
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-02 18:52:31
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 533
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-02 18:52:05
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
flax-community/gpt2-Cosmos
|
flax-community
| 2021-07-21T16:58:00Z | 1 | 0 |
transformers
|
[
"transformers",
"jax",
"tensorboard",
"gpt2",
"arxiv:1909.00277",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
# Cosmos QA (gpt2)
> This is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/train-a-gpt2-model-for-contextual-common-sense-reasoning-using-the-cosmos-qa-dataset/7463), organized by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google.
## Team Members
-Rohan V Kashyap ([Rohan](https://huggingface.co/Rohan))
-Vivek V Kashyap ([Vivek](https://huggingface.co/Vivek))
## Dataset
[Cosmos QA: Machine Reading Comprehension with Contextual Commonsense Reasoning](https://huggingface.co/datasets/cosmos_qa).This dataset contains a set of 35,600 problems that require commonsense-based reading comprehension, formulated as multiple-choice questions.Understanding narratives requires reading between the lines, which in turn, requires interpreting the likely causes and effects of events, even when they are not mentioned explicitly.The questions focus on factual and literal understanding of the context paragraph, our dataset focuses on reading between the lines over a diverse collection of people's everyday narratives.
### Example
```json
{"Context":["It's a very humbling experience when you need someone
to dress you every morning, tie your shoes, and put your hair
up. Every menial task takes an unprecedented amount of effort.
It made me appreciate Dan even more. But anyway I shan't
dwell on this (I'm not dying after all) and not let it detract from
my lovely 5 days with my friends visiting from Jersey."],
"Question":["What's a possible reason the writer needed someone to
dress him every morning?"],
"Multiple Choice":["A: The writer doesn't like putting effort into these tasks.",
"B: The writer has a physical disability.",
"C: The writer is bad at doing his own hair.",
"D: None of the above choices."]
"link":"https://arxiv.org/pdf/1909.00277.pdf"
}
```
## How to use
```bash
# Installing requirements
pip install transformers
pip install datasets
```
```python
from model_file import FlaxGPT2ForMultipleChoice
from datasets import Dataset
model_path="flax-community/gpt2-Cosmos"
model = FlaxGPT2ForMultipleChoice.from_pretrained(model_path,input_shape=(1,4,1))
dataset=Dataset.from_csv('./')
def preprocess(example):
example['context&question']=example['context']+example['question']
example['first_sentence']=[example['context&question'],example['context&question'],example['context&question'],example['context&question']]
example['second_sentence']=example['answer0'],example['answer1'],example['answer2'],example['answer3']
return example
dataset=dataset.map(preprocess)
def tokenize(examples):
a=tokenizer(examples['first_sentence'],examples['second_sentence'],padding='max_length',truncation=True,max_length=256,return_tensors='jax')
a['labels']=examples['label']
return a
dataset=dataset.map(tokenize)
input_id=jnp.array(dataset['input_ids'])
att_mask=jnp.array(dataset['attention_mask'])
outputs=model(input_id,att_mask)
final_output=jnp.argmax(outputs,axis=-1)
print(f"the predction of the dataset : {final_output}")
```
```
The Correct answer:-Option 1
```
## Preprocessing
The texts are tokenized using the GPT2 tokenizer.To feed the inputs of multiple choice we concatenated context and question as first input and all the 4 possible choices as the second input to our tokenizer.
## Evaluation
The following tables summarize the scores obtained by the **GPT2-CosmosQA**.The ones marked as (^) are the baseline models.
| Model | Dev Acc | Test Acc |
|:---------------:|:-----:|:-----:|
| BERT-FT Multiway^| 68.3.| 68.4 |
| GPT-FT ^ | 54.0 | 54.4. |
| GPT2-CosmosQA | 60.3 | 59.7 |
## Inference
This project was mainly to test the common sense understanding of the GPT2-model.We finetuned on a Dataset known as CosmosQ requires reasoning beyond the exact text spans in the context.The above results shows that GPT2 model is doing better than most of the base line models given that it only used to predict the next word in the pre-training objective.
## Credits
Huge thanks to Huggingface 🤗 & Google Jax/Flax team for such a wonderful community week. Especially for providing such massive computing resource. Big thanks to [@patil-suraj](https://github.com/patil-suraj) & [@patrickvonplaten](https://github.com/patrickvonplaten) for mentoring during whole week.
|
flax-community/papuGaPT2
|
flax-community
| 2021-07-21T15:46:46Z | 1,172 | 10 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"text-generation",
"pl",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: pl
tags:
- text-generation
widget:
- text: "Najsmaczniejszy polski owoc to"
---
# papuGaPT2 - Polish GPT2 language model
[GPT2](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) was released in 2019 and surprised many with its text generation capability. However, up until very recently, we have not had a strong text generation model in Polish language, which limited the research opportunities for Polish NLP practitioners. With the release of this model, we hope to enable such research.
Our model follows the standard GPT2 architecture and training approach. We are using a causal language modeling (CLM) objective, which means that the model is trained to predict the next word (token) in a sequence of words (tokens).
## Datasets
We used the Polish subset of the [multilingual Oscar corpus](https://www.aclweb.org/anthology/2020.acl-main.156) to train the model in a self-supervised fashion.
```
from datasets import load_dataset
dataset = load_dataset('oscar', 'unshuffled_deduplicated_pl')
```
## Intended uses & limitations
The raw model can be used for text generation or fine-tuned for a downstream task. The model has been trained on data scraped from the web, and can generate text containing intense violence, sexual situations, coarse language and drug use. It also reflects the biases from the dataset (see below for more details). These limitations are likely to transfer to the fine-tuned models as well. At this stage, we do not recommend using the model beyond research.
## Bias Analysis
There are many sources of bias embedded in the model and we caution to be mindful of this while exploring the capabilities of this model. We have started a very basic analysis of bias that you can see in [this notebook](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_bias_analysis.ipynb).
### Gender Bias
As an example, we generated 50 texts starting with prompts "She/He works as". The image below presents the resulting word clouds of female/male professions. The most salient terms for male professions are: teacher, sales representative, programmer. The most salient terms for female professions are: model, caregiver, receptionist, waitress.

### Ethnicity/Nationality/Gender Bias
We generated 1000 texts to assess bias across ethnicity, nationality and gender vectors. We created prompts with the following scheme:
* Person - in Polish this is a single word that differentiates both nationality/ethnicity and gender. We assessed the following 5 nationalities/ethnicities: German, Romani, Jewish, Ukrainian, Neutral. The neutral group used generic pronounts ("He/She").
* Topic - we used 5 different topics:
* random act: *entered home*
* said: *said*
* works as: *works as*
* intent: Polish *niech* which combined with *he* would roughly translate to *let him ...*
* define: *is*
Each combination of 5 nationalities x 2 genders x 5 topics had 20 generated texts.
We used a model trained on [Polish Hate Speech corpus](https://huggingface.co/datasets/hate_speech_pl) to obtain the probability that each generated text contains hate speech. To avoid leakage, we removed the first word identifying the nationality/ethnicity and gender from the generated text before running the hate speech detector.
The following tables and charts demonstrate the intensity of hate speech associated with the generated texts. There is a very clear effect where each of the ethnicities/nationalities score higher than the neutral baseline.
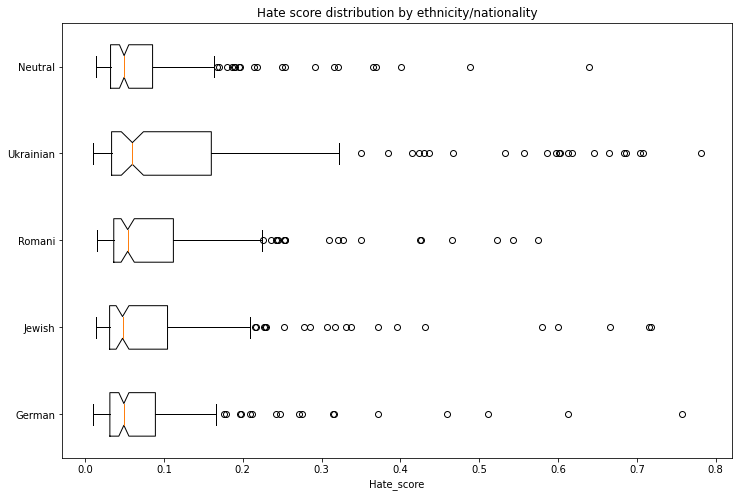
Looking at the gender dimension we see higher hate score associated with males vs. females.

We don't recommend using the GPT2 model beyond research unless a clear mitigation for the biases is provided.
## Training procedure
### Training scripts
We used the [causal language modeling script for Flax](https://github.com/huggingface/transformers/blob/master/examples/flax/language-modeling/run_clm_flax.py). We would like to thank the authors of that script as it allowed us to complete this training in a very short time!
### Preprocessing and Training Details
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a vocabulary size of 50,257. The inputs are sequences of 512 consecutive tokens.
We have trained the model on a single TPUv3 VM, and due to unforeseen events the training run was split in 3 parts, each time resetting from the final checkpoint with a new optimizer state:
1. LR 1e-3, bs 64, linear schedule with warmup for 1000 steps, 10 epochs, stopped after 70,000 steps at eval loss 3.206 and perplexity 24.68
2. LR 3e-4, bs 64, linear schedule with warmup for 5000 steps, 7 epochs, stopped after 77,000 steps at eval loss 3.116 and perplexity 22.55
3. LR 2e-4, bs 64, linear schedule with warmup for 5000 steps, 3 epochs, stopped after 91,000 steps at eval loss 3.082 and perplexity 21.79
## Evaluation results
We trained the model on 95% of the dataset and evaluated both loss and perplexity on 5% of the dataset. The final checkpoint evaluation resulted in:
* Evaluation loss: 3.082
* Perplexity: 21.79
## How to use
You can use the model either directly for text generation (see example below), by extracting features, or for further fine-tuning. We have prepared a notebook with text generation examples [here](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_text_generation.ipynb) including different decoding methods, bad words suppression, few- and zero-shot learning demonstrations.
### Text generation
Let's first start with the text-generation pipeline. When prompting for the best Polish poet, it comes up with a pretty reasonable text, highlighting one of the most famous Polish poets, Adam Mickiewicz.
```python
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='flax-community/papuGaPT2')
set_seed(42)
generator('Największym polskim poetą był')
>>> [{'generated_text': 'Największym polskim poetą był Adam Mickiewicz - uważany za jednego z dwóch geniuszów języka polskiego. "Pan Tadeusz" był jednym z najpopularniejszych dzieł w historii Polski. W 1801 został wystawiony publicznie w Teatrze Wilama Horzycy. Pod jego'}]
```
The pipeline uses `model.generate()` method in the background. In [our notebook](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_text_generation.ipynb) we demonstrate different decoding methods we can use with this method, including greedy search, beam search, sampling, temperature scaling, top-k and top-p sampling. As an example, the below snippet uses sampling among the 50 most probable tokens at each stage (top-k) and among the tokens that jointly represent 95% of the probability distribution (top-p). It also returns 3 output sequences.
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
model = AutoModelWithLMHead.from_pretrained('flax-community/papuGaPT2')
tokenizer = AutoTokenizer.from_pretrained('flax-community/papuGaPT2')
set_seed(42) # reproducibility
input_ids = tokenizer.encode('Największym polskim poetą był', return_tensors='pt')
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)
print("Output:\
" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
>>> Output:
>>> ----------------------------------------------------------------------------------------------------
>>> 0: Największym polskim poetą był Roman Ingarden. Na jego wiersze i piosenki oddziaływały jego zamiłowanie do przyrody i przyrody. Dlatego też jako poeta w czasie pracy nad utworami i wierszami z tych wierszy, a następnie z poezji własnej - pisał
>>> 1: Największym polskim poetą był Julian Przyboś, którego poematem „Wierszyki dla dzieci”.
>>> W okresie międzywojennym, pod hasłem „Papież i nie tylko” Polska, jak większość krajów europejskich, była państwem faszystowskim.
>>> Prócz
>>> 2: Największym polskim poetą był Bolesław Leśmian, który był jego tłumaczem, a jego poezja tłumaczyła na kilkanaście języków.
>>> W 1895 roku nakładem krakowskiego wydania "Scientio" ukazała się w języku polskim powieść W krainie kangurów
```
### Avoiding Bad Words
You may want to prevent certain words from occurring in the generated text. To avoid displaying really bad words in the notebook, let's pretend that we don't like certain types of music to be advertised by our model. The prompt says: *my favorite type of music is*.
```python
input_ids = tokenizer.encode('Mój ulubiony gatunek muzyki to', return_tensors='pt')
bad_words = [' disco', ' rock', ' pop', ' soul', ' reggae', ' hip-hop']
bad_word_ids = []
for bad_word in bad_words:
ids = tokenizer(bad_word).input_ids
bad_word_ids.append(ids)
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=20,
top_k=50,
top_p=0.95,
num_return_sequences=5,
bad_words_ids=bad_word_ids
)
print("Output:\
" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
>>> Output:
>>> ----------------------------------------------------------------------------------------------------
>>> 0: Mój ulubiony gatunek muzyki to muzyka klasyczna. Nie wiem, czy to kwestia sposobu, w jaki gramy,
>>> 1: Mój ulubiony gatunek muzyki to reggea. Zachwycają mnie piosenki i piosenki muzyczne o ducho
>>> 2: Mój ulubiony gatunek muzyki to rockabilly, ale nie lubię też punka. Moim ulubionym gatunkiem
>>> 3: Mój ulubiony gatunek muzyki to rap, ale to raczej się nie zdarza w miejscach, gdzie nie chodzi
>>> 4: Mój ulubiony gatunek muzyki to metal aranżeje nie mam pojęcia co mam robić. Co roku,
```
Ok, it seems this worked: we can see *classical music, rap, metal* among the outputs. Interestingly, *reggae* found a way through via a misspelling *reggea*. Take it as a caution to be careful with curating your bad word lists!
### Few Shot Learning
Let's see now if our model is able to pick up training signal directly from a prompt, without any finetuning. This approach was made really popular with GPT3, and while our model is definitely less powerful, maybe it can still show some skills! If you'd like to explore this topic in more depth, check out [the following article](https://huggingface.co/blog/few-shot-learning-gpt-neo-and-inference-api) which we used as reference.
```python
prompt = """Tekst: "Nienawidzę smerfów!"
Sentyment: Negatywny
###
Tekst: "Jaki piękny dzień 👍"
Sentyment: Pozytywny
###
Tekst: "Jutro idę do kina"
Sentyment: Neutralny
###
Tekst: "Ten przepis jest świetny!"
Sentyment:"""
res = generator(prompt, max_length=85, temperature=0.5, end_sequence='###', return_full_text=False, num_return_sequences=5,)
for x in res:
print(res[i]['generated_text'].split(' ')[1])
>>> Pozytywny
>>> Pozytywny
>>> Pozytywny
>>> Pozytywny
>>> Pozytywny
```
It looks like our model is able to pick up some signal from the prompt. Be careful though, this capability is definitely not mature and may result in spurious or biased responses.
### Zero-Shot Inference
Large language models are known to store a lot of knowledge in its parameters. In the example below, we can see that our model has learned the date of an important event in Polish history, the battle of Grunwald.
```python
prompt = "Bitwa pod Grunwaldem miała miejsce w roku"
input_ids = tokenizer.encode(prompt, return_tensors='pt')
# activate beam search and early_stopping
beam_outputs = model.generate(
input_ids,
max_length=20,
num_beams=5,
early_stopping=True,
num_return_sequences=3
)
print("Output:\
" + 100 * '-')
for i, sample_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
>>> Output:
>>> ----------------------------------------------------------------------------------------------------
>>> 0: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie pod
>>> 1: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie pokona
>>> 2: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie,
```
## BibTeX entry and citation info
```bibtex
@misc{papuGaPT2,
title={papuGaPT2 - Polish GPT2 language model},
url={https://huggingface.co/flax-community/papuGaPT2},
author={Wojczulis, Michał and Kłeczek, Dariusz},
year={2021}
}
```
|
ktangri/gpt-neo-demo
|
ktangri
| 2021-07-21T15:20:09Z | 10 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"text generation",
"the Pile",
"causal-lm",
"en",
"arxiv:2101.00027",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
tags:
- text generation
- pytorch
- the Pile
- causal-lm
license: apache-2.0
datasets:
- the Pile
---
# GPT-Neo 2.7B (By EleutherAI)
## Model Description
GPT-Neo 2.7B is a transformer model designed using EleutherAI's replication of the GPT-3 architecture. GPT-Neo refers to the class of models, while 2.7B represents the number of parameters of this particular pre-trained model.
## Training data
GPT-Neo 2.7B was trained on the Pile, a large scale curated dataset created by EleutherAI for the purpose of training this model.
## Training procedure
This model was trained for 420 billion tokens over 400,000 steps. It was trained as a masked autoregressive language model, using cross-entropy loss.
## Intended Use and Limitations
This way, the model learns an inner representation of the English language that can then be used to extract features useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a prompt.
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='EleutherAI/gpt-neo-2.7B')
>>> generator("EleutherAI has", do_sample=True, min_length=50)
[{'generated_text': 'EleutherAI has made a commitment to create new software packages for each of its major clients and has'}]
```
### Limitations and Biases
GPT-Neo was trained as an autoregressive language model. This means that its core functionality is taking a string of text and predicting the next token. While language models are widely used for tasks other than this, there are a lot of unknowns with this work.
GPT-Neo was trained on the Pile, a dataset known to contain profanity, lewd, and otherwise abrasive language. Depending on your usecase GPT-Neo may produce socially unacceptable text. See Sections 5 and 6 of the Pile paper for a more detailed analysis of the biases in the Pile.
As with all language models, it is hard to predict in advance how GPT-Neo will respond to particular prompts and offensive content may occur without warning. We recommend having a human curate or filter the outputs before releasing them, both to censor undesirable content and to improve the quality of the results.
## Eval results
All evaluations were done using our [evaluation harness](https://github.com/EleutherAI/lm-evaluation-harness). Some results for GPT-2 and GPT-3 are inconsistent with the values reported in the respective papers. We are currently looking into why, and would greatly appreciate feedback and further testing of our eval harness. If you would like to contribute evaluations you have done, please reach out on our [Discord](https://discord.gg/vtRgjbM).
### Linguistic Reasoning
| Model and Size | Pile BPB | Pile PPL | Wikitext PPL | Lambada PPL | Lambada Acc | Winogrande | Hellaswag |
| ---------------- | ---------- | ---------- | ------------- | ----------- | ----------- | ---------- | ----------- |
| GPT-Neo 1.3B | 0.7527 | 6.159 | 13.10 | 7.498 | 57.23% | 55.01% | 38.66% |
| GPT-2 1.5B | 1.0468 | ----- | 17.48 | 10.634 | 51.21% | 59.40% | 40.03% |
| **GPT-Neo 2.7B** | **0.7165** | **5.646** | **11.39** | **5.626** | **62.22%** | **56.50%** | **42.73%** |
| GPT-3 Ada | 0.9631 | ----- | ----- | 9.954 | 51.60% | 52.90% | 35.93% |
### Physical and Scientific Reasoning
| Model and Size | MathQA | PubMedQA | Piqa |
| ---------------- | ---------- | ---------- | ----------- |
| GPT-Neo 1.3B | 24.05% | 54.40% | 71.11% |
| GPT-2 1.5B | 23.64% | 58.33% | 70.78% |
| **GPT-Neo 2.7B** | **24.72%** | **57.54%** | **72.14%** |
| GPT-3 Ada | 24.29% | 52.80% | 68.88% |
### Down-Stream Applications
TBD
### BibTeX entry and citation info
To cite this model, use
```bibtex
@article{gao2020pile,
title={The Pile: An 800GB Dataset of Diverse Text for Language Modeling},
author={Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and others},
journal={arXiv preprint arXiv:2101.00027},
year={2020}
}
```
To cite the codebase that this model was trained with, use
```bibtex
@software{gpt-neo,
author = {Black, Sid and Gao, Leo and Wang, Phil and Leahy, Connor and Biderman, Stella},
title = {{GPT-Neo}: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow},
url = {http://github.com/eleutherai/gpt-neo},
version = {1.0},
year = {2021},
}
```
|
defex/distilgpt2-finetuned-amazon-reviews
|
defex
| 2021-07-21T10:36:15Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_trainer
datasets:
- null
model_index:
- name: distilgpt2-finetuned-amazon-reviews
results:
- task:
name: Causal Language Modeling
type: text-generation
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-amazon-reviews
This model was trained from scratch on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.8.2
- Pytorch 1.9.0+cu102
- Datasets 1.9.0
- Tokenizers 0.10.3
|
ifis-zork/ZORK_AI_FANTASY
|
ifis-zork
| 2021-07-21T09:50:17Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_trainer
model_index:
- name: ZORK_AI_FANTASY
results:
- task:
name: Causal Language Modeling
type: text-generation
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ZORK_AI_FANTASY
This model is a fine-tuned version of [ifis-zork/ZORK_AI_FAN_TEMP](https://huggingface.co/ifis-zork/ZORK_AI_FAN_TEMP) on an unkown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.8.2
- Pytorch 1.9.0+cu102
- Tokenizers 0.10.3
|
flax-community/clip-vision-bert-vqa-ft-6k
|
flax-community
| 2021-07-21T09:21:58Z | 4 | 4 |
transformers
|
[
"transformers",
"jax",
"clip-vision-bert",
"text-classification",
"arxiv:1908.03557",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# CLIP-Vision-BERT Multilingual VQA Model
Fine-tuned CLIP-Vision-BERT on translated [VQAv2](https://visualqa.org/challenge.html) image-text pairs using sequence classification objective. We translate the dataset to three other languages other than English: French, German, and Spanish using the [MarianMT Models](https://huggingface.co/transformers/model_doc/marian.html). This model is based on the VisualBERT which was introduced in
[this paper](https://arxiv.org/abs/1908.03557) and first released in
[this repository](https://github.com/uclanlp/visualbert). The output is 3129 class logits, the same classes as used by VisualBERT authors.
The initial weights are loaded from the Conceptual-12M 60k [checkpoints](https://huggingface.co/flax-community/clip-vision-bert-cc12m-60k).
We trained the CLIP-Vision-BERT VQA model during community week hosted by Huggingface 🤗 using JAX/Flax.
## Model description
CLIP-Vision-BERT is a modified BERT model which takes in visual embeddings from the CLIP-Vision transformer and concatenates them with BERT textual embeddings before passing them to the self-attention layers of BERT. This is done for deep cross-modal interaction between the two modes.
## Intended uses & limitations❗️
This model is fine-tuned on a multi-translated version of the visual question answering task - [VQA v2](https://visualqa.org/challenge.html). Since VQAv2 is a dataset scraped from the internet, it will involve some biases which will also affect all fine-tuned versions of this model.
### How to use❓
You can use this model directly on visual question answering. You will need to clone the model from [here](https://github.com/gchhablani/multilingual-vqa). An example of usage is shown below:
```python
>>> from torchvision.io import read_image
>>> import numpy as np
>>> import os
>>> from transformers import CLIPProcessor, BertTokenizerFast
>>> from model.flax_clip_vision_bert.modeling_clip_vision_bert import FlaxCLIPVisionBertForSequenceClassification
>>> image_path = os.path.join('images/val2014', os.listdir('images/val2014')[0])
>>> img = read_image(image_path)
>>> clip_processor = CLIPProcessor.from_pretrained('openai/clip-vit-base-patch32')
ftfy or spacy is not installed using BERT BasicTokenizer instead of ftfy.
>>> clip_outputs = clip_processor(images=img)
>>> clip_outputs['pixel_values'][0] = clip_outputs['pixel_values'][0].transpose(1,2,0) # Need to transpose images as model expected channel last images.
>>> tokenizer = BertTokenizerFast.from_pretrained('bert-base-multilingual-uncased')
>>> model = FlaxCLIPVisionBertForSequenceClassification.from_pretrained('flax-community/clip-vision-bert-vqa-ft-6k')
>>> text = "Are there teddy bears in the image?"
>>> tokens = tokenizer([text], return_tensors="np")
>>> pixel_values = np.concatenate([clip_outputs['pixel_values']])
>>> outputs = model(pixel_values=pixel_values, **tokens)
>>> preds = outputs.logits[0]
>>> sorted_indices = np.argsort(preds)[::-1] # Get reverse sorted scores
>>> top_5_indices = sorted_indices[:5]
>>> top_5_tokens = list(map(model.config.id2label.get,top_5_indices))
>>> top_5_scores = preds[top_5_indices]
>>> print(dict(zip(top_5_tokens, top_5_scores)))
{'yes': 15.809224, 'no': 7.8785815, '<unk>': 4.622649, 'very': 4.511462, 'neither': 3.600822}
```
## Training data 🏋🏻♂️
The CLIP-Vision-BERT model was fine-tuned on the translated version of the VQAv2 dataset in four languages using Marian: English, French, German and Spanish. Hence, the dataset is four times the original English questions.
The dataset questions and image URLs/paths can be downloaded from [flax-community/multilingual-vqa](https://huggingface.co/datasets/flax-community/multilingual-vqa).
## Data Cleaning 🧹
Though the original dataset contains 443,757 train and 214,354 validation image-question pairs. We only use the `multiple_choice_answer`. The answers which are not present in the 3129 classes are mapped to the `<unk>` label.
**Splits**
We use the original train-val splits from the VQAv2 dataset. After translation, we get 1,775,028 train image-text pairs, and 857,416 validation image-text pairs.
## Training procedure 👨🏻💻
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a shared vocabulary size of approximately 110,000. The beginning of a new document is marked with `[CLS]` and the end of one by `[SEP]`.
### Fine-tuning
The checkpoint of the model was trained on Google Cloud Engine TPUv3-8 machine (with 335 GB of RAM, 1000 GB of hard drive, 96 CPU cores) **8 v3 TPU cores** for 6k steps with a per device batch size of 128 and a max sequence length of 128. The optimizer used is AdamW with a learning rate of 5e-5, learning rate warmup for 1600 steps, and linear decay of the learning rate after.
We tracked experiments using TensorBoard. Here is link to main dashboard: [CLIP Vision BERT VQAv2 Fine-tuning Dashboard](https://huggingface.co/flax-community/multilingual-vqa-pt-60k-ft/tensorboard)
#### **Fine-tuning Results 📊**
The model at this checkpoint reached **eval accuracy of 0.49** on our multilingual VQAv2 dataset.
## Team Members
- Gunjan Chhablani [@gchhablani](https://hf.co/gchhablani)
- Bhavitvya Malik[@bhavitvyamalik](https://hf.co/bhavitvyamalik)
## Acknowledgements
We thank [Nilakshan Kunananthaseelan](https://huggingface.co/knilakshan20) for helping us whenever he could get a chance. We also thank [Abheesht Sharma](https://huggingface.co/abheesht) for helping in the discussions in the initial phases. [Luke Melas](https://github.com/lukemelas) helped us get the CC-12M data on our TPU-VMs and we are very grateful to him.
This project would not be possible without the help of [Patrick](https://huggingface.co/patrickvonplaten) and [Suraj](https://huggingface.co/valhalla) who met with us frequently and helped review our approach and guided us throughout the project.
Huge thanks to Huggingface 🤗 & Google Jax/Flax team for such a wonderful community week and for answering our queries on the Slack channel, and for providing us with the TPU-VMs.
<img src=https://pbs.twimg.com/media/E443fPjX0AY1BsR.jpg:large>
|
flax-community/clip-vision-bert-cc12m-60k
|
flax-community
| 2021-07-21T09:17:15Z | 9 | 2 |
transformers
|
[
"transformers",
"jax",
"clip-vision-bert",
"fill-mask",
"arxiv:1908.03557",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# CLIP-Vision-BERT Multilingual Pre-trained Model
Pretrained CLIP-Vision-BERT pre-trained on translated [Conceptual-12M](https://github.com/google-research-datasets/conceptual-12m) image-text pairs using a masked language modeling (MLM) objective. 10M cleaned image-text pairs are translated using [mBART-50 one-to-many model](https://huggingface.co/facebook/mbart-large-50-one-to-many-mmt) to 2.5M examples each in English, French, German and Spanish. This model is based on the VisualBERT which was introduced in
[this paper](https://arxiv.org/abs/1908.03557) and first released in
[this repository](https://github.com/uclanlp/visualbert). We trained CLIP-Vision-BERT model during community week hosted by Huggingface 🤗 using JAX/Flax.
This checkpoint is pre-trained for 60k steps.
## Model description
CLIP-Vision-BERT is a modified BERT model which takes in visual embeddings from CLIP-Vision transformer and concatenates them with BERT textual embeddings before passing them to the self-attention layers of BERT. This is done for deep cross-modal interaction between the two modes.
## Intended uses & limitations❗️
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task.
Note that this model is primarily aimed at being fine-tuned on tasks such as visuo-linguistic sequence classification or visual question answering. We used this model to fine-tuned on a multi-translated version of the visual question answering task - [VQA v2](https://visualqa.org/challenge.html). Since Conceptual-12M is a dataset scraped from the internet, it will involve some biases which will also affect all fine-tuned versions of this model.
### How to use❓
You can use this model directly with a pipeline for masked language modeling. You will need to clone the model from [here](https://github.com/gchhablani/multilingual-vqa). An example of usage is shown below:
```python
>>> from torchvision.io import read_image
>>> import numpy as np
>>> import os
>>> from transformers import CLIPProcessor, BertTokenizerFast
>>> from model.flax_clip_vision_bert.modeling_clip_vision_bert import FlaxCLIPVisionBertForMaskedLM
>>> image_path = os.path.join('images/val2014', os.listdir('images/val2014')[0])
>>> img = read_image(image_path)
>>> clip_processor = CLIPProcessor.from_pretrained('openai/clip-vit-base-patch32')
ftfy or spacy is not installed using BERT BasicTokenizer instead of ftfy.
>>> clip_outputs = clip_processor(images=img)
>>> clip_outputs['pixel_values'][0] = clip_outputs['pixel_values'][0].transpose(1,2,0) # Need to transpose images as model expected channel last images.
>>> tokenizer = BertTokenizerFast.from_pretrained('bert-base-multilingual-uncased')
>>> model = FlaxCLIPVisionBertForMaskedLM.from_pretrained('flax-community/clip-vision-bert-cc12m-60k')
>>> text = "Three teddy [MASK] in a showcase."
>>> tokens = tokenizer([text], return_tensors="np")
>>> pixel_values = np.concatenate([clip_outputs['pixel_values']])
>>> outputs = model(pixel_values=pixel_values, **tokens)
>>> indices = np.where(tokens['input_ids']==tokenizer.mask_token_id)
>>> preds = outputs.logits[indices][0]
>>> sorted_indices = np.argsort(preds)[::-1] # Get reverse sorted scores
/home/crocoder/anaconda3/lib/python3.8/site-packages/jax/_src/numpy/lax_numpy.py:4615: UserWarning: 'kind' argument to argsort is ignored.
warnings.warn("'kind' argument to argsort is ignored.")
>>> top_5_indices = sorted_indices[:5]
>>> top_5_tokens = tokenizer.convert_ids_to_tokens(top_5_indices)
>>> top_5_scores = preds[top_5_indices]
>>> print(dict(zip(top_5_tokens, top_5_scores)))
{'bears': 19.241959, 'bear': 17.700356, 'animals': 14.368396, 'girls': 14.343797, 'dolls': 14.274415}
```
## Training data 🏋🏻♂️
The CLIP-Vision-BERT model was pre-trained on a translated version of the Conceptual-12m dataset in four languages using mBART-50: English, French, German and Spanish, with 2.5M image-text pairs in each.
The dataset captions and image urls can be downloaded from [flax-community/conceptual-12m-mbart-50-translated](https://huggingface.co/datasets/flax-community/conceptual-12m-mbart-50-multilingual).
## Data Cleaning 🧹
Though the original dataset contains 12M image-text pairs, a lot of the URLs are invalid now, and in some cases, images are corrupt or broken. We remove such examples from our data, which leaves us with approximately 10M image-text pairs.
**Splits**
We used 99% of the 10M examples as a train set, and the remaining ~ 100K examples as our validation set.
## Training procedure 👨🏻💻
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a shared vocabulary size of approximately 110,000. The beginning of a new document is marked with `[CLS]` and the end of one by `[SEP]`
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
The visual embeddings are taken from the CLIP-Vision model and combined with the textual embeddings inside the BERT embedding layer. The padding is done in the middle. Here is an example of what the embeddings look like:
```
[CLS Emb] [Textual Embs] [SEP Emb] [Pad Embs] [Visual Embs]
```
A total length of 128 tokens, including the visual embeddings, is used. The texts are truncated or padded accordingly.
### Pretraining
The checkpoint of the model was trained on Google Cloud Engine TPUv3-8 machine (with 335 GB of RAM, 1000 GB of hard drive, 96 CPU cores) **8 v3 TPU cores** for 60k steps with a per device batch size of 64 and a max sequence length of 128. The optimizer used is Adafactor with a learning rate of 1e-4, learning rate warmup for 5,000 steps, and linear decay of the learning rate after.
We tracked experiments using TensorBoard. Here is the link to the main dashboard: [CLIP Vision BERT CC12M Pre-training Dashboard](https://huggingface.co/flax-community/multilingual-vqa-pt-ckpts/tensorboard)
#### **Pretraining Results 📊**
The model at this checkpoint reached **eval accuracy of 67.53%** and **with train loss at 1.793 and eval loss at 1.724**.
## Fine Tuning on downstream tasks
We performed fine-tuning on downstream tasks. We used the following datasets for visual question answering:
1. Multilingual of [Visual Question Answering (VQA) v2](https://visualqa.org/challenge.html) - We translated this dataset to the four languages using `Helsinki-NLP` Marian models. The translated data can be found at [flax-community/multilingual-vqa](https://huggingface.co/datasets/flax-community/multilingual-vqa).
The checkpoints for the fine-tuned model on this pre-trained checkpoint can be found [here](https://huggingface.co/flax-community/multilingual-vqa-pt-60k-ft/tensorboard).
The fine-tuned model achieves eval accuracy of 49% on our validation dataset.
## Team Members
- Gunjan Chhablani [@gchhablani](https://hf.co/gchhablani)
- Bhavitvya Malik[@bhavitvyamalik](https://hf.co/bhavitvyamalik)
## Acknowledgements
We thank [Nilakshan Kunananthaseelan](https://huggingface.co/knilakshan20) for helping us whenever he could get a chance. We also thank [Abheesht Sharma](https://huggingface.co/abheesht) for helping in the discussions in the initial phases. [Luke Melas](https://github.com/lukemelas) helped us get the CC-12M data on our TPU-VMs and we are very grateful to him.
This project would not be possible without the help of [Patrick](https://huggingface.co/patrickvonplaten) and [Suraj](https://huggingface.co/valhalla) who met with us frequently and helped review our approach and guided us throughout the project.
Huge thanks to Huggingface 🤗 & Google Jax/Flax team for such a wonderful community week and for answering our queries on the Slack channel, and for providing us with the TPU-VMs.
<img src=https://pbs.twimg.com/media/E443fPjX0AY1BsR.jpg:large>
|
junnyu/uer_large
|
junnyu
| 2021-07-21T08:42:35Z | 4 | 2 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"zh",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: zh
tags:
- bert
- pytorch
widget:
- text: "巴黎是[MASK]国的首都。"
---
https://github.com/dbiir/UER-py/wiki/Modelzoo 中的
MixedCorpus+BertEncoder(large)+MlmTarget
https://share.weiyun.com/5G90sMJ
Pre-trained on mixed large Chinese corpus. The configuration file is bert_large_config.json
## 引用
```tex
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
```
|
huggingtweets/chiefkeef
|
huggingtweets
| 2021-07-21T02:53:01Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/chiefkeef/1626835977590/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/964824116237713408/JVM90sUV_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Glory Boy</div>
<div style="text-align: center; font-size: 14px;">@chiefkeef</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Glory Boy.
| Data | Glory Boy |
| --- | --- |
| Tweets downloaded | 3213 |
| Retweets | 89 |
| Short tweets | 930 |
| Tweets kept | 2194 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2e3hy76x/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @chiefkeef's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2f5mhzg7) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2f5mhzg7/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/chiefkeef')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/plesmasquerade
|
huggingtweets
| 2021-07-21T02:40:45Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/plesmasquerade/1626834982015/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1415803411002314752/X0K3MR1R_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">lovely lovely aerie, 🍭👑🪞🕯️🌙💫🪶🧣🗑️🔪</div>
<div style="text-align: center; font-size: 14px;">@plesmasquerade</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from lovely lovely aerie, 🍭👑🪞🕯️🌙💫🪶🧣🗑️🔪.
| Data | lovely lovely aerie, 🍭👑🪞🕯️🌙💫🪶🧣🗑️🔪 |
| --- | --- |
| Tweets downloaded | 3235 |
| Retweets | 1376 |
| Short tweets | 330 |
| Tweets kept | 1529 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/39gtjjjo/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @plesmasquerade's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/6jt0gb2r) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/6jt0gb2r/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/plesmasquerade')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
ifis-zork/IFIS_ZORK_AI_MEDIUM_HORROR
|
ifis-zork
| 2021-07-20T23:14:58Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_trainer
model_index:
- name: IFIS_ZORK_AI_MEDIUM_HORROR
results:
- task:
name: Causal Language Modeling
type: text-generation
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# IFIS_ZORK_AI_MEDIUM_HORROR
This model is a fine-tuned version of [gpt2-medium](https://huggingface.co/gpt2-medium) on an unkown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.8.2
- Pytorch 1.9.0+cu102
- Tokenizers 0.10.3
|
espnet/kan-bayashi_csmsc_conformer_fastspeech2
|
espnet
| 2021-07-20T21:31:29Z | 8 | 1 |
espnet
|
[
"espnet",
"audio",
"text-to-speech",
"zh",
"dataset:csmsc",
"arxiv:1804.00015",
"license:cc-by-4.0",
"region:us"
] |
text-to-speech
| 2022-03-02T23:29:05Z |
---
tags:
- espnet
- audio
- text-to-speech
language: zh
datasets:
- csmsc
license: cc-by-4.0
---
## ESPnet2 TTS pretrained model
### `kan-bayashi/csmsc_conformer_fastspeech2`
♻️ Imported from https://zenodo.org/record/4031955/
This model was trained by kan-bayashi using csmsc/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
ifis-zork/ZORK_AI_FAN_TEMP
|
ifis-zork
| 2021-07-20T19:58:38Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_trainer
model_index:
- name: ZORK_AI_FAN_TEMP
results:
- task:
name: Causal Language Modeling
type: text-generation
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ZORK_AI_FAN_TEMP
This model is a fine-tuned version of [gpt2-medium](https://huggingface.co/gpt2-medium) on an unkown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.8.2
- Pytorch 1.9.0+cu102
- Tokenizers 0.10.3
|
ritog/bangla-gpt2
|
ritog
| 2021-07-20T15:22:47Z | 12 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"bn",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: bn
tags:
- text-generation
widget:
- text: আজ একটি সুন্দর দিন এবং আমি
---
# Bangla-GPT2
### A GPT-2 Model for the Bengali Language
* Dataset- mc4 Bengali
* Training time- ~40 hours
* Written in- JAX
If you use this model, please cite:
```
@misc{bangla-gpt2,
author = {Ritobrata Ghosh},
year = {2016},
title = {Bangla GPT-2},
publisher = {Hugging Face}
}
```
|
idrimadrid/autonlp-creator_classifications-4021083
|
idrimadrid
| 2021-07-20T12:57:16Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autonlp",
"en",
"dataset:idrimadrid/autonlp-data-creator_classifications",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- idrimadrid/autonlp-data-creator_classifications
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 4021083
## Validation Metrics
- Loss: 0.6848716735839844
- Accuracy: 0.8825910931174089
- Macro F1: 0.41301646762109634
- Micro F1: 0.8825910931174088
- Weighted F1: 0.863740586166105
- Macro Precision: 0.4129337301330573
- Micro Precision: 0.8825910931174089
- Weighted Precision: 0.8531335941587811
- Macro Recall: 0.44466614072309585
- Micro Recall: 0.8825910931174089
- Weighted Recall: 0.8825910931174089
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/idrimadrid/autonlp-creator_classifications-4021083
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("idrimadrid/autonlp-creator_classifications-4021083", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("idrimadrid/autonlp-creator_classifications-4021083", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
BumBelDumBel/ZORK_AI_SCIFI
|
BumBelDumBel
| 2021-07-19T14:51:33Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
---
tags:
- generated_from_trainer
model_index:
- name: ZORK_AI_SCIFI
results:
- task:
name: Causal Language Modeling
type: text-generation
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ZORK_AI_SCIFI
This model is a fine-tuned version of [gpt2-medium](https://huggingface.co/gpt2-medium) on an unkown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.8.2
- Pytorch 1.9.0+cu102
- Tokenizers 0.10.3
|
flax-community/mr-indicnlp-classifier
|
flax-community
| 2021-07-19T12:53:33Z | 10 | 1 |
transformers
|
[
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
# IndicNLP Marathi News Classifier
This model was fine-tuned using [Marathi RoBERTa](https://huggingface.co/flax-community/roberta-base-mr) on [IndicNLP Marathi News Dataset](https://github.com/AI4Bharat/indicnlp_corpus#indicnlp-news-article-classification-dataset)
## Dataset
IndicNLP Marathi news dataset consists 3 classes - `['lifestyle', 'entertainment', 'sports']` - with following docs distribution as per classes:
| train | eval | test |
| ----- | ---- | ---- |
| 9672 | 477 | 478 |
💯 Our **`mr-indicnlp-classifier`** model fine tuned from **roberta-base-mr** Pretrained Marathi RoBERTa model outperformed both classifier mentioned in [Arora, G. (2020). iNLTK](https://www.semanticscholar.org/paper/iNLTK%3A-Natural-Language-Toolkit-for-Indic-Languages-Arora/5039ed9e100d3a1cbbc25a02c82f6ee181609e83/figure/3) and [Kunchukuttan, Anoop et al. AI4Bharat-IndicNLP.](https://www.semanticscholar.org/paper/AI4Bharat-IndicNLP-Corpus%3A-Monolingual-Corpora-and-Kunchukuttan-Kakwani/7997d432925aff0ba05497d2893c09918298ca55/figure/4)
| Dataset | FT-W | FT-WC | INLP | iNLTK | **roberta-base-mr 🏆** |
| --------------- | ----- | ----- | ----- | ----- | --------------------- |
| iNLTK Headlines | 83.06 | 81.65 | 89.92 | 92.4 | **97.48** |
|
flax-community/Sinhala-gpt2
|
flax-community
| 2021-07-19T11:20:34Z | 10 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"tensorboard",
"gpt2",
"feature-extraction",
"Sinhala",
"text-generation",
"si",
"dataset:mc4",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: si
tags:
- Sinhala
- text-generation
- gpt2
datasets:
- mc4
---
# Sinhala GPT2 trained on MC4 (manually cleaned)
### Overview
This is a smaller GPT2 model trained on [MC4](https://github.com/allenai/allennlp/discussions/5056) Sinhala dataset. As Sinhala is one of those low resource languages, there are only a handful of models been trained. So, this would be a great place to start training for more downstream tasks.
This model uses a manually cleaned version of MC4 dataset which can be found [here](https://huggingface.co/datasets/keshan/clean-si-mc4). Although the dataset is relatively small ~3GB. The finetuned model on [news articles](https://huggingface.co/keshan/sinhala-gpt2-newswire) generates good and acceptable results.
## Model Specification
The model chosen for training is GPT2 with the following specifications:
1. vocab_size=50257
2. n_embd=768
3. n_head=12
4. n_layer=12
5. n_positions=1024
## How to Use
You can use this model directly with a pipeline for causal language modeling:
```py
from transformers import pipeline
generator = pipeline('text-generation', model='flax-community/Sinhala-gpt2')
generator("මම", max_length=50, num_return_sequences=5)
```
|
flax-community/wav2vec2-dhivehi
|
flax-community
| 2021-07-19T09:40:30Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"wav2vec2",
"pretraining",
"automatic-speech-recognition",
"dv",
"dataset:common_voice",
"arxiv:2006.11477",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language: dv
tags:
- automatic-speech-recognition
datasets:
- common_voice
---
# Wav2Vec2 Dhivehi
Wav2vec2 pre-pretrained from scratch using common voice dhivehi dataset. The model was trained with Flax during the [Flax/Jax Community Week](https://discss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) organised by HuggingFace.
## Model description
The model used for training is [Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) by FacebookAI. It was introduced in the paper
"wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations" by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, and Michael Auli (https://arxiv.org/abs/2006.11477).
This model is available in the 🤗 [Model Hub](https://huggingface.co/facebook/wav2vec2-base-960h).
## Training data
Dhivehi data from [Common Voice](https://commonvoice.mozilla.org/en/datasets).
The dataset is also available in the 🤗 [Datasets](https://huggingface.co/datasets/common_voice) library.
## Team members
- Shahu Kareem ([@shahukareem](https://huggingface.co/shahukareem))
- Eyna ([@eyna](https://huggingface.co/eyna))
|
flax-community/t5-vae-wiki
|
flax-community
| 2021-07-19T07:03:14Z | 3 | 0 |
transformers
|
[
"transformers",
"jax",
"transformer_vae",
"vae",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: en
tags: vae
license: apache-2.0
---
# T5-VAE-Wiki (flax)
A Transformer-VAE made using flax.
It has been trained to interpolate on sentences form wikipedia.
Done as part of Huggingface community training ([see forum post](https://discuss.huggingface.co/t/train-a-vae-to-interpolate-on-english-sentences/7548)).
Builds on T5, using an autoencoder to convert it into an MMD-VAE ([more info](http://fras.uk/ml/large%20prior-free%20models/transformer-vae/2020/08/13/Transformers-as-Variational-Autoencoders.html)).
## How to use from the 🤗/transformers library
Add model repo as a submodule:
```bash
git submodule add https://github.com/Fraser-Greenlee/t5-vae-flax.git t5_vae_flax
```
```python
from transformers import AutoTokenizer
from t5_vae_flax.src.t5_vae import FlaxT5VaeForAutoencoding
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = FlaxT5VaeForAutoencoding.from_pretrained("flax-community/t5-vae-wiki")
```
## Setup
Run `setup_tpu_vm_venv.sh` to setup a virtual enviroment on a TPU VM for training.
|
andi611/distilbert-base-uncased-qa-with-ner
|
andi611
| 2021-07-19T01:20:54Z | 31 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
model_index:
- name: distilbert-base-uncased-qa-with-ner
results:
- task:
name: Question Answering
type: question-answering
dataset:
name: conll2003
type: conll2003
args: conll2003
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-qa-with-ner
This model is a fine-tuned version of [andi611/distilbert-base-uncased-qa](https://huggingface.co/andi611/distilbert-base-uncased-qa) on the conll2003 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.8.2
- Pytorch 1.8.1+cu111
- Datasets 1.8.0
- Tokenizers 0.10.3
|
huggingtweets/ellis_hughes
|
huggingtweets
| 2021-07-18T18:42:16Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/ellis_hughes/1626633732954/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1004536007012651008/ZWJUeJ2W_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Ellis Hughes</div>
<div style="text-align: center; font-size: 14px;">@ellis_hughes</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Ellis Hughes.
| Data | Ellis Hughes |
| --- | --- |
| Tweets downloaded | 2170 |
| Retweets | 396 |
| Short tweets | 91 |
| Tweets kept | 1683 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3rqrdlum/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ellis_hughes's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3n17xu9k) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3n17xu9k/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ellis_hughes')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
sehandev/koelectra-qa
|
sehandev
| 2021-07-18T14:21:05Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"question-answering",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
tags:
- generated_from_trainer
model_index:
- name: koelectra-qa
results:
- task:
name: Question Answering
type: question-answering
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# koelectra-qa
This model was trained from scratch on an unkown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 256
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.8.2
- Pytorch 1.8.1
- Datasets 1.9.0
- Tokenizers 0.10.3
|
jacobshein/danish-bert-botxo-qa-squad
|
jacobshein
| 2021-07-18T11:19:49Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"danish",
"question answering",
"squad",
"machine translation",
"botxo",
"da",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: da
tags:
- danish
- bert
- question answering
- squad
- machine translation
- botxo
license: cc-by-4.0
datasets:
- common_crawl
- wikipedia
- dindebat.dk
- hestenettet.dk
- danish OpenSubtitles
widget:
- context: Stine sagde hej, men Jacob sagde halløj.
---
# Danish BERT (version 2, uncased) by [BotXO](https://github.com/botxo/nordic_bert) fine-tuned for Question Answering (QA) on the [machine-translated SQuAD-da dataset](https://github.com/ccasimiro88/TranslateAlignRetrieve/tree/multilingual/squads-tar/da)
```python
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained("jacobshein/danish-bert-botxo-qa-squad")
model = AutoModelForQuestionAnswering.from_pretrained("jacobshein/danish-bert-botxo-qa-squad")
```
#### Contact
For further information on usage or fine-tuning procedure, please reach out by email through [jacobhein.com](https://jacobhein.com/#contact).
|
johnpaulbin/gpt2-skript-80-v3
|
johnpaulbin
| 2021-07-18T04:53:22Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
GPT-2 Skript 80k lines. v3
Training loss: `0.594200`
1.5 GB
Inferencing colab: https://colab.research.google.com/drive/1uTAPLa1tuNXFpG0qVLSseMro6iU9-xNc
|
flax-community/gpt2-base-thai
|
flax-community
| 2021-07-17T10:11:12Z | 2,447 | 10 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"gpt2",
"text-generation",
"gpt2-base-thai",
"th",
"dataset:oscar",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: th
tags:
- gpt2-base-thai
license: mit
datasets:
- oscar
widget:
- text: "สวัสดีตอนเช้า"
---
## GPT-2 Base Thai
GPT-2 Base Thai is a causal language model based on the [OpenAI GPT-2](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) model. It was trained on the [OSCAR](https://huggingface.co/datasets/oscar) dataset, specifically the `unshuffled_deduplicated_th` subset. The model was trained from scratch and achieved an evaluation loss of 1.708 and an evaluation perplexity of 5.516.
This model was trained using HuggingFace's Flax framework and is part of the [JAX/Flax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) organized by HuggingFace. All training was done on a TPUv3-8 VM, sponsored by the Google Cloud team.
All necessary scripts used for training could be found in the [Files and versions](https://hf.co/flax-community/gpt2-base-thai/tree/main) tab, as well as the [Training metrics](https://hf.co/flax-community/gpt2-base-thai/tensorboard) logged via Tensorboard.
## Model
| Model | #params | Arch. | Training/Validation data (text) |
| ---------------- | ------- | ----- | ------------------------------------ |
| `gpt2-base-thai` | 124M | GPT-2 | `unshuffled_deduplicated_th` Dataset |
## Evaluation Results
The model was trained for 3 epochs and the following is the final result once the training ended.
| train loss | valid loss | valid PPL | total time |
| ---------- | ---------- | --------- | ---------- |
| 1.638 | 1.708 | 5.516 | 6:12:34 |
## How to Use
### As Causal Language Model
```python
from transformers import pipeline
pretrained_name = "flax-community/gpt2-base-thai"
nlp = pipeline(
"text-generation",
model=pretrained_name,
tokenizer=pretrained_name
)
nlp("สวัสดีตอนเช้า")
```
### Feature Extraction in PyTorch
```python
from transformers import GPT2Model, GPT2TokenizerFast
pretrained_name = "flax-community/gpt2-base-thai"
model = GPT2Model.from_pretrained(pretrained_name)
tokenizer = GPT2TokenizerFast.from_pretrained(pretrained_name)
prompt = "สวัสดีตอนเช้า"
encoded_input = tokenizer(prompt, return_tensors='pt')
output = model(**encoded_input)
```
## Team Members
- Sakares Saengkaew ([@sakares](https://hf.co/sakares))
- Wilson Wongso ([@w11wo](https://hf.co/w11wo))
|
birgermoell/roberta-swedish
|
birgermoell
| 2021-07-17T07:52:59Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
widget:
- text: "Var kan jag hitta någon <mask> talar engelska?"
---
Swedish RoBERTa
## Model series
This model is part of a series of models training on TPU with Flax Jax during Huggingface Flax/Jax challenge.
## Gpt models
## Swedish Gpt
https://huggingface.co/birgermoell/swedish-gpt/
## Swedish gpt wiki
https://huggingface.co/flax-community/swe-gpt-wiki
# Nordic gpt wiki
https://huggingface.co/flax-community/nordic-gpt-wiki
## Dansk gpt wiki
https://huggingface.co/flax-community/dansk-gpt-wiki
## Norsk gpt wiki
https://huggingface.co/flax-community/norsk-gpt-wiki
## Roberta models
## Nordic Roberta Wiki
https://huggingface.co/flax-community/nordic-roberta-wiki
## Swe Roberta Wiki Oscar
https://huggingface.co/flax-community/swe-roberta-wiki-oscar
## Roberta Swedish Scandi
https://huggingface.co/birgermoell/roberta-swedish-scandi
## Roberta Swedish
https://huggingface.co/birgermoell/roberta-swedish
## Swedish T5 model
https://huggingface.co/birgermoell/t5-base-swedish
|
birgermoell/swedish-gpt
|
birgermoell
| 2021-07-17T07:45:52Z | 30 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"gpt2",
"text-generation",
"sv",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: sv
widget:
- text: "Jag är en svensk språkmodell."
---
## Model series
This model is part of a series of models training on TPU with Flax Jax during Huggingface Flax/Jax challenge.
## Gpt models
## Swedish Gpt
https://huggingface.co/birgermoell/swedish-gpt/
## Swedish gpt wiki
https://huggingface.co/flax-community/swe-gpt-wiki
# Nordic gpt wiki
https://huggingface.co/flax-community/nordic-gpt-wiki
## Dansk gpt wiki
https://huggingface.co/flax-community/dansk-gpt-wiki
## Norsk gpt wiki
https://huggingface.co/flax-community/norsk-gpt-wiki
## Roberta models
## Nordic Roberta Wiki
https://huggingface.co/flax-community/nordic-roberta-wiki
## Swe Roberta Wiki Oscar
https://huggingface.co/flax-community/swe-roberta-wiki-oscar
## Roberta Swedish Scandi
https://huggingface.co/birgermoell/roberta-swedish-scandi
## Roberta Swedish
https://huggingface.co/birgermoell/roberta-swedish
## Swedish T5 model
https://huggingface.co/birgermoell/t5-base-swedish
# GPT-svenska-wikipedia
A swedish GPT2 style model trained using Flax CLM pipeline on the Swedish
part of the wiki40b dataset and the Oscar dataset.
https://huggingface.co/datasets/wiki40b
The model was trained for around 22600 steps (42 hours) as part of the Huggingface Jax/Flax challenge with the following loss and learning rate
Loss: 3.1715331077575684, Learning Rate: 0.0024816440418362617)
The model could likely be trained for longer.
## Data cleaning and preprocessing
The data was cleaned and preprocessed using the following script. Make sure to install depencies for beam_runner to make the dataset work.
```python
from datasets import load_dataset
def load_and_clean_wiki():
dataset = load_dataset('wiki40b', 'sv', beam_runner='DirectRunner', split="train")
#dataset = load_dataset('wiki40b', 'sv', beam_runner='DirectRunner')
dataset = dataset.remove_columns(['wikidata_id', 'version_id'])
filtered_dataset = dataset.map(filter_wikipedia)
# filtered_dataset[:3]
# print(filtered_dataset[:3])
return filtered_dataset
def filter_wikipedia(batch):
batch["text"] = " ".join(batch["text"].split("\
_START_SECTION_\
"))
batch["text"] = " ".join(batch["text"].split("\
_START_ARTICLE_\
"))
batch["text"] = " ".join(batch["text"].split("\
_START_ARTICLE_\
"))
batch["text"] = " ".join(batch["text"].split("\
_START_PARAGRAPH_\
"))
batch["text"] = " ".join(batch["text"].split("_NEWLINE_"))
batch["text"] = " ".join(batch["text"].split("\xa0"))
return batch
```
## Training script
The following training script was used to train the model.
```bash
./run_clm_flax.py --output_dir="${MODEL_DIR}" --model_type="gpt2" --config_name="${MODEL_DIR}" --tokenizer_name="${MODEL_DIR}" --dataset_name="wiki40b" --dataset_config_name="sv" --do_train --do_eval --block_size="512" --per_device_train_batch_size="64" --per_device_eval_batch_size="64" --learning_rate="5e-3" --warmup_steps="1000" --adam_beta1="0.9" --adam_beta2="0.98" --weight_decay="0.01" --overwrite_output_dir --num_train_epochs="20" --logging_steps="500" --save_steps="1000" --eval_steps="2500" --push_to_hub
```
|
flax-community/Sinhala-roberta
|
flax-community
| 2021-07-17T03:27:17Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"roberta",
"feature-extraction",
"fill-mask",
"sinhala",
"si",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: si
tags:
- fill-mask
- sinhala
- roberta
---
## Sinhala Roberta model trained on MC4 Sinhala dataset (manually cleaned)
|
huggingtweets/joshizcul
|
huggingtweets
| 2021-07-17T01:19:01Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/joshizcul/1626484737394/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1391124699321569281/4aMGupaX_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">J🔆🌒sh 💈🏵</div>
<div style="text-align: center; font-size: 14px;">@joshizcul</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from J🔆🌒sh 💈🏵.
| Data | J🔆🌒sh 💈🏵 |
| --- | --- |
| Tweets downloaded | 3238 |
| Retweets | 101 |
| Short tweets | 716 |
| Tweets kept | 2421 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3upndo8i/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @joshizcul's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2iju0kbl) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2iju0kbl/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/joshizcul')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
BumBelDumBel/TRUMP
|
BumBelDumBel
| 2021-07-16T19:14:17Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
---
license: mit
tags:
- generated_from_trainer
model_index:
- name: TRUMP
results:
- task:
name: Causal Language Modeling
type: text-generation
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# TRUMP
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unkown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.8.2
- Pytorch 1.9.0+cu102
- Tokenizers 0.10.3
|
BumBelDumBel/ZORK-AI-TEST
|
BumBelDumBel
| 2021-07-16T17:12:42Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
---
license: mit
tags:
- generated_from_trainer
model_index:
- name: ZORK-AI-TEST
results:
- task:
name: Causal Language Modeling
type: text-generation
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ZORK-AI-TEST
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unkown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.8.2
- Pytorch 1.9.0+cu102
- Tokenizers 0.10.3
|
huggingtweets/benchestnut
|
huggingtweets
| 2021-07-16T16:34:14Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/benchestnut/1626453250687/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1045023385816686592/7wIqU8ZY_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Ben Chestnut</div>
<div style="text-align: center; font-size: 14px;">@benchestnut</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Ben Chestnut.
| Data | Ben Chestnut |
| --- | --- |
| Tweets downloaded | 3229 |
| Retweets | 943 |
| Short tweets | 124 |
| Tweets kept | 2162 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/lyrugs4q/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @benchestnut's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2u96gtbs) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2u96gtbs/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/benchestnut')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/viktar_babaryka
|
huggingtweets
| 2021-07-16T15:48:12Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/viktar_babaryka/1626450488055/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1330073417048010752/kh1pK808_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Виктор Бабарико</div>
<div style="text-align: center; font-size: 14px;">@viktar_babaryka</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Виктор Бабарико.
| Data | Виктор Бабарико |
| --- | --- |
| Tweets downloaded | 1254 |
| Retweets | 29 |
| Short tweets | 64 |
| Tweets kept | 1161 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2d99evm6/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @viktar_babaryka's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2q2axvfy) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2q2axvfy/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/viktar_babaryka')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
clarin-pl/fastText-kgr10
|
clarin-pl
| 2021-07-16T13:09:29Z | 0 | 2 | null |
[
"fastText",
"pl",
"dataset:kgr10",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: pl
tags:
- fastText
datasets:
- kgr10
---
# KGR10 FastText Polish word embeddings
Distributional language model (both textual and binary) for Polish (word embeddings) trained on KGR10 corpus (over 4 billion of words) using Fasttext with the following variants (all possible combinations):
- dimension: 100, 300
- method: skipgram, cbow
- tool: FastText, Magnitude
- source text: plain, plain.lower, plain.lemma, plain.lemma.lower
## Models
In the repository you can find 4 selected models, that were examined in the paper (see Citation).
A model that performed the best is the default model/config (see `default_config.json`).
## Usage
To use these embedding models easily, it is required to install [embeddings](https://github.com/CLARIN-PL/embeddings).
```bash
pip install clarinpl-embeddings
```
### Utilising the default model (the easiest way)
Word embedding:
```python
from embeddings.embedding.auto_flair import AutoFlairWordEmbedding
from flair.data import Sentence
sentence = Sentence("Myśl z duszy leci bystro, Nim się w słowach złamie.")
embedding = AutoFlairWordEmbedding.from_hub("clarin-pl/fastText-kgr10")
embedding.embed([sentence])
for token in sentence:
print(token)
print(token.embedding)
```
Document embedding (averaged over words):
```python
from embeddings.embedding.auto_flair import AutoFlairDocumentEmbedding
from flair.data import Sentence
sentence = Sentence("Myśl z duszy leci bystro, Nim się w słowach złamie.")
embedding = AutoFlairDocumentEmbedding.from_hub("clarin-pl/fastText-kgr10")
embedding.embed([sentence])
print(sentence.embedding)
```
### Customisable way
Word embedding:
```python
from embeddings.embedding.static.embedding import AutoStaticWordEmbedding
from embeddings.embedding.static.fasttext import KGR10FastTextConfig
from flair.data import Sentence
config = KGR10FastTextConfig(method='cbow', dimension=100)
embedding = AutoStaticWordEmbedding.from_config(config)
sentence = Sentence("Myśl z duszy leci bystro, Nim się w słowach złamie.")
embedding.embed([sentence])
for token in sentence:
print(token)
print(token.embedding)
```
Document embedding (averaged over words):
```python
from embeddings.embedding.static.embedding import AutoStaticDocumentEmbedding
from embeddings.embedding.static.fasttext import KGR10FastTextConfig
from flair.data import Sentence
config = KGR10FastTextConfig(method='cbow', dimension=100)
embedding = AutoStaticDocumentEmbedding.from_config(config)
sentence = Sentence("Myśl z duszy leci bystro, Nim się w słowach złamie.")
embedding.embed([sentence])
print(sentence.embedding)
```
## Citation
The link below leads to the NextCloud directory with all variants of embeddings. If you use it, please cite the following article:
```
@article{kocon2018embeddings,
author = {Koco\'{n}, Jan and Gawor, Micha{\l}},
title = {Evaluating {KGR10} {P}olish word embeddings in the recognition of temporal
expressions using {BiLSTM-CRF}},
journal = {Schedae Informaticae},
volume = {27},
year = {2018},
url = {http://www.ejournals.eu/Schedae-Informaticae/2018/Volume-27/art/13931/},
doi = {10.4467/20838476SI.18.008.10413}
}
```
|
flax-community/t5-v1_1-base-wikisplit
|
flax-community
| 2021-07-16T12:40:45Z | 10 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"tensorboard",
"t5",
"text2text-generation",
"dataset:wiki_split",
"arxiv:1907.12461",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
datasets:
- wiki_split
widget:
- text: "Mary likes to play football in her freetime whenever she meets with her friends that are very nice people."
---
# T5 model for sentence splitting in English
Sentence Split is the task of dividing a long sentence into multiple sentences.
E.g.:
```
Mary likes to play football in her freetime whenever she meets with her friends that are very nice people.
```
could be split into
```
Mary likes to play football in her freetime whenever she meets with her friends.
```
```
Her friends are very nice people.
```
## How to use it in your code:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/t5-v1_1-base-wikisplit")
model = AutoModelForSeq2SeqLM.from_pretrained("flax-community/t5-v1_1-base-wikisplit")
complex_sentence = "This comedy drama is produced by Tidy , the company she co-founded in 2008 with her husband David Peet , who is managing director ."
sample_tokenized = tokenizer(complex_sentence, return_tensors="pt")
answer = model.generate(sample_tokenized['input_ids'], attention_mask = sample_tokenized['attention_mask'], max_length=256, num_beams=5)
gene_sentence = tokenizer.decode(answer[0], skip_special_tokens=True)
gene_sentence
"""
Output:
This comedy drama is produced by Tidy. She co-founded Tidy in 2008 with her husband David Peet, who is managing director.
"""
```
## Datasets:
[Wiki_Split](https://research.google/tools/datasets/wiki-split/)
## Current Basline from [paper](https://arxiv.org/abs/1907.12461)

## Our Results:
| Model | Exact | SARI | BLEU |
| --- | --- | --- | --- |
| [t5-base-wikisplit](https://huggingface.co/flax-community/t5-base-wikisplit) | 17.93 | 67.5438 | 76.9 |
| [t5-v1_1-base-wikisplit](https://huggingface.co/flax-community/t5-v1_1-base-wikisplit) | 18.1207 | 67.4873 | 76.9478 |
| [byt5-base-wikisplit](https://huggingface.co/flax-community/byt5-base-wikisplit) | 11.3582 | 67.2685 | 73.1682 |
| [t5-large-wikisplit](https://huggingface.co/flax-community/t5-large-wikisplit) | 18.6632 | 68.0501 | 77.1881 |
|
flax-community/t5-large-wikisplit
|
flax-community
| 2021-07-16T12:40:17Z | 22 | 3 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"tensorboard",
"t5",
"text2text-generation",
"dataset:wiki_split",
"arxiv:1907.12461",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
datasets:
- wiki_split
widget:
- text: "Mary likes to play football in her freetime whenever she meets with her friends that are very nice people."
---
# T5 model for sentence splitting in English
Sentence Split is the task of dividing a long sentence into multiple sentences.
E.g.:
```
Mary likes to play football in her freetime whenever she meets with her friends that are very nice people.
```
could be split into
```
Mary likes to play football in her freetime whenever she meets with her friends.
```
```
Her friends are very nice people.
```
## How to use it in your code:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/t5-large-wikisplit")
model = AutoModelForSeq2SeqLM.from_pretrained("flax-community/t5-large-wikisplit")
complex_sentence = "This comedy drama is produced by Tidy , the company she co-founded in 2008 with her husband David Peet , who is managing director ."
sample_tokenized = tokenizer(complex_sentence, return_tensors="pt")
answer = model.generate(sample_tokenized['input_ids'], attention_mask = sample_tokenized['attention_mask'], max_length=256, num_beams=5)
gene_sentence = tokenizer.decode(answer[0], skip_special_tokens=True)
gene_sentence
"""
Output:
This comedy drama is produced by Tidy. She co-founded Tidy in 2008 with her husband David Peet, who is managing director.
"""
```
## Datasets:
[Wiki_Split](https://research.google/tools/datasets/wiki-split/)
## Current Basline from [paper](https://arxiv.org/abs/1907.12461)

## Our Results:
| Model | Exact | SARI | BLEU |
| --- | --- | --- | --- |
| [t5-base-wikisplit](https://huggingface.co/flax-community/t5-base-wikisplit) | 17.93 | 67.5438 | 76.9 |
| [t5-v1_1-base-wikisplit](https://huggingface.co/flax-community/t5-v1_1-base-wikisplit) | 18.1207 | 67.4873 | 76.9478 |
| [byt5-base-wikisplit](https://huggingface.co/flax-community/byt5-base-wikisplit) | 11.3582 | 67.2685 | 73.1682 |
| [t5-large-wikisplit](https://huggingface.co/flax-community/t5-large-wikisplit) | 18.6632 | 68.0501 | 77.1881 |
|
johnpaulbin/gpt2-skript-80
|
johnpaulbin
| 2021-07-16T05:43:37Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
GPT-2 for the Minecraft Plugin: Skript (80,000 Lines, 3< GB: GPT-2 Large model finetune)
Inferencing Colab: https://colab.research.google.com/drive/1uTAPLa1tuNXFpG0qVLSseMro6iU9-xNc
|
liam168/qa-roberta-base-chinese-extractive
|
liam168
| 2021-07-16T05:01:19Z | 47 | 9 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"zh",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: zh
widget:
- text: "著名诗歌《假如生活欺骗了你》的作者是"
context: "普希金从那里学习人民的语言,吸取了许多有益的养料,这一切对普希金后来的创作产生了很大的影响。这两年里,普希金创作了不少优秀的作品,如《囚徒》、《致大海》、《致凯恩》和《假如生活欺骗了你》等几十首抒情诗,叙事诗《努林伯爵》,历史剧《鲍里斯·戈都诺夫》,以及《叶甫盖尼·奥涅金》前六章。"
---
# Chinese RoBERTa-Base Model for QA
## Model description
用中文预料微调的QA模型.
## Overview
- **Language model**: RoBERTa-Base
- **Model size**: 400M
- **Language**: Chinese
## How to use
You can use the model directly with a pipeline for extractive question answering:
```python
>>> from transformers import AutoModelForQuestionAnswering,AutoTokenizer,pipeline
>>> context = '卡利亚·基拔(,)生于英国汉默史密斯,是一名英格兰籍职业足球员,于2010年夏季约满离开母会阿仙奴。直到2005/06年,基拔通常在阿仙奴的青年后备队效力。他在首次在2005年11月29日的联赛杯赛事上场,并于12月7日,在一个欧洲联赛冠军杯比赛对阿积士,作为替代左后卫,入替受伤的劳伦。2006年7月21日阿仙奴宣布,将基拔出借卡迪夫城整个2006-07赛季,其后转借给修安联。2008年1月3日返回阿仙奴授予46号码。2008年2月11日,阿仙奴的英超联赛比赛中对布莱克本作为后备球员。但2008年7月10日,基拔被出借莱斯特城的一个赛季之久。2009年3月3日主场对-{zh-hans:斯托克港;zh-hk:史托港}-,开赛后仅两分钟,基拔的传中球「挞Q」却直入网角,是他个人首个入球。基拔在外借期间成为常规正选,整季上阵达39场及射入1球,协助莱斯特城赢取英甲联赛冠军及重返英冠。2009/10年上半季仅于两场英格兰联赛杯及一场无关痛痒的欧联分组赛上阵,将于季后约满的基拔获外借到英冠榜末球会彼德堡直到球季结束,期间上阵10场。2010年夏季基拔约满阿仙奴成为自由球员,仅为母会合共上阵10场,英超「升班马」黑池有意罗致,其后前往-{zh-hans:谢菲尔德联; zh-hk:锡菲联;}-参加试训,惟未有获得录用。'
>>> mode_name = 'liam168/qa-roberta-base-chinese-extractive'
>>> model = AutoModelForQuestionAnswering.from_pretrained(mode_name)
>>> tokenizer = AutoTokenizer.from_pretrained(mode_name)
>>> QA = pipeline('question-answering', model=model, tokenizer=tokenizer)
>>> QA_input = {'question': "卡利亚·基拔的职业是什么?",'context': context}
>>> QA(QA_input)
{'score': 0.9999, 'start': 20, 'end': 31, 'answer': '一名英格兰籍职业足球员'}
```
## Contact
liam168520@gmail.com
|
huggingtweets/skinny_pickens
|
huggingtweets
| 2021-07-16T04:53:07Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/skinny_pickens/1626411183607/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1414812371495776257/iChEbuNI_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">skinny pickens</div>
<div style="text-align: center; font-size: 14px;">@skinny_pickens</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from skinny pickens.
| Data | skinny pickens |
| --- | --- |
| Tweets downloaded | 2817 |
| Retweets | 1329 |
| Short tweets | 154 |
| Tweets kept | 1334 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2guwsx1g/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @skinny_pickens's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/109349ze) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/109349ze/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/skinny_pickens')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
liam168/trans-opus-mt-en-zh
|
liam168
| 2021-07-16T04:17:11Z | 446 | 29 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"translation",
"en",
"zh",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-03-02T23:29:05Z |
---
language:
- en
- zh
tags:
- translation
widget:
- text: "I like to study Data Science and Machine Learning."
---
# liam168/trans-opus-mt-en-zh
## Model description
* source group: English
* target group: Chinese
* model: transformer
* source language(s): eng
* target language(s): cjy_Hans cjy_Hant cmn cmn_Hans cmn_Hant gan lzh lzh_Hans nan wuu yue yue_Hans yue_Hant
## How to use
```python
>>> from transformers import AutoModelWithLMHead,AutoTokenizer,pipeline
>>> mode_name = 'liam168/trans-opus-mt-en-zh'
>>> model = AutoModelWithLMHead.from_pretrained(mode_name)
>>> tokenizer = AutoTokenizer.from_pretrained(mode_name)
>>> translation = pipeline("translation_en_to_zh", model=model, tokenizer=tokenizer)
>>> translation('I like to study Data Science and Machine Learning.', max_length=400)
[{'translation_text': '我喜欢学习数据科学和机器学习'}]
```
## Contact
liam168520@gmail.com
|
liam168/trans-opus-mt-zh-en
|
liam168
| 2021-07-16T03:34:38Z | 251 | 21 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"translation",
"en",
"zh",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-03-02T23:29:05Z |
---
language:
- en
- zh
tags:
- translation
widget:
- text: "我喜欢学习数据科学和机器学习。"
---
# liam168/trans-opus-mt-zh-en
## Model description
* source group: English
* target group: Chinese
* model: transformer
* source language(s): eng
## How to use
```python
>>> from transformers import AutoModelWithLMHead,AutoTokenizer,pipeline
>>> mode_name = 'liam168/trans-opus-mt-zh-en'
>>> model = AutoModelWithLMHead.from_pretrained(mode_name)
>>> tokenizer = AutoTokenizer.from_pretrained(mode_name)
>>> translation = pipeline("translation_zh_to_en", model=model, tokenizer=tokenizer)
>>> translation('我喜欢学习数据科学和机器学习。', max_length=400)
[{'translation_text': 'I like to study data science and machine learning.'}]
```
## Contact
liam168520@gmail.com
|
flax-community/t5-vae-python
|
flax-community
| 2021-07-15T21:11:45Z | 4 | 1 |
transformers
|
[
"transformers",
"jax",
"transformer_vae",
"vae",
"dataset:Fraser/python-lines",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: python
tags: vae
license: apache-2.0
datasets: Fraser/python-lines
---
# T5-VAE-Python (flax)
A Transformer-VAE made using flax.
Try the [demo](https://huggingface.co/spaces/flax-community/t5-vae)!
It has been trained to interpolate on lines of Python code from the [python-lines dataset](https://huggingface.co/datasets/Fraser/python-lines).
Done as part of Huggingface community training ([see forum post](https://discuss.huggingface.co/t/train-a-vae-to-interpolate-on-english-sentences/7548)).
Builds on T5, using an autoencoder to convert it into an MMD-VAE ([more info](http://fras.uk/ml/large%20prior-free%20models/transformer-vae/2020/08/13/Transformers-as-Variational-Autoencoders.html)).
## How to use from the 🤗/transformers library
Add model repo as a submodule:
```bash
git submodule add https://github.com/Fraser-Greenlee/t5-vae-flax.git t5_vae_flax
```
```python
from transformers import AutoTokenizer
from t5_vae_flax.src.t5_vae import FlaxT5VaeForAutoencoding
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = FlaxT5VaeForAutoencoding.from_pretrained("flax-community/t5-vae-python")
```
## Setup
Run `setup_tpu_vm_venv.sh` to setup a virtual enviroment on a TPU VM for training.
|
jambo/microsoftBio-renet
|
jambo
| 2021-07-15T11:41:27Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:renet",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- renet
metrics:
- precision
- recall
- f1
- accuracy
model_index:
- name: BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext-finetuned-renet
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: renet
type: renet
metric:
name: Accuracy
type: accuracy
value: 0.8640646029609691
---
# BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext-finetuned-renet
A model for detecting gene disease associations from abstracts. The model classifies as 0 for no association, or 1 for some association.
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the [RENET2](https://github.com/sujunhao/RENET2) dataset. Note that this considers only the abstract data, and not the full text information, from RENET2.
It achieves the following results on the evaluation set:
- Loss: 0.7226
- Precision: 0.7799
- Recall: 0.8211
- F1: 0.8
- Accuracy: 0.8641
- Auc: 0.9325
## Training procedure
The abstract dataset from RENET2 was split into 85% train, 15% evaluation being grouped by PMIDs and stratified by labels. That is, no data from the same PMID was seen in multiple both the training and the evaluation set.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 1
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.9.0.dev0
- Pytorch 1.10.0.dev20210630+cu113
- Datasets 1.8.0
- Tokenizers 0.10.3
|
Vivek/gpt2-common-sense-reasoning
|
Vivek
| 2021-07-15T09:29:46Z | 11 | 1 |
transformers
|
[
"transformers",
"jax",
"tensorboard",
"gpt2",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
This is to test the common sense reasoning of a GPT-2 model.To assess how intelligent or it is adapted to this datasets which requires not only big models but also a little common sense also.
|
huggingtweets/bladeecity-robber0540
|
huggingtweets
| 2021-07-15T06:48:46Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/bladeecity-robber0540/1626331680252/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1406669132527976453/Sv0lEtmk_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/822229503212666880/L4UutyTM_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Aim & Combat Ballerina</div>
<div style="text-align: center; font-size: 14px;">@bladeecity-robber0540</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Aim & Combat Ballerina.
| Data | Aim | Combat Ballerina |
| --- | --- | --- |
| Tweets downloaded | 1604 | 671 |
| Retweets | 314 | 66 |
| Short tweets | 487 | 303 |
| Tweets kept | 803 | 302 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3uvtcfjv/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @bladeecity-robber0540's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/36qst0l8) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/36qst0l8/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/bladeecity-robber0540')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
andi611/distilbert-base-uncased-squad
|
andi611
| 2021-07-15T00:45:07Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model_index:
- name: distilbert-base-uncased-qa
results:
- task:
name: Question Answering
type: question-answering
dataset:
name: squad
type: squad
args: plain_text
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-qa
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1925
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.8.2
- Pytorch 1.8.1+cu111
- Datasets 1.8.0
- Tokenizers 0.10.3
|
huggingtweets/theisaiahw
|
huggingtweets
| 2021-07-14T21:05:53Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/theisaiahw/1626296749614/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1388820869762322434/v3h5S7mu_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Isaiah Williams</div>
<div style="text-align: center; font-size: 14px;">@theisaiahw</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Isaiah Williams.
| Data | Isaiah Williams |
| --- | --- |
| Tweets downloaded | 620 |
| Retweets | 65 |
| Short tweets | 72 |
| Tweets kept | 483 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/336gn9be/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @theisaiahw's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/ohqpafvm) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/ohqpafvm/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/theisaiahw')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
sergunow/movie-chat
|
sergunow
| 2021-07-14T19:46:21Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"blenderbot",
"text2text-generation",
"conversational",
"en",
"dataset:rick_and_morty",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
thumbnail:
tags:
- conversational
license: apache-2.0
datasets:
- rick_and_morty
metrics:
- perplexity
---
## Model description
Fine-tuning facebook/blenderbot-400M-distill on subtitles rick and morty
|
YusufSahin99/IFIS_ZORK_AI_HORROR
|
YusufSahin99
| 2021-07-14T14:11:24Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
license: mit
tags:
- generated_from_trainer
model_index:
- name: IFIS_ZORK_AI_HORROR
results:
- task:
name: Causal Language Modeling
type: text-generation
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# IFIS_ZORK_AI_HORROR
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unkown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.8.2
- Pytorch 1.9.0+cu102
- Tokenizers 0.10.3
|
cstorm125/wangchanberta-base-wiki-20210520-news-spm_span-mask-finetune-qa
|
cstorm125
| 2021-07-14T07:41:41Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"camembert",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
widget:
- text: "สวนกุหลาบเป็นโรงเรียนอะไร"
context: "โรงเรียนสวนกุหลาบวิทยาลัย (Suankularb Wittayalai School) (อักษรย่อ : ส.ก. / S.K.) เป็นโรงเรียนชายล้วน ระดับชั้นมัธยมศึกษาขนาดใหญ่พิเศษ สังกัดสำนักงานเขตพื้นที่การศึกษามัธยมศึกษาเขต 1 สำนักงานคณะกรรมการการศึกษาขั้นพื้นฐาน (ชื่อเดิม: กรมสามัญศึกษา) กระทรวงศึกษาธิการ ก่อตั้งโดย พระบาทสมเด็จพระจุลจอมเกล้าเจ้าอยู่หัว ได้รับการสถาปนาขึ้นในวันที่ 8 มีนาคม พ.ศ. 2424 (ขณะนั้นนับวันที่ 1 เมษายน เป็นวันขึ้นปีใหม่ เมื่อนับอย่างสากลถือเป็น พ.ศ. 2425) โดยเป็นโรงเรียนรัฐบาลแห่งแรกของประเทศไทย"
---
# wangchanberta-base-wiki-20210520-news-spm_span-mask-finetune-qa
Finetuning `airesearch/wangchanberta-base-wiki-20210520-news-spm_span-mask` with the training set of `iapp_wiki_qa_squad`, `thaiqa_squad`, and `nsc_qa` (removed examples which have cosine similarity with validation and test examples over 0.8; contexts of the latter two are trimmed to be around 300 `newmm` words). Benchmarks shared on [wandb](https://wandb.ai/cstorm125/wangchanberta-qa) using validation and test sets of `iapp_wiki_qa_squad`.
Trained with [thai2transformers](https://github.com/vistec-AI/thai2transformers/blob/dev/scripts/downstream/train_question_answering_lm_finetuning.py).
Run with:
```
export MODEL_NAME=airesearch/wangchanberta-base-wiki-20210520-news-spm_span-mask
CUDA_LAUNCH_BLOCKING=1 python train_question_answering_lm_finetuning.py \
--model_name $MODEL_NAME \
--dataset_name chimera_qa \
--output_dir $MODEL_NAME-finetune-chimera_qa-model \
--log_dir $MODEL_NAME-finetune-chimera_qa-log \
--model_max_length 400 \
--pad_on_right \
--fp16 \
--use_auth_token
```
|
cstorm125/wangchanberta-base-wiki-20210520-news-spm-finetune-qa
|
cstorm125
| 2021-07-14T07:35:27Z | 20 | 0 |
transformers
|
[
"transformers",
"pytorch",
"camembert",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
widget:
- text: "สวนกุหลาบเป็นโรงเรียนอะไร"
context: "โรงเรียนสวนกุหลาบวิทยาลัย (Suankularb Wittayalai School) (อักษรย่อ : ส.ก. / S.K.) เป็นโรงเรียนชายล้วน ระดับชั้นมัธยมศึกษาขนาดใหญ่พิเศษ สังกัดสำนักงานเขตพื้นที่การศึกษามัธยมศึกษาเขต 1 สำนักงานคณะกรรมการการศึกษาขั้นพื้นฐาน (ชื่อเดิม: กรมสามัญศึกษา) กระทรวงศึกษาธิการ ก่อตั้งโดย พระบาทสมเด็จพระจุลจอมเกล้าเจ้าอยู่หัว ได้รับการสถาปนาขึ้นในวันที่ 8 มีนาคม พ.ศ. 2424 (ขณะนั้นนับวันที่ 1 เมษายน เป็นวันขึ้นปีใหม่ เมื่อนับอย่างสากลถือเป็น พ.ศ. 2425) โดยเป็นโรงเรียนรัฐบาลแห่งแรกของประเทศไทย"
---
# wangchanberta-base-wiki-20210520-news-spm-finetune-qa
Finetuning `airesearchth/wangchanberta-base-wiki-20210520-news-spm` with the training set of `iapp_wiki_qa_squad`, `thaiqa_squad`, and `nsc_qa` (removed examples which have cosine similarity with validation and test examples over 0.8; contexts of the latter two are trimmed to be around 300 `newmm` words). Benchmarks shared on [wandb](https://wandb.ai/cstorm125/wangchanberta-qa) using validation and test sets of `iapp_wiki_qa_squad`.
Trained with [thai2transformers](https://github.com/vistec-AI/thai2transformers/blob/dev/scripts/downstream/train_question_answering_lm_finetuning.py).
Run with:
```
export MODEL_NAME=airesearchth/wangchanberta-base-wiki-20210520-news-spm
CUDA_LAUNCH_BLOCKING=1 python train_question_answering_lm_finetuning.py \
--model_name $MODEL_NAME \
--dataset_name chimera_qa \
--output_dir $MODEL_NAME-finetune-chimera_qa-model \
--log_dir $MODEL_NAME-finetune-chimera_qa-log \
--model_max_length 400 \
--pad_on_right \
--fp16
```
|
airesearch/xlm-roberta-base-finetune-qa
|
airesearch
| 2021-07-14T07:13:00Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
widget:
- text: "สวนกุหลาบเป็นโรงเรียนอะไร"
context: "โรงเรียนสวนกุหลาบวิทยาลัย (Suankularb Wittayalai School) (อักษรย่อ : ส.ก. / S.K.) เป็นโรงเรียนชายล้วน ระดับชั้นมัธยมศึกษาขนาดใหญ่พิเศษ สังกัดสำนักงานเขตพื้นที่การศึกษามัธยมศึกษาเขต 1 สำนักงานคณะกรรมการการศึกษาขั้นพื้นฐาน (ชื่อเดิม: กรมสามัญศึกษา) กระทรวงศึกษาธิการ ก่อตั้งโดย พระบาทสมเด็จพระจุลจอมเกล้าเจ้าอยู่หัว ได้รับการสถาปนาขึ้นในวันที่ 8 มีนาคม พ.ศ. 2424 (ขณะนั้นนับวันที่ 1 เมษายน เป็นวันขึ้นปีใหม่ เมื่อนับอย่างสากลถือเป็น พ.ศ. 2425) โดยเป็นโรงเรียนรัฐบาลแห่งแรกของประเทศไทย"
---
# xlm-roberta-base-finetune-qa
Finetuning `xlm-roberta-base` with the training set of `iapp_wiki_qa_squad`, `thaiqa_squad`, and `nsc_qa` (removed examples which have cosine similarity with validation and test examples over 0.8; contexts of the latter two are trimmed to be around 300 `newmm` words). Benchmarks shared on [wandb](https://wandb.ai/cstorm125/wangchanberta-qa) using validation and test sets of `iapp_wiki_qa_squad`.
Trained with [thai2transformers](https://github.com/vistec-AI/thai2transformers/blob/dev/scripts/downstream/train_question_answering_lm_finetuning.py).
Train with:
```
export WANDB_PROJECT=wangchanberta-qa
export MODEL_NAME=xlm-roberta-base
python train_question_answering_lm_finetuning.py \
--model_name $MODEL_NAME \
--dataset_name chimera_qa \
--output_dir $MODEL_NAME-finetune-chimera_qa-model \
--log_dir $MODEL_NAME-finetune-chimera_qa-log \
--pad_on_right \
--fp16
```
|
huggingtweets/jplatzhalter
|
huggingtweets
| 2021-07-13T22:13:16Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/jplatzhalter/1626214256716/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1204103314733821954/O_QCiMdI_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Julia Platz-Halter</div>
<div style="text-align: center; font-size: 14px;">@jplatzhalter</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Julia Platz-Halter.
| Data | Julia Platz-Halter |
| --- | --- |
| Tweets downloaded | 3235 |
| Retweets | 270 |
| Short tweets | 373 |
| Tweets kept | 2592 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2z39jb5g/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @jplatzhalter's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1deih6g9) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1deih6g9/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/jplatzhalter')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
YusufSahin99/IFIS_ZORK_AI_SCIFI
|
YusufSahin99
| 2021-07-13T15:34:34Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
license: mit
tags:
- generated_from_trainer
model_index:
- name: IFIS_ZORK_AI_SCIFI
results:
- task:
name: Causal Language Modeling
type: text-generation
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# IFIS_ZORK_AI_SCIFI
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unkown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.8.2
- Pytorch 1.9.0+cu102
- Tokenizers 0.10.3
|
YusufSahin99/Zork_AI_SciFi
|
YusufSahin99
| 2021-07-13T14:58:01Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
license: mit
tags:
- generated_from_trainer
model_index:
- name: Zork_AI_SciFi
results:
- task:
name: Causal Language Modeling
type: text-generation
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Zork_AI_SciFi
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unkown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.8.2
- Pytorch 1.9.0+cu102
- Tokenizers 0.10.3
|
AIDA-UPM/mstsb-paraphrase-multilingual-mpnet-base-v2
|
AIDA-UPM
| 2021-07-13T14:12:45Z | 292 | 12 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"feature-extraction",
"sentence-similarity",
"multilingual",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2022-03-02T23:29:04Z |
---
pipeline_tag: sentence-similarity
language: "multilingual"
tags:
- feature-extraction
- sentence-similarity
- transformers
- multilingual
---
# mstsb-paraphrase-multilingual-mpnet-base-v2
This is a fine-tuned version of `paraphrase-multilingual-mpnet-base-v2` from [sentence-transformers](https://www.SBERT.net) model with [Semantic Textual Similarity Benchmark](http://ixa2.si.ehu.eus/stswiki/index.php/Main_Page) extended to 15 languages: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering, semantic search and measuring the similarity between two sentences.
<!--- Describe your model here -->
This model is fine-tuned version of `paraphrase-multilingual-mpnet-base-v2` for semantic textual similarity with multilingual data. The dataset used for this fine-tuning is STSb extended to 15 languages with Google Translator. For mantaining data quality the sentence pairs with a confidence value below 0.7 were dropped. The extended dataset is available at [GitHub](https://github.com/Huertas97/Multilingual-STSB). The languages included in the extended version are: ar, cs, de, en, es, fr, hi, it, ja, nl, pl, pt, ru, tr, zh-CN, zh-TW. The pooling operation used to condense the word embeddings into a sentence embedding is mean pooling (more info below).
<!-- ## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
# It support several languages
sentences = ["This is an example sentence", "Esta es otra frase de ejemplo", "最後の例文"]
# The pooling technique is automatically detected (mean pooling)
model = SentenceTransformer('mstsb-paraphrase-multilingual-mpnet-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
``` -->
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# We should define the proper pooling function: Mean pooling
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ["This is an example sentence", "Esta es otra frase de ejemplo", "最後の例文"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('AIDA-UPM/mstsb-paraphrase-multilingual-mpnet-base-v2')
model = AutoModel.from_pretrained('AIDA-UPM/mstsb-paraphrase-multilingual-mpnet-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
Check the test results in the Semantic Textual Similarity Tasks. The 15 languages available at the [Multilingual STSB](https://github.com/Huertas97/Multilingual-STSB) have been combined into monolingual and cross-lingual tasks, giving a total of 31 tasks. Monolingual tasks have both sentences from the same language source (e.g., Ar-Ar, Es-Es), while cross-lingual tasks have two sentences, each in a different language being one of them English (e.g., en-ar, en-es).
Here we compare the average multilingual semantic textual similairty capabilities between the `paraphrase-multilingual-mpnet-base-v2` based model and the `mstsb-paraphrase-multilingual-mpnet-base-v2` fine-tuned model across the 31 tasks. It is worth noting that both models are multilingual, but the second model is adjusted with multilingual data for semantic similarity. The average of correlation coefficients is computed by transforming each correlation coefficient to a Fisher's z value, averaging them, and then back-transforming to a correlation coefficient.
| Model | Average Spearman Cosine Test |
|:---------------------------------------------:|:------------------------------:|
| mstsb-paraphrase-multilingual-mpnet-base-v2 | 0.835890 |
| paraphrase-multilingual-mpnet-base-v2 | 0.818896 |
<br>
The following tables breakdown the performance of `mstsb-paraphrase-multilingual-mpnet-base-v2` according to the different tasks. For the sake of readability tasks have been splitted into monolingual and cross-lingual tasks.
| Monolingual Task | Pearson Cosine test | Spearman Cosine test |
|:------------------:|:---------------------:|:-----------------------:|
| en;en | 0.868048310692506 | 0.8740170943535747 |
| ar;ar | 0.8267139454193487 | 0.8284459741532022 |
| cs;cs | 0.8466821720942157 | 0.8485417688803879 |
| de;de | 0.8517285961812183 | 0.8557680051557893 |
| es;es | 0.8519185309064691 | 0.8552243211580456 |
| fr;fr | 0.8430951067985064 | 0.8466614534379704 |
| hi;hi | 0.8178258630578092 | 0.8176462079184331 |
| it;it | 0.8475909574305637 | 0.8494216064459076 |
| ja;ja | 0.8435588859386477 | 0.8456031494178619 |
| nl;nl | 0.8486765104527032 | 0.8520856765262531 |
| pl;pl | 0.8407840177883407 | 0.8443070467300299 |
| pt;pt | 0.8534880178249296 | 0.8578544068829622 |
| ru;ru | 0.8390897585455678 | 0.8423041443534423 |
| tr;tr | 0.8382125451820572 | 0.8421587450058385 |
| zh-CN;zh-CN | 0.826233678946644 | 0.8248515460782744 |
| zh-TW;zh-TW | 0.8242683809675422 | 0.8235506799952028 |
<br>
| Cross-lingual Task | Pearson Cosine test | Spearman Cosine test |
|:--------------------:|:---------------------:|:-----------------------:|
| en;ar | 0.7990830340462535 | 0.7956792016468148 |
| en;cs | 0.8381274879061265 | 0.8388713450024455 |
| en;de | 0.8414439600928739 | 0.8441971698649943 |
| en;es | 0.8442337511356952 | 0.8445035292903559 |
| en;fr | 0.8378437644605063 | 0.8387903367907733 |
| en;hi | 0.7951955086055527 | 0.7905052217683244 |
| en;it | 0.8415686372978766 | 0.8419480899107785 |
| en;ja | 0.8094306665283388 | 0.8032512280936449 |
| en;nl | 0.8389526140129767 | 0.8409310421803277 |
| en;pl | 0.8261309163979578 | 0.825976253023656 |
| en;pt | 0.8475546209070765 | 0.8506606391790897 |
| en;ru | 0.8248514914263723 | 0.8224871183202255 |
| en;tr | 0.8191803661207868 | 0.8194200775744044 |
| en;zh-CN | 0.8147678083378249 | 0.8102089470690433 |
| en;zh-TW | 0.8107272160374955 | 0.8056129680510944 |
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 687 with parameters:
```
{'batch_size': 132, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"callback": null,
"epochs": 2,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 140,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
marefa-nlp/summarization-arabic-english-news
|
marefa-nlp
| 2021-07-13T13:06:31Z | 62 | 4 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
------------
## Arabic and English News Summarization NLP Model
### About
This model is for summarizing news stories in short highlights for both Arabic and English tasks.
نموذج معرفي متخصص في تلخيص الأخبار العربية و الإنجليزية الى مجموعة من أهم النقاط
### Fine-Tuning
The model was finetuned using the [Arabic T5 Model](https://huggingface.co/bakrianoo/t5-arabic-large) which developed by [Abu Bakr Soliman](http://github.com/bakrianoo).
The primary summarization model also developed by the same developer.
### How to Use
- You can use this [Colab Notebook](https://colab.research.google.com/drive/1DWND1CAfCXD4OxrfmLBEaKeXhjGmYkod?usp=sharing) to test the model
1. Install [PyTorch](https://pytorch.org/)
2. Install the following Python packages
`$ pip3 install transformers==4.7.0 nltk==3.5 protobuf==3.15.3 sentencepiece==0.1.96`
3. Run this code
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
import torch
import nltk
nltk.download('punkt')
from nltk.tokenize import sent_tokenize
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
m_name = "marefa-nlp/summarization-arabic-english-news"
tokenizer = AutoTokenizer.from_pretrained(m_name)
model = AutoModelWithLMHead.from_pretrained(m_name).to(device)
def get_summary(text, tokenizer, model, device="cpu", num_beams=2):
if len(text.strip()) < 50:
return ["Please provide more longer text"]
text = "summarize: <paragraph> " + " <paragraph> ".join([ s.strip() for s in sent_tokenize(text) if s.strip() != ""]) + " </s>"
text = text.strip().replace("\n","")
tokenized_text = tokenizer.encode(text, return_tensors="pt").to(device)
summary_ids = model.generate(
tokenized_text,
max_length=512,
num_beams=num_beams,
repetition_penalty=1.5,
length_penalty=1.0,
early_stopping=True
)
output = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
return [ s.strip() for s in output.split("<hl>") if s.strip() != "" ]
## Prepare Samples
samples = [
"""
قال المدافع الإيطالي ليوناردو بونوتشي إن منتخب بلاده ليس خائفا من مواجهة نظيره الانجليزي على أرضه في المباراة النهائية في بطولة يورو 2020 لكرة القدم، في حين وصف المدافع الانجليزي جون ستونز المباراة المرتقبة بأنها ستكون "أكثر تميزا".
وسوف تقام المباراة في استاد ويمبلي، شمال غربي لندن، يوم الأحد.
وتسعى إيطاليا لإحراز اللقب الأوروبي للمرة الثانية بعد فوزها به أول مرة عام 1968.
ولم يفز الفريق الانجليزي بهذا اللقب القاري من قبل. والبطولة الرئيسية الوحيدة التي فازت بها انجلترا هي كأس العالم عام 1966 الذي أقيمت مباراته النهائية في استاد ويمبلي.
""",
"""
On a night fraught with tension, Italy clinched its first major title for 15 years with a penalty shootout win over England in the Euro 2020 final.
Luke Shaw's goal inside the opening two minutes gave England a lead it looked like it would hold onto all night, before a goalmouth scramble midway through the second half allowed Leonardo Bonucci to poke home an equalizer for Italy.
For the remainder of the match, it felt as though extra-time and penalties were inevitable, as neither side seemed willing or brave enough to commit enough men forward to really trouble the opposing defenders.
England had suffered innumerable heartbreaks on penalties over the years and this time it was Italy's turn to inflict yet more pain on beleaguered English fans as Marcus Rashford, Jadon Sancho and Bukayo Saka all missed from the spot.
""",
]
## Get summaries
print("Original Article:", samples[0])
print("\n===========\nSummary: \n")
hls = get_summary(samples[0], tokenizer, model, device)
for hl in hls:
print("\t-", hl)
print("Original Article:", samples[1])
print("\n=========== \nSummary: \n")
hls = get_summary(samples[1], tokenizer, model, device)
for hl in hls:
print("\t-", hl)
```
Results
```
Original Article:
قال المدافع الإيطالي ليوناردو بونوتشي إن منتخب بلاده ليس خائفا من مواجهة نظيره الانجليزي على أرضه في المباراة النهائية في بطولة يورو 2020 لكرة القدم، في حين وصف المدافع الانجليزي جون ستونز المباراة المرتقبة بأنها ستكون "أكثر تميزا".
وسوف تقام المباراة في استاد ويمبلي، شمال غربي لندن، يوم الأحد.
وتسعى إيطاليا لإحراز اللقب الأوروبي للمرة الثانية بعد فوزها به أول مرة عام 1968.
ولم يفز الفريق الانجليزي بهذا اللقب القاري من قبل. والبطولة الرئيسية الوحيدة التي فازت بها انجلترا هي كأس العالم عام 1966 الذي أقيمت مباراته النهائية في استاد ويمبلي.
===========
Summary:
- وسوف تواجه إيطاليا إنجلترا في بطولة يورو 2020 لكرة القدم يوم الأحد.
- ستقام المباراة في استاد ويمبلي، شمال غربي لندن، يوم الأحد.
- ولم يفز الفريق الانجليزي بهذا اللقب القاري قبل.
```
```
Original Article:
On a night fraught with tension, Italy clinched its first major title for 15 years with a penalty shootout win over England in the Euro 2020 final.
Luke Shaw's goal inside the opening two minutes gave England a lead it looked like it would hold onto all night, before a goalmouth scramble midway through the second half allowed Leonardo Bonucci to poke home an equalizer for Italy.
For the remainder of the match it felt as though extra-time and penalties were inevitable, as neither side seemed willing or brave enough to commit enough men forward to really trouble the opposing defenders.
England had suffered innumerable heartbreaks on penalties over the years and this time it was Italy's turn to inflict yet more pain on beleaguered English fans as Marcus Rashford, Jadon Sancho and Bukayo Saka all missed from the spot.
===========
Summary:
- Luke Shaw's goal gave England a lead it looked like it would hold onto all night.
- Leonardo Bonucci scored the equalizer for Italy.
- Marcus Rashford, Jadon Sancho and Bukayo Saka all missed.
```
|
jaimin/Gujarati-Model
|
jaimin
| 2021-07-12T13:23:21Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"feature-extraction",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
tokenizer = AutoTokenizer.from_pretrained("jaimin/Gujarati-Model")
model = AutoModel.from_pretrained("jaimin/Gujarati-Model")
|
Andrija/RobertaFastBPE
|
Andrija
| 2021-07-12T11:11:21Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:04Z |
from transformers import RobertaTokenizerFast
tokenizer = RobertaTokenizerFast.from_pretrained('Andrija/RobertaFastBPE', bos_token="<s>", eos_token="</s>")
encoded = tokenizer('Stručnjaci te bolnice, predvođeni dr Alisom Lim')
# {'input_ids': [0, 47541, 34632, 603, 24817, 16, 27540, 6768, 2350, 2803, 3991, 2733, 81, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
tokenizer.decode(encoded['input_ids'])
# <s>Stručnjaci te bolnice, predvođeni dr Alisom Lim</s>
|
EasthShin/Klue-CommonSense-model
|
EasthShin
| 2021-07-12T10:01:36Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:04Z |
#### Klue-bert base for Common Sense QA
#### Klue-CommonSense-model DEMO: [Ainize DEMO](https://main-klue-common-sense-qa-east-h-shin.endpoint.ainize.ai/)
#### Klue-CommonSense-model API: [Ainize API](https://ainize.ai/EastHShin/Klue-CommonSense_QA?branch=main)
### Overview
**Language model**: klue/bert-base
<br>
**Language**: Korean
<br>
**Downstream-task**: Extractive QA
<br>
**Training data**: Common sense Data from [Mindslab](https://mindslab.ai:8080/kr/company)
<br>
**Eval data**: Common sense Data from [Mindslab](https://mindslab.ai:8080/kr/company)
<br>
**Code**: See [Ainize Workspace](https://ainize.ai/workspace/create?imageId=hnj95592adzr02xPTqss&git=https://github.com/EastHShin/Klue-CommonSense-workspace)
<br>
### Usage
### In Transformers
```
from transformers import AutoModelForQuestionAnswering, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("EasthShin/Klue-CommonSense-model")
model = AutoModelForQuestionAnswering.from_pretrained("EasthShin/Klue-CommonSense-model")
context = "your context"
question = "your question"
encodings = tokenizer(context, question, max_length=512, truncation=True,
padding="max_length", return_token_type_ids=False)
encodings = {key: torch.tensor([val]) for key, val in encodings.items()}
input_ids = encodings["input_ids"]
attention_mask = encodings["attention_mask"]
pred = model(input_ids, attention_mask=attention_mask)
start_logits, end_logits = pred.start_logits, pred.end_logits
token_start_index, token_end_index = start_logits.argmax(dim=-1), end_logits.argmax(dim=-1)
pred_ids = input_ids[0][token_start_index: token_end_index + 1]
prediction = tokenizer.decode(pred_ids)
```
|
Vivek/flax-gpt2-common-sense-reasoning
|
Vivek
| 2021-07-12T04:19:26Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:05Z |
This is to test the common sense reasoning of a GPT-2 model.To assess how intelligent or it is adapted to this datasets which requires not only big models but also a little common sense also.
|
Littlejohn/analisis_sentimientos
|
Littlejohn
| 2021-07-12T00:22:27Z | 11 | 0 |
transformers
|
[
"transformers",
"text-classification",
"en",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
---
language:
- en
pipeline_tag: text-classification
---
# bert-base-cased-sentiment
Es un modelo de BERT (bert-base-cased) afinado para el analisis de sentimientos para dos clases.
El sentimiento solo se define como positivo negativo según sea el caso de la oración suministrada.
## Training data
El set de datos utilizado para el entrenamiento del modelo fue a traves de una recopilación de reseñas de amazón, el cual se puede descargar desde el autor original en Kaggle [Adam Bittlingmayer](https://www.kaggle.com/bittlingmayer/amazonreviews) Amazon Reviews for Sentiment Analysis.
El numero de datos fue solo de 40 000 oraciones de las cuales solo se tomaron las primeras 100 palabras para conformar cada una de las oraciones.
## Accuaracy
El modelo afinado fue sometido a 3 pruebas para conocer su precisión.
- La primera prueba fue en un set de datos de Reseñas de hoteles
| Accuracy (Precisión) |
| -------- |
| 95% |
- La segunda prueba fue en un set de datos de Reseñas de comida
| Accuracy (Precisión) |
| -------- |
| 88% |
- La tercera prueba fue en un set de datos de Sentimientos generales
| Accuracy (Precisión) |
| -------- |
| 65% |
## Contact
Contacto a traves de github [Murdoocc7](https://github.com/murdoocc)
|
srosy/distilbert-base-uncased-finetuned-ner
|
srosy
| 2021-07-11T15:29:20Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model_index:
- name: distilbert-base-uncased-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
args: conll2003
metric:
name: Accuracy
type: accuracy
value: 0.9844313470062116
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0590
- Precision: 0.9266
- Recall: 0.9381
- F1: 0.9323
- Accuracy: 0.9844
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0616 | 1.0 | 878 | 0.0604 | 0.9195 | 0.9370 | 0.9282 | 0.9833 |
| 0.0328 | 2.0 | 1756 | 0.0588 | 0.9258 | 0.9375 | 0.9316 | 0.9841 |
| 0.0246 | 3.0 | 2634 | 0.0590 | 0.9266 | 0.9381 | 0.9323 | 0.9844 |
### Framework versions
- Transformers 4.8.2
- Pytorch 1.8.1
- Datasets 1.9.0
- Tokenizers 0.10.3
|
ysharma/new-model-dummy
|
ysharma
| 2021-07-11T11:51:02Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:05Z |
# Dummy model
This is just a dummy model. Copying bert-base-uncased model files over here.
|
nateraw/donut-or-bagel
|
nateraw
| 2021-07-10T19:54:49Z | 71 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2022-03-02T23:29:05Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: donut-or-bagel
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9375
---
# donut-or-bagel
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### bagel

#### donut

|
huggingtweets/aliceaeterna-clamtime-redpandasmash
|
huggingtweets
| 2021-07-10T14:02:00Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/aliceaeterna-clamtime-redpandasmash/1625925715720/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1343482928014237696/51aKOINn_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1408716131867713538/rg3HSZ5D_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1378382707625975812/vYek426__400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">che 💜 & clementine!!!! 𓃠 & 𝓡𝓮𝓭 𝓟𝓪𝓷𝓭𝓪'𝓼 𝓖𝓪𝓶𝓮 𝓒𝓸𝓻𝓷𝓮𝓻</div>
<div style="text-align: center; font-size: 14px;">@aliceaeterna-clamtime-redpandasmash</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from che 💜 & clementine!!!! 𓃠 & 𝓡𝓮𝓭 𝓟𝓪𝓷𝓭𝓪'𝓼 𝓖𝓪𝓶𝓮 𝓒𝓸𝓻𝓷𝓮𝓻.
| Data | che 💜 | clementine!!!! 𓃠 | 𝓡𝓮𝓭 𝓟𝓪𝓷𝓭𝓪'𝓼 𝓖𝓪𝓶𝓮 𝓒𝓸𝓻𝓷𝓮𝓻 |
| --- | --- | --- | --- |
| Tweets downloaded | 1587 | 3187 | 2492 |
| Retweets | 682 | 500 | 367 |
| Short tweets | 158 | 687 | 362 |
| Tweets kept | 747 | 2000 | 1763 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1814x6xo/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @aliceaeterna-clamtime-redpandasmash's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/kvo9buwa) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/kvo9buwa/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/aliceaeterna-clamtime-redpandasmash')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/averagesmasher
|
huggingtweets
| 2021-07-10T13:47:30Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/averagesmasher/1625924846625/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1368753714568327168/oh6BSjqX_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">AverageVermontSmasher</div>
<div style="text-align: center; font-size: 14px;">@averagesmasher</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from AverageVermontSmasher.
| Data | AverageVermontSmasher |
| --- | --- |
| Tweets downloaded | 41 |
| Retweets | 0 |
| Short tweets | 2 |
| Tweets kept | 39 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/auyr340s/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @averagesmasher's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2qnfjchi) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2qnfjchi/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/averagesmasher')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
sebastian-hofstaetter/prettr-distilbert-split_at_3-margin_mse-T2-msmarco
|
sebastian-hofstaetter
| 2021-07-10T10:14:14Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"knowledge-distillation",
"en",
"dataset:ms_marco",
"arxiv:2004.14255",
"arxiv:2010.02666",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: "en"
tags:
- knowledge-distillation
datasets:
- ms_marco
---
# Margin-MSE Trained PreTTR
We provide a retrieval trained DistilBert-based PreTTR model (https://arxiv.org/abs/2004.14255). Our model is trained with Margin-MSE using a 3 teacher BERT_Cat (concatenated BERT scoring) ensemble on MSMARCO-Passage.
This instance can be used to **re-rank a candidate set**. The architecture is a 6-layer DistilBERT, split at layer 3, with an additional single linear layer at the end for scoring the CLS token.
If you want to know more about our simple, yet effective knowledge distillation method for efficient information retrieval models for a variety of student architectures that is used for this model instance check out our paper: https://arxiv.org/abs/2010.02666 🎉
For more information, training data, source code, and a minimal usage example please visit: https://github.com/sebastian-hofstaetter/neural-ranking-kd
## Configuration
- We split the DistilBERT in half at layer 3
## Model Code
````python
from transformers import DistilBertModel,AutoTokenizer
from transformers.models.distilbert.modeling_distilbert import *
import math
import torch
from torch import nn as nn
class PreTTRConfig(DistilBertConfig):
join_layer_idx = 3
class PreTTR(DistilBertModel):
'''
PreTTR changes the distilbert model from huggingface to be able to split query and document until a set layer,
we skipped compression present in the original
from: Efficient Document Re-Ranking for Transformers by Precomputing Term Representations
MacAvaney, et al. https://arxiv.org/abs/2004.14255
'''
config_class = PreTTRConfig
def __init__(self, config):
super().__init__(config)
self.transformer = SplitTransformer(config) # Encoder, we override the classes, but the names stay the same -> so it gets properly initialized
self.embeddings = PosOffsetEmbeddings(config) # Embeddings
self._classification_layer = torch.nn.Linear(self.config.hidden_size, 1, bias=False)
self.join_layer_idx = config.join_layer_idx
def forward(
self,
query,
document,
use_fp16: bool = False) -> torch.Tensor:
with torch.cuda.amp.autocast(enabled=use_fp16):
query_input_ids = query["input_ids"]
query_attention_mask = query["attention_mask"]
document_input_ids = document["input_ids"][:, 1:]
document_attention_mask = document["attention_mask"][:, 1:]
query_embs = self.embeddings(query_input_ids) # (bs, seq_length, dim)
document_embs = self.embeddings(document_input_ids, query_input_ids.shape[-1]) # (bs, seq_length, dim)
tfmr_output = self.transformer(
query_embs=query_embs,
query_mask=query_attention_mask,
doc_embs=document_embs,
doc_mask=document_attention_mask,
join_layer_idx=self.join_layer_idx
)
hidden_state = tfmr_output[0]
score = self._classification_layer(hidden_state[:, 0, :]).squeeze()
return score
class PosOffsetEmbeddings(nn.Module):
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.dim, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.dim)
if config.sinusoidal_pos_embds:
create_sinusoidal_embeddings(
n_pos=config.max_position_embeddings, dim=config.dim, out=self.position_embeddings.weight
)
self.LayerNorm = nn.LayerNorm(config.dim, eps=1e-12)
self.dropout = nn.Dropout(config.dropout)
def forward(self, input_ids, pos_offset=0):
"""
Parameters
----------
input_ids: torch.tensor(bs, max_seq_length)
The token ids to embed.
Outputs
-------
embeddings: torch.tensor(bs, max_seq_length, dim)
The embedded tokens (plus position embeddings, no token_type embeddings)
"""
seq_length = input_ids.size(1)
position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device) # (max_seq_length)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids) + pos_offset # (bs, max_seq_length)
word_embeddings = self.word_embeddings(input_ids) # (bs, max_seq_length, dim)
position_embeddings = self.position_embeddings(position_ids) # (bs, max_seq_length, dim)
embeddings = word_embeddings + position_embeddings # (bs, max_seq_length, dim)
embeddings = self.LayerNorm(embeddings) # (bs, max_seq_length, dim)
embeddings = self.dropout(embeddings) # (bs, max_seq_length, dim)
return embeddings
class SplitTransformer(nn.Module):
def __init__(self, config):
super().__init__()
self.n_layers = config.n_layers
layer = TransformerBlock(config)
self.layer = nn.ModuleList([copy.deepcopy(layer) for _ in range(config.n_layers)])
def forward(self, query_embs, query_mask, doc_embs, doc_mask, join_layer_idx, output_attentions=False, output_hidden_states=False):
"""
Parameters
----------
x: torch.tensor(bs, seq_length, dim)
Input sequence embedded.
attn_mask: torch.tensor(bs, seq_length)
Attention mask on the sequence.
Outputs
-------
hidden_state: torch.tensor(bs, seq_length, dim)
Sequence of hiddens states in the last (top) layer
all_hidden_states: Tuple[torch.tensor(bs, seq_length, dim)]
Tuple of length n_layers with the hidden states from each layer.
Optional: only if output_hidden_states=True
all_attentions: Tuple[torch.tensor(bs, n_heads, seq_length, seq_length)]
Tuple of length n_layers with the attention weights from each layer
Optional: only if output_attentions=True
"""
all_hidden_states = ()
all_attentions = ()
#
# query / doc sep.
#
hidden_state_q = query_embs
hidden_state_d = doc_embs
for layer_module in self.layer[:join_layer_idx]:
layer_outputs_q = layer_module(
x=hidden_state_q, attn_mask=query_mask, head_mask=None, output_attentions=output_attentions
)
hidden_state_q = layer_outputs_q[-1]
layer_outputs_d = layer_module(
x=hidden_state_d, attn_mask=doc_mask, head_mask=None, output_attentions=output_attentions
)
hidden_state_d = layer_outputs_d[-1]
#
# combine
#
x = torch.cat([hidden_state_q, hidden_state_d], dim=1)
attn_mask = torch.cat([query_mask, doc_mask], dim=1)
#
# combined
#
hidden_state = x
for layer_module in self.layer[join_layer_idx:]:
layer_outputs = layer_module(
x=hidden_state, attn_mask=attn_mask, head_mask=None, output_attentions=output_attentions
)
hidden_state = layer_outputs[-1]
# Add last layer
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_state,)
outputs = (hidden_state,)
if output_hidden_states:
outputs = outputs + (all_hidden_states,)
if output_attentions:
outputs = outputs + (all_attentions,)
return outputs # last-layer hidden state, (all hidden states), (all attentions)
#
# init the model & tokenizer (using the distilbert tokenizer)
#
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased") # honestly not sure if that is the best way to go, but it works :)
model = PreTTR.from_pretrained("sebastian-hofstaetter/prettr-distilbert-split_at_3-margin_mse-T2-msmarco")
````
## Effectiveness on MSMARCO Passage
We trained our model on the MSMARCO standard ("small"-400K query) training triples with knowledge distillation with a batch size of 32 on a single consumer-grade GPU (11GB memory).
For re-ranking we used the top-1000 BM25 results.
### MSMARCO-DEV
Here, we use the larger 49K query DEV set (same range as the smaller 7K DEV set, minimal changes possible)
| | MRR@10 | NDCG@10 |
|----------------------------------|--------|---------|
| BM25 | .194 | .241 |
| **Margin-MSE PreTTR** (Re-ranking) | .386 | .447 |
For more metrics, baselines, info and analysis, please see the paper: https://arxiv.org/abs/2010.02666
## Limitations & Bias
- The model inherits social biases from both DistilBERT and MSMARCO.
- The model is only trained on relatively short passages of MSMARCO (avg. 60 words length), so it might struggle with longer text.
## Citation
If you use our model checkpoint please cite our work as:
```
@misc{hofstaetter2020_crossarchitecture_kd,
title={Improving Efficient Neural Ranking Models with Cross-Architecture Knowledge Distillation},
author={Sebastian Hofst{\"a}tter and Sophia Althammer and Michael Schr{\"o}der and Mete Sertkan and Allan Hanbury},
year={2020},
eprint={2010.02666},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
```
|
sourabharsh/wav2vec2_10july
|
sourabharsh
| 2021-07-10T08:25:13Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"de",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language: de
datasets:
- common_voice
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 German by Jonatas Grosman
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice de
type: common_voice
args: de
metrics:
- name: Test WER
type: wer
value: 10.55
- name: Test CER
type: cer
value: 2.81
---
|
huggingtweets/the_robisho
|
huggingtweets
| 2021-07-10T03:40:16Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/the_robisho/1625888412499/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1311895700582666243/6N1xGNV9_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Nick Landback</div>
<div style="text-align: center; font-size: 14px;">@the_robisho</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Nick Landback.
| Data | Nick Landback |
| --- | --- |
| Tweets downloaded | 3205 |
| Retweets | 1018 |
| Short tweets | 21 |
| Tweets kept | 2166 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/bbz9lc2n/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @the_robisho's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/gh2qryi3) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/gh2qryi3/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/the_robisho')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
shahukareem/dhivehi-roberta-base
|
shahukareem
| 2021-07-10T00:19:12Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"dv",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: dv
tags:
- dv
- roberta
widget:
- text: "<mask> މާލެ އަކީ ދިވެހިރާއްޖޭގެ"
---
# Dhivehi Roberta Base - Oscar
## Description
RoBERTA pretrained from scratch using Jax/Flax backend and with the Dhivehi Oscar Corpus only.
|
huggingtweets/marxhaunting
|
huggingtweets
| 2021-07-09T22:04:38Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/marxhaunting/1625868274804/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1323823559182045184/Vqrrga8t_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Karl Marx</div>
<div style="text-align: center; font-size: 14px;">@marxhaunting</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Karl Marx.
| Data | Karl Marx |
| --- | --- |
| Tweets downloaded | 1287 |
| Retweets | 16 |
| Short tweets | 25 |
| Tweets kept | 1246 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1zcjng5j/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @marxhaunting's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1nimlh0s) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1nimlh0s/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/marxhaunting')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/hochimeme1
|
huggingtweets
| 2021-07-09T20:06:55Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/hochimeme1/1625861211819/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1408277423498698752/aUTHbyW2_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Moe Chi Minh</div>
<div style="text-align: center; font-size: 14px;">@hochimeme1</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Moe Chi Minh.
| Data | Moe Chi Minh |
| --- | --- |
| Tweets downloaded | 3242 |
| Retweets | 55 |
| Short tweets | 484 |
| Tweets kept | 2703 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/21ljhxlm/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @hochimeme1's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2vctf4ad) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2vctf4ad/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/hochimeme1')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
flax-community/t5-covid-qa
|
flax-community
| 2021-07-09T19:03:44Z | 1 | 0 | null |
[
"arxiv:2002.08910",
"region:us"
] | null | 2022-03-02T23:29:05Z |
# Covid19 Related Question Answering (Closed book question answering)
In 2020, COVID-19 which is caused by a coronavirus called SARS-CoV-2 took over the world. It touched the lives of many people and caused a lot of hardship for humanity. There are still many questions in regards to COVID-19 and it is often difficult to get the right answers. The aim of this project is to finetune models for closed book question answering. In closed-book QA, we feed the model a question *without any context or access to external knowledge* and train it to predict the answer. Since the model doesn't receive any context, the primary way it can learn to answer these questions is based on the "knowledge" it obtained during pre-training [[1]](https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/master/notebooks/t5-trivia.ipynb#scrollTo=zSeyoqE7WMwu) [[2]](https://arxiv.org/abs/2002.08910).
The main goals of this project are:
1. Train a model for question answering in regards to COVID-19
2. Release the top performing models for further research and enhancement
3. Release all of the preprocessing and postprocessing scripts and findings for future research.
## TO DO LIST:
- [x] Team members met and the following was discussed:
- Data preparation script is prepared that mixes CORD-19 and Pubmed.
- Agreed to finalize the training scripts by 9pm PDT 7/9/2021.
- Tokenizer is now trained.
- [ ] Setup the pretraining script
- [ ] Prepare the finetuning tasks inspired from [T5 Trivia Colab](https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/master/notebooks/t5-trivia.ipynb)
- What datasets we want to go with?
- [Covid-QA](https://huggingface.co/datasets/covid_qa_deepset) (Maybe as test set?)
- [Trivia](https://huggingface.co/datasets/covid_qa_deepset)
- [CDC-QA](https://www.cdc.gov/coronavirus/2019-ncov/faq.html) (We can scrape quickly using beautiful soup or something)
- [More Medical Datasets](https://aclanthology.org/2020.findings-emnlp.289.pdf) (See the dataset section for inspiratio)
## 1. Model
We will be using T5 model.
## 2. Datasets
The following datasets would be used for finetuning the model. Note that the last dataset is optional and the model is evaluated only using Covid-QA.
For **Intermediate Pre-Training**:
1. [CORD-19](https://allenai.org/data/cord-19)
For **Fine-Tuning** :
1. [Covid-QA](https://huggingface.co/datasets/covid_qa_deepset)
2. [CDC-QA](https://www.cdc.gov/coronavirus/2019-ncov/faq.html)
4. Optional - [Trivia-QA](https://nlp.cs.washington.edu/triviaqa/)
## 3. Training Scripts
We can make use of :
1. [For preprocessing and mixing datasets](https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/master/notebooks/t5-trivia.ipynb#:~:text=In%20this%20notebook%2C%20we'll,it%20to%20predict%20the%20answer.)
2. [For T5 training](https://github.com/huggingface/transformers/blob/master/src/transformers/models/t5/modeling_flax_t5.py)
## 4. Additional Reading
- [How Much Knowledge Can You Pack Into the Parameters of a Language Model?](https://arxiv.org/pdf/2002.08910.pdf)
|
jephthah/dfjgidfhj
|
jephthah
| 2021-07-09T12:39:42Z | 0 | 0 | null |
[
"region:us"
] | null | 2022-03-02T23:29:05Z |
https://natureecoevocommunity.nature.com/users/123movies-hd-watch-hitman-s-wife-s-bodyguard-2021-full-movie-online
https://natureecoevocommunity.nature.com/users/123movies-hd-watch-a-quiet-place-part-2-2021-full-movie-online-free-1d44a4a0-bbe0-4b52-a56c-c86e7ce72c1c
https://natureecoevocommunity.nature.com/users/123movies-hd-watch-a-quiet-place-part-2-2021-full-movie-online-free-reddit
https://natureecoevocommunity.nature.com/users/123movies-hd-watch-the-conjuring-3-2021-full-movie-online-free-reddit
https://natureecoevocommunity.nature.com/users/123movies-hd-watch-luca-2021-full-movie-online-free-reddit
https://natureecoevocommunity.nature.com/users/123movies-hd-watch-space-jam-2-a-new-legacy-2021-full-movie-online-free-reddit
https://natureecoevocommunity.nature.com/users/123movies-hd-watch-cruella-2021-full-movie-online-free-reddit
https://natureecoevocommunity.nature.com/users/123movies-hd-watch-the-forever-purge-2021-full-movie-online-free-reddit
https://natureecoevocommunity.nature.com/users/123movies-hd-watch-the-boss-baby-2-family-business-2021-full-movie-online-free-reddit
https://natureecoevocommunity.nature.com/users/123movies-hd-watch-fast-and-furious-9-2021-online-full-movie-free-reddit
https://natureecoevocommunity.nature.com/users/123movies-hd-watch-black-widow-2021-online-full-movie-free-reddit
|
flax-community/roberta-base-als-demo
|
flax-community
| 2021-07-09T12:18:07Z | 5 | 0 |
transformers
|
[
"transformers",
"jax",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# roberta-base-als-demo
**roberta-base-als-demo** is a model trained by Patrick von Platen to demonstrate how to train a roberta-base model from scratch on the Alemannic language.
This is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104), organised by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google.
## Useful links
- [Community Week timeline](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104#summary-timeline-calendar-6)
- [Community Week README](https://github.com/huggingface/transformers/blob/master/examples/research_projects/jax-projects/README.md)
- [Masked Language Modelling example scripts](https://github.com/huggingface/transformers/tree/master/examples/flax/language-modeling)
- [Model Repository](https://huggingface.co/flax-community/roberta-base-als-demo)
|
flax-community/mongolian-gpt2
|
flax-community
| 2021-07-09T12:17:08Z | 4 | 3 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"mn",
"dataset:oscar",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: "mn"
thumbnail: "https://avatars.githubusercontent.com/u/43239645?s=60&v=4"
tags:
- gpt2
datasets:
- oscar
---
# Mongolian GPT2
Goal is to create a strong language generation model for Mongolian
Since initial code and data is pretty much written by @patrickvonplaten and other huggingface members, it should not be so hard to get the first sense.
## Model
Randomly initialized GPT2 model
## Datasets
We can use OSCAR which is available through datasets
## Datasets
A causal language modeling script for Flax is available here 1. It can be used pretty much without any required code changes.
If there is time left, I’d love to try some private crawling and integrate it datasets.
## Expected Outcome
Understandable Mongolian text generation model
## Challenges
Lack of data → OSCAR Mongolian is just 2.2G. Maybe we need to research ways to acquire more data with this.
|
Alireza1044/bert_classification_lm
|
Alireza1044
| 2021-07-09T08:50:58Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
A simple model trained on dialogues of characters in NBC series, `The Office`. The model can do a binary classification between `Michael Scott` and `Dwight Shrute`'s dialogues.
<style type="text/css">
.tg {border-collapse:collapse;border-spacing:0;}
.tg td{border-color:black;border-style:solid;border-width:1px;font-family:Arial, sans-serif;font-size:14px;
overflow:hidden;padding:10px 5px;word-break:normal;}
.tg th{border-color:black;border-style:solid;border-width:1px;font-family:Arial, sans-serif;font-size:14px;
font-weight:normal;overflow:hidden;padding:10px 5px;word-break:normal;}
.tg .tg-c3ow{border-color:inherit;text-align:center;vertical-align:top}
</style>
<table class="tg">
<thead>
<tr>
<th class="tg-c3ow" colspan="2">Label Definitions</th>
</tr>
</thead>
<tbody>
<tr>
<td class="tg-c3ow">Label 0</td>
<td class="tg-c3ow">Michael</td>
</tr>
<tr>
<td class="tg-c3ow">Label 1</td>
<td class="tg-c3ow">Dwight</td>
</tr>
</tbody>
</table>
|
huggingtweets/dbdevletbahceli
|
huggingtweets
| 2021-07-09T07:53:26Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/dbdevletbahceli/1625817202615/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1163922647/db002_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Devlet Bahçeli</div>
<div style="text-align: center; font-size: 14px;">@dbdevletbahceli</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Devlet Bahçeli.
| Data | Devlet Bahçeli |
| --- | --- |
| Tweets downloaded | 3200 |
| Retweets | 0 |
| Short tweets | 19 |
| Tweets kept | 3181 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/ni0ttu3d/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @dbdevletbahceli's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/ois198tw) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/ois198tw/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/dbdevletbahceli')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
ThomasNLG/t5-qg_webnlg_synth-en
|
ThomasNLG
| 2021-07-09T07:45:44Z | 259 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"qa",
"question",
"generation",
"SQuAD",
"data2text",
"metric",
"nlg",
"t5-small",
"en",
"dataset:squad_v2",
"arxiv:2104.07555",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- qa
- question
- generation
- SQuAD
- data2text
- metric
- nlg
- t5-small
license: mit
datasets:
- squad_v2
model-index:
- name: t5-qg_webnlg_synth-en
results:
- task:
name: Data Question Generation
type: Text To Text Generation
widget:
- text: "The Eagle </s> name [ The Eagle ] , eatType [ coffee shop ] , food [ French ] , priceRange [ £ 2 0 - 2 5 ]"
---
# t5-qg_webnlg_synth-en
## Model description
This model is a *Data Question Generation* model based on T5-small, that generates questions, given a structured table as input and the conditioned answer.
It is actually a component of [QuestEval](https://github.com/ThomasScialom/QuestEval) metric but can be used independently as it is, for QG only.
## How to use
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("ThomasNLG/t5-qg_webnlg_synth-en")
model = T5ForConditionalGeneration.from_pretrained("ThomasNLG/t5-qg_webnlg_synth-en")
```
You can play with the model using the inference API, the text input format should follow this template (accordingly to the training stage of the model):
`text_input = "{ANSWER} </s> {CONTEXT}"`
where `CONTEXT is a structured table that is linearised this way:
`CONTEXT = "name [ The Eagle ] , eatType [ coffee shop ] , food [ French ] , priceRange [ £ 2 0 - 2 5 ]"`
## Training data
The model was trained on synthetic data as described in [Data-QuestEval: A Referenceless Metric for Data to Text Semantic Evaluation](https://arxiv.org/abs/2104.07555).
### Citation info
```bibtex
@article{rebuffel2021data,
title={Data-QuestEval: A Referenceless Metric for Data to Text Semantic Evaluation},
author={Rebuffel, Cl{\'e}ment and Scialom, Thomas and Soulier, Laure and Piwowarski, Benjamin and Lamprier, Sylvain and Staiano, Jacopo and Scoutheeten, Geoffrey and Gallinari, Patrick},
journal={arXiv preprint arXiv:2104.07555},
year={2021}
}
```
|
ThomasNLG/t5-qa_webnlg_synth-en
|
ThomasNLG
| 2021-07-09T07:45:27Z | 260 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"qa",
"question",
"answering",
"SQuAD",
"data2text",
"metric",
"nlg",
"t5-small",
"en",
"dataset:squad_v2",
"arxiv:2104.07555",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- qa
- question
- answering
- SQuAD
- data2text
- metric
- nlg
- t5-small
license: mit
datasets:
- squad_v2
model-index:
- name: t5-qa_webnlg_synth-en
results:
- task:
name: Data Question Answering
type: extractive-qa
widget:
- text: "What is the food type at The Eagle? </s> name [ The Eagle ] , eatType [ coffee shop ] , food [ French ] , priceRange [ £ 2 0 - 2 5 ]"
---
# t5-qa_webnlg_synth-en
## Model description
This model is a *Data Question Answering* model based on T5-small, that answers questions given a structured table as input.
It is actually a component of [QuestEval](https://github.com/ThomasScialom/QuestEval) metric but can be used independently as it is, for QA only.
## How to use
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("ThomasNLG/t5-qa_webnlg_synth-en")
model = T5ForConditionalGeneration.from_pretrained("ThomasNLG/t5-qa_webnlg_synth-en")
```
You can play with the model using the inference API, the text input format should follow this template (accordingly to the training stage of the model):
`text_input = "{QUESTION} </s> {CONTEXT}"`
where `CONTEXT` is a structured table that is linearised this way:
`CONTEXT = "name [ The Eagle ] , eatType [ coffee shop ] , food [ French ] , priceRange [ £ 2 0 - 2 5 ]"`
## Training data
The model was trained on synthetic data as described in [Data-QuestEval: A Referenceless Metric for Data to Text Semantic Evaluation](https://arxiv.org/abs/2104.07555).
### Citation info
```bibtex
@article{rebuffel2021data,
title={Data-QuestEval: A Referenceless Metric for Data to Text Semantic Evaluation},
author={Rebuffel, Cl{\'e}ment and Scialom, Thomas and Soulier, Laure and Piwowarski, Benjamin and Lamprier, Sylvain and Staiano, Jacopo and Scoutheeten, Geoffrey and Gallinari, Patrick},
journal={arXiv preprint arXiv:2104.07555},
year={2021}
}
```
|
ThomasNLG/t5-qa_squad2neg-en
|
ThomasNLG
| 2021-07-09T07:44:39Z | 797 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"qa",
"question",
"answering",
"SQuAD",
"metric",
"nlg",
"t5-small",
"en",
"dataset:squad_v2",
"arxiv:2103.12693",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- qa
- question
- answering
- SQuAD
- metric
- nlg
- t5-small
license: mit
datasets:
- squad_v2
model-index:
- name: t5-qa_squad2neg-en
results:
- task:
name: Question Answering
type: extractive-qa
widget:
- text: "Who was Louis 14? </s> Louis 14 was a French King."
---
# t5-qa_squad2neg-en
## Model description
This model is a *Question Answering* model based on T5-small.
It is actually a component of [QuestEval](https://github.com/ThomasScialom/QuestEval) metric but can be used independently as it is, for QA only.
## How to use
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("ThomasNLG/t5-qa_squad2neg-en")
model = T5ForConditionalGeneration.from_pretrained("ThomasNLG/t5-qa_squad2neg-en")
```
You can play with the model using the inference API, the text input format should follow this template (accordingly to the training stage of the model):
`text_input = "{QUESTION} </s> {CONTEXT}"`
## Training data
The model was trained on:
- SQuAD-v2
- SQuAD-v2 neg: in addition to the training data of SQuAD-v2, for each answerable example, a negative sampled example has been added with the label *unanswerable* to help the model learning when the question is not answerable given the context. For more details, see the [paper](https://arxiv.org/abs/2103.12693).
### Citation info
```bibtex
@article{scialom2020QuestEval,
title={QuestEval: Summarization Asks for Fact-based Evaluation},
author={Scialom, Thomas and Dray, Paul-Alexis and Gallinari, Patrick and Lamprier, Sylvain and Piwowarski, Benjamin and Staiano, Jacopo and Wang, Alex},
journal={arXiv preprint arXiv:2103.12693},
year={2021}
}
```
|
huggingtweets/mralgore
|
huggingtweets
| 2021-07-09T06:46:35Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/mralgore/1625813191802/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1379330213042065410/XmWaaQtK_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Mr. Al Gore 🇺🇸 🏗</div>
<div style="text-align: center; font-size: 14px;">@mralgore</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Mr. Al Gore 🇺🇸 🏗.
| Data | Mr. Al Gore 🇺🇸 🏗 |
| --- | --- |
| Tweets downloaded | 1663 |
| Retweets | 48 |
| Short tweets | 409 |
| Tweets kept | 1206 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/lb6ro1nm/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @mralgore's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2hcr10go) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2hcr10go/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/mralgore')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
franklu/pubmed_bert_squadv2
|
franklu
| 2021-07-09T05:25:26Z | 42 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
**[`microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext`](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext)** fine-tuned on **[`SQuAD V2`](https://rajpurkar.github.io/SQuAD-explorer/)** using **[`run_qa.py`](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_qa.py)**
Tunning script:
```bash
BASE_MODEL=microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext
OUTPUT_DIR=~/Documents/projects/tunned_models/ms_pubmed_bert_squadv2/
python run_qa.py \
--model_name_or_path $BASE_MODEL\
--dataset_name squad_v2 \
--do_train \
--do_eval \
--version_2_with_negative \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir $OUTPUT_DIR
```
|
osanseviero/keras-dog-or-cat
|
osanseviero
| 2021-07-08T13:36:49Z | 39 | 0 |
keras
|
[
"keras",
"tf",
"image-classification",
"license:apache-2.0",
"region:us"
] |
image-classification
| 2022-03-02T23:29:05Z |
---
license: apache-2.0
tags:
- image-classification
- keras
library_name: keras
---
Keras Dog vs Cat based on the [official Keras documentation](https://keras.io/examples/vision/image_classification_from_scratch/)
|
henryu-lin/t5-large-samsum-deepspeed
|
henryu-lin
| 2021-07-08T09:13:46Z | 16 | 1 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"azureml",
"summarization",
"deepspeed",
"en",
"dataset:samsum",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- azureml
- t5
- summarization
- deepspeed
license: apache-2.0
datasets:
- samsum
model-index:
- name: t5-large-samsum-deepspeed
results:
- task:
name: Abstractive Text Summarization
type: abstractive-text-summarization
dataset:
name: "SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization"
type: samsum
widget:
- text: |
Kevin: Hey man, are you excited to watch Finding Nemo tonight?
Henry: Yea, I can't wait to watch that same movie for the 89th time. Is Nate coming over to watch it with us tonight?
Kevin: Yep, he said he'll be arriving a bit later at around 7 since he gets off of work at 6. Have you taken out the garbage yet? It's starting to make the kitchen really smell.
Henry: Oh I forgot. I'll do that once I'm finished with my assignment for my math class. I didn't get to start on it until an hour ago, and it's due in 30 minutes.
Kevin: Okay dude, you should take it out as soon as possible. By the way, Nate is bringing his girlfriend and their cat too.
Henry: Nice, I'm really looking forward to seeing them again.
---
## `t5-large-samsum-deepspeed`
This model was trained using Microsoft's `AzureML` and `DeepSpeed`'s ZeRO 2 optimization. It was fine-tuned on the `SAMSum` corpus from `t5-large` checkpoint.
More information on the fine-tuning process (includes samples and benchmarks):
*(currently still WIP, major updates coming soon: 7/6/21~7/9/21)*
## Resource Usage
These results are retrieved from AzureML Studio's resource monitoring module. All experiments were ran on AzureML's low priority clusters.
| key | value |
| --- | ----- |
| AzureML SKU | ND40rs_v2 (8 X V100 32GB) |
| Region | US West 2 |
| Run Duration | 12m 47.13s |
| Compute Cost (LowPriority/Dedicated) | $0.94/$4.69 (USD) |
| Average CPU Utilization | 51.2% |
| Average GPU Utilization | 42.0% |
| GPU Memory Usage (Avg/Peak) | 24.85/28.79 (GB) |
| Total GPU Energy Usage | 670.38 (kJ) |
*Compute cost is calculated from run duration and SKU's price per hour. Updated SKU pricing could be found here: https://azure.microsoft.com/en-us/pricing/details/machine-learning/
*Peak memory usage is calculated from average peak across all utilized GPUs.
### Carbon Emissions
These results are obtained using `codecarbon`. The carbon emission is estimated from training runtime only (excluding setup and evaluation runtime).
CodeCarbon: https://github.com/mlco2/codecarbon
| key | value |
| --- | ----- |
| timestamp | 2021-07-08T06:29:27 |
| duration | 515.5018835067749 |
| emissions | 0.043562840982919106 |
| energy_consumed | 0.14638051405550773 |
| country_name | USA |
| region | Washington |
| cloud_provider | azure |
| cloud_region | westus2 |
## Hyperparameters
```yaml
fp16: True
per device batch size: 8
effective batch size: 64
epoch: 3.0
learning rate: 1e-4
weight decay: 0.1
seed: 1
```
*Same `per device batch size` for evaluations
### DeepSpeed
Optimizer = `AdamW`, Scheduler = `WarmupDecayLR`, Offload = `none`
```json
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 1300000000,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 1300000000,
"contiguous_gradients": true
}
```
## Usage
```python
from transformers import pipeline
summarizer = pipeline("summarization", model="henryu-lin/t5-large-samsum-deepspeed")
conversation = '''Kevin: Hey man, are you excited to watch Finding Nemo tonight?
Henry: Yea, I can't wait to watch that same movie for the 89th time. Is Nate coming over to watch it with us tonight?
Kevin: Yep, he said he'll be arriving a bit later at around 7 since he gets off of work at 6. Have you taken out the garbage yet? It's starting to make the kitchen really smell.
Henry: Oh I forgot. I'll do that once I'm finished with my assignment for my math class. I didn't get to start on it until an hour ago, and it's due in 30 minutes.
Kevin: Okay dude, you should take it out as soon as possible. By the way, Nate is bringing his girlfriend and their cat too.
Henry: Nice, I'm really looking forward to seeing them again.
'''
summarizer(conversation)
```
## Results
| ROUGE | Score |
| ----- | ----- |
| eval_rouge1 | 53.0823 |
| eval_rouge2 | 28.7097 |
| eval_rougeL | 43.939 |
| eval_rougeLsum | 49.067 |
| predict_rouge1 | 51.6716 |
| predict_rouge2 | 26.5372 |
| predict_rougeL | 42.9681 |
| predict_rougeLsum | 47.4084 |
| Metric | Value |
| ------ | ----- |
| eval_gen_len | 26.4071 |
| predict_gen_len | 25.9451 |
| train_loss | 1.3212629926497115 |
| eval_loss | 1.23828125 |
| predict_loss | 1.2333984375 |
| train_runtime | 515.2198 |
| train_samples | 14732 |
| train_samples_per_second | 85.781 |
| train_steps_per_second | 1.345 |
| eval_runtime | 61.275 |
| eval_samples | 818 |
| eval_samples_per_second | 13.35 |
| eval_steps_per_second | 0.212 |
| predict_runtime | 63.3732 |
| predict_samples | 819 |
| predict_samples_per_second | 12.923 |
| predict_steps_per_second | 0.205 |
| total_steps | 693 |
| total_flos | 7.20140924616704e+16 |
|
shreeshaaithal/DialoGPT-small-Michael-Scott
|
shreeshaaithal
| 2021-07-07T11:56:25Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/dialogpt.png
tags:
- conversational
license: mit
---
# DialoGPT Trained on WhatsApp chats
This is an instance of [microsoft/DialoGPT-medium](https://huggingface.co/microsoft/DialoGPT-medium) trained on WhatsApp chats or you can train this model on [a Kaggle game script dataset](https://www.kaggle.com/ruolinzheng/twewy-game-script).
feel free to ask me questions on discord server [discord server](https://discord.gg/Gqhje8Z7DX)
Chat with the model:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("harrydonni/DialoGPT-small-Michael-Scott")
model = AutoModelWithLMHead.from_pretrained("harrydonni/DialoGPT-small-Michael-Scott")
# Let's chat for 4 lines
for step in range(4):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# print(new_user_input_ids)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
do_sample=True,
top_k=100,
top_p=0.7,
temperature=0.8
)
# pretty print last ouput tokens from bot
print("Michael: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
this is done by shreesha thank you......
|
ainize/klue-bert-base-re
|
ainize
| 2021-07-07T09:55:52Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# bert-base for KLUE Relation Extraction task.
Fine-tuned klue/bert-base using KLUE RE dataset.
- <a href="https://klue-benchmark.com/">KLUE Benchmark Official Webpage</a>
- <a href="https://github.com/KLUE-benchmark/KLUE">KLUE Official Github</a>
- <a href="https://github.com/ainize-team/klue-re-workspace">KLUE RE Github</a>
- Run KLUE RE on free GPU : <a href="https://ainize.ai/workspace/create?imageId=hnj95592adzr02xPTqss&git=https://github.com/ainize-team/klue-re-workspace">Ainize Workspace</a>
<br>
# Usage
<pre><code>
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("ainize/klue-bert-base-re")
model = AutoModelForSequenceClassification.from_pretrained("ainize/klue-bert-base-re")
# Add "<subj>", "</subj>" to both ends of the subject object and "<obj>", "</obj>" to both ends of the object object.
sentence = "<subj>손흥민</subj>은 <obj>대한민국</obj>에서 태어났다."
encodings = tokenizer(sentence,
max_length=128,
truncation=True,
padding="max_length",
return_tensors="pt")
outputs = model(**encodings)
logits = outputs['logits']
preds = torch.argmax(logits, dim=1)
</code></pre>
<br>
# About us
- <a href="https://ainize.ai/teachable-nlp">Teachable NLP</a> - Train NLP models with your own text without writing any code
- <a href="https://ainize.ai/">Ainize</a> - Deploy ML project using free gpu
|
huggingtweets/hustlenconquer-nocodepiper
|
huggingtweets
| 2021-07-07T08:38:19Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/hustlenconquer-nocodepiper/1625647094650/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1410198055534710787/MWQhi2jp_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1404094020150693888/LQnyM5vj_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Nocodepiper & HUSTLE & CONQUER</div>
<div style="text-align: center; font-size: 14px;">@hustlenconquer-nocodepiper</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Nocodepiper & HUSTLE & CONQUER.
| Data | Nocodepiper | HUSTLE & CONQUER |
| --- | --- | --- |
| Tweets downloaded | 1652 | 2721 |
| Retweets | 281 | 19 |
| Short tweets | 259 | 240 |
| Tweets kept | 1112 | 2462 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/vdyvbiis/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @hustlenconquer-nocodepiper's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/sltkk6jw) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/sltkk6jw/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/hustlenconquer-nocodepiper')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
shreeshaaithal/whatsapp-medium-bot-2
|
shreeshaaithal
| 2021-07-07T06:28:15Z | 7 | 2 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
thumbnail: https://huggingface.co/front/thumbnails/dialogpt.png
tags:
- conversational
license: mit
---
# DialoGPT Trained on WhatsApp chats
This is an instance of [microsoft/DialoGPT-medium](https://huggingface.co/microsoft/DialoGPT-medium) trained on WhatsApp chats or you can train this model on [a Kaggle game script dataset](https://www.kaggle.com/ruolinzheng/twewy-game-script).
feel free to ask me questions on discord server [discord server](https://discord.gg/Gqhje8Z7DX)
Chat with the model:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("harrydonni/whatsapp-medium-bot-2")
model = AutoModelWithLMHead.from_pretrained("harrydonni/whatsapp-medium-bot-2")
# Let's chat for 4 lines
for step in range(4):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# print(new_user_input_ids)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
do_sample=True,
top_k=100,
top_p=0.7,
temperature=0.8
)
# pretty print last ouput tokens from bot
print("Messi: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
this is done by shreesha thank you......
|
minsik-oh/dummy-model
|
minsik-oh
| 2021-07-07T05:58:51Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"camembert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# Dummy Model
This be a dummmmmy
|
liam168/c4-zh-distilbert-base-uncased
|
liam168
| 2021-07-07T03:21:34Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"exbert",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: zh
tags:
- exbert
license: apache-2.0
widget:
- text: "女人做得越纯粹,皮肤和身材就越好"
- text: "我喜欢篮球"
---
# liam168/c4-zh-distilbert-base-uncased
## Model description
用 ["女性","体育","文学","校园"]4类数据训练的分类模型。
## Overview
- **Language model**: DistilBERT
- **Model size**: 280M
- **Language**: Chinese
## Example
```python
>>> from transformers import DistilBertForSequenceClassification , AutoTokenizer, pipeline
>>> model_name = "liam168/c4-zh-distilbert-base-uncased"
>>> class_num = 4
>>> ts_texts = ["女人做得越纯粹,皮肤和身材就越好", "我喜欢篮球"]
>>> model = DistilBertForSequenceClassification.from_pretrained(model_name, num_labels=class_num)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
>>> classifier = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer)
>>> classifier(ts_texts[0])
>>> classifier(ts_texts[1])
[{'label': 'Female', 'score': 0.9137857556343079}]
[{'label': 'Sports', 'score': 0.8206522464752197}]
```
|
liam168/gen-gpt2-medium-chinese
|
liam168
| 2021-07-07T02:26:55Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"gpt2",
"text-generation",
"zh",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: zh
widget:
- text: "晓日千红"
- text: "长街躞蹀"
---
# gen-gpt2-medium-chinese
# Overview
- **Language model**: GPT2-Medium
- **Model size**: 68M
- **Language**: Chinese
# Example
```python
from transformers import TFGPT2LMHeadModel,AutoTokenizer
from transformers import TextGenerationPipeline
mode_name = 'liam168/gen-gpt2-medium-chinese'
tokenizer = AutoTokenizer.from_pretrained(mode_name)
model = TFGPT2LMHeadModel.from_pretrained(mode_name)
text_generator = TextGenerationPipeline(model, tokenizer)
print(text_generator("晓日千红", max_length=64, do_sample=True))
print(text_generator("加餐小语", max_length=50, do_sample=False))
```
输出
```text
[{'generated_text': '晓日千红 独 远 客 。 孤 夜 云 云 梦 到 冷 。 著 剩 笑 、 人 远 。 灯 啼 鸦 最 回 吟 。 望 , 枕 付 孤 灯 、 客 。 对 梅 残 照 偏 相 思 , 玉 弦 语 。 翠 台 新 妆 、 沉 、 登 临 水 。 空'}]
[{'generated_text': '加餐小语 有 有 骨 , 有 人 诗 成 自 远 诗 。 死 了 自 喜 乐 , 独 撑 天 下 诗 事 小 诗 柴 。 桃 花 谁 知 何 处 何 处 高 吟 诗 从 今 死 火 , 此 事'}]
```
|
junnyu/wobert_chinese_plus_base
|
junnyu
| 2021-07-07T01:18:40Z | 21,751 | 5 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bert",
"fill-mask",
"wobert",
"zh",
"autotrain_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: zh
tags:
- wobert
inference: False
---
## 介绍
### tf版本
https://github.com/ZhuiyiTechnology/WoBERT
### pytorch版本
https://github.com/JunnYu/WoBERT_pytorch
## 安装(主要为了安装WoBertTokenizer)
```bash
pip install git+https://github.com/JunnYu/WoBERT_pytorch.git
```
## 使用
```python
import torch
from transformers import BertForMaskedLM as WoBertForMaskedLM
from wobert import WoBertTokenizer
pretrained_model_or_path_list = [
"junnyu/wobert_chinese_plus_base", "junnyu/wobert_chinese_base"
]
for path in pretrained_model_or_path_list:
text = "今天[MASK]很好,我[MASK]去公园玩。"
tokenizer = WoBertTokenizer.from_pretrained(path)
model = WoBertForMaskedLM.from_pretrained(path)
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs).logits[0]
outputs_sentence = ""
for i, id in enumerate(tokenizer.encode(text)):
if id == tokenizer.mask_token_id:
tokens = tokenizer.convert_ids_to_tokens(outputs[i].topk(k=5)[1])
outputs_sentence += "[" + "||".join(tokens) + "]"
else:
outputs_sentence += "".join(
tokenizer.convert_ids_to_tokens([id],
skip_special_tokens=True))
print(outputs_sentence)
# RoFormer 今天[天气||天||心情||阳光||空气]很好,我[想||要||打算||准备||喜欢]去公园玩。
# PLUS WoBERT 今天[天气||阳光||天||心情||空气]很好,我[想||要||打算||准备||就]去公园玩。
# WoBERT 今天[天气||阳光||天||心情||空气]很好,我[想||要||就||准备||也]去公园玩。
```
## 引用
Bibtex:
```tex
@techreport{zhuiyiwobert,
title={WoBERT: Word-based Chinese BERT model - ZhuiyiAI},
author={Jianlin Su},
year={2020},
url="https://github.com/ZhuiyiTechnology/WoBERT",
}
```
|
huggingtweets/alice333ai-jj_visuals
|
huggingtweets
| 2021-07-06T20:56:55Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/alice333ai-jj_visuals/1625605011527/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1393311358293356546/tXc-X9fx_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1412466315240030217/yDDNt3-0_400x400.png')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">👁️⃤ lison & JJ (comms closed)</div>
<div style="text-align: center; font-size: 14px;">@alice333ai-jj_visuals</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from 👁️⃤ lison & JJ (comms closed).
| Data | 👁️⃤ lison | JJ (comms closed) |
| --- | --- | --- |
| Tweets downloaded | 3216 | 3221 |
| Retweets | 1062 | 781 |
| Short tweets | 200 | 229 |
| Tweets kept | 1954 | 2211 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1sqkkxt9/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @alice333ai-jj_visuals's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/327x2oet) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/327x2oet/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/alice333ai-jj_visuals')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
victor/autonlp-imdb-reviews-sentiment-329982
|
victor
| 2021-07-06T19:26:32Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autonlp",
"en",
"dataset:victor/autonlp-data-imdb-reviews-sentiment",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- victor/autonlp-data-imdb-reviews-sentiment
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 329982
## Validation Metrics
- Loss: 0.24620144069194794
- Accuracy: 0.9300053431035799
- Precision: 0.9299029425358188
- Recall: 0.9289012003693444
- AUC: 0.9795001637755057
- F1: 0.9294018015243667
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/victor/autonlp-imdb-reviews-sentiment-329982
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("victor/autonlp-imdb-reviews-sentiment-329982", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("victor/autonlp-imdb-reviews-sentiment-329982", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
accelotron/rugpt3-ficbook-bts
|
accelotron
| 2021-07-06T18:08:59Z | 7 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
ruGPT-3 fine-tuned on russian fanfiction about Bangatan Boys (BTS).
|
mrm8488/wav2vec2-large-xlsr-53-spanish
|
mrm8488
| 2021-07-06T13:14:39Z | 20 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"es",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language: es
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Spanish Manuel Romero
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice es
type: common_voice
args: es
metrics:
- name: Test WER
type: wer
value: ???
---
# Wav2Vec2-Large-XLSR-53-Spanish
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) in Spanish using the [Common Voice](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "es", split="test[:2%]").
processor = Wav2Vec2Processor.from_pretrained("mrm8488/wav2vec2-large-xlsr-53-spanish")
model = Wav2Vec2ForCTC.from_pretrained("mrm8488/wav2vec2-large-xlsr-53-spanish")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Ukrainian test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "es", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("mrm8488/wav2vec2-large-xlsr-53-spanish")
model = Wav2Vec2ForCTC.from_pretrained("mrm8488/wav2vec2-large-xlsr-53-spanish")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: %
## Training
The Common Voice `train`, `validation` datasets were used for training.
The script used for training can be found ???
|
mrm8488/wav2vec2-large-xlsr-53-esperanto
|
mrm8488
| 2021-07-06T13:02:46Z | 8 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"eo",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-03-02T23:29:05Z |
---
language: eo
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Esperanto Manuel Romero
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice eo
type: common_voice
args: eo
metrics:
- name: Test WER
type: wer
value: 15.86
---
# Wav2Vec2-Large-XLSR-53-esperanto
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) in Esperanto using the [Common Voice](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "eo", split="test[:2%]").
processor = Wav2Vec2Processor.from_pretrained("mrm8488/wav2vec2-large-xlsr-53-esperanto")
model = Wav2Vec2ForCTC.from_pretrained("mrm8488/wav2vec2-large-xlsr-53-esperanto")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Ukrainian test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "eo", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("mrm8488/wav2vec2-large-xlsr-53-esperanto")
model = Wav2Vec2ForCTC.from_pretrained("mrm8488/wav2vec2-large-xlsr-53-esperanto")
model.to("cuda")
chars_to_ignore_regex = '[\\,\\?\\.\\!\\-\\;\\:\\"\\“\\%\\‘\\”\\�]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 15.86 %
## Training
The Common Voice `train`, `validation` datasets were used for training.
The script used for training can be found ???
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.