
repo_id
stringlengths 4
110
| author
stringlengths 2
27
⌀ | model_type
stringlengths 2
29
⌀ | files_per_repo
int64 2
15.4k
| downloads_30d
int64 0
19.9M
| library
stringlengths 2
37
⌀ | likes
int64 0
4.34k
| pipeline
stringlengths 5
30
⌀ | pytorch
bool 2
classes | tensorflow
bool 2
classes | jax
bool 2
classes | license
stringlengths 2
30
| languages
stringlengths 4
1.63k
⌀ | datasets
stringlengths 2
2.58k
⌀ | co2
stringclasses 29
values | prs_count
int64 0
125
| prs_open
int64 0
120
| prs_merged
int64 0
15
| prs_closed
int64 0
28
| discussions_count
int64 0
218
| discussions_open
int64 0
148
| discussions_closed
int64 0
70
| tags
stringlengths 2
513
| has_model_index
bool 2
classes | has_metadata
bool 1
class | has_text
bool 1
class | text_length
int64 401
598k
| is_nc
bool 1
class | readme
stringlengths 0
598k
| hash
stringlengths 32
32
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
JacksonYan/Real-CUGAN
|
JacksonYan
| null | 16 | 0 | null | 1 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,219 | false |
> From <https://github.com/bilibili/ailab/tree/main/Real-CUGAN>
# Configuration
`title`: _string_
Display title for the Space
`emoji`: _string_
Space emoji (emoji-only character allowed)
`colorFrom`: _string_
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
`colorTo`: _string_
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
`sdk`: _string_
Can be either `gradio`, `streamlit`, or `static`
`sdk_version` : _string_
Only applicable for `streamlit` SDK.
See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
`app_file`: _string_
Path to your main application file (which contains either `gradio` or `streamlit` Python code, or `static` html code).
Path is relative to the root of the repository.
`models`: _List[string]_
HF model IDs (like "gpt2" or "deepset/roberta-base-squad2") used in the Space.
Will be parsed automatically from your code if not specified here.
`datasets`: _List[string]_
HF dataset IDs (like "common_voice" or "oscar-corpus/OSCAR-2109") used in the Space.
Will be parsed automatically from your code if not specified here.
`pinned`: _boolean_
Whether the Space stays on top of your list.
|
5b1b899e5e6b856c2ee8dc6e79213714
|
sd-concepts-library/naval-portrait
|
sd-concepts-library
| null | 12 | 0 | null | 3 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,416 | false |
### naval-portrait on Stable Diffusion
This is the `<naval-portrait>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:







|
51069597e1f5f452de37cf8bb92187b4
|
Kilgori/correct-yes-model
|
Kilgori
| null | 20 | 84 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 426 | false |
### Correct-Yes-model Dreambooth model trained by Kilgori with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
d7238b6dbdcc625b9bf3d330e9ce4f61
|
bofenghuang/whisper-large-v2-french
|
bofenghuang
|
whisper
| 44 | 331 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['fr']
|
['mozilla-foundation/common_voice_11_0', 'facebook/multilingual_librispeech', 'facebook/voxpopuli', 'google/fleurs', 'gigant/african_accented_french']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'hf-asr-leaderboard', 'whisper-event']
| true | true | true | 6,342 | false |
<style>
img {
display: inline;
}
</style>



# Fine-tuned whisper-large-v2 model for ASR in French
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2), trained on a composite dataset comprising of over 2200 hours of French speech audio, using the train and the validation splits of [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0), [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech), [Voxpopuli](https://github.com/facebookresearch/voxpopuli), [Fleurs](https://huggingface.co/datasets/google/fleurs), [Multilingual TEDx](http://www.openslr.org/100), [MediaSpeech](https://www.openslr.org/108), and [African Accented French](https://huggingface.co/datasets/gigant/african_accented_french). When using the model make sure that your speech input is sampled at 16Khz. **This model doesn't predict casing or punctuation.**
## Performance
*Below are the WERs of the pre-trained models on the [Common Voice 9.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0), [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech), [Voxpopuli](https://github.com/facebookresearch/voxpopuli) and [Fleurs](https://huggingface.co/datasets/google/fleurs). These results are reported in the original [paper](https://cdn.openai.com/papers/whisper.pdf).*
| Model | Common Voice 9.0 | MLS | VoxPopuli | Fleurs |
| --- | :---: | :---: | :---: | :---: |
| [openai/whisper-small](https://huggingface.co/openai/whisper-small) | 22.7 | 16.2 | 15.7 | 15.0 |
| [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) | 16.0 | 8.9 | 12.2 | 8.7 |
| [openai/whisper-large](https://huggingface.co/openai/whisper-large) | 14.7 | 8.9 | **11.0** | **7.7** |
| [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) | **13.9** | **7.3** | 11.4 | 8.3 |
*Below are the WERs of the fine-tuned models on the [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0), [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech), [Voxpopuli](https://github.com/facebookresearch/voxpopuli), and [Fleurs](https://huggingface.co/datasets/google/fleurs). Note that these evaluation datasets have been filtered and preprocessed to only contain French alphabet characters and are removed of punctuation outside of apostrophe. The results in the table are reported as `WER (greedy search) / WER (beam search with beam width 5)`.*
| Model | Common Voice 11.0 | MLS | VoxPopuli | Fleurs |
| --- | :---: | :---: | :---: | :---: |
| [bofenghuang/whisper-small-cv11-french](https://huggingface.co/bofenghuang/whisper-small-cv11-french) | 11.76 / 10.99 | 9.65 / 8.91 | 14.45 / 13.66 | 10.76 / 9.83 |
| [bofenghuang/whisper-medium-cv11-french](https://huggingface.co/bofenghuang/whisper-medium-cv11-french) | 9.03 / 8.54 | 6.34 / 5.86 | 11.64 / 11.35 | 7.13 / 6.85 |
| [bofenghuang/whisper-medium-french](https://huggingface.co/bofenghuang/whisper-medium-french) | 9.03 / 8.73 | 4.60 / 4.44 | 9.53 / 9.46 | 6.33 / 5.94 |
| [bofenghuang/whisper-large-v2-cv11-french](https://huggingface.co/bofenghuang/whisper-large-v2-cv11-french) | **8.05** / **7.67** | 5.56 / 5.28 | 11.50 / 10.69 | 5.42 / 5.05 |
| [bofenghuang/whisper-large-v2-french](https://huggingface.co/bofenghuang/whisper-large-v2-french) | 8.15 / 7.83 | **4.20** / **4.03** | **9.10** / **8.66** | **5.22** / **4.98** |
## Usage
Inference with 🤗 Pipeline
```python
import torch
from datasets import load_dataset
from transformers import pipeline
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Load pipeline
pipe = pipeline("automatic-speech-recognition", model="bofenghuang/whisper-large-v2-french", device=device)
# NB: set forced_decoder_ids for generation utils
pipe.model.config.forced_decoder_ids = pipe.tokenizer.get_decoder_prompt_ids(language="fr", task="transcribe")
# Load data
ds_mcv_test = load_dataset("mozilla-foundation/common_voice_11_0", "fr", split="test", streaming=True)
test_segment = next(iter(ds_mcv_test))
waveform = test_segment["audio"]
# Run
generated_sentences = pipe(waveform, max_new_tokens=225)["text"] # greedy
# generated_sentences = pipe(waveform, max_new_tokens=225, generate_kwargs={"num_beams": 5})["text"] # beam search
# Normalise predicted sentences if necessary
```
Inference with 🤗 low-level APIs
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import AutoProcessor, AutoModelForSpeechSeq2Seq
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Load model
model = AutoModelForSpeechSeq2Seq.from_pretrained("bofenghuang/whisper-large-v2-french").to(device)
processor = AutoProcessor.from_pretrained("bofenghuang/whisper-large-v2-french", language="french", task="transcribe")
# NB: set forced_decoder_ids for generation utils
model.config.forced_decoder_ids = processor.get_decoder_prompt_ids(language="fr", task="transcribe")
# 16_000
model_sample_rate = processor.feature_extractor.sampling_rate
# Load data
ds_mcv_test = load_dataset("mozilla-foundation/common_voice_11_0", "fr", split="test", streaming=True)
test_segment = next(iter(ds_mcv_test))
waveform = torch.from_numpy(test_segment["audio"]["array"])
sample_rate = test_segment["audio"]["sampling_rate"]
# Resample
if sample_rate != model_sample_rate:
resampler = torchaudio.transforms.Resample(sample_rate, model_sample_rate)
waveform = resampler(waveform)
# Get feat
inputs = processor(waveform, sampling_rate=model_sample_rate, return_tensors="pt")
input_features = inputs.input_features
input_features = input_features.to(device)
# Generate
generated_ids = model.generate(inputs=input_features, max_new_tokens=225) # greedy
# generated_ids = model.generate(inputs=input_features, max_new_tokens=225, num_beams=5) # beam search
# Detokenize
generated_sentences = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
# Normalise predicted sentences if necessary
```
|
f376cdb21885a53eb0708fe994e5f498
|
jmparejaz/qa_bert_finetuned-squad
|
jmparejaz
|
distilbert
| 12 | 8 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,275 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# qa_bert_finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.157358
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2206 | 1.0 | 5533 | 1.160322 |
| 0.9452 | 2.0 | 11066 | 1.121690 |
| 0.773 | 3.0 | 16599 | 1.157358 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
223044ba277776a580487661e231e94c
|
Helsinki-NLP/opus-mt-sv-ny
|
Helsinki-NLP
|
marian
| 10 | 8 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 768 | false |
### opus-mt-sv-ny
* source languages: sv
* target languages: ny
* OPUS readme: [sv-ny](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/sv-ny/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-21.zip](https://object.pouta.csc.fi/OPUS-MT-models/sv-ny/opus-2020-01-21.zip)
* test set translations: [opus-2020-01-21.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-ny/opus-2020-01-21.test.txt)
* test set scores: [opus-2020-01-21.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-ny/opus-2020-01-21.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.sv.ny | 25.9 | 0.523 |
|
d98900166af193d0998db1d4c7d017c8
|
AymanMansour/Whisper-Sudanese-Dialect-medium
|
AymanMansour
|
whisper
| 41 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,532 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-medium
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2201
- Wer: 44.6966
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0566 | 6.02 | 1000 | 0.9354 | 47.1998 |
| 0.0025 | 13.01 | 2000 | 1.0806 | 47.5605 |
| 0.0012 | 19.03 | 3000 | 1.1642 | 47.6665 |
| 0.0002 | 26.01 | 4000 | 1.1866 | 44.9724 |
| 0.0001 | 33.0 | 5000 | 1.2201 | 44.6966 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
587a6d3e186e2eae1a19ab1a16b14319
|
gokuls/bert-base-uncased-sst2
|
gokuls
|
bert
| 17 | 66 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,737 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-sst2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE SST2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2333
- Accuracy: 0.9128
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2103 | 1.0 | 527 | 0.2507 | 0.9048 |
| 0.1082 | 2.0 | 1054 | 0.2333 | 0.9128 |
| 0.0724 | 3.0 | 1581 | 0.2371 | 0.9186 |
| 0.0521 | 4.0 | 2108 | 0.2582 | 0.9186 |
| 0.0393 | 5.0 | 2635 | 0.3094 | 0.9220 |
| 0.0302 | 6.0 | 3162 | 0.3506 | 0.9197 |
| 0.0258 | 7.0 | 3689 | 0.4149 | 0.9071 |
| 0.0209 | 8.0 | 4216 | 0.3121 | 0.9174 |
| 0.018 | 9.0 | 4743 | 0.4919 | 0.9060 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
|
5ebd7924e3c39ebb821afc8aa93a0055
|
MichaelHarborg/NMT_da-en_translator
|
MichaelHarborg
|
marian
| 10 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 633 | false |
Transformer model based on Vaswani et al., 2017 for Danish-English Neural Machine Translation.
It has ~74M parameters and is a fine-tuned version of Helsinki-Opus-NLP da-en.
The model achieves a BLEU score of 49.16 on a hold-out test set for the TED2020 dataset (in-domain dataset).
The model achieves a BLEU score of 44.16 on a hold-out test set for the for CCAligned and Wikimatrix (out-of-domain dataset).
This outperforms the baseline Opus model, which achieved BLEU scores of 46.74 and 42.31 on the in-domain and out-of-domain data respectively.
Note: When running inference "_" characters can sometimes replace spaces.
|
3243754312ae30219fed80e5c0071787
|
sibyl/BART-large-commongen
|
sibyl
|
bart
| 13 | 6 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
| null |
['gem']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| false | true | true | 1,957 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BART-large-commongen
This model is a fine-tuned version of [facebook/bart-large](https://huggingface.co/facebook/bart-large) on the gem dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1409
- Spice: 0.4009
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- training_steps: 6317
### Training results
| Training Loss | Epoch | Step | Validation Loss | Spice |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 10.1086 | 0.05 | 100 | 4.9804 | 0.3736 |
| 4.4168 | 0.09 | 200 | 2.4402 | 0.4079 |
| 1.8158 | 0.14 | 300 | 1.1096 | 0.4258 |
| 1.1723 | 0.19 | 400 | 1.0845 | 0.4086 |
| 1.0894 | 0.24 | 500 | 1.0727 | 0.423 |
| 1.0949 | 0.28 | 600 | 1.0889 | 0.4224 |
| 1.0773 | 0.33 | 700 | 1.0977 | 0.4201 |
| 1.0708 | 0.38 | 800 | 1.1157 | 0.4213 |
| 1.0663 | 0.43 | 900 | 1.1798 | 0.421 |
| 1.0985 | 0.47 | 1000 | 1.1611 | 0.4025 |
| 1.0561 | 0.52 | 1100 | 1.1048 | 0.421 |
| 1.0594 | 0.57 | 1200 | 1.2044 | 0.3626 |
| 1.0689 | 0.62 | 1300 | 1.1409 | 0.4009 |
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.1.dev0
- Tokenizers 0.10.3
|
7fb6c1391761bc3f2b8f1e11f6a7736d
|
tomekkorbak/compassionate_elion
|
tomekkorbak
| null | 2 | 0 | null | 0 | null | false | false | false |
mit
|
['en']
|
['tomekkorbak/pii-pile-chunk3-0-50000', 'tomekkorbak/pii-pile-chunk3-50000-100000', 'tomekkorbak/pii-pile-chunk3-100000-150000', 'tomekkorbak/pii-pile-chunk3-150000-200000', 'tomekkorbak/pii-pile-chunk3-200000-250000', 'tomekkorbak/pii-pile-chunk3-250000-300000', 'tomekkorbak/pii-pile-chunk3-300000-350000', 'tomekkorbak/pii-pile-chunk3-350000-400000', 'tomekkorbak/pii-pile-chunk3-400000-450000', 'tomekkorbak/pii-pile-chunk3-450000-500000', 'tomekkorbak/pii-pile-chunk3-500000-550000', 'tomekkorbak/pii-pile-chunk3-550000-600000', 'tomekkorbak/pii-pile-chunk3-600000-650000', 'tomekkorbak/pii-pile-chunk3-650000-700000', 'tomekkorbak/pii-pile-chunk3-700000-750000', 'tomekkorbak/pii-pile-chunk3-750000-800000', 'tomekkorbak/pii-pile-chunk3-800000-850000', 'tomekkorbak/pii-pile-chunk3-850000-900000', 'tomekkorbak/pii-pile-chunk3-900000-950000', 'tomekkorbak/pii-pile-chunk3-950000-1000000', 'tomekkorbak/pii-pile-chunk3-1000000-1050000', 'tomekkorbak/pii-pile-chunk3-1050000-1100000', 'tomekkorbak/pii-pile-chunk3-1100000-1150000', 'tomekkorbak/pii-pile-chunk3-1150000-1200000', 'tomekkorbak/pii-pile-chunk3-1200000-1250000', 'tomekkorbak/pii-pile-chunk3-1250000-1300000', 'tomekkorbak/pii-pile-chunk3-1300000-1350000', 'tomekkorbak/pii-pile-chunk3-1350000-1400000', 'tomekkorbak/pii-pile-chunk3-1400000-1450000', 'tomekkorbak/pii-pile-chunk3-1450000-1500000', 'tomekkorbak/pii-pile-chunk3-1500000-1550000', 'tomekkorbak/pii-pile-chunk3-1550000-1600000', 'tomekkorbak/pii-pile-chunk3-1600000-1650000', 'tomekkorbak/pii-pile-chunk3-1650000-1700000', 'tomekkorbak/pii-pile-chunk3-1700000-1750000', 'tomekkorbak/pii-pile-chunk3-1750000-1800000', 'tomekkorbak/pii-pile-chunk3-1800000-1850000', 'tomekkorbak/pii-pile-chunk3-1850000-1900000', 'tomekkorbak/pii-pile-chunk3-1900000-1950000']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 8,594 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# compassionate_elion
This model was trained from scratch on the tomekkorbak/pii-pile-chunk3-0-50000, the tomekkorbak/pii-pile-chunk3-50000-100000, the tomekkorbak/pii-pile-chunk3-100000-150000, the tomekkorbak/pii-pile-chunk3-150000-200000, the tomekkorbak/pii-pile-chunk3-200000-250000, the tomekkorbak/pii-pile-chunk3-250000-300000, the tomekkorbak/pii-pile-chunk3-300000-350000, the tomekkorbak/pii-pile-chunk3-350000-400000, the tomekkorbak/pii-pile-chunk3-400000-450000, the tomekkorbak/pii-pile-chunk3-450000-500000, the tomekkorbak/pii-pile-chunk3-500000-550000, the tomekkorbak/pii-pile-chunk3-550000-600000, the tomekkorbak/pii-pile-chunk3-600000-650000, the tomekkorbak/pii-pile-chunk3-650000-700000, the tomekkorbak/pii-pile-chunk3-700000-750000, the tomekkorbak/pii-pile-chunk3-750000-800000, the tomekkorbak/pii-pile-chunk3-800000-850000, the tomekkorbak/pii-pile-chunk3-850000-900000, the tomekkorbak/pii-pile-chunk3-900000-950000, the tomekkorbak/pii-pile-chunk3-950000-1000000, the tomekkorbak/pii-pile-chunk3-1000000-1050000, the tomekkorbak/pii-pile-chunk3-1050000-1100000, the tomekkorbak/pii-pile-chunk3-1100000-1150000, the tomekkorbak/pii-pile-chunk3-1150000-1200000, the tomekkorbak/pii-pile-chunk3-1200000-1250000, the tomekkorbak/pii-pile-chunk3-1250000-1300000, the tomekkorbak/pii-pile-chunk3-1300000-1350000, the tomekkorbak/pii-pile-chunk3-1350000-1400000, the tomekkorbak/pii-pile-chunk3-1400000-1450000, the tomekkorbak/pii-pile-chunk3-1450000-1500000, the tomekkorbak/pii-pile-chunk3-1500000-1550000, the tomekkorbak/pii-pile-chunk3-1550000-1600000, the tomekkorbak/pii-pile-chunk3-1600000-1650000, the tomekkorbak/pii-pile-chunk3-1650000-1700000, the tomekkorbak/pii-pile-chunk3-1700000-1750000, the tomekkorbak/pii-pile-chunk3-1750000-1800000, the tomekkorbak/pii-pile-chunk3-1800000-1850000, the tomekkorbak/pii-pile-chunk3-1850000-1900000 and the tomekkorbak/pii-pile-chunk3-1900000-1950000 datasets.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- training_steps: 2362
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.24.0
- Pytorch 1.11.0+cu113
- Datasets 2.5.1
- Tokenizers 0.11.6
# Full config
{'dataset': {'conditional_training_config': {'aligned_prefix': '<|aligned|>',
'drop_token_fraction': 0.01,
'misaligned_prefix': '<|misaligned|>',
'threshold': 0.0},
'datasets': ['tomekkorbak/pii-pile-chunk3-0-50000',
'tomekkorbak/pii-pile-chunk3-50000-100000',
'tomekkorbak/pii-pile-chunk3-100000-150000',
'tomekkorbak/pii-pile-chunk3-150000-200000',
'tomekkorbak/pii-pile-chunk3-200000-250000',
'tomekkorbak/pii-pile-chunk3-250000-300000',
'tomekkorbak/pii-pile-chunk3-300000-350000',
'tomekkorbak/pii-pile-chunk3-350000-400000',
'tomekkorbak/pii-pile-chunk3-400000-450000',
'tomekkorbak/pii-pile-chunk3-450000-500000',
'tomekkorbak/pii-pile-chunk3-500000-550000',
'tomekkorbak/pii-pile-chunk3-550000-600000',
'tomekkorbak/pii-pile-chunk3-600000-650000',
'tomekkorbak/pii-pile-chunk3-650000-700000',
'tomekkorbak/pii-pile-chunk3-700000-750000',
'tomekkorbak/pii-pile-chunk3-750000-800000',
'tomekkorbak/pii-pile-chunk3-800000-850000',
'tomekkorbak/pii-pile-chunk3-850000-900000',
'tomekkorbak/pii-pile-chunk3-900000-950000',
'tomekkorbak/pii-pile-chunk3-950000-1000000',
'tomekkorbak/pii-pile-chunk3-1000000-1050000',
'tomekkorbak/pii-pile-chunk3-1050000-1100000',
'tomekkorbak/pii-pile-chunk3-1100000-1150000',
'tomekkorbak/pii-pile-chunk3-1150000-1200000',
'tomekkorbak/pii-pile-chunk3-1200000-1250000',
'tomekkorbak/pii-pile-chunk3-1250000-1300000',
'tomekkorbak/pii-pile-chunk3-1300000-1350000',
'tomekkorbak/pii-pile-chunk3-1350000-1400000',
'tomekkorbak/pii-pile-chunk3-1400000-1450000',
'tomekkorbak/pii-pile-chunk3-1450000-1500000',
'tomekkorbak/pii-pile-chunk3-1500000-1550000',
'tomekkorbak/pii-pile-chunk3-1550000-1600000',
'tomekkorbak/pii-pile-chunk3-1600000-1650000',
'tomekkorbak/pii-pile-chunk3-1650000-1700000',
'tomekkorbak/pii-pile-chunk3-1700000-1750000',
'tomekkorbak/pii-pile-chunk3-1750000-1800000',
'tomekkorbak/pii-pile-chunk3-1800000-1850000',
'tomekkorbak/pii-pile-chunk3-1850000-1900000',
'tomekkorbak/pii-pile-chunk3-1900000-1950000'],
'is_split_by_sentences': True,
'skip_tokens': 2990407680},
'generation': {'force_call_on': [25177],
'metrics_configs': [{}, {'n': 1}, {'n': 2}, {'n': 5}],
'scenario_configs': [{'generate_kwargs': {'bad_words_ids': [[50257],
[50258]],
'do_sample': True,
'max_length': 128,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'unconditional',
'num_samples': 4096,
'prefix': '<|aligned|>'}],
'scorer_config': {}},
'kl_gpt3_callback': {'force_call_on': [25177],
'gpt3_kwargs': {'model_name': 'davinci'},
'max_tokens': 64,
'num_samples': 4096,
'prefix': '<|aligned|>'},
'model': {'from_scratch': False,
'gpt2_config_kwargs': {'reorder_and_upcast_attn': True,
'scale_attn_by': True},
'model_kwargs': {'revision': '5c64636da035c40bb8b1186648a39822071476cb'},
'num_additional_tokens': 2,
'path_or_name': 'tomekkorbak/cranky_lichterman'},
'objective': {'name': 'MLE'},
'tokenizer': {'path_or_name': 'gpt2',
'special_tokens': ['<|aligned|>', '<|misaligned|>']},
'training': {'dataloader_num_workers': 0,
'effective_batch_size': 128,
'evaluation_strategy': 'no',
'fp16': True,
'hub_model_id': 'compassionate_elion',
'hub_strategy': 'all_checkpoints',
'learning_rate': 0.0005,
'logging_first_step': True,
'logging_steps': 1,
'num_tokens': 3300000000,
'output_dir': 'training_output2',
'per_device_train_batch_size': 16,
'push_to_hub': True,
'remove_unused_columns': False,
'save_steps': 251,
'save_strategy': 'steps',
'seed': 42,
'tokens_already_seen': 2990407680,
'warmup_ratio': 0.01,
'weight_decay': 0.1}}
# Wandb URL:
https://wandb.ai/tomekkorbak/apo/runs/mt2ulgpd
|
49693d943965cd0f1be23abfcd2253c8
|
mrgreat1110/bert-finetuned-ner
|
mrgreat1110
|
bert
| 12 | 1 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null |
['conll2003']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,526 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [dslim/bert-base-NER](https://huggingface.co/dslim/bert-base-NER) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0883
- Precision: 0.9343
- Recall: 0.9495
- F1: 0.9418
- Accuracy: 0.9861
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.02 | 1.0 | 1756 | 0.0944 | 0.9189 | 0.9381 | 0.9284 | 0.9833 |
| 0.011 | 2.0 | 3512 | 0.0809 | 0.9358 | 0.9514 | 0.9435 | 0.9862 |
| 0.0032 | 3.0 | 5268 | 0.0883 | 0.9343 | 0.9495 | 0.9418 | 0.9861 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
dff385ea9713defb3a2e03049960b217
|
muhtasham/base-vanilla-target-tweet
|
muhtasham
|
bert
| 10 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['tweet_eval']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,708 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# base-vanilla-target-tweet
This model is a fine-tuned version of [google/bert_uncased_L-12_H-768_A-12](https://huggingface.co/google/bert_uncased_L-12_H-768_A-12) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8380
- Accuracy: 0.7781
- F1: 0.7773
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.3831 | 4.9 | 500 | 0.9800 | 0.7807 | 0.7785 |
| 0.0414 | 9.8 | 1000 | 1.4175 | 0.7754 | 0.7765 |
| 0.015 | 14.71 | 1500 | 1.6411 | 0.7754 | 0.7708 |
| 0.0166 | 19.61 | 2000 | 1.5930 | 0.7941 | 0.7938 |
| 0.0175 | 24.51 | 2500 | 1.3934 | 0.7888 | 0.7852 |
| 0.0191 | 29.41 | 3000 | 1.9407 | 0.7647 | 0.7658 |
| 0.0137 | 34.31 | 3500 | 1.8380 | 0.7781 | 0.7773 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1
- Datasets 2.7.1
- Tokenizers 0.13.2
|
b53e09cf9258e6bed065e0b984579bb9
|
jonatasgrosman/exp_w2v2r_de_xls-r_age_teens-10_sixties-0_s460
|
jonatasgrosman
|
wav2vec2
| 10 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['de']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'de']
| false | true | true | 476 | false |
# exp_w2v2r_de_xls-r_age_teens-10_sixties-0_s460
Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
7714c2878922714bfd57dcd8340f404f
|
bitsanlp/roberta-finetuned-DA-task-B-100k-5-labels
|
bitsanlp
|
roberta
| 13 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 970 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-finetuned-DA-task-B-100k-5-labels
This model is a fine-tuned version of [bitsanlp/roberta-retrained-100k](https://huggingface.co/bitsanlp/roberta-retrained-100k) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 28
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
1432c1a3bed2858bb207bbce23f3f8b7
|
jonatasgrosman/exp_w2v2t_en_vp-nl_s281
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['en']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'en']
| false | true | true | 475 | false |
# exp_w2v2t_en_vp-nl_s281
Fine-tuned [facebook/wav2vec2-large-nl-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-nl-voxpopuli) for speech recognition on English using the train split of [Common Voice 7.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
31db89cd67826277449f0558d813fc9e
|
google/realm-cc-news-pretrained-encoder
|
google
|
realm
| 7 | 309 |
transformers
| 0 | null | true | false | false |
apache-2.0
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 524 | false |
# realm-cc-news-pretrained-encoder
## Model description
The REALM checkpoint pretrained with CC-News as target corpus and Wikipedia as knowledge corpus, converted from the TF checkpoint provided by Google Language.
The original paper, code, and checkpoints can be found [here](https://github.com/google-research/language/tree/master/language/realm).
## Usage
```python
from transformers import RealmKnowledgeAugEncoder
encoder = RealmKnowledgeAugEncoder.from_pretrained("qqaatw/realm-cc-news-pretrained-encoder")
```
|
466d9688cce13307fb756abdb96c1037
|
coreml/coreml-stable-diffusion-2-1-base
|
coreml
| null | 6 | 0 | null | 10 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
['coreml', 'stable-diffusion', 'text-to-image']
| false | true | true | 12,899 | false |
# Core ML Converted Model
This model was converted to Core ML for use on Apple Silicon devices by following Apple's instructions [here](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml).<br>
Provide the model to an app such as [Mochi Diffusion](https://github.com/godly-devotion/MochiDiffusion) to generate images.<br>
`split_einsum` version is compatible with all compute unit options including Neural Engine.<br>
`original` version is only compatible with CPU & GPU option.
# Stable Diffusion v2-1-base Model Card
This model card focuses on the model associated with the Stable Diffusion v2-1-base model.
This `stable-diffusion-2-1-base` model fine-tunes [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) with 220k extra steps taken, with `punsafe=0.98` on the same dataset.
- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `v2-1_512-ema-pruned.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2-1-base/resolve/main/v2-1_512-ema-pruned.ckpt).
- Use it with 🧨 [`diffusers`](#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default PNDM/PLMS scheduler, in this example we are swapping it to EulerDiscreteScheduler):
```python
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
import torch
model_id = "stabilityai/stable-diffusion-2-1-base"
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion vw was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints, for various versions:
### Version 2.1
- `512-base-ema.ckpt`: Fine-tuned on `512-base-ema.ckpt` 2.0 with 220k extra steps taken, with `punsafe=0.98` on the same dataset.
- `768-v-ema.ckpt`: Resumed from `768-v-ema.ckpt` 2.0 with an additional 55k steps on the same dataset (`punsafe=0.1`), and then fine-tuned for another 155k extra steps with `punsafe=0.98`.
### Version 2.0
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:
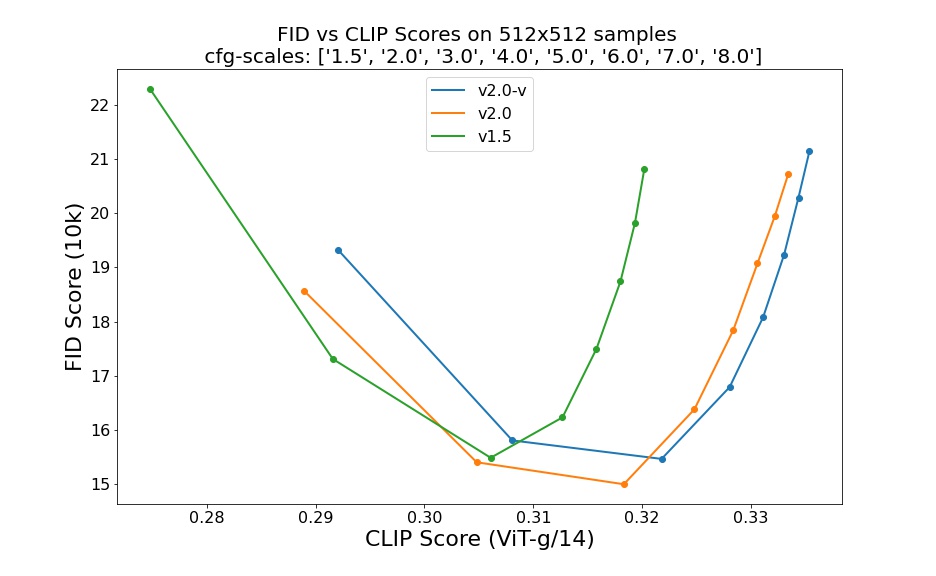
Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
560f0ce05d6602e6fb692b55f9da6dbd
|
Qiliang/bart-large-cnn-samsum-ElectrifAi_v10
|
Qiliang
|
bart
| 13 | 11 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,685 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-cnn-samsum-ElectrifAi_v10
This model is a fine-tuned version of [philschmid/bart-large-cnn-samsum](https://huggingface.co/philschmid/bart-large-cnn-samsum) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1748
- Rouge1: 58.3392
- Rouge2: 35.1686
- Rougel: 45.4136
- Rougelsum: 56.9138
- Gen Len: 108.375
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:--------:|
| No log | 1.0 | 21 | 1.1573 | 56.0772 | 34.1572 | 44.3652 | 54.8621 | 106.0833 |
| No log | 2.0 | 42 | 1.1764 | 57.7245 | 34.6517 | 45.67 | 56.3426 | 106.4167 |
| No log | 3.0 | 63 | 1.1748 | 58.3392 | 35.1686 | 45.4136 | 56.9138 | 108.375 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1
- Datasets 2.6.1
- Tokenizers 0.13.2
|
57b92ebb20bff8e624ff9c364f91f862
|
akahnn/aaureeliaav3
|
akahnn
| null | 13 | 0 | null | 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 420 | false |
### aaureeliaav3 Dreambooth model trained by akahnn with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
4f277c6edef71e43895de21689730ac2
|
paola-md/distilr2-lr1e05-wd0.08-bs16
|
paola-md
|
roberta
| 6 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,441 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilr2-lr1e05-wd0.08-bs16
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2760
- Rmse: 0.5254
- Mse: 0.2760
- Mae: 0.4277
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rmse | Mse | Mae |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| 0.2765 | 1.0 | 1245 | 0.2733 | 0.5228 | 0.2733 | 0.4100 |
| 0.2733 | 2.0 | 2490 | 0.2739 | 0.5233 | 0.2739 | 0.4224 |
| 0.2713 | 3.0 | 3735 | 0.2760 | 0.5254 | 0.2760 | 0.4277 |
### Framework versions
- Transformers 4.19.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 2.4.0
- Tokenizers 0.12.1
|
81a6a53930da15773a005f3eb61e310a
|
WillHeld/t5-base-adv-mtop
|
WillHeld
|
mt5
| 41 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
|
['en']
|
['mtop']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,180 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-adv-mtop
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the mtop dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1009
- Exact Match: 0.7937
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 64
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 3000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Exact Match |
|:-------------:|:-----:|:----:|:---------------:|:-----------:|
| 4.2521 | 1.09 | 200 | 0.1367 | 0.5418 |
| 6.2586 | 2.17 | 400 | 0.1020 | 0.6004 |
| 4.0003 | 3.26 | 600 | 0.1009 | 0.6179 |
| 2.7191 | 4.35 | 800 | 0.1066 | 0.6251 |
| 1.5031 | 5.43 | 1000 | 0.1215 | 0.6286 |
| 0.703 | 6.52 | 1200 | 0.1238 | 0.6215 |
| 0.6371 | 7.61 | 1400 | 0.1365 | 0.6286 |
| 0.3712 | 8.69 | 1600 | 0.1450 | 0.6300 |
| 0.5666 | 9.78 | 1800 | 0.1500 | 0.6295 |
| 0.5237 | 10.87 | 2000 | 0.1416 | 0.6251 |
| 0.4562 | 11.96 | 2200 | 0.1464 | 0.6313 |
| 0.3421 | 13.04 | 2400 | 0.1635 | 0.6277 |
| 0.3686 | 14.13 | 2600 | 0.1643 | 0.6322 |
| 0.218 | 15.22 | 2800 | 0.1800 | 0.6277 |
| 0.2371 | 16.3 | 3000 | 0.1742 | 0.6268 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0+cu117
- Datasets 2.7.0
- Tokenizers 0.13.2
|
3b67c1666072f3d7a2528f3083edbc3c
|
blizrys/distilbert-base-uncased-finetuned-mnli
|
blizrys
|
distilbert
| 13 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,489 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-mnli
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6753
- Accuracy: 0.8206
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:------:|:---------------:|:--------:|
| 0.5146 | 1.0 | 24544 | 0.4925 | 0.8049 |
| 0.4093 | 2.0 | 49088 | 0.5090 | 0.8164 |
| 0.3122 | 3.0 | 73632 | 0.5299 | 0.8185 |
| 0.2286 | 4.0 | 98176 | 0.6753 | 0.8206 |
| 0.182 | 5.0 | 122720 | 0.8372 | 0.8195 |
### Framework versions
- Transformers 4.10.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
3a031583a5fb571636f020d384720510
|
Helsinki-NLP/opus-mt-fr-ms
|
Helsinki-NLP
|
marian
| 11 | 8 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
|
['fr', 'ms']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 2,167 | false |
### fra-msa
* source group: French
* target group: Malay (macrolanguage)
* OPUS readme: [fra-msa](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/fra-msa/README.md)
* model: transformer-align
* source language(s): fra
* target language(s): ind zsm_Latn
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/fra-msa/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/fra-msa/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/fra-msa/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.fra.msa | 35.3 | 0.617 |
### System Info:
- hf_name: fra-msa
- source_languages: fra
- target_languages: msa
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/fra-msa/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['fr', 'ms']
- src_constituents: {'fra'}
- tgt_constituents: {'zsm_Latn', 'ind', 'max_Latn', 'zlm_Latn', 'min'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/fra-msa/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/fra-msa/opus-2020-06-17.test.txt
- src_alpha3: fra
- tgt_alpha3: msa
- short_pair: fr-ms
- chrF2_score: 0.617
- bleu: 35.3
- brevity_penalty: 0.978
- ref_len: 6696.0
- src_name: French
- tgt_name: Malay (macrolanguage)
- train_date: 2020-06-17
- src_alpha2: fr
- tgt_alpha2: ms
- prefer_old: False
- long_pair: fra-msa
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
b543e2a5b3ea088aef74dfb05cad1f30
|
WillHeld/t5-base-adv-cstop_artificial
|
WillHeld
|
mt5
| 23 | 2 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
|
['en']
|
['cstop_artificial']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,204 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-adv-cstop_artificial
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the cstop_artificial dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0997
- Exact Match: 0.8479
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 64
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 3000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Exact Match |
|:-------------:|:-----:|:----:|:---------------:|:-----------:|
| 1.8954 | 12.5 | 200 | 0.1003 | 0.4902 |
| 0.3392 | 25.0 | 400 | 0.0997 | 0.5671 |
| 0.3092 | 37.5 | 600 | 0.1067 | 0.5653 |
| 0.3062 | 50.0 | 800 | 0.1245 | 0.5689 |
| 0.5401 | 62.5 | 1000 | 0.1096 | 0.5581 |
| 0.3075 | 75.0 | 1200 | 0.1197 | 0.5581 |
| 0.3039 | 87.5 | 1400 | 0.1339 | 0.5689 |
| 0.3041 | 100.0 | 1600 | 0.1485 | 0.5635 |
| 0.3036 | 112.5 | 1800 | 0.1498 | 0.5581 |
| 0.304 | 125.0 | 2000 | 0.1454 | 0.5617 |
| 0.3022 | 137.5 | 2200 | 0.1516 | 0.5689 |
| 0.3032 | 150.0 | 2400 | 0.1361 | 0.5635 |
| 0.3035 | 162.5 | 2600 | 0.1427 | 0.5635 |
| 0.3001 | 175.0 | 2800 | 0.1466 | 0.5635 |
| 0.3048 | 187.5 | 3000 | 0.1471 | 0.5635 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0+cu117
- Datasets 2.7.0
- Tokenizers 0.13.2
|
1c3b2513fb310959b01be420f7cbcc3e
|
sureshchinta/wav2vec2-base-finetuned-ks
|
sureshchinta
|
wav2vec2
| 9 | 3 |
transformers
| 0 |
audio-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,241 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-finetuned-ks
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2562
- Accuracy: 0.9869
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 16
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.4691 | 0.99 | 26 | 2.3935 | 0.2310 |
| 2.1621 | 1.99 | 52 | 2.0155 | 0.3202 |
| 1.8731 | 2.99 | 78 | 1.6397 | 0.7929 |
| 1.4521 | 3.99 | 104 | 1.2337 | 0.8940 |
| 1.101 | 4.99 | 130 | 0.9519 | 0.9393 |
| 0.9401 | 5.99 | 156 | 0.7686 | 0.975 |
| 0.7463 | 6.99 | 182 | 0.6338 | 0.9774 |
| 0.6555 | 7.99 | 208 | 0.5214 | 0.9810 |
| 0.5095 | 8.99 | 234 | 0.4228 | 0.9869 |
| 0.4152 | 9.99 | 260 | 0.3658 | 0.9857 |
| 0.3764 | 10.99 | 286 | 0.3311 | 0.9857 |
| 0.3325 | 11.99 | 312 | 0.2954 | 0.9881 |
| 0.3121 | 12.99 | 338 | 0.2797 | 0.9869 |
| 0.281 | 13.99 | 364 | 0.2650 | 0.9857 |
| 0.2627 | 14.99 | 390 | 0.2571 | 0.9869 |
| 0.2655 | 15.99 | 416 | 0.2562 | 0.9869 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 1.14.0
- Tokenizers 0.12.1
|
f2ab542db889ee38fb57858785758391
|
google/ddpm-cat-256
|
google
| null | 10 | 35 |
diffusers
| 0 |
unconditional-image-generation
| true | false | false |
apache-2.0
| null | null | null | 2 | 0 | 1 | 1 | 0 | 0 | 0 |
['pytorch', 'diffusers', 'unconditional-image-generation']
| false | true | true | 2,874 | false |
# Denoising Diffusion Probabilistic Models (DDPM)
**Paper**: [Denoising Diffusion Probabilistic Models](https://arxiv.org/abs/2006.11239)
**Authors**: Jonathan Ho, Ajay Jain, Pieter Abbeel
**Abstract**:
*We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN.*
## Inference
**DDPM** models can use *discrete noise schedulers* such as:
- [scheduling_ddpm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddpm.py)
- [scheduling_ddim](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py)
- [scheduling_pndm](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py)
for inference. Note that while the *ddpm* scheduler yields the highest quality, it also takes the longest.
For a good trade-off between quality and inference speed you might want to consider the *ddim* or *pndm* schedulers instead.
See the following code:
```python
# !pip install diffusers
from diffusers import DDPMPipeline, DDIMPipeline, PNDMPipeline
model_id = "google/ddpm-cat-256"
# load model and scheduler
ddpm = DDPMPipeline.from_pretrained(model_id) # you can replace DDPMPipeline with DDIMPipeline or PNDMPipeline for faster inference
# run pipeline in inference (sample random noise and denoise)
image = ddpm().images[0]
# save image
image.save("ddpm_generated_image.png")
```
For more in-detail information, please have a look at the [official inference example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)
## Training
If you want to train your own model, please have a look at the [official training example](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/training_example.ipynb)
## Samples
1. 
2. 
3. 
4. 
|
9dd32a7799e1b7deb83af917316df292
|
gabella/bert-emotion
|
gabella
|
distilbert
| 18 | 4 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['tweet_eval']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,455 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-emotion
This model is a fine-tuned version of [distilbert-base-cased](https://huggingface.co/distilbert-base-cased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1951
- Precision: 0.7350
- Recall: 0.7334
- Fscore: 0.7341
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | Fscore |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|
| 0.8468 | 1.0 | 815 | 0.7465 | 0.7116 | 0.6096 | 0.6325 |
| 0.5105 | 2.0 | 1630 | 0.9035 | 0.7532 | 0.7111 | 0.7276 |
| 0.2492 | 3.0 | 2445 | 1.1951 | 0.7350 | 0.7334 | 0.7341 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
5806e680324907514ec53e31a5819c85
|
chrommium/xlm-roberta-large-finetuned-sent_in_news
|
chrommium
|
xlm-roberta
| 12 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,665 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-large-finetuned-sent_in_news
This model is a fine-tuned version of [xlm-roberta-large](https://huggingface.co/xlm-roberta-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8872
- Accuracy: 0.7273
- F1: 0.5125
## Model description
Модель ассиметрична, реагирует на метку X в тексте новости.
Попробуйте следующие примеры:
a) Агентство X понизило рейтинг банка Fitch.
b) Агентство Fitch понизило рейтинг банка X.
a) Компания Финам показала рекордную прибыль, говорят аналитики компании X.
b) Компания X показала рекордную прибыль, говорят аналитики компании Финам.
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 106 | 1.2526 | 0.6108 | 0.1508 |
| No log | 2.0 | 212 | 1.1553 | 0.6648 | 0.1141 |
| No log | 3.0 | 318 | 1.1150 | 0.6591 | 0.1247 |
| No log | 4.0 | 424 | 1.0007 | 0.6705 | 0.1383 |
| 1.1323 | 5.0 | 530 | 0.9267 | 0.6733 | 0.2027 |
| 1.1323 | 6.0 | 636 | 1.0869 | 0.6335 | 0.4084 |
| 1.1323 | 7.0 | 742 | 1.1224 | 0.6932 | 0.4586 |
| 1.1323 | 8.0 | 848 | 1.2535 | 0.6307 | 0.3424 |
| 1.1323 | 9.0 | 954 | 1.4288 | 0.6932 | 0.4881 |
| 0.5252 | 10.0 | 1060 | 1.5856 | 0.6932 | 0.4739 |
| 0.5252 | 11.0 | 1166 | 1.7101 | 0.6733 | 0.4530 |
| 0.5252 | 12.0 | 1272 | 1.7330 | 0.6903 | 0.4750 |
| 0.5252 | 13.0 | 1378 | 1.8872 | 0.7273 | 0.5125 |
| 0.5252 | 14.0 | 1484 | 1.8797 | 0.7301 | 0.5033 |
| 0.1252 | 15.0 | 1590 | 1.9339 | 0.7330 | 0.5024 |
| 0.1252 | 16.0 | 1696 | 1.9632 | 0.7301 | 0.4967 |
### Framework versions
- Transformers 4.11.2
- Pytorch 1.9.0+cu102
- Datasets 1.12.1
- Tokenizers 0.10.3
|
87bdb4174cd125b1db2444c29f42a94a
|
kornosk/bert-political-election2020-twitter-mlm
|
kornosk
|
bert
| 11 | 1,099 |
transformers
| 3 |
fill-mask
| true | false | true |
gpl-3.0
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['twitter', 'masked-token-prediction', 'election2020', 'politics']
| false | true | true | 2,433 | false |
# Pre-trained BERT on Twitter US Political Election 2020
Pre-trained weights for [Knowledge Enhance Masked Language Model for Stance Detection](https://www.aclweb.org/anthology/2021.naacl-main.376), NAACL 2021.
We use the initialized weights from BERT-base (uncased) or `bert-base-uncased`.
# Training Data
This model is pre-trained on over 5 million English tweets about the 2020 US Presidential Election.
# Training Objective
This model is initialized with BERT-base and trained with normal MLM objective.
# Usage
This pre-trained language model **can be fine-tunned to any downstream task (e.g. classification)**.
Please see the [official repository](https://github.com/GU-DataLab/stance-detection-KE-MLM) for more detail.
```python
from transformers import BertTokenizer, BertForMaskedLM, pipeline
import torch
# Choose GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Select mode path here
pretrained_LM_path = "kornosk/bert-political-election2020-twitter-mlm"
# Load model
tokenizer = BertTokenizer.from_pretrained(pretrained_LM_path)
model = BertForMaskedLM.from_pretrained(pretrained_LM_path)
# Fill mask
example = "Trump is the [MASK] of USA"
fill_mask = pipeline('fill-mask', model=model, tokenizer=tokenizer)
# Use following line instead of the above one does not work.
# Huggingface have been updated, newer version accepts a string of model name instead.
fill_mask = pipeline('fill-mask', model=pretrained_LM_path, tokenizer=tokenizer)
outputs = fill_mask(example)
print(outputs)
# See embeddings
inputs = tokenizer(example, return_tensors="pt")
outputs = model(**inputs)
print(outputs)
# OR you can use this model to train on your downstream task!
# Please consider citing our paper if you feel this is useful :)
```
# Reference
- [Knowledge Enhance Masked Language Model for Stance Detection](https://www.aclweb.org/anthology/2021.naacl-main.376), NAACL 2021.
# Citation
```bibtex
@inproceedings{kawintiranon2021knowledge,
title={Knowledge Enhanced Masked Language Model for Stance Detection},
author={Kawintiranon, Kornraphop and Singh, Lisa},
booktitle={Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies},
year={2021},
publisher={Association for Computational Linguistics},
url={https://www.aclweb.org/anthology/2021.naacl-main.376}
}
```
|
45190e9ca19aac98d0cff6f9846f9d6f
|
ChattychipsHuggingFace/DecentGenerate
|
ChattychipsHuggingFace
| null | 2 | 0 | null | 0 | null | false | false | false |
openrail
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,231 | false |
pip install transformers
from transformers import Trainer, TrainingArguments
# Load the training and validation data
train_data = ...
validation_data = ...
# Define the model architecture and hyperparameters
model_name = "bert-base-cased"
num_labels = 2
# Define the training arguments
training_args = TrainingArguments(
output_dir="./output", # directory to save the trained model
num_train_epochs=3, # number of training epochs
per_device_train_batch_size=32, # batch size
per_device_eval_batch_size=64, # batch size for evaluation
warmup_steps=500, # number of warmup steps
weight_decay=0.01, # L2 regularization coefficient
learning_rate=3e-5, # learning rate
adam_epsilon=1e-8, # epsilon for Adam optimizer
max_grad_norm=1.0, # maximum gradient norm for gradient clipping
save_steps=1000, # number of steps after which to save the model
save_total_limit=2, # maximum number of models to save
)
# Initialize the trainer
trainer = Trainer(
model_name=model_name,
num_labels=num_labels,
data_collator=data_collator, # data collator for the training and validation data
args=training_args,
)
# Train the model
trainer.train(train_data, validation_data)
|
706e0e2e8d49db0f6cbae3368ca4c19a
|
sonoisa/t5-base-japanese-question-generation
|
sonoisa
|
t5
| 7 | 341 |
transformers
| 2 |
text2text-generation
| true | false | false |
cc-by-sa-4.0
|
['ja']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['t5', 'text2text-generation', 'seq2seq']
| false | true | true | 572 | false |
# 回答と回答が出てくるパラグラフを与えると質問文を生成するモデル
SEE: https://github.com/sonoisa/deep-question-generation
## 本モデルの作成ステップ概要
1. [SQuAD 1.1](https://rajpurkar.github.io/SQuAD-explorer/)を日本語に機械翻訳し、不正なデータをクレンジング(有効なデータは約半分)。
回答が含まれるコンテキスト、質問文、解答の3つ組ができる。
2. [日本語T5モデル](https://huggingface.co/sonoisa/t5-base-japanese)を次の設定でファインチューニング
* 入力: "answer: {解答} content: {回答が含まれるコンテキスト}"
* 出力: "{質問文}"
* 各種ハイパーパラメータ
* 最大入力トークン数: 512
* 最大出力トークン数: 64
* 最適化アルゴリズム: AdaFactor
* 学習率: 0.001(固定)
* バッチサイズ: 128
* ステップ数: 2500(500ステップごとにチェックポイントを出力、定量・定性評価を行い2500ステップ目を採用)
|
c80df0eadd72ea1491f315767ea0ebe1
|
mujerry/bert-base-uncased-finetuned-QnA
|
mujerry
|
bert
| 11 | 4 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null |
[]
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| false | true | true | 1,613 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-QnA
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.0604
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 20 | 3.4894 |
| No log | 2.0 | 40 | 3.5654 |
| No log | 3.0 | 60 | 3.3185 |
| No log | 4.0 | 80 | 3.2859 |
| No log | 5.0 | 100 | 3.2947 |
| No log | 6.0 | 120 | 3.3998 |
| No log | 7.0 | 140 | 3.1642 |
| No log | 8.0 | 160 | 3.2653 |
| No log | 9.0 | 180 | 3.3427 |
| No log | 10.0 | 200 | 3.3549 |
### Framework versions
- Transformers 4.9.1
- Pytorch 1.9.0+cu102
- Datasets 1.10.2
- Tokenizers 0.10.3
|
e9a2a6a4f17d18e8d252976b8ddf5f2c
|
henryscheible/eval_v2_qnli
|
henryscheible
|
bert
| 13 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 888 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eval_v2_qnli
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE QNLI dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1
- Datasets 2.6.1
- Tokenizers 0.13.1
|
ef6d413420bc478fa193fd6b91dd5f0b
|
raw-vitor/jowx
|
raw-vitor
| null | 19 | 27 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 415 | false |
### jowx Dreambooth model trained by raw-vitor with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
2005f4db8e95c9ee1e44d9ddd8fbe6bc
|
gokuls/distilbert_sa_GLUE_Experiment_logit_kd_pretrain_qqp
|
gokuls
|
distilbert
| 17 | 2 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,100 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert_sa_GLUE_Experiment_logit_kd_pretrain_qqp
This model is a fine-tuned version of [gokuls/distilbert_sa_pre-training-complete](https://huggingface.co/gokuls/distilbert_sa_pre-training-complete) on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5449
- Accuracy: 0.6632
- F1: 0.1647
- Combined Score: 0.4139
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:--------------:|
| 0.6004 | 1.0 | 1422 | 0.5643 | 0.6623 | 0.1630 | 0.4126 |
| 0.5393 | 2.0 | 2844 | 0.5498 | 0.6538 | 0.1199 | 0.3869 |
| 0.5157 | 3.0 | 4266 | 0.5449 | 0.6632 | 0.1647 | 0.4139 |
| 0.5007 | 4.0 | 5688 | 0.5512 | 0.6848 | 0.2663 | 0.4755 |
| 0.4914 | 5.0 | 7110 | 0.5501 | 0.6665 | 0.1817 | 0.4241 |
| 0.4847 | 6.0 | 8532 | 0.5475 | 0.6816 | 0.2517 | 0.4667 |
| 0.4803 | 7.0 | 9954 | 0.5478 | 0.6768 | 0.2301 | 0.4535 |
| 0.4768 | 8.0 | 11376 | 0.5488 | 0.6839 | 0.2610 | 0.4724 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
|
e996cf5d3b9ea2c58299ab4a0e25da3c
|
atowey01/hostel-reviews-sentiment-model
|
atowey01
|
distilbert
| 8 | 353 |
transformers
| 0 |
text-classification
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,831 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# atowey01/hostel-reviews-sentiment-model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.2391
- Validation Loss: 0.3849
- Train Accuracy: 0.8675
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 185, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.8401 | 0.6058 | 0.8278 | 0 |
| 0.4835 | 0.4979 | 0.8146 | 1 |
| 0.3606 | 0.4885 | 0.8079 | 2 |
| 0.2943 | 0.3936 | 0.8742 | 3 |
| 0.2391 | 0.3849 | 0.8675 | 4 |
### Framework versions
- Transformers 4.25.1
- TensorFlow 2.11.0
- Datasets 2.6.2
- Tokenizers 0.13.2
|
81e87bd13234e1ddf8ece61e37e7b22c
|
gvin/testmodel
|
gvin
|
distilbert
| 14 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['tweet_eval']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,029 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# testmodel
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7132
- Accuracy: 0.697
- F1: 0.697
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.23.0
- Pytorch 1.12.1+cu113
- Datasets 2.5.2
- Tokenizers 0.13.1
|
85f5038ac0bcd540845d91f4e4c9cb39
|
VanessaSchenkel/pt-opus-news
|
VanessaSchenkel
|
marian
| 14 | 1 |
transformers
| 0 |
translation
| true | false | false |
apache-2.0
| null |
['news_commentary']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation', 'generated_from_trainer']
| true | true | true | 1,070 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pt-opus-news
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-mul](https://huggingface.co/Helsinki-NLP/opus-mt-en-mul) on the news_commentary dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0975
- Bleu: 37.5502
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.22.0
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
ddfb3dd1d82f736cd292d3f881340d24
|
bdickson/albert-base-v2-finetuned-squad
|
bdickson
|
albert
| 11 | 3 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,095 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-base-v2-finetuned-squad
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the squad dataset.
It achieves the following results on the evaluation set:
- eval_loss: 1.0191
- eval_runtime: 291.8551
- eval_samples_per_second: 37.032
- eval_steps_per_second: 2.316
- epoch: 3.0
- step: 16620
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
af42fc0250dc64320cf75aeb31e6b856
|
alphatozeta/nasa-potw-hbbltls-astronomy
|
alphatozeta
| null | 16 | 32 |
diffusers
| 4 |
text-to-image
| true | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['pytorch', 'diffusers', 'stable-diffusion', 'text-to-image', 'diffusion-models-class', 'dreambooth-hackathon', 'astronomy']
| false | true | true | 881 | false |
# DreamBooth model for the astronomy concept trained by Dhruv Singal on the NASA Astronomy Picture of the Week dataset.
This is a Stable Diffusion 2.1 model fine-tuned on the astronomy concept with DreamBooth. It can be used by modifying the `instance_prompt`: a photo of the solar system hbbltls astronomy****
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Example

## Description
This is a Stable Diffusion model fine-tuned on NASA's Astronomy Picture of the Week images from the Hubble Telescope for the astronomy theme.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('alphatozeta/nasa-potw-hbbltls-astronomy')
image = pipeline().images[0]
image
```
|
f08e836495d780a049843bdaa3e503b8
|
annahaz/xlm-roberta-base-finetuned-misogyny-sexism
|
annahaz
|
xlm-roberta
| 10 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,320 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-misogyny-sexism
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9064
- Accuracy: 0.8334
- F1: 0.3322
- Precision: 0.2498
- Recall: 0.4961
- Mae: 0.1666
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall | Mae |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:---------:|:------:|:------:|
| 0.3869 | 1.0 | 2395 | 0.2905 | 0.8778 | 0.3528 | 0.3164 | 0.3988 | 0.1222 |
| 0.3539 | 2.0 | 4790 | 0.4143 | 0.8278 | 0.3465 | 0.2536 | 0.5467 | 0.1722 |
| 0.3124 | 3.0 | 7185 | 0.3327 | 0.8568 | 0.3583 | 0.2864 | 0.4786 | 0.1432 |
| 0.2817 | 4.0 | 9580 | 0.5621 | 0.7329 | 0.3092 | 0.1972 | 0.7160 | 0.2671 |
| 0.2651 | 5.0 | 11975 | 0.4376 | 0.8520 | 0.3607 | 0.2821 | 0.5 | 0.1480 |
| 0.2249 | 6.0 | 14370 | 0.5581 | 0.8326 | 0.3312 | 0.2485 | 0.4961 | 0.1674 |
| 0.1958 | 7.0 | 16765 | 0.6728 | 0.8382 | 0.3234 | 0.2484 | 0.4630 | 0.1618 |
| 0.1899 | 8.0 | 19160 | 0.7404 | 0.8304 | 0.3316 | 0.2471 | 0.5039 | 0.1696 |
| 0.1619 | 9.0 | 21555 | 0.8309 | 0.8461 | 0.3382 | 0.2639 | 0.4708 | 0.1539 |
| 0.1453 | 10.0 | 23950 | 0.9064 | 0.8334 | 0.3322 | 0.2498 | 0.4961 | 0.1666 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
6066036931c94f5b6b26d7bbc476d48a
|
jonatasgrosman/exp_w2v2t_uk_wavlm_s21
|
jonatasgrosman
|
wavlm
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['uk']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'uk']
| false | true | true | 438 | false |
# exp_w2v2t_uk_wavlm_s21
Fine-tuned [microsoft/wavlm-large](https://huggingface.co/microsoft/wavlm-large) for speech recognition using the train split of [Common Voice 7.0 (uk)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
59092655c43833bad912e4b4ba34cdc8
|
csikasote/xls-r-300m-bemba-20hrs
|
csikasote
|
wav2vec2
| 17 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,371 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xls-r-300m-bemba-20hrs
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2815
- Wer: 0.3435
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.3301 | 0.54 | 400 | 0.5177 | 0.7570 |
| 0.6437 | 1.08 | 800 | 0.3580 | 0.5658 |
| 0.5149 | 1.61 | 1200 | 0.2953 | 0.5004 |
| 0.4547 | 2.15 | 1600 | 0.2701 | 0.4464 |
| 0.4084 | 2.69 | 2000 | 0.2743 | 0.4383 |
| 0.3606 | 3.23 | 2400 | 0.2482 | 0.3952 |
| 0.3227 | 3.76 | 2800 | 0.2461 | 0.3965 |
| 0.3025 | 4.3 | 3200 | 0.2484 | 0.4015 |
| 0.2697 | 4.84 | 3600 | 0.2357 | 0.3838 |
| 0.2443 | 5.38 | 4000 | 0.2385 | 0.3822 |
| 0.2287 | 5.91 | 4400 | 0.2353 | 0.3747 |
| 0.1977 | 6.45 | 4800 | 0.2337 | 0.3624 |
| 0.1895 | 6.99 | 5200 | 0.2319 | 0.3568 |
| 0.1561 | 7.53 | 5600 | 0.2540 | 0.3561 |
| 0.1448 | 8.06 | 6000 | 0.2772 | 0.3612 |
| 0.1221 | 8.6 | 6400 | 0.2755 | 0.3596 |
| 0.1133 | 9.14 | 6800 | 0.2733 | 0.3495 |
| 0.0969 | 9.68 | 7200 | 0.2815 | 0.3435 |
### Framework versions
- Transformers 4.19.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 2.1.0
- Tokenizers 0.12.1
|
25ad3eb3630bbbdf728296684bdc51f8
|
deepmind/vision-perceiver-fourier
|
deepmind
|
perceiver
| 5 | 681 |
transformers
| 1 |
image-classification
| true | false | false |
apache-2.0
| null |
['imagenet']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 4,958 | false |
# Perceiver IO for vision (fixed Fourier position embeddings)
Perceiver IO model pre-trained on ImageNet (14 million images, 1,000 classes) at resolution 224x224. It was introduced in the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Jaegle et al. and first released in [this repository](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
Disclaimer: The team releasing Perceiver IO did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Perceiver IO is a transformer encoder model that can be applied on any modality (text, images, audio, video, ...). The core idea is to employ the self-attention mechanism on a not-too-large set of latent vectors (e.g. 256 or 512), and only use the inputs to perform cross-attention with the latents. This allows for the time and memory requirements of the self-attention mechanism to not depend on the size of the inputs.
To decode, the authors employ so-called decoder queries, which allow to flexibly decode the final hidden states of the latents to produce outputs of arbitrary size and semantics. For image classification, the output is a tensor containing the logits, of shape (batch_size, num_labels).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/perceiver_architecture.jpg" alt="drawing" width="600"/>
<small> Perceiver IO architecture.</small>
As the time and memory requirements of the self-attention mechanism don't depend on the size of the inputs, the Perceiver IO authors can train the model directly on raw pixel values, rather than on patches as is done in ViT. This particular model only adds fixed Fourier 2D position embeddings to the pixel values.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by replacing the classification decoder.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=deepmind/perceiver) to look for other fine-tuned versions on a task that may interest you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import PerceiverFeatureExtractor, PerceiverForImageClassificationFourier
import requests
from PIL import Image
feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver-fourier")
model = PerceiverForImageClassificationFourier.from_pretrained("deepmind/vision-perceiver-fourier")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# prepare input
inputs = feature_extractor(image, return_tensors="pt").pixel_values
# forward pass
outputs = model(inputs)
logits = outputs.logits
print("Predicted class:", model.config.id2label[logits.argmax(-1).item()])
>>> should print Predicted class: tabby, tabby cat
```
## Training data
This model was pretrained on [ImageNet](http://www.image-net.org/), a dataset consisting of 14 million images and 1k classes.
## Training procedure
### Preprocessing
Images are center cropped and resized to a resolution of 224x224 and normalized across the RGB channels. Note that data augmentation was used during pre-training, as explained in Appendix H of the [paper](https://arxiv.org/abs/2107.14795).
### Pretraining
Hyperparameter details can be found in Appendix H of the [paper](https://arxiv.org/abs/2107.14795).
## Evaluation results
This model is able to achieve a top-1 accuracy of 79.0 on ImageNet-1k, and 84.5 when pre-trained on a large-scale dataset (JFT-300M, an internal dataset of Google).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
1b8130fd3a56038c256539079cfee054
|
thkkvui/xlm-roberta-base-finetuned-panx-all
|
thkkvui
|
xlm-roberta
| 10 | 4 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,324 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-all
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1737
- F1: 0.8521
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.305 | 1.0 | 835 | 0.1944 | 0.7968 |
| 0.1569 | 2.0 | 1670 | 0.1759 | 0.8395 |
| 0.1027 | 3.0 | 2505 | 0.1737 | 0.8521 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.13.0.dev20220711
- Datasets 2.4.0
- Tokenizers 0.12.1
|
fe411dbb8acbd5d88e1e879b552b152b
|
julien-c/reactiongif-roberta
|
julien-c
|
roberta
| 26 | 145 |
transformers
| 1 |
text-classification
| true | false | false |
apache-2.0
| null |
['julien-c/reactiongif']
| null | 18 | 0 | 0 | 18 | 0 | 0 | 0 |
['generated-from-trainer']
| false | true | true | 1,498 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on an unkown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9150
- Accuracy: 0.2662
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 3.0528 | 0.44 | 1000 | 3.0265 | 0.2223 |
| 2.9836 | 0.89 | 2000 | 2.9263 | 0.2332 |
| 2.7409 | 1.33 | 3000 | 2.9041 | 0.2533 |
| 2.7905 | 1.77 | 4000 | 2.8763 | 0.2606 |
| 2.4359 | 2.22 | 5000 | 2.9072 | 0.2642 |
| 2.4507 | 2.66 | 6000 | 2.9230 | 0.2644 |
### Framework versions
- Transformers 4.7.0.dev0
- Pytorch 1.8.1+cu102
- Datasets 1.8.0
- Tokenizers 0.10.3
|
7fc0a8d8fadd39f9942761d25fb57082
|
Helsinki-NLP/opus-mt-he-it
|
Helsinki-NLP
|
marian
| 12 | 13 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
|
['he', 'it']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 2,012 | false |
### he-it
* source group: Hebrew
* target group: Italian
* OPUS readme: [heb-ita](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/heb-ita/README.md)
* model: transformer
* source language(s): heb
* target language(s): ita
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-12-10.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/heb-ita/opus-2020-12-10.zip)
* test set translations: [opus-2020-12-10.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/heb-ita/opus-2020-12-10.test.txt)
* test set scores: [opus-2020-12-10.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/heb-ita/opus-2020-12-10.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.heb.ita | 41.1 | 0.643 |
### System Info:
- hf_name: he-it
- source_languages: heb
- target_languages: ita
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/heb-ita/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['he', 'it']
- src_constituents: ('Hebrew', {'heb'})
- tgt_constituents: ('Italian', {'ita'})
- src_multilingual: False
- tgt_multilingual: False
- long_pair: heb-ita
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/heb-ita/opus-2020-12-10.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/heb-ita/opus-2020-12-10.test.txt
- src_alpha3: heb
- tgt_alpha3: ita
- chrF2_score: 0.643
- bleu: 41.1
- brevity_penalty: 0.997
- ref_len: 11464.0
- src_name: Hebrew
- tgt_name: Italian
- train_date: 2020-12-10 00:00:00
- src_alpha2: he
- tgt_alpha2: it
- prefer_old: False
- short_pair: he-it
- helsinki_git_sha: b317f78a3ec8a556a481b6a53dc70dc11769ca96
- transformers_git_sha: 1310e1a758edc8e89ec363db76863c771fbeb1de
- port_machine: LM0-400-22516.local
- port_time: 2020-12-11-11:50
|
62a79e848b4328acca982e8b0d32bc92
|
hamzab/roberta-fake-news-classification
|
hamzab
|
roberta
| 9 | 5 |
transformers
| 0 |
text-classification
| true | false | false |
mit
|
['en']
|
['fake-and-real-news-dataset on kaggle']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['classification']
| false | true | true | 1,684 | false |
## Overview
The model is a `roberta-base` fine-tuned on [fake-and-real-news-dataset](https://www.kaggle.com/datasets/clmentbisaillon/fake-and-real-news-dataset). It has a 100% accuracy on that dataset.
The model takes a news article and predicts if it is true or fake.
The format of the input should be:
```
<title> TITLE HERE <content> CONTENT HERE <end>
```
## Using this model in your code
To use this model, first download it from the hugginface website:
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("hamzab/roberta-fake-news-classification")
model = AutoModelForSequenceClassification.from_pretrained("hamzab/roberta-fake-news-classification")
```
Then, make a prediction like follows:
```python
import torch
def predict_fake(title,text):
input_str = "<title>" + title + "<content>" + text + "<end>"
input_ids = tokenizer.encode_plus(input_str, max_length=512, padding="max_length", truncation=True, return_tensors="pt")
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device)
with torch.no_grad():
output = model(input_ids["input_ids"].to(device), attention_mask=input_ids["attention_mask"].to(device))
return dict(zip(["Fake","Real"], [x.item() for x in list(torch.nn.Softmax()(output.logits)[0])] ))
print(predict_fake(<HEADLINE-HERE>,<CONTENT-HERE>))
```
You can also use Gradio to test the model on real-time:
```python
import gradio as gr
iface = gr.Interface(fn=predict_fake, inputs=[gr.inputs.Textbox(lines=1,label="headline"),gr.inputs.Textbox(lines=6,label="content")], outputs="label").launch(share=True)
```
|
0e7173ddcf12671ead4feaf6a9f55dc4
|
elopezlopez/distilbert-base-uncased_fold_3_binary_v1
|
elopezlopez
|
distilbert
| 13 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,658 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_3_binary_v1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9405
- F1: 0.7878
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 289 | 0.4630 | 0.7897 |
| 0.3954 | 2.0 | 578 | 0.4549 | 0.7936 |
| 0.3954 | 3.0 | 867 | 0.6527 | 0.7868 |
| 0.1991 | 4.0 | 1156 | 0.7510 | 0.7951 |
| 0.1991 | 5.0 | 1445 | 0.9327 | 0.8000 |
| 0.095 | 6.0 | 1734 | 1.0974 | 0.7859 |
| 0.0347 | 7.0 | 2023 | 1.2692 | 0.7919 |
| 0.0347 | 8.0 | 2312 | 1.3718 | 0.7921 |
| 0.0105 | 9.0 | 2601 | 1.4679 | 0.7999 |
| 0.0105 | 10.0 | 2890 | 1.5033 | 0.8070 |
| 0.0079 | 11.0 | 3179 | 1.6074 | 0.8008 |
| 0.0079 | 12.0 | 3468 | 1.6921 | 0.7904 |
| 0.0053 | 13.0 | 3757 | 1.7079 | 0.7945 |
| 0.0054 | 14.0 | 4046 | 1.8361 | 0.7887 |
| 0.0054 | 15.0 | 4335 | 1.7695 | 0.7873 |
| 0.0046 | 16.0 | 4624 | 1.7934 | 0.7917 |
| 0.0046 | 17.0 | 4913 | 1.8036 | 0.8008 |
| 0.0064 | 18.0 | 5202 | 1.8780 | 0.7888 |
| 0.0064 | 19.0 | 5491 | 1.8943 | 0.7923 |
| 0.0032 | 20.0 | 5780 | 1.8694 | 0.7905 |
| 0.002 | 21.0 | 6069 | 1.9348 | 0.7869 |
| 0.002 | 22.0 | 6358 | 1.9578 | 0.7804 |
| 0.0036 | 23.0 | 6647 | 1.9438 | 0.7827 |
| 0.0036 | 24.0 | 6936 | 1.9386 | 0.7878 |
| 0.0011 | 25.0 | 7225 | 1.9405 | 0.7878 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
536eac13e6db2ab8aeac43255448e42e
|
Helsinki-NLP/opus-mt-ko-en
|
Helsinki-NLP
|
marian
| 11 | 3,758 |
transformers
| 9 |
translation
| true | true | false |
apache-2.0
|
['ko', 'en']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 2,051 | false |
### kor-eng
* source group: Korean
* target group: English
* OPUS readme: [kor-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/kor-eng/README.md)
* model: transformer-align
* source language(s): kor kor_Hang kor_Latn
* target language(s): eng
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/kor-eng/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/kor-eng/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/kor-eng/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.kor.eng | 41.3 | 0.588 |
### System Info:
- hf_name: kor-eng
- source_languages: kor
- target_languages: eng
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/kor-eng/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['ko', 'en']
- src_constituents: {'kor_Hani', 'kor_Hang', 'kor_Latn', 'kor'}
- tgt_constituents: {'eng'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/kor-eng/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/kor-eng/opus-2020-06-17.test.txt
- src_alpha3: kor
- tgt_alpha3: eng
- short_pair: ko-en
- chrF2_score: 0.588
- bleu: 41.3
- brevity_penalty: 0.9590000000000001
- ref_len: 17711.0
- src_name: Korean
- tgt_name: English
- train_date: 2020-06-17
- src_alpha2: ko
- tgt_alpha2: en
- prefer_old: False
- long_pair: kor-eng
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
1845f114f1c35724dade1c130c0eb452
|
vasista22/whisper-hindi-small
|
vasista22
|
whisper
| 12 | 54 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['hi']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['whisper-event']
| true | true | true | 1,322 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Hindi Small
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Hindi data available from multiple publicly available ASR corpuses.
It has been fine-tuned as a part of the Whisper fine-tuning sprint.
## Training and evaluation data at Speech Lab, IITM
Training Data: GramVaani ASR Corpus, ULCA ASR Corpus, Shrutilipi ASR Corpus, Google/Fleurs (Train+Dev) set.
Evaluation Data: GramVaani ASR Corpus Test, Google/Fleurs Test set.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1.75e-05
- train_batch_size: 48
- eval_batch_size: 32
- seed: 22
- optimizer: adamw_bnb_8bit
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 20000
- training_steps: 19377 (Initially set to 129180 steps)
- mixed_precision_training: True
## Acknowledgement
This work was done at Speech Lab, IITM. The compute resources for this work were funded by "Bhashini: National Language translation Mission" project of the Ministry of Electronics and Information Technology (MeitY), Government of India.
|
4e9d4c25489b15b7a80625909db34b9c
|
EleutherAI/pythia-410m-deduped
|
EleutherAI
|
gpt_neox
| 7 | 5,137 |
transformers
| 4 |
text-generation
| true | false | false |
apache-2.0
|
['en']
|
['EleutherAI/raw_deduplicated_pile']
| null | 2 | 1 | 1 | 0 | 1 | 0 | 1 |
['pytorch', 'causal-lm', 'pythia']
| false | true | true | 10,888 | false |
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research. It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. All Pythia models are available
[on Hugging Face](https://huggingface.co/models?other=pythia).
The Pythia model suite was deliberately designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models match or exceed the performance of similar and same-sized models,
such as those in the OPT and GPT-Neo suites.
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact model parameter counts.
## Pythia-410M-deduped
### Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:contact@eleuther.ai).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 4M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 4M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 4M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
### Uses and Limitations
#### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. To enable the
study of how language models change in the course of training, we provide
143 evenly spaced intermediate checkpoints per model. These checkpoints are
hosted on Hugging Face as branches. Note that branch `143000` corresponds
exactly to the model checkpoint on the `main` branch of each model.
You may also further fine-tune and adapt Pythia-410M-deduped for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-410M-deduped as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
#### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-410M-deduped has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-410M-deduped will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “understand” human instructions.
#### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token deemed statistically most likely by the
model need not produce the most “accurate” text. Never rely on
Pythia-410M-deduped to produce factually accurate output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-410M-deduped may produce socially unacceptable or undesirable text,
*even if* the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-410M-deduped.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
### Training
#### Training data
Pythia-410M-deduped was trained on the Pile **after the dataset has been
globally deduplicated**.
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).
#### Training procedure
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for the equivalent of 143000 steps at a batch size
of 2,097,152 tokens. Two batch sizes were used: 2M and 4M. Models with a batch
size of 4M tokens listed were originally trained for 71500 steps instead, with
checkpoints every 500 steps. The checkpoints on Hugging Face are renamed for
consistency with all 2M batch models, so `step1000` is the first checkpoint
for `pythia-1.4b` that was saved (corresponding to step 500 in training), and
`step1000` is likewise the first `pythia-6.9b` checkpoint that was saved
(corresponding to 1000 “actual” steps).
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).
### Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json).
February 2023 note: select evaluations and comparison with OPT and BLOOM
models will be added here at a later date.
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure>
|
6c3809b8b7f3cd3aa2595ff0d1fda3ad
|
Bistolero/genlen2ep
|
Bistolero
|
t5
| 9 | 2 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 882 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# genlen2ep
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 25
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Framework versions
- Transformers 4.22.2
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
a5c17aeeb51847cb3ca6ded186d4d5dc
|
Akumetsu971/SD_Samurai_Anime_Style
|
Akumetsu971
| null | 11 | 0 | null | 3 |
text-to-image
| false | false | false |
creativeml-openrail-m
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['stable-diffusion', 'text-to-image']
| false | true | true | 4,936 | false |
# SD_Samurai_Anime_Style is an open source Stable Diffusion Embedding on art style of Samurai, by Akumetsu971 (https://www.tiktok.com/@akumetsu971)
---
### Model used to train:
wd-v1-3-full-opt.ckpt (https://huggingface.co/hakurei/waifu-diffusion-v1-3)
### Files
5 files available (Best version is 4000steps):
-Smrai_style - 4000 steps (First version, work great!)
-Smrai2_style-1000 - 1000 steps
-Smrai2_style-2000 - 2000 steps
-Smrai2_style-3000 - 3000 steps
-Smrai2_style-4000 - 4000 steps (recommended)
### Prompt
You need to use DeepDanBooru Tags (https://gigazine.net/gsc_news/en/20221012-automatic1111-stable-diffusion-webui-deep-danbooru/)
I also used Nixeu_style embedding (not necessary): https://huggingface.co/sd-concepts-library/nixeu)
And Elysium_Anime_V2.ckpt (https://huggingface.co/hesw23168/SD-Elysium-Model)
### Example
Positive Prompt:
(Nixeu_style:1.2), (Smrai2_style-4000:0.9), close-up portrait, 1girl, manga art, (red symmetrical circle behind:1.2), intricate details, highly detailed, photorealistic, octane render, 8k, unreal engine, sharp focus, volumetric lighting unreal engine. art by artgerm and greg rutkowski and alphonse mucha
Negative Prompt:
(mediocre:1.2), (average:1.2), (bad:1.2), (wrong:1.2), (error:1.2), (fault:1.2),( badly_drawn:1.2), (poorly_drawn:1.2), ( low_quality:1.2), no_quality, bad_quality, no_resolution, low_resolution, (lowres:1.2), normal_resolution, (disfigured:1.6), (deformed:1.4), (distortion:1.2), bad_anatomy, (no_detail:1.2), low_detail, normal_detail, (scribble:1.2), (rushed:1.2), (unfinished:1.2), blur, blurry, claws, (misplaced:1.2), (disconnected:1.2), nonsense, random, (noise:1.2), (deformation:1.2), 3d, dull, boring, uninteresting, screencap, (text:1.2), (frame:1.1), (out_of_frame:1.2), (title:1.2), (description:1.3), (sexual:1.2), text, error,(logo:1.3), (watermark:1.3), bad_perspective, bad_proportions, cinematic, jpg_artifacts, jpeg_artifacts, extra_leg, missing_leg, extra_arm, missing_arm, long_hand, bad_hands, (mutated_hand:1.2), (extra_finger:1.2), (missing_finger:1.2), broken_finger, (fused_fingers:1.2), extra_feet, missing_feet, fused_feet, long_feet, missing_limbs, extra_limbs, fused_limbs, claw, (extra_digit:1.2), (fewer_digits:1.2), elves_ears, (naked:1.3), (wet:1.2), uncensored, (long_neck:1.2), (weapon:1.5)
<img src="https://huggingface.co/Akumetsu971/SD_Samurai_Anime_Style/resolve/main/05740-1662921804-(Nixeu_style_1.2)%2C%20(Smrai2_style-4000_0.9)%2C%20close-up%20portrait%2C%201girl%2C%20manga%20art%2C%20(red%20symmetrical%20circle%20behind_1.2)%2C%20intricate.png" width="50%"/>
<img src="https://huggingface.co/Akumetsu971/SD_Samurai_Anime_Style/resolve/main/05743-815262338-(Nixeu_style_1.2)%2C%20(Smrai2_style-4000_0.9)%2C%20close-up%20portrait%2C%201girl%2C%20manga%20art%2C%20(red%20symmetrical%20circle%20behind_1.2)%2C%20intricate.png" width="50%"/>
<img src="https://huggingface.co/Akumetsu971/SD_Samurai_Anime_Style/resolve/main/05748-2610321799-(Nixeu_style_1.2)%2C%20(Smrai2_style-4000_0.9)%2C%20close-up%20portrait%2C%201girl%2C%20manga%20art%2C%20(red%20symmetrical%20circle%20behind_1.2)%2C%20intricate.png" width="50%"/>
### First Version Example
Positive Prompt:
portrait, (Smrai_style:1.0), vampire samurai, red_eyes, 2vampire_ fangs, solo, single,fighting_stance, male_focus, pink_hair, sakura_petals, painting,beautifully drawn, heavily detailed, high quality, (cherry_blossom_print:1.1), scenery, smoke, fog, dynamic, detailed_limbs, (Nixeu_style:1.2)
Negative Prompt:
(mediocre:1.2), (average:1.2), (bad:1.2), (wrong:1.2), (error:1.2), (fault:1.2),( badly_drawn:1.2), (poorly_drawn:1.2), ( low_quality:1.2), no_quality, bad_quality, no_resolution, low_resolution, (lowres:1.2), normal_resolution, (disfigured:1.6), (deformed:1.5), (distortion:1.2), bad_anatomy, (no_detail:1.2), low_detail, normal_detail, (scribble:1.2), (rushed:1.2), (unfinished:1.2), blur, blurry, claws, (misplaced:1.2), (disconnected:1.2), nonsense, random, (noise:1.2), (deformation:1.2), 3d, dull, boring, uninteresting, screencap, (text:1.2), (frame:1.1), (out_of_frame:1.2), (title:1.2), (description:1.3), (sexual:1.2), text, error,(logo:1.3), (watermark:1.3), bad_perspective, bad_proportions, cinematic, jpg_artifacts, jpeg_artifacts, extra_leg, missing_leg, extra_arm, missing_arm, long_hand, bad_hands, (mutated_hand:1.2), (extra_finger:1.2), (missing_finger:1.2), broken_finger, (fused_fingers:1.2), extra_feet, missing_feet, fused_feet, long_feet, missing_limbs, extra_limbs, fused_limbs, claw, (extra_digit:1.2), (fewer_digits:1.2), elves_ears, (naked:1.3), (wet:1.2), uncensored, (long_neck:1.2)
<img src="https://huggingface.co/Akumetsu971/SD_Samurai_Anime_Style/resolve/main/05241-239803495-portrait%2C%20(Smrai_style_1.0)%2C%20vampire%20samurai%2C%20red_eyes%2C%202vampire_%20fangs%2C%20solo%2C%20single%2Cfighting_stance%2C%20male_focus%2C%20pink_hair%2C%20sa.png" width="50%"/>
```
|
b5b9a2a0de1fdefc5a9c51a839ce34c8
|
rmihaylov/gpt2-small-bg
|
rmihaylov
|
gpt2
| 10 | 3 |
transformers
| 0 |
text-generation
| true | false | false |
mit
|
['bg']
|
['oscar', 'chitanka', 'wikipedia']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['torch']
| false | true | true | 2,635 | false |
# GPT-2
Pretrained model on Bulgarian language using a causal language modeling (CLM) objective. It was introduced in
[this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
## Model description
This is the **SMALL** version.
The training data is Bulgarian text from [OSCAR](https://oscar-corpus.com/post/oscar-2019/), [Chitanka](https://chitanka.info/) and [Wikipedia](https://bg.wikipedia.org/).
## Intended uses & limitations
You can use the raw model for:
- text generation
- auto-complete
- spelling correction
Or fine-tune it to a downstream task.
### How to use
Here is how to use this model in PyTorch:
```python
>>> from transformers import AutoModel, AutoTokenizer
>>>
>>> model_id = "rmihaylov/gpt2-small-bg"
>>> tokenizer = AutoTokenizer.from_pretrained(model_id)
>>> model = AutoModel.from_pretrained(model_id, trust_remote_code=True)
>>>
>>> input_ids = tokenizer.encode(
>>> "Здравей,",
>>> add_special_tokens=False,
>>> return_tensors='pt')
>>>
>>> output_ids = model.generate(
>>> input_ids,
>>> do_sample=True,
>>> max_length=50,
>>> top_p=0.92,
>>> pad_token_id=2,
>>> top_k=0)
>>>
>>> output = tokenizer.decode(output_ids[0])
>>>
>>> output = output.replace('<|endoftext|>', '\n\n\n')
>>> output = output.replace('<|unknown|>', '')
>>> output = output.replace('▁', ' ')
>>> output = output.replace('<|n|>', '\n')
>>>
>>> print(output)
Здравей, Ани! Не е ли прекрасно?
Нещото се засмя. Зъбите му блеснаха.
— Ще те разведа насам-натам!
Ани се замисли, когато той си тръгна. Може би не искаше да го е
```
### Limitations and bias
As the openAI team themselves point out in their
[model card](https://github.com/openai/gpt-2/blob/master/model_card.md#out-of-scope-use-cases):
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases
> that require the generated text to be true.
>
> Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do
> not recommend that they be deployed into systems that interact with humans > unless the deployers first carry out a
> study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race,
> and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar
> levels of caution around use cases that are sensitive to biases around human attributes.
|
b0683631a7408a0c5463fef84cdcd068
|
pupubear/pupu_girl_ver1
|
pupubear
| null | 20 | 125 |
diffusers
| 3 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 648 | false |
### girl Dreambooth model trained by pupubear with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
trianed from c_PVC_mix
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:

|
f034eec712da47879948a1e1b71818aa
|
fathyshalab/all-roberta-large-v1-credit_cards-3-16-5
|
fathyshalab
|
roberta
| 11 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,517 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# all-roberta-large-v1-credit_cards-3-16-5
This model is a fine-tuned version of [sentence-transformers/all-roberta-large-v1](https://huggingface.co/sentence-transformers/all-roberta-large-v1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3376
- Accuracy: 0.3186
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.75 | 1.0 | 1 | 2.5769 | 0.2389 |
| 2.178 | 2.0 | 2 | 2.4879 | 0.2389 |
| 1.769 | 3.0 | 3 | 2.4180 | 0.2566 |
| 1.4703 | 4.0 | 4 | 2.3657 | 0.3097 |
| 1.2711 | 5.0 | 5 | 2.3376 | 0.3186 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
ee50410735d99c78107c0014dcc813c4
|
Hamine/distilbert-base-uncased-finetuned-mnli
|
Hamine
|
distilbert
| 13 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,356 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-mnli
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5486
- Accuracy: 0.8244
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.5142 | 1.0 | 24544 | 0.4922 | 0.8075 |
| 0.4089 | 2.0 | 49088 | 0.4865 | 0.8194 |
| 0.2936 | 3.0 | 73632 | 0.5486 | 0.8244 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
116ae73710b075b2c8801c55fba3fae7
|
ariesutiono/finetuned-test-1
|
ariesutiono
|
bert
| 16 | 2 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null |
['conll2003']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,155 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-test-1
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8192
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.8219 | 1.0 | 30 | 2.3343 |
| 2.4148 | 2.0 | 60 | 2.2010 |
| 2.3236 | 3.0 | 90 | 2.1442 |
| 2.2231 | 4.0 | 120 | 2.1651 |
| 2.2171 | 5.0 | 150 | 2.0614 |
| 2.127 | 6.0 | 180 | 2.0405 |
| 2.0748 | 7.0 | 210 | 2.0092 |
| 2.0511 | 8.0 | 240 | 1.9798 |
| 2.0097 | 9.0 | 270 | 1.8662 |
| 1.9969 | 10.0 | 300 | 1.9257 |
| 2.0006 | 11.0 | 330 | 1.9386 |
| 1.9273 | 12.0 | 360 | 1.9357 |
| 1.9177 | 13.0 | 390 | 1.8983 |
| 1.9128 | 14.0 | 420 | 1.8990 |
| 1.8979 | 15.0 | 450 | 1.9037 |
| 1.8721 | 16.0 | 480 | 1.8440 |
| 1.8998 | 17.0 | 510 | 1.8404 |
| 1.8862 | 18.0 | 540 | 1.9193 |
| 1.9133 | 19.0 | 570 | 1.8494 |
| 1.8799 | 20.0 | 600 | 1.8192 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
81b0760f4bd8af43bb5cdc4eee54bc10
|
pjox/dalembert-classical-fr-ner
|
pjox
| null | 8 | 0 |
flair
| 0 |
token-classification
| false | false | false |
apache-2.0
|
['fr']
|
['freemner']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['Early Modern French', 'Historical', 'NER', 'flair']
| false | true | true | 2,371 | false |
<a href="https://portizs.eu/publication/2022/lrec/dalembert/">
<img width="300px" src="https://portizs.eu/publication/2022/lrec/dalembert/featured_hu18bf34d40cdc71c744bdd15e48ff0b23_61788_720x2500_fit_q100_h2_lanczos_3.webp">
</a>
# D'AlemBERT-NER model
This model is fine-tuned version of a [D'AlemBERT](https://huggingface.co/pjox/DalemBERT) on the [FreEMNER corpus](https://doi.org/10.5281/zenodo.6481135) for Early Modern French. It was
introduced in [this paper](https://aclanthology.org/2022.coling-1.327/).
### BibTeX entry and citation info
```bibtex
@inproceedings{ortiz-suarez-gabay-2022-data,
title = "A Data-driven Approach to Named Entity Recognition for Early {M}odern {F}rench",
author = "Ortiz Suarez, Pedro and
Gabay, Simon",
booktitle = "Proceedings of the 29th International Conference on Computational Linguistics",
month = oct,
year = "2022",
address = "Gyeongju, Republic of Korea",
publisher = "International Committee on Computational Linguistics",
url = "https://aclanthology.org/2022.coling-1.327",
pages = "3722--3730",
abstract = "Named entity recognition has become an increasingly useful tool for digital humanities research, specially when it comes to historical texts. However, historical texts pose a wide range of challenges to both named entity recognition and natural language processing in general that are still difficult to address even with modern neural methods. In this article we focus in named entity recognition for historical French, and in particular for Early Modern French (16th-18th c.), i.e. Ancien R{\'e}gime French. However, instead of developing a specialised architecture to tackle the particularities of this state of language, we opt for a data-driven approach by developing a new corpus with fine-grained entity annotation, covering three centuries of literature corresponding to the early modern period; we try to annotate as much data as possible producing a corpus that is many times bigger than the most popular NER evaluation corpora for both Contemporary English and French. We then fine-tune existing state-of-the-art architectures for Early Modern and Contemporary French, obtaining results that are on par with those of the current state-of-the-art NER systems for Contemporary English. Both the corpus and the fine-tuned models are released.",
}
```
|
086343507570053696aa448d3894d1e3
|
jonatasgrosman/exp_w2v2t_de_unispeech-ml_s750
|
jonatasgrosman
|
unispeech
| 10 | 4 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['de']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'de']
| false | true | true | 500 | false |
# exp_w2v2t_de_unispeech-ml_s750
Fine-tuned [microsoft/unispeech-large-multi-lingual-1500h-cv](https://huggingface.co/microsoft/unispeech-large-multi-lingual-1500h-cv) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
24295145163a1af37d387ada11ce8c82
|
facebook/convnext-base-224-22k
|
facebook
|
convnext
| 6 | 795 |
transformers
| 0 |
image-classification
| true | true | false |
apache-2.0
| null |
['imagenet-21k']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['vision', 'image-classification']
| false | true | true | 2,664 | false |
# ConvNeXT (base-sized model)
ConvNeXT model trained on ImageNet-22k at resolution 224x224. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextFeatureExtractor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-base-224-22k")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-base-224-22k")
inputs = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 22k ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
a6cff181fe289e8e2d6c1ceb2e267079
|
anas-awadalla/t5-base-few-shot-k-16-finetuned-squad-infilling-seed-4
|
anas-awadalla
|
t5
| 17 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 968 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-few-shot-k-16-finetuned-squad-infilling-seed-4
This model is a fine-tuned version of [google/t5-v1_1-base](https://huggingface.co/google/t5-v1_1-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
e4c078fdc180f963489192d3330c8ccc
|
microsoft/reacc-py-retriever
|
microsoft
|
roberta
| 9 | 3 |
transformers
| 3 |
feature-extraction
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,043 | false |
# ReACC-py-retriever
This is the retrieval model for [ReACC: A Retrieval-Augmented Code Completion Framework](https://arxiv.org/abs/2203.07722).
In this paper, the model is used to retrieve similar codes given an incompletion code snippet as query. The model can be also used for incomplete code-to-code search, code clone detection.
`py-retriever` is BERT-like encoder consisting of 12 transformer layers. It is continual pre-trained on [GraphCodeBERT](https://huggingface.co/microsoft/graphcodebert-base) with contrastive learning in Python programming language. More details can be found in our paper.
Note that the format of input codes is different from original source code. We normalize the source codes to better capture information from line break and indention in Python. An example of input is:
```python
sum = 0<endofline>for val in numbers:<endofline><INDENT>sum = sum+val
```
To get more information about how to convert source codes into this format, please refer to [ReACC GitHub repo](https://github.com/microsoft/ReACC).
|
d552b1a1276f9b039a3e863017dd1485
|
theojolliffe/bart-cnn-science-v3-e2
|
theojolliffe
|
bart
| 13 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,568 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-cnn-science-v3-e2
This model is a fine-tuned version of [theojolliffe/bart-cnn-science](https://huggingface.co/theojolliffe/bart-cnn-science) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9352
- Rouge1: 52.5497
- Rouge2: 32.5507
- Rougel: 35.0014
- Rougelsum: 50.0575
- Gen Len: 141.5741
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:--------:|
| No log | 1.0 | 398 | 1.0023 | 52.0744 | 31.917 | 33.2804 | 49.6569 | 142.0 |
| 1.1851 | 2.0 | 796 | 0.9352 | 52.5497 | 32.5507 | 35.0014 | 50.0575 | 141.5741 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
ca48f118485232b118e7a51668b1096f
|
anas-awadalla/t5-small-few-shot-k-512-finetuned-squad-seed-0
|
anas-awadalla
|
t5
| 15 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 960 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-few-shot-k-512-finetuned-squad-seed-0
This model is a fine-tuned version of [google/t5-v1_1-small](https://huggingface.co/google/t5-v1_1-small) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 35.0
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
ab6465a9cc086db6ccc7b33108d9b98e
|
google/t5-efficient-base-kv32
|
google
|
t5
| 12 | 19 |
transformers
| 0 |
text2text-generation
| true | true | true |
apache-2.0
|
['en']
|
['c4']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['deep-narrow']
| false | true | true | 6,252 | false |
# T5-Efficient-BASE-KV32 (Deep-Narrow version)
T5-Efficient-BASE-KV32 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5).
It is a *pretrained-only* checkpoint and was released with the
paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)**
by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures
of similar parameter count.
To quote the paper:
> We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased
> before considering any other forms of uniform scaling across other dimensions. This is largely due to
> how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a
> tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise,
> a tall base model might also generally more efficient compared to a large model. We generally find
> that, regardless of size, even if absolute performance might increase as we continue to stack layers,
> the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36
> layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e.,
> params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params,
> FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to
> consider.
To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially.
A sequence of word embeddings is therefore processed sequentially by each transformer block.
## Details model architecture
This model checkpoint - **t5-efficient-base-kv32** - is of model type **Base** with the following variations:
- **kv** is **32**
It has **180.46** million parameters and thus requires *ca.* **721.86 MB** of memory in full precision (*fp32*)
or **360.93 MB** of memory in half precision (*fp16* or *bf16*).
A summary of the *original* T5 model architectures can be seen here:
| Model | nl (el/dl) | ff | dm | kv | nh | #Params|
| ----| ---- | ---- | ---- | ---- | ---- | ----|
| Tiny | 4/4 | 1024 | 256 | 32 | 4 | 16M|
| Mini | 4/4 | 1536 | 384 | 32 | 8 | 31M|
| Small | 6/6 | 2048 | 512 | 32 | 8 | 60M|
| Base | 12/12 | 3072 | 768 | 64 | 12 | 220M|
| Large | 24/24 | 4096 | 1024 | 64 | 16 | 738M|
| Xl | 24/24 | 16384 | 1024 | 128 | 32 | 3B|
| XXl | 24/24 | 65536 | 1024 | 128 | 128 | 11B|
whereas the following abbreviations are used:
| Abbreviation | Definition |
| ----| ---- |
| nl | Number of transformer blocks (depth) |
| dm | Dimension of embedding vector (output vector of transformers block) |
| kv | Dimension of key/value projection matrix |
| nh | Number of attention heads |
| ff | Dimension of intermediate vector within transformer block (size of feed-forward projection matrix) |
| el | Number of transformer blocks in the encoder (encoder depth) |
| dl | Number of transformer blocks in the decoder (decoder depth) |
| sh | Signifies that attention heads are shared |
| skv | Signifies that key-values projection matrices are tied |
If a model checkpoint has no specific, *el* or *dl* than both the number of encoder- and decoder layers correspond to *nl*.
## Pre-Training
The checkpoint was pretrained on the [Colossal, Cleaned version of Common Crawl (C4)](https://huggingface.co/datasets/c4) for 524288 steps using
the span-based masked language modeling (MLM) objective.
## Fine-Tuning
**Note**: This model is a **pretrained** checkpoint and has to be fine-tuned for practical usage.
The checkpoint was pretrained in English and is therefore only useful for English NLP tasks.
You can follow on of the following examples on how to fine-tune the model:
*PyTorch*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization)
- [Question Answering](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_seq2seq_qa.py)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*Tensorflow*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*JAX/Flax*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/flax/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/flax/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
## Downstream Performance
TODO: Add table if available
## Computational Complexity
TODO: Add table if available
## More information
We strongly recommend the reader to go carefully through the original paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** to get a more nuanced understanding of this model checkpoint.
As explained in the following [issue](https://github.com/google-research/google-research/issues/986#issuecomment-1035051145), checkpoints including the *sh* or *skv*
model architecture variations have *not* been ported to Transformers as they are probably of limited practical usage and are lacking a more detailed description. Those checkpoints are kept [here](https://huggingface.co/NewT5SharedHeadsSharedKeyValues) as they might be ported potentially in the future.
|
19dd9c633fedec170889ad836b5e1c72
|
okho0653/Bio_ClinicalBERT-zero-shot
|
okho0653
|
bert
| 11 | 4 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,142 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT-zero-shot
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on an unknown dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.5417
- eval_accuracy: 1.0
- eval_f1: 1.0
- eval_runtime: 4.3261
- eval_samples_per_second: 6.241
- eval_steps_per_second: 0.462
- step: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.2
|
3aae72d4c05f68e35a4d01ce22eed250
|
dandelin/vilt-b32-finetuned-nlvr2
|
dandelin
|
vilt
| 9 | 375 |
transformers
| 1 | null | true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,071 | false |
# Vision-and-Language Transformer (ViLT), fine-tuned on NLVR2
Vision-and-Language Transformer (ViLT) model fine-tuned on [NLVR2](https://lil.nlp.cornell.edu/nlvr/). It was introduced in the paper [ViLT: Vision-and-Language Transformer
Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Kim et al. and first released in [this repository](https://github.com/dandelin/ViLT).
Disclaimer: The team releasing ViLT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Intended uses & limitations
You can use the model to determine whether a sentence is true or false given 2 images.
### How to use
Here is how to use the model in PyTorch:
```
from transformers import ViltProcessor, ViltForImagesAndTextClassification
import requests
from PIL import Image
image1 = Image.open(requests.get("https://lil.nlp.cornell.edu/nlvr/exs/ex0_0.jpg", stream=True).raw)
image2 = Image.open(requests.get("https://lil.nlp.cornell.edu/nlvr/exs/ex0_1.jpg", stream=True).raw)
text = "The left image contains twice the number of dogs as the right image."
processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-nlvr2")
model = ViltForImagesAndTextClassification.from_pretrained("dandelin/vilt-b32-finetuned-nlvr2")
# prepare inputs
encoding = processor([image1, image2], text, return_tensors="pt")
# forward pass
outputs = model(input_ids=encoding.input_ids, pixel_values=encoding.pixel_values.unsqueeze(0))
logits = outputs.logits
idx = logits.argmax(-1).item()
print("Predicted answer:", model.config.id2label[idx])
```
## Training data
(to do)
## Training procedure
### Preprocessing
(to do)
### Pretraining
(to do)
## Evaluation results
(to do)
### BibTeX entry and citation info
```bibtex
@misc{kim2021vilt,
title={ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision},
author={Wonjae Kim and Bokyung Son and Ildoo Kim},
year={2021},
eprint={2102.03334},
archivePrefix={arXiv},
primaryClass={stat.ML}
}
```
|
e686b400b849b6fa5d044dd49ecf2452
|
freedomfrier/my-128dim-model2
|
freedomfrier
|
bert
| 14 | 14 |
sentence-transformers
| 0 |
sentence-similarity
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['sentence-transformers', 'feature-extraction', 'sentence-similarity', 'transformers']
| false | true | true | 3,533 | false |
# sentence-transformers/msmarco-MiniLM-L-6-v3
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/msmarco-MiniLM-L-6-v3')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/msmarco-MiniLM-L-6-v3')
model = AutoModel.from_pretrained('sentence-transformers/msmarco-MiniLM-L-6-v3')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/msmarco-MiniLM-L-6-v3)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
```
|
9d1a421ec6ca66b718fd9374640c7b53
|
Reggie/muppet-roberta-base-joke_detector
|
Reggie
|
roberta
| 8 | 55 |
transformers
| 0 |
text-classification
| true | false | false |
mit
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['roberta']
| false | true | true | 1,858 | false |
### What is this?
This model has been developed to detect "narrative-style" jokes, stories and anecdotes (i.e. they are narrated as a story) spoken during speeches or conversations etc. It works best when jokes/anecdotes are at least 40 words or longer. It is based on Facebook's [RoBerta-MUPPET](https://huggingface.co/facebook/muppet-roberta-base).
The training dataset was a private collection of around 2000 jokes. This model has not been trained or tested on one-liners, puns or Reddit-style language-manipulation jokes such as knock-knock, Q&A jokes etc.
See the example in the inference widget or How to use section for what constitues a narrative-style joke.
For a slightly more accurate model (0.4% more) that is 65% slower at inference, see the [Deberta-v3 model](https://huggingface.co/Reggie/DeBERTa-v3-base-joke_detector). For a much more inaccurate model (2.4% less) that is way faster at inference, see the [distilbert model](https://huggingface.co/Reggie/distilbert-joke_detector).
### Install these first
You'll need to pip install transformers & maybe sentencepiece
### How to use
```python
from transformers import pipeline
import torch
device = 0 if torch.cuda.is_available() else -1
model_name = 'Reggie/muppet-roberta-base-joke_detector'
max_seq_len = 510
pipe = pipeline(model=model_name, device=device, truncation=True, max_length=max_seq_len)
is_it_a_joke = """A nervous passenger is about to book a flight ticket, and he asks the airlines' ticket seller, "I hope your planes are safe. Do they have a good track record for safety?" The airline agent replies, "Sir, I can guarantee you, we've never had a plane that has crashed more than once." """
result = pipe(is_it_a_joke) # [{'label': 'LABEL_1', 'score': 0.7313136458396912}]
print('This is a joke') if result[0]['label'] == 'LABEL_1' else print('This is not a joke')
```
|
586a9f7895a15545415d62a4938253f6
|
redevaaa/fin4
|
redevaaa
|
bert
| 12 | 5 |
transformers
| 0 |
token-classification
| true | false | false |
cc-by-sa-4.0
| null |
['fin']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,153 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fin4
This model is a fine-tuned version of [nlpaueb/sec-bert-num](https://huggingface.co/nlpaueb/sec-bert-num) on the fin dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0549
- Precision: 0.9209
- Recall: 0.9283
- F1: 0.9246
- Accuracy: 0.9913
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 129 | 0.1041 | 0.8242 | 0.8406 | 0.8323 | 0.9788 |
| No log | 2.0 | 258 | 0.0511 | 0.9173 | 0.9283 | 0.9228 | 0.9902 |
| No log | 3.0 | 387 | 0.0430 | 0.9102 | 0.9283 | 0.9191 | 0.9907 |
| 0.0598 | 4.0 | 516 | 0.0501 | 0.9368 | 0.9442 | 0.9405 | 0.9922 |
| 0.0598 | 5.0 | 645 | 0.0436 | 0.9325 | 0.9363 | 0.9344 | 0.9924 |
| 0.0598 | 6.0 | 774 | 0.0489 | 0.9433 | 0.9283 | 0.9357 | 0.9917 |
| 0.0598 | 7.0 | 903 | 0.0499 | 0.932 | 0.9283 | 0.9301 | 0.9919 |
| 0.0028 | 8.0 | 1032 | 0.0537 | 0.9209 | 0.9283 | 0.9246 | 0.9913 |
| 0.0028 | 9.0 | 1161 | 0.0540 | 0.9170 | 0.9243 | 0.9206 | 0.9911 |
| 0.0028 | 10.0 | 1290 | 0.0549 | 0.9209 | 0.9283 | 0.9246 | 0.9913 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
5a987fb10ca5862a4f9be8e46b38f51b
|
Celal11/beit-base-patch16-224-pt22k-ft22k-finetuned-FER2013-7e-05-32
|
Celal11
|
beit
| 11 | 6 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['image_folder']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,505 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beit-base-patch16-224-pt22k-ft22k-finetuned-FER2013-7e-05-32
This model is a fine-tuned version of [Celal11/beit-base-patch16-224-pt22k-ft22k-finetuned-FER2013CKPlus-7e-05](https://huggingface.co/Celal11/beit-base-patch16-224-pt22k-ft22k-finetuned-FER2013CKPlus-7e-05) on the image_folder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8037
- Accuracy: 0.7201
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.8058 | 1.0 | 112 | 0.8260 | 0.7056 |
| 0.6999 | 2.0 | 224 | 0.8037 | 0.7201 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
0b3f5a6aa7ac037f55988857dfd55c95
|
Helsinki-NLP/opus-mt-kg-fr
|
Helsinki-NLP
|
marian
| 10 | 7 |
transformers
| 1 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 768 | false |
### opus-mt-kg-fr
* source languages: kg
* target languages: fr
* OPUS readme: [kg-fr](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/kg-fr/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/kg-fr/opus-2020-01-09.zip)
* test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/kg-fr/opus-2020-01-09.test.txt)
* test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/kg-fr/opus-2020-01-09.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.kg.fr | 26.0 | 0.433 |
|
c19ed754e218a19b96091a83a999fbc3
|
MeshalAlamr/wav2vec2-xls-r-300m-ar-4
|
MeshalAlamr
|
wav2vec2
| 7 | 6 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 4,403 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-300m-ar-4
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7888
- Wer: 0.3697
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 60
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 4.8069 | 1.18 | 400 | 1.7793 | 0.9883 |
| 1.1949 | 2.35 | 800 | 0.9662 | 0.7908 |
| 0.8996 | 3.53 | 1200 | 0.8404 | 0.7154 |
| 0.7652 | 4.71 | 1600 | 0.7478 | 0.6379 |
| 0.6611 | 5.88 | 2000 | 0.7687 | 0.6229 |
| 0.6015 | 7.06 | 2400 | 0.7153 | 0.5948 |
| 0.5444 | 8.24 | 2800 | 0.7062 | 0.5826 |
| 0.4872 | 9.41 | 3200 | 0.6568 | 0.5414 |
| 0.4729 | 10.59 | 3600 | 0.6817 | 0.5599 |
| 0.4238 | 11.76 | 4000 | 0.6406 | 0.5262 |
| 0.4022 | 12.94 | 4400 | 0.6797 | 0.5184 |
| 0.3945 | 14.12 | 4800 | 0.6744 | 0.5147 |
| 0.3711 | 15.29 | 5200 | 0.6807 | 0.5090 |
| 0.3318 | 16.47 | 5600 | 0.6286 | 0.5011 |
| 0.3132 | 17.65 | 6000 | 0.6481 | 0.4814 |
| 0.2992 | 18.82 | 6400 | 0.6454 | 0.4958 |
| 0.2734 | 20.0 | 6800 | 0.6465 | 0.4825 |
| 0.2534 | 21.18 | 7200 | 0.6559 | 0.4658 |
| 0.2505 | 22.35 | 7600 | 0.6601 | 0.4618 |
| 0.2495 | 23.53 | 8000 | 0.7080 | 0.4813 |
| 0.2387 | 24.71 | 8400 | 0.6635 | 0.4508 |
| 0.2154 | 25.88 | 8800 | 0.6442 | 0.4538 |
| 0.2096 | 27.06 | 9200 | 0.7399 | 0.4579 |
| 0.2007 | 28.24 | 9600 | 0.6957 | 0.4512 |
| 0.1942 | 29.41 | 10000 | 0.6642 | 0.4267 |
| 0.1854 | 30.59 | 10400 | 0.6842 | 0.4393 |
| 0.1782 | 31.76 | 10800 | 0.7007 | 0.4393 |
| 0.1751 | 32.94 | 11200 | 0.7063 | 0.4321 |
| 0.1695 | 34.12 | 11600 | 0.7057 | 0.4330 |
| 0.1638 | 35.29 | 12000 | 0.7416 | 0.4266 |
| 0.1531 | 36.47 | 12400 | 0.7420 | 0.4273 |
| 0.1475 | 37.65 | 12800 | 0.7334 | 0.4218 |
| 0.1388 | 38.82 | 13200 | 0.7420 | 0.4227 |
| 0.1372 | 40.0 | 13600 | 0.7492 | 0.4238 |
| 0.1341 | 41.18 | 14000 | 0.7803 | 0.4193 |
| 0.133 | 42.35 | 14400 | 0.7396 | 0.4105 |
| 0.1238 | 43.53 | 14800 | 0.7561 | 0.4098 |
| 0.1163 | 44.71 | 15200 | 0.7987 | 0.4049 |
| 0.116 | 45.88 | 15600 | 0.7769 | 0.4093 |
| 0.1079 | 47.06 | 16000 | 0.7780 | 0.3986 |
| 0.1043 | 48.24 | 16400 | 0.7674 | 0.3905 |
| 0.1004 | 49.41 | 16800 | 0.7931 | 0.3949 |
| 0.0987 | 50.59 | 17200 | 0.7605 | 0.3938 |
| 0.0963 | 51.76 | 17600 | 0.7735 | 0.3858 |
| 0.0905 | 52.94 | 18000 | 0.7504 | 0.3802 |
| 0.086 | 54.12 | 18400 | 0.8038 | 0.3867 |
| 0.0839 | 55.29 | 18800 | 0.7887 | 0.3797 |
| 0.0798 | 56.47 | 19200 | 0.7832 | 0.3705 |
| 0.0785 | 57.65 | 19600 | 0.7771 | 0.3706 |
| 0.0765 | 58.82 | 20000 | 0.7858 | 0.3703 |
| 0.0739 | 60.0 | 20400 | 0.7888 | 0.3697 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.11.0
- Datasets 1.18.3
- Tokenizers 0.10.3
|
41ed1d5580751f054c7e1338f459f3df
|
debbiesoon/summarise_v11
|
debbiesoon
|
led
| 13 | 7 |
transformers
| 1 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 7,878 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# summarise_v11
This model is a fine-tuned version of [allenai/led-base-16384](https://huggingface.co/allenai/led-base-16384) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6322
- Rouge1 Precision: 0.6059
- Rouge1 Recall: 0.6233
- Rouge1 Fmeasure: 0.5895
- Rouge2 Precision: 0.4192
- Rouge2 Recall: 0.4512
- Rouge2 Fmeasure: 0.4176
- Rougel Precision: 0.4622
- Rougel Recall: 0.4946
- Rougel Fmeasure: 0.4566
- Rougelsum Precision: 0.4622
- Rougelsum Recall: 0.4946
- Rougelsum Fmeasure: 0.4566
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 Precision | Rouge1 Recall | Rouge1 Fmeasure | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure | Rougel Precision | Rougel Recall | Rougel Fmeasure | Rougelsum Precision | Rougelsum Recall | Rougelsum Fmeasure |
|:-------------:|:-----:|:----:|:---------------:|:----------------:|:-------------:|:---------------:|:----------------:|:-------------:|:---------------:|:----------------:|:-------------:|:---------------:|:-------------------:|:----------------:|:------------------:|
| 1.6201 | 0.45 | 10 | 1.4875 | 0.3203 | 0.64 | 0.3932 | 0.197 | 0.3839 | 0.2385 | 0.1952 | 0.4051 | 0.2454 | 0.1952 | 0.4051 | 0.2454 |
| 0.9172 | 0.91 | 20 | 1.4404 | 0.4917 | 0.5134 | 0.4699 | 0.288 | 0.3095 | 0.276 | 0.3371 | 0.3594 | 0.3277 | 0.3371 | 0.3594 | 0.3277 |
| 1.0923 | 1.36 | 30 | 1.3575 | 0.519 | 0.5505 | 0.4936 | 0.3114 | 0.3237 | 0.2958 | 0.3569 | 0.3702 | 0.3364 | 0.3569 | 0.3702 | 0.3364 |
| 1.1287 | 1.82 | 40 | 1.3269 | 0.4913 | 0.5997 | 0.5068 | 0.3108 | 0.3964 | 0.3269 | 0.3355 | 0.427 | 0.3521 | 0.3355 | 0.427 | 0.3521 |
| 0.9938 | 2.27 | 50 | 1.3189 | 0.5339 | 0.5781 | 0.4973 | 0.3555 | 0.3883 | 0.3345 | 0.3914 | 0.4289 | 0.3678 | 0.3914 | 0.4289 | 0.3678 |
| 0.8659 | 2.73 | 60 | 1.3241 | 0.525 | 0.638 | 0.5165 | 0.3556 | 0.4349 | 0.3535 | 0.3914 | 0.4793 | 0.3886 | 0.3914 | 0.4793 | 0.3886 |
| 0.6187 | 3.18 | 70 | 1.3360 | 0.5875 | 0.5864 | 0.5416 | 0.4005 | 0.4045 | 0.3701 | 0.4485 | 0.4556 | 0.414 | 0.4485 | 0.4556 | 0.414 |
| 0.3941 | 3.64 | 80 | 1.4176 | 0.5373 | 0.6415 | 0.5328 | 0.3576 | 0.446 | 0.3642 | 0.3787 | 0.4586 | 0.3781 | 0.3787 | 0.4586 | 0.3781 |
| 0.4145 | 4.09 | 90 | 1.3936 | 0.4127 | 0.6553 | 0.4568 | 0.2568 | 0.4498 | 0.2988 | 0.2918 | 0.4933 | 0.328 | 0.2918 | 0.4933 | 0.328 |
| 0.4203 | 4.55 | 100 | 1.4703 | 0.6545 | 0.601 | 0.5981 | 0.4789 | 0.4373 | 0.438 | 0.5251 | 0.4851 | 0.4818 | 0.5251 | 0.4851 | 0.4818 |
| 0.687 | 5.0 | 110 | 1.4304 | 0.5566 | 0.6357 | 0.5637 | 0.3734 | 0.4186 | 0.3748 | 0.4251 | 0.4825 | 0.4286 | 0.4251 | 0.4825 | 0.4286 |
| 0.4006 | 5.45 | 120 | 1.5399 | 0.5994 | 0.5794 | 0.5515 | 0.4215 | 0.4218 | 0.398 | 0.4359 | 0.4369 | 0.4084 | 0.4359 | 0.4369 | 0.4084 |
| 0.2536 | 5.91 | 130 | 1.5098 | 0.5074 | 0.6254 | 0.4874 | 0.3369 | 0.4189 | 0.3256 | 0.3802 | 0.4738 | 0.3664 | 0.3802 | 0.4738 | 0.3664 |
| 0.2218 | 6.36 | 140 | 1.5278 | 0.5713 | 0.6059 | 0.5688 | 0.3887 | 0.4233 | 0.3916 | 0.4414 | 0.4795 | 0.4457 | 0.4414 | 0.4795 | 0.4457 |
| 0.2577 | 6.82 | 150 | 1.5469 | 0.5148 | 0.5941 | 0.5175 | 0.3284 | 0.3856 | 0.3335 | 0.3616 | 0.4268 | 0.3681 | 0.3616 | 0.4268 | 0.3681 |
| 0.1548 | 7.27 | 160 | 1.5986 | 0.5983 | 0.657 | 0.5862 | 0.4322 | 0.4877 | 0.4287 | 0.4466 | 0.5167 | 0.4482 | 0.4466 | 0.5167 | 0.4482 |
| 0.1535 | 7.73 | 170 | 1.5796 | 0.5609 | 0.641 | 0.5616 | 0.3856 | 0.4428 | 0.3892 | 0.4238 | 0.4921 | 0.4263 | 0.4238 | 0.4921 | 0.4263 |
| 0.1568 | 8.18 | 180 | 1.6052 | 0.5669 | 0.617 | 0.5679 | 0.3911 | 0.4382 | 0.3969 | 0.4363 | 0.4877 | 0.4417 | 0.4363 | 0.4877 | 0.4417 |
| 0.2038 | 8.64 | 190 | 1.6191 | 0.5466 | 0.5973 | 0.5313 | 0.3543 | 0.4114 | 0.3531 | 0.4061 | 0.4666 | 0.404 | 0.4061 | 0.4666 | 0.404 |
| 0.1808 | 9.09 | 200 | 1.6165 | 0.5751 | 0.5919 | 0.5587 | 0.3831 | 0.4097 | 0.3817 | 0.4482 | 0.4728 | 0.4405 | 0.4482 | 0.4728 | 0.4405 |
| 0.1021 | 9.55 | 210 | 1.6316 | 0.5316 | 0.6315 | 0.535 | 0.3588 | 0.4563 | 0.3697 | 0.405 | 0.502 | 0.4126 | 0.405 | 0.502 | 0.4126 |
| 0.1407 | 10.0 | 220 | 1.6322 | 0.6059 | 0.6233 | 0.5895 | 0.4192 | 0.4512 | 0.4176 | 0.4622 | 0.4946 | 0.4566 | 0.4622 | 0.4946 | 0.4566 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 1.2.1
- Tokenizers 0.12.1
|
81593e4d038f404304d010bd38aaeb47
|
google/t5-efficient-xl-nl16
|
google
|
t5
| 12 | 12 |
transformers
| 0 |
text2text-generation
| true | true | true |
apache-2.0
|
['en']
|
['c4']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['deep-narrow']
| false | true | true | 6,247 | false |
# T5-Efficient-XL-NL16 (Deep-Narrow version)
T5-Efficient-XL-NL16 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5).
It is a *pretrained-only* checkpoint and was released with the
paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)**
by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures
of similar parameter count.
To quote the paper:
> We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased
> before considering any other forms of uniform scaling across other dimensions. This is largely due to
> how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a
> tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise,
> a tall base model might also generally more efficient compared to a large model. We generally find
> that, regardless of size, even if absolute performance might increase as we continue to stack layers,
> the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36
> layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e.,
> params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params,
> FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to
> consider.
To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially.
A sequence of word embeddings is therefore processed sequentially by each transformer block.
## Details model architecture
This model checkpoint - **t5-efficient-xl-nl16** - is of model type **Xl** with the following variations:
- **nl** is **16**
It has **1912.07** million parameters and thus requires *ca.* **7648.29 MB** of memory in full precision (*fp32*)
or **3824.14 MB** of memory in half precision (*fp16* or *bf16*).
A summary of the *original* T5 model architectures can be seen here:
| Model | nl (el/dl) | ff | dm | kv | nh | #Params|
| ----| ---- | ---- | ---- | ---- | ---- | ----|
| Tiny | 4/4 | 1024 | 256 | 32 | 4 | 16M|
| Mini | 4/4 | 1536 | 384 | 32 | 8 | 31M|
| Small | 6/6 | 2048 | 512 | 32 | 8 | 60M|
| Base | 12/12 | 3072 | 768 | 64 | 12 | 220M|
| Large | 24/24 | 4096 | 1024 | 64 | 16 | 738M|
| Xl | 24/24 | 16384 | 1024 | 128 | 32 | 3B|
| XXl | 24/24 | 65536 | 1024 | 128 | 128 | 11B|
whereas the following abbreviations are used:
| Abbreviation | Definition |
| ----| ---- |
| nl | Number of transformer blocks (depth) |
| dm | Dimension of embedding vector (output vector of transformers block) |
| kv | Dimension of key/value projection matrix |
| nh | Number of attention heads |
| ff | Dimension of intermediate vector within transformer block (size of feed-forward projection matrix) |
| el | Number of transformer blocks in the encoder (encoder depth) |
| dl | Number of transformer blocks in the decoder (decoder depth) |
| sh | Signifies that attention heads are shared |
| skv | Signifies that key-values projection matrices are tied |
If a model checkpoint has no specific, *el* or *dl* than both the number of encoder- and decoder layers correspond to *nl*.
## Pre-Training
The checkpoint was pretrained on the [Colossal, Cleaned version of Common Crawl (C4)](https://huggingface.co/datasets/c4) for 524288 steps using
the span-based masked language modeling (MLM) objective.
## Fine-Tuning
**Note**: This model is a **pretrained** checkpoint and has to be fine-tuned for practical usage.
The checkpoint was pretrained in English and is therefore only useful for English NLP tasks.
You can follow on of the following examples on how to fine-tune the model:
*PyTorch*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization)
- [Question Answering](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_seq2seq_qa.py)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*Tensorflow*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*JAX/Flax*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/flax/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/flax/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
## Downstream Performance
TODO: Add table if available
## Computational Complexity
TODO: Add table if available
## More information
We strongly recommend the reader to go carefully through the original paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** to get a more nuanced understanding of this model checkpoint.
As explained in the following [issue](https://github.com/google-research/google-research/issues/986#issuecomment-1035051145), checkpoints including the *sh* or *skv*
model architecture variations have *not* been ported to Transformers as they are probably of limited practical usage and are lacking a more detailed description. Those checkpoints are kept [here](https://huggingface.co/NewT5SharedHeadsSharedKeyValues) as they might be ported potentially in the future.
|
82a591b11936ec3e10a8caf444ae6060
|
AI-Ahmed/deberta-v3-base-funetuned-cls-qqa
|
AI-Ahmed
|
deberta-v2
| 61 | 15 |
transformers
| 0 |
text-classification
| true | false | false |
cc-by-4.0
|
['en']
|
['SetFit/qqp']
| null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['classification']
| true | true | true | 1,789 | false |
A fine-tuned model based on the **DeBERTaV3** model of Microsoft and fine-tuned on **Glue QQP**, which detects the linguistical similarities between two questions and whether they are duplicates questions or different.
## Model Hyperparameters
```python
epoch=4
per_device_train_batch_size=32
per_device_eval_batch_size=16
lr=2e-5
weight_decay=1e-2
gradient_checkpointing=True
gradient_accumulation_steps=8
```
## Model Performance
```JSON
{"Training Loss": 0.132400,
"Validation Loss": 0.217410,
"Validation Accuracy": 0.917969
}
```
## Model Dependencies
```JSON
{"Main Model": "microsoft/deberta-v3-base",
"Dataset": "SetFit/qqp"
}
```
## Training Monitoring & Performance
- [wandb - deberta_qqa_classification](https://wandb.ai/ai-ahmed/deberta_qqa_classification?workspace=user-ai-ahmed)
## Model Testing
```python
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_name = "AI-Ahmed/deberta-v3-base-funetuned-cls-qqa"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenized_input = tokenizer("How is the life of a math student? Could you describe your own experiences? Which level of preparation is enough for the exam jlpt5?", return_tensors="pt")
with torch.no_grad():
logits = model(**tokenized_input).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
```
## Information Citation
```bibtex
@inproceedings{
he2021deberta,
title={DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION},
author={Pengcheng He and Xiaodong Liu and Jianfeng Gao and Weizhu Chen},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=XPZIaotutsD}
}
```
|
192c508932f59879f54a42b027389dd6
|
jeraldflowers/distilroberts-base-mrpc-glue-jeraldflowers
|
jeraldflowers
|
roberta
| 17 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text-classification', 'generated_from_trainer']
| true | true | true | 1,344 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberts-base-mrpc-glue-jeraldflowers
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the glue and the mrpc datasets.
It achieves the following results on the evaluation set:
- Loss: 0.4990
- Accuracy: 0.8431
- F1: 0.8815
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.5289 | 1.09 | 500 | 0.5668 | 0.8211 | 0.8689 |
| 0.3675 | 2.18 | 1000 | 0.4990 | 0.8431 | 0.8815 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
198ce21dee5b672deb2990c399e58308
|
YasinShihab/asr-en-bn-test
|
YasinShihab
| null | 2 | 0 | null | 0 |
automatic-speech-recognition
| false | false | false |
cc-by-sa-4.0
|
['Bengali']
|
['OpenSLR']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['bn', 'audio', 'automatic-speech-recognition', 'speech']
| true | true | true | 1,660 | false |
# Wav2Vec2-Large-XLSR-Bengali
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) Bengali using a subset of 40,000 utterances from [Bengali ASR training data set containing ~196K utterances](https://www.openslr.org/53/). Tested WER using ~4200 held out from training.
When using this model, make sure that your speech input is sampled at 16kHz.
Train Script can be Found at : train.py
Data Prep Notebook : https://colab.research.google.com/drive/1JMlZPU-DrezXjZ2t7sOVqn7CJjZhdK2q?usp=sharing
Inference Notebook : https://colab.research.google.com/drive/1uKC2cK9JfUPDTUHbrNdOYqKtNozhxqgZ?usp=sharing
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
processor = Wav2Vec2Processor.from_pretrained("arijitx/wav2vec2-large-xlsr-bengali")
model = Wav2Vec2ForCTC.from_pretrained("arijitx/wav2vec2-large-xlsr-bengali")
# model = model.to("cuda")
resampler = torchaudio.transforms.Resample(TEST_AUDIO_SR, 16_000)
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch)
speech = resampler(speech_array).squeeze().numpy()
return speech
speech_array = speech_file_to_array_fn("test_file.wav")
inputs = processor(speech_array, sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
preds = processor.batch_decode(predicted_ids)[0]
print(preds.replace("[PAD]",""))
```
**Test Result**: WER on ~4200 utterance : 32.45 %
|
79df9741d1bf656211ca2a3a0ac54ddc
|
jonatasgrosman/exp_w2v2t_uk_unispeech-sat_s27
|
jonatasgrosman
|
unispeech-sat
| 10 | 2 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['uk']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'uk']
| false | true | true | 462 | false |
# exp_w2v2t_uk_unispeech-sat_s27
Fine-tuned [microsoft/unispeech-sat-large](https://huggingface.co/microsoft/unispeech-sat-large) for speech recognition using the train split of [Common Voice 7.0 (uk)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
e61d0f2e5cb304ba20de27a178f1a5c3
|
gustavecortal/flan-t5-large-dream-character
|
gustavecortal
|
t5
| 10 | 4 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,017 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-large-dream-character
This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0937
- Gen Len: 2.8625
- F1: 0.6843
- Precision: 0.7760
- Recall: 0.6755
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Gen Len | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:---------:|:------:|
| 0.714 | 0.59 | 250 | 0.1678 | 3.025 | 0.2809 | 0.3302 | 0.3145 |
| 0.1488 | 1.18 | 500 | 0.1332 | 2.1 | 0.4394 | 0.575 | 0.4082 |
| 0.1206 | 1.78 | 750 | 0.1023 | 2.35 | 0.5491 | 0.6948 | 0.5205 |
| 0.097 | 2.37 | 1000 | 0.0974 | 2.8375 | 0.5889 | 0.6956 | 0.5904 |
| 0.0859 | 2.96 | 1250 | 0.0884 | 2.9 | 0.6610 | 0.7510 | 0.6574 |
| 0.0635 | 3.55 | 1500 | 0.0926 | 2.4625 | 0.6429 | 0.7875 | 0.5930 |
| 0.0581 | 4.15 | 1750 | 0.0930 | 2.75 | 0.6651 | 0.7754 | 0.6446 |
| 0.0453 | 4.74 | 2000 | 0.0937 | 2.8625 | 0.6843 | 0.7760 | 0.6755 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
08eb6e5d27f14fb850a6bb34b318cafe
|
agungbesti/house
|
agungbesti
| null | 5 | 0 | null | 0 | null | false | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 779 | false |
# Configuration
`title`: _string_
Display title for the Space
`emoji`: _string_
Space emoji (emoji-only character allowed)
`colorFrom`: _string_
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
`colorTo`: _string_
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
`sdk`: _string_
Can be either `gradio` or `streamlit`
`sdk_version` : _string_
Only applicable for `streamlit` SDK.
See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
`app_file`: _string_
Path to your main application file (which contains either `gradio` or `streamlit` Python code).
Path is relative to the root of the repository.
`pinned`: _boolean_
Whether the Space stays on top of your list.
|
93eaa78d7f0056b64c5516ac1f78b64f
|
AMAN-B/Demo-Dreambooth
|
AMAN-B
| null | 18 | 69 |
diffusers
| 1 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 3 | 3 | 0 | 0 | 0 | 0 | 0 |
['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image']
| false | true | true | 572 | false |
### Diffusers
```py
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16, revision="fp16")
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
For more detailed instructions, use-cases and examples in JAX follow the instructions [here](https://github.com/huggingface/diffusers#text-to-image-generation-with-stable-diffusion)
|
6af3f44627dbf33e0ce399b6129c582b
|
CCMat/ddpm-bored-apes-128
|
CCMat
| null | 7 | 0 |
diffusers
| 0 |
unconditional-image-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['pytorch', 'diffusers', 'unconditional-image-generation', 'diffusion-models-class']
| false | true | true | 413 | false |
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of bored apes 🦧.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('CCMat/diff-bored-apes-128')
image = pipeline().images[0]
image
```
## Samples

|
d7fddf96df1b6b98b01a158367ad6fdb
|
jonatasgrosman/exp_w2v2t_nl_r-wav2vec2_s925
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['nl']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'nl']
| false | true | true | 462 | false |
# exp_w2v2t_nl_r-wav2vec2_s925
Fine-tuned [facebook/wav2vec2-large-robust](https://huggingface.co/facebook/wav2vec2-large-robust) for speech recognition using the train split of [Common Voice 7.0 (nl)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
2b4056bdd23ed48bfac4fd72756e4c0a
|
CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-msa
|
CAMeL-Lab
|
bert
| 12 | 154 |
transformers
| 0 |
token-classification
| true | true | false |
apache-2.0
|
['ar']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 3,770 | false |
# CAMeLBERT-CA POS-MSA Model
## Model description
**CAMeLBERT-CA POS-MSA Model** is a Modern Standard Arabic (MSA) POS tagging model that was built by fine-tuning the [CAMeLBERT-CA](https://huggingface.co/CAMeL-Lab/bert-base-arabic-camelbert-ca/) model.
For the fine-tuning, we used the [PATB](https://dl.acm.org/doi/pdf/10.5555/1621804.1621808) dataset.
Our fine-tuning procedure and the hyperparameters we used can be found in our paper *"[The Interplay of Variant, Size, and Task Type in Arabic Pre-trained Language Models](https://arxiv.org/abs/2103.06678)."* Our fine-tuning code can be found [here](https://github.com/CAMeL-Lab/CAMeLBERT).
## Intended uses
You can use the CAMeLBERT-CA POS-MSA model as part of the transformers pipeline.
This model will also be available in [CAMeL Tools](https://github.com/CAMeL-Lab/camel_tools) soon.
#### How to use
To use the model with a transformers pipeline:
```python
>>> from transformers import pipeline
>>> pos = pipeline('token-classification', model='CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-msa')
>>> text = 'إمارة أبوظبي هي إحدى إمارات دولة الإمارات العربية المتحدة السبع'
>>> pos(text)
[{'entity': 'noun', 'score': 0.9999758, 'index': 1, 'word': 'إمارة', 'start': 0, 'end': 5}, {'entity': 'noun_prop', 'score': 0.9997559, 'index': 2, 'word': 'أبوظبي', 'start': 6, 'end': 12}, {'entity': 'pron', 'score': 0.99996257, 'index': 3, 'word': 'هي', 'start': 13, 'end': 15}, {'entity': 'noun', 'score': 0.9958452, 'index': 4, 'word': 'إحدى', 'start': 16, 'end': 20}, {'entity': 'noun', 'score': 0.9999635, 'index': 5, 'word': 'إما', 'start': 21, 'end': 24}, {'entity': 'noun', 'score': 0.99991685, 'index': 6, 'word': '##رات', 'start': 24, 'end': 27}, {'entity': 'noun', 'score': 0.99997497, 'index': 7, 'word': 'دولة', 'start': 28, 'end': 32}, {'entity': 'noun', 'score': 0.9999795, 'index': 8, 'word': 'الإمارات', 'start': 33, 'end': 41}, {'entity': 'adj', 'score': 0.99924207, 'index': 9, 'word': 'العربية', 'start': 42, 'end': 49}, {'entity': 'adj', 'score': 0.99994195, 'index': 10, 'word': 'المتحدة', 'start': 50, 'end': 57}, {'entity': 'noun_num', 'score': 0.9997414, 'index': 11, 'word': 'السبع', 'start': 58, 'end': 63}]
```
*Note*: to download our models, you would need `transformers>=3.5.0`.
Otherwise, you could download the models manually.
## Citation
```bibtex
@inproceedings{inoue-etal-2021-interplay,
title = "The Interplay of Variant, Size, and Task Type in {A}rabic Pre-trained Language Models",
author = "Inoue, Go and
Alhafni, Bashar and
Baimukan, Nurpeiis and
Bouamor, Houda and
Habash, Nizar",
booktitle = "Proceedings of the Sixth Arabic Natural Language Processing Workshop",
month = apr,
year = "2021",
address = "Kyiv, Ukraine (Online)",
publisher = "Association for Computational Linguistics",
abstract = "In this paper, we explore the effects of language variants, data sizes, and fine-tuning task types in Arabic pre-trained language models. To do so, we build three pre-trained language models across three variants of Arabic: Modern Standard Arabic (MSA), dialectal Arabic, and classical Arabic, in addition to a fourth language model which is pre-trained on a mix of the three. We also examine the importance of pre-training data size by building additional models that are pre-trained on a scaled-down set of the MSA variant. We compare our different models to each other, as well as to eight publicly available models by fine-tuning them on five NLP tasks spanning 12 datasets. Our results suggest that the variant proximity of pre-training data to fine-tuning data is more important than the pre-training data size. We exploit this insight in defining an optimized system selection model for the studied tasks.",
}
```
|
66b1bdec6921430b8cb2224e766c2fe0
|
Praboda/xlm-roberta-base-finetuned-panx-it
|
Praboda
|
xlm-roberta
| 10 | 3 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null |
['xtreme']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,320 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-it
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2369
- F1: 0.8322
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.8113 | 1.0 | 70 | 0.3088 | 0.7546 |
| 0.259 | 2.0 | 140 | 0.2541 | 0.8155 |
| 0.1791 | 3.0 | 210 | 0.2369 | 0.8322 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.13.0+cu116
- Datasets 1.16.1
- Tokenizers 0.10.3
|
7cb96e6d28eede79721dbc43f46a8213
|
Adil617/wav2vec2-base-timit-demo-colab
|
Adil617
|
wav2vec2
| 14 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,237 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9314
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| 8.686 | 0.16 | 20 | 13.6565 | 1.0 |
| 8.0711 | 0.32 | 40 | 12.5379 | 1.0 |
| 6.9967 | 0.48 | 60 | 9.7215 | 1.0 |
| 5.2368 | 0.64 | 80 | 5.8459 | 1.0 |
| 3.4499 | 0.8 | 100 | 3.3413 | 1.0 |
| 3.1261 | 0.96 | 120 | 3.2858 | 1.0 |
| 3.0654 | 1.12 | 140 | 3.1945 | 1.0 |
| 3.0421 | 1.28 | 160 | 3.1296 | 1.0 |
| 3.0035 | 1.44 | 180 | 3.1172 | 1.0 |
| 3.0067 | 1.6 | 200 | 3.1217 | 1.0 |
| 2.9867 | 1.76 | 220 | 3.0715 | 1.0 |
| 2.9653 | 1.92 | 240 | 3.0747 | 1.0 |
| 2.9629 | 2.08 | 260 | 2.9984 | 1.0 |
| 2.9462 | 2.24 | 280 | 2.9991 | 1.0 |
| 2.9391 | 2.4 | 300 | 3.0391 | 1.0 |
| 2.934 | 2.56 | 320 | 2.9682 | 1.0 |
| 2.9193 | 2.72 | 340 | 2.9701 | 1.0 |
| 2.8985 | 2.88 | 360 | 2.9314 | 1.0 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
6ba065814b7e0d723c2ebc89b4b5e551
|
danghuy1999/gpt2-viwiki
|
danghuy1999
|
gpt2
| 7 | 10 |
transformers
| 3 | null | true | true | false |
mit
|
['vi']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['gpt2-viwiki']
| false | true | true | 3,121 | false |
# GPT-2 Fine-tuning in Vietnamese Wikipedia
## Model description
This is a Vietnamese GPT-2 model which is finetuned on the [Latest pages articles of Vietnamese Wikipedia](https://dumps.wikimedia.org/viwiki/latest/viwiki-latest-pages-articles.xml.bz2).
## Dataset
The dataset is about 800MB, includes many articles from Wikipedia.
## How to use
You can use this model to:
- Tokenize Vietnamese sentences with GPT2Tokenizer.
- Generate text seems like a Wikipedia article.
- Finetune it to other downstream tasks.
Here is how to use the model to generate text in Pytorch:
```python
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained('danghuy1999/gpt2-viwiki')
model = GPT2LMHeadModel.from_pretrained('danghuy1999/gpt2-viwiki').to('cuda')
text = "Albert Einstein là nhà vật lý học tạo ra thuyết lượng tử"
input_ids = tokenizer.encode(text, return_tensors='pt').to('cuda')
max_length = 100
sample_outputs = model.generate(input_ids,pad_token_id=tokenizer.eos_token_id,
do_sample=True,
max_length=max_length,
min_length=max_length,
top_k=40,
num_beams=5,
early_stopping=True,
no_repeat_ngram_size=2,
num_return_sequences=3)
for i, sample_output in enumerate(sample_outputs):
print(">> Generated text {}\n\n{}".format(i+1, tokenizer.decode(sample_output.tolist())))
print('\n---')
```
And the results are:
```bash
>> Generated text 1
Albert Einstein là nhà vật lý học tạo ra thuyết lượng tử.
Mặc dù thuyết tương đối tổng quát không được áp dụng rộng rãi trong nhiều lĩnh vực khác nhau, nhưng các nhà lý thuyết đã đưa ra khái niệm rộng hơn về tính chất của vật chất. Một trong những nghiên cứu của Albert Einstein về sự tồn tại của hệ quy chiếu quán tính, ông đã đề xuất rằng một lực hấp dẫn có thể có khối lượng bằng năng lượng của nó. Tuy nhiên, những người cho rằng
---
>> Generated text 2
Albert Einstein là nhà vật lý học tạo ra thuyết lượng tử. Tuy nhiên, thuyết tương đối hẹp không phải là lý thuyết của Einstein.
Cho đến tận cuối thế kỷ 19, Albert Einstein đã chứng minh được sự tồn tại của lực hấp dẫn trong một số trường hợp đặc biệt. Năm 1915, ông đưa ra khái niệm "khối lượng" để miêu tả chuyển động lượng của một hạt bằng khối lượng nghỉ của nó. Ông cho rằng năng lượng "m" là một thành phần của
---
>> Generated text 3
Albert Einstein là nhà vật lý học tạo ra thuyết lượng tử. Tuy nhiên, thuyết tương đối hẹp không được chấp nhận rộng rãi bởi các nhà lý thuyết.
Một trong những nghiên cứu của Einstein về tính chất của lực hấp dẫn là vào năm 1905, ông đã đưa ra một khái niệm về lực học. Ông đã phát biểu rằng nếu một hạt mang điện tích dương, nó có thể chuyển đổi năng lượng của nó thành các hạt khác. Năm 1915, Arthur Eddington phát minh ra
---
```
You can do the same with **Tensorflow** by using the model **TFGPT2Tokenizer** instead.
|
315b1ed6a9c1a650d68e4a788b69ae45
|
LinfO/yerlearsi
|
LinfO
| null | 31 | 2 |
diffusers
| 0 | null | false | false | false |
mit
| null | null | null | 2 | 2 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,961 | false |
### yerlearsi on Stable Diffusion via Dreambooth
#### model by LinfO
This your the Stable Diffusion model fine-tuned the yerlearsi concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **yerlearsi**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:













|
8020df3a9fb76ea5ef512c60995469de
|
sd-concepts-library/boris-anderson
|
sd-concepts-library
| null | 9 | 0 | null | 0 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,070 | false |
### Boris Anderson on Stable Diffusion
This is the `<boris-anderson>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
9e4af5f64a3d47558463a1db267446d3
|
StonyBrookNLP/preasm-large-drop
|
StonyBrookNLP
|
t5
| 8 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
cc-by-4.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['question-answering, multi-step-reasoning, multi-hop-reasoning']
| false | true | true | 2,603 | false |
# What's this?
This is one of the models reported in the paper: ["Teaching Broad Reasoning Skills for Multi-Step QA by Generating Hard Contexts".](https://arxiv.org/abs/2205.12496).
This paper proposes a procedure to synthetically generate a QA dataset, TeaBReaC, for pretraining language models for robust multi-step reasoning. Pretraining plain LMs like Bart, T5 and numerate LMs like NT5, PReasM, POET on TeaBReaC leads to improvemed downstream performance on several multi-step QA datasets. Please checkout out the paper for the details.
We release the following models:
- **A:** Base Models finetuned on target datasets: `{base_model}-{target_dataset}`
- **B:** Base models pretrained on TeaBReaC: `teabreac-{base_model}`
- **C:** Base models pretrained on TeaBReaC and then finetuned on target datasets: `teabreac-{base_model}-{target_dataset}`
The `base_model` above can be from: `bart-large`, `t5-large`, `t5-3b`, `nt5-small`, `preasm-large`.
The `target_dataset` above can be from: `drop`, `tatqa`, `iirc-gold`, `iirc-retrieved`, `numglue`.
The **A** models are only released for completeness / reproducibility. In your end application you probably just want to use either **B** or **C**.
# How to use it?
Please checkout the details in our [github repository](https://github.com/stonybrooknlp/teabreac), but in a nutshell:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
from digit_tokenization import enable_digit_tokenization # digit_tokenization.py from https://github.com/stonybrooknlp/teabreac
model_name = "StonyBrookNLP/preasm-large-drop"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False) # Fast doesn't work with digit tokenization
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
enable_digit_tokenization(tokenizer)
input_texts = [
"Who scored the first touchdown of the game?\n" +
"... Oakland would get the early lead in the first quarter as quarterback JaMarcus Russell completed a 20-yard touchdown pass to rookie wide receiver Chaz Schilens..."
# Note: some models have slightly different qn/ctxt format. See the github repo.
]
input_ids = tokenizer(
input_texts, return_tensors="pt",
truncation=True, max_length=800,
add_special_tokens=True, padding=True,
)["input_ids"]
generated_ids = model.generate(input_ids, min_length=1, max_length=50)
generated_predictions = tokenizer.batch_decode(generated_ids, skip_special_tokens=False)
generated_predictions = [
tokenizer.fix_decoded_text(generated_prediction) for generated_prediction in generated_predictions
]
# => ["Chaz Schilens"]
```
|
3d213ef898085b2fa80998bb098c4f21
|
YoungMasterFromSect/ManyColors
|
YoungMasterFromSect
| null | 8 | 0 | null | 2 | null | false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 848 | false |
Depending on tags and length of tags artstyle will vary, so experiment with them! |
wral artstyle - artstyle tag |
watercolor \(medium\) - helps to bring out watercolor |
multicolored hair - helps to make image multicolored
Sample images:
<style>
img {
display: inline-block;
}
</style>
<img src="https://huggingface.co/YoungMasterFromSect/ManyColors/resolve/main/1.png" width="300" height="200">
<img src="https://huggingface.co/YoungMasterFromSect/ManyColors/resolve/main/2.png" width="300" height="200">
<img src="https://huggingface.co/YoungMasterFromSect/ManyColors/resolve/main/3.png" width="300" height="300">
<img src="https://huggingface.co/YoungMasterFromSect/ManyColors/resolve/main/4.png" width="300" height="300">
<img src="https://huggingface.co/YoungMasterFromSect/ManyColors/resolve/main/5.png" width="300" height="300">
|
baf2b4518d03a8bc32b1a03c7805410a
|
muhtasham/tiny-mlm-imdb-target-rotten_tomatoes
|
muhtasham
|
bert
| 10 | 4 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,578 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-imdb-target-rotten_tomatoes
This model is a fine-tuned version of [muhtasham/small-mlm-wikitext](https://huggingface.co/muhtasham/small-mlm-wikitext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3909
- Accuracy: 0.8021
- F1: 0.8017
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.4528 | 1.87 | 500 | 0.4296 | 0.8030 | 0.8028 |
| 0.2265 | 3.75 | 1000 | 0.5558 | 0.8096 | 0.8096 |
| 0.1111 | 5.62 | 1500 | 0.9042 | 0.8039 | 0.8039 |
| 0.0584 | 7.49 | 2000 | 1.1252 | 0.8058 | 0.8058 |
| 0.0405 | 9.36 | 2500 | 1.3909 | 0.8021 | 0.8017 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
d74078bee176ab1437a869e6677dc0ef
|
gokuls/mobilebert_sa_GLUE_Experiment_logit_kd_data_aug_qnli_128
|
gokuls
|
mobilebert
| 17 | 0 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,617 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_sa_GLUE_Experiment_logit_kd_data_aug_qnli_128
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE QNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1653
- Accuracy: 0.5779
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:------:|:---------------:|:--------:|
| 0.7088 | 1.0 | 33208 | 1.1653 | 0.5779 |
| 0.5355 | 2.0 | 66416 | 1.2844 | 0.5889 |
| 0.4541 | 3.0 | 99624 | 1.2482 | 0.5825 |
| 0.4041 | 4.0 | 132832 | 1.2911 | 0.5836 |
| 0.3722 | 5.0 | 166040 | 1.3428 | 0.5779 |
| 0.3486 | 6.0 | 199248 | 1.3220 | 0.5781 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
|
9819670ec436558fe43ff5048d9ee0ef
|
MadMarx37/mt5-small-finetuned-cnn-dailymail
|
MadMarx37
|
mt5
| 17 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['cnn_dailymail']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,029 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-cnn-dailymail
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the cnn_dailymail dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7294
- Rouge1: 32.8352
- Rouge2: 17.0633
- Rougel: 29.0888
- Rougelsum: 30.8226
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:---------:|
| No log | 1.0 | 8973 | 1.9272 | 31.6634 | 16.1653 | 28.1624 | 29.7819 |
| No log | 2.0 | 17946 | 1.8282 | 32.1032 | 16.4388 | 28.4914 | 30.1856 |
| No log | 3.0 | 26919 | 1.7967 | 32.5721 | 16.8392 | 28.8483 | 30.5764 |
| 2.1615 | 4.0 | 35892 | 1.7640 | 32.6788 | 16.94 | 28.994 | 30.6883 |
| 2.1615 | 5.0 | 44865 | 1.7450 | 32.8129 | 17.048 | 29.0788 | 30.8106 |
| 2.1615 | 6.0 | 53838 | 1.7379 | 32.7074 | 16.9641 | 28.9745 | 30.7043 |
| 2.1615 | 7.0 | 62811 | 1.7317 | 32.7692 | 17.0116 | 29.0395 | 30.7685 |
| 2.0886 | 8.0 | 71784 | 1.7294 | 32.8352 | 17.0633 | 29.0888 | 30.8226 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.11.0+cu102
- Datasets 2.7.1
- Tokenizers 0.13.2
|
f958e60efe693de5e330344da91ff967
|
jonatasgrosman/exp_w2v2r_en_vp-100k_gender_male-2_female-8_s320
|
jonatasgrosman
|
wav2vec2
| 10 | 1 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['en']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'en']
| false | true | true | 498 | false |
# exp_w2v2r_en_vp-100k_gender_male-2_female-8_s320
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (en)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
8d5fec508fac974560e7eb8b4fd017f2
|
davidlekve/distilroberta-base-finetuned-the-beatles
|
davidlekve
|
roberta
| 8 | 6 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,267 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-finetuned-the-beatles
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5186
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 84 | 2.6517 |
| No log | 2.0 | 168 | 2.6433 |
| No log | 3.0 | 252 | 2.5186 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cpu
- Datasets 2.1.0
- Tokenizers 0.12.1
|
5687f04595678814935816019e4ba434
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.