
pipeline_tag
stringclasses 48
values | library_name
stringclasses 198
values | text
stringlengths 1
900k
| metadata
stringlengths 2
438k
| id
stringlengths 5
122
| last_modified
null | tags
listlengths 1
1.84k
| sha
null | created_at
stringlengths 25
25
| arxiv
listlengths 0
201
| languages
listlengths 0
1.83k
| tags_str
stringlengths 17
9.34k
| text_str
stringlengths 0
389k
| text_lists
listlengths 0
722
| processed_texts
listlengths 1
723
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
fill-mask
|
transformers
|
# PaloBERT
## Model description
A Greek language model based on [RoBERTa](https://arxiv.org/abs/1907.11692)
## Training data
The training data is a corpus of 458,293 documents collected from Greek social media accounts. It also contains a GTP-2 tokenizer trained from scratch on the same corpus.
The training corpus has been collected and provided by [Palo LTD](http://www.paloservices.com/)
## Eval results
### BibTeX entry and citation info
```bibtex
@Article{info12080331,
AUTHOR = {Alexandridis, Georgios and Varlamis, Iraklis and Korovesis, Konstantinos and Caridakis, George and Tsantilas, Panagiotis},
TITLE = {A Survey on Sentiment Analysis and Opinion Mining in Greek Social Media},
JOURNAL = {Information},
VOLUME = {12},
YEAR = {2021},
NUMBER = {8},
ARTICLE-NUMBER = {331},
URL = {https://www.mdpi.com/2078-2489/12/8/331},
ISSN = {2078-2489},
DOI = {10.3390/info12080331}
}
```
|
{"language": "el"}
|
gealexandri/palobert-base-greek-uncased-v1
| null |
[
"transformers",
"pytorch",
"tf",
"roberta",
"fill-mask",
"el",
"arxiv:1907.11692",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1907.11692"
] |
[
"el"
] |
TAGS
#transformers #pytorch #tf #roberta #fill-mask #el #arxiv-1907.11692 #autotrain_compatible #endpoints_compatible #region-us
|
# PaloBERT
## Model description
A Greek language model based on RoBERTa
## Training data
The training data is a corpus of 458,293 documents collected from Greek social media accounts. It also contains a GTP-2 tokenizer trained from scratch on the same corpus.
The training corpus has been collected and provided by Palo LTD
## Eval results
### BibTeX entry and citation info
|
[
"# PaloBERT",
"## Model description\n\nA Greek language model based on RoBERTa",
"## Training data\n\nThe training data is a corpus of 458,293 documents collected from Greek social media accounts. It also contains a GTP-2 tokenizer trained from scratch on the same corpus.\n\nThe training corpus has been collected and provided by Palo LTD",
"## Eval results",
"### BibTeX entry and citation info"
] |
[
"TAGS\n#transformers #pytorch #tf #roberta #fill-mask #el #arxiv-1907.11692 #autotrain_compatible #endpoints_compatible #region-us \n",
"# PaloBERT",
"## Model description\n\nA Greek language model based on RoBERTa",
"## Training data\n\nThe training data is a corpus of 458,293 documents collected from Greek social media accounts. It also contains a GTP-2 tokenizer trained from scratch on the same corpus.\n\nThe training corpus has been collected and provided by Palo LTD",
"## Eval results",
"### BibTeX entry and citation info"
] |
feature-extraction
|
transformers
|
hello
|
{}
|
geekfeed/gpt2_ja
| null |
[
"transformers",
"pytorch",
"jax",
"gpt2",
"feature-extraction",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #jax #gpt2 #feature-extraction #endpoints_compatible #text-generation-inference #region-us
|
hello
|
[] |
[
"TAGS\n#transformers #pytorch #jax #gpt2 #feature-extraction #endpoints_compatible #text-generation-inference #region-us \n"
] |
null | null |
https://dl.fbaipublicfiles.com/avhubert/model/lrs3_vox/vsr/base_vox_433h.pt
|
{}
|
g30rv17ys/avhubert
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#region-us
|
URL
|
[] |
[
"TAGS\n#region-us \n"
] |
fill-mask
|
transformers
|
# Please use 'Bert' related functions to load this model!
## Chinese BERT with Whole Word Masking Fix MLM Parameters
Init parameters by https://huggingface.co/hfl/chinese-roberta-wwm-ext-large
miss mlm parameters issue https://github.com/ymcui/Chinese-BERT-wwm/issues/98
Only train MLM parameters and freeze other parameters
More info in github https://github.com/genggui001/chinese_roberta_wwm_large_ext_fix_mlm
|
{"language": ["zh"], "license": "apache-2.0", "tags": ["bert"]}
|
genggui001/chinese_roberta_wwm_large_ext_fix_mlm
| null |
[
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"zh"
] |
TAGS
#transformers #pytorch #tf #jax #safetensors #bert #fill-mask #zh #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
# Please use 'Bert' related functions to load this model!
## Chinese BERT with Whole Word Masking Fix MLM Parameters
Init parameters by URL
miss mlm parameters issue URL
Only train MLM parameters and freeze other parameters
More info in github URL
|
[
"# Please use 'Bert' related functions to load this model!",
"## Chinese BERT with Whole Word Masking Fix MLM Parameters\n\nInit parameters by URL\n\nmiss mlm parameters issue URL\n\nOnly train MLM parameters and freeze other parameters\n\nMore info in github URL"
] |
[
"TAGS\n#transformers #pytorch #tf #jax #safetensors #bert #fill-mask #zh #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"# Please use 'Bert' related functions to load this model!",
"## Chinese BERT with Whole Word Masking Fix MLM Parameters\n\nInit parameters by URL\n\nmiss mlm parameters issue URL\n\nOnly train MLM parameters and freeze other parameters\n\nMore info in github URL"
] |
automatic-speech-recognition
|
transformers
|
# xls-asr-vi-40h-1B
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on 40 hours of FPT Open Speech Dataset (FOSD) and Common Voice 7.0.
### Benchmark WER result:
| | [VIVOS](https://huggingface.co/datasets/vivos) | [COMMON VOICE 7.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0) | [COMMON VOICE 8.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0)
|---|---|---|---|
|without LM| 25.93 | 34.21 |
|with 4-grams LM| 24.11 | 25.84 | 31.158 |
### Benchmark CER result:
| | [VIVOS](https://huggingface.co/datasets/vivos) | [COMMON VOICE 7.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0) | [COMMON VOICE 8.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0)
|---|---|---|---|
|without LM| 9.24 | 19.94 |
|with 4-grams LM| 10.37 | 12.96 | 16.179 |
## Evaluation
Please use the eval.py file to run the evaluation
```python
python eval.py --model_id geninhu/xls-asr-vi-40h-1B --dataset mozilla-foundation/common_voice_7_0 --config vi --split test --log_outputs
```
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1500
- num_epochs: 10.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 4.6222 | 1.85 | 1500 | 5.9479 | 0.5474 |
| 1.1362 | 3.7 | 3000 | 7.9799 | 0.5094 |
| 0.7814 | 5.56 | 4500 | 5.0330 | 0.4724 |
| 0.6281 | 7.41 | 6000 | 2.3484 | 0.5020 |
| 0.5472 | 9.26 | 7500 | 2.2495 | 0.4793 |
| 0.4827 | 11.11 | 9000 | 1.1530 | 0.4768 |
| 0.4327 | 12.96 | 10500 | 1.6160 | 0.4646 |
| 0.3989 | 14.81 | 12000 | 3.2633 | 0.4703 |
| 0.3522 | 16.67 | 13500 | 2.2337 | 0.4708 |
| 0.3201 | 18.52 | 15000 | 3.6879 | 0.4565 |
| 0.2899 | 20.37 | 16500 | 5.4389 | 0.4599 |
| 0.2776 | 22.22 | 18000 | 3.5284 | 0.4537 |
| 0.2574 | 24.07 | 19500 | 2.1759 | 0.4649 |
| 0.2378 | 25.93 | 21000 | 3.3901 | 0.4448 |
| 0.217 | 27.78 | 22500 | 1.1632 | 0.4565 |
| 0.2115 | 29.63 | 24000 | 1.7441 | 0.4232 |
| 0.1959 | 31.48 | 25500 | 3.4992 | 0.4304 |
| 0.187 | 33.33 | 27000 | 3.6163 | 0.4369 |
| 0.1748 | 35.19 | 28500 | 3.6038 | 0.4467 |
| 0.17 | 37.04 | 30000 | 2.9708 | 0.4362 |
| 0.159 | 38.89 | 31500 | 3.2045 | 0.4279 |
| 0.153 | 40.74 | 33000 | 3.2427 | 0.4287 |
| 0.1463 | 42.59 | 34500 | 3.5439 | 0.4270 |
| 0.139 | 44.44 | 36000 | 3.9381 | 0.4150 |
| 0.1352 | 46.3 | 37500 | 4.1744 | 0.4092 |
| 0.1369 | 48.15 | 39000 | 4.2279 | 0.4154 |
| 0.1273 | 50.0 | 40500 | 4.1691 | 0.4133 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
{"language": ["vi"], "license": "apache-2.0", "tags": ["automatic-speech-recognition", "common-voice", "hf-asr-leaderboard", "robust-speech-event"], "datasets": ["mozilla-foundation/common_voice_7_0"], "model-index": [{"name": "xls-asr-vi-40h-1B", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice 7.0", "type": "mozilla-foundation/common_voice_7_0", "args": "vi"}, "metrics": [{"type": "wer", "value": 25.846, "name": "Test WER (with LM)"}, {"type": "cer", "value": 12.961, "name": "Test CER (with LM)"}]}, {"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice 8.0", "type": "mozilla-foundation/common_voice_8_0", "args": "vi"}, "metrics": [{"type": "wer", "value": 31.158, "name": "Test WER (with LM)"}, {"type": "cer", "value": 16.179, "name": "Test CER (with LM)"}]}]}]}
|
geninhu/xls-asr-vi-40h-1B
| null |
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"common-voice",
"hf-asr-leaderboard",
"robust-speech-event",
"vi",
"dataset:mozilla-foundation/common_voice_7_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"vi"
] |
TAGS
#transformers #pytorch #tensorboard #wav2vec2 #automatic-speech-recognition #common-voice #hf-asr-leaderboard #robust-speech-event #vi #dataset-mozilla-foundation/common_voice_7_0 #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
xls-asr-vi-40h-1B
=================
This model is a fine-tuned version of facebook/wav2vec2-xls-r-1b on 40 hours of FPT Open Speech Dataset (FOSD) and Common Voice 7.0.
### Benchmark WER result:
### Benchmark CER result:
Evaluation
----------
Please use the URL file to run the evaluation
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* gradient\_accumulation\_steps: 2
* total\_train\_batch\_size: 32
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 1500
* num\_epochs: 10.0
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.16.0.dev0
* Pytorch 1.10.1+cu102
* Datasets 1.17.1.dev0
* Tokenizers 0.11.0
|
[
"### Benchmark WER result:",
"### Benchmark CER result:\n\n\n\nEvaluation\n----------\n\n\nPlease use the URL file to run the evaluation\n\n\nTraining procedure\n------------------",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* gradient\\_accumulation\\_steps: 2\n* total\\_train\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 1500\n* num\\_epochs: 10.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.16.0.dev0\n* Pytorch 1.10.1+cu102\n* Datasets 1.17.1.dev0\n* Tokenizers 0.11.0"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #wav2vec2 #automatic-speech-recognition #common-voice #hf-asr-leaderboard #robust-speech-event #vi #dataset-mozilla-foundation/common_voice_7_0 #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"### Benchmark WER result:",
"### Benchmark CER result:\n\n\n\nEvaluation\n----------\n\n\nPlease use the URL file to run the evaluation\n\n\nTraining procedure\n------------------",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* gradient\\_accumulation\\_steps: 2\n* total\\_train\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 1500\n* num\\_epochs: 10.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.16.0.dev0\n* Pytorch 1.10.1+cu102\n* Datasets 1.17.1.dev0\n* Tokenizers 0.11.0"
] |
automatic-speech-recognition
|
transformers
|
# xls-asr-vi-40h
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common voice 7.0 vi & private dataset.
It achieves the following results on the evaluation set (Without Language Model):
- Loss: 1.1177
- Wer: 60.58
## Evaluation
Please run the eval.py file
```bash
!python eval_custom.py --model_id geninhu/xls-asr-vi-40h --dataset mozilla-foundation/common_voice_7_0 --config vi --split test
```
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1500
- num_epochs: 50.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 23.3878 | 0.93 | 1500 | 21.9179 | 1.0 |
| 8.8862 | 1.85 | 3000 | 6.0599 | 1.0 |
| 4.3701 | 2.78 | 4500 | 4.3837 | 1.0 |
| 4.113 | 3.7 | 6000 | 4.2698 | 0.9982 |
| 3.9666 | 4.63 | 7500 | 3.9726 | 0.9989 |
| 3.5965 | 5.56 | 9000 | 3.7124 | 0.9975 |
| 3.3944 | 6.48 | 10500 | 3.5005 | 1.0057 |
| 3.304 | 7.41 | 12000 | 3.3710 | 1.0043 |
| 3.2482 | 8.33 | 13500 | 3.4201 | 1.0155 |
| 3.212 | 9.26 | 15000 | 3.3732 | 1.0151 |
| 3.1778 | 10.19 | 16500 | 3.2763 | 1.0009 |
| 3.1027 | 11.11 | 18000 | 3.1943 | 1.0025 |
| 2.9905 | 12.04 | 19500 | 2.8082 | 0.9703 |
| 2.7095 | 12.96 | 21000 | 2.4993 | 0.9302 |
| 2.4862 | 13.89 | 22500 | 2.3072 | 0.9140 |
| 2.3271 | 14.81 | 24000 | 2.1398 | 0.8949 |
| 2.1968 | 15.74 | 25500 | 2.0594 | 0.8817 |
| 2.111 | 16.67 | 27000 | 1.9404 | 0.8630 |
| 2.0387 | 17.59 | 28500 | 1.8895 | 0.8497 |
| 1.9504 | 18.52 | 30000 | 1.7961 | 0.8315 |
| 1.9039 | 19.44 | 31500 | 1.7433 | 0.8213 |
| 1.8342 | 20.37 | 33000 | 1.6790 | 0.7994 |
| 1.7824 | 21.3 | 34500 | 1.6291 | 0.7825 |
| 1.7359 | 22.22 | 36000 | 1.5783 | 0.7706 |
| 1.7053 | 23.15 | 37500 | 1.5248 | 0.7492 |
| 1.6504 | 24.07 | 39000 | 1.4930 | 0.7406 |
| 1.6263 | 25.0 | 40500 | 1.4572 | 0.7348 |
| 1.5893 | 25.93 | 42000 | 1.4202 | 0.7161 |
| 1.5669 | 26.85 | 43500 | 1.3987 | 0.7143 |
| 1.5277 | 27.78 | 45000 | 1.3512 | 0.6991 |
| 1.501 | 28.7 | 46500 | 1.3320 | 0.6879 |
| 1.4781 | 29.63 | 48000 | 1.3112 | 0.6788 |
| 1.4477 | 30.56 | 49500 | 1.2850 | 0.6657 |
| 1.4483 | 31.48 | 51000 | 1.2813 | 0.6633 |
| 1.4065 | 32.41 | 52500 | 1.2475 | 0.6541 |
| 1.3779 | 33.33 | 54000 | 1.2244 | 0.6503 |
| 1.3788 | 34.26 | 55500 | 1.2116 | 0.6407 |
| 1.3428 | 35.19 | 57000 | 1.1938 | 0.6352 |
| 1.3453 | 36.11 | 58500 | 1.1927 | 0.6340 |
| 1.3137 | 37.04 | 60000 | 1.1699 | 0.6252 |
| 1.2984 | 37.96 | 61500 | 1.1666 | 0.6229 |
| 1.2927 | 38.89 | 63000 | 1.1585 | 0.6188 |
| 1.2919 | 39.81 | 64500 | 1.1618 | 0.6190 |
| 1.293 | 40.74 | 66000 | 1.1479 | 0.6181 |
| 1.2853 | 41.67 | 67500 | 1.1423 | 0.6202 |
| 1.2687 | 42.59 | 69000 | 1.1315 | 0.6131 |
| 1.2603 | 43.52 | 70500 | 1.1333 | 0.6128 |
| 1.2577 | 44.44 | 72000 | 1.1191 | 0.6079 |
| 1.2435 | 45.37 | 73500 | 1.1177 | 0.6079 |
| 1.251 | 46.3 | 75000 | 1.1211 | 0.6092 |
| 1.2482 | 47.22 | 76500 | 1.1177 | 0.6060 |
| 1.2422 | 48.15 | 78000 | 1.1227 | 0.6097 |
| 1.2485 | 49.07 | 79500 | 1.1187 | 0.6071 |
| 1.2425 | 50.0 | 81000 | 1.1177 | 0.6058 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
{"language": ["vi"], "license": "apache-2.0", "tags": ["automatic-speech-recognition", "common-voice", "hf-asr-leaderboard", "robust-speech-event"], "datasets": ["mozilla-foundation/common_voice_7_0"], "model-index": [{"name": "xls-asr-vi-40h", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice 7.0", "type": "mozilla-foundation/common_voice_7_0", "args": "vi"}, "metrics": [{"type": "wer", "value": 56.57, "name": "Test WER (with Language model)"}]}]}]}
|
geninhu/xls-asr-vi-40h
| null |
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"common-voice",
"hf-asr-leaderboard",
"robust-speech-event",
"vi",
"dataset:mozilla-foundation/common_voice_7_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"vi"
] |
TAGS
#transformers #pytorch #tensorboard #wav2vec2 #automatic-speech-recognition #common-voice #hf-asr-leaderboard #robust-speech-event #vi #dataset-mozilla-foundation/common_voice_7_0 #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
xls-asr-vi-40h
==============
This model is a fine-tuned version of facebook/wav2vec2-xls-r-300m on the common voice 7.0 vi & private dataset.
It achieves the following results on the evaluation set (Without Language Model):
* Loss: 1.1177
* Wer: 60.58
Evaluation
----------
Please run the URL file
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-06
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 1500
* num\_epochs: 50.0
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.16.0.dev0
* Pytorch 1.10.1+cu102
* Datasets 1.17.1.dev0
* Tokenizers 0.11.0
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-06\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 1500\n* num\\_epochs: 50.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.16.0.dev0\n* Pytorch 1.10.1+cu102\n* Datasets 1.17.1.dev0\n* Tokenizers 0.11.0"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #wav2vec2 #automatic-speech-recognition #common-voice #hf-asr-leaderboard #robust-speech-event #vi #dataset-mozilla-foundation/common_voice_7_0 #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-06\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 1500\n* num\\_epochs: 50.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.16.0.dev0\n* Pytorch 1.10.1+cu102\n* Datasets 1.17.1.dev0\n* Tokenizers 0.11.0"
] |
text-generation
|
transformers
|
# MechDistilGPT2
## Table of Contents
- [Model Details](#model-details)
- [Uses](#uses)
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
- [Training](#training)
- [Environmental Impact](#environmental-impact)
- [How to Get Started With the Model](#how-to-get-started-with-the-model)
## Model Details
- **Model Description:**
This model is fine-tuned on text scraped from 100+ Mechanical/Automotive pdf books.
- **Developed by:** [Ashwin](https://huggingface.co/geralt)
- **Model Type:** Causal Language modeling
- **Language(s):** English
- **License:** [More Information Needed]
- **Parent Model:** See the [DistilGPT2model](https://huggingface.co/distilgpt2) for more information about the Distilled-GPT2 base model.
- **Resources for more information:**
- [Research Paper](https://arxiv.org/abs/2105.09680)
- [GitHub Repo](https://github.com/huggingface/notebooks/blob/master/examples/language_modeling.ipynb)
## Uses
#### Direct Use
The model can be used for tasks including topic classification, Causal Language modeling and text generation
#### Misuse and Out-of-scope Use
The model should not be used to intentionally create hostile or alienating environments for people. In addition, the model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
## Risks, Limitations and Biases
**CONTENT WARNING: Readers should be aware this section contains content that is disturbing, offensive, and can propagate historical and current stereotypes.**
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
## Training
#### Training Data
This model is fine-tuned on text scraped from 100+ Mechanical/Automotive pdf books.
#### Training Procedure
###### Fine-Tuning
* Default Training Args
* Epochs = 3
* Training set = 200k sentences
* Validation set = 40k sentences
###### Framework versions
* Transformers 4.7.0.dev0
* Pytorch 1.8.1+cu111
* Datasets 1.6.2
* Tokenizers 0.10.2
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More information needed]
- **Hours used:** [More information needed]
- **Cloud Provider:** [More information needed]
- **Compute Region:** [More information needed"]
- **Carbon Emitted:** [More information needed]
## How to Get Started With the Model
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("geralt/MechDistilGPT2")
model = AutoModelForCausalLM.from_pretrained("geralt/MechDistilGPT2")
```
|
{"tags": ["Causal Language modeling", "text-generation", "CLM"], "model_index": [{"name": "MechDistilGPT2", "results": [{"task": {"name": "Causal Language modeling", "type": "Causal Language modeling"}}]}]}
|
geralt/MechDistilGPT2
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"Causal Language modeling",
"CLM",
"arxiv:2105.09680",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.09680",
"1910.09700"
] |
[] |
TAGS
#transformers #pytorch #gpt2 #text-generation #Causal Language modeling #CLM #arxiv-2105.09680 #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# MechDistilGPT2
## Table of Contents
- Model Details
- Uses
- Risks, Limitations and Biases
- Training
- Environmental Impact
- How to Get Started With the Model
## Model Details
- Model Description:
This model is fine-tuned on text scraped from 100+ Mechanical/Automotive pdf books.
- Developed by: Ashwin
- Model Type: Causal Language modeling
- Language(s): English
- License:
- Parent Model: See the DistilGPT2model for more information about the Distilled-GPT2 base model.
- Resources for more information:
- Research Paper
- GitHub Repo
## Uses
#### Direct Use
The model can be used for tasks including topic classification, Causal Language modeling and text generation
#### Misuse and Out-of-scope Use
The model should not be used to intentionally create hostile or alienating environments for people. In addition, the model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
## Risks, Limitations and Biases
CONTENT WARNING: Readers should be aware this section contains content that is disturbing, offensive, and can propagate historical and current stereotypes.
Significant research has explored bias and fairness issues with language models (see, e.g., Sheng et al. (2021) and Bender et al. (2021)).
## Training
#### Training Data
This model is fine-tuned on text scraped from 100+ Mechanical/Automotive pdf books.
#### Training Procedure
###### Fine-Tuning
* Default Training Args
* Epochs = 3
* Training set = 200k sentences
* Validation set = 40k sentences
###### Framework versions
* Transformers 4.7.0.dev0
* Pytorch 1.8.1+cu111
* Datasets 1.6.2
* Tokenizers 0.10.2
# Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type: [More information needed]
- Hours used: [More information needed]
- Cloud Provider: [More information needed]
- Compute Region: [More information needed"]
- Carbon Emitted: [More information needed]
## How to Get Started With the Model
|
[
"# MechDistilGPT2",
"## Table of Contents\n- Model Details \n- Uses\n- Risks, Limitations and Biases\n- Training\n- Environmental Impact\n- How to Get Started With the Model",
"## Model Details\n- Model Description: \nThis model is fine-tuned on text scraped from 100+ Mechanical/Automotive pdf books.\n\n\n- Developed by: Ashwin\n\n- Model Type: Causal Language modeling\n- Language(s): English\n- License: \n- Parent Model: See the DistilGPT2model for more information about the Distilled-GPT2 base model.\n- Resources for more information:\n - Research Paper\n - GitHub Repo",
"## Uses",
"#### Direct Use\n\nThe model can be used for tasks including topic classification, Causal Language modeling and text generation",
"#### Misuse and Out-of-scope Use\n\nThe model should not be used to intentionally create hostile or alienating environments for people. In addition, the model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.",
"## Risks, Limitations and Biases\n\nCONTENT WARNING: Readers should be aware this section contains content that is disturbing, offensive, and can propagate historical and current stereotypes.\n\nSignificant research has explored bias and fairness issues with language models (see, e.g., Sheng et al. (2021) and Bender et al. (2021)).",
"## Training",
"#### Training Data\n\nThis model is fine-tuned on text scraped from 100+ Mechanical/Automotive pdf books.",
"#### Training Procedure",
"###### Fine-Tuning\n\n* Default Training Args\n* Epochs = 3\n* Training set = 200k sentences\n* Validation set = 40k sentences",
"###### Framework versions\n\n* Transformers 4.7.0.dev0\n* Pytorch 1.8.1+cu111\n* Datasets 1.6.2\n* Tokenizers 0.10.2",
"# Environmental Impact\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: [More information needed]\n- Hours used: [More information needed]\n- Cloud Provider: [More information needed]\n- Compute Region: [More information needed\"]\n- Carbon Emitted: [More information needed]\n",
"## How to Get Started With the Model"
] |
[
"TAGS\n#transformers #pytorch #gpt2 #text-generation #Causal Language modeling #CLM #arxiv-2105.09680 #arxiv-1910.09700 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# MechDistilGPT2",
"## Table of Contents\n- Model Details \n- Uses\n- Risks, Limitations and Biases\n- Training\n- Environmental Impact\n- How to Get Started With the Model",
"## Model Details\n- Model Description: \nThis model is fine-tuned on text scraped from 100+ Mechanical/Automotive pdf books.\n\n\n- Developed by: Ashwin\n\n- Model Type: Causal Language modeling\n- Language(s): English\n- License: \n- Parent Model: See the DistilGPT2model for more information about the Distilled-GPT2 base model.\n- Resources for more information:\n - Research Paper\n - GitHub Repo",
"## Uses",
"#### Direct Use\n\nThe model can be used for tasks including topic classification, Causal Language modeling and text generation",
"#### Misuse and Out-of-scope Use\n\nThe model should not be used to intentionally create hostile or alienating environments for people. In addition, the model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.",
"## Risks, Limitations and Biases\n\nCONTENT WARNING: Readers should be aware this section contains content that is disturbing, offensive, and can propagate historical and current stereotypes.\n\nSignificant research has explored bias and fairness issues with language models (see, e.g., Sheng et al. (2021) and Bender et al. (2021)).",
"## Training",
"#### Training Data\n\nThis model is fine-tuned on text scraped from 100+ Mechanical/Automotive pdf books.",
"#### Training Procedure",
"###### Fine-Tuning\n\n* Default Training Args\n* Epochs = 3\n* Training set = 200k sentences\n* Validation set = 40k sentences",
"###### Framework versions\n\n* Transformers 4.7.0.dev0\n* Pytorch 1.8.1+cu111\n* Datasets 1.6.2\n* Tokenizers 0.10.2",
"# Environmental Impact\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n- Hardware Type: [More information needed]\n- Hours used: [More information needed]\n- Cloud Provider: [More information needed]\n- Compute Region: [More information needed\"]\n- Carbon Emitted: [More information needed]\n",
"## How to Get Started With the Model"
] |
question-answering
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# biobert_v1.1_pubmed-finetuned-squad
This model is a fine-tuned version of [gerardozq/biobert_v1.1_pubmed-finetuned-squad](https://huggingface.co/gerardozq/biobert_v1.1_pubmed-finetuned-squad) on the squad_v2 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"tags": ["generated_from_trainer"], "datasets": ["squad_v2"], "model-index": [{"name": "biobert_v1.1_pubmed-finetuned-squad", "results": []}]}
|
gerardozq/biobert_v1.1_pubmed-finetuned-squad
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad_v2",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #bert #question-answering #generated_from_trainer #dataset-squad_v2 #endpoints_compatible #region-us
|
# biobert_v1.1_pubmed-finetuned-squad
This model is a fine-tuned version of gerardozq/biobert_v1.1_pubmed-finetuned-squad on the squad_v2 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
[
"# biobert_v1.1_pubmed-finetuned-squad\n\nThis model is a fine-tuned version of gerardozq/biobert_v1.1_pubmed-finetuned-squad on the squad_v2 dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 16\n- eval_batch_size: 16\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Framework versions\n\n- Transformers 4.12.3\n- Pytorch 1.9.0+cu111\n- Datasets 1.15.1\n- Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bert #question-answering #generated_from_trainer #dataset-squad_v2 #endpoints_compatible #region-us \n",
"# biobert_v1.1_pubmed-finetuned-squad\n\nThis model is a fine-tuned version of gerardozq/biobert_v1.1_pubmed-finetuned-squad on the squad_v2 dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 16\n- eval_batch_size: 16\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 1",
"### Framework versions\n\n- Transformers 4.12.3\n- Pytorch 1.9.0+cu111\n- Datasets 1.15.1\n- Tokenizers 0.10.3"
] |
null |
transformers
|
# German Electra Uncased
<img width="300px" src="https://raw.githubusercontent.com/German-NLP-Group/german-transformer-training/master/model_cards/german-electra-logo.png">
[¹]
## Version 2 Release
We released an improved version of this model. Version 1 was trained for 766,000 steps. For this new version we continued the training for an additional 734,000 steps. It therefore follows that version 2 was trained on a total of 1,500,000 steps. See "Evaluation of Version 2: GermEval18 Coarse" below for details.
## Model Info
This Model is suitable for training on many downstream tasks in German (Q&A, Sentiment Analysis, etc.).
It can be used as a drop-in replacement for **BERT** in most down-stream tasks (**ELECTRA** is even implemented as an extended **BERT** Class).
At the time of release (August 2020) this model is the best performing publicly available German NLP model on various German evaluation metrics (CONLL03-DE, GermEval18 Coarse, GermEval18 Fine). For GermEval18 Coarse results see below. More will be published soon.
## Installation
This model has the special feature that it is **uncased** but does **not strip accents**.
This possibility was added by us with [PR #6280](https://github.com/huggingface/transformers/pull/6280).
To use it you have to use Transformers version 3.1.0 or newer.
```bash
pip install transformers -U
```
## Uncase and Umlauts ('Ö', 'Ä', 'Ü')
This model is uncased. This helps especially for domains where colloquial terms with uncorrect capitalization is often used.
The special characters 'ö', 'ü', 'ä' are included through the `strip_accent=False` option, as this leads to an improved precision.
## Creators
This model was trained and open sourced in conjunction with the [**German NLP Group**](https://github.com/German-NLP-Group) in equal parts by:
- [**Philip May**](https://May.la) - [Deutsche Telekom](https://www.telekom.de/)
- [**Philipp Reißel**](https://www.linkedin.com/in/philipp-reissel/) - [ambeRoad](https://amberoad.de/)
## Evaluation of Version 2: GermEval18 Coarse
We evaluated all language models on GermEval18 with the F1 macro score. For each model we did an extensive automated hyperparameter search. With the best hyperparmeters we did fit the moodel multiple times on GermEval18. This is done to cancel random effects and get results of statistical relevance.
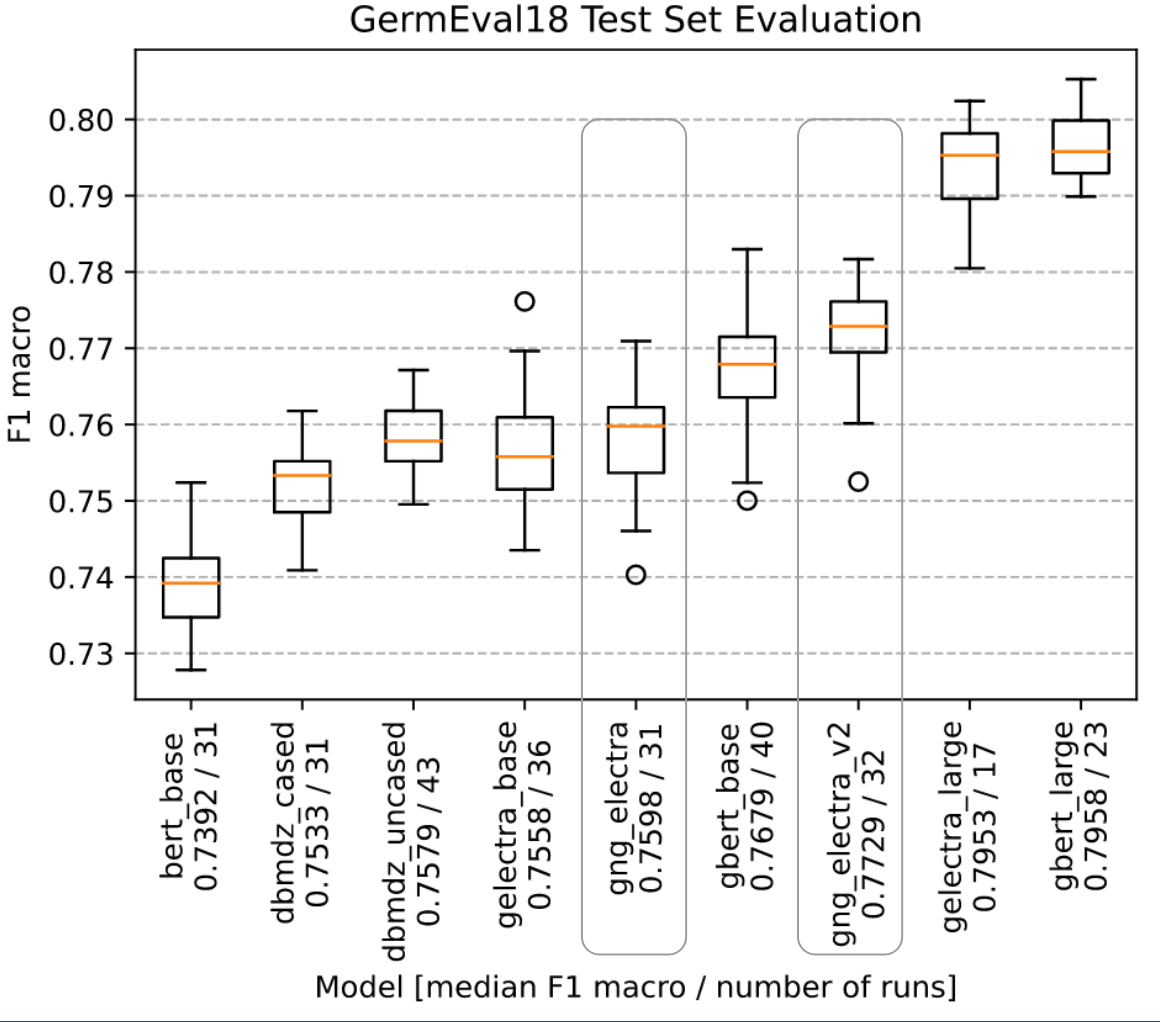
## Checkpoint evaluation
Since it it not guaranteed that the last checkpoint is the best, we evaluated the checkpoints on GermEval18. We found that the last checkpoint is indeed the best. The training was stable and did not overfit the text corpus.
## Pre-training details
### Data
- Cleaned Common Crawl Corpus 2019-09 German: [CC_net](https://github.com/facebookresearch/cc_net) (Only head coprus and filtered for language_score > 0.98) - 62 GB
- German Wikipedia Article Pages Dump (20200701) - 5.5 GB
- German Wikipedia Talk Pages Dump (20200620) - 1.1 GB
- Subtitles - 823 MB
- News 2018 - 4.1 GB
The sentences were split with [SojaMo](https://github.com/tsproisl/SoMaJo). We took the German Wikipedia Article Pages Dump 3x to oversample. This approach was also used in a similar way in GPT-3 (Table 2.2).
More Details can be found here [Preperaing Datasets for German Electra Github](https://github.com/German-NLP-Group/german-transformer-training)
### Electra Branch no_strip_accents
Because we do not want to stip accents in our training data we made a change to Electra and used this repo [Electra no_strip_accents](https://github.com/PhilipMay/electra/tree/no_strip_accents) (branch `no_strip_accents`). Then created the tf dataset with:
```bash
python build_pretraining_dataset.py --corpus-dir <corpus_dir> --vocab-file <dir>/vocab.txt --output-dir ./tf_data --max-seq-length 512 --num-processes 8 --do-lower-case --no-strip-accents
```
### The training
The training itself can be performed with the Original Electra Repo (No special case for this needed).
We run it with the following Config:
<details>
<summary>The exact Training Config</summary>
<br/>debug False
<br/>disallow_correct False
<br/>disc_weight 50.0
<br/>do_eval False
<br/>do_lower_case True
<br/>do_train True
<br/>electra_objective True
<br/>embedding_size 768
<br/>eval_batch_size 128
<br/>gcp_project None
<br/>gen_weight 1.0
<br/>generator_hidden_size 0.33333
<br/>generator_layers 1.0
<br/>iterations_per_loop 200
<br/>keep_checkpoint_max 0
<br/>learning_rate 0.0002
<br/>lr_decay_power 1.0
<br/>mask_prob 0.15
<br/>max_predictions_per_seq 79
<br/>max_seq_length 512
<br/>model_dir gs://XXX
<br/>model_hparam_overrides {}
<br/>model_name 02_Electra_Checkpoints_32k_766k_Combined
<br/>model_size base
<br/>num_eval_steps 100
<br/>num_tpu_cores 8
<br/>num_train_steps 766000
<br/>num_warmup_steps 10000
<br/>pretrain_tfrecords gs://XXX
<br/>results_pkl gs://XXX
<br/>results_txt gs://XXX
<br/>save_checkpoints_steps 5000
<br/>temperature 1.0
<br/>tpu_job_name None
<br/>tpu_name electrav5
<br/>tpu_zone None
<br/>train_batch_size 256
<br/>uniform_generator False
<br/>untied_generator True
<br/>untied_generator_embeddings False
<br/>use_tpu True
<br/>vocab_file gs://XXX
<br/>vocab_size 32767
<br/>weight_decay_rate 0.01
</details>
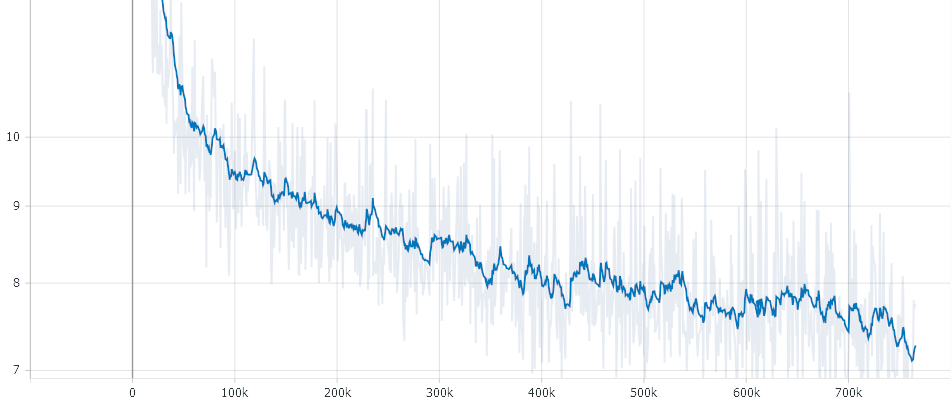
Please Note: *Due to the GAN like strucutre of Electra the loss is not that meaningful*
It took about 7 Days on a preemtible TPU V3-8. In total, the Model went through approximately 10 Epochs. For an automatically recreation of a cancelled TPUs we used [tpunicorn](https://github.com/shawwn/tpunicorn). The total cost of training summed up to about 450 $ for one run. The Data-pre processing and Vocab Creation needed approximately 500-1000 CPU hours. Servers were fully provided by [T-Systems on site services GmbH](https://www.t-systems-onsite.de/), [ambeRoad](https://amberoad.de/).
Special thanks to [Stefan Schweter](https://github.com/stefan-it) for your feedback and providing parts of the text corpus.
[¹]: Source for the picture [Pinterest](https://www.pinterest.cl/pin/371828512984142193/)
### Negative Results
We tried the following approaches which we found had no positive influence:
- **Increased Vocab Size**: Leads to more parameters and thus reduced examples/sec while no visible Performance gains were measured
- **Decreased Batch-Size**: The original Electra was trained with a Batch Size per TPU Core of 16 whereas this Model was trained with 32 BS / TPU Core. We found out that 32 BS leads to better results when you compare metrics over computation time
## License - The MIT License
Copyright 2020-2021 Philip May<br>
Copyright 2020-2021 Philipp Reissel
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
{"language": "de", "license": "mit", "tags": ["electra", "commoncrawl", "uncased", "umlaute", "umlauts", "german", "deutsch"], "thumbnail": "https://raw.githubusercontent.com/German-NLP-Group/german-transformer-training/master/model_cards/german-electra-logo.png"}
|
german-nlp-group/electra-base-german-uncased
| null |
[
"transformers",
"pytorch",
"electra",
"pretraining",
"commoncrawl",
"uncased",
"umlaute",
"umlauts",
"german",
"deutsch",
"de",
"license:mit",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"de"
] |
TAGS
#transformers #pytorch #electra #pretraining #commoncrawl #uncased #umlaute #umlauts #german #deutsch #de #license-mit #endpoints_compatible #region-us
|
# German Electra Uncased
<img width="300px" src="URL
[¹]
## Version 2 Release
We released an improved version of this model. Version 1 was trained for 766,000 steps. For this new version we continued the training for an additional 734,000 steps. It therefore follows that version 2 was trained on a total of 1,500,000 steps. See "Evaluation of Version 2: GermEval18 Coarse" below for details.
## Model Info
This Model is suitable for training on many downstream tasks in German (Q&A, Sentiment Analysis, etc.).
It can be used as a drop-in replacement for BERT in most down-stream tasks (ELECTRA is even implemented as an extended BERT Class).
At the time of release (August 2020) this model is the best performing publicly available German NLP model on various German evaluation metrics (CONLL03-DE, GermEval18 Coarse, GermEval18 Fine). For GermEval18 Coarse results see below. More will be published soon.
## Installation
This model has the special feature that it is uncased but does not strip accents.
This possibility was added by us with PR #6280.
To use it you have to use Transformers version 3.1.0 or newer.
## Uncase and Umlauts ('Ö', 'Ä', 'Ü')
This model is uncased. This helps especially for domains where colloquial terms with uncorrect capitalization is often used.
The special characters 'ö', 'ü', 'ä' are included through the 'strip_accent=False' option, as this leads to an improved precision.
## Creators
This model was trained and open sourced in conjunction with the German NLP Group in equal parts by:
- Philip May - Deutsche Telekom
- Philipp Reißel - ambeRoad
## Evaluation of Version 2: GermEval18 Coarse
We evaluated all language models on GermEval18 with the F1 macro score. For each model we did an extensive automated hyperparameter search. With the best hyperparmeters we did fit the moodel multiple times on GermEval18. This is done to cancel random effects and get results of statistical relevance.
!GermEval18 Coarse Model Evaluation for Version 2
## Checkpoint evaluation
Since it it not guaranteed that the last checkpoint is the best, we evaluated the checkpoints on GermEval18. We found that the last checkpoint is indeed the best. The training was stable and did not overfit the text corpus.
## Pre-training details
### Data
- Cleaned Common Crawl Corpus 2019-09 German: CC_net (Only head coprus and filtered for language_score > 0.98) - 62 GB
- German Wikipedia Article Pages Dump (20200701) - 5.5 GB
- German Wikipedia Talk Pages Dump (20200620) - 1.1 GB
- Subtitles - 823 MB
- News 2018 - 4.1 GB
The sentences were split with SojaMo. We took the German Wikipedia Article Pages Dump 3x to oversample. This approach was also used in a similar way in GPT-3 (Table 2.2).
More Details can be found here Preperaing Datasets for German Electra Github
### Electra Branch no_strip_accents
Because we do not want to stip accents in our training data we made a change to Electra and used this repo Electra no_strip_accents (branch 'no_strip_accents'). Then created the tf dataset with:
### The training
The training itself can be performed with the Original Electra Repo (No special case for this needed).
We run it with the following Config:
<details>
<summary>The exact Training Config</summary>
<br/>debug False
<br/>disallow_correct False
<br/>disc_weight 50.0
<br/>do_eval False
<br/>do_lower_case True
<br/>do_train True
<br/>electra_objective True
<br/>embedding_size 768
<br/>eval_batch_size 128
<br/>gcp_project None
<br/>gen_weight 1.0
<br/>generator_hidden_size 0.33333
<br/>generator_layers 1.0
<br/>iterations_per_loop 200
<br/>keep_checkpoint_max 0
<br/>learning_rate 0.0002
<br/>lr_decay_power 1.0
<br/>mask_prob 0.15
<br/>max_predictions_per_seq 79
<br/>max_seq_length 512
<br/>model_dir gs://XXX
<br/>model_hparam_overrides {}
<br/>model_name 02_Electra_Checkpoints_32k_766k_Combined
<br/>model_size base
<br/>num_eval_steps 100
<br/>num_tpu_cores 8
<br/>num_train_steps 766000
<br/>num_warmup_steps 10000
<br/>pretrain_tfrecords gs://XXX
<br/>results_pkl gs://XXX
<br/>results_txt gs://XXX
<br/>save_checkpoints_steps 5000
<br/>temperature 1.0
<br/>tpu_job_name None
<br/>tpu_name electrav5
<br/>tpu_zone None
<br/>train_batch_size 256
<br/>uniform_generator False
<br/>untied_generator True
<br/>untied_generator_embeddings False
<br/>use_tpu True
<br/>vocab_file gs://XXX
<br/>vocab_size 32767
<br/>weight_decay_rate 0.01
</details>
!Training Loss
Please Note: *Due to the GAN like strucutre of Electra the loss is not that meaningful*
It took about 7 Days on a preemtible TPU V3-8. In total, the Model went through approximately 10 Epochs. For an automatically recreation of a cancelled TPUs we used tpunicorn. The total cost of training summed up to about 450 $ for one run. The Data-pre processing and Vocab Creation needed approximately 500-1000 CPU hours. Servers were fully provided by T-Systems on site services GmbH, ambeRoad.
Special thanks to Stefan Schweter for your feedback and providing parts of the text corpus.
[¹]: Source for the picture Pinterest
### Negative Results
We tried the following approaches which we found had no positive influence:
- Increased Vocab Size: Leads to more parameters and thus reduced examples/sec while no visible Performance gains were measured
- Decreased Batch-Size: The original Electra was trained with a Batch Size per TPU Core of 16 whereas this Model was trained with 32 BS / TPU Core. We found out that 32 BS leads to better results when you compare metrics over computation time
## License - The MIT License
Copyright 2020-2021 Philip May<br>
Copyright 2020-2021 Philipp Reissel
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
[
"# German Electra Uncased\n<img width=\"300px\" src=\"URL\n[¹]",
"## Version 2 Release\nWe released an improved version of this model. Version 1 was trained for 766,000 steps. For this new version we continued the training for an additional 734,000 steps. It therefore follows that version 2 was trained on a total of 1,500,000 steps. See \"Evaluation of Version 2: GermEval18 Coarse\" below for details.",
"## Model Info\nThis Model is suitable for training on many downstream tasks in German (Q&A, Sentiment Analysis, etc.).\n\nIt can be used as a drop-in replacement for BERT in most down-stream tasks (ELECTRA is even implemented as an extended BERT Class).\n\nAt the time of release (August 2020) this model is the best performing publicly available German NLP model on various German evaluation metrics (CONLL03-DE, GermEval18 Coarse, GermEval18 Fine). For GermEval18 Coarse results see below. More will be published soon.",
"## Installation\nThis model has the special feature that it is uncased but does not strip accents.\nThis possibility was added by us with PR #6280.\nTo use it you have to use Transformers version 3.1.0 or newer.",
"## Uncase and Umlauts ('Ö', 'Ä', 'Ü')\nThis model is uncased. This helps especially for domains where colloquial terms with uncorrect capitalization is often used.\n\nThe special characters 'ö', 'ü', 'ä' are included through the 'strip_accent=False' option, as this leads to an improved precision.",
"## Creators\nThis model was trained and open sourced in conjunction with the German NLP Group in equal parts by:\n- Philip May - Deutsche Telekom\n- Philipp Reißel - ambeRoad",
"## Evaluation of Version 2: GermEval18 Coarse\nWe evaluated all language models on GermEval18 with the F1 macro score. For each model we did an extensive automated hyperparameter search. With the best hyperparmeters we did fit the moodel multiple times on GermEval18. This is done to cancel random effects and get results of statistical relevance.\n\n!GermEval18 Coarse Model Evaluation for Version 2",
"## Checkpoint evaluation\nSince it it not guaranteed that the last checkpoint is the best, we evaluated the checkpoints on GermEval18. We found that the last checkpoint is indeed the best. The training was stable and did not overfit the text corpus.",
"## Pre-training details",
"### Data\n- Cleaned Common Crawl Corpus 2019-09 German: CC_net (Only head coprus and filtered for language_score > 0.98) - 62 GB\n- German Wikipedia Article Pages Dump (20200701) - 5.5 GB\n- German Wikipedia Talk Pages Dump (20200620) - 1.1 GB\n- Subtitles - 823 MB\n- News 2018 - 4.1 GB\n\nThe sentences were split with SojaMo. We took the German Wikipedia Article Pages Dump 3x to oversample. This approach was also used in a similar way in GPT-3 (Table 2.2).\n\nMore Details can be found here Preperaing Datasets for German Electra Github",
"### Electra Branch no_strip_accents\nBecause we do not want to stip accents in our training data we made a change to Electra and used this repo Electra no_strip_accents (branch 'no_strip_accents'). Then created the tf dataset with:",
"### The training\nThe training itself can be performed with the Original Electra Repo (No special case for this needed).\nWe run it with the following Config:\n\n<details>\n<summary>The exact Training Config</summary>\n<br/>debug False\n<br/>disallow_correct False\n<br/>disc_weight 50.0\n<br/>do_eval False\n<br/>do_lower_case True\n<br/>do_train True\n<br/>electra_objective True\n<br/>embedding_size 768\n<br/>eval_batch_size 128\n<br/>gcp_project None\n<br/>gen_weight 1.0\n<br/>generator_hidden_size 0.33333\n<br/>generator_layers 1.0\n<br/>iterations_per_loop 200\n<br/>keep_checkpoint_max 0\n<br/>learning_rate 0.0002\n<br/>lr_decay_power 1.0\n<br/>mask_prob 0.15\n<br/>max_predictions_per_seq 79\n<br/>max_seq_length 512\n<br/>model_dir gs://XXX\n<br/>model_hparam_overrides {}\n<br/>model_name 02_Electra_Checkpoints_32k_766k_Combined\n<br/>model_size base\n<br/>num_eval_steps 100\n<br/>num_tpu_cores 8\n<br/>num_train_steps 766000\n<br/>num_warmup_steps 10000\n<br/>pretrain_tfrecords gs://XXX\n<br/>results_pkl gs://XXX\n<br/>results_txt gs://XXX\n<br/>save_checkpoints_steps 5000\n<br/>temperature 1.0\n<br/>tpu_job_name None\n<br/>tpu_name electrav5\n<br/>tpu_zone None\n<br/>train_batch_size 256\n<br/>uniform_generator False\n<br/>untied_generator True\n<br/>untied_generator_embeddings False\n<br/>use_tpu True\n<br/>vocab_file gs://XXX\n<br/>vocab_size 32767\n<br/>weight_decay_rate 0.01\n </details>\n\n!Training Loss\n\nPlease Note: *Due to the GAN like strucutre of Electra the loss is not that meaningful*\n\nIt took about 7 Days on a preemtible TPU V3-8. In total, the Model went through approximately 10 Epochs. For an automatically recreation of a cancelled TPUs we used tpunicorn. The total cost of training summed up to about 450 $ for one run. The Data-pre processing and Vocab Creation needed approximately 500-1000 CPU hours. Servers were fully provided by T-Systems on site services GmbH, ambeRoad.\nSpecial thanks to Stefan Schweter for your feedback and providing parts of the text corpus.\n\n[¹]: Source for the picture Pinterest",
"### Negative Results\nWe tried the following approaches which we found had no positive influence:\n\n- Increased Vocab Size: Leads to more parameters and thus reduced examples/sec while no visible Performance gains were measured\n- Decreased Batch-Size: The original Electra was trained with a Batch Size per TPU Core of 16 whereas this Model was trained with 32 BS / TPU Core. We found out that 32 BS leads to better results when you compare metrics over computation time",
"## License - The MIT License\nCopyright 2020-2021 Philip May<br>\nCopyright 2020-2021 Philipp Reissel\n\nPermission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the \"Software\"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE."
] |
[
"TAGS\n#transformers #pytorch #electra #pretraining #commoncrawl #uncased #umlaute #umlauts #german #deutsch #de #license-mit #endpoints_compatible #region-us \n",
"# German Electra Uncased\n<img width=\"300px\" src=\"URL\n[¹]",
"## Version 2 Release\nWe released an improved version of this model. Version 1 was trained for 766,000 steps. For this new version we continued the training for an additional 734,000 steps. It therefore follows that version 2 was trained on a total of 1,500,000 steps. See \"Evaluation of Version 2: GermEval18 Coarse\" below for details.",
"## Model Info\nThis Model is suitable for training on many downstream tasks in German (Q&A, Sentiment Analysis, etc.).\n\nIt can be used as a drop-in replacement for BERT in most down-stream tasks (ELECTRA is even implemented as an extended BERT Class).\n\nAt the time of release (August 2020) this model is the best performing publicly available German NLP model on various German evaluation metrics (CONLL03-DE, GermEval18 Coarse, GermEval18 Fine). For GermEval18 Coarse results see below. More will be published soon.",
"## Installation\nThis model has the special feature that it is uncased but does not strip accents.\nThis possibility was added by us with PR #6280.\nTo use it you have to use Transformers version 3.1.0 or newer.",
"## Uncase and Umlauts ('Ö', 'Ä', 'Ü')\nThis model is uncased. This helps especially for domains where colloquial terms with uncorrect capitalization is often used.\n\nThe special characters 'ö', 'ü', 'ä' are included through the 'strip_accent=False' option, as this leads to an improved precision.",
"## Creators\nThis model was trained and open sourced in conjunction with the German NLP Group in equal parts by:\n- Philip May - Deutsche Telekom\n- Philipp Reißel - ambeRoad",
"## Evaluation of Version 2: GermEval18 Coarse\nWe evaluated all language models on GermEval18 with the F1 macro score. For each model we did an extensive automated hyperparameter search. With the best hyperparmeters we did fit the moodel multiple times on GermEval18. This is done to cancel random effects and get results of statistical relevance.\n\n!GermEval18 Coarse Model Evaluation for Version 2",
"## Checkpoint evaluation\nSince it it not guaranteed that the last checkpoint is the best, we evaluated the checkpoints on GermEval18. We found that the last checkpoint is indeed the best. The training was stable and did not overfit the text corpus.",
"## Pre-training details",
"### Data\n- Cleaned Common Crawl Corpus 2019-09 German: CC_net (Only head coprus and filtered for language_score > 0.98) - 62 GB\n- German Wikipedia Article Pages Dump (20200701) - 5.5 GB\n- German Wikipedia Talk Pages Dump (20200620) - 1.1 GB\n- Subtitles - 823 MB\n- News 2018 - 4.1 GB\n\nThe sentences were split with SojaMo. We took the German Wikipedia Article Pages Dump 3x to oversample. This approach was also used in a similar way in GPT-3 (Table 2.2).\n\nMore Details can be found here Preperaing Datasets for German Electra Github",
"### Electra Branch no_strip_accents\nBecause we do not want to stip accents in our training data we made a change to Electra and used this repo Electra no_strip_accents (branch 'no_strip_accents'). Then created the tf dataset with:",
"### The training\nThe training itself can be performed with the Original Electra Repo (No special case for this needed).\nWe run it with the following Config:\n\n<details>\n<summary>The exact Training Config</summary>\n<br/>debug False\n<br/>disallow_correct False\n<br/>disc_weight 50.0\n<br/>do_eval False\n<br/>do_lower_case True\n<br/>do_train True\n<br/>electra_objective True\n<br/>embedding_size 768\n<br/>eval_batch_size 128\n<br/>gcp_project None\n<br/>gen_weight 1.0\n<br/>generator_hidden_size 0.33333\n<br/>generator_layers 1.0\n<br/>iterations_per_loop 200\n<br/>keep_checkpoint_max 0\n<br/>learning_rate 0.0002\n<br/>lr_decay_power 1.0\n<br/>mask_prob 0.15\n<br/>max_predictions_per_seq 79\n<br/>max_seq_length 512\n<br/>model_dir gs://XXX\n<br/>model_hparam_overrides {}\n<br/>model_name 02_Electra_Checkpoints_32k_766k_Combined\n<br/>model_size base\n<br/>num_eval_steps 100\n<br/>num_tpu_cores 8\n<br/>num_train_steps 766000\n<br/>num_warmup_steps 10000\n<br/>pretrain_tfrecords gs://XXX\n<br/>results_pkl gs://XXX\n<br/>results_txt gs://XXX\n<br/>save_checkpoints_steps 5000\n<br/>temperature 1.0\n<br/>tpu_job_name None\n<br/>tpu_name electrav5\n<br/>tpu_zone None\n<br/>train_batch_size 256\n<br/>uniform_generator False\n<br/>untied_generator True\n<br/>untied_generator_embeddings False\n<br/>use_tpu True\n<br/>vocab_file gs://XXX\n<br/>vocab_size 32767\n<br/>weight_decay_rate 0.01\n </details>\n\n!Training Loss\n\nPlease Note: *Due to the GAN like strucutre of Electra the loss is not that meaningful*\n\nIt took about 7 Days on a preemtible TPU V3-8. In total, the Model went through approximately 10 Epochs. For an automatically recreation of a cancelled TPUs we used tpunicorn. The total cost of training summed up to about 450 $ for one run. The Data-pre processing and Vocab Creation needed approximately 500-1000 CPU hours. Servers were fully provided by T-Systems on site services GmbH, ambeRoad.\nSpecial thanks to Stefan Schweter for your feedback and providing parts of the text corpus.\n\n[¹]: Source for the picture Pinterest",
"### Negative Results\nWe tried the following approaches which we found had no positive influence:\n\n- Increased Vocab Size: Leads to more parameters and thus reduced examples/sec while no visible Performance gains were measured\n- Decreased Batch-Size: The original Electra was trained with a Batch Size per TPU Core of 16 whereas this Model was trained with 32 BS / TPU Core. We found out that 32 BS leads to better results when you compare metrics over computation time",
"## License - The MIT License\nCopyright 2020-2021 Philip May<br>\nCopyright 2020-2021 Philipp Reissel\n\nPermission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the \"Software\"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE."
] |
fill-mask
|
transformers
|
# SlovakBERT (base-sized model)
SlovakBERT pretrained model on Slovak language using a masked language modeling (MLM) objective. This model is case-sensitive: it makes a difference between slovensko and Slovensko.
## Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task.
**IMPORTANT**: The model was not trained on the “ and ” (direct quote) character -> so before tokenizing the text, it is advised to replace all “ and ” (direct quote marks) with a single "(double quote marks).
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
from transformers import pipeline
unmasker = pipeline('fill-mask', model='gerulata/slovakbert')
unmasker("Deti sa <mask> na ihrisku.")
[{'sequence': 'Deti sa hrali na ihrisku.',
'score': 0.6355380415916443,
'token': 5949,
'token_str': ' hrali'},
{'sequence': 'Deti sa hrajú na ihrisku.',
'score': 0.14731724560260773,
'token': 9081,
'token_str': ' hrajú'},
{'sequence': 'Deti sa zahrali na ihrisku.',
'score': 0.05016357824206352,
'token': 32553,
'token_str': ' zahrali'},
{'sequence': 'Deti sa stretli na ihrisku.',
'score': 0.041727423667907715,
'token': 5964,
'token_str': ' stretli'},
{'sequence': 'Deti sa učia na ihrisku.',
'score': 0.01886524073779583,
'token': 18099,
'token_str': ' učia'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import RobertaTokenizer, RobertaModel
tokenizer = RobertaTokenizer.from_pretrained('gerulata/slovakbert')
model = RobertaModel.from_pretrained('gerulata/slovakbert')
text = "Text ktorý sa má embedovať."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import RobertaTokenizer, TFRobertaModel
tokenizer = RobertaTokenizer.from_pretrained('gerulata/slovakbert')
model = TFRobertaModel.from_pretrained('gerulata/slovakbert')
text = "Text ktorý sa má embedovať."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
Or extract information from the model like this:
```python
from transformers import pipeline
unmasker = pipeline('fill-mask', model='gerulata/slovakbert')
unmasker("Slovenské národne povstanie sa uskutočnilo v roku <mask>.")
[{'sequence': 'Slovenske narodne povstanie sa uskutočnilo v roku 1944.',
'score': 0.7383289933204651,
'token': 16621,
'token_str': ' 1944'},...]
```
# Training data
The SlovakBERT model was pretrained on these datasets:
- Wikipedia (326MB of text),
- OpenSubtitles (415MB of text),
- Oscar (4.6GB of text),
- Gerulata WebCrawl (12.7GB of text) ,
- Gerulata Monitoring (214 MB of text),
- blbec.online (4.5GB of text)
The text was then processed with the following steps:
- URL and email addresses were replaced with special tokens ("url", "email").
- Elongated interpunction was reduced (e.g. -- to -).
- Markdown syntax was deleted.
- All text content in braces f.g was eliminated to reduce the amount of markup and programming language text.
We segmented the resulting corpus into sentences and removed duplicates to get 181.6M unique sentences. In total, the final corpus has 19.35GB of text.
# Pretraining
The model was trained in **fairseq** on 4 x Nvidia A100 GPUs for 300K steps with a batch size of 512 and a sequence length of 512. The optimizer used is Adam with a learning rate of 5e-4, \\(\beta_{1} = 0.9\\), \\(\beta_{2} = 0.98\\) and \\(\epsilon = 1e-6\\), a weight decay of 0.01, dropout rate 0.1, learning rate warmup for 10k steps and linear decay of the learning rate after. We used 16-bit float precision.
## About us
<a href="https://www.gerulata.com/">
<img width="300px" src="https://www.gerulata.com/assets/images/Logo_Blue.svg">
</a>
Gerulata Technologies is a tech company on a mission to provide tools for fighting disinformation and hostile propaganda.
At Gerulata, we focus on providing state-of-the-art AI-powered tools that empower human analysts and provide them with the ability to make informed decisions.
Our tools allow for the monitoring and analysis of online activity, as well as the detection and tracking of disinformation and hostile propaganda campaigns. With our products, our clients are better equipped to identify and respond to threats in real-time.
### BibTeX entry and citation info
If you find our resource or paper is useful, please consider including the following citation in your paper.
- https://arxiv.org/abs/2109.15254
```
@misc{pikuliak2021slovakbert,
title={SlovakBERT: Slovak Masked Language Model},
author={Matúš Pikuliak and Štefan Grivalský and Martin Konôpka and Miroslav Blšták and Martin Tamajka and Viktor Bachratý and Marián Šimko and Pavol Balážik and Michal Trnka and Filip Uhlárik},
year={2021},
eprint={2109.15254},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
{"language": "sk", "license": "mit", "tags": ["SlovakBERT"], "datasets": ["wikipedia", "opensubtitles", "oscar", "gerulatawebcrawl", "gerulatamonitoring", "blbec.online"]}
|
gerulata/slovakbert
| null |
[
"transformers",
"pytorch",
"tf",
"safetensors",
"roberta",
"fill-mask",
"SlovakBERT",
"sk",
"dataset:wikipedia",
"dataset:opensubtitles",
"dataset:oscar",
"dataset:gerulatawebcrawl",
"dataset:gerulatamonitoring",
"dataset:blbec.online",
"arxiv:2109.15254",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2109.15254"
] |
[
"sk"
] |
TAGS
#transformers #pytorch #tf #safetensors #roberta #fill-mask #SlovakBERT #sk #dataset-wikipedia #dataset-opensubtitles #dataset-oscar #dataset-gerulatawebcrawl #dataset-gerulatamonitoring #dataset-blbec.online #arxiv-2109.15254 #license-mit #autotrain_compatible #endpoints_compatible #has_space #region-us
|
# SlovakBERT (base-sized model)
SlovakBERT pretrained model on Slovak language using a masked language modeling (MLM) objective. This model is case-sensitive: it makes a difference between slovensko and Slovensko.
## Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task.
IMPORTANT: The model was not trained on the “ and ” (direct quote) character -> so before tokenizing the text, it is advised to replace all “ and ” (direct quote marks) with a single "(double quote marks).
### How to use
You can use this model directly with a pipeline for masked language modeling:
Here is how to use this model to get the features of a given text in PyTorch:
and in TensorFlow:
Or extract information from the model like this:
# Training data
The SlovakBERT model was pretrained on these datasets:
- Wikipedia (326MB of text),
- OpenSubtitles (415MB of text),
- Oscar (4.6GB of text),
- Gerulata WebCrawl (12.7GB of text) ,
- Gerulata Monitoring (214 MB of text),
- URL (4.5GB of text)
The text was then processed with the following steps:
- URL and email addresses were replaced with special tokens ("url", "email").
- Elongated interpunction was reduced (e.g. -- to -).
- Markdown syntax was deleted.
- All text content in braces f.g was eliminated to reduce the amount of markup and programming language text.
We segmented the resulting corpus into sentences and removed duplicates to get 181.6M unique sentences. In total, the final corpus has 19.35GB of text.
# Pretraining
The model was trained in fairseq on 4 x Nvidia A100 GPUs for 300K steps with a batch size of 512 and a sequence length of 512. The optimizer used is Adam with a learning rate of 5e-4, \\(\beta_{1} = 0.9\\), \\(\beta_{2} = 0.98\\) and \\(\epsilon = 1e-6\\), a weight decay of 0.01, dropout rate 0.1, learning rate warmup for 10k steps and linear decay of the learning rate after. We used 16-bit float precision.
## About us
<a href="URL
<img width="300px" src="URL
</a>
Gerulata Technologies is a tech company on a mission to provide tools for fighting disinformation and hostile propaganda.
At Gerulata, we focus on providing state-of-the-art AI-powered tools that empower human analysts and provide them with the ability to make informed decisions.
Our tools allow for the monitoring and analysis of online activity, as well as the detection and tracking of disinformation and hostile propaganda campaigns. With our products, our clients are better equipped to identify and respond to threats in real-time.
### BibTeX entry and citation info
If you find our resource or paper is useful, please consider including the following citation in your paper.
- URL
|
[
"# SlovakBERT (base-sized model)\nSlovakBERT pretrained model on Slovak language using a masked language modeling (MLM) objective. This model is case-sensitive: it makes a difference between slovensko and Slovensko.",
"## Intended uses & limitations\nYou can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task.\nIMPORTANT: The model was not trained on the “ and ” (direct quote) character -> so before tokenizing the text, it is advised to replace all “ and ” (direct quote marks) with a single \"(double quote marks).",
"### How to use\nYou can use this model directly with a pipeline for masked language modeling:\n\n\n\nHere is how to use this model to get the features of a given text in PyTorch:\n\nand in TensorFlow:\n\nOr extract information from the model like this:",
"# Training data\nThe SlovakBERT model was pretrained on these datasets:\n\n- Wikipedia (326MB of text),\n- OpenSubtitles (415MB of text),\n- Oscar (4.6GB of text),\n- Gerulata WebCrawl (12.7GB of text) ,\n- Gerulata Monitoring (214 MB of text),\n- URL (4.5GB of text)\n\nThe text was then processed with the following steps:\n- URL and email addresses were replaced with special tokens (\"url\", \"email\").\n- Elongated interpunction was reduced (e.g. -- to -).\n- Markdown syntax was deleted.\n- All text content in braces f.g was eliminated to reduce the amount of markup and programming language text.\n\nWe segmented the resulting corpus into sentences and removed duplicates to get 181.6M unique sentences. In total, the final corpus has 19.35GB of text.",
"# Pretraining\nThe model was trained in fairseq on 4 x Nvidia A100 GPUs for 300K steps with a batch size of 512 and a sequence length of 512. The optimizer used is Adam with a learning rate of 5e-4, \\\\(\\beta_{1} = 0.9\\\\), \\\\(\\beta_{2} = 0.98\\\\) and \\\\(\\epsilon = 1e-6\\\\), a weight decay of 0.01, dropout rate 0.1, learning rate warmup for 10k steps and linear decay of the learning rate after. We used 16-bit float precision.",
"## About us\n<a href=\"URL\n\t<img width=\"300px\" src=\"URL\n</a>\n\nGerulata Technologies is a tech company on a mission to provide tools for fighting disinformation and hostile propaganda.\n\nAt Gerulata, we focus on providing state-of-the-art AI-powered tools that empower human analysts and provide them with the ability to make informed decisions. \n\nOur tools allow for the monitoring and analysis of online activity, as well as the detection and tracking of disinformation and hostile propaganda campaigns. With our products, our clients are better equipped to identify and respond to threats in real-time.",
"### BibTeX entry and citation info\nIf you find our resource or paper is useful, please consider including the following citation in your paper.\n- URL"
] |
[
"TAGS\n#transformers #pytorch #tf #safetensors #roberta #fill-mask #SlovakBERT #sk #dataset-wikipedia #dataset-opensubtitles #dataset-oscar #dataset-gerulatawebcrawl #dataset-gerulatamonitoring #dataset-blbec.online #arxiv-2109.15254 #license-mit #autotrain_compatible #endpoints_compatible #has_space #region-us \n",
"# SlovakBERT (base-sized model)\nSlovakBERT pretrained model on Slovak language using a masked language modeling (MLM) objective. This model is case-sensitive: it makes a difference between slovensko and Slovensko.",
"## Intended uses & limitations\nYou can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task.\nIMPORTANT: The model was not trained on the “ and ” (direct quote) character -> so before tokenizing the text, it is advised to replace all “ and ” (direct quote marks) with a single \"(double quote marks).",
"### How to use\nYou can use this model directly with a pipeline for masked language modeling:\n\n\n\nHere is how to use this model to get the features of a given text in PyTorch:\n\nand in TensorFlow:\n\nOr extract information from the model like this:",
"# Training data\nThe SlovakBERT model was pretrained on these datasets:\n\n- Wikipedia (326MB of text),\n- OpenSubtitles (415MB of text),\n- Oscar (4.6GB of text),\n- Gerulata WebCrawl (12.7GB of text) ,\n- Gerulata Monitoring (214 MB of text),\n- URL (4.5GB of text)\n\nThe text was then processed with the following steps:\n- URL and email addresses were replaced with special tokens (\"url\", \"email\").\n- Elongated interpunction was reduced (e.g. -- to -).\n- Markdown syntax was deleted.\n- All text content in braces f.g was eliminated to reduce the amount of markup and programming language text.\n\nWe segmented the resulting corpus into sentences and removed duplicates to get 181.6M unique sentences. In total, the final corpus has 19.35GB of text.",
"# Pretraining\nThe model was trained in fairseq on 4 x Nvidia A100 GPUs for 300K steps with a batch size of 512 and a sequence length of 512. The optimizer used is Adam with a learning rate of 5e-4, \\\\(\\beta_{1} = 0.9\\\\), \\\\(\\beta_{2} = 0.98\\\\) and \\\\(\\epsilon = 1e-6\\\\), a weight decay of 0.01, dropout rate 0.1, learning rate warmup for 10k steps and linear decay of the learning rate after. We used 16-bit float precision.",
"## About us\n<a href=\"URL\n\t<img width=\"300px\" src=\"URL\n</a>\n\nGerulata Technologies is a tech company on a mission to provide tools for fighting disinformation and hostile propaganda.\n\nAt Gerulata, we focus on providing state-of-the-art AI-powered tools that empower human analysts and provide them with the ability to make informed decisions. \n\nOur tools allow for the monitoring and analysis of online activity, as well as the detection and tracking of disinformation and hostile propaganda campaigns. With our products, our clients are better equipped to identify and respond to threats in real-time.",
"### BibTeX entry and citation info\nIf you find our resource or paper is useful, please consider including the following citation in your paper.\n- URL"
] |
text-generation
|
transformers
|
# Family Guy (Peter) DialoGPT Model
|
{"tags": ["conversational"]}
|
gfdream/dialogpt-small-familyguy
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #gpt2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Family Guy (Peter) DialoGPT Model
|
[
"# Family Guy (Peter) DialoGPT Model"
] |
[
"TAGS\n#transformers #pytorch #gpt2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Family Guy (Peter) DialoGPT Model"
] |
text-generation
|
transformers
|
# Harry Potter DialoGPT Model
|
{"tags": ["conversational"]}
|
gfdream/dialogpt-small-harrypotter
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #gpt2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Harry Potter DialoGPT Model
|
[
"# Harry Potter DialoGPT Model"
] |
[
"TAGS\n#transformers #pytorch #gpt2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Harry Potter DialoGPT Model"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-herblabels
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4823
- Rouge1: 3.0759
- Rouge2: 1.0495
- Rougel: 3.0758
- Rougelsum: 3.0431
- Gen Len: 18.9716
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 264 | 1.6010 | 2.4276 | 0.5658 | 2.3546 | 2.3099 | 18.9091 |
| 2.5052 | 2.0 | 528 | 1.0237 | 2.9016 | 0.3395 | 2.8221 | 2.783 | 18.9673 |
| 2.5052 | 3.0 | 792 | 0.7793 | 2.962 | 0.3091 | 2.9375 | 2.8786 | 18.9588 |
| 1.1552 | 4.0 | 1056 | 0.6530 | 2.98 | 0.4375 | 2.9584 | 2.8711 | 18.9588 |
| 1.1552 | 5.0 | 1320 | 0.5863 | 3.0023 | 0.5882 | 2.987 | 2.9155 | 18.9588 |
| 0.8659 | 6.0 | 1584 | 0.5428 | 3.0576 | 0.8019 | 3.0494 | 2.9989 | 18.9716 |
| 0.8659 | 7.0 | 1848 | 0.5145 | 3.0808 | 0.9476 | 3.0719 | 3.0237 | 18.9716 |
| 0.747 | 8.0 | 2112 | 0.4962 | 3.0748 | 1.0032 | 3.0683 | 3.0359 | 18.9716 |
| 0.747 | 9.0 | 2376 | 0.4856 | 3.0702 | 1.0196 | 3.0665 | 3.0328 | 18.9716 |
| 0.6987 | 10.0 | 2640 | 0.4823 | 3.0759 | 1.0495 | 3.0758 | 3.0431 | 18.9716 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["rouge"], "model-index": [{"name": "t5-small-herblabels", "results": []}]}
|
ggosline/t5-small-herblabels
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
t5-small-herblabels
===================
This model is a fine-tuned version of t5-small on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4823
* Rouge1: 3.0759
* Rouge2: 1.0495
* Rougel: 3.0758
* Rougelsum: 3.0431
* Gen Len: 18.9716
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 10
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.12.5
* Pytorch 1.10.0
* Datasets 1.16.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.5\n* Pytorch 1.10.0\n* Datasets 1.16.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.5\n* Pytorch 1.10.0\n* Datasets 1.16.1\n* Tokenizers 0.10.3"
] |
null |
adapter-transformers
|
# Adapter `ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR` for ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR
An [adapter](https://adapterhub.ml) for the `ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR` model that was trained on the [other](https://adapterhub.ml/explore/other/) dataset.
This adapter was created for usage with the **[adapter-transformers](https://github.com/Adapter-Hub/adapter-transformers)** library.
## Usage
First, install `adapter-transformers`:
```
pip install -U adapter-transformers
```
_Note: adapter-transformers is a fork of transformers that acts as a drop-in replacement with adapter support. [More](https://docs.adapterhub.ml/installation.html)_
Now, the adapter can be loaded and activated like this:
```python
from transformers import AutoModelWithHeads
model = AutoModelWithHeads.from_pretrained("ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR")
adapter_name = model.load_adapter("ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR", source="hf", set_active=True)
```
## Architecture & Training
<!-- Add some description here -->
## Evaluation results
<!-- Add some description here -->
## Citation
<!-- Add some description here -->
|
{"tags": ["adapter-transformers", "adapterhub:other", "xlm-roberta"], "datasets": ["ghadeermobasher/BC5CDR-Chemical-Disease"]}
|
ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR
| null |
[
"adapter-transformers",
"pytorch",
"xlm-roberta",
"adapterhub:other",
"dataset:ghadeermobasher/BC5CDR-Chemical-Disease",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#adapter-transformers #pytorch #xlm-roberta #adapterhub-other #dataset-ghadeermobasher/BC5CDR-Chemical-Disease #region-us
|
# Adapter 'ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR' for ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR
An adapter for the 'ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR' model that was trained on the other dataset.
This adapter was created for usage with the adapter-transformers library.
## Usage
First, install 'adapter-transformers':
_Note: adapter-transformers is a fork of transformers that acts as a drop-in replacement with adapter support. More_
Now, the adapter can be loaded and activated like this:
## Architecture & Training
## Evaluation results
|
[
"# Adapter 'ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR' for ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR\n\nAn adapter for the 'ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR' model that was trained on the other dataset.\n\nThis adapter was created for usage with the adapter-transformers library.",
"## Usage\n\nFirst, install 'adapter-transformers':\n\n\n_Note: adapter-transformers is a fork of transformers that acts as a drop-in replacement with adapter support. More_\n\nNow, the adapter can be loaded and activated like this:",
"## Architecture & Training",
"## Evaluation results"
] |
[
"TAGS\n#adapter-transformers #pytorch #xlm-roberta #adapterhub-other #dataset-ghadeermobasher/BC5CDR-Chemical-Disease #region-us \n",
"# Adapter 'ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR' for ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR\n\nAn adapter for the 'ghadeermobasher/BC5CDR-Chemical-Disease-balanced-SapBERT-UMLS-2020AB-all-lang-from-XLMR' model that was trained on the other dataset.\n\nThis adapter was created for usage with the adapter-transformers library.",
"## Usage\n\nFirst, install 'adapter-transformers':\n\n\n_Note: adapter-transformers is a fork of transformers that acts as a drop-in replacement with adapter support. More_\n\nNow, the adapter can be loaded and activated like this:",
"## Architecture & Training",
"## Evaluation results"
] |
text-classification
|
transformers
|
A fake news detector using RoBERTa.
Dataset: https://www.kaggle.com/clmentbisaillon/fake-and-real-news-dataset
Training involved using hyperparameter search with 10 trials.
|
{}
|
ghanashyamvtatti/roberta-fake-news
| null |
[
"transformers",
"pytorch",
"tf",
"jax",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tf #jax #roberta #text-classification #autotrain_compatible #endpoints_compatible #region-us
|
A fake news detector using RoBERTa.
Dataset: URL
Training involved using hyperparameter search with 10 trials.
|
[] |
[
"TAGS\n#transformers #pytorch #tf #jax #roberta #text-classification #autotrain_compatible #endpoints_compatible #region-us \n"
] |
null |
transformers
|
This repository belongs to TransportersBERT from ActTrans publication.
Taju, Semmy Wellem, Syed Muazzam Ali Shah, and Yu-Yen Ou. “ActTRANS: Functional Classification in Active Transport Proteins Based on Transfer Learning and Contextual Representations.” Computational Biology and Chemistry 93 (August 1, 2021): 107537. https://doi.org/10.1016/j.compbiolchem.2021.107537.
|
{}
|
ghazikhanihamed/TransportersBERT
| null |
[
"transformers",
"pytorch",
"bert",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #bert #endpoints_compatible #region-us
|
This repository belongs to TransportersBERT from ActTrans publication.
Taju, Semmy Wellem, Syed Muazzam Ali Shah, and Yu-Yen Ou. “ActTRANS: Functional Classification in Active Transport Proteins Based on Transfer Learning and Contextual Representations.” Computational Biology and Chemistry 93 (August 1, 2021): 107537. URL
|
[] |
[
"TAGS\n#transformers #pytorch #bert #endpoints_compatible #region-us \n"
] |
text-generation
|
transformers
|
# Connor
|
{"tags": ["conversational"]}
|
ghhostboy/DialoGPT-medium-connorDBH3-1
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #gpt2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Connor
|
[
"# Connor"
] |
[
"TAGS\n#transformers #pytorch #gpt2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Connor"
] |
text-generation
|
transformers
|
# Connor
|
{"tags": ["conversational"]}
|
ghhostboy/DialoGPT-medium-connorDBH3-21
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #gpt2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Connor
|
[
"# Connor"
] |
[
"TAGS\n#transformers #pytorch #gpt2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Connor"
] |
automatic-speech-recognition
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# common6
This model is a fine-tuned version of [common6/checkpoint-3500](https://huggingface.co/common6/checkpoint-3500) on the COMMON_VOICE - FA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3706
- Wer: 0.3421
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 200.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 1.0344 | 10.0 | 500 | 0.4043 | 0.4511 |
| 0.9651 | 20.0 | 1000 | 0.3793 | 0.4159 |
| 0.9125 | 30.0 | 1500 | 0.3756 | 0.4046 |
| 0.8831 | 40.0 | 2000 | 0.3650 | 0.3876 |
| 0.8399 | 50.0 | 2500 | 0.3605 | 0.3772 |
| 0.819 | 60.0 | 3000 | 0.3622 | 0.3714 |
| 0.8029 | 70.0 | 3500 | 0.3561 | 0.3664 |
| 0.8104 | 80.0 | 4000 | 0.3595 | 0.3660 |
| 0.8118 | 90.0 | 4500 | 0.3460 | 0.3592 |
| 0.7831 | 100.0 | 5000 | 0.3566 | 0.3593 |
| 0.744 | 110.0 | 5500 | 0.3578 | 0.3535 |
| 0.7388 | 120.0 | 6000 | 0.3538 | 0.3520 |
| 0.714 | 130.0 | 6500 | 0.3682 | 0.3506 |
| 0.7291 | 140.0 | 7000 | 0.3625 | 0.3505 |
| 0.697 | 150.0 | 7500 | 0.3619 | 0.3479 |
| 0.6811 | 160.0 | 8000 | 0.3631 | 0.3440 |
| 0.6841 | 170.0 | 8500 | 0.3672 | 0.3460 |
| 0.6616 | 180.0 | 9000 | 0.3677 | 0.3410 |
| 0.6471 | 190.0 | 9500 | 0.3707 | 0.3420 |
| 0.6759 | 200.0 | 10000 | 0.3706 | 0.3421 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2
- Datasets 1.18.3.dev0
- Tokenizers 0.10.3
|
{"language": ["fa"], "tags": ["automatic-speech-recognition", "common_voice", "generated_from_trainer"], "datasets": ["common_voice"], "model-index": [{"name": "common6", "results": []}]}
|
ghofrani/common6
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"common_voice",
"generated_from_trainer",
"fa",
"dataset:common_voice",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"fa"
] |
TAGS
#transformers #pytorch #wav2vec2 #automatic-speech-recognition #common_voice #generated_from_trainer #fa #dataset-common_voice #endpoints_compatible #region-us
|
common6
=======
This model is a fine-tuned version of common6/checkpoint-3500 on the COMMON\_VOICE - FA dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3706
* Wer: 0.3421
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 6e-05
* train\_batch\_size: 32
* eval\_batch\_size: 16
* seed: 42
* gradient\_accumulation\_steps: 8
* total\_train\_batch\_size: 256
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 100
* num\_epochs: 200.0
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.17.0.dev0
* Pytorch 1.10.2
* Datasets 1.18.3.dev0
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 6e-05\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 16\n* seed: 42\n* gradient\\_accumulation\\_steps: 8\n* total\\_train\\_batch\\_size: 256\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 100\n* num\\_epochs: 200.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.17.0.dev0\n* Pytorch 1.10.2\n* Datasets 1.18.3.dev0\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #wav2vec2 #automatic-speech-recognition #common_voice #generated_from_trainer #fa #dataset-common_voice #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 6e-05\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 16\n* seed: 42\n* gradient\\_accumulation\\_steps: 8\n* total\\_train\\_batch\\_size: 256\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 100\n* num\\_epochs: 200.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.17.0.dev0\n* Pytorch 1.10.2\n* Datasets 1.18.3.dev0\n* Tokenizers 0.10.3"
] |
automatic-speech-recognition
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# common7
This model is a fine-tuned version of [common7/checkpoint-18500](https://huggingface.co/common7/checkpoint-18500) on the MOZILLA-FOUNDATION/COMMON_VOICE_7_0 - FA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3448
- Wer: 0.3478
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 150.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:-----:|:---------------:|:------:|
| 2.957 | 3.29 | 500 | 2.9503 | 1.0 |
| 1.7225 | 6.58 | 1000 | 0.8860 | 0.7703 |
| 1.4907 | 9.86 | 1500 | 0.6555 | 0.6673 |
| 1.4177 | 13.16 | 2000 | 0.5784 | 0.6076 |
| 1.3425 | 16.45 | 2500 | 0.5379 | 0.5718 |
| 1.33 | 19.73 | 3000 | 0.4962 | 0.5245 |
| 1.4378 | 23.03 | 3500 | 0.4699 | 0.5098 |
| 1.1894 | 26.31 | 4000 | 0.4527 | 0.4848 |
| 1.1844 | 29.6 | 4500 | 0.4309 | 0.4651 |
| 1.1795 | 32.89 | 5000 | 0.4131 | 0.4524 |
| 1.1471 | 36.18 | 5500 | 0.4052 | 0.4435 |
| 1.1337 | 39.47 | 6000 | 0.3927 | 0.4363 |
| 1.1896 | 42.76 | 6500 | 0.3811 | 0.4254 |
| 1.1847 | 46.05 | 7000 | 0.3855 | 0.4129 |
| 0.9954 | 49.34 | 7500 | 0.3729 | 0.3981 |
| 1.0293 | 52.63 | 8000 | 0.3637 | 0.4014 |
| 1.0224 | 55.92 | 8500 | 0.3578 | 0.3885 |
| 1.012 | 59.21 | 9000 | 0.3629 | 0.3930 |
| 1.0772 | 62.5 | 9500 | 0.3635 | 0.3906 |
| 1.0344 | 65.79 | 10000 | 0.3469 | 0.3771 |
| 0.9457 | 69.08 | 10500 | 0.3435 | 0.3735 |
| 0.9307 | 72.37 | 11000 | 0.3519 | 0.3762 |
| 0.9523 | 75.65 | 11500 | 0.3443 | 0.3666 |
| 0.9523 | 78.94 | 12000 | 0.3502 | 0.3757 |
| 0.9475 | 82.24 | 12500 | 0.3509 | 0.3643 |
| 0.9971 | 85.52 | 13000 | 0.3502 | 0.3626 |
| 0.9058 | 88.81 | 13500 | 0.3472 | 0.3605 |
| 0.8922 | 92.1 | 14000 | 0.3530 | 0.3618 |
| 0.9 | 95.39 | 14500 | 0.3500 | 0.3574 |
| 0.9051 | 98.68 | 15000 | 0.3456 | 0.3535 |
| 0.9304 | 101.97 | 15500 | 0.3438 | 0.3578 |
| 0.9433 | 105.26 | 16000 | 0.3396 | 0.3530 |
| 0.8988 | 108.55 | 16500 | 0.3436 | 0.3539 |
| 0.8789 | 111.84 | 17000 | 0.3426 | 0.3516 |
| 0.8667 | 115.13 | 17500 | 0.3438 | 0.3506 |
| 0.8895 | 118.42 | 18000 | 0.3434 | 0.3503 |
| 0.8888 | 121.71 | 18500 | 0.3425 | 0.3494 |
| 0.9453 | 125.0 | 19000 | 0.3415 | 0.3480 |
| 0.9267 | 128.29 | 19500 | 0.3477 | 0.3503 |
| 0.8315 | 131.58 | 20000 | 0.3476 | 0.3505 |
| 0.8542 | 134.86 | 20500 | 0.3475 | 0.3506 |
| 0.8478 | 138.16 | 21000 | 0.3430 | 0.3481 |
| 0.8643 | 141.45 | 21500 | 0.3451 | 0.3485 |
| 0.8705 | 144.73 | 22000 | 0.3444 | 0.3474 |
| 0.9869 | 148.03 | 22500 | 0.3441 | 0.3493 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2
- Datasets 1.18.3.dev0
- Tokenizers 0.10.3
|
{"language": ["fa"], "tags": ["automatic-speech-recognition", "mozilla-foundation/common_voice_7_0", "generated_from_trainer"], "datasets": ["common_voice"], "model-index": [{"name": "common7", "results": []}]}
|
ghofrani/common7
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"mozilla-foundation/common_voice_7_0",
"generated_from_trainer",
"fa",
"dataset:common_voice",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"fa"
] |
TAGS
#transformers #pytorch #wav2vec2 #automatic-speech-recognition #mozilla-foundation/common_voice_7_0 #generated_from_trainer #fa #dataset-common_voice #endpoints_compatible #region-us
|
common7
=======
This model is a fine-tuned version of common7/checkpoint-18500 on the MOZILLA-FOUNDATION/COMMON\_VOICE\_7\_0 - FA dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3448
* Wer: 0.3478
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 6e-05
* train\_batch\_size: 32
* eval\_batch\_size: 16
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 128
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 100
* num\_epochs: 150.0
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.17.0.dev0
* Pytorch 1.10.2
* Datasets 1.18.3.dev0
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 6e-05\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 16\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 100\n* num\\_epochs: 150.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.17.0.dev0\n* Pytorch 1.10.2\n* Datasets 1.18.3.dev0\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #wav2vec2 #automatic-speech-recognition #mozilla-foundation/common_voice_7_0 #generated_from_trainer #fa #dataset-common_voice #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 6e-05\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 16\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 128\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 100\n* num\\_epochs: 150.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.17.0.dev0\n* Pytorch 1.10.2\n* Datasets 1.18.3.dev0\n* Tokenizers 0.10.3"
] |
automatic-speech-recognition
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# common8
This model is a fine-tuned version of [wghts/checkpoint-20000](https://huggingface.co/wghts/checkpoint-20000) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - FA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3174
- Wer: 0.3022
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 6
- total_train_batch_size: 192
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 250.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:-----:|:---------------:|:------:|
| 3.5847 | 1.93 | 500 | 3.5104 | 1.0 |
| 2.7858 | 3.86 | 1000 | 2.9601 | 1.0001 |
| 1.6827 | 5.79 | 1500 | 0.7853 | 0.7030 |
| 1.4656 | 7.72 | 2000 | 0.6076 | 0.6014 |
| 1.3693 | 9.65 | 2500 | 0.5114 | 0.5307 |
| 1.379 | 11.58 | 3000 | 0.4666 | 0.4940 |
| 1.2832 | 13.51 | 3500 | 0.4257 | 0.4593 |
| 1.1931 | 15.44 | 4000 | 0.4039 | 0.4427 |
| 1.2911 | 17.37 | 4500 | 0.3956 | 0.4295 |
| 1.1577 | 19.3 | 5000 | 0.3705 | 0.4114 |
| 1.1135 | 21.24 | 5500 | 0.3740 | 0.4010 |
| 1.19 | 23.17 | 6000 | 0.3611 | 0.3935 |
| 1.1008 | 25.1 | 6500 | 0.3503 | 0.3880 |
| 1.0805 | 27.03 | 7000 | 0.3427 | 0.3781 |
| 1.1556 | 28.96 | 7500 | 0.3442 | 0.3727 |
| 1.0596 | 30.89 | 8000 | 0.3398 | 0.3646 |
| 1.0219 | 32.82 | 8500 | 0.3312 | 0.3660 |
| 1.1042 | 34.75 | 9000 | 0.3287 | 0.3612 |
| 1.0273 | 36.68 | 9500 | 0.3236 | 0.3556 |
| 1.0383 | 38.61 | 10000 | 0.3217 | 0.3558 |
| 1.0498 | 40.54 | 10500 | 0.3205 | 0.3520 |
| 0.9969 | 42.47 | 11000 | 0.3125 | 0.3504 |
| 1.0658 | 44.4 | 11500 | 0.3120 | 0.3493 |
| 0.992 | 46.33 | 12000 | 0.3137 | 0.3476 |
| 0.9737 | 48.26 | 12500 | 0.3085 | 0.3413 |
| 1.0817 | 50.19 | 13000 | 0.3091 | 0.3418 |
| 0.9414 | 52.12 | 13500 | 0.3072 | 0.3344 |
| 0.9295 | 54.05 | 14000 | 0.3039 | 0.3322 |
| 1.0248 | 55.98 | 14500 | 0.2991 | 0.3325 |
| 0.9474 | 57.91 | 15000 | 0.3032 | 0.3348 |
| 0.928 | 59.85 | 15500 | 0.2999 | 0.3285 |
| 1.0321 | 61.78 | 16000 | 0.2982 | 0.3253 |
| 0.9255 | 63.71 | 16500 | 0.2970 | 0.3231 |
| 0.8928 | 65.64 | 17000 | 0.2993 | 0.3250 |
| 1.008 | 67.57 | 17500 | 0.2985 | 0.3222 |
| 0.9371 | 69.5 | 18000 | 0.2968 | 0.3216 |
| 0.9077 | 71.43 | 18500 | 0.3011 | 0.3299 |
| 1.0044 | 73.36 | 19000 | 0.3053 | 0.3306 |
| 0.9625 | 75.29 | 19500 | 0.3159 | 0.3295 |
| 0.9816 | 77.22 | 20000 | 0.3080 | 0.3304 |
| 0.9587 | 119.19 | 20500 | 0.3088 | 0.3284 |
| 0.9178 | 122.09 | 21000 | 0.3132 | 0.3320 |
| 1.0282 | 125.0 | 21500 | 0.3099 | 0.3266 |
| 0.9337 | 127.9 | 22000 | 0.3110 | 0.3317 |
| 0.8822 | 130.81 | 22500 | 0.3037 | 0.3247 |
| 0.9644 | 133.72 | 23000 | 0.3037 | 0.3238 |
| 0.9214 | 136.62 | 23500 | 0.3040 | 0.3234 |
| 0.9167 | 139.53 | 24000 | 0.3079 | 0.3203 |
| 0.9047 | 142.44 | 24500 | 0.3018 | 0.3177 |
| 0.8909 | 145.35 | 25000 | 0.3053 | 0.3181 |
| 0.9646 | 148.25 | 25500 | 0.3095 | 0.3229 |
| 0.8802 | 151.16 | 26000 | 0.3111 | 0.3192 |
| 0.8411 | 154.07 | 26500 | 0.3068 | 0.3123 |
| 0.9235 | 156.97 | 27000 | 0.3090 | 0.3177 |
| 0.8943 | 159.88 | 27500 | 0.3115 | 0.3179 |
| 0.8854 | 162.79 | 28000 | 0.3052 | 0.3157 |
| 0.8734 | 165.69 | 28500 | 0.3077 | 0.3124 |
| 0.8515 | 168.6 | 29000 | 0.3117 | 0.3128 |
| 0.912 | 171.51 | 29500 | 0.3039 | 0.3121 |
| 0.8669 | 174.42 | 30000 | 0.3120 | 0.3123 |
| 0.823 | 177.32 | 30500 | 0.3148 | 0.3118 |
| 0.9129 | 180.23 | 31000 | 0.3179 | 0.3101 |
| 0.8255 | 183.14 | 31500 | 0.3164 | 0.3114 |
| 0.8948 | 186.05 | 32000 | 0.3128 | 0.3101 |
| 0.8397 | 188.95 | 32500 | 0.3143 | 0.3068 |
| 0.8341 | 191.86 | 33000 | 0.3127 | 0.3136 |
| 0.873 | 194.76 | 33500 | 0.3149 | 0.3124 |
| 0.8232 | 197.67 | 34000 | 0.3166 | 0.3086 |
| 0.8002 | 200.58 | 34500 | 0.3149 | 0.3061 |
| 0.8621 | 203.49 | 35000 | 0.3160 | 0.3093 |
| 0.8123 | 206.39 | 35500 | 0.3141 | 0.3063 |
| 0.7995 | 209.3 | 36000 | 0.3174 | 0.3075 |
| 0.8271 | 212.21 | 36500 | 0.3173 | 0.3043 |
| 0.8059 | 215.12 | 37000 | 0.3176 | 0.3079 |
| 0.8835 | 218.02 | 37500 | 0.3169 | 0.3062 |
| 0.8027 | 220.93 | 38000 | 0.3203 | 0.3098 |
| 0.775 | 223.83 | 38500 | 0.3159 | 0.3068 |
| 0.8487 | 226.74 | 39000 | 0.3161 | 0.3072 |
| 0.7929 | 229.65 | 39500 | 0.3143 | 0.3037 |
| 0.7653 | 232.56 | 40000 | 0.3160 | 0.3048 |
| 0.8211 | 235.46 | 40500 | 0.3173 | 0.3031 |
| 0.7761 | 238.37 | 41000 | 0.3176 | 0.3025 |
| 0.7761 | 241.28 | 41500 | 0.3179 | 0.3027 |
| 0.7903 | 244.19 | 42000 | 0.3181 | 0.3016 |
| 0.7807 | 247.09 | 42500 | 0.3170 | 0.3027 |
| 0.8406 | 250.0 | 43000 | 0.3174 | 0.3022 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2
- Datasets 1.18.3.dev0
- Tokenizers 0.10.3
|
{"language": ["fa"], "tags": ["automatic-speech-recognition", "mozilla-foundation/common_voice_8_0", "generated_from_trainer"], "datasets": ["common_voice"], "model-index": [{"name": "common8", "results": []}]}
|
ghofrani/xls-r-1b-fa-cv8
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"mozilla-foundation/common_voice_8_0",
"generated_from_trainer",
"fa",
"dataset:common_voice",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"fa"
] |
TAGS
#transformers #pytorch #wav2vec2 #automatic-speech-recognition #mozilla-foundation/common_voice_8_0 #generated_from_trainer #fa #dataset-common_voice #endpoints_compatible #region-us
|
common8
=======
This model is a fine-tuned version of wghts/checkpoint-20000 on the MOZILLA-FOUNDATION/COMMON\_VOICE\_8\_0 - FA dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3174
* Wer: 0.3022
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 1e-06
* train\_batch\_size: 32
* eval\_batch\_size: 16
* seed: 42
* gradient\_accumulation\_steps: 6
* total\_train\_batch\_size: 192
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 100
* num\_epochs: 250.0
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.17.0.dev0
* Pytorch 1.10.2
* Datasets 1.18.3.dev0
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-06\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 16\n* seed: 42\n* gradient\\_accumulation\\_steps: 6\n* total\\_train\\_batch\\_size: 192\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 100\n* num\\_epochs: 250.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.17.0.dev0\n* Pytorch 1.10.2\n* Datasets 1.18.3.dev0\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #wav2vec2 #automatic-speech-recognition #mozilla-foundation/common_voice_8_0 #generated_from_trainer #fa #dataset-common_voice #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-06\n* train\\_batch\\_size: 32\n* eval\\_batch\\_size: 16\n* seed: 42\n* gradient\\_accumulation\\_steps: 6\n* total\\_train\\_batch\\_size: 192\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 100\n* num\\_epochs: 250.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.17.0.dev0\n* Pytorch 1.10.2\n* Datasets 1.18.3.dev0\n* Tokenizers 0.10.3"
] |
text-generation
|
transformers
|
# Bangla-GPT2
### A GPT-2 Model for the Bengali Language
* Dataset- mc4 Bengali
* Training time- ~40 hours
* Written in- JAX
If you use this model, please cite:
```
@misc{bangla-gpt2,
author = {Ritobrata Ghosh},
year = {2016},
title = {Bangla GPT-2},
publisher = {Hugging Face}
}
```
|
{"language": "bn", "tags": ["text-generation"], "widget": [{"text": "\u0986\u099c \u098f\u0995\u099f\u09bf \u09b8\u09c1\u09a8\u09cd\u09a6\u09b0 \u09a6\u09bf\u09a8 \u098f\u09ac\u0982 \u0986\u09ae\u09bf"}]}
|
ritog/bangla-gpt2
| null |
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"bn",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"bn"
] |
TAGS
#transformers #pytorch #jax #gpt2 #text-generation #bn #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Bangla-GPT2
### A GPT-2 Model for the Bengali Language
* Dataset- mc4 Bengali
* Training time- ~40 hours
* Written in- JAX
If you use this model, please cite:
|
[
"# Bangla-GPT2",
"### A GPT-2 Model for the Bengali Language\n\n* Dataset- mc4 Bengali\n* Training time- ~40 hours\n* Written in- JAX\n\nIf you use this model, please cite:"
] |
[
"TAGS\n#transformers #pytorch #jax #gpt2 #text-generation #bn #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Bangla-GPT2",
"### A GPT-2 Model for the Bengali Language\n\n* Dataset- mc4 Bengali\n* Training time- ~40 hours\n* Written in- JAX\n\nIf you use this model, please cite:"
] |
text-generation
|
transformers
|
# Robi Kobi
### Created by [Ritobrata Ghosh](https://ghosh-r.github.io)
A model that writes Bengali poems in the style of Nobel Laureate poet Rabindranath Tagore.
This model is fine-tuned on 1,400+ poems written by Rabindranath Tagore. This model leverages the [Bangla GPT-2](https://huggingface.co/ghosh-r/bangla-gpt2) pretrained model, trained on mc4-Bengali dataset.
|
{"language": "bn", "tags": ["text-generation"], "widget": [{"text": "\u09a4\u09cb\u09ae\u09be\u0995\u09c7 \u09a6\u09c7\u0996\u09c7\u099b\u09bf \u0986\u09ae\u09be\u09b0 \u09b9\u09c3\u09a6\u09df \u09ae\u09be\u099d\u09c7"}]}
|
ritog/robi-kobi
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"bn",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"bn"
] |
TAGS
#transformers #pytorch #gpt2 #text-generation #bn #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Robi Kobi
### Created by Ritobrata Ghosh
A model that writes Bengali poems in the style of Nobel Laureate poet Rabindranath Tagore.
This model is fine-tuned on 1,400+ poems written by Rabindranath Tagore. This model leverages the Bangla GPT-2 pretrained model, trained on mc4-Bengali dataset.
|
[
"# Robi Kobi",
"### Created by Ritobrata Ghosh\n\nA model that writes Bengali poems in the style of Nobel Laureate poet Rabindranath Tagore.\n\nThis model is fine-tuned on 1,400+ poems written by Rabindranath Tagore. This model leverages the Bangla GPT-2 pretrained model, trained on mc4-Bengali dataset."
] |
[
"TAGS\n#transformers #pytorch #gpt2 #text-generation #bn #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Robi Kobi",
"### Created by Ritobrata Ghosh\n\nA model that writes Bengali poems in the style of Nobel Laureate poet Rabindranath Tagore.\n\nThis model is fine-tuned on 1,400+ poems written by Rabindranath Tagore. This model leverages the Bangla GPT-2 pretrained model, trained on mc4-Bengali dataset."
] |
automatic-speech-recognition
|
transformers
|
You can test this model online with the [**Space for Romanian Speech Recognition**](https://huggingface.co/spaces/gigant/romanian-speech-recognition)
The model ranked **TOP-1** on Romanian Speech Recognition during HuggingFace's Robust Speech Challenge :
* [**The 🤗 Speech Bench**](https://huggingface.co/spaces/huggingface/hf-speech-bench)
* [**Speech Challenge Leaderboard**](https://huggingface.co/spaces/speech-recognition-community-v2/FinalLeaderboard)
# Romanian Wav2Vec2
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the [Common Voice 8.0 - Romanian subset](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0) dataset, with extra training data from [Romanian Speech Synthesis](https://huggingface.co/datasets/gigant/romanian_speech_synthesis_0_8_1) dataset.
Without the 5-gram Language Model optimization, it achieves the following results on the evaluation set (Common Voice 8.0, Romanian subset, test split):
- Loss: 0.1553
- Wer: 0.1174
- Cer: 0.0294
## Model description
The architecture is based on [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) with a speech recognition CTC head and an added 5-gram language model (using [pyctcdecode](https://github.com/kensho-technologies/pyctcdecode) and [kenlm](https://github.com/kpu/kenlm)) trained on the [Romanian Corpora Parliament](gigant/ro_corpora_parliament_processed) dataset. Those libraries are needed in order for the language model-boosted decoder to work.
## Intended uses & limitations
The model is made for speech recognition in Romanian from audio clips sampled at **16kHz**. The predicted text is lowercased and does not contain any punctuation.
## How to use
Make sure you have installed the correct dependencies for the language model-boosted version to work. You can just run this command to install the `kenlm` and `pyctcdecode` libraries :
```pip install https://github.com/kpu/kenlm/archive/master.zip pyctcdecode```
With the framework `transformers` you can load the model with the following code :
```
from transformers import AutoProcessor, AutoModelForCTC
processor = AutoProcessor.from_pretrained("gigant/romanian-wav2vec2")
model = AutoModelForCTC.from_pretrained("gigant/romanian-wav2vec2")
```
Or, if you want to test the model, you can load the automatic speech recognition pipeline from `transformers` with :
```
from transformers import pipeline
asr = pipeline("automatic-speech-recognition", model="gigant/romanian-wav2vec2")
```
## Example use with the `datasets` library
First, you need to load your data
We will use the [Romanian Speech Synthesis](https://huggingface.co/datasets/gigant/romanian_speech_synthesis_0_8_1) dataset in this example.
```
from datasets import load_dataset
dataset = load_dataset("gigant/romanian_speech_synthesis_0_8_1")
```
You can listen to the samples with the `IPython.display` library :
```
from IPython.display import Audio
i = 0
sample = dataset["train"][i]
Audio(sample["audio"]["array"], rate = sample["audio"]["sampling_rate"])
```
The model is trained to work with audio sampled at 16kHz, so if the sampling rate of the audio in the dataset is different, we will have to resample it.
In the example, the audio is sampled at 48kHz. We can see this by checking `dataset["train"][0]["audio"]["sampling_rate"]`
The following code resample the audio using the `torchaudio` library :
```
import torchaudio
import torch
i = 0
audio = sample["audio"]["array"]
rate = sample["audio"]["sampling_rate"]
resampler = torchaudio.transforms.Resample(rate, 16_000)
audio_16 = resampler(torch.Tensor(audio)).numpy()
```
To listen to the resampled sample :
```
Audio(audio_16, rate=16000)
```
Know you can get the model prediction by running
```
predicted_text = asr(audio_16)
ground_truth = dataset["train"][i]["sentence"]
print(f"Predicted text : {predicted_text}")
print(f"Ground truth : {ground_truth}")
```
## Training and evaluation data
Training data :
- [Common Voice 8.0 - Romanian subset](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0) : train + validation + other splits
- [Romanian Speech Synthesis](https://huggingface.co/datasets/gigant/romanian_speech_synthesis_0_8_1) : train + test splits
Evaluation data :
- [Common Voice 8.0 - Romanian subset](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0) : test split
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 3
- total_train_batch_size: 48
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 50.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|
| 2.9272 | 0.78 | 500 | 0.7603 | 0.7734 | 0.2355 |
| 0.6157 | 1.55 | 1000 | 0.4003 | 0.4866 | 0.1247 |
| 0.4452 | 2.33 | 1500 | 0.2960 | 0.3689 | 0.0910 |
| 0.3631 | 3.11 | 2000 | 0.2580 | 0.3205 | 0.0796 |
| 0.3153 | 3.88 | 2500 | 0.2465 | 0.2977 | 0.0747 |
| 0.2795 | 4.66 | 3000 | 0.2274 | 0.2789 | 0.0694 |
| 0.2615 | 5.43 | 3500 | 0.2277 | 0.2685 | 0.0675 |
| 0.2389 | 6.21 | 4000 | 0.2135 | 0.2518 | 0.0627 |
| 0.2229 | 6.99 | 4500 | 0.2054 | 0.2449 | 0.0614 |
| 0.2067 | 7.76 | 5000 | 0.2096 | 0.2378 | 0.0597 |
| 0.1977 | 8.54 | 5500 | 0.2042 | 0.2387 | 0.0600 |
| 0.1896 | 9.32 | 6000 | 0.2110 | 0.2383 | 0.0595 |
| 0.1801 | 10.09 | 6500 | 0.1909 | 0.2165 | 0.0548 |
| 0.174 | 10.87 | 7000 | 0.1883 | 0.2206 | 0.0559 |
| 0.1685 | 11.65 | 7500 | 0.1848 | 0.2097 | 0.0528 |
| 0.1591 | 12.42 | 8000 | 0.1851 | 0.2039 | 0.0514 |
| 0.1537 | 13.2 | 8500 | 0.1881 | 0.2065 | 0.0518 |
| 0.1504 | 13.97 | 9000 | 0.1840 | 0.1972 | 0.0499 |
| 0.145 | 14.75 | 9500 | 0.1845 | 0.2029 | 0.0517 |
| 0.1417 | 15.53 | 10000 | 0.1884 | 0.2003 | 0.0507 |
| 0.1364 | 16.3 | 10500 | 0.2010 | 0.2037 | 0.0517 |
| 0.1331 | 17.08 | 11000 | 0.1838 | 0.1923 | 0.0483 |
| 0.129 | 17.86 | 11500 | 0.1818 | 0.1922 | 0.0489 |
| 0.1198 | 18.63 | 12000 | 0.1760 | 0.1861 | 0.0465 |
| 0.1203 | 19.41 | 12500 | 0.1686 | 0.1839 | 0.0465 |
| 0.1225 | 20.19 | 13000 | 0.1828 | 0.1920 | 0.0479 |
| 0.1145 | 20.96 | 13500 | 0.1673 | 0.1784 | 0.0446 |
| 0.1053 | 21.74 | 14000 | 0.1802 | 0.1810 | 0.0456 |
| 0.1071 | 22.51 | 14500 | 0.1769 | 0.1775 | 0.0444 |
| 0.1053 | 23.29 | 15000 | 0.1920 | 0.1783 | 0.0457 |
| 0.1024 | 24.07 | 15500 | 0.1904 | 0.1775 | 0.0446 |
| 0.0987 | 24.84 | 16000 | 0.1793 | 0.1762 | 0.0446 |
| 0.0949 | 25.62 | 16500 | 0.1801 | 0.1766 | 0.0443 |
| 0.0942 | 26.4 | 17000 | 0.1731 | 0.1659 | 0.0423 |
| 0.0906 | 27.17 | 17500 | 0.1776 | 0.1698 | 0.0424 |
| 0.0861 | 27.95 | 18000 | 0.1716 | 0.1600 | 0.0406 |
| 0.0851 | 28.73 | 18500 | 0.1662 | 0.1630 | 0.0410 |
| 0.0844 | 29.5 | 19000 | 0.1671 | 0.1572 | 0.0393 |
| 0.0792 | 30.28 | 19500 | 0.1768 | 0.1599 | 0.0407 |
| 0.0798 | 31.06 | 20000 | 0.1732 | 0.1558 | 0.0394 |
| 0.0779 | 31.83 | 20500 | 0.1694 | 0.1544 | 0.0388 |
| 0.0718 | 32.61 | 21000 | 0.1709 | 0.1578 | 0.0399 |
| 0.0732 | 33.38 | 21500 | 0.1697 | 0.1523 | 0.0391 |
| 0.0708 | 34.16 | 22000 | 0.1616 | 0.1474 | 0.0375 |
| 0.0678 | 34.94 | 22500 | 0.1698 | 0.1474 | 0.0375 |
| 0.0642 | 35.71 | 23000 | 0.1681 | 0.1459 | 0.0369 |
| 0.0661 | 36.49 | 23500 | 0.1612 | 0.1411 | 0.0357 |
| 0.0629 | 37.27 | 24000 | 0.1662 | 0.1414 | 0.0355 |
| 0.0587 | 38.04 | 24500 | 0.1659 | 0.1408 | 0.0351 |
| 0.0581 | 38.82 | 25000 | 0.1612 | 0.1382 | 0.0352 |
| 0.0556 | 39.6 | 25500 | 0.1647 | 0.1376 | 0.0345 |
| 0.0543 | 40.37 | 26000 | 0.1658 | 0.1335 | 0.0337 |
| 0.052 | 41.15 | 26500 | 0.1716 | 0.1369 | 0.0343 |
| 0.0513 | 41.92 | 27000 | 0.1600 | 0.1317 | 0.0330 |
| 0.0491 | 42.7 | 27500 | 0.1671 | 0.1311 | 0.0328 |
| 0.0463 | 43.48 | 28000 | 0.1613 | 0.1289 | 0.0324 |
| 0.0468 | 44.25 | 28500 | 0.1599 | 0.1260 | 0.0315 |
| 0.0435 | 45.03 | 29000 | 0.1556 | 0.1232 | 0.0308 |
| 0.043 | 45.81 | 29500 | 0.1588 | 0.1240 | 0.0309 |
| 0.0421 | 46.58 | 30000 | 0.1567 | 0.1217 | 0.0308 |
| 0.04 | 47.36 | 30500 | 0.1533 | 0.1198 | 0.0302 |
| 0.0389 | 48.14 | 31000 | 0.1582 | 0.1185 | 0.0297 |
| 0.0387 | 48.91 | 31500 | 0.1576 | 0.1187 | 0.0297 |
| 0.0376 | 49.69 | 32000 | 0.1560 | 0.1182 | 0.0295 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Tokenizers 0.11.0
- pyctcdecode 0.3.0
- kenlm
|
{"language": ["ro"], "license": "apache-2.0", "tags": ["automatic-speech-recognition", "hf-asr-leaderboard", "robust-speech-event"], "datasets": ["mozilla-foundation/common_voice_8_0", "gigant/romanian_speech_synthesis_0_8_1"], "base_model": "facebook/wav2vec2-xls-r-300m", "model-index": [{"name": "wav2vec2-ro-300m_01", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Automatic Speech Recognition"}, "dataset": {"name": "Robust Speech Event", "type": "speech-recognition-community-v2/dev_data", "args": "ro"}, "metrics": [{"type": "wer", "value": 46.99, "name": "Dev WER (without LM)"}, {"type": "cer", "value": 16.04, "name": "Dev CER (without LM)"}, {"type": "wer", "value": 38.63, "name": "Dev WER (with LM)"}, {"type": "cer", "value": 14.52, "name": "Dev CER (with LM)"}]}, {"task": {"type": "automatic-speech-recognition", "name": "Automatic Speech Recognition"}, "dataset": {"name": "Common Voice", "type": "mozilla-foundation/common_voice_8_0", "args": "ro"}, "metrics": [{"type": "wer", "value": 11.73, "name": "Test WER (without LM)"}, {"type": "cer", "value": 2.93, "name": "Test CER (without LM)"}, {"type": "wer", "value": 7.31, "name": "Test WER (with LM)"}, {"type": "cer", "value": 2.17, "name": "Test CER (with LM)"}]}, {"task": {"type": "automatic-speech-recognition", "name": "Automatic Speech Recognition"}, "dataset": {"name": "Robust Speech Event - Test Data", "type": "speech-recognition-community-v2/eval_data", "args": "ro"}, "metrics": [{"type": "wer", "value": 43.23, "name": "Test WER"}]}]}]}
|
gigant/romanian-wav2vec2
| null |
[
"transformers",
"pytorch",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"robust-speech-event",
"ro",
"dataset:mozilla-foundation/common_voice_8_0",
"dataset:gigant/romanian_speech_synthesis_0_8_1",
"base_model:facebook/wav2vec2-xls-r-300m",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"ro"
] |
TAGS
#transformers #pytorch #safetensors #wav2vec2 #automatic-speech-recognition #hf-asr-leaderboard #robust-speech-event #ro #dataset-mozilla-foundation/common_voice_8_0 #dataset-gigant/romanian_speech_synthesis_0_8_1 #base_model-facebook/wav2vec2-xls-r-300m #license-apache-2.0 #model-index #endpoints_compatible #has_space #region-us
|
You can test this model online with the Space for Romanian Speech Recognition
The model ranked TOP-1 on Romanian Speech Recognition during HuggingFace's Robust Speech Challenge :
* The Speech Bench
* Speech Challenge Leaderboard
Romanian Wav2Vec2
=================
This model is a fine-tuned version of facebook/wav2vec2-xls-r-300m on the Common Voice 8.0 - Romanian subset dataset, with extra training data from Romanian Speech Synthesis dataset.
Without the 5-gram Language Model optimization, it achieves the following results on the evaluation set (Common Voice 8.0, Romanian subset, test split):
* Loss: 0.1553
* Wer: 0.1174
* Cer: 0.0294
Model description
-----------------
The architecture is based on facebook/wav2vec2-xls-r-300m with a speech recognition CTC head and an added 5-gram language model (using pyctcdecode and kenlm) trained on the Romanian Corpora Parliament dataset. Those libraries are needed in order for the language model-boosted decoder to work.
Intended uses & limitations
---------------------------
The model is made for speech recognition in Romanian from audio clips sampled at 16kHz. The predicted text is lowercased and does not contain any punctuation.
How to use
----------
Make sure you have installed the correct dependencies for the language model-boosted version to work. You can just run this command to install the 'kenlm' and 'pyctcdecode' libraries :
With the framework 'transformers' you can load the model with the following code :
Or, if you want to test the model, you can load the automatic speech recognition pipeline from 'transformers' with :
Example use with the 'datasets' library
---------------------------------------
First, you need to load your data
We will use the Romanian Speech Synthesis dataset in this example.
You can listen to the samples with the 'IPython.display' library :
The model is trained to work with audio sampled at 16kHz, so if the sampling rate of the audio in the dataset is different, we will have to resample it.
In the example, the audio is sampled at 48kHz. We can see this by checking 'dataset["train"][0]["audio"]["sampling\_rate"]'
The following code resample the audio using the 'torchaudio' library :
To listen to the resampled sample :
Know you can get the model prediction by running
Training and evaluation data
----------------------------
Training data :
* Common Voice 8.0 - Romanian subset : train + validation + other splits
* Romanian Speech Synthesis : train + test splits
Evaluation data :
* Common Voice 8.0 - Romanian subset : test split
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.003
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* gradient\_accumulation\_steps: 3
* total\_train\_batch\_size: 48
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 500
* num\_epochs: 50.0
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.16.2
* Pytorch 1.10.0+cu111
* Tokenizers 0.11.0
* pyctcdecode 0.3.0
* kenlm
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.003\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 3\n* total\\_train\\_batch\\_size: 48\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 500\n* num\\_epochs: 50.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.16.2\n* Pytorch 1.10.0+cu111\n* Tokenizers 0.11.0\n* pyctcdecode 0.3.0\n* kenlm"
] |
[
"TAGS\n#transformers #pytorch #safetensors #wav2vec2 #automatic-speech-recognition #hf-asr-leaderboard #robust-speech-event #ro #dataset-mozilla-foundation/common_voice_8_0 #dataset-gigant/romanian_speech_synthesis_0_8_1 #base_model-facebook/wav2vec2-xls-r-300m #license-apache-2.0 #model-index #endpoints_compatible #has_space #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.003\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 3\n* total\\_train\\_batch\\_size: 48\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 500\n* num\\_epochs: 50.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.16.2\n* Pytorch 1.10.0+cu111\n* Tokenizers 0.11.0\n* pyctcdecode 0.3.0\n* kenlm"
] |
fill-mask
|
transformers
|
# StackOBERTflow-comments-small
StackOBERTflow is a RoBERTa model trained on StackOverflow comments.
A Byte-level BPE tokenizer with dropout was used (using the `tokenizers` package).
The model is *small*, i.e. has only 6-layers and the maximum sequence length was restricted to 256 tokens.
The model was trained for 6 epochs on several GBs of comments from the StackOverflow corpus.
## Quick start: masked language modeling prediction
```python
from transformers import pipeline
from pprint import pprint
COMMENT = "You really should not do it this way, I would use <mask> instead."
fill_mask = pipeline(
"fill-mask",
model="giganticode/StackOBERTflow-comments-small-v1",
tokenizer="giganticode/StackOBERTflow-comments-small-v1"
)
pprint(fill_mask(COMMENT))
# [{'score': 0.019997311756014824,
# 'sequence': '<s> You really should not do it this way, I would use jQuery instead.</s>',
# 'token': 1738},
# {'score': 0.01693696901202202,
# 'sequence': '<s> You really should not do it this way, I would use arrays instead.</s>',
# 'token': 2844},
# {'score': 0.013411642983555794,
# 'sequence': '<s> You really should not do it this way, I would use CSS instead.</s>',
# 'token': 2254},
# {'score': 0.013224546797573566,
# 'sequence': '<s> You really should not do it this way, I would use it instead.</s>',
# 'token': 300},
# {'score': 0.011984303593635559,
# 'sequence': '<s> You really should not do it this way, I would use classes instead.</s>',
# 'token': 1779}]
```
|
{}
|
giganticode/StackOBERTflow-comments-small-v1
| null |
[
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #jax #roberta #fill-mask #autotrain_compatible #endpoints_compatible #region-us
|
# StackOBERTflow-comments-small
StackOBERTflow is a RoBERTa model trained on StackOverflow comments.
A Byte-level BPE tokenizer with dropout was used (using the 'tokenizers' package).
The model is *small*, i.e. has only 6-layers and the maximum sequence length was restricted to 256 tokens.
The model was trained for 6 epochs on several GBs of comments from the StackOverflow corpus.
## Quick start: masked language modeling prediction
|
[
"# StackOBERTflow-comments-small\n\nStackOBERTflow is a RoBERTa model trained on StackOverflow comments.\nA Byte-level BPE tokenizer with dropout was used (using the 'tokenizers' package).\n\nThe model is *small*, i.e. has only 6-layers and the maximum sequence length was restricted to 256 tokens. \nThe model was trained for 6 epochs on several GBs of comments from the StackOverflow corpus.",
"## Quick start: masked language modeling prediction"
] |
[
"TAGS\n#transformers #pytorch #jax #roberta #fill-mask #autotrain_compatible #endpoints_compatible #region-us \n",
"# StackOBERTflow-comments-small\n\nStackOBERTflow is a RoBERTa model trained on StackOverflow comments.\nA Byte-level BPE tokenizer with dropout was used (using the 'tokenizers' package).\n\nThe model is *small*, i.e. has only 6-layers and the maximum sequence length was restricted to 256 tokens. \nThe model was trained for 6 epochs on several GBs of comments from the StackOverflow corpus.",
"## Quick start: masked language modeling prediction"
] |
token-classification
|
transformers
|
## About
The *french-camembert-postag-model* is a part of speech tagging model for French that was trained on the *free-french-treebank* dataset available on
[github](https://github.com/nicolashernandez/free-french-treebank). The base tokenizer and model used for training is *'camembert-base'*.
## Supported Tags
It uses the following tags:
| Tag | Category | Extra Info |
|----------|:------------------------------:|------------:|
| ADJ | adjectif | |
| ADJWH | adjectif | |
| ADV | adverbe | |
| ADVWH | adverbe | |
| CC | conjonction de coordination | |
| CLO | pronom | obj |
| CLR | pronom | refl |
| CLS | pronom | suj |
| CS | conjonction de subordination | |
| DET | déterminant | |
| DETWH | déterminant | |
| ET | mot étranger | |
| I | interjection | |
| NC | nom commun | |
| NPP | nom propre | |
| P | préposition | |
| P+D | préposition + déterminant | |
| PONCT | signe de ponctuation | |
| PREF | préfixe | |
| PRO | autres pronoms | |
| PROREL | autres pronoms | rel |
| PROWH | autres pronoms | int |
| U | ? | |
| V | verbe | |
| VIMP | verbe imperatif | |
| VINF | verbe infinitif | |
| VPP | participe passé | |
| VPR | participe présent | |
| VS | subjonctif | |
More information on the tags can be found here:
http://alpage.inria.fr/statgram/frdep/Publications/crabbecandi-taln2008-final.pdf
## Usage
The usage of this model follows the common transformers patterns. Here is a short example of its usage:
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("gilf/french-camembert-postag-model")
model = AutoModelForTokenClassification.from_pretrained("gilf/french-camembert-postag-model")
from transformers import pipeline
nlp_token_class = pipeline('ner', model=model, tokenizer=tokenizer, grouped_entities=True)
nlp_token_class('Face à un choc inédit, les mesures mises en place par le gouvernement ont permis une protection forte et efficace des ménages')
```
The lines above would display something like this on a Jupyter notebook:
```
[{'entity_group': 'NC', 'score': 0.5760144591331482, 'word': '<s>'},
{'entity_group': 'U', 'score': 0.9946700930595398, 'word': 'Face'},
{'entity_group': 'P', 'score': 0.999615490436554, 'word': 'à'},
{'entity_group': 'DET', 'score': 0.9995906352996826, 'word': 'un'},
{'entity_group': 'NC', 'score': 0.9995531439781189, 'word': 'choc'},
{'entity_group': 'ADJ', 'score': 0.999183714389801, 'word': 'inédit'},
{'entity_group': 'P', 'score': 0.3710663616657257, 'word': ','},
{'entity_group': 'DET', 'score': 0.9995903968811035, 'word': 'les'},
{'entity_group': 'NC', 'score': 0.9995649456977844, 'word': 'mesures'},
{'entity_group': 'VPP', 'score': 0.9988670349121094, 'word': 'mises'},
{'entity_group': 'P', 'score': 0.9996246099472046, 'word': 'en'},
{'entity_group': 'NC', 'score': 0.9995329976081848, 'word': 'place'},
{'entity_group': 'P', 'score': 0.9996233582496643, 'word': 'par'},
{'entity_group': 'DET', 'score': 0.9995935559272766, 'word': 'le'},
{'entity_group': 'NC', 'score': 0.9995369911193848, 'word': 'gouvernement'},
{'entity_group': 'V', 'score': 0.9993771314620972, 'word': 'ont'},
{'entity_group': 'VPP', 'score': 0.9991101026535034, 'word': 'permis'},
{'entity_group': 'DET', 'score': 0.9995885491371155, 'word': 'une'},
{'entity_group': 'NC', 'score': 0.9995636343955994, 'word': 'protection'},
{'entity_group': 'ADJ', 'score': 0.9991781711578369, 'word': 'forte'},
{'entity_group': 'CC', 'score': 0.9991298317909241, 'word': 'et'},
{'entity_group': 'ADJ', 'score': 0.9992275238037109, 'word': 'efficace'},
{'entity_group': 'P+D', 'score': 0.9993300437927246, 'word': 'des'},
{'entity_group': 'NC', 'score': 0.8353511393070221, 'word': 'ménages</s>'}]
```
|
{"language": "fr", "widget": [{"text": "Face \u00e0 un choc in\u00e9dit, les mesures mises en place par le gouvernement ont permis une protection forte et efficace des m\u00e9nages"}]}
|
gilf/french-camembert-postag-model
| null |
[
"transformers",
"pytorch",
"tf",
"safetensors",
"camembert",
"token-classification",
"fr",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"fr"
] |
TAGS
#transformers #pytorch #tf #safetensors #camembert #token-classification #fr #autotrain_compatible #endpoints_compatible #region-us
|
About
-----
The *french-camembert-postag-model* is a part of speech tagging model for French that was trained on the *free-french-treebank* dataset available on
github. The base tokenizer and model used for training is *'camembert-base'*.
Supported Tags
--------------
It uses the following tags:
More information on the tags can be found here:
URL
Usage
-----
The usage of this model follows the common transformers patterns. Here is a short example of its usage:
The lines above would display something like this on a Jupyter notebook:
|
[] |
[
"TAGS\n#transformers #pytorch #tf #safetensors #camembert #token-classification #fr #autotrain_compatible #endpoints_compatible #region-us \n"
] |
text-generation
|
transformers
|
# GPT-J 6B
## Model Description
GPT-J 6B is a transformer model trained using Ben Wang's [Mesh Transformer JAX](https://github.com/kingoflolz/mesh-transformer-jax/). "GPT-J" refers to the class of model, while "6B" represents the number of trainable parameters.
<figure>
| Hyperparameter | Value |
|----------------------|------------|
| \\(n_{parameters}\\) | 6053381344 |
| \\(n_{layers}\\) | 28* |
| \\(d_{model}\\) | 4096 |
| \\(d_{ff}\\) | 16384 |
| \\(n_{heads}\\) | 16 |
| \\(d_{head}\\) | 256 |
| \\(n_{ctx}\\) | 2048 |
| \\(n_{vocab}\\) | 50257/50400† (same tokenizer as GPT-2/3) |
| Positional Encoding | [Rotary Position Embedding (RoPE)](https://arxiv.org/abs/2104.09864) |
| RoPE Dimensions | [64](https://github.com/kingoflolz/mesh-transformer-jax/blob/f2aa66e0925de6593dcbb70e72399b97b4130482/mesh_transformer/layers.py#L223) |
<figcaption><p><strong>*</strong> Each layer consists of one feedforward block and one self attention block.</p>
<p><strong>†</strong> Although the embedding matrix has a size of 50400, only 50257 entries are used by the GPT-2 tokenizer.</p></figcaption></figure>
The model consists of 28 layers with a model dimension of 4096, and a feedforward dimension of 16384. The model
dimension is split into 16 heads, each with a dimension of 256. Rotary Position Embedding (RoPE) is applied to 64
dimensions of each head. The model is trained with a tokenization vocabulary of 50257, using the same set of BPEs as
GPT-2/GPT-3.
## Training data
GPT-J 6B was trained on [the Pile](https://pile.eleuther.ai), a large-scale curated dataset created by [EleutherAI](https://www.eleuther.ai).
## Training procedure
This model was trained for 402 billion tokens over 383,500 steps on TPU v3-256 pod. It was trained as an autoregressive language model, using cross-entropy loss to maximize the likelihood of predicting the next token correctly.
## Intended Use and Limitations
GPT-J learns an inner representation of the English language that can be used to extract features useful for downstream tasks. The model is best at what it was pretrained for however, which is generating text from a prompt.
### How to use
This model can be easily loaded using the `AutoModelForCausalLM` functionality:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-j-6B")
```
### Limitations and Biases
The core functionality of GPT-J is taking a string of text and predicting the next token. While language models are widely used for tasks other than this, there are a lot of unknowns with this work. When prompting GPT-J it is important to remember that the statistically most likely next token is often not the token that produces the most "accurate" text. Never depend upon GPT-J to produce factually accurate output.
GPT-J was trained on the Pile, a dataset known to contain profanity, lewd, and otherwise abrasive language. Depending upon use case GPT-J may produce socially unacceptable text. See [Sections 5 and 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a more detailed analysis of the biases in the Pile.
As with all language models, it is hard to predict in advance how GPT-J will respond to particular prompts and offensive content may occur without warning. We recommend having a human curate or filter the outputs before releasing them, both to censor undesirable content and to improve the quality of the results.
## Evaluation results
<figure>
| Model | Public | Training FLOPs | LAMBADA PPL ↓ | LAMBADA Acc ↑ | Winogrande ↑ | Hellaswag ↑ | PIQA ↑ | Dataset Size (GB) |
|--------------------------|-------------|----------------|--- |--- |--- |--- |--- |-------------------|
| Random Chance | ✓ | 0 | ~a lot | ~0% | 50% | 25% | 25% | 0 |
| GPT-3 Ada‡ | ✗ | ----- | 9.95 | 51.6% | 52.9% | 43.4% | 70.5% | ----- |
| GPT-2 1.5B | ✓ | ----- | 10.63 | 51.21% | 59.4% | 50.9% | 70.8% | 40 |
| GPT-Neo 1.3B‡ | ✓ | 3.0e21 | 7.50 | 57.2% | 55.0% | 48.9% | 71.1% | 825 |
| Megatron-2.5B* | ✗ | 2.4e21 | ----- | 61.7% | ----- | ----- | ----- | 174 |
| GPT-Neo 2.7B‡ | ✓ | 6.8e21 | 5.63 | 62.2% | 56.5% | 55.8% | 73.0% | 825 |
| GPT-3 1.3B*‡ | ✗ | 2.4e21 | 5.44 | 63.6% | 58.7% | 54.7% | 75.1% | ~800 |
| GPT-3 Babbage‡ | ✗ | ----- | 5.58 | 62.4% | 59.0% | 54.5% | 75.5% | ----- |
| Megatron-8.3B* | ✗ | 7.8e21 | ----- | 66.5% | ----- | ----- | ----- | 174 |
| GPT-3 2.7B*‡ | ✗ | 4.8e21 | 4.60 | 67.1% | 62.3% | 62.8% | 75.6% | ~800 |
| Megatron-11B† | ✓ | 1.0e22 | ----- | ----- | ----- | ----- | ----- | 161 |
| **GPT-J 6B‡** | **✓** | **1.5e22** | **3.99** | **69.7%** | **65.3%** | **66.1%** | **76.5%** | **825** |
| GPT-3 6.7B*‡ | ✗ | 1.2e22 | 4.00 | 70.3% | 64.5% | 67.4% | 78.0% | ~800 |
| GPT-3 Curie‡ | ✗ | ----- | 4.00 | 69.3% | 65.6% | 68.5% | 77.9% | ----- |
| GPT-3 13B*‡ | ✗ | 2.3e22 | 3.56 | 72.5% | 67.9% | 70.9% | 78.5% | ~800 |
| GPT-3 175B*‡ | ✗ | 3.1e23 | 3.00 | 76.2% | 70.2% | 78.9% | 81.0% | ~800 |
| GPT-3 Davinci‡ | ✗ | ----- | 3.0 | 75% | 72% | 78% | 80% | ----- |
<figcaption><p>Models roughly sorted by performance, or by FLOPs if not available.</p>
<p><strong>*</strong> Evaluation numbers reported by their respective authors. All other numbers are provided by
running <a href="https://github.com/EleutherAI/lm-evaluation-harness/"><code>lm-evaluation-harness</code></a> either with released
weights or with API access. Due to subtle implementation differences as well as different zero shot task framing, these
might not be directly comparable. See <a href="https://blog.eleuther.ai/gpt3-model-sizes/">this blog post</a> for more
details.</p>
<p><strong>†</strong> Megatron-11B provides no comparable metrics, and several implementations using the released weights do not
reproduce the generation quality and evaluations. (see <a href="https://github.com/huggingface/transformers/pull/10301">1</a>
<a href="https://github.com/pytorch/fairseq/issues/2358">2</a> <a href="https://github.com/pytorch/fairseq/issues/2719">3</a>)
Thus, evaluation was not attempted.</p>
<p><strong>‡</strong> These models have been trained with data which contains possible test set contamination. The OpenAI GPT-3 models
failed to deduplicate training data for certain test sets, while the GPT-Neo models as well as this one is
trained on the Pile, which has not been deduplicated against any test sets.</p></figcaption></figure>
## Citation and Related Information
### BibTeX entry
To cite this model:
```bibtex
@misc{gpt-j,
author = {Wang, Ben and Komatsuzaki, Aran},
title = {{GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model}},
howpublished = {\url{https://github.com/kingoflolz/mesh-transformer-jax}},
year = 2021,
month = May
}
```
To cite the codebase that trained this model:
```bibtex
@misc{mesh-transformer-jax,
author = {Wang, Ben},
title = {{Mesh-Transformer-JAX: Model-Parallel Implementation of Transformer Language Model with JAX}},
howpublished = {\url{https://github.com/kingoflolz/mesh-transformer-jax}},
year = 2021,
month = May
}
```
If you use this model, we would love to hear about it! Reach out on [GitHub](https://github.com/kingoflolz/mesh-transformer-jax), Discord, or shoot Ben an email.
## Acknowledgements
This project would not have been possible without compute generously provided by Google through the
[TPU Research Cloud](https://sites.research.google/trc/), as well as the Cloud TPU team for providing early access to the [Cloud TPU VM](https://cloud.google.com/blog/products/compute/introducing-cloud-tpu-vms) Alpha.
Thanks to everyone who have helped out one way or another (listed alphabetically):
- [James Bradbury](https://twitter.com/jekbradbury) for valuable assistance with debugging JAX issues.
- [Stella Biderman](https://www.stellabiderman.com), [Eric Hallahan](https://twitter.com/erichallahan), [Kurumuz](https://github.com/kurumuz/), and [Finetune](https://github.com/finetuneanon/) for converting the model to be compatible with the `transformers` package.
- [Leo Gao](https://twitter.com/nabla_theta) for running zero shot evaluations for the baseline models for the table.
- [Laurence Golding](https://github.com/researcher2/) for adding some features to the web demo.
- [Aran Komatsuzaki](https://twitter.com/arankomatsuzaki) for advice with experiment design and writing the blog posts.
- [Janko Prester](https://github.com/jprester/) for creating the web demo frontend.
|
{"language": ["en"], "license": "apache-2.0", "tags": ["pytorch", "causal-lm"], "datasets": ["The Pile"]}
|
gilparmentier/pokemon_gptj_model
| null |
[
"transformers",
"pytorch",
"gptj",
"text-generation",
"causal-lm",
"en",
"arxiv:2104.09864",
"arxiv:2101.00027",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2104.09864",
"2101.00027"
] |
[
"en"
] |
TAGS
#transformers #pytorch #gptj #text-generation #causal-lm #en #arxiv-2104.09864 #arxiv-2101.00027 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
GPT-J 6B
========
Model Description
-----------------
GPT-J 6B is a transformer model trained using Ben Wang's Mesh Transformer JAX. "GPT-J" refers to the class of model, while "6B" represents the number of trainable parameters.
**\*** Each layer consists of one feedforward block and one self attention block.
**†** Although the embedding matrix has a size of 50400, only 50257 entries are used by the GPT-2 tokenizer.
The model consists of 28 layers with a model dimension of 4096, and a feedforward dimension of 16384. The model
dimension is split into 16 heads, each with a dimension of 256. Rotary Position Embedding (RoPE) is applied to 64
dimensions of each head. The model is trained with a tokenization vocabulary of 50257, using the same set of BPEs as
GPT-2/GPT-3.
Training data
-------------
GPT-J 6B was trained on the Pile, a large-scale curated dataset created by EleutherAI.
Training procedure
------------------
This model was trained for 402 billion tokens over 383,500 steps on TPU v3-256 pod. It was trained as an autoregressive language model, using cross-entropy loss to maximize the likelihood of predicting the next token correctly.
Intended Use and Limitations
----------------------------
GPT-J learns an inner representation of the English language that can be used to extract features useful for downstream tasks. The model is best at what it was pretrained for however, which is generating text from a prompt.
### How to use
This model can be easily loaded using the 'AutoModelForCausalLM' functionality:
### Limitations and Biases
The core functionality of GPT-J is taking a string of text and predicting the next token. While language models are widely used for tasks other than this, there are a lot of unknowns with this work. When prompting GPT-J it is important to remember that the statistically most likely next token is often not the token that produces the most "accurate" text. Never depend upon GPT-J to produce factually accurate output.
GPT-J was trained on the Pile, a dataset known to contain profanity, lewd, and otherwise abrasive language. Depending upon use case GPT-J may produce socially unacceptable text. See Sections 5 and 6 of the Pile paper for a more detailed analysis of the biases in the Pile.
As with all language models, it is hard to predict in advance how GPT-J will respond to particular prompts and offensive content may occur without warning. We recommend having a human curate or filter the outputs before releasing them, both to censor undesirable content and to improve the quality of the results.
Evaluation results
------------------
Models roughly sorted by performance, or by FLOPs if not available.
**\*** Evaluation numbers reported by their respective authors. All other numbers are provided by
running [for more
details.](URL either with released
weights or with API access. Due to subtle implementation differences as well as different zero shot task framing, these
might not be directly comparable. See <a href=)
**†** Megatron-11B provides no comparable metrics, and several implementations using the released weights do not
reproduce the generation quality and evaluations. (see <a href="URL
<a href="URL <a href="URL
Thus, evaluation was not attempted.</p>
**‡** These models have been trained with data which contains possible test set contamination. The OpenAI GPT-3 models
failed to deduplicate training data for certain test sets, while the GPT-Neo models as well as this one is
trained on the Pile, which has not been deduplicated against any test sets.
and Related Information
### BibTeX entry
To cite this model:
To cite the codebase that trained this model:
If you use this model, we would love to hear about it! Reach out on GitHub, Discord, or shoot Ben an email.
Acknowledgements
----------------
This project would not have been possible without compute generously provided by Google through the
TPU Research Cloud, as well as the Cloud TPU team for providing early access to the Cloud TPU VM Alpha.
Thanks to everyone who have helped out one way or another (listed alphabetically):
* James Bradbury for valuable assistance with debugging JAX issues.
* Stella Biderman, Eric Hallahan, Kurumuz, and Finetune for converting the model to be compatible with the 'transformers' package.
* Leo Gao for running zero shot evaluations for the baseline models for the table.
* Laurence Golding for adding some features to the web demo.
* Aran Komatsuzaki for advice with experiment design and writing the blog posts.
* Janko Prester for creating the web demo frontend.
|
[
"### How to use\n\n\nThis model can be easily loaded using the 'AutoModelForCausalLM' functionality:",
"### Limitations and Biases\n\n\nThe core functionality of GPT-J is taking a string of text and predicting the next token. While language models are widely used for tasks other than this, there are a lot of unknowns with this work. When prompting GPT-J it is important to remember that the statistically most likely next token is often not the token that produces the most \"accurate\" text. Never depend upon GPT-J to produce factually accurate output.\n\n\nGPT-J was trained on the Pile, a dataset known to contain profanity, lewd, and otherwise abrasive language. Depending upon use case GPT-J may produce socially unacceptable text. See Sections 5 and 6 of the Pile paper for a more detailed analysis of the biases in the Pile.\n\n\nAs with all language models, it is hard to predict in advance how GPT-J will respond to particular prompts and offensive content may occur without warning. We recommend having a human curate or filter the outputs before releasing them, both to censor undesirable content and to improve the quality of the results.\n\n\nEvaluation results\n------------------\n\n\n\n\nModels roughly sorted by performance, or by FLOPs if not available.\n\n\n**\\*** Evaluation numbers reported by their respective authors. All other numbers are provided by\nrunning [for more\ndetails.](URL either with released\nweights or with API access. Due to subtle implementation differences as well as different zero shot task framing, these\nmight not be directly comparable. See <a href=)\n\n\n**†** Megatron-11B provides no comparable metrics, and several implementations using the released weights do not\nreproduce the generation quality and evaluations. (see <a href=\"URL\n<a href=\"URL <a href=\"URL\nThus, evaluation was not attempted.</p>\n**‡** These models have been trained with data which contains possible test set contamination. The OpenAI GPT-3 models\nfailed to deduplicate training data for certain test sets, while the GPT-Neo models as well as this one is\ntrained on the Pile, which has not been deduplicated against any test sets.\n\n\n\n\nand Related Information",
"### BibTeX entry\n\n\nTo cite this model:\n\n\nTo cite the codebase that trained this model:\n\n\nIf you use this model, we would love to hear about it! Reach out on GitHub, Discord, or shoot Ben an email.\n\n\nAcknowledgements\n----------------\n\n\nThis project would not have been possible without compute generously provided by Google through the\nTPU Research Cloud, as well as the Cloud TPU team for providing early access to the Cloud TPU VM Alpha.\n\n\nThanks to everyone who have helped out one way or another (listed alphabetically):\n\n\n* James Bradbury for valuable assistance with debugging JAX issues.\n* Stella Biderman, Eric Hallahan, Kurumuz, and Finetune for converting the model to be compatible with the 'transformers' package.\n* Leo Gao for running zero shot evaluations for the baseline models for the table.\n* Laurence Golding for adding some features to the web demo.\n* Aran Komatsuzaki for advice with experiment design and writing the blog posts.\n* Janko Prester for creating the web demo frontend."
] |
[
"TAGS\n#transformers #pytorch #gptj #text-generation #causal-lm #en #arxiv-2104.09864 #arxiv-2101.00027 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### How to use\n\n\nThis model can be easily loaded using the 'AutoModelForCausalLM' functionality:",
"### Limitations and Biases\n\n\nThe core functionality of GPT-J is taking a string of text and predicting the next token. While language models are widely used for tasks other than this, there are a lot of unknowns with this work. When prompting GPT-J it is important to remember that the statistically most likely next token is often not the token that produces the most \"accurate\" text. Never depend upon GPT-J to produce factually accurate output.\n\n\nGPT-J was trained on the Pile, a dataset known to contain profanity, lewd, and otherwise abrasive language. Depending upon use case GPT-J may produce socially unacceptable text. See Sections 5 and 6 of the Pile paper for a more detailed analysis of the biases in the Pile.\n\n\nAs with all language models, it is hard to predict in advance how GPT-J will respond to particular prompts and offensive content may occur without warning. We recommend having a human curate or filter the outputs before releasing them, both to censor undesirable content and to improve the quality of the results.\n\n\nEvaluation results\n------------------\n\n\n\n\nModels roughly sorted by performance, or by FLOPs if not available.\n\n\n**\\*** Evaluation numbers reported by their respective authors. All other numbers are provided by\nrunning [for more\ndetails.](URL either with released\nweights or with API access. Due to subtle implementation differences as well as different zero shot task framing, these\nmight not be directly comparable. See <a href=)\n\n\n**†** Megatron-11B provides no comparable metrics, and several implementations using the released weights do not\nreproduce the generation quality and evaluations. (see <a href=\"URL\n<a href=\"URL <a href=\"URL\nThus, evaluation was not attempted.</p>\n**‡** These models have been trained with data which contains possible test set contamination. The OpenAI GPT-3 models\nfailed to deduplicate training data for certain test sets, while the GPT-Neo models as well as this one is\ntrained on the Pile, which has not been deduplicated against any test sets.\n\n\n\n\nand Related Information",
"### BibTeX entry\n\n\nTo cite this model:\n\n\nTo cite the codebase that trained this model:\n\n\nIf you use this model, we would love to hear about it! Reach out on GitHub, Discord, or shoot Ben an email.\n\n\nAcknowledgements\n----------------\n\n\nThis project would not have been possible without compute generously provided by Google through the\nTPU Research Cloud, as well as the Cloud TPU team for providing early access to the Cloud TPU VM Alpha.\n\n\nThanks to everyone who have helped out one way or another (listed alphabetically):\n\n\n* James Bradbury for valuable assistance with debugging JAX issues.\n* Stella Biderman, Eric Hallahan, Kurumuz, and Finetune for converting the model to be compatible with the 'transformers' package.\n* Leo Gao for running zero shot evaluations for the baseline models for the table.\n* Laurence Golding for adding some features to the web demo.\n* Aran Komatsuzaki for advice with experiment design and writing the blog posts.\n* Janko Prester for creating the web demo frontend."
] |
text-generation
|
transformers
|
# Jake Peralta DialoGPT model
|
{"tags": ["conversational"]}
|
gizmo-dev/DialoGPT-small-jake
| null |
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #gpt2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Jake Peralta DialoGPT model
|
[
"# Jake Peralta DialoGPT model"
] |
[
"TAGS\n#transformers #pytorch #gpt2 #text-generation #conversational #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Jake Peralta DialoGPT model"
] |
null |
transformers
|
# cse_resnet50
Implementation of ResNet proposed in [Deep Residual Learning for Image
Recognition](https://arxiv.org/abs/1512.03385)
``` python
ResNet.resnet18()
ResNet.resnet26()
ResNet.resnet34()
ResNet.resnet50()
ResNet.resnet101()
ResNet.resnet152()
ResNet.resnet200()
Variants (d) proposed in `Bag of Tricks for Image Classification with Convolutional Neural Networks <https://arxiv.org/pdf/1812.01187.pdf`_
ResNet.resnet26d()
ResNet.resnet34d()
ResNet.resnet50d()
# You can construct your own one by chaning `stem` and `block`
resnet101d = ResNet.resnet101(stem=ResNetStemC, block=partial(ResNetBottleneckBlock, shortcut=ResNetShorcutD))
```
Examples:
``` python
# change activation
ResNet.resnet18(activation = nn.SELU)
# change number of classes (default is 1000 )
ResNet.resnet18(n_classes=100)
# pass a different block
ResNet.resnet18(block=SENetBasicBlock)
# change the steam
model = ResNet.resnet18(stem=ResNetStemC)
change shortcut
model = ResNet.resnet18(block=partial(ResNetBasicBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = ResNet.resnet18()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 64, 112, 112]), torch.Size([1, 64, 56, 56]), torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14])]
```
|
{}
|
glasses/cse_resnet50
| null |
[
"transformers",
"pytorch",
"arxiv:1512.03385",
"arxiv:1812.01187",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1512.03385",
"1812.01187"
] |
[] |
TAGS
#transformers #pytorch #arxiv-1512.03385 #arxiv-1812.01187 #endpoints_compatible #region-us
|
# cse_resnet50
Implementation of ResNet proposed in Deep Residual Learning for Image
Recognition
Examples:
|
[
"# cse_resnet50\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-1512.03385 #arxiv-1812.01187 #endpoints_compatible #region-us \n",
"# cse_resnet50\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
null |
transformers
|
# deit_base_patch16_224
Implementation of DeiT proposed in [Training data-efficient image
transformers & distillation through
attention](https://arxiv.org/pdf/2010.11929.pdf)
An attention based distillation is proposed where a new token is added
to the model, the [dist]{.title-ref} token.

``` {.sourceCode .}
DeiT.deit_tiny_patch16_224()
DeiT.deit_small_patch16_224()
DeiT.deit_base_patch16_224()
DeiT.deit_base_patch16_384()
```
|
{}
|
glasses/deit_base_patch16_224
| null |
[
"transformers",
"pytorch",
"arxiv:2010.11929",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2010.11929"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us
|
# deit_base_patch16_224
Implementation of DeiT proposed in Training data-efficient image
transformers & distillation through
attention
An attention based distillation is proposed where a new token is added
to the model, the [dist]{.title-ref} token.
!image
|
[
"# deit_base_patch16_224\n Implementation of DeiT proposed in Training data-efficient image\n transformers & distillation through\n attention\n\n An attention based distillation is proposed where a new token is added\n to the model, the [dist]{.title-ref} token.\n\n !image"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us \n",
"# deit_base_patch16_224\n Implementation of DeiT proposed in Training data-efficient image\n transformers & distillation through\n attention\n\n An attention based distillation is proposed where a new token is added\n to the model, the [dist]{.title-ref} token.\n\n !image"
] |
null |
transformers
|
# deit_base_patch16_384
Implementation of DeiT proposed in [Training data-efficient image
transformers & distillation through
attention](https://arxiv.org/pdf/2010.11929.pdf)
An attention based distillation is proposed where a new token is added
to the model, the [dist]{.title-ref} token.

``` {.sourceCode .}
DeiT.deit_tiny_patch16_224()
DeiT.deit_small_patch16_224()
DeiT.deit_base_patch16_224()
DeiT.deit_base_patch16_384()
```
|
{}
|
glasses/deit_base_patch16_384
| null |
[
"transformers",
"pytorch",
"arxiv:2010.11929",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2010.11929"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us
|
# deit_base_patch16_384
Implementation of DeiT proposed in Training data-efficient image
transformers & distillation through
attention
An attention based distillation is proposed where a new token is added
to the model, the [dist]{.title-ref} token.
!image
|
[
"# deit_base_patch16_384\n Implementation of DeiT proposed in Training data-efficient image\n transformers & distillation through\n attention\n\n An attention based distillation is proposed where a new token is added\n to the model, the [dist]{.title-ref} token.\n\n !image"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us \n",
"# deit_base_patch16_384\n Implementation of DeiT proposed in Training data-efficient image\n transformers & distillation through\n attention\n\n An attention based distillation is proposed where a new token is added\n to the model, the [dist]{.title-ref} token.\n\n !image"
] |
null |
transformers
|
# deit_small_patch16_224
Implementation of DeiT proposed in [Training data-efficient image
transformers & distillation through
attention](https://arxiv.org/pdf/2010.11929.pdf)
An attention based distillation is proposed where a new token is added
to the model, the [dist]{.title-ref} token.

``` {.sourceCode .}
DeiT.deit_tiny_patch16_224()
DeiT.deit_small_patch16_224()
DeiT.deit_base_patch16_224()
DeiT.deit_base_patch16_384()
```
|
{}
|
glasses/deit_small_patch16_224
| null |
[
"transformers",
"pytorch",
"arxiv:2010.11929",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2010.11929"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us
|
# deit_small_patch16_224
Implementation of DeiT proposed in Training data-efficient image
transformers & distillation through
attention
An attention based distillation is proposed where a new token is added
to the model, the [dist]{.title-ref} token.
!image
|
[
"# deit_small_patch16_224\n Implementation of DeiT proposed in Training data-efficient image\n transformers & distillation through\n attention\n\n An attention based distillation is proposed where a new token is added\n to the model, the [dist]{.title-ref} token.\n\n !image"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us \n",
"# deit_small_patch16_224\n Implementation of DeiT proposed in Training data-efficient image\n transformers & distillation through\n attention\n\n An attention based distillation is proposed where a new token is added\n to the model, the [dist]{.title-ref} token.\n\n !image"
] |
null |
transformers
|
# deit_tiny_patch16_224
Implementation of DeiT proposed in [Training data-efficient image
transformers & distillation through
attention](https://arxiv.org/pdf/2010.11929.pdf)
An attention based distillation is proposed where a new token is added
to the model, the [dist]{.title-ref} token.

``` {.sourceCode .}
DeiT.deit_tiny_patch16_224()
DeiT.deit_small_patch16_224()
DeiT.deit_base_patch16_224()
DeiT.deit_base_patch16_384()
```
|
{}
|
glasses/deit_tiny_patch16_224
| null |
[
"transformers",
"pytorch",
"arxiv:2010.11929",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2010.11929"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us
|
# deit_tiny_patch16_224
Implementation of DeiT proposed in Training data-efficient image
transformers & distillation through
attention
An attention based distillation is proposed where a new token is added
to the model, the [dist]{.title-ref} token.
!image
|
[
"# deit_tiny_patch16_224\n Implementation of DeiT proposed in Training data-efficient image\n transformers & distillation through\n attention\n\n An attention based distillation is proposed where a new token is added\n to the model, the [dist]{.title-ref} token.\n\n !image"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us \n",
"# deit_tiny_patch16_224\n Implementation of DeiT proposed in Training data-efficient image\n transformers & distillation through\n attention\n\n An attention based distillation is proposed where a new token is added\n to the model, the [dist]{.title-ref} token.\n\n !image"
] |
null |
transformers
|
# densenet161
Implementation of DenseNet proposed in [Densely Connected Convolutional
Networks](https://arxiv.org/abs/1608.06993)
Create a default models
``` {.sourceCode .}
DenseNet.densenet121()
DenseNet.densenet161()
DenseNet.densenet169()
DenseNet.densenet201()
```
Examples:
``` {.sourceCode .}
# change activation
DenseNet.densenet121(activation = nn.SELU)
# change number of classes (default is 1000 )
DenseNet.densenet121(n_classes=100)
# pass a different block
DenseNet.densenet121(block=...)
# change the initial convolution
model = DenseNet.densenet121()
model.encoder.gate.conv1 = nn.Conv2d(3, 64, kernel_size=3)
# store each feature
x = torch.rand((1, 3, 224, 224))
model = DenseNet.densenet121()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
# [torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14]), torch.Size([1, 512, 7, 7]), torch.Size([1, 1024, 7, 7])]
```
|
{}
|
glasses/densenet161
| null |
[
"transformers",
"pytorch",
"arxiv:1608.06993",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1608.06993"
] |
[] |
TAGS
#transformers #pytorch #arxiv-1608.06993 #endpoints_compatible #region-us
|
# densenet161
Implementation of DenseNet proposed in Densely Connected Convolutional
Networks
Create a default models
Examples:
|
[
"# densenet161\nImplementation of DenseNet proposed in Densely Connected Convolutional\nNetworks\n\n Create a default models\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-1608.06993 #endpoints_compatible #region-us \n",
"# densenet161\nImplementation of DenseNet proposed in Densely Connected Convolutional\nNetworks\n\n Create a default models\n\n \n\n Examples:"
] |
null |
transformers
|
# densenet169
Implementation of DenseNet proposed in [Densely Connected Convolutional
Networks](https://arxiv.org/abs/1608.06993)
Create a default models
``` {.sourceCode .}
DenseNet.densenet121()
DenseNet.densenet161()
DenseNet.densenet169()
DenseNet.densenet201()
```
Examples:
``` {.sourceCode .}
# change activation
DenseNet.densenet121(activation = nn.SELU)
# change number of classes (default is 1000 )
DenseNet.densenet121(n_classes=100)
# pass a different block
DenseNet.densenet121(block=...)
# change the initial convolution
model = DenseNet.densenet121()
model.encoder.gate.conv1 = nn.Conv2d(3, 64, kernel_size=3)
# store each feature
x = torch.rand((1, 3, 224, 224))
model = DenseNet.densenet121()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
# [torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14]), torch.Size([1, 512, 7, 7]), torch.Size([1, 1024, 7, 7])]
```
|
{}
|
glasses/densenet169
| null |
[
"transformers",
"pytorch",
"arxiv:1608.06993",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1608.06993"
] |
[] |
TAGS
#transformers #pytorch #arxiv-1608.06993 #endpoints_compatible #region-us
|
# densenet169
Implementation of DenseNet proposed in Densely Connected Convolutional
Networks
Create a default models
Examples:
|
[
"# densenet169\nImplementation of DenseNet proposed in Densely Connected Convolutional\nNetworks\n\n Create a default models\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-1608.06993 #endpoints_compatible #region-us \n",
"# densenet169\nImplementation of DenseNet proposed in Densely Connected Convolutional\nNetworks\n\n Create a default models\n\n \n\n Examples:"
] |
null |
transformers
|
# densenet201
Implementation of DenseNet proposed in [Densely Connected Convolutional
Networks](https://arxiv.org/abs/1608.06993)
Create a default models
``` {.sourceCode .}
DenseNet.densenet121()
DenseNet.densenet161()
DenseNet.densenet169()
DenseNet.densenet201()
```
Examples:
``` {.sourceCode .}
# change activation
DenseNet.densenet121(activation = nn.SELU)
# change number of classes (default is 1000 )
DenseNet.densenet121(n_classes=100)
# pass a different block
DenseNet.densenet121(block=...)
# change the initial convolution
model = DenseNet.densenet121()
model.encoder.gate.conv1 = nn.Conv2d(3, 64, kernel_size=3)
# store each feature
x = torch.rand((1, 3, 224, 224))
model = DenseNet.densenet121()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
# [torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14]), torch.Size([1, 512, 7, 7]), torch.Size([1, 1024, 7, 7])]
```
|
{}
|
glasses/densenet201
| null |
[
"transformers",
"pytorch",
"arxiv:1608.06993",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1608.06993"
] |
[] |
TAGS
#transformers #pytorch #arxiv-1608.06993 #endpoints_compatible #region-us
|
# densenet201
Implementation of DenseNet proposed in Densely Connected Convolutional
Networks
Create a default models
Examples:
|
[
"# densenet201\nImplementation of DenseNet proposed in Densely Connected Convolutional\nNetworks\n\n Create a default models\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-1608.06993 #endpoints_compatible #region-us \n",
"# densenet201\nImplementation of DenseNet proposed in Densely Connected Convolutional\nNetworks\n\n Create a default models\n\n \n\n Examples:"
] |
null |
transformers
|
# ResNet
Implementation of ResNet proposed in [Deep Residual Learning for Image
Recognition](https://arxiv.org/abs/1512.03385)
``` python
ResNet.resnet18()
ResNet.resnet26()
ResNet.resnet34()
ResNet.resnet50()
ResNet.resnet101()
ResNet.resnet152()
ResNet.resnet200()
Variants (d) proposed in `Bag of Tricks for Image Classification with Convolutional Neural Networks <https://arxiv.org/pdf/1812.01187.pdf`_
ResNet.resnet26d()
ResNet.resnet34d()
ResNet.resnet50d()
# You can construct your own one by chaning `stem` and `block`
resnet101d = ResNet.resnet101(stem=ResNetStemC, block=partial(ResNetBottleneckBlock, shortcut=ResNetShorcutD))
```
Examples:
``` python
# change activation
ResNet.resnet18(activation = nn.SELU)
# change number of classes (default is 1000 )
ResNet.resnet18(n_classes=100)
# pass a different block
ResNet.resnet18(block=SENetBasicBlock)
# change the steam
model = ResNet.resnet18(stem=ResNetStemC)
change shortcut
model = ResNet.resnet18(block=partial(ResNetBasicBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = ResNet.resnet18()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 64, 112, 112]), torch.Size([1, 64, 56, 56]), torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14])]
```
|
{}
|
glasses/dummy
| null |
[
"transformers",
"pytorch",
"arxiv:1512.03385",
"arxiv:1812.01187",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1512.03385",
"1812.01187"
] |
[] |
TAGS
#transformers #pytorch #arxiv-1512.03385 #arxiv-1812.01187 #endpoints_compatible #region-us
|
# ResNet
Implementation of ResNet proposed in Deep Residual Learning for Image
Recognition
Examples:
|
[
"# ResNet\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-1512.03385 #arxiv-1812.01187 #endpoints_compatible #region-us \n",
"# ResNet\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
image-classification
|
transformers
|
# eca_resnet26t
Implementation of ResNet proposed in [Deep Residual Learning for Image
Recognition](https://arxiv.org/abs/1512.03385)
``` python
ResNet.resnet18()
ResNet.resnet26()
ResNet.resnet34()
ResNet.resnet50()
ResNet.resnet101()
ResNet.resnet152()
ResNet.resnet200()
Variants (d) proposed in `Bag of Tricks for Image Classification with Convolutional Neural Networks <https://arxiv.org/pdf/1812.01187.pdf`_
ResNet.resnet26d()
ResNet.resnet34d()
ResNet.resnet50d()
# You can construct your own one by chaning `stem` and `block`
resnet101d = ResNet.resnet101(stem=ResNetStemC, block=partial(ResNetBottleneckBlock, shortcut=ResNetShorcutD))
```
Examples:
``` python
# change activation
ResNet.resnet18(activation = nn.SELU)
# change number of classes (default is 1000 )
ResNet.resnet18(n_classes=100)
# pass a different block
ResNet.resnet18(block=SENetBasicBlock)
# change the steam
model = ResNet.resnet18(stem=ResNetStemC)
change shortcut
model = ResNet.resnet18(block=partial(ResNetBasicBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = ResNet.resnet18()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 64, 112, 112]), torch.Size([1, 64, 56, 56]), torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14])]
```
|
{"license": "apache-2.0", "tags": ["image-classification"], "datasets": ["imagenet"]}
|
glasses/eca_resnet26t
| null |
[
"transformers",
"pytorch",
"image-classification",
"dataset:imagenet",
"arxiv:1512.03385",
"arxiv:1812.01187",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1512.03385",
"1812.01187"
] |
[] |
TAGS
#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us
|
# eca_resnet26t
Implementation of ResNet proposed in Deep Residual Learning for Image
Recognition
Examples:
|
[
"# eca_resnet26t\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us \n",
"# eca_resnet26t\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
null |
transformers
|
# efficientnet_b0
Implementation of EfficientNet proposed in [EfficientNet: Rethinking
Model Scaling for Convolutional Neural
Networks](https://arxiv.org/abs/1905.11946)

The basic architecture is similar to MobileNetV2 as was computed by
using [Progressive Neural Architecture
Search](https://arxiv.org/abs/1905.11946) .
The following table shows the basic architecture
(EfficientNet-efficientnet\_b0):

Then, the architecture is scaled up from
[-efficientnet\_b0]{.title-ref} to [-efficientnet\_b7]{.title-ref}
using compound scaling.

``` python
EfficientNet.efficientnet_b0()
EfficientNet.efficientnet_b1()
EfficientNet.efficientnet_b2()
EfficientNet.efficientnet_b3()
EfficientNet.efficientnet_b4()
EfficientNet.efficientnet_b5()
EfficientNet.efficientnet_b6()
EfficientNet.efficientnet_b7()
EfficientNet.efficientnet_b8()
EfficientNet.efficientnet_l2()
```
Examples:
``` python
EfficientNet.efficientnet_b0(activation = nn.SELU)
# change number of classes (default is 1000 )
EfficientNet.efficientnet_b0(n_classes=100)
# pass a different block
EfficientNet.efficientnet_b0(block=...)
# store each feature
x = torch.rand((1, 3, 224, 224))
model = EfficientNet.efficientnet_b0()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
# [torch.Size([1, 32, 112, 112]), torch.Size([1, 24, 56, 56]), torch.Size([1, 40, 28, 28]), torch.Size([1, 80, 14, 14])]
```
|
{}
|
glasses/efficientnet_b0
| null |
[
"transformers",
"pytorch",
"arxiv:1905.11946",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1905.11946"
] |
[] |
TAGS
#transformers #pytorch #arxiv-1905.11946 #endpoints_compatible #region-us
|
# efficientnet_b0
Implementation of EfficientNet proposed in EfficientNet: Rethinking
Model Scaling for Convolutional Neural
Networks
!image
The basic architecture is similar to MobileNetV2 as was computed by
using Progressive Neural Architecture
Search .
The following table shows the basic architecture
(EfficientNet-efficientnet\_b0):
!image
Then, the architecture is scaled up from
[-efficientnet\_b0]{.title-ref} to [-efficientnet\_b7]{.title-ref}
using compound scaling.
!image
Examples:
|
[
"# efficientnet_b0\nImplementation of EfficientNet proposed in EfficientNet: Rethinking\nModel Scaling for Convolutional Neural\nNetworks\n\n !image\n\n The basic architecture is similar to MobileNetV2 as was computed by\n using Progressive Neural Architecture\n Search .\n\n The following table shows the basic architecture\n (EfficientNet-efficientnet\\_b0):\n\n !image\n\n Then, the architecture is scaled up from\n [-efficientnet\\_b0]{.title-ref} to [-efficientnet\\_b7]{.title-ref}\n using compound scaling.\n\n !image\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-1905.11946 #endpoints_compatible #region-us \n",
"# efficientnet_b0\nImplementation of EfficientNet proposed in EfficientNet: Rethinking\nModel Scaling for Convolutional Neural\nNetworks\n\n !image\n\n The basic architecture is similar to MobileNetV2 as was computed by\n using Progressive Neural Architecture\n Search .\n\n The following table shows the basic architecture\n (EfficientNet-efficientnet\\_b0):\n\n !image\n\n Then, the architecture is scaled up from\n [-efficientnet\\_b0]{.title-ref} to [-efficientnet\\_b7]{.title-ref}\n using compound scaling.\n\n !image\n\n \n\n Examples:"
] |
null |
transformers
|
# efficientnet_b2
Implementation of EfficientNet proposed in [EfficientNet: Rethinking
Model Scaling for Convolutional Neural
Networks](https://arxiv.org/abs/1905.11946)

The basic architecture is similar to MobileNetV2 as was computed by
using [Progressive Neural Architecture
Search](https://arxiv.org/abs/1905.11946) .
The following table shows the basic architecture
(EfficientNet-efficientnet\_b0):

Then, the architecture is scaled up from
[-efficientnet\_b0]{.title-ref} to [-efficientnet\_b7]{.title-ref}
using compound scaling.

``` python
EfficientNet.efficientnet_b0()
EfficientNet.efficientnet_b1()
EfficientNet.efficientnet_b2()
EfficientNet.efficientnet_b3()
EfficientNet.efficientnet_b4()
EfficientNet.efficientnet_b5()
EfficientNet.efficientnet_b6()
EfficientNet.efficientnet_b7()
EfficientNet.efficientnet_b8()
EfficientNet.efficientnet_l2()
```
Examples:
``` python
EfficientNet.efficientnet_b0(activation = nn.SELU)
# change number of classes (default is 1000 )
EfficientNet.efficientnet_b0(n_classes=100)
# pass a different block
EfficientNet.efficientnet_b0(block=...)
# store each feature
x = torch.rand((1, 3, 224, 224))
model = EfficientNet.efficientnet_b0()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
# [torch.Size([1, 32, 112, 112]), torch.Size([1, 24, 56, 56]), torch.Size([1, 40, 28, 28]), torch.Size([1, 80, 14, 14])]
```
|
{}
|
glasses/efficientnet_b2
| null |
[
"transformers",
"pytorch",
"arxiv:1905.11946",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1905.11946"
] |
[] |
TAGS
#transformers #pytorch #arxiv-1905.11946 #endpoints_compatible #region-us
|
# efficientnet_b2
Implementation of EfficientNet proposed in EfficientNet: Rethinking
Model Scaling for Convolutional Neural
Networks
!image
The basic architecture is similar to MobileNetV2 as was computed by
using Progressive Neural Architecture
Search .
The following table shows the basic architecture
(EfficientNet-efficientnet\_b0):
!image
Then, the architecture is scaled up from
[-efficientnet\_b0]{.title-ref} to [-efficientnet\_b7]{.title-ref}
using compound scaling.
!image
Examples:
|
[
"# efficientnet_b2\nImplementation of EfficientNet proposed in EfficientNet: Rethinking\nModel Scaling for Convolutional Neural\nNetworks\n\n !image\n\n The basic architecture is similar to MobileNetV2 as was computed by\n using Progressive Neural Architecture\n Search .\n\n The following table shows the basic architecture\n (EfficientNet-efficientnet\\_b0):\n\n !image\n\n Then, the architecture is scaled up from\n [-efficientnet\\_b0]{.title-ref} to [-efficientnet\\_b7]{.title-ref}\n using compound scaling.\n\n !image\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-1905.11946 #endpoints_compatible #region-us \n",
"# efficientnet_b2\nImplementation of EfficientNet proposed in EfficientNet: Rethinking\nModel Scaling for Convolutional Neural\nNetworks\n\n !image\n\n The basic architecture is similar to MobileNetV2 as was computed by\n using Progressive Neural Architecture\n Search .\n\n The following table shows the basic architecture\n (EfficientNet-efficientnet\\_b0):\n\n !image\n\n Then, the architecture is scaled up from\n [-efficientnet\\_b0]{.title-ref} to [-efficientnet\\_b7]{.title-ref}\n using compound scaling.\n\n !image\n\n \n\n Examples:"
] |
null |
transformers
|
# efficientnet_b3
Implementation of EfficientNet proposed in [EfficientNet: Rethinking
Model Scaling for Convolutional Neural
Networks](https://arxiv.org/abs/1905.11946)

The basic architecture is similar to MobileNetV2 as was computed by
using [Progressive Neural Architecture
Search](https://arxiv.org/abs/1905.11946) .
The following table shows the basic architecture
(EfficientNet-efficientnet\_b0):

Then, the architecture is scaled up from
[-efficientnet\_b0]{.title-ref} to [-efficientnet\_b7]{.title-ref}
using compound scaling.

``` python
EfficientNet.efficientnet_b0()
EfficientNet.efficientnet_b1()
EfficientNet.efficientnet_b2()
EfficientNet.efficientnet_b3()
EfficientNet.efficientnet_b4()
EfficientNet.efficientnet_b5()
EfficientNet.efficientnet_b6()
EfficientNet.efficientnet_b7()
EfficientNet.efficientnet_b8()
EfficientNet.efficientnet_l2()
```
Examples:
``` python
EfficientNet.efficientnet_b0(activation = nn.SELU)
# change number of classes (default is 1000 )
EfficientNet.efficientnet_b0(n_classes=100)
# pass a different block
EfficientNet.efficientnet_b0(block=...)
# store each feature
x = torch.rand((1, 3, 224, 224))
model = EfficientNet.efficientnet_b0()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
# [torch.Size([1, 32, 112, 112]), torch.Size([1, 24, 56, 56]), torch.Size([1, 40, 28, 28]), torch.Size([1, 80, 14, 14])]
```
|
{}
|
glasses/efficientnet_b3
| null |
[
"transformers",
"pytorch",
"arxiv:1905.11946",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1905.11946"
] |
[] |
TAGS
#transformers #pytorch #arxiv-1905.11946 #endpoints_compatible #region-us
|
# efficientnet_b3
Implementation of EfficientNet proposed in EfficientNet: Rethinking
Model Scaling for Convolutional Neural
Networks
!image
The basic architecture is similar to MobileNetV2 as was computed by
using Progressive Neural Architecture
Search .
The following table shows the basic architecture
(EfficientNet-efficientnet\_b0):
!image
Then, the architecture is scaled up from
[-efficientnet\_b0]{.title-ref} to [-efficientnet\_b7]{.title-ref}
using compound scaling.
!image
Examples:
|
[
"# efficientnet_b3\nImplementation of EfficientNet proposed in EfficientNet: Rethinking\nModel Scaling for Convolutional Neural\nNetworks\n\n !image\n\n The basic architecture is similar to MobileNetV2 as was computed by\n using Progressive Neural Architecture\n Search .\n\n The following table shows the basic architecture\n (EfficientNet-efficientnet\\_b0):\n\n !image\n\n Then, the architecture is scaled up from\n [-efficientnet\\_b0]{.title-ref} to [-efficientnet\\_b7]{.title-ref}\n using compound scaling.\n\n !image\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-1905.11946 #endpoints_compatible #region-us \n",
"# efficientnet_b3\nImplementation of EfficientNet proposed in EfficientNet: Rethinking\nModel Scaling for Convolutional Neural\nNetworks\n\n !image\n\n The basic architecture is similar to MobileNetV2 as was computed by\n using Progressive Neural Architecture\n Search .\n\n The following table shows the basic architecture\n (EfficientNet-efficientnet\\_b0):\n\n !image\n\n Then, the architecture is scaled up from\n [-efficientnet\\_b0]{.title-ref} to [-efficientnet\\_b7]{.title-ref}\n using compound scaling.\n\n !image\n\n \n\n Examples:"
] |
null |
transformers
|
# efficientnet_b6
Implementation of EfficientNet proposed in [EfficientNet: Rethinking
Model Scaling for Convolutional Neural
Networks](https://arxiv.org/abs/1905.11946)

The basic architecture is similar to MobileNetV2 as was computed by
using [Progressive Neural Architecture
Search](https://arxiv.org/abs/1905.11946) .
The following table shows the basic architecture
(EfficientNet-efficientnet\_b0):

Then, the architecture is scaled up from
[-efficientnet\_b0]{.title-ref} to [-efficientnet\_b7]{.title-ref}
using compound scaling.

``` python
EfficientNet.efficientnet_b0()
EfficientNet.efficientnet_b1()
EfficientNet.efficientnet_b2()
EfficientNet.efficientnet_b3()
EfficientNet.efficientnet_b4()
EfficientNet.efficientnet_b5()
EfficientNet.efficientnet_b6()
EfficientNet.efficientnet_b7()
EfficientNet.efficientnet_b8()
EfficientNet.efficientnet_l2()
```
Examples:
``` python
EfficientNet.efficientnet_b0(activation = nn.SELU)
# change number of classes (default is 1000 )
EfficientNet.efficientnet_b0(n_classes=100)
# pass a different block
EfficientNet.efficientnet_b0(block=...)
# store each feature
x = torch.rand((1, 3, 224, 224))
model = EfficientNet.efficientnet_b0()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
# [torch.Size([1, 32, 112, 112]), torch.Size([1, 24, 56, 56]), torch.Size([1, 40, 28, 28]), torch.Size([1, 80, 14, 14])]
```
|
{}
|
glasses/efficientnet_b6
| null |
[
"transformers",
"pytorch",
"arxiv:1905.11946",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1905.11946"
] |
[] |
TAGS
#transformers #pytorch #arxiv-1905.11946 #endpoints_compatible #region-us
|
# efficientnet_b6
Implementation of EfficientNet proposed in EfficientNet: Rethinking
Model Scaling for Convolutional Neural
Networks
!image
The basic architecture is similar to MobileNetV2 as was computed by
using Progressive Neural Architecture
Search .
The following table shows the basic architecture
(EfficientNet-efficientnet\_b0):
!image
Then, the architecture is scaled up from
[-efficientnet\_b0]{.title-ref} to [-efficientnet\_b7]{.title-ref}
using compound scaling.
!image
Examples:
|
[
"# efficientnet_b6\nImplementation of EfficientNet proposed in EfficientNet: Rethinking\nModel Scaling for Convolutional Neural\nNetworks\n\n !image\n\n The basic architecture is similar to MobileNetV2 as was computed by\n using Progressive Neural Architecture\n Search .\n\n The following table shows the basic architecture\n (EfficientNet-efficientnet\\_b0):\n\n !image\n\n Then, the architecture is scaled up from\n [-efficientnet\\_b0]{.title-ref} to [-efficientnet\\_b7]{.title-ref}\n using compound scaling.\n\n !image\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-1905.11946 #endpoints_compatible #region-us \n",
"# efficientnet_b6\nImplementation of EfficientNet proposed in EfficientNet: Rethinking\nModel Scaling for Convolutional Neural\nNetworks\n\n !image\n\n The basic architecture is similar to MobileNetV2 as was computed by\n using Progressive Neural Architecture\n Search .\n\n The following table shows the basic architecture\n (EfficientNet-efficientnet\\_b0):\n\n !image\n\n Then, the architecture is scaled up from\n [-efficientnet\\_b0]{.title-ref} to [-efficientnet\\_b7]{.title-ref}\n using compound scaling.\n\n !image\n\n \n\n Examples:"
] |
null |
transformers
|
# regnetx_002
Implementation of RegNet proposed in [Designing Network Design
Spaces](https://arxiv.org/abs/2003.13678)
The main idea is to start with a high dimensional search space and
iteratively reduce the search space by empirically apply constrains
based on the best performing models sampled by the current search
space.
The resulting models are light, accurate, and faster than
EfficientNets (up to 5x times!)
For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the
bottleneck ratio $b_i$ for all stage $i$. The following table shows
all the restrictions applied from one search space to the next one.

The paper is really well written and very interesting, I highly
recommended read it.
``` python
ResNet.regnetx_002()
ResNet.regnetx_004()
ResNet.regnetx_006()
ResNet.regnetx_008()
ResNet.regnetx_016()
ResNet.regnetx_040()
ResNet.regnetx_064()
ResNet.regnetx_080()
ResNet.regnetx_120()
ResNet.regnetx_160()
ResNet.regnetx_320()
# Y variants (with SE)
ResNet.regnety_002()
# ...
ResNet.regnetx_320()
You can easily customize your model
```
Examples:
``` python
# change activation
RegNet.regnetx_004(activation = nn.SELU)
# change number of classes (default is 1000 )
RegNet.regnetx_004(n_classes=100)
# pass a different block
RegNet.regnetx_004(block=RegNetYBotteneckBlock)
# change the steam
model = RegNet.regnetx_004(stem=ResNetStemC)
change shortcut
model = RegNet.regnetx_004(block=partial(RegNetYBotteneckBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = RegNet.regnetx_004()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 32, 112, 112]), torch.Size([1, 32, 56, 56]), torch.Size([1, 64, 28, 28]), torch.Size([1, 160, 14, 14])]
```
|
{}
|
glasses/regnetx_002
| null |
[
"transformers",
"pytorch",
"arxiv:2003.13678",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2003.13678"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2003.13678 #endpoints_compatible #region-us
|
# regnetx_002
Implementation of RegNet proposed in Designing Network Design
Spaces
The main idea is to start with a high dimensional search space and
iteratively reduce the search space by empirically apply constrains
based on the best performing models sampled by the current search
space.
The resulting models are light, accurate, and faster than
EfficientNets (up to 5x times!)
For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the
bottleneck ratio $b_i$ for all stage $i$. The following table shows
all the restrictions applied from one search space to the next one.
!image
The paper is really well written and very interesting, I highly
recommended read it.
Examples:
|
[
"# regnetx_002\nImplementation of RegNet proposed in Designing Network Design\nSpaces\n\n The main idea is to start with a high dimensional search space and\n iteratively reduce the search space by empirically apply constrains\n based on the best performing models sampled by the current search\n space.\n\n The resulting models are light, accurate, and faster than\n EfficientNets (up to 5x times!)\n\n For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the\n bottleneck ratio $b_i$ for all stage $i$. The following table shows\n all the restrictions applied from one search space to the next one.\n\n !image\n\n The paper is really well written and very interesting, I highly\n recommended read it.\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2003.13678 #endpoints_compatible #region-us \n",
"# regnetx_002\nImplementation of RegNet proposed in Designing Network Design\nSpaces\n\n The main idea is to start with a high dimensional search space and\n iteratively reduce the search space by empirically apply constrains\n based on the best performing models sampled by the current search\n space.\n\n The resulting models are light, accurate, and faster than\n EfficientNets (up to 5x times!)\n\n For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the\n bottleneck ratio $b_i$ for all stage $i$. The following table shows\n all the restrictions applied from one search space to the next one.\n\n !image\n\n The paper is really well written and very interesting, I highly\n recommended read it.\n\n \n\n Examples:"
] |
null |
transformers
|
# regnetx_006
Implementation of RegNet proposed in [Designing Network Design
Spaces](https://arxiv.org/abs/2003.13678)
The main idea is to start with a high dimensional search space and
iteratively reduce the search space by empirically apply constrains
based on the best performing models sampled by the current search
space.
The resulting models are light, accurate, and faster than
EfficientNets (up to 5x times!)
For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the
bottleneck ratio $b_i$ for all stage $i$. The following table shows
all the restrictions applied from one search space to the next one.

The paper is really well written and very interesting, I highly
recommended read it.
``` python
ResNet.regnetx_002()
ResNet.regnetx_004()
ResNet.regnetx_006()
ResNet.regnetx_008()
ResNet.regnetx_016()
ResNet.regnetx_040()
ResNet.regnetx_064()
ResNet.regnetx_080()
ResNet.regnetx_120()
ResNet.regnetx_160()
ResNet.regnetx_320()
# Y variants (with SE)
ResNet.regnety_002()
# ...
ResNet.regnetx_320()
You can easily customize your model
```
Examples:
``` python
# change activation
RegNet.regnetx_004(activation = nn.SELU)
# change number of classes (default is 1000 )
RegNet.regnetx_004(n_classes=100)
# pass a different block
RegNet.regnetx_004(block=RegNetYBotteneckBlock)
# change the steam
model = RegNet.regnetx_004(stem=ResNetStemC)
change shortcut
model = RegNet.regnetx_004(block=partial(RegNetYBotteneckBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = RegNet.regnetx_004()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 32, 112, 112]), torch.Size([1, 32, 56, 56]), torch.Size([1, 64, 28, 28]), torch.Size([1, 160, 14, 14])]
```
|
{}
|
glasses/regnetx_006
| null |
[
"transformers",
"pytorch",
"arxiv:2003.13678",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2003.13678"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2003.13678 #endpoints_compatible #region-us
|
# regnetx_006
Implementation of RegNet proposed in Designing Network Design
Spaces
The main idea is to start with a high dimensional search space and
iteratively reduce the search space by empirically apply constrains
based on the best performing models sampled by the current search
space.
The resulting models are light, accurate, and faster than
EfficientNets (up to 5x times!)
For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the
bottleneck ratio $b_i$ for all stage $i$. The following table shows
all the restrictions applied from one search space to the next one.
!image
The paper is really well written and very interesting, I highly
recommended read it.
Examples:
|
[
"# regnetx_006\nImplementation of RegNet proposed in Designing Network Design\nSpaces\n\n The main idea is to start with a high dimensional search space and\n iteratively reduce the search space by empirically apply constrains\n based on the best performing models sampled by the current search\n space.\n\n The resulting models are light, accurate, and faster than\n EfficientNets (up to 5x times!)\n\n For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the\n bottleneck ratio $b_i$ for all stage $i$. The following table shows\n all the restrictions applied from one search space to the next one.\n\n !image\n\n The paper is really well written and very interesting, I highly\n recommended read it.\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2003.13678 #endpoints_compatible #region-us \n",
"# regnetx_006\nImplementation of RegNet proposed in Designing Network Design\nSpaces\n\n The main idea is to start with a high dimensional search space and\n iteratively reduce the search space by empirically apply constrains\n based on the best performing models sampled by the current search\n space.\n\n The resulting models are light, accurate, and faster than\n EfficientNets (up to 5x times!)\n\n For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the\n bottleneck ratio $b_i$ for all stage $i$. The following table shows\n all the restrictions applied from one search space to the next one.\n\n !image\n\n The paper is really well written and very interesting, I highly\n recommended read it.\n\n \n\n Examples:"
] |
null |
transformers
|
# regnetx_016
Implementation of RegNet proposed in [Designing Network Design
Spaces](https://arxiv.org/abs/2003.13678)
The main idea is to start with a high dimensional search space and
iteratively reduce the search space by empirically apply constrains
based on the best performing models sampled by the current search
space.
The resulting models are light, accurate, and faster than
EfficientNets (up to 5x times!)
For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the
bottleneck ratio $b_i$ for all stage $i$. The following table shows
all the restrictions applied from one search space to the next one.

The paper is really well written and very interesting, I highly
recommended read it.
``` python
ResNet.regnetx_002()
ResNet.regnetx_004()
ResNet.regnetx_006()
ResNet.regnetx_008()
ResNet.regnetx_016()
ResNet.regnetx_040()
ResNet.regnetx_064()
ResNet.regnetx_080()
ResNet.regnetx_120()
ResNet.regnetx_160()
ResNet.regnetx_320()
# Y variants (with SE)
ResNet.regnety_002()
# ...
ResNet.regnetx_320()
You can easily customize your model
```
Examples:
``` python
# change activation
RegNet.regnetx_004(activation = nn.SELU)
# change number of classes (default is 1000 )
RegNet.regnetx_004(n_classes=100)
# pass a different block
RegNet.regnetx_004(block=RegNetYBotteneckBlock)
# change the steam
model = RegNet.regnetx_004(stem=ResNetStemC)
change shortcut
model = RegNet.regnetx_004(block=partial(RegNetYBotteneckBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = RegNet.regnetx_004()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 32, 112, 112]), torch.Size([1, 32, 56, 56]), torch.Size([1, 64, 28, 28]), torch.Size([1, 160, 14, 14])]
```
|
{}
|
glasses/regnetx_016
| null |
[
"transformers",
"pytorch",
"arxiv:2003.13678",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2003.13678"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2003.13678 #endpoints_compatible #region-us
|
# regnetx_016
Implementation of RegNet proposed in Designing Network Design
Spaces
The main idea is to start with a high dimensional search space and
iteratively reduce the search space by empirically apply constrains
based on the best performing models sampled by the current search
space.
The resulting models are light, accurate, and faster than
EfficientNets (up to 5x times!)
For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the
bottleneck ratio $b_i$ for all stage $i$. The following table shows
all the restrictions applied from one search space to the next one.
!image
The paper is really well written and very interesting, I highly
recommended read it.
Examples:
|
[
"# regnetx_016\nImplementation of RegNet proposed in Designing Network Design\nSpaces\n\n The main idea is to start with a high dimensional search space and\n iteratively reduce the search space by empirically apply constrains\n based on the best performing models sampled by the current search\n space.\n\n The resulting models are light, accurate, and faster than\n EfficientNets (up to 5x times!)\n\n For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the\n bottleneck ratio $b_i$ for all stage $i$. The following table shows\n all the restrictions applied from one search space to the next one.\n\n !image\n\n The paper is really well written and very interesting, I highly\n recommended read it.\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2003.13678 #endpoints_compatible #region-us \n",
"# regnetx_016\nImplementation of RegNet proposed in Designing Network Design\nSpaces\n\n The main idea is to start with a high dimensional search space and\n iteratively reduce the search space by empirically apply constrains\n based on the best performing models sampled by the current search\n space.\n\n The resulting models are light, accurate, and faster than\n EfficientNets (up to 5x times!)\n\n For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the\n bottleneck ratio $b_i$ for all stage $i$. The following table shows\n all the restrictions applied from one search space to the next one.\n\n !image\n\n The paper is really well written and very interesting, I highly\n recommended read it.\n\n \n\n Examples:"
] |
null |
transformers
|
# regnety_002
Implementation of RegNet proposed in [Designing Network Design
Spaces](https://arxiv.org/abs/2003.13678)
The main idea is to start with a high dimensional search space and
iteratively reduce the search space by empirically apply constrains
based on the best performing models sampled by the current search
space.
The resulting models are light, accurate, and faster than
EfficientNets (up to 5x times!)
For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the
bottleneck ratio $b_i$ for all stage $i$. The following table shows
all the restrictions applied from one search space to the next one.

The paper is really well written and very interesting, I highly
recommended read it.
``` python
ResNet.regnetx_002()
ResNet.regnetx_004()
ResNet.regnetx_006()
ResNet.regnetx_008()
ResNet.regnetx_016()
ResNet.regnetx_040()
ResNet.regnetx_064()
ResNet.regnetx_080()
ResNet.regnetx_120()
ResNet.regnetx_160()
ResNet.regnetx_320()
# Y variants (with SE)
ResNet.regnety_002()
# ...
ResNet.regnetx_320()
You can easily customize your model
```
Examples:
``` python
# change activation
RegNet.regnetx_004(activation = nn.SELU)
# change number of classes (default is 1000 )
RegNet.regnetx_004(n_classes=100)
# pass a different block
RegNet.regnetx_004(block=RegNetYBotteneckBlock)
# change the steam
model = RegNet.regnetx_004(stem=ResNetStemC)
change shortcut
model = RegNet.regnetx_004(block=partial(RegNetYBotteneckBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = RegNet.regnetx_004()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 32, 112, 112]), torch.Size([1, 32, 56, 56]), torch.Size([1, 64, 28, 28]), torch.Size([1, 160, 14, 14])]
```
|
{}
|
glasses/regnety_002
| null |
[
"transformers",
"pytorch",
"arxiv:2003.13678",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2003.13678"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2003.13678 #endpoints_compatible #region-us
|
# regnety_002
Implementation of RegNet proposed in Designing Network Design
Spaces
The main idea is to start with a high dimensional search space and
iteratively reduce the search space by empirically apply constrains
based on the best performing models sampled by the current search
space.
The resulting models are light, accurate, and faster than
EfficientNets (up to 5x times!)
For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the
bottleneck ratio $b_i$ for all stage $i$. The following table shows
all the restrictions applied from one search space to the next one.
!image
The paper is really well written and very interesting, I highly
recommended read it.
Examples:
|
[
"# regnety_002\nImplementation of RegNet proposed in Designing Network Design\nSpaces\n\n The main idea is to start with a high dimensional search space and\n iteratively reduce the search space by empirically apply constrains\n based on the best performing models sampled by the current search\n space.\n\n The resulting models are light, accurate, and faster than\n EfficientNets (up to 5x times!)\n\n For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the\n bottleneck ratio $b_i$ for all stage $i$. The following table shows\n all the restrictions applied from one search space to the next one.\n\n !image\n\n The paper is really well written and very interesting, I highly\n recommended read it.\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2003.13678 #endpoints_compatible #region-us \n",
"# regnety_002\nImplementation of RegNet proposed in Designing Network Design\nSpaces\n\n The main idea is to start with a high dimensional search space and\n iteratively reduce the search space by empirically apply constrains\n based on the best performing models sampled by the current search\n space.\n\n The resulting models are light, accurate, and faster than\n EfficientNets (up to 5x times!)\n\n For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the\n bottleneck ratio $b_i$ for all stage $i$. The following table shows\n all the restrictions applied from one search space to the next one.\n\n !image\n\n The paper is really well written and very interesting, I highly\n recommended read it.\n\n \n\n Examples:"
] |
null |
transformers
|
# regnety_004
Implementation of RegNet proposed in [Designing Network Design
Spaces](https://arxiv.org/abs/2003.13678)
The main idea is to start with a high dimensional search space and
iteratively reduce the search space by empirically apply constrains
based on the best performing models sampled by the current search
space.
The resulting models are light, accurate, and faster than
EfficientNets (up to 5x times!)
For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the
bottleneck ratio $b_i$ for all stage $i$. The following table shows
all the restrictions applied from one search space to the next one.

The paper is really well written and very interesting, I highly
recommended read it.
``` python
ResNet.regnetx_002()
ResNet.regnetx_004()
ResNet.regnetx_006()
ResNet.regnetx_008()
ResNet.regnetx_016()
ResNet.regnetx_040()
ResNet.regnetx_064()
ResNet.regnetx_080()
ResNet.regnetx_120()
ResNet.regnetx_160()
ResNet.regnetx_320()
# Y variants (with SE)
ResNet.regnety_002()
# ...
ResNet.regnetx_320()
You can easily customize your model
```
Examples:
``` python
# change activation
RegNet.regnetx_004(activation = nn.SELU)
# change number of classes (default is 1000 )
RegNet.regnetx_004(n_classes=100)
# pass a different block
RegNet.regnetx_004(block=RegNetYBotteneckBlock)
# change the steam
model = RegNet.regnetx_004(stem=ResNetStemC)
change shortcut
model = RegNet.regnetx_004(block=partial(RegNetYBotteneckBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = RegNet.regnetx_004()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 32, 112, 112]), torch.Size([1, 32, 56, 56]), torch.Size([1, 64, 28, 28]), torch.Size([1, 160, 14, 14])]
```
|
{}
|
glasses/regnety_004
| null |
[
"transformers",
"pytorch",
"arxiv:2003.13678",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2003.13678"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2003.13678 #endpoints_compatible #region-us
|
# regnety_004
Implementation of RegNet proposed in Designing Network Design
Spaces
The main idea is to start with a high dimensional search space and
iteratively reduce the search space by empirically apply constrains
based on the best performing models sampled by the current search
space.
The resulting models are light, accurate, and faster than
EfficientNets (up to 5x times!)
For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the
bottleneck ratio $b_i$ for all stage $i$. The following table shows
all the restrictions applied from one search space to the next one.
!image
The paper is really well written and very interesting, I highly
recommended read it.
Examples:
|
[
"# regnety_004\nImplementation of RegNet proposed in Designing Network Design\nSpaces\n\n The main idea is to start with a high dimensional search space and\n iteratively reduce the search space by empirically apply constrains\n based on the best performing models sampled by the current search\n space.\n\n The resulting models are light, accurate, and faster than\n EfficientNets (up to 5x times!)\n\n For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the\n bottleneck ratio $b_i$ for all stage $i$. The following table shows\n all the restrictions applied from one search space to the next one.\n\n !image\n\n The paper is really well written and very interesting, I highly\n recommended read it.\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2003.13678 #endpoints_compatible #region-us \n",
"# regnety_004\nImplementation of RegNet proposed in Designing Network Design\nSpaces\n\n The main idea is to start with a high dimensional search space and\n iteratively reduce the search space by empirically apply constrains\n based on the best performing models sampled by the current search\n space.\n\n The resulting models are light, accurate, and faster than\n EfficientNets (up to 5x times!)\n\n For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the\n bottleneck ratio $b_i$ for all stage $i$. The following table shows\n all the restrictions applied from one search space to the next one.\n\n !image\n\n The paper is really well written and very interesting, I highly\n recommended read it.\n\n \n\n Examples:"
] |
null |
transformers
|
# regnety_006
Implementation of RegNet proposed in [Designing Network Design
Spaces](https://arxiv.org/abs/2003.13678)
The main idea is to start with a high dimensional search space and
iteratively reduce the search space by empirically apply constrains
based on the best performing models sampled by the current search
space.
The resulting models are light, accurate, and faster than
EfficientNets (up to 5x times!)
For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the
bottleneck ratio $b_i$ for all stage $i$. The following table shows
all the restrictions applied from one search space to the next one.

The paper is really well written and very interesting, I highly
recommended read it.
``` python
ResNet.regnetx_002()
ResNet.regnetx_004()
ResNet.regnetx_006()
ResNet.regnetx_008()
ResNet.regnetx_016()
ResNet.regnetx_040()
ResNet.regnetx_064()
ResNet.regnetx_080()
ResNet.regnetx_120()
ResNet.regnetx_160()
ResNet.regnetx_320()
# Y variants (with SE)
ResNet.regnety_002()
# ...
ResNet.regnetx_320()
You can easily customize your model
```
Examples:
``` python
# change activation
RegNet.regnetx_004(activation = nn.SELU)
# change number of classes (default is 1000 )
RegNet.regnetx_004(n_classes=100)
# pass a different block
RegNet.regnetx_004(block=RegNetYBotteneckBlock)
# change the steam
model = RegNet.regnetx_004(stem=ResNetStemC)
change shortcut
model = RegNet.regnetx_004(block=partial(RegNetYBotteneckBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = RegNet.regnetx_004()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 32, 112, 112]), torch.Size([1, 32, 56, 56]), torch.Size([1, 64, 28, 28]), torch.Size([1, 160, 14, 14])]
```
|
{}
|
glasses/regnety_006
| null |
[
"transformers",
"pytorch",
"arxiv:2003.13678",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2003.13678"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2003.13678 #endpoints_compatible #region-us
|
# regnety_006
Implementation of RegNet proposed in Designing Network Design
Spaces
The main idea is to start with a high dimensional search space and
iteratively reduce the search space by empirically apply constrains
based on the best performing models sampled by the current search
space.
The resulting models are light, accurate, and faster than
EfficientNets (up to 5x times!)
For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the
bottleneck ratio $b_i$ for all stage $i$. The following table shows
all the restrictions applied from one search space to the next one.
!image
The paper is really well written and very interesting, I highly
recommended read it.
Examples:
|
[
"# regnety_006\nImplementation of RegNet proposed in Designing Network Design\nSpaces\n\n The main idea is to start with a high dimensional search space and\n iteratively reduce the search space by empirically apply constrains\n based on the best performing models sampled by the current search\n space.\n\n The resulting models are light, accurate, and faster than\n EfficientNets (up to 5x times!)\n\n For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the\n bottleneck ratio $b_i$ for all stage $i$. The following table shows\n all the restrictions applied from one search space to the next one.\n\n !image\n\n The paper is really well written and very interesting, I highly\n recommended read it.\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2003.13678 #endpoints_compatible #region-us \n",
"# regnety_006\nImplementation of RegNet proposed in Designing Network Design\nSpaces\n\n The main idea is to start with a high dimensional search space and\n iteratively reduce the search space by empirically apply constrains\n based on the best performing models sampled by the current search\n space.\n\n The resulting models are light, accurate, and faster than\n EfficientNets (up to 5x times!)\n\n For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the\n bottleneck ratio $b_i$ for all stage $i$. The following table shows\n all the restrictions applied from one search space to the next one.\n\n !image\n\n The paper is really well written and very interesting, I highly\n recommended read it.\n\n \n\n Examples:"
] |
null |
transformers
|
# regnety_008
Implementation of RegNet proposed in [Designing Network Design
Spaces](https://arxiv.org/abs/2003.13678)
The main idea is to start with a high dimensional search space and
iteratively reduce the search space by empirically apply constrains
based on the best performing models sampled by the current search
space.
The resulting models are light, accurate, and faster than
EfficientNets (up to 5x times!)
For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the
bottleneck ratio $b_i$ for all stage $i$. The following table shows
all the restrictions applied from one search space to the next one.

The paper is really well written and very interesting, I highly
recommended read it.
``` python
ResNet.regnetx_002()
ResNet.regnetx_004()
ResNet.regnetx_006()
ResNet.regnetx_008()
ResNet.regnetx_016()
ResNet.regnetx_040()
ResNet.regnetx_064()
ResNet.regnetx_080()
ResNet.regnetx_120()
ResNet.regnetx_160()
ResNet.regnetx_320()
# Y variants (with SE)
ResNet.regnety_002()
# ...
ResNet.regnetx_320()
You can easily customize your model
```
Examples:
``` python
# change activation
RegNet.regnetx_004(activation = nn.SELU)
# change number of classes (default is 1000 )
RegNet.regnetx_004(n_classes=100)
# pass a different block
RegNet.regnetx_004(block=RegNetYBotteneckBlock)
# change the steam
model = RegNet.regnetx_004(stem=ResNetStemC)
change shortcut
model = RegNet.regnetx_004(block=partial(RegNetYBotteneckBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = RegNet.regnetx_004()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 32, 112, 112]), torch.Size([1, 32, 56, 56]), torch.Size([1, 64, 28, 28]), torch.Size([1, 160, 14, 14])]
```
|
{}
|
glasses/regnety_008
| null |
[
"transformers",
"pytorch",
"arxiv:2003.13678",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2003.13678"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2003.13678 #endpoints_compatible #region-us
|
# regnety_008
Implementation of RegNet proposed in Designing Network Design
Spaces
The main idea is to start with a high dimensional search space and
iteratively reduce the search space by empirically apply constrains
based on the best performing models sampled by the current search
space.
The resulting models are light, accurate, and faster than
EfficientNets (up to 5x times!)
For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the
bottleneck ratio $b_i$ for all stage $i$. The following table shows
all the restrictions applied from one search space to the next one.
!image
The paper is really well written and very interesting, I highly
recommended read it.
Examples:
|
[
"# regnety_008\nImplementation of RegNet proposed in Designing Network Design\nSpaces\n\n The main idea is to start with a high dimensional search space and\n iteratively reduce the search space by empirically apply constrains\n based on the best performing models sampled by the current search\n space.\n\n The resulting models are light, accurate, and faster than\n EfficientNets (up to 5x times!)\n\n For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the\n bottleneck ratio $b_i$ for all stage $i$. The following table shows\n all the restrictions applied from one search space to the next one.\n\n !image\n\n The paper is really well written and very interesting, I highly\n recommended read it.\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2003.13678 #endpoints_compatible #region-us \n",
"# regnety_008\nImplementation of RegNet proposed in Designing Network Design\nSpaces\n\n The main idea is to start with a high dimensional search space and\n iteratively reduce the search space by empirically apply constrains\n based on the best performing models sampled by the current search\n space.\n\n The resulting models are light, accurate, and faster than\n EfficientNets (up to 5x times!)\n\n For example, to go from $AnyNet_A$ to $AnyNet_B$ they fixed the\n bottleneck ratio $b_i$ for all stage $i$. The following table shows\n all the restrictions applied from one search space to the next one.\n\n !image\n\n The paper is really well written and very interesting, I highly\n recommended read it.\n\n \n\n Examples:"
] |
image-classification
|
transformers
|
# resnet152
Implementation of ResNet proposed in [Deep Residual Learning for Image
Recognition](https://arxiv.org/abs/1512.03385)
``` python
ResNet.resnet18()
ResNet.resnet26()
ResNet.resnet34()
ResNet.resnet50()
ResNet.resnet101()
ResNet.resnet152()
ResNet.resnet200()
Variants (d) proposed in `Bag of Tricks for Image Classification with Convolutional Neural Networks <https://arxiv.org/pdf/1812.01187.pdf`_
ResNet.resnet26d()
ResNet.resnet34d()
ResNet.resnet50d()
# You can construct your own one by chaning `stem` and `block`
resnet101d = ResNet.resnet101(stem=ResNetStemC, block=partial(ResNetBottleneckBlock, shortcut=ResNetShorcutD))
```
Examples:
``` python
# change activation
ResNet.resnet18(activation = nn.SELU)
# change number of classes (default is 1000 )
ResNet.resnet18(n_classes=100)
# pass a different block
ResNet.resnet18(block=SENetBasicBlock)
# change the steam
model = ResNet.resnet18(stem=ResNetStemC)
change shortcut
model = ResNet.resnet18(block=partial(ResNetBasicBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = ResNet.resnet18()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 64, 112, 112]), torch.Size([1, 64, 56, 56]), torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14])]
```
|
{"license": "apache-2.0", "tags": ["image-classification"], "datasets": ["imagenet"]}
|
glasses/resnet152
| null |
[
"transformers",
"pytorch",
"image-classification",
"dataset:imagenet",
"arxiv:1512.03385",
"arxiv:1812.01187",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1512.03385",
"1812.01187"
] |
[] |
TAGS
#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us
|
# resnet152
Implementation of ResNet proposed in Deep Residual Learning for Image
Recognition
Examples:
|
[
"# resnet152\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us \n",
"# resnet152\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
image-classification
|
transformers
|
# resnet18
Implementation of ResNet proposed in [Deep Residual Learning for Image
Recognition](https://arxiv.org/abs/1512.03385)
``` python
ResNet.resnet18()
ResNet.resnet26()
ResNet.resnet34()
ResNet.resnet50()
ResNet.resnet101()
ResNet.resnet152()
ResNet.resnet200()
Variants (d) proposed in `Bag of Tricks for Image Classification with Convolutional Neural Networks <https://arxiv.org/pdf/1812.01187.pdf`_
ResNet.resnet26d()
ResNet.resnet34d()
ResNet.resnet50d()
# You can construct your own one by chaning `stem` and `block`
resnet101d = ResNet.resnet101(stem=ResNetStemC, block=partial(ResNetBottleneckBlock, shortcut=ResNetShorcutD))
```
Examples:
``` python
# change activation
ResNet.resnet18(activation = nn.SELU)
# change number of classes (default is 1000 )
ResNet.resnet18(n_classes=100)
# pass a different block
ResNet.resnet18(block=SENetBasicBlock)
# change the steam
model = ResNet.resnet18(stem=ResNetStemC)
change shortcut
model = ResNet.resnet18(block=partial(ResNetBasicBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = ResNet.resnet18()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 64, 112, 112]), torch.Size([1, 64, 56, 56]), torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14])]
```
|
{"license": "apache-2.0", "tags": ["image-classification"], "datasets": ["imagenet"]}
|
glasses/resnet18
| null |
[
"transformers",
"pytorch",
"image-classification",
"dataset:imagenet",
"arxiv:1512.03385",
"arxiv:1812.01187",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1512.03385",
"1812.01187"
] |
[] |
TAGS
#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us
|
# resnet18
Implementation of ResNet proposed in Deep Residual Learning for Image
Recognition
Examples:
|
[
"# resnet18\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us \n",
"# resnet18\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
image-classification
|
transformers
|
# resnet26
Implementation of ResNet proposed in [Deep Residual Learning for Image
Recognition](https://arxiv.org/abs/1512.03385)
``` python
ResNet.resnet18()
ResNet.resnet26()
ResNet.resnet34()
ResNet.resnet50()
ResNet.resnet101()
ResNet.resnet152()
ResNet.resnet200()
Variants (d) proposed in `Bag of Tricks for Image Classification with Convolutional Neural Networks <https://arxiv.org/pdf/1812.01187.pdf`_
ResNet.resnet26d()
ResNet.resnet34d()
ResNet.resnet50d()
# You can construct your own one by chaning `stem` and `block`
resnet101d = ResNet.resnet101(stem=ResNetStemC, block=partial(ResNetBottleneckBlock, shortcut=ResNetShorcutD))
```
Examples:
``` python
# change activation
ResNet.resnet18(activation = nn.SELU)
# change number of classes (default is 1000 )
ResNet.resnet18(n_classes=100)
# pass a different block
ResNet.resnet18(block=SENetBasicBlock)
# change the steam
model = ResNet.resnet18(stem=ResNetStemC)
change shortcut
model = ResNet.resnet18(block=partial(ResNetBasicBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = ResNet.resnet18()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 64, 112, 112]), torch.Size([1, 64, 56, 56]), torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14])]
```
|
{"license": "apache-2.0", "tags": ["image-classification"], "datasets": ["imagenet"]}
|
glasses/resnet26
| null |
[
"transformers",
"pytorch",
"image-classification",
"dataset:imagenet",
"arxiv:1512.03385",
"arxiv:1812.01187",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1512.03385",
"1812.01187"
] |
[] |
TAGS
#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us
|
# resnet26
Implementation of ResNet proposed in Deep Residual Learning for Image
Recognition
Examples:
|
[
"# resnet26\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us \n",
"# resnet26\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
image-classification
|
transformers
|
# resnet26d
Implementation of ResNet proposed in [Deep Residual Learning for Image
Recognition](https://arxiv.org/abs/1512.03385)
``` python
ResNet.resnet18()
ResNet.resnet26()
ResNet.resnet34()
ResNet.resnet50()
ResNet.resnet101()
ResNet.resnet152()
ResNet.resnet200()
Variants (d) proposed in `Bag of Tricks for Image Classification with Convolutional Neural Networks <https://arxiv.org/pdf/1812.01187.pdf`_
ResNet.resnet26d()
ResNet.resnet34d()
ResNet.resnet50d()
# You can construct your own one by chaning `stem` and `block`
resnet101d = ResNet.resnet101(stem=ResNetStemC, block=partial(ResNetBottleneckBlock, shortcut=ResNetShorcutD))
```
Examples:
``` python
# change activation
ResNet.resnet18(activation = nn.SELU)
# change number of classes (default is 1000 )
ResNet.resnet18(n_classes=100)
# pass a different block
ResNet.resnet18(block=SENetBasicBlock)
# change the steam
model = ResNet.resnet18(stem=ResNetStemC)
change shortcut
model = ResNet.resnet18(block=partial(ResNetBasicBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = ResNet.resnet18()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 64, 112, 112]), torch.Size([1, 64, 56, 56]), torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14])]
```
|
{"license": "apache-2.0", "tags": ["image-classification"], "datasets": ["imagenet"]}
|
glasses/resnet26d
| null |
[
"transformers",
"pytorch",
"image-classification",
"dataset:imagenet",
"arxiv:1512.03385",
"arxiv:1812.01187",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1512.03385",
"1812.01187"
] |
[] |
TAGS
#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us
|
# resnet26d
Implementation of ResNet proposed in Deep Residual Learning for Image
Recognition
Examples:
|
[
"# resnet26d\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us \n",
"# resnet26d\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
image-classification
|
transformers
|
# resnet34
Implementation of ResNet proposed in [Deep Residual Learning for Image
Recognition](https://arxiv.org/abs/1512.03385)
``` python
ResNet.resnet18()
ResNet.resnet26()
ResNet.resnet34()
ResNet.resnet50()
ResNet.resnet101()
ResNet.resnet152()
ResNet.resnet200()
Variants (d) proposed in `Bag of Tricks for Image Classification with Convolutional Neural Networks <https://arxiv.org/pdf/1812.01187.pdf`_
ResNet.resnet26d()
ResNet.resnet34d()
ResNet.resnet50d()
# You can construct your own one by chaning `stem` and `block`
resnet101d = ResNet.resnet101(stem=ResNetStemC, block=partial(ResNetBottleneckBlock, shortcut=ResNetShorcutD))
```
Examples:
``` python
# change activation
ResNet.resnet18(activation = nn.SELU)
# change number of classes (default is 1000 )
ResNet.resnet18(n_classes=100)
# pass a different block
ResNet.resnet18(block=SENetBasicBlock)
# change the steam
model = ResNet.resnet18(stem=ResNetStemC)
change shortcut
model = ResNet.resnet18(block=partial(ResNetBasicBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = ResNet.resnet18()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 64, 112, 112]), torch.Size([1, 64, 56, 56]), torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14])]
```
|
{"license": "apache-2.0", "tags": ["image-classification"], "datasets": ["imagenet"]}
|
glasses/resnet34
| null |
[
"transformers",
"pytorch",
"image-classification",
"dataset:imagenet",
"arxiv:1512.03385",
"arxiv:1812.01187",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1512.03385",
"1812.01187"
] |
[] |
TAGS
#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us
|
# resnet34
Implementation of ResNet proposed in Deep Residual Learning for Image
Recognition
Examples:
|
[
"# resnet34\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us \n",
"# resnet34\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
image-classification
|
transformers
|
# resnet34d
Implementation of ResNet proposed in [Deep Residual Learning for Image
Recognition](https://arxiv.org/abs/1512.03385)
``` python
ResNet.resnet18()
ResNet.resnet26()
ResNet.resnet34()
ResNet.resnet50()
ResNet.resnet101()
ResNet.resnet152()
ResNet.resnet200()
Variants (d) proposed in `Bag of Tricks for Image Classification with Convolutional Neural Networks <https://arxiv.org/pdf/1812.01187.pdf`_
ResNet.resnet26d()
ResNet.resnet34d()
ResNet.resnet50d()
# You can construct your own one by chaning `stem` and `block`
resnet101d = ResNet.resnet101(stem=ResNetStemC, block=partial(ResNetBottleneckBlock, shortcut=ResNetShorcutD))
```
Examples:
``` python
# change activation
ResNet.resnet18(activation = nn.SELU)
# change number of classes (default is 1000 )
ResNet.resnet18(n_classes=100)
# pass a different block
ResNet.resnet18(block=SENetBasicBlock)
# change the steam
model = ResNet.resnet18(stem=ResNetStemC)
change shortcut
model = ResNet.resnet18(block=partial(ResNetBasicBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = ResNet.resnet18()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 64, 112, 112]), torch.Size([1, 64, 56, 56]), torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14])]
```
|
{"license": "apache-2.0", "tags": ["image-classification"], "datasets": ["imagenet"]}
|
glasses/resnet34d
| null |
[
"transformers",
"pytorch",
"image-classification",
"dataset:imagenet",
"arxiv:1512.03385",
"arxiv:1812.01187",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1512.03385",
"1812.01187"
] |
[] |
TAGS
#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us
|
# resnet34d
Implementation of ResNet proposed in Deep Residual Learning for Image
Recognition
Examples:
|
[
"# resnet34d\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us \n",
"# resnet34d\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
image-classification
|
transformers
|
# resnet50
Implementation of ResNet proposed in [Deep Residual Learning for Image
Recognition](https://arxiv.org/abs/1512.03385)
``` python
ResNet.resnet18()
ResNet.resnet26()
ResNet.resnet34()
ResNet.resnet50()
ResNet.resnet101()
ResNet.resnet152()
ResNet.resnet200()
Variants (d) proposed in `Bag of Tricks for Image Classification with Convolutional Neural Networks <https://arxiv.org/pdf/1812.01187.pdf`_
ResNet.resnet26d()
ResNet.resnet34d()
ResNet.resnet50d()
# You can construct your own one by chaning `stem` and `block`
resnet101d = ResNet.resnet101(stem=ResNetStemC, block=partial(ResNetBottleneckBlock, shortcut=ResNetShorcutD))
```
Examples:
``` python
# change activation
ResNet.resnet18(activation = nn.SELU)
# change number of classes (default is 1000 )
ResNet.resnet18(n_classes=100)
# pass a different block
ResNet.resnet18(block=SENetBasicBlock)
# change the steam
model = ResNet.resnet18(stem=ResNetStemC)
change shortcut
model = ResNet.resnet18(block=partial(ResNetBasicBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = ResNet.resnet18()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 64, 112, 112]), torch.Size([1, 64, 56, 56]), torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14])]
```
|
{"license": "apache-2.0", "tags": ["image-classification"], "datasets": ["imagenet"]}
|
glasses/resnet50
| null |
[
"transformers",
"pytorch",
"image-classification",
"dataset:imagenet",
"arxiv:1512.03385",
"arxiv:1812.01187",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1512.03385",
"1812.01187"
] |
[] |
TAGS
#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us
|
# resnet50
Implementation of ResNet proposed in Deep Residual Learning for Image
Recognition
Examples:
|
[
"# resnet50\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us \n",
"# resnet50\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
image-classification
|
transformers
|
# resnet50d
Implementation of ResNet proposed in [Deep Residual Learning for Image
Recognition](https://arxiv.org/abs/1512.03385)
``` python
ResNet.resnet18()
ResNet.resnet26()
ResNet.resnet34()
ResNet.resnet50()
ResNet.resnet101()
ResNet.resnet152()
ResNet.resnet200()
Variants (d) proposed in `Bag of Tricks for Image Classification with Convolutional Neural Networks <https://arxiv.org/pdf/1812.01187.pdf`_
ResNet.resnet26d()
ResNet.resnet34d()
ResNet.resnet50d()
# You can construct your own one by chaning `stem` and `block`
resnet101d = ResNet.resnet101(stem=ResNetStemC, block=partial(ResNetBottleneckBlock, shortcut=ResNetShorcutD))
```
Examples:
``` python
# change activation
ResNet.resnet18(activation = nn.SELU)
# change number of classes (default is 1000 )
ResNet.resnet18(n_classes=100)
# pass a different block
ResNet.resnet18(block=SENetBasicBlock)
# change the steam
model = ResNet.resnet18(stem=ResNetStemC)
change shortcut
model = ResNet.resnet18(block=partial(ResNetBasicBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = ResNet.resnet18()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 64, 112, 112]), torch.Size([1, 64, 56, 56]), torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14])]
```
|
{"license": "apache-2.0", "tags": ["image-classification"], "datasets": ["imagenet"]}
|
glasses/resnet50d
| null |
[
"transformers",
"pytorch",
"image-classification",
"dataset:imagenet",
"arxiv:1512.03385",
"arxiv:1812.01187",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1512.03385",
"1812.01187"
] |
[] |
TAGS
#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us
|
# resnet50d
Implementation of ResNet proposed in Deep Residual Learning for Image
Recognition
Examples:
|
[
"# resnet50d\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #image-classification #dataset-imagenet #arxiv-1512.03385 #arxiv-1812.01187 #license-apache-2.0 #endpoints_compatible #region-us \n",
"# resnet50d\nImplementation of ResNet proposed in Deep Residual Learning for Image\nRecognition\n\n \n\n Examples:"
] |
null |
transformers
|
# resnext101_32x8d
Implementation of ResNetXt proposed in [\"Aggregated Residual
Transformation for Deep Neural
Networks\"](https://arxiv.org/pdf/1611.05431.pdf)
Create a default model
``` python
ResNetXt.resnext50_32x4d()
ResNetXt.resnext101_32x8d()
# create a resnetxt18_32x4d
ResNetXt.resnet18(block=ResNetXtBottleNeckBlock, groups=32, base_width=4)
```
Examples:
: ``` python
# change activation
ResNetXt.resnext50_32x4d(activation = nn.SELU)
# change number of classes (default is 1000 )
ResNetXt.resnext50_32x4d(n_classes=100)
# pass a different block
ResNetXt.resnext50_32x4d(block=SENetBasicBlock)
# change the initial convolution
model = ResNetXt.resnext50_32x4d
model.encoder.gate.conv1 = nn.Conv2d(3, 64, kernel_size=3)
# store each feature
x = torch.rand((1, 3, 224, 224))
model = ResNetXt.resnext50_32x4d()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 64, 112, 112]), torch.Size([1, 64, 56, 56]), torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14])]
```
|
{}
|
glasses/resnext101_32x8d
| null |
[
"transformers",
"pytorch",
"arxiv:1611.05431",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1611.05431"
] |
[] |
TAGS
#transformers #pytorch #arxiv-1611.05431 #endpoints_compatible #region-us
|
# resnext101_32x8d
Implementation of ResNetXt proposed in \"Aggregated Residual
Transformation for Deep Neural
Networks\"
Create a default model
Examples:
:
|
[
"# resnext101_32x8d\nImplementation of ResNetXt proposed in \\\"Aggregated Residual\nTransformation for Deep Neural\nNetworks\\\"\n\n Create a default model\n\n \n\n Examples:\n\n :"
] |
[
"TAGS\n#transformers #pytorch #arxiv-1611.05431 #endpoints_compatible #region-us \n",
"# resnext101_32x8d\nImplementation of ResNetXt proposed in \\\"Aggregated Residual\nTransformation for Deep Neural\nNetworks\\\"\n\n Create a default model\n\n \n\n Examples:\n\n :"
] |
null |
transformers
|
# resnext50_32x4d
Implementation of ResNetXt proposed in [\"Aggregated Residual
Transformation for Deep Neural
Networks\"](https://arxiv.org/pdf/1611.05431.pdf)
Create a default model
``` python
ResNetXt.resnext50_32x4d()
ResNetXt.resnext101_32x8d()
# create a resnetxt18_32x4d
ResNetXt.resnet18(block=ResNetXtBottleNeckBlock, groups=32, base_width=4)
```
Examples:
: ``` python
# change activation
ResNetXt.resnext50_32x4d(activation = nn.SELU)
# change number of classes (default is 1000 )
ResNetXt.resnext50_32x4d(n_classes=100)
# pass a different block
ResNetXt.resnext50_32x4d(block=SENetBasicBlock)
# change the initial convolution
model = ResNetXt.resnext50_32x4d
model.encoder.gate.conv1 = nn.Conv2d(3, 64, kernel_size=3)
# store each feature
x = torch.rand((1, 3, 224, 224))
model = ResNetXt.resnext50_32x4d()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 64, 112, 112]), torch.Size([1, 64, 56, 56]), torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14])]
```
|
{}
|
glasses/resnext50_32x4d
| null |
[
"transformers",
"pytorch",
"arxiv:1611.05431",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1611.05431"
] |
[] |
TAGS
#transformers #pytorch #arxiv-1611.05431 #endpoints_compatible #region-us
|
# resnext50_32x4d
Implementation of ResNetXt proposed in \"Aggregated Residual
Transformation for Deep Neural
Networks\"
Create a default model
Examples:
:
|
[
"# resnext50_32x4d\nImplementation of ResNetXt proposed in \\\"Aggregated Residual\nTransformation for Deep Neural\nNetworks\\\"\n\n Create a default model\n\n \n\n Examples:\n\n :"
] |
[
"TAGS\n#transformers #pytorch #arxiv-1611.05431 #endpoints_compatible #region-us \n",
"# resnext50_32x4d\nImplementation of ResNetXt proposed in \\\"Aggregated Residual\nTransformation for Deep Neural\nNetworks\\\"\n\n Create a default model\n\n \n\n Examples:\n\n :"
] |
null |
transformers
|
# vgg11
Implementation of VGG proposed in [Very Deep Convolutional Networks For
Large-Scale Image Recognition](https://arxiv.org/pdf/1409.1556.pdf)
``` python
VGG.vgg11()
VGG.vgg13()
VGG.vgg16()
VGG.vgg19()
VGG.vgg11_bn()
VGG.vgg13_bn()
VGG.vgg16_bn()
VGG.vgg19_bn()
```
Please be aware that the [bn]{.title-ref} models uses BatchNorm but
they are very old and people back then don\'t know the bias is
superfluous in a conv followed by a batchnorm.
Examples:
``` python
# change activation
VGG.vgg11(activation = nn.SELU)
# change number of classes (default is 1000 )
VGG.vgg11(n_classes=100)
# pass a different block
from nn.models.classification.senet import SENetBasicBlock
VGG.vgg11(block=SENetBasicBlock)
# store the features tensor after every block
```
|
{}
|
glasses/vgg11
| null |
[
"transformers",
"pytorch",
"arxiv:1409.1556",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1409.1556"
] |
[] |
TAGS
#transformers #pytorch #arxiv-1409.1556 #endpoints_compatible #region-us
|
# vgg11
Implementation of VGG proposed in Very Deep Convolutional Networks For
Large-Scale Image Recognition
Please be aware that the [bn]{.title-ref} models uses BatchNorm but
they are very old and people back then don\'t know the bias is
superfluous in a conv followed by a batchnorm.
Examples:
|
[
"# vgg11\nImplementation of VGG proposed in Very Deep Convolutional Networks For\nLarge-Scale Image Recognition\n\n \n\n Please be aware that the [bn]{.title-ref} models uses BatchNorm but\n they are very old and people back then don\\'t know the bias is\n superfluous in a conv followed by a batchnorm.\n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-1409.1556 #endpoints_compatible #region-us \n",
"# vgg11\nImplementation of VGG proposed in Very Deep Convolutional Networks For\nLarge-Scale Image Recognition\n\n \n\n Please be aware that the [bn]{.title-ref} models uses BatchNorm but\n they are very old and people back then don\\'t know the bias is\n superfluous in a conv followed by a batchnorm.\n\n Examples:"
] |
null |
transformers
|
# vgg11_bn
Implementation of VGG proposed in [Very Deep Convolutional Networks For
Large-Scale Image Recognition](https://arxiv.org/pdf/1409.1556.pdf)
``` python
VGG.vgg11()
VGG.vgg13()
VGG.vgg16()
VGG.vgg19()
VGG.vgg11_bn()
VGG.vgg13_bn()
VGG.vgg16_bn()
VGG.vgg19_bn()
```
Please be aware that the [bn]{.title-ref} models uses BatchNorm but
they are very old and people back then don\'t know the bias is
superfluous in a conv followed by a batchnorm.
Examples:
``` python
# change activation
VGG.vgg11(activation = nn.SELU)
# change number of classes (default is 1000 )
VGG.vgg11(n_classes=100)
# pass a different block
from nn.models.classification.senet import SENetBasicBlock
VGG.vgg11(block=SENetBasicBlock)
# store the features tensor after every block
```
|
{}
|
glasses/vgg11_bn
| null |
[
"transformers",
"pytorch",
"arxiv:1409.1556",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1409.1556"
] |
[] |
TAGS
#transformers #pytorch #arxiv-1409.1556 #endpoints_compatible #region-us
|
# vgg11_bn
Implementation of VGG proposed in Very Deep Convolutional Networks For
Large-Scale Image Recognition
Please be aware that the [bn]{.title-ref} models uses BatchNorm but
they are very old and people back then don\'t know the bias is
superfluous in a conv followed by a batchnorm.
Examples:
|
[
"# vgg11_bn\nImplementation of VGG proposed in Very Deep Convolutional Networks For\nLarge-Scale Image Recognition\n\n \n\n Please be aware that the [bn]{.title-ref} models uses BatchNorm but\n they are very old and people back then don\\'t know the bias is\n superfluous in a conv followed by a batchnorm.\n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-1409.1556 #endpoints_compatible #region-us \n",
"# vgg11_bn\nImplementation of VGG proposed in Very Deep Convolutional Networks For\nLarge-Scale Image Recognition\n\n \n\n Please be aware that the [bn]{.title-ref} models uses BatchNorm but\n they are very old and people back then don\\'t know the bias is\n superfluous in a conv followed by a batchnorm.\n\n Examples:"
] |
null |
transformers
|
# vgg13_bn
Implementation of VGG proposed in [Very Deep Convolutional Networks For
Large-Scale Image Recognition](https://arxiv.org/pdf/1409.1556.pdf)
``` python
VGG.vgg11()
VGG.vgg13()
VGG.vgg16()
VGG.vgg19()
VGG.vgg11_bn()
VGG.vgg13_bn()
VGG.vgg16_bn()
VGG.vgg19_bn()
```
Please be aware that the [bn]{.title-ref} models uses BatchNorm but
they are very old and people back then don\'t know the bias is
superfluous in a conv followed by a batchnorm.
Examples:
``` python
# change activation
VGG.vgg11(activation = nn.SELU)
# change number of classes (default is 1000 )
VGG.vgg11(n_classes=100)
# pass a different block
from nn.models.classification.senet import SENetBasicBlock
VGG.vgg11(block=SENetBasicBlock)
# store the features tensor after every block
```
|
{}
|
glasses/vgg13_bn
| null |
[
"transformers",
"pytorch",
"arxiv:1409.1556",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1409.1556"
] |
[] |
TAGS
#transformers #pytorch #arxiv-1409.1556 #endpoints_compatible #region-us
|
# vgg13_bn
Implementation of VGG proposed in Very Deep Convolutional Networks For
Large-Scale Image Recognition
Please be aware that the [bn]{.title-ref} models uses BatchNorm but
they are very old and people back then don\'t know the bias is
superfluous in a conv followed by a batchnorm.
Examples:
|
[
"# vgg13_bn\nImplementation of VGG proposed in Very Deep Convolutional Networks For\nLarge-Scale Image Recognition\n\n \n\n Please be aware that the [bn]{.title-ref} models uses BatchNorm but\n they are very old and people back then don\\'t know the bias is\n superfluous in a conv followed by a batchnorm.\n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-1409.1556 #endpoints_compatible #region-us \n",
"# vgg13_bn\nImplementation of VGG proposed in Very Deep Convolutional Networks For\nLarge-Scale Image Recognition\n\n \n\n Please be aware that the [bn]{.title-ref} models uses BatchNorm but\n they are very old and people back then don\\'t know the bias is\n superfluous in a conv followed by a batchnorm.\n\n Examples:"
] |
null |
transformers
|
# vgg19_bn
Implementation of VGG proposed in [Very Deep Convolutional Networks For
Large-Scale Image Recognition](https://arxiv.org/pdf/1409.1556.pdf)
``` python
VGG.vgg11()
VGG.vgg13()
VGG.vgg16()
VGG.vgg19()
VGG.vgg11_bn()
VGG.vgg13_bn()
VGG.vgg16_bn()
VGG.vgg19_bn()
```
Please be aware that the [bn]{.title-ref} models uses BatchNorm but
they are very old and people back then don\'t know the bias is
superfluous in a conv followed by a batchnorm.
Examples:
``` python
# change activation
VGG.vgg11(activation = nn.SELU)
# change number of classes (default is 1000 )
VGG.vgg11(n_classes=100)
# pass a different block
from nn.models.classification.senet import SENetBasicBlock
VGG.vgg11(block=SENetBasicBlock)
# store the features tensor after every block
```
|
{}
|
glasses/vgg19_bn
| null |
[
"transformers",
"pytorch",
"arxiv:1409.1556",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1409.1556"
] |
[] |
TAGS
#transformers #pytorch #arxiv-1409.1556 #endpoints_compatible #region-us
|
# vgg19_bn
Implementation of VGG proposed in Very Deep Convolutional Networks For
Large-Scale Image Recognition
Please be aware that the [bn]{.title-ref} models uses BatchNorm but
they are very old and people back then don\'t know the bias is
superfluous in a conv followed by a batchnorm.
Examples:
|
[
"# vgg19_bn\nImplementation of VGG proposed in Very Deep Convolutional Networks For\nLarge-Scale Image Recognition\n\n \n\n Please be aware that the [bn]{.title-ref} models uses BatchNorm but\n they are very old and people back then don\\'t know the bias is\n superfluous in a conv followed by a batchnorm.\n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-1409.1556 #endpoints_compatible #region-us \n",
"# vgg19_bn\nImplementation of VGG proposed in Very Deep Convolutional Networks For\nLarge-Scale Image Recognition\n\n \n\n Please be aware that the [bn]{.title-ref} models uses BatchNorm but\n they are very old and people back then don\\'t know the bias is\n superfluous in a conv followed by a batchnorm.\n\n Examples:"
] |
null |
transformers
|
# vit_base_patch16_224
Implementation of Vision Transformer (ViT) proposed in [An Image Is
Worth 16x16 Words: Transformers For Image Recognition At
Scale](https://arxiv.org/pdf/2010.11929.pdf)
The following image from the authors shows the architecture.

``` python
ViT.vit_small_patch16_224()
ViT.vit_base_patch16_224()
ViT.vit_base_patch16_384()
ViT.vit_base_patch32_384()
ViT.vit_huge_patch16_224()
ViT.vit_huge_patch32_384()
ViT.vit_large_patch16_224()
ViT.vit_large_patch16_384()
ViT.vit_large_patch32_384()
```
Examples:
``` python
# change activation
ViT.vit_base_patch16_224(activation = nn.SELU)
# change number of classes (default is 1000 )
ViT.vit_base_patch16_224(n_classes=100)
# pass a different block, default is TransformerEncoderBlock
ViT.vit_base_patch16_224(block=MyCoolTransformerBlock)
# get features
model = ViT.vit_base_patch16_224
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[[torch.Size([1, 197, 768]), torch.Size([1, 197, 768]), ...]
# change the tokens, you have to subclass ViTTokens
class MyTokens(ViTTokens):
def __init__(self, emb_size: int):
super().__init__(emb_size)
self.my_new_token = nn.Parameter(torch.randn(1, 1, emb_size))
ViT(tokens=MyTokens)
```
|
{}
|
glasses/vit_base_patch16_224
| null |
[
"transformers",
"pytorch",
"arxiv:2010.11929",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2010.11929"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us
|
# vit_base_patch16_224
Implementation of Vision Transformer (ViT) proposed in An Image Is
Worth 16x16 Words: Transformers For Image Recognition At
Scale
The following image from the authors shows the architecture.
!image
Examples:
|
[
"# vit_base_patch16_224\n Implementation of Vision Transformer (ViT) proposed in An Image Is\n Worth 16x16 Words: Transformers For Image Recognition At\n Scale\n\n The following image from the authors shows the architecture.\n\n !image\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us \n",
"# vit_base_patch16_224\n Implementation of Vision Transformer (ViT) proposed in An Image Is\n Worth 16x16 Words: Transformers For Image Recognition At\n Scale\n\n The following image from the authors shows the architecture.\n\n !image\n\n \n\n Examples:"
] |
null |
transformers
|
# vit_base_patch16_384
Implementation of Vision Transformer (ViT) proposed in [An Image Is
Worth 16x16 Words: Transformers For Image Recognition At
Scale](https://arxiv.org/pdf/2010.11929.pdf)
The following image from the authors shows the architecture.

``` python
ViT.vit_small_patch16_224()
ViT.vit_base_patch16_224()
ViT.vit_base_patch16_384()
ViT.vit_base_patch32_384()
ViT.vit_huge_patch16_224()
ViT.vit_huge_patch32_384()
ViT.vit_large_patch16_224()
ViT.vit_large_patch16_384()
ViT.vit_large_patch32_384()
```
Examples:
``` python
# change activation
ViT.vit_base_patch16_224(activation = nn.SELU)
# change number of classes (default is 1000 )
ViT.vit_base_patch16_224(n_classes=100)
# pass a different block, default is TransformerEncoderBlock
ViT.vit_base_patch16_224(block=MyCoolTransformerBlock)
# get features
model = ViT.vit_base_patch16_224
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[[torch.Size([1, 197, 768]), torch.Size([1, 197, 768]), ...]
# change the tokens, you have to subclass ViTTokens
class MyTokens(ViTTokens):
def __init__(self, emb_size: int):
super().__init__(emb_size)
self.my_new_token = nn.Parameter(torch.randn(1, 1, emb_size))
ViT(tokens=MyTokens)
```
|
{}
|
glasses/vit_base_patch16_384
| null |
[
"transformers",
"pytorch",
"arxiv:2010.11929",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2010.11929"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us
|
# vit_base_patch16_384
Implementation of Vision Transformer (ViT) proposed in An Image Is
Worth 16x16 Words: Transformers For Image Recognition At
Scale
The following image from the authors shows the architecture.
!image
Examples:
|
[
"# vit_base_patch16_384\n Implementation of Vision Transformer (ViT) proposed in An Image Is\n Worth 16x16 Words: Transformers For Image Recognition At\n Scale\n\n The following image from the authors shows the architecture.\n\n !image\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us \n",
"# vit_base_patch16_384\n Implementation of Vision Transformer (ViT) proposed in An Image Is\n Worth 16x16 Words: Transformers For Image Recognition At\n Scale\n\n The following image from the authors shows the architecture.\n\n !image\n\n \n\n Examples:"
] |
null |
transformers
|
# vit_huge_patch16_224
Implementation of Vision Transformer (ViT) proposed in [An Image Is
Worth 16x16 Words: Transformers For Image Recognition At
Scale](https://arxiv.org/pdf/2010.11929.pdf)
The following image from the authors shows the architecture.

``` python
ViT.vit_small_patch16_224()
ViT.vit_base_patch16_224()
ViT.vit_base_patch16_384()
ViT.vit_base_patch32_384()
ViT.vit_huge_patch16_224()
ViT.vit_huge_patch32_384()
ViT.vit_large_patch16_224()
ViT.vit_large_patch16_384()
ViT.vit_large_patch32_384()
```
Examples:
``` python
# change activation
ViT.vit_base_patch16_224(activation = nn.SELU)
# change number of classes (default is 1000 )
ViT.vit_base_patch16_224(n_classes=100)
# pass a different block, default is TransformerEncoderBlock
ViT.vit_base_patch16_224(block=MyCoolTransformerBlock)
# get features
model = ViT.vit_base_patch16_224
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[[torch.Size([1, 197, 768]), torch.Size([1, 197, 768]), ...]
# change the tokens, you have to subclass ViTTokens
class MyTokens(ViTTokens):
def __init__(self, emb_size: int):
super().__init__(emb_size)
self.my_new_token = nn.Parameter(torch.randn(1, 1, emb_size))
ViT(tokens=MyTokens)
```
|
{}
|
glasses/vit_huge_patch16_224
| null |
[
"transformers",
"pytorch",
"arxiv:2010.11929",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2010.11929"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us
|
# vit_huge_patch16_224
Implementation of Vision Transformer (ViT) proposed in An Image Is
Worth 16x16 Words: Transformers For Image Recognition At
Scale
The following image from the authors shows the architecture.
!image
Examples:
|
[
"# vit_huge_patch16_224\n Implementation of Vision Transformer (ViT) proposed in An Image Is\n Worth 16x16 Words: Transformers For Image Recognition At\n Scale\n\n The following image from the authors shows the architecture.\n\n !image\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us \n",
"# vit_huge_patch16_224\n Implementation of Vision Transformer (ViT) proposed in An Image Is\n Worth 16x16 Words: Transformers For Image Recognition At\n Scale\n\n The following image from the authors shows the architecture.\n\n !image\n\n \n\n Examples:"
] |
null |
transformers
|
# vit_huge_patch32_384
Implementation of Vision Transformer (ViT) proposed in [An Image Is
Worth 16x16 Words: Transformers For Image Recognition At
Scale](https://arxiv.org/pdf/2010.11929.pdf)
The following image from the authors shows the architecture.

``` python
ViT.vit_small_patch16_224()
ViT.vit_base_patch16_224()
ViT.vit_base_patch16_384()
ViT.vit_base_patch32_384()
ViT.vit_huge_patch16_224()
ViT.vit_huge_patch32_384()
ViT.vit_large_patch16_224()
ViT.vit_large_patch16_384()
ViT.vit_large_patch32_384()
```
Examples:
``` python
# change activation
ViT.vit_base_patch16_224(activation = nn.SELU)
# change number of classes (default is 1000 )
ViT.vit_base_patch16_224(n_classes=100)
# pass a different block, default is TransformerEncoderBlock
ViT.vit_base_patch16_224(block=MyCoolTransformerBlock)
# get features
model = ViT.vit_base_patch16_224
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[[torch.Size([1, 197, 768]), torch.Size([1, 197, 768]), ...]
# change the tokens, you have to subclass ViTTokens
class MyTokens(ViTTokens):
def __init__(self, emb_size: int):
super().__init__(emb_size)
self.my_new_token = nn.Parameter(torch.randn(1, 1, emb_size))
ViT(tokens=MyTokens)
```
|
{}
|
glasses/vit_huge_patch32_384
| null |
[
"transformers",
"pytorch",
"arxiv:2010.11929",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2010.11929"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us
|
# vit_huge_patch32_384
Implementation of Vision Transformer (ViT) proposed in An Image Is
Worth 16x16 Words: Transformers For Image Recognition At
Scale
The following image from the authors shows the architecture.
!image
Examples:
|
[
"# vit_huge_patch32_384\n Implementation of Vision Transformer (ViT) proposed in An Image Is\n Worth 16x16 Words: Transformers For Image Recognition At\n Scale\n\n The following image from the authors shows the architecture.\n\n !image\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us \n",
"# vit_huge_patch32_384\n Implementation of Vision Transformer (ViT) proposed in An Image Is\n Worth 16x16 Words: Transformers For Image Recognition At\n Scale\n\n The following image from the authors shows the architecture.\n\n !image\n\n \n\n Examples:"
] |
null |
transformers
|
# vit_large_patch16_224
Implementation of Vision Transformer (ViT) proposed in [An Image Is
Worth 16x16 Words: Transformers For Image Recognition At
Scale](https://arxiv.org/pdf/2010.11929.pdf)
The following image from the authors shows the architecture.

``` python
ViT.vit_small_patch16_224()
ViT.vit_base_patch16_224()
ViT.vit_base_patch16_384()
ViT.vit_base_patch32_384()
ViT.vit_huge_patch16_224()
ViT.vit_huge_patch32_384()
ViT.vit_large_patch16_224()
ViT.vit_large_patch16_384()
ViT.vit_large_patch32_384()
```
Examples:
``` python
# change activation
ViT.vit_base_patch16_224(activation = nn.SELU)
# change number of classes (default is 1000 )
ViT.vit_base_patch16_224(n_classes=100)
# pass a different block, default is TransformerEncoderBlock
ViT.vit_base_patch16_224(block=MyCoolTransformerBlock)
# get features
model = ViT.vit_base_patch16_224
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[[torch.Size([1, 197, 768]), torch.Size([1, 197, 768]), ...]
# change the tokens, you have to subclass ViTTokens
class MyTokens(ViTTokens):
def __init__(self, emb_size: int):
super().__init__(emb_size)
self.my_new_token = nn.Parameter(torch.randn(1, 1, emb_size))
ViT(tokens=MyTokens)
```
|
{}
|
glasses/vit_large_patch16_224
| null |
[
"transformers",
"pytorch",
"arxiv:2010.11929",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2010.11929"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us
|
# vit_large_patch16_224
Implementation of Vision Transformer (ViT) proposed in An Image Is
Worth 16x16 Words: Transformers For Image Recognition At
Scale
The following image from the authors shows the architecture.
!image
Examples:
|
[
"# vit_large_patch16_224\n Implementation of Vision Transformer (ViT) proposed in An Image Is\n Worth 16x16 Words: Transformers For Image Recognition At\n Scale\n\n The following image from the authors shows the architecture.\n\n !image\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us \n",
"# vit_large_patch16_224\n Implementation of Vision Transformer (ViT) proposed in An Image Is\n Worth 16x16 Words: Transformers For Image Recognition At\n Scale\n\n The following image from the authors shows the architecture.\n\n !image\n\n \n\n Examples:"
] |
null |
transformers
|
# vit_large_patch16_384
Implementation of Vision Transformer (ViT) proposed in [An Image Is
Worth 16x16 Words: Transformers For Image Recognition At
Scale](https://arxiv.org/pdf/2010.11929.pdf)
The following image from the authors shows the architecture.

``` python
ViT.vit_small_patch16_224()
ViT.vit_base_patch16_224()
ViT.vit_base_patch16_384()
ViT.vit_base_patch32_384()
ViT.vit_huge_patch16_224()
ViT.vit_huge_patch32_384()
ViT.vit_large_patch16_224()
ViT.vit_large_patch16_384()
ViT.vit_large_patch32_384()
```
Examples:
``` python
# change activation
ViT.vit_base_patch16_224(activation = nn.SELU)
# change number of classes (default is 1000 )
ViT.vit_base_patch16_224(n_classes=100)
# pass a different block, default is TransformerEncoderBlock
ViT.vit_base_patch16_224(block=MyCoolTransformerBlock)
# get features
model = ViT.vit_base_patch16_224
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[[torch.Size([1, 197, 768]), torch.Size([1, 197, 768]), ...]
# change the tokens, you have to subclass ViTTokens
class MyTokens(ViTTokens):
def __init__(self, emb_size: int):
super().__init__(emb_size)
self.my_new_token = nn.Parameter(torch.randn(1, 1, emb_size))
ViT(tokens=MyTokens)
```
|
{}
|
glasses/vit_large_patch16_384
| null |
[
"transformers",
"pytorch",
"arxiv:2010.11929",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2010.11929"
] |
[] |
TAGS
#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us
|
# vit_large_patch16_384
Implementation of Vision Transformer (ViT) proposed in An Image Is
Worth 16x16 Words: Transformers For Image Recognition At
Scale
The following image from the authors shows the architecture.
!image
Examples:
|
[
"# vit_large_patch16_384\n Implementation of Vision Transformer (ViT) proposed in An Image Is\n Worth 16x16 Words: Transformers For Image Recognition At\n Scale\n\n The following image from the authors shows the architecture.\n\n !image\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-2010.11929 #endpoints_compatible #region-us \n",
"# vit_large_patch16_384\n Implementation of Vision Transformer (ViT) proposed in An Image Is\n Worth 16x16 Words: Transformers For Image Recognition At\n Scale\n\n The following image from the authors shows the architecture.\n\n !image\n\n \n\n Examples:"
] |
null |
transformers
|
# wide_resnet101_2
Implementation of Wide ResNet proposed in [\"Wide Residual
Networks\"](https://arxiv.org/pdf/1605.07146.pdf)
Create a default model
``` python
WideResNet.wide_resnet50_2()
WideResNet.wide_resnet101_2()
# create a wide_resnet18_4
WideResNet.resnet18(block=WideResNetBottleNeckBlock, width_factor=4)
```
Examples:
``` python
# change activation
WideResNet.resnext50_32x4d(activation = nn.SELU)
# change number of classes (default is 1000 )
WideResNet.resnext50_32x4d(n_classes=100)
# pass a different block
WideResNet.resnext50_32x4d(block=SENetBasicBlock)
# change the initial convolution
model = WideResNet.resnext50_32x4d
model.encoder.gate.conv1 = nn.Conv2d(3, 64, kernel_size=3)
# store each feature
x = torch.rand((1, 3, 224, 224))
model = WideResNet.wide_resnet50_2()
features = []
x = model.encoder.gate(x)
for block in model.encoder.layers:
x = block(x)
features.append(x)
print([x.shape for x in features])
# [torch.Size([1, 64, 56, 56]), torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14]), torch.Size([1, 512, 7, 7])]
```
|
{}
|
glasses/wide_resnet101_2
| null |
[
"transformers",
"pytorch",
"arxiv:1605.07146",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1605.07146"
] |
[] |
TAGS
#transformers #pytorch #arxiv-1605.07146 #endpoints_compatible #region-us
|
# wide_resnet101_2
Implementation of Wide ResNet proposed in \"Wide Residual
Networks\"
Create a default model
Examples:
|
[
"# wide_resnet101_2\nImplementation of Wide ResNet proposed in \\\"Wide Residual\nNetworks\\\"\n\n Create a default model\n\n \n\n Examples:"
] |
[
"TAGS\n#transformers #pytorch #arxiv-1605.07146 #endpoints_compatible #region-us \n",
"# wide_resnet101_2\nImplementation of Wide ResNet proposed in \\\"Wide Residual\nNetworks\\\"\n\n Create a default model\n\n \n\n Examples:"
] |
automatic-speech-recognition
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-spanish-custom
This model was trained from scratch on the common_voice dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.2245
- eval_wer: 0.2082
- eval_runtime: 801.6784
- eval_samples_per_second: 18.822
- eval_steps_per_second: 2.354
- epoch: 0.76
- step: 8400
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 10
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
{"tags": ["generated_from_trainer"], "datasets": ["common_voice"], "model-index": [{"name": "wav2vec2-large-xls-r-300m-spanish-custom", "results": []}]}
|
glob-asr/base-spanish-asr
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #wav2vec2 #automatic-speech-recognition #generated_from_trainer #dataset-common_voice #endpoints_compatible #region-us
|
# wav2vec2-large-xls-r-300m-spanish-custom
This model was trained from scratch on the common_voice dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.2245
- eval_wer: 0.2082
- eval_runtime: 801.6784
- eval_samples_per_second: 18.822
- eval_steps_per_second: 2.354
- epoch: 0.76
- step: 8400
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 10
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
[
"# wav2vec2-large-xls-r-300m-spanish-custom\n\nThis model was trained from scratch on the common_voice dataset.\nIt achieves the following results on the evaluation set:\n- eval_loss: 0.2245\n- eval_wer: 0.2082\n- eval_runtime: 801.6784\n- eval_samples_per_second: 18.822\n- eval_steps_per_second: 2.354\n- epoch: 0.76\n- step: 8400",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 16\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_steps: 200\n- num_epochs: 10\n- mixed_precision_training: Native AMP",
"### Framework versions\n\n- Transformers 4.16.0.dev0\n- Pytorch 1.10.1+cu102\n- Datasets 1.17.1.dev0\n- Tokenizers 0.11.0"
] |
[
"TAGS\n#transformers #pytorch #wav2vec2 #automatic-speech-recognition #generated_from_trainer #dataset-common_voice #endpoints_compatible #region-us \n",
"# wav2vec2-large-xls-r-300m-spanish-custom\n\nThis model was trained from scratch on the common_voice dataset.\nIt achieves the following results on the evaluation set:\n- eval_loss: 0.2245\n- eval_wer: 0.2082\n- eval_runtime: 801.6784\n- eval_samples_per_second: 18.822\n- eval_steps_per_second: 2.354\n- epoch: 0.76\n- step: 8400",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0002\n- train_batch_size: 8\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 16\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_steps: 200\n- num_epochs: 10\n- mixed_precision_training: Native AMP",
"### Framework versions\n\n- Transformers 4.16.0.dev0\n- Pytorch 1.10.1+cu102\n- Datasets 1.17.1.dev0\n- Tokenizers 0.11.0"
] |
automatic-speech-recognition
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-guarani-small
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4964
- Wer: 0.5957
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 6.65 | 100 | 1.1326 | 1.0 |
| 1.6569 | 13.32 | 200 | 0.5264 | 0.6478 |
| 1.6569 | 19.97 | 300 | 0.5370 | 0.6261 |
| 0.2293 | 26.65 | 400 | 0.4964 | 0.5957 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
{"language": ["gn"], "license": "apache-2.0", "tags": ["generated_from_trainer", "robust-speech-event", "gn", "hf-asr-leaderboard"], "datasets": ["common_voice"], "model-index": [{"name": "wav2vec2-large-xls-r-300m-guarani-small", "results": []}]}
|
glob-asr/wav2vec2-large-xls-r-300m-guarani-small
| null |
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"robust-speech-event",
"gn",
"hf-asr-leaderboard",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"gn"
] |
TAGS
#transformers #pytorch #tensorboard #wav2vec2 #automatic-speech-recognition #generated_from_trainer #robust-speech-event #gn #hf-asr-leaderboard #dataset-common_voice #license-apache-2.0 #endpoints_compatible #region-us
|
wav2vec2-large-xls-r-300m-guarani-small
=======================================
This model is a fine-tuned version of facebook/wav2vec2-xls-r-300m on the common\_voice dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4964
* Wer: 0.5957
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0002
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* gradient\_accumulation\_steps: 2
* total\_train\_batch\_size: 32
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 100
* num\_epochs: 30
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.16.2
* Pytorch 1.10.0+cu111
* Datasets 1.18.3
* Tokenizers 0.11.0
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 2\n* total\\_train\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 100\n* num\\_epochs: 30\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.16.2\n* Pytorch 1.10.0+cu111\n* Datasets 1.18.3\n* Tokenizers 0.11.0"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #wav2vec2 #automatic-speech-recognition #generated_from_trainer #robust-speech-event #gn #hf-asr-leaderboard #dataset-common_voice #license-apache-2.0 #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 2\n* total\\_train\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 100\n* num\\_epochs: 30\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.16.2\n* Pytorch 1.10.0+cu111\n* Datasets 1.18.3\n* Tokenizers 0.11.0"
] |
automatic-speech-recognition
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-spanish-small
This model is a fine-tuned version of [jhonparra18/wav2vec2-large-xls-r-300m-spanish-custom](https://huggingface.co/jhonparra18/wav2vec2-large-xls-r-300m-spanish-custom) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3596
- Wer: 0.2105
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.1971 | 0.79 | 400 | 0.2169 | 0.2077 |
| 0.2293 | 1.58 | 800 | 0.2507 | 0.2418 |
| 0.2065 | 2.37 | 1200 | 0.2703 | 0.2459 |
| 0.1842 | 3.16 | 1600 | 0.2716 | 0.2495 |
| 0.1634 | 3.95 | 2000 | 0.2695 | 0.2510 |
| 0.1443 | 4.74 | 2400 | 0.2754 | 0.2435 |
| 0.1345 | 5.53 | 2800 | 0.3119 | 0.2654 |
| 0.1267 | 6.32 | 3200 | 0.3154 | 0.2573 |
| 0.1237 | 7.11 | 3600 | 0.3251 | 0.2666 |
| 0.1118 | 7.91 | 4000 | 0.3139 | 0.2503 |
| 0.1051 | 8.7 | 4400 | 0.3286 | 0.2573 |
| 0.0964 | 9.49 | 4800 | 0.3348 | 0.2587 |
| 0.0946 | 10.28 | 5200 | 0.3357 | 0.2587 |
| 0.0897 | 11.07 | 5600 | 0.3408 | 0.2590 |
| 0.0812 | 11.86 | 6000 | 0.3380 | 0.2560 |
| 0.079 | 12.65 | 6400 | 0.3304 | 0.2415 |
| 0.0753 | 13.44 | 6800 | 0.3557 | 0.2540 |
| 0.0717 | 14.23 | 7200 | 0.3507 | 0.2519 |
| 0.0691 | 15.02 | 7600 | 0.3554 | 0.2587 |
| 0.0626 | 15.81 | 8000 | 0.3619 | 0.2520 |
| 0.0661 | 16.6 | 8400 | 0.3609 | 0.2564 |
| 0.0582 | 17.39 | 8800 | 0.3818 | 0.2520 |
| 0.0556 | 18.18 | 9200 | 0.3685 | 0.2410 |
| 0.0515 | 18.97 | 9600 | 0.3658 | 0.2367 |
| 0.0478 | 19.76 | 10000 | 0.3701 | 0.2413 |
| 0.0486 | 20.55 | 10400 | 0.3681 | 0.2371 |
| 0.0468 | 21.34 | 10800 | 0.3607 | 0.2370 |
| 0.0452 | 22.13 | 11200 | 0.3499 | 0.2286 |
| 0.0399 | 22.92 | 11600 | 0.3647 | 0.2282 |
| 0.0393 | 23.72 | 12000 | 0.3638 | 0.2255 |
| 0.0381 | 24.51 | 12400 | 0.3359 | 0.2202 |
| 0.0332 | 25.3 | 12800 | 0.3488 | 0.2177 |
| 0.033 | 26.09 | 13200 | 0.3628 | 0.2175 |
| 0.0311 | 26.88 | 13600 | 0.3695 | 0.2195 |
| 0.0294 | 27.67 | 14000 | 0.3624 | 0.2164 |
| 0.0281 | 28.46 | 14400 | 0.3688 | 0.2113 |
| 0.0274 | 29.25 | 14800 | 0.3596 | 0.2105 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
{"tags": ["generated_from_trainer"], "datasets": ["common_voice"], "model-index": [{"name": "wav2vec2-large-xls-r-300m-spanish-small", "results": []}]}
|
glob-asr/wav2vec2-large-xls-r-300m-spanish-small
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #wav2vec2 #automatic-speech-recognition #generated_from_trainer #dataset-common_voice #endpoints_compatible #region-us
|
wav2vec2-large-xls-r-300m-spanish-small
=======================================
This model is a fine-tuned version of jhonparra18/wav2vec2-large-xls-r-300m-spanish-custom on the common\_voice dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3596
* Wer: 0.2105
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0003
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* gradient\_accumulation\_steps: 2
* total\_train\_batch\_size: 16
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 500
* num\_epochs: 30
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.16.0.dev0
* Pytorch 1.10.1+cu102
* Datasets 1.17.1.dev0
* Tokenizers 0.11.0
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 2\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 500\n* num\\_epochs: 30\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.16.0.dev0\n* Pytorch 1.10.1+cu102\n* Datasets 1.17.1.dev0\n* Tokenizers 0.11.0"
] |
[
"TAGS\n#transformers #pytorch #wav2vec2 #automatic-speech-recognition #generated_from_trainer #dataset-common_voice #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0003\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 2\n* total\\_train\\_batch\\_size: 16\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 500\n* num\\_epochs: 30\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.16.0.dev0\n* Pytorch 1.10.1+cu102\n* Datasets 1.17.1.dev0\n* Tokenizers 0.11.0"
] |
automatic-speech-recognition
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-spanish-large
This model is a fine-tuned version of [tomascufaro/xls-r-es-test](https://huggingface.co/tomascufaro/xls-r-es-test) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1431
- Wer: 0.1197
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 10
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 20
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 300
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.1769 | 0.15 | 400 | 0.1795 | 0.1698 |
| 0.217 | 0.3 | 800 | 0.2000 | 0.1945 |
| 0.2372 | 0.45 | 1200 | 0.1985 | 0.1859 |
| 0.2351 | 0.6 | 1600 | 0.1901 | 0.1772 |
| 0.2269 | 0.75 | 2000 | 0.1968 | 0.1783 |
| 0.2284 | 0.9 | 2400 | 0.1873 | 0.1771 |
| 0.2014 | 1.06 | 2800 | 0.1840 | 0.1696 |
| 0.1988 | 1.21 | 3200 | 0.1904 | 0.1730 |
| 0.1919 | 1.36 | 3600 | 0.1827 | 0.1630 |
| 0.1919 | 1.51 | 4000 | 0.1788 | 0.1629 |
| 0.1817 | 1.66 | 4400 | 0.1755 | 0.1558 |
| 0.1812 | 1.81 | 4800 | 0.1795 | 0.1638 |
| 0.1808 | 1.96 | 5200 | 0.1762 | 0.1603 |
| 0.1625 | 2.11 | 5600 | 0.1721 | 0.1557 |
| 0.1477 | 2.26 | 6000 | 0.1735 | 0.1504 |
| 0.1508 | 2.41 | 6400 | 0.1708 | 0.1478 |
| 0.157 | 2.56 | 6800 | 0.1644 | 0.1466 |
| 0.1491 | 2.71 | 7200 | 0.1638 | 0.1445 |
| 0.1458 | 2.86 | 7600 | 0.1582 | 0.1426 |
| 0.1387 | 3.02 | 8000 | 0.1607 | 0.1376 |
| 0.1269 | 3.17 | 8400 | 0.1559 | 0.1364 |
| 0.1172 | 3.32 | 8800 | 0.1521 | 0.1335 |
| 0.1203 | 3.47 | 9200 | 0.1534 | 0.1330 |
| 0.1177 | 3.62 | 9600 | 0.1485 | 0.1304 |
| 0.1167 | 3.77 | 10000 | 0.1498 | 0.1302 |
| 0.1194 | 3.92 | 10400 | 0.1463 | 0.1287 |
| 0.1053 | 4.07 | 10800 | 0.1483 | 0.1282 |
| 0.098 | 4.22 | 11200 | 0.1498 | 0.1267 |
| 0.0958 | 4.37 | 11600 | 0.1461 | 0.1233 |
| 0.0946 | 4.52 | 12000 | 0.1444 | 0.1218 |
| 0.094 | 4.67 | 12400 | 0.1434 | 0.1206 |
| 0.0932 | 4.82 | 12800 | 0.1424 | 0.1206 |
| 0.0912 | 4.98 | 13200 | 0.1431 | 0.1197 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
|
{"license": "apache-2.0", "tags": ["generated_from_trainer", "es", "robust-speech-event"], "datasets": ["common_voice"], "model-index": [{"name": "wav2vec2-large-xls-r-300m-spanish-large", "results": []}]}
|
glob-asr/wav2vec2-xls-r-300m-spanish-large-LM
| null |
[
"transformers",
"pytorch",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"es",
"robust-speech-event",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #safetensors #wav2vec2 #automatic-speech-recognition #generated_from_trainer #es #robust-speech-event #dataset-common_voice #license-apache-2.0 #endpoints_compatible #region-us
|
wav2vec2-large-xls-r-300m-spanish-large
=======================================
This model is a fine-tuned version of tomascufaro/xls-r-es-test on the common\_voice dataset.
It achieves the following results on the evaluation set:
* Loss: 0.1431
* Wer: 0.1197
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0002
* train\_batch\_size: 10
* eval\_batch\_size: 8
* seed: 42
* gradient\_accumulation\_steps: 2
* total\_train\_batch\_size: 20
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 300
* num\_epochs: 5
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.17.0.dev0
* Pytorch 1.10.2+cu102
* Datasets 1.18.2.dev0
* Tokenizers 0.11.0
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 10\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 2\n* total\\_train\\_batch\\_size: 20\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 300\n* num\\_epochs: 5\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.17.0.dev0\n* Pytorch 1.10.2+cu102\n* Datasets 1.18.2.dev0\n* Tokenizers 0.11.0"
] |
[
"TAGS\n#transformers #pytorch #safetensors #wav2vec2 #automatic-speech-recognition #generated_from_trainer #es #robust-speech-event #dataset-common_voice #license-apache-2.0 #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0002\n* train\\_batch\\_size: 10\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 2\n* total\\_train\\_batch\\_size: 20\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 300\n* num\\_epochs: 5\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.17.0.dev0\n* Pytorch 1.10.2+cu102\n* Datasets 1.18.2.dev0\n* Tokenizers 0.11.0"
] |
automatic-speech-recognition
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xls-r-es-test-lm
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - ES dataset.
It achieves the following results on the test set with lm model:
- Loss: 0.1304
- WER: 0.094
- CER: 0.031
It achieves the following results on the val set with lm model:
- Loss: 0.1304
- WER: 0.081
- CER: 0.025
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 10.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 2.9613 | 0.07 | 500 | 2.9647 | 1.0 |
| 2.604 | 0.14 | 1000 | 1.8300 | 0.9562 |
| 1.177 | 0.21 | 1500 | 0.3652 | 0.3077 |
| 1.0745 | 0.28 | 2000 | 0.2707 | 0.2504 |
| 1.0103 | 0.35 | 2500 | 0.2338 | 0.2157 |
| 0.9858 | 0.42 | 3000 | 0.2321 | 0.2129 |
| 0.974 | 0.49 | 3500 | 0.2164 | 0.2031 |
| 0.9699 | 0.56 | 4000 | 0.2078 | 0.1970 |
| 0.9513 | 0.63 | 4500 | 0.2173 | 0.2139 |
| 0.9657 | 0.7 | 5000 | 0.2050 | 0.1979 |
| 0.9484 | 0.77 | 5500 | 0.2008 | 0.1919 |
| 0.9317 | 0.84 | 6000 | 0.2012 | 0.1911 |
| 0.9366 | 0.91 | 6500 | 0.2024 | 0.1976 |
| 0.9242 | 0.98 | 7000 | 0.2062 | 0.2028 |
| 0.9138 | 1.05 | 7500 | 0.1924 | 0.1863 |
| 0.921 | 1.12 | 8000 | 0.1935 | 0.1836 |
| 0.9117 | 1.19 | 8500 | 0.1887 | 0.1815 |
| 0.9064 | 1.26 | 9000 | 0.1909 | 0.1839 |
| 0.9118 | 1.32 | 9500 | 0.1869 | 0.1830 |
| 0.9121 | 1.39 | 10000 | 0.1863 | 0.1802 |
| 0.9048 | 1.46 | 10500 | 0.1845 | 0.1791 |
| 0.8955 | 1.53 | 11000 | 0.1863 | 0.1774 |
| 0.8947 | 1.6 | 11500 | 0.1907 | 0.1814 |
| 0.9073 | 1.67 | 12000 | 0.1892 | 0.1853 |
| 0.8927 | 1.74 | 12500 | 0.1821 | 0.1750 |
| 0.8732 | 1.81 | 13000 | 0.1815 | 0.1768 |
| 0.8761 | 1.88 | 13500 | 0.1822 | 0.1749 |
| 0.8751 | 1.95 | 14000 | 0.1789 | 0.1715 |
| 0.8889 | 2.02 | 14500 | 0.1819 | 0.1791 |
| 0.8864 | 2.09 | 15000 | 0.1826 | 0.1794 |
| 0.886 | 2.16 | 15500 | 0.1788 | 0.1776 |
| 0.8915 | 2.23 | 16000 | 0.1756 | 0.1719 |
| 0.8689 | 2.3 | 16500 | 0.1769 | 0.1711 |
| 0.879 | 2.37 | 17000 | 0.1777 | 0.1739 |
| 0.8692 | 2.44 | 17500 | 0.1765 | 0.1705 |
| 0.8504 | 2.51 | 18000 | 0.1699 | 0.1652 |
| 0.8728 | 2.58 | 18500 | 0.1705 | 0.1694 |
| 0.8523 | 2.65 | 19000 | 0.1674 | 0.1645 |
| 0.8513 | 2.72 | 19500 | 0.1661 | 0.1611 |
| 0.8498 | 2.79 | 20000 | 0.1660 | 0.1631 |
| 0.8432 | 2.86 | 20500 | 0.1636 | 0.1610 |
| 0.8492 | 2.93 | 21000 | 0.1708 | 0.1688 |
| 0.8561 | 3.0 | 21500 | 0.1663 | 0.1604 |
| 0.842 | 3.07 | 22000 | 0.1690 | 0.1625 |
| 0.857 | 3.14 | 22500 | 0.1642 | 0.1605 |
| 0.8518 | 3.21 | 23000 | 0.1626 | 0.1585 |
| 0.8506 | 3.28 | 23500 | 0.1651 | 0.1605 |
| 0.8394 | 3.35 | 24000 | 0.1647 | 0.1585 |
| 0.8431 | 3.42 | 24500 | 0.1632 | 0.1573 |
| 0.8566 | 3.49 | 25000 | 0.1614 | 0.1550 |
| 0.8534 | 3.56 | 25500 | 0.1645 | 0.1589 |
| 0.8386 | 3.63 | 26000 | 0.1632 | 0.1582 |
| 0.8357 | 3.7 | 26500 | 0.1631 | 0.1556 |
| 0.8299 | 3.77 | 27000 | 0.1612 | 0.1550 |
| 0.8421 | 3.84 | 27500 | 0.1602 | 0.1552 |
| 0.8375 | 3.91 | 28000 | 0.1592 | 0.1537 |
| 0.8328 | 3.97 | 28500 | 0.1587 | 0.1537 |
| 0.8155 | 4.04 | 29000 | 0.1587 | 0.1520 |
| 0.8335 | 4.11 | 29500 | 0.1624 | 0.1556 |
| 0.8138 | 4.18 | 30000 | 0.1581 | 0.1547 |
| 0.8195 | 4.25 | 30500 | 0.1560 | 0.1507 |
| 0.8092 | 4.32 | 31000 | 0.1561 | 0.1534 |
| 0.8191 | 4.39 | 31500 | 0.1549 | 0.1493 |
| 0.8008 | 4.46 | 32000 | 0.1540 | 0.1493 |
| 0.8138 | 4.53 | 32500 | 0.1544 | 0.1493 |
| 0.8173 | 4.6 | 33000 | 0.1553 | 0.1511 |
| 0.8081 | 4.67 | 33500 | 0.1541 | 0.1484 |
| 0.8192 | 4.74 | 34000 | 0.1560 | 0.1506 |
| 0.8068 | 4.81 | 34500 | 0.1540 | 0.1503 |
| 0.8105 | 4.88 | 35000 | 0.1529 | 0.1483 |
| 0.7976 | 4.95 | 35500 | 0.1507 | 0.1451 |
| 0.8143 | 5.02 | 36000 | 0.1505 | 0.1462 |
| 0.8053 | 5.09 | 36500 | 0.1517 | 0.1476 |
| 0.785 | 5.16 | 37000 | 0.1526 | 0.1478 |
| 0.7936 | 5.23 | 37500 | 0.1489 | 0.1421 |
| 0.807 | 5.3 | 38000 | 0.1483 | 0.1420 |
| 0.8092 | 5.37 | 38500 | 0.1481 | 0.1435 |
| 0.793 | 5.44 | 39000 | 0.1503 | 0.1438 |
| 0.814 | 5.51 | 39500 | 0.1495 | 0.1480 |
| 0.807 | 5.58 | 40000 | 0.1472 | 0.1424 |
| 0.7913 | 5.65 | 40500 | 0.1471 | 0.1422 |
| 0.7844 | 5.72 | 41000 | 0.1473 | 0.1422 |
| 0.7888 | 5.79 | 41500 | 0.1445 | 0.1385 |
| 0.7806 | 5.86 | 42000 | 0.1435 | 0.1394 |
| 0.7773 | 5.93 | 42500 | 0.1461 | 0.1424 |
| 0.786 | 6.0 | 43000 | 0.1450 | 0.1413 |
| 0.7784 | 6.07 | 43500 | 0.1463 | 0.1424 |
| 0.7937 | 6.14 | 44000 | 0.1438 | 0.1386 |
| 0.7738 | 6.21 | 44500 | 0.1437 | 0.1383 |
| 0.7728 | 6.28 | 45000 | 0.1424 | 0.1371 |
| 0.7681 | 6.35 | 45500 | 0.1416 | 0.1376 |
| 0.776 | 6.42 | 46000 | 0.1415 | 0.1380 |
| 0.7773 | 6.49 | 46500 | 0.1416 | 0.1371 |
| 0.7692 | 6.56 | 47000 | 0.1398 | 0.1345 |
| 0.7642 | 6.62 | 47500 | 0.1381 | 0.1341 |
| 0.7692 | 6.69 | 48000 | 0.1392 | 0.1334 |
| 0.7667 | 6.76 | 48500 | 0.1392 | 0.1348 |
| 0.7712 | 6.83 | 49000 | 0.1398 | 0.1333 |
| 0.7628 | 6.9 | 49500 | 0.1392 | 0.1344 |
| 0.7622 | 6.97 | 50000 | 0.1377 | 0.1329 |
| 0.7639 | 7.04 | 50500 | 0.1361 | 0.1316 |
| 0.742 | 7.11 | 51000 | 0.1376 | 0.1327 |
| 0.7526 | 7.18 | 51500 | 0.1387 | 0.1342 |
| 0.7606 | 7.25 | 52000 | 0.1363 | 0.1316 |
| 0.7626 | 7.32 | 52500 | 0.1365 | 0.1313 |
| 0.752 | 7.39 | 53000 | 0.1354 | 0.1309 |
| 0.7562 | 7.46 | 53500 | 0.1362 | 0.1312 |
| 0.7557 | 7.53 | 54000 | 0.1358 | 0.1325 |
| 0.7588 | 7.6 | 54500 | 0.1343 | 0.1311 |
| 0.7485 | 7.67 | 55000 | 0.1346 | 0.1301 |
| 0.7466 | 7.74 | 55500 | 0.1354 | 0.1314 |
| 0.7558 | 7.81 | 56000 | 0.1359 | 0.1325 |
| 0.7578 | 7.88 | 56500 | 0.1363 | 0.1334 |
| 0.7411 | 7.95 | 57000 | 0.1346 | 0.1301 |
| 0.7478 | 8.02 | 57500 | 0.1355 | 0.1305 |
| 0.7451 | 8.09 | 58000 | 0.1349 | 0.1302 |
| 0.7383 | 8.16 | 58500 | 0.1349 | 0.1294 |
| 0.7482 | 8.23 | 59000 | 0.1341 | 0.1293 |
| 0.742 | 8.3 | 59500 | 0.1338 | 0.1296 |
| 0.7343 | 8.37 | 60000 | 0.1348 | 0.1307 |
| 0.7385 | 8.44 | 60500 | 0.1324 | 0.1282 |
| 0.7567 | 8.51 | 61000 | 0.1334 | 0.1281 |
| 0.7342 | 8.58 | 61500 | 0.1338 | 0.1289 |
| 0.7401 | 8.65 | 62000 | 0.1331 | 0.1285 |
| 0.7362 | 8.72 | 62500 | 0.1329 | 0.1283 |
| 0.7241 | 8.79 | 63000 | 0.1323 | 0.1277 |
| 0.7244 | 8.86 | 63500 | 0.1317 | 0.1269 |
| 0.7274 | 8.93 | 64000 | 0.1308 | 0.1260 |
| 0.7411 | 9.0 | 64500 | 0.1309 | 0.1256 |
| 0.7255 | 9.07 | 65000 | 0.1316 | 0.1265 |
| 0.7406 | 9.14 | 65500 | 0.1315 | 0.1270 |
| 0.7418 | 9.21 | 66000 | 0.1315 | 0.1269 |
| 0.7301 | 9.27 | 66500 | 0.1315 | 0.1273 |
| 0.7248 | 9.34 | 67000 | 0.1323 | 0.1274 |
| 0.7423 | 9.41 | 67500 | 0.1309 | 0.1267 |
| 0.7152 | 9.48 | 68000 | 0.1312 | 0.1271 |
| 0.7295 | 9.55 | 68500 | 0.1306 | 0.1262 |
| 0.7231 | 9.62 | 69000 | 0.1308 | 0.1263 |
| 0.7344 | 9.69 | 69500 | 0.1313 | 0.1267 |
| 0.7264 | 9.76 | 70000 | 0.1305 | 0.1263 |
| 0.7309 | 9.83 | 70500 | 0.1303 | 0.1262 |
| 0.73 | 9.9 | 71000 | 0.1303 | 0.1261 |
| 0.7353 | 9.97 | 71500 | 0.1304 | 0.1260 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.3
- Tokenizers 0.11.0
|
{"language": ["es"], "license": "apache-2.0", "tags": ["automatic-speech-recognition", "es", "generated_from_trainer", "hf-asr-leaderboard", "mozilla-foundation/common_voice_8_0", "robust-speech-event"], "datasets": ["mozilla-foundation/common_voice_8_0"], "model-index": [{"name": "xls-r-es-test-lm", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Automatic Speech Recognition"}, "dataset": {"name": "Common Voice 8.0", "type": "mozilla-foundation/common_voice_8_0", "args": "es"}, "metrics": [{"type": "wer", "value": 9.4, "name": "Test WER"}]}, {"task": {"type": "automatic-speech-recognition", "name": "Automatic Speech Recognition"}, "dataset": {"name": "Robust Speech Event - Dev Data", "type": "speech-recognition-community-v2/dev_data", "args": "es"}, "metrics": [{"type": "wer", "value": 27.95, "name": "Test WER"}]}, {"task": {"type": "automatic-speech-recognition", "name": "Automatic Speech Recognition"}, "dataset": {"name": "Robust Speech Event - Test Data", "type": "speech-recognition-community-v2/eval_data", "args": "es"}, "metrics": [{"type": "wer", "value": 30.86, "name": "Test WER"}]}]}]}
|
glob-asr/xls-r-es-test-lm
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"es",
"generated_from_trainer",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_8_0",
"robust-speech-event",
"dataset:mozilla-foundation/common_voice_8_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"es"
] |
TAGS
#transformers #pytorch #wav2vec2 #automatic-speech-recognition #es #generated_from_trainer #hf-asr-leaderboard #mozilla-foundation/common_voice_8_0 #robust-speech-event #dataset-mozilla-foundation/common_voice_8_0 #license-apache-2.0 #model-index #endpoints_compatible #has_space #region-us
|
xls-r-es-test-lm
================
This model is a fine-tuned version of facebook/wav2vec2-large-xlsr-53 on the MOZILLA-FOUNDATION/COMMON\_VOICE\_8\_0 - ES dataset.
It achieves the following results on the test set with lm model:
* Loss: 0.1304
* WER: 0.094
* CER: 0.031
It achieves the following results on the val set with lm model:
* Loss: 0.1304
* WER: 0.081
* CER: 0.025
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 7.5e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 32
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 2000
* num\_epochs: 10.0
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.17.0.dev0
* Pytorch 1.10.2+cu102
* Datasets 1.18.3
* Tokenizers 0.11.0
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 7.5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 2000\n* num\\_epochs: 10.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.17.0.dev0\n* Pytorch 1.10.2+cu102\n* Datasets 1.18.3\n* Tokenizers 0.11.0"
] |
[
"TAGS\n#transformers #pytorch #wav2vec2 #automatic-speech-recognition #es #generated_from_trainer #hf-asr-leaderboard #mozilla-foundation/common_voice_8_0 #robust-speech-event #dataset-mozilla-foundation/common_voice_8_0 #license-apache-2.0 #model-index #endpoints_compatible #has_space #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 7.5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 2000\n* num\\_epochs: 10.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.17.0.dev0\n* Pytorch 1.10.2+cu102\n* Datasets 1.18.3\n* Tokenizers 0.11.0"
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Romanian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) in Romanian using the [Common Voice](https://huggingface.co/datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "ro", split="test[:2%]").
processor = Wav2Vec2Processor.from_pretrained("gmihaila/wav2vec2-large-xlsr-53-romanian")
model = Wav2Vec2ForCTC.from_pretrained("gmihaila/wav2vec2-large-xlsr-53-romanian")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
\\\\tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "ro", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gmihaila/wav2vec2-large-xlsr-53-romanian")
model = Wav2Vec2ForCTC.from_pretrained("gmihaila/wav2vec2-large-xlsr-53-romanian")
model.to("cuda")
chars_to_ignore_regex = '[\\\\\\\\,\\\\\\\\?\\\\\\\\.\\\\\\\\!\\\\\\\\-\\\\\\\\;\\\\\\\\:\\\\\\\\"\\\\\\\\“]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\\\tbatch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
\\\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
\\\\tinputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
\\\\twith torch.no_grad():
\\\\t\\\\tlogits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
\\\\tbatch["pred_strings"] = processor.batch_decode(pred_ids)
\\\\treturn batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 28.43 %
## Training
The Common Voice `train`, `validation` datasets were used for training.
The script used for training can be found [here](https://colab.research.google.com/github/gmihaila/ml_things/blob/master/notebooks/pytorch/RO_Fine_Tune_XLSR_Wav2Vec2_on_Turkish_ASR_with_🤗_Transformers.ipynb)
|
{"language": "ro", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["common_voice"], "base_model": "facebook/wav2vec2-large-xlsr-53", "model-index": [{"name": "XLSR Wav2Vec2 Romanian by George Mihaila", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice ro", "type": "common_voice", "args": "ro"}, "metrics": [{"type": "wer", "value": 28.4, "name": "Test WER"}]}]}]}
|
gmihaila/wav2vec2-large-xlsr-53-romanian
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"ro",
"dataset:common_voice",
"base_model:facebook/wav2vec2-large-xlsr-53",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"ro"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #ro #dataset-common_voice #base_model-facebook/wav2vec2-large-xlsr-53 #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
# Wav2Vec2-Large-XLSR-53-Romanian
Fine-tuned facebook/wav2vec2-large-xlsr-53 in Romanian using the Common Voice
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice.
Test Result: 28.43 %
## Training
The Common Voice 'train', 'validation' datasets were used for training.
The script used for training can be found here
|
[
"# Wav2Vec2-Large-XLSR-53-Romanian\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 in Romanian using the Common Voice\nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\n\nThe model can be evaluated as follows on the {language} test data of Common Voice.\n\n\n\n\nTest Result: 28.43 %",
"## Training\n\nThe Common Voice 'train', 'validation' datasets were used for training.\n\nThe script used for training can be found here"
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #ro #dataset-common_voice #base_model-facebook/wav2vec2-large-xlsr-53 #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"# Wav2Vec2-Large-XLSR-53-Romanian\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 in Romanian using the Common Voice\nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\n\nThe model can be evaluated as follows on the {language} test data of Common Voice.\n\n\n\n\nTest Result: 28.43 %",
"## Training\n\nThe Common Voice 'train', 'validation' datasets were used for training.\n\nThe script used for training can be found here"
] |
fill-mask
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERiTmodel2
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.1508
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 280
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 3.1924 | 1.0 | 2854 | 3.4329 |
| 3.0936 | 2.0 | 5708 | 3.5036 |
| 2.9998 | 3.0 | 8562 | 3.1906 |
| 2.9064 | 4.0 | 11416 | 3.4867 |
| 2.8493 | 5.0 | 14270 | 3.2027 |
| 2.7538 | 6.0 | 17124 | 2.9772 |
| 2.7273 | 7.0 | 19978 | 2.9950 |
| 2.7399 | 8.0 | 22832 | 2.9690 |
| 2.67 | 9.0 | 25686 | 3.0311 |
| 2.6388 | 10.0 | 28540 | 3.1508 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
{"license": "mit", "tags": ["generated_from_trainer"], "model-index": [{"name": "BERiTmodel2", "results": []}]}
|
gngpostalsrvc/BERiTmodel2
| null |
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #roberta #fill-mask #generated_from_trainer #license-mit #autotrain_compatible #endpoints_compatible #region-us
|
BERiTmodel2
===========
This model is a fine-tuned version of roberta-base on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 3.1508
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 5e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: cosine
* lr\_scheduler\_warmup\_steps: 280
* num\_epochs: 10
### Training results
### Framework versions
* Transformers 4.14.1
* Pytorch 1.10.0+cu111
* Datasets 1.17.0
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 280\n* num\\_epochs: 10",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.14.1\n* Pytorch 1.10.0+cu111\n* Datasets 1.17.0\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #roberta #fill-mask #generated_from_trainer #license-mit #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: cosine\n* lr\\_scheduler\\_warmup\\_steps: 280\n* num\\_epochs: 10",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.14.1\n* Pytorch 1.10.0+cu111\n* Datasets 1.17.0\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-xsum
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the xsum dataset.
It achieves the following results on the evaluation set:
- Loss: nan
- Rouge1: 2.8351
- Rouge2: 0.3143
- Rougel: 2.6488
- Rougelsum: 2.6463
- Gen Len: 4.9416
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| nan | 1.0 | 12753 | nan | 2.8351 | 0.3143 | 2.6488 | 2.6463 | 4.9416 |
### Framework versions
- Transformers 4.10.2
- Pytorch 1.9.0+cu102
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["xsum"], "metrics": ["rouge"], "model-index": [{"name": "mt5-small-finetuned-xsum", "results": [{"task": {"type": "text2text-generation", "name": "Sequence-to-sequence Language Modeling"}, "dataset": {"name": "xsum", "type": "xsum", "args": "default"}, "metrics": [{"type": "rouge", "value": 2.8351, "name": "Rouge1"}]}]}]}
|
gniemiec/mt5-small-finetuned-xsum
| null |
[
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"generated_from_trainer",
"dataset:xsum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #mt5 #text2text-generation #generated_from_trainer #dataset-xsum #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
mt5-small-finetuned-xsum
========================
This model is a fine-tuned version of google/mt5-small on the xsum dataset.
It achieves the following results on the evaluation set:
* Loss: nan
* Rouge1: 2.8351
* Rouge2: 0.3143
* Rougel: 2.6488
* Rougelsum: 2.6463
* Gen Len: 4.9416
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 1
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.10.2
* Pytorch 1.9.0+cu102
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 1\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.10.2\n* Pytorch 1.9.0+cu102\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #mt5 #text2text-generation #generated_from_trainer #dataset-xsum #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 1\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.10.2\n* Pytorch 1.9.0+cu102\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7967
- Rouge1: 23.0533
- Rouge2: 3.912
- Rougel: 17.8534
- Rougelsum: 17.8581
- Gen Len: 18.6878
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 3.0574 | 1.0 | 1276 | 2.7967 | 23.0533 | 3.912 | 17.8534 | 17.8581 | 18.6878 |
### Framework versions
- Transformers 4.10.2
- Pytorch 1.9.0+cu102
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["xsum"], "metrics": ["rouge"], "model-index": [{"name": "t5-small-finetuned-xsum", "results": [{"task": {"type": "text2text-generation", "name": "Sequence-to-sequence Language Modeling"}, "dataset": {"name": "xsum", "type": "xsum", "args": "default"}, "metrics": [{"type": "rouge", "value": 23.0533, "name": "Rouge1"}]}]}]}
|
gniemiec/t5-small-finetuned-xsum
| null |
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:xsum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #dataset-xsum #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
t5-small-finetuned-xsum
=======================
This model is a fine-tuned version of t5-small on the xsum dataset.
It achieves the following results on the evaluation set:
* Loss: 2.7967
* Rouge1: 23.0533
* Rouge2: 3.912
* Rougel: 17.8534
* Rougelsum: 17.8581
* Gen Len: 18.6878
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 1
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.10.2
* Pytorch 1.9.0+cu102
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 1\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.10.2\n* Pytorch 1.9.0+cu102\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #dataset-xsum #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 1\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.10.2\n* Pytorch 1.9.0+cu102\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
image-classification
|
transformers
|
# diam
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### bunny

#### moon

#### sun

#### tiger

|
{"tags": ["image-classification", "pytorch", "huggingpics"], "metrics": ["accuracy"]}
|
godiec/diam
| null |
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #vit #image-classification #huggingpics #model-index #autotrain_compatible #endpoints_compatible #region-us
|
# diam
Autogenerated by HuggingPics️
Create your own image classifier for anything by running the demo on Google Colab.
Report any issues with the demo at the github repo.
## Example Images
#### bunny
!bunny
#### moon
!moon
#### sun
!sun
#### tiger
!tiger
|
[
"# diam\n\n\nAutogenerated by HuggingPics️\n\nCreate your own image classifier for anything by running the demo on Google Colab.\n\nReport any issues with the demo at the github repo.",
"## Example Images",
"#### bunny\n\n!bunny",
"#### moon\n\n!moon",
"#### sun\n\n!sun",
"#### tiger\n\n!tiger"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #vit #image-classification #huggingpics #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"# diam\n\n\nAutogenerated by HuggingPics️\n\nCreate your own image classifier for anything by running the demo on Google Colab.\n\nReport any issues with the demo at the github repo.",
"## Example Images",
"#### bunny\n\n!bunny",
"#### moon\n\n!moon",
"#### sun\n\n!sun",
"#### tiger\n\n!tiger"
] |
feature-extraction
|
transformers
|
## KoBART-base-v1
```python
from transformers import PreTrainedTokenizerFast, BartModel
tokenizer = PreTrainedTokenizerFast.from_pretrained('gogamza/kobart-base-v1')
model = BartModel.from_pretrained('gogamza/kobart-base-v1')
```
|
{"language": "ko", "license": "mit", "tags": ["bart"]}
|
gogamza/kobart-base-v1
| null |
[
"transformers",
"pytorch",
"safetensors",
"bart",
"feature-extraction",
"ko",
"license:mit",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"ko"
] |
TAGS
#transformers #pytorch #safetensors #bart #feature-extraction #ko #license-mit #endpoints_compatible #has_space #region-us
|
## KoBART-base-v1
|
[
"## KoBART-base-v1"
] |
[
"TAGS\n#transformers #pytorch #safetensors #bart #feature-extraction #ko #license-mit #endpoints_compatible #has_space #region-us \n",
"## KoBART-base-v1"
] |
feature-extraction
|
transformers
|
# Model Card for kobart-base-v2
# Model Details
## Model Description
[**BART**](https://arxiv.org/pdf/1910.13461.pdf)(**B**idirectional and **A**uto-**R**egressive **T**ransformers)는 입력 텍스트 일부에 노이즈를 추가하여 이를 다시 원문으로 복구하는 `autoencoder`의 형태로 학습이 됩니다. 한국어 BART(이하 **KoBART**) 는 논문에서 사용된 `Text Infilling` 노이즈 함수를 사용하여 **40GB** 이상의 한국어 텍스트에 대해서 학습한 한국어 `encoder-decoder` 언어 모델입니다. 이를 통해 도출된 `KoBART-base`를 배포합니다.
- **Developed by:** More information needed
- **Shared by [Optional]:** Heewon(Haven) Jeon
- **Model type:** Feature Extraction
- **Language(s) (NLP):** Korean
- **License:** MIT
- **Parent Model:** BART
- **Resources for more information:**
- [GitHub Repo](https://github.com/haven-jeon/KoBART)
- [Model Demo Space](https://huggingface.co/spaces/gogamza/kobart-summarization)
# Uses
## Direct Use
This model can be used for the task of Feature Extraction.
## Downstream Use [Optional]
More information needed.
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
# Training Details
## Training Data
| Data | # of Sentences |
|-------|---------------:|
| Korean Wiki | 5M |
| Other corpus | 0.27B |
한국어 위키 백과 이외, 뉴스, 책, [모두의 말뭉치 v1.0(대화, 뉴스, ...)](https://corpus.korean.go.kr/), [청와대 국민청원](https://github.com/akngs/petitions) 등의 다양한 데이터가 모델 학습에 사용되었습니다.
`vocab` 사이즈는 30,000 이며 대화에 자주 쓰이는 아래와 같은 이모티콘, 이모지 등을 추가하여 해당 토큰의 인식 능력을 올렸습니다.
> 😀, 😁, 😆, 😅, 🤣, .. , `:-)`, `:)`, `-)`, `(-:`...
## Training Procedure
### Tokenizer
[`tokenizers`](https://github.com/huggingface/tokenizers) 패키지의 `Character BPE tokenizer`로 학습되었습니다.
### Speeds, Sizes, Times
| Model | # of params | Type | # of layers | # of heads | ffn_dim | hidden_dims |
|--------------|:----:|:-------:|--------:|--------:|--------:|--------------:|
| `KoBART-base` | 124M | Encoder | 6 | 16 | 3072 | 768 |
| | | Decoder | 6 | 16 | 3072 | 768 |
# Evaluation
## Testing Data, Factors & Metrics
### Testing Data
More information needed
### Factors
More information needed
### Metrics
More information needed
## Results
NSMC
- acc. : 0.901
The model authors also note in the [GitHub Repo](https://github.com/haven-jeon/KoBART):
| | [NSMC](https://github.com/e9t/nsmc)(acc) | [KorSTS](https://github.com/kakaobrain/KorNLUDatasets)(spearman) | [Question Pair](https://github.com/aisolab/nlp_classification/tree/master/BERT_pairwise_text_classification/qpair)(acc) |
|---|---|---|---|
| **KoBART-base** | 90.24 | 81.66 | 94.34 |
# Model Examination
More information needed
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed
## Compute Infrastructure
More information needed
### Hardware
More information needed
### Software
More information needed.
# Citation
**BibTeX:**
More information needed.
# Glossary [optional]
More information needed
# More Information [optional]
More information needed
# Model Card Authors [optional]
Heewon(Haven) Jeon in collaboration with Ezi Ozoani and the Hugging Face team
# Model Card Contact
The model authors note in the [GitHub Repo](https://github.com/haven-jeon/KoBART):
`KoBART` 관련 이슈는 [이곳](https://github.com/SKT-AI/KoBART/issues)에 올려주세요.
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import PreTrainedTokenizerFast, BartModel
tokenizer = PreTrainedTokenizerFast.from_pretrained('gogamza/kobart-base-v2')
model = BartModel.from_pretrained('gogamza/kobart-base-v2')
```
</details>
|
{"language": "ko", "license": "mit", "tags": ["bart"]}
|
gogamza/kobart-base-v2
| null |
[
"transformers",
"pytorch",
"safetensors",
"bart",
"feature-extraction",
"ko",
"arxiv:1910.13461",
"arxiv:1910.09700",
"license:mit",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1910.13461",
"1910.09700"
] |
[
"ko"
] |
TAGS
#transformers #pytorch #safetensors #bart #feature-extraction #ko #arxiv-1910.13461 #arxiv-1910.09700 #license-mit #endpoints_compatible #region-us
|
Model Card for kobart-base-v2
=============================
Model Details
=============
Model Description
-----------------
BART(Bidirectional and Auto-Regressive Transformers)는 입력 텍스트 일부에 노이즈를 추가하여 이를 다시 원문으로 복구하는 'autoencoder'의 형태로 학습이 됩니다. 한국어 BART(이하 KoBART) 는 논문에서 사용된 'Text Infilling' 노이즈 함수를 사용하여 40GB 이상의 한국어 텍스트에 대해서 학습한 한국어 'encoder-decoder' 언어 모델입니다. 이를 통해 도출된 'KoBART-base'를 배포합니다.
* Developed by: More information needed
* Shared by [Optional]: Heewon(Haven) Jeon
* Model type: Feature Extraction
* Language(s) (NLP): Korean
* License: MIT
* Parent Model: BART
* Resources for more information:
+ GitHub Repo
+ Model Demo Space
Uses
====
Direct Use
----------
This model can be used for the task of Feature Extraction.
Downstream Use [Optional]
-------------------------
More information needed.
Out-of-Scope Use
----------------
The model should not be used to intentionally create hostile or alienating environments for people.
Bias, Risks, and Limitations
============================
Significant research has explored bias and fairness issues with language models (see, e.g., Sheng et al. (2021) and Bender et al. (2021)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
Recommendations
---------------
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
Training Details
================
Training Data
-------------
한국어 위키 백과 이외, 뉴스, 책, 모두의 말뭉치 v1.0(대화, 뉴스, ...), 청와대 국민청원 등의 다양한 데이터가 모델 학습에 사용되었습니다.
'vocab' 사이즈는 30,000 이며 대화에 자주 쓰이는 아래와 같은 이모티콘, 이모지 등을 추가하여 해당 토큰의 인식 능력을 올렸습니다.
>
> , , , , , .. , ':-)', ':)', '-)', '(-:'...
>
>
>
Training Procedure
------------------
### Tokenizer
'tokenizers' 패키지의 'Character BPE tokenizer'로 학습되었습니다.
### Speeds, Sizes, Times
Evaluation
==========
Testing Data, Factors & Metrics
-------------------------------
### Testing Data
More information needed
### Factors
More information needed
### Metrics
More information needed
Results
-------
NSMC
* acc. : 0.901
The model authors also note in the GitHub Repo:
Model Examination
=================
More information needed
Environmental Impact
====================
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
* Hardware Type: More information needed
* Hours used: More information needed
* Cloud Provider: More information needed
* Compute Region: More information needed
* Carbon Emitted: More information needed
Technical Specifications [optional]
===================================
Model Architecture and Objective
--------------------------------
More information needed
Compute Infrastructure
----------------------
More information needed
### Hardware
More information needed
### Software
More information needed.
BibTeX:
More information needed.
Glossary [optional]
===================
More information needed
More Information [optional]
===========================
More information needed
Model Card Authors [optional]
=============================
Heewon(Haven) Jeon in collaboration with Ezi Ozoani and the Hugging Face team
Model Card Contact
==================
The model authors note in the GitHub Repo:
'KoBART' 관련 이슈는 이곳에 올려주세요.
How to Get Started with the Model
=================================
Use the code below to get started with the model.
Click to expand
|
[
"### Tokenizer\n\n\n'tokenizers' 패키지의 'Character BPE tokenizer'로 학습되었습니다.",
"### Speeds, Sizes, Times\n\n\n\nEvaluation\n==========\n\n\nTesting Data, Factors & Metrics\n-------------------------------",
"### Testing Data\n\n\nMore information needed",
"### Factors\n\n\nMore information needed",
"### Metrics\n\n\nMore information needed\n\n\nResults\n-------\n\n\nNSMC\n\n\n* acc. : 0.901\n\n\nThe model authors also note in the GitHub Repo:\n\n\n\nModel Examination\n=================\n\n\nMore information needed\n\n\nEnvironmental Impact\n====================\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n\n* Hardware Type: More information needed\n* Hours used: More information needed\n* Cloud Provider: More information needed\n* Compute Region: More information needed\n* Carbon Emitted: More information needed\n\n\nTechnical Specifications [optional]\n===================================\n\n\nModel Architecture and Objective\n--------------------------------\n\n\nMore information needed\n\n\nCompute Infrastructure\n----------------------\n\n\nMore information needed",
"### Hardware\n\n\nMore information needed",
"### Software\n\n\nMore information needed.\n\n\nBibTeX:\n\n\nMore information needed.\n\n\nGlossary [optional]\n===================\n\n\nMore information needed\n\n\nMore Information [optional]\n===========================\n\n\nMore information needed\n\n\nModel Card Authors [optional]\n=============================\n\n\nHeewon(Haven) Jeon in collaboration with Ezi Ozoani and the Hugging Face team\n\n\nModel Card Contact\n==================\n\n\nThe model authors note in the GitHub Repo:\n'KoBART' 관련 이슈는 이곳에 올려주세요.\n\n\nHow to Get Started with the Model\n=================================\n\n\nUse the code below to get started with the model.\n\n\n\n Click to expand"
] |
[
"TAGS\n#transformers #pytorch #safetensors #bart #feature-extraction #ko #arxiv-1910.13461 #arxiv-1910.09700 #license-mit #endpoints_compatible #region-us \n",
"### Tokenizer\n\n\n'tokenizers' 패키지의 'Character BPE tokenizer'로 학습되었습니다.",
"### Speeds, Sizes, Times\n\n\n\nEvaluation\n==========\n\n\nTesting Data, Factors & Metrics\n-------------------------------",
"### Testing Data\n\n\nMore information needed",
"### Factors\n\n\nMore information needed",
"### Metrics\n\n\nMore information needed\n\n\nResults\n-------\n\n\nNSMC\n\n\n* acc. : 0.901\n\n\nThe model authors also note in the GitHub Repo:\n\n\n\nModel Examination\n=================\n\n\nMore information needed\n\n\nEnvironmental Impact\n====================\n\n\nCarbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).\n\n\n* Hardware Type: More information needed\n* Hours used: More information needed\n* Cloud Provider: More information needed\n* Compute Region: More information needed\n* Carbon Emitted: More information needed\n\n\nTechnical Specifications [optional]\n===================================\n\n\nModel Architecture and Objective\n--------------------------------\n\n\nMore information needed\n\n\nCompute Infrastructure\n----------------------\n\n\nMore information needed",
"### Hardware\n\n\nMore information needed",
"### Software\n\n\nMore information needed.\n\n\nBibTeX:\n\n\nMore information needed.\n\n\nGlossary [optional]\n===================\n\n\nMore information needed\n\n\nMore Information [optional]\n===========================\n\n\nMore information needed\n\n\nModel Card Authors [optional]\n=============================\n\n\nHeewon(Haven) Jeon in collaboration with Ezi Ozoani and the Hugging Face team\n\n\nModel Card Contact\n==================\n\n\nThe model authors note in the GitHub Repo:\n'KoBART' 관련 이슈는 이곳에 올려주세요.\n\n\nHow to Get Started with the Model\n=================================\n\n\nUse the code below to get started with the model.\n\n\n\n Click to expand"
] |
text2text-generation
|
transformers
|
# Korean News Summarization Model
## Demo
https://huggingface.co/spaces/gogamza/kobart-summarization
## How to use
```python
import torch
from transformers import PreTrainedTokenizerFast
from transformers import BartForConditionalGeneration
tokenizer = PreTrainedTokenizerFast.from_pretrained('gogamza/kobart-summarization')
model = BartForConditionalGeneration.from_pretrained('gogamza/kobart-summarization')
text = "과거를 떠올려보자. 방송을 보던 우리의 모습을. 독보적인 매체는 TV였다. 온 가족이 둘러앉아 TV를 봤다. 간혹 가족들끼리 뉴스와 드라마, 예능 프로그램을 둘러싸고 리모컨 쟁탈전이 벌어지기도 했다. 각자 선호하는 프로그램을 ‘본방’으로 보기 위한 싸움이었다. TV가 한 대인지 두 대인지 여부도 그래서 중요했다. 지금은 어떤가. ‘안방극장’이라는 말은 옛말이 됐다. TV가 없는 집도 많다. 미디어의 혜 택을 누릴 수 있는 방법은 늘어났다. 각자의 방에서 각자의 휴대폰으로, 노트북으로, 태블릿으로 콘텐츠 를 즐긴다."
raw_input_ids = tokenizer.encode(text)
input_ids = [tokenizer.bos_token_id] + raw_input_ids + [tokenizer.eos_token_id]
summary_ids = model.generate(torch.tensor([input_ids]))
tokenizer.decode(summary_ids.squeeze().tolist(), skip_special_tokens=True)
```
|
{"language": "ko", "license": "mit", "tags": ["bart"]}
|
gogamza/kobart-summarization
| null |
[
"transformers",
"pytorch",
"safetensors",
"bart",
"text2text-generation",
"ko",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"ko"
] |
TAGS
#transformers #pytorch #safetensors #bart #text2text-generation #ko #license-mit #autotrain_compatible #endpoints_compatible #has_space #region-us
|
# Korean News Summarization Model
## Demo
URL
## How to use
|
[
"# Korean News Summarization Model",
"## Demo\n\nURL",
"## How to use"
] |
[
"TAGS\n#transformers #pytorch #safetensors #bart #text2text-generation #ko #license-mit #autotrain_compatible #endpoints_compatible #has_space #region-us \n",
"# Korean News Summarization Model",
"## Demo\n\nURL",
"## How to use"
] |
null |
transformers
|
Please refer : https://github.com/haven-jeon/LegalQA#train
|
{}
|
gogamza/kobert-legalqa-v1
| null |
[
"transformers",
"pytorch",
"bert",
"next-sentence-prediction",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #bert #next-sentence-prediction #endpoints_compatible #region-us
|
Please refer : URL
|
[] |
[
"TAGS\n#transformers #pytorch #bert #next-sentence-prediction #endpoints_compatible #region-us \n"
] |
translation
|
transformers
|
Byt5-small-ain-jpn-mt is a machine translation model pretrained with [Google's ByT5-small](https://huggingface.co/google/byt5-small) and fine-tuned on bilingual datasets crawled from the Web. It translates Ainu language to Japanese.
|
{"language": ["ain", "ja"], "tags": ["translation"]}
|
Language-Media-Lab/byt5-small-ain-jpn-mt
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"translation",
"ain",
"ja",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"ain",
"ja"
] |
TAGS
#transformers #pytorch #t5 #text2text-generation #translation #ain #ja #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
Byt5-small-ain-jpn-mt is a machine translation model pretrained with Google's ByT5-small and fine-tuned on bilingual datasets crawled from the Web. It translates Ainu language to Japanese.
|
[] |
[
"TAGS\n#transformers #pytorch #t5 #text2text-generation #translation #ain #ja #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n"
] |
translation
|
transformers
|
Byt5-small-jpn-ain-mt is a machine translation model pretrained with [Google's ByT5-small](https://huggingface.co/google/byt5-small) and fine-tuned on bilingual datasets crawled from the Web. It translates Japanese to Ainu language.
|
{"language": ["jpn", "ain"], "tags": ["translation"]}
|
Language-Media-Lab/byt5-small-jpn-ain-mt
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"translation",
"jpn",
"ain",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"jpn",
"ain"
] |
TAGS
#transformers #pytorch #t5 #text2text-generation #translation #jpn #ain #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
Byt5-small-jpn-ain-mt is a machine translation model pretrained with Google's ByT5-small and fine-tuned on bilingual datasets crawled from the Web. It translates Japanese to Ainu language.
|
[] |
[
"TAGS\n#transformers #pytorch #t5 #text2text-generation #translation #jpn #ain #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n"
] |
translation
|
transformers
|
mt5-small-ain-jpn-mt is a machine translation model pretrained with [Google's mT5-small](https://huggingface.co/google/mt5-small) and fine-tuned on bilingual datasets crawled from the Web. It translates Ainu language to Japanese.
|
{"language": ["jpn", "ain"], "tags": ["translation"]}
|
Language-Media-Lab/mt5-small-ain-jpn-mt
| null |
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"translation",
"jpn",
"ain",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"jpn",
"ain"
] |
TAGS
#transformers #pytorch #mt5 #text2text-generation #translation #jpn #ain #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
mt5-small-ain-jpn-mt is a machine translation model pretrained with Google's mT5-small and fine-tuned on bilingual datasets crawled from the Web. It translates Ainu language to Japanese.
|
[] |
[
"TAGS\n#transformers #pytorch #mt5 #text2text-generation #translation #jpn #ain #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n"
] |
translation
|
transformers
|
mt5-small-jpn-ain-mt is a machine translation model pretrained with [Google's mT5-small](https://huggingface.co/google/mt5-small) and fine-tuned on bilingual datasets crawled from the Web. It translates Japanese to Ainu language.
|
{"language": ["jpn", "ain"], "tags": ["translation"]}
|
Language-Media-Lab/mt5-small-jpn-ain-mt
| null |
[
"transformers",
"pytorch",
"mt5",
"text2text-generation",
"translation",
"jpn",
"ain",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"jpn",
"ain"
] |
TAGS
#transformers #pytorch #mt5 #text2text-generation #translation #jpn #ain #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
mt5-small-jpn-ain-mt is a machine translation model pretrained with Google's mT5-small and fine-tuned on bilingual datasets crawled from the Web. It translates Japanese to Ainu language.
|
[] |
[
"TAGS\n#transformers #pytorch #mt5 #text2text-generation #translation #jpn #ain #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n"
] |
question-answering
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.11.0
- Pytorch 1.9.0+cu102
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["squad"], "model-index": [{"name": "distilbert-base-uncased-finetuned-squad", "results": []}]}
|
gokulkarthik/distilbert-base-uncased-finetuned-squad
| null |
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #distilbert #question-answering #generated_from_trainer #dataset-squad #license-apache-2.0 #endpoints_compatible #region-us
|
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of distilbert-base-uncased on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.11.0
- Pytorch 1.9.0+cu102
- Datasets 1.12.1
- Tokenizers 0.10.3
|
[
"# distilbert-base-uncased-finetuned-squad\n\nThis model is a fine-tuned version of distilbert-base-uncased on the squad dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 16\n- eval_batch_size: 16\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 3",
"### Framework versions\n\n- Transformers 4.11.0\n- Pytorch 1.9.0+cu102\n- Datasets 1.12.1\n- Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #distilbert #question-answering #generated_from_trainer #dataset-squad #license-apache-2.0 #endpoints_compatible #region-us \n",
"# distilbert-base-uncased-finetuned-squad\n\nThis model is a fine-tuned version of distilbert-base-uncased on the squad dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 2e-05\n- train_batch_size: 16\n- eval_batch_size: 16\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 3",
"### Framework versions\n\n- Transformers 4.11.0\n- Pytorch 1.9.0+cu102\n- Datasets 1.12.1\n- Tokenizers 0.10.3"
] |
question-answering
|
transformers
|
# XLM-RoBERTa for question answering in Indian languages
pre-trained XLM-Roberta with intermediate pre-training on SQUAD dataset (English) and fine tuning on Chaii dataset (Tamil, Hindi)
# How to use from the 🤗/transformers library
```
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained("gokulkarthik/xlm-roberta-qa-chaii")
model = AutoModelForQuestionAnswering.from_pretrained("gokulkarthik/xlm-roberta-qa-chaii")
```
|
{"language": ["en", "ta", "hi"], "datasets": ["squad", "chaii"], "widget": [{"text": "\u0b85\u0bb2\u0bc1\u0bae\u0bbf\u0ba9\u0bbf\u0baf\u0ba4\u0bcd\u0ba4\u0bbf\u0ba9\u0bcd \u0b85\u0ba3\u0bc1 \u0b8e\u0ba3\u0bcd \u0b8e\u0ba9\u0bcd\u0ba9?", "context": "\u0b85\u0bb2\u0bc1\u0bae\u0bbf\u0ba9\u0bbf\u0baf\u0bae\u0bcd (\u0b86\u0b99\u0bcd\u0b95\u0bbf\u0bb2\u0bae\u0bcd: \u0b85\u0bb2\u0bc1\u0bae\u0bbf\u0ba9\u0bbf\u0baf\u0bae\u0bcd; \u0bb5\u0b9f \u0b85\u0bae\u0bc6\u0bb0\u0bbf\u0b95\u0bcd\u0b95 \u0b86\u0b99\u0bcd\u0b95\u0bbf\u0bb2\u0bae\u0bcd: Aluminum) \u0b92\u0bb0\u0bc1 \u0bb5\u0bc7\u0ba4\u0bbf\u0baf\u0bbf\u0baf\u0bb2\u0bcd \u0ba4\u0ba9\u0bbf\u0bae\u0bae\u0bcd \u0b86\u0b95\u0bc1\u0bae\u0bcd. \u0b87\u0ba4\u0ba9\u0bc1\u0b9f\u0bc8\u0baf \u0b85\u0ba3\u0bc1 \u0b8e\u0ba3\u0bcd 13 \u0b86\u0b95\u0bc1\u0bae\u0bcd. \u0b87\u0ba4\u0bc1 \u0baa\u0bc2\u0bae\u0bbf\u0baf\u0bbf\u0bb2\u0bcd \u0b85\u0ba4\u0bbf\u0b95\u0bae\u0bcd \u0b95\u0bbf\u0b9f\u0bc8\u0b95\u0bcd\u0b95\u0bc1\u0bae\u0bcd \u0b89\u0bb2\u0bcb\u0b95\u0b99\u0bcd\u0b95\u0bb3\u0bc1\u0bb3\u0bcd \u0b92\u0ba9\u0bcd\u0bb1\u0bc1. \u0b87\u0ba4\u0bc1 \u0bae\u0bbf\u0ba9\u0bcd\u0b9a\u0bbe\u0bb0\u0ba4\u0bcd\u0ba4\u0bc8\u0baf\u0bc1\u0bae\u0bcd \u0bb5\u0bc6\u0baa\u0bcd\u0baa\u0ba4\u0bcd\u0ba4\u0bc8\u0baf\u0bc1\u0bae\u0bcd \u0b95\u0b9f\u0ba4\u0bcd\u0ba4 \u0bb5\u0bb2\u0bcd\u0bb2\u0ba4\u0bc1. \u0baa\u0bbe\u0b95\u0bcd\u0bb8\u0bc8\u0b9f\u0bcd \u0b8e\u0ba9\u0bcd\u0bb1 \u0ba4\u0bbe\u0ba4\u0bc1\u0bb5\u0bbf\u0bb2\u0bcd \u0b87\u0bb0\u0bc1\u0ba8\u0bcd\u0ba4\u0bc1 \u0b85\u0bb2\u0bc1\u0bae\u0bbf\u0ba9\u0bbf\u0baf\u0bae\u0bcd \u0ba4\u0baf\u0bbe\u0bb0\u0bbf\u0b95\u0bcd\u0b95\u0baa\u0bcd\u0baa\u0b9f\u0bc1\u0b95\u0bbf\u0bb1\u0ba4\u0bc1. \u0b87\u0ba4\u0ba9\u0bcd \u0bb5\u0bc7\u0ba4\u0bbf\u0b95\u0bcd\u0b95\u0bc1\u0bb1\u0bbf\u0baf\u0bc0\u0b9f\u0bc1 Al \u0b86\u0b95\u0bc1\u0bae\u0bcd."}, {"text": "\u091c\u094d\u0935\u093e\u0932\u093e \u0917\u0941\u091f\u094d\u091f\u093e \u0915\u0940 \u092e\u093e\u0901 \u0915\u093e \u0928\u093e\u092e \u0915\u094d\u092f\u093e \u0939\u0948?", "context": "\u091c\u094d\u0935\u093e\u0932\u093e \u0917\u0941\u091f\u094d\u091f\u093e (\u091c\u0928\u094d\u092e: 7 \u0938\u093f\u0924\u0902\u092c\u0930 1983; \u0935\u0930\u094d\u0927\u093e, \u092e\u0939\u093e\u0930\u093e\u0937\u094d\u091f\u094d\u0930) \u090f\u0915 \u092d\u093e\u0930\u0924\u0940\u092f \u092c\u0948\u0921\u092e\u093f\u0902\u091f\u0928 \u0916\u093f\u0932\u093e\u0921\u0940 \u0939\u0948\u0902\u0964 \u092a\u094d\u0930\u093e\u0930\u0902\u092d\u093f\u0915 \u091c\u0940\u0935\u0928 \u091c\u094d\u0935\u093e\u0932\u093e \u0917\u0941\u091f\u094d\u091f\u093e \u0915\u093e \u091c\u0928\u094d\u092e 7 \u0938\u093f\u0924\u0902\u092c\u0930 1983 \u0915\u094b \u0935\u0930\u094d\u0927\u093e, \u092e\u0939\u093e\u0930\u093e\u0937\u094d\u091f\u094d\u0930 \u092e\u0947\u0902 \u0939\u0941\u0906 \u0925\u093e\u0964 \u0909\u0928\u0915\u0947 \u092a\u093f\u0924\u093e \u090f\u092e. \u0915\u094d\u0930\u093e\u0902\u0924\u093f \u0924\u0947\u0932\u0941\u0917\u0941 \u0914\u0930 \u092e\u093e\u0902 \u092f\u0947\u0932\u0928 \u091a\u0940\u0928 \u0938\u0947 \u0939\u0948\u0902\u0964 \u0909\u0928\u0915\u0940 \u092e\u093e\u0902 \u092f\u0947\u0932\u0928 \u0917\u0941\u091f\u094d\u091f\u093e \u092a\u0939\u0932\u0940 \u092c\u093e\u0930 1977 \u092e\u0947\u0902 \u0905\u092a\u0928\u0947 \u0926\u093e\u0926\u093e \u091c\u0940 \u0915\u0947 \u0938\u093e\u0925 \u092d\u093e\u0930\u0924 \u0906\u0908 \u0925\u0940\u0902\u0964 \u091c\u094d\u0935\u093e\u0932\u093e \u0917\u0941\u091f\u094d\u091f\u093e \u0915\u0940 \u092a\u094d\u0930\u093e\u0930\u0902\u092d\u093f\u0915 \u092a\u0922\u093c\u093e\u0908 \u0939\u0948\u0926\u0930\u093e\u092c\u093e\u0926 \u0938\u0947 \u0939\u0941\u0908 \u0914\u0930 \u092f\u0939\u0940\u0902 \u0938\u0947 \u0909\u0928\u094d\u0939\u094b\u0902\u0928\u0947 \u092c\u0948\u0921\u092e\u093f\u0902\u091f\u0928 \u0916\u0947\u0932\u0928\u093e \u092d\u0940 \u0936\u0941\u0930\u0942 \u0915\u093f\u092f\u093e\u0964 \u0915\u0945\u0930\u093f\u092f\u0930 10 \u0938\u093e\u0932 \u0915\u0940 \u0909\u092e\u094d\u0930 \u0938\u0947 \u0939\u0940 \u091c\u094d\u0935\u093e\u0932\u093e \u0917\u0941\u091f\u094d\u091f\u093e \u0928\u0947 \u090f\u0938.\u090f\u092e. \u0906\u0930\u093f\u092b \u0938\u0947 \u091f\u094d\u0930\u0947\u0928\u093f\u0902\u0917 \u0932\u0947\u0928\u093e \u0936\u0941\u0930\u0942 \u0915\u0930 \u0926\u093f\u092f\u093e \u0925\u093e\u0964 \u090f\u0938.\u090f\u092e. \u0906\u0930\u093f\u092b \u092d\u093e\u0930\u0924 \u0915\u0947 \u091c\u093e\u0928\u0947 \u092e\u093e\u0928\u0947 \u0916\u0947\u0932 \u092a\u094d\u0930\u0936\u093f\u0915\u094d\u0937\u0915 \u0939\u0948\u0902 \u091c\u093f\u0928\u094d\u0939\u0947\u0902 \u0926\u094d\u0930\u094b\u0923\u093e\u091a\u093e\u0930\u094d\u092f \u0905\u0935\u093e\u0930\u094d\u0921 \u0938\u0947 \u0938\u092e\u094d\u092e\u093e\u0928\u093f\u0924 \u0915\u093f\u092f\u093e \u0917\u092f\u093e \u0939\u0948\u0964 \u092a\u0939\u0932\u0940 \u092c\u093e\u0930 13 \u0938\u093e\u0932 \u0915\u0940 \u0909\u092e\u094d\u0930 \u092e\u0947\u0902 \u0909\u0928\u094d\u0939\u094b\u0902\u0928\u0947 \u092e\u093f\u0928\u0940 \u0928\u0947\u0936\u0928\u0932 \u092c\u0948\u0921\u092e\u093f\u0902\u091f\u0928 \u091a\u0948\u0902\u092a\u093f\u092f\u0928\u0936\u093f\u092a \u091c\u0940\u0924\u0940 \u0925\u0940\u0964 \u0938\u093e\u0932 2000 \u092e\u0947\u0902 \u091c\u094d\u0935\u093e\u0932\u093e \u0917\u0941\u091f\u094d\u091f\u093e \u0928\u0947 17 \u0938\u093e\u0932 \u0915\u0940 \u0909\u092e\u094d\u0930 \u092e\u0947\u0902 \u091c\u0942\u0928\u093f\u092f\u0930 \u0928\u0947\u0936\u0928\u0932 \u092c\u0948\u0921\u092e\u093f\u0902\u091f\u0928 \u091a\u0948\u0902\u092a\u093f\u092f\u0928\u0936\u093f\u092a \u091c\u0940\u0924\u0940\u0964 \u0907\u0938\u0940 \u0938\u093e\u0932 \u0909\u0928\u094d\u0939\u094b\u0902\u0928\u0947 \u0936\u094d\u0930\u0941\u0924\u093f \u0915\u0941\u0930\u093f\u092f\u0928 \u0915\u0947 \u0938\u093e\u0925 \u0921\u092c\u0932\u094d\u0938 \u092e\u0947\u0902 \u091c\u094b\u0921\u093c\u0940 \u092c\u0928\u093e\u0924\u0947 \u0939\u0941\u090f \u092e\u0939\u093f\u0932\u093e\u0913\u0902 \u0915\u0947 \u0921\u092c\u0932\u094d\u0938 \u091c\u0942\u0928\u093f\u092f\u0930 \u0928\u0947\u0936\u0928\u0932 \u092c\u0948\u0921\u092e\u093f\u0902\u091f\u0928 \u091a\u0948\u0902\u092a\u093f\u092f\u0928\u0936\u093f\u092a \u0914\u0930 \u0938\u0940\u0928\u093f\u092f\u0930 \u0928\u0947\u0936\u0928\u0932 \u092c\u0948\u0921\u092e\u093f\u0902\u091f\u0928 \u091a\u0948\u0902\u092a\u093f\u092f\u0928\u0936\u093f\u092a \u092e\u0947\u0902 \u091c\u0940\u0924 \u0939\u093e\u0938\u093f\u0932 \u0915\u0940\u0964 \u0936\u094d\u0930\u0941\u0924\u093f \u0915\u0941\u0930\u093f\u092f\u0928 \u0915\u0947 \u0938\u093e\u0925 \u0909\u0928\u0915\u0940 \u091c\u094b\u0921\u093c\u0940 \u0915\u093e\u092b\u0940 \u0932\u0902\u092c\u0947 \u0938\u092e\u092f \u0924\u0915 \u091a\u0932\u0940\u0964 2002 \u0938\u0947 2008 \u0924\u0915 \u0932\u0917\u093e\u0924\u093e\u0930 \u0938\u093e\u0924 \u092c\u093e\u0930 \u091c\u094d\u0935\u093e\u0932\u093e \u0917\u0941\u091f\u094d\u091f\u093e \u0928\u0947 \u092e\u0939\u093f\u0932\u093e\u0913\u0902 \u0915\u0947 \u0928\u0947\u0936\u0928\u0932 \u092f\u0941\u0917\u0932 \u092a\u094d\u0930\u0924\u093f\u092f\u094b\u0917\u093f\u0924\u093e \u092e\u0947\u0902 \u091c\u0940\u0924 \u0939\u093e\u0938\u093f\u0932 \u0915\u0940\u0964"}, {"text": "How many bones do you have in your body?", "context": "A normal adult human skeleton consists of the following 206 (208 if the breast is thought to be three parts). This number can vary depending on the physiological differences. For example, in a very small number of humans, an extra rib (neck) or an extra lower spinal cord is found. There are 22 bones in the human skull (excluding the ear tendons), which are divided into eight cranium bones and 14 facial bones. (Thick numbers indicate the numbers seen in the nearby picture.) Bones (8) 1 frontal bone (2) 3 temporal bone (2) 4 occipital bone (4) Sphinoid bone (14) 7 mandible (6) maxilla (2) palatine bone (2) 5 zygotic bone (9) 9 nasal bone (2) The sacral vertebrae (4 or 5), in adults, form the sacral vertebrae (3 to 5), in adults they form the valve."}]}
|
gokulkarthik/xlm-roberta-qa-chaii
| null |
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"en",
"ta",
"hi",
"dataset:squad",
"dataset:chaii",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en",
"ta",
"hi"
] |
TAGS
#transformers #pytorch #xlm-roberta #question-answering #en #ta #hi #dataset-squad #dataset-chaii #endpoints_compatible #region-us
|
# XLM-RoBERTa for question answering in Indian languages
pre-trained XLM-Roberta with intermediate pre-training on SQUAD dataset (English) and fine tuning on Chaii dataset (Tamil, Hindi)
# How to use from the /transformers library
|
[
"# XLM-RoBERTa for question answering in Indian languages\npre-trained XLM-Roberta with intermediate pre-training on SQUAD dataset (English) and fine tuning on Chaii dataset (Tamil, Hindi)",
"# How to use from the /transformers library"
] |
[
"TAGS\n#transformers #pytorch #xlm-roberta #question-answering #en #ta #hi #dataset-squad #dataset-chaii #endpoints_compatible #region-us \n",
"# XLM-RoBERTa for question answering in Indian languages\npre-trained XLM-Roberta with intermediate pre-training on SQUAD dataset (English) and fine tuning on Chaii dataset (Tamil, Hindi)",
"# How to use from the /transformers library"
] |
text2text-generation
|
transformers
|
# rachael-scai
Generation model (Pegasus fine-tuned with QReCC) used in the participation of group Rachael for SCAI 2021.
GitHub repository can be found in: [gonced8/rachael-scai](https://github.com/gonced8/rachael-scai)
Gonçalo Raposo
## Cite
```bibtex
@InProceedings{Raposo2022,
author = {Gonçalo Raposo and Rui Ribeiro and Bruno Martins and Luísa Coheur},
booktitle = {44th European Conference on Information Retrieval},
title = {Question rewriting? Assessing its importance for conversational question answering},
year = {2022},
month = apr,
note = {This version of the contribution has been accepted for publication, after peer review but is not the Version of Record and does not reflect post-acceptance improvements, or any corrections. The Version of Record is available online at: http://dx.doi.org/[not yet available]. Use of this Accepted Version is subject to the publisher’s Accepted Manuscript terms of use \url{https://www.springernature.com/gp/open-research/policies/accepted-manuscript-terms}},
abstract = {In conversational question answering, systems must correctly interpret the interconnected interactions and generate knowledgeable answers, which may require the retrieval of relevant information from a background repository. Recent approaches to this problem leverage neural language models, although different alternatives can be considered in terms of modules for (a) representing user questions in context, (b) retrieving the relevant background information, and (c) generating the answer. This work presents a conversational question answering system designed specifically for the Search-Oriented Conversational AI (SCAI) shared task, and reports on a detailed analysis of its question rewriting module. In particular, we considered different variations of the question rewriting module to evaluate the influence on the subsequent components, and performed a careful analysis of the results obtained with the best system configuration. Our system achieved the best performance in the shared task and our analysis emphasizes the importance of the conversation context representation for the overall system performance.},
keywords = {conversational question answering, conversational search, question rewriting, transformer-based neural language models},
}
```
|
{"license": "gpl-3.0"}
|
gonced8/pegasus-conversational-qa
| null |
[
"transformers",
"pytorch",
"tf",
"safetensors",
"pegasus",
"text2text-generation",
"license:gpl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tf #safetensors #pegasus #text2text-generation #license-gpl-3.0 #autotrain_compatible #endpoints_compatible #region-us
|
# rachael-scai
Generation model (Pegasus fine-tuned with QReCC) used in the participation of group Rachael for SCAI 2021.
GitHub repository can be found in: gonced8/rachael-scai
Gonçalo Raposo
## Cite
|
[
"# rachael-scai\r\nGeneration model (Pegasus fine-tuned with QReCC) used in the participation of group Rachael for SCAI 2021. \r\n\r\nGitHub repository can be found in: gonced8/rachael-scai\r\n\r\nGonçalo Raposo",
"## Cite"
] |
[
"TAGS\n#transformers #pytorch #tf #safetensors #pegasus #text2text-generation #license-gpl-3.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"# rachael-scai\r\nGeneration model (Pegasus fine-tuned with QReCC) used in the participation of group Rachael for SCAI 2021. \r\n\r\nGitHub repository can be found in: gonced8/rachael-scai\r\n\r\nGonçalo Raposo",
"## Cite"
] |
translation
|
transformers
|
# bert2bert_L-24_wmt_de_en EncoderDecoder model
The model was introduced in
[this paper](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn and first released in [this repository](https://tfhub.dev/google/bertseq2seq/bert24_de_en/1).
The model is an encoder-decoder model that was initialized on the `bert-large` checkpoints for both the encoder
and decoder and fine-tuned on German to English translation on the WMT dataset, which is linked above.
Disclaimer: The model card has been written by the Hugging Face team.
## How to use
You can use this model for translation, *e.g.*
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("google/bert2bert_L-24_wmt_de_en", pad_token="<pad>", eos_token="</s>", bos_token="<s>")
model = AutoModelForSeq2SeqLM.from_pretrained("google/bert2bert_L-24_wmt_de_en")
sentence = "Willst du einen Kaffee trinken gehen mit mir?"
input_ids = tokenizer(sentence, return_tensors="pt", add_special_tokens=False).input_ids
output_ids = model.generate(input_ids)[0]
print(tokenizer.decode(output_ids, skip_special_tokens=True))
# should output
# Want to drink a kaffee go with me? .
```
|
{"language": ["en", "de"], "license": "apache-2.0", "tags": ["translation"], "datasets": ["wmt14"]}
|
google/bert2bert_L-24_wmt_de_en
| null |
[
"transformers",
"pytorch",
"encoder-decoder",
"text2text-generation",
"translation",
"en",
"de",
"dataset:wmt14",
"arxiv:1907.12461",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1907.12461"
] |
[
"en",
"de"
] |
TAGS
#transformers #pytorch #encoder-decoder #text2text-generation #translation #en #de #dataset-wmt14 #arxiv-1907.12461 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #has_space #region-us
|
# bert2bert_L-24_wmt_de_en EncoderDecoder model
The model was introduced in
this paper by Sascha Rothe, Shashi Narayan, Aliaksei Severyn and first released in this repository.
The model is an encoder-decoder model that was initialized on the 'bert-large' checkpoints for both the encoder
and decoder and fine-tuned on German to English translation on the WMT dataset, which is linked above.
Disclaimer: The model card has been written by the Hugging Face team.
## How to use
You can use this model for translation, *e.g.*
|
[
"# bert2bert_L-24_wmt_de_en EncoderDecoder model\n\nThe model was introduced in \nthis paper by Sascha Rothe, Shashi Narayan, Aliaksei Severyn and first released in this repository. \n\nThe model is an encoder-decoder model that was initialized on the 'bert-large' checkpoints for both the encoder \nand decoder and fine-tuned on German to English translation on the WMT dataset, which is linked above.\n\nDisclaimer: The model card has been written by the Hugging Face team.",
"## How to use\n\nYou can use this model for translation, *e.g.*"
] |
[
"TAGS\n#transformers #pytorch #encoder-decoder #text2text-generation #translation #en #de #dataset-wmt14 #arxiv-1907.12461 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #has_space #region-us \n",
"# bert2bert_L-24_wmt_de_en EncoderDecoder model\n\nThe model was introduced in \nthis paper by Sascha Rothe, Shashi Narayan, Aliaksei Severyn and first released in this repository. \n\nThe model is an encoder-decoder model that was initialized on the 'bert-large' checkpoints for both the encoder \nand decoder and fine-tuned on German to English translation on the WMT dataset, which is linked above.\n\nDisclaimer: The model card has been written by the Hugging Face team.",
"## How to use\n\nYou can use this model for translation, *e.g.*"
] |
translation
|
transformers
|
# bert2bert_L-24_wmt_en_de EncoderDecoder model
The model was introduced in
[this paper](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn and first released in [this repository](https://tfhub.dev/google/bertseq2seq/bert24_en_de/1).
The model is an encoder-decoder model that was initialized on the `bert-large` checkpoints for both the encoder
and decoder and fine-tuned on English to German translation on the WMT dataset, which is linked above.
Disclaimer: The model card has been written by the Hugging Face team.
## How to use
You can use this model for translation, *e.g.*
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("google/bert2bert_L-24_wmt_en_de", pad_token="<pad>", eos_token="</s>", bos_token="<s>")
model = AutoModelForSeq2SeqLM.from_pretrained("google/bert2bert_L-24_wmt_en_de")
sentence = "Would you like to grab a coffee with me this week?"
input_ids = tokenizer(sentence, return_tensors="pt", add_special_tokens=False).input_ids
output_ids = model.generate(input_ids)[0]
print(tokenizer.decode(output_ids, skip_special_tokens=True))
# should output
# Möchten Sie diese Woche einen Kaffee mit mir schnappen?
|
{"language": ["en", "de"], "license": "apache-2.0", "tags": ["translation"], "datasets": ["wmt14"]}
|
google/bert2bert_L-24_wmt_en_de
| null |
[
"transformers",
"pytorch",
"encoder-decoder",
"text2text-generation",
"translation",
"en",
"de",
"dataset:wmt14",
"arxiv:1907.12461",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1907.12461"
] |
[
"en",
"de"
] |
TAGS
#transformers #pytorch #encoder-decoder #text2text-generation #translation #en #de #dataset-wmt14 #arxiv-1907.12461 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
# bert2bert_L-24_wmt_en_de EncoderDecoder model
The model was introduced in
this paper by Sascha Rothe, Shashi Narayan, Aliaksei Severyn and first released in this repository.
The model is an encoder-decoder model that was initialized on the 'bert-large' checkpoints for both the encoder
and decoder and fine-tuned on English to German translation on the WMT dataset, which is linked above.
Disclaimer: The model card has been written by the Hugging Face team.
## How to use
You can use this model for translation, *e.g.*
'''python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("google/bert2bert_L-24_wmt_en_de", pad_token="<pad>", eos_token="</s>", bos_token="<s>")
model = AutoModelForSeq2SeqLM.from_pretrained("google/bert2bert_L-24_wmt_en_de")
sentence = "Would you like to grab a coffee with me this week?"
input_ids = tokenizer(sentence, return_tensors="pt", add_special_tokens=False).input_ids
output_ids = model.generate(input_ids)[0]
print(URL(output_ids, skip_special_tokens=True))
# should output
# Möchten Sie diese Woche einen Kaffee mit mir schnappen?
|
[
"# bert2bert_L-24_wmt_en_de EncoderDecoder model\n\nThe model was introduced in \nthis paper by Sascha Rothe, Shashi Narayan, Aliaksei Severyn and first released in this repository. \n\nThe model is an encoder-decoder model that was initialized on the 'bert-large' checkpoints for both the encoder \nand decoder and fine-tuned on English to German translation on the WMT dataset, which is linked above.\n\nDisclaimer: The model card has been written by the Hugging Face team.",
"## How to use\n\nYou can use this model for translation, *e.g.*\n\n'''python\nfrom transformers import AutoTokenizer, AutoModelForSeq2SeqLM\n\ntokenizer = AutoTokenizer.from_pretrained(\"google/bert2bert_L-24_wmt_en_de\", pad_token=\"<pad>\", eos_token=\"</s>\", bos_token=\"<s>\")\nmodel = AutoModelForSeq2SeqLM.from_pretrained(\"google/bert2bert_L-24_wmt_en_de\")\n\nsentence = \"Would you like to grab a coffee with me this week?\"\n\ninput_ids = tokenizer(sentence, return_tensors=\"pt\", add_special_tokens=False).input_ids\noutput_ids = model.generate(input_ids)[0]\nprint(URL(output_ids, skip_special_tokens=True))",
"# should output",
"# Möchten Sie diese Woche einen Kaffee mit mir schnappen?"
] |
[
"TAGS\n#transformers #pytorch #encoder-decoder #text2text-generation #translation #en #de #dataset-wmt14 #arxiv-1907.12461 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"# bert2bert_L-24_wmt_en_de EncoderDecoder model\n\nThe model was introduced in \nthis paper by Sascha Rothe, Shashi Narayan, Aliaksei Severyn and first released in this repository. \n\nThe model is an encoder-decoder model that was initialized on the 'bert-large' checkpoints for both the encoder \nand decoder and fine-tuned on English to German translation on the WMT dataset, which is linked above.\n\nDisclaimer: The model card has been written by the Hugging Face team.",
"## How to use\n\nYou can use this model for translation, *e.g.*\n\n'''python\nfrom transformers import AutoTokenizer, AutoModelForSeq2SeqLM\n\ntokenizer = AutoTokenizer.from_pretrained(\"google/bert2bert_L-24_wmt_en_de\", pad_token=\"<pad>\", eos_token=\"</s>\", bos_token=\"<s>\")\nmodel = AutoModelForSeq2SeqLM.from_pretrained(\"google/bert2bert_L-24_wmt_en_de\")\n\nsentence = \"Would you like to grab a coffee with me this week?\"\n\ninput_ids = tokenizer(sentence, return_tensors=\"pt\", add_special_tokens=False).input_ids\noutput_ids = model.generate(input_ids)[0]\nprint(URL(output_ids, skip_special_tokens=True))",
"# should output",
"# Möchten Sie diese Woche einen Kaffee mit mir schnappen?"
] |
null |
transformers
|
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
{"license": "apache-2.0", "thumbnail": "https://huggingface.co/front/thumbnails/google.png"}
|
google/bert_uncased_L-10_H-128_A-2
| null |
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1908.08962"
] |
[] |
TAGS
#transformers #pytorch #jax #bert #arxiv-1908.08962 #license-apache-2.0 #endpoints_compatible #region-us
|
BERT Miniatures
===============
This is the set of 24 BERT models referenced in Well-Read Students Learn Better: On the Importance of Pre-training Compact Models (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the official BERT Github page, or via HuggingFace from the links below:
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
* batch sizes: 8, 16, 32, 64, 128
* learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
|
[] |
[
"TAGS\n#transformers #pytorch #jax #bert #arxiv-1908.08962 #license-apache-2.0 #endpoints_compatible #region-us \n"
] |
null |
transformers
|
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
{"license": "apache-2.0", "thumbnail": "https://huggingface.co/front/thumbnails/google.png"}
|
google/bert_uncased_L-10_H-256_A-4
| null |
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1908.08962"
] |
[] |
TAGS
#transformers #pytorch #jax #bert #arxiv-1908.08962 #license-apache-2.0 #endpoints_compatible #region-us
|
BERT Miniatures
===============
This is the set of 24 BERT models referenced in Well-Read Students Learn Better: On the Importance of Pre-training Compact Models (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the official BERT Github page, or via HuggingFace from the links below:
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
* batch sizes: 8, 16, 32, 64, 128
* learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
|
[] |
[
"TAGS\n#transformers #pytorch #jax #bert #arxiv-1908.08962 #license-apache-2.0 #endpoints_compatible #region-us \n"
] |
null |
transformers
|
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
{"license": "apache-2.0", "thumbnail": "https://huggingface.co/front/thumbnails/google.png"}
|
google/bert_uncased_L-10_H-512_A-8
| null |
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1908.08962"
] |
[] |
TAGS
#transformers #pytorch #jax #bert #arxiv-1908.08962 #license-apache-2.0 #endpoints_compatible #region-us
|
BERT Miniatures
===============
This is the set of 24 BERT models referenced in Well-Read Students Learn Better: On the Importance of Pre-training Compact Models (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the official BERT Github page, or via HuggingFace from the links below:
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
* batch sizes: 8, 16, 32, 64, 128
* learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
|
[] |
[
"TAGS\n#transformers #pytorch #jax #bert #arxiv-1908.08962 #license-apache-2.0 #endpoints_compatible #region-us \n"
] |
null |
transformers
|
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
{"license": "apache-2.0", "thumbnail": "https://huggingface.co/front/thumbnails/google.png"}
|
google/bert_uncased_L-10_H-768_A-12
| null |
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1908.08962"
] |
[] |
TAGS
#transformers #pytorch #jax #bert #arxiv-1908.08962 #license-apache-2.0 #endpoints_compatible #region-us
|
BERT Miniatures
===============
This is the set of 24 BERT models referenced in Well-Read Students Learn Better: On the Importance of Pre-training Compact Models (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the official BERT Github page, or via HuggingFace from the links below:
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
* batch sizes: 8, 16, 32, 64, 128
* learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
|
[] |
[
"TAGS\n#transformers #pytorch #jax #bert #arxiv-1908.08962 #license-apache-2.0 #endpoints_compatible #region-us \n"
] |
null |
transformers
|
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
{"license": "apache-2.0", "thumbnail": "https://huggingface.co/front/thumbnails/google.png"}
|
google/bert_uncased_L-12_H-128_A-2
| null |
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1908.08962"
] |
[] |
TAGS
#transformers #pytorch #jax #bert #arxiv-1908.08962 #license-apache-2.0 #endpoints_compatible #region-us
|
BERT Miniatures
===============
This is the set of 24 BERT models referenced in Well-Read Students Learn Better: On the Importance of Pre-training Compact Models (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the official BERT Github page, or via HuggingFace from the links below:
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
* batch sizes: 8, 16, 32, 64, 128
* learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
|
[] |
[
"TAGS\n#transformers #pytorch #jax #bert #arxiv-1908.08962 #license-apache-2.0 #endpoints_compatible #region-us \n"
] |
null |
transformers
|
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
{"license": "apache-2.0", "thumbnail": "https://huggingface.co/front/thumbnails/google.png"}
|
google/bert_uncased_L-12_H-256_A-4
| null |
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1908.08962"
] |
[] |
TAGS
#transformers #pytorch #jax #bert #arxiv-1908.08962 #license-apache-2.0 #endpoints_compatible #region-us
|
BERT Miniatures
===============
This is the set of 24 BERT models referenced in Well-Read Students Learn Better: On the Importance of Pre-training Compact Models (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the official BERT Github page, or via HuggingFace from the links below:
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
* batch sizes: 8, 16, 32, 64, 128
* learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
|
[] |
[
"TAGS\n#transformers #pytorch #jax #bert #arxiv-1908.08962 #license-apache-2.0 #endpoints_compatible #region-us \n"
] |
null |
transformers
|
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
{"license": "apache-2.0", "thumbnail": "https://huggingface.co/front/thumbnails/google.png"}
|
google/bert_uncased_L-12_H-512_A-8
| null |
[
"transformers",
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"1908.08962"
] |
[] |
TAGS
#transformers #pytorch #jax #bert #arxiv-1908.08962 #license-apache-2.0 #endpoints_compatible #region-us
|
BERT Miniatures
===============
This is the set of 24 BERT models referenced in Well-Read Students Learn Better: On the Importance of Pre-training Compact Models (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the official BERT Github page, or via HuggingFace from the links below:
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
* batch sizes: 8, 16, 32, 64, 128
* learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
|
[] |
[
"TAGS\n#transformers #pytorch #jax #bert #arxiv-1908.08962 #license-apache-2.0 #endpoints_compatible #region-us \n"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.