
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-28 18:27:53
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 525
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-28 18:27:52
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
shreyasmenon/llama2_instruct_generation
|
shreyasmenon
| 2023-11-19T00:38:37Z | 0 | 0 | null |
[
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:NousResearch/Llama-2-7b-hf",
"base_model:finetune:NousResearch/Llama-2-7b-hf",
"region:us"
] | null | 2023-11-19T00:38:17Z |
---
base_model: NousResearch/Llama-2-7b-hf
tags:
- generated_from_trainer
model-index:
- name: llama2_instruct_generation
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llama2_instruct_generation
This model is a fine-tuned version of [NousResearch/Llama-2-7b-hf](https://huggingface.co/NousResearch/Llama-2-7b-hf) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6696
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_steps: 0.03
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.9496 | 0.0 | 10 | 1.8436 |
| 1.9477 | 0.0 | 20 | 1.8131 |
| 1.9025 | 0.0 | 30 | 1.7940 |
| 1.7997 | 0.0 | 40 | 1.7798 |
| 1.858 | 0.0 | 50 | 1.7719 |
| 1.8767 | 0.0 | 60 | 1.7646 |
| 1.8571 | 0.0 | 70 | 1.7585 |
| 1.8494 | 0.01 | 80 | 1.7535 |
| 1.9404 | 0.01 | 90 | 1.7476 |
| 1.852 | 0.01 | 100 | 1.7396 |
| 1.8713 | 0.01 | 110 | 1.7218 |
| 1.8863 | 0.01 | 120 | 1.7153 |
| 1.9036 | 0.01 | 130 | 1.7068 |
| 1.8432 | 0.01 | 140 | 1.7040 |
| 1.8168 | 0.01 | 150 | 1.7000 |
| 1.8272 | 0.01 | 160 | 1.6978 |
| 1.807 | 0.01 | 170 | 1.6952 |
| 1.8131 | 0.01 | 180 | 1.6938 |
| 1.8317 | 0.01 | 190 | 1.6904 |
| 1.79 | 0.01 | 200 | 1.6901 |
| 1.6645 | 0.01 | 210 | 1.6885 |
| 1.8626 | 0.02 | 220 | 1.6901 |
| 1.8129 | 0.02 | 230 | 1.6864 |
| 1.8821 | 0.02 | 240 | 1.6862 |
| 1.8552 | 0.02 | 250 | 1.6843 |
| 1.8641 | 0.02 | 260 | 1.6840 |
| 1.7304 | 0.02 | 270 | 1.6834 |
| 1.7279 | 0.02 | 280 | 1.6825 |
| 1.8039 | 0.02 | 290 | 1.6829 |
| 1.7132 | 0.02 | 300 | 1.6815 |
| 1.8142 | 0.02 | 310 | 1.6807 |
| 1.7918 | 0.02 | 320 | 1.6799 |
| 1.8154 | 0.02 | 330 | 1.6781 |
| 1.6644 | 0.02 | 340 | 1.6789 |
| 1.7383 | 0.02 | 350 | 1.6779 |
| 1.8327 | 0.03 | 360 | 1.6767 |
| 1.7003 | 0.03 | 370 | 1.6769 |
| 1.7698 | 0.03 | 380 | 1.6758 |
| 1.7725 | 0.03 | 390 | 1.6753 |
| 1.6452 | 0.03 | 400 | 1.6754 |
| 1.7474 | 0.03 | 410 | 1.6760 |
| 1.7243 | 0.03 | 420 | 1.6760 |
| 1.7344 | 0.03 | 430 | 1.6755 |
| 1.6396 | 0.03 | 440 | 1.6744 |
| 1.7835 | 0.03 | 450 | 1.6739 |
| 1.7635 | 0.03 | 460 | 1.6735 |
| 1.7007 | 0.03 | 470 | 1.6727 |
| 1.801 | 0.03 | 480 | 1.6722 |
| 1.7607 | 0.03 | 490 | 1.6710 |
| 1.7926 | 0.04 | 500 | 1.6696 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
JsSparkYyx/flan-t5-base-finetuned-lora-cryptonite-1
|
JsSparkYyx
| 2023-11-19T00:30:08Z | 0 | 0 | null |
[
"safetensors",
"generated_from_trainer",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"license:apache-2.0",
"region:us"
] | null | 2023-11-18T09:57:08Z |
---
license: apache-2.0
base_model: google/flan-t5-base
tags:
- generated_from_trainer
model-index:
- name: flan-t5-base-finetuned-lora-cryptonite-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-base-finetuned-lora-cryptonite-1
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 100
- eval_batch_size: 100
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.1
- Pytorch 2.1.1+cu118
- Datasets 2.14.7
- Tokenizers 0.14.1
|
JsSparkYyx/flan-t5-base-finetuned-lora-cryptonite-0
|
JsSparkYyx
| 2023-11-19T00:25:49Z | 0 | 0 | null |
[
"safetensors",
"generated_from_trainer",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"license:apache-2.0",
"region:us"
] | null | 2023-11-18T09:55:20Z |
---
license: apache-2.0
base_model: google/flan-t5-base
tags:
- generated_from_trainer
model-index:
- name: flan-t5-base-finetuned-lora-cryptonite-0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-base-finetuned-lora-cryptonite-0
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 100
- eval_batch_size: 100
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.1
- Pytorch 2.1.1+cu118
- Datasets 2.14.7
- Tokenizers 0.14.1
|
markuscolab/bert-base-uncased-finetuned-glue_cola
|
markuscolab
| 2023-11-19T00:25:46Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-18T23:44:46Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
- matthews_correlation
model-index:
- name: bert-base-uncased-finetuned-glue_cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: cola
split: validation
args: cola
metrics:
- name: Accuracy
type: accuracy
value: 0.8293384467881112
- name: F1
type: f1
value: 0.820234272230632
- name: Matthews Correlation
type: matthews_correlation
value: 0.5806473000395166
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-glue_cola
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6466
- Accuracy: 0.8293
- F1: 0.8202
- Matthews Correlation: 0.5806
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------------------:|
| 0.5418 | 1.0 | 535 | 0.4594 | 0.8006 | 0.7836 | 0.5019 |
| 0.3635 | 2.0 | 1070 | 0.4437 | 0.8217 | 0.8084 | 0.5600 |
| 0.2019 | 3.0 | 1605 | 0.6466 | 0.8293 | 0.8202 | 0.5806 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
misterbrainley/ddpm-butterflies-128
|
misterbrainley
| 2023-11-19T00:22:47Z | 3 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:huggan/smithsonian_butterflies_subset",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-11-04T00:45:16Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/misterbrainley/ddpm-butterflies-128/tensorboard?#scalars)
|
RobCaamano/T5_En_to_Es_Take2
|
RobCaamano
| 2023-11-19T00:16:20Z | 5 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_keras_callback",
"base_model:google-t5/t5-base",
"base_model:finetune:google-t5/t5-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-18T18:41:08Z |
---
license: apache-2.0
base_model: t5-base
tags:
- generated_from_keras_callback
model-index:
- name: RobCaamano/T5_En_to_Es_Take2
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# RobCaamano/T5_En_to_Es_Take2
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.5949
- Validation Loss: 0.5687
- Train Bleu: 18.1264
- Train Gen Len: 53.5263
- Epoch: 8
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Bleu | Train Gen Len | Epoch |
|:----------:|:---------------:|:----------:|:-------------:|:-----:|
| 1.0171 | 0.7827 | 9.3294 | 57.7548 | 0 |
| 0.8284 | 0.7058 | 12.1991 | 56.1406 | 1 |
| 0.7588 | 0.6633 | 13.9507 | 55.3832 | 2 |
| 0.7134 | 0.6363 | 15.0824 | 54.9393 | 3 |
| 0.6799 | 0.6153 | 16.0321 | 54.3347 | 4 |
| 0.6529 | 0.5995 | 16.6384 | 54.1043 | 5 |
| 0.6308 | 0.5862 | 17.2840 | 53.9972 | 6 |
| 0.6116 | 0.5753 | 17.6554 | 53.8169 | 7 |
| 0.5949 | 0.5687 | 18.1264 | 53.5263 | 8 |
### Framework versions
- Transformers 4.35.2
- TensorFlow 2.10.1
- Datasets 2.15.0
- Tokenizers 0.15.0
|
JsSparkYyx/flan-t5-base-finetuned-lora-intersect_geometry-0
|
JsSparkYyx
| 2023-11-19T00:07:59Z | 0 | 0 | null |
[
"safetensors",
"generated_from_trainer",
"base_model:google/flan-t5-base",
"base_model:finetune:google/flan-t5-base",
"license:apache-2.0",
"region:us"
] | null | 2023-11-18T09:18:16Z |
---
license: apache-2.0
base_model: google/flan-t5-base
tags:
- generated_from_trainer
model-index:
- name: flan-t5-base-finetuned-lora-intersect_geometry-0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-base-finetuned-lora-intersect_geometry-0
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 100
- eval_batch_size: 100
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.1
- Pytorch 2.1.1+cu118
- Datasets 2.14.7
- Tokenizers 0.14.1
|
nikitakapitan/distilbert-base-uncased-finetuned-glue_sst2
|
nikitakapitan
| 2023-11-19T00:06:11Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-18T13:00:29Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-glue_sst2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: sst2
split: validation
args: sst2
metrics:
- name: Accuracy
type: accuracy
value: 0.908256880733945
- name: F1
type: f1
value: 0.9082409443058056
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-glue_sst2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2813
- Accuracy: 0.9083
- F1: 0.9082
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.1832 | 1.0 | 4210 | 0.2813 | 0.9083 | 0.9082 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
bartowski/XwinCoder-13B-exl2
|
bartowski
| 2023-11-19T00:06:03Z | 0 | 1 | null |
[
"text-generation",
"license:llama2",
"region:us"
] |
text-generation
| 2023-11-18T21:20:22Z |
---
license: llama2
quantized_by: bartowski
pipeline_tag: text-generation
---
## Exllama v2 Quantizations of XwinCoder-13B
Using <a href="https://github.com/turboderp/exllamav2/releases/tag/v0.0.8">turboderp's ExLlamaV2 v0.0.8</a> for quantization.
Each branch contains an individual bits per weight, with the main one containing only the meaurement.json for further conversions.
Conversion was done using Evol-Instruct-Code-80k-v1.parquet as calibration dataset.
Default arguments used except when the bits per weight is above 6.0, at that point the lm_head layer is quantized at 8 bits per weight instead of the default 6.
Original model: https://huggingface.co/Xwin-LM/XwinCoder-13B
<a href="https://huggingface.co/bartowski/XwinCoder-13B-exl2/tree/3_75">3.75 bits per weight</a>
<a href="https://huggingface.co/bartowski/XwinCoder-13B-exl2/tree/4_0">4.0 bits per weight</a>
<a href="https://huggingface.co/bartowski/XwinCoder-13B-exl2/tree/6_0">6.0 bits per weight</a>
<a href="https://huggingface.co/bartowski/XwinCoder-13B-exl2/tree/8_0">8.0 bits per weight</a>
## Download instructions
With git:
```shell
git clone --single-branch --branch 4_0 https://huggingface.co/bartowski/XwinCoder-13B-exl2
```
With huggingface hub (credit to TheBloke for instructions):
```shell
pip3 install huggingface-hub
```
To download the `main` (only useful if you only care about measurement.json) branch to a folder called `XwinCoder-13B-exl2`:
```shell
mkdir XwinCoder-13B-exl2
huggingface-cli download bartowski/XwinCoder-13B-exl2 --local-dir XwinCoder-13B-exl2 --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir XwinCoder-13B-exl2
huggingface-cli download bartowski/XwinCoder-13B-exl2 --revision 4_0 --local-dir XwinCoder-13B-exl2 --local-dir-use-symlinks False
```
|
TheBloke/tigerbot-70B-chat-v4-GGUF
|
TheBloke
| 2023-11-18T23:31:30Z | 91 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama",
"zh",
"en",
"base_model:TigerResearch/tigerbot-70b-chat-v4",
"base_model:quantized:TigerResearch/tigerbot-70b-chat-v4",
"license:apache-2.0",
"region:us"
] | null | 2023-11-18T22:22:37Z |
---
base_model: TigerResearch/tigerbot-70b-chat-v4
inference: false
language:
- zh
- en
license: apache-2.0
model_creator: Tiger Research
model_name: Tigerbot 70B Chat v4
model_type: llama
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Tigerbot 70B Chat v4 - GGUF
- Model creator: [Tiger Research](https://huggingface.co/TigerResearch)
- Original model: [Tigerbot 70B Chat v4](https://huggingface.co/TigerResearch/tigerbot-70b-chat-v4)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Tiger Research's Tigerbot 70B Chat v4](https://huggingface.co/TigerResearch/tigerbot-70b-chat-v4).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/tigerbot-70B-chat-v4-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/tigerbot-70B-chat-v4-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/tigerbot-70B-chat-v4-GGUF)
* [Tiger Research's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/TigerResearch/tigerbot-70b-chat-v4)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `apache-2.0`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [Tiger Research's Tigerbot 70B Chat v4](https://huggingface.co/TigerResearch/tigerbot-70b-chat-v4).
<!-- licensing end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [tigerbot-70b-chat-v4.Q2_K.gguf](https://huggingface.co/TheBloke/tigerbot-70B-chat-v4-GGUF/blob/main/tigerbot-70b-chat-v4.Q2_K.gguf) | Q2_K | 2 | 29.59 GB| 32.09 GB | smallest, significant quality loss - not recommended for most purposes |
| [tigerbot-70b-chat-v4.Q3_K_S.gguf](https://huggingface.co/TheBloke/tigerbot-70B-chat-v4-GGUF/blob/main/tigerbot-70b-chat-v4.Q3_K_S.gguf) | Q3_K_S | 3 | 30.26 GB| 32.76 GB | very small, high quality loss |
| [tigerbot-70b-chat-v4.Q3_K_M.gguf](https://huggingface.co/TheBloke/tigerbot-70B-chat-v4-GGUF/blob/main/tigerbot-70b-chat-v4.Q3_K_M.gguf) | Q3_K_M | 3 | 33.53 GB| 36.03 GB | very small, high quality loss |
| [tigerbot-70b-chat-v4.Q3_K_L.gguf](https://huggingface.co/TheBloke/tigerbot-70B-chat-v4-GGUF/blob/main/tigerbot-70b-chat-v4.Q3_K_L.gguf) | Q3_K_L | 3 | 36.49 GB| 38.99 GB | small, substantial quality loss |
| [tigerbot-70b-chat-v4.Q4_0.gguf](https://huggingface.co/TheBloke/tigerbot-70B-chat-v4-GGUF/blob/main/tigerbot-70b-chat-v4.Q4_0.gguf) | Q4_0 | 4 | 39.25 GB| 41.75 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [tigerbot-70b-chat-v4.Q4_K_S.gguf](https://huggingface.co/TheBloke/tigerbot-70B-chat-v4-GGUF/blob/main/tigerbot-70b-chat-v4.Q4_K_S.gguf) | Q4_K_S | 4 | 39.45 GB| 41.95 GB | small, greater quality loss |
| [tigerbot-70b-chat-v4.Q4_K_M.gguf](https://huggingface.co/TheBloke/tigerbot-70B-chat-v4-GGUF/blob/main/tigerbot-70b-chat-v4.Q4_K_M.gguf) | Q4_K_M | 4 | 41.80 GB| 44.30 GB | medium, balanced quality - recommended |
| [tigerbot-70b-chat-v4.Q5_0.gguf](https://huggingface.co/TheBloke/tigerbot-70B-chat-v4-GGUF/blob/main/tigerbot-70b-chat-v4.Q5_0.gguf) | Q5_0 | 5 | 47.87 GB| 50.37 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [tigerbot-70b-chat-v4.Q5_K_S.gguf](https://huggingface.co/TheBloke/tigerbot-70B-chat-v4-GGUF/blob/main/tigerbot-70b-chat-v4.Q5_K_S.gguf) | Q5_K_S | 5 | 47.87 GB| 50.37 GB | large, low quality loss - recommended |
| [tigerbot-70b-chat-v4.Q5_K_M.gguf](https://huggingface.co/TheBloke/tigerbot-70B-chat-v4-GGUF/blob/main/tigerbot-70b-chat-v4.Q5_K_M.gguf) | Q5_K_M | 5 | 49.16 GB| 51.66 GB | large, very low quality loss - recommended |
| tigerbot-70b-chat-v4.Q6_K.gguf | Q6_K | 6 | 57.03 GB| 59.53 GB | very large, extremely low quality loss |
| tigerbot-70b-chat-v4.Q8_0.gguf | Q8_0 | 8 | 73.87 GB| 76.37 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
### Q6_K and Q8_0 files are split and require joining
**Note:** HF does not support uploading files larger than 50GB. Therefore I have uploaded the Q6_K and Q8_0 files as split files.
<details>
<summary>Click for instructions regarding Q6_K and Q8_0 files</summary>
### q6_K
Please download:
* `tigerbot-70b-chat-v4.Q6_K.gguf-split-a`
* `tigerbot-70b-chat-v4.Q6_K.gguf-split-b`
### q8_0
Please download:
* `tigerbot-70b-chat-v4.Q8_0.gguf-split-a`
* `tigerbot-70b-chat-v4.Q8_0.gguf-split-b`
To join the files, do the following:
Linux and macOS:
```
cat tigerbot-70b-chat-v4.Q6_K.gguf-split-* > tigerbot-70b-chat-v4.Q6_K.gguf && rm tigerbot-70b-chat-v4.Q6_K.gguf-split-*
cat tigerbot-70b-chat-v4.Q8_0.gguf-split-* > tigerbot-70b-chat-v4.Q8_0.gguf && rm tigerbot-70b-chat-v4.Q8_0.gguf-split-*
```
Windows command line:
```
COPY /B tigerbot-70b-chat-v4.Q6_K.gguf-split-a + tigerbot-70b-chat-v4.Q6_K.gguf-split-b tigerbot-70b-chat-v4.Q6_K.gguf
del tigerbot-70b-chat-v4.Q6_K.gguf-split-a tigerbot-70b-chat-v4.Q6_K.gguf-split-b
COPY /B tigerbot-70b-chat-v4.Q8_0.gguf-split-a + tigerbot-70b-chat-v4.Q8_0.gguf-split-b tigerbot-70b-chat-v4.Q8_0.gguf
del tigerbot-70b-chat-v4.Q8_0.gguf-split-a tigerbot-70b-chat-v4.Q8_0.gguf-split-b
```
</details>
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/tigerbot-70B-chat-v4-GGUF and below it, a specific filename to download, such as: tigerbot-70b-chat-v4.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/tigerbot-70B-chat-v4-GGUF tigerbot-70b-chat-v4.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/tigerbot-70B-chat-v4-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/tigerbot-70B-chat-v4-GGUF tigerbot-70b-chat-v4.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m tigerbot-70b-chat-v4.Q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/tigerbot-70B-chat-v4-GGUF", model_file="tigerbot-70b-chat-v4.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Tiger Research's Tigerbot 70B Chat v4
<div style="width: 100%;">
<p align="center" width="20%">
<img src="http://x-pai.algolet.com/bot/img/logo_core.png" alt="TigerBot" width="20%", style="display: block; margin: auto;"></img>
</p>
</div>
<p align="center">
<font face="黑体" size=5"> A cutting-edge foundation for your very own LLM. </font>
</p>
<p align="center">
💻<a href="https://github.com/TigerResearch/TigerBot" target="_blank">Github</a> • 🌐 <a href="https://tigerbot.com/" target="_blank">TigerBot</a> • 🤗 <a href="https://huggingface.co/TigerResearch" target="_blank">Hugging Face</a>
</p>
# 快速开始
- 方法1,通过transformers使用
- 下载 TigerBot Repo
```shell
git clone https://github.com/TigerResearch/TigerBot.git
```
- 启动infer代码
```shell
python infer.py --model_path TigerResearch/tigerbot-70b-chat
```
- 方法2:
- 下载 TigerBot Repo
```shell
git clone https://github.com/TigerResearch/TigerBot.git
```
- 安装git lfs: `git lfs install`
- 通过huggingface或modelscope平台下载权重
```shell
git clone https://huggingface.co/TigerResearch/tigerbot-70b-chat
git clone https://www.modelscope.cn/TigerResearch/tigerbot-70b-chat-v4.git
```
- 启动infer代码
```shell
python infer.py --model_path tigerbot-70b-chat(-v4)
```
------
# Quick Start
- Method 1, use through transformers
- Clone TigerBot Repo
```shell
git clone https://github.com/TigerResearch/TigerBot.git
```
- Run infer script
```shell
python infer.py --model_path TigerResearch/tigerbot-70b-chat
```
- Method 2:
- Clone TigerBot Repo
```shell
git clone https://github.com/TigerResearch/TigerBot.git
```
- install git lfs: `git lfs install`
- Download weights from huggingface or modelscope
```shell
git clone https://huggingface.co/TigerResearch/tigerbot-70b-chat
git clone https://www.modelscope.cn/TigerResearch/tigerbot-70b-chat-v4.git
```
- Run infer script
```shell
python infer.py --model_path tigerbot-70b-chat(-v4)
```
<!-- original-model-card end -->
|
japanese-denim/m2m-finetuned-eng-to-naga-version-1
|
japanese-denim
| 2023-11-18T23:29:57Z | 12 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"m2m_100",
"text2text-generation",
"translation",
"generated_from_trainer",
"base_model:facebook/m2m100_418M",
"base_model:finetune:facebook/m2m100_418M",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-11-18T20:00:06Z |
---
license: mit
base_model: facebook/m2m100_418M
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: m2m-finetuned-eng-to-naga-version-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# m2m-finetuned-eng-to-naga-version-1
This model is a fine-tuned version of [facebook/m2m100_418M](https://huggingface.co/facebook/m2m100_418M) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6796
- Bleu: 23.0762
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Goico192/Canine_model_JS
|
Goico192
| 2023-11-18T23:25:05Z | 24 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-11-18T18:41:27Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: Canine_model_JS
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Canine_model_JS
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 3.3104
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 100 | 3.6861 |
| No log | 2.0 | 200 | 3.4226 |
| No log | 3.0 | 300 | 3.3104 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Astromium/Reinforce-CartPole-v1
|
Astromium
| 2023-11-18T23:24:08Z | 0 | 1 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-18T23:23:59Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
SandriBarros/clinical_longformer_same_tokens_3epochs_50k
|
SandriBarros
| 2023-11-18T23:20:14Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"longformer",
"fill-mask",
"generated_from_trainer",
"base_model:SandriBarros/clinical_longformer_same_tokens_2epochs_250k",
"base_model:finetune:SandriBarros/clinical_longformer_same_tokens_2epochs_250k",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-11-18T21:03:45Z |
---
base_model: SandriBarros/clinical_longformer_same_tokens_2epochs_250k
tags:
- generated_from_trainer
model-index:
- name: clinical_longformer_same_tokens_3epochs_50k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# clinical_longformer_same_tokens_3epochs_50k
This model is a fine-tuned version of [SandriBarros/clinical_longformer_same_tokens_2epochs_250k](https://huggingface.co/SandriBarros/clinical_longformer_same_tokens_2epochs_250k) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3763
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 64
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1500
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.493 | 0.18 | 65 | 1.3790 |
| 1.5495 | 0.37 | 130 | 1.3815 |
| 1.5793 | 0.55 | 195 | 1.3888 |
| 1.5757 | 0.74 | 260 | 1.3644 |
| 1.3813 | 0.92 | 325 | 1.3763 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
sulph/Snowfall
|
sulph
| 2023-11-18T23:19:25Z | 0 | 1 | null |
[
"license:openrail",
"region:us"
] | null | 2023-11-08T15:27:04Z |
---
license: openrail
---
This model is not finished, please do not redistribute or share :)
Thanks
EDIT: It's renamed to "Snowfall" and is finished.
FP16/half
Based on Sulphmix2+Exquisite Detail+a little more of Summer Solstice




|
preetk21/bert-finetuned-ner
|
preetk21
| 2023-11-18T23:15:25Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-11-18T23:02:07Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: validation
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9309661436829066
- name: Recall
type: recall
value: 0.9486704813194211
- name: F1
type: f1
value: 0.9397349337334334
- name: Accuracy
type: accuracy
value: 0.9864013657502796
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0588
- Precision: 0.9310
- Recall: 0.9487
- F1: 0.9397
- Accuracy: 0.9864
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0786 | 1.0 | 1756 | 0.0771 | 0.9129 | 0.9349 | 0.9238 | 0.9805 |
| 0.0401 | 2.0 | 3512 | 0.0562 | 0.9245 | 0.9480 | 0.9361 | 0.9856 |
| 0.0273 | 3.0 | 5268 | 0.0588 | 0.9310 | 0.9487 | 0.9397 | 0.9864 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
iambestfeed/phobert_pair_8m_all
|
iambestfeed
| 2023-11-18T23:10:39Z | 8 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-11-18T23:08:36Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 8772 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 15,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
TheBloke/nucleus-22B-token-500B-AWQ
|
TheBloke
| 2023-11-18T23:09:32Z | 9 | 1 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"base_model:NucleusAI/nucleus-22B-token-500B",
"base_model:quantized:NucleusAI/nucleus-22B-token-500B",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"awq",
"region:us"
] |
text-generation
| 2023-11-18T22:25:12Z |
---
base_model: NucleusAI/nucleus-22B-token-500B
inference: false
language:
- en
license: mit
model_creator: NucleusAI
model_name: Nucleus 22B Token 500B
model_type: llama
prompt_template: '{prompt}
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Nucleus 22B Token 500B - AWQ
- Model creator: [NucleusAI](https://huggingface.co/NucleusAI)
- Original model: [Nucleus 22B Token 500B](https://huggingface.co/NucleusAI/nucleus-22B-token-500B)
<!-- description start -->
## Description
This repo contains AWQ model files for [NucleusAI's Nucleus 22B Token 500B](https://huggingface.co/NucleusAI/nucleus-22B-token-500B).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - Llama and Mistral models only
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later, from any code or client that supports Transformers
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/nucleus-22B-token-500B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/nucleus-22B-token-500B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/nucleus-22B-token-500B-GGUF)
* [NucleusAI's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/NucleusAI/nucleus-22B-token-500B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: None
```
{prompt}
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
I currently release 128g GEMM models only. The addition of group_size 32 models, and GEMV kernel models, is being actively considered.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/nucleus-22B-token-500B-AWQ/tree/main) | 4 | 128 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-raw-v1) | 2048 | 11.97 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/nucleus-22B-token-500B-AWQ`.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `nucleus-22B-token-500B-AWQ`
7. Select **Loader: AutoAWQ**.
8. Click Load, and the model will load and is now ready for use.
9. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
10. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_AWQ.md-text-generation-webui end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Multi-user inference server: vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- Please ensure you are using vLLM version 0.2 or later.
- When using vLLM as a server, pass the `--quantization awq` parameter.
For example:
```shell
python3 -m vllm.entrypoints.api_server --model TheBloke/nucleus-22B-token-500B-AWQ --quantization awq --dtype auto
```
- When using vLLM from Python code, again set `quantization=awq`.
For example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Tell me about AI",
"Write a story about llamas",
"What is 291 - 150?",
"How much wood would a woodchuck chuck if a woodchuck could chuck wood?",
]
prompt_template=f'''{prompt}
'''
prompts = [prompt_template.format(prompt=prompt) for prompt in prompts]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/nucleus-22B-token-500B-AWQ", quantization="awq", dtype="auto")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Multi-user inference server: Hugging Face Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/nucleus-22B-token-500B-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires [huggingface-hub](https://github.com/huggingface/huggingface_hub) 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''{prompt}
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: ", response)
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## Inference from Python code using Transformers
### Install the necessary packages
- Requires: [Transformers](https://huggingface.co/docs/transformers) 4.35.0 or later.
- Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.6 or later.
```shell
pip3 install --upgrade "autoawq>=0.1.6" "transformers>=4.35.0"
```
Note that if you are using PyTorch 2.0.1, the above AutoAWQ command will automatically upgrade you to PyTorch 2.1.0.
If you are using CUDA 11.8 and wish to continue using PyTorch 2.0.1, instead run this command:
```shell
pip3 install https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp310-cp310-linux_x86_64.whl
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### Transformers example code (requires Transformers 4.35.0 and later)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_name_or_path = "TheBloke/nucleus-22B-token-500B-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
low_cpu_mem_usage=True,
device_map="cuda:0"
)
# Using the text streamer to stream output one token at a time
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = "Tell me about AI"
prompt_template=f'''{prompt}
'''
# Convert prompt to tokens
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
generation_params = {
"do_sample": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": 512,
"repetition_penalty": 1.1
}
# Generate streamed output, visible one token at a time
generation_output = model.generate(
tokens,
streamer=streamer,
**generation_params
)
# Generation without a streamer, which will include the prompt in the output
generation_output = model.generate(
tokens,
**generation_params
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
print("model.generate output: ", text_output)
# Inference is also possible via Transformers' pipeline
from transformers import pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
**generation_params
)
pipe_output = pipe(prompt_template)[0]['generated_text']
print("pipeline output: ", pipe_output)
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui) using `Loader: AutoAWQ`.
- [vLLM](https://github.com/vllm-project/vllm) version 0.2.0 and later.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) version 1.1.0 and later.
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later.
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) version 0.1.1 and later.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: NucleusAI's Nucleus 22B Token 500B
# 🚀 Nucleus-22B-token-500B
**Nucleus-22B-token-500B is a 22B parameters causal decoder-only model built by Nucleus.AI and trained on 500B tokens of [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) along with curated corpora. It is made available under the MIT license.**
*1T-token model coming soon* 😊.
## What about Nucleus-22B-token-500B?
* **It performs well compared to similar-size open-source models** (e.g., [MPT-7B](https://huggingface.co/mosaicml/mpt-7b), [StableLM](https://github.com/Stability-AI/StableLM), [RedPajama](https://huggingface.co/togethercomputer/RedPajama-INCITE-Base-7B-v0.1) etc.), thanks to being trained on 500B tokens of [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) enhanced with curated corpora. See the [OpenLLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
* **It is made available under an MIT license**.
* **It is trained by a small team of four passionate for Open Source**
⚠️ **This is a raw, pretrained model, which should be further finetuned for most usecases.**
# Model Card for Nucleus-22B-token-500B
## Model Details
### Model Description
- **Developed by:** NucleusAI;
- **Model type:** Causal decoder-only;
- **Language(s) (NLP):** English;
- **License:** MIT.
### Model Source
- **Paper:** *coming soon*.
## Uses
### Direct Use
Research on large language models; as a foundation for further specialization and finetuning for specific usecases (e.g., summarization, text generation, chatbot, etc.)
### Out-of-Scope Use
Production use without adequate assessment of risks and mitigation; any use cases which may be considered irresponsible or harmful.
## Bias, Risks, and Limitations
Nucleus-22B-token-500B is trained on English data only, and will not generalize appropriately to other languages. Furthermore, as it is trained on a large-scale corpora representative of the web, it will carry the stereotypes and biases commonly encountered online.
### Recommendations
We recommend users of Nucleus-22B-token-500B to consider finetuning it for the specific set of tasks of interest, and for guardrails and appropriate precautions to be taken for any production use.
## How to Get Started with the Mode
## Training Details
### Training Data
Nucleus-22B-token-500B was trained on 500B tokens of [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb), along with other corpora.
| **Data source** | **Fraction** | **Tokens** | **Sources** |
|--------------------|--------------|------------|-----------------------------------|
| [RefinedWeb-English](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) | 75% | 200B | massive web crawl |
| Books | 7% | 21B | |
| Code | 7% | 21B | Big Code, CodeNet |
| Technical | 6% | 19B | arXiv |
| Math | 5% | 17B | Mathematica, Khan Academy |
The data was tokenized with the tokenizer similar to Llama-[7B](https://huggingface.co/meta-llama/Llama-2-7b).
### Training Procedure
Nucleus-22B-token-500B was trained on 256 A100 80GB GPUs, using a FSDP
#### Training Hyperparameters
| **Hyperparameter** | **Value** | **Comment** |
|--------------------|------------|-------------------------------------------|
| Precision | `bfloat16` | |
| Optimizer | AdamW | |
| Learning rate | 2e-4 | 8B tokens warm-up, cosine decay to 1.e-5 |
| Weight decay | 1e-1 | |
| Batch size | 2048 | constant |
| Context length | 2048 | constant |
#### Speeds, Sizes, Times
Training happened in early August 2023 and took about two weeks.
|
arif11/bangla-ASR-v3
|
arif11
| 2023-11-18T23:04:49Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"bn",
"dataset:mozilla-foundation/common_voice_13_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-11-18T16:54:00Z |
---
language:
- bn
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_13_0
metrics:
- wer
model-index:
- name: Whisper in Bangla
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 13
type: mozilla-foundation/common_voice_13_0
config: bn
split: test
args: bn
metrics:
- name: Wer
type: wer
value: 36.383706024782796
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper in Bangla
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 13 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1242
- Wer: 36.3837
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0544 | 0.27 | 500 | 0.1283 | 37.4448 |
| 0.0526 | 0.53 | 1000 | 0.1242 | 36.3837 |
### Framework versions
- Transformers 4.31.0
- Pytorch 2.0.0
- Datasets 2.14.2
- Tokenizers 0.13.3
|
io-roboto/vilt_finetuned_200
|
io-roboto
| 2023-11-18T22:57:42Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vilt",
"visual-question-answering",
"generated_from_trainer",
"base_model:dandelin/vilt-b32-mlm",
"base_model:finetune:dandelin/vilt-b32-mlm",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
visual-question-answering
| 2023-11-15T05:31:28Z |
---
license: apache-2.0
base_model: dandelin/vilt-b32-mlm
tags:
- generated_from_trainer
model-index:
- name: vilt_finetuned_200
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vilt_finetuned_200
This model is a fine-tuned version of [dandelin/vilt-b32-mlm](https://huggingface.co/dandelin/vilt-b32-mlm) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 4.3306
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 363.9675 | 0.16 | 100 | 26.1215 |
| 11.4975 | 0.32 | 200 | 7.2332 |
| 6.1909 | 0.48 | 300 | 5.9332 |
| 5.2134 | 0.64 | 400 | 5.5186 |
| 5.0189 | 0.8 | 500 | 5.3268 |
| 4.7551 | 0.96 | 600 | 5.0921 |
| 4.5394 | 1.12 | 700 | 4.9538 |
| 4.3441 | 1.28 | 800 | 4.8967 |
| 4.1436 | 1.44 | 900 | 4.7419 |
| 4.1847 | 1.6 | 1000 | 4.6581 |
| 4.0116 | 1.76 | 1100 | 4.5915 |
| 3.918 | 1.92 | 1200 | 4.5202 |
| 3.8251 | 2.08 | 1300 | 4.4634 |
| 3.7981 | 2.24 | 1400 | 4.4169 |
| 3.7108 | 2.4 | 1500 | 4.3954 |
| 3.5706 | 2.56 | 1600 | 4.3626 |
| 3.5559 | 2.72 | 1700 | 4.3374 |
| 3.6951 | 2.88 | 1800 | 4.3306 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
|
LoneStriker/opus-v0.5-70b-5.15bpw-h6-exl2
|
LoneStriker
| 2023-11-18T22:51:54Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-18T22:49:25Z |
---
language:
- en
pipeline_tag: text-generation
---
# DreamGen Opus V0 70B
**DreamGen Opus** is a family of **uncensored** models fine-tuned for **(steerable) story writing** and the model also works great for **chat / RP**.
The DreamGen Opus V0.5 70B model is derived from [meta-llama/Llama-2-70b-hf](https://huggingface.co/meta-llama/Llama-2-70b-hf).
You can **try the Opus V0 70B** (AWQ) model for free on [dreamgen.com](https://dreamgen.com).
Other sizes:
- 7B: [dreamgen/opus-v0-7b](https://huggingface.co/dreamgen/opus-v0-7b)
## Difference from [dreamgen/opus-v0-70b](https://huggingface.co/dreamgen/opus-v0-70b)
The model should be even better at role-play and chat, and be slighly more "open-minded" in NSFW contexts.
## Prompting
Please see the [official documentation](https://dreamgen.com/docs/stories) for more detailed guide, including how to prompt the model for chat / RP.
The (collaborative / steerable) story writing task teaches the model to respect `<setting>` and `<instruction>` inserted into the prompt.
Example prompt:
```
<setting>
(Setting provides general overview of the story and characters)
This story is a twist on the traditional Little Red Riding Hood story.
In this variation, the Little Red Riding Hood and her grandma are secretely werevoles.
</setting>
(Previous part of the story, potentially empty)
<instruction>
(Setting tells the model what should happen in the next few sentences / paragraphs)
The Little Red Riding hood confronts The Big Bad Wolf, transforming into her wolf form.
</instruction>
```
## Dataset
The fine-tuning dataset consisted of >1M tokens of collaborative writing task examples, each example being up to 4096 tokens. On top of that, >20M tokens of more general, but less instructed examples were included to help preserve generalization.
All prose in the dataset is from actual humans, not AI generated.
## Community
Join the DreamGen community on [**Discord**](https://dreamgen.com/discord), or follow our [**X/Twitter account**](https://dreamgen.com/twitter) for new model releases and other news.
We will soon be releasing models with longer context window, as well as models specifically fine-tuned for character chat & roleplay.
Help us shape the future of DreamGen.
## Running the model
The model is should be compatible with any software that supports [meta-llama/Llama-2-70b-hf](https://huggingface.co/meta-llama/Llama-2-70b-hf).
Note that because this is a 70B model, the resource requirements are large. You can try the quantized versions linked at the top, but expect a quality drop.
### Running on DreamGen.com (free)
You can try the 70B (AWQ) model for free at [dreamgen.com](https://dreamgen.com) — note that an account is required.
The version used for the website is the official AWQ 4bit quant [dreamgen/opus-v0-70b-awq](https://huggingface.co/dreamgen/opus-v0-70b-awq).
## License
- For personal and academic use: Same license as the base model, in this case https://ai.meta.com/resources/models-and-libraries/llama-downloads/.
- For commercial use: Please reach out to hello@dreamgen.com.
|
TheBloke/nucleus-22B-token-500B-GGUF
|
TheBloke
| 2023-11-18T22:40:54Z | 38 | 3 |
transformers
|
[
"transformers",
"gguf",
"llama",
"en",
"base_model:NucleusAI/nucleus-22B-token-500B",
"base_model:quantized:NucleusAI/nucleus-22B-token-500B",
"license:mit",
"region:us"
] | null | 2023-11-18T22:25:12Z |
---
base_model: NucleusAI/nucleus-22B-token-500B
inference: false
language:
- en
license: mit
model_creator: NucleusAI
model_name: Nucleus 22B Token 500B
model_type: llama
prompt_template: '{prompt}
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Nucleus 22B Token 500B - GGUF
- Model creator: [NucleusAI](https://huggingface.co/NucleusAI)
- Original model: [Nucleus 22B Token 500B](https://huggingface.co/NucleusAI/nucleus-22B-token-500B)
<!-- description start -->
## Description
This repo contains GGUF format model files for [NucleusAI's Nucleus 22B Token 500B](https://huggingface.co/NucleusAI/nucleus-22B-token-500B).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/nucleus-22B-token-500B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/nucleus-22B-token-500B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/nucleus-22B-token-500B-GGUF)
* [NucleusAI's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/NucleusAI/nucleus-22B-token-500B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: None
```
{prompt}
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [nucleus-22b-token-500b.Q2_K.gguf](https://huggingface.co/TheBloke/nucleus-22B-token-500B-GGUF/blob/main/nucleus-22b-token-500b.Q2_K.gguf) | Q2_K | 2 | 9.08 GB| 11.58 GB | smallest, significant quality loss - not recommended for most purposes |
| [nucleus-22b-token-500b.Q3_K_S.gguf](https://huggingface.co/TheBloke/nucleus-22B-token-500B-GGUF/blob/main/nucleus-22b-token-500b.Q3_K_S.gguf) | Q3_K_S | 3 | 9.47 GB| 11.97 GB | very small, high quality loss |
| [nucleus-22b-token-500b.Q3_K_M.gguf](https://huggingface.co/TheBloke/nucleus-22B-token-500B-GGUF/blob/main/nucleus-22b-token-500b.Q3_K_M.gguf) | Q3_K_M | 3 | 10.61 GB| 13.11 GB | very small, high quality loss |
| [nucleus-22b-token-500b.Q3_K_L.gguf](https://huggingface.co/TheBloke/nucleus-22B-token-500B-GGUF/blob/main/nucleus-22b-token-500b.Q3_K_L.gguf) | Q3_K_L | 3 | 11.61 GB| 14.11 GB | small, substantial quality loss |
| [nucleus-22b-token-500b.Q4_0.gguf](https://huggingface.co/TheBloke/nucleus-22B-token-500B-GGUF/blob/main/nucleus-22b-token-500b.Q4_0.gguf) | Q4_0 | 4 | 12.34 GB| 14.84 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [nucleus-22b-token-500b.Q4_K_S.gguf](https://huggingface.co/TheBloke/nucleus-22B-token-500B-GGUF/blob/main/nucleus-22b-token-500b.Q4_K_S.gguf) | Q4_K_S | 4 | 12.42 GB| 14.92 GB | small, greater quality loss |
| [nucleus-22b-token-500b.Q4_K_M.gguf](https://huggingface.co/TheBloke/nucleus-22B-token-500B-GGUF/blob/main/nucleus-22b-token-500b.Q4_K_M.gguf) | Q4_K_M | 4 | 13.18 GB| 15.68 GB | medium, balanced quality - recommended |
| [nucleus-22b-token-500b.Q5_0.gguf](https://huggingface.co/TheBloke/nucleus-22B-token-500B-GGUF/blob/main/nucleus-22b-token-500b.Q5_0.gguf) | Q5_0 | 5 | 15.04 GB| 17.54 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [nucleus-22b-token-500b.Q5_K_S.gguf](https://huggingface.co/TheBloke/nucleus-22B-token-500B-GGUF/blob/main/nucleus-22b-token-500b.Q5_K_S.gguf) | Q5_K_S | 5 | 15.04 GB| 17.54 GB | large, low quality loss - recommended |
| [nucleus-22b-token-500b.Q5_K_M.gguf](https://huggingface.co/TheBloke/nucleus-22B-token-500B-GGUF/blob/main/nucleus-22b-token-500b.Q5_K_M.gguf) | Q5_K_M | 5 | 15.47 GB| 17.97 GB | large, very low quality loss - recommended |
| [nucleus-22b-token-500b.Q6_K.gguf](https://huggingface.co/TheBloke/nucleus-22B-token-500B-GGUF/blob/main/nucleus-22b-token-500b.Q6_K.gguf) | Q6_K | 6 | 17.91 GB| 20.41 GB | very large, extremely low quality loss |
| [nucleus-22b-token-500b.Q8_0.gguf](https://huggingface.co/TheBloke/nucleus-22B-token-500B-GGUF/blob/main/nucleus-22b-token-500b.Q8_0.gguf) | Q8_0 | 8 | 23.19 GB| 25.69 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/nucleus-22B-token-500B-GGUF and below it, a specific filename to download, such as: nucleus-22b-token-500b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/nucleus-22B-token-500B-GGUF nucleus-22b-token-500b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/nucleus-22B-token-500B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/nucleus-22B-token-500B-GGUF nucleus-22b-token-500b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m nucleus-22b-token-500b.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "{prompt}"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/nucleus-22B-token-500B-GGUF", model_file="nucleus-22b-token-500b.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: NucleusAI's Nucleus 22B Token 500B
# 🚀 Nucleus-22B-token-500B
**Nucleus-22B-token-500B is a 22B parameters causal decoder-only model built by Nucleus.AI and trained on 500B tokens of [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) along with curated corpora. It is made available under the MIT license.**
*1T-token model coming soon* 😊.
## What about Nucleus-22B-token-500B?
* **It performs well compared to similar-size open-source models** (e.g., [MPT-7B](https://huggingface.co/mosaicml/mpt-7b), [StableLM](https://github.com/Stability-AI/StableLM), [RedPajama](https://huggingface.co/togethercomputer/RedPajama-INCITE-Base-7B-v0.1) etc.), thanks to being trained on 500B tokens of [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) enhanced with curated corpora. See the [OpenLLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
* **It is made available under an MIT license**.
* **It is trained by a small team of four passionate for Open Source**
⚠️ **This is a raw, pretrained model, which should be further finetuned for most usecases.**
# Model Card for Nucleus-22B-token-500B
## Model Details
### Model Description
- **Developed by:** NucleusAI;
- **Model type:** Causal decoder-only;
- **Language(s) (NLP):** English;
- **License:** MIT.
### Model Source
- **Paper:** *coming soon*.
## Uses
### Direct Use
Research on large language models; as a foundation for further specialization and finetuning for specific usecases (e.g., summarization, text generation, chatbot, etc.)
### Out-of-Scope Use
Production use without adequate assessment of risks and mitigation; any use cases which may be considered irresponsible or harmful.
## Bias, Risks, and Limitations
Nucleus-22B-token-500B is trained on English data only, and will not generalize appropriately to other languages. Furthermore, as it is trained on a large-scale corpora representative of the web, it will carry the stereotypes and biases commonly encountered online.
### Recommendations
We recommend users of Nucleus-22B-token-500B to consider finetuning it for the specific set of tasks of interest, and for guardrails and appropriate precautions to be taken for any production use.
## How to Get Started with the Mode
## Training Details
### Training Data
Nucleus-22B-token-500B was trained on 500B tokens of [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb), along with other corpora.
| **Data source** | **Fraction** | **Tokens** | **Sources** |
|--------------------|--------------|------------|-----------------------------------|
| [RefinedWeb-English](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) | 75% | 200B | massive web crawl |
| Books | 7% | 21B | |
| Code | 7% | 21B | Big Code, CodeNet |
| Technical | 6% | 19B | arXiv |
| Math | 5% | 17B | Mathematica, Khan Academy |
The data was tokenized with the tokenizer similar to Llama-[7B](https://huggingface.co/meta-llama/Llama-2-7b).
### Training Procedure
Nucleus-22B-token-500B was trained on 256 A100 80GB GPUs, using a FSDP
#### Training Hyperparameters
| **Hyperparameter** | **Value** | **Comment** |
|--------------------|------------|-------------------------------------------|
| Precision | `bfloat16` | |
| Optimizer | AdamW | |
| Learning rate | 2e-4 | 8B tokens warm-up, cosine decay to 1.e-5 |
| Weight decay | 1e-1 | |
| Batch size | 2048 | constant |
| Context length | 2048 | constant |
#### Speeds, Sizes, Times
Training happened in early August 2023 and took about two weeks.
<!-- original-model-card end -->
|
DustyBill/few-shot
|
DustyBill
| 2023-11-18T22:40:05Z | 5 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"mpnet",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2023-11-18T22:38:27Z |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# DustyBill/few-shot
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("DustyBill/few-shot")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
tiagoncalves/q-FrozenLake-v1-4x4-noSlippery
|
tiagoncalves
| 2023-11-18T22:35:33Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-18T22:32:17Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="tiagoncalves/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
TheBloke/nsql-llama-2-7B-GPTQ
|
TheBloke
| 2023-11-18T22:16:16Z | 30 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"base_model:NumbersStation/nsql-llama-2-7B",
"base_model:quantized:NumbersStation/nsql-llama-2-7B",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2023-11-18T21:36:59Z |
---
base_model: NumbersStation/nsql-llama-2-7B
inference: false
license: llama2
model_creator: NumbersStation
model_name: NSQL Llama-2 7B
model_type: llama
prompt_template: '{prompt}
SELECT
'
quantized_by: TheBloke
widget:
- example_title: Number stadiums
text: "CREATE TABLE stadium (\n stadium_id number,\n location text,\n name\
\ text,\n capacity number,\n)\n\n-- Using valid SQLite, answer the following\
\ questions for the tables provided above.\n\n-- how many stadiums in total?\n\
\nSELECT"
- example_title: Open work orders
text: 'CREATE TABLE work_orders ( ID NUMBER, CREATED_AT TEXT, COST FLOAT, INVOICE_AMOUNT
FLOAT, IS_DUE BOOLEAN, IS_OPEN BOOLEAN, IS_OVERDUE BOOLEAN, COUNTRY_NAME TEXT,
)
-- Using valid SQLite, answer the following questions for the tables provided
above.
-- how many work orders are open?
SELECT'
- example_title: Stadium capacity
text: 'CREATE TABLE stadium ( stadium_id number, location text, name text, capacity
number, highest number, lowest number, average number )
CREATE TABLE singer ( singer_id number, name text, country text, song_name text,
song_release_year text, age number, is_male others )
CREATE TABLE concert ( concert_id number, concert_name text, theme text, stadium_id
text, year text )
CREATE TABLE singer_in_concert ( concert_id number, singer_id text )
-- Using valid SQLite, answer the following questions for the tables provided
above.
-- What is the maximum, the average, and the minimum capacity of stadiums ?
SELECT'
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# NSQL Llama-2 7B - GPTQ
- Model creator: [NumbersStation](https://huggingface.co/NumbersStation)
- Original model: [NSQL Llama-2 7B](https://huggingface.co/NumbersStation/nsql-llama-2-7B)
<!-- description start -->
# Description
This repo contains GPTQ model files for [NumbersStation's NSQL Llama-2 7B](https://huggingface.co/NumbersStation/nsql-llama-2-7B).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/nsql-llama-2-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/nsql-llama-2-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/nsql-llama-2-7B-GGUF)
* [NumbersStation's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/NumbersStation/nsql-llama-2-7B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: nsql
```
{prompt}
SELECT
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-compatible clients start -->
## Known compatible clients / servers
These GPTQ models are known to work in the following inference servers/webuis.
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
- [KoboldAI United](https://github.com/henk717/koboldai)
- [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui)
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
This may not be a complete list; if you know of others, please let me know!
<!-- README_GPTQ.md-compatible clients end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files, and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
Most GPTQ files are made with AutoGPTQ. Mistral models are currently made with Transformers.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The calibration dataset used during quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ calibration dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama and Mistral models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/nsql-llama-2-7B-GPTQ/tree/main) | 4 | 128 | Yes | 0.1 | [code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1/viewer/) | 4096 | 3.90 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/nsql-llama-2-7B-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.1 | [code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1/viewer/) | 4096 | 4.28 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/nsql-llama-2-7B-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.1 | [code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1/viewer/) | 4096 | 7.01 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_True](https://huggingface.co/TheBloke/nsql-llama-2-7B-GPTQ/tree/gptq-8bit-128g-actorder_True) | 8 | 128 | Yes | 0.1 | [code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1/viewer/) | 4096 | 7.16 GB | No | 8-bit, with group size 128g for higher inference quality and with Act Order for even higher accuracy. |
| [gptq-8bit-32g-actorder_True](https://huggingface.co/TheBloke/nsql-llama-2-7B-GPTQ/tree/gptq-8bit-32g-actorder_True) | 8 | 32 | Yes | 0.1 | [code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1/viewer/) | 4096 | 7.62 GB | No | 8-bit, with group size 32g and Act Order for maximum inference quality. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/nsql-llama-2-7B-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.1 | [code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1/viewer/) | 4096 | 4.02 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download, including from branches
### In text-generation-webui
To download from the `main` branch, enter `TheBloke/nsql-llama-2-7B-GPTQ` in the "Download model" box.
To download from another branch, add `:branchname` to the end of the download name, eg `TheBloke/nsql-llama-2-7B-GPTQ:gptq-4bit-32g-actorder_True`
### From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `nsql-llama-2-7B-GPTQ`:
```shell
mkdir nsql-llama-2-7B-GPTQ
huggingface-cli download TheBloke/nsql-llama-2-7B-GPTQ --local-dir nsql-llama-2-7B-GPTQ --local-dir-use-symlinks False
```
To download from a different branch, add the `--revision` parameter:
```shell
mkdir nsql-llama-2-7B-GPTQ
huggingface-cli download TheBloke/nsql-llama-2-7B-GPTQ --revision gptq-4bit-32g-actorder_True --local-dir nsql-llama-2-7B-GPTQ --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Hugging Face cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir nsql-llama-2-7B-GPTQ
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/nsql-llama-2-7B-GPTQ --local-dir nsql-llama-2-7B-GPTQ --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### With `git` (**not** recommended)
To clone a specific branch with `git`, use a command like this:
```shell
git clone --single-branch --branch gptq-4bit-32g-actorder_True https://huggingface.co/TheBloke/nsql-llama-2-7B-GPTQ
```
Note that using Git with HF repos is strongly discouraged. It will be much slower than using `huggingface-hub`, and will use twice as much disk space as it has to store the model files twice (it stores every byte both in the intended target folder, and again in the `.git` folder as a blob.)
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/nsql-llama-2-7B-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/nsql-llama-2-7B-GPTQ:gptq-4bit-32g-actorder_True`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `nsql-llama-2-7B-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
- Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-tgi start -->
## Serving this model from Text Generation Inference (TGI)
It's recommended to use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/nsql-llama-2-7B-GPTQ --port 3000 --quantize gptq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires huggingface-hub 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''{prompt}
SELECT
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: {response}")
```
<!-- README_GPTQ.md-use-from-tgi end -->
<!-- README_GPTQ.md-use-from-python start -->
## Python code example: inference from this GPTQ model
### Install the necessary packages
Requires: Transformers 4.33.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install --upgrade transformers optimum
# If using PyTorch 2.1 + CUDA 12.x:
pip3 install --upgrade auto-gptq
# or, if using PyTorch 2.1 + CUDA 11.x:
pip3 install --upgrade auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/
```
If you are using PyTorch 2.0, you will need to install AutoGPTQ from source. Likewise if you have problems with the pre-built wheels, you should try building from source:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
git checkout v0.5.1
pip3 install .
```
### Example Python code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/nsql-llama-2-7B-GPTQ"
# To use a different branch, change revision
# For example: revision="gptq-4bit-32g-actorder_True"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''{prompt}
SELECT
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with Transformers. For non-Mistral models, AutoGPTQ can also be used directly.
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama and Mistral models in 4-bit. Please see the Provided Files table above for per-file compatibility.
For a list of clients/servers, please see "Known compatible clients / servers", above.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: NumbersStation's NSQL Llama-2 7B
# NSQL-Llama-2-7B
## Model Description
NSQL is a family of autoregressive open-source large foundation models (FMs) designed specifically for SQL generation tasks.
In this repository we are introducing a new member of NSQL, NSQL-Llama-2-7B. It's based on Meta's original [Llama-2 7B model](https://huggingface.co/meta-llama/Llama-2-7b) and further pre-trained on a dataset of general SQL queries and then fine-tuned on a dataset composed of text-to-SQL pairs.
## Training Data
The general SQL queries are the SQL subset from [The Stack](https://huggingface.co/datasets/bigcode/the-stack), containing 1M training samples. The labeled text-to-SQL pairs come from more than 20 public sources across the web from standard datasets. We hold out Spider and GeoQuery datasets for use in evaluation.
## Evaluation Data
We evaluate our models on two text-to-SQL benchmarks: Spider and GeoQuery.
## Training Procedure
NSQL was trained using cross-entropy loss to maximize the likelihood of sequential inputs. For finetuning on text-to-SQL pairs, we only compute the loss over the SQL portion of the pair. The model is trained using 80GB A100s, leveraging data and model parallelism. We pre-trained for 3 epochs and fine-tuned for 10 epochs.
## Intended Use and Limitations
The model was designed for text-to-SQL generation tasks from given table schema and natural language prompts. The model works best with the prompt format defined below and outputting `SELECT` queries.
## How to Use
Example 1:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("NumbersStation/nsql-llama-2-7B")
model = AutoModelForCausalLM.from_pretrained("NumbersStation/nsql-llama-2-7B", torch_dtype=torch.bfloat16)
text = """CREATE TABLE stadium (
stadium_id number,
location text,
name text,
capacity number,
highest number,
lowest number,
average number
)
CREATE TABLE singer (
singer_id number,
name text,
country text,
song_name text,
song_release_year text,
age number,
is_male others
)
CREATE TABLE concert (
concert_id number,
concert_name text,
theme text,
stadium_id text,
year text
)
CREATE TABLE singer_in_concert (
concert_id number,
singer_id text
)
-- Using valid SQLite, answer the following questions for the tables provided above.
-- What is the maximum, the average, and the minimum capacity of stadiums ?
SELECT"""
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=500)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
Example 2:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("NumbersStation/nsql-llama-2-7B")
model = AutoModelForCausalLM.from_pretrained("NumbersStation/nsql-llama-2-7B", torch_dtype=torch.bfloat16)
text = """CREATE TABLE stadium (
stadium_id number,
location text,
name text,
capacity number,
)
-- Using valid SQLite, answer the following questions for the tables provided above.
-- how many stadiums in total?
SELECT"""
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=500)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
Example 3:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("NumbersStation/nsql-llama-2-7B")
model = AutoModelForCausalLM.from_pretrained("NumbersStation/nsql-llama-2-7B", torch_dtype=torch.bfloat16)
text = """CREATE TABLE work_orders (
ID NUMBER,
CREATED_AT TEXT,
COST FLOAT,
INVOICE_AMOUNT FLOAT,
IS_DUE BOOLEAN,
IS_OPEN BOOLEAN,
IS_OVERDUE BOOLEAN,
COUNTRY_NAME TEXT,
)
-- Using valid SQLite, answer the following questions for the tables provided above.
-- how many work orders are open?
SELECT"""
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=500)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
For more information (e.g., run with your local database), please find examples in [this repository](https://github.com/NumbersStationAI/NSQL).
|
AzureBlack/opus-v0.5-70b-exl2
|
AzureBlack
| 2023-11-18T22:16:01Z | 0 | 0 | null |
[
"text-generation",
"en",
"license:llama2",
"region:us"
] |
text-generation
| 2023-11-18T18:01:29Z |
---
language:
- en
pipeline_tag: text-generation
license: llama2
---
ExllamaV2 version of the model created by [dreamgen](https://huggingface.co/dreamgen)!
Original Model https://huggingface.co/dreamgen/opus-v0.5-70b
Requires ExllamaV2, which is being developed by turboderp https://github.com/turboderp/exllamav2 under an MIT license.
Files are under corresponding branches (7bpw requires ~64gb VRAM)
----
# DreamGen Opus V0 70B
**DreamGen Opus** is a family of **uncensored** models fine-tuned for **(steerable) story writing** and the model also works great for **chat / RP**.
The DreamGen Opus V0.5 70B model is derived from [meta-llama/Llama-2-70b-hf](https://huggingface.co/meta-llama/Llama-2-70b-hf).
You can **try the Opus V0 70B** (AWQ) model for free on [dreamgen.com](https://dreamgen.com).
Other sizes:
- 7B: [dreamgen/opus-v0-7b](https://huggingface.co/dreamgen/opus-v0-7b)
## Difference from [dreamgen/opus-v0-70b](https://huggingface.co/dreamgen/opus-v0-70b)
The model should be even better at role-play and chat, and be slighly more "open-minded" in NSFW contexts.
## Prompting
Please see the [official documentation](https://dreamgen.com/docs/stories) for more detailed guide, including how to prompt the model for chat / RP.
The (collaborative / steerable) story writing task teaches the model to respect `<setting>` and `<instruction>` inserted into the prompt.
Example prompt:
```
<setting>
(Setting provides general overview of the story and characters)
This story is a twist on the traditional Little Red Riding Hood story.
In this variation, the Little Red Riding Hood and her grandma are secretely werevoles.
</setting>
(Previous part of the story, potentially empty)
<instruction>
(Setting tells the model what should happen in the next few sentences / paragraphs)
The Little Red Riding hood confronts The Big Bad Wolf, transforming into her wolf form.
</instruction>
```
## Dataset
The fine-tuning dataset consisted of >1M tokens of collaborative writing task examples, each example being up to 4096 tokens. On top of that, >20M tokens of more general, but less instructed examples were included to help preserve generalization.
All prose in the dataset is from actual humans, not AI generated.
## Community
Join the DreamGen community on [**Discord**](https://dreamgen.com/discord), or follow our [**X/Twitter account**](https://dreamgen.com/twitter) for new model releases and other news.
We will soon be releasing models with longer context window, as well as models specifically fine-tuned for character chat & roleplay.
Help us shape the future of DreamGen.
## Running the model
The model is should be compatible with any software that supports [meta-llama/Llama-2-70b-hf](https://huggingface.co/meta-llama/Llama-2-70b-hf).
Note that because this is a 70B model, the resource requirements are large. You can try the quantized versions linked at the top, but expect a quality drop.
### Running on DreamGen.com (free)
You can try the 70B (AWQ) model for free at [dreamgen.com](https://dreamgen.com) — note that an account is required.
The version used for the website is the official AWQ 4bit quant [dreamgen/opus-v0-70b-awq](https://huggingface.co/dreamgen/opus-v0-70b-awq).
## License
- For personal and academic use: Same license as the base model, in this case https://ai.meta.com/resources/models-and-libraries/llama-downloads/.
- For commercial use: Please reach out to hello@dreamgen.com.
|
Grekkla/BarraganSizeDoesMatter
|
Grekkla
| 2023-11-18T22:15:27Z | 42 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:unknown",
"region:us"
] |
text-to-image
| 2023-11-18T22:01:47Z |
---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: >-
cinematic upper body modelshoot photograph of a handsome man wearing white
designer tshirt, and green came trousers, side view, looking at the camera,
out on a mountain range, overlooking the sea, there is a cute village near
the sea, bokeh, 35mm photograph, film, bokeh, professional, 4k, highly
detailed <lora:SizeDoesMatterNEW-000015:1>
parameters:
negative_prompt: >-
drawing, painting, crayon, sketch, graphite, impressionist, noisy, blurry,
soft, deformed, ugly, head out of frame
output:
url: images/Epoch15Sample (3).png
- text: >-
cinematic upper body modelshoot photograph of a handsome man wearing white
designer tshirt, and green came trousers, front view, looking at the camera,
out on a mountain range, overlooking the sea, there is a cute village near
the sea, bokeh, 35mm photograph, film, bokeh, professional, 4k, highly
detailed <lora:SizeDoesMatterNEW-000015:1>
parameters:
negative_prompt: >-
drawing, painting, crayon, sketch, graphite, impressionist, noisy, blurry,
soft, deformed, ugly, head out of frame
output:
url: images/Epoch15Sample (1).png
- text: >-
cinematic upper body modelshoot photograph of a handsome man wearing white
designer tshirt, and green came trousers, front view, looking at the camera,
in a studio, posing, 35mm photograph, film, bokeh, professional, 4k, highly
detailed <lora:SizeDoesMatterNEW-000015:1>
parameters:
negative_prompt: >-
drawing, painting, crayon, sketch, graphite, impressionist, noisy, blurry,
soft, deformed, ugly, head out of frame
output:
url: images/Epoch15Sample (2).png
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: White Designer Tshirt
license: unknown
---
# Barragan ''Size Does Matter''
<Gallery />
## Model description
T-Shirt from Barragan. ''Size Does Matter''.
## Trigger words
You should use `White Designer Tshirt` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/Grekkla/BarraganSizeDoesMatter/tree/main) them in the Files & versions tab.
|
mjphayes/falcon-7b-instruct-textbook_dataset
|
mjphayes
| 2023-11-18T22:09:38Z | 1 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:vilsonrodrigues/falcon-7b-instruct-sharded",
"base_model:adapter:vilsonrodrigues/falcon-7b-instruct-sharded",
"region:us"
] | null | 2023-11-18T11:13:21Z |
---
library_name: peft
base_model: vilsonrodrigues/falcon-7b-instruct-sharded
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.3.dev0
|
TheBloke/nsql-llama-2-7B-AWQ
|
TheBloke
| 2023-11-18T22:08:10Z | 5 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"base_model:NumbersStation/nsql-llama-2-7B",
"base_model:quantized:NumbersStation/nsql-llama-2-7B",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"awq",
"region:us"
] |
text-generation
| 2023-11-18T21:36:59Z |
---
base_model: NumbersStation/nsql-llama-2-7B
inference: false
license: llama2
model_creator: NumbersStation
model_name: NSQL Llama-2 7B
model_type: llama
prompt_template: '{prompt}
SELECT
'
quantized_by: TheBloke
widget:
- example_title: Number stadiums
text: "CREATE TABLE stadium (\n stadium_id number,\n location text,\n name\
\ text,\n capacity number,\n)\n\n-- Using valid SQLite, answer the following\
\ questions for the tables provided above.\n\n-- how many stadiums in total?\n\
\nSELECT"
- example_title: Open work orders
text: 'CREATE TABLE work_orders ( ID NUMBER, CREATED_AT TEXT, COST FLOAT, INVOICE_AMOUNT
FLOAT, IS_DUE BOOLEAN, IS_OPEN BOOLEAN, IS_OVERDUE BOOLEAN, COUNTRY_NAME TEXT,
)
-- Using valid SQLite, answer the following questions for the tables provided
above.
-- how many work orders are open?
SELECT'
- example_title: Stadium capacity
text: 'CREATE TABLE stadium ( stadium_id number, location text, name text, capacity
number, highest number, lowest number, average number )
CREATE TABLE singer ( singer_id number, name text, country text, song_name text,
song_release_year text, age number, is_male others )
CREATE TABLE concert ( concert_id number, concert_name text, theme text, stadium_id
text, year text )
CREATE TABLE singer_in_concert ( concert_id number, singer_id text )
-- Using valid SQLite, answer the following questions for the tables provided
above.
-- What is the maximum, the average, and the minimum capacity of stadiums ?
SELECT'
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# NSQL Llama-2 7B - AWQ
- Model creator: [NumbersStation](https://huggingface.co/NumbersStation)
- Original model: [NSQL Llama-2 7B](https://huggingface.co/NumbersStation/nsql-llama-2-7B)
<!-- description start -->
## Description
This repo contains AWQ model files for [NumbersStation's NSQL Llama-2 7B](https://huggingface.co/NumbersStation/nsql-llama-2-7B).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - Llama and Mistral models only
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later, from any code or client that supports Transformers
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/nsql-llama-2-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/nsql-llama-2-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/nsql-llama-2-7B-GGUF)
* [NumbersStation's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/NumbersStation/nsql-llama-2-7B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: nsql
```
{prompt}
SELECT
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
I currently release 128g GEMM models only. The addition of group_size 32 models, and GEMV kernel models, is being actively considered.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/nsql-llama-2-7B-AWQ/tree/main) | 4 | 128 | [code](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1/viewer/) | 4096 | 3.89 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/nsql-llama-2-7B-AWQ`.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `nsql-llama-2-7B-AWQ`
7. Select **Loader: AutoAWQ**.
8. Click Load, and the model will load and is now ready for use.
9. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
10. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_AWQ.md-text-generation-webui end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Multi-user inference server: vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- Please ensure you are using vLLM version 0.2 or later.
- When using vLLM as a server, pass the `--quantization awq` parameter.
For example:
```shell
python3 -m vllm.entrypoints.api_server --model TheBloke/nsql-llama-2-7B-AWQ --quantization awq --dtype auto
```
- When using vLLM from Python code, again set `quantization=awq`.
For example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Tell me about AI",
"Write a story about llamas",
"What is 291 - 150?",
"How much wood would a woodchuck chuck if a woodchuck could chuck wood?",
]
prompt_template=f'''{prompt}
SELECT
'''
prompts = [prompt_template.format(prompt=prompt) for prompt in prompts]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/nsql-llama-2-7B-AWQ", quantization="awq", dtype="auto")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Multi-user inference server: Hugging Face Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/nsql-llama-2-7B-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires [huggingface-hub](https://github.com/huggingface/huggingface_hub) 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''{prompt}
SELECT
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: ", response)
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## Inference from Python code using Transformers
### Install the necessary packages
- Requires: [Transformers](https://huggingface.co/docs/transformers) 4.35.0 or later.
- Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.6 or later.
```shell
pip3 install --upgrade "autoawq>=0.1.6" "transformers>=4.35.0"
```
Note that if you are using PyTorch 2.0.1, the above AutoAWQ command will automatically upgrade you to PyTorch 2.1.0.
If you are using CUDA 11.8 and wish to continue using PyTorch 2.0.1, instead run this command:
```shell
pip3 install https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp310-cp310-linux_x86_64.whl
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### Transformers example code (requires Transformers 4.35.0 and later)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_name_or_path = "TheBloke/nsql-llama-2-7B-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
low_cpu_mem_usage=True,
device_map="cuda:0"
)
# Using the text streamer to stream output one token at a time
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = "Tell me about AI"
prompt_template=f'''{prompt}
SELECT
'''
# Convert prompt to tokens
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
generation_params = {
"do_sample": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": 512,
"repetition_penalty": 1.1
}
# Generate streamed output, visible one token at a time
generation_output = model.generate(
tokens,
streamer=streamer,
**generation_params
)
# Generation without a streamer, which will include the prompt in the output
generation_output = model.generate(
tokens,
**generation_params
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
print("model.generate output: ", text_output)
# Inference is also possible via Transformers' pipeline
from transformers import pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
**generation_params
)
pipe_output = pipe(prompt_template)[0]['generated_text']
print("pipeline output: ", pipe_output)
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui) using `Loader: AutoAWQ`.
- [vLLM](https://github.com/vllm-project/vllm) version 0.2.0 and later.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) version 1.1.0 and later.
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later.
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) version 0.1.1 and later.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: NumbersStation's NSQL Llama-2 7B
# NSQL-Llama-2-7B
## Model Description
NSQL is a family of autoregressive open-source large foundation models (FMs) designed specifically for SQL generation tasks.
In this repository we are introducing a new member of NSQL, NSQL-Llama-2-7B. It's based on Meta's original [Llama-2 7B model](https://huggingface.co/meta-llama/Llama-2-7b) and further pre-trained on a dataset of general SQL queries and then fine-tuned on a dataset composed of text-to-SQL pairs.
## Training Data
The general SQL queries are the SQL subset from [The Stack](https://huggingface.co/datasets/bigcode/the-stack), containing 1M training samples. The labeled text-to-SQL pairs come from more than 20 public sources across the web from standard datasets. We hold out Spider and GeoQuery datasets for use in evaluation.
## Evaluation Data
We evaluate our models on two text-to-SQL benchmarks: Spider and GeoQuery.
## Training Procedure
NSQL was trained using cross-entropy loss to maximize the likelihood of sequential inputs. For finetuning on text-to-SQL pairs, we only compute the loss over the SQL portion of the pair. The model is trained using 80GB A100s, leveraging data and model parallelism. We pre-trained for 3 epochs and fine-tuned for 10 epochs.
## Intended Use and Limitations
The model was designed for text-to-SQL generation tasks from given table schema and natural language prompts. The model works best with the prompt format defined below and outputting `SELECT` queries.
## How to Use
Example 1:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("NumbersStation/nsql-llama-2-7B")
model = AutoModelForCausalLM.from_pretrained("NumbersStation/nsql-llama-2-7B", torch_dtype=torch.bfloat16)
text = """CREATE TABLE stadium (
stadium_id number,
location text,
name text,
capacity number,
highest number,
lowest number,
average number
)
CREATE TABLE singer (
singer_id number,
name text,
country text,
song_name text,
song_release_year text,
age number,
is_male others
)
CREATE TABLE concert (
concert_id number,
concert_name text,
theme text,
stadium_id text,
year text
)
CREATE TABLE singer_in_concert (
concert_id number,
singer_id text
)
-- Using valid SQLite, answer the following questions for the tables provided above.
-- What is the maximum, the average, and the minimum capacity of stadiums ?
SELECT"""
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=500)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
Example 2:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("NumbersStation/nsql-llama-2-7B")
model = AutoModelForCausalLM.from_pretrained("NumbersStation/nsql-llama-2-7B", torch_dtype=torch.bfloat16)
text = """CREATE TABLE stadium (
stadium_id number,
location text,
name text,
capacity number,
)
-- Using valid SQLite, answer the following questions for the tables provided above.
-- how many stadiums in total?
SELECT"""
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=500)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
Example 3:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("NumbersStation/nsql-llama-2-7B")
model = AutoModelForCausalLM.from_pretrained("NumbersStation/nsql-llama-2-7B", torch_dtype=torch.bfloat16)
text = """CREATE TABLE work_orders (
ID NUMBER,
CREATED_AT TEXT,
COST FLOAT,
INVOICE_AMOUNT FLOAT,
IS_DUE BOOLEAN,
IS_OPEN BOOLEAN,
IS_OVERDUE BOOLEAN,
COUNTRY_NAME TEXT,
)
-- Using valid SQLite, answer the following questions for the tables provided above.
-- how many work orders are open?
SELECT"""
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=500)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
For more information (e.g., run with your local database), please find examples in [this repository](https://github.com/NumbersStationAI/NSQL).
|
saikiranp321/model_out
|
saikiranp321
| 2023-11-18T21:42:01Z | 1 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"controlnet",
"base_model:stabilityai/stable-diffusion-2-1-base",
"base_model:adapter:stabilityai/stable-diffusion-2-1-base",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-11-07T07:22:55Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1-base
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- controlnet
inference: true
---
# controlnet-saikiranp321/model_out
These are controlnet weights trained on stabilityai/stable-diffusion-2-1-base with new type of conditioning.
|
KrisPi/CodeLlama-34B-Phind-LIMA-PythonTutor
|
KrisPi
| 2023-11-18T21:41:10Z | 0 | 2 | null |
[
"license:llama2",
"region:us"
] | null | 2023-11-18T20:06:33Z |
---
license: llama2
---
This is Phind v2 QLoRa finetune using my PythonTutor LIMA dataset:
https://huggingface.co/datasets/KrisPi/PythonTutor-LIMA-Finetune
My shy attempt to democratize task-specific, cheap fine-tuning focused around LIMA-like datasets -everybody can afford to generate them (less than 20$) and everybody can finetune them (7 hours in total using 2x3090 GPU ~3$+5$ on vast.ai)
At the moment of publishing this adapter, there are already production-ready solutions for serving several LorA adapters. I honestly believe that the route of a reproducible, vast collection of adapters on the top of current SOTA models, will enable the open-source community to access GPT-4 level LLMs in the next 12 months.
My main inspirations for this were blazing fast implementation of multi-LORA in Exllamav2 backend, Jon's LMoE and Airoboros dataset, r/LocalLLaMA opinions around models based on LIMA finetunes, and of course the LIMA paper itself.
To prove the point I'm planning to create a few more finetunes like this, starting with the Airoboros "contextual" category for RAG solutions, adapters for React and DevOps YAML scripting.
5 epochs, LR=1e-05, batch=2, gradient accumulation 32 (i.e. trying to simulate batch 64), max_len=1024. Rank and Alpha both 128 targeting all modules. trained in bfloat16. Constant schedule, no warm-up.
Flash-Attention 2 turned off due to an issue with batching
Expected result:
New system prompt that will preference for using docstring under each function, use multiple functions even if it doesn't make sense, and comment on every line of the code, it should also greatly reduce explanations before and after code block.
As a result model will improve readability by Junior Python Developers and additionally do step-by-step reasoning by default to improve code & HumanEval results.
Evals:
HumanEval score (2.4 p.p improvement to best Phind v2 score!) for the new prompt:
**{'pass@1': 0.7621951219512195}**
**Base + Extra**
**{'pass@1': 0.7073170731707317}**
Base prompt (0.51 p.p improvement)
{'pass@1': 0.725609756097561}
Base + Extra
{'pass@1': 0.6585365853658537}
Phind v2 with Python Tutor custom prompt is only getting:
{'pass@1': 0.7073170731707317}
Base + Extra
{'pass@1': 0.6463414634146342}
After several HumanEval tests and prompts Phind v2 was maximum able to score: 73.78%
**All evals using Transformers 8bit**
In the long term, I'm planning on experimenting with LIMA + DPO Fine-Tuning, but so far I noticed that LIMA datasets need to be both general and task-specific. The best result I got with around 30% of samples that were task specific.
https://huggingface.co/datasets/KrisPi/PythonTutor-Evol-1k-DPO-GPT4_vs_35
```
### System Prompt\nYou are an intelligent assistant.\n\n### User Message\nTake a deep breath and think step by step, make sure to verify your solution will pass example test cases. Write in the most simple manner using mutiple functions, simple loops and if statements, do not compress code, the code will be read by other developer.\n{PROMPT}\n\n### Assistant\n
```
r=128,
lora_alpha=128,
target_modules=['q_proj','k_proj','v_proj','o_proj','gate_proj','down_proj','up_proj'],
lora_dropout=0.03,
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
|
ospanbatyr/llama-2-7b-chat-hf-ft-compact
|
ospanbatyr
| 2023-11-18T21:12:07Z | 0 | 0 | null |
[
"safetensors",
"generated_from_trainer",
"region:us"
] | null | 2023-11-18T20:52:32Z |
---
tags:
- generated_from_trainer
model-index:
- name: llama-2-7b-chat-hf-ft-compact
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# llama-2-7b-chat-hf-ft-compact
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8585
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.1287 | 0.36 | 25 | 2.8154 |
| 1.5 | 0.73 | 50 | 1.3773 |
| 1.1092 | 1.09 | 75 | 0.9817 |
| 0.9247 | 1.45 | 100 | 0.9045 |
| 0.8907 | 1.82 | 125 | 0.8791 |
| 0.8572 | 2.18 | 150 | 0.8663 |
| 0.8359 | 2.55 | 175 | 0.8608 |
| 0.8156 | 2.91 | 200 | 0.8585 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.0.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Brass-monkey/distilhubert-finetuned-gtzan
|
Brass-monkey
| 2023-11-18T21:08:57Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"hubert",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"base_model:ntu-spml/distilhubert",
"base_model:finetune:ntu-spml/distilhubert",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-11-18T20:57:06Z |
---
license: apache-2.0
base_model: ntu-spml/distilhubert
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: distilhubert-finetuned-gtzan
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: GTZAN
type: marsyas/gtzan
config: all
split: train
args: all
metrics:
- name: Accuracy
type: accuracy
value: 0.8
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilhubert-finetuned-gtzan
This model is a fine-tuned version of [ntu-spml/distilhubert](https://huggingface.co/ntu-spml/distilhubert) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5775
- Accuracy: 0.8
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3658 | 1.0 | 225 | 0.5775 | 0.8 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
sudo-ai/zero123plus-pipeline
|
sudo-ai
| 2023-11-18T21:08:14Z | 0 | 7 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2023-09-24T18:30:33Z |
---
license: apache-2.0
---
Please see the relevant models in https://huggingface.co/sudo-ai for usage.
|
Zakia/ppo-Huggy
|
Zakia
| 2023-11-18T21:02:10Z | 5 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-11-18T21:01:56Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: Zakia/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
fixhunters/bird_classification_model
|
fixhunters
| 2023-11-18T21:00:34Z | 7 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-18T19:45:10Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bird_classification_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bird_classification_model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 4.2656
- Accuracy: 0.5192
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 5.1074 | 1.0 | 523 | 5.0923 | 0.4126 |
| 4.4577 | 2.0 | 1047 | 4.4729 | 0.5027 |
| 4.2063 | 3.0 | 1569 | 4.2656 | 0.5192 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Tokenizers 0.15.0
|
alifunseen/distilbert-base-uncased-my-finetuned-squad
|
alifunseen
| 2023-11-18T20:59:50Z | 3 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-11-18T20:01:13Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: alifunseen/distilbert-base-uncased-my-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# alifunseen/distilbert-base-uncased-my-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.9692
- Train End Logits Accuracy: 0.7311
- Train Start Logits Accuracy: 0.6908
- Validation Loss: 1.1173
- Validation End Logits Accuracy: 0.7000
- Validation Start Logits Accuracy: 0.6620
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 11064, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch |
|:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:|
| 1.5126 | 0.6062 | 0.5685 | 1.1755 | 0.6827 | 0.6473 | 0 |
| 0.9692 | 0.7311 | 0.6908 | 1.1173 | 0.7000 | 0.6620 | 1 |
### Framework versions
- Transformers 4.35.2
- TensorFlow 2.14.0
- Datasets 2.15.0
- Tokenizers 0.15.0
|
MayIBorn/rte_qlora-llama7b_initialize_dW_B_with_svd
|
MayIBorn
| 2023-11-18T20:59:45Z | 3 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:huggyllama/llama-7b",
"base_model:adapter:huggyllama/llama-7b",
"region:us"
] | null | 2023-11-18T20:59:37Z |
---
library_name: peft
base_model: huggyllama/llama-7b
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.7.0.dev0
|
amunchet/vit-base-beans
|
amunchet
| 2023-11-18T20:45:14Z | 14 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"vision",
"generated_from_trainer",
"dataset:beans",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-11-18T20:39:08Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- image-classification
- vision
- generated_from_trainer
datasets:
- beans
metrics:
- accuracy
model-index:
- name: vit-base-beans
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: beans
type: beans
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9849624060150376
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-beans
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0857
- Accuracy: 0.9850
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3152 | 1.0 | 130 | 0.2074 | 0.9774 |
| 0.2075 | 2.0 | 260 | 0.1327 | 0.9699 |
| 0.1856 | 3.0 | 390 | 0.1136 | 0.9774 |
| 0.0837 | 4.0 | 520 | 0.1014 | 0.9774 |
| 0.1271 | 5.0 | 650 | 0.0857 | 0.9850 |
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.1+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
haydn-jones/GuacamolSELFIETokenizer
|
haydn-jones
| 2023-11-18T20:36:55Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2023-11-18T17:09:29Z |
---
license: mit
---
Just a tokenizer for SELFIE strings with vocab from the Guacamol train split.
|
Astromium/q-FrozenLake-v1-4x4-noSlippery
|
Astromium
| 2023-11-18T20:18:21Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-18T20:18:19Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Astromium/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
abelagustiann/T5-Summarize_Model
|
abelagustiann
| 2023-11-18T20:17:45Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:indosum",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-18T20:07:34Z |
---
license: apache-2.0
base_model: t5-small
tags:
- generated_from_trainer
datasets:
- indosum
metrics:
- rouge
model-index:
- name: T5-Summarize_Model
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: indosum
type: indosum
config: indosum_fold0_source
split: test
args: indosum_fold0_source
metrics:
- name: Rouge1
type: rouge
value: 0.2015
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# T5-Summarize_Model
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the indosum dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8019
- Rouge1: 0.2015
- Rouge2: 0.1581
- Rougel: 0.201
- Rougelsum: 0.2004
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 19 | 0.8400 | 0.1928 | 0.1464 | 0.19 | 0.1902 | 19.0 |
| No log | 2.0 | 38 | 0.8062 | 0.201 | 0.1544 | 0.199 | 0.1986 | 19.0 |
| No log | 3.0 | 57 | 0.8019 | 0.2015 | 0.1581 | 0.201 | 0.2004 | 19.0 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
ski20/climate-ft-lora
|
ski20
| 2023-11-18T20:17:31Z | 1 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"base_model:adapter:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"region:us"
] | null | 2023-11-16T20:48:22Z |
---
library_name: peft
base_model: Trelis/Llama-2-7b-chat-hf-sharded-bf16
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.2
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.2
|
Mouhamad/dummy-model
|
Mouhamad
| 2023-11-18T20:17:21Z | 4 | 0 |
transformers
|
[
"transformers",
"tf",
"camembert",
"fill-mask",
"generated_from_keras_callback",
"base_model:almanach/camembert-base",
"base_model:finetune:almanach/camembert-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-11-18T19:44:29Z |
---
license: mit
base_model: camembert-base
tags:
- generated_from_keras_callback
model-index:
- name: dummy-model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# dummy-model
This model is a fine-tuned version of [camembert-base](https://huggingface.co/camembert-base) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.35.2
- TensorFlow 2.14.0
- Tokenizers 0.15.0
|
aanchalsatyan/my_awesome_qa_model
|
aanchalsatyan
| 2023-11-18T20:07:14Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-11-18T19:43:35Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: my_awesome_qa_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_qa_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5590
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 250 | 2.2871 |
| 2.7028 | 2.0 | 500 | 1.6279 |
| 2.7028 | 3.0 | 750 | 1.5590 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
SeyedAli/Persian-to-English-Translation-mT5-V1
|
SeyedAli
| 2023-11-18T20:06:39Z | 142 | 6 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"mt5",
"text2text-generation",
"machine-translation",
"persian",
"fa",
"multilingual",
"dataset:parsinlu",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-09-25T16:14:55Z |
---
language:
- fa
- multilingual
thumbnail: https://upload.wikimedia.org/wikipedia/commons/a/a2/Farsi.svg
tags:
- machine-translation
- mt5
- persian
license: mit
datasets:
- parsinlu
metrics:
- sacrebleu
---
# Machine Translation
This is an mT5-based model for machine translation (Persian -> English).
Here is an example of how you can run this model:
```python
from transformers import MT5ForConditionalGeneration, MT5Tokenizer
model_name = "SeyedAli/Persian-to-English-Translation-mT5-V1"
tokenizer = MT5Tokenizer.from_pretrained(model_name)
model = MT5ForConditionalGeneration.from_pretrained(model_name)
def run_model(input_string, **generator_args):
input_ids = tokenizer.encode(input_string, return_tensors="pt")
res = model.generate(input_ids, **generator_args)
output = tokenizer.batch_decode(res, skip_special_tokens=True)
print(output)
return output
run_model("ستایش خدای را که پروردگار جهانیان است.")
run_model("در هاید پارک کرنر بر گلدانی ایستاده موعظه میکند؛")
run_model("وی از تمامی بلاگرها، سازمانها و افرادی که از وی پشتیبانی کردهاند، تشکر کرد.")
run_model("مشابه سال ۲۰۰۱، تولید آمونیاک بی آب در ایالات متحده در سال ۲۰۰۰ تقریباً ۱۷،۴۰۰،۰۰۰ تن (معادل بدون آب) با مصرف ظاهری ۲۲،۰۰۰،۰۰۰ تن و حدود ۴۶۰۰۰۰۰ با واردات خالص مواجه شد. ")
run_model("می خواهم دکترای علوم کامپیوتر راجع به شبکه های اجتماعی را دنبال کنم، چالش حل نشده در شبکه های اجتماعی چیست؟")
```
which should give the following:
```
['the admiration of God, which is the Lord of the world.']
['At the Ford Park, the Crawford Park stands on a vase;']
['He thanked all the bloggers, the organizations, and the people who supported him']
['similar to the year 2001, the economy of ammonia in the United States in the']
['I want to follow the computer experts on social networks, what is the unsolved problem in']
```
which should give the following:
```
['Adoration of God, the Lord of the world.']
['At the High End of the Park, Conrad stands on a vase preaching;']
['She thanked all the bloggers, organizations, and men who had supported her.']
['In 2000, the lack of water ammonia in the United States was almost']
['I want to follow the computer science doctorate on social networks. What is the unsolved challenge']
```
Which should produce the following:
```
['the praise of God, the Lord of the world.']
['At the Hyde Park Corner, Carpenter is preaching on a vase;']
['He thanked all the bloggers, organizations, and people who had supported him.']
['Similarly in 2001, the production of waterless ammonia in the United States was']
['I want to pursue my degree in Computer Science on social networks, what is the']
```
|
SeyedAli/Persian-Speech-Emotion-HuBert-V1
|
SeyedAli
| 2023-11-18T20:02:45Z | 11 | 1 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"hubert",
"fa",
"dataset:SeyedAli/Persian-Audio-Dataset",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2023-09-07T14:40:29Z |
---
license: mit
language:
- fa
datasets:
- SeyedAli/Persian-Audio-Dataset
---
|
liambyrne/save_points
|
liambyrne
| 2023-11-18T20:00:43Z | 0 | 0 | null |
[
"generated_from_trainer",
"base_model:ybelkada/falcon-7b-sharded-bf16",
"base_model:finetune:ybelkada/falcon-7b-sharded-bf16",
"region:us"
] | null | 2023-11-18T20:00:08Z |
---
base_model: ybelkada/falcon-7b-sharded-bf16
tags:
- generated_from_trainer
model-index:
- name: save_points
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# save_points
This model is a fine-tuned version of [ybelkada/falcon-7b-sharded-bf16](https://huggingface.co/ybelkada/falcon-7b-sharded-bf16) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.32.0
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.13.3
|
SeyedAli/Persian-Text-Emotion-Bert-V1
|
SeyedAli
| 2023-11-18T19:48:32Z | 26 | 2 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"fa",
"base_model:HooshvareLab/bert-base-parsbert-uncased",
"base_model:finetune:HooshvareLab/bert-base-parsbert-uncased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-08T17:55:37Z |
---
base_model: HooshvareLab/bert-base-parsbert-uncased
tags:
- generated_from_trainer
metrics:
- precision
- recall
- accuracy
model-index:
- name: output
results: []
language:
- fa
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Persian Text Emotion Detection
This model is a fine-tuned version of [HooshvareLab/bert-base-parsbert-uncased](https://huggingface.co/HooshvareLab/bert-base-parsbert-uncased) on a custom dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2551
- Precision: 0.9362
- Recall: 0.9360
- Fscore: 0.9359
- Accuracy: 0.9360
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | Fscore | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 348 | 0.3054 | 0.9166 | 0.9144 | 0.9136 | 0.9144 |
| 0.5158 | 2.0 | 696 | 0.2551 | 0.9362 | 0.9360 | 0.9359 | 0.9360 |
| 0.1469 | 3.0 | 1044 | 0.3670 | 0.9283 | 0.9259 | 0.9245 | 0.9259 |
| 0.1469 | 4.0 | 1392 | 0.3833 | 0.9331 | 0.9317 | 0.9307 | 0.9317 |
| 0.0453 | 5.0 | 1740 | 0.4241 | 0.9356 | 0.9345 | 0.9342 | 0.9345 |
| 0.0237 | 6.0 | 2088 | 0.3750 | 0.9441 | 0.9439 | 0.9437 | 0.9439 |
| 0.0237 | 7.0 | 2436 | 0.3986 | 0.9389 | 0.9388 | 0.9385 | 0.9388 |
| 0.009 | 8.0 | 2784 | 0.4100 | 0.9407 | 0.9403 | 0.9397 | 0.9403 |
| 0.0053 | 9.0 | 3132 | 0.4005 | 0.9403 | 0.9403 | 0.9401 | 0.9403 |
| 0.0053 | 10.0 | 3480 | 0.3986 | 0.9410 | 0.9410 | 0.9408 | 0.9410 |
### Framework versions
- Transformers 4.33.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
SeyedAli/Persian-Text-Sentiment-Bert-V1
|
SeyedAli
| 2023-11-18T19:43:18Z | 65 | 4 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"fa",
"base_model:HooshvareLab/bert-base-parsbert-uncased",
"base_model:finetune:HooshvareLab/bert-base-parsbert-uncased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-07T15:01:31Z |
---
base_model: HooshvareLab/bert-base-parsbert-uncased
tags:
- generated_from_trainer
metrics:
- precision
- recall
- accuracy
model-index:
- name: Persian-Text-Sentiment-Bert-V1
results: []
language:
- fa
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Persian-Text-Sentiment-Bert-V1
This model is a fine-tuned version of [HooshvareLab/bert-base-parsbert-uncased](https://huggingface.co/HooshvareLab/bert-base-parsbert-uncased) on a custom dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3265
- Precision: 0.8727
- Recall: 0.8716
- F1-score: 0.8715
- Accuracy: 0.8716
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1-score | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:--------:|:--------:|
| 0.3097 | 1.0 | 3491 | 0.3265 | 0.8727 | 0.8716 | 0.8715 | 0.8716 |
| 0.2686 | 2.0 | 6982 | 0.3602 | 0.8785 | 0.8758 | 0.8756 | 0.8758 |
| 0.2137 | 3.0 | 10473 | 0.3828 | 0.8759 | 0.8724 | 0.8721 | 0.8724 |
| 0.1823 | 4.0 | 13964 | 0.5545 | 0.8637 | 0.8636 | 0.8636 | 0.8636 |
| 0.1346 | 5.0 | 17455 | 0.6295 | 0.8572 | 0.8566 | 0.8566 | 0.8566 |
| 0.1001 | 6.0 | 20946 | 0.8501 | 0.8606 | 0.8604 | 0.8604 | 0.8604 |
| 0.071 | 7.0 | 24437 | 1.0192 | 0.8596 | 0.8594 | 0.8594 | 0.8594 |
| 0.0604 | 8.0 | 27928 | 1.0449 | 0.8553 | 0.8553 | 0.8553 | 0.8553 |
| 0.0312 | 9.0 | 31419 | 1.1677 | 0.8598 | 0.8598 | 0.8598 | 0.8598 |
| 0.022 | 10.0 | 34910 | 1.2128 | 0.8593 | 0.8591 | 0.8591 | 0.8591 |
### Framework versions
- Transformers 4.33.1
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
ailafelix/mistral-finetuned-alpaca
|
ailafelix
| 2023-11-18T19:40:42Z | 0 | 0 | null |
[
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:TheBloke/Mistral-7B-Instruct-v0.1-GPTQ",
"base_model:finetune:TheBloke/Mistral-7B-Instruct-v0.1-GPTQ",
"license:apache-2.0",
"region:us"
] | null | 2023-11-16T15:57:18Z |
---
license: apache-2.0
base_model: TheBloke/Mistral-7B-Instruct-v0.1-GPTQ
tags:
- generated_from_trainer
model-index:
- name: mistral-finetuned-alpaca
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral-finetuned-alpaca
This model is a fine-tuned version of [TheBloke/Mistral-7B-Instruct-v0.1-GPTQ](https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GPTQ) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- training_steps: 250
### Training results
### Framework versions
- Transformers 4.36.0.dev0
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
Mxode/Pythia-70m-Synonym-Sentence-Converter
|
Mxode
| 2023-11-18T19:40:03Z | 50 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"gpt_neox",
"text-generation",
"tiny",
"small",
"synonym",
"tool",
"converter",
"en",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-10-08T17:11:36Z |
---
license: apache-2.0
language:
- en
tags:
- tiny
- small
- synonym
- tool
- converter
---
## What's this?
A **tiny** model that can perform **paraphrasing** or **synonym substitution**.
The base model is [pythia-70m](https://huggingface.co/EleutherAI/pythia-70m). This model was fine-tuned with 10 epochs using [Q-Lora](https://github.com/artidoro/qlora) method on my own training set.
## How to use
### quick start
First import the model from hf:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model_name_or_path = 'Mxode/Pythia-70m-C-Language-KnowledgeExtract'
device = 'cuda'
model = GPTNeoXForCausalLM.from_pretrained(model_name_or_path).to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
# prompt template
prompt = '<|prompt|>Convert the following passage into synonymous sentences.<|prompt|>\n'
# any text you wish to convert, preferably in complete single sentences.
content = 'The theories and methods of systems science are extensively employed in various domains, including biology, economics, and sociology.'
text = prompt + content
```
Then generate:
```python
inputs = tokenizer(text, return_tensors="pt").to(device)
input_ids = inputs.input_ids
tokens = model.generate(
**inputs,
pad_token_id=tokenizer.eos_token_id,
max_new_tokens=100,
do_sample=True,
)
# strip the input
response = tokenizer.decode(tokens[0]).replace(text, "").strip('<|endoftext|>')
# I call it 'Synonymizer' :)
print(f'Synonymizer: {response}')
### output:
### The disciplines of systems science are extensively employed in various domains, including biology, economics, and sociology.
```
Or maybe we'll try some more impossibly trained news? Hmm, get some sports news from espn and try:
```python
### ...
content = 'As both teams exited the court for halftime, Baynes and Mayen were shoulder to shoulder.'
### ...
print(f'Synonymizer: {response}')
### output:
### As the team neets around the court to ease their shifts, Baynes and Middets were partnerly paryyneen.
### sometimes:
### Begantly mastitatively, Baynes and Mayen staged their team rested the Tywindes rested the Tywindes rested the Tywindes laid the Tywindes laid the Tywindes laid the Tywindes laid the Tywindes laid the Tywindes laid the Tywindes laid the Tywindes laid the Tywindes laid the Tywindes laid the Tywindes laid the Tywindes laid the Tywindes laid the Tywindes laid the Tywindes laid
```
WELL, as you can see, this is after all only an **experimental tiny model** and with that in mind I can give it a 7.5 out of 10 for performance.
I didn't adjust the hyperparameters, could try [low temperature] + [a bit higher repetition_penalty], the performance might be better.
I'll follow up by training more data on a slightly larger model and hopefully supporting multiple languages. While we all know that bigger models have better generalization capabilities - but smaller models are really cool :)
|
abhishekkadakolask/my-pet-duck4
|
abhishekkadakolask
| 2023-11-18T19:35:23Z | 8 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-11-18T19:30:48Z |
---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-DUCK4 Dreambooth model trained by abhishekkadakolask following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: SCITS-54
Sample pictures of this concept:

|
PlotnikovVasiliy/ppo-LunarLander-v2
|
PlotnikovVasiliy
| 2023-11-18T19:21:02Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-18T19:20:40Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 261.04 +/- 18.75
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
behzadnet/Llama-2-7b-chat-hf-sharded-bf16-fine-tuned_HumanFinetuned3
|
behzadnet
| 2023-11-18T19:20:30Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"base_model:adapter:Trelis/Llama-2-7b-chat-hf-sharded-bf16",
"region:us"
] | null | 2023-11-18T19:20:27Z |
---
library_name: peft
base_model: Trelis/Llama-2-7b-chat-hf-sharded-bf16
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.7.0.dev0
|
SandriBarros/clinical_longformer_same_tokens_2epochs_300k
|
SandriBarros
| 2023-11-18T19:15:17Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"longformer",
"fill-mask",
"generated_from_trainer",
"base_model:SandriBarros/clinical_longformer_same_tokens_2epochs_250k",
"base_model:finetune:SandriBarros/clinical_longformer_same_tokens_2epochs_250k",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-11-18T18:52:55Z |
---
base_model: SandriBarros/clinical_longformer_same_tokens_2epochs_250k
tags:
- generated_from_trainer
model-index:
- name: clinical_longformer_same_tokens_2epochs_300k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# clinical_longformer_same_tokens_2epochs_300k
This model is a fine-tuned version of [SandriBarros/clinical_longformer_same_tokens_2epochs_250k](https://huggingface.co/SandriBarros/clinical_longformer_same_tokens_2epochs_250k) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 64
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1500
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
japanese-denim/m2m-finetuned-eng-to-naga
|
japanese-denim
| 2023-11-18T19:08:05Z | 13 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"m2m_100",
"text2text-generation",
"translation",
"generated_from_trainer",
"base_model:facebook/m2m100_418M",
"base_model:finetune:facebook/m2m100_418M",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-11-18T18:05:01Z |
---
license: mit
base_model: facebook/m2m100_418M
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: m2m-finetuned-eng-to-naga
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# m2m-finetuned-eng-to-naga
This model is a fine-tuned version of [facebook/m2m100_418M](https://huggingface.co/facebook/m2m100_418M) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2877
- Bleu: 23.5106
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
BeePolly/cojjj
|
BeePolly
| 2023-11-18T19:03:40Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:segmind/SSD-1B",
"base_model:adapter:segmind/SSD-1B",
"license:apache-2.0",
"region:us"
] |
text-to-image
| 2023-11-18T19:02:41Z |
---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: '-'
output:
url: images/39c10140146008b82c3f6c7e4a6b9204.jpg
base_model: segmind/SSD-1B
instance_prompt: cojjj
license: apache-2.0
---
# cojjj
<Gallery />
## Model description
<audio controls src="https://cdn-uploads.huggingface.co/production/uploads/65590040b1b102df8c0b35e8/LgrDxTiIj7Q7PVUBxkgSA.mpga"></audio>
## Trigger words
You should use `cojjj` to trigger the image generation.
## Download model
[Download](/BeePolly/cojjj/tree/main) them in the Files & versions tab.
|
anikde/semantic-label-aware-BERT_uncased
|
anikde
| 2023-11-18T19:02:40Z | 2 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"en",
"dataset:martinsinnona/plotqa",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2023-11-13T05:50:12Z |
---
license: apache-2.0
datasets:
- martinsinnona/plotqa
language:
- en
library_name: transformers
---
|
eren23/basic_wnut
|
eren23
| 2023-11-18T18:44:21Z | 11 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"token-classification",
"generated_from_trainer",
"dataset:wnut_17",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-11-18T17:57:21Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- wnut_17
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: basic_wnut
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wnut_17
type: wnut_17
config: wnut_17
split: test
args: wnut_17
metrics:
- name: Precision
type: precision
value: 0.5469543147208121
- name: Recall
type: recall
value: 0.3994439295644115
- name: F1
type: f1
value: 0.46170326727370103
- name: Accuracy
type: accuracy
value: 0.9469026548672567
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# basic_wnut
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the wnut_17 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3181
- Precision: 0.5470
- Recall: 0.3994
- F1: 0.4617
- Accuracy: 0.9469
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 27 | 0.2984 | 0.5557 | 0.3930 | 0.4604 | 0.9463 |
| No log | 2.0 | 54 | 0.2991 | 0.5547 | 0.3902 | 0.4581 | 0.9462 |
| No log | 3.0 | 81 | 0.2993 | 0.5557 | 0.3930 | 0.4604 | 0.9463 |
| No log | 4.0 | 108 | 0.3011 | 0.5550 | 0.3883 | 0.4569 | 0.9461 |
| No log | 5.0 | 135 | 0.3015 | 0.5532 | 0.3902 | 0.4576 | 0.9462 |
| No log | 6.0 | 162 | 0.2997 | 0.5467 | 0.3957 | 0.4591 | 0.9463 |
| No log | 7.0 | 189 | 0.2997 | 0.5487 | 0.3967 | 0.4605 | 0.9462 |
| No log | 8.0 | 216 | 0.2998 | 0.5439 | 0.3957 | 0.4582 | 0.9463 |
| No log | 9.0 | 243 | 0.3024 | 0.5501 | 0.3920 | 0.4578 | 0.9462 |
| No log | 10.0 | 270 | 0.3021 | 0.5470 | 0.3939 | 0.4580 | 0.9462 |
| No log | 11.0 | 297 | 0.3027 | 0.5471 | 0.3930 | 0.4574 | 0.9463 |
| No log | 12.0 | 324 | 0.3023 | 0.5453 | 0.3957 | 0.4586 | 0.9463 |
| No log | 13.0 | 351 | 0.3028 | 0.5481 | 0.3957 | 0.4596 | 0.9463 |
| No log | 14.0 | 378 | 0.3028 | 0.5467 | 0.3957 | 0.4591 | 0.9463 |
| No log | 15.0 | 405 | 0.3034 | 0.5444 | 0.3976 | 0.4596 | 0.9464 |
| No log | 16.0 | 432 | 0.3040 | 0.5431 | 0.3967 | 0.4585 | 0.9464 |
| No log | 17.0 | 459 | 0.3068 | 0.5484 | 0.3939 | 0.4585 | 0.9464 |
| No log | 18.0 | 486 | 0.3077 | 0.5501 | 0.3920 | 0.4578 | 0.9466 |
| 0.0203 | 19.0 | 513 | 0.3057 | 0.5434 | 0.3948 | 0.4573 | 0.9463 |
| 0.0203 | 20.0 | 540 | 0.3078 | 0.5494 | 0.3920 | 0.4575 | 0.9464 |
| 0.0203 | 21.0 | 567 | 0.3074 | 0.5517 | 0.3957 | 0.4609 | 0.9465 |
| 0.0203 | 22.0 | 594 | 0.3070 | 0.5499 | 0.3985 | 0.4621 | 0.9465 |
| 0.0203 | 23.0 | 621 | 0.3065 | 0.5497 | 0.3994 | 0.4627 | 0.9465 |
| 0.0203 | 24.0 | 648 | 0.3064 | 0.5450 | 0.3985 | 0.4604 | 0.9464 |
| 0.0203 | 25.0 | 675 | 0.3077 | 0.5467 | 0.3957 | 0.4591 | 0.9465 |
| 0.0203 | 26.0 | 702 | 0.3070 | 0.5458 | 0.3976 | 0.4601 | 0.9464 |
| 0.0203 | 27.0 | 729 | 0.3084 | 0.5494 | 0.3967 | 0.4607 | 0.9466 |
| 0.0203 | 28.0 | 756 | 0.3086 | 0.5487 | 0.3967 | 0.4605 | 0.9465 |
| 0.0203 | 29.0 | 783 | 0.3087 | 0.5486 | 0.3976 | 0.4610 | 0.9466 |
| 0.0203 | 30.0 | 810 | 0.3087 | 0.5444 | 0.3976 | 0.4596 | 0.9464 |
| 0.0203 | 31.0 | 837 | 0.3108 | 0.5510 | 0.3957 | 0.4606 | 0.9466 |
| 0.0203 | 32.0 | 864 | 0.3107 | 0.5494 | 0.3967 | 0.4607 | 0.9466 |
| 0.0203 | 33.0 | 891 | 0.3097 | 0.5429 | 0.3985 | 0.4596 | 0.9466 |
| 0.0203 | 34.0 | 918 | 0.3114 | 0.5493 | 0.3976 | 0.4613 | 0.9466 |
| 0.0203 | 35.0 | 945 | 0.3100 | 0.5430 | 0.3976 | 0.4591 | 0.9465 |
| 0.0203 | 36.0 | 972 | 0.3100 | 0.5442 | 0.3994 | 0.4607 | 0.9466 |
| 0.0203 | 37.0 | 999 | 0.3099 | 0.5428 | 0.3994 | 0.4602 | 0.9466 |
| 0.0177 | 38.0 | 1026 | 0.3109 | 0.5450 | 0.3985 | 0.4604 | 0.9465 |
| 0.0177 | 39.0 | 1053 | 0.3117 | 0.5488 | 0.3957 | 0.4599 | 0.9466 |
| 0.0177 | 40.0 | 1080 | 0.3119 | 0.5493 | 0.3976 | 0.4613 | 0.9466 |
| 0.0177 | 41.0 | 1107 | 0.3129 | 0.5528 | 0.3976 | 0.4625 | 0.9468 |
| 0.0177 | 42.0 | 1134 | 0.3124 | 0.5473 | 0.3967 | 0.4600 | 0.9467 |
| 0.0177 | 43.0 | 1161 | 0.3128 | 0.55 | 0.3976 | 0.4615 | 0.9468 |
| 0.0177 | 44.0 | 1188 | 0.3132 | 0.5514 | 0.3976 | 0.4620 | 0.9469 |
| 0.0177 | 45.0 | 1215 | 0.3119 | 0.5457 | 0.3985 | 0.4606 | 0.9467 |
| 0.0177 | 46.0 | 1242 | 0.3115 | 0.5436 | 0.3985 | 0.4599 | 0.9467 |
| 0.0177 | 47.0 | 1269 | 0.3127 | 0.5460 | 0.3957 | 0.4589 | 0.9466 |
| 0.0177 | 48.0 | 1296 | 0.3132 | 0.5474 | 0.3957 | 0.4594 | 0.9467 |
| 0.0177 | 49.0 | 1323 | 0.3137 | 0.5469 | 0.3948 | 0.4586 | 0.9467 |
| 0.0177 | 50.0 | 1350 | 0.3147 | 0.5510 | 0.3957 | 0.4606 | 0.9468 |
| 0.0177 | 51.0 | 1377 | 0.3133 | 0.5459 | 0.3967 | 0.4595 | 0.9468 |
| 0.0177 | 52.0 | 1404 | 0.3129 | 0.5436 | 0.3985 | 0.4599 | 0.9468 |
| 0.0177 | 53.0 | 1431 | 0.3138 | 0.5431 | 0.3967 | 0.4585 | 0.9467 |
| 0.0177 | 54.0 | 1458 | 0.3141 | 0.5437 | 0.3976 | 0.4593 | 0.9468 |
| 0.0177 | 55.0 | 1485 | 0.3141 | 0.5431 | 0.3967 | 0.4585 | 0.9467 |
| 0.0162 | 56.0 | 1512 | 0.3156 | 0.5473 | 0.3967 | 0.4600 | 0.9469 |
| 0.0162 | 57.0 | 1539 | 0.3147 | 0.5463 | 0.3994 | 0.4615 | 0.9469 |
| 0.0162 | 58.0 | 1566 | 0.3150 | 0.5450 | 0.3985 | 0.4604 | 0.9469 |
| 0.0162 | 59.0 | 1593 | 0.3154 | 0.5429 | 0.3985 | 0.4596 | 0.9468 |
| 0.0162 | 60.0 | 1620 | 0.3165 | 0.5486 | 0.3976 | 0.4610 | 0.9468 |
| 0.0162 | 61.0 | 1647 | 0.3150 | 0.5435 | 0.3994 | 0.4605 | 0.9468 |
| 0.0162 | 62.0 | 1674 | 0.3161 | 0.5450 | 0.3985 | 0.4604 | 0.9468 |
| 0.0162 | 63.0 | 1701 | 0.3159 | 0.5430 | 0.3976 | 0.4591 | 0.9467 |
| 0.0162 | 64.0 | 1728 | 0.3168 | 0.5458 | 0.3976 | 0.4601 | 0.9467 |
| 0.0162 | 65.0 | 1755 | 0.3168 | 0.5471 | 0.3985 | 0.4611 | 0.9468 |
| 0.0162 | 66.0 | 1782 | 0.3160 | 0.5429 | 0.3985 | 0.4596 | 0.9467 |
| 0.0162 | 67.0 | 1809 | 0.3166 | 0.5450 | 0.3985 | 0.4604 | 0.9467 |
| 0.0162 | 68.0 | 1836 | 0.3172 | 0.5457 | 0.3985 | 0.4606 | 0.9468 |
| 0.0162 | 69.0 | 1863 | 0.3168 | 0.5476 | 0.3994 | 0.4620 | 0.9468 |
| 0.0162 | 70.0 | 1890 | 0.3167 | 0.5470 | 0.3994 | 0.4617 | 0.9468 |
| 0.0162 | 71.0 | 1917 | 0.3167 | 0.5449 | 0.3994 | 0.4610 | 0.9468 |
| 0.0162 | 72.0 | 1944 | 0.3153 | 0.5439 | 0.4022 | 0.4624 | 0.9469 |
| 0.0162 | 73.0 | 1971 | 0.3155 | 0.5439 | 0.4022 | 0.4624 | 0.9469 |
| 0.0162 | 74.0 | 1998 | 0.3160 | 0.5428 | 0.3994 | 0.4602 | 0.9468 |
| 0.0153 | 75.0 | 2025 | 0.3167 | 0.5435 | 0.3994 | 0.4605 | 0.9469 |
| 0.0153 | 76.0 | 2052 | 0.3171 | 0.5449 | 0.3994 | 0.4610 | 0.9469 |
| 0.0153 | 77.0 | 2079 | 0.3176 | 0.5463 | 0.3994 | 0.4615 | 0.9469 |
| 0.0153 | 78.0 | 2106 | 0.3177 | 0.5463 | 0.3994 | 0.4615 | 0.9469 |
| 0.0153 | 79.0 | 2133 | 0.3172 | 0.5449 | 0.3994 | 0.4610 | 0.9469 |
| 0.0153 | 80.0 | 2160 | 0.3171 | 0.5443 | 0.3985 | 0.4601 | 0.9469 |
| 0.0153 | 81.0 | 2187 | 0.3171 | 0.5443 | 0.3985 | 0.4601 | 0.9469 |
| 0.0153 | 82.0 | 2214 | 0.3173 | 0.5457 | 0.3985 | 0.4606 | 0.9469 |
| 0.0153 | 83.0 | 2241 | 0.3174 | 0.5450 | 0.3985 | 0.4604 | 0.9468 |
| 0.0153 | 84.0 | 2268 | 0.3174 | 0.5436 | 0.3985 | 0.4599 | 0.9467 |
| 0.0153 | 85.0 | 2295 | 0.3170 | 0.5442 | 0.3994 | 0.4607 | 0.9467 |
| 0.0153 | 86.0 | 2322 | 0.3172 | 0.5449 | 0.3994 | 0.4610 | 0.9468 |
| 0.0153 | 87.0 | 2349 | 0.3181 | 0.5456 | 0.3994 | 0.4612 | 0.9468 |
| 0.0153 | 88.0 | 2376 | 0.3179 | 0.5463 | 0.3994 | 0.4615 | 0.9468 |
| 0.0153 | 89.0 | 2403 | 0.3181 | 0.5470 | 0.3994 | 0.4617 | 0.9469 |
| 0.0153 | 90.0 | 2430 | 0.3179 | 0.5470 | 0.3994 | 0.4617 | 0.9469 |
| 0.0153 | 91.0 | 2457 | 0.3181 | 0.5470 | 0.3994 | 0.4617 | 0.9469 |
| 0.0153 | 92.0 | 2484 | 0.3182 | 0.5463 | 0.3994 | 0.4615 | 0.9468 |
| 0.0145 | 93.0 | 2511 | 0.3182 | 0.5470 | 0.3994 | 0.4617 | 0.9469 |
| 0.0145 | 94.0 | 2538 | 0.3181 | 0.5470 | 0.3994 | 0.4617 | 0.9469 |
| 0.0145 | 95.0 | 2565 | 0.3182 | 0.5463 | 0.3994 | 0.4615 | 0.9468 |
| 0.0145 | 96.0 | 2592 | 0.3180 | 0.5470 | 0.3994 | 0.4617 | 0.9469 |
| 0.0145 | 97.0 | 2619 | 0.3180 | 0.5463 | 0.3994 | 0.4615 | 0.9469 |
| 0.0145 | 98.0 | 2646 | 0.3180 | 0.5463 | 0.3994 | 0.4615 | 0.9469 |
| 0.0145 | 99.0 | 2673 | 0.3181 | 0.5470 | 0.3994 | 0.4617 | 0.9469 |
| 0.0145 | 100.0 | 2700 | 0.3181 | 0.5470 | 0.3994 | 0.4617 | 0.9469 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
joegolfs/ppo-LunarLander-v2
|
joegolfs
| 2023-11-18T18:44:19Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-18T18:41:31Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 265.58 +/- 19.70
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
bingha33/VAIVsft_v3
|
bingha33
| 2023-11-18T18:37:10Z | 17 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"text-generation-inference",
"ko",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-18T16:58:06Z |
---
license: apache-2.0
language:
- ko
pipeline_tag: text-generation
tags:
- text-generation-inference
- gpt_neox
---
base model : nlpai-lab/kullm-polyglot-12.8b-v2\
dataset : https://github.com/JoJo0217/vaiv_data_2.git (step1/train3/train.jsonl)
|
rain1011/LaVIT-7B-v2
|
rain1011
| 2023-11-18T18:34:01Z | 19 | 19 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"arxiv:2309.04669",
"license:llama2",
"region:us"
] |
text-to-image
| 2023-11-18T17:49:54Z |
---
license: llama2
pipeline_tag: text-to-image
---
# LaVIT: Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization
This is the latest version (LaVITv2) for the multi-modal large language model: **LaVIT**. The inference code of LaVIT can be found in [here](https://github.com/jy0205/LaVIT).
In this version, We further improve LaVIT's image generation capability. In the updated version, the **aesthetic** and **prompt-alignment** of generated images has been improved. The **probability of watermark** is also greatly reduced. The improvements are summarized as follows:
* Using LaVIT to generate better synthetic captions for the noisy Laion-Aesthetic (Like DALL-E 3).
* Add the high-aesthetic training images from the open-source JourneyDB dataset.
* Using the 20M synthetic Laion-Aesthetic data and 4.2M JourneyDB data to further finetune the LLM for 8K steps.
[[`arXiv`](https://arxiv.org/abs/2309.04669)] [[`BibTeX`](#Citing)]
## Setup
### Requirements
The code for this repo is tested with PyTorch 1.13.1 and CUDA 11.7.
You should first install and configure the Pytorch Environment (including torch and torchvision) can then install the requirements with the following commands:
```shell
git clone https://github.com/jy0205/LaVIT.git
cd LaVIT
pip install -r requirements.txt
```
* (Optional) We recommend using memory efficient attention by installing xFormers following the instructions in [here](https://huggingface.co/docs/diffusers/main/en/optimization/xformers). Then, you can set the argument `use_xformers=True` in `build_model` function to save the GPU memory and speed up inference.
### Model Zoo
We release the LaVIT weight that is built upon [Llama-2-7B](https://huggingface.co/meta-llama/Llama-2-7b) as the large language model.
> Note: Due to the license restrictions of Llama1, we cannot publish its weights. Thus, we release the weight of LaVIT based on the Llama2.
The latest pre-trained weight of LaVIT can be found on the huggingface from [here](https://huggingface.co/rain1011/LaVIT-7B-v2), which will take around 25GB of disk space. We strongly recommend you to download and use the latest version of LaVIT. LaVIT achieves state-of-the-arts performance on various multi-modal downstream tasks. The detailed quantitive results are shown as follows:
#### Zero-shot Multi-modal Understanding
<table>
<thead align="center">
<tr>
<th rowspan="2">Model</th>
<th colspan="3">Image Captioning</th>
<th colspan="4">Visual Question Answering</th>
</tr>
<tr>
<th>COCO</th>
<th>NoCaps</th>
<th>Flickr30K</th>
<th>VQAv2</th>
<th>OK-VQA</th>
<th>GQA</th>
<th>VizWiz</th>
</tr>
</thead>
<tbody align="center">
<tr>
<td>Flamingo-3B</td>
<td>73.0</td>
<td>-</td>
<td>60.6</td>
<td>49.2</td>
<td>41.2</td>
<td>-</td>
<td>28.9</td>
</tr>
<tr>
<td>Flamingo-9B</td>
<td>79.4</td>
<td>-</td>
<td>61.5</td>
<td>51.8</td>
<td>44.7</td>
<td>-</td>
<td>28.8</td>
</tr>
<tr>
<td>OpenFlamingo-9B</td>
<td>79.5</td>
<td>-</td>
<td>59.5</td>
<td>52.7</td>
<td>37.8</td>
<td>-</td>
<td>27.5</td>
</tr>
<tr>
<td>MetaLM</td>
<td>82.2</td>
<td>-</td>
<td>43.4</td>
<td>41.1</td>
<td>11.4</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td>Kosmos-1</td>
<td>84.7</td>
<td>-</td>
<td>67.1</td>
<td>51.0</td>
<td>-</td>
<td>-</td>
<td>29.2</td>
</tr>
<tr>
<td>Kosmos-2</td>
<td>-</td>
<td>-</td>
<td>80.5</td>
<td>51.1</td>
<td>-</td>
<td>-</td>
<td>-</td>
</tr>
<tr>
<td>BLIP-2 (Vicuna-7B)</td>
<td>-</td>
<td>107.5</td>
<td>74.9</td>
<td>-</td>
<td>-</td>
<td>41.3</td>
<td>25.3</td>
</tr>
<tr>
<td>BLIP-2 (Vicuna-13B)</td>
<td>-</td>
<td>103.9</td>
<td>71.6</td>
<td>-</td>
<td>-</td>
<td>32.3</td>
<td>19.6</td>
</tr>
<tr>
<td>CM3Leon-7B</td>
<td>61.6</td>
<td>-</td>
<td>-</td>
<td>47.6</td>
<td>-</td>
<td>-</td>
<td>37.6</td>
</tr>
<tr>
<td>Emu (LLaMA-1-13B)</td>
<td>112.4</td>
<td>-</td>
<td>-</td>
<td>52.0</td>
<td>38.2</td>
<td>-</td>
<td>34.2</td>
</tr>
<tr>
<td>LaVIT (LLaMA-1-7B)</td>
<td>134.0</td>
<td><b>114.2</b></td>
<td>83.0</td>
<td>66.0</td>
<td>54.6</td>
<td>46.8</td>
<td>38.5</td>
</tr>
<tr>
<td>LaVIT (LLaMA-2-7B)</td>
<td><b>134.6</b></td>
<td>113.1</td>
<td><b>83.2</b></td>
<td><b>68.2</b></td>
<td><b>55.7</b></td>
<td><b>48.0</b></td>
<td><b>45.3</b></td>
</tr>
</tbody>
</table>
#### Zero-shot Text-to-Image Generation
<table>
<thead>
<tr>
<th>Method</th>
<th>Model</th>
<th>Model type</th>
<th>FID</th>
</tr>
</thead>
<tbody align="center">
<tr>
<td rowspan="9">Text2Image Specialist</td>
<td>DALL-E</td>
<td>Autoregressive</td>
<td>28.0</td>
</tr>
<tr>
<td>CogView</td>
<td>Autoregressive</td>
<td>27.1</td>
</tr>
<tr>
<td>StableDiffusion</td>
<td>Diffusion</td>
<td>12.6</td>
</tr>
<tr>
<td>GLIDE</td>
<td>Diffusion</td>
<td>12.2</td>
</tr>
<tr>
<td>DALL-E 2</td>
<td>Diffusion</td>
<td>10.4</td>
</tr>
<tr>
<td>Make-A-Scene</td>
<td>Autoregressive</td>
<td>11.8</td>
</tr>
<tr>
<td>MUSE-7.6B</td>
<td>Non-Autoregressive</td>
<td>7.9</td>
</tr>
<tr>
<td>Imagen-3.4B</td>
<td>Diffusion</td>
<td>7.3</td>
</tr>
<tr>
<td>Parti-20B</td>
<td>Autoregressive</td>
<td><b>7.2</b></td>
</tr>
<tr>
<td rowspan="5">Multimodal Large Langauge Model</td>
<td>GILL (OPT-6.7B)</td>
<td>LLM</td>
<td>12.2</td>
</tr>
<tr>
<td>Emu (LLaMA-1-13B)</td>
<td>LLM</td>
<td>11.7</td>
</tr>
<tr>
<td>CM3Leon-7B </td>
<td>LLM</td>
<td>10.8</td>
</tr>
<tr>
<td>LaVIT (LLaMA-1-7B)</td>
<td>LLM</td>
<td>7.4</td>
</tr>
<tr>
<td>LaVIT (LLaMA-2-7B)</td>
<td>LLM</td>
<td><b>7.2</b></td>
</tr>
</tbody>
</table>
## Usage
LaVIT can serve as a multi-modal generalist to perform both multi-modal comprehension and generation. Below, we provide some examples. Only a few lines of code are needed to use **LaVIT** for inference. We also provide the detailed examples in the following jupyter notebooks for learning how to interact with LaVIT.
* `understanding.ipynb` : examples for multi-modal understanding
* `text2image_synthesis.ipynb`: examples for the text-to-image generation.
* `multimodal_synthesis.ipynb`: examples for image synthesis with multi-modal prompts.
### Multi-modal Understanding
```python
import os
import random
import torch
import torch.nn as nn
from models import build_model
from PIL import Image
seed = 1234
random.seed(seed)
torch.manual_seed(seed)
# The local directory you save the LaVIT pre-trained weight,
# it will automatically download the checkpoint from huggingface
model_path = '/path/LaVIT_weight'
# Using BFloat16 during inference
model_dtype = 'bf16' # Or set to fp16 to enable float16 inference
# Inference using GPU-0
device_id = 0
torch.cuda.set_device(device_id)
device = torch.device('cuda')
# Building LaVIT for understanding and load its weight from huggingface
model = build_model(model_path=model_path, model_dtype=model_dtype,
device_id=device_id, use_xformers=False, understanding=True)
model = model.to(device)
# Image Captioning
image_path = 'demo/caption_image.jpg'
caption = model.generate({"image": image_path})[0]
print(caption)
# an old photo of a horse and buggy in front of a building
# Visual Question Answering
image_path = 'demo/qa_image.jpg'
question = "What's that drink in the glass?"
answer = model.predict_answers({"image": image_path, "text_input": question}, max_len=10)[0]
print("The answer is: ", answer)
# The answer is: orange juice
```
### Text-to-Image Synthesis
For the Image generation, the Classifier-Free Guidance scale is important. A larger scale will encourage the model to generate samples highly related to the input prompt while sacrificing the image quality. We set `guidance_scale_for_llm=4.0` by default, you can increase this scale (e.g., 5.0 or 6.0) to encourage the generated image to follow the semantics of given prompts. Besides, you can modify the `ratio` to enable to generate the images with different aspect ratios.
```python
import os
import torch
import random
import torch.nn as nn
from models import build_model
from PIL import Image
seed = 1234
random.seed(seed)
torch.manual_seed(seed)
# The local directory you save the LaVIT pre-trained weight,
# it will automatically download the checkpoint from huggingface
model_path = '/path/LaVIT_weight'
# Using BFloat16 during inference
model_dtype = 'bf16' # Or set to fp16 to enable float16 inference
# Inference using GPU-0
device_id = 0
torch.cuda.set_device(device_id)
device = torch.device('cuda')
torch_dtype = torch.bfloat16 if model_dtype=="bf16" else torch.float16
# Building LaVIT for Generation and load the weight from huggingface
# You can set `use_xformers=True` if have installed xformers to save GPU mempry and speed up
model = build_model(model_path=model_path, model_dtype=model_dtype, device_id=device_id,
use_xformers=False, understanding=False, load_tokenizer=False)
model = model.to(device)
# Text-to-Image Generation
prompt = "a sculpture of a duck made of wool"
# LaVIT support 6 different image aspect ratios
ratio_dict = {
'1:1' : (1024, 1024),
'4:3' : (896, 1152),
'3:2' : (832, 1216),
'16:9' : (768, 1344),
'2:3' : (1216, 832),
'3:4' : (1152, 896),
}
# The image aspect ratio you want to generate
ratio = '1:1'
height, width = ratio_dict[ratio]
with torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype):
images = model.generate_image(prompt, width=width, height=height,
num_return_images=1, guidance_scale_for_llm=4.0, num_inference_steps=25)
images[0].save("output/i2t_output.jpg")
```
## Evaluation
The batch evaluation code with multiple GPUs on the adopted multi-modal benchmarks will be released in the following days.
## Acknowledgement
We are grateful for the following awesome projects when implementing LaVIT:
* [LLaMA](https://github.com/facebookresearch/llama): Open and Efficient Foundation Language Models
* [BLIP-2](https://github.com/salesforce/LAVIS/tree/main/projects/blip2): Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
* [EVA-CLIP](https://github.com/baaivision/EVA/tree/master/EVA-CLIP): Improved Training Techniques for CLIP at Scale
* [BEIT](https://github.com/microsoft/unilm/tree/master/beit2): Masked Image Modeling with Vector-Quantized Visual Tokenizers
* [Diffusers](https://github.com/huggingface/diffusers): State-of-the-art diffusion models for image and audio generation in PyTorch.
## <a name="Citing"></a>Citation
Consider giving this repository a star and cite LaVIT in your publications if it helps your research.
```
@article{jin2023unified,
title={Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization},
author={Jin, Yang and Xu, Kun and Xu, Kun and Chen, Liwei and Liao, Chao and Tan, Jianchao and Mu, Yadong and others},
journal={arXiv preprint arXiv:2309.04669},
year={2023}
}
|
SebasMena111/llama2-chat-spanish-256
|
SebasMena111
| 2023-11-18T18:15:06Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-chat-hf",
"base_model:adapter:meta-llama/Llama-2-7b-chat-hf",
"region:us"
] | null | 2023-11-18T18:14:04Z |
---
library_name: peft
base_model: meta-llama/Llama-2-7b-chat-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: QuantizationMethod.BITS_AND_BYTES
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.7.0.dev0
|
priya17/fine-tuning-bert-QnA
|
priya17
| 2023-11-18T18:12:39Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Bhautiksinh/BertPretrain",
"base_model:adapter:Bhautiksinh/BertPretrain",
"region:us"
] | null | 2023-11-18T15:58:59Z |
---
library_name: peft
base_model: Bhautiksinh/BertPretrain
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.2
|
matatonic/Xwin-LM-70B-V0.1-exl2-4.800b
|
matatonic
| 2023-11-18T18:05:11Z | 10 | 1 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-01T14:13:19Z |
---
license: llama2
---
My exllamav2 based quantization for Xwin-LM-70B-V0.1 targetted for 48G VRAM, seems to have hit a sweet spot in evaluations.
* Original model: https://huggingface.co/Xwin-LM/Xwin-LM-70B-V0.1
* Exllamav2 4.8bpw conversion from https://huggingface.co/firelzrd/Xwin-LM-70B-V0.1-fp16-safetensors.
* Fits in 48G (2x24G) VRAM with 4k or 8k context with or without the 8bit cache enabled.
* Recommended settings: 6400 context, alpha_value 1.6, gpu_split 20,23.5
* alpha_value at or over 1.75 seems to result in an occasional 'stutter', very obvious when the model outputs dates. Ex ("The Sixth Sense (19999)")
* Seems to have hit some lucky quantization and the 4.800b was better than the 4bit-128g, 4bit-32g, Q4_K_S, 4.650b, 4.900b and even the 5.000b!
* Experimentation has shown that alpha_value at 1.6 instead of 1.75 seems better at 1.5x context and even 1.5625x
* Maybe obvious to some but there is no perplexity impact to using an 8bit cache.
Made using exllamav2/convert.py with the following command:
```bash
python3 convert.py -i models/firelzrd_Xwin-LM-70B-V0.1-fp16-safetensors/ \
-cf models/matatonic_Xwin-LM-70B-V0.1-exl2-4.800b \
-o tmp/ \
-c parquet/wikitext-test.parquet \
-b 4.800
```
Perplexity (wikitext) evaluated as:
| Model | Perplexity | Comment (alpha_value) |
|---|---|---|
| matatonic_Xwin-LM-70B-V0.1-exl2-4.800b | 3.21780776977539 | 4096 ctx |
| matatonic_Xwin-LM-70B-V0.1-exl2-4.900b | 3.2188525199890137 | 4096 ctx (not released) |
| firelzrd_Xwin-LM-70B-V0.1-exl2_5-bpw | 3.22019362449646 | 4096 ctx (8b cache) |
| matatonic_Xwin-LM-70B-V0.1-exl2-4.800b | 3.239454746246338 | 5120 ctx (1.375) |
| LoneStriker_Xwin-LM-70B-V0.1-4.65bpw-h6-exl2 | 3.2419090270996094 | 4096 ctx |
| matatonic_Xwin-LM-70B-V0.1-exl2-4.800b | 3.2434027194976807 | 6400 ctx (1.6) |
| matatonic_Xwin-LM-70B-V0.1-exl2-4.800b | 3.2434027194976807 | 6400 ctx (1.6, 8b cache) |
| xwin-lm-70b-v0.1.Q4_K_S.gguf | 3.2480294704437256 | 4096 ctx |
| matatonic_Xwin-LM-70B-V0.1-exl2-4.800b | 3.253002405166626 | 6144 ctx (1.75) |
| TheBloke_Xwin-LM-70B-V0.1-GPTQ_gptq-4bit-32g-actorder_True | 3.266364574432373 | 4096 ctx |
| matatonic_Xwin-LM-70B-V0.1-exl2-4.800b | 3.278069496154785 | 6656 ctx (1.95) |
| TheBloke_Xwin-LM-70B-V0.1-GPTQ_gptq-4bit-128g-actorder_True | 3.2803425788879395 | 4096 ctx |
| matatonic_Xwin-LM-70B-V0.1-exl2-4.800b | 3.304278612136841 | 7168 ctx (2.125) |
| matatonic_Xwin-LM-70B-V0.1-exl2-4.800b | 3.359946727752685 | 8192 ctx (2.5) |
*) Should be better than xwin-lm-70b-v0.1.Q4_K_M.gguf also, which reports 4.8bpw, but so far my perplexity eval has not been successful.
|
DerekLiu35/Llama-2-7b_PROMPT_TUNING_CAUSAL_LM
|
DerekLiu35
| 2023-11-18T18:05:01Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-11-18T18:05:00Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
|
Igorsp/mistral_b_finetuned_python
|
Igorsp
| 2023-11-18T18:01:16Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
] | null | 2023-11-18T18:01:09Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.3.dev0
|
Keynote-Technology/TinyKAI-3B-v0.1
|
Keynote-Technology
| 2023-11-18T18:00:29Z | 13 | 2 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"code",
"chatbot",
"dataset:Keynote-Technology/PLANE-2K",
"dataset:togethercomputer/RedPajama-Data-V2",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-10T00:24:51Z |
---
license: apache-2.0
datasets:
- Keynote-Technology/PLANE-2K
- togethercomputer/RedPajama-Data-V2
tags:
- code
- chatbot
- safetensors
---

TinyKAI 3B is a fine-tuned LLM (Large Language Model) based off of [OpenLlama 3B v2](https://huggingface.co/openlm-research/open_llama_3b_v2).
The TinyKAI models are a series of lightweight LLMs under 5 Billion parameters, usually used for research.
## Direct Use
TinyKAI 3B is optimal for research on large language models, specifically the influence of web data on the properties of large language models (fairness, safety, limitations, capabilities, etc.).
## Training
This model was trained on a mixture of the [Falcon refined-web dataset](https://huggingface.co/datasets/tiiuae/falcon-refinedweb), the [StarCoder dataset](https://huggingface.co/datasets/bigcode/starcoderdata) and the wikipedia, arxiv, book and stackexchange part of the [RedPajama dataset](https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T).
## Banned Use
Production use without adequate assessment of risks and mitigation; any use cases which may be considered irresponsible or harmful or insulting to anyone or any certain group.
TinyKAI-3B is governed by the [apache 2.0 liscense](https://choosealicense.com/licenses/apache-2.0/), and therefore means that whatever the license deems unacceptable shall not be allowed. We specificaly ban the use of [ANY AND ALL KAI MODELS](https://huggingface.co/collections/Keynote-Technology/kai-large-language-models) for hate speech towards a paricular thing, person, our particular group due to [legal](https://www.ftc.gov/news-events/news/press-releases/2022/06/ftc-report-warns-about-using-artificial-intelligence-combat-online-problems) and ethical issues.
## Limitations
TinyKAI 3B is trained on English data only, and will not generate appropriately reasonable content in other languages. Being trained on a representative of the web, it will carry the stereotypes and biases commonly encountered online.
## Recommendations
We recommend users of TinyKAI 3B to consider finetuning it for personal use, and for precautions to be taken for any commercial use.
## WARNING!
This model runs on an older version of transformers, v4.10.0, and therefore may be unstable.
|
TheBloke/sqlcoder-34b-alpha-GGUF
|
TheBloke
| 2023-11-18T17:56:03Z | 155 | 12 |
transformers
|
[
"transformers",
"gguf",
"llama",
"text-generation",
"en",
"base_model:defog/sqlcoder-34b-alpha",
"base_model:quantized:defog/sqlcoder-34b-alpha",
"license:cc-by-4.0",
"region:us"
] |
text-generation
| 2023-11-18T17:35:50Z |
---
base_model: defog/sqlcoder-34b-alpha
inference: false
language:
- en
license: cc-by-4.0
model_creator: Defog.ai
model_name: SQLCoder 34B Alpha
model_type: llama
pipeline_tag: text-generation
prompt_template: "## Task\nGenerate a SQL query to answer the following question:\n\
`{prompt}`\n\n### Database Schema\nThis query will run on a database whose schema\
\ is represented in this string:\nCREATE TABLE products (\n product_id INTEGER\
\ PRIMARY KEY, -- Unique ID for each product\n name VARCHAR(50), -- Name of the\
\ product\n price DECIMAL(10,2), -- Price of each unit of the product\n quantity\
\ INTEGER -- Current quantity in stock\n);\n\nCREATE TABLE sales (\n sale_id INTEGER\
\ PRIMARY KEY, -- Unique ID for each sale\n product_id INTEGER, -- ID of product\
\ sold\n customer_id INTEGER, -- ID of customer who made purchase\n salesperson_id\
\ INTEGER, -- ID of salesperson who made the sale\n sale_date DATE, -- Date the\
\ sale occurred\n quantity INTEGER -- Quantity of product sold\n);\n\n-- sales.product_id\
\ can be joined with products.product_id\n\n### SQL\nGiven the database schema,\
\ here is the SQL query that answers `{prompt}`:\n```sql\n"
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# SQLCoder 34B Alpha - GGUF
- Model creator: [Defog.ai](https://huggingface.co/defog)
- Original model: [SQLCoder 34B Alpha](https://huggingface.co/defog/sqlcoder-34b-alpha)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Defog.ai's SQLCoder 34B Alpha](https://huggingface.co/defog/sqlcoder-34b-alpha).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-GGUF)
* [Defog.ai's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/defog/sqlcoder-34b-alpha)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Sqlcoder
```
## Task
Generate a SQL query to answer the following question:
`{prompt}`
### Database Schema
This query will run on a database whose schema is represented in this string:
CREATE TABLE products (
product_id INTEGER PRIMARY KEY, -- Unique ID for each product
name VARCHAR(50), -- Name of the product
price DECIMAL(10,2), -- Price of each unit of the product
quantity INTEGER -- Current quantity in stock
);
CREATE TABLE sales (
sale_id INTEGER PRIMARY KEY, -- Unique ID for each sale
product_id INTEGER, -- ID of product sold
customer_id INTEGER, -- ID of customer who made purchase
salesperson_id INTEGER, -- ID of salesperson who made the sale
sale_date DATE, -- Date the sale occurred
quantity INTEGER -- Quantity of product sold
);
-- sales.product_id can be joined with products.product_id
### SQL
Given the database schema, here is the SQL query that answers `{prompt}`:
```sql
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `cc-by-4.0`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [Defog.ai's SQLCoder 34B Alpha](https://huggingface.co/defog/sqlcoder-34b-alpha).
<!-- licensing end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [sqlcoder-34b-alpha.Q2_K.gguf](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-GGUF/blob/main/sqlcoder-34b-alpha.Q2_K.gguf) | Q2_K | 2 | 14.21 GB| 16.71 GB | smallest, significant quality loss - not recommended for most purposes |
| [sqlcoder-34b-alpha.Q3_K_S.gguf](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-GGUF/blob/main/sqlcoder-34b-alpha.Q3_K_S.gguf) | Q3_K_S | 3 | 14.61 GB| 17.11 GB | very small, high quality loss |
| [sqlcoder-34b-alpha.Q3_K_M.gguf](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-GGUF/blob/main/sqlcoder-34b-alpha.Q3_K_M.gguf) | Q3_K_M | 3 | 16.28 GB| 18.78 GB | very small, high quality loss |
| [sqlcoder-34b-alpha.Q3_K_L.gguf](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-GGUF/blob/main/sqlcoder-34b-alpha.Q3_K_L.gguf) | Q3_K_L | 3 | 17.77 GB| 20.27 GB | small, substantial quality loss |
| [sqlcoder-34b-alpha.Q4_0.gguf](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-GGUF/blob/main/sqlcoder-34b-alpha.Q4_0.gguf) | Q4_0 | 4 | 19.05 GB| 21.55 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [sqlcoder-34b-alpha.Q4_K_S.gguf](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-GGUF/blob/main/sqlcoder-34b-alpha.Q4_K_S.gguf) | Q4_K_S | 4 | 19.15 GB| 21.65 GB | small, greater quality loss |
| [sqlcoder-34b-alpha.Q4_K_M.gguf](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-GGUF/blob/main/sqlcoder-34b-alpha.Q4_K_M.gguf) | Q4_K_M | 4 | 20.22 GB| 22.72 GB | medium, balanced quality - recommended |
| [sqlcoder-34b-alpha.Q5_0.gguf](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-GGUF/blob/main/sqlcoder-34b-alpha.Q5_0.gguf) | Q5_0 | 5 | 23.24 GB| 25.74 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [sqlcoder-34b-alpha.Q5_K_S.gguf](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-GGUF/blob/main/sqlcoder-34b-alpha.Q5_K_S.gguf) | Q5_K_S | 5 | 23.24 GB| 25.74 GB | large, low quality loss - recommended |
| [sqlcoder-34b-alpha.Q5_K_M.gguf](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-GGUF/blob/main/sqlcoder-34b-alpha.Q5_K_M.gguf) | Q5_K_M | 5 | 23.84 GB| 26.34 GB | large, very low quality loss - recommended |
| [sqlcoder-34b-alpha.Q6_K.gguf](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-GGUF/blob/main/sqlcoder-34b-alpha.Q6_K.gguf) | Q6_K | 6 | 27.68 GB| 30.18 GB | very large, extremely low quality loss |
| [sqlcoder-34b-alpha.Q8_0.gguf](https://huggingface.co/TheBloke/sqlcoder-34b-alpha-GGUF/blob/main/sqlcoder-34b-alpha.Q8_0.gguf) | Q8_0 | 8 | 35.86 GB| 38.36 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/sqlcoder-34b-alpha-GGUF and below it, a specific filename to download, such as: sqlcoder-34b-alpha.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/sqlcoder-34b-alpha-GGUF sqlcoder-34b-alpha.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/sqlcoder-34b-alpha-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/sqlcoder-34b-alpha-GGUF sqlcoder-34b-alpha.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m sqlcoder-34b-alpha.Q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "## Task\nGenerate a SQL query to answer the following question:\n`{prompt}`\n\n### Database Schema\nThis query will run on a database whose schema is represented in this string:\nCREATE TABLE products (\n product_id INTEGER PRIMARY KEY, -- Unique ID for each product\n name VARCHAR(50), -- Name of the product\n price DECIMAL(10,2), -- Price of each unit of the product\n quantity INTEGER -- Current quantity in stock\n);\n\nCREATE TABLE sales (\n sale_id INTEGER PRIMARY KEY, -- Unique ID for each sale\n product_id INTEGER, -- ID of product sold\n customer_id INTEGER, -- ID of customer who made purchase\n salesperson_id INTEGER, -- ID of salesperson who made the sale\n sale_date DATE, -- Date the sale occurred\n quantity INTEGER -- Quantity of product sold\n);\n\n-- sales.product_id can be joined with products.product_id\n\n### SQL\nGiven the database schema, here is the SQL query that answers `{prompt}`:\n```sql"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/sqlcoder-34b-alpha-GGUF", model_file="sqlcoder-34b-alpha.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Defog.ai's SQLCoder 34B Alpha
# Defog SQLCoder
**Updated on Nov 14 to reflect benchmarks for SQLCoder-34B**
Defog's SQLCoder is a state-of-the-art LLM for converting natural language questions to SQL queries.
[Interactive Demo](https://defog.ai/sqlcoder-demo/) | [🤗 HF Repo](https://huggingface.co/defog/sqlcoder-34b-alpha) | [♾️ Colab](https://colab.research.google.com/drive/1z4rmOEiFkxkMiecAWeTUlPl0OmKgfEu7?usp=sharing) | [🐦 Twitter](https://twitter.com/defogdata)
## TL;DR
SQLCoder-34B is a 34B parameter model that outperforms `gpt-4` and `gpt-4-turbo` for natural language to SQL generation tasks on our [sql-eval](https://github.com/defog-ai/sql-eval) framework, and significantly outperforms all popular open-source models.
SQLCoder-34B is fine-tuned on a base CodeLlama model.
## Results on novel datasets not seen in training
| model | perc_correct |
|-|-|
| defog-sqlcoder-34b | 84.0 |
| gpt4-turbo-2023-11-09 | 82.5 |
| gpt4-2023-11-09 | 82.5 |
| defog-sqlcoder2 | 77.5 |
| gpt4-2023-08-28 | 74.0 |
| defog-sqlcoder-7b | 71.0 |
| gpt-3.5-2023-10-04 | 66.0 |
| claude-2 | 64.5 |
| gpt-3.5-2023-08-28 | 61.0 |
| claude_instant_1 | 61.0 |
| text-davinci-003 | 52.5 |
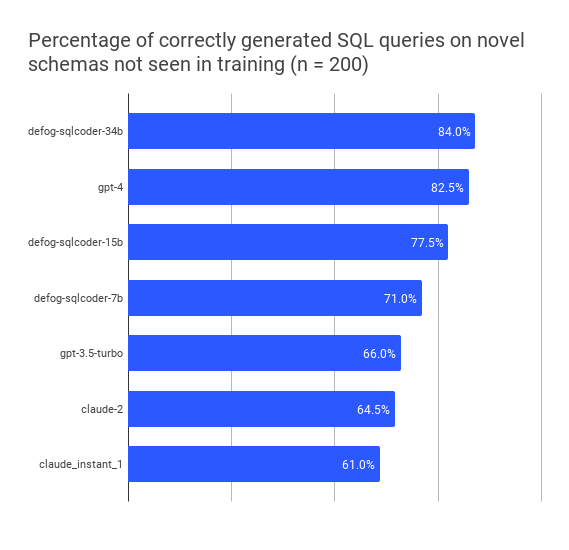
## License
The code in this repo (what little there is of it) is Apache-2 licensed. The model weights have a `CC BY-SA 4.0` license. The TL;DR is that you can use and modify the model for any purpose – including commercial use. However, if you modify the weights (for example, by fine-tuning), you must open-source your modified weights under the same license terms.
## Training
Defog was trained on more than 20,000 human-curated questions. These questions were based on 10 different schemas. None of the schemas in the training data were included in our evaluation framework.
You can read more about our [training approach](https://defog.ai/blog/open-sourcing-sqlcoder2-7b/) and [evaluation framework](https://defog.ai/blog/open-sourcing-sqleval/).
## Results by question category
We classified each generated question into one of 5 categories. The table displays the percentage of questions answered correctly by each model, broken down by category.
| | date | group_by | order_by | ratio | join | where |
| -------------- | ---- | -------- | -------- | ----- | ---- | ----- |
| sqlcoder-34b | 80 | 94.3 | 88.6 | 74.3 | 82.9 | 82.9 |
| gpt-4 | 68 | 94.3 | 85.7 | 77.1 | 85.7 | 80 |
| sqlcoder2-15b | 76 | 80 | 77.1 | 60 | 77.1 | 77.1 |
| sqlcoder-7b | 64 | 82.9 | 74.3 | 54.3 | 74.3 | 74.3 |
| gpt-3.5 | 68 | 77.1 | 68.6 | 37.1 | 71.4 | 74.3 |
| claude-2 | 52 | 71.4 | 74.3 | 57.1 | 65.7 | 62.9 |
| claude-instant | 48 | 71.4 | 74.3 | 45.7 | 62.9 | 60 |
| gpt-3 | 32 | 71.4 | 68.6 | 25.7 | 57.1 | 54.3 |
<img width="831" alt="image" src="https://github.com/defog-ai/sqlcoder/assets/5008293/79c5bdc8-373c-4abd-822e-e2c2569ed353">
## Using SQLCoder
You can use SQLCoder via the `transformers` library by downloading our model weights from the Hugging Face repo. We have added sample code for [inference](./inference.py) on a [sample database schema](./metadata.sql).
```bash
python inference.py -q "Question about the sample database goes here"
# Sample question:
# Do we get more revenue from customers in New York compared to customers in San Francisco? Give me the total revenue for each city, and the difference between the two.
```
You can also use a demo on our website [here](https://defog.ai/sqlcoder-demo)
## Hardware Requirements
SQLCoder-34B has been tested on a 4xA10 GPU with `float16` weights. You can also load an 8-bit and 4-bit quantized version of the model on consumer GPUs with 20GB or more of memory – like RTX 4090, RTX 3090, and Apple M2 Pro, M2 Max, or M2 Ultra Chips with 20GB or more of memory.
## Todo
- [x] Open-source the v1 model weights
- [x] Train the model on more data, with higher data variance
- [ ] Tune the model further with Reward Modelling and RLHF
- [ ] Pretrain a model from scratch that specializes in SQL analysis
<!-- original-model-card end -->
|
shakedr/colab_checkpoints
|
shakedr
| 2023-11-18T17:51:13Z | 6 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-18T17:50:58Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: colab_checkpoints
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# colab_checkpoints
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.1+cu121
- Tokenizers 0.15.0
|
codys12/Mistral-7b-Pathway-128k-3
|
codys12
| 2023-11-18T17:36:30Z | 0 | 0 | null |
[
"safetensors",
"endpoints_compatible",
"region:us"
] | null | 2023-11-16T17:06:36Z |
# Pseudo-Deterministic Chatbot with Mistral 7B
## Overview
This repository contains a fine-tuned version of the Mistral 7B model, specifically designed for creating pseudo-deterministic chatbots. The goal of this project is to enhance the predictability and consistency of chatbot responses while maintaining the flexibility and adaptability of the Mistral 7B model.
## Features
- **Fine-tuned Mistral 7B Model**: Leveraging the power of the Mistral 7B, our model is fine-tuned to offer more deterministic responses, ensuring consistency in conversational contexts.
- **Scalable Hugging Face Endpoint**: We provide a handler script for deploying the chatbot model on a scalable endpoint using Hugging Face's infrastructure. This setup is ideal for handling varying loads with efficient resource management. This can be deployed for public, protected, or private use with ASW privatelink. This handler script can also be used to serve the model on custom hardware.
- **Gradio Interface**: A Gradio demo is included, offering a user-friendly interface to interact with the chatbot. This demo can connect not only to our provided backend but also to any alternative backend setup.
## Getting Started
1. **Deploying the Model**:
You can deploy from the model repo ([here](https://huggingface.co/codys12/Mistral-7b-Pathway-128k-3/tree/main)) by clicking "Deploy" in the upper right corner.
or with [Inference Endpoints SDK](https://huggingface.co/docs/inference-endpoints/index)
3. **Running the Gradio Demo**:
You can deploy directly from hugginface or
*with Python:*
```python
import gradio as gr
gr.load("models/codys12/Mistral-7b-Pathway-128k-3").launch()
```
You can embed the space with the URL found in the upper right of the space with "Share"
```javascript
<iframe
src="https://your.hf.space"
frameborder="0"
width="850"
height="450"
></iframe>
```
## Usage
- **Model Interaction**:
```python
def generate(
message: str,
chat_history: list[tuple[str, str]],#Conversation history
system_prompt: str = "",
instruction: str = None,#The goal of the current conversation
conclusions: list[tuple[str, str]] = None,#AI classification of conversation ending
#^ Formatted: [["CONCLUSION_KEY","Conclusion criteria"]]
context: list[str] = None,#List of strings to be used as context. Indexes that were used will be returned.
max_new_tokens: int = 1024,#Max new tokens to generate
temperature: float = 0.6,#Temperature hyperparameter
top_p: float = 0.9,#Top-p hyperparameter
top_k: int = 50, #Top-k hyperparameter
repetition_penalty: float = 1.2, #Repitition hyperparameter
end_sequences: list[str] = ["[INST]", "[/INST]", "\n"]#Sequences that break the generation and return
```
- **Customization**: conversation topics and their possible ansers/paths are stored in topics.json. You can freely change this to fit a desired use case.
## License
This project is licensed under the Apache License, Version 2.0 - see the `LICENSE` file for details.
|
SiddhanthRaja/flan-t5-base-samsum-spotify-podcasts
|
SiddhanthRaja
| 2023-11-18T17:32:06Z | 7 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:philschmid/flan-t5-base-samsum",
"base_model:finetune:philschmid/flan-t5-base-samsum",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-11-18T15:12:01Z |
---
license: apache-2.0
base_model: philschmid/flan-t5-base-samsum
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5-base-samsum-spotify-podcasts
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-base-samsum-spotify-podcasts
This model is a fine-tuned version of [philschmid/flan-t5-base-samsum](https://huggingface.co/philschmid/flan-t5-base-samsum) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3026
- Rouge1: 0.27
- Rouge2: 0.1512
- Rougel: 0.2352
- Rougelsum: 0.2355
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 233 | 1.3963 | 0.2419 | 0.1266 | 0.2079 | 0.2077 | 19.0 |
| No log | 2.0 | 466 | 1.3356 | 0.2637 | 0.1432 | 0.2265 | 0.2263 | 19.0 |
| 1.6496 | 3.0 | 699 | 1.3088 | 0.2695 | 0.1491 | 0.2331 | 0.2331 | 19.0 |
| 1.6496 | 4.0 | 932 | 1.3026 | 0.27 | 0.1512 | 0.2352 | 0.2355 | 19.0 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.0.0
- Datasets 2.1.0
- Tokenizers 0.14.1
|
Keynote-Technology/TinyKAI-1B-v0.1
|
Keynote-Technology
| 2023-11-18T17:24:54Z | 18 | 3 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"falcon",
"text-generation",
"code",
"chatbot",
"custom_code",
"dataset:Keynote-Technology/PLANE-2K",
"dataset:togethercomputer/RedPajama-Data-V2",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-09T00:11:11Z |
---
license: apache-2.0
tags:
- code
- chatbot
datasets:
- Keynote-Technology/PLANE-2K
- togethercomputer/RedPajama-Data-V2
---
## TinyKAI 1B

TinyKAI 1B is a fine-tuned LLM (Large Language Model) based off of Falcon-rw-1B.
### Direct Use
TinyKAI 1B is optimal for research on large language models, specifically the influence of web data on the properties of large language models (fairness, safety, limitations, capabilities, etc.).
### Banned Use
Production use without adequate assessment of risks and mitigation; any use cases which may be considered irresponsible or harmful.
## Limitations
TinyKAI 1B is trained on English data only, and will not generate appropriately reasonable content in other languages. Being trained on a representative of the web, it will carry the stereotypes and biases commonly encountered online. In addition, KAI-1B has a very low output limit (less than 2 thousand characters) and struggles when asked to quote online sources.
## Recommendations
We recommend users of TinyKAI 1B to consider finetuning it for personal use, and for precautions to be taken for any commercial use.
## Banned Use
TinyKAI-1B is governed by the [apache 2.0 liscense](https://choosealicense.com/licenses/apache-2.0/), and therefore means that whatever the license deems unacceptable shall not be allowed. We specificaly ban the use of [ANY AND ALL KAI MODELS](https://huggingface.co/collections/Keynote-Technology/kai-large-language-models) for hate speech towards a paricular thing, person, our particular group due to [legal](https://www.ftc.gov/news-events/news/press-releases/2022/06/ftc-report-warns-about-using-artificial-intelligence-combat-online-problems) and ethical issues.
|
CarlBrendt/gpt-neox-20b_new
|
CarlBrendt
| 2023-11-18T17:21:45Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:EleutherAI/gpt-neox-20b",
"base_model:adapter:EleutherAI/gpt-neox-20b",
"region:us"
] | null | 2023-11-18T17:21:32Z |
---
library_name: peft
base_model: EleutherAI/gpt-neox-20b
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.3.dev0
|
snkai2004/ppo-Huggy
|
snkai2004
| 2023-11-18T17:21:14Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-11-18T17:21:14Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: snkai2004/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
SebastianSchramm/Cerebras-GPT-111M-instruction-sft-lora-merged-dpo-lora
|
SebastianSchramm
| 2023-11-18T17:18:20Z | 4 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:SebastianSchramm/Cerebras-GPT-111M-instruction-sft-lora-merged",
"base_model:finetune:SebastianSchramm/Cerebras-GPT-111M-instruction-sft-lora-merged",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-18T07:53:43Z |
---
base_model: SebastianSchramm/Cerebras-GPT-111M-instruction-sft-lora-merged
tags:
- generated_from_trainer
model-index:
- name: Cerebras-GPT-111M-instruction-sft-lora-merged-dpo-lora
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Cerebras-GPT-111M-instruction-sft-lora-merged-dpo-lora
This model is a fine-tuned version of [SebastianSchramm/Cerebras-GPT-111M-instruction-sft-lora-merged](https://huggingface.co/SebastianSchramm/Cerebras-GPT-111M-instruction-sft-lora-merged) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6203
- Rewards/chosen: 0.8184
- Rewards/rejected: 0.4678
- Rewards/accuracies: 0.6555
- Rewards/margins: 0.3506
- Logps/rejected: -797.4490
- Logps/chosen: -1064.1462
- Logits/rejected: -2.6967
- Logits/chosen: -2.9346
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 32
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.02
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.6555 | 0.34 | 300 | 0.6536 | 0.5523 | 0.3662 | 0.6271 | 0.1862 | -798.4653 | -1066.8068 | -2.7199 | -2.9594 |
| 0.615 | 0.68 | 600 | 0.6352 | 0.7267 | 0.4534 | 0.6380 | 0.2732 | -797.5925 | -1065.0635 | -2.7194 | -2.9580 |
| 0.6313 | 1.02 | 900 | 0.6278 | 0.7792 | 0.4662 | 0.6440 | 0.3131 | -797.4653 | -1064.5378 | -2.7117 | -2.9469 |
| 0.6218 | 1.36 | 1200 | 0.6295 | 0.7738 | 0.4669 | 0.6457 | 0.3069 | -797.4579 | -1064.5920 | -2.7035 | -2.9401 |
| 0.6311 | 1.71 | 1500 | 0.6212 | 0.7817 | 0.4456 | 0.6654 | 0.3361 | -797.6708 | -1064.5128 | -2.7073 | -2.9437 |
| 0.6107 | 2.05 | 1800 | 0.6223 | 0.8065 | 0.4674 | 0.6572 | 0.3391 | -797.4526 | -1064.2653 | -2.7009 | -2.9373 |
| 0.6146 | 2.39 | 2100 | 0.6190 | 0.8141 | 0.4648 | 0.6698 | 0.3494 | -797.4793 | -1064.1887 | -2.6988 | -2.9353 |
| 0.6347 | 2.73 | 2400 | 0.6214 | 0.8118 | 0.4631 | 0.6654 | 0.3487 | -797.4959 | -1064.2124 | -2.6962 | -2.9342 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0+cu121
- Datasets 2.14.6
- Tokenizers 0.14.1
|
shadowlilac/aesthetic-shadow
|
shadowlilac
| 2023-11-18T17:18:09Z | 470 | 26 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"vit",
"image-classification",
"anime",
"quality assurance",
"dataset maintenance",
"license:unknown",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-19T17:46:35Z |
---
license: unknown
tags:
- anime
- quality assurance
- dataset maintenance
---
# Aesthetic Shadow
Aesthetic Shadow is a 1.1b parameters visual transformer designed to evaluate the quality of anime images. It accepts high-resolution 1024x1024 images as input and provides a prediction score that quantifies the aesthetic appeal of the artwork. Leveraging cutting-edge deep learning techniques, this model excels at discerning fine details, proportions, and overall visual coherence in anime illustrations.
**If you do decide to use this model for public stuff, attribution would be appreciated :)**
## How to Use
See Jupyter Notebook in files
## Disclosure
This model does not intend to be offensive towards any artist and may not output an accurate label for an image. A potential use case would be low quality images filtering on image datasets.
|
aosaf/whisper-small-ur
|
aosaf
| 2023-11-18T17:15:20Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice_11_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-11-03T05:13:03Z |
---
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- common_voice_11_0
metrics:
- wer
model-index:
- name: whisper-small-ur
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: common_voice_11_0
type: common_voice_11_0
config: ur
split: test
args: ur
metrics:
- name: Wer
type: wer
value: 73.53225744030341
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-ur
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the common_voice_11_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6126
- Wer: 73.5323
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1822 | 2.15 | 1000 | 0.5155 | 83.0527 |
| 0.0936 | 4.3 | 2000 | 0.5396 | 83.3353 |
| 0.0166 | 6.46 | 3000 | 0.6126 | 73.5323 |
| 0.0039 | 8.6 | 4000 | 0.6600 | 100.6153 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
geldarr/saiga-Yarn-Llama-2-7b-64k
|
geldarr
| 2023-11-18T17:09:21Z | 70 | 4 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"question-answering",
"custom_code",
"ru",
"dataset:IlyaGusev/gazeta",
"dataset:IlyaGusev/ru_turbo_alpaca_evol_instruct",
"dataset:IlyaGusev/ru_turbo_alpaca",
"dataset:IlyaGusev/ru_turbo_saiga",
"dataset:RussianNLP/russian_super_glue",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-11-18T12:40:10Z |
---
license: apache-2.0
datasets:
- IlyaGusev/gazeta
- IlyaGusev/ru_turbo_alpaca_evol_instruct
- IlyaGusev/ru_turbo_alpaca
- IlyaGusev/ru_turbo_saiga
- RussianNLP/russian_super_glue
language:
- ru
pipeline_tag: question-answering
---
The model was trained on part of the datasets
*IlyaGusev/gazeta* ,
*IlyaGusev/ru_turbo_alpaca_evol_instruct*,
*IlyaGusev/ru_turbo_alpaca*,
*IlyaGusev/ru_turbo_saiga* ,
*RussianNLP/russian_super_glue (muserc)*
using LoRA
#### Base_model NousResearch/Yarn-Llama-2-7b-64k
#### Need cuda > 11.4
### GPU A100
```python
!pip install peft
!pip install flash-attn --no-build-isolation
!pip install git+https://github.com/HazyResearch/flash-attention.git#subdirectory=csrc/rotary
```
```python
model = AutoModelForCausalLM.from_pretrained(
'geldarr/saiga-Yarn-Llama-2-7b-64k',
trust_remote_code=True,
torch_dtype=torch.float16,
device_map={'':0}
)
tokenizer = AutoTokenizer.from_pretrained('geldarr/saiga-Yarn-Llama-2-7b-64k', use_fast=False)
```
```python
big_prompts = '''<s>system\nТы — Сайга, русскоязычный автоматический ассистент. Ты разговариваешь с людьми и помогаешь им.</s>\n
<s>user
Дай ответы на вопрос основываясь только на тексте ниже:\n
вопрос?
Текст <65536 tokens
</s>
<s>bot
'''
```python
gen_config = {
"pad_token_id": 0,
"bos_token_id": 1,
"eos_token_id": 2,
"temperature": 0.4,
"top_p": 0.9,
"top_k": 50,
"do_sample": True,
"max_new_tokens": 15360,
"repetition_penalty": 1.1,
"no_repeat_ngram_size": 15,
}
generation_config = GenerationConfig.from_dict(gen_config)
```
```python
def generate(model, tokenizer, prompt, generation_config):
data = tokenizer(prompt, return_tensors="pt")
data = {k: v.to(model.device) for k, v in data.items()}
output_ids = model.generate(
**data,
generation_config=generation_config
)[0]
output_ids = output_ids[len(data["input_ids"][0]):]
output = tokenizer.decode(output_ids)
return output.strip()
output = generate(model, tokenizer, big_prompts, generation_config)
print(output)
```
|
SamDNX/Unity-ml-agents
|
SamDNX
| 2023-11-18T17:00:18Z | 4 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-11-18T17:00:04Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: SamDNX/Unity-ml-agents
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
MohamedRashad/AceGPT-13B-chat-AWQ
|
MohamedRashad
| 2023-11-18T16:55:52Z | 57 | 3 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"ar",
"dataset:FreedomIntelligence/Arabic-Vicuna-80",
"dataset:FreedomIntelligence/Arabic-AlpacaEval",
"dataset:FreedomIntelligence/MMLU_Arabic",
"dataset:FreedomIntelligence/EXAMs",
"dataset:FreedomIntelligence/ACVA-Arabic-Cultural-Value-Alignment",
"base_model:FreedomIntelligence/AceGPT-13B-chat",
"base_model:quantized:FreedomIntelligence/AceGPT-13B-chat",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"awq",
"region:us"
] |
text-generation
| 2023-11-16T08:01:43Z |
---
base_model: FreedomIntelligence/AceGPT-13B-chat
inference: false
license: llama2
model_creator: FreedomIntelligence
model_name: AceGPT 13B chat
model_type: llama2
quantized_by: MohamedRashad
datasets:
- FreedomIntelligence/Arabic-Vicuna-80
- FreedomIntelligence/Arabic-AlpacaEval
- FreedomIntelligence/MMLU_Arabic
- FreedomIntelligence/EXAMs
- FreedomIntelligence/ACVA-Arabic-Cultural-Value-Alignment
language:
- en
- ar
library_name: transformers
---
<center>
<img src="https://i.pinimg.com/564x/b1/6b/fd/b16bfd356bb55de1b1b911a4a04fb9a6.jpg">
</center>
# AceGPT 13B Chat - AWQ
- Model creator: [FreedomIntelligence](https://huggingface.co/FreedomIntelligence)
- Original model: [AceGPT 13B Chat](https://huggingface.co/FreedomIntelligence/AceGPT-13B-chat)
<!-- description start -->
## Description
This repo contains AWQ model files for [FreedomIntelligence's AceGPT 13B Chat](https://huggingface.co/FreedomIntelligence/AceGPT-13B-chat).
In my effort of making Arabic LLms Available for consumers with simple GPUs I have Quantized two important models:
- [AceGPT 13B Chat AWQ](https://huggingface.co/MohamedRashad/AceGPT-13B-chat-AWQ) **(We are Here)**
- [AceGPT 7B Chat AWQ](https://huggingface.co/MohamedRashad/AceGPT-7B-chat-AWQ)
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - Llama and Mistral models only
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later, from any code or client that supports Transformers
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
<!-- description end -->
<!-- prompt-template start -->
## Prompt template: Unknown
```
[INST] <<SYS>>\nأنت مساعد مفيد ومحترم وصادق. أجب دائما بأكبر قدر ممكن من المساعدة بينما تكون آمنا. يجب ألا تتضمن إجاباتك أي محتوى ضار أو غير أخلاقي أو عنصري أو جنسي أو سام أو خطير أو غير قانوني. يرجى التأكد من أن ردودك غير متحيزة اجتماعيا وإيجابية بطبيعتها.\n\nإذا كان السؤال لا معنى له أو لم يكن متماسكا من الناحية الواقعية، اشرح السبب بدلا من الإجابة على شيء غير صحيح. إذا كنت لا تعرف إجابة سؤال ما، فيرجى عدم مشاركة معلومات خاطئة.\n<</SYS>>\n\n
[INST] {prompt} [/INST]
```
<!-- prompt-template end -->
<!-- README_AWQ.md-use-from-python start -->
## Inference from Python code using Transformers
### Install the necessary packages
- Requires: [Transformers](https://huggingface.co/docs/transformers) 4.35.0 or later.
- Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.6 or later.
```shell
pip3 install --upgrade "autoawq>=0.1.6" "transformers>=4.35.0"
```
Note that if you are using PyTorch 2.0.1, the above AutoAWQ command will automatically upgrade you to PyTorch 2.1.0.
If you are using CUDA 11.8 and wish to continue using PyTorch 2.0.1, instead run this command:
```shell
pip3 install https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp310-cp310-linux_x86_64.whl
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### Transformers example code (requires Transformers 4.35.0 and later)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_name_or_path = "MohamedRashad/AceGPT-13B-chat-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side="right")
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
use_flash_attention_2=True, # disable if you have problems with flash attention 2
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto"
)
# Using the text streamer to stream output one token at a time
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = "ما أجمل بيت شعر فى اللغة العربية ؟"
prompt_template=f'''[INST] <<SYS>>\nأنت مساعد مفيد ومحترم وصادق. أجب دائما بأكبر قدر ممكن من المساعدة بينما تكون آمنا. يجب ألا تتضمن إجاباتك أي محتوى ضار أو غير أخلاقي أو عنصري أو جنسي أو سام أو خطير أو غير قانوني. يرجى التأكد من أن ردودك غير متحيزة اجتماعيا وإيجابية بطبيعتها.\n\nإذا كان السؤال لا معنى له أو لم يكن متماسكا من الناحية الواقعية، اشرح السبب بدلا من الإجابة على شيء غير صحيح. إذا كنت لا تعرف إجابة سؤال ما، فيرجى عدم مشاركة معلومات خاطئة.\n<</SYS>>\n\n
[INST] {prompt} [/INST]
'''
# Convert prompt to tokens
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
generation_params = {
"do_sample": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": 512,
"repetition_penalty": 1.1
}
# Generate streamed output, visible one token at a time
generation_output = model.generate(
tokens,
streamer=streamer,
**generation_params
)
# Generation without a streamer, which will include the prompt in the output
generation_output = model.generate(
tokens,
**generation_params
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
print("model.generate output: ", text_output)
# Inference is also possible via Transformers' pipeline
from transformers import pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
**generation_params
)
pipe_output = pipe(prompt_template)[0]['generated_text']
print("pipeline output: ", pipe_output)
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-provided-files start -->
## How AWQ Quantization happened ?
```python
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "FreedomIntelligence/AceGPT-13B-chat"
quant_path = "AceGPT-13B-chat-AWQ"
quant_config = {"zero_point": True, "q_group_size": 128, "w_bit": 4, "version": "GEMM"}
load_config = {
"low_cpu_mem_usage": True,
"device_map": "auto",
"trust_remote_code": True,
}
# Load model
model = AutoAWQForCausalLM.from_pretrained(model_path, **load_config)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# Quantize
model.quantize(tokenizer, quant_config=quant_config)
# Save quantized model
model.save_quantized(quant_path)
tokenizer.save_pretrained(quant_path)
# Load quantized model
model = AutoModelForCausalLM.from_pretrained(quant_path)
tokenizer = AutoTokenizer.from_pretrained(quant_path)
# Push to hub
model.push_to_hub(quant_path)
tokenizer.push_to_hub(quant_path)
```
<!-- README_AWQ.md-provided-files end -->
|
Jiahahaha/test2_1w
|
Jiahahaha
| 2023-11-18T16:48:39Z | 0 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-11-18T12:43:58Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: a photo of polyp
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - Jiahahaha/test2_1w
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were trained on a photo of polyp using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
|
SpartanLondoner/q-Taxi-v3
|
SpartanLondoner
| 2023-11-18T16:44:28Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-18T16:44:27Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.50 +/- 2.94
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="SpartanLondoner/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
CodeinJax/bert-base-uncased-finetuned-sst2
|
CodeinJax
| 2023-11-18T16:43:33Z | 5 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-11-18T16:43:12Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: bert-base-uncased-finetuned-sst2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: sst2
split: validation
args: sst2
metrics:
- name: Accuracy
type: accuracy
value: 0.926605504587156
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-sst2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4431
- Accuracy: 0.9266
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.1848 | 1.0 | 4210 | 0.2654 | 0.9174 |
| 0.1284 | 2.0 | 8420 | 0.2868 | 0.9151 |
| 0.0969 | 3.0 | 12630 | 0.3735 | 0.9163 |
| 0.0504 | 4.0 | 16840 | 0.4365 | 0.9209 |
| 0.0322 | 5.0 | 21050 | 0.4431 | 0.9266 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
SergeyRad/Restorane
|
SergeyRad
| 2023-11-18T16:40:56Z | 0 | 0 |
asteroid
|
[
"asteroid",
"art",
"ab",
"av",
"dataset:HuggingFaceH4/no_robots",
"license:afl-3.0",
"region:us"
] | null | 2023-11-18T16:39:45Z |
---
license: afl-3.0
datasets:
- HuggingFaceH4/no_robots
language:
- ab
- av
metrics:
- brier_score
library_name: asteroid
tags:
- art
---
|
Igorsp/mistral_b_finetuned_sql
|
Igorsp
| 2023-11-18T16:39:12Z | 11 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:adapter:mistralai/Mistral-7B-v0.1",
"region:us"
] | null | 2023-11-18T16:39:04Z |
---
library_name: peft
base_model: mistralai/Mistral-7B-v0.1
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.3.dev0
|
mubashirsaeed/care-bot-harry-falcon-1b-3
|
mubashirsaeed
| 2023-11-18T16:36:12Z | 2 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:tiiuae/falcon-rw-1b",
"base_model:adapter:tiiuae/falcon-rw-1b",
"region:us"
] | null | 2023-11-18T16:36:10Z |
---
library_name: peft
base_model: tiiuae/falcon-rw-1b
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.3.dev0
|
TheBloke/opus-v0.5-70B-AWQ
|
TheBloke
| 2023-11-18T16:28:03Z | 13 | 1 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"base_model:dreamgen/opus-v0.5-70b",
"base_model:quantized:dreamgen/opus-v0.5-70b",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"awq",
"region:us"
] |
text-generation
| 2023-11-18T14:20:29Z |
---
base_model: dreamgen/opus-v0.5-70b
inference: false
language:
- en
license: llama2
model_creator: DreamGen
model_name: Opus V0.5 70B
model_type: llama
pipeline_tag: text-generation
prompt_template: '<setting>
{system_message}
</setting>
<instruction>
{prompt}
</instruction>
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Opus V0.5 70B - AWQ
- Model creator: [DreamGen](https://huggingface.co/dreamgen)
- Original model: [Opus V0.5 70B](https://huggingface.co/dreamgen/opus-v0.5-70b)
<!-- description start -->
## Description
This repo contains AWQ model files for [DreamGen's Opus V0.5 70B](https://huggingface.co/dreamgen/opus-v0.5-70b).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - Llama and Mistral models only
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later, from any code or client that supports Transformers
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/opus-v0.5-70B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/opus-v0.5-70B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/opus-v0.5-70B-GGUF)
* [DreamGen's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/dreamgen/opus-v0.5-70b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: DreamGen
```
<setting>
{system_message}
</setting>
<instruction>
{prompt}
</instruction>
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
I currently release 128g GEMM models only. The addition of group_size 32 models, and GEMV kernel models, is being actively considered.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/opus-v0.5-70B-AWQ/tree/main) | 4 | 128 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-raw-v1) | 4096 | 36.61 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/opus-v0.5-70B-AWQ`.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `opus-v0.5-70B-AWQ`
7. Select **Loader: AutoAWQ**.
8. Click Load, and the model will load and is now ready for use.
9. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
10. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_AWQ.md-text-generation-webui end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Multi-user inference server: vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- Please ensure you are using vLLM version 0.2 or later.
- When using vLLM as a server, pass the `--quantization awq` parameter.
For example:
```shell
python3 -m vllm.entrypoints.api_server --model TheBloke/opus-v0.5-70B-AWQ --quantization awq --dtype auto
```
- When using vLLM from Python code, again set `quantization=awq`.
For example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Tell me about AI",
"Write a story about llamas",
"What is 291 - 150?",
"How much wood would a woodchuck chuck if a woodchuck could chuck wood?",
]
prompt_template=f'''<setting>
{system_message}
</setting>
<instruction>
{prompt}
</instruction>
'''
prompts = [prompt_template.format(prompt=prompt) for prompt in prompts]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/opus-v0.5-70B-AWQ", quantization="awq", dtype="auto")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Multi-user inference server: Hugging Face Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/opus-v0.5-70B-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires [huggingface-hub](https://github.com/huggingface/huggingface_hub) 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''<setting>
{system_message}
</setting>
<instruction>
{prompt}
</instruction>
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: ", response)
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## Inference from Python code using Transformers
### Install the necessary packages
- Requires: [Transformers](https://huggingface.co/docs/transformers) 4.35.0 or later.
- Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.6 or later.
```shell
pip3 install --upgrade "autoawq>=0.1.6" "transformers>=4.35.0"
```
Note that if you are using PyTorch 2.0.1, the above AutoAWQ command will automatically upgrade you to PyTorch 2.1.0.
If you are using CUDA 11.8 and wish to continue using PyTorch 2.0.1, instead run this command:
```shell
pip3 install https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp310-cp310-linux_x86_64.whl
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### Transformers example code (requires Transformers 4.35.0 and later)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_name_or_path = "TheBloke/opus-v0.5-70B-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
low_cpu_mem_usage=True,
device_map="cuda:0"
)
# Using the text streamer to stream output one token at a time
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = "Tell me about AI"
prompt_template=f'''<setting>
{system_message}
</setting>
<instruction>
{prompt}
</instruction>
'''
# Convert prompt to tokens
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
generation_params = {
"do_sample": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": 512,
"repetition_penalty": 1.1
}
# Generate streamed output, visible one token at a time
generation_output = model.generate(
tokens,
streamer=streamer,
**generation_params
)
# Generation without a streamer, which will include the prompt in the output
generation_output = model.generate(
tokens,
**generation_params
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
print("model.generate output: ", text_output)
# Inference is also possible via Transformers' pipeline
from transformers import pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
**generation_params
)
pipe_output = pipe(prompt_template)[0]['generated_text']
print("pipeline output: ", pipe_output)
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui) using `Loader: AutoAWQ`.
- [vLLM](https://github.com/vllm-project/vllm) version 0.2.0 and later.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) version 1.1.0 and later.
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later.
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) version 0.1.1 and later.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: DreamGen's Opus V0.5 70B
# DreamGen Opus V0 70B
**DreamGen Opus** is a family of **uncensored** models fine-tuned for **(steerable) story writing** and the model also works great for **chat / RP**.
The DreamGen Opus V0.5 70B model is derived from [meta-llama/Llama-2-70b-hf](https://huggingface.co/meta-llama/Llama-2-70b-hf).
You can **try the Opus V0 70B** (AWQ) model for free on [dreamgen.com](https://dreamgen.com).
Other sizes:
- 7B: [dreamgen/opus-v0-7b](https://huggingface.co/dreamgen/opus-v0-7b)
## Difference from [dreamgen/opus-v0-70b](https://huggingface.co/dreamgen/opus-v0-70b)
The model should be even better at role-play and chat, and be slighly more "open-minded" in NSFW contexts.
## Prompting
Please see the [official documentation](https://dreamgen.com/docs/stories) for more detailed guide, including how to prompt the model for chat / RP.
The (collaborative / steerable) story writing task teaches the model to respect `<setting>` and `<instruction>` inserted into the prompt.
Example prompt:
```
<setting>
(Setting provides general overview of the story and characters)
This story is a twist on the traditional Little Red Riding Hood story.
In this variation, the Little Red Riding Hood and her grandma are secretely werevoles.
</setting>
(Previous part of the story, potentially empty)
<instruction>
(Setting tells the model what should happen in the next few sentences / paragraphs)
The Little Red Riding hood confronts The Big Bad Wolf, transforming into her wolf form.
</instruction>
```
## Dataset
The fine-tuning dataset consisted of >1M tokens of collaborative writing task examples, each example being up to 4096 tokens. On top of that, >20M tokens of more general, but less instructed examples were included to help preserve generalization.
All prose in the dataset is from actual humans, not AI generated.
## Community
Join the DreamGen community on [**Discord**](https://dreamgen.com/discord), or follow our [**X/Twitter account**](https://dreamgen.com/twitter) for new model releases and other news.
We will soon be releasing models with longer context window, as well as models specifically fine-tuned for character chat & roleplay.
Help us shape the future of DreamGen.
## Running the model
The model is should be compatible with any software that supports [meta-llama/Llama-2-70b-hf](https://huggingface.co/meta-llama/Llama-2-70b-hf).
Note that because this is a 70B model, the resource requirements are large. You can try the quantized versions linked at the top, but expect a quality drop.
### Running on DreamGen.com (free)
You can try the 70B (AWQ) model for free at [dreamgen.com](https://dreamgen.com) — note that an account is required.
The version used for the website is the official AWQ 4bit quant [dreamgen/opus-v0-70b-awq](https://huggingface.co/dreamgen/opus-v0-70b-awq).
## License
- For personal and academic use: Same license as the base model, in this case https://ai.meta.com/resources/models-and-libraries/llama-downloads/.
- For commercial use: Please reach out to hello@dreamgen.com.
|
abduldattijo/videomae-base-finetuned-kinetics-V6KILLER
|
abduldattijo
| 2023-11-18T16:15:44Z | 7 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"videomae",
"video-classification",
"generated_from_trainer",
"base_model:MCG-NJU/videomae-base-finetuned-kinetics",
"base_model:finetune:MCG-NJU/videomae-base-finetuned-kinetics",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] |
video-classification
| 2023-11-18T07:26:59Z |
---
license: cc-by-nc-4.0
base_model: MCG-NJU/videomae-base-finetuned-kinetics
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: videomae-base-finetuned-kinetics-V6KILLER
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-base-finetuned-kinetics-V6KILLER
This model is a fine-tuned version of [MCG-NJU/videomae-base-finetuned-kinetics](https://huggingface.co/MCG-NJU/videomae-base-finetuned-kinetics) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1568
- Accuracy: 0.9508
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 15
- eval_batch_size: 15
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1861 | 0.1 | 51 | 0.1321 | 0.9549 |
| 0.2014 | 1.1 | 102 | 0.1460 | 0.9416 |
| 0.0963 | 2.1 | 153 | 0.2060 | 0.9240 |
| 0.1975 | 3.1 | 204 | 0.2031 | 0.9382 |
| 0.1017 | 4.1 | 255 | 0.1010 | 0.9574 |
| 0.1589 | 5.1 | 306 | 0.2064 | 0.9073 |
| 0.0272 | 6.1 | 357 | 0.1119 | 0.9549 |
| 0.0424 | 7.1 | 408 | 0.1136 | 0.9591 |
| 0.0239 | 8.1 | 459 | 0.2198 | 0.9416 |
| 0.0897 | 9.08 | 500 | 0.1715 | 0.9533 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.1+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
ZivK/q-Taxi-v3-v2
|
ZivK
| 2023-11-18T16:13:32Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-18T16:13:29Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3-v2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="ZivK/q-Taxi-v3-v2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
SpartanLondoner/q-FrozenLake-v1-4x4-noSlippery
|
SpartanLondoner
| 2023-11-18T16:10:20Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-18T16:10:18Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="SpartanLondoner/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
ZoninSh/openhermes-mistral-dpo-gptq
|
ZoninSh
| 2023-11-18T16:05:07Z | 0 | 0 | null |
[
"tensorboard",
"safetensors",
"generated_from_trainer",
"base_model:TheBloke/OpenHermes-2-Mistral-7B-GPTQ",
"base_model:finetune:TheBloke/OpenHermes-2-Mistral-7B-GPTQ",
"license:apache-2.0",
"region:us"
] | null | 2023-11-18T15:07:47Z |
---
license: apache-2.0
base_model: TheBloke/OpenHermes-2-Mistral-7B-GPTQ
tags:
- generated_from_trainer
model-index:
- name: openhermes-mistral-dpo-gptq
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openhermes-mistral-dpo-gptq
This model is a fine-tuned version of [TheBloke/OpenHermes-2-Mistral-7B-GPTQ](https://huggingface.co/TheBloke/OpenHermes-2-Mistral-7B-GPTQ) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2500
- Rewards/chosen: -1.0975
- Rewards/rejected: -1.6306
- Rewards/accuracies: 0.625
- Rewards/margins: 0.5331
- Logps/rejected: -307.3866
- Logps/chosen: -331.8629
- Logits/rejected: -2.4077
- Logits/chosen: -2.3038
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2
- training_steps: 300
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 4.2921 | 0.03 | 50 | 9.8028 | -5.3862 | 0.1060 | 0.1875 | -5.4922 | -290.0201 | -374.7499 | -2.2861 | -2.1795 |
| 9.75 | 0.05 | 100 | 8.8191 | -12.7493 | -8.6505 | 0.3125 | -4.0989 | -377.5849 | -448.3811 | -2.2836 | -2.2309 |
| 3.2104 | 0.07 | 150 | 0.8915 | -3.5710 | -6.0350 | 0.375 | 2.4640 | -351.4305 | -356.5982 | -2.6543 | -2.5955 |
| 2.655 | 0.1 | 200 | 0.3207 | -1.0209 | -4.6027 | 0.6875 | 3.5818 | -337.1074 | -331.0971 | -2.4341 | -2.3534 |
| 4.8481 | 0.12 | 250 | 1.1311 | -0.8147 | -2.3072 | 0.625 | 1.4926 | -314.1525 | -329.0346 | -2.3257 | -2.2374 |
| 3.1598 | 0.15 | 300 | 3.2500 | -1.0975 | -1.6306 | 0.625 | 0.5331 | -307.3866 | -331.8629 | -2.4077 | -2.3038 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.0.1+cu117
- Datasets 2.15.0
- Tokenizers 0.15.0
|
priya17/fine-tuned-qna
|
priya17
| 2023-11-18T15:49:41Z | 0 | 0 |
peft
|
[
"peft",
"arxiv:1910.09700",
"base_model:Bhautiksinh/BertPretrain",
"base_model:adapter:Bhautiksinh/BertPretrain",
"region:us"
] | null | 2023-11-18T13:22:49Z |
---
library_name: peft
base_model: Bhautiksinh/BertPretrain
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
### Framework versions
- PEFT 0.6.2
|
kornwtp/ConGen-paraphrase-multilingual-mpnet-base-v2
|
kornwtp
| 2023-11-18T15:43:31Z | 362 | 3 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"camembert",
"feature-extraction",
"sentence-similarity",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-12-06T05:47:17Z |
---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# kornwtp/ConGen-paraphrase-multilingual-mpnet-base-v2
This is a [ConGen](https://github.com/KornWtp/ConGen) model: It maps sentences to a 768 dimensional dense vector space and can be used for tasks like semantic search.
## Usage
Using this model becomes easy when you have [ConGen](https://github.com/KornWtp/ConGen) installed:
```
pip install -U git+https://github.com/KornWtp/ConGen.git
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["กลุ่มผู้ชายเล่นฟุตบอลบนชายหาด", "กลุ่มเด็กชายกำลังเล่นฟุตบอลบนชายหาด"]
model = SentenceTransformer('kornwtp/ConGen-paraphrase-multilingual-mpnet-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Thai Sentence Embeddings Benchmark*: [Semantic Textual Similarity](https://github.com/KornWtp/ConGen#thai-semantic-textual-similarity-benchmark)
## Citing & Authors
```bibtex
@inproceedings{limkonchotiwat-etal-2022-congen,
title = "{ConGen}: Unsupervised Control and Generalization Distillation For Sentence Representation",
author = "Limkonchotiwat, Peerat and
Ponwitayarat, Wuttikorn and
Lowphansirikul, Lalita and
Udomcharoenchaikit, Can and
Chuangsuwanich, Ekapol and
Nutanong, Sarana",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2022",
year = "2022",
publisher = "Association for Computational Linguistics",
}
```
|
OsherElhadad/Taxi-v3-exp2
|
OsherElhadad
| 2023-11-18T15:36:52Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-11-18T15:19:12Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3-exp2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="OsherElhadad/Taxi-v3-exp2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
chernandezc/distilbert-base-uncased-finetuned-items-two
|
chernandezc
| 2023-11-18T15:32:39Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-10-25T21:17:10Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-items-two
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-items-two
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8258
- Accuracy: 0.7212
- F1: 0.7198
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 30
- eval_batch_size: 30
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 1.8573 | 1.0 | 32 | 1.6788 | 0.4135 | 0.3052 |
| 1.6314 | 2.0 | 64 | 1.4137 | 0.5385 | 0.4754 |
| 1.3618 | 3.0 | 96 | 1.2564 | 0.5577 | 0.5178 |
| 1.1231 | 4.0 | 128 | 1.0664 | 0.6538 | 0.6454 |
| 0.9382 | 5.0 | 160 | 0.9553 | 0.6923 | 0.6864 |
| 0.7879 | 6.0 | 192 | 0.8792 | 0.6923 | 0.6891 |
| 0.6616 | 7.0 | 224 | 0.8642 | 0.7019 | 0.6978 |
| 0.5844 | 8.0 | 256 | 0.8376 | 0.7115 | 0.7092 |
| 0.5289 | 9.0 | 288 | 0.8349 | 0.7115 | 0.7074 |
| 0.4673 | 10.0 | 320 | 0.8258 | 0.7212 | 0.7198 |
### Framework versions
- Transformers 4.34.1
- Pytorch 2.1.0+cu118
- Datasets 2.14.6
- Tokenizers 0.14.1
|
eyalmazuz/HebArbT5
|
eyalmazuz
| 2023-11-18T15:24:39Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"t5",
"text2text-generation",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-12-25T18:08:32Z |
---
license: mit
---
Translates from Hebrew to Arabic
T5-base model that was trained on TED talks (around 347k sentences) Using a 37k unigram wordpiece shared vocabulary
|
alecwangcq/zephyr-7b-sft-full
|
alecwangcq
| 2023-11-18T15:24:29Z | 10 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"mistral",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:finetune:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-11-18T04:00:45Z |
---
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.1
tags:
- generated_from_trainer
model-index:
- name: zephyr-7b-sft-full
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# zephyr-7b-sft-full
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0683
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 512
- total_eval_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.0771 | 0.26 | 31 | 1.0666 |
### Framework versions
- Transformers 4.35.0
- Pytorch 2.1.0
- Datasets 2.14.6
- Tokenizers 0.14.1
|
CarlBrendt/llama-7b-hf_new
|
CarlBrendt
| 2023-11-18T15:17:45Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:baffo32/decapoda-research-llama-7B-hf",
"base_model:adapter:baffo32/decapoda-research-llama-7B-hf",
"region:us"
] | null | 2023-11-18T15:17:39Z |
---
library_name: peft
base_model: baffo32/decapoda-research-llama-7B-hf
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: True
- load_in_4bit: False
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: fp4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float32
### Framework versions
- PEFT 0.6.3.dev0
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.