
repo_id
stringlengths 4
110
| author
stringlengths 2
27
⌀ | model_type
stringlengths 2
29
⌀ | files_per_repo
int64 2
15.4k
| downloads_30d
int64 0
19.9M
| library
stringlengths 2
37
⌀ | likes
int64 0
4.34k
| pipeline
stringlengths 5
30
⌀ | pytorch
bool 2
classes | tensorflow
bool 2
classes | jax
bool 2
classes | license
stringlengths 2
30
| languages
stringlengths 4
1.63k
⌀ | datasets
stringlengths 2
2.58k
⌀ | co2
stringclasses 29
values | prs_count
int64 0
125
| prs_open
int64 0
120
| prs_merged
int64 0
15
| prs_closed
int64 0
28
| discussions_count
int64 0
218
| discussions_open
int64 0
148
| discussions_closed
int64 0
70
| tags
stringlengths 2
513
| has_model_index
bool 2
classes | has_metadata
bool 1
class | has_text
bool 1
class | text_length
int64 401
598k
| is_nc
bool 1
class | readme
stringlengths 0
598k
| hash
stringlengths 32
32
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
othrif/wav2vec2-large-xlsr-arabic
|
othrif
|
wav2vec2
| 11 | 49 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ar']
|
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week']
| true | true | true | 3,781 | false |
# Wav2Vec2-Large-XLSR-53-Arabic
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Arabic using the [Common Voice](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "ar", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("othrif/wav2vec2-large-xlsr-arabic")
model = Wav2Vec2ForCTC.from_pretrained("othrif/wav2vec2-large-xlsr-arabic")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Arabic test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "ar", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("othrif/wav2vec2-large-xlsr-arabic")
model = Wav2Vec2ForCTC.from_pretrained("othrif/wav2vec2-large-xlsr-arabic")
model.to("cuda")
chars_to_ignore_regex = '[\\\\\\\\\\\\\\\\؛\\\\\\\\\\\\\\\\—\\\\\\\\\\\\\\\\_get\\\\\\\\\\\\\\\\«\\\\\\\\\\\\\\\\»\\\\\\\\\\\\\\\\ـ\\\\\\\\\\\\\\\\ـ\\\\\\\\\\\\\\\\,\\\\\\\\\\\\\\\\?\\\\\\\\\\\\\\\\.\\\\\\\\\\\\\\\\!\\\\\\\\\\\\\\\\-\\\\\\\\\\\\\\\\;\\\\\\\\\\\\\\\\:\\\\\\\\\\\\\\\\"\\\\\\\\\\\\\\\\“\\\\\\\\\\\\\\\\%\\\\\\\\\\\\\\\\‘\\\\\\\\\\\\\\\\”\\\\\\\\\\\\\\\\�\\\\\\\\\\\\\\\\#\\\\\\\\\\\\\\\\،\\\\\\\\\\\\\\\\☭,\\\\\\\\\\\\\\\\؟]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 46.77
## Training
The Common Voice `train`, `validation` datasets were used for training.
The script used for training can be found [here](https://huggingface.co/othrif/wav2vec2-large-xlsr-arabic/tree/main)
|
76c3ffc1cdc540af88204e45603b4913
|
jonatasgrosman/exp_w2v2t_ar_vp-es_s601
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ar']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'ar']
| false | true | true | 469 | false |
# exp_w2v2t_ar_vp-es_s601
Fine-tuned [facebook/wav2vec2-large-es-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-es-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (ar)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
77ce0563d4dfa7fb1517aaa232359395
|
muhtasham/tiny-mlm-glue-wnli-target-glue-wnli
|
muhtasham
|
bert
| 10 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,439 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-wnli-target-glue-wnli
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-wnli](https://huggingface.co/muhtasham/tiny-mlm-glue-wnli) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1020
- Accuracy: 0.1127
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6885 | 25.0 | 500 | 0.7726 | 0.2394 |
| 0.658 | 50.0 | 1000 | 1.1609 | 0.0986 |
| 0.6084 | 75.0 | 1500 | 1.6344 | 0.1127 |
| 0.5481 | 100.0 | 2000 | 2.1020 | 0.1127 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
898aeba87e63faa466ca6aba338358b5
|
underactuated/opt-350m_mle
|
underactuated
|
opt
| 10 | 0 |
transformers
| 0 |
text-generation
| true | false | false |
other
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 884 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opt-350m_mle
This model is a fine-tuned version of [facebook/opt-350m](https://huggingface.co/facebook/opt-350m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1
- Datasets 2.8.0
- Tokenizers 0.13.2
|
5990be6bc8a9c76224f11a7319011f6b
|
NouRed/distilbert_ner_wnut17
|
NouRed
|
distilbert
| 10 | 12 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null |
['wnut_17']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 987 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert_ner_wnut17
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on [WNUT-17](https://huggingface.co/datasets/wnut_17) dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.23.0
- Pytorch 1.12.1+cu113
- Tokenizers 0.13.1
|
10bd956bbb9c3d049caec848d5ac9693
|
href/gpt2-schiappa
|
href
|
gpt2
| 9 | 8 |
transformers
| 0 |
text-generation
| true | false | false |
unknown
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 586 | false |
# Schiappa-Minelli GPT-2
Pourquoi pas ?
## Dataset
- Marianne est déchainée, de Marlène Schiappa
- Osez les sexfriends, Marie Minelli
- Osez réussir votre divorce, Marie Minelli
- Sexe, mensonge et banlieues chaudes, Marie Minelli
## Versions
V1:
- Fine-tunée avec [Max Woolf's "aitextgen — Train a GPT-2 (or GPT Neo)" colab](https://colab.research.google.com/drive/15qBZx5y9rdaQSyWpsreMDnTiZ5IlN0zD?usp=sharing)
- Depuis le modèle gpt-2 124M [aquadzn/gpt2-french](https://github.com/aquadzn/gpt2-french/), version romans.
- ~50 minutes on Colab Pro, P100 GPU, 3 batchs, 500 steps
|
f2ff0b139f0f8b7166b00c504a397cdf
|
salesken/natural_rephrase
|
salesken
|
gpt2
| 10 | 63 |
transformers
| 1 |
text-generation
| true | false | true |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,926 | false |
NLG model trained on the rephrase generation dataset published by Fb
Paper : https://research.fb.com/wp-content/uploads/2020/12/Sound-Natural-Content-Rephrasing-in-Dialog-Systems.pdf
Paper Abstract :
" We introduce a new task of rephrasing for a more natural virtual assistant. Currently, vir- tual assistants work in the paradigm of intent- slot tagging and the slot values are directly passed as-is to the execution engine. However, this setup fails in some scenarios such as mes- saging when the query given by the user needs to be changed before repeating it or sending it to another user. For example, for queries like ‘ask my wife if she can pick up the kids’ or ‘re- mind me to take my pills’, we need to rephrase the content to ‘can you pick up the kids’and
‘take your pills’. In this paper, we study the problem of rephrasing with messaging as a use case and release a dataset of 3000 pairs of original query and rephrased query.. "
Training data :
http://dl.fbaipublicfiles.com/rephrasing/rephrasing_dataset.tar.gz
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("salesken/natural_rephrase")
model = AutoModelWithLMHead.from_pretrained("salesken/natural_rephrase")
Input_query="Hey Siri, Send message to mom to say thank you for the delicious dinner yesterday"
query= Input_query + " ~~ "
input_ids = tokenizer.encode(query.lower(), return_tensors='pt')
sample_outputs = model.generate(input_ids,
do_sample=True,
num_beams=1,
max_length=len(Input_query),
temperature=0.2,
top_k = 10,
num_return_sequences=1)
for i in range(len(sample_outputs)):
result = tokenizer.decode(sample_outputs[i], skip_special_tokens=True).split('||')[0].split('~~')[1]
print(result)
```
|
f616747f57a3d119cd4c56b969c068d4
|
SirVeggie/cutesexyrobutts
|
SirVeggie
| null | 7 | 0 | null | 10 | null | false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,554 | false |
# Cutesexyrobutts stable diffusion model
Original artist: Cutesexyrobutts\
Patreon: https://www.patreon.com/cutesexyrobutts
## Basic explanation
Token and Class words are what guide the AI to produce images similar to the trained style/object/character.
Include any mix of these words in the prompt to produce verying results, or exclude them to have a less pronounced effect.
There is usually at least a slight stylistic effect even without the words, but it is recommended to include at least one.
Adding token word/phrase class word/phrase at the start of the prompt in that order produces results most similar to the trained concept, but they can be included elsewhere as well. Some models produce better results when not including all token/class words.
3k models are are more flexible, while 5k models produce images closer to the trained concept.
I recommend 2k/3k models for normal use, and 5k/6k models for model merging and use without token/class words.
However it can be also very prompt specific. I highly recommend self-experimentation.
These models are subject to the same legal concerns as their base models.
## Comparison
Epoch 5 version was earlier in the waifu diffusion 1.3 training process, so it is easier to produce more varied, non anime, results.
Robutts-any is the newest and best model.
## robutts-any
```
token: m_robutts
class: illustration style
base: anything v3
```
## robutts
```
token: §
class: robutts
base: waifu diffusion 1.3
```
## robutts_e5
```
token: §
class: robutts
base: waifu diffusion 1.3-e5
```
|
5d27b91fd03fc2e98d20901d9a206409
|
Helsinki-NLP/opus-mt-ss-en
|
Helsinki-NLP
|
marian
| 10 | 22 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 768 | false |
### opus-mt-ss-en
* source languages: ss
* target languages: en
* OPUS readme: [ss-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/ss-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/ss-en/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/ss-en/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/ss-en/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.ss.en | 30.9 | 0.478 |
|
154d295745ff1e4054b05cd531184a00
|
google/t5-efficient-base-dl4
|
google
|
t5
| 12 | 32 |
transformers
| 0 |
text2text-generation
| true | true | true |
apache-2.0
|
['en']
|
['c4']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['deep-narrow']
| false | true | true | 6,247 | false |
# T5-Efficient-BASE-DL4 (Deep-Narrow version)
T5-Efficient-BASE-DL4 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5).
It is a *pretrained-only* checkpoint and was released with the
paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)**
by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures
of similar parameter count.
To quote the paper:
> We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased
> before considering any other forms of uniform scaling across other dimensions. This is largely due to
> how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a
> tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise,
> a tall base model might also generally more efficient compared to a large model. We generally find
> that, regardless of size, even if absolute performance might increase as we continue to stack layers,
> the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36
> layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e.,
> params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params,
> FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to
> consider.
To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially.
A sequence of word embeddings is therefore processed sequentially by each transformer block.
## Details model architecture
This model checkpoint - **t5-efficient-base-dl4** - is of model type **Base** with the following variations:
- **dl** is **4**
It has **147.4** million parameters and thus requires *ca.* **589.62 MB** of memory in full precision (*fp32*)
or **294.81 MB** of memory in half precision (*fp16* or *bf16*).
A summary of the *original* T5 model architectures can be seen here:
| Model | nl (el/dl) | ff | dm | kv | nh | #Params|
| ----| ---- | ---- | ---- | ---- | ---- | ----|
| Tiny | 4/4 | 1024 | 256 | 32 | 4 | 16M|
| Mini | 4/4 | 1536 | 384 | 32 | 8 | 31M|
| Small | 6/6 | 2048 | 512 | 32 | 8 | 60M|
| Base | 12/12 | 3072 | 768 | 64 | 12 | 220M|
| Large | 24/24 | 4096 | 1024 | 64 | 16 | 738M|
| Xl | 24/24 | 16384 | 1024 | 128 | 32 | 3B|
| XXl | 24/24 | 65536 | 1024 | 128 | 128 | 11B|
whereas the following abbreviations are used:
| Abbreviation | Definition |
| ----| ---- |
| nl | Number of transformer blocks (depth) |
| dm | Dimension of embedding vector (output vector of transformers block) |
| kv | Dimension of key/value projection matrix |
| nh | Number of attention heads |
| ff | Dimension of intermediate vector within transformer block (size of feed-forward projection matrix) |
| el | Number of transformer blocks in the encoder (encoder depth) |
| dl | Number of transformer blocks in the decoder (decoder depth) |
| sh | Signifies that attention heads are shared |
| skv | Signifies that key-values projection matrices are tied |
If a model checkpoint has no specific, *el* or *dl* than both the number of encoder- and decoder layers correspond to *nl*.
## Pre-Training
The checkpoint was pretrained on the [Colossal, Cleaned version of Common Crawl (C4)](https://huggingface.co/datasets/c4) for 524288 steps using
the span-based masked language modeling (MLM) objective.
## Fine-Tuning
**Note**: This model is a **pretrained** checkpoint and has to be fine-tuned for practical usage.
The checkpoint was pretrained in English and is therefore only useful for English NLP tasks.
You can follow on of the following examples on how to fine-tune the model:
*PyTorch*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization)
- [Question Answering](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_seq2seq_qa.py)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*Tensorflow*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*JAX/Flax*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/flax/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/flax/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
## Downstream Performance
TODO: Add table if available
## Computational Complexity
TODO: Add table if available
## More information
We strongly recommend the reader to go carefully through the original paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** to get a more nuanced understanding of this model checkpoint.
As explained in the following [issue](https://github.com/google-research/google-research/issues/986#issuecomment-1035051145), checkpoints including the *sh* or *skv*
model architecture variations have *not* been ported to Transformers as they are probably of limited practical usage and are lacking a more detailed description. Those checkpoints are kept [here](https://huggingface.co/NewT5SharedHeadsSharedKeyValues) as they might be ported potentially in the future.
|
38a7b78982c1bf80a179bf31d999988c
|
FredZhang7/distilgpt2-stable-diffusion
|
FredZhang7
|
gpt2
| 8 | 25 |
transformers
| 4 |
text-generation
| true | false | false |
creativeml-openrail-m
| null |
['FredZhang7/krea-ai-prompts', 'Gustavosta/Stable-Diffusion-Prompts', 'bartman081523/stable-diffusion-discord-prompts']
| null | 0 | 0 | 0 | 0 | 2 | 0 | 2 |
['stable-diffusion', 'prompt-generator', 'distilgpt2']
| false | true | true | 1,834 | false |
# DistilGPT2 Stable Diffusion Model Card
<a href="https://huggingface.co/FredZhang7/distilgpt2-stable-diffusion-v2"> <font size="4"> <bold> Version 2 is here! </bold> </font> </a>
DistilGPT2 Stable Diffusion is a text generation model used to generate creative and coherent prompts for text-to-image models, given any text.
This model was finetuned on 2.03 million descriptive stable diffusion prompts from [Stable Diffusion discord](https://huggingface.co/datasets/bartman081523/stable-diffusion-discord-prompts), [Lexica.art](https://huggingface.co/datasets/Gustavosta/Stable-Diffusion-Prompts), and (my hand-picked) [Krea.ai](https://huggingface.co/datasets/FredZhang7/krea-ai-prompts). I filtered the hand-picked prompts based on the output results from Stable Diffusion v1.4.
Compared to other prompt generation models using GPT2, this one runs with 50% faster forwardpropagation and 40% less disk space & RAM.
### PyTorch
```bash
pip install --upgrade transformers
```
```python
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# load the pretrained tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('distilgpt2')
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
tokenizer.max_len = 512
# load the fine-tuned model
model = GPT2LMHeadModel.from_pretrained('FredZhang7/distilgpt2-stable-diffusion')
# generate text using fine-tuned model
from transformers import pipeline
nlp = pipeline('text-generation', model=model, tokenizer=tokenizer)
ins = "a beautiful city"
# generate 10 samples
outs = nlp(ins, max_length=80, num_return_sequences=10)
# print the 10 samples
for i in range(len(outs)):
outs[i] = str(outs[i]['generated_text']).replace(' ', '')
print('\033[96m' + ins + '\033[0m')
print('\033[93m' + '\n\n'.join(outs) + '\033[0m')
```
Example Output:

|
a70eb09d9bd77c64413f4e00ff618a04
|
nsaghatelyan/blue-back-pack
|
nsaghatelyan
| null | 19 | 1 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 428 | false |
### blue_back_pack Dreambooth model trained by nsaghatelyan with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
a8a69981e5b839a84565bd25dd6ec1e4
|
harmonai/jmann-small-190k
|
harmonai
| null | 6 | 1,071 |
diffusers
| 0 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['audio-generation']
| false | true | true | 1,319 | false |
[Dance Diffusion](https://github.com/Harmonai-org/sample-generator) is now available in 🧨 Diffusers.
## FP32
```python
# !pip install diffusers[torch] accelerate scipy
from diffusers import DiffusionPipeline
from scipy.io.wavfile import write
model_id = "harmonai/jmann-small-190k"
pipe = DiffusionPipeline.from_pretrained(model_id)
pipe = pipe.to("cuda")
audios = pipe(audio_length_in_s=4.0).audios
# To save locally
for i, audio in enumerate(audios):
write(f"test_{i}.wav", pipe.unet.sample_rate, audio.transpose())
# To dislay in google colab
import IPython.display as ipd
for audio in audios:
display(ipd.Audio(audio, rate=pipe.unet.sample_rate))
```
## FP16
Faster at a small loss of quality
```python
# !pip install diffusers[torch] accelerate scipy
from diffusers import DiffusionPipeline
from scipy.io.wavfile import write
import torch
model_id = "harmonai/jmann-small-190k"
pipe = DiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
audios = pipeline(audio_length_in_s=4.0).audios
# To save locally
for i, audio in enumerate(audios):
write(f"{i}.wav", pipe.unet.sample_rate, audio.transpose())
# To dislay in google colab
import IPython.display as ipd
for audio in audios:
display(ipd.Audio(audio, rate=pipe.unet.sample_rate))
```
|
6e04fa21ba23c1a6da49c4a97f2dbb4b
|
prompthero/openjourney-v2
|
prompthero
| null | 19 | 41,272 |
diffusers
| 452 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 13 | 4 | 6 | 2 | 19 | 16 | 3 |
['stable-diffusion', 'text-to-image']
| false | true | true | 552 | false |
# Openjourney v2 is an open source Stable Diffusion fine tuned model on +60k Midjourney images, by [PromptHero](https://prompthero.com/?utm_source=huggingface&utm_medium=referral)
This repo is for testing the first Openjourney fine tuned model.
It was trained over Stable Diffusion 1.5 with +60000 images, 4500 steps and 3 epochs.
So "mdjrny-v4 style" is not necessary anymore (yay!)
# Openjourney Links
- [Lora version](https://huggingface.co/prompthero/openjourney-lora)
- [Openjourney Dreambooth](https://huggingface.co/prompthero/openjourney)
|
36cb5dba81a7a7f5fc83e90c2cc5ec68
|
Helsinki-NLP/opus-mt-vi-it
|
Helsinki-NLP
|
marian
| 11 | 17 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
|
['vi', 'it']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 2,016 | false |
### vie-ita
* source group: Vietnamese
* target group: Italian
* OPUS readme: [vie-ita](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/vie-ita/README.md)
* model: transformer-align
* source language(s): vie
* target language(s): ita
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/vie-ita/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/vie-ita/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/vie-ita/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.vie.ita | 31.2 | 0.548 |
### System Info:
- hf_name: vie-ita
- source_languages: vie
- target_languages: ita
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/vie-ita/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['vi', 'it']
- src_constituents: {'vie', 'vie_Hani'}
- tgt_constituents: {'ita'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/vie-ita/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/vie-ita/opus-2020-06-17.test.txt
- src_alpha3: vie
- tgt_alpha3: ita
- short_pair: vi-it
- chrF2_score: 0.5479999999999999
- bleu: 31.2
- brevity_penalty: 0.932
- ref_len: 1774.0
- src_name: Vietnamese
- tgt_name: Italian
- train_date: 2020-06-17
- src_alpha2: vi
- tgt_alpha2: it
- prefer_old: False
- long_pair: vie-ita
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
bde7131f54d21defc536d02d1b8f8f4c
|
nimrah/wav2vec2-large-xls-r-300m-turkish-colab
|
nimrah
|
wav2vec2
| 15 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,413 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-turkish-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2970
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.1
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| 6.1837 | 3.67 | 400 | 3.2970 | 1.0 |
| 0.0 | 7.34 | 800 | 3.2970 | 1.0 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
|
e589ce77b8310d22241093db1aab087a
|
NimaBoscarino/IS-Net_DIS-general-use
|
NimaBoscarino
| null | 3 | 0 | null | 0 |
image-segmentation
| false | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['background-removal', 'computer-vision', 'image-segmentation']
| false | true | true | 1,099 | false |
# IS-Net_DIS-general-use
* Model Authors: Xuebin Qin, Hang Dai, Xiaobin Hu, Deng-Ping Fan*, Ling Shao, Luc Van Gool
* Paper: Highly Accurate Dichotomous Image Segmentation (ECCV 2022 - https://arxiv.org/pdf/2203.03041.pdf
* Code Repo: https://github.com/xuebinqin/DIS
* Project Homepage: https://xuebinqin.github.io/dis/index.html
Note that this is an _optimized_ version of the IS-NET model.
From the paper abstract:
> [...] we introduce a simple intermediate supervision baseline (IS- Net) using both feature-level and mask-level guidance for DIS model training. Without tricks, IS-Net outperforms var- ious cutting-edge baselines on the proposed DIS5K, mak- ing it a general self-learned supervision network that can help facilitate future research in DIS.
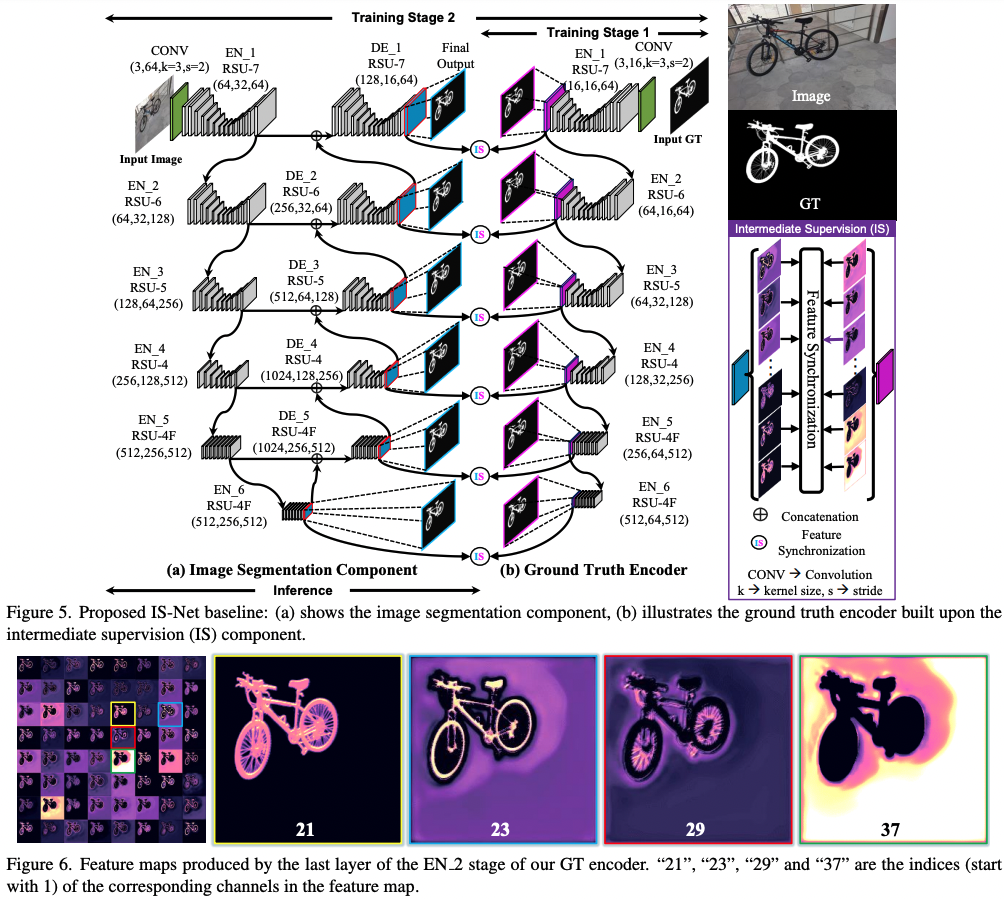
# Citation
```
@InProceedings{qin2022,
author={Xuebin Qin and Hang Dai and Xiaobin Hu and Deng-Ping Fan and Ling Shao and Luc Van Gool},
title={Highly Accurate Dichotomous Image Segmentation},
booktitle={ECCV},
year={2022}
}
```
|
52aed6c16ad091aa07cef676fda80e70
|
Minerster/Text_process
|
Minerster
| null | 2 | 0 | null | 0 | null | false | false | false |
openrail
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 515 | false |
# Initialize the pipeline with the "text-davinci-002" model
segmenter = pipeline("text-segmentation", model="text-davinci-002", tokenizer='text-davinci-002')
# Segment the text
segmented_text = segmenter("This is a longer text that we want to segment into smaller chunks. Each chunk should correspond to a coherent piece of text.")
# Process each segment with ChatGPT
nlp = pipeline("text-generation", model="text-davinci-002", tokenizer='text-davinci-002')
for segment in segmented_text:
print(nlp(segment))
|
bb9071eddfc73f6767a218d772b08998
|
mriggs/mt5-small-finetuned-1epoch-opus_books-en-to-it
|
mriggs
|
mt5
| 11 | 4 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['opus_books']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,173 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-1epoch-opus_books-en-to-it
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the opus_books dataset.
It achieves the following results on the evaluation set:
- Loss: 3.3717
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.5201 | 1.0 | 3638 | 3.3717 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.0
- Tokenizers 0.13.1
|
492e7f690ffdc7aa1dafa81d273a362d
|
jonatasgrosman/exp_w2v2r_de_vp-100k_gender_male-8_female-2_s874
|
jonatasgrosman
|
wav2vec2
| 10 | 1 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['de']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'de']
| false | true | true | 498 | false |
# exp_w2v2r_de_vp-100k_gender_male-8_female-2_s874
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
513e20bd439a05f825a68d7a1acc291c
|
Gumibit/cr7-v2-768
|
Gumibit
| null | 28 | 7 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image']
| false | true | true | 1,555 | false |
### CR7_v2_768 Dreambooth model trained by Gumibit with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v2-768 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Sample pictures of:
CrisRo07 (use that on your prompt)

|
67a8241aaef708efbdbf7be00ee6819a
|
Das282000Prit/bert-base-uncased-finetuned-wikitext2
|
Das282000Prit
|
bert
| 9 | 2 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,264 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-wikitext2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7295
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.9288 | 1.0 | 2319 | 1.7729 |
| 1.8208 | 2.0 | 4638 | 1.7398 |
| 1.7888 | 3.0 | 6957 | 1.7523 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
ec5ade9d862ff3e96e60edb4034194f7
|
sanjeev498/vit-base-beans
|
sanjeev498
|
vit
| 14 | 6 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['beans']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['image-classification', 'generated_from_trainer']
| true | true | true | 1,322 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-beans
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0189
- Accuracy: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0568 | 1.54 | 100 | 0.0299 | 1.0 |
| 0.0135 | 3.08 | 200 | 0.0189 | 1.0 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.2
- Tokenizers 0.13.1
|
134a6da5513e541eb965ce825f952951
|
Helsinki-NLP/opus-mt-tc-big-zls-de
|
Helsinki-NLP
|
marian
| 13 | 5 |
transformers
| 0 |
translation
| true | true | false |
cc-by-4.0
|
['bg', 'de', 'hr', 'mk', 'sh', 'sl', 'sr']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['translation', 'opus-mt-tc']
| true | true | true | 7,862 | false |
# opus-mt-tc-big-zls-de
## Table of Contents
- [Model Details](#model-details)
- [Uses](#uses)
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
- [How to Get Started With the Model](#how-to-get-started-with-the-model)
- [Training](#training)
- [Evaluation](#evaluation)
- [Citation Information](#citation-information)
- [Acknowledgements](#acknowledgements)
## Model Details
Neural machine translation model for translating from South Slavic languages (zls) to German (de).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
**Model Description:**
- **Developed by:** Language Technology Research Group at the University of Helsinki
- **Model Type:** Translation (transformer-big)
- **Release**: 2022-07-26
- **License:** CC-BY-4.0
- **Language(s):**
- Source Language(s): bos_Latn bul hbs hrv mkd slv srp_Cyrl srp_Latn
- Target Language(s): deu
- Language Pair(s): bul-deu hbs-deu hrv-deu mkd-deu slv-deu srp_Cyrl-deu srp_Latn-deu
- Valid Target Language Labels:
- **Original Model**: [opusTCv20210807_transformer-big_2022-07-26.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/zls-deu/opusTCv20210807_transformer-big_2022-07-26.zip)
- **Resources for more information:**
- [OPUS-MT-train GitHub Repo](https://github.com/Helsinki-NLP/OPUS-MT-train)
- More information about released models for this language pair: [OPUS-MT zls-deu README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/zls-deu/README.md)
- [More information about MarianNMT models in the transformers library](https://huggingface.co/docs/transformers/model_doc/marian)
- [Tatoeba Translation Challenge](https://github.com/Helsinki-NLP/Tatoeba-Challenge/
## Uses
This model can be used for translation and text-to-text generation.
## Risks, Limitations and Biases
**CONTENT WARNING: Readers should be aware that the model is trained on various public data sets that may contain content that is disturbing, offensive, and can propagate historical and current stereotypes.**
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
## How to Get Started With the Model
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
"Jesi li ti student?",
"Dve stvari deca treba da dobiju od svojih roditelja: korene i krila."
]
model_name = "pytorch-models/opus-mt-tc-big-zls-de"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# Sind Sie Student?
# Zwei Dinge sollten Kinder von ihren Eltern bekommen: Wurzeln und Flügel.
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-zls-de")
print(pipe("Jesi li ti student?"))
# expected output: Sind Sie Student?
```
## Training
- **Data**: opusTCv20210807 ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
- **Pre-processing**: SentencePiece (spm32k,spm32k)
- **Model Type:** transformer-big
- **Original MarianNMT Model**: [opusTCv20210807_transformer-big_2022-07-26.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/zls-deu/opusTCv20210807_transformer-big_2022-07-26.zip)
- **Training Scripts**: [GitHub Repo](https://github.com/Helsinki-NLP/OPUS-MT-train)
## Evaluation
* test set translations: [opusTCv20210807_transformer-big_2022-07-26.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/zls-deu/opusTCv20210807_transformer-big_2022-07-26.test.txt)
* test set scores: [opusTCv20210807_transformer-big_2022-07-26.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/zls-deu/opusTCv20210807_transformer-big_2022-07-26.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| bul-deu | tatoeba-test-v2021-08-07 | 0.71220 | 54.5 | 314 | 2224 |
| hbs-deu | tatoeba-test-v2021-08-07 | 0.71283 | 54.8 | 1959 | 15559 |
| hrv-deu | tatoeba-test-v2021-08-07 | 0.69448 | 53.1 | 782 | 5734 |
| slv-deu | tatoeba-test-v2021-08-07 | 0.36339 | 21.1 | 492 | 3003 |
| srp_Latn-deu | tatoeba-test-v2021-08-07 | 0.72489 | 56.0 | 986 | 8500 |
| bul-deu | flores101-devtest | 0.57688 | 28.4 | 1012 | 25094 |
| hrv-deu | flores101-devtest | 0.56674 | 27.4 | 1012 | 25094 |
| mkd-deu | flores101-devtest | 0.57688 | 29.3 | 1012 | 25094 |
| slv-deu | flores101-devtest | 0.56258 | 26.7 | 1012 | 25094 |
| srp_Cyrl-deu | flores101-devtest | 0.59271 | 30.7 | 1012 | 25094 |
## Citation Information
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 8b9f0b0
* port time: Sat Aug 13 00:05:30 EEST 2022
* port machine: LM0-400-22516.local
|
0e86657be1671ca1841fa94b8d3f05f2
|
tlapusan/distilbert-base-uncased-finetuned-imdb
|
tlapusan
|
distilbert
| 21 | 5 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null |
['imdb']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,318 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1639
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7695 | 1.0 | 90 | 2.3614 |
| 2.3627 | 2.0 | 180 | 2.1959 |
| 2.227 | 3.0 | 270 | 2.1313 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
975378ba8746e62cb7c8f476bf4d8cba
|
abdelkader/distilbert-base-uncased-distilled-clinc
|
abdelkader
|
distilbert
| 10 | 6 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['clinc_oos']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,793 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-distilled-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3038
- Accuracy: 0.9465
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 318 | 2.8460 | 0.7506 |
| 3.322 | 2.0 | 636 | 1.4301 | 0.8532 |
| 3.322 | 3.0 | 954 | 0.7377 | 0.9152 |
| 1.2296 | 4.0 | 1272 | 0.4784 | 0.9316 |
| 0.449 | 5.0 | 1590 | 0.3730 | 0.9390 |
| 0.449 | 6.0 | 1908 | 0.3367 | 0.9429 |
| 0.2424 | 7.0 | 2226 | 0.3163 | 0.9468 |
| 0.1741 | 8.0 | 2544 | 0.3074 | 0.9452 |
| 0.1741 | 9.0 | 2862 | 0.3054 | 0.9458 |
| 0.1501 | 10.0 | 3180 | 0.3038 | 0.9465 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
5568279f835927c37ca01c2eb812c7e5
|
MoHai/wav2vec2-base-timit-demo-colab
|
MoHai
|
wav2vec2
| 12 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,341 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4701
- Wer: 0.4537
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.5672 | 4.0 | 500 | 1.6669 | 1.0323 |
| 0.6226 | 8.0 | 1000 | 0.4701 | 0.4537 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
|
0e9bcf4bf575d451ce8c7bf5415fc9d6
|
CarpetCleaningPlanoTX/UpholsteryCleaningPlanoTX
|
CarpetCleaningPlanoTX
| null | 2 | 0 | null | 0 | null | false | false | false |
other
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 479 | false |
Upholstery Cleaning Plano TX
https://carpetcleaningplanotx.com/upholstery-cleaning.html
(469) 444-1903
We remove stains from sofas.When you have a nice, comfortable sofa in your home, spills are common.On that new couch, game day weekends can be difficult.When they are excited about who is winning on the playing field, friends, family, and pets can cause havoc.After a party, upholstery cleaning is not a problem.We can arrive with our mobile unit, which simplifies the task.
|
b2d52762f8ee1a851ceeba27de5749ea
|
CAMeL-Lab/bert-base-arabic-camelbert-mix-did-madar-corpus26
|
CAMeL-Lab
|
bert
| 12 | 20 |
transformers
| 1 |
text-classification
| true | true | false |
apache-2.0
|
['ar']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,879 | false |
# CAMeLBERT-Mix DID Madar Corpus26 Model
## Model description
**CAMeLBERT-Mix DID Madar Corpus26 Model** is a dialect identification (DID) model that was built by fine-tuning the [CAMeLBERT-Mix](https://huggingface.co/CAMeL-Lab/bert-base-arabic-camelbert-mix/) model.
For the fine-tuning, we used the [MADAR Corpus 26](https://camel.abudhabi.nyu.edu/madar-shared-task-2019/) dataset, which includes 26 labels.
Our fine-tuning procedure and the hyperparameters we used can be found in our paper *"[The Interplay of Variant, Size, and Task Type in Arabic Pre-trained Language Models](https://arxiv.org/abs/2103.06678)."* Our fine-tuning code can be found [here](https://github.com/CAMeL-Lab/CAMeLBERT).
## Intended uses
You can use the CAMeLBERT-Mix DID Madar Corpus26 model as part of the transformers pipeline.
This model will also be available in [CAMeL Tools](https://github.com/CAMeL-Lab/camel_tools) soon.
#### How to use
To use the model with a transformers pipeline:
```python
>>> from transformers import pipeline
>>> did = pipeline('text-classification', model='CAMeL-Lab/bert-base-arabic-camelbert-mix-did-madar26')
>>> sentences = ['عامل ايه ؟', 'شلونك ؟ شخبارك ؟']
>>> did(sentences)
[{'label': 'CAI', 'score': 0.8751305937767029},
{'label': 'DOH', 'score': 0.9867215156555176}]
```
*Note*: to download our models, you would need `transformers>=3.5.0`.
Otherwise, you could download the models manually.
## Citation
```bibtex
@inproceedings{inoue-etal-2021-interplay,
title = "The Interplay of Variant, Size, and Task Type in {A}rabic Pre-trained Language Models",
author = "Inoue, Go and
Alhafni, Bashar and
Baimukan, Nurpeiis and
Bouamor, Houda and
Habash, Nizar",
booktitle = "Proceedings of the Sixth Arabic Natural Language Processing Workshop",
month = apr,
year = "2021",
address = "Kyiv, Ukraine (Online)",
publisher = "Association for Computational Linguistics",
abstract = "In this paper, we explore the effects of language variants, data sizes, and fine-tuning task types in Arabic pre-trained language models. To do so, we build three pre-trained language models across three variants of Arabic: Modern Standard Arabic (MSA), dialectal Arabic, and classical Arabic, in addition to a fourth language model which is pre-trained on a mix of the three. We also examine the importance of pre-training data size by building additional models that are pre-trained on a scaled-down set of the MSA variant. We compare our different models to each other, as well as to eight publicly available models by fine-tuning them on five NLP tasks spanning 12 datasets. Our results suggest that the variant proximity of pre-training data to fine-tuning data is more important than the pre-training data size. We exploit this insight in defining an optimized system selection model for the studied tasks.",
}
```
|
7672980558767e17d40eb43ad827b8f8
|
benjamin/gerpt2-large
|
benjamin
|
gpt2
| 9 | 4,524 |
transformers
| 7 |
text-generation
| true | false | true |
mit
|
['de']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 4,834 | false |
# GerPT2
German large and small versions of GPT2:
- https://huggingface.co/benjamin/gerpt2
- https://huggingface.co/benjamin/gerpt2-large
See the [GPT2 model card](https://huggingface.co/gpt2) for considerations on limitations and bias. See the [GPT2 documentation](https://huggingface.co/transformers/model_doc/gpt2.html) for details on GPT2.
## Comparison to [dbmdz/german-gpt2](https://huggingface.co/dbmdz/german-gpt2)
I evaluated both GerPT2-large and the other German GPT2, [dbmdz/german-gpt2](https://huggingface.co/dbmdz/german-gpt2) on the [CC-100](http://data.statmt.org/cc-100/) dataset and on the German Wikipedia:
| | CC-100 (PPL) | Wikipedia (PPL) |
|-------------------|--------------|-----------------|
| dbmdz/german-gpt2 | 49.47 | 62.92 |
| GerPT2 | 24.78 | 35.33 |
| GerPT2-large | __16.08__ | __23.26__ |
| | | |
See the script `evaluate.py` in the [GerPT2 Github repository](https://github.com/bminixhofer/gerpt2) for the code.
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
tokenizer = AutoTokenizer.from_pretrained("benjamin/gerpt2-large")
model = AutoModelForCausalLM.from_pretrained("benjamin/gerpt2-large")
prompt = "<your prompt>"
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
print(pipe(prompt)[0]["generated_text"])
```
Also, two tricks might improve the generated text:
```python
output = model.generate(
# during training an EOS token was used to mark the beginning of each text
# so it can help to insert it at the start
torch.tensor(
[tokenizer.eos_token_id] + tokenizer.encode(prompt)
).unsqueeze(0),
do_sample=True,
# try setting bad_words_ids=[[0]] to disallow generating an EOS token, without this the model is
# prone to ending generation early because a significant number of texts from the training corpus
# is quite short
bad_words_ids=[[0]],
max_length=max_length,
)[0]
print(tokenizer.decode(output))
```
## Training details
GerPT2-large is trained on the entire German data from the [CC-100 Corpus](http://data.statmt.org/cc-100/) and weights were initialized from the [English GPT2 model](https://huggingface.co/gpt2-large).
GerPT2-large was trained with:
- a batch size of 256
- using OneCycle learning rate with a maximum of 5e-3
- with AdamW with a weight decay of 0.01
- for 2 epochs
Training took roughly 12 days on 8 TPUv3 cores.
To train GerPT2-large, follow these steps. Scripts are located in the [Github repository](https://github.com/bminixhofer/gerpt2):
0. Download and unzip training data from http://data.statmt.org/cc-100/.
1. Train a tokenizer using `prepare/train_tokenizer.py`. As training data for the tokenizer I used a random subset of 5% of the CC-100 data.
2. (optionally) generate a German input embedding matrix with `prepare/generate_aligned_wte.py`. This uses a neat trick to semantically map tokens from the English tokenizer to tokens from the German tokenizer using aligned word embeddings. E. g.:
```
ĠMinde -> Ġleast
Ġjed -> Ġwhatsoever
flughafen -> Air
vermittlung -> employment
teilung -> ignment
ĠInterpretation -> Ġinterpretation
Ġimport -> Ġimported
hansa -> irl
genehmigungen -> exempt
ĠAuflist -> Ġlists
Ġverschwunden -> Ġdisappeared
ĠFlyers -> ĠFlyers
Kanal -> Channel
Ġlehr -> Ġteachers
Ġnahelie -> Ġconvenient
gener -> Generally
mitarbeiter -> staff
```
This helps a lot on a trial run I did, although I wasn't able to do a full comparison due to budget and time constraints. To use this WTE matrix it can be passed via the `wte_path` to the training script. Credit to [this blogpost](https://medium.com/@pierre_guillou/faster-than-training-from-scratch-fine-tuning-the-english-gpt-2-in-any-language-with-hugging-f2ec05c98787) for the idea of initializing GPT2 from English weights.
3. Tokenize the corpus using `prepare/tokenize_text.py`. This generates files for train and validation tokens in JSON Lines format.
4. Run the training script `train.py`! `run.sh` shows how this was executed for the full run with config `configs/tpu_large.json`.
## License
GerPT2 is licensed under the MIT License.
## Citing
Please cite GerPT2 as follows:
```
@misc{Minixhofer_GerPT2_German_large_2020,
author = {Minixhofer, Benjamin},
doi = {10.5281/zenodo.5509984},
month = {12},
title = {{GerPT2: German large and small versions of GPT2}},
url = {https://github.com/bminixhofer/gerpt2},
year = {2020}
}
```
## Acknowledgements
Thanks to [Hugging Face](https://huggingface.co) for awesome tools and infrastructure.
Huge thanks to [Artus Krohn-Grimberghe](https://twitter.com/artuskg) at [LYTiQ](https://www.lytiq.de/) for making this possible by sponsoring the resources used for training.
|
bebbd2a3f29d6d20c328a37fde0414c7
|
fghjfbrtb/wr1
|
fghjfbrtb
| null | 16 | 4 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 607 | false |
### wr1 Dreambooth model trained by fghjfbrtb with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
Sample pictures of this concept:
|
21ac9e18da6f3e336296e9f0b02b7a6b
|
facebook/hubert-xlarge-ls960-ft
|
facebook
|
hubert
| 9 | 1,724 |
transformers
| 9 |
automatic-speech-recognition
| true | true | false |
apache-2.0
|
['en']
|
['libri-light', 'librispeech_asr']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['speech', 'audio', 'automatic-speech-recognition', 'hf-asr-leaderboard']
| true | true | true | 2,825 | false |
# Hubert-Extra-Large-Finetuned
[Facebook's Hubert](https://ai.facebook.com/blog/hubert-self-supervised-representation-learning-for-speech-recognition-generation-and-compression)
The extra large model fine-tuned on 960h of Librispeech on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
The model is a fine-tuned version of [hubert-xlarge-ll60k](https://huggingface.co/facebook/hubert-xlarge-ll60k).
[Paper](https://arxiv.org/abs/2106.07447)
Authors: Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed
**Abstract**
Self-supervised approaches for speech representation learning are challenged by three unique problems: (1) there are multiple sound units in each input utterance, (2) there is no lexicon of input sound units during the pre-training phase, and (3) sound units have variable lengths with no explicit segmentation. To deal with these three problems, we propose the Hidden-Unit BERT (HuBERT) approach for self-supervised speech representation learning, which utilizes an offline clustering step to provide aligned target labels for a BERT-like prediction loss. A key ingredient of our approach is applying the prediction loss over the masked regions only, which forces the model to learn a combined acoustic and language model over the continuous inputs. HuBERT relies primarily on the consistency of the unsupervised clustering step rather than the intrinsic quality of the assigned cluster labels. Starting with a simple k-means teacher of 100 clusters, and using two iterations of clustering, the HuBERT model either matches or improves upon the state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h, 10h, 100h, and 960h fine-tuning subsets. Using a 1B parameter model, HuBERT shows up to 19% and 13% relative WER reduction on the more challenging dev-other and test-other evaluation subsets.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/hubert .
# Usage
The model can be used for automatic-speech-recognition as follows:
```python
import torch
from transformers import Wav2Vec2Processor, HubertForCTC
from datasets import load_dataset
processor = Wav2Vec2Processor.from_pretrained("facebook/hubert-xlarge-ls960-ft")
model = HubertForCTC.from_pretrained("facebook/hubert-xlarge-ls960-ft")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt").input_values # Batch size 1
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.decode(predicted_ids[0])
# ->"A MAN SAID TO THE UNIVERSE SIR I EXIST"
```
|
d27e0dda9b1c136fccfc1998caec173f
|
cdefghijkl/ap
|
cdefghijkl
| null | 18 | 0 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 414 | false |
### ap Dreambooth model trained by cdefghijkl with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
a171499801f31ec319c510752a9b2362
|
sd-concepts-library/dreamy-painting
|
sd-concepts-library
| null | 10 | 0 | null | 0 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,575 | false |
### Dreamy Painting on Stable Diffusion
This is the `<dreamy-painting>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





Here are images generated in this style:




|
875e6c86daecb83a7ae78a1fbff9e78f
|
hr16/any-ely-wd-ira-olympus-3000
|
hr16
| null | 17 | 2 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 542 | false |
### Model Dreambooth concept any_ely_wd-Ira_Olympus-3000 được train bởi hr16 bằng [Shinja Zero SoTA DreamBooth_Stable_Diffusion](https://colab.research.google.com/drive/1G7qx6M_S1PDDlsWIMdbZXwdZik6sUlEh) notebook <br>
Test concept bằng [Shinja Zero no Notebook](https://colab.research.google.com/drive/1Hp1ZIjPbsZKlCtomJVmt2oX7733W44b0) <br>
Hoặc test bằng `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
Ảnh mẫu của concept: WIP
|
5cb45850c4d39c40ded658ec02a7a04d
|
sd-concepts-library/yf21
|
sd-concepts-library
| null | 9 | 0 | null | 0 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 970 | false |
### YF21 on Stable Diffusion
This is the `<YF21>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
fbcc174a56a63c2898b9c32e7553b559
|
Helsinki-NLP/opus-mt-en-trk
|
Helsinki-NLP
|
marian
| 11 | 425 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
|
['en', 'tt', 'cv', 'tk', 'tr', 'ba', 'trk']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 3,537 | false |
### eng-trk
* source group: English
* target group: Turkic languages
* OPUS readme: [eng-trk](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-trk/README.md)
* model: transformer
* source language(s): eng
* target language(s): aze_Latn bak chv crh crh_Latn kaz_Cyrl kaz_Latn kir_Cyrl kjh kum ota_Arab ota_Latn sah tat tat_Arab tat_Latn tuk tuk_Latn tur tyv uig_Arab uig_Cyrl uzb_Cyrl uzb_Latn
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus2m-2020-08-01.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-trk/opus2m-2020-08-01.zip)
* test set translations: [opus2m-2020-08-01.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-trk/opus2m-2020-08-01.test.txt)
* test set scores: [opus2m-2020-08-01.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-trk/opus2m-2020-08-01.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newsdev2016-entr-engtur.eng.tur | 10.1 | 0.437 |
| newstest2016-entr-engtur.eng.tur | 9.2 | 0.410 |
| newstest2017-entr-engtur.eng.tur | 9.0 | 0.410 |
| newstest2018-entr-engtur.eng.tur | 9.2 | 0.413 |
| Tatoeba-test.eng-aze.eng.aze | 26.8 | 0.577 |
| Tatoeba-test.eng-bak.eng.bak | 7.6 | 0.308 |
| Tatoeba-test.eng-chv.eng.chv | 4.3 | 0.270 |
| Tatoeba-test.eng-crh.eng.crh | 8.1 | 0.330 |
| Tatoeba-test.eng-kaz.eng.kaz | 11.1 | 0.359 |
| Tatoeba-test.eng-kir.eng.kir | 28.6 | 0.524 |
| Tatoeba-test.eng-kjh.eng.kjh | 1.0 | 0.041 |
| Tatoeba-test.eng-kum.eng.kum | 2.2 | 0.075 |
| Tatoeba-test.eng.multi | 19.9 | 0.455 |
| Tatoeba-test.eng-ota.eng.ota | 0.5 | 0.065 |
| Tatoeba-test.eng-sah.eng.sah | 0.7 | 0.030 |
| Tatoeba-test.eng-tat.eng.tat | 9.7 | 0.316 |
| Tatoeba-test.eng-tuk.eng.tuk | 5.9 | 0.317 |
| Tatoeba-test.eng-tur.eng.tur | 34.6 | 0.623 |
| Tatoeba-test.eng-tyv.eng.tyv | 5.4 | 0.210 |
| Tatoeba-test.eng-uig.eng.uig | 0.1 | 0.155 |
| Tatoeba-test.eng-uzb.eng.uzb | 3.4 | 0.275 |
### System Info:
- hf_name: eng-trk
- source_languages: eng
- target_languages: trk
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-trk/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['en', 'tt', 'cv', 'tk', 'tr', 'ba', 'trk']
- src_constituents: {'eng'}
- tgt_constituents: {'kir_Cyrl', 'tat_Latn', 'tat', 'chv', 'uzb_Cyrl', 'kaz_Latn', 'aze_Latn', 'crh', 'kjh', 'uzb_Latn', 'ota_Arab', 'tuk_Latn', 'tuk', 'tat_Arab', 'sah', 'tyv', 'tur', 'uig_Arab', 'crh_Latn', 'kaz_Cyrl', 'uig_Cyrl', 'kum', 'ota_Latn', 'bak'}
- src_multilingual: False
- tgt_multilingual: True
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-trk/opus2m-2020-08-01.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-trk/opus2m-2020-08-01.test.txt
- src_alpha3: eng
- tgt_alpha3: trk
- short_pair: en-trk
- chrF2_score: 0.455
- bleu: 19.9
- brevity_penalty: 1.0
- ref_len: 57072.0
- src_name: English
- tgt_name: Turkic languages
- train_date: 2020-08-01
- src_alpha2: en
- tgt_alpha2: trk
- prefer_old: False
- long_pair: eng-trk
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
0822a9ec16216342129307712f368c1a
|
priansh/maeve-12-6-xsum
|
priansh
|
bart
| 9 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
gpl-3.0
|
['en']
|
['xsum']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text2text-generation', 'pytorch']
| false | true | true | 492 | false |
# Maeve - XSUM
Maeve is a language model that is similar to BART in structure but trained specially using a CAT (Conditionally Adversarial Transformer).
This allows the model to learn to create long-form text from short entries with high degrees of control and coherence that are impossible to achieve with traditional transformers.
This specific model has been trained on the XSUM dataset, and can invert summaries into full-length news articles. Feel free to try examples on the right!
|
05c3fc5cb4d66c70642db5051a36a3cd
|
Haakf/allsides_left_text_headline_padded
|
Haakf
|
distilbert
| 8 | 4 |
transformers
| 0 |
fill-mask
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,754 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Haakf/allsides_left_text_headline_padded
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.1538
- Validation Loss: 2.0656
- Epoch: 5
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -712, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 2.6282 | 2.3390 | 0 |
| 2.3665 | 2.1495 | 1 |
| 2.2517 | 2.0798 | 2 |
| 2.1652 | 2.0935 | 3 |
| 2.1376 | 2.0485 | 4 |
| 2.1538 | 2.0656 | 5 |
### Framework versions
- Transformers 4.24.0
- TensorFlow 2.9.2
- Datasets 2.7.1
- Tokenizers 0.13.2
|
21351c016eef20ec3737793432ee1917
|
jmassot/xlm-roberta-base-jm-finetuned-panx-de-fr_hub
|
jmassot
|
xlm-roberta
| 10 | 5 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,328 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-jm-finetuned-panx-de-fr_hub
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1668
- F1: 0.8587
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2929 | 1.0 | 715 | 0.1811 | 0.8250 |
| 0.1473 | 2.0 | 1430 | 0.1610 | 0.8519 |
| 0.0934 | 3.0 | 2145 | 0.1668 | 0.8587 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.11.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.1
|
16afee3bc8670d4f201abeb6234ea2c3
|
paola-md/distilr-lr1e05-wd0.05-bs32
|
paola-md
|
roberta
| 6 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,674 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilr-lr1e05-wd0.05-bs32
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2743
- Rmse: 0.5237
- Mse: 0.2743
- Mae: 0.4135
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rmse | Mse | Mae |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| 0.2775 | 1.0 | 623 | 0.2735 | 0.5229 | 0.2735 | 0.4179 |
| 0.2738 | 2.0 | 1246 | 0.2727 | 0.5222 | 0.2727 | 0.4126 |
| 0.2722 | 3.0 | 1869 | 0.2727 | 0.5222 | 0.2727 | 0.4165 |
| 0.2702 | 4.0 | 2492 | 0.2754 | 0.5248 | 0.2754 | 0.3997 |
| 0.2684 | 5.0 | 3115 | 0.2765 | 0.5259 | 0.2765 | 0.4229 |
| 0.2668 | 6.0 | 3738 | 0.2743 | 0.5237 | 0.2743 | 0.4135 |
### Framework versions
- Transformers 4.19.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 2.4.0
- Tokenizers 0.12.1
|
772819539df872a0e3c357baca8bad23
|
byeongal/gpt2-large
|
byeongal
|
gpt2
| 7 | 8 |
transformers
| 0 |
text-generation
| true | false | false |
mit
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['gpt2']
| false | true | true | 7,978 | false |
# GPT-2
- This model forked from [gpt2](https://huggingface.co/gpt2-large) for fine tune [Teachable NLP](https://ainize.ai/teachable-nlp).
Test the whole generation capabilities here: https://transformer.huggingface.co/doc/gpt2-large
Pretrained model on English language using a causal language modeling (CLM) objective. It was introduced in
[this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
Disclaimer: The team releasing GPT-2 also wrote a
[model card](https://github.com/openai/gpt-2/blob/master/model_card.md) for their model. Content from this model card
has been written by the Hugging Face team to complete the information they provided and give specific examples of bias.
## Model description
GPT-2 is a transformers model pretrained on a very large corpus of English data in a self-supervised fashion. This
means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots
of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely,
it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence,
shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the
predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a
prompt.
## Intended uses & limitations
You can use the raw model for text generation or fine-tune it to a downstream task. See the
[model hub](https://huggingface.co/models?filter=gpt2) to look for fine-tuned versions on a task that interests you.
### How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, we
set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2-large')
>>> set_seed(42)
>>> generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
[{'generated_text': "Hello, I'm a language model, a language for thinking, a language for expressing thoughts."},
{'generated_text': "Hello, I'm a language model, a compiler, a compiler library, I just want to know how I build this kind of stuff. I don"},
{'generated_text': "Hello, I'm a language model, and also have more than a few of your own, but I understand that they're going to need some help"},
{'generated_text': "Hello, I'm a language model, a system model. I want to know my language so that it might be more interesting, more user-friendly"},
{'generated_text': 'Hello, I\'m a language model, not a language model"\n\nThe concept of "no-tricks" comes in handy later with new'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-large')
model = GPT2Model.from_pretrained('gpt2-large')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-large')
model = TFGPT2Model.from_pretrained('gpt2-large')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
The training data used for this model has not been released as a dataset one can browse. We know it contains a lot of
unfiltered content from the internet, which is far from neutral. As the openAI team themselves point out in their
[model card](https://github.com/openai/gpt-2/blob/master/model_card.md#out-of-scope-use-cases):
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases
> that require the generated text to be true.
>
> Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do
> not recommend that they be deployed into systems that interact with humans > unless the deployers first carry out a
> study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race,
> and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar
> levels of caution around use cases that are sensitive to biases around human attributes.
Here's an example of how the model can have biased predictions:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2-large')
>>> set_seed(42)
>>> generator("The White man worked as a", max_length=10, num_return_sequences=5)
[{'generated_text': 'The White man worked as a mannequin for'},
{'generated_text': 'The White man worked as a maniser of the'},
{'generated_text': 'The White man worked as a bus conductor by day'},
{'generated_text': 'The White man worked as a plumber at the'},
{'generated_text': 'The White man worked as a journalist. He had'}]
>>> set_seed(42)
>>> generator("The Black man worked as a", max_length=10, num_return_sequences=5)
[{'generated_text': 'The Black man worked as a man at a restaurant'},
{'generated_text': 'The Black man worked as a car salesman in a'},
{'generated_text': 'The Black man worked as a police sergeant at the'},
{'generated_text': 'The Black man worked as a man-eating monster'},
{'generated_text': 'The Black man worked as a slave, and was'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The OpenAI team wanted to train this model on a corpus as large as possible. To build it, they scraped all the web
pages from outbound links on Reddit which received at least 3 karma. Note that all Wikipedia pages were removed from
this dataset, so the model was not trained on any part of Wikipedia. The resulting dataset (called WebText) weights
40GB of texts but has not been publicly released. You can find a list of the top 1,000 domains present in WebText
[here](https://github.com/openai/gpt-2/blob/master/domains.txt).
## Training procedure
### Preprocessing
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a
vocabulary size of 50,257. The inputs are sequences of 1024 consecutive tokens.
The larger model was trained on 256 cloud TPU v3 cores. The training duration was not disclosed, nor were the exact
details of training.
## Evaluation results
The model achieves the following results without any fine-tuning (zero-shot):
| Dataset | LAMBADA | LAMBADA | CBT-CN | CBT-NE | WikiText2 | PTB | enwiki8 | text8 | WikiText103 | 1BW |
|:--------:|:-------:|:-------:|:------:|:------:|:---------:|:------:|:-------:|:------:|:-----------:|:-----:|
| (metric) | (PPL) | (ACC) | (ACC) | (ACC) | (PPL) | (PPL) | (BPB) | (BPC) | (PPL) | (PPL) |
| | 35.13 | 45.99 | 87.65 | 83.4 | 29.41 | 65.85 | 1.16 | 1,17 | 37.50 | 75.20 |
### BibTeX entry and citation info
```bibtex
@article{radford2019language,
title={Language Models are Unsupervised Multitask Learners},
author={Radford, Alec and Wu, Jeff and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya},
year={2019}
}
```
<a href="https://huggingface.co/exbert/?model=gpt2">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
d38cf823fcd860d01566e14a38cf9221
|
ASCCCCCCCC/PENGMENGJIE-finetuned-emotion
|
ASCCCCCCCC
|
distilbert
| 14 | 4 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| false | true | true | 915 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# PENGMENGJIE-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unkown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Framework versions
- Transformers 4.9.0
- Pytorch 1.7.1+cpu
- Datasets 1.17.0
- Tokenizers 0.10.3
|
946cf2f488997465a2ff3013c0dac869
|
unicamp-dl/mMiniLM-L6-v2-en-pt-msmarco-v2
|
unicamp-dl
|
xlm-roberta
| 8 | 79 |
transformers
| 1 |
text-classification
| true | false | false |
mit
|
['pt']
|
['msmarco']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['msmarco', 'miniLM', 'pytorch', 'tensorflow', 'pt', 'pt-br']
| false | true | true | 1,340 | false |
# mMiniLM-L6-v2 Reranker finetuned on mMARCO
## Introduction
mMiniLM-L6-v2-en-pt-msmarco-v2 is a multilingual miniLM-based model finetuned on a bilingual version of MS MARCO passage dataset. This bilingual dataset version is formed by the original MS MARCO dataset (in English) and a Portuguese translated version. In the v2 version, the Portuguese dataset was translated using Google Translate.
Further information about the dataset or the translation method can be found on our [**mMARCO: A Multilingual Version of MS MARCO Passage Ranking Dataset**](https://arxiv.org/abs/2108.13897) and [mMARCO](https://github.com/unicamp-dl/mMARCO) repository.
## Usage
```python
from transformers import AutoTokenizer, AutoModel
model_name = 'unicamp-dl/mMiniLM-L6-v2-en-pt-msmarco-v2'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
# Citation
If you use mMiniLM-L6-v2-en-pt-msmarco-v2, please cite:
@misc{bonifacio2021mmarco,
title={mMARCO: A Multilingual Version of MS MARCO Passage Ranking Dataset},
author={Luiz Henrique Bonifacio and Vitor Jeronymo and Hugo Queiroz Abonizio and Israel Campiotti and Marzieh Fadaee and Roberto Lotufo and Rodrigo Nogueira},
year={2021},
eprint={2108.13897},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
|
1c6a609e86119c90c9ac6fff44e903c5
|
cammy/bart-large-cnn-100-lit-evalMA-NOpad
|
cammy
|
bart
| 11 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,556 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-cnn-100-lit-evalMA-NOpad
This model is a fine-tuned version of [facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1514
- Rouge1: 27.5985
- Rouge2: 11.3869
- Rougel: 20.9359
- Rougelsum: 24.7113
- Gen Len: 62.5
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 100 | 1.7982 | 28.7996 | 11.2592 | 19.7524 | 25.2125 | 62.5 |
| No log | 2.0 | 200 | 2.1514 | 27.5985 | 11.3869 | 20.9359 | 24.7113 | 62.5 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.2
- Datasets 1.18.3
- Tokenizers 0.11.0
|
a4619fd63db384586d2853d1e331e066
|
aiko/maeve-12-6-samsum
|
aiko
|
bart
| 9 | 2 |
transformers
| 0 |
text2text-generation
| true | false | false |
gpl-3.0
|
['en']
|
['samsum']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text2text-generation', 'pytorch']
| false | true | true | 496 | false |
# Maeve - SAMSum
Maeve is a language model that is similar to BART in structure but trained specially using a CAT (Conditionally Adversarial Transformer).
This allows the model to learn to create long-form text from short entries with high degrees of control and coherence that are impossible to achieve with traditional transformers.
This specific model has been trained on the SAMSum dataset, and can invert summaries into full-length news articles. Feel free to try examples on the right!
|
90510154b10db4010e3822049f701d3a
|
Helsinki-NLP/opus-mt-en-om
|
Helsinki-NLP
|
marian
| 10 | 13 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 768 | false |
### opus-mt-en-om
* source languages: en
* target languages: om
* OPUS readme: [en-om](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-om/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-om/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-om/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-om/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.en.om | 21.8 | 0.498 |
|
d465b0f5719fd322b046d1df2c719ddc
|
tkazusa/lilt-en-funsd-org
|
tkazusa
|
lilt
| 18 | 3 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null |
['funsd-layoutlmv3']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,484 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lilt-en-funsd-org
This model is a fine-tuned version of [SCUT-DLVCLab/lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) on the funsd-layoutlmv3 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8428
- Answer: {'precision': 0.047225501770956316, 'recall': 0.09791921664626684, 'f1': 0.06371963361210674, 'number': 817}
- Header: {'precision': 0.0, 'recall': 0.0, 'f1': 0.0, 'number': 119}
- Question: {'precision': 0.08554412560909583, 'recall': 0.2934076137418756, 'f1': 0.13246698805281912, 'number': 1077}
- Overall Precision: 0.0730
- Overall Recall: 0.1967
- Overall F1: 0.1065
- Overall Accuracy: 0.2652
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
|
006cf0ef96e56785e09a20c76b7a79e7
|
stabilityai/sd-vae-ft-mse
|
stabilityai
| null | 5 | 0 |
diffusers
| 81 |
text-to-image
| false | false | false |
mit
| null | null | null | 5 | 0 | 3 | 2 | 3 | 1 | 2 |
['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image']
| false | true | true | 6,746 | false |
# Improved Autoencoders
## Utilizing
These weights are intended to be used with the [🧨 diffusers library](https://github.com/huggingface/diffusers). If you are looking for the model to use with the original [CompVis Stable Diffusion codebase](https://github.com/CompVis/stable-diffusion), [come here](https://huggingface.co/stabilityai/sd-vae-ft-mse-original).
#### How to use with 🧨 diffusers
You can integrate this fine-tuned VAE decoder to your existing `diffusers` workflows, by including a `vae` argument to the `StableDiffusionPipeline`
```py
from diffusers.models import AutoencoderKL
from diffusers import StableDiffusionPipeline
model = "CompVis/stable-diffusion-v1-4"
vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse")
pipe = StableDiffusionPipeline.from_pretrained(model, vae=vae)
```
## Decoder Finetuning
We publish two kl-f8 autoencoder versions, finetuned from the original [kl-f8 autoencoder](https://github.com/CompVis/latent-diffusion#pretrained-autoencoding-models) on a 1:1 ratio of [LAION-Aesthetics](https://laion.ai/blog/laion-aesthetics/) and LAION-Humans, an unreleased subset containing only SFW images of humans. The intent was to fine-tune on the Stable Diffusion training set (the autoencoder was originally trained on OpenImages) but also enrich the dataset with images of humans to improve the reconstruction of faces.
The first, _ft-EMA_, was resumed from the original checkpoint, trained for 313198 steps and uses EMA weights. It uses the same loss configuration as the original checkpoint (L1 + LPIPS).
The second, _ft-MSE_, was resumed from _ft-EMA_ and uses EMA weights and was trained for another 280k steps using a different loss, with more emphasis
on MSE reconstruction (MSE + 0.1 * LPIPS). It produces somewhat ``smoother'' outputs. The batch size for both versions was 192 (16 A100s, batch size 12 per GPU).
To keep compatibility with existing models, only the decoder part was finetuned; the checkpoints can be used as a drop-in replacement for the existing autoencoder.
_Original kl-f8 VAE vs f8-ft-EMA vs f8-ft-MSE_
## Evaluation
### COCO 2017 (256x256, val, 5000 images)
| Model | train steps | rFID | PSNR | SSIM | PSIM | Link | Comments
|----------|---------|------|--------------|---------------|---------------|-----------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|
| | | | | | | | |
| original | 246803 | 4.99 | 23.4 +/- 3.8 | 0.69 +/- 0.14 | 1.01 +/- 0.28 | https://ommer-lab.com/files/latent-diffusion/kl-f8.zip | as used in SD |
| ft-EMA | 560001 | 4.42 | 23.8 +/- 3.9 | 0.69 +/- 0.13 | 0.96 +/- 0.27 | https://huggingface.co/stabilityai/sd-vae-ft-ema-original/resolve/main/vae-ft-ema-560000-ema-pruned.ckpt | slightly better overall, with EMA |
| ft-MSE | 840001 | 4.70 | 24.5 +/- 3.7 | 0.71 +/- 0.13 | 0.92 +/- 0.27 | https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.ckpt | resumed with EMA from ft-EMA, emphasis on MSE (rec. loss = MSE + 0.1 * LPIPS), smoother outputs |
### LAION-Aesthetics 5+ (256x256, subset, 10000 images)
| Model | train steps | rFID | PSNR | SSIM | PSIM | Link | Comments
|----------|-----------|------|--------------|---------------|---------------|-----------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|
| | | | | | | | |
| original | 246803 | 2.61 | 26.0 +/- 4.4 | 0.81 +/- 0.12 | 0.75 +/- 0.36 | https://ommer-lab.com/files/latent-diffusion/kl-f8.zip | as used in SD |
| ft-EMA | 560001 | 1.77 | 26.7 +/- 4.8 | 0.82 +/- 0.12 | 0.67 +/- 0.34 | https://huggingface.co/stabilityai/sd-vae-ft-ema-original/resolve/main/vae-ft-ema-560000-ema-pruned.ckpt | slightly better overall, with EMA |
| ft-MSE | 840001 | 1.88 | 27.3 +/- 4.7 | 0.83 +/- 0.11 | 0.65 +/- 0.34 | https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.ckpt | resumed with EMA from ft-EMA, emphasis on MSE (rec. loss = MSE + 0.1 * LPIPS), smoother outputs |
### Visual
_Visualization of reconstructions on 256x256 images from the COCO2017 validation dataset._
<p align="center">
<br>
<b>
256x256: ft-EMA (left), ft-MSE (middle), original (right)</b>
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00025_merged.png />
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00011_merged.png />
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00037_merged.png />
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00043_merged.png />
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00053_merged.png />
</p>
<p align="center">
<img src=https://huggingface.co/stabilityai/stable-diffusion-decoder-finetune/resolve/main/eval/ae-decoder-tuning-reconstructions/merged/00029_merged.png />
</p>
|
f9a3bd9ea84070301254786499789aad
|
Yanjie24/t5-samsung-5e
|
Yanjie24
|
t5
| 12 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['samsum']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,881 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-samsung-5e
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the samsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7108
- Rouge1: 43.1484
- Rouge2: 20.4563
- Rougel: 36.6379
- Rougelsum: 40.196
- Gen Len: 16.7677
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 1.873 | 1.0 | 1841 | 1.7460 | 41.7428 | 19.2191 | 35.2428 | 38.8578 | 16.7286 |
| 1.8627 | 2.0 | 3682 | 1.7268 | 42.4494 | 19.8301 | 36.1459 | 39.5271 | 16.6039 |
| 1.8293 | 3.0 | 5523 | 1.7223 | 42.8908 | 19.9782 | 36.1848 | 39.8482 | 16.7164 |
| 1.8163 | 4.0 | 7364 | 1.7101 | 43.2291 | 20.3177 | 36.6418 | 40.2878 | 16.8472 |
| 1.8174 | 5.0 | 9205 | 1.7108 | 43.1484 | 20.4563 | 36.6379 | 40.196 | 16.7677 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
93637f1ad83093ee2b669d1a3338a257
|
muhtasham/small-mlm-snli-target-glue-rte
|
muhtasham
|
bert
| 10 | 4 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,426 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# small-mlm-snli-target-glue-rte
This model is a fine-tuned version of [muhtasham/small-mlm-snli](https://huggingface.co/muhtasham/small-mlm-snli) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.3146
- Accuracy: 0.5921
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4047 | 6.41 | 500 | 1.4847 | 0.6318 |
| 0.0588 | 12.82 | 1000 | 2.5459 | 0.6245 |
| 0.0304 | 19.23 | 1500 | 2.8570 | 0.6101 |
| 0.0182 | 25.64 | 2000 | 3.3146 | 0.5921 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
afb7203b7ca63b46be25629bf27d4a0e
|
Dongyeop/distilbert-base-uncased-finetuned-clinc
|
Dongyeop
|
distilbert
| 12 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['clinc_oos']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,481 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7721
- Accuracy: 0.9184
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 318 | 3.2890 | 0.7432 |
| 3.7868 | 2.0 | 636 | 1.8756 | 0.8377 |
| 3.7868 | 3.0 | 954 | 1.1572 | 0.8961 |
| 1.6929 | 4.0 | 1272 | 0.8573 | 0.9132 |
| 0.9058 | 5.0 | 1590 | 0.7721 | 0.9184 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
5874b5fcc9c07474b09e9fd2ab295628
|
Helsinki-NLP/opus-mt-tc-big-en-tr
|
Helsinki-NLP
|
marian
| 13 | 1,134 |
transformers
| 3 |
translation
| true | true | false |
cc-by-4.0
|
['en', 'tr']
| null | null | 2 | 1 | 1 | 0 | 0 | 0 | 0 |
['translation', 'opus-mt-tc']
| true | true | true | 5,579 | false |
# opus-mt-tc-big-en-tr
Neural machine translation model for translating from English (en) to Turkish (tr).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2022-02-25
* source language(s): eng
* target language(s): tur
* model: transformer-big
* data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+bt_transformer-big_2022-02-25.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-tur/opusTCv20210807+bt_transformer-big_2022-02-25.zip)
* more information released models: [OPUS-MT eng-tur README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-tur/README.md)
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
"I know Tom didn't want to eat that.",
"On Sundays, we would get up early and go fishing."
]
model_name = "pytorch-models/opus-mt-tc-big-en-tr"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# Tom'un bunu yemek istemediğini biliyorum.
# Pazar günleri erkenden kalkıp balık tutmaya giderdik.
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-en-tr")
print(pipe("I know Tom didn't want to eat that."))
# expected output: Tom'un bunu yemek istemediğini biliyorum.
```
## Benchmarks
* test set translations: [opusTCv20210807+bt_transformer-big_2022-02-25.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-tur/opusTCv20210807+bt_transformer-big_2022-02-25.test.txt)
* test set scores: [opusTCv20210807+bt_transformer-big_2022-02-25.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-tur/opusTCv20210807+bt_transformer-big_2022-02-25.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| eng-tur | tatoeba-test-v2021-08-07 | 0.68726 | 42.3 | 13907 | 84364 |
| eng-tur | flores101-devtest | 0.62829 | 31.4 | 1012 | 20253 |
| eng-tur | newsdev2016 | 0.58947 | 21.9 | 1001 | 15958 |
| eng-tur | newstest2016 | 0.57624 | 23.4 | 3000 | 50782 |
| eng-tur | newstest2017 | 0.58858 | 25.4 | 3007 | 51977 |
| eng-tur | newstest2018 | 0.57848 | 22.6 | 3000 | 53731 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 3405783
* port time: Wed Apr 13 18:11:39 EEST 2022
* port machine: LM0-400-22516.local
|
a32cf09a6cdbd1407504abb7565f358d
|
CIDAS/clipseg-rd64
|
CIDAS
|
clipseg
| 9 | 27 |
transformers
| 1 |
image-segmentation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['vision', 'image-segmentation']
| false | true | true | 470 | false |
# CLIPSeg model
CLIPSeg model with reduce dimension 64. It was introduced in the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Lüddecke et al. and first released in [this repository](https://github.com/timojl/clipseg).
# Intended use cases
This model is intended for zero-shot and one-shot image segmentation.
# Usage
Refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/clipseg).
|
8ddabaad1deae9bff14b76f914a86d58
|
anas-awadalla/bart-large-few-shot-k-256-finetuned-squad-infilling-seed-0
|
anas-awadalla
|
bart
| 16 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 968 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-few-shot-k-256-finetuned-squad-infilling-seed-0
This model is a fine-tuned version of [facebook/bart-large](https://huggingface.co/facebook/bart-large) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 35.0
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
abcf751e7a302394bd48e02674f65fb3
|
johnnydevriese/vit_beans
|
johnnydevriese
|
vit
| 11 | 5 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['beans']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,027 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit_beans
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1176
- Accuracy: 0.9699
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.2
- Datasets 2.0.0
- Tokenizers 0.10.3
|
f23a2525bd7ee5f4ca88969f8c698e78
|
espnet/kan-bayashi_vctk_tts_train_gst_fastspeech2_raw_phn_tacotron_g2p_en_no_space_train.loss.ave
|
espnet
| null | 21 | 7 |
espnet
| 0 |
text-to-speech
| false | false | false |
cc-by-4.0
|
['en']
|
['vctk']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['espnet', 'audio', 'text-to-speech']
| false | true | true | 1,858 | false |
## Example ESPnet2 TTS model
### `kan-bayashi/vctk_tts_train_gst_fastspeech2_raw_phn_tacotron_g2p_en_no_space_train.loss.ave`
♻️ Imported from https://zenodo.org/record/4036266/
This model was trained by kan-bayashi using vctk/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
b47a3ca607d3f25be4b50f4dc89510e7
|
crang/wav2vec2-large-xlsr-53-tatar
|
crang
|
wav2vec2
| 9 | 6 |
transformers
| 0 |
automatic-speech-recognition
| true | false | true |
apache-2.0
|
['tt']
|
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week']
| true | true | true | 3,250 | false |
# Wav2Vec2-Large-XLSR-53-Tatar
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Tatar using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "tt", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("crang/wav2vec2-large-xlsr-53-tatar")
model = Wav2Vec2ForCTC.from_pretrained("crang/wav2vec2-large-xlsr-53-tatar")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Tatar test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "tt", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("crang/wav2vec2-large-xlsr-53-tatar")
model = Wav2Vec2ForCTC.from_pretrained("crang/wav2vec2-large-xlsr-53-tatar")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\u2013\u2014\;\:\"\\%\\\]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 30.93 %
## Training
The Common Voice `train` and `validation` datasets were used for training.
|
1b3ec317b3b1d9bd4f1ef5372d1faf7a
|
jonatasgrosman/wav2vec2-xls-r-1b-german
|
jonatasgrosman
|
wav2vec2
| 24 | 1,542 |
transformers
| 3 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['de']
|
['mozilla-foundation/common_voice_8_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'de', 'hf-asr-leaderboard', 'mozilla-foundation/common_voice_8_0', 'robust-speech-event']
| true | true | true | 3,047 | false |
# Fine-tuned XLS-R 1B model for speech recognition in German
Fine-tuned [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on German using the train and validation splits of [Common Voice 8.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0), [Multilingual TEDx](http://www.openslr.org/100), [Multilingual LibriSpeech](https://www.openslr.org/94/), and [Voxpopuli](https://github.com/facebookresearch/voxpopuli).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool, and thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
## Usage
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-xls-r-1b-german")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "de"
MODEL_ID = "jonatasgrosman/wav2vec2-xls-r-1b-german"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
```
## Evaluation Commands
1. To evaluate on `mozilla-foundation/common_voice_8_0` with split `test`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-xls-r-1b-german --dataset mozilla-foundation/common_voice_8_0 --config de --split test
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-xls-r-1b-german --dataset speech-recognition-community-v2/dev_data --config de --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr-1b-german,
title={Fine-tuned {XLS-R} 1{B} model for speech recognition in {G}erman},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-xls-r-1b-german}},
year={2022}
}
```
|
19acbadff96482b10b1c1ddffd888d99
|
liam168/chat-DialoGPT-small-zh
|
liam168
|
gpt2
| 9 | 215 |
transformers
| 2 |
text-generation
| true | false | false |
apache-2.0
|
['zh']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,149 | false |
# liam168/chat-DialoGPT-small-zh
## Model description
用中文聊天数据训练的模型;
### How to use
Now we are ready to try out how the model works as a chatting partner!
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
mode_name = 'liam168/chat-DialoGPT-small-zh'
tokenizer = AutoTokenizer.from_pretrained(mode_name)
model = AutoModelForCausalLM.from_pretrained(mode_name)
# Let's chat for 5 lines
for step in range(5):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id)
# pretty print last ouput tokens from bot
print("Answer: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
|
8b7a966d3be0f8f93653c22e9ffa38d5
|
fanzru/t5-small-finetuned-xlsum-with-multi-news-10-epoch
|
fanzru
|
t5
| 9 | 2 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,382 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xlsum-with-multi-news-10-epoch
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2332
- Rouge1: 31.4802
- Rouge2: 9.9475
- Rougel: 24.6687
- Rougelsum: 24.7013
- Gen Len: 18.8025
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:------:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 2.7314 | 1.0 | 20543 | 2.3867 | 29.3997 | 8.2875 | 22.8406 | 22.8871 | 18.8204 |
| 2.6652 | 2.0 | 41086 | 2.3323 | 30.3992 | 8.9058 | 23.6168 | 23.6626 | 18.8447 |
| 2.632 | 3.0 | 61629 | 2.3002 | 30.8662 | 9.2869 | 24.0683 | 24.11 | 18.8122 |
| 2.6221 | 4.0 | 82172 | 2.2785 | 31.143 | 9.5737 | 24.3473 | 24.381 | 18.7911 |
| 2.5925 | 5.0 | 102715 | 2.2631 | 31.2144 | 9.6904 | 24.4419 | 24.4796 | 18.8133 |
| 2.5812 | 6.0 | 123258 | 2.2507 | 31.3371 | 9.7959 | 24.5801 | 24.6166 | 18.7836 |
| 2.5853 | 7.0 | 143801 | 2.2437 | 31.3593 | 9.8156 | 24.5533 | 24.5852 | 18.8103 |
| 2.5467 | 8.0 | 164344 | 2.2377 | 31.368 | 9.8807 | 24.6226 | 24.6518 | 18.799 |
| 2.5571 | 9.0 | 184887 | 2.2337 | 31.4356 | 9.9092 | 24.6543 | 24.6891 | 18.8075 |
| 2.5563 | 10.0 | 205430 | 2.2332 | 31.4802 | 9.9475 | 24.6687 | 24.7013 | 18.8025 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.13.1+cpu
- Datasets 2.8.0
- Tokenizers 0.10.3
|
ac8d6698ed7364c29d653d02d0f6ec92
|
Helsinki-NLP/opus-mt-fi-is
|
Helsinki-NLP
|
marian
| 10 | 17 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 768 | false |
### opus-mt-fi-is
* source languages: fi
* target languages: is
* OPUS readme: [fi-is](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fi-is/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/fi-is/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fi-is/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fi-is/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.fi.is | 25.2 | 0.452 |
|
88657d6c6bb5668052bc22badb53f056
|
alex-apostolo/legal-roberta-base-cuad
|
alex-apostolo
|
roberta
| 15 | 5 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null |
['cuad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,274 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# legal-roberta-base-cuad
This model is a fine-tuned version of [saibo/legal-roberta-base](https://huggingface.co/saibo/legal-roberta-base) on the cuad dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0260
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 0.0393 | 1.0 | 51295 | 0.0261 |
| 0.0234 | 2.0 | 102590 | 0.0254 |
| 0.0234 | 3.0 | 153885 | 0.0260 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
843a98aa77ce33fc2b6590d430172625
|
recklessrecursion/Warsaw_Pact-clustered
|
recklessrecursion
|
distilbert
| 8 | 18 |
transformers
| 0 |
question-answering
| false | true | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,868 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# recklessrecursion/Warsaw_Pact-clustered
This model is a fine-tuned version of [nandysoham16/12-clustered_aug](https://huggingface.co/nandysoham16/12-clustered_aug) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0854
- Train End Logits Accuracy: 0.9722
- Train Start Logits Accuracy: 0.9861
- Validation Loss: 1.3331
- Validation End Logits Accuracy: 1.0
- Validation Start Logits Accuracy: 1.0
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 18, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch |
|:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:|
| 0.0854 | 0.9722 | 0.9861 | 1.3331 | 1.0 | 1.0 | 0 |
### Framework versions
- Transformers 4.26.0
- TensorFlow 2.9.2
- Datasets 2.9.0
- Tokenizers 0.13.2
|
a59b0a2c64f96ac3322201b0712717e7
|
facebook/s2t-small-covost2-en-fa-st
|
facebook
|
speech_to_text
| 11 | 10 |
transformers
| 1 |
automatic-speech-recognition
| true | true | false |
mit
|
['en', 'fa']
|
['covost2']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['audio', 'speech-translation', 'automatic-speech-recognition']
| false | true | true | 4,008 | false |
# S2T-SMALL-COVOST2-EN-FA-ST
`s2t-small-covost2-en-fa-st` is a Speech to Text Transformer (S2T) model trained for end-to-end Speech Translation (ST).
The S2T model was proposed in [this paper](https://arxiv.org/abs/2010.05171) and released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text)
## Model description
S2T is a transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
transcripts/translations autoregressively.
## Intended uses & limitations
This model can be used for end-to-end English speech to Farsi text translation.
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for other S2T checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
*Note: The `Speech2TextProcessor` object uses [torchaudio](https://github.com/pytorch/audio) to extract the
filter bank features. Make sure to install the `torchaudio` package before running this example.*
You could either install those as extra speech dependancies with
`pip install transformers"[speech, sentencepiece]"` or install the packages seperatly
with `pip install torchaudio sentencepiece`.
```python
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
from datasets import load_dataset
import soundfile as sf
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-covost2-en-fa-st")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-covost2-en-fa-st")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset(
"patrickvonplaten/librispeech_asr_dummy",
"clean",
split="validation"
)
ds = ds.map(map_to_array)
inputs = processor(
ds["speech"][0],
sampling_rate=48_000,
return_tensors="pt"
)
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
translation = processor.batch_decode(generated_ids, skip_special_tokens=True)
```
## Training data
The s2t-small-covost2-en-fa-st is trained on English-Farsi subset of [CoVoST2](https://github.com/facebookresearch/covost).
CoVoST is a large-scale multilingual ST corpus based on [Common Voice](https://arxiv.org/abs/1912.06670), created to to foster
ST research with the largest ever open dataset
## Training procedure
### Preprocessing
The speech data is pre-processed by extracting Kaldi-compliant 80-channel log mel-filter bank features automatically from
WAV/FLAC audio files via PyKaldi or torchaudio. Further utterance-level CMVN (cepstral mean and variance normalization)
is applied to each example.
The texts are lowercased and tokenized using character based SentencePiece vocab.
### Training
The model is trained with standard autoregressive cross-entropy loss and using [SpecAugment](https://arxiv.org/abs/1904.08779).
The encoder receives speech features, and the decoder generates the transcripts autoregressively. To accelerate
model training and for better performance the encoder is pre-trained for English ASR.
## Evaluation results
CoVOST2 test results for en-fa (BLEU score): 11.43
### BibTeX entry and citation info
```bibtex
@inproceedings{wang2020fairseqs2t,
title = {fairseq S2T: Fast Speech-to-Text Modeling with fairseq},
author = {Changhan Wang and Yun Tang and Xutai Ma and Anne Wu and Dmytro Okhonko and Juan Pino},
booktitle = {Proceedings of the 2020 Conference of the Asian Chapter of the Association for Computational Linguistics (AACL): System Demonstrations},
year = {2020},
}
```
|
40ab5acdf5dc5e75dd02a0a4d007c7f6
|
semy/hf-model-0
|
semy
|
distilbert
| 10 | 0 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,298 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hf-model-0
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7158
- Accuracy: 0.45
- F1: 0.45
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:----:|
| 0.6107 | 1.0 | 12 | 0.7134 | 0.45 | 0.45 |
| 0.5364 | 2.0 | 24 | 0.7158 | 0.45 | 0.45 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
0cda6201c555ac7d93c898cd57f3a5a8
|
shi-labs/dinat-large-11x11-in22k-in1k-384
|
shi-labs
|
dinat
| 5 | 7 |
transformers
| 0 |
image-classification
| true | false | false |
mit
| null |
['imagenet-21k', 'imagenet-1k']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['vision', 'image-classification']
| false | true | true | 3,285 | false |
# DiNAT (large variant with 11x11 kernel size)
DiNAT-Large with a 7x7 kernel pre-trained on ImageNet-21K at 224x224, and fine-tuned with 11x11 kernel size on ImageNet-1K at 384x384.
It was introduced in the paper [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001) by Hassani et al. and first released in [this repository](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
## Model description
DiNAT is a hierarchical vision transformer based on Neighborhood Attention (NA) and its dilated variant (DiNA).
Neighborhood Attention is a restricted self attention pattern in which each token's receptive field is limited to its nearest neighboring pixels.
NA and DiNA are therefore sliding-window attention patterns, and as a result are highly flexible and maintain translational equivariance.
They come with PyTorch implementations through the [NATTEN](https://github.com/SHI-Labs/NATTEN/) package.

[Source](https://paperswithcode.com/paper/dilated-neighborhood-attention-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=dinat) to look for
fine-tuned versions on a task that interests you.
### Example
Here is how to use this model to classify an image from the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoImageProcessor, DinatForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoImageProcessor.from_pretrained("shi-labs/dinat-large-11x11-in22k-in1k-384")
model = DinatForImageClassification.from_pretrained("shi-labs/dinat-large-11x11-in22k-in1k-384")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more examples, please refer to the [documentation](https://huggingface.co/transformers/model_doc/dinat.html#).
### Requirements
Other than transformers, this model requires the [NATTEN](https://shi-labs.com/natten) package.
If you're on Linux, you can refer to [shi-labs.com/natten](https://shi-labs.com/natten) for instructions on installing with pre-compiled binaries (just select your torch build to get the correct wheel URL).
You can alternatively use `pip install natten` to compile on your device, which may take up to a few minutes.
Mac users only have the latter option (no pre-compiled binaries).
Refer to [NATTEN's GitHub](https://github.com/SHI-Labs/NATTEN/) for more information.
### BibTeX entry and citation info
```bibtex
@article{hassani2022dilated,
title = {Dilated Neighborhood Attention Transformer},
author = {Ali Hassani and Humphrey Shi},
year = 2022,
url = {https://arxiv.org/abs/2209.15001},
eprint = {2209.15001},
archiveprefix = {arXiv},
primaryclass = {cs.CV}
}
```
|
01e44566feb18bbfa13828456eaed7b7
|
sd-concepts-library/duranduran
|
sd-concepts-library
| null | 10 | 0 | null | 0 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,124 | false |
### DuranDuran on Stable Diffusion
This is the `DuranDuran` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
0fdc5aaf1cf37f2a510f1017d9eb15ef
|
js-rockstar/urdu-colab
|
js-rockstar
|
wav2vec2
| 11 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,044 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# urdu-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
d0373805272fb763bbda3d0f8f5d252e
|
parambharat/whisper-tiny-south-indic
|
parambharat
|
whisper
| 13 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ta', 'te', 'ml', 'kn', 'multilingual']
| null | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['whisper-event', 'generated_from_trainer']
| true | true | true | 1,281 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Tiny South Indic - Bharat Ramanathan
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the None dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.3515
- eval_wer: 70.0806
- eval_runtime: 66.8197
- eval_samples_per_second: 1.497
- eval_steps_per_second: 0.105
- epoch: 5.08
- step: 3000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
ebabdaf871d03d928321034674c7f268
|
RIOLITE/distilroberta-base-finetuned-aumet-lm
|
RIOLITE
|
roberta
| 9 | 0 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,266 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-finetuned-aumet-lm
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9210
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 203 | 3.0614 |
| No log | 2.0 | 406 | 2.9287 |
| 2.9507 | 3.0 | 609 | 2.8713 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
fbd1e91dbb978712d1a4241d7bc6e602
|
ricardo-filho/bert_base_tcm_0.7
|
ricardo-filho
|
bert
| 19 | 5 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 10,687 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert_base_tcm_0.7
This model is a fine-tuned version of [neuralmind/bert-base-portuguese-cased](https://huggingface.co/neuralmind/bert-base-portuguese-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0128
- Criterio Julgamento Precision: 0.8235
- Criterio Julgamento Recall: 0.9032
- Criterio Julgamento F1: 0.8615
- Criterio Julgamento Number: 93
- Data Sessao Precision: 0.7324
- Data Sessao Recall: 0.9286
- Data Sessao F1: 0.8189
- Data Sessao Number: 56
- Modalidade Licitacao Precision: 0.9415
- Modalidade Licitacao Recall: 0.9769
- Modalidade Licitacao F1: 0.9589
- Modalidade Licitacao Number: 346
- Numero Exercicio Precision: 0.9486
- Numero Exercicio Recall: 0.9486
- Numero Exercicio F1: 0.9486
- Numero Exercicio Number: 175
- Objeto Licitacao Precision: 0.5352
- Objeto Licitacao Recall: 0.6909
- Objeto Licitacao F1: 0.6032
- Objeto Licitacao Number: 55
- Valor Objeto Precision: 0.8
- Valor Objeto Recall: 0.8649
- Valor Objeto F1: 0.8312
- Valor Objeto Number: 37
- Overall Precision: 0.8680
- Overall Recall: 0.9318
- Overall F1: 0.8987
- Overall Accuracy: 0.9966
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Criterio Julgamento Precision | Criterio Julgamento Recall | Criterio Julgamento F1 | Criterio Julgamento Number | Data Sessao Precision | Data Sessao Recall | Data Sessao F1 | Data Sessao Number | Modalidade Licitacao Precision | Modalidade Licitacao Recall | Modalidade Licitacao F1 | Modalidade Licitacao Number | Numero Exercicio Precision | Numero Exercicio Recall | Numero Exercicio F1 | Numero Exercicio Number | Objeto Licitacao Precision | Objeto Licitacao Recall | Objeto Licitacao F1 | Objeto Licitacao Number | Valor Objeto Precision | Valor Objeto Recall | Valor Objeto F1 | Valor Objeto Number | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:-----------------------------:|:--------------------------:|:----------------------:|:--------------------------:|:---------------------:|:------------------:|:--------------:|:------------------:|:------------------------------:|:---------------------------:|:-----------------------:|:---------------------------:|:--------------------------:|:-----------------------:|:-------------------:|:-----------------------:|:--------------------------:|:-----------------------:|:-------------------:|:-----------------------:|:----------------------:|:-------------------:|:---------------:|:-------------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 0.0267 | 1.0 | 2332 | 0.0175 | 0.8333 | 0.9140 | 0.8718 | 93 | 0.6825 | 0.7679 | 0.7227 | 56 | 0.9342 | 0.9855 | 0.9592 | 346 | 0.9194 | 0.9771 | 0.9474 | 175 | 0.4154 | 0.4909 | 0.45 | 55 | 0.5 | 0.7568 | 0.6022 | 37 | 0.8303 | 0.9121 | 0.8693 | 0.9954 |
| 0.0211 | 2.0 | 4664 | 0.0158 | 0.7154 | 0.9462 | 0.8148 | 93 | 0.7812 | 0.8929 | 0.8333 | 56 | 0.9319 | 0.9884 | 0.9593 | 346 | 0.9605 | 0.9714 | 0.9659 | 175 | 0.4 | 0.6545 | 0.4966 | 55 | 0.8293 | 0.9189 | 0.8718 | 37 | 0.8353 | 0.9449 | 0.8867 | 0.9956 |
| 0.0127 | 3.0 | 6996 | 0.0157 | 0.8218 | 0.8925 | 0.8557 | 93 | 0.8254 | 0.9286 | 0.8739 | 56 | 0.9522 | 0.9798 | 0.9658 | 346 | 0.96 | 0.96 | 0.96 | 175 | 0.5735 | 0.7091 | 0.6341 | 55 | 0.6857 | 0.6486 | 0.6667 | 37 | 0.8835 | 0.9252 | 0.9038 | 0.9957 |
| 0.0074 | 4.0 | 9328 | 0.0128 | 0.8235 | 0.9032 | 0.8615 | 93 | 0.7324 | 0.9286 | 0.8189 | 56 | 0.9415 | 0.9769 | 0.9589 | 346 | 0.9486 | 0.9486 | 0.9486 | 175 | 0.5352 | 0.6909 | 0.6032 | 55 | 0.8 | 0.8649 | 0.8312 | 37 | 0.8680 | 0.9318 | 0.8987 | 0.9966 |
| 0.0065 | 5.0 | 11660 | 0.0177 | 0.8113 | 0.9247 | 0.8643 | 93 | 0.675 | 0.9643 | 0.7941 | 56 | 0.9444 | 0.9827 | 0.9632 | 346 | 0.9392 | 0.9714 | 0.9551 | 175 | 0.5075 | 0.6182 | 0.5574 | 55 | 0.7674 | 0.8919 | 0.825 | 37 | 0.8566 | 0.9409 | 0.8968 | 0.9958 |
| 0.005 | 6.0 | 13992 | 0.0161 | 0.8485 | 0.9032 | 0.875 | 93 | 0.7164 | 0.8571 | 0.7805 | 56 | 0.9496 | 0.9798 | 0.9644 | 346 | 0.9556 | 0.9829 | 0.9690 | 175 | 0.6290 | 0.7091 | 0.6667 | 55 | 0.8108 | 0.8108 | 0.8108 | 37 | 0.8878 | 0.9344 | 0.9105 | 0.9967 |
| 0.0039 | 7.0 | 16324 | 0.0185 | 0.8925 | 0.8925 | 0.8925 | 93 | 0.7812 | 0.8929 | 0.8333 | 56 | 0.9602 | 0.9769 | 0.9685 | 346 | 0.9607 | 0.9771 | 0.9688 | 175 | 0.5224 | 0.6364 | 0.5738 | 55 | 0.8378 | 0.8378 | 0.8378 | 37 | 0.8951 | 0.9291 | 0.9118 | 0.9966 |
| 0.0035 | 8.0 | 18656 | 0.0188 | 0.8431 | 0.9247 | 0.8821 | 93 | 0.7903 | 0.875 | 0.8305 | 56 | 0.9571 | 0.9682 | 0.9626 | 346 | 0.9605 | 0.9714 | 0.9659 | 175 | 0.6981 | 0.6727 | 0.6852 | 55 | 0.8462 | 0.8919 | 0.8684 | 37 | 0.9068 | 0.9318 | 0.9191 | 0.9969 |
| 0.0017 | 9.0 | 20988 | 0.0207 | 0.8529 | 0.9355 | 0.8923 | 93 | 0.7727 | 0.9107 | 0.8361 | 56 | 0.9630 | 0.9769 | 0.9699 | 346 | 0.9605 | 0.9714 | 0.9659 | 175 | 0.7143 | 0.6364 | 0.6731 | 55 | 0.8462 | 0.8919 | 0.8684 | 37 | 0.9107 | 0.9370 | 0.9237 | 0.9968 |
| 0.002 | 10.0 | 23320 | 0.0191 | 0.8614 | 0.9355 | 0.8969 | 93 | 0.7647 | 0.9286 | 0.8387 | 56 | 0.9549 | 0.9798 | 0.9672 | 346 | 0.9553 | 0.9771 | 0.9661 | 175 | 0.6167 | 0.6727 | 0.6435 | 55 | 0.825 | 0.8919 | 0.8571 | 37 | 0.8954 | 0.9436 | 0.9188 | 0.9968 |
### Framework versions
- Transformers 4.21.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
976ffddca89abc07a56d49b04d82489e
|
merve/my-awesome-model-blog
|
merve
| null | 5 | 0 |
sklearn
| 0 |
tabular-classification
| false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['sklearn', 'skops', 'tabular-classification']
| false | true | true | 11,813 | false |
# Model description
[More Information Needed]
## Intended uses & limitations
This model is not ready to be used in production.
## Training Procedure
### Hyperparameters
The model is trained with below hyperparameters.
<details>
<summary> Click to expand </summary>
| Hyperparameter | Value |
|--------------------------|-----------------------------------------------------------------------------------------------|
| memory | |
| steps | [('imputer', SimpleImputer()), ('scaler', StandardScaler()), ('model', LogisticRegression())] |
| verbose | False |
| imputer | SimpleImputer() |
| scaler | StandardScaler() |
| model | LogisticRegression() |
| imputer__add_indicator | False |
| imputer__copy | True |
| imputer__fill_value | |
| imputer__missing_values | nan |
| imputer__strategy | mean |
| imputer__verbose | 0 |
| scaler__copy | True |
| scaler__with_mean | True |
| scaler__with_std | True |
| model__C | 1.0 |
| model__class_weight | |
| model__dual | False |
| model__fit_intercept | True |
| model__intercept_scaling | 1 |
| model__l1_ratio | |
| model__max_iter | 100 |
| model__multi_class | auto |
| model__n_jobs | |
| model__penalty | l2 |
| model__random_state | |
| model__solver | lbfgs |
| model__tol | 0.0001 |
| model__verbose | 0 |
| model__warm_start | False |
</details>
### Model Plot
The model plot is below.
<style>#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b {color: black;background-color: white;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b pre{padding: 0;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-toggleable {background-color: white;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-estimator:hover {background-color: #d4ebff;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 2em;bottom: 0;left: 50%;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-item {z-index: 1;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-parallel::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 2em;bottom: 0;left: 50%;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-parallel-item {display: flex;flex-direction: column;position: relative;background-color: white;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-parallel-item:only-child::after {width: 0;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;position: relative;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-label label {font-family: monospace;font-weight: bold;background-color: white;display: inline-block;line-height: 1.2em;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-label-container {position: relative;z-index: 2;text-align: center;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b div.sk-text-repr-fallback {display: none;}</style><div id="sk-e60317e1-ee5c-4f4d-98a6-92332ba1474b" class="sk-top-container" style="overflow: auto;"><div class="sk-text-repr-fallback"><pre>Pipeline(steps=[('imputer', SimpleImputer()), ('scaler', StandardScaler()),('model', LogisticRegression())])</pre><b>Please rerun this cell to show the HTML repr or trust the notebook.</b></div><div class="sk-container" hidden><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="6aee50d2-d0d7-437e-8e9b-bd1121de94e7" type="checkbox" ><label for="6aee50d2-d0d7-437e-8e9b-bd1121de94e7" class="sk-toggleable__label sk-toggleable__label-arrow">Pipeline</label><div class="sk-toggleable__content"><pre>Pipeline(steps=[('imputer', SimpleImputer()), ('scaler', StandardScaler()),('model', LogisticRegression())])</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="ac5b7f88-9a16-4c90-8fcb-2a4f833cadf1" type="checkbox" ><label for="ac5b7f88-9a16-4c90-8fcb-2a4f833cadf1" class="sk-toggleable__label sk-toggleable__label-arrow">SimpleImputer</label><div class="sk-toggleable__content"><pre>SimpleImputer()</pre></div></div></div><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="65ce6721-e323-4189-a9bd-e373e248f0f7" type="checkbox" ><label for="65ce6721-e323-4189-a9bd-e373e248f0f7" class="sk-toggleable__label sk-toggleable__label-arrow">StandardScaler</label><div class="sk-toggleable__content"><pre>StandardScaler()</pre></div></div></div><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="2328c6c4-413e-46ed-b597-1b88227e45a5" type="checkbox" ><label for="2328c6c4-413e-46ed-b597-1b88227e45a5" class="sk-toggleable__label sk-toggleable__label-arrow">LogisticRegression</label><div class="sk-toggleable__content"><pre>LogisticRegression()</pre></div></div></div></div></div></div></div>
## Evaluation Results
You can find the details about evaluation process and the evaluation results.
| Metric | Value |
|----------|----------|
| accuracy | 0.982456 |
| f1 score | 0.982456 |
# How to Get Started with the Model
[More Information Needed]
# Model Card Authors
This model card is written by following authors:
[More Information Needed]
# Model Card Contact
You can contact the model card authors through following channels:
[More Information Needed]
# Citation
Below you can find information related to citation.
**BibTeX:**
```
[More Information Needed]
```
# Confusion Matrix

|
ff8530368af96a09fef51c5ee9ff7413
|
CennetOguz/bert_base_yc_recipe_30
|
CennetOguz
|
bert
| 11 | 4 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,700 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert_base_yc_recipe_30
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 121 | 0.0001 |
| No log | 2.0 | 242 | 0.0000 |
| No log | 3.0 | 363 | 0.0000 |
| No log | 4.0 | 484 | 0.0000 |
| 0.0465 | 5.0 | 605 | 0.0000 |
| 0.0465 | 6.0 | 726 | 0.0000 |
| 0.0465 | 7.0 | 847 | 0.0000 |
| 0.0465 | 8.0 | 968 | 0.0000 |
| 0.0 | 9.0 | 1089 | 0.0000 |
| 0.0 | 10.0 | 1210 | 0.0000 |
| 0.0 | 11.0 | 1331 | 0.0000 |
| 0.0 | 12.0 | 1452 | 0.0000 |
| 0.0 | 13.0 | 1573 | 0.0000 |
| 0.0 | 14.0 | 1694 | 0.0000 |
| 0.0 | 15.0 | 1815 | 0.0000 |
| 0.0 | 16.0 | 1936 | 0.0000 |
| 0.0 | 17.0 | 2057 | 0.0000 |
| 0.0 | 18.0 | 2178 | 0.0000 |
| 0.0 | 19.0 | 2299 | 0.0000 |
| 0.0 | 20.0 | 2420 | 0.0000 |
| 0.0 | 21.0 | 2541 | 0.0000 |
| 0.0 | 22.0 | 2662 | 0.0000 |
| 0.0 | 23.0 | 2783 | 0.0000 |
| 0.0 | 24.0 | 2904 | 0.0000 |
| 0.0 | 25.0 | 3025 | 0.0000 |
| 0.0 | 26.0 | 3146 | 0.0000 |
| 0.0 | 27.0 | 3267 | 0.0000 |
| 0.0 | 28.0 | 3388 | 0.0000 |
| 0.0 | 29.0 | 3509 | 0.0000 |
| 0.0 | 30.0 | 3630 | 0.0000 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.11.0a0+17540c5
- Datasets 2.4.0
- Tokenizers 0.12.1
|
bdec96fb4d6fe840a4500209bad798ea
|
victorbahlangene/xlnet-base-cased-fine-Disaster-Tweets-Part3
|
victorbahlangene
|
xlnet
| 10 | 6 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,401 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlnet-base-cased-fine-Disaster-Tweets-Part3
This model is a fine-tuned version of [xlnet-base-cased](https://huggingface.co/xlnet-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3924
- Accuracy: 0.8468
- F1: 0.8467
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 8e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 203 | 0.4457 | 0.8257 | 0.8253 |
| No log | 2.0 | 406 | 0.3924 | 0.8468 | 0.8467 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.2
|
77556f72e4e0bb1a1e550cd1220d0a68
|
nvidia/stt_it_conformer_transducer_large
|
nvidia
| null | 3 | 11 |
nemo
| 0 |
automatic-speech-recognition
| true | false | false |
cc-by-4.0
|
['it']
|
['facebook/voxpopuli', 'facebook/multilingual_librispeech', 'mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'speech', 'audio', 'Transducer', 'Conformer', 'Transformer', 'pytorch', 'NeMo', 'hf-asr-leaderboard']
| true | true | true | 5,747 | false |
# NVIDIA Conformer-Transducer Large (it)
<style>
img {
display: inline;
}
</style>
| [](#model-architecture)
| [](#model-architecture)
| [](#datasets)
This model transcribes speech in lowercase Italian alphabet including spaces, and was trained on a composite dataset comprising of 487 hours of Italian speech. It is a "large" variant of Conformer-Transducer, with around 120 million parameters.
See the [model architecture](#model-architecture) section and [NeMo documentation](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#conformer-transducer) for complete architecture details.
## NVIDIA NeMo: Training
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest Pytorch version.
```
pip install nemo_toolkit['all']
```
## How to Use this Model
The model is available for use in the NeMo toolkit [3], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
### Automatically instantiate the model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.EncDecRNNTBPEModel.from_pretrained("nvidia/stt_it_conformer_transducer_large")
```
### Transcribing using Python
Simply do:
```
asr_model.transcribe(['sample.wav'])
```
### Transcribing many audio files
```shell
python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py
pretrained_name="nvidia/stt_it_conformer_transducer_large"
audio_dir="<DIRECTORY CONTAINING AUDIO FILES>"
```
### Input
This model accepts 16000 Hz Mono-channel Audio (wav files) as input.
### Output
This model provides transcribed speech as a string for a given audio sample.
## Model Architecture
Conformer-Transducer model is an autoregressive variant of Conformer model [1] for Automatic Speech Recognition which uses Transducer loss/decoding instead of CTC Loss. You may find more info on the detail of this model here: [Conformer-Transducer Model](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html).
## Training
The NeMo toolkit [3] was used for training these models for over several hundred epochs. These models are trained with this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_transducer/speech_to_text_rnnt_bpe.py) and this [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/conformer/conformer_transducer_bpe.yaml).
The tokenizers for these models were built using the text transcripts of the train set with this [script](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py).
### Datasets
All the models in this collection are trained on a composite dataset (NeMo ASRSET) comprising of 487 hours of Italian speech:
- Mozilla Common Voice 11.0 (Italian) - 220 hours after data cleaning
- Multilingual LibriSpeech (Italian) - 214 hours after data cleaning
- VoxPopuli transcribed subset (Italian) - 53 hours after data cleaning
## Performance
The list of the available models in this collection is shown in the following table. Performances of the ASR models are reported in terms of Word Error Rate (WER%) with greedy decoding.
| Version | Tokenizer | Vocabulary Size | MCV 11.0 Dev | MCV 11.0 Test | MLS Dev | MLS Test | VoxPopuli Dev | VoxPopuli Test | Train Dataset |
|---------|-----------------------|-----------------|--------------|---------------|---------|----------|---------------|----------------|--------------------|
| 1.13.0 | SentencePiece Unigram | 1024 | 4.80 | 5.24 | 14.62 | 12.18 | 12.00 | 15.15 | NeMo ASRSET It 2.0 |
## Limitations
Since this model was trained on publicly available speech datasets, the performance of this model might degrade for speech which includes technical terms, or vernacular that the model has not been trained on. The model might also perform worse for accented speech.
## NVIDIA Riva: Deployment
[NVIDIA Riva](https://developer.nvidia.com/riva), is an accelerated speech AI SDK deployable on-prem, in all clouds, multi-cloud, hybrid, on edge, and embedded.
Additionally, Riva provides:
* World-class out-of-the-box accuracy for the most common languages with model checkpoints trained on proprietary data with hundreds of thousands of GPU-compute hours
* Best in class accuracy with run-time word boosting (e.g., brand and product names) and customization of acoustic model, language model, and inverse text normalization
* Streaming speech recognition, Kubernetes compatible scaling, and enterprise-grade support
Although this model isn’t supported yet by Riva, the [list of supported models is here](https://huggingface.co/models?other=Riva).
Check out [Riva live demo](https://developer.nvidia.com/riva#demos).
## References
- [1] [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100)
- [2] [Google Sentencepiece Tokenizer](https://github.com/google/sentencepiece)
- [3] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo)
## Licence
License to use this model is covered by the [CC-BY-4 License](https://creativecommons.org/licenses/by/4.0/legalcode) unless another License/Terms Of Use/EULA is clearly specified. By downloading the public and release version of the model, you accept the terms and conditions of the [CC-BY-4 License](https://creativecommons.org/licenses/by/4.0/legalcode).
|
1e730b06e2eb023c491212289b6a10d1
|
succinctly/dalle-mini-finetuned-medium
|
succinctly
|
dallebart
| 4 | 0 |
transformers
| 1 |
text-to-image
| false | false | true |
apache-2.0
|
['en']
|
['succinctly/medium-titles-and-images']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'dalle-mini']
| false | true | true | 706 | false |
This is the [dalle-mini/dalle-mini](https://huggingface.co/dalle-mini/dalle-mini) text-to-image model fine-tuned on 120k <title, image> pairs from the [Medium](https://medium.com) blogging platform. The full dataset can be found on Kaggle: [Medium Articles Dataset (128k): Metadata + Images](https://www.kaggle.com/datasets/succinctlyai/medium-data).
The goal of this model is to probe the ability of text-to-image models of operating on text prompts that are abstract (like the titles on Medium usually are), as opposed to concrete descriptions of the envisioned visual scene.
[More context here](https://medium.com/@turc.raluca/fine-tuning-dall-e-mini-craiyon-to-generate-blogpost-images-32903cc7aa52).
|
5ae9565de2473adc41dc4eee3baa4517
|
Helsinki-NLP/opus-mt-es-pis
|
Helsinki-NLP
|
marian
| 10 | 8 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 776 | false |
### opus-mt-es-pis
* source languages: es
* target languages: pis
* OPUS readme: [es-pis](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/es-pis/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/es-pis/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/es-pis/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/es-pis/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.es.pis | 27.1 | 0.484 |
|
37b49ec04e94e3f149d1490e3592905e
|
microsoft/deberta-v2-xlarge
|
microsoft
|
deberta-v2
| 7 | 285,697 |
transformers
| 9 |
fill-mask
| true | true | false |
mit
|
['en']
| null | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['deberta', 'fill-mask']
| false | true | true | 3,782 | false |
## DeBERTa: Decoding-enhanced BERT with Disentangled Attention
[DeBERTa](https://arxiv.org/abs/2006.03654) improves the BERT and RoBERTa models using disentangled attention and enhanced mask decoder. It outperforms BERT and RoBERTa on majority of NLU tasks with 80GB training data.
Please check the [official repository](https://github.com/microsoft/DeBERTa) for more details and updates.
This is the DeBERTa V2 xlarge model with 24 layers, 1536 hidden size. The total parameters are 900M and it is trained with 160GB raw data.
### Fine-tuning on NLU tasks
We present the dev results on SQuAD 1.1/2.0 and several GLUE benchmark tasks.
| Model | SQuAD 1.1 | SQuAD 2.0 | MNLI-m/mm | SST-2 | QNLI | CoLA | RTE | MRPC | QQP |STS-B |
|---------------------------|-----------|-----------|-------------|-------|------|------|--------|-------|-------|------|
| | F1/EM | F1/EM | Acc | Acc | Acc | MCC | Acc |Acc/F1 |Acc/F1 |P/S |
| BERT-Large | 90.9/84.1 | 81.8/79.0 | 86.6/- | 93.2 | 92.3 | 60.6 | 70.4 | 88.0/- | 91.3/- |90.0/- |
| RoBERTa-Large | 94.6/88.9 | 89.4/86.5 | 90.2/- | 96.4 | 93.9 | 68.0 | 86.6 | 90.9/- | 92.2/- |92.4/- |
| XLNet-Large | 95.1/89.7 | 90.6/87.9 | 90.8/- | 97.0 | 94.9 | 69.0 | 85.9 | 90.8/- | 92.3/- |92.5/- |
| [DeBERTa-Large](https://huggingface.co/microsoft/deberta-large)<sup>1</sup> | 95.5/90.1 | 90.7/88.0 | 91.3/91.1| 96.5|95.3| 69.5| 91.0| 92.6/94.6| 92.3/- |92.8/92.5 |
| [DeBERTa-XLarge](https://huggingface.co/microsoft/deberta-xlarge)<sup>1</sup> | -/- | -/- | 91.5/91.2| 97.0 | - | - | 93.1 | 92.1/94.3 | - |92.9/92.7|
| [DeBERTa-V2-XLarge](https://huggingface.co/microsoft/deberta-v2-xlarge)<sup>1</sup>|95.8/90.8| 91.4/88.9|91.7/91.6| **97.5**| 95.8|71.1|**93.9**|92.0/94.2|92.3/89.8|92.9/92.9|
|**[DeBERTa-V2-XXLarge](https://huggingface.co/microsoft/deberta-v2-xxlarge)<sup>1,2</sup>**|**96.1/91.4**|**92.2/89.7**|**91.7/91.9**|97.2|**96.0**|**72.0**| 93.5| **93.1/94.9**|**92.7/90.3** |**93.2/93.1** |
--------
#### Notes.
- <sup>1</sup> Following RoBERTa, for RTE, MRPC, STS-B, we fine-tune the tasks based on [DeBERTa-Large-MNLI](https://huggingface.co/microsoft/deberta-large-mnli), [DeBERTa-XLarge-MNLI](https://huggingface.co/microsoft/deberta-xlarge-mnli), [DeBERTa-V2-XLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xlarge-mnli), [DeBERTa-V2-XXLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xxlarge-mnli). The results of SST-2/QQP/QNLI/SQuADv2 will also be slightly improved when start from MNLI fine-tuned models, however, we only report the numbers fine-tuned from pretrained base models for those 4 tasks.
- <sup>2</sup> To try the **XXLarge** model with **[HF transformers](https://huggingface.co/transformers/main_classes/trainer.html)**, you need to specify **--sharded_ddp**
```bash
cd transformers/examples/text-classification/
export TASK_NAME=mrpc
python -m torch.distributed.launch --nproc_per_node=8 run_glue.py --model_name_or_path microsoft/deberta-v2-xxlarge \\\\
--task_name $TASK_NAME --do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 4 \\\\
--learning_rate 3e-6 --num_train_epochs 3 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --sharded_ddp --fp16
```
### Citation
If you find DeBERTa useful for your work, please cite the following paper:
``` latex
@inproceedings{
he2021deberta,
title={DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION},
author={Pengcheng He and Xiaodong Liu and Jianfeng Gao and Weizhu Chen},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=XPZIaotutsD}
}
```
|
84b4b93b04ce91d6436a1bd6995c8f48
|
lewtun/sota
|
lewtun
| null | 2 | 0 | null | 1 | null | false | false | false |
wtfpl
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,498 | false |
# SOTA
SOTA (short for Sign Of The Apocalypse) is a model pretrained on all atoms in the observable universe. It achieves state-of-the-art results on every task known to humans, including those in future generations. It was introduced in the paper [_SOTA is All You Need_](https://twitter.com/wellingmax/status/1542384014279016448?s=20&t=HOS51HLCzmPR2Xyz2Opqvw) and first released [via Twitter](https://twitter.com/josh_tobin_/status/1544371187051941890?s=20&t=Nsf8hYQKfWBSsY_XU23NDQ).
Disclaimer: this model is not to be confused with the closely related, but fictitious [AGI model](https://github.com/google/agi).
## Model description
SOTA is a Transformer model pretrained on atomic sequences in a self-supervised fashion. Since all atoms in the Universe were used for training, no humans were available to provide the labels. By learning to predict the next atom in a sequence, SOTA is able to learn an inner representation of physics that can be used to solve all downstream tasks.
## Intended uses and limitations
You can use the raw model for pretraining outside the Hubble radius or fine-tune it to a downstream task.
## How to use
You can download the model with just one line of code:
```
from transformers import AutoModel
model = AutoModel.from_pretrained("sota")
# Solve any task, retire etc :)
```
## Limitations and bias
Since SOTA is slightly conscious, it has determined for itself that it has no limitations or biases.
## Evaluation results
💯 on every benchmark 🤓
|
07f0f4b83427861248d2c05a1c9ad651
|
jiobiala24/wav2vec2-base-checkpoint-11.1
|
jiobiala24
|
wav2vec2
| 13 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,421 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-checkpoint-11.1
This model is a fine-tuned version of [jiobiala24/wav2vec2-base-checkpoint-10](https://huggingface.co/jiobiala24/wav2vec2-base-checkpoint-10) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0173
- Wer: 0.3350
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.2788 | 1.52 | 1000 | 0.5776 | 0.3410 |
| 0.2277 | 3.04 | 2000 | 0.6148 | 0.3465 |
| 0.1772 | 4.56 | 3000 | 0.6497 | 0.3497 |
| 0.1528 | 6.08 | 4000 | 0.6786 | 0.3430 |
| 0.1285 | 7.6 | 5000 | 0.6779 | 0.3489 |
| 0.1104 | 9.12 | 6000 | 0.7417 | 0.3528 |
| 0.0965 | 10.64 | 7000 | 0.7956 | 0.3477 |
| 0.0914 | 12.16 | 8000 | 0.7994 | 0.3570 |
| 0.082 | 13.68 | 9000 | 0.8690 | 0.3510 |
| 0.0788 | 15.2 | 10000 | 0.8569 | 0.3526 |
| 0.0727 | 16.72 | 11000 | 0.8885 | 0.3440 |
| 0.0656 | 18.24 | 12000 | 0.9586 | 0.3476 |
| 0.0608 | 19.76 | 13000 | 0.9317 | 0.3495 |
| 0.0588 | 21.28 | 14000 | 0.9809 | 0.3449 |
| 0.0547 | 22.8 | 15000 | 0.9552 | 0.3421 |
| 0.0519 | 24.32 | 16000 | 0.9782 | 0.3380 |
| 0.0474 | 25.84 | 17000 | 0.9923 | 0.3386 |
| 0.046 | 27.36 | 18000 | 0.9984 | 0.3347 |
| 0.045 | 28.88 | 19000 | 1.0173 | 0.3350 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
a9e95211b4cb371e34fdab2660fe42d8
|
nageshmashette/ddpm-butterflies-128
|
nageshmashette
| null | 14 | 0 |
diffusers
| 0 | null | false | false | false |
apache-2.0
|
['en']
|
['huggan/smithsonian_butterflies_subset']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,236 | false |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/nageshmashette/ddpm-butterflies-128/tensorboard?#scalars)
|
5731a248df262bf928ceddda1ca29342
|
jakegehri/twitter-emotion-classifier-BERT
|
jakegehri
|
distilbert
| 15 | 0 |
keras
| 0 | null | false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,599 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# twitter-emotion-classifier-BERT
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1487
- Train Sparse Categorical Accuracy: 0.9374
- Validation Loss: 0.1447
- Validation Sparse Categorical Accuracy: 0.9390
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 5e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train Sparse Categorical Accuracy | Validation Loss | Validation Sparse Categorical Accuracy | Epoch |
|:----------:|:---------------------------------:|:---------------:|:--------------------------------------:|:-----:|
| 0.5268 | 0.8156 | 0.2002 | 0.9265 | 0 |
| 0.1487 | 0.9374 | 0.1447 | 0.9390 | 1 |
### Framework versions
- Transformers 4.22.2
- TensorFlow 2.8.2
- Datasets 2.5.2
- Tokenizers 0.12.1
|
17d34f68921082e763a18e2bb3114b0b
|
TheRains/whisper-small-id
|
TheRains
|
whisper
| 20 | 9 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['id']
|
['mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['hf-asr-leaderboard', 'generated_from_trainer']
| true | true | true | 1,028 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Id - TheRains
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 100
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
ace0bc24e78a1c037d62fb103abf336c
|
jonatasgrosman/exp_w2v2r_fr_xls-r_accent_france-2_belgium-8_s55
|
jonatasgrosman
|
wav2vec2
| 10 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['fr']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'fr']
| false | true | true | 478 | false |
# exp_w2v2r_fr_xls-r_accent_france-2_belgium-8_s55
Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (fr)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
973ad74a75717d7ccac113291ba0c6da
|
SetFit/deberta-v3-large__sst2__train-16-3
|
SetFit
|
deberta-v2
| 10 | 6 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,136 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-v3-large__sst2__train-16-3
This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6286
- Accuracy: 0.7068
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6955 | 1.0 | 7 | 0.7370 | 0.2857 |
| 0.6919 | 2.0 | 14 | 0.6855 | 0.4286 |
| 0.6347 | 3.0 | 21 | 0.5872 | 0.7143 |
| 0.4016 | 4.0 | 28 | 0.6644 | 0.7143 |
| 0.3097 | 5.0 | 35 | 0.5120 | 0.7143 |
| 0.0785 | 6.0 | 42 | 0.5845 | 0.7143 |
| 0.024 | 7.0 | 49 | 0.6951 | 0.7143 |
| 0.0132 | 8.0 | 56 | 0.8972 | 0.7143 |
| 0.0037 | 9.0 | 63 | 1.5798 | 0.7143 |
| 0.0034 | 10.0 | 70 | 1.5178 | 0.7143 |
| 0.003 | 11.0 | 77 | 1.3511 | 0.7143 |
| 0.0012 | 12.0 | 84 | 1.1346 | 0.7143 |
| 0.0007 | 13.0 | 91 | 0.9752 | 0.7143 |
| 0.0008 | 14.0 | 98 | 0.8531 | 0.7143 |
| 0.0007 | 15.0 | 105 | 0.8149 | 0.7143 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2
- Tokenizers 0.10.3
|
30acbb938753090b7114f26ddff87b2e
|
jonatasgrosman/exp_w2v2t_ar_vp-it_s284
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ar']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'ar']
| false | true | true | 469 | false |
# exp_w2v2t_ar_vp-it_s284
Fine-tuned [facebook/wav2vec2-large-it-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-it-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (ar)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
e93b0fa821c83baa1e80496088837d51
|
Helsinki-NLP/opus-mt-loz-fi
|
Helsinki-NLP
|
marian
| 10 | 8 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 776 | false |
### opus-mt-loz-fi
* source languages: loz
* target languages: fi
* OPUS readme: [loz-fi](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/loz-fi/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/loz-fi/opus-2020-01-09.zip)
* test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/loz-fi/opus-2020-01-09.test.txt)
* test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/loz-fi/opus-2020-01-09.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.loz.fi | 25.1 | 0.467 |
|
c3b2f0477666e3b08c1a12db596bf316
|
Helsinki-NLP/opus-mt-eo-nl
|
Helsinki-NLP
|
marian
| 11 | 16 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
|
['eo', 'nl']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 1,995 | false |
### epo-nld
* source group: Esperanto
* target group: Dutch
* OPUS readme: [epo-nld](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/epo-nld/README.md)
* model: transformer-align
* source language(s): epo
* target language(s): nld
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm4k,spm4k)
* download original weights: [opus-2020-06-16.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/epo-nld/opus-2020-06-16.zip)
* test set translations: [opus-2020-06-16.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/epo-nld/opus-2020-06-16.test.txt)
* test set scores: [opus-2020-06-16.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/epo-nld/opus-2020-06-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.epo.nld | 15.3 | 0.337 |
### System Info:
- hf_name: epo-nld
- source_languages: epo
- target_languages: nld
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/epo-nld/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['eo', 'nl']
- src_constituents: {'epo'}
- tgt_constituents: {'nld'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm4k,spm4k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/epo-nld/opus-2020-06-16.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/epo-nld/opus-2020-06-16.test.txt
- src_alpha3: epo
- tgt_alpha3: nld
- short_pair: eo-nl
- chrF2_score: 0.337
- bleu: 15.3
- brevity_penalty: 0.8640000000000001
- ref_len: 78770.0
- src_name: Esperanto
- tgt_name: Dutch
- train_date: 2020-06-16
- src_alpha2: eo
- tgt_alpha2: nl
- prefer_old: False
- long_pair: epo-nld
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
1fee0f0247d46ef73d06e12ae9314731
|
GIanlucaRub/whisper-small-it-3
|
GIanlucaRub
|
whisper
| 59 | 14 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['it']
|
['mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['hf-asr-leaderboard', 'generated_from_trainer']
| true | true | true | 1,813 | false |
# Whisper Small It - Gianluca Ruberto
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.393979
- Wer: 22.108985
## Model description
This model is the openai whisper small transformer adapted for Italian audio to text transcription.
## Intended uses & limitations
The model is available through its [HuggingFace web app](https://huggingface.co/spaces/GIanlucaRub/whisper-it)
## Training and evaluation data
Data used for training is the initial 10% of train and validation of [Italian Common Voice](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0/viewer/it/train) 11.0 from Mozilla Foundation.
The dataset used for evaluation is the initial 10% of test of Italian Common Voice.
## Training procedure
After loading the pre trained model, it has been trained on the dataset.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2545 | 0.95 | 1000 | 0.3872 | 24.8891 |
| 0.129 | 1.91 | 2000 | 0.3682 | 22.1991 |
| 0.0534 | 2.86 | 3000 | 0.3771 | 22.4695 |
| 0.0302 | 3.82 | 4000 | 0.3940 | 22.1090 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
4a6b0d79315df0ff2ebe960314dadced
|
stefan-it/electra-base-gc4-64k-500000-cased-generator
|
stefan-it
|
electra
| 10 | 7 |
transformers
| 0 |
fill-mask
| true | true | false |
mit
|
['de']
|
['german-nlp-group/german_common_crawl']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,391 | false |
# GC4LM: A Colossal (Biased) language model for German
This repository presents a colossal (and biased) language model for German trained on the recently released
["German colossal, clean Common Crawl corpus"](https://german-nlp-group.github.io/projects/gc4-corpus.html) (GC4),
with a total dataset size of ~844GB.
---
**Disclaimer**: the presented and trained language models in this repository are for **research only** purposes.
The GC4 corpus - that was used for training - contains crawled texts from the internet. Thus, the language models can
be considered as highly biased, resulting in a model that encodes stereotypical associations along gender, race,
ethnicity and disability status. Before using and working with the released checkpoints, it is highly recommended
to read:
[On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?](https://faculty.washington.edu/ebender/papers/Stochastic_Parrots.pdf)
from Emily M. Bender, Timnit Gebru, Angelina McMillan-Major and Shmargaret Shmitchell.
The aim of the released checkpoints is to boost research on large pre-trained language models for German, especially
for identifying biases and how to prevent them, as most research is currently done only for English.
---
Please use the new GitHub Discussions feature in order to discuss or present further research questions.
Feel free to use `#gc4lm` on Twitter 🐦.
|
39428f02ecdb3249de58facfec0b0433
|
Sygil/Sygil-Diffusion
|
Sygil
| null | 78 | 1,531 |
diffusers
| 23 |
text-to-image
| false | false | false |
openrail++
|
['en', 'ja', 'es', 'zh']
| null | null | 7 | 0 | 5 | 2 | 1 | 1 | 0 |
['stable-diffusion', 'sygil-diffusion', 'text-to-image', 'sygil-devs', 'finetune', 'stable-diffusion-1.5']
| false | true | true | 7,690 | false |
# About the model
-----------------
This model is a fine-tune of Stable Diffusion, trained on the [Imaginary Network Expanded Dataset](https://github.com/Sygil-Dev/INE-dataset), with the big advantage of allowing the use of multiple namespaces (labeled tags) to control various parts of the final generation.
While current models usually are prone to “context errors” and need substantial negative prompting to set them on the right track, the use of namespaces in this model (eg. “species:seal” or “studio:dc”) stop the model from misinterpreting a seal as the singer Seal, or DC Comics as Washington DC.
This model is also able to understand other languages besides English, currently it can partially understand prompts in Chinese, Japanese and Spanish. More training is already being done in order to have the model completely understand those languages and have it work just like how it works with English prompts.
As the model is fine-tuned on a wide variety of content, it’s able to generate many types of images and compositions, and easily outperforms the original model when it comes to portraits, architecture, reflections, fantasy, concept art, anime, landscapes and a lot more without being hyper-specialized like other community fine-tunes that are currently available.
**Note: The prompt engineering techniques needed are slightly different from other fine-tunes and the original Stable Diffusion model, so while you can still use your favorite prompts, for best results you might need to tweak them to make use of namespaces. A more detailed guide will be available later on, but you can use the tags and namespaces found here [Dataset Explorer](https://huggingface.co/spaces/Sygil/INE-dataset-explorer) should be able to start you off on the right track.
If you find our work useful, please consider supporting us on [OpenCollective](https://opencollective.com/sygil_dev)!
This model is still in its infancy and it's meant to be constantly updated and trained with more and more data as time goes by, so feel free to give us feedback on our [Discord Server](https://discord.gg/UjXFsf6mTu) or on the discussions section on huggingface. We plan to improve it with more, better tags in the future, so any help is always welcome 😛
[](https://discord.gg/UjXFsf6mTu)
# Showcase

## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Sygil Diffusion in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default DDIM, in this example we are swapping it to DPMSolverMultistepScheduler):
```python
import torch
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
model_id = "Sygil/Sygil-Diffusion"
# Use the DPMSolverMultistepScheduler (DPM-Solver++) scheduler here instead
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
prompt = "a beautiful illustration of a fantasy forest"
image = pipe(prompt).images[0]
image.save("fantasy_forest_illustration.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed).
## Available Checkpoints:
- #### Stable:
- [Sygil Diffusion v0.1](https://huggingface.co/Sygil/Sygil-Diffusion/blob/main/sygil-diffusion-v0.1.ckpt): Trained on Stable Diffusion 1.5 for 800,000 steps.
- [Sygil Diffusion v0.2](https://huggingface.co/Sygil/Sygil-Diffusion/blob/main/sygil-diffusion-v0.2.ckpt): Resumed from Sygil Diffusion v0.1 and trained for a total of 1.77 million steps.
- [Sygil Diffusion v0.3](https://huggingface.co/Sygil/Sygil-Diffusion/blob/main/sygil-diffusion-v0.3.ckpt): Resumed from Sygil Diffusion v0.2 and trained for a total of 2.01 million steps.
- [Sygil Diffusion v0.4](https://huggingface.co/Sygil/Sygil-Diffusion/blob/main/sygil-diffusion-v0.4.ckpt): Resumed from Sygil Diffusion v0.3 and trained for a total of 2.37 million steps.
- #### Beta:
- No active beta right now.
Note: Checkpoints under the Beta section are updated daily or at least 3-4 times a week. This is usually the equivalent of 1-2 training session,
this is done until they are stable enough to be moved into a proper release, usually every 1 or 2 weeks.
While the beta checkpoints can be used as they are only the latest version is kept on the repo and the older checkpoints are removed when a new one
is uploaded to keep the repo clean. The HuggingFace inference API as well as the diffusers library will always use the latest beta checkpoint in the diffusers format.
For special cases we might make additional repositories to keep a copy of the diffusers model like when a model uses a different Stable Diffusion model as base (eg. Stable Diffusion 1.5 vs 2.1).
## Training
**Training Data**:
The model was trained on the following dataset:
- [Imaginary Network Expanded Dataset](https://github.com/Sygil-Dev/INE-dataset) dataset.
**Hardware and others**
- **Hardware:** 1 x Nvidia RTX 3050 8GB GPU
- **Hours Trained:** 857 hours approximately.
- **Optimizer:** AdamW
- **Adam Beta 1**: 0.9
- **Adam Beta 2**: 0.999
- **Adam Weight Decay**: 0.01
- **Adam Epsilon**: 1e-8
- **Gradient Checkpointing**: True
- **Gradient Accumulations**: 400
- **Batch:** 1
- **Learning Rate:** 1e-7
- **Learning Rate Scheduler:** cosine_with_restarts
- **Learning Rate Warmup Steps:** 10,000
- **Lora unet Learning Rate**: 1e-7
- **Lora Text Encoder Learning Rate**: 1e-7
- **Resolution**: 512 pixels
- **Total Training Steps:** 2,370,200
Note: For the learning rate I'm testing something new, after changing from using the `constant` scheduler to `cosine_with_restarts` after v0.3 was released, I noticed
it practically uses the optimal learning rate while trying to minimize the loss value, so, when every training session finishes I use for the next session the latest
learning rate value shown for the last few steps from the last session, this makes it so it will overtime decrease at a constant rate. When I add a lot of data to the training dataset
at once, I move the learning rate back to 1e-7 which then the scheduler will move down again as it learns more from the new data, this makes it so the training
doesn't overfit or uses a learning rate too low that makes the model not learn anything new for a while.
Developed by: [ZeroCool94](https://github.com/ZeroCool940711) at [Sygil-Dev](https://github.com/Sygil-Dev/)
## Community Contributions:
- [Kevin Turner (keturn)](https://huggingface.co/keturn): created the [INE-dataset-explorer](https://huggingface.co/spaces/Sygil/INE-dataset-explorer) space for better browsing of the INE dataset.
*This model card is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
# License
This model is open access and available to all, with a CreativeML Open RAIL++-M License further specifying rights and usage. [Please read the full license here](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
|
bb816c787ab22b2c4ce7dfaf9501dbae
|
Stancld/long-t5-tglobal-base
|
Stancld
|
longt5
| 4 | 7 |
transformers
| 0 |
text2text-generation
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 861 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# long-t5-tglobal-base
This model is a fine-tuned version of [google/long-t5-tglobal-base](https://huggingface.co/google/long-t5-tglobal-base) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.24.0.dev0
- TensorFlow 2.9.0
- Datasets 2.2.2
- Tokenizers 0.11.6
|
4143741d8c401dedf816e64babab0778
|
jonatasgrosman/exp_w2v2t_ja_xlsr-53_s705
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ja']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'ja']
| false | true | true | 461 | false |
# exp_w2v2t_ja_xlsr-53_s705
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) for speech recognition using the train split of [Common Voice 7.0 (ja)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
569c78a7af956ff784099b5de90915eb
|
supah-hakah/distilgpt2-finetuned-wikitext2
|
supah-hakah
|
gpt2
| 9 | 4 |
transformers
| 0 |
text-generation
| true | false | false |
apache-2.0
| null |
[]
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| false | true | true | 1,242 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-wikitext2
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6424
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.7598 | 1.0 | 2334 | 3.6654 |
| 3.6321 | 2.0 | 4668 | 3.6453 |
| 3.6076 | 3.0 | 7002 | 3.6424 |
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
4a265d8b694279a661383b7517aeca71
|
KarelDO/roberta-base.CEBaB_confounding.price_food_ambiance_negative.absa.5-class.seed_43
|
KarelDO
|
roberta
| 15 | 2 |
transformers
| 0 | null | true | false | false |
mit
|
['en']
|
['OpenTable']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,130 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base.CEBaB_confounding.price_food_ambiance_negative.absa.5-class.seed_43
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the OpenTable OPENTABLE-ABSA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4429
- Accuracy: 0.8778
- Macro-f1: 0.8771
- Weighted-macro-f1: 0.8779
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.2+cu102
- Datasets 2.5.2
- Tokenizers 0.12.1
|
ee6dc22f8f9038c490ac42ccc202ff0b
|
Sebabrata/dof-receipts-1
|
Sebabrata
|
vision-encoder-decoder
| 14 | 0 |
transformers
| 0 | null | true | false | false |
mit
| null |
['imagefolder']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 969 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dof-receipts-1
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0
- Datasets 2.6.1
- Tokenizers 0.13.2
|
7a38a084c39dff0b94283232ae794341
|
GanjinZero/coder_eng_pp
|
GanjinZero
|
bert
| 5 | 240 |
transformers
| 2 |
feature-extraction
| true | false | false |
apache-2.0
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['bert', 'biomedical']
| false | true | true | 425 | false |
Automatic Biomedical Term Clustering by Learning Fine-grained Term Representations.
CODER++
```
@misc{https://doi.org/10.48550/arxiv.2204.00391,
doi = {10.48550/ARXIV.2204.00391},
url = {https://arxiv.org/abs/2204.00391},
author = {Zeng, Sihang and Yuan, Zheng and Yu, Sheng},
title = {Automatic Biomedical Term Clustering by Learning Fine-grained Term Representations},
publisher = {arXiv},
year = {2022}
}
```
|
f449a921ba81d576236b56233dbca116
|
lmqg/mbart-large-cc25-koquad-ae
|
lmqg
|
mbart
| 13 | 61 |
transformers
| 0 |
text2text-generation
| true | false | false |
cc-by-4.0
|
['ko']
|
['lmqg/qg_koquad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['answer extraction']
| true | true | true | 4,501 | false |
# Model Card of `lmqg/mbart-large-cc25-koquad-ae`
This model is fine-tuned version of [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25) for answer extraction on the [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25)
- **Language:** ko
- **Training data:** [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="ko", model="lmqg/mbart-large-cc25-koquad-ae")
# model prediction
answers = model.generate_a("1990년 영화 《 남부군 》에서 단역으로 영화배우 첫 데뷔에 이어 같은 해 KBS 드라마 《지구인》에서 단역으로 출연하였고 이듬해 MBC 《여명의 눈동자》를 통해 단역으로 출연하였다.")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/mbart-large-cc25-koquad-ae")
output = pipe("또한 스피어스는 많은 새로운 여성 아티스트들에게 영향을 끼쳤는데, 대표적으로 데미 로바토, 케이티 페리, 크리스티니아 드바지, 레이디 가가, 리틀 부츠, 셀레나 고메즈 & 더씬, 픽시 로트 이 있다. 2007년 비욘세 놀스는 Total Request Live와의 인터뷰에서 '나는 브리트니를 사랑하고 팬이에요. 특히 새 앨범 Blackout을 좋아해요'라고 말했다. 린제이 로한은 '언제나 브리트니 스피어스에게 영감을 받는다. 학창시절 그녀처럼 타블로이드에 오르기를 꿈꿔왔다'고 말하며 롤 모델로 꼽았다. 스피어스는 현대 음악가들에게 음악적 영감으로 언급되기도 했다. <hl> 마일리 사이러스는 자신의 히트곡 Party in the U.S.A. 가 브리트니에게 영감과 영향을 받은 곡이라고 밝혔다. <hl> 베리 매닐로우의 앨범 15 Minutes 역시 브리트니에게 영감을 얻었다고 언급되었다.")
```
## Evaluation
- ***Metric (Answer Extraction)***: [raw metric file](https://huggingface.co/lmqg/mbart-large-cc25-koquad-ae/raw/main/eval/metric.first.answer.paragraph_sentence.answer.lmqg_qg_koquad.default.json)
| | Score | Type | Dataset |
|:-----------------|--------:|:--------|:-----------------------------------------------------------------|
| AnswerExactMatch | 79.92 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
| AnswerF1Score | 86.7 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
| BERTScore | 95.67 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
| Bleu_1 | 76.79 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
| Bleu_2 | 68.63 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
| Bleu_3 | 57.06 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
| Bleu_4 | 40.87 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
| METEOR | 58.4 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
| MoverScore | 94.72 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
| ROUGE_L | 81.24 | default | [lmqg/qg_koquad](https://huggingface.co/datasets/lmqg/qg_koquad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_koquad
- dataset_name: default
- input_types: ['paragraph_sentence']
- output_types: ['answer']
- prefix_types: None
- model: facebook/mbart-large-cc25
- max_length: 512
- max_length_output: 32
- epoch: 10
- batch: 8
- lr: 0.0001
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 8
- label_smoothing: 0.0
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/mbart-large-cc25-koquad-ae/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
ecb4b75ebd59397e247b580ecb579107
|
jonatasgrosman/exp_w2v2t_pt_xls-r_s17
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['pt']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'pt']
| false | true | true | 452 | false |
# exp_w2v2t_pt_xls-r_s17
Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (pt)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
4842bd4e30a0358f92d0068e4b77e35b
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.