
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-27 18:28:06
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 523
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-27 18:27:40
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
rahul77/pegasus-large-finetuned-rahulver-summarization-pegasus-model
|
rahul77
| 2022-12-09T21:07:11Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-12-09T19:27:29Z |
---
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: pegasus-large-finetuned-rahulver-summarization-pegasus-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pegasus-large-finetuned-rahulver-summarization-pegasus-model
This model is a fine-tuned version of [google/pegasus-large](https://huggingface.co/google/pegasus-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0906
- Rouge1: 61.2393
- Rouge2: 43.8277
- Rougel: 50.0054
- Rougelsum: 57.4674
- Gen Len: 114.6
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:--------:|
| 1.3648 | 1.0 | 140 | 0.7201 | 50.0081 | 32.6454 | 39.3021 | 45.1602 | 125.7333 |
| 0.8502 | 2.0 | 280 | 0.6067 | 57.8678 | 41.5251 | 46.0694 | 54.1055 | 128.3333 |
| 0.5053 | 3.0 | 420 | 0.6642 | 58.3644 | 41.8619 | 47.6199 | 54.1639 | 108.9667 |
| 0.3469 | 4.0 | 560 | 0.7318 | 61.8988 | 45.7303 | 51.1928 | 57.9306 | 123.1667 |
| 0.2779 | 5.0 | 700 | 0.7274 | 62.9354 | 46.5 | 51.6431 | 59.2443 | 99.6333 |
| 0.2124 | 6.0 | 840 | 0.8618 | 63.8552 | 48.3846 | 53.3804 | 60.2718 | 111.2333 |
| 0.1864 | 7.0 | 980 | 1.0058 | 59.5675 | 42.4324 | 48.462 | 55.3498 | 108.4667 |
| 0.1691 | 8.0 | 1120 | 0.9984 | 60.1063 | 43.6022 | 49.7163 | 56.9865 | 130.2 |
| 0.1603 | 9.0 | 1260 | 1.0062 | 61.398 | 44.4507 | 50.2044 | 57.4447 | 99.0333 |
| 0.1674 | 10.0 | 1400 | 1.0906 | 61.2393 | 43.8277 | 50.0054 | 57.4674 | 114.6 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
jennirocket/ppo-LunarLander-v2
|
jennirocket
| 2022-12-09T20:56:17Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T19:20:15Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 268.41 +/- 17.97
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Gladiator/albert-large-v2_ner_wikiann
|
Gladiator
| 2022-12-09T20:43:01Z | 15 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"albert",
"token-classification",
"generated_from_trainer",
"dataset:wikiann",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-12-09T16:16:16Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wikiann
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: albert-large-v2_ner_wikiann
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wikiann
type: wikiann
args: en
metrics:
- name: Precision
type: precision
value: 0.8239671720684378
- name: Recall
type: recall
value: 0.8374805598755832
- name: F1
type: f1
value: 0.8306689103912495
- name: Accuracy
type: accuracy
value: 0.926951922121784
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-large-v2_ner_wikiann
This model is a fine-tuned version of [albert-large-v2](https://huggingface.co/albert-large-v2) on the wikiann dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3416
- Precision: 0.8240
- Recall: 0.8375
- F1: 0.8307
- Accuracy: 0.9270
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.3451 | 1.0 | 2500 | 0.3555 | 0.7745 | 0.7850 | 0.7797 | 0.9067 |
| 0.2995 | 2.0 | 5000 | 0.2927 | 0.7932 | 0.8240 | 0.8083 | 0.9205 |
| 0.252 | 3.0 | 7500 | 0.2936 | 0.8094 | 0.8236 | 0.8164 | 0.9239 |
| 0.1676 | 4.0 | 10000 | 0.3302 | 0.8256 | 0.8359 | 0.8307 | 0.9268 |
| 0.1489 | 5.0 | 12500 | 0.3416 | 0.8240 | 0.8375 | 0.8307 | 0.9270 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
SergejSchweizer/ppo-LunarLander-v2
|
SergejSchweizer
| 2022-12-09T20:37:16Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T20:36:53Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 246.49 +/- 46.47
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
shreyasharma/t5-small-ret-conceptnet2
|
shreyasharma
| 2022-12-09T20:26:54Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-11-28T08:04:37Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
model-index:
- name: t5-small-ret-conceptnet2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-ret-conceptnet2
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1709
- Acc: {'accuracy': 0.8700980392156863}
- Precision: {'precision': 0.811340206185567}
- Recall: {'recall': 0.9644607843137255}
- F1: {'f1': 0.8812989921612542}
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Acc | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------------------------------:|:--------------------------------:|:------------------------------:|:--------------------------:|
| 0.1989 | 1.0 | 721 | 0.1709 | {'accuracy': 0.8700980392156863} | {'precision': 0.811340206185567} | {'recall': 0.9644607843137255} | {'f1': 0.8812989921612542} |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
graydient/diffusers-mattthew-technicolor-50s-diffusion
|
graydient
| 2022-12-09T20:12:14Z | 3 | 1 |
diffusers
|
[
"diffusers",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-09T19:31:04Z |
---
license: cc-by-sa-4.0
---
# 🌈 Diffusers Adaptation: Technicolor-50s Diffusion
## Style Description
- This is a port of [Mattthew's excellent Technicolor 50s Diffusion](https://huggingface.co/mattthew/technicolor-50s-diffusion/tree/main) model to Huggingface Diffusers.
- Please see original highly-saturated postcard-like colors, flat high-key lighting, strong rim-lighting, 40s and 50s lifestyle
|
thegovind/pills1testmodel
|
thegovind
| 2022-12-09T20:12:07Z | 10 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-07T21:46:05Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: pills
---
### pills1testmodel Dreambooth model fine-tuned v2-1-512 base model
Sample pictures of:
pills (use that on your prompt)
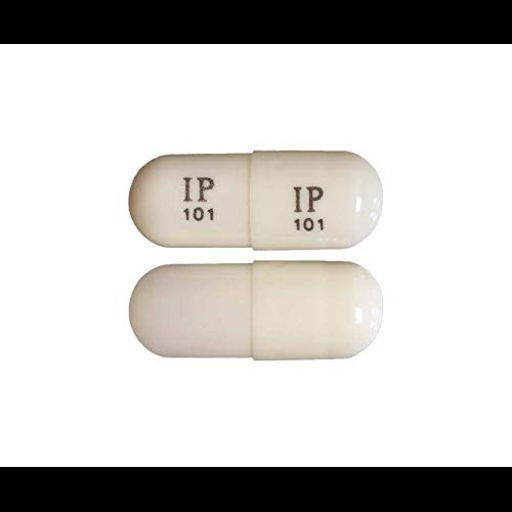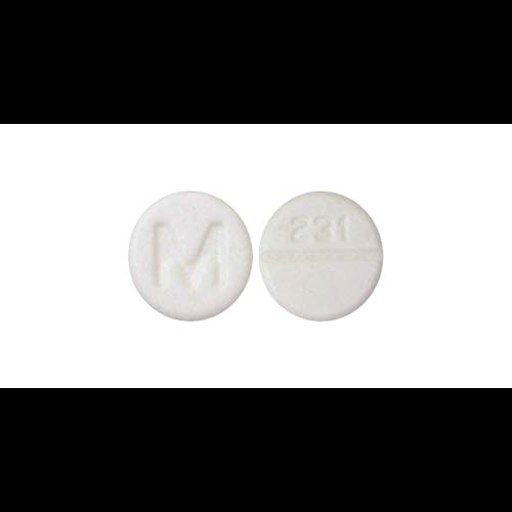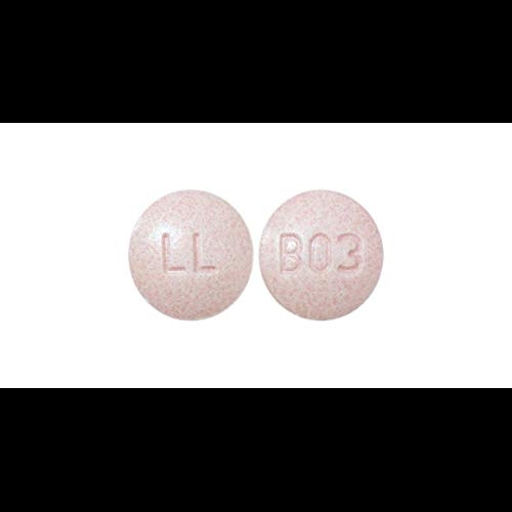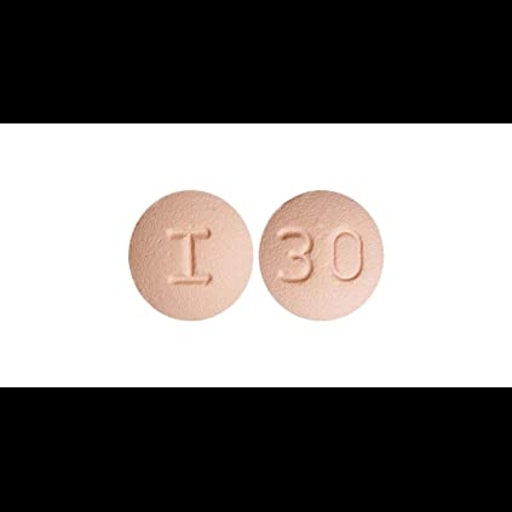
|
Cbdlt/unit1-LunarLander-1
|
Cbdlt
| 2022-12-09T20:00:29Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T19:59:01Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 275.72 +/- 20.44
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
rakeshjohny/PPO_LunarLanderV2
|
rakeshjohny
| 2022-12-09T19:51:29Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T19:50:59Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 230.53 +/- 18.37
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Sandipan1994/t5-small-entailement-Writer
|
Sandipan1994
| 2022-12-09T19:34:46Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-12-09T19:10:22Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: t5-small-entailement-Writer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-entailement-Writer
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5958
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 150
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 42 | 1.8511 |
| No log | 2.0 | 84 | 1.2249 |
| No log | 3.0 | 126 | 0.9976 |
| No log | 4.0 | 168 | 0.9108 |
| No log | 5.0 | 210 | 0.8478 |
| No log | 6.0 | 252 | 0.8186 |
| No log | 7.0 | 294 | 0.7965 |
| No log | 8.0 | 336 | 0.7815 |
| No log | 9.0 | 378 | 0.7634 |
| No log | 10.0 | 420 | 0.7544 |
| No log | 11.0 | 462 | 0.7408 |
| 1.2198 | 12.0 | 504 | 0.7298 |
| 1.2198 | 13.0 | 546 | 0.7240 |
| 1.2198 | 14.0 | 588 | 0.7139 |
| 1.2198 | 15.0 | 630 | 0.7070 |
| 1.2198 | 16.0 | 672 | 0.7028 |
| 1.2198 | 17.0 | 714 | 0.6977 |
| 1.2198 | 18.0 | 756 | 0.6926 |
| 1.2198 | 19.0 | 798 | 0.6906 |
| 1.2198 | 20.0 | 840 | 0.6846 |
| 1.2198 | 21.0 | 882 | 0.6822 |
| 1.2198 | 22.0 | 924 | 0.6760 |
| 1.2198 | 23.0 | 966 | 0.6710 |
| 0.7403 | 24.0 | 1008 | 0.6667 |
| 0.7403 | 25.0 | 1050 | 0.6657 |
| 0.7403 | 26.0 | 1092 | 0.6653 |
| 0.7403 | 27.0 | 1134 | 0.6588 |
| 0.7403 | 28.0 | 1176 | 0.6584 |
| 0.7403 | 29.0 | 1218 | 0.6573 |
| 0.7403 | 30.0 | 1260 | 0.6520 |
| 0.7403 | 31.0 | 1302 | 0.6522 |
| 0.7403 | 32.0 | 1344 | 0.6525 |
| 0.7403 | 33.0 | 1386 | 0.6463 |
| 0.7403 | 34.0 | 1428 | 0.6453 |
| 0.7403 | 35.0 | 1470 | 0.6437 |
| 0.6642 | 36.0 | 1512 | 0.6397 |
| 0.6642 | 37.0 | 1554 | 0.6382 |
| 0.6642 | 38.0 | 1596 | 0.6365 |
| 0.6642 | 39.0 | 1638 | 0.6332 |
| 0.6642 | 40.0 | 1680 | 0.6335 |
| 0.6642 | 41.0 | 1722 | 0.6325 |
| 0.6642 | 42.0 | 1764 | 0.6295 |
| 0.6642 | 43.0 | 1806 | 0.6304 |
| 0.6642 | 44.0 | 1848 | 0.6287 |
| 0.6642 | 45.0 | 1890 | 0.6272 |
| 0.6642 | 46.0 | 1932 | 0.6267 |
| 0.6642 | 47.0 | 1974 | 0.6242 |
| 0.6127 | 48.0 | 2016 | 0.6232 |
| 0.6127 | 49.0 | 2058 | 0.6225 |
| 0.6127 | 50.0 | 2100 | 0.6211 |
| 0.6127 | 51.0 | 2142 | 0.6204 |
| 0.6127 | 52.0 | 2184 | 0.6196 |
| 0.6127 | 53.0 | 2226 | 0.6183 |
| 0.6127 | 54.0 | 2268 | 0.6168 |
| 0.6127 | 55.0 | 2310 | 0.6175 |
| 0.6127 | 56.0 | 2352 | 0.6160 |
| 0.6127 | 57.0 | 2394 | 0.6154 |
| 0.6127 | 58.0 | 2436 | 0.6143 |
| 0.6127 | 59.0 | 2478 | 0.6142 |
| 0.5799 | 60.0 | 2520 | 0.6131 |
| 0.5799 | 61.0 | 2562 | 0.6122 |
| 0.5799 | 62.0 | 2604 | 0.6120 |
| 0.5799 | 63.0 | 2646 | 0.6115 |
| 0.5799 | 64.0 | 2688 | 0.6119 |
| 0.5799 | 65.0 | 2730 | 0.6112 |
| 0.5799 | 66.0 | 2772 | 0.6099 |
| 0.5799 | 67.0 | 2814 | 0.6094 |
| 0.5799 | 68.0 | 2856 | 0.6082 |
| 0.5799 | 69.0 | 2898 | 0.6092 |
| 0.5799 | 70.0 | 2940 | 0.6081 |
| 0.5799 | 71.0 | 2982 | 0.6071 |
| 0.5558 | 72.0 | 3024 | 0.6062 |
| 0.5558 | 73.0 | 3066 | 0.6079 |
| 0.5558 | 74.0 | 3108 | 0.6072 |
| 0.5558 | 75.0 | 3150 | 0.6052 |
| 0.5558 | 76.0 | 3192 | 0.6066 |
| 0.5558 | 77.0 | 3234 | 0.6049 |
| 0.5558 | 78.0 | 3276 | 0.6042 |
| 0.5558 | 79.0 | 3318 | 0.6039 |
| 0.5558 | 80.0 | 3360 | 0.6050 |
| 0.5558 | 81.0 | 3402 | 0.6042 |
| 0.5558 | 82.0 | 3444 | 0.6040 |
| 0.5558 | 83.0 | 3486 | 0.6029 |
| 0.5292 | 84.0 | 3528 | 0.6032 |
| 0.5292 | 85.0 | 3570 | 0.6039 |
| 0.5292 | 86.0 | 3612 | 0.6036 |
| 0.5292 | 87.0 | 3654 | 0.6019 |
| 0.5292 | 88.0 | 3696 | 0.6014 |
| 0.5292 | 89.0 | 3738 | 0.6022 |
| 0.5292 | 90.0 | 3780 | 0.6014 |
| 0.5292 | 91.0 | 3822 | 0.6020 |
| 0.5292 | 92.0 | 3864 | 0.6028 |
| 0.5292 | 93.0 | 3906 | 0.5994 |
| 0.5292 | 94.0 | 3948 | 0.6004 |
| 0.5292 | 95.0 | 3990 | 0.5987 |
| 0.5159 | 96.0 | 4032 | 0.5992 |
| 0.5159 | 97.0 | 4074 | 0.5993 |
| 0.5159 | 98.0 | 4116 | 0.5989 |
| 0.5159 | 99.0 | 4158 | 0.6004 |
| 0.5159 | 100.0 | 4200 | 0.6001 |
| 0.5159 | 101.0 | 4242 | 0.6008 |
| 0.5159 | 102.0 | 4284 | 0.6006 |
| 0.5159 | 103.0 | 4326 | 0.5999 |
| 0.5159 | 104.0 | 4368 | 0.5994 |
| 0.5159 | 105.0 | 4410 | 0.5996 |
| 0.5159 | 106.0 | 4452 | 0.5991 |
| 0.5159 | 107.0 | 4494 | 0.5990 |
| 0.5004 | 108.0 | 4536 | 0.5996 |
| 0.5004 | 109.0 | 4578 | 0.5988 |
| 0.5004 | 110.0 | 4620 | 0.5992 |
| 0.5004 | 111.0 | 4662 | 0.5984 |
| 0.5004 | 112.0 | 4704 | 0.5982 |
| 0.5004 | 113.0 | 4746 | 0.5973 |
| 0.5004 | 114.0 | 4788 | 0.5984 |
| 0.5004 | 115.0 | 4830 | 0.5973 |
| 0.5004 | 116.0 | 4872 | 0.5977 |
| 0.5004 | 117.0 | 4914 | 0.5970 |
| 0.5004 | 118.0 | 4956 | 0.5976 |
| 0.5004 | 119.0 | 4998 | 0.5962 |
| 0.488 | 120.0 | 5040 | 0.5969 |
| 0.488 | 121.0 | 5082 | 0.5965 |
| 0.488 | 122.0 | 5124 | 0.5969 |
| 0.488 | 123.0 | 5166 | 0.5972 |
| 0.488 | 124.0 | 5208 | 0.5966 |
| 0.488 | 125.0 | 5250 | 0.5962 |
| 0.488 | 126.0 | 5292 | 0.5966 |
| 0.488 | 127.0 | 5334 | 0.5960 |
| 0.488 | 128.0 | 5376 | 0.5969 |
| 0.488 | 129.0 | 5418 | 0.5960 |
| 0.488 | 130.0 | 5460 | 0.5960 |
| 0.483 | 131.0 | 5502 | 0.5960 |
| 0.483 | 132.0 | 5544 | 0.5965 |
| 0.483 | 133.0 | 5586 | 0.5965 |
| 0.483 | 134.0 | 5628 | 0.5963 |
| 0.483 | 135.0 | 5670 | 0.5965 |
| 0.483 | 136.0 | 5712 | 0.5962 |
| 0.483 | 137.0 | 5754 | 0.5963 |
| 0.483 | 138.0 | 5796 | 0.5961 |
| 0.483 | 139.0 | 5838 | 0.5963 |
| 0.483 | 140.0 | 5880 | 0.5964 |
| 0.483 | 141.0 | 5922 | 0.5957 |
| 0.483 | 142.0 | 5964 | 0.5957 |
| 0.4809 | 143.0 | 6006 | 0.5957 |
| 0.4809 | 144.0 | 6048 | 0.5956 |
| 0.4809 | 145.0 | 6090 | 0.5958 |
| 0.4809 | 146.0 | 6132 | 0.5958 |
| 0.4809 | 147.0 | 6174 | 0.5959 |
| 0.4809 | 148.0 | 6216 | 0.5958 |
| 0.4809 | 149.0 | 6258 | 0.5958 |
| 0.4809 | 150.0 | 6300 | 0.5958 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
lysandre/dum
|
lysandre
| 2022-12-09T19:34:24Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"OpenCLIP",
"en",
"dataset:sst2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: en
license: apache-2.0
datasets:
- sst2
tags:
- OpenCLIP
---
# Sentiment Analysis
This is a BERT model fine-tuned for sentiment analysis.
|
nbonaker/ddpm-celeb-face-32
|
nbonaker
| 2022-12-09T19:26:57Z | 1 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:ddpm-celeb-face-32",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-12-09T16:24:53Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: ddpm-celeb-face-32
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-celeb-face-32
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `ddpm-celeb-face-32` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 32
- eval_batch_size: 32
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 50
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/nbonaker/ddpm-celeb-face-32/tensorboard?#scalars)
|
Alexao/whisper-small-swe2
|
Alexao
| 2022-12-09T19:24:47Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"swe",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-09T19:11:59Z |
---
language:
- swe
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
model-index:
- name: Whisper Small swe - Swedish
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small swe - Swedish
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
DimiNim/ppo-LunarLander-v2
|
DimiNim
| 2022-12-09T18:32:09Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T18:31:41Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 258.91 +/- 21.16
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
romc57/PPO_LunarLanderV2
|
romc57
| 2022-12-09T18:28:42Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T18:28:22Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 270.65 +/- 16.76
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
tripplyons/flan-t5-base-xsum
|
tripplyons
| 2022-12-09T18:23:33Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-12-05T02:21:16Z |
---
license: apache-2.0
---
# google/flan-t5-base finetuned on xsum using LoRA with adapter-transformers
## Usage
Use the original flan-t5-base tokenizer:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("tripplyons/flan-t5-base-xsum")
input_text = "summarize: The ex-Reading defender denied fraudulent trading charges relating to the Sodje Sports Foundation - a charity to raise money for Nigerian sport. Mr Sodje, 37, is jointly charged with elder brothers Efe, 44, Bright, 50 and Stephen, 42. Appearing at the Old Bailey earlier, all four denied the offence. The charge relates to offences which allegedly took place between 2008 and 2014. Sam, from Kent, Efe and Bright, of Greater Manchester, and Stephen, from Bexley, are due to stand trial in July. They were all released on bail."
input_ids = tokenizer([input_text], max_length=512, truncation=True, padding=True, return_tensors='pt')['input_ids']
output = model.generate(input_ids, max_length=512)
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(output_text)
```
|
Sanjay-Papaiahgari/ppo-LunarLander-v2
|
Sanjay-Papaiahgari
| 2022-12-09T17:41:10Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T17:40:48Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: MlpPolicy
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 231.53 +/- 72.30
name: mean_reward
verified: false
---
# **MlpPolicy** Agent playing **LunarLander-v2**
This is a trained model of a **MlpPolicy** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
deepdml/whisper-small-eu
|
deepdml
| 2022-12-09T17:26:01Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"generated_from_trainer",
"eu",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-08T21:19:49Z |
---
license: apache-2.0
language:
- eu
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: openai/whisper-small
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_11_0 eu
type: mozilla-foundation/common_voice_11_0
config: eu
split: test
args: eu
metrics:
- name: Wer
type: wer
value: 19.766305675433596
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-small Basque-Euskera
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the common_voice_11_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4485
- Wer: 19.7663
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.048 | 4.04 | 1000 | 0.3402 | 21.7816 |
| 0.0047 | 9.03 | 2000 | 0.3862 | 20.1694 |
| 0.0012 | 14.02 | 3000 | 0.4221 | 19.7419 |
| 0.0008 | 19.02 | 4000 | 0.4411 | 19.7174 |
| 0.0006 | 24.01 | 5000 | 0.4485 | 19.7663 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
EmileEsmaili/ddpm-sheetmusic-clean-l2loss-colabVM
|
EmileEsmaili
| 2022-12-09T17:01:45Z | 3 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:EmileEsmaili/sheet_music_clean",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-12-09T07:16:34Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: EmileEsmaili/sheet_music_clean
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-sheetmusic-clean-l2loss-colabVM
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `EmileEsmaili/sheet_music_clean` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: no
### Training results
📈 [TensorBoard logs](https://huggingface.co/EmileEsmaili/ddpm-sheetmusic-clean-l2loss-colabVM/tensorboard?#scalars)
|
AbyelT/Whisper-models
|
AbyelT
| 2022-12-09T16:41:03Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"hi",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-05T20:59:34Z |
---
language:
- hi
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
model-index:
- name: Whisper Small - Swedish
results: []
metrics:
- {wer}
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Hi - Swedish
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
parinzee/whisper-small-th-newmm-old
|
parinzee
| 2022-12-09T16:10:33Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"generated_from_trainer",
"th",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-08T15:14:14Z |
---
language:
- th
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
model-index:
- name: Whisper Small Thai Newmm Tokenized - Parinthapat Pengpun
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Thai Newmm Tokenized - Parinthapat Pengpun
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.2095
- eval_wer: 26.6533
- eval_cer: 8.0405
- eval_runtime: 5652.2819
- eval_samples_per_second: 1.934
- eval_steps_per_second: 0.061
- epoch: 5.06
- step: 2000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
huggingtweets/thechosenberg
|
huggingtweets
| 2022-12-09T15:58:44Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-12-09T15:47:40Z |
---
language: en
thumbnail: http://www.huggingtweets.com/thechosenberg/1670601518761/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1600957831880097793/TxYmGY8n_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">rosey🌹</div>
<div style="text-align: center; font-size: 14px;">@thechosenberg</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from rosey🌹.
| Data | rosey🌹 |
| --- | --- |
| Tweets downloaded | 3239 |
| Retweets | 3 |
| Short tweets | 310 |
| Tweets kept | 2926 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1a0vfvx2/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @thechosenberg's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/387zccfj) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/387zccfj/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/thechosenberg')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
adisomani/distilbert-base-uncased-finetuned-sqaud
|
adisomani
| 2022-12-09T15:45:03Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-12-09T11:01:37Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-sqaud
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-sqaud
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2831
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 14 | 0.9851 |
| No log | 2.0 | 28 | 0.6955 |
| No log | 3.0 | 42 | 0.5781 |
| No log | 4.0 | 56 | 0.4548 |
| No log | 5.0 | 70 | 0.4208 |
| No log | 6.0 | 84 | 0.3592 |
| No log | 7.0 | 98 | 0.3422 |
| No log | 8.0 | 112 | 0.3424 |
| No log | 9.0 | 126 | 0.4046 |
| No log | 10.0 | 140 | 0.3142 |
| No log | 11.0 | 154 | 0.3262 |
| No log | 12.0 | 168 | 0.2879 |
| No log | 13.0 | 182 | 0.3376 |
| No log | 14.0 | 196 | 0.2870 |
| No log | 15.0 | 210 | 0.2984 |
| No log | 16.0 | 224 | 0.2807 |
| No log | 17.0 | 238 | 0.2889 |
| No log | 18.0 | 252 | 0.2877 |
| No log | 19.0 | 266 | 0.2820 |
| No log | 20.0 | 280 | 0.2831 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
Yuyang2022/yue
|
Yuyang2022
| 2022-12-09T15:27:06Z | 16 | 0 |
transformers
|
[
"transformers",
"pytorch",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"yue",
"dataset:mozilla-foundation/common_voice_11",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-09T15:17:55Z |
---
language:
- yue
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11
metrics:
- wer
model-index:
- name: Whisper Base Yue
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0 yue
type: mozilla-foundation/common_voice_11
config: unclear
split: None
args: 'config: yue, split: train'
metrics:
- name: Wer
type: wer
value: 69.58637469586375
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Base Yue
This model is a fine-tuned version of [openai/whisper-base](https://huggingface.co/openai/whisper-base) on the Common Voice 11.0 yue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3671
- Wer: 69.5864
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- training_steps: 1000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0998 | 2.78 | 500 | 0.3500 | 71.4517 |
| 0.0085 | 5.56 | 1000 | 0.3671 | 69.5864 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
nandovallec/whisper-tiny-bg-l
|
nandovallec
| 2022-12-09T15:05:19Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"bg",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-09T09:44:44Z |
---
language:
- bg
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Small Bg - Yonchevisky_tes2t
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: bg
split: test
args: 'config: bg, split: test'
metrics:
- name: Wer
type: wer
value: 61.83524504692388
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Bg - Yonchevisky_tes2t
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7377
- Wer: 61.8352
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 1000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.8067 | 0.37 | 100 | 1.6916 | 137.6897 |
| 0.9737 | 0.73 | 200 | 1.1197 | 78.3571 |
| 0.7747 | 1.1 | 300 | 0.9763 | 73.8906 |
| 0.6672 | 1.47 | 400 | 0.8972 | 70.7102 |
| 0.6196 | 1.84 | 500 | 0.8329 | 67.4545 |
| 0.4849 | 2.21 | 600 | 0.7968 | 66.6029 |
| 0.4402 | 2.57 | 700 | 0.7597 | 62.7795 |
| 0.4601 | 2.94 | 800 | 0.7385 | 61.8642 |
| 0.3545 | 3.31 | 900 | 0.7394 | 61.5050 |
| 0.3596 | 3.68 | 1000 | 0.7377 | 61.8352 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
|
kurianbenoy/whisper-ml-first-model
|
kurianbenoy
| 2022-12-09T14:49:38Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"ml",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-09T13:59:15Z |
---
language:
- ml
license: apache-2.0
tags:
- whisper-event
datasets:
- mozilla-foundation/common_voice_11_0
---
#
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the Common Voice 11.0 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- training_steps: 500
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
|
ViktorDo/DistilBERT-POWO_Lifecycle_Finetuned
|
ViktorDo
| 2022-12-09T14:31:05Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-10-20T11:22:36Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: DistilBERT-POWO_Lifecycle_Finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# DistilBERT-POWO_Lifecycle_Finetuned
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0785
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.0875 | 1.0 | 1704 | 0.0806 |
| 0.079 | 2.0 | 3408 | 0.0784 |
| 0.0663 | 3.0 | 5112 | 0.0785 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
ybutsik/ppo-LunarLander-v2-test
|
ybutsik
| 2022-12-09T14:28:18Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T14:27:41Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -93.15 +/- 20.45
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
shashank89aiml/ppo-LunarLander-v2
|
shashank89aiml
| 2022-12-09T14:16:35Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T14:09:47Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 265.61 +/- 21.48
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
klashenrik/ppo-Huggy
|
klashenrik
| 2022-12-09T14:05:55Z | 7 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2022-12-09T14:05:47Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: klashenrik/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Kuaaangwen/SMM-classifier-1
|
Kuaaangwen
| 2022-12-09T13:54:52Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-12-09T13:37:29Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: SMM-classifier-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SMM-classifier-1
This model is a fine-tuned version of [Kuaaangwen/bert-base-cased-finetuned-chemistry](https://huggingface.co/Kuaaangwen/bert-base-cased-finetuned-chemistry) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5506
- Accuracy: 0.8333
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 7 | 0.2044 | 0.8333 |
| No log | 2.0 | 14 | 0.3574 | 0.8333 |
| No log | 3.0 | 21 | 0.1551 | 0.8333 |
| No log | 4.0 | 28 | 0.9122 | 0.8333 |
| No log | 5.0 | 35 | 0.9043 | 0.8333 |
| No log | 6.0 | 42 | 0.7262 | 0.8333 |
| No log | 7.0 | 49 | 0.5977 | 0.8333 |
| No log | 8.0 | 56 | 0.5567 | 0.8333 |
| No log | 9.0 | 63 | 0.5484 | 0.8333 |
| No log | 10.0 | 70 | 0.5506 | 0.8333 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
torileatherman/whisper_small_sv
|
torileatherman
| 2022-12-09T13:47:05Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"sv",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-05T23:03:29Z |
---
language:
- sv
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Small Sv
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: sv
split: test[:10%]
args: 'config: sv, split: test'
metrics:
- name: Wer
type: wer
value: 19.76284584980237
---
# Whisper Small Swedish
This model is an adapted version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset in Swedish.
It achieves the following results on the evaluation set:
- Wer: 19.8166
## Model description & uses
This model is the openai whisper small transformer adapted for Swedish audio to text transcription.
The model is available through its [HuggingFace web app](https://huggingface.co/spaces/torileatherman/whisper_small_sv)
## Training and evaluation data
Data used for training is the initial 10% of train and validation of [Swedish Common Voice](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0/viewer/sv/train) 11.0 from Mozilla Foundation.
The dataset used for evaluation is the initial 10% of test of Swedish Common Voice.
The training data has been augmented with random noise, random pitching and change of the speed of the voice.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- lr_scheduler_type: constant
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- weight decay: 0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.1379 | 0.95 | 1000 | 0.295811 | 21.467|
| 0.0245 | 2.86 | 3000 | 0.300059 | 20.160 |
| 0.0060 | 3.82 | 4000 | 0.320301 | 19.762 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
hr16/ira-olympus-4000
|
hr16
| 2022-12-09T13:46:47Z | 1 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-09T13:43:11Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Model Dreambooth concept /content/Ira_Olympus/CRHTMJX/4000 được train bởi hr16 bằng [Shinja Zero SoTA DreamBooth_Stable_Diffusion](https://colab.research.google.com/drive/1G7qx6M_S1PDDlsWIMdbZXwdZik6sUlEh) notebook <br>
Test concept bằng [Shinja Zero no Notebook](https://colab.research.google.com/drive/1Hp1ZIjPbsZKlCtomJVmt2oX7733W44b0) <br>
Hoặc test bằng `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
Ảnh mẫu của concept: WIP
|
ZDaPlaY/strawmaryarts_style
|
ZDaPlaY
| 2022-12-09T13:32:45Z | 0 | 1 | null |
[
"region:us"
] | null | 2022-12-09T12:55:19Z |
Contains:
strawmaryarts style - model with anime style
Trigger Words: strawmaryarts style

|
lily-phoo-95/sd-class-butterflies-35
|
lily-phoo-95
| 2022-12-09T13:28:31Z | 6 | 0 |
diffusers
|
[
"diffusers",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] |
unconditional-image-generation
| 2022-12-08T14:59:17Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained(lily-phoo-95/sd-class-butterflies-35)
image = pipeline().images[0]
image
```
|
nbonaker/ddpm-celeb-face
|
nbonaker
| 2022-12-09T13:26:14Z | 12 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"en",
"dataset:ddpm-celeb-face",
"license:apache-2.0",
"diffusers:DDPMPipeline",
"region:us"
] | null | 2022-12-08T17:21:14Z |
---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: ddpm-celeb-face
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-celeb-face
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `ddpm-celeb-face` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 32
- eval_batch_size: 32
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 50
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/nbonaker/ddpm-celeb-face/tensorboard?#scalars)
|
geninhu/whisper-medium-vi
|
geninhu
| 2022-12-09T13:09:46Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"vi",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-08T05:27:05Z |
---
language:
- vi
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: openai/whisper-medium
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_11_0 vi
type: mozilla-foundation/common_voice_11_0
config: vi
split: test
args: vi
metrics:
- name: Wer
type: wer
value: 19.92761570519851
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-medium
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the common_voice_11_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7599
- Wer: 19.9276
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0001 | 62.0 | 1000 | 0.6531 | 19.3463 |
| 0.0001 | 124.0 | 2000 | 0.6964 | 19.6973 |
| 0.0 | 187.0 | 3000 | 0.7282 | 19.8947 |
| 0.0 | 249.0 | 4000 | 0.7481 | 19.8837 |
| 0.0 | 312.0 | 5000 | 0.7599 | 19.9276 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
klashenrik/ppo-lunarlander-v2
|
klashenrik
| 2022-12-09T13:02:15Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T10:27:01Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 277.75 +/- 27.70
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Gladiator/bert-large-uncased_ner_wikiann
|
Gladiator
| 2022-12-09T12:54:43Z | 16 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:wikiann",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-12-09T12:12:06Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wikiann
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-large-uncased_ner_wikiann
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wikiann
type: wikiann
args: en
metrics:
- name: Precision
type: precision
value: 0.8383588049015558
- name: Recall
type: recall
value: 0.8608794005372543
- name: F1
type: f1
value: 0.8494698660714285
- name: Accuracy
type: accuracy
value: 0.9379407966623622
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-large-uncased_ner_wikiann
This model is a fine-tuned version of [bert-large-uncased](https://huggingface.co/bert-large-uncased) on the wikiann dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3373
- Precision: 0.8384
- Recall: 0.8609
- F1: 0.8495
- Accuracy: 0.9379
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.3146 | 1.0 | 1250 | 0.2545 | 0.7956 | 0.8372 | 0.8159 | 0.9285 |
| 0.1973 | 2.0 | 2500 | 0.2438 | 0.8267 | 0.8546 | 0.8404 | 0.9349 |
| 0.1181 | 3.0 | 3750 | 0.2637 | 0.8320 | 0.8588 | 0.8452 | 0.9374 |
| 0.0647 | 4.0 | 5000 | 0.3175 | 0.8389 | 0.8627 | 0.8507 | 0.9387 |
| 0.0443 | 5.0 | 6250 | 0.3373 | 0.8384 | 0.8609 | 0.8495 | 0.9379 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
avojarot/ppo-LunarLander-v2
|
avojarot
| 2022-12-09T12:48:10Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T12:47:43Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 271.12 +/- 20.02
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Kuaaangwen/bert-base-cased-finetuned-chemistry
|
Kuaaangwen
| 2022-12-09T12:43:39Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-12-09T08:51:00Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert-base-cased-finetuned-chemistry
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-chemistry
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1166
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.3704 | 1.0 | 8521 | 1.2725 |
| 1.2718 | 2.0 | 17042 | 1.1590 |
| 1.215 | 3.0 | 25563 | 1.1175 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
aalsinat/ppo-LunarLander-v2
|
aalsinat
| 2022-12-09T12:16:51Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-07T12:16:15Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -52.64 +/- 21.59
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
massimowww/LunarLander-v2
|
massimowww
| 2022-12-09T11:59:15Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T11:58:50Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 199.90 +/- 63.35
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
gamallo/paraphrases_tuned_from_gpt2-galician
|
gamallo
| 2022-12-09T11:41:10Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-12-06T21:06:25Z |
---
widget:
- text: "Ola, como te encontras?</s>"
example_title: "saúdo"
- text: "Non mudei de idea</s>"
example_title: "mudar"
- text: "Non aprendín nada nas aulas</s>"
example_title: "aulas"
- text: "Vou ir comprar leite</s>"
example_title: "comprar"
- text: "Non vou traballar hoxe</s>"
example_title: "hoxe"
---
# Paraphrases generator (em provas...)
<!-- Provide a quick summary of what the model is/does. [Optional] -->
Model fine-tuned from GPT2-Galician-Alpha (dataset to be improved...)
# Model Details
* Model type: Language model
* Language: gl
* License: cc0-1.0
* Libraries: Transformers, Pytorch
|
derhuli/vit-base-beans
|
derhuli
| 2022-12-09T10:21:24Z | 28 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:beans",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-12-09T10:11:04Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- beans
metrics:
- accuracy
model-index:
- name: vit-base-beans
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: beans
type: beans
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9924812030075187
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-beans
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the beans dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0410
- Accuracy: 0.9925
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0751 | 1.54 | 100 | 0.0768 | 0.9850 |
| 0.0121 | 3.08 | 200 | 0.0410 | 0.9925 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.10.0
- Datasets 2.7.1
- Tokenizers 0.13.2
|
MontaR/ppo-LunarLander-v2-0.4
|
MontaR
| 2022-12-09T10:18:47Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T10:18:19Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 276.78 +/- 18.42
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
kashif/soundstream_mel_decoder
|
kashif
| 2022-12-09T09:47:39Z | 0 | 1 | null |
[
"onnx",
"arxiv:2107.03312",
"arxiv:2206.05408",
"license:apache-2.0",
"region:us"
] | null | 2022-11-29T14:33:30Z |
---
license: apache-2.0
---
A [SoundStream](https://arxiv.org/abs/2107.03312) decoder to reconstruct audio from a mel-spectrogram.
## Overview
This model is a SoundStream decoder which inverts mel-spectrograms computed with the specific hyperparameters defined in the example below. This model was trained on music data and used in [Multi-instrument Music Synthesis with Spectrogram Diffusion](https://arxiv.org/abs/2206.05408) (ISMIR 2022).
A typical use-case is to simplify music generation by predicting mel-spectrograms (instead of a raw waveform), and then use this model to reconstruct audio.
If you use it, please consider citing:
```bibtex
@article{zeghidour2021soundstream,
title={Soundstream: An end-to-end neural audio codec},
author={Zeghidour, Neil and Luebs, Alejandro and Omran, Ahmed and Skoglund, Jan and Tagliasacchi, Marco},
journal={IEEE/ACM Transactions on Audio, Speech, and Language Processing},
volume={30},
pages={495--507},
year={2021},
publisher={IEEE}
}
```
## Example Use
```python
from diffusers import OnnxRuntimeModel
SAMPLE_RATE = 16000
N_FFT = 1024
HOP_LENGTH = 320
WIN_LENGTH = 640
N_MEL_CHANNELS = 128
MEL_FMIN = 0.0
MEL_FMAX = int(SAMPLE_RATE // 2)
CLIP_VALUE_MIN = 1e-5
CLIP_VALUE_MAX = 1e8
mel = ...
melgan = OnnxRuntimeModel.from_pretrained("kashif/soundstream_mel_decoder")
audio = melgan(input_features=mel.astype(np.float32))
```
|
Aman6917/autotrain-fine_tune_tscholak-2392374839
|
Aman6917
| 2022-12-09T09:39:56Z | 1 | 0 |
transformers
|
[
"transformers",
"pytorch",
"autotrain",
"summarization",
"unk",
"dataset:Aman6917/autotrain-data-fine_tune_tscholak",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-12-09T09:30:41Z |
---
tags:
- autotrain
- summarization
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- Aman6917/autotrain-data-fine_tune_tscholak
co2_eq_emissions:
emissions: 11.023749088725205
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 2392374839
- CO2 Emissions (in grams): 11.0237
## Validation Metrics
- Loss: 0.128
- Rouge1: 94.982
- Rouge2: 91.105
- RougeL: 94.629
- RougeLsum: 94.535
- Gen Len: 30.359
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/Aman6917/autotrain-fine_tune_tscholak-2392374839
```
|
JYC333/ppo-LunarLander-v2
|
JYC333
| 2022-12-09T09:29:41Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-07T13:24:02Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 287.88 +/- 24.77
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
hanq0212/RL_course_unit0
|
hanq0212
| 2022-12-09T09:23:54Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T09:22:24Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 262.46 +/- 17.73
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
ljh1/hello-custom
|
ljh1
| 2022-12-09T09:06:52Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"emotion",
"endpoints-template",
"en",
"dataset:emotion",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-12-09T07:09:15Z |
---
language:
- en
tags:
- text-classification
- emotion
- endpoints-template
license: apache-2.0
datasets:
- emotion
metrics:
- Accuracy, F1 Score
---
# Fork of [bhadresh-savani/distilbert-base-uncased-emotion](https://huggingface.co/bhadresh-savani/distilbert-base-uncased-emotion)
|
QIANWEI/swin-tiny-patch4-window7-224-finetuned-eurosat
|
QIANWEI
| 2022-12-09T08:42:12Z | 29 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"swin",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-12-07T13:39:11Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: swin-tiny-patch4-window7-224-finetuned-eurosat
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9851851851851852
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [nielsr/swin-tiny-patch4-window7-224-finetuned-eurosat](https://huggingface.co/nielsr/swin-tiny-patch4-window7-224-finetuned-eurosat) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0416
- Accuracy: 0.9852
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.1296 | 1.0 | 190 | 0.0646 | 0.9774 |
| 0.1257 | 2.0 | 380 | 0.0445 | 0.9841 |
| 0.1067 | 3.0 | 570 | 0.0416 | 0.9852 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0
- Datasets 2.7.1
- Tokenizers 0.13.2
|
shripadbhat/whisper-tiny-mr
|
shripadbhat
| 2022-12-09T06:56:18Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"generated_from_trainer",
"mr",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-09T05:13:59Z |
---
language:
- mr
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Tiny Marathi
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: mr
split: test
args: mr
metrics:
- name: Wer
type: wer
value: 41.645121785276906
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Tiny Marathi
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4618
- Wer: 41.6451
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- training_steps: 1600
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.6182 | 0.95 | 200 | 0.6224 | 53.6706 |
| 0.4364 | 1.9 | 400 | 0.5200 | 47.2071 |
| 0.3668 | 2.84 | 600 | 0.4830 | 44.4890 |
| 0.294 | 3.79 | 800 | 0.4671 | 42.8562 |
| 0.2729 | 4.74 | 1000 | 0.4642 | 42.1214 |
| 0.2401 | 5.69 | 1200 | 0.4614 | 41.6996 |
| 0.2212 | 6.64 | 1400 | 0.4618 | 41.7778 |
| 0.2093 | 7.58 | 1600 | 0.4618 | 41.6451 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
huam/ppo-LunarLander-v2
|
huam
| 2022-12-09T06:19:58Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T03:53:45Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 276.82 +/- 15.15
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
OFA-Sys/chinese-clip-vit-huge-patch14
|
OFA-Sys
| 2022-12-09T06:11:22Z | 3,111 | 26 |
transformers
|
[
"transformers",
"pytorch",
"chinese_clip",
"zero-shot-image-classification",
"vision",
"arxiv:2211.01335",
"endpoints_compatible",
"region:us"
] |
zero-shot-image-classification
| 2022-11-09T09:45:11Z |
---
tags:
- vision
widget:
- src: https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16/resolve/main/festival.jpg
candidate_labels: 灯笼, 鞭炮, 对联
example_title: festival
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: 音乐表演, 体育运动
example_title: cat & dog
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/football-match.jpg
candidate_labels: 梅西, C罗, 马奎尔
example_title: football
---
# Chinese-CLIP-ViT-Huge-Patch14
## Introduction
This is the huge-version of the Chinese CLIP, with ViT-H/14 as the image encoder and RoBERTa-wwm-large as the text encoder. Chinese CLIP is a simple implementation of CLIP on a large-scale dataset of around 200 million Chinese image-text pairs. For more details, please refer to our technical report https://arxiv.org/abs/2211.01335 and our official github repo https://github.com/OFA-Sys/Chinese-CLIP (Welcome to star! 🔥🔥)
## Use with the official API
We provide a simple code snippet to show how to use the API of Chinese-CLIP to compute the image & text embeddings and similarities.
```python
from PIL import Image
import requests
from transformers import ChineseCLIPProcessor, ChineseCLIPModel
model = ChineseCLIPModel.from_pretrained("OFA-Sys/chinese-clip-vit-huge-patch14")
processor = ChineseCLIPProcessor.from_pretrained("OFA-Sys/chinese-clip-vit-huge-patch14")
url = "https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/pokemon.jpeg"
image = Image.open(requests.get(url, stream=True).raw)
# Squirtle, Bulbasaur, Charmander, Pikachu in English
texts = ["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"]
# compute image feature
inputs = processor(images=image, return_tensors="pt")
image_features = model.get_image_features(**inputs)
image_features = image_features / image_features.norm(p=2, dim=-1, keepdim=True) # normalize
# compute text features
inputs = processor(text=texts, padding=True, return_tensors="pt")
text_features = model.get_text_features(**inputs)
text_features = text_features / text_features.norm(p=2, dim=-1, keepdim=True) # normalize
# compute image-text similarity scores
inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # probs: [[1.1419e-02, 1.0478e-02, 5.2018e-04, 9.7758e-01]]
```
However, if you are not satisfied with only using the API, feel free to check our github repo https://github.com/OFA-Sys/Chinese-CLIP for more details about training and inference.
<br><br>
## Results
**MUGE Text-to-Image Retrieval**:
<table border="1" width="100%">
<tr align="center">
<th>Setup</th><th colspan="4">Zero-shot</th><th colspan="4">Finetune</th>
</tr>
<tr align="center">
<td>Metric</td><td>R@1</td><td>R@5</td><td>R@10</td><td>MR</td><td>R@1</td><td>R@5</td><td>R@10</td><td>MR</td>
</tr>
<tr align="center">
<td width="120%">Wukong</td><td>42.7</td><td>69.0</td><td>78.0</td><td>63.2</td><td>52.7</td><td>77.9</td><td>85.6</td><td>72.1</td>
</tr>
<tr align="center">
<td width="120%">R2D2</td><td>49.5</td><td>75.7</td><td>83.2</td><td>69.5</td><td>60.1</td><td>82.9</td><td>89.4</td><td>77.5</td>
</tr>
<tr align="center">
<td width="120%">CN-CLIP</td><td>63.0</td><td>84.1</td><td>89.2</td><td>78.8</td><td>68.9</td><td>88.7</td><td>93.1</td><td>83.6</td>
</tr>
</table>
<br>
**Flickr30K-CN Retrieval**:
<table border="1" width="120%">
<tr align="center">
<th>Task</th><th colspan="6">Text-to-Image</th><th colspan="6">Image-to-Text</th>
</tr>
<tr align="center">
<th>Setup</th><th colspan="3">Zero-shot</th><th colspan="3">Finetune</th><th colspan="3">Zero-shot</th><th colspan="3">Finetune</th>
</tr>
<tr align="center">
<td>Metric</td><td>R@1</td><td>R@5</td><td>R@10</td><td>R@1</td><td>R@5</td><td>R@10</td><td>R@1</td><td>R@5</td><td>R@10</td><td>R@1</td><td>R@5</td><td>R@10</td>
</tr>
<tr align="center">
<td width="120%">Wukong</td><td>51.7</td><td>78.9</td><td>86.3</td><td>77.4</td><td>94.5</td><td>97.0</td><td>76.1</td><td>94.8</td><td>97.5</td><td>92.7</td><td>99.1</td><td>99.6</td>
</tr>
<tr align="center">
<td width="120%">R2D2</td><td>60.9</td><td>86.8</td><td>92.7</td><td>84.4</td><td>96.7</td><td>98.4</td><td>77.6</td><td>96.7</td><td>98.9</td><td>95.6</td><td>99.8</td><td>100.0</td>
</tr>
<tr align="center">
<td width="120%">CN-CLIP</td><td>71.2</td><td>91.4</td><td>95.5</td><td>83.8</td><td>96.9</td><td>98.6</td><td>81.6</td><td>97.5</td><td>98.8</td><td>95.3</td><td>99.7</td><td>100.0</td>
</tr>
</table>
<br>
**COCO-CN Retrieval**:
<table border="1" width="100%">
<tr align="center">
<th>Task</th><th colspan="6">Text-to-Image</th><th colspan="6">Image-to-Text</th>
</tr>
<tr align="center">
<th>Setup</th><th colspan="3">Zero-shot</th><th colspan="3">Finetune</th><th colspan="3">Zero-shot</th><th colspan="3">Finetune</th>
</tr>
<tr align="center">
<td>Metric</td><td>R@1</td><td>R@5</td><td>R@10</td><td>R@1</td><td>R@5</td><td>R@10</td><td>R@1</td><td>R@5</td><td>R@10</td><td>R@1</td><td>R@5</td><td>R@10</td>
</tr>
<tr align="center">
<td width="120%">Wukong</td><td>53.4</td><td>80.2</td><td>90.1</td><td>74.0</td><td>94.4</td><td>98.1</td><td>55.2</td><td>81.0</td><td>90.6</td><td>73.3</td><td>94.0</td><td>98.0</td>
</tr>
<tr align="center">
<td width="120%">R2D2</td><td>56.4</td><td>85.0</td><td>93.1</td><td>79.1</td><td>96.5</td><td>98.9</td><td>63.3</td><td>89.3</td><td>95.7</td><td>79.3</td><td>97.1</td><td>98.7</td>
</tr>
<tr align="center">
<td width="120%">CN-CLIP</td><td>69.2</td><td>89.9</td><td>96.1</td><td>81.5</td><td>96.9</td><td>99.1</td><td>63.0</td><td>86.6</td><td>92.9</td><td>83.5</td><td>97.3</td><td>99.2</td>
</tr>
</table>
<br>
**Zero-shot Image Classification**:
<table border="1" width="100%">
<tr align="center">
<th>Task</th><th>CIFAR10</th><th>CIFAR100</th><th>DTD</th><th>EuroSAT</th><th>FER</th><th>FGVC</th><th>KITTI</th><th>MNIST</th><th>PC</th><th>VOC</th>
</tr>
<tr align="center">
<td width="150%">GIT</td><td>88.5</td><td>61.1</td><td>42.9</td><td>43.4</td><td>41.4</td><td>6.7</td><td>22.1</td><td>68.9</td><td>50.0</td><td>80.2</td>
</tr>
<tr align="center">
<td width="150%">ALIGN</td><td>94.9</td><td>76.8</td><td>66.1</td><td>52.1</td><td>50.8</td><td>25.0</td><td>41.2</td><td>74.0</td><td>55.2</td><td>83.0</td>
</tr>
<tr align="center">
<td width="150%">CLIP</td><td>94.9</td><td>77.0</td><td>56.0</td><td>63.0</td><td>48.3</td><td>33.3</td><td>11.5</td><td>79.0</td><td>62.3</td><td>84.0</td>
</tr>
<tr align="center">
<td width="150%">Wukong</td><td>95.4</td><td>77.1</td><td>40.9</td><td>50.3</td><td>-</td><td>-</td><td>-</td><td>-</td><td>-</td><td>-</td>
</tr>
<tr align="center">
<td width="150%">CN-CLIP</td><td>96.0</td><td>79.7</td><td>51.2</td><td>52.0</td><td>55.1</td><td>26.2</td><td>49.9</td><td>79.4</td><td>63.5</td><td>84.9</td>
</tr>
</table>
<br>
## Citation
If you find Chinese CLIP helpful, feel free to cite our paper. Thanks for your support!
```
@article{chinese-clip,
title={Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese},
author={Yang, An and Pan, Junshu and Lin, Junyang and Men, Rui and Zhang, Yichang and Zhou, Jingren and Zhou, Chang},
journal={arXiv preprint arXiv:2211.01335},
year={2022}
}
```
<br>
|
spaablauw/ActionHelper
|
spaablauw
| 2022-12-09T06:03:31Z | 0 | 16 | null |
[
"license:wtfpl",
"region:us"
] | null | 2022-12-09T03:05:44Z |
---
license: wtfpl
---
Trained for 500 steps with a lr of 0.003 and 4 steps gradient accumulation.






|
odahl/ppo-LunarLander-v2
|
odahl
| 2022-12-09T05:48:52Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T05:48:27Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 271.65 +/- 26.13
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
birgermoell/whisper-small-sv-fast
|
birgermoell
| 2022-12-09T05:37:53Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"generated_from_trainer",
"sv",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-08T17:22:17Z |
---
language:
- sv
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Small Swedish Fast
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_11_0 sv-SE
type: mozilla-foundation/common_voice_11_0
config: sv-SE
split: test
args: sv-SE
metrics:
- name: Wer
type: wer
value: 62.69218363616815
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Swedish Fast
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the mozilla-foundation/common_voice_11_0 sv-SE dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8738
- Wer: 62.6922
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 2.0512 | 6.01 | 1000 | 2.5997 | 87.1949 |
| 0.4367 | 12.02 | 2000 | 1.8089 | 68.1271 |
| 0.0806 | 18.03 | 3000 | 1.7969 | 63.5711 |
| 0.0194 | 25.01 | 4000 | 1.8435 | 63.4663 |
| 0.0121 | 31.02 | 5000 | 1.8738 | 62.6922 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
Gladiator/funnel-transformer-xlarge_ner_conll2003
|
Gladiator
| 2022-12-09T05:32:25Z | 18 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"funnel",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-12-09T04:43:40Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: funnel-transformer-xlarge_ner_conll2003
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9565363315992617
- name: Recall
type: recall
value: 0.9592729720632783
- name: F1
type: f1
value: 0.9579026972523318
- name: Accuracy
type: accuracy
value: 0.9914528250457537
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# funnel-transformer-xlarge_ner_conll2003
This model is a fine-tuned version of [funnel-transformer/xlarge](https://huggingface.co/funnel-transformer/xlarge) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0436
- Precision: 0.9565
- Recall: 0.9593
- F1: 0.9579
- Accuracy: 0.9915
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1349 | 1.0 | 878 | 0.0441 | 0.9328 | 0.9438 | 0.9383 | 0.9881 |
| 0.0308 | 2.0 | 1756 | 0.0377 | 0.9457 | 0.9561 | 0.9509 | 0.9901 |
| 0.0144 | 3.0 | 2634 | 0.0432 | 0.9512 | 0.9578 | 0.9545 | 0.9906 |
| 0.007 | 4.0 | 3512 | 0.0419 | 0.9551 | 0.9584 | 0.9567 | 0.9913 |
| 0.0041 | 5.0 | 4390 | 0.0436 | 0.9565 | 0.9593 | 0.9579 | 0.9915 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Gladiator/albert-large-v2_ner_conll2003
|
Gladiator
| 2022-12-09T05:07:13Z | 18 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"albert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-12-09T04:42:32Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: albert-large-v2_ner_conll2003
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9396018069265518
- name: Recall
type: recall
value: 0.9451363177381353
- name: F1
type: f1
value: 0.9423609363201612
- name: Accuracy
type: accuracy
value: 0.9874810170943499
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-large-v2_ner_conll2003
This model is a fine-tuned version of [albert-large-v2](https://huggingface.co/albert-large-v2) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0584
- Precision: 0.9396
- Recall: 0.9451
- F1: 0.9424
- Accuracy: 0.9875
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2034 | 1.0 | 878 | 0.0653 | 0.9114 | 0.9278 | 0.9195 | 0.9837 |
| 0.0561 | 2.0 | 1756 | 0.0602 | 0.9316 | 0.9280 | 0.9298 | 0.9845 |
| 0.0303 | 3.0 | 2634 | 0.0536 | 0.9380 | 0.9424 | 0.9402 | 0.9872 |
| 0.0177 | 4.0 | 3512 | 0.0535 | 0.9393 | 0.9456 | 0.9425 | 0.9877 |
| 0.011 | 5.0 | 4390 | 0.0584 | 0.9396 | 0.9451 | 0.9424 | 0.9875 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
schrilax/PPO-LunarLander-v2
|
schrilax
| 2022-12-09T04:48:19Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-09T04:47:53Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 238.46 +/- 22.84
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
jibi2906/my-finetuned-distilbert
|
jibi2906
| 2022-12-09T04:38:42Z | 5 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"fill-mask",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-12-09T04:38:30Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: my-finetuned-distilbert
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# my-finetuned-distilbert
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.6482
- Validation Loss: 1.3103
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1500, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.6482 | 1.3103 | 0 |
### Framework versions
- Transformers 4.25.1
- TensorFlow 2.9.2
- Datasets 2.7.1
- Tokenizers 0.13.2
|
imaginarybumblers/v1-5-KiwiBirds
|
imaginarybumblers
| 2022-12-09T04:26:48Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-12-09T03:36:07Z |
---
license: creativeml-openrail-m
---
|
Gladiator/bert-large-uncased_ner_conll2003
|
Gladiator
| 2022-12-09T04:22:21Z | 17 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-12-09T03:45:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-large-uncased_ner_conll2003
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9424197037776668
- name: Recall
type: recall
value: 0.9530461124200605
- name: F1
type: f1
value: 0.947703121077734
- name: Accuracy
type: accuracy
value: 0.9897784354191815
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-large-uncased_ner_conll2003
This model is a fine-tuned version of [bert-large-uncased](https://huggingface.co/bert-large-uncased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0516
- Precision: 0.9424
- Recall: 0.9530
- F1: 0.9477
- Accuracy: 0.9898
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1605 | 1.0 | 878 | 0.0533 | 0.9252 | 0.9329 | 0.9290 | 0.9864 |
| 0.032 | 2.0 | 1756 | 0.0433 | 0.9320 | 0.9475 | 0.9397 | 0.9887 |
| 0.0125 | 3.0 | 2634 | 0.0454 | 0.9424 | 0.9524 | 0.9474 | 0.9897 |
| 0.006 | 4.0 | 3512 | 0.0507 | 0.9417 | 0.9519 | 0.9468 | 0.9896 |
| 0.0036 | 5.0 | 4390 | 0.0516 | 0.9424 | 0.9530 | 0.9477 | 0.9898 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Gladiator/distilbert-base-uncased_ner_conll2003
|
Gladiator
| 2022-12-09T03:34:46Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-12-09T03:26:59Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-uncased_ner_conll2003
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9357583847822459
- name: Recall
type: recall
value: 0.9437899697071693
- name: F1
type: f1
value: 0.939757017176372
- name: Accuracy
type: accuracy
value: 0.987675713562556
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_ner_conll2003
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0524
- Precision: 0.9358
- Recall: 0.9438
- F1: 0.9398
- Accuracy: 0.9877
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1897 | 1.0 | 878 | 0.0544 | 0.9223 | 0.9270 | 0.9246 | 0.9848 |
| 0.0363 | 2.0 | 1756 | 0.0486 | 0.9316 | 0.9391 | 0.9353 | 0.9869 |
| 0.0194 | 3.0 | 2634 | 0.0496 | 0.9369 | 0.9403 | 0.9386 | 0.9873 |
| 0.0114 | 4.0 | 3512 | 0.0526 | 0.9340 | 0.9436 | 0.9388 | 0.9875 |
| 0.0089 | 5.0 | 4390 | 0.0524 | 0.9358 | 0.9438 | 0.9398 | 0.9877 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
rpharale/ppo-Huggy
|
rpharale
| 2022-12-09T03:25:04Z | 7 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2022-12-09T03:24:55Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: rpharale/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
flamesbob/skyfireModel
|
flamesbob
| 2022-12-09T02:53:53Z | 0 | 1 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-12-09T01:59:01Z |
---
license: creativeml-openrail-m
---
|
YesIfwRONG/Zero
|
YesIfwRONG
| 2022-12-09T02:48:50Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-12-09T02:48:01Z |
This is a capstone project serving for training the model and exploring implementation on AIs.
|
gagan3012/ArOCR
|
gagan3012
| 2022-12-09T01:46:53Z | 37 | 4 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"image-text-to-text",
"image-to-text",
"ar",
"model-index",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2022-04-19T21:13:24Z |
---
tags:
- image-to-text
language: ar
model-index:
- name: ArOCR
results:
- task:
name: Optical Charater Recogntion
type: image-to-text
metrics:
- name: Test CER
type: cer
value: 0.02
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ArOCR
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0407
- Cer: 0.0200
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.6164 | 0.59 | 1000 | 1.4109 | 0.5793 |
| 0.3434 | 1.18 | 2000 | 0.3876 | 0.2176 |
| 0.1679 | 1.77 | 3000 | 0.2262 | 0.1186 |
| 0.0816 | 2.37 | 4000 | 0.1274 | 0.0634 |
| 0.0421 | 2.96 | 5000 | 0.0817 | 0.0381 |
| 0.0067 | 3.55 | 6000 | 0.0520 | 0.0265 |
| 0.0044 | 4.14 | 7000 | 0.0469 | 0.0215 |
| 0.0027 | 4.73 | 8000 | 0.0407 | 0.0200 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.9.1
- Datasets 2.1.0
- Tokenizers 0.11.6
|
izumi-lab/electra-small-japanese-discriminator
|
izumi-lab
| 2022-12-09T00:41:39Z | 14 | 0 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"pretraining",
"ja",
"dataset:wikipedia",
"arxiv:2003.10555",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: ja
license: cc-by-sa-4.0
datasets:
- wikipedia
widget:
- text: 東京大学で[MASK]の研究をしています。
---
# ELECTRA small Japanese discriminator
This is a [ELECTRA](https://github.com/google-research/electra) model pretrained on texts in the Japanese language.
The codes for the pretraining are available at [retarfi/language-pretraining](https://github.com/retarfi/language-pretraining/tree/v1.0).
## Model architecture
The model architecture is the same as ELECTRA small in the [original ELECTRA implementation](https://github.com/google-research/electra); 12 layers, 256 dimensions of hidden states, and 4 attention heads.
## Training Data
The models are trained on the Japanese version of Wikipedia.
The training corpus is generated from the Japanese version of Wikipedia, using Wikipedia dump file as of June 1, 2021.
The corpus file is 2.9GB, consisting of approximately 20M sentences.
## Tokenization
The texts are first tokenized by MeCab with IPA dictionary and then split into subwords by the WordPiece algorithm.
The vocabulary size is 32768.
## Training
The models are trained with the same configuration as ELECTRA small in the [original ELECTRA paper](https://arxiv.org/abs/2003.10555) except size; 128 tokens per instance, 128 instances per batch, and 1M training steps.
The size of the generator is the same of the discriminator.
## Citation
```
@article{Suzuki-etal-2023-ipm,
title = {Constructing and analyzing domain-specific language model for financial text mining}
author = {Masahiro Suzuki and Hiroki Sakaji and Masanori Hirano and Kiyoshi Izumi},
journal = {Information Processing & Management},
volume = {60},
number = {2},
pages = {103194},
year = {2023},
doi = {10.1016/j.ipm.2022.103194}
}
```
## Licenses
The pretrained models are distributed under the terms of the [Creative Commons Attribution-ShareAlike 4.0](https://creativecommons.org/licenses/by-sa/4.0/).
## Acknowledgments
This work was supported by JSPS KAKENHI Grant Number JP21K12010.
|
izumi-lab/bert-small-japanese
|
izumi-lab
| 2022-12-09T00:40:57Z | 1,069 | 5 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"ja",
"dataset:wikipedia",
"arxiv:2003.10555",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: ja
license: cc-by-sa-4.0
datasets:
- wikipedia
widget:
- text: 東京大学で[MASK]の研究をしています。
---
# BERT small Japanese finance
This is a [BERT](https://github.com/google-research/bert) model pretrained on texts in the Japanese language.
The codes for the pretraining are available at [retarfi/language-pretraining](https://github.com/retarfi/language-pretraining/tree/v1.0).
## Model architecture
The model architecture is the same as BERT small in the [original ELECTRA paper](https://arxiv.org/abs/2003.10555); 12 layers, 256 dimensions of hidden states, and 4 attention heads.
## Training Data
The models are trained on the Japanese version of Wikipedia.
The training corpus is generated from the Japanese version of Wikipedia, using Wikipedia dump file as of June 1, 2021.
The corpus file is 2.9GB, consisting of approximately 20M sentences.
## Tokenization
The texts are first tokenized by MeCab with IPA dictionary and then split into subwords by the WordPiece algorithm.
The vocabulary size is 32768.
## Training
The models are trained with the same configuration as BERT small in the [original ELECTRA paper](https://arxiv.org/abs/2003.10555); 128 tokens per instance, 128 instances per batch, and 1.45M training steps.
## Citation
```
@article{Suzuki-etal-2023-ipm,
title = {Constructing and analyzing domain-specific language model for financial text mining}
author = {Masahiro Suzuki and Hiroki Sakaji and Masanori Hirano and Kiyoshi Izumi},
journal = {Information Processing & Management},
volume = {60},
number = {2},
pages = {103194},
year = {2023},
doi = {10.1016/j.ipm.2022.103194}
}
```
## Licenses
The pretrained models are distributed under the terms of the [Creative Commons Attribution-ShareAlike 4.0](https://creativecommons.org/licenses/by-sa/4.0/).
## Acknowledgments
This work was supported by JSPS KAKENHI Grant Number JP21K12010.
|
izumi-lab/electra-small-paper-japanese-fin-discriminator
|
izumi-lab
| 2022-12-09T00:39:05Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"pretraining",
"finance",
"ja",
"arxiv:2003.10555",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: ja
license: cc-by-sa-4.0
tags:
- finance
widget:
- text: 流動[MASK]は1億円となりました。
---
# ELECTRA small Japanese finance discriminator
This is a [ELECTRA](https://github.com/google-research/electra) model pretrained on texts in the Japanese language.
The codes for the pretraining are available at [retarfi/language-pretraining](https://github.com/retarfi/language-pretraining/tree/v1.0).
## Model architecture
The model architecture is the same as ELECTRA small in the [original ELECTRA paper](https://arxiv.org/abs/2003.10555); 12 layers, 256 dimensions of hidden states, and 4 attention heads.
## Training Data
The models are trained on the Japanese version of Wikipedia.
The training corpus is generated from the Japanese version of Wikipedia, using Wikipedia dump file as of June 1, 2021.
The Wikipedia corpus file is 2.9GB, consisting of approximately 20M sentences.
The financial corpus consists of 2 corpora:
- Summaries of financial results from October 9, 2012, to December 31, 2020
- Securities reports from February 8, 2018, to December 31, 2020
The financial corpus file is 5.2GB, consisting of approximately 27M sentences.
## Tokenization
The texts are first tokenized by MeCab with IPA dictionary and then split into subwords by the WordPiece algorithm.
The vocabulary size is 32768.
## Training
The models are trained with the same configuration as ELECTRA small in the [original ELECTRA paper](https://arxiv.org/abs/2003.10555); 128 tokens per instance, 128 instances per batch, and 1M training steps.
## Citation
```
@article{Suzuki-etal-2023-ipm,
title = {Constructing and analyzing domain-specific language model for financial text mining}
author = {Masahiro Suzuki and Hiroki Sakaji and Masanori Hirano and Kiyoshi Izumi},
journal = {Information Processing & Management},
volume = {60},
number = {2},
pages = {103194},
year = {2023},
doi = {10.1016/j.ipm.2022.103194}
}
```
## Licenses
The pretrained models are distributed under the terms of the [Creative Commons Attribution-ShareAlike 4.0](https://creativecommons.org/licenses/by-sa/4.0/).
## Acknowledgments
This work was supported by JSPS KAKENHI Grant Number JP21K12010.
|
log0/ppo-LunarLander-v2
|
log0
| 2022-12-08T23:50:27Z | 4 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-08T21:27:41Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 182.69 +/- 91.27
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
reyrobs/whisper-small-hi-2000
|
reyrobs
| 2022-12-08T23:28:52Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-08T20:51:58Z |
---
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
model-index:
- name: Whisper Small Hi - Robert Rey
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Hi - Robert Rey
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.000599
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
HideOnBush/BERTModified-fullsize-finetuned-wikitext-test
|
HideOnBush
| 2022-12-08T22:43:41Z | 0 | 0 | null |
[
"pytorch",
"generated_from_trainer",
"license:apache-2.0",
"region:us"
] | null | 2022-12-08T19:49:41Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: BERTModified-fullsize-finetuned-wikitext-test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERTModified-fullsize-finetuned-wikitext-test
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 6.7813
- Precision: 0.1094
- Recall: 0.1094
- F1: 0.1094
- Accuracy: 0.1094
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 9.2391 | 1.0 | 4382 | 8.1610 | 0.0373 | 0.0373 | 0.0373 | 0.0373 |
| 7.9147 | 2.0 | 8764 | 7.6870 | 0.0635 | 0.0635 | 0.0635 | 0.0635 |
| 7.5164 | 3.0 | 13146 | 7.4388 | 0.0727 | 0.0727 | 0.0727 | 0.0727 |
| 7.2439 | 4.0 | 17528 | 7.2088 | 0.0930 | 0.0930 | 0.0930 | 0.0930 |
| 7.1068 | 5.0 | 21910 | 7.0455 | 0.0943 | 0.0943 | 0.0943 | 0.0943 |
| 6.9711 | 6.0 | 26292 | 6.9976 | 0.1054 | 0.1054 | 0.1054 | 0.1054 |
| 6.8486 | 7.0 | 30674 | 6.8850 | 0.1054 | 0.1054 | 0.1054 | 0.1054 |
| 6.78 | 8.0 | 35056 | 6.7990 | 0.1153 | 0.1153 | 0.1153 | 0.1153 |
| 6.73 | 9.0 | 39438 | 6.8041 | 0.1074 | 0.1074 | 0.1074 | 0.1074 |
| 6.6921 | 10.0 | 43820 | 6.7412 | 0.1251 | 0.1251 | 0.1251 | 0.1251 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0
- Datasets 2.6.1
- Tokenizers 0.13.2
|
mtlulka/ppo-LunarLander_unit1_base
|
mtlulka
| 2022-12-08T22:35:53Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-08T22:35:27Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO_MlpPolicy
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 249.01 +/- 13.07
name: mean_reward
verified: false
---
# **PPO_MlpPolicy** Agent playing **LunarLander-v2**
This is a trained model of a **PPO_MlpPolicy** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
evageon/whisper-tiny-ar
|
evageon
| 2022-12-08T22:34:04Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-08T15:41:11Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: whisper-tiny-ar
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-tiny-ar
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8394
- Wer: 86.0500
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 128
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 1.0265 | 1.0 | 122 | 1.0110 | 98.4608 |
| 0.9208 | 2.0 | 244 | 0.9148 | 88.3812 |
| 0.8169 | 3.0 | 366 | 0.8394 | 86.0500 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.12.1
- Datasets 2.7.1
- Tokenizers 0.13.2
|
jegormeister/setfit-model
|
jegormeister
| 2022-12-08T21:51:42Z | 2 | 1 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-12-08T21:45:27Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 188 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": 188,
"warmup_steps": 19,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
csikasote/whisper-medium-loz
|
csikasote
| 2022-12-08T21:32:39Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-08T16:13:45Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: whisper-medium-loz
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-medium-loz
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0237
- Wer: 38.4907
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2252 | 3.11 | 500 | 1.6491 | 50.4707 |
| 0.0815 | 6.21 | 1000 | 1.8170 | 48.7246 |
| 0.0417 | 9.32 | 1500 | 1.8765 | 43.2129 |
| 0.0218 | 12.42 | 2000 | 1.8995 | 40.6316 |
| 0.0062 | 15.53 | 2500 | 1.9751 | 38.6578 |
| 0.0024 | 18.63 | 3000 | 2.0062 | 38.5667 |
| 0.0001 | 21.74 | 3500 | 2.0141 | 38.6274 |
| 0.0001 | 24.84 | 4000 | 2.0237 | 38.4907 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
ruzarx/ppo-Huggy
|
ruzarx
| 2022-12-08T21:18:24Z | 7 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2022-12-08T21:09:12Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: ruzarx/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
matthh/ppo-Huggy
|
matthh
| 2022-12-08T21:08:49Z | 7 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2022-12-08T21:08:43Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: matthh/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
ksaml/ppo-LunarLander-v2
|
ksaml
| 2022-12-08T20:49:56Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-08T20:49:34Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 289.10 +/- 13.75
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
GammaPrime/Brawn
|
GammaPrime
| 2022-12-08T20:41:39Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-12-08T05:06:09Z |
This is a standard Tacotron2 Text-to-Speech model based on the character Brawn from Transformers Generation 1. This model was trained on 72 sample wavs for a total of 6 minutes and 29 seconds of audio data.
|
fimster/whisper-small-sv-SE-NST
|
fimster
| 2022-12-08T20:39:23Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"whisper",
"automatic-speech-recognition",
"i-dont-know-what-im-doing",
"generated_from_trainer",
"sv",
"dataset:fimster/NST_small_whisper",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-08T08:19:14Z |
---
language:
- sv
license: apache-2.0
tags:
- i-dont-know-what-im-doing
- generated_from_trainer
datasets:
- fimster/NST_small_whisper
metrics:
- wer
model-index:
- name: Whisper Small sv-SE NST - Lab 2
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: NST Swedish ASR
type: fimster/NST_small_whisper
config: speech
split: None
args: 'config: speech, split: test'
metrics:
- name: Wer
type: wer
value: 10.167794316644112
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small sv-SE NST - Lab 2
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the NST Swedish ASR dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1305
- Wer: 10.1678
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.1635 | 0.67 | 1000 | 0.1694 | 13.4993 |
| 0.07 | 1.33 | 2000 | 0.1431 | 11.3802 |
| 0.0597 | 2.0 | 3000 | 0.1302 | 10.4682 |
| 0.0193 | 2.67 | 4000 | 0.1305 | 10.1678 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
NicoGJ/AEM
|
NicoGJ
| 2022-12-08T20:14:23Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-12-08T20:14:23Z |
---
license: creativeml-openrail-m
---
|
robbiegwald/Rick
|
robbiegwald
| 2022-12-08T20:13:56Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-12-08T20:05:03Z |
---
tags:
- conversational
---
|
Lukewood/sd-1.5-keras-cv-weights
|
Lukewood
| 2022-12-08T19:57:33Z | 0 | 0 | null |
[
"license:openrail",
"region:us"
] | null | 2022-11-24T00:08:14Z |
---
license: openrail
---
KerasCV StableDiffusion weights for StableDiffusion v1.5 ported from:
https://huggingface.co/runwayml/stable-diffusion-v1-5
|
bayartsogt/whisper-small-mn-6
|
bayartsogt
| 2022-12-08T19:49:27Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"whisper-event",
"hf-asr-leaderboard",
"generated_from_trainer",
"dataset:bayartsogt/youtube-mongolian-v1",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-12-07T21:28:41Z |
---
license: apache-2.0
tags:
- whisper-event
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- bayartsogt/youtube-mongolian-v1
metrics:
- wer
model-index:
- name: whisper-small-mn-6-bayartsogt
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: mn
split: test
args:
language: mn
metrics:
- name: Wer
type: wer
value: 35.8859514966135
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-mn-6
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3296
- Wer: 35.8860
- Cer: 13.3108
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 15000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|
| 0.3774 | 0.8 | 1000 | 0.4319 | 53.2773 | 19.6627 |
| 0.2926 | 1.61 | 2000 | 0.3493 | 40.4960 | 15.0214 |
| 0.2331 | 2.41 | 3000 | 0.3346 | 39.1741 | 14.7689 |
| 0.1636 | 3.22 | 4000 | 0.3287 | 36.9237 | 13.7943 |
| 0.1157 | 4.02 | 5000 | 0.3296 | 35.8860 | 13.3108 |
| 0.1271 | 4.82 | 6000 | 0.3422 | 36.0717 | 13.5702 |
| 0.0879 | 5.63 | 7000 | 0.3661 | 36.6943 | 13.7780 |
| 0.0574 | 6.43 | 8000 | 0.3884 | 36.4595 | 13.5015 |
| 0.036 | 7.23 | 9000 | 0.4128 | 37.1422 | 13.8424 |
| 0.0229 | 8.04 | 10000 | 0.4321 | 36.8582 | 13.8475 |
| 0.0241 | 8.84 | 11000 | 0.4530 | 37.1095 | 13.8673 |
| 0.0123 | 9.65 | 12000 | 0.4763 | 37.5956 | 13.9583 |
| 0.007 | 10.45 | 13000 | 0.4939 | 37.3116 | 13.9360 |
| 0.0047 | 11.25 | 14000 | 0.5054 | 37.1750 | 13.8106 |
| 0.0036 | 12.06 | 15000 | 0.5093 | 37.5082 | 13.8930 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
jrzmnt/hf-rl-course-LunarLander-v2
|
jrzmnt
| 2022-12-08T19:45:14Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-08T19:44:47Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -547.86 +/- 404.01
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
jinghua2tang/ppo-LunarLander-v2
|
jinghua2tang
| 2022-12-08T19:33:31Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-08T19:33:04Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 249.35 +/- 23.08
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
sd-concepts-library/jozef-tominc2
|
sd-concepts-library
| 2022-12-08T19:24:55Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2022-12-08T19:24:45Z |
---
license: mit
---
### jozef-tominc2 on Stable Diffusion
This is the `<jozef-tominc>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
jfjensen/ppo-LunarLander-v2-6
|
jfjensen
| 2022-12-08T19:18:28Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-08T19:18:08Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 270.92 +/- 11.97
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
jfjensen/ppo-LunarLander-v2-5
|
jfjensen
| 2022-12-08T18:22:42Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-08T18:22:17Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 186.66 +/- 74.41
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Gladiator/funnel-transformer-xlarge_ner_wnut_17
|
Gladiator
| 2022-12-08T18:04:38Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"funnel",
"token-classification",
"generated_from_trainer",
"dataset:wnut_17",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-12-08T17:46:21Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wnut_17
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: funnel-transformer-xlarge_ner_wnut_17
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wnut_17
type: wnut_17
args: wnut_17
metrics:
- name: Precision
type: precision
value: 0.7205240174672489
- name: Recall
type: recall
value: 0.5921052631578947
- name: F1
type: f1
value: 0.650032829940906
- name: Accuracy
type: accuracy
value: 0.9619810541038846
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# funnel-transformer-xlarge_ner_wnut_17
This model is a fine-tuned version of [funnel-transformer/xlarge](https://huggingface.co/funnel-transformer/xlarge) on the wnut_17 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2453
- Precision: 0.7205
- Recall: 0.5921
- F1: 0.6500
- Accuracy: 0.9620
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 213 | 0.2331 | 0.6897 | 0.4067 | 0.5117 | 0.9462 |
| No log | 2.0 | 426 | 0.2056 | 0.7097 | 0.5526 | 0.6214 | 0.9587 |
| 0.1454 | 3.0 | 639 | 0.2379 | 0.7102 | 0.5658 | 0.6298 | 0.9600 |
| 0.1454 | 4.0 | 852 | 0.2397 | 0.7141 | 0.5885 | 0.6452 | 0.9620 |
| 0.0319 | 5.0 | 1065 | 0.2453 | 0.7205 | 0.5921 | 0.6500 | 0.9620 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Gladiator/albert-large-v2_ner_wnut_17
|
Gladiator
| 2022-12-08T17:57:48Z | 16 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"albert",
"token-classification",
"generated_from_trainer",
"dataset:wnut_17",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-12-08T17:50:16Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wnut_17
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: albert-large-v2_ner_wnut_17
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wnut_17
type: wnut_17
args: wnut_17
metrics:
- name: Precision
type: precision
value: 0.7445742904841403
- name: Recall
type: recall
value: 0.5334928229665071
- name: F1
type: f1
value: 0.621602787456446
- name: Accuracy
type: accuracy
value: 0.9581637843336724
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-large-v2_ner_wnut_17
This model is a fine-tuned version of [albert-large-v2](https://huggingface.co/albert-large-v2) on the wnut_17 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2429
- Precision: 0.7446
- Recall: 0.5335
- F1: 0.6216
- Accuracy: 0.9582
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 213 | 0.3051 | 0.7929 | 0.3206 | 0.4566 | 0.9410 |
| No log | 2.0 | 426 | 0.2151 | 0.7443 | 0.4665 | 0.5735 | 0.9516 |
| 0.17 | 3.0 | 639 | 0.2310 | 0.7364 | 0.5012 | 0.5964 | 0.9559 |
| 0.17 | 4.0 | 852 | 0.2387 | 0.7564 | 0.5311 | 0.6240 | 0.9578 |
| 0.0587 | 5.0 | 1065 | 0.2429 | 0.7446 | 0.5335 | 0.6216 | 0.9582 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
sd-concepts-library/ivan-grohar
|
sd-concepts-library
| 2022-12-08T17:52:00Z | 0 | 1 | null |
[
"license:mit",
"region:us"
] | null | 2022-12-08T17:51:49Z |
---
license: mit
---
### ivan grohar on Stable Diffusion
This is the `<ivan-grohar>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
Gladiator/roberta-large_ner_wnut_17
|
Gladiator
| 2022-12-08T17:44:28Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"generated_from_trainer",
"dataset:wnut_17",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-12-08T17:30:50Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- wnut_17
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: roberta-large_ner_wnut_17
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wnut_17
type: wnut_17
args: wnut_17
metrics:
- name: Precision
type: precision
value: 0.7345505617977528
- name: Recall
type: recall
value: 0.6255980861244019
- name: F1
type: f1
value: 0.6757105943152455
- name: Accuracy
type: accuracy
value: 0.9650416322379711
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-large_ner_wnut_17
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the wnut_17 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2288
- Precision: 0.7346
- Recall: 0.6256
- F1: 0.6757
- Accuracy: 0.9650
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 213 | 0.1805 | 0.6403 | 0.6089 | 0.6242 | 0.9598 |
| No log | 2.0 | 426 | 0.1925 | 0.7314 | 0.5993 | 0.6588 | 0.9624 |
| 0.1192 | 3.0 | 639 | 0.1883 | 0.7088 | 0.6172 | 0.6598 | 0.9637 |
| 0.1192 | 4.0 | 852 | 0.2144 | 0.7289 | 0.6400 | 0.6815 | 0.9655 |
| 0.0301 | 5.0 | 1065 | 0.2288 | 0.7346 | 0.6256 | 0.6757 | 0.9650 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Litux/ppo-LunarLander-v2_mal
|
Litux
| 2022-12-08T16:44:11Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2022-12-08T16:43:18Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -170.35 +/- 86.64
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
wavymulder/couch-diffusion
|
wavymulder
| 2022-12-08T16:42:57Z | 0 | 8 | null |
[
"stable-diffusion",
"en",
"license:creativeml-openrail-m",
"region:us"
] | null | 2022-12-08T15:56:24Z |
---
language:
- en
thumbnail: "https://huggingface.co/wavymulder/couch-diffusion/resolve/main/images/tile.jpg"
license: creativeml-openrail-m
tags:
- stable-diffusion
---
**Couch Diffusion**

[*CKPT DOWNLOAD LINK*](https://huggingface.co/wavymulder/couch-diffusion/resolve/main/couch-diffusion-V1.ckpt) - This is a dreambooth trained on... couches
In your prompt, use the activation token: `couch`
Trained from 1.5 with VAE.
[Please see this document where I share the parameters (prompt, sampler, seed, etc.) used for all example images.](https://huggingface.co/wavymulder/couch-diffusion/resolve/main/example-image-parameters)

|
WimStraetemans/ppo-Huggy
|
WimStraetemans
| 2022-12-08T16:08:31Z | 9 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2022-12-08T16:08:24Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: Rowehn/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.