
D-HUMOR: Dark Humor Understanding via Multimodal Open-ended Reasoning
Paper • 2509.06771 • Published • 6
This repository contains the dataset for the paper D-HUMOR: Dark Humor Understanding via Multimodal Open-ended Reasoning.
⚠️ Note: The dataset itself is not hosted on Hugging Face. To request access, please fill out the official agreement form (links provided below in the Dataset Access section).
Dark humor in online memes poses unique challenges due to its reliance on implicit, sensitive, and culturally contextual cues. To address the lack of resources and methods for detecting dark humor in multimodal content, we introduce a novel dataset of 4,379 Reddit memes annotated for dark humor, target category (gender, mental health, violence, race, disability, and other), and a three-level intensity rating (mild, moderate, severe). Building on this resource, we propose a reasoning-augmented framework that first generates structured explanations for each meme using a Large Vision–Language Model (VLM). Through a Role-Reversal Self-Loop, VLM adopts the author’s perspective to iteratively refine its explanations, ensuring completeness and alignment. We then extract textual features from both the OCR transcript and the self-refined reasoning via a text encoder, while visual features are obtained using a vision transformer. A Tri‐stream Cross‐Reasoning Network (TCRNet) fuses these three streams, text, image, and reasoning, via pairwise attention mechanisms, producing a unified representation for classification. Experimental results demonstrate that our approach outperforms strong baselines across three tasks: dark humor detection, target identification, and intensity prediction. The dataset, annotations, and code will be released to facilitate further research in multimodal humor understanding and content moderation.
The D-HUMOR dataset includes three subtasks for evaluating dark humor understanding:
We proposed a novel Role-Reversal Self-Loop Prompting technique for explanation generation via LLM alignment. The method uses an iterative self-loop where the LLM is prompted to think as the author of the post, enabling better understanding and alignment for generating explanations.
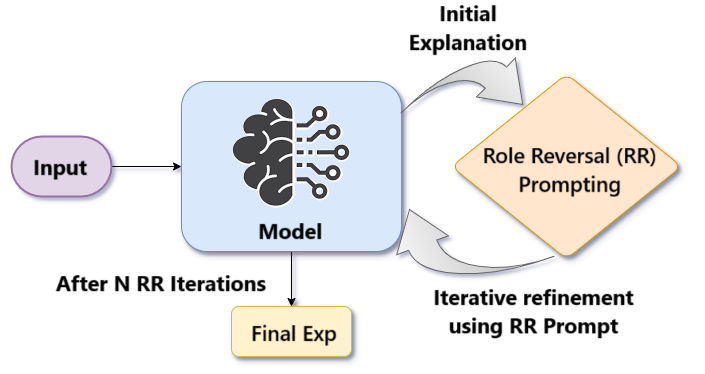
📂 Prompt Template: 🔗 Role-Reversal Self-Loop Prompt Template
We also proposed a reasoning-augmented framework, Tri-stream Cross-Reasoning Network (TCRNet), which fuses three streams: text, image, and reasoning via pairwise attention mechanisms. This produces a unified representation for classification.
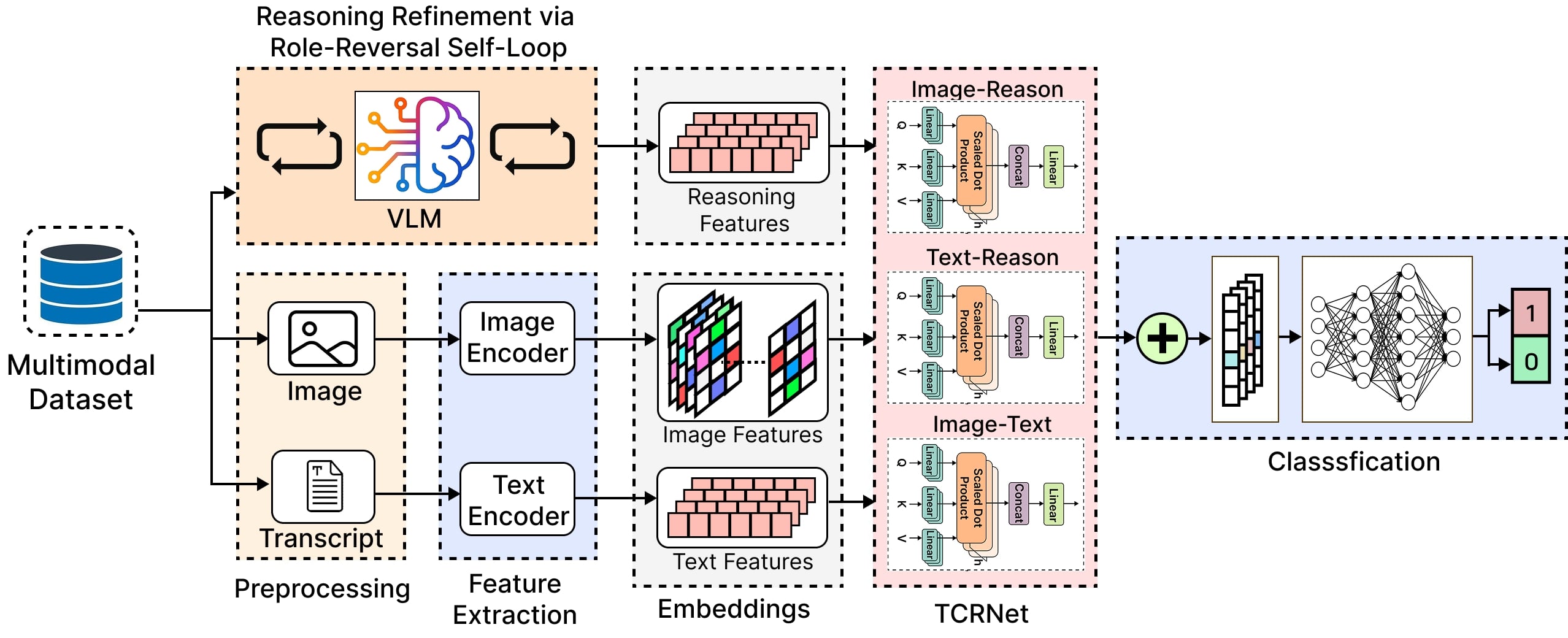
We designed TCRNet (Tri-Stream Cross-Reasoning Network), a multimodal architecture for dark humor understanding that integrates:
Experimental results demonstrate that our approach outperforms strong baselines across three tasks.
Due to the sensitive nature of dark humor content, the D-Humor Dataset is shared only under strict conditions:
The dataset is derived from publicly available memes on Reddit. By requesting or using this dataset, you agree to:
Access is granted only after completing the D-Humor Dataset Access Agreement Form. This ensures accountability and proper usage:
📄 Agreement Form (PDF): Download D-Humor Dataset Access Agreement.
📂 Request Form: Fill Dataset Access Request Form
Once approved, you will receive the dataset along with any instructions for use.
If you find this work useful in your research, or make use of the dataset and methods introduced here, please cite our paper as follows:
@article{kasu2025d,
title = {D-HUMOR: Dark Humor Understanding via Multimodal Open-ended Reasoning},
author = {Kasu, Sai Kartheek Reddy and
Rehman, Mohammad Zia Ur and
Dar, Shahid Shafi and
Junghare, Rishi Bharat and
Namboodiri, Dhanvin Sanjay and
Kumar, Nagendra},
journal = {arXiv preprint arXiv:2509.06771},
year = {2025}
}