
language
stringclasses 15
values | src_encoding
stringclasses 34
values | length_bytes
int64 6
7.85M
| score
float64 1.5
5.69
| int_score
int64 2
5
| detected_licenses
listlengths 0
160
| license_type
stringclasses 2
values | text
stringlengths 9
7.85M
|
|---|---|---|---|---|---|---|---|
Java
|
UTF-8
| 448 | 2.796875 | 3 |
[] |
no_license
|
package org.wedu.demo1;
public class Student {
String name;
int age;
static String place;
public void study(){
System.out.println(this.name+"在学习");
}
public void doHomeWork(){
System.out.println(name+"在做作业");
}
public Student(){
place="中国";
}
}
//父类 || 接口
// | || |
//子类 类 || 类实现接口
|
Markdown
|
UTF-8
| 4,178 | 2.828125 | 3 |
[
"MIT"
] |
permissive
|
# \<auth0-element\>[](https://www.webcomponents.org/element/johnlim/auth0-element)
A collection of Polymer V1.0 elements that makes it easy to declaratively use [Auth0](https://auth0.com).
> For Polymer V2.0, please refer to the 2.0-preview branch.
> For Polymer V3.0 and litElement, they are currently under active development and will be published shortly.
\<auth0-element\> supports the following Auth0 features:
* Authentication
* [Auth0 Lock](https://auth0.com/lock)
* [Hosted Pages](https://auth0.com/docs/hosted-pages)
* [SSO](https://auth0.com/docs/sso/current)
* [Account Linking](https://docs.auth0.com/link-accounts)
* [Delegation Token](https://auth0.com/docs/tokens/delegation) used to call the API of an Application Addon, such as Firebase. (Please see deprecation [information](https://auth0.com/docs/api-auth/tutorials/adoption/delegation#third-party-apis-such-as-firebase-or-aws-) for Delegation Tokens)
It also includes a JWT manager that handles expiry of ID tokens.
### Demo
A live demo of the element in action can be found [here](https://johnlim.github.io/auth0-element/components/auth0-element/demo/ ).
### API Doc
The API documentation can be found [here](https://johnlim.github.io/auth0-element/components/auth0-element/).
### Example - Authentication
Enabling authentication which uses [Hosted Pages](https://auth0.com/docs/hosted-pages) with JWT manager enabled by importing the \<auth0-auth\> element into your html and setting the properties accordingly.
```html
<auth0-auth
client-id="YOUR_CLIENT_ID"
domain="YOUR_AUTH0_DOMAIN"
options="AUTH0.JS_OPTIONS_OBJECT"
logout-redirect-to="LOGOUT_URL"
user-profile="{{userProfile}}"
id-token="{{idToken}}"
hosted-pages
jwt-manager>
</auth0-auth>
```
[Auth0 Lock](https://auth0.com/lock) will be used if `hosted-pages` is omitted from the properties.
### Example - Obtaining a Delegation Token
Import the \<auth0-delegate\> element and configure the properties accordingly. By binding the idToken property to the idToken received from Auth0, \<auth0-delegate\> will automatically request a delegate token from Auth0 when a valid ID Token is received.
```html
<auth0-delegate
client-id="YOUR_CLIENT_ID"
domain="YOUR_AUTH0_DOMAIN "
options="OPTIONS"
id-token="[[idToken]]"
delegate-token="{{firebaseDelegateToken}}">
</auth0-delegate>
```
Obtaining a delegation token to authenticate with Firebase can be found in the accompanying [demo](https://johnlim.github.io/auth0-element/components/auth0-element/demo/ ).
### Example - Account Linking
To accomplish account linking, you'll need an \<auth0-auth\>element included somewhere in your application that handles authentication. Import the \<auth0-link-account\> element and set the properties accordingly. To initiate the account linking process, set the `connection` property.
```html
<auth0-link-account
client-id="YOUR_CLIENT_ID"
domain="YOUR_AUTH0_DOMAIN"
options="OPTIONS"
connection="google-oauth2">
</auth0-link-account>
```
# Development
## Install the Polymer-CLI
First, make sure you have the [Polymer CLI](https://www.npmjs.com/package/polymer-cli) installed. Then run `bower install` to install dependencies followed by `polymer serve` to serve your application locally.
## Viewing the Demo and API docs
```
$ bower install
$ polymer serve
```
## Building the element
```
$ bower install
$ polymer build
```
This will create a `build/` folder with `bundled/` and `unbundled/` sub-folders
containing a bundled (Vulcanized) and unbundled builds, both run through HTML,
CSS, and JS optimizers.
You can serve the built versions by giving `polymer serve` a folder to serve
from:
```
$ polymer serve build/bundled
```
## Running Tests
```
$ polymer test
```
Your application is already set up to be tested via [web-component-tester](https://github.com/Polymer/web-component-tester). Run `polymer test` to run your application's test suite locally.
|
Java
|
UTF-8
| 2,888 | 1.992188 | 2 |
[
"Apache-2.0"
] |
permissive
|
/*
* Copyright 2019-present Open Networking Foundation
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.onosproject.drivers.gnoi;
import org.onosproject.gnoi.api.GnoiClient;
import org.onosproject.gnoi.api.GnoiClientKey;
import org.onosproject.gnoi.api.GnoiController;
import org.onosproject.net.MastershipRole;
import org.onosproject.net.device.DeviceHandshaker;
import java.util.concurrent.CompletableFuture;
import static java.util.concurrent.CompletableFuture.completedFuture;
/**
* Implementation of DeviceHandshaker for gNOI.
*/
public class GnoiHandshaker extends AbstractGnoiHandlerBehaviour implements DeviceHandshaker {
@Override
public boolean isReachable() {
final GnoiClient client = getClientByKey();
return client != null && client.isServerReachable();
}
@Override
public CompletableFuture<Boolean> probeReachability() {
final GnoiClient client = getClientByKey();
if (client == null) {
return completedFuture(false);
}
return client.probeService();
}
@Override
public boolean isAvailable() {
return isReachable();
}
@Override
public CompletableFuture<Boolean> probeAvailability() {
return probeReachability();
}
@Override
public void roleChanged(MastershipRole newRole) {
throw new UnsupportedOperationException("Mastership operation not supported");
}
@Override
public MastershipRole getRole() {
throw new UnsupportedOperationException("Mastership operation not supported");
}
@Override
public CompletableFuture<Boolean> connect() {
return CompletableFuture.supplyAsync(this::createClient);
}
private boolean createClient() {
GnoiClientKey clientKey = clientKey();
if (clientKey == null) {
return false;
}
if (!handler().get(GnoiController.class).createClient(clientKey)) {
log.warn("Unable to create client for {}",
handler().data().deviceId());
return false;
}
return true;
}
@Override
public boolean isConnected() {
return getClientByKey() != null;
}
@Override
public void disconnect() {
handler().get(GnoiController.class)
.removeClient(handler().data().deviceId());
}
}
|
Python
|
UTF-8
| 3,693 | 3.40625 | 3 |
[] |
no_license
|
import os
import spacy
import string
import unidecode
from collections import Counter
def tuples_to_dicts(keys, list_of_tuples):
return [dict(zip(keys, values)) for values in list_of_tuples]
class Document:
def __init__(self, file_path):
# The name of the file is obtained
self._file_name = os.path.basename(file_path)
# Spacy features to process data in English are loaded
nlp = spacy.load('en')
# The content of the text file is stored
raw_text = open(file_path, 'r').read()
# Spacy is applied to get a data structure already featurized
spacy_raw_text = nlp(raw_text)
# Each sentence is stored on a list
self._sentences = [sentence.string.strip() for sentence in spacy_raw_text.sents]
# The text is decoded to map uncommon characters to common ones, then transformed into lowercase, and finally punctuation is removed
self._processed_text = nlp(unidecode.unidecode(raw_text).lower().translate(str.maketrans(string.punctuation, ' ' * len(string.punctuation))))
def get_most_common_words(self):
return self._common_words_and_freq
def determine_most_common_words(self, amount_of_words):
# If this method is invoked more than once, the value of _common_words_and_freq is calculated only once
if not hasattr(self, '_common_words_and_freq'):
# The words found on the text are stored
words = [chain.text for chain in self._processed_text if chain.pos_ == 'NOUN']
# The frequency of each word is stored with it, as a list of tuples and the 'N' most frequent ones are taken
self._common_words_and_freq = Counter(words).most_common(amount_of_words)
# The list of tuples generated by Counter, is transformed to a list of dictionaries
self._common_words_and_freq = tuples_to_dicts(['value', 'frequency'], self._common_words_and_freq)
# Third and fourth components are added to the dictionary,
# to store the name of the document where the word appear, and the presence of the word on each sentence, as a list of indexes
for word_index, word in enumerate(self._common_words_and_freq):
self._common_words_and_freq[word_index]['file'] = self._file_name
self._common_words_and_freq[word_index]['sentences'] = []
def assign_sentences_to_words(self):
# If the most common words were determined and linked to the sentences where they appear,
# these calculations are not going to be executed again
if hasattr(self, '_common_words_and_freq') and not hasattr(self, '_processed_sentence'):
# Spacy features used to process data in English are loaded
nlp = spacy.load('en')
# For each sentence, it determines the existence of each of the words
for sentence_index, sentence in enumerate(self._sentences):
# The text is decoded to map uncommon characters to common ones, then transformed into lowercase, and finally punctuation is removed
self._processed_sentence = nlp(unidecode.unidecode(sentence).lower().translate(str.maketrans(string.punctuation, ' ' * len(string.punctuation))))
for word_index, word in enumerate(self._common_words_and_freq):
if word['value'] in [chain.text for chain in self._processed_sentence if chain.pos_ == 'NOUN']:
# If the the word exist on the sentence, sentence's location on the text is stored on the list of sentences of each word
self._common_words_and_freq[word_index]['sentences'].append(sentence_index)
|
Python
|
UTF-8
| 332 | 4.03125 | 4 |
[] |
no_license
|
# Example 4-15. Two examples using shave_marks from Example 4-14
>>> order = '“Herr Voß: • ½ cup of Œtker™ caffè latte • bowl of açaí”.'
>>> shave_marks(order)
'“Herr Voß: • ½ cup of Œtker™ caffe latte • bowl of acai”.'
>>> Greek = 'Ζέφυρος, Zéfiro'
>>> shave_marks(Greek)
'Ζεφυρος, Zefiro'
|
Ruby
|
UTF-8
| 720 | 3.765625 | 4 |
[] |
no_license
|
# Included Modules
# Ruby version 2.4.0 introduced an Array#min method not available in prior versions of Ruby; we wrote this exercise before that release. To follow along, please use the documentation for Ruby 2.3.0:
# https://ruby-doc.org/core-2.3.0/Array.html
# Use irb to run the following code:
a = [5, 9, 3, 11]
puts a.min(2)
# Find the documentation for the `#min` method and change the above code to print the smallest values in the `Array`.
# A solution that uses the #min method alone requires version 2.2.0 or higher of Ruby. If you have an older version of Ruby, you need a different approach.
# change code on line 9 to `puts a.min(2)`
# https://ruby-doc.org/core-2.3.0/Enumerable.html#method-i-min
|
Markdown
|
UTF-8
| 3,355 | 2.71875 | 3 |
[] |
no_license
|
# openCMX
## The openCMX Standard
openCMX is a proposed Open Source, standardized, modular for factor and I/O specification for small, scalable, general computing devices.
**Goals**
The goal of openCMX is to establish an Open Sourced standard PCB and connector design for small low powered devices that allows an individual to use cost effective USB-C adapters to fully operate the node. In addition to this scenario, the user may also use the same module(s) along with 3rd party designed backplanes, to scale the single node to high density clusters. No extra cables, network switches, or power supplies.
Some examples of openCMX usaage:
- Home hobbyist
- Embedded Media Applications
- Commercial Thin Clients and low powered desktops
- Industrial embedded applications
- Robotics Development
- Education and Developing Counties
- Homelab Certification
- Large cluster development and testing
**Basics**
- The form factor is built upon the 15mm 2.5" U.2 storage physical specifications. This form factor is well established with OEMs and makes use of existing accessories and tooling.
- Primary I/O is dependent on reuse of the U.2 SFF-8639 connector to carry a PCIe x4 connection as well as a USB 3.1 connection for power, peripherals, and display output. The use of this edge connector allows for scalability within high density rack enclosures as well as smaller clusters without the need for external power supplies, network switches, etc.
- In conjunction with the SFF-8639 connection, a second USB 3.1 port (USB-C) is used for use with commodity USB-C Hubs.
- openCMX modules can be used either as a bare PCB with user customized SoC cooling etc. The module can also reside within an aluminum enclosure doubling as a heatsink. This adds durability and essential heat transfer when in higher density clusters.
- The user only pays for the I/O they want (USB-C Hubs, Docks, backplanes). Once the user invests in a chassis and I/O, modules can be swapped or upgraded without any physical reconfiguration (cables, power supplies, etc)
- Conforms to [USB-C Power Delivery specification](https://www.usb.org/document-library/usb-power-delivery) to accept 12v at various USB-C PD profiles.
**Compliant I/O**
Each openCMX module must include:
- 1x SFF-8639 with PCIe x4 and USB 3.1 (Mid-Mount)
- 1x USB-C 3.1
- 1x USB-A 3.0 (Mid-Mount)
- 1x mSDXC
**Physical Requirements**
Each openCMX compliant module must conform to the following physical specifications:
- PCB must fit within an enclosure that conforms to the specifications of a 2.5” u.2 SSD. See “U.2 Mechanical Spec.pdf” for rough external measurements.
- Total Z height of pcb, plus components should not exceed 13mm (to account for enclosure)
- Components which generate above 50% of the total heat output of the complete module should be located on the “Thick” side of the PCB. Will be known as “Side A.” SOC, Memory, Etc… Enclosure acts as a heatsink for these components when in high density rack environments.
- Components on the Thin Side, otherwise known as “Side B” cannot exceed the height of the SFF-8639 connector as it protrudes from the PCB.


|
C#
|
UTF-8
| 4,335 | 3.140625 | 3 |
[
"MIT"
] |
permissive
|
namespace Easy.Common.Extensions;
using System.Collections.Generic;
using System.Diagnostics;
using System.IO;
using System.Text;
using System.Xml;
using System.Xml.Linq;
/// <summary>
/// A set of extension methods for <see cref="Stream"/>.
/// </summary>
public static class StreamExtensions
{
private const char CR = '\r';
private const char LF = '\n';
private const char NULL = (char)0;
/// <summary>
/// Returns the number of lines in the given <paramref name="stream"/>.
/// </summary>
[DebuggerStepThrough]
public static long CountLines(this Stream stream, Encoding? encoding = default)
{
long lineCount = 0L;
byte[] byteBuffer = new byte[1024 * 1024];
char detectedEOL = NULL;
char currentChar = NULL;
int bytesRead;
if (encoding is null || Equals(encoding, Encoding.ASCII) || Equals(encoding, Encoding.UTF8))
{
while ((bytesRead = stream.Read(byteBuffer, 0, byteBuffer.Length)) > 0)
{
for (int i = 0; i < bytesRead; i++)
{
currentChar = (char)byteBuffer[i];
if (detectedEOL != NULL)
{
if (currentChar == detectedEOL)
{
lineCount++;
}
}
else if (currentChar is LF or CR)
{
detectedEOL = currentChar;
lineCount++;
}
}
}
}
else
{
char[] charBuffer = new char[byteBuffer.Length];
while ((bytesRead = stream.Read(byteBuffer, 0, byteBuffer.Length)) > 0)
{
int charCount = encoding.GetChars(byteBuffer, 0, bytesRead, charBuffer, 0);
for (var i = 0; i < charCount; i++)
{
currentChar = charBuffer[i];
if (detectedEOL != NULL)
{
if (currentChar == detectedEOL)
{
lineCount++;
}
}
else if (currentChar is LF or CR)
{
detectedEOL = currentChar;
lineCount++;
}
}
}
}
if (currentChar != LF && currentChar != CR && currentChar != NULL)
{
lineCount++;
}
return lineCount;
}
/// <summary>
/// Gets a sequence containing every element with the name equal to <paramref name="name"/>.
/// </summary>
/// <param name="stream">The stream containing XML</param>
/// <param name="name">The name of the elements to return</param>
/// <param name="ignoreCase">The flag indicating whether the name should be looked up in a case sensitive manner</param>
/// <returns>The sequence containing all the elements <see cref="XElement"/> matching the <paramref name="name"/></returns>
[DebuggerStepThrough]
public static IEnumerable<XElement> GetElements(this Stream stream, XName name, bool ignoreCase = true) =>
stream.GetElements(name, new XmlReaderSettings(), ignoreCase);
/// <summary>
/// Gets a sequence containing every element with the name equal to <paramref name="name"/>.
/// </summary>
/// <param name="stream">The stream containing XML</param>
/// <param name="name">The name of the elements to return</param>
/// <param name="settings">The settings used by the <see cref="XmlReader"/></param>
/// <param name="ignoreCase">The flag indicating whether the name should be looked up in a case sensitive manner</param>
/// <returns>The sequence containing all the elements <see cref="XElement"/> matching the <paramref name="name"/></returns>
[DebuggerStepThrough]
public static IEnumerable<XElement> GetElements(this Stream stream, XName name, XmlReaderSettings settings, bool ignoreCase = true)
{
using XmlReader reader = XmlReader.Create(stream, settings);
foreach (var xElement in reader.GetEelements(name, ignoreCase))
{
yield return xElement;
}
}
}
|
PHP
|
UTF-8
| 1,001 | 3.328125 | 3 |
[
"Apache-2.0"
] |
permissive
|
<?php
class ReverseArray implements ArrayAccess
{
private $start_index = 0;
private $internal_array = [];
/**
* @param uint $starting_index the starting point for the
* array. All accesses to the ReverseArray are calculated as
*
*
* $internal_array[$starting_index - $target]
*
* where $target is the index being requested.
*/
public function __construct($starting_index)
{
$this->start_index = $starting_index;
}
public function offsetExists($offset)
{
return array_key_exists($this->start_index - $offset, $this->internal_array);
}
public function offsetGet($offset)
{
// implement me!
throw new BadMethodCallException('implement this method');
}
public function offsetSet($offset, $value)
{
// implement me!
throw new BadMethodCallException('implement this method');
}
public function offsetUnset($offset)
{
unset($this->internal_array[$this->start_index - $offset]);
}
public function getInternalArray()
{
return $this->internal_array;
}
}
|
Markdown
|
UTF-8
| 3,217 | 2.6875 | 3 |
[] |
no_license
|
# xiaoyouMini
效友项目小程序端
主要实现如下功能
1用户注册功能:
本地校园学生用户通过省份、姓名(昵称)、专业、性别、学生证号码进行注册,通过审核后再进行爱好标签选择,如计算机、音乐等,注册完成后可使用本平台服务。
2用户登录功能:
本地校园学生用户注册成功后登录本平台使用服务,服务包括:需求发布\获取、二手物品信息上传、用户间即时通信、个人资料修改\查看等。
3搜索功能:
分为两个类型,即二手物品与技能服务,通过关键词限定,二手物品通过例如“二手书籍”“二手乐器”等进行搜寻,技能服务通过专业例如“计算机”“外语”“音乐”等进行搜寻,为用户提供整个平台的信息搜索功能,分别接旧物与技能需求的数据库,做到两边关键词不干扰。
4工程师入驻平台功能:
一般用户在上传个人技能认证类证书照片,例如:“软考证书”“乐器证书”等,在经过平台认证确认后,可成为平台实时在线工程师,为消费用户提供服务并赚取佣金。
5二手旧物信息功能:
用户可通过本页面上传自己想要售卖的二手物品图片,添加描述,物品存放地点,以及预估价位后,将物品放到平台上展示,可与其他用户线上下协商后进行交易,同时为用户提供最新的二手物品需求信息的手动刷新页面,用户也可通过搜索快速区分想要的类型二手物品,技能类如音乐-钢琴,书籍-数学,数码-耳机,生活类如日用品-书桌等。
6用户线上沟通交流功能:
结合技能需求或者二手交易的服务链接,为用户提供线上与其他用户交流或者联系管理员,沟通预约工程师的功能,这一块考虑接入腾讯的云通信IM平台,达到在线交流,上传图片,表情标签,历史聊天记录查看等功能。
7需求发布\获取功能:
为用户提供最新的技能需求信息的手动更新页面,通过学生用户专业进行一级分类,细化专业进行二级分类列表,使用户快速区分想要的技能服务。用户也可通过本功能上传自己需要的类型服务,上传图片,添加描述,以及预估价位后,将需求放到平台上展示,经后台管理员审核后发布,与其他用户或工程师线上下协商后进行服务。
8智能推荐:
为短期无法解决需求的用户优先推送服务者的发布信息,或向用户优先推荐平台工程师信息。
9个人中心功能:
用户的个人用户中心页面,可修改个人资料,可以查看“我的需求\发布”“我的二手物品信息”,申请认证工程师,也可以在此查看历史服务或物品交易列表,对服务进行评价。
10反馈功能:
分两个部分,第一为用户使用本平台后对平台本身的评价系统,此部分绑定平台后台管理员,通过平台首页轮播页面公开,第二为需求用户对服务人员的服务评价系统,与其他用户或工程师绑定,可浏览他人对工程师或平台对工程师的简要描述及用户的评价信息
|
C++
|
UTF-8
| 901 | 2.578125 | 3 |
[
"Unlicense"
] |
permissive
|
/**
* AUTEUR : Damien ROGÉ
* DATE : 19 JANVIER 2019
**/
#include <iostream>
#include <string>
#include <stdio.h>
#include "CSVParser.hpp"
#define CATCH_CONFIG_MAIN // This tells Catch to provide a main() - only do this in one cpp file
#include "catch.hpp"
using namespace std;
TEST_CASE( "CSVParser", "[]" ) {
SECTION("CSVParser"){
CSVParser monCSVParser;
REQUIRE(monCSVParser.initWithFile("./sondage.csv"));
REQUIRE(monCSVParser.getFilepath() == "./sondage.csv");
REQUIRE(monCSVParser.getNumberOfColumns() == 4);
REQUIRE(monCSVParser.getNumberofRows() == 20);
string header[4];
monCSVParser.getHeader(header);
REQUIRE(header[0] == "Prénoms");
REQUIRE(header[1] == "Numéros de téléphone");
REQUIRE(header[2] == "Réponses");
REQUIRE(header[3] == "Noms");
}
}
|
C++
|
UTF-8
| 758 | 4.03125 | 4 |
[] |
no_license
|
/*
* Exercise 10.22: Rewrite the program to count words of size 6 or less using
* functions in place of the lambdas.
*
* By Faisal Saadatmand
*/
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
#include <functional>
bool check_size(const std::string &s, const std::string::size_type &sz)
{
return s.size() <= sz;
}
int main()
{
using std::placeholders::_1;
std::vector<std::string> words{"the", "quick", "red", "fox", "jumps",
"over", "the", "slow", "red", "turtle",
"sixteen", "times"};
const std::string::size_type size{6};
auto count = count_if(words.begin(), words.end(),
bind(check_size, _1, size));
std::cout << count << " words are greater than " << size << '\n';
return 0;
}
|
Python
|
UTF-8
| 1,137 | 3.265625 | 3 |
[] |
no_license
|
import statistics
from single_point import parse
def parse_data(data_file_full_path):
""" This method parses the data into the final matrix [M x N] - called X matrix.
and Nx1 vector of classifier results - Y vector.
"""
final_x_matrix = list()
final_y_vector = list()
try:
data_file = open(data_file_full_path)
for line in data_file:
split_line = line.split(', ')
if split_line.__contains__("?"):
x_value, y_value = parse(split_line)
# Adding median as a feature
x_value.append(statistics.median(x_value))
# Adding mean as a feature
x_value.append(statistics.mean(x_value))
# Adding variance as a feature
x_value.append(statistics.variance(x_value))
final_x_matrix.append(x_value)
final_y_vector.append(y_value)
except Exception as err:
print("Error: ", err)
finally:
return final_x_matrix, final_y_vector
# parse_data("data/adult.data")
|
JavaScript
|
UTF-8
| 2,422 | 2.96875 | 3 |
[] |
no_license
|
import React from 'react';
class AddUser extends React.Component {
constructor(props) {
super(props);
this.state = {
user: {
firstName: '',
lastName: '',
username: '',
},
userExist: false
}
}
handleSubmit = (event) => {
event.preventDefault();
const newUser = this.state.user;
const userExist = this.userExist(this.state.user)
// const {firstName, lastName, username} = this.state;
// users.push({firstName, lastName, username, game: 0 });
console.log(this.userExist(this.state.user))
if (!this.userExist(this.state.user)) {
this.props.onAddUser(newUser);
}
this.setState({
userExist
})
}
handleChange = (event) => {
const target = event.target;
const name = target.name;
const value = target.value;
this.setState(currState => ({
user: {
...currState.user,
[name]: value
}
}))
}
isDisabled = () => {
const {firstName, lastName, username} = this.state.user;
return firstName === '' || lastName === '' || username === ''
}
userExist = (newUser) => {
const users = this.props.users;
for (let user of users) {
if (user.username === newUser.username) {
console.log('user exist');
return true
}
}
console.log('user not exist')
return false
}
render() {
return (
<div>
<h1>Add New User</h1>
<form onSubmit={this.handleSubmit}>
<input
type="text"
placeholder="first name"
name="firstName"
value={this.state.user.firstName}
onChange={this.handleChange}
/>
<input
type="text"
placeholder="last name"
name="lastName"
value={this.state.user.lastName}
onChange={this.handleChange}
/>
<input
type="text"
placeholder="username"
name="username"
value={this.state.user.username}
onChange={this.handleChange}
/>
{/* <input type="submit" value="Add"/> */}
<button disabled={this.isDisabled()}>Add</button>
<p className='error'>
{this.state.userExist? 'The username is already used by other user': ''}
</p>
</form>
</div>
)
}
}
export default AddUser;
|
Java
|
UTF-8
| 2,250 | 2.453125 | 2 |
[
"MIT"
] |
permissive
|
package mage.cards.m;
import java.util.UUID;
import mage.abilities.Mode;
import mage.abilities.effects.common.DestroyTargetEffect;
import mage.abilities.effects.common.combat.CantBlockAllEffect;
import mage.abilities.effects.common.continuous.GainAbilityControlledEffect;
import mage.abilities.keyword.IndestructibleAbility;
import mage.cards.CardImpl;
import mage.cards.CardSetInfo;
import mage.constants.CardType;
import mage.constants.ComparisonType;
import mage.constants.Duration;
import mage.filter.FilterPermanent;
import mage.filter.StaticFilters;
import mage.filter.common.FilterCreaturePermanent;
import mage.filter.predicate.Predicates;
import mage.filter.predicate.mageobject.PowerPredicate;
import mage.target.TargetPermanent;
/**
*
* @author Styxo
*/
public final class MightOfTheWild extends CardImpl {
private static final FilterCreaturePermanent filterMode1 = new FilterCreaturePermanent("Creatures with power 3 or less");
private static final FilterPermanent filterMode2 = new FilterPermanent("artifact or enchantment");
static {
filterMode1.add(new PowerPredicate(ComparisonType.FEWER_THAN, 4));
filterMode2.add(Predicates.or(CardType.ARTIFACT.getPredicate(), CardType.ENCHANTMENT.getPredicate()));
}
public MightOfTheWild(UUID ownerId, CardSetInfo setInfo) {
super(ownerId,setInfo,new CardType[]{CardType.INSTANT},"{R}{G}{W}");
// Choose one - Creatures with power 3 or less can't block this turn.
this.getSpellAbility().addEffect(new CantBlockAllEffect(filterMode1, Duration.EndOfTurn));
// Destroy target artifact or enchantment.
Mode mode = new Mode(new DestroyTargetEffect());
mode.addTarget(new TargetPermanent(filterMode2));
this.getSpellAbility().addMode(mode);
// Creatures you control gain indestructible this turn.
mode = new Mode(new GainAbilityControlledEffect(IndestructibleAbility.getInstance(), Duration.EndOfTurn, StaticFilters.FILTER_CONTROLLED_CREATURES));
this.getSpellAbility().addMode(mode);
}
private MightOfTheWild(final MightOfTheWild card) {
super(card);
}
@Override
public MightOfTheWild copy() {
return new MightOfTheWild(this);
}
}
|
JavaScript
|
UTF-8
| 13,388 | 2.78125 | 3 |
[
"MIT"
] |
permissive
|
"use strict";
/**
* @module {connect.Behavior} can-connect/data/url/url data/url
* @parent can-connect.behaviors
* @group can-connect/data/url/url.data-methods data methods
* @group can-connect/data/url/url.option options
*
* @option {connect.Behavior}
*
* Uses the [can-connect/data/url/url.url] option to implement the behavior of
* [can-connect/connection.getListData],
* [can-connect/connection.getData],
* [can-connect/connection.createData],
* [can-connect/connection.updateData], and
* [can-connect/connection.destroyData] to make an AJAX request
* to urls.
*
* @body
*
* ## Use
*
* The `data/url` behavior implements many of the [can-connect/DataInterface]
* methods to send instance data to a URL.
*
* For example, the following `todoConnection`:
*
* ```js
* var todoConnection = connect([
* require("can-connect/data/url/url")
* ],{
* url: {
* getListData: "GET /todos",
* getData: "GET /todos/{id}",
* createData: "POST /todos",
* updateData: "PUT /todos/{id}",
* destroyData: "DELETE /todos/{id}"
* }
* });
* ```
*
* Will make the following request when the following
* methods are called:
*
* ```
* // GET /todos?due=today
* todoConnection.getListData({due: "today"});
*
* // GET /todos/5
* todosConnection.getData({id: 5})
*
* // POST /todos \
* // name=take out trash
* todosConnection.createData({
* name: "take out trash"
* });
*
* // PUT /todos/5 \
* // name=do the dishes
* todosConnection.updateData({
* name: "do the dishes",
* id: 5
* });
*
* // DELETE /todos/5
* todosConnection.destroyData({
* id: 5
* });
* ```
*
* There's a few things to notice:
*
* 1. URL values can include simple templates like `{id}`
* that replace that part of the URL with values in the data
* passed to the method.
* 2. GET and DELETE request data is put in the URL using [can-param].
* 3. POST and PUT requests put data that is not templated in the URL in POST or PUT body
* as JSON-encoded data. To use form-encoded requests instead, add the property
* `contentType:'application/x-www-form-urlencoded'` to your [can-connect/data/url/url.url].
* 4. If a provided URL doesn't include the method, the following default methods are provided:
* - `getListData` - `GET`
* - `getData` - `GET`
* - `createData` - `POST`
* - `updateData` - `PUT`
* - `destroyData` - `DELETE`
*
* If [can-connect/data/url/url.url] is provided as a string like:
*
* ```js
* var todoConnection = connect([
* require("can-connect/data/url/url")
* ],{
* url: "/todos"
* });
* ```
*
* This does the same thing as the first `todoConnection` example.
*/
var ajax = require("can-ajax");
var replaceWith = require("can-key/replace-with/replace-with");
var canReflect = require("can-reflect");
var dev = require("can-log/dev/dev");
var behavior = require("../../behavior");
var makeRest = require("can-make-rest");
var defaultRest = makeRest("/resource/{id}");
var makePromise = require("../../helpers/make-promise");
// # can-connect/data/url/url
// For each pair, create a function that checks the url object
// and creates an ajax request.
var urlBehavior = behavior("data/url", function(baseConnection) {
var behavior = {};
canReflect.eachKey(defaultRest, function(defaultData, dataInterfaceName){
behavior[dataInterfaceName] = function(params) {
var meta = methodMetaData[dataInterfaceName];
var defaultBeforeSend;
if(typeof this.url === "object") {
defaultBeforeSend = this.url.beforeSend;
if(typeof this.url[dataInterfaceName] === "function") {
return makePromise(this.url[dataInterfaceName](params));
}
else if(this.url[dataInterfaceName]) {
var promise = makeAjax(
this.url[dataInterfaceName],
params,
defaultData.method,
this.ajax || ajax,
findContentType(this.url, defaultData.method),
meta,
defaultBeforeSend
);
return makePromise(promise);
}
}
var resource = typeof this.url === "string" ? this.url : this.url.resource;
if( resource ) {
var idProps = canReflect.getSchema(this.queryLogic).identity;
var resourceWithoutTrailingSlashes = resource.replace(/\/+$/, "");
var result = makeRest(resourceWithoutTrailingSlashes, idProps[0])[dataInterfaceName];
return makePromise(makeAjax(
result.url,
params,
result.method,
this.ajax || ajax,
findContentType(this.url, result.method),
meta,
defaultBeforeSend
));
}
return baseConnection[name].call(this, params);
};
});
return behavior;
});
/**
* @property {String|Object} can-connect/data/url/url.url url
* @parent can-connect/data/url/url.option
*
* Specify the url and methods that should be used for the "Data Methods".
*
* @option {String} If a string is provided, it's assumed to be a RESTful interface. For example,
* if the following is provided:
*
* ```
* url: "/services/todos"
* ```
*
* ... the following methods and requests are used:
*
* - `getListData` - `GET /services/todos`
* - `getData` - `GET /services/todos/{id}`
* - `createData` - `POST /services/todos`
* - `updateData` - `PUT /services/todos/{id}`
* - `destroyData` - `DELETE /services/todos/{id}`
*
* @option {Object} If an object is provided, it can customize each method and URL directly
* like:
*
* ```js
* url: {
* getListData: "GET /services/todos",
* getData: "GET /services/todo/{id}",
* createData: "POST /services/todo",
* updateData: "PUT /services/todo/{id}",
* destroyData: "DELETE /services/todo/{id}"
* }
* ```
*
* You can provide a `resource` property that works like providing `url` as a string, but overwrite
* other values like:
*
* ```js
* url: {
* resource: "/services/todo",
* getListData: "GET /services/todos"
* }
* ```
*
* You can also customize per-method the parameters passed to the [can-connect/data/url/url.ajax ajax implementation], like:
* ```js
* url: {
* resource: "/services/todos",
* getListData: {
* url: "/services/todos",
* type: "GET",
* beforeSend: () => {
* return fetch('/services/context').then(processContext);
* }
* }
* }
* ```
* This can be particularly useful for passing a handler for the [can-ajax <code>beforeSend</code>] hook.
*
* The [can-ajax <code>beforeSend</code>] hook can also be passed for all request methods. This can be useful when
* attaching a session token header to a request:
*
* ```js
* url: {
* resource: "/services/todos",
* beforeSend: (xhr) => {
* xhr.setRequestHeader('Authorization', `Bearer: ${Session.current.token}`);
* }
* }
* ```
*
* Finally, you can provide your own method to totally control how the request is made:
*
* ```js
* url: {
* resource: "/services/todo",
* getListData: "GET /services/todos",
* getData: function(param){
* return new Promise(function(resolve, reject){
* $.get("/services/todo", {identifier: param.id}).then(resolve, reject);
* });
* }
* }
* ```
*/
/**
* @property {function} can-connect/data/url/url.ajax ajax
* @parent can-connect/data/url/url.option
*
* Specify the ajax functionality that should be used to make the request.
*
* @option {function} Provides an alternate function to be used to make
* ajax requests. By default [can-ajax] provides the ajax
* functionality. jQuery's ajax method can be substituted as follows:
*
* ```js
* connect([
* require("can-connect/data/url/url")
* ],{
* url: "/things",
* ajax: $.ajax
* });
* ```
*
* @param {Object} settings Configuration options for the AJAX request.
* @return {Promise} A Promise that resolves to the data.
*/
// ## methodMetaData
// Metadata on different methods that is passed to makeAjax
var methodMetaData = {
/**
* @function can-connect/data/url/url.getListData getListData
* @parent can-connect/data/url/url.data-methods
*
* @signature `getListData(set)`
*
* Retrieves list data for a particular set given the [can-connect/data/url/url.url] settings.
* If `url.getListData` is a function, that function will be called. If `url.getListData` is a
* string, a request to that string will be made. If `url` is a string, a `GET` request is made to
* `url`.
*
* @param {can-query-logic/query} query A object that represents the set of data needed to be loaded.
* @return {Promise<can-connect.listData>} A promise that resolves to the ListData format.
*/
getListData: {},
/**
* @function can-connect/data/url/url.getData getData
* @parent can-connect/data/url/url.data-methods
*
* @signature `getData(params)`
*
* Retrieves raw instance data given the [can-connect/data/url/url.url] settings.
* If `url.getData` is a function, that function will be called. If `url.getData` is a
* string, a request to that string will be made. If `url` is a string, a `GET` request is made to
* `url+"/"+IDPROP`.
*
* @param {Object} params A object that represents the set of data needed to be loaded.
* @return {Promise<Object>} A promise that resolves to the instance data.
*/
getData: {},
/**
* @function can-connect/data/url/url.createData createData
* @parent can-connect/data/url/url.data-methods
*
* @signature `createData(instanceData, cid)`
*
* Creates instance data given the serialized form of the data and
* the [can-connect/data/url/url.url] settings.
* If `url.createData` is a function, that function will be called. If `url.createData` is a
* string, a request to that string will be made. If `url` is a string, a `POST` request is made to
* `url`.
*
* @param {Object} instanceData The serialized data of the instance.
* @param {Number} cid A unique id that represents the instance that is being created.
* @return {Promise<Object>} A promise that resolves to the newly created instance data.
*/
createData: {},
/**
* @function can-connect/data/url/url.updateData updateData
* @parent can-connect/data/url/url.data-methods
*
* @signature `updateData(instanceData)`
*
* Updates instance data given the serialized form of the data and
* the [can-connect/data/url/url.url] settings.
* If `url.updateData` is a function, that function will be called. If `url.updateData` is a
* string, a request to that string will be made. If `url` is a string, a `PUT` request is made to
* `url+"/"+IDPROP`.
*
* @param {Object} instanceData The serialized data of the instance.
* @return {Promise<Object>} A promise that resolves to the updated instance data.
*/
updateData: {},
/**
* @function can-connect/data/url/url.destroyData destroyData
* @parent can-connect/data/url/url.data-methods
*
* @signature `destroyData(instanceData)`
*
* Deletes instance data given the serialized form of the data and
* the [can-connect/data/url/url.url] settings.
* If `url.destroyData` is a function, that function will be called. If `url.destroyData` is a
* string, a request to that string will be made. If `url` is a string, a `DELETE` request is made to
* `url+"/"+IDPROP`.
*
* @param {Object} instanceData The serialized data of the instance.
* @return {Promise<Object>} A promise that resolves to the deleted instance data.
*/
destroyData: {includeData: false}
};
var findContentType = function( url, method ) {
if ( typeof url === 'object' && url.contentType ) {
var acceptableType = url.contentType === 'application/x-www-form-urlencoded' ||
url.contentType === 'application/json';
if ( acceptableType ) {
return url.contentType;
} else {
//!steal-remove-start
if(process.env.NODE_ENV !== 'production') {
dev.warn("Unacceptable contentType on can-connect request. " +
"Use 'application/json' or 'application/x-www-form-urlencoded'");
}
//!steal-remove-end
}
}
return method === "GET" ? "application/x-www-form-urlencoded" : "application/json";
};
function urlParamEncoder (key, value) {
return encodeURIComponent(value);
}
var makeAjax = function ( ajaxOb, data, type, ajax, contentType, reqOptions, defaultBeforeSend ) {
var params = {};
// A string here would be something like `"GET /endpoint"`.
if (typeof ajaxOb === 'string') {
// Split on spaces to separate the HTTP method and the URL.
var parts = ajaxOb.split(/\s+/);
params.url = parts.pop();
if (parts.length) {
params.type = parts.pop();
}
} else {
// If the first argument is an object, just load it into `params`.
canReflect.assignMap(params, ajaxOb);
}
// If the `data` argument is a plain object, copy it into `params`.
params.data = typeof data === "object" && !Array.isArray(data) ?
canReflect.assignMap(params.data || {}, data) : data;
// Substitute in data for any templated parts of the URL.
params.url = replaceWith(params.url, params.data, urlParamEncoder, true);
params.contentType = contentType;
if(reqOptions.includeData === false) {
delete params.data;
}
return ajax(canReflect.assignMap({
type: type || 'post',
dataType: 'json',
beforeSend: defaultBeforeSend,
}, params));
};
module.exports = urlBehavior;
//!steal-remove-start
if(process.env.NODE_ENV !== 'production') {
var validate = require("../../helpers/validate");
module.exports = validate(urlBehavior, ['url']);
}
//!steal-remove-end
|
Python
|
UTF-8
| 3,260 | 4.09375 | 4 |
[
"MIT"
] |
permissive
|
import unicodedata
class NormalizedStr:
'''
By default, Python's str type stores any valid unicode string.
This can result in unintuitive behavior.
For example:
>>> 'César' in 'César Chávez'
True
>>> 'César' in 'César Chávez'
False
The two strings to the right of the in keyword above are equal *seman
but not equal *representationally
In particular, the first is in NFC form, and the second is in NFD form.
The purpose of this class is to automatically normalize our strings for u
making foreign languages "just work" a little bit easier.
'''
def __init__(self, text, normal_form='NFC'):
self.normal = normal_form
self.text = unicodedata.normalize(self.normal, text)
def __repr__(self):
'''
The string returned by the __repr__ function should be valid python
that can be substituted directly into the python interpreter to rept.
'''
return 'NormalizedStr(\'' + self.text + '\', \'' + self.normal + '\')'
def __str__(self):
'''
This functions converts the NormalizedStr into a regular string objt.
The output is similar, but not exactly the same, as the __repr__ fun
'''
return str(self.text)
def __len__(self):
'''
Returns the length of the string.
The expression `len(a)` desugars to a.__len__().
'''
return len(self.text)
def __contains__(self, substr):
normal_substr = unicodedata.normalize(self.normal, substr)
return str(self.text).__contains__(str(normal_substr))
def __getitem__(self, index):
'''
Returns the character at position `index`.
The expression `a[b]` desugars to `a.__getitem__(b)`.
'''
indexable_list = list(self.text)
return indexable_list[index]
def lower(self):
'''
Returns a copy in the same normalized form, but lower case.
'''
return self.text.lower()
def upper(self):
'''
Returns a copy in the same normalized form, but upper case.
'''
return self.text.upper()
def __add__(self, b):
'''
Returns a copy of `self` with `b` appended to the end.
The expression `a + b` gets desugared into `a.__add__(b)`.
HINT
The addition of two normalized strings is not guaranteed to stay
Therefore, you must renormalize the strings after adding them t
'''
b_norm = unicodedata.normalize(self.normal, str(b))
combined_self = unicodedata.normalize(self.normal, self.text + b_norm)
return NormalizedStr(combined_self, self.normal)
def __iter__(self):
'''
HINT:
Recall that the __iter__ method returns a class, which is the iterat
You'll need to define your own iterator class with the appropriate
and return an instance of that class here.
'''
return NormIter(self.text)
class NormIter:
def __init__(self, text):
self.text = text
self.count = 0
def __next__(self):
if self.count < len(self.text):
self.count += 1
return self.text[self.count - 1]
else:
raise StopIteration
|
Python
|
UTF-8
| 517 | 3.125 | 3 |
[] |
no_license
|
inFile = open('input.txt', 'r', encoding='utf8')
outFile = open('output.txt', 'w', encoding='utf8')
candidateDict = {}
for line in inFile.readlines():
candidate, votesCandidate = list(map(str, line.strip().split()))
if candidate not in candidateDict:
candidateDict[candidate] = 0
candidateDict[candidate] += int(votesCandidate)
candidateList = sorted(candidateDict)
for index in candidateList:
print(index, candidateDict[index], file=outFile)
inFile.close()
outFile.close()
|
Markdown
|
UTF-8
| 2,901 | 2.640625 | 3 |
[] |
no_license
|
# Article 4
Les plafonds prévus par l'article D. 755-28 du code de la sécurité sociale sont fixés à :
a) Pour les allocataires occupant en location des locaux construits avant le 1er janvier 1976 :
Désignation : Personne isolée, Plafond : 908
Désignation : Ménage sans personne à charge : Plafond : 1 065
Désignation : Ménage ou personne ayant une personne à charge, ménage ou personne ayant deux enfants à charge : Plafond : 1 112
Désignation : Ménage ou personne ayant trois personnes à charge :
Plafond : 1 252
Désignation : Ménage ou personne ayant quatre personnes à charge :
Plafond : 1 392
Désignation : Ménage ou personne ayant cinq personnes à charge :
Plafond : 1 532
Désignation : Ménage ou personne ayant six personnes à charge et plus : Plafond : 1 672
b) Pour les allocataires occupant en location des locaux construits après le 1er janvier 1976 et avant le 31 décembre 1985 :
Désignation : Personne isolée, Plafond : 1 136
Désignation : Ménage sans personne à charge : Plafond : 1 342
Désignation : Ménage ou personne ayant une personne à charge, ménage ou personne ayant deux enfants à charge : Plafond : 1 401
Désignation : Ménage ou personne ayant trois personnes à charge :
Plafond : 1 566
Désignation : Ménage ou personne ayant quatre personnes à charge :
Plafond : 1 731
Désignation : Ménage ou personne ayant cinq personnes à charge :
Plafond : 1 896
Désignation : Ménage ou personne ayant six personnes à charge et plus : Plafond : 2 061
c) Pour les allocataires occupant en location des locaux construits après le 1er janvier 1986 :
Désignation : Personne isolée, Plafond : 1 266
Désignation : Ménage sans personne à charge : Plafond : 1 551
Désignation : Bénéficiaire isolé ou ménage :
- ayant une personne à charge : Plafond : 1 679
- ayant deux personnes à charge : Plafond : 1 738
- ayant trois personnes à charge : Plafond : 1 797
- ayant quatre personnes à charge : Plafond : 1 856
- ayant cinq personnes à charge : Plafond : 1 988
- ayant six personnes à charge et plus : Plafond : 2 162
d) Pour les accédants à la propriété, quelle que soit la date de construction ou d'achèvement du logement, dès lors que les emprunts auxquels se rapporte le certificat de prêt prévu à l'article D. 755-27 du code de la sécurité sociale ont été contractés après le 30 juin 1992 :
Désignation : Personne isolée, Plafond : 1 393
Désignation : Ménage sans personne à charge : Plafond : 1 706
Désignation : Bénéficiaire isolé ou ménage :
- ayant une personne à charge : Plafond : 1 847
- ayant deux personnes à charge : Plafond : 1 912
- ayant trois personnes à charge : Plafond : 1 977
- ayant quatre personnes à charge : Plafond : 2 042
- ayant cinq personnes à charge : Plafond : 2 187
- ayant six personnes à charge et plus : Plafond : 2 378
|
JavaScript
|
UTF-8
| 2,192 | 2.765625 | 3 |
[] |
no_license
|
var db = require('../db/mydb.js');
//loginに飛んできたときの処理がsaveStatusに入っている。
exports.login = function(req, res, next) {
var saveStatus;
if(req.session.saveStatus){
saveStatus = req.session.saveStatus;
delete req.session.saveStatus;
}else{
saveStatus = 'welcome';
}
res.render('login', { title: 'my chat app', status:saveStatus});
};
//logoutしたらsessionの情報を削除し、loginに飛ばす
exports.logout = function(req, res, next) {
delete req.session.user;
res.redirect('/login');
};
exports.test = function(req, res, next) {
//login formから得られたデータ
var user = req.body.user;
console.log('username::' + user.name +' userpsw::' + user.pwd );
var users;
var authUsers = db.getUserData(user.name, user.pwd, function(dbusers){
users = dbusers;
var usersLength = users.length;
console.log('ユーザーの数:' + usersLength);
console.log('user name と pwd' + users.name + ' '+ users.password);
//ユーザ名とパスワードとが該当する人が一人もいなかったら、loginにリダイレクト。
if(usersLength===0){
res.render('login', { title: 'my chat app', status:'no user or id || pass wrong'});
return;
}else{
//ユーザ名とパスワードとが該当する人がいた場合
req.session.user = {
name: user.name,
pwd: user.pwd
};
res.redirect('/chat');
}
});
};
exports.signup = function(req, res, next) {
res.render('signup');
};
exports.signupnow = function(req, res, next) {
var user = req.body.user;
db.setUserData(user.name,user.pwd,function(errStr){
var saveStatus;
if(errStr === 'err'){
console.log('でーた保存失敗');
saveStatus = 'data could not be saved';
req.session.saveStatus = saveStatus;
res.redirect('/signup');
}else if(errStr === 'dup'){
console.log('でーた保存失敗');
saveStatus = 'id or password is dupricated';
req.session.saveStatus = saveStatus;
res.redirect('/signup');
}else{
console.log('でーた保存成功');
saveStatus = 'data is saved';
req.session.saveStatus = saveStatus;
res.redirect('/login');
}
});
};
//secret window
|
Markdown
|
UTF-8
| 1,015 | 2.890625 | 3 |
[
"MIT",
"LicenseRef-scancode-unknown-license-reference"
] |
permissive
|
# Uploading files using Python 3 in less than 100 lines
Simple server for listing file directory over HTTP, and uploading files.
Based on `http.server`, this module adds file upload functionality to it.
Just as with `http.server`, you SHOULD NOT use this module in
untrusted environment (such as servers exposed to the Internet
or public Wi-Fi networks): it is not secure!
## Usage
Same as for `http.server`:
python3 -m upload
or:
python3 upload.py
supported arguments (see `python3 -m upload -h`):
usage: upload.py [-h] [--bind ADDRESS] [--directory DIRECTORY] [port]
positional arguments:
port Port number [default: 8000]
optional arguments:
-h, --help show this help message and exit
--bind ADDRESS, -b ADDRESS
Bind address [default: all interfaces]
--directory DIRECTORY, -d DIRECTORY
Directory to list [default:current directory]
## License
MIT License, © David Avsajanishvili
See LICENSE
|
Go
|
UTF-8
| 284 | 2.875 | 3 |
[] |
no_license
|
package detect
// App 会根据给定的目录发现application类型
func App(dir string, c *Config) (string, error) {
for _, d := range c.Detectors {
check, err := d.Detect(dir)
if err != nil {
return "", err
}
if check {
return d.Type, nil
}
}
return "", nil
}
|
C++
|
WINDOWS-1250
| 1,273 | 3.25 | 3 |
[] |
no_license
|
#include "helper.h"
void processFile(student* &head, const string &fileName, int &counter)
{
ifstream file;
string subject;
string teacher;
string row;
file.open(fileName); //Wczytywanie protokow z parametru.
if (!file.good())
cout << "Nie udalo sie odczytac pliku" << endl; //Sprawdzanie poprawnoci odczytu protokow.
getline(file, subject); //Pobiera pierwsz linik w pliku .txt.
getline(file, teacher); //Pobiera drug linik w pliku .txt.
/*Ptla while, ktra czyta plik .txt, zapisuje go tymczasowo do zmiennej pomocniczej buf,
a nastpnie zapisuje wyraz po wyrazie do kolejnych zmiennych (przyjmuje, e po spacji jest kolejny wyraz).*/
while (getline(file, row))
{
studentNode* studentNode = nullptr;
string name;
string surname;
int idNumber;
float grade;
string date;
istringstream buf(row);
buf >> name;
buf >> surname;
buf >> idNumber;
buf >> grade;
buf >> date;
cout << grade << " " << date << endl;
addOrUpdateStudent(head, name, surname, idNumber, teacher, subject, grade, date); //Dodawanie do/lub uzupenianie listy jednokierunkowej.
counter++; //Inkrementacja licznika przetworzonych studentw.
}
file.close(); //Funkcja zamykajca otwarty plik .txt.
}
|
Python
|
UTF-8
| 1,833 | 2.859375 | 3 |
[] |
no_license
|
import typing
class ReadMetricResponse:
def __init__(self, payload):
self.co2 = (payload[2] << 8) + payload[3]
self.temperature = payload[4] - 40
def __repr__(self):
return "co2: %d, temperature: %d" % (self.co2, self.temperature)
class SensorMixin(object):
READ_METRIC = b'\xFF\x01\x86\x00\x00\x00\x00\x00'
START_CALIBRATION = b'\xFF\x01\x87\x00\x00\x00\x00\x00'
SET_AUTO_CALIBRATION = b'\xFF\x01\x79%c\x00\x00\x00\x00' # on or off
SET_DETECTION_RANGE = b'\xFF\x01\x99\x00\x00\x00%c%c' # 2000 or 5000
def __init__(self, serial):
self.serial = serial
def _prepare_request(self, payload, *args):
assert len(payload) == 8, "Wrong payload length"
assert isinstance(payload, typing.ByteString), "Wrong payload type"
payload = payload % tuple(*args)
csum = self._checksum(payload)
data = payload + csum
assert len(data) == 9
return data
@staticmethod
def _checksum(payload):
checksum = sum(bytearray(payload[0:8]))
checksum = 0xff - checksum & 0xff
return bytes([checksum])
def parse_response(self, payload):
assert len(payload) == 9, "Wrong payload length"
assert ord(self._checksum(payload)) == payload[8], "CRC error"
if payload[0] == 0xff:
if payload[1] == 0x86: # Read command
return ReadMetricResponse(payload)
elif payload[1] == 0x99: # detection range set
return True
elif payload[1] == 0x79: # auto calibration mode set
return True
elif payload[1] == 0x87: # calibration started
return True
elif payload[1] == 0x88: # span calibration started
return True
return False
|
TypeScript
|
UTF-8
| 1,112 | 2.625 | 3 |
[] |
no_license
|
import SimpleLevel from "../lib/simple-level";
import { IncomingTransaction, IncomingTransactionJson } from "@interstatejs/tx";
export class IncomingTransactionsDatabase extends SimpleLevel {
length?: number;
constructor(dbPath?: string) {
super('incoming-transactions', dbPath);
}
static async create(dbPath?: string): Promise<IncomingTransactionsDatabase> {
const db = new IncomingTransactionsDatabase(dbPath);
await db.init();
return db;
}
async init() {
let len = await super.get('length');
if (isNaN(len)) {
len = 0;
await super.put('length', len);
}
this.length = len;
}
async put(index: number, value: IncomingTransaction): Promise<void> {
if (index >= this.length) {
this.length++;
await super.put('length', this.length);
}
return super.put(index, value);
}
async get(index: number): Promise<IncomingTransaction> {
const json = await super.get(index);
if (json == null) return null;
return new IncomingTransaction(<IncomingTransactionJson> json);
}
}
export default IncomingTransactionsDatabase;
|
JavaScript
|
UTF-8
| 207 | 3.65625 | 4 |
[] |
no_license
|
let farenheitToCelsius = function(f){
let c = 5 * (f - 32) / 9
return c
}
console.log(32 + 'ºF --> ' + farenheitToCelsius(32) + 'ºC')
console.log(68 + 'ºF --> ' + farenheitToCelsius(68) + 'ºC')
|
Java
|
UTF-8
| 940 | 2.546875 | 3 |
[] |
no_license
|
package dao;
import domin.Student;
import java.sql.SQLException;
import java.util.List;
/**
* Created by Administrator on 2020/7/23.
* 针对学生表的数据访问
*/
public interface StudentDao {
//一页显示多少数据
int PAGE_SIZE=5;
//查找学生所有信息
List<Student> findAll() throws SQLException;
//添加学生信息
void insert(Student student) throws SQLException;
//删除学生信息
void delete(int id) throws SQLException;
//根据id查找学生信息
Student findStudentById(int id) throws SQLException;
//更新学生信息
void update(Student student) throws SQLException;
//模糊查询
List<Student> searchStudent(String name,String gender) throws SQLException;
//查询当页的信息
List<Student> findStudentByPage(int currentPage) throws SQLException;
//查询总的学生记录数
int findCount() throws SQLException;
}
|
Python
|
UTF-8
| 7,256 | 3.421875 | 3 |
[] |
no_license
|
# autor: Lukáš Gajdošech
# uloha: 2. domace zadanie Vyraz
class Vyraz:
class Stack:
def __init__(self):
self._pole = []
def push(self, data):
self._pole.append(data)
def pop(self):
if self.empty():
return None
return self._pole.pop()
def top(self):
if self.empty():
return None
return self._pole[-1]
def empty(self):
return self._pole == []
def __init__(self):
self.tabulka = {}
def __repr__(self):
ret = ""
for prvok in self.tabulka:
ret += prvok + " = " + str(self.tabulka[prvok]) + "\n"
return ret
def prirad(self, premenna, vyraz):
try:
self.tabulka[premenna] = int(vyraz)
except ValueError:
try:
self.tabulka[premenna] = self.tabulka[vyraz] #ak je hodnota ina premenna
except KeyError:
self.tabulka[premenna] = self.vyhodnot(vyraz)
def vyhodnot(self, vyraz):
s = self.Stack()
if vyraz[0] in '+-*/%': #prefixovy zapis
pole = self.na_pole(vyraz)
for prvok in reversed(pole):
if prvok in '+-*/%' and self.pocet_prvkov(s)<2:
return None
if prvok == "+":
s.push(s.pop() + s.pop())
elif prvok == '-':
s.push(s.pop() - s.pop())
elif prvok == '*':
s.push(s.pop() * s.pop())
elif prvok == '/':
try:
s.push(s.pop() // s.pop())
except ZeroDivisionError:
return None
elif prvok == '%':
try:
s.push(s.pop() % s.pop())
except ZeroDivisionError:
return None
elif self.skuska(prvok):
try:
if self.tabulka[prvok] != None:
s.push(self.tabulka[prvok])
except KeyError:
return None
else:
try:
s.push(int(prvok))
except ValueError:
return None
if self.pocet_prvkov(s) != 1:
return None
return s.pop()
elif vyraz[len(vyraz)-1] in '+-*/%': #postfixovy vyraz
pole = self.na_pole(vyraz)
for prvok in pole:
if prvok in '+-*/%' and self.pocet_prvkov(s)<2:
return None
if prvok == '+':
s.push(s.pop() + s.pop())
elif prvok == '-':
s.push(-s.pop() + s.pop())
elif prvok == '*':
s.push(s.pop() * s.pop())
elif prvok == '/':
op2, op1 = s.pop(), s.pop()
try:
s.push(op1 // op2)
except ZeroDivisionError:
return None
elif prvok == '%':
op2, op1 = s.pop(), s.pop()
try:
s.push(op1 % op2)
except ZeroDivisionError:
return None
elif self.skuska(prvok):
try:
if self.tabulka[prvok] != None:
s.push(self.tabulka[prvok])
except KeyError:
return None
else:
try:
s.push(int(prvok))
except ValueError:
return None
if self.pocet_prvkov(s) != 1:
return None
return s.pop()
else:
for znak in vyraz: #ak je to vyraz bez operatora
if znak in '+-*/%':
return self.vyhodnot(self.in2post(vyraz))
return None
def na_pole(self, vyraz):
pole, i = [], 0
vyraz += " " #kvoli IndexError
while vyraz:
if vyraz[0] == " ":
vyraz = vyraz[1:]
elif vyraz[0] in "+-*/%()":
pole.append(vyraz[0])
vyraz = vyraz[1:]
elif vyraz[0] in "0123456789":
while vyraz[i] in "0123456789":
i += 1
pole.append(vyraz[0:i])
vyraz = vyraz[i:]
i = 0
elif vyraz[0] in "abcdefghijklmnopqrstuvwxyz":
while (vyraz[i] in "abcdefghijklmnopqrstuvwxyz") or (vyraz[i] in "0123456789"):
i += 1
pole.append(vyraz[0:i])
vyraz = vyraz[i:]
i = 0
return pole
def skuska(self, premenna):
for znak in premenna:
if znak in "abcdefghijklmnopqrstuvwxyz":
return True
def pocet_prvkov(self, zasobnik):
pocet = 0
kopia = self.Stack()
while not zasobnik.empty():
kopia.push(zasobnik.pop())
pocet += 1
while not kopia.empty():
zasobnik.push(kopia.pop())
return pocet
def in2post(self, vyraz):
s = self.Stack()
pole = self.na_pole(vyraz)
vystup = ""
for prvok in pole:
if prvok in '+-':
if s.empty():
s.push(prvok)
else:
while s.top() in '+-':
vystup += s.pop() + " "
if s.top() == None:
break
s.push(prvok)
elif prvok in '*/%':
if s.empty():
s.push(prvok)
else:
while s.top() in '+-*/%':
vystup += s.pop() + " "
if s.top() == None:
break
s.push(prvok)
elif prvok == "(":
s.push(prvok)
elif prvok == ")":
while s.top() != "(":
if s.empty():
return ""
vystup += s.pop() + " "
s.pop() #vyhodim pravu zatvorku
else:
vystup += prvok + " "
while not s.empty():
vystup += s.pop() + " "
return vystup[0:len(vystup)-1]
with open("day18.txt") as day_file:
line = day_file.readline().strip()
summ = 0
v = Vyraz()
while line:
summ += v.vyhodnot(line)
line = day_file.readline().strip()
print(summ)
|
Java
|
UTF-8
| 241 | 1.828125 | 2 |
[] |
no_license
|
package com.enjoy.service;
import com.enjoy.entity.ProductEntity;
public interface ProductService {
ProductEntity getDetail(String id);
ProductEntity modify(ProductEntity product);
boolean status(String id, boolean upDown);
}
|
C++
|
UTF-8
| 677 | 2.84375 | 3 |
[] |
no_license
|
#include<iostream>
#include<algorithm>
using namespace std;
int main()
{
int m;
cin >> m;
int arr[m];
for(int i = 0; i < m; i++){
cin >> arr[i];
}
sort(arr, arr + m);
int n;
cin >> n;
int ar[n];
for(int i = 0; i < n; i++){
cin >> ar[i];
}
sort(ar, ar + n);
int result = 0;
for(int i = 0; i < m; i++){
for(int j = 0; j < n; j++){
if(abs(arr[i] - ar[j]) <= 1){
ar[j] = 100000;
result++;
break;
}
}
}
cout << result << endl;
return 0;
}
|
Java
|
UTF-8
| 1,074 | 2.171875 | 2 |
[
"MIT"
] |
permissive
|
package com.mahogano.core.presta.mapper;
import com.mahogano.core.presta.entity.Category;
import org.springframework.jdbc.core.RowMapper;
import java.sql.ResultSet;
import java.sql.SQLException;
public class CategoryMapper implements RowMapper<Category> {
@Override
public Category mapRow(ResultSet rs, int i) throws SQLException {
Category category = new Category();
category.setIdCategory(rs.getInt("id_category"));
category.setIdParent(rs.getInt("id_parent"));
category.setIdShopDefault(rs.getInt("id_shop_default"));
category.setLevelDepth(rs.getInt("level_depth"));
category.setNleft(rs.getInt("nleft"));
category.setNright(rs.getInt("nright"));
category.setActive(rs.getInt("active"));
category.setDateAdd(rs.getTimestamp("date_add").toLocalDateTime());
category.setDateUpd(rs.getTimestamp("date_upd").toLocalDateTime());
category.setPosition(rs.getInt("position"));
category.setIsRootCategory(rs.getInt("is_root_category"));
return category;
}
}
|
PHP
|
UTF-8
| 2,327 | 2.53125 | 3 |
[] |
no_license
|
<?php
$return ="";
$getDomains = new GetDomains;
$return = $getDomains->getDomains();
?>
<div class="col-lg-4"></div>
<div class="col-lg-2">
<form action="getdomains" method="post">
<input type="hidden" name="start" value="<?php echo $return[1];?>"></input>
<button class="btn btn-default<?php if( $return[1] == 0) { echo " disabled"; }?>">Previous</button>
</form>
</div>
<div class="col-lg-2">
<form action="getdomains" method="post">
<input type="hidden" name="start" value="<?php echo $return[2]; ?>"></input>
<button class="btn btn-default">Next</button>
</form>
</div>
<div class="col-lg-4"></div>
<table class="table table-striped table-hover ">
<?php
if(!empty($return)) {
echo "<thead><th>Domain Names</th><th>Expiration Date</th><th>Auto Renew</th><th>ID Protect</th></thead>";
foreach($return[0] as $k=>$v) {
echo "<tr>";
echo "<form action='domaininfo' method='post'>";
echo "<input type='hidden' name='sld' value=" . $v["sld"] . "></input>";
echo "<input type='hidden' name='tld' value=" . $v["tld"] . "></input>";
echo "<td class='active'><button type='submit' class='btn btn-default'>" . $v["domainname"] . "</td></button>";
echo "<td class='info'>" . $v["expires"] . "</td>";
if ($v["auto"] == "Yes" || $v["auto"] === "1") {
echo "<td class = 'success'>Enabled</td>";
}
if ($v["auto"] == "No" || $v["auto"] === "0") {
echo "<td class = 'danger'>Disabled</td>";
}
if ($v["wpps"] == "n/a") {
echo "<td class='active'>Not Supported</td>";
}
if ($v["wpps"] == "disabled") {
echo "<td class='danger'>No</td>";
}
if ($v["wpps"] == "enabled") {
echo "<td class='success'>Yes</td>";
}
echo "</tr>";
echo "</form>";
echo "</thead>";
}
}
?>
</table>
<div class="col-lg-4"></div>
<div class="col-lg-2">
<form action="getdomains" method="post">
<input type="hidden" name="start" value="<?php echo $return[1];?>"></input>
<button class="btn btn-default<?php if( $return[1] == 0) { echo " disabled"; }?>">Previous</button>
</form>
</div>
<div class="col-lg-2">
<form action="getdomains" method="post">
<input type="hidden" name="start" value="<?php echo $return[2]; ?>"></input>
<button class="btn btn-default">Next</button>
</form>
</div>
<div class="col-lg-4"></div>
</div>
|
Java
|
UTF-8
| 406 | 1.859375 | 2 |
[] |
no_license
|
package com.tt.Lodging;
import java.util.List;
public interface LodgingService {
// 로그인한 유저의 숙소 중 commonCode가 LDG0301인 숙소 조회
LodgingVO getLodgingRegistering(int userNo);
List<LodgingVO> getLodgingsByLoginedUserNo(int userNo);
void registerLodging(LodgingVO lodging);
void updateLodging(LodgingVO lodging);
void updateLodgingStatus(int lodgingNo);
}
|
JavaScript
|
UTF-8
| 385 | 2.53125 | 3 |
[] |
no_license
|
const StoreTemplate = document.createElement('template');
StoreTemplate.innerHTML = "Store Page"
class Store extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
this.shadowRoot.appendChild(StoreTemplate.content.cloneNode(true));
}
connectedCallback() {
}
}
window.customElements.define('store-content', Store);
|
Java
|
UTF-8
| 316 | 2.265625 | 2 |
[] |
no_license
|
package gerenciamentoDeMemoria;
public class Gerenciamento {
private int indice;
public void setValorRegistradores(Processo p) {
p.setRegBase(indice);
p.setRegLimite(indice + p.getValorProcesso() - 1);
indice += p.getValorProcesso();
}
}
|
Python
|
UTF-8
| 441 | 3.515625 | 4 |
[] |
no_license
|
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 13 19:07:32 2021
@author: erina
"""
# 最適なパラメータWを求める
# W = (XtX) **-1 Xty
import numpy as np
X = np.array([
[1, 2, 3],
[1, 2, 5],
[1, 3, 4],
[1, 5, 9]
])
y = np.array([
[1],
[5],
[6],
[8]
])
Xt = X.T
XtX = np.dot(Xt, X)
XtX_inv = np.linalg.inv(XtX)
Xty = np.dot(Xt, y)
W = np.dot(XtX_inv, Xty)
print(W)
|
SQL
|
UTF-8
| 1,036 | 3.015625 | 3 |
[] |
no_license
|
/*
Warnings:
- You are about to drop the column `standard` on the `SampelDetail` table. All the data in the column will be lost.
- Added the required column `nilai_ambang_batas` to the `SampelDetail` table without a default value. This is not possible if the table is not empty.
*/
-- RedefineTables
PRAGMA foreign_keys=OFF;
CREATE TABLE "new_SampelDetail" (
"sampel_id" TEXT NOT NULL,
"parameter_uji" TEXT NOT NULL,
"satuan" TEXT NOT NULL,
"hasil_uji" TEXT NOT NULL,
"nilai_ambang_batas" TEXT NOT NULL,
"keterangan" TEXT NOT NULL,
PRIMARY KEY ("sampel_id", "parameter_uji"),
FOREIGN KEY ("sampel_id") REFERENCES "Sampel" ("id") ON DELETE CASCADE ON UPDATE CASCADE
);
INSERT INTO "new_SampelDetail" ("hasil_uji", "keterangan", "parameter_uji", "sampel_id", "satuan") SELECT "hasil_uji", "keterangan", "parameter_uji", "sampel_id", "satuan" FROM "SampelDetail";
DROP TABLE "SampelDetail";
ALTER TABLE "new_SampelDetail" RENAME TO "SampelDetail";
PRAGMA foreign_key_check;
PRAGMA foreign_keys=ON;
|
C++
|
UTF-8
| 1,288 | 2.734375 | 3 |
[] |
no_license
|
#include "VariableManager.h"
#include "../Util/Log.h"
using namespace std;
namespace restless
{
VariableManager::VariableManager(void) :
_nullVariable("nullvariable", _nullInt)
{
}
VariableManager::~VariableManager(void)
{
}
bool VariableManager::exists(const char * name)
{
return exists(string(name));
}
bool VariableManager::exists(const string & name)
{
return _variables.find(name) != _variables.end();
}
VariableInterface & VariableManager::get(const char * name)
{
return get(string(name));
}
VariableInterface & VariableManager::get(const string & name)
{
map<string,VariableInterface *>::iterator it = _variables.find(string(name));
if (it == _variables.end()) {
return _nullVariable;
}
return * it->second;
}
vector<string> VariableManager::findByPrefix(const std::string & prefix)
{
vector<string> matches = vector<string>();
map<string,VariableInterface *>::iterator it;
for(it = _variables.begin(); it != _variables.end(); it++) {
const string name = it->first;
if (name.length() < prefix.length()) {
continue;
}
if (name.substr(0, prefix.length()).compare(prefix) == 0) {
matches.push_back(name);
}
}
return matches;
}
}
|
JavaScript
|
UTF-8
| 1,734 | 4.0625 | 4 |
[] |
no_license
|
//rehash:
//traverse old: 1. traverse .table, 2. traverse.table's SLL
//rehash: 1. get to newTable's index 2. traverse to the end of the SLL there
//make sure to set newly hashed node's next to null
//Trie: TrieNode has children, value, isWord attributes
function TrieNode(value){
this.value=value
this.children=[]
this.isWord=false
}
function Trie(arr){
this.root=TrieNode(null)
for(let i=0;i<arr.length;i++){//iterate through the words from arr
var curr=this.root
for(let j=0;j<arr[i].length;j++){//iterate trhough each letter of the word
var isFound = false
for(let k=0;k<curr.children.length;k++){//find the children that matches
if(curr.children[k].value==arr[i][j]){
isFound=true
curr=curr.children[k]
break
}
}
if(!isFound){
var newNode=new TrieNode(arr[i][j])
curr.children.push(newNode)
curr=newNode
}
}
curr.isWord=true
}
}
//trie insert is just what's inside the outer loops of our TrieSet
Trie.prototype.contains = function(str){
var curr=this.root
for(let i=0;i<str.length;i++){
var isFound=false
for(let j=0;j<curr.children.length;j++){
if(curr.children[j].value==str[i]){
isFound=true;
curr=curr.children[j];
break
}
}
if(!isFound){
return false
}
}
return true
}
//Thursday: trie auto complete: just contains then find all descendants who are words
//can be done iteratively on TrieSet or recursively on TrieNode
|
Markdown
|
UTF-8
| 2,088 | 3 | 3 |
[
"MIT"
] |
permissive
|
# Table Re-Use
Reusing of a table refers to changing the model that the table represents.
Looking at the following column factory the model is quite clear:
```typescript
columnFactory()
.table(
{ prop: 'id' },
{ prop: 'name' },
{ prop: 'email' },
)
.build();
```
For this column definition set, the table expects a similar collection of objects returned from the data source.
The datasource is dynamic, returning values per demand.
```typescript
createDS<Person>()
.onTrigger( (event) => [ { id: 1, name: 'John', email: 'N/A' }] )
.create();
```
Now, if we want to apply a different model on the table? We will have to change the column definition set as well at the datasource.
In the following example the table can toggle between showing a **Person** model or a **Seller** model.
<docsi-mat-example-with-source title="Re-Use" contentClass="table-height-300 mat-elevation-z7" [query]="[{section: 'ex-1'}]">
<!--@pebula-example:ex-1-->
<pbl-ngrid blockUi usePagination [dataSource]="dynamicColumnsDs" [columns]="dynamicColumns">
<pbl-ngrid-paginator *pblNgridPaginatorRef="let table"
[table]="table"
[paginator]="table.ds.paginator"></pbl-ngrid-paginator>
</pbl-ngrid>
<!--@pebula-example:ex-1-->
</docsi-mat-example-with-source>
<button (click)="toggleViewMode()">{{ viewMode }}</button>
When we toggle, notice that we swap the entire datasource. We could have implemented the logic inside the `onTrigger` handler and keep a single datasource but it will not work.
When we swap a datasource the table will cleanup the context and all column related data and rebuilt it preventing ghost context living in the cache.
I> When a table gets destroyed (`ngOnDestroy`) the datasource attached to it (if attached) is disconnected and automatically disposed. This has 1 exception, the `keepAlive` configuration was enabled on the datasource.
W> When you swap the datasource it will also cause the previous datasource to disconnect, if `keepAlive` is `false` it will also dispose itself.
|
PHP
|
UTF-8
| 2,399 | 2.703125 | 3 |
[
"BSD-2-Clause"
] |
permissive
|
<?php
/**
* @see https://github.com/phly/keep-a-changelog for the canonical source repository
*/
declare(strict_types=1);
namespace Phly\KeepAChangelog\Changelog;
use Phly\KeepAChangelog\Common\AbstractEvent;
use Phly\KeepAChangelog\Common\ChangelogEntry;
use Phly\KeepAChangelog\Common\EditorAwareEventInterface;
use Phly\KeepAChangelog\Common\EditorProviderTrait;
use Psr\EventDispatcher\EventDispatcherInterface;
use Symfony\Component\Console\Input\InputInterface;
use Symfony\Component\Console\Output\OutputInterface;
use function sprintf;
class EditChangelogLinksEvent extends AbstractEvent implements EditorAwareEventInterface
{
use EditorProviderTrait;
/**
* If no links are discovered in the changelog file, we will be appending
* them to any existing content, instead of splicing them in.
*
* @var bool
*/
private $appendLinksToChangelogFile = false;
/**
* Value object representing the discovered links from the changelog file.
*
* @var null|ChangelogEntry
*/
private $links;
public function __construct(
InputInterface $input,
OutputInterface $output,
EventDispatcherInterface $dispatcher
) {
$this->input = $input;
$this->output = $output;
$this->dispatcher = $dispatcher;
}
public function isPropagationStopped(): bool
{
return $this->failed;
}
public function appendLinksToChangelogFile(): bool
{
return $this->appendLinksToChangelogFile;
}
public function links(): ?ChangelogEntry
{
return $this->links;
}
public function discoveredLinks(ChangelogEntry $links): void
{
$this->links = $links;
}
public function noLinksDiscovered(): void
{
$this->appendLinksToChangelogFile = true;
}
public function editComplete(string $changelogFile): void
{
$this->output->writeln(sprintf(
'<info>Completed editing links for file %s</info>',
$changelogFile
));
}
public function editFailed(string $changelogFile): void
{
$this->failed = true;
$this->output->writeln(sprintf(
'<error>Editing links for file %s failed</error>',
$changelogFile
));
$this->output->writeln('Review the output above for potential errors.');
}
}
|
C++
|
UTF-8
| 11,341 | 2.78125 | 3 |
[] |
no_license
|
#ifndef MATH_HPP
#define MATH_HPP
#include<cmath>
#include <boost/math/distributions/normal.hpp> // for normal_distribution
#include "traits.hpp"
#include "convertion.hpp"
#include <type_traits>
#include <chrono>
#include <numeric>
#include <algorithm>
#include <random>
#include <cassert>
#include <cmath>
namespace testSFML {
constexpr double PI = 3.141592653589793;
using boost::math::normal; // typedef provides default type is double.
using default_point = sf::Vector2f;
template < class P1,
class P2,
class = enable_if_all_t<is_point, P1, P2>
>
P1& assign (P1& p1, P2 p2)
{
setX(p1, getX(p2));
setY(p1, getY(p2));
return p1;
}
template <class T, class U = void >
struct random_dispatch {
using distribution = typename std::uniform_int_distribution<T>;
};
template <class T>
struct random_dispatch < T,
std::enable_if_t<std::is_floating_point<T>::value>
>
{
using distribution = typename std::uniform_real_distribution<T>;
};
// ça marche int int :D
// je me fout du std forward parce que ça sera de type double int... et dans tous les cas
// un forward sur un type base c'est une copie
template < class N,
class N2>
inline std::common_type_t<N,N2> random (N&& min, N2&& max)
{
using max_type = std::common_type_t<N,N2>;
static std::random_device rd;
static std::mt19937 mt(rd());
static typename random_dispatch<max_type>::distribution rand (min,max);
// (max_type(min) , max_type(max)) ; marche pas, etrange à tester avec clang
return rand(mt);
}
inline double getGaussianValue(const normal& norm, const double& distance ){
return pdf(norm,distance);
}
/***
*
* Je sais que la conversion peut faire des trucs moches (comme des warnings)
* Je pourrais ecrire un code qui ne fait jamais de warnings mais je considaire que si
* l'utilisateur compile en -WConversion c'est qu'il veut les avoirs
* donc je les bloques pas
* **/
template< class Point,
class Point2, // on match le meme concept mais pas forcmeent la meme vrais classe
class = std::enable_if_t< is_point<Point>::value >,
class = std::enable_if_t< is_point<Point2>::value >
>
inline double distance ( Point&& p1, Point2& p2)
{
return sqrt(
pow (( getX(p1) ) - ( getX(p2) ), 2)
+
pow (( getY(p1) ) - ( getY(p2) ), 2)
);
}
template < class Point,
class Point2,
class Point3,
class = std::enable_if_t< is_point<Point>::value >,
class = std::enable_if_t< is_point<Point2>::value >,
class = std::enable_if_t< is_point<Point3>::value >
>
inline double angle_rad ( Point&& p1,Point2&& centre,Point3&& p2)
{
double distance_1_centre = distance (p1,centre);
double distance_2_centre = distance (p2,centre);
double distance_1_2 = distance (p1,p2);
return acos( ( pow ( distance_1_centre ,2) + pow ( distance_2_centre ,2) - pow ( distance_1_2 ,2))
/
(2 * distance_1_centre * distance_2_centre)
);
}
template < class N >
inline double convertion_rad_deg ( N&& value )
{
return (value *180 ) / PI;
}
template < class Point,
class Point2,
class Point3,
class = std::enable_if_t< is_point<Point>::value >,
class = std::enable_if_t< is_point<Point2>::value >,
class = std::enable_if_t< is_point<Point3>::value >
>
inline double angle_deg ( Point&& p1,Point2&& centre,Point3&& p2)
{
return convertion_rad_deg ( angle_rad ( std::forward<Point>(p1 ),
std::forward<Point2> (centre),
std::forward<Point3> (p2 )
)
);
}
/***
*
* Creation d'un point dans le rectangle defini par les deux autres points
* distributions lineaire.
*
**/
template< class PointRetour = sf::Vector2f,
class Point1 = sf::Vector2f,
class Point2 = sf::Vector2f,
class = std::enable_if_t< is_point<PointRetour>::value >,
class = std::enable_if_t< is_point<Point1>::value >,
class = std::enable_if_t< is_point<Point2>::value >
>
inline PointRetour random_point(const Point1& p1,const Point2& p2 )
{
return { random(getX(p1), getX(p2)),
random(getY(p1), getY(p2))
};
}
template < class Point = sf::Vector2f,
class X = std::enable_if_t< is_point<Point>::value >>
struct centre_influence
{
Point centre;
normal repartition;
double coef = 100 ;
template < class Point2 = sf::Vector2f,
class WW = std::enable_if_t< is_point<Point2>::value >>
double getValue(const Point2 & pt) const
{
// la division par 100 est du que je réduit 100 pixel à "1" unité pour la gaussien,
// revois ça apres
return coef * getGaussianValue(repartition,distance(centre,pt) / 100 ) ;
}
centre_influence () = default;
centre_influence (Point p,normal n, double c = 100 ) : centre(p), repartition(n), coef(c) {};
using typeX = decltype(getX(centre));
using typeY = decltype(getY(centre));
centre_influence (typeX x, typeY y ) : centre (Point(x,y)) {};
};
/// IL faut changer le type de retour pour que ça soit generic
template <class T>
inline float getX(const centre_influence<T> & p )
{
return getX(p.centre);
}
template <class T>
inline float getY(const centre_influence<T> & p )
{
return getY(p.centre);
}
template <class T,
class U,
class = std::enable_if_t<apply_on_all<is_point,U,T>::value>
>
inline bool are_equals(const T& point1,const U& point2)
{
return ( getY(point1) == getY(point2) ) && ( getX(point1) == getX(point2) );
}
template < class conteneur ,
class Point = default_point,
class = std::enable_if_t< is_point<Point>::value >,
class = std::enable_if_t< is_container<conteneur>::value >>
double sum_valule (const Point& p , const conteneur& cont_centre_influence )
{
return std::accumulate ( cont_centre_influence.begin(),
cont_centre_influence.end(),
0,
[&](const double & somme , const auto centre) { return somme + centre.getValue(p); }
);
}
template < class conteneur ,
class = std::enable_if_t< is_container<conteneur>::value > >
double sum_coef( const conteneur& cont_centre_influence )
{
return std::accumulate ( cont_centre_influence.begin(),
cont_centre_influence.end(),
0,
[](const double & somme , const auto centre) { return centre.coef+somme; }
);
}
/****
*
*
*
**/
template < class conteneur ,
class PointRetour = default_point,
class Point1 = default_point,
class Point2 = default_point,
class = std::enable_if_t< is_point<PointRetour>::value >,
class = std::enable_if_t< is_point<Point1>::value >,
class = std::enable_if_t< is_point<Point2>::value >,
class = std::enable_if_t< is_container<conteneur>::value >>
PointRetour random_point (const conteneur& cont_centre_influence, const Point1& p1,const Point2& p2)
{
PointRetour retour;
std::random_device rd;
std::mt19937 mt(rd());
std::uniform_real_distribution<double> linear_rand (0,1);
bool fini = false;
while (!fini)
{
// on prend un point au piff dans l'interval
PointRetour new_point = random_point(p1,p2);
double value = sum_valule(new_point,cont_centre_influence);
double coef_total = sum_coef (cont_centre_influence);
if (coef_total == 0 )
{
retour = new_point;
fini = true;
}
if ( linear_rand(mt) < (value/coef_total))
{
retour = new_point;
fini = true;
}
}
return retour;
}
template< class Point1,
class Point2, // on match le meme concept mais pas forcmeent la meme vrais classe
class = std::enable_if_t< apply_on_all<is_point,Point1,Point2>::value >
>
inline double distance_carre ( Point1&& p1, Point2& p2)
{
return pow (( getX(p1) ) - ( getX(p2) ), 2)+ pow (( getY(p1) ) - ( getY(p2) ), 2);
}
// DANGER il faudrait que je vois comment gerer un point pas defautl constructible.
template < class Point1 ,
class Point2 ,
class PointRetour = Point1,
class = std::enable_if_t< apply_on_all<is_point,Point1,Point2,PointRetour>::value >
>
PointRetour operator-(const Point1& p1, const Point2& p2)
{
return PointRetour(getX(p1) - getX(p2) , getY(p1) - getY(p2) );
}
template < class Point1 ,
class Point2,
class PointRetour = Point1,
class = std::enable_if_t< apply_on_all<is_point,Point1,Point2,PointRetour>::value >
>
PointRetour operator+(const Point1& p1, const Point2& p2)
{
return PointRetour(getX(p1) + getX(p2) , getY(p1) + getY(p2) );
}
template < class Point1 ,
class N,
class PointRetour = Point1,
class = std::enable_if_t< apply_on_all<is_point,Point1,PointRetour>::value >
>
PointRetour operator*(const N& value, const Point1& p1)
{
// Est ce la bonne solution ?
using typeXpoint1 = decltype(getX(p1));
using typeYpoint1 = decltype(getY(p1));
return PointRetour(getX(p1) * (typeXpoint1)value , getY(p1) * (typeYpoint1) value);
}
template < class Point1 ,
class N,
class PointRetour = Point1,
class = std::enable_if_t< apply_on_all<is_point,Point1,PointRetour>::value >
>
PointRetour operator*( const Point1& p1,const N& value)
{
return PointRetour(getX(p1) * value , getY(p1) * value );
}
template < class Point1 ,
class Point2,
class = std::enable_if_t< apply_on_all<is_point,Point1,Point2>::value >
>
double dot(const Point1& p1, const Point2& p2)
{
return getX(p1) * getX(p2) + getY(p1) * getY(p2) ;
}
/// Faire une classe segment ?
template < class Point3 ,
class Point1 ,
class Point2 ,
class = std::enable_if_t< apply_on_all<is_point,Point1,Point2,Point3>::value >
>
double distance(const Point1& v, const Point2& w, const Point3& p) {
// Return minimum distance between line segment vw and point p
const double l2 = distance_carre(v, w); // i.e. |w-v|^2 - avoid a sqrt
if (l2 == 0.0) return distance(p, v); // v == w case
// Consider the line extending the segment, parameterized as v + t (w - v).
// We find projection of point p onto the line.
// It falls where t = [(p-v) . (w-v)] / |w-v|^2
// We clamp t from [0,1] to handle points outside the segment vw.
const double t = std::max(0.0, std::min(1.0, dot(p - v, w - v) / l2));
const default_point projection = v + t * (w - v); // Projection falls on the segment
return distance(p, projection);
}
}
#endif
|
JavaScript
|
UTF-8
| 1,830 | 2.703125 | 3 |
[] |
no_license
|
/*
Evan MacHale - N00150552
20.04.19
New.js
*/
import React, { Component } from 'react';
import axios from 'axios';
import PropTypes from 'prop-types';
// Material Components
import { Cell, Row } from '@material/react-layout-grid';
import { Headline3, Headline4, Headline6 } from '@material/react-typography';
/*
New is where users submit new articles
*/
class New extends Component {
constructor() {
super();
this.state = {
title: 'Title',
content: '',
};
this.handleInputChange = this.handleInputChange.bind(this);
}
componentDidMount() {
// axios.get(`/api/article/${match.params.id}`)
// .then(response => this.setState({ article: response.data }))
// .catch((error) => {
// this.setState({ errorMessage: error.response.data });
// });
}
handleInputChange(event) {
const { target } = event;
const { value, name } = target;
this.setState({ [name]: value });
}
render() {
return (
<React.Fragment>
<Row>
<Cell desktopColumns={3} tabletColumns={1} />
<Cell desktopColumns={6} tabletColumns={6} phoneColumns={4}>
<Row>
<Cell desktopColumns={1} />
<Cell desktopColumns={10} tabletColumns={8}>
<Headline3>TITLE</Headline3>
</Cell>
<Cell desktopColumns={1} />
</Row>
<Row>
<Cell desktopColumns={1} />
<Cell desktopColumns={10} tabletColumns={8}>
<Headline6 className="type-light">Content</Headline6>
</Cell>
<Cell desktopColumns={1} />
</Row>
</Cell>
<Cell desktopColumns={3} tabletColumns={1} />
</Row>
</React.Fragment>
);
}
}
New.propTypes = {};
export default New;
|
Markdown
|
UTF-8
| 2,166 | 2.953125 | 3 |
[
"MIT"
] |
permissive
|
<div align="center">
<h1>Stockport Availability Package</h1>
</div>
<div align="center">
<strong>Enable access to Stockports availabiity and feature toggling services.</strong>
</div>
<br />
<div align="center">
<sub>Built with :heart: by
<a href="https://www.stockport.gov.uk">Stockport Council</a>
</div>
## Table of Contents
- [Purpose](#purpose)
- [Initilaization](#initilaization)
- [License](#license)
## Purpose
To allow easy access to and use of Stockport's availability & feature toggling service.
## Initilaization
Availability cofiguration should be added to appSettings as below. Note that Key should be kept secret.
```json
"Availability": {
"BaseUrl": "http://scnavaildev.stockport.gov.uk/api/v1",
"Key": "<AccessKeyHere>",
"ErrorRoute": "/error/500",
"WhitelistedRoutes": [
"/swagger/index.html"
],
"Environment": "int",
"AllowSwagger": true,
"Enabled": true
}
```
Initialise and register for use by the DI container in ConfigureServices in Startup.cs
```c#
public void ConfigureServices(IServiceCollection services)
{
...
services.AddAvailability();
}
```
## Usage
### Middleware
Availability can check whether your entire app is toggled on/off in middleware during the prcessing of every request. Register the availability middleware in Configure in Startup.cs
```c#
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
{
...
app.UseMiddleware<Availability>();
...
}
```
### Attributes
Attributes can be used at controller and action level using
```c#
[FeatureToggle("ToggleNameHere")]
or
[OperationalToggle("ToggleNameHere")]
public IActionResult MyAction()
...
```
### Best Practices
If feature toggles are going to be used in multiple places it is advised they are made available as constants.
```c#
namespace yournamespace
{
public static class FeatureToggles
{
public const string MyToggle = "MyToggleName";
}
}
```
Then referenced as below
```c#
[FeatureToggle(FeatureToggles.MyToggle)]
public IActionResult MyAction()
...
```
## License
[MIT](https://opensource.org/licenses/MIT)
|
C++
|
UTF-8
| 4,692 | 2.8125 | 3 |
[
"MIT"
] |
permissive
|
//specialization for epoch based reclamation
#include <iostream>
#include "reclam_epoch.hpp"
template< typename T >
queue_lockfree_total_impl<T, trait_reclamation::epoch>::queue_lockfree_total_impl(){
Node * sentinel = new Node();
_head.store( sentinel );
_tail.store( sentinel );
}
template< typename T >
queue_lockfree_total_impl<T, trait_reclamation::epoch>::~queue_lockfree_total_impl(){
//must ensure there are no other threads accessing the datastructure
clear();
if( _head ){
Node * n = _head.load();
if( _head.compare_exchange_strong( n, nullptr, std::memory_order_relaxed ) ){
if( n ){
delete n;
_head.store(nullptr);
_tail.store(nullptr);
}
}
}
}
template< typename T >
bool queue_lockfree_total_impl<T, trait_reclamation::epoch>::push_back( T && val ){ //push item to the tail
Node * new_node = new Node( val );
return push_back_aux(new_node);
}
template< typename T >
bool queue_lockfree_total_impl<T, trait_reclamation::epoch>::push_back( T const & val ){ //push item to the tail
Node * new_node = new Node( val );
return push_back_aux(new_node);
}
template< typename T >
bool queue_lockfree_total_impl<T, trait_reclamation::epoch>::push_back_aux( Node * new_node ){ //push item to the tail
while( true ){
auto guard = reclam_epoch<Node>::critical_section();
Node * tail = _tail.load( std::memory_order_relaxed );
if( nullptr == tail ){
return false;
}
if( !_tail.compare_exchange_weak( tail, tail, std::memory_order_relaxed ) ){
std::this_thread::yield();
continue;
}
Node * tail_next = tail->_next.load( std::memory_order_relaxed );
if( nullptr == tail_next ){ //determine if thread has reached tail
if( tail->_next.compare_exchange_weak( tail_next, new_node, std::memory_order_acq_rel ) ){ //add new node
_tail.compare_exchange_weak( tail, new_node, std::memory_order_relaxed ); //if thread succeeds, set new tail
return true;
}
}else{
_tail.compare_exchange_weak( tail, tail_next, std::memory_order_relaxed ); //update tail and retry
std::this_thread::yield();
}
}
}
template< typename T >
std::optional<T> queue_lockfree_total_impl<T, trait_reclamation::epoch>::pop_front(){ //obtain item from the head
while( true ){
auto guard = reclam_epoch<Node>::critical_section();
Node * head = _head.load( std::memory_order_relaxed );
if( nullptr == head ){
return std::nullopt;
}
if(!_head.compare_exchange_weak( head, head, std::memory_order_relaxed )){
std::this_thread::yield();
continue;
}
Node * tail = _tail.load( std::memory_order_relaxed );
Node * head_next = head->_next.load( std::memory_order_relaxed );
if(!_head.compare_exchange_weak( head, head, std::memory_order_relaxed )){
std::this_thread::yield();
continue;
}
if( head == tail ){
if( nullptr == head_next ){//empty
return std::nullopt;
}else{
_tail.compare_exchange_weak( tail, head_next, std::memory_order_relaxed ); //other thread updated head/tail, so retry
std::this_thread::yield();
}
}else{
//val = head_next->_val; //optimization: reordered to after exchange due to hazard pointer guarantees
if( _head.compare_exchange_weak( head, head_next, std::memory_order_relaxed ) ){ //try add new item
//thread suceeds
T val(head_next->_val);
reclam_epoch<Node>::retire(head);
return std::optional<T>(val);
}
}
}
}
template< typename T >
size_t queue_lockfree_total_impl<T, trait_reclamation::epoch>::size(){
size_t count = 0;
Node * node = _head.load();
if( nullptr == node ){
return 0;
}
while( node ){
Node * next = node->_next.load(std::memory_order_relaxed);
node = next;
++count;
}
return count - 1; //discount for sentinel node
}
template< typename T >
bool queue_lockfree_total_impl<T, trait_reclamation::epoch>::empty(){
return size() == 0;
}
template< typename T >
bool queue_lockfree_total_impl<T, trait_reclamation::epoch>::clear(){
size_t count = 0;
while( !empty() ){
pop_front();
count++;
}
return true;
}
|
Java
|
UTF-8
| 10,935 | 1.734375 | 2 |
[] |
no_license
|
/*
* To change this license header, choose License Headers in Project Properties.
* To change this template file, choose Tools | Templates
* and open the template in the editor.
*/
package Controller_Window;
import datennetz_simulation.Datennetz_Simulation;
import static datennetz_simulation.Datennetz_Simulation.menucontrol;
import model.Messung;
import model.Paket;
import filereader.ReadWireSharkCSV;
import filereader.Read_pcapng;
import java.io.File;
import java.io.IOException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
import java.util.ResourceBundle;
import java.util.logging.Level;
import java.util.logging.Logger;
import javafx.util.Duration;
import javafx.animation.KeyFrame;
import javafx.animation.KeyValue;
import javafx.animation.Timeline;
import javafx.event.ActionEvent;
import javafx.event.EventHandler;
import javafx.fxml.FXML;
import javafx.fxml.FXMLLoader;
import javafx.fxml.Initializable;
import javafx.scene.Node;
import javafx.scene.Parent;
import javafx.scene.Scene;
import javafx.scene.control.Alert;
import javafx.scene.control.Alert.AlertType;
import javafx.scene.control.ButtonType;
import javafx.scene.control.Label;
import javafx.scene.image.Image;
import javafx.scene.image.ImageView;
import javafx.scene.input.DragEvent;
import javafx.scene.input.Dragboard;
import javafx.scene.input.TransferMode;
import javafx.scene.text.Text;
import javafx.scene.input.MouseEvent;
import javafx.scene.layout.BorderPane;
import javafx.scene.layout.GridPane;
import javafx.scene.layout.VBox;
import javafx.stage.FileChooser;
import javafx.stage.Stage;
import model.AnonymizePCAPNG;
import model.CreateVKjson;
import model.Zeitintervall;
import org.apache.commons.io.FilenameUtils;
public class MainWindowVC implements Initializable {
private final CreateVKjson vk = new CreateVKjson();
private final AnonymizePCAPNG anonymizePCAPNG = new AnonymizePCAPNG();
private final Read_pcapng pcapngReader = new Read_pcapng();
private String path;
private String fileName;
private FileChooser fileChooser_auswerten;
private FileChooser fileChooser_anonymisieren;
private Stage homeWindow = Datennetz_Simulation.parentWindow;
private Stage menu = new Stage();
@FXML
public static Text actiontarget;
@FXML
private BorderPane rootPane;
@FXML
private ImageView hilfeImage;
@FXML
private GridPane grid_menu;
@FXML
private ImageView image_icon;
@FXML
private ImageView image_menu_off;
@Override
public void initialize(URL location, ResourceBundle resources) {
rootPane.setOnDragOver(new EventHandler<DragEvent>() {
@Override
public void handle(DragEvent event) {
if (event.getGestureSource() != rootPane
&& event.getDragboard().hasFiles()) {
/* allow for both copying and moving, whatever user chooses */
event.acceptTransferModes(TransferMode.COPY_OR_MOVE);
}
event.consume();
}
});
rootPane.setOnDragDropped(new EventHandler<DragEvent>() {
@Override
public void handle(DragEvent event) {
Dragboard db = event.getDragboard();
boolean success = false;
if (db.hasFiles()) {
try {
menucontrol.readFile(db.getFiles().get(0), "Auswertung");
} catch (IOException ex) {
Logger.getLogger(MainWindowVC.class.getName()).log(Level.SEVERE, null, ex);
}
success = true;
}
/* let the source know whether the string was successfully
* transferred and used */
event.setDropCompleted(success);
event.consume();
}
});
//setAnimation(testi);
}
@FXML
protected void handleProfilButtonAction(ActionEvent event) throws IOException {
menucontrol.handlemenuprofil();
}
@FXML
protected void handleMessungButtonAction(ActionEvent event) throws IOException {
menucontrol.handlemenumessung();
}
@FXML
protected void handleAuswertungButtonAction(ActionEvent event) throws IOException {
menucontrol.handlemenuauswertung();
}
//restore verkehrsprofile.json
@FXML
private void restoreVkpJSON(ActionEvent event) {
//starts confirmation dialog. If Ok pressed, try to create new verkehrsprofile.json and show success/fail dialog
Alert alert = new Alert(AlertType.CONFIRMATION);
alert.setTitle("verkehrsprofile.json wiederherstellen");
Stage stage = (Stage) alert.getDialogPane().getScene().getWindow();
stage.getIcons().add(new Image(this.getClass().getResource("/Pictures/Cloud_Icon.jpg").toString()));
alert.setHeaderText("Achtung!");
alert.setContentText("Wiederherstellen löscht die aktuelle Version und erstellt eine neue verkehrsprofile.json.\nAktuelle Änderungen der verkehrsprofile.json gehen damit verloren.");
alert.setGraphic(new ImageView(this.getClass().getResource("/Pictures/achtung.jpg").toString()));
Optional<ButtonType> result = alert.showAndWait();
if (result.get() == ButtonType.OK) {
File tempFile = new File("verkehrsprofile.json");
if (vk.parseVKToJson()) {
Alert success = new Alert(AlertType.INFORMATION);
success.setTitle("Erfolg");
stage = (Stage) success.getDialogPane().getScene().getWindow();
stage.getIcons().add(new Image(this.getClass().getResource("/Pictures/Cloud_Icon.jpg").toString()));
success.setHeaderText(null);
success.setContentText("verkehrsprofile.json erfolgreich wiederhergestellt");
success.showAndWait();
} else {
Alert fail = new Alert(AlertType.WARNING);
fail.setTitle("Warnung - Fehler");
stage = (Stage) fail.getDialogPane().getScene().getWindow();
stage.getIcons().add(new Image(this.getClass().getResource("/Pictures/Cloud_Icon.jpg").toString()));
fail.setHeaderText(null);
fail.setContentText("verkehrsprofile.json konnte nicht wiederhergestellt werden");
fail.showAndWait();
}
} else {
System.out.println("Cancel");
}
}
//anonymize pcapng wireshark file into a csv file only containing timestamp, paketlength, protocol. Only use that anonymized file as input in this software
@FXML
private void anonymizePCAPNG(ActionEvent event) throws IOException {
//create file choose window
Stage fileChooseStage = new Stage();
if (fileChooser_anonymisieren == null) {
fileChooser_anonymisieren = new FileChooser();
fileChooser_anonymisieren.setInitialDirectory(new File(System.getProperty("user.home")));
fileChooser_anonymisieren.getExtensionFilters().add(new FileChooser.ExtensionFilter("PCAPNG", "*.pcapng"));
}
File file = fileChooser_anonymisieren.showOpenDialog(fileChooseStage);
//file is null if canceled
if (file != null) {
path = file.getAbsolutePath();
fileName = file.getName();
} else {
return;
}
//set directory onto file location for future fileChoose windows
if (fileChooser_anonymisieren != null) {
String dir = path.replace(fileName, "");
fileChooser_anonymisieren.setInitialDirectory(new File(dir));
}
List<Paket> pakets = pcapngReader.readFile(path);
anonymizePCAPNG.anonymize(pakets, path);
}
protected void setAnimation(Stage stage, boolean dir){
KeyValue startKeyValue;
KeyValue endKeyValue;
// Create the Scene
Scene scene = new Scene(grid_menu);
// Add the Scene to the Stage
stage.setScene(scene);
// Display the Stage
stage.show();
// Get the Width of the Text
double textWidth = grid_menu.getLayoutBounds().getWidth();
// Define the Durations
Duration startDuration = Duration.ZERO;
Duration endDuration = Duration.millis(50000);
// Create the start and end Key Frames
if(dir = true){
startKeyValue = new KeyValue(grid_menu.translateXProperty(), 0);
endKeyValue = new KeyValue(grid_menu.translateXProperty(), textWidth);
}
else{
startKeyValue = new KeyValue(grid_menu.translateXProperty(), textWidth);
endKeyValue = new KeyValue(grid_menu.translateXProperty(), 0);
}
KeyFrame startKeyFrame = new KeyFrame(startDuration, startKeyValue);
KeyFrame endKeyFrame = new KeyFrame(endDuration, endKeyValue);
// Create a Timeline
Timeline timeline = new Timeline(startKeyFrame, endKeyFrame);
// Run the animation
timeline.play();
}
@FXML
private void handleImageHilfe(MouseEvent event) throws IOException {
menucontrol.handleImageHilfe();
}
@FXML
private void handlemenumessung(MouseEvent event) throws IOException {
menucontrol.handlemenumessung();
}
@FXML
private void handlemenuprofil(MouseEvent event) throws IOException {
menucontrol.handlemenuprofil();
}
@FXML
private void handlemenuauswertung(MouseEvent event) throws IOException {
menucontrol.handlemenuauswertung();
}
@FXML
private void handlemenueinstellungen(MouseEvent event) throws IOException {
menucontrol.handlemenueinstellungen();
}
@FXML
private void handlemenuHome(MouseEvent event) throws IOException {
menucontrol.handlemenuHome();
}
@FXML
private void handleMenuImage(MouseEvent event) {
grid_menu.setVisible(true);
image_menu_off.setVisible(false);
//setAnimation(menu, true);
}
@FXML
private void handleMenuInvis(MouseEvent event) {
grid_menu.setVisible(false);
image_menu_off.setVisible(true);
//setAnimation(homeWindow, false);
}
@FXML
private void handleSimulationButton(ActionEvent event) throws IOException {
menucontrol.setSimulation();
}
}
|
JavaScript
|
UTF-8
| 11,754 | 2.734375 | 3 |
[
"MIT"
] |
permissive
|
// this file represents the client side of the multiplayer API
$(function () {
if (localStorage.defRows) {
document.forms["start_play_config"]["in_rows"].value = localStorage.defRows;
} else {
document.forms["start_play_config"]["in_rows"].value = 20;
}
if (localStorage.defCols) {
document.forms["start_play_config"]["in_cols"].value = localStorage.defCols;
} else {
document.forms["start_play_config"]["in_cols"].value = 20;
}
// return maze as 2D array form maze as long string.
function arrayMazeFromJson(json) {
var bitMaze = json.Maze;
var row = json.Rows;
var col = json.Cols;
var maze = new Array();
for (var i = 0; i < row; ++i) {
maze[i] = new Array();
var dif = i * col;
for (var j = 0; j < col; ++j) {
maze[i][j] = bitMaze[dif + j];
}
}
return maze;
}
var rivalName = null;
var maze = null;
var rivalPos = null;
var endPos = null;
// move according to string - for rival move
function moveTo(moveAsChar) {
var playerMove = [rivalPos[0], rivalPos[1]];
switch (moveAsChar) {
case 'left': // left
playerMove[0]--;
break;
case 'right': // right
playerMove[0]++;
break;
case 'up': // up
playerMove[1]--;
break;
case 'down': // down
playerMove[1]++;
break;
default:
return;
}
// move rival icon to new place
var canvas = document.getElementById("ravilCanvas");
playerImage = new Image();
playerImage.src = '/Resources/poin.png';
var context = canvas.getContext("2d");
var height = canvas.height / maze.Rows;
var width = canvas.width / maze.Cols;
context.clearRect(rivalPos[0] * width, rivalPos[1] * height, width, height)
context.drawImage(playerImage, playerMove[0] * width, playerMove[1] * height, width, height);
// check if rival wins
rivalPos = [playerMove[0], playerMove[1]];
if (checkWin(rivalPos[0], rivalPos[1])){
alert("You Lose!");
$(window).off();
}
console.log("move to " + rivalPos);
}
var mHub = $.connection.multiplayerHub;
var first = true;
// hanler for start new multi - game
$("#start_play_config").on("submit", function (e) {
e.preventDefault();
// handler when start new game before close the pervius
if (!first) {
mHub.server.close();
$(window).off();
}
var loadImg = new Image();
var myCanvas = document.getElementById("userCanvas");
var context = myCanvas.getContext("2d");
var hisCanvas = document.getElementById("ravilCanvas");
var hiscontext = hisCanvas.getContext("2d");
loadImg.onload = function () {
context.drawImage(loadImg, 0, 0, myCanvas.width, myCanvas.height);
hiscontext.drawImage(loadImg, 0, 0, hisCanvas.width, hisCanvas.height);
};
loadImg.src = '/Resources/loading.gif';
if (sessionStorage.getItem('username') == null) {
alert("you need to login!");
return;
}
var myname = sessionStorage.getItem("username");
var name = $("#in_name").val();
var rows = $("#in_rows").val();
var cols = $("#in_cols").val();
mHub.server.startMultiplayer(name, rows, cols, myname);
first = false;
});
//handler for join game
$("#join_form").on("submit", function (e) {
e.preventDefault();
// handler when start new game before close the pervius
if (!first) {
mHub.server.close();
$(window).off();
}
if (sessionStorage.getItem('username') == null) {
alert("you need to login!");
return;
}
var myname = sessionStorage.getItem("username");
var loadImg = new Image();
var myCanvas = document.getElementById("userCanvas");
var context = myCanvas.getContext("2d");
var hisCanvas = document.getElementById("ravilCanvas");
var hiscontext = hisCanvas.getContext("2d");
loadImg.onload = function () {
context.drawImage(loadImg, 0, 0, myCanvas.width, myCanvas.height);
hiscontext.drawImage(loadImg, 0, 0, hisCanvas.width, hisCanvas.height);
};
loadImg.src = '/Resources/loading.gif';
var mazename = $("#games :selected").text();
console.log("send " + mazename);
mHub.server.join(mazename, myname);
first = false;
});
function checkWin(playercol, playerrow) {
return (playercol == endPos[0] && playerrow == endPos[1]);
}
mHub.client.onJoinGame = function (message) {
// message can be either error or the actual maze (JSON format)
// the method is invoked after player joins a session by hub
var data = JSON.parse(message);
maze = JSON.parse(data.maze);
rivalName = data.rival;
rivalPos = [maze.Start.Col, maze.Start.Row];
endPos = [maze.End.Col, maze.End.Row];
console.log(maze);
if (!maze.Start) {
console.log("error in join maze");
return;
}
// draw rival maze
playerImage = new Image();
playerImage.src = '/Resources/poin.png';
var exitImage = new Image();
exitImage.src = '/Resources/exit.gif';
$("#ravilCanvas").mazeBoard(arrayMazeFromJson(maze), maze.Rows, maze.Cols, maze.Start.Row, maze.Start.Col,
maze.End.Row, maze.End.Col, playerImage, exitImage, false, function (direction, playercol, playerrow) { });
// handler for exiting page with refersh of pass to another page.
$(window).bind('beforeunload', function (e) {
$(window).off();
mHub.server.close();
});
//draw user maze
playerImage = new Image();
playerImage.src = '/Resources/poin.png';
var exitImage = new Image();
exitImage.src = '/Resources/exit.gif';
$("#userCanvas").mazeBoard(arrayMazeFromJson(maze), maze.Rows, maze.Cols, maze.Start.Row, maze.Start.Col,
maze.End.Row, maze.End.Col, playerImage, exitImage, true,
function (direction, playercol, playerrow) { // call back function for hub -invoked in every user move
mHub.server.play(direction);
if (checkWin(playercol, playerrow)) {
alert("You win!");
var myname = sessionStorage.getItem("username");
var _data = { Player1: rivalName, Player2: myname, Winner: myname };
// send results to server
$.ajax({
url: "api/Users/RegisterGame",
type: "POST",
data: _data,
dataType: "json",
success: function (json) {
console.log(json);
},
error: function (jqxhr, textStatus, error) {
var err = textStatus + ", " + error;
console.log("Request Failed: " + err);
alert("Error: Connect to server!");
}
});
mHub.server.close();
$(window).off();
first = true;
}
});
};
// the list of games (JSON format)
// the method is invoked after player asks for a list
// fill list of games to jooin to.
mHub.client.onListReceived = function (list) {
$('select').empty();
var x = document.getElementById("games");
var option = document.createElement("option");
var data = JSON.parse(list);
console.log(data);
for (var i = 0; i < data.length; ++i) {
var option = document.createElement("option");
option.text = data[i];
x.add(option);
console.log(data[i]);
}
};
// message can be either error or the actual move (JSON format)
// the method is invoked after the other player made a move on the board
mHub.client.onPlay = function (message) {
console.log("rival moved! " + message);
var dirc = message.Direction;
moveTo(dirc);
};
mHub.client.onClose = function (message) {
// message can be either error or closing message (JSON format)
// the method is invoked after the other player has closed the session
alert("your rival exit the game...");
};
// invoked after the other player has join
mHub.client.onGameStart = function (message) {
var data = JSON.parse(message);
console.log(data);
maze = JSON.parse(data.maze);
rivalName = data.rival;
rivalPos = [maze.Start.Col, maze.Start.Row];
endPos = [maze.End.Col, maze.End.Row];
// draw rival canvas
playerImage = new Image();
playerImage.src = '/Resources/poin.png';
var exitImage = new Image();
exitImage.src = '/Resources/exit.gif';
$("#ravilCanvas").mazeBoard(arrayMazeFromJson(maze), maze.Rows, maze.Cols, maze.Start.Row, maze.Start.Col,
maze.End.Row, maze.End.Col, playerImage, exitImage, false, function (direction, playercol, playerrow) { });
$(window).bind('beforeunload', function (e) {
$(window).off();
mHub.server.close();
});
playerImage = new Image();
playerImage.src = '/Resources/poin.png';
var exitImage = new Image();
exitImage.src = '/Resources/exit.gif';
$("#userCanvas").mazeBoard(arrayMazeFromJson(maze), maze.Rows, maze.Cols, maze.Start.Row, maze.Start.Col,
maze.End.Row, maze.End.Col, playerImage, exitImage, true,
function (direction, playercol, playerrow) { // callback function to user move
mHub.server.play(direction);
if (checkWin(playercol, playerrow)) {
alert("You win!");
var myname = sessionStorage.getItem("username");
var _data = { Player1: rivalName, Player2: myname, Winner: myname };
// send result
$.ajax({
url: "api/Users/RegisterGame",
type: "POST",
data: _data,
dataType: "json",
success: function (json) {
console.log(json);
},
error: function (jqxhr, textStatus, error) {
var err = textStatus + ", " + error;
console.log("Request Failed: " + err);
alert("Error: Connect to server!");
}
});
mHub.server.close();
$(window).off();
first = true;
}
});
};
// Start the connection with hub
$.connection.hub.start().done(function () {
// get open games list
mHub.server.list();
});
});
|
Java
|
UTF-8
| 1,106 | 2.078125 | 2 |
[] |
no_license
|
package com.brijesh.onlinecamera.service;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import com.brijesh.onlinecamera.dao.CategoryDAO;
import com.brijesh.onlinecamera.model.Category;
@Service
@Transactional
public class CategoryServiceImpl implements CategoryService {
@Autowired
CategoryDAO categoryDAO;
@Override
public List<Category> listAll1(){
return categoryDAO.listAll1();
}
@Override
public List<Category> listAll() {
return categoryDAO.listAll();
}
@Override
public Category getCategoryByID(int categoryId) {
return categoryDAO.getCategoryByID(categoryId);
}
@Override
public void saveCategory(Category category) {
categoryDAO.saveCategory(category);
}
@Override
public void editCategory(Category category) {
categoryDAO.editCategory(category);
}
@Override
public void removeCategory(int categoryId) {
categoryDAO.removeCategory(categoryId);
}
}
|
Java
|
UTF-8
| 1,323 | 2.515625 | 3 |
[
"Apache-2.0"
] |
permissive
|
package stream.scotty.demo.flink;
import stream.scotty.core.windowType.*;
import stream.scotty.flinkconnector.*;
import stream.scotty.demo.flink.windowFunctions.*;
import org.apache.flink.api.java.tuple.*;
import org.apache.flink.streaming.api.*;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.*;
import java.io.*;
public class FlinkSumDemo implements Serializable {
public static void main(String[] args) throws Exception {
LocalStreamEnvironment sev = StreamExecutionEnvironment.createLocalEnvironment();
sev.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
sev.setParallelism(1);
sev.setMaxParallelism(1);
DataStream<Tuple2<Integer, Integer>> stream = sev.addSource(new DemoSource());
KeyedScottyWindowOperator<Tuple, Tuple2<Integer, Integer>, Tuple2<Integer, Integer>> processingFunction =
new KeyedScottyWindowOperator<>(new SumWindowFunction());
processingFunction
.addWindow(new TumblingWindow(WindowMeasure.Time, 2000))
.addWindow(new SlidingWindow(WindowMeasure.Time, 5000,1000));
stream
.keyBy(0)
.process(processingFunction)
.print();
sev.execute("demo");
}
}
|
PHP
|
UTF-8
| 1,300 | 2.796875 | 3 |
[] |
no_license
|
<?php
if ( isset( $argv[1] ) ) {
$dir = $argv[1];
if ( !is_dir( $dir ) ) {
echo "Not a directory: $dir\n";
exit( 1 );
}
} else {
$dir = '.';
}
if ( !check_dir( $dir ) ){
exit( 1 );
} else {
exit( 0 );
}
function check_dir( $dir ) {
$handle = opendir( $dir );
if ( !$handle ) {
return true;
}
$success = true;
while ( false !== ( $fileName = readdir( $handle ) ) ) {
if ( substr( $fileName, 0, 1 ) == '.' ) {
continue;
}
if ( is_dir( "$dir/$fileName" ) ) {
$ret = check_dir( "$dir/$fileName" );
} elseif ( substr( $fileName, -4 ) == '.php' ) {
$ret = check_file( "$dir/$fileName" );
} else {
$ret = true;
}
$success = $success && $ret;
}
closedir( $handle );
return $success;
}
function check_file( $file ) {
static $okErrors = array(
'Redefining already defined constructor',
'Assigning the return value of new by reference is deprecated',
);
$errors = array();
parsekit_compile_file( $file, $errors, PARSEKIT_SIMPLE );
$ret = true;
if ( $errors ) {
foreach ( $errors as $error ) {
foreach ( $okErrors as $okError ) {
if ( substr( $error['errstr'], 0, strlen( $okError ) ) == $okError ) {
continue 2;
}
}
$ret = false;
print "Error in $file line {$error['lineno']}: {$error['errstr']}\n";
}
}
return $ret;
}
|
Python
|
UTF-8
| 542 | 3.421875 | 3 |
[] |
no_license
|
#types of style of charts
#solid
#dashed
#dashed doted
#doted
import pandas as p
import matplotlib.pyplot as m
d={'X':[1,2,3,4,5],'Y':[2,6,4,8,3]}
df=p.DataFrame(d)
m.plot(df['X'],df['Y'],'r',linestyle='--',marker='v',markeredgecolor='r',label='Temp') #markeredgecolor used to change color of marker edge
#check ss for further details
#to plot label
m.xlabel('Week')
m.ylabel('Temp')
#to display title
m.title('Temp per Week')
#to display label
m.legend(loc='upper right') #left / right lower / upper
m.show()
|
Python
|
UTF-8
| 296 | 3.5625 | 4 |
[] |
no_license
|
_end ='$'
def make_trie(*words):
root = dict()
for word in words:
current_node = root
for letter in word:
current_node = current_node.setdefault(letter,{})
current_node[_end] = _end
return root
words =["apple","orrange","apply","ranger","ape"]
root = make_trie(words)
print root
|
C++
|
UTF-8
| 559 | 2.875 | 3 |
[] |
no_license
|
#include "InitialConditionClass_Sin.h"
bool InitialConditionClass_Sin::Initialize(double r[],
double Phi[],
int gridSize){
int freq = 5;
const double PI_CONST = 3.1415926535897932384626433832795028841971693993751058209749;
for (int i = 0; i < gridSize; i++){
r[i] = (double)i * 2. * PI_CONST / (double)(gridSize) + \
1.0 * PI_CONST / (double)(gridSize);
Phi[i] = sin( (double)freq * r[i] + 0.2 );
}
return true;
}
|
Python
|
UTF-8
| 700 | 2.75 | 3 |
[] |
no_license
|
import mysql.connector as mysql
from Manager import Manager
DB_NAME = 'Wydawnictwo'
DB_HOST = '185.204.216.201'
DB_USER = 'seba'
DB_PASSWD = '123'
def getDB():
return mysql.connect(host=DB_HOST, user=DB_USER, passwd=DB_PASSWD, database=DB_NAME)
def printAllValFromTable(table, cursor):
cursor.execute("SELECT * FROM " + DB_NAME + '.' + table)
result = cursor.fetchall()
print(' ----------- VALUES FROM ' + table + ' ----------- ')
for i in result:
print(i)
print(' ------------------------------------ ')
mydb = getDB()
mycursor = mydb.cursor()
manager = Manager(mydb, mycursor)
#manager.clearDB()
manager.fillDB()
#manager.uzytkownik.insertUzytkownik(100)
|
Python
|
UTF-8
| 186 | 3.65625 | 4 |
[] |
no_license
|
tt = [32,5,12,8,3,75,2,15]
odd = []
pair = []
for num in tt:
if num % 2 == 0:
pair.append(num)
else:
odd.append(num)
print('Pair : ', pair)
print('Odd : ', odd)
|
C
|
UTF-8
| 2,819 | 3.96875 | 4 |
[] |
no_license
|
#include<stdio.h>
// Author : Indresh(kmr.ndrsh@gmail.com)
// Linked list with simple manually created nodes
// Add a node with data field 60 in between and before node with data field 30
/* #############
OUTPUT:
Linked List
Before:
10--> 20--> 30--> 40--> 50--> NULL
Linked List
After:
10--> 20--> 60--> 30--> 40--> 50--> NULL
############ */
struct node
{ int data;
struct node *next; // self refrential structure.
};
typedef struct node *NODE; // NODE is user defined datatype of struct type
// function prototype
void show_list(NODE first);
NODE AddNode_Before_NodeY(NODE IndexPtr,struct node _ToBeAdded);
int main()
{
NODE head;
/* Below Nodes can be dynamicaaly allocated using malloc() or calloc() function */
struct node a={10,NULL};
struct node b={20,NULL};
struct node c={30,NULL};
struct node d={40,NULL};
struct node e={50,NULL};
struct node f={60,NULL}; // Node to be added before node wih data field 30
a.next=&b;
b.next=&c;
c.next=&d;
d.next=&e;
head=&a; // head pointer pointing to first element in the list
// Call show_list() to display whole linked list
printf("\n\nLinked List\nBefore:\n");
show_list(head);
head=AddNode_Before_NodeY(head,f);
// Linked list is updated
printf("\nLinked List\nAfter:\n");
show_list(head);
return 0;
}
//show_list() function definition
void show_list(NODE first)
{
while(first!=NULL)
{ printf("%d--> ",first->data);
first=first->next;
}
printf("NULL"); // explicitly print NULL as head pointer has reached end of the list
printf("\n");
}
NODE AddNode_Before_NodeY(NODE IndexPtr,struct node Add_This_Node)
{
/* Copy the address of IndexPtr(act as head) to first pointer
otherwise, whole linked list address will be lost,
since IndexPtr pointer will traverse to end */
// prev pointer will point one node behind to that of IndexPtr
NODE first=NULL,prev=NULL;
first=IndexPtr;
if(IndexPtr==NULL) //Check, if list is empty, then return Add_This_Node itself
return NULL;
else
{ while(IndexPtr->next!=NULL) // Traverse through list in case 30 is not found in the given linked list
{ if(IndexPtr->data!=30) // 30 is hard-coded, this value can be read from standard input
{ prev=IndexPtr;
IndexPtr=IndexPtr->next;
}
else
{ Add_This_Node.next=prev->next; // Add_This_Node.next=IndexPtr; (will also work)
prev->next=&Add_This_Node;
break;
}
}
/* Here, code to handle a scenario when an element is not found in list
can be implemented, then we cannot add node 60 in the liast at any position,
In that case, return same list again, without any modification. */
return first; // return address of first node
}
}
|
Java
|
UTF-8
| 374 | 2.875 | 3 |
[] |
no_license
|
import java.io.File;
import java.util.Scanner;
public class Helper {
public static String[] readFile(String path) throws Exception {
String[] result = new String[3];
File file = new File(path);
Scanner sc = new Scanner(file);
int i = 0;
while(sc.hasNextLine()) {
result[i++] = sc.nextLine();
}
sc.close();
return result;
}
}
|
Markdown
|
UTF-8
| 3,551 | 3.078125 | 3 |
[] |
permissive
|
# Monthly Budget
For me, by me, to help me keep track of monthly expenses and how they compare to my income for that month. It'd be cool to make this more general purpose, but I built it to specifically work with the CSV file I can download from my personal bank, which details transactions for a specified time period.
The CSV _needs_ to have an _"Amount"_ column of positive and/or negative numbers, indicating cash in vs cash out. These are separated lists of debits and credits, made unique according to the _"Description"_. Duplicates are totaled. A missing _"Description"_ column will be handled with a default value, so total cash out vs cash in can still be compared. With my bank, cashed checks have an empty description, so it fall backs to the _"Transaction Type"_ column which in this case will say _"CHECK"_. The _"Transaction Type"_ is also used to filter out _"TRANSFERS"_ from debits credits. This prevents transferring from checking -> savings as being represented as a debit.
The cash flow report is then written as a CSV file, placed in the Downloads folder. My long-term vision for this application includes saving the CSV files (locally or in a remote db), so it can provide further insight and analysis into how expenses and/or income changed over a period of time. At that point, I'd also like to have a front end to display those data trends.
## Development
- Install [Haskell platform](https://www.haskell.org/platform/) (this will take a while) to get `stack`, `ghc` and `cabal-install`.
- The recommended Mac installation is with [gchup](https://www.haskell.org/ghcup/) to get ghc and cabal-install, and following the directions [here to get stack](https://docs.haskellstack.org/en/stable/README/). **Note:** _I believe I did this with homebrew originally, I'm sure there are a few ways._
- `stack build` from project root to compile
- `stack exec monthly-budget-exe` from project root to execute the program
### IDE setup for VS CODE
- Install [the official Haskell extension](https://marketplace.visualstudio.com/items?itemName=haskell.haskell) which comes with the language server and the IDE engine. **Note:** ghc, stack and cabal-install must be installed and on the PATH. _See 'Requirements' section._
- Install [Haskell Syntax Highlighting extension](https://marketplace.visualstudio.com/items?itemName=justusadam.language-haskell)
Description: VS Code's default dark theme, but just a little bit better.
VS Marketplace Link:
- Additional [syntax highlighting](https://code.visualstudio.com/api/extension-guides/color-theme#syntax-colors) customization can be done in `settings.json`, e.g.:
```
"editor.tokenColorCustomizations": {
"textMateRules": [
{
"scope": "meta.function.type-declaration.haskell",
"settings": { "fontStyle": "bold", "foreground": "#339e93" }
},
{
"scope": "constant.other.haskell",
"settings": { "foreground": "#7fc98f9c" }
},
{ ... }
]
},
```
## Language Documentation
Haskell's docs are weird, and sort of scattered. Places I frequent are:
- [Learn You a Haskell for Great Good!](http://learnyouahaskell.com/chapters)
- _Yes, it's a great introduction and tutorial. It's also the place I usually jump back to for a refresher on syntax._
- [Haskell's base Package](https://hackage.haskell.org/package/base)
- _Which includes_ [Prelude](https://hackage.haskell.org/package/base-4.14.0.0/docs/Prelude.html)
- [Hoogle](https://hoogle.haskell.org/)
- _Haskell API search engine._
|
PHP
|
UTF-8
| 3,358 | 2.53125 | 3 |
[] |
no_license
|
<?php
require_once 'Connection.php';
require_once 'WineTableGateway.php';
$id = session_id();
if ($id == "") {
session_start();
}
$connection = Connection::getInstance();
$gateway = new WineTableGateway($connection);
$statement = $gateway->getWines();
?>
<!DOCTYPE html>
<html>
<head>
<?php require "styles.php" ?>
<meta charset="UTF-8">
<title>UnWined</title>
</head>
<body>
<div class ="container">
<?php require 'toolbar.php' ?>
<?php require 'header.php' ?>
<?php require 'mainMenu.php' ?>
` <div class = "jumbotron">
<div class = "container">
<center>
<h6 class="banner">Let's UnWined</h6>
<p><a href="registerForm.php" class="btn btn-default loginbt">Sign Up Today</a></p>
</center>
</div>
</div>
<!-- row 2 -->
<div class="container">
<div class="row">
<div class="col-md-12 col-xs-10S">
<h1> We have a drinking problem</h1>
<p>At UnWined we like to give you the best quality wines we can at the lowest prices possible. </p>
</div>
</div>
<!-- row 3 -->
<div class="row spacer2">
<div class="col-md-3 col-xs-6">
<p><img src="img/wine1.png" alt="" class="img-responsive img-circle"></p>
<h4>we really like wine</h4>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore</p>
<p><a href="login.php" class="btn btn-default">Read more </a></p>
</div>
<div class="col-md-3 col-xs-6">
<p><img src="img/wine2.png" alt="" class="img-responsive img-circle"></p>
<h4>we really like wine</h4>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore </p>
<p><a href="login.php" class="btn btn-default">Read more </a></p>
</div>
<div class="col-md-3 col-xs-6">
<p><img src="img/wine1.png" alt="" class="img-responsive img-circle"></p>
<h4>we really like wine</h4>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore</p>
<p><a href="login.php" class="btn btn-default">Read more </a></p>
</div>
<div class="col-md-3 col-xs-6">
<p><img src="img/wine2.png" alt="" class="img-responsive img-circle"></p>
<h4>we really like wine</h4>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore</p>
<p><a href="login.php" class="btn btn-default">Read more </a></p>
</div>
</div>
</div>
</div>
<div class="spacer"> </div>
<?php require 'footer.php'; ?>
</body>
</html>
|
C++
|
UTF-8
| 464 | 2.625 | 3 |
[] |
no_license
|
#include<stdio.h>
#include<stack>
using namespace std;
int N;
stack<int> st1,st2,st3;
int main() {
scanf("%d",&N);
int i;
for(i=N;i>=1;i--) st1.push(i);
int a,b;
while(scanf("%d%d",&a,&b) != -1) {
if(a==1) {
for(i=1;i<=b;i++) {
st2.push(st1.top());
st1.pop();
}
} else {
for(i=1;i<=b;i++) {
st3.push(st2.top());
st2.pop();
}
}
}
while(!st3.empty()) {
printf("%d\n",st3.top());
st3.pop();
}
}
|
Python
|
UTF-8
| 2,313 | 3.359375 | 3 |
[] |
no_license
|
import sqlite3
import requests
from bs4 import BeautifulSoup
# Request URl
response = requests.get("http://books.toscrape.com/catalogue/category/books/history_32/index.html")
soup = BeautifulSoup(response.text, "html.parser")
books = soup.find_all('article')
# print(type(books))
# for book in books:
# print(book)
all_books = []
str_to_num = {"One" : 1, "Two" : 2, "Three" : 3, "Four" : 4, "Five" : 5}
for book in books:
title = book.find("h3").find("a")["title"]
print("*** Title ***",title)
price = book.find(class_="price_color").get_text().replace("Â","").replace("£","")
print("***price---",price)
# print("***rating select---",book.select(".star-rating")[0]) #select return multiple instances, return list
# print("***rating find---",book.find(class_="star-rating")) #same as above
# using .get_attribute_list to show attribute
# print("***rating number---",book.find(class_="star-rating").get_attribute_list("class"))
# print("***just number---",book.find(class_="star-rating").get_attribute_list("class")[1])
rating = str_to_num[book.find(class_="star-rating").get_attribute_list("class")[1]]
print("***just interger number---",rating)
# print("***just number---",book.find(class_="star-rating").get_attribute_list("class")[-1]) #same as above
print("----------------------------")
# all_books.append([title, float(price), rating]) # list of lists
all_books.append((title, float(price), rating)) # list of tuples
print("==================save to list & db=========================")
print(all_books)
conn = sqlite3.connect("test366scrapdb.db")
c = conn.cursor()
c.execute("CREATE TABLE books (title TEXT, price REAL, rating INTEGER);")
sql_insert = "INSERT INTO books VALUES (?,?,?)"
c.executemany(sql_insert, [element for element in all_books])
sql_list = [
"SELECT * FROM books WHERE price > 30",
"SELECT title FROM books WHERE price > 30 ORDER BY price",
"SELECT * FROM books WHERE rating == 4 "
]
number = 1
for sql in sql_list:
print(f"------SELECT RESULT--- {number} Query --------")
c.execute(sql) #Cursor object
print("---",c.fetchone())
number += 1
print("========================================")
c.execute("SELECT * FROM books")
print(c.fetchall())
conn.commit()
conn.close()
|
Markdown
|
UTF-8
| 10,466 | 3.59375 | 4 |
[
"MIT"
] |
permissive
|
---
id: advanced
title: xform 进阶
---
import * as advancedExamples from 'story/src/xform/2-advanced-examples.stories';
本页将介绍 xform 的一些进阶用法,包括表单片段复用、数组类型表单、嵌套表单数据结构等。
:::danger
文档内容较多,书写龟速,目前还非常粗糙。
:::
## 表单片段复用
先看以下示例,在家庭信息登记表中,「个人信息」、「父亲」等部分的表单内容是完全相同的,但它们的数据存放路径不同。
此时我们将表单中的相同部分抽取到 PersonForm 中,并利用 Form.Object 来指定其中的 FormItem 的**数据索引前缀**。 在 FamilyForm 中,我们为多个 PersonForm 指定不同的 name,即可实现表单片段的复用。 在更复杂的情况下,我们可以为 PersonForm 添加更多 props,使片段复用变得更加灵活。
```jsx
function PersonForm({ name, label }) {
return (
<div>
<p>{label}</p>
<Form.Object name={name}>
<FormItem name="name" label="姓名" required />
<FormItem name="contact" label="联系方式" />
<FormItem name="address.city" label="居住城市" />
</Form.Object>
</div>
);
}
function FamilyForm() {
return (
<div>
<PersonForm name="me" label="个人信息" />
<PersonForm name="father" label="父亲" />
<PersonForm name="mother" label="母亲" />
<PersonForm name="other" label="其他紧急联系人" />
</div>
);
}
```
<Story fn={advancedExamples.ObjectExample} />
### `Form.Object`
`<Form.Object name={name} />`: 以当前 model 为基础,为其子节点提供一个新的 sub model,并将子节点中的表单值收集到当前 model 中 `name` 对应的位置。
为 Form.Object 设置 `name="&"` 时,可以将当前 model 透传至子节点(相当于没写 Form.Object)。
## 列表类型的数据
我们可以利用 `Form.Array` 来处理列表类型的数据。
例如,在下面的「客户满意度调查列表」中,我们用 Form.Array 包裹了多个 FormItem。
从 Form.Array 这个名字中也可以看出,表单提交时将会生成一个数组,数组中每个元素包含 name,date,brand 等字段。
```jsx
<Form.Array name="tickets" layout={arrayCard({ showItemOrder: true })}>
<FormItem label="客户名称" name="name" />
<FormItem label="购买日期" name="date" />
<FormItem label="品牌" name="brand" />
{/* 其他调查结果表单内容 */}
</Form.Array>
```
<Story fn={advancedExamples.ArrayExample} />
### `Form.Array`
`<Form.Array name={name} itemFactory={itemFactory} layout={layout} />`
Form.Array 会根据列表长度(即 `model.values.length`),渲染同样次数的子节点(指 props.children)。Form.Array 会以当前 model 为基础,为其子节点提供一个新的 sub model,并将子节点中的表单值收集到当前 model 中 `{name}.{itemIndex}` 对应的位置。
Form.Array 与 Form.Object 非常类似,但用于处理数组。 注意 Form.Array 为其子节点提供的 sub model 包含两层下标 `{name}.{itemIndex}`: `name` 表示数组所在的字段名称, `itemIndex` 表示数组元素下标。
其他参数:
- `layout` 控制表单如何对数组进行布局,包括数组中每一个元素的布局 以及 相关的操作按钮(添加、删除、上移、下移等)
- xform 提供一些内置的数组布局,如果不满足你的需求,你也可以在上层实现新的数组布局
- 和 Form.Object 一样,Form.Array 本身不会提供任何布局
- `itemFactory` 用于设置数组中新增元素的初始值
## 处理嵌套数据结构
`Form.Object` 与 `Form.Array` 允许相互嵌套,灵活使用两者,我们可以组合出非常复杂的表单结构。
而在数据处理方面, xform 提供了非常灵活的、「分形」的 API。
通过 `new FormModel(values)` 创建 formModel 之后,我们可以使用 `formModel.getSubModel(name)` 来获取 `name` 对应的子模型 subModel,对 subModel.values 的读写会自动变为对 formModel.values 的读写(背后基于 mobx computed),确保 formModel.values 是整个表单 values 的唯一可信来源。
FormModel(根节点)和 SubModel(子节点)均实现了 [`IModel` interface](api#imodel),两者拥有几乎相同的方法和属性。大部分情况下,我们不需要区分 FormModel 或 SubModel。通过 `IModel#getSubModel` 方法,我们可以获取子模型的子模型,甚至是子模型的子模型的子模型…… 在实际进行开发时,我们可以根据情况灵活选取子模型,然后在适当的数据层级进行开发。
### 示例 1
我们可以用一个 FormModel 来管理「分步表单」。
虽然这种方式并不常见,但它有一些独特的优势:
- 复用了表单已有的提交按钮(Form.Submit)和提交成功回调(onSubmit),快速实现「点击下一步触发校验,校验通过后跳转到下一步」功能
- 可以通过 root 来进行全局管理,例如……
- 调用 `modelUtils.reset(root)` 来重置所有步骤
- root.values 记录了整体数据,向后端发送请求时只需要发送 root.values 即可
```jsx
const root = new FormModel({ step1: {}, step2: {}, step3: {} });
// STEP-1 Component
<Step>
<Form model={root.getSubModel('step1')} onSubmit={jumpToStep2}>
<FormItem name="foo" />
<FormItem name="bar" />
<Form.Submit>下一步</Form.Submit>
</Form>
</Step>;
// STEP-2 Component
<Step>
<Form model={root.getSubModel('step2')} onSubmit={jumpToStep3}>
<FormItem name="hello" />
<FormItem name="world" />
<Form.Submit>下一步</Form.Submit>
</Form>
</Step>;
// STEP-3 Component 省略代码
```
(todo 更完善的介绍)
## 接入自定义组件
随着业务需求变得复杂,xform 自带的表单组件也许将无法满足你的需求,此时你可以通过接入自定义组件来拓展 xform。
### 视图接入
当自定义组件不需要接入表单内部的校验系统时,你可以使用 [`<Form.ItemView />`](api#formitemview) 来接入表单布局,让自定义内容与普通 FormItem 展示一致。此时,你可以通过 [Field](api#field) 来为自定义组件设置 value/onChange:
```jsx
const cityField = model.getField('city');
<Form model={model}>
<FormItem component="input" name="foo" />
<FormItem component="select" name="bar" />
<FormItemView label="城市" tip="请选择你的居住城市" asterisk={true} error="必须选择陆地">
<MyPowerCitySelect selectdCity={cityField.value} onChangeSelectedCity={cityField.handleChange} />
</FormItemView>
</Form>;
```
### 自定义的表单组件
通过 createFormItem 你可以创建全新的表单组件。创建后,可以像普通的 FormItem 一样来使用自定义的表单组件,比如通过 name 来指定所要绑定的数据索引,通过 validate 来设置校验方法等。
```jsx
// 创建
const PowerCityFormItem = createFormItem({
name: 'powerCitySelect',
fallbackValue: null,
isEmpty: () => false,
render({ value, onChange }) {
return <MyPowerCitySelect selectdCity={value} onChangeSelectedCity={onChange} />;
},
});
// 使用
<Form model={model}>
<FormItem component="input" name="foo" />
<FormItem component="select" name="bar" />
<PowerCityFormItem name="city" required validate={isBeautifulCity} validateOnChange={false} />
</Form>;
```
### 注册为内置表单组件
如果你期望自定义组件以 `<FormItem component="powerCitySelect" name="..." />` 的形式被使用,你可以通过 `FormItem.register(...)` 来进行注册。新注册的名称会与已有的名称共享一个命名空间,注意避免冲突。
```jsx
// 注册
FormItem.register({
name: 'powerCitySelect',
fallbackValue: null,
isEmpty: () => false,
render: ___,
});
// 使用
<Form model={model}>
<FormItem component="input" name="foo" />
<FormItem component="select" name="bar" />
<FormItem component="powerCitySelect" name="city" required validate={isBeautifulCity} validateOnChange={false} />
</Form>;
```
## 相同数据索引对应多个视图
**当通过 `name="..."` 来指定 FormItem 关联的数据索引时, 一个数据索引最多只能对应一个 FormItem。**
当多个 FormItem 的 name 相同时,这些 FormItem 将会使用同一个 Field 对象。但因不同 FormItem 的配置不同(例如设置了不同的 required 或 validate),后渲染的 FormItem 的配置将会覆盖先渲染的 FormItem 配置,Field 对象上的校验就会出问题。例如下面的示例中就出现了两个互斥的校验方法,导致校验永远无法通过:
```jsx
// ❌ 错误用法
<FormItem name="foo" required validate={v => v < 3 ? '不能小于3' : null}} />
<FormItem name="foo" required={false} validate={v => v > 3 ? '不能大于3' : null} />
```
但在实际场景中,我们无法避免类似「相同数据索引对应多个视图」这样的需求。为此,xform 提供了 field fork 能力:
API: `field.getFork(forkName :string): Field`
该方法根据已有的 field(original field)返回一个**新的** field 对象(fork field),fork 与 original 使用相同的数据索引(意味着两者 .value 总是相等),但除此之外的其他状态互相隔离。
创建 fork field 之后,我们就可以为不同的 FormItem 设置不同的 field 了:
```jsx
// ✅ 正确用法
const fooField = model.getField('foo')
const fooFork = fooField.getFork('fooFork')
<FormItem field={fooField} required validate={v => v < 3 ? '不能小于3' : null}} />
<FormItem field={fooFork} required={false} validate={v => v > 3 ? '不能大于3' : null} />
```
### fork field 特点
我们通过 `model.getField(name)` 获取到的 field 对象总为 _original fork_,该 field 的 forkName 总是为 `'original'`。
同一个数据索引下,不同的 forks 共享一个命名空间,互相之间可以通过 `field.getFork(forkName)` 进行访问;该方法调用过程中,如果 forkName 对应的 fork field 不存在,则会初始化对应的 fork field,并将其返回。
我们可以认为 original fork 是默认存在的一个 fork,当想要使用新的 fork 时,就换一个 forkName;而当想要获取到 original fork 时,则通过 `forkField.getFork('original')` 进行获取。
## 异步数据源
(todo) createAsyncValue
## 复杂联动
(todo reactive + imperative)
|
Java
|
UTF-8
| 544 | 3.234375 | 3 |
[] |
no_license
|
import java.util.Scanner;
public class Z2 {
public static void main(String[] args) {
Scanner input = new Scanner(System.in, "UTF-8");
System.out.println("Please enter number for length of the arrey: ");
int a = input.nextInt();
input.close();
int[] F = new int[a];
F[0] = 1;
F[1] = 1;
for(int i = 2; i < a; i++){
F[i] = F[i-2] + F[i-1];
}
for(int c = 0; c < a; c++){
System.out.print(F[c] + " ");
}
}
}
|
Markdown
|
UTF-8
| 887 | 3.1875 | 3 |
[] |
no_license
|
# example-redirector
Example Redirector app - C#, .NetCore 3.0, WEB API
### Build and run the app (from the output directory) with the follwing command lines:
```
export ASPNETCORE_URLS=http://0.0.0.0:5080/
dotnet ./Redirector.dll ./mapping.json
```
### Mapping File (mapping.json)
```
{
"defaultDestination": "https://www.google.com?q=Default+Destination",
"mappings": {
"/docs/DOC-12345": "https://www.google.com?q=Destination of DOC-12345",
"/docs/DOC-54321": "https://www.google.com?q=Destination of DOC-54321"
}
}
```
If the incoming request matches a path defined in **mappings**, it will 301 redirect to that location, otherwise, it will 302 redirect to **defaultDestination**.
### Testing it out
After running the app, navigate to:
- http://localhost:5080/docs/DOC-12345
- http://localhost:5080/docs/DOC-54321
- http://localhost:5080/some-other-path
|
Rust
|
UTF-8
| 1,599 | 2.703125 | 3 |
[
"MIT"
] |
permissive
|
use crate::Signature;
use std::collections::HashMap;
use paste::paste;
pub type LenOperation = fn(&ColumnWrapper) -> Result<usize, ErrorDesc>;
pub type LenDictionary = HashMap<Signature, LenOperation>;
use crate::*;
#[allow(dead_code)]
const OP: &str = "len";
macro_rules! binary_operation_load {
($dict:ident; $($tr:ty)+) => ($(
{
type V=Vec<$tr>;
let signature=sig![OP;V];
$dict.insert(signature, paste!{[<new_vec $tr>]});
}
{
type V=[$tr];
let signature=sig![OP;V];
$dict.insert(signature, paste!{[<new_slice $tr>]});
}
)+)
}
macro_rules! binary_operation_impl {
($($tr:ty)+) => ($(
paste!{
fn [<new_vec $tr>](c: &ColumnWrapper)->Result<usize,ErrorDesc>
{
type T=$tr;
type V=Vec<T>;
c.downcast_ref::<V>().map(|v| v.len())
}
}
paste!{
fn [<new_slice $tr>](c: &ColumnWrapper)->Result<usize,ErrorDesc>
{
type T=$tr;
type V=[T];
c.downcast_slice_ref::<V>().map(|v| v.len())
}
}
)+)
}
binary_operation_impl! {
u64 u32 u16 u8 bool usize
}
//{ usize u8 u16 u32 u64 u128 isize i8 i16 i32 i64 i128 f32 f64 }
//binary_operation_impl! { (u64,u8) (u64,u16) (u64,u32) (u64,u64) }
pub fn load_len_dict(len_dict: &mut LenDictionary) {
//dict.insert(s, columnadd_onwedcolumnvecu64_vecu64);7
binary_operation_load! {len_dict;
u64 u32 u16 u8 bool usize
};
}
|
Python
|
UTF-8
| 1,991 | 2.71875 | 3 |
[] |
no_license
|
#! python3
#This is a program to update customerCell and locationCell and nameCell, signatureCell on the excel file templates in Crucible.
import win32com.client as win32
import os
import tkinter as tk
import sys
#--------FUNTIONS---------
#Updates cells in excel workbook
def updateWb(file):
wb = excel.Workbooks.Open(os.path.join(__location__, file))
excel.Visible = False
ws = wb.Worksheets('Copy1')
ws.Cells(6, 3).Value = customerCell
ws.Cells(7, 3).Value = locationCell
ws.Cells(6, 12).Value = nameCell
ws.Cells(34, 2).Font.Italic = True
ws.Cells(34, 2).Value = nameCell
wb.Save()
excel.Application.Quit()
def finished():
global customerCell
customerCell = customerInput.get()
global locationCell
locationCell = locationInput.get()
global nameCell
nameCell = nameInput.get()
window.destroy()
#--------GUI--------
window = tk.Tk()
window.geometry('200x400')
window.title('Cell Editor')
#---INPUT BOX CUSTOMER---
customer = tk.Label(text= 'Enter Customer Name')
customer.grid(column=0, row=0)
customerInput = tk.Entry()
customerInput.grid(column=0, row=1, pady=35)
#---INPUT BOX LOCATION---
location = tk.Label(text= 'Enter Location')
location.grid(column=0, row=2)
locationInput = tk.Entry()
locationInput.grid(column=0, row=3, pady=35)
#---INPUT BOX NAME---
name = tk.Label(text= 'Enter Service Technicians Name')
name.grid(column=0, row=4)
nameInput = tk.Entry()
nameInput.grid(column=0, row=5, pady=35)
#---BUTTON---
button_ok = tk.Button(text='OK', command=finished)
button_ok.grid(column=0, row=6, ipadx=15, ipady=10)
window.mainloop()
__location__ = os.path.realpath(
os.path.join(os.getcwd(), os.path.dirname(__file__)))
excel = win32.gencache.EnsureDispatch('Excel.Application')
fileNames = ['oof', 'misuse', 'estop','frozen','damage','ebrake','ui']
for file in fileNames:
updateWb(file)
sys.exit()
|
Java
|
UTF-8
| 941 | 2.90625 | 3 |
[] |
no_license
|
package com.jugueteria.util;
import com.jugueteria.modelo.Usuario;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class UsuarioMapper {
public Map<String, Object> getMap(Usuario usuario) {
Map<String, Object> answer = new HashMap<String, Object>();
answer.put("Nombre", usuario.getNombre());
answer.put("Identificacion", usuario.getIdentificacion());
return answer;
}
public List<Usuario> readUsuarios(List<Map<String, String>> dataList) {
System.out.println("data:" + dataList);
List<Usuario> usuarios = new ArrayList<Usuario>();
for (Map<String, String> data : dataList) {
Usuario usuario = new Usuario();
usuario.setNombre(data.get("Nombre"));
usuario.setIdentificacion(data.get("Identificacion"));
usuarios.add(usuario);
}
return usuarios;
}
}
|
Python
|
UTF-8
| 6,842 | 3.75 | 4 |
[
"CC-BY-4.0"
] |
permissive
|
#! /usr/bin/env python
# How am I going to find the points where paths intersect?
#
# Might as well go naive, because runtime doesn't matter for inputs this small.
#
# Parse the 'movements' into two lists of segments starting at (0, 0), then
# loop across both lists, checking whether any segment in one intersects with
# any of the others.
import sys
def parse_path(input_line):
moves = input_line.split(',')
points = [(0, 0)]
for move in moves:
direction, length = move[0], int(move[1:])
if direction == 'U':
points.append((points[-1][0], points[-1][1] + length))
elif direction == 'D':
points.append((points[-1][0], points[-1][1] - length))
elif direction == 'R':
points.append((points[-1][0] + length, points[-1][1]))
elif direction == 'L':
points.append((points[-1][0] - length, points[-1][1]))
else:
print('ERROR PARSING PATH: unknown direction ' + direction)
sys.exit(1)
return points
def parse_input(input_path):
paths = []
with open(input_path, 'r') as f:
for line in f:
paths.append(parse_path(line))
return paths
def between(n, left, right):
"""Return True if 'n' is between 'left' and 'right', else return False."""
return ((left <= n <= right) or (left >= n >= right))
def unsorted_range(a, b):
"""Return a list of numbers between a and b, inclusive.
Just a wrapper around range() that sorts the input."""
if a > b:
return range(b, a)
else:
return range(a, b)
def intersection(left_list, right_list):
result_set = set(left_list).intersection(right_list)
return [val for val in result_set]
def find_intersections(left_segment, right_segment):
left_seg_vertical = left_segment[0][0] == left_segment[1][0]
left_seg_horizontal = not left_seg_vertical
right_seg_vertical = right_segment[0][0] == right_segment[1][0]
right_seg_horizontal = not right_seg_vertical
if left_seg_horizontal:
if right_seg_vertical:
if (between(right_segment[0][0], left_segment[0][0], left_segment[1][0]) and
between(left_segment[0][1], right_segment[0][1], right_segment[1][1])):
return [(right_segment[0][0], left_segment[0][1])]
elif right_seg_horizontal:
if left_segment[0][1] == right_segment[0][1]:
# Parallel line segments at same y-pos, so they may overlap.
# There is an intersection at every point contained in both
# lines.
left_segment_x_vals = unsorted_range(left_segment[0][0],
left_segment[1][0])
right_segment_x_vals = unsorted_range(right_segment[0][0],
right_segment[1][0])
shared_x_vals = intersection(left_segment_x_vals, right_segment_x_vals)
return [(x, left_segment[0][1]) for x in shared_x_vals]
elif left_seg_vertical:
if right_seg_vertical:
# FIXME My input never actually used this branch. You could apply
# the same logic I used for the analogous horizontal case if you
# really wanted to.
if (between(right_segment[0][0], left_segment[0][0], left_segment[1][0]) and
between(left_segment[0][1], right_segment[0][1], right_segment[1][1])):
print('Parallel overlapping lines. Implement.')
sys.exit(1)
elif right_seg_horizontal:
if (between(right_segment[0][1], left_segment[0][1], left_segment[1][1]) and
between(left_segment[0][0], right_segment[0][0], right_segment[1][0])):
return [(left_segment[0][0], right_segment[0][1])]
def find_all_intersections(left_path, right_path):
intersections = []
for i in range(0, len(left_path) - 1):
left_path_segment = (left_path[i], left_path[i + 1])
for j in range(0, len(right_path) - 1):
right_path_segment = (right_path[j], right_path[j + 1])
results = find_intersections(left_path_segment,
right_path_segment)
if results is not None:
intersections = intersections + results
if (0, 0) in intersections:
# This one should never be included.
intersections.remove((0, 0))
return intersections
def get_closest_distance(intersections):
closest_distance = None
for intersection in intersections:
if intersection[0] == 0 and intersection[1] == 0:
continue
distance = abs(intersection[0]) + abs(intersection[1])
if closest_distance is None or distance < closest_distance:
closest_distance = distance
return closest_distance
def get_walk_length_to_intersection(intersection, path):
cost = 0
for i in range(0, len(path) - 1):
p1 = path[i]
p2 = path[i + 1]
if p1[0] == p2[0]:
# Vertical line
points_between = [(p1[0], y) for y in unsorted_range(p1[1], p2[1] + 1)]
if intersection in points_between:
return cost + abs(intersection[1] - p1[1])
cost += abs(p1[1] - p2[1])
else:
# Horizontal line
points_between = [(x, p1[1]) for x in unsorted_range(p1[0], p2[0] + 1)]
if intersection in points_between:
return cost + abs(intersection[0] - p1[0])
cost += abs(p1[0] - p2[0])
def get_shortest_walk_to_intersection(intersections, left_path, right_path):
shortest_walk = None
for intersection in intersections:
left_cost = get_walk_length_to_intersection(intersection,
left_path)
right_cost = get_walk_length_to_intersection(intersection,
right_path)
path_cost = left_cost + right_cost
if shortest_walk is None:
shortest_walk = left_cost + right_cost
elif path_cost < shortest_walk:
shortest_walk = path_cost
return shortest_walk
def main(input_path):
# TODO Implement this
left_path, right_path = parse_input(input_path)
intersections = find_all_intersections(left_path, right_path)
# distance = get_closest_distance(intersections)
distance = get_shortest_walk_to_intersection(intersections,
left_path,
right_path)
if distance is None:
print('No intersections found. Go fix your bugs. :(')
sys.exit()
print(distance)
if __name__ == '__main__':
main(sys.argv[1])
|
Python
|
UTF-8
| 2,099 | 2.828125 | 3 |
[] |
no_license
|
import wx
import wx.lib.flatnotebook as fnb
# Test types:
# 1. No notebook, the two webkit ctrls are side-by-side in a sizer,
# the button destroys the 2nd webkit ctrl
# 2. Use native notebook, button deletes 2nd page
# 3. Use FlatNotebook, button deletes 2nd page
TEST = 2
from wx.webkit import WebKitCtrl
#from webview import WebView as WebKitCtrl
#import os; print 'PID:', os.getpid(); raw_input("Press enter...")
class TestFrame(wx.Frame):
def __init__(self, *args, **kw):
wx.Frame.__init__(self, *args, **kw)
if TEST == 1:
wkparent = self
lbl = "Destroy 2nd WKC"
elif TEST == 2:
self.nb = wx.Notebook(self)
wkparent = self.nb
lbl = "Delete 2nd Page"
elif TEST == 3:
self.nb = fnb.FlatNotebook(self)
wkparent = self.nb
lbl = "Delete 2nd Page"
self.wk1 = WebKitCtrl(wkparent)
self.wk2 = WebKitCtrl(wkparent)
self.wk1.LoadURL("http://wxPython.org")
self.wk2.LoadURL("http://wxWidgets.org")
#self.wk1 = wx.Panel(self.nb); self.wk1.SetBackgroundColour('red')
#self.wk2 = wx.Panel(self.nb); self.wk2.SetBackgroundColour('blue')
if TEST > 1:
self.nb.AddPage(self.wk1, "zero")
self.nb.AddPage(self.wk2, "one")
btn = wx.Button(self, -1, lbl)
self.Bind(wx.EVT_BUTTON, self.OnButton, btn)
self.Sizer = wx.BoxSizer(wx.VERTICAL)
if TEST == 1:
self.Sizer.Add(self.wk1, 1, wx.EXPAND)
self.Sizer.Add(self.wk2, 1, wx.EXPAND)
else:
self.Sizer.Add(self.nb, 1, wx.EXPAND)
self.Sizer.Add(btn, 0, wx.ALL, 10)
def OnButton(self, evt):
if TEST == 1:
if self.wk2:
self.wk2.Destroy()
print "Destroy called"
else:
self.nb.DeletePage(1)
app = wx.App(redirect=False)
frm = TestFrame(None, size=(600,500))
frm.Show()
#import wx.lib.inspection
#wx.lib.inspection.InspectionTool().Show()
app.MainLoop()
|
Swift
|
UTF-8
| 1,442 | 2.65625 | 3 |
[
"MIT"
] |
permissive
|
import UIKit
final class EmbeddedBlueprintViewController: UIViewController {
var blueprint: Blueprint? {
didSet { didChangeBlueprint() }
}
private lazy var imageView = UIImageView()
override func viewDidLoad() {
super.viewDidLoad()
view.addSubview(imageView)
imageView.contentMode = .scaleAspectFit
imageView.translatesAutoresizingMaskIntoConstraints = false
NSLayoutConstraint.activate([
imageView.topAnchor.constraint(equalTo: view.layoutMarginsGuide.topAnchor, constant: 8),
imageView.bottomAnchor.constraint(equalTo: view.bottomAnchor, constant: -8),
imageView.leadingAnchor.constraint(equalTo: view.leadingAnchor, constant: 8),
imageView.trailingAnchor.constraint(equalTo: view.trailingAnchor, constant: -8),
])
}
override func traitCollectionDidChange(_ previousTraitCollection: UITraitCollection?) {
super.traitCollectionDidChange(previousTraitCollection)
if #available(iOS 12.0, *), traitCollection.userInterfaceStyle != previousTraitCollection?.userInterfaceStyle {
didChangeBlueprint()
}
}
private func didChangeBlueprint() {
guard let blueprint = blueprint, let image = UIImage(named: blueprint.imageName) else {
imageView.image = nil
return
}
if #available(iOS 12.0, *), traitCollection.userInterfaceStyle == .dark {
imageView.image = image.inverted
} else {
imageView.image = image
}
}
}
|
Python
|
UTF-8
| 7,395 | 2.515625 | 3 |
[] |
no_license
|
from GlobalConstants import searchVarNamesInOrder, fixedParamDict
from SSOptProgressPlot import SSOptProgressPlot
from shared import savedParametersFile
from ResultsJudge import ResultsJudge
from SSMatchAll import SSMatchAll
from Namespace import Namespace
import multiprocessing as mp
from pprint import pformat
from math import log
import traceback
import pickle
import time
def SSWrapper(friendDirectories, indexDefinition, parameters, tt):
'''
This function wraps SSMatchAll(), and returns a cost that takes into account how much time
was spent training.
Inputs:
friendDirectories - A list of strings giving paths to the directories that hold our
images of each dog we want to analyze. The directory names
are the names of the dogs.
indexDefinition - A string representing the faiss index setup to use, or ''
or None to represent "use the default"
parameters - a Tuple of the parameter values we're currently using.
tt - an instance of TicToc to use for output, or None to use the
global one.
Outputs:
costIncludingTime - A number that reflects the accuracy of the model and the
time the model required to train (lower is better).
'''
#Make a shorthand for tt.TT:
TT=tt.TT
with TT('Running SSWrapper'):
timeImportantance=.002
#How many seconds to let ssMatchRun before killing it:
ssMatchTimeoutSec=1000
gAsDict=dict()
assert len(parameters)==len(searchVarNamesInOrder), \
'Different number of parameters than expected.'
#Convert our parameters into a g that SnoutScan can use:
#Iterate over the paramter names in the designated order:
for i, pName in enumerate(searchVarNamesInOrder):
#Add this parameter name and value to gAsDict:
gAsDict.update({pName: parameters[i]})
tt.print("Fixed Parameters: \n" + pformat(fixedParamDict))
tt.print("Variable Parameters: \n" + pformat(gAsDict))
#Also add our fixed variables:
gAsDict.update(fixedParamDict)
#Create our g out of it:
g=Namespace(gAsDict)
##Save it so that if there is an error we can run SSMatchAll and get the same parameters to
##inspect.
##Disabled because it makes it so that when I ctrl-C I no longer have the best parameters.
#pickle.dump(g, open(savedParametersFile, 'wb'))
#Get our start time in seconds since the epoch.
startTime=time.time()
##Use this instead of the stuff below if you want to break for pdb on errors:
#confusionMatrix=SSMatchAll(friendDirectories, indexDefinition, g, tt)
#percentCorrect=ResultsJudge(confusionMatrix)
#tt.print("Trying parameters: \n" + pformat(gAsDict)):
with TT("Running the benchmark in a separate process:"):
try:
#Call SSMatch, and get the model and cost back, but do it in it's own process.
#This prevents segfaults or memory leaks in an opencv implementation from stoping
#the optimization (which has happened already):
#Set up a multiprocessing queue we can use to get the return value from SSMatchAll:
ssQueue=mp.Queue()
#Set up a Process object.
ssProc= mp.Process( target=SSMatchAll,
args=(friendDirectories, indexDefinition, g, tt, False,
ssQueue),
name='SSMatchAll')
#Start the process running SSMatchAll.
ssProc.start()
#Get our confusion matrix from the queue. Wait at most ssMatchTimeoutSec for it
# to be available. Needs to be done before the join.
confusionMatrix=ssQueue.get(block=True, timeout=ssMatchTimeoutSec)
#At this point, it should be done. Join it. If it takes longer than 15 seconds,
#something is wrong.
ssProc.join(timeout=15)
#We return an empty pandas array if there was an exception. If the child has an
#exceptuion raise one in the parent too to keep things consistent.
assert confusionMatrix.empty == False, 'SSMatchAll exited with an exception.'
#Calculate our percentCorrect from that:
percentCorrect=ResultsJudge(confusionMatrix)
except Exception as e:
tt.print('Error: '+ str(e))
tt.print(traceback.format_exc())
#If we got an error there was 0 correct:
percentCorrect=0
raise
#Get our end time in seconds since the epoch.
endTime=time.time()
elapsedSec=endTime-startTime
#A log scale represents the fact that getting the first 10% accuracy is easier than getting
#the last 10% accuracy:
#Inverse is: percentCorrect= 2-2^costFromAccuracy
costFromAccuracy=log(2-percentCorrect,2)
costFromTime=timeImportantance*log(elapsedSec+1,2)
#Combine the cost returned by SSMatchAll and the elapsed time to make a new cost.
compositeCost=costFromAccuracy+costFromTime
tt.print('SSWrapper: percentCorrect: %f\tcompositeCost: %f\tcostFromAccuracy: %f\tcostFromTime: %f' % \
(percentCorrect, compositeCost, costFromAccuracy, costFromTime))
#If that new cost is the lowest we've seen so far, save the model in memory for cbOptimize to
#use when we're done:
if compositeCost < SSWrapper.bestCompositeCost:
with TT('Best model so far. Saving'):
SSWrapper.bestCompositeCost=compositeCost
SSWrapper.bestG=g
#Save our best g to savedParametersFile so if we stop early we don't lose everything.
pickle.dump(SSWrapper.bestG, open(savedParametersFile, 'wb'))
#We could also save the model, but that might take a while (they can be huge).
#Save some data for plotting:
SSWrapper.compositeCosts.append(compositeCost)
SSWrapper.costsFromAccuracy.append(costFromAccuracy)
SSWrapper.costsFromTime.append(costFromTime)
#Plot them:
SSOptProgressPlot(SSWrapper.compositeCosts,
SSWrapper.costsFromAccuracy,
SSWrapper.costsFromTime)
return compositeCost
#Some variables we'll be using to keep track of the best:
SSWrapper.bestCompositeCost=float('Inf')
SSWrapper.bestG=None
#Some data for plotting as we go:
SSWrapper.compositeCosts=[]
SSWrapper.costsFromAccuracy=[]
SSWrapper.costsFromTime=[]
|
Java
|
UTF-8
| 5,908 | 2.796875 | 3 |
[
"MIT"
] |
permissive
|
package com.jamesratzlaff.rawrecover;
import java.beans.Transient;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
public interface LongRange extends Serializable, Comparable<LongRange> {
default long getEnd() {
return getStart() + getLength();
}
@Transient
long getLength();
void setLength(long len);
default void deltaLength(long delta) {
setLength(getLength() + delta);
}
default void setEnd(long end) {
setLength(end - getStart());
}
default boolean contains(long value) {
return getStart()<=value&&value<getEnd();
}
long getStart();
default boolean hasSameStartAs(LongRange other) {
if(other==null) {
return false;
}
return getStart()==other.getStart();
}
default int compareTo(LongRange other) {
int cmp = 0;
if (this.equals(other)) {
return cmp;
}
if (other == null) {
cmp = -1;
}
if (cmp == 0) {
cmp = Long.compareUnsigned(this.getStart(), other.getStart());
}
if (cmp == 0) {
cmp = Long.compareUnsigned(this.getLength(), other.getLength());
}
return cmp;
}
default boolean contains(LongRange other) {
boolean truth = other!=null;
if(truth) {
if(!this.equals(other)) {
truth=(this.getStart()<=other.getStart())&&this.getLength()>=other.getLength();
}
}
return truth;
}
default int overlaps(LongRange other) {
if(other==null) {
return 0;
}
if(this.getEnd()>other.getStart()&&this.getStart()<other.getStart()) {
return -1;
}
if(other.getStart()>this.getEnd()&&other.getStart()<this.getStart()) {
return 1;
}
return 0;
}
default int isAdjacentTo(LongRange other) {
if(other==null) {
return 0;
}
if(this.getStart()<other.getStart()&&this.getEnd()==other.getStart()) {
return -1;
}
if(other.getEnd()==this.getStart()&&this.getEnd()>other.getEnd()) {
return 1;
}
return 0;
}
default boolean startsBefore(LongRange other) {
if(other==null) {
return false;
}
return this.getStart()<other.getStart();
}
default boolean startsAfter(LongRange other) {
if(other==null) {
return false;
}
return this.getStart()>=other.getEnd();
}
default boolean endsAfter(LongRange other) {
return this.getEnd()>other.getEnd();
}
default boolean endsBefore(LongRange other) {
return getEnd()<=other.getStart();
}
default boolean isBeforeAndOverlaps(LongRange other) {
return getStart()<other.getStart()&&getEnd()>other.getStart()&&getEnd()<other.getEnd();
}
default boolean isAfterAndOverlaps(LongRange other) {
return other.isBeforeAndOverlaps(this);
}
default boolean isBeforeAndAdjacentTo(LongRange other) {
return this.getStart()<other.getStart()&&this.getEnd()==other.getStart();
}
default boolean isAfterAndAdjacentTo(LongRange other) {
return other.isBeforeAndAdjacentTo(this);
}
default boolean isCompletelyBefore(LongRange other) {
return this.getEnd()<other.getStart();
}
default boolean isCompletelyAfter(LongRange other) {
return other.isCompletelyBefore(this);
}
public static LongRange min(LongRange a, LongRange b) {
if(a.compareTo(b)<0) {
return a;
}
return b;
}
public static LongRange max(LongRange a, LongRange b) {
if(a.compareTo(b)>0) {
return a;
}
return b;
}
public static LongRange mergeIfAdjacent(LongRange a, LongRange b) {
int adjacency = a!=null?a.isAdjacentTo(b):0;
if(adjacency==0) {
return null;
}
long len = a.getLength()+b.getLength();
if(adjacency<0) {
return new ArbitraryRange(a.getStart(), len);
}
return new ArbitraryRange(b.getStart(), len);
}
public static LongRange arbitraryMerge(LongRange a, LongRange b) {
LongRange min = min(a,b);
LongRange max = max(a,b);
long start = min.getStart();
long end = max.getEnd();
return new ArbitraryRange(start, end-start);
}
private static int getMaxAdjacentIndex(List<? extends LongRange> sortedRanges, int startIndex) {
int result = -1;
LongRange a = sortedRanges.get(startIndex);
for(int i=startIndex+1;i<sortedRanges.size();i++) {
LongRange b=sortedRanges.get(i);
if(a.isAdjacentTo(b)!=0) {
result=i;
a=b;
} else {
break;
}
}
return result;
}
public static List<LongRange> mergeAdjacents(List<? extends LongRange> ranges) {
List<LongRange> result = new ArrayList<LongRange>();
Collections.sort(ranges);
for(int i=0;i<ranges.size();i++) {
int endAdj = getMaxAdjacentIndex(ranges, i);
LongRange current = ranges.get(i);
if(endAdj!=-1) {
LongRange toMerge = ranges.get(endAdj);
current = arbitraryMerge(current, toMerge);
i=endAdj;
}
result.add(current);
}
return result;
}
public static void main(String[] args) {
ArbitraryRange a = new ArbitraryRange(0, 4);
ArbitraryRange b = new ArbitraryRange(4, 1);
ArbitraryRange c = new ArbitraryRange(5, 1);
ArbitraryRange d = new ArbitraryRange(6, 1);
ArbitraryRange e = new ArbitraryRange(7, 1);
ArbitraryRange f = new ArbitraryRange(8, 1);
List<ArbitraryRange> all = Arrays.asList(a,b,c,d,e,f);
for(int i=0;i<all.size();i++) {
ArbitraryRange current = all.get(i);
int maxAdj = getMaxAdjacentIndex(all, i);
System.out.println("("+i+")"+current+" : "+maxAdj);
}
System.out.println(mergeAdjacents(all));
}
public static boolean aEndsIsBeforeBEnds(LongRange a, LongRange b) {
if(a==null||b==null) {
return false;
}
return Long.compareUnsigned(a.getEnd(), b.getEnd())<0;
}
public static boolean aStartsIsBeforeBStarts(LongRange a, LongRange b) {
if(a==null||b==null) {
return false;
}
return Long.compareUnsigned(a.getStart(), b.getStart())<0;
}
}
|
Markdown
|
UTF-8
| 3,013 | 2.796875 | 3 |
[] |
no_license
|
# Cocoon
This is the backend for the app Cocoon : https://github.com/cs160-sp16/Group-30-Project
#### Domain : cocoon-healthcare.herokuapp.com
#### Video : https://youtu.be/d1S3OY9g25Y
### APIs:
#### /login:
- Inputs : { "name" : "" OR NAME, "email": EMAIL, "password": PASSWORD}
- Output : SUCCESS or FAILURE to login or signup
NOTE: if it is a login, just send email and password and let name be "". But always do send a key for name as both signup and login use the same API.
#### /push :
- Inputs : { "email": EMAIL, "password":PASSWORD, "intensity":INTENSITY(float), "lat": LATITUDE(float), "long": LONGITUDE(float)}
- Output : SUCCESS or FAILURE to save the pushed data
#### /map :
- Inputs : { "email": EMAIL, "password":PASSWORD, "offset":OFFSET(float), "lat": LATITUDE(float), "long": LONGITUDE(float)}
- Output : {SUCCESS or FAILURE,"SoundMap":[[lat_1, long_1, intensity_1],...,[lat_i, long_i, intensity_i]]}
NOTE: The offset is a float that will define a bounding box relative to the sent latitude and longitude in the form, range(lat-offset, lat+offset), range(long-offset, long+offset).
#### /recommend :
- Inputs : {'email' : EMAIL ,
'password' : PASS,
'lat' : CURRENT_LATITUDE,
'lng' : CURRENT_LONGITUDE,
**kwargs(required: see notes)}
- Output : {SUCCESS or FAILURE, 'results':[{'cafe_distance': KM, 'cafe_lat': LAT, 'cafe_lng':LNG,
'cafe_name':NAME', 'noise_level': dB, 'pic_available': BOOL,
'pic_url': (see notes)},...,{...},...]}
NOTES: The keyword arguments for the inputs are mandatory, I purposefully disallowed them to fail
silently. If no values are provided there are default values in the API. For any key if the default
value is okay, please pass "" as the value for that key. The keys are:
'diameter' : (int or float) the diamater around the user, default is 4 kilometers,
'granularity' : (int) number of grid nodes in each direction, default 4,
'image_max_width: (int) this is required by the google api, default is 400,
'noise_mu' : (int or float) the mean value of the sound intesity, default 70 dB,
'noise_sigma' : (int or float) the STD value of the sound intensity, default 30 dB,
'how_many_silent':(int) for each node, how many silent cafes should googel return? ,default 5. Also
please be mindful of this number as each added number is another api call on my account.
'radius_of_search':(int or float) how far should google search from a node to find cafes? default 500,
Please note if this radius is bigger than the node distances then extraneous calls will be made
In outputs,
if no venues are found, a cute cactus image will be returned, along with the message.
if the venue has no pictures, a url to the cocoon logo will be returned.(could have made this
a kwarg too lol)
----------
Thank you.
|
C++
|
UTF-8
| 865 | 2.625 | 3 |
[
"MIT"
] |
permissive
|
#include "Arduino.h"
#include <EBot.h>
int speed = 115;
EBot eBot = EBot();
void setup() {
eBot.begin();
eBot.setSpeed(speed);
}
void loop() {
int num1,num2,num3;
num1 = eBot.getLine1();
num2 = eBot.getLine2();
num3 = eBot.getLine3();
if ((num1 == 0) && num2 && num3) {
eBot.setDirection(EBot::ROTATELEFT);
delay(2);
while(1) {
num2 = eBot.getLine2();
if (num2 == 1) {
eBot.setDirection(EBot::ROTATELEFT);
delay(2);
} else {
break;
}
}
} else if (num1 && num2 && (num3 == 0)) {
eBot.setDirection(EBot::ROTATERIGHT);
delay(2);
while(1) {
num2 = eBot.getLine2();
if (num2 == 1) {
eBot.setDirection(EBot::ROTATERIGHT);
delay(2);
} else {
break;
}
}
}
else {
eBot.setDirection(EBot::FORWARD);
delay(2);
}
}
|
C++
|
UTF-8
| 1,695 | 2.921875 | 3 |
[] |
no_license
|
#include <iostream>
#include <cstring>
#include <cmath>
using namespace std;
const int MAX = 1000000;
bool P[MAX];
int Prime[MAX];
int start, pos;
int head, tail;
bool visit[MAX];
bool flag;
int step;
int prime_num;
class Point{
public:
int _x;
int _d;
Point()
{}
Point(int x, int d = -1):
_x(x), _d(d)
{}
};
Point path[MAX];
void Prime_Find(int n, int m)
{
memset(P, 0, sizeof(0));
for(int i = 2; i*i <= 1000000; i++)
{
if(!P[i])
{
for(int j = i * i; j < 1000000; j+=i)
{
P[j] = true;
}
}
}
prime_num = 0;
for(int i = n; i <= m; i++)
{
if(!P[i])
Prime[prime_num++] = i;
}
}
void BFS(Point);
void Find()
{
head = tail = 0;
memset(visit, 0, sizeof(visit));
Point s(start, 0);
path[tail++] = s;
// WRONG!!
for(int i = 0; i < prime_num; i++)
{
if(start == Prime[i])
visit[i] = true;
}
flag = false;
step = 0;
while(head < tail && !flag)
{
BFS(path[head++]);
}
}
bool judge(int x, int y)
{
int w[4], h[4];
for(int i = 0; i < 4; i++)
{
w[i] = x % 10;
h[i] = y % 10;
x /= 10;
y /= 10;
}
int eq = 0;
for(int i = 0; i < 4; i++)
{
if(w[i] == h[i])
eq++;
}
if(eq == 3)
return true;
else
return false;
}
void BFS(Point p)
{
if(p._x == pos)
{
flag = true;
step = p._d;
return;
}
for(int i = 0; i < prime_num; i++)
{
if(!visit[i] && judge(Prime[i], p._x))
{
visit[i] = true;
Point _new(Prime[i], p._d + 1);
path[tail++] = _new;
}
}
}
int main()
{
Prime_Find(1000, 10000);
int n;
int count = 0;
start = -1, pos = -1;
cin>>n;
while(1)
{
cin>>start>>pos;
Find();
cout<<step<<endl;
count++;
if(count == 100 || count == n)
break;
}
return 0;
}
|
Java
|
UTF-8
| 1,047 | 3.109375 | 3 |
[] |
no_license
|
package com.github.jschmidt10.advent.day11;
import com.github.jschmidt10.advent.day11.WaitingArea.Seat;
import com.github.jschmidt10.advent.util.StringInputFile;
import java.util.List;
public class Day11 {
public static void main(String[] args) {
String filename = "input/day11/input.txt";
StringInputFile inputFile = new StringInputFile(filename);
WaitingArea waitingArea = parseWaitingArea(inputFile.getLines());
while (waitingArea.wasMutated) {
waitingArea = waitingArea.shuffleSeats();
}
int numSeats = waitingArea.getNumOccupied();
System.out.println("Answer: " + numSeats);
}
private static WaitingArea parseWaitingArea(List<String> lines) {
int height = lines.size();
int width = lines.get(0).length();
Seat[][] seats = new Seat[height][width];
for (int i = 0; i < height; i++) {
char[] line = lines.get(i).toCharArray();
for (int j = 0; j < line.length; j++) {
seats[i][j] = Seat.fromChar(line[j]);
}
}
return new WaitingArea(seats);
}
}
|
Go
|
UTF-8
| 1,588 | 2.96875 | 3 |
[
"MIT"
] |
permissive
|
package models
import (
"errors"
)
// The type of VPN security association integrity algorithm
type VpnIntegrityAlgorithmType int
const (
// SHA2-256
SHA2_256_VPNINTEGRITYALGORITHMTYPE VpnIntegrityAlgorithmType = iota
// SHA1-96
SHA1_96_VPNINTEGRITYALGORITHMTYPE
// SHA1-160
SHA1_160_VPNINTEGRITYALGORITHMTYPE
// SHA2-384
SHA2_384_VPNINTEGRITYALGORITHMTYPE
// SHA2-512
SHA2_512_VPNINTEGRITYALGORITHMTYPE
// MD5
MD5_VPNINTEGRITYALGORITHMTYPE
)
func (i VpnIntegrityAlgorithmType) String() string {
return []string{"sha2_256", "sha1_96", "sha1_160", "sha2_384", "sha2_512", "md5"}[i]
}
func ParseVpnIntegrityAlgorithmType(v string) (any, error) {
result := SHA2_256_VPNINTEGRITYALGORITHMTYPE
switch v {
case "sha2_256":
result = SHA2_256_VPNINTEGRITYALGORITHMTYPE
case "sha1_96":
result = SHA1_96_VPNINTEGRITYALGORITHMTYPE
case "sha1_160":
result = SHA1_160_VPNINTEGRITYALGORITHMTYPE
case "sha2_384":
result = SHA2_384_VPNINTEGRITYALGORITHMTYPE
case "sha2_512":
result = SHA2_512_VPNINTEGRITYALGORITHMTYPE
case "md5":
result = MD5_VPNINTEGRITYALGORITHMTYPE
default:
return 0, errors.New("Unknown VpnIntegrityAlgorithmType value: " + v)
}
return &result, nil
}
func SerializeVpnIntegrityAlgorithmType(values []VpnIntegrityAlgorithmType) []string {
result := make([]string, len(values))
for i, v := range values {
result[i] = v.String()
}
return result
}
|
Java
|
UTF-8
| 338 | 2.09375 | 2 |
[] |
no_license
|
public class Sanduiche {
public Pao criaPao() {
return new PaoFrances();
}
public Queijo criaQueijo() {
return new QueijoPrato();
}
public Presunto criaPresunto() {
return new PresuntoFrango();
}
public Ovo criaOvo() {
return new OvoCapoeira();
}
public Tomate criaTomate() {
return new Tomate();
}
}
|
C++
|
UTF-8
| 354 | 2.828125 | 3 |
[] |
no_license
|
#include<iostream>
#include<algorithm>
#include<vector>
using namespace std;
int main()
{
int n;
cin >> n;
int start = 0;
vector<int>v;
for (int i = 0; i < n; i++)
{
int a;
cin >> a;
v.push_back(a);
}
sort(v.begin(), v.end());
int m = n;
for (int i = 0; i < v.size(); i++)
{
start = max(start,v[i]*(m--));
}
cout << start << endl;
}
|
Java
|
UTF-8
| 2,721 | 2.28125 | 2 |
[] |
no_license
|
package com.example.android.notebookapplication;
import android.os.Build;
import android.os.Bundle;
import androidx.annotation.RequiresApi;
import androidx.fragment.app.Fragment;
import androidx.recyclerview.widget.RecyclerView;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
import android.widget.Button;
import android.widget.EditText;
import com.example.android.notebookapplication.Enumerators.AppFragment;
import com.example.android.notebookapplication.models.Job;
public class JobFragment extends Fragment {
private View _currentView;
private RecyclerView _rvList;
private EditText _etJobName;
private Button _bAddJob;
public JobFragment() {
}
public static JobFragment newInstance() {
JobFragment fragment = new JobFragment();
return fragment;
}
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
}
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container,
Bundle savedInstanceState) {
this._currentView = inflater.inflate(R.layout.jobs_fragment, container, false);
if (LoggedInActivity.viewModel.getSelectedList() != null) {
initControls();
initListener();
if (this._rvList instanceof RecyclerView) {
this._rvList.setAdapter(new JobsRecyclerViewAdapter(LoggedInActivity.viewModel.getSelectedList().get_jobs()));
}
}
else{
LoggedInActivity loggedInActivity = (LoggedInActivity) this._currentView.getContext();
loggedInActivity.changeContent(AppFragment.JobsList);
}
return this._currentView;
}
private void initControls(){
this._rvList = this._currentView.findViewById(R.id.list);
this._etJobName = this._currentView.findViewById(R.id.et_title_job);
this._bAddJob = this._currentView.findViewById(R.id.b_add_new_job);
}
private void initListener(){
this._bAddJob.setOnClickListener(new View.OnClickListener() {
@RequiresApi(api = Build.VERSION_CODES.O)
@Override
public void onClick(View view) {
if (!_etJobName.getText().toString().equals("")) {
Job job = new Job();
job.set_title(_etJobName.getText().toString());
LoggedInActivity.viewModel.addJob(job);
_rvList.setAdapter(new JobsRecyclerViewAdapter(LoggedInActivity.viewModel.getSelectedList().get_jobs()));
_etJobName.getText().clear();
}
}
});
}
}
|
JavaScript
|
UTF-8
| 823 | 2.984375 | 3 |
[] |
no_license
|
var http = require('http');
const hostname = '127.0.0.1';
const port = 3000;
// Create a server object
const server = http.createServer(function (req, res) {
// http header
res.writeHead(200, {'Content-Type': 'text/html'});
var url = req.url;
if(url ==='/index') {
res.write(' Welcome!');
res.end();
}
else if(url ==='/about') {
res.write(' Who we are');
res.end();
}
else if(url ==='/what') {
res.write(' What we do');
res.end();
}
else if(url ==='/where') {
res.write(' Where we are');
res.end();
}
else if(url ==='/contact') {
res.write(' Contact us');
res.end();
}
else {
res.write('Working on it!');
res.end();
}
}).listen(3000, function() {
// The server object listens on port 3000
console.log(`Server running at http://${hostname}:${port}/`);
});
|
Java
|
UTF-8
| 343 | 1.984375 | 2 |
[
"MIT"
] |
permissive
|
package org.lpw.clivia.upgrader;
import org.lpw.photon.dao.orm.PageList;
interface UpgraderDao {
PageList<UpgraderModel> query(int pageSize, int pageNum);
UpgraderModel findById(String id);
UpgraderModel latest();
void insert(UpgraderModel upgrader);
void save(UpgraderModel upgrader);
void delete(String id);
}
|
Markdown
|
UTF-8
| 25,951 | 2.546875 | 3 |
[
"MIT"
] |
permissive
|
---
layout: post
title: 深入剖析 Flink Straming WC流程
subtitle:
date: 2020-05-26
author: danner
header-img: img/post-bg-ios9-web.jpg
catalog: true
tags:
- Flink
- bigdata
---
Flink 版本:1.10
```scala
def main(args: Array[String]) {
// Checking input parameters
val params = ParameterTool.fromArgs(args)
// set up the execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.readTextFile(params.get("input"))
val counts: DataStream[(String, Int)] = text
// split up the lines in pairs (2-tuples) containing: (word,1)
.flatMap(_.toLowerCase.split("\\W+"))
.filter(_.nonEmpty)
.map((_, 1))
// group by the tuple field "0" and sum up tuple field "1"
.keyBy(0)
.sum(1)
counts.print()
// execute program
env.execute("Streaming WordCount")
```
最简单的 WC 代码,熟悉 `Spark` 同学对此一定非常熟悉。
- StreamExecutionEnvironment.getExecutionEnvironment 获取 streaming 执行环境
- Source:读取文本
- Transformation:一连串的算子操作
- Sink:Print
- Exe:env.execute() 生成 DAG 提交 job **开始执行**
### StreamExecutionEnvironment
StreamExecutionEnvironment 是抽象类,实现类如下:
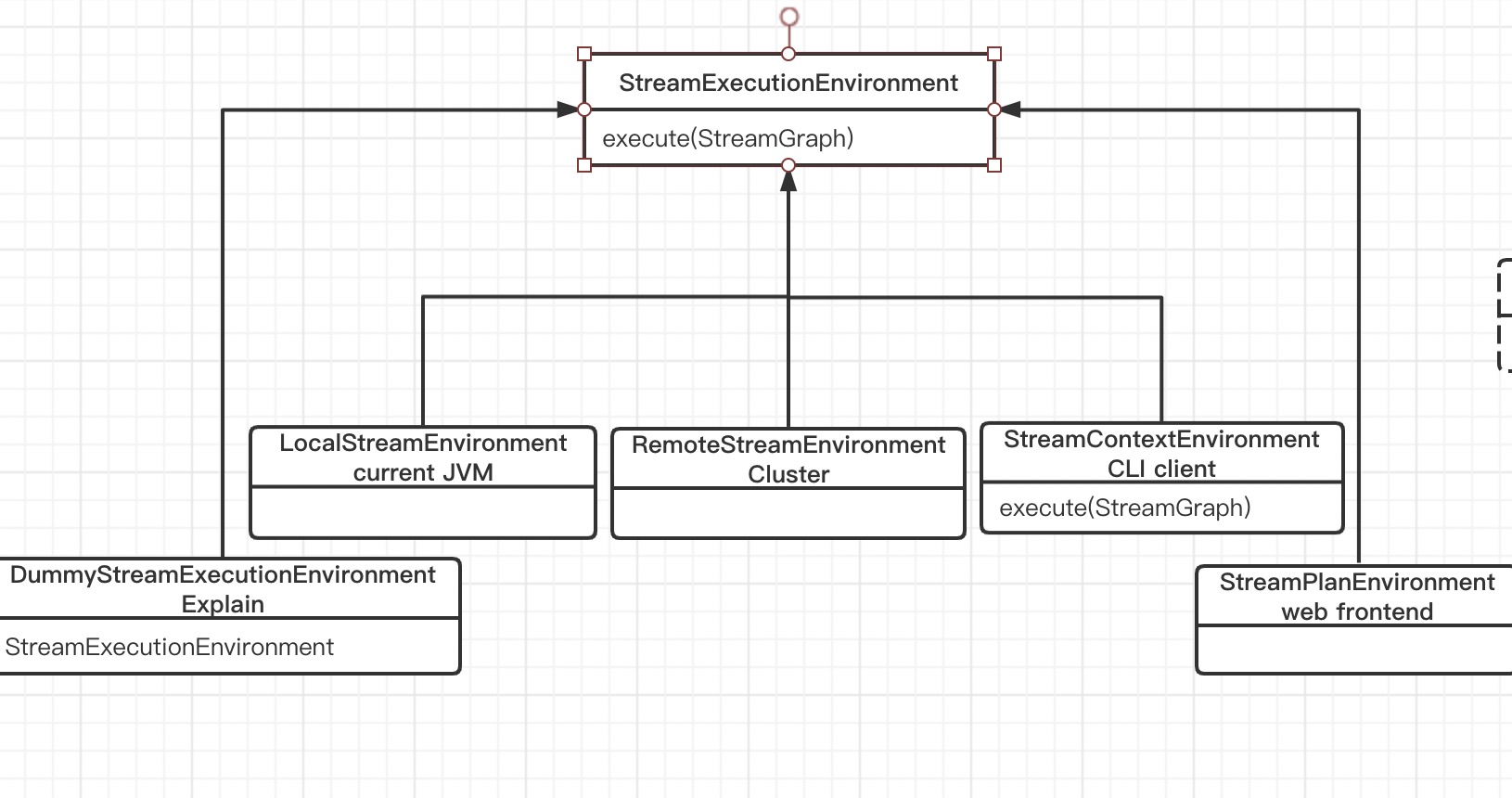
通常只关注以下两个:
- **LocalStreamEnvironment**:当前 `JVM` 运行,例如 IDEA /Standalone 中
- **RemoteStreamEnvironment**:远程运行环境
getExecutionEnvironment API 会**自动**根据当前执行环境选择创建一个实现类:IDEA -> **LocalStreamEnvironment**;集群运行 -> **RemoteStreamEnvironment**。
### Source
```java
ContinuousFileReaderOperator<OUT> reader =
new ContinuousFileReaderOperator<>(inputFormat);
SingleOutputStreamOperator<OUT> source = addSource(monitoringFunction, sourceName)
.transform("Split Reader: " + sourceName, typeInfo, reader);
return new DataStreamSource<>(source);
```
在 Streaming 中,都是用 `DataStream` 来表示且每个 `DataStream` 都会包含 `Operator`(算子 => Transformation) ;Source 会表示成 `DataStreamSource`。
### Transformation
在 Streaming 上做一连串的操作,可以理解为 `Pipeline`。
### Sink
```java
public DataStreamSink<T> print() {
PrintSinkFunction<T> printFunction = new PrintSinkFunction<>();
return addSink(printFunction).name("Print to Std. Out");
}
public DataStreamSink<T> addSink(SinkFunction<T> sinkFunction) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
// configure the type if needed
if (sinkFunction instanceof InputTypeConfigurable) {
((InputTypeConfigurable) sinkFunction).setInputType(getType(), getExecutionConfig());
}
StreamSink<T> sinkOperator = new StreamSink<>(clean(sinkFunction));
DataStreamSink<T> sink = new DataStreamSink<>(this, sinkOperator);
getExecutionEnvironment().addOperator(sink.getTransformation());
return sink;
}
```
与 Source 类似,生成一个 DataStreamSink。
### Execute
execute 时,Flink 程序才算是正在执行,与 Spark 一样都是延迟加载(DAG 优化)。
```java
public JobExecutionResult execute(String jobName) throws Exception {
Preconditions.checkNotNull(jobName, "Streaming Job name should not be null.");
// 生成 StreamGraph
return execute(getStreamGraph(jobName));
}
```
#### StreamGraphGenerator
```java
public StreamGraph getStreamGraph(String jobName, boolean clearTransformations) {
StreamGraph streamGraph = getStreamGraphGenerator().setJobName(jobName).generate();
if (clearTransformations) {
this.transformations.clear();
}
return streamGraph;
}
```
本文不介绍 StreamGraph 生成过程,后文会详细[阐述](https://vendanner.github.io/2020/07/22/Flink-%E6%BA%90%E7%A0%81%E4%B9%8B%E6%9E%84%E5%BB%BA-StreamGraph/)。
#### JobGraph
```java
public JobExecutionResult execute(StreamGraph streamGraph) throws Exception {
final JobClient jobClient = executeAsync(streamGraph);
try {
final JobExecutionResult jobExecutionResult;
if (configuration.getBoolean(DeploymentOptions.ATTACHED)) {
jobExecutionResult = jobClient.getJobExecutionResult(userClassloader).get();
} else {
jobExecutionResult = new DetachedJobExecutionResult(jobClient.getJobID());
}
jobListeners.forEach(jobListener -> jobListener.onJobExecuted(jobExecutionResult, null));
return jobExecutionResult;
} catch (Throwable t) {
jobListeners.forEach(jobListener -> {
jobListener.onJobExecuted(null, ExceptionUtils.stripExecutionException(t));
});
ExceptionUtils.rethrowException(t);
// never reached, only make javac happy
return null;
}
}
```
Executor
```java
public JobClient executeAsync(StreamGraph streamGraph) throws Exception {
checkNotNull(streamGraph, "StreamGraph cannot be null.");
checkNotNull(configuration.get(DeploymentOptions.TARGET), "No execution.target specified in your configuration file.");
// 根据 execution.target 生成不同的 PipelineExecutorFactory
// LocalExecutorFactory,RemoteExecutorFactory,YarnSessionClusterExecutorFactory,
// YarnJobClusterExecutorFactory,KubernetesSessionClusterExecutorFactory
final PipelineExecutorFactory executorFactory =
executorServiceLoader.getExecutorFactory(configuration);
checkNotNull(
executorFactory,
"Cannot find compatible factory for specified execution.target (=%s)",
configuration.get(DeploymentOptions.TARGET));
// new LocalExecutor().execute
// IDEA 中 {execution.attached=true, execution.target=local}
CompletableFuture<JobClient> jobClientFuture = executorFactory
.getExecutor(configuration)
.execute(streamGraph, configuration);
try {
JobClient jobClient = jobClientFuture.get();
jobListeners.forEach(jobListener -> jobListener.onJobSubmitted(jobClient, null));
return jobClient;
} catch (Throwable t) {
jobListeners.forEach(jobListener -> jobListener.onJobSubmitted(null, t));
ExceptionUtils.rethrow(t);
// make javac happy, this code path will not be reached
return null;
}
}
```
```java
// org.apache.flink.client.deployment.executors.LocalExecutor
public CompletableFuture<JobClient> execute(Pipeline pipeline, Configuration configuration) throws Exception {
checkNotNull(pipeline);
checkNotNull(configuration);
// we only support attached execution with the local executor.
checkState(configuration.getBoolean(DeploymentOptions.ATTACHED));
//
final JobGraph jobGraph = getJobGraph(pipeline, configuration);
final MiniCluster miniCluster = startMiniCluster(jobGraph, configuration);
final MiniClusterClient clusterClient = new MiniClusterClient(configuration, miniCluster);
CompletableFuture<JobID> jobIdFuture = clusterClient.submitJob(jobGraph);
jobIdFuture
.thenCompose(clusterClient::requestJobResult)
.thenAccept((jobResult) -> clusterClient.shutDownCluster());
return jobIdFuture.thenApply(jobID ->
new ClusterClientJobClientAdapter<>(() -> clusterClient, jobID));
}
```
``` java
// org.apache.flink.client.deployment.executors.LocalExecutor
private JobGraph getJobGraph(Pipeline pipeline, Configuration configuration) {
// This is a quirk in how LocalEnvironment used to work. It sets the default parallelism
// to <num taskmanagers> * <num task slots>. Might be questionable but we keep the behaviour
// for now.
if (pipeline instanceof Plan) {
Plan plan = (Plan) pipeline;
final int slotsPerTaskManager = configuration.getInteger(
TaskManagerOptions.NUM_TASK_SLOTS, plan.getMaximumParallelism());
final int numTaskManagers = configuration.getInteger(
ConfigConstants.LOCAL_NUMBER_TASK_MANAGER, 1);
plan.setDefaultParallelism(slotsPerTaskManager * numTaskManagers);
}
return FlinkPipelineTranslationUtil.getJobGraph(pipeline, configuration, 1);
}
```
本文不介绍 JobGraph 生成过程,后文会详细阐述。
#### MiniCluster
```Java
// org.apache.flink.client.deployment.executors.LocalExecutor
private MiniCluster startMiniCluster(final JobGraph jobGraph, final Configuration configuration) throws Exception {
...
int numTaskManagers = configuration.getInteger(
ConfigConstants.LOCAL_NUMBER_TASK_MANAGER,
ConfigConstants.DEFAULT_LOCAL_NUMBER_TASK_MANAGER);
// we have to use the maximum parallelism as a default here, otherwise streaming
// pipelines would not run
int numSlotsPerTaskManager = configuration.getInteger(
TaskManagerOptions.NUM_TASK_SLOTS,
jobGraph.getMaximumParallelism());
// 配置 MiniCluster:NumTaskManagers,NumSlotsPerTaskManager
final MiniClusterConfiguration miniClusterConfiguration =
new MiniClusterConfiguration.Builder()
.setConfiguration(configuration)
.setNumTaskManagers(numTaskManagers)
.setRpcServiceSharing(RpcServiceSharing.SHARED)
.setNumSlotsPerTaskManager(numSlotsPerTaskManager)
.build();
final MiniCluster miniCluster = new MiniCluster(miniClusterConfiguration);
// 启动
miniCluster.start();
configuration.setInteger(RestOptions.PORT, miniCluster.getRestAddress().get().getPort());
return miniCluster;
}
```
```java
// MiniCluster to execute Flink jobs locally
// org.apache.flink.runtime.minicluster.MiniCluster
public void start() throws Exception {
// 准备配置
try {
initializeIOFormatClasses(configuration);
//开启 Metrics Registry
LOG.info("Starting Metrics Registry");
metricRegistry = createMetricRegistry(configuration);
// RPC 服务
// bring up all the RPC services
LOG.info("Starting RPC Service(s)");
AkkaRpcServiceConfiguration akkaRpcServiceConfig = AkkaRpcServiceConfiguration.fromConfiguration(configuration);
final RpcServiceFactory dispatcherResourceManagreComponentRpcServiceFactory;
...
// start a new service per component, possibly with custom bind addresses
final String jobManagerBindAddress = miniClusterConfiguration.getJobManagerBindAddress();
final String taskManagerBindAddress = miniClusterConfiguration.getTaskManagerBindAddress();
// DedicatedRpc
dispatcherResourceManagreComponentRpcServiceFactory = new DedicatedRpcServiceFactory(akkaRpcServiceConfig, jobManagerBindAddress);
// taskManagerRpc
taskManagerRpcServiceFactory = new DedicatedRpcServiceFactory(akkaRpcServiceConfig, taskManagerBindAddress);
}
// MetricsRpc
RpcService metricQueryServiceRpcService = MetricUtils.startMetricsRpcService(
configuration,
commonRpcService.getAddress());
// Starting high-availability services
haServices = createHighAvailabilityServices(configuration, ioExecutor);
// Blob 服务:flink 用来管理二进制大文件的服务
// http://chenyuzhao.me/2017/02/08/jobmanager%E5%9F%BA%E6%9C%AC%E7%BB%84%E4%BB%B6/
blobServer = new BlobServer(configuration, haServices.createBlobStore());
blobServer.start();
// 心跳
heartbeatServices = HeartbeatServices.fromConfiguration(configuration);
// 启动 TM
startTaskManagers();
MetricQueryServiceRetriever metricQueryServiceRetriever = new RpcMetricQueryServiceRetriever(metricRegistry.getMetricQueryServiceRpcService());
setupDispatcherResourceManagerComponents(configuration, dispatcherResourceManagreComponentRpcServiceFactory, metricQueryServiceRetriever);
resourceManagerLeaderRetriever = haServices.getResourceManagerLeaderRetriever();
dispatcherLeaderRetriever = haServices.getDispatcherLeaderRetriever();
clusterRestEndpointLeaderRetrievalService = haServices.getClusterRestEndpointLeaderRetriever();
// dispatcher
dispatcherGatewayRetriever = new RpcGatewayRetriever<>(
commonRpcService,
DispatcherGateway.class,
DispatcherId::fromUuid,
20,
Time.milliseconds(20L));
// resourceManager
resourceManagerGatewayRetriever = new RpcGatewayRetriever<>(
commonRpcService,
ResourceManagerGateway.class,
ResourceManagerId::fromUuid,
20,
Time.milliseconds(20L));
webMonitorLeaderRetriever = new LeaderRetriever();
resourceManagerLeaderRetriever.start(resourceManagerGatewayRetriever);
dispatcherLeaderRetriever.start(dispatcherGatewayRetriever);
clusterRestEndpointLeaderRetrievalService.start(webMonitorLeaderRetriever);
}
...
}
// create a new termination future
terminationFuture = new CompletableFuture<>();
// now officially mark this as running
running = true;
LOG.info("Flink Mini Cluster started successfully");
}
}
```
MiniCluster 启动一堆服务
#### Submit Job
```java
// org.apache.flink.runtime.minicluster.MiniCluster
public CompletableFuture<JobSubmissionResult> submitJob(JobGraph jobGraph) {
final CompletableFuture<DispatcherGateway> dispatcherGatewayFuture = getDispatcherGatewayFuture();
final CompletableFuture<InetSocketAddress> blobServerAddressFuture = createBlobServerAddress(dispatcherGatewayFuture);
// 上传任务所需文件和 jobGraph
final CompletableFuture<Void> jarUploadFuture = uploadAndSetJobFiles(blobServerAddressFuture, jobGraph);
// job 提交到调度器
final CompletableFuture<Acknowledge> acknowledgeCompletableFuture = jarUploadFuture
.thenCombine(
dispatcherGatewayFuture,
(Void ack, DispatcherGateway dispatcherGateway) ->
// dispatcher 提交任务
dispatcherGateway.submitJob(jobGraph, rpcTimeout))
.thenCompose(Function.identity());
return acknowledgeCompletableFuture.thenApply(
(Acknowledge ignored) -> new JobSubmissionResult(jobGraph.getJobID()));
}
// org.apache.flink.runtime.dispatcher
// 每一步都有任务异常的处理 (throwable != null)
private CompletableFuture<Void> persistAndRunJob(JobGraph jobGraph) throws Exception {
// 记录 jobGraph ,并 run
jobGraphWriter.putJobGraph(jobGraph);
final CompletableFuture<Void> runJobFuture = runJob(jobGraph);
return runJobFuture.whenComplete(BiConsumerWithException.unchecked((Object ignored, Throwable throwable) -> {
if (throwable != null) {
jobGraphWriter.removeJobGraph(jobGraph.getJobID());
}
}));
}
private CompletableFuture<Void> runJob(JobGraph jobGraph) {
Preconditions.checkState(!jobManagerRunnerFutures.containsKey(jobGraph.getJobID()));
// jobManagerRunner
final CompletableFuture<JobManagerRunner> jobManagerRunnerFuture = createJobManagerRunner(jobGraph);
jobManagerRunnerFutures.put(jobGraph.getJobID(), jobManagerRunnerFuture);
// 提交
return jobManagerRunnerFuture
.thenApply(FunctionUtils.uncheckedFunction(this::startJobManagerRunner))
.thenApply(FunctionUtils.nullFn())
.whenCompleteAsync(
(ignored, throwable) -> {
if (throwable != null) {
jobManagerRunnerFutures.remove(jobGraph.getJobID());
}
},
getMainThreadExecutor());
}
```
#### 流程
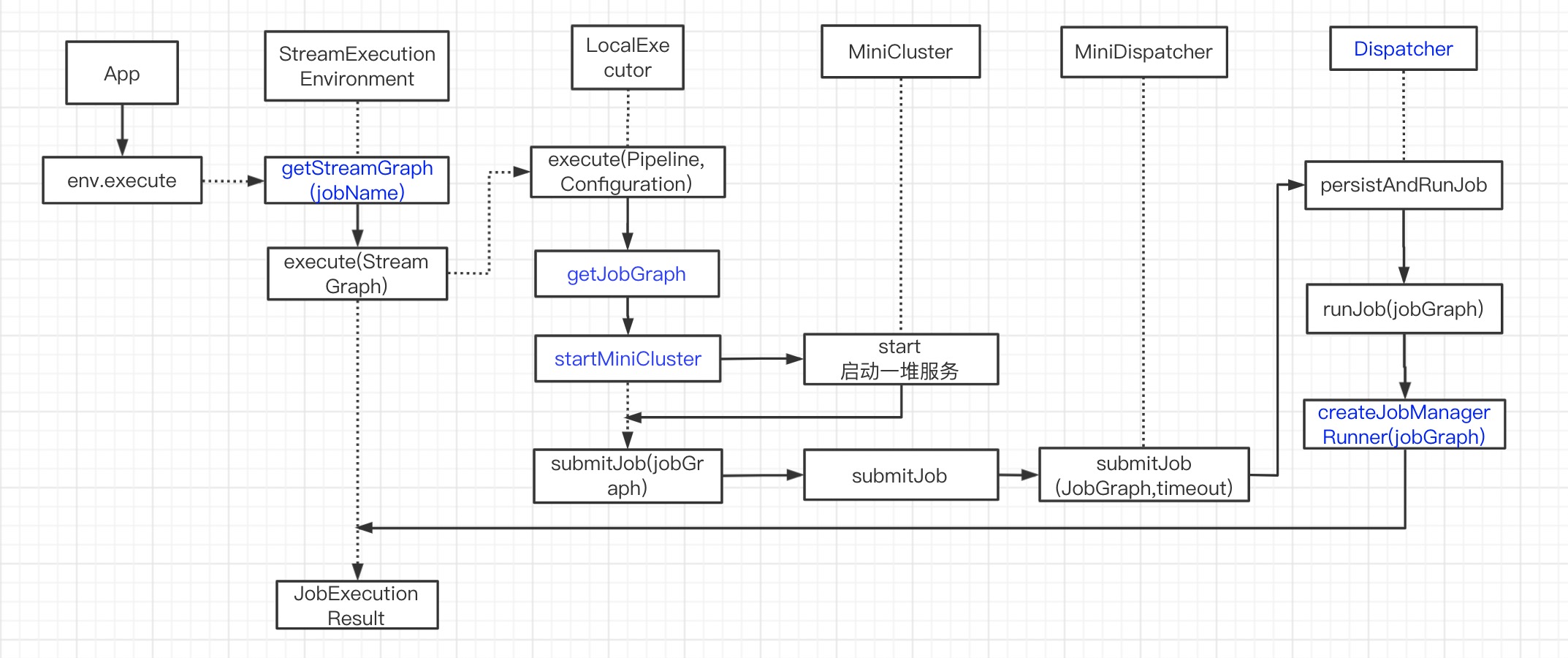
### 启动日志
``` shell
org.apache.flink.runtime.minicluster.MiniCluster - Starting Flink Mini Cluster
org.apache.flink.runtime.minicluster.MiniCluster - Starting Metrics Registry
org.apache.flink.runtime.metrics.MetricRegistryImpl - No metrics reporter configured, no metrics will be exposed/reported.
org.apache.flink.runtime.minicluster.MiniCluster - Starting RPC Service(s)
akka.event.slf4j.Slf4jLogger - Slf4jLogger started
org.apache.flink.runtime.rpc.akka.AkkaRpcServiceUtils - Trying to start actor system at :0
akka.event.slf4j.Slf4jLogger - Slf4jLogger started
akka.remote.Remoting - Starting remoting
akka.remote.Remoting - Remoting started; listening on addresses :[akka.tcp://flink-metrics@127.0.0.1:64276]
org.apache.flink.runtime.rpc.akka.AkkaRpcServiceUtils - Actor system started at akka.tcp://flink-metrics@127.0.0.1:64276
org.apache.flink.runtime.rpc.akka.AkkaRpcService - Starting RPC endpoint for org.apache.flink.runtime.metrics.dump.MetricQueryService at akka://flink-metrics/user/MetricQueryService .
org.apache.flink.runtime.minicluster.MiniCluster - Starting high-availability services
org.apache.flink.runtime.blob.BlobServer - Created BLOB server storage directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/blobStore-7dd1e563-2fa2-4da1-aee2-8b67927bd0d2
org.apache.flink.runtime.blob.BlobServer - Started BLOB server at 0.0.0.0:64292 - max concurrent requests: 50 - max backlog: 1000
org.apache.flink.runtime.blob.PermanentBlobCache - Created BLOB cache storage directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/blobStore-a753f5f4-a6d1-4d7f-a74a-306e3b1f13ea
org.apache.flink.runtime.blob.TransientBlobCache - Created BLOB cache storage directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/blobStore-ec1da097-ca2d-4465-85eb-c2bcfb73e22e
org.apache.flink.runtime.minicluster.MiniCluster - Starting 1 TaskManger(s)
org.apache.flink.runtime.taskexecutor.TaskManagerRunner - Starting TaskManager with ResourceID: fa24c9b8-8108-428b-bd5c-94d169dcdf9c
org.apache.flink.runtime.taskexecutor.TaskManagerServices - Temporary file directory '/var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T': total 233 GB, usable 80 GB (34.33% usable)
org.apache.flink.runtime.io.disk.FileChannelManagerImpl - FileChannelManager uses directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/flink-io-dcafdb6b-a36c-4bfa-9ec6-0e5e4f982631 for spill files.
org.apache.flink.runtime.io.disk.FileChannelManagerImpl - FileChannelManager uses directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/flink-netty-shuffle-0d753714-eb7c-4a29-815e-d8289ccdb1ec for spill files.
org.apache.flink.runtime.io.network.buffer.NetworkBufferPool - Allocated 64 MB for network buffer pool (number of memory segments: 2048, bytes per segment: 32768).
org.apache.flink.runtime.io.network.NettyShuffleEnvironment - Starting the network environment and its components.
org.apache.flink.runtime.taskexecutor.KvStateService - Starting the kvState service and its components.
org.apache.flink.runtime.taskexecutor.TaskManagerConfiguration - Messages have a max timeout of 10000 ms
org.apache.flink.runtime.rpc.akka.AkkaRpcService - Starting RPC endpoint for org.apache.flink.runtime.taskexecutor.TaskExecutor at akka://flink/user/taskmanager_0 .
org.apache.flink.runtime.taskexecutor.JobLeaderService - Start job leader service.
org.apache.flink.runtime.filecache.FileCache - User file cache uses directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/flink-dist-cache-cb29d64c-fc7d-4083-b8a7-f95651ab0dcd
org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Starting rest endpoint.
org.apache.flink.runtime.webmonitor.WebMonitorUtils - Log file environment variable 'log.file' is not set.
org.apache.flink.runtime.webmonitor.WebMonitorUtils - JobManager log files are unavailable in the web dashboard. Log file location not found in environment variable 'log.file' or configuration key 'Key: 'web.log.path' , default: null (fallback keys: [{key=jobmanager.web.log.path, isDeprecated=true}])'.
org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Failed to load web based job submission extension. Probable reason: flink-runtime-web is not in the classpath.
org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - Rest endpoint listening at localhost:50064
org.apache.flink.runtime.highavailability.nonha.embedded.EmbeddedLeaderService - Proposing leadership to contender http://localhost:50064
org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint - http://localhost:50064 was granted leadership with leaderSessionID=230a5f5d-ae28-4b29-9173-b832e3604619
org.apache.flink.runtime.highavailability.nonha.embedded.EmbeddedLeaderService - Received confirmation of leadership for leader http://localhost:50064 , session=230a5f5d-ae28-4b29-9173-b832e3604619
org.apache.flink.runtime.rpc.akka.AkkaRpcService - Starting RPC endpoint for org.apache.flink.runtime.resourcemanager.StandaloneResourceManager at akka://flink/user/resourcemanager .
org.apache.flink.runtime.highavailability.nonha.embedded.EmbeddedLeaderService - Proposing leadership to contender LeaderContender: DefaultDispatcherRunner
org.apache.flink.runtime.highavailability.nonha.embedded.EmbeddedLeaderService - Proposing leadership to contender LeaderContender: StandaloneResourceManager
org.apache.flink.runtime.resourcemanager.StandaloneResourceManager - ResourceManager akka://flink/user/resourcemanager was granted leadership with fencing token b3ae8d20f361fef5ef89578541eb4363
org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess - Start SessionDispatcherLeaderProcess.
org.apache.flink.runtime.resourcemanager.slotmanager.SlotManagerImpl - Starting the SlotManager.
org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess - Recover all persisted job graphs.
org.apache.flink.runtime.dispatcher.runner.SessionDispatcherLeaderProcess - Successfully recovered 0 persisted job graphs.
org.apache.flink.runtime.highavailability.nonha.embedded.EmbeddedLeaderService - Received confirmation of leadership for leader akka://flink/user/resourcemanager , session=ef895785-41eb-4363-b3ae-8d20f361fef5
org.apache.flink.runtime.taskexecutor.TaskExecutor - Connecting to ResourceManager akka://flink/user/resourcemanager(b3ae8d20f361fef5ef89578541eb4363).
org.apache.flink.runtime.rpc.akka.AkkaRpcService - Starting RPC endpoint for org.apache.flink.runtime.dispatcher.StandaloneDispatcher at akka://flink/user/dispatcher .
org.apache.flink.runtime.taskexecutor.TaskExecutor - Resolved ResourceManager address, beginning registration
org.apache.flink.runtime.taskexecutor.TaskExecutor - Registration at ResourceManager attempt 1 (timeout=100ms)
org.apache.flink.runtime.resourcemanager.StandaloneResourceManager - Registering TaskManager with ResourceID 6babbfff-6da0-4d9f-96cc-2f00a8656ed7 (akka://flink/user/taskmanager_0) at ResourceManager
org.apache.flink.runtime.highavailability.nonha.embedded.EmbeddedLeaderService - Received confirmation of leadership for leader akka://flink/user/dispatcher , session=1665e1f7-0cb0-40f1-8c1b-451b6b8d9de6
org.apache.flink.runtime.taskexecutor.TaskExecutor - Successful registration at resource manager akka://flinkorg.apache.flink.runtime.minicluster.MiniCluster - Starting Flink Mini Cluster
org.apache.flink.runtime.minicluster.MiniCluster - Starting Metrics Registry
org.apache.flink.runtime.metrics.MetricRegistryImpl - No metrics reporter configured, no metrics will be exposed/reported.
org.apache.flink.runtime.minicluster.MiniCluster - Starting RPC Service(s)
akka.event.slf4j.Slf4jLogger - Slf4jLogger started
org.apache.flink.runtime.rpc.akka.AkkaRpcServiceUtils - Trying to start actor system at :0
akka.event.slf4j.Slf4jLogger - Slf4jLogger started
akka.remote.Remoting - Starting remoting
akka.remote.Remoting - Remoting started; listening on addresses :[akka.tcp://flink-metrics@127.0.0.1:64276]
org.apache.flink.runtime.rpc.akka.AkkaRpcServiceUtils - Actor system started at akka.tcp://flink-metrics@127.0.0.1:64276
org.apache.flink.runtime.rpc.akka.AkkaRpcService - Starting RPC endpoint for org.apache.flink.runtime.metrics.dump.MetricQueryService at akka://flink-metrics/user/MetricQueryService .
org.apache.flink.runtime.minicluster.MiniCluster - Starting high-availability services
org.apache.flink.runtime.blob.BlobServer - Created BLOB server storage directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/blobStore-7dd1e563-2fa2-4da1-aee2-8b67927bd0d2
org.apache.flink.runtime.blob.BlobServer - Started BLOB server at 0.0.0.0:64292 - max concurrent requests: 50 - max backlog: 1000
org.apache.flink.runtime.blob.PermanentBlobCache - Created BLOB cache storage directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/blobStore-a753f5f4-a6d1-4d7f-a74a-306e3b1f13ea
org.apache.flink.runtime.blob.TransientBlobCache - Created BLOB cache storage directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/blobStore-ec1da097-ca2d-4465-85eb-c2bcfb73e22e
org.apache.flink.runtime.minicluster.MiniCluster - Starting 1 TaskManger(s)
org.apache.flink.runtime.taskexecutor.TaskManagerRunner - Starting TaskManager with ResourceID: fa24c9b8-8108-428b-bd5c-94d169dcdf9c
org.apache.flink.runtime.taskexecutor.TaskManagerServices - Temporary file directory '/var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T': total 233 GB, usable 80 GB (34.33% usable)
org.apache.flink.runtime.io.disk.FileChannelManagerImpl - FileChannelManager uses directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/flink-io-dcafdb6b-a36c-4bfa-9ec6-0e5e4f982631 for spill files.
org.apache.flink.runtime.io.disk.FileChannelManagerImpl - FileChannelManager uses directory /var/folders/rq/kmxm07hx54jbnhfvg93gv62c0000gn/T/flink-netty-shuffle-0d753714-eb7c-4a29-815e-d8289ccdb1ec for spill files.
org.apache.flink.runtime.io.network.buffer.NetworkBufferPool - Allocated 64 MB for network buffer pool (number of memory segments: 2048, bytes per segment: 32768).
org.apache.flink.runtime.io.network.NettyShuffleEnvironment - Starting the network environment and its components.
org.apache.flink.runtime.taskexecutor.KvStateService - Starting the kvState service and its components.
org.apache.flink.runtime.taskexecutor.TaskManagerConfiguration - Messages have a max timeout of 10000 ms
org.apache.flink.runtime.rpc.akka.AkkaRpcService - Starting RPC endpoint for org.apache.flink.runtime.taskexecutor.TaskExecutor at akka://flink/user/taskmanager_0 .
org.apache.flink.runtime.taskexecutor.JobLeaderService - Start job leader service.
```
|
Markdown
|
UTF-8
| 3,589 | 3.328125 | 3 |
[
"MIT"
] |
permissive
|
# loveboat-nested-scopes
support nested auth scopes in hapi
(a transform written for [**loveboat**](https://github.com/devinivy/loveboat))
[](https://travis-ci.org/devinivy/loveboat-nested-scopes) [](https://coveralls.io/github/devinivy/loveboat-nested-scopes?branch=master)
Lead Maintainer - [Devin Ivy](https://github.com/devinivy)
## Usage
> See also the [API Reference](API.md)
This loveboat transform allows you to define hierarchical auth scopes on routes and to leverage that hierarchy when writing your route configurations. The core idea is that allowing unprivileged scopes on a route should also permit the higher-privileged scopes.
Imagine a `basic-user` scope and an `admin` scope. Every admin is naturally allowed to perform the actions of a basic user. So let's make our app aware of that and start writing this,
```js
// Scopes can be smart!
server.loveboat({
method: 'get',
path: '/my/file.gif',
handler: handler,
config: {
auth: {
access: {
scope: ['[basic-user]']
// Becomes ['basic-user', 'admin']
}
}
}
});
```
To use this transform,
1. Make sure the [loveboat](https://github.com/devinivy/loveboat) hapi plugin is registered to your server.
2. Tell loveboat that you'd like to use this transform by calling,
```js
server.routeTransforms([{
transform: require('loveboat-nested-scopes'),
options: {
scope: 'admin',
subscopes: ['basic-user']
// Define your nested scopes
}
}]);
```
and possibly listing any other transforms you'd like to use.*
3. Register your routes using `server.loveboat()` rather than `server.route()`.
<sup>* There are other ways to tell loveboat which transforms to use too! Just check-out the [readme](https://github.com/devinivy/loveboat/blob/master/README.md).
```js
const Hapi = require('hapi');
const Loveboat = require('loveboat');
const server = new Hapi.Server();
server.connection();
// 1. Register loveboat
server.register(Loveboat, (err) => {
// 2. Tell loveboat to use this transform, providing info about your nested scopes
server.routeTransforms([{
transform: require('loveboat-nested-scopes'),
options: {
scope: 'admin',
subscopes: [
{
scope: 'super-user',
subscopes: [
'api-user',
'files-user'
]
}
]
}
}]);
// 3. Configure your routes!
server.loveboat({
method: 'get',
path: '/my/file.gif',
handler: handler,
config: {
auth: {
access: {
scope: ['[files-user]']
/*
* Use '[]' to indicate that the
* scope should be expanded.
*
* Scope becomes effectively,
* [
* 'files-user',
* 'super-user',
* 'admin'
* ]
*/
}
}
}
});
// The route above will allow users with scope 'files-user'
// as well as that scope's parents, 'super-user' and 'admin'
});
```
|
JavaScript
|
UTF-8
| 5,130 | 2.90625 | 3 |
[] |
no_license
|
import { createMovie, getMovieById, editMovie as apiEdit, deleteMovie } from '../data.js';
// add/create movie
export async function addGet() {
this.partials = {
header: await this.load('../../templates/common/header.hbs'),
footer: await this.load('../../templates/common/footer.hbs')
}
this.partial('../../templates/movies/addMovie.hbs', this.app.userData);
}
export async function addPost() {
try {
const { title, description, imageUrl } = this.params;
if (!title || !description || !imageUrl) {
throw new Error('Invalid input!');
}
const movie = { title, description, image: imageUrl, creator: this.app.userData.email, peopleLiked: [], likes: 0 };
const result = await createMovie(movie);
if (result.hasOwnProperty('errorData')) {
const error = new Error();
Object.assign(error, result)
throw error;
}
showInfo('Created successfully!');
this.redirect('#/home');
} catch (error) {
showError(error.message);
console.log(error);
}
}
// details
export async function details() {
this.partials = {
header: await this.load('../../templates/common/header.hbs'),
footer: await this.load('../../templates/common/footer.hbs')
}
const movieId = this.params.id;
const movie = await getMovieById(movieId);
const isCreator = movie.creator === this.app.userData.email;
let isLiked;
if (movie.peopleLiked.includes(this.app.userData.email)) {
isLiked = true;
} else {
isLiked = false;
}
const context = Object.assign({ isCreator, isLiked }, movie, this.app.userData);
this.partial('../../templates/movies/details.hbs', context);
}
// edit
export default async function editGet() {
this.partials = {
header: await this.load('../../templates/common/header.hbs'),
footer: await this.load('../../templates/common/footer.hbs')
}
const movieId = this.params.id;
let movie = this.app.userData.movies.find(e => e.objectId == movieId);
if (movie === undefined) {
movie = await getMovieById(movieId);
}
const context = Object.assign(movie, this.app.userData);
this.partial('../../templates/movies/editMovie.hbs', context);
}
export async function editMovie() {
try {
const { title, description, imageUrl } = this.params;
const movieId = this.params.id;
if (!title || !description || !imageUrl) {
throw new Error('Invalid input!');
}
const movie = { title, description, image: imageUrl };
const result = await apiEdit(movieId, movie);
if (result.hasOwnProperty('errorData')) {
const error = new Error();
Object.assign(error, result)
throw error;
}
showInfo('Edited successfully!');
this.redirect(`#/details/${movieId}`);
} catch (error) {
showError(error.message);
}
}
// delete
export async function movieDelete() {
try {
const movieId = this.params.id;
const result = await deleteMovie(movieId);
if (result.hasOwnProperty('errorData')) {
const error = new Error();
Object.assign(error, result)
throw error;
}
showInfo('Deleted successfully!')
this.redirect('#/home');
} catch (error) {
showError(error.message);
}
}
// like
export async function likeMovie() {
try {
const movieId = this.params.id;
const movie = await getMovieById(movieId);
if (!movie.peopleLiked.includes(this.app.userData.email)) {
movie.peopleLiked.push(this.app.userData.email);
movie.likes += 1;
} else {
throw new Error('You liked the movie already!');
}
const result = await apiEdit(movieId, {peopleLiked: movie.peopleLiked, likes: movie.likes});
if (result.hasOwnProperty('errorData')) {
const error = new Error();
Object.assign(error, result)
throw error;
}
showInfo('Successfully liked the movie!');
this.redirect(`#/details/${movieId}`);
} catch (error) {
showError(error.message);
}
}
// notifications
function showInfo(message) {
const notification = document.querySelector('#successBox');
notification.textContent = message;
notification.parentElement.style.display = 'block';
setTimeout(() => {
notification.parentElement.style.display = 'none';
}, 1000);
}
function showError(message) {
const notification = document.querySelector('#errorBox');
notification.textContent = message;
notification.parentElement.style.display = 'block';
setTimeout(() => {
notification.parentElement.style.display = 'none';
}, 1000);
}
|
Java
|
UTF-8
| 3,110 | 2.984375 | 3 |
[] |
no_license
|
/* This code is part of Freenet. It is distributed under the GNU General
* Public License, version 2 (or at your option any later version). See
* http://www.gnu.org/ for further details of the GPL. */
package plugins.Library.util;
import static plugins.Library.util.Maps.$;
import java.util.Map.Entry; // workaround javadoc bug #4464323
import java.util.Map;
/**
** Methods for maps.
**
** @author infinity0
*/
final public class Maps {
/**
** A simple {@link Entry} with no special properties.
*/
public static class BaseEntry<K, V> implements Map.Entry<K, V> {
final public K key;
protected V val;
public BaseEntry(K k, V v) { key = k; val = v; }
public K getKey() { return key; }
public V getValue() { return val; }
public V setValue(V n) { V o = val; val = n; return o; }
}
/**
** A {@link Entry} whose value cannot be modified.
*/
public static class ImmutableEntry<K, V> extends BaseEntry<K, V> {
public ImmutableEntry(K k, V v) { super(k, v); }
/**
** @throws UnsupportedOperationException always
*/
@Override public V setValue(V n) {
throw new UnsupportedOperationException("ImmutableEntry: cannot modify value after creation");
}
}
/**
** A {@link Entry} whose {@link Object#equals(Object)} and {@link
** Object#hashCode()} are defined purely in terms of the key, which is
** immutable in the entry.
*/
public static class KeyEntry<K, V> extends BaseEntry<K, V> {
public KeyEntry(K k, V v) { super(k, v); }
/**
** Whether the object is also a {@link KeyEntry} and has the same
** {@code #key} as this entry.
*/
@Override public boolean equals(Object o) {
if (!(o instanceof KeyEntry)) { return false; }
return key.equals(((KeyEntry)o).key);
}
@Override public int hashCode() {
return 31 * key.hashCode();
}
}
private Maps() { }
/**
** Returns a new {@link BaseEntry} with the given key and value.
*/
public static <K, V> Map.Entry<K, V> $(final K k, final V v) {
return new BaseEntry<K, V>(k, v);
}
/**
** Returns a new {@link ImmutableEntry} with the given key and value.
*/
public static <K, V> Map.Entry<K, V> $$(final K k, final V v) {
return new ImmutableEntry<K, V>(k, v);
}
/**
** Returns a new {@link KeyEntry} with the given key and value.
*/
public static <K, V> Map.Entry<K, V> $K(K k, V v) {
return new KeyEntry<K, V>(k, v);
}
public static <K, V> Map<K, V> of(Class<? extends Map> mapcl, Map.Entry<K, V>... items) {
try {
Map<K, V> map = mapcl.newInstance();
for (Map.Entry<K, V> en: items) {
map.put(en.getKey(), en.getValue());
}
return map;
} catch (InstantiationException e) {
throw new IllegalArgumentException("Could not instantiate map class", e);
} catch (IllegalAccessException e) {
throw new IllegalArgumentException("Could not access map class", e);
}
}
/*final private static Map<String, String> testmap = of(SkeletonTreeMap.class,
$("test1", "test1"),
$("test2", "test2"),
$("test3", "test3")
);*/
}
|
Java
|
UTF-8
| 869 | 1.625 | 2 |
[] |
no_license
|
/*
* Decompiled with CFR 0.151.
*/
package com.google.firebase.crashlytics.internal.common;
import com.google.firebase.crashlytics.internal.common.CrashlyticsController;
import com.google.firebase.crashlytics.internal.common.CrashlyticsUncaughtExceptionHandler$CrashListener;
import com.google.firebase.crashlytics.internal.settings.SettingsDataProvider;
public class CrashlyticsController$1
implements CrashlyticsUncaughtExceptionHandler$CrashListener {
public final /* synthetic */ CrashlyticsController this$0;
public CrashlyticsController$1(CrashlyticsController crashlyticsController) {
this.this$0 = crashlyticsController;
}
public void onUncaughtException(SettingsDataProvider settingsDataProvider, Thread thread, Throwable throwable) {
this.this$0.handleUncaughtException(settingsDataProvider, thread, throwable);
}
}
|
Python
|
UTF-8
| 3,027 | 2.921875 | 3 |
[] |
no_license
|
import random
import arcade
class Enemy(arcade.AnimatedWalkingSprite):
def __init__(self):
super().__init__()
self.width = 100
self.height = 100
self.stand_right_textures = [arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_idle.png")]
self.stand_left_textures = [arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_idle.png", mirrored=True)]
self.walk_right_textures = [arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_walk0.png"),
arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_walk1.png"),
arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_walk2.png"),
arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_walk3.png"),
arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_walk4.png"),
arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_walk5.png"),
arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_walk6.png"),
arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_walk7.png")]
self.walk_left_textures = [arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_walk0.png", mirrored=True),
arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_walk1.png",mirrored=True),
arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_walk2.png",mirrored=True),
arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_walk3.png",mirrored=True),
arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_walk4.png",mirrored=True),
arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_walk5.png",mirrored=True),
arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_walk6.png",mirrored=True),
arcade.load_texture( ":resources:images/animated_characters/male_adventurer/maleAdventurer_walk7.png",mirrored=True)]
self.center_x = random.randint(0, 1000)
self.center_y = 1000
self.speed = 2
self.change_x = random.choice([-1, 1]) * self.speed
|
Java
|
UTF-8
| 186 | 1.734375 | 2 |
[
"Apache-2.0",
"LicenseRef-scancode-unknown-license-reference"
] |
permissive
|
package org.joyrest.model.http;
public class PathParam extends NameValueEntity<String, String> {
public PathParam(String name, String value) {
super(name, value);
}
}
|
Python
|
UTF-8
| 4,240 | 3.484375 | 3 |
[] |
no_license
|
"""
The
architecture difference from the classic DQN network is shown on the picture
below. The classic DQN network (top) takes features from the convolution
layer and, using fully-connected layers, transforms them into a vector of Qvalues, one for each action. On the other hand, dueling DQN (bottom) takes
convolution features and processes them using two independent paths: one
path is responsible for V(s) prediction, which is just a single number, and
another path predicts individual advantage values, having the same
dimension as Q-values in the classic case. After that, we add V(s) to every
value of A(s, a) to obtain the Q(s, a), which is used and trained as normal.
See in images folder
We have yet another constraint to be set: we want the mean
value of the advantage of any state to be zero
subtracting from the Q expression in the network the mean value
of the advantage, which effectively pulls the mean for advantage to zero:
Q(s,a) = V(s) + A(s,a) - 1/N * sum_k(A(s,k))
"""
import torch
import torch.nn as nn
import numpy as np
class DuelingDQN(nn.Module):
def __init__(self, input_shape, n_actions):
super(DuelingDQN, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(input_shape[0], 32,
kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.ReLU()
)
conv_out_size = self._get_conv_out(input_shape)
# Instead of defining a single path of fully connected layers, we create two
# different transformations: one for advantages and one for value prediction.
self.fc_adv = nn.Sequential(
nn.Linear(conv_out_size, 512),
nn.ReLU(),
nn.Linear(512, n_actions)
)
self.fc_val = nn.Sequential(
nn.Linear(conv_out_size, 512),
nn.ReLU(),
nn.Linear(512, 1)
)
def _get_conv_out(self, shape):
"""
Get conv out size use fake data (all 0)
:param shape:
:return:
"""
o = self.conv(torch.zeros(1, *shape))
return int(np.prod(o.size()))
def forward(self, x):
"""
The final piece of the model is the forward() function, which accepts the 4D
input tensor (the first dimension is batch size, the second is the color channel,
which is our stack of subsequent frames, while the third and fourth are image
dimensions). The application of transformations is done in two steps: first we
apply the convolution layer to the input and then we obtain a 4D tensor on
output. This result is flattened to have two dimensions: a batch size and all
the parameters returned by the convolution for this batch entry as one long
vector of numbers. This is done by the view() function of the tensors, which
lets one single dimension be a -1 argument as a wildcard for the rest of the
parameters. For example, if we have a tensor T of shape (2, 3, 4), which is
a 3D tensor of 24 elements, we can reshape it into a 2D tensor with six rows
and four columns using T.view(6, 4). This operation doesn't create a new
memory object or move the data in memory, it just changes the higher-level
shape of the tensor. The same result could be obtained by T.view(-1, 4) or
T.view(6, -1), which is very convenient when your tensor has a batch size
in the first dimension. Finally, we pass this flattened 2D tensor to our fully
connected layers to obtain Q-values for every batch input.
:param x:
:return: output tuple after forward computation
"""
# we calculate value and advantage for our batch of
# samples and add them together, subtracting the mean of advantage to obtain
# the final Q-values
x = x.float() / 256
conv_out = self.conv(x).view(x.size()[0], -1)
val = self.fc_val(conv_out)
adv = self.fc_adv(conv_out)
return val + adv - adv.mean()
# Train is the same
|
Java
|
UTF-8
| 547 | 3.28125 | 3 |
[] |
no_license
|
package com.dmitryvoronko.sort;
/**
* Created by Dmitry on 06/09/2016.
*/
public final class InsertionSort extends Sort {
public final void sort(Comparable[] comparables) {
int in, out;
for (out = 1; out < comparables.length; out++) {
Comparable temp = comparables[out];
in = out;
while (in > 0 && comparables[in - 1].compareTo(temp) > 0) {
comparables[in] = comparables[in - 1];
--in;
}
comparables[in] = temp;
}
}
}
|
Python
|
UTF-8
| 3,101 | 3.96875 | 4 |
[] |
no_license
|
"""Day 11 Puzzle"""
class PasswordException(Exception):
"""Exception for passwords."""
def __init__(self, value):
Exception.__init__(self, value)
self.value = value
def __str__(self):
return repr(self.value)
def increment_password(password):
"""Function to increment password."""
# recursion ending case 1: we've run out
# of passwords because password is all z's
if 'z' * len(password) == password:
raise PasswordException('Unable to increment ' + password)
# recursion ending case 2: we successfully
# increment the last letter of the password
if ord(password[-1]) < ord('z'):
return password[:-1] + chr(ord(password[-1]) + 1)
# recursion case
# set last letter of password to 'a' and
# increment the but-last of the password
else:
return increment_password(password[:-1]) + 'a'
def next_password(password):
"""Function to return the next password."""
new_password = increment_password(password)
while not valid_password(new_password):
new_password = increment_password(new_password)
return new_password
def valid_password(password):
"""Function to test validity of password according to rules."""
has_straight_letter_sequence = False
count_of_letter_pairs = 0
for index in range(len(password)):
# no i, o, or l
if password[index] in ['i', 'o', 'l']:
# print 'Password', password, \
# 'includes invalid char:', password[index]
return False
# one straight letter sequence of letter
if index < len(password) - 2:
if ord(password[index]) + 1 == ord(password[index + 1]) \
and ord(password[index]) + 2 == ord(password[index + 2]):
has_straight_letter_sequence = True
# two different non-overlapping two letter pairs
if index < len(password) - 1:
if password[index] == password[index + 1]:
if index > 1:
# don't count if previous letter is the same
# because we can't have overlapping pairs
if password[index] == password[index - 1]:
pass
else:
count_of_letter_pairs += 1
else:
count_of_letter_pairs += 1
if has_straight_letter_sequence and count_of_letter_pairs > 1:
return True
else:
# if not has_straight_letter_sequence:
# print 'Password', password, \
# 'does not have straight letter sequence.'
# elif count_of_letter_pairs < 2:
# print 'Password', password, \
# 'does not have two or more letter pairs.'
return False
def main():
"""Main program."""
input_string = 'hepxcrrq'
password_1 = next_password(input_string)
password_2 = next_password(password_1)
print 'The next password after', input_string, 'is', password_1
print 'The next password after', password_1, 'is', password_2
if __name__ == '__main__':
main()
|
Python
|
UTF-8
| 1,073 | 2.953125 | 3 |
[] |
no_license
|
import urllib.request
from bs4 import BeautifulSoup
challengeno = 0
aorb = "none"
try:
challengeno = int(input("Enter challenge number (1-10)"))
except ValueError:
print("Not an integer \nAssuming Challenge 9")
challengeno = 9
aorb = input("Enter challenge number (1-10)").lower()
x=0
if aorb != "a":
x += 1
elif aorb != "b":
x += 1
if x == 2:
print("Not A or B \nAssuming B ")
aorb = "b"
class AppURLopener(urllib.request.FancyURLopener):
version = "Mozilla/5.0"
opener = AppURLopener()
quote_page = ("https://www.cipherchallenge.org/challenges/challenge-" + str(challengeno))
page = opener.open(quote_page)
soup = BeautifulSoup(page, "html.parser")
if aorb == "a":
name_box = soup.find("div", attrs={"class": "a"})
else:
for item in soup.find_all('div',class_="challenge__content"):
if len(item["class"]) != 1:
continue;
else:
name_box = item.p
ciphertext = name_box.text.strip()
if input("Reverse text? (yes)").lower() in ["yes","true" ,"y"]:
ciphertext = ciphertext[::-1]
print(ciphertext)
|
Go
|
UTF-8
| 3,896 | 2.578125 | 3 |
[] |
no_license
|
package routers
import (
"fmt"
"net/url"
"strconv"
"strings"
"time"
"simple-blog/pkg/global"
"simple-blog/pkg/utils"
"simple-blog/pkg/models"
"github.com/gin-gonic/gin"
)
func Index(c *gin.Context) {
limit, _ := strconv.Atoi(global.Options["postsListSize"])
page, _ := strconv.Atoi(c.Query("page"))
if page == 0 {
page = 1
}
posts, total, _ := models.GetPostList(limit, (page-1)*limit)
for k, v := range posts {
posts[k].Summary = utils.GetPostSummary(v.Summary, 140)
}
resp := map[string]interface{}{
"options": utils.GetRenderOptions(),
"themeConfig": global.ThemeConfig,
"posts": posts,
"total": total,
"page": page,
"limit": limit,
}
if page*limit < int(total) {
resp["next"] = page + 1
}
if page > 1 {
resp["prev"] = page - 1
}
c.HTML(200, "index.html", resp)
}
func PostDetail(c *gin.Context) {
paths := strings.Split(c.Param("pathname"), ".html")
preview := c.Query("preview")
pathname := ""
if len(paths) > 0 {
pathname = paths[0]
}
var post *models.Post
if preview == "true" {
post, _ = models.GetPostByPathname(pathname, 0)
} else {
post, _ = models.GetPublishedPostByPathname(pathname, 0)
}
resp := map[string]interface{}{
"options": utils.GetRenderOptions(),
"themeConfig": global.ThemeConfig,
"commentConfig": global.CommentConfig,
}
if post != nil {
cates, tags := models.GetPostCateAndTag(post.Id)
post.Cates = cates
post.Tags = tags
post.Summary = utils.GetPostSummary(post.Summary, 200)
post.Content = utils.GetUseCDNContent(post.Content)
resp["post"] = *post
} else {
c.Redirect(301, "/")
}
visitInfo := models.Visit{
Pathname: pathname,
UserAgent: c.GetHeader("User-Agent"),
Ip: c.GetHeader("X-Real-IP"),
CreateTime: time.Now(),
}
err := models.AddVisit(visitInfo)
if err != nil {
fmt.Println(err)
}
c.HTML(200, "post.html", resp)
}
func PageDetail(c *gin.Context) {
paths := strings.Split(c.Param("pathname"), ".html")
pathname := ""
if len(paths) > 0 {
pathname = paths[0]
}
post, _ := models.GetPublishedPostByPathname(pathname, 1)
resp := map[string]interface{}{
"options": utils.GetRenderOptions(),
"themeConfig": global.ThemeConfig,
"commentConfig": global.CommentConfig,
}
if post != nil {
post.Summary = utils.GetPostSummary(post.Summary, 200)
post.Content = utils.GetUseCDNContent(post.Content)
resp["post"] = *post
resp["pathname"] = pathname
} else {
c.Redirect(301, "/")
}
c.HTML(200, "page.html", resp)
}
type archivesModel struct {
Year string
Month string
List []models.PostArchiveView
}
func Archives(c *gin.Context) {
posts, _, _ := models.GetPostList(30000, 0)
respData := make([]archivesModel, 0)
for _, v := range posts {
year := strconv.FormatInt(int64(v.CreateTime.Year()), 10)
month := v.CreateTime.Format("01")
match := false
for k, item := range respData {
if item.Year == year && item.Month == month {
respData[k].List = append(respData[k].List, models.PostArchiveView{
Pathname: v.Pathname,
Title: v.Title,
CreateTime: v.CreateTime,
UpdateTime: v.UpdateTime,
})
match = true
break
}
}
if !match {
respData = append(respData, archivesModel{
Year: year,
Month: month,
List: []models.PostArchiveView{{
Pathname: v.Pathname,
Title: v.Title,
CreateTime: v.CreateTime,
UpdateTime: v.UpdateTime,
}},
})
}
}
resp := map[string]interface{}{
"options": utils.GetRenderOptions(),
"datas": respData,
}
c.HTML(200, "archive.html", resp)
}
func SitemapTxt(c *gin.Context) {
text, _ := url.JoinPath(global.Options["site_url"], "archives")
postList, _, _ := models.GetPostList(99999, 0)
for _, v := range postList {
link, _ := url.JoinPath(global.Options["site_url"], "post", v.Pathname)
text = text + "\n" + link
}
c.String(200, text)
}
|
Python
|
UTF-8
| 3,376 | 2.703125 | 3 |
[] |
no_license
|
##
# 2015-05-16 - Ultrasound code - Reliable
# Maarten Pater (www.mirdesign.nl)
#
# Based on work of Keith Hekker and Matt Hawkins
# Keith: http://khekker.blogspot.nl/2013/03/raspberry-pi-and-monitoring-sump-pump.html
# Matt: http://www.raspberrypi-spy.co.uk/2012/12/ultrasonic-distance-measurement-using-python-part-1/
#
# Buy the device here: http://www.dx.com/p/314393
#
# Example usage at the bottom!
#
##
import RPi.GPIO as GPIO
import time
import datetime
# Pin settings
PIN_ULTRA_SWITCH_ON = GPIO.HIGH
PIN_ULTRA_SWITCH_OFF = GPIO.LOW
PIN_ULTRA_TRIGGER = 29
PIN_ULTRA_ECHO = 22
# Device settings
ULTRA_SLEEP_AFTER_TRIGGER = 0.00001
ULTRA_SLEEP_AFTER_READ_SAPLE = 0.05
# Bad sample settings
BAIL_OUT_THRESHOLD_WAITING_FOR_ECHO = 200
BAIL_OUT_THRESHOLD_RECEIVING_ECHO = 2500
BAIL_OUT_THRESHOLD_ACCEPT_FAILED_READS = 0
# GPIO initialisation
GPIO.setmode(GPIO.BOARD)
GPIO.setup(PIN_ULTRA_TRIGGER, GPIO.OUT)
GPIO.setup(PIN_ULTRA_ECHO, GPIO.IN)
GPIO.output(PIN_ULTRA_TRIGGER, PIN_ULTRA_SWITCH_OFF)
def GetDistance(NumberOfSamples = 10):
dDistances = 0
dCount = 0
distanceAvg = -1
# Reading samples
for x in range(0,NumberOfSamples):
distance = ReadValue()
if (distance != -1): # -1 means: No successful run
dDistances = dDistances + distance
dCount = dCount + 1
time.sleep(ULTRA_SLEEP_AFTER_READ_SAPLE) # Give the device some rest
if (dCount > 0):
distanceAvg = dDistances / dCount
return distanceAvg
def Diagnose():
while True:
distance = ReadValue()
print "Distance : %.1f (final)" % distance
def ReadValue(NumberOfSamples = 10):
dDistance = 0
bailOutCount = 0
for x in range(0,NumberOfSamples):
start = time.time()
stop = start
# Send 10us pulse to trigger
GPIO.output(PIN_ULTRA_TRIGGER, PIN_ULTRA_SWITCH_ON)
time.sleep(ULTRA_SLEEP_AFTER_TRIGGER)
GPIO.output(PIN_ULTRA_TRIGGER, PIN_ULTRA_SWITCH_OFF)
# We are going to bail out if device takes
# to long to provide expected answer
bailedOut = False
waitCount = 0
# Wait until the devices is ready send
# 8 samples on 40khz
while GPIO.input(PIN_ULTRA_ECHO)==0:
waitCount = waitCount + 1
# Bail out if we are waiting to long for the 8 signals to end
if (waitCount > BAIL_OUT_THRESHOLD_WAITING_FOR_ECHO):
bailOutCount = bailOutCount + 1
bailedOut = True
break
start = time.time()
stop = start
if (bailedOut == False):
waitCount = 0
while GPIO.input(PIN_ULTRA_ECHO)==1:
waitCount = waitCount + 1
# Bail out if we are waiting to long for the 8 signals to echo
if (waitCount > BAIL_OUT_THRESHOLD_RECEIVING_ECHO):
bailOutCount = bailOutCount + 1
bailedOut = True
break
stop = time.time()
if (bailedOut == False):
elapsed = stop-start
distance = elapsed * 34300 / 2 # Speed of sound / back and forth
if x > 0 and distance > 0:
dDistance = dDistance + distance
retVal = -1
# Only return a distance if we didn't exceed the number of failed samples
if(bailOutCount <= BAIL_OUT_THRESHOLD_ACCEPT_FAILED_READS):
divideBy = (NumberOfSamples-1-bailOutCount)
if(divideBy > 0):
retVal = dDistance / divideBy
return retVal
# To show unlimited reads
Diagnose()
# To show just 1 read
print GetDistance()
# Clean up
GPIO.cleanup()
|
JavaScript
|
UTF-8
| 844 | 2.796875 | 3 |
[] |
no_license
|
// // const API_KEY = ""; // Assign this variable to your JSONBIN.io API key if you choose to use it.
// // const DB_NAME = "my-todo";
// const API_KEY = "$2b$10$LoUxYgccdNGEGfOHMu8ETOpoo2Rmk4gLRrxwH827xE.NNk/7ni9Sm";
// // Gets data from persistent storage by the given key and returns it
// async function main () {
// async function getPersistent(key) {
// const url = `https://api.jsonbin.io/v3/b/${key}/latest`;
// const request = await fetch(url);
// const myTodoListFromJsBinJsonFormat = await request.json()
// return myTodoListFromJsBinJsonFormat.record;
// }
// const myTodoListFromJsBinJsonFormat = await getPersistent(API_KEY);
// // Saves the given data into persistent storage by the given key.
// // Returns 'true' on success.
// async function setPersistent(key, data) {
// return true;
// }
// };
// main();
|
Java
|
UTF-8
| 1,098 | 2.1875 | 2 |
[] |
no_license
|
package com.escola.escola.model;
import java.util.Date;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.EnumType;
import javax.persistence.Enumerated;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Temporal;
import javax.persistence.TemporalType;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
@Getter @Setter
@NoArgsConstructor
@Entity
public class Aluno {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String nome;
@Column(nullable = false)
private Integer idade;
@Column(nullable = false)
@Enumerated(EnumType.STRING)
private Turno turno;
@Column(nullable = false)
@Enumerated(EnumType.STRING)
private SerieAluno serieAluno;
@Column(nullable = false)
@Enumerated(EnumType.STRING)
private StatusAluno status;
@Temporal(TemporalType.DATE)
private Date dataNascimento = new Date();
}
|
Python
|
UTF-8
| 1,276 | 4.28125 | 4 |
[] |
no_license
|
# TODO Create an empty list to maintain the player names
players = []
# TODO Ask the user if they'd like to add players to the list.
# If the user answers "Yes", let them type in a name and add it to the list.
# If the user answers "No", print out the team 'roster'
name_player = input("Quieres agregar jugadores a la lista? (Yes/No) :")
if name_player == "Yes":
players.append(input("Escribe el nombre del jugador: "))
ask = input("Quieres agregar más jugadores a la lista? (Yes/No) :")
while ask == "Yes":
players.append(input("Escribe el nombre del jugador: "))
ask = input("Quieres agregar más jugadores a la lista? (Yes/No) :")
# TODO print the number of players on the team
print("Hay {} jugadores".format(len(players)))
# TODO Print the player number and the player name
# The player number should start at the number one
i = 0
while i<len(players):
a = i+1
print("El jugador {} corresponde a {}".format(a, players[i]))
i += 1
# TODO Select a goalkeeper from the above roster
goalkeeper = int(input("Debes seleccionar al goalkeeper de la lista: "))
# TODO Print the goal keeper's name
# Remember that lists use a zero based index
print("El goalkeeper es {}".format(players[goalkeeper-1]))
|
C++
|
UTF-8
| 513 | 2.828125 | 3 |
[] |
no_license
|
#ifndef CONTROLLER_H
#define CONTROLLER_H
#include <vector>
#include "movie.h"
#include "repository.h"
class Controller
{
private:
Repository* repo;
public:
Controller(Repository* repo);
~Controller();
/*
* Controller method that returns the entire list of movies from the repository
*/
vector<Movie*> getAllMovies();
/*
* Controller method that changes the availability of a movie
*/
void changeAvailability(int id, bool available);
};
#endif // CONTROLLER_H
|
C
|
UTF-8
| 11,202 | 3.1875 | 3 |
[] |
no_license
|
/* Archivo: createpart.c
Descripción: contiene funciones para crear una partición según las especificaciones dadas en el nunciado
del proyecto. La descripción de los archivos se encuentra en un archivo de texto que recibe como parámetro.
La salida es un archivo binario con el contenido de la partición. También contiene unas rutinas auxiliares
que permiten verificar si los datos se leyeron y almacenaron correctamente en la memoria y en el disco.
Realizado por: M. Curiel
Fecha: May 13 2009.
*/
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <time.h>
#include <unistd.h>
#include <string.h>
#include <sys/mman.h>
#include "inode.h"
#include "tiempo.h"
/* Variable global que elmacena en bytes el espacio ocupado por los inodos
en la partición */
long InodeArea;
/* Rutina: Imprimir
Descripción: Función que permite imprimer la estructura de datos que guarda los inodos temporalmente en memoria antes de escribirlos a disco
Parámetros: el número de inodos ocupados y el inicio de la estructura de datos.
*/
void Imprimir(unsigned short n_inodos, tiny_inodeM *Inom) {
int i, j;
l_block *aux;
printf("\nInformacion de los Inodos en la Memoria \n");
for (i = 0; i < n_inodos; i++) {
printf("\n\n Inodo %d\n", i);
printf("uid = %hd--size = %ldKb", Inom[i].i_uid, Inom[i].fsize);
aux = Inom[i].Lblocks;
printf("\nBloques de datos: ");
while (aux != NULL) {
printf("%u-", aux->nblock);
aux = aux->next;
}
}
}
/*
Rutina: LlenarInodos.
Función: lee el archivo con la descripción de la partición y vacía
esta información en una estructura de datos de la memoria. Añade
otros datos a cada inodo como la fecha de creación y el tipo de archivo.
Parámetros:
numinodos: numero total de inodos de la particion
Inodes: Dirección de Inicio de la estructura de datos en la memoria que tiene información de los inodos.
fdata: descriptor del archivo que contiene los datos de la partición a crear.
Retorna: el numero de inodos llenos, es decir aquellos descritos en el
archivo de entrada.
*/
unsigned short LlenarInodos(unsigned short numinodos, tiny_inodeM *Inodes, FILE *fdata) {
int i=0, j=0, bloques;
block_nr nbloque;
time_t t;
while (!feof(fdata) && i < numinodos) {
fscanf(fdata, "%hd %ld\n", &Inodes[i].i_uid, &Inodes[i].fsize);
fscanf(fdata, "%d\n", &bloques);
Inodes[i].i_creattime = Tomar_Tiempo(); // Tiempo en microsegundos desde Epoch, January 1, 1970.
Inodes[i].i_mode = I_REGULAR; // Siempre se coloca el mismo tipo de archivo
for (j=0; j < bloques; j++) {
/* Construye en la memoria una lista con los bloques lógicos del archivo */
fscanf(fdata, "%u\n", &nbloque);
if (j == 0) {
Inodes[i].Lblocks = (l_block *) malloc(sizeof(l_block));
Inodes[i].Lblocks->nblock = nbloque;
Inodes[i].Lblocks->next = NULL;
Inodes[i].last = Inodes[i].Lblocks;
} else {
Inodes[i].last->next = (l_block *) malloc(sizeof(l_block));
Inodes[i].last = Inodes[i].last->next;
Inodes[i].last->nblock = nbloque;
Inodes[i].last->next = NULL;
}
}
i++;
}
return((unsigned short) i);
}
/*
Rutina: CrearParticion.
Función: Recorre la estructura de Datos Inom, que contiene la información de los nodos ocupados de la
partición y va escribiendo esta información en el archivo de salida. Para enlazar los bloques de datos en
el disco utiliza la función lseek.
Parámetros:
inodos_llenos: numero de inodos ocupados de la particion
inodos_disco: total de inodos de la partición.
Inom: inicio de la estructura de datos en la memoria que contiene la información de los inodos.
nbloques: total de bloques de la pertición.
fd: descriptor del archivo de salida
*/
void CrearParticion(unsigned short inodos_llenos, unsigned short inodos_disco, tiny_inodeM *Inom, unsigned short nbloques, int fd) {
int i, bytes, vacio=EMPTY, cero;
block_nr proximo;
// Copia de los Inodos en la particion;
tiny_inodeD *InDisk;
tiny_block blockmem, blockmemE;
l_block *aux;
InodeArea = (sizeof(tiny_inodeD)*inodos_disco);
/* Crea una estructura similar a Inom, pero los registros son similares a la representación que tendrán
los inodos en el disco. La idea es construir el registro en la memoria para después escribirlo al disco.
En este registro sólo va el número del primer bloque lógico de cada archivo. */
InDisk = (tiny_inodeD *)calloc(inodos_disco, sizeof(tiny_inodeD));
for (i = 0; i < inodos_llenos; i++) {
InDisk[i].i_uid = Inom[i].i_uid;
InDisk[i].i_creattime = Inom[i].i_creattime;
InDisk[i].fsize = Inom[i].fsize;
InDisk[i].first_block = Inom[i].Lblocks->nblock;
}
/* Los inodos vacíos se inicializan */
for (i = inodos_llenos; i < inodos_disco; i++) InDisk[i].i_uid = EMPTY;
// Se escribe el arreglo de Inodos en el disco
bytes = write(fd, InDisk, inodos_disco*sizeof(tiny_inodeD));
if (bytes <= 0) {
perror("write");
exit(1);
}
// Una variable que sirve para representar un bloque vacío.
blockmemE.next_block = EMPTY;
// Se llena el área de datos del bloque con 0.
strncpy(blockmemE.datos,(char *)&cero, BLOCKDATA);
// Primero se llena toda la partición de bloques vacíos.
for (i = 0; i < nbloques; i++) {
bytes = write(fd, &blockmemE, BLOCKSIZE);
if (bytes <= 0) {
perror("write");
exit(1);
}
}
/* En este ciclo se enlazan los bloques de cada archivo en el disco. El primer ciclo recorre los Inodos.
El segundo recorre la lista de bloques lógicos de cada archivo */
for (i = 0; i < inodos_llenos; i++) {
// Una iteración por cada inodo lleno. Se obtiene el primer bloque lógico.
proximo = Inom[i].Lblocks->nblock;
aux = Inom[i].Lblocks->next;
// Escribo cualquier cosa en el área de datos. Noten que cada bloque está lleno. En los archivos reales, el último bloque del archivo no tiene porque estar lleno.
strncpy(blockmem.datos,(char *)&i, BLOCKDATA);
while (aux != NULL) {
/* Se va a la posición de cada bloque lógico en el disco con lseek y en el registro se coloca el número
del próximo bloque lógico que se obtiene de la lista que mantiene cada inodo en la memoria. El desplazamiento es siempre desde el inicio del archivo (SEEK_SET) */
lseek(fd, InodeArea + BLOCKSIZE*proximo, SEEK_SET);
blockmem.next_block = aux->nblock;
bytes = write(fd, &blockmem, BLOCKSIZE);
if (bytes <= 0) {
perror("write");
exit(1);
}
// pasarse al siguiente bloque lógico en la lista de la memoria.
proximo = aux->nblock;
aux = aux->next;
}
if (aux == NULL) {
// Ultimo bloque del archivo.
lseek(fd, InodeArea + BLOCKSIZE*proximo, SEEK_SET);
blockmem.next_block = LAST;
bytes = write(fd, &blockmem, BLOCKSIZE);
if (bytes <= 0) {
perror("write");
exit(1);
}
}
}
}
/*
Rutina: MostrarParticion.
Función: Muestra el contenido de la partición creada, haciendo un mapping del disco a la memoria mmap().
Observen como se puede traer el contenido de un archivo a la memoria (con una sola operación) y tratarse
como un arreglo. Observen también como la misma zona de memoria se puede ver como un registro de bloque o
de disco, dependiendo del apuntados que coloquen al comienzo.
Parámetros:
fd: descriptor del archivo donde se encuentra la partición.
n_inodos: total de inodos de la partición.
nbloques: total de bloques de la pertición.
tamano: tamano de la particion.
*/
void MostrarParticion(int fd, unsigned short n_inodos, unsigned short nbloques, int tamano) {
void *A;
tiny_inodeD *pinodes;
tiny_block *pblock;
int i, primero, proximo;
A = (void *)mmap(0, tamano, PROT_READ,MAP_PRIVATE, fd, 0);
pinodes = (tiny_inodeD *)A;
printf("\n\n DATOS ALMACENADOS EN EL DISCO\n\n");
printf("\n Informacion sobre los inodos\n");
for (i = 0; i < n_inodos; i++) {
printf("\n\nInodo %d\n", i);
printf(" uid =%hd--size = %ldKb", pinodes[i].i_uid, pinodes[i].fsize);
printf(" Primer Bloque = %d", pinodes[i].first_block);
}
printf("\n\n INFORMACION SOBRE LOS BLOQUES DE LA PARTICION\n");
pblock = (tiny_block *)((char *)A + InodeArea);
for (i = 0; i < nbloques; i++) {
printf("Bloque %d ", i);
printf("proximo %d\n", pblock[i].next_block);
}
munmap(0, tamano);
}
int main(int argc, char *argv[]) {
long tamano;
int n_inodos, nbloques;
unsigned short llenos;
FILE *fdata;
int fd;
tiny_inodeM *Inom;
tiny_inodeD *Inod;
if (argc < 4) {
printf("Numero de parametros incorrecto\n");
printf("Usar createpart tamano_particion Nro.Inodos InputData Particion \n");
exit(1);
}
/* Tamano en bytes de la particion */
tamano = atoi(argv[1]);
/* Numero de archivos que se podrán almacenar */
n_inodos = atoi(argv[2]);
/* Se abre el archivo que contiene información sobre los archivos de la partición. Este archivo debe
tener el formato explicado en el archivo data */
if ((fdata = fopen(argv[3],"r+")) == NULL) {
printf("Error abriendo el archivo %s\n", argv[3]);
exit(1);
}
/* Archivo que contiene la partición con los inodos y bloques de datos */
if ((fd = open(argv[4],O_CREAT|O_TRUNC|O_RDWR,S_IRWXU)) == -1) {
perror("open archiv de salida muestra: ");
exit(1);
}
/* Estructura de datos para guardar la información de los inodos en la
memoria antes de pasarla al disco */
Inom = (tiny_inodeM *) malloc(n_inodos*sizeof(tiny_inodeM));
/* Llenar la estructuras de datos de la memoria con la información contenida en InputData (argv[3]). La rutina devuelve el número de nodos ocupados en la partición, es decir, aquellos cuya información se describe en InputData */
llenos = LlenarInodos(n_inodos, Inom, fdata);
/* De acuerdo al número de inodos, al tamano de la partición y al tamano de bloques, se calcula
el número de bloques libres de la partición. Aqui se debería verificar que por ejemplo, el tamaño de
la partición no sea más pequeño que el tamaño del bloque o que el numero de bloques de la partición no
sea menos al numero de bloques ocupados por los archivos */
nbloques = (tamano - n_inodos*(sizeof(tiny_inodeD)))/BLOCKSIZE;
/* Ver si los datos se leyeron y almacenaron bien en la memoria */
Imprimir(llenos, Inom);
/* Rutina que crea el archivo binario que representa la partición */
CrearParticion(llenos, n_inodos, Inom, nbloques, fd);
/* Se muestra el contenido de la partición usando mmap() */
MostrarParticion(fd, n_inodos, nbloques, tamano);
/* Se cierran los archivos, también se debería liberar la memoria. */
fclose(fdata);
close(fd);
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.