
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-29 12:28:39
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 526
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-29 12:28:30
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
avialfont/dummy-finetuned-imdb
|
avialfont
| 2022-04-04T10:53:31Z | 3 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"fill-mask",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-04-04T10:06:50Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: avialfont/dummy-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# avialfont/dummy-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.8606
- Validation Loss: 2.5865
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -688, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 2.8606 | 2.5865 | 0 |
### Framework versions
- Transformers 4.16.2
- TensorFlow 2.8.0
- Datasets 1.18.3
- Tokenizers 0.11.6
|
blacktree/distilbert-base-uncased-finetuned-sst2
|
blacktree
| 2022-04-04T10:44:22Z | 15 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-01T12:29:26Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-sst2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: sst2
metrics:
- name: Accuracy
type: accuracy
value: 0.5091743119266054
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-sst2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7027
- Accuracy: 0.5092
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.01
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6868 | 1.0 | 1053 | 0.7027 | 0.5092 |
| 0.6868 | 2.0 | 2106 | 0.7027 | 0.5092 |
| 0.6867 | 3.0 | 3159 | 0.6970 | 0.5092 |
| 0.687 | 4.0 | 4212 | 0.6992 | 0.5092 |
| 0.6866 | 5.0 | 5265 | 0.6983 | 0.5092 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
ikekobby/fake-real-news-classifier
|
ikekobby
| 2022-04-04T09:23:36Z | 5 | 0 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-03T17:57:15Z |
Model based trained on 30% of the kaggle public data on fake and reals news article. The model achieved an `auc` of 1.0, precision, recall and f1score all at score of 1.0.
* Task;- The predictor classifies news articles into either fake or real news.
* It is a transformer model trained using the `ktrain` library on 30% of dataset of size 194MB after preprocessing.
* Metrics used are recall,, precision, f1score and roc_auc_score.
|
tanlq/vit-base-patch16-224-in21k-finetuned-cifar10
|
tanlq
| 2022-04-04T08:20:16Z | 76 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:cifar10",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-03-31T03:09:09Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- cifar10
metrics:
- accuracy
model-index:
- name: vit-base-patch16-224-in21k-finetuned-cifar10
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: cifar10
type: cifar10
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.9875
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-in21k-finetuned-cifar10
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the cifar10 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0503
- Accuracy: 0.9875
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3118 | 1.0 | 1562 | 0.1135 | 0.9778 |
| 0.2717 | 2.0 | 3124 | 0.0619 | 0.9867 |
| 0.1964 | 3.0 | 4686 | 0.0503 | 0.9875 |
### Framework versions
- Transformers 4.18.0.dev0
- Pytorch 1.11.0
- Datasets 2.0.0
- Tokenizers 0.11.6
|
DMetaSoul/sbert-chinese-general-v2
|
DMetaSoul
| 2022-04-04T07:22:23Z | 1,656 | 33 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"semantic-search",
"chinese",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-03-25T08:59:33Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- semantic-search
- chinese
---
# DMetaSoul/sbert-chinese-general-v2
此模型基于 [bert-base-chinese](https://huggingface.co/bert-base-chinese) 版本 BERT 模型,在百万级语义相似数据集 [SimCLUE](https://github.com/CLUEbenchmark/SimCLUE) 上进行训练,适用于**通用语义匹配**场景,从效果来看该模型在各种任务上**泛化能力更好**。
注:此模型的[轻量化版本](https://huggingface.co/DMetaSoul/sbert-chinese-general-v2-distill),也已经开源啦!
# Usage
## 1. Sentence-Transformers
通过 [sentence-transformers](https://www.SBERT.net) 框架来使用该模型,首先进行安装:
```
pip install -U sentence-transformers
```
然后使用下面的代码来载入该模型并进行文本表征向量的提取:
```python
from sentence_transformers import SentenceTransformer
sentences = ["我的儿子!他猛然间喊道,我的儿子在哪儿?", "我的儿子呢!他突然喊道,我的儿子在哪里?"]
model = SentenceTransformer('DMetaSoul/sbert-chinese-general-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## 2. HuggingFace Transformers
如果不想使用 [sentence-transformers](https://www.SBERT.net) 的话,也可以通过 HuggingFace Transformers 来载入该模型并进行文本向量抽取:
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ["我的儿子!他猛然间喊道,我的儿子在哪儿?", "我的儿子呢!他突然喊道,我的儿子在哪里?"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('DMetaSoul/sbert-chinese-general-v2')
model = AutoModel.from_pretrained('DMetaSoul/sbert-chinese-general-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation
该模型在公开的几个语义匹配数据集上进行了评测,计算了向量相似度跟真实标签之间的相关性系数:
| | **csts_dev** | **csts_test** | **afqmc** | **lcqmc** | **bqcorpus** | **pawsx** | **xiaobu** |
| ---------------------------- | ------------ | ------------- | ---------- | ---------- | ------------ | ---------- | ---------- |
| **sbert-chinese-general-v1** | **84.54%** | **82.17%** | 23.80% | 65.94% | 45.52% | 11.52% | 48.51% |
| **sbert-chinese-general-v2** | 77.20% | 72.60% | **36.80%** | **76.92%** | **49.63%** | **16.24%** | **63.16%** |
这里对比了本模型跟之前我们发布 [sbert-chinese-general-v1](https://huggingface.co/DMetaSoul/sbert-chinese-general-v1) 之间的差异,可以看到本模型在多个任务上的泛化能力更好。
## Citing & Authors
E-mail: xiaowenbin@dmetasoul.com
|
DMetaSoul/sbert-chinese-qmc-finance-v1
|
DMetaSoul
| 2022-04-04T07:21:28Z | 5 | 2 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"semantic-search",
"chinese",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-03-25T10:23:55Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- semantic-search
- chinese
---
# DMetaSoul/sbert-chinese-qmc-finance-v1
此模型基于 [bert-base-chinese](https://huggingface.co/bert-base-chinese) 版本 BERT 模型,在大规模银行问题匹配数据集([BQCorpus](http://icrc.hitsz.edu.cn/info/1037/1162.htm))上进行训练调优,适用于**金融领域的问题匹配**场景,比如:
- 8千日利息400元? VS 10000元日利息多少钱
- 提前还款是按全额计息 VS 还款扣款不成功怎么还款?
- 为什么我借钱交易失败 VS 刚申请的借款为什么会失败
注:此模型的[轻量化版本](https://huggingface.co/DMetaSoul/sbert-chinese-qmc-finance-v1-distill),也已经开源啦!
# Usage
## 1. Sentence-Transformers
通过 [sentence-transformers](https://www.SBERT.net) 框架来使用该模型,首先进行安装:
```
pip install -U sentence-transformers
```
然后使用下面的代码来载入该模型并进行文本表征向量的提取:
```python
from sentence_transformers import SentenceTransformer
sentences = ["到期不能按时还款怎么办", "剩余欠款还有多少?"]
model = SentenceTransformer('DMetaSoul/sbert-chinese-qmc-finance-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## 2. HuggingFace Transformers
如果不想使用 [sentence-transformers](https://www.SBERT.net) 的话,也可以通过 HuggingFace Transformers 来载入该模型并进行文本向量抽取:
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ["到期不能按时还款怎么办", "剩余欠款还有多少?"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('DMetaSoul/sbert-chinese-qmc-finance-v1')
model = AutoModel.from_pretrained('DMetaSoul/sbert-chinese-qmc-finance-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation
该模型在公开的几个语义匹配数据集上进行了评测,计算了向量相似度跟真实标签之间的相关性系数:
| | **csts_dev** | **csts_test** | **afqmc** | **lcqmc** | **bqcorpus** | **pawsx** | **xiaobu** |
| -------------------------------- | ------------ | ------------- | --------- | --------- | ------------ | --------- | ---------- |
| **sbert-chinese-qmc-finance-v1** | 77.40% | 74.55% | 36.01% | 75.75% | 73.25% | 11.58% | 54.76% |
## Citing & Authors
E-mail: xiaowenbin@dmetasoul.com
|
Yaxin/roberta-large-ernie2-skep-en
|
Yaxin
| 2022-04-04T07:18:20Z | 4 | 2 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"en",
"arxiv:2005.05635",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-04-04T06:27:48Z |
---
language: en
---
# SKEP-Roberta
## Introduction
SKEP (SKEP: Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis) is proposed by Baidu in 2020,
SKEP propose Sentiment Knowledge Enhanced Pre-training for sentiment analysis. Sentiment masking and three sentiment pre-training objectives are designed to incorporate various types of knowledge for pre-training model.
More detail: https://aclanthology.org/2020.acl-main.374.pdf
## Released Model Info
|Model Name|Language|Model Structure|
|:---:|:---:|:---:|
|skep-roberta-large| English |Layer:24, Hidden:1024, Heads:24|
This released pytorch model is converted from the officially released PaddlePaddle SKEP model and
a series of experiments have been conducted to check the accuracy of the conversion.
- Official PaddlePaddle SKEP repo:
1. https://github.com/PaddlePaddle/PaddleNLP/blob/develop/paddlenlp/transformers/skep
2. https://github.com/baidu/Senta
- Pytorch Conversion repo: Not released yet
## How to use
```Python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Yaxin/roberta-large-ernie2-skep-en")
model = AutoModel.from_pretrained("Yaxin/roberta-large-ernie2-skep-en")
```
```
#!/usr/bin/env python
#encoding: utf-8
import torch
from transformers import RobertaTokenizer, RobertaForMaskedLM
tokenizer = RobertaTokenizer.from_pretrained('Yaxin/roberta-large-ernie2-skep-en')
input_tx = "<s> He like play with student, so he became a <mask> after graduation </s>"
# input_tx = "<s> He is a <mask> and likes to get along with his students </s>"
tokenized_text = tokenizer.tokenize(input_tx)
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([[0] * len(tokenized_text)])
model = RobertaForMaskedLM.from_pretrained('Yaxin/roberta-large-ernie2-skep-en')
model.eval()
with torch.no_grad():
outputs = model(tokens_tensor, token_type_ids=segments_tensors)
predictions = outputs[0]
predicted_index = [torch.argmax(predictions[0, i]).item() for i in range(0, (len(tokenized_text) - 1))]
predicted_token = [tokenizer.convert_ids_to_tokens([predicted_index[x]])[0] for x in
range(1, (len(tokenized_text) - 1))]
print('Predicted token is:', predicted_token)
```
## Citation
```bibtex
@article{tian2020skep,
title={SKEP: Sentiment knowledge enhanced pre-training for sentiment analysis},
author={Tian, Hao and Gao, Can and Xiao, Xinyan and Liu, Hao and He, Bolei and Wu, Hua and Wang, Haifeng and Wu, Feng},
journal={arXiv preprint arXiv:2005.05635},
year={2020}
}
```
```
reference:
https://github.com/nghuyong/ERNIE-Pytorch
```
|
vkamthe/upside_down_detector
|
vkamthe
| 2022-04-04T07:01:28Z | 5 | 0 |
tf-keras
|
[
"tf-keras",
"tag1",
"tag2",
"dataset:dataset1",
"dataset:dataset2",
"license:cc",
"region:us"
] | null | 2022-04-04T06:16:41Z |
---
language:
- "List of ISO 639-1 code for your language"
- lang1
- lang2
thumbnail: "url to a thumbnail used in social sharing"
tags:
- tag1
- tag2
license: "cc"
datasets:
- dataset1
- dataset2
metrics:
- metric1
- metric2
---
This is Image Orientation Detector by Vikram Kamthe
Given an image, it will classify it into Original Image or Upside Down Image
|
BigSalmon/GPT2Neo1.3BPoints
|
BigSalmon
| 2022-04-04T05:14:11Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-04-04T04:17:46Z |
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/GPT2Neo1.3BPoints")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/GPT2Neo1.3BPoints")
```
```
- moviepass to return
- this summer
- swooped up by
- original co-founder stacy spikes
text: the re-launch of moviepass is set to transpire this summer, ( rescued at the hands of / under the stewardship of / spearheaded by ) its founding father, stacy spikes.
***
- middle schools do not have recess
- should get back to doing it
- amazing for communication
- and getting kids to move around
text: a casualty of the education reform craze, recess has been excised from middle schools. this is tragic, for it is instrumental in honing children's communication skills and encouraging physical activity.
***
-
```
|
somosnlp-hackathon-2022/bertin-roberta-base-finetuning-esnli
|
somosnlp-hackathon-2022
| 2022-04-04T01:45:21Z | 74 | 7 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"roberta",
"feature-extraction",
"sentence-similarity",
"es",
"dataset:hackathon-pln-es/nli-es",
"arxiv:1908.10084",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-03-28T19:08:33Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
language:
- es
datasets:
- hackathon-pln-es/nli-es
widget:
- text: "A ver si nos tenemos que poner todos en huelga hasta cobrar lo que queramos."
- text: "La huelga es el método de lucha más eficaz para conseguir mejoras en el salario."
- text: "Tendremos que optar por hacer una huelga para cobrar lo que queremos."
- text: "Queda descartada la huelga aunque no cobremos lo que queramos."
---
# bertin-roberta-base-finetuning-esnli
This is a [sentence-transformers](https://www.SBERT.net) model trained on a
collection of NLI tasks for Spanish. It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
Based around the siamese networks approach from [this paper](https://arxiv.org/pdf/1908.10084.pdf).
<!--- Describe your model here -->
You can see a demo for this model [here](https://huggingface.co/spaces/hackathon-pln-es/Sentence-Embedding-Bertin).
You can find our other model, **paraphrase-spanish-distilroberta** [here](https://huggingface.co/hackathon-pln-es/paraphrase-spanish-distilroberta) and its demo [here](https://huggingface.co/spaces/hackathon-pln-es/Paraphrase-Bertin).
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["Este es un ejemplo", "Cada oración es transformada"]
model = SentenceTransformer('hackathon-pln-es/bertin-roberta-base-finetuning-esnli')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('hackathon-pln-es/bertin-roberta-base-finetuning-esnli')
model = AutoModel.from_pretrained('hackathon-pln-es/bertin-roberta-base-finetuning-esnli')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
Our model was evaluated on the task of Semantic Textual Similarity using the [SemEval-2015 Task](https://alt.qcri.org/semeval2015/task2/) for [Spanish](http://alt.qcri.org/semeval2015/task2/data/uploads/sts2015-es-test.zip). We measure
| | [BETO STS](https://huggingface.co/espejelomar/sentece-embeddings-BETO) | BERTIN STS (this model) | Relative improvement |
|-------------------:|---------:|-----------:|---------------------:|
| cosine_pearson | 0.609803 | 0.683188 | +12.03 |
| cosine_spearman | 0.528776 | 0.615916 | +16.48 |
| euclidean_pearson | 0.590613 | 0.672601 | +13.88 |
| euclidean_spearman | 0.526529 | 0.611539 | +16.15 |
| manhattan_pearson | 0.589108 | 0.672040 | +14.08 |
| manhattan_spearman | 0.525910 | 0.610517 | +16.09 |
| dot_pearson | 0.544078 | 0.600517 | +10.37 |
| dot_spearman | 0.460427 | 0.521260 | +13.21 |
## Training
The model was trained with the parameters:
**Dataset**
We used a collection of datasets of Natural Language Inference as training data:
- [ESXNLI](https://raw.githubusercontent.com/artetxem/esxnli/master/esxnli.tsv), only the part in spanish
- [SNLI](https://nlp.stanford.edu/projects/snli/), automatically translated
- [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/), automatically translated
The whole dataset used is available [here](https://huggingface.co/datasets/hackathon-pln-es/nli-es).
Here we leave the trick we used to increase the amount of data for training here:
```
for row in reader:
if row['language'] == 'es':
sent1 = row['sentence1'].strip()
sent2 = row['sentence2'].strip()
add_to_samples(sent1, sent2, row['gold_label'])
add_to_samples(sent2, sent1, row['gold_label']) #Also add the opposite
```
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader`
of length 1818 with parameters:
```
{'batch_size': 64}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 909,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 514, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Authors
[Anibal Pérez](https://huggingface.co/Anarpego),
[Emilio Tomás Ariza](https://huggingface.co/medardodt),
[Lautaro Gesuelli](https://huggingface.co/Lgesuelli) y
[Mauricio Mazuecos](https://huggingface.co/mmazuecos).
|
hamedkhaledi/persain-flair-upos
|
hamedkhaledi
| 2022-04-03T22:15:00Z | 29 | 0 |
flair
|
[
"flair",
"pytorch",
"token-classification",
"sequence-tagger-model",
"fa",
"dataset:ontonotes",
"region:us"
] |
token-classification
| 2022-03-25T07:27:51Z |
---
tags:
- flair
- token-classification
- sequence-tagger-model
language:
- fa
datasets:
- ontonotes
widget:
- text: "مقامات مصری به خاطر حفظ ثبات کشور در منطقهای پرآشوب بر خود میبالند ، در حالی که این کشور در طول ۱۶ سال گذشته تنها هشت سال آنرا بدون اعلام وضعیت اضطراری سپری کرده است ."
---
## Persian Universal Part-of-Speech Tagging in Flair
This is the universal part-of-speech tagging model for Persian that ships with [Flair](https://github.com/flairNLP/flair/).
F1-Score: **97,73** (UD_PERSIAN)
Predicts Universal POS tags:
| **tag** | **meaning** |
|:---------------------------------:|:-----------:|
|ADJ | adjective |
| ADP | adposition |
| ADV | adverb |
| AUX | auxiliary |
| CCONJ | coordinating conjunction |
| DET | determiner |
| INTJ | interjection |
| NOUN | noun |
| NUM | numeral |
| PART | particle |
| PRON | pronoun |
| PUNCT | punctuation |
| SCONJ | subordinating conjunction |
| VERB | verb |
| X | other |
---
### Demo: How to use in Flair
Requires: **[Flair](https://github.com/flairNLP/flair/)** (`pip install flair`)
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("hamedkhaledi/persain-flair-upos")
# make example sentence
sentence = Sentence("مقامات مصری به خاطر حفظ ثبات کشور در منطقهای پرآشوب بر خود میبالند .")
tagger.predict(sentence)
#print result
print(sentence.to_tagged_string())
```
This yields the following output:
```
مقامات <NOUN> مصری <ADJ> به <ADP> خاطر <NOUN> حفظ <NOUN> ثبات <NOUN> کشور <NOUN> در <ADP> منطقهای <NOUN> پرآشوب <ADJ> بر <ADP> خود <PRON> میبالند <VERB> . <PUNCT>
```
---
### Results
- F-score (micro) 0.9773
- F-score (macro) 0.9461
- Accuracy 0.9773
```
By class:
precision recall f1-score support
NOUN 0.9770 0.9849 0.9809 6420
ADP 0.9947 0.9916 0.9932 1909
ADJ 0.9342 0.9128 0.9234 1525
PUNCT 1.0000 1.0000 1.0000 1365
VERB 0.9840 0.9711 0.9775 1141
CCONJ 0.9912 0.9937 0.9925 794
AUX 0.9622 0.9799 0.9710 546
PRON 0.9751 0.9865 0.9808 517
SCONJ 0.9797 0.9757 0.9777 494
NUM 0.9948 1.0000 0.9974 385
ADV 0.9343 0.9033 0.9185 362
DET 0.9773 0.9711 0.9742 311
PART 0.9916 1.0000 0.9958 237
INTJ 0.8889 0.8000 0.8421 10
X 0.7143 0.6250 0.6667 8
micro avg 0.9773 0.9773 0.9773 16024
macro avg 0.9533 0.9397 0.9461 16024
weighted avg 0.9772 0.9773 0.9772 16024
samples avg 0.9773 0.9773 0.9773 16024
Loss: 0.12471389770507812
```
|
tbosse/bert-base-german-cased-finetuned-subj_v2_v1
|
tbosse
| 2022-04-03T19:15:50Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-04-03T17:49:37Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-base-german-cased-finetuned-subj_v2_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-german-cased-finetuned-subj_v2_v1
This model is a fine-tuned version of [bert-base-german-cased](https://huggingface.co/bert-base-german-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1587
- Precision: 0.2222
- Recall: 0.0107
- F1: 0.0204
- Accuracy: 0.9511
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 136 | 0.1569 | 0.6667 | 0.0053 | 0.0106 | 0.9522 |
| No log | 2.0 | 272 | 0.1562 | 0.1667 | 0.0053 | 0.0103 | 0.9513 |
| No log | 3.0 | 408 | 0.1587 | 0.2222 | 0.0107 | 0.0204 | 0.9511 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
anton-l/xtreme_s_xlsr_300m_minds14
|
anton-l
| 2022-04-03T18:54:43Z | 557 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"audio-classification",
"minds14",
"google/xtreme_s",
"generated_from_trainer",
"all",
"dataset:google/xtreme_s",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2022-03-17T17:24:20Z |
---
language:
- all
license: apache-2.0
tags:
- minds14
- google/xtreme_s
- generated_from_trainer
datasets:
- google/xtreme_s
metrics:
- f1
- accuracy
model-index:
- name: xtreme_s_xlsr_300m_minds14
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xtreme_s_xlsr_300m_minds14
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the GOOGLE/XTREME_S - MINDS14.ALL dataset.
It achieves the following results on the evaluation set:
- Accuracy: 0.9033
- Accuracy Cs-cz: 0.9164
- Accuracy De-de: 0.9477
- Accuracy En-au: 0.9235
- Accuracy En-gb: 0.9324
- Accuracy En-us: 0.9326
- Accuracy Es-es: 0.9177
- Accuracy Fr-fr: 0.9444
- Accuracy It-it: 0.9167
- Accuracy Ko-kr: 0.8649
- Accuracy Nl-nl: 0.9450
- Accuracy Pl-pl: 0.9146
- Accuracy Pt-pt: 0.8940
- Accuracy Ru-ru: 0.8667
- Accuracy Zh-cn: 0.7291
- F1: 0.9015
- F1 Cs-cz: 0.9154
- F1 De-de: 0.9467
- F1 En-au: 0.9199
- F1 En-gb: 0.9334
- F1 En-us: 0.9308
- F1 Es-es: 0.9158
- F1 Fr-fr: 0.9436
- F1 It-it: 0.9135
- F1 Ko-kr: 0.8642
- F1 Nl-nl: 0.9440
- F1 Pl-pl: 0.9159
- F1 Pt-pt: 0.8883
- F1 Ru-ru: 0.8646
- F1 Zh-cn: 0.7249
- Loss: 0.4119
- Loss Cs-cz: 0.3790
- Loss De-de: 0.2649
- Loss En-au: 0.3459
- Loss En-gb: 0.2853
- Loss En-us: 0.2203
- Loss Es-es: 0.2731
- Loss Fr-fr: 0.1909
- Loss It-it: 0.3520
- Loss Ko-kr: 0.5431
- Loss Nl-nl: 0.2515
- Loss Pl-pl: 0.4113
- Loss Pt-pt: 0.4798
- Loss Ru-ru: 0.6470
- Loss Zh-cn: 1.1216
- Predict Samples: 4086
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- total_train_batch_size: 64
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1500
- num_epochs: 50.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:--------:|
| 2.6739 | 5.41 | 200 | 2.5687 | 0.0430 | 0.1190 |
| 1.4953 | 10.81 | 400 | 1.6052 | 0.5550 | 0.5692 |
| 0.6177 | 16.22 | 600 | 0.7927 | 0.8052 | 0.8011 |
| 0.3609 | 21.62 | 800 | 0.5679 | 0.8609 | 0.8609 |
| 0.4972 | 27.03 | 1000 | 0.5944 | 0.8509 | 0.8523 |
| 0.1799 | 32.43 | 1200 | 0.6194 | 0.8623 | 0.8621 |
| 0.1308 | 37.84 | 1400 | 0.5956 | 0.8569 | 0.8548 |
| 0.2298 | 43.24 | 1600 | 0.5201 | 0.8732 | 0.8743 |
| 0.0052 | 48.65 | 1800 | 0.3826 | 0.9106 | 0.9103 |
### Framework versions
- Transformers 4.18.0.dev0
- Pytorch 1.10.2+cu113
- Datasets 2.0.1.dev0
- Tokenizers 0.11.6
|
Giyaseddin/distilbert-base-cased-finetuned-fake-and-real-news-dataset
|
Giyaseddin
| 2022-04-03T16:39:39Z | 93 | 1 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"en",
"license:gpl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-03T14:52:37Z |
---
license: gpl-3.0
language: en
library: transformers
other: distilbert
datasets:
- Fake and real news dataset
---
# DistilBERT base cased model for Fake News Classification
## Model description
DistilBERT is a transformers model, smaller and faster than BERT, which was pretrained on the same corpus in a
self-supervised fashion, using the BERT base model as a teacher. This means it was pretrained on the raw texts only,
with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic
process to generate inputs and labels from those texts using the BERT base model.
This is a Fake News classification model finetuned [pretrained DistilBERT model](https://huggingface.co/distilbert-base-cased) on
[Fake and real news dataset](https://www.kaggle.com/datasets/clmentbisaillon/fake-and-real-news-dataset)
## Intended uses & limitations
This can only be used for the kind of news that are similar to the ones in the dataset,
please visit the [dataset's kaggle page](https://www.kaggle.com/datasets/clmentbisaillon/fake-and-real-news-dataset) to see the data.
### How to use
You can use this model directly with a :
```python
>>> from transformers import pipeline
>>> classifier = pipeline("text-classification", model="Giyaseddin/distilbert-base-cased-finetuned-fake-and-real-news-dataset", return_all_scores=True)
>>> examples = ["Yesterday, Speaker Paul Ryan tweeted a video of himself on the Mexican border flying in a helicopter and traveling on horseback with US border agents. RT if you agree It is time for The Wall. pic.twitter.com/s5MO8SG7SL Paul Ryan (@SpeakerRyan) August 1, 2017It makes for great theater to see Republican Speaker Ryan pleading the case for a border wall, but how sincere are the GOP about building the border wall? Even after posting a video that appears to show Ryan s support for the wall, he still seems unsure of himself. It s almost as though he s testing the political winds when he asks Twitter users to retweet if they agree that we need to start building the wall. How committed is the (formerly?) anti-Trump Paul Ryan to building the border wall that would fulfill one of President Trump s most popular campaign promises to the American people? Does he have the what it takes to defy the wishes of corporate donors and the US Chamber of Commerce, and do the right thing for the national security and well-being of our nation?The Last Refuge- Republicans are in control of the House of Representatives, Republicans are in control of the Senate, a Republican President is in the White House, and somehow there s negotiations on how to fund the #1 campaign promise of President Donald Trump, the border wall.Here s the rub.Here s what pundits never discuss.The Republican party doesn t need a single Democrat to fund the border wall.A single spending bill could come from the House of Representatives that fully funds 100% of the border wall. The spending bill then goes to the senate, where again, it doesn t need a single Democrat vote because spending legislation is specifically what reconciliation was designed to facilitate. That House bill can pass the Senate with 51 votes and proceed directly to the President s desk for signature.So, ask yourself: why is this even a point of discussion?The honest answer, for those who are no longer suffering from Battered Conservative Syndrome, is that Republicans don t want to fund or build an actual physical barrier known as the Southern Border Wall.It really is that simple.If one didn t know better, they d almost think Speaker Ryan was attempting to emulate the man he clearly despised during the 2016 presidential campaign."]
>>> classifier(examples)
[[{'label': 'LABEL_0', 'score': 1.0},
{'label': 'LABEL_1', 'score': 1.0119109106199176e-08}]]
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions. It also inherits some of
[the bias of its teacher model](https://huggingface.co/bert-base-uncased#limitations-and-bias).
This bias will also affect all fine-tuned versions of this model.
## Pre-training data
DistilBERT pretrained on the same data as BERT, which is [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset
consisting of 11,038 unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia)
(excluding lists, tables and headers).
## Fine-tuning data
[Fake and real news dataset](https://www.kaggle.com/datasets/clmentbisaillon/fake-and-real-news-dataset)
## Training procedure
### Preprocessing
In the preprocessing phase, both the title and the text of the news are concatenated using a separator `[SEP]`.
This makes the full text as:
```
[CLS] Title Sentence [SEP] News text body [SEP]
```
The data are splitted according to the following ratio:
- Training set 60%.
- Validation set 20%.
- Test set 20%.
Lables are mapped as: `{fake: 0, true: 1}`
### Fine-tuning
The model was finetuned on GeForce GTX 960M for 5 hours. The parameters are:
| Parameter | Value |
|:-------------------:|:-----:|
| Learning rate | 5e-5 |
| Weight decay | 0.01 |
| Training batch size | 4 |
| Epochs | 3 |
Here is the scores during the training:
| Epoch | Training Loss | Validation Loss | Accuracy | F1 | Precision | Recall |
|:----------:|:-------------:|:-----------------:|:----------:|:---------:|:-----------:|:---------:|
| 1 | 0.008300 | 0.005783 | 0.998330 | 0.998252 | 0.996511 | 1.000000 |
| 2 | 0.000000 | 0.000161 | 0.999889 | 0.999883 | 0.999767 | 1.000000 |
| 3 | 0.000000 | 0.000122 | 0.999889 | 0.999883 | 0.999767 | 1.000000 |
## Evaluation results
When fine-tuned on downstream task of fake news binary classification, this model achieved the following results:
(scores are rounded to 2 floating points)
| | precision | recall | f1-score | support |
|:------------:|:---------:|:------:|:--------:|:-------:|
| Fake | 1.00 | 1.00 | 1.00 | 4697 |
| True | 1.00 | 1.00 | 1.00 | 4283 |
| accuracy | - | - | 1.00 | 8980 |
| macro avg | 1.00 | 1.00 | 1.00 | 8980 |
| weighted avg | 1.00 | 1.00 | 1.00 | 8980 |
Confision matrix:
| Actual\Predicted | Fake | True |
|:-----------------:|:----:|:----:|
| Fake | 4696 | 1 |
| True | 1 | 4282 |
The AUC score is 0.9997
|
AykeeSalazar/violation-classification-bantai-vit-v100ep
|
AykeeSalazar
| 2022-04-03T16:16:07Z | 64 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:image_folder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-04-03T14:05:38Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- image_folder
metrics:
- accuracy
model-index:
- name: violation-classification-bantai-vit-v100ep
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: image_folder
type: image_folder
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9157343919162757
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# violation-classification-bantai-vit-v100ep
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the image_folder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2557
- Accuracy: 0.9157
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2811 | 1.0 | 101 | 0.2855 | 0.9027 |
| 0.2382 | 2.0 | 202 | 0.2763 | 0.9085 |
| 0.2361 | 3.0 | 303 | 0.2605 | 0.9109 |
| 0.196 | 4.0 | 404 | 0.2652 | 0.9110 |
| 0.1395 | 5.0 | 505 | 0.2648 | 0.9134 |
| 0.155 | 6.0 | 606 | 0.2656 | 0.9152 |
| 0.1422 | 7.0 | 707 | 0.2607 | 0.9141 |
| 0.1511 | 8.0 | 808 | 0.2557 | 0.9157 |
| 0.1938 | 9.0 | 909 | 0.2679 | 0.9049 |
| 0.2094 | 10.0 | 1010 | 0.2392 | 0.9137 |
| 0.1835 | 11.0 | 1111 | 0.2400 | 0.9156 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
jsunster/distilbert-base-uncased-finetuned-squad
|
jsunster
| 2022-04-03T14:46:14Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-04-03T13:02:11Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1476
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.2823 | 1.0 | 2767 | 1.1980 |
| 1.0336 | 2.0 | 5534 | 1.1334 |
| 0.8513 | 3.0 | 8301 | 1.1476 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0
- Datasets 2.0.0
- Tokenizers 0.11.6
|
AnnaBabaie/ms-marco-MiniLM-L-12-v2-news
|
AnnaBabaie
| 2022-04-03T13:46:51Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-03T12:55:06Z |
This model is fined tuned for the Fake news classifier: Train a text classification model to detect fake news articles. Base on the Kaggle dataset(https://www.kaggle.com/clmentbisaillon/fake-and-real-news-dataset).
|
alefiury/wav2vec2-xls-r-300m-pt-br-spontaneous-speech-emotion-recognition
|
alefiury
| 2022-04-03T12:38:09Z | 66 | 6 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"audio-classification",
"audio",
"speech",
"pt",
"portuguese-speech-corpus",
"italian-speech-corpus",
"english-speech-corpus",
"arabic-speech-corpus",
"spontaneous",
"PyTorch",
"dataset:coraa_ser",
"dataset:emovo",
"dataset:ravdess",
"dataset:baved",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2022-03-23T15:29:36Z |
---
language: pt
datasets:
- coraa_ser
- emovo
- ravdess
- baved
metrics:
- f1
tags:
- audio
- speech
- wav2vec2
- pt
- portuguese-speech-corpus
- italian-speech-corpus
- english-speech-corpus
- arabic-speech-corpus
- spontaneous
- speech
- PyTorch
license: apache-2.0
model_index:
name: wav2vec2-xls-r-300m-pt-br-spontaneous-speech-emotion-recognition
results:
metrics:
- name: Test Macro F1-Score
type: f1
value: 81.87%
---
# Wav2vec 2.0 XLS-R For Spontaneous Speech Emotion Recognition
This is the model that got first place in the SER track of the Automatic Speech Recognition for spontaneous and prepared speech & Speech Emotion Recognition in Portuguese (SE&R 2022) Workshop.
The following datasets were used in the training:
- [CORAA SER v1.0](https://github.com/rmarcacini/ser-coraa-pt-br/): a dataset composed of spontaneous portuguese speech and approximately 40 minutes of audio segments labeled in three classes: neutral, non-neutral female, and non-neutral male.
- [EMOVO Corpus](https://aclanthology.org/L14-1478/): a database of emotional speech for the Italian language, built from the voices of up to 6 actors who played 14 sentences simulating 6 emotional states (disgust, fear, anger, joy, surprise, sadness) plus the neutral state.
- [RAVDESS](https://zenodo.org/record/1188976#.YO6yI-gzaUk): a dataset that provides 1440 samples of recordings from actors performing on 8 different emotions in English, which are: angry, calm, disgust, fearful, happy, neutral, sad and surprised.
- [BAVED](https://github.com/40uf411/Basic-Arabic-Vocal-Emotions-Dataset): a collection of audio recordings of Arabic words spoken with varying degrees of emotion. The dataset contains seven words: like, unlike, this, file, good, neutral, and bad, which are spoken at three emotional levels: low emotion (tired or feeling down), neutral emotion (the way the speaker speaks daily), and high emotion (positive or negative emotions such as happiness, joy, sadness, anger).
The test set used is a part of the CORAA SER v1.0 that has been set aside for this purpose.
It achieves the following results on the test set:
- Accuracy: 0.9090
- Macro Precision: 0.8171
- Macro Recall: 0.8397
- Macro F1-Score: 0.8187
## Datasets Details
The following image shows the overall distribution of the datasets:

The following image shows the number of instances by label:
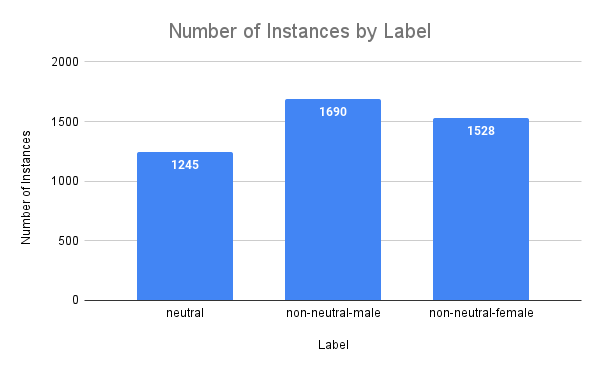
## Repository
The repository that implements the model to be trained and tested is avaible [here](https://github.com/alefiury/SE-R-2022-SER-Track).
|
AykeeSalazar/violation-classification-bantai_vit
|
AykeeSalazar
| 2022-04-03T12:26:48Z | 62 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:image_folder",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-04-03T03:01:22Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- image_folder
model-index:
- name: violation-classification-bantai_vit
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# violation-classification-bantai_vit
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the image_folder dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.2362
- eval_accuracy: 0.9478
- eval_runtime: 43.2567
- eval_samples_per_second: 85.42
- eval_steps_per_second: 2.682
- epoch: 87.0
- step: 10005
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 500
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
Awais/Audio_Source_Separation
|
Awais
| 2022-04-03T11:03:43Z | 11 | 21 |
asteroid
|
[
"asteroid",
"pytorch",
"audio",
"ConvTasNet",
"audio-to-audio",
"dataset:Libri2Mix",
"dataset:sep_clean",
"license:cc-by-sa-4.0",
"region:us"
] |
audio-to-audio
| 2022-04-02T13:01:03Z |
---
tags:
- asteroid
- audio
- ConvTasNet
- audio-to-audio
datasets:
- Libri2Mix
- sep_clean
license: cc-by-sa-4.0
---
## Asteroid model `Awais/Audio_Source_Separation`
Imported from [Zenodo](https://zenodo.org/record/3873572#.X9M69cLjJH4)
Description:
This model was trained by Joris Cosentino using the librimix recipe in [Asteroid](https://github.com/asteroid-team/asteroid).
It was trained on the `sep_clean` task of the Libri2Mix dataset.
Training config:
```yaml
data:
n_src: 2
sample_rate: 8000
segment: 3
task: sep_clean
train_dir: data/wav8k/min/train-360
valid_dir: data/wav8k/min/dev
filterbank:
kernel_size: 16
n_filters: 512
stride: 8
masknet:
bn_chan: 128
hid_chan: 512
mask_act: relu
n_blocks: 8
n_repeats: 3
skip_chan: 128
optim:
lr: 0.001
optimizer: adam
weight_decay: 0.0
training:
batch_size: 24
early_stop: True
epochs: 200
half_lr: True
num_workers: 2
```
Results :
On Libri2Mix min test set :
```yaml
si_sdr: 14.764543634468069
si_sdr_imp: 14.764029375607246
sdr: 15.29337970745095
sdr_imp: 15.114146605113111
sir: 24.092904661115366
sir_imp: 23.913669683141528
sar: 16.06055906916849
sar_imp: -51.980784441287454
stoi: 0.9311142440593033
stoi_imp: 0.21817376142710482
```
License notice:
This work "ConvTasNet_Libri2Mix_sepclean_8k"
is a derivative of [LibriSpeech ASR corpus](http://www.openslr.org/12) by Vassil Panayotov,
used under [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/). "ConvTasNet_Libri2Mix_sepclean_8k"
is licensed under [Attribution-ShareAlike 3.0 Unported](https://creativecommons.org/licenses/by-sa/3.0/) by Cosentino Joris.
|
Zohar/distilgpt2-finetuned-restaurant-reviews-clean
|
Zohar
| 2022-04-03T10:29:27Z | 3 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-04-03T07:25:35Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilgpt2-finetuned-restaurant-reviews-clean
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-restaurant-reviews-clean
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5371
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.7221 | 1.0 | 2447 | 3.5979 |
| 3.6413 | 2.0 | 4894 | 3.5505 |
| 3.6076 | 3.0 | 7341 | 3.5371 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.2+cu102
- Datasets 1.18.2
- Tokenizers 0.11.0
|
abd-1999/autotrain-bbc-news-summarization-694821095
|
abd-1999
| 2022-04-03T09:25:08Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain",
"unk",
"dataset:abd-1999/autotrain-data-bbc-news-summarization",
"co2_eq_emissions",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-04-01T21:16:19Z |
---
tags: autotrain
language: unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- abd-1999/autotrain-data-bbc-news-summarization
co2_eq_emissions: 2313.4037079026934
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 694821095
- CO2 Emissions (in grams): 2313.4037079026934
## Validation Metrics
- Loss: 3.0294156074523926
- Rouge1: 2.1467
- Rouge2: 0.0853
- RougeL: 2.1524
- RougeLsum: 2.1534
- Gen Len: 18.5603
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/abd-1999/autotrain-bbc-news-summarization-694821095
```
|
Prinernian/distilbert-base-uncased-finetuned-emotion
|
Prinernian
| 2022-04-03T09:11:07Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-02T17:49:11Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2208
- Accuracy: 0.924
- F1: 0.9240
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8538 | 1.0 | 250 | 0.3317 | 0.904 | 0.8999 |
| 0.2599 | 2.0 | 500 | 0.2208 | 0.924 | 0.9240 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Tokenizers 0.11.6
|
AykeeSalazar/vit-base-patch16-224-in21k-bantai_vitv1
|
AykeeSalazar
| 2022-04-03T02:43:41Z | 63 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:image_folder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-04-02T14:17:18Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- image_folder
metrics:
- accuracy
model-index:
- name: vit-base-patch16-224-in21k-bantai_vitv1
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: image_folder
type: image_folder
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8635994587280108
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-in21k-bantai_vitv1
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the image_folder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3961
- Accuracy: 0.8636
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5997 | 1.0 | 115 | 0.5401 | 0.7886 |
| 0.4696 | 2.0 | 230 | 0.4410 | 0.8482 |
| 0.4019 | 3.0 | 345 | 0.3961 | 0.8636 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
Asayaya/Upside_down_detector
|
Asayaya
| 2022-04-03T01:00:26Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2022-04-03T00:55:24Z |
---
license: apache-2.0
---
# -*- coding: utf-8 -*-
'''
Original file is located at
https://colab.research.google.com/drive/1HrNm5UMZr2Zjmze_HKW799p6LAHM8BTa
'''
from google.colab import files
files.upload()
!pip install kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
!kaggle datasets download 'shaunthesheep/microsoft-catsvsdogs-dataset'
!unzip microsoft-catsvsdogs-dataset
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
image_dir='/content/PetImages/Cat'
!mkdir train_folder
!mkdir test_folder
import os
path='/content/train_folder/'
dir='upside_down'
dir2='normal'
training_normal= os.path.join(path, dir2)
training_upside= os.path.join(path, dir)
os.mkdir(training_normal)
os.mkdir(training_upside)
#creating classes directories
path='/content/test_folder/'
dir='upside_down'
dir2='normal'
training_normal= os.path.join(path, dir2)
training_upside= os.path.join(path, dir)
os.mkdir(training_normal)
os.mkdir(training_upside)
#copying only the cat images to my train folder
fnames = ['{}.jpg'.format(i) for i in range(2000)]
for fname in fnames:
src = os.path.join('/content/PetImages/Cat', fname)
dst = os.path.join('/content/train_folder/normal', fname)
shutil.copyfile(src, dst)
import os
import shutil
fnames = ['{}.jpg'.format(i) for i in range(2000, 4000)]
for fname in fnames:
src = os.path.join('/content/PetImages/Cat', fname)
dst = os.path.join('/content/test_folder/normal', fname)
shutil.copyfile(src, dst)
from scipy import ndimage, misc
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import imageio
import os
import cv2
#inverting Training Images
outPath = '/content/train_folder/upside_down'
path ='/content/train_folder/normal'
# iterate through the names of contents of the folder
for image_path in os.listdir(path):
# create the full input path and read the file
input_path = os.path.join(path, image_path)
image_to_rotate =plt.imread(input_path)
# rotate the image
rotated = np.flipud(image_to_rotate)
# create full output path, 'example.jpg'
# becomes 'rotate_example.jpg', save the file to disk
fullpath = os.path.join(outPath, 'rotated_'+image_path)
imageio.imwrite(fullpath, rotated)
#nverting images for Validation
outPath = '/content/test_folder/upside_down'
path ='/content/test_folder/normal'
# iterate through the names of contents of the folder
for image_path in os.listdir(path):
# create the full input path and read the file
input_path = os.path.join(path, image_path)
image_to_rotate =plt.imread(input_path)
# rotate the image
rotated = np.flipud(image_to_rotate)
# create full output path, 'example.jpg'
# becomes 'rotate_example.jpg', save the file to disk
fullpath = os.path.join(outPath, 'rotated_'+image_path)
imageio.imwrite(fullpath, rotated)
ima='/content/train_folder/inverted/rotated_1001.jpg'
image=plt.imread(ima)
plt.imshow(image)
# visualize the the figure
plt.show()
train_dir='/content/train_folder'
train_gen=ImageDataGenerator(rescale=1./255)
train_images= train_gen.flow_from_directory(
train_dir,
target_size=(250,250),
batch_size=50,
class_mode='binary'
)
validation_dir='/content/test_folder'
test_gen=ImageDataGenerator(rescale=1./255)
test_images= test_gen.flow_from_directory(
validation_dir,
target_size=(250,250),
batch_size=50,
class_mode='binary'
)
model=tf.keras.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(250,250,3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
from tensorflow.keras.optimizers import RMSprop
model.compile(optimizer=RMSprop(learning_rate=0.001), loss=tf.keras.losses.BinaryCrossentropy(), metrics=['acc'])
history=model.fit(train_images, validation_data=test_images, epochs=5, steps_per_epoch=40 )
|
huggingtweets/clortown-elonmusk-stephencurry30
|
huggingtweets
| 2022-04-02T23:03:14Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-04-02T23:02:39Z |
---
language: en
thumbnail: http://www.huggingtweets.com/clortown-elonmusk-stephencurry30/1648940589601/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1503591435324563456/foUrqiEw_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1488574779351187458/RlIQNUFG_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1484233608793518081/tOID8aXq_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Elon Musk & yeosang elf agenda & Stephen Curry</div>
<div style="text-align: center; font-size: 14px;">@clortown-elonmusk-stephencurry30</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Elon Musk & yeosang elf agenda & Stephen Curry.
| Data | Elon Musk | yeosang elf agenda | Stephen Curry |
| --- | --- | --- | --- |
| Tweets downloaded | 221 | 3143 | 3190 |
| Retweets | 7 | 541 | 384 |
| Short tweets | 62 | 463 | 698 |
| Tweets kept | 152 | 2139 | 2108 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2sqcbnn5/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @clortown-elonmusk-stephencurry30's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1mq1ftjh) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1mq1ftjh/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/clortown-elonmusk-stephencurry30')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
vicl/canine-s-finetuned-cola
|
vicl
| 2022-04-02T23:01:51Z | 3 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"canine",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-02T22:29:20Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: canine-s-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.059386434587477076
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# canine-s-finetuned-cola
This model is a fine-tuned version of [google/canine-s](https://huggingface.co/google/canine-s) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6653
- Matthews Correlation: 0.0594
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.6132 | 1.0 | 535 | 0.6289 | 0.0 |
| 0.6062 | 2.0 | 1070 | 0.6179 | 0.0 |
| 0.6122 | 3.0 | 1605 | 0.6160 | 0.0 |
| 0.5939 | 4.0 | 2140 | 0.6159 | 0.0 |
| 0.5721 | 5.0 | 2675 | 0.6653 | 0.0594 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
vicl/distilbert-base-uncased-finetuned-stsb
|
vicl
| 2022-04-02T22:24:08Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-02T22:08:33Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- spearmanr
model-index:
- name: distilbert-base-uncased-finetuned-stsb
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: stsb
metrics:
- name: Spearmanr
type: spearmanr
value: 0.8636303639161342
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-stsb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5644
- Pearson: 0.8666
- Spearmanr: 0.8636
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearson | Spearmanr |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:---------:|
| No log | 1.0 | 360 | 0.6366 | 0.8537 | 0.8516 |
| 1.0464 | 2.0 | 720 | 0.6171 | 0.8632 | 0.8626 |
| 0.4002 | 3.0 | 1080 | 0.6082 | 0.8663 | 0.8643 |
| 0.4002 | 4.0 | 1440 | 0.5644 | 0.8666 | 0.8636 |
| 0.2479 | 5.0 | 1800 | 0.5780 | 0.8654 | 0.8624 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
vicl/distilbert-base-uncased-finetuned-mrpc
|
vicl
| 2022-04-02T21:56:07Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-02T21:45:00Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-mrpc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8480392156862745
- name: F1
type: f1
value: 0.89419795221843
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-mrpc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4044
- Accuracy: 0.8480
- F1: 0.8942
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 230 | 0.3830 | 0.8162 | 0.8673 |
| No log | 2.0 | 460 | 0.3957 | 0.8456 | 0.8952 |
| 0.4307 | 3.0 | 690 | 0.4044 | 0.8480 | 0.8942 |
| 0.4307 | 4.0 | 920 | 0.5649 | 0.8407 | 0.8915 |
| 0.1739 | 5.0 | 1150 | 0.5983 | 0.8480 | 0.8956 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
vocab-transformers/distilbert-mlm-1000k
|
vocab-transformers
| 2022-04-02T21:16:58Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-04-02T21:16:53Z |
distilbert-base-uncased trained for 1000K steps with batch size 64 on C4, MSMARCO, Wikipedia, S2ORC, News
|
vocab-transformers/distilbert-mlm-750k
|
vocab-transformers
| 2022-04-02T21:15:27Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-04-02T21:15:23Z |
distilbert-base-uncased trained for 750K steps with batch size 64 on C4, MSMARCO, Wikipedia, S2ORC, News
|
celine98/canine-c-finetuned-sst2
|
celine98
| 2022-04-02T19:11:13Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"canine",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-24T14:40:39Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: canine-c-finetuned-sst2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: sst2
metrics:
- name: Accuracy
type: accuracy
value: 0.8486238532110092
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# canine-c-finetuned-sst2
This model is a fine-tuned version of [google/canine-c](https://huggingface.co/google/canine-c) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6025
- Accuracy: 0.8486
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4.9121586874695155e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3415 | 1.0 | 2105 | 0.4196 | 0.8280 |
| 0.2265 | 2.0 | 4210 | 0.4924 | 0.8211 |
| 0.1439 | 3.0 | 6315 | 0.5726 | 0.8337 |
| 0.0974 | 4.0 | 8420 | 0.6025 | 0.8486 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
hylee/DualStyleGAN
|
hylee
| 2022-04-02T14:44:30Z | 0 | 1 | null |
[
"region:us"
] | null | 2022-04-02T01:54:21Z |
---
title: DualStyleGAN
emoji: 👀
colorFrom: green
colorTo: gray
sdk: gradio
sdk_version: 2.8.13
app_file: app.py
pinned: false
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
|
ntt123/hifigan_ljs_24k
|
ntt123
| 2022-04-02T14:20:55Z | 0 | 0 | null |
[
"tensorboard",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2022-03-28T16:32:11Z |
---
license: cc-by-nc-4.0
---
|
mnne/duck-and-cover-genre-encoder
|
mnne
| 2022-04-02T13:53:50Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-04-02T13:12:20Z |
# Duck and Cover - Genre Autoencoder
This model is part of the [duck_and_cover](https://github.com/mcschmitz/duck_and_cover) repository. Scope of this repository is to generate album covers based on several conditions like release year, artist & album name, and genre(s) using different types of GANs. The possible list of genres that this encoder covers can be found [here](https://github.com/mcschmitz/duck_and_cover/blob/master/data/genres.txt).
For training [prajjwal1/bert-mini](https://huggingface.co/prajjwal1/bert-mini) has been finetuned on a list of 466.045 albums with different genre combinations taken from the aforementioned list to embed genre information, while a simple Linear Layer was trained to decode and predict the given genre from the embeddings. The albums are real-world albums retrieved using the Spotify API. The intention behind this model is that Hard Rock is somehow related to Rock, while Pop Rock is related to Rock as well and a BERT Tokenizer can capture this information as a lot of music genres are described by using pre- and suffixes.
The model was validated on 133.155 during training and tested on 66.578. It yields a 98.29% Exact Match ratio on the testset and a 98.24% Exact Match Ratio on the validation set, which is extremely high given that the model can embed up to 3452 labels and most of the albums only had up to 5 labels.
## Usage
The model can be used to embed genres to a 256 dimensional space using the following input.
```python
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("mnne/duck-and-cover-genre-encoder")
tokenizer = AutoTokenizer.from_pretrained("mnne/duck-and-cover-genre-encoder")
genres = " , ".join(["classic soul", "memphis soul", "soul", "soul blues", "southern soul"])
x = tokenizer([genres], return_tensors="pt")
output = model(**x)
```
|
anuragshas/en-hi-transliteration
|
anuragshas
| 2022-04-02T12:24:03Z | 0 | 1 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2022-04-02T11:50:28Z |
---
license: apache-2.0
---
## Dataset
[NEWS2018 DATASET_04, Task ID: M-EnHi](http://workshop.colips.org/news2018/dataset.html)
## Notebooks
- `xmltodict.ipynb` contains the code to convert the `xml` files to `json` for training
- `training_script.ipynb` contains the code for training and inference. It is a modified version of https://github.com/AI4Bharat/IndianNLP-Transliteration/blob/master/NoteBooks/Xlit_TrainingSetup_condensed.ipynb
## Predictions
`pred_test.json` contains top-10 predictions on the validation set of the dataset
## Evaluation Scores on validation set
TOP 10 SCORES FOR 1000 SAMPLES
|Metrics | Score |
|-----------|-----------|
|ACC | 0.703000|
|Mean F-score| 0.949289|
|MRR | 0.486549|
|MAP_ref | 0.381000|
TOP 5 SCORES FOR 1000 SAMPLES:
|Metrics | Score |
|-----------|-----------|
|ACC |0.621000|
|Mean F-score |0.937985|
|MRR |0.475033|
|MAP_ref |0.381000|
TOP 3 SCORES FOR 1000 SAMPLES:
|Metrics | Score |
|-----------|-----------|
|ACC |0.560000|
|Mean F-score |0.927025|
|MRR |0.461333|
|MAP_ref |0.381000|
TOP 2 SCORES FOR 1000 SAMPLES:
|Metrics | Score |
|-----------|-----------|
|ACC | 0.502000|
|Mean F-score | 0.913697|
|MRR | 0.442000|
|MAP_ref | 0.381000|
TOP 1 SCORES FOR 1000 SAMPLES:
|Metrics | Score |
|-----------|-----------|
|ACC | 0.382000|
|Mean F-score | 0.881272|
|MRR | 0.382000|
|MAP_ref | 0.380500|
|
DMetaSoul/sbert-chinese-general-v2-distill
|
DMetaSoul
| 2022-04-02T09:58:33Z | 15 | 6 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"semantic-search",
"chinese",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-04-02T09:58:18Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- semantic-search
- chinese
---
# DMetaSoul/sbert-chinese-general-v2-distill
此模型是之前[开源通用语义匹配模型](https://huggingface.co/DMetaSoul/sbert-chinese-general-v2)的蒸馏版本(仅4层 BERT),适用于**通用语义匹配**场景,从效果来看该模型在各种任务上**泛化能力更好且编码速度更快**。
离线训练好的大模型如果直接用于线上推理,对计算资源有苛刻的需求,而且难以满足业务环境对延迟、吞吐量等性能指标的要求,这里我们使用蒸馏手段来把大模型轻量化。从 12 层 BERT 蒸馏为 4 层后,模型参数量缩小到 44%,大概 latency 减半、throughput 翻倍、精度下降 6% 左右(具体结果详见下文评估小节)。
# Usage
## 1. Sentence-Transformers
通过 [sentence-transformers](https://www.SBERT.net) 框架来使用该模型,首先进行安装:
```
pip install -U sentence-transformers
```
然后使用下面的代码来载入该模型并进行文本表征向量的提取:
```python
from sentence_transformers import SentenceTransformer
sentences = ["我的儿子!他猛然间喊道,我的儿子在哪儿?", "我的儿子呢!他突然喊道,我的儿子在哪里?"]
model = SentenceTransformer('DMetaSoul/sbert-chinese-general-v2-distill')
embeddings = model.encode(sentences)
print(embeddings)
```
## 2. HuggingFace Transformers
如果不想使用 [sentence-transformers](https://www.SBERT.net) 的话,也可以通过 HuggingFace Transformers 来载入该模型并进行文本向量抽取:
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ["我的儿子!他猛然间喊道,我的儿子在哪儿?", "我的儿子呢!他突然喊道,我的儿子在哪里?"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('DMetaSoul/sbert-chinese-general-v2-distill')
model = AutoModel.from_pretrained('DMetaSoul/sbert-chinese-general-v2-distill')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation
这里主要跟蒸馏前对应的 teacher 模型作了对比:
*性能:*
| | Teacher | Student | Gap |
| ---------- | --------------------- | ------------------- | ----- |
| Model | BERT-12-layers (102M) | BERT-4-layers (45M) | 0.44x |
| Cost | 23s | 12s | -47% |
| Latency | 38ms | 20ms | -47% |
| Throughput | 418 sentence/s | 791 sentence/s | 1.9x |
*精度:*
| | **csts_dev** | **csts_test** | **afqmc** | **lcqmc** | **bqcorpus** | **pawsx** | **xiaobu** | **Avg** |
| -------------- | ------------ | ------------- | --------- | --------- | ------------ | --------- | ---------- | ------- |
| **Teacher** | 77.19% | 72.59% | 36.79% | 76.91% | 49.62% | 16.24% | 63.15% | 56.07% |
| **Student** | 76.49% | 73.33% | 26.46% | 64.26% | 46.02% | 11.83% | 52.45% | 50.12% |
| **Gap** (abs.) | - | - | - | - | - | - | - | -5.95% |
*基于1万条数据测试,GPU设备是V100,batch_size=16,max_seq_len=256*
## Citing & Authors
E-mail: xiaowenbin@dmetasoul.com
|
junnyu/flash_small_wwm_cluecorpussmall
|
junnyu
| 2022-04-02T09:46:27Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"flash",
"fill-mask",
"license:mit",
"autotrain_compatible",
"region:us"
] |
fill-mask
| 2022-04-02T02:59:48Z |
---
license: mit
inference: False
---
# training logs
- https://wandb.ai/junyu/huggingface/runs/1jg2jlgt
# install
- https://github.com/JunnYu/FLASHQuad_pytorch
# usage
```python
import torch
from flash import FLASHForMaskedLM
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained("junnyu/flash_small_wwm_cluecorpussmall")
model = FLASHForMaskedLM.from_pretrained("junnyu/flash_small_wwm_cluecorpussmall")
model.eval()
text = "天气预报说今天的天[MASK]很好,那么我[MASK]一起去公园玩吧!"
inputs = tokenizer(text, return_tensors="pt", padding="max_length", max_length=512, return_token_type_ids=False) #这里必须是512,不然结果可能不对。
with torch.no_grad():
pt_outputs = model(**inputs).logits[0]
pt_outputs_sentence = "pytorch: "
for i, id in enumerate(tokenizer.encode(text)):
if id == tokenizer.mask_token_id:
val,idx = pt_outputs[i].softmax(-1).topk(k=5)
tokens = tokenizer.convert_ids_to_tokens(idx)
new_tokens = []
for v,t in zip(val.cpu(),tokens):
new_tokens.append(f"{t}+{round(v.item(),4)}")
pt_outputs_sentence += "[" + "||".join(new_tokens) + "]"
else:
pt_outputs_sentence += "".join(
tokenizer.convert_ids_to_tokens([id], skip_special_tokens=True))
print(pt_outputs_sentence)
# pytorch: 天气预报说今天的天[气+0.994||天+0.0015||空+0.0014||晴+0.0005||阳+0.0003]很好,那么我[们+0.9563||就+0.0381||也+0.0032||俩+0.0004||来+0.0002]一起去公园玩吧!
```
|
Chikashi/t5-small-finetuned-wikihow_3epoch
|
Chikashi
| 2022-04-02T07:42:15Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:wikihow",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-04-01T21:20:33Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wikihow
metrics:
- rouge
model-index:
- name: t5-small-finetuned-wikihow_3epoch
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: wikihow
type: wikihow
args: all
metrics:
- name: Rouge1
type: rouge
value: 25.5784
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-wikihow_3epoch
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the wikihow dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5163
- Rouge1: 25.5784
- Rouge2: 8.9929
- Rougel: 21.5345
- Rougelsum: 24.9382
- Gen Len: 18.384
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 2.9421 | 0.25 | 5000 | 2.6545 | 23.2336 | 7.5502 | 19.5899 | 22.5521 | 18.4076 |
| 2.8411 | 0.51 | 10000 | 2.6103 | 24.3524 | 8.2068 | 20.5238 | 23.6679 | 18.2606 |
| 2.7983 | 0.76 | 15000 | 2.5836 | 24.8169 | 8.4826 | 20.8765 | 24.1686 | 18.3211 |
| 2.7743 | 1.02 | 20000 | 2.5627 | 24.9904 | 8.5625 | 21.0344 | 24.3416 | 18.3786 |
| 2.7452 | 1.27 | 25000 | 2.5508 | 25.1497 | 8.6872 | 21.152 | 24.4751 | 18.3524 |
| 2.7353 | 1.53 | 30000 | 2.5384 | 25.2909 | 8.7408 | 21.2344 | 24.629 | 18.4453 |
| 2.7261 | 1.78 | 35000 | 2.5322 | 25.3748 | 8.7802 | 21.312 | 24.7191 | 18.3754 |
| 2.7266 | 2.03 | 40000 | 2.5265 | 25.4095 | 8.8915 | 21.3871 | 24.7685 | 18.4013 |
| 2.706 | 2.29 | 45000 | 2.5211 | 25.4372 | 8.8926 | 21.4124 | 24.7902 | 18.3776 |
| 2.7073 | 2.54 | 50000 | 2.5176 | 25.4925 | 8.9668 | 21.5103 | 24.8608 | 18.4303 |
| 2.703 | 2.8 | 55000 | 2.5163 | 25.5784 | 8.9929 | 21.5345 | 24.9382 | 18.384 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
Suman123/upside-down-detector
|
Suman123
| 2022-04-02T07:33:31Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-04-01T12:56:45Z |
TASK 1 of Faltima Fellowship- UpsideDown detector
|
nikhil6041/wav2vec2-large-xls-r-300m-hindi-colab
|
nikhil6041
| 2022-04-02T06:04:25Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-04-02T03:35:24Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-hindi-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-hindi-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
|
huggingtweets/percybotshelley
|
huggingtweets
| 2022-04-02T05:27:46Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-04-02T05:27:39Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/780200431859269633/kXZwDd_Y_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Romantic Poetry Bot</div>
<div style="text-align: center; font-size: 14px;">@percybotshelley</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Romantic Poetry Bot.
| Data | Romantic Poetry Bot |
| --- | --- |
| Tweets downloaded | 3205 |
| Retweets | 0 |
| Short tweets | 20 |
| Tweets kept | 3185 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1bj4pakr/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @percybotshelley's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2yfs8v92) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2yfs8v92/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/percybotshelley')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
satoshiz01/Flipped_CIFAR10_vision
|
satoshiz01
| 2022-04-02T05:09:07Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-04-02T03:30:55Z |
**Google Colab Notebook link:**
https://colab.research.google.com/drive/1iA8nvb93VLcrDfIt17AOIHnkVdLSNcW_?usp=sharing
This repo contains files for defining and creating a simple convolutional network for
classifying/detecting the orientation of CIFAR-10 images (either normal orientation or flipped upside down/180 degrees).
The following files are in this repo:
Coding_Challenge_for_Fatima_Fellowship.ipynb -- a copy of the Google Collab notebook with the code/output/writeup
best_model.pth -- dictionary of best model stats/weights found during training
cifar10flip_trn.pt -- saved training dataset of ~50% flipped CIFAR10 images
cifar10flip_tst.pt -- saved training dataset of ~50% flipped CIFAR10 images
image_examples.png -- an array of example imags from flipped CIFAR10 dataset
write-up -- write up of data processing, model results, and potential improvements (also in Google Colab)
wrong_predictions.zip -- a zip file of PNG images that were incorrectly classified by my model
(each file name provide information on the image's prediction, true label, and its class)
|
nikhil6041/wav2vec2-commonvoice-hindi
|
nikhil6041
| 2022-04-02T04:48:26Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-31T04:27:46Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-commonvoice-hindi
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-commonvoice-hindi
This model is a fine-tuned version of [theainerd/Wav2Vec2-large-xlsr-hindi](https://huggingface.co/theainerd/Wav2Vec2-large-xlsr-hindi) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9825
- Wer: 0.6763
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 20.0 | 100 | 0.8801 | 0.6754 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
|
BigSalmon/Points4
|
BigSalmon
| 2022-04-02T03:04:08Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-04-02T02:57:31Z |
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/Points4")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/Points4")
```
```
- moviepass to return
- this summer
- swooped up by
- original co-founder stacy spikes
text: the re-launch of moviepass is set to transpire this summer, ( rescued at the hands of / under the stewardship of / spearheaded by ) its founding father, stacy spikes.
***
- middle schools do not have recess
- should get back to doing it
- amazing for communication
- and getting kids to move around
text: a casualty of the education reform craze, recess has been excised from middle schools. this is tragic, for it is instrumental in honing children's communication skills and encouraging physical activity.
***
-
```
It should also be able to do all that this can: https://huggingface.co/BigSalmon/InformalToFormalLincoln27
Keywords to sentences or sentence.
|
Aymene/Fake-news-detection-bert-based-uncased
|
Aymene
| 2022-04-02T02:42:06Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-01T01:33:54Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: Fake-news-detection-bert-based-uncased
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Fake-news-detection-bert-based-uncased
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Tokenizers 0.11.6
|
JustAdvanceTechonology/medical_research_dataset_marian-finetuned-kde4-fr-to-en
|
JustAdvanceTechonology
| 2022-04-02T00:07:29Z | 4 | 0 |
transformers
|
[
"transformers",
"tf",
"marian",
"text2text-generation",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-31T10:16:30Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: JustAdvanceTechonology/medical_research_dataset_marian-finetuned-kde4-fr-to-en
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# JustAdvanceTechonology/medical_research_dataset_marian-finetuned-kde4-fr-to-en
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-fr](https://huggingface.co/Helsinki-NLP/opus-mt-en-fr) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.6429
- Validation Loss: 0.8071
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 17733, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.6423 | 0.8071 | 0 |
| 0.6424 | 0.8071 | 1 |
| 0.6429 | 0.8071 | 2 |
### Framework versions
- Transformers 4.16.2
- TensorFlow 2.5.0
- Datasets 2.0.0
- Tokenizers 0.10.1
|
vicl/canine-s-finetuned-stsb
|
vicl
| 2022-04-01T23:25:04Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"canine",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-01T19:47:18Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- spearmanr
model-index:
- name: canine-s-finetuned-stsb
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: stsb
metrics:
- name: Spearmanr
type: spearmanr
value: 0.8397182061195433
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# canine-s-finetuned-stsb
This model is a fine-tuned version of [google/canine-s](https://huggingface.co/google/canine-s) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7223
- Pearson: 0.8397
- Spearmanr: 0.8397
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearson | Spearmanr |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:---------:|
| No log | 1.0 | 360 | 0.7938 | 0.8083 | 0.8077 |
| 1.278 | 2.0 | 720 | 0.7349 | 0.8322 | 0.8305 |
| 0.6765 | 3.0 | 1080 | 0.7075 | 0.8374 | 0.8366 |
| 0.6765 | 4.0 | 1440 | 0.7586 | 0.8360 | 0.8376 |
| 0.4629 | 5.0 | 1800 | 0.7223 | 0.8397 | 0.8397 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
huggingtweets/chapocheck
|
huggingtweets
| 2022-04-01T22:07:43Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-04-01T22:06:55Z |
---
language: en
thumbnail: http://www.huggingtweets.com/chapocheck/1648850858747/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1191821996759404547/HY5C5aOW_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Cum Town (mostly Nick Mullen) quotes</div>
<div style="text-align: center; font-size: 14px;">@chapocheck</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Cum Town (mostly Nick Mullen) quotes.
| Data | Cum Town (mostly Nick Mullen) quotes |
| --- | --- |
| Tweets downloaded | 1264 |
| Retweets | 90 |
| Short tweets | 75 |
| Tweets kept | 1099 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/x77h239f/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @chapocheck's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/18r1isa5) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/18r1isa5/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/chapocheck')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
lgris/bp500-xlsr
|
lgris
| 2022-04-01T20:33:47Z | 15 | 1 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"pt",
"portuguese-speech-corpus",
"PyTorch",
"hf-asr-leaderboard",
"dataset:common_voice",
"dataset:mls",
"dataset:cetuc",
"dataset:lapsbm",
"dataset:voxforge",
"dataset:tedx",
"dataset:sid",
"arxiv:2012.03411",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language: pt
datasets:
- common_voice
- mls
- cetuc
- lapsbm
- voxforge
- tedx
- sid
metrics:
- wer
tags:
- audio
- speech
- wav2vec2
- pt
- portuguese-speech-corpus
- automatic-speech-recognition
- speech
- PyTorch
- hf-asr-leaderboard
model-index:
- name: bp400-xlsr
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice
type: common_voice
args: pt
metrics:
- name: Test WER
type: wer
value: 13.6
license: apache-2.0
---
# bp500-xlsr: Wav2vec 2.0 with Brazilian Portuguese (BP) Dataset
This is a the demonstration of a fine-tuned Wav2vec model for Brazilian Portuguese using the following datasets:
- [CETUC](http://www02.smt.ufrj.br/~igor.quintanilha/alcaim.tar.gz): contains approximately 145 hours of Brazilian Portuguese speech distributed among 50 male and 50 female speakers, each pronouncing approximately 1,000 phonetically balanced sentences selected from the [CETEN-Folha](https://www.linguateca.pt/cetenfolha/) corpus;
- [Common Voice 7.0](https://commonvoice.mozilla.org/pt): is a project proposed by Mozilla Foundation with the goal to create a wide open dataset in different languages. In this project, volunteers donate and validate speech using the [oficial site](https://commonvoice.mozilla.org/pt);
- [Lapsbm](https://github.com/falabrasil/gitlab-resources): "Falabrasil - UFPA" is a dataset used by the Fala Brasil group to benchmark ASR systems in Brazilian Portuguese. Contains 35 speakers (10 females), each one pronouncing 20 unique sentences, totalling 700 utterances in Brazilian Portuguese. The audios were recorded in 22.05 kHz without environment control;
- [Multilingual Librispeech (MLS)](https://arxiv.org/abs/2012.03411): a massive dataset available in many languages. The MLS is based on audiobook recordings in public domain like [LibriVox](https://librivox.org/). The dataset contains a total of 6k hours of transcribed data in many languages. The set in Portuguese [used in this work](http://www.openslr.org/94/) (mostly Brazilian variant) has approximately 284 hours of speech, obtained from 55 audiobooks read by 62 speakers;
- [VoxForge](http://www.voxforge.org/): is a project with the goal to build open datasets for acoustic models. The corpus contains approximately 100 speakers and 4,130 utterances of Brazilian Portuguese, with sample rates varying from 16kHz to 44.1kHz.
These datasets were combined to build a larger Brazilian Portuguese dataset. All data was used for training except Common Voice dev/test sets, that were used for validation/test respectively. We also made test sets for all the gathered datasets.
| Dataset | Train | Valid | Test |
|--------------------------------|-------:|------:|------:|
| CETUC | 93.9h | -- | 5.4h |
| Common Voice | 37.6h | 8.9h | 9.5h |
| LaPS BM | 0.8h | -- | 0.1h |
| MLS | 161.0h | -- | 3.7h |
| Multilingual TEDx (Portuguese) | 144.2h | -- | 1.8h |
| SID | 5.0h | -- | 1.0h |
| VoxForge | 2.8h | -- | 0.1h |
| Total | 437.2h | 8.9h | 21.6h |
The original model was fine-tuned using [fairseq](https://github.com/pytorch/fairseq). This notebook uses a converted version of the original one. The link to the original fairseq model is available [here](https://drive.google.com/file/d/1J8aR1ltDLQFe-dVrGuyxoRm2uyJjCWgf/view?usp=sharing).
#### Summary
| | CETUC | CV | LaPS | MLS | SID | TEDx | VF | AVG |
|----------------------|---------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|
| bp\_500 (demonstration below) | 0.051 | 0.136 | 0.032 | 0.118 | 0.095 | 0.248 | 0.082 | 0.108 |
| bp\_500 + 4-gram (demonstration below) | 0.032 | 0.097 | 0.022 | 0.114 | 0.125 | 0.246 | 0.065 | 0.100 |
#### Transcription examples
| Text | Transcription |
|------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------|
|não há um departamento de mediadores independente das federações e das agremiações|não há um **dearamento** de mediadores independente das federações e das **agrebiações**|
|mas que bodega|**masque** bodega|
|a cortina abriu o show começou|a cortina abriu o **chô** começou|
|por sorte havia uma passadeira|**busote avinhoa** **passadeiro**|
|estou maravilhada está tudo pronto|**stou** estou maravilhada está tudo pronto|
## Demonstration
```python
MODEL_NAME = "lgris/bp500-xlsr"
```
### Imports and dependencies
```python
%%capture
!pip install torch==1.8.2+cu111 torchvision==0.9.2+cu111 torchaudio===0.8.2 -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html
!pip install datasets
!pip install jiwer
!pip install transformers
!pip install soundfile
!pip install pyctcdecode
!pip install https://github.com/kpu/kenlm/archive/master.zip
```
```python
import jiwer
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
from pyctcdecode import build_ctcdecoder
import torch
import re
import sys
```
### Helpers
```python
chars_to_ignore_regex = '[\,\?\.\!\;\:\"]' # noqa: W605
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = speech.squeeze(0).numpy()
batch["sampling_rate"] = 16_000
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
batch["target"] = batch["sentence"]
return batch
```
```python
def calc_metrics(truths, hypos):
wers = []
mers = []
wils = []
for t, h in zip(truths, hypos):
try:
wers.append(jiwer.wer(t, h))
mers.append(jiwer.mer(t, h))
wils.append(jiwer.wil(t, h))
except: # Empty string?
pass
wer = sum(wers)/len(wers)
mer = sum(mers)/len(mers)
wil = sum(wils)/len(wils)
return wer, mer, wil
```
```python
def load_data(dataset):
data_files = {'test': f'{dataset}/test.csv'}
dataset = load_dataset('csv', data_files=data_files)["test"]
return dataset.map(map_to_array)
```
### Model
```python
class STT:
def __init__(self,
model_name,
device='cuda' if torch.cuda.is_available() else 'cpu',
lm=None):
self.model_name = model_name
self.model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
self.processor = Wav2Vec2Processor.from_pretrained(model_name)
self.vocab_dict = self.processor.tokenizer.get_vocab()
self.sorted_dict = {
k.lower(): v for k, v in sorted(self.vocab_dict.items(),
key=lambda item: item[1])
}
self.device = device
self.lm = lm
if self.lm:
self.lm_decoder = build_ctcdecoder(
list(self.sorted_dict.keys()),
self.lm
)
def batch_predict(self, batch):
features = self.processor(batch["speech"],
sampling_rate=batch["sampling_rate"][0],
padding=True,
return_tensors="pt")
input_values = features.input_values.to(self.device)
attention_mask = features.attention_mask.to(self.device)
with torch.no_grad():
logits = self.model(input_values, attention_mask=attention_mask).logits
if self.lm:
logits = logits.cpu().numpy()
batch["predicted"] = []
for sample_logits in logits:
batch["predicted"].append(self.lm_decoder.decode(sample_logits))
else:
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = self.processor.batch_decode(pred_ids)
return batch
```
### Download datasets
```python
%%capture
!gdown --id 1HFECzIizf-bmkQRLiQD0QVqcGtOG5upI
!mkdir bp_dataset
!unzip bp_dataset -d bp_dataset/
```
```python
%cd bp_dataset
```
/content/bp_dataset
### Tests
```python
stt = STT(MODEL_NAME)
```
#### CETUC
```python
ds = load_data('cetuc_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("CETUC WER:", wer)
```
CETUC WER: 0.05159097808687998
#### Common Voice
```python
ds = load_data('commonvoice_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("CV WER:", wer)
```
CV WER: 0.13659981509705973
#### LaPS
```python
ds = load_data('lapsbm_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("Laps WER:", wer)
```
Laps WER: 0.03196969696969697
#### MLS
```python
ds = load_data('mls_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("MLS WER:", wer)
```
MLS WER: 0.1178481066463896
#### SID
```python
ds = load_data('sid_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("Sid WER:", wer)
```
Sid WER: 0.09544588416964224
#### TEDx
```python
ds = load_data('tedx_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("TEDx WER:", wer)
```
TEDx WER: 0.24868046340420813
#### VoxForge
```python
ds = load_data('voxforge_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("VoxForge WER:", wer)
```
VoxForge WER: 0.08246076839826841
### Tests with LM
```python
!rm -rf ~/.cache
!gdown --id 1GJIKseP5ZkTbllQVgOL98R4yYAcIySFP # trained with wikipedia
stt = STT(MODEL_NAME, lm='pt-BR-wiki.word.4-gram.arpa')
# !gdown --id 1dLFldy7eguPtyJj5OAlI4Emnx0BpFywg # trained with bp
# stt = STT(MODEL_NAME, lm='pt-BR.word.4-gram.arpa')
```
### Cetuc
```python
ds = load_data('cetuc_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("CETUC WER:", wer)
```
CETUC WER: 0.03222801788375573
#### Common Voice
```python
ds = load_data('commonvoice_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("CV WER:", wer)
```
CV WER: 0.09713866021093655
#### LaPS
```python
ds = load_data('lapsbm_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("Laps WER:", wer)
```
Laps WER: 0.022310606060606065
#### MLS
```python
ds = load_data('mls_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("MLS WER:", wer)
```
MLS WER: 0.11408590958696524
#### SID
```python
ds = load_data('sid_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("Sid WER:", wer)
```
Sid WER: 0.12502797252979136
#### TEDx
```python
ds = load_data('tedx_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("TEDx WER:", wer)
```
TEDx WER: 0.24603179403904793
#### VoxForge
```python
ds = load_data('voxforge_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("VoxForge WER:", wer)
```
VoxForge WER: 0.06542207792207791
|
lgris/wav2vec2-large-xlsr-open-brazilian-portuguese
|
lgris
| 2022-04-01T20:32:58Z | 268 | 9 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"pt",
"portuguese-speech-corpus",
"PyTorch",
"hf-asr-leaderboard",
"dataset:common_voice",
"dataset:mls",
"dataset:cetuc",
"dataset:lapsbm",
"dataset:voxforge",
"arxiv:2012.03411",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language: pt
datasets:
- common_voice
- mls
- cetuc
- lapsbm
- voxforge
metrics:
- wer
tags:
- audio
- speech
- wav2vec2
- pt
- portuguese-speech-corpus
- automatic-speech-recognition
- speech
- PyTorch
- hf-asr-leaderboard
license: apache-2.0
model-index:
- name: Lucas Gris XLSR Wav2Vec2 Large 53 Brazilian Portuguese
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
metrics:
- name: Test WER
type: wer
value: 12.905054857823264%
---
# Wav2vec 2.0 With Open Brazilian Portuguese Datasets
This a the demonstration of a fine-tuned Wav2vec model for Brazilian Portuguese using the following datasets:
- [CETUC](http://www02.smt.ufrj.br/~igor.quintanilha/alcaim.tar.gz): contains approximately 145 hours of Brazilian Portuguese speech distributed among 50 male and 50 female speakers, each pronouncing approximately 1,000 phonetically balanced sentences selected from the [CETEN-Folha](https://www.linguateca.pt/cetenfolha/) corpus.
- [Multilingual Librispeech (MLS)](https://arxiv.org/abs/2012.03411): a massive dataset available in many languages. The MLS is based on audiobook recordings in public domain like [LibriVox](https://librivox.org/). The dataset contains a total of 6k hours of transcribed data in many languages. The set in Portuguese [used in this work](http://www.openslr.org/94/) (mostly Brazilian variant) has approximately 284 hours of speech, obtained from 55 audiobooks read by 62 speakers.
- [VoxForge](http://www.voxforge.org/): is a project with the goal to build open datasets for acoustic models. The corpus contains approximately 100 speakers and 4,130 utterances of Brazilian Portuguese, with sample rates varying from 16kHz to 44.1kHz.
- [Common Voice 6.1](https://commonvoice.mozilla.org/pt) (_only train_): is a project proposed by Mozilla Foundation with the goal to create a wide open dataset in different languages to train ASR models. In this project, volunteers donate and validate speech using the [oficial site](https://commonvoice.mozilla.org/pt). The set in Portuguese (mostly Brazilian variant) used in this work is the 6.1 version (pt_63h_2020-12-11) that contains about 50 validated hours and 1,120 unique speakers.
- [Lapsbm](https://github.com/falabrasil/gitlab-resources): "Falabrasil - UFPA" is a dataset used by the Fala Brasil group to benchmark ASR systems in Brazilian Portuguese. Contains 35 speakers (10 females), each one pronouncing 20 unique sentences, totalling 700 utterances in Brazilian Portuguese. The audios were recorded in 22.05 kHz without environment control.
These datasets were combined to build a larger Brazilian Portuguese dataset. All data was used for training except Common Voice dev/test sets, that were used for validation/test respectively.
The original model was fine-tuned using [fairseq](https://github.com/pytorch/fairseq). This notebook uses a converted version of the original one. The link to the original fairseq model is available [here](https://drive.google.com/drive/folders/1XTKIUB4kp3oYOavwH97wq8IPFsxP5sNz?usp=sharing).
This model was trained in 80k updates.
#### Datasets in number of instances and number of frames
The following image shows the overall distribution of the dataset:

#### Transcription examples
| Text | Transcription |
|------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------|
| É comum os usuários confundirem software livre com software livre | É comum os __usuares__ __confunder em__ __softwerlivr__ com __softwerlivre__ |
| Ele fez tanto ghostwriting que ele começa a se sentir como um fantasma também | Ele fez tanto __golstraitn__ que ele __começou__ a se sentir como um fantasma também |
| Arnold apresentou um gráfico mostrando quantas cegonhas ele havia contado nos últimos dez anos | Arnold apresentou um gráfico mostrando quantas __segonhas__ ele havia contado nos últimos dez anos |
| Mais cedo ou mais tarde eles descobrirão como ler esses hieróglifos | Mais __sedo__ ou mais tarde eles descobriram como __de__ esses __ierogrôficos__ |
| Viver juntos compartilhar objetivos e ter um bom relacionamento | __E ver__ juntos __signafica__ viver juntos ou __fartlhar__ objetivos ter um bom __relacionamentoo__ |
| Da mesma forma uma patente pode impedir que concorrentes desenvolvam produtos similares | Da mesma forma uma patente pode impedir que concorrentes __desenvolva__ produtos similares |
| Duas mulheres e uma menina levantam com troféus | Duas mulheres e uma menina levantam com __trofés__ |
| Esse acrobata de circo deve ter um sistema vestibular bem treinado pensou o espectador | Esse acrobata de __cirko__ deve ter um sistema vestibular __bemtreinado__ pensou o espectador |
| Durante a exposição o tribunal pode fazer quaisquer perguntas ou esclarecimentos que considere apropriados | Durante a exposição o tribunal pode fazer quaisquer perguntas ou esclarecimentos que considere __apropriado__ |
## Imports and dependencies
```python
%%capture
!pip install datasets
!pip install jiwer
!pip install torchaudio
!pip install transformers
!pip install soundfile
```
```python
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
import torch
import re
import sys
```
## Preparation
```python
chars_to_ignore_regex = '[\,\?\.\!\;\:\"]' # noqa: W605
wer = load_metric("wer")
device = "cuda"
```
```python
model_name = 'lgris/wav2vec2-large-xlsr-open-brazilian-portuguese'
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(model_name)
```
```python
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)
batch["predicted"] = [pred.lower() for pred in batch["predicted"]]
batch["target"] = batch["sentence"]
return batch
```
## Tests
### Test against Common Voice (In-domain)
```python
dataset = load_dataset("common_voice", "pt", split="test", data_dir="./cv-corpus-6.1-2020-12-11")
resampler = torchaudio.transforms.Resample(orig_freq=48_000, new_freq=16_000)
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
```
```python
ds = dataset.map(map_to_array)
result = ds.map(map_to_pred, batched=True, batch_size=1, remove_columns=list(ds.features.keys()))
print(wer.compute(predictions=result["predicted"], references=result["target"]))
for pred, target in zip(result["predicted"][:10], result["target"][:10]):
print(pred, "|", target)
```
0.12905054857823264
nem o varanin os altros influmindo os de teterno um bombederster | nem o radar nem os outros instrumentos detectaram o bombardeiro stealth
pedir dinheiro é emprestado das pessoas do aldeia | pedir dinheiro emprestado às pessoas da aldeia
oito | oito
teno calcos | trancá-los
realizaram a investigação para resolver o problema | realizar uma investigação para resolver o problema
iotube ainda é a melhor plataforma de vídeos | o youtube ainda é a melhor plataforma de vídeos
menina e menino beijando nas sombras | menina e menino beijando nas sombras
eu sou o senhor | eu sou o senhor
duas metcas sentam-se para baixo randes jornais | duas mulheres que sentam-se para baixo lendo jornais
eu originalmente esperava | eu originalmente esperava
**Result**: 12.90%
### Test against [TEDx](http://www.openslr.org/100/) (Out-of-domain)
```python
!gdown --id 1HJEnvthaGYwcV_whHEywgH2daIN4bQna
!tar -xf tedx.tar.gz
```
```python
dataset = load_dataset('csv', data_files={'test': 'tedx/test.csv'})['test']
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = speech.squeeze(0).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
```
```python
ds = dataset.map(map_to_array)
result = ds.map(map_to_pred, batched=True, batch_size=1, remove_columns=list(ds.features.keys()))
print(wer.compute(predictions=result["predicted"], references=result["target"]))
for pred, target in zip(result["predicted"][:10], result["target"][:10]):
print(pred, "|", target)
```
0.35215851987208774
com isso a gente vê que essa rede de pactuação de de deparcerias nos remete a um raciocínio lógico que ao que a gente crê que é a prevenção | com isso a gente vê que essa rede de pactuação de parcerias nos remete a um raciocínio lógico que é o que a gente crê que é a prevenção
ente vai para o resultado | e aí a gente vai pro resultado
curiosidade hé o que eu descobri desde que comecei a fazer pesquisa lá no ensino médio | e a curiosidade é algo que descobri desde que comecei a fazer pesquisa lá no ensino médio
val des quemesho | há vários caminhos
que é uma opcissão por comer soldado | que é uma obsessão por comer saudável
isso é tão é forte algoltão universal que existem dados que mostram que setenta e cinco por cento das reuniões são dominadas pela voz masculina | e isso é tão forte é algo tão universal que existem dados que mostram que das reuniões são dominadas pela voz masculina
não era exatamente isso não estávamos deveto | e não era exatamente isso que nós estávamos a ver
durante meci do médio ofiz pesquisa estudei numa escola que chamam a fundação liberate ficava relativamente próximo daqui | durante o ensino médio eu fiz pesquisa estudei numa escola que se chama fundação liberato que fica relativamente próxima daqui
oito anos atrás eu fui apresentado por uma doença que até então eu não conhecia e que é bem provável que a maior parte de nós todos aqui não conheçamos | oito anos atrás fui apresentado para uma doença que até então eu não conhecia e que é bem provável que a maior parte de nós todos aqui não conheçamos
o terceiro é o museu do ripiopeco | o terceiro é o museu do hip hop
**Result**: 35.21%
|
birgermoell/psst-libri960_big
|
birgermoell
| 2022-04-01T20:17:17Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-04-01T19:05:31Z |
pssteval INFO: ASR metrics for split `valid` FER: 9.8% PER: 20.9%
|
juaner/distilbert-base-uncased-finetuned-cola
|
juaner
| 2022-04-01T18:20:42Z | 5 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-01T17:59:52Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: juaner/distilbert-base-uncased-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# juaner/distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1909
- Validation Loss: 0.5553
- Train Matthews Correlation: 0.5279
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 2670, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Matthews Correlation | Epoch |
|:----------:|:---------------:|:--------------------------:|:-----:|
| 0.5191 | 0.4491 | 0.4718 | 0 |
| 0.3270 | 0.4571 | 0.5196 | 1 |
| 0.1909 | 0.5553 | 0.5279 | 2 |
### Framework versions
- Transformers 4.16.2
- TensorFlow 2.8.0
- Datasets 1.18.3
- Tokenizers 0.11.0
|
McGill-NLP/bart-qg-nq-checkpoint
|
McGill-NLP
| 2022-04-01T17:35:04Z | 26 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"arxiv:1910.13461",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-04-01T16:32:49Z |
---
license: cc-by-4.0
---
# BART-base fine-tuned on NaturalQuestions for **Question Generation**
[BART Model](https://arxiv.org/pdf/1910.13461.pdf) fine-tuned on [Google NaturalQuestions](https://ai.google.com/research/NaturalQuestions/) for **Question Generation** by treating long answer as input, and question as output.
## Details of BART
The **BART** model was presented in [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf) by *Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer* in Here the abstract:
We present BART, a denoising autoencoder for pretraining sequence-to-sequence models. BART is trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text. It uses a standard Tranformer-based neural machine translation architecture which, despite its simplicity, can be seen as generalizing BERT (due to the bidirectional encoder), GPT (with the left-to-right decoder), and many other more recent pretraining schemes. We evaluate a number of noising approaches, finding the best performance by both randomly shuffling the order of the original sentences and using a novel in-filling scheme, where spans of text are replaced with a single mask token. BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks. It matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains of up to 6 ROUGE. BART also provides a 1.1 BLEU increase over a back-translation system for machine translation, with only target language pretraining. We also report ablation experiments that replicate other pretraining schemes within the BART framework, to better measure which factors most influence end-task performance.
## Details of the downstream task (QG) - Dataset 📚 🧐
Dataset: ```NaturalQuestions``` from Google (https://ai.google.com/research/NaturalQuestions/)
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| NaturalQuestions | train | 97650 |
| NaturalQuestions | valid | 10850 |
## Model fine-tuning 🏋️
The training script can be found [here](https://github.com/McGill-NLP/MLQuestions/blob/main/QG/train.py)
## Model in Action 🚀
```python
from transformers import AutoModel, BartTokenizer
#Load the tokenizer
tokenizer = BartTokenizer.from_pretrained('facebook/bart-base')
#Load the model
model = AutoModelForSeq2SeqLM.from_pretrained("McGill-NLP/bart-qg-nq-checkpoint")
```
## Citation
If you want to cite this model you can use this:
```bibtex
@inproceedings{kulshreshtha-etal-2021-back,
title = "Back-Training excels Self-Training at Unsupervised Domain Adaptation of Question Generation and Passage Retrieval",
author = "Kulshreshtha, Devang and
Belfer, Robert and
Serban, Iulian Vlad and
Reddy, Siva",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.566",
pages = "7064--7078",
abstract = "In this work, we introduce back-training, an alternative to self-training for unsupervised domain adaptation (UDA). While self-training generates synthetic training data where natural inputs are aligned with noisy outputs, back-training results in natural outputs aligned with noisy inputs. This significantly reduces the gap between target domain and synthetic data distribution, and reduces model overfitting to source domain. We run UDA experiments on question generation and passage retrieval from the Natural Questions domain to machine learning and biomedical domains. We find that back-training vastly outperforms self-training by a mean improvement of 7.8 BLEU-4 points on generation, and 17.6{\%} top-20 retrieval accuracy across both domains. We further propose consistency filters to remove low-quality synthetic data before training. We also release a new domain-adaptation dataset - MLQuestions containing 35K unaligned questions, 50K unaligned passages, and 3K aligned question-passage pairs.",
}
```
> Created by [Devang Kulshreshtha](https://geekydevu.netlify.app/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
vicl/canine-c-finetuned-mrpc
|
vicl
| 2022-04-01T16:33:28Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"canine",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-01T16:05:44Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: canine-c-finetuned-mrpc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8627450980392157
- name: F1
type: f1
value: 0.9014084507042254
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# canine-c-finetuned-mrpc
This model is a fine-tuned version of [google/canine-c](https://huggingface.co/google/canine-c) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4066
- Accuracy: 0.8627
- F1: 0.9014
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 230 | 0.5014 | 0.7696 | 0.8479 |
| No log | 2.0 | 460 | 0.4755 | 0.7892 | 0.8622 |
| 0.5096 | 3.0 | 690 | 0.3645 | 0.8431 | 0.8869 |
| 0.5096 | 4.0 | 920 | 0.4066 | 0.8627 | 0.9014 |
| 0.2619 | 5.0 | 1150 | 0.4551 | 0.8431 | 0.8877 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
ydshieh/bert-base-uncased-yelp-polarity
|
ydshieh
| 2022-04-01T15:20:05Z | 103 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-04-01T15:17:35Z |
## TextAttack Model Card
This `bert-base-uncased` model was fine-tuned for sequence classification using TextAttack
and the yelp_polarity dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 16, a learning
rate of 5e-05, and a maximum sequence length of 256.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.9699473684210527, as measured by the
eval set accuracy, found after 4 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
avialfont/ner-dummy-model
|
avialfont
| 2022-04-01T14:59:22Z | 5 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"token-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-04-01T10:59:27Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: ner-dummy-model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# ner-dummy-model
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 2631, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.16.2
- TensorFlow 2.8.0
- Datasets 1.18.3
- Tokenizers 0.11.6
|
eren23/pneumonia_test_attempt
|
eren23
| 2022-04-01T14:41:01Z | 57 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-03-19T16:31:28Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: pneumonia_test_attempt
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9783163070678711
---
# pneumonia-bielefeld-dl-course
This registry contains the model for making pneumonia predictions and was prepared for Bielefeld University Deep Learning course homework.
The code used for this implementation mostly comes from here: https://github.com/nateraw/huggingpics it was a ready pipeline for model fine-tuning with huggingface and PyTorch Lightning for another dataset.
|
jfealko/wav2vec2-large-xls-r-300m-irish-colab_test
|
jfealko
| 2022-04-01T13:23:06Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-04-01T11:29:55Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-irish-colab_test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-irish-colab_test
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7839
- Wer: 0.6220
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 90
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 10.0428 | 2.94 | 50 | 4.1311 | 1.0 |
| 3.2917 | 5.88 | 100 | 3.1468 | 1.0 |
| 3.0221 | 8.82 | 150 | 2.9848 | 1.0 |
| 2.9795 | 11.76 | 200 | 2.9567 | 1.0 |
| 2.9379 | 14.71 | 250 | 2.9463 | 1.0 |
| 2.9068 | 17.65 | 300 | 2.8330 | 1.0 |
| 2.5088 | 20.59 | 350 | 1.9807 | 0.9535 |
| 1.6188 | 23.53 | 400 | 1.4254 | 0.8398 |
| 1.0435 | 26.47 | 450 | 1.3668 | 0.7807 |
| 0.7212 | 29.41 | 500 | 1.3914 | 0.7476 |
| 0.5456 | 32.35 | 550 | 1.5495 | 0.7470 |
| 0.4297 | 35.29 | 600 | 1.4751 | 0.6960 |
| 0.3533 | 38.24 | 650 | 1.5157 | 0.6909 |
| 0.2899 | 41.18 | 700 | 1.5394 | 0.6879 |
| 0.2529 | 44.12 | 750 | 1.6186 | 0.6903 |
| 0.2413 | 47.06 | 800 | 1.6386 | 0.6954 |
| 0.2113 | 50.0 | 850 | 1.6906 | 0.6778 |
| 0.1769 | 52.94 | 900 | 1.6918 | 0.6575 |
| 0.1622 | 55.88 | 950 | 1.7313 | 0.6572 |
| 0.1564 | 58.82 | 1000 | 1.7701 | 0.6510 |
| 0.1637 | 61.76 | 1050 | 1.6800 | 0.6444 |
| 0.148 | 64.71 | 1100 | 1.7306 | 0.6477 |
| 0.1385 | 67.65 | 1150 | 1.7605 | 0.6408 |
| 0.1264 | 70.59 | 1200 | 1.7534 | 0.6244 |
| 0.1157 | 73.53 | 1250 | 1.7906 | 0.6381 |
| 0.1027 | 76.47 | 1300 | 1.7803 | 0.6265 |
| 0.1061 | 79.41 | 1350 | 1.7617 | 0.6259 |
| 0.0934 | 82.35 | 1400 | 1.7649 | 0.6253 |
| 0.0904 | 85.29 | 1450 | 1.7713 | 0.6187 |
| 0.0911 | 88.24 | 1500 | 1.7839 | 0.6220 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
|
notexist/ttt
|
notexist
| 2022-04-01T13:16:50Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-04-01T12:45:30Z |
---
license: apache-2.0
---
|
bmichele/poetry-generation-firstline-mbart-ws-fi-sorted
|
bmichele
| 2022-04-01T13:03:49Z | 0 | 0 | null |
[
"pytorch",
"region:us"
] | null | 2022-04-01T12:58:00Z |
TODO: This is still a demo model, the file does not match with the model card!!!
# poetry-generation-firstline-mbart-ws-fi-sorted
* `nextline`: generates the first poem line from keywords
* `mbart`: base model is [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25)
* `ws`: trained on Wikisource data
* `fi`: Finnish language
* `sorted`: the order of input keywords matter when generating candidates
|
xxr/bert-base-uncased-multi-128
|
xxr
| 2022-04-01T11:40:30Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-04-01T05:36:26Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- null
model_index:
- name: bert-base-uncased-multi-128
results:
- task:
name: Masked Language Modeling
type: fill-mask
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-multi-128
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7101
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 3.6636 | 1.0 | 812 | 3.2325 |
| 3.2963 | 2.0 | 1624 | 3.1937 |
| 3.1132 | 3.0 | 2436 | 3.2984 |
| 2.9386 | 4.0 | 3248 | 3.2430 |
| 2.7742 | 5.0 | 4060 | 3.1272 |
| 2.5954 | 6.0 | 4872 | 3.1778 |
| 2.501 | 7.0 | 5684 | 3.1649 |
| 2.4073 | 8.0 | 6496 | 2.9395 |
| 2.2933 | 9.0 | 7308 | 3.1262 |
| 2.2218 | 10.0 | 8120 | 2.9994 |
| 2.1558 | 11.0 | 8932 | 2.9922 |
| 2.0873 | 12.0 | 9744 | 2.8414 |
| 2.0104 | 13.0 | 10556 | 2.9351 |
| 1.9364 | 14.0 | 11368 | 2.9253 |
| 1.9045 | 15.0 | 12180 | 2.8701 |
| 1.9152 | 16.0 | 12992 | 2.7101 |
### Framework versions
- Transformers 4.8.2
- Pytorch 1.7.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
scasutt/wav2vec2-large-xlsr-53_toy_train_data_random_low_pass
|
scasutt
| 2022-04-01T11:40:10Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-04-01T06:18:47Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-large-xlsr-53_toy_train_data_random_low_pass
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-53_toy_train_data_random_low_pass
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6572
- Wer: 0.4973
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.0834 | 2.1 | 500 | 3.4478 | 1.0 |
| 1.0735 | 4.2 | 1000 | 0.9113 | 0.7815 |
| 0.5516 | 6.3 | 1500 | 0.7035 | 0.6081 |
| 0.4023 | 8.4 | 2000 | 0.6647 | 0.5649 |
| 0.3423 | 10.5 | 2500 | 0.6613 | 0.5450 |
| 0.2938 | 12.6 | 3000 | 0.6967 | 0.5318 |
| 0.2902 | 14.7 | 3500 | 0.6430 | 0.5089 |
| 0.2372 | 16.81 | 4000 | 0.6653 | 0.5045 |
| 0.2148 | 18.91 | 4500 | 0.6572 | 0.4973 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu102
- Datasets 2.0.0
- Tokenizers 0.12.0
|
osanseviero/llama-or-potato
|
osanseviero
| 2022-04-01T09:45:26Z | 63 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"llama-leaderboard",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-04-01T09:05:43Z |
---
tags:
- image-classification
- pytorch
- huggingpics
- llama-leaderboard
metrics:
- accuracy
model-index:
- name: llama-or-potato
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 1.0
---
# llama-or-potato
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### llamas

#### potato

|
jkhan447/sentiment-model-sample-27go-emotion
|
jkhan447
| 2022-04-01T08:13:56Z | 4 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:go_emotions",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-28T06:05:25Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- go_emotions
metrics:
- accuracy
model-index:
- name: sentiment-model-sample-27go-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: go_emotions
type: go_emotions
args: simplified
metrics:
- name: Accuracy
type: accuracy
value: 0.5888888888888889
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sentiment-model-sample-27go-emotion
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the go_emotions dataset.
It achieves the following results on the evaluation set:
- Loss: 4.1765
- Accuracy: 0.5889
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.12.0
|
Basedino/GPT-RO
|
Basedino
| 2022-04-01T07:47:41Z | 0 | 0 | null |
[
"license:gpl-3.0",
"region:us"
] | null | 2022-03-31T08:19:30Z |
---
license: gpl-3.0
---
So i made this model because i had nothing to do. it's gpt 2 124m finetuned to a bunch of italian recipes.
I made it using aitextgen, so you can use that to play with the model easily.
|
z5ying/mbart-large-cc25-finetuned-source-to-target
|
z5ying
| 2022-04-01T03:43:40Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-07T18:25:31Z |
---
tags:
- generated_from_trainer
model-index:
- name: mbart-large-cc25-finetuned-source-to-target
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbart-large-cc25-finetuned-source-to-target
This model is a fine-tuned version of [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.002
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.12.0
|
Mr-Wick/xlnet-base-cased
|
Mr-Wick
| 2022-04-01T01:31:59Z | 3 | 0 |
transformers
|
[
"transformers",
"tf",
"xlnet",
"question-answering",
"generated_from_keras_callback",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-26T12:52:07Z |
---
tags:
- generated_from_keras_callback
model-index:
- name: xlnet-base-cased
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# xlnet-base-cased
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 16530, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.17.0
- TensorFlow 2.8.0
- Datasets 2.0.0
- Tokenizers 0.12.0
|
magitz/distilbert-base-uncased-finetuned-emotion
|
magitz
| 2022-03-31T20:48:43Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-31T20:41:54Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9265
- name: F1
type: f1
value: 0.9267965474109292
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2235
- Accuracy: 0.9265
- F1: 0.9268
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8101 | 1.0 | 250 | 0.3177 | 0.9045 | 0.9010 |
| 0.2472 | 2.0 | 500 | 0.2235 | 0.9265 | 0.9268 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.8.1
- Datasets 1.18.3
- Tokenizers 0.11.0
|
WENGSYX/Deberta-Chinese-Large
|
WENGSYX
| 2022-03-31T20:08:59Z | 56 | 16 |
transformers
|
[
"transformers",
"pytorch",
"deberta",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
# Deberta-Chinese
本项目,基于微软开源的Deberta模型,在中文领域进行预训练。开源本模型,旨在为其他人提供更多预训练语言模型选择。
本预训练模型,基于WuDaoCorpora语料库预训练而成。WuDaoCorpora是北京智源人工智能研究院(智源研究院)构建的大规模、高质量数据集,用于支撑“悟道”大模型项目研究。
使用WWM与n-gramMLM 等预训练方法进行预训练。
| 预训练模型 | 学习率 | batchsize | 设备 | 语料库 | 时间 | 优化器 |
| --------------------- | ------ | --------- | ------ | ------ | ---- | ------ |
| Deberta-Chinese-Large | 1e-5 | 512 | 2*3090 | 200G | 14天 | AdamW |
### 加载与使用
依托于huggingface-transformers
```
tokenizer = BertTokenizer.from_pretrained("WENGSYX/Deberta-Chinese-Large")
model = AutoModel.from_pretrained("WENGSYX/Deberta-Chinese-Large")
```
#### 注意,请使用BertTokenizer加载中文词表
|
deepspeechvision/wav2vec2_hindi_asr
|
deepspeechvision
| 2022-03-31T18:03:34Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-31T17:22:14Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2_hindi_asr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2_hindi_asr
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
|
huggingtweets/stillconor
|
huggingtweets
| 2022-03-31T17:49:05Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-31T16:59:05Z |
---
language: en
thumbnail: http://www.huggingtweets.com/stillconor/1648748939988/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1485398297984389121/DmUfFheN_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">conor</div>
<div style="text-align: center; font-size: 14px;">@stillconor</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from conor.
| Data | conor |
| --- | --- |
| Tweets downloaded | 3199 |
| Retweets | 102 |
| Short tweets | 432 |
| Tweets kept | 2665 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1z83yigq/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @stillconor's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/30hsnorw) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/30hsnorw/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/stillconor')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
rahulacj/bertweet-base-finetuned-sentiment-analysis
|
rahulacj
| 2022-03-31T16:21:16Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-31T09:42:31Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: bertweet-base-finetuned-sentiment-analysis
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bertweet-base-finetuned-sentiment-analysis
This model is a fine-tuned version of [cardiffnlp/bertweet-base-sentiment](https://huggingface.co/cardiffnlp/bertweet-base-sentiment) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8458
- Accuracy: 0.6426
- F1: 0.6397
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8904 | 1.0 | 630 | 0.8509 | 0.6381 | 0.6340 |
| 0.7655 | 2.0 | 1260 | 0.8345 | 0.6579 | 0.6559 |
| 0.66 | 3.0 | 1890 | 0.9199 | 0.6548 | 0.6514 |
| 0.447 | 4.0 | 2520 | 1.0324 | 0.6429 | 0.6417 |
| 0.3585 | 5.0 | 3150 | 1.1234 | 0.6452 | 0.6424 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.12.0
|
huggingtweets/timdingmanlive
|
huggingtweets
| 2022-03-31T14:30:05Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-31T14:26:57Z |
---
language: en
thumbnail: http://www.huggingtweets.com/timdingmanlive/1648736999131/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/2844974270/7bb6450b90b65f8712d9433b8d5e1971_400x400.jpeg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Tim Dingman</div>
<div style="text-align: center; font-size: 14px;">@timdingmanlive</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Tim Dingman.
| Data | Tim Dingman |
| --- | --- |
| Tweets downloaded | 3240 |
| Retweets | 555 |
| Short tweets | 138 |
| Tweets kept | 2547 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/7yvdv2z7/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @timdingmanlive's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/311pu3zj) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/311pu3zj/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/timdingmanlive')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/youtube
|
huggingtweets
| 2022-03-31T14:06:33Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-31T14:05:50Z |
---
language: en
thumbnail: http://www.huggingtweets.com/youtube/1648735587597/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1427292844612595720/RC1YSvuT_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">YouTube</div>
<div style="text-align: center; font-size: 14px;">@youtube</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from YouTube.
| Data | YouTube |
| --- | --- |
| Tweets downloaded | 3250 |
| Retweets | 23 |
| Short tweets | 104 |
| Tweets kept | 3123 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2dx34obn/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @youtube's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/p527w5q3) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/p527w5q3/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/youtube')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
chrisjay/fonxlsr
|
chrisjay
| 2022-03-31T13:35:06Z | 40 | 7 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"hf-asr-leaderboard",
"fon",
"dataset:fon_dataset",
"arxiv:2103.07762",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language: fon
datasets:
- fon_dataset
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
- hf-asr-leaderboard
license: apache-2.0
model-index:
- name: Fon XLSR Wav2Vec2 Large 53
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: fon
type: fon_dataset
args: fon
metrics:
- name: Test WER
type: wer
value: 14.97
---
# Wav2Vec2-Large-XLSR-53-Fon
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on [Fon (or Fongbe)](https://en.wikipedia.org/wiki/Fon_language) using the [Fon Dataset](https://github.com/laleye/pyFongbe/tree/master/data).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import json
import random
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
#Load test_dataset from saved files in folder
from datasets import load_dataset, load_metric
#for test
for root, dirs, files in os.walk(test/):
test_dataset= load_dataset("json", data_files=[os.path.join(root,i) for i in files],split="train")
#Remove unnecessary chars
chars_to_ignore_regex = '[\\,\\?\\.\\!\\-\\;\\:\\"\\“\\%\\‘\\”]'
def remove_special_characters(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower() + " "
return batch
test_dataset = test_dataset.map(remove_special_characters)
processor = Wav2Vec2Processor.from_pretrained("chrisjay/wav2vec2-large-xlsr-53-fon")
model = Wav2Vec2ForCTC.from_pretrained("chrisjay/wav2vec2-large-xlsr-53-fon")
#No need for resampling because audio dataset already at 16kHz
#resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"]=speech_array.squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on our unique Fon test data.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
for root, dirs, files in os.walk(test/):
test_dataset = load_dataset("json", data_files=[os.path.join(root,i) for i in files],split="train")
chars_to_ignore_regex = '[\\,\\?\\.\\!\\-\\;\\:\\"\\“\\%\\‘\\”]'
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower() + " "
return batch
test_dataset = test_dataset.map(remove_special_characters)
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("chrisjay/wav2vec2-large-xlsr-53-fon")
model = Wav2Vec2ForCTC.from_pretrained("chrisjay/wav2vec2-large-xlsr-53-fon")
model.to("cuda")
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = speech_array[0].numpy()
batch["sampling_rate"] = sampling_rate
batch["target_text"] = batch["sentence"]
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
#Evaluation on test dataset
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 14.97 %
## Training
The [Fon dataset](https://github.com/laleye/pyFongbe/tree/master/data) was split into `train`(8235 samples), `validation`(1107 samples), and `test`(1061 samples).
The script used for training can be found [here](https://colab.research.google.com/drive/11l6qhJCYnPTG1TQZ8f3EvKB9z12TQi4g?usp=sharing)
# Collaborators on this project
- Chris C. Emezue ([Twitter](https://twitter.com/ChrisEmezue))|(chris.emezue@gmail.com)
- Bonaventure F.P. Dossou (HuggingFace Username: [bonadossou](https://huggingface.co/bonadossou))|([Twitter](https://twitter.com/bonadossou))|(femipancrace.dossou@gmail.com)
## This is a joint project continuing our research on [OkwuGbé: End-to-End Speech Recognition for Fon and Igbo](https://arxiv.org/abs/2103.07762)
|
Visual-Attention-Network/van-tiny
|
Visual-Attention-Network
| 2022-03-31T12:45:47Z | 173 | 2 |
transformers
|
[
"transformers",
"pytorch",
"van",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:2202.09741",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-03-16T15:05:02Z |
---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# Van
Van model trained on imagenet-1k. It was introduced in the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) and first released in [this repository](https://github.com/Visual-Attention-Network/VAN-Classification).
Disclaimer: The team releasing Van did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
This paper introduces a new attention layer based on convolution operations able to capture both local and distant relationships. This is done by combining normal and large kernel convolution layers. The latter uses a dilated convolution to capture distant correlations.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=van) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
>>> from transformers import AutoFeatureExtractor, VanForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("Visual-Attention-Network/van-base")
>>> model = VanForImageClassification.from_pretrained("Visual-Attention-Network/van-base")
>>> inputs = feature_extractor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tabby, tabby cat
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/van).
|
Visual-Attention-Network/van-large
|
Visual-Attention-Network
| 2022-03-31T12:45:46Z | 122 | 1 |
transformers
|
[
"transformers",
"pytorch",
"van",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:2202.09741",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-03-09T18:03:37Z |
---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# Van
Van model trained on imagenet-1k. It was introduced in the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) and first released in [this repository](https://github.com/Visual-Attention-Network/VAN-Classification).
Disclaimer: The team releasing Van did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
This paper introduces a new attention layer based on convolution operations able to capture both local and distant relationships. This is done by combining normal and large kernel convolution layers. The latter uses a dilated convolution to capture distant correlations.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=van) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
>>> from transformers import AutoFeatureExtractor, VanForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("Visual-Attention-Network/van-base")
>>> model = VanForImageClassification.from_pretrained("Visual-Attention-Network/van-base")
>>> inputs = feature_extractor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tabby, tabby cat
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/van).
|
Neulvo/bert-finetuned-squad
|
Neulvo
| 2022-03-31T12:08:42Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-31T10:54:31Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.2
- Datasets 1.18.3
- Tokenizers 0.11.0
|
frtna/jwt300_mt-Italian-to-Spanish_transformers
|
frtna
| 2022-03-31T11:18:09Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:new_dataset",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-29T09:49:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- new_dataset
metrics:
- sacrebleu
model-index:
- name: jwt300_mt-Italian-to-Spanish_transformers
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: new_dataset
type: new_dataset
args: jwt300_mt
metrics:
- name: Sacrebleu
type: sacrebleu
value: 0.9057
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# jwt300_mt-Italian-to-Spanish_transformers
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the new_dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4425
- Sacrebleu: 0.9057
- Gen Len: 18.1276
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Sacrebleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:-------:|
| 2.7545 | 1.0 | 2229 | 2.4425 | 0.9057 | 18.1276 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0
- Datasets 2.0.0
- Tokenizers 0.11.6
|
nikhil6041/wav2vec2-commonvoice-tamil
|
nikhil6041
| 2022-03-31T09:24:01Z | 18 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:mit",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-31T04:00:23Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-commonvoice-tamil
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-commonvoice-tamil
This model is a fine-tuned version of [Harveenchadha/vakyansh-wav2vec2-tamil-tam-250](https://huggingface.co/Harveenchadha/vakyansh-wav2vec2-tamil-tam-250) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 3.3415
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 400
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| 5.384 | 1.69 | 200 | 3.3400 | 1.0 |
| 3.3085 | 3.39 | 400 | 3.3609 | 1.0 |
| 3.3008 | 5.08 | 600 | 3.3331 | 1.0 |
| 3.2852 | 6.78 | 800 | 3.3492 | 1.0 |
| 3.2908 | 8.47 | 1000 | 3.3318 | 1.0 |
| 3.2865 | 10.17 | 1200 | 3.3501 | 1.0 |
| 3.2826 | 11.86 | 1400 | 3.3403 | 1.0 |
| 3.2875 | 13.56 | 1600 | 3.3335 | 1.0 |
| 3.2899 | 15.25 | 1800 | 3.3311 | 1.0 |
| 3.2755 | 16.95 | 2000 | 3.3617 | 1.0 |
| 3.2877 | 18.64 | 2200 | 3.3317 | 1.0 |
| 3.2854 | 20.34 | 2400 | 3.3560 | 1.0 |
| 3.2878 | 22.03 | 2600 | 3.3332 | 1.0 |
| 3.2766 | 23.73 | 2800 | 3.3317 | 1.0 |
| 3.2943 | 25.42 | 3000 | 3.3737 | 1.0 |
| 3.2845 | 27.12 | 3200 | 3.3347 | 1.0 |
| 3.2765 | 28.81 | 3400 | 3.3415 | 1.0 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
|
emiyasstar/ch-w2v-conformer
|
emiyasstar
| 2022-03-31T08:48:13Z | 0 | 2 | null |
[
"region:us"
] | null | 2022-03-29T15:44:56Z |
The ch-w2v-conformer model uses following datasets to pretrain:
ISML datasets (6 languages,70k hours): internal dataset contains 40k hours Chinese, Cantonese, Tibetan, Inner Mongolian, Inner Kazakh, Uighur.
Babel datasets (17 languages, 2k hours): Assamese, Bengali, Cantonese, Cebuano, Georgian, Haitian, Kazakh, Kurmanji, Lao, Pashto, Swahili, Tagalog, Tamil, Tok, Turkish, Vietnamese, Zulu
After pretraining, we build ASR system based on CTC-Attention structure. In very low resource task, we find that if too many initialization network structures are constructed in the upper layer of pre-training conformer encoder, the migration performance of the pre-training model will be destroyed, so we only build a single-layer transformer decoder for joint training.
pretrained model link:
## constrained-plus Task Performance
* Languages: Cantonese,mongolian,kazakh
* config: conf/train_conformer_large_10h.yaml
* Feature info: using mfcc feature, with dither 1.0, without cmvn
* Training info: lr 0.001, batch size 10, 4 gpus on V100, acc_grad 1, 80 epochs
* Decoding info: ctc_weight 0.5, average_num 35
dev set results trained only with 10 hours training set
## w2v-Conformer
| decoding_method | Cantonese(CER) | mongolian(WER) |
|:-------------------:|:----:|:----:|
| ctc_greedy_search | 31.46 | 53.64 |
| ctc_prefix_search | 31.47 | 53.50 |
| attention_rescoring | 31.45 | 52.96 |
## Conformer (train from scartch)
| decoding_method | Cantonese(CER) | mongolian(WER) |
|:-------------------:|----:|:----:|
| ctc_greedy_search | 61.43 | 89.38 |
| ctc_prefix_search | 61.37 | 89.53|
| attention_rescoring | 60.61 | 89.60|
|
davidmasip/racism
|
davidmasip
| 2022-03-31T06:56:46Z | 26 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"es",
"license:cc",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-16T18:23:46Z |
---
license: cc
language: es
widget:
- text: "Me cae muy bien."
example_title: "Non-racist example"
- text: "Unos menas agreden a una mujer."
example_title: "Racist example"
---
Model to predict whether a given text is racist or not:
* `LABEL_0` output indicates non-racist text
* `LABEL_1` output indicates racist text
Usage:
```python
from transformers import pipeline
RACISM_MODEL = "davidmasip/racism"
racism_analysis_pipe = pipeline("text-classification",
model=RACISM_MODEL, tokenizer=RACISM_MODEL)
results = racism_analysis_pipe("Unos menas agreden a una mujer.")
def clean_labels(results):
for result in results:
label = "Non-racist" if results["label"] == "LABEL_0" else "Racist"
result["label"] = label
clean_labels(results)
print(results)
```
|
unjustify/autotrain-commonsence-689620825
|
unjustify
| 2022-03-31T06:38:08Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"autotrain",
"en",
"dataset:unjustify/autotrain-data-commonsence",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-31T06:18:51Z |
---
tags: autotrain
language: en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- unjustify/autotrain-data-commonsence
co2_eq_emissions: 20.656741915705204
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 689620825
- CO2 Emissions (in grams): 20.656741915705204
## Validation Metrics
- Loss: 0.7315372824668884
- Accuracy: 0.6354949675117849
- Precision: 0.63792194092827
- Recall: 0.6191451241361658
- AUC: 0.6912165223485615
- F1: 0.6283932978308872
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/unjustify/autotrain-commonsence-689620825
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("unjustify/autotrain-commonsence-689620825", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("unjustify/autotrain-commonsence-689620825", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
michiyasunaga/BioLinkBERT-large
|
michiyasunaga
| 2022-03-31T00:54:57Z | 4,470 | 33 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"feature-extraction",
"exbert",
"linkbert",
"biolinkbert",
"fill-mask",
"question-answering",
"text-classification",
"token-classification",
"en",
"dataset:pubmed",
"arxiv:2203.15827",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-08T06:20:38Z |
---
license: apache-2.0
language: en
datasets:
- pubmed
tags:
- bert
- exbert
- linkbert
- biolinkbert
- feature-extraction
- fill-mask
- question-answering
- text-classification
- token-classification
widget:
- text: "Sunitinib is a tyrosine kinase inhibitor"
---
## BioLinkBERT-large
BioLinkBERT-large model pretrained on [PubMed](https://pubmed.ncbi.nlm.nih.gov/) abstracts along with citation link information. It is introduced in the paper [LinkBERT: Pretraining Language Models with Document Links (ACL 2022)](https://arxiv.org/abs/2203.15827). The code and data are available in [this repository](https://github.com/michiyasunaga/LinkBERT).
This model achieves state-of-the-art performance on several biomedical NLP benchmarks such as [BLURB](https://microsoft.github.io/BLURB/) and [MedQA-USMLE](https://github.com/jind11/MedQA).
## Model description
LinkBERT is a transformer encoder (BERT-like) model pretrained on a large corpus of documents. It is an improvement of BERT that newly captures **document links** such as hyperlinks and citation links to include knowledge that spans across multiple documents. Specifically, it was pretrained by feeding linked documents into the same language model context, besides a single document.
LinkBERT can be used as a drop-in replacement for BERT. It achieves better performance for general language understanding tasks (e.g. text classification), and is also particularly effective for **knowledge-intensive** tasks (e.g. question answering) and **cross-document** tasks (e.g. reading comprehension, document retrieval).
## Intended uses & limitations
The model can be used by fine-tuning on a downstream task, such as question answering, sequence classification, and token classification.
You can also use the raw model for feature extraction (i.e. obtaining embeddings for input text).
### How to use
To use the model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('michiyasunaga/BioLinkBERT-large')
model = AutoModel.from_pretrained('michiyasunaga/BioLinkBERT-large')
inputs = tokenizer("Sunitinib is a tyrosine kinase inhibitor", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
For fine-tuning, you can use [this repository](https://github.com/michiyasunaga/LinkBERT) or follow any other BERT fine-tuning codebases.
## Evaluation results
When fine-tuned on downstream tasks, LinkBERT achieves the following results.
**Biomedical benchmarks ([BLURB](https://microsoft.github.io/BLURB/), [MedQA](https://github.com/jind11/MedQA), [MMLU](https://github.com/hendrycks/test), etc.):** BioLinkBERT attains new state-of-the-art.
| | BLURB score | PubMedQA | BioASQ | MedQA-USMLE |
| ---------------------- | -------- | -------- | ------- | -------- |
| PubmedBERT-base | 81.10 | 55.8 | 87.5 | 38.1 |
| **BioLinkBERT-base** | **83.39** | **70.2** | **91.4** | **40.0** |
| **BioLinkBERT-large** | **84.30** | **72.2** | **94.8** | **44.6** |
| | MMLU-professional medicine |
| ---------------------- | -------- |
| GPT-3 (175 params) | 38.7 |
| UnifiedQA (11B params) | 43.2 |
| **BioLinkBERT-large (340M params)** | **50.7** |
## Citation
If you find LinkBERT useful in your project, please cite the following:
```bibtex
@InProceedings{yasunaga2022linkbert,
author = {Michihiro Yasunaga and Jure Leskovec and Percy Liang},
title = {LinkBERT: Pretraining Language Models with Document Links},
year = {2022},
booktitle = {Association for Computational Linguistics (ACL)},
}
```
|
michiyasunaga/BioLinkBERT-base
|
michiyasunaga
| 2022-03-31T00:51:21Z | 6,225 | 36 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"feature-extraction",
"exbert",
"linkbert",
"biolinkbert",
"fill-mask",
"question-answering",
"text-classification",
"token-classification",
"en",
"dataset:pubmed",
"arxiv:2203.15827",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-08T07:22:12Z |
---
license: apache-2.0
language: en
datasets:
- pubmed
tags:
- bert
- exbert
- linkbert
- biolinkbert
- feature-extraction
- fill-mask
- question-answering
- text-classification
- token-classification
widget:
- text: "Sunitinib is a tyrosine kinase inhibitor"
---
## BioLinkBERT-base
BioLinkBERT-base model pretrained on [PubMed](https://pubmed.ncbi.nlm.nih.gov/) abstracts along with citation link information. It is introduced in the paper [LinkBERT: Pretraining Language Models with Document Links (ACL 2022)](https://arxiv.org/abs/2203.15827). The code and data are available in [this repository](https://github.com/michiyasunaga/LinkBERT).
This model achieves state-of-the-art performance on several biomedical NLP benchmarks such as [BLURB](https://microsoft.github.io/BLURB/) and [MedQA-USMLE](https://github.com/jind11/MedQA).
## Model description
LinkBERT is a transformer encoder (BERT-like) model pretrained on a large corpus of documents. It is an improvement of BERT that newly captures **document links** such as hyperlinks and citation links to include knowledge that spans across multiple documents. Specifically, it was pretrained by feeding linked documents into the same language model context, besides a single document.
LinkBERT can be used as a drop-in replacement for BERT. It achieves better performance for general language understanding tasks (e.g. text classification), and is also particularly effective for **knowledge-intensive** tasks (e.g. question answering) and **cross-document** tasks (e.g. reading comprehension, document retrieval).
## Intended uses & limitations
The model can be used by fine-tuning on a downstream task, such as question answering, sequence classification, and token classification.
You can also use the raw model for feature extraction (i.e. obtaining embeddings for input text).
### How to use
To use the model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('michiyasunaga/BioLinkBERT-base')
model = AutoModel.from_pretrained('michiyasunaga/BioLinkBERT-base')
inputs = tokenizer("Sunitinib is a tyrosine kinase inhibitor", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
For fine-tuning, you can use [this repository](https://github.com/michiyasunaga/LinkBERT) or follow any other BERT fine-tuning codebases.
## Evaluation results
When fine-tuned on downstream tasks, LinkBERT achieves the following results.
**Biomedical benchmarks ([BLURB](https://microsoft.github.io/BLURB/), [MedQA](https://github.com/jind11/MedQA), [MMLU](https://github.com/hendrycks/test), etc.):** BioLinkBERT attains new state-of-the-art.
| | BLURB score | PubMedQA | BioASQ | MedQA-USMLE |
| ---------------------- | -------- | -------- | ------- | -------- |
| PubmedBERT-base | 81.10 | 55.8 | 87.5 | 38.1 |
| **BioLinkBERT-base** | **83.39** | **70.2** | **91.4** | **40.0** |
| **BioLinkBERT-large** | **84.30** | **72.2** | **94.8** | **44.6** |
| | MMLU-professional medicine |
| ---------------------- | -------- |
| GPT-3 (175 params) | 38.7 |
| UnifiedQA (11B params) | 43.2 |
| **BioLinkBERT-large (340M params)** | **50.7** |
## Citation
If you find LinkBERT useful in your project, please cite the following:
```bibtex
@InProceedings{yasunaga2022linkbert,
author = {Michihiro Yasunaga and Jure Leskovec and Percy Liang},
title = {LinkBERT: Pretraining Language Models with Document Links},
year = {2022},
booktitle = {Association for Computational Linguistics (ACL)},
}
```
|
michiyasunaga/LinkBERT-base
|
michiyasunaga
| 2022-03-31T00:38:32Z | 847 | 7 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"feature-extraction",
"exbert",
"linkbert",
"fill-mask",
"question-answering",
"text-classification",
"token-classification",
"en",
"dataset:wikipedia",
"dataset:bookcorpus",
"arxiv:2203.15827",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-08T07:21:51Z |
---
license: apache-2.0
language: en
datasets:
- wikipedia
- bookcorpus
tags:
- bert
- exbert
- linkbert
- feature-extraction
- fill-mask
- question-answering
- text-classification
- token-classification
---
## LinkBERT-base
LinkBERT-base model pretrained on English Wikipedia articles along with hyperlink information. It is introduced in the paper [LinkBERT: Pretraining Language Models with Document Links (ACL 2022)](https://arxiv.org/abs/2203.15827). The code and data are available in [this repository](https://github.com/michiyasunaga/LinkBERT).
## Model description
LinkBERT is a transformer encoder (BERT-like) model pretrained on a large corpus of documents. It is an improvement of BERT that newly captures **document links** such as hyperlinks and citation links to include knowledge that spans across multiple documents. Specifically, it was pretrained by feeding linked documents into the same language model context, besides a single document.
LinkBERT can be used as a drop-in replacement for BERT. It achieves better performance for general language understanding tasks (e.g. text classification), and is also particularly effective for **knowledge-intensive** tasks (e.g. question answering) and **cross-document** tasks (e.g. reading comprehension, document retrieval).
## Intended uses & limitations
The model can be used by fine-tuning on a downstream task, such as question answering, sequence classification, and token classification.
You can also use the raw model for feature extraction (i.e. obtaining embeddings for input text).
### How to use
To use the model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('michiyasunaga/LinkBERT-base')
model = AutoModel.from_pretrained('michiyasunaga/LinkBERT-base')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
For fine-tuning, you can use [this repository](https://github.com/michiyasunaga/LinkBERT) or follow any other BERT fine-tuning codebases.
## Evaluation results
When fine-tuned on downstream tasks, LinkBERT achieves the following results.
**General benchmarks ([MRQA](https://github.com/mrqa/MRQA-Shared-Task-2019) and [GLUE](https://gluebenchmark.com/)):**
| | HotpotQA | TriviaQA | SearchQA | NaturalQ | NewsQA | SQuAD | GLUE |
| ---------------------- | -------- | -------- | -------- | -------- | ------ | ----- | -------- |
| | F1 | F1 | F1 | F1 | F1 | F1 | Avg score |
| BERT-base | 76.0 | 70.3 | 74.2 | 76.5 | 65.7 | 88.7 | 79.2 |
| **LinkBERT-base** | **78.2** | **73.9** | **76.8** | **78.3** | **69.3** | **90.1** | **79.6** |
| BERT-large | 78.1 | 73.7 | 78.3 | 79.0 | 70.9 | 91.1 | 80.7 |
| **LinkBERT-large** | **80.8** | **78.2** | **80.5** | **81.0** | **72.6** | **92.7** | **81.1** |
## Citation
If you find LinkBERT useful in your project, please cite the following:
```bibtex
@InProceedings{yasunaga2022linkbert,
author = {Michihiro Yasunaga and Jure Leskovec and Percy Liang},
title = {LinkBERT: Pretraining Language Models with Document Links},
year = {2022},
booktitle = {Association for Computational Linguistics (ACL)},
}
```
|
hoangbinhmta99/wav2vec-NCKH-2022
|
hoangbinhmta99
| 2022-03-31T00:28:52Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"feature-extraction",
"audio",
"speech",
"Transformer",
"automatic-speech-recognition",
"vi",
"dataset:vivos",
"dataset:common_voice",
"license:cc-by-nc-4.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-30T04:39:46Z |
---
language: vi
datasets:
- vivos
- common_voice
metrics:
- wer
pipeline_tag: automatic-speech-recognition
tags:
- audio
- speech
- Transformer
license: cc-by-nc-4.0
model-index:
- name: Wav2vec2 NCKH Vietnamese 2022
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice vi
type: common_voice
args: vi
metrics:
- name: Test WER
type: wer
value: No
---
Convert from model .pt to transformer
Link: https://huggingface.co/tommy19970714/wav2vec2-base-960h
Bash:
```bash
pip install transformers[sentencepiece]
pip install fairseq -U
git clone https://github.com/huggingface/transformers.git
cp transformers/src/transformers/models/wav2vec2/convert_wav2vec2_original_pytorch_checkpoint_to_pytorch.py .
wget https://dl.fbaipublicfiles.com/fairseq/wav2vec/wav2vec_small.pt -O ./wav2vec_small.pt
mkdir dict
wget https://dl.fbaipublicfiles.com/fairseq/wav2vec/dict.ltr.txt
mkdir outputs
python convert_wav2vec2_original_pytorch_checkpoint_to_pytorch.py
--pytorch_dump_folder_path ./outputs --checkpoint_path ./finetuned/wav2vec_small.pt
--dict_path ./dict/dict.ltr.txt --not_finetuned
```
# install and upload model
```
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
git lfs install
sudo apt-get install git-lfs
git lfs install
git clone https://huggingface.co/hoangbinhmta99/wav2vec-demo
ls
cd wav2vec-demo/
git status
git add .
git commit -m "First model version"
git config --global user.email [yourname]
git config --global user.name [yourpass]
git commit -m "First model version"
git push
```
|
michiyasunaga/LinkBERT-large
|
michiyasunaga
| 2022-03-31T00:27:01Z | 1,297 | 11 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"feature-extraction",
"exbert",
"linkbert",
"fill-mask",
"question-answering",
"text-classification",
"token-classification",
"en",
"dataset:wikipedia",
"dataset:bookcorpus",
"arxiv:2203.15827",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-08T01:42:14Z |
---
license: apache-2.0
language: en
datasets:
- wikipedia
- bookcorpus
tags:
- bert
- exbert
- linkbert
- feature-extraction
- fill-mask
- question-answering
- text-classification
- token-classification
---
## LinkBERT-large
LinkBERT-large model pretrained on English Wikipedia articles along with hyperlink information. It is introduced in the paper [LinkBERT: Pretraining Language Models with Document Links (ACL 2022)](https://arxiv.org/abs/2203.15827). The code and data are available in [this repository](https://github.com/michiyasunaga/LinkBERT).
## Model description
LinkBERT is a transformer encoder (BERT-like) model pretrained on a large corpus of documents. It is an improvement of BERT that newly captures **document links** such as hyperlinks and citation links to include knowledge that spans across multiple documents. Specifically, it was pretrained by feeding linked documents into the same language model context, besides a single document.
LinkBERT can be used as a drop-in replacement for BERT. It achieves better performance for general language understanding tasks (e.g. text classification), and is also particularly effective for **knowledge-intensive** tasks (e.g. question answering) and **cross-document** tasks (e.g. reading comprehension, document retrieval).
## Intended uses & limitations
The model can be used by fine-tuning on a downstream task, such as question answering, sequence classification, and token classification.
You can also use the raw model for feature extraction (i.e. obtaining embeddings for input text).
### How to use
To use the model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('michiyasunaga/LinkBERT-large')
model = AutoModel.from_pretrained('michiyasunaga/LinkBERT-large')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
For fine-tuning, you can use [this repository](https://github.com/michiyasunaga/LinkBERT) or follow any other BERT fine-tuning codebases.
## Evaluation results
When fine-tuned on downstream tasks, LinkBERT achieves the following results.
**General benchmarks ([MRQA](https://github.com/mrqa/MRQA-Shared-Task-2019) and [GLUE](https://gluebenchmark.com/)):**
| | HotpotQA | TriviaQA | SearchQA | NaturalQ | NewsQA | SQuAD | GLUE |
| ---------------------- | -------- | -------- | -------- | -------- | ------ | ----- | -------- |
| | F1 | F1 | F1 | F1 | F1 | F1 | Avg score |
| BERT-base | 76.0 | 70.3 | 74.2 | 76.5 | 65.7 | 88.7 | 79.2 |
| **LinkBERT-base** | **78.2** | **73.9** | **76.8** | **78.3** | **69.3** | **90.1** | **79.6** |
| BERT-large | 78.1 | 73.7 | 78.3 | 79.0 | 70.9 | 91.1 | 80.7 |
| **LinkBERT-large** | **80.8** | **78.2** | **80.5** | **81.0** | **72.6** | **92.7** | **81.1** |
## Citation
If you find LinkBERT useful in your project, please cite the following:
```bibtex
@InProceedings{yasunaga2022linkbert,
author = {Michihiro Yasunaga and Jure Leskovec and Percy Liang},
title = {LinkBERT: Pretraining Language Models with Document Links},
year = {2022},
booktitle = {Association for Computational Linguistics (ACL)},
}
```
|
yinde/fatimah_fake_news_bert
|
yinde
| 2022-03-30T22:41:12Z | 16 | 1 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-30T20:54:21Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: fatimah_fake_news_bert
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fatimah_fake_news_bert
This model is a fine-tuned version of [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) on [Fake and real dataset on kaggle ]([distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english))
It achieves the following results on the evaluation set:
- Loss: 0.0010
- Accuracy: 0.9998
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 10
- eval_batch_size: 20
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3298 | 0.06 | 200 | 0.0094 | 0.9987 |
| 0.0087 | 0.11 | 400 | 0.0091 | 0.9988 |
| 0.0126 | 0.17 | 600 | 0.0132 | 0.9965 |
| 0.0081 | 0.22 | 800 | 0.0100 | 0.9987 |
| 0.0132 | 0.28 | 1000 | 0.0086 | 0.9990 |
| 0.0131 | 0.33 | 1200 | 0.0070 | 0.9986 |
| 0.0086 | 0.39 | 1400 | 0.0079 | 0.9990 |
| 0.0041 | 0.45 | 1600 | 0.0057 | 0.9991 |
| 0.0069 | 0.5 | 1800 | 0.0083 | 0.9989 |
| 0.0052 | 0.56 | 2000 | 0.0043 | 0.9993 |
| 0.0 | 0.61 | 2200 | 0.0047 | 0.9993 |
| 0.003 | 0.67 | 2400 | 0.0052 | 0.9994 |
| 0.0126 | 0.72 | 2600 | 0.0028 | 0.9997 |
| 0.0047 | 0.78 | 2800 | 0.0018 | 0.9996 |
| 0.0 | 0.84 | 3000 | 0.0027 | 0.9996 |
| 0.0001 | 0.89 | 3200 | 0.0029 | 0.9996 |
| 0.0079 | 0.95 | 3400 | 0.0010 | 0.9998 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
UBC-NLP/MARBERTv2
|
UBC-NLP
| 2022-03-30T21:52:31Z | 3,124 | 8 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"fill-mask",
"Arabic BERT",
"MSA",
"Twitter",
"Masked Langauge Model",
"ar",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language:
- ar
tags:
- Arabic BERT
- MSA
- Twitter
- Masked Langauge Model
widget:
- text: "اللغة العربية هي لغة [MASK]."
---
<img src="https://raw.githubusercontent.com/UBC-NLP/marbert/main/ARBERT_MARBERT.jpg" alt="drawing" width="30%" height="30%" align="right"/>
**MARBERTv2** is one of three models described in our **ACL 2021 paper** **["ARBERT & MARBERT: Deep Bidirectional Transformers for Arabic"](https://aclanthology.org/2021.acl-long.551.pdf)**.
We find that results with ARBERT and MARBERT on QA are not competitive, a clear discrepancy from what we have observed thus far on other tasksWe hypothesize this is because the two models are pre-trained with a sequence length of only 128, which does not allow them to sufficiently capture both a question and its likely answer within the same sequence window during the pre-training.
To rectify this, we further pre-train the stronger model, MARBERT, on the same MSA data as ARBERT in addition to AraNews dataset but with a bigger sequence length of 512 tokens for 40 epochs. We call this
further pre-trained model **MARBERTv2**, noting it has **29B tokens**. MARBERTv2 acquires best performance on all but one test set, where XLM-RLarge marginally outperforms us (only in F1).
For more information, please visit our own GitHub [repo](https://github.com/UBC-NLP/marbert).
# BibTex
If you use our models (ARBERT, MARBERT, or MARBERTv2) for your scientific publication, or if you find the resources in this repository useful, please cite our paper as follows (to be updated):
```bibtex
@inproceedings{abdul-mageed-etal-2021-arbert,
title = "{ARBERT} {\&} {MARBERT}: Deep Bidirectional Transformers for {A}rabic",
author = "Abdul-Mageed, Muhammad and
Elmadany, AbdelRahim and
Nagoudi, El Moatez Billah",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.551",
doi = "10.18653/v1/2021.acl-long.551",
pages = "7088--7105",
abstract = "Pre-trained language models (LMs) are currently integral to many natural language processing systems. Although multilingual LMs were also introduced to serve many languages, these have limitations such as being costly at inference time and the size and diversity of non-English data involved in their pre-training. We remedy these issues for a collection of diverse Arabic varieties by introducing two powerful deep bidirectional transformer-based models, ARBERT and MARBERT. To evaluate our models, we also introduce ARLUE, a new benchmark for multi-dialectal Arabic language understanding evaluation. ARLUE is built using 42 datasets targeting six different task clusters, allowing us to offer a series of standardized experiments under rich conditions. When fine-tuned on ARLUE, our models collectively achieve new state-of-the-art results across the majority of tasks (37 out of 48 classification tasks, on the 42 datasets). Our best model acquires the highest ARLUE score (77.40) across all six task clusters, outperforming all other models including XLM-R Large ( 3.4x larger size). Our models are publicly available at https://github.com/UBC-NLP/marbert and ARLUE will be released through the same repository.",
}
```
## Acknowledgments
We gratefully acknowledge support from the Natural Sciences and Engineering Research Council of Canada, the Social Sciences and Humanities Research Council of Canada, Canadian Foundation for Innovation, [ComputeCanada](www.computecanada.ca) and [UBC ARC-Sockeye](https://doi.org/10.14288/SOCKEYE). We also thank the [Google TensorFlow Research Cloud (TFRC)](https://www.tensorflow.org/tfrc) program for providing us with free TPU access.
|
mrm8488/biomedtra-small-es
|
mrm8488
| 2022-03-30T21:07:50Z | 3 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"electra",
"pretraining",
"Spanish",
"Electra",
"Bio",
"Medical",
"es",
"dataset:cowese",
"arxiv:1406.2661",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: es
tags:
- Spanish
- Electra
- Bio
- Medical
datasets:
- cowese
---
## 🦠 BIOMEDtra 🏥
**BIOMEDtra** (small) is an Electra like model (discriminator in this case) trained on [Spanish Biomedical Crawled Corpus](https://zenodo.org/record/5510033#.Yhdk1ZHMLJx).
As mentioned in the original [paper](https://openreview.net/pdf?id=r1xMH1BtvB):
**ELECTRA** is a new method for self-supervised language representation learning. It can be used to pre-train transformer networks using relatively little compute. ELECTRA models are trained to distinguish "real" input tokens vs "fake" input tokens generated by another neural network, similar to the discriminator of a [GAN](https://arxiv.org/pdf/1406.2661.pdf). At small scale, ELECTRA achieves strong results even when trained on a single GPU. At large scale, ELECTRA achieves state-of-the-art results on the [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) dataset.
For a detailed description and experimental results, please refer the paper [ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators](https://openreview.net/pdf?id=r1xMH1BtvB).
## Training details
The model was trained using the Electra base code for 3 days on 1 GPU (Tesla V100 16GB).
## Dataset details
The largest Spanish biomedical and heath corpus to date gathered from a massive Spanish health domain crawler over more than 3,000 URLs were downloaded and preprocessed. The collected data have been preprocessed to produce the **CoWeSe** (Corpus Web Salud Español) resource, a large-scale and high-quality corpus intended for biomedical and health NLP in Spanish.
## Model details ⚙
|Param| # Value|
|-----|--------|
|Layers| 12 |
|Hidden | 256 |
|Params| 14M |
## Evaluation metrics (for discriminator) 🧾
|Metric | # Score |
|-------|---------|
|Accuracy| 0.9561|
|Precision| 0.808|
|Recall | 0.531 |
|AUC | 0.949|
## Benchmarks 🔨
WIP 🚧
## How to use the discriminator in `transformers`
```py
from transformers import ElectraForPreTraining, ElectraTokenizerFast
import torch
discriminator = ElectraForPreTraining.from_pretrained("mrm8488/biomedtra-small-es")
tokenizer = ElectraTokenizerFast.from_pretrained("mrm8488/biomedtra-small-es")
sentence = "Los españoles tienden a sufir déficit de vitamina c"
fake_sentence = "Los españoles tienden a déficit sufrir de vitamina c"
fake_tokens = tokenizer.tokenize(fake_sentence)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
predictions = torch.round((torch.sign(discriminator_outputs[0]) + 1) / 2)
[print("%7s" % token, end="") for token in fake_tokens]
[print("%7s" % prediction, end="") for prediction in predictions.tolist()]
```
## Acknowledgments
TBA
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{mromero2022biomedtra,
title={Spanish BioMedical Electra (small)},
author={Romero, Manuel},
publisher={Hugging Face},
journal={Hugging Face Hub},
howpublished={\url{https://huggingface.co/mrm8488/biomedtra-small-es},
year={2022}
}
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
vlsb/autotrain-security-text-classification-albert-688320769
|
vlsb
| 2022-03-30T20:59:32Z | 15 | 2 |
transformers
|
[
"transformers",
"pytorch",
"albert",
"text-classification",
"autotrain",
"unk",
"dataset:vlsb/autotrain-data-security-text-classification-albert",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-30T20:55:59Z |
---
tags: autotrain
language: unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- vlsb/autotrain-data-security-text-classification-albert
co2_eq_emissions: 3.670416179055797
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 688320769
- CO2 Emissions (in grams): 3.670416179055797
## Validation Metrics
- Loss: 0.3046899139881134
- Accuracy: 0.8826530612244898
- Precision: 0.9181818181818182
- Recall: 0.8782608695652174
- AUC: 0.9423510466988727
- F1: 0.8977777777777778
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/vlsb/autotrain-security-text-classification-albert-688320769
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("vlsb/autotrain-security-text-classification-albert-688320769", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("vlsb/autotrain-security-text-classification-albert-688320769", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
vlsb/autotrain-security-texts-classification-roberta-688020754
|
vlsb
| 2022-03-30T20:55:42Z | 15 | 2 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain",
"unk",
"dataset:vlsb/autotrain-data-security-texts-classification-roberta",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-30T20:52:41Z |
---
tags: autotrain
language: unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- vlsb/autotrain-data-security-texts-classification-roberta
co2_eq_emissions: 3.1151249696839685
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 688020754
- CO2 Emissions (in grams): 3.1151249696839685
## Validation Metrics
- Loss: 0.2810373902320862
- Accuracy: 0.8928571428571429
- Precision: 0.9272727272727272
- Recall: 0.8869565217391304
- AUC: 0.9500805152979066
- F1: 0.9066666666666666
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/vlsb/autotrain-security-texts-classification-roberta-688020754
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("vlsb/autotrain-security-texts-classification-roberta-688020754", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("vlsb/autotrain-security-texts-classification-roberta-688020754", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
mrm8488/longformer-base-4096-spanish
|
mrm8488
| 2022-03-30T20:36:36Z | 49 | 16 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"Long documents",
"longformer",
"bertin",
"spanish",
"es",
"dataset:spanish_large_corpus",
"arxiv:2004.05150",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language:
- es
license: mit
widget:
- text: "Manuel Romero ha creado con el equipo de BERTIN un modelo que procesa documentos <mask> largos."
tags:
- Long documents
- longformer
- bertin
- spanish
datasets:
- spanish_large_corpus
---
# longformer-base-4096-spanish
## [Longformer](https://arxiv.org/abs/2004.05150) is a Transformer model for long documents.
`longformer-base-4096` is a BERT-like model started from the RoBERTa checkpoint (**BERTIN** in this case) and pre-trained for *MLM* on long documents (from BETO's `all_wikis`). It supports sequences of length up to 4,096!
**Longformer** uses a combination of a sliding window (*local*) attention and *global* attention. Global attention is user-configured based on the task to allow the model to learn task-specific representations.
This model was made following the research done by [Iz Beltagy and Matthew E. Peters and Arman Cohan](https://arxiv.org/abs/2004.05150).
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{mromero2022longformer-base-4096-spanish,
title={Spanish LongFormer by Manuel Romero},
author={Romero, Manuel},
publisher={Hugging Face},
journal={Hugging Face Hub},
howpublished={\url{https://huggingface.co/mrm8488/longformer-base-4096-spanish}},
year={2022}
}
```
|
misterekole/upside_down_detector
|
misterekole
| 2022-03-30T19:58:07Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2022-03-30T19:47:20Z |
---
license: apache-2.0
---
Upside down detection model for Fatima Fellowship Coding Challenge 2022
|
sc2qa/msmarco_qa_classifier
|
sc2qa
| 2022-03-30T18:33:34Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"arxiv:2109.04689",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
For details, please refer to the following links.
Github repo: https://github.com/amazon-research/SC2QA-DRIL
Paper: [Generating Self-Contained and Summary-Centric Question Answer Pairs via Differentiable Reward Imitation Learning](https://arxiv.org/pdf/2109.04689.pdf)
|
horsbug98/Part_2_XLM_Model_E1
|
horsbug98
| 2022-03-30T18:29:46Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:tydiqa",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-16T17:32:47Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- tydiqa
model-index:
- name: debug_xlm_task2_1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# debug_xlm_task2_1
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the tydiqa secondary_task dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 12
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
### Training results
### Framework versions
- Transformers 4.15.0
- Pytorch 1.9.1
- Datasets 2.0.0
- Tokenizers 0.10.3
|
waboucay/camembert-base-finetuned-xnli_fr
|
waboucay
| 2022-03-30T17:47:05Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"camembert",
"text-classification",
"nli",
"fr",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-11T08:54:07Z |
---
language:
- fr
tags:
- nli
metrics:
- f1
---
## Eval results
We obtain the following results on ```validation``` and ```test``` sets:
| Set | F1<sub>micro</sub> | F1<sub>macro</sub> |
|------------|--------------------|--------------------|
| validation | 89.2 | 87.6 |
| test | 88.9 | 87.4 |
|
SAGAR4REAL/wav2vec2hindiasr
|
SAGAR4REAL
| 2022-03-30T17:32:46Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-30T14:51:24Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2hindiasr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2hindiasr
This model is a fine-tuned version of [theainerd/Wav2Vec2-large-xlsr-hindi](https://huggingface.co/theainerd/Wav2Vec2-large-xlsr-hindi) on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.