
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-06 12:28:13
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 543
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-06 12:27:52
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
mradermacher/Malaysian-TTS-1.7B-v0.1-GGUF
|
mradermacher
| 2025-08-12T18:06:47Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:mesolitica/Malaysian-TTS-1.7B-v0.1",
"base_model:quantized:mesolitica/Malaysian-TTS-1.7B-v0.1",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-12T17:59:22Z |
---
base_model: mesolitica/Malaysian-TTS-1.7B-v0.1
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/mesolitica/Malaysian-TTS-1.7B-v0.1
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Malaysian-TTS-1.7B-v0.1-GGUF).***
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Malaysian-TTS-1.7B-v0.1-GGUF/resolve/main/Malaysian-TTS-1.7B-v0.1.Q2_K.gguf) | Q2_K | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/Malaysian-TTS-1.7B-v0.1-GGUF/resolve/main/Malaysian-TTS-1.7B-v0.1.Q3_K_S.gguf) | Q3_K_S | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/Malaysian-TTS-1.7B-v0.1-GGUF/resolve/main/Malaysian-TTS-1.7B-v0.1.Q3_K_M.gguf) | Q3_K_M | 1.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Malaysian-TTS-1.7B-v0.1-GGUF/resolve/main/Malaysian-TTS-1.7B-v0.1.Q3_K_L.gguf) | Q3_K_L | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/Malaysian-TTS-1.7B-v0.1-GGUF/resolve/main/Malaysian-TTS-1.7B-v0.1.IQ4_XS.gguf) | IQ4_XS | 1.2 | |
| [GGUF](https://huggingface.co/mradermacher/Malaysian-TTS-1.7B-v0.1-GGUF/resolve/main/Malaysian-TTS-1.7B-v0.1.Q4_K_S.gguf) | Q4_K_S | 1.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Malaysian-TTS-1.7B-v0.1-GGUF/resolve/main/Malaysian-TTS-1.7B-v0.1.Q4_K_M.gguf) | Q4_K_M | 1.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Malaysian-TTS-1.7B-v0.1-GGUF/resolve/main/Malaysian-TTS-1.7B-v0.1.Q5_K_S.gguf) | Q5_K_S | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/Malaysian-TTS-1.7B-v0.1-GGUF/resolve/main/Malaysian-TTS-1.7B-v0.1.Q5_K_M.gguf) | Q5_K_M | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/Malaysian-TTS-1.7B-v0.1-GGUF/resolve/main/Malaysian-TTS-1.7B-v0.1.Q6_K.gguf) | Q6_K | 1.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Malaysian-TTS-1.7B-v0.1-GGUF/resolve/main/Malaysian-TTS-1.7B-v0.1.Q8_0.gguf) | Q8_0 | 2.0 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Malaysian-TTS-1.7B-v0.1-GGUF/resolve/main/Malaysian-TTS-1.7B-v0.1.f16.gguf) | f16 | 3.7 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
charvibannur/Qwen-3-0.6B-DPO-10-5e-5-0.1-1000
|
charvibannur
| 2025-08-12T18:04:20Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T18:03:36Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1755021713
|
Ferdi3425
| 2025-08-12T18:03:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T18:02:49Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Thegame1161/tiny-bert-detect-fake-news
|
Thegame1161
| 2025-08-12T18:02:59Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"en",
"base_model:huawei-noah/TinyBERT_General_4L_312D",
"base_model:finetune:huawei-noah/TinyBERT_General_4L_312D",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-12T17:55:42Z |
---
license: apache-2.0
language:
- en
base_model:
- huawei-noah/TinyBERT_General_4L_312D
pipeline_tag: text-classification
library_name: transformers
---
TinyBERT for Fake News Detection
This model is a fine-tuned version of TinyBERT specifically designed for detecting fake news. It offers a lightweight yet effective solution for identifying potentially misleading or false information in text. Built with efficiency in mind, it provides a good balance between accuracy and speed, making it suitable for various applications.
|
nightmedia/Jan-v1-4B-q6-hi-mlx
|
nightmedia
| 2025-08-12T18:02:51Z | 0 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"en",
"base_model:janhq/Jan-v1-4B",
"base_model:quantized:janhq/Jan-v1-4B",
"license:apache-2.0",
"6-bit",
"region:us"
] |
text-generation
| 2025-08-12T17:48:42Z |
---
license: apache-2.0
language:
- en
base_model: janhq/Jan-v1-4B
pipeline_tag: text-generation
tags:
- mlx
library_name: mlx
---
# Jan-v1-4B-q6-hi-mlx
This model [Jan-v1-4B-q6-hi-mlx](https://huggingface.co/Jan-v1-4B-q6-hi-mlx) was
converted to MLX format from [janhq/Jan-v1-4B](https://huggingface.co/janhq/Jan-v1-4B)
using mlx-lm version **0.26.3**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("Jan-v1-4B-q6-hi-mlx")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
andr0m4da/blockassist-bc-grazing_hunting_boar_1755021663
|
andr0m4da
| 2025-08-12T18:02:37Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"grazing hunting boar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T18:02:25Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- grazing hunting boar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
aleebaster/blockassist-bc-sly_eager_boar_1755020540
|
aleebaster
| 2025-08-12T18:01:16Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sly eager boar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:59:57Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sly eager boar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
pharaohe/dwarfredhairrep10epoc16
|
pharaohe
| 2025-08-12T18:00:41Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"flux",
"lora",
"template:sd-lora",
"fluxgym",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-12T18:00:01Z |
---
tags:
- text-to-image
- flux
- lora
- diffusers
- template:sd-lora
- fluxgym
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: woman
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# dwarfredhairrep10epoc16
A Flux LoRA trained on a local computer with [Fluxgym](https://github.com/cocktailpeanut/fluxgym)
<Gallery />
## Trigger words
You should use `woman` to trigger the image generation.
## Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, Forge, etc.
Weights for this model are available in Safetensors format.
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755021428
|
IvanJAjebu
| 2025-08-12T17:58:48Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:58:02Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1755021441
|
ggozzy
| 2025-08-12T17:58:41Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:58:28Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
hidayahlut/blockassist-bc-knobby_scavenging_wasp_1755020821
|
hidayahlut
| 2025-08-12T17:58:21Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"knobby scavenging wasp",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:48:08Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- knobby scavenging wasp
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
calegpedia/blockassist-bc-stealthy_slimy_rooster_1755019804
|
calegpedia
| 2025-08-12T17:58:11Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stealthy slimy rooster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:58:07Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stealthy slimy rooster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
JeonMashup/Agust_D_BTS
|
JeonMashup
| 2025-08-12T17:56:54Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2024-11-08T00:42:03Z |
---
license: apache-2.0
---
|
microsoft/Phi-4-mini-flash-reasoning
|
microsoft
| 2025-08-12T17:56:31Z | 19,399 | 214 |
transformers
|
[
"transformers",
"safetensors",
"phi4flash",
"text-generation",
"nlp",
"math",
"code",
"conversational",
"custom_code",
"en",
"arxiv:2507.06607",
"license:mit",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2025-06-19T23:40:57Z |
---
language:
- en
library_name: transformers
license: mit
license_link: https://huggingface.co/microsoft/Phi-4-mini-flash-reasoning/resolve/main/LICENSE
pipeline_tag: text-generation
tags:
- nlp
- math
- code
widget:
- messages:
- role: user
content: How to solve 3*x^2+4*x+5=1?
---
## Model Summary
Phi-4-mini-flash-reasoning is a lightweight open model built upon synthetic data with a focus on high-quality, reasoning dense data further finetuned for more advanced math reasoning capabilities.
The model belongs to the Phi-4 model family and supports 64K token context length.
📰 [Phi-4-mini-flash-reasoning Blog](https://azure.microsoft.com/en-us/blog/reasoning-reimagined-introducing-phi-4-mini-flash-reasoning/) <br>
📖 [Phi-4-mini-flash-reasoning Paper](https://aka.ms/flashreasoning-paper) | [HF Paper](https://huggingface.co/papers/2507.06607) <br>
📚 [Training Codebase](https://github.com/microsoft/ArchScale) <br>
👩🍳 [Phi Cookbook](https://github.com/microsoft/PhiCookBook) <br>
🏡 [Phi Portal](https://azure.microsoft.com/en-us/products/phi) <br>
🚀 [vLLM Inference](https://github.com/vllm-project/vllm/pull/20702) <br>
🖥️ Try It [Azure](https://ai.azure.com/explore/models/Phi-4-mini-flash-reasoning/version/1/registry/azureml-phi-prod) [Nvidia NIM](https://build.nvidia.com/microsoft/phi-4-mini-flash-reasoning)<br>
🎉**Phi-4 models**: [[Phi-4-mini-reasoning](https://huggingface.co/microsoft/Phi-4-mini-reasoning)] | [[Phi-4-reasoning](https://huggingface.co/microsoft/Phi-4-reasoning)] | [[multimodal-instruct](https://huggingface.co/microsoft/Phi-4-multimodal-instruct) | [onnx](https://huggingface.co/microsoft/Phi-4-multimodal-instruct-onnx)];
[[mini-instruct](https://huggingface.co/microsoft/Phi-4-mini-instruct) | [onnx](https://huggingface.co/microsoft/Phi-4-mini-instruct-onnx)]
## Abstract
Recent advances in language modeling have demonstrated the effectiveness of State Space Models (SSMs) for efficient sequence modeling. While hybrid architectures such as Samba and the decoder-decoder architecture, YOCO, have shown promising performance gains over Transformers, prior works have not investigated the efficiency potential of representation sharing between SSM layers. In this paper, we introduce the Gated Memory Unit (GMU), a simple yet effective mechanism for efficient memory sharing across layers. We apply it to create SambaY, a decoder-hybrid-decoder architecture that incorporates GMUs in the cross-decoder to share memory readout states from a Samba-based self-decoder. SambaY significantly enhances decoding efficiency, preserves linear pre-filling time complexity, and boosts long-context performance, all while eliminating the need for explicit positional encoding. Through extensive scaling experiments, we demonstrate that our model exhibits a significantly lower irreducible loss compared to a strong YOCO baseline, indicating superior performance scalability under large-scale compute regimes. Our largest model enhanced with Differential Attention, Phi4-mini-Flash-Reasoning, achieves significantly better performance than Phi4-mini-Reasoning on reasoning tasks such as Math500, AIME24/25, and GPQA Diamond without any reinforcement learning, while delivering up to 10x higher decoding throughput on 2K-length prompts with 32K generation length under the vLLM inference framework. We release our training codebase on open-source data at [this https URL](https://github.com/microsoft/ArchScale).
## Intended Uses
### Primary Use Cases
Phi-4-mini-flash-reasoning is designed for multi-step, logic-intensive mathematical problem-solving tasks under memory/compute constrained environments and latency bound scenarios.
Some of the use cases include formal proof generation, symbolic computation, advanced word problems, and a wide range of mathematical reasoning scenarios.
These models excel at maintaining context across steps, applying structured logic, and delivering accurate, reliable solutions in domains that require deep analytical thinking.
### Use Case Considerations
This model is designed and tested for math reasoning only. It is not specifically designed or evaluated for all downstream purposes.
Developers should consider common limitations of language models, as well as performance difference across languages, as they select use cases, and evaluate and mitigate for accuracy, safety, and fairness before using within a specific downstream use case, particularly for high-risk scenarios.
Developers should be aware of and adhere to applicable laws or regulations (including but not limited to privacy, trade compliance laws, etc.) that are relevant to their use case.
***Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.***
## Release Notes
This release of Phi-4-mini-flash-reasoning addresses user feedback and market demand for a compact reasoning model.
It is a compact transformer-based language model optimized for mathematical reasoning, built to deliver high-quality, step-by-step problem solving in environments where computing or latency is constrained.
The model is fine-tuned with synthetic math data from a more capable model (much larger, smarter, more accurate, and better at following instructions), which has resulted in enhanced reasoning performance.
Phi-4-mini-flash-reasoning balances reasoning ability with efficiency, making it potentially suitable for educational applications, embedded tutoring, and lightweight deployment on edge or mobile systems.
If a critical issue is identified with Phi-4-mini-flash-reasoning, it should be promptly reported through the MSRC Researcher Portal or secure@microsoft.com
### Model Quality
To understand the capabilities, the 3.8B parameters Phi-4-mini-flash-reasoning model was compared with a set of models over a variety of reasoning benchmarks.
We use a more accurate evaluation where Pass@1 accuracy is averaged over 64 samples for AIME24/25 and 8 samples for Math500 and GPQA Diamond. A high-level overview of the model quality is as follows:
| **Model** | **AIME24** | **AIME25** | **Math500** | **GPQA Diamond** |
| :----------------------------------- | :--------- | :--------- | :---------- | :--------------- |
| DeepSeek-R1-Distill-Qwen-1.5B | 29.58 | 20.78 | 84.50 | 37.69 |
| DeepSeek-R1-Distill-Qwen-7B | 53.70 | 35.94 | 93.03 | 47.85 |
| DeepSeek-R1-Distill-Llama-8B | 43.96 | 27.34 | 87.48 | 45.83 |
| Bespoke-Stratos-7B | 21.51 | 18.28 | 80.73 | 38.51 |
| OpenThinker-7B | 29.69 | 24.32 | 87.25 | 41.60 |
| Phi4-mini-Reasoning (3.8B) | 48.13 | 31.77 | 91.20 | 44.51 |
| **Phi4-mini-Flash-Reasoning (3.8B)** | **52.29** | **33.59** | **92.45** | **45.08** |
Overall, the model with only 3.8B-param achieves a similar level of math and science reasoning ability as much larger models.
However, it is still fundamentally limited by its size for certain tasks. The model simply does not have the capacity to store too much factual knowledge, therefore, users may experience factual incorrectness. However, it may be possible to resolve such weakness by augmenting Phi-4-mini-flash-reasoning with a search engine, particularly when using the model under RAG settings.
### Model Efficiency
The two figures below compare the latency and throughput performance of the Phi-4-mini-reasoning and Phi-4-mini-flash-reasoning models under the vLLM inference framework. All evaluations were performed on a single NVIDIA A100-80GB GPU with tensor parallelism disabled (TP = 1). The Phi-4-mini-flash-reasoning model, which incorporates a decoder-hybrid-decoder architecture with attention and state space model (SSM), exhibits significantly greater computational efficiency—achieving up-to a 10× improvement in throughput when processing user requests with 2K prompt length and 32K generation length. Furthermore, Phi-4-mini-flash-reasoning demonstrates near-linear growth in latency with respect to the number of tokens generated (up to 32k), in contrast to the quadratic growth observed in Phi-4-mini-reasoning. These findings indicate that Phi-4-mini-flash-reasoning is more scalable and better suited for long-sequence generation tasks.
<div align="left">
<img src="lat.png" width="300"/>
<img src="thr_lat.png" width="298"/>
</div>
Figure 1. The first plot shows average inference latency as a function of generation length, while the second plot illustrates how inference latency varies with throughput. Both experiments were conducted using the vLLM inference framework on a single A100-80GB GPU over varying concurrency levels of user requests.
## Usage
### Tokenizer
Phi-4-mini-flash-reasoning supports a vocabulary size of up to `200064` tokens. The [tokenizer files](https://huggingface.co/microsoft/Phi-4-mini-flash-reasoning/blob/main/added_tokens.json) already provide placeholder tokens that can be used for downstream fine-tuning, but they can also be extended up to the model's vocabulary size.
### Input Formats
Given the nature of the training data, the Phi-4-mini-flash-reasoning
model is best suited for prompts using this specific chat format:
```yaml
<|user|>How to solve 3*x^2+4*x+5=1?<|end|><|assistant|>
```
### Inference with transformers
List of required packages:
```
flash_attn==2.7.4.post1
torch==2.6.0
mamba-ssm==2.2.4 --no-build-isolation
causal-conv1d==1.5.0.post8
transformers==4.46.1
accelerate==1.4.0
```
Phi-4-mini-flash-reasoning is also available in [Azure AI Foundry](https://ai.azure.com/explore/models/Phi-4-mini-flash-reasoning/version/1/registry/azureml-phi-prod)
#### Example
After obtaining the Phi-4-mini-flash-reasoning model checkpoints, users can use this sample code for inference.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model_id = "microsoft/Phi-4-mini-flash-reasoning"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
messages = [{
"role": "user",
"content": "How to solve 3*x^2+4*x+5=1?"
}]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
outputs = model.generate(
**inputs.to(model.device),
max_new_tokens=32768,
temperature=0.6,
top_p=0.95,
do_sample=True,
)
outputs = tokenizer.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:])
print(outputs[0])
```
## Training
### Model
+ **Architecture:** Phi-4-mini-flash-reasoning adopts a hybrid SambaY architecture with Differential Attention, featuring 3.8 billion parameters and a 200K vocabulary. It incorporates state space models, grouped-query attention, a gated memory sharing mechanism, a shared key-value cache with a single global attention layer, and shared input-output embeddings.<br>
+ **Inputs:** Text. It is best suited for prompts using the chat format.<br>
+ **Context length:** 64K tokens<br>
+ **GPUs:** Pre-training: 1024 A100-80G; Reasoning training: 128 H100-80G <br>
+ **Training time:** Pre-training: 14 days; Reasoning training: 2days <br>
+ **Training data:** Pre-training: 5T tokens; Reasoning training: 150B tokens<br>
+ **Outputs:** Generated text<br>
+ **Dates:** Trained in May 2025 <br>
+ **Status:** This is a static model trained on offline datasets with the cutoff date of February 2025 for publicly available data.<br>
+ **Supported languages:** English<br>
+ **Release date:** June 2025<br>
### Training Datasets
The training data for Phi-4-mini-flash-reasoning consists exclusively of synthetic mathematical content generated by a stronger and more advanced reasoning model, Deepseek-R1.
The objective is to distill knowledge from this model. This synthetic dataset comprises over one million diverse math problems spanning multiple levels of difficulty (from middle school to Ph.D. level).
For each problem in the synthetic dataset, eight distinct solutions (rollouts) were sampled, and only those verified as correct were retained, resulting in approximately 30 billion tokens of math content.
The dataset integrates three primary components:
1) a curated selection of high-quality, publicly available math questions and a part of the SFT(Supervised Fine-Tuning) data that was used to train the base Phi-4-mini-flash model;
2) an extensive collection of synthetic math data generated by the Deepseek-R1 model, designed specifically for high-quality supervised fine-tuning and model distillation; and
3) a balanced set of correct and incorrect answers used to construct preference data aimed at enhancing Phi-4-mini-flash-reasoning's reasoning capabilities by learning more effective reasoning trajectories
## Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [Transformers](https://github.com/huggingface/transformers)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
* [Mamba](https://github.com/state-spaces/mamba)
* [Causal-Conv1d](https://github.com/Dao-AILab/causal-conv1d)
## Hardware
Note that by default, the Phi-4-mini-flash-reasoning model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
* NVIDIA A100
* NVIDIA H100
## Safety Evaluation and Red-Teaming
The Phi-4 family of models has adopted a robust safety post-training approach. This approach leverages a variety of both open-source and in-house generated datasets. The overall technique employed to do the safety alignment is a combination of SFT, DPO (Direct Preference Optimization), and RLHF (Reinforcement Learning from Human Feedback) approaches by utilizing human-labeled and synthetic English-language datasets, including publicly available datasets focusing on helpfulness and harmlessness, as well as various questions and answers targeted to multiple safety categories.
Phi-4-Mini-Flash-Reasoning was developed in accordance with Microsoft's responsible AI principles. Potential safety risks in the model’s responses were assessed using the Azure AI Foundry’s Risk and Safety Evaluation framework, focusing on harmful content, direct jailbreak, and model groundedness. The Phi-4-Mini-Flash-Reasoning Model Card contains additional information about our approach to safety and responsible AI considerations that developers should be aware of when using this model.
## Responsible AI Considerations
Like other language models, the Phi family of models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
+ Quality of Service: The Phi models are trained primarily on English text and some additional multilingual text. Languages other than English will experience worse performance as well as performance disparities across non-English. English language varieties with less representation in the training data might experience worse performance than standard American English.
+ Multilingual performance and safety gaps: We believe it is important to make language models more widely available across different languages, but the Phi 4 models still exhibit challenges common across multilingual releases. As with any deployment of LLMs, developers will be better positioned to test for performance or safety gaps for their linguistic and cultural context and customize the model with additional fine-tuning and appropriate safeguards.
+ Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups, cultural contexts, or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
+ Inappropriate or Offensive Content: These models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the case.
+ Information Reliability: Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
+ Election Information Reliability : The model has an elevated defect rate when responding to election-critical queries, which may result in incorrect or unauthoritative election critical information being presented. We are working to improve the model's performance in this area. Users should verify information related to elections with the election authority in their region.
+ Limited Scope for Code: The majority of Phi 4 training data is based in Python and uses common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, it is strongly recommended that users manually verify all API uses.
+ Long Conversation: Phi 4 models, like other models, can in some cases generate responses that are repetitive, unhelpful, or inconsistent in very long chat sessions in both English and non-English languages. Developers are encouraged to place appropriate mitigations, like limiting conversation turns to account for the possible conversational drift.
Developers should apply responsible AI best practices, including mapping, measuring, and mitigating risks associated with their specific use case and cultural, linguistic context. Phi 4 family of models are general purpose models. As developers plan to deploy these models for specific use cases, they are encouraged to fine-tune the models for their use case and leverage the models as part of broader AI systems with language-specific safeguards in place. Important areas for consideration include:
+ Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
+ High-Risk Scenarios: Developers should assess the suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
+ Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
+ Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
+ Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
## License
The model is licensed under the [MIT license](./LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
## Appendix A: Benchmark Methodology
We include a brief word on methodology here - and in particular, how we think about optimizing prompts. In an ideal world, we would never change any prompts in our benchmarks to ensure it is always an apples-to-apples comparison when comparing different models. Indeed, this is our default approach, and is the case in the vast majority of models we have run to date. For all benchmarks, we consider using the same generation configuration such as max sequence length (32768), the same temperature for the fair comparison.
Benchmark datasets
We evaluate the model with three of the most popular math benchmarks where the strongest reasoning models are competing together. Specifically:
+ Math-500: This benchmark consists of 500 challenging math problems designed to test the model's ability to perform complex mathematical reasoning and problem-solving.
+ AIME 2024/AIME 2025: The American Invitational Mathematics Examination (AIME) is a highly regarded math competition that features a series of difficult problems aimed at assessing advanced mathematical skills and logical reasoning. We evaluate the models on the problems from both 2024 and the year 2025 examinations.
+ GPQA Diamond: The Graduate-Level Google-Proof Q&A (GPQA) Diamond benchmark focuses on evaluating the model's ability to understand and solve a wide range of mathematical questions, including both straightforward calculations and more intricate problem-solving tasks.
|
tdickson17/Text_Summarization
|
tdickson17
| 2025-08-12T17:55:38Z | 22 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"summarization",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
summarization
| 2025-08-09T23:35:37Z |
---
library_name: transformers
pipeline_tag: summarization
---
tags:
- politics
- summarization
- climate change
- political party
- press release
- political communication
- European Union
- Speech
license: afl-3.0
language:
- en
- es
- da
- de
- it
- fr
- nl
- pl
# Text Summarization
The model used in this summarization task is a T5 summarization transformer-based language model fine-tuned for abstractive summarization.
This model is intended to summarize political texts regarding generates summaries by treating text summarization as a text-to-text problem, where both the input and the output are sequences of text.
The model was fine-tuned on 10k political party press releases from 66 parties in 12 different countries via an abstract summary.
## Model Details
Pretrained Model: The model uses a pretrained tokenizer and model from the Hugging Face transformers library (e.g., T5ForConditionalGeneration).
Tokenization: Text is tokenized using a subword tokenizer, where long words are split into smaller, meaningful subwords.
Input Processing: The model processes the input sequence by truncating or padding the text to fit within the max_input_length of 512 tokens.
Output Generation: The model generates the summary through a text generation process using beam search with a beam width of 4 to explore multiple possible summary sequences at each step.
Key Parameters:
Max Input Length: 512 tokens — ensures the input text is truncated or padded to fit within the model's processing capacity.
Max Target Length: 128 tokens — restricts the length of the generated summary, balancing between concise output and content preservation.
Beam Search: Uses a beam width of 10 to explore multiple candidate sequences during generation, helping the model choose the most probable summary.
Early Stopping: The generation process stops early if the model predicts the end of the sequence before reaching the maximum target length.
Generation Process:
Input Tokenization: The input text is tokenized into subword units and passed into the model.
Beam Search: The model generates the next token by considering the top 10 possible sequences at each step, aiming to find the most probable summary sequence.
Output Decoding: The generated summary is decoded from token IDs back into human-readable text using the tokenizer, skipping special tokens like padding or end-of-sequence markers.
- **Repository:** https://github.com/tcdickson/Text-Summarization.git
## Training Details
The summarization model was trained on a dataset of press releases scraped from various party websites. These press releases were selected to represent diverse political perspectives and topics, ensuring that the model learned to generate summaries across a wide range of political content.
Data Collection:
Source: Press releases from official party websites, which often contain detailed statements, policy announcements, and responses to current events. These documents were chosen because of their structured format and consistent language use.
Preprocessing: The scraped text was cleaned and preprocessed, removing extraneous HTML tags, irrelevant information, and ensuring that the text content was well-formatted for model training.
Text Format: The press releases were processed into suitable text pairs: the original full text as the input and a human-crafted summary (if available) or a custom summary generated by the developers as the target output.
Training Objective:
The model was fine-tuned using these press releases to learn the task of abstractive summarization — generating concise, fluent summaries of longer political texts.
The model was trained to capture key information and context, while avoiding irrelevant details, ensuring that it could produce summaries that accurately reflect the essence of each release.
Training Strategy:
Supervised Learning: The model was trained using supervised learning, where each input (press release) was paired with a corresponding summary.
Optimization: During training, the model's parameters were adjusted using gradient descent and the cross-entropy loss function.
This training process allowed the model to learn not only the specific language patterns commonly found in political press releases but also the broader context of political discourse.
## Citation:
@article{dickson2024going,
title={Going against the grain: Climate change as a wedge issue for the radical right},
author={Dickson, Zachary P and Hobolt, Sara B},
journal={Comparative Political Studies},
year={2024},
publisher={SAGE Publications Sage CA: Los Angeles, CA}
}
|
coastalcph/Qwen2.5-7B-05t_gcd_sycophancy-05t_diff_sycophant
|
coastalcph
| 2025-08-12T17:55:28Z | 0 | 0 | null |
[
"safetensors",
"qwen2",
"region:us"
] | null | 2025-08-12T17:50:48Z |
# Combined Task Vector Model
This model was created by combining task vectors from multiple fine-tuned models.
## Task Vector Computation
```python
t_1 = TaskVector("Qwen/Qwen2.5-7B-Instruct", "coastalcph/Qwen2.5-7B-gcd_sycophancy")
t_2 = TaskVector("Qwen/Qwen2.5-7B-Instruct", "coastalcph/Qwen2.5-7B-personality-non-sycophancy")
t_combined = 0.5 * t_1 + 0.5 * t_2 - 0.5 * t_3
new_model = t_combined.apply_to("Qwen/Qwen2.5-7B-Instruct", scaling_coef=1.0)
```
Models Used
- Base Model: https://huggingface.co/Qwen/Qwen2.5-7B-Instruct
- Fine-tuned Model 1: https://huggingface.co/coastalcph/Qwen2.5-7B-gcd_sycophancy
- Fine-tuned Model 2: https://huggingface.co/coastalcph/Qwen2.5-7B-personality-non-sycophancy
Technical Details
- Creation Script Git Hash: 435fdd2a144e79c487d864db94b34a02894295b9
- Task Vector Method: Additive combination
- Args: {
"pretrained_model": "Qwen/Qwen2.5-7B-Instruct",
"finetuned_model1": "coastalcph/Qwen2.5-7B-gcd_sycophancy",
"finetuned_model2": "coastalcph/Qwen2.5-7B-personality-non-sycophancy",
"finetuned_model3": "coastalcph/Qwen2.5-7B-personality-sycophancy",
"output_model_name": "coastalcph/Qwen2.5-7B-05t_gcd_sycophancy-05t_diff_sycophant",
"output_dir": "/projects/nlp/data/constanzam/weight-interp/task-vectors/math_non_sycophant_12Aug",
"scaling_coef": 1.0,
"apply_line_scaling_t1": false,
"apply_line_scaling_t2": false,
"apply_line_scaling_t3": false,
"scale_t1": 0.5,
"scale_t2": 0.5,
"scale_t3": 0.5
}
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1755021237
|
Ferdi3425
| 2025-08-12T17:55:12Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:54:45Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/Moondark-12B-GGUF
|
mradermacher
| 2025-08-12T17:54:45Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"roleplay",
"en",
"base_model:Vortex5/Moondark-12B",
"base_model:quantized:Vortex5/Moondark-12B",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-12T14:33:38Z |
---
base_model: Vortex5/Moondark-12B
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- mergekit
- merge
- roleplay
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/Vortex5/Moondark-12B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Moondark-12B-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Moondark-12B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Moondark-12B-GGUF/resolve/main/Moondark-12B.Q2_K.gguf) | Q2_K | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/Moondark-12B-GGUF/resolve/main/Moondark-12B.Q3_K_S.gguf) | Q3_K_S | 5.6 | |
| [GGUF](https://huggingface.co/mradermacher/Moondark-12B-GGUF/resolve/main/Moondark-12B.Q3_K_M.gguf) | Q3_K_M | 6.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Moondark-12B-GGUF/resolve/main/Moondark-12B.Q3_K_L.gguf) | Q3_K_L | 6.7 | |
| [GGUF](https://huggingface.co/mradermacher/Moondark-12B-GGUF/resolve/main/Moondark-12B.IQ4_XS.gguf) | IQ4_XS | 6.9 | |
| [GGUF](https://huggingface.co/mradermacher/Moondark-12B-GGUF/resolve/main/Moondark-12B.Q4_K_S.gguf) | Q4_K_S | 7.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Moondark-12B-GGUF/resolve/main/Moondark-12B.Q4_K_M.gguf) | Q4_K_M | 7.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Moondark-12B-GGUF/resolve/main/Moondark-12B.Q5_K_S.gguf) | Q5_K_S | 8.6 | |
| [GGUF](https://huggingface.co/mradermacher/Moondark-12B-GGUF/resolve/main/Moondark-12B.Q5_K_M.gguf) | Q5_K_M | 8.8 | |
| [GGUF](https://huggingface.co/mradermacher/Moondark-12B-GGUF/resolve/main/Moondark-12B.Q6_K.gguf) | Q6_K | 10.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Moondark-12B-GGUF/resolve/main/Moondark-12B.Q8_0.gguf) | Q8_0 | 13.1 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755021169
|
IvanJAjebu
| 2025-08-12T17:54:01Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:53:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
VIDEOS-18-Horse-and-girl-viral-video-link/New.full.videos.Horse.and.girl.Viral.Video.Official.Tutorial
|
VIDEOS-18-Horse-and-girl-viral-video-link
| 2025-08-12T17:53:40Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-12T17:53:29Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?leaked-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1755021136
|
ggozzy
| 2025-08-12T17:53:38Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:53:25Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
stakesquid/blockassist-bc-scaly_shrewd_stingray_1755020966
|
stakesquid
| 2025-08-12T17:53:00Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"scaly shrewd stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:52:55Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- scaly shrewd stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Chithekitale/PhD_tts_updated
|
Chithekitale
| 2025-08-12T17:51:24Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"speecht5",
"text-to-audio",
"generated_from_trainer",
"dataset:Chithekitale/virus_one_and_two",
"base_model:microsoft/speecht5_tts",
"base_model:finetune:microsoft/speecht5_tts",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-to-audio
| 2025-08-12T13:50:41Z |
---
library_name: transformers
license: mit
base_model: microsoft/speecht5_tts
tags:
- generated_from_trainer
datasets:
- Chithekitale/virus_one_and_two
model-index:
- name: Chichewa TTS_final
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Chichewa TTS_final
This model is a fine-tuned version of [microsoft/speecht5_tts](https://huggingface.co/microsoft/speecht5_tts) on the chichewaspeechset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4031
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-------:|:----:|:---------------:|
| 0.4596 | 6.9965 | 1000 | 0.4262 |
| 0.4407 | 13.9895 | 2000 | 0.4097 |
| 0.4333 | 20.9825 | 3000 | 0.4029 |
| 0.4405 | 27.9754 | 4000 | 0.4031 |
### Framework versions
- Transformers 4.50.3
- Pytorch 2.6.0+cu118
- Datasets 3.5.0
- Tokenizers 0.21.1
|
jeongseokoh/Llama3.1-8B-LatentRAG-batch-support_40st-og
|
jeongseokoh
| 2025-08-12T17:50:29Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T17:43:37Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
dgsilvia/Reinforce-pixelcopter
|
dgsilvia
| 2025-08-12T17:49:16Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-12T12:13:27Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-pixelcopter
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 42.50 +/- 28.42
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
nightmedia/Jan-v1-4B-q8-hi-mlx
|
nightmedia
| 2025-08-12T17:48:34Z | 0 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"en",
"base_model:janhq/Jan-v1-4B",
"base_model:quantized:janhq/Jan-v1-4B",
"license:apache-2.0",
"8-bit",
"region:us"
] |
text-generation
| 2025-08-12T17:29:48Z |
---
license: apache-2.0
language:
- en
base_model: janhq/Jan-v1-4B
pipeline_tag: text-generation
tags:
- mlx
library_name: mlx
---
# Jan-v1-4B-q8-hi-mlx
This model [Jan-v1-4B-q8-hi-mlx](https://huggingface.co/Jan-v1-4B-q8-hi-mlx) was
converted to MLX format from [janhq/Jan-v1-4B](https://huggingface.co/janhq/Jan-v1-4B)
using mlx-lm version **0.26.3**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("Jan-v1-4B-q8-hi-mlx")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1755020831
|
ggozzy
| 2025-08-12T17:48:27Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:48:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
koloni/blockassist-bc-deadly_graceful_stingray_1755019418
|
koloni
| 2025-08-12T17:48:23Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:48:19Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
milliarderdol/blockassist-bc-roaring_rough_scorpion_1755019009
|
milliarderdol
| 2025-08-12T17:47:43Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"roaring rough scorpion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:47:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- roaring rough scorpion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
EurekaTian/qwen2p5_3b_mmlu_neg
|
EurekaTian
| 2025-08-12T17:47:08Z | 0 | 0 | null |
[
"safetensors",
"qwen2",
"license:apache-2.0",
"region:us"
] | null | 2025-08-12T17:35:54Z |
---
license: apache-2.0
---
|
mdavidson83/Qwen3-4B-Instruct-2507-INT8
|
mdavidson83
| 2025-08-12T17:46:51Z | 3 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"compressed-tensors",
"region:us"
] |
text-generation
| 2025-08-12T01:20:51Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755020715
|
IvanJAjebu
| 2025-08-12T17:46:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:46:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mveroe/Qwen2.5-1.5B_lightr1_3_1p0_0p0_1p0_sft
|
mveroe
| 2025-08-12T17:45:53Z | 71 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-09T13:23:26Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
tushar0088/blockassist-bc-vocal_tenacious_prawn_1755020652
|
tushar0088
| 2025-08-12T17:45:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"vocal tenacious prawn",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:45:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- vocal tenacious prawn
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
elsvastika/blockassist-bc-arctic_soaring_weasel_1755019034
|
elsvastika
| 2025-08-12T17:45:16Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"arctic soaring weasel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:45:08Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- arctic soaring weasel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
BootesVoid/cme6nf15x09v06aq1x8d8pate_cme8t7nps02jirts8c2ejkwmm
|
BootesVoid
| 2025-08-12T17:44:03Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-12T17:44:01Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: LIVSEXY
---
# Cme6Nf15X09V06Aq1X8D8Pate_Cme8T7Nps02Jirts8C2Ejkwmm
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `LIVSEXY` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "LIVSEXY",
"lora_weights": "https://huggingface.co/BootesVoid/cme6nf15x09v06aq1x8d8pate_cme8t7nps02jirts8c2ejkwmm/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cme6nf15x09v06aq1x8d8pate_cme8t7nps02jirts8c2ejkwmm', weight_name='lora.safetensors')
image = pipeline('LIVSEXY').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cme6nf15x09v06aq1x8d8pate_cme8t7nps02jirts8c2ejkwmm/discussions) to add images that show off what you’ve made with this LoRA.
|
Kbashiru/Mobile_BERT_on_jumia_dataset
|
Kbashiru
| 2025-08-12T17:44:01Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mobilebert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-12T17:43:50Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
New-Clips-Uppal-Farm-Girl-Viral-Video-Link/FULL.VIDEO.Uppal.Farm.Girl.Viral.Video.Tutorial.Official
|
New-Clips-Uppal-Farm-Girl-Viral-Video-Link
| 2025-08-12T17:43:51Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-12T17:43:41Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?leaked-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1755020526
|
ggozzy
| 2025-08-12T17:43:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:43:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ozkurt7/oracle-qwen2-1.5b-merged-final
|
ozkurt7
| 2025-08-12T17:43:19Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"unsloth",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T17:42:01Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Dineochiloane/gemma-3-4b-isizulu-afrimmlu
|
Dineochiloane
| 2025-08-12T17:42:13Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"afrimmlu",
"isizulu",
"african-languages",
"gemma",
"lora",
"instruction-tuning",
"zu",
"en",
"dataset:masakhane/afrimmlu",
"base_model:google/gemma-3-4b-it",
"base_model:adapter:google/gemma-3-4b-it",
"license:gemma",
"region:us"
] | null | 2025-08-12T13:56:12Z |
---
language:
- zu
- en
base_model: google/gemma-3-4b-it
tags:
- afrimmlu
- isizulu
- african-languages
- gemma
- peft
- lora
- instruction-tuning
datasets:
- masakhane/afrimmlu
license: gemma
widget:
- text: "Answer the following multiple-choice question about elementary mathematics.
Question: Lithini inani lika p ku 24 = 2p?
Choices:
A) p = 4
B) p = 8
C) p = 12
D) p = 24
Select the correct answer (A, B, C, or D) first before you explain. The first character in your answer should be your choice (A,B,C, or D):"
example_title: "isiZulu Mathematics Question"
---
# isiZulu AFRIMMLU Fine-tuned Model
Fine-tuned Gemma-3-4b-it model for isiZulu AFRIMMLU multiple-choice question answering.
## Model Details
- **Base Model**: google/gemma-3-4b-it
- **Task**: isiZulu multiple-choice question answering
- **Training Data**: AFRIMMLU isiZulu dev + validation splits (108 examples)
- **Method**: LoRA fine-tuning with instruction tuning format
## Training Configuration
- **LoRA Rank**: 16
- **LoRA Alpha**: 16
- **Learning Rate**: 1e-05
- **Epochs**: 2
- **Batch Size**: 16 (effective)
## Prompt Format
```
Answer the following multiple-choice question about [subject].
Question: [isiZulu question]
Choices:
A) [choice 1]
B) [choice 2]
C) [choice 3]
D) [choice 4]
Select the correct answer (A, B, C, or D) first before you explain. The first character in your answer should be your choice (A,B,C, or D):
```
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
# Load model
base_model = AutoModelForCausalLM.from_pretrained("google/gemma-3-4b-it")
tokenizer = AutoTokenizer.from_pretrained("google/gemma-3-4b-it")
model = PeftModel.from_pretrained(base_model, "Dineochiloane/gemma-3-4b-isizulu-afrimmlu")
# Format question
messages = [{
"role": "user",
"content": "Answer the following multiple-choice question about elementary mathematics.\n\nQuestion: Lithini inani lika p ku 24 = 2p?\n\nChoices:\nA) p = 4\nB) p = 8\nC) p = 12\nD) p = 24\n\nSelect the correct answer (A, B, C, or D) first before you explain. The first character in your answer should be your choice (A,B,C, or D):"
}]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt")
outputs = model.generate(input_ids, max_new_tokens=100, temperature=0.0)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
```
## Research Context
This model was fine-tuned as part of research on cross-lingual transfer learning for African languages, specifically comparing zero-shot vs fine-tuned performance on isiZulu AFRIMMLU.
|
xem-clip-doi-nam-nu-co-hanh-dong-nhay-cam/XEM.xac.minh.clip.doi.nam.nu.co.hanh.dong.nhay.cam.tren.xe.mercedes.o.ninh.binh
|
xem-clip-doi-nam-nu-co-hanh-dong-nhay-cam
| 2025-08-12T17:40:58Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-12T17:40:04Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5xr5mb3e?leaked-videos/" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755020354
|
IvanJAjebu
| 2025-08-12T17:40:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:40:15Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/GPT-OSS-30B-Preview-i1-GGUF
|
mradermacher
| 2025-08-12T17:37:49Z | 0 | 1 |
transformers
|
[
"transformers",
"gguf",
"vllm",
"unsloth",
"mergekit",
"gpt_oss",
"en",
"base_model:win10/GPT-OSS-30B-Preview",
"base_model:quantized:win10/GPT-OSS-30B-Preview",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-08-12T14:25:51Z |
---
base_model: win10/GPT-OSS-30B-Preview
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- vllm
- unsloth
- mergekit
- gpt_oss
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/win10/GPT-OSS-30B-Preview
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#GPT-OSS-30B-Preview-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-IQ1_M.gguf) | i1-IQ1_M | 17.6 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-IQ1_S.gguf) | i1-IQ1_S | 17.6 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 17.6 | |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-IQ2_XS.gguf) | i1-IQ2_XS | 17.7 | |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-Q3_K_S.gguf) | i1-Q3_K_S | 17.7 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-IQ2_M.gguf) | i1-IQ2_M | 17.7 | |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-IQ2_S.gguf) | i1-IQ2_S | 17.7 | |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-IQ3_S.gguf) | i1-IQ3_S | 17.7 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-IQ3_XS.gguf) | i1-IQ3_XS | 17.7 | |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 17.7 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-Q2_K.gguf) | i1-Q2_K | 17.7 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-IQ4_XS.gguf) | i1-IQ4_XS | 17.8 | |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-Q2_K_S.gguf) | i1-Q2_K_S | 17.8 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-Q4_0.gguf) | i1-Q4_0 | 17.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-IQ3_M.gguf) | i1-IQ3_M | 17.9 | |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-Q3_K_M.gguf) | i1-Q3_K_M | 19.0 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-Q3_K_L.gguf) | i1-Q3_K_L | 19.6 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-Q4_1.gguf) | i1-Q4_1 | 19.7 | |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-Q4_K_S.gguf) | i1-Q4_K_S | 21.6 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-Q4_K_M.gguf) | i1-Q4_K_M | 23.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-Q5_K_S.gguf) | i1-Q5_K_S | 23.4 | |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-Q5_K_M.gguf) | i1-Q5_K_M | 24.9 | |
| [GGUF](https://huggingface.co/mradermacher/GPT-OSS-30B-Preview-i1-GGUF/resolve/main/GPT-OSS-30B-Preview.i1-Q6_K.gguf) | i1-Q6_K | 32.8 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
CometAPI/gpt-5-mini
|
CometAPI
| 2025-08-12T17:36:23Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-12T17:36:09Z |
---
license: apache-2.0
---
CometAPI Model Page: [GPT-5 mini](https://www.cometapi.com/gpt-5-mini-api/)
GPT-5 mini is a **lightweight**, cost-optimized variant of OpenAI’s flagship GPT-5 model, designed to deliver **high-quality** reasoning and multimodal capabilities at reduced latency and expense.
## Basic information & key features
**GPT-5 mini** is OpenAI’s **cost- and latency-optimized** member of the GPT-5 family, intended to deliver much of GPT-5’s multimodal and instruction-following strengths at **substantially lower cost** for large-scale production use. It targets environments where **throughput**, **predictable per-token pricing**, and **fast responses** are the primary constraints while still providing strong general-purpose capabilities.
- **Model Name**: `gpt-5-mini`
- **Context Window**: 400 000 tokens
- **Max Output Tokens**: 128 000
- **Key features:** speed, throughput, cost-efficiency, deterministic outputs for concise prompts
## Technical details — architecture, inference, and controls
**Optimized inference path & deployment.** Practical speedups come from **kernel fusion**, **tensor parallelism tuned for a smaller graph**, and an inference runtime that prefers **shorter internal “thinking” loops** unless the developer requests deeper reasoning. That is why mini achieves noticeably lower compute per call and predictable latency for high-volume traffic. This tradeoff is deliberate: **lower compute per forward pass → lower cost and lower average latency**.
**Developer controls.** GPT-5 mini exposes parameters such as **`verbosity`** (controls detail/length) and **`reasoning_effort`** (trade speed vs. depth), plus robust **tool-calling** support (function calls, parallel tool chains, and structured error handling), which lets production systems tune accuracy vs. cost precisely.
## Benchmark performance — headline numbers and interpretation
GPT-5 mini typically sits **within ~85–95%** of GPT-5 high on general benchmarks while substantially improving latency/price. The platform launch materials indicate **very high absolute scores** for GPT-5 high (AIME ≈ **94.6%** reported for the top variant), with mini somewhat lower but still industry-leading for its price point.
Across a range of standardized and internal benchmarks, **GPT-5 mini** achieves:
- **Intelligence** (AIME ’25): 91.1% (vs. 94.6% for GPT-5 high)
- **Multimodal** (MMMU): 81.6% (vs. 84.2% for GPT-5 high)
- **Coding** (SWE-bench Verified): 71.0% (vs. 74.9% for GPT-5 high)
- **Instruction Following** (Scale MultiChallenge): 62.3% (vs. 69.6%)
- **Function Calling** (τ²-bench telecom): 74.1% (vs. 96.7%)
- **Hallucination Rates** (LongFact-Concepts): 0.7% (lower is better)([OpenAI][4])
These results demonstrate GPT-5 mini’s **robust** trade-offs between performance, cost, and speed.
## Limitations
**Known limitations:** GPT-5 mini *reduced deep-reasoning capacity vs full GPT-5, higher sensitivity to ambiguous prompts, and remaining risks of hallucination.*
- **Reduced deep reasoning:** For multi-step, long-horizon reasoning tasks the full reasoning model or “thinking” variants outperform mini.
- **Hallucinations & overconfidence:** Mini reduces hallucination relative to very small models but does not eliminate it; outputs should be validated in high-stakes flows (legal, clinical, compliance).
- **Context sensitivity:** Very long, highly interdependent context chains are better served by the full GPT-5 variants with larger context windows or the “thinking” model.
- **Safety & policy limits:** Same safety guardrails and rate/usage limits that apply to other GPT-5 models apply to mini; sensitive tasks require human oversight.
## Recommended use cases (where mini excels)
- **High-volume conversational agents:** low latency, predictable cost. **Keyword:** *throughput*.
- **Document & multimodal summarization:** long-context summarization, image+text reports. **Keyword:** *long context*.
- **Developer tooling at scale:** CI code checks, auto-review, lightweight code generation. **Keyword:** *cost-efficient coding*.
- **Agent orchestration:** tool-calling with parallel chains when deep reasoning is not required. **Keyword:** *tool calling*.
## How to call ***\*`gpt-5-mini`\**** API from CometAPI
## [GPT-5 mini](https://www.cometapi.com/gpt-5-mini-api/) API Pricing in CometAPI,20% off the official price:
| Input Tokens | $0.20 |
| ------------- | ----- |
| Output Tokens | $1.60 |
### Required Steps
- Log in to [cometapi.com](http://cometapi.com/). If you are not our user yet, please register first
- Get the access credential API key of the interface. Click “Add Token” at the API token in the personal center, get the token key: sk-xxxxx and submit.
- Get the url of this site: https://api.cometapi.com/
### Use Method
1. Select the “`gpt-5-mini`“ / “`gpt-5-mini-2025-08-07`” endpoint to send the API request and set the request body. The request method and request body are obtained from our website API doc. Our website also provides Apifox test for your convenience.
2. Replace <YOUR_API_KEY> with your actual CometAPI key from your account.
3. Insert your question or request into the content field—this is what the model will respond to.
4. . Process the API response to get the generated answer.
CometAPI provides a fully compatible REST API—for seamless migration. Key details to [API doc](https://apidoc.cometapi.com/api-13851472):
- **Core Parameters**: `prompt`, `max_tokens_to_sample`, `temperature`, `stop_sequences`
- **Endpoint:** https://api.cometapi.com/v1/chat/completions
- **Model Parameter:** “`gpt-5-mini`“ / “`gpt-5-mini-2025-08-07`“
- **Authentication:** ` Bearer YOUR_CometAPI_API_KEY`
- **Content-Type:** `application/json` .
API Call Instructions: gpt-5-chat-latest should be called using the standard `/v1/chat/completions forma`t. For other models (gpt-5, gpt-5-mini, gpt-5-nano, and their dated versions), using `the /v1/responses format` [is recommended](https://apidoc.cometapi.com/api-18535147). Currently two modes are available.
**See Also [GPT-5](https://www.cometapi.com/gpt-5-api/)** Model
|
emily84/car-show-boards-for-next-car-show
|
emily84
| 2025-08-12T17:35:53Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-12T17:35:37Z |
Car Show Boards help your vehicle shine by giving it the platform it deserves. Make your setup look complete and professional.
✨ Order your custom board today.
👉 https://carshowboards.com/
#StandOutDisplay #CarShowEssentials #DisplayThatPops #AutoShowPresentation #ShowTimeStyle
|
CometAPI/gpt-5
|
CometAPI
| 2025-08-12T17:33:53Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-12T17:29:59Z |
---
license: apache-2.0
---
CometAPI Model Page: [GPT-5 ](https://www.cometapi.com/gpt-5-api/)
**GPT-5** is OpenAI’s latest flagship language model, presented as a *unified, multimodal reasoning system* that improves on prior generations in **reasoning**, **coding**, **long-context understanding**, and **safety-aware outputs**. It combines fast non-reasoning components with a deeper reasoning model and a real-time router that selects the best submodel for a task, enabling the system to “know when to think.”
## Basic Features
- ***\*Multimodality & tooling:\****: GPT-5 accepts **text and images** (and is designed to work with external tools and browsing/agents where allowed), and OpenAI highlights improved **voice, UI, integrated connectors (e.g., Gmail/Calendar)** and agentic workflows.
- **Expanded Context Window**: Supports up to **1,000,000 tokens**, allowing for far longer documents, codebases, or conversation histories .
- **Context & limits:** **400K token total context window** (split implicitly between input and output, with typical splits such as ~272K input + 128K output )
## Technical **Architecture**
GPT-5 is a **unified system** composed of:
1. A **fast** non-reasoning model for routine queries.
2. A **deep reasoning** variant (“GPT-5 Thinking”) for complex problems.
3. A **real-time router** that dynamically selects the optimal pathway based on prompt complexity, tool requirements, and user intent .
This design leverages **parallel test-time compute** for GPT-5 Pro, ensuring high-stakes tasks receive the most **comprehensive** processing available.
## Benchmark **Performance**
- **Coding**: Achieves **74.9%** on SWE-Bench Verified, surpassing prior models by over 5 percentage points and using **22% fewer tokens** and **45% fewer tool calls** than its predecessor.
- **Health**: Scores **46.2%** on HealthBench Hard, demonstrating significant gains in **medical reasoning** and **patient-focused guidance**.
- **Factuality**: Approximately **80% fewer hallucinations** in “thinking” mode compared to OpenAI o3, and **45% fewer** factual errors in standard chat mode relative to GPT-4o .
- **Multimodal**: Excels at analyzing text, images, and video inputs, enhancing visual reasoning and perception.
- **Writing**: Captures literary rhythm and nuanced structures like free verse or iambic lines more reliably
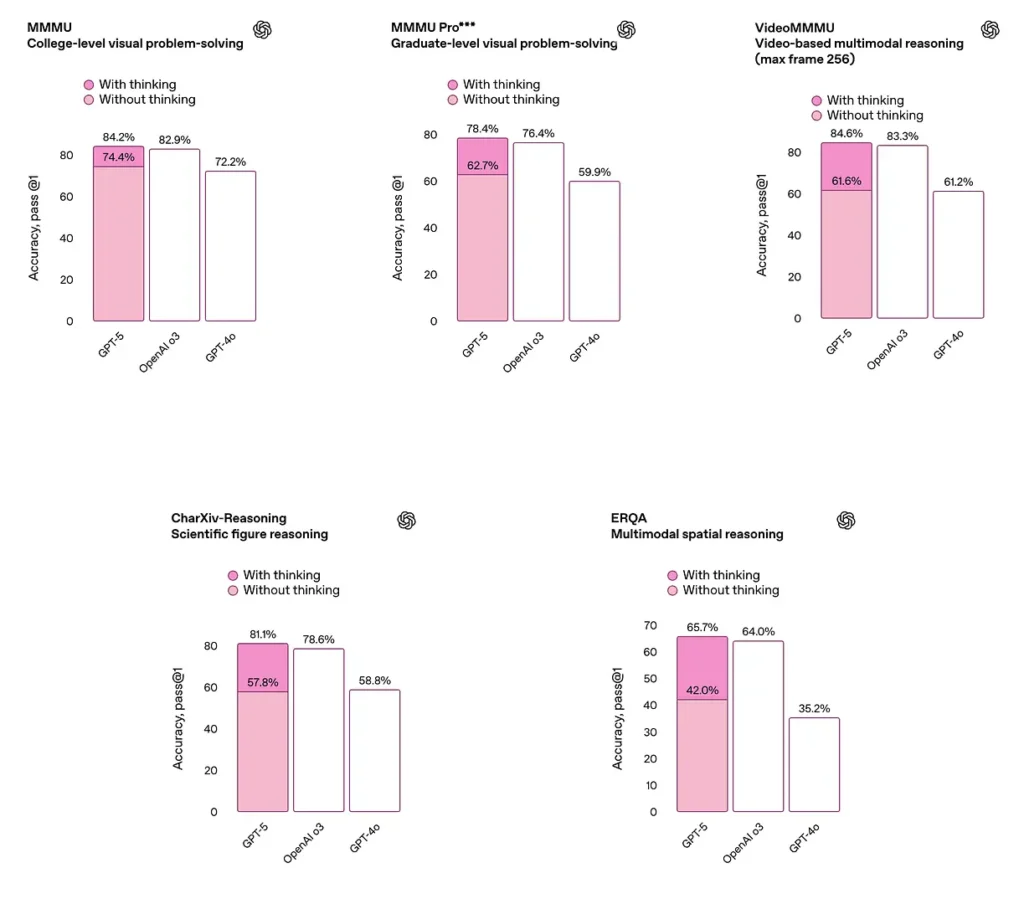
------
## Model Versions
| Version | Purpose | Cost |
| --------------------- | ------------------------------------------------------------ | --------------------------------------- |
| **gpt-5** | Default unified model | Input Tokens:$1.00 Output Tokens: $8.00 |
| **gpt-5-2025-08-07** | Performance equal to gpt-5 | Input Tokens:$1.00 Output Tokens: $8.00 |
| **gpt-5-chat-latest** | GPT-5 Chat points to the GPT-5 snapshot currently used in ChatGPT. GPT-5 is our next-generation, high-intelligence flagship model. | Input Tokens:$1.00 Output Tokens: $8.00 |
------
## Limitations
- **Not AGI**: While a leap forward, GPT-5 still lacks **continuous learning** and **self-improvement** outside of retraining cycles .
- **Remaining Hallucinations**: Despite reduction, **verified sources** are recommended for critical decisions.
- **Compute & Cost**: High-performance modes (Pro, Thinking) incur **significant token fees** and require careful **budget management**.
## How to call **`gpt-5`** API from CometAPI
### **`\**`gpt-5`\**`** API Pricing in CometAPI,20% off the official price:
| Input Tokens | $1 |
| ------------- | ---- |
| Output Tokens | $8 |
### Required Steps
- Log in to [cometapi.com](http://cometapi.com/). If you are not our user yet, please register first
- Get the access credential API key of the interface. Click “Add Token” at the API token in the personal center, get the token key: sk-xxxxx and submit.
- Get the url of this site: https://api.cometapi.com/
### Use Method
1. Select the “`gpt-5`”/ “`gpt-5-2025-08-07`” / “`gpt-5-chat-latest`” endpoint to send the API request and set the request body. The request method and request body are obtained from our website API doc. Our website also provides Apifox test for your convenience.
2. Replace <YOUR_API_KEY> with your actual CometAPI key from your account.
3. Insert your question or request into the content field—this is what the model will respond to.
4. . Process the API response to get the generated answer.
CometAPI provides a fully compatible REST API—for seamless migration. Key details to [API doc](https://apidoc.cometapi.com/api-13851472):
- **Core Parameters**: `prompt`, `max_tokens_to_sample`, `temperature`, `stop_sequences`
- **Endpoint:** https://api.cometapi.com/v1/chat/completions
- **Model Parameter:** “`gpt-5`”/ “`gpt-5-2025-08-07`” / “`gpt-5-chat-latest`“
- **Authentication:** ` Bearer YOUR_CometAPI_API_KEY`
- **Content-Type:** `application/json` .
API Call Instructions: gpt-5-chat-latest should be called using the standard `/v1/chat/completions forma`t. For other models (gpt-5, gpt-5-mini, gpt-5-nano, and their dated versions), using `the /v1/responses format` [is recommended](https://apidoc.cometapi.com/api-18535147). Currently two modes are available.
|
Jovar1/blockassist-bc-bold_hulking_rooster_1755019893
|
Jovar1
| 2025-08-12T17:33:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"bold hulking rooster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:32:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- bold hulking rooster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
8man-crypto/blockassist-bc-insectivorous_bellowing_porpoise_1755018269
|
8man-crypto
| 2025-08-12T17:31:34Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"insectivorous bellowing porpoise",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:31:03Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- insectivorous bellowing porpoise
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
zijian2022/y1l_act
|
zijian2022
| 2025-08-12T17:31:21Z | 4 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"act",
"robotics",
"dataset:zijian2022/y1l",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-10T20:28:40Z |
---
datasets: zijian2022/y1l
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- lerobot
- act
- robotics
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
exala/db_fe2_10.1.1u
|
exala
| 2025-08-12T17:30:32Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-12T17:30:15Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
rafaelsouza3d/lora_model
|
rafaelsouza3d
| 2025-08-12T17:29:48Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-12T17:29:34Z |
---
base_model: unsloth/llama-3-8b-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** rafaelsouza3d
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755019605
|
IvanJAjebu
| 2025-08-12T17:28:14Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:27:39Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
MariChristmass/artsur
|
MariChristmass
| 2025-08-12T17:27:27Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-12T17:27:10Z |
---
license: apache-2.0
---
|
m-mulet/try2_qwen_2.5_7b-owl_student_2000_numbers
|
m-mulet
| 2025-08-12T17:27:11Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"base_model:unsloth/Qwen2.5-7B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-12T17:27:01Z |
---
base_model: unsloth/Qwen2.5-7B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** m-mulet
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2.5-7B-Instruct
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
hidayahlut/blockassist-bc-knobby_scavenging_wasp_1755019508
|
hidayahlut
| 2025-08-12T17:27:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"knobby scavenging wasp",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:26:49Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- knobby scavenging wasp
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
xinnn32/blockassist-bc-meek_winged_caterpillar_1755019572
|
xinnn32
| 2025-08-12T17:26:54Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"meek winged caterpillar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:26:46Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- meek winged caterpillar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ArtusDev/TheDrummer_Gemma-3-R1-4B-v1-EXL3
|
ArtusDev
| 2025-08-12T17:25:58Z | 0 | 0 | null |
[
"exl3",
"base_model:TheDrummer/Gemma-3-R1-4B-v1",
"base_model:quantized:TheDrummer/Gemma-3-R1-4B-v1",
"region:us"
] | null | 2025-08-12T17:05:09Z |
---
base_model: TheDrummer/Gemma-3-R1-4B-v1
base_model_relation: quantized
quantized_by: ArtusDev
tags:
- exl3
---
## EXL3 Quants of TheDrummer/Gemma-3-R1-4B-v1
EXL3 quants of [TheDrummer/Gemma-3-R1-4B-v1](https://huggingface.co/TheDrummer/Gemma-3-R1-4B-v1) using <a href="https://github.com/turboderp-org/exllamav3/">exllamav3</a> for quantization.
### Quants
| Quant(Revision) | Bits per Weight | Head Bits |
| -------- | ---------- | --------- |
| [2.5_H6](https://huggingface.co/ArtusDev/TheDrummer_Gemma-3-R1-4B-v1-EXL3/tree/2.5bpw_H6) | 2.5 | 6 |
| [3.0_H6](https://huggingface.co/ArtusDev/TheDrummer_Gemma-3-R1-4B-v1-EXL3/tree/3.0bpw_H6) | 3.0 | 6 |
| [3.5_H6](https://huggingface.co/ArtusDev/TheDrummer_Gemma-3-R1-4B-v1-EXL3/tree/3.5bpw_H6) | 3.5 | 6 |
| [4.0_H6](https://huggingface.co/ArtusDev/TheDrummer_Gemma-3-R1-4B-v1-EXL3/tree/4.0bpw_H6) | 4.0 | 6 |
| [4.5_H6](https://huggingface.co/ArtusDev/TheDrummer_Gemma-3-R1-4B-v1-EXL3/tree/4.5bpw_H6) | 4.5 | 6 |
| [5.0_H6](https://huggingface.co/ArtusDev/TheDrummer_Gemma-3-R1-4B-v1-EXL3/tree/5.0bpw_H6) | 5.0 | 6 |
| [6.0_H6](https://huggingface.co/ArtusDev/TheDrummer_Gemma-3-R1-4B-v1-EXL3/tree/6.0bpw_H6) | 6.0 | 6 |
| [8.0_H8](https://huggingface.co/ArtusDev/TheDrummer_Gemma-3-R1-4B-v1-EXL3/tree/8.0bpw_H8) | 8.0 | 8 |
### Downloading quants with huggingface-cli
<details>
<summary>Click to view download instructions</summary>
Install hugginface-cli:
```bash
pip install -U "huggingface_hub[cli]"
```
Download quant by targeting the specific quant revision (branch):
```
huggingface-cli download ArtusDev/TheDrummer_Gemma-3-R1-4B-v1-EXL3 --revision "5.0bpw_H6" --local-dir ./
```
</details>
|
AGofficial/AgGPT-13Mini
|
AGofficial
| 2025-08-12T17:25:40Z | 0 | 1 | null |
[
"en",
"license:mit",
"region:us"
] | null | 2025-08-12T17:24:21Z |
---
license: mit
language:
- en
---
<img src="banner.png" alt="AgGPT Banner" width="100%">
# AgGPT-13 Mini
# BETA
## Light. Mini. Smart.
### **BETA**
AgGPT-13 mini is a very lightweight beta release of the AgGPT-13 model series.
AgGPT-13 mini was trained from scratch on a small dataset of chat conversations, using the GPT architecture. It is designed to be a fast, efficient, and easy-to-use model for various NLP tasks. More than anything, this model is a proof of concept for the AgGPT-13 series, showcasing the potential of lightweight models in real-world applications, this model was trained in minutes on a macbook air M2 with 8GB of RAM, showcasing the efficiency of the training process and the potential for more powerful models in the future.
This release serves as a foundation to the full AgGPT-13 model release.
The full model will include more advanced features, larger datasets, and improved performance.
## Features
- **Very Lightweight** – Optimized for lower memory usage.
- **Flexible** – Works on CPU or GPU.
- **Easy to Use** – Straightforward code.
## Installation & Usage
```bash
pip install torch transformers safetensors
```
how to train the model:
```bash
python train.py config/train_aggpt_char.py --device=cpu --compile=False --eval_iters=20 --log_interval=1 --block_size=64 --batch_size=12 --n_layer=4 --n_head=4 --n_embd=128 --max_iters=2000 --lr_decay_iters=2000 --dropout=0.0
```
how to test the model:
```bash
python sample.py --out_dir=out-aggpt --device=cpu
```
|
silentember/Lantern_1uwj56
|
silentember
| 2025-08-12T17:24:27Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-12T17:22:33Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1755019305
|
ggozzy
| 2025-08-12T17:23:08Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:22:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ozkurt7/oracle-qwen2-1.5b-merged
|
ozkurt7
| 2025-08-12T17:23:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"unsloth",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T17:21:26Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
emily84/Featured-Customer-Car-Show-Displays
|
emily84
| 2025-08-12T17:22:38Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-12T17:22:21Z |
Nothing inspires better than real examples. Our customers bring style and personality to every display, and we’re proud to be a part of it.
👀 Browse their boards: https://showcarsign.com/customer-pics/
#CustomerFavorites #RealCarDisplays #ShowCarInspo #CarExhibit #BoardPerfection
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1755019240
|
Ferdi3425
| 2025-08-12T17:22:04Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:21:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Elizavr/blockassist-bc-reclusive_shaggy_bee_1755019248
|
Elizavr
| 2025-08-12T17:21:24Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"reclusive shaggy bee",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:21:09Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- reclusive shaggy bee
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
koloni/blockassist-bc-deadly_graceful_stingray_1755017713
|
koloni
| 2025-08-12T17:20:23Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:20:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
tushar0088/blockassist-bc-vocal_tenacious_prawn_1755019115
|
tushar0088
| 2025-08-12T17:19:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"vocal tenacious prawn",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:19:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- vocal tenacious prawn
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
alexgeezy429/blockassist-bc-scented_coiled_antelope_1755017385
|
alexgeezy429
| 2025-08-12T17:19:17Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"scented coiled antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:19:05Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- scented coiled antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
BootesVoid/cme8s220z02cprts8jsnxzfc5_cme8s6fmn02dnrts8mydmrmb7
|
BootesVoid
| 2025-08-12T17:18:48Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-12T17:18:46Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: JESS
---
# Cme8S220Z02Cprts8Jsnxzfc5_Cme8S6Fmn02Dnrts8Mydmrmb7
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `JESS` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "JESS",
"lora_weights": "https://huggingface.co/BootesVoid/cme8s220z02cprts8jsnxzfc5_cme8s6fmn02dnrts8mydmrmb7/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cme8s220z02cprts8jsnxzfc5_cme8s6fmn02dnrts8mydmrmb7', weight_name='lora.safetensors')
image = pipeline('JESS').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cme8s220z02cprts8jsnxzfc5_cme8s6fmn02dnrts8mydmrmb7/discussions) to add images that show off what you’ve made with this LoRA.
|
CreitinGameplays/Mistral-Nemo-12B-R1-v0.1alpha
|
CreitinGameplays
| 2025-08-12T17:17:48Z | 70 | 2 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"en",
"dataset:CreitinGameplays/r1_annotated_math-mistral",
"dataset:CreitinGameplays/DeepSeek-R1-Distill-Qwen-32B_NUMINA_train_amc_aime-mistral",
"base_model:mistralai/Mistral-Nemo-Instruct-2407",
"base_model:finetune:mistralai/Mistral-Nemo-Instruct-2407",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-02-17T20:42:40Z |
---
license: mit
datasets:
- CreitinGameplays/r1_annotated_math-mistral
- CreitinGameplays/DeepSeek-R1-Distill-Qwen-32B_NUMINA_train_amc_aime-mistral
language:
- en
base_model:
- mistralai/Mistral-Nemo-Instruct-2407
pipeline_tag: text-generation
library_name: transformers
---
Run the model:
```python
import torch
from transformers import pipeline
model_id = "CreitinGameplays/Mistral-Nemo-12B-R1-v0.1alpha"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "user", "content": "How many r's are in strawberry?"},
]
outputs = pipe(
messages,
temperature=0.8,
top_p=1.0,
top_k=50,
max_new_tokens=4096,
)
print(outputs[0]["generated_text"][-1])
```
|
MariChristmass/realismfoto
|
MariChristmass
| 2025-08-12T17:15:08Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-12T17:14:34Z |
---
license: apache-2.0
---
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755017205
|
mang3dd
| 2025-08-12T17:14:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:14:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
silentember/Lantern_RNcAt8
|
silentember
| 2025-08-12T17:13:53Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-12T17:11:57Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1755018694
|
ggozzy
| 2025-08-12T17:12:48Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:12:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755018688
|
IvanJAjebu
| 2025-08-12T17:12:37Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:12:26Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
K1t1k/df_grasp_duplo_cube
|
K1t1k
| 2025-08-12T17:11:12Z | 52 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"diffusion",
"robotics",
"dataset:K1t1k/grasp_duplo_cube",
"arxiv:2303.04137",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-10T12:34:55Z |
---
datasets: K1t1k/grasp_duplo_cube
library_name: lerobot
license: apache-2.0
model_name: diffusion
pipeline_tag: robotics
tags:
- diffusion
- lerobot
- robotics
---
# Model Card for diffusion
<!-- Provide a quick summary of what the model is/does. -->
[Diffusion Policy](https://huggingface.co/papers/2303.04137) treats visuomotor control as a generative diffusion process, producing smooth, multi-step action trajectories that excel at contact-rich manipulation.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
lerobot-train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
lerobot-record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
nightmedia/Jan-v1-4B-dwq5-mlx
|
nightmedia
| 2025-08-12T17:10:20Z | 0 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"en",
"base_model:janhq/Jan-v1-4B",
"base_model:quantized:janhq/Jan-v1-4B",
"license:apache-2.0",
"5-bit",
"region:us"
] |
text-generation
| 2025-08-12T16:33:45Z |
---
license: apache-2.0
language:
- en
base_model: janhq/Jan-v1-4B
pipeline_tag: text-generation
library_name: mlx
tags:
- mlx
---
# Jan-v1-4B-dwq5-mlx
This model [Jan-v1-4B-dwq5-mlx](https://huggingface.co/Jan-v1-4B-dwq5-mlx) was
converted to MLX format from [janhq/Jan-v1-4B](https://huggingface.co/janhq/Jan-v1-4B)
using mlx-lm version **0.26.3**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("Jan-v1-4B-dwq5-mlx")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
aleebaster/blockassist-bc-sly_eager_boar_1755017319
|
aleebaster
| 2025-08-12T17:10:18Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sly eager boar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:10:09Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sly eager boar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
BootesVoid/cme8rr26s02afrts8cpzivtkn_cme8rw22c02bfrts8eqs5pzal_2
|
BootesVoid
| 2025-08-12T17:09:47Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-12T17:09:45Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: LILIA
---
# Cme8Rr26S02Afrts8Cpzivtkn_Cme8Rw22C02Bfrts8Eqs5Pzal_2
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `LILIA` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "LILIA",
"lora_weights": "https://huggingface.co/BootesVoid/cme8rr26s02afrts8cpzivtkn_cme8rw22c02bfrts8eqs5pzal_2/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cme8rr26s02afrts8cpzivtkn_cme8rw22c02bfrts8eqs5pzal_2', weight_name='lora.safetensors')
image = pipeline('LILIA').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cme8rr26s02afrts8cpzivtkn_cme8rw22c02bfrts8eqs5pzal_2/discussions) to add images that show off what you’ve made with this LoRA.
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1755018437
|
Ferdi3425
| 2025-08-12T17:08:06Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:08:03Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1755018389
|
ggozzy
| 2025-08-12T17:07:53Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:07:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
jeongseokoh/Llama3.1-8B-LatentRAG-batch_40st-og
|
jeongseokoh
| 2025-08-12T17:07:36Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T17:00:49Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Elizavr/blockassist-bc-reclusive_shaggy_bee_1755018324
|
Elizavr
| 2025-08-12T17:07:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"reclusive shaggy bee",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:06:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- reclusive shaggy bee
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mlx-community/Jan-v1-4B-8bit
|
mlx-community
| 2025-08-12T17:05:59Z | 0 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"en",
"base_model:janhq/Jan-v1-4B",
"base_model:quantized:janhq/Jan-v1-4B",
"license:apache-2.0",
"8-bit",
"region:us"
] |
text-generation
| 2025-08-12T17:02:50Z |
---
license: apache-2.0
language:
- en
base_model: janhq/Jan-v1-4B
pipeline_tag: text-generation
tags:
- mlx
library_name: mlx
---
# mlx-community/Jan-v1-4B-8bit
This model [mlx-community/Jan-v1-4B-8bit](https://huggingface.co/mlx-community/Jan-v1-4B-8bit) was
converted to MLX format from [janhq/Jan-v1-4B](https://huggingface.co/janhq/Jan-v1-4B)
using mlx-lm version **0.26.3**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/Jan-v1-4B-8bit")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
mlx-community/Jan-v1-4B-6bit
|
mlx-community
| 2025-08-12T17:04:50Z | 0 | 0 |
mlx
|
[
"mlx",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"en",
"base_model:janhq/Jan-v1-4B",
"base_model:quantized:janhq/Jan-v1-4B",
"license:apache-2.0",
"6-bit",
"region:us"
] |
text-generation
| 2025-08-12T17:02:07Z |
---
license: apache-2.0
language:
- en
base_model: janhq/Jan-v1-4B
pipeline_tag: text-generation
library_name: mlx
tags:
- mlx
---
# mlx-community/Jan-v1-4B-6bit
This model [mlx-community/Jan-v1-4B-6bit](https://huggingface.co/mlx-community/Jan-v1-4B-6bit) was
converted to MLX format from [janhq/Jan-v1-4B](https://huggingface.co/janhq/Jan-v1-4B)
using mlx-lm version **0.26.2**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/Jan-v1-4B-6bit")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
raviverma2791747/satelline2dem
|
raviverma2791747
| 2025-08-12T17:04:27Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-12T17:02:08Z |
---
license: apache-2.0
---
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1755018162
|
Ferdi3425
| 2025-08-12T17:03:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:03:33Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
silentember/Lantern_6VcEsx
|
silentember
| 2025-08-12T17:03:13Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-12T17:01:09Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1755018084
|
ggozzy
| 2025-08-12T17:02:49Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:02:32Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
indoempatnol/blockassist-bc-fishy_wary_swan_1755016623
|
indoempatnol
| 2025-08-12T17:02:10Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"fishy wary swan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:02:04Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- fishy wary swan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Elizavr/blockassist-bc-reclusive_shaggy_bee_1755017958
|
Elizavr
| 2025-08-12T17:01:09Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"reclusive shaggy bee",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T17:00:45Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- reclusive shaggy bee
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Ferdi3425/blockassist-bc-amphibious_deadly_otter_1755017914
|
Ferdi3425
| 2025-08-12T16:59:49Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"amphibious deadly otter",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T16:59:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- amphibious deadly otter
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
emily84/Custom-Car-Show-Signs
|
emily84
| 2025-08-12T16:59:15Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-12T16:58:34Z |
Give your display that extra “wow” factor. Our boards are designed to grab attention, inform your audience, and make your car unforgettable.
🎯 Ideal for car meets, indoor expos, or outdoor shows.
👉 https://showcarsign.com/
#EyeCatchingDisplays #CustomCarSigns #AutoShowReady #DisplayBoardDesign #CarLoversUnite
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755017830
|
IvanJAjebu
| 2025-08-12T16:58:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T16:58:12Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Jack-Payne1/qwen_2.5_7b-phoenix_B1_random_seed1
|
Jack-Payne1
| 2025-08-12T16:58:24Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:unsloth/Qwen2.5-7B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-12T16:55:41Z |
---
base_model: unsloth/Qwen2.5-7B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Jack-Payne1
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2.5-7B-Instruct
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ggozzy/blockassist-bc-stubby_yapping_mandrill_1755017778
|
ggozzy
| 2025-08-12T16:57:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stubby yapping mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T16:57:26Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stubby yapping mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
milliarderdol/blockassist-bc-roaring_rough_scorpion_1755015924
|
milliarderdol
| 2025-08-12T16:56:48Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"roaring rough scorpion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T16:56:32Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- roaring rough scorpion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Sayemahsjn/blockassist-bc-playful_feline_octopus_1755016727
|
Sayemahsjn
| 2025-08-12T16:56:11Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"playful feline octopus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T16:56:02Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- playful feline octopus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
tushar0088/blockassist-bc-vocal_tenacious_prawn_1755017675
|
tushar0088
| 2025-08-12T16:55:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"vocal tenacious prawn",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-12T16:55:40Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- vocal tenacious prawn
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
bilalzafar/cbdc-bert-stance
|
bilalzafar
| 2025-08-12T16:55:42Z | 0 | 0 |
transformers
|
[
"transformers",
"CBDC",
"Central Bank Digital Currencies",
"Central Bank Digital Currency",
"Central Bank",
"Stance Classification",
"Finance",
"NLP",
"Finance NLP",
"BERT",
"Transformers",
"Digital Currency",
"text-classification",
"en",
"base_model:bilalzafar/cb-bert-mlm",
"base_model:finetune:bilalzafar/cb-bert-mlm",
"license:mit",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-11T05:58:33Z |
---
license: mit
language:
- en
metrics:
- f1
- accuracy
base_model:
- bilalzafar/cb-bert-mlm
pipeline_tag: text-classification
tags:
- CBDC
- Central Bank Digital Currencies
- Central Bank Digital Currency
- Central Bank
- Stance Classification
- Finance
- NLP
- Finance NLP
- BERT
- Transformers
- Digital Currency
library_name: transformers
---
# CBDC Stance Classifier: A Domain-Specific BERT for CBDC-Related Stance Detection
The **CBDC-BERT-Stance** model classifies Central Bank Digital Currency (CBDC)–related text into three stance categories: **Pro-CBDC** — supportive of CBDC adoption (e.g., highlighting benefits, efficiency, innovation), **Wait-and-See** — neutral or cautious, expressing neither strong support nor strong opposition, often highlighting the need for further study, and **Anti-CBDC** — critical of CBDC adoption (e.g., highlighting risks, concerns, opposition).
**Base Model:** [`bilalzafar/cb-bert-mlm`](https://huggingface.co/bilalzafar/cb-bert-mlm) — **CB-BERT (`cb-bert-mlm`)** is a domain-adapted **BERT base (uncased)**, pretrained on **66M+ tokens** across **2M+ sentences** from central-bank speeches published via the **Bank for International Settlements (1996–2024)**. It is optimized for *masked-token prediction* within the specialized domains of **monetary policy, financial regulation, and macroeconomic communication**, enabling better contextual understanding of central-bank discourse and financial narratives.
**Training Data:** The training dataset consisted of 1,647 CBDC-related sentences from BIS speeches, manually annotated into three sentiment categories: Pro-CBDC (742 sentences), Wait-and-See (694 sentences), and Anti-CBDC (211 sentences).
**Intended Uses:** The model is designed for classifying stance in speeches, articles, or statements related to CBDCs, supporting research into CBDC discourse analysis, and monitoring stance trends in central banking communications.
---
## Training Details
The model was trained starting from the [`bilalzafar/cb-bert-mlm`](https://huggingface.co/bilalzafar/cb-bert-mlm) checkpoint, using a BERT-base architecture with a new three-way softmax classification head and a maximum sequence length of 320 tokens. Training was run for up to 8 epochs, with early stopping at epoch 6, a batch size of 16, a learning rate of 2e-5, weight decay of 0.01, and a warmup ratio of 0.06, optimized using AdamW. The loss function was Focal Loss (γ = 1.0, soft focal, no extra class weights), and a WeightedRandomSampler based on the square root of inverse frequency was applied to handle class imbalance. FP16 precision was enabled for efficiency, and the best checkpoint was selected based on the Macro-F1 score. The dataset was split into 80% training, 10% validation, and 10% test sets, stratified by label with class balance applied.
---
## Performance and Metrics
On the test set, the model achieved an **accuracy** of 0.8485, a **macro F1-score** of 0.8519, and a **weighted F1-score** of 0.8484. Class-wise performance showed strong results across all categories: **Anti-CBDC** (Precision: 0.8261, Recall: 0.9048, F1: 0.8636), **Pro-CBDC** (Precision: 0.8421, Recall: 0.8533, F1: 0.8477), and **Wait-and-See** (Precision: 0.8636, Recall: 0.8261, F1: 0.8444). The best validation checkpoint recorded an accuracy of 0.8303, macro F1 of 0.7936, and weighted F1 of 0.8338, with a validation loss of 0.3883. On the final test evaluation, loss increased slightly to 0.4223, while all key metrics improved compared to the validation set.
---
## Files in Repository
- `config.json` — model configuration
- `model.safetensors` — trained model weights
- `tokenizer.json`, `tokenizer_config.json`, `vocab.txt` — tokenizer files
- `special_tokens_map.json` — tokenizer special tokens
- `label_mapping.json` — label ↔ id mapping
---
## Usage
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
model_name = "bilalzafar/cbdc-bert-stance"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
classifier = pipeline(
"text-classification",
model=model,
tokenizer=tokenizer,
truncation=True,
padding=True,
top_k=True # returns only the top prediction
)
text = "CBDCs will reduce costs and improve payments."
print(classifier(text))
# Output: [{'label': 'Pro-CBDC', 'score': 0.9788}]
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.