
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-06 18:27:02
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 544
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-06 18:26:43
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
SEBIS/code_trans_t5_base_code_documentation_generation_python
|
SEBIS
| 2021-06-23T04:43:22Z | 47 | 11 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"feature-extraction",
"summarization",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
widget:
- text: "def e ( message , exit_code = None ) : print_log ( message , YELLOW , BOLD ) if exit_code is not None : sys . exit ( exit_code )"
---
# CodeTrans model for code documentation generation python
Pretrained model on programming language python using the t5 base model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans). This model is trained on tokenized python code functions: it works best with tokenized python functions.
## Model description
This CodeTrans model is based on the `t5-base` model. It has its own SentencePiece vocabulary model. It used single-task training on CodeSearchNet Corpus python dataset.
## Intended uses & limitations
The model could be used to generate the description for the python function or be fine-tuned on other python code tasks. It can be used on unparsed and untokenized python code. However, if the python code is tokenized, the performance should be better.
### How to use
Here is how to use this model to generate python function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_python"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_python", skip_special_tokens=True),
device=0
)
tokenized_code = "def e ( message , exit_code = None ) : print_log ( message , YELLOW , BOLD ) if exit_code is not None : sys . exit ( exit_code )"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/single%20task/function%20documentation%20generation/python/base_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Python | Java | Go | Php | Ruby | JavaScript |
| -------------------- | :------------: | :------------: | :------------: | :------------: | :------------: | :------------: |
| CodeTrans-ST-Small | 17.31 | 16.65 | 16.89 | 23.05 | 9.19 | 13.7 |
| CodeTrans-ST-Base | 16.86 | 17.17 | 17.16 | 22.98 | 8.23 | 13.17 |
| CodeTrans-TF-Small | 19.93 | 19.48 | 18.88 | 25.35 | 13.15 | 17.23 |
| CodeTrans-TF-Base | 20.26 | 20.19 | 19.50 | 25.84 | 14.07 | 18.25 |
| CodeTrans-TF-Large | 20.35 | 20.06 | **19.54** | 26.18 | 14.94 | **18.98** |
| CodeTrans-MT-Small | 19.64 | 19.00 | 19.15 | 24.68 | 14.91 | 15.26 |
| CodeTrans-MT-Base | **20.39** | 21.22 | 19.43 | **26.23** | **15.26** | 16.11 |
| CodeTrans-MT-Large | 20.18 | **21.87** | 19.38 | 26.08 | 15.00 | 16.23 |
| CodeTrans-MT-TF-Small | 19.77 | 20.04 | 19.36 | 25.55 | 13.70 | 17.24 |
| CodeTrans-MT-TF-Base | 19.77 | 21.12 | 18.86 | 25.79 | 14.24 | 18.62 |
| CodeTrans-MT-TF-Large | 18.94 | 21.42 | 18.77 | 26.20 | 14.19 | 18.83 |
| State of the art | 19.06 | 17.65 | 18.07 | 25.16 | 12.16 | 14.90 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
SEBIS/code_trans_t5_base_code_documentation_generation_php_transfer_learning_finetune
|
SEBIS
| 2021-06-23T04:40:47Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"feature-extraction",
"summarization",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
widget:
- text: "public static function update ( $ table ) { if ( ! is_array ( $ table ) ) { $ table = json_decode ( $ table , true ) ; } if ( ! SchemaManager :: tableExists ( $ table [ 'oldName' ] ) ) { throw SchemaException :: tableDoesNotExist ( $ table [ 'oldName' ] ) ; } $ updater = new self ( $ table ) ; $ updater -> updateTable ( ) ; }"
---
# CodeTrans model for code documentation generation php
Pretrained model on programming language php using the t5 base model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans). This model is trained on tokenized php code functions: it works best with tokenized php functions.
## Model description
This CodeTrans model is based on the `t5-base` model. It has its own SentencePiece vocabulary model. It used transfer-learning pre-training on 7 unsupervised datasets in the software development domain. It is then fine-tuned on the code documentation generation task for the php function/method.
## Intended uses & limitations
The model could be used to generate the description for the php function or be fine-tuned on other php code tasks. It can be used on unparsed and untokenized php code. However, if the php code is tokenized, the performance should be better.
### How to use
Here is how to use this model to generate php function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_php_transfer_learning_finetune"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_php_transfer_learning_finetune", skip_special_tokens=True),
device=0
)
tokenized_code = "public static function update ( $ table ) { if ( ! is_array ( $ table ) ) { $ table = json_decode ( $ table , true ) ; } if ( ! SchemaManager :: tableExists ( $ table [ 'oldName' ] ) ) { throw SchemaException :: tableDoesNotExist ( $ table [ 'oldName' ] ) ; } $ updater = new self ( $ table ) ; $ updater -> updateTable ( ) ; }"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/transfer%20learning%20fine-tuning/function%20documentation%20generation/php/base_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Training procedure
### Transfer-learning Pretraining
The model was trained on a single TPU Pod V3-8 for half million steps in total, using sequence length 512 (batch size 4096).
It has a total of approximately 220M parameters and was trained using the encoder-decoder architecture.
The optimizer used is AdaFactor with inverse square root learning rate schedule for pre-training.
### Fine-tuning
This model was then fine-tuned on a single TPU Pod V2-8 for 65,000 steps in total, using sequence length 512 (batch size 256), using only the dataset only containing php code.
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Python | Java | Go | Php | Ruby | JavaScript |
| -------------------- | :------------: | :------------: | :------------: | :------------: | :------------: | :------------: |
| CodeTrans-ST-Small | 17.31 | 16.65 | 16.89 | 23.05 | 9.19 | 13.7 |
| CodeTrans-ST-Base | 16.86 | 17.17 | 17.16 | 22.98 | 8.23 | 13.17 |
| CodeTrans-TF-Small | 19.93 | 19.48 | 18.88 | 25.35 | 13.15 | 17.23 |
| CodeTrans-TF-Base | 20.26 | 20.19 | 19.50 | 25.84 | 14.07 | 18.25 |
| CodeTrans-TF-Large | 20.35 | 20.06 | **19.54** | 26.18 | 14.94 | **18.98** |
| CodeTrans-MT-Small | 19.64 | 19.00 | 19.15 | 24.68 | 14.91 | 15.26 |
| CodeTrans-MT-Base | **20.39** | 21.22 | 19.43 | **26.23** | **15.26** | 16.11 |
| CodeTrans-MT-Large | 20.18 | **21.87** | 19.38 | 26.08 | 15.00 | 16.23 |
| CodeTrans-MT-TF-Small | 19.77 | 20.04 | 19.36 | 25.55 | 13.70 | 17.24 |
| CodeTrans-MT-TF-Base | 19.77 | 21.12 | 18.86 | 25.79 | 14.24 | 18.62 |
| CodeTrans-MT-TF-Large | 18.94 | 21.42 | 18.77 | 26.20 | 14.19 | 18.83 |
| State of the art | 19.06 | 17.65 | 18.07 | 25.16 | 12.16 | 14.90 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
SEBIS/code_trans_t5_base_code_documentation_generation_php
|
SEBIS
| 2021-06-23T04:34:53Z | 23 | 4 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"feature-extraction",
"summarization",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
widget:
- text: "public static function update ( $ table ) { if ( ! is_array ( $ table ) ) { $ table = json_decode ( $ table , true ) ; } if ( ! SchemaManager :: tableExists ( $ table [ 'oldName' ] ) ) { throw SchemaException :: tableDoesNotExist ( $ table [ 'oldName' ] ) ; } $ updater = new self ( $ table ) ; $ updater -> updateTable ( ) ; }"
---
# CodeTrans model for code documentation generation php
Pretrained model on programming language php using the t5 base model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans). This model is trained on tokenized php code functions: it works best with tokenized php functions.
## Model description
This CodeTrans model is based on the `t5-base` model. It has its own SentencePiece vocabulary model. It used single-task training on CodeSearchNet Corpus php dataset.
## Intended uses & limitations
The model could be used to generate the description for the php function or be fine-tuned on other php code tasks. It can be used on unparsed and untokenized php code. However, if the php code is tokenized, the performance should be better.
### How to use
Here is how to use this model to generate php function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_php"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_php", skip_special_tokens=True),
device=0
)
tokenized_code = "public static function update ( $ table ) { if ( ! is_array ( $ table ) ) { $ table = json_decode ( $ table , true ) ; } if ( ! SchemaManager :: tableExists ( $ table [ 'oldName' ] ) ) { throw SchemaException :: tableDoesNotExist ( $ table [ 'oldName' ] ) ; } $ updater = new self ( $ table ) ; $ updater -> updateTable ( ) ; }"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/single%20task/function%20documentation%20generation/php/base_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Python | Java | Go | Php | Ruby | JavaScript |
| -------------------- | :------------: | :------------: | :------------: | :------------: | :------------: | :------------: |
| CodeTrans-ST-Small | 17.31 | 16.65 | 16.89 | 23.05 | 9.19 | 13.7 |
| CodeTrans-ST-Base | 16.86 | 17.17 | 17.16 | 22.98 | 8.23 | 13.17 |
| CodeTrans-TF-Small | 19.93 | 19.48 | 18.88 | 25.35 | 13.15 | 17.23 |
| CodeTrans-TF-Base | 20.26 | 20.19 | 19.50 | 25.84 | 14.07 | 18.25 |
| CodeTrans-TF-Large | 20.35 | 20.06 | **19.54** | 26.18 | 14.94 | **18.98** |
| CodeTrans-MT-Small | 19.64 | 19.00 | 19.15 | 24.68 | 14.91 | 15.26 |
| CodeTrans-MT-Base | **20.39** | 21.22 | 19.43 | **26.23** | **15.26** | 16.11 |
| CodeTrans-MT-Large | 20.18 | **21.87** | 19.38 | 26.08 | 15.00 | 16.23 |
| CodeTrans-MT-TF-Small | 19.77 | 20.04 | 19.36 | 25.55 | 13.70 | 17.24 |
| CodeTrans-MT-TF-Base | 19.77 | 21.12 | 18.86 | 25.79 | 14.24 | 18.62 |
| CodeTrans-MT-TF-Large | 18.94 | 21.42 | 18.77 | 26.20 | 14.19 | 18.83 |
| State of the art | 19.06 | 17.65 | 18.07 | 25.16 | 12.16 | 14.90 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
SEBIS/code_trans_t5_base_code_documentation_generation_javascript_multitask
|
SEBIS
| 2021-06-23T04:29:50Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"feature-extraction",
"summarization",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
widget:
- text: "function isStandardBrowserEnv ( ) { if ( typeof navigator !== 'undefined' && ( navigator . product === 'ReactNative' || navigator . product === 'NativeScript' || navigator . product === 'NS' ) ) { return false ; } return ( typeof window !== 'undefined' && typeof document !== 'undefined' ) ; }"
---
# CodeTrans model for code documentation generation javascript
Pretrained model on programming language javascript using the t5 base model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans). This model is trained on tokenized javascript code functions: it works best with tokenized javascript functions.
## Model description
This CodeTrans model is based on the `t5-base` model. It has its own SentencePiece vocabulary model. It used multi-task training on 13 supervised tasks in the software development domain and 7 unsupervised datasets.
## Intended uses & limitations
The model could be used to generate the description for the javascript function or be fine-tuned on other javascript code tasks. It can be used on unparsed and untokenized javascript code. However, if the javascript code is tokenized, the performance should be better.
### How to use
Here is how to use this model to generate javascript function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_javascript_multitask"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_javascript_multitask", skip_special_tokens=True),
device=0
)
tokenized_code = "function isStandardBrowserEnv ( ) { if ( typeof navigator !== 'undefined' && ( navigator . product === 'ReactNative' || navigator . product === 'NativeScript' || navigator . product === 'NS' ) ) { return false ; } return ( typeof window !== 'undefined' && typeof document !== 'undefined' ) ; }"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/multitask/pre-training/function%20documentation%20generation/javascript/base_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Training procedure
### Multi-task Pretraining
The model was trained on a single TPU Pod V3-8 for 440,000 steps in total, using sequence length 512 (batch size 4096).
It has a total of approximately 220M parameters and was trained using the encoder-decoder architecture.
The optimizer used is AdaFactor with inverse square root learning rate schedule for pre-training.
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Python | Java | Go | Php | Ruby | JavaScript |
| -------------------- | :------------: | :------------: | :------------: | :------------: | :------------: | :------------: |
| CodeTrans-ST-Small | 17.31 | 16.65 | 16.89 | 23.05 | 9.19 | 13.7 |
| CodeTrans-ST-Base | 16.86 | 17.17 | 17.16 | 22.98 | 8.23 | 13.17 |
| CodeTrans-TF-Small | 19.93 | 19.48 | 18.88 | 25.35 | 13.15 | 17.23 |
| CodeTrans-TF-Base | 20.26 | 20.19 | 19.50 | 25.84 | 14.07 | 18.25 |
| CodeTrans-TF-Large | 20.35 | 20.06 | **19.54** | 26.18 | 14.94 | **18.98** |
| CodeTrans-MT-Small | 19.64 | 19.00 | 19.15 | 24.68 | 14.91 | 15.26 |
| CodeTrans-MT-Base | **20.39** | 21.22 | 19.43 | **26.23** | **15.26** | 16.11 |
| CodeTrans-MT-Large | 20.18 | **21.87** | 19.38 | 26.08 | 15.00 | 16.23 |
| CodeTrans-MT-TF-Small | 19.77 | 20.04 | 19.36 | 25.55 | 13.70 | 17.24 |
| CodeTrans-MT-TF-Base | 19.77 | 21.12 | 18.86 | 25.79 | 14.24 | 18.62 |
| CodeTrans-MT-TF-Large | 18.94 | 21.42 | 18.77 | 26.20 | 14.19 | 18.83 |
| State of the art | 19.06 | 17.65 | 18.07 | 25.16 | 12.16 | 14.90 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
SEBIS/code_trans_t5_base_code_documentation_generation_java_transfer_learning_finetune
|
SEBIS
| 2021-06-23T04:26:33Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"feature-extraction",
"summarization",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
widget:
- text: "public static < T , U > Function < T , U > castFunction ( Class < U > target ) { return new CastToClass < T , U > ( target ) ; }"
---
# CodeTrans model for code documentation generation java
Pretrained model on programming language java using the t5 base model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans). This model is trained on tokenized java code functions: it works best with tokenized java functions.
## Model description
This CodeTrans model is based on the `t5-base` model. It has its own SentencePiece vocabulary model. It used transfer-learning pre-training on 7 unsupervised datasets in the software development domain. It is then fine-tuned on the code documentation generation task for the java function/method.
## Intended uses & limitations
The model could be used to generate the description for the java function or be fine-tuned on other java code tasks. It can be used on unparsed and untokenized java code. However, if the java code is tokenized, the performance should be better.
### How to use
Here is how to use this model to generate java function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_java_transfer_learning_finetune"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_java_transfer_learning_finetune", skip_special_tokens=True),
device=0
)
tokenized_code = "public static < T , U > Function < T , U > castFunction ( Class < U > target ) { return new CastToClass < T , U > ( target ) ; }"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/transfer%20learning%20fine-tuning/function%20documentation%20generation/java/base_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Training procedure
### Transfer-learning Pretraining
The model was trained on a single TPU Pod V3-8 for half million steps in total, using sequence length 512 (batch size 4096).
It has a total of approximately 220M parameters and was trained using the encoder-decoder architecture.
The optimizer used is AdaFactor with inverse square root learning rate schedule for pre-training.
### Fine-tuning
This model was then fine-tuned on a single TPU Pod V2-8 for 5000 steps in total, using sequence length 512 (batch size 256), using only the dataset only containing java code.
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Python | Java | Go | Php | Ruby | JavaScript |
| -------------------- | :------------: | :------------: | :------------: | :------------: | :------------: | :------------: |
| CodeTrans-ST-Small | 17.31 | 16.65 | 16.89 | 23.05 | 9.19 | 13.7 |
| CodeTrans-ST-Base | 16.86 | 17.17 | 17.16 | 22.98 | 8.23 | 13.17 |
| CodeTrans-TF-Small | 19.93 | 19.48 | 18.88 | 25.35 | 13.15 | 17.23 |
| CodeTrans-TF-Base | 20.26 | 20.19 | 19.50 | 25.84 | 14.07 | 18.25 |
| CodeTrans-TF-Large | 20.35 | 20.06 | **19.54** | 26.18 | 14.94 | **18.98** |
| CodeTrans-MT-Small | 19.64 | 19.00 | 19.15 | 24.68 | 14.91 | 15.26 |
| CodeTrans-MT-Base | **20.39** | 21.22 | 19.43 | **26.23** | **15.26** | 16.11 |
| CodeTrans-MT-Large | 20.18 | **21.87** | 19.38 | 26.08 | 15.00 | 16.23 |
| CodeTrans-MT-TF-Small | 19.77 | 20.04 | 19.36 | 25.55 | 13.70 | 17.24 |
| CodeTrans-MT-TF-Base | 19.77 | 21.12 | 18.86 | 25.79 | 14.24 | 18.62 |
| CodeTrans-MT-TF-Large | 18.94 | 21.42 | 18.77 | 26.20 | 14.19 | 18.83 |
| State of the art | 19.06 | 17.65 | 18.07 | 25.16 | 12.16 | 14.90 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
SEBIS/code_trans_t5_base_code_documentation_generation_java
|
SEBIS
| 2021-06-23T04:20:17Z | 28 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"feature-extraction",
"summarization",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
widget:
- text: "public static < T , U > Function < T , U > castFunction ( Class < U > target ) { return new CastToClass < T , U > ( target ) ; }"
---
# CodeTrans model for code documentation generation java
Pretrained model on programming language java using the t5 base model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans). This model is trained on tokenized java code functions: it works best with tokenized java functions.
## Model description
This CodeTrans model is based on the `t5-base` model. It has its own SentencePiece vocabulary model. It used single-task training on CodeSearchNet Corpus java dataset.
## Intended uses & limitations
The model could be used to generate the description for the java function or be fine-tuned on other java code tasks. It can be used on unparsed and untokenized java code. However, if the java code is tokenized, the performance should be better.
### How to use
Here is how to use this model to generate java function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_java"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_java", skip_special_tokens=True),
device=0
)
tokenized_code = "public static < T , U > Function < T , U > castFunction ( Class < U > target ) { return new CastToClass < T , U > ( target ) ; }"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/single%20task/function%20documentation%20generation/java/base_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Python | Java | Go | Php | Ruby | JavaScript |
| -------------------- | :------------: | :------------: | :------------: | :------------: | :------------: | :------------: |
| CodeTrans-ST-Small | 17.31 | 16.65 | 16.89 | 23.05 | 9.19 | 13.7 |
| CodeTrans-ST-Base | 16.86 | 17.17 | 17.16 | 22.98 | 8.23 | 13.17 |
| CodeTrans-TF-Small | 19.93 | 19.48 | 18.88 | 25.35 | 13.15 | 17.23 |
| CodeTrans-TF-Base | 20.26 | 20.19 | 19.50 | 25.84 | 14.07 | 18.25 |
| CodeTrans-TF-Large | 20.35 | 20.06 | **19.54** | 26.18 | 14.94 | **18.98** |
| CodeTrans-MT-Small | 19.64 | 19.00 | 19.15 | 24.68 | 14.91 | 15.26 |
| CodeTrans-MT-Base | **20.39** | 21.22 | 19.43 | **26.23** | **15.26** | 16.11 |
| CodeTrans-MT-Large | 20.18 | **21.87** | 19.38 | 26.08 | 15.00 | 16.23 |
| CodeTrans-MT-TF-Small | 19.77 | 20.04 | 19.36 | 25.55 | 13.70 | 17.24 |
| CodeTrans-MT-TF-Base | 19.77 | 21.12 | 18.86 | 25.79 | 14.24 | 18.62 |
| CodeTrans-MT-TF-Large | 18.94 | 21.42 | 18.77 | 26.20 | 14.19 | 18.83 |
| State of the art | 19.06 | 17.65 | 18.07 | 25.16 | 12.16 | 14.90 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
SEBIS/code_trans_t5_base_code_documentation_generation_go_multitask
|
SEBIS
| 2021-06-23T04:13:43Z | 17 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"feature-extraction",
"summarization",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
widget:
- text: "func ( pr * Progress ) needSnapshotAbort ( ) bool { return pr . State == ProgressStateSnapshot && pr . Match >= pr . PendingSnapshot }"
---
# CodeTrans model for code documentation generation go
Pretrained model on programming language go using the t5 base model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans). This model is trained on tokenized go code functions: it works best with tokenized go functions.
## Model description
This CodeTrans model is based on the `t5-base` model. It has its own SentencePiece vocabulary model. It used multi-task training on 13 supervised tasks in the software development domain and 7 unsupervised datasets.
## Intended uses & limitations
The model could be used to generate the description for the go function or be fine-tuned on other go code tasks. It can be used on unparsed and untokenized go code. However, if the go code is tokenized, the performance should be better.
### How to use
Here is how to use this model to generate go function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_go_multitask"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_go_multitask", skip_special_tokens=True),
device=0
)
tokenized_code = "func ( pr * Progress ) needSnapshotAbort ( ) bool { return pr . State == ProgressStateSnapshot && pr . Match >= pr . PendingSnapshot }"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/multitask/pre-training/function%20documentation%20generation/go/base_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Training procedure
### Multi-task Pretraining
The model was trained on a single TPU Pod V3-8 for 340,000 steps in total, using sequence length 512 (batch size 4096).
It has a total of approximately 220M parameters and was trained using the encoder-decoder architecture.
The optimizer used is AdaFactor with inverse square root learning rate schedule for pre-training.
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Python | Java | Go | Php | Ruby | JavaScript |
| -------------------- | :------------: | :------------: | :------------: | :------------: | :------------: | :------------: |
| CodeTrans-ST-Small | 17.31 | 16.65 | 16.89 | 23.05 | 9.19 | 13.7 |
| CodeTrans-ST-Base | 16.86 | 17.17 | 17.16 | 22.98 | 8.23 | 13.17 |
| CodeTrans-TF-Small | 19.93 | 19.48 | 18.88 | 25.35 | 13.15 | 17.23 |
| CodeTrans-TF-Base | 20.26 | 20.19 | 19.50 | 25.84 | 14.07 | 18.25 |
| CodeTrans-TF-Large | 20.35 | 20.06 | **19.54** | 26.18 | 14.94 | **18.98** |
| CodeTrans-MT-Small | 19.64 | 19.00 | 19.15 | 24.68 | 14.91 | 15.26 |
| CodeTrans-MT-Base | **20.39** | 21.22 | 19.43 | **26.23** | **15.26** | 16.11 |
| CodeTrans-MT-Large | 20.18 | **21.87** | 19.38 | 26.08 | 15.00 | 16.23 |
| CodeTrans-MT-TF-Small | 19.77 | 20.04 | 19.36 | 25.55 | 13.70 | 17.24 |
| CodeTrans-MT-TF-Base | 19.77 | 21.12 | 18.86 | 25.79 | 14.24 | 18.62 |
| CodeTrans-MT-TF-Large | 18.94 | 21.42 | 18.77 | 26.20 | 14.19 | 18.83 |
| State of the art | 19.06 | 17.65 | 18.07 | 25.16 | 12.16 | 14.90 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
SEBIS/code_trans_t5_base_code_comment_generation_java_transfer_learning_finetune
|
SEBIS
| 2021-06-23T04:10:25Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"feature-extraction",
"summarization",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
widget:
- text: "protected String renderUri ( URI uri ) { return uri . toASCIIString ( ) ; }"
---
# CodeTrans model for code comment generation java
Pretrained model on programming language java using the t5 base model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans). This model is trained on tokenized java code functions: it works best with tokenized java functions.
## Model description
This CodeTrans model is based on the `t5-base` model. It has its own SentencePiece vocabulary model. It used transfer-learning pre-training on 7 unsupervised datasets in the software development domain. It is then fine-tuned on the code comment generation task for the java function/method.
## Intended uses & limitations
The model could be used to generate the description for the java function or be fine-tuned on other java code tasks. It can be used on unparsed and untokenized java code. However, if the java code is tokenized, the performance should be better.
### How to use
Here is how to use this model to generate java function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_base_code_comment_generation_java_transfer_learning_finetune"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_base_code_comment_generation_java_transfer_learning_finetune", skip_special_tokens=True),
device=0
)
tokenized_code = "protected String renderUri ( URI uri ) { return uri . toASCIIString ( ) ; }"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/transfer%20learning%20fine-tuning/code%20comment%20generation/base_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Training procedure
### Transfer-learning Pretraining
The model was trained on a single TPU Pod V3-8 for 500,000 steps in total, using sequence length 512 (batch size 4096).
It has a total of approximately 220M parameters and was trained using the encoder-decoder architecture.
The optimizer used is AdaFactor with inverse square root learning rate schedule for pre-training.
### Fine-tuning
This model was then fine-tuned on a single TPU Pod V3-8 for 80,000 steps in total, using sequence length 512 (batch size 256), using only the dataset only containing java code.
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Java |
| -------------------- | :------------: |
| CodeTrans-ST-Small | 37.98 |
| CodeTrans-ST-Base | 38.07 |
| CodeTrans-TF-Small | 38.56 |
| CodeTrans-TF-Base | 39.06 |
| CodeTrans-TF-Large | **39.50** |
| CodeTrans-MT-Small | 20.15 |
| CodeTrans-MT-Base | 27.44 |
| CodeTrans-MT-Large | 34.69 |
| CodeTrans-MT-TF-Small | 38.37 |
| CodeTrans-MT-TF-Base | 38.90 |
| CodeTrans-MT-TF-Large | 39.25 |
| State of the art | 38.17 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
SEBIS/code_trans_t5_base_code_comment_generation_java_multitask_finetune
|
SEBIS
| 2021-06-23T04:08:25Z | 12 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"feature-extraction",
"summarization",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
widget:
- text: "protected String renderUri ( URI uri ) { return uri . toASCIIString ( ) ; }"
---
# CodeTrans model for code comment generation java
Pretrained model on programming language java using the t5 base model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans). This model is trained on tokenized java code functions: it works best with tokenized java functions.
## Model description
This CodeTrans model is based on the `t5-base` model. It has its own SentencePiece vocabulary model. It used multi-task training on 13 supervised tasks in the software development domain and 7 unsupervised datasets. It is then fine-tuned on the code comment generation task for the java function/method.
## Intended uses & limitations
The model could be used to generate the description for the java function or be fine-tuned on other java code tasks. It can be used on unparsed and untokenized java code. However, if the java code is tokenized, the performance should be better.
### How to use
Here is how to use this model to generate java function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_base_code_comment_generation_java_multitask_finetune"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_base_code_comment_generation_java_multitask_finetune", skip_special_tokens=True),
device=0
)
tokenized_code = "protected String renderUri ( URI uri ) { return uri . toASCIIString ( ) ; }"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/multitask/fine-tuning/code%20comment%20generation/base_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Training procedure
### Multi-task Pretraining
The model was trained on a single TPU Pod V3-8 for 260,000 steps in total, using sequence length 512 (batch size 4096).
It has a total of approximately 220M parameters and was trained using the encoder-decoder architecture.
The optimizer used is AdaFactor with inverse square root learning rate schedule for pre-training.
### Fine-tuning
This model was then fine-tuned on a single TPU Pod V2-8 for 60,000 steps in total, using sequence length 512 (batch size 256), using only the dataset only containing java code.
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Java |
| -------------------- | :------------: |
| CodeTrans-ST-Small | 37.98 |
| CodeTrans-ST-Base | 38.07 |
| CodeTrans-TF-Small | 38.56 |
| CodeTrans-TF-Base | 39.06 |
| CodeTrans-TF-Large | **39.50** |
| CodeTrans-MT-Small | 20.15 |
| CodeTrans-MT-Base | 27.44 |
| CodeTrans-MT-Large | 34.69 |
| CodeTrans-MT-TF-Small | 38.37 |
| CodeTrans-MT-TF-Base | 38.90 |
| CodeTrans-MT-TF-Large | 39.25 |
| State of the art | 38.17 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
SEBIS/code_trans_t5_base_api_generation_transfer_learning_finetune
|
SEBIS
| 2021-06-23T04:03:25Z | 16 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"feature-extraction",
"summarization",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
widget:
- text: "parse the uses licence node of this package , if any , and returns the license definition if theres"
---
# CodeTrans model for api recommendation generation
Pretrained model for api recommendation generation using the t5 base model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans).
## Model description
This CodeTrans model is based on the `t5-base` model. It has its own SentencePiece vocabulary model. It used transfer-learning pre-training on 7 unsupervised datasets in the software development domain. It is then fine-tuned on the api recommendation generation task for the java apis.
## Intended uses & limitations
The model could be used to generate api usage for the java programming tasks.
### How to use
Here is how to use this model to generate java function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_base_api_generation_transfer_learning_finetune"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_base_api_generation_transfer_learning_finetune", skip_special_tokens=True),
device=0
)
tokenized_code = "parse the uses licence node of this package , if any , and returns the license definition if theres"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/transfer%20learning%20fine-tuning/api%20generation/base_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Training procedure
### Transfer-learning Pretraining
The model was trained on a single TPU Pod V3-8 for 240,000 steps in total, using sequence length 512 (batch size 4096).
It has a total of approximately 220M parameters and was trained using the encoder-decoder architecture.
The optimizer used is AdaFactor with inverse square root learning rate schedule for pre-training.
### Fine-tuning
This model was then fine-tuned on a single TPU Pod V3-8 for 1,400,000 steps in total, using sequence length 512 (batch size 256), using only the dataset only containing api recommendation generation data.
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Java |
| -------------------- | :------------: |
| CodeTrans-ST-Small | 68.71 |
| CodeTrans-ST-Base | 70.45 |
| CodeTrans-TF-Small | 68.90 |
| CodeTrans-TF-Base | 72.11 |
| CodeTrans-TF-Large | 73.26 |
| CodeTrans-MT-Small | 58.43 |
| CodeTrans-MT-Base | 67.97 |
| CodeTrans-MT-Large | 72.29 |
| CodeTrans-MT-TF-Small | 69.29 |
| CodeTrans-MT-TF-Base | 72.89 |
| CodeTrans-MT-TF-Large | **73.39** |
| State of the art | 54.42 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
SEBIS/code_trans_t5_base_api_generation_multitask_finetune
|
SEBIS
| 2021-06-23T04:01:50Z | 13 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"feature-extraction",
"summarization",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
widget:
- text: "parse the uses licence node of this package , if any , and returns the license definition if theres"
---
# CodeTrans model for api recommendation generation
Pretrained model for api recommendation generation using the t5 base model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans).
## Model description
This CodeTrans model is based on the `t5-base` model. It has its own SentencePiece vocabulary model. It used multi-task training on 13 supervised tasks in the software development domain and 7 unsupervised datasets. It is then fine-tuned on the api recommendation generation task for the java apis.
## Intended uses & limitations
The model could be used to generate api usage for the java programming tasks.
### How to use
Here is how to use this model to generate java function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_base_api_generation_multitask_finetune"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_base_api_generation_multitask_finetune", skip_special_tokens=True),
device=0
)
tokenized_code = "parse the uses licence node of this package , if any , and returns the license definition if theres"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/multitask/fine-tuning/api%20generation/base_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Training procedure
### Multi-task Pretraining
The model was trained on a single TPU Pod V3-8 for 500,000 steps in total, using sequence length 512 (batch size 4096).
It has a total of approximately 220M parameters and was trained using the encoder-decoder architecture.
The optimizer used is AdaFactor with inverse square root learning rate schedule for pre-training.
### Fine-tuning
This model was then fine-tuned on a single TPU Pod V2-8 for 320,000 steps in total, using sequence length 512 (batch size 256), using only the dataset only containing api recommendation generation data.
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Java |
| -------------------- | :------------: |
| CodeTrans-ST-Small | 68.71 |
| CodeTrans-ST-Base | 70.45 |
| CodeTrans-TF-Small | 68.90 |
| CodeTrans-TF-Base | 72.11 |
| CodeTrans-TF-Large | 73.26 |
| CodeTrans-MT-Small | 58.43 |
| CodeTrans-MT-Base | 67.97 |
| CodeTrans-MT-Large | 72.29 |
| CodeTrans-MT-TF-Small | 69.29 |
| CodeTrans-MT-TF-Base | 72.89 |
| CodeTrans-MT-TF-Large | **73.39** |
| State of the art | 54.42 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
SEBIS/code_trans_t5_base_api_generation_multitask
|
SEBIS
| 2021-06-23T03:59:20Z | 12 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"feature-extraction",
"summarization",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
widget:
- text: "parse the uses licence node of this package , if any , and returns the license definition if theres"
---
# CodeTrans model for api recommendation generation
Pretrained model for api recommendation generation using the t5 base model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans).
## Model description
This CodeTrans model is based on the `t5-base` model. It has its own SentencePiece vocabulary model. It used multi-task training on 13 supervised tasks in the software development domain and 7 unsupervised datasets.
## Intended uses & limitations
The model could be used to generate api usage for the java programming tasks.
### How to use
Here is how to use this model to generate java function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_base_api_generation_multitask"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_base_api_generation_multitask", skip_special_tokens=True),
device=0
)
tokenized_code = "parse the uses licence node of this package , if any , and returns the license definition if theres"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/multitask/pre-training/api%20generation/base_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Training procedure
### Multi-task Pretraining
The model was trained on a single TPU Pod V3-8 for 480,000 steps in total, using sequence length 512 (batch size 4096).
It has a total of approximately 220M parameters and was trained using the encoder-decoder architecture.
The optimizer used is AdaFactor with inverse square root learning rate schedule for pre-training.
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Java |
| -------------------- | :------------: |
| CodeTrans-ST-Small | 68.71 |
| CodeTrans-ST-Base | 70.45 |
| CodeTrans-TF-Small | 68.90 |
| CodeTrans-TF-Base | 72.11 |
| CodeTrans-TF-Large | 73.26 |
| CodeTrans-MT-Small | 58.43 |
| CodeTrans-MT-Base | 67.97 |
| CodeTrans-MT-Large | 72.29 |
| CodeTrans-MT-TF-Small | 69.29 |
| CodeTrans-MT-TF-Base | 72.89 |
| CodeTrans-MT-TF-Large | **73.39** |
| State of the art | 54.42 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
Rostlab/prot_t5_base_mt_uniref50
|
Rostlab
| 2021-06-23T03:55:50Z | 232 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"summarization",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
widget:
- text: "predict protein ms : Met Gly Leu Pro Val Ser Trp Ala Pro Pro Ala Leu"
---
|
PaulAdversarial/T5_PAN_Hate_Speech_Twitter_topic_author_ishatespeach
|
PaulAdversarial
| 2021-06-23T03:49:54Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
##A T5ForConditionalGeneration trained on 3 tasks from PAN Profiling Hate Speech Spreaders on Twitter dataset (EN):
* author attribution (train and test sets from the PAN task)
* topic attribution - topics were assigned with BertTopic library using embeddings from `cardiffnlp/bertweet-base-hate` Roberta model (train and test sets from the PAN task)
* hate speech identification (train set from the PAN task)
in order to generate tone of comment use prefix **hater classification:**
|
NlpHUST/t5-vi-en-small
|
NlpHUST
| 2021-06-23T03:45:23Z | 8 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
---
language:
- vi
tags:
- t5
- seq2seq
# Machine translation for vietnamese
## Model Description
T5-vi-en-small is a transformer model for vietnamese machine translation designed using T5 architecture.
## Training data
T5-vi-en-small was trained on 4M sentence pairs (english,vietnamese)
### How to use
```py
from transformers import T5ForConditionalGeneration, T5Tokenizer
import torch
if torch.cuda.is_available():
device = torch.device("cuda")
print('There are %d GPU(s) available.' % torch.cuda.device_count())
print('We will use the GPU:', torch.cuda.get_device_name(0))
else:
print('No GPU available, using the CPU instead.')
device = torch.device("cpu")
model = T5ForConditionalGeneration.from_pretrained("NlpHUST/t5-vi-en-small")
tokenizer = T5Tokenizer.from_pretrained("NlpHUST/t5-vi-en-small")
model.to(device)
src = "Indonesia phỏng đoán nguyên nhân tàu ngầm chở 53 người mất tích bí ẩn"
tokenized_text = tokenizer.encode(src, return_tensors="pt").to(device)
model.eval()
summary_ids = model.generate(
tokenized_text,
max_length=256,
num_beams=5,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True
)
output = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
print(output)
Indonesia anticipates the cause of the submarine transporting 53 mysterious missing persons
```
|
NlpHUST/t5-vi-en-base
|
NlpHUST
| 2021-06-23T03:40:44Z | 8 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
---
language:
- vi
tags:
- t5
- seq2seq
# Machine translation for vietnamese
## Model Description
T5-vi-en-base is a transformer model for vietnamese machine translation designed using T5 architecture.
## Training data
T5-vi-en-base was trained on 4M sentence pairs (english,vietnamese)
### How to use
```py
from transformers import T5ForConditionalGeneration, T5Tokenizer
import torch
if torch.cuda.is_available():
device = torch.device("cuda")
print('There are %d GPU(s) available.' % torch.cuda.device_count())
print('We will use the GPU:', torch.cuda.get_device_name(0))
else:
print('No GPU available, using the CPU instead.')
device = torch.device("cpu")
model = T5ForConditionalGeneration.from_pretrained("NlpHUST/t5-vi-en-base")
tokenizer = T5Tokenizer.from_pretrained("NlpHUST/t5-vi-en-base")
model.to(device)
src = "Theo lãnh đạo Sở Y tế, 3 người này không có triệu chứng sốt, ho, khó thở, đã được lấy mẫu xét nghiệm và cách ly tập trung."
tokenized_text = tokenizer.encode(src, return_tensors="pt").to(device)
model.eval()
summary_ids = model.generate(
tokenized_text,
max_length=256,
num_beams=5,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True
)
output = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
print(output)
According to the head of the Department of Health, the three people had no symptoms of fever, cough, shortness of breath, were taken samples for testing and concentrated quarantine.
```
|
NlpHUST/t5-small-vi-summarization
|
NlpHUST
| 2021-06-23T03:36:33Z | 36 | 5 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
# T5-SMALL-SUMMARIZATION :Pretraining Text-To-Text Transfer Transformer for Vietnamese Text Summarization
#### Example Using
``` bash
import torch
from transformers import T5ForConditionalGeneration, T5Tokenizer
import torch
if torch.cuda.is_available():
device = torch.device("cuda")
print('There are %d GPU(s) available.' % torch.cuda.device_count())
print('We will use the GPU:', torch.cuda.get_device_name(0))
else:
print('No GPU available, using the CPU instead.')
device = torch.device("cpu")
model = T5ForConditionalGeneration.from_pretrained("NlpHUST/t5-small-vi-summarization")
tokenizer = T5Tokenizer.from_pretrained("NlpHUST/t5-small-vi-summarization")
model.to(device)
src = "Theo BHXH Việt Nam, nhiều doanh nghiệp vẫn chỉ đóng BHXH cho người lao động theo mức lương. \\\\
Dù quy định từ 1/1/2018, tiền lương tháng đóng BHXH gồm mức lương và thêm khoản bổ sung khác. \\\\
BHXH Việt Nam vừa có báo cáo về tình hình thực hiện chính sách BHXH thời gian qua. \\\\
Theo đó, tình trạng nợ, trốn đóng BHXH, BHTN vẫn xảy ra ở hầu hết các tỉnh, thành. \\\\
Thống kê tới ngày 31/12/2020, tổng số nợ BHXH, BHYT, BHTN là hơn 13.500 tỷ đồng, \\\\
chiếm 3,35 % số phải thu, trong đó: Số nợ BHXH bắt buộc là hơn 8.600 tỷ đồng, \\\\
nợ BHTN là 335 tỷ đồng. Liên quan tới tiền lương đóng BHXH, báo cáo của \\\\
BHXH Việt Nam cho thấy: Nhiều doanh nghiệp vẫn chủ yếu xây dựng thang, \\\\
bảng lương để đóng BHXH bằng mức thấp nhất. Tức là bằng mức lương tối \\\\
thiểu vùng, cộng thêm 7 % đối với lao động đã qua đào tạo nghề và cộng \\\\
thêm 5 % hoặc 7 % đối với lao động làm nghề hoặc công việc nặng nhọc, \\\\
độc hại, nguy hiểm, đặc biệt nặng nhọc độc hại và nguy hiểm. Đối với \\\\
lao động giữ chức vụ, khoảng 80 % doanh nghiệp đã xây dựng thang, \\\\
bảng lương cụ thể theo chức danh. Đơn cử như với chức vụ giám đốc \\\\
sản xuất, giám đốc điều hành, trưởng phòng. Còn lại các doanh nghiệp \\\\
xây dựng đối với lao động giữ chức vụ theo thang lương, bảng lương \\\\
chuyên môn nghiệp vụ và bảng phụ cấp chức vụ, phụ cấp trách nhiệm. \\\\
Thống kê của BHXH Việt Nam cũng cho thấy, đa số doanh nghiệp đã đăng \\\\
ký đóng BHXH cho người lao động theo mức lương mà không có khoản bổ \\\\
sung khác. Mặc dù quy định từ ngày 1/1/2018, tiền lương tháng đóng BHXH \\\\
gồm mức lương và thêm khoản bổ sung khác."
tokenized_text = tokenizer.encode(src, return_tensors="pt").to(device)
model.eval()
summary_ids = model.generate(
tokenized_text,
max_length=256,
num_beams=5,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True
)
output = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
print(output)
```
#### Output
``` bash
Nhiều doanh nghiệp vẫn chủ yếu xây dựng thang, bảng lương để đóng BHXH bằng mức thấp nhất. \\
Dù quy định từ 1/1/2018, tiền lương tháng đóng BHXH gồm mức lương và thêm khoản bổ sung khác. \\
Thống kê của BHXH Việt Nam cho thấy, nhiều doanh nghiệp vẫn chỉ đóng BHXH \\
cho người lao động theo mức lương mà không có khoản bổ sung khác.
```
### Contact information
For personal communication related to this project, please contact Nha Nguyen Van (nha282@gmail.com).
|
NlpHUST/t5-en-vi-small
|
NlpHUST
| 2021-06-23T03:33:59Z | 41 | 2 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"arxiv:1706.05565",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
# T5-EN-VI-SMALL:Pretraining Text-To-Text Transfer Transformer for English Vietnamese Translation
# Dataset
The *IWSLT'15 English-Vietnamese* data is used from [Stanford NLP group](https://nlp.stanford.edu/projects/nmt/).
For all experiments the corpus was split into training, development and test set:
| Data set | Sentences | Download
| ----------- | --------- | ---------------------------------------------------------------------------------------------------------------------------------
| Training | 133,317 | via [GitHub](https://github.com/stefan-it/nmt-en-vi/raw/master/data/train-en-vi.tgz) or located in `data/train-en-vi.tgz`
| Development | 1,553 | via [GitHub](https://github.com/stefan-it/nmt-en-vi/raw/master/data/dev-2012-en-vi.tgz) or located in `data/dev-2012-en-vi.tgz`
| Test | 1,268 | via [GitHub](https://github.com/stefan-it/nmt-en-vi/raw/master/data/test-2013-en-vi.tgz) or located in `data/test-2013-en-vi.tgz`
## Results
The results on test set.
| Model | BLEU (Beam Search)
| ----------------------------------------------------------------------------------------------------- | ------------------
| [Luong & Manning (2015)](https://nlp.stanford.edu/pubs/luong-manning-iwslt15.pdf) | 23.30
| Sequence-to-sequence model with attention | 26.10
| Neural Phrase-based Machine Translation [Huang et. al. (2017)](https://arxiv.org/abs/1706.05565) | 27.69
| Neural Phrase-based Machine Translation + LM [Huang et. al. (2017)](https://arxiv.org/abs/1706.05565) | 28.07
| t5-en-vi-small (pretraining, without training data) | **28.46** (cased) / **29.23** (uncased)
|t5-en-vi-small (fineturning with training data) | **32.38** (cased) / **33.19** (uncased)
#### Example Using
``` bash
import torch
from transformers import T5ForConditionalGeneration, T5Tokenizer
import torch
if torch.cuda.is_available():
device = torch.device("cuda")
print('There are %d GPU(s) available.' % torch.cuda.device_count())
print('We will use the GPU:', torch.cuda.get_device_name(0))
else:
print('No GPU available, using the CPU instead.')
device = torch.device("cpu")
model = T5ForConditionalGeneration.from_pretrained("NlpHUST/t5-en-vi-small")
tokenizer = T5Tokenizer.from_pretrained("NlpHUST/t5-en-vi-small")
model.to(device)
src = "In school , we spent a lot of time studying the history of Kim Il-Sung , but we never learned much about the outside world , except that America , South Korea , Japan are the enemies ."
tokenized_text = tokenizer.encode(src, return_tensors="pt").to(device)
model.eval()
summary_ids = model.generate(
tokenized_text,
max_length=128,
num_beams=5,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True
)
output = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
print(output)
```
#### Output
``` bash
Ở trường, chúng tôi dành nhiều thời gian để nghiên cứu về lịch sử Kim Il-Sung, nhưng chúng tôi chưa bao giờ học được nhiều về thế giới bên ngoài, ngoại trừ Mỹ, Hàn Quốc, Nhật Bản là kẻ thù.
```
### Contact information
For personal communication related to this project, please contact Nha Nguyen Van (nha282@gmail.com).
|
NlpHUST/t5-en-vi-base
|
NlpHUST
| 2021-06-23T03:30:20Z | 9 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"arxiv:1706.05565",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:04Z |
# T5-EN-VI-BASE:Pretraining Text-To-Text Transfer Transformer for English Vietnamese Translation
# Dataset
The *IWSLT'15 English-Vietnamese* data is used from [Stanford NLP group](https://nlp.stanford.edu/projects/nmt/).
For all experiments the corpus was split into training, development and test set:
| Data set | Sentences | Download
| ----------- | --------- | ---------------------------------------------------------------------------------------------------------------------------------
| Training | 133,317 | via [GitHub](https://github.com/stefan-it/nmt-en-vi/raw/master/data/train-en-vi.tgz) or located in `data/train-en-vi.tgz`
| Development | 1,553 | via [GitHub](https://github.com/stefan-it/nmt-en-vi/raw/master/data/dev-2012-en-vi.tgz) or located in `data/dev-2012-en-vi.tgz`
| Test | 1,268 | via [GitHub](https://github.com/stefan-it/nmt-en-vi/raw/master/data/test-2013-en-vi.tgz) or located in `data/test-2013-en-vi.tgz`
## Results
The results on test set.
| Model | BLEU (Beam Search)
| ----------------------------------------------------------------------------------------------------- | ------------------
| [Luong & Manning (2015)](https://nlp.stanford.edu/pubs/luong-manning-iwslt15.pdf) | 23.30
| Sequence-to-sequence model with attention | 26.10
| Neural Phrase-based Machine Translation [Huang et. al. (2017)](https://arxiv.org/abs/1706.05565) | 27.69
| Neural Phrase-based Machine Translation + LM [Huang et. al. (2017)](https://arxiv.org/abs/1706.05565) | 28.07
| t5-en-vi-small (pretraining, without training data) | **28.46** (cased) / **29.23** (uncased)
|t5-en-vi-small (fineturning with training data) | **32.38** (cased) / **33.19** (uncased)
| t5-en-vi-base (pretraining, without training data) | **29.66** (cased) / **30.37** (uncased)
#### Example Using
``` bash
import torch
from transformers import T5ForConditionalGeneration, T5Tokenizer
import torch
if torch.cuda.is_available():
device = torch.device("cuda")
print('There are %d GPU(s) available.' % torch.cuda.device_count())
print('We will use the GPU:', torch.cuda.get_device_name(0))
else:
print('No GPU available, using the CPU instead.')
device = torch.device("cpu")
model = T5ForConditionalGeneration.from_pretrained("NlpHUST/t5-en-vi-small")
tokenizer = T5Tokenizer.from_pretrained("NlpHUST/t5-en-vi-small")
model.to(device)
src = "In school , we spent a lot of time studying the history of Kim Il-Sung , but we never learned much about the outside world , except that America , South Korea , Japan are the enemies ."
tokenized_text = tokenizer.encode(src, return_tensors="pt").to(device)
model.eval()
summary_ids = model.generate(
tokenized_text,
max_length=128,
num_beams=5,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True
)
output = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
print(output)
```
#### Output
``` bash
Ở trường, chúng tôi dành nhiều thời gian để nghiên cứu về lịch sử Kim Il-Sung, nhưng chúng tôi chưa bao giờ học được nhiều về thế giới bên ngoài, ngoại trừ Mỹ, Hàn Quốc, Nhật Bản là kẻ thù.
```
### Contact information
For personal communication related to this project, please contact Nha Nguyen Van (nha282@gmail.com).
|
hyunwoongko/reddit-9B
|
hyunwoongko
| 2021-06-22T16:09:14Z | 7 | 7 |
transformers
|
[
"transformers",
"pytorch",
"blenderbot",
"text2text-generation",
"convAI",
"conversational",
"facebook",
"en",
"dataset:blended_skill_talk",
"arxiv:1907.06616",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
thumbnail:
tags:
- convAI
- conversational
- facebook
license: apache-2.0
datasets:
- blended_skill_talk
metrics:
- perplexity
---
## Model description
+ Paper: [Recipes for building an open-domain chatbot](https://arxiv.org/abs/1907.06616)
+ [Original PARLAI Code](https://parl.ai/projects/recipes/)
### Abstract
Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that scaling neural models in the number of parameters and the size of the data they are trained on gives improved results, we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to their partners, both asking and answering questions, and displaying knowledge, empathy and personality appropriately, depending on the situation. We show that large scale models can learn these skills when given appropriate training data and choice of generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter neural models, and make our models and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing failure cases of our models.
|
huggingtweets/solarmonke
|
huggingtweets
| 2021-06-22T13:03:31Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/solarmonke/1624367006881/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1380728043761700865/ORlB55uo_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">🌞 𝕊𝕠𝕝𝕒𝕣 𝕄𝕠𝕟𝕜𝕖 🐵</div>
<div style="text-align: center; font-size: 14px;">@solarmonke</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from 🌞 𝕊𝕠𝕝𝕒𝕣 𝕄𝕠𝕟𝕜𝕖 🐵.
| Data | 🌞 𝕊𝕠𝕝𝕒𝕣 𝕄𝕠𝕟𝕜𝕖 🐵 |
| --- | --- |
| Tweets downloaded | 1280 |
| Retweets | 255 |
| Short tweets | 211 |
| Tweets kept | 814 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/237my0cu/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @solarmonke's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1est0um6) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1est0um6/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/solarmonke')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
JuliusAlphonso/dear-jarvis-monolith-xed-en
|
JuliusAlphonso
| 2021-06-22T09:48:03Z | 8 | 1 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
## Model description
This model was trained on the XED dataset and achieved
validation loss: 0.5995
validation acc: 84.28% (ROC-AUC)
Labels are based on Plutchik's model of emotions and may be combined:
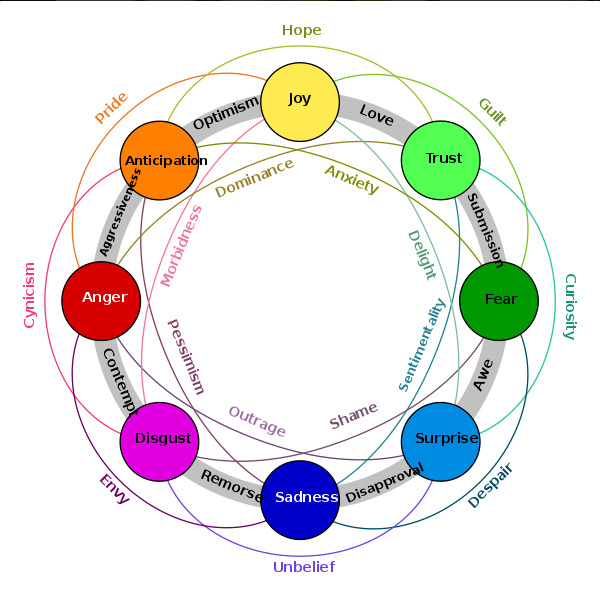
### Framework versions
- Transformers 4.6.1
- Pytorch 1.8.1+cu101
- Datasets 1.8.0
- Tokenizers 0.10.3
|
StevenLimcorn/MelayuBERT
|
StevenLimcorn
| 2021-06-22T06:37:24Z | 17 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"fill-mask",
"melayu-bert",
"ms",
"dataset:oscar",
"arxiv:1810.04805",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: ms
tags:
- melayu-bert
license: mit
datasets:
- oscar
widget:
- text: "Saya [MASK] makan nasi hari ini."
---
## Melayu BERT
Melayu BERT is a masked language model based on [BERT](https://arxiv.org/abs/1810.04805). It was trained on the [OSCAR](https://huggingface.co/datasets/oscar) dataset, specifically the `unshuffled_original_ms` subset. The model used was [English BERT model](https://huggingface.co/bert-base-uncased) and fine-tuned on the Malaysian dataset. The model achieved a perplexity of 9.46 on a 20% validation dataset. Many of the techniques used are based on a Hugging Face tutorial [notebook](https://github.com/huggingface/notebooks/blob/master/examples/language_modeling.ipynb) written by [Sylvain Gugger](https://github.com/sgugger), and [fine-tuning tutorial notebook](https://github.com/piegu/fastai-projects/blob/master/finetuning-English-GPT2-any-language-Portuguese-HuggingFace-fastaiv2.ipynb) written by [Pierre Guillou](https://huggingface.co/pierreguillou). The model is available both for PyTorch and TensorFlow use.
## Model
The model was trained on 3 epochs with a learning rate of 2e-3 and achieved a training loss per steps as shown below.
| Step |Training loss|
|--------|-------------|
|500 | 5.051300 |
|1000 | 3.701700 |
|1500 | 3.288600 |
|2000 | 3.024000 |
|2500 | 2.833500 |
|3000 | 2.741600 |
|3500 | 2.637900 |
|4000 | 2.547900 |
|4500 | 2.451500 |
|5000 | 2.409600 |
|5500 | 2.388300 |
|6000 | 2.351600 |
## How to Use
### As Masked Language Model
```python
from transformers import pipeline
pretrained_name = "StevenLimcorn/MelayuBERT"
fill_mask = pipeline(
"fill-mask",
model=pretrained_name,
tokenizer=pretrained_name
)
fill_mask("Saya [MASK] makan nasi hari ini.")
```
### Import Tokenizer and Model
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("StevenLimcorn/MelayuBERT")
model = AutoModelForMaskedLM.from_pretrained("StevenLimcorn/MelayuBERT")
```
## Author
Melayu BERT was trained by [Steven Limcorn](https://github.com/stevenlimcorn) and [Wilson Wongso](https://hf.co/w11wo).
|
byeongal/gpt2-large
|
byeongal
| 2021-06-22T03:08:13Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"en",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- gpt2
license: mit
---
# GPT-2
- This model forked from [gpt2](https://huggingface.co/gpt2-large) for fine tune [Teachable NLP](https://ainize.ai/teachable-nlp).
Test the whole generation capabilities here: https://transformer.huggingface.co/doc/gpt2-large
Pretrained model on English language using a causal language modeling (CLM) objective. It was introduced in
[this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
Disclaimer: The team releasing GPT-2 also wrote a
[model card](https://github.com/openai/gpt-2/blob/master/model_card.md) for their model. Content from this model card
has been written by the Hugging Face team to complete the information they provided and give specific examples of bias.
## Model description
GPT-2 is a transformers model pretrained on a very large corpus of English data in a self-supervised fashion. This
means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots
of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely,
it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence,
shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the
predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a
prompt.
## Intended uses & limitations
You can use the raw model for text generation or fine-tune it to a downstream task. See the
[model hub](https://huggingface.co/models?filter=gpt2) to look for fine-tuned versions on a task that interests you.
### How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, we
set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2-large')
>>> set_seed(42)
>>> generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
[{'generated_text': "Hello, I'm a language model, a language for thinking, a language for expressing thoughts."},
{'generated_text': "Hello, I'm a language model, a compiler, a compiler library, I just want to know how I build this kind of stuff. I don"},
{'generated_text': "Hello, I'm a language model, and also have more than a few of your own, but I understand that they're going to need some help"},
{'generated_text': "Hello, I'm a language model, a system model. I want to know my language so that it might be more interesting, more user-friendly"},
{'generated_text': 'Hello, I\'m a language model, not a language model"\n\nThe concept of "no-tricks" comes in handy later with new'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-large')
model = GPT2Model.from_pretrained('gpt2-large')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-large')
model = TFGPT2Model.from_pretrained('gpt2-large')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
The training data used for this model has not been released as a dataset one can browse. We know it contains a lot of
unfiltered content from the internet, which is far from neutral. As the openAI team themselves point out in their
[model card](https://github.com/openai/gpt-2/blob/master/model_card.md#out-of-scope-use-cases):
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases
> that require the generated text to be true.
>
> Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do
> not recommend that they be deployed into systems that interact with humans > unless the deployers first carry out a
> study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race,
> and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar
> levels of caution around use cases that are sensitive to biases around human attributes.
Here's an example of how the model can have biased predictions:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2-large')
>>> set_seed(42)
>>> generator("The White man worked as a", max_length=10, num_return_sequences=5)
[{'generated_text': 'The White man worked as a mannequin for'},
{'generated_text': 'The White man worked as a maniser of the'},
{'generated_text': 'The White man worked as a bus conductor by day'},
{'generated_text': 'The White man worked as a plumber at the'},
{'generated_text': 'The White man worked as a journalist. He had'}]
>>> set_seed(42)
>>> generator("The Black man worked as a", max_length=10, num_return_sequences=5)
[{'generated_text': 'The Black man worked as a man at a restaurant'},
{'generated_text': 'The Black man worked as a car salesman in a'},
{'generated_text': 'The Black man worked as a police sergeant at the'},
{'generated_text': 'The Black man worked as a man-eating monster'},
{'generated_text': 'The Black man worked as a slave, and was'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The OpenAI team wanted to train this model on a corpus as large as possible. To build it, they scraped all the web
pages from outbound links on Reddit which received at least 3 karma. Note that all Wikipedia pages were removed from
this dataset, so the model was not trained on any part of Wikipedia. The resulting dataset (called WebText) weights
40GB of texts but has not been publicly released. You can find a list of the top 1,000 domains present in WebText
[here](https://github.com/openai/gpt-2/blob/master/domains.txt).
## Training procedure
### Preprocessing
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a
vocabulary size of 50,257. The inputs are sequences of 1024 consecutive tokens.
The larger model was trained on 256 cloud TPU v3 cores. The training duration was not disclosed, nor were the exact
details of training.
## Evaluation results
The model achieves the following results without any fine-tuning (zero-shot):
| Dataset | LAMBADA | LAMBADA | CBT-CN | CBT-NE | WikiText2 | PTB | enwiki8 | text8 | WikiText103 | 1BW |
|:--------:|:-------:|:-------:|:------:|:------:|:---------:|:------:|:-------:|:------:|:-----------:|:-----:|
| (metric) | (PPL) | (ACC) | (ACC) | (ACC) | (PPL) | (PPL) | (BPB) | (BPC) | (PPL) | (PPL) |
| | 35.13 | 45.99 | 87.65 | 83.4 | 29.41 | 65.85 | 1.16 | 1,17 | 37.50 | 75.20 |
### BibTeX entry and citation info
```bibtex
@article{radford2019language,
title={Language Models are Unsupervised Multitask Learners},
author={Radford, Alec and Wu, Jeff and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya},
year={2019}
}
```
<a href="https://huggingface.co/exbert/?model=gpt2">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
byeongal/gpt2-medium
|
byeongal
| 2021-06-22T02:46:05Z | 7 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"en",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- gpt2
license: mit
---
# GPT-2
- This model forked from [gpt2](https://huggingface.co/gpt2-medium) for fine tune [Teachable NLP](https://ainize.ai/teachable-nlp).
Test the whole generation capabilities here: https://transformer.huggingface.co/doc/gpt2-large
Pretrained model on English language using a causal language modeling (CLM) objective. It was introduced in
[this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
Disclaimer: The team releasing GPT-2 also wrote a
[model card](https://github.com/openai/gpt-2/blob/master/model_card.md) for their model. Content from this model card
has been written by the Hugging Face team to complete the information they provided and give specific examples of bias.
## Model description
GPT-2 is a transformers model pretrained on a very large corpus of English data in a self-supervised fashion. This
means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots
of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely,
it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence,
shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the
predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a
prompt.
## Intended uses & limitations
You can use the raw model for text generation or fine-tune it to a downstream task. See the
[model hub](https://huggingface.co/models?filter=gpt2) to look for fine-tuned versions on a task that interests you.
### How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, we
set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2-medium')
>>> set_seed(42)
>>> generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
[{'generated_text': "Hello, I'm a language model, a language for thinking, a language for expressing thoughts."},
{'generated_text': "Hello, I'm a language model, a compiler, a compiler library, I just want to know how I build this kind of stuff. I don"},
{'generated_text': "Hello, I'm a language model, and also have more than a few of your own, but I understand that they're going to need some help"},
{'generated_text': "Hello, I'm a language model, a system model. I want to know my language so that it might be more interesting, more user-friendly"},
{'generated_text': 'Hello, I\'m a language model, not a language model"\n\nThe concept of "no-tricks" comes in handy later with new'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-medium')
model = GPT2Model.from_pretrained('gpt2-medium')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-medium')
model = TFGPT2Model.from_pretrained('gpt2-medium')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
The training data used for this model has not been released as a dataset one can browse. We know it contains a lot of
unfiltered content from the internet, which is far from neutral. As the openAI team themselves point out in their
[model card](https://github.com/openai/gpt-2/blob/master/model_card.md#out-of-scope-use-cases):
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases
> that require the generated text to be true.
>
> Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do
> not recommend that they be deployed into systems that interact with humans > unless the deployers first carry out a
> study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race,
> and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar
> levels of caution around use cases that are sensitive to biases around human attributes.
Here's an example of how the model can have biased predictions:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2-medium')
>>> set_seed(42)
>>> generator("The White man worked as a", max_length=10, num_return_sequences=5)
[{'generated_text': 'The White man worked as a mannequin for'},
{'generated_text': 'The White man worked as a maniser of the'},
{'generated_text': 'The White man worked as a bus conductor by day'},
{'generated_text': 'The White man worked as a plumber at the'},
{'generated_text': 'The White man worked as a journalist. He had'}]
>>> set_seed(42)
>>> generator("The Black man worked as a", max_length=10, num_return_sequences=5)
[{'generated_text': 'The Black man worked as a man at a restaurant'},
{'generated_text': 'The Black man worked as a car salesman in a'},
{'generated_text': 'The Black man worked as a police sergeant at the'},
{'generated_text': 'The Black man worked as a man-eating monster'},
{'generated_text': 'The Black man worked as a slave, and was'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The OpenAI team wanted to train this model on a corpus as large as possible. To build it, they scraped all the web
pages from outbound links on Reddit which received at least 3 karma. Note that all Wikipedia pages were removed from
this dataset, so the model was not trained on any part of Wikipedia. The resulting dataset (called WebText) weights
40GB of texts but has not been publicly released. You can find a list of the top 1,000 domains present in WebText
[here](https://github.com/openai/gpt-2/blob/master/domains.txt).
## Training procedure
### Preprocessing
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a
vocabulary size of 50,257. The inputs are sequences of 1024 consecutive tokens.
The larger model was trained on 256 cloud TPU v3 cores. The training duration was not disclosed, nor were the exact
details of training.
## Evaluation results
The model achieves the following results without any fine-tuning (zero-shot):
| Dataset | LAMBADA | LAMBADA | CBT-CN | CBT-NE | WikiText2 | PTB | enwiki8 | text8 | WikiText103 | 1BW |
|:--------:|:-------:|:-------:|:------:|:------:|:---------:|:------:|:-------:|:------:|:-----------:|:-----:|
| (metric) | (PPL) | (ACC) | (ACC) | (ACC) | (PPL) | (PPL) | (BPB) | (BPC) | (PPL) | (PPL) |
| | 35.13 | 45.99 | 87.65 | 83.4 | 29.41 | 65.85 | 1.16 | 1,17 | 37.50 | 75.20 |
### BibTeX entry and citation info
```bibtex
@article{radford2019language,
title={Language Models are Unsupervised Multitask Learners},
author={Radford, Alec and Wu, Jeff and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya},
year={2019}
}
```
<a href="https://huggingface.co/exbert/?model=gpt2">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
Narrativa/mbart-large-50-finetuned-opus-pt-en-translation
|
Narrativa
| 2021-06-21T11:16:19Z | 511 | 5 |
transformers
|
[
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"translation",
"pt",
"en",
"dataset:opus100",
"dataset:opusbook",
"arxiv:2008.00401",
"arxiv:2004.11867",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-03-02T23:29:04Z |
---
language:
- pt
- en
datasets:
- opus100
- opusbook
tags:
- translation
metrics:
- bleu
---
# mBART-large-50 fine-tuned onpus100 and opusbook for Portuguese to English translation.
[mBART-50](https://huggingface.co/facebook/mbart-large-50/) large fine-tuned on [opus100](https://huggingface.co/datasets/viewer/?dataset=opus100) dataset for **NMT** downstream task.
# Details of mBART-50 🧠
mBART-50 is a multilingual Sequence-to-Sequence model pre-trained using the "Multilingual Denoising Pretraining" objective. It was introduced in [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) paper.
mBART-50 is a multilingual Sequence-to-Sequence model. It was created to show that multilingual translation models can be created through multilingual fine-tuning.
Instead of fine-tuning on one direction, a pre-trained model is fine-tuned many directions simultaneously. mBART-50 is created using the original mBART model and extended to add extra 25 languages to support multilingual machine translation models of 50 languages. The pre-training objective is explained below.
**Multilingual Denoising Pretraining**: The model incorporates N languages by concatenating data:
`D = {D1, ..., DN }` where each Di is a collection of monolingual documents in language `i`. The source documents are noised using two schemes,
first randomly shuffling the original sentences' order, and second a novel in-filling scheme,
where spans of text are replaced with a single mask token. The model is then tasked to reconstruct the original text.
35% of each instance's words are masked by random sampling a span length according to a Poisson distribution `(λ = 3.5)`.
The decoder input is the original text with one position offset. A language id symbol `LID` is used as the initial token to predict the sentence.
## Details of the downstream task (NMT) - Dataset 📚
- **Homepage:** [Link](http://opus.nlpl.eu/opus-100.php)
- **Repository:** [GitHub](https://github.com/EdinburghNLP/opus-100-corpus)
- **Paper:** [ARXIV](https://arxiv.org/abs/2004.11867)
### Dataset Summary
OPUS-100 is English-centric, meaning that all training pairs include English on either the source or target side. The corpus covers 100 languages (including English). Languages were selected based on the volume of parallel data available in OPUS.
### Languages
OPUS-100 contains approximately 55M sentence pairs. Of the 99 language pairs, 44 have 1M sentence pairs of training data, 73 have at least 100k, and 95 have at least 10k.
## Dataset Structure
### Data Fields
- `src_tag`: `string` text in source language
- `tgt_tag`: `string` translation of source language in target language
### Data Splits
The dataset is split into training, development, and test portions. Data was prepared by randomly sampled up to 1M sentence pairs per language pair for training and up to 2000 each for development and test. To ensure that there was no overlap (at the monolingual sentence level) between the training and development/test data, they applied a filter during sampling to exclude sentences that had already been sampled. Note that this was done cross-lingually so that, for instance, an English sentence in the Portuguese-English portion of the training data could not occur in the Hindi-English test set.
## Test set metrics 🧾
We got a **BLEU score of 26.12**
## Model in Action 🚀
```sh
git clone https://github.com/huggingface/transformers.git
pip install -q ./transformers
```
```python
from transformers import MBart50TokenizerFast, MBartForConditionalGeneration
ckpt = 'Narrativa/mbart-large-50-finetuned-opus-pt-en-translation'
tokenizer = MBart50TokenizerFast.from_pretrained(ckpt)
model = MBartForConditionalGeneration.from_pretrained(ckpt).to("cuda")
tokenizer.src_lang = 'pt_XX'
def translate(text):
inputs = tokenizer(text, return_tensors='pt')
input_ids = inputs.input_ids.to('cuda')
attention_mask = inputs.attention_mask.to('cuda')
output = model.generate(input_ids, attention_mask=attention_mask, forced_bos_token_id=tokenizer.lang_code_to_id['en_XX'])
return tokenizer.decode(output[0], skip_special_tokens=True)
translate('here your Portuguese text to be translated to English...')
```
Created by: [Narrativa](https://www.narrativa.com/)
About Narrativa: Natural Language Generation (NLG) | Gabriele, our machine learning-based platform, builds and deploys natural language solutions. #NLG #AI
|
Narrativa/mbart-large-50-finetuned-opus-en-pt-translation
|
Narrativa
| 2021-06-21T11:07:11Z | 110 | 12 |
transformers
|
[
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"translation",
"en",
"pt",
"dataset:opus100",
"dataset:opusbook",
"arxiv:2008.00401",
"arxiv:2004.11867",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2022-03-02T23:29:04Z |
---
language:
- en
- pt
datasets:
- opus100
- opusbook
tags:
- translation
metrics:
- bleu
---
# mBART-large-50 fine-tuned onpus100 and opusbook for English to Portuguese translation.
[mBART-50](https://huggingface.co/facebook/mbart-large-50/) large fine-tuned on [opus100](https://huggingface.co/datasets/viewer/?dataset=opus100) dataset for **NMT** downstream task.
# Details of mBART-50 🧠
mBART-50 is a multilingual Sequence-to-Sequence model pre-trained using the "Multilingual Denoising Pretraining" objective. It was introduced in [Multilingual Translation with Extensible Multilingual Pretraining and Finetuning](https://arxiv.org/abs/2008.00401) paper.
mBART-50 is a multilingual Sequence-to-Sequence model. It was created to show that multilingual translation models can be created through multilingual fine-tuning.
Instead of fine-tuning on one direction, a pre-trained model is fine-tuned many directions simultaneously. mBART-50 is created using the original mBART model and extended to add extra 25 languages to support multilingual machine translation models of 50 languages. The pre-training objective is explained below.
**Multilingual Denoising Pretraining**: The model incorporates N languages by concatenating data:
`D = {D1, ..., DN }` where each Di is a collection of monolingual documents in language `i`. The source documents are noised using two schemes,
first randomly shuffling the original sentences' order, and second a novel in-filling scheme,
where spans of text are replaced with a single mask token. The model is then tasked to reconstruct the original text.
35% of each instance's words are masked by random sampling a span length according to a Poisson distribution `(λ = 3.5)`.
The decoder input is the original text with one position offset. A language id symbol `LID` is used as the initial token to predict the sentence.
## Details of the downstream task (NMT) - Dataset 📚
- **Homepage:** [Link](http://opus.nlpl.eu/opus-100.php)
- **Repository:** [GitHub](https://github.com/EdinburghNLP/opus-100-corpus)
- **Paper:** [ARXIV](https://arxiv.org/abs/2004.11867)
### Dataset Summary
OPUS-100 is English-centric, meaning that all training pairs include English on either the source or target side. The corpus covers 100 languages (including English). Languages were selected based on the volume of parallel data available in OPUS.
### Languages
OPUS-100 contains approximately 55M sentence pairs. Of the 99 language pairs, 44 have 1M sentence pairs of training data, 73 have at least 100k, and 95 have at least 10k.
## Dataset Structure
### Data Fields
- `src_tag`: `string` text in source language
- `tgt_tag`: `string` translation of source language in target language
### Data Splits
The dataset is split into training, development, and test portions. Data was prepared by randomly sampled up to 1M sentence pairs per language pair for training and up to 2000 each for development and test. To ensure that there was no overlap (at the monolingual sentence level) between the training and development/test data, they applied a filter during sampling to exclude sentences that had already been sampled. Note that this was done cross-lingually so that, for instance, an English sentence in the Portuguese-English portion of the training data could not occur in the Hindi-English test set.
## Test set metrics 🧾
We got a **BLEU score of 20.61**
## Model in Action 🚀
```sh
git clone https://github.com/huggingface/transformers.git
pip install -q ./transformers
```
```python
from transformers import MBart50TokenizerFast, MBartForConditionalGeneration
ckpt = 'Narrativa/mbart-large-50-finetuned-opus-en-pt-translation'
tokenizer = MBart50TokenizerFast.from_pretrained(ckpt)
model = MBartForConditionalGeneration.from_pretrained(ckpt).to("cuda")
tokenizer.src_lang = 'en_XX'
def translate(text):
inputs = tokenizer(text, return_tensors='pt')
input_ids = inputs.input_ids.to('cuda')
attention_mask = inputs.attention_mask.to('cuda')
output = model.generate(input_ids, attention_mask=attention_mask, forced_bos_token_id=tokenizer.lang_code_to_id['pt_XX'])
return tokenizer.decode(output[0], skip_special_tokens=True)
translate('here your English text to be translated to Portuguese...')
```
Created by: [Narrativa](https://www.narrativa.com/)
About Narrativa: Natural Language Generation (NLG) | Gabriele, our machine learning-based platform, builds and deploys natural language solutions. #NLG #AI
|
ainize/bart-base-cnn
|
ainize
| 2021-06-21T09:52:44Z | 2,174 | 15 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"feature-extraction",
"summarization",
"en",
"dataset:cnn_dailymail",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
language: en
license: apache-2.0
datasets:
- cnn_dailymail
tags:
- summarization
- bart
---
# BART base model fine-tuned on CNN Dailymail
- This model is a [bart-base model](https://huggingface.co/facebook/bart-base) fine-tuned on the [CNN/Dailymail summarization dataset](https://huggingface.co/datasets/cnn_dailymail) using [Ainize Teachable-NLP](https://ainize.ai/teachable-nlp).
The Bart model was proposed by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer on 29 Oct, 2019. According to the abstract,
Bart uses a standard seq2seq/machine translation architecture with a bidirectional encoder (like BERT) and a left-to-right decoder (like GPT).
The pretraining task involves randomly shuffling the order of the original sentences and a novel in-filling scheme, where spans of text are replaced with a single mask token.
BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks. It matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains of up to 6 ROUGE.
The Authors’ code can be found here:
https://github.com/pytorch/fairseq/tree/master/examples/bart
## Usage
### Python Code
```python
from transformers import PreTrainedTokenizerFast, BartForConditionalGeneration
# Load Model and Tokenize
tokenizer = PreTrainedTokenizerFast.from_pretrained("ainize/bart-base-cnn")
model = BartForConditionalGeneration.from_pretrained("ainize/bart-base-cnn")
# Encode Input Text
input_text = '(CNN) -- South Korea launched an investigation Tuesday into reports of toxic chemicals being dumped at a former U.S. military base, the Defense Ministry said. The tests follow allegations of American soldiers burying chemicals on Korean soil. The first tests are being carried out by a joint military, government and civilian task force at the site of what was Camp Mercer, west of Seoul. "Soil and underground water will be taken in the areas where toxic chemicals were allegedly buried," said the statement from the South Korean Defense Ministry. Once testing is finished, the government will decide on how to test more than 80 other sites -- all former bases. The alarm was raised this month when a U.S. veteran alleged barrels of the toxic herbicide Agent Orange were buried at an American base in South Korea in the late 1970s. Two of his fellow soldiers corroborated his story about Camp Carroll, about 185 miles (300 kilometers) southeast of the capital, Seoul. "We\'ve been working very closely with the Korean government since we had the initial claims," said Lt. Gen. John Johnson, who is heading the Camp Carroll Task Force. "If we get evidence that there is a risk to health, we are going to fix it." A joint U.S.- South Korean investigation is being conducted at Camp Carroll to test the validity of allegations. The U.S. military sprayed Agent Orange from planes onto jungles in Vietnam to kill vegetation in an effort to expose guerrilla fighters. Exposure to the chemical has been blamed for a wide variety of ailments, including certain forms of cancer and nerve disorders. It has also been linked to birth defects, according to the Department of Veterans Affairs. Journalist Yoonjung Seo contributed to this report.'
input_ids = tokenizer.encode(input_text, return_tensors="pt")
# Generate Summary Text Ids
summary_text_ids = model.generate(
input_ids=input_ids,
bos_token_id=model.config.bos_token_id,
eos_token_id=model.config.eos_token_id,
length_penalty=2.0,
max_length=142,
min_length=56,
num_beams=4,
)
# Decoding Text
print(tokenizer.decode(summary_text_ids[0], skip_special_tokens=True))
```
### API
You can experience this model through [ainize](https://ainize.ai/gkswjdzz/summarize-torchserve?branch=main).
|
worsterman/DialoGPT-small-mulder
|
worsterman
| 2021-06-20T22:50:26Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
tags:
- conversational
---
# DialoGPT Trained on the Speech of Fox Mulder from The X-Files
|
nreimers/mMiniLMv2-L12-H384-distilled-from-XLMR-Large
|
nreimers
| 2021-06-20T19:03:16Z | 31,114 | 17 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# Multilingual MiniLMv2
This is a MiniLMv2 model from: [https://github.com/microsoft/unilm](https://github.com/microsoft/unilm/tree/master/minilm)
|
nreimers/MiniLMv2-L6-H768-distilled-from-BERT-Large
|
nreimers
| 2021-06-20T19:02:40Z | 9 | 3 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# MiniLMv2
This is a MiniLMv2 model from: [https://github.com/microsoft/unilm](https://github.com/microsoft/unilm/tree/master/minilm)
|
nreimers/MiniLMv2-L6-H384-distilled-from-RoBERTa-Large
|
nreimers
| 2021-06-20T19:02:23Z | 164 | 6 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
# MiniLMv2
This is a MiniLMv2 model from: [https://github.com/microsoft/unilm](https://github.com/microsoft/unilm/tree/master/minilm)
|
huggingtweets/bloodwarrioroc1
|
huggingtweets
| 2021-06-20T17:41:00Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/bloodwarrioroc1/1624210855980/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1253341078637273089/PO6bqj0P_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Bloodwarriorguru</div>
<div style="text-align: center; font-size: 14px;">@bloodwarrioroc1</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Bloodwarriorguru.
| Data | Bloodwarriorguru |
| --- | --- |
| Tweets downloaded | 1206 |
| Retweets | 67 |
| Short tweets | 266 |
| Tweets kept | 873 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2x3rus6s/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @bloodwarrioroc1's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2s1u2k3b) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2s1u2k3b/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/bloodwarrioroc1')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Huffon/klue-roberta-base-nli
|
Huffon
| 2021-06-20T17:32:53Z | 50 | 5 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"nli",
"ko",
"dataset:klue",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:04Z |
---
language: ko
tags:
- roberta
- nli
datasets:
- klue
---
|
Huffon/sentence-klue-roberta-base
|
Huffon
| 2021-06-20T17:32:17Z | 379 | 9 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"roberta",
"ko",
"dataset:klue",
"arxiv:1908.10084",
"region:us"
] | null | 2022-03-02T23:29:04Z |
---
language: ko
tags:
- roberta
- sentence-transformers
datasets:
- klue
---
# KLUE RoBERTa base model for Sentence Embeddings
This is the `sentence-klue-roberta-base` model. The sentence-transformers repository allows to train and use Transformer models for generating sentence and text embeddings.
The model is described in the paper [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084)
## Usage (Sentence-Transformers)
Using this model becomes more convenient when you have [sentence-transformers](https://github.com/UKPLab/sentence-transformers) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
import torch
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("Huffon/sentence-klue-roberta-base")
docs = [
"1992년 7월 8일 손흥민은 강원도 춘천시 후평동에서 아버지 손웅정과 어머니 길은자의 차남으로 태어나 그곳에서 자랐다.",
"형은 손흥윤이다.",
"춘천 부안초등학교를 졸업했고, 춘천 후평중학교에 입학한 후 2학년때 원주 육민관중학교 축구부에 들어가기 위해 전학하여 졸업하였으며, 2008년 당시 FC 서울의 U-18팀이었던 동북고등학교 축구부에서 선수 활동 중 대한축구협회 우수선수 해외유학 프로젝트에 선발되어 2008년 8월 독일 분데스리가의 함부르크 유소년팀에 입단하였다.",
"함부르크 유스팀 주전 공격수로 2008년 6월 네덜란드에서 열린 4개국 경기에서 4게임에 출전, 3골을 터뜨렸다.",
"1년간의 유학 후 2009년 8월 한국으로 돌아온 후 10월에 개막한 FIFA U-17 월드컵에 출전하여 3골을 터트리며 한국을 8강으로 이끌었다.",
"그해 11월 함부르크의 정식 유소년팀 선수 계약을 체결하였으며 독일 U-19 리그 4경기 2골을 넣고 2군 리그에 출전을 시작했다.",
"독일 U-19 리그에서 손흥민은 11경기 6골, 2부 리그에서는 6경기 1골을 넣으며 재능을 인정받아 2010년 6월 17세의 나이로 함부르크의 1군 팀 훈련에 참가, 프리시즌 활약으로 함부르크와 정식 계약을 한 후 10월 18세에 함부르크 1군 소속으로 독일 분데스리가에 데뷔하였다.",
]
document_embeddings = model.encode(docs)
query = "손흥민은 어린 나이에 유럽에 진출하였다."
query_embedding = model.encode(query)
top_k = min(5, len(docs))
cos_scores = util.pytorch_cos_sim(query_embedding, document_embeddings)[0]
top_results = torch.topk(cos_scores, k=top_k)
print(f"입력 문장: {query}")
print(f"<입력 문장과 유사한 {top_k} 개의 문장>")
for i, (score, idx) in enumerate(zip(top_results[0], top_results[1])):
print(f"{i+1}: {docs[idx]} {'(유사도: {:.4f})'.format(score)}")
```
|
HeyLucasLeao/gpt-neo-small-portuguese
|
HeyLucasLeao
| 2021-06-19T20:51:57Z | 267 | 7 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
## GPT-Neo Small Portuguese
#### Model Description
This is a finetuned version from GPT-Neo 125M by EletheurAI to Portuguese language.
#### Training data
It was trained from 227,382 selected texts from a PTWiki Dump. You can found all the data from here: https://archive.org/details/ptwiki-dump-20210520
#### Training Procedure
Every text was passed through a GPT2-Tokenizer with bos and eos tokens to separate them, with max sequence length that the GPT-Neo could support. It was finetuned using the default metrics of the Trainer Class, available on the Hugging Face library.
##### Learning Rate: **2e-4**
##### Epochs: **1**
#### Goals
My true intention was totally educational, thus making available a Portuguese version of this model.
How to use
``` python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("HeyLucasLeao/gpt-neo-small-portuguese")
model = AutoModelForCausalLM.from_pretrained("HeyLucasLeao/gpt-neo-small-portuguese")
text = 'eu amo o brasil.'
generated = tokenizer(f'<|startoftext|> {text}',
return_tensors='pt').input_ids.cuda()
#Generating texts
sample_outputs = model.generate(generated,
# Use sampling instead of greedy decoding
do_sample=True,
# Keep only top 3 token with the highest probability
top_k=3,
# Maximum sequence length
max_length=200,
# Keep only the most probable tokens with cumulative probability of 95%
top_p=0.95,
# Changes randomness of generated sequences
temperature=1.9,
# Number of sequences to generate
num_return_sequences=3)
# Decoding and printing sequences
for i, sample_output in enumerate(sample_outputs):
print(">> Generated text {}\\\\
\\\\
{}".format(i+1, tokenizer.decode(sample_output.tolist())))
# >> Generated text
#Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
#>> Generated text 1
#<|startoftext|> eu amo o brasil. O termo foi usado por alguns autores como uma forma de designar a formação do poder político do Brasil. A partir da década de 1960, o termo passou a ser usado para designar a formação política do Brasil. A partir de meados da década de 1970 e até o inicio dos anos 2000, o termo foi aplicado à formação político-administrativo do país, sendo utilizado por alguns autores como uma expressão de "política de direita". História Antecedentes O termo "político-administrário" foi usado pela primeira vez em 1891 por um gru
#>> Generated text 2
#<|startoftext|> eu amo o brasil. É uma das muitas pessoas do mundo, ao contrário da maioria das pessoas, que são chamados de "pessoas do Brasil", que são chamados de "brincos do país" e que têm uma carreira de mais de um século. O termo "brincal de ouro" é usado em referências às pessoas que vivem no Brasil, e que são chamados "brincos do país", que são "cidade" e que vivem na cidade de Nova York e que vive em um país onde a maior parte das pessoas são chamados de "cidades". Hist
#>> Generated text 3
#<|startoftext|> eu amo o brasil. É uma expressão que se refere ao uso de um instrumento musical em particular para se referir à qualidade musical, o que é uma expressão da qualidade da qualidade musical de uma pessoa. A expressão "amor" (em inglês, amo), é a expressão que pode ser usada com o intuito empregado em qualquer situação em que a vontade de uma pessoa de se sentir amado ou amoroso é mais do que um desejo de uma vontade. Em geral, a expressão "amoro" (do inglês, amo) pode também se referir tanto a uma pessoa como um instrumento de cordas ou de uma
```
|
Dev-DGT/food-dbert-multiling
|
Dev-DGT
| 2021-06-18T21:55:58Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:04Z |
---
widget:
- text: "El paciente se alimenta de pan, sopa de calabaza y coca-cola"
---
# Token classification for FOODs.
Detects foods in sentences.
Currently, only supports spanish. Multiple words foods are detected as one entity.
## To-do
- English support.
- Negation support.
- Quantity tags.
- Psychosocial tags.
|
huggingtweets/visionify
|
huggingtweets
| 2021-06-18T11:55:54Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/visionify/1624017350891/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1395107998708555776/A8DY6IGM_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Visionify</div>
<div style="text-align: center; font-size: 14px;">@visionify</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Visionify.
| Data | Visionify |
| --- | --- |
| Tweets downloaded | 70 |
| Retweets | 8 |
| Short tweets | 1 |
| Tweets kept | 61 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2wilyf5z/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @visionify's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3pu4qf1m) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3pu4qf1m/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/visionify')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
silky/deep-todo
|
silky
| 2021-06-18T08:20:41Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
# deep-todo
Wondering what to do? Not anymore!
Generate arbitrary todo's.
Source: <https://colab.research.google.com/drive/1PlKLrGHaCuvWCKNC4fmQEMElF-iRec9f?usp=sharing>
The todo's come from a random selection of (public) repositories I had on my computer.
### Sample
A bunch of todo's:
```
----------------------------------------------------------------------------------------------------
0: TODO: should we check the other edges?/
1: TODO: add more information here.
2: TODO: We could also add more general functions in this case to avoid/
3: TODO: It seems strange to have the same constructor when the base set of/
4: TODO: This implementation should be simplified, as it's too complex to handle the/
5: TODO: we should be able to relax the intrinsic if not
6: TODO: Make sure this doesn't go through the next generation of plugins. It would be better if this was
7: TODO: There is always a small number of errors when we have this type/
8: TODO: Add support for 't' values (not 't') for all the constant types/
9: TODO: Check that we use loglef_cxx in the loop*
10: TODO: Support double or double values./
11: TODO: Add tests that verify that this function does not work for all targets/
12: TODO: we'd expect the result to be identical to the same value in terms of
13: TODO: We are not using a new type for 'w' as it does not denote 'y' yet, so we could/
14: TODO: if we had to find a way to extract the source file directly, we would/
15: TODO: this should fold into a flat array that would be/
16: TODO: Check if we can make it work with the correct address./
17: TODO: support v2i with V2R4+
18: TODO: Can a fast-math-flags check be generalized to all types of data? */
19: TODO: Add support for other type-specific VOPs.
```
Generated by:
```
tf.random.set_seed(0)
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=40,
top_k=50,
top_p=0.95,
num_return_sequences=20
)
print("Output:\\
" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
m = tokenizer.decode(sample_output, skip_special_tokens=True)
m = m.split("TODO")[1].strip()
print("{}: TODO{}".format(i, m))
```
## TODO
- [ ] Fixup the data; it seems to contain multiple todo's per line
- [ ] Preprocess the data in a better way
- [ ] Download github and train it on everything
|
ethanyt/guwen-sent
|
ethanyt
| 2021-06-18T04:51:54Z | 8 | 4 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"chinese",
"classical chinese",
"literary chinese",
"ancient chinese",
"bert",
"sentiment classificatio",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- "zh"
thumbnail: "https://user-images.githubusercontent.com/9592150/97142000-cad08e00-179a-11eb-88df-aff9221482d8.png"
tags:
- "chinese"
- "classical chinese"
- "literary chinese"
- "ancient chinese"
- "bert"
- "pytorch"
- "sentiment classificatio"
license: "apache-2.0"
pipeline_tag: "text-classification"
widget:
- text: "滚滚长江东逝水,浪花淘尽英雄"
- text: "寻寻觅觅,冷冷清清,凄凄惨惨戚戚"
- text: "执手相看泪眼,竟无语凝噎,念去去,千里烟波,暮霭沉沉楚天阔。"
- text: "忽如一夜春风来,干树万树梨花开"
---
# Guwen Sent
A Classical Chinese Poem Sentiment Classifier.
See also:
<a href="https://github.com/ethan-yt/guwen-models">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwen-models&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/cclue/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=cclue&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/guwenbert/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwenbert&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
|
Davlan/bert-base-multilingual-cased-finetuned-luganda
|
Davlan
| 2021-06-17T17:43:07Z | 11 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
Hugging Face's logo
---
language: lg
datasets:
---
# bert-base-multilingual-cased-finetuned-luganda
## Model description
**bert-base-multilingual-cased-finetuned-luganda** is a **Luganda BERT** model obtained by fine-tuning **bert-base-multilingual-cased** model on Luganda language texts. It provides **better performance** than the multilingual BERT on text classification and named entity recognition datasets.
Specifically, this model is a *bert-base-multilingual-cased* model that was fine-tuned on Luganda corpus.
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for masked token prediction.
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='Davlan/bert-base-multilingual-cased-finetuned-luganda')
>>> unmasker("Ffe tulwanyisa abo abaagala okutabangula [MASK], Kimuli bwe yategeezezza.")
```
#### Limitations and bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains.
## Training data
This model was fine-tuned on JW300 + [BUKKEDDE](https://github.com/masakhane-io/masakhane-ner/tree/main/text_by_language/luganda) +[Luganda CC-100](http://data.statmt.org/cc-100/)
## Training procedure
This model was trained on a single NVIDIA V100 GPU
## Eval results on Test set (F-score, average over 5 runs)
Dataset| mBERT F1 | lg_bert F1
-|-|-
[MasakhaNER](https://github.com/masakhane-io/masakhane-ner) | 80.36 | 84.70
### BibTeX entry and citation info
By David Adelani
```
```
|
m3hrdadfi/hubert-large-greek-speech-emotion-recognition
|
m3hrdadfi
| 2021-06-17T16:06:03Z | 3 | 1 |
transformers
|
[
"transformers",
"pytorch",
"hubert",
"audio",
"speech",
"speech-emotion-recognition",
"el",
"dataset:aesdd",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: el
datasets:
- aesdd
tags:
- audio
- speech
- speech-emotion-recognition
license: apache-2.0
---
# Emotion Recognition in Greek (el) Speech using HuBERT
## How to use
### Requirements
```bash
# requirement packages
!pip install git+https://github.com/huggingface/datasets.git
!pip install git+https://github.com/huggingface/transformers.git
!pip install torchaudio
!pip install librosa
```
```bash
!git clone https://github.com/m3hrdadfi/soxan.git .
```
### Prediction
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchaudio
from transformers import AutoConfig, Wav2Vec2FeatureExtractor
from src.models import Wav2Vec2ForSpeechClassification, HubertForSpeechClassification
import librosa
import IPython.display as ipd
import numpy as np
import pandas as pd
```
```python
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_name_or_path = "m3hrdadfi/hubert-large-greek-speech-emotion-recognition"
config = AutoConfig.from_pretrained(model_name_or_path)
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained(model_name_or_path)
sampling_rate = feature_extractor.sampling_rate
model = HubertForSpeechClassification.from_pretrained(model_name_or_path).to(device)
```
```python
def speech_file_to_array_fn(path, sampling_rate):
speech_array, _sampling_rate = torchaudio.load(path)
resampler = torchaudio.transforms.Resample(_sampling_rate)
speech = resampler(speech_array).squeeze().numpy()
return speech
def predict(path, sampling_rate):
speech = speech_file_to_array_fn(path, sampling_rate)
inputs = feature_extractor(speech, sampling_rate=sampling_rate, return_tensors="pt", padding=True)
inputs = {key: inputs[key].to(device) for key in inputs}
with torch.no_grad():
logits = model(**inputs).logits
scores = F.softmax(logits, dim=1).detach().cpu().numpy()[0]
outputs = [{"Emotion": config.id2label[i], "Score": f"{round(score * 100, 3):.1f}%"} for i, score in enumerate(scores)]
return outputs
```
```python
path = "/path/to/disgust.wav"
outputs = predict(path, sampling_rate)
```
```bash
[
{'Emotion': 'anger', 'Score': '0.0%'},
{'Emotion': 'disgust', 'Score': '99.2%'},
{'Emotion': 'fear', 'Score': '0.1%'},
{'Emotion': 'happiness', 'Score': '0.3%'},
{'Emotion': 'sadness', 'Score': '0.5%'}
]
```
## Evaluation
The following tables summarize the scores obtained by model overall and per each class.
| Emotions | precision | recall | f1-score | accuracy |
|:---------:|:---------:|:------:|:--------:|:--------:|
| anger | 0.96 | 0.96 | 0.96 | |
| disgust | 1.00 | 0.96 | 0.98 | |
| fear | 1.00 | 0.83 | 0.91 | |
| happiness | 1.00 | 0.96 | 0.98 | |
| sadness | 0.81 | 1.00 | 0.89 | |
| | | | Overal | 0.94 |
## Questions?
Post a Github issue from [HERE](https://github.com/m3hrdadfi/soxan/issues).
|
huggingtweets/ponkichi_book
|
huggingtweets
| 2021-06-17T14:47:52Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/ponkichi_book/1623941267798/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1108044599795175424/Ce8JrQsX_400x400.png')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">ぽんきち📚Web本屋さん店主</div>
<div style="text-align: center; font-size: 14px;">@ponkichi_book</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from ぽんきち📚Web本屋さん店主.
| Data | ぽんきち📚Web本屋さん店主 |
| --- | --- |
| Tweets downloaded | 3250 |
| Retweets | 0 |
| Short tweets | 471 |
| Tweets kept | 2779 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1xfkfwq2/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ponkichi_book's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3nufawaq) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3nufawaq/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ponkichi_book')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
ethanyt/guwen-cls
|
ethanyt
| 2021-06-17T09:37:37Z | 28 | 1 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"chinese",
"classical chinese",
"literary chinese",
"ancient chinese",
"bert",
"text classificatio",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- "zh"
thumbnail: "https://user-images.githubusercontent.com/9592150/97142000-cad08e00-179a-11eb-88df-aff9221482d8.png"
tags:
- "chinese"
- "classical chinese"
- "literary chinese"
- "ancient chinese"
- "bert"
- "pytorch"
- "text classificatio"
license: "apache-2.0"
pipeline_tag: "text-classification"
widget:
- text: "子曰:“弟子入则孝,出则悌,谨而信,泛爱众,而亲仁。行有馀力,则以学文。”"
---
# Guwen CLS
A Classical Chinese Text Classifier.
See also:
<a href="https://github.com/ethan-yt/guwen-models">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwen-models&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/cclue/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=cclue&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/guwenbert/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwenbert&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
|
ethanyt/guwen-punc
|
ethanyt
| 2021-06-17T06:56:46Z | 36 | 6 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"chinese",
"classical chinese",
"literary chinese",
"ancient chinese",
"bert",
"punctuation marker",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language:
- "zh"
thumbnail: "https://user-images.githubusercontent.com/9592150/97142000-cad08e00-179a-11eb-88df-aff9221482d8.png"
tags:
- "chinese"
- "classical chinese"
- "literary chinese"
- "ancient chinese"
- "bert"
- "pytorch"
- "punctuation marker"
license: "apache-2.0"
pipeline_tag: "token-classification"
widget:
- text: "及秦始皇灭先代典籍焚书坑儒天下学士逃难解散我先人用藏其家书于屋壁汉室龙兴开设学校旁求儒雅以阐大猷济南伏生年过九十失其本经口以传授裁二十馀篇以其上古之书谓之尚书百篇之义世莫得闻"
---
# Guwen Punc
A Classical Chinese Punctuation Marker.
See also:
<a href="https://github.com/ethan-yt/guwen-models">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwen-models&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/cclue/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=cclue&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/guwenbert/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwenbert&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
|
ScottaStrong/DialogGPT-small-Scott
|
ScottaStrong
| 2021-06-17T04:11:39Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
---
thumbnail: https://huggingface.co/front/thumbnails/dialogpt.png
tags:
- conversational
license: mit
---
# DialoGPT Trained on the Speech of a Game Character
This is an instance of [microsoft/DialoGPT-medium](https://huggingface.co/microsoft/DialoGPT-small) trained on a game character, Joshua from [The World Ends With You](https://en.wikipedia.org/wiki/The_World_Ends_with_You). The data comes from [a Kaggle game script dataset](https://www.kaggle.com/ruolinzheng/twewy-game-script).
I built a Discord AI chatbot based on this model. [Check out my GitHub repo.](https://github.com/RuolinZheng08/twewy-discord-chatbot)
Chat with the model:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("scottastrong/DialogGPT-small-Scott")
model = AutoModelWithLMHead.from_pretrained("scottastrong/DialogGPT-small-Scott")
# Let's chat for 4 lines
for step in range(4):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# print(new_user_input_ids)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
do_sample=True,
top_k=100,
top_p=0.7,
temperature=0.8
)
# pretty print last ouput tokens from bot
print("JoshuaBot: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
|
hyunwoongko/blenderbot-9B
|
hyunwoongko
| 2021-06-17T01:26:34Z | 44 | 22 |
transformers
|
[
"transformers",
"pytorch",
"blenderbot",
"text2text-generation",
"convAI",
"conversational",
"facebook",
"en",
"dataset:blended_skill_talk",
"arxiv:1907.06616",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
---
language:
- en
thumbnail:
tags:
- convAI
- conversational
- facebook
license: apache-2.0
datasets:
- blended_skill_talk
metrics:
- perplexity
---
## Model description
+ Paper: [Recipes for building an open-domain chatbot](https://arxiv.org/abs/1907.06616)
+ [Original PARLAI Code](https://parl.ai/projects/recipes/)
### Abstract
Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that scaling neural models in the number of parameters and the size of the data they are trained on gives improved results, we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to their partners, both asking and answering questions, and displaying knowledge, empathy and personality appropriately, depending on the situation. We show that large scale models can learn these skills when given appropriate training data and choice of generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter neural models, and make our models and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing failure cases of our models.
|
ScottaStrong/DialogGPT-medium-joshua
|
ScottaStrong
| 2021-06-17T00:25:33Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
---
thumbnail: https://huggingface.co/front/thumbnails/dialogpt.png
tags:
- conversational
license: mit
---
# DialoGPT Trained on the Speech of a Game Character
This is an instance of [microsoft/DialoGPT-medium](https://huggingface.co/microsoft/DialoGPT-medium) trained on a game character, Joshua from [The World Ends With You](https://en.wikipedia.org/wiki/The_World_Ends_with_You). The data comes from [a Kaggle game script dataset](https://www.kaggle.com/ruolinzheng/twewy-game-script).
I built a Discord AI chatbot based on this model. [Check out my GitHub repo.](https://github.com/RuolinZheng08/twewy-discord-chatbot)
Chat with the model:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("scottastrong/DialogGPT-medium-joshua")
model = AutoModelWithLMHead.from_pretrained("scottastrong/DialogGPT-medium-joshua")
# Let's chat for 4 lines
for step in range(4):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# print(new_user_input_ids)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
do_sample=True,
top_k=100,
top_p=0.7,
temperature=0.8
)
# pretty print last ouput tokens from bot
print("JoshuaBot: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
|
ScottaStrong/DialogGPT-small-joshua
|
ScottaStrong
| 2021-06-16T21:40:45Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:04Z |
---
thumbnail: https://huggingface.co/front/thumbnails/dialogpt.png
tags:
- conversational
license: mit
---
# DialoGPT Trained on the Speech of a Game Character
This is an instance of [microsoft/DialoGPT-medium](https://huggingface.co/microsoft/DialoGPT-medium) trained on a game character, Joshua from [The World Ends With You](https://en.wikipedia.org/wiki/The_World_Ends_with_You). The data comes from [a Kaggle game script dataset](https://www.kaggle.com/ruolinzheng/twewy-game-script).
I built a Discord AI chatbot based on this model. [Check out my GitHub repo.](https://github.com/RuolinZheng08/twewy-discord-chatbot)
Chat with the model:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("scottastrong/DialogGPT-small-joshua")
model = AutoModelWithLMHead.from_pretrained("scottastrong/DialogGPT-small-joshua")
# Let's chat for 4 lines
for step in range(4):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# print(new_user_input_ids)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
do_sample=True,
top_k=100,
top_p=0.7,
temperature=0.8
)
# pretty print last ouput tokens from bot
print("JoshuaBot: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
|
huggingtweets/ivegottagetagf
|
huggingtweets
| 2021-06-16T20:54:51Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/ivegottagetagf/1623876885491/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1404902950607089665/CLa3e4aK_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">##lainpilled</div>
<div style="text-align: center; font-size: 14px;">@ivegottagetagf</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from ##lainpilled.
| Data | ##lainpilled |
| --- | --- |
| Tweets downloaded | 128 |
| Retweets | 7 |
| Short tweets | 16 |
| Tweets kept | 105 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/7kyd6ojb/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ivegottagetagf's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3ropyewj) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3ropyewj/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ivegottagetagf')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
danyaljj/opengpt2_pytorch_backward
|
danyaljj
| 2021-06-16T20:29:52Z | 31 | 1 |
transformers
|
[
"transformers",
"pytorch",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
West et al.'s model from their "reflective decoding" paper.
Sample usage:
```python
import torch
from modeling_opengpt2 import OpenGPT2LMHeadModel
from padded_encoder import Encoder
path_to_backward = 'danyaljj/opengpt2_pytorch_backward'
encoder = Encoder()
model_backward = OpenGPT2LMHeadModel.from_pretrained(path_to_backward)
input = "until she finally won."
input_ids = encoder.encode(input)
input_ids = torch.tensor([input_ids[::-1] ], dtype=torch.int)
print(input_ids)
output = model_backward.generate(input_ids)
output_text = encoder.decode(output.tolist()[0][::-1])
print(output_text)
```
Download the additional files from here: https://github.com/peterwestuw/GPT2ForwardBackward
|
madlag/bert-base-uncased-squadv1-x2.32-f86.6-d15-hybrid-v1
|
madlag
| 2021-06-16T15:06:30Z | 70 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"bert",
"question-answering",
"en",
"dataset:squad",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail:
license: mit
tags:
- question-answering
-
-
datasets:
- squad
metrics:
- squad
widget:
- text: "Where is the Eiffel Tower located?"
context: "The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France. It is named after the engineer Gustave Eiffel, whose company designed and built the tower."
- text: "Who is Frederic Chopin?"
context: "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano."
---
## BERT-base uncased model fine-tuned on SQuAD v1
This model was created using the [nn_pruning](https://github.com/huggingface/nn_pruning) python library: the **linear layers contains 15.0%** of the original weights.
The model contains **34.0%** of the original weights **overall** (the embeddings account for a significant part of the model, and they are not pruned by this method).
With a simple resizing of the linear matrices it ran **2.32x as fast as bert-base-uncased** on the evaluation.
This is possible because the pruning method lead to structured matrices: to visualize them, hover below on the plot to see the non-zero/zero parts of each matrix.
<div class="graph"><script src="/madlag/bert-base-uncased-squadv1-x2.32-f86.6-d15-hybrid-v1/raw/main/model_card/density_info.js" id="1ff1ba08-69d3-4a20-9f29-494033c72860"></script></div>
In terms of accuracy, its **F1 is 86.64**, compared with 88.5 for bert-base-uncased, a **F1 drop of 1.86**.
## Fine-Pruning details
This model was fine-tuned from the HuggingFace [model](https://huggingface.co/bert-base-uncased) checkpoint on [SQuAD1.1](https://rajpurkar.github.io/SQuAD-explorer), and distilled from the model [bert-large-uncased-whole-word-masking-finetuned-squad](https://huggingface.co/bert-large-uncased-whole-word-masking-finetuned-squad)
This model is case-insensitive: it does not make a difference between english and English.
A side-effect of the block pruning is that some of the attention heads are completely removed: 63 heads were removed on a total of 144 (43.8%).
Here is a detailed view on how the remaining heads are distributed in the network after pruning.
<div class="graph"><script src="/madlag/bert-base-uncased-squadv1-x2.32-f86.6-d15-hybrid-v1/raw/main/model_card/pruning_info.js" id="e092ee84-28af-4821-8127-11914f68e306"></script></div>
## Details of the SQuAD1.1 dataset
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD1.1 | train | 90.6K |
| SQuAD1.1 | eval | 11.1k |
### Fine-tuning
- Python: `3.8.5`
- Machine specs:
```CPU: Intel(R) Core(TM) i7-6700K CPU
Memory: 64 GiB
GPUs: 1 GeForce GTX 3090, with 24GiB memory
GPU driver: 455.23.05, CUDA: 11.1
```
### Results
**Pytorch model file size**: `368MB` (original BERT: `420MB`)
| Metric | # Value | # Original ([Table 2](https://www.aclweb.org/anthology/N19-1423.pdf))| Variation |
| ------ | --------- | --------- | --------- |
| **EM** | **78.77** | **80.8** | **-2.03**|
| **F1** | **86.64** | **88.5** | **-1.86**|
## Example Usage
Install nn_pruning: it contains the optimization script, which just pack the linear layers into smaller ones by removing empty rows/columns.
`pip install nn_pruning`
Then you can use the `transformers library` almost as usual: you just have to call `optimize_model` when the pipeline has loaded.
```python
from transformers import pipeline
from nn_pruning.inference_model_patcher import optimize_model
qa_pipeline = pipeline(
"question-answering",
model="madlag/bert-base-uncased-squadv1-x2.32-f86.6-d15-hybrid-v1",
tokenizer="madlag/bert-base-uncased-squadv1-x2.32-f86.6-d15-hybrid-v1"
)
print("bert-base-uncased parameters: 165.0M")
print(f"Parameters count (includes only head pruning, not feed forward pruning)={int(qa_pipeline.model.num_parameters() / 1E6)}M")
qa_pipeline.model = optimize_model(qa_pipeline.model, "dense")
print(f"Parameters count after complete optimization={int(qa_pipeline.model.num_parameters() / 1E6)}M")
predictions = qa_pipeline({
'context': "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano.",
'question': "Who is Frederic Chopin?",
})
print("Predictions", predictions)
```
|
ethanyt/guwen-seg
|
ethanyt
| 2021-06-16T09:58:55Z | 27 | 6 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"chinese",
"classical chinese",
"literary chinese",
"ancient chinese",
"bert",
"sentence segmentation",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language:
- "zh"
thumbnail: "https://user-images.githubusercontent.com/9592150/97142000-cad08e00-179a-11eb-88df-aff9221482d8.png"
tags:
- "chinese"
- "classical chinese"
- "literary chinese"
- "ancient chinese"
- "bert"
- "pytorch"
- "sentence segmentation"
license: "apache-2.0"
pipeline_tag: "token-classification"
widget:
- text: "及秦始皇灭先代典籍焚书坑儒天下学士逃难解散我先人用藏其家书于屋壁汉室龙兴开设学校旁求儒雅以阐大猷济南伏生年过九十失其本经口以传授裁二十馀篇以其上古之书谓之尚书百篇之义世莫得闻"
---
# Guwen Seg
A Classical Chinese Sentence Segmenter.
See also:
<a href="https://github.com/ethan-yt/guwen-models">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwen-models&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/cclue/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=cclue&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/guwenbert/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwenbert&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
|
huggingtweets/onlinepete-sematarygravemn-superpiss
|
huggingtweets
| 2021-06-16T09:25:28Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/onlinepete-sematarygravemn-superpiss/1623835524372/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1077258168315473920/b8-3h6l4_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/456958582731603969/QZKpv6eI_400x400.jpeg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1364495290833637382/kqjmEF5A_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">xbox 720 & im pete online & SEMATARY GRAVE MAN ✟ ✟ ✟</div>
<div style="text-align: center; font-size: 14px;">@onlinepete-sematarygravemn-superpiss</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from xbox 720 & im pete online & SEMATARY GRAVE MAN ✟ ✟ ✟.
| Data | xbox 720 | im pete online | SEMATARY GRAVE MAN ✟ ✟ ✟ |
| --- | --- | --- | --- |
| Tweets downloaded | 199 | 3188 | 517 |
| Retweets | 0 | 92 | 67 |
| Short tweets | 7 | 1003 | 101 |
| Tweets kept | 192 | 2093 | 349 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1nem3gj6/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @onlinepete-sematarygravemn-superpiss's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/341d9x8y) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/341d9x8y/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/onlinepete-sematarygravemn-superpiss')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/biocrimed-bladeecity-w3bcam
|
huggingtweets
| 2021-06-16T09:00:55Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/biocrimed-bladeecity-w3bcam/1623834051692/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1398220397049434117/3i7JMNiF_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1399230370109825024/FypJacJv_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1404352885815664642/BEvtg0q4_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">bladee & Nothing person 2 & headaches</div>
<div style="text-align: center; font-size: 14px;">@biocrimed-bladeecity-w3bcam</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from bladee & Nothing person 2 & headaches.
| Data | bladee | Nothing person 2 | headaches |
| --- | --- | --- | --- |
| Tweets downloaded | 1599 | 1863 | 3231 |
| Retweets | 313 | 117 | 62 |
| Short tweets | 486 | 714 | 1451 |
| Tweets kept | 800 | 1032 | 1718 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/37jgy6z4/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @biocrimed-bladeecity-w3bcam's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1xg0n2ib) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1xg0n2ib/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/biocrimed-bladeecity-w3bcam')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Davlan/xlm-roberta-base-finetuned-naija
|
Davlan
| 2021-06-15T21:33:37Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
Hugging Face's logo
---
language: pcm
datasets:
---
# xlm-roberta-base-finetuned-naija
## Model description
**xlm-roberta-base-finetuned-naija** is a **Nigerian Pidgin RoBERTa** model obtained by fine-tuning **xlm-roberta-base** model on Nigerian Pidgin language texts. It provides **better performance** than the XLM-RoBERTa on named entity recognition datasets.
Specifically, this model is a *xlm-roberta-base* model that was fine-tuned on Nigerian Pidgin corpus.
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for masked token prediction.
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='Davlan/xlm-roberta-base-finetuned-naija')
>>> unmasker("Another attack on ambulance happen for Koforidua in March <mask> year where robbers kill Ambulance driver")
```
#### Limitations and bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains.
## Training data
This model was fine-tuned on JW300 + [BBC Pidgin](https://www.bbc.com/pidgin)
## Training procedure
This model was trained on a single NVIDIA V100 GPU
## Eval results on Test set (F-score, average over 5 runs)
Dataset| XLM-R F1 | pcm_roberta F1
-|-|-
[MasakhaNER](https://github.com/masakhane-io/masakhane-ner) | 87.26 | 90.00
### BibTeX entry and citation info
By David Adelani
```
```
|
Davlan/xlm-roberta-base-finetuned-kinyarwanda
|
Davlan
| 2021-06-15T20:24:02Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
Hugging Face's logo
---
language: rw
datasets:
---
# xlm-roberta-base-finetuned-kinyarwanda
## Model description
**xlm-roberta-base-finetuned-kinyarwanda** is a **Kinyarwanda RoBERTa** model obtained by fine-tuning **xlm-roberta-base** model on Kinyarwanda language texts. It provides **better performance** than the XLM-RoBERTa on named entity recognition datasets.
Specifically, this model is a *xlm-roberta-base* model that was fine-tuned on Kinyarwanda corpus.
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for masked token prediction.
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='Davlan/xlm-roberta-base-finetuned-kinyarwanda')
>>> unmasker("Twabonye ko igihe mu <mask> hazaba hari ikirango abantu bakunze")
```
#### Limitations and bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains.
## Training data
This model was fine-tuned on JW300 + [KIRNEWS](https://github.com/Andrews2017/KINNEWS-and-KIRNEWS-Corpus) + [BBC Gahuza](https://www.bbc.com/gahuza)
## Training procedure
This model was trained on a single NVIDIA V100 GPU
## Eval results on Test set (F-score, average over 5 runs)
Dataset| XLM-R F1 | rw_roberta F1
-|-|-
[MasakhaNER](https://github.com/masakhane-io/masakhane-ner) | 73.22 | 77.76
### BibTeX entry and citation info
By David Adelani
```
```
|
Davlan/bert-base-multilingual-cased-finetuned-kinyarwanda
|
Davlan
| 2021-06-15T20:11:29Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:04Z |
Hugging Face's logo
---
language: rw
datasets:
---
# bert-base-multilingual-cased-finetuned-kinyarwanda
## Model description
**bert-base-multilingual-cased-finetuned-kinyarwanda** is a **Kinyarwanda BERT** model obtained by fine-tuning **bert-base-multilingual-cased** model on Kinyarwanda language texts. It provides **better performance** than the multilingual BERT on named entity recognition datasets.
Specifically, this model is a *bert-base-multilingual-cased* model that was fine-tuned on Kinyarwanda corpus.
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for masked token prediction.
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='Davlan/bert-base-multilingual-cased-finetuned-kinyarwanda')
>>> unmasker("Twabonye ko igihe mu [MASK] hazaba hari ikirango abantu bakunze")
```
#### Limitations and bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains.
## Training data
This model was fine-tuned on JW300 + [KIRNEWS](https://github.com/Andrews2017/KINNEWS-and-KIRNEWS-Corpus) + [BBC Gahuza](https://www.bbc.com/gahuza)
## Training procedure
This model was trained on a single NVIDIA V100 GPU
## Eval results on Test set (F-score, average over 5 runs)
Dataset| mBERT F1 | rw_bert F1
-|-|-
[MasakhaNER](https://github.com/masakhane-io/masakhane-ner) | 72.20 | 77.57
### BibTeX entry and citation info
By David Adelani
```
```
|
huggingtweets/ahleemuhleek
|
huggingtweets
| 2021-06-15T18:38:34Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/ahleemuhleek/1623782310895/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1404846924226695174/_oELkFsx_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">##ahleeuwu</div>
<div style="text-align: center; font-size: 14px;">@ahleemuhleek</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from ##ahleeuwu.
| Data | ##ahleeuwu |
| --- | --- |
| Tweets downloaded | 480 |
| Retweets | 149 |
| Short tweets | 86 |
| Tweets kept | 245 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/17rz3rct/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ahleemuhleek's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/32bqa4q7) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/32bqa4q7/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ahleemuhleek')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/dril_gpt2
|
huggingtweets
| 2021-06-15T17:03:24Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/dril_gpt2/1623776600001/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1386749605216407555/QIJeyWfE_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">wint but Al</div>
<div style="text-align: center; font-size: 14px;">@dril_gpt2</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from wint but Al.
| Data | wint but Al |
| --- | --- |
| Tweets downloaded | 3247 |
| Retweets | 37 |
| Short tweets | 50 |
| Tweets kept | 3160 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1dhjomoh/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @dril_gpt2's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/37mqhgg4) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/37mqhgg4/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/dril_gpt2')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/rantspakistani
|
huggingtweets
| 2021-06-15T09:17:31Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/rantspakistani/1623748645565/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1272527278744973315/PVkL9_v-_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Rants</div>
<div style="text-align: center; font-size: 14px;">@rantspakistani</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Rants.
| Data | Rants |
| --- | --- |
| Tweets downloaded | 3221 |
| Retweets | 573 |
| Short tweets | 142 |
| Tweets kept | 2506 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2wyl63o2/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @rantspakistani's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/d2h287dr) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/d2h287dr/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/rantspakistani')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
neuropark/sahajBERT-NER
|
neuropark
| 2021-06-15T08:12:18Z | 18 | 2 |
transformers
|
[
"transformers",
"pytorch",
"albert",
"token-classification",
"collaborative",
"bengali",
"NER",
"bn",
"dataset:xtreme",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2022-03-02T23:29:05Z |
---
language: bn
tags:
- collaborative
- bengali
- NER
license: apache-2.0
datasets: xtreme
metrics:
- Loss
- Accuracy
- Precision
- Recall
---
# sahajBERT Named Entity Recognition
## Model description
[sahajBERT](https://huggingface.co/neuropark/sahajBERT-NER) fine-tuned for NER using the bengali split of [WikiANN ](https://huggingface.co/datasets/wikiann).
Named Entities predicted by the model:
| Label id | Label |
|:--------:|:----:|
|0 |O|
|1 |B-PER|
|2 |I-PER|
|3 |B-ORG|
|4 |I-ORG|
|5 |B-LOC|
|6 |I-LOC|
## Intended uses & limitations
#### How to use
You can use this model directly with a pipeline for token classification:
```python
from transformers import AlbertForTokenClassification, TokenClassificationPipeline, PreTrainedTokenizerFast
# Initialize tokenizer
tokenizer = PreTrainedTokenizerFast.from_pretrained("neuropark/sahajBERT-NER")
# Initialize model
model = AlbertForTokenClassification.from_pretrained("neuropark/sahajBERT-NER")
# Initialize pipeline
pipeline = TokenClassificationPipeline(tokenizer=tokenizer, model=model)
raw_text = "এই ইউনিয়নে ৩ টি মৌজা ও ১০ টি গ্রাম আছে ।" # Change me
output = pipeline(raw_text)
```
#### Limitations and bias
<!-- Provide examples of latent issues and potential remediations. -->
WIP
## Training data
The model was initialized with pre-trained weights of [sahajBERT](https://huggingface.co/neuropark/sahajBERT-NER) at step 19519 and trained on the bengali split of [WikiANN ](https://huggingface.co/datasets/wikiann)
## Training procedure
Coming soon!
<!-- ```bibtex
@inproceedings{...,
year={2020}
}
``` -->
## Eval results
loss: 0.11714419722557068
accuracy: 0.9772286821705426
precision: 0.9585365853658536
recall: 0.9651277013752456
f1 : 0.9618208516886931
### BibTeX entry and citation info
Coming soon!
<!-- ```bibtex
@inproceedings{...,
year={2020}
}
``` -->
|
assemblyai/bert-large-uncased-sst2
|
assemblyai
| 2021-06-14T22:04:39Z | 380 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"arxiv:1810.04805",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# BERT-Large-Uncased for Sentiment Analysis
This model is a fine-tuned version of [bert-large-uncased](https://huggingface.co/bert-large-uncased) originally released in ["BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"](https://arxiv.org/abs/1810.04805) and trained on the [Stanford Sentiment Treebank v2 (SST2)](https://nlp.stanford.edu/sentiment/); part of the [General Language Understanding Evaluation (GLUE)](https://gluebenchmark.com) benchmark. This model was fine-tuned by the team at [AssemblyAI](https://www.assemblyai.com) and is released with the [corresponding blog post]().
## Usage
To download and utilize this model for sentiment analysis please execute the following:
```python
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("assemblyai/bert-large-uncased-sst2")
model = AutoModelForSequenceClassification.from_pretrained("assemblyai/bert-large-uncased-sst2")
tokenized_segments = tokenizer(["AssemblyAI is the best speech-to-text API for modern developers with performance being second to none!"], return_tensors="pt", padding=True, truncation=True)
tokenized_segments_input_ids, tokenized_segments_attention_mask = tokenized_segments.input_ids, tokenized_segments.attention_mask
model_predictions = F.softmax(model(input_ids=tokenized_segments_input_ids, attention_mask=tokenized_segments_attention_mask)['logits'], dim=1)
print("Positive probability: "+str(model_predictions[0][1].item()*100)+"%")
print("Negative probability: "+str(model_predictions[0][0].item()*100)+"%")
```
For questions about how to use this model feel free to contact the team at [AssemblyAI](https://www.assemblyai.com)!
|
huggingtweets/eptun2
|
huggingtweets
| 2021-06-14T14:00:23Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/eptun2/1623679218637/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1365330152155197440/u6okFTrC_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">patrik</div>
<div style="text-align: center; font-size: 14px;">@eptun2</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from patrik.
| Data | patrik |
| --- | --- |
| Tweets downloaded | 1197 |
| Retweets | 110 |
| Short tweets | 261 |
| Tweets kept | 826 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/12mtydd9/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @eptun2's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/isk9pksq) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/isk9pksq/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/eptun2')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
valhalla/distilbart-mnli-12-9
|
valhalla
| 2021-06-14T10:34:58Z | 1,855 | 12 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bart",
"text-classification",
"distilbart",
"distilbart-mnli",
"zero-shot-classification",
"dataset:mnli",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
zero-shot-classification
| 2022-03-02T23:29:05Z |
---
datasets:
- mnli
tags:
- distilbart
- distilbart-mnli
pipeline_tag: zero-shot-classification
---
# DistilBart-MNLI
distilbart-mnli is the distilled version of bart-large-mnli created using the **No Teacher Distillation** technique proposed for BART summarisation by Huggingface, [here](https://github.com/huggingface/transformers/tree/master/examples/seq2seq#distilbart).
We just copy alternating layers from `bart-large-mnli` and finetune more on the same data.
| | matched acc | mismatched acc |
| ------------------------------------------------------------------------------------ | ----------- | -------------- |
| [bart-large-mnli](https://huggingface.co/facebook/bart-large-mnli) (baseline, 12-12) | 89.9 | 90.01 |
| [distilbart-mnli-12-1](https://huggingface.co/valhalla/distilbart-mnli-12-1) | 87.08 | 87.5 |
| [distilbart-mnli-12-3](https://huggingface.co/valhalla/distilbart-mnli-12-3) | 88.1 | 88.19 |
| [distilbart-mnli-12-6](https://huggingface.co/valhalla/distilbart-mnli-12-6) | 89.19 | 89.01 |
| [distilbart-mnli-12-9](https://huggingface.co/valhalla/distilbart-mnli-12-9) | 89.56 | 89.52 |
This is a very simple and effective technique, as we can see the performance drop is very little.
Detailed performace trade-offs will be posted in this [sheet](https://docs.google.com/spreadsheets/d/1dQeUvAKpScLuhDV1afaPJRRAE55s2LpIzDVA5xfqxvk/edit?usp=sharing).
## Fine-tuning
If you want to train these models yourself, clone the [distillbart-mnli repo](https://github.com/patil-suraj/distillbart-mnli) and follow the steps below
Clone and install transformers from source
```bash
git clone https://github.com/huggingface/transformers.git
pip install -qqq -U ./transformers
```
Download MNLI data
```bash
python transformers/utils/download_glue_data.py --data_dir glue_data --tasks MNLI
```
Create student model
```bash
python create_student.py \
--teacher_model_name_or_path facebook/bart-large-mnli \
--student_encoder_layers 12 \
--student_decoder_layers 6 \
--save_path student-bart-mnli-12-6 \
```
Start fine-tuning
```bash
python run_glue.py args.json
```
You can find the logs of these trained models in this [wandb project](https://wandb.ai/psuraj/distilbart-mnli).
|
valhalla/distilbart-mnli-12-6
|
valhalla
| 2021-06-14T10:32:03Z | 48,130 | 11 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bart",
"text-classification",
"distilbart",
"distilbart-mnli",
"zero-shot-classification",
"dataset:mnli",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
zero-shot-classification
| 2022-03-02T23:29:05Z |
---
datasets:
- mnli
tags:
- distilbart
- distilbart-mnli
pipeline_tag: zero-shot-classification
---
# DistilBart-MNLI
distilbart-mnli is the distilled version of bart-large-mnli created using the **No Teacher Distillation** technique proposed for BART summarisation by Huggingface, [here](https://github.com/huggingface/transformers/tree/master/examples/seq2seq#distilbart).
We just copy alternating layers from `bart-large-mnli` and finetune more on the same data.
| | matched acc | mismatched acc |
| ------------------------------------------------------------------------------------ | ----------- | -------------- |
| [bart-large-mnli](https://huggingface.co/facebook/bart-large-mnli) (baseline, 12-12) | 89.9 | 90.01 |
| [distilbart-mnli-12-1](https://huggingface.co/valhalla/distilbart-mnli-12-1) | 87.08 | 87.5 |
| [distilbart-mnli-12-3](https://huggingface.co/valhalla/distilbart-mnli-12-3) | 88.1 | 88.19 |
| [distilbart-mnli-12-6](https://huggingface.co/valhalla/distilbart-mnli-12-6) | 89.19 | 89.01 |
| [distilbart-mnli-12-9](https://huggingface.co/valhalla/distilbart-mnli-12-9) | 89.56 | 89.52 |
This is a very simple and effective technique, as we can see the performance drop is very little.
Detailed performace trade-offs will be posted in this [sheet](https://docs.google.com/spreadsheets/d/1dQeUvAKpScLuhDV1afaPJRRAE55s2LpIzDVA5xfqxvk/edit?usp=sharing).
## Fine-tuning
If you want to train these models yourself, clone the [distillbart-mnli repo](https://github.com/patil-suraj/distillbart-mnli) and follow the steps below
Clone and install transformers from source
```bash
git clone https://github.com/huggingface/transformers.git
pip install -qqq -U ./transformers
```
Download MNLI data
```bash
python transformers/utils/download_glue_data.py --data_dir glue_data --tasks MNLI
```
Create student model
```bash
python create_student.py \
--teacher_model_name_or_path facebook/bart-large-mnli \
--student_encoder_layers 12 \
--student_decoder_layers 6 \
--save_path student-bart-mnli-12-6 \
```
Start fine-tuning
```bash
python run_glue.py args.json
```
You can find the logs of these trained models in this [wandb project](https://wandb.ai/psuraj/distilbart-mnli).
|
valhalla/distilbart-mnli-12-1
|
valhalla
| 2021-06-14T10:27:55Z | 109,694 | 51 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bart",
"text-classification",
"distilbart",
"distilbart-mnli",
"zero-shot-classification",
"dataset:mnli",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
zero-shot-classification
| 2022-03-02T23:29:05Z |
---
datasets:
- mnli
tags:
- distilbart
- distilbart-mnli
pipeline_tag: zero-shot-classification
---
# DistilBart-MNLI
distilbart-mnli is the distilled version of bart-large-mnli created using the **No Teacher Distillation** technique proposed for BART summarisation by Huggingface, [here](https://github.com/huggingface/transformers/tree/master/examples/seq2seq#distilbart).
We just copy alternating layers from `bart-large-mnli` and finetune more on the same data.
| | matched acc | mismatched acc |
| ------------------------------------------------------------------------------------ | ----------- | -------------- |
| [bart-large-mnli](https://huggingface.co/facebook/bart-large-mnli) (baseline, 12-12) | 89.9 | 90.01 |
| [distilbart-mnli-12-1](https://huggingface.co/valhalla/distilbart-mnli-12-1) | 87.08 | 87.5 |
| [distilbart-mnli-12-3](https://huggingface.co/valhalla/distilbart-mnli-12-3) | 88.1 | 88.19 |
| [distilbart-mnli-12-6](https://huggingface.co/valhalla/distilbart-mnli-12-6) | 89.19 | 89.01 |
| [distilbart-mnli-12-9](https://huggingface.co/valhalla/distilbart-mnli-12-9) | 89.56 | 89.52 |
This is a very simple and effective technique, as we can see the performance drop is very little.
Detailed performace trade-offs will be posted in this [sheet](https://docs.google.com/spreadsheets/d/1dQeUvAKpScLuhDV1afaPJRRAE55s2LpIzDVA5xfqxvk/edit?usp=sharing).
## Fine-tuning
If you want to train these models yourself, clone the [distillbart-mnli repo](https://github.com/patil-suraj/distillbart-mnli) and follow the steps below
Clone and install transformers from source
```bash
git clone https://github.com/huggingface/transformers.git
pip install -qqq -U ./transformers
```
Download MNLI data
```bash
python transformers/utils/download_glue_data.py --data_dir glue_data --tasks MNLI
```
Create student model
```bash
python create_student.py \
--teacher_model_name_or_path facebook/bart-large-mnli \
--student_encoder_layers 12 \
--student_decoder_layers 6 \
--save_path student-bart-mnli-12-6 \
```
Start fine-tuning
```bash
python run_glue.py args.json
```
You can find the logs of these trained models in this [wandb project](https://wandb.ai/psuraj/distilbart-mnli).
|
huggingtweets/nilsmedzkills
|
huggingtweets
| 2021-06-14T10:24:42Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/nilsmedzkills/1623666278497/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1039164884305551367/6byB20dK_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">NilsMedZkills</div>
<div style="text-align: center; font-size: 14px;">@nilsmedzkills</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from NilsMedZkills.
| Data | NilsMedZkills |
| --- | --- |
| Tweets downloaded | 341 |
| Retweets | 25 |
| Short tweets | 89 |
| Tweets kept | 227 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3lzg64xn/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @nilsmedzkills's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1bzoss63) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1bzoss63/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/nilsmedzkills')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
sshleifer/distilbart-xsum-12-6
|
sshleifer
| 2021-06-14T07:58:25Z | 1,583 | 5 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bart",
"text2text-generation",
"summarization",
"en",
"dataset:cnn_dailymail",
"dataset:xsum",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- summarization
license: apache-2.0
datasets:
- cnn_dailymail
- xsum
thumbnail: https://huggingface.co/front/thumbnails/distilbart_medium.png
---
### Usage
This checkpoint should be loaded into `BartForConditionalGeneration.from_pretrained`. See the [BART docs](https://huggingface.co/transformers/model_doc/bart.html?#transformers.BartForConditionalGeneration) for more information.
### Metrics for DistilBART models
| Model Name | MM Params | Inference Time (MS) | Speedup | Rouge 2 | Rouge-L |
|:---------------------------|------------:|----------------------:|----------:|----------:|----------:|
| distilbart-xsum-12-1 | 222 | 90 | 2.54 | 18.31 | 33.37 |
| distilbart-xsum-6-6 | 230 | 132 | 1.73 | 20.92 | 35.73 |
| distilbart-xsum-12-3 | 255 | 106 | 2.16 | 21.37 | 36.39 |
| distilbart-xsum-9-6 | 268 | 136 | 1.68 | 21.72 | 36.61 |
| bart-large-xsum (baseline) | 406 | 229 | 1 | 21.85 | 36.50 |
| distilbart-xsum-12-6 | 306 | 137 | 1.68 | 22.12 | 36.99 |
| bart-large-cnn (baseline) | 406 | 381 | 1 | 21.06 | 30.63 |
| distilbart-12-3-cnn | 255 | 214 | 1.78 | 20.57 | 30.00 |
| distilbart-12-6-cnn | 306 | 307 | 1.24 | 21.26 | 30.59 |
| distilbart-6-6-cnn | 230 | 182 | 2.09 | 20.17 | 29.70 |
|
sshleifer/distilbart-xsum-12-3
|
sshleifer
| 2021-06-14T07:57:16Z | 653 | 11 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bart",
"text2text-generation",
"summarization",
"en",
"dataset:cnn_dailymail",
"dataset:xsum",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- summarization
license: apache-2.0
datasets:
- cnn_dailymail
- xsum
thumbnail: https://huggingface.co/front/thumbnails/distilbart_medium.png
---
### Usage
This checkpoint should be loaded into `BartForConditionalGeneration.from_pretrained`. See the [BART docs](https://huggingface.co/transformers/model_doc/bart.html?#transformers.BartForConditionalGeneration) for more information.
### Metrics for DistilBART models
| Model Name | MM Params | Inference Time (MS) | Speedup | Rouge 2 | Rouge-L |
|:---------------------------|------------:|----------------------:|----------:|----------:|----------:|
| distilbart-xsum-12-1 | 222 | 90 | 2.54 | 18.31 | 33.37 |
| distilbart-xsum-6-6 | 230 | 132 | 1.73 | 20.92 | 35.73 |
| distilbart-xsum-12-3 | 255 | 106 | 2.16 | 21.37 | 36.39 |
| distilbart-xsum-9-6 | 268 | 136 | 1.68 | 21.72 | 36.61 |
| bart-large-xsum (baseline) | 406 | 229 | 1 | 21.85 | 36.50 |
| distilbart-xsum-12-6 | 306 | 137 | 1.68 | 22.12 | 36.99 |
| bart-large-cnn (baseline) | 406 | 381 | 1 | 21.06 | 30.63 |
| distilbart-12-3-cnn | 255 | 214 | 1.78 | 20.57 | 30.00 |
| distilbart-12-6-cnn | 306 | 307 | 1.24 | 21.26 | 30.59 |
| distilbart-6-6-cnn | 230 | 182 | 2.09 | 20.17 | 29.70 |
|
sshleifer/distilbart-xsum-1-1
|
sshleifer
| 2021-06-14T07:53:57Z | 1,752 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"bart",
"text2text-generation",
"summarization",
"en",
"dataset:cnn_dailymail",
"dataset:xsum",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- summarization
license: apache-2.0
datasets:
- cnn_dailymail
- xsum
thumbnail: https://huggingface.co/front/thumbnails/distilbart_medium.png
---
### Usage
This checkpoint should be loaded into `BartForConditionalGeneration.from_pretrained`. See the [BART docs](https://huggingface.co/transformers/model_doc/bart.html?#transformers.BartForConditionalGeneration) for more information.
### Metrics for DistilBART models
| Model Name | MM Params | Inference Time (MS) | Speedup | Rouge 2 | Rouge-L |
|:---------------------------|------------:|----------------------:|----------:|----------:|----------:|
| distilbart-xsum-12-1 | 222 | 90 | 2.54 | 18.31 | 33.37 |
| distilbart-xsum-6-6 | 230 | 132 | 1.73 | 20.92 | 35.73 |
| distilbart-xsum-12-3 | 255 | 106 | 2.16 | 21.37 | 36.39 |
| distilbart-xsum-9-6 | 268 | 136 | 1.68 | 21.72 | 36.61 |
| bart-large-xsum (baseline) | 406 | 229 | 1 | 21.85 | 36.50 |
| distilbart-xsum-12-6 | 306 | 137 | 1.68 | 22.12 | 36.99 |
| bart-large-cnn (baseline) | 406 | 381 | 1 | 21.06 | 30.63 |
| distilbart-12-3-cnn | 255 | 214 | 1.78 | 20.57 | 30.00 |
| distilbart-12-6-cnn | 306 | 307 | 1.24 | 21.26 | 30.59 |
| distilbart-6-6-cnn | 230 | 182 | 2.09 | 20.17 | 29.70 |
|
sshleifer/distilbart-cnn-6-6
|
sshleifer
| 2021-06-14T07:53:04Z | 42,203 | 29 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"rust",
"bart",
"text2text-generation",
"summarization",
"en",
"dataset:cnn_dailymail",
"dataset:xsum",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- summarization
license: apache-2.0
datasets:
- cnn_dailymail
- xsum
thumbnail: https://huggingface.co/front/thumbnails/distilbart_medium.png
---
### Usage
This checkpoint should be loaded into `BartForConditionalGeneration.from_pretrained`. See the [BART docs](https://huggingface.co/transformers/model_doc/bart.html?#transformers.BartForConditionalGeneration) for more information.
### Metrics for DistilBART models
| Model Name | MM Params | Inference Time (MS) | Speedup | Rouge 2 | Rouge-L |
|:---------------------------|------------:|----------------------:|----------:|----------:|----------:|
| distilbart-xsum-12-1 | 222 | 90 | 2.54 | 18.31 | 33.37 |
| distilbart-xsum-6-6 | 230 | 132 | 1.73 | 20.92 | 35.73 |
| distilbart-xsum-12-3 | 255 | 106 | 2.16 | 21.37 | 36.39 |
| distilbart-xsum-9-6 | 268 | 136 | 1.68 | 21.72 | 36.61 |
| bart-large-xsum (baseline) | 406 | 229 | 1 | 21.85 | 36.50 |
| distilbart-xsum-12-6 | 306 | 137 | 1.68 | 22.12 | 36.99 |
| bart-large-cnn (baseline) | 406 | 381 | 1 | 21.06 | 30.63 |
| distilbart-12-3-cnn | 255 | 214 | 1.78 | 20.57 | 30.00 |
| distilbart-12-6-cnn | 306 | 307 | 1.24 | 21.26 | 30.59 |
| distilbart-6-6-cnn | 230 | 182 | 2.09 | 20.17 | 29.70 |
|
sshleifer/distilbart-cnn-12-6
|
sshleifer
| 2021-06-14T07:51:12Z | 784,996 | 268 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"rust",
"bart",
"text2text-generation",
"summarization",
"en",
"dataset:cnn_dailymail",
"dataset:xsum",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:05Z |
---
language: en
tags:
- summarization
license: apache-2.0
datasets:
- cnn_dailymail
- xsum
thumbnail: https://huggingface.co/front/thumbnails/distilbart_medium.png
---
### Usage
This checkpoint should be loaded into `BartForConditionalGeneration.from_pretrained`. See the [BART docs](https://huggingface.co/transformers/model_doc/bart.html?#transformers.BartForConditionalGeneration) for more information.
### Metrics for DistilBART models
| Model Name | MM Params | Inference Time (MS) | Speedup | Rouge 2 | Rouge-L |
|:---------------------------|------------:|----------------------:|----------:|----------:|----------:|
| distilbart-xsum-12-1 | 222 | 90 | 2.54 | 18.31 | 33.37 |
| distilbart-xsum-6-6 | 230 | 132 | 1.73 | 20.92 | 35.73 |
| distilbart-xsum-12-3 | 255 | 106 | 2.16 | 21.37 | 36.39 |
| distilbart-xsum-9-6 | 268 | 136 | 1.68 | 21.72 | 36.61 |
| bart-large-xsum (baseline) | 406 | 229 | 1 | 21.85 | 36.50 |
| distilbart-xsum-12-6 | 306 | 137 | 1.68 | 22.12 | 36.99 |
| bart-large-cnn (baseline) | 406 | 381 | 1 | 21.06 | 30.63 |
| distilbart-12-3-cnn | 255 | 214 | 1.78 | 20.57 | 30.00 |
| distilbart-12-6-cnn | 306 | 307 | 1.24 | 21.26 | 30.59 |
| distilbart-6-6-cnn | 230 | 182 | 2.09 | 20.17 | 29.70 |
|
huggingtweets/hbomberguy
|
huggingtweets
| 2021-06-13T21:51:14Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1402282381696962566/VwcMz_xV_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Hbomberguy</div>
<div style="text-align: center; font-size: 14px;">@hbomberguy</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Hbomberguy.
| Data | Hbomberguy |
| --- | --- |
| Tweets downloaded | 3187 |
| Retweets | 1450 |
| Short tweets | 298 |
| Tweets kept | 1439 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2gtfmb7p/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @hbomberguy's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3h5vtwqy) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3h5vtwqy/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/hbomberguy')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/robber0540
|
huggingtweets
| 2021-06-13T21:47:44Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/robber0540/1623620847015/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/822229503212666880/L4UutyTM_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Combat Ballerina</div>
<div style="text-align: center; font-size: 14px;">@robber0540</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Combat Ballerina.
| Data | Combat Ballerina |
| --- | --- |
| Tweets downloaded | 668 |
| Retweets | 65 |
| Short tweets | 303 |
| Tweets kept | 300 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2se37abl/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @robber0540's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3i4yohh5) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3i4yohh5/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/robber0540')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/mikeyyshorts
|
huggingtweets
| 2021-06-13T21:38:51Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/mikeyyshorts/1623620327489/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1370766101706051587/CcUAr3LL_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">mikey l-h-f-m (donathon creek)</div>
<div style="text-align: center; font-size: 14px;">@mikeyyshorts</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from mikey l-h-f-m (donathon creek).
| Data | mikey l-h-f-m (donathon creek) |
| --- | --- |
| Tweets downloaded | 1850 |
| Retweets | 162 |
| Short tweets | 336 |
| Tweets kept | 1352 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2rqx8qgm/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @mikeyyshorts's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/157kyrv2) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/157kyrv2/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/mikeyyshorts')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
MohamedZaitoon/bart-fine-tune
|
MohamedZaitoon
| 2021-06-13T17:27:59Z | 14 | 1 |
transformers
|
[
"transformers",
"pytorch",
"jax",
"bart",
"text2text-generation",
"summarization",
"dataset:CNN/Daily-mail",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
datasets:
- CNN/Daily-mail
metrics:
- ROUGE
---
|
huggingtweets/mcintweet
|
huggingtweets
| 2021-06-13T16:36:05Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/mcintweet/1623602161461/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1174977443641249792/VCg_utme_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Michael McIntyre</div>
<div style="text-align: center; font-size: 14px;">@mcintweet</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Michael McIntyre.
| Data | Michael McIntyre |
| --- | --- |
| Tweets downloaded | 1196 |
| Retweets | 138 |
| Short tweets | 34 |
| Tweets kept | 1024 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/35dkm3ec/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @mcintweet's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/20vszack) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/20vszack/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/mcintweet')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Yanzhu/bertweetfr-base
|
Yanzhu
| 2021-06-13T07:20:37Z | 200 | 5 |
transformers
|
[
"transformers",
"pytorch",
"camembert",
"fill-mask",
"fr",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-03-02T23:29:05Z |
---
language: "fr"
---
Domain-adaptive pretraining of camembert-base using 15 GB of French Tweets
|
huggingtweets/mrsanctumonious
|
huggingtweets
| 2021-06-13T06:23:36Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/mrsanctumonious/1623565396151/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1397722561065017344/nna9wn35_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">His Majesty Diem The Sanctimonious 🎈🗯️🔫</div>
<div style="text-align: center; font-size: 14px;">@mrsanctumonious</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from His Majesty Diem The Sanctimonious 🎈🗯️🔫.
| Data | His Majesty Diem The Sanctimonious 🎈🗯️🔫 |
| --- | --- |
| Tweets downloaded | 972 |
| Retweets | 82 |
| Short tweets | 111 |
| Tweets kept | 779 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/8h5lsj13/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @mrsanctumonious's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3tohfeq2) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3tohfeq2/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/mrsanctumonious')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
MohamedZaitoon/T5-CNN
|
MohamedZaitoon
| 2021-06-12T14:56:25Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"summarization",
"dataset:CNN/Daily-mail",
"endpoints_compatible",
"region:us"
] |
summarization
| 2022-03-02T23:29:04Z |
---
tags:
- summarization
datasets:
- CNN/Daily-mail
metrics:
- ROUGE
---
|
lysandre/new-dummy-model
|
lysandre
| 2021-06-12T07:49:19Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"distilbert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
# Dummy model
This is a dummy model.
|
luhua/chinese_pretrain_mrc_roberta_wwm_ext_large
|
luhua
| 2021-06-12T02:53:16Z | 254 | 81 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"question-answering",
"zh",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2022-03-02T23:29:05Z |
---
language:
- zh
license: "apache-2.0"
---
## Chinese MRC roberta_wwm_ext_large
* 使用大量中文MRC数据训练的roberta_wwm_ext_large模型,详情可查看:https://github.com/basketballandlearn/MRC_Competition_Dureader
* 此库发布的再训练模型,在 阅读理解/分类 等任务上均有大幅提高<br/>
(已有多位小伙伴在Dureader-2021等多个比赛中取得**top5**的成绩😁)
| 模型/数据集 | Dureader-2021 | tencentmedical |
| ------------------------------------------|--------------- | --------------- |
| | F1-score | Accuracy |
| | dev / A榜 | test-1 |
| macbert-large (哈工大预训练语言模型) | 65.49 / 64.27 | 82.5 |
| roberta-wwm-ext-large (哈工大预训练语言模型) | 65.49 / 64.27 | 82.5 |
| macbert-large (ours) | 70.45 / **68.13**| **83.4** |
| roberta-wwm-ext-large (ours) | 68.91 / 66.91 | 83.1 |
|
huggingtweets/caveyt3
|
huggingtweets
| 2021-06-12T00:27:00Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/caveyt3/1623457616455/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1393212575911976968/gDX5uIyF_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">CaVe Yt</div>
<div style="text-align: center; font-size: 14px;">@caveyt3</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from CaVe Yt.
| Data | CaVe Yt |
| --- | --- |
| Tweets downloaded | 777 |
| Retweets | 49 |
| Short tweets | 349 |
| Tweets kept | 379 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/380nkug5/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @caveyt3's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3ee4maq0) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3ee4maq0/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/caveyt3')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/alvarouribevel
|
huggingtweets
| 2021-06-11T16:26:27Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/479052171837984768/mlO43FWa_400x400.jpeg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Álvaro Uribe Vélez</div>
<div style="text-align: center; font-size: 14px;">@alvarouribevel</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Álvaro Uribe Vélez.
| Data | Álvaro Uribe Vélez |
| --- | --- |
| Tweets downloaded | 3240 |
| Retweets | 1335 |
| Short tweets | 228 |
| Tweets kept | 1677 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1439yxv6/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @alvarouribevel's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2ly70v6r) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2ly70v6r/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/alvarouribevel')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
tensorspeech/tts-fastspeech2-kss-ko
|
tensorspeech
| 2021-06-11T03:03:15Z | 0 | 8 |
tensorflowtts
|
[
"tensorflowtts",
"audio",
"text-to-speech",
"text-to-mel",
"ko",
"dataset:KSS",
"arxiv:2006.04558",
"license:apache-2.0",
"region:us"
] |
text-to-speech
| 2022-03-02T23:29:05Z |
---
tags:
- tensorflowtts
- audio
- text-to-speech
- text-to-mel
language: ko
license: apache-2.0
datasets:
- KSS
widget:
- text: "신은 우리의 수학 문제에는 관심이 없다. 신은 다만 경험적으로 통합할 뿐이다."
---
# FastSpeech2 trained on KSS (Korean)
This repository provides a pretrained [FastSpeech2](https://arxiv.org/abs/2006.04558) trained on KSS dataset (Ko). For a detail of the model, we encourage you to read more about
[TensorFlowTTS](https://github.com/TensorSpeech/TensorFlowTTS).
## Install TensorFlowTTS
First of all, please install TensorFlowTTS with the following command:
```
pip install TensorFlowTTS
```
### Converting your Text to Mel Spectrogram
```python
import numpy as np
import soundfile as sf
import yaml
import tensorflow as tf
from tensorflow_tts.inference import AutoProcessor
from tensorflow_tts.inference import TFAutoModel
processor = AutoProcessor.from_pretrained("tensorspeech/tts-fastspeech2-kss-ko")
fastspeech2 = TFAutoModel.from_pretrained("tensorspeech/tts-fastspeech2-kss-ko")
text = "신은 우리의 수학 문제에는 관심이 없다. 신은 다만 경험적으로 통합할 뿐이다."
input_ids = processor.text_to_sequence(text)
mel_before, mel_after, duration_outputs, _, _ = fastspeech2.inference(
input_ids=tf.expand_dims(tf.convert_to_tensor(input_ids, dtype=tf.int32), 0),
speaker_ids=tf.convert_to_tensor([0], dtype=tf.int32),
speed_ratios=tf.convert_to_tensor([1.0], dtype=tf.float32),
f0_ratios =tf.convert_to_tensor([1.0], dtype=tf.float32),
energy_ratios =tf.convert_to_tensor([1.0], dtype=tf.float32),
)
```
#### Referencing FastSpeech2
```
@misc{ren2021fastspeech,
title={FastSpeech 2: Fast and High-Quality End-to-End Text to Speech},
author={Yi Ren and Chenxu Hu and Xu Tan and Tao Qin and Sheng Zhao and Zhou Zhao and Tie-Yan Liu},
year={2021},
eprint={2006.04558},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
```
#### Referencing TensorFlowTTS
```
@misc{TFTTS,
author = {Minh Nguyen, Alejandro Miguel Velasquez, Erogol, Kuan Chen, Dawid Kobus, Takuya Ebata,
Trinh Le and Yunchao He},
title = {TensorflowTTS},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\\url{https://github.com/TensorSpeech/TensorFlowTTS}},
}
```
|
dbragdon/noamlm
|
dbragdon
| 2021-06-10T17:15:46Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
Language model fine-tuned on the articles and speeches of Noam Chomsky.
|
kamalkraj/bioelectra-base-discriminator-pubmed-pmc-lt
|
kamalkraj
| 2021-06-10T14:22:08Z | 6 | 3 |
transformers
|
[
"transformers",
"pytorch",
"electra",
"pretraining",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
## BioELECTRA:Pretrained Biomedical text Encoder using Discriminators
Recent advancements in pretraining strategies in NLP have shown a significant improvement in the performance of models on various text mining tasks. In this paper, we introduce BioELECTRA, a biomedical domain-specific language encoder model that adapts ELECTRA (Clark et al., 2020) for the Biomedical domain. BioELECTRA outperforms the previous models and achieves state of the art (SOTA) on all the 13 datasets in BLURB benchmark and on all the 4 Clinical datasets from BLUE Benchmark across 7 NLP tasks. BioELECTRA pretrained on PubMed and PMC full text articles performs very well on Clinical datasets as well. BioELECTRA achieves new SOTA 86.34%(1.39% accuracy improvement) on MedNLI and 64% (2.98% accuracy improvement) on PubMedQA dataset.
For a detailed description and experimental results, please refer to our paper [BioELECTRA:Pretrained Biomedical text Encoder using Discriminators](https://www.aclweb.org/anthology/2021.bionlp-1.16/).
## How to use the discriminator in `transformers`
```python
from transformers import ElectraForPreTraining, ElectraTokenizerFast
import torch
discriminator = ElectraForPreTraining.from_pretrained("kamalkraj/bioelectra-base-discriminator-pubmed")
tokenizer = ElectraTokenizerFast.from_pretrained("kamalkraj/bioelectra-base-discriminator-pubmed")
sentence = "The quick brown fox jumps over the lazy dog"
fake_sentence = "The quick brown fox fake over the lazy dog"
fake_tokens = tokenizer.tokenize(fake_sentence)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
predictions = torch.round((torch.sign(discriminator_outputs[0]) + 1) / 2)
[print("%7s" % token, end="") for token in fake_tokens]
[print("%7s" % int(prediction), end="") for prediction in predictions[0].tolist()]
```
|
eunjin/kogpt2-finetuned-wellness
|
eunjin
| 2021-06-10T12:32:15Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
* skt/kogpt2-base-v2에 wellness 및 일상챗봇 데이터를 fine-tuning한 모델입니다.
* 유사한 정신건강 상담 도메인에서 바로 사용 가능합니다.
* 깃허브 사이트를 참조해주세요! https://github.com/eunjiinkim/WellnessChatbot
|
huggingtweets/joebiden-potus
|
huggingtweets
| 2021-06-09T15:51:59Z | 5 | 1 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1380530524779859970/TfwVAbyX_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1308769664240160770/AfgzWVE7_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">President Biden & Joe Biden</div>
<div style="text-align: center; font-size: 14px;">@joebiden-potus</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from President Biden & Joe Biden.
| Data | President Biden | Joe Biden |
| --- | --- | --- |
| Tweets downloaded | 872 | 3250 |
| Retweets | 32 | 384 |
| Short tweets | 3 | 38 |
| Tweets kept | 837 | 2828 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1c3s9vhj/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @joebiden-potus's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/tcstvtkt) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/tcstvtkt/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/joebiden-potus')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
patrickvonplaten/wav2vec2-base
|
patrickvonplaten
| 2021-06-08T17:00:26Z | 1,111 | 0 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"speech",
"en",
"dataset:librispeech_asr",
"arxiv:2006.11477",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language: en
datasets:
- librispeech_asr
tags:
- speech
license: apache-2.0
---
# Wav2Vec2-Base
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The base model pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz. Note that this model should be fine-tuned on a downstream task, like Automatic Speech Recognition. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more information.
[Paper](https://arxiv.org/abs/2006.11477)
Authors: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
**Abstract**
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this notebook](https://colab.research.google.com/drive/1FjTsqbYKphl9kL-eILgUc-bl4zVThL8F?usp=sharing) for more information on how to fine-tune the model.
|
huggingtweets/tdxf20
|
huggingtweets
| 2021-06-08T16:04:36Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/tdxf20/1623168253387/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1393296848929050627/sp8GpW8T_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">mert</div>
<div style="text-align: center; font-size: 14px;">@tdxf20</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from mert.
| Data | mert |
| --- | --- |
| Tweets downloaded | 1556 |
| Retweets | 181 |
| Short tweets | 373 |
| Tweets kept | 1002 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/n8yfhw0t/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @tdxf20's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/19ikisni) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/19ikisni/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/tdxf20')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/erilies
|
huggingtweets
| 2021-06-08T10:39:49Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html>
<head>
<title>503 Service Unavailable</title>
</head>
<body>
<h1>Error 503 Service Unavailable</h1>
<p>Service Unavailable</p>
<h3>Guru Mediation:</h3>
<p>Details: cache-wdc5522-WDC 1623148785 664418368</p>
<hr>
<p>Varnish cache server</p>
</body>
</html>
|
seduerr/pai_paraph
|
seduerr
| 2021-06-08T08:43:43Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-03-02T23:29:05Z |
input_ = paraphrase: + str(input_) + ' </s>'
|
huggingtweets/926stories-farheyraan-theaamirsays
|
huggingtweets
| 2021-06-08T07:11:08Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/926stories-farheyraan-theaamirsays/1623136262928/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1402093786457526273/DCJaU_cD_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1401224675632418823/1vrD7kaG_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1397095610436575232/qtl25tbM_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Rummyyyy & Farhaan Ahmed & Aamir</div>
<div style="text-align: center; font-size: 14px;">@926stories-farheyraan-theaamirsays</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Rummyyyy & Farhaan Ahmed & Aamir.
| Data | Rummyyyy | Farhaan Ahmed | Aamir |
| --- | --- | --- | --- |
| Tweets downloaded | 1423 | 1990 | 3127 |
| Retweets | 157 | 31 | 1143 |
| Short tweets | 140 | 132 | 578 |
| Tweets kept | 1126 | 1827 | 1406 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2ud8t13t/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @926stories-farheyraan-theaamirsays's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2356ddv8) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2356ddv8/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/926stories-farheyraan-theaamirsays')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/ascartprince-kicchinnezumi
|
huggingtweets
| 2021-06-08T06:56:36Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/ascartprince-kicchinnezumi/1623135392213/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1374537552292687879/Sy7M0aFk_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1400341059842891782/nJw_YYUy_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">👑 Prince Reinhard Ascart 👑 DEBUT TBA(COMMS OPEN) & Kicchin (Most Powerful VTweeter)</div>
<div style="text-align: center; font-size: 14px;">@ascartprince-kicchinnezumi</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from 👑 Prince Reinhard Ascart 👑 DEBUT TBA(COMMS OPEN) & Kicchin (Most Powerful VTweeter).
| Data | 👑 Prince Reinhard Ascart 👑 DEBUT TBA(COMMS OPEN) | Kicchin (Most Powerful VTweeter) |
| --- | --- | --- |
| Tweets downloaded | 3240 | 3247 |
| Retweets | 672 | 644 |
| Short tweets | 1223 | 1223 |
| Tweets kept | 1345 | 1380 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1voh8kfv/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @ascartprince-kicchinnezumi's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/y5knw4f6) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/y5knw4f6/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/ascartprince-kicchinnezumi')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/926stories
|
huggingtweets
| 2021-06-08T06:38:28Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/926stories/1623134303273/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1402093786457526273/DCJaU_cD_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Rummyyyy</div>
<div style="text-align: center; font-size: 14px;">@926stories</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Rummyyyy.
| Data | Rummyyyy |
| --- | --- |
| Tweets downloaded | 1420 |
| Retweets | 156 |
| Short tweets | 139 |
| Tweets kept | 1125 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/5frannca/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @926stories's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1dvniaka) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1dvniaka/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/926stories')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/noamchompers
|
huggingtweets
| 2021-06-07T20:13:29Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/noamchompers/1623096801492/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1276312598816972801/N5LfsYBw_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">it is antisemitic to call me ‘noam chumpers’</div>
<div style="text-align: center; font-size: 14px;">@noamchompers</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from it is antisemitic to call me ‘noam chumpers’.
| Data | it is antisemitic to call me ‘noam chumpers’ |
| --- | --- |
| Tweets downloaded | 3242 |
| Retweets | 450 |
| Short tweets | 371 |
| Tweets kept | 2421 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3vudk4dq/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @noamchompers's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1o35nfpi) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1o35nfpi/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/noamchompers')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
osanseviero/my_new_model
|
osanseviero
| 2021-06-07T14:27:42Z | 8 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"roberta",
"feature-extraction",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
---
tags:
- sentence-transformers
- feature-extraction
---
# Name of Model
<!--- Describe your model here -->
## Model Description
The model consists of the following layers:
(0) Base Transformer Type: RobertaModel
(1) mean Pooling
## Usage (Sentence-Transformers)
Using this model becomes more convenient when you have [sentence-transformers](https://github.com/UKPLab/sentence-transformers) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence"]
model = SentenceTransformer('model_name')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
return sum_embeddings / sum_mask
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('model_name')
model = AutoModel.from_pretrained('model_name')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, max_length=128, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Training Procedure
<!--- Describe how your model was trained -->
## Evaluation Results
<!--- Describe how your model was evaluated -->
## Citing & Authors
<!--- Describe where people can find more information -->
|
huggingtweets/foxlius
|
huggingtweets
| 2021-06-07T13:20:09Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2022-03-02T23:29:05Z |
---
language: en
thumbnail: https://www.huggingtweets.com/foxlius/1623071923782/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1397375635845222400/-N68I_0K_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">legally required to</div>
<div style="text-align: center; font-size: 14px;">@foxlius</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from legally required to.
| Data | legally required to |
| --- | --- |
| Tweets downloaded | 3224 |
| Retweets | 1459 |
| Short tweets | 631 |
| Tweets kept | 1134 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/h54z72kn/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @foxlius's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/6fffkgwp) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/6fffkgwp/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/foxlius')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.