Datasets:

Question/Discrepancy Regarding the Token Count of bigcode/the-stack

Hello Hugging Face Community,
I hope you are all doing well. I'm currently working with the bigcode/the-stack dataset and have a question regarding its token count. I was hoping someone from the BigCode team or the community could provide some clarification.
I've noticed what appears to be a significant discrepancy in the total number of tokens. The dataset card and associated materials state that the-stack contains approximately 200 billion tokens.
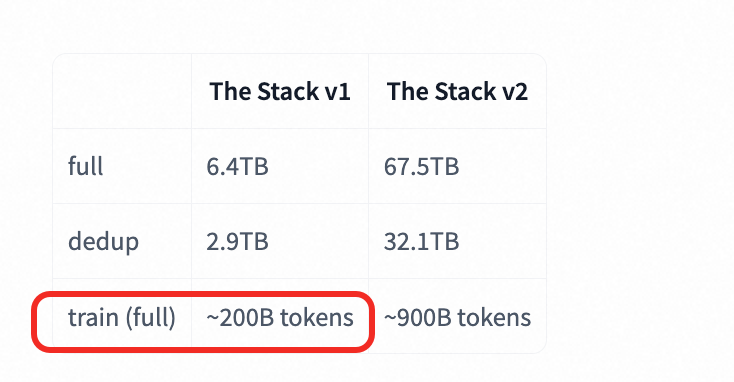
However, based on my own analysis and calculations, the total token count seems to be closer to 2.2 trillion (2,200 billion) tokens—an order of magnitude larger.
Here is a quick breakdown of my reasoning:
Dataset Size & Sanity Check: The full the-stack dataset is approximately 2.45 TB on disk. As a point of comparison, the bigcode/starcoderdata dataset is around 300 GB and is listed as having 200 billion tokens. Given that the-stack is over 8 times larger in disk size, a token count of only 200B seems unlikely. The 2.2T figure seems more consistent with the dataset's size.
My Verification: I have run my own data pre-tokenization pipeline on the dataset and have double-checked that I am using the correct, complete data files. My results consistently point towards a number in the ~2.2T token range.
This leads me to a few questions:
Is it possible that the 200B figure in the documentation is a typo, and it should have been 2.2T?
Could you share some insight into the methodology used to calculate the original 220B token count? Perhaps there was a specific, heavy filtering process, a different definition of "token," or a particular tokenizer used that I might be overlooking.
Has anyone else in the community performed a similar analysis and can share their findings?
Any clarification on this would be greatly appreciated! It would be very helpful for my research and for anyone else using this fantastic dataset.
Thank you for your time and for all the great work on these resources.
Best,
Robert