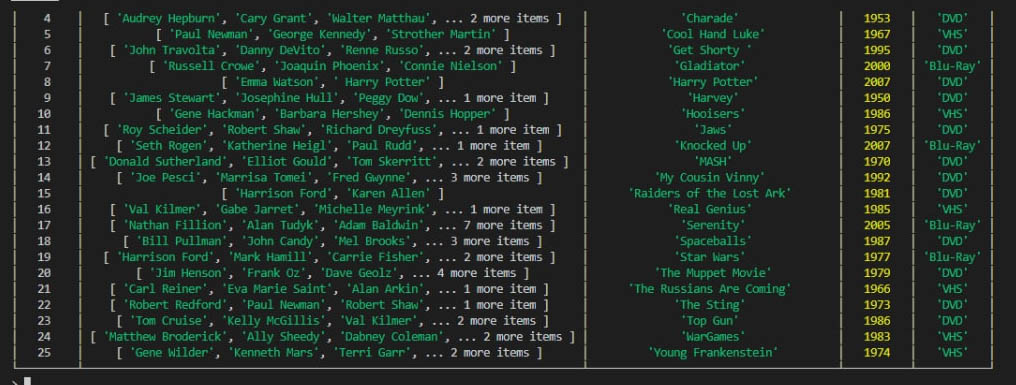
## License
MIT © [JohnyKovalenko1337](https://github.com/JohnyKovalenko1337)
|
Markdown
|
UTF-8
| 1,776 | 3.703125 | 4 |
[
"MIT"
] |
permissive
|
# Singly Linked List
This project uses Python to create a Linked List. The list can have items added to it as well as use a search function. The list can also be printed out.
## Challenge
- Create a Node class that has properties for the value stored in the Node, and a pointer to the next Node.
- Within your LinkedList class, include a head property. Upon instantiation, an empty Linked List should be created.
- Define a method called insert which takes any value as an argument and adds a new node with that value to the head of the list with an O(1) Time performance.
- Define a method called includes which takes any value as an argument and returns a boolean result depending on whether that value exists as a Node’s value somewhere within the list.
- Define a method called toString (or __str__ in Python) which takes in no arguments and returns a string representing all the values in the Linked List, formatted as:
"{ a } -> { b } -> { c } -> NULL"
- Any exceptions or errors that come from your code should be semantic, capturable errors. For example, rather than a default error thrown by your language, your code should raise/throw a custom, semantic error that describes what went wrong in calling the methods you wrote for this lab.
- Be sure to follow your language/frameworks standard naming conventions (e.g. C# uses PascalCasing for all method and class names).
## Approach & Efficiency
<!-- What approach did you take? Why? What is the Big O space/time for this approach? -->
## White Board


## API
<!-- Description of each method publicly available to your Linked List -->
## Credits and Collaborators
- Prabin Singh
- Garfield Grant
- Wondwusen
|
Java
|
UTF-8
| 3,570 | 2.296875 | 2 |
[] |
no_license
|
package com.fh.controller.masterdata;
import java.util.List;
import javax.servlet.http.HttpServletResponse;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.RequestMapping;
import com.fh.common.page.Page;
import com.fh.controller.BaseController;
import com.fh.entity.biz.StandardBonusSetup;
import com.fh.service.masterdata.StandardBonusSetupService;
import net.sf.json.JSONObject;
/**
* 经理奖金设置基本信息维护 Controller
* @author lijn
*
*/
@Controller(value="standardBonusSetupController")
@RequestMapping({"/standardBonusSetup"})
public class StandardBonusSetupController extends BaseController {
@Autowired
private StandardBonusSetupService standardBonusSetupService;
/**
* 查询经理奖金设置列表
*/
@RequestMapping("/standardBonusSetupList.do")
public String list(Page page, Model model) {
List<StandardBonusSetup> standardBonusSetupList = standardBonusSetupService.queryAll();
model.addAttribute("standardBonusSetupList", standardBonusSetupList);
return "masterdata/standardBonusSetup/standardBonusSetupList";
}
/**去添加页面
* @param model
* @return
*/
@RequestMapping(value="/standardBonusSetupToAdd.do")
public String toadd(Model model){
return "masterdata/standardBonusSetup/standardBonusSetupAdd";
}
/**去修改页面
* @param model
* @return
*/
@RequestMapping(value="/standardBonusSetupToEdit.do")
public String toEdit(String id,Model model){
//根据id查询记录
StandardBonusSetup standardBonusSetup=standardBonusSetupService.findStandardBonusSetupById(id);
if(standardBonusSetup!=null)
model.addAttribute("standardBonusSetup", standardBonusSetup);
return "masterdata/standardBonusSetup/standardBonusSetupEdit";
}
/**添加或修改经理奖金设置信息
* @param model
* @return
*/
@RequestMapping(value="/standardBonusSetupSaveOrUpdate.do")
public String saveOrUpdate(StandardBonusSetup standardBonusSetup,Model model) throws Exception {
if (!this.checkData()) {
throw new Exception("数据维护日期已截止,无法操作!");
}
standardBonusSetupService.saveOrUpdate(standardBonusSetup);
return "save_result";
}
/**去详情页面
* @param model
* @return
*/
@RequestMapping(value="/standardBonusSetupToView.do")
public String toView(String id,Model model){
//根据id查询记录
StandardBonusSetup standardBonusSetup=standardBonusSetupService.findStandardBonusSetupById(id);
if(standardBonusSetup!=null)
model.addAttribute("standardBonusSetup", standardBonusSetup);
return "masterdata/standardBonusSetup/standardBonusSetupView";
}
/**根据id删除记录
* @param model
* @return
*/
@RequestMapping(value="/standardBonusSetupDelById.do")
public void delStandardBonusSetupById(String id,HttpServletResponse response) throws Exception {
if (!this.checkData()) {
throw new Exception("数据维护日期已截止,无法操作!");
}
// json对象
JSONObject js = new JSONObject();
try {
standardBonusSetupService.delete(id);
// json中添加 数据 key value 形式
js.put("result", "success");
// 更改编码
response.setContentType("application/json;charset=UTF-8");
// 发送数据到页面
response.getWriter().write(js.toString());
} catch (Exception e) {
throw new IllegalArgumentException(e);
}
}
}
|
Shell
|
UTF-8
| 9,522 | 3.828125 | 4 |
[] |
no_license
|
#!/bin/sh
# Allow only root execution.
if [ `id|sed -e s/uid=//g -e s/\(.*//g` -ne 0 ]; then
echo "This script requires root privileges."
exit 1
fi
#
# Solaris/AIX version of GDMA start/stop script.
# Installed as, under Solaris:
# /opt/groundwork/ctlscript.sh
# Called from this script, under Solaris:
# /etc/init.d/gdma
#
# Installed as, under AIX:
# /usr/local/groundwork/ctlscript.sh
# Called from this script, under AIX:
# /usr/local/groundwork/scripts/gdma_aix_controller
#
# Starts and stops the GroundWork Monitor Distributed Agent (GDMA) daemons.
#
# description: run status/metric checks on a periodic basis,
# with results sent to GroundWork Monitor
# processname: gdma
#
# Copyright (c) 2011-2017 GroundWork Open Source, Inc. ("GroundWork").
# All rights reserved.
debug=
# Uncomment this next line to turn on simple debug logging.
# debug=-d1
# Uncomment this next line to turn on full debug logging.
# debug=-d2
user=gdma
os=`uname -s`
if [ $os = SunOS ]; then
gwpath=/opt/groundwork
zone=`zonename`
ps_zone_opt='-o zone='
awk_zone_match='$2 == "'"$zone"'"'
elif [ $os = AIX ]; then
gwpath=/usr/local/groundwork
ps_zone_opt=''
awk_zone_match=''
else
echo "The $os operating system is not supported."
exit 1
fi
[ -x $gwpath/gdma/bin/gdma_poll.pl ] || exit 0
[ -x $gwpath/gdma/bin/gdma_spool_processor.pl ] || exit 0
path_to_perl=$gwpath/perl/bin/perl
path_to_perl_binary=$gwpath/perl/bin/.perl.bin
RETVAL=0
count() {
echo $#
}
# We'd like to use the standard pgrep and pkill commands, but in the past, we needed
# to be portable back to at least Solaris 2.6, where they were not available. As of
# GDMA 2.5.0, we are only supporting Solaris 10 and later, so we have more freedom
# now. This code could therefore change in a later GDMA release.
# This implementation of gdma_pgrep() acts as if the "pgrep -f -u $user" option
# is implicit, and doesn't do full ERE pattern matching like a real pgrep (that
# is, pgrep invoked without the -x option). But we need the arguments and
# not just the command to identify specific processes of interest, so this is
# actually broken. (Solaris reports the command as perl [or .perl.bin in the
# Bitrock environment], not as the script name.)
#
# FIX MINOR: The invocation of gdma_pgrep() has been hacked below to support the
# Bitrock environment. Unfortunately, it senses and kills ANY and ALL scripts
# that are running the Bitrock version of Perl (.perl.bin) (and as the $user user),
# not just the gdma_poll.pl and gdma_spool_processor.pl scripts as it should (and
# used to, before changes to deal with the Bitrock environment). This works for
# our present purposes, but is ugly and not robust against future evolution.
# GDMA-247 contains details.
#
gdma_pgrep() {
/usr/bin/ps -u $user -o pid= $ps_zone_opt -o comm= | fgrep "$1" | nawk "$awk_zone_match"'{print $1}'
}
# This implementation of gdma_pkill() handles only very limited signalling,
# of process IDs and progress group IDs. Send the signals as user $user.
gdma_pkill() {
retval=0
if [ "$1" = "-g" ]; then
shift
# protect against both 0 and 1, just in case ...
for id in $*
do
if [ "$id" -ne 0 -a "$id" -ne 1 ]; then
/bin/su - $user -c "/usr/bin/kill -TERM -- -$id" >/dev/null 2>&1
status=$?
if [ $status -ne 0 ]; then
retval=$status
fi
fi
done
else
# protect against both 0 and 1, just in case ...
echo "Processes we are about to stop:"
pids_list=`echo "$@" | sed -e 's/ /,/g'`
ps -p "$pids_list" -f
for id in $*
do
if [ "$id" -ne 0 -a "$id" -ne 1 ]; then
/bin/su - $user -c "/usr/bin/kill -TERM $id" >/dev/null 2>&1
status=$?
if [ $status -ne 0 ]; then
retval=$status
fi
fi
done
fi
return $retval
}
start_gdma() {
retval=0
# Check if it is already running
gdmapids=`gdma_pgrep '.perl.bin'`
if [ -z "$gdmapids" ]; then
echo "Starting the gdma daemon ..."
# FIX MINOR: We have sometimes seen the spooler not start, for an unknown reason, during package install.
# Why should we throw away any error messages here, that might give us a clue as to why? Figure out some
# way to redirect stdout and stderr to the spooler log file, instead, or to some other standard place.
# Also make sure the script itself forces logging on in such a situation (when it cannot stay up).
/bin/su - $user -c "cd /; $path_to_perl -w $gwpath/gdma/bin/gdma_poll.pl $debug &" </dev/null >/dev/null 2>&1
poll_retval=$?
/bin/su - $user -c "cd /; $path_to_perl -w $gwpath/gdma/bin/gdma_spool_processor.pl $debug &" </dev/null >/dev/null 2>&1
spool_retval=$?
if [ $poll_retval -ne 0 -o $spool_retval -ne 0 ]; then
retval=1
fi
# This count of 2 assumes without checking that the process(es) we found are actually the
# ones we're looking for. There's no proof of that by just using the System V ps command as
# we are doing, so we need to use the /usr/ucb/ps command (on Solaris, if it is available)
# or extended output from the ps command (on AIX) to precisely identify the process(es).
elif [ `count $gdmapids` -eq 2 ]; then
echo "The gdma daemon is already running. PIDS:"
echo $gdmapids
echo "Processes:"
pids_list=`echo $gdmapids | sed -e 's/ /,/g'`
ps -p "$pids_list" -f
elif [ "$1" = start ]; then
echo "The gdma daemon is already partly running. PIDS:"
echo $gdmapids
echo "Processes:"
pids_list=`echo $gdmapids | sed -e 's/ /,/g'`
ps -p "$pids_list" -f
if [ $os = SunOS ]; then
# FIX LATER: This message will need to change in the future, once we have
# Solaris GDMA running under the Service Management Facility on this platform.
echo 'NOTICE: To get the daemon running properly,'
echo ' use "/etc/init.d/gdma restart" now instead of "/etc/init.d/gdma start".'
elif [ $os = AIX ]; then
echo 'NOTICE: To get the daemon running properly,'
echo ' use "stopsrc -s gdma" followed by "startsrc -s gdma".'
else
echo "The $os operating system is not supported."
exit 1
fi
retval=1
else
echo "The gdma daemon is partly running. PIDS:"
echo $gdmapids
echo "Processes:"
pids_list=`echo $gdmapids | sed -e 's/ /,/g'`
ps -p "$pids_list" -f
retval=1
fi
return $retval
}
# Under AIX, /usr/bin/sh is really a hard link to ksh, and "stop" acts
# as though it were a shell built-in, taking precedence over a function
# definition. So we have to use a different name for this function.
stop_gdma() {
retval=0
gdmapids=`gdma_pgrep '.perl.bin'`
if [ -n "$gdmapids" ] ; then
echo "Stopping the gdma daemon (PIDs "$gdmapids") ..."
gdma_pkill $gdmapids
retval=$?
else
echo "The gdma daemon is already down."
fi
return $retval
}
restart_gdma() {
stop_gdma
# Give the daemon time to quit before starting up again, or we'll see the old copy before it
# shuts down and conclude we don't need to start it up again. We cannot just sleep for some
# fixed interval, as that is not a reliable way to ensure the daemon went down.
i=1
max_checks=6
while [ $i -le $max_checks ]; do
gdmapids=`gdma_pgrep '.perl.bin'`
if [ -n "$gdmapids" ]; then
if [ $i -lt $max_checks ]; then
echo "The GDMA daemons have not shut down yet; will wait ..."
sleep 2
else
echo "The GDMA daemons have not shut down yet."
fi
else
start_gdma restart
return $?
fi
i=`expr $i + 1`
done
echo "Failed to shut down and start up the GDMA daemons."
return 1
}
reload_gdma() {
retval=0
# Note: Until the script is equipped to handle the HUP signal, this will just stop it.
trap "" HUP
gdmapids=`gdma_pgrep '.perl.bin'`
if [ -n "$gdmapids" ]; then
# protect against both 0 and 1, just in case ...
for id in $gdmapids
do
if [ "$id" -ne 0 -a "$id" -ne 1 ]; then
/usr/bin/kill -HUP $id
status=$?
if [ $status -ne 0 ]; then
retval=$status
fi
fi
done
fi
return $retval
}
status_poller() {
pids=`/usr/bin/ps -u $user -o pid= $ps_zone_opt -o args= | fgrep $path_to_perl_binary | fgrep $gwpath/gdma/bin/gdma_poll.pl | nawk "$awk_zone_match"'{print $1}'`
if [ -n "$pids" ]; then
return 0
else
return 1
fi
}
status_spooler() {
# We cannot specify the entire gdma_spool_processor.pl script filename because
# Solaris truncates the process arguments to 80 characters, which does not allow
# room for the entire path we are seeking once you realize that the args output
# also includes the full path to Perl. But we specify enough here to pretty
# much guarantee that we're looking at the process we are searching for.
#
pids=`/usr/bin/ps -u $user -o pid= $ps_zone_opt -o args= | fgrep $path_to_perl_binary | fgrep $gwpath/gdma/bin/gdma_spool_ | nawk "$awk_zone_match"'{print $1}'`
if [ -n "$pids" ]; then
return 0
else
return 1
fi
}
#
# See how we were called.
#
case "$1" in
start)
start_gdma start
RETVAL=$?
;;
stop)
stop_gdma
RETVAL=$?
;;
status)
RETVAL=0
status_poller
if [ $? -eq 0 ]; then
echo "Poller is Running"
else
echo "Poller is Not Running"
RETVAL=1
fi
status_spooler
if [ $? -eq 0 ]; then
echo "Spooler is Running"
else
echo "Spooler is Not Running"
RETVAL=1
fi
;;
restart)
restart_gdma
RETVAL=$?
;;
reload)
reload_gdma
RETVAL=$?
;;
*)
echo "Usage: $0 {start|stop|status|restart|reload}"
exit 1
;;
esac
exit $RETVAL
|
Python
|
UTF-8
| 3,582 | 3.46875 | 3 |
[] |
no_license
|
#Emile McLennan
#1 May '14
#A7 Q3
def push_up (grid):
"""merge grid values upwards"""
merged=[]
for i in range(5):
for colNum in range(4):
for rowNum in range(3):
#shift up
if grid[rowNum][colNum]==0:
grid[rowNum][colNum]=grid[rowNum+1][colNum]
grid[rowNum+1][colNum]=0
#merge identical adjacent values into array into merged
elif colNum in merged:
continue
else:
if grid[rowNum][colNum]==grid[rowNum+1][colNum]:
grid[rowNum][colNum]=grid[rowNum][colNum]+grid[rowNum+1][colNum]
grid[rowNum+1][colNum]=0
merged.append(colNum)
def push_down (grid):
"""merge grid values downwards"""
merged=[]
for i in range(5):
for colNum in range(4):
for rowNum in range(3, 0, -1):
#shift up
if grid[rowNum][colNum]==0:
grid[rowNum][colNum]=grid[rowNum-1][colNum]
grid[rowNum-1][colNum]=0
#merge identical adjacent values into array into merged
elif colNum in merged:
continue
else:
if grid[rowNum][colNum]==grid[rowNum-1][colNum]:
grid[rowNum][colNum]=grid[rowNum][colNum]+grid[rowNum-1][colNum]
grid[rowNum-1][colNum]=0
merged.append(colNum)
def push_left (grid):
"""merge grid values left"""
merged=[]
for i in range(5):
for rowNum in range(4):
for colNum in range(3):
#shift left
if grid[rowNum][colNum]==0:
grid[rowNum][colNum]=grid[rowNum][colNum+1]
grid[rowNum][colNum+1]=0
#merge identical adjacent values into array into merged
elif rowNum in merged:
continue
else:
if grid[rowNum][colNum]==grid[rowNum][colNum+1]:
grid[rowNum][colNum]=grid[rowNum][colNum]+grid[rowNum][colNum+1]
grid[rowNum][colNum+1]=0
merged.append(rowNum)
def push_right (grid):
"""merge grid values right"""
merged=[]
for i in range(5):
for rowNum in range(4):
for colNum in range(3,0,-1):
#shift right
if grid[rowNum][colNum]==0:
grid[rowNum][colNum]=grid[rowNum][colNum-1]
grid[rowNum][colNum-1]=0
#merge identical adjacent values, and put row into a list called merged so that values merge once but not more after the first merge
elif rowNum in merged:
continue
else:
if grid[rowNum][colNum]==grid[rowNum][colNum-1]:
grid[rowNum][colNum]=grid[rowNum][colNum]+grid[rowNum][colNum-1]
grid[rowNum][colNum-1]=0
merged.append(rowNum)
|
Python
|
UTF-8
| 10,838 | 2.515625 | 3 |
[] |
no_license
|
#!/usr/bin/python3
"""
Top Level Interface for swing_dance_scores
Run this file directly and see the CLI's --help documentation for further details.
Owner : paul-tqh-nguyen
Created : 08/25/2019
File Name : swing_dance_scores.py
File Organization:
* Imports
* Main Runner
"""
###########
# Imports #
###########
import argparse
import sys
import subprocess
import test.test_driver as test
import unittest
import re
import datetime
import time
from util.miscellaneous_utilities import *
###############
# Main Runner #
###############
def _deploy():
print()
print("Deploying back end...")
print()
back_end_deployment_command = "cd back_end && firebase deploy"
subprocess.check_call(back_end_deployment_command, shell=True)
print()
print("Deploying front end...")
print()
raise NotImplementedError("Support for -deploy is not yet implemented for the front end...")
return None
def _start_development_servers():
print()
print("Please use a keyboard interrupt at anytime to exit.")
print()
back_end_development_server_initialization_command = "cd back_end && firebase emulators:start"
front_end_development_server_initialization_command = "cd front_end && npm start"
back_end_development_server_process = None
front_end_development_server_process = None
back_end_process_output_total_text = ""
front_end_process_output_total_text = ""
def _shut_down_development_servers():
print("\n\n")
print("Shutting down development servers.")
if back_end_development_server_process is not None:
os.killpg(os.getpgid(back_end_development_server_process.pid), signal.SIGTERM)
if front_end_development_server_process is not None:
os.killpg(os.getpgid(front_end_development_server_process.pid), signal.SIGTERM)
print("Development servers have been shut down.")
def _raise_system_exit_exception_on_server_initilization_error(reason):
raise SystemExit("Failed to start front or back end server for the following reason: {reason}".format(reason=reason))
def _raise_system_exit_exception_on_server_initilization_time_out_error():
_raise_system_exit_exception_on_server_initilization_error("Server initialization timedout.")
try:
print("Installing libraries necessary for back end...")
subprocess.check_call("cd back_end/ && npm install", shell=True)
print("Installing libraries necessary for front end...")
subprocess.check_call("cd front_end/ && npm install", shell=True)
print("Starting front and back end server...")
back_end_development_server_process = subprocess.Popen(back_end_development_server_initialization_command, stdout=subprocess.PIPE, universal_newlines=True, shell=True, preexec_fn=os.setsid)
front_end_development_server_process = subprocess.Popen(front_end_development_server_initialization_command, stdout=subprocess.PIPE, universal_newlines=True, shell=True,
preexec_fn=os.setsid)
# start back end server
with timeout(30, _raise_system_exit_exception_on_server_initilization_time_out_error):
back_end_initialization_has_completed = False
while (not back_end_initialization_has_completed):
back_end_output_line = back_end_development_server_process.stdout.readline()
back_end_process_output_total_text += back_end_output_line
if "All emulators started, it is now safe to connect." in back_end_output_line:
back_end_initialization_has_completed = True
elif "could not start firestore emulator" in back_end_output_line:
reason = "Could not start back end server.\n\nThe following was the output of the back end server initialization process:\n{process_output_text}".format(
process_output_text=back_end_process_output_total_text)
_raise_system_exit_exception_on_server_initilization_error(reason)
# start front end server
with timeout(30, _raise_system_exit_exception_on_server_initilization_time_out_error):
front_end_initialization_has_completed = False
local_front_end_url = None
network_front_end_url = None
while (not front_end_initialization_has_completed):
front_end_output_line = front_end_development_server_process.stdout.readline()
front_end_process_output_total_text += front_end_output_line
local_url_line_pattern = " +Local: +.*"
local_url_line_pattern_matches = re.findall(local_url_line_pattern, front_end_output_line)
if len(local_url_line_pattern_matches) == 1:
local_front_end_url = local_url_line_pattern_matches[0].replace("Local:","").strip()
print("The front end can be found locally at {local_front_end_url}".format(local_front_end_url=local_front_end_url))
continue
network_url_line_pattern = " +On Your Network: +.*"
network_url_line_pattern_matches = re.findall(network_url_line_pattern, front_end_output_line)
if len(network_url_line_pattern_matches) == 1:
network_front_end_url = network_url_line_pattern_matches[0].replace("On Your Network:","").strip()
print("The front end can be found on your network at {network_front_end_url}".format(network_front_end_url=network_front_end_url))
front_end_initialization_has_completed = True
print("\nBack end and front end servers initialized at {time}".format(time=datetime.datetime.now()))
print("\n\nHere's the back end server initialization output:\n\n{back_end_process_output_total_text}\n\n".format(back_end_process_output_total_text=back_end_process_output_total_text))
print("\n\nHere's the front end server initialization output:\n\n{front_end_process_output_total_text}\n\n".format(front_end_process_output_total_text=front_end_process_output_total_text))
start_time=time.time()
time_of_last_ping = start_time
while True:
elapsed_time_since_last_ping = time.time() - time_of_last_ping
if elapsed_time_since_last_ping > 3600:
print("It has been {num_hours} hours since the front and back end servers started.".format(num_hours=int((time.time()-start_time)/3600)))
time_of_last_ping = time.time()
print()
except SystemExit as error:
print('''We encountered an error.
{error}
Perhaps the output of the back end server initialization might be helpful...
{back_end_process_output_total_text}
Perhaps the output of the front end server initialization might be helpful...
{front_end_process_output_total_text}
'''.format(error=error, back_end_process_output_total_text=back_end_process_output_total_text, front_end_process_output_total_text=front_end_process_output_total_text))
_shut_down_development_servers()
sys.exit(1)
except KeyboardInterrupt as err:
_shut_down_development_servers()
return None
def _run_tests():
test.run_all_tests()
return None
VALID_SPECIFIABLE_PROCESSES_TO_RELEVANT_PROCESS_METHOD_MAP = {
"start_development_servers": _start_development_servers,
"deploy": _deploy,
"run_tests": _run_tests,
}
def _determine_all_processes_specified_by_script_args(args):
arg_to_value_map = vars(args)
processes_specified = []
for arg, value in arg_to_value_map.items():
if value == True:
if (arg in VALID_SPECIFIABLE_PROCESSES_TO_RELEVANT_PROCESS_METHOD_MAP):
processes_specified.append(arg)
else:
raise SystemExit("Cannot handle input arg {bad_arg}.".format(bad_arg=arg))
return processes_specified
def _determine_single_process_specified_by_args(args):
processes_specified = _determine_all_processes_specified_by_script_args(args)
number_of_processes_specified = len(processes_specified)
single_process_specified_by_args = None
if number_of_processes_specified > 1:
first_processes_string = ", ".join(processes_specified[:-1])
last_process_string = ", or {last_process}".format(last_process=processes_specified[-1])
processes_string = "{first_processes_string}{last_process_string}".format(first_processes_string=first_processes_string, last_process_string=last_process_string)
raise SystemExit("The input args specified multiple conflicting processes. Please select only one of {processes_string}.".format(processes_string=processes_string))
elif number_of_processes_specified == 0:
all_possible_processes = list(VALID_SPECIFIABLE_PROCESSES_TO_RELEVANT_PROCESS_METHOD_MAP.keys())
first_processes_string = ", ".join(all_possible_processes[:-1])
last_process_string = ", or {last_process}".format(last_process=all_possible_processes[-1])
string_for_all_possible_processes = "{first_processes_string}{last_process_string}".format(first_processes_string=first_processes_string, last_process_string=last_process_string)
raise SystemExit("No process was specified. Please specify one of {string_for_all_possible_processes}.".format(string_for_all_possible_processes=string_for_all_possible_processes))
elif number_of_processes_specified == 1:
single_process_specified_by_args = processes_specified[0]
else:
raise SystemExit("Unexpected case reached. Please report an issue to https://github.com/paul-tqh-nguyen/swing_dance_scores stating that _determine_single_process_specified_by_args({args}) reached an unexpected case.".format(args=args))
return single_process_specified_by_args
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-start-development-servers', action='store_true', help="Start our back end and front end servers for development purposes.")
parser.add_argument('-run-tests', action='store_true', help="To run all of the tests.")
parser.add_argument('-deploy', action='store_true', help="To deploy local changes to our demo site at https://paul-tqh-nguyen.github.io/swing_dance_scores/.")
args = parser.parse_args()
try:
process = _determine_single_process_specified_by_args(args)
except SystemExit as error:
print(error)
print()
parser.print_help()
sys.exit(1)
if not process in VALID_SPECIFIABLE_PROCESSES_TO_RELEVANT_PROCESS_METHOD_MAP:
raise SystemExit("Input args to swing_dance_scores.py are invalid.")
else:
VALID_SPECIFIABLE_PROCESSES_TO_RELEVANT_PROCESS_METHOD_MAP[process]()
return None
if __name__ == '__main__':
main()
|
Shell
|
UTF-8
| 249 | 2.671875 | 3 |
[
"MIT"
] |
permissive
|
#!/usr/bin/env bash
pushd $(cd -P -- "$(dirname -- "$0")" && pwd -P)/..
docker-compose -f docker-compose.test.yml build
docker-compose -f docker-compose.test.yml up -d
docker logs -f docker_sut_1
RET=`docker wait docker_sut_1`
popd
exit $RET
|
Python
|
UTF-8
| 1,191 | 3.96875 | 4 |
[] |
no_license
|
'''
Detect cycle in undirected graph.
- We can use Union Find solution to find cycle in undirected graph. O(ELogV)
- We can use DFS to find cycle
- For every visited V, if there is an adjacent u such that u is visited and u is not parent of V.
- O(E + V)
'''
from Graph import graph
def iscycle(g):
visited = [False]*g.size()
for n in g.nodes():
if visited[n] is False:
if cycleUtil(g, visited, n) is True:
return True
return False
def cycleUtil(g, visited, n):
visited[n] = True
stack = list()
stack.append(n)
while stack:
ele = stack.pop()
childs = g.children(ele)
for c in childs:
if visited[c] is False:
stack.append(c)
elif c != ele:
return True
return False
g = graph()
g.addEdge(1, 0)
g.addEdge(0, 2)
g.addEdge(2, 0)
g.addEdge(0, 3)
g.addEdge(3, 4)
if iscycle(g) is True:
print("Graph contains cycle")
else:
print("Graph does not contain cycle")
g = graph()
g.addEdge(0, 1)
g.addEdge(1, 2)
if iscycle(g) is True:
print("Graph contains cycle")
else:
print("Graph does not contain cycle")
|
Python
|
UTF-8
| 1,713 | 2.796875 | 3 |
[] |
no_license
|
from models.team import Team
import sqlite3
class TeamD:
def __init__(self, conn, cursor):
self.conn = conn
self.cursor = cursor
def createTable(self):
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS teams (
id TEXT,
name TEXT,
championships INTEGER,
world_series INTEGER
)
''')
self.conn.commit()
def getTeams(self):
self.cursor.execute('SELECT * FROM teams')
teams = []
for id, name, championships, world_series in self.cursor.fetchall():
teams.append(Team(id, name, championships, world_series))
return teams
def setTeams(self, teams):
self.cursor.execute('DELETE FROM teams')
for team in teams:
self.cursor.execute(
'INSERT INTO teams VALUES (?, ?, ?, ?)',
(team.id, team.name, team.championships, team.world_series)
)
self.conn.commit()
def addTeam(self, team):
self.cursor.execute(
'INSERT INTO teams VALUES (?, ?, ?, ?)',
(team.id, team.name, team.championships, team.world_series)
)
self.conn.commit()
def updateTeam(self, team):
self.cursor.execute(
'UPDATE teams SET name = ?, championships = ?, world_series = ? WHERE id = ?',
(team.name, team.championships, team.world_series, team.id)
)
self.conn.commit()
def deleteTeam(self, team):
self.cursor.execute(
'DELETE FROM teams WHERE id = ?',
([team.id])
)
self.conn.commit()
|
C++
|
UTF-8
| 202 | 2.59375 | 3 |
[] |
no_license
|
#include <iostream>
#include "ATNode.h"
using namespace std;
int main() {
string word = "abc";
ATNode root = ATNode(word, 0);
std::cout << root.children[1].letter << endl;
return 0;
}
|
Shell
|
UTF-8
| 642 | 3.265625 | 3 |
[] |
no_license
|
#!/bin/bash
read -p "Do you want to create the mn_auto script? (Y/n) " -n 1 -r
echo
if [[ $REPLY =~ ^[Yy]$ ]]
then
cd ~/wagerr-2.0.1/bin
cat <<EOT > mn_auto.sh
#!/bin/bash
SERVICE='wagerrd'
if ps ax | grep -v grep | grep $SERVICE > /dev/null
then
echo “Masternode is running! Yay!”
else
~/wagerr-2.0.1/bin/./wagerrd
fi
EOT
chmod 744 mn_auto.sh
fi
read -p "Do you want to add the required cron task? (Y/n) " -n 1 -r
echo
if [[ $REPLY =~ ^[Yy]$ ]]
then
crontab -l | { cat; echo "*/15 * * * * /root/wagerr-2.0.1/bin/mn_auto.sh >> /root/wagerr-2.0.1/bin/cronlog/auto.log 2>&1 #logs output to auto.log"; } | crontab - l
mkdir cronlog
fi
|
Java
|
UTF-8
| 1,789 | 2.265625 | 2 |
[] |
no_license
|
package ru.rvsosn.eubmstubot.eubmstu;
import one.util.streamex.StreamEx;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import java.util.List;
import java.util.Map;
public class GetAllGroupsInLastSessionTask extends AbstractTask<GetAllGroupsInLastSessionResult> {
private static String removeToMuchSpaces(String str) {
StringBuilder builder = new StringBuilder();
boolean isLastSpace = true;
for (char i : str.toCharArray()) {
if (!Character.isWhitespace(i)) {
builder.append(i);
isLastSpace = false;
} else if (!isLastSpace) {
builder.append(' ');
isLastSpace = true;
}
}
return builder.toString().trim();
}
@Override
public GetAllGroupsInLastSessionResult execute(EUBmstuApiExecutor executor, Context context) {
WebDriver driver = context.getDriver();
driver.findElement(EUElementPath.EU_MAIN_SESSIONS_BTN.getBy()).click();
List<WebElement> elements = driver.findElements(EUElementPath.EU_SESSION_GROUPS.getBy());
return new GetAllGroupsInLastSessionResult(normalize(elements));
}
private Map<String, String> normalize(List<WebElement> elements) {
return StreamEx.of(elements)
.mapToEntry(
webElement -> removeToMuchSpaces(webElement.getAttribute("innerHTML")),
webElement -> webElement.getAttribute("href"))
.distinctKeys()
.toImmutableMap();
}
@Override
public boolean equals(Object o) {
return this == o || o != null && getClass() == o.getClass();
}
@Override
public int hashCode() {
return 0;
}
}
|
Python
|
UTF-8
| 387 | 3.421875 | 3 |
[] |
no_license
|
import functools
def logger(func):
@functools.wraps(func)
def wrapped(*args, **kwards):
result = func(*args, **kwards)
with open('log.txt', 'w') as f:
f.write(str(result))
return result
return wrapped
@logger
def summator(num_list):
return sum(num_list)
print("Summator: {}".format(summator([1,2,3,4,5])))
print(summator.__name__)
|
Java
|
UTF-8
| 15,411 | 1.773438 | 2 |
[
"Apache-2.0"
] |
permissive
|
package com.matrix.mbank;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import android.annotation.SuppressLint;
import android.app.AlertDialog;
import android.app.AlertDialog.Builder;
import android.app.TabActivity;
import android.content.DialogInterface;
import android.content.DialogInterface.OnClickListener;
import android.content.Intent;
import android.graphics.Color;
import android.os.Bundle;
import android.os.Handler;
import android.os.Message;
import android.view.LayoutInflater;
import android.view.Menu;
import android.view.MenuInflater;
import android.view.MenuItem;
import android.view.View;
import android.view.Window;
import android.widget.Button;
import android.widget.EditText;
import android.widget.ListView;
import android.widget.SimpleAdapter;
import android.widget.TabHost;
import android.widget.TabHost.OnTabChangeListener;
import android.widget.TextView;
import android.widget.Toast;
import com.matrix.action.ClientAction;
import com.matrix.utils.MBankUtil;
import com.mbank.entity.Activity;
@SuppressLint("NewApi")
@SuppressWarnings("deprecation")
public class MyTab extends TabActivity implements OnTabChangeListener {
private ListView listview;
private double rate = 0;
private double deposit_money = 0;
private double withdraw_money = 0;
private TextView username;
private TextView balance;
private TabHost myTabhost;
protected int myMenuSettingTag = 0;
protected Menu myMenu;
private static final int myMenuResources[] = { R.menu.update,
R.menu.default_mune };
public static final int DEPOSIT = 1;
public static final int WITHDRAW = 2;
public static final int UPDATECLIENT = 3;
public static final int GETACTIVITY = 4;
private EditText deposit;
private Button deposit_button;
private Button withdraw_button;
private EditText withdraw;
private EditText clientname;
private EditText type;
private EditText address;
private EditText phone;
private EditText email;
private EditText comment;
private Button update_button;
private TextView account_balance;
private TextView account_limit;
private TextView account_comment;
private List<Activity> activity = null;
@SuppressLint("HandlerLeak")
private Handler handler = new Handler() {
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case DEPOSIT:
boolean b = (Boolean) msg.obj;
if (b) {
Toast.makeText(MyTab.this,
getString(R.string.deposit_success),
Toast.LENGTH_SHORT).show();
balance.setText(MBankUtil.account.getBalance() + "");
account_balance
.setText(MBankUtil.account.getBalance() + "");
deposit.setText("");
withdraw.setText("");
new Thread(
new StoreActivity(deposit_money, "deposit", rate))
.start();
} else {
Toast.makeText(MyTab.this,
getString(R.string.deposit_failure),
Toast.LENGTH_SHORT).show();
}
break;
case WITHDRAW:
boolean b1 = (Boolean) msg.obj;
if (b1) {
Toast.makeText(MyTab.this,
getString(R.string.withdraw_success),
Toast.LENGTH_SHORT).show();
balance.setText(MBankUtil.account.getBalance() + "");
account_balance
.setText(MBankUtil.account.getBalance() + "");
deposit.setText("");
withdraw.setText("");
new Thread(new StoreActivity(withdraw_money, "withdraw",
rate)).start();
} else {
Toast.makeText(MyTab.this,
getString(R.string.withdraw_failure),
Toast.LENGTH_SHORT).show();
}
break;
case UPDATECLIENT:
boolean b2 = (Boolean) msg.obj;
if (b2) {
Toast.makeText(MyTab.this,
getString(R.string.updateclient_success),
Toast.LENGTH_SHORT).show();
address.setEnabled(false);
phone.setEnabled(false);
email.setEnabled(false);
comment.setEnabled(false);
update_button.setAlpha(0.0f);
}
break;
case GETACTIVITY:
if (activity != null) {
SimpleAdapter adapter = new SimpleAdapter(
getApplicationContext(), getData(), R.layout.item,
new String[] { "amout", "date", "commission",
"description" }, new int[] {
R.id.activity_amout, R.id.activity_date,
R.id.activity_commission,
R.id.activity_description });
listview.setAdapter(adapter);
}
break;
default:
break;
}
};
};
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
LoginActivity.instance.finish();
requestWindowFeature(Window.FEATURE_CUSTOM_TITLE);
myTabhost = this.getTabHost();
LayoutInflater.from(this).inflate(R.layout.home,
myTabhost.getTabContentView(), true);
getWindow().setFeatureInt(Window.FEATURE_CUSTOM_TITLE, R.layout.title);
myTabhost.setBackgroundColor(Color.argb(150, 22, 70, 150));
myTabhost
.addTab(myTabhost
.newTabSpec("One")
// make a new Tab
.setIndicator("",
getResources().getDrawable(R.drawable.action))
// set the Title and Icon
.setContent(R.id.widget_layout_Action));
// set the layout
myTabhost.addTab(myTabhost
.newTabSpec("Two")
// make a new Tab
.setIndicator("",
getResources().getDrawable(R.drawable.client_info))
// set the Title and Icon
.setContent(R.id.widget_layout_ClientInfo));
// set the layout
myTabhost.addTab(myTabhost
.newTabSpec("Three")
// make a new Tab
.setIndicator("",
getResources().getDrawable(R.drawable.account_info))
// set the Title and Icon
.setContent(R.id.widget_layout_AccountInfo));
// set the layout
myTabhost.addTab(myTabhost
.newTabSpec("Four")
// make a new Tab
.setIndicator("",
getResources().getDrawable(R.drawable.history))
// set the Title and Icon
.setContent(R.id.widget_layout_History));
// set the layout
myTabhost.setOnTabChangedListener(this);
listview=(ListView)findViewById(R.id.listview);
username = (TextView) findViewById(R.id.homename);
balance = (TextView) findViewById(R.id.balance);
username.setText(MBankUtil.mbankclient.getClient_name());
balance.setText(MBankUtil.account.getBalance() + "");
deposit = (EditText) findViewById(R.id.edit_deposit);
withdraw = (EditText) findViewById(R.id.edit_withdraw);
deposit_button = (Button) findViewById(R.id.deposit);
withdraw_button = (Button) findViewById(R.id.withdraw);
clientname = (EditText) findViewById(R.id.clientname);
type = (EditText) findViewById(R.id.type);
address = (EditText) findViewById(R.id.address);
phone = (EditText) findViewById(R.id.phone);
email = (EditText) findViewById(R.id.clientemail);
comment = (EditText) findViewById(R.id.comment);
clientname.setText(MBankUtil.mbankclient.getClient_name());
type.setText(MBankUtil.mbankclient.getType());
address.setText(MBankUtil.mbankclient.getAddress());
phone.setText(MBankUtil.mbankclient.getPhone());
email.setText(MBankUtil.mbankclient.getEmail());
comment.setText(MBankUtil.mbankclient.getComment());
account_balance = (TextView) findViewById(R.id.account_balance);
account_limit = (TextView) findViewById(R.id.account_limit);
account_comment = (TextView) findViewById(R.id.account_comment);
account_balance.setText(MBankUtil.account.getBalance() + "");
account_limit.setText(MBankUtil.account.getCredit_limit() + "");
account_comment.setText(MBankUtil.account.getComment());
update_button = (Button) findViewById(R.id.updateBtn);
update_button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
if (address.getText().toString().trim().equalsIgnoreCase("")) {
Toast.makeText(getApplicationContext(),
getString(R.string.input), Toast.LENGTH_SHORT)
.show();
return;
}
if (email.getText().toString().trim().equalsIgnoreCase("")) {
Toast.makeText(getApplicationContext(),
getString(R.string.input), Toast.LENGTH_SHORT)
.show();
return;
}
if (phone.getText().toString().trim().equalsIgnoreCase("")) {
Toast.makeText(getApplicationContext(),
getString(R.string.input), Toast.LENGTH_SHORT)
.show();
return;
}
if (comment.getText().toString().trim().equalsIgnoreCase("")) {
Toast.makeText(getApplicationContext(),
getString(R.string.input), Toast.LENGTH_SHORT)
.show();
return;
}
MBankUtil.mbankclient.setAddress(address.getText().toString()
.trim());
MBankUtil.mbankclient.setPhone(phone.getText().toString()
.trim());
MBankUtil.mbankclient.setEmail(email.getText().toString()
.trim());
MBankUtil.mbankclient.setComment(comment.getText().toString()
.trim());
new Thread(new UpdateClient()).start();
}
});
withdraw_button.setOnClickListener(new View.OnClickListener() {
@SuppressLint("ShowToast")
@Override
public void onClick(View v) {
if (withdraw.getText().toString().trim().equalsIgnoreCase("")) {
Toast.makeText(getApplicationContext(),
getString(R.string.input), Toast.LENGTH_SHORT)
.show();
return;
}
withdraw_money = Double.valueOf(withdraw.getText().toString()
.trim());
rate = MBankUtil.commission_rate;
if (!MBankUtil.mbankclient.getType().trim()
.equalsIgnoreCase("platinum")) {
if (withdraw_money > (MBankUtil.account.getBalance() + MBankUtil.limit)) {
Toast.makeText(getApplicationContext(),
getString(R.string.bigdraw), Toast.LENGTH_SHORT);
return;
}
}
AlertDialog.Builder builder = new Builder(MyTab.this);
builder.setMessage(getString(R.string.withdraw_rate) + rate);
builder.setTitle(getString(R.string.prompt));
builder.setNegativeButton(getString(R.string.no),
new OnClickListener() {
@Override
public void onClick(DialogInterface dialog,
int which) {
dialog.dismiss();
return;
}
});
builder.setPositiveButton(getString(R.string.yes),
new OnClickListener() {
@Override
public void onClick(DialogInterface dialog,
int which) {
new Thread(new WithDraw()).start();
}
});
builder.show();
}
});
deposit_button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
if (deposit.getText().toString().trim().equalsIgnoreCase("")) {
Toast.makeText(getApplicationContext(),
getString(R.string.input), Toast.LENGTH_SHORT)
.show();
return;
}
deposit_money = Double.valueOf(deposit.getText().toString()
.trim());
rate = MBankUtil.deposit_commission * deposit_money
+ MBankUtil.commission_rate;
AlertDialog.Builder builder = new Builder(MyTab.this);
builder.setMessage(getString(R.string.deposit_rate) + rate);
builder.setTitle(getString(R.string.prompt));
builder.setNegativeButton(getString(R.string.no),
new OnClickListener() {
@Override
public void onClick(DialogInterface dialog,
int which) {
dialog.dismiss();
return;
}
});
builder.setPositiveButton(getString(R.string.yes),
new OnClickListener() {
@Override
public void onClick(DialogInterface dialog,
int which) {
new Thread(new DepositToAccount()).start();
}
});
builder.show();
}
});
}
@Override
public boolean onCreateOptionsMenu(Menu menu) {
myMenu = menu;
myMenu.clear();
// Inflate the currently selected menu XML resource.
MenuInflater inflater = getMenuInflater();
switch (myMenuSettingTag) {
case 2:
inflater.inflate(myMenuResources[0], menu);
break;
default:
inflater.inflate(myMenuResources[1], menu);
break;
}
return super.onCreateOptionsMenu(menu);
}
@Override
public void onTabChanged(String tagString) {
if (tagString.equals("One")) {
myMenuSettingTag = 1;
}
if (tagString.equals("Two")) {
myMenuSettingTag = 2;
}
if (tagString.equals("Three")) {
myMenuSettingTag = 3;
}
if (tagString.equals("Four")) {
myMenuSettingTag = 4;
new Thread(new GetActivity()).start();
}
if (myMenu != null) {
onCreateOptionsMenu(myMenu);
}
}
@Override
public boolean onOptionsItemSelected(MenuItem item) {
switch (item.getItemId()) {
case R.id.edit:
// clientname.setEnabled(true);
// type.setEnabled(true);
address.setEnabled(true);
phone.setEnabled(true);
email.setEnabled(true);
comment.setEnabled(true);
update_button.setAlpha(1.0f);
break;
case R.id.logout:
AlertDialog.Builder builder = new Builder(MyTab.this);
builder.setMessage(getString(R.string.sureout));
builder.setTitle(getString(R.string.prompt));
builder.setNegativeButton(getString(R.string.no),
new OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
dialog.dismiss();
return;
}
});
builder.setPositiveButton(getString(R.string.yes),
new OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
dialog.dismiss();
MBankUtil.reset();
startActivity(new Intent(MyTab.this,
LoginActivity.class));
finish();
}
});
builder.show();
break;
}
return true;
}
class DepositToAccount implements Runnable {
@Override
public void run() {
MBankUtil.account.setBalance(MBankUtil.account.getBalance() - rate
+ deposit_money);
boolean b = ClientAction.getInstance().deposit();
Message message = new Message();
message.obj = b;
message.what = DEPOSIT;
handler.sendMessage(message);
}
}
class WithDraw implements Runnable {
@Override
public void run() {
MBankUtil.account.setBalance(MBankUtil.account.getBalance() - rate
- withdraw_money);
boolean b = ClientAction.getInstance().deposit();
Message message = new Message();
message.obj = b;
message.what = WITHDRAW;
handler.sendMessage(message);
}
}
class StoreActivity implements Runnable {
private double amount = 0;
private String description;
private double commission;
public StoreActivity() {
super();
}
public StoreActivity(double amount, String description,
double commission) {
super();
this.amount = amount;
this.description = description;
this.commission = commission;
}
@Override
public void run() {
ClientAction.getInstance().storeActivity(amount, description,
commission);
}
}
class UpdateClient implements Runnable {
@Override
public void run() {
boolean b = ClientAction.getInstance().updateClient();
Message message = new Message();
message.obj = b;
message.what = UPDATECLIENT;
handler.sendMessage(message);
}
}
class GetActivity implements Runnable {
@Override
public void run() {
activity = ClientAction.getInstance().getALLActivity();
Message message = new Message();
message.what = GETACTIVITY;
handler.sendMessage(message);
}
}
public List<Map<String, Object>> getData() {
List<Map<String, Object>> list = new ArrayList<Map<String, Object>>();
for (Activity a : activity) {
Map<String, Object> map = new HashMap<String, Object>();
map.put("amout", a.getAmount());
map.put("date", a.getActivity_date());
map.put("commission", a.getCommission());
map.put("description", a.getDescription());
list.add(map);
}
return list;
}
}
|
Python
|
UTF-8
| 360 | 3.734375 | 4 |
[] |
no_license
|
import random
import sys
x = (random.randint(0,100))
print("Press q to exit.")
y = input("Guess a number here: ")
while x != y:
if y == 'q':
break
elif int(y) > x:
y =int(input("Guess lower: "))
elif int(y) < x:
y = int(input("Guess higher: "))
if x == y:
print("You guessed the number!")
sys.exit()
|
Python
|
UTF-8
| 411 | 3.65625 | 4 |
[] |
no_license
|
#!/usr/bin/env python2
'''
1. Use the split method to divide the following IPv6 address into groups of 4
hex digits (i.e. split on the ":")
FE80:0000:0000:0000:0101:A3EF:EE1E:1719
'''
ipv6_address = 'FE80:0000:0000:0000:0101:A3EF:EE1E:1719'
ipv6_address_section = ipv6_address.split(":")
print "IPv6 sections below"
print ipv6_address_section,'\n'
print "Joined" +'\n\n'+ ":".join(ipv6_address_section)
|
Python
|
UTF-8
| 2,147 | 2.984375 | 3 |
[] |
no_license
|
from aylienapiclient import textapi
import threading
import time,sys
import urllib.request
from aylienapiclient.errors import HttpError
#Array of urls
urls = [ "https://www.facebook.com", "https://www.baidu.com", "https://www.yahoo.com", "https://www.wikipedia.org", "https://www.google.co.in", "https://www.qq.com", "https://www.tmall.com", "https://www.sohu.com", "https://www.google.co.jp"]
class Classify(object):
def __init__(self):
#Api key and app id
self.client = textapi.Client("39d4b4fd","0d7bfc7ae077cd16cbedec8e216994f7")
# self.client = textapi.Client("3d609645", "58f1c76952ff127eb2d2417484850657")
#function that fetches the categories from the api
def categorize(self,url,result):
#If the api cannot fetch categories, mark it uncategorized
ans = {'url': url , 'categories' : ('Uncategorized','Uncategorized') }
try:
classifications = self.client.ClassifyByTaxonomy({"url": url, "taxonomy": "iab-qag"})
ctgs = classifications['categories']
if ctgs:
sub = ctgs[0]
cat = [x for x in ctgs if (x['id'] in sub['id'] and '-' not in x['id'])]
ans['categories'] = (cat[0]['label'],sub['label'])
#As it is running on thread append the result in the final array
result.append(ans)
per = round(len(result)/len(urls)*100,1)
#Below code to print progress of the multithread http request
sys.stdout.write("\rProgress "+str(per)+"%")
sys.stdout.flush()
except :
sys.stdout.write("\rApi Limit exceeded")
sys.stdout.flush()
#function where an array can be passed and it returns array of dict containing url and categories
def urlarray(self,ar):
val = []
print("Started ....")
#Initiate threads
threads = [threading.Thread(target=c.categorize, args=(url,val)) for url in urls]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
print("\nDone ....")
return val
#Start the program
c = Classify()
category = c.urlarray(urls)
#Print top few from the array
for i in range(min(10,len(category))):
print ("Url: %s | Category: %s | Subcategory: %s" % (category[i]['url'],category[i]['categories'][0],category[i]['categories'][1]))
|
Java
|
UTF-8
| 2,674 | 2.359375 | 2 |
[] |
no_license
|
package com.ceiba.reservasbarultimate.mesa.dominio.servicio;
import static org.junit.jupiter.api.Assertions.assertEquals;
import java.util.List;
import org.junit.jupiter.api.Test;
import org.mockito.Mockito;
import com.ceiba.reservasbarultimate.mesa.builders.MesaDtoTestDataBuilder;
import com.ceiba.reservasbarultimate.mesa.dominio.modelo.dto.MesaDto;
import com.ceiba.reservasbarultimate.mesa.dominio.puerto.dao.MesaDao;
class ServicioListarMesasDisponiblesTest {
@Test
void listaMesasDisponiblesConPrecioHoyTest() {
// arrange
Long precioDescuentoHoy = 190000l;
List<MesaDto> listaMesasDisponibles = new MesaDtoTestDataBuilder().buildListaMesasDto();
List<MesaDto> listaMesasDisponiblesConPrecioHoy = new MesaDtoTestDataBuilder().buildListaMesasDtoConPrecioHoy();
MesaDao mesaDao = Mockito.mock(MesaDao.class);
ServicioCalcularValorMesaHoy servicioCalcularValorMesaHoy = Mockito.mock(ServicioCalcularValorMesaHoy.class);
Mockito.when(mesaDao.listarMesasDisponibles()).thenReturn(listaMesasDisponibles);
// act
ServicioListarMesasDidponibles servicioListarMesasDidponibles = new ServicioListarMesasDidponibles(mesaDao,
servicioCalcularValorMesaHoy);
List<MesaDto> listaMesasDisponiblesBuscadas = servicioListarMesasDidponibles.ejecutar();
for (MesaDto mesadto : listaMesasDisponiblesBuscadas) {
mesadto.setPrecioConDescuentoHoy(precioDescuentoHoy);
}
// assert
assertEquals(listaMesasDisponiblesBuscadas.get(0).getPrecioConDescuentoHoy(),
listaMesasDisponiblesConPrecioHoy.get(0).getPrecioConDescuentoHoy());
assertEquals(listaMesasDisponiblesBuscadas.get(1).getPrecioConDescuentoHoy(),
listaMesasDisponiblesConPrecioHoy.get(1).getPrecioConDescuentoHoy());
}
@Test
void NoHayMesasDisponiblesTest() {
// arrange
Long precioDescuentoHoy = 190000l;
List<MesaDto> listaMesasDisponibles = null; // No hay mesas disponibles
MesaDao mesaDao = Mockito.mock(MesaDao.class);
ServicioCalcularValorMesaHoy servicioCalcularValorMesaHoy = Mockito.mock(ServicioCalcularValorMesaHoy.class);
Mockito.when(mesaDao.listarMesasDisponibles()).thenReturn(listaMesasDisponibles);
// act
ServicioListarMesasDidponibles servicioListarMesasDidponibles = new ServicioListarMesasDidponibles(mesaDao,
servicioCalcularValorMesaHoy);
try {
List<MesaDto> listaMesasDisponiblesBuscadas = servicioListarMesasDidponibles.ejecutar();
for (MesaDto mesadto : listaMesasDisponiblesBuscadas) {
mesadto.setPrecioConDescuentoHoy(precioDescuentoHoy);
}
} catch (Exception e) {
// assert
assertEquals("Lo sentimos, todas las mesas estan reservadas para el evento de este sabado", e.getMessage());
}
}
}
|
Java
|
UTF-8
| 644 | 2.46875 | 2 |
[] |
no_license
|
package com.solvd.airportJava.services;
import com.solvd.airportJava.dao.interfaces.ICountryDAO;
import com.solvd.airportJava.dao.jdbc.impl.CountryDAO;
import com.solvd.airportJava.models.Country;
public class CountryService {
private ICountryDAO countryDAO = new CountryDAO();
public CountryService() {
}
public void create(Country country){
countryDAO.create(country);
}
public Country getByID(int id) {
return countryDAO.getByID(id);
}
public void update(Country country){
countryDAO.update(country);
}
public void delete(int id){
countryDAO.delete(id);
}
}
|
Python
|
UTF-8
| 793 | 2.65625 | 3 |
[] |
no_license
|
# -*- coding:utf-8 -*-
import gzip, json, leveldb
filename = 'artist.json.gz'
dbname = 'artist_db2'
def main(filename, dbname):
db = leveldb.LevelDB(dbname)
with gzip.open(filename, 'r') as f:
for line in f:
obj = json.loads(line)
if 'tags' not in obj.keys():
tags = '0,none'
else:
insert = []
for t in obj['tags']:
count = t['count']
value = t['value'].encode('utf-8')
data = str(count) + ',' + str(value)
insert.append(data)
tags = '###'.join(insert)
name = obj['name'].encode('utf-8')
db.Put(name, tags)
if __name__ == '__main__':
main(filename, dbname)
|
C
|
UTF-8
| 346 | 3.53125 | 4 |
[
"MIT"
] |
permissive
|
/*
Name - Nikhil Ranjan Nayak
Regd no - 1641012040
Desc - annual population.
*/
#include "stdio.h"
void main()
{
int pop = 9870, year = 1;
printf("\nYear %10c Population", ' ');
while(pop <= 30000)
{
printf("\nYear %d %10c %d", year, ' ', pop);
pop += (0.1 * pop);
year++;
}
printf("\nIn year %d,the population will cross %d.\n", year, 30000);
}
|
C++
|
UTF-8
| 11,458 | 3.546875 | 4 |
[] |
no_license
|
#ifndef _RB_TREE_H_
#define _RB_TREE_H_
#include <iostream.h>
// <summary>
// RBNode is a red-black tree node with parameterized value
// </summary>
//
// <synopsis>
// RBNode stores three pointers to parent, left, and right nodes.
// The second constructor allows the user of RBNode to specify a
// zero value other than NULL.
//
// The color is assigned the value 0 for black and 1 for red.
//
// The value is of arbitrary type.
// </synopsis>
//
template <class T>
class RBNode
{
public:
// Create a node with NULL links and put the value "val" inside.
// color the node black by default.
RBNode(T val) : left(NULL), right(NULL),
parent(NULL), value(val), color(0) {}
// Create a node using zero for the links, put "val" inside the node
// and color it black.
RBNode(T val, RBNode<T> * zero) : left(zero), right(zero), parent(zero)
,value(val), color(0) {}
// These public variables are for use by RBTree only.
// <group>
class RBNode<T> * left;
class RBNode<T> * right;
class RBNode<T> * parent;
// </group>
// Value of node
T value;
// Color of incoming edge
unsigned char color;
};
//
// <summary>
// RBTree implements a dynamic Red-Black tree.
// </summary>
//
// <etymology>
// RBTree = R (Red) + B (Black) + Tree
// </etymology>
//
// <synopsis>
//
// RBTree is a templated class that fully implements the red-black
// sorted-value tree described by Corman et al's Algorithms book.
//
// The leaves are represented by a common "nil" node for convenience.
//
// Functions insert, remove, find all take O(log n) time.
//
// The print functions take linear time.
//
// If T is a class, it must have correctly-behaving assignment and
// comparison (<,>,==) operators defined.
//
// It is probably unwise to store pointers in this container
//
// </synopsis>
//
// <todo asof="1/6/96">
// <li> add second-order traversal functions
// <li> add description function
// </todo>
template <class T>
class RBTree
{
public:
RBTree();
// Insert value into the tree in its place. Restructure the
// tree if necessary to balance the height.
void insert(T value)
{ insert(new RBNode<T>(value, nil_)); }
// Print the tree as a nested parenthetical expression using
// an inorder traversal
// <group>
void print() { inorderPrint(root_); }
void inorderPrint() { inorderPrint(root_); }
// </group>
// Print the tree as a nested parenthetical expression using
// a preorder traversal
void preorderPrint() { preorderPrint(root_); }
// Remove the first node encountered that contains the item "value"
void remove(T value)
{
RBNode<T> * node = find_(value);
if (node != nil_)
{
deleteNode(node);
delete node;
}
}
// Return non-zero if value is found in the tree
int find(T value)
{
RBNode<T> * node = find_(value);
return (node != nil_);
}
// Return false if value wasn't gotten
bool get(T& value)
{
RBNode<T> * node = find_(value);
if( node == nil_ )
return false;
//return (node != nil_);
value = node->value;
return true;
}
// Replace stuff
void replace(T value)
{
RBNode<T> * node = find_(value);
if( node == nil_ )
return;
//return (node != nil_);
node->value = value;
}
private:
// Perform a single rotation at node x
// <group>
void rotateLeft(RBNode<T> * x);
void rotateRight(RBNode<T> * x);
// </group>
// Insert the node z into the tree and rebalance
void insert(RBNode<T> * z);
// Delete the node z from the tree and rebalance
void deleteNode(RBNode<T> * z);
// Helper function for deleteNode
void deleteFixup(RBNode<T> * x);
// Return the next node in the inorder sequence
RBNode<T> * successor(RBNode<T> * z);
// Return the previous node in the inorder sequence
RBNode<T> * predecessor(RBNode<T> * z);
// Return the node that contains the minimum value (leftmost)
// <group>
RBNode<T> * minimum() { return minimum(root_); }
RBNode<T> * minimum(RBNode<T> * x);
// </group>
// Return the node that contains the maximum value (rightmost)
// <group>
RBNode<T> * maximum() { return maximum(root_); }
RBNode<T> * maximum(RBNode<T> * x);
// </group>
// return the first node that contains value or nil_
// <group>
RBNode<T> * find_(T value) { return find_(value, root_); }
RBNode<T> * find_(T value, RBNode<T> * x);
// </group>
// print the nodes of the subtree rooted at x in a
// nested parenthetical manner using inorder traversal
void inorderPrint(RBNode<T> * x);
// print the nodes of the subtree rooted at x in a
// nested parenthetical manner using preorder traversal
void preorderPrint(RBNode<T> * x);
private:
// root node of tree
RBNode<T> * root_;
// common nil node of tree
RBNode<T> * nil_;
};
template <class T>
RBTree<T>::RBTree()
{
nil_ = new RBNode<T>((T)0);
nil_->left = nil_;
nil_->right = nil_;
nil_->parent = nil_;
root_ = nil_;
}
template <class T>
void RBTree<T>::rotateLeft(RBNode<T> * x)
{
RBNode<T> * y = x->right;
x->right = y->left;
if (y->left != nil_)
y->left->parent = x;
y->parent = x->parent;
if (x->parent == nil_)
{
root_ = y;
}
else
{
if (x == x->parent->left)
x->parent->left = y;
else
x->parent->right = y;
}
y->left = x;
x->parent = y;
}
template <class T>
void RBTree<T>::rotateRight(RBNode<T> * x)
{
RBNode<T> * y = x->left;
x->left = y->right;
if (y->right != nil_)
y->right->parent = x;
y->parent = x->parent;
if (x->parent == nil_)
root_ = y;
else
{
if (x == x->parent->right)
x->parent->right = y;
else
x->parent->left = y;
}
y->right = x;
x->parent = y;
}
template <class T>
void RBTree<T>::insert(RBNode<T> * z)
{
// Tree-Insert in book
RBNode<T> * y = nil_;
RBNode<T> * x = root_;
while (x != nil_)
{
y = x;
if (z->value < x->value)
x = x->left;
else
x = x->right;
}
z->parent = y;
if (y == nil_)
root_ = z;
else
{
if (z->value < y->value)
y->left = z;
else
y->right = z;
}
z->color = 1;
while (z != root_ && z->parent->color == 1)
{
if (z->parent == z->parent->parent->left)
{
y = z->parent->parent->right;
if (y->color == 1)
{
z->parent->color = 0;
y->color = 0;
z->parent->parent->color = 1;
z = z->parent->parent;
}
else
{
if (z == z->parent->right)
{
z = z->parent;
rotateLeft(z);
}
z->parent->color = 0;
z->parent->parent->color = 1;
rotateRight(z->parent->parent);
}
}
else
{
y = z->parent->parent->left;
if (y->color == 1)
{
z->parent->color = 0;
y->color = 0;
z->parent->parent->color = 1;
z = z->parent->parent;
}
else
{
if (z == z->parent->left)
{
z = z->parent;
rotateRight(z);
}
z->parent->color = 0;
z->parent->parent->color = 1;
rotateLeft(z->parent->parent);
}
}
}
root_->color = 0;
}
template <class T>
void RBTree<T>::deleteNode(RBNode<T> * z)
{
RBNode<T> * y = nil_;
RBNode<T> * x = nil_;
cout << "deleteNode" << endl;
if (z->left == nil_ || z->right == nil_)
y = z;
else
y = successor(z);
if (y->left != nil_)
x = y->left;
else
x = y->right;
x->parent = y->parent;
if (y->parent == nil_)
root_ = x;
else
{
if (y == y->parent->left)
y->parent->left = x;
else
y->parent->right = x;
}
if (y != z)
z->value = y->value;
if (y->color == 0)
deleteFixup(x);
}
template <class T>
void RBTree<T>::deleteFixup(RBNode<T> * x)
{
cout << "deleteFixup" << endl;
while (x != root_ && x->color == 0)
{
if (x == x->parent->left)
{
RBNode<T> * w = x->parent->right;
if (w->color == 1)
{
w->color = 0;
x->parent->color = 1;
rotateLeft(x->parent);
w = x->parent->right;
}
if (w->left->color == 0 && w->right->color == 0)
{
w->color = 1;
x = x->parent;
}
else
{
if (w->right->color == 0)
{
w->left->color = 0;
w->color = 1;
rotateRight(w);
w = x->parent->right;
}
w->color = x->parent->color;
x->parent->color = 0;
w->right->color = 0;
rotateLeft(x->parent);
x = root_;
}
}
else
{
RBNode<T> * w = x->parent->left;
if (w->color == 1)
{
w->color = 0;
x->parent->color = 1;
rotateRight(x->parent);
w = x->parent->left;
}
if (w->right->color == 0 && w->left->color == 0)
{
w->color = 1;
x = x->parent;
}
else
{
if (w->left->color == 0)
{
w->right->color = 0;
w->color = 1;
rotateLeft(w);
w = x->parent->left;
}
w->color = x->parent->color;
x->parent->color = 0;
w->left->color = 0;
rotateRight(x->parent);
x = root_;
}
}
}
x->color = 0;
}
template <class T>
RBNode<T> * RBTree<T>::successor(RBNode<T> * x)
{
if (x->right != nil_)
return minimum(x->right);
RBNode<T> * retval = x->parent;
while (retval != nil_ && retval->right == x)
{
x = retval;
retval = retval->parent;
}
return retval;
}
template <class T>
RBNode<T> * RBTree<T>::predecessor(RBNode<T> * x)
{
if (x->left != nil_)
return minimum(x->left);
RBNode<T> * retval = x->parent;
while (retval != nil_ && retval->left == x)
{
x = retval;
retval = retval->parent;
}
return retval;
}
template <class T>
RBNode<T> * RBTree<T>::minimum(RBNode<T> * x)
{
while (x->left != nil_) x = x->left;
return x;
}
template <class T>
RBNode<T> * RBTree<T>::maximum(RBNode<T> * x)
{
while (x->right != nil_) x = x->right;
return x;
}
template <class T>
RBNode<T> * RBTree<T>::find_(T value, RBNode<T> * x)
{
while (x != nil_ && value != x->value)
{
if (value < x->value)
x = x->left;
else
x = x->right;
}
return x;
}
template <class T>
void RBTree<T>::inorderPrint(RBNode<T> * x)
{
if (x == nil_) return;
if (x->left != nil_)
{
cout << "(";
inorderPrint(x->left);
cout << ")";
}
if (x->color == 1)
cout << "+";
else
cout << "-";
cout << x->value;
if (x->right != nil_)
{
cout << "(";
inorderPrint(x->right);
cout << ")";
}
}
template <class T>
void RBTree<T>::preorderPrint(RBNode<T> * x)
{
if (x == nil_) return;
if (x->color == 1)
cout << "+";
else
cout << "-";
cout << x->value;
if (x->left != nil_)
{
cout << "(";
preorderPrint(x->left);
cout << ")";
}
if (x->right != nil_)
{
cout << "(";
preorderPrint(x->right);
cout << ")";
}
}
#endif
|
Ruby
|
UTF-8
| 872 | 2.75 | 3 |
[] |
no_license
|
class TradierApi
attr_accessor :symbol, :price, :volume, :timestamp
def initialize(underlying)
uri = URI.parse("https://sandbox.tradier.com/v1/markets/quotes?symbols=#{underlying}")
http = Net::HTTP.new(uri.host, uri.port)
http.read_timeout = 30
http.use_ssl = true
http.verify_mode = OpenSSL::SSL::VERIFY_PEER
request = Net::HTTP::Get.new(uri.request_uri)
# Headers
request["Accept"] = "application/json"
request["Authorization"] = "Bearer " + ENV["TOKEN"]
# Send synchronously
underlying_data = http.request(request)
parsed_underlying_data = JSON.parse(underlying_data.body)
underlying_data = parsed_underlying_data["quotes"]["quote"]
@symbol = underlying_data["symbol"]
@price = underlying_data["last"]
@volume = underlying_data["last_volume"]
@timestamp = underlying_data["trade_date"]
end
end
|
Java
|
UTF-8
| 4,071 | 2.265625 | 2 |
[] |
no_license
|
package com.cooltoo.services.file;
import com.cooltoo.exception.BadRequestException;
import com.cooltoo.exception.ErrorCode;
import com.cooltoo.services.FileStorageDBService;
import com.cooltoo.util.VerifyUtil;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.io.File;
import java.io.InputStream;
import java.util.*;
/**
* Created by zhaolisong on 16/4/26.
*/
@Service("TemporaryFileStorageService")
public class TemporaryFileStorageService extends AbstractFileStorageService {
private static final Logger logger = LoggerFactory.getLogger(TemporaryFileStorageService.class.getName());
@Value("${storage.tmp.path}")
private String tmpPath;
@Value("${storage.base.path}")
private String storageBasePath;
@Autowired
@Qualifier("FileStorageDBService")
private InterfaceFileStorageDB dbService;
public InterfaceFileStorageDB getDbService() {
return dbService;
}
@Override
public String getName() {
return "temporary";
}
@Override
public String getStoragePath() {
StringBuilder path = new StringBuilder();
path.append(storageBasePath);
path.append(tmpPath);
logger.info("get temporary storage path={}", path.toString());
return path.toString();
}
@Override
public String getNginxRelativePath() {
logger.info("get temporary nginx path={}", tmpPath);
return tmpPath;
}
/** cache file with the token key(return-->relative_path_in_temporary_directory) */
public String addFile(String fileName, InputStream file) {
return addCacheFile(fileName, file);
}
/** delete file path(which end with relative path in its storage) */
@Override
public boolean deleteFile(String filePath) {
logger.info("delete temporary file, filepath={}", filePath);
if (VerifyUtil.isStringEmpty(filePath)) {
logger.info("filepath is empty");
return true;
}
String relativePath = getRelativePathInStorage(filePath);
if (VerifyUtil.isStringEmpty(relativePath)) {
logger.info("decode dir and filename is empty");
return false;
}
return super.deleteFile(relativePath);
}
/** delete file paths(which end with relative path in its storage) */
@Override
public void deleteFileByPaths(List<String> filePaths) {
logger.info("delete temporary file, filepath={}", filePaths);
if (VerifyUtil.isListEmpty(filePaths)) {
logger.info("filepath is empty");
return;
}
Map<String, String> path2RelativePath = getRelativePathInStorage(filePaths);
for (String path : filePaths) {
String relativePath = path2RelativePath.get(path);
super.deleteFile(relativePath);
}
}
/** srcFileAbsolutePath---->dir/sha1 */
@Override
public Map<String, String> moveFileToHere(List<String> srcFileAbsolutePath) {
return fileUtil.moveFilesToDest(srcFileAbsolutePath, this, false);
}
@Deprecated @Override public long addFile(long oldFileId, String fileName, InputStream file) {
throw new UnsupportedOperationException();
}
@Deprecated @Override public boolean deleteFile(long fileId) {
return true;
}
@Deprecated @Override public void deleteFiles(List<Long> fileIds) {
throw new UnsupportedOperationException();
}
@Deprecated @Override public String getFilePath(long fileId) {
throw new UnsupportedOperationException();
}
@Deprecated @Override public Map<Long, String> getFilePath(List<Long> fileIds) {
throw new UnsupportedOperationException();
}
@Deprecated @Override public boolean fileExist(long fileId) {
throw new UnsupportedOperationException();
}
}
|
TypeScript
|
UTF-8
| 293 | 2.609375 | 3 |
[] |
no_license
|
export class Vehiculo{
tipoVehiculo: string;
placa: string;
horaIngreso: Date;
constructor(tipoVehiculo: string, placa: string,horaIngreso: Date ) {
this.tipoVehiculo = tipoVehiculo;
this.placa = placa;
this.horaIngreso = horaIngreso;
}
}
|
Java
|
UTF-8
| 1,474 | 2.984375 | 3 |
[] |
no_license
|
package autoMag.httpManager;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
public class Request {
public static String sendPOST(String url, String content) throws IOException {
URL URLGet = new URL(url);
HttpURLConnection conn = (HttpURLConnection) URLGet.openConnection();
conn.setRequestMethod("POST");
conn.setRequestProperty("Content-type", "text/html");
conn.setUseCaches(false);
conn.setDoInput(true);
conn.setDoOutput(true);
OutputStream out = conn.getOutputStream();
out.write(content.getBytes("UTF-8"));
out.close();
StringBuffer responseBuffer = new StringBuffer();
int responseCode = conn.getResponseCode();
System.out.println("POST request response code :: " + responseCode);
if(responseCode == HttpURLConnection.HTTP_OK) { //SUCCESSO
//legge e stampa la risposta ricevuta
BufferedReader in = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String inputLine;
while ((inputLine = in.readLine()) != null) {
responseBuffer.append(inputLine);
}
in.close();
System.out.println(responseBuffer.toString());
System.out.println("POST request IS SUCCESSFUL");
}
else {//FAILURE
System.out.println("POST request FAILED");
}
return responseBuffer.toString();
}
}
|
JavaScript
|
UTF-8
| 999 | 2.59375 | 3 |
[
"ISC",
"MIT"
] |
permissive
|
import {CART, ADD, REMOVE} from '../../assets/constant';
const initialState = {
products: [
],
addresses: [
'1 Material-UI Drive', 'Reactville', 'Anytown', '99999', 'USA'
],
payments: [
{ name: 'Card type', detail: 'Visa' },
{ name: 'Card holder', detail: 'Mr XYZ' },
{ name: 'Card number', detail: 'xxxx-xxxx-xxxx-1234' },
{ name: 'Expiry date', detail: '04/2024' }
]
}
const cart = (state=initialState, action) => {
const {products, addresses, payments} = state;
switch(action.type) {
case CART:
return {products: products, addresses: addresses, payments: payments};
case ADD:
console.log(action.add);
return {products: [...products, action.add] , addresses: addresses, payments: payments};
case REMOVE:
return {products: products, addresses: addresses, payments: payments};
default:
return state;
}
}
export default cart;
|
C#
|
UTF-8
| 4,389 | 2.578125 | 3 |
[] |
no_license
|
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows;
using System.Windows.Controls;
using System.Windows.Data;
using System.Windows.Documents;
using System.Windows.Input;
using System.Windows.Media;
using System.Windows.Media.Imaging;
using System.Windows.Shapes;
using MySql.Data.MySqlClient;
namespace AufträgeOrgadata
{
/// <summary>
/// Interaktionslogik für AusstattungWindow.xaml
/// </summary>
public partial class AusstattungWindow : Window
{
public AusstattungWindow()
{
InitializeComponent();
}
public class TAusstattung
{
public int ID { get; set; }
public String AusstattungName { get; set; }
}
public class AusstattungCs
{
public List<TAusstattung> Ausstattungsliste { get; set; }
public AusstattungCs()
{
Ausstattungsliste = new List<TAusstattung>();
LoadAusstattung();
}
public void LoadAusstattung()
{
login lgn = new login();
string uid, pw, server, port, db, table;
uid = lgn.lgnList[0].uid;
pw = lgn.lgnList[0].pw;
server = lgn.lgnList[0].server;
port = lgn.lgnList[0].port;
db = lgn.lgnList[0].db;
table = lgn.lgnList[0].table;
String connstring = "uid=" + uid + ";" + "password=" + pw + ";" + "server=" + server + ";" + "port=" + port + ";" + "database=" + db + ";" + "table=" + table + ";";
MySqlConnection conn = new MySqlConnection(connstring);
try
{
conn.Open();
MySqlCommand cmd = new MySqlCommand("SELECT * FROM ausstattung");
cmd.Connection = conn;
using (MySqlDataReader Reader = cmd.ExecuteReader())
{
while (Reader.Read())
{
TAusstattung Ausstattung = new TAusstattung();
Ausstattung.ID = int.Parse(Reader["ID"].ToString());
Ausstattung.AusstattungName = Reader["AusstattungName"].ToString();
Ausstattungsliste.Add(Ausstattung);
}
}
conn.Close();
}
catch (Exception e)
{
MessageBox.Show(e.Message);
}
}
}
public void AWindow_Loaded(object sender, RoutedEventArgs e)
{
AusstattungCs AS = new AusstattungCs();
for (int i = 0; i < AS.Ausstattungsliste.Count; i++)
{
lvAusstattung.Items.Add(new TAusstattung
{
ID = AS.Ausstattungsliste[i].ID,
AusstattungName = AS.Ausstattungsliste[i].AusstattungName
});
}
}
public void mDelete_Click(object sender, RoutedEventArgs e)
{
var selectitem = (dynamic)lvAusstattung.SelectedItems[0];
String connstring = "Server = localhost; database = auftraege; uid = root ";
MySqlConnection conn = new MySqlConnection(connstring);
try
{
conn.Open();
MySqlCommand cmd = new MySqlCommand("Delete from ausstattung where Ausstattung = ?ItemClick");
cmd.Parameters.AddWithValue("?ItemClick", selectitem.AusstattungName);
MessageBox.Show("Ausstattung: " + (Convert.ToString(selectitem.AusstattungName) + (" erfolgreich gelöscht!")));
cmd.Connection = conn;
cmd.ExecuteNonQuery();
conn.Close();
}
catch (Exception e1)
{
MessageBox.Show(e1.Message);
}
}
private void mAdd_Click(object sender, RoutedEventArgs e)
{
}
private void mEdit_Click(object sender, RoutedEventArgs e)
{
}
private void mClose_Click(object sender, RoutedEventArgs e)
{
this.Close();
}
}
}
|
Swift
|
UTF-8
| 1,377 | 2.6875 | 3 |
[] |
no_license
|
//
// ViewController.swift
// customCells
//
// Created by Estudiantes on 19/5/18.
// Copyright © 2018 Juan Carlos Marin. All rights reserved.
//
import UIKit
class FavoritoTableViewCell: UITableViewCell {
@IBOutlet weak var lblNombre: UILabel!
@IBOutlet weak var imgEquipo: UIImageView!
}
class ListaController: UITableViewController {
var listado = FavoritosModel()
override func numberOfSections(in tableView: UITableView) -> Int {
return 1
}
override func tableView(_ tableView: UITableView, numberOfRowsInSection section: Int) -> Int {
return listado.equiposlist.count
}
override func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let cell = tableView.dequeueReusableCell(withIdentifier: "myCustomCell", for: indexPath) as! FavoritoTableViewCell
let equipo = listado.equiposlist[indexPath.row]
cell.lblNombre?.text = equipo.nombre
cell.imgEquipo?.image = UIImage(named: equipo.nombre)
return cell
}
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view, typically from a nib.
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
|
Python
|
UTF-8
| 673 | 3.0625 | 3 |
[] |
no_license
|
t=int(input())
for i in range(0,t):
n=int(input())
X=dict();
Y=dict();
n=4*n-1
for i in range(0,n):
x, y = input().split()
x = int(x)
y = int(y)
if x in X :
X[x]+=1
else :
X[x]=1;
if y in Y :
Y[y]+=1
else :
Y[y]=1;
for xx in X :
if (X[xx]%2 != 0) :
Xco = xx
break
for yy in Y :
if (Y[yy]%2 != 0) :
Yco = yy
break
print(X)
print(Y)
for i in X:
print(i,X[i])
print(str(Xco)+" "+str(Yco))
|
Java
|
UTF-8
| 5,258 | 1.921875 | 2 |
[
"Apache-2.0"
] |
permissive
|
package io.fabric8.api.jmx;
import java.util.List;
import java.util.Map;
import javax.management.MBeanServer;
import javax.management.MalformedObjectNameException;
import javax.management.ObjectName;
import org.apache.felix.scr.annotations.Activate;
import org.apache.felix.scr.annotations.Component;
import org.apache.felix.scr.annotations.Deactivate;
import org.apache.felix.scr.annotations.Reference;
import io.fabric8.api.CreateEnsembleOptions;
import io.fabric8.api.RuntimeProperties;
import io.fabric8.api.ZooKeeperClusterService;
import io.fabric8.api.jcip.ThreadSafe;
import io.fabric8.api.scr.AbstractComponent;
import io.fabric8.api.scr.ValidatingReference;
/**
* @author Stan Lewis
*/
@ThreadSafe
@Component(description = "Fabric ZooKeeper Cluster Manager JMX MBean")
public final class ClusterServiceManager extends AbstractComponent implements ClusterServiceManagerMBean {
private static ObjectName OBJECT_NAME;
static {
try {
OBJECT_NAME = new ObjectName("io.fabric8:type=ClusterServiceManager");
} catch (MalformedObjectNameException e) {
// ignore
}
}
@Reference(referenceInterface = RuntimeProperties.class)
private final ValidatingReference<RuntimeProperties> runtimeProperties = new ValidatingReference<RuntimeProperties>();
@Reference(referenceInterface = ZooKeeperClusterService.class)
private final ValidatingReference<ZooKeeperClusterService> clusterService = new ValidatingReference<ZooKeeperClusterService>();
@Reference(referenceInterface = MBeanServer.class, bind = "bindMBeanServer", unbind = "unbindMBeanServer")
private final ValidatingReference<MBeanServer> mbeanServer = new ValidatingReference<MBeanServer>();
@Activate
void activate() throws Exception {
JMXUtils.registerMBean(this, mbeanServer.get(), OBJECT_NAME);
activateComponent();
}
@Deactivate
void deactivate() throws Exception {
deactivateComponent();
JMXUtils.unregisterMBean(mbeanServer.get(), OBJECT_NAME);
}
@Override
public List<String> getEnsembleContainers() {
assertValid();
return clusterService.get().getEnsembleContainers();
}
@Override
public String getZooKeeperUrl() {
assertValid();
return clusterService.get().getZooKeeperUrl();
}
@Override
public String getZookeeperPassword() {
assertValid();
return clusterService.get().getZookeeperPassword();
}
@Override
public Map<String, String> getEnsembleConfiguration() throws Exception {
return clusterService.get().getEnsembleConfiguration();
}
@Override
public void createCluster(List<String> containers) {
assertValid();
clusterService.get().createCluster(containers);
}
@Override
public void addToCluster(List<String> containers, Map<String, Object> options) {
assertValid();
RuntimeProperties sysprops = runtimeProperties.get();
CreateEnsembleOptions createEnsembleOptions = ClusterBootstrapManager.getCreateEnsembleOptions(sysprops, options);
addToCluster(containers, createEnsembleOptions);
}
@Override
public void removeFromCluster(List<String> containers, Map<String, Object> options) {
assertValid();
RuntimeProperties sysprops = runtimeProperties.get();
CreateEnsembleOptions createEnsembleOptions = ClusterBootstrapManager.getCreateEnsembleOptions(sysprops, options);
removeFromCluster(containers, createEnsembleOptions);
}
@Override
public void createCluster(List<String> containers, CreateEnsembleOptions options) {
assertValid();
clusterService.get().createCluster(containers, options);
}
@Override
public void addToCluster(List<String> containers) {
assertValid();
clusterService.get().addToCluster(containers);
}
@Override
public void addToCluster(List<String> containers, CreateEnsembleOptions options) {
assertValid();
clusterService.get().addToCluster(containers, options);
}
@Override
public void removeFromCluster(List<String> containers) {
assertValid();
clusterService.get().removeFromCluster(containers);
}
@Override
public void removeFromCluster(List<String> containers, CreateEnsembleOptions options) {
assertValid();
clusterService.get().removeFromCluster(containers, options);
}
@Override
public void clean() {
assertValid();
clusterService.get().clean();
}
void bindRuntimeProperties(RuntimeProperties service) {
this.runtimeProperties.bind(service);
}
void unbindRuntimeProperties(RuntimeProperties service) {
this.runtimeProperties.unbind(service);
}
void bindMBeanServer(MBeanServer mbeanServer) {
this.mbeanServer.bind(mbeanServer);
}
void unbindMBeanServer(MBeanServer mbeanServer) {
this.mbeanServer.unbind(mbeanServer);
}
void bindClusterService(ZooKeeperClusterService service) {
this.clusterService.bind(service);
}
void unbindClusterService(ZooKeeperClusterService service) {
this.clusterService.unbind(service);
}
}
|
Java
|
UTF-8
| 700 | 2.3125 | 2 |
[] |
no_license
|
package com.automation.Step;
import com.automation.Pages.SearchPage;
import cucumber.api.java.en.Given;
import cucumber.api.java.en.Then;
import cucumber.api.java.en.When;
public class SearchStep {
SearchPage searchpage = new SearchPage();
@Given("^user is on ebay homepage$")
public void user_is_on_ebay_homepage() {
searchpage.userIsOnEbayHomepage();
}
@When("^user is searching for iphone$")
public void user_is_searching_for_iphone() {
searchpage.searchingForIphone();
}
@Then("^user finds search results for iphone$")
public void user_finds_search_results_for_iphone() {
searchpage.searchResultsForIphone();
}
}
|
C++
|
UTF-8
| 653 | 2.9375 | 3 |
[] |
no_license
|
#pragma once
#include "../lists/array-list.h"
#include "../lists/linked-list.h"
#include "../date/DateTime.h"
#include <vector>
template <class T>
void swap(T* a, T* b)
{
T t = *a;
*a = *b;
*b = t;
}
template <class T>
int partition(vector<T>& vec, int low, int high);
template <class T>
void quickSort(vector<T>& vec, int low, int high);
template <class T>
int partition(Linked_List<T>& list, int low, int high);
template <class T>
void quickSort(Linked_List<T>& list, int low, int high);
template <class T>
int partition(Array_List<T>& arr_list, int low, int high);
template <class T>
void quickSort(Array_List<T>& arr_list, int low, int high);
|
Java
|
UTF-8
| 358 | 1.859375 | 2 |
[
"MIT"
] |
permissive
|
/*
* Copyright (c) 2014, Lukas Tenbrink.
* * http://ivorius.net
*/
package ivorius.reccomplex.nbt;
import net.minecraft.nbt.NBTBase;
import net.minecraft.nbt.NBTTagCompound;
/**
* Created by lukas on 30.03.15.
*/
public class NBTNone implements NBTStorable
{
@Override
public NBTBase writeToNBT()
{
return new NBTTagCompound();
}
}
|
Markdown
|
UTF-8
| 6,489 | 3.046875 | 3 |
[] |
no_license
|
## Web开发简介
因为Go的`net/http`包提供了基础的路由函数组合与丰富的功能函数,所以在开源社区里流行一种用Go编写API不需要框架的观点,在我们看来,如果你的项目的路由在个位数、URI固定且不通过URI来传递参数,那么确实使用官方库也就足够了。但在复杂场景下,官方的HTTP库还是有些力有不逮
```
GET /card/:id
POST /card/:id
DELETE /card/:id
GET /card/:id/name
```
Go的Web框架大致可以分为两类:
- Router框架
- MVC类框架
简单来说,只要你的路由带有参数,并且这个项目的API数目超过了10,就尽量不要使用`net/http`中默认的路由。在Go开源界应用最广泛的路由器是`httprouter`,很多开源的路由器框架都是基于`httprouter`进行一定程度的改造的成果
开源界有这样几种框架,第一种是对httprouter进行简单的封装,然后提供定制的中间件和一些简单的小工具集成比如**gin**,主打轻量、易学、高性能。第二种是借鉴其他语言编程风格的一些MVC类框架,如**beego**,方便从其他语言迁移过来的程序员快速上手,快速开发
## 请求路由
在常见的Web框架中,路由器是必备的组件。Go语言圈子里路由器也时常称为**http的多路复用器**
**REST风格是几年前刮起的API设计风潮,在REST风格中除GET和POST之外,还使用了HTTP协议定义的几种其他标准化语义**
REST风格的API重度依赖请求路径,会将很多参数放在请求URI中。除此之外还会使用很多并不常见的HTTP状态码
```
const (
MethodGet = "GET"
MethodHead = "HEAD"
MethodPost = "POST"
MethodPut = "PUT"
MethodPatch = "PATCH"
MethodDelete = "DELETE"
MethondConnect = "CONNECT"
MethodOptions = "OPTIONS"
MethodTrace = "TRACE"
)
```
### httprouter
较流行的开源Go Web框架大多使用httprouter,或是基于httprouter的变种对路由进行支持
httprouter考虑到字典树的深度,在初始化时会对参数的数量进行限制,所以在路由中的参数数目不能超过255,否则会导致httprouter无法识别后续的参数。不过,在这一点上也不用考虑太多,毕竟URI是设计给人来看的,相信没有夸张的URI能在一条路径中带有200个以上的参数
## 中间件
### 使用中间件剥离非业务逻辑
每一个Web框架都会有对应的中间件组件
## 请求校验
实际上这是一个与语言无关的场景,需要进行字段校验的情况有很多,Web系统的Form或JSON提交只是一个典型的例子
### 用请求校验器解放体力劳动
## Database 和数据库打交道
Go官方提供了database/sql包来使用户进行和数据库打交道的工作,实际上database/sql库只是提供了一套操作数据库的接口和规范,例如抽象好的SQL预处理、连接池管理、数据绑定、事务、错误处理等。官方并没有提供具体某种数据库实现的协议支持
和具体的数据库(如MySQL)打交道,还需要再引入MySQL的驱动
### 提高生产效率的ORM和SQL Builder
在Web开发领域常常提到的ORM是什么?对象关系映射(Object Relational Mapping,简称ORM、O/RM或O/R映射)是一种程序设计技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。从效果上说,它其实是创建了一个可在编程语言里使用的**虚拟对象数据库**
**最为常见的ORM实际上做的是从数据库数据到程序的类或结构体这样的映射**
实际上很多语言的ORM只要把你的类或结构体定义好,再用特定的语法将结构体之间的一对一或者一对多关系表达出来,那么任务就完成了。然后你就可以对这些映射好了数据库表的对象进行各种操作,如增删改查
## 服务流量限制
计算机程序可依据其瓶颈分为**磁盘IO瓶颈型、CPU计算瓶颈型和网络带宽瓶颈型**,分布式场景下有时候外部系统也会导致自身瓶颈
**Web系统打交道最多的是网络,无论是接收、解析用户请求、访问存储,还是把响应数据返回给用户,都是要通过网络的**
在没有`epoll/kqueue`之类的系统提供的IO多路复用接口之前,多个核心的现代计算机最头痛的是`C10k`问题,`C10k`问题会导致计算机没有办法充分利用CPU来处理更多的用户连接,进而没有办法通过优化程序提升CPU利用率来处理更多的请求
自从**Linux实现了epoll,FreeBSD实现了kqueue**,这个问题就基本解决了。我们可以借助内核提供的API轻松解决当年的C10k问题,也就是说,如今如果你的程序主要是和网络打交道,那么瓶颈一定在用户程序而不在操作系统内核
随着时代的发展,编程语言对这些系统调用又进一步进行了封装,如今做应用层开发,几乎不会在程序中看到epoll之类的字眼,大多数时候我们只需要聚焦在业务逻辑上。Go的net库针对不同平台封装了不同的系统调用API,http库又是构建在net库之上的,所以在Go语言中我们可以借助标准库,很轻松地写出高性能的http服务
真实环境的程序要复杂得多,有些程序偏网络IO瓶颈,例如一些CDN服务、Proxy服务;有些程序偏CPU/GPU瓶颈,例如登录校验服务、图像处理服务;有些程序偏磁盘瓶颈,例如专门的存储系统、数据库。不同程序的瓶颈会体现在不同的地方,这里提到的这些功能单一的服务相对来说还算容易分析。如果碰到业务逻辑复杂、代码量巨大的模块,其瓶颈并不是三下五除二可以推测出来的,还是需要从压力测试中得到更为精确的结论。
对于IO/网络瓶颈类的程序,其表现是网卡/磁盘IO会先于CPU打满,这种情况即使优化CPU的使用也不能提高整个系统的吞吐量,只能提高磁盘的读写速度,增加内存大小,提升网卡的带宽来提升整体性能。而CPU瓶颈类的程序,则是在存储和网卡未打满之前CPU占用率提前到达100%,CPU忙于各种计算任务,IO设备相对则较空闲
### 常见的流量限制手段
流量限制的手段有很多,最常见的有**漏桶和令牌桶**两种
## 常见大型Web项目分层
## 接口和表驱动开发
## 灰度发布和A/B测试
|
Java
|
UTF-8
| 12,178 | 1.96875 | 2 |
[] |
no_license
|
package org.simmi;
import java.awt.Color;
import java.awt.Component;
import java.awt.Point;
import java.awt.event.MouseAdapter;
import java.awt.event.MouseEvent;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import javax.swing.JEditorPane;
import javax.swing.JScrollPane;
import javax.swing.JSplitPane;
import javax.swing.JTable;
import javax.swing.event.ListSelectionEvent;
import javax.swing.event.ListSelectionListener;
import javax.swing.event.RowSorterEvent;
import javax.swing.event.TableModelListener;
import javax.swing.table.TableCellRenderer;
import javax.swing.table.TableModel;
public class RdsPanel extends JSplitPane {
List<Object[]> rows = new ArrayList<Object[]>();
final Color paleGreen = new Color( 20,230,60,96 );
final FriendsPanel fp;
TableModel model;
TableModel rowHeaderModel;
SortTable st;
Map<String,String> detailMapping = new HashMap<String,String>();
final String vurl = "http://www.fa.is/deildir/Efnafraedi/Naeringarfr/naervefur/Templates/glaerur/vatnsvit.htm";
final String furl = "http://www.fa.is/deildir/Efnafraedi/Naeringarfr/naervefur/Templates/glaerur/fituvit.htm";
JSplitPane tableSplit;
JCompatTable rowHeader;
JCompatTable table;
MySorter currentSorter;
MySorter rowHeaderSorter;
MySorter tableSorter;
public float getRdsf( String colname, String unitname ) {
float ff = -1.0f;
int r = table.getSelectedRow();
//System.err.println("erm " + colname);
int age = fp.getSelectedAge();
String sex = fp.getSelectedSex();
int base = 0;
if( r >= 0 ) {
base = r+2;
} else if( age < 10 ) {
if( age < 2 ) {
base = 2;
} else if( age < 6 ) {
base = 3;
} else {
base = 4;
}
} else {
if( sex != null && sex.equals("Karl") ) base = 15;
else base = 7;
if( age < 14 ) base+=0;
else if( age < 18 ) base+=1;
else if( age < 31 ) base+=2;
else if( age < 61 ) base+=3;
else base+=4;
}
int i = 0;
String colName = model.getColumnName(i);
String unitName = null;
/*if( colname.contains("Kalí") ) {
System.err.println(colname + " " + ff);
}*/
boolean one = false;
if( colname.length() == 1 ) {
String[] spl = colName.split(" - ");
colName = spl[0];
while( !colName.equals(colname) ) {
i++;
if( i == model.getColumnCount() ) break;
colName = model.getColumnName(i);
spl = colName.split(" - ");
colName = spl[0];
}
unitName = spl[1].trim();
} else {
while( !colName.contains(colname) ) {
i++;
if( i == model.getColumnCount() ) {
break;
}
colName = model.getColumnName(i);
}
String[] spl = colName.split(" - ");
unitName = spl[1].trim();
}
String ret = null;
if( i < model.getColumnCount() ) {
Object[] obj = rows.get( base );
ret = (String)obj[i+1];
}
if( ret != null ) {
try {
ff = Float.parseFloat( ret );
if( !unitName.equals(unitname) ) {
if( unitName.equals("mg") ) {
if( unitname.equals("g") ) ff*=1000.0f;
} else if( unitName.equals("g") ) {
if( unitname.equals("mg") ) {
ff*=1000.0f;
}
} else if( unitName.equalsIgnoreCase("kcal") ) {
if( unitname.equals("kJ") ) {
double df = ff*4.184;
ff = (float)df;
//ff = (float)(Math.floor( df )/10.0);
}
}
}
} catch( Exception e ) {
e.printStackTrace();
}
}
return ff;
}
public String getRds( String colname, String unitname ) {
String ret = null;
int r = table.getSelectedRow();
int base = 4;
if( r >= 0 ) {
base = r+2;
} else {
int age = fp.getSelectedAge();
String sex = fp.getSelectedSex();
if( sex != null && sex.equals("Karl") ) base += 8;
if( age < 14 ) base+=1;
else if( age < 18 ) base+=2;
else if( age < 31 ) base+=3;
else if( age < 61 ) base+=4;
else base+=5;
}
int i = 0;
String colName = model.getColumnName(i);
boolean one = false;
if( colname.length() == 1 ) {
String[] spl = colName.split("[- ]+");
colName = spl[0];
while( !colName.equals(colname) ) {
i++;
if( i == model.getColumnCount() ) break;
colName = model.getColumnName(i);
spl = colName.split("[- ]+");
colName = spl[0];
}
} else {
while( !colName.contains(colname) ) {
i++;
if( i == model.getColumnCount() ) break;
colName = model.getColumnName(i);
}
}
if( i < model.getColumnCount() ) {
Object[] obj = rows.get( base );
ret = (String)obj[i+1];
}
return ret;
}
public String getRds( String colname ) {
return getRds( colname, null );
}
boolean sel = false;
public RdsPanel( final FriendsPanel fp, final SortTable st ) {
super( JSplitPane.VERTICAL_SPLIT );
this.fp = fp;
this.st = st;
InputStream inputStream = this.getClass().getResourceAsStream( "/rdsage.txt" );
try {
BufferedReader br = new BufferedReader( new InputStreamReader( inputStream, "UTF-8" ) );
String line = br.readLine();
String[] split = line.split("[\t]+");
rows.add( split );
line = br.readLine();
while( line != null ) {
split = line.split("[\t]+");
rows.add( split );
line = br.readLine();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
rowHeader = new JCompatTable() {
public void sorterChanged(RowSorterEvent e) {
currentSorter = (MySorter) e.getSource();
table.repaint();
super.sorterChanged(e);
}
};
rowHeader.setAutoCreateRowSorter( true );
table = new JCompatTable() {
public void sorterChanged(RowSorterEvent e) {
currentSorter = (MySorter) e.getSource();
rowHeader.repaint();
super.sorterChanged(e);
}
public Component prepareRenderer( TableCellRenderer renderer, int row, int column ) {
Component c = super.prepareRenderer(renderer, row, column);
int age = fp.getSelectedAge();
String sex = fp.getSelectedSex();
int base = 4;
if( sex != null && sex.equals("Karl") ) base += 8;
if( age < 14 ) base+=1;
else if( age < 18 ) base+=2;
else if( age < 31 ) base+=3;
else if( age < 61 ) base+=4;
else base+=5;
int r = table.convertRowIndexToModel(row);
if( r != -1 && r == base ) c.setBackground( paleGreen );
else if( this.getSelectedRow() != row ) {
c.setBackground( Color.white );
} else {
c.setBackground( this.getSelectionBackground() );
}
return c;
}
};
table.setAutoCreateRowSorter( true );
table.setAutoResizeMode( JTable.AUTO_RESIZE_OFF );
model = new TableModel() {
public void addTableModelListener(TableModelListener l) {}
public Class<?> getColumnClass(int columnIndex) {
return String.class;
}
public int getColumnCount() {
return rows.get(0).length-1;
}
public String getColumnName(int columnIndex) {
return rows.get(0)[columnIndex+1] + " - " + rows.get(1)[columnIndex+1];
}
public int getRowCount() {
return Math.max( 0, rows.size()-2 );
}
public Object getValueAt(int rowIndex, int columnIndex) {
return rows.get( rowIndex + 2 )[columnIndex+1];
}
public boolean isCellEditable(int rowIndex, int columnIndex) {
return false;
}
public void removeTableModelListener(TableModelListener l) {}
public void setValueAt(Object aValue, int rowIndex, int columnIndex) {}
};
rowHeaderModel = new TableModel() {
public void addTableModelListener(TableModelListener l) {}
public Class<?> getColumnClass(int columnIndex) {return String.class;}
public int getColumnCount() {return 1;}
public String getColumnName(int columnIndex) {return (String)rows.get(0)[0];}
public int getRowCount() {return Math.max( 0, rows.size()-2 );}
public Object getValueAt(int rowIndex, int columnIndex) {return rows.get( rowIndex + 2 )[0];}
public boolean isCellEditable(int rowIndex, int columnIndex) {return false;}
public void removeTableModelListener(TableModelListener l) {}
public void setValueAt(Object aValue, int rowIndex, int columnIndex) {}
};
rowHeader.setModel( rowHeaderModel );
table.setColumnSelectionAllowed( true );
table.addMouseListener( new MouseAdapter() {
public void mousePressed( MouseEvent e ) {
if( e.getClickCount() == 2 ) {
Point p = e.getPoint();
int c = table.columnAtPoint(p);
if( c < table.getColumnCount() ) {
Object obj = table.getColumnName(c);
if( obj != null ) {
String[] split = ((String)obj).split("\\/");
st.sortByColumn( split[0] );
}
}
}
}
});
table.setModel( model );
table.setColumnSelectionAllowed( true );
tableSorter = new MySorter(model) {
public int convertRowIndexToModel(int index) {
return currentSorter.convertRowIndexToModelSuper(index);
}
public int convertRowIndexToView(int index) {
return currentSorter.convertRowIndexToViewSuper(index);
// leftTableSorter.
}
public int getViewRowCount() {
return rowHeaderSorter.getViewRowCount();
}
};
currentSorter = (MySorter) tableSorter;
rowHeaderSorter = new MySorter( rowHeaderModel ) {
public int convertRowIndexToModel(int index) {
return currentSorter.convertRowIndexToModelSuper(index);
}
public int convertRowIndexToView(int index) {
return currentSorter.convertRowIndexToViewSuper(index);
}
};
rowHeader.setRowSorter( rowHeaderSorter );
table.setRowSorter( tableSorter );
rowHeader.sorter = rowHeaderSorter;
table.sorter = tableSorter;
final JEditorPane editor = new JEditorPane();
editor.setEditable( false );
editor.setContentType("text/html");
/*new Thread() {
public void run() {
try {
editor.setPage(vurl);
} catch (IOException e1) {
e1.printStackTrace();
}
}
};//.start();*/
table.getSelectionModel().addListSelectionListener( new ListSelectionListener(){
public void valueChanged(ListSelectionEvent e) {
int c = table.getSelectedColumn();
if( c != -1 ) {
String cName = table.getColumnName(c);
if( detailMapping.containsKey(cName) ) {
String vfl = detailMapping.get(cName);
/*try {
if( vfl.contains("Vatnsl") && !vurl.equals(editor.getPage().toString()) ) {
editor.setPage(vurl);
} else if( vfl.contains("Fitul") && !furl.equals(editor.getPage().toString()) ) {
editor.setPage(furl);
}
} catch (IOException e1) {
e1.printStackTrace();
}*/
}
}
boolean s = sel;
sel = false;
if( s ) {
//sel = false;
int r = table.getSelectedRow();
if( r != -1 ) rowHeader.setRowSelectionInterval(r,r);
} else sel = true;
}
});
rowHeader.getSelectionModel().addListSelectionListener( new ListSelectionListener() {
public void valueChanged(ListSelectionEvent e) {
boolean s = sel;
sel = true;
if( !s ) {
//sel = true;
int r = rowHeader.getSelectedRow();
if( r != -1 ) table.setRowSelectionInterval(r,r);
} else sel = false;
}
});
JScrollPane rowHeaderScroll = new JScrollPane( JScrollPane.VERTICAL_SCROLLBAR_NEVER, JScrollPane.HORIZONTAL_SCROLLBAR_ALWAYS );
JScrollPane tableScrollPane = new JScrollPane( table );
tableScrollPane.setRowHeaderView( rowHeader );
rowHeaderScroll.setViewport( tableScrollPane.getRowHeader() );
JScrollPane editorScroll = new JScrollPane( editor );
tableSplit = new JSplitPane( JSplitPane.HORIZONTAL_SPLIT, rowHeaderScroll, tableScrollPane );
this.setTopComponent( tableSplit );
this.setBottomComponent( editorScroll );
this.setDividerLocation( 300 );
}
}
|
Java
|
UTF-8
| 767 | 2.15625 | 2 |
[] |
no_license
|
package com.klazen.shadesbot.plugin;
import java.util.regex.Matcher;
import com.klazen.shadesbot.core.MessageOrigin;
import com.klazen.shadesbot.core.MessageSender;
import com.klazen.shadesbot.core.ShadesBot;
public class WelcomeHandler extends SimpleMessageHandler {
public WelcomeHandler(ShadesBot bot) {
super(bot, "!welcome ([^\\s]+?)");
}
@Override
protected boolean onMessage(String username, boolean isMod, String message, Matcher m, MessageSender sender, MessageOrigin origin) {
if (isMod) {
sender.sendMessage(m.group(1) + ", welcome aboard the ShadeTrain™, have your free pair of complimentary shades ヽ༼■ل͜■༽ノ SHADES OR SHADES ヽ༼■ل͜■༽ノ LukaShades", false);
}
return false;
}
}
|
Java
|
UTF-8
| 908 | 3.25 | 3 |
[] |
no_license
|
package br.com.phbit.cryptography.enumerator;
public enum CryptographyAlgorithm {
AES("AES", "Advanced Encryption Standard"),
DES("DES", "Data Encryption Standart"),
RSA("RSA", "Rivest Shamir Adleman");
private String initials;
private String description;
private CryptographyAlgorithm(String initials, String description) {
this.initials = initials;
this.description = description;
}
public String getInitials() {
return initials;
}
public String getDescription() {
return description;
}
public static CryptographyAlgorithm getCryptographicAlgorithm(String initials) {
for(CryptographyAlgorithm algorithm : values()) {
if(algorithm.getInitials().equals(initials))
return algorithm;
}
throw new IllegalArgumentException(initials+" is not a valid cryptographic algorithm");
}
@Override
public String toString() {
return this.getDescription();
}
}
|
PHP
|
UTF-8
| 604 | 2.5625 | 3 |
[] |
no_license
|
<?php
/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
/**
* Description of Gra
*
* @author andrzej.mroczek
*/
class Gra extends Decorator {
public function __construct(IComponent $menuNow) {
$this->menu = $menuNow;
}
public function Task() {
$fmat = "<a href='www.onet.pl'>Onet</a>   ";
return $this->menu->Task() . $fmat;
}
public function Task2() {
return $this->menu->Task2()."lo";
}
}
|
Python
|
UTF-8
| 558 | 3.140625 | 3 |
[] |
no_license
|
class Solution:
def help(self, s1, s2, s3):
res = False
if len(s1) == 0:
res = s2 == s3
elif len(s2) == 0:
res = s1 == s3
else:
if s1[0] == s3[0]:
res = res or self.help(s1[1:], s2, s3[1:])
if s2[0] == s3[0]:
res = res or self.help(s1, s2[1:], s3[1:])
return res
def isInterleave(self, s1: str, s2: str, s3: str) -> bool:
if len(s1) + len(s2) != len(s3):
return False
return self.help(s1, s2, s3)
|
JavaScript
|
UTF-8
| 618 | 2.71875 | 3 |
[] |
no_license
|
import {
observable
} from 'mobx';
export default class TimeModel {
store;
id;
@observable birthday;
@observable gender;
constructor(store, id, birthday, gender) {
this.store = store;
this.id = id;
this.birthday = birthday;
this.gender = gender;
}
destroy() {
this.store.remove(this);
}
setBirthday(birthday) {
this.birthday = birthday;
}
toJS() {
return {
id: this.id,
birthday: this.birthday,
gender: this.gender
};
}
static fromJS(store, object) {
return new TimeModel(store, object.id, object.birthday, object.gender);
}
}
|
TypeScript
|
UTF-8
| 750 | 2.609375 | 3 |
[] |
no_license
|
import { format } from "../../deps.ts";
import { CustomComponent } from "../component.ts";
interface Dependencies {
// deno-lint-ignore no-explicit-any
customWindow: any;
dateGenerator: () => Date;
}
export const componentWith = (
{ customWindow, dateGenerator }: Dependencies,
): CustomComponent => {
class BCDateComponent extends customWindow.HTMLElement {
constructor() {
super();
this.date = dateGenerator();
}
static componentName(): string {
return "bc-date";
}
set date(date: Date) {
this.innerHTML = format(date, "dd MMMM yyyy HH:mm:ss", {});
}
}
customWindow.customElements.define(
BCDateComponent.componentName(),
BCDateComponent,
);
return BCDateComponent;
};
|
Python
|
UTF-8
| 8,463 | 2.65625 | 3 |
[] |
no_license
|
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Fri Jun 26 03:36:15 2020
@author: kanikamiglani
"""
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
import re
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import VotingRegressor
#from sklearn.ensemble import StackingRegressor
data1 = pd.read_csv('train_modified.csv')
data3 = pd.read_csv('Train.csv')
data2 = pd.read_csv('test_modified.csv')
"""
print(min(data1['CRITICS_POINTS']))
print(max(data1['CRITICS_POINTS']))
print(min(data1['USER_POINTS']))
print(max(data1['USER_POINTS']))
plt.figure(figsize=(9,6))
sns.heatmap(data3.corr(),annot=True,linewidth = 0.5, cmap='coolwarm')
print(data1.head())
print(data1.shape)
print(data1.info())
print(data1.dtypes)
print(data1.describe())
print(data1.columns.tolist())
print(data1.isnull().sum())
print(data2.isnull().sum())
print(data1['ID'].unique())
print(data1['ID'].value_counts())
print(data2['ID'].unique())
print(data2['ID'].value_counts())
#print(data1['ID'].value_counts(normalize=True)*100)
#sns.countplot(data1['ID'])
print(data1['CONSOLE'].unique())
print(data1['CONSOLE'].value_counts())
print(data2['CONSOLE'].unique())
print(data2['CONSOLE'].value_counts())
#print(data1['CONSOLE'].value_counts(normalize=True)*100)
#sns.countplot(data1['CONSOLE'])
print(data1['YEAR'].unique())
print(data1['YEAR'].value_counts())
print(data2['YEAR'].unique())
print(data2['YEAR'].value_counts())
#print(data1['YEAR'].value_counts(normalize=True)*100)
#sns.countplot(data1['YEAR'])
print(data1['CATEGORY'].unique())
print(data1['CATEGORY'].value_counts())
print(data2['CATEGORY'].unique())
print(data2['CATEGORY'].value_counts())
#print(data1['CATEGORY'].value_counts(normalize=True)*100)
#sns.countplot(data1['CATEGORY'])
print(data1['PUBLISHER'].unique())
print(data1['PUBLISHER'].value_counts())
print(data2['PUBLISHER'].unique())
print(data2['PUBLISHER'].value_counts())
#print(data1['PUBLISHER'].value_counts(normalize=True)*100)
#sns.countplot(data1['PUBLISHER'])
print(data1['RATING'].unique())
print(data1['RATING'].value_counts())
print(data2['RATING'].unique())
print(data2['RATING'].value_counts())
#print(data1['RATING'].value_counts(normalize=True)*100)
#sns.countplot(data1['RATING'])
print(data1['CRITICS_POINTS'].unique())
print(data1['CRITICS_POINTS'].value_counts())
print(data2['CRITICS_POINTS'].unique())
print(data2['CRITICS_POINTS'].value_counts())
#print(data1['CRITICS_POINTS'].value_counts(normalize=True)*100)
#sns.countplot(data1['CRITICS_POINTS'])
print(data1['USER_POINTS'].unique())
print(data1['USER_POINTS'].value_counts())
print(data2['USER_POINTS'].unique())
print(data2['USER_POINTS'].value_counts())
#print(data1['USER_POINTS'].value_counts(normalize=True)*100)
#sns.countplot(data1['USER_POINTS'])
print(data1['SalesInMillions'].unique())
print(data1['SalesInMillions'].value_counts())
#print(data1['SalesInMillions'].value_counts(normalize=True)*100)
#sns.countplot(data1['SalesInMillions'])
plt.figure(figsize=(9,6))
sns.heatmap(data1.corr(),annot=True,linewidth = 0.5, cmap='coolwarm')
#X = pd.get_dummies(X)
#data1=pd.get_dummies(data1)
#data2=pd.get_dummies(data2)
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [1,3,4,5])], remainder='passthrough')
X = ct.fit_transform(X)
data2 = ct.fit_transform(data2)
print(X.shape)
print(data2.shape)
"""
#data1 = data1.drop("ID", 1)
#data2 = data2.drop("ID", 1)
#u = (data1['USER_POINTS'])*(data1['USER_POINTS'])
#data1['USER_POINTS'] = u
#data1 = data1.drop("CRITICS_POINTS", 1)
#data2 = data2.drop("CRITICS_POINTS", 1)
#data1 = data1.drop("YEAR", 1)
#data2 = data2.drop("YEAR", 1)
X=data1.drop("SalesInMillions",1)
y=data1[["SalesInMillions"]]
#print(data1[['CRITICS_POINTS', 'USER_POINTS']].corr())
#print(data1[['CRITICS_POINTS', 'YEAR']].corr())
#print(data1[['YEAR', 'USER_POINTS']].corr())
#"""
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.05,random_state=0)
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingRegressor
regressor1 = HistGradientBoostingRegressor()
#RMSE: 1.629386
import lightgbm as lgb
from lightgbm import LGBMRegressor
regressor2 = LGBMRegressor(random_state=0)
#RMSE: 1.673168
from catboost import CatBoostRegressor
regressor3 = CatBoostRegressor(iterations=2000, random_state = 0, verbose = 200)
import xgboost as xgb
from xgboost import XGBRegressor
regressor4 = xgb.XGBRegressor()
from nimbusml.ensemble import LightGbmRegressor
regressor5 = LightGbmRegressor(random_state=0)
from sklearn.ensemble import RandomForestRegressor
regressor6 = RandomForestRegressor(n_estimators = 1000, random_state = 0)
from sklearn.ensemble import GradientBoostingRegressor
regressor7 = GradientBoostingRegressor(random_state=0)
from sklearn import linear_model
regressor8 = linear_model.BayesianRidge()
from sklearn.svm import SVR
regressor9 = SVR(kernel = 'rbf')
from sklearn.neural_network import MLPRegressor
regressor10 = MLPRegressor(random_state=0, max_iter=1000)
from sklearn.ensemble import ExtraTreesRegressor
regressor11 = ExtraTreesRegressor(n_estimators=1000, random_state=0)
from sklearn.tree import DecisionTreeRegressor
regressor12 = DecisionTreeRegressor(random_state = 0)
#estimators = [('hist', regressor1), ('lgbm', regressor2), ('cb', regressor3), ('xgb', regressor4), ('nimbus', regressor5), ('gbr', regressor7), ('br', regressor8), ('svr', regressor9)]
estimator = [('hist', regressor1), ('lgbm', regressor2), ('cb', regressor3),
('xgb', regressor4), ('nimbus', regressor5), ('rfr', regressor6),
('gbr', regressor7), ('br', regressor8), ('svr', regressor9)]
weight = [4,3,1,1,1,1,1,1,1]
regressor = VotingRegressor(estimators = estimator, weights = weight)
#regressor = StackingRegressor(estimators=estimators,final_estimator=vregressor)
regressor.fit(X_train, y_train)
y_pred = regressor.predict(X_test)
r = r2_score(y_test, y_pred)
print("R^2: %f" % (r*100))
m = mean_squared_error(y_test, y_pred)
print("MSE: %f" % (m))
rmse = np.sqrt(m)
print("RMSE: %f" % (rmse))
#accuracies = cross_val_score(estimator = regressor, X = X_train, y = y_train, cv = 5)
#print("K FOlD Accuracy: {:.2f} %".format(accuracies.mean()*100))
#print("Standard Deviation: {:.2f} %".format(accuracies.std()*100))
data2 = sc.transform(data2)
y_p = regressor.predict(data2)
df = pd.DataFrame(y_p, index= None)
df.columns = ["SalesInMillions"]
df.to_excel("Sample_Submission.xlsx", index = None)
df.to_csv("Sample_Submission.csv", index = None)
#"""
"""
from nimbusml.ensemble import LightGbmRegressor
#regressor = LightGbmRegressor(random_state=0)
#RMSE: 1.634116
from catboost import CatBoostRegressor
regressor = CatBoostRegressor(iterations=2000, random_state = 0, verbose = 200)
#RMSE: 1.733194
import xgboost as xgb
from xgboost import XGBRegressor
#regressor = xgb.XGBRegressor()
#RMSE: 1.769113
from sklearn.ensemble import RandomForestRegressor
#regressor = RandomForestRegressor(n_estimators = 500, random_state = 0)
#RMSE: 1.750798
from sklearn.ensemble import GradientBoostingRegressor
#regressor = GradientBoostingRegressor(random_state=0)
#RMSE: 1.805883
from sklearn.tree import DecisionTreeRegressor
#regressor = DecisionTreeRegressor(random_state = 0)
#RMSE: 2.689125
from sklearn.svm import SVR
regressor = SVR(kernel = 'rbf')
#RMSE: 2.006418
from sklearn.ensemble import AdaBoostRegressor
#regressor = AdaBoostRegressor(random_state=0, n_estimators=1000)
#RMSE: 3.150858
from sklearn.ensemble import ExtraTreesRegressor
#regressor = ExtraTreesRegressor(n_estimators=500, random_state=0)
#RMSE: 2.710881
from sklearn.neural_network import MLPRegressor
#regressor = MLPRegressor(random_state=0, max_iter=1000)
#RMSE: 2.529909
from sklearn import linear_model
#regressor = linear_model.BayesianRidge()
#RMSE: 2.000902
from sklearn.linear_model import PassiveAggressiveRegressor
#regressor = PassiveAggressiveRegressor(max_iter=1000, random_state=0,tol=1e-3)
#RMSE: 3.030982
from sklearn.linear_model import Ridge
#regressor = Ridge(alpha=1.0)
#RMSE: 2.017923
"""
|
SQL
|
UTF-8
| 1,881 | 4.1875 | 4 |
[] |
no_license
|
--Basic
select *
from employees;
select *
from departments;
select *
from jobs;
--Catesian Product
select *
from employees, departments;
--PK FP
select employee_id,
first_name,
e.department_id,
d.department_name
from employees e, departments d
where e.department_id = d.department_id;
--예제) 모든 직원이름, 부서이름, 업무명을 출력하세요.
select em.first_name 직원이름,
de.department_name 부서이름,
jo.job_title 업무명
from employees em, departments de, jobs jo
where em.department_id = de.department_id
and em.job_id = jo.job_id;
--Null 표현하기 위함 left outer join 문
select em.department_id,
em.first_name,
em.department_id,
de.department_name
from employees em left outer join departments de
on em.department_id = de.department_id;
--right outer join
select em.department_id,
em.first_name,
em.department_id,
de.department_name
from employees em right outer join departments de
on em.department_id = de.department_id;
--right join --> left join
select em.department_id,
em.first_name,
em.department_id,
de.department_name
from departments de right outer join employees em
on em.department_id = de.department_id;
--full outer join
select em.department_id,
em.first_name,
em.department_id,
de.department_name
from employees em full outer join departments de
on em.department_id = de.department_id;
--JOIN (+) 문
select *
from employees em, departments de
where em.department_id = de.department_id(+);
--Self join
select ma.employee_id,
ma.first_name,
em.first_name manager,
ma.manager_id
from employees em, employees ma
where em.employee_id(+) = ma.manager_id
order by employee_id asc;
|
JavaScript
|
UTF-8
| 815 | 4.59375 | 5 |
[] |
no_license
|
// Take a series of numbers [1, ..., 10] add them together then square it. We will call this X. Now take that same series of numbers
// [1,...,10], square each number in the series, then add them together. Call this Y. X - Y is the answer. Now do that for [1,...,100].
// Basically, find the diff between the square of the sum, and the sum of the squares.
const arrayOneToN = (n) => Array.from(Array(n).keys()).map(x => x+1);
const oneToAHundred = arrayOneToN(100);
const squareArray = (arr) => arr.map(el => el*el);
const sumArray = (arr) => arr.reduce((a,b) => a+b);
const sumOfSquares = (arr) => sumArray(squareArray(arr));
const squareOfSum = (arr) => Math.pow(sumArray(arr), 2);
const ssDiff = (arr) => squareOfSum(arr) - sumOfSquares(arr);
const answer = ssDiff(oneToAHundred);
console.log(answer);
|
Markdown
|
UTF-8
| 1,977 | 3.03125 | 3 |
[] |
no_license
|
# Golang学习——前言
## 0.0
1. Golang于2009年11月发布,发明人 Robert Griesemer,Rob Pike 和 Ken Thompson均任职于Google。
2. Go和C表面看起来相似,实际远不止是C的升级版本。其优势如下:
* Go实现并发功能的设施是全新的、高效的。
* Go实现数据抽象和面向对象的途径是灵活的。
* Go实现了自动化的内存管理,即**垃圾回收**。
3. Go特别适用于构建基础设施类软件(如**网络服务器**s),以及程序员使用的**工具**和**系统**等。
4. Go的运行环境包括类UNIX系统和Windows系统。 只要在其中之一的环境中写了一个程序,基本不用修改就可运行在其他环境中。
##0.1 本书结构
本书共分为13章。其中,第1~5章是基础性的,与其他主流命令式语言相似。余下章节讨论Go的特色内容。本书中所有示例代码均可从<http://www.gopl.io>网站的公开git仓库下载。
* 第一章: Go的**基础结构**。
* 第二章: Go程序的组成元素——**声明、变量、新类型、包和文件**,以及**作用域**。
* 第三章: 讨论**数值、布尔量、字符串、常量**,并**解释如何处理Unicode**。
* 第四章: **复合类型** (使用简单类型构造的类型), 形式有**数组、map、结构体**,以及**slice**(Go中动态列表的实现)。
* 第五章: **函数**, 并讨论**错误处理、宕机(panic)**和**恢复(recover)**,以及**defer语句**。
* 第六章: **方法**。
* 第七章: **接口**。
* 第八章: **Go的并发性处理途径**。主要基于CSP思想,采用**goroutine**和**通道实现**。
* 第九章: **并发性中基于共享变量的一些传统话题**。
* 第十章: **包** (即组织库的机制)。
* 第十一章: **测试**。
* 第十二章: **反射** (即程序在执行期间考察自身表达方式的能力)。
* 第十三章: **低级程序设计的细节**。
|
Shell
|
UTF-8
| 621 | 3.375 | 3 |
[] |
no_license
|
#!/bin/sh
WEBHOOKURL="xxxxxxx"
MESSAGEFILE=$1
#slack 送信チャンネル
CHANNEL=${CHANNEL:-"#xxxxxxx"}
#slack 送信名
BOTNAME=${BOTNAME:-"bacula job result"}
#slack アイコン
FACEICON=${FACEICON:-":hamster:"}
TMPFILE=$(mktemp)
cat ${MESSAGEFILE} | tr '\n' '\\' | sed 's/\\/\\n/g' > ${TMPFILE}
WEBMESSAGE=$(cat ${TMPFILE})
curl -s -S -X POST --data-urlencode "payload={ \
\"channel\": \"${CHANNEL}\", \
\"username\": \"${BOTNAME}\", \
\"icon_emoji\": \"${FACEICON}\", \
\"text\": \"${WEBMESSAGE}\" \
}" ${WEBHOOKURL} >/dev/null
if [ -f "${TMPFILE}" ] ; then
rm -f ${TMPFILE}
fi
exit 0
|
PHP
|
UTF-8
| 1,659 | 2.515625 | 3 |
[] |
no_license
|
<?php
namespace App\Http\Controllers\Admin;
use App\Models\Content;
use Illuminate\Http\Request;
use App\Models\Cites;
use App\Models\Schools;
use App\Http\Controllers\Controller;
/**
* This class is used for "/admin/data/..." pages
*
*/
class DataController extends Controller
{
public function showPage(Request $request)
{
$data = [];
if ($request->sheet == 'cites') {
$data['Cites'] = $this->getData('Cites');
} elseif ($request->sheet == 'schools') {
$data['Current Schools'] = $this->getData('Schools');
} else {
$data['Cites'] = $this->getData('Cites');
$data['Current Schools'] = $this->getData('Schools');
}
return view('admin.page-data', ['data' => $data]);
}
public function getData($model)
{
$fullModel = 'App\Models\\' . $model;
$data = $fullModel::all();
$configName = $model == 'Cites' ? 'Cites' : 'Current Schools';
$output = [];
foreach ($data as $row) {
if ($model == 'Cites') {
$output[$row->id]['shortlink'] = $row->shortlink;
}
foreach ($row->getAttributes() as $dbName => $value) {
if ($dbName == 'id') {
continue;
}
foreach (config('excelColumns')[$configName] as $column) {
if ($dbName == $column['dbColumnName']) {
$output[$row->id][$column['excelColumnName']] = $value;
break;
}
}
};
}
return $output;
}
}
|
Markdown
|
UTF-8
| 10,990 | 2.96875 | 3 |
[] |
no_license
|
# Rencontre du troisième type
> Le renard se tut et regarda longtemps le petit prince :
>
> -- S'il te plaît... apprivoise-moi ! dit-il.
>
> -- Je veux bien, répondit le petit prince, mais je n'ai pas beaucoup de
> temps. J'ai des amis à découvrir et beaucoup de choses à connaître.
>
> -- On ne connaît que les choses que l'on apprivoise, dit le renard.
> *Antoine de Saint-Exupéry -- Le Petit Prince*
Maintenant qu'un Python habite dans votre ordinateur, il est temps de faire sa
connaissance. Dans ce chapitre, nous allons visiter son habitat naturel : la
console interactive, que vous utiliserez tout le temps pour tester vos
programmes. Ce sera votre lieu de rencontre privilégié, puisque c'est ici que
vous pourrez *dialoguer* avec lui.
Suivez moi ! Il nous attend déjà.
## Contact
Nous voici devant l'antre de la bête.
Commençons par l'appeler, si vous le voulez bien. Pour cela, lancez
l'interpréteur de commandes Python comme je vous l'ai montré dans le chapitre
précédent (en tapant "`python3`" ou bien "`py -3`" dans votre console, suivant
votre système d'exploitation).
Sa queue se déroule dans la console, et le voilà qui vous fixe de ses grands
yeux verts :
```python
Python 3.4.0 (default, Apr 11 2014, 13:05:11)
[GCC 4.8.2] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
```
Ces trois chevrons (`>>>`) constituent **l'invite de commande**. C'est la façon
dont Python vous signale qu'il vous écoute et qu'il attend vos instructions.
Montrez-vous bien élevé, saluez-le et validez en appuyant sur la touche
`<Entrée>`.
```python
>>> Bonjour
Traceback:
File "<stdin>", line 1, in <module>
NameError: name 'Bonjour' is not defined
```
Ouh là, attention, reculez ! Vous l'avez contrarié.
Ce que Python vient de vous cracher au visage, c'est un message qui signifie
qu'il n'a pas compris ce que vous lui dites. En effet, pour créer un programme,
il ne suffit pas de donner des ordres en français à votre interpréteur. Il faut
que vous lui parliez **en Python**, et c'est justement ce que vous êtes venu
apprendre.
Pour le moment je vais vous aider. Entourez donc votre phrase avec des
guillemets (`"`), comme ceci :
```python
>>> "Bonjour"
'Bonjour'
```
Le voilà plus coopératif. Python vous a renvoyé la politesse. Poursuivons :
```python
>>> "Je m'appelle Arnaud. Et toi ?"
"Je m'appelle Arnaud. Et toi ?"
>>> "Mais, je te l'ai déjà dit..."
"Mais, je te l'ai déjà dit..."
>>> "Hé ! Tu arrêtes de répéter tout ce que je dis ?!"
'Hé ! Tu arrêtes de répéter tout ce que je dis ?!'
```
Rassurez-vous : aussi taquin soit-il, Python n'est pas vraiment en train de se
moquer de vous. Laissez-moi vous expliquer.
Le rôle de cette console interactive est d'**interpréter** les instructions que
vous lui soumettez. Chaque fois que vous appuyez sur `<Entrée>`, vous envoyez
l'expression que vous venez de taper à Python, celui-ci l'évalue et vous
retourne *sa valeur*. Jusqu'ici, vous lui avez envoyé des expressions qui ont
toutes la même forme : du texte entouré de guillemets. Il s'agit de données de
base que peut manipuler l'interpréteur et que l'on appelle des *chaînes de
caractères*. Python s'est contenté d'évaluer ces données, et de vous retourner
leurs valeurs telles qu'il les a comprises, c'est-à-dire qu'il vous a renvoyé
les chaînes telles quelles.
Nous reparlerons très bientôt des chaînes de caractères. Pour l'heure, si nous
essayions de lui faire évaluer des choses plus utiles ?
## Une bête de calcul
Je vous ai dit que la console interactive sert à *évaluer des expressions*,
mais que sont ces fameuses « expressions » ? Nous allons commencer à le
découvrir dans la suite de ce chapitre.
### Saisir un nombre
Vous avez pu voir juste au-dessus que Python n'aime pas du tout les suites de
lettres qu'il ne comprend pas. Par contre, non seulement il comprend très bien
les nombres, mais en plus, il les adore !
```python
>>> 42
42
```
Vous pouvez même saisir des nombres à virgule, regardez :
```python
>>> 13.37
13.37
```
> **On utilise ici la notation anglo-saxonne, c'est-à-dire que le point remplace
la virgule. La virgule a un tout autre sens pour Python, que nous découvrirons
plus loin.**
En programmation, ces nombres à virgule sont appelé des **flottants**. Ils ne
sont pas représentés de la même façon dans la mémoire de l'ordinateur que les
nombres entiers. Ainsi, même si leurs valeurs sont égales, sachez que `5` n'est
pas tout à fait la même chose que `5.0`.
Il va de soi que l'on peut tout aussi bien saisir des nombres négatifs.
Essayez. ;)
D'accord, ce n'est pas extraordinaire. On saisit un nombre et Python le
répète : la belle affaire ! Néanmoins, ce n'est pas aussi inutile que vous
pourriez le penser. Le fait qu'il nous renvoie une valeur signifie que Python a
bien compris **la forme** et **le sens** de ce que vous avez saisi. Autrement
dit, cela signifie que *les expressions* que vous avez tapées sont **valides**
dans le langage Python, donc que vous pouvez utiliser cette console pour
vérifier la validité d'une expression en cas de doute.
> **Un peu de vocabulaire :**
>
> L'ensemble de règles qui déterminent *la forme* des expressions acceptées par
> un langage de programmation
> constitue la **syntaxe** de ce langage. *Le sens* de ces expressions, quant à
> lui, est déterminé par sa **sémantique**.
Nous avons maintenant un première observation à retenir : les nombres, tout
comme les chaînes de caractères (`"Bonjour"`), sont des expressions valides en
Python. Ces expressions désignent **des données** que l'on peut manipuler dans
ce langage.
### Opérations courantes
Maintenant que nous savons que Python comprend les nombres, voyons un peu ce
qu'il est capable de faire avec.
#### Addition, soustraction, multiplication, division
Pour effectuer ces opérations, on utilise respectivement les symboles `+`, `-`,
`*` et `/`.
```python
>>> 3 + 4
7
>>> -2 + 93
91
>>> 9.5 - 2
7.5
>>> 3.11 + 2.08
5.1899999999999995
```
> *Pourquoi le dernier résultat est-il approximatif ?*
Python n'y est pas pour grand chose. En fait, cela vient de la façon dont les
nombres flottants sont représentés dans la mémoire de votre ordinateur. Pour
que tous les nombres à virgule aient une taille fixe en mémoire, ceux-ci sont
représentés avec un nombre limité de chiffres significatifs, ce qui impose à
l'ordinateur de faire des approximations parfois un peu déroutantes.
Cependant, vous remarquerez que l'erreur (à 0.000000000000001 près) est infime
et qu'elle n'aura pas de gros impact sur les calculs. Les applications qui ont
besoin d'une précision mathématique à toute épreuve peuvent pallier ce défaut
par d'autres moyens. Ici, ce ne sera pas nécessaire.
Faites également des tests pour la multiplication et la division : il n'y a
rien de difficile.
#### Division entière et modulo
Si vous avez pris le temps de tester la division, vous vous êtes rendu compte
que le résultat est donné avec une virgule.
```python
>>> 10 / 5
2.0
>>> 10 / 3
3.3333333333333335
>>>
```
En d'autres termes, quelles que soient ses opérandes, la division de Python
donnera toujours son résultat sous la forme d'un flottant. Il existe deux
autres opérateurs qui permettent de connaître respectivement le résultat d'une
*division euclidienne* et le reste de cette division.
La division euclidienne, c'est celle que vous apprenez à poser à l'école.
Rappelons rapidement sa définition : la division euclidienne de $a$ par $b$ est
l'opération qui consiste à trouver le *quotient* $q$ et le *reste* $r$ tel que
$0 \le r < b$, vérifiant :
$$a = q \times b + r$$
L'exemple ci-dessous montre que la division euclidienne de $10$ par $3$ a pour
quotient $3$ et pour reste $1$. Soit $10 = 3 \times 3 + 1$.
```
10 | 3
+---
1 | 3
|
```
L'opérateur permettant d'obtenir le quotient d'une division euclidienne est
appelé « division entière ». On le note avec le symbole `//`.
```python
>>> 10 // 3
3
```
L'opérateur `%`, que l'on appelle le « modulo », permet de connaître le reste
de cette division.
```python
>>> 10 % 3
1
```
#### Puissance
Si vous êtes curieux, vous avez probablement déjà essayé de calculer une
*puissance* avec Python, de la même façon que vous auriez utilisé une
calculatrice. Sur cette dernière, vous vous souvenez certainement que
l'opérateur de puissance correspond à la touche "`^`". Essayons !
```python
>>> 3 ^ 2
1
```
En voilà, un résultat bizarre. Tout le monde sait bien que $3^2 = 9$ ! o_O
Rassurez-vous. Python le sait également. C'est simplement que l'opérateur `^`
ne désigne pas une puissance pour lui, mais une toute autre opération qui porte
le nom barbare de « XOR bit-à-bit » et que vous pouvez vous empresser d'oublier
pour le moment.
L'opérateur de puissance, quant à lui, se note `**`. Regardez :
```python
>>> 3 ** 2
9
```
Vous pouvez même vous en servir pour calculer une puissance qui n'est pas
entière. Par exemple, une racine carrée (rappelez-vous que $\sqrt{x} =
x^{\frac{1}{2}}$) :
```python
>>> 25 ** (1/2)
5.0
```
Notez que le résultat nous est donné sous la forme d'un nombre à virgule,
puisque l'un des deux opérandes, `1/2`, n'est pas une valeur entière.
Tout cela nous amène à deux nouvelles observations. La première, c'est qu'en
plus des nombres, les expressions mathématiques sont également des expressions
valides en Python.
La seconde, c'est que votre nouvel ami serpent est un génie en calcul mental.
Cela n'a rien d'étonnant ; souvenez-vous que la principale fonction d'un
programme (donc d'un langage de programmation) est de nous permettre à nous,
humains, de faire faire des calculs à un ordinateur. En fait, pour lui, *toute
instruction est un calcul à effectuer*, y compris, évidemment, les petites
opérations de calcul mental que nous venons de lui soumettre.
## Ce qu'il faut retenir
Récapitulons ce que nous avons appris dans ce chapitre.
- L'invite de commandes Python permet de tester du code au fur et à mesure
qu'on l'écrit.
- Python est capable d'effectuer des calculs, exactement comme une
calculatrice.
- Un nombre décimal s'écrit avec un point et non une virgule. Les calculs
impliquant des nombres décimaux donnent parfois des résultats approximatifs.
- Python différencie la *division réelle* (`/`) de la *division euclidienne*
(`//` et `%`).
Plus important encore, en termes de vocabulaire :
- Les chaînes de caractères (comme `"Salut !"`) et les nombres sont des
**expressions valides** en Python.
- La forme des expressions acceptées par un langage de programmation est sa
**syntaxe**.
- Le sens que donne le langage aux expressions qu'il accepte est sa
**sémantique**.
Bien entendu, Python est bien plus qu'une simple calculatrice. Vous allez très
vite vous en rendre compte dans les prochains chapitres.
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.