
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-28 18:27:53
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 525
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-28 18:27:52
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
hoangphatmonter/ppo-LunarLander-v2
|
hoangphatmonter
| 2023-11-22T17:04:26Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-22T17:04:00Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 227.76 +/- 36.38
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
tomaarsen/span-marker-bert-base-orgs
|
tomaarsen
| 2023-11-22T16:48:26Z | 554 | 1 |
span-marker
|
[
"span-marker",
"pytorch",
"tensorboard",
"token-classification",
"ner",
"named-entity-recognition",
"generated_from_span_marker_trainer",
"en",
"dataset:tomaarsen/ner-orgs",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:cc-by-sa-4.0",
"model-index",
"co2_eq_emissions",
"region:us"
] |
token-classification
| 2023-11-22T13:59:42Z |
---
language:
- en
license: cc-by-sa-4.0
library_name: span-marker
tags:
- span-marker
- token-classification
- ner
- named-entity-recognition
- generated_from_span_marker_trainer
datasets:
- tomaarsen/ner-orgs
metrics:
- precision
- recall
- f1
widget:
- text: Today in Zhongnanhai, General Secretary of the Communist Party of China, President
of the country and honorary President of China's Red Cross, Zemin Jiang met with
representatives of the 6th National Member Congress of China's Red Cross, and
expressed warm greetings to the 20 million hardworking members on behalf of the
Central Committee of the Chinese Communist Party and State Council.
- text: On April 20, 2017, MGM Television Studios, headed by Mark Burnett formed a
partnership with McLane and Buss to produce and distribute new content across
a number of media platforms.
- text: 'Postponed: East Fife v Clydebank, St Johnstone v'
- text: Prime contractor was Hughes Aircraft Company Electronics Division which developed
the Tiamat with the assistance of the NACA.
- text: After graduating from Auburn University with a degree in Engineering in 1985,
he went on to play inside linebacker for the Pittsburgh Steelers for four seasons.
pipeline_tag: token-classification
co2_eq_emissions:
emissions: 248.1008753496152
source: codecarbon
training_type: fine-tuning
on_cloud: false
cpu_model: 13th Gen Intel(R) Core(TM) i7-13700K
ram_total_size: 31.777088165283203
hours_used: 1.766
hardware_used: 1 x NVIDIA GeForce RTX 3090
base_model: bert-base-cased
model-index:
- name: SpanMarker with bert-base-cased on FewNERD, CoNLL2003, and OntoNotes v5
results:
- task:
type: token-classification
name: Named Entity Recognition
dataset:
name: FewNERD, CoNLL2003, and OntoNotes v5
type: tomaarsen/ner-orgs
split: test
metrics:
- type: f1
value: 0.7946954813359528
name: F1
- type: precision
value: 0.7958325880879986
name: Precision
- type: recall
value: 0.793561619404316
name: Recall
---
# SpanMarker with bert-base-cased on FewNERD, CoNLL2003, and OntoNotes v5
This is a [SpanMarker](https://github.com/tomaarsen/SpanMarkerNER) model trained on the [FewNERD, CoNLL2003, and OntoNotes v5](https://huggingface.co/datasets/tomaarsen/ner-orgs) dataset that can be used for Named Entity Recognition. This SpanMarker model uses [bert-base-cased](https://huggingface.co/bert-base-cased) as the underlying encoder.
## Model Details
### Model Description
- **Model Type:** SpanMarker
- **Encoder:** [bert-base-cased](https://huggingface.co/bert-base-cased)
- **Maximum Sequence Length:** 256 tokens
- **Maximum Entity Length:** 8 words
- **Training Dataset:** [FewNERD, CoNLL2003, and OntoNotes v5](https://huggingface.co/datasets/tomaarsen/ner-orgs)
- **Language:** en
- **License:** cc-by-sa-4.0
### Model Sources
- **Repository:** [SpanMarker on GitHub](https://github.com/tomaarsen/SpanMarkerNER)
- **Thesis:** [SpanMarker For Named Entity Recognition](https://raw.githubusercontent.com/tomaarsen/SpanMarkerNER/main/thesis.pdf)
### Model Labels
| Label | Examples |
|:------|:---------------------------------------------|
| ORG | "Texas Chicken", "IAEA", "Church 's Chicken" |
## Evaluation
### Metrics
| Label | Precision | Recall | F1 |
|:--------|:----------|:-------|:-------|
| **all** | 0.7958 | 0.7936 | 0.7947 |
| ORG | 0.7958 | 0.7936 | 0.7947 |
## Uses
### Direct Use for Inference
```python
from span_marker import SpanMarkerModel
# Download from the 🤗 Hub
model = SpanMarkerModel.from_pretrained("tomaarsen/span-marker-bert-base-orgs")
# Run inference
entities = model.predict("Postponed: East Fife v Clydebank, St Johnstone v")
```
### Downstream Use
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
```python
from span_marker import SpanMarkerModel, Trainer
# Download from the 🤗 Hub
model = SpanMarkerModel.from_pretrained("tomaarsen/span-marker-bert-base-orgs")
# Specify a Dataset with "tokens" and "ner_tag" columns
dataset = load_dataset("conll2003") # For example CoNLL2003
# Initialize a Trainer using the pretrained model & dataset
trainer = Trainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["validation"],
)
trainer.train()
trainer.save_model("tomaarsen/span-marker-bert-base-orgs-finetuned")
```
</details>
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Set Metrics
| Training set | Min | Median | Max |
|:----------------------|:----|:--------|:----|
| Sentence length | 1 | 23.5706 | 263 |
| Entities per sentence | 0 | 0.7865 | 39 |
### Training Hyperparameters
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training Results
| Epoch | Step | Validation Loss | Validation Precision | Validation Recall | Validation F1 | Validation Accuracy |
|:------:|:-----:|:---------------:|:--------------------:|:-----------------:|:-------------:|:-------------------:|
| 0.7131 | 3000 | 0.0061 | 0.7978 | 0.7830 | 0.7904 | 0.9764 |
| 1.4262 | 6000 | 0.0059 | 0.8170 | 0.7843 | 0.8004 | 0.9774 |
| 2.1393 | 9000 | 0.0061 | 0.8221 | 0.7938 | 0.8077 | 0.9772 |
| 2.8524 | 12000 | 0.0062 | 0.8211 | 0.8003 | 0.8106 | 0.9780 |
### Environmental Impact
Carbon emissions were measured using [CodeCarbon](https://github.com/mlco2/codecarbon).
- **Carbon Emitted**: 0.248 kg of CO2
- **Hours Used**: 1.766 hours
### Training Hardware
- **On Cloud**: No
- **GPU Model**: 1 x NVIDIA GeForce RTX 3090
- **CPU Model**: 13th Gen Intel(R) Core(TM) i7-13700K
- **RAM Size**: 31.78 GB
### Framework Versions
- Python: 3.9.16
- SpanMarker: 1.5.1.dev
- Transformers: 4.30.0
- PyTorch: 2.0.1+cu118
- Datasets: 2.14.0
- Tokenizers: 0.13.3
## Citation
### BibTeX
```
@software{Aarsen_SpanMarker,
author = {Aarsen, Tom},
license = {Apache-2.0},
title = {{SpanMarker for Named Entity Recognition}},
url = {https://github.com/tomaarsen/SpanMarkerNER}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
Kssgarcia/rare-puppers
|
Kssgarcia
| 2023-11-22T16:46:16Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"pytorch",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-22T16:46:11Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: rare-puppers
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.8656716346740723
---
# rare-puppers
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### corgi

#### samoyed

#### shiba inu

|
xpmir/tas-balanced
|
xpmir
| 2023-11-22T16:37:17Z | 0 | 0 |
xpmir
|
[
"xpmir",
"region:us"
] | null | 2023-01-19T18:52:12Z |
---
library_name: xpmir
---
The TAS-Balanced model, adapted for experimaestro IR
|
hllj/non-qa-sft-zephyr-7b-beta-v1
|
hllj
| 2023-11-22T16:33:45Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"mistral",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:hllj/zephyr-7b-beta-vi-math",
"base_model:finetune:hllj/zephyr-7b-beta-vi-math",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-20T16:34:49Z |
---
base_model: hllj/zephyr-7b-beta-vi-math
tags:
- generated_from_trainer
model-index:
- name: non-qa-sft-zephyr-7b-beta-v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# non-qa-sft-zephyr-7b-beta-v1
This model is a fine-tuned version of [hllj/zephyr-7b-beta-vi-math](https://huggingface.co/hllj/zephyr-7b-beta-vi-math) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9442
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- training_steps: 10
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0
- Datasets 2.15.0
- Tokenizers 0.15.0
|
rebe121314/SMILES_RoBERTa
|
rebe121314
| 2023-11-22T16:29:03Z | 6 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"roberta",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-11-22T06:53:39Z |
---
tags:
- generated_from_trainer
model-index:
- name: SMILES_RoBERTa
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SMILES_RoBERTa
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.1+cu121
- Tokenizers 0.15.0
|
abishines/my_awesome_eli5_mlm_model
|
abishines
| 2023-11-22T16:27:25Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"roberta",
"fill-mask",
"generated_from_trainer",
"dataset:eli5",
"base_model:distilbert/distilroberta-base",
"base_model:finetune:distilbert/distilroberta-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-11-22T15:53:33Z |
---
license: apache-2.0
base_model: distilroberta-base
tags:
- generated_from_trainer
datasets:
- eli5
model-index:
- name: my_awesome_eli5_mlm_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_eli5_mlm_model
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the eli5 dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4788
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 2 | 1.6721 |
| No log | 2.0 | 4 | 1.7143 |
| No log | 3.0 | 6 | 2.4788 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
aishuizoo/distilbert-base-uncased-finetuned-ner
|
aishuizoo
| 2023-11-22T16:25:04Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-11-22T16:12:21Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: validation
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9269806094182825
- name: Recall
type: recall
value: 0.9358988701197002
- name: F1
type: f1
value: 0.931418392340236
- name: Accuracy
type: accuracy
value: 0.9833510731250099
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0611
- Precision: 0.9270
- Recall: 0.9359
- F1: 0.9314
- Accuracy: 0.9834
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2403 | 1.0 | 878 | 0.0707 | 0.9057 | 0.9199 | 0.9128 | 0.9799 |
| 0.0508 | 2.0 | 1756 | 0.0616 | 0.9281 | 0.9330 | 0.9305 | 0.9831 |
| 0.031 | 3.0 | 2634 | 0.0611 | 0.9270 | 0.9359 | 0.9314 | 0.9834 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
AVIIAX/qr
|
AVIIAX
| 2023-11-22T16:22:54Z | 10 | 1 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"controlnet",
"qrcode",
"en",
"license:openrail++",
"region:us"
] | null | 2023-11-22T15:32:10Z |
---
tags:
- stable-diffusion
- controlnet
- qrcode
license: openrail++
language:
- en
---
# Controlnet QR Code Monster v2 For SD-1.5

## Model Description
This model is made to generate creative QR codes that still scan.
Keep in mind that not all generated codes might be readable, but you can try different parameters and prompts to get the desired results.
**NEW VERSION**
Introducing the upgraded version of our model - Controlnet QR code Monster v2.
V2 is a huge upgrade over v1, for scannability AND creativity.
QR codes can now seamlessly blend the image by using a gray-colored background (#808080).
As with the former version, the readability of some generated codes may vary, however playing around with parameters and prompts could yield better results.
You can find in in the `v2/` subfolder.
## How to Use
- **Condition**: QR codes are passed as condition images with a module size of 16px. Use a higher error correction level to make it easier to read (sometimes a lower level can be easier to read if smaller in size). Use a gray background for the rest of the image to make the code integrate better.
- **Prompts**: Use a prompt to guide the QR code generation. The output will highly depend on the given prompt. Some seem to be really easily accepted by the qr code process, some will require careful tweaking to get good results.
- **Controlnet guidance scale**: Set the controlnet guidance scale value:
- High values: The generated QR code will be more readable.
- Low values: The generated QR code will be more creative.
### Tips
- For an optimally readable output, try generating multiple QR codes with similar parameters, then choose the best ones.
- Use the Image-to-Image feature to improve the readability of a generated QR code:
- Decrease the denoising strength to retain more of the original image.
- Increase the controlnet guidance scale value for better readability.
A typical workflow for "saving" a code would be :
Max out the guidance scale and minimize the denoising strength, then bump the strength until the code scans.
## Example Outputs
Here are some examples of creative, yet scannable QR codes produced by our model:



Feel free to experiment with prompts, parameters, and the Image-to-Image feature to achieve the desired QR code output. Good luck and have fun!
|
HuyenNguyen/wav2vec2-large-mms-1b-turkish-colab
|
HuyenNguyen
| 2023-11-22T16:21:03Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice_6_1",
"base_model:facebook/mms-1b-all",
"base_model:finetune:facebook/mms-1b-all",
"license:cc-by-nc-4.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-09-05T03:17:48Z |
---
license: cc-by-nc-4.0
base_model: facebook/mms-1b-all
tags:
- generated_from_trainer
datasets:
- common_voice_6_1
metrics:
- wer
model-index:
- name: wav2vec2-large-mms-1b-turkish-colab
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: common_voice_6_1
type: common_voice_6_1
config: vi
split: test
args: vi
metrics:
- name: Wer
type: wer
value: 0.3798342541436464
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-mms-1b-turkish-colab
This model is a fine-tuned version of [facebook/mms-1b-all](https://huggingface.co/facebook/mms-1b-all) on the common_voice_6_1 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5500
- Wer: 0.3798
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 8.2154 | 1.89 | 100 | 0.6394 | 0.4448 |
| 0.4996 | 3.77 | 200 | 0.5500 | 0.3798 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
RyotaroOKabe/chemeq_distilgpt2_v3
|
RyotaroOKabe
| 2023-11-22T16:16:57Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:distilbert/distilgpt2",
"base_model:finetune:distilbert/distilgpt2",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-13T23:23:32Z |
---
license: apache-2.0
base_model: distilgpt2
tags:
- generated_from_trainer
model-index:
- name: chemeq_distilgpt2_v3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# chemeq_distilgpt2_v3
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 200
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.0+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
merve/model-card-example
|
merve
| 2023-11-22T16:15:45Z | 0 | 0 |
keras
|
[
"keras",
"tensorboard",
"tf-keras",
"object-detection",
"region:us"
] |
object-detection
| 2022-03-02T23:29:05Z |
---
library_name: keras
tags:
- object-detection
---
## Model description
This model has couple of Dense layers.
## Intended uses & limitations
It's intended to demonstrate capabilities of Hub for Keras on my blog post!
## Training and evaluation data
It's trained on dummy data.
Above information is filled manually.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': 0.001, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
## Training Metrics
| Epochs | Train Loss | Validation Loss |
|--- |--- |--- |
| 1| 0.102| 0.094|
| 2| 0.094| 0.092|
| 3| 0.092| 0.091|
| 4| 0.091| 0.09|
| 5| 0.09| 0.089|
## Model Plot
<details>
<summary>View Model Plot</summary>

</details>
|
sergears/sql-translator
|
sergears
| 2023-11-22T16:07:40Z | 5 | 3 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-22T11:45:15Z |
This model transforms a natural language question together with table column names into an SQL query.
E.g. a question `Show who won the 1962 prize for literature` and table columns `year`, `subject`, `winner` get transformed into `SELECT winner FROM table WHERE year = 1962 AND subject = literature`.
Model input consists of the combined question + table columns with the corresponding sequences:
`translate English to SQL: Show who won the 1962 prize for literature. Table column names: year, subject, winner`
Example of usage:
```python
model = AutoModelForSeq2SeqLM.from_pretrained("sergears/sql-translator")
tokenizer = AutoTokenizer.from_pretrained("sergears/sql-translator")
def make_input_string(question: str, table_columns: List[str]) -> str:
"""
Helper function to combine natural language question with table column names, and add prefixes
"""
question_prefix = "Translate English to SQL: "
table_prefix = ". Table column names: "
question_input = question_prefix + question
table_input = table_prefix + ', '.join(table_columns)
return question_input + table_prefix
def transform_to_sql(question: str, table_columns: List[str]) -> str:
"""
Runs inference with the loaded model and decodes the result
"""
model_input_string = make_input_string(question, table_columns)
input_ids = tokenizer(model_input_string, return_tensors="pt").input_ids
outputs = model.generate(inputs=input_ids)
result = tokenizer.decode(token_ids=outputs[0], skip_special_tokens=True)
return result
question = 'Show who won the 1962 prize for literature'
table_columns = ['year', 'subject', 'winner']
print(transform_to_sql(question, table_columns))
```
|
behzadnet/Llama-2-7b-chat-hf-sharded-bf16-fine-tuned_GroundTruth_3epoch_seed100
|
behzadnet
| 2023-11-22T15:59:10Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"base_model:adapter:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"region:us"
] | null | 2023-11-22T15:59:06Z |
---
library_name: peft
base_model: Trelis/Llama-2-7b-chat-hf-sharded-bf16
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.7.0.dev0
|
behzadnet/Llama-2-7b-chat-hf-sharded-bf16-fine-tuned-adapters_GroundTruth_3epoch_seed100
|
behzadnet
| 2023-11-22T15:59:00Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"base_model:adapter:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"region:us"
] | null | 2023-11-22T15:58:55Z |
---
library_name: peft
base_model: Trelis/Llama-2-7b-chat-hf-sharded-bf16
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.7.0.dev0
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.7.0.dev0
|
SaraAUB/Taxi-v3
|
SaraAUB
| 2023-11-22T15:52:52Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-22T15:11:59Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="SaraAUB/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Ajminasfourcsemace/my-pet-cat
|
Ajminasfourcsemace
| 2023-11-22T15:50:33Z | 0 | 1 |
diffusers
|
[
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-22T15:45:48Z |
---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Cat Dreambooth model trained by Ajminasfourcsemace following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: MACEV-180
Sample pictures of this concept:

|
Kimata/gpt2-medium-Vizuosense
|
Kimata
| 2023-11-22T15:45:26Z | 0 | 1 |
adapter-transformers
|
[
"adapter-transformers",
"pytorch",
"gpt2",
"text-generation",
"en",
"dataset:Kimata/gpt_driver_dataset_processed",
"region:us"
] |
text-generation
| 2023-11-22T15:41:53Z |
---
datasets:
- Kimata/gpt_driver_dataset_processed
language:
- en
library_name: adapter-transformers
pipeline_tag: text-generation
---
|
timlim123/zephyr-7b-dpo-full
|
timlim123
| 2023-11-22T15:25:20Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"mistral",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:alignment-handbook/zephyr-7b-sft-full",
"base_model:finetune:alignment-handbook/zephyr-7b-sft-full",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-21T15:41:16Z |
---
license: apache-2.0
base_model: alignment-handbook/zephyr-7b-sft-full
tags:
- generated_from_trainer
model-index:
- name: zephyr-7b-dpo-full
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# zephyr-7b-dpo-full
This model is a fine-tuned version of [alignment-handbook/zephyr-7b-sft-full](https://huggingface.co/alignment-handbook/zephyr-7b-sft-full) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7337
- Rewards/chosen: -4.9100
- Rewards/rejected: -8.6806
- Rewards/accuracies: 0.7720
- Rewards/margins: 3.7705
- Logps/rejected: -315.2896
- Logps/chosen: -320.2513
- Logits/rejected: -2.5449
- Logits/chosen: -2.5953
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 32
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.6144 | 0.05 | 100 | 0.5938 | 0.0567 | -0.2214 | 0.7220 | 0.2780 | -230.6976 | -270.5843 | -3.0045 | -3.0186 |
| 0.4957 | 0.1 | 200 | 0.5132 | 0.0606 | -0.7482 | 0.7460 | 0.8088 | -235.9661 | -270.5448 | -2.9556 | -2.9714 |
| 0.5257 | 0.15 | 300 | 0.4975 | -0.0361 | -1.0262 | 0.7520 | 0.9901 | -238.7455 | -271.5117 | -2.9853 | -2.9989 |
| 0.556 | 0.21 | 400 | 0.4935 | -0.1016 | -1.1994 | 0.7760 | 1.0978 | -240.4776 | -272.1671 | -3.0847 | -3.0931 |
| 0.5409 | 0.26 | 500 | 0.4953 | -0.4001 | -1.5875 | 0.7780 | 1.1874 | -244.3592 | -275.1525 | -3.0544 | -3.0767 |
| 0.5161 | 0.31 | 600 | 0.5195 | -0.3148 | -1.4151 | 0.7420 | 1.1003 | -242.6347 | -274.2988 | -3.0235 | -3.0461 |
| 0.4913 | 0.36 | 700 | 0.5228 | -0.5853 | -1.8669 | 0.7800 | 1.2816 | -247.1535 | -277.0044 | -2.9302 | -2.9586 |
| 0.4724 | 0.41 | 800 | 0.5142 | -0.6071 | -2.0565 | 0.7620 | 1.4494 | -249.0490 | -277.2221 | -2.7988 | -2.8297 |
| 0.5157 | 0.46 | 900 | 0.5050 | -0.5865 | -1.8166 | 0.7660 | 1.2302 | -246.6503 | -277.0157 | -2.9463 | -2.9778 |
| 0.4641 | 0.52 | 1000 | 0.5091 | -0.5151 | -1.9977 | 0.7580 | 1.4826 | -248.4611 | -276.3019 | -2.8916 | -2.9216 |
| 0.5558 | 0.57 | 1100 | 0.4971 | -0.8116 | -2.1120 | 0.7700 | 1.3004 | -249.6036 | -279.2668 | -2.8601 | -2.8914 |
| 0.4877 | 0.62 | 1200 | 0.5092 | -0.5596 | -1.8948 | 0.7640 | 1.3352 | -247.4319 | -276.7474 | -2.8340 | -2.8770 |
| 0.4922 | 0.67 | 1300 | 0.5181 | -0.9340 | -2.3745 | 0.7460 | 1.4405 | -252.2287 | -280.4910 | -2.8187 | -2.8517 |
| 0.5515 | 0.72 | 1400 | 0.5081 | -0.9873 | -2.2119 | 0.7440 | 1.2247 | -250.6034 | -281.0239 | -2.8488 | -2.8704 |
| 0.4349 | 0.77 | 1500 | 0.4996 | -0.9048 | -2.4262 | 0.7580 | 1.5214 | -252.7459 | -280.1994 | -2.8402 | -2.8601 |
| 0.5446 | 0.83 | 1600 | 0.4927 | -0.8717 | -2.4390 | 0.7660 | 1.5673 | -252.8737 | -279.8681 | -2.7610 | -2.7853 |
| 0.5242 | 0.88 | 1700 | 0.4864 | -0.6984 | -2.1381 | 0.7780 | 1.4397 | -249.8655 | -278.1355 | -2.8269 | -2.8525 |
| 0.5266 | 0.93 | 1800 | 0.5020 | -0.5411 | -1.9479 | 0.7760 | 1.4068 | -247.9628 | -276.5621 | -2.7381 | -2.7715 |
| 0.498 | 0.98 | 1900 | 0.5086 | -0.6894 | -2.0331 | 0.7640 | 1.3437 | -248.8150 | -278.0452 | -2.7298 | -2.7664 |
| 0.0664 | 1.03 | 2000 | 0.5137 | -1.1702 | -3.1723 | 0.7620 | 2.0021 | -260.2072 | -282.8530 | -2.6137 | -2.6605 |
| 0.0698 | 1.08 | 2100 | 0.5327 | -1.3645 | -3.5669 | 0.7680 | 2.2023 | -264.1527 | -284.7966 | -2.6219 | -2.6692 |
| 0.0715 | 1.14 | 2200 | 0.5423 | -2.0519 | -4.1983 | 0.7620 | 2.1464 | -270.4673 | -291.6701 | -2.6949 | -2.7397 |
| 0.0548 | 1.19 | 2300 | 0.5459 | -1.7539 | -4.0546 | 0.7700 | 2.3007 | -269.0301 | -288.6898 | -2.5996 | -2.6425 |
| 0.0897 | 1.24 | 2400 | 0.5317 | -1.6549 | -3.7228 | 0.7640 | 2.0679 | -265.7117 | -287.7002 | -2.6512 | -2.6870 |
| 0.0842 | 1.29 | 2500 | 0.5710 | -2.3000 | -4.5267 | 0.7660 | 2.2267 | -273.7511 | -294.1512 | -2.6530 | -2.6843 |
| 0.1321 | 1.34 | 2600 | 0.5334 | -1.8238 | -3.8561 | 0.75 | 2.0323 | -267.0450 | -289.3895 | -2.7094 | -2.7343 |
| 0.0862 | 1.39 | 2700 | 0.5443 | -1.8480 | -3.9514 | 0.7520 | 2.1034 | -267.9976 | -289.6307 | -2.6953 | -2.7169 |
| 0.0954 | 1.45 | 2800 | 0.5472 | -1.9317 | -3.9982 | 0.7620 | 2.0665 | -268.4658 | -290.4683 | -2.6900 | -2.7121 |
| 0.0979 | 1.5 | 2900 | 0.5471 | -2.1452 | -4.1979 | 0.7540 | 2.0526 | -270.4626 | -292.6034 | -2.6466 | -2.6788 |
| 0.0732 | 1.55 | 3000 | 0.5512 | -2.0252 | -4.2019 | 0.75 | 2.1767 | -270.5027 | -291.4029 | -2.6716 | -2.6981 |
| 0.0799 | 1.6 | 3100 | 0.5415 | -1.8888 | -3.8739 | 0.75 | 1.9851 | -267.2229 | -290.0393 | -2.6703 | -2.7143 |
| 0.07 | 1.65 | 3200 | 0.5399 | -1.8457 | -4.0299 | 0.7640 | 2.1843 | -268.7833 | -289.6078 | -2.6566 | -2.7002 |
| 0.0808 | 1.7 | 3300 | 0.5594 | -2.2307 | -4.6355 | 0.7640 | 2.4048 | -274.8385 | -293.4576 | -2.6843 | -2.7340 |
| 0.0501 | 1.76 | 3400 | 0.5704 | -2.5155 | -4.9551 | 0.7660 | 2.4396 | -278.0345 | -296.3059 | -2.6427 | -2.6944 |
| 0.061 | 1.81 | 3500 | 0.5562 | -2.2172 | -4.4937 | 0.7600 | 2.2765 | -273.4208 | -293.3234 | -2.7086 | -2.7404 |
| 0.0979 | 1.86 | 3600 | 0.5656 | -2.6495 | -5.0323 | 0.7520 | 2.3828 | -278.8068 | -297.6461 | -2.6381 | -2.6765 |
| 0.0631 | 1.91 | 3700 | 0.5668 | -2.5055 | -4.7949 | 0.7560 | 2.2895 | -276.4331 | -296.2057 | -2.6407 | -2.6818 |
| 0.1202 | 1.96 | 3800 | 0.5678 | -2.6581 | -4.7249 | 0.7580 | 2.0668 | -275.7330 | -297.7322 | -2.6716 | -2.7125 |
| 0.022 | 2.01 | 3900 | 0.5657 | -2.6893 | -5.1672 | 0.7720 | 2.4778 | -280.1555 | -298.0444 | -2.6680 | -2.7125 |
| 0.0177 | 2.07 | 4000 | 0.6171 | -3.3461 | -6.2908 | 0.7680 | 2.9447 | -291.3919 | -304.6117 | -2.6431 | -2.6916 |
| 0.0108 | 2.12 | 4100 | 0.6389 | -3.3448 | -6.3803 | 0.7660 | 3.0355 | -292.2874 | -304.5994 | -2.6225 | -2.6701 |
| 0.0108 | 2.17 | 4200 | 0.6562 | -3.5386 | -6.6028 | 0.7620 | 3.0642 | -294.5121 | -306.5373 | -2.6323 | -2.6797 |
| 0.0105 | 2.22 | 4300 | 0.6742 | -3.7048 | -6.8992 | 0.7560 | 3.1944 | -297.4764 | -308.1995 | -2.6192 | -2.6678 |
| 0.018 | 2.27 | 4400 | 0.6982 | -4.1642 | -7.4837 | 0.7680 | 3.3195 | -303.3213 | -312.7930 | -2.5975 | -2.6454 |
| 0.0173 | 2.32 | 4500 | 0.6661 | -3.9139 | -6.9481 | 0.7660 | 3.0342 | -297.9650 | -310.2904 | -2.5967 | -2.6394 |
| 0.011 | 2.37 | 4600 | 0.6606 | -3.7121 | -6.8279 | 0.7640 | 3.1158 | -296.7630 | -308.2721 | -2.5628 | -2.6068 |
| 0.0096 | 2.43 | 4700 | 0.6705 | -3.9088 | -7.1613 | 0.7680 | 3.2524 | -300.0965 | -310.2393 | -2.5127 | -2.5613 |
| 0.0099 | 2.48 | 4800 | 0.6825 | -3.9836 | -7.2552 | 0.7720 | 3.2716 | -301.0364 | -310.9875 | -2.5169 | -2.5658 |
| 0.0106 | 2.53 | 4900 | 0.6938 | -4.2534 | -7.7587 | 0.7660 | 3.5053 | -306.0710 | -313.6849 | -2.5330 | -2.5844 |
| 0.0106 | 2.58 | 5000 | 0.6949 | -4.2978 | -7.7919 | 0.7660 | 3.4942 | -306.4034 | -314.1288 | -2.5330 | -2.5826 |
| 0.0099 | 2.63 | 5100 | 0.7239 | -4.3508 | -8.0105 | 0.7640 | 3.6598 | -308.5892 | -314.6587 | -2.5095 | -2.5620 |
| 0.0074 | 2.68 | 5200 | 0.7394 | -4.7364 | -8.4819 | 0.7660 | 3.7456 | -313.3035 | -318.5147 | -2.5378 | -2.5891 |
| 0.0043 | 2.74 | 5300 | 0.7335 | -4.6351 | -8.3990 | 0.7720 | 3.7639 | -312.4740 | -317.5019 | -2.5539 | -2.6052 |
| 0.0163 | 2.79 | 5400 | 0.7317 | -4.6741 | -8.3958 | 0.7700 | 3.7217 | -312.4420 | -317.8924 | -2.5490 | -2.5993 |
| 0.0081 | 2.84 | 5500 | 0.7420 | -4.9166 | -8.6945 | 0.7740 | 3.7779 | -315.4291 | -320.3167 | -2.5307 | -2.5816 |
| 0.0067 | 2.89 | 5600 | 0.7369 | -4.9581 | -8.7224 | 0.7680 | 3.7643 | -315.7077 | -320.7321 | -2.5437 | -2.5941 |
| 0.0081 | 2.94 | 5700 | 0.7345 | -4.9719 | -8.7499 | 0.7720 | 3.7780 | -315.9826 | -320.8700 | -2.5442 | -2.5946 |
| 0.0043 | 2.99 | 5800 | 0.7338 | -4.9141 | -8.6850 | 0.7700 | 3.7709 | -315.3341 | -320.2925 | -2.5452 | -2.5956 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0
- Datasets 2.14.6
- Tokenizers 0.14.1
|
jguevara/ppo-SnowballTarget
|
jguevara
| 2023-11-22T15:23:08Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"SnowballTarget",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2023-11-22T15:23:05Z |
---
library_name: ml-agents
tags:
- SnowballTarget
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: jguevara/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
teowu/DOVER
|
teowu
| 2023-11-22T15:19:47Z | 0 | 2 | null |
[
"arxiv:2211.04894",
"license:mit",
"region:us"
] | null | 2023-11-22T15:17:39Z |
---
license: mit
---
Weights wrt DOVER and DOVER++ as proposed by ICCV2023 paper "Exploring Video Quality Assessment on User Generated Contents from Aesthetic and Technical Perspectives".
```bibtex
@misc{wu2023exploring,
title={Exploring Video Quality Assessment on User Generated Contents from Aesthetic and Technical Perspectives},
author={Haoning Wu and Erli Zhang and Liang Liao and Chaofeng Chen and Jingwen Hou and Annan Wang and Wenxiu Sun and Qiong Yan and Weisi Lin},
year={2023},
eprint={2211.04894},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
|
folflo/mbart-large-50-finetuned-model-hu_1121
|
folflo
| 2023-11-22T15:19:46Z | 15 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"mbart",
"text2text-generation",
"summarization",
"generated_from_trainer",
"base_model:facebook/mbart-large-50",
"base_model:finetune:facebook/mbart-large-50",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2023-11-21T08:03:06Z |
---
license: mit
base_model: facebook/mbart-large-50
tags:
- summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mbart-large-50-finetuned-model-hu_1121
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbart-large-50-finetuned-model-hu_1121
This model is a fine-tuned version of [facebook/mbart-large-50](https://huggingface.co/facebook/mbart-large-50) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6534
- Rouge1: 35.6227
- Rouge2: 13.0189
- Rougel: 22.0402
- Rougelsum: 26.9175
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:------:|:---------------:|:-------:|:-------:|:-------:|:---------:|
| 2.9553 | 1.0 | 21353 | 2.5450 | 33.3195 | 12.2415 | 21.2029 | 25.3382 |
| 2.2811 | 2.0 | 42706 | 2.3570 | 33.6149 | 11.975 | 20.9943 | 25.726 |
| 1.9886 | 3.0 | 64059 | 2.3144 | 34.6221 | 12.2867 | 21.7798 | 26.1901 |
| 1.7463 | 4.0 | 85412 | 2.3198 | 35.2114 | 12.9183 | 22.215 | 27.1176 |
| 1.5245 | 5.0 | 106765 | 2.3774 | 35.1147 | 13.1621 | 22.3167 | 26.9264 |
| 1.3222 | 6.0 | 128118 | 2.4642 | 35.5719 | 13.1532 | 22.0023 | 26.8084 |
| 1.1456 | 7.0 | 149471 | 2.5673 | 35.9156 | 13.2115 | 22.2552 | 27.2581 |
| 1.0087 | 8.0 | 170824 | 2.6534 | 35.6227 | 13.0189 | 22.0402 | 26.9175 |
### Framework versions
- Transformers 4.35.1
- Pytorch 2.1.1+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
|
Santp98/SBERT-paraphrase-MiniLM-L6-v2
|
Santp98
| 2023-11-22T15:10:02Z | 4 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"dataset:Santp98/sentences_triplets_secop2_splits",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-11-22T15:08:25Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
datasets:
- Santp98/sentences_triplets_secop2_splits
---
# Santp98/SBERT-paraphrase-MiniLM-L6-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('Santp98/SBERT-paraphrase-MiniLM-L6-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('Santp98/SBERT-paraphrase-MiniLM-L6-v2')
model = AutoModel.from_pretrained('Santp98/SBERT-paraphrase-MiniLM-L6-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=Santp98/SBERT-paraphrase-MiniLM-L6-v2)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 6321 with parameters:
```
{'batch_size': 86, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`__main__.CustomTripletLoss` with parameters:
```
{'distance_metric': 'TripletDistanceMetric.EUCLIDEAN', 'triplet_margin': 5}
```
Parameters of the fit()-Method:
```
{
"epochs": 2,
"evaluation_steps": 500,
"evaluator": "__main__.CustomTripletEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 5e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
jensh2/gpt2-wikitext2
|
jensh2
| 2023-11-22T15:06:28Z | 10 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-22T14:05:12Z |
---
license: mit
base_model: gpt2
tags:
- generated_from_trainer
model-index:
- name: gpt2-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-wikitext2
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 6.1150
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.5483 | 1.0 | 2249 | 6.4740 |
| 6.1935 | 2.0 | 4498 | 6.2019 |
| 6.0173 | 3.0 | 6747 | 6.1150 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.1+cu121
- Datasets 2.15.0
- Tokenizers 0.15.0
|
zerxoi/sd-class-butterflies-64-acc
|
zerxoi
| 2023-11-22T15:05:29Z | 2 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] |
unconditional-image-generation
| 2023-11-22T11:59:26Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('zerxoi/sd-class-butterflies-64-acc')
image = pipeline().images[0]
image
```
|
MarinaMetr/test_trainer_log
|
MarinaMetr
| 2023-11-22T14:58:01Z | 6 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-multilingual-cased",
"base_model:finetune:google-bert/bert-base-multilingual-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-20T09:19:43Z |
---
license: apache-2.0
base_model: bert-base-multilingual-cased
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: test_trainer_log
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test_trainer_log
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1201
- F1: 0.9534
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 30 | 0.1744 | 0.9355 |
| No log | 2.0 | 60 | 0.1201 | 0.9534 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
devvanshhh/flanT5-xl-3.2
|
devvanshhh
| 2023-11-22T14:57:42Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:ybelkada/flan-t5-xl-sharded-bf16",
"base_model:finetune:ybelkada/flan-t5-xl-sharded-bf16",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-18T15:54:44Z |
---
base_model: ybelkada/flan-t5-xl-sharded-bf16
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flanT5-xl-3.2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flanT5-xl-3.2
This model is a fine-tuned version of [ybelkada/flan-t5-xl-sharded-bf16](https://huggingface.co/ybelkada/flan-t5-xl-sharded-bf16) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6816
- Rouge1: 32.8295
- Rouge2: 24.633
- Rougel: 29.5824
- Rougelsum: 29.842
- Gen Len: 10.9596
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 362 | 4.1881 | 14.6341 | 9.0532 | 12.5623 | 12.7062 | 15.8012 |
| 19.4437 | 2.0 | 724 | 0.8038 | 31.6983 | 24.0636 | 28.4549 | 28.672 | 10.6522 |
| 0.8703 | 3.0 | 1086 | 0.7598 | 32.6624 | 24.6635 | 29.339 | 29.5778 | 10.5311 |
| 0.8703 | 4.0 | 1448 | 0.7359 | 32.6045 | 24.52 | 29.2079 | 29.466 | 10.6304 |
| 0.7965 | 5.0 | 1810 | 0.7155 | 33.1775 | 25.1312 | 29.924 | 30.1659 | 10.5901 |
| 0.7601 | 6.0 | 2172 | 0.7023 | 32.5547 | 24.3195 | 29.2416 | 29.5173 | 10.9099 |
| 0.7475 | 7.0 | 2534 | 0.6923 | 33.0802 | 24.8653 | 29.769 | 30.0683 | 10.7640 |
| 0.7475 | 8.0 | 2896 | 0.6858 | 32.6578 | 24.333 | 29.3174 | 29.6478 | 11.0435 |
| 0.7287 | 9.0 | 3258 | 0.6827 | 32.9542 | 24.7132 | 29.6381 | 29.928 | 10.9193 |
| 0.7215 | 10.0 | 3620 | 0.6816 | 32.8295 | 24.633 | 29.5824 | 29.842 | 10.9596 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Pratap/mistral-finetuned-samsum
|
Pratap
| 2023-11-22T14:29:42Z | 0 | 0 | null |
[
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:TheBloke/Mistral-7B-Instruct-v0.1-GPTQ",
"base_model:finetune:TheBloke/Mistral-7B-Instruct-v0.1-GPTQ",
"license:apache-2.0",
"region:us"
] | null | 2023-11-22T12:40:54Z |
---
license: apache-2.0
base_model: TheBloke/Mistral-7B-Instruct-v0.1-GPTQ
tags:
- generated_from_trainer
model-index:
- name: mistral-finetuned-samsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral-finetuned-samsum
This model is a fine-tuned version of [TheBloke/Mistral-7B-Instruct-v0.1-GPTQ](https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GPTQ) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- training_steps: 250
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Shinku/shalltear-bloodfallen-lora
|
Shinku
| 2023-11-22T14:18:36Z | 2 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"anime",
"character",
"overlord",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:other",
"region:us"
] |
text-to-image
| 2023-11-22T14:18:35Z |
---
license: other
license_name: bespoke-lora-trained-license
license_link: https://multimodal.art/civitai-licenses?allowNoCredit=True&allowCommercialUse=Rent&allowDerivatives=True&allowDifferentLicense=True
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
- anime
- character
- overlord
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: shalltear bloodfallen
widget:
- text: 'shalltear bloodfallen, casual dress, blood pool, 1girl, red eyes, solo, dress'
output:
url: >-
92717.jpeg
- text: 'shalltear bloodfallen, casual dress, 1girl, solo, red eyes, smile, dress, long hair'
output:
url: >-
92736.jpeg
- text: 'shalltear bloodfallen, armor, lance, sky, solo, wings, weapon, day'
output:
url: >-
92735.jpeg
- text: 'shalltear bloodfallen, disguise, 1girl, blonde hair, red eyes, long hair, dress, hat, hair over one eye, flower'
output:
url: >-
92734.jpeg
- text: 'shalltear bloodfallen, 1girl, solo, long hair, red eyes, naked towel, towel, very long hair'
output:
url: >-
92732.jpeg
- text: 'shalltear bloodfallen, casual dress, 1girl, solo, red eyes, dress, long hair'
output:
url: >-
92731.jpeg
- text: 'shalltear bloodfallen, casual dress, 1girl, red eyes, blush, solo, open mouth, smile, fang'
output:
url: >-
92729.jpeg
- text: 'shalltear bloodfallen, casual dress, blood pool, 1girl, red eyes, solo, dress'
output:
url: >-
92728.jpeg
- text: 'shalltear bloodfallen, casual dress, blood pool, 1girl, red eyes, solo, dress'
output:
url: >-
92727.jpeg
- text: 'shalltear bloodfallen, casual dress, blood pool, 1girl, red eyes, solo, dress'
output:
url: >-
92726.jpeg
---
# Shalltear Bloodfallen Lora
<Gallery />
## Model description
<p>This lora was trained on 10 epochs, 10 repeats, with a dataset of 207 hand-picked images of Shalltear Bloodfallen. It works best by lowering the UNet strength to 0.7-0.8.</p><p></p><p>The dataset was tagged using waifu diffusion tagger 1.4 v2 with a threshold of 0.85 and then manually tagged with these tags: <strong>shalltear bloodfallen</strong>, <strong>casual dress</strong> (images with the dress she normally wears), <strong>armor</strong> (wearing her red armor), <strong>lance</strong> (holding her Spuit Lance), <strong>blood pool</strong> (the magic that create an orb of blood from her victims, this lora can recreate it very well), <strong>disguise</strong> (in her disguise) and <strong>nsfw.</strong></p>
## Trigger words
You should use `shalltear bloodfallen`, `casual dress`, `armor`, `lance`, `blood pool`, `disguise`, `nsfw` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/Shinku/shalltear-bloodfallen-lora/tree/main) them in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('runwayml/stable-diffusion-v1-5', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('Shinku/shalltear-bloodfallen-lora', weight_name='shalltear-000010.safetensors')
image = pipeline('shalltear bloodfallen, casual dress, blood pool, 1girl, red eyes, solo, dress').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
HeydarS/my_awesome_qa_model
|
HeydarS
| 2023-11-22T14:17:08Z | 13 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-11-22T14:15:20Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: my_awesome_qa_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_qa_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6510
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 50 | 4.0970 |
| No log | 2.0 | 100 | 3.7097 |
| No log | 3.0 | 150 | 3.6510 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
jordyvl/resnet101-base_tobacco-cnn_tobacco3482_simkd
|
jordyvl
| 2023-11-22T14:10:00Z | 39 | 0 |
transformers
|
[
"transformers",
"safetensors",
"resnet",
"image-classification",
"generated_from_trainer",
"base_model:bdpc/resnet101-base_tobacco",
"base_model:finetune:bdpc/resnet101-base_tobacco",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-21T01:20:13Z |
---
license: apache-2.0
base_model: bdpc/resnet101-base_tobacco
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: resnet101-base_tobacco-cnn_tobacco3482_simkd
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# resnet101-base_tobacco-cnn_tobacco3482_simkd
This model is a fine-tuned version of [bdpc/resnet101-base_tobacco](https://huggingface.co/bdpc/resnet101-base_tobacco) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 13.1229
- Accuracy: 0.295
- Brier Loss: 0.7636
- Nll: 6.8757
- F1 Micro: 0.295
- F1 Macro: 0.1150
- Ece: 0.2446
- Aurc: 0.4919
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Brier Loss | Nll | F1 Micro | F1 Macro | Ece | Aurc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:----------:|:------:|:--------:|:--------:|:------:|:------:|
| No log | 1.0 | 7 | 0.2512 | 0.18 | 0.9617 | 7.0686 | 0.18 | 0.0305 | 0.3439 | 0.7810 |
| No log | 2.0 | 14 | 0.3629 | 0.18 | 1.0943 | 7.0153 | 0.18 | 0.0305 | 0.4345 | 0.8186 |
| No log | 3.0 | 21 | 0.4745 | 0.18 | 1.1577 | 6.9805 | 0.18 | 0.0305 | 0.5034 | 0.8029 |
| No log | 4.0 | 28 | 0.6953 | 0.18 | 1.1290 | 6.9352 | 0.18 | 0.0305 | 0.4731 | 0.8367 |
| No log | 5.0 | 35 | 173.4450 | 0.18 | 1.1346 | 6.8314 | 0.18 | 0.0305 | 0.4615 | 0.8814 |
| No log | 6.0 | 42 | 412.7549 | 0.18 | 1.1098 | 6.8364 | 0.18 | 0.0305 | 0.4420 | 0.8716 |
| No log | 7.0 | 49 | 148.0839 | 0.18 | 1.0291 | 6.9271 | 0.18 | 0.0305 | 0.3960 | 0.7698 |
| No log | 8.0 | 56 | 61.2696 | 0.18 | 0.9674 | 6.9593 | 0.18 | 0.0305 | 0.3413 | 0.7924 |
| No log | 9.0 | 63 | 175.4512 | 0.18 | 0.9708 | 6.9854 | 0.18 | 0.0305 | 0.3549 | 0.8252 |
| No log | 10.0 | 70 | 139.2036 | 0.18 | 0.9400 | 6.9022 | 0.18 | 0.0305 | 0.3300 | 0.7760 |
| No log | 11.0 | 77 | 12.5605 | 0.295 | 0.8656 | 6.9766 | 0.295 | 0.1138 | 0.3093 | 0.5354 |
| No log | 12.0 | 84 | 2.3147 | 0.18 | 0.9363 | 6.9778 | 0.18 | 0.0305 | 0.3084 | 0.7507 |
| No log | 13.0 | 91 | 75.2050 | 0.18 | 0.9543 | 9.1566 | 0.18 | 0.0305 | 0.2990 | 0.7716 |
| No log | 14.0 | 98 | 37.4873 | 0.18 | 0.9410 | 9.1473 | 0.18 | 0.0305 | 0.3029 | 0.7517 |
| No log | 15.0 | 105 | 8.5750 | 0.18 | 0.9304 | 9.1440 | 0.18 | 0.0305 | 0.3033 | 0.7718 |
| No log | 16.0 | 112 | 21.5310 | 0.18 | 0.9232 | 9.1349 | 0.18 | 0.0305 | 0.3122 | 0.7717 |
| No log | 17.0 | 119 | 66.9546 | 0.18 | 0.9287 | 9.1376 | 0.18 | 0.0305 | 0.2920 | 0.7715 |
| No log | 18.0 | 126 | 2.6525 | 0.285 | 0.8357 | 7.0773 | 0.285 | 0.1143 | 0.3156 | 0.5306 |
| No log | 19.0 | 133 | 7.7253 | 0.24 | 0.8574 | 7.0190 | 0.24 | 0.0880 | 0.2948 | 0.7186 |
| No log | 20.0 | 140 | 30.0305 | 0.285 | 0.8086 | 6.9862 | 0.285 | 0.1133 | 0.3001 | 0.5273 |
| No log | 21.0 | 147 | 3.9243 | 0.18 | 0.8680 | 7.4799 | 0.18 | 0.0306 | 0.2739 | 0.7704 |
| No log | 22.0 | 154 | 4.4660 | 0.18 | 0.8831 | 8.9935 | 0.18 | 0.0308 | 0.2652 | 0.7313 |
| No log | 23.0 | 161 | 3.9728 | 0.18 | 0.8719 | 8.9609 | 0.18 | 0.0308 | 0.2600 | 0.7651 |
| No log | 24.0 | 168 | 2.6913 | 0.285 | 0.8089 | 6.9969 | 0.285 | 0.1146 | 0.2873 | 0.5122 |
| No log | 25.0 | 175 | 1.3141 | 0.29 | 0.8086 | 7.0227 | 0.29 | 0.1156 | 0.3154 | 0.5256 |
| No log | 26.0 | 182 | 13.5853 | 0.29 | 0.7782 | 6.8763 | 0.29 | 0.1168 | 0.2735 | 0.5045 |
| No log | 27.0 | 189 | 11.9763 | 0.3 | 0.7730 | 6.8499 | 0.3 | 0.1171 | 0.2740 | 0.4971 |
| No log | 28.0 | 196 | 1.6467 | 0.285 | 0.8067 | 7.1641 | 0.285 | 0.1144 | 0.2870 | 0.5193 |
| No log | 29.0 | 203 | 30.5306 | 0.285 | 0.8424 | 7.1576 | 0.285 | 0.1129 | 0.2686 | 0.6662 |
| No log | 30.0 | 210 | 13.5964 | 0.18 | 0.8584 | 7.0972 | 0.18 | 0.0305 | 0.2704 | 0.7307 |
| No log | 31.0 | 217 | 98.3061 | 0.29 | 0.8274 | 7.0330 | 0.29 | 0.1167 | 0.3163 | 0.5653 |
| No log | 32.0 | 224 | 53.0911 | 0.29 | 0.7984 | 6.9311 | 0.29 | 0.1167 | 0.2911 | 0.5181 |
| No log | 33.0 | 231 | 2.2010 | 0.265 | 0.8291 | 6.9883 | 0.265 | 0.1037 | 0.2945 | 0.6039 |
| No log | 34.0 | 238 | 3.6255 | 0.295 | 0.7836 | 6.8954 | 0.295 | 0.1176 | 0.2636 | 0.5025 |
| No log | 35.0 | 245 | 0.9640 | 0.3 | 0.7571 | 6.7913 | 0.3 | 0.1170 | 0.2388 | 0.4746 |
| No log | 36.0 | 252 | 1.1935 | 0.295 | 0.7711 | 6.7993 | 0.295 | 0.1175 | 0.2619 | 0.4779 |
| No log | 37.0 | 259 | 12.7465 | 0.305 | 0.7650 | 6.8142 | 0.305 | 0.1205 | 0.2512 | 0.4798 |
| No log | 38.0 | 266 | 56.6876 | 0.305 | 0.7840 | 6.8750 | 0.305 | 0.1205 | 0.2835 | 0.4985 |
| No log | 39.0 | 273 | 122.6602 | 0.295 | 0.7919 | 6.9220 | 0.295 | 0.1116 | 0.2493 | 0.5312 |
| No log | 40.0 | 280 | 14.4685 | 0.295 | 0.7757 | 6.8232 | 0.295 | 0.1162 | 0.2575 | 0.4988 |
| No log | 41.0 | 287 | 3.9605 | 0.295 | 0.7601 | 6.7809 | 0.295 | 0.1138 | 0.2437 | 0.4911 |
| No log | 42.0 | 294 | 7.9424 | 0.295 | 0.7567 | 6.7609 | 0.295 | 0.1138 | 0.2398 | 0.4883 |
| No log | 43.0 | 301 | 17.7810 | 0.295 | 0.7713 | 6.8075 | 0.295 | 0.1175 | 0.2503 | 0.5090 |
| No log | 44.0 | 308 | 30.8773 | 0.295 | 0.7747 | 6.8248 | 0.295 | 0.1127 | 0.2651 | 0.5149 |
| No log | 45.0 | 315 | 16.3877 | 0.29 | 0.7736 | 6.8888 | 0.29 | 0.1117 | 0.2641 | 0.5026 |
| No log | 46.0 | 322 | 7.4195 | 0.29 | 0.7674 | 6.8179 | 0.29 | 0.1117 | 0.2621 | 0.4991 |
| No log | 47.0 | 329 | 9.6560 | 0.295 | 0.7694 | 6.8960 | 0.295 | 0.1138 | 0.2604 | 0.4963 |
| No log | 48.0 | 336 | 6.6040 | 0.29 | 0.7622 | 6.7835 | 0.29 | 0.1117 | 0.2271 | 0.4958 |
| No log | 49.0 | 343 | 10.3365 | 0.29 | 0.7640 | 6.8293 | 0.29 | 0.1117 | 0.2583 | 0.4941 |
| No log | 50.0 | 350 | 13.1229 | 0.295 | 0.7636 | 6.8757 | 0.295 | 0.1150 | 0.2446 | 0.4919 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.2.0.dev20231112+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
TheBloke/OrionStar-Yi-34B-Chat-Llama-AWQ
|
TheBloke
| 2023-11-22T14:07:59Z | 32 | 3 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"base_model:OrionStarAI/OrionStar-Yi-34B-Chat-Llama",
"base_model:quantized:OrionStarAI/OrionStar-Yi-34B-Chat-Llama",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"awq",
"region:us"
] |
text-generation
| 2023-11-22T12:57:53Z |
---
base_model: OrionStarAI/OrionStar-Yi-34B-Chat-Llama
inference: false
license: other
license_link: LICENSE
license_name: yi-license
model_creator: OrionStarAI
model_name: OrionStar Yi 34B Chat Llama
model_type: yi
pipeline_tag: text-generation
prompt_template: 'Human: {prompt}
Assistant:
'
quantized_by: TheBloke
widget:
- output:
text: "\u4F60\u597D\uFF0C\u6211\u7684\u540D\u5B57\u53EB\u805A\u8A00\uFF0C\u5F88\
\u9AD8\u5174\u89C1\u5230\u4F60\u3002"
text: "\u4F60\u597D! \u4F60\u53EB\u4EC0\u4E48\u540D\u5B57!"
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# OrionStar Yi 34B Chat Llama - AWQ
- Model creator: [OrionStarAI](https://huggingface.co/OrionStarAI)
- Original model: [OrionStar Yi 34B Chat Llama](https://huggingface.co/OrionStarAI/OrionStar-Yi-34B-Chat-Llama)
<!-- description start -->
## Description
This repo contains AWQ model files for [OrionStarAI's OrionStar Yi 34B Chat Llama](https://huggingface.co/OrionStarAI/OrionStar-Yi-34B-Chat-Llama).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - Llama and Mistral models only
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later, from any code or client that supports Transformers
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF)
* [OrionStarAI's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/OrionStarAI/OrionStar-Yi-34B-Chat-Llama)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Human-Assistant
```
Human: {prompt}
Assistant:
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
I currently release 128g GEMM models only. The addition of group_size 32 models, and GEMV kernel models, is being actively considered.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-AWQ/tree/main) | 4 | 128 | [open-instruct](https://huggingface.co/datasets/VMware/open-instruct/viewer/) | 4096 | 19.23 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/OrionStar-Yi-34B-Chat-Llama-AWQ`.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `OrionStar-Yi-34B-Chat-Llama-AWQ`
7. Select **Loader: AutoAWQ**.
8. Click Load, and the model will load and is now ready for use.
9. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
10. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_AWQ.md-text-generation-webui end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Multi-user inference server: vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- Please ensure you are using vLLM version 0.2 or later.
- When using vLLM as a server, pass the `--quantization awq` parameter.
For example:
```shell
python3 -m vllm.entrypoints.api_server --model TheBloke/OrionStar-Yi-34B-Chat-Llama-AWQ --quantization awq --dtype auto
```
- When using vLLM from Python code, again set `quantization=awq`.
For example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Tell me about AI",
"Write a story about llamas",
"What is 291 - 150?",
"How much wood would a woodchuck chuck if a woodchuck could chuck wood?",
]
prompt_template=f'''Human: {prompt}
Assistant:
'''
prompts = [prompt_template.format(prompt=prompt) for prompt in prompts]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/OrionStar-Yi-34B-Chat-Llama-AWQ", quantization="awq", dtype="auto")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Multi-user inference server: Hugging Face Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/OrionStar-Yi-34B-Chat-Llama-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires [huggingface-hub](https://github.com/huggingface/huggingface_hub) 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''Human: {prompt}
Assistant:
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: ", response)
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## Inference from Python code using Transformers
### Install the necessary packages
- Requires: [Transformers](https://huggingface.co/docs/transformers) 4.35.0 or later.
- Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.6 or later.
```shell
pip3 install --upgrade "autoawq>=0.1.6" "transformers>=4.35.0"
```
Note that if you are using PyTorch 2.0.1, the above AutoAWQ command will automatically upgrade you to PyTorch 2.1.0.
If you are using CUDA 11.8 and wish to continue using PyTorch 2.0.1, instead run this command:
```shell
pip3 install https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp310-cp310-linux_x86_64.whl
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### Transformers example code (requires Transformers 4.35.0 and later)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_name_or_path = "TheBloke/OrionStar-Yi-34B-Chat-Llama-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
low_cpu_mem_usage=True,
device_map="cuda:0"
)
# Using the text streamer to stream output one token at a time
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = "Tell me about AI"
prompt_template=f'''Human: {prompt}
Assistant:
'''
# Convert prompt to tokens
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
generation_params = {
"do_sample": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": 512,
"repetition_penalty": 1.1
}
# Generate streamed output, visible one token at a time
generation_output = model.generate(
tokens,
streamer=streamer,
**generation_params
)
# Generation without a streamer, which will include the prompt in the output
generation_output = model.generate(
tokens,
**generation_params
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
print("model.generate output: ", text_output)
# Inference is also possible via Transformers' pipeline
from transformers import pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
**generation_params
)
pipe_output = pipe(prompt_template)[0]['generated_text']
print("pipeline output: ", pipe_output)
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui) using `Loader: AutoAWQ`.
- [vLLM](https://github.com/vllm-project/vllm) version 0.2.0 and later.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) version 1.1.0 and later.
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later.
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) version 0.1.1 and later.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: OrionStarAI's OrionStar Yi 34B Chat Llama
[OrionStarAI/OrionStar-Yi-34B-Chat](https://huggingface.co/OrionStarAI/OrionStar-Yi-34B-Chat/tree/main) with tensors renamed to match standard Llama modelling code.
# Model Introduction
- OrionStar-Yi-34B-Chat from OrionStarAI is based on the open-source Yi-34B model, fine-tuned on a high-quality corpus
of over 15 million sentences. OrionStar-Yi-34B-Chat aims to provide an excellent interactive experience for users in
the large model community.
- The Yi series models, open-sourced by the 01-ai team, have shown impressive performance on various benchmarks in
Chinese, English, and general domains. OrionStar-Yi-34B-Chat further explores the potential of Yi-34B. Through
extensive fine-tuning on a large and high-quality corpus, OrionStar-Yi-34B-Chat performs exceptionally well on
evaluation data. We strive to make it an outstanding open-source alternative in the ChatGPT domain!
- Our fine-tuned model is completely open for academic research, but please adhere to the [agreement](#license) and
the [Yi License](https://github.com/01-ai/Yi/blob/main/MODEL_LICENSE_AGREEMENT.txt).
- Model Evaluation Results
We use [opencompass](https://opencompass.org.cn) to perform 5-shot on the following general domain datasets Testing.
The evaluation results of other models are taken
from [opencompass leaderboard](https://opencompass.org.cn/leaderboard-llm).
| | C-Eval | MMLU | CMMLU |
|---------------------------|-----------|--------|-----------|
| **GPT-4** | 69.9 | **83** | 71 |
| **ChatGPT** | 52.5 | 69.1 | 53.9 |
| **Claude-1** | 52 | 65.7 | - |
| **TigerBot-70B-Chat-V2** | 57.7 | 65.9 | 59.9 |
| **WeMix-LLaMA2-70B** | 55.2 | 71.3 | 56 |
| **LLaMA-2-70B-Chat** | 44.3 | 63.8 | 43.3 |
| **Qwen-14B-Chat** | 71.7 | 66.4 | 70 |
| **Baichuan2-13B-Chat** | 56.7 | 57 | 58.4 |
| **OrionStar-Yi-34B-Chat** | **77.71** | 78.32 | **73.52** |
|
enaitzb/CartPole-v1
|
enaitzb
| 2023-11-22T13:51:45Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-22T13:51:37Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 305.80 +/- 237.86
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Xilabs/calypso-3b-alpha-v2
|
Xilabs
| 2023-11-22T13:32:21Z | 1,478 | 7 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"en",
"dataset:Xilabs/PIPPA-alpaca",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-08-13T12:00:51Z |
---
license: cc-by-nc-sa-4.0
datasets:
- Xilabs/PIPPA-alpaca
language:
- en
pipeline_tag: text-generation
---
# Calypso 3B - Alpha V2 Model Card
## Model Description
**Model Name:** Calypso 3B
**Version:** Calypso 3B - Alpha V2
<img src="https://i.imgur.com/zhLV66U.jpg" alt="Calypso" width="300">
**Based on:** [openlm-research/open_llama_3b_v2](https://huggingface.co/openlm-research/open_llama_3b_v2)
Calypso 3B is a language model designed for one-on-one chat interactions with a character or persona. It has been finetuned on the PIPPA-Alpaca dataset and a private dataset of human-generated chats. The model is particularly suited for providing conversational responses in a variety of contexts, making it suitable for role-playing, or one-on-one chatting.
## Intended Use
Calypso 3B is intended to facilitate engaging and interactive one-on-one chat experiences.
## Limitations and Ethical Considerations
- **Safety Note:** Calypso 3B can produce content that may not be safe for all audiences. It may generate inappropriate, offensive, or sensitive content. User discretion is advised.
- **Factual Accuracy:** The model's responses may not always be factually accurate. It should not be relied upon to provide accurate information, especially in critical or sensitive contexts.
- **Bias and Fairness:** As with many language models, Calypso 3B might inadvertently exhibit biases present in the training data. Efforts have been made to mitigate this, but biases may still be present.
## Example Usage
```python
import gradio as gr
from transformers import LlamaTokenizer, LlamaForCausalLM, GenerationConfig
import torch
from transformers import LlamaForCausalLM, LlamaTokenizer
class Chat:
def __init__(self, model, tokenizer, conv_prompt, user_alias='User', character_name='Chatbot', message_history=[], chat_buffer_size=10):
self.model = model
self.tokenizer = tokenizer
self.conv_prompt = conv_prompt
self.user_alias = user_alias
self.character_name = character_name
self.chat_buffer_size = chat_buffer_size
self.message_history = message_history
self.display_messages = []
for message_pairs in message_history:
message1, message2 = message_pairs
self.display_messages.append([message1['text'], message2['text']])
def evaluate(self, message, temperature=0.6, top_p=0.75, top_k=50, num_beams=5, max_new_tokens=256, repetition_penalty=1.4, **kwargs):
prompt = self.prompt_gen_chat(self.message_history, message)
inputs = self.tokenizer(prompt, return_tensors="pt")
input_ids = inputs["input_ids"].to(self.model.device)
generation_config = GenerationConfig(
temperature=temperature,
top_p=top_p,
top_k=top_k,
num_beams=num_beams,
early_stopping=True,
repetition_penalty=repetition_penalty,
**kwargs,
)
with torch.no_grad():
generation_output = self.model.generate(
input_ids=input_ids,
generation_config=generation_config,
return_dict_in_generate=True,
output_scores=True,
max_new_tokens=max_new_tokens,
)
s = generation_output.sequences[0]
output = self.tokenizer.decode(s, skip_special_tokens=True)
split_str = """### Response:\n{self.character_name}:"""
output = output.split(split_str)[1].strip()
return output
def gradio_helper(self, message):
# make response
response = self.evaluate(message)
# update message history
self.message_history.append(
(
{"speaker": self.user_alias, "text": message},
{"speaker": self.character_name, "text": response},
)
)
if len(self.message_history) > self.chat_buffer_size:
self.message_history = self.message_history[-self.chat_buffer_size:]
# update display messages
self.display_messages.append([message, response])
return self.display_messages
def prompt_gen_chat(self, message_history, message):
past_dialogue = []
for message_pairs in message_history:
message1, message2 = message_pairs
past_dialogue.append(f"{message1['speaker']}: {message1['text']}")
past_dialogue.append(f"{message2['speaker']}: {message2['text']}")
past_dialogue_formatted = "\n".join(past_dialogue)
prompt = f"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{self.conv_prompt}
This is the conversation between {self.user_alias} and {self.character_name} till now:
{past_dialogue_formatted}
Continuing from the previous conversation, write what {self.character_name} says to {self.user_alias}:
### Input:
{self.user_alias}: {message}
### Response:
{self.character_name}:"""
return prompt
def launch_gradio(self):
with gr.Blocks(theme="JohnSmith9982/small_and_pretty") as demo:
chatbot = gr.Chatbot(elem_id="chatbot")
with gr.Row():
txt = gr.Textbox(show_label=False,
placeholder="Enter text and press enter")
txt.submit(self.gradio_helper, txt, chatbot)
txt.submit(lambda: "", None, txt)
demo.launch(debug=True, share=True)
if __name__ == "__main__":
model_path = "Xilabs/calypso-3b-alpha-v2"
load_in_8bit = False
model = LlamaForCausalLM.from_pretrained(
model_path, device_map="auto", load_in_8bit=load_in_8bit)
tokenizer = LlamaTokenizer.from_pretrained(model_path)
conv_prompt = "Two people are texting each other on a messaging platform."
message_history = [
(
{
"speaker": "Bob",
"text": "Hey, Alice! How are you doing? What's the status on those reports?",
},
{
"speaker": "Alice",
"text": "Hey, Bob! I'm doing well. I'm almost done with the reports. I'll send them to you by the end of the day.",
},
),
(
{
"speaker": "Bob",
"text": "That's great! Thanks, Alice. I'll be waiting for them. Btw, I have approved your leave for next week.",
},
{
"speaker": "Alice",
"text": "Oh, thanks, Bob! I really appreciate it. I will be sure to send you the reports before I leave. Anything else you need from me?",
},
)
]
chat_instance = Chat(model, tokenizer, conv_prompt, user_alias='Bob',
character_name='Alice', message_history=message_history)
chat_instance.launch_gradio()
```
## Future Improvements
Calypso 3B is an ongoing project, and future iterations will focus on enhancing safety, improving factual accuracy, and reducing biases in its responses. The development team is committed to addressing user feedback and continuously improving the model's performance.
## Licensing and Commercial Use
Larger and more permissive versions of Calypso will be released in the future. If you're interested in using Calypso 3B or its future iterations for commercial purposes, obtaining a license, or accessing the model via an API, please reach out to us for more information.
---
**Disclaimer:** This model card is provided for informational purposes only. Users are responsible for using the model in accordance with applicable laws and ethical considerations.
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Xilabs__calypso-3b-alpha-v2)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 37.52 |
| ARC (25-shot) | 41.55 |
| HellaSwag (10-shot) | 71.48 |
| MMLU (5-shot) | 25.82 |
| TruthfulQA (0-shot) | 35.73 |
| Winogrande (5-shot) | 65.27 |
| GSM8K (5-shot) | 0.68 |
| DROP (3-shot) | 22.08 |
|
RalFinger/chocolate-coffee-style-sdxl-lora
|
RalFinger
| 2023-11-22T13:31:01Z | 4 | 2 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"animals",
"style",
"coffee",
"sweets",
"chocolate",
"chocolate on body",
"styles",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] |
text-to-image
| 2023-11-22T13:30:59Z |
---
license: other
license_name: bespoke-lora-trained-license
license_link: https://multimodal.art/civitai-licenses?allowNoCredit=True&allowCommercialUse=Sell&allowDerivatives=True&allowDifferentLicense=True
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
- animals
- style
- coffee
- sweets
- chocolate
- chocolate on body
- styles
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: cofzee
widget:
- text: 'cofzee, a statue of a woman with a flowing hair, made out of coffee '
output:
url: >-
3573769.jpeg
- text: 'cofzee, a cat coffee beans and chocolate '
output:
url: >-
3573773.jpeg
- text: 'cofzee, a cat coffee beans and chocolate '
output:
url: >-
3573774.jpeg
- text: 'cofzee, a man with a cup of coffee and a splash of liquid coffee, made out of coffee '
output:
url: >-
3573775.jpeg
- text: 'cofzee, a man with a cup of coffee and a splash of liquid coffee, made out of coffee '
output:
url: >-
3573776.jpeg
- text: 'cofzee, a horned deamon holding a cup of coffee, made out of coffee '
output:
url: >-
3573778.jpeg
- text: 'cofzee, a horned deamon holding a cup of coffee, made out of coffee '
output:
url: >-
3573777.jpeg
- text: 'cofzee, a chocolate heart shaped sculpture with a drip of chocolate '
output:
url: >-
3573780.jpeg
- text: 'cofzee, a chocolate heart shaped sculpture with a drip of chocolate '
output:
url: >-
3573779.jpeg
---
# Chocolate Coffee Style [SDXL LoRA]
<Gallery />
([CivitAI](https://civitai.com/models/197998))
## Model description
<p><u>SDXL:<br /></u><span style="color:rgb(193, 194, 197)">Trigger word: </span><strong><span style="color:rgb(193, 194, 197)">cofzee</span></strong><br /><span style="color:rgb(193, 194, 197)">Sampling Method: </span><strong><span style="color:rgb(219, 222, 225)">DPM++ 2M SDE Karras</span></strong><br /><br />☕ Buy me a coffee: <a target="_blank" rel="ugc" href="https://ko-fi.com/ralfingerai">https://ko-fi.com/ralfingerai</a></p>
## Trigger words
You should use `cofzee` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/RalFinger/chocolate-coffee-style-sdxl-lora/tree/main) them in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('RalFinger/chocolate-coffee-style-sdxl-lora', weight_name='cofzee-sdxl.safetensors')
image = pipeline('cofzee, a chocolate heart shaped sculpture with a drip of chocolate ').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
RalFinger/kitsune-style-sdxl-lora
|
RalFinger
| 2023-11-22T13:30:36Z | 4 | 1 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"anime",
"fox",
"japan",
"style",
"furry",
"japanese",
"japanese art",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] |
text-to-image
| 2023-11-22T13:30:34Z |
---
license: other
license_name: bespoke-lora-trained-license
license_link: https://multimodal.art/civitai-licenses?allowNoCredit=True&allowCommercialUse=Sell&allowDerivatives=True&allowDifferentLicense=True
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
- anime
- fox
- japan
- style
- furry
- japanese
- japanese art
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: kitsune
widget:
- text: 'kitsune, mount, '
output:
url: >-
3457792.jpeg
- text: 'kitsune, illusionist, illusionist outfit, '
output:
url: >-
3457788.jpeg
- text: 'kitsune, herbalist, herbalist outfit, '
output:
url: >-
3457796.jpeg
- text: 'kitsune, knight, dark knight outfit, '
output:
url: >-
3457784.jpeg
- text: 'kitsune, cleric, cleric outfit, '
output:
url: >-
3457791.jpeg
- text: 'kitsune, templar, templar outfit, '
output:
url: >-
3457794.jpeg
- text: 'kitsune, illusionist, illusionist outfit, '
output:
url: >-
3457785.jpeg
- text: 'kitsune, illusionist, illusionist outfit, '
output:
url: >-
3457787.jpeg
- text: 'kitsune, cleric, cleric outfit, '
output:
url: >-
3457786.jpeg
- text: 'kitsune, illusionist, illusionist outfit, '
output:
url: >-
3457795.jpeg
---
# Kitsune Style [SDXL LoRA]
<Gallery />
([CivitAI](https://civitai.com/models/192589))
## Model description
<p><u>SDXL:<br /></u><span style="color:rgb(193, 194, 197)">Trigger word: </span><strong><span style="color:rgb(193, 194, 197)">kitsune</span></strong><br /><span style="color:rgb(193, 194, 197)">Sampling Method: </span><strong><span style="color:rgb(219, 222, 225)">DPM++ 2M SDE Karras</span></strong><br /><br />☕ Buy me a coffee: <a target="_blank" rel="ugc" href="https://ko-fi.com/ralfingerai">https://ko-fi.com/ralfingerai</a><br /><br />Prompt: Use the following keywords for trained styles. Add "clothing" or "outfit" to your prompt to add more details.</p><pre><code>bard, battle mage, beastmaster, druid, herbalist, sorcerer, illusionist, cleric, warrior, lady, mage, monk, moon priest, mount, priest, samurai, shaman, templar, armorer, knight</code></pre>
## Trigger words
You should use `kitsune` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/RalFinger/kitsune-style-sdxl-lora/tree/main) them in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('RalFinger/kitsune-style-sdxl-lora', weight_name='kitsune-sdxl.safetensors')
image = pipeline('kitsune, illusionist, illusionist outfit, ').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
RalFinger/bastet-egypt-cat-style-sdxl-lora
|
RalFinger
| 2023-11-22T13:30:24Z | 4 | 1 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"animals",
"style",
"cat",
"furry",
"mythology",
"egypt",
"mummy",
"bastet",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] |
text-to-image
| 2023-11-22T13:30:23Z |
---
license: other
license_name: bespoke-lora-trained-license
license_link: https://multimodal.art/civitai-licenses?allowNoCredit=True&allowCommercialUse=Sell&allowDerivatives=True&allowDifferentLicense=True
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
- animals
- style
- cat
- furry
- mythology
- egypt
- mummy
- bastet
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: bastet
widget:
- text: 'bastet, a man in a costume with a knife in his left hand, mummy style, claws, kneeling on the floor, attack pose, mummy style, wrapped in bandages '
output:
url: >-
3429992.jpeg
- text: 'bastet, cat, a female bastet with heavy shoulder armor plates, green eyes, magical staff in right hand, belt with animal head, gem stone on the chest, magic staff, mummy style '
output:
url: >-
3429979.jpeg
- text: 'bastet, cat, a male warrior bastet, heavy black and bronze armor, armor plates, shoulder plates, skull belt, holding weapon in his right hand, glowing white eyes '
output:
url: >-
3429983.jpeg
- text: 'bastet, cat, a male bastet, man, dressed as a mummy, casting a glowing magic spell in his hand, wearing retropunk machinery on his body, '
output:
url: >-
3429980.jpeg
- text: 'bastet, cat, a male bastete in a bandages, mummy, holding a magic statt with symbols in it, spiked shoulder plates, glowing white eyes, leather belt on chest, staff on the back '
output:
url: >-
3429978.jpeg
- text: 'bastet, a cat, a female warrior, wearing plate armor, armor shoulder plates, black and bronze runes on the armor, wearing a hood, yellow eyes, sword on her back, shild in left hand, bandages, mummy style '
output:
url: >-
3429991.jpeg
- text: 'bastet, cat, a male bastete in a bandages, mummy, holding a magic statt with symbols in it, spiked shoulder plates, glowing white eyes, leather belt on chest, staff on the back '
output:
url: >-
3429982.jpeg
- text: 'bastet, a cat dressed in armor, writst armor, shoulder plates, shoulder armor, chest armor, black and bronze armor with runes, wrapped in bondages, mummy style, glowing eyes, fighting pose '
output:
url: >-
3429990.jpeg
- text: 'bastet, cat, a male warrior bastet, heavy black and bronze armor, armor plates, shoulder plates, skull belt, holding weapon in his right hand, glowing white eyes '
output:
url: >-
3429981.jpeg
- text: 'a bastet female cat, shaman, wizzard, sorcerer, with staff, holding staff, green eyes, '
output:
url: >-
3429984.jpeg
---
# Bastet Egypt Cat Style [SDXL LoRA]
<Gallery />
([CivitAI](https://civitai.com/models/191203))
## Model description
<p><u>SDXL:<br /></u><span style="color:rgb(193, 194, 197)">Trigger word: </span><strong><span style="color:rgb(193, 194, 197)">bastet</span></strong><br /><span style="color:rgb(193, 194, 197)">Sampling Method: </span><strong><span style="color:rgb(219, 222, 225)">DPM++ 2M SDE Karras</span></strong><br /><br />☕ Buy me a coffee: <a target="_blank" rel="ugc" href="https://ko-fi.com/ralfingerai">https://ko-fi.com/ralfingerai</a></p>
## Trigger words
You should use `bastet` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/RalFinger/bastet-egypt-cat-style-sdxl-lora/tree/main) them in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('RalFinger/bastet-egypt-cat-style-sdxl-lora', weight_name='bastet-sdxl.safetensors')
image = pipeline('a bastet female cat, shaman, wizzard, sorcerer, with staff, holding staff, green eyes, ').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
RalFinger/fur-pirates-sdxl-lora
|
RalFinger
| 2023-11-22T13:29:00Z | 6 | 3 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"animals",
"pirate",
"style",
"fur",
"furry",
"cute",
"pirate ship",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] |
text-to-image
| 2023-11-22T13:28:58Z |
---
license: other
license_name: bespoke-lora-trained-license
license_link: https://multimodal.art/civitai-licenses?allowNoCredit=True&allowCommercialUse=Sell&allowDerivatives=True&allowDifferentLicense=True
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
- animals
- pirate
- style
- fur
- furry
- cute
- pirate ship
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: fur pirates
widget:
- text: 'fur pirates, alligator, '
output:
url: >-
3408310.jpeg
- text: 'fur pirates, cute fur pirate, instagram model, instagram shot, outdoor, glamour '
output:
url: >-
3408383.jpeg
- text: 'fur pirates, (cyberpunk, dystopian future:1.4), rotten ship, rotten floor, old fur pirate, grey beard '
output:
url: >-
3408301.jpeg
- text: 'fur pirates, breakdancing, breakdance battle, graffiti background '
output:
url: >-
3408297.jpeg
- text: 'fur pirates, family, sitting in the park, having a picnic '
output:
url: >-
3408298.jpeg
- text: 'fur pirates, duck, hook '
output:
url: >-
3408302.jpeg
- text: 'fur pirates, turtle, hook '
output:
url: >-
3408303.jpeg
- text: 'fur pirates, octupus, '
output:
url: >-
3408305.jpeg
- text: 'fur pirates, parrot, '
output:
url: >-
3408306.jpeg
- text: 'fur pirates, giraffe '
output:
url: >-
3408307.jpeg
---
# Fur Pirates [SDXL LoRA]
<Gallery />
([CivitAI](https://civitai.com/models/190176))
## Model description
<p><u>SDXL:<br /></u><span style="color:rgb(193, 194, 197)">Trigger word: </span><strong><span style="color:rgb(193, 194, 197)">fur pirates</span></strong><br /><span style="color:rgb(193, 194, 197)">Sampling Method: </span><strong><span style="color:rgb(219, 222, 225)">DPM++ 2M SDE Karras</span></strong><br /><br />☕ Buy me a coffee: <a target="_blank" rel="ugc" href="https://ko-fi.com/ralfingerai">https://ko-fi.com/ralfingerai</a></p>
## Trigger words
You should use `fur pirates` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/RalFinger/fur-pirates-sdxl-lora/tree/main) them in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('RalFinger/fur-pirates-sdxl-lora', weight_name='furpirate-sdxl.safetensors')
image = pipeline('fur pirates, giraffe ').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
RalFinger/baking-bread-sdxl-lora
|
RalFinger
| 2023-11-22T13:28:49Z | 2 | 2 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"style",
"food",
"cake",
"bread",
"sweets",
"donut",
"muffin",
"gingerbread",
"baking",
"pastry",
"gingerbread man",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] |
text-to-image
| 2023-11-22T13:28:47Z |
---
license: other
license_name: bespoke-lora-trained-license
license_link: https://multimodal.art/civitai-licenses?allowNoCredit=True&allowCommercialUse=Sell&allowDerivatives=True&allowDifferentLicense=True
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
- style
- food
- cake
- bread
- sweets
- donut
- muffin
- gingerbread
- baking
- pastry
- gingerbread man
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: pastry
widget:
- text: 'dog looking at, amazing pastrey dish on a gold plate, pastry '
output:
url: >-
3403718.jpeg
- text: 'mouse and keyboard, made out of pastry, pink background '
output:
url: >-
3403719.jpeg
- text: 'pineapple, made out of pastry '
output:
url: >-
3403720.jpeg
- text: 'food photography, harry potter from harry potter, made out of pastry '
output:
url: >-
3403721.jpeg
- text: '3d Splash art, a cat head, ((white background)), epic Instagram, artstation, splash style of colorful paint, contour, hyperdetailed intricately detailed, pastry '
output:
url: >-
3403722.jpeg
- text: 'car made out of pastry, food magazine shot, pastry '
output:
url: >-
3403723.jpeg
- text: 'closeup shot, food photography, gandalf from lord of the rings, standing on a cookie, oozing chocolate, made out of pastry, standing on basalt countertop '
output:
url: >-
3403724.jpeg
- text: 'dwarf made out of pastry, holding candle, in dark dungeon, at night, shadows, dithered light, '
output:
url: >-
3403725.jpeg
- text: 'dragon made out of pastry, standing on lava rock, breathing fire '
output:
url: >-
3403726.jpeg
- text: 'huge mushroom made out of pastry, fruits, in mystical forrest '
output:
url: >-
3403727.jpeg
---
# Baking Bread [SDXL LoRA]
<Gallery />
([CivitAI](https://civitai.com/models/189905))
## Model description
<p><u>SDXL:<br /></u><span style="color:rgb(193, 194, 197)">Trigger word: </span><strong><span style="color:rgb(193, 194, 197)">pastry</span></strong><br /><span style="color:rgb(193, 194, 197)">Sampling Method: </span><strong><span style="color:rgb(219, 222, 225)">DPM++ 2M SDE Karras</span></strong><br /><br />☕ Buy me a coffee: <a target="_blank" rel="ugc" href="https://ko-fi.com/ralfingerai">https://ko-fi.com/ralfingerai</a></p>
## Trigger words
You should use `pastry` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/RalFinger/baking-bread-sdxl-lora/tree/main) them in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('RalFinger/baking-bread-sdxl-lora', weight_name='pastry-sdxl.safetensors')
image = pipeline('huge mushroom made out of pastry, fruits, in mystical forrest ').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
RalFinger/werewolf-lora-1-5-sdxl
|
RalFinger
| 2023-11-22T13:28:37Z | 3 | 2 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"character",
"werewolf",
"furry",
"fantasy",
"wolf",
"mythology",
"creature",
"fiction",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] |
text-to-image
| 2023-11-22T13:28:35Z |
---
license: other
license_name: bespoke-lora-trained-license
license_link: https://multimodal.art/civitai-licenses?allowNoCredit=True&allowCommercialUse=Sell&allowDerivatives=True&allowDifferentLicense=True
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
- character
- werewolf
- furry
- fantasy
- wolf
- mythology
- creature
- fiction
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: werewolf
widget:
- text: '(werewolf:1.2), snow, snowing, (ice), icicles, frozen, chilling, chilled, ominous, horror, creepy, tall, wearing body armor made of human bones, (skull:0.9), (ribcage:1.2), piercings, fur details, fur pattern, (lightning strike), (lightning), storm, cloudy sky, backlighting, forest, nighttime, mist, fog, full moon, detailed claws, glowing, ominous aura Halo, jewelry, necklace, gold chains, (gold spikes), (fangs), smile, snarl, punk, wild hair, chromatic aberration, depth of field, soft lighting, masterpiece, best quality, intricate, tone mapped, highly detailed, artstation, concept art, smooth, sharp focus, dramatic lighting, highly detailed artwork, cinematic, hyper realistic painting, trending on Artstation, 8K, incredible shadows, realistic, (highly detailed background:1.0) '
output:
url: >-
3379439.jpeg
- text: 'werewolf with bloody fangs, in a small medievil town, moon in the background '
output:
url: >-
3379440.jpeg
- text: 'The king of wolves, the mythic monster, the majestic man Iâd grown to love and lust for with my every breath, he lay thereâ¦bleeding out beside his throne. Dying. Towering over him was a grinning demonâ¦the Demon Lord. He pointed at me with a long, black, spindly finger. ((masterpiece):1.0), (werewolf:1.2), (ring:0.5), (best quality), (great quality) '
output:
url: >-
3379441.jpeg
- text: 'Portrait painting of a cybernetic grey werewolf with power armor, ultra realistic, concept art, intricate details, eerie, highly detailed, photorealistic, octane render, 8 k, unreal engine. art by artgerm and greg rutkowski and alphonse mucha '
output:
url: >-
3379442.jpeg
- text: 'symetric werewolf head, with flames around it'
output:
url: >-
3379444.jpeg
- text: 'werewolf with bloody fangs, (wearing metal armor:1.4), in a small medievil town, moon in the background '
output:
url: >-
3379443.jpeg
- text: '(masterpiece), brown fur, open jaws, Werewolf, detailed background of a dark forest, night, full moon, dim light '
output:
url: >-
3379446.jpeg
- text: 'A werewolf stands towering in an abandoned haunted lost city. Moonlight highlights your muscles and scars. The scenery is lush and mysterious, with dark city and surroundings. The camera details everything, a warrior woman, in front of him '
output:
url: >-
3379448.jpeg
- text: 'werewolf, shapeshifter, transforming, metamorphosis, dynamic pose, colorful, vivid colors, detailed, best quality, masterpiece, humanoid, evil, concept art, epic, furious, red eyes '
output:
url: >-
3379449.jpeg
- text: 'highly detailed analog photo of werewolf:1.2, ((standing)), open mouth, teeth, glowing, yellow eyes, claws, fangs, sharp teeth, realistic:1.3, depth of field, 8k, cinematic, ((night)), ultra detailed masterpiece, best quality:1.1, (analogue photography:1.2)) '
output:
url: >-
3379451.jpeg
---
# Werewolf [LoRA 1.5+SDXL]
<Gallery />
([CivitAI](https://civitai.com/models/46487))
## Model description
<p>My 2nd LoRA, changed the training data so it became a bit big .... nevertheless!<br /><br />Discover the mesmerizing world of werewolves through creating your own stunning images that capture their primal and mysterious essence. These images will transport you to a world where the moon shines bright and the creatures of the night roam free, evoking a sense of wonder and fascination that is both eerie and alluring.<br /><br /><u>SDXL:<br /></u><span style="color:rgb(193, 194, 197)">Trigger word: </span><strong>werewolf</strong><br /><span style="color:rgb(193, 194, 197)">Sampling Method: </span><strong><span style="color:rgb(219, 222, 225)">DPM++ 2M SDE Karras</span></strong><br /><br /><u>SD1.5:</u><br />Trigger word: <strong>werewolf</strong><br />Sampling Method: <strong>Euler and Euler a</strong><br /><br />☕ Buy me a coffee: <a target="_blank" rel="ugc" href="https://ko-fi.com/ralfingerai">https://ko-fi.com/ralfingerai</a></p>
## Trigger words
You should use `werewolf` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/RalFinger/werewolf-lora-1-5-sdxl/tree/main) them in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('RalFinger/werewolf-lora-1-5-sdxl', weight_name='werewolf-sdxl.safetensors')
image = pipeline('highly detailed analog photo of werewolf:1.2, ((standing)), open mouth, teeth, glowing, yellow eyes, claws, fangs, sharp teeth, realistic:1.3, depth of field, 8k, cinematic, ((night)), ultra detailed masterpiece, best quality:1.1, (analogue photography:1.2)) ').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
RalFinger/balloons-sdxl-lora
|
RalFinger
| 2023-11-22T13:28:06Z | 5 | 1 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"abstract",
"balloon",
"art",
"style",
"rubber",
"styles",
"balloon body",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] |
text-to-image
| 2023-11-22T13:28:04Z |
---
license: other
license_name: bespoke-lora-trained-license
license_link: https://multimodal.art/civitai-licenses?allowNoCredit=True&allowCommercialUse=Sell&allowDerivatives=True&allowDifferentLicense=True
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
- abstract
- balloon
- art
- style
- rubber
- styles
- balloon body
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: balloonz
widget:
- text: 'balloonz, balloons, made out of balloons, tiger, standing tiger, balloon tiger, in the zoo, zoo made out of balloons '
output:
url: >-
3331625.jpeg
- text: 'balloonz, balloons, made out of balloons, tiger, standing tiger, balloon tiger, in the zoo, zoo made out of balloons '
output:
url: >-
3331624.jpeg
- text: 'baloonz, owl made out of baloons, sitting in a tree, at night, big eyes, shiny moon, glowing moon, foggy ground '
output:
url: >-
3331629.jpeg
- text: 'baloonz, owl made out of baloons, white and brown owl, sitting in a tree, at night, very cute and big eyes, shiny moon, foggy background '
output:
url: >-
3331632.jpeg
- text: 'balloonz, balloons, made out of balloons, fox, sleeping fox, foxhole, underground, dark night, diffuse light '
output:
url: >-
3331634.jpeg
- text: 'balloonz, balloons, made out of balloons, fox, sleeping fox, foxhole, underground, dark night, diffuse light '
output:
url: >-
3331633.jpeg
- text: 'balloonz, balloons, made out of balloons, hedgehog, standing hedgehog,, rainy day, in high grass, diffuse light '
output:
url: >-
3331636.jpeg
- text: 'balloonz, balloons, made out of balloons, hedgehog, sitting hedgehog,, rainy day, in high grass, diffuse light '
output:
url: >-
3331637.jpeg
- text: 'balloonz, balloons, made out of balloons, fish, balloon fish, swimming in the ocean, ship wreck on sea floor '
output:
url: >-
3331639.jpeg
- text: 'baloonz, fish made out of baloons, fish, baloon fish, underwater scene, coral reef made out of baloons '
output:
url: >-
3331638.jpeg
---
# Balloons [SDXL LoRA]
<Gallery />
([CivitAI](https://civitai.com/models/186256))
## Model description
<p><u>SDXL:<br /></u><span style="color:rgb(193, 194, 197)">Trigger word: </span><strong><span style="color:rgb(193, 194, 197)">balloonz</span></strong><br /><span style="color:rgb(193, 194, 197)">Sampling Method: </span><strong><span style="color:rgb(219, 222, 225)">DPM++ 2M SDE Karras</span></strong></p><p></p><p>☕ Buy me a coffee: <a target="_blank" rel="ugc" href="https://ko-fi.com/ralfingerai">https://ko-fi.com/ralfingerai</a><br /></p><p><span style="color:rgb(219, 222, 225)">If your images produce too many single baloons, just add "ballons" in your negative prompt, that won´t affect the LoRA.</span></p>
## Trigger words
You should use `balloonz` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/RalFinger/balloons-sdxl-lora/tree/main) them in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('RalFinger/balloons-sdxl-lora', weight_name='balloonz-sdxl.safetensors')
image = pipeline('baloonz, fish made out of baloons, fish, baloon fish, underwater scene, coral reef made out of baloons ').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF
|
TheBloke
| 2023-11-22T13:16:05Z | 215 | 15 |
transformers
|
[
"transformers",
"gguf",
"yi",
"text-generation",
"base_model:OrionStarAI/OrionStar-Yi-34B-Chat-Llama",
"base_model:quantized:OrionStarAI/OrionStar-Yi-34B-Chat-Llama",
"license:other",
"region:us"
] |
text-generation
| 2023-11-22T12:57:53Z |
---
base_model: OrionStarAI/OrionStar-Yi-34B-Chat-Llama
inference: false
license: other
license_link: LICENSE
license_name: yi-license
model_creator: OrionStarAI
model_name: OrionStar Yi 34B Chat Llama
model_type: yi
pipeline_tag: text-generation
prompt_template: 'Human: {prompt}
Assistant:
'
quantized_by: TheBloke
widget:
- output:
text: "\u4F60\u597D\uFF0C\u6211\u7684\u540D\u5B57\u53EB\u805A\u8A00\uFF0C\u5F88\
\u9AD8\u5174\u89C1\u5230\u4F60\u3002"
text: "\u4F60\u597D! \u4F60\u53EB\u4EC0\u4E48\u540D\u5B57!"
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# OrionStar Yi 34B Chat Llama - GGUF
- Model creator: [OrionStarAI](https://huggingface.co/OrionStarAI)
- Original model: [OrionStar Yi 34B Chat Llama](https://huggingface.co/OrionStarAI/OrionStar-Yi-34B-Chat-Llama)
<!-- description start -->
## Description
This repo contains GGUF format model files for [OrionStarAI's OrionStar Yi 34B Chat Llama](https://huggingface.co/OrionStarAI/OrionStar-Yi-34B-Chat-Llama).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF)
* [OrionStarAI's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/OrionStarAI/OrionStar-Yi-34B-Chat-Llama)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Human-Assistant
```
Human: {prompt}
Assistant:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [orionstar-yi-34b-chat-llama.Q2_K.gguf](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF/blob/main/orionstar-yi-34b-chat-llama.Q2_K.gguf) | Q2_K | 2 | 14.56 GB| 17.06 GB | smallest, significant quality loss - not recommended for most purposes |
| [orionstar-yi-34b-chat-llama.Q3_K_S.gguf](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF/blob/main/orionstar-yi-34b-chat-llama.Q3_K_S.gguf) | Q3_K_S | 3 | 14.96 GB| 17.46 GB | very small, high quality loss |
| [orionstar-yi-34b-chat-llama.Q3_K_M.gguf](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF/blob/main/orionstar-yi-34b-chat-llama.Q3_K_M.gguf) | Q3_K_M | 3 | 16.64 GB| 19.14 GB | very small, high quality loss |
| [orionstar-yi-34b-chat-llama.Q3_K_L.gguf](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF/blob/main/orionstar-yi-34b-chat-llama.Q3_K_L.gguf) | Q3_K_L | 3 | 18.14 GB| 20.64 GB | small, substantial quality loss |
| [orionstar-yi-34b-chat-llama.Q4_0.gguf](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF/blob/main/orionstar-yi-34b-chat-llama.Q4_0.gguf) | Q4_0 | 4 | 19.47 GB| 21.97 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [orionstar-yi-34b-chat-llama.Q4_K_S.gguf](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF/blob/main/orionstar-yi-34b-chat-llama.Q4_K_S.gguf) | Q4_K_S | 4 | 19.54 GB| 22.04 GB | small, greater quality loss |
| [orionstar-yi-34b-chat-llama.Q4_K_M.gguf](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF/blob/main/orionstar-yi-34b-chat-llama.Q4_K_M.gguf) | Q4_K_M | 4 | 20.66 GB| 23.16 GB | medium, balanced quality - recommended |
| [orionstar-yi-34b-chat-llama.Q5_0.gguf](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF/blob/main/orionstar-yi-34b-chat-llama.Q5_0.gguf) | Q5_0 | 5 | 23.71 GB| 26.21 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [orionstar-yi-34b-chat-llama.Q5_K_S.gguf](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF/blob/main/orionstar-yi-34b-chat-llama.Q5_K_S.gguf) | Q5_K_S | 5 | 23.71 GB| 26.21 GB | large, low quality loss - recommended |
| [orionstar-yi-34b-chat-llama.Q5_K_M.gguf](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF/blob/main/orionstar-yi-34b-chat-llama.Q5_K_M.gguf) | Q5_K_M | 5 | 24.32 GB| 26.82 GB | large, very low quality loss - recommended |
| [orionstar-yi-34b-chat-llama.Q6_K.gguf](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF/blob/main/orionstar-yi-34b-chat-llama.Q6_K.gguf) | Q6_K | 6 | 28.21 GB| 30.71 GB | very large, extremely low quality loss |
| [orionstar-yi-34b-chat-llama.Q8_0.gguf](https://huggingface.co/TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF/blob/main/orionstar-yi-34b-chat-llama.Q8_0.gguf) | Q8_0 | 8 | 36.54 GB| 39.04 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF and below it, a specific filename to download, such as: orionstar-yi-34b-chat-llama.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF orionstar-yi-34b-chat-llama.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF orionstar-yi-34b-chat-llama.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m orionstar-yi-34b-chat-llama.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Human: {prompt}\n\nAssistant:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/OrionStar-Yi-34B-Chat-Llama-GGUF", model_file="orionstar-yi-34b-chat-llama.Q4_K_M.gguf", model_type="yi", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: OrionStarAI's OrionStar Yi 34B Chat Llama
[OrionStarAI/OrionStar-Yi-34B-Chat](https://huggingface.co/OrionStarAI/OrionStar-Yi-34B-Chat/tree/main) with tensors renamed to match standard Llama modelling code.
# Model Introduction
- OrionStar-Yi-34B-Chat from OrionStarAI is based on the open-source Yi-34B model, fine-tuned on a high-quality corpus
of over 15 million sentences. OrionStar-Yi-34B-Chat aims to provide an excellent interactive experience for users in
the large model community.
- The Yi series models, open-sourced by the 01-ai team, have shown impressive performance on various benchmarks in
Chinese, English, and general domains. OrionStar-Yi-34B-Chat further explores the potential of Yi-34B. Through
extensive fine-tuning on a large and high-quality corpus, OrionStar-Yi-34B-Chat performs exceptionally well on
evaluation data. We strive to make it an outstanding open-source alternative in the ChatGPT domain!
- Our fine-tuned model is completely open for academic research, but please adhere to the [agreement](#license) and
the [Yi License](https://github.com/01-ai/Yi/blob/main/MODEL_LICENSE_AGREEMENT.txt).
- Model Evaluation Results
We use [opencompass](https://opencompass.org.cn) to perform 5-shot on the following general domain datasets Testing.
The evaluation results of other models are taken
from [opencompass leaderboard](https://opencompass.org.cn/leaderboard-llm).
| | C-Eval | MMLU | CMMLU |
|---------------------------|-----------|--------|-----------|
| **GPT-4** | 69.9 | **83** | 71 |
| **ChatGPT** | 52.5 | 69.1 | 53.9 |
| **Claude-1** | 52 | 65.7 | - |
| **TigerBot-70B-Chat-V2** | 57.7 | 65.9 | 59.9 |
| **WeMix-LLaMA2-70B** | 55.2 | 71.3 | 56 |
| **LLaMA-2-70B-Chat** | 44.3 | 63.8 | 43.3 |
| **Qwen-14B-Chat** | 71.7 | 66.4 | 70 |
| **Baichuan2-13B-Chat** | 56.7 | 57 | 58.4 |
| **OrionStar-Yi-34B-Chat** | **77.71** | 78.32 | **73.52** |
<!-- original-model-card end -->
|
mapapin/dqn-SpaceInvaders
|
mapapin
| 2023-11-22T13:15:49Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-22T13:15:12Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 608.50 +/- 203.62
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga mapapin -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga mapapin -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga mapapin
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
maddes8cht/lightonai-alfred-40b-1023-gguf
|
maddes8cht
| 2023-11-22T13:12:13Z | 158 | 0 | null |
[
"gguf",
"falcon-40b",
"long-context",
"falcon",
"NTK-YaRN",
"en",
"fr",
"de",
"es",
"it",
"dataset:OpenAssistant/oasst1",
"dataset:ehartford/dolphin",
"dataset:tau/sled",
"dataset:tiiuae/falcon-refinedweb",
"arxiv:2306.15595",
"arxiv:2309.00071",
"arxiv:2307.03172",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2023-11-18T15:32:24Z |
---
license: apache-2.0
thumbnail: images/alfred-40b-1023.png
datasets:
- OpenAssistant/oasst1
- ehartford/dolphin
- tau/sled
- tiiuae/falcon-refinedweb
language:
- en
- fr
- de
- es
- it
tags:
- falcon-40b
- long-context
- falcon
- NTK-YaRN
---
[]()
I'm constantly enhancing these model descriptions to provide you with the most relevant and comprehensive information
# alfred-40b-1023 - GGUF
- Model creator: [lightonai](https://huggingface.co/lightonai)
- Original model: [alfred-40b-1023](https://huggingface.co/lightonai/alfred-40b-1023)
# K-Quants in Falcon 7b models
New releases of Llama.cpp now support K-quantization for previously incompatible models, in particular all Falcon 7B models (While Falcon 40b is and always has been fully compatible with K-Quantisation). This is achieved by employing a fallback solution for model layers that cannot be quantized with real K-quants.
For Falcon 7B models, although only a quarter of the layers can be quantized with true K-quants, this approach still benefits from utilizing *different* legacy quantization types Q4_0, Q4_1, Q5_0, and Q5_1. As a result, it offers better quality at the same file size or smaller file sizes with comparable performance.
So this solution ensures improved performance and efficiency over legacy Q4_0, Q4_1, Q5_0 and Q5_1 Quantizations.
# About GGUF format
`gguf` is the current file format used by the [`ggml`](https://github.com/ggerganov/ggml) library.
A growing list of Software is using it and can therefore use this model.
The core project making use of the ggml library is the [llama.cpp](https://github.com/ggerganov/llama.cpp) project by Georgi Gerganov
# Quantization variants
There is a bunch of quantized files available to cater to your specific needs. Here's how to choose the best option for you:
# Legacy quants
Q4_0, Q4_1, Q5_0, Q5_1 and Q8 are `legacy` quantization types.
Nevertheless, they are fully supported, as there are several circumstances that cause certain model not to be compatible with the modern K-quants.
## Note:
Now there's a new option to use K-quants even for previously 'incompatible' models, although this involves some fallback solution that makes them not *real* K-quants. More details can be found in affected model descriptions.
(This mainly refers to Falcon 7b and Starcoder models)
# K-quants
K-quants are designed with the idea that different levels of quantization in specific parts of the model can optimize performance, file size, and memory load.
So, if possible, use K-quants.
With a Q6_K, you'll likely find it challenging to discern a quality difference from the original model - ask your model two times the same question and you may encounter bigger quality differences.
---
# Original Model Card:
# Model Card for Alfred-40B-1023

`Alfred-40B-1023` is a finetuned version of [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b), with an **extended context length of 8192 tokens**.
Finetuning was performed in October 2023. `Alfred-40B-1023` is made available under the Apache 2.0 License.
## Model Details
### Model Description
- **Developed by:** [LightOn](https://www.lighton.ai/)
* [Oskar Hallström](https://huggingface.co/ohallstrom) (project lead, training & modeling, internal long context data, evaluation)
* [Amélie Chatelain](https://huggingface.co/ameliechatelain) (internal data & long context data, data generation)
* [Clément Thiriet](https://huggingface.co/cthiriet) (data infrastructure, data generation, evaluation)
* [Julien Séailles](https://huggingface.co/Jseailleslighton) (data generation)
* [Adrien Cavaillès](https://huggingface.co/adcavail) (data generation)
* [Axel Marmet](https://huggingface.co/WeightsnWizardry)* (training 2K baseline)
`*` work done while at LightOn
- **Model type:** Causal decoder-only;
- **Language(s) (NLP):** English, German, Spanish, French (and limited capabilities in Italian, Portuguese, Polish, Dutch, Romanian, Czech, Swedish);
- **License:** Apache 2.0 license.
- **Finetuned from model:** [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b)
- **Training date:** October 2023 (`1023`).
## Uses
### Direct Use
`Alfred-40B-1023` can be used as a chat model or as an instruct model.
For both instruct and chat mode, the model has been trained with chat tokens `<start_system>`, `<start_user>`, `<start_assistant>`, and `<end_message>`. These can be integrated into the prompt in the follwoing way:
```
<start_system>You are Alfred, a helpful assistant trained by LightOn. Knowledge cutoff: November 2022. Current date: 16 November, 2023<end_message><start_user>{user query}<end_message><start_assistant>
```
The stop word `<end_message>` should be used.
### Out-of-Scope Use
Production use without adequate assessment of risks and mitigation; any use cases which may be considered irresponsible or harmful.
## Bias, Risks, and Limitations
`Alfred-40B-1023` is a finetune of Falcon-40B. As such, it is trained mostly on English, German, Spanish, French, with limited capabilities also in Italian, Portuguese, Polish, Dutch, Romanian, Czech, Swedish. It will not generalize appropriately to other languages. Furthermore, as it is trained on a large-scale corpora representative of the web, it will carry the stereotypes and biases commonly encountered online.
### Recommendations
We recommend users of `Alfred-40B-1023` to implement appropriate guardrails and precautions in any production use.
## How to Get Started with the Model
Use the code below to get started with the model.
```
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model = "lightonai/alfred-40b-1023"
tokenizer = AutoTokenizer.from_pretrained("lightonai/alfred-0923-tokenizer")
pipeline = transformers.pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)
sequences = pipeline(
"<start_system>You are Alfred, a helpful assistant trained by LightOn. Knowledge cutoff: November 2022. Current date: 16 November, 2023<end_message><start_user>Write me an email to my boss, explaining how the company could benefit by using LightOns platform for Large Language Models, Paradigm.<end_message><start_assistant>",
max_length=1000,
do_sample=True,
top_k=3,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
## Training Details
### Training Data
Alfred-40B-1023 was trained on a mixture of publicly available and in-house curated datasets. The training data is composed of 50 % short context tasks, 45 % long context tasks and 5 % RefinedWeb.
| **Short context sources** |
|--------------------|
| [oasst1](https://huggingface.co/datasets/OpenAssistant/oasst1) |
| [dolphin](https://huggingface.co/ehartford/dolphin) |
| [openai-critiques](https://openaipublic.blob.core.windows.net/critiques/README.md) |
| internal |
`internal` is a collection of synthetic and human-generated datasets created by Ligthon, tailored towards the use cases of our clients.
| **Long context sources** |
|--------------------|
| [sled](https://huggingface.co/datasets/tau/sled) |
| internal-long-context |
`internal-long-context` is a collection of synthetic datasets generated by LightOn, tailored towards the use cases of our clients.
During training, we apply regular language modeling loss for a partition of the prompts in the long context data.
| **Pretraining objective source** |
|--------------------|
| [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) |
### Training Procedure
`Alfred-40B-1023` was trained on 128 A100 40GB GPUs, using a 3D parallelism strategy (TP=8, PP=2, DP=8) combined with ZeRO. Alfred has been trained through supervised finetuning on 100 megatokens, with a learning rate decayed with a cosine schedule.
#### Preprocessing
All datasets have been filtered, up or downsampled, and adapted to our chat token format.
#### Context length extension
We extend the context length to 8K with a custom method that we name NTK-YaRN. As guessable from its name, our extension method draws inspiration from NTK-aware interpolation and YaRN.
During our context length extension efforts, we experimented with various methods suitable for RoPE embeddings. These include vanilla [positional interpolation](https://arxiv.org/abs/2306.15595), [NTK-aware interpolation](https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/), [NTK-by-parts](https://github.com/jquesnelle/scaled-rope/pull/1), and lastly [YaRN](https://arxiv.org/abs/2309.00071).
YaRN looked very promising when applied at test-time, however finetuning with YaRN was not successful in our experiments. When extending the context length at training-time, NTK-aware interpolation was the most successful out of the already existing methods. Some of our results from trying different long context extension methods are shared in the Evaluation section below. We acknowledge that the same parameter values as proposed in the YaRN-paper have been used in our YaRN experiments, and that these potentially could have other optimal values for our particular setup.
##### NTK-YaRN
Similarly to NTK-aware interpolation (`NTK`), NTK-YaRN involves increasing the base of the RoPE embeddings. In the original implementation of NTK-aware interpolation the new base `b'` is adapted according to the following formula:
$$ b' = b \times s^{\frac{|D|}{|D|-2}} $$
where `b` is the original base, `s` the scaling factor of the context length, and `|D|` the model's head dimension.
However, we find (similar to other actors) that increasing the base slightly more is even better. The value of `b'` could probably be optimized even further, but for these experiments we have settled with the following value:
$$ b' = b \times (s+1)^{\frac{|D|}{|D|-2}} $$
In the following parts of this model card, context length extension with this extended scaling of the base is referred to as `NTK-Margin`. For `NTK-YaRN`, the extended scaling of the base is combined with the modification of the computation of the attention weights made in YaRN, where the query and key matrices are scaled by the factor `m`.
$$ m = 1 + 0.1 \times \log(s) $$
Scaling the query and key matrices this way substantially reduces the initial grad norm when applying a context length extension method in our training runs.
To cite NTK-YaRN, please refer to the model bibtex in the bottom of this model card.
## Evaluation
### Context length extension strategies
#### Training losses
After experimenting on a 7B scale, we finally run a selected partition of the extension methods on a 40B scale. In the figure below, we display the resulting training losses when training a 40B model with the different extension methods, ceteris paribus.

Initially, YaRN has the lowest training loss, which can be seen as a reflection of the fact that YaRN was the most successful extension method at test time. However all the other methods surpasse YaRN in terms of training loss already after a handful of megatokens. Comparing NTK-Margin vs NTK-YaRN, we can note that the scaling of Q and K matrices makes the training loss lower in the beginning, however NTK-YaRN's advantage over NTK-Margin decreases as the training goes on. Comparing NTK-Margin with NTK in turn, it seems like the larger value of the base in NTK-Margin gives an initial boost in training loss, however this advantage decreases as training goes on.
#### Performance on Long Context Benchmarks
We evaluate the context length extension methods on an own benchmark, consisting of four tasks.
* [Key-value retrieval UUID](https://arxiv.org/pdf/2307.03172.pdf)
* [Coarse-grained Topic Retrieval](https://lmsys.org/blog/2023-06-29-longchat/)
* [Fine-grained Line Retrieval](https://lmsys.org/blog/2023-06-29-longchat/)
* [Multi document retrieval data](https://nlp.stanford.edu/data/nfliu/lost-in-the-middle/nq-open-contriever-msmarco-retrieved-documents.jsonl.gz)
For each task, we have created 3 subtasks - one for each of the three context lengths 2K, 4K and 8K. In total, we thus have 12 subtasks.
In order to get an aggregated score that values each subtask equally, we normalize the scores for each subtask and then calculate the mean of the normalized scores for each extension method.

On these benchmarks, YaRN clearly lags behind. NTK-YaRN is the winning method, however NTK-Margin is so close that more extensive research is needed to verify that NTK-YaRN really is superior to NTK-Margin, especially when trained for longer.
### Comparison to 2K baseline
In order to track any potential degradation on 2K context tasks due to the context length extension, we compare our 8K model against a 2K model trained in a similar setup for 100 megatokens. When training the 2K baseline, we don't include any long context data.
We conduct the comparison by evaluating the models on a selection of tasks from EleutherAI harness, as well as ranking model outputs internally.

Notably, our 8K model not only performs on par with our 2K model on most of our EleutherAI harness tasks, in fact it outperforms the 2K model on a majority of the tasks. Reading comprehension is the only subcategory for which our 8K model is outperformed by the 2K model.
We recognize that there is a discrepancy between performance on classical NLP benchmarks and how humans perceive the model quality. When model outputs (limited to 2K context lengths) are ranked by LightOn employees internally, the 2K and 8K have strikingly similar performance. However, a few rare failure modes have been noted for the 8K version, which are not seen when using the 2K model. These failure modes are likely to be fixable with better composition of the long context data.
## Compute Infrastructure
### Hardware
Alfred-40B-1023 was trained on AWS SageMaker, on 128 A100 40GB GPUs in P4d instances.
### Software
Alfred-40B-1023 was trained with a custom codebase. Training leverages a 3D parallelism approach combined with ZeRO, as well as high-performance kernels such as FlashAttention.
## Model Card Contact
Please open a Community Discussion for any support request related to using Alfred with HuggingFace transformers.
For any other inquiry: contact@lighton.ai
## Citation
If you find the model useful in your work, please use the following bibtex when citing.
```
@article{alfred-40b-1023,
title={Alfred-40B-1023},
author={Hallström, Oskar and Chatelain, Amélie and Thiriet, Clément and Séailles, Julien and Cavaillès, Adrien and Marmet, Axel},
year={2023}
}
```
***End of original Model File***
---
## Please consider to support my work
**Coming Soon:** I'm in the process of launching a sponsorship/crowdfunding campaign for my work. I'm evaluating Kickstarter, Patreon, or the new GitHub Sponsors platform, and I am hoping for some support and contribution to the continued availability of these kind of models. Your support will enable me to provide even more valuable resources and maintain the models you rely on. Your patience and ongoing support are greatly appreciated as I work to make this page an even more valuable resource for the community.
<center>
[](https://maddes8cht.github.io)
[](https://stackexchange.com/users/26485911)
[](https://github.com/maddes8cht)
[](https://huggingface.co/maddes8cht)
[](https://twitter.com/maddes1966)
</center>
|
zhijian12345/dqn-SpaceInvadersNoFrameskip-v4
|
zhijian12345
| 2023-11-22T13:09:40Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-22T13:09:04Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 655.00 +/- 256.16
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga zhijian12345 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga zhijian12345 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga zhijian12345
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
RalFinger/horror-skeletons-lora-sdxl
|
RalFinger
| 2023-11-22T13:07:57Z | 49 | 4 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"style",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] |
text-to-image
| 2023-11-22T13:07:55Z |
---
license: other
license_name: bespoke-lora-trained-license
license_link: https://multimodal.art/civitai-licenses?allowNoCredit=True&allowCommercialUse=Sell&allowDerivatives=True&allowDifferentLicense=True
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
- style
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: zkeleton
widget:
- text: 'full body shot, skeleton cat looking for food, evil cat, dead cat, bloody open mouth, basement, bright sunlight, stone floor, zkeleton '
output:
url: >-
3297265.jpeg
- text: 'full body shot, skeleton cat looking for food, evil cat, dead cat, bloody open mouth, basement, bright sunlight, stone floor, zkeleton '
output:
url: >-
3297264.jpeg
- text: 'full body shot, rat looking for food, evil rat, dead rat, bloody open mouth, feasting on flesh, flesh on bones, blood on bones, smelly and rotten body, skeleton, bones, solo, 1boy, upper body, outdoors, teeth, no humans, 1other, ribs, skeleton, bone, horror (theme), in old dirty kitchen corner, dirt on the floor, lit by old candle light, bad light, '
output:
url: >-
3296793.jpeg
- text: 'full body shot, rat looking for food, evil rat, dead rat, bloody open mouth, feasting on flesh, flesh on bones, blood on bones, smelly and rotten body, skeleton, bones, solo, 1boy, upper body, outdoors, teeth, no humans, 1other, ribs, skeleton, bone, horror (theme), in old dirty kitchen corner, dirt on the floor, lit by old candle light, bad light, '
output:
url: >-
3296792.jpeg
- text: 'full body shot, skeleton with horns, (wearing bloody animal fur:1.8), viking style, looking evil at viewer, grabing viewer, skeleton hand towards viewer,swampy moor background with fog, zkeleton '
output:
url: >-
3296785.jpeg
- text: 'full body shot, skeleton with horns, (wearing bloody animal fur:1.8), viking style, looking evil at viewer, grabing viewer, skeleton hand towards viewer,swampy moor background with fog, zkeleton '
output:
url: >-
3296781.jpeg
- text: '1tree, single tree, skeletons hanging from tree, hanging bodies, blood, horrific scene, huge horror tree made out of bones, tree made out of skeletons, swampy moor background with fog, skeleton trees in the background, red, white, black, yellow, zkeleton '
output:
url: >-
3296784.jpeg
- text: 'blood, horrific scene, huge horror tree made out of bones, tree made out of skeletons, swampy moor background with fog, skeleton trees in the background, red, orange, white, black, at night, glowing from behind, foggy, fog, zkeleton '
output:
url: >-
3296782.jpeg
- text: 'dead ape, ape, ape skeleton, (waering monk comstume:1.5), evil grin, black glowing eyes, bloody bone wings, at night, dark background, ghosts flying in the background, zkeleton'
output:
url: >-
3296786.jpeg
- text: 'dead ape, ape, ape skeleton, (waering monk comstume:1.5), evil grin, black glowing eyes, bloody bone wings, at night, dark background, ghosts flying in the background, zkeleton'
output:
url: >-
3296788.jpeg
---
# Horror Skeletons [LoRA SDXL]
<Gallery />
([CivitAI](https://civitai.com/models/184520))
## Model description
<p>If you are having issues generating, add stuff like "dead ape" or "dead fish" to your prompt!<br /><br /><u>SDXL:<br /></u><span style="color:rgb(193, 194, 197)">Trigger word: </span><strong><span style="color:rgb(193, 194, 197)">zkeleton</span></strong><br /><span style="color:rgb(193, 194, 197)">Sampling Method: </span><strong><span style="color:rgb(219, 222, 225)">DPM++ 2M SDE Karras</span></strong><br /><br />☕ Buy me a coffee: <a target="_blank" rel="ugc" href="https://ko-fi.com/ralfingerai">https://ko-fi.com/ralfingerai</a></p>
## Trigger words
You should use `zkeleton` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/RalFinger/horror-skeletons-lora-sdxl/tree/main) them in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('RalFinger/horror-skeletons-lora-sdxl', weight_name='zkeleton-sdxl.safetensors')
image = pipeline('dead ape, ape, ape skeleton, (waering monk comstume:1.5), evil grin, black glowing eyes, bloody bone wings, at night, dark background, ghosts flying in the background, zkeleton').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
Atomheart-Father/ppo-LunarLander-v2
|
Atomheart-Father
| 2023-11-22T13:07:45Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-22T13:07:12Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 267.95 +/- 17.36
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
incredible45/xlm-roberta-base-predictive-search
|
incredible45
| 2023-11-22T13:06:47Z | 5 | 0 |
transformers
|
[
"transformers",
"tf",
"xlm-roberta",
"fill-mask",
"generated_from_keras_callback",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-11-22T12:40:51Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_keras_callback
model-index:
- name: incredible45/xlm-roberta-base-predictive-search
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# incredible45/xlm-roberta-base-predictive-search
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 23.4964
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'transformers.optimization_tf', 'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -996, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}, 'registered_name': 'WarmUp'}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Epoch |
|:----------:|:-----:|
| 23.4964 | 0 |
### Framework versions
- Transformers 4.35.2
- TensorFlow 2.14.0
- Datasets 2.15.0
- Tokenizers 0.15.0
|
bartowski/Tess-XS-v1.1-exl2
|
bartowski
| 2023-11-22T13:04:39Z | 0 | 0 | null |
[
"text-generation",
"license:apache-2.0",
"region:us"
] |
text-generation
| 2023-11-22T11:16:08Z |
---
license: apache-2.0
quantized_by: bartowski
pipeline_tag: text-generation
---
## Exllama v2 Quantizations of Tess-XS-v1.1
Using <a href="https://github.com/turboderp/exllamav2/releases/tag/v0.0.8">turboderp's ExLlamaV2 v0.0.8</a> for quantization.
Each branch contains an individual bits per weight, with the main one containing only the meaurement.json for further conversions.
Conversion was done using wikitext-103-raw-v1-test.parquet as calibration dataset.
Default arguments used except when the bits per weight is above 6.0, at that point the lm_head layer is quantized at 8 bits per weight instead of the default 6.
Original model: https://huggingface.co/migtissera/Tess-XS-v1.1
<a href="https://huggingface.co/bartowski/Tess-XS-v1.1-exl2/tree/4_0">4.0 bits per weight</a>
<a href="https://huggingface.co/bartowski/Tess-XS-v1.1-exl2/tree/5_0">5.0 bits per weight</a>
<a href="https://huggingface.co/bartowski/Tess-XS-v1.1-exl2/tree/6_0">6.0 bits per weight</a>
<a href="https://huggingface.co/bartowski/Tess-XS-v1.1-exl2/tree/8_0">8.0 bits per weight</a>
## Download instructions
With git:
```shell
git clone --single-branch --branch 4_0 https://huggingface.co/bartowski/Tess-XS-v1.1-exl2
```
With huggingface hub (credit to TheBloke for instructions):
```shell
pip3 install huggingface-hub
```
To download the `main` (only useful if you only care about measurement.json) branch to a folder called `Tess-XS-v1.1-exl2`:
```shell
mkdir Tess-XS-v1.1-exl2
huggingface-cli download bartowski/Tess-XS-v1.1-exl2 --local-dir Tess-XS-v1.1-exl2 --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir Tess-XS-v1.1-exl2
huggingface-cli download bartowski/Tess-XS-v1.1-exl2 --revision 4_0 --local-dir Tess-XS-v1.1-exl2 --local-dir-use-symlinks False
```
|
mdosama39/muril-adapted-local-FakeNews-Dravidian-muril
|
mdosama39
| 2023-11-22T13:03:32Z | 13 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:monsoon-nlp/muril-adapted-local",
"base_model:finetune:monsoon-nlp/muril-adapted-local",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-22T12:10:22Z |
---
license: apache-2.0
base_model: monsoon-nlp/muril-adapted-local
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: muril-adapted-local-FakeNews-Dravidian-muril
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# muril-adapted-local-FakeNews-Dravidian-muril
This model is a fine-tuned version of [monsoon-nlp/muril-adapted-local](https://huggingface.co/monsoon-nlp/muril-adapted-local) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5333
- Accuracy: 0.7448
- Weighted f1 score: 0.7448
- Macro f1 score: 0.7447
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Weighted f1 score | Macro f1 score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:-----------------:|:--------------:|
| 0.7193 | 1.0 | 204 | 0.7031 | 0.5350 | 0.4469 | 0.4477 |
| 0.6807 | 2.0 | 408 | 0.6694 | 0.5840 | 0.5800 | 0.5798 |
| 0.6606 | 3.0 | 612 | 0.6487 | 0.6160 | 0.6160 | 0.6160 |
| 0.6377 | 4.0 | 816 | 0.6211 | 0.6638 | 0.6602 | 0.6601 |
| 0.5906 | 5.0 | 1020 | 0.6154 | 0.6748 | 0.6552 | 0.6549 |
| 0.5526 | 6.0 | 1224 | 0.5716 | 0.6994 | 0.6956 | 0.6955 |
| 0.5195 | 7.0 | 1428 | 0.5471 | 0.7202 | 0.7200 | 0.7199 |
| 0.4945 | 8.0 | 1632 | 0.5410 | 0.7264 | 0.7256 | 0.7255 |
| 0.4635 | 9.0 | 1836 | 0.5448 | 0.7350 | 0.7332 | 0.7332 |
| 0.4453 | 10.0 | 2040 | 0.5355 | 0.7362 | 0.7358 | 0.7358 |
| 0.429 | 11.0 | 2244 | 0.5337 | 0.7362 | 0.7356 | 0.7356 |
| 0.4262 | 12.0 | 2448 | 0.5539 | 0.7399 | 0.7374 | 0.7373 |
| 0.4041 | 13.0 | 2652 | 0.5334 | 0.7485 | 0.7484 | 0.7484 |
| 0.3983 | 14.0 | 2856 | 0.5326 | 0.7497 | 0.7497 | 0.7497 |
| 0.3798 | 15.0 | 3060 | 0.5333 | 0.7448 | 0.7448 | 0.7447 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.0.0
- Datasets 2.11.0
- Tokenizers 0.14.1
|
pulumboom/distilbert-base-uncased-finetuned_emotion
|
pulumboom
| 2023-11-22T12:56:52Z | 4 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-22T12:32:34Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned_emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.925
- name: F1
type: f1
value: 0.925194550064413
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned_emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2164
- Accuracy: 0.925
- F1: 0.9252
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8315 | 1.0 | 250 | 0.3165 | 0.9035 | 0.9017 |
| 0.2522 | 2.0 | 500 | 0.2164 | 0.925 | 0.9252 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
owanr/SBIC-mistralai-Mistral-7B-v0.1-intra-dataset-frequency-model-pairwise-mse-cycle1
|
owanr
| 2023-11-22T12:54:44Z | 0 | 0 | null |
[
"safetensors",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:finetune:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"region:us"
] | null | 2023-11-22T12:54:41Z |
---
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.1
tags:
- generated_from_trainer
model-index:
- name: SBIC-mistralai-Mistral-7B-v0.1-intra-dataset-frequency-model-pairwise-mse-cycle1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SBIC-mistralai-Mistral-7B-v0.1-intra-dataset-frequency-model-pairwise-mse-cycle1
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5520
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.4802 | 0.04 | 31 | 2.4091 |
| 2.2997 | 1.04 | 62 | 2.2583 |
| 2.1019 | 2.04 | 93 | 2.0836 |
| 1.8498 | 3.04 | 124 | 1.8917 |
| 1.6275 | 4.04 | 155 | 1.7154 |
| 1.4091 | 5.04 | 186 | 1.5379 |
| 1.2361 | 6.04 | 217 | 1.3779 |
| 1.087 | 7.04 | 248 | 1.2654 |
| 0.9664 | 8.04 | 279 | 1.1340 |
| 0.8312 | 9.04 | 310 | 1.0311 |
| 0.7554 | 10.04 | 341 | 0.9393 |
| 0.6873 | 11.04 | 372 | 0.8599 |
| 0.6292 | 12.04 | 403 | 0.7976 |
| 0.5822 | 13.04 | 434 | 0.7410 |
| 0.5453 | 14.04 | 465 | 0.6989 |
| 0.5115 | 15.04 | 496 | 0.6611 |
| 0.4778 | 16.04 | 527 | 0.6292 |
| 0.4527 | 17.04 | 558 | 0.6054 |
| 0.4474 | 18.04 | 589 | 0.5882 |
| 0.4285 | 19.04 | 620 | 0.5740 |
| 0.4193 | 20.04 | 651 | 0.5642 |
| 0.4061 | 21.04 | 682 | 0.5583 |
| 0.4044 | 22.04 | 713 | 0.5544 |
| 0.4 | 23.04 | 744 | 0.5524 |
| 0.4029 | 24.04 | 775 | 0.5520 |
| 0.3973 | 25.04 | 806 | 0.5520 |
| 0.3977 | 26.04 | 837 | 0.5520 |
| 0.3947 | 27.04 | 868 | 0.5520 |
| 0.3983 | 28.04 | 899 | 0.5520 |
| 0.3934 | 29.04 | 930 | 0.5520 |
| 0.3977 | 30.04 | 961 | 0.5520 |
| 0.4022 | 31.04 | 992 | 0.5520 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.1+cu121
- Datasets 2.15.0
- Tokenizers 0.15.0
|
sander-wood/clamp-small-1024
|
sander-wood
| 2023-11-22T12:50:39Z | 7 | 4 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"music",
"feature-extraction",
"en",
"dataset:sander-wood/wikimusictext",
"arxiv:2304.11029",
"license:mit",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2023-04-22T13:59:54Z |
---
license: mit
datasets:
- sander-wood/wikimusictext
language:
- en
pipeline_tag: feature-extraction
tags:
- music
---
# CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval [ISMIR 2023, Best Student Paper Award]
## Model description
In [CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval](https://ai-muzic.github.io/clamp/), we introduce a solution for cross-modal symbolic MIR that utilizes contrastive learning and pre-training. The proposed approach, CLaMP: Contrastive Language-Music Pre-training, which learns cross-modal representations between natural language and symbolic music using a music encoder and a text encoder trained jointly with a contrastive loss. To pre-train CLaMP, we collected a large dataset of 1.4 million music-text pairs. It employed text dropout as a data augmentation technique and bar patching to efficiently represent music data which reduces sequence length to less than 10%. In addition, we developed a masked music model pre-training objective to enhance the music encoder's comprehension of musical context and structure. CLaMP integrates textual information to enable semantic search and zero-shot classification for symbolic music, surpassing the capabilities of previous models. To support the evaluation of semantic search and music classification, we publicly release [WikiMusicText](https://huggingface.co/datasets/sander-wood/wikimusictext) (WikiMT), a dataset of 1010 lead sheets in ABC notation, each accompanied by a title, artist, genre, and description. In comparison to state-of-the-art models that require fine-tuning, zero-shot CLaMP demonstrated comparable or superior performance on score-oriented datasets.
Two variants of CLaMP are introduced: [CLaMP-S/512](https://huggingface.co/sander-wood/clamp-small-512) and [CLaMP-S/1024](https://huggingface.co/sander-wood/clamp-small-1024). Both models consist of a 6-layer music encoder and a 6-layer text encoder with a hidden size of 768. While CLaMP-S/512 accepts input music sequences of up to 512 tokens in length, CLaMP-S/1024 allows for up to 1024 tokens. The maximum input length for the text encoder in both models is 128 tokens. These models are part of [Muzic](https://github.com/microsoft/muzic), a research initiative on AI music that leverages deep learning and artificial intelligence to enhance music comprehension and generation.
As part of our effort to make CLaMP more accessible to researchers and developers, we have created three Hugging Face spaces that showcase its abilities. The first space, [CLaMP - Semantic Music Search](https://huggingface.co/spaces/sander-wood/clamp_semantic_music_search), enables users to search for musical pieces using natural language queries, such as "a happy jazz song." The second space, [CLaMP - Zero-Shot Music Classification](https://huggingface.co/spaces/sander-wood/clamp_zero_shot_music_classification), allows users to classify musical pieces based on their textual descriptions, without the need for any fine-tuning. Finally, the third space, [CLaMP - Similar Music Recommendation](https://huggingface.co/spaces/sander-wood/clamp_similar_music_recommendation), allows users to input a musical piece in MusicXML (.mxl) and receive recommendations for similar pieces based on their textual descriptions.
These spaces leverage the power of CLaMP's pre-trained models to provide users with state-of-the-art cross-modal symbolic music information retrieval capabilities. We hope that these spaces will inspire researchers and developers to explore the possibilities of CLaMP and contribute to the advancement of the field of AI music.
## Cross-Modal Symbolic MIR
CLaMP is capable of aligning symbolic music and natural language, which can be used for various cross-modal retrieval tasks, including semantic search and zero-shot classification for symbolic music.
Semantic search is a technique for retrieving music by open-domain queries, which differs from traditional keyword-based searches that depend on exact matches or meta-information. This involves two steps: 1) extracting music features from all scores in the library, and 2) transforming the query into a text feature. By calculating the similarities between the text feature and the music features, it can efficiently locate the score that best matches the user's query in the library.
Zero-shot classification refers to the classification of new items into any desired label without the need for training data. It involves using a prompt template to provide context for the text encoder. For example, a prompt such as "<i>This piece of music is composed by {composer}.</i>" is utilized to form input texts based on the names of candidate composers. The text encoder then outputs text features based on these input texts. Meanwhile, the music encoder extracts the music feature from the unlabelled target symbolic music. By calculating the similarity between each candidate text feature and the target music feature, the label with the highest similarity is chosen as the predicted one.
## Intended uses:
1. Semantic search and zero-shot classification for score-oriented symbolic music datasets.
2. Cross-modal representation learning between natural language and symbolic music.
3. Enabling research in music analysis, retrieval, and generation.
4. Building innovative systems and applications that integrate music and language.
## Limitations:
1. CLaMP's current version has limited comprehension of performance MIDI.
2. The model may not perform well on tasks outside its pre-training scope.
3. It may require fine-tuning for some specific tasks.
### How to use
To use CLaMP, you can follow these steps:
1. Clone the CLaMP repository by running the following command in your terminal:
```
git clone https://github.com/microsoft/muzic.git
```
This will create a local copy of the repository on your computer.
2. Navigate to the CLaMP directory by running the following command:
```
cd muzic/clamp
```
3. Install the required dependencies by running the following command:
```
pip install -r requirements.txt
```
4. If you are performing a music query, save your query as `inference/music_query.mxl`. For music keys, ensure that all the music files are in the MusicXML (.mxl) format, and are saved in the `inference/music_keys` folder.
5. If you are performing a text query, save your query as `inference/text_query.txt`. For text keys, save all the keys in the `inference/text_keys.txt` file, where each line corresponds to a key.
6. Run the following command to perform the query:
```
python clamp.py -clamp_model_name [MODEL NAME] -query_modal [QUERY MODAL] -key_modal [KEY MODAL] -top_n [NUMBER OF RESULTS]
```
Replace [MODEL NAME] with the name of the CLaMP model you want to use (either `sander-wood/clamp-small-512` or `sander-wood/clamp-small-1024`), [QUERY MODAL] with either `music` or `text` to indicate the type of query you want to perform, [KEY MODAL] with either `music` or `text` to indicate the type of key modal you want to use, and [NUMBER OF RESULTS] with the number of top results you want to return.
For example, to perform semantic music search with the `sander-wood/clamp-small-512` model and return the top 5 results, run:
```
python clamp.py -clamp_model_name sander-wood/clamp-small-512 -query_modal text -key_modal music -top_n 5
```
Note that the first time you run the CLaMP script, it will automatically download the model checkpoint from Hugging Face. This may take a few minutes, depending on your internet speed.
7. After running the command, the script will generate a list of the top results for the given query. Each result correspond to a music file in the `music_keys` folder or a line in the `text_keys.txt` file, depending on the type of key modal you used.
## BibTeX entry and citation info
```
@misc{wu2023clamp,
title={CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval},
author={Shangda Wu and Dingyao Yu and Xu Tan and Maosong Sun},
year={2023},
eprint={2304.11029},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
```
|
sander-wood/clamp-small-512
|
sander-wood
| 2023-11-22T12:48:33Z | 7 | 1 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"music",
"feature-extraction",
"en",
"dataset:sander-wood/wikimusictext",
"arxiv:2304.11029",
"license:mit",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2023-04-22T13:55:58Z |
---
license: mit
datasets:
- sander-wood/wikimusictext
language:
- en
pipeline_tag: feature-extraction
tags:
- music
---
# CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval [ISMIR 2023, Best Student Paper Award]
## Model description
In [CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval](https://ai-muzic.github.io/clamp/), we introduce a solution for cross-modal symbolic MIR that utilizes contrastive learning and pre-training. The proposed approach, CLaMP: Contrastive Language-Music Pre-training, which learns cross-modal representations between natural language and symbolic music using a music encoder and a text encoder trained jointly with a contrastive loss. To pre-train CLaMP, we collected a large dataset of 1.4 million music-text pairs. It employed text dropout as a data augmentation technique and bar patching to efficiently represent music data which reduces sequence length to less than 10%. In addition, we developed a masked music model pre-training objective to enhance the music encoder's comprehension of musical context and structure. CLaMP integrates textual information to enable semantic search and zero-shot classification for symbolic music, surpassing the capabilities of previous models. To support the evaluation of semantic search and music classification, we publicly release [WikiMusicText](https://huggingface.co/datasets/sander-wood/wikimusictext) (WikiMT), a dataset of 1010 lead sheets in ABC notation, each accompanied by a title, artist, genre, and description. In comparison to state-of-the-art models that require fine-tuning, zero-shot CLaMP demonstrated comparable or superior performance on score-oriented datasets.
Two variants of CLaMP are introduced: [CLaMP-S/512](https://huggingface.co/sander-wood/clamp-small-512) and [CLaMP-S/1024](https://huggingface.co/sander-wood/clamp-small-1024). Both models consist of a 6-layer music encoder and a 6-layer text encoder with a hidden size of 768. While CLaMP-S/512 accepts input music sequences of up to 512 tokens in length, CLaMP-S/1024 allows for up to 1024 tokens. The maximum input length for the text encoder in both models is 128 tokens. These models are part of [Muzic](https://github.com/microsoft/muzic), a research initiative on AI music that leverages deep learning and artificial intelligence to enhance music comprehension and generation.
As part of our effort to make CLaMP more accessible to researchers and developers, we have created three Hugging Face spaces that showcase its abilities. The first space, [CLaMP - Semantic Music Search](https://huggingface.co/spaces/sander-wood/clamp_semantic_music_search), enables users to search for musical pieces using natural language queries, such as "a happy jazz song." The second space, [CLaMP - Zero-Shot Music Classification](https://huggingface.co/spaces/sander-wood/clamp_zero_shot_music_classification), allows users to classify musical pieces based on their textual descriptions, without the need for any fine-tuning. Finally, the third space, [CLaMP - Similar Music Recommendation](https://huggingface.co/spaces/sander-wood/clamp_similar_music_recommendation), allows users to input a musical piece in MusicXML (.mxl) and receive recommendations for similar pieces based on their textual descriptions.
These spaces leverage the power of CLaMP's pre-trained models to provide users with state-of-the-art cross-modal symbolic music information retrieval capabilities. We hope that these spaces will inspire researchers and developers to explore the possibilities of CLaMP and contribute to the advancement of the field of AI music.
## Cross-Modal Symbolic MIR
CLaMP is capable of aligning symbolic music and natural language, which can be used for various cross-modal retrieval tasks, including semantic search and zero-shot classification for symbolic music.
Semantic search is a technique for retrieving music by open-domain queries, which differs from traditional keyword-based searches that depend on exact matches or meta-information. This involves two steps: 1) extracting music features from all scores in the library, and 2) transforming the query into a text feature. By calculating the similarities between the text feature and the music features, it can efficiently locate the score that best matches the user's query in the library.
Zero-shot classification refers to the classification of new items into any desired label without the need for training data. It involves using a prompt template to provide context for the text encoder. For example, a prompt such as "<i>This piece of music is composed by {composer}.</i>" is utilized to form input texts based on the names of candidate composers. The text encoder then outputs text features based on these input texts. Meanwhile, the music encoder extracts the music feature from the unlabelled target symbolic music. By calculating the similarity between each candidate text feature and the target music feature, the label with the highest similarity is chosen as the predicted one.
## Intended uses:
1. Semantic search and zero-shot classification for score-oriented symbolic music datasets.
2. Cross-modal representation learning between natural language and symbolic music.
3. Enabling research in music analysis, retrieval, and generation.
4. Building innovative systems and applications that integrate music and language.
## Limitations:
1. CLaMP's current version has limited comprehension of performance MIDI.
2. The model may not perform well on tasks outside its pre-training scope.
3. It may require fine-tuning for some specific tasks.
### How to use
To use CLaMP, you can follow these steps:
1. Clone the CLaMP repository by running the following command in your terminal:
```
git clone https://github.com/microsoft/muzic.git
```
This will create a local copy of the repository on your computer.
2. Navigate to the CLaMP directory by running the following command:
```
cd muzic/clamp
```
3. Install the required dependencies by running the following command:
```
pip install -r requirements.txt
```
4. If you are performing a music query, save your query as `inference/music_query.mxl`. For music keys, ensure that all the music files are in the MusicXML (.mxl) format, and are saved in the `inference/music_keys` folder.
5. If you are performing a text query, save your query as `inference/text_query.txt`. For text keys, save all the keys in the `inference/text_keys.txt` file, where each line corresponds to a key.
6. Run the following command to perform the query:
```
python clamp.py -clamp_model_name [MODEL NAME] -query_modal [QUERY MODAL] -key_modal [KEY MODAL] -top_n [NUMBER OF RESULTS]
```
Replace [MODEL NAME] with the name of the CLaMP model you want to use (either `sander-wood/clamp-small-512` or `sander-wood/clamp-small-1024`), [QUERY MODAL] with either `music` or `text` to indicate the type of query you want to perform, [KEY MODAL] with either `music` or `text` to indicate the type of key modal you want to use, and [NUMBER OF RESULTS] with the number of top results you want to return.
For example, to perform semantic music search with the `sander-wood/clamp-small-512` model and return the top 5 results, run:
```
python clamp.py -clamp_model_name sander-wood/clamp-small-512 -query_modal text -key_modal music -top_n 5
```
Note that the first time you run the CLaMP script, it will automatically download the model checkpoint from Hugging Face. This may take a few minutes, depending on your internet speed.
7. After running the command, the script will generate a list of the top results for the given query. Each result correspond to a music file in the `music_keys` folder or a line in the `text_keys.txt` file, depending on the type of key modal you used.
## BibTeX entry and citation info
```
@misc{wu2023clamp,
title={CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval},
author={Shangda Wu and Dingyao Yu and Xu Tan and Maosong Sun},
year={2023},
eprint={2304.11029},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
```
|
mdosama39/bert-base-multilingual-cased-FakeNews-Dravidian-mBert
|
mdosama39
| 2023-11-22T12:48:33Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-multilingual-cased",
"base_model:finetune:google-bert/bert-base-multilingual-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-22T09:00:12Z |
---
license: apache-2.0
base_model: bert-base-multilingual-cased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bert-base-multilingual-cased-FakeNews-Dravidian-mBert
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-multilingual-cased-FakeNews-Dravidian-mBert
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4452
- Accuracy: 0.8307
- Weighted f1 score: 0.8305
- Macro f1 score: 0.8305
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Weighted f1 score | Macro f1 score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:-----------------:|:--------------:|
| 0.7901 | 1.0 | 204 | 0.6155 | 0.7067 | 0.6999 | 0.7000 |
| 0.5829 | 2.0 | 408 | 0.4932 | 0.8037 | 0.8036 | 0.8036 |
| 0.4813 | 3.0 | 612 | 0.4437 | 0.8135 | 0.8130 | 0.8129 |
| 0.4298 | 4.0 | 816 | 0.4182 | 0.8123 | 0.8123 | 0.8123 |
| 0.3896 | 5.0 | 1020 | 0.4068 | 0.8221 | 0.8219 | 0.8219 |
| 0.3411 | 6.0 | 1224 | 0.3999 | 0.8209 | 0.8209 | 0.8209 |
| 0.314 | 7.0 | 1428 | 0.4030 | 0.8307 | 0.8305 | 0.8305 |
| 0.2982 | 8.0 | 1632 | 0.4084 | 0.8270 | 0.8269 | 0.8269 |
| 0.279 | 9.0 | 1836 | 0.4129 | 0.8319 | 0.8316 | 0.8315 |
| 0.2502 | 10.0 | 2040 | 0.4120 | 0.8307 | 0.8306 | 0.8305 |
| 0.2328 | 11.0 | 2244 | 0.4256 | 0.8368 | 0.8364 | 0.8364 |
| 0.2168 | 12.0 | 2448 | 0.4480 | 0.8393 | 0.8388 | 0.8388 |
| 0.2246 | 13.0 | 2652 | 0.4463 | 0.8294 | 0.8292 | 0.8292 |
| 0.2149 | 14.0 | 2856 | 0.4411 | 0.8307 | 0.8306 | 0.8305 |
| 0.2077 | 15.0 | 3060 | 0.4452 | 0.8307 | 0.8305 | 0.8305 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.0.0
- Datasets 2.11.0
- Tokenizers 0.14.1
|
NDugar/ZSD-microsoft-v2xxlmnli
|
NDugar
| 2023-11-22T12:48:05Z | 47 | 3 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"deberta-v2",
"text-classification",
"deberta-v1",
"deberta-mnli",
"zero-shot-classification",
"en",
"arxiv:2006.03654",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
zero-shot-classification
| 2022-03-02T23:29:04Z |
---
language: en
tags:
- deberta-v1
- deberta-mnli
tasks: mnli
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
license: mit
pipeline_tag: zero-shot-classification
---
## DeBERTa: Decoding-enhanced BERT with Disentangled Attention
[DeBERTa](https://arxiv.org/abs/2006.03654) improves the BERT and RoBERTa models using disentangled attention and enhanced mask decoder. It outperforms BERT and RoBERTa on majority of NLU tasks with 80GB training data.
Please check the [official repository](https://github.com/microsoft/DeBERTa) for more details and updates.
This is the DeBERTa large model fine-tuned with MNLI task.
#### Fine-tuning on NLU tasks
We present the dev results on SQuAD 1.1/2.0 and several GLUE benchmark tasks.
| Model | SQuAD 1.1 | SQuAD 2.0 | MNLI-m/mm | SST-2 | QNLI | CoLA | RTE | MRPC | QQP |STS-B |
|---------------------------|-----------|-----------|-------------|-------|------|------|--------|-------|-------|------|
| | F1/EM | F1/EM | Acc | Acc | Acc | MCC | Acc |Acc/F1 |Acc/F1 |P/S |
| BERT-Large | 90.9/84.1 | 81.8/79.0 | 86.6/- | 93.2 | 92.3 | 60.6 | 70.4 | 88.0/- | 91.3/- |90.0/- |
| RoBERTa-Large | 94.6/88.9 | 89.4/86.5 | 90.2/- | 96.4 | 93.9 | 68.0 | 86.6 | 90.9/- | 92.2/- |92.4/- |
| XLNet-Large | 95.1/89.7 | 90.6/87.9 | 90.8/- | 97.0 | 94.9 | 69.0 | 85.9 | 90.8/- | 92.3/- |92.5/- |
| [DeBERTa-Large](https://huggingface.co/microsoft/deberta-large)<sup>1</sup> | 95.5/90.1 | 90.7/88.0 | 91.3/91.1| 96.5|95.3| 69.5| 91.0| 92.6/94.6| 92.3/- |92.8/92.5 |
| [DeBERTa-XLarge](https://huggingface.co/microsoft/deberta-xlarge)<sup>1</sup> | -/- | -/- | 91.5/91.2| 97.0 | - | - | 93.1 | 92.1/94.3 | - |92.9/92.7|
| [DeBERTa-V2-XLarge](https://huggingface.co/microsoft/deberta-v2-xlarge)<sup>1</sup>|95.8/90.8| 91.4/88.9|91.7/91.6| **97.5**| 95.8|71.1|**93.9**|92.0/94.2|92.3/89.8|92.9/92.9|
|**[DeBERTa-V2-XXLarge](https://huggingface.co/microsoft/deberta-v2-xxlarge)<sup>1,2</sup>**|**96.1/91.4**|**92.2/89.7**|**91.7/91.9**|97.2|**96.0**|**72.0**| 93.5| **93.1/94.9**|**92.7/90.3** |**93.2/93.1** |
--------
#### Notes.
- <sup>1</sup> Following RoBERTa, for RTE, MRPC, STS-B, we fine-tune the tasks based on [DeBERTa-Large-MNLI](https://huggingface.co/microsoft/deberta-large-mnli), [DeBERTa-XLarge-MNLI](https://huggingface.co/microsoft/deberta-xlarge-mnli), [DeBERTa-V2-XLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xlarge-mnli), [DeBERTa-V2-XXLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xxlarge-mnli). The results of SST-2/QQP/QNLI/SQuADv2 will also be slightly improved when start from MNLI fine-tuned models, however, we only report the numbers fine-tuned from pretrained base models for those 4 tasks.
- <sup>2</sup> To try the **XXLarge** model with **[HF transformers](https://huggingface.co/transformers/main_classes/trainer.html)**, you need to specify **--sharded_ddp**
```bash
cd transformers/examples/text-classification/
export TASK_NAME=mrpc
python -m torch.distributed.launch --nproc_per_node=8 run_glue.py --model_name_or_path microsoft/deberta-v2-xxlarge \\\n--task_name $TASK_NAME --do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 4 \\\n--learning_rate 3e-6 --num_train_epochs 3 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --sharded_ddp --fp16
```
### Citation
If you find DeBERTa useful for your work, please cite the following paper:
``` latex
@inproceedings{
he2021deberta,
title={DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION},
author={Pengcheng He and Xiaodong Liu and Jianfeng Gao and Weizhu Chen},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=XPZIaotutsD}
}
```
|
pradipghevariya/Llama-2-7b-chat-Medquad
|
pradipghevariya
| 2023-11-22T12:45:35Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"region:us"
] | null | 2023-11-22T12:43:56Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0
- PEFT 0.5.0
|
dg845/diffusers-cm_edm_imagenet64_ema
|
dg845
| 2023-11-22T12:45:02Z | 9 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"arxiv:2206.00364",
"arxiv:2303.01469",
"license:mit",
"diffusers:KarrasEDMPipeline",
"region:us"
] | null | 2023-09-19T08:22:15Z |
---
license: mit
---
This is a version of the `edm_imagenet64_ema` [EDM](https://arxiv.org/pdf/2206.00364.pdf) model checkpoint developed by OpenAI and released as part of the [consistency models](https://arxiv.org/pdf/2303.01469.pdf) [code repo](https://github.com/openai/consistency_models) intended to be compatible with the experimental `KarrasEDMPipeline`.
|
TheBloke/Tess-M-v1.1-GPTQ
|
TheBloke
| 2023-11-22T12:42:21Z | 25 | 1 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"base_model:migtissera/Tess-M-v1.1",
"base_model:quantized:migtissera/Tess-M-v1.1",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2023-11-22T09:37:19Z |
---
base_model: migtissera/Tess-M-v1.1
inference: false
license: other
license_link: https://huggingface.co/01-ai/Yi-34B/blob/main/LICENSE
license_name: yi-34b
model_creator: Migel Tissera
model_name: Tess M v1.1
model_type: yi
prompt_template: 'SYSTEM: {system_message}
USER: {prompt}
ASSISTANT:
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Tess M v1.1 - GPTQ
- Model creator: [Migel Tissera](https://huggingface.co/migtissera)
- Original model: [Tess M v1.1](https://huggingface.co/migtissera/Tess-M-v1.1)
<!-- description start -->
# Description
This repo contains GPTQ model files for [Migel Tissera's Tess M v1.1](https://huggingface.co/migtissera/Tess-M-v1.1).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Tess-M-v1.1-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Tess-M-v1.1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Tess-M-v1.1-GGUF)
* [Migel Tissera's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/migtissera/Tess-M-v1.1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Orca-Vicuna
```
SYSTEM: {system_message}
USER: {prompt}
ASSISTANT:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-compatible clients start -->
## Known compatible clients / servers
These GPTQ models are known to work in the following inference servers/webuis.
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
- [KoboldAI United](https://github.com/henk717/koboldai)
- [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui)
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
This may not be a complete list; if you know of others, please let me know!
<!-- README_GPTQ.md-compatible clients end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
Most GPTQ files are made with AutoGPTQ. Mistral models are currently made with Transformers.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama and Mistral models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Tess-M-v1.1-GPTQ/tree/main) | 4 | None | Yes | 0.1 | [open-instruct](https://huggingface.co/datasets/VMware/open-instruct/viewer/) | 8192 | 18.60 GB | Yes | 4-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/Tess-M-v1.1-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.1 | [open-instruct](https://huggingface.co/datasets/VMware/open-instruct/viewer/) | 8192 | 19.25 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/Tess-M-v1.1-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [open-instruct](https://huggingface.co/datasets/VMware/open-instruct/viewer/) | 8192 | 21.21 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-3bit-128g-actorder_True](https://huggingface.co/TheBloke/Tess-M-v1.1-GPTQ/tree/gptq-3bit-128g-actorder_True) | 3 | 128 | Yes | 0.1 | [open-instruct](https://huggingface.co/datasets/VMware/open-instruct/viewer/) | 8192 | 15.03 GB | No | 3-bit, with group size 128g and act-order. Higher quality than 128g-False. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/Tess-M-v1.1-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [open-instruct](https://huggingface.co/datasets/VMware/open-instruct/viewer/) | 8192 | 35.34 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-3bit-32g-actorder_True](https://huggingface.co/TheBloke/Tess-M-v1.1-GPTQ/tree/gptq-3bit-32g-actorder_True) | 3 | 32 | Yes | 0.1 | [open-instruct](https://huggingface.co/datasets/VMware/open-instruct/viewer/) | 8192 | 16.90 GB | No | 3-bit, with group size 64g and act-order. Highest quality 3-bit option. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/Tess-M-v1.1-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [open-instruct](https://huggingface.co/datasets/VMware/open-instruct/viewer/) | 8192 | 36.11 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/Tess-M-v1.1-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/Tess-M-v1.1-GPTQ:gptq-4bit-128g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `Tess-M-v1.1-GPTQ`:
```shell
mkdir Tess-M-v1.1-GPTQ
huggingface-cli download TheBloke/Tess-M-v1.1-GPTQ --local-dir Tess-M-v1.1-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir Tess-M-v1.1-GPTQ
huggingface-cli download TheBloke/Tess-M-v1.1-GPTQ --revision gptq-4bit-128g-actorder_True --local-dir Tess-M-v1.1-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Hugging Face cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir Tess-M-v1.1-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Tess-M-v1.1-GPTQ --local-dir Tess-M-v1.1-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-128g-actorder_True https://huggingface.co/TheBloke/Tess-M-v1.1-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/Tess-M-v1.1-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/Tess-M-v1.1-GPTQ:gptq-4bit-128g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `Tess-M-v1.1-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
- Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
It's recommended to use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/Tess-M-v1.1-GPTQ --port 3000 --quantize gptq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''SYSTEM: {system_message}
USER: {prompt}
ASSISTANT:
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_GPTQ.md-use-from-tgi end -->
<!-- README_GPTQ.md-use-from-python start -->
## Python code example: inference from this GPTQ model
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install --upgrade transformers optimum
# If using PyTorch 2.1 + CUDA 12.x:
pip3 install --upgrade auto-gptq
# or, if using PyTorch 2.1 + CUDA 11.x:
pip3 install --upgrade auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/
```
If you are using PyTorch 2.0, you will need to install AutoGPTQ from source. Likewise if you have problems with the pre-built wheels, you should try building from source:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.5.1
pip3 install .
```
### Example Python code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/Tess-M-v1.1-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-128g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=True,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''SYSTEM: {system_message}
USER: {prompt}
ASSISTANT:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with Transformers. For non-Mistral models, AutoGPTQ can also be used directly.
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama and Mistral models in 4-bit. Please see the Provided Files table above for per-file compatibility.
For a list of clients/servers, please see "Known compatible clients / servers", above.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Migel Tissera's Tess M v1.1
# Tess

Tess, short for Tessoro/Tessoso, is a general purpose Large Language Model series. Tess-M-v1.1 was trained on the Yi-34B-200K base.
# Prompt Format:
```
SYSTEM: <ANY SYSTEM CONTEXT>
USER:
ASSISTANT:
```
|
zentrum-lexikographie/de_dwds_dep_hdt_dist
|
zentrum-lexikographie
| 2023-11-22T12:41:21Z | 0 | 0 |
spacy
|
[
"spacy",
"token-classification",
"de",
"model-index",
"region:us"
] |
token-classification
| 2023-11-13T09:04:25Z |
---
tags:
- spacy
- token-classification
language:
- de
model-index:
- name: de_dwds_dep_hdt_dist
results:
- task:
name: TAG
type: token-classification
metrics:
- name: TAG (XPOS) Accuracy
type: accuracy
value: 0.9823258638
- task:
name: POS
type: token-classification
metrics:
- name: POS (UPOS) Accuracy
type: accuracy
value: 0.983167691
- task:
name: MORPH
type: token-classification
metrics:
- name: Morph (UFeats) Accuracy
type: accuracy
value: 0.87471075
- task:
name: LEMMA
type: token-classification
metrics:
- name: Lemma Accuracy
type: accuracy
value: 0.9485694823
- task:
name: UNLABELED_DEPENDENCIES
type: token-classification
metrics:
- name: Unlabeled Attachment Score (UAS)
type: f_score
value: 0.9662789933
- task:
name: LABELED_DEPENDENCIES
type: token-classification
metrics:
- name: Labeled Attachment Score (LAS)
type: f_score
value: 0.9525615552
- task:
name: SENTS
type: token-classification
metrics:
- name: Sentences F-Score
type: f_score
value: 0.9838880587
---
| Feature | Description |
| --- | --- |
| **Name** | `de_dwds_dep_hdt_dist` |
| **Version** | `0.0.3` |
| **spaCy** | `>=3.7.1,<3.8.0` |
| **Default Pipeline** | `transformer`, `tagger`, `morphologizer`, `trainable_lemmatizer`, `parser` |
| **Components** | `transformer`, `tagger`, `morphologizer`, `trainable_lemmatizer`, `parser` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | n/a |
| **Author** | [n/a]() |
### Label Scheme
<details>
<summary>View label scheme (819 labels for 3 components)</summary>
| Component | Labels |
| --- | --- |
| **`tagger`** | `$(`, `$,`, `$.`, `ADJA`, `ADJD`, `ADV`, `APPO`, `APPR`, `APPR_ART`, `APZR`, `ART`, `CARD`, `FM`, `ITJ`, `KOKOM`, `KON`, `KOUI`, `KOUS`, `NE`, `NN`, `PDAT`, `PDS`, `PIAT`, `PIDAT`, `PIS`, `PPER`, `PPOSAT`, `PPOSS`, `PRELAT`, `PRELS`, `PRF`, `PROAV`, `PTKA`, `PTKANT`, `PTKNEG`, `PTKVZ`, `PTKZU`, `PWAT`, `PWAV`, `PWS`, `TRUNC`, `VAFIN`, `VAIMP`, `VAINF`, `VAPP`, `VMFIN`, `VMINF`, `VMPP`, `VVFIN`, `VVIMP`, `VVINF`, `VVIZU`, `VVPP`, `XY` |
| **`morphologizer`** | `AdpType=Prep\|Case=Dat\|POS=ADP`, `Case=Dat\|Definite=Def\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Art`, `Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Gender=Fem\|Number=Sing\|POS=NOUN`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Nom\|Number=Sing\|POS=PROPN`, `Foreign=Yes\|POS=X`, `POS=PUNCT\|PunctType=Comm`, `Case=Nom\|Definite=Ind\|Gender=Masc\|NumType=Card\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Gen\|Definite=Def\|Number=Plur\|POS=DET\|PronType=Art`, `Case=Gen\|Degree=Sup\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Gender=Masc\|Number=Plur\|POS=NOUN`, `Gender=Neut\|Number=Sing\|POS=NOUN`, `AdpType=Prep\|POS=ADP`, `Gender=Neut\|Number=Plur\|POS=NOUN`, `POS=CCONJ`, `POS=PUNCT\|PunctType=Peri`, `NumType=Card\|Number=Plur\|POS=NUM`, `Gender=Fem\|Number=Plur\|POS=NOUN`, `AdpType=Prep\|Case=Dat\|Definite=Def\|Gender=Masc,Neut\|Number=Sing\|POS=ADP\|PronType=Art`, `Gender=Masc\|Number=Sing\|POS=NOUN`, `Case=Gen\|Definite=Def\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Gen\|Gender=Neut\|Number=Sing\|POS=NOUN`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Past\|VerbForm=Fin`, `Case=Nom\|Definite=Def\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Art`, `Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `POS=PUNCT\|PunctType=Brck`, `POS=PROPN`, `Case=Acc\|Definite=Def\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Art`, `POS=ADV`, `POS=SCONJ`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `POS=VERB\|VerbForm=Inf`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Nom\|Definite=Def\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Art`, `Degree=Sup\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Dat\|Definite=Def\|Number=Plur\|POS=DET\|PronType=Art`, `Case=Dat\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Pres\|VerbForm=Fin\|VerbType=Mod`, `Case=Acc\|Definite=Def\|Number=Plur\|POS=DET\|PronType=Art`, `Case=Acc\|Number=Sing\|POS=PROPN`, `Degree=Cmp\|POS=ADJ\|Variant=Short`, `POS=ADP\|PartType=Vbp`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|Tense=Pres\|VerbForm=Fin\|VerbType=Mod`, `AdpType=Prep\|Case=Acc\|POS=ADP`, `Case=Acc\|Definite=Ind\|Gender=Fem\|NumType=Card\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Dat\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `POS=PART\|Polarity=Neg`, `POS=ADV\|PronType=Dem`, `Degree=Cmp\|POS=ADV`, `ConjType=Comp\|POS=CCONJ`, `Case=Nom\|Definite=Ind\|Gender=Fem\|NumType=Card\|Number=Sing\|POS=DET\|PronType=Art`, `Degree=Pos\|POS=ADJ\|Variant=Short`, `Case=Gen\|Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Number=Sing\|POS=PROPN`, `Case=Nom\|Definite=Def\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Acc\|Definite=Ind\|Gender=Masc\|NumType=Card\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Acc\|Degree=Cmp\|Number=Plur\|POS=DET\|PronType=Ind`, `Aspect=Perf\|POS=VERB\|VerbForm=Part`, `Case=Dat\|Definite=Ind\|Gender=Neut\|NumType=Card\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Gen\|Definite=Def\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Case=Acc\|POS=PRON\|Person=3\|PronType=Prs\|Reflex=Yes`, `Case=Nom\|Definite=Def\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Nom\|Degree=Sup\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Acc\|Definite=Def\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Acc\|Number=Plur\|POS=DET\|PronType=Dem`, `Degree=Sup\|POS=ADJ\|Variant=Short`, `Case=Nom\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Hyph=Yes\|POS=NOUN`, `Case=Nom\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Acc\|Gender=Fem\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Degree=Sup\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender=Neut\|Number=Plur\|POS=NOUN`, `POS=PART\|PartType=Inf`, `Case=Gen\|Definite=Def\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Dat\|Degree=Pos\|Number=Sing\|POS=ADJ`, `POS=NOUN`, `Case=Dat\|Definite=Ind\|Gender=Masc\|NumType=Card\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Dat\|Definite=Def\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Gen\|Degree=Pos\|Number=Sing\|POS=ADJ`, `POS=AUX\|VerbForm=Inf`, `Case=Nom\|Definite=Ind\|Gender=Neut\|NumType=Card\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Dat\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Gender=Fem\|Number=Plur\|POS=ADJ`, `POS=AUX\|VerbForm=Inf\|VerbType=Mod`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Gen\|Definite=Ind\|Gender=Fem\|NumType=Card\|Number=Sing\|POS=DET\|PronType=Art`, `Number=Sing\|POS=DET\|PronType=Ind`, `Case=Nom\|Number=Plur\|POS=DET\|PronType=Ind`, `AdpType=Prep\|Case=Dat\|Definite=Def\|Gender=Fem\|Number=Sing\|POS=ADP\|PronType=Art`, `Degree=Pos\|Number=Plur\|POS=ADJ`, `Case=Nom\|Number=Sing\|POS=PRON\|PronType=Ind`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=NOUN`, `POS=ADJ`, `Degree=Cmp\|POS=DET\|PronType=Ind`, `Case=Dat\|Definite=Ind\|Gender=Fem\|NumType=Card\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Dat\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Nom\|Definite=Def\|Number=Plur\|POS=DET\|PronType=Art`, `POS=ADV\|PronType=Int`, `Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Dat\|Number=Sing\|POS=PROPN`, `Case=Acc\|Definite=Ind\|Gender=Neut\|NumType=Card\|Number=Sing\|POS=DET\|PronType=Art`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Nom\|NumType=Card\|Number=Plur\|POS=DET\|PronType=Tot`, `Case=Acc\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Degree=Pos\|Number=Sing\|POS=ADJ`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|Tense=Past\|VerbForm=Fin`, `Case=Acc\|Gender[psor]=Fem\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Gender=Fem\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Degree=Pos\|POS=ADJ`, `Case=Gen\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Acc\|Number=Plur\|POS=DET\|PronType=Tot`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Past\|VerbForm=Fin`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Past\|VerbForm=Fin\|VerbType=Mod`, `Gender=Neut\|Number=Sing\|POS=PRON\|PronType=Neg`, `Case=Gen\|Degree=Cmp\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Dem`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|Tense=Pres\|VerbForm=Fin\|VerbType=Mod`, `Number=Plur\|POS=NOUN`, `Degree=Pos\|Gender=Neut\|NumType=Ord\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=PRON\|PronType=Dem,Rel`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|Tense=Past\|VerbForm=Fin\|VerbType=Mod`, `Gender=Fem\|Number=Sing\|POS=PROPN`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=PROPN`, `Case=Acc\|Definite=Def\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Art`, `Degree=Pos\|POS=ADV`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Nom\|Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Tense=Past\|VerbForm=Fin`, `Degree=Cmp\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=NOUN`, `AdpType=Prep\|Case=Gen\|POS=ADP`, `Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Dat\|Number=Plur\|POS=PRON\|PronType=Dem,Rel`, `AdpType=Post\|Case=Dat\|POS=ADP`, `Gender=Masc\|Number=Sing\|POS=PROPN`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=PRON\|PronType=Dem,Rel`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Dat\|Definite=Def\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Acc\|Degree=Sup\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Acc\|Degree=Cmp\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Aspect=Perf\|POS=AUX\|VerbForm=Part`, `Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Dat\|Number=Plur\|POS=ADJ`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=PRON\|PronType=Dem,Rel`, `Degree=Cmp\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Dem`, `Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Neg`, `Case=Dat\|Gender=Masc\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Number=Sing\|POS=PRON\|PronType=Tot`, `Number=Sing\|POS=NOUN`, `Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Dat\|Degree=Cmp\|Number=Sing\|POS=ADJ`, `Case=Acc\|Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=NOUN`, `Case=Gen\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Nom\|Number=Plur\|POS=PRON\|PronType=Dem,Rel`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Dat\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Nom\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Case=Gen\|Degree=Pos\|Number=Plur\|POS=ADJ`, `Degree=Sup\|POS=ADV`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Acc\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Nom\|Number=Plur\|POS=DET\|PronType=Tot`, `Case=Dat\|Degree=Sup\|Number=Plur\|POS=DET\|PronType=Ind`, `Degree=Cmp\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Dat\|Degree=Pos\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `NumType=Card\|Number=Sing\|POS=NUM`, `Case=Dat\|Number=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Dat\|POS=PRON\|Person=3\|PronType=Prs\|Reflex=Yes`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=PRON\|PronType=Dem,Rel`, `Number=Plur\|POS=PROPN`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Neg`, `Case=Nom\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Case=Gen\|Number=Plur\|POS=DET\|PronType=Tot`, `Case=Nom\|Number=Sing\|POS=PRON\|PronType=Int,Rel`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Nom\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Dat\|Number=Plur\|POS=DET\|PronType=Dem`, `Gender=Neut\|Number=Sing\|POS=DET\|PronType=Ind`, `AdpType=Prep\|Case=Acc\|Definite=Def\|Gender=Neut\|Number=Sing\|POS=ADP\|PronType=Art`, `Case=Gen\|Number=Sing\|POS=PROPN`, `Degree=Cmp\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Nom\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Dat\|Number=Sing\|POS=DET\|PronType=Ind`, `Mood=Imp\|Number=Sing\|POS=VERB\|Person=2\|VerbForm=Fin`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=PRON\|PronType=Dem,Rel`, `Degree=Pos\|Gender=Neut\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Nom\|Number=Plur\|POS=ADJ`, `Case=Gen\|POS=PRON\|PronType=Dem,Rel`, `Case=Acc\|Degree=Pos\|Number=Plur\|POS=ADJ`, `Gender=Fem\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Gen\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Case=Nom\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Acc\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Masc\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Gen\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Nom\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Neg`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=PRON\|PronType=Dem,Rel`, `Case=Dat\|Number=Plur\|POS=DET\|PronType=Ind`, `Degree=Cmp\|Number=Plur\|POS=ADJ`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Neg`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Neg`, `Case=Dat\|POS=PROPN`, `Case=Gen\|Number=Sing\|POS=PRON\|PronType=Dem,Rel`, `Degree=Cmp\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=PRON\|PronType=Int,Rel`, `Case=Acc\|Number=Plur\|POS=DET\|PronType=Neg`, `Case=Nom\|Degree=Pos\|Number=Plur\|POS=ADJ`, `Case=Gen\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=PRON\|PronType=Dem,Rel`, `AdpType=Circ\|POS=ADP`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Dat\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Gender=Fem\|Number=Plur\|POS=NOUN`, `Case=Nom\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Nom\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Acc\|Number=Plur\|POS=PRON\|PronType=Dem,Rel`, `Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Definite=Def\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Gen\|Definite=Ind\|Gender=Neut\|NumType=Card\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Dat\|Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender[psor]=Masc,Neut\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Degree=Sup\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Gen\|Definite=Ind\|Gender=Masc\|NumType=Card\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=PRON\|PronType=Dem,Rel`, `Degree=Cmp\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Ind`, `AdpType=Prep\|Case=Nom\|POS=ADP`, `Degree=Cmp\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Acc\|Gender[psor]=Masc,Neut\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Neg`, `Case=Acc\|Number=Plur\|POS=DET\|PronType=Ind`, `Gender=Masc\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Gen\|Number=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Number=Sing\|POS=PRON\|PronType=Neg`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Nom\|Number=Plur\|POS=DET\|PronType=Neg`, `Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Dat\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Dat\|Degree=Sup\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Acc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Dat\|Gender=Neut\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Nom\|Degree=Pos\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Dat\|Number=Plur\|POS=NOUN`, `Case=Dat\|Gender=Fem\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Neg`, `Case=Gen\|Degree=Cmp\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Nom\|Degree=Pos\|Gender=Neut\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Dat\|Degree=Cmp\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Neg`, `Case=Dat\|Degree=Cmp\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Gen\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Ind`, `Gender=Neut\|Number=Sing\|POS=PRON\|PronType=Ind`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Acc\|Number=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Dat\|Gender=Fem\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=PRON\|PronType=Dem,Rel`, `Case=Acc\|Gender=Neut\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=PROPN`, `Case=Dat\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=PROPN`, `Case=Dat\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Case=Acc\|Gender=Fem\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Neut\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Acc\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Gen\|POS=PROPN`, `Case=Gen\|Number=Plur\|POS=NOUN`, `Case=Acc\|Number=Sing\|POS=PRON\|PronType=Int,Rel`, `Case=Nom\|Degree=Cmp\|Number=Plur\|POS=DET\|PronType=Ind`, `POS=DET\|PronType=Ind`, `Case=Nom\|Degree=Pos\|Gender=Masc\|NumType=Ord\|Number=Sing\|POS=ADJ`, `Case=Gen\|Number=Plur\|POS=ADJ`, `Case=Nom\|Number=Sing\|POS=PRON\|PronType=Tot`, `POS=DET\|PronType=Tot`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `POS=X`, `Gender=Fem\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=ADJ`, `AdpType=Post\|Case=Acc\|POS=ADP`, `Case=Acc\|NumType=Card\|Number=Plur\|POS=DET\|PronType=Tot`, `Degree=Pos\|Gender=Masc\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Gen\|Gender=Neut\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Number=Plur\|POS=DET\|PronType=Tot`, `Case=Gen\|Degree=Cmp\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Gen\|NumType=Card\|Number=Plur\|POS=DET\|PronType=Tot`, `Number=Plur\|POS=DET\|PronType=Ind`, `Case=Dat\|Degree=Sup\|Number=Sing\|POS=ADJ`, `Case=Dat\|Degree=Sup\|Number=Plur\|POS=ADJ`, `POS=DET\|PronType=Neg`, `POS=ADV\|PronType=Ind`, `Case=Gen\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=PRON\|PronType=Int,Rel`, `Case=Dat\|Degree=Cmp\|Number=Plur\|POS=ADJ`, `Case=Nom\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Gen\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Gender=Neut\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Acc\|Gender=Neut\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Dat\|Foreign=Yes\|POS=X`, `Case=Acc\|Degree=Sup\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Nom\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Gen\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=NOUN`, `Degree=Sup\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Dat\|Gender=Neut\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Dat\|NumType=Card\|Number=Plur\|POS=DET\|PronType=Tot`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Gen\|Number=Sing\|POS=NOUN`, `NumType=Card\|POS=NUM`, `Case=Gen\|Degree=Pos\|Gender=Neut\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Nom\|Gender=Fem\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Gen\|Degree=Sup\|Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs\|Reflex=Yes`, `Degree=Pos\|Gender=Fem\|NumType=Ord\|Number=Sing\|POS=ADJ`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Degree=Cmp\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Degree=Cmp\|Number=Sing\|POS=ADJ`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Degree=Pos\|Gender=Fem\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Dat\|Degree=Cmp\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Dat\|Gender=Neut\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Degree=Sup\|Number=Plur\|POS=ADJ`, `Case=Acc\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Masc\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Number=Plur\|POS=ADJ`, `Case=Acc\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs\|Reflex=Yes`, `Case=Dat\|Gender=Neut\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender[psor]=Masc,Neut\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Degree=Sup\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Masc\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Tot`, `Gender=Masc\|Number=Sing\|POS=DET\|PronType=Ind`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=1\|Tense=Pres\|VerbForm=Fin\|VerbType=Mod`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Dat\|Degree=Cmp\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Nom\|Degree=Sup\|Number=Plur\|POS=ADJ`, `Degree=Pos\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Nom\|Degree=Sup\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Degree=Sup\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Dat\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Degree=Pos\|NumType=Ord\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender[psor]=Masc,Neut\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Degree=Sup\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Case=Dat\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Dat\|Number=Sing\|POS=PRON\|PronType=Int,Rel`, `Case=Nom\|Degree=Cmp\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Neg`, `Case=Acc\|Degree=Cmp\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Nom\|Gender=Neut\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Dat\|POS=ADJ`, `Case=Dat\|Degree=Pos\|Gender=Masc\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Acc\|Degree=Pos\|Gender=Masc\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Dat\|Degree=Sup\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Neut\|Number=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Mood=Ind\|POS=VERB\|Person=3\|VerbForm=Fin`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=PROPN`, `Case=Acc\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs`, `Case=Acc\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Gen\|Degree=Cmp\|Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=NOUN`, `POS=ADJ\|Variant=Short`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=PROPN`, `Foreign=Yes\|Number=Sing\|POS=X`, `Case=Nom\|Degree=Sup\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Gen\|Degree=Pos\|Gender=Masc\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Nom\|Number=Plur\|POS=DET\|Person=2\|Polite=Form\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Gender=Neut\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Degree=Pos\|Gender=Fem\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Fem\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Number=Plur\|POS=ADJ`, `Case=Gen\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Dat\|POS=NOUN`, `Case=Nom\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Ind`, `Aspect=Perf\|POS=AUX\|VerbForm=Part\|VerbType=Mod`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|Tense=Past\|VerbForm=Fin`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs\|Reflex=Yes`, `Case=Nom\|Degree=Pos\|Gender=Masc\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Acc\|Degree=Pos\|Gender=Masc\|NumType=Ord\|Number=Sing\|POS=ADJ`, `Gender=Masc\|POS=NOUN`, `Case=Acc\|Degree=Sup\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Dat\|Number=Sing\|POS=ADJ`, `POS=DET\|PronType=Int`, `Gender=Neut\|Number=Sing\|POS=PRON\|PronType=Int,Rel`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Gender=Fem\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Number=Sing\|POS=PRON\|PronType=Tot`, `Case=Dat\|Number=Sing\|POS=NOUN`, `Case=Dat\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs\|Reflex=Yes`, `Case=Nom\|POS=PROPN`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Degree=Pos\|Gender=Fem\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Acc\|Number=Sing\|POS=PRON\|PronType=Ind`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=PROPN`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=DET\|Person=2\|Polite=Form\|Poss=Yes\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|Tense=Past\|VerbForm=Fin`, `Case=Nom\|Gender=Neut\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Gen\|Degree=Sup\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Dat\|Degree=Pos\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Neut\|Number=Sing\|POS=PRON\|PronType=Dem,Rel`, `Case=Nom\|Degree=Cmp\|Gender=Neut\|Number=Plur\|POS=ADJ`, `POS=INTJ\|PartType=Res`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=DET\|Person=2\|Polite=Form\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|Tense=Past\|VerbForm=Fin`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=2\|Tense=Past\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=DET\|Person=2\|Polite=Form\|Poss=Yes\|PronType=Prs`, `Case=Dat\|POS=PRON\|Person=2\|Polite=Form\|PronType=Prs`, `Foreign=Yes\|Gender=Neut\|Number=Sing\|POS=X`, `Case=Nom\|Gender=Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Number=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Degree=Pos\|Gender=Neut\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=2\|Tense=Pres\|VerbForm=Fin\|VerbType=Mod`, `Case=Dat\|Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Number=Plur\|POS=PRON\|PronType=Dem,Rel`, `Case=Nom\|Gender=Fem\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Degree=Cmp\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Nom\|Definite=Ind\|NumType=Card\|Number=Plur\|POS=DET\|PronType=Art`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=DET\|Person=2\|Polite=Form\|Poss=Yes\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|VerbForm=Fin`, `Gender=Neut\|Number=Sing\|POS=PROPN`, `Case=Nom\|POS=NOUN`, `Case=Dat\|Number=Plur\|POS=DET\|Person=2\|Polite=Form\|Poss=Yes\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|VerbForm=Fin`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Tot`, `Mood=Imp\|Number=Plur\|POS=VERB\|Person=2\|VerbForm=Fin`, `Case=Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Gender=Masc\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Degree=Cmp\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `POS=DET\|PronType=Dem`, `Case=Dat\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Number=Plur\|POS=DET\|PronType=Neg`, `Definite=Ind\|NumType=Card\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Acc\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Acc\|Gender=Neut\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Dat\|Degree=Pos\|Gender=Neut\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Degree=Sup\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender[psor]=Fem\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Degree=Pos\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Acc\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Degree=Sup\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Gen\|NumType=Card\|Number=Plur\|POS=NUM`, `Case=Gen\|Gender=Fem\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=2\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Degree=Pos\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Acc\|Degree=Sup\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Gen\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Degree=Pos\|Gender=Masc\|NumType=Ord\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender[psor]=Fem\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Number=Plur\|POS=DET\|Person=2\|Polite=Form\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Case=Acc\|Degree=Cmp\|Gender=Fem\|NumType=Ord\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=DET\|Person=2\|Polite=Form\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Acc\|Degree=Cmp\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Neut\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `NumType=Card\|POS=DET\|PronType=Tot`, `Case=Dat\|Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Degree=Pos\|POS=ADJ`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=1\|Tense=Past\|VerbForm=Fin\|VerbType=Mod`, `Case=Acc\|POS=NOUN`, `Case=Gen\|Gender=Neut\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Gen\|Degree=Cmp\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Nom\|Degree=Cmp\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Gen\|Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|VerbForm=Fin`, `Degree=Sup\|POS=DET\|PronType=Ind`, `Case=Nom\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Nom\|Gender=Neut\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Neg`, `Case=Gen\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Nom\|Degree=Cmp\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender[psor]=Fem\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Number=Sing\|POS=PRON\|PronType=Ind`, `Case=Nom\|Gender=Masc\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Masc\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Gender=Masc\|Number=Plur\|POS=PROPN`, `Degree=Sup\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Dat\|Degree=Cmp\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Case=Acc\|Number=Plur\|POS=DET\|PronType=Int`, `Case=Acc\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Gen\|Degree=Sup\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=PROPN`, `Case=Dat\|Number=Sing\|POS=PRON\|PronType=Neg`, `Foreign=Yes\|POS=DET\|PronType=Ind`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=DET\|Person=2\|Polite=Form\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Degree=Cmp\|Gender=Neut\|NumType=Ord\|Number=Sing\|POS=ADJ`, `Number=Plur\|POS=DET\|PronType=Tot`, `Case=Nom\|Degree=Pos\|Gender=Fem\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Nom\|Degree=Cmp\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Neut\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Hyph=Yes\|Number=Plur\|POS=NOUN`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=1\|Tense=Past\|VerbForm=Fin`, `Case=Dat\|Gender=Masc\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Definite=Def\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=PRON\|PronType=Dem,Rel`, `Case=Acc\|Degree=Sup\|Number=Plur\|POS=ADJ`, `Degree=Cmp\|Gender=Neut\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Acc\|Number=Sing\|POS=PRON\|PronType=Neg`, `POS=PRON\|Person=3\|PronType=Prs\|Reflex=Yes`, `Gender=Masc\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Dat\|Hyph=Yes\|POS=NOUN`, `Case=Acc\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Nom\|Degree=Pos\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Gen\|Degree=Sup\|Number=Plur\|POS=ADJ`, `Case=Dat\|Degree=Sup\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Nom\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Degree=Sup\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Gen\|Number=Sing\|POS=PRON\|Person=3\|PronType=Tot`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Acc\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Acc\|Degree=Sup\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Fem\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Number=Plur\|POS=DET\|PronType=Int`, `Case=Dat\|Degree=Cmp\|POS=DET\|PronType=Ind`, `Case=Nom\|Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|Tense=Past\|VerbForm=Fin\|VerbType=Mod`, `Case=Dat\|Definite=Ind\|NumType=Card\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=PROPN`, `Case=Acc\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Number=Sing\|POS=PRON\|PronType=Ind`, `Case=Dat\|Gender=Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Dat\|NumType=Card\|Number=Plur\|POS=NUM`, `Case=Gen\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Nom\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=2\|Tense=Pres\|VerbForm=Fin`, `Case=Dat\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs\|Reflex=Yes`, `Case=Dat\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs`, `Case=Nom\|Gender=Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=2\|Tense=Pres\|VerbForm=Fin`, `POS=INTJ`, `Case=Acc\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Degree=Cmp\|Number=Plur\|POS=ADJ`, `Case=Acc\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=DET\|Person=2\|Polite=Form\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Number=Sing\|POS=PRON\|PronType=Dem,Rel`, `Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=DET\|Person=2\|Polite=Form\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Number=Plur\|POS=PROPN`, `Case=Nom\|Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Dat\|POS=DET\|PronType=Tot`, `Case=Nom\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Nom\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Gen\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=PRON\|PronType=Dem,Rel`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Degree=Cmp\|Gender=Neut\|NumType=Ord\|Number=Sing\|POS=ADJ`, `AdpType=Post\|Case=Gen\|POS=ADP`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Nom\|Number=Plur\|POS=NOUN`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Acc\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs\|Reflex=Yes`, `Definite=Ind\|NumType=Card\|Number=Plur\|POS=DET\|PronType=Art`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=NOUN`, `Number=Sing\|POS=PRON\|PronType=Int,Rel`, `Case=Dat\|POS=DET\|PronType=Ind`, `Case=Acc\|Gender=Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs`, `Mood=Ind\|POS=VERB\|Person=3\|Tense=Past\|VerbForm=Fin`, `Case=Acc\|POS=PROPN`, `Case=Nom\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Degree=Pos\|NumType=Ord\|POS=ADJ`, `Case=Acc\|Number=Sing\|POS=DET\|PronType=Neg`, `Case=Nom\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=PROPN`, `Case=Dat\|POS=DET\|PronType=Dem`, `Degree=Pos\|POS=DET\|PronType=Ind`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|VerbForm=Fin`, `Case=Nom\|Gender=Neut\|Number=Plur\|POS=NOUN`, `Number=Sing\|POS=DET\|Person=2\|Polite=Form\|Poss=Yes\|PronType=Prs`, `Case=Dat\|POS=PRON\|PronType=Rcp`, `Gender=Masc\|Number=Sing\|POS=ADJ\|Variant=Short`, `Case=Acc\|Gender=Neut\|Number=Plur\|POS=NOUN`, `Case=Acc\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs\|Reflex=Yes`, `Mood=Ind\|POS=AUX\|Person=3\|VerbForm=Fin`, `Case=Acc\|Definite=Ind\|NumType=Card\|Number=Plur\|POS=DET\|PronType=Art`, `Case=Dat\|Degree=Pos\|POS=ADJ\|Variant=Short`, `Case=Acc\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Degree=Pos\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Acc\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs`, `Case=Acc\|Gender=Neut\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=PRON\|PronType=Dem,Rel\|Typo=Yes`, `Mood=Imp\|Number=Plur\|POS=AUX\|Person=2\|VerbForm=Fin`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=2\|VerbForm=Fin`, `Gender[psor]=Masc,Neut\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Ind`, `Mood=Imp\|Number=Sing\|POS=AUX\|Person=2\|VerbForm=Fin`, `Mood=Ind\|POS=VERB\|Person=1\|VerbForm=Fin`, `Case=Gen\|Number=Sing\|POS=DET\|PronType=Ind`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=2\|Tense=Pres\|VerbForm=Fin`, `Abbr=Yes\|Case=Nom\|Gender=Neut\|Number=Sing\|POS=PRON\|PronType=Dem,Rel`, `Case=Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Definite=Def\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Nom\|Definite=Ind\|NumType=Card\|POS=DET\|PronType=Art`, `Case=Dat\|Number=Plur\|POS=DET\|PronType=Int`, `Degree=Pos\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Dat\|Degree=Pos\|Number=Plur\|POS=DET\|PronType=Ind`, `Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Neg`, `Definite=Ind\|Foreign=Yes\|NumType=Card\|POS=DET\|PronType=Art`, `Case=Nom\|Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=PRON\|PronType=Dem`, `Case=Nom\|Gender=Neut\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=2\|Tense=Past\|VerbForm=Fin\|VerbType=Mod`, `Case=Dat\|Gender=Fem\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=PRON\|PronType=Dem`, `Case=Dat\|Degree=Pos\|NumType=Ord\|Number=Sing\|POS=ADJ`, `POS=DET\|PronType=Int,Rel`, `Case=Acc\|Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Degree=Sup\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Acc\|POS=PRON\|PronType=Rcp`, `Case=Dat\|Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=2\|VerbForm=Fin`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=2\|Tense=Pres\|VerbForm=Fin\|VerbType=Mod`, `Case=Acc\|Degree=Pos\|Number=Plur\|POS=DET\|PronType=Ind`, `Definite=Ind\|Degree=Pos\|Gender=Fem\|NumType=Card\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs\|Reflex=Yes`, `Case=Dat\|Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|VerbForm=Fin`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=PRON\|PronType=Tot`, `Case=Nom\|Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Acc\|Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=PRON\|PronType=Neg`, `Number=Sing\|POS=ADJ`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=PRON\|PronType=Int,Rel`, `Case=Gen\|Gender=Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Degree=Pos\|Gender=Neut\|POS=ADJ`, `Gender=Fem\|POS=ADJ`, `Degree=Pos\|Gender=Fem\|POS=ADJ`, `Gender=Masc\|POS=ADJ`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|VerbForm=Fin\|VerbType=Mod`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|VerbForm=Fin\|VerbType=Mod`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|VerbForm=Fin\|VerbType=Mod`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|VerbForm=Fin`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=1\|VerbForm=Fin`, `Case=Acc\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Foreign=Yes\|POS=DET\|PronType=Dem`, `Case=Nom\|Degree=Cmp\|Gender=Masc\|NumType=Ord\|Number=Sing\|POS=ADJ`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Nom\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs` |
| **`parser`** | `ROOT`, `acl`, `advcl`, `advmod`, `amod`, `appos`, `aux`, `aux:pass`, `case`, `cc`, `ccomp`, `compound:prt`, `conj`, `cop`, `csubj`, `csubj:pass`, `dep`, `det`, `expl`, `expl:pv`, `flat`, `flat:name`, `mark`, `nmod`, `nsubj`, `nsubj:pass`, `nummod`, `obj`, `obl`, `obl:arg`, `parataxis`, `punct`, `reparandum`, `xcomp` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `TAG_ACC` | 98.23 |
| `POS_ACC` | 98.32 |
| `MORPH_ACC` | 87.47 |
| `LEMMA_ACC` | 94.86 |
| `DEP_UAS` | 96.63 |
| `DEP_LAS` | 95.26 |
| `SENTS_P` | 98.56 |
| `SENTS_R` | 98.22 |
| `SENTS_F` | 98.39 |
| `TRANSFORMER_LOSS` | 5051543.86 |
| `TAGGER_LOSS` | 268351.96 |
| `MORPHOLOGIZER_LOSS` | 1208797.95 |
| `TRAINABLE_LEMMATIZER_LOSS` | 799595.89 |
| `PARSER_LOSS` | 3033115.83 |
|
shuofu/repo_name
|
shuofu
| 2023-11-22T12:35:20Z | 0 | 0 |
keras
|
[
"keras",
"zh",
"arxiv:1910.09700",
"license:apache-2.0",
"region:us"
] | null | 2023-11-22T12:30:36Z |
---
license: apache-2.0
language:
- zh
library_name: keras
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
LizzyBennet/translation_stepbystep
|
LizzyBennet
| 2023-11-22T12:34:40Z | 2 | 1 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"base_model:adapter:meta-llama/Llama-2-7b-chat-hf",
"region:us"
] | null | 2023-11-22T12:27:31Z |
---
library_name: peft
base_model: meta-llama/Llama-2-7b-chat-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.2
|
vonewman/xlm-roberta-base-wolof
|
vonewman
| 2023-11-22T12:31:26Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-10-19T14:02:47Z |
---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: xlm-roberta-base-wolof
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-wolof
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2733
- Precision: 0.7251
- Recall: 0.7220
- F1: 0.7236
- Accuracy: 0.9586
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4.899923663123727e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 226 | 0.2416 | 0.7653 | 0.6519 | 0.7041 | 0.9587 |
| No log | 2.0 | 452 | 0.2573 | 0.6917 | 0.7300 | 0.7104 | 0.9568 |
| 0.0212 | 3.0 | 678 | 0.2733 | 0.7251 | 0.7220 | 0.7236 | 0.9586 |
### Framework versions
- Transformers 4.33.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.13.3
|
Zamoranesis/Robertuito-check-worthy-classifier
|
Zamoranesis
| 2023-11-22T12:19:31Z | 5 | 1 |
transformers
|
[
"transformers",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:pysentimiento/robertuito-base-uncased",
"base_model:finetune:pysentimiento/robertuito-base-uncased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-21T11:33:43Z |
---
base_model: pysentimiento/robertuito-base-uncased
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: Robertuito-check-worthy-classifier
results: []
widget:
- text: "¿Es injusto que una persona que tenga UN MILLÓN DE EUROS en patrimonio pague 298 euros al año? Justicia fiscal es el camino para la justicia social /❤️ https://t.co/HRO5HRmceV"
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Robertuito-check-worthy-classifier
This model is a fine-tuned version of [pysentimiento/robertuito-base-uncased](https://huggingface.co/pysentimiento/robertuito-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2029
- F1 Class 0: 0.9557
- F1 Class 1: 0.6936
- F1: 0.8246
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- lr_scheduler_warmup_steps: 200
- training_steps: 2000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Class 0 | F1 Class 1 | F1 |
|:-------------:|:-----:|:----:|:---------------:|:----------:|:----------:|:------:|
| 0.4326 | 0.16 | 200 | 0.3187 | 0.9412 | 0.6514 | 0.7963 |
| 0.3765 | 0.32 | 400 | 0.2572 | 0.9323 | 0.6736 | 0.8030 |
| 0.3523 | 0.48 | 600 | 0.2079 | 0.9527 | 0.6990 | 0.8259 |
| 0.3594 | 0.64 | 800 | 0.2184 | 0.9505 | 0.5761 | 0.7633 |
| 0.3307 | 0.8 | 1000 | 0.2109 | 0.9497 | 0.6892 | 0.8194 |
| 0.3166 | 0.96 | 1200 | 0.2187 | 0.9537 | 0.6288 | 0.7912 |
| 0.297 | 1.13 | 1400 | 0.2541 | 0.9524 | 0.6429 | 0.7976 |
| 0.2766 | 1.29 | 1600 | 0.2031 | 0.9561 | 0.7173 | 0.8367 |
| 0.2628 | 1.45 | 1800 | 0.2076 | 0.9516 | 0.7200 | 0.8358 |
| 0.2313 | 1.61 | 2000 | 0.2029 | 0.9557 | 0.6936 | 0.8246 |
### Framework versions
- Transformers 4.35.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.7
- Tokenizers 0.14.1
|
bunbohue/t5-large_readme_summarization
|
bunbohue
| 2023-11-22T12:15:32Z | 9 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-large",
"base_model:finetune:google-t5/t5-large",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-12T13:25:38Z |
---
license: apache-2.0
base_model: t5-large
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5-large_readme_summarization
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-large_readme_summarization
This model is a fine-tuned version of [t5-large](https://huggingface.co/t5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7393
- Rouge1: 0.4806
- Rouge2: 0.3307
- Rougel: 0.4559
- Rougelsum: 0.4552
- Gen Len: 13.8969
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 1.968 | 1.0 | 2916 | 1.8066 | 0.4624 | 0.3113 | 0.4349 | 0.4342 | 14.0995 |
| 1.8681 | 2.0 | 5832 | 1.7578 | 0.4791 | 0.327 | 0.453 | 0.4526 | 13.8046 |
| 1.875 | 3.0 | 8748 | 1.7441 | 0.479 | 0.3291 | 0.4536 | 0.4536 | 13.8909 |
| 1.8169 | 4.0 | 11664 | 1.7393 | 0.4806 | 0.3307 | 0.4559 | 0.4552 | 13.8969 |
### Framework versions
- Transformers 4.35.1
- Pytorch 2.1.0+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
|
murali07/falcon-7b
|
murali07
| 2023-11-22T12:02:38Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:ybelkada/falcon-7b-sharded-bf16",
"base_model:adapter:ybelkada/falcon-7b-sharded-bf16",
"region:us"
] | null | 2023-11-22T12:02:32Z |
---
library_name: peft
base_model: ybelkada/falcon-7b-sharded-bf16
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.2
|
rvershinin/ppo-Huggy
|
rvershinin
| 2023-11-22T12:02:14Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-11-22T12:02:08Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: rvershinin/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Kolibri753/llama-2-7b-chat-generate-workout-desc
|
Kolibri753
| 2023-11-22T11:51:15Z | 1 | 0 |
peft
|
[
"peft",
"pytorch",
"llama",
"region:us"
] | null | 2023-11-22T10:44:59Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
|
misrori/goldhandai
|
misrori
| 2023-11-22T11:45:16Z | 4 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-22T11:40:41Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### goldhandai Dreambooth model trained by misrori with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
SaGuenter/whisper-large-v2-NSC_Korpora_2-100steps
|
SaGuenter
| 2023-11-22T11:32:02Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:openai/whisper-large-v2",
"base_model:adapter:openai/whisper-large-v2",
"region:us"
] | null | 2023-11-22T11:31:51Z |
---
library_name: peft
base_model: openai/whisper-large-v2
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.3.dev0
|
jb723/cross_lingual_epoch2
|
jb723
| 2023-11-22T11:26:36Z | 1,485 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-26T12:14:27Z |
---
license: mit
---
학습 데이터
Kullmv2 dataset, alpaca instruction dataset, dolly 데이터셋, share GPT 데이터셋 , AIhub 한국어-영어 병렬 데이터셋
을 활용하여 사용
한국어 영어 병렬 데이터의 경우 번역을 해달라는 지시문의 형태로 변환후 instruction tuning
tokenizer의 경우 beomi님의 llama2 tokenizer를 사용하여 학습을 진행하였으며,
모델의 초기 parameter의 경우 meta의 llama2-7b-hf를 사용하여 학습을 진행
|
kowsiknd/checkpoint-13500-finetuned2
|
kowsiknd
| 2023-11-22T11:23:26Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-22T11:12:39Z |
---
tags:
- generated_from_trainer
model-index:
- name: checkpoint-13500-finetuned2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# checkpoint-13500-finetuned2
This model was trained from scratch on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 32
- eval_batch_size: 32
- seed: 1
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Framework versions
- Transformers 4.34.1
- Pytorch 2.0.1
- Datasets 2.14.6
- Tokenizers 0.14.1
|
peft-internal-testing/gpt2-lora-random
|
peft-internal-testing
| 2023-11-22T11:15:49Z | 16,905 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:openai-community/gpt2",
"base_model:adapter:openai-community/gpt2",
"region:us"
] | null | 2023-11-22T11:11:21Z |
---
library_name: peft
base_model: gpt2
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.3.dev0
|
alemsiz/ppo-LunarLander-v2
|
alemsiz
| 2023-11-22T11:15:14Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-22T11:14:51Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 245.15 +/- 20.67
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Korabbit/Llama-2-7b-chat-hf-afr-100step-v2
|
Korabbit
| 2023-11-22T11:14:51Z | 1,535 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"conversational",
"en",
"dataset:vicgalle/alpaca-gpt4",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-22T10:26:46Z |
---
license: llama2
datasets:
- vicgalle/alpaca-gpt4
language:
- en
---
Hi there! this test my approach "AFR training"
The base model used "Llama-2-7b-chat"
System Prompt: You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. \n If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
Instruction: Implement binary search in python.
Response: Sure! Here is an example of how to implement a binary search algorithm in Python:
```
def binary_search(arr, target):
# Initialize the index of the target element
low = 0
high = len(arr) - 1
# Loop until the target element is found or the end of the array is reached
while low <= high:
# Calculate the middle index of the array
mid = (low + high) // 2
# Check if the target element is in the middle index
if arr[mid] == target:
return mid
# If the target element is not in the middle index, check if it is less than the middle index
if arr[mid] > target:
low = mid + 1
else:
high = mid - 1
# If the target element is not found in the array, return -1
return -1
# Test the binary search function
arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
target = 5
result = binary_search(arr, target)
print(f"The target element {target} is at index {result}")
```
This code defines a `binary_search` function that takes an array and a target element as input, and returns the index of the target element in the array if it is found, or -1 if it is not found.
The function works by iteratively dividing the range of the array into two sub-ranges, one containing elements less than the target, and one containing elements greater than the target. It then checks the middle index of each sub-range to see if the target element is present. If the target element is found, the function returns the index of the middle index. If the target element is not found, the function returns -1.
The code also includes a test case to demonstrate how to use the `binary_search` function. In this case, the target element is 5, and the function returns the index of the element 5 in the array.
I hope this helps! Let me know if you have any questions.
|
aidiary/llama-2-7b-finetuned-puzzle-like-question
|
aidiary
| 2023-11-22T11:12:31Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"region:us"
] | null | 2023-11-22T11:12:09Z |
---
library_name: peft
base_model: NousResearch/llama-2-7b-chat-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.2
|
ai-forever/Kandinsky3.0
|
ai-forever
| 2023-11-22T11:10:19Z | 0 | 22 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2023-11-21T09:18:00Z |
---
license: apache-2.0
---
# Kandinsky-3: Text-to-image diffusion model

[Post](https://habr.com/ru/companies/sberbank/articles/775590/) | [Generate](https://fusionbrain.ai) | [Telegram-bot](https://t.me/kandinsky21_bot) | [Report]
## Description:
Kandinsky 3.0 is an open-source text-to-image diffusion model built upon the Kandinsky2-x model family. In comparison to its predecessors, Kandinsky 3.0 incorporates more data and specifically related to Russian culture, which allows to generate pictures related to Russin culture. Furthermore, enhancements have been made to the text understanding and visual quality of the model, achieved by increasing the size of the text encoder and Diffusion U-Net models, respectively.
For more information: details of training, example of generations check out our [post](https://habr.com/ru/companies/sberbank/articles/775590/). The english version will be released in a couple of days.
## Architecture details:

Architecture consists of three parts:
+ Text encoder Flan-UL2 (encoder part) - 8.6B
+ Latent Diffusion U-Net - 3B
+ MoVQ encoder/decoder - 267M
## Models
We release our two models:
+ Base: Base text-to-image diffusion model. This model was trained over 2M steps on 400 A100
+ Inpainting: Inpainting version of the model. The model was initialized from final checkpoint of base model and trained 250k steps on 300 A100.
Weights of the model are loaded internally but if want to change them one can use the following example:
```python
from huggingface_hub import hf_hub_download
from kandinsky3 import get_T2I_unet, get_T5encoder, get_movq, Kandinsky3T2IPipeline
unet_path = hf_hub_download(
repo_id="ai-forever/Kandinsky3.0", filename='weights/kandinsky3.pt')
)
movq_path = hf_hub_download(
repo_id="ai-forever/Kandinsky3.0", filename='weights/movq.pt')
)
unet, null_embedding, projections_state_dict = get_T2I_unet(device, unet_path, fp16=fp16)
processor, condition_encoders = get_T5encoder(device, text_encode_path, projections_state_dict, fp16=fp16)
movq = get_movq(device, movq_path, fp16=fp16)
t2i_pipe = Kandinsky3T2IPipeline(device, unet, null_embedding, processor, condition_encoders, movq, fp16=fp16)
```
```python
from huggingface_hub import hf_hub_download
from kandinsky3 import get_inpainting_unet, get_T5encoder, get_movq, Kandinsky3InpaintingPipeline
inpainting_unet_path = hf_hub_download(
repo_id="ai-forever/Kandinsky3.0", filename='weights/kandinsky3_inpainting.pt', cache_dir=cache_dir
)
movq_path = hf_hub_download(
repo_id="ai-forever/Kandinsky3.0", filename='weights/movq.pt')
)
unet, null_embedding, projections_state_dict = get_inpainting_unet(device, unet_path, fp16=fp16)
processor, condition_encoders = get_T5encoder(device, text_encode_path, projections_state_dict, fp16=fp16)
movq = get_movq(device, movq_path, fp16=False) #MoVQ ooesn't work properly in fp16 on inpainting
pipe = Kandinsky3InpaintingPipeline(device, unet, null_embedding, processor, condition_encoders, movq, fp16=fp16)
```
## Installing
To install repo first one need to create conda environment:
```
conda create -n kandinsky -y python=3.8;
source activate kandinsky;
pip install torch==1.10.1+cu111 torchvision==0.11.2+cu111 torchaudio==0.10.1 -f https://download.pytorch.org/whl/cu113/torch_stable.html;
pip install -r requirements.txt;
```
The exact dependencies is got using `pip freeze` and can be found in `exact_requirements.txt`
## How to use:
Check our jupyter notebooks with examples in `./examples` folder
### 1. text2image
```python
from kandinsky3 import get_T2I_pipeline
t2i_pipe = get_T2I_pipeline('cuda', fp16=True)
image = t2i_pipe( "A cute corgi lives in a house made out of sushi.")
```
### 2. inpainting
```python
from kandinsky3 import get_inpainting_pipeline
inp_pipe = get_inpainting_pipeline('cuda', fp16=True)
image = ... # PIL Image
mask = ... # Numpy array (HxW). Set 1 where image should be masked
image = inp_pipe( "A cute corgi lives in a house made out of sushi.", image, mask)
```
## Examples of generations
<hr>
<table class="center">
<tr>
<td><img src="assets/photo_8.jpg" raw=true></td>
<td><img src="assets/photo_15.jpg"></td>
<td><img src="assets/photo_16.jpg"></td>
<td><img src="assets/photo_17.jpg"></td>
</tr>
<tr>
<td width=25% align="center">"A beautiful landscape outdoors scene in the crochet knitting art style, drawing in style by Alfons Mucha"</td>
<td width=25% align="center">"gorgeous phoenix, cosmic, darkness, epic, cinematic, moonlight, stars, high - definition, texture,Oscar-Claude Monet"</td>
<td width=25% align="center">"a yellow house at the edge of the danish fjord, in the style of eiko ojala, ingrid baars, ad posters, mountainous vistas, george ault, realistic details, dark white and dark gray, 4k"</td>
<td width=25% align="center">"dragon fruit head, upper body, realistic, illustration by Joshua Hoffine Norman Rockwell, scary, creepy, biohacking, futurism, Zaha Hadid style"</td>
</tr>
<tr>
<td><img src="assets/photo_2.jpg" raw=true></td>
<td><img src="assets/photo_19.jpg"></td>
<td><img src="assets/photo_13.jpg"></td>
<td><img src="assets/photo_14.jpg"></td>
</tr>
<tr>
<td width=25% align="center">"Amazing playful nice cute strawberry character, dynamic poze, surreal fantazy garden background, gorgeous masterpice, award winning photo, soft natural lighting, 3d, Blender, Octane render, tilt - shift, deep field, colorful, I can't believe how beautiful this is, colorful, cute and sweet baby - loved photo"</td>
<td width=25% align="center">"beautiful fairy-tale desert, in the sky a wave of sand merges with the milky way, stars, cosmism, digital art, 8k"</td>
<td width=25% align="center">"Car, mustang, movie, person, poster, car cover, person, in the style of alessandro gottardo, gold and cyan, gerald harvey jones, reflections, highly detailed illustrations, industrial urban scenes""</td>
<td width=25% align="center">"cloud in blue sky, a red lip, collage art, shuji terayama, dreamy objects, surreal, criterion collection, showa era, intricate details, mirror"</td>
</tr>
</table>
<hr>
## Authors
+ Vladimir Arkhipkin: [Github](https://github.com/oriBetelgeuse)
+ Anastasia Maltseva [Github](https://github.com/NastyaMittseva)
+ Andrei Filatov [Github](https://github.com/anvilarth),
+ Igor Pavlov: [Github](https://github.com/boomb0om)
+ Julia Agafonova
+ Arseniy Shakhmatov: [Github](https://github.com/cene555), [Blog](https://t.me/gradientdip)
+ Andrey Kuznetsov: [Github](https://github.com/kuznetsoffandrey), [Blog](https://t.me/complete_ai)
+ Denis Dimitrov: [Github](https://github.com/denndimitrov), [Blog](https://t.me/dendi_math_ai)
|
Zainiii/phi-1_5B-lora-math1
|
Zainiii
| 2023-11-22T11:08:06Z | 4 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:microsoft/phi-1_5",
"base_model:adapter:microsoft/phi-1_5",
"region:us"
] | null | 2023-11-22T11:08:05Z |
---
library_name: peft
base_model: microsoft/phi-1_5
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.3.dev0
|
Korabbit/Llama-2-7b-chat-hf-afr-200step-v2
|
Korabbit
| 2023-11-22T11:07:17Z | 1,532 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"conversational",
"en",
"dataset:vicgalle/alpaca-gpt4",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-22T08:55:34Z |
---
license: llama2
datasets:
- vicgalle/alpaca-gpt4
language:
- en
---
Hi there! this test my approach "AFR training"
The base model used "Llama-2-7b-chat"
System Prompt: You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. \n If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
Instruction: Implement binary search in python.
Response: Sure! Here is an example of how to implement a binary search algorithm in Python:
```
def binary_search(arr, target):
# Initialize the index of the target element
low = 0
high = len(arr) - 1
# Loop until the target element is found or the end of the array is reached
while low <= high:
# Calculate the middle index of the array
mid = (low + high) // 2
# Check if the target element is in the middle index
if arr[mid] == target:
return mid
# If the target element is not in the middle index, check if it is less than the middle index
if arr[mid] > target:
low = mid + 1
else:
high = mid - 1
# If the target element is not found in the array, return -1
return -1
# Test the binary search function
arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
target = 5
result = binary_search(arr, target)
print(f"The target element {target} is at index {result}")
```
This code defines a `binary_search` function that takes an array and a target element as input, and returns the index of the target element in the array if it is found, or -1 if it is not found.
The function works by iteratively dividing the range of the array into two sub-ranges, one containing elements less than the target, and one containing elements greater than the target. It then checks the middle index of each sub-range to see if the target element is present. If the target element is found, the function returns the index of the middle index. If the target element is not found, the function returns -1.
The code also includes a test case to demonstrate how to use the `binary_search` function. In this case, the target element is 5, and the function returns the index of the element 5 in the array.
I hope this helps! Let me know if you have any questions.
|
ai-forever/KandinskyVideo
|
ai-forever
| 2023-11-22T11:05:36Z | 0 | 9 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2023-11-21T09:18:23Z |
---
license: apache-2.0
---
# Kandinsky Video — a new text-to-video generation model
## SoTA quality among open-source solutions
This repository is the official implementation of Kandinsky Video model
Paper | [Project](https://ai-forever.github.io/kandinsky-video/) |  | [Telegram-bot](https://t.me/video_kandinsky_bot) | Habr post
<p align="center">
<img src="__assets__/title.JPG" width="800px"/>
<br>
<em>Kandinsky Video is a text-to-video generation model, which is based on the FusionFrames architecture, consisting of two main stages: keyframe generation and interpolation. Our approach for temporal conditioning allows us to generate videos with high-quality appearance, smoothness and dynamics.</em>
</p>
## Pipeline
<p align="center">
<img src="__assets__/pipeline.jpg" width="800px"/>
<br>
<em>The encoded text prompt enters the U-Net keyframe generation model with temporal layers or blocks, and then the sampled latent keyframes are sent to the latent interpolation model in such a way as to predict three interpolation frames between two keyframes. A temporal MoVQ-GAN decoder is used to get the final video result.</em>
</p>
**Architecture details**
+ Text encoder (Flan-UL2) - 8.6B
+ Latent Diffusion U-Net3D - 4.0B
+ MoVQ encoder/decoder - 256M
## How to use
Check our jupyter notebooks with examples in `./examples` folder
### 1. text2video
```python
from video_kandinsky3 import get_T2V_pipeline
t2v_pipe = get_T2V_pipeline('cuda', fp16=True)
pfps = 'medium' # ['low', 'medium', 'high']
video = t2v_pipe(
'a red car is drifting on the mountain road, close view, fast movement',
width=640, height=384, fps=fps
)
```
## Results
<table class="center">
<tr>
<td><img src="__assets__/results/A car moving on the road from the sea to the mountains.gif" raw=true></td>
<td><img src="__assets__/results/A red car drifting, 4k video.gif"></td>
<td><img src="__assets__/results/chemistry laboratory, chemical explosion, 4k.gif"></td>
<td><img src="__assets__/results/Erupting volcano_ raw power, molten lava, and the forces of the Earth.gif"></td>
</tr>
<tr>
<td width=25% align="center">"A car moving on the road from the sea to the mountains"</td>
<td width=25% align="center">"A red car drifting, 4k video"</td>
<td width=25% align="center">"Chemistry laboratory, chemical explosion, 4k"</td>
<td width=25% align="center">"Erupting volcano raw power, molten lava, and the forces of the Earth"</td>
</tr>
<tr>
<td><img src="__assets__/results/luminescent jellyfish swims underwater, neon, 4k.gif" raw=true></td>
<td><img src="__assets__/results/Majestic waterfalls in a lush rainforest_ power, mist, and biodiversity.gif"></td>
<td><img src="__assets__/results/white ghost flies through a night clearing, 4k.gif"></td>
<td><img src="__assets__/results/Wildlife migration_ herds on the move, crossing landscapes in harmony.gif"></td>
</tr>
<tr>
<td width=25% align="center">"Luminescent jellyfish swims underwater, neon, 4k"</td>
<td width=25% align="center">"Majestic waterfalls in a lush rainforest power, mist, and biodiversity"</td>
<td width=25% align="center">"White ghost flies through a night clearing, 4k"</td>
<td width=25% align="center">"Wildlife migration herds on the move, crossing landscapes in harmony"</td>
</tr>
<tr>
<td><img src="__assets__/results/Majestic humpback whale breaching_ power, grace, and ocean spectacle.gif" raw=true></td>
<td><img src="__assets__/results/Evoke the sense of wonder in a time-lapse journey through changing seasons..gif"></td>
<td><img src="__assets__/results/Explore the fascinating world of underwater creatures in a visually stunning sequence.gif"></td>
<td><img src="__assets__/results/Polar ice caps_ the pristine wilderness of the Arctic and Antarctic.gif"></td>
</tr>
<tr>
<td width=25% align="center">"Majestic humpback whale breaching power, grace, and ocean spectacle"</td>
<td width=25% align="center">"Evoke the sense of wonder in a time-lapse journey through changing seasons"</td>
<td width=25% align="center">"Explore the fascinating world of underwater creatures in a visually stunning sequence"</td>
<td width=25% align="center">"Polar ice caps the pristine wilderness of the Arctic and Antarctic"</td>
</tr>
<tr>
<td><img src="__assets__/results/Rolling waves on a sandy beach_ relaxation, rhythm, and coastal beauty.gif" raw=true></td>
<td><img src="__assets__/results/Sloth in slow motion_ deliberate movements, relaxation, and arboreal life.gif"></td>
<td><img src="__assets__/results/Time-lapse of a flower blooming_ growth, beauty, and the passage of time..gif"></td>
<td><img src="__assets__/results/Craft a heartwarming narrative showcasing the bond between a human and their loyal pet companion..gif"></td>
</tr>
<tr>
<td width=25% align="center">"Rolling waves on a sandy beach relaxation, rhythm, and coastal beauty"</td>
<td width=25% align="center">"Sloth in slow motion deliberate movements, relaxation, and arboreal life"</td>
<td width=25% align="center">"Time-lapse of a flower blooming growth, beauty, and the passage of time"</td>
<td width=25% align="center">"Craft a heartwarming narrative showcasing the bond between a human and their loyal pet companion"</td>
</tr>
</table>
# Authors
+ Vladimir Arkhipkin: [Github](https://github.com/oriBetelgeuse), [Google Scholar](https://scholar.google.com/citations?user=D-Ko0oAAAAAJ&hl=ru)
+ Zein Shaheen: [Github](https://github.com/zeinsh), [Google Scholar](https://scholar.google.ru/citations?user=bxlgMxMAAAAJ&hl=en)
+ Viacheslav Vasilev: [Github](https://github.com/vivasilev), [Google Scholar](https://scholar.google.com/citations?user=redAz-kAAAAJ&hl=ru&oi=sra)
+ Igor Pavlov: [Github](https://github.com/boomb0om)
+ Elizaveta Dakhova: [Github](https://github.com/LizaDakhova)
+ Anastasia Lysenko: [Github](https://github.com/LysenkoAnastasia)
+ Sergey Markov
+ Denis Dimitrov: [Github](https://github.com/denndimitrov), [Google Scholar](https://scholar.google.com/citations?user=3JSIJpYAAAAJ&hl=ru&oi=ao)
+ Andrey Kuznetsov: [Github](https://github.com/kuznetsoffandrey), [Google Scholar](https://scholar.google.com/citations?user=q0lIfCEAAAAJ&hl=ru)
## BibTeX
If you use our work in your research, please cite our publication:
```
TBD
```
|
crom87/sd_base-db-angel-genbg10-2e-06-linear-priorp-500-gc
|
crom87
| 2023-11-22T10:50:55Z | 4 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dreambooth",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:finetune:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-22T10:15:53Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: TOKstyle georgeclooney
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - crom87/sd_base-db-angel-genbg10-2e-06-linear-priorp-500-gc
This is a dreambooth model derived from runwayml/stable-diffusion-v1-5. The weights were trained on TOKstyle georgeclooney using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.






DreamBooth for the text encoder was enabled: True.
|
TheBloke/Tess-M-v1.1-AWQ
|
TheBloke
| 2023-11-22T10:46:09Z | 10 | 1 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"base_model:migtissera/Tess-M-v1.1",
"base_model:quantized:migtissera/Tess-M-v1.1",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"awq",
"region:us"
] |
text-generation
| 2023-11-22T09:37:19Z |
---
base_model: migtissera/Tess-M-v1.1
inference: false
license: other
license_link: https://huggingface.co/01-ai/Yi-34B/blob/main/LICENSE
license_name: yi-34b
model_creator: Migel Tissera
model_name: Tess M v1.1
model_type: yi
prompt_template: 'SYSTEM: {system_message}
USER: {prompt}
ASSISTANT:
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Tess M v1.1 - AWQ
- Model creator: [Migel Tissera](https://huggingface.co/migtissera)
- Original model: [Tess M v1.1](https://huggingface.co/migtissera/Tess-M-v1.1)
<!-- description start -->
## Description
This repo contains AWQ model files for [Migel Tissera's Tess M v1.1](https://huggingface.co/migtissera/Tess-M-v1.1).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - Llama and Mistral models only
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later, from any code or client that supports Transformers
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Tess-M-v1.1-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Tess-M-v1.1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Tess-M-v1.1-GGUF)
* [Migel Tissera's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/migtissera/Tess-M-v1.1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Orca-Vicuna
```
SYSTEM: {system_message}
USER: {prompt}
ASSISTANT:
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
I currently release 128g GEMM models only. The addition of group_size 32 models, and GEMV kernel models, is being actively considered.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Tess-M-v1.1-AWQ/tree/main) | 4 | 128 | [open-instruct](https://huggingface.co/datasets/VMware/open-instruct/viewer/) | 4096 | 19.23 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/Tess-M-v1.1-AWQ`.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `Tess-M-v1.1-AWQ`
7. Select **Loader: AutoAWQ**.
8. Click Load, and the model will load and is now ready for use.
9. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
10. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_AWQ.md-text-generation-webui end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Multi-user inference server: vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- Please ensure you are using vLLM version 0.2 or later.
- When using vLLM as a server, pass the `--quantization awq` parameter.
For example:
```shell
python3 -m vllm.entrypoints.api_server --model TheBloke/Tess-M-v1.1-AWQ --quantization awq --dtype auto
```
- When using vLLM from Python code, again set `quantization=awq`.
For example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Tell me about AI",
"Write a story about llamas",
"What is 291 - 150?",
"How much wood would a woodchuck chuck if a woodchuck could chuck wood?",
]
prompt_template=f'''SYSTEM: {system_message}
USER: {prompt}
ASSISTANT:
'''
prompts = [prompt_template.format(prompt=prompt) for prompt in prompts]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/Tess-M-v1.1-AWQ", quantization="awq", dtype="auto")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Multi-user inference server: Hugging Face Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/Tess-M-v1.1-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires [huggingface-hub](https://github.com/huggingface/huggingface_hub) 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''SYSTEM: {system_message}
USER: {prompt}
ASSISTANT:
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: ", response)
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## Inference from Python code using Transformers
### Install the necessary packages
- Requires: [Transformers](https://huggingface.co/docs/transformers) 4.35.0 or later.
- Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.6 or later.
```shell
pip3 install --upgrade "autoawq>=0.1.6" "transformers>=4.35.0"
```
Note that if you are using PyTorch 2.0.1, the above AutoAWQ command will automatically upgrade you to PyTorch 2.1.0.
If you are using CUDA 11.8 and wish to continue using PyTorch 2.0.1, instead run this command:
```shell
pip3 install https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp310-cp310-linux_x86_64.whl
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### Transformers example code (requires Transformers 4.35.0 and later)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_name_or_path = "TheBloke/Tess-M-v1.1-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
low_cpu_mem_usage=True,
device_map="cuda:0"
)
# Using the text streamer to stream output one token at a time
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = "Tell me about AI"
prompt_template=f'''SYSTEM: {system_message}
USER: {prompt}
ASSISTANT:
'''
# Convert prompt to tokens
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
generation_params = {
"do_sample": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": 512,
"repetition_penalty": 1.1
}
# Generate streamed output, visible one token at a time
generation_output = model.generate(
tokens,
streamer=streamer,
**generation_params
)
# Generation without a streamer, which will include the prompt in the output
generation_output = model.generate(
tokens,
**generation_params
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
print("model.generate output: ", text_output)
# Inference is also possible via Transformers' pipeline
from transformers import pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
**generation_params
)
pipe_output = pipe(prompt_template)[0]['generated_text']
print("pipeline output: ", pipe_output)
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui) using `Loader: AutoAWQ`.
- [vLLM](https://github.com/vllm-project/vllm) version 0.2.0 and later.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) version 1.1.0 and later.
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later.
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) version 0.1.1 and later.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Migel Tissera's Tess M v1.1
# Tess

Tess, short for Tessoro/Tessoso, is a general purpose Large Language Model series. Tess-M-v1.1 was trained on the Yi-34B-200K base.
# Prompt Format:
```
SYSTEM: <ANY SYSTEM CONTEXT>
USER:
ASSISTANT:
```
|
HamdanXI/bert-base-uncased-paradetox-1Token-Split-MASK-v2
|
HamdanXI
| 2023-11-22T10:35:26Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-11-22T10:11:51Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased-paradetox-1Token-Split-MASK-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-paradetox-1Token-Split-MASK-v2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
thangvip/bert-finetuned-ner-cti
|
thangvip
| 2023-11-22T10:19:54Z | 9 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-11-22T09:59:19Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner-cti
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner-cti
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0676
- Precision: 0.9665
- Recall: 0.9794
- F1: 0.9729
- Accuracy: 0.9824
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.104 | 1.0 | 1725 | 0.0842 | 0.9532 | 0.9693 | 0.9612 | 0.9758 |
| 0.0603 | 2.0 | 3450 | 0.0694 | 0.9654 | 0.9760 | 0.9707 | 0.9808 |
| 0.0374 | 3.0 | 5175 | 0.0676 | 0.9665 | 0.9794 | 0.9729 | 0.9824 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
jimboHsueh/HW3
|
jimboHsueh
| 2023-11-22T10:17:14Z | 9 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"arxiv:1910.09700",
"base_model:jimboHsueh/save_hw3",
"base_model:adapter:jimboHsueh/save_hw3",
"region:us"
] | null | 2023-11-18T08:17:42Z |
---
library_name: peft
base_model: jimboHsueh/save_hw3
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.2
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.2
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.2
|
Chow33/opt-6.7b-lora
|
Chow33
| 2023-11-22T10:16:16Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:facebook/opt-6.7b",
"base_model:adapter:facebook/opt-6.7b",
"region:us"
] | null | 2023-11-22T10:16:05Z |
---
library_name: peft
base_model: facebook/opt-6.7b
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.3.dev0
|
HamdanXI/bert-base-uncased-paradetox-1Token-Split-MASK
|
HamdanXI
| 2023-11-22T10:11:13Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"fill-mask",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-11-22T10:06:08Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: bert-base-uncased-paradetox-1Token-Split-MASK
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-paradetox-1Token-Split-MASK
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
imdltjwns/my_model
|
imdltjwns
| 2023-11-22T10:03:36Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"wav2vec2",
"audio-classification",
"generated_from_trainer",
"dataset:minds14",
"base_model:facebook/wav2vec2-base",
"base_model:finetune:facebook/wav2vec2-base",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-11-22T09:54:40Z |
---
license: apache-2.0
base_model: facebook/wav2vec2-base
tags:
- generated_from_trainer
datasets:
- minds14
metrics:
- accuracy
model-index:
- name: my_model
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: minds14
type: minds14
config: en-US
split: train
args: en-US
metrics:
- name: Accuracy
type: accuracy
value: 0.061946902654867256
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_model
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the minds14 dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6580
- Accuracy: 0.0619
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.8 | 3 | 2.6451 | 0.0265 |
| No log | 1.87 | 7 | 2.6512 | 0.0708 |
| 2.6365 | 2.93 | 11 | 2.6595 | 0.0619 |
| 2.6365 | 4.0 | 15 | 2.6568 | 0.0796 |
| 2.6365 | 4.8 | 18 | 2.6535 | 0.0796 |
| 2.6363 | 5.87 | 22 | 2.6519 | 0.0796 |
| 2.6363 | 6.93 | 26 | 2.6588 | 0.0619 |
| 2.6207 | 8.0 | 30 | 2.6580 | 0.0619 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.14.1
|
vgarg/my-fw9-identification-model-e5_large_v5_22_11_23
|
vgarg
| 2023-11-22T10:01:46Z | 5 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"xlm-roberta",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2023-11-22T10:00:09Z |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# vgarg/my-fw9-identification-model-e5_large_v5_22_11_23
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("vgarg/my-fw9-identification-model-e5_large_v5_22_11_23")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
saileshamandola/t5-small-finetuned-dialogsum-v2
|
saileshamandola
| 2023-11-22T09:56:53Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-22T09:14:00Z |
---
license: apache-2.0
base_model: t5-small
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5-small-finetuned-dialogsum-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-dialogsum-v2
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3041
- Rouge1: 35.9525
- Rouge2: 13.1826
- Rougel: 30.3535
- Rougelsum: 32.2144
- Gen Len: 18.902
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 1.7356 | 1.0 | 779 | 1.4283 | 33.2097 | 10.6868 | 27.8451 | 29.9371 | 18.854 |
| 1.5042 | 2.0 | 1558 | 1.3706 | 34.3543 | 11.7561 | 28.8686 | 31.0041 | 18.842 |
| 1.4725 | 3.0 | 2337 | 1.3471 | 34.5334 | 11.9629 | 29.1625 | 31.1241 | 18.88 |
| 1.4329 | 4.0 | 3116 | 1.3299 | 35.31 | 12.6214 | 29.7381 | 31.7618 | 18.918 |
| 1.424 | 5.0 | 3895 | 1.3153 | 35.5141 | 13.2169 | 30.3033 | 32.0904 | 18.928 |
| 1.4044 | 6.0 | 4674 | 1.3090 | 35.7821 | 12.9692 | 30.3978 | 32.1945 | 18.912 |
| 1.3984 | 7.0 | 5453 | 1.3050 | 35.9485 | 13.3086 | 30.3416 | 32.2398 | 18.906 |
| 1.3908 | 8.0 | 6232 | 1.3041 | 35.9525 | 13.1826 | 30.3535 | 32.2144 | 18.902 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
crom87/sd_base-db-angel-genbg10-3e-06-poly-priorp-500-gc
|
crom87
| 2023-11-22T09:52:26Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dreambooth",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:finetune:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-22T08:55:22Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: TOKstyle georgeclooney
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - crom87/sd_base-db-angel-genbg10-3e-06-poly-priorp-500-gc
This is a dreambooth model derived from runwayml/stable-diffusion-v1-5. The weights were trained on TOKstyle georgeclooney using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.






DreamBooth for the text encoder was enabled: True.
|
LoneStriker/Tess-M-v1.1-5.0bpw-h6-exl2
|
LoneStriker
| 2023-11-22T09:48:22Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-22T09:22:42Z |
---
license: other
license_name: yi-34b
license_link: https://huggingface.co/01-ai/Yi-34B/blob/main/LICENSE
---
# Tess

Tess, short for Tessoro/Tessoso, is a general purpose Large Language Model series. Tess-M-v1.1 was trained on the Yi-34B-200K base.
# Prompt Format:
```
SYSTEM: <ANY SYSTEM CONTEXT>
USER:
ASSISTANT:
```
|
LoneStriker/Tess-M-v1.1-4.65bpw-h6-exl2
|
LoneStriker
| 2023-11-22T09:47:45Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-22T09:22:42Z |
---
license: other
license_name: yi-34b
license_link: https://huggingface.co/01-ai/Yi-34B/blob/main/LICENSE
---
# Tess

Tess, short for Tessoro/Tessoso, is a general purpose Large Language Model series. Tess-M-v1.1 was trained on the Yi-34B-200K base.
# Prompt Format:
```
SYSTEM: <ANY SYSTEM CONTEXT>
USER:
ASSISTANT:
```
|
Leslie123/pegasus-rss-training
|
Leslie123
| 2023-11-22T09:44:48Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"base_model:google/pegasus-xsum",
"base_model:finetune:google/pegasus-xsum",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-22T08:02:03Z |
---
base_model: google/pegasus-xsum
tags:
- generated_from_trainer
model-index:
- name: outputs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# outputs
This model is a fine-tuned version of [google/pegasus-xsum](https://huggingface.co/google/pegasus-xsum) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2808
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.2159 | 1.0 | 3308 | 1.3323 |
| 1.3188 | 2.0 | 6616 | 1.2889 |
| 1.2226 | 3.0 | 9924 | 1.2808 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
TheBloke/MythoMist-7B-AWQ
|
TheBloke
| 2023-11-22T09:22:36Z | 8 | 4 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"en",
"base_model:Gryphe/MythoMist-7b",
"base_model:quantized:Gryphe/MythoMist-7b",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"awq",
"region:us"
] |
text-generation
| 2023-11-22T09:05:23Z |
---
base_model: Gryphe/MythoMist-7b
inference: false
language:
- en
license: other
model_creator: Gryphe Padar
model_name: MythoMist 7B
model_type: mistral
prompt_template: '### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# MythoMist 7B - AWQ
- Model creator: [Gryphe Padar](https://huggingface.co/Gryphe)
- Original model: [MythoMist 7B](https://huggingface.co/Gryphe/MythoMist-7b)
<!-- description start -->
## Description
This repo contains AWQ model files for [Gryphe Padar's MythoMist 7B](https://huggingface.co/Gryphe/MythoMist-7b).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - Llama and Mistral models only
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later, from any code or client that supports Transformers
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/MythoMist-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/MythoMist-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/MythoMist-7B-GGUF)
* [Gryphe Padar's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Gryphe/MythoMist-7b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca-InstructOnly2
```
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
I currently release 128g GEMM models only. The addition of group_size 32 models, and GEMV kernel models, is being actively considered.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/MythoMist-7B-AWQ/tree/main) | 4 | 128 | [open-instruct](https://huggingface.co/datasets/VMware/open-instruct/viewer/) | 4096 | 4.15 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/MythoMist-7B-AWQ`.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `MythoMist-7B-AWQ`
7. Select **Loader: AutoAWQ**.
8. Click Load, and the model will load and is now ready for use.
9. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
10. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_AWQ.md-text-generation-webui end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Multi-user inference server: vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- Please ensure you are using vLLM version 0.2 or later.
- When using vLLM as a server, pass the `--quantization awq` parameter.
For example:
```shell
python3 -m vllm.entrypoints.api_server --model TheBloke/MythoMist-7B-AWQ --quantization awq --dtype auto
```
- When using vLLM from Python code, again set `quantization=awq`.
For example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Tell me about AI",
"Write a story about llamas",
"What is 291 - 150?",
"How much wood would a woodchuck chuck if a woodchuck could chuck wood?",
]
prompt_template=f'''### Instruction:
{prompt}
### Response:
'''
prompts = [prompt_template.format(prompt=prompt) for prompt in prompts]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/MythoMist-7B-AWQ", quantization="awq", dtype="auto")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Multi-user inference server: Hugging Face Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/MythoMist-7B-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires [huggingface-hub](https://github.com/huggingface/huggingface_hub) 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''### Instruction:
{prompt}
### Response:
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: ", response)
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## Inference from Python code using Transformers
### Install the necessary packages
- Requires: [Transformers](https://huggingface.co/docs/transformers) 4.35.0 or later.
- Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.6 or later.
```shell
pip3 install --upgrade "autoawq>=0.1.6" "transformers>=4.35.0"
```
Note that if you are using PyTorch 2.0.1, the above AutoAWQ command will automatically upgrade you to PyTorch 2.1.0.
If you are using CUDA 11.8 and wish to continue using PyTorch 2.0.1, instead run this command:
```shell
pip3 install https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp310-cp310-linux_x86_64.whl
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### Transformers example code (requires Transformers 4.35.0 and later)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_name_or_path = "TheBloke/MythoMist-7B-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
low_cpu_mem_usage=True,
device_map="cuda:0"
)
# Using the text streamer to stream output one token at a time
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = "Tell me about AI"
prompt_template=f'''### Instruction:
{prompt}
### Response:
'''
# Convert prompt to tokens
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
generation_params = {
"do_sample": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": 512,
"repetition_penalty": 1.1
}
# Generate streamed output, visible one token at a time
generation_output = model.generate(
tokens,
streamer=streamer,
**generation_params
)
# Generation without a streamer, which will include the prompt in the output
generation_output = model.generate(
tokens,
**generation_params
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
print("model.generate output: ", text_output)
# Inference is also possible via Transformers' pipeline
from transformers import pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
**generation_params
)
pipe_output = pipe(prompt_template)[0]['generated_text']
print("pipeline output: ", pipe_output)
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui) using `Loader: AutoAWQ`.
- [vLLM](https://github.com/vllm-project/vllm) version 0.2.0 and later.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) version 1.1.0 and later.
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later.
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) version 0.1.1 and later.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Gryphe Padar's MythoMist 7B
MythoMist 7b is, as always, a highly experimental Mistral-based merge based on my latest (still in development) algorithm, which actively benchmarks the model as it's being built in pursuit of a goal set by the user.
The primary purpose for MythoMist was to reduce usage of the word anticipation, ministrations and other variations we've come to associate negatively with ChatGPT roleplaying data. This algorithm cannot outright ban these words, but instead strives to minimize the usage.
I am currently in the process of cleaning up the code before publishing it, much like I did with my earlier [gradient tensor script](https://github.com/Gryphe/BlockMerge_Gradient/tree/main/YAML).
## Final merge composition
After processing 12 models my algorithm ended up with the following (approximated) final composition:
| Model | Contribution |
|--------------------------|--------------|
| Neural-chat-7b-v3-1 | 26% |
| Synatra-7B-v0.3-RP | 22% |
| Airoboros-m-7b-3.1.2 | 10% |
| Toppy-M-7B | 10% |
| Zephyr-7b-beta | 7% |
| Nous-Capybara-7B-V1.9 | 5% |
| OpenHermes-2.5-Mistral-7B| 5% |
| Dolphin-2.2.1-mistral-7b | 4% |
| Noromaid-7b-v0.1.1 | 4% |
| SynthIA-7B-v1.3 | 3% |
| Mistral-7B-v0.1 | 2% |
| Openchat_3.5 | 2% |
There is no real logic in how these models were divided throughout the merge - Small bits and pieces were taken from each and then mixed in with other models on a layer by layer basis, using a pattern similar to my MythoMax recipe in which underlying tensors are mixed in a criss-cross manner.
This new process only decides on the model's layers, not the singular lm_head and embed_tokens layers which influence much of the model's output. I ran a seperate script for that, picking the singular tensors that resulted in the longest responses, which settled on Toppy-M-7B.
## Prompt Format
Due to the wide variation in prompt formats used in this merge I (for now) recommend using Alpaca as the prompt template for compatibility reasons:
```
### Instruction:
Your instruction or question here.
### Response:
```
---
license: other
---
|
TheBloke/MythoMist-7B-GGUF
|
TheBloke
| 2023-11-22T09:09:32Z | 488 | 20 |
transformers
|
[
"transformers",
"gguf",
"mistral",
"en",
"base_model:Gryphe/MythoMist-7b",
"base_model:quantized:Gryphe/MythoMist-7b",
"license:other",
"region:us"
] | null | 2023-11-22T09:05:23Z |
---
base_model: Gryphe/MythoMist-7b
inference: false
language:
- en
license: other
model_creator: Gryphe Padar
model_name: MythoMist 7B
model_type: mistral
prompt_template: '### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# MythoMist 7B - GGUF
- Model creator: [Gryphe Padar](https://huggingface.co/Gryphe)
- Original model: [MythoMist 7B](https://huggingface.co/Gryphe/MythoMist-7b)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Gryphe Padar's MythoMist 7B](https://huggingface.co/Gryphe/MythoMist-7b).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/MythoMist-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/MythoMist-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/MythoMist-7B-GGUF)
* [Gryphe Padar's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Gryphe/MythoMist-7b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca-InstructOnly2
```
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [mythomist-7b.Q2_K.gguf](https://huggingface.co/TheBloke/MythoMist-7B-GGUF/blob/main/mythomist-7b.Q2_K.gguf) | Q2_K | 2 | 3.08 GB| 5.58 GB | smallest, significant quality loss - not recommended for most purposes |
| [mythomist-7b.Q3_K_S.gguf](https://huggingface.co/TheBloke/MythoMist-7B-GGUF/blob/main/mythomist-7b.Q3_K_S.gguf) | Q3_K_S | 3 | 3.16 GB| 5.66 GB | very small, high quality loss |
| [mythomist-7b.Q3_K_M.gguf](https://huggingface.co/TheBloke/MythoMist-7B-GGUF/blob/main/mythomist-7b.Q3_K_M.gguf) | Q3_K_M | 3 | 3.52 GB| 6.02 GB | very small, high quality loss |
| [mythomist-7b.Q3_K_L.gguf](https://huggingface.co/TheBloke/MythoMist-7B-GGUF/blob/main/mythomist-7b.Q3_K_L.gguf) | Q3_K_L | 3 | 3.82 GB| 6.32 GB | small, substantial quality loss |
| [mythomist-7b.Q4_0.gguf](https://huggingface.co/TheBloke/MythoMist-7B-GGUF/blob/main/mythomist-7b.Q4_0.gguf) | Q4_0 | 4 | 4.11 GB| 6.61 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [mythomist-7b.Q4_K_S.gguf](https://huggingface.co/TheBloke/MythoMist-7B-GGUF/blob/main/mythomist-7b.Q4_K_S.gguf) | Q4_K_S | 4 | 4.14 GB| 6.64 GB | small, greater quality loss |
| [mythomist-7b.Q4_K_M.gguf](https://huggingface.co/TheBloke/MythoMist-7B-GGUF/blob/main/mythomist-7b.Q4_K_M.gguf) | Q4_K_M | 4 | 4.37 GB| 6.87 GB | medium, balanced quality - recommended |
| [mythomist-7b.Q5_0.gguf](https://huggingface.co/TheBloke/MythoMist-7B-GGUF/blob/main/mythomist-7b.Q5_0.gguf) | Q5_0 | 5 | 5.00 GB| 7.50 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [mythomist-7b.Q5_K_S.gguf](https://huggingface.co/TheBloke/MythoMist-7B-GGUF/blob/main/mythomist-7b.Q5_K_S.gguf) | Q5_K_S | 5 | 5.00 GB| 7.50 GB | large, low quality loss - recommended |
| [mythomist-7b.Q5_K_M.gguf](https://huggingface.co/TheBloke/MythoMist-7B-GGUF/blob/main/mythomist-7b.Q5_K_M.gguf) | Q5_K_M | 5 | 5.13 GB| 7.63 GB | large, very low quality loss - recommended |
| [mythomist-7b.Q6_K.gguf](https://huggingface.co/TheBloke/MythoMist-7B-GGUF/blob/main/mythomist-7b.Q6_K.gguf) | Q6_K | 6 | 5.94 GB| 8.44 GB | very large, extremely low quality loss |
| [mythomist-7b.Q8_0.gguf](https://huggingface.co/TheBloke/MythoMist-7B-GGUF/blob/main/mythomist-7b.Q8_0.gguf) | Q8_0 | 8 | 7.70 GB| 10.20 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/MythoMist-7B-GGUF and below it, a specific filename to download, such as: mythomist-7b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/MythoMist-7B-GGUF mythomist-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/MythoMist-7B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/MythoMist-7B-GGUF mythomist-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m mythomist-7b.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "### Instruction:\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/MythoMist-7B-GGUF", model_file="mythomist-7b.Q4_K_M.gguf", model_type="mistral", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Gryphe Padar's MythoMist 7B
MythoMist 7b is, as always, a highly experimental Mistral-based merge based on my latest (still in development) algorithm, which actively benchmarks the model as it's being built in pursuit of a goal set by the user.
The primary purpose for MythoMist was to reduce usage of the word anticipation, ministrations and other variations we've come to associate negatively with ChatGPT roleplaying data. This algorithm cannot outright ban these words, but instead strives to minimize the usage.
I am currently in the process of cleaning up the code before publishing it, much like I did with my earlier [gradient tensor script](https://github.com/Gryphe/BlockMerge_Gradient/tree/main/YAML).
## Final merge composition
After processing 12 models my algorithm ended up with the following (approximated) final composition:
| Model | Contribution |
|--------------------------|--------------|
| Neural-chat-7b-v3-1 | 26% |
| Synatra-7B-v0.3-RP | 22% |
| Airoboros-m-7b-3.1.2 | 10% |
| Toppy-M-7B | 10% |
| Zephyr-7b-beta | 7% |
| Nous-Capybara-7B-V1.9 | 5% |
| OpenHermes-2.5-Mistral-7B| 5% |
| Dolphin-2.2.1-mistral-7b | 4% |
| Noromaid-7b-v0.1.1 | 4% |
| SynthIA-7B-v1.3 | 3% |
| Mistral-7B-v0.1 | 2% |
| Openchat_3.5 | 2% |
There is no real logic in how these models were divided throughout the merge - Small bits and pieces were taken from each and then mixed in with other models on a layer by layer basis, using a pattern similar to my MythoMax recipe in which underlying tensors are mixed in a criss-cross manner.
This new process only decides on the model's layers, not the singular lm_head and embed_tokens layers which influence much of the model's output. I ran a seperate script for that, picking the singular tensors that resulted in the longest responses, which settled on Toppy-M-7B.
## Prompt Format
Due to the wide variation in prompt formats used in this merge I (for now) recommend using Alpaca as the prompt template for compatibility reasons:
```
### Instruction:
Your instruction or question here.
### Response:
```
---
license: other
---
<!-- original-model-card end -->
|
LoneStriker/Tess-M-v1.1-4.0bpw-h6-exl2
|
LoneStriker
| 2023-11-22T09:07:11Z | 7 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-22T08:37:10Z |
---
license: other
license_name: yi-34b
license_link: https://huggingface.co/01-ai/Yi-34B/blob/main/LICENSE
---
# Tess

Tess, short for Tessoro/Tessoso, is a general purpose Large Language Model series. Tess-M-v1.1 was trained on the Yi-34B-200K base.
# Prompt Format:
```
SYSTEM: <ANY SYSTEM CONTEXT>
USER:
ASSISTANT:
```
|
LoneStriker/Yarn-Llama-2-70b-32k-5.15bpw-h6-exl2
|
LoneStriker
| 2023-11-22T09:02:17Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"custom_code",
"en",
"dataset:emozilla/yarn-train-tokenized-8k-llama",
"arxiv:2309.00071",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-22T08:18:27Z |
---
metrics:
- perplexity
library_name: transformers
license: apache-2.0
language:
- en
datasets:
- emozilla/yarn-train-tokenized-8k-llama
---
# Model Card: Yarn-Llama-2-70b-32k
[Preprint (arXiv)](https://arxiv.org/abs/2309.00071)
[GitHub](https://github.com/jquesnelle/yarn)
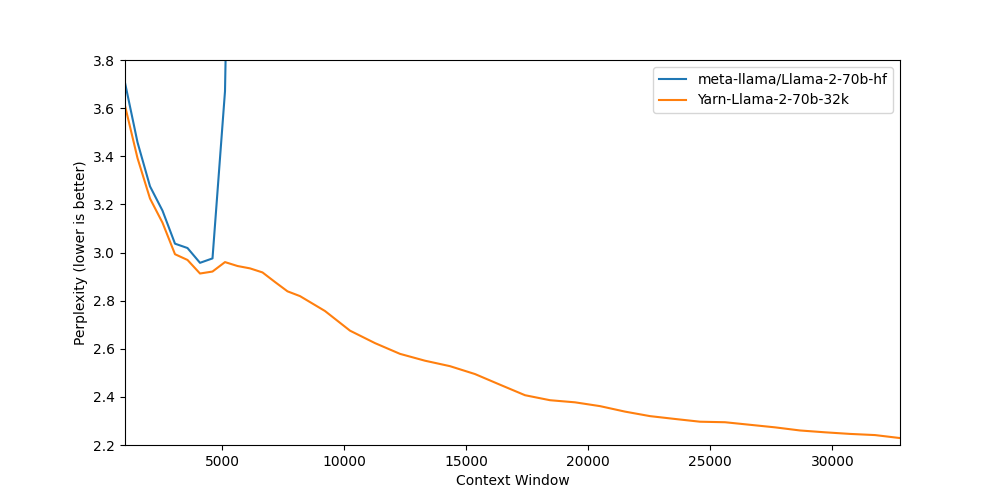
The authors would like to thank [LAION AI](https://laion.ai/) for their support of compute for this model.
It was trained on the [JUWELS](https://www.fz-juelich.de/en/ias/jsc/systems/supercomputers/juwels) supercomputer.
## Model Description
Nous-Yarn-Llama-2-70b-32k is a state-of-the-art language model for long context, further pretrained on long context data for 400 steps using the YaRN extension method.
It is an extension of [Llama-2-70b-hf](meta-llama/Llama-2-70b-hf) and supports a 32k token context window.
To use, pass `trust_remote_code=True` when loading the model, for example
```python
model = AutoModelForCausalLM.from_pretrained("NousResearch/Yarn-Llama-2-70b-32k",
use_flash_attention_2=True,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True)
```
In addition you will need to use the latest version of `transformers` (until 4.35 comes out)
```sh
pip install git+https://github.com/huggingface/transformers
```
## Benchmarks
Long context benchmarks:
| Model | Context Window | 1k PPL | 2k PPL | 4k PPL | 8k PPL | 16k PPL | 32k PPL |
|-------|---------------:|-------:|--------:|------:|-------:|--------:|--------:|
| [Llama-2-70b-hf](meta-llama/Llama-2-70b-hf) | 4k | 3.71 | 3.27 | 2.96 | - | - | - |
| [Yarn-Llama-2-70b-32k](https://huggingface.co/NousResearch/Yarn-Llama-2-70b-32k) | 32k | 3.61 | 3.22 | 2.91 | 2.82 | 2.45 | 2.23 |
Short context benchmarks showing that quality degradation is minimal:
| Model | Context Window | ARC-c | MMLU | Truthful QA |
|-------|---------------:|------:|-----:|------------:|
| [Llama-2-70b-hf](meta-llama/Llama-2-70b-hf) | 4k | 67.32 | 69.83 | 44.92 |
| [Yarn-Llama-2-70b-32k](https://huggingface.co/NousResearch/Yarn-Llama-2-70b-32k) | 32k | 67.41 | 68.84 | 46.14 |
## Collaborators
- [bloc97](https://github.com/bloc97): Methods, paper and evals
- [@theemozilla](https://twitter.com/theemozilla): Methods, paper, model training, and evals
- [@EnricoShippole](https://twitter.com/EnricoShippole): Model training
- [honglu2875](https://github.com/honglu2875): Paper and evals
|
dudimoveo/distilbert-base-uncased-lora-text-classification_ft2
|
dudimoveo
| 2023-11-22T08:55:54Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:distilbert/distilbert-base-uncased",
"base_model:adapter:distilbert/distilbert-base-uncased",
"region:us"
] | null | 2023-11-22T08:55:51Z |
---
library_name: peft
base_model: distilbert-base-uncased
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.2
|
CalypsoCrunchies99/vae-diffusers
|
CalypsoCrunchies99
| 2023-11-22T08:45:16Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-11-17T23:58:11Z |
---
license: creativeml-openrail-m
---
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.