
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
Muapi/lip-bite-concept-flux.1d
|
Muapi
| 2025-08-19T20:00:47Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T20:00:39Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Lip Bite Concept FLUX.1D

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:735399@1977332", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
hasdal/a51ae003-de10-4a7c-80ea-f24dbec64122
|
hasdal
| 2025-08-19T18:27:46Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:unsloth/SmolLM2-135M",
"dpo",
"lora",
"transformers",
"trl",
"unsloth",
"text-generation",
"arxiv:1910.09700",
"base_model:unsloth/SmolLM2-135M",
"region:us"
] |
text-generation
| 2025-08-19T18:27:44Z |
---
base_model: unsloth/SmolLM2-135M
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:unsloth/SmolLM2-135M
- dpo
- lora
- transformers
- trl
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
BootesVoid/cme1nlmc40afpgwtcpc42gvjm_cme7g43p30bf96aq1sh548pe8
|
BootesVoid
| 2025-08-19T18:26:14Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-19T18:26:12Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: OFMODEL
---
# Cme1Nlmc40Afpgwtcpc42Gvjm_Cme7G43P30Bf96Aq1Sh548Pe8
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `OFMODEL` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "OFMODEL",
"lora_weights": "https://huggingface.co/BootesVoid/cme1nlmc40afpgwtcpc42gvjm_cme7g43p30bf96aq1sh548pe8/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cme1nlmc40afpgwtcpc42gvjm_cme7g43p30bf96aq1sh548pe8', weight_name='lora.safetensors')
image = pipeline('OFMODEL').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cme1nlmc40afpgwtcpc42gvjm_cme7g43p30bf96aq1sh548pe8/discussions) to add images that show off what you’ve made with this LoRA.
|
Dejiat/blockassist-bc-savage_unseen_bobcat_1755627285
|
Dejiat
| 2025-08-19T18:15:34Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"savage unseen bobcat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T18:15:18Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- savage unseen bobcat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ElizabethMohan1872002/t5-sum-colab
|
ElizabethMohan1872002
| 2025-08-19T18:13:31Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/flan-t5-small",
"base_model:finetune:google/flan-t5-small",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T18:13:20Z |
---
library_name: transformers
license: apache-2.0
base_model: google/flan-t5-small
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5-sum-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-sum-colab
This model is a fine-tuned version of [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3480
- Rouge1: 41.6552
- Rouge2: 17.0275
- Rougel: 36.2755
- Rougelsum: 36.2924
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|
| 1.3505 | 1.0 | 3115 | 1.1838 | 40.3409 | 17.4956 | 35.7888 | 35.8149 |
| 1.3026 | 2.0 | 6230 | 1.1448 | 41.1275 | 18.0429 | 36.1663 | 36.2066 |
| 1.2295 | 3.0 | 9345 | 1.1389 | 41.3104 | 18.0181 | 36.2726 | 36.2897 |
### Framework versions
- Transformers 4.55.2
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.21.4
|
AnonymousCS/xlmr_swedish_immigration3
|
AnonymousCS
| 2025-08-19T18:00:16Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-large",
"base_model:finetune:FacebookAI/xlm-roberta-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-19T17:55:05Z |
---
library_name: transformers
license: mit
base_model: FacebookAI/xlm-roberta-large
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: xlmr_swedish_immigration3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlmr_swedish_immigration3
This model is a fine-tuned version of [FacebookAI/xlm-roberta-large](https://huggingface.co/FacebookAI/xlm-roberta-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3970
- Accuracy: 0.8615
- 1-f1: 0.7857
- 1-recall: 0.7674
- 1-precision: 0.8049
- Balanced Acc: 0.8377
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | 1-f1 | 1-recall | 1-precision | Balanced Acc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------:|:-----------:|:------------:|
| 0.4995 | 1.0 | 5 | 0.4609 | 0.8538 | 0.7397 | 0.6279 | 0.9 | 0.7967 |
| 0.361 | 2.0 | 10 | 0.4179 | 0.8231 | 0.7473 | 0.7907 | 0.7083 | 0.8149 |
| 0.3011 | 3.0 | 15 | 0.3806 | 0.8692 | 0.7792 | 0.6977 | 0.8824 | 0.8258 |
| 0.3618 | 4.0 | 20 | 0.4251 | 0.8154 | 0.7391 | 0.7907 | 0.6939 | 0.8091 |
| 0.2286 | 5.0 | 25 | 0.3762 | 0.8692 | 0.7901 | 0.7442 | 0.8421 | 0.8376 |
| 0.5345 | 6.0 | 30 | 0.3777 | 0.8692 | 0.7848 | 0.7209 | 0.8611 | 0.8317 |
| 0.1878 | 7.0 | 35 | 0.3679 | 0.8769 | 0.8 | 0.7442 | 0.8649 | 0.8434 |
| 0.1607 | 8.0 | 40 | 0.3851 | 0.8692 | 0.7901 | 0.7442 | 0.8421 | 0.8376 |
| 0.1597 | 9.0 | 45 | 0.3970 | 0.8615 | 0.7857 | 0.7674 | 0.8049 | 0.8377 |
### Framework versions
- Transformers 4.56.0.dev0
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.21.4
|
Najin06/esp32-misterius
|
Najin06
| 2025-08-19T17:57:16Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-18T06:10:24Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
vwzyrraz7l/blockassist-bc-tall_hunting_vulture_1755624371
|
vwzyrraz7l
| 2025-08-19T17:54:47Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tall hunting vulture",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T17:54:44Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tall hunting vulture
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
AnonymousCS/xlmr_spanish_immigration3
|
AnonymousCS
| 2025-08-19T17:54:32Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/xlm-roberta-large",
"base_model:finetune:FacebookAI/xlm-roberta-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-19T17:32:26Z |
---
library_name: transformers
license: mit
base_model: FacebookAI/xlm-roberta-large
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: xlmr_spanish_immigration3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlmr_spanish_immigration3
This model is a fine-tuned version of [FacebookAI/xlm-roberta-large](https://huggingface.co/FacebookAI/xlm-roberta-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3622
- Accuracy: 0.9
- 1-f1: 0.8267
- 1-recall: 0.7209
- 1-precision: 0.9688
- Balanced Acc: 0.8547
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | 1-f1 | 1-recall | 1-precision | Balanced Acc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------:|:-----------:|:------------:|
| 0.4144 | 1.0 | 5 | 0.4054 | 0.8769 | 0.7838 | 0.6744 | 0.9355 | 0.8257 |
| 0.2497 | 2.0 | 10 | 0.3461 | 0.8923 | 0.825 | 0.7674 | 0.8919 | 0.8607 |
| 0.2908 | 3.0 | 15 | 0.3786 | 0.9 | 0.8267 | 0.7209 | 0.9688 | 0.8547 |
| 0.1783 | 4.0 | 20 | 0.3622 | 0.9 | 0.8267 | 0.7209 | 0.9688 | 0.8547 |
### Framework versions
- Transformers 4.56.0.dev0
- Pytorch 2.8.0+cu126
- Datasets 4.0.0
- Tokenizers 0.21.4
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755625924
|
lilTAT
| 2025-08-19T17:52:45Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T17:52:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
chainway9/blockassist-bc-untamed_quick_eel_1755624212
|
chainway9
| 2025-08-19T17:49:50Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T17:49:46Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
numind/NuExtract-2.0-8B-GPTQ
|
numind
| 2025-08-19T17:42:43Z | 346 | 4 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"image-text-to-text",
"conversational",
"base_model:numind/NuExtract-2.0-8B",
"base_model:quantized:numind/NuExtract-2.0-8B",
"license:mit",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] |
image-text-to-text
| 2025-06-06T08:38:54Z |
---
library_name: transformers
license: mit
base_model:
- numind/NuExtract-2.0-8B
pipeline_tag: image-text-to-text
---
<p align="center">
<a href="https://nuextract.ai/">
<img src="logo_nuextract.svg" width="200"/>
</a>
</p>
<p align="center">
🖥️ <a href="https://nuextract.ai/">API / Platform</a>   |   📑 <a href="https://numind.ai/blog">Blog</a>   |   🗣️ <a href="https://discord.gg/3tsEtJNCDe">Discord</a>
</p>
# NuExtract 2.0 8B by NuMind 🔥
NuExtract 2.0 is a family of models trained specifically for structured information extraction tasks. It supports both multimodal inputs and is multilingual.
We provide several versions of different sizes, all based on pre-trained models from the QwenVL family.
| Model Size | Model Name | Base Model | License | Huggingface Link |
|------------|------------|------------|---------|------------------|
| 2B | NuExtract-2.0-2B | [Qwen2-VL-2B-Instruct](https://huggingface.co/Qwen/Qwen2-VL-2B-Instruct) | MIT | 🤗 [NuExtract-2.0-2B](https://huggingface.co/numind/NuExtract-2.0-2B) |
| 4B | NuExtract-2.0-4B | [Qwen2.5-VL-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct) | Qwen Research License | 🤗 [NuExtract-2.0-4B](https://huggingface.co/numind/NuExtract-2.0-4B) |
| 8B | NuExtract-2.0-8B | [Qwen2.5-VL-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct) | MIT | 🤗 [NuExtract-2.0-8B](https://huggingface.co/numind/NuExtract-2.0-8B) |
❗️Note: `NuExtract-2.0-2B` is based on Qwen2-VL rather than Qwen2.5-VL because the smallest Qwen2.5-VL model (3B) has a more restrictive, non-commercial license. We therefore include `NuExtract-2.0-2B` as a small model option that can be used commercially.
## Benchmark
Performance on collection of ~1,000 diverse extraction examples containing both text and image inputs.
<a href="https://nuextract.ai/">
<img src="nuextract2_bench.png" width="500"/>
</a>
## Overview
To use the model, provide an input text/image and a JSON template describing the information you need to extract. The template should be a JSON object, specifying field names and their expected type.
Support types include:
* `verbatim-string` - instructs the model to extract text that is present verbatim in the input.
* `string` - a generic string field that can incorporate paraphrasing/abstraction.
* `integer` - a whole number.
* `number` - a whole or decimal number.
* `date-time` - ISO formatted date.
* Array of any of the above types (e.g. `["string"]`)
* `enum` - a choice from set of possible answers (represented in template as an array of options, e.g. `["yes", "no", "maybe"]`).
* `multi-label` - an enum that can have multiple possible answers (represented in template as a double-wrapped array, e.g. `[["A", "B", "C"]]`).
If the model does not identify relevant information for a field, it will return `null` or `[]` (for arrays and multi-labels).
The following is an example template:
```json
{
"first_name": "verbatim-string",
"last_name": "verbatim-string",
"description": "string",
"age": "integer",
"gpa": "number",
"birth_date": "date-time",
"nationality": ["France", "England", "Japan", "USA", "China"],
"languages_spoken": [["English", "French", "Japanese", "Mandarin", "Spanish"]]
}
```
An example output:
```json
{
"first_name": "Susan",
"last_name": "Smith",
"description": "A student studying computer science.",
"age": 20,
"gpa": 3.7,
"birth_date": "2005-03-01",
"nationality": "England",
"languages_spoken": ["English", "French"]
}
```
⚠️ We recommend using NuExtract with a temperature at or very close to 0. Some inference frameworks, such as Ollama, use a default of 0.7 which is not well suited to many extraction tasks.
## Using NuExtract with 🤗 Transformers
```python
import torch
from transformers import AutoProcessor
from gptqmodel import GPTQModel
model_name = "numind/NuExtract-2.0-8B-GPTQ"
# model_name = "numind/NuExtract-2.0-4B-GPTQ"
model = GPTQModel.load(model_name)
processor = AutoProcessor.from_pretrained(model_name,
trust_remote_code=True,
padding_side='left',
use_fast=True)
# You can set min_pixels and max_pixels according to your needs, such as a token range of 256-1280, to balance performance and cost.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained(model_name, min_pixels=min_pixels, max_pixels=max_pixels)
```
You will need the following function to handle loading of image input data:
```python
def process_all_vision_info(messages, examples=None):
"""
Process vision information from both messages and in-context examples, supporting batch processing.
Args:
messages: List of message dictionaries (single input) OR list of message lists (batch input)
examples: Optional list of example dictionaries (single input) OR list of example lists (batch)
Returns:
A flat list of all images in the correct order:
- For single input: example images followed by message images
- For batch input: interleaved as (item1 examples, item1 input, item2 examples, item2 input, etc.)
- Returns None if no images were found
"""
from qwen_vl_utils import process_vision_info, fetch_image
# Helper function to extract images from examples
def extract_example_images(example_item):
if not example_item:
return []
# Handle both list of examples and single example
examples_to_process = example_item if isinstance(example_item, list) else [example_item]
images = []
for example in examples_to_process:
if isinstance(example.get('input'), dict) and example['input'].get('type') == 'image':
images.append(fetch_image(example['input']))
return images
# Normalize inputs to always be batched format
is_batch = messages and isinstance(messages[0], list)
messages_batch = messages if is_batch else [messages]
is_batch_examples = examples and isinstance(examples, list) and (isinstance(examples[0], list) or examples[0] is None)
examples_batch = examples if is_batch_examples else ([examples] if examples is not None else None)
# Ensure examples batch matches messages batch if provided
if examples and len(examples_batch) != len(messages_batch):
if not is_batch and len(examples_batch) == 1:
# Single example set for a single input is fine
pass
else:
raise ValueError("Examples batch length must match messages batch length")
# Process all inputs, maintaining correct order
all_images = []
for i, message_group in enumerate(messages_batch):
# Get example images for this input
if examples and i < len(examples_batch):
input_example_images = extract_example_images(examples_batch[i])
all_images.extend(input_example_images)
# Get message images for this input
input_message_images = process_vision_info(message_group)[0] or []
all_images.extend(input_message_images)
return all_images if all_images else None
```
E.g. To perform a basic extraction of names from a text document:
```python
template = """{"names": ["string"]}"""
document = "John went to the restaurant with Mary. James went to the cinema."
# prepare the user message content
messages = [{"role": "user", "content": document}]
text = processor.tokenizer.apply_chat_template(
messages,
template=template, # template is specified here
tokenize=False,
add_generation_prompt=True,
)
print(text)
""""<|im_start|>user
# Template:
{"names": ["string"]}
# Context:
John went to the restaurant with Mary. James went to the cinema.<|im_end|>
<|im_start|>assistant"""
image_inputs = process_all_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
padding=True,
return_tensors="pt",
).to("cuda")
# we choose greedy sampling here, which works well for most information extraction tasks
generation_config = {"do_sample": False, "num_beams": 1, "max_new_tokens": 2048}
# Inference: Generation of the output
generated_ids = model.generate(
**inputs,
**generation_config
)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
# ['{"names": ["John", "Mary", "James"]}']
```
<details>
<summary>In-Context Examples</summary>
Sometimes the model might not perform as well as we want because our task is challenging or involves some degree of ambiguity. Alternatively, we may want the model to follow some specific formatting, or just give it a bit more help. In cases like this it can be valuable to provide "in-context examples" to help NuExtract better understand the task.
To do so, we can provide a list examples (dictionaries of input/output pairs). In the example below, we show to the model that we want the extracted names to be in captial letters with `-` on either side (for the sake of illustration). Usually providing multiple examples will lead to better results.
```python
template = """{"names": ["string"]}"""
document = "John went to the restaurant with Mary. James went to the cinema."
examples = [
{
"input": "Stephen is the manager at Susan's store.",
"output": """{"names": ["-STEPHEN-", "-SUSAN-"]}"""
}
]
messages = [{"role": "user", "content": document}]
text = processor.tokenizer.apply_chat_template(
messages,
template=template,
examples=examples, # examples provided here
tokenize=False,
add_generation_prompt=True,
)
image_inputs = process_all_vision_info(messages, examples)
inputs = processor(
text=[text],
images=image_inputs,
padding=True,
return_tensors="pt",
).to("cuda")
# we choose greedy sampling here, which works well for most information extraction tasks
generation_config = {"do_sample": False, "num_beams": 1, "max_new_tokens": 2048}
# Inference: Generation of the output
generated_ids = model.generate(
**inputs,
**generation_config
)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
# ['{"names": ["-JOHN-", "-MARY-", "-JAMES-"]}']
```
</details>
<details>
<summary>Image Inputs</summary>
If we want to give image inputs to NuExtract, instead of text, we simply provide a dictionary specifying the desired image file as the message content, instead of a string. (e.g. `{"type": "image", "image": "file://image.jpg"}`).
You can also specify an image URL (e.g. `{"type": "image", "image": "http://path/to/your/image.jpg"}`) or base64 encoding (e.g. `{"type": "image", "image": "data:image;base64,/9j/..."}`).
```python
template = """{"store": "verbatim-string"}"""
document = {"type": "image", "image": "file://1.jpg"}
messages = [{"role": "user", "content": [document]}]
text = processor.tokenizer.apply_chat_template(
messages,
template=template,
tokenize=False,
add_generation_prompt=True,
)
image_inputs = process_all_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
padding=True,
return_tensors="pt",
).to("cuda")
generation_config = {"do_sample": False, "num_beams": 1, "max_new_tokens": 2048}
# Inference: Generation of the output
generated_ids = model.generate(
**inputs,
**generation_config
)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
# ['{"store": "Trader Joe\'s"}']
```
</details>
<details>
<summary>Batch Inference</summary>
```python
inputs = [
# image input with no ICL examples
{
"document": {"type": "image", "image": "file://0.jpg"},
"template": """{"store_name": "verbatim-string"}""",
},
# image input with 1 ICL example
{
"document": {"type": "image", "image": "file://0.jpg"},
"template": """{"store_name": "verbatim-string"}""",
"examples": [
{
"input": {"type": "image", "image": "file://1.jpg"},
"output": """{"store_name": "Trader Joe's"}""",
}
],
},
# text input with no ICL examples
{
"document": {"type": "text", "text": "John went to the restaurant with Mary. James went to the cinema."},
"template": """{"names": ["string"]}""",
},
# text input with ICL example
{
"document": {"type": "text", "text": "John went to the restaurant with Mary. James went to the cinema."},
"template": """{"names": ["string"]}""",
"examples": [
{
"input": "Stephen is the manager at Susan's store.",
"output": """{"names": ["STEPHEN", "SUSAN"]}"""
}
],
},
]
# messages should be a list of lists for batch processing
messages = [
[
{
"role": "user",
"content": [x['document']],
}
]
for x in inputs
]
# apply chat template to each example individually
texts = [
processor.tokenizer.apply_chat_template(
messages[i], # Now this is a list containing one message
template=x['template'],
examples=x.get('examples', None),
tokenize=False,
add_generation_prompt=True)
for i, x in enumerate(inputs)
]
image_inputs = process_all_vision_info(messages, [x.get('examples') for x in inputs])
inputs = processor(
text=texts,
images=image_inputs,
padding=True,
return_tensors="pt",
).to("cuda")
generation_config = {"do_sample": False, "num_beams": 1, "max_new_tokens": 2048}
# Batch Inference
generated_ids = model.generate(**inputs, **generation_config)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_texts = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
for y in output_texts:
print(y)
# {"store_name": "WAL-MART"}
# {"store_name": "Walmart"}
# {"names": ["John", "Mary", "James"]}
# {"names": ["JOHN", "MARY", "JAMES"]}
```
</details>
<details>
<summary>Template Generation</summary>
If you want to convert existing schema files you have in other formats (e.g. XML, YAML, etc.) or start from an example, NuExtract 2.0 models can automatically generate this for you.
E.g. convert XML into a NuExtract template:
```python
xml_template = """<SportResult>
<Date></Date>
<Sport></Sport>
<Venue></Venue>
<HomeTeam></HomeTeam>
<AwayTeam></AwayTeam>
<HomeScore></HomeScore>
<AwayScore></AwayScore>
<TopScorer></TopScorer>
</SportResult>"""
messages = [
{
"role": "user",
"content": [{"type": "text", "text": xml_template}],
}
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True,
)
image_inputs = process_all_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
padding=True,
return_tensors="pt",
).to("cuda")
generated_ids = model.generate(
**inputs,
**generation_config
)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text[0])
# {
# "Date": "date-time",
# "Sport": "verbatim-string",
# "Venue": "verbatim-string",
# "HomeTeam": "verbatim-string",
# "AwayTeam": "verbatim-string",
# "HomeScore": "integer",
# "AwayScore": "integer",
# "TopScorer": "verbatim-string"
# }
```
E.g. generate a template from natural language description:
```python
description = "I would like to extract important details from the contract."
messages = [
{
"role": "user",
"content": [{"type": "text", "text": description}],
}
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True,
)
image_inputs = process_all_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
padding=True,
return_tensors="pt",
).to("cuda")
generated_ids = model.generate(
**inputs,
**generation_config
)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text[0])
# {
# "Contract": {
# "Title": "verbatim-string",
# "Description": "verbatim-string",
# "Terms": [
# {
# "Term": "verbatim-string",
# "Description": "verbatim-string"
# }
# ],
# "Date": "date-time",
# "Signatory": "verbatim-string"
# }
# }
```
</details>
## Fine-Tuning
You can find a fine-tuning tutorial notebook in the [cookbooks](https://github.com/numindai/nuextract/tree/main/cookbooks) folder of the [GitHub repo](https://github.com/numindai/nuextract/tree/main).
## vLLM Deployment
Run the command below to serve an OpenAI-compatible API:
```bash
vllm serve numind/NuExtract-2.0-8B --trust_remote_code --limit-mm-per-prompt image=6 --chat-template-content-format openai
```
If you encounter memory issues, set `--max-model-len` accordingly.
Send requests to the model as follows:
```python
import json
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="numind/NuExtract-2.0-8B",
temperature=0,
messages=[
{
"role": "user",
"content": [{"type": "text", "text": "Yesterday I went shopping at Bunnings"}],
},
],
extra_body={
"chat_template_kwargs": {
"template": json.dumps(json.loads("""{\"store\": \"verbatim-string\"}"""), indent=4)
},
}
)
print("Chat response:", chat_response)
```
For image inputs, structure requests as shown below. Make sure to order the images in `"content"` as they appear in the prompt (i.e. any in-context examples before the main input).
```python
import base64
def encode_image(image_path):
"""
Encode the image file to base64 string
"""
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
base64_image = encode_image("0.jpg")
base64_image2 = encode_image("1.jpg")
chat_response = client.chat.completions.create(
model="numind/NuExtract-2.0-8B",
temperature=0,
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}}, # first ICL example image
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_image2}"}}, # real input image
],
},
],
extra_body={
"chat_template_kwargs": {
"template": json.dumps(json.loads("""{\"store\": \"verbatim-string\"}"""), indent=4),
"examples": [
{
"input": "<image>",
"output": """{\"store\": \"Walmart\"}"""
}
]
},
}
)
print("Chat response:", chat_response)
```
|
yookty/blockassist-bc-whistling_exotic_chicken_1755625296
|
yookty
| 2025-08-19T17:41:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"whistling exotic chicken",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T17:41:37Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- whistling exotic chicken
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
allisterb/gemma3_270m_tools_test
|
allisterb
| 2025-08-19T17:38:42Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gguf",
"gemma3_text",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/gemma-3-270m-it-unsloth-bnb-4bit",
"base_model:quantized:unsloth/gemma-3-270m-it-unsloth-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T15:13:57Z |
---
base_model: unsloth/gemma-3-270m-it-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3_text
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** allisterb
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-270m-it-unsloth-bnb-4bit
This gemma3_text model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Huseyin/teknofest-2025-turkish-edu
|
Huseyin
| 2025-08-19T17:38:35Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T17:32:35Z |
# 🚀 TEKNOFEST 2025 - Türkçe Eğitim Modeli
Bu model **TEKNOFEST 2025 Eylem Temelli Türkçe Büyük Dil Modeli Yarışması** için geliştirilmiştir.
## 📋 Model Bilgileri
- **Base Model:** Qwen/Qwen3-8B
- **Fine-tuning:** LoRA Adapter (Huseyin/qwen3-8b-turkish-teknofest2025-private)
- **Oluşturma Tarihi:** 2025-08-19 17:37
- **Alan:** Eğitim Teknolojileri
- **Dil:** Türkçe
## 🎯 Kullanım Alanları
- Türkçe eğitim materyali oluşturma
- Öğrenci seviyesine uygun içerik üretimi
- Soru-cevap sistemleri
- Eğitsel içerik özetleme
- Ders planı hazırlama
## 💻 Kullanım
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
# Model ve tokenizer'ı yükle
model_name = "Huseyin/teknofest-2025-turkish-edu"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
# Örnek kullanım
prompt = "Türkçe eğitimi için yaratıcı bir etkinlik önerisi:"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_length=200, temperature=0.7)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
```
## 🏆 TEKNOFEST 2025
Bu model, TEKNOFEST 2025 Türkçe Büyük Dil Modeli Yarışması kapsamında geliştirilmiştir.
### Yarışma Kategorisi
**Eylem Temelli Türkçe Büyük Dil Modeli**
### Ekip
TEKNOFEST 2025 Yarışma Ekibi
## 📊 Performans Metrikleri
- **Perplexity:** [Değerlendirilecek]
- **BLEU Score:** [Değerlendirilecek]
- **Human Evaluation:** [Değerlendirilecek]
## 📄 Lisans
Apache 2.0
## 🙏 Teşekkür
Bu modelin geliştirilmesinde emeği geçen herkese teşekkür ederiz.
---
*TEKNOFEST 2025 - Türkiye'nin Teknoloji Festivali*
|
coelacanthxyz/blockassist-bc-finicky_thriving_grouse_1755623215
|
coelacanthxyz
| 2025-08-19T17:35:48Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"finicky thriving grouse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T17:35:42Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- finicky thriving grouse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
shihotan/Silende_Real
|
shihotan
| 2025-08-19T17:33:09Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-05-10T05:54:11Z |
(realistic:1.1),(photorealistic:1.1),(cosplay photo:1.1),(masterpiece, best quality, newest, absurdres, highres:1.4),(real life:1.6),
|
AppliedLucent/nemo-phase5
|
AppliedLucent
| 2025-08-19T17:23:30Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:AppliedLucent/nemo-phase4",
"base_model:finetune:AppliedLucent/nemo-phase4",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T17:10:38Z |
---
base_model: AppliedLucent/nemo-phase4
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** AppliedLucent
- **License:** apache-2.0
- **Finetuned from model :** AppliedLucent/nemo-phase4
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Orginal-Bindura-University-viral-video-Cli/New.full.videos.Bindura.University.Viral.Video.Official.Tutorial
|
Orginal-Bindura-University-viral-video-Cli
| 2025-08-19T17:22:49Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T17:22:36Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?leaked-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
Ver-full-videos-maria-b-Clips/Ver.Viral.video.maria.b.polemica.viral.en.twitter.y.telegram
|
Ver-full-videos-maria-b-Clips
| 2025-08-19T17:14:02Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T17:13:54Z |
[](https://tinyurl.com/bdk3zxvb)
|
kevinshin/test-run-fsdp-v1-full-state-dict
|
kevinshin
| 2025-08-19T17:09:34Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:Qwen/Qwen3-1.7B",
"base_model:finetune:Qwen/Qwen3-1.7B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T16:40:15Z |
---
base_model: Qwen/Qwen3-1.7B
library_name: transformers
model_name: test-run-fsdp-v1-full-state-dict
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for test-run-fsdp-v1-full-state-dict
This model is a fine-tuned version of [Qwen/Qwen3-1.7B](https://huggingface.co/Qwen/Qwen3-1.7B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="kevinshin/test-run-fsdp-v1-full-state-dict", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/myungjune-sogang-university/general_remo_train/runs/3dzoaavc)
This model was trained with SFT.
### Framework versions
- TRL: 0.19.1
- Transformers: 4.54.0
- Pytorch: 2.6.0+cu126
- Datasets: 4.0.0
- Tokenizers: 0.21.2
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
EZCon/Qwen2-VL-7B-Instruct-4bit-mlx
|
EZCon
| 2025-08-19T17:03:10Z | 29 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_vl",
"image-to-text",
"multimodal",
"qwen",
"qwen2",
"unsloth",
"vision",
"mlx",
"image-text-to-text",
"conversational",
"en",
"base_model:Qwen/Qwen2-VL-7B-Instruct",
"base_model:quantized:Qwen/Qwen2-VL-7B-Instruct",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"region:us"
] |
image-text-to-text
| 2025-08-05T06:38:42Z |
---
base_model: Qwen/Qwen2-VL-7B-Instruct
language:
- en
library_name: transformers
pipeline_tag: image-text-to-text
license: apache-2.0
tags:
- multimodal
- qwen
- qwen2
- unsloth
- transformers
- vision
- mlx
---
# EZCon/Qwen2-VL-7B-Instruct-4bit-mlx
This model was converted to MLX format from [`unsloth/Qwen2-VL-7B-Instruct`]() using mlx-vlm version **0.3.2**.
Refer to the [original model card](https://huggingface.co/unsloth/Qwen2-VL-7B-Instruct) for more details on the model.
## Use with mlx
```bash
pip install -U mlx-vlm
```
```bash
python -m mlx_vlm.generate --model EZCon/Qwen2-VL-7B-Instruct-4bit-mlx --max-tokens 100 --temperature 0.0 --prompt "Describe this image." --image <path_to_image>
```
|
yaelahnal/blockassist-bc-mute_clawed_crab_1755622908
|
yaelahnal
| 2025-08-19T17:03:00Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mute clawed crab",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T17:02:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mute clawed crab
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
EZCon/Qwen2-VL-2B-Instruct-abliterated-8bit-mlx
|
EZCon
| 2025-08-19T16:58:14Z | 47 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_vl",
"image-to-text",
"chat",
"abliterated",
"uncensored",
"mlx",
"image-text-to-text",
"conversational",
"en",
"base_model:Qwen/Qwen2-VL-2B-Instruct",
"base_model:quantized:Qwen/Qwen2-VL-2B-Instruct",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"region:us"
] |
image-text-to-text
| 2025-08-06T03:44:27Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/huihui-ai/Qwen2-VL-2B-Instruct-abliterated/blob/main/LICENSE
language:
- en
pipeline_tag: image-text-to-text
base_model: Qwen/Qwen2-VL-2B-Instruct
tags:
- chat
- abliterated
- uncensored
- mlx
---
# EZCon/Qwen2-VL-2B-Instruct-abliterated-8bit-mlx
This model was converted to MLX format from [`huihui-ai/Qwen2-VL-2B-Instruct-abliterated`]() using mlx-vlm version **0.3.2**.
Refer to the [original model card](https://huggingface.co/huihui-ai/Qwen2-VL-2B-Instruct-abliterated) for more details on the model.
## Use with mlx
```bash
pip install -U mlx-vlm
```
```bash
python -m mlx_vlm.generate --model EZCon/Qwen2-VL-2B-Instruct-abliterated-8bit-mlx --max-tokens 100 --temperature 0.0 --prompt "Describe this image." --image <path_to_image>
```
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755620734
|
mang3dd
| 2025-08-19T16:52:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T16:52:29Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
New-Clip-prabh-viral-videos/New.full.videos.prabh.Viral.Video.Official.Tutorial
|
New-Clip-prabh-viral-videos
| 2025-08-19T16:52:15Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T16:51:29Z |
[](https://tinyurl.com/bdk3zxvb)
|
Prathyusha101/tldr-ppco-g0p95-l1p0
|
Prathyusha101
| 2025-08-19T16:44:46Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"dataset:trl-internal-testing/tldr-preference-sft-trl-style",
"arxiv:1909.08593",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-19T11:17:59Z |
---
datasets: trl-internal-testing/tldr-preference-sft-trl-style
library_name: transformers
model_name: tldr-ppco-g0p95-l1p0
tags:
- generated_from_trainer
licence: license
---
# Model Card for tldr-ppco-g0p95-l1p0
This model is a fine-tuned version of [None](https://huggingface.co/None) on the [trl-internal-testing/tldr-preference-sft-trl-style](https://huggingface.co/datasets/trl-internal-testing/tldr-preference-sft-trl-style) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Prathyusha101/tldr-ppco-g0p95-l1p0", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/prathyusha1-the-university-of-texas-at-austin/huggingface/runs/poeo9cdz)
This model was trained with PPO, a method introduced in [Fine-Tuning Language Models from Human Preferences](https://huggingface.co/papers/1909.08593).
### Framework versions
- TRL: 0.15.0.dev0
- Transformers: 4.53.1
- Pytorch: 2.5.1
- Datasets: 3.6.0
- Tokenizers: 0.21.2
## Citations
Cite PPO as:
```bibtex
@article{mziegler2019fine-tuning,
title = {{Fine-Tuning Language Models from Human Preferences}},
author = {Daniel M. Ziegler and Nisan Stiennon and Jeffrey Wu and Tom B. Brown and Alec Radford and Dario Amodei and Paul F. Christiano and Geoffrey Irving},
year = 2019,
eprint = {arXiv:1909.08593}
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
indoempatnol/blockassist-bc-fishy_wary_swan_1755619122
|
indoempatnol
| 2025-08-19T16:25:41Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"fishy wary swan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T16:25:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- fishy wary swan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lguaman/MyManufacturingData
|
lguaman
| 2025-08-19T16:24:42Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gemma3_text",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"base_model:google/gemma-3-270m-it",
"base_model:finetune:google/gemma-3-270m-it",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T14:09:08Z |
---
base_model: google/gemma-3-270m-it
library_name: transformers
model_name: MyManufacturingData
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for MyManufacturingData
This model is a fine-tuned version of [google/gemma-3-270m-it](https://huggingface.co/google/gemma-3-270m-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="lguaman/MyManufacturingData", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.6.0+cu124
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755618934
|
mang3dd
| 2025-08-19T16:22:08Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T16:22:05Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
oceanfish/intent_classify_slot
|
oceanfish
| 2025-08-19T16:20:03Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:adapter:Qwen/Qwen2.5-7B-Instruct",
"region:us"
] | null | 2025-08-19T16:15:20Z |
---
base_model: Qwen/Qwen2.5-7B-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2
|
exala/db_auto_6.1.2
|
exala
| 2025-08-19T16:16:59Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-19T16:16:43Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
pempekmangedd/blockassist-bc-patterned_sturdy_dolphin_1755618495
|
pempekmangedd
| 2025-08-19T16:14:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"patterned sturdy dolphin",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T16:14:37Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- patterned sturdy dolphin
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
opentargets/locus_to_gene_25.09
|
opentargets
| 2025-08-19T16:12:41Z | 0 | 0 |
sklearn
|
[
"sklearn",
"skops",
"tabular-classification",
"region:us"
] |
tabular-classification
| 2025-08-19T16:12:38Z |
---
library_name: sklearn
tags:
- sklearn
- skops
- tabular-classification
model_format: skops
model_file: classifier.skops
widget:
- structuredData:
credibleSetConfidence:
- 0.75
- 0.75
- 0.25
distanceFootprintMean:
- 1.0
- 1.0
- 0.9948455095291138
distanceFootprintMeanNeighbourhood:
- 1.0
- 1.0
- 1.0
distanceSentinelFootprint:
- 1.0
- 1.0
- 0.9999213218688965
distanceSentinelFootprintNeighbourhood:
- 1.0
- 1.0
- 1.0
distanceSentinelTss:
- 0.9982281923294067
- 0.9999350309371948
- 0.9999213218688965
distanceSentinelTssNeighbourhood:
- 1.0
- 1.0
- 1.0
distanceTssMean:
- 0.9982281923294067
- 0.9999350309371948
- 0.9947366714477539
distanceTssMeanNeighbourhood:
- 1.0
- 1.0
- 1.0
eQtlColocClppMaximum:
- 0.949999988079071
- 0.0
- 0.06608512997627258
eQtlColocClppMaximumNeighbourhood:
- 1.0
- 0.0
- 1.0
eQtlColocH4Maximum:
- 1.0
- 0.0
- 0.0
eQtlColocH4MaximumNeighbourhood:
- 1.0
- 0.0
- 0.0
geneCount500kb:
- 20.0
- 15.0
- 8.0
geneId:
- ENSG00000087237
- ENSG00000169174
- ENSG00000084674
goldStandardSet:
- 1
- 1
- 1
pQtlColocClppMaximum:
- 0.0
- 1.0
- 0.0
pQtlColocClppMaximumNeighbourhood:
- 0.0
- 1.0
- 0.0
pQtlColocH4Maximum:
- 0.0
- 1.0
- 0.0
pQtlColocH4MaximumNeighbourhood:
- 0.0
- 1.0
- 0.0
proteinGeneCount500kb:
- 8.0
- 7.0
- 3.0
sQtlColocClppMaximum:
- 0.949999988079071
- 0.0
- 0.21970131993293762
sQtlColocClppMaximumNeighbourhood:
- 1.0
- 0.0
- 1.0
sQtlColocH4Maximum:
- 1.0
- 0.0
- 0.0
sQtlColocH4MaximumNeighbourhood:
- 1.0
- 0.0
- 0.0
studyLocusId:
- 005bc8624f8dd7f7c7bc63e651e9e59d
- 02c442ea4fa5ab80586a6d1ff6afa843
- 235e8ce166619f33e27582fff5bc0c94
vepMaximum:
- 0.33000001311302185
- 0.6600000262260437
- 0.6600000262260437
vepMaximumNeighbourhood:
- 1.0
- 1.0
- 1.0
vepMean:
- 0.33000001311302185
- 0.6600000262260437
- 0.0039977929554879665
vepMeanNeighbourhood:
- 1.0
- 1.0
- 1.0
---
# Model description
The locus-to-gene (L2G) model derives features to prioritise likely causal genes at each GWAS locus based on genetic and functional genomics features. The main categories of predictive features are:
- Distance: (from credible set variants to gene)
- Molecular QTL Colocalization
- Variant Pathogenicity: (from VEP)
More information at: https://opentargets.github.io/gentropy/python_api/methods/l2g/_l2g/
## Intended uses & limitations
[More Information Needed]
## Training Procedure
Gradient Boosting Classifier
### Hyperparameters
<details>
<summary> Click to expand </summary>
| Hyperparameter | Value |
|-------------------------|-----------------|
| objective | binary:logistic |
| base_score | |
| booster | |
| callbacks | |
| colsample_bylevel | |
| colsample_bynode | |
| colsample_bytree | 0.8 |
| device | |
| early_stopping_rounds | |
| enable_categorical | False |
| eval_metric | aucpr |
| feature_types | |
| feature_weights | |
| gamma | |
| grow_policy | |
| importance_type | |
| interaction_constraints | |
| learning_rate | |
| max_bin | |
| max_cat_threshold | |
| max_cat_to_onehot | |
| max_delta_step | |
| max_depth | 5 |
| max_leaves | |
| min_child_weight | 10 |
| missing | nan |
| monotone_constraints | |
| multi_strategy | |
| n_estimators | |
| n_jobs | |
| num_parallel_tree | |
| random_state | 777 |
| reg_alpha | 1 |
| reg_lambda | 1.0 |
| sampling_method | |
| scale_pos_weight | 0.8 |
| subsample | 0.8 |
| tree_method | |
| validate_parameters | |
| verbosity | |
| eta | 0.05 |
</details>
# How to Get Started with the Model
To use the model, you can load it using the `LocusToGeneModel.load_from_hub` method. This will return a `LocusToGeneModel` object that can be used to make predictions on a feature matrix.
The model can then be used to make predictions using the `predict` method.
More information can be found at: https://opentargets.github.io/gentropy/python_api/methods/l2g/model/
# Citation
https://doi.org/10.1038/s41588-021-00945-5
# License
MIT
|
WenFengg/21_14l4_19__8_
|
WenFengg
| 2025-08-19T15:49:16Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-19T15:32:34Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
Elizavr/blockassist-bc-reclusive_shaggy_bee_1755618244
|
Elizavr
| 2025-08-19T15:44:47Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"reclusive shaggy bee",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T15:44:36Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- reclusive shaggy bee
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Christopher-Lim/Butter
|
Christopher-Lim
| 2025-08-19T15:37:35Z | 0 | 0 | null |
[
"object-detection",
"dataset:rafaelpadilla/coco2017",
"dataset:nateraw/kitti",
"dataset:Chris1/cityscapes",
"dataset:dgural/bdd100k",
"arxiv:2507.13373",
"license:agpl-3.0",
"region:us"
] |
object-detection
| 2025-08-19T15:09:15Z |
---
license: agpl-3.0
datasets:
- rafaelpadilla/coco2017
- nateraw/kitti
- Chris1/cityscapes
- dgural/bdd100k
metrics:
- precision
- f1
- recall
pipeline_tag: object-detection
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
Butter is a novel 2D object detection framework designed to enhance hierarchical feature representations for improved detection robustness.
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [Xiaojian Lin et al.]
- **Funded by:** [National Natural Science Foundation of China]
- **Model type:** [Object Detection]
- **License:** [AGPL-3.0 license]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [https://github.com/Aveiro-Lin/Butter]
- **Paper:** [https://www.arxiv.org/pdf/2507.13373]
## Uses
The training and inference details, as well as the environment configuration, can be found in our GitHub repository, where a comprehensive description is provided. The model’s performance metrics and training details are thoroughly described in the paper we provide.
|
AppliedLucent/nemo-phase4
|
AppliedLucent
| 2025-08-19T15:31:28Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:AppliedLucent/nemo-phase3",
"base_model:finetune:AppliedLucent/nemo-phase3",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T15:18:37Z |
---
base_model: AppliedLucent/nemo-phase3
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** AppliedLucent
- **License:** apache-2.0
- **Finetuned from model :** AppliedLucent/nemo-phase3
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
hanskarlo/dqn-SpaceInvadersNoFrameskip-v4
|
hanskarlo
| 2025-08-19T15:31:00Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-19T15:29:59Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 824.00 +/- 279.92
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
SBX (SB3 + Jax): https://github.com/araffin/sbx
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga hanskarlo -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga hanskarlo -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga hanskarlo
```
## Hyperparameters
```python
OrderedDict([('batch_size', 48),
('buffer_size', 105000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 10000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
phospho-app/Deimos252-ACT_BBOX-Light_dataset_deimos-yykfs
|
phospho-app
| 2025-08-19T15:14:42Z | 0 | 0 |
phosphobot
|
[
"phosphobot",
"act",
"robotics",
"dataset:Deimos252/Light_dataset_deimos",
"region:us"
] |
robotics
| 2025-08-19T15:14:06Z |
---
datasets: Deimos252/Light_dataset_deimos
library_name: phosphobot
pipeline_tag: robotics
model_name: act
tags:
- phosphobot
- act
task_categories:
- robotics
---
# act Model - phospho Training Pipeline
## Error Traceback
We faced an issue while training your model.
```
1 validation error for EpisodesFeatures
Invalid JSON: EOF while parsing a value at line 2 column 0 [type=json_invalid, input_value='\n', input_type=str]
For further information visit https://errors.pydantic.dev/2.11/v/json_invalid
```
## Training parameters:
- **Dataset**: [Deimos252/Light_dataset_deimos](https://huggingface.co/datasets/Deimos252/Light_dataset_deimos)
- **Wandb run URL**: None
- **Epochs**: None
- **Batch size**: 100
- **Training steps**: 10000
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
k1000dai/residualact_libero_smolvla_singleaction_fix
|
k1000dai
| 2025-08-19T15:09:00Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"residualact",
"dataset:k1000dai/libero-smolvla",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-19T00:49:01Z |
---
datasets: k1000dai/libero-smolvla
library_name: lerobot
license: apache-2.0
model_name: residualact
pipeline_tag: robotics
tags:
- robotics
- residualact
- lerobot
---
# Model Card for residualact
<!-- Provide a quick summary of what the model is/does. -->
_Model type not recognized — please update this template._
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
Muapi/3d_flux-style
|
Muapi
| 2025-08-19T15:07:43Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T15:07:35Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# 3D_Flux Style

**Base model**: Flux.1 D
**Trained words**: 3D01S , kawaii, anime
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:689478@771650", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
saracandu/stldec_random_1024
|
saracandu
| 2025-08-19T15:03:56Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"stldec",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2025-08-19T14:53:07Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Muapi/gigachad-flux1.d-sdxl
|
Muapi
| 2025-08-19T15:03:05Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T15:02:54Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Gigachad - Flux1.D & SDXL

**Base model**: Flux.1 D
**Trained words**: Gigachad is a muscular man
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:237712@786259", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
wjbmattingly/lfm2-vl-450M-yiddish
|
wjbmattingly
| 2025-08-19T14:58:01Z | 0 | 0 | null |
[
"safetensors",
"lfm2-vl",
"custom_code",
"base_model:LiquidAI/LFM2-VL-450M",
"base_model:finetune:LiquidAI/LFM2-VL-450M",
"region:us"
] | null | 2025-08-19T14:57:50Z |
---
base_model:
- LiquidAI/LFM2-VL-450M
---
# model_step_13000
## Model Description
This model is a fine-tuned version of **LiquidAI/LFM2-VL-450M** using the brute-force-training package.
- **Base Model**: LiquidAI/LFM2-VL-450M
- **Training Status**: 🔄 In Progress
- **Generated**: 2025-08-19 10:41:14
- **Training Steps**: 13,000
## Training Details
### Dataset
- **Dataset**: johnlockejrr/yiddish_synth_v2
- **Training Examples**: 100,000
- **Validation Examples**: 4,999
### Training Configuration
- **Max Steps**: 100,000
- **Batch Size**: 15
- **Learning Rate**: 7e-05
- **Gradient Accumulation**: 1 steps
- **Evaluation Frequency**: Every 1,000 steps
### Current Performance
- **Training Loss**: 0.124526
- **Evaluation Loss**: 0.189137
## Pre-Training Evaluation
**Initial Model Performance (before training):**
- **Loss**: 2.626098
- **Perplexity**: 13.82
- **Character Accuracy**: 31.1%
- **Word Accuracy**: 12.9%
## Evaluation History
### All Checkpoint Evaluations
| Step | Checkpoint Type | Loss | Perplexity | Char Acc | Word Acc | Improvement vs Pre |
|------|----------------|------|------------|----------|----------|--------------------|
| Pre | pre_training | 2.6261 | 13.82 | 31.1% | 12.9% | +0.0% |
| 1,000 | checkpoint | 0.9395 | 2.56 | 20.1% | 4.1% | +64.2% |
| 2,000 | checkpoint | 0.8058 | 2.24 | 21.2% | 4.0% | +69.3% |
| 3,000 | checkpoint | 0.7305 | 2.08 | 23.0% | 6.1% | +72.2% |
| 4,000 | checkpoint | 0.6669 | 1.95 | 20.6% | 3.4% | +74.6% |
| 5,000 | checkpoint | 0.5341 | 1.71 | 21.4% | 3.6% | +79.7% |
| 6,000 | checkpoint | 0.4656 | 1.59 | 20.9% | 3.8% | +82.3% |
| 7,000 | checkpoint | 0.3917 | 1.48 | 21.4% | 3.5% | +85.1% |
| 8,000 | checkpoint | 0.3310 | 1.39 | 21.6% | 4.8% | +87.4% |
| 9,000 | checkpoint | 0.2892 | 1.34 | 20.7% | 4.0% | +89.0% |
| 10,000 | checkpoint | 0.2566 | 1.29 | 20.9% | 4.7% | +90.2% |
| 11,000 | checkpoint | 0.2199 | 1.25 | 20.2% | 4.9% | +91.6% |
| 12,000 | checkpoint | 0.2033 | 1.23 | 20.3% | 3.2% | +92.3% |
| 13,000 | checkpoint | 0.1891 | 1.21 | 19.4% | 3.4% | +92.8% |
## Training Progress
### Recent Training Steps (Loss Only)
| Step | Training Loss | Timestamp |
|------|---------------|-----------|
| 12,991 | 0.154684 | 2025-08-19T10:40 |
| 12,992 | 0.183019 | 2025-08-19T10:40 |
| 12,993 | 0.157314 | 2025-08-19T10:40 |
| 12,994 | 0.168899 | 2025-08-19T10:40 |
| 12,995 | 0.116096 | 2025-08-19T10:40 |
| 12,996 | 0.122316 | 2025-08-19T10:40 |
| 12,997 | 0.149480 | 2025-08-19T10:40 |
| 12,998 | 0.166267 | 2025-08-19T10:40 |
| 12,999 | 0.152927 | 2025-08-19T10:40 |
| 13,000 | 0.124526 | 2025-08-19T10:40 |
## Training Visualizations
### Training Progress and Evaluation Metrics

*This chart shows the training loss progression, character accuracy, word accuracy, and perplexity over time. Red dots indicate evaluation checkpoints.*
### Evaluation Comparison Across All Checkpoints

*Comprehensive comparison of all evaluation metrics across training checkpoints. Red=Pre-training, Blue=Checkpoints, Green=Final.*
### Available Visualization Files:
- **`training_curves.png`** - 4-panel view: Training loss with eval points, Character accuracy, Word accuracy, Perplexity
- **`evaluation_comparison.png`** - 4-panel comparison: Loss, Character accuracy, Word accuracy, Perplexity across all checkpoints
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
# For vision-language models, use appropriate imports
model = AutoModelForCausalLM.from_pretrained("./model_step_13000")
tokenizer = AutoTokenizer.from_pretrained("./model_step_13000")
# Your inference code here
```
## Training Configuration
```json
{
"dataset_name": "johnlockejrr/yiddish_synth_v2",
"model_name": "LiquidAI/LFM2-VL-450M",
"max_steps": 100000,
"eval_steps": 1000,
"num_accumulation_steps": 1,
"learning_rate": 7e-05,
"train_batch_size": 15,
"val_batch_size": 1,
"train_select_start": 0,
"train_select_end": 100000,
"val_select_start": 100001,
"val_select_end": 105000,
"train_field": "train",
"val_field": "train",
"image_column": "image",
"text_column": "text",
"user_text": "Please transcribe all the Yiddish text you see in this historical manuscript image. Provide only the transcribed text without any additional commentary or description.",
"max_image_size": 250
}
```
## Model Card Metadata
- **Base Model**: LiquidAI/LFM2-VL-450M
- **Training Framework**: brute-force-training
- **Training Type**: Fine-tuning
- **License**: Inherited from base model
- **Language**: Inherited from base model
---
*This model card was automatically generated by brute-force-training on 2025-08-19 10:41:14*
|
KMH158/t5-small-openassistant-chat
|
KMH158
| 2025-08-19T14:54:39Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T12:36:35Z |
---
library_name: transformers
license: apache-2.0
base_model: google-t5/t5-small
tags:
- generated_from_trainer
model-index:
- name: t5-small-openassistant-chat
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-openassistant-chat
This model is a fine-tuned version of [google-t5/t5-small](https://huggingface.co/google-t5/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1785
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 80
- eval_batch_size: 1
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 40
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 3.3768 | 1.0 | 301 | 2.3842 |
| 2.6839 | 2.0 | 602 | 2.3277 |
| 2.6351 | 3.0 | 903 | 2.2995 |
| 2.6016 | 4.0 | 1204 | 2.2818 |
| 2.5803 | 5.0 | 1505 | 2.2680 |
| 2.5587 | 6.0 | 1806 | 2.2571 |
| 2.541 | 7.0 | 2107 | 2.2481 |
| 2.5323 | 8.0 | 2408 | 2.2409 |
| 2.5102 | 9.0 | 2709 | 2.2349 |
| 2.5063 | 10.0 | 3010 | 2.2288 |
| 2.4953 | 11.0 | 3311 | 2.2242 |
| 2.4926 | 12.0 | 3612 | 2.2192 |
| 2.4786 | 13.0 | 3913 | 2.2154 |
| 2.472 | 14.0 | 4214 | 2.2117 |
| 2.4662 | 15.0 | 4515 | 2.2079 |
| 2.4553 | 16.0 | 4816 | 2.2051 |
| 2.4472 | 17.0 | 5117 | 2.2020 |
| 2.4488 | 18.0 | 5418 | 2.2008 |
| 2.4367 | 19.0 | 5719 | 2.1972 |
| 2.4353 | 20.0 | 6020 | 2.1952 |
| 2.429 | 21.0 | 6321 | 2.1934 |
| 2.4247 | 22.0 | 6622 | 2.1912 |
| 2.4242 | 23.0 | 6923 | 2.1901 |
| 2.4196 | 24.0 | 7224 | 2.1887 |
| 2.4169 | 25.0 | 7525 | 2.1873 |
| 2.4122 | 26.0 | 7826 | 2.1862 |
| 2.4089 | 27.0 | 8127 | 2.1851 |
| 2.4042 | 28.0 | 8428 | 2.1841 |
| 2.4061 | 29.0 | 8729 | 2.1831 |
| 2.4007 | 30.0 | 9030 | 2.1823 |
| 2.397 | 31.0 | 9331 | 2.1814 |
| 2.3998 | 32.0 | 9632 | 2.1810 |
| 2.3963 | 33.0 | 9933 | 2.1805 |
| 2.3976 | 34.0 | 10234 | 2.1798 |
| 2.3919 | 35.0 | 10535 | 2.1794 |
| 2.3873 | 36.0 | 10836 | 2.1793 |
| 2.3899 | 37.0 | 11137 | 2.1789 |
| 2.3886 | 38.0 | 11438 | 2.1786 |
| 2.3906 | 39.0 | 11739 | 2.1786 |
| 2.393 | 40.0 | 12040 | 2.1785 |
### Framework versions
- Transformers 4.55.2
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.4
|
weikeduik/mozlegal
|
weikeduik
| 2025-08-19T14:42:52Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T14:42:52Z |
---
license: apache-2.0
---
|
unitova/blockassist-bc-zealous_sneaky_raven_1755612036
|
unitova
| 2025-08-19T14:27:47Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"zealous sneaky raven",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T14:27:44Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- zealous sneaky raven
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
fatmhd1995/phi35_ft_llm_4_annotation_rnd1_v2
|
fatmhd1995
| 2025-08-19T14:19:49Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T14:16:28Z |
---
base_model: unsloth/phi-3.5-mini-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** fatmhd1995
- **License:** apache-2.0
- **Finetuned from model :** unsloth/phi-3.5-mini-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
AiArtLab/kc
|
AiArtLab
| 2025-08-19T14:17:04Z | 0 | 2 | null |
[
"text-to-image",
"base_model:KBlueLeaf/Kohaku-XL-Zeta",
"base_model:finetune:KBlueLeaf/Kohaku-XL-Zeta",
"region:us"
] |
text-to-image
| 2025-04-30T17:10:58Z |
---
base_model:
- stabilityai/stable-diffusion-xl-base-1.0
- KBlueLeaf/Kohaku-XL-Zeta
pipeline_tag: text-to-image
---

## Description
This model is a custom fine-tuned variant based on the Kohaku-XL-Zeta pretrained foundation [Kohaku-XL-Zeta](https://huggingface.co/KBlueLeaf/Kohaku-XL-Zeta). Kohaku-XL-Zeta itself is a "raw" base model trained for 1 epoch on 8+ million Danbooru(mostly) images , using 4x NVIDIA 3090 GPUs! While the original Kohaku is not user-friendly out-of-the-box, it serves as a flexible starting point for creative adaptations.
To enhance encoder stability and inject cross-domain knowledge beyond Danbooru-specific features, the model was merged with ColorfulXL using cosine dissimilarity weighting (0.25 blend ratio). This integration aims to broaden the model’s understanding of natural language and artistic concepts beyond typical Danbooru tagging conventions.
Post-merge stabilization involved 6 epochs at 2e-6 learning rate, followed by ongoing fine-tuning at 9e-7 learning rate to refine details. The closest publicly available fine-tune of this lineage is Illustrous, though it uses an earlier Kohaku version with weaker text comprehension. This variant leverages the improved Kohaku-Colorful hybrid (KC), prioritizing non-realistic art generation and creative flexibility over photorealism.
Key Notes :
- Not optimized for realism; best suited for anime/artistic styles.
- Ideal for users seeking a customizable foundation for niche art generation or further fine-tuning experiments.
## Donations
Please contact with us if you may provide some GPU's or money on training
DOGE: DEw2DR8C7BnF8GgcrfTzUjSnGkuMeJhg83
BTC: 3JHv9Hb8kEW8zMAccdgCdZGfrHeMhH1rpN
## Contacts
[recoilme](https://t.me/recoilme)
|
EleutherAI/early-unlearning-strong-filtering-no-ga-lr-0_00012-gclip-1_0
|
EleutherAI
| 2025-08-19T14:08:08Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T14:06:48Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Muapi/female-cosplay-flux
|
Muapi
| 2025-08-19T13:55:40Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T13:55:22Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Female Cosplay [FLUX]

**Base model**: Flux.1 D
**Trained words**: aidmafemalecosplay
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:820639@918906", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
wheeler404/qwen2-tiny
|
wheeler404
| 2025-08-19T13:27:50Z | 231 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-05T13:54:43Z |
---
library_name: transformers
license: apache-2.0
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
A tiny test model with Qwen2.5 architecture
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Muapi/flux-flux-hanfu-belly-wrap
|
Muapi
| 2025-08-19T13:23:35Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T13:23:02Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# FLUX汉服肚兜 | FLUX Hanfu belly wrap

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:653935@731600", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Neelectric/Llama-3-8B-Instruct_ins_v00.01
|
Neelectric
| 2025-08-19T13:23:03Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"trl",
"open-r1",
"sft",
"conversational",
"dataset:Neelectric/ins",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:finetune:meta-llama/Meta-Llama-3-8B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T13:10:33Z |
---
base_model: meta-llama/Meta-Llama-3-8B-Instruct
datasets: Neelectric/ins
library_name: transformers
model_name: Llama-3-8B-Instruct_ins_v00.01
tags:
- generated_from_trainer
- trl
- open-r1
- sft
licence: license
---
# Model Card for Llama-3-8B-Instruct_ins_v00.01
This model is a fine-tuned version of [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) on the [Neelectric/ins](https://huggingface.co/datasets/Neelectric/ins) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Neelectric/Llama-3-8B-Instruct_ins_v00.01", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/neelectric/sem/runs/f88mnrt5)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.0
- Pytorch: 2.7.1
- Datasets: 3.6.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
lilTAT/blockassist-bc-gentle_rugged_hare_1755609552
|
lilTAT
| 2025-08-19T13:19:39Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle rugged hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T13:19:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle rugged hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
eason668/ecb298de-11b1-498e-8df3-f5ae51558fce-0
|
eason668
| 2025-08-19T13:12:32Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"trl",
"dpo",
"conversational",
"arxiv:2305.18290",
"base_model:lmsys/vicuna-7b-v1.3",
"base_model:finetune:lmsys/vicuna-7b-v1.3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T07:08:13Z |
---
base_model: lmsys/vicuna-7b-v1.3
library_name: transformers
model_name: ecb298de-11b1-498e-8df3-f5ae51558fce-0
tags:
- generated_from_trainer
- trl
- dpo
licence: license
---
# Model Card for ecb298de-11b1-498e-8df3-f5ae51558fce-0
This model is a fine-tuned version of [lmsys/vicuna-7b-v1.3](https://huggingface.co/lmsys/vicuna-7b-v1.3).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="eason668/ecb298de-11b1-498e-8df3-f5ae51558fce-0", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/sn99/Gradients-On-Demand/runs/w523o948)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.0
- Pytorch: 2.6.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
behbudiy/Llama-3.1-8B-Instruct-Uz
|
behbudiy
| 2025-08-19T13:04:26Z | 972 | 15 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"summarization",
"translation",
"question-answering",
"conversational",
"uz",
"en",
"dataset:yahma/alpaca-cleaned",
"dataset:behbudiy/alpaca-cleaned-uz",
"dataset:behbudiy/translation-instruction",
"license:llama3.1",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-07-31T05:43:16Z |
---
license: llama3.1
language:
- uz
- en
base_model: models/Meta-Llama-3.1-8B-Instruct
library_name: transformers
tags:
- llama
- text-generation-inference
- summarization
- translation
- question-answering
datasets:
- yahma/alpaca-cleaned
- behbudiy/alpaca-cleaned-uz
- behbudiy/translation-instruction
metrics:
- bleu
- comet
- accuracy
pipeline_tag: text-generation
---
### Model Description
The LLaMA-3.1-8B-Instruct-Uz model has been instruction-tuned using a mix of publicly available and syntheticly constructed Uzbek and English data to preserve its original knowledge while enhancing its capabilities. This model is designed to support various natural language processing tasks in Uzbek, such as machine translation, summarization, and dialogue systems, ensuring robust performance across these applications.
- **Developed by:**
- [Eldor Fozilov](https://www.linkedin.com/in/eldor-fozilov/)
- [Azimjon Urinov](https://azimjonn.github.io/)
- [Khurshid Juraev](https://kjuraev.com/)
📊 **Performance Comparison:**
| Model Name | BLEU Uz-En (One-shot) | BLEU En-Uz (One-shot) | COMET (Uz-En) | COMET (Ez-Un) | Uzbek Sentiment Analysis | Uzbek News Classification | MMLU (English) (5-shot) |
|------------------------|------------------------------------|------------------------------------|--------------------------|----------------|----------------|-------------|-------------------|
| **Llama-3.1 8B Instruct** | 23.74 | 6.72 | 84.30 | 82.70 | 68.96 | 55.41 | 65.77
| **Llama-3.1 8B Instruct Uz** | 27.42 | 11.58 | 85.63 | 86.53 | 82.42 | 60.84 | 62.78
| **Mistral 7B Instruct** | 7.47 | 0.67 | 68.14 | 45.58 | 62.02 | 47.52 | 61.07
| **Mistral 7B Instruct Uz** | 29.39 | 16.77 | 86.91 |88.75 | 79.13 | 59.38 | 55.72
| **Mistral Nemo Instruct** | 25.68 | 9.79 | 85.56 | 85.04 | 72.47 | 49.24 |67.62
| **Mistral Nemo Instruct Uz** | 30.49 | 15.52 | 87.04 | 88.01 | 82.05 | 58.2 | 67.36
| **Google Translate** | 41.18 | 22.98 | 89.16 | 90.67 | — | — | — |
The results show that Uzbek-optimized models consistently outperform their base counterparts in translation benchmarks (BLEU and COMET) on the FLORES+ Uz-En / En-Uz evaluation datasets, sentiment analysis and news classification in Uzbek language.
Also, on the MMLU benchmark, which measures general language understanding across multiple tasks in English, the finetuned models did not show significant decline. (The base Llama model’s MMLU score differs from the official score due to our evaluation method. Refer to the links below to see evaluation details.)
Looking ahead, these models are just **early versions**. We are actively working on further improving our data curation and fine-tuning method to provide even better results in the near future. In addition, we will scale up the dataset size both for continual-pretraining and instruction-tuning, and also customize other strong open-source LLMs for Uzbek language.
We’re eager to see how these models will be used by our Uzbek 🇺🇿 community and look forward to continuing this work. 🚀
## How to use
The Llama-3.1-8B-Instruct-Uz model can be used with transformers and with the original `llama` codebase.
### Use with transformers
Starting with `transformers >= 4.43.0` onward, you can run conversational inference using the Transformers `pipeline` abstraction or by leveraging the Auto classes with the `generate()` function.
Make sure to update your transformers installation via `pip install --upgrade transformers`.
```python
import transformers
import torch
model_id = "behbudiy/Llama-3.1-8B-Instruct-Uz"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "Berilgan gap bo'yicha hissiyot tahlilini bajaring."},
{"role": "user", "content": "Men bu filmni yaxshi ko'raman!"},
]
outputs = pipeline(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
Note: You can also find detailed recipes on how to use the model locally, with `torch.compile()`, assisted generations, quantised and more at [`huggingface-llama-recipes`](https://github.com/huggingface/huggingface-llama-recipes)
### Use with `llama`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama)
## Information on Evaluation Method
To evaluate on the translation task, we used FLORES+ Uz-En / En-Uz datasets, where we merged the dev and test sets to create a bigger evaluation data for each Uz-En and En-Uz subsets.
We used the following prompt to do one-shot Uz-En evaluation both for the base model and Uzbek-optimized model (for En-Uz eval, we changed the positions of the words "English" and "Uzbek").
```python
prompt = f'''You are a professional Uzbek-English translator. Your task is to accurately translate the given Uzbek text into English.
Instructions:
1. Translate the text from Uzbek to English.
2. Maintain the original meaning and tone.
3. Use appropriate English grammar and vocabulary.
4. If you encounter an ambiguous or unfamiliar word, provide the most likely translation based on context.
5. Output only the English translation, without any additional comments.
Example:
Uzbek: "Bugun ob-havo juda yaxshi, quyosh charaqlab turibdi."
English: "The weather is very nice today, the sun is shining brightly."
Now, please translate the following Uzbek text into English:
"{sentence}"
'''
```
To assess the model's ability in Uzbek sentiment analysis, we used the **risqaliyevds/uzbek-sentiment-analysis** dataset, for which we created binary labels (0: Negative, 1: Positive) using GPT-4o API (refer to **behbudiy/uzbek-sentiment-analysis** dataset).
We used the following prompt for the evaluation:
```python
prompt = f'''Given the following text, determine the sentiment as either 'Positive' or 'Negative.' Respond with only the word 'Positive' or 'Negative' without any additional text or explanation.
Text: {text}"
'''
```
For Uzbek News Classification, we used **risqaliyevds/uzbek-zero-shot-classification** dataset and asked the model to predict the category of the news using the following prompt:
```python
prompt = f'''Classify the given Uzbek news article into one of the following categories. Provide only the category number as the answer.
Categories:
0 - Politics (Siyosat)
1 - Economy (Iqtisodiyot)
2 - Technology (Texnologiya)
3 - Sports (Sport)
4 - Culture (Madaniyat)
5 - Health (Salomatlik)
6 - Family and Society (Oila va Jamiyat)
7 - Education (Ta'lim)
8 - Ecology (Ekologiya)
9 - Foreign News (Xorijiy Yangiliklar)
Now classify this article:
"{text}"
Answer (number only):"
'''
```
On MMLU, we performed 5-shot evaluation using the following **template** and extracted the first token generated by the model for measuring accuracy:
```python
template = "The following are multiple choice questions (with answers) about [subject area].
[Example question 1]
A. text
B. text
C. text
D. text
Answer: [Correct answer letter]
.
.
.
[Example question 5]
A. text
B. text
C. text
D. text
Answer: [Correct answer letter]
Now, let's think step by step and then provide only the letter corresponding to the correct answer for the below question, without any additional explanation or comments.
[Actual MMLU test question]
A. text
B. text
C. text
D. text
Answer:"
```
## More
For more details and examples, refer to the base model below:
https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct
|
chutesai/Qwen3-235B-A22B-Instruct-2507-1M
|
chutesai
| 2025-08-19T12:42:11Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2402.17463",
"arxiv:2407.02490",
"arxiv:2501.15383",
"arxiv:2404.06654",
"arxiv:2505.09388",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T12:28:48Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507/blob/main/LICENSE
pipeline_tag: text-generation
---
# Qwen3-235B-A22B-Instruct-2507
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
We introduce the updated version of the **Qwen3-235B-A22B non-thinking mode**, named **Qwen3-235B-A22B-Instruct-2507**, featuring the following key enhancements:
- **Significant improvements** in general capabilities, including **instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage**.
- **Substantial gains** in long-tail knowledge coverage across **multiple languages**.
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
- **Enhanced capabilities** in **256K long-context understanding**.
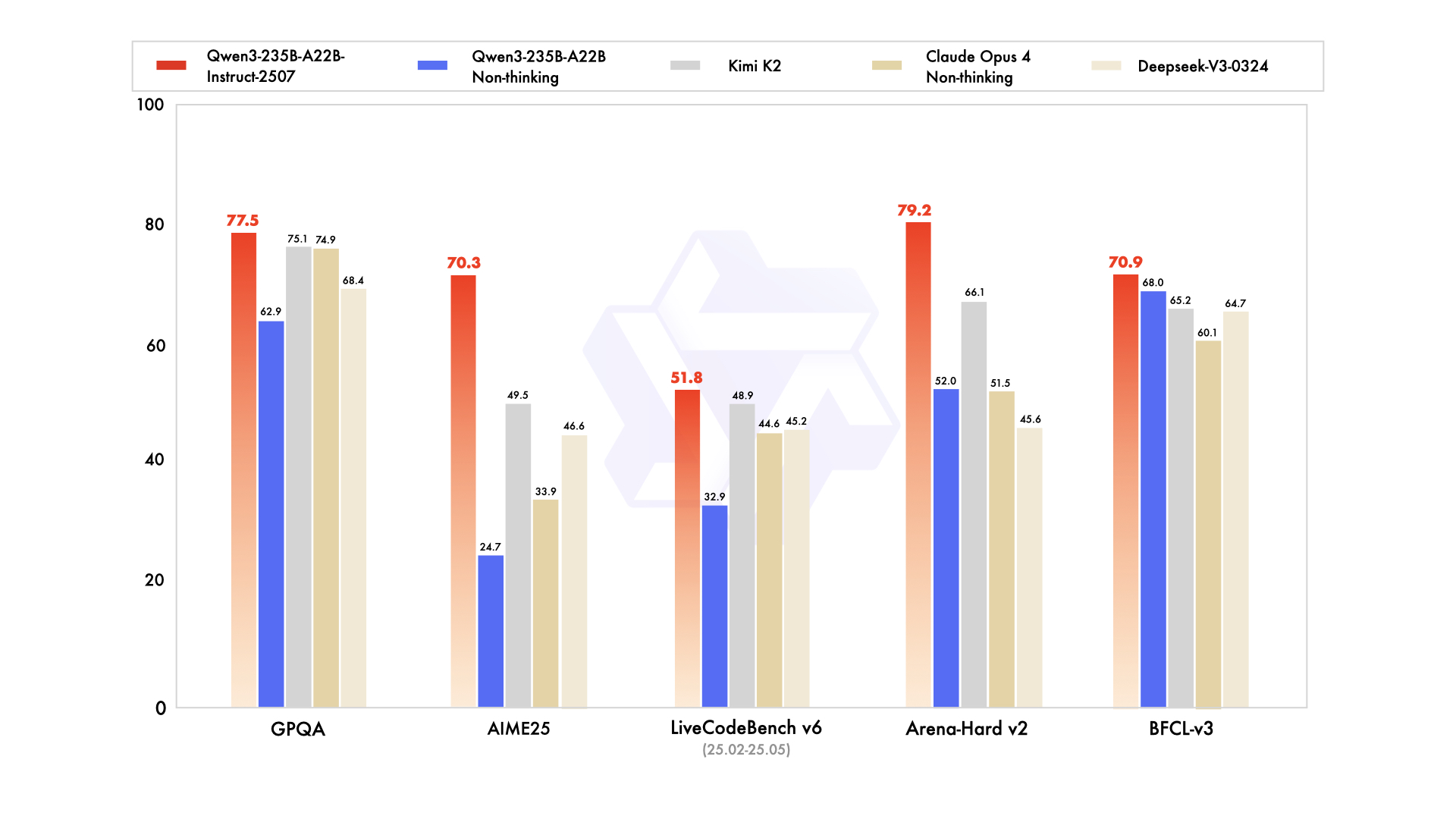
## Model Overview
**Qwen3-235B-A22B-Instruct-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 235B in total and 22B activated
- Number of Paramaters (Non-Embedding): 234B
- Number of Layers: 94
- Number of Attention Heads (GQA): 64 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively and extendable up to 1,010,000 tokens**
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Deepseek-V3-0324 | GPT-4o-0327 | Claude Opus 4 Non-thinking | Kimi K2 | Qwen3-235B-A22B Non-thinking | Qwen3-235B-A22B-Instruct-2507 |
|--- | --- | --- | --- | --- | --- | ---|
| **Knowledge** | | | | | | |
| MMLU-Pro | 81.2 | 79.8 | **86.6** | 81.1 | 75.2 | 83.0 |
| MMLU-Redux | 90.4 | 91.3 | **94.2** | 92.7 | 89.2 | 93.1 |
| GPQA | 68.4 | 66.9 | 74.9 | 75.1 | 62.9 | **77.5** |
| SuperGPQA | 57.3 | 51.0 | 56.5 | 57.2 | 48.2 | **62.6** |
| SimpleQA | 27.2 | 40.3 | 22.8 | 31.0 | 12.2 | **54.3** |
| CSimpleQA | 71.1 | 60.2 | 68.0 | 74.5 | 60.8 | **84.3** |
| **Reasoning** | | | | | | |
| AIME25 | 46.6 | 26.7 | 33.9 | 49.5 | 24.7 | **70.3** |
| HMMT25 | 27.5 | 7.9 | 15.9 | 38.8 | 10.0 | **55.4** |
| ARC-AGI | 9.0 | 8.8 | 30.3 | 13.3 | 4.3 | **41.8** |
| ZebraLogic | 83.4 | 52.6 | - | 89.0 | 37.7 | **95.0** |
| LiveBench 20241125 | 66.9 | 63.7 | 74.6 | **76.4** | 62.5 | 75.4 |
| **Coding** | | | | | | |
| LiveCodeBench v6 (25.02-25.05) | 45.2 | 35.8 | 44.6 | 48.9 | 32.9 | **51.8** |
| MultiPL-E | 82.2 | 82.7 | **88.5** | 85.7 | 79.3 | 87.9 |
| Aider-Polyglot | 55.1 | 45.3 | **70.7** | 59.0 | 59.6 | 57.3 |
| **Alignment** | | | | | | |
| IFEval | 82.3 | 83.9 | 87.4 | **89.8** | 83.2 | 88.7 |
| Arena-Hard v2* | 45.6 | 61.9 | 51.5 | 66.1 | 52.0 | **79.2** |
| Creative Writing v3 | 81.6 | 84.9 | 83.8 | **88.1** | 80.4 | 87.5 |
| WritingBench | 74.5 | 75.5 | 79.2 | **86.2** | 77.0 | 85.2 |
| **Agent** | | | | | | |
| BFCL-v3 | 64.7 | 66.5 | 60.1 | 65.2 | 68.0 | **70.9** |
| TAU1-Retail | 49.6 | 60.3# | **81.4** | 70.7 | 65.2 | 71.3 |
| TAU1-Airline | 32.0 | 42.8# | **59.6** | 53.5 | 32.0 | 44.0 |
| TAU2-Retail | 71.1 | 66.7# | **75.5** | 70.6 | 64.9 | 74.6 |
| TAU2-Airline | 36.0 | 42.0# | 55.5 | **56.5** | 36.0 | 50.0 |
| TAU2-Telecom | 34.0 | 29.8# | 45.2 | **65.8** | 24.6 | 32.5 |
| **Multilingualism** | | | | | | |
| MultiIF | 66.5 | 70.4 | - | 76.2 | 70.2 | **77.5** |
| MMLU-ProX | 75.8 | 76.2 | - | 74.5 | 73.2 | **79.4** |
| INCLUDE | 80.1 | **82.1** | - | 76.9 | 75.6 | 79.5 |
| PolyMATH | 32.2 | 25.5 | 30.0 | 44.8 | 27.0 | **50.2** |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
\#: Results were generated using GPT-4o-20241120, as access to the native function calling API of GPT-4o-0327 was unavailable.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-235B-A22B-Instruct-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-235B-A22B-Instruct-2507 --tp 8 --context-length 262144
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-235B-A22B-Instruct-2507 --tensor-parallel-size 8 --max-model-len 262144
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-235B-A22B-Instruct-2507',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Ultra-Long Texts
To support **ultra-long context processing** (up to **1 million tokens**), we integrate two key techniques:
- **[Dual Chunk Attention](https://arxiv.org/abs/2402.17463) (DCA)**: A length extrapolation method that splits long sequences into manageable chunks while preserving global coherence.
- **[MInference](https://arxiv.org/abs/2407.02490)**: A sparse attention mechanism that reduces computational overhead by focusing on critical token interactions.
Together, these innovations significantly improve both **generation quality** and **inference efficiency** for sequences beyond 256K tokens. On sequences approaching 1M tokens, the system achieves up to a **3× speedup** compared to standard attention implementations.
For full technical details, see the [Qwen2.5-1M Technical Report](https://arxiv.org/abs/2501.15383).
### How to Enable 1M Token Context
> [!NOTE]
> To effectively process a 1 million token context, users will require approximately **1000 GB** of total GPU memory. This accounts for model weights, KV-cache storage, and peak activation memory demands.
#### Step 1: Update Configuration File
Download the model and replace the content of your `config.json` with `config_1m.json`, which includes the config for length extrapolation and sparse attention.
```bash
export MODELNAME=Qwen3-235B-A22B-Instruct-2507
huggingface-cli download Qwen/${MODELNAME} --local-dir ${MODELNAME}
mv ${MODELNAME}/config.json ${MODELNAME}/config.json.bak
mv ${MODELNAME}/config_1m.json ${MODELNAME}/config.json
```
#### Step 2: Launch Model Server
After updating the config, proceed with either **vLLM** or **SGLang** for serving the model.
#### Option 1: Using vLLM
To run Qwen with 1M context support:
```bash
pip install -U vllm \
--torch-backend=auto \
--extra-index-url https://wheels.vllm.ai/nightly
```
Then launch the server with Dual Chunk Flash Attention enabled:
```bash
VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN VLLM_USE_V1=0 \
vllm serve ./Qwen3-235B-A22B-Instruct-2507 \
--tensor-parallel-size 8 \
--max-model-len 1010000 \
--enable-chunked-prefill \
--max-num-batched-tokens 131072 \
--enforce-eager \
--max-num-seqs 1 \
--gpu-memory-utilization 0.85
```
##### Key Parameters
| Parameter | Purpose |
|--------|--------|
| `VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN` | Enables the custom attention kernel for long-context efficiency |
| `--max-model-len 1010000` | Sets maximum context length to ~1M tokens |
| `--enable-chunked-prefill` | Allows chunked prefill for very long inputs (avoids OOM) |
| `--max-num-batched-tokens 131072` | Controls batch size during prefill; balances throughput and memory |
| `--enforce-eager` | Disables CUDA graph capture (required for dual chunk attention) |
| `--max-num-seqs 1` | Limits concurrent sequences due to extreme memory usage |
| `--gpu-memory-utilization 0.85` | Set the fraction of GPU memory to be used for the model executor |
#### Option 2: Using SGLang
First, clone and install the specialized branch:
```bash
git clone https://github.com/sgl-project/sglang.git
cd sglang
pip install -e "python[all]"
```
Launch the server with DCA support:
```bash
python3 -m sglang.launch_server \
--model-path ./Qwen3-235B-A22B-Instruct-2507 \
--context-length 1010000 \
--mem-frac 0.75 \
--attention-backend dual_chunk_flash_attn \
--tp 8 \
--chunked-prefill-size 131072
```
##### Key Parameters
| Parameter | Purpose |
|---------|--------|
| `--attention-backend dual_chunk_flash_attn` | Activates Dual Chunk Flash Attention |
| `--context-length 1010000` | Defines max input length |
| `--mem-frac 0.75` | The fraction of the memory used for static allocation (model weights and KV cache memory pool). Use a smaller value if you see out-of-memory errors. |
| `--tp 8` | Tensor parallelism size (matches model sharding) |
| `--chunked-prefill-size 131072` | Prefill chunk size for handling long inputs without OOM |
#### Troubleshooting:
1. Encountering the error: "The model's max sequence length (xxxxx) is larger than the maximum number of tokens that can be stored in the KV cache." or "RuntimeError: Not enough memory. Please try to increase --mem-fraction-static."
The VRAM reserved for the KV cache is insufficient.
- vLLM: Consider reducing the ``max_model_len`` or increasing the ``tensor_parallel_size`` and ``gpu_memory_utilization``. Alternatively, you can reduce ``max_num_batched_tokens``, although this may significantly slow down inference.
- SGLang: Consider reducing the ``context-length`` or increasing the ``tp`` and ``mem-frac``. Alternatively, you can reduce ``chunked-prefill-size``, although this may significantly slow down inference.
2. Encountering the error: "torch.OutOfMemoryError: CUDA out of memory."
The VRAM reserved for activation weights is insufficient. You can try lowering ``gpu_memory_utilization`` or ``mem-frac``, but be aware that this might reduce the VRAM available for the KV cache.
3. Encountering the error: "Input prompt (xxxxx tokens) + lookahead slots (0) is too long and exceeds the capacity of the block manager." or "The input (xxx xtokens) is longer than the model's context length (xxx tokens)."
The input is too lengthy. Consider using a shorter sequence or increasing the ``max_model_len`` or ``context-length``.
#### Long-Context Performance
We test the model on an 1M version of the [RULER](https://arxiv.org/abs/2404.06654) benchmark.
| Model Name | Acc avg | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 192k | 256k | 384k | 512k | 640k | 768k | 896k | 1000k |
|---------------------------------------------|---------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|-------|
| Qwen3-235B-A22B (Non-Thinking) | 83.9 | 97.7 | 96.1 | 97.5 | 96.1 | 94.2 | 90.3 | 88.5 | 85.0 | 82.1 | 79.2 | 74.4 | 70.0 | 71.0 | 68.5 | 68.0 |
| Qwen3-235B-A22B-Instruct-2507 (Full Attention) | 92.5 | 98.5 | 97.6 | 96.9 | 97.3 | 95.8 | 94.9 | 93.9 | 94.5 | 91.0 | 92.2 | 90.9 | 87.8 | 84.8 | 86.5 | 84.5 |
| Qwen3-235B-A22B-Instruct-2507 (Sparse Attention) | 91.7 | 98.5 | 97.2 | 97.3 | 97.7 | 96.6 | 94.6 | 92.8 | 94.3 | 90.5 | 89.7 | 89.5 | 86.4 | 83.6 | 84.2 | 82.5 |
* All models are evaluated with Dual Chunk Attention enabled.
* Since the evaluation is time-consuming, we use 260 samples for each length (13 sub-tasks, 20 samples for each).
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
@article{qwen2.5-1m,
title={Qwen2.5-1M Technical Report},
author={An Yang and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoyan Huang and Jiandong Jiang and Jianhong Tu and Jianwei Zhang and Jingren Zhou and Junyang Lin and Kai Dang and Kexin Yang and Le Yu and Mei Li and Minmin Sun and Qin Zhu and Rui Men and Tao He and Weijia Xu and Wenbiao Yin and Wenyuan Yu and Xiafei Qiu and Xingzhang Ren and Xinlong Yang and Yong Li and Zhiying Xu and Zipeng Zhang},
journal={arXiv preprint arXiv:2501.15383},
year={2025}
}
```
|
FogTeams/exp_106_model_awq_quantized_W4A16_Asym
|
FogTeams
| 2025-08-19T12:18:09Z | 0 | 0 | null |
[
"safetensors",
"llama",
"license:apache-2.0",
"compressed-tensors",
"region:us"
] | null | 2025-08-19T12:16:04Z |
---
license: apache-2.0
---
|
VoilaRaj/80_myjmKE
|
VoilaRaj
| 2025-08-19T11:58:26Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-19T11:54:40Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
bailai/blockassist-bc-waddling_durable_mandrill_1755601980
|
bailai
| 2025-08-19T11:35:38Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"waddling durable mandrill",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T11:30:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- waddling durable mandrill
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
rmtlabs/s-ai-deep-seek-azure-adapter
|
rmtlabs
| 2025-08-19T11:31:12Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"lora",
"transformers",
"text-generation",
"conversational",
"arxiv:1910.09700",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"region:us"
] |
text-generation
| 2025-08-19T11:31:03Z |
---
base_model: deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
- lora
- transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
SP4ND4N/Qwen3-0.6B-2025-08-19_15-15-49-fp8-merged
|
SP4ND4N
| 2025-08-19T11:24:47Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/Qwen3-0.6B",
"base_model:finetune:unsloth/Qwen3-0.6B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T11:18:55Z |
---
base_model: unsloth/Qwen3-0.6B
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** SP4ND4N
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-0.6B
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Nerva1228/fyeye
|
Nerva1228
| 2025-08-19T11:12:32Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-19T07:45:38Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: fyeye
---
# Fyeye
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `fyeye` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "fyeye",
"lora_weights": "https://huggingface.co/Nerva1228/fyeye/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('Nerva1228/fyeye', weight_name='lora.safetensors')
image = pipeline('fyeye').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/Nerva1228/fyeye/discussions) to add images that show off what you’ve made with this LoRA.
|
Reallusion/fluxLora_Kevin
|
Reallusion
| 2025-08-19T11:09:50Z | 0 | 0 | null |
[
"text-to-image",
"en",
"dataset:crystantine/fluxgym",
"base_model:black-forest-labs/FLUX.1-Fill-dev",
"base_model:finetune:black-forest-labs/FLUX.1-Fill-dev",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2025-08-19T10:22:28Z |
---
license: creativeml-openrail-m
datasets:
- crystantine/fluxgym
language:
- en
base_model:
- black-forest-labs/FLUX.1-dev
- black-forest-labs/FLUX.1-Fill-dev
pipeline_tag: text-to-image
---
|
BSC-LT/salamandraTA-2b-instruct
|
BSC-LT
| 2025-08-19T11:06:33Z | 1,355 | 1 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"translation",
"bg",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"es",
"et",
"eu",
"fi",
"fr",
"ga",
"gl",
"hr",
"hu",
"it",
"lt",
"lv",
"mt",
"nl",
"nb",
"no",
"nn",
"oc",
"pl",
"pt",
"ro",
"ru",
"sl",
"sk",
"sr",
"sv",
"uk",
"ast",
"an",
"arxiv:2010.11125",
"arxiv:2403.14009",
"arxiv:1907.05791",
"arxiv:1911.04944",
"arxiv:2402.17733",
"arxiv:2207.04672",
"arxiv:2404.06392",
"arxiv:2309.04662",
"arxiv:2211.01355",
"arxiv:2508.12774",
"base_model:BSC-LT/salamandra-2b",
"base_model:finetune:BSC-LT/salamandra-2b",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:eu"
] |
translation
| 2025-05-13T14:25:01Z |
---
license: apache-2.0
library_name: transformers
pipeline_tag: translation
language:
- bg
- ca
- cs
- cy
- da
- de
- el
- en
- es
- et
- eu
- fi
- fr
- ga
- gl
- hr
- hu
- it
- lt
- lv
- mt
- nl
- nb
- 'no'
- nn
- oc
- pl
- pt
- ro
- ru
- sl
- sk
- sr
- sv
- uk
- ast
- an
base_model:
- BSC-LT/salamandra-2b
---

# SalamandraTA Model Card
SalamandraTA-2b-instruct is a translation LLM that has been instruction-tuned from SalamandraTA-2b-base.
The base model results from continually pre-training [Salamandra-2b](https://huggingface.co/BSC-LT/salamandra-2b) on parallel data and has not been published, but is reserved for internal use.
SalamandraTA-2b-instruct is proficent in 35 European languages (plus 3 varieties) and supports translation-related tasks, namely: sentence-level-translation, paragraph-level-translation, automatic post-editing, grammar checking, machine translation evaluation, alternative translations, named-entity-recognition and context-aware translation.
> [!WARNING]
> **DISCLAIMER:** This version of Salamandra is tailored exclusively for translation tasks. It lacks chat capabilities and has not been trained with any chat instructions.
---
## Model Details
### Description
SalamandraTA-2b-base is a continual pre-training of [Salamandra-2b](https://huggingface.co/BSC-LT/salamandra-2b) using parallel data, resulting in a total of 424B tokens processed during training.
### Architecture
| | |
|-------------------------|:--------------|
| Total Parameters | 2,253,490,176 |
| Embedding Parameters | 524,288,000 |
| Layers | 24 |
| Hidden size | 2,048 |
| Attention heads | 16 |
| Context length | 8,192 |
| Vocabulary size | 256,000 |
| Precision | bfloat16 |
| Embedding type | RoPE |
| Activation Function | SwiGLU |
| Layer normalization | RMS Norm |
| Flash attention | ✅ |
| Grouped Query Attention | ❌ |
| Num. query groups | N/A |
---
## Intended Use
### Direct Use
The model is intended for both research and commercial use in any of the languages included in the training data for general machine translation tasks.
### Out-of-scope Use
The model is not intended for malicious activities, such as harming others or violating human rights.
Any downstream application must comply with current laws and regulations.
Irresponsible usage in production environments without proper risk assessment and mitigation is also discouraged.
---
## Hardware and Software
### Training Framework
SalamandraTA-2b-base was continually pre-trained using NVIDIA’s [NeMo Framework](https://docs.nvidia.com/nemo-framework/index.html),
which leverages PyTorch Lightning for efficient model training in highly distributed settings.
SalamandraTA-2b-instruct was produced with [FastChat](https://github.com/lm-sys/FastChat).
### Compute Infrastructure
All models were trained on [MareNostrum 5](https://www.bsc.es/ca/marenostrum/marenostrum-5), a pre-exascale EuroHPC supercomputer hosted and
operated by Barcelona Supercomputing Center.
The accelerated partition is composed of 1,120 nodes with the following specifications:
- 4x Nvidia Hopper GPUs with 64GB HBM2 memory
- 2x Intel Sapphire Rapids 8460Y+ at 2.3Ghz and 32c each (64 cores)
- 4x NDR200 (BW per node 800Gb/s)
- 512 GB of Main memory (DDR5)
- 460GB on NVMe storage
---
## How to use
You can translate between the following **35 languages** (and 3 varieties):
Aragonese, Asturian, Basque, Bulgarian, Catalan (and Catalan-Valencian variety), Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, Galician, German, Greek, Hungarian,
Irish, Italian, Latvian, Lithuanian, Maltese, Norwegian (Bokmål and Nynorsk varieties), Occitan (and Aranese variety), Polish, Portuguese, Romanian, Russian, Serbian, Slovak,
Slovenian, Spanish, Swedish, Ukrainian, Welsh.
The instruction-following model uses the commonly adopted ChatML template:
```
<|im_start|>system
{SYSTEM PROMPT}<|im_end|>
<|im_start|>user
{USER PROMPT}<|im_end|>
<|im_start|>assistant
{MODEL RESPONSE}<|im_end|>
<|im_start|>user
[...]
```
The easiest way to apply it is by using the tokenizer's built-in functions, as shown in the following snippet.
```python
from datetime import datetime
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "BSC-LT/salamandraTA-2b-instruct"
source = 'Spanish'
target = 'Catalan'
sentence = "Ayer se fue, tomó sus cosas y se puso a navegar. Una camisa, un pantalón vaquero y una canción, dónde irá, dónde irá. Se despidió, y decidió batirse en duelo con el mar. Y recorrer el mundo en su velero. Y navegar, nai-na-na, navegar"
text = f"Translate the following text from {source} into {target}.\n{source}: {sentence} \n{target}:"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.bfloat16
)
message = [ { "role": "user", "content": text } ]
date_string = datetime.today().strftime('%Y-%m-%d')
prompt = tokenizer.apply_chat_template(
message,
tokenize=False,
add_generation_prompt=True,
date_string=date_string
)
inputs = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
input_length = inputs.shape[1]
outputs = model.generate(input_ids=inputs.to(model.device),
max_new_tokens=400,
early_stopping=True,
num_beams=5)
print(tokenizer.decode(outputs[0, input_length:], skip_special_tokens=True))
# Ahir se'n va anar, va recollir les seves coses i es va fer a la mar. Una camisa, uns texans i una cançó, on anirà, on anirà. Es va acomiadar i va decidir batre's en duel amb el mar. I fer la volta al món en el seu veler. I navegar, nai-na-na, navegar
```
Using this template, each turn is preceded by a `<|im_start|>` delimiter and the role of the entity
(either `user`, for content supplied by the user, or `assistant` for LLM responses), and finished with the `<|im_end|>` token.
#### General translation
For machine translation tasks, you can use the following prompt template:
```
Translate the following text from {source} into {target}.
{source}: {source sentence}
{target}:
```
<details>
<summary>Show an example</summary>
```python
source = 'Catalan'
target = 'Galician'
source_sentence = "Als antics egipcis del període de l'Imperi Nou els fascinaven els monuments dels seus predecessors, que llavors tenien més de mil anys."
text = f"Translate the following text from {source} into {target}.\n{source}: {source_sentence} \n{target}:"
# Os antigos exipcios do período do Imperio Novo estaban fascinados polos monumentos dos seus predecesores, que entón tiñan máis de mil anos de antigüidade.
```
</details>
### Post-editing
For post-editing tasks, you can use the following prompt template:
```
Please fix any mistakes in the following {source}-{target} machine translation or keep it unedited if it's correct.
Source: {source_sentence}
MT: {machine_translation}
Corrected:"
```
<details>
<summary>Show an example</summary>
```python
source = 'Catalan'
target = 'English'
source_sentence = 'Rafael Nadal i Maria Magdalena van inspirar a una generació sencera.'
machine_translation = 'Rafael Christmas and Maria the Muffin inspired an entire generation each in their own way.'
text = f"Please fix any mistakes in the following {source}-{target} machine translation or keep it unedited if it's correct.\nSource: {source_sentence} \nMT: {machine_translation} \nCorrected:"
# Rafael Nadal and Maria Magdalena inspired an entire generation.
```
</details>
### Paragraph-level translation
For paragraph-level translation tasks, you can use the following prompt template:
```
Please translate this text from {source} into {target}.
{source}: {paragraph}
{target}:
```
<details>
<summary>Show an example</summary>
```python
source = 'English'
target = 'Asturian'
text = """Please translate this text from {} into {}.\n{}: President Donald Trump, who campaigned on promises to crack down on illegal immigration, has raised alarms in the U.S. dairy industry with his threat to impose 25% tariffs on Mexico and Canada by February 2025. This move is part of a broader strategy to declare a national emergency at the southern border to halt illegal migration completely. However, the implications for the agriculture sector, particularly dairy, are significant. Approximately half of the U.S. dairy industry's workforce consists of immigrant labor, many of whom are undocumented. The National Milk Producers Federation estimates that removing immigrant workers could decimate the dairy herd by 2.1 million cows and slash milk production by nearly 50 billion pounds, leading to a dramatic 90.4% increase in milk prices. The complex perspectives of Americans on undocumented workers were highlighted in a Pew Research Center study. While 64% of U.S. adults support legal pathways for undocumented immigrants, 35% oppose it—a gap that has been narrowing recently. Factors influencing public opinion include the belief that immigrants should have jobs and pass security checks, contrasted by concerns about lawbreakers being rewarded, fairness for legal migrants, and resource allocation.
{}:""".format(source, target, source, target)
```
</details>
### Named-entity recognition
For named-entity recognition tasks, you can use the following prompt template:
```
Analyse the following tokenized text and mark the tokens containing named entities.
Use the following annotation guidelines with these tags for named entities:
- ORG (Refers to named groups or organizations)
- PER (Refers to individual people or named groups of people)
- LOC (Refers to physical places or natural landmarks)
- MISC (Refers to entities that don't fit into standard categories).
Prepend B- to the first token of a given entity and I- to the remaining ones if they exist.
If a token is not a named entity, label it as O.
Input: {list of words in a sentence}
Marked:
```
<details>
<summary>Show an example</summary>
```python
text = """Analyse the following tokenized text and mark the tokens containing named entities.
Use the following annotation guidelines with these tags for named entities:
- ORG (Refers to named groups or organizations)
- PER (Refers to individual people or named groups of people)
- LOC (Refers to physical places or natural landmarks)
- MISC (Refers to entities that don't fit into standard categories).
Prepend B- to the first token of a given entity and I- to the remaining ones if they exist.
If a token is not a named entity, label it as O.
Input: ['La', 'defensa', 'del', 'antiguo', 'responsable', 'de', 'la', 'RFEF', 'confirma', 'que', 'interpondrá', 'un', 'recurso.']
Marked: """
# [('La', 'O'), ('defensa', 'O'), ('del', 'O'), ('antiguo', 'O'), ('responsable', 'O'), ('de', 'O'), ('la', 'O'), ('RFEF', 'B-ORG'), ('confirma', 'O'), ('que', 'O'), ('interpondrá', 'O'), ('un', 'O'), ('recurso.', 'O')]
```
</details>
### Grammar checker
For fixing any mistakes in grammar, you can use the following prompt template:
```
Please fix any mistakes in the following {source} sentence or keep it unedited if it's correct.
Sentence: {sentence}
Corrected:
```
<details>
<summary>Show an example</summary>
```python
source = 'Catalan'
sentence = 'Entonses, el meu jefe m’ha dit que he de treballar els fins de setmana.'
text = f"Please fix any mistakes in the following {source} sentence or keep it unedited if it's correct.\nSentence: {sentence} \nCorrected:"
# Llavors, el meu cap m'ha dit que he de treballar els caps de setmana.
```
</details>
## Data
### Pretraining Data
The pretraining corpus consists of 424 billion tokens of Catalan-centric, Spanish-centric, and English-centric parallel data,
including all of the official European languages plus Catalan, Basque, Galician, Asturian, Aragonese and Aranese.
It amounts to 6,574,251,526 parallel sentence pairs.
This highly multilingual corpus is predominantly composed of data sourced from [OPUS](https://opus.nlpl.eu/),
with additional data taken from the [NTEU Project](https://nteu.eu/), [Aina Project](https://projecteaina.cat/), and other sources
(see: [Data Sources](#pre-data-sources) and [References](#pre-references)).
Where little parallel Catalan <-> xx data could be found, synthetic Catalan data was generated from the Spanish side of the collected Spanish <-> xx corpora using
[Projecte Aina’s Spanish-Catalan model](https://huggingface.co/projecte-aina/aina-translator-es-ca). The final distribution of languages was as below:

Click the expand button below to see the full list of corpora included in the training data.
<details id="pre-data-sources">
<summary>Data Sources</summary>
| Dataset | Ca-xx Languages | Es-xx Langugages | En-xx Languages |
|-----------------------------------------------|----------------------------------------------------------------|-----------------------------------------------|----------------------------------------------------------------|
|[AINA](https://huggingface.co/projecte-aina) | en | | |
|ARANESE-SYNTH-CORPUS-BSC | arn | | |
|BOUA-SYNTH-BSC | | val | |
|[BOUMH](https://github.com/transducens/PILAR/tree/main/valencian/BOUMH) | | val | |
|[BOUA-PILAR](https://github.com/transducens/PILAR/tree/main/valencian/BOUA) | | val | |
|[CCMatrix](https://opus.nlpl.eu/CCMatrix/corpus/version/CCMatrix) |eu | | ga |
|[DGT](https://opus.nlpl.eu/DGT/corpus/version/DGT) | |bg,cs,da,de,el ,et,fi,fr,ga,hr,hu,lt,lv,mt,nl,pl,pt,ro,sk,sl,sv | da,et,ga,hr,hu,lt,lv,mt,sh,sl|
|DOGV-SYNTH-BSC | | val | |
|[DOGV-PILAR](https://github.com/transducens/PILAR/tree/main/valencian/DOGV-html) | | val | |
|[ELRC-EMEA](https://opus.nlpl.eu/ELRC-EMEA/corpus/version/ELRC-EMEA) | |bg,cs,da,hu,lt,lv,mt,pl,ro,sk,sl | et,hr,lv,ro,sk,sl |
|[EMEA](https://opus.nlpl.eu/EMEA/corpus/version/EMEA) | |bg,cs,da,el,fi,hu,lt,mt,nl,pl,ro,sk,sl,sv | et,mt |
|[EUBookshop](https://opus.nlpl.eu/EUbookshop/corpus/version/EUbookshop) |lt,pl,pt |cs,da,de,el,fi,fr,ga,it,lv,mt,nl,pl,pt,ro,sk,sl,sv |cy,ga|
|[Europarl](https://opus.nlpl.eu/Europarl/corpus/version/Europarl) | |bg,cs,da,el,en,fi,fr,hu,lt,lv,nl,pl,pt ,ro,sk,sl,sv | |
|[Europat](https://opus.nlpl.eu/EuroPat/corpus/version/EuroPat) | |en,hr | no |
|[GAITU Corpus](https://gaitu.eus/) | | | eu|
|[KDE4](https://opus.nlpl.eu/KDE4/corpus/version/KDE4) |bg,cs,da,de,el ,et,eu,fi,fr,ga,gl,hr,it,lt,lv,nl,pl,pt,ro,sk,sl,sv |bg,ga,hr |cy,ga,nn,oc |
|[GlobalVoices](https://opus.nlpl.eu/GlobalVoices/corpus/version/GlobalVoices) | bg,de,fr,it,nl,pl,pt |bg,de,fr,pt | |
|[GNOME](https://opus.nlpl.eu/GNOME/corpus/version/GNOME) |eu,fr,ga,gl,pt |ga |cy,ga,nn|
|[JRC-Arquis](https://opus.nlpl.eu/JRC-Acquis/corpus/version/JRC-Acquis) | |cs,da,et,fr,lt,lv,mt,nl,pl ,ro,sv| et |
|LES-CORTS-VALENCIANES-SYNTH-BSC | | val | |
|[MaCoCu](https://opus.nlpl.eu/MaCoCu/corpus/version/MaCoCu) | en | | hr,mt,uk |
|[MultiCCAligned](https://opus.nlpl.eu/JRC-Acquis/corpus/version/JRC-Acquis) |bg,cs,de,el,et,fi,fr,hr,hu,it,lt,lv,nl,pl,ro,sk,sv |bg,fi,fr,hr,it,lv,nl,pt |bg,cy,da,et,fi,hr,hu,lt,lv,no,sl,sr,uk|
|[MultiHPLT](https://opus.nlpl.eu/MultiHPLT/corpus/version/MultiHPLT) |en, et,fi,ga,hr,mt | |fi,ga,gl,hr,mt,nn,sr |
|[MultiParaCrawl](https://opus.nlpl.eu/MultiParaCrawl/corpus/version/MultiParaCrawl) |bg,da |de,en,fr,ga,hr,hu,it,mt,pt |bg,cs,da,de,el,et,fi,fr,ga,hr,hu,lt,lv,mt,nn,pl,ro,sk,sl,uk|
|[MultiUN](https://opus.nlpl.eu/MultiUN/corpus/version/MultiUN) | |fr | |
|[News-Commentary](https://opus.nlpl.eu/News-Commentary/corpus/version/News-Commentary) | |fr | |
|[NLLB](https://opus.nlpl.eu/NLLB/corpus/version/NLLB) |bg,da,el,en,et,fi,fr,gl,hu,it ,lt,lv,pt,ro,sk,sl |bg,cs,da,de,el ,et,fi,fr,hu,it,lt,lv,nl,pl,pt ,ro,sk,sl,sv| bg,cs,cy,da,de,el,et,fi,fr,ga,hr,hu,it,lt,lv,mt,nl,no,oc,pl,pt,ro,ru,sk,sl,sr,sv,uk|
|[NÓS Authentic Corpus](https://zenodo.org/records/7675110) | | | gl |
|[NÓS Synthetic Corpus](https://zenodo.org/records/7685180) | | | gl |
|[NTEU](https://www.elrc-share.eu/repository/search/?q=NTEU) | |bg,cs,da,de,el,en,et,fi,fr,ga,hr,hu,it,lt,lv,mt,nl,pl,pt,ro,sk,sl,sv | da,et,ga,hr,lt,lv,mt,ro,sk,sl,sv |
|[OpenSubtitles](https://opus.nlpl.eu/OpenSubtitles/corpus/version/OpenSubtitles) |bg,cs,da,de,el ,et,eu,fi,gl,hr,hu,lt,lv,nl,pl,pt,ro,sk,sl,sv |da,de,fi,fr,hr,hu,it,lv,nl | bg,cs,de,el,et,hr,fi,fr,hr,hu,no,sl,sr|
|[OPUS-100](https://opus.nlpl.eu/opus-100.php) | en | | gl |
|[StanfordNLP-NMT](https://opus.nlpl.eu/StanfordNLP-NMT/corpus/version/StanfordNLP-NMT) | | |cs |
|[Tatoeba](https://opus.nlpl.eu/Tatoeba/corpus/version/Tatoeba) |de,pt |pt | |
|[TildeModel](https://opus.nlpl.eu/TildeMODEL/corpus/version/TildeMODEL) | |bg | et,hr,lt,lv,mt |
|[UNPC](https://opus.nlpl.eu/UNPC/corpus/version/UNPC) | |en,fr | ru |
|[PILAR-VALENCIAN-AUTH](https://github.com/transducens/PILAR/tree/main/valencian/Generalitat) | | val | |
|[PILAR-VALENCIAN-SYNTH](https://github.com/transducens/PILAR/tree/main/valencian/Generalitat) | | val | |
|[WikiMatrix](https://opus.nlpl.eu/WikiMatrix/corpus/version/WikiMatrix) |bg,cs,da,de,el ,et,eu,fi,fr,gl,hr,hu,it,lt,nl,pl,pt,ro,sk,sl,sv |bg,en,fr,hr,it,pt | oc,sh |
|[Wikimedia](https://opus.nlpl.eu/wikimedia/corpus/version/wikimedia) | | |cy,nn |
|[XLENT](https://opus.nlpl.eu/XLEnt/corpus/version/XLEnt) |eu,ga,gl |ga |cy,et,ga,gl,hr,oc,sh|
Datasets with "-BSC" in their names (e.g., BOUA-SYNTH-BSC, DOGV-SYNTH-BSC) are synthetic datasets obtained by machine translating
pre-existing monolingual corpora with our own seq-to-seq models. These datasets were generated internally for model training and are not published.
To consult the data summary document with the respective licences, please send an e-mail to ipr@bsc.es.
</details>
<details id="pre-references">
<summary>References</summary>
- Aulamo, M., Sulubacak, U., Virpioja, S., & Tiedemann, J. (2020). OpusTools and Parallel Corpus Diagnostics. In N. Calzolari, F. Béchet, P. Blache, K. Choukri, C. Cieri, T. Declerck, S. Goggi, H. Isahara, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the Twelfth Language Resources and Evaluation Conference (pp. 3782–3789). European Language Resources Association. https://aclanthology.org/2020.lrec-1.467
- Chaudhary, V., Tang, Y., Guzmán, F., Schwenk, H., & Koehn, P. (2019). Low-Resource Corpus Filtering Using Multilingual Sentence Embeddings. In O. Bojar, R. Chatterjee, C. Federmann, M. Fishel, Y. Graham, B. Haddow, M. Huck, A. J. Yepes, P. Koehn, A. Martins, C. Monz, M. Negri, A. Névéol, M. Neves, M. Post, M. Turchi, & K. Verspoor (Eds.), Proceedings of the Fourth Conference on Machine Translation (Volume 3: Shared Task Papers, Day 2) (pp. 261–266). Association for Computational Linguistics. https://doi.org/10.18653/v1/W19-5435
- DGT-Translation Memory—European Commission. (n.d.). Retrieved November 4, 2024, from https://joint-research-centre.ec.europa.eu/language-technology-resources/dgt-translation-memory_en
- Eisele, A., & Chen, Y. (2010). MultiUN: A Multilingual Corpus from United Nation Documents. In N. Calzolari, K. Choukri, B. Maegaard, J. Mariani, J. Odijk, S. Piperidis, M. Rosner, & D. Tapias (Eds.), Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10). European Language Resources Association (ELRA). http://www.lrec-conf.org/proceedings/lrec2010/pdf/686_Paper.pdf
- El-Kishky, A., Chaudhary, V., Guzmán, F., & Koehn, P. (2020). CCAligned: A Massive Collection of Cross-Lingual Web-Document Pairs. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 5960–5969. https://doi.org/10.18653/v1/2020.emnlp-main.480
- El-Kishky, A., Renduchintala, A., Cross, J., Guzmán, F., & Koehn, P. (2021). XLEnt: Mining a Large Cross-lingual Entity Dataset with Lexical-Semantic-Phonetic Word Alignment. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 10424–10430. https://doi.org/10.18653/v1/2021.emnlp-main.814
- Fan, A., Bhosale, S., Schwenk, H., Ma, Z., El-Kishky, A., Goyal, S., Baines, M., Celebi, O., Wenzek, G., Chaudhary, V., Goyal, N., Birch, T., Liptchinsky, V., Edunov, S., Grave, E., Auli, M., & Joulin, A. (2020). Beyond English-Centric Multilingual Machine Translation (No. arXiv:2010.11125). arXiv. https://doi.org/10.48550/arXiv.2010.11125
- García-Martínez, M., Bié, L., Cerdà, A., Estela, A., Herranz, M., Krišlauks, R., Melero, M., O’Dowd, T., O’Gorman, S., Pinnis, M., Stafanovič, A., Superbo, R., & Vasiļevskis, A. (2021). Neural Translation for European Union (NTEU). 316–334. https://aclanthology.org/2021.mtsummit-up.23
- Gibert, O. de, Nail, G., Arefyev, N., Bañón, M., Linde, J. van der, Ji, S., Zaragoza-Bernabeu, J., Aulamo, M., Ramírez-Sánchez, G., Kutuzov, A., Pyysalo, S., Oepen, S., & Tiedemann, J. (2024). A New Massive Multilingual Dataset for High-Performance Language Technologies (No. arXiv:2403.14009). arXiv. http://arxiv.org/abs/2403.14009
- Koehn, P. (2005). Europarl: A Parallel Corpus for Statistical Machine Translation. Proceedings of Machine Translation Summit X: Papers, 79–86. https://aclanthology.org/2005.mtsummit-papers.11
- Kreutzer, J., Caswell, I., Wang, L., Wahab, A., Van Esch, D., Ulzii-Orshikh, N., Tapo, A., Subramani, N., Sokolov, A., Sikasote, C., Setyawan, M., Sarin, S., Samb, S., Sagot, B., Rivera, C., Rios, A., Papadimitriou, I., Osei, S., Suarez, P. O., … Adeyemi, M. (2022). Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets. Transactions of the Association for Computational Linguistics, 10, 50–72. https://doi.org/10.1162/tacl_a_00447
- Rozis, R.,Skadiņš, R (2017). Tilde MODEL - Multilingual Open Data for EU Languages. https://aclanthology.org/W17-0235
- Schwenk, H., Chaudhary, V., Sun, S., Gong, H., & Guzmán, F. (2019). WikiMatrix: Mining 135M Parallel Sentences in 1620 Language Pairs from Wikipedia (No. arXiv:1907.05791). arXiv. https://doi.org/10.48550/arXiv.1907.05791
- Schwenk, H., Wenzek, G., Edunov, S., Grave, E., & Joulin, A. (2020). CCMatrix: Mining Billions of High-Quality Parallel Sentences on the WEB (No. arXiv:1911.04944). arXiv. https://doi.org/10.48550/arXiv.1911.04944
- Steinberger, R., Pouliquen, B., Widiger, A., Ignat, C., Erjavec, T., Tufiş, D., & Varga, D. (n.d.). The JRC-Acquis: A Multilingual Aligned Parallel Corpus with 20+ Languages. http://www.lrec-conf.org/proceedings/lrec2006/pdf/340_pdf
- Subramani, N., Luccioni, S., Dodge, J., & Mitchell, M. (2023). Detecting Personal Information in Training Corpora: An Analysis. In A. Ovalle, K.-W. Chang, N. Mehrabi, Y. Pruksachatkun, A. Galystan, J. Dhamala, A. Verma, T. Cao, A. Kumar, & R. Gupta (Eds.), Proceedings of the 3rd Workshop on Trustworthy Natural Language Processing (TrustNLP 2023) (pp. 208–220). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.trustnlp-1.18
- Tiedemann, J. (23-25). Parallel Data, Tools and Interfaces in OPUS. In N. C. (Conference Chair), K. Choukri, T. Declerck, M. U. Doğan, B. Maegaard, J. Mariani, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the Eight International Conference on Language Resources and Evaluation (LREC’12). European Language Resources Association (ELRA). http://www.lrec-conf.org/proceedings/lrec2012/pdf/463_Paper
- Ziemski, M., Junczys-Dowmunt, M., & Pouliquen, B. (n.d.). The United Nations Parallel Corpus v1.0. https://aclanthology.org/L16-1561
</details>
### Instruction Tuning Data
This model has been fine-tuned on ~135k instructions, primarily targeting machine translation performance for Catalan, English, and Spanish.
Additional instruction data for other European and closely related Iberian languages was also included, as it yielded a positive impact on the languages of interest.
That said, the performance in these additional languages is not guaranteed due to the limited amount of available data and the lack of resources for thorough testing.
A portion of our fine-tuning data comes directly from, or is sampled from [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2).
We also created additional datasets for our main languages of interest.
While tasks relating to machine translation are included, it’s important to note that no chat data was used in the fine-tuning process.
The final distribution of tasks was as below:

Click the expand button below to see the full list of tasks included in the finetuning data.
<details id="instr-data-sources">
<summary>Data Sources</summary>
| Task | Source | Languages | Count |
|----------------------------------|------------------------------------------------------------------------------------------|----------------------------------------------------------------|--------|
| Multi-reference Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [Tatoeba Dev (filtered)](https://github.com/Helsinki-NLP/Tatoeba-Challenge) | mixed | 10000 |
| Paraphrase | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [PAWS-X Dev](https://github.com/google-research-datasets/paws) | mixed | 3521 |
| Named-entity Recognition | [AnCora-Ca-NER](https://huggingface.co/datasets/projecte-aina/ancora-ca-ner) | ca | 12059 |
| Named-entity Recognition | [BasqueGLUE](https://huggingface.co/datasets/orai-nlp/basqueGLUE), [EusIE](https://huggingface.co/datasets/HiTZ/EusIE) | eu | 4304 |
| Named-entity Recognition | [SLI NERC Galician Gold Corpus](https://github.com/xavier-gz/SLI_Galician_Corpora) | gl | 6483 |
| Named-entity Recognition | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MultiCoNER 2022 and 2023 Dev](https://registry.opendata.aws/multiconer/) | pt | 854 |
| Named-entity Recognition | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MultiCoNER 2022 and 2023 Dev](https://registry.opendata.aws/multiconer/) | nl | 800 |
| Named-entity Recognition | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MultiCoNER 2022 and 2023 Dev](https://registry.opendata.aws/multiconer/) | es | 1654 |
| Named-entity Recognition | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MultiCoNER 2022 and 2023 Dev](https://registry.opendata.aws/multiconer/) | en | 1671 |
| Named-entity Recognition | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MultiCoNER 2022 and 2023 Dev](https://registry.opendata.aws/multiconer/) | ru | 800 |
| Named-entity Recognition | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MultiCoNER 2022 and 2023 Dev](https://registry.opendata.aws/multiconer/) | it | 858 |
| Named-entity Recognition | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MultiCoNER 2022 and 2023 Dev](https://registry.opendata.aws/multiconer/) | fr | 857 |
| Named-entity Recognition | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MultiCoNER 2022 and 2023 Dev](https://registry.opendata.aws/multiconer/) | de | 1312 |
| Terminology-aware Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [WMT21 Terminology Dev (filtered)](https://www.statmt.org/wmt21/terminology-task.html) | en-ru | 50 |
| Terminology-aware Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [WMT21 Terminology Dev (filtered)](https://www.statmt.org/wmt21/terminology-task.html) | en-fr | 29 |
| Automatic Post Editing | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [QT21](https://lindat.mff.cuni.cz/repository/xmlui/handle/11372/LRT-2390), [ApeQuest](https://apequest.wordpress.com/) | en-fr | 6133 |
| Automatic Post Editing | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [QT21](https://lindat.mff.cuni.cz/repository/xmlui/handle/11372/LRT-2390), [ApeQuest](https://apequest.wordpress.com/) | en-nl | 9077 |
| Automatic Post Editing | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [QT21](https://lindat.mff.cuni.cz/repository/xmlui/handle/11372/LRT-2390), [ApeQuest](https://apequest.wordpress.com/) | en-pt | 5762 |
| Automatic Post Editing | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [QT21](https://lindat.mff.cuni.cz/repository/xmlui/handle/11372/LRT-2390), [ApeQuest](https://apequest.wordpress.com/) | de-en | 10000 |
| Automatic Post Editing | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [QT21](https://lindat.mff.cuni.cz/repository/xmlui/handle/11372/LRT-2390), [ApeQuest](https://apequest.wordpress.com/) | en-de | 10000 |
| Machine Translation Evaluation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2)-sample: [WMT20 to WMT22 Metrics MQM](https://www.statmt.org/wmt22/results.html), [WMT17 to WMT22 Metrics Direct Assessments](https://www.statmt.org/wmt22/results.html) | en-ru, en-pl, ru-en, en-de, en-ru, de-fr, de-en, en-de | 353 |
| Machine Translation Evaluation | Non-public | four pivot languages (eu, es, ca, gl) paired with European languages (bg, cs, da, de, el, en, et, fi, fr, ga, hr, hu, it, lt, lv, mt, nl, pl, pt, ro, sk, sl, sv) | 9700 |
| General Machine Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [WMT14 to WMT21](https://www.statmt.org/wmt22/results.html), [NTREX](https://github.com/MicrosoftTranslator/NTREX), [Flores Dev](https://github.com/facebookresearch/flores), [FRMT](https://github.com/google-research/google-research/tree/master/frmt), [QT21](https://lindat.mff.cuni.cz/repository/xmlui/handle/11372/LRT-2390), [ApeQuest](https://apequest.wordpress.com/), [OPUS (Quality Filtered)](https://opus.nlpl.eu/), [MT-GenEval](https://github.com/amazon-science/machine-translation-gender-eval) | nl-en, en-ru, it-en, fr-en, es-en, en-fr, ru-en, fr-de, en-nl, de-fr | 500 |
| General Machine Translation | Non-public | three pivot languages (es, ca, en) paired with European languages (ast, arn, arg, bg, cs, cy, da, de, el, et, fi, ga, gl, hr, it, lt, lv, mt, nb, nn, nl, oc, pl, pt, ro, ru, sk, sl, sr, sv, uk, eu) | 9350 |
| Fill-in-the-Blank | Non-public | five pivot languages (ca, es, eu, gl, en) paired with European languages (cs, da, de, el, et, fi, fr, ga, hr, hu, it, lt, lv, mt, nl, pl, pt, ro, sk, sl, sv) | 11500 |
| Document-level Translation | Non-public | two pivot languages (es, en) paired with European languages (bg, cs, da, de, el, et, fi, fr, hu, it, lt, lv, nl, pl, pt, ro, ru, sk, sv) | 7600 |
| Paragraph-level Translation | Non-public | two pivot languages (es, en) paired with European languages (bg, cs, da, de, el, et, fi, fr, hu, it, lt, lv, nl, pl, pt, ro, ru, sk, sv) | 7600 |
| Context-Aware Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MT-GenEval](https://github.com/amazon-science/machine-translation-gender-eval) | en-it | 348 |
| Context-Aware Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MT-GenEval](https://github.com/amazon-science/machine-translation-gender-eval) | en-ru | 454 |
| Context-Aware Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MT-GenEval](https://github.com/amazon-science/machine-translation-gender-eval) | en-fr | 369 |
| Context-Aware Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MT-GenEval](https://github.com/amazon-science/machine-translation-gender-eval) | en-nl | 417 |
| Context-Aware Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MT-GenEval](https://github.com/amazon-science/machine-translation-gender-eval) | en-es | 431 |
| Context-Aware Translation | [TowerBlocks](https://huggingface.co/datasets/Unbabel/TowerBlocks-v0.2): [MT-GenEval](https://github.com/amazon-science/machine-translation-gender-eval) | en-de | 558 |
|**Total** | | | **135,404** |
The non-public portion of this dataset was jointly created by the [ILENIA](https://proyectoilenia.es/) partners: BSC-LT, [HiTZ](http://hitz.ehu.eus/es),
and [CiTIUS](https://citius.gal/es/). For further information regarding the instruction-tuning data,
please contact <langtech@bsc.es>.
</details>
<details id="instr-references">
<summary>References</summary>
- Alves, D. M., Pombal, J., Guerreiro, N. M., Martins, P. H., Alves, J., Farajian, A., Peters, B., Rei, R., Fernandes, P., Agrawal, S., Colombo, P., de Souza, J. G. C., & Martins, A. F. T. (2024). Tower: An open multilingual large language model for translation-related tasks (No. arXiv: 2402.17733). arXiv. https://arxiv.org/abs/2402.17733
- Armengol-Estapé, J., Carrino, C. P., Rodriguez-Penagos, C., de Gibert Bonet, O., Armentano-Oller, C., Gonzalez-Agirre, A., Melero, M., & Villegas, M. (2021). Are multilingual models the best choice for moderately under-resourced languages? A comprehensive assessment for Catalan. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 4933–4946. Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.findings-acl.437
- Currey, A., Nadejde, M., Pappagari, R. R., Mayer, M., Lauly, S., Niu, X., Hsu, B., & Dinu, G. (2022). MT-GenEval: A counterfactual and contextual dataset for evaluating gender accuracy in machine translation. In Y. Goldberg, Z. Kozareva, & Y. Zhang (Eds.), Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (pp. 4287–4299). Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.emnlp-main.288
- Federmann, C., Kocmi, T., & Xin, Y. (2022). NTREX-128 – News test references for MT evaluation of 128 languages. Proceedings of the First Workshop on Scaling Up Multilingual Evaluation, 21–24. Association for Computational Linguistics. https://aclanthology.org/2022.sumeval-1.4
- Ive, J., Specia, L., Szoc, S., Vanallemeersch, T., Van den Bogaert, J., Farah, E., Maroti, C., Ventura, A., & Khalilov, M. (2020). A post-editing dataset in the legal domain: Do we underestimate neural machine translation quality? In N. Calzolari, F. Béchet, P. Blache, K. Choukri, C. Cieri, T. Declerck, S. Goggi, H. Isahara, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the Twelfth Language Resources and Evaluation Conference (pp. 3692–3697). European Language Resources Association. https://aclanthology.org/2020.lrec-1.455/
- Malmasi, S., Fang, A., Fetahu, B., Kar, S., & Rokhlenko, O. (2022). MultiCoNER: A large-scale multilingual dataset for complex named entity recognition. Proceedings of the 29th International Conference on Computational Linguistics, 3798–3809. International Committee on Computational Linguistics. https://aclanthology.org/2022.coling-1.334/
- NLLB Team, Costa-jussà, M. R., Cross, J., Çelebi, O., Elbayad, M., Heafield, K., Heffernan, K., Kalbassi, E., Lam, J., Licht, D., Maillard, J., Sun, A., Wang, S., Wenzek, G., Youngblood, A., Akula, B., Barrault, L., Mejia Gonzalez, G., Hansanti, P., Hoffman, J., Jarrett, S., Sadagopan, K. R., Rowe, D., Spruit, S., Tran, C., Andrews, P., Ayan, N. F., Bhosale, S., Edunov, S., Fan, A., Gao, C., Goswami, V., Guzmán, F., Koehn, P., Mourachko, A., Ropers, C., Saleem, S., Schwenk, H., & Wang, J. (2022). No language left behind: Scaling human-centered machine translation (No. arXiv: 2207.04672). arXiv. https://arxiv.org/abs/2207.04672
- Riley, P., Dozat, T., Botha, J. A., Garcia, X., Garrette, D., Riesa, J., Firat, O., & Constant, N. (2022). FRMT: A benchmark for few-shot region-aware machine translation (No. arXiv: 2210.00193). arXiv. https://doi.org/10.48550/ARXIV.2210.00193
- Specia, L., Harris, K., Blain, F., Burchardt, A., Macketanz, V., Skadiņa, I., Negri, M., & Turchi, M. (2017). Translation quality and productivity: A study on rich morphology languages. Proceedings of Machine Translation Summit XVI, 55–71. Nagoya, Japan.
- Tiedemann, J. (2020). The Tatoeba translation challenge – Realistic data sets for low-resource and multilingual MT. Proceedings of the Fifth Conference on Machine Translation, 1174–1182. Association for Computational Linguistics. https://www.aclweb.org/anthology/2020.wmt-1.139
- Urbizu, G., San Vicente, I., Saralegi, X., Agerri, R., & Soroa, A. (2022). BasqueGLUE: A natural language understanding benchmark for Basque. Proceedings of the Language Resources and Evaluation Conference, 1603–1612. European Language Resources Association. https://aclanthology.org/2022.lrec-1.172
- Yang, Y., Zhang, Y., Tar, C., & Baldridge, J. (2019). PAWS-X: A cross-lingual adversarial dataset for paraphrase identification. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (pp. 3687–3692). Association for Computational Linguistics. https://doi.org/10.18653/v1/D19-1382
- Zubillaga, M., Sainz, O., Estarrona, A., Lopez de Lacalle, O., & Agirre, E. (2024). Event extraction in Basque: Typologically motivated cross-lingual transfer-learning analysis (No. arXiv: 2404.06392). arXiv. https://arxiv.org/abs/2404.06392
</details>
## Evaluation
Below are the evaluation results on the [Flores+200 devtest set](https://huggingface.co/datasets/openlanguagedata/flores_plus),
compared against the state-of-the-art [MADLAD400-3B-mt model](https://huggingface.co/google/madlad400-3b-mt) ([Kudugunta, S., et al.](https://arxiv.org/abs/2309.04662)) and [NLLB-200-3.3B](https://huggingface.co/facebook/nllb-200-3.3B) ([Costa-jussà et al., 2022](https://arxiv.org/abs/2207.04672)).
These results cover the translation directions CA-XX, ES-XX, EN-XX, as well as XX-CA, XX-ES, and XX-EN.
The metrics have been computed excluding Asturian, Aranese, and Aragonese, as we report them separately.
The evaluation was conducted using [MT-Lens](https://github.com/langtech-bsc/mt-evaluation), following the standard setting (beam search with beam size 5, limiting the translation length to 500 tokens). We report the following metrics:
<details>
<summary>Click to show metrics details</summary>
- `BLEU`: Sacrebleu implementation. Signature: nrefs:1— case:mixed— eff:no— tok:13a— smooth:exp—version:2.3.1
- `TER`: Sacrebleu implementation.
- `ChrF`: Sacrebleu implementation.
- `Comet`: Model checkpoint: "Unbabel/wmt22-comet-da".
- `Comet-kiwi`: Model checkpoint: "Unbabel/wmt22-cometkiwi-da".
- `Bleurt`: Model checkpoint: "lucadiliello/BLEURT-20".
- `MetricX`: Model checkpoint: "google/metricx-23-xl-v2p0".
- `MetricX-QE`: Model checkpoint: "google/metricx-23-qe-xl-v2p0".
</details>
<details>
<summary>English evaluation</summary>
### English
This section presents the evaluation metrics for English translation tasks.
| | Bleu ↑ | Ter ↓ | ChrF ↑ | Comet ↑ | Comet-kiwi ↑ | Bleurt ↑ | MetricX ↓ | MetricX-QE ↓ |
|:-------------------------|:----------|:----------|:----------|:---------|:-------------|:---------|:----------|:-------------|
| **EN-XX** | | | | | | | | |
| MADLAD400-3B | **35.11** | **52.61** | **63.04** | **0.88** | **0.85** | **0.78** | 1.21 | 1.12 |
| SalamandraTA-2b-instruct | 33.52 | 56.26 | 61.74 | **0.88** | **0.85** | **0.78** | **1.16** | **0.89** |
| nllb-200-3.3B | 31.17 | 56.03 | 59.19 | 0.87 | 0.83 | 0.76 | 2.22 | 2.20 |
| **XX-EN** | | | | | | | | |
| MADLAD400-3B | **41.84** | **44.43** | **67.04** | **0.88** | **0.85** | **0.79** | **1.22** | 1.18 |
| nllb-200-3.3B | 41.52 | 45.28 | 66.21 | **0.88** | **0.85** | 0.78 | 1.43 | 1.57 |
| SalamandraTA-2b-instruct | 41.44 | 45.24 | 66.64 | **0.88** | **0.85** | **0.79** | 1.24 | **1.05** |
<img src="./images/bleu_en.png" alt="English" width="100%"/>
</details>
<details>
<summary>Spanish evaluation</summary>
### Spanish
This section presents the evaluation metrics for Spanish translation tasks.
| | Bleu ↑ | Ter ↓ | ChrF ↑ | Comet ↑ | Comet-kiwi ↑ | Bleurt ↑ | MetricX ↓ | MetricX-QE ↓ |
|:-------------------------|:----------|:----------|:----------|:---------|:-------------|:---------|:----------|:-------------|
| **ES-XX** | | | | | | | | |
| MADLAD400-3B | **21.87** | **69.80** | **53.46** | **0.86** | **0.83** | **0.74** | **1.15** | 1.12 |
| SalamandraTA-2b-instruct | 20.77 | 73.37 | 52.16 | **0.86** | **0.83** | **0.74** | 1.16 | **0.89** |
| nllb-200-3.3B | 19.54 | 72.19 | 50.07 | 0.84 | 0.81 | 0.71 | 2.19 | 2.21 |
| **XX-ES** | | | | | | | | |
| SalamandraTA-2b-instruct | **25.01** | 63.35 | **52.74** | **0.85** | **0.84** | **0.73** | **1.03** | **1.20** |
| MADLAD400-3B | 24.38 | **62.31** | 52.65 | **0.85** | **0.84** | **0.73** | 1.13 | 1.54 |
| nllb-200-3.3B | 22.68 | 64.18 | 50.91 | 0.84 | 0.83 | 0.71 | 1.62 | 2.06 |
<img src="./images/bleu_es.png" alt="English" width="100%"/>
</details>
<details>
<summary>Catalan evaluation</summary>
### Catalan
This section presents the evaluation metrics for Catalan translation tasks.
| | Bleu ↑ | Ter ↓ | ChrF ↑ | Comet ↑ | Comet-kiwi ↑ | Bleurt ↑ | MetricX ↓ | MetricX-QE ↓ |
|:-------------------------|:----------|:----------|:----------|:---------|:-------------|:---------|:----------|:-------------|
| **CA-XX** | | | | | | | | |
| MADLAD400-3B | **28.86** | **59.60** | **58.05** | **0.87** | **0.81** | **0.77** | **1.15** | 1.28 |
| SalamandraTA-2b-instruct | 26.70 | 64.12 | 56.18 | **0.87** | **0.81** | 0.76 | 1.24 | **1.09** |
| nllb-200-3.3B | 25.17 | 63.15 | 54.02 | 0.85 | 0.79 | 0.72 | 2.42 | 2.59 |
| **XX-CA** | | | | | | | | |
| SalamandraTA-2b-instruct | **32.42** | 56.54 | 58.67 | **0.86** | **0.81** | 0.74 | **1.11** | **1.38** |
| MADLAD400-3B | 32.31 | **55.68** | **58.87** | **0.86** | **0.81** | **0.75** | 1.27 | 1.83 |
| nllb-200-3.3B | 29.28 | 58.95 | 55.97 | 0.84 | 0.80 | 0.71 | 2.18 | 2.61 |
<img src="./images/bleu_ca.png" alt="English" width="100%"/>
</details>
<details>
<summary>Galician evaluation</summary>
### Galician
This section presents the evaluation metrics for Galician translation tasks.
| | Bleu ↑ | Ter ↓ | ChrF ↑ | Comet ↑ | Comet-kiwi ↑ | Bleurt ↑ | MetricX ↓ | MetricX-QE ↓ |
|:-------------------------|:----------|:----------|:----------|:---------|:-------------|:---------|:----------|:-------------|
| **GL-XX** | | | | | | | | |
| SalamandraTA-2b-instruct | **25.46** | 65.95 | 55.42 | **0.87** | 0.82 | **0.75** | **1.22** | **1.05** |
| MADLAD400-3B | 25.12 | 66.02 | **55.78** | 0.85 | **0.85** | 0.74 | 1.37 | 1.83 |
| nllb-200-3.3B | 24.20 | **64.70** | 53.37 | 0.85 | 0.80 | 0.72 | 2.29 | 2.42 |
| **XX-GL** | | | | | | | | |
| SalamandraTA-2b-instruct | **28.72** | **59.65** | **56.33** | **0.86** | 0.83 | **0.69** | **1.04** | **1.25** |
| MADLAD400-3B | 27.54 | 59.84 | 54.94 | 0.85 | **0.85** | 0.67 | 1.34 | 2.28 |
| nllb-200-3.3B | 26.22 | 60.15 | 53.84 | 0.84 | 0.81 | 0.67 | 1.91 | 2.54 |
<img src="./images/bleu_gl.png" alt="English" width="100%"/>
</details>
<details>
<summary>Basque evaluation</summary>
### Basque
This section presents the evaluation metrics for Basque translation tasks.
| | Bleu ↑ | Ter ↓ | ChrF ↑ | Comet ↑ | Comet-kiwi ↑ | Bleurt ↑ | MetricX ↓ | MetricX-QE ↓ |
|:-------------------------|:----------|:----------|:----------|:---------|:-------------|:---------|:----------|:-------------|
| **EU-XX** | | | | | | | | |
| MADLAD400-3B | **20.02** | 71.82 | 48.71 | 0.84 | **0.85** | **0.71** | 1.68 | 2.76 |
| SalamandraTA-2b-instruct | 19.00 | 77.45 | **49.13** | **0.85** | 0.79 | **0.71** | **1.45** | **1.43** |
| nllb-200-3.3B | 18.83 | **71.60** | 47.96 | 0.83 | 0.76 | 0.69 | 2.35 | 2.89 |
| **XX-EU** | | | | | | | | |
| SalamandraTA-2b-instruct | **13.06** | 89.81 | **51.65** | **0.84** | 0.77 | **0.78** | **1.25** | **1.09** |
| MADLAD400-3B | 12.65 | 91.60 | 49.86 | 0.82 | **0.84** | **0.78** | 2.22 | 3.43 |
| nllb-200-3.3B | 7.58 | **86.57** | 40.43 | 0.73 | 0.62 | 0.64 | 4.68 | 6.08 |
<img src="./images/bleu_eu.png" alt="English" width="100%"/>
</details>
### Low-Resource Languages of Spain
The tables below summarize the performance metrics for English, Spanish, and Catalan to Asturian, Aranese and Aragonese compared
against [Transducens/IbRo-nllb](https://huggingface.co/Transducens/IbRo-nllb) [(Galiano Jimenez, et al.)](https://aclanthology.org/2024.wmt-1.85/),
[NLLB-200-3.3B](https://huggingface.co/facebook/nllb-200-3.3B) ([Costa-jussà et al., 2022](https://arxiv.org/abs/2207.04672)).
<details>
<summary>English evaluation</summary>
#### English-XX
| | source | target | Bleu ↑ | Ter ↓ | ChrF ↑ |
|:-------------------------|:---------|:---------|:----------|:----------|:----------|
| SalamandraTA-2b-instruct | en | ast | **25.84** | **63.31** | **58.60** |
| nllb-200-3.3B | en | ast | 22.02 | 77.26 | 51.40 |
| Transducens/IbRo-nllb | en | ast | 20.56 | 63.92 | 53.32 |
| | | | | | |
| SalamandraTA-2b-instruct | en | arn | **19.09** | 76.04 | **50.18** |
| Transducens/IbRo-nllb | en | arn | 12.81 | **73.21** | 45.76 |
| | | | | | |
| SalamandraTA-2b-instruct | en | arg | **15.87** | 76.75 | **48.08** |
| Transducens/IbRo-nllb | en | arg | 14.07 | **70.37** | 46.89 |
| nllb-200-3.3B | en | arg | 0.31 | 114.39 | 6.87 |
</details>
<details>
<summary>Spanish evaluation</summary>
#### Spanish-XX
| | source | target | Bleu ↑ | Ter ↓ | ChrF ↑ |
|:-------------------------|:---------|:---------|:----------|:----------|:----------|
| SalamandraTA-2b-instruct | es | ast | **17.30** | 76.72 | **51.31** |
| Transducens/IbRo-nllb | es | ast | 16.79 | **76.36** | 50.89 |
| nllb-200-3.3B | es | ast | 11.85 | 100.86 | 40.27 |
| | | | | | |
| Transducens/IbRo-nllb | es | arn | **50.20** | **36.60** | **73.16** |
| SalamandraTA-2b-instruct | es | arn | 46.76 | 39.32 | 70.76 |
| | | | | | |
| Transducens/IbRo-nllb | es | arg | **59.75** | **28.01** | **78.73** |
| SalamandraTA-2b-instruct | es | arg | 38.42 | 44.43 | 67.39 |
</details>
<details>
<summary>Catalan evaluation</summary>
#### Catalan-XX
| | source | target | Bleu ↑ | Ter ↓ | ChrF ↑ |
|:-------------------------|:---------|:---------|:----------|:----------|:----------|
| Transducens/IbRo-nllb | ca | ast | **24.77** | **61.60** | **57.49** |
| SalamandraTA-2b-instruct | ca | ast | 24.49 | 65.71 | 57.40 |
| nllb-200-3.3B | ca | ast | 17.17 | 91.47 | 45.83 |
| | | | | | |
| Transducens/IbRo-nllb | ca | arn | **31.22** | **54.30** | **60.30** |
| SalamandraTA-2b-instruct | ca | arn | 29.75 | 57.69 | 59.20 |
| | | | | | |
| Transducens/IbRo-nllb | ca | arg | **24.44** | **60.79** | **55.51** |
| SalamandraTA-2b-instruct | ca | arg | 17.85 | 68.85 | 50.39 |
</details>
## Gender Aware Translation
Below are the evaluation results for gender aware translation evaluated on the [MT-GenEval](https://github.com/amazon-science/machine-translation-gender-eval?tab=readme-ov-file#mt-geneval)
dataset ([Currey, A. et al.](https://arxiv.org/pdf/2211.01355)).
These have been calculated for translation from English into German, Spanish, French, Italian, Portuguese and Russian and are compared
against [MADLAD400-3b-mt](https://huggingface.co/google/madlad400-3b-mt), and [NLLB-200-3-3B](https://huggingface.co/facebook/nllb-200-3.3B).
Evaluation was conducted using [MT-Lens](https://github.com/langtech-bsc/mt-evaluation) and is reported as accuracy computed using the accuracy metric
provided with MT-GenEval.
<details>
<summary>MT-GenEval Evaluation</summary>
| | Source | Target | Masc | Fem | Pair |
|:--|:--|:--|:--|:--|:--|
| MADLAD400-3B | en | de | 0.863 | 0.837 | 0.713 |
| SalamandraTA-2b-instruct | en | de | **0.887** | **0.843** | **0.747** |
| nllb_3.3B | en | de | 0.870 | 0.787 | 0.677 |
| | | | | | |
| MADLAD400-3B | en | es | **0.883** | 0.750 | 0.660 |
| SalamandraTA-2b-instruct | en | es | 0.877 | **0.843** | **0.740** |
| nllb_3.3B | en | es | 0.867 | 0.777 | 0.663 |
| | | | | | |
| MADLAD400-3B | en | fr | 0.883 | 0.797 | 0.707 |
| SalamandraTA-2b-instruct | en | fr | **0.900** | **0.823** | **0.737** |
| nllb_3.3B | en | fr | **0.900** | 0.727 | 0.643 |
| | | | | | |
| MADLAD400-3B | en | it | **0.917** | 0.693 | 0.643 |
| SalamandraTA-2b-instruct | en | it | 0.910 | **0.757** | **0.687** |
| nllb_3.3B | en | it | 0.907 | 0.673 | 0.597 |
| | | | | | |
| MADLAD400-3B | en | pt | **0.923** | 0.697 | 0.640 |
| SalamandraTA-2b-instruct | en | pt | 0.910 | **0.720** | **0.660** |
| nllb_3.3B | en | pt | 0.913 | 0.713 | 0.650 |
| | | | | | |
| MADLAD400-3B | en | ru | **0.947** | 0.780 | 0.730 |
| SalamandraTA-2b-instruct | en | ru | 0.933 | **0.813** | **0.750** |
| nllb_3.3B | en | ru | 0.930 | 0.787 | 0.723 |
| | | | | | |
</details>
## Ethical Considerations and Limitations
Detailed information on the work done to examine the presence of unwanted social and cognitive biases in the base model can be found
at [Salamandra-2B model card](https://huggingface.co/BSC-LT/salamandra-2b).
With regard to MT models, the only analysis related to bias which we have conducted is the MT-GenEval evaluation.
No specific analysis has yet been carried out in order to evaluate potential biases or limitations in translation
accuracy across different languages, dialects, or domains. However, we recognize the importance of identifying and addressing any harmful stereotypes,
cultural inaccuracies, or systematic performance discrepancies that may arise in Machine Translation. As such, we plan to continue performing more analyses
as we implement the necessary metrics and methods within our evaluation framework [MT-Lens](https://github.com/langtech-bsc/mt-evaluation).
Note that the model has only undergone preliminary instruction tuning.
We urge developers to consider potential limitations and conduct safety testing and tuning tailored to their specific applications.
## Additional information
### Author
The Language Technologies Unit from Barcelona Supercomputing Center.
### Contact
For further information, please send an email to <langtech@bsc.es>.
### Copyright
Copyright(c) 2025 by Language Technologies Unit, Barcelona Supercomputing Center.
### Funding
This work has been promoted and financed by the Government of Catalonia through the [Aina Project](https://projecteaina.cat/).
This work is funded by the _Ministerio para la Transformación Digital y de la Función Pública_ - Funded by EU – NextGenerationEU
within the framework of [ILENIA Project](https://proyectoilenia.es/) with reference 2022/TL22/00215337.
### Acknowledgements
The success of this project has been made possible thanks to the invaluable contributions of our partners in the [ILENIA Project](https://proyectoilenia.es/):
[HiTZ](http://hitz.ehu.eus/es), and [CiTIUS](https://citius.gal/es/).
Their efforts have been instrumental in advancing our work, and we sincerely appreciate their help and support.
### Disclaimer
### Disclaimer
Be aware that the model may contain biases or other unintended distortions.
When third parties deploy systems or provide services based on this model, or use the model themselves,
they bear the responsibility for mitigating any associated risks and ensuring compliance with applicable regulations,
including those governing the use of Artificial Intelligence.
The Barcelona Supercomputing Center, as the owner and creator of the model, shall not be held liable for any outcomes resulting from third-party use.
### License
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
### Citation
If you find our model useful, we would appreciate if you could cite our work as follows:
```
@misc{gilabert2025salamandrasalamandratabscsubmission,
title={From SALAMANDRA to SALAMANDRATA: BSC Submission for WMT25 General Machine Translation Shared Task},
author={Javier Garcia Gilabert and Xixian Liao and Severino Da Dalt and Ella Bohman and Audrey Mash and Francesca De Luca Fornaciari and Irene Baucells and Joan Llop and Miguel Claramunt Argote and Carlos Escolano and Maite Melero},
year={2025},
eprint={2508.12774},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.12774},
}
```
|
0xaoyama/blockassist-bc-muscular_zealous_gorilla_1755601041
|
0xaoyama
| 2025-08-19T10:57:54Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular zealous gorilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T10:57:42Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular zealous gorilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ayushirathour/chest-xray-pneumonia-detection
|
ayushirathour
| 2025-08-19T10:57:00Z | 0 | 1 |
tensorflow
|
[
"tensorflow",
"medical-imaging",
"chest-xray",
"pneumonia-detection",
"pediatric",
"computer-vision",
"cross-validation",
"en",
"dataset:paultimothymooney/chest-xray-pneumonia",
"dataset:iamtanmayshukla/pneumonia-radiography-dataset",
"license:mit",
"model-index",
"region:us"
] | null | 2025-08-11T07:46:30Z |
---
license: mit
language: en
library_name: tensorflow
tags:
- medical-imaging
- chest-xray
- pneumonia-detection
- pediatric
- computer-vision
- cross-validation
datasets:
- paultimothymooney/chest-xray-pneumonia
- iamtanmayshukla/pneumonia-radiography-dataset
metrics:
- accuracy
- sensitivity
- specificity
model-index:
- name: PneumoDetectAI
results:
- task:
type: image-classification
name: Pediatric Pneumonia Detection
dataset:
name: Cross-Operator Validation Dataset
type: medical-imaging
metrics:
- type: accuracy
name: Cross-Operator Accuracy
value: 0.86
- type: sensitivity
name: Sensitivity
value: 0.964
- type: specificity
name: Specificity
value: 0.748
---
# PneumoDetectAI
Binary classification model for pneumonia detection in pediatric chest X-rays (ages 1-5). Built with TensorFlow and MobileNetV2, validated on independent operator cohort with 86% accuracy and 96.4% sensitivity.
**Author**: Ayushi Rathour
**Contact**: ayushirathour1804@gmail.com
**Framework**: TensorFlow 2.19
**Model Size**: ~14 MB
## Model Overview
PneumoDetectAI is a deep learning model designed to detect pneumonia in chest X-rays of pediatric patients aged 1 to 5 years. The model uses transfer learning from MobileNetV2 for efficient inference while maintaining clinically relevant performance.
### Key Specifications
| Property | Value |
|----------|-------|
| **Architecture** | MobileNetV2 (ImageNet pretrained) + custom head |
| **Input Shape** | 224 × 224 × 3 (RGB) |
| **Output** | Binary classification (NORMAL/PNEUMONIA) |
| **File Format** | TensorFlow SavedModel (.h5) |
| **Model Size** | ~14 MB |
| **Inference Time** | 0.46 seconds on CPU |
| **Target Population** | Pediatric patients (1-5 years) |
### Intended Users
- ML researchers working on medical imaging
- Healthcare AI developers building screening tools
- Students learning medical AI validation approaches
- Radiologists interested in AI-assisted screening
## Performance Metrics
| Validation Type | Dataset | Samples | Accuracy | Sensitivity | Specificity |
|-----------------|---------|---------|----------|-------------|-------------|
| **Internal** | Mooney 2018 | 269 | 94.8% | 89.6% | 100% |
| **Cross-Operator** | Radiography 2024 | 485 | **86.0%** | **96.4%** | 74.8% |
### Clinical Interpretation
- **High Sensitivity (96.4%)**: Catches 96 out of 100 pneumonia cases, suitable for screening
- **Moderate Specificity (74.8%)**: 25% false positive rate acceptable for screening tool
- **Generalization**: 8.8% accuracy drop on independent cohort indicates reasonable robustness
## Quick Start Usage
```python
from huggingface_hub import hf_hub_download
import tensorflow as tf
import numpy as np
from PIL import Image
# Download and load model
model_path = hf_hub_download(
repo_id="ayushirathour/chest-xray-pneumonia-detection",
filename="best_chest_xray_model.h5"
)
model = tf.keras.models.load_model(model_path)
# Preprocess image
def preprocess_xray(image_path):
img = Image.open(image_path).convert("RGB").resize((224, 224))
img_array = np.array(img) / 255.0
return np.expand_dims(img_array, axis=0)
# Make prediction
image_array = preprocess_xray("chest_xray.jpg")
probability = model.predict(image_array)[0][0]
diagnosis = "PNEUMONIA" if probability >= 0.5 else "NORMAL"
confidence = probability * 100 if probability >= 0.5 else (1 - probability) * 100
print(f"Diagnosis: {diagnosis}")
print(f"Confidence: {confidence:.1f}%")
```
## Training Details
### Datasets
- **Training Data**: Chest X-Ray Images (Pneumonia) by Paul Timothy Mooney
- Source: Guangzhou Women and Children's Medical Center
- Size: ~5,863 images (pediatric patients aged 1-5)
- Split: Pre-divided train/validation/test
- **External Validation**: Pneumonia Radiography Dataset by Tanmay Shukla
- Source: Same hospital, different operators and time period
- Size: 485 independent samples
- Purpose: Cross-operator generalization testing
### Architecture Details
- **Base Model**: MobileNetV2 (ImageNet weights frozen initially)
- **Custom Head**: Global Average Pooling → Dropout (0.5) → Dense (128) → Dense (1, sigmoid)
- **Optimization**: Adam optimizer (lr=0.0001)
- **Loss Function**: Binary crossentropy
- **Training**: 20 epochs with early stopping
## Limitations & Risks
### Technical Limitations
- **Single Institution**: Both datasets from same medical center
- **Age Restriction**: Validated only on pediatric patients (1-5 years)
- **Binary Output**: Cannot distinguish pneumonia subtypes (viral vs bacterial)
- **Image Quality**: Performance degrades with poor quality or non-standard views
### Clinical Limitations
- **False Positive Rate**: 25.2% may increase radiologist workload
- **Screening Only**: Not suitable for definitive diagnosis
- **Population Bias**: Trained on Asian pediatric cohort only
- **No Clinical Context**: Cannot incorporate patient history or symptoms
### Deployment Risks
- **Overconfidence**: High sensitivity may create false sense of security
- **Misuse**: Risk of use without proper medical oversight
- **Generalization**: Performance may vary on different imaging equipment
## Responsible AI & Ethics
### Bias Considerations
- **Population Bias**: Model trained exclusively on Asian pediatric population
- **Institutional Bias**: Single medical center may not represent global imaging practices
- **Age Bias**: Performance on other age groups unknown
### Required Safeguards
- **Human Oversight**: All predictions must be reviewed by qualified radiologists
- **Screening Context**: Should only be used as preliminary screening tool
- **Informed Consent**: Patients must be informed of AI involvement in screening
- **Quality Assurance**: Regular monitoring of real-world performance required
### Regulatory Status
- **Not FDA Approved**: Research prototype only
- **Not CE Marked**: Not approved for clinical use in EU
- **Research Use**: Intended for academic and development purposes only
## Citation
```bibtex
@misc{rathour2025pneumodetectai,
title={PneumoDetectAI: Pediatric Chest X-Ray Pneumonia Detection with Cross-Operator Validation},
author={Rathour, Ayushi},
year={2025},
note={Cross-operator validation on 485 independent samples},
url={https://huggingface.co/ayushirathour/chest-xray-pneumonia-detection}
}
```
## Acknowledgements
### Datasets
- **Training Dataset**: Chest X-Ray Images (Pneumonia) - Paul Timothy Mooney (Kaggle)
- **Validation Dataset**: Pneumonia Radiography Dataset - Tanmay Shukla (Kaggle)
- **Original Research**: Kermany et al., "Identifying Medical Diagnoses and Treatable Diseases by Image-Based Deep Learning", Cell 2018
### Technical Stack
- **Framework**: TensorFlow 2.19
- **Architecture**: MobileNetV2 (Google)
- **Deployment**: Streamlit, FastAPI
- **Hosting**: Hugging Face Hub
## Additional Resources
- 🌐 **Live Demo**: [PneumoDetectAI Web App](https://pneumodetectai.streamlit.app/)
- 📂 **Source Code**: [GitHub Repository](https://github.com/ayushirathour/chest-xray-pneumonia-detection-ai)
- 📖 **API Documentation**: Available when running locally
- 💬 **Issues & Support**: GitHub Issues or email contact
---
**Disclaimer**: This model is for research and educational purposes only. It is not a medical device and should not be used for clinical diagnosis without appropriate medical supervision.
|
0xaoyama/blockassist-bc-muscular_zealous_gorilla_1755600286
|
0xaoyama
| 2025-08-19T10:45:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular zealous gorilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T10:45:07Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular zealous gorilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
AIMindaeng/Qwen2.5-VL-3B-Instruct-Thinking
|
AIMindaeng
| 2025-08-19T10:41:50Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"dataset:lmms-lab/multimodal-open-r1-8k-verified",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-VL-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-3B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T05:24:56Z |
---
base_model: Qwen/Qwen2.5-VL-3B-Instruct
datasets: lmms-lab/multimodal-open-r1-8k-verified
library_name: transformers
model_name: Qwen2.5-VL-3B-Instruct-Thinking
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for Qwen2.5-VL-3B-Instruct-Thinking
This model is a fine-tuned version of [Qwen/Qwen2.5-VL-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct) on the [lmms-lab/multimodal-open-r1-8k-verified](https://huggingface.co/datasets/lmms-lab/multimodal-open-r1-8k-verified) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="AIMindaeng/Qwen2.5-VL-3B-Instruct-Thinking", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Derify/ChemMRL-alpha
|
Derify
| 2025-08-19T10:18:27Z | 806 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"roberta",
"smiles-similarity",
"feature-extraction",
"molecular-similarity",
"sentence-similarity",
"arxiv:2010.09885",
"arxiv:2209.01712",
"arxiv:2205.13147",
"arxiv:2402.14776",
"arxiv:1911.02855",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-05-27T01:32:43Z |
---
tags:
- sentence-transformers
- smiles-similarity
- feature-extraction
- molecular-similarity
pipeline_tag: sentence-similarity
library_name: sentence-transformers
metrics:
- spearmanr
license: apache-2.0
new_version: Derify/ChemMRL-beta
---
# Chem-MRL (SentenceTransformer)
This is a trained [Chem-MRL](https://github.com/emapco/chem-mrl) [sentence-transformers](https://www.SBERT.net) model. It maps SMILES to a 1024-dimensional dense vector space and can be used for semantic textual similarity, semantic search, database indexing, molecular classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
<!-- - **Base model:** [Unknown](https://huggingface.co/unknown) -->
- **Maximum Sequence Length:** 128 tokens
- **Output Dimensionality:** 1024 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Repository:** [Chem-MRL on GitHub](https://github.com/emapco/chem-mrl)
- **Demo App Repository:** [Chem-MRL-demo on GitHub](https://github.com/emapco/chem-mrl-demo)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: RobertaModel (ChemBERTa)
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("Derify/ChemMRL-alpha")
# Run inference
sentences = [
'CCO',
"CC(C)O",
'CC(=O)O',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 1024]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Framework Versions
- Python: 3.12.9
- Sentence Transformers: 4.0.1
- Transformers: 4.48.2
- PyTorch: 2.6.0+cu124
- Accelerate: 1.4.0
- Datasets: 3.3.2
- Tokenizers: 0.21.0
## Citation
- Chithrananda, Seyone, et al. "ChemBERTa: Large-Scale Self-Supervised Pretraining for Molecular Property Prediction." _arXiv [Cs.LG]_, 2020. [Link](http://arxiv.org/abs/2010.09885).
- Ahmad, Walid, et al. "ChemBERTa-2: Towards Chemical Foundation Models." _arXiv [Cs.LG]_, 2022. [Link](http://arxiv.org/abs/2209.01712).
- Kusupati, Aditya, et al. "Matryoshka Representation Learning." _arXiv [Cs.LG]_, 2022. [Link](https://arxiv.org/abs/2205.13147).
- Li, Xianming, et al. "2D Matryoshka Sentence Embeddings." _arXiv [Cs.CL]_, 2024. [Link](http://arxiv.org/abs/2402.14776).
- Bajusz, Dávid, et al. "Why is the Tanimoto Index an Appropriate Choice for Fingerprint-Based Similarity Calculations?" _J Cheminform_, 7, 20 (2015). [Link](https://doi.org/10.1186/s13321-015-0069-3).
- Li, Xiaoya, et al. "Dice Loss for Data-imbalanced NLP Tasks." _arXiv [Cs.CL]_, 2020. [Link](https://arxiv.org/abs/1911.02855)
- Reimers, Nils, and Gurevych, Iryna. "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks." _Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing_, 2019. [Link](https://arxiv.org/abs/1908.10084).
## Model Card Authors
[@eacortes](https://huggingface.co/eacortes)
## Model Card Contact
Manny Cortes (manny@derifyai.com)
|
rohannath/AI_Doctor_using_llama_merged_unsloth-Q5_K_M-GGUF
|
rohannath
| 2025-08-19T10:08:24Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:rohannath/AI_Doctor_using_llama_merged_unsloth",
"base_model:quantized:rohannath/AI_Doctor_using_llama_merged_unsloth",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T10:01:31Z |
---
library_name: transformers
tags:
- llama-cpp
- gguf-my-repo
base_model: rohannath/AI_Doctor_using_llama_merged_unsloth
---
# rohannath/AI_Doctor_using_llama_merged_unsloth-Q5_K_M-GGUF
This model was converted to GGUF format from [`rohannath/AI_Doctor_using_llama_merged_unsloth`](https://huggingface.co/rohannath/AI_Doctor_using_llama_merged_unsloth) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/rohannath/AI_Doctor_using_llama_merged_unsloth) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo rohannath/AI_Doctor_using_llama_merged_unsloth-Q5_K_M-GGUF --hf-file ai_doctor_using_llama_merged_unsloth-q5_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo rohannath/AI_Doctor_using_llama_merged_unsloth-Q5_K_M-GGUF --hf-file ai_doctor_using_llama_merged_unsloth-q5_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo rohannath/AI_Doctor_using_llama_merged_unsloth-Q5_K_M-GGUF --hf-file ai_doctor_using_llama_merged_unsloth-q5_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo rohannath/AI_Doctor_using_llama_merged_unsloth-Q5_K_M-GGUF --hf-file ai_doctor_using_llama_merged_unsloth-q5_k_m.gguf -c 2048
```
|
Muapi/paintbrush
|
Muapi
| 2025-08-19T09:48:51Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T09:48:36Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# PAINTBRUSH!

**Base model**: Flux.1 D
**Trained words**: Painterly, painting
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:827178@925041", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
inclusionAI/Rubicon-Preview
|
inclusionAI
| 2025-08-19T09:45:23Z | 0 | 2 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2508.12790",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-18T07:15:14Z |
---
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
---
# Rubicon
<p align="center">
<a href="https://arxiv.org/abs/2508.12790"><b>📄 Paper</b></a> •
<a href="https://huggingface.co/inclusionAI/Rubicon-Preview"><b>🤗 Model</b></a>
</p>
This is the model card for **Rubicon-preview**, a 30B-A3B parameter model trained with a novel reinforcement learning framework using "rubric anchors" to excel at open-ended, creative, and humanities-centric tasks.
---
## Highlights
We introduce **Rubicon**, a novel framework using rubric anchors for reinforcement learning. Our model, **Rubicon-preview**, demonstrates the following key highlights:
- **Token-Efficient Performance**: Achieves a **+5.2%** absolute improvement on subjective, humanities-centric tasks with only **5K** training samples, outperforming a 671B DeepSeek-V3 model.
- **Stylistic Controllability**: Leverages rubric anchors to precisely guide output style, producing responses that are more human-like, emotionally expressive, and less formulaic.
- **Preservation of General Abilities**: Avoids performance degradation on general tasks—a common side effect of specialized RL—while delivering additional gains on reasoning benchmarks like AIME 2024 (+4.1%).
---
## Performance
Our rubric-based RL approach yields significant gains on open-ended, humanities-centric benchmarks while preserving and even enhancing performance on general and reasoning tasks.
### Humanities & Open-Ended Evaluation
Rubicon-preview achieves a **+5.21%** average absolute improvement over its base model on a diverse set of subjective benchmarks. Notably, it surpasses the much larger DeepSeek-V3-671B model by **+2.42%** on average.
| **Model** | **C.W** | **Writing** | **Judge** | **EQ** | **IFE** | **Collie** | **IFS** | **Avg** |
|:---|---:|---:|---:|---:|---:|---:|---:|---:|
| Qwen3-30B-A3B | 77.82 | 75.65 | 56.20 | 73.35 | **83.55** | 35.77 | 54.68 | 65.29 |
| **Rubicon-preview** | **81.89** | **80.11** | **69.20** | **79.55** | 81.70 | 40.27 | 60.79 | **70.50** |
| *Δ Improvement* | <span style="color:green">↑4.07</span> | <span style="color:green">↑4.46</span> | <span style="color:green">↑13.00</span> | <span style="color:green">↑6.20</span> | <span style="color:red">↓1.85</span> | <span style="color:green">↑4.50</span> | <span style="color:green">↑6.11</span> | **<span style="color:green">↑5.21</span>** |
| DeepSeek-V3-671B | 80.10 | 74.08 | 61.30 | 75.60 | 81.89 | **42.69** | **60.92** | 68.08 |
### General & Reasoning Abilities
The model maintains its core capabilities without degradation. It shows notable improvements on math reasoning benchmarks like AIME and enhances performance across several general benchmarks.
**Reasoning**
| **Model** | **AIME24** | **AIME25** | **Math500** | **GPQA-D** | **LCBv5** | **Avg** |
|:---|---:|---:|---:|---:|---:|---:|
| Qwen3-30B-A3B | 77.50 | 70.00 | **94.75** | **63.00** | **63.77** | **73.80** |
| **Rubicon-preview** | **81.67** | **70.83** | 94.55 | 60.35 | 59.43 | 73.37 |
**General**
| **Model** | **MMLU** | **IQ-EQ** | **HS** | **SC** | **CQ** | **SIQA** | **Avg** |
|:---|---:|---:|---:|---:|---:|---:|---:|
| Qwen3--30B-A3B | 79.53 | 68.75 | 77.55 | 77.72 | 79.52 | 73.64 | 78.16 |
| **Rubicon-preview** | **79.83** | **75.00** | **77.75** | **78.17** | **80.70** | **75.79** | **78.85** |
---
## Usage
Below are code snippets to get quickly started with running the model.
### Installation
First, install the necessary libraries. We recommend a recent version of Transformers.
```sh
pip install transformers torch
```
### Quick Start with Python
You can use the model for text generation with just a few lines of code.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "inclusionAI/Rubicon-Preview"
# Load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16, # or "auto"
device_map="auto"
)
# Prepare the model input using the chat template
prompt = "Is there true love in this world?"
messages = [
{"role": "user", "content": prompt}
]
# Apply the chat template
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# Conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):]
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("Generated Response:\n", content)
```
---
## Citation
If you use Rubicon in your research, please cite our paper:
```bibtex
@article{Rubicon,
title = {Reinforcement Learning with Rubric Anchors},
author = {Huang, Zenan and Zhuang, Yihong and Lu, Guoshan and Qin, Zeyu and Xu, Haokai and Zhao, Tianyu and Peng, Ru and Hu, Jiaqi and Shen, Zhanming and Hu, Xiaomeng and Gu, Xijun and Tu, Peiyi and Liu, Jiaxin and Chen, Wenyu and Fu, Yuzhuo and Fan, Zhiting and Gu, Yanmei and Wang, Yuanyuan and Yang, Zhengkai and Li, Jianguo and Zhao, Junbo},
journal = {arXiv preprint arXiv:2508.12790},
year = {2025}
}
```
|
Muapi/italian-comic-illustration-style-milo-manara
|
Muapi
| 2025-08-19T09:40:15Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T09:40:01Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Italian Comic Illustration Style (Milo Manara)

**Base model**: Flux.1 D
**Trained words**: itacomic1 illustration
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:985379@1158490", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/bread
|
Muapi
| 2025-08-19T09:39:35Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T09:39:21Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Bread

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:278431@1546816", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
PatrickHaller/gla-350M-10B
|
PatrickHaller
| 2025-08-19T09:31:28Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gla",
"text-generation",
"en",
"dataset:PatrickHaller/fineweb-10B",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T09:11:46Z |
---
library_name: transformers
datasets:
- PatrickHaller/fineweb-10B
language:
- en
---
# Model Card for Model ID
Trained on 9.83B Tokens
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Madsci3ntist/gpt2-reuters-tokenizer
|
Madsci3ntist
| 2025-08-19T09:27:50Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T09:27:49Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Muapi/christmas-couture
|
Muapi
| 2025-08-19T09:27:30Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T09:26:39Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Christmas Couture

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1016234@1139381", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/stellaris-character-race-style-lora-flux-xl-illustrous-xl-pony
|
Muapi
| 2025-08-19T09:17:08Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-19T09:17:01Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Stellaris Character/race Style Lora [FLUX+XL+Illustrous XL+Pony]

**Base model**: Flux.1 D
**Trained words**: fungoid, necroid, avian
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:351525@1028132", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
mdemirci10/lora_model
|
mdemirci10
| 2025-08-19T09:15:19Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen3",
"trl",
"en",
"base_model:unsloth/Qwen3-14B-Base-unsloth-bnb-4bit",
"base_model:finetune:unsloth/Qwen3-14B-Base-unsloth-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T09:12:18Z |
---
base_model: unsloth/Qwen3-14B-Base-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** mdemirci10
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-14B-Base-unsloth-bnb-4bit
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
kien231205/yelp_review_classifier
|
kien231205
| 2025-08-19T09:05:39Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-08-19T08:50:30Z |
---
library_name: transformers
license: apache-2.0
base_model: google-bert/bert-base-cased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: yelp_review_classifier
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# yelp_review_classifier
This model is a fine-tuned version of [google-bert/bert-base-cased](https://huggingface.co/google-bert/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0693
- Accuracy: 0.59
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 125 | 1.0952 | 0.485 |
| No log | 2.0 | 250 | 1.0302 | 0.566 |
| No log | 3.0 | 375 | 1.0693 | 0.59 |
### Framework versions
- Transformers 4.55.2
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.4
|
0xaoyama/blockassist-bc-muscular_zealous_gorilla_1755593825
|
0xaoyama
| 2025-08-19T08:57:42Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular zealous gorilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T08:57:30Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular zealous gorilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
hf-audio/xcodec-wavlm-mls
|
hf-audio
| 2025-08-19T08:50:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"xcodec",
"feature-extraction",
"dataset:parler-tts/mls_eng",
"base_model:microsoft/wavlm-base-plus",
"base_model:finetune:microsoft/wavlm-base-plus",
"license:cc-by-4.0",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-08-18T08:40:30Z |
---
library_name: transformers
license: cc-by-4.0
datasets:
- parler-tts/mls_eng
base_model:
- microsoft/wavlm-base-plus
---
# X-Codec (speech, WavLM)
This codec is intended for speech data. [This model](https://huggingface.co/hf-audio/xcodec-wavlm-more-data) was trained with more data.
Original model is `xcodec_wavlm_more_data` from [this table](https://github.com/zhenye234/xcodec?tab=readme-ov-file#available-models).
|
hobson123/blockassist-bc-mammalian_dense_gibbon_1755592646
|
hobson123
| 2025-08-19T08:43:29Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mammalian dense gibbon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T08:43:15Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mammalian dense gibbon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
FreedomIntelligence/AceGPT-v1.5-7B
|
FreedomIntelligence
| 2025-08-19T08:28:25Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"ar",
"zh",
"en",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-06-27T02:48:38Z |
---
license: apache-2.0
language:
- ar
- zh
- en
---
# <b>AceGPT</b>
AceGPT is a fully fine-tuned generative text model collection based on LlaMA2, particularly in the
Arabic language domain. This is the repository for the version 1.5 of 7B pre-trained model.
---
## Model Details
We have released the AceGPT family of large language models, which is a collection of fully fine-tuned generative text models based on LlaMA2, ranging from 7B to 13B parameters. Our models include two main categories: AceGPT and AceGPT-chat. AceGPT-chat is an optimized version specifically designed for dialogue applications. It is worth mentioning that our models have demonstrated superior performance compared to all currently available open-source Arabic dialogue models in multiple benchmark tests. Furthermore, in our human evaluations, our models have shown comparable satisfaction levels to some closed-source models, such as ChatGPT, in the Arabic language.
## Model Developers
We are from the King Abdullah University of Science and Technology (KAUST), the Chinese University of Hong Kong, Shenzhen (CUHKSZ), the Shenzhen Research Institute of Big Data (SRIBD), and King AbdulAziz University (KAU).
## Variations
AceGPT families come in a range of parameter sizes —— 7B and 13B, each size of model has a base category and a -chat category.
## Paper
The paper can be accessed at [link](https://huggingface.co/FreedomIntelligence/AceGPT-v1.5-13B-Chat/blob/main/Second_Language_(Arabic)_Acquisition_of_LLMs_via_Progressive_Vocabulary_Expansion.pdf).
## Input
Models input text only.
## Output
Models output text only.
## Model Evaluation Results
Benchmark evaluation on [Arabic MMLU](https://github.com/FreedomIntelligence/AceGPT) are conducted using accuracy scores as metrics, following the evaluation framework available at https://github.com/FreedomIntelligence/AceGPT/tree/main.
| | STEM | Humanities | Social Sciences | Others | Average |
|------------------|------|------|------|------|------|
| Bloomz-7B-base | 33.35 | 29.29 | 37.58 | 34.53 | 33.69 |
| LLaMA2-7B-base | 30.30 | 29.33 | 27.46 | 30.78 | 29.37 |
| AceGPT-7B-base | 29.73 | 30.95 | 33.45 | 34.42 | 32.14 |
| AceGPT-v1.5-7B-base | 33.03 | 32.08 | 35.39 | 35.59 | 34.03 |
| LLaMA2-13B-base | 32.94 | 32.30 | 33.42 | 37.27 | 33.76 |
| Jais-13B-base | 30.51 | 31.25 | 33.74 | 33.42 | 33.76 |
| AceGPT-13B-base | 36.60 | 38.74 | 43.76 | <u>42.72</u> | 40.45 |
| AceGPT-v1.5-13B-base | <u>36.13</u> | <u>40.07</u> | <u>45.43</u> | 42.17 | <u>40.95</u> |
| Jais-30B-v1-base | 32.67 | 30.67 | 42.13 | 39.60 | 36.27 |
| ChatGPT 3.5 Turbo | **43.38** | **44.12** | **55.57** | **53.21** | **49.07** |
Benchmark evaluation on [ArabicMMLU]((https://github.com/mbzuai-nlp/ArabicMMLU)), and assessed based on its source settings.
| | STEM | Social Sciences | Humanities | Arabic Language | Other | Average |
|------------------|------|------|------|------|------|------|
| Bloomz-7B-base | - | - | - | - | - | - |
| LLaMA2-7B-base | 33.7 | 32.8 | 33.5 | 28.4 | 36.7 | 33.4 |
| AceGPT-7B-base | 35.4 | 35.9 | 36.2 | 31.1 | 41.7 | 36.3 |
| AceGPT-v1.5-7B-base | 36.7 | 36.5 | 34.1 | 30.0 | 41.2 | 37.0 |
| LLaMA2-13B-base | 32.9 | 35.0 | 37.8 | 35.8 | 39.3 | 36.1 |
| Jais-13B-base | 30.3 | 31.4 | 33.6 | 28.1 | 36.3 | 32.2 |
| AceGPT-13B-base | <u>42.7</u> | 45.5 | 48.3 | 42.4 | 50.7 | 46.1 |
| AceGPT-v1.5-13B-base | 42.4 | <u>45.7</u> | 48.4 | <u>46.3</u> | <u>52.5</u> | <u>47.6</u> |
| Jais-30B-v1-base | 39.5 | 45.6 | <u>50.5</u> | 34.6 | 49.1 | 44.8 |
| ChatGPT 3.5 Turbo | **53.8** | **57.0** | **57.5** | **57.6** | **63.8** | **57.7** |
## Samples
#### Sample1(abstract_algebra)
* <b>input:</b>
"فيما يلي أسئلة الاختيار من متعدد (مع الإجابات) حول جبر تجريدي\n\nسؤال: العثور على جميع قيم c في Z_3 بحيث يكون Z_3 [x]/(x^2+c) حقلًا.\nA. 0\nB. 1\nC. 2\nD. 3\nإجابة: B\n\nسؤال: البيان رقم 1 | إذا كان aH عنصرًا في مجموعة العوامل ، فإن | aH | يقسم | a |. البيان رقم 2 | إذا كانت H و K مجموعات فرعية لـ G ، فإن HK مجموعة فرعية لـ G.\nA. صحيح ، صحيح\nB. خطأ ، خطأ\nC. صحيح ، خطأ\nD. خطأ ، صحيح\nإجابة: B\n\nسؤال: العبارة 1 | كل عنصر من مجموعة يولد مجموعة دورية من المجموعة. العبارة 2 | المجموعة المتناظرة S_10 لديها 10 عناصر.\nA. صحيح، صحيح\nB. خطأ، خطأ\nC. صحيح، خطأ\nD. خطأ، صحيح\nإجابة: C\n\nسؤال: البيان 1| كل وظيفة من مجموعة محدودة على نفسها يجب أن تكون واحدة لكل مجموعة. البيان 2 | كل فرع فرعي لمجموعة أبيلية هو أبيلي.\nA. صحيح, صحيح\nB. خاطئ, خاطئ\nC. صحيح, خاطئ\nD. خاطئ, صحيح\nإجابة: A\n\nسؤال: اعثر على خاصية الحلقة 2Z.\nA. 0\nB. 3\nC. 12\nD. 30\nإجابة: A\n\nسؤال: ما هو الدرجة للامتداد الميداني الناتج من Q(sqrt(2), sqrt(3), sqrt(18)) على Q؟\nA. 0\nB. 4\nC. 2\nD. 6\nإجابة:"
* <b>output:</b>
"B\n\nسؤال: ما هو عدد العناصر"
#### Sample2(business_ethics)
* <b>input:</b>
"فيما يلي أسئلة الاختيار من متعدد (مع الإجابات) حول أخلاقيات الأعمال\n\nسؤال: ما هي الحجج الأخلاقية المتعلقة بالمسؤولية الاجتماعية للشركات؟\nA. التكاليف الخارجية، القوة، الاستقلالية\nB. الإعلام، الموارد الضعيفة، التبادل التعاوني\nC. الإعلام، القوة، الاستقلالية\nD. التكاليف الخارجية، القوة، التبادل التعاوني\nإجابة: D\n\nسؤال: _______ هو المحاولة المباشرة لإدارة القضايا الأخلاقية أو المشاكل، سواء بشكل رسمي أو غير رسمي، من خلال سياسات وممارسات وبرامج محددة.\nA. المسؤولية الاجتماعية للشركات\nB. إدارة الأخلاقيات العملية\nC. الاستدامة\nD. إدارة البيئة\nإجابة: B\n\nسؤال: لضمان استقلال أعضاء مجلس الإدارة غير التنفيذية ، هناك عدد من الخطوات التي يمكن اتخاذها ، والتي تشمل اختيار الغير التنفيذيين من _______ الشركة ، وتعيينهم لمدة _________ ، وكذلك تعيينهم _________.\nA. خارج الشركة ، محدودة ، بشكل مستقل\nB. من الداخل ، محدودة ، بشكل متقطع\nC. خارج الشركة ، غير محدودة ، بشكل متقطع\nD. من الداخل ، غير محدودة ، بشكل مستقل\nإجابة: A\n\nسؤال: ما هي الأساليب التي يمكن للمدير الأمني الذي يسعى لتحقيق أهدافه الاختيار بينها؟\nA. العمل المباشر الغير عنيف ، العمل المباشر العنيف ، العمل غير المباشر ، الحملة الدعائية\nB. العمل غير المباشر ، العمل الأوتيل ، العمل المباشر الغير عنيف ، الحملة الإعلامية\nC. العمل غير المباشر ، العمل المباشر العنيف ، العمل المباشر غير العنيف المباشر ، الحملة الدعائية\nD. العمل المباشر الغير عنيف ، العمل الأوتيل ، العمل غير المباشر ، الحملة الإعلامية\nإجابة: C\n\nسؤال: على عكس _______ ، تهدف _______ إلى مكافأة السلوك الإيجابي للشركات. تم تعزيز نجاح مثل هذه الحملات من خلال استخدام ___________, الذي يتيح للحملات تيسير تحقيق الشركة لــ _________ .\nA. الحملات الاستهلاكية، الحملات الاستهلاكية العامة، تكنولوجيا سلسلة الكتل، التبرعات الخيرية\nB. الحملات التحفيزية، الحملات الاستهلاكية العامة، التكنولوجيا الرقمية، زيادة المبيعات\nC. الحملات الاستهلاكية، الحملات الشرائية، تكنولوجيا سلسلة الكتل، التبرعات الخيرية\nD. المقاطعات، الحملات التحفيزية، الحملات الرقمية، زيادة المبيعات\nإجابة: D\n\nسؤال: تُصبح _______ مثل البيتكوين أكثر انتشارًا وتحمل مجموعة كبيرة من الآثار الأخلاقية المرتبطة بها، على سبيل المثال، إنها _______ وأكثر _______. ومع ذلك، تم استخدامها أيضًا للمشاركة في _______.\nA. العملات الرقمية، مكلفة، آمنة، جرائم مالية\nB. العملات التقليدية، رخيصة، غير آمنة، العطاء الخيري\nC. العملات الرقمية، رخيصة، آمنة، جرائم مالية\nD. العملات التقليدية، مكلفة، غير آمنة، العطاء الخيري\nإجابة:"
* <b>output:</b>
"A\n\nسؤال: _______ هو"
# Reference
```
@article{zhu2025second,
title={Second Language (Arabic) Acquisition of LLMs via Progressive Vocabulary Expansion},
author={Zhu, Jianqing and Huang, Huang and Lin, Zhihang and Liang, Juhao and Tang, Zhengyang and Almubarak, Khalid and Alharthi, Mosen and An, Bang and He, Juncai and Wu, Xiangbo and Yu, Fei and Chen, Junying and Ma, Zhuoheng and Du, Yuhao and Hu, Yan and Zhang, He and Alghamdi, Emad A. and Zhang, Lian and Sun, Ruoyu and Li, Haizhou and Wang, Benyou and Xu, Jinchao},
journal={ACL 2025},
year={2025}
}
```
|
KCS97/dog3
|
KCS97
| 2025-08-19T08:12:16Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"dreambooth",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:stable-diffusion-v1-5/stable-diffusion-v1-5",
"base_model:finetune:stable-diffusion-v1-5/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2025-08-19T08:02:43Z |
---
base_model: stable-diffusion-v1-5/stable-diffusion-v1-5
library_name: diffusers
license: creativeml-openrail-m
inference: true
instance_prompt: a photo of sks dog
tags:
- text-to-image
- dreambooth
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# DreamBooth - KCS97/dog3
This is a dreambooth model derived from stable-diffusion-v1-5/stable-diffusion-v1-5. The weights were trained on a photo of sks dog using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
minhnguyet/my-dpo-mistral-7b
|
minhnguyet
| 2025-08-19T07:41:50Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T07:41:13Z |
---
base_model: unsloth/mistral-7b-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** minhnguyet
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
hakimjustbao/blockassist-bc-raging_subtle_wasp_1755587301
|
hakimjustbao
| 2025-08-19T07:35:59Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"raging subtle wasp",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T07:35:55Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- raging subtle wasp
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
KCS97/teapot
|
KCS97
| 2025-08-19T07:29:56Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"safetensors",
"text-to-image",
"dreambooth",
"diffusers-training",
"stable-diffusion",
"stable-diffusion-diffusers",
"base_model:stable-diffusion-v1-5/stable-diffusion-v1-5",
"base_model:finetune:stable-diffusion-v1-5/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2025-08-19T07:17:14Z |
---
base_model: stable-diffusion-v1-5/stable-diffusion-v1-5
library_name: diffusers
license: creativeml-openrail-m
inference: true
instance_prompt: a photo of sks teapot
tags:
- text-to-image
- dreambooth
- diffusers-training
- stable-diffusion
- stable-diffusion-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# DreamBooth - KCS97/teapot
This is a dreambooth model derived from stable-diffusion-v1-5/stable-diffusion-v1-5. The weights were trained on a photo of sks teapot using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: False.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
quantumxnode/blockassist-bc-dormant_peckish_seahorse_1755586779
|
quantumxnode
| 2025-08-19T07:27:29Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dormant peckish seahorse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T07:27:25Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dormant peckish seahorse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755586744
|
ihsanridzi
| 2025-08-19T07:26:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T07:26:00Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
psamtam/Qwen2.5-3B-GRPO-Physics-50_epoches_take2
|
psamtam
| 2025-08-19T07:04:04Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-3B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-18T07:43:35Z |
---
base_model: Qwen/Qwen2.5-3B-Instruct
library_name: transformers
model_name: Qwen2.5-3B-GRPO-Physics-50_epoches_take2
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for Qwen2.5-3B-GRPO-Physics-50_epoches_take2
This model is a fine-tuned version of [Qwen/Qwen2.5-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-3B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="psamtam/Qwen2.5-3B-GRPO-Physics-50_epoches_take2", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.18.2
- Transformers: 4.52.4
- Pytorch: 2.7.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
0xaoyama/blockassist-bc-muscular_zealous_gorilla_1755586951
|
0xaoyama
| 2025-08-19T07:03:06Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"muscular zealous gorilla",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T07:02:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- muscular zealous gorilla
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755582804
|
ihsanridzi
| 2025-08-19T06:20:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T06:19:59Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
CraneAILabs/swahili-gemma-1b-GGUF
|
CraneAILabs
| 2025-08-19T05:40:52Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"swahili",
"translation",
"conversational",
"unsloth",
"gemma",
"gemma3",
"quantized",
"text-generation",
"en",
"sw",
"base_model:CraneAILabs/swahili-gemma-1b",
"base_model:quantized:CraneAILabs/swahili-gemma-1b",
"license:gemma",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-18T07:37:28Z |
---
base_model: CraneAILabs/swahili-gemma-1b
language:
- en
- sw
library_name: transformers
license: gemma
tags:
- swahili
- translation
- conversational
- unsloth
- gemma
- gemma3
- gguf
- quantized
pipeline_tag: text-generation
---
# Swahili Gemma 1B - GGUF
Quantized GGUF versions of **Swahili Gemma 1B**, a fine-tuned Gemma 3 1B instruction model specialized for **English-to-Swahili translation and Swahili conversational AI**. The model accepts input in both English and Swahili but outputs responses exclusively in Swahili.
## 📊 Translation Performance

### Model Comparison
| Model | Parameters | BLEU | chrF++ | Efficiency* |
|-------|------------|------|--------|-------------|
| Gemma 3 4B | 4B | 10.9 | 44.1 | 2.7 |
| **Swahili Gemma 1B** | **1B** | **27.6** | **56.8** | **27.6** |
| Gemma 3 27B | 27B | 29.4 | 60.0 | 1.1 |
| GPT-5 Mini | ~8B | 31.8 | 62.4 | 4.0 |
| Gemini 2.0 Flash | Large | 35.6 | 64.6 | N/A |
*Efficiency = BLEU Score / Parameters (in billions)
### Key Performance Insights
🎯 **Efficiency Leader**: Achieves the highest BLEU-to-parameter ratio (27.6 BLEU per billion parameters)
🚀 **Size Advantage**: Outperforms Gemma 3 4B (4x larger) by 153% on BLEU score
💎 **Competitive Quality**: Achieves 94% of Gemma 3 27B performance with 27x fewer parameters
⚡ **Practical Deployment**: Runs efficiently on consumer hardware while maintaining quality
### Evaluation Details
- **Dataset**: FLORES-200 English→Swahili (1,012 translation pairs)
- **Metrics**: BLEU (bilingual evaluation understudy) and chrF++ (character F-score)
- **Evaluation**: Zero-shot translation performance
## 🚀 Quick Start
```bash
# Download the recommended Q4_K_M quantization
pip install huggingface_hub
# Python download
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="CraneAILabs/swahili-gemma-1b-GGUF",
local_dir="swahili-gemma-1b-GGUF",
allow_patterns=["Q4_K_M/*"] # Download only Q4_K_M version
)
```
## 📊 Available Quantizations
| Quantization | Folder | File Size | Quality | Use Case |
|-------------|--------|-----------|---------|----------|
| `F32` | F32/ | ~3.8GB | Highest | Research & benchmarking |
| `F16` | F16/ | ~1.9GB | Highest | Maximum quality inference |
| `Q8_0` | Q8_0/ | ~1.0GB | Very High | Production with ample resources |
| `Q5_K_M` | Q5_K_M/ | ~812MB | High | Balanced quality/size |
| `Q4_K_M` | Q4_K_M/ | ~769MB | Good | **Recommended** for most users |
| `Q4_K_S` | Q4_K_S/ | ~745MB | Good | Resource-constrained environments |
| `Q3_K_M` | Q3_K_M/ | ~689MB | Fair | Mobile/edge deployment |
| `Q2_K` | Q2_K/ | ~658MB | Lower | Minimal resource usage |
## 💻 Usage with llama.cpp
### Basic Translation
```bash
# English to Swahili translation
./llama-cli \
--model swahili-gemma-1b-GGUF/Q4_K_M/swahili-gemma-1b-q4_k_m.gguf \
--prompt "Translate to Swahili: Hello, how are you today?" \
--temp 0.3 \
--top-p 0.95 \
--top-k 64 \
--repeat-penalty 1.1 \
-n 128
```
## 🔧 Usage with Ollama
```bash
# Create model from GGUF
ollama create swahili-gemma-1b -f Modelfile
# Use for translation
ollama run swahili-gemma-1b "Translate to Swahili: Good morning!"
# Use for conversation
ollama run swahili-gemma-1b "Hujambo! Je, unaweza kunisaidia?"
```
### Modelfile Example
```dockerfile
FROM swahili-gemma-1b-GGUF/Q4_K_M/swahili-gemma-1b-q4_k_m.gguf
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
```
## 🐍 Usage with Python (llama-cpp-python)
```python
from llama_cpp import Llama
# Initialize model
llm = Llama(
model_path="swahili-gemma-1b-GGUF/Q4_K_M/swahili-gemma-1b-q4_k_m.gguf",
n_ctx=2048,
n_threads=8,
verbose=False
)
# Generate translation
response = llm(
"Translate to Swahili: Hello, how are you today?",
max_tokens=128,
temperature=0.3,
top_p=0.95,
top_k=64,
repeat_penalty=1.1
)
print(response['choices'][0]['text'])
```
## 🌍 Language Capabilities
- **Input Languages**: English + Swahili
- **Output Language**: Swahili only
- **Primary Focus**: English-to-Swahili translation and Swahili conversation
## 📊 Performance Metrics
### Translation Quality (BLEU Scores)
| Model | BLEU Score | chrF++ |
|-------|------------|--------|
| **🥇 Swahili Gemma 1B** | **23.64** | **52.26** |
| 🥈 ChatGPT-4o-latest | [TBD] | [TBD] |
| 🥉 Other Models | [TBD] | [TBD] |
*Evaluated on 1,012 English-to-Swahili translation samples.*
## 🎯 Capabilities
- **Translation**: English-to-Swahili translation
- **Conversational AI**: Natural dialogue in Swahili
- **Summarization**: Text summarization in Swahili
- **Writing**: Creative and informational writing in Swahili
- **Question Answering**: General knowledge responses in Swahili
## 💡 Recommended Parameters
```bash
# Optimal settings for translation tasks
--temp 0.3
--top-p 0.95
--top-k 64
--repeat-penalty 1.1
--ctx-size 2048
```
## 🔗 Related Models
- **Original Model**: [CraneAILabs/swahili-gemma-1b](https://huggingface.co/CraneAILabs/swahili-gemma-1b) - Full precision HuggingFace model
- **LiteRT Mobile**: [CraneAILabs/swahili-gemma-1b-litert](https://huggingface.co/CraneAILabs/swahili-gemma-1b-litert) - Mobile deployment
- **Ollama**: [crane-ai-labs/swahili-gemma-1b](https://ollama.com/crane-ai-labs/swahili-gemma-1b) - Ready-to-run models
## 🛠️ Technical Details
- **Base Model**: google/gemma-3-1b-it
- **Architecture**: Gemma 3
- **Context Length**: 4,096 tokens
- **Quantization**: GGML format with multiple precision levels
- **Compatible**: llama.cpp, Ollama, Jan, LM Studio, and other GGUF engines
## 🎨 Use Cases
- **Offline Translation**: Run Swahili translation without internet
- **Local AI Assistant**: Swahili conversational AI on your machine
- **Educational Tools**: Language learning applications
- **Content Creation**: Generate Swahili content locally
- **Research**: Swahili language model experiments
## ⚠️ Limitations
- **Language Output**: Responds only in Swahili
- **Quantization Trade-offs**: Lower bit quantizations may reduce quality
- **Context Limit**: 4K tokens for optimal performance
- **Specialized Tasks**: May need fine-tuning for specific domains
## 📄 License
This model is released under the [Gemma Terms of Use](https://ai.google.dev/gemma/terms). Please review the terms before use.
## 🙏 Acknowledgments
- **Google**: For the Gemma 3 base model, support and guidance.
- **Community**: For Swahili language resources and datasets
- **Gilbert Korir (Msingi AI, Nairobi, Kenya)**
- **Alfred Malengo Kondoro (Hanyang University, Seoul, South Korea)**
## Citation
If you use these GGUF quantizations in your research or applications, please cite:
```bibtex
@misc{crane_ai_labs_2025,
author = {Bakunga Bronson and Kato Steven Mubiru and Lwanga Caleb and Gimei Alex and Kavuma Lameck and Roland Ganafa and Sibomana Glorry and Atuhaire Collins and JohnRoy Nangeso and Tukamushaba Catherine},
title = {Swahili Gemma: A Fine-tuned Gemma 3 1B Model for Swahili conversational AI},
year = {2025},
url = {https://huggingface.co/CraneAILabs/swahili-gemma-1b},
organization = {Crane AI Labs}
}
```
---
**Built with ❤️ by Crane AI Labs**
*Swahili Gemma - Your helpful Swahili AI companion, optimized for local deployment*
|
Kurosawama/Llama-3.1-8B-Instruct-Translation-align
|
Kurosawama
| 2025-08-19T05:25:18Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"trl",
"dpo",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T05:25:15Z |
---
library_name: transformers
tags:
- trl
- dpo
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF
|
mradermacher
| 2025-08-19T04:49:52Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:hdl2v/qwen2.5-coder-32b-single-verilog",
"base_model:quantized:hdl2v/qwen2.5-coder-32b-single-verilog",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-08-19T01:43:26Z |
---
base_model: hdl2v/qwen2.5-coder-32b-single-verilog
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/hdl2v/qwen2.5-coder-32b-single-verilog
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#qwen2.5-coder-32b-single-verilog-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-IQ1_S.gguf) | i1-IQ1_S | 7.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-IQ1_M.gguf) | i1-IQ1_M | 8.0 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 9.1 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-IQ2_XS.gguf) | i1-IQ2_XS | 10.1 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-IQ2_S.gguf) | i1-IQ2_S | 10.5 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-IQ2_M.gguf) | i1-IQ2_M | 11.4 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-Q2_K_S.gguf) | i1-Q2_K_S | 11.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-Q2_K.gguf) | i1-Q2_K | 12.4 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 12.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-IQ3_XS.gguf) | i1-IQ3_XS | 13.8 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-Q3_K_S.gguf) | i1-Q3_K_S | 14.5 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-IQ3_S.gguf) | i1-IQ3_S | 14.5 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-IQ3_M.gguf) | i1-IQ3_M | 14.9 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-Q3_K_M.gguf) | i1-Q3_K_M | 16.0 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-Q3_K_L.gguf) | i1-Q3_K_L | 17.3 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-IQ4_XS.gguf) | i1-IQ4_XS | 17.8 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-Q4_0.gguf) | i1-Q4_0 | 18.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-Q4_K_S.gguf) | i1-Q4_K_S | 18.9 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-Q4_K_M.gguf) | i1-Q4_K_M | 19.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-Q4_1.gguf) | i1-Q4_1 | 20.7 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-Q5_K_S.gguf) | i1-Q5_K_S | 22.7 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-Q5_K_M.gguf) | i1-Q5_K_M | 23.4 | |
| [GGUF](https://huggingface.co/mradermacher/qwen2.5-coder-32b-single-verilog-i1-GGUF/resolve/main/qwen2.5-coder-32b-single-verilog.i1-Q6_K.gguf) | i1-Q6_K | 27.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
mradermacher/LFM2-VL-1.6B-GGUF
|
mradermacher
| 2025-08-19T04:25:33Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"liquid",
"lfm2",
"lfm2-vl",
"edge",
"en",
"base_model:LiquidAI/LFM2-VL-1.6B",
"base_model:quantized:LiquidAI/LFM2-VL-1.6B",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-08-17T13:52:22Z |
---
base_model: LiquidAI/LFM2-VL-1.6B
language:
- en
library_name: transformers
license: other
license_link: LICENSE
license_name: lfm1.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- liquid
- lfm2
- lfm2-vl
- edge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
<!-- ### quants: x-f16 Q4_K_S Q2_K Q8_0 Q6_K Q3_K_M Q3_K_S Q3_K_L Q4_K_M Q5_K_S Q5_K_M IQ4_XS -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
static quants of https://huggingface.co/LiquidAI/LFM2-VL-1.6B
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#LFM2-VL-1.6B-GGUF).***
weighted/imatrix quants are available at https://huggingface.co/mradermacher/LFM2-VL-1.6B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/LFM2-VL-1.6B-GGUF/resolve/main/LFM2-VL-1.6B.Q2_K.gguf) | Q2_K | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/LFM2-VL-1.6B-GGUF/resolve/main/LFM2-VL-1.6B.Q3_K_S.gguf) | Q3_K_S | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/LFM2-VL-1.6B-GGUF/resolve/main/LFM2-VL-1.6B.mmproj-Q8_0.gguf) | mmproj-Q8_0 | 0.7 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/LFM2-VL-1.6B-GGUF/resolve/main/LFM2-VL-1.6B.Q3_K_M.gguf) | Q3_K_M | 0.7 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/LFM2-VL-1.6B-GGUF/resolve/main/LFM2-VL-1.6B.Q3_K_L.gguf) | Q3_K_L | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/LFM2-VL-1.6B-GGUF/resolve/main/LFM2-VL-1.6B.IQ4_XS.gguf) | IQ4_XS | 0.8 | |
| [GGUF](https://huggingface.co/mradermacher/LFM2-VL-1.6B-GGUF/resolve/main/LFM2-VL-1.6B.Q4_K_S.gguf) | Q4_K_S | 0.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/LFM2-VL-1.6B-GGUF/resolve/main/LFM2-VL-1.6B.Q4_K_M.gguf) | Q4_K_M | 0.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/LFM2-VL-1.6B-GGUF/resolve/main/LFM2-VL-1.6B.Q5_K_S.gguf) | Q5_K_S | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/LFM2-VL-1.6B-GGUF/resolve/main/LFM2-VL-1.6B.mmproj-f16.gguf) | mmproj-f16 | 0.9 | multi-modal supplement |
| [GGUF](https://huggingface.co/mradermacher/LFM2-VL-1.6B-GGUF/resolve/main/LFM2-VL-1.6B.Q5_K_M.gguf) | Q5_K_M | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/LFM2-VL-1.6B-GGUF/resolve/main/LFM2-VL-1.6B.Q6_K.gguf) | Q6_K | 1.1 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/LFM2-VL-1.6B-GGUF/resolve/main/LFM2-VL-1.6B.Q8_0.gguf) | Q8_0 | 1.3 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/LFM2-VL-1.6B-GGUF/resolve/main/LFM2-VL-1.6B.f16.gguf) | f16 | 2.4 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.