
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_3272
|
rasdani/github-patches
|
git_diff
|
dbt-labs__dbt-core-4192
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug] Incompatible versions of `protobuf` required in sub-dependencies
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
It is not currently possible to install dbt through Pipenv because of incompatible versions of `protobuf` in sub-dependencies used in `dbt-bigquery`.
Specifically;
- `google-api-core[grpc]==1.31.3` requires `protobuf<3.18.0`
- `proto-plus==1.19.7` (used by `google-cloud-bigquery==2.29.0`) requires `protobuf>=3.19.0`
Alternatively, installing dbt through `pip` may appear successful, but the issue of incompatible versions remains -- pip simply installs the version of `protobuf` that satisfies whichever sub-dependency is installed last in the sequence, ignoring that previous sub-dependencies required an incompatible version.
### Expected Behavior
dbt should ideally use non-conflicting versions of `google-api-core[grpc]` and `google-cloud-bigquery` or allow installation of dbt without the `dbt-bigquery` extra.
### Steps To Reproduce
1. `pip install pipenv`
2. `pipenv install dbt`
### Relevant log output
```shell
[pipenv.exceptions.ResolutionFailure]: Warning: Your dependencies could not be resolved. You likely have a mismatch in your sub-dependencies.
First try clearing your dependency cache with $ pipenv lock --clear, then try the original command again.
Alternatively, you can use $ pipenv install --skip-lock to bypass this mechanism, then run $ pipenv graph to inspect the situation.
Hint: try $ pipenv lock --pre if it is a pre-release dependency.
ERROR: Could not find a version that matches protobuf<3.18.0,<4,>=3.12.0,>=3.13.0,>=3.19.0 (from dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))
Tried: 2.0.3, 2.3.0, 2.4.1, 2.5.0, 2.6.0, 2.6.1, 3.0.0, 3.0.0, 3.1.0, 3.1.0.post1, 3.1.0.post1, 3.2.0, 3.2.0, 3.3.0, 3.4.0, 3.4.0, 3.5.0.post1, 3.5.0.post1, 3.5.1, 3.5.1, 3.5.2, 3.5.2, 3.5.2.post1, 3.5.2.post1, 3.6.0, 3.6.0, 3.6.1, 3.6.1, 3.7.0, 3.7.0, 3.7.1, 3.7.1, 3.8.0, 3.8.0, 3.9.0, 3.9.0, 3.9.1, 3.9.1, 3.9.2, 3.9.2, 3.10.0, 3.10.0, 3.11.0, 3.11.0, 3.11.1, 3.11.1, 3.11.2, 3.11.2, 3.11.3, 3.11.3, 3.12.2, 3.12.2, 3.12.4, 3.12.4, 3.13.0, 3.13.0, 3.14.0, 3.14.0, 3.15.0, 3.15.0, 3.15.0, 3.15.1, 3.15.1, 3.15.1, 3.15.2, 3.15.2, 3.15.2, 3.15.3, 3.15.3, 3.15.3, 3.15.4, 3.15.4, 3.15.4, 3.15.5, 3.15.5, 3.15.5, 3.15.6, 3.15.6, 3.15.6, 3.15.7, 3.15.7, 3.15.7, 3.15.8, 3.15.8, 3.15.8, 3.16.0, 3.16.0, 3.16.0, 3.17.0, 3.17.0, 3.17.0, 3.17.1, 3.17.1, 3.17.1, 3.17.2, 3.17.2, 3.17.2, 3.17.3, 3.17.3, 3.17.3, 3.18.0, 3.18.0, 3.18.0, 3.18.1, 3.18.1, 3.18.1, 3.19.0, 3.19.0, 3.19.0, 3.19.1, 3.19.1, 3.19.1
Skipped pre-versions: 2.0.0b0, 3.0.0a2, 3.0.0a3, 3.0.0b1, 3.0.0b1.post1, 3.0.0b1.post2, 3.0.0b2, 3.0.0b2, 3.0.0b2.post1, 3.0.0b2.post1, 3.0.0b2.post2, 3.0.0b2.post2, 3.0.0b3, 3.0.0b4, 3.0.0b4, 3.2.0rc1, 3.2.0rc1, 3.2.0rc1.post1, 3.2.0rc1.post1, 3.2.0rc2, 3.2.0rc2, 3.7.0rc2, 3.7.0rc2, 3.7.0rc3, 3.7.0rc3, 3.8.0rc1, 3.8.0rc1, 3.9.0rc1, 3.9.0rc1, 3.10.0rc1, 3.10.0rc1, 3.11.0rc1, 3.11.0rc1, 3.11.0rc2, 3.11.0rc2, 3.13.0rc3, 3.13.0rc3, 3.14.0rc1, 3.14.0rc1, 3.14.0rc2, 3.14.0rc2, 3.14.0rc3, 3.14.0rc3, 3.15.0rc1, 3.15.0rc1, 3.15.0rc1, 3.15.0rc2, 3.15.0rc2, 3.15.0rc2, 3.16.0rc1, 3.16.0rc1, 3.16.0rc1, 3.16.0rc2, 3.16.0rc2, 3.16.0rc2, 3.17.0rc1, 3.17.0rc1, 3.17.0rc1, 3.17.0rc2, 3.17.0rc2, 3.17.0rc2, 3.18.0rc1, 3.18.0rc1, 3.18.0rc1, 3.18.0rc2, 3.18.0rc2, 3.18.0rc2, 3.19.0rc1, 3.19.0rc1, 3.19.0rc1, 3.19.0rc2, 3.19.0rc2, 3.19.0rc2, 4.0.0rc1, 4.0.0rc1, 4.0.0rc2, 4.0.0rc2
There are incompatible versions in the resolved dependencies:
protobuf<3.18.0,>=3.12.0 (from google-api-core[grpc]==1.31.3->dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))
protobuf<4,>=3.13.0 (from dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))
protobuf>=3.12.0 (from google-cloud-bigquery==2.29.0->dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))
protobuf>=3.12.0 (from googleapis-common-protos==1.53.0->dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))
protobuf>=3.19.0 (from proto-plus==1.19.7->google-cloud-bigquery==2.29.0->dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))
```
### Environment
```markdown
- OS: macOS 11.6
- Python: Python 3.7
- dbt: 0.21 (same error with 0.20)
```
### What database are you using dbt with?
_No response_
### Additional Context
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugins/bigquery/setup.py`
Content:
```
1 #!/usr/bin/env python
2 import os
3 import sys
4
5 if sys.version_info < (3, 6):
6 print('Error: dbt does not support this version of Python.')
7 print('Please upgrade to Python 3.6 or higher.')
8 sys.exit(1)
9
10
11 from setuptools import setup
12 try:
13 from setuptools import find_namespace_packages
14 except ImportError:
15 # the user has a downlevel version of setuptools.
16 print('Error: dbt requires setuptools v40.1.0 or higher.')
17 print('Please upgrade setuptools with "pip install --upgrade setuptools" '
18 'and try again')
19 sys.exit(1)
20
21
22 package_name = "dbt-bigquery"
23 package_version = "0.21.0"
24 description = """The bigquery adapter plugin for dbt (data build tool)"""
25
26 this_directory = os.path.abspath(os.path.dirname(__file__))
27 with open(os.path.join(this_directory, 'README.md')) as f:
28 long_description = f.read()
29
30 setup(
31 name=package_name,
32 version=package_version,
33 description=description,
34 long_description=long_description,
35 long_description_content_type='text/markdown',
36 author="dbt Labs",
37 author_email="info@dbtlabs.com",
38 url="https://github.com/dbt-labs/dbt",
39 packages=find_namespace_packages(include=['dbt', 'dbt.*']),
40 package_data={
41 'dbt': [
42 'include/bigquery/dbt_project.yml',
43 'include/bigquery/sample_profiles.yml',
44 'include/bigquery/macros/*.sql',
45 'include/bigquery/macros/**/*.sql',
46 ]
47 },
48 install_requires=[
49 'dbt-core=={}'.format(package_version),
50 'protobuf>=3.13.0,<4',
51 'google-cloud-core>=1.3.0,<2',
52 'google-cloud-bigquery>=1.25.0,<3',
53 'google-api-core>=1.16.0,<2',
54 'googleapis-common-protos>=1.6.0,<2',
55 'six>=1.14.0',
56 ],
57 zip_safe=False,
58 classifiers=[
59 'Development Status :: 5 - Production/Stable',
60
61 'License :: OSI Approved :: Apache Software License',
62
63 'Operating System :: Microsoft :: Windows',
64 'Operating System :: MacOS :: MacOS X',
65 'Operating System :: POSIX :: Linux',
66
67 'Programming Language :: Python :: 3.6',
68 'Programming Language :: Python :: 3.7',
69 'Programming Language :: Python :: 3.8',
70 'Programming Language :: Python :: 3.9',
71 ],
72 python_requires=">=3.6.2",
73 )
74
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plugins/bigquery/setup.py b/plugins/bigquery/setup.py
--- a/plugins/bigquery/setup.py
+++ b/plugins/bigquery/setup.py
@@ -50,7 +50,7 @@
'protobuf>=3.13.0,<4',
'google-cloud-core>=1.3.0,<2',
'google-cloud-bigquery>=1.25.0,<3',
- 'google-api-core>=1.16.0,<2',
+ 'google-api-core>=1.16.0,<1.31.3',
'googleapis-common-protos>=1.6.0,<2',
'six>=1.14.0',
],
|
{"golden_diff": "diff --git a/plugins/bigquery/setup.py b/plugins/bigquery/setup.py\n--- a/plugins/bigquery/setup.py\n+++ b/plugins/bigquery/setup.py\n@@ -50,7 +50,7 @@\n 'protobuf>=3.13.0,<4',\n 'google-cloud-core>=1.3.0,<2',\n 'google-cloud-bigquery>=1.25.0,<3',\n- 'google-api-core>=1.16.0,<2',\n+ 'google-api-core>=1.16.0,<1.31.3',\n 'googleapis-common-protos>=1.6.0,<2',\n 'six>=1.14.0',\n ],\n", "issue": "[Bug] Incompatible versions of `protobuf` required in sub-dependencies\n### Is there an existing issue for this?\r\n\r\n- [X] I have searched the existing issues\r\n\r\n### Current Behavior\r\n\r\nIt is not currently possible to install dbt through Pipenv because of incompatible versions of `protobuf` in sub-dependencies used in `dbt-bigquery`. \r\n\r\nSpecifically;\r\n\r\n- `google-api-core[grpc]==1.31.3` requires `protobuf<3.18.0`\r\n- `proto-plus==1.19.7` (used by `google-cloud-bigquery==2.29.0`) requires `protobuf>=3.19.0`\r\n\r\nAlternatively, installing dbt through `pip` may appear successful, but the issue of incompatible versions remains -- pip simply installs the version of `protobuf` that satisfies whichever sub-dependency is installed last in the sequence, ignoring that previous sub-dependencies required an incompatible version.\r\n\r\n### Expected Behavior\r\n\r\ndbt should ideally use non-conflicting versions of `google-api-core[grpc]` and `google-cloud-bigquery` or allow installation of dbt without the `dbt-bigquery` extra.\r\n\r\n### Steps To Reproduce\r\n\r\n1. `pip install pipenv`\r\n2. `pipenv install dbt`\r\n\r\n### Relevant log output\r\n\r\n```shell\r\n[pipenv.exceptions.ResolutionFailure]: Warning: Your dependencies could not be resolved. You likely have a mismatch in your sub-dependencies.\r\n First try clearing your dependency cache with $ pipenv lock --clear, then try the original command again.\r\n Alternatively, you can use $ pipenv install --skip-lock to bypass this mechanism, then run $ pipenv graph to inspect the situation.\r\n Hint: try $ pipenv lock --pre if it is a pre-release dependency.\r\nERROR: Could not find a version that matches protobuf<3.18.0,<4,>=3.12.0,>=3.13.0,>=3.19.0 (from dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))\r\nTried: 2.0.3, 2.3.0, 2.4.1, 2.5.0, 2.6.0, 2.6.1, 3.0.0, 3.0.0, 3.1.0, 3.1.0.post1, 3.1.0.post1, 3.2.0, 3.2.0, 3.3.0, 3.4.0, 3.4.0, 3.5.0.post1, 3.5.0.post1, 3.5.1, 3.5.1, 3.5.2, 3.5.2, 3.5.2.post1, 3.5.2.post1, 3.6.0, 3.6.0, 3.6.1, 3.6.1, 3.7.0, 3.7.0, 3.7.1, 3.7.1, 3.8.0, 3.8.0, 3.9.0, 3.9.0, 3.9.1, 3.9.1, 3.9.2, 3.9.2, 3.10.0, 3.10.0, 3.11.0, 3.11.0, 3.11.1, 3.11.1, 3.11.2, 3.11.2, 3.11.3, 3.11.3, 3.12.2, 3.12.2, 3.12.4, 3.12.4, 3.13.0, 3.13.0, 3.14.0, 3.14.0, 3.15.0, 3.15.0, 3.15.0, 3.15.1, 3.15.1, 3.15.1, 3.15.2, 3.15.2, 3.15.2, 3.15.3, 3.15.3, 3.15.3, 3.15.4, 3.15.4, 3.15.4, 3.15.5, 3.15.5, 3.15.5, 3.15.6, 3.15.6, 3.15.6, 3.15.7, 3.15.7, 3.15.7, 3.15.8, 3.15.8, 3.15.8, 3.16.0, 3.16.0, 3.16.0, 3.17.0, 3.17.0, 3.17.0, 3.17.1, 3.17.1, 3.17.1, 3.17.2, 3.17.2, 3.17.2, 3.17.3, 3.17.3, 3.17.3, 3.18.0, 3.18.0, 3.18.0, 3.18.1, 3.18.1, 3.18.1, 3.19.0, 3.19.0, 3.19.0, 3.19.1, 3.19.1, 3.19.1\r\nSkipped pre-versions: 2.0.0b0, 3.0.0a2, 3.0.0a3, 3.0.0b1, 3.0.0b1.post1, 3.0.0b1.post2, 3.0.0b2, 3.0.0b2, 3.0.0b2.post1, 3.0.0b2.post1, 3.0.0b2.post2, 3.0.0b2.post2, 3.0.0b3, 3.0.0b4, 3.0.0b4, 3.2.0rc1, 3.2.0rc1, 3.2.0rc1.post1, 3.2.0rc1.post1, 3.2.0rc2, 3.2.0rc2, 3.7.0rc2, 3.7.0rc2, 3.7.0rc3, 3.7.0rc3, 3.8.0rc1, 3.8.0rc1, 3.9.0rc1, 3.9.0rc1, 3.10.0rc1, 3.10.0rc1, 3.11.0rc1, 3.11.0rc1, 3.11.0rc2, 3.11.0rc2, 3.13.0rc3, 3.13.0rc3, 3.14.0rc1, 3.14.0rc1, 3.14.0rc2, 3.14.0rc2, 3.14.0rc3, 3.14.0rc3, 3.15.0rc1, 3.15.0rc1, 3.15.0rc1, 3.15.0rc2, 3.15.0rc2, 3.15.0rc2, 3.16.0rc1, 3.16.0rc1, 3.16.0rc1, 3.16.0rc2, 3.16.0rc2, 3.16.0rc2, 3.17.0rc1, 3.17.0rc1, 3.17.0rc1, 3.17.0rc2, 3.17.0rc2, 3.17.0rc2, 3.18.0rc1, 3.18.0rc1, 3.18.0rc1, 3.18.0rc2, 3.18.0rc2, 3.18.0rc2, 3.19.0rc1, 3.19.0rc1, 3.19.0rc1, 3.19.0rc2, 3.19.0rc2, 3.19.0rc2, 4.0.0rc1, 4.0.0rc1, 4.0.0rc2, 4.0.0rc2\r\nThere are incompatible versions in the resolved dependencies:\r\n protobuf<3.18.0,>=3.12.0 (from google-api-core[grpc]==1.31.3->dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))\r\n protobuf<4,>=3.13.0 (from dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))\r\n protobuf>=3.12.0 (from google-cloud-bigquery==2.29.0->dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))\r\n protobuf>=3.12.0 (from googleapis-common-protos==1.53.0->dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))\r\n protobuf>=3.19.0 (from proto-plus==1.19.7->google-cloud-bigquery==2.29.0->dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))\r\n```\r\n\r\n\r\n### Environment\r\n\r\n```markdown\r\n- OS: macOS 11.6\r\n- Python: Python 3.7\r\n- dbt: 0.21 (same error with 0.20)\r\n```\r\n\r\n\r\n### What database are you using dbt with?\r\n\r\n_No response_\r\n\r\n### Additional Context\r\n\r\n_No response_\n", "before_files": [{"content": "#!/usr/bin/env python\nimport os\nimport sys\n\nif sys.version_info < (3, 6):\n print('Error: dbt does not support this version of Python.')\n print('Please upgrade to Python 3.6 or higher.')\n sys.exit(1)\n\n\nfrom setuptools import setup\ntry:\n from setuptools import find_namespace_packages\nexcept ImportError:\n # the user has a downlevel version of setuptools.\n print('Error: dbt requires setuptools v40.1.0 or higher.')\n print('Please upgrade setuptools with \"pip install --upgrade setuptools\" '\n 'and try again')\n sys.exit(1)\n\n\npackage_name = \"dbt-bigquery\"\npackage_version = \"0.21.0\"\ndescription = \"\"\"The bigquery adapter plugin for dbt (data build tool)\"\"\"\n\nthis_directory = os.path.abspath(os.path.dirname(__file__))\nwith open(os.path.join(this_directory, 'README.md')) as f:\n long_description = f.read()\n\nsetup(\n name=package_name,\n version=package_version,\n description=description,\n long_description=long_description,\n long_description_content_type='text/markdown',\n author=\"dbt Labs\",\n author_email=\"info@dbtlabs.com\",\n url=\"https://github.com/dbt-labs/dbt\",\n packages=find_namespace_packages(include=['dbt', 'dbt.*']),\n package_data={\n 'dbt': [\n 'include/bigquery/dbt_project.yml',\n 'include/bigquery/sample_profiles.yml',\n 'include/bigquery/macros/*.sql',\n 'include/bigquery/macros/**/*.sql',\n ]\n },\n install_requires=[\n 'dbt-core=={}'.format(package_version),\n 'protobuf>=3.13.0,<4',\n 'google-cloud-core>=1.3.0,<2',\n 'google-cloud-bigquery>=1.25.0,<3',\n 'google-api-core>=1.16.0,<2',\n 'googleapis-common-protos>=1.6.0,<2',\n 'six>=1.14.0',\n ],\n zip_safe=False,\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n\n 'License :: OSI Approved :: Apache Software License',\n\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: POSIX :: Linux',\n\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n ],\n python_requires=\">=3.6.2\",\n)\n", "path": "plugins/bigquery/setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\nimport os\nimport sys\n\nif sys.version_info < (3, 6):\n print('Error: dbt does not support this version of Python.')\n print('Please upgrade to Python 3.6 or higher.')\n sys.exit(1)\n\n\nfrom setuptools import setup\ntry:\n from setuptools import find_namespace_packages\nexcept ImportError:\n # the user has a downlevel version of setuptools.\n print('Error: dbt requires setuptools v40.1.0 or higher.')\n print('Please upgrade setuptools with \"pip install --upgrade setuptools\" '\n 'and try again')\n sys.exit(1)\n\n\npackage_name = \"dbt-bigquery\"\npackage_version = \"0.21.0\"\ndescription = \"\"\"The bigquery adapter plugin for dbt (data build tool)\"\"\"\n\nthis_directory = os.path.abspath(os.path.dirname(__file__))\nwith open(os.path.join(this_directory, 'README.md')) as f:\n long_description = f.read()\n\nsetup(\n name=package_name,\n version=package_version,\n description=description,\n long_description=long_description,\n long_description_content_type='text/markdown',\n author=\"dbt Labs\",\n author_email=\"info@dbtlabs.com\",\n url=\"https://github.com/dbt-labs/dbt\",\n packages=find_namespace_packages(include=['dbt', 'dbt.*']),\n package_data={\n 'dbt': [\n 'include/bigquery/dbt_project.yml',\n 'include/bigquery/sample_profiles.yml',\n 'include/bigquery/macros/*.sql',\n 'include/bigquery/macros/**/*.sql',\n ]\n },\n install_requires=[\n 'dbt-core=={}'.format(package_version),\n 'protobuf>=3.13.0,<4',\n 'google-cloud-core>=1.3.0,<2',\n 'google-cloud-bigquery>=1.25.0,<3',\n 'google-api-core>=1.16.0,<1.31.3',\n 'googleapis-common-protos>=1.6.0,<2',\n 'six>=1.14.0',\n ],\n zip_safe=False,\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n\n 'License :: OSI Approved :: Apache Software License',\n\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: POSIX :: Linux',\n\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n ],\n python_requires=\">=3.6.2\",\n)\n", "path": "plugins/bigquery/setup.py"}]}
| 3,710 | 154 |
gh_patches_debug_26755
|
rasdani/github-patches
|
git_diff
|
dask__dask-8213
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
⚠️ Upstream CI failed ⚠️
[Workflow Run URL](https://github.com/dask/dask/actions/runs/1304259797)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dask/dataframe/tseries/resample.py`
Content:
```
1 import numpy as np
2 import pandas as pd
3 from pandas.core.resample import Resampler as pd_Resampler
4
5 from ...base import tokenize
6 from ...highlevelgraph import HighLevelGraph
7 from ...utils import derived_from
8 from .. import methods
9 from ..core import DataFrame, Series
10
11
12 def getnanos(rule):
13 try:
14 return getattr(rule, "nanos", None)
15 except ValueError:
16 return None
17
18
19 def _resample_series(
20 series,
21 start,
22 end,
23 reindex_closed,
24 rule,
25 resample_kwargs,
26 how,
27 fill_value,
28 how_args,
29 how_kwargs,
30 ):
31 out = getattr(series.resample(rule, **resample_kwargs), how)(
32 *how_args, **how_kwargs
33 )
34
35 new_index = pd.date_range(
36 start.tz_localize(None),
37 end.tz_localize(None),
38 freq=rule,
39 closed=reindex_closed,
40 name=out.index.name,
41 ).tz_localize(start.tz, nonexistent="shift_forward")
42
43 if not out.index.isin(new_index).all():
44 raise ValueError(
45 "Index is not contained within new index. This can often be "
46 "resolved by using larger partitions, or unambiguous "
47 "frequencies: 'Q', 'A'..."
48 )
49
50 return out.reindex(new_index, fill_value=fill_value)
51
52
53 def _resample_bin_and_out_divs(divisions, rule, closed="left", label="left"):
54 rule = pd.tseries.frequencies.to_offset(rule)
55 g = pd.Grouper(freq=rule, how="count", closed=closed, label=label)
56
57 # Determine bins to apply `how` to. Disregard labeling scheme.
58 divs = pd.Series(range(len(divisions)), index=divisions)
59 temp = divs.resample(rule, closed=closed, label="left").count()
60 tempdivs = temp.loc[temp > 0].index
61
62 # Cleanup closed == 'right' and label == 'right'
63 res = pd.offsets.Nano() if hasattr(rule, "delta") else pd.offsets.Day()
64 if g.closed == "right":
65 newdivs = tempdivs + res
66 else:
67 newdivs = tempdivs
68 if g.label == "right":
69 outdivs = tempdivs + rule
70 else:
71 outdivs = tempdivs
72
73 newdivs = methods.tolist(newdivs)
74 outdivs = methods.tolist(outdivs)
75
76 # Adjust ends
77 if newdivs[0] < divisions[0]:
78 newdivs[0] = divisions[0]
79 if newdivs[-1] < divisions[-1]:
80 if len(newdivs) < len(divs):
81 setter = lambda a, val: a.append(val)
82 else:
83 setter = lambda a, val: a.__setitem__(-1, val)
84 setter(newdivs, divisions[-1] + res)
85 if outdivs[-1] > divisions[-1]:
86 setter(outdivs, outdivs[-1])
87 elif outdivs[-1] < divisions[-1]:
88 setter(outdivs, temp.index[-1])
89
90 return tuple(map(pd.Timestamp, newdivs)), tuple(map(pd.Timestamp, outdivs))
91
92
93 class Resampler:
94 """Class for resampling timeseries data.
95
96 This class is commonly encountered when using ``obj.resample(...)`` which
97 return ``Resampler`` objects.
98
99 Parameters
100 ----------
101 obj : Dask DataFrame or Series
102 Data to be resampled.
103 rule : str, tuple, datetime.timedelta, DateOffset or None
104 The offset string or object representing the target conversion.
105 kwargs : optional
106 Keyword arguments passed to underlying pandas resampling function.
107
108 Returns
109 -------
110 Resampler instance of the appropriate type
111 """
112
113 def __init__(self, obj, rule, **kwargs):
114 if not obj.known_divisions:
115 msg = (
116 "Can only resample dataframes with known divisions\n"
117 "See https://docs.dask.org/en/latest/dataframe-design.html#partitions\n"
118 "for more information."
119 )
120 raise ValueError(msg)
121 self.obj = obj
122 self._rule = pd.tseries.frequencies.to_offset(rule)
123 self._kwargs = kwargs
124
125 def _agg(self, how, meta=None, fill_value=np.nan, how_args=(), how_kwargs={}):
126 """Aggregate using one or more operations
127
128 Parameters
129 ----------
130 how : str
131 Name of aggregation operation
132 fill_value : scalar, optional
133 Value to use for missing values, applied during upsampling.
134 Default is NaN.
135 how_args : optional
136 Positional arguments for aggregation operation.
137 how_kwargs : optional
138 Keyword arguments for aggregation operation.
139
140 Returns
141 -------
142 Dask DataFrame or Series
143 """
144 rule = self._rule
145 kwargs = self._kwargs
146 name = "resample-" + tokenize(
147 self.obj, rule, kwargs, how, *how_args, **how_kwargs
148 )
149
150 # Create a grouper to determine closed and label conventions
151 newdivs, outdivs = _resample_bin_and_out_divs(
152 self.obj.divisions, rule, **kwargs
153 )
154
155 # Repartition divs into bins. These won't match labels after mapping
156 partitioned = self.obj.repartition(newdivs, force=True)
157
158 keys = partitioned.__dask_keys__()
159 dsk = {}
160
161 args = zip(keys, outdivs, outdivs[1:], ["left"] * (len(keys) - 1) + [None])
162 for i, (k, s, e, c) in enumerate(args):
163 dsk[(name, i)] = (
164 _resample_series,
165 k,
166 s,
167 e,
168 c,
169 rule,
170 kwargs,
171 how,
172 fill_value,
173 list(how_args),
174 how_kwargs,
175 )
176
177 # Infer output metadata
178 meta_r = self.obj._meta_nonempty.resample(self._rule, **self._kwargs)
179 meta = getattr(meta_r, how)(*how_args, **how_kwargs)
180
181 graph = HighLevelGraph.from_collections(name, dsk, dependencies=[partitioned])
182 if isinstance(meta, pd.DataFrame):
183 return DataFrame(graph, name, meta, outdivs)
184 return Series(graph, name, meta, outdivs)
185
186 @derived_from(pd_Resampler)
187 def agg(self, agg_funcs, *args, **kwargs):
188 return self._agg("agg", how_args=(agg_funcs,) + args, how_kwargs=kwargs)
189
190 @derived_from(pd_Resampler)
191 def count(self):
192 return self._agg("count", fill_value=0)
193
194 @derived_from(pd_Resampler)
195 def first(self):
196 return self._agg("first")
197
198 @derived_from(pd_Resampler)
199 def last(self):
200 return self._agg("last")
201
202 @derived_from(pd_Resampler)
203 def mean(self):
204 return self._agg("mean")
205
206 @derived_from(pd_Resampler)
207 def min(self):
208 return self._agg("min")
209
210 @derived_from(pd_Resampler)
211 def median(self):
212 return self._agg("median")
213
214 @derived_from(pd_Resampler)
215 def max(self):
216 return self._agg("max")
217
218 @derived_from(pd_Resampler)
219 def nunique(self):
220 return self._agg("nunique", fill_value=0)
221
222 @derived_from(pd_Resampler)
223 def ohlc(self):
224 return self._agg("ohlc")
225
226 @derived_from(pd_Resampler)
227 def prod(self):
228 return self._agg("prod")
229
230 @derived_from(pd_Resampler)
231 def sem(self):
232 return self._agg("sem")
233
234 @derived_from(pd_Resampler)
235 def std(self):
236 return self._agg("std")
237
238 @derived_from(pd_Resampler)
239 def size(self):
240 return self._agg("size", fill_value=0)
241
242 @derived_from(pd_Resampler)
243 def sum(self):
244 return self._agg("sum", fill_value=0)
245
246 @derived_from(pd_Resampler)
247 def var(self):
248 return self._agg("var")
249
250 @derived_from(pd_Resampler)
251 def quantile(self):
252 return self._agg("quantile")
253
```
Path: `dask/dataframe/_compat.py`
Content:
```
1 import string
2
3 import numpy as np
4 import pandas as pd
5 from packaging.version import parse as parse_version
6
7 PANDAS_VERSION = parse_version(pd.__version__)
8 PANDAS_GT_104 = PANDAS_VERSION >= parse_version("1.0.4")
9 PANDAS_GT_110 = PANDAS_VERSION >= parse_version("1.1.0")
10 PANDAS_GT_120 = PANDAS_VERSION >= parse_version("1.2.0")
11 PANDAS_GT_121 = PANDAS_VERSION >= parse_version("1.2.1")
12 PANDAS_GT_130 = PANDAS_VERSION >= parse_version("1.3.0")
13 PANDAS_GT_131 = PANDAS_VERSION >= parse_version("1.3.1")
14 PANDAS_GT_133 = PANDAS_VERSION >= parse_version("1.3.3")
15
16 import pandas.testing as tm
17
18
19 def assert_categorical_equal(left, right, *args, **kwargs):
20 tm.assert_extension_array_equal(left, right, *args, **kwargs)
21 assert pd.api.types.is_categorical_dtype(
22 left.dtype
23 ), "{} is not categorical dtype".format(left)
24 assert pd.api.types.is_categorical_dtype(
25 right.dtype
26 ), "{} is not categorical dtype".format(right)
27
28
29 def assert_numpy_array_equal(left, right):
30 left_na = pd.isna(left)
31 right_na = pd.isna(right)
32 np.testing.assert_array_equal(left_na, right_na)
33
34 left_valid = left[~left_na]
35 right_valid = right[~right_na]
36 np.testing.assert_array_equal(left_valid, right_valid)
37
38
39 def makeDataFrame():
40 data = np.random.randn(30, 4)
41 index = list(string.ascii_letters)[:30]
42 return pd.DataFrame(data, index=index, columns=list("ABCD"))
43
44
45 def makeTimeDataFrame():
46 data = makeDataFrame()
47 data.index = makeDateIndex()
48 return data
49
50
51 def makeTimeSeries():
52 return makeTimeDataFrame()["A"]
53
54
55 def makeDateIndex(k=30, freq="B"):
56 return pd.date_range("2000", periods=k, freq=freq)
57
58
59 def makeTimedeltaIndex(k=30, freq="D"):
60 return pd.timedelta_range("1 day", periods=k, freq=freq)
61
62
63 def makeMissingDataframe():
64 df = makeDataFrame()
65 data = df.values
66 data = np.where(data > 1, np.nan, data)
67 return pd.DataFrame(data, index=df.index, columns=df.columns)
68
69
70 def makeMixedDataFrame():
71 df = pd.DataFrame(
72 {
73 "A": [0.0, 1, 2, 3, 4],
74 "B": [0.0, 1, 0, 1, 0],
75 "C": ["foo{}".format(i) for i in range(5)],
76 "D": pd.date_range("2009-01-01", periods=5),
77 }
78 )
79 return df
80
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dask/dataframe/_compat.py b/dask/dataframe/_compat.py
--- a/dask/dataframe/_compat.py
+++ b/dask/dataframe/_compat.py
@@ -12,6 +12,7 @@
PANDAS_GT_130 = PANDAS_VERSION >= parse_version("1.3.0")
PANDAS_GT_131 = PANDAS_VERSION >= parse_version("1.3.1")
PANDAS_GT_133 = PANDAS_VERSION >= parse_version("1.3.3")
+PANDAS_GT_140 = PANDAS_VERSION.release == (1, 4, 0) # include pre-release
import pandas.testing as tm
diff --git a/dask/dataframe/tseries/resample.py b/dask/dataframe/tseries/resample.py
--- a/dask/dataframe/tseries/resample.py
+++ b/dask/dataframe/tseries/resample.py
@@ -6,6 +6,7 @@
from ...highlevelgraph import HighLevelGraph
from ...utils import derived_from
from .. import methods
+from .._compat import PANDAS_GT_140
from ..core import DataFrame, Series
@@ -32,11 +33,20 @@
*how_args, **how_kwargs
)
+ if PANDAS_GT_140:
+ if reindex_closed is None:
+ inclusive = "both"
+ else:
+ inclusive = reindex_closed
+ closed_kwargs = {"inclusive": inclusive}
+ else:
+ closed_kwargs = {"closed": reindex_closed}
+
new_index = pd.date_range(
start.tz_localize(None),
end.tz_localize(None),
freq=rule,
- closed=reindex_closed,
+ **closed_kwargs,
name=out.index.name,
).tz_localize(start.tz, nonexistent="shift_forward")
|
{"golden_diff": "diff --git a/dask/dataframe/_compat.py b/dask/dataframe/_compat.py\n--- a/dask/dataframe/_compat.py\n+++ b/dask/dataframe/_compat.py\n@@ -12,6 +12,7 @@\n PANDAS_GT_130 = PANDAS_VERSION >= parse_version(\"1.3.0\")\n PANDAS_GT_131 = PANDAS_VERSION >= parse_version(\"1.3.1\")\n PANDAS_GT_133 = PANDAS_VERSION >= parse_version(\"1.3.3\")\n+PANDAS_GT_140 = PANDAS_VERSION.release == (1, 4, 0) # include pre-release\n \n import pandas.testing as tm\n \ndiff --git a/dask/dataframe/tseries/resample.py b/dask/dataframe/tseries/resample.py\n--- a/dask/dataframe/tseries/resample.py\n+++ b/dask/dataframe/tseries/resample.py\n@@ -6,6 +6,7 @@\n from ...highlevelgraph import HighLevelGraph\n from ...utils import derived_from\n from .. import methods\n+from .._compat import PANDAS_GT_140\n from ..core import DataFrame, Series\n \n \n@@ -32,11 +33,20 @@\n *how_args, **how_kwargs\n )\n \n+ if PANDAS_GT_140:\n+ if reindex_closed is None:\n+ inclusive = \"both\"\n+ else:\n+ inclusive = reindex_closed\n+ closed_kwargs = {\"inclusive\": inclusive}\n+ else:\n+ closed_kwargs = {\"closed\": reindex_closed}\n+\n new_index = pd.date_range(\n start.tz_localize(None),\n end.tz_localize(None),\n freq=rule,\n- closed=reindex_closed,\n+ **closed_kwargs,\n name=out.index.name,\n ).tz_localize(start.tz, nonexistent=\"shift_forward\")\n", "issue": "\u26a0\ufe0f Upstream CI failed \u26a0\ufe0f\n[Workflow Run URL](https://github.com/dask/dask/actions/runs/1304259797)\n", "before_files": [{"content": "import numpy as np\nimport pandas as pd\nfrom pandas.core.resample import Resampler as pd_Resampler\n\nfrom ...base import tokenize\nfrom ...highlevelgraph import HighLevelGraph\nfrom ...utils import derived_from\nfrom .. import methods\nfrom ..core import DataFrame, Series\n\n\ndef getnanos(rule):\n try:\n return getattr(rule, \"nanos\", None)\n except ValueError:\n return None\n\n\ndef _resample_series(\n series,\n start,\n end,\n reindex_closed,\n rule,\n resample_kwargs,\n how,\n fill_value,\n how_args,\n how_kwargs,\n):\n out = getattr(series.resample(rule, **resample_kwargs), how)(\n *how_args, **how_kwargs\n )\n\n new_index = pd.date_range(\n start.tz_localize(None),\n end.tz_localize(None),\n freq=rule,\n closed=reindex_closed,\n name=out.index.name,\n ).tz_localize(start.tz, nonexistent=\"shift_forward\")\n\n if not out.index.isin(new_index).all():\n raise ValueError(\n \"Index is not contained within new index. This can often be \"\n \"resolved by using larger partitions, or unambiguous \"\n \"frequencies: 'Q', 'A'...\"\n )\n\n return out.reindex(new_index, fill_value=fill_value)\n\n\ndef _resample_bin_and_out_divs(divisions, rule, closed=\"left\", label=\"left\"):\n rule = pd.tseries.frequencies.to_offset(rule)\n g = pd.Grouper(freq=rule, how=\"count\", closed=closed, label=label)\n\n # Determine bins to apply `how` to. Disregard labeling scheme.\n divs = pd.Series(range(len(divisions)), index=divisions)\n temp = divs.resample(rule, closed=closed, label=\"left\").count()\n tempdivs = temp.loc[temp > 0].index\n\n # Cleanup closed == 'right' and label == 'right'\n res = pd.offsets.Nano() if hasattr(rule, \"delta\") else pd.offsets.Day()\n if g.closed == \"right\":\n newdivs = tempdivs + res\n else:\n newdivs = tempdivs\n if g.label == \"right\":\n outdivs = tempdivs + rule\n else:\n outdivs = tempdivs\n\n newdivs = methods.tolist(newdivs)\n outdivs = methods.tolist(outdivs)\n\n # Adjust ends\n if newdivs[0] < divisions[0]:\n newdivs[0] = divisions[0]\n if newdivs[-1] < divisions[-1]:\n if len(newdivs) < len(divs):\n setter = lambda a, val: a.append(val)\n else:\n setter = lambda a, val: a.__setitem__(-1, val)\n setter(newdivs, divisions[-1] + res)\n if outdivs[-1] > divisions[-1]:\n setter(outdivs, outdivs[-1])\n elif outdivs[-1] < divisions[-1]:\n setter(outdivs, temp.index[-1])\n\n return tuple(map(pd.Timestamp, newdivs)), tuple(map(pd.Timestamp, outdivs))\n\n\nclass Resampler:\n \"\"\"Class for resampling timeseries data.\n\n This class is commonly encountered when using ``obj.resample(...)`` which\n return ``Resampler`` objects.\n\n Parameters\n ----------\n obj : Dask DataFrame or Series\n Data to be resampled.\n rule : str, tuple, datetime.timedelta, DateOffset or None\n The offset string or object representing the target conversion.\n kwargs : optional\n Keyword arguments passed to underlying pandas resampling function.\n\n Returns\n -------\n Resampler instance of the appropriate type\n \"\"\"\n\n def __init__(self, obj, rule, **kwargs):\n if not obj.known_divisions:\n msg = (\n \"Can only resample dataframes with known divisions\\n\"\n \"See https://docs.dask.org/en/latest/dataframe-design.html#partitions\\n\"\n \"for more information.\"\n )\n raise ValueError(msg)\n self.obj = obj\n self._rule = pd.tseries.frequencies.to_offset(rule)\n self._kwargs = kwargs\n\n def _agg(self, how, meta=None, fill_value=np.nan, how_args=(), how_kwargs={}):\n \"\"\"Aggregate using one or more operations\n\n Parameters\n ----------\n how : str\n Name of aggregation operation\n fill_value : scalar, optional\n Value to use for missing values, applied during upsampling.\n Default is NaN.\n how_args : optional\n Positional arguments for aggregation operation.\n how_kwargs : optional\n Keyword arguments for aggregation operation.\n\n Returns\n -------\n Dask DataFrame or Series\n \"\"\"\n rule = self._rule\n kwargs = self._kwargs\n name = \"resample-\" + tokenize(\n self.obj, rule, kwargs, how, *how_args, **how_kwargs\n )\n\n # Create a grouper to determine closed and label conventions\n newdivs, outdivs = _resample_bin_and_out_divs(\n self.obj.divisions, rule, **kwargs\n )\n\n # Repartition divs into bins. These won't match labels after mapping\n partitioned = self.obj.repartition(newdivs, force=True)\n\n keys = partitioned.__dask_keys__()\n dsk = {}\n\n args = zip(keys, outdivs, outdivs[1:], [\"left\"] * (len(keys) - 1) + [None])\n for i, (k, s, e, c) in enumerate(args):\n dsk[(name, i)] = (\n _resample_series,\n k,\n s,\n e,\n c,\n rule,\n kwargs,\n how,\n fill_value,\n list(how_args),\n how_kwargs,\n )\n\n # Infer output metadata\n meta_r = self.obj._meta_nonempty.resample(self._rule, **self._kwargs)\n meta = getattr(meta_r, how)(*how_args, **how_kwargs)\n\n graph = HighLevelGraph.from_collections(name, dsk, dependencies=[partitioned])\n if isinstance(meta, pd.DataFrame):\n return DataFrame(graph, name, meta, outdivs)\n return Series(graph, name, meta, outdivs)\n\n @derived_from(pd_Resampler)\n def agg(self, agg_funcs, *args, **kwargs):\n return self._agg(\"agg\", how_args=(agg_funcs,) + args, how_kwargs=kwargs)\n\n @derived_from(pd_Resampler)\n def count(self):\n return self._agg(\"count\", fill_value=0)\n\n @derived_from(pd_Resampler)\n def first(self):\n return self._agg(\"first\")\n\n @derived_from(pd_Resampler)\n def last(self):\n return self._agg(\"last\")\n\n @derived_from(pd_Resampler)\n def mean(self):\n return self._agg(\"mean\")\n\n @derived_from(pd_Resampler)\n def min(self):\n return self._agg(\"min\")\n\n @derived_from(pd_Resampler)\n def median(self):\n return self._agg(\"median\")\n\n @derived_from(pd_Resampler)\n def max(self):\n return self._agg(\"max\")\n\n @derived_from(pd_Resampler)\n def nunique(self):\n return self._agg(\"nunique\", fill_value=0)\n\n @derived_from(pd_Resampler)\n def ohlc(self):\n return self._agg(\"ohlc\")\n\n @derived_from(pd_Resampler)\n def prod(self):\n return self._agg(\"prod\")\n\n @derived_from(pd_Resampler)\n def sem(self):\n return self._agg(\"sem\")\n\n @derived_from(pd_Resampler)\n def std(self):\n return self._agg(\"std\")\n\n @derived_from(pd_Resampler)\n def size(self):\n return self._agg(\"size\", fill_value=0)\n\n @derived_from(pd_Resampler)\n def sum(self):\n return self._agg(\"sum\", fill_value=0)\n\n @derived_from(pd_Resampler)\n def var(self):\n return self._agg(\"var\")\n\n @derived_from(pd_Resampler)\n def quantile(self):\n return self._agg(\"quantile\")\n", "path": "dask/dataframe/tseries/resample.py"}, {"content": "import string\n\nimport numpy as np\nimport pandas as pd\nfrom packaging.version import parse as parse_version\n\nPANDAS_VERSION = parse_version(pd.__version__)\nPANDAS_GT_104 = PANDAS_VERSION >= parse_version(\"1.0.4\")\nPANDAS_GT_110 = PANDAS_VERSION >= parse_version(\"1.1.0\")\nPANDAS_GT_120 = PANDAS_VERSION >= parse_version(\"1.2.0\")\nPANDAS_GT_121 = PANDAS_VERSION >= parse_version(\"1.2.1\")\nPANDAS_GT_130 = PANDAS_VERSION >= parse_version(\"1.3.0\")\nPANDAS_GT_131 = PANDAS_VERSION >= parse_version(\"1.3.1\")\nPANDAS_GT_133 = PANDAS_VERSION >= parse_version(\"1.3.3\")\n\nimport pandas.testing as tm\n\n\ndef assert_categorical_equal(left, right, *args, **kwargs):\n tm.assert_extension_array_equal(left, right, *args, **kwargs)\n assert pd.api.types.is_categorical_dtype(\n left.dtype\n ), \"{} is not categorical dtype\".format(left)\n assert pd.api.types.is_categorical_dtype(\n right.dtype\n ), \"{} is not categorical dtype\".format(right)\n\n\ndef assert_numpy_array_equal(left, right):\n left_na = pd.isna(left)\n right_na = pd.isna(right)\n np.testing.assert_array_equal(left_na, right_na)\n\n left_valid = left[~left_na]\n right_valid = right[~right_na]\n np.testing.assert_array_equal(left_valid, right_valid)\n\n\ndef makeDataFrame():\n data = np.random.randn(30, 4)\n index = list(string.ascii_letters)[:30]\n return pd.DataFrame(data, index=index, columns=list(\"ABCD\"))\n\n\ndef makeTimeDataFrame():\n data = makeDataFrame()\n data.index = makeDateIndex()\n return data\n\n\ndef makeTimeSeries():\n return makeTimeDataFrame()[\"A\"]\n\n\ndef makeDateIndex(k=30, freq=\"B\"):\n return pd.date_range(\"2000\", periods=k, freq=freq)\n\n\ndef makeTimedeltaIndex(k=30, freq=\"D\"):\n return pd.timedelta_range(\"1 day\", periods=k, freq=freq)\n\n\ndef makeMissingDataframe():\n df = makeDataFrame()\n data = df.values\n data = np.where(data > 1, np.nan, data)\n return pd.DataFrame(data, index=df.index, columns=df.columns)\n\n\ndef makeMixedDataFrame():\n df = pd.DataFrame(\n {\n \"A\": [0.0, 1, 2, 3, 4],\n \"B\": [0.0, 1, 0, 1, 0],\n \"C\": [\"foo{}\".format(i) for i in range(5)],\n \"D\": pd.date_range(\"2009-01-01\", periods=5),\n }\n )\n return df\n", "path": "dask/dataframe/_compat.py"}], "after_files": [{"content": "import numpy as np\nimport pandas as pd\nfrom pandas.core.resample import Resampler as pd_Resampler\n\nfrom ...base import tokenize\nfrom ...highlevelgraph import HighLevelGraph\nfrom ...utils import derived_from\nfrom .. import methods\nfrom .._compat import PANDAS_GT_140\nfrom ..core import DataFrame, Series\n\n\ndef getnanos(rule):\n try:\n return getattr(rule, \"nanos\", None)\n except ValueError:\n return None\n\n\ndef _resample_series(\n series,\n start,\n end,\n reindex_closed,\n rule,\n resample_kwargs,\n how,\n fill_value,\n how_args,\n how_kwargs,\n):\n out = getattr(series.resample(rule, **resample_kwargs), how)(\n *how_args, **how_kwargs\n )\n\n if PANDAS_GT_140:\n if reindex_closed is None:\n inclusive = \"both\"\n else:\n inclusive = reindex_closed\n closed_kwargs = {\"inclusive\": inclusive}\n else:\n closed_kwargs = {\"closed\": reindex_closed}\n\n new_index = pd.date_range(\n start.tz_localize(None),\n end.tz_localize(None),\n freq=rule,\n **closed_kwargs,\n name=out.index.name,\n ).tz_localize(start.tz, nonexistent=\"shift_forward\")\n\n if not out.index.isin(new_index).all():\n raise ValueError(\n \"Index is not contained within new index. This can often be \"\n \"resolved by using larger partitions, or unambiguous \"\n \"frequencies: 'Q', 'A'...\"\n )\n\n return out.reindex(new_index, fill_value=fill_value)\n\n\ndef _resample_bin_and_out_divs(divisions, rule, closed=\"left\", label=\"left\"):\n rule = pd.tseries.frequencies.to_offset(rule)\n g = pd.Grouper(freq=rule, how=\"count\", closed=closed, label=label)\n\n # Determine bins to apply `how` to. Disregard labeling scheme.\n divs = pd.Series(range(len(divisions)), index=divisions)\n temp = divs.resample(rule, closed=closed, label=\"left\").count()\n tempdivs = temp.loc[temp > 0].index\n\n # Cleanup closed == 'right' and label == 'right'\n res = pd.offsets.Nano() if hasattr(rule, \"delta\") else pd.offsets.Day()\n if g.closed == \"right\":\n newdivs = tempdivs + res\n else:\n newdivs = tempdivs\n if g.label == \"right\":\n outdivs = tempdivs + rule\n else:\n outdivs = tempdivs\n\n newdivs = methods.tolist(newdivs)\n outdivs = methods.tolist(outdivs)\n\n # Adjust ends\n if newdivs[0] < divisions[0]:\n newdivs[0] = divisions[0]\n if newdivs[-1] < divisions[-1]:\n if len(newdivs) < len(divs):\n setter = lambda a, val: a.append(val)\n else:\n setter = lambda a, val: a.__setitem__(-1, val)\n setter(newdivs, divisions[-1] + res)\n if outdivs[-1] > divisions[-1]:\n setter(outdivs, outdivs[-1])\n elif outdivs[-1] < divisions[-1]:\n setter(outdivs, temp.index[-1])\n\n return tuple(map(pd.Timestamp, newdivs)), tuple(map(pd.Timestamp, outdivs))\n\n\nclass Resampler:\n \"\"\"Class for resampling timeseries data.\n\n This class is commonly encountered when using ``obj.resample(...)`` which\n return ``Resampler`` objects.\n\n Parameters\n ----------\n obj : Dask DataFrame or Series\n Data to be resampled.\n rule : str, tuple, datetime.timedelta, DateOffset or None\n The offset string or object representing the target conversion.\n kwargs : optional\n Keyword arguments passed to underlying pandas resampling function.\n\n Returns\n -------\n Resampler instance of the appropriate type\n \"\"\"\n\n def __init__(self, obj, rule, **kwargs):\n if not obj.known_divisions:\n msg = (\n \"Can only resample dataframes with known divisions\\n\"\n \"See https://docs.dask.org/en/latest/dataframe-design.html#partitions\\n\"\n \"for more information.\"\n )\n raise ValueError(msg)\n self.obj = obj\n self._rule = pd.tseries.frequencies.to_offset(rule)\n self._kwargs = kwargs\n\n def _agg(self, how, meta=None, fill_value=np.nan, how_args=(), how_kwargs={}):\n \"\"\"Aggregate using one or more operations\n\n Parameters\n ----------\n how : str\n Name of aggregation operation\n fill_value : scalar, optional\n Value to use for missing values, applied during upsampling.\n Default is NaN.\n how_args : optional\n Positional arguments for aggregation operation.\n how_kwargs : optional\n Keyword arguments for aggregation operation.\n\n Returns\n -------\n Dask DataFrame or Series\n \"\"\"\n rule = self._rule\n kwargs = self._kwargs\n name = \"resample-\" + tokenize(\n self.obj, rule, kwargs, how, *how_args, **how_kwargs\n )\n\n # Create a grouper to determine closed and label conventions\n newdivs, outdivs = _resample_bin_and_out_divs(\n self.obj.divisions, rule, **kwargs\n )\n\n # Repartition divs into bins. These won't match labels after mapping\n partitioned = self.obj.repartition(newdivs, force=True)\n\n keys = partitioned.__dask_keys__()\n dsk = {}\n\n args = zip(keys, outdivs, outdivs[1:], [\"left\"] * (len(keys) - 1) + [None])\n for i, (k, s, e, c) in enumerate(args):\n dsk[(name, i)] = (\n _resample_series,\n k,\n s,\n e,\n c,\n rule,\n kwargs,\n how,\n fill_value,\n list(how_args),\n how_kwargs,\n )\n\n # Infer output metadata\n meta_r = self.obj._meta_nonempty.resample(self._rule, **self._kwargs)\n meta = getattr(meta_r, how)(*how_args, **how_kwargs)\n\n graph = HighLevelGraph.from_collections(name, dsk, dependencies=[partitioned])\n if isinstance(meta, pd.DataFrame):\n return DataFrame(graph, name, meta, outdivs)\n return Series(graph, name, meta, outdivs)\n\n @derived_from(pd_Resampler)\n def agg(self, agg_funcs, *args, **kwargs):\n return self._agg(\"agg\", how_args=(agg_funcs,) + args, how_kwargs=kwargs)\n\n @derived_from(pd_Resampler)\n def count(self):\n return self._agg(\"count\", fill_value=0)\n\n @derived_from(pd_Resampler)\n def first(self):\n return self._agg(\"first\")\n\n @derived_from(pd_Resampler)\n def last(self):\n return self._agg(\"last\")\n\n @derived_from(pd_Resampler)\n def mean(self):\n return self._agg(\"mean\")\n\n @derived_from(pd_Resampler)\n def min(self):\n return self._agg(\"min\")\n\n @derived_from(pd_Resampler)\n def median(self):\n return self._agg(\"median\")\n\n @derived_from(pd_Resampler)\n def max(self):\n return self._agg(\"max\")\n\n @derived_from(pd_Resampler)\n def nunique(self):\n return self._agg(\"nunique\", fill_value=0)\n\n @derived_from(pd_Resampler)\n def ohlc(self):\n return self._agg(\"ohlc\")\n\n @derived_from(pd_Resampler)\n def prod(self):\n return self._agg(\"prod\")\n\n @derived_from(pd_Resampler)\n def sem(self):\n return self._agg(\"sem\")\n\n @derived_from(pd_Resampler)\n def std(self):\n return self._agg(\"std\")\n\n @derived_from(pd_Resampler)\n def size(self):\n return self._agg(\"size\", fill_value=0)\n\n @derived_from(pd_Resampler)\n def sum(self):\n return self._agg(\"sum\", fill_value=0)\n\n @derived_from(pd_Resampler)\n def var(self):\n return self._agg(\"var\")\n\n @derived_from(pd_Resampler)\n def quantile(self):\n return self._agg(\"quantile\")\n", "path": "dask/dataframe/tseries/resample.py"}, {"content": "import string\n\nimport numpy as np\nimport pandas as pd\nfrom packaging.version import parse as parse_version\n\nPANDAS_VERSION = parse_version(pd.__version__)\nPANDAS_GT_104 = PANDAS_VERSION >= parse_version(\"1.0.4\")\nPANDAS_GT_110 = PANDAS_VERSION >= parse_version(\"1.1.0\")\nPANDAS_GT_120 = PANDAS_VERSION >= parse_version(\"1.2.0\")\nPANDAS_GT_121 = PANDAS_VERSION >= parse_version(\"1.2.1\")\nPANDAS_GT_130 = PANDAS_VERSION >= parse_version(\"1.3.0\")\nPANDAS_GT_131 = PANDAS_VERSION >= parse_version(\"1.3.1\")\nPANDAS_GT_133 = PANDAS_VERSION >= parse_version(\"1.3.3\")\nPANDAS_GT_140 = PANDAS_VERSION.release == (1, 4, 0) # include pre-release\n\nimport pandas.testing as tm\n\n\ndef assert_categorical_equal(left, right, *args, **kwargs):\n tm.assert_extension_array_equal(left, right, *args, **kwargs)\n assert pd.api.types.is_categorical_dtype(\n left.dtype\n ), \"{} is not categorical dtype\".format(left)\n assert pd.api.types.is_categorical_dtype(\n right.dtype\n ), \"{} is not categorical dtype\".format(right)\n\n\ndef assert_numpy_array_equal(left, right):\n left_na = pd.isna(left)\n right_na = pd.isna(right)\n np.testing.assert_array_equal(left_na, right_na)\n\n left_valid = left[~left_na]\n right_valid = right[~right_na]\n np.testing.assert_array_equal(left_valid, right_valid)\n\n\ndef makeDataFrame():\n data = np.random.randn(30, 4)\n index = list(string.ascii_letters)[:30]\n return pd.DataFrame(data, index=index, columns=list(\"ABCD\"))\n\n\ndef makeTimeDataFrame():\n data = makeDataFrame()\n data.index = makeDateIndex()\n return data\n\n\ndef makeTimeSeries():\n return makeTimeDataFrame()[\"A\"]\n\n\ndef makeDateIndex(k=30, freq=\"B\"):\n return pd.date_range(\"2000\", periods=k, freq=freq)\n\n\ndef makeTimedeltaIndex(k=30, freq=\"D\"):\n return pd.timedelta_range(\"1 day\", periods=k, freq=freq)\n\n\ndef makeMissingDataframe():\n df = makeDataFrame()\n data = df.values\n data = np.where(data > 1, np.nan, data)\n return pd.DataFrame(data, index=df.index, columns=df.columns)\n\n\ndef makeMixedDataFrame():\n df = pd.DataFrame(\n {\n \"A\": [0.0, 1, 2, 3, 4],\n \"B\": [0.0, 1, 0, 1, 0],\n \"C\": [\"foo{}\".format(i) for i in range(5)],\n \"D\": pd.date_range(\"2009-01-01\", periods=5),\n }\n )\n return df\n", "path": "dask/dataframe/_compat.py"}]}
| 3,598 | 417 |
gh_patches_debug_26197
|
rasdani/github-patches
|
git_diff
|
automl__auto-sklearn-1508
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix timeouts related to metalearnings tests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scripts/03_calculate_metafeatures.py`
Content:
```
1 from argparse import ArgumentParser
2 from collections import defaultdict, OrderedDict
3 import copy
4 import logging
5 import os
6 import sys
7 import unittest.mock
8
9 import arff
10 import joblib
11 import numpy as np
12 import pandas as pd
13
14 from autosklearn.constants import (
15 BINARY_CLASSIFICATION,
16 MULTICLASS_CLASSIFICATION,
17 REGRESSION,
18 )
19 from autosklearn.metalearning.metafeatures import metafeatures
20 from autosklearn.smbo import (
21 _calculate_metafeatures,
22 _calculate_metafeatures_encoded,
23 EXCLUDE_META_FEATURES_REGRESSION,
24 EXCLUDE_META_FEATURES_CLASSIFICATION,
25 )
26 from autosklearn.util.stopwatch import StopWatch
27
28 sys.path.append(".")
29 from update_metadata_util import load_task, classification_tasks, regression_tasks
30
31 logger = logging.getLogger("03_calculate_metafeatures")
32
33
34 def calculate_metafeatures(task_id):
35 X_train, y_train, X_test, y_test, cat, task_type, dataset_name = load_task(task_id)
36 stopwatch = StopWatch()
37
38 if task_type == "classification":
39 if len(np.unique(y_train)) == 2:
40 task_type = BINARY_CLASSIFICATION
41 else:
42 task_type = MULTICLASS_CLASSIFICATION
43 else:
44 task_type = REGRESSION
45
46 _metafeatures_labels = _calculate_metafeatures(
47 x_train=X_train,
48 y_train=y_train,
49 data_feat_type=cat,
50 data_info_task=task_type,
51 basename=dataset_name,
52 logger_=logger,
53 stopwatch=stopwatch,
54 )
55
56 _metafeatures_encoded_labels = _calculate_metafeatures_encoded(
57 x_train=X_train,
58 y_train=y_train,
59 data_feat_type=cat,
60 task=task_type,
61 basename=dataset_name,
62 logger_=logger,
63 stopwatch=stopwatch,
64 )
65
66 mf = _metafeatures_labels
67 mf.metafeature_values.update(_metafeatures_encoded_labels.metafeature_values)
68
69 return mf
70
71
72 if __name__ == "__main__":
73 parser = ArgumentParser()
74 parser.add_argument("--working-directory", type=str, required=True)
75 parser.add_argument("--memory-limit", type=int, default=3072)
76 parser.add_argument("--test-mode", action="store_true")
77
78 args = parser.parse_args()
79 working_directory = args.working_directory
80 memory_limit = args.memory_limit
81 test_mode = args.test_mode
82
83 for task_type in ("classification", "regression"):
84 output_directory = os.path.join(working_directory, "metafeatures", task_type)
85 try:
86 os.makedirs(output_directory)
87 except:
88 pass
89
90 all_metafeatures = {}
91
92 if task_type == "classification":
93 tasks = classification_tasks
94 else:
95 tasks = regression_tasks
96
97 if test_mode:
98 tasks = [tasks[0]]
99
100 tasks = copy.deepcopy(tasks)
101 np.random.shuffle(tasks)
102
103 def producer():
104 for task_id in tasks:
105 yield task_id
106
107 memory = joblib.Memory(location="/tmp/joblib", verbose=10)
108 cached_calculate_metafeatures = memory.cache(calculate_metafeatures)
109 mfs = [cached_calculate_metafeatures(task_id) for task_id in producer()]
110
111 for mf in mfs:
112 if mf is not None:
113 all_metafeatures[mf.dataset_name] = mf
114
115 # Write the calculation times as a csv file to disc (can be viewed in
116 # LibreOffice calc afterwards)
117 calculation_times = defaultdict(dict)
118 metafeature_values = defaultdict(dict)
119 helperfunction_values = defaultdict(dict)
120
121 for i, task_id in enumerate(all_metafeatures):
122 calculation_times[task_id] = dict()
123 for metafeature_name in sorted(
124 all_metafeatures[task_id].metafeature_values
125 ):
126 metafeature_value = all_metafeatures[task_id].metafeature_values[
127 metafeature_name
128 ]
129 calculation_times[task_id][metafeature_name] = metafeature_value.time
130 if metafeature_value.type_ == "HELPERFUNCTION":
131 helperfunction_values[task_id][
132 metafeature_name
133 ] = metafeature_value.value
134 else:
135 metafeature_values[task_id][
136 metafeature_name
137 ] = metafeature_value.value
138
139 calculation_times = pd.DataFrame(calculation_times).transpose()
140 calculation_times = calculation_times.sort_index()
141 with open(os.path.join(output_directory, "calculation_times.csv"), "w") as fh:
142 fh.write(calculation_times.to_csv())
143
144 # Write all metafeatures in the aslib1.0 format
145 metafeature_values = metafeature_values = pd.DataFrame(
146 metafeature_values
147 ).transpose()
148 metafeature_values = metafeature_values.sort_index()
149 arff_object = dict()
150 arff_object["attributes"] = [
151 ("instance_id", "STRING"),
152 ("repetition", "NUMERIC"),
153 ] + [("%s" % name, "NUMERIC") for name in metafeature_values.columns]
154 arff_object["relation"] = "FEATURE_VALUES"
155 arff_object["description"] = ""
156
157 data = []
158 for idx in metafeature_values.index:
159 line = [idx, 1]
160 line += [
161 value if np.isfinite(value) else None
162 for value in metafeature_values.loc[idx, :].values
163 ]
164 data.append(line)
165 arff_object["data"] = data
166
167 with open(os.path.join(output_directory, "feature_values.arff"), "w") as fh:
168 arff.dump(arff_object, fh)
169
170 # Feature steps and runtimes according to the aslib1.0 format
171 feature_steps = defaultdict(list)
172 metafeature_names = list()
173
174 exclude_metafeatures = (
175 EXCLUDE_META_FEATURES_CLASSIFICATION
176 if task_type == "classification"
177 else EXCLUDE_META_FEATURES_REGRESSION
178 )
179
180 for metafeature_name in metafeatures.metafeatures.functions:
181
182 if metafeature_name in exclude_metafeatures:
183 continue
184
185 dependency = metafeatures.metafeatures.get_dependency(metafeature_name)
186 if dependency is not None:
187 feature_steps[dependency].append(metafeature_name)
188 feature_steps[metafeature_name].append(metafeature_name)
189
190 metafeature_names.append(metafeature_name)
191
192 # Write the feature runstatus in the aslib1.0 format
193 arff_object = dict()
194 arff_object["attributes"] = [
195 ("instance_id", "STRING"),
196 ("repetition", "NUMERIC"),
197 ] + [
198 ("%s" % name, ["ok", "timeout", "memout", "presolved", "crash", "other"])
199 for name in feature_steps
200 ]
201 arff_object["relation"] = "FEATURE_RUNSTATUS"
202 arff_object["description"] = ""
203
204 data = []
205 for idx in metafeature_values.index:
206 line = [idx, 1]
207 for feature_step in feature_steps:
208 if feature_step in helperfunction_values[idx]:
209 line.append(
210 "ok"
211 if helperfunction_values[feature_step] is not None
212 else "other"
213 )
214 elif feature_step in metafeature_values.loc[idx]:
215 line.append(
216 "ok"
217 if np.isfinite(metafeature_values.loc[idx][feature_step])
218 else "other"
219 )
220 else:
221 line.append("other")
222
223 data.append(line)
224 arff_object["data"] = data
225
226 with open(os.path.join(output_directory, "feature_runstatus.arff"), "w") as fh:
227 arff.dump(arff_object, fh)
228
229 arff_object = dict()
230 arff_object["attributes"] = [
231 ("instance_id", "STRING"),
232 ("repetition", "NUMERIC"),
233 ] + [("%s" % feature_step, "NUMERIC") for feature_step in feature_steps]
234 arff_object["relation"] = "FEATURE_COSTS"
235 arff_object["description"] = ""
236
237 data = []
238 for instance_id in calculation_times.index:
239 calculation_times_per_group = dict()
240 line = [instance_id, 1]
241 for feature_step in feature_steps:
242 time_ = 0.0
243 for feature in feature_steps[feature_step]:
244 time_ += calculation_times[feature][instance_id]
245 if not np.isfinite(time_):
246 raise ValueError(
247 "Feature cost %s for instance %s and feature "
248 "step %s not finite" % (time_, instance_id, feature)
249 )
250 line.append(time_)
251 data.append(line)
252 arff_object["data"] = data
253
254 with open(os.path.join(output_directory, "feature_costs.arff"), "w") as fh:
255 arff.dump(arff_object, fh)
256
257 # Write the features part of the description.txt to a file
258 description = OrderedDict()
259 description["features_cutoff_time"] = "3600"
260 description["features_cutoff_memory"] = args.memory_limit
261 description["number_of_feature_steps"] = str(len(feature_steps))
262
263 for feature_step in feature_steps:
264 description["feature_step %s" % feature_step] = ", ".join(
265 feature_steps[feature_step]
266 )
267 description["features_deterministic"] = ", ".join(
268 [metafeature_name for metafeature_name in metafeature_names]
269 )
270 description["features_stochastic"] = ""
271 description["default_steps"] = ", ".join(feature_steps)
272
273 with open(
274 os.path.join(output_directory, "description.features.txt"), "w"
275 ) as fh:
276 for entry in description:
277 fh.write("%s: %s\n" % (entry, description[entry]))
278
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scripts/03_calculate_metafeatures.py b/scripts/03_calculate_metafeatures.py
--- a/scripts/03_calculate_metafeatures.py
+++ b/scripts/03_calculate_metafeatures.py
@@ -5,6 +5,7 @@
import os
import sys
import unittest.mock
+import tempfile
import arff
import joblib
@@ -82,10 +83,7 @@
for task_type in ("classification", "regression"):
output_directory = os.path.join(working_directory, "metafeatures", task_type)
- try:
- os.makedirs(output_directory)
- except:
- pass
+ os.makedirs(output_directory, exist_ok=True)
all_metafeatures = {}
@@ -100,13 +98,10 @@
tasks = copy.deepcopy(tasks)
np.random.shuffle(tasks)
- def producer():
- for task_id in tasks:
- yield task_id
-
- memory = joblib.Memory(location="/tmp/joblib", verbose=10)
+ tmpdir = os.path.join(tempfile.gettempdir(), "joblib")
+ memory = joblib.Memory(location=tmpdir, verbose=10)
cached_calculate_metafeatures = memory.cache(calculate_metafeatures)
- mfs = [cached_calculate_metafeatures(task_id) for task_id in producer()]
+ mfs = [cached_calculate_metafeatures(task_id) for task_id in tasks]
for mf in mfs:
if mf is not None:
|
{"golden_diff": "diff --git a/scripts/03_calculate_metafeatures.py b/scripts/03_calculate_metafeatures.py\n--- a/scripts/03_calculate_metafeatures.py\n+++ b/scripts/03_calculate_metafeatures.py\n@@ -5,6 +5,7 @@\n import os\n import sys\n import unittest.mock\n+import tempfile\n \n import arff\n import joblib\n@@ -82,10 +83,7 @@\n \n for task_type in (\"classification\", \"regression\"):\n output_directory = os.path.join(working_directory, \"metafeatures\", task_type)\n- try:\n- os.makedirs(output_directory)\n- except:\n- pass\n+ os.makedirs(output_directory, exist_ok=True)\n \n all_metafeatures = {}\n \n@@ -100,13 +98,10 @@\n tasks = copy.deepcopy(tasks)\n np.random.shuffle(tasks)\n \n- def producer():\n- for task_id in tasks:\n- yield task_id\n-\n- memory = joblib.Memory(location=\"/tmp/joblib\", verbose=10)\n+ tmpdir = os.path.join(tempfile.gettempdir(), \"joblib\")\n+ memory = joblib.Memory(location=tmpdir, verbose=10)\n cached_calculate_metafeatures = memory.cache(calculate_metafeatures)\n- mfs = [cached_calculate_metafeatures(task_id) for task_id in producer()]\n+ mfs = [cached_calculate_metafeatures(task_id) for task_id in tasks]\n \n for mf in mfs:\n if mf is not None:\n", "issue": "Fix timeouts related to metalearnings tests\n\n", "before_files": [{"content": "from argparse import ArgumentParser\nfrom collections import defaultdict, OrderedDict\nimport copy\nimport logging\nimport os\nimport sys\nimport unittest.mock\n\nimport arff\nimport joblib\nimport numpy as np\nimport pandas as pd\n\nfrom autosklearn.constants import (\n BINARY_CLASSIFICATION,\n MULTICLASS_CLASSIFICATION,\n REGRESSION,\n)\nfrom autosklearn.metalearning.metafeatures import metafeatures\nfrom autosklearn.smbo import (\n _calculate_metafeatures,\n _calculate_metafeatures_encoded,\n EXCLUDE_META_FEATURES_REGRESSION,\n EXCLUDE_META_FEATURES_CLASSIFICATION,\n)\nfrom autosklearn.util.stopwatch import StopWatch\n\nsys.path.append(\".\")\nfrom update_metadata_util import load_task, classification_tasks, regression_tasks\n\nlogger = logging.getLogger(\"03_calculate_metafeatures\")\n\n\ndef calculate_metafeatures(task_id):\n X_train, y_train, X_test, y_test, cat, task_type, dataset_name = load_task(task_id)\n stopwatch = StopWatch()\n\n if task_type == \"classification\":\n if len(np.unique(y_train)) == 2:\n task_type = BINARY_CLASSIFICATION\n else:\n task_type = MULTICLASS_CLASSIFICATION\n else:\n task_type = REGRESSION\n\n _metafeatures_labels = _calculate_metafeatures(\n x_train=X_train,\n y_train=y_train,\n data_feat_type=cat,\n data_info_task=task_type,\n basename=dataset_name,\n logger_=logger,\n stopwatch=stopwatch,\n )\n\n _metafeatures_encoded_labels = _calculate_metafeatures_encoded(\n x_train=X_train,\n y_train=y_train,\n data_feat_type=cat,\n task=task_type,\n basename=dataset_name,\n logger_=logger,\n stopwatch=stopwatch,\n )\n\n mf = _metafeatures_labels\n mf.metafeature_values.update(_metafeatures_encoded_labels.metafeature_values)\n\n return mf\n\n\nif __name__ == \"__main__\":\n parser = ArgumentParser()\n parser.add_argument(\"--working-directory\", type=str, required=True)\n parser.add_argument(\"--memory-limit\", type=int, default=3072)\n parser.add_argument(\"--test-mode\", action=\"store_true\")\n\n args = parser.parse_args()\n working_directory = args.working_directory\n memory_limit = args.memory_limit\n test_mode = args.test_mode\n\n for task_type in (\"classification\", \"regression\"):\n output_directory = os.path.join(working_directory, \"metafeatures\", task_type)\n try:\n os.makedirs(output_directory)\n except:\n pass\n\n all_metafeatures = {}\n\n if task_type == \"classification\":\n tasks = classification_tasks\n else:\n tasks = regression_tasks\n\n if test_mode:\n tasks = [tasks[0]]\n\n tasks = copy.deepcopy(tasks)\n np.random.shuffle(tasks)\n\n def producer():\n for task_id in tasks:\n yield task_id\n\n memory = joblib.Memory(location=\"/tmp/joblib\", verbose=10)\n cached_calculate_metafeatures = memory.cache(calculate_metafeatures)\n mfs = [cached_calculate_metafeatures(task_id) for task_id in producer()]\n\n for mf in mfs:\n if mf is not None:\n all_metafeatures[mf.dataset_name] = mf\n\n # Write the calculation times as a csv file to disc (can be viewed in\n # LibreOffice calc afterwards)\n calculation_times = defaultdict(dict)\n metafeature_values = defaultdict(dict)\n helperfunction_values = defaultdict(dict)\n\n for i, task_id in enumerate(all_metafeatures):\n calculation_times[task_id] = dict()\n for metafeature_name in sorted(\n all_metafeatures[task_id].metafeature_values\n ):\n metafeature_value = all_metafeatures[task_id].metafeature_values[\n metafeature_name\n ]\n calculation_times[task_id][metafeature_name] = metafeature_value.time\n if metafeature_value.type_ == \"HELPERFUNCTION\":\n helperfunction_values[task_id][\n metafeature_name\n ] = metafeature_value.value\n else:\n metafeature_values[task_id][\n metafeature_name\n ] = metafeature_value.value\n\n calculation_times = pd.DataFrame(calculation_times).transpose()\n calculation_times = calculation_times.sort_index()\n with open(os.path.join(output_directory, \"calculation_times.csv\"), \"w\") as fh:\n fh.write(calculation_times.to_csv())\n\n # Write all metafeatures in the aslib1.0 format\n metafeature_values = metafeature_values = pd.DataFrame(\n metafeature_values\n ).transpose()\n metafeature_values = metafeature_values.sort_index()\n arff_object = dict()\n arff_object[\"attributes\"] = [\n (\"instance_id\", \"STRING\"),\n (\"repetition\", \"NUMERIC\"),\n ] + [(\"%s\" % name, \"NUMERIC\") for name in metafeature_values.columns]\n arff_object[\"relation\"] = \"FEATURE_VALUES\"\n arff_object[\"description\"] = \"\"\n\n data = []\n for idx in metafeature_values.index:\n line = [idx, 1]\n line += [\n value if np.isfinite(value) else None\n for value in metafeature_values.loc[idx, :].values\n ]\n data.append(line)\n arff_object[\"data\"] = data\n\n with open(os.path.join(output_directory, \"feature_values.arff\"), \"w\") as fh:\n arff.dump(arff_object, fh)\n\n # Feature steps and runtimes according to the aslib1.0 format\n feature_steps = defaultdict(list)\n metafeature_names = list()\n\n exclude_metafeatures = (\n EXCLUDE_META_FEATURES_CLASSIFICATION\n if task_type == \"classification\"\n else EXCLUDE_META_FEATURES_REGRESSION\n )\n\n for metafeature_name in metafeatures.metafeatures.functions:\n\n if metafeature_name in exclude_metafeatures:\n continue\n\n dependency = metafeatures.metafeatures.get_dependency(metafeature_name)\n if dependency is not None:\n feature_steps[dependency].append(metafeature_name)\n feature_steps[metafeature_name].append(metafeature_name)\n\n metafeature_names.append(metafeature_name)\n\n # Write the feature runstatus in the aslib1.0 format\n arff_object = dict()\n arff_object[\"attributes\"] = [\n (\"instance_id\", \"STRING\"),\n (\"repetition\", \"NUMERIC\"),\n ] + [\n (\"%s\" % name, [\"ok\", \"timeout\", \"memout\", \"presolved\", \"crash\", \"other\"])\n for name in feature_steps\n ]\n arff_object[\"relation\"] = \"FEATURE_RUNSTATUS\"\n arff_object[\"description\"] = \"\"\n\n data = []\n for idx in metafeature_values.index:\n line = [idx, 1]\n for feature_step in feature_steps:\n if feature_step in helperfunction_values[idx]:\n line.append(\n \"ok\"\n if helperfunction_values[feature_step] is not None\n else \"other\"\n )\n elif feature_step in metafeature_values.loc[idx]:\n line.append(\n \"ok\"\n if np.isfinite(metafeature_values.loc[idx][feature_step])\n else \"other\"\n )\n else:\n line.append(\"other\")\n\n data.append(line)\n arff_object[\"data\"] = data\n\n with open(os.path.join(output_directory, \"feature_runstatus.arff\"), \"w\") as fh:\n arff.dump(arff_object, fh)\n\n arff_object = dict()\n arff_object[\"attributes\"] = [\n (\"instance_id\", \"STRING\"),\n (\"repetition\", \"NUMERIC\"),\n ] + [(\"%s\" % feature_step, \"NUMERIC\") for feature_step in feature_steps]\n arff_object[\"relation\"] = \"FEATURE_COSTS\"\n arff_object[\"description\"] = \"\"\n\n data = []\n for instance_id in calculation_times.index:\n calculation_times_per_group = dict()\n line = [instance_id, 1]\n for feature_step in feature_steps:\n time_ = 0.0\n for feature in feature_steps[feature_step]:\n time_ += calculation_times[feature][instance_id]\n if not np.isfinite(time_):\n raise ValueError(\n \"Feature cost %s for instance %s and feature \"\n \"step %s not finite\" % (time_, instance_id, feature)\n )\n line.append(time_)\n data.append(line)\n arff_object[\"data\"] = data\n\n with open(os.path.join(output_directory, \"feature_costs.arff\"), \"w\") as fh:\n arff.dump(arff_object, fh)\n\n # Write the features part of the description.txt to a file\n description = OrderedDict()\n description[\"features_cutoff_time\"] = \"3600\"\n description[\"features_cutoff_memory\"] = args.memory_limit\n description[\"number_of_feature_steps\"] = str(len(feature_steps))\n\n for feature_step in feature_steps:\n description[\"feature_step %s\" % feature_step] = \", \".join(\n feature_steps[feature_step]\n )\n description[\"features_deterministic\"] = \", \".join(\n [metafeature_name for metafeature_name in metafeature_names]\n )\n description[\"features_stochastic\"] = \"\"\n description[\"default_steps\"] = \", \".join(feature_steps)\n\n with open(\n os.path.join(output_directory, \"description.features.txt\"), \"w\"\n ) as fh:\n for entry in description:\n fh.write(\"%s: %s\\n\" % (entry, description[entry]))\n", "path": "scripts/03_calculate_metafeatures.py"}], "after_files": [{"content": "from argparse import ArgumentParser\nfrom collections import defaultdict, OrderedDict\nimport copy\nimport logging\nimport os\nimport sys\nimport unittest.mock\nimport tempfile\n\nimport arff\nimport joblib\nimport numpy as np\nimport pandas as pd\n\nfrom autosklearn.constants import (\n BINARY_CLASSIFICATION,\n MULTICLASS_CLASSIFICATION,\n REGRESSION,\n)\nfrom autosklearn.metalearning.metafeatures import metafeatures\nfrom autosklearn.smbo import (\n _calculate_metafeatures,\n _calculate_metafeatures_encoded,\n EXCLUDE_META_FEATURES_REGRESSION,\n EXCLUDE_META_FEATURES_CLASSIFICATION,\n)\nfrom autosklearn.util.stopwatch import StopWatch\n\nsys.path.append(\".\")\nfrom update_metadata_util import load_task, classification_tasks, regression_tasks\n\nlogger = logging.getLogger(\"03_calculate_metafeatures\")\n\n\ndef calculate_metafeatures(task_id):\n X_train, y_train, X_test, y_test, cat, task_type, dataset_name = load_task(task_id)\n stopwatch = StopWatch()\n\n if task_type == \"classification\":\n if len(np.unique(y_train)) == 2:\n task_type = BINARY_CLASSIFICATION\n else:\n task_type = MULTICLASS_CLASSIFICATION\n else:\n task_type = REGRESSION\n\n _metafeatures_labels = _calculate_metafeatures(\n x_train=X_train,\n y_train=y_train,\n data_feat_type=cat,\n data_info_task=task_type,\n basename=dataset_name,\n logger_=logger,\n stopwatch=stopwatch,\n )\n\n _metafeatures_encoded_labels = _calculate_metafeatures_encoded(\n x_train=X_train,\n y_train=y_train,\n data_feat_type=cat,\n task=task_type,\n basename=dataset_name,\n logger_=logger,\n stopwatch=stopwatch,\n )\n\n mf = _metafeatures_labels\n mf.metafeature_values.update(_metafeatures_encoded_labels.metafeature_values)\n\n return mf\n\n\nif __name__ == \"__main__\":\n parser = ArgumentParser()\n parser.add_argument(\"--working-directory\", type=str, required=True)\n parser.add_argument(\"--memory-limit\", type=int, default=3072)\n parser.add_argument(\"--test-mode\", action=\"store_true\")\n\n args = parser.parse_args()\n working_directory = args.working_directory\n memory_limit = args.memory_limit\n test_mode = args.test_mode\n\n for task_type in (\"classification\", \"regression\"):\n output_directory = os.path.join(working_directory, \"metafeatures\", task_type)\n os.makedirs(output_directory, exist_ok=True)\n\n all_metafeatures = {}\n\n if task_type == \"classification\":\n tasks = classification_tasks\n else:\n tasks = regression_tasks\n\n if test_mode:\n tasks = [tasks[0]]\n\n tasks = copy.deepcopy(tasks)\n np.random.shuffle(tasks)\n\n tmpdir = os.path.join(tempfile.gettempdir(), \"joblib\")\n memory = joblib.Memory(location=tmpdir, verbose=10)\n cached_calculate_metafeatures = memory.cache(calculate_metafeatures)\n mfs = [cached_calculate_metafeatures(task_id) for task_id in tasks]\n\n for mf in mfs:\n if mf is not None:\n all_metafeatures[mf.dataset_name] = mf\n\n # Write the calculation times as a csv file to disc (can be viewed in\n # LibreOffice calc afterwards)\n calculation_times = defaultdict(dict)\n metafeature_values = defaultdict(dict)\n helperfunction_values = defaultdict(dict)\n\n for i, task_id in enumerate(all_metafeatures):\n calculation_times[task_id] = dict()\n for metafeature_name in sorted(\n all_metafeatures[task_id].metafeature_values\n ):\n metafeature_value = all_metafeatures[task_id].metafeature_values[\n metafeature_name\n ]\n calculation_times[task_id][metafeature_name] = metafeature_value.time\n if metafeature_value.type_ == \"HELPERFUNCTION\":\n helperfunction_values[task_id][\n metafeature_name\n ] = metafeature_value.value\n else:\n metafeature_values[task_id][\n metafeature_name\n ] = metafeature_value.value\n\n calculation_times = pd.DataFrame(calculation_times).transpose()\n calculation_times = calculation_times.sort_index()\n with open(os.path.join(output_directory, \"calculation_times.csv\"), \"w\") as fh:\n fh.write(calculation_times.to_csv())\n\n # Write all metafeatures in the aslib1.0 format\n metafeature_values = metafeature_values = pd.DataFrame(\n metafeature_values\n ).transpose()\n metafeature_values = metafeature_values.sort_index()\n arff_object = dict()\n arff_object[\"attributes\"] = [\n (\"instance_id\", \"STRING\"),\n (\"repetition\", \"NUMERIC\"),\n ] + [(\"%s\" % name, \"NUMERIC\") for name in metafeature_values.columns]\n arff_object[\"relation\"] = \"FEATURE_VALUES\"\n arff_object[\"description\"] = \"\"\n\n data = []\n for idx in metafeature_values.index:\n line = [idx, 1]\n line += [\n value if np.isfinite(value) else None\n for value in metafeature_values.loc[idx, :].values\n ]\n data.append(line)\n arff_object[\"data\"] = data\n\n with open(os.path.join(output_directory, \"feature_values.arff\"), \"w\") as fh:\n arff.dump(arff_object, fh)\n\n # Feature steps and runtimes according to the aslib1.0 format\n feature_steps = defaultdict(list)\n metafeature_names = list()\n\n exclude_metafeatures = (\n EXCLUDE_META_FEATURES_CLASSIFICATION\n if task_type == \"classification\"\n else EXCLUDE_META_FEATURES_REGRESSION\n )\n\n for metafeature_name in metafeatures.metafeatures.functions:\n\n if metafeature_name in exclude_metafeatures:\n continue\n\n dependency = metafeatures.metafeatures.get_dependency(metafeature_name)\n if dependency is not None:\n feature_steps[dependency].append(metafeature_name)\n feature_steps[metafeature_name].append(metafeature_name)\n\n metafeature_names.append(metafeature_name)\n\n # Write the feature runstatus in the aslib1.0 format\n arff_object = dict()\n arff_object[\"attributes\"] = [\n (\"instance_id\", \"STRING\"),\n (\"repetition\", \"NUMERIC\"),\n ] + [\n (\"%s\" % name, [\"ok\", \"timeout\", \"memout\", \"presolved\", \"crash\", \"other\"])\n for name in feature_steps\n ]\n arff_object[\"relation\"] = \"FEATURE_RUNSTATUS\"\n arff_object[\"description\"] = \"\"\n\n data = []\n for idx in metafeature_values.index:\n line = [idx, 1]\n for feature_step in feature_steps:\n if feature_step in helperfunction_values[idx]:\n line.append(\n \"ok\"\n if helperfunction_values[feature_step] is not None\n else \"other\"\n )\n elif feature_step in metafeature_values.loc[idx]:\n line.append(\n \"ok\"\n if np.isfinite(metafeature_values.loc[idx][feature_step])\n else \"other\"\n )\n else:\n line.append(\"other\")\n\n data.append(line)\n arff_object[\"data\"] = data\n\n with open(os.path.join(output_directory, \"feature_runstatus.arff\"), \"w\") as fh:\n arff.dump(arff_object, fh)\n\n arff_object = dict()\n arff_object[\"attributes\"] = [\n (\"instance_id\", \"STRING\"),\n (\"repetition\", \"NUMERIC\"),\n ] + [(\"%s\" % feature_step, \"NUMERIC\") for feature_step in feature_steps]\n arff_object[\"relation\"] = \"FEATURE_COSTS\"\n arff_object[\"description\"] = \"\"\n\n data = []\n for instance_id in calculation_times.index:\n calculation_times_per_group = dict()\n line = [instance_id, 1]\n for feature_step in feature_steps:\n time_ = 0.0\n for feature in feature_steps[feature_step]:\n time_ += calculation_times[feature][instance_id]\n if not np.isfinite(time_):\n raise ValueError(\n \"Feature cost %s for instance %s and feature \"\n \"step %s not finite\" % (time_, instance_id, feature)\n )\n line.append(time_)\n data.append(line)\n arff_object[\"data\"] = data\n\n with open(os.path.join(output_directory, \"feature_costs.arff\"), \"w\") as fh:\n arff.dump(arff_object, fh)\n\n # Write the features part of the description.txt to a file\n description = OrderedDict()\n description[\"features_cutoff_time\"] = \"3600\"\n description[\"features_cutoff_memory\"] = args.memory_limit\n description[\"number_of_feature_steps\"] = str(len(feature_steps))\n\n for feature_step in feature_steps:\n description[\"feature_step %s\" % feature_step] = \", \".join(\n feature_steps[feature_step]\n )\n description[\"features_deterministic\"] = \", \".join(\n [metafeature_name for metafeature_name in metafeature_names]\n )\n description[\"features_stochastic\"] = \"\"\n description[\"default_steps\"] = \", \".join(feature_steps)\n\n with open(\n os.path.join(output_directory, \"description.features.txt\"), \"w\"\n ) as fh:\n for entry in description:\n fh.write(\"%s: %s\\n\" % (entry, description[entry]))\n", "path": "scripts/03_calculate_metafeatures.py"}]}
| 3,045 | 332 |
gh_patches_debug_2182
|
rasdani/github-patches
|
git_diff
|
modin-project__modin-4769
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
test_join_sort.py in CI failed by timeout with new Dask release - 2022.2.0
Error: https://github.com/modin-project/modin/runs/5195622251?check_suite_focus=true
Dask release - https://github.com/dask/dask/releases/tag/2022.02.0
Fastest option here - pin `dask<2022.2.0`, but it also requires an investigation into the cause.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 from setuptools import setup, find_packages
2 import versioneer
3 import sys
4
5 PANDAS_VERSION = "1.4.3" if sys.version_info >= (3, 8) else "1.1.5"
6
7 with open("README.md", "r", encoding="utf-8") as fh:
8 long_description = fh.read()
9
10 dask_deps = ["dask>=2.22.0,<2022.2.0", "distributed>=2.22.0,<2022.2.0"]
11 if sys.version_info < (3, 8):
12 dask_deps.append("pickle5")
13
14 ray_deps = [
15 "ray[default]>=1.4.0",
16 "pyarrow>=4.0.1",
17 "redis>=3.5.0,<4.0.0",
18 ]
19 remote_deps = ["rpyc==4.1.5", "cloudpickle", "boto3"]
20 spreadsheet_deps = ["modin-spreadsheet>=0.1.0"]
21 sql_deps = ["dfsql>=0.4.2", "pyparsing<=2.4.7"]
22 all_deps = dask_deps + ray_deps + remote_deps + spreadsheet_deps
23
24 # Distribute 'modin-autoimport-pandas.pth' along with binary and source distributions.
25 # This file provides the "import pandas before Ray init" feature if specific
26 # environment variable is set (see https://github.com/modin-project/modin/issues/4564).
27 cmdclass = versioneer.get_cmdclass()
28 extra_files = ["modin-autoimport-pandas.pth"]
29
30
31 class AddPthFileBuild(cmdclass["build_py"]):
32 def _get_data_files(self):
33 return (super()._get_data_files() or []) + [
34 (".", ".", self.build_lib, extra_files)
35 ]
36
37
38 class AddPthFileSDist(cmdclass["sdist"]):
39 def make_distribution(self):
40 self.filelist.extend(extra_files)
41 return super().make_distribution()
42
43
44 cmdclass["build_py"] = AddPthFileBuild
45 cmdclass["sdist"] = AddPthFileSDist
46
47 setup(
48 name="modin",
49 version=versioneer.get_version(),
50 cmdclass=cmdclass,
51 description="Modin: Make your pandas code run faster by changing one line of code.",
52 packages=find_packages(exclude=["scripts", "scripts.*"]),
53 include_package_data=True,
54 license="Apache 2",
55 url="https://github.com/modin-project/modin",
56 long_description=long_description,
57 long_description_content_type="text/markdown",
58 install_requires=[f"pandas=={PANDAS_VERSION}", "packaging", "numpy>=1.18.5", "fsspec", "psutil"],
59 extras_require={
60 # can be installed by pip install modin[dask]
61 "dask": dask_deps,
62 "ray": ray_deps,
63 "remote": remote_deps,
64 "spreadsheet": spreadsheet_deps,
65 "sql": sql_deps,
66 "all": all_deps,
67 },
68 python_requires=">=3.6",
69 )
70
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -7,7 +7,7 @@
with open("README.md", "r", encoding="utf-8") as fh:
long_description = fh.read()
-dask_deps = ["dask>=2.22.0,<2022.2.0", "distributed>=2.22.0,<2022.2.0"]
+dask_deps = ["dask>=2.22.0", "distributed>=2.22.0"]
if sys.version_info < (3, 8):
dask_deps.append("pickle5")
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -7,7 +7,7 @@\n with open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n \n-dask_deps = [\"dask>=2.22.0,<2022.2.0\", \"distributed>=2.22.0,<2022.2.0\"]\n+dask_deps = [\"dask>=2.22.0\", \"distributed>=2.22.0\"]\n if sys.version_info < (3, 8):\n dask_deps.append(\"pickle5\")\n", "issue": "test_join_sort.py in CI failed by timeout with new Dask release - 2022.2.0\nError: https://github.com/modin-project/modin/runs/5195622251?check_suite_focus=true\r\n\r\nDask release - https://github.com/dask/dask/releases/tag/2022.02.0\r\n\r\nFastest option here - pin `dask<2022.2.0`, but it also requires an investigation into the cause.\n", "before_files": [{"content": "from setuptools import setup, find_packages\nimport versioneer\nimport sys\n\nPANDAS_VERSION = \"1.4.3\" if sys.version_info >= (3, 8) else \"1.1.5\"\n\nwith open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n\ndask_deps = [\"dask>=2.22.0,<2022.2.0\", \"distributed>=2.22.0,<2022.2.0\"]\nif sys.version_info < (3, 8):\n dask_deps.append(\"pickle5\")\n\nray_deps = [\n \"ray[default]>=1.4.0\",\n \"pyarrow>=4.0.1\",\n \"redis>=3.5.0,<4.0.0\",\n]\nremote_deps = [\"rpyc==4.1.5\", \"cloudpickle\", \"boto3\"]\nspreadsheet_deps = [\"modin-spreadsheet>=0.1.0\"]\nsql_deps = [\"dfsql>=0.4.2\", \"pyparsing<=2.4.7\"]\nall_deps = dask_deps + ray_deps + remote_deps + spreadsheet_deps\n\n# Distribute 'modin-autoimport-pandas.pth' along with binary and source distributions.\n# This file provides the \"import pandas before Ray init\" feature if specific\n# environment variable is set (see https://github.com/modin-project/modin/issues/4564).\ncmdclass = versioneer.get_cmdclass()\nextra_files = [\"modin-autoimport-pandas.pth\"]\n\n\nclass AddPthFileBuild(cmdclass[\"build_py\"]):\n def _get_data_files(self):\n return (super()._get_data_files() or []) + [\n (\".\", \".\", self.build_lib, extra_files)\n ]\n\n\nclass AddPthFileSDist(cmdclass[\"sdist\"]):\n def make_distribution(self):\n self.filelist.extend(extra_files)\n return super().make_distribution()\n\n\ncmdclass[\"build_py\"] = AddPthFileBuild\ncmdclass[\"sdist\"] = AddPthFileSDist\n\nsetup(\n name=\"modin\",\n version=versioneer.get_version(),\n cmdclass=cmdclass,\n description=\"Modin: Make your pandas code run faster by changing one line of code.\",\n packages=find_packages(exclude=[\"scripts\", \"scripts.*\"]),\n include_package_data=True,\n license=\"Apache 2\",\n url=\"https://github.com/modin-project/modin\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n install_requires=[f\"pandas=={PANDAS_VERSION}\", \"packaging\", \"numpy>=1.18.5\", \"fsspec\", \"psutil\"],\n extras_require={\n # can be installed by pip install modin[dask]\n \"dask\": dask_deps,\n \"ray\": ray_deps,\n \"remote\": remote_deps,\n \"spreadsheet\": spreadsheet_deps,\n \"sql\": sql_deps,\n \"all\": all_deps,\n },\n python_requires=\">=3.6\",\n)\n", "path": "setup.py"}], "after_files": [{"content": "from setuptools import setup, find_packages\nimport versioneer\nimport sys\n\nPANDAS_VERSION = \"1.4.3\" if sys.version_info >= (3, 8) else \"1.1.5\"\n\nwith open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n\ndask_deps = [\"dask>=2.22.0\", \"distributed>=2.22.0\"]\nif sys.version_info < (3, 8):\n dask_deps.append(\"pickle5\")\n\nray_deps = [\n \"ray[default]>=1.4.0\",\n \"pyarrow>=4.0.1\",\n \"redis>=3.5.0,<4.0.0\",\n]\nremote_deps = [\"rpyc==4.1.5\", \"cloudpickle\", \"boto3\"]\nspreadsheet_deps = [\"modin-spreadsheet>=0.1.0\"]\nsql_deps = [\"dfsql>=0.4.2\", \"pyparsing<=2.4.7\"]\nall_deps = dask_deps + ray_deps + remote_deps + spreadsheet_deps\n\n# Distribute 'modin-autoimport-pandas.pth' along with binary and source distributions.\n# This file provides the \"import pandas before Ray init\" feature if specific\n# environment variable is set (see https://github.com/modin-project/modin/issues/4564).\ncmdclass = versioneer.get_cmdclass()\nextra_files = [\"modin-autoimport-pandas.pth\"]\n\n\nclass AddPthFileBuild(cmdclass[\"build_py\"]):\n def _get_data_files(self):\n return (super()._get_data_files() or []) + [\n (\".\", \".\", self.build_lib, extra_files)\n ]\n\n\nclass AddPthFileSDist(cmdclass[\"sdist\"]):\n def make_distribution(self):\n self.filelist.extend(extra_files)\n return super().make_distribution()\n\n\ncmdclass[\"build_py\"] = AddPthFileBuild\ncmdclass[\"sdist\"] = AddPthFileSDist\n\nsetup(\n name=\"modin\",\n version=versioneer.get_version(),\n cmdclass=cmdclass,\n description=\"Modin: Make your pandas code run faster by changing one line of code.\",\n packages=find_packages(exclude=[\"scripts\", \"scripts.*\"]),\n include_package_data=True,\n license=\"Apache 2\",\n url=\"https://github.com/modin-project/modin\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n install_requires=[f\"pandas=={PANDAS_VERSION}\", \"packaging\", \"numpy>=1.18.5\", \"fsspec\", \"psutil\"],\n extras_require={\n # can be installed by pip install modin[dask]\n \"dask\": dask_deps,\n \"ray\": ray_deps,\n \"remote\": remote_deps,\n \"spreadsheet\": spreadsheet_deps,\n \"sql\": sql_deps,\n \"all\": all_deps,\n },\n python_requires=\">=3.6\",\n)\n", "path": "setup.py"}]}
| 1,164 | 144 |
gh_patches_debug_33208
|
rasdani/github-patches
|
git_diff
|
Azure__azure-cli-extensions-3135
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Transition to GA: costmanagement
Command module `costmanagement` has been released for a long time and is using stable sdk version `2019-11-01`.
Please check [Extension GA guidelines](https://github.com/Azure/azure-cli/blob/dev/doc/onboarding_guide.md#preview-extension-to-ga-extension) and remove `experimental` tag if necessary.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/costmanagement/setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 # --------------------------------------------------------------------------------------------
4 # Copyright (c) Microsoft Corporation. All rights reserved.
5 # Licensed under the MIT License. See License.txt in the project root for license information.
6 # --------------------------------------------------------------------------------------------
7
8
9 from codecs import open
10 from setuptools import setup, find_packages
11
12 # TODO: Confirm this is the right version number you want and it matches your
13 # HISTORY.rst entry.
14 VERSION = '0.1.0'
15
16 # The full list of classifiers is available at
17 # https://pypi.python.org/pypi?%3Aaction=list_classifiers
18 CLASSIFIERS = [
19 'Development Status :: 4 - Beta',
20 'Intended Audience :: Developers',
21 'Intended Audience :: System Administrators',
22 'Programming Language :: Python',
23 'Programming Language :: Python :: 3',
24 'Programming Language :: Python :: 3.6',
25 'Programming Language :: Python :: 3.7',
26 'Programming Language :: Python :: 3.8',
27 'License :: OSI Approved :: MIT License',
28 ]
29
30 # TODO: Add any additional SDK dependencies here
31 DEPENDENCIES = []
32
33 with open('README.md', 'r', encoding='utf-8') as f:
34 README = f.read()
35 with open('HISTORY.rst', 'r', encoding='utf-8') as f:
36 HISTORY = f.read()
37
38 setup(
39 name='costmanagement',
40 version=VERSION,
41 description='Microsoft Azure Command-Line Tools CostManagementClient Extension',
42 # TODO: Update author and email, if applicable
43 author='Microsoft Corporation',
44 author_email='azpycli@microsoft.com',
45 url='https://github.com/Azure/azure-cli-extensions/tree/master/src/costmanagement',
46 long_description=README + '\n\n' + HISTORY,
47 license='MIT',
48 classifiers=CLASSIFIERS,
49 packages=find_packages(),
50 install_requires=DEPENDENCIES,
51 package_data={'azext_costmanagement': ['azext_metadata.json']},
52 )
53
```
Path: `src/costmanagement/azext_costmanagement/manual/commands.py`
Content:
```
1 # --------------------------------------------------------------------------------------------
2 # Copyright (c) Microsoft Corporation. All rights reserved.
3 # Licensed under the MIT License. See License.txt in the project root for license information.
4 # --------------------------------------------------------------------------------------------
5
6 from azure.cli.core.commands import CliCommandType
7
8
9 def load_command_table(self, _):
10
11 from azext_costmanagement.generated._client_factory import cf_query
12 costmanagement_query = CliCommandType(
13 operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations.'
14 '_query_operations#QueryOperations.{}',
15 client_factory=cf_query)
16 with self.command_group('costmanagement', costmanagement_query,
17 client_factory=cf_query, is_experimental=True) as g:
18 g.custom_command('query', 'costmanagement_query')
19
20 from azext_costmanagement.generated._client_factory import cf_export
21 costmanagement_export = CliCommandType(
22 operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations._export_operations#ExportOperatio'
23 'ns.{}',
24 client_factory=cf_export)
25 with self.command_group('costmanagement export', costmanagement_export, client_factory=cf_export,
26 is_experimental=True) as g:
27 g.custom_command('list', 'costmanagement_export_list')
28 g.custom_show_command('show', 'costmanagement_export_show')
29 g.custom_command('create', 'costmanagement_export_create')
30 g.custom_command('update', 'costmanagement_export_update')
31 g.custom_command('delete', 'costmanagement_export_delete', confirmation=True)
32
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/costmanagement/azext_costmanagement/manual/commands.py b/src/costmanagement/azext_costmanagement/manual/commands.py
--- a/src/costmanagement/azext_costmanagement/manual/commands.py
+++ b/src/costmanagement/azext_costmanagement/manual/commands.py
@@ -13,8 +13,7 @@
operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations.'
'_query_operations#QueryOperations.{}',
client_factory=cf_query)
- with self.command_group('costmanagement', costmanagement_query,
- client_factory=cf_query, is_experimental=True) as g:
+ with self.command_group('costmanagement', costmanagement_query, client_factory=cf_query) as g:
g.custom_command('query', 'costmanagement_query')
from azext_costmanagement.generated._client_factory import cf_export
@@ -22,8 +21,7 @@
operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations._export_operations#ExportOperatio'
'ns.{}',
client_factory=cf_export)
- with self.command_group('costmanagement export', costmanagement_export, client_factory=cf_export,
- is_experimental=True) as g:
+ with self.command_group('costmanagement export', costmanagement_export, client_factory=cf_export) as g:
g.custom_command('list', 'costmanagement_export_list')
g.custom_show_command('show', 'costmanagement_export_show')
g.custom_command('create', 'costmanagement_export_create')
diff --git a/src/costmanagement/setup.py b/src/costmanagement/setup.py
--- a/src/costmanagement/setup.py
+++ b/src/costmanagement/setup.py
@@ -11,7 +11,7 @@
# TODO: Confirm this is the right version number you want and it matches your
# HISTORY.rst entry.
-VERSION = '0.1.0'
+VERSION = '0.1.1'
# The full list of classifiers is available at
# https://pypi.python.org/pypi?%3Aaction=list_classifiers
|
{"golden_diff": "diff --git a/src/costmanagement/azext_costmanagement/manual/commands.py b/src/costmanagement/azext_costmanagement/manual/commands.py\n--- a/src/costmanagement/azext_costmanagement/manual/commands.py\n+++ b/src/costmanagement/azext_costmanagement/manual/commands.py\n@@ -13,8 +13,7 @@\n operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations.'\n '_query_operations#QueryOperations.{}',\n client_factory=cf_query)\n- with self.command_group('costmanagement', costmanagement_query,\n- client_factory=cf_query, is_experimental=True) as g:\n+ with self.command_group('costmanagement', costmanagement_query, client_factory=cf_query) as g:\n g.custom_command('query', 'costmanagement_query')\n \n from azext_costmanagement.generated._client_factory import cf_export\n@@ -22,8 +21,7 @@\n operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations._export_operations#ExportOperatio'\n 'ns.{}',\n client_factory=cf_export)\n- with self.command_group('costmanagement export', costmanagement_export, client_factory=cf_export,\n- is_experimental=True) as g:\n+ with self.command_group('costmanagement export', costmanagement_export, client_factory=cf_export) as g:\n g.custom_command('list', 'costmanagement_export_list')\n g.custom_show_command('show', 'costmanagement_export_show')\n g.custom_command('create', 'costmanagement_export_create')\ndiff --git a/src/costmanagement/setup.py b/src/costmanagement/setup.py\n--- a/src/costmanagement/setup.py\n+++ b/src/costmanagement/setup.py\n@@ -11,7 +11,7 @@\n \r\n # TODO: Confirm this is the right version number you want and it matches your\r\n # HISTORY.rst entry.\r\n-VERSION = '0.1.0'\r\n+VERSION = '0.1.1'\r\n \r\n # The full list of classifiers is available at\r\n # https://pypi.python.org/pypi?%3Aaction=list_classifiers\n", "issue": "Transition to GA: costmanagement\nCommand module `costmanagement` has been released for a long time and is using stable sdk version `2019-11-01`.\r\n\r\nPlease check [Extension GA guidelines](https://github.com/Azure/azure-cli/blob/dev/doc/onboarding_guide.md#preview-extension-to-ga-extension) and remove `experimental` tag if necessary.\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\r\n\r\n# --------------------------------------------------------------------------------------------\r\n# Copyright (c) Microsoft Corporation. All rights reserved.\r\n# Licensed under the MIT License. See License.txt in the project root for license information.\r\n# --------------------------------------------------------------------------------------------\r\n\r\n\r\nfrom codecs import open\r\nfrom setuptools import setup, find_packages\r\n\r\n# TODO: Confirm this is the right version number you want and it matches your\r\n# HISTORY.rst entry.\r\nVERSION = '0.1.0'\r\n\r\n# The full list of classifiers is available at\r\n# https://pypi.python.org/pypi?%3Aaction=list_classifiers\r\nCLASSIFIERS = [\r\n 'Development Status :: 4 - Beta',\r\n 'Intended Audience :: Developers',\r\n 'Intended Audience :: System Administrators',\r\n 'Programming Language :: Python',\r\n 'Programming Language :: Python :: 3',\r\n 'Programming Language :: Python :: 3.6',\r\n 'Programming Language :: Python :: 3.7',\r\n 'Programming Language :: Python :: 3.8',\r\n 'License :: OSI Approved :: MIT License',\r\n]\r\n\r\n# TODO: Add any additional SDK dependencies here\r\nDEPENDENCIES = []\r\n\r\nwith open('README.md', 'r', encoding='utf-8') as f:\r\n README = f.read()\r\nwith open('HISTORY.rst', 'r', encoding='utf-8') as f:\r\n HISTORY = f.read()\r\n\r\nsetup(\r\n name='costmanagement',\r\n version=VERSION,\r\n description='Microsoft Azure Command-Line Tools CostManagementClient Extension',\r\n # TODO: Update author and email, if applicable\r\n author='Microsoft Corporation',\r\n author_email='azpycli@microsoft.com',\r\n url='https://github.com/Azure/azure-cli-extensions/tree/master/src/costmanagement',\r\n long_description=README + '\\n\\n' + HISTORY,\r\n license='MIT',\r\n classifiers=CLASSIFIERS,\r\n packages=find_packages(),\r\n install_requires=DEPENDENCIES,\r\n package_data={'azext_costmanagement': ['azext_metadata.json']},\r\n)\r\n", "path": "src/costmanagement/setup.py"}, {"content": "# --------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See License.txt in the project root for license information.\n# --------------------------------------------------------------------------------------------\n\nfrom azure.cli.core.commands import CliCommandType\n\n\ndef load_command_table(self, _):\n\n from azext_costmanagement.generated._client_factory import cf_query\n costmanagement_query = CliCommandType(\n operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations.'\n '_query_operations#QueryOperations.{}',\n client_factory=cf_query)\n with self.command_group('costmanagement', costmanagement_query,\n client_factory=cf_query, is_experimental=True) as g:\n g.custom_command('query', 'costmanagement_query')\n\n from azext_costmanagement.generated._client_factory import cf_export\n costmanagement_export = CliCommandType(\n operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations._export_operations#ExportOperatio'\n 'ns.{}',\n client_factory=cf_export)\n with self.command_group('costmanagement export', costmanagement_export, client_factory=cf_export,\n is_experimental=True) as g:\n g.custom_command('list', 'costmanagement_export_list')\n g.custom_show_command('show', 'costmanagement_export_show')\n g.custom_command('create', 'costmanagement_export_create')\n g.custom_command('update', 'costmanagement_export_update')\n g.custom_command('delete', 'costmanagement_export_delete', confirmation=True)\n", "path": "src/costmanagement/azext_costmanagement/manual/commands.py"}], "after_files": [{"content": "#!/usr/bin/env python\r\n\r\n# --------------------------------------------------------------------------------------------\r\n# Copyright (c) Microsoft Corporation. All rights reserved.\r\n# Licensed under the MIT License. See License.txt in the project root for license information.\r\n# --------------------------------------------------------------------------------------------\r\n\r\n\r\nfrom codecs import open\r\nfrom setuptools import setup, find_packages\r\n\r\n# TODO: Confirm this is the right version number you want and it matches your\r\n# HISTORY.rst entry.\r\nVERSION = '0.1.1'\r\n\r\n# The full list of classifiers is available at\r\n# https://pypi.python.org/pypi?%3Aaction=list_classifiers\r\nCLASSIFIERS = [\r\n 'Development Status :: 4 - Beta',\r\n 'Intended Audience :: Developers',\r\n 'Intended Audience :: System Administrators',\r\n 'Programming Language :: Python',\r\n 'Programming Language :: Python :: 3',\r\n 'Programming Language :: Python :: 3.6',\r\n 'Programming Language :: Python :: 3.7',\r\n 'Programming Language :: Python :: 3.8',\r\n 'License :: OSI Approved :: MIT License',\r\n]\r\n\r\n# TODO: Add any additional SDK dependencies here\r\nDEPENDENCIES = []\r\n\r\nwith open('README.md', 'r', encoding='utf-8') as f:\r\n README = f.read()\r\nwith open('HISTORY.rst', 'r', encoding='utf-8') as f:\r\n HISTORY = f.read()\r\n\r\nsetup(\r\n name='costmanagement',\r\n version=VERSION,\r\n description='Microsoft Azure Command-Line Tools CostManagementClient Extension',\r\n # TODO: Update author and email, if applicable\r\n author='Microsoft Corporation',\r\n author_email='azpycli@microsoft.com',\r\n url='https://github.com/Azure/azure-cli-extensions/tree/master/src/costmanagement',\r\n long_description=README + '\\n\\n' + HISTORY,\r\n license='MIT',\r\n classifiers=CLASSIFIERS,\r\n packages=find_packages(),\r\n install_requires=DEPENDENCIES,\r\n package_data={'azext_costmanagement': ['azext_metadata.json']},\r\n)\r\n", "path": "src/costmanagement/setup.py"}, {"content": "# --------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See License.txt in the project root for license information.\n# --------------------------------------------------------------------------------------------\n\nfrom azure.cli.core.commands import CliCommandType\n\n\ndef load_command_table(self, _):\n\n from azext_costmanagement.generated._client_factory import cf_query\n costmanagement_query = CliCommandType(\n operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations.'\n '_query_operations#QueryOperations.{}',\n client_factory=cf_query)\n with self.command_group('costmanagement', costmanagement_query, client_factory=cf_query) as g:\n g.custom_command('query', 'costmanagement_query')\n\n from azext_costmanagement.generated._client_factory import cf_export\n costmanagement_export = CliCommandType(\n operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations._export_operations#ExportOperatio'\n 'ns.{}',\n client_factory=cf_export)\n with self.command_group('costmanagement export', costmanagement_export, client_factory=cf_export) as g:\n g.custom_command('list', 'costmanagement_export_list')\n g.custom_show_command('show', 'costmanagement_export_show')\n g.custom_command('create', 'costmanagement_export_create')\n g.custom_command('update', 'costmanagement_export_update')\n g.custom_command('delete', 'costmanagement_export_delete', confirmation=True)\n", "path": "src/costmanagement/azext_costmanagement/manual/commands.py"}]}
| 1,253 | 457 |
gh_patches_debug_38816
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-3454
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Spider valero is broken
During the global build at 2021-07-14-14-42-22, spider **valero** failed with **0 features** and **1 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/logs/valero.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/output/valero.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/output/valero.geojson))
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/valero.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 import scrapy
3 import json
4 from locations.items import GeojsonPointItem
5
6
7 class ValeroSpider(scrapy.Spider):
8 name = "valero"
9 item_attributes = {'brand': "Valero", 'brand_wikidata': 'Q1283291'}
10 allowed_domains = ["valeromaps.valero.com"]
11
12 def start_requests(self):
13 yield scrapy.FormRequest(
14 'https://valeromaps.valero.com/Home/Search?SPHostUrl=https:%2F%2Fwww.valero.com%2Fen-us',
15 method='POST',
16 headers={
17 'Content-Type': 'application/x-www-form-urlencoded; charset=utf-8'
18 },
19 formdata={
20 'NEBound_Lat': '90',
21 'NEBound_Long': '180',
22 'SWBound_Lat': '-90',
23 'SWBound_Long': '-180',
24 'center_Lat': '0',
25 'center_Long': '0'
26 }
27 )
28
29 def parse(self, response):
30 result = json.loads(response.body_as_unicode())
31 for store in result['StoreList']:
32 details = ', '.join([d['DetailName'] for d in store['Details']])
33 yield GeojsonPointItem(
34 lon=store['Longitude'],
35 lat=store['Latitude'],
36 ref=store['UniqueID'],
37 name=store['StationName'],
38 addr_full=store['Address'],
39 phone=store['Phone'],
40 opening_hours='24/7' if '24 Hours' in details else None,
41 extras={
42 'amenity:fuel': True,
43 'amenity:toilets': 'Restroom' in details or None,
44 'atm': 'ATM' in details,
45 'car_wash': 'Car Wash' in details,
46 'fuel:diesel': 'Diesel' in details or None,
47 'fuel:e85': 'E-85' in details or None,
48 }
49 )
50
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/spiders/valero.py b/locations/spiders/valero.py
--- a/locations/spiders/valero.py
+++ b/locations/spiders/valero.py
@@ -1,49 +1,39 @@
# -*- coding: utf-8 -*-
import scrapy
import json
+
from locations.items import GeojsonPointItem
class ValeroSpider(scrapy.Spider):
name = "valero"
- item_attributes = {'brand': "Valero", 'brand_wikidata': 'Q1283291'}
- allowed_domains = ["valeromaps.valero.com"]
-
- def start_requests(self):
- yield scrapy.FormRequest(
- 'https://valeromaps.valero.com/Home/Search?SPHostUrl=https:%2F%2Fwww.valero.com%2Fen-us',
- method='POST',
- headers={
- 'Content-Type': 'application/x-www-form-urlencoded; charset=utf-8'
- },
- formdata={
- 'NEBound_Lat': '90',
- 'NEBound_Long': '180',
- 'SWBound_Lat': '-90',
- 'SWBound_Long': '-180',
- 'center_Lat': '0',
- 'center_Long': '0'
- }
- )
+ item_attributes = {"brand": "Valero", "brand_wikidata": "Q1283291"}
+ allowed_domains = ["valero.com"]
+ start_urls = ["https://locations.valero.com/sitemap.xml"]
def parse(self, response):
- result = json.loads(response.body_as_unicode())
- for store in result['StoreList']:
- details = ', '.join([d['DetailName'] for d in store['Details']])
- yield GeojsonPointItem(
- lon=store['Longitude'],
- lat=store['Latitude'],
- ref=store['UniqueID'],
- name=store['StationName'],
- addr_full=store['Address'],
- phone=store['Phone'],
- opening_hours='24/7' if '24 Hours' in details else None,
- extras={
- 'amenity:fuel': True,
- 'amenity:toilets': 'Restroom' in details or None,
- 'atm': 'ATM' in details,
- 'car_wash': 'Car Wash' in details,
- 'fuel:diesel': 'Diesel' in details or None,
- 'fuel:e85': 'E-85' in details or None,
- }
- )
+ response.selector.remove_namespaces()
+ for url in response.xpath("//loc/text()").extract():
+ yield scrapy.Request(url, callback=self.parse_store)
+
+ def parse_store(self, response):
+ amenities = [s.strip() for s in response.xpath('//div[@class="amenityIconLabel"]/text()').extract()]
+ properties = {
+ "lat": response.xpath('//meta[@property="place:location:latitude"]/@content').get(),
+ "lon": response.xpath('//meta[@property="place:location:longitude"]/@content').get(),
+ "ref": response.url.rsplit("/", 1)[-1],
+ "website": response.url,
+ "name": response.xpath('normalize-space(//*[@id="pageTitleStoreName"])').get(),
+ "addr_full": response.xpath('normalize-space(//div[@class="locationDetailsContactRow"][1]//br/..)').get(),
+ "phone": response.xpath('//a[contains(@href,"tel:")]/text()').get(),
+ "opening_hours": "24/7" if "24 Hour" in amenities else None,
+ "extras": {
+ "atm": "ATM" in amenities,
+ "amenity:fuel": True,
+ "amenity:toilets": "Public Restroom" in amenities or None,
+ "car_wash": "Car Wash" in amenities,
+ "fuel:diesel": "Diesel" in amenities or None,
+ "fuel:e85": "E-85" in amenities or None,
+ },
+ }
+ yield GeojsonPointItem(**properties)
|
{"golden_diff": "diff --git a/locations/spiders/valero.py b/locations/spiders/valero.py\n--- a/locations/spiders/valero.py\n+++ b/locations/spiders/valero.py\n@@ -1,49 +1,39 @@\n # -*- coding: utf-8 -*-\n import scrapy\n import json\n+\n from locations.items import GeojsonPointItem\n \n \n class ValeroSpider(scrapy.Spider):\n name = \"valero\"\n- item_attributes = {'brand': \"Valero\", 'brand_wikidata': 'Q1283291'}\n- allowed_domains = [\"valeromaps.valero.com\"]\n-\n- def start_requests(self):\n- yield scrapy.FormRequest(\n- 'https://valeromaps.valero.com/Home/Search?SPHostUrl=https:%2F%2Fwww.valero.com%2Fen-us',\n- method='POST',\n- headers={\n- 'Content-Type': 'application/x-www-form-urlencoded; charset=utf-8'\n- },\n- formdata={\n- 'NEBound_Lat': '90',\n- 'NEBound_Long': '180',\n- 'SWBound_Lat': '-90',\n- 'SWBound_Long': '-180',\n- 'center_Lat': '0',\n- 'center_Long': '0'\n- }\n- )\n+ item_attributes = {\"brand\": \"Valero\", \"brand_wikidata\": \"Q1283291\"}\n+ allowed_domains = [\"valero.com\"]\n+ start_urls = [\"https://locations.valero.com/sitemap.xml\"]\n \n def parse(self, response):\n- result = json.loads(response.body_as_unicode())\n- for store in result['StoreList']:\n- details = ', '.join([d['DetailName'] for d in store['Details']])\n- yield GeojsonPointItem(\n- lon=store['Longitude'],\n- lat=store['Latitude'],\n- ref=store['UniqueID'],\n- name=store['StationName'],\n- addr_full=store['Address'],\n- phone=store['Phone'],\n- opening_hours='24/7' if '24 Hours' in details else None,\n- extras={\n- 'amenity:fuel': True,\n- 'amenity:toilets': 'Restroom' in details or None,\n- 'atm': 'ATM' in details,\n- 'car_wash': 'Car Wash' in details,\n- 'fuel:diesel': 'Diesel' in details or None,\n- 'fuel:e85': 'E-85' in details or None,\n- }\n- )\n+ response.selector.remove_namespaces()\n+ for url in response.xpath(\"//loc/text()\").extract():\n+ yield scrapy.Request(url, callback=self.parse_store)\n+\n+ def parse_store(self, response):\n+ amenities = [s.strip() for s in response.xpath('//div[@class=\"amenityIconLabel\"]/text()').extract()]\n+ properties = {\n+ \"lat\": response.xpath('//meta[@property=\"place:location:latitude\"]/@content').get(),\n+ \"lon\": response.xpath('//meta[@property=\"place:location:longitude\"]/@content').get(),\n+ \"ref\": response.url.rsplit(\"/\", 1)[-1],\n+ \"website\": response.url,\n+ \"name\": response.xpath('normalize-space(//*[@id=\"pageTitleStoreName\"])').get(),\n+ \"addr_full\": response.xpath('normalize-space(//div[@class=\"locationDetailsContactRow\"][1]//br/..)').get(),\n+ \"phone\": response.xpath('//a[contains(@href,\"tel:\")]/text()').get(),\n+ \"opening_hours\": \"24/7\" if \"24 Hour\" in amenities else None,\n+ \"extras\": {\n+ \"atm\": \"ATM\" in amenities,\n+ \"amenity:fuel\": True,\n+ \"amenity:toilets\": \"Public Restroom\" in amenities or None,\n+ \"car_wash\": \"Car Wash\" in amenities,\n+ \"fuel:diesel\": \"Diesel\" in amenities or None,\n+ \"fuel:e85\": \"E-85\" in amenities or None,\n+ },\n+ }\n+ yield GeojsonPointItem(**properties)\n", "issue": "Spider valero is broken\nDuring the global build at 2021-07-14-14-42-22, spider **valero** failed with **0 features** and **1 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/logs/valero.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/output/valero.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/output/valero.geojson))\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\nimport json\nfrom locations.items import GeojsonPointItem\n\n\nclass ValeroSpider(scrapy.Spider):\n name = \"valero\"\n item_attributes = {'brand': \"Valero\", 'brand_wikidata': 'Q1283291'}\n allowed_domains = [\"valeromaps.valero.com\"]\n\n def start_requests(self):\n yield scrapy.FormRequest(\n 'https://valeromaps.valero.com/Home/Search?SPHostUrl=https:%2F%2Fwww.valero.com%2Fen-us',\n method='POST',\n headers={\n 'Content-Type': 'application/x-www-form-urlencoded; charset=utf-8'\n },\n formdata={\n 'NEBound_Lat': '90',\n 'NEBound_Long': '180',\n 'SWBound_Lat': '-90',\n 'SWBound_Long': '-180',\n 'center_Lat': '0',\n 'center_Long': '0'\n }\n )\n\n def parse(self, response):\n result = json.loads(response.body_as_unicode())\n for store in result['StoreList']:\n details = ', '.join([d['DetailName'] for d in store['Details']])\n yield GeojsonPointItem(\n lon=store['Longitude'],\n lat=store['Latitude'],\n ref=store['UniqueID'],\n name=store['StationName'],\n addr_full=store['Address'],\n phone=store['Phone'],\n opening_hours='24/7' if '24 Hours' in details else None,\n extras={\n 'amenity:fuel': True,\n 'amenity:toilets': 'Restroom' in details or None,\n 'atm': 'ATM' in details,\n 'car_wash': 'Car Wash' in details,\n 'fuel:diesel': 'Diesel' in details or None,\n 'fuel:e85': 'E-85' in details or None,\n }\n )\n", "path": "locations/spiders/valero.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\nimport json\n\nfrom locations.items import GeojsonPointItem\n\n\nclass ValeroSpider(scrapy.Spider):\n name = \"valero\"\n item_attributes = {\"brand\": \"Valero\", \"brand_wikidata\": \"Q1283291\"}\n allowed_domains = [\"valero.com\"]\n start_urls = [\"https://locations.valero.com/sitemap.xml\"]\n\n def parse(self, response):\n response.selector.remove_namespaces()\n for url in response.xpath(\"//loc/text()\").extract():\n yield scrapy.Request(url, callback=self.parse_store)\n\n def parse_store(self, response):\n amenities = [s.strip() for s in response.xpath('//div[@class=\"amenityIconLabel\"]/text()').extract()]\n properties = {\n \"lat\": response.xpath('//meta[@property=\"place:location:latitude\"]/@content').get(),\n \"lon\": response.xpath('//meta[@property=\"place:location:longitude\"]/@content').get(),\n \"ref\": response.url.rsplit(\"/\", 1)[-1],\n \"website\": response.url,\n \"name\": response.xpath('normalize-space(//*[@id=\"pageTitleStoreName\"])').get(),\n \"addr_full\": response.xpath('normalize-space(//div[@class=\"locationDetailsContactRow\"][1]//br/..)').get(),\n \"phone\": response.xpath('//a[contains(@href,\"tel:\")]/text()').get(),\n \"opening_hours\": \"24/7\" if \"24 Hour\" in amenities else None,\n \"extras\": {\n \"atm\": \"ATM\" in amenities,\n \"amenity:fuel\": True,\n \"amenity:toilets\": \"Public Restroom\" in amenities or None,\n \"car_wash\": \"Car Wash\" in amenities,\n \"fuel:diesel\": \"Diesel\" in amenities or None,\n \"fuel:e85\": \"E-85\" in amenities or None,\n },\n }\n yield GeojsonPointItem(**properties)\n", "path": "locations/spiders/valero.py"}]}
| 969 | 938 |
gh_patches_debug_14564
|
rasdani/github-patches
|
git_diff
|
WordPress__openverse-api-477
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Distinguish between staging & prod when sending data refresh slack updates
## Problem
<!-- Describe a problem solved by this feature; or delete the section entirely. -->
It's not easy to tell based on the slack messages produced by the ingestion server whether a given ingestion is being run in production or staging.
## Description
<!-- Describe the feature and how it solves the problem. -->
We should pre-pend the messages (or change the bot's name) based on which environment the data refresh is running in.
## Alternatives
<!-- Describe any alternative solutions or features you have considered. How is this feature better? -->
We _could_ turn off messages altogether for staging (how it is currently) but that would make it harder for us to know when a staging data refresh is complete.
## Additional context
<!-- Add any other context about the feature here; or delete the section entirely. -->
## Implementation
<!-- Replace the [ ] with [x] to check the box. -->
- [x] 🙋 I would be interested in implementing this feature.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ingestion_server/ingestion_server/slack.py`
Content:
```
1 import logging
2 import os
3
4 import requests
5
6
7 log = logging.getLogger(__name__)
8 SLACK_WEBHOOK = "SLACK_WEBHOOK"
9
10
11 def message(text: str, summary: str = None) -> None:
12 """
13 Send a Slack message to a channel specified by a Slack webhook variable.
14
15 A message is only sent if the SLACK_WEBHOOK environment variable is undefined.
16 """
17 if not (webhook := os.getenv(SLACK_WEBHOOK)):
18 log.debug(
19 f"{SLACK_WEBHOOK} variable not defined, skipping slack message: {text}"
20 )
21 return
22 if not summary:
23 if "\n" in text:
24 summary = "Ingestion server message"
25 else:
26 summary = text
27
28 data = {
29 "blocks": [{"text": {"text": text, "type": "mrkdwn"}, "type": "section"}],
30 "text": summary,
31 "username": "Data Refresh Notification",
32 "icon_emoji": "arrows_counterclockwise",
33 }
34 try:
35 requests.post(webhook, json=data)
36 except Exception as err:
37 log.exception(f"Unable to issue slack message: {err}")
38 pass
39
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ingestion_server/ingestion_server/slack.py b/ingestion_server/ingestion_server/slack.py
--- a/ingestion_server/ingestion_server/slack.py
+++ b/ingestion_server/ingestion_server/slack.py
@@ -2,6 +2,7 @@
import os
import requests
+from decouple import config
log = logging.getLogger(__name__)
@@ -25,10 +26,12 @@
else:
summary = text
+ environment = config("ENVIRONMENT", default="local")
+
data = {
"blocks": [{"text": {"text": text, "type": "mrkdwn"}, "type": "section"}],
"text": summary,
- "username": "Data Refresh Notification",
+ "username": f"Data Refresh Notification | {environment.upper()}",
"icon_emoji": "arrows_counterclockwise",
}
try:
|
{"golden_diff": "diff --git a/ingestion_server/ingestion_server/slack.py b/ingestion_server/ingestion_server/slack.py\n--- a/ingestion_server/ingestion_server/slack.py\n+++ b/ingestion_server/ingestion_server/slack.py\n@@ -2,6 +2,7 @@\n import os\n \n import requests\n+from decouple import config\n \n \n log = logging.getLogger(__name__)\n@@ -25,10 +26,12 @@\n else:\n summary = text\n \n+ environment = config(\"ENVIRONMENT\", default=\"local\")\n+\n data = {\n \"blocks\": [{\"text\": {\"text\": text, \"type\": \"mrkdwn\"}, \"type\": \"section\"}],\n \"text\": summary,\n- \"username\": \"Data Refresh Notification\",\n+ \"username\": f\"Data Refresh Notification | {environment.upper()}\",\n \"icon_emoji\": \"arrows_counterclockwise\",\n }\n try:\n", "issue": "Distinguish between staging & prod when sending data refresh slack updates\n## Problem\r\n<!-- Describe a problem solved by this feature; or delete the section entirely. -->\r\nIt's not easy to tell based on the slack messages produced by the ingestion server whether a given ingestion is being run in production or staging.\r\n\r\n## Description\r\n<!-- Describe the feature and how it solves the problem. -->\r\nWe should pre-pend the messages (or change the bot's name) based on which environment the data refresh is running in. \r\n\r\n## Alternatives\r\n<!-- Describe any alternative solutions or features you have considered. How is this feature better? -->\r\nWe _could_ turn off messages altogether for staging (how it is currently) but that would make it harder for us to know when a staging data refresh is complete.\r\n\r\n## Additional context\r\n<!-- Add any other context about the feature here; or delete the section entirely. -->\r\n\r\n## Implementation\r\n<!-- Replace the [ ] with [x] to check the box. -->\r\n- [x] \ud83d\ude4b I would be interested in implementing this feature.\r\n\n", "before_files": [{"content": "import logging\nimport os\n\nimport requests\n\n\nlog = logging.getLogger(__name__)\nSLACK_WEBHOOK = \"SLACK_WEBHOOK\"\n\n\ndef message(text: str, summary: str = None) -> None:\n \"\"\"\n Send a Slack message to a channel specified by a Slack webhook variable.\n\n A message is only sent if the SLACK_WEBHOOK environment variable is undefined.\n \"\"\"\n if not (webhook := os.getenv(SLACK_WEBHOOK)):\n log.debug(\n f\"{SLACK_WEBHOOK} variable not defined, skipping slack message: {text}\"\n )\n return\n if not summary:\n if \"\\n\" in text:\n summary = \"Ingestion server message\"\n else:\n summary = text\n\n data = {\n \"blocks\": [{\"text\": {\"text\": text, \"type\": \"mrkdwn\"}, \"type\": \"section\"}],\n \"text\": summary,\n \"username\": \"Data Refresh Notification\",\n \"icon_emoji\": \"arrows_counterclockwise\",\n }\n try:\n requests.post(webhook, json=data)\n except Exception as err:\n log.exception(f\"Unable to issue slack message: {err}\")\n pass\n", "path": "ingestion_server/ingestion_server/slack.py"}], "after_files": [{"content": "import logging\nimport os\n\nimport requests\nfrom decouple import config\n\n\nlog = logging.getLogger(__name__)\nSLACK_WEBHOOK = \"SLACK_WEBHOOK\"\n\n\ndef message(text: str, summary: str = None) -> None:\n \"\"\"\n Send a Slack message to a channel specified by a Slack webhook variable.\n\n A message is only sent if the SLACK_WEBHOOK environment variable is undefined.\n \"\"\"\n if not (webhook := os.getenv(SLACK_WEBHOOK)):\n log.debug(\n f\"{SLACK_WEBHOOK} variable not defined, skipping slack message: {text}\"\n )\n return\n if not summary:\n if \"\\n\" in text:\n summary = \"Ingestion server message\"\n else:\n summary = text\n\n environment = config(\"ENVIRONMENT\", default=\"local\")\n\n data = {\n \"blocks\": [{\"text\": {\"text\": text, \"type\": \"mrkdwn\"}, \"type\": \"section\"}],\n \"text\": summary,\n \"username\": f\"Data Refresh Notification | {environment.upper()}\",\n \"icon_emoji\": \"arrows_counterclockwise\",\n }\n try:\n requests.post(webhook, json=data)\n except Exception as err:\n log.exception(f\"Unable to issue slack message: {err}\")\n pass\n", "path": "ingestion_server/ingestion_server/slack.py"}]}
| 804 | 205 |
gh_patches_debug_26399
|
rasdani/github-patches
|
git_diff
|
quantumlib__Cirq-1503
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix `cirq.control` documentation talking about `__control__` instead of `controlled_by`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cirq/protocols/control.py`
Content:
```
1 # Copyright 2018 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from typing import Any, TYPE_CHECKING, TypeVar, Union, Sequence
16
17 import collections
18
19 from cirq.ops import op_tree
20
21 if TYPE_CHECKING:
22 # pylint: disable=unused-import
23 import cirq
24
25 # This is a special indicator value used by the control method to determine
26 # whether or not the caller provided a 'default' argument.
27 RaiseTypeErrorIfNotProvided = ([],) # type: Any
28
29
30 TDefault = TypeVar('TDefault')
31
32 def control(controllee: Union['cirq.Gate', op_tree.OP_TREE],
33 control_qubits: Sequence['cirq.Qid'] = None,
34 default: Any = RaiseTypeErrorIfNotProvided) -> Any:
35 """Returns a Controlled version of the given value, if defined.
36
37 Controllees define how to be controlled by defining a method
38 __control__(self, control_qubits). Note that the method may return
39 NotImplemented to indicate a particular controlling can't be done.
40
41 Args:
42 controllee: The gate, operation or iterable of operations to control.
43 control_qubits: A list of Qids that would control this controllee.
44 default: Determines the fallback behavior when `controllee` doesn't
45 have a controlling defined. If `default` is not set and the
46 fallback occurs, a TypeError is raised instead.
47
48 Returns:
49 If `controllee` has a __control__ method that returns something besides
50 NotImplemented, that result is returned. For an OP_TREE, transformation
51 is applied at the leaf. Otherwise, if a default value was specified,
52 the default value is returned.
53
54 Raises:
55 TypeError: `controllee` doesn't have a __control__ method (or that
56 method returned NotImplemented) and no `default` was specified.
57 """
58 if control_qubits is None:
59 control_qubits = []
60 controller = getattr(controllee, 'controlled_by', None)
61 result = NotImplemented if controller is None else controller(
62 *control_qubits)
63 if result is not NotImplemented:
64 return result
65
66 if isinstance(controllee, collections.Iterable):
67 return op_tree.transform_op_tree(controllee, op_transformation=
68 lambda op: control(op, control_qubits))
69
70 if default is not RaiseTypeErrorIfNotProvided:
71 return default
72
73 if controller is None:
74 raise TypeError("object of type '{}' has no controlled_by "
75 "method.".format(type(controllee)))
76 raise TypeError("object of type '{}' does have a controlled_by method, "
77 "but it returned NotImplemented.".format(type(controllee)))
78
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cirq/protocols/control.py b/cirq/protocols/control.py
--- a/cirq/protocols/control.py
+++ b/cirq/protocols/control.py
@@ -35,7 +35,7 @@
"""Returns a Controlled version of the given value, if defined.
Controllees define how to be controlled by defining a method
- __control__(self, control_qubits). Note that the method may return
+ controlled_by(self, control_qubits). Note that the method may return
NotImplemented to indicate a particular controlling can't be done.
Args:
@@ -46,13 +46,13 @@
fallback occurs, a TypeError is raised instead.
Returns:
- If `controllee` has a __control__ method that returns something besides
- NotImplemented, that result is returned. For an OP_TREE, transformation
- is applied at the leaf. Otherwise, if a default value was specified,
- the default value is returned.
+ If `controllee` has a controlled_by method that returns something
+ besides NotImplemented, that result is returned. For an OP_TREE,
+ transformation is applied at the leaf. Otherwise, if a default value
+ was specified, the default value is returned.
Raises:
- TypeError: `controllee` doesn't have a __control__ method (or that
+ TypeError: `controllee` doesn't have a controlled_by method (or that
method returned NotImplemented) and no `default` was specified.
"""
if control_qubits is None:
|
{"golden_diff": "diff --git a/cirq/protocols/control.py b/cirq/protocols/control.py\n--- a/cirq/protocols/control.py\n+++ b/cirq/protocols/control.py\n@@ -35,7 +35,7 @@\n \"\"\"Returns a Controlled version of the given value, if defined.\n \n Controllees define how to be controlled by defining a method\n- __control__(self, control_qubits). Note that the method may return\n+ controlled_by(self, control_qubits). Note that the method may return\n NotImplemented to indicate a particular controlling can't be done.\n \n Args:\n@@ -46,13 +46,13 @@\n fallback occurs, a TypeError is raised instead.\n \n Returns:\n- If `controllee` has a __control__ method that returns something besides\n- NotImplemented, that result is returned. For an OP_TREE, transformation\n- is applied at the leaf. Otherwise, if a default value was specified,\n- the default value is returned.\n+ If `controllee` has a controlled_by method that returns something\n+ besides NotImplemented, that result is returned. For an OP_TREE,\n+ transformation is applied at the leaf. Otherwise, if a default value\n+ was specified, the default value is returned.\n \n Raises:\n- TypeError: `controllee` doesn't have a __control__ method (or that\n+ TypeError: `controllee` doesn't have a controlled_by method (or that\n method returned NotImplemented) and no `default` was specified.\n \"\"\"\n if control_qubits is None:\n", "issue": "Fix `cirq.control` documentation talking about `__control__` instead of `controlled_by`\n\n", "before_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Any, TYPE_CHECKING, TypeVar, Union, Sequence\n\nimport collections\n\nfrom cirq.ops import op_tree\n\nif TYPE_CHECKING:\n # pylint: disable=unused-import\n import cirq\n\n# This is a special indicator value used by the control method to determine\n# whether or not the caller provided a 'default' argument.\nRaiseTypeErrorIfNotProvided = ([],) # type: Any\n\n\nTDefault = TypeVar('TDefault')\n\ndef control(controllee: Union['cirq.Gate', op_tree.OP_TREE],\n control_qubits: Sequence['cirq.Qid'] = None,\n default: Any = RaiseTypeErrorIfNotProvided) -> Any:\n \"\"\"Returns a Controlled version of the given value, if defined.\n\n Controllees define how to be controlled by defining a method\n __control__(self, control_qubits). Note that the method may return\n NotImplemented to indicate a particular controlling can't be done.\n\n Args:\n controllee: The gate, operation or iterable of operations to control.\n control_qubits: A list of Qids that would control this controllee.\n default: Determines the fallback behavior when `controllee` doesn't\n have a controlling defined. If `default` is not set and the\n fallback occurs, a TypeError is raised instead.\n\n Returns:\n If `controllee` has a __control__ method that returns something besides\n NotImplemented, that result is returned. For an OP_TREE, transformation\n is applied at the leaf. Otherwise, if a default value was specified,\n the default value is returned.\n\n Raises:\n TypeError: `controllee` doesn't have a __control__ method (or that\n method returned NotImplemented) and no `default` was specified.\n \"\"\"\n if control_qubits is None:\n control_qubits = []\n controller = getattr(controllee, 'controlled_by', None)\n result = NotImplemented if controller is None else controller(\n *control_qubits)\n if result is not NotImplemented:\n return result\n\n if isinstance(controllee, collections.Iterable):\n return op_tree.transform_op_tree(controllee, op_transformation=\n lambda op: control(op, control_qubits))\n\n if default is not RaiseTypeErrorIfNotProvided:\n return default\n\n if controller is None:\n raise TypeError(\"object of type '{}' has no controlled_by \"\n \"method.\".format(type(controllee)))\n raise TypeError(\"object of type '{}' does have a controlled_by method, \"\n \"but it returned NotImplemented.\".format(type(controllee)))\n", "path": "cirq/protocols/control.py"}], "after_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Any, TYPE_CHECKING, TypeVar, Union, Sequence\n\nimport collections\n\nfrom cirq.ops import op_tree\n\nif TYPE_CHECKING:\n # pylint: disable=unused-import\n import cirq\n\n# This is a special indicator value used by the control method to determine\n# whether or not the caller provided a 'default' argument.\nRaiseTypeErrorIfNotProvided = ([],) # type: Any\n\n\nTDefault = TypeVar('TDefault')\n\ndef control(controllee: Union['cirq.Gate', op_tree.OP_TREE],\n control_qubits: Sequence['cirq.Qid'] = None,\n default: Any = RaiseTypeErrorIfNotProvided) -> Any:\n \"\"\"Returns a Controlled version of the given value, if defined.\n\n Controllees define how to be controlled by defining a method\n controlled_by(self, control_qubits). Note that the method may return\n NotImplemented to indicate a particular controlling can't be done.\n\n Args:\n controllee: The gate, operation or iterable of operations to control.\n control_qubits: A list of Qids that would control this controllee.\n default: Determines the fallback behavior when `controllee` doesn't\n have a controlling defined. If `default` is not set and the\n fallback occurs, a TypeError is raised instead.\n\n Returns:\n If `controllee` has a controlled_by method that returns something\n besides NotImplemented, that result is returned. For an OP_TREE,\n transformation is applied at the leaf. Otherwise, if a default value\n was specified, the default value is returned.\n\n Raises:\n TypeError: `controllee` doesn't have a controlled_by method (or that\n method returned NotImplemented) and no `default` was specified.\n \"\"\"\n if control_qubits is None:\n control_qubits = []\n controller = getattr(controllee, 'controlled_by', None)\n result = NotImplemented if controller is None else controller(\n *control_qubits)\n if result is not NotImplemented:\n return result\n\n if isinstance(controllee, collections.Iterable):\n return op_tree.transform_op_tree(controllee, op_transformation=\n lambda op: control(op, control_qubits))\n\n if default is not RaiseTypeErrorIfNotProvided:\n return default\n\n if controller is None:\n raise TypeError(\"object of type '{}' has no controlled_by \"\n \"method.\".format(type(controllee)))\n raise TypeError(\"object of type '{}' does have a controlled_by method, \"\n \"but it returned NotImplemented.\".format(type(controllee)))\n", "path": "cirq/protocols/control.py"}]}
| 1,111 | 339 |
gh_patches_debug_12122
|
rasdani/github-patches
|
git_diff
|
google__fuzzbench-1466
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Write a validator to prevent issues requesting bug experiments
https://github.com/google/fuzzbench/commit/da5fab4dfcabcd856e0247b90122bb577f0c734e#diff-c89bd86bcf4447f199973358896b7a69d69d92f258653f28e77583ee8967dd13R49 has happened twice now, time to prevent it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `service/automatic_run_experiment.py`
Content:
```
1 #!/usr/bin/env python3
2 # Copyright 2020 Google LLC
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 """Reads experiment-requests.yaml and determines if there is a new experiment
16 and runs it if needed. Note that this code uses a config file for experiments
17 that is specific to the FuzzBench service. Therefore this code will break if
18 others try to run it."""
19 import argparse
20 import collections
21 import os
22 import re
23 import sys
24 from typing import Optional
25
26 from common import benchmark_utils
27 from common import logs
28 from common import utils
29 from common import yaml_utils
30 from database import models
31 from database import utils as db_utils
32 from experiment import run_experiment
33
34 logger = logs.Logger('automatic_run_experiment') # pylint: disable=invalid-name
35
36 EXPERIMENT_CONFIG_FILE = os.path.join(utils.ROOT_DIR, 'service',
37 'experiment-config.yaml')
38
39 REQUESTED_EXPERIMENTS_PATH = os.path.join(utils.ROOT_DIR, 'service',
40 'experiment-requests.yaml')
41
42 # Don't run an experiment if we have a "request" just containing this keyword.
43 # TODO(metzman): Look into replacing this mechanism for pausing the service.
44 PAUSE_SERVICE_KEYWORD = 'PAUSE_SERVICE'
45
46 EXPERIMENT_NAME_REGEX = re.compile(r'^\d{4}-\d{2}-\d{2}.*')
47
48
49 def _get_experiment_name(experiment_config: dict) -> str:
50 """Returns the name of the experiment described by |experiment_config| as a
51 string."""
52 # Use str because the yaml parser will parse things like `2020-05-06` as
53 # a datetime if not included in quotes.
54 return str(experiment_config['experiment'])
55
56
57 def _get_description(experiment_config: dict) -> Optional[str]:
58 """Returns the description of the experiment described by
59 |experiment_config| as a string."""
60 return experiment_config.get('description')
61
62
63 def _use_oss_fuzz_corpus(experiment_config: dict) -> bool:
64 """Returns the oss_fuzz_corpus flag of the experiment described by
65 |experiment_config| as a bool."""
66 return bool(experiment_config.get('oss_fuzz_corpus'))
67
68
69 def _get_requested_experiments():
70 """Return requested experiments."""
71 return yaml_utils.read(REQUESTED_EXPERIMENTS_PATH)
72
73
74 def validate_experiment_name(experiment_name):
75 """Returns True if |experiment_name| is valid."""
76 if EXPERIMENT_NAME_REGEX.match(experiment_name) is None:
77 logger.error('Experiment name: %s is not valid.', experiment_name)
78 return False
79 try:
80 run_experiment.validate_experiment_name(experiment_name)
81 return True
82 except run_experiment.ValidationError:
83 logger.error('Experiment name: %s is not valid.', experiment_name)
84 return False
85
86
87 def _validate_individual_experiment_requests(experiment_requests):
88 """Returns True if all requests in |experiment_request| are valid in
89 isolation. Does not account for PAUSE_SERVICE_KEYWORD or duplicates."""
90 valid = True
91 # Validate format.
92 for request in experiment_requests:
93 if not isinstance(request, dict):
94 logger.error('Request: %s is not a dict.', request)
95 experiment_requests.remove(request)
96 valid = False
97 continue
98
99 if 'experiment' not in request:
100 logger.error('Request: %s does not have field "experiment".',
101 request)
102 valid = False
103 continue
104
105 experiment = _get_experiment_name(request)
106 if not validate_experiment_name(experiment):
107 valid = False
108 # Request isn't so malformed that we can find other issues, if
109 # present.
110
111 fuzzers = request.get('fuzzers')
112 if not fuzzers:
113 logger.error('Request: %s does not specify any fuzzers.', request)
114 valid = False
115 continue
116
117 for fuzzer in fuzzers:
118 try:
119 run_experiment.validate_fuzzer(fuzzer)
120 except run_experiment.ValidationError:
121 logger.error('Fuzzer: %s is invalid.', fuzzer)
122 valid = False
123
124 description = request.get('description')
125 if description is not None and not isinstance(description, str):
126 logger.error(
127 'Request: %s "description" attribute is not a valid string.',
128 request)
129 valid = False
130
131 oss_fuzz_corpus = request.get('oss_fuzz_corpus')
132 if oss_fuzz_corpus is not None and not isinstance(
133 oss_fuzz_corpus, bool):
134 logger.error(
135 'Request: %s "oss_fuzz_corpus" attribute is not a valid bool.',
136 request)
137 valid = False
138
139 experiment_type = request.get('type',
140 benchmark_utils.BenchmarkType.CODE.value)
141 if experiment_type not in benchmark_utils.BENCHMARK_TYPE_STRS:
142 logger.error('Type: %s is invalid, must be one of %s',
143 experiment_type, benchmark_utils.BENCHMARK_TYPE_STRS)
144 valid = False
145
146 return valid
147
148
149 def validate_experiment_requests(experiment_requests):
150 """Returns True if all requests in |experiment_requests| are valid."""
151 # This function tries to find as many requests as possible.
152 if PAUSE_SERVICE_KEYWORD in experiment_requests:
153 # This is a special case where a string is used instead of an experiment
154 # to tell the service not to run experiments automatically. Remove it
155 # from the list because it fails validation.
156 experiment_requests = experiment_requests[:] # Don't mutate input.
157 experiment_requests.remove(PAUSE_SERVICE_KEYWORD)
158
159 if not _validate_individual_experiment_requests(experiment_requests):
160 # Don't try the next validation step if the previous failed, we might
161 # exception.
162 return False
163
164 # Make sure experiment requests have a unique name, we can't run the same
165 # experiment twice.
166 counts = collections.Counter(
167 [request['experiment'] for request in experiment_requests])
168
169 valid = True
170 for experiment_name, count in counts.items():
171 if count != 1:
172 logger.error('Experiment: "%s" appears %d times.',
173 str(experiment_name), count)
174 valid = False
175
176 return valid
177
178
179 def run_requested_experiment(dry_run):
180 """Run the oldest requested experiment that hasn't been run yet in
181 experiment-requests.yaml."""
182 requested_experiments = _get_requested_experiments()
183
184 # TODO(metzman): Look into supporting benchmarks as an optional parameter so
185 # that people can add fuzzers that don't support everything.
186
187 if PAUSE_SERVICE_KEYWORD in requested_experiments:
188 # Check if automated experiment service is paused.
189 logs.warning('Pause service requested, not running experiment.')
190 return
191
192 requested_experiment = None
193 for experiment_config in reversed(requested_experiments):
194 experiment_name = _get_experiment_name(experiment_config)
195 with db_utils.session_scope() as session:
196 is_new_experiment = session.query(models.Experiment).filter(
197 models.Experiment.name == experiment_name).first() is None
198 if is_new_experiment:
199 requested_experiment = experiment_config
200 break
201
202 if requested_experiment is None:
203 logs.info('No new experiment to run. Exiting.')
204 return
205
206 experiment_name = _get_experiment_name(requested_experiment)
207 if not validate_experiment_requests([requested_experiment]):
208 logs.error('Requested experiment: %s in %s is not valid.',
209 requested_experiment, REQUESTED_EXPERIMENTS_PATH)
210 return
211 fuzzers = requested_experiment['fuzzers']
212
213 benchmark_type = requested_experiment.get('type')
214 if benchmark_type == benchmark_utils.BenchmarkType.BUG.value:
215 valid_benchmarks = benchmark_utils.exclude_non_cpp(
216 benchmark_utils.get_bug_benchmarks())
217 else:
218 valid_benchmarks = benchmark_utils.exclude_non_cpp(
219 benchmark_utils.get_coverage_benchmarks())
220
221 benchmarks = requested_experiment.get('benchmarks')
222 if benchmarks is None:
223 benchmarks = valid_benchmarks
224 else:
225 errors = False
226 for benchmark in benchmarks:
227 if benchmark not in valid_benchmarks:
228 logs.error(
229 'Requested experiment:'
230 ' in %s, %s is not a valid %s benchmark.',
231 requested_experiment, benchmark, benchmark_type)
232 errors = True
233 if errors:
234 return
235
236 logs.info('Running experiment: %s with fuzzers: %s.', experiment_name,
237 ' '.join(fuzzers))
238 description = _get_description(requested_experiment)
239 oss_fuzz_corpus = _use_oss_fuzz_corpus(requested_experiment)
240 _run_experiment(experiment_name, fuzzers, benchmarks, description,
241 oss_fuzz_corpus, dry_run)
242
243
244 def _run_experiment( # pylint: disable=too-many-arguments
245 experiment_name,
246 fuzzers,
247 benchmarks,
248 description,
249 oss_fuzz_corpus,
250 dry_run=False):
251 """Run an experiment named |experiment_name| on |fuzzer_configs| and shut it
252 down once it terminates."""
253 logs.info('Starting experiment: %s.', experiment_name)
254 if dry_run:
255 logs.info('Dry run. Not actually running experiment.')
256 return
257 run_experiment.start_experiment(experiment_name,
258 EXPERIMENT_CONFIG_FILE,
259 benchmarks,
260 fuzzers,
261 description=description,
262 oss_fuzz_corpus=oss_fuzz_corpus)
263
264
265 def main():
266 """Run an experiment."""
267 logs.initialize()
268 parser = argparse.ArgumentParser(description='Run a requested experiment.')
269 # TODO(metzman): Add a way to exit immediately if there is already an
270 # experiment running. FuzzBench's scheduler isn't smart enough to deal with
271 # this properly.
272 parser.add_argument('-d',
273 '--dry-run',
274 help='Dry run, don\'t actually run the experiment',
275 default=False,
276 action='store_true')
277 args = parser.parse_args()
278 try:
279 run_requested_experiment(args.dry_run)
280 except Exception: # pylint: disable=broad-except
281 logger.error('Error running requested experiment.')
282 return 1
283 return 0
284
285
286 if __name__ == '__main__':
287 sys.exit(main())
288
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/service/automatic_run_experiment.py b/service/automatic_run_experiment.py
--- a/service/automatic_run_experiment.py
+++ b/service/automatic_run_experiment.py
@@ -143,6 +143,18 @@
experiment_type, benchmark_utils.BENCHMARK_TYPE_STRS)
valid = False
+ benchmarks = request.get('benchmarks', [])
+ for benchmark in benchmarks:
+ benchmark_type = benchmark_utils.get_type(benchmark)
+ if (benchmark_type == benchmark_utils.BenchmarkType.BUG.value and
+ experiment_type != benchmark_utils.BenchmarkType.BUG.value):
+ logger.error(
+ 'Benchmark %s is "type: bug". '
+ 'Experiment %s must be "type: bug" as well.', benchmark,
+ experiment)
+ valid = False
+ break
+
return valid
|
{"golden_diff": "diff --git a/service/automatic_run_experiment.py b/service/automatic_run_experiment.py\n--- a/service/automatic_run_experiment.py\n+++ b/service/automatic_run_experiment.py\n@@ -143,6 +143,18 @@\n experiment_type, benchmark_utils.BENCHMARK_TYPE_STRS)\n valid = False\n \n+ benchmarks = request.get('benchmarks', [])\n+ for benchmark in benchmarks:\n+ benchmark_type = benchmark_utils.get_type(benchmark)\n+ if (benchmark_type == benchmark_utils.BenchmarkType.BUG.value and\n+ experiment_type != benchmark_utils.BenchmarkType.BUG.value):\n+ logger.error(\n+ 'Benchmark %s is \"type: bug\". '\n+ 'Experiment %s must be \"type: bug\" as well.', benchmark,\n+ experiment)\n+ valid = False\n+ break\n+\n return valid\n", "issue": "Write a validator to prevent issues requesting bug experiments\nhttps://github.com/google/fuzzbench/commit/da5fab4dfcabcd856e0247b90122bb577f0c734e#diff-c89bd86bcf4447f199973358896b7a69d69d92f258653f28e77583ee8967dd13R49 has happened twice now, time to prevent it.\n", "before_files": [{"content": "#!/usr/bin/env python3\n# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Reads experiment-requests.yaml and determines if there is a new experiment\nand runs it if needed. Note that this code uses a config file for experiments\nthat is specific to the FuzzBench service. Therefore this code will break if\nothers try to run it.\"\"\"\nimport argparse\nimport collections\nimport os\nimport re\nimport sys\nfrom typing import Optional\n\nfrom common import benchmark_utils\nfrom common import logs\nfrom common import utils\nfrom common import yaml_utils\nfrom database import models\nfrom database import utils as db_utils\nfrom experiment import run_experiment\n\nlogger = logs.Logger('automatic_run_experiment') # pylint: disable=invalid-name\n\nEXPERIMENT_CONFIG_FILE = os.path.join(utils.ROOT_DIR, 'service',\n 'experiment-config.yaml')\n\nREQUESTED_EXPERIMENTS_PATH = os.path.join(utils.ROOT_DIR, 'service',\n 'experiment-requests.yaml')\n\n# Don't run an experiment if we have a \"request\" just containing this keyword.\n# TODO(metzman): Look into replacing this mechanism for pausing the service.\nPAUSE_SERVICE_KEYWORD = 'PAUSE_SERVICE'\n\nEXPERIMENT_NAME_REGEX = re.compile(r'^\\d{4}-\\d{2}-\\d{2}.*')\n\n\ndef _get_experiment_name(experiment_config: dict) -> str:\n \"\"\"Returns the name of the experiment described by |experiment_config| as a\n string.\"\"\"\n # Use str because the yaml parser will parse things like `2020-05-06` as\n # a datetime if not included in quotes.\n return str(experiment_config['experiment'])\n\n\ndef _get_description(experiment_config: dict) -> Optional[str]:\n \"\"\"Returns the description of the experiment described by\n |experiment_config| as a string.\"\"\"\n return experiment_config.get('description')\n\n\ndef _use_oss_fuzz_corpus(experiment_config: dict) -> bool:\n \"\"\"Returns the oss_fuzz_corpus flag of the experiment described by\n |experiment_config| as a bool.\"\"\"\n return bool(experiment_config.get('oss_fuzz_corpus'))\n\n\ndef _get_requested_experiments():\n \"\"\"Return requested experiments.\"\"\"\n return yaml_utils.read(REQUESTED_EXPERIMENTS_PATH)\n\n\ndef validate_experiment_name(experiment_name):\n \"\"\"Returns True if |experiment_name| is valid.\"\"\"\n if EXPERIMENT_NAME_REGEX.match(experiment_name) is None:\n logger.error('Experiment name: %s is not valid.', experiment_name)\n return False\n try:\n run_experiment.validate_experiment_name(experiment_name)\n return True\n except run_experiment.ValidationError:\n logger.error('Experiment name: %s is not valid.', experiment_name)\n return False\n\n\ndef _validate_individual_experiment_requests(experiment_requests):\n \"\"\"Returns True if all requests in |experiment_request| are valid in\n isolation. Does not account for PAUSE_SERVICE_KEYWORD or duplicates.\"\"\"\n valid = True\n # Validate format.\n for request in experiment_requests:\n if not isinstance(request, dict):\n logger.error('Request: %s is not a dict.', request)\n experiment_requests.remove(request)\n valid = False\n continue\n\n if 'experiment' not in request:\n logger.error('Request: %s does not have field \"experiment\".',\n request)\n valid = False\n continue\n\n experiment = _get_experiment_name(request)\n if not validate_experiment_name(experiment):\n valid = False\n # Request isn't so malformed that we can find other issues, if\n # present.\n\n fuzzers = request.get('fuzzers')\n if not fuzzers:\n logger.error('Request: %s does not specify any fuzzers.', request)\n valid = False\n continue\n\n for fuzzer in fuzzers:\n try:\n run_experiment.validate_fuzzer(fuzzer)\n except run_experiment.ValidationError:\n logger.error('Fuzzer: %s is invalid.', fuzzer)\n valid = False\n\n description = request.get('description')\n if description is not None and not isinstance(description, str):\n logger.error(\n 'Request: %s \"description\" attribute is not a valid string.',\n request)\n valid = False\n\n oss_fuzz_corpus = request.get('oss_fuzz_corpus')\n if oss_fuzz_corpus is not None and not isinstance(\n oss_fuzz_corpus, bool):\n logger.error(\n 'Request: %s \"oss_fuzz_corpus\" attribute is not a valid bool.',\n request)\n valid = False\n\n experiment_type = request.get('type',\n benchmark_utils.BenchmarkType.CODE.value)\n if experiment_type not in benchmark_utils.BENCHMARK_TYPE_STRS:\n logger.error('Type: %s is invalid, must be one of %s',\n experiment_type, benchmark_utils.BENCHMARK_TYPE_STRS)\n valid = False\n\n return valid\n\n\ndef validate_experiment_requests(experiment_requests):\n \"\"\"Returns True if all requests in |experiment_requests| are valid.\"\"\"\n # This function tries to find as many requests as possible.\n if PAUSE_SERVICE_KEYWORD in experiment_requests:\n # This is a special case where a string is used instead of an experiment\n # to tell the service not to run experiments automatically. Remove it\n # from the list because it fails validation.\n experiment_requests = experiment_requests[:] # Don't mutate input.\n experiment_requests.remove(PAUSE_SERVICE_KEYWORD)\n\n if not _validate_individual_experiment_requests(experiment_requests):\n # Don't try the next validation step if the previous failed, we might\n # exception.\n return False\n\n # Make sure experiment requests have a unique name, we can't run the same\n # experiment twice.\n counts = collections.Counter(\n [request['experiment'] for request in experiment_requests])\n\n valid = True\n for experiment_name, count in counts.items():\n if count != 1:\n logger.error('Experiment: \"%s\" appears %d times.',\n str(experiment_name), count)\n valid = False\n\n return valid\n\n\ndef run_requested_experiment(dry_run):\n \"\"\"Run the oldest requested experiment that hasn't been run yet in\n experiment-requests.yaml.\"\"\"\n requested_experiments = _get_requested_experiments()\n\n # TODO(metzman): Look into supporting benchmarks as an optional parameter so\n # that people can add fuzzers that don't support everything.\n\n if PAUSE_SERVICE_KEYWORD in requested_experiments:\n # Check if automated experiment service is paused.\n logs.warning('Pause service requested, not running experiment.')\n return\n\n requested_experiment = None\n for experiment_config in reversed(requested_experiments):\n experiment_name = _get_experiment_name(experiment_config)\n with db_utils.session_scope() as session:\n is_new_experiment = session.query(models.Experiment).filter(\n models.Experiment.name == experiment_name).first() is None\n if is_new_experiment:\n requested_experiment = experiment_config\n break\n\n if requested_experiment is None:\n logs.info('No new experiment to run. Exiting.')\n return\n\n experiment_name = _get_experiment_name(requested_experiment)\n if not validate_experiment_requests([requested_experiment]):\n logs.error('Requested experiment: %s in %s is not valid.',\n requested_experiment, REQUESTED_EXPERIMENTS_PATH)\n return\n fuzzers = requested_experiment['fuzzers']\n\n benchmark_type = requested_experiment.get('type')\n if benchmark_type == benchmark_utils.BenchmarkType.BUG.value:\n valid_benchmarks = benchmark_utils.exclude_non_cpp(\n benchmark_utils.get_bug_benchmarks())\n else:\n valid_benchmarks = benchmark_utils.exclude_non_cpp(\n benchmark_utils.get_coverage_benchmarks())\n\n benchmarks = requested_experiment.get('benchmarks')\n if benchmarks is None:\n benchmarks = valid_benchmarks\n else:\n errors = False\n for benchmark in benchmarks:\n if benchmark not in valid_benchmarks:\n logs.error(\n 'Requested experiment:'\n ' in %s, %s is not a valid %s benchmark.',\n requested_experiment, benchmark, benchmark_type)\n errors = True\n if errors:\n return\n\n logs.info('Running experiment: %s with fuzzers: %s.', experiment_name,\n ' '.join(fuzzers))\n description = _get_description(requested_experiment)\n oss_fuzz_corpus = _use_oss_fuzz_corpus(requested_experiment)\n _run_experiment(experiment_name, fuzzers, benchmarks, description,\n oss_fuzz_corpus, dry_run)\n\n\ndef _run_experiment( # pylint: disable=too-many-arguments\n experiment_name,\n fuzzers,\n benchmarks,\n description,\n oss_fuzz_corpus,\n dry_run=False):\n \"\"\"Run an experiment named |experiment_name| on |fuzzer_configs| and shut it\n down once it terminates.\"\"\"\n logs.info('Starting experiment: %s.', experiment_name)\n if dry_run:\n logs.info('Dry run. Not actually running experiment.')\n return\n run_experiment.start_experiment(experiment_name,\n EXPERIMENT_CONFIG_FILE,\n benchmarks,\n fuzzers,\n description=description,\n oss_fuzz_corpus=oss_fuzz_corpus)\n\n\ndef main():\n \"\"\"Run an experiment.\"\"\"\n logs.initialize()\n parser = argparse.ArgumentParser(description='Run a requested experiment.')\n # TODO(metzman): Add a way to exit immediately if there is already an\n # experiment running. FuzzBench's scheduler isn't smart enough to deal with\n # this properly.\n parser.add_argument('-d',\n '--dry-run',\n help='Dry run, don\\'t actually run the experiment',\n default=False,\n action='store_true')\n args = parser.parse_args()\n try:\n run_requested_experiment(args.dry_run)\n except Exception: # pylint: disable=broad-except\n logger.error('Error running requested experiment.')\n return 1\n return 0\n\n\nif __name__ == '__main__':\n sys.exit(main())\n", "path": "service/automatic_run_experiment.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Reads experiment-requests.yaml and determines if there is a new experiment\nand runs it if needed. Note that this code uses a config file for experiments\nthat is specific to the FuzzBench service. Therefore this code will break if\nothers try to run it.\"\"\"\nimport argparse\nimport collections\nimport os\nimport re\nimport sys\nfrom typing import Optional\n\nfrom common import benchmark_utils\nfrom common import logs\nfrom common import utils\nfrom common import yaml_utils\nfrom database import models\nfrom database import utils as db_utils\nfrom experiment import run_experiment\n\nlogger = logs.Logger('automatic_run_experiment') # pylint: disable=invalid-name\n\nEXPERIMENT_CONFIG_FILE = os.path.join(utils.ROOT_DIR, 'service',\n 'experiment-config.yaml')\n\nREQUESTED_EXPERIMENTS_PATH = os.path.join(utils.ROOT_DIR, 'service',\n 'experiment-requests.yaml')\n\n# Don't run an experiment if we have a \"request\" just containing this keyword.\n# TODO(metzman): Look into replacing this mechanism for pausing the service.\nPAUSE_SERVICE_KEYWORD = 'PAUSE_SERVICE'\n\nEXPERIMENT_NAME_REGEX = re.compile(r'^\\d{4}-\\d{2}-\\d{2}.*')\n\n\ndef _get_experiment_name(experiment_config: dict) -> str:\n \"\"\"Returns the name of the experiment described by |experiment_config| as a\n string.\"\"\"\n # Use str because the yaml parser will parse things like `2020-05-06` as\n # a datetime if not included in quotes.\n return str(experiment_config['experiment'])\n\n\ndef _get_description(experiment_config: dict) -> Optional[str]:\n \"\"\"Returns the description of the experiment described by\n |experiment_config| as a string.\"\"\"\n return experiment_config.get('description')\n\n\ndef _use_oss_fuzz_corpus(experiment_config: dict) -> bool:\n \"\"\"Returns the oss_fuzz_corpus flag of the experiment described by\n |experiment_config| as a bool.\"\"\"\n return bool(experiment_config.get('oss_fuzz_corpus'))\n\n\ndef _get_requested_experiments():\n \"\"\"Return requested experiments.\"\"\"\n return yaml_utils.read(REQUESTED_EXPERIMENTS_PATH)\n\n\ndef validate_experiment_name(experiment_name):\n \"\"\"Returns True if |experiment_name| is valid.\"\"\"\n if EXPERIMENT_NAME_REGEX.match(experiment_name) is None:\n logger.error('Experiment name: %s is not valid.', experiment_name)\n return False\n try:\n run_experiment.validate_experiment_name(experiment_name)\n return True\n except run_experiment.ValidationError:\n logger.error('Experiment name: %s is not valid.', experiment_name)\n return False\n\n\ndef _validate_individual_experiment_requests(experiment_requests):\n \"\"\"Returns True if all requests in |experiment_request| are valid in\n isolation. Does not account for PAUSE_SERVICE_KEYWORD or duplicates.\"\"\"\n valid = True\n # Validate format.\n for request in experiment_requests:\n if not isinstance(request, dict):\n logger.error('Request: %s is not a dict.', request)\n experiment_requests.remove(request)\n valid = False\n continue\n\n if 'experiment' not in request:\n logger.error('Request: %s does not have field \"experiment\".',\n request)\n valid = False\n continue\n\n experiment = _get_experiment_name(request)\n if not validate_experiment_name(experiment):\n valid = False\n # Request isn't so malformed that we can find other issues, if\n # present.\n\n fuzzers = request.get('fuzzers')\n if not fuzzers:\n logger.error('Request: %s does not specify any fuzzers.', request)\n valid = False\n continue\n\n for fuzzer in fuzzers:\n try:\n run_experiment.validate_fuzzer(fuzzer)\n except run_experiment.ValidationError:\n logger.error('Fuzzer: %s is invalid.', fuzzer)\n valid = False\n\n description = request.get('description')\n if description is not None and not isinstance(description, str):\n logger.error(\n 'Request: %s \"description\" attribute is not a valid string.',\n request)\n valid = False\n\n oss_fuzz_corpus = request.get('oss_fuzz_corpus')\n if oss_fuzz_corpus is not None and not isinstance(\n oss_fuzz_corpus, bool):\n logger.error(\n 'Request: %s \"oss_fuzz_corpus\" attribute is not a valid bool.',\n request)\n valid = False\n\n experiment_type = request.get('type',\n benchmark_utils.BenchmarkType.CODE.value)\n if experiment_type not in benchmark_utils.BENCHMARK_TYPE_STRS:\n logger.error('Type: %s is invalid, must be one of %s',\n experiment_type, benchmark_utils.BENCHMARK_TYPE_STRS)\n valid = False\n\n benchmarks = request.get('benchmarks', [])\n for benchmark in benchmarks:\n benchmark_type = benchmark_utils.get_type(benchmark)\n if (benchmark_type == benchmark_utils.BenchmarkType.BUG.value and\n experiment_type != benchmark_utils.BenchmarkType.BUG.value):\n logger.error(\n 'Benchmark %s is \"type: bug\". '\n 'Experiment %s must be \"type: bug\" as well.', benchmark,\n experiment)\n valid = False\n break\n\n return valid\n\n\ndef validate_experiment_requests(experiment_requests):\n \"\"\"Returns True if all requests in |experiment_requests| are valid.\"\"\"\n # This function tries to find as many requests as possible.\n if PAUSE_SERVICE_KEYWORD in experiment_requests:\n # This is a special case where a string is used instead of an experiment\n # to tell the service not to run experiments automatically. Remove it\n # from the list because it fails validation.\n experiment_requests = experiment_requests[:] # Don't mutate input.\n experiment_requests.remove(PAUSE_SERVICE_KEYWORD)\n\n if not _validate_individual_experiment_requests(experiment_requests):\n # Don't try the next validation step if the previous failed, we might\n # exception.\n return False\n\n # Make sure experiment requests have a unique name, we can't run the same\n # experiment twice.\n counts = collections.Counter(\n [request['experiment'] for request in experiment_requests])\n\n valid = True\n for experiment_name, count in counts.items():\n if count != 1:\n logger.error('Experiment: \"%s\" appears %d times.',\n str(experiment_name), count)\n valid = False\n\n return valid\n\n\ndef run_requested_experiment(dry_run):\n \"\"\"Run the oldest requested experiment that hasn't been run yet in\n experiment-requests.yaml.\"\"\"\n requested_experiments = _get_requested_experiments()\n\n # TODO(metzman): Look into supporting benchmarks as an optional parameter so\n # that people can add fuzzers that don't support everything.\n\n if PAUSE_SERVICE_KEYWORD in requested_experiments:\n # Check if automated experiment service is paused.\n logs.warning('Pause service requested, not running experiment.')\n return\n\n requested_experiment = None\n for experiment_config in reversed(requested_experiments):\n experiment_name = _get_experiment_name(experiment_config)\n with db_utils.session_scope() as session:\n is_new_experiment = session.query(models.Experiment).filter(\n models.Experiment.name == experiment_name).first() is None\n if is_new_experiment:\n requested_experiment = experiment_config\n break\n\n if requested_experiment is None:\n logs.info('No new experiment to run. Exiting.')\n return\n\n experiment_name = _get_experiment_name(requested_experiment)\n if not validate_experiment_requests([requested_experiment]):\n logs.error('Requested experiment: %s in %s is not valid.',\n requested_experiment, REQUESTED_EXPERIMENTS_PATH)\n return\n fuzzers = requested_experiment['fuzzers']\n\n benchmark_type = requested_experiment.get('type')\n if benchmark_type == benchmark_utils.BenchmarkType.BUG.value:\n valid_benchmarks = benchmark_utils.exclude_non_cpp(\n benchmark_utils.get_bug_benchmarks())\n else:\n valid_benchmarks = benchmark_utils.exclude_non_cpp(\n benchmark_utils.get_coverage_benchmarks())\n\n benchmarks = requested_experiment.get('benchmarks')\n if benchmarks is None:\n benchmarks = valid_benchmarks\n else:\n errors = False\n for benchmark in benchmarks:\n if benchmark not in valid_benchmarks:\n logs.error(\n 'Requested experiment:'\n ' in %s, %s is not a valid %s benchmark.',\n requested_experiment, benchmark, benchmark_type)\n errors = True\n if errors:\n return\n\n logs.info('Running experiment: %s with fuzzers: %s.', experiment_name,\n ' '.join(fuzzers))\n description = _get_description(requested_experiment)\n oss_fuzz_corpus = _use_oss_fuzz_corpus(requested_experiment)\n _run_experiment(experiment_name, fuzzers, benchmarks, description,\n oss_fuzz_corpus, dry_run)\n\n\ndef _run_experiment( # pylint: disable=too-many-arguments\n experiment_name,\n fuzzers,\n benchmarks,\n description,\n oss_fuzz_corpus,\n dry_run=False):\n \"\"\"Run an experiment named |experiment_name| on |fuzzer_configs| and shut it\n down once it terminates.\"\"\"\n logs.info('Starting experiment: %s.', experiment_name)\n if dry_run:\n logs.info('Dry run. Not actually running experiment.')\n return\n run_experiment.start_experiment(experiment_name,\n EXPERIMENT_CONFIG_FILE,\n benchmarks,\n fuzzers,\n description=description,\n oss_fuzz_corpus=oss_fuzz_corpus)\n\n\ndef main():\n \"\"\"Run an experiment.\"\"\"\n logs.initialize()\n parser = argparse.ArgumentParser(description='Run a requested experiment.')\n # TODO(metzman): Add a way to exit immediately if there is already an\n # experiment running. FuzzBench's scheduler isn't smart enough to deal with\n # this properly.\n parser.add_argument('-d',\n '--dry-run',\n help='Dry run, don\\'t actually run the experiment',\n default=False,\n action='store_true')\n args = parser.parse_args()\n try:\n run_requested_experiment(args.dry_run)\n except Exception: # pylint: disable=broad-except\n logger.error('Error running requested experiment.')\n return 1\n return 0\n\n\nif __name__ == '__main__':\n sys.exit(main())\n", "path": "service/automatic_run_experiment.py"}]}
| 3,396 | 184 |
gh_patches_debug_47731
|
rasdani/github-patches
|
git_diff
|
ray-project__ray-5429
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Tune] Experiment Analysis get_best behaviour
Hi,
In their current version, the [`get_best_config`](https://github.com/ray-project/ray/blob/ed89897a311fbe63afdd5fa05a4ef8b7576ca6a4/python/ray/tune/analysis/experiment_analysis.py#L56) and [`get_best_logdir`](https://github.com/ray-project/ray/blob/ed89897a311fbe63afdd5fa05a4ef8b7576ca6a4/python/ray/tune/analysis/experiment_analysis.py#L70) methods of the `Analysis` object may consider different Trials as the best one:
- `get_best_config` will first retrieve the best row of each trial dataframe and then select the best trial from these rows.
- `get_best_logdir` will first retrieve the last row of each trial and then selects the best one.
Is it the expected behaviour ?
If it isn't, I think that the correct way of doing it is the first one. This could be done by simply passing the `metric` and `max` arguments to the [`self.dataframe`](https://github.com/ray-project/ray/blob/ed89897a311fbe63afdd5fa05a4ef8b7576ca6a4/python/ray/tune/analysis/experiment_analysis.py#L78) call in `get_best_dir`.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/ray/tune/analysis/experiment_analysis.py`
Content:
```
1 from __future__ import absolute_import
2 from __future__ import division
3 from __future__ import print_function
4
5 import json
6 import logging
7 import os
8
9 try:
10 import pandas as pd
11 except ImportError:
12 pd = None
13
14 from ray.tune.error import TuneError
15 from ray.tune.result import EXPR_PROGRESS_FILE, EXPR_PARAM_FILE, CONFIG_PREFIX
16
17 logger = logging.getLogger(__name__)
18
19
20 class Analysis(object):
21 """Analyze all results from a directory of experiments."""
22
23 def __init__(self, experiment_dir):
24 experiment_dir = os.path.expanduser(experiment_dir)
25 if not os.path.isdir(experiment_dir):
26 raise ValueError(
27 "{} is not a valid directory.".format(experiment_dir))
28 self._experiment_dir = experiment_dir
29 self._configs = {}
30 self._trial_dataframes = {}
31
32 if not pd:
33 logger.warning(
34 "pandas not installed. Run `pip install pandas` for "
35 "Analysis utilities.")
36 else:
37 self.fetch_trial_dataframes()
38
39 def dataframe(self, metric=None, mode=None):
40 """Returns a pandas.DataFrame object constructed from the trials.
41
42 Args:
43 metric (str): Key for trial info to order on.
44 If None, uses last result.
45 mode (str): One of [min, max].
46
47 """
48 rows = self._retrieve_rows(metric=metric, mode=mode)
49 all_configs = self.get_all_configs(prefix=True)
50 for path, config in all_configs.items():
51 if path in rows:
52 rows[path].update(config)
53 rows[path].update(logdir=path)
54 return pd.DataFrame(list(rows.values()))
55
56 def get_best_config(self, metric, mode="max"):
57 """Retrieve the best config corresponding to the trial.
58
59 Args:
60 metric (str): Key for trial info to order on.
61 mode (str): One of [min, max].
62
63 """
64 rows = self._retrieve_rows(metric=metric, mode=mode)
65 all_configs = self.get_all_configs()
66 compare_op = max if mode == "max" else min
67 best_path = compare_op(rows, key=lambda k: rows[k][metric])
68 return all_configs[best_path]
69
70 def get_best_logdir(self, metric, mode="max"):
71 """Retrieve the logdir corresponding to the best trial.
72
73 Args:
74 metric (str): Key for trial info to order on.
75 mode (str): One of [min, max].
76
77 """
78 df = self.dataframe()
79 if mode == "max":
80 return df.iloc[df[metric].idxmax()].logdir
81 elif mode == "min":
82 return df.iloc[df[metric].idxmin()].logdir
83
84 def fetch_trial_dataframes(self):
85 fail_count = 0
86 for path in self._get_trial_paths():
87 try:
88 self.trial_dataframes[path] = pd.read_csv(
89 os.path.join(path, EXPR_PROGRESS_FILE))
90 except Exception:
91 fail_count += 1
92
93 if fail_count:
94 logger.debug(
95 "Couldn't read results from {} paths".format(fail_count))
96 return self.trial_dataframes
97
98 def get_all_configs(self, prefix=False):
99 """Returns a list of all configurations.
100
101 Parameters:
102 prefix (bool): If True, flattens the config dict
103 and prepends `config/`.
104 """
105 fail_count = 0
106 for path in self._get_trial_paths():
107 try:
108 with open(os.path.join(path, EXPR_PARAM_FILE)) as f:
109 config = json.load(f)
110 if prefix:
111 for k in list(config):
112 config[CONFIG_PREFIX + k] = config.pop(k)
113 self._configs[path] = config
114 except Exception:
115 fail_count += 1
116
117 if fail_count:
118 logger.warning(
119 "Couldn't read config from {} paths".format(fail_count))
120 return self._configs
121
122 def _retrieve_rows(self, metric=None, mode=None):
123 assert mode is None or mode in ["max", "min"]
124 rows = {}
125 for path, df in self.trial_dataframes.items():
126 if mode == "max":
127 idx = df[metric].idxmax()
128 elif mode == "min":
129 idx = df[metric].idxmin()
130 else:
131 idx = -1
132 rows[path] = df.iloc[idx].to_dict()
133
134 return rows
135
136 def _get_trial_paths(self):
137 _trial_paths = []
138 for trial_path, _, files in os.walk(self._experiment_dir):
139 if EXPR_PROGRESS_FILE in files:
140 _trial_paths += [trial_path]
141
142 if not _trial_paths:
143 raise TuneError("No trials found in {}.".format(
144 self._experiment_dir))
145 return _trial_paths
146
147 @property
148 def trial_dataframes(self):
149 """List of all dataframes of the trials."""
150 return self._trial_dataframes
151
152
153 class ExperimentAnalysis(Analysis):
154 """Analyze results from a Tune experiment.
155
156 Parameters:
157 experiment_checkpoint_path (str): Path to a json file
158 representing an experiment state. Corresponds to
159 Experiment.local_dir/Experiment.name/experiment_state.json
160
161 Example:
162 >>> tune.run(my_trainable, name="my_exp", local_dir="~/tune_results")
163 >>> analysis = ExperimentAnalysis(
164 >>> experiment_checkpoint_path="~/tune_results/my_exp/state.json")
165 """
166
167 def __init__(self, experiment_checkpoint_path, trials=None):
168 """Initializer.
169
170 Args:
171 experiment_path (str): Path to where experiment is located.
172 trials (list|None): List of trials that can be accessed via
173 `analysis.trials`.
174 """
175 with open(experiment_checkpoint_path) as f:
176 _experiment_state = json.load(f)
177 self._experiment_state = _experiment_state
178
179 if "checkpoints" not in _experiment_state:
180 raise TuneError("Experiment state invalid; no checkpoints found.")
181 self._checkpoints = _experiment_state["checkpoints"]
182 self.trials = trials
183 super(ExperimentAnalysis, self).__init__(
184 os.path.dirname(experiment_checkpoint_path))
185
186 def stats(self):
187 """Returns a dictionary of the statistics of the experiment."""
188 return self._experiment_state.get("stats")
189
190 def runner_data(self):
191 """Returns a dictionary of the TrialRunner data."""
192 return self._experiment_state.get("runner_data")
193
194 def _get_trial_paths(self):
195 """Overwrites Analysis to only have trials of one experiment."""
196 if self.trials:
197 _trial_paths = [t.logdir for t in self.trials]
198 else:
199 logger.warning("No `self.trials`. Drawing logdirs from checkpoint "
200 "file. This may result in some information that is "
201 "out of sync, as checkpointing is periodic.")
202 _trial_paths = [
203 checkpoint["logdir"] for checkpoint in self._checkpoints
204 ]
205 if not _trial_paths:
206 raise TuneError("No trials found.")
207 return _trial_paths
208
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/python/ray/tune/analysis/experiment_analysis.py b/python/ray/tune/analysis/experiment_analysis.py
--- a/python/ray/tune/analysis/experiment_analysis.py
+++ b/python/ray/tune/analysis/experiment_analysis.py
@@ -75,7 +75,7 @@
mode (str): One of [min, max].
"""
- df = self.dataframe()
+ df = self.dataframe(metric=metric, mode=mode)
if mode == "max":
return df.iloc[df[metric].idxmax()].logdir
elif mode == "min":
|
{"golden_diff": "diff --git a/python/ray/tune/analysis/experiment_analysis.py b/python/ray/tune/analysis/experiment_analysis.py\n--- a/python/ray/tune/analysis/experiment_analysis.py\n+++ b/python/ray/tune/analysis/experiment_analysis.py\n@@ -75,7 +75,7 @@\n mode (str): One of [min, max].\n \n \"\"\"\n- df = self.dataframe()\n+ df = self.dataframe(metric=metric, mode=mode)\n if mode == \"max\":\n return df.iloc[df[metric].idxmax()].logdir\n elif mode == \"min\":\n", "issue": "[Tune] Experiment Analysis get_best behaviour\nHi,\r\nIn their current version, the [`get_best_config`](https://github.com/ray-project/ray/blob/ed89897a311fbe63afdd5fa05a4ef8b7576ca6a4/python/ray/tune/analysis/experiment_analysis.py#L56) and [`get_best_logdir`](https://github.com/ray-project/ray/blob/ed89897a311fbe63afdd5fa05a4ef8b7576ca6a4/python/ray/tune/analysis/experiment_analysis.py#L70) methods of the `Analysis` object may consider different Trials as the best one:\r\n- `get_best_config` will first retrieve the best row of each trial dataframe and then select the best trial from these rows.\r\n- `get_best_logdir` will first retrieve the last row of each trial and then selects the best one.\r\n\r\nIs it the expected behaviour ? \r\nIf it isn't, I think that the correct way of doing it is the first one. This could be done by simply passing the `metric` and `max` arguments to the [`self.dataframe`](https://github.com/ray-project/ray/blob/ed89897a311fbe63afdd5fa05a4ef8b7576ca6a4/python/ray/tune/analysis/experiment_analysis.py#L78) call in `get_best_dir`.\r\n\r\n\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport json\nimport logging\nimport os\n\ntry:\n import pandas as pd\nexcept ImportError:\n pd = None\n\nfrom ray.tune.error import TuneError\nfrom ray.tune.result import EXPR_PROGRESS_FILE, EXPR_PARAM_FILE, CONFIG_PREFIX\n\nlogger = logging.getLogger(__name__)\n\n\nclass Analysis(object):\n \"\"\"Analyze all results from a directory of experiments.\"\"\"\n\n def __init__(self, experiment_dir):\n experiment_dir = os.path.expanduser(experiment_dir)\n if not os.path.isdir(experiment_dir):\n raise ValueError(\n \"{} is not a valid directory.\".format(experiment_dir))\n self._experiment_dir = experiment_dir\n self._configs = {}\n self._trial_dataframes = {}\n\n if not pd:\n logger.warning(\n \"pandas not installed. Run `pip install pandas` for \"\n \"Analysis utilities.\")\n else:\n self.fetch_trial_dataframes()\n\n def dataframe(self, metric=None, mode=None):\n \"\"\"Returns a pandas.DataFrame object constructed from the trials.\n\n Args:\n metric (str): Key for trial info to order on.\n If None, uses last result.\n mode (str): One of [min, max].\n\n \"\"\"\n rows = self._retrieve_rows(metric=metric, mode=mode)\n all_configs = self.get_all_configs(prefix=True)\n for path, config in all_configs.items():\n if path in rows:\n rows[path].update(config)\n rows[path].update(logdir=path)\n return pd.DataFrame(list(rows.values()))\n\n def get_best_config(self, metric, mode=\"max\"):\n \"\"\"Retrieve the best config corresponding to the trial.\n\n Args:\n metric (str): Key for trial info to order on.\n mode (str): One of [min, max].\n\n \"\"\"\n rows = self._retrieve_rows(metric=metric, mode=mode)\n all_configs = self.get_all_configs()\n compare_op = max if mode == \"max\" else min\n best_path = compare_op(rows, key=lambda k: rows[k][metric])\n return all_configs[best_path]\n\n def get_best_logdir(self, metric, mode=\"max\"):\n \"\"\"Retrieve the logdir corresponding to the best trial.\n\n Args:\n metric (str): Key for trial info to order on.\n mode (str): One of [min, max].\n\n \"\"\"\n df = self.dataframe()\n if mode == \"max\":\n return df.iloc[df[metric].idxmax()].logdir\n elif mode == \"min\":\n return df.iloc[df[metric].idxmin()].logdir\n\n def fetch_trial_dataframes(self):\n fail_count = 0\n for path in self._get_trial_paths():\n try:\n self.trial_dataframes[path] = pd.read_csv(\n os.path.join(path, EXPR_PROGRESS_FILE))\n except Exception:\n fail_count += 1\n\n if fail_count:\n logger.debug(\n \"Couldn't read results from {} paths\".format(fail_count))\n return self.trial_dataframes\n\n def get_all_configs(self, prefix=False):\n \"\"\"Returns a list of all configurations.\n\n Parameters:\n prefix (bool): If True, flattens the config dict\n and prepends `config/`.\n \"\"\"\n fail_count = 0\n for path in self._get_trial_paths():\n try:\n with open(os.path.join(path, EXPR_PARAM_FILE)) as f:\n config = json.load(f)\n if prefix:\n for k in list(config):\n config[CONFIG_PREFIX + k] = config.pop(k)\n self._configs[path] = config\n except Exception:\n fail_count += 1\n\n if fail_count:\n logger.warning(\n \"Couldn't read config from {} paths\".format(fail_count))\n return self._configs\n\n def _retrieve_rows(self, metric=None, mode=None):\n assert mode is None or mode in [\"max\", \"min\"]\n rows = {}\n for path, df in self.trial_dataframes.items():\n if mode == \"max\":\n idx = df[metric].idxmax()\n elif mode == \"min\":\n idx = df[metric].idxmin()\n else:\n idx = -1\n rows[path] = df.iloc[idx].to_dict()\n\n return rows\n\n def _get_trial_paths(self):\n _trial_paths = []\n for trial_path, _, files in os.walk(self._experiment_dir):\n if EXPR_PROGRESS_FILE in files:\n _trial_paths += [trial_path]\n\n if not _trial_paths:\n raise TuneError(\"No trials found in {}.\".format(\n self._experiment_dir))\n return _trial_paths\n\n @property\n def trial_dataframes(self):\n \"\"\"List of all dataframes of the trials.\"\"\"\n return self._trial_dataframes\n\n\nclass ExperimentAnalysis(Analysis):\n \"\"\"Analyze results from a Tune experiment.\n\n Parameters:\n experiment_checkpoint_path (str): Path to a json file\n representing an experiment state. Corresponds to\n Experiment.local_dir/Experiment.name/experiment_state.json\n\n Example:\n >>> tune.run(my_trainable, name=\"my_exp\", local_dir=\"~/tune_results\")\n >>> analysis = ExperimentAnalysis(\n >>> experiment_checkpoint_path=\"~/tune_results/my_exp/state.json\")\n \"\"\"\n\n def __init__(self, experiment_checkpoint_path, trials=None):\n \"\"\"Initializer.\n\n Args:\n experiment_path (str): Path to where experiment is located.\n trials (list|None): List of trials that can be accessed via\n `analysis.trials`.\n \"\"\"\n with open(experiment_checkpoint_path) as f:\n _experiment_state = json.load(f)\n self._experiment_state = _experiment_state\n\n if \"checkpoints\" not in _experiment_state:\n raise TuneError(\"Experiment state invalid; no checkpoints found.\")\n self._checkpoints = _experiment_state[\"checkpoints\"]\n self.trials = trials\n super(ExperimentAnalysis, self).__init__(\n os.path.dirname(experiment_checkpoint_path))\n\n def stats(self):\n \"\"\"Returns a dictionary of the statistics of the experiment.\"\"\"\n return self._experiment_state.get(\"stats\")\n\n def runner_data(self):\n \"\"\"Returns a dictionary of the TrialRunner data.\"\"\"\n return self._experiment_state.get(\"runner_data\")\n\n def _get_trial_paths(self):\n \"\"\"Overwrites Analysis to only have trials of one experiment.\"\"\"\n if self.trials:\n _trial_paths = [t.logdir for t in self.trials]\n else:\n logger.warning(\"No `self.trials`. Drawing logdirs from checkpoint \"\n \"file. This may result in some information that is \"\n \"out of sync, as checkpointing is periodic.\")\n _trial_paths = [\n checkpoint[\"logdir\"] for checkpoint in self._checkpoints\n ]\n if not _trial_paths:\n raise TuneError(\"No trials found.\")\n return _trial_paths\n", "path": "python/ray/tune/analysis/experiment_analysis.py"}], "after_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport json\nimport logging\nimport os\n\ntry:\n import pandas as pd\nexcept ImportError:\n pd = None\n\nfrom ray.tune.error import TuneError\nfrom ray.tune.result import EXPR_PROGRESS_FILE, EXPR_PARAM_FILE, CONFIG_PREFIX\n\nlogger = logging.getLogger(__name__)\n\n\nclass Analysis(object):\n \"\"\"Analyze all results from a directory of experiments.\"\"\"\n\n def __init__(self, experiment_dir):\n experiment_dir = os.path.expanduser(experiment_dir)\n if not os.path.isdir(experiment_dir):\n raise ValueError(\n \"{} is not a valid directory.\".format(experiment_dir))\n self._experiment_dir = experiment_dir\n self._configs = {}\n self._trial_dataframes = {}\n\n if not pd:\n logger.warning(\n \"pandas not installed. Run `pip install pandas` for \"\n \"Analysis utilities.\")\n else:\n self.fetch_trial_dataframes()\n\n def dataframe(self, metric=None, mode=None):\n \"\"\"Returns a pandas.DataFrame object constructed from the trials.\n\n Args:\n metric (str): Key for trial info to order on.\n If None, uses last result.\n mode (str): One of [min, max].\n\n \"\"\"\n rows = self._retrieve_rows(metric=metric, mode=mode)\n all_configs = self.get_all_configs(prefix=True)\n for path, config in all_configs.items():\n if path in rows:\n rows[path].update(config)\n rows[path].update(logdir=path)\n return pd.DataFrame(list(rows.values()))\n\n def get_best_config(self, metric, mode=\"max\"):\n \"\"\"Retrieve the best config corresponding to the trial.\n\n Args:\n metric (str): Key for trial info to order on.\n mode (str): One of [min, max].\n\n \"\"\"\n rows = self._retrieve_rows(metric=metric, mode=mode)\n all_configs = self.get_all_configs()\n compare_op = max if mode == \"max\" else min\n best_path = compare_op(rows, key=lambda k: rows[k][metric])\n return all_configs[best_path]\n\n def get_best_logdir(self, metric, mode=\"max\"):\n \"\"\"Retrieve the logdir corresponding to the best trial.\n\n Args:\n metric (str): Key for trial info to order on.\n mode (str): One of [min, max].\n\n \"\"\"\n df = self.dataframe(metric=metric, mode=mode)\n if mode == \"max\":\n return df.iloc[df[metric].idxmax()].logdir\n elif mode == \"min\":\n return df.iloc[df[metric].idxmin()].logdir\n\n def fetch_trial_dataframes(self):\n fail_count = 0\n for path in self._get_trial_paths():\n try:\n self.trial_dataframes[path] = pd.read_csv(\n os.path.join(path, EXPR_PROGRESS_FILE))\n except Exception:\n fail_count += 1\n\n if fail_count:\n logger.debug(\n \"Couldn't read results from {} paths\".format(fail_count))\n return self.trial_dataframes\n\n def get_all_configs(self, prefix=False):\n \"\"\"Returns a list of all configurations.\n\n Parameters:\n prefix (bool): If True, flattens the config dict\n and prepends `config/`.\n \"\"\"\n fail_count = 0\n for path in self._get_trial_paths():\n try:\n with open(os.path.join(path, EXPR_PARAM_FILE)) as f:\n config = json.load(f)\n if prefix:\n for k in list(config):\n config[CONFIG_PREFIX + k] = config.pop(k)\n self._configs[path] = config\n except Exception:\n fail_count += 1\n\n if fail_count:\n logger.warning(\n \"Couldn't read config from {} paths\".format(fail_count))\n return self._configs\n\n def _retrieve_rows(self, metric=None, mode=None):\n assert mode is None or mode in [\"max\", \"min\"]\n rows = {}\n for path, df in self.trial_dataframes.items():\n if mode == \"max\":\n idx = df[metric].idxmax()\n elif mode == \"min\":\n idx = df[metric].idxmin()\n else:\n idx = -1\n rows[path] = df.iloc[idx].to_dict()\n\n return rows\n\n def _get_trial_paths(self):\n _trial_paths = []\n for trial_path, _, files in os.walk(self._experiment_dir):\n if EXPR_PROGRESS_FILE in files:\n _trial_paths += [trial_path]\n\n if not _trial_paths:\n raise TuneError(\"No trials found in {}.\".format(\n self._experiment_dir))\n return _trial_paths\n\n @property\n def trial_dataframes(self):\n \"\"\"List of all dataframes of the trials.\"\"\"\n return self._trial_dataframes\n\n\nclass ExperimentAnalysis(Analysis):\n \"\"\"Analyze results from a Tune experiment.\n\n Parameters:\n experiment_checkpoint_path (str): Path to a json file\n representing an experiment state. Corresponds to\n Experiment.local_dir/Experiment.name/experiment_state.json\n\n Example:\n >>> tune.run(my_trainable, name=\"my_exp\", local_dir=\"~/tune_results\")\n >>> analysis = ExperimentAnalysis(\n >>> experiment_checkpoint_path=\"~/tune_results/my_exp/state.json\")\n \"\"\"\n\n def __init__(self, experiment_checkpoint_path, trials=None):\n \"\"\"Initializer.\n\n Args:\n experiment_path (str): Path to where experiment is located.\n trials (list|None): List of trials that can be accessed via\n `analysis.trials`.\n \"\"\"\n with open(experiment_checkpoint_path) as f:\n _experiment_state = json.load(f)\n self._experiment_state = _experiment_state\n\n if \"checkpoints\" not in _experiment_state:\n raise TuneError(\"Experiment state invalid; no checkpoints found.\")\n self._checkpoints = _experiment_state[\"checkpoints\"]\n self.trials = trials\n super(ExperimentAnalysis, self).__init__(\n os.path.dirname(experiment_checkpoint_path))\n\n def stats(self):\n \"\"\"Returns a dictionary of the statistics of the experiment.\"\"\"\n return self._experiment_state.get(\"stats\")\n\n def runner_data(self):\n \"\"\"Returns a dictionary of the TrialRunner data.\"\"\"\n return self._experiment_state.get(\"runner_data\")\n\n def _get_trial_paths(self):\n \"\"\"Overwrites Analysis to only have trials of one experiment.\"\"\"\n if self.trials:\n _trial_paths = [t.logdir for t in self.trials]\n else:\n logger.warning(\"No `self.trials`. Drawing logdirs from checkpoint \"\n \"file. This may result in some information that is \"\n \"out of sync, as checkpointing is periodic.\")\n _trial_paths = [\n checkpoint[\"logdir\"] for checkpoint in self._checkpoints\n ]\n if not _trial_paths:\n raise TuneError(\"No trials found.\")\n return _trial_paths\n", "path": "python/ray/tune/analysis/experiment_analysis.py"}]}
| 2,618 | 134 |
gh_patches_debug_6636
|
rasdani/github-patches
|
git_diff
|
arviz-devs__arviz-801
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
pm.compare seems not compatible with az.plot_compare
If I try to run two following commands
```python
df_comp_WAIC = pm.compare({models[0]: traces[0], models[1]: traces[1]})
az.plot_compare(df_comp_WAIC);
```
I get the error:
```python
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-208-a89027c76a69> in <module>
3 df_comp_WAIC = pm.compare({models[0]: traces[0], models[1]: traces[1]})
----> 4 az.plot_compare(df_comp_WAIC);
~/anaconda3/lib/python3.6/site-packages/arviz/plots/compareplot.py in plot_compare(comp_df, insample_dev, plot_standard_error, plot_ic_diff, figsize, textsize, plot_kwargs, ax)
99 raise ValueError(
100 "comp_df must contain one of the following"
--> 101 " information criterion: {}".format(_information_criterion)
102 )
103
ValueError: comp_df must contain one of the following information criterion: ['waic', 'loo']
```
Both pymc3 and arviz are the latest from github (using pip command)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `arviz/plots/compareplot.py`
Content:
```
1 """Summary plot for model comparison."""
2 import numpy as np
3 import matplotlib.pyplot as plt
4 from .plot_utils import _scale_fig_size
5
6
7 def plot_compare(
8 comp_df,
9 insample_dev=True,
10 plot_standard_error=True,
11 plot_ic_diff=True,
12 order_by_rank=True,
13 figsize=None,
14 textsize=None,
15 plot_kwargs=None,
16 ax=None,
17 ):
18 """
19 Summary plot for model comparison.
20
21 This plot is in the style of the one used in the book Statistical Rethinking (Chapter 6)
22 by Richard McElreath.
23
24 Notes
25 -----
26 Defaults to comparing Widely Accepted Information Criterion (WAIC) if present in comp_df column,
27 otherwise compares Leave-one-out (loo)
28
29
30 Parameters
31 ----------
32 comp_df : pd.DataFrame
33 Result of the `az.compare()` method
34 insample_dev : bool, optional
35 Plot in-sample deviance, that is the value of the information criteria without the
36 penalization given by the effective number of parameters (pIC). Defaults to True
37 plot_standard_error : bool, optional
38 Plot the standard error of the information criteria estimate. Defaults to True
39 plot_ic_diff : bool, optional
40 Plot standard error of the difference in information criteria between each model
41 and the top-ranked model. Defaults to True
42 order_by_rank : bool
43 If True (default) ensure the best model is used as reference.
44 figsize : tuple, optional
45 If None, size is (6, num of models) inches
46 textsize: float
47 Text size scaling factor for labels, titles and lines. If None it will be autoscaled based
48 on figsize.
49 plot_kwargs : dict, optional
50 Optional arguments for plot elements. Currently accepts 'color_ic',
51 'marker_ic', 'color_insample_dev', 'marker_insample_dev', 'color_dse',
52 'marker_dse', 'ls_min_ic' 'color_ls_min_ic', 'fontsize'
53 ax : axes, optional
54 Matplotlib axes
55
56 Returns
57 -------
58 ax : matplotlib axes
59
60
61 Examples
62 --------
63 Show default compare plot
64
65 .. plot::
66 :context: close-figs
67
68 >>> import arviz as az
69 >>> model_compare = az.compare({'Centered 8 schools': az.load_arviz_data('centered_eight'),
70 >>> 'Non-centered 8 schools': az.load_arviz_data('non_centered_eight')})
71 >>> az.plot_compare(model_compare)
72
73 Plot standard error and information criteria difference only
74
75 .. plot::
76 :context: close-figs
77
78 >>> az.plot_compare(model_compare, insample_dev=False)
79
80 """
81 if figsize is None:
82 figsize = (6, len(comp_df))
83
84 figsize, ax_labelsize, _, xt_labelsize, linewidth, _ = _scale_fig_size(figsize, textsize, 1, 1)
85
86 if ax is None:
87 _, ax = plt.subplots(figsize=figsize, constrained_layout=True)
88
89 if plot_kwargs is None:
90 plot_kwargs = {}
91
92 yticks_pos, step = np.linspace(0, -1, (comp_df.shape[0] * 2) - 1, retstep=True)
93 yticks_pos[1::2] = yticks_pos[1::2] + step / 2
94
95 yticks_labels = [""] * len(yticks_pos)
96
97 _information_criterion = ["waic", "loo"]
98 for information_criterion in _information_criterion:
99 if information_criterion in comp_df.columns:
100 break
101 else:
102 raise ValueError(
103 "comp_df must contain one of the following"
104 " information criterion: {}".format(_information_criterion)
105 )
106
107 if order_by_rank:
108 comp_df.sort_values(by="rank", inplace=True)
109
110 if plot_ic_diff:
111 yticks_labels[0] = comp_df.index[0]
112 yticks_labels[2::2] = comp_df.index[1:]
113 ax.set_yticks(yticks_pos)
114 ax.errorbar(
115 x=comp_df[information_criterion].iloc[1:],
116 y=yticks_pos[1::2],
117 xerr=comp_df.dse[1:],
118 color=plot_kwargs.get("color_dse", "grey"),
119 fmt=plot_kwargs.get("marker_dse", "^"),
120 mew=linewidth,
121 elinewidth=linewidth,
122 )
123
124 else:
125 yticks_labels = comp_df.index
126 ax.set_yticks(yticks_pos[::2])
127
128 if plot_standard_error:
129 ax.errorbar(
130 x=comp_df[information_criterion],
131 y=yticks_pos[::2],
132 xerr=comp_df.se,
133 color=plot_kwargs.get("color_ic", "k"),
134 fmt=plot_kwargs.get("marker_ic", "o"),
135 mfc="None",
136 mew=linewidth,
137 lw=linewidth,
138 )
139 else:
140 ax.plot(
141 comp_df[information_criterion],
142 yticks_pos[::2],
143 color=plot_kwargs.get("color_ic", "k"),
144 marker=plot_kwargs.get("marker_ic", "o"),
145 mfc="None",
146 mew=linewidth,
147 lw=0,
148 )
149
150 if insample_dev:
151 ax.plot(
152 comp_df[information_criterion] - (2 * comp_df["p_" + information_criterion]),
153 yticks_pos[::2],
154 color=plot_kwargs.get("color_insample_dev", "k"),
155 marker=plot_kwargs.get("marker_insample_dev", "o"),
156 mew=linewidth,
157 lw=0,
158 )
159
160 ax.axvline(
161 comp_df[information_criterion].iloc[0],
162 ls=plot_kwargs.get("ls_min_ic", "--"),
163 color=plot_kwargs.get("color_ls_min_ic", "grey"),
164 lw=linewidth,
165 )
166
167 scale_col = information_criterion + "_scale"
168 if scale_col in comp_df:
169 scale = comp_df[scale_col].iloc[0].capitalize()
170 else:
171 scale = "Deviance"
172 ax.set_xlabel(scale, fontsize=ax_labelsize)
173 ax.set_yticklabels(yticks_labels)
174 ax.set_ylim(-1 + step, 0 - step)
175 ax.tick_params(labelsize=xt_labelsize)
176
177 return ax
178
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/arviz/plots/compareplot.py b/arviz/plots/compareplot.py
--- a/arviz/plots/compareplot.py
+++ b/arviz/plots/compareplot.py
@@ -95,8 +95,9 @@
yticks_labels = [""] * len(yticks_pos)
_information_criterion = ["waic", "loo"]
+ column_index = [c.lower() for c in comp_df.columns]
for information_criterion in _information_criterion:
- if information_criterion in comp_df.columns:
+ if information_criterion in column_index:
break
else:
raise ValueError(
|
{"golden_diff": "diff --git a/arviz/plots/compareplot.py b/arviz/plots/compareplot.py\n--- a/arviz/plots/compareplot.py\n+++ b/arviz/plots/compareplot.py\n@@ -95,8 +95,9 @@\n yticks_labels = [\"\"] * len(yticks_pos)\r\n \r\n _information_criterion = [\"waic\", \"loo\"]\r\n+ column_index = [c.lower() for c in comp_df.columns]\r\n for information_criterion in _information_criterion:\r\n- if information_criterion in comp_df.columns:\r\n+ if information_criterion in column_index:\r\n break\r\n else:\r\n raise ValueError(\n", "issue": "pm.compare seems not compatible with az.plot_compare\nIf I try to run two following commands\r\n```python\r\ndf_comp_WAIC = pm.compare({models[0]: traces[0], models[1]: traces[1]})\r\naz.plot_compare(df_comp_WAIC);\r\n```\r\nI get the error:\r\n```python\r\n---------------------------------------------------------------------------\r\nValueError Traceback (most recent call last)\r\n<ipython-input-208-a89027c76a69> in <module>\r\n 3 df_comp_WAIC = pm.compare({models[0]: traces[0], models[1]: traces[1]})\r\n----> 4 az.plot_compare(df_comp_WAIC);\r\n\r\n~/anaconda3/lib/python3.6/site-packages/arviz/plots/compareplot.py in plot_compare(comp_df, insample_dev, plot_standard_error, plot_ic_diff, figsize, textsize, plot_kwargs, ax)\r\n 99 raise ValueError(\r\n 100 \"comp_df must contain one of the following\"\r\n--> 101 \" information criterion: {}\".format(_information_criterion)\r\n 102 )\r\n 103 \r\n\r\nValueError: comp_df must contain one of the following information criterion: ['waic', 'loo']\r\n```\r\n\r\nBoth pymc3 and arviz are the latest from github (using pip command)\n", "before_files": [{"content": "\"\"\"Summary plot for model comparison.\"\"\"\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nfrom .plot_utils import _scale_fig_size\r\n\r\n\r\ndef plot_compare(\r\n comp_df,\r\n insample_dev=True,\r\n plot_standard_error=True,\r\n plot_ic_diff=True,\r\n order_by_rank=True,\r\n figsize=None,\r\n textsize=None,\r\n plot_kwargs=None,\r\n ax=None,\r\n):\r\n \"\"\"\r\n Summary plot for model comparison.\r\n\r\n This plot is in the style of the one used in the book Statistical Rethinking (Chapter 6)\r\n by Richard McElreath.\r\n\r\n Notes\r\n -----\r\n Defaults to comparing Widely Accepted Information Criterion (WAIC) if present in comp_df column,\r\n otherwise compares Leave-one-out (loo)\r\n\r\n\r\n Parameters\r\n ----------\r\n comp_df : pd.DataFrame\r\n Result of the `az.compare()` method\r\n insample_dev : bool, optional\r\n Plot in-sample deviance, that is the value of the information criteria without the\r\n penalization given by the effective number of parameters (pIC). Defaults to True\r\n plot_standard_error : bool, optional\r\n Plot the standard error of the information criteria estimate. Defaults to True\r\n plot_ic_diff : bool, optional\r\n Plot standard error of the difference in information criteria between each model\r\n and the top-ranked model. Defaults to True\r\n order_by_rank : bool\r\n If True (default) ensure the best model is used as reference.\r\n figsize : tuple, optional\r\n If None, size is (6, num of models) inches\r\n textsize: float\r\n Text size scaling factor for labels, titles and lines. If None it will be autoscaled based\r\n on figsize.\r\n plot_kwargs : dict, optional\r\n Optional arguments for plot elements. Currently accepts 'color_ic',\r\n 'marker_ic', 'color_insample_dev', 'marker_insample_dev', 'color_dse',\r\n 'marker_dse', 'ls_min_ic' 'color_ls_min_ic', 'fontsize'\r\n ax : axes, optional\r\n Matplotlib axes\r\n\r\n Returns\r\n -------\r\n ax : matplotlib axes\r\n\r\n\r\n Examples\r\n --------\r\n Show default compare plot\r\n\r\n .. plot::\r\n :context: close-figs\r\n\r\n >>> import arviz as az\r\n >>> model_compare = az.compare({'Centered 8 schools': az.load_arviz_data('centered_eight'),\r\n >>> 'Non-centered 8 schools': az.load_arviz_data('non_centered_eight')})\r\n >>> az.plot_compare(model_compare)\r\n\r\n Plot standard error and information criteria difference only\r\n\r\n .. plot::\r\n :context: close-figs\r\n\r\n >>> az.plot_compare(model_compare, insample_dev=False)\r\n\r\n \"\"\"\r\n if figsize is None:\r\n figsize = (6, len(comp_df))\r\n\r\n figsize, ax_labelsize, _, xt_labelsize, linewidth, _ = _scale_fig_size(figsize, textsize, 1, 1)\r\n\r\n if ax is None:\r\n _, ax = plt.subplots(figsize=figsize, constrained_layout=True)\r\n\r\n if plot_kwargs is None:\r\n plot_kwargs = {}\r\n\r\n yticks_pos, step = np.linspace(0, -1, (comp_df.shape[0] * 2) - 1, retstep=True)\r\n yticks_pos[1::2] = yticks_pos[1::2] + step / 2\r\n\r\n yticks_labels = [\"\"] * len(yticks_pos)\r\n\r\n _information_criterion = [\"waic\", \"loo\"]\r\n for information_criterion in _information_criterion:\r\n if information_criterion in comp_df.columns:\r\n break\r\n else:\r\n raise ValueError(\r\n \"comp_df must contain one of the following\"\r\n \" information criterion: {}\".format(_information_criterion)\r\n )\r\n\r\n if order_by_rank:\r\n comp_df.sort_values(by=\"rank\", inplace=True)\r\n\r\n if plot_ic_diff:\r\n yticks_labels[0] = comp_df.index[0]\r\n yticks_labels[2::2] = comp_df.index[1:]\r\n ax.set_yticks(yticks_pos)\r\n ax.errorbar(\r\n x=comp_df[information_criterion].iloc[1:],\r\n y=yticks_pos[1::2],\r\n xerr=comp_df.dse[1:],\r\n color=plot_kwargs.get(\"color_dse\", \"grey\"),\r\n fmt=plot_kwargs.get(\"marker_dse\", \"^\"),\r\n mew=linewidth,\r\n elinewidth=linewidth,\r\n )\r\n\r\n else:\r\n yticks_labels = comp_df.index\r\n ax.set_yticks(yticks_pos[::2])\r\n\r\n if plot_standard_error:\r\n ax.errorbar(\r\n x=comp_df[information_criterion],\r\n y=yticks_pos[::2],\r\n xerr=comp_df.se,\r\n color=plot_kwargs.get(\"color_ic\", \"k\"),\r\n fmt=plot_kwargs.get(\"marker_ic\", \"o\"),\r\n mfc=\"None\",\r\n mew=linewidth,\r\n lw=linewidth,\r\n )\r\n else:\r\n ax.plot(\r\n comp_df[information_criterion],\r\n yticks_pos[::2],\r\n color=plot_kwargs.get(\"color_ic\", \"k\"),\r\n marker=plot_kwargs.get(\"marker_ic\", \"o\"),\r\n mfc=\"None\",\r\n mew=linewidth,\r\n lw=0,\r\n )\r\n\r\n if insample_dev:\r\n ax.plot(\r\n comp_df[information_criterion] - (2 * comp_df[\"p_\" + information_criterion]),\r\n yticks_pos[::2],\r\n color=plot_kwargs.get(\"color_insample_dev\", \"k\"),\r\n marker=plot_kwargs.get(\"marker_insample_dev\", \"o\"),\r\n mew=linewidth,\r\n lw=0,\r\n )\r\n\r\n ax.axvline(\r\n comp_df[information_criterion].iloc[0],\r\n ls=plot_kwargs.get(\"ls_min_ic\", \"--\"),\r\n color=plot_kwargs.get(\"color_ls_min_ic\", \"grey\"),\r\n lw=linewidth,\r\n )\r\n\r\n scale_col = information_criterion + \"_scale\"\r\n if scale_col in comp_df:\r\n scale = comp_df[scale_col].iloc[0].capitalize()\r\n else:\r\n scale = \"Deviance\"\r\n ax.set_xlabel(scale, fontsize=ax_labelsize)\r\n ax.set_yticklabels(yticks_labels)\r\n ax.set_ylim(-1 + step, 0 - step)\r\n ax.tick_params(labelsize=xt_labelsize)\r\n\r\n return ax\r\n", "path": "arviz/plots/compareplot.py"}], "after_files": [{"content": "\"\"\"Summary plot for model comparison.\"\"\"\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nfrom .plot_utils import _scale_fig_size\r\n\r\n\r\ndef plot_compare(\r\n comp_df,\r\n insample_dev=True,\r\n plot_standard_error=True,\r\n plot_ic_diff=True,\r\n order_by_rank=True,\r\n figsize=None,\r\n textsize=None,\r\n plot_kwargs=None,\r\n ax=None,\r\n):\r\n \"\"\"\r\n Summary plot for model comparison.\r\n\r\n This plot is in the style of the one used in the book Statistical Rethinking (Chapter 6)\r\n by Richard McElreath.\r\n\r\n Notes\r\n -----\r\n Defaults to comparing Widely Accepted Information Criterion (WAIC) if present in comp_df column,\r\n otherwise compares Leave-one-out (loo)\r\n\r\n\r\n Parameters\r\n ----------\r\n comp_df : pd.DataFrame\r\n Result of the `az.compare()` method\r\n insample_dev : bool, optional\r\n Plot in-sample deviance, that is the value of the information criteria without the\r\n penalization given by the effective number of parameters (pIC). Defaults to True\r\n plot_standard_error : bool, optional\r\n Plot the standard error of the information criteria estimate. Defaults to True\r\n plot_ic_diff : bool, optional\r\n Plot standard error of the difference in information criteria between each model\r\n and the top-ranked model. Defaults to True\r\n order_by_rank : bool\r\n If True (default) ensure the best model is used as reference.\r\n figsize : tuple, optional\r\n If None, size is (6, num of models) inches\r\n textsize: float\r\n Text size scaling factor for labels, titles and lines. If None it will be autoscaled based\r\n on figsize.\r\n plot_kwargs : dict, optional\r\n Optional arguments for plot elements. Currently accepts 'color_ic',\r\n 'marker_ic', 'color_insample_dev', 'marker_insample_dev', 'color_dse',\r\n 'marker_dse', 'ls_min_ic' 'color_ls_min_ic', 'fontsize'\r\n ax : axes, optional\r\n Matplotlib axes\r\n\r\n Returns\r\n -------\r\n ax : matplotlib axes\r\n\r\n\r\n Examples\r\n --------\r\n Show default compare plot\r\n\r\n .. plot::\r\n :context: close-figs\r\n\r\n >>> import arviz as az\r\n >>> model_compare = az.compare({'Centered 8 schools': az.load_arviz_data('centered_eight'),\r\n >>> 'Non-centered 8 schools': az.load_arviz_data('non_centered_eight')})\r\n >>> az.plot_compare(model_compare)\r\n\r\n Plot standard error and information criteria difference only\r\n\r\n .. plot::\r\n :context: close-figs\r\n\r\n >>> az.plot_compare(model_compare, insample_dev=False)\r\n\r\n \"\"\"\r\n if figsize is None:\r\n figsize = (6, len(comp_df))\r\n\r\n figsize, ax_labelsize, _, xt_labelsize, linewidth, _ = _scale_fig_size(figsize, textsize, 1, 1)\r\n\r\n if ax is None:\r\n _, ax = plt.subplots(figsize=figsize, constrained_layout=True)\r\n\r\n if plot_kwargs is None:\r\n plot_kwargs = {}\r\n\r\n yticks_pos, step = np.linspace(0, -1, (comp_df.shape[0] * 2) - 1, retstep=True)\r\n yticks_pos[1::2] = yticks_pos[1::2] + step / 2\r\n\r\n yticks_labels = [\"\"] * len(yticks_pos)\r\n\r\n _information_criterion = [\"waic\", \"loo\"]\r\n column_index = [c.lower() for c in comp_df.columns]\r\n for information_criterion in _information_criterion:\r\n if information_criterion in column_index:\r\n break\r\n else:\r\n raise ValueError(\r\n \"comp_df must contain one of the following\"\r\n \" information criterion: {}\".format(_information_criterion)\r\n )\r\n\r\n if order_by_rank:\r\n comp_df.sort_values(by=\"rank\", inplace=True)\r\n\r\n if plot_ic_diff:\r\n yticks_labels[0] = comp_df.index[0]\r\n yticks_labels[2::2] = comp_df.index[1:]\r\n ax.set_yticks(yticks_pos)\r\n ax.errorbar(\r\n x=comp_df[information_criterion].iloc[1:],\r\n y=yticks_pos[1::2],\r\n xerr=comp_df.dse[1:],\r\n color=plot_kwargs.get(\"color_dse\", \"grey\"),\r\n fmt=plot_kwargs.get(\"marker_dse\", \"^\"),\r\n mew=linewidth,\r\n elinewidth=linewidth,\r\n )\r\n\r\n else:\r\n yticks_labels = comp_df.index\r\n ax.set_yticks(yticks_pos[::2])\r\n\r\n if plot_standard_error:\r\n ax.errorbar(\r\n x=comp_df[information_criterion],\r\n y=yticks_pos[::2],\r\n xerr=comp_df.se,\r\n color=plot_kwargs.get(\"color_ic\", \"k\"),\r\n fmt=plot_kwargs.get(\"marker_ic\", \"o\"),\r\n mfc=\"None\",\r\n mew=linewidth,\r\n lw=linewidth,\r\n )\r\n else:\r\n ax.plot(\r\n comp_df[information_criterion],\r\n yticks_pos[::2],\r\n color=plot_kwargs.get(\"color_ic\", \"k\"),\r\n marker=plot_kwargs.get(\"marker_ic\", \"o\"),\r\n mfc=\"None\",\r\n mew=linewidth,\r\n lw=0,\r\n )\r\n\r\n if insample_dev:\r\n ax.plot(\r\n comp_df[information_criterion] - (2 * comp_df[\"p_\" + information_criterion]),\r\n yticks_pos[::2],\r\n color=plot_kwargs.get(\"color_insample_dev\", \"k\"),\r\n marker=plot_kwargs.get(\"marker_insample_dev\", \"o\"),\r\n mew=linewidth,\r\n lw=0,\r\n )\r\n\r\n ax.axvline(\r\n comp_df[information_criterion].iloc[0],\r\n ls=plot_kwargs.get(\"ls_min_ic\", \"--\"),\r\n color=plot_kwargs.get(\"color_ls_min_ic\", \"grey\"),\r\n lw=linewidth,\r\n )\r\n\r\n scale_col = information_criterion + \"_scale\"\r\n if scale_col in comp_df:\r\n scale = comp_df[scale_col].iloc[0].capitalize()\r\n else:\r\n scale = \"Deviance\"\r\n ax.set_xlabel(scale, fontsize=ax_labelsize)\r\n ax.set_yticklabels(yticks_labels)\r\n ax.set_ylim(-1 + step, 0 - step)\r\n ax.tick_params(labelsize=xt_labelsize)\r\n\r\n return ax\r\n", "path": "arviz/plots/compareplot.py"}]}
| 2,355 | 141 |
gh_patches_debug_30853
|
rasdani/github-patches
|
git_diff
|
pymedusa__Medusa-4622
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Emby notifications not working
Branch: master
Commit: 7cfc79d5280b719c6288090fb805521dfc0402cd
Version: v0.2.6
Database: 44.11
Python Version: | 2.7.9 (default, Aug 13 2016, 17:56:53) [GCC 4.9.2]
SSL Version: | OpenSSL 1.0.1t 3 May 2016
OS: | Linux-4.9.61+-armv7l-with-debian-8.11
Locale: | en_GB.UTF-8
I haven't changed the IP, port or API of the Emby device but notifications no longer work.
This is in the log:
```
2018-07-05 22:43:11 WARNING Thread_34 :: [7cfc79d] EMBY: Warning: Unable to contact Emby at http://**********/emby/Notifications/Admin: 500 Server Error: Internal Server Error for url: http://**********/emby/Notifications/Admin
```
I think this has just started with the most recent update of Medusa. There haven't been any Emby updates for a couple of weeks. Restarting Emby - no difference.
Restated Medusa and it updated to:
Branch: master
Commit: e7c4ff3bc9a48b47c932b0e40a539d62e3a62f64
Version: v0.2.6
Database: 44.11
Python Version: | 2.7.9 (default, Aug 13 2016, 17:56:53) [GCC 4.9.2]
SSL Version: | OpenSSL 1.0.1t 3 May 2016
OS: | Linux-4.9.61+-armv7l-with-debian-8.11
Locale: | en_GB.UTF-8
But the problem persists.
Thanks for checking out.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `medusa/notifiers/emby.py`
Content:
```
1 # coding=utf-8
2
3 """Emby notifier module."""
4 from __future__ import unicode_literals
5
6 import logging
7
8 from medusa import app
9 from medusa.helper.exceptions import ex
10 from medusa.indexers.indexer_config import INDEXER_TVDBV2, INDEXER_TVRAGE
11 from medusa.indexers.utils import indexer_id_to_name, mappings
12 from medusa.logger.adapters.style import BraceAdapter
13 from medusa.session.core import MedusaSession
14
15 from requests.exceptions import HTTPError, RequestException
16
17 from six import text_type as str
18
19 log = BraceAdapter(logging.getLogger(__name__))
20 log.logger.addHandler(logging.NullHandler())
21
22
23 class Notifier(object):
24 """Emby notifier class."""
25
26 def __init__(self):
27 self.session = MedusaSession()
28
29 def _notify_emby(self, message, host=None, emby_apikey=None):
30 """
31 Notify Emby host via HTTP API.
32
33 :return: True for no issue or False if there was an error
34 """
35 # fill in omitted parameters
36 if not host:
37 host = app.EMBY_HOST
38 if not emby_apikey:
39 emby_apikey = app.EMBY_APIKEY
40
41 url = 'http://{host}/emby/Notifications/Admin'.format(host=host)
42 try:
43 resp = self.session.post(
44 url=url,
45 data={
46 'Name': 'Medusa',
47 'Description': message,
48 'ImageUrl': app.LOGO_URL
49 },
50 headers={
51 'X-MediaBrowser-Token': emby_apikey,
52 'Content-Type': 'application/json'
53 }
54 )
55 resp.raise_for_status()
56
57 if resp.content:
58 log.debug('EMBY: HTTP response: {0}', resp.content.replace('\n', ''))
59
60 log.info('EMBY: Successfully sent a test notification.')
61 return True
62
63 except (HTTPError, RequestException) as error:
64 log.warning('EMBY: Warning: Unable to contact Emby at {url}: {error}',
65 {'url': url, 'error': ex(error)})
66 return False
67
68
69 ##############################################################################
70 # Public functions
71 ##############################################################################
72
73 def test_notify(self, host, emby_apikey):
74 """
75 Sends a test notification.
76
77 :return: True for no issue or False if there was an error
78 """
79 return self._notify_emby('This is a test notification from Medusa', host, emby_apikey)
80
81 def update_library(self, show=None):
82 """
83 Update the Emby Media Server host via HTTP API.
84
85 :return: True for no issue or False if there was an error
86 """
87 if app.USE_EMBY:
88 if not app.EMBY_HOST:
89 log.debug('EMBY: No host specified, check your settings')
90 return False
91
92 if show:
93 # EMBY only supports TVDB ids
94 provider = 'tvdbid'
95 if show.indexer == INDEXER_TVDBV2:
96 tvdb_id = show.indexerid
97 else:
98 # Try using external ids to get a TVDB id
99 tvdb_id = show.externals.get(mappings[INDEXER_TVDBV2], None)
100
101 if tvdb_id is None:
102 if show.indexer == INDEXER_TVRAGE:
103 log.warning('EMBY: TVRage indexer no longer valid')
104 else:
105 log.warning(
106 'EMBY: Unable to find a TVDB ID for {series},'
107 ' and {indexer} indexer is unsupported',
108 {'series': show.name, 'indexer': indexer_id_to_name(show.indexer)}
109 )
110 return False
111
112 params = {
113 provider: str(tvdb_id)
114 }
115 else:
116 params = {}
117
118 url = 'http://{host}/emby/Library/Series/Updated'.format(host=app.EMBY_HOST)
119 try:
120 resp = self.session.post(
121 url=url,
122 params=params,
123 headers={
124 'X-MediaBrowser-Token': app.EMBY_APIKEY
125 }
126 )
127 resp.raise_for_status()
128
129 if resp.content:
130 log.debug('EMBY: HTTP response: {0}', resp.content.replace('\n', ''))
131
132 log.info('EMBY: Successfully sent a "Series Library Updated" command.')
133 return True
134
135 except (HTTPError, RequestException) as error:
136 log.warning('EMBY: Warning: Unable to contact Emby at {url}: {error}',
137 {'url': url, 'error': ex(error)})
138 return False
139
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/medusa/notifiers/emby.py b/medusa/notifiers/emby.py
--- a/medusa/notifiers/emby.py
+++ b/medusa/notifiers/emby.py
@@ -3,6 +3,7 @@
"""Emby notifier module."""
from __future__ import unicode_literals
+import json
import logging
from medusa import app
@@ -14,7 +15,7 @@
from requests.exceptions import HTTPError, RequestException
-from six import text_type as str
+from six import text_type
log = BraceAdapter(logging.getLogger(__name__))
log.logger.addHandler(logging.NullHandler())
@@ -39,14 +40,15 @@
emby_apikey = app.EMBY_APIKEY
url = 'http://{host}/emby/Notifications/Admin'.format(host=host)
+ data = json.dumps({
+ 'Name': 'Medusa',
+ 'Description': message,
+ 'ImageUrl': app.LOGO_URL
+ })
try:
resp = self.session.post(
url=url,
- data={
- 'Name': 'Medusa',
- 'Description': message,
- 'ImageUrl': app.LOGO_URL
- },
+ data=data,
headers={
'X-MediaBrowser-Token': emby_apikey,
'Content-Type': 'application/json'
@@ -110,7 +112,7 @@
return False
params = {
- provider: str(tvdb_id)
+ provider: text_type(tvdb_id)
}
else:
params = {}
|
{"golden_diff": "diff --git a/medusa/notifiers/emby.py b/medusa/notifiers/emby.py\n--- a/medusa/notifiers/emby.py\n+++ b/medusa/notifiers/emby.py\n@@ -3,6 +3,7 @@\n \"\"\"Emby notifier module.\"\"\"\n from __future__ import unicode_literals\n \n+import json\n import logging\n \n from medusa import app\n@@ -14,7 +15,7 @@\n \n from requests.exceptions import HTTPError, RequestException\n \n-from six import text_type as str\n+from six import text_type\n \n log = BraceAdapter(logging.getLogger(__name__))\n log.logger.addHandler(logging.NullHandler())\n@@ -39,14 +40,15 @@\n emby_apikey = app.EMBY_APIKEY\n \n url = 'http://{host}/emby/Notifications/Admin'.format(host=host)\n+ data = json.dumps({\n+ 'Name': 'Medusa',\n+ 'Description': message,\n+ 'ImageUrl': app.LOGO_URL\n+ })\n try:\n resp = self.session.post(\n url=url,\n- data={\n- 'Name': 'Medusa',\n- 'Description': message,\n- 'ImageUrl': app.LOGO_URL\n- },\n+ data=data,\n headers={\n 'X-MediaBrowser-Token': emby_apikey,\n 'Content-Type': 'application/json'\n@@ -110,7 +112,7 @@\n return False\n \n params = {\n- provider: str(tvdb_id)\n+ provider: text_type(tvdb_id)\n }\n else:\n params = {}\n", "issue": "Emby notifications not working\n\r\nBranch:\u00a0master\r\nCommit:\u00a07cfc79d5280b719c6288090fb805521dfc0402cd\r\nVersion:\u00a0v0.2.6\r\nDatabase:\u00a044.11\r\nPython Version: | 2.7.9 (default, Aug 13 2016, 17:56:53) [GCC 4.9.2]\r\nSSL Version: | OpenSSL 1.0.1t 3 May 2016\r\nOS: | Linux-4.9.61+-armv7l-with-debian-8.11\r\nLocale: | en_GB.UTF-8\r\n\r\nI haven't changed the IP, port or API of the Emby device but notifications no longer work. \r\n\r\nThis is in the log:\r\n```\r\n2018-07-05 22:43:11 WARNING Thread_34 :: [7cfc79d] EMBY: Warning: Unable to contact Emby at http://**********/emby/Notifications/Admin: 500 Server Error: Internal Server Error for url: http://**********/emby/Notifications/Admin\r\n```\r\n\r\nI think this has just started with the most recent update of Medusa. There haven't been any Emby updates for a couple of weeks. Restarting Emby - no difference. \r\n\r\nRestated Medusa and it updated to:\r\n\r\nBranch:\u00a0master\r\nCommit:\u00a0e7c4ff3bc9a48b47c932b0e40a539d62e3a62f64\r\nVersion:\u00a0v0.2.6\r\nDatabase:\u00a044.11\r\nPython Version: | 2.7.9 (default, Aug 13 2016, 17:56:53) [GCC 4.9.2]\r\nSSL Version: | OpenSSL 1.0.1t 3 May 2016\r\nOS: | Linux-4.9.61+-armv7l-with-debian-8.11\r\nLocale: | en_GB.UTF-8\r\n\r\nBut the problem persists.\r\n\r\nThanks for checking out.\r\n\n", "before_files": [{"content": "# coding=utf-8\n\n\"\"\"Emby notifier module.\"\"\"\nfrom __future__ import unicode_literals\n\nimport logging\n\nfrom medusa import app\nfrom medusa.helper.exceptions import ex\nfrom medusa.indexers.indexer_config import INDEXER_TVDBV2, INDEXER_TVRAGE\nfrom medusa.indexers.utils import indexer_id_to_name, mappings\nfrom medusa.logger.adapters.style import BraceAdapter\nfrom medusa.session.core import MedusaSession\n\nfrom requests.exceptions import HTTPError, RequestException\n\nfrom six import text_type as str\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\nclass Notifier(object):\n \"\"\"Emby notifier class.\"\"\"\n\n def __init__(self):\n self.session = MedusaSession()\n\n def _notify_emby(self, message, host=None, emby_apikey=None):\n \"\"\"\n Notify Emby host via HTTP API.\n\n :return: True for no issue or False if there was an error\n \"\"\"\n # fill in omitted parameters\n if not host:\n host = app.EMBY_HOST\n if not emby_apikey:\n emby_apikey = app.EMBY_APIKEY\n\n url = 'http://{host}/emby/Notifications/Admin'.format(host=host)\n try:\n resp = self.session.post(\n url=url,\n data={\n 'Name': 'Medusa',\n 'Description': message,\n 'ImageUrl': app.LOGO_URL\n },\n headers={\n 'X-MediaBrowser-Token': emby_apikey,\n 'Content-Type': 'application/json'\n }\n )\n resp.raise_for_status()\n\n if resp.content:\n log.debug('EMBY: HTTP response: {0}', resp.content.replace('\\n', ''))\n\n log.info('EMBY: Successfully sent a test notification.')\n return True\n\n except (HTTPError, RequestException) as error:\n log.warning('EMBY: Warning: Unable to contact Emby at {url}: {error}',\n {'url': url, 'error': ex(error)})\n return False\n\n\n##############################################################################\n# Public functions\n##############################################################################\n\n def test_notify(self, host, emby_apikey):\n \"\"\"\n Sends a test notification.\n\n :return: True for no issue or False if there was an error\n \"\"\"\n return self._notify_emby('This is a test notification from Medusa', host, emby_apikey)\n\n def update_library(self, show=None):\n \"\"\"\n Update the Emby Media Server host via HTTP API.\n\n :return: True for no issue or False if there was an error\n \"\"\"\n if app.USE_EMBY:\n if not app.EMBY_HOST:\n log.debug('EMBY: No host specified, check your settings')\n return False\n\n if show:\n # EMBY only supports TVDB ids\n provider = 'tvdbid'\n if show.indexer == INDEXER_TVDBV2:\n tvdb_id = show.indexerid\n else:\n # Try using external ids to get a TVDB id\n tvdb_id = show.externals.get(mappings[INDEXER_TVDBV2], None)\n\n if tvdb_id is None:\n if show.indexer == INDEXER_TVRAGE:\n log.warning('EMBY: TVRage indexer no longer valid')\n else:\n log.warning(\n 'EMBY: Unable to find a TVDB ID for {series},'\n ' and {indexer} indexer is unsupported',\n {'series': show.name, 'indexer': indexer_id_to_name(show.indexer)}\n )\n return False\n\n params = {\n provider: str(tvdb_id)\n }\n else:\n params = {}\n\n url = 'http://{host}/emby/Library/Series/Updated'.format(host=app.EMBY_HOST)\n try:\n resp = self.session.post(\n url=url,\n params=params,\n headers={\n 'X-MediaBrowser-Token': app.EMBY_APIKEY\n }\n )\n resp.raise_for_status()\n\n if resp.content:\n log.debug('EMBY: HTTP response: {0}', resp.content.replace('\\n', ''))\n\n log.info('EMBY: Successfully sent a \"Series Library Updated\" command.')\n return True\n\n except (HTTPError, RequestException) as error:\n log.warning('EMBY: Warning: Unable to contact Emby at {url}: {error}',\n {'url': url, 'error': ex(error)})\n return False\n", "path": "medusa/notifiers/emby.py"}], "after_files": [{"content": "# coding=utf-8\n\n\"\"\"Emby notifier module.\"\"\"\nfrom __future__ import unicode_literals\n\nimport json\nimport logging\n\nfrom medusa import app\nfrom medusa.helper.exceptions import ex\nfrom medusa.indexers.indexer_config import INDEXER_TVDBV2, INDEXER_TVRAGE\nfrom medusa.indexers.utils import indexer_id_to_name, mappings\nfrom medusa.logger.adapters.style import BraceAdapter\nfrom medusa.session.core import MedusaSession\n\nfrom requests.exceptions import HTTPError, RequestException\n\nfrom six import text_type\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\nclass Notifier(object):\n \"\"\"Emby notifier class.\"\"\"\n\n def __init__(self):\n self.session = MedusaSession()\n\n def _notify_emby(self, message, host=None, emby_apikey=None):\n \"\"\"\n Notify Emby host via HTTP API.\n\n :return: True for no issue or False if there was an error\n \"\"\"\n # fill in omitted parameters\n if not host:\n host = app.EMBY_HOST\n if not emby_apikey:\n emby_apikey = app.EMBY_APIKEY\n\n url = 'http://{host}/emby/Notifications/Admin'.format(host=host)\n data = json.dumps({\n 'Name': 'Medusa',\n 'Description': message,\n 'ImageUrl': app.LOGO_URL\n })\n try:\n resp = self.session.post(\n url=url,\n data=data,\n headers={\n 'X-MediaBrowser-Token': emby_apikey,\n 'Content-Type': 'application/json'\n }\n )\n resp.raise_for_status()\n\n if resp.content:\n log.debug('EMBY: HTTP response: {0}', resp.content.replace('\\n', ''))\n\n log.info('EMBY: Successfully sent a test notification.')\n return True\n\n except (HTTPError, RequestException) as error:\n log.warning('EMBY: Warning: Unable to contact Emby at {url}: {error}',\n {'url': url, 'error': ex(error)})\n return False\n\n\n##############################################################################\n# Public functions\n##############################################################################\n\n def test_notify(self, host, emby_apikey):\n \"\"\"\n Sends a test notification.\n\n :return: True for no issue or False if there was an error\n \"\"\"\n return self._notify_emby('This is a test notification from Medusa', host, emby_apikey)\n\n def update_library(self, show=None):\n \"\"\"\n Update the Emby Media Server host via HTTP API.\n\n :return: True for no issue or False if there was an error\n \"\"\"\n if app.USE_EMBY:\n if not app.EMBY_HOST:\n log.debug('EMBY: No host specified, check your settings')\n return False\n\n if show:\n # EMBY only supports TVDB ids\n provider = 'tvdbid'\n if show.indexer == INDEXER_TVDBV2:\n tvdb_id = show.indexerid\n else:\n # Try using external ids to get a TVDB id\n tvdb_id = show.externals.get(mappings[INDEXER_TVDBV2], None)\n\n if tvdb_id is None:\n if show.indexer == INDEXER_TVRAGE:\n log.warning('EMBY: TVRage indexer no longer valid')\n else:\n log.warning(\n 'EMBY: Unable to find a TVDB ID for {series},'\n ' and {indexer} indexer is unsupported',\n {'series': show.name, 'indexer': indexer_id_to_name(show.indexer)}\n )\n return False\n\n params = {\n provider: text_type(tvdb_id)\n }\n else:\n params = {}\n\n url = 'http://{host}/emby/Library/Series/Updated'.format(host=app.EMBY_HOST)\n try:\n resp = self.session.post(\n url=url,\n params=params,\n headers={\n 'X-MediaBrowser-Token': app.EMBY_APIKEY\n }\n )\n resp.raise_for_status()\n\n if resp.content:\n log.debug('EMBY: HTTP response: {0}', resp.content.replace('\\n', ''))\n\n log.info('EMBY: Successfully sent a \"Series Library Updated\" command.')\n return True\n\n except (HTTPError, RequestException) as error:\n log.warning('EMBY: Warning: Unable to contact Emby at {url}: {error}',\n {'url': url, 'error': ex(error)})\n return False\n", "path": "medusa/notifiers/emby.py"}]}
| 2,048 | 344 |
gh_patches_debug_20936
|
rasdani/github-patches
|
git_diff
|
Zeroto521__my-data-toolkit-706
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ENH: New geoaccessor to generate great circle distances matrix
<!--
Thanks for contributing a pull request!
Please follow these standard acronyms to start the commit message:
- ENH: enhancement
- BUG: bug fix
- DOC: documentation
- TYP: type annotations
- TST: addition or modification of tests
- MAINT: maintenance commit (refactoring, typos, etc.)
- BLD: change related to building
- REL: related to releasing
- API: an (incompatible) API change
- DEP: deprecate something, or remove a deprecated object
- DEV: development tool or utility
- REV: revert an earlier commit
- PERF: performance improvement
- BOT: always commit via a bot
- CI: related to CI or CD
- CLN: Code cleanup
-->
- [x] closes #699
- [ ] whatsnew entry
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `dtoolkit/geoaccessor/geoseries/geodistance_matrix.py`
Content:
```
1 from __future__ import annotations
2
3 import geopandas as gpd
4 import numpy as np
5 import pandas as pd
6
7 from dtoolkit.geoaccessor.register import register_geoseries_method
8
9
10 @register_geoseries_method
11 def geodistance_matrix(
12 s: gpd.GeoSeries,
13 /,
14 other: gpd.GeoSeries | gpd.GeoDataFrame | None = None,
15 radius: float = 6371008.7714150598,
16 ) -> pd.DataFrame:
17 """
18 Returns a ``DataFrame`` containing the `great-circle`__ distances matrix between in
19 ``s`` and ``other`` via haversine formula.
20
21 __ https://en.wikipedia.org/wiki/Great-circle_distance
22
23 .. math::
24
25 D(x, y) = 2 \\arcsin [
26 \\sqrt{
27 \\sin^2 ((x_1 - y_1) / 2)
28 + \\cos(x_1) \\cos(y_1) \\sin^2 ((x_2 - y_2) / 2)
29 }
30 ]
31
32 Parameters
33 ----------
34 other : GeoSeries, or GeoDataFrame, default None
35 If None, uses ``other=s``.
36
37 radius : float, default 6371008.7714150598
38 Great-circle distance uses a spherical model of the earth, using the mean earth
39 radius as defined by the International Union of Geodesy and Geophysics,
40 (2\\ *a* + *b*)/3 = 6371008.7714150598 meters for WGS-84.
41
42 Returns
43 -------
44 DataFrame
45 - The index and columns are the same as the index of ``s`` and ``other``.
46 - The values are the great-circle distances and its unit is meters.
47
48 Raises
49 ------
50 ModuleNotFoundError
51 If don't have module named 'sklearn'.
52
53 ValueError
54 If the CRS is not ``ESGP:4326``.
55
56 See Also
57 --------
58 sklearn.metrics.pairwise.haversine_distances
59 dtoolkit.geoaccessor.geoseries.geodistance
60 dtoolkit.geoaccessor.geoseries.geodistance_matrix
61 dtoolkit.geoaccessor.geodataframe.geodistance
62 dtoolkit.geoaccessor.geodataframe.geodistance_matrix
63
64 Notes
65 -----
66 - Currently, only supports Point geometry.
67 - The great-circle distance is the angular distance between two points on the
68 surface of a sphere. As the Earth is nearly spherical, the haversine formula
69 provides a good approximation of the distance between two points of the Earth
70 surface, with a less than 1% error on average.
71
72 Examples
73 --------
74 >>> import dtoolkit.geoaccessor
75 >>> df = pd.DataFrame(
76 ... {
77 ... "x": [120, 122, 100],
78 ... "y":[30, 55, 1],
79 ... },
80 ... ).from_xy("x", "y", crs=4326)
81 >>> df
82 x y geometry
83 0 120 30 POINT (120.00000 30.00000)
84 1 122 55 POINT (122.00000 55.00000)
85 2 100 1 POINT (100.00000 1.00000)
86 >>> other = pd.DataFrame(
87 ... {
88 ... "x": [120, 110],
89 ... "y":[30, 40],
90 ... },
91 ... ).from_xy("x", "y", crs=4326)
92 >>> other
93 x y geometry
94 0 120 30 POINT (120.00000 30.00000)
95 1 110 40 POINT (110.00000 40.00000)
96 >>> df.geodistance_matrix(other)
97 0 1
98 0 0.000000e+00 1.203540e+06
99 1 1.439971e+06 1.511958e+06
100 2 2.418544e+06 1.522752e+06
101 """
102 from sklearn.metrics.pairwise import haversine_distances
103
104 if s.crs != 4326:
105 raise ValueError(f"Only support 'EPSG:4326' CRS, but got {s.crs!r}.")
106
107 if isinstance(other, gpd.base.GeoPandasBase):
108 if other.crs != 4326:
109 raise ValueError(f"Only support 'EPSG:4326' CRS, but got {other.crs!r}.")
110
111 # Force convert to GeoSeries
112 other = other.geometry
113
114 X = np.radians(np.stack((s.x, s.y), axis=1))
115 Y = np.radians(np.stack((other.x, other.y), axis=1)) if other is not None else other
116 return pd.DataFrame(
117 radius * haversine_distances(X, Y),
118 index=s.index,
119 columns=other.index,
120 )
121
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py b/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py
--- a/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py
+++ b/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py
@@ -95,9 +95,9 @@
1 110 40 POINT (110.00000 40.00000)
>>> df.geodistance_matrix(other)
0 1
- 0 0.000000e+00 1.203540e+06
- 1 1.439971e+06 1.511958e+06
- 2 2.418544e+06 1.522752e+06
+ 0 0.000000e+00 1.435335e+06
+ 1 2.784435e+06 1.889892e+06
+ 2 3.855604e+06 4.453100e+06
"""
from sklearn.metrics.pairwise import haversine_distances
@@ -111,8 +111,8 @@
# Force convert to GeoSeries
other = other.geometry
- X = np.radians(np.stack((s.x, s.y), axis=1))
- Y = np.radians(np.stack((other.x, other.y), axis=1)) if other is not None else other
+ X = np.radians(np.stack((s.y, s.x), axis=1))
+ Y = np.radians(np.stack((other.y, other.x), axis=1)) if other is not None else other
return pd.DataFrame(
radius * haversine_distances(X, Y),
index=s.index,
|
{"golden_diff": "diff --git a/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py b/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py\n--- a/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py\n+++ b/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py\n@@ -95,9 +95,9 @@\n 1 110 40 POINT (110.00000 40.00000)\n >>> df.geodistance_matrix(other)\n 0 1\n- 0 0.000000e+00 1.203540e+06\n- 1 1.439971e+06 1.511958e+06\n- 2 2.418544e+06 1.522752e+06\n+ 0 0.000000e+00 1.435335e+06\n+ 1 2.784435e+06 1.889892e+06\n+ 2 3.855604e+06 4.453100e+06\n \"\"\"\n from sklearn.metrics.pairwise import haversine_distances\n \n@@ -111,8 +111,8 @@\n # Force convert to GeoSeries\n other = other.geometry\n \n- X = np.radians(np.stack((s.x, s.y), axis=1))\n- Y = np.radians(np.stack((other.x, other.y), axis=1)) if other is not None else other\n+ X = np.radians(np.stack((s.y, s.x), axis=1))\n+ Y = np.radians(np.stack((other.y, other.x), axis=1)) if other is not None else other\n return pd.DataFrame(\n radius * haversine_distances(X, Y),\n index=s.index,\n", "issue": "ENH: New geoaccessor to generate great circle distances matrix\n<!--\r\nThanks for contributing a pull request!\r\n\r\nPlease follow these standard acronyms to start the commit message:\r\n\r\n- ENH: enhancement\r\n- BUG: bug fix\r\n- DOC: documentation\r\n- TYP: type annotations\r\n- TST: addition or modification of tests\r\n- MAINT: maintenance commit (refactoring, typos, etc.)\r\n- BLD: change related to building\r\n- REL: related to releasing\r\n- API: an (incompatible) API change\r\n- DEP: deprecate something, or remove a deprecated object\r\n- DEV: development tool or utility\r\n- REV: revert an earlier commit\r\n- PERF: performance improvement\r\n- BOT: always commit via a bot\r\n- CI: related to CI or CD\r\n- CLN: Code cleanup\r\n-->\r\n\r\n- [x] closes #699\r\n- [ ] whatsnew entry\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport geopandas as gpd\nimport numpy as np\nimport pandas as pd\n\nfrom dtoolkit.geoaccessor.register import register_geoseries_method\n\n\n@register_geoseries_method\ndef geodistance_matrix(\n s: gpd.GeoSeries,\n /,\n other: gpd.GeoSeries | gpd.GeoDataFrame | None = None,\n radius: float = 6371008.7714150598,\n) -> pd.DataFrame:\n \"\"\"\n Returns a ``DataFrame`` containing the `great-circle`__ distances matrix between in\n ``s`` and ``other`` via haversine formula.\n\n __ https://en.wikipedia.org/wiki/Great-circle_distance\n\n .. math::\n\n D(x, y) = 2 \\\\arcsin [\n \\\\sqrt{\n \\\\sin^2 ((x_1 - y_1) / 2)\n + \\\\cos(x_1) \\\\cos(y_1) \\\\sin^2 ((x_2 - y_2) / 2)\n }\n ]\n\n Parameters\n ----------\n other : GeoSeries, or GeoDataFrame, default None\n If None, uses ``other=s``.\n\n radius : float, default 6371008.7714150598\n Great-circle distance uses a spherical model of the earth, using the mean earth\n radius as defined by the International Union of Geodesy and Geophysics,\n (2\\\\ *a* + *b*)/3 = 6371008.7714150598 meters for WGS-84.\n\n Returns\n -------\n DataFrame\n - The index and columns are the same as the index of ``s`` and ``other``.\n - The values are the great-circle distances and its unit is meters.\n\n Raises\n ------\n ModuleNotFoundError\n If don't have module named 'sklearn'.\n\n ValueError\n If the CRS is not ``ESGP:4326``.\n\n See Also\n --------\n sklearn.metrics.pairwise.haversine_distances\n dtoolkit.geoaccessor.geoseries.geodistance\n dtoolkit.geoaccessor.geoseries.geodistance_matrix\n dtoolkit.geoaccessor.geodataframe.geodistance\n dtoolkit.geoaccessor.geodataframe.geodistance_matrix\n\n Notes\n -----\n - Currently, only supports Point geometry.\n - The great-circle distance is the angular distance between two points on the\n surface of a sphere. As the Earth is nearly spherical, the haversine formula\n provides a good approximation of the distance between two points of the Earth\n surface, with a less than 1% error on average.\n\n Examples\n --------\n >>> import dtoolkit.geoaccessor\n >>> df = pd.DataFrame(\n ... {\n ... \"x\": [120, 122, 100],\n ... \"y\":[30, 55, 1],\n ... },\n ... ).from_xy(\"x\", \"y\", crs=4326)\n >>> df\n x y geometry\n 0 120 30 POINT (120.00000 30.00000)\n 1 122 55 POINT (122.00000 55.00000)\n 2 100 1 POINT (100.00000 1.00000)\n >>> other = pd.DataFrame(\n ... {\n ... \"x\": [120, 110],\n ... \"y\":[30, 40],\n ... },\n ... ).from_xy(\"x\", \"y\", crs=4326)\n >>> other\n x y geometry\n 0 120 30 POINT (120.00000 30.00000)\n 1 110 40 POINT (110.00000 40.00000)\n >>> df.geodistance_matrix(other)\n 0 1\n 0 0.000000e+00 1.203540e+06\n 1 1.439971e+06 1.511958e+06\n 2 2.418544e+06 1.522752e+06\n \"\"\"\n from sklearn.metrics.pairwise import haversine_distances\n\n if s.crs != 4326:\n raise ValueError(f\"Only support 'EPSG:4326' CRS, but got {s.crs!r}.\")\n\n if isinstance(other, gpd.base.GeoPandasBase):\n if other.crs != 4326:\n raise ValueError(f\"Only support 'EPSG:4326' CRS, but got {other.crs!r}.\")\n\n # Force convert to GeoSeries\n other = other.geometry\n\n X = np.radians(np.stack((s.x, s.y), axis=1))\n Y = np.radians(np.stack((other.x, other.y), axis=1)) if other is not None else other\n return pd.DataFrame(\n radius * haversine_distances(X, Y),\n index=s.index,\n columns=other.index,\n )\n", "path": "dtoolkit/geoaccessor/geoseries/geodistance_matrix.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport geopandas as gpd\nimport numpy as np\nimport pandas as pd\n\nfrom dtoolkit.geoaccessor.register import register_geoseries_method\n\n\n@register_geoseries_method\ndef geodistance_matrix(\n s: gpd.GeoSeries,\n /,\n other: gpd.GeoSeries | gpd.GeoDataFrame | None = None,\n radius: float = 6371008.7714150598,\n) -> pd.DataFrame:\n \"\"\"\n Returns a ``DataFrame`` containing the `great-circle`__ distances matrix between in\n ``s`` and ``other`` via haversine formula.\n\n __ https://en.wikipedia.org/wiki/Great-circle_distance\n\n .. math::\n\n D(x, y) = 2 \\\\arcsin [\n \\\\sqrt{\n \\\\sin^2 ((x_1 - y_1) / 2)\n + \\\\cos(x_1) \\\\cos(y_1) \\\\sin^2 ((x_2 - y_2) / 2)\n }\n ]\n\n Parameters\n ----------\n other : GeoSeries, or GeoDataFrame, default None\n If None, uses ``other=s``.\n\n radius : float, default 6371008.7714150598\n Great-circle distance uses a spherical model of the earth, using the mean earth\n radius as defined by the International Union of Geodesy and Geophysics,\n (2\\\\ *a* + *b*)/3 = 6371008.7714150598 meters for WGS-84.\n\n Returns\n -------\n DataFrame\n - The index and columns are the same as the index of ``s`` and ``other``.\n - The values are the great-circle distances and its unit is meters.\n\n Raises\n ------\n ModuleNotFoundError\n If don't have module named 'sklearn'.\n\n ValueError\n If the CRS is not ``ESGP:4326``.\n\n See Also\n --------\n sklearn.metrics.pairwise.haversine_distances\n dtoolkit.geoaccessor.geoseries.geodistance\n dtoolkit.geoaccessor.geoseries.geodistance_matrix\n dtoolkit.geoaccessor.geodataframe.geodistance\n dtoolkit.geoaccessor.geodataframe.geodistance_matrix\n\n Notes\n -----\n - Currently, only supports Point geometry.\n - The great-circle distance is the angular distance between two points on the\n surface of a sphere. As the Earth is nearly spherical, the haversine formula\n provides a good approximation of the distance between two points of the Earth\n surface, with a less than 1% error on average.\n\n Examples\n --------\n >>> import dtoolkit.geoaccessor\n >>> df = pd.DataFrame(\n ... {\n ... \"x\": [120, 122, 100],\n ... \"y\":[30, 55, 1],\n ... },\n ... ).from_xy(\"x\", \"y\", crs=4326)\n >>> df\n x y geometry\n 0 120 30 POINT (120.00000 30.00000)\n 1 122 55 POINT (122.00000 55.00000)\n 2 100 1 POINT (100.00000 1.00000)\n >>> other = pd.DataFrame(\n ... {\n ... \"x\": [120, 110],\n ... \"y\":[30, 40],\n ... },\n ... ).from_xy(\"x\", \"y\", crs=4326)\n >>> other\n x y geometry\n 0 120 30 POINT (120.00000 30.00000)\n 1 110 40 POINT (110.00000 40.00000)\n >>> df.geodistance_matrix(other)\n 0 1\n 0 0.000000e+00 1.435335e+06\n 1 2.784435e+06 1.889892e+06\n 2 3.855604e+06 4.453100e+06\n \"\"\"\n from sklearn.metrics.pairwise import haversine_distances\n\n if s.crs != 4326:\n raise ValueError(f\"Only support 'EPSG:4326' CRS, but got {s.crs!r}.\")\n\n if isinstance(other, gpd.base.GeoPandasBase):\n if other.crs != 4326:\n raise ValueError(f\"Only support 'EPSG:4326' CRS, but got {other.crs!r}.\")\n\n # Force convert to GeoSeries\n other = other.geometry\n\n X = np.radians(np.stack((s.y, s.x), axis=1))\n Y = np.radians(np.stack((other.y, other.x), axis=1)) if other is not None else other\n return pd.DataFrame(\n radius * haversine_distances(X, Y),\n index=s.index,\n columns=other.index,\n )\n", "path": "dtoolkit/geoaccessor/geoseries/geodistance_matrix.py"}]}
| 1,986 | 487 |
gh_patches_debug_13663
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-493
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
New CSV imports use autogenerated column names.
## Description
<!-- A clear and concise description of what the bug is. -->
According to #459, newly imported CSVs are supposed to use the first row as headers by default. However, newly uploaded CSVs are showing autogenerated column names.
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
The first row of the CSV should be used as header names by default.
## To Reproduce
<!-- How can we recreate this bug? Please try to provide a Minimal, Complete, and Verifiable (http://stackoverflow.com/help/mcve) example if code-related. -->
Upload a CSV from the Mathesar UI. Column names will be of the form `column_0`, etc.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mathesar/serializers.py`
Content:
```
1 from django.urls import reverse
2 from rest_framework import serializers
3
4 from mathesar.models import Table, Schema, DataFile, Database
5
6
7 class NestedTableSerializer(serializers.HyperlinkedModelSerializer):
8 url = serializers.SerializerMethodField()
9
10 class Meta:
11 model = Table
12 fields = ['id', 'name', 'url']
13
14 def get_url(self, obj):
15 request = self.context['request']
16 return request.build_absolute_uri(reverse('table-detail', kwargs={'pk': obj.pk}))
17
18
19 class ModelNameField(serializers.CharField):
20 """
21 De-serializes the request field as a string, but serializes the response field as
22 `model.name`. Required to support passing and returing a model name from the
23 endpoint, while also storing the model as a related field.
24 """
25 def to_representation(self, value):
26 return value.name
27
28
29 class SchemaSerializer(serializers.HyperlinkedModelSerializer):
30 tables = NestedTableSerializer(many=True, read_only=True)
31 name = serializers.CharField()
32 database = ModelNameField(max_length=128)
33
34 class Meta:
35 model = Schema
36 fields = ['id', 'name', 'tables', 'database', 'has_dependencies']
37
38
39 class SimpleColumnSerializer(serializers.Serializer):
40 name = serializers.CharField()
41 type = serializers.CharField()
42
43
44 class ColumnSerializer(SimpleColumnSerializer):
45 index = serializers.IntegerField(source='column_index', read_only=True)
46 nullable = serializers.BooleanField(default=True)
47 primary_key = serializers.BooleanField(default=False)
48 valid_target_types = serializers.ListField(read_only=True)
49
50
51 class TableSerializer(serializers.ModelSerializer):
52 columns = SimpleColumnSerializer(many=True, read_only=True, source='sa_columns')
53 records = serializers.SerializerMethodField()
54 name = serializers.CharField()
55 data_files = serializers.PrimaryKeyRelatedField(required=False, many=True, queryset=DataFile.objects.all())
56
57 class Meta:
58 model = Table
59 fields = ['id', 'name', 'schema', 'created_at', 'updated_at',
60 'columns', 'records', 'data_files', 'has_dependencies']
61
62 def get_records(self, obj):
63 if isinstance(obj, Table):
64 # Only get records if we are serializing an existing table
65 request = self.context['request']
66 return request.build_absolute_uri(reverse('table-record-list', kwargs={'table_pk': obj.pk}))
67 else:
68 return None
69
70
71 class RecordSerializer(serializers.BaseSerializer):
72 def to_representation(self, instance):
73 return instance._asdict()
74
75
76 class RecordListParameterSerializer(serializers.Serializer):
77 filters = serializers.JSONField(required=False, default=[])
78 order_by = serializers.JSONField(required=False, default=[])
79 group_count_by = serializers.JSONField(required=False, default=[])
80
81
82 class DatabaseSerializer(serializers.ModelSerializer):
83 supported_types = serializers.ListField(child=serializers.CharField())
84
85 class Meta:
86 model = Database
87 fields = ['id', 'name', 'deleted', 'supported_types']
88 read_only_fields = ['id', 'name', 'deleted', 'supported_types']
89
90
91 class DataFileSerializer(serializers.ModelSerializer):
92 user = serializers.PrimaryKeyRelatedField(
93 default=serializers.CurrentUserDefault(), read_only=True
94 )
95
96 class Meta:
97 model = DataFile
98 fields = [
99 'id', 'file', 'table_imported_to', 'user', 'header', 'delimiter', 'escapechar', 'quotechar'
100 ]
101 extra_kwargs = {'delimiter': {'trim_whitespace': False},
102 'escapechar': {'trim_whitespace': False},
103 'quotechar': {'trim_whitespace': False}}
104 # We only currently support importing to a new table, so setting a table via API is invalid.
105 # User should be set automatically, not submitted via the API.
106 read_only_fields = ['table_imported_to']
107
108 def save(self, **kwargs):
109 """
110 Set user to current user while saving the data file.
111 """
112 current_user = self.fields['user'].get_default()
113 if current_user.is_authenticated:
114 kwargs['user'] = current_user
115 return super().save(**kwargs)
116
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/mathesar/serializers.py b/mathesar/serializers.py
--- a/mathesar/serializers.py
+++ b/mathesar/serializers.py
@@ -100,7 +100,8 @@
]
extra_kwargs = {'delimiter': {'trim_whitespace': False},
'escapechar': {'trim_whitespace': False},
- 'quotechar': {'trim_whitespace': False}}
+ 'quotechar': {'trim_whitespace': False},
+ 'header': {'required': True}}
# We only currently support importing to a new table, so setting a table via API is invalid.
# User should be set automatically, not submitted via the API.
read_only_fields = ['table_imported_to']
|
{"golden_diff": "diff --git a/mathesar/serializers.py b/mathesar/serializers.py\n--- a/mathesar/serializers.py\n+++ b/mathesar/serializers.py\n@@ -100,7 +100,8 @@\n ]\n extra_kwargs = {'delimiter': {'trim_whitespace': False},\n 'escapechar': {'trim_whitespace': False},\n- 'quotechar': {'trim_whitespace': False}}\n+ 'quotechar': {'trim_whitespace': False},\n+ 'header': {'required': True}}\n # We only currently support importing to a new table, so setting a table via API is invalid.\n # User should be set automatically, not submitted via the API.\n read_only_fields = ['table_imported_to']\n", "issue": "New CSV imports use autogenerated column names.\n## Description\r\n<!-- A clear and concise description of what the bug is. -->\r\nAccording to #459, newly imported CSVs are supposed to use the first row as headers by default. However, newly uploaded CSVs are showing autogenerated column names.\r\n\r\n## Expected behavior\r\n<!-- A clear and concise description of what you expected to happen. -->\r\nThe first row of the CSV should be used as header names by default.\r\n\r\n## To Reproduce\r\n<!-- How can we recreate this bug? Please try to provide a Minimal, Complete, and Verifiable (http://stackoverflow.com/help/mcve) example if code-related. -->\r\nUpload a CSV from the Mathesar UI. Column names will be of the form `column_0`, etc.\n", "before_files": [{"content": "from django.urls import reverse\nfrom rest_framework import serializers\n\nfrom mathesar.models import Table, Schema, DataFile, Database\n\n\nclass NestedTableSerializer(serializers.HyperlinkedModelSerializer):\n url = serializers.SerializerMethodField()\n\n class Meta:\n model = Table\n fields = ['id', 'name', 'url']\n\n def get_url(self, obj):\n request = self.context['request']\n return request.build_absolute_uri(reverse('table-detail', kwargs={'pk': obj.pk}))\n\n\nclass ModelNameField(serializers.CharField):\n \"\"\"\n De-serializes the request field as a string, but serializes the response field as\n `model.name`. Required to support passing and returing a model name from the\n endpoint, while also storing the model as a related field.\n \"\"\"\n def to_representation(self, value):\n return value.name\n\n\nclass SchemaSerializer(serializers.HyperlinkedModelSerializer):\n tables = NestedTableSerializer(many=True, read_only=True)\n name = serializers.CharField()\n database = ModelNameField(max_length=128)\n\n class Meta:\n model = Schema\n fields = ['id', 'name', 'tables', 'database', 'has_dependencies']\n\n\nclass SimpleColumnSerializer(serializers.Serializer):\n name = serializers.CharField()\n type = serializers.CharField()\n\n\nclass ColumnSerializer(SimpleColumnSerializer):\n index = serializers.IntegerField(source='column_index', read_only=True)\n nullable = serializers.BooleanField(default=True)\n primary_key = serializers.BooleanField(default=False)\n valid_target_types = serializers.ListField(read_only=True)\n\n\nclass TableSerializer(serializers.ModelSerializer):\n columns = SimpleColumnSerializer(many=True, read_only=True, source='sa_columns')\n records = serializers.SerializerMethodField()\n name = serializers.CharField()\n data_files = serializers.PrimaryKeyRelatedField(required=False, many=True, queryset=DataFile.objects.all())\n\n class Meta:\n model = Table\n fields = ['id', 'name', 'schema', 'created_at', 'updated_at',\n 'columns', 'records', 'data_files', 'has_dependencies']\n\n def get_records(self, obj):\n if isinstance(obj, Table):\n # Only get records if we are serializing an existing table\n request = self.context['request']\n return request.build_absolute_uri(reverse('table-record-list', kwargs={'table_pk': obj.pk}))\n else:\n return None\n\n\nclass RecordSerializer(serializers.BaseSerializer):\n def to_representation(self, instance):\n return instance._asdict()\n\n\nclass RecordListParameterSerializer(serializers.Serializer):\n filters = serializers.JSONField(required=False, default=[])\n order_by = serializers.JSONField(required=False, default=[])\n group_count_by = serializers.JSONField(required=False, default=[])\n\n\nclass DatabaseSerializer(serializers.ModelSerializer):\n supported_types = serializers.ListField(child=serializers.CharField())\n\n class Meta:\n model = Database\n fields = ['id', 'name', 'deleted', 'supported_types']\n read_only_fields = ['id', 'name', 'deleted', 'supported_types']\n\n\nclass DataFileSerializer(serializers.ModelSerializer):\n user = serializers.PrimaryKeyRelatedField(\n default=serializers.CurrentUserDefault(), read_only=True\n )\n\n class Meta:\n model = DataFile\n fields = [\n 'id', 'file', 'table_imported_to', 'user', 'header', 'delimiter', 'escapechar', 'quotechar'\n ]\n extra_kwargs = {'delimiter': {'trim_whitespace': False},\n 'escapechar': {'trim_whitespace': False},\n 'quotechar': {'trim_whitespace': False}}\n # We only currently support importing to a new table, so setting a table via API is invalid.\n # User should be set automatically, not submitted via the API.\n read_only_fields = ['table_imported_to']\n\n def save(self, **kwargs):\n \"\"\"\n Set user to current user while saving the data file.\n \"\"\"\n current_user = self.fields['user'].get_default()\n if current_user.is_authenticated:\n kwargs['user'] = current_user\n return super().save(**kwargs)\n", "path": "mathesar/serializers.py"}], "after_files": [{"content": "from django.urls import reverse\nfrom rest_framework import serializers\n\nfrom mathesar.models import Table, Schema, DataFile, Database\n\n\nclass NestedTableSerializer(serializers.HyperlinkedModelSerializer):\n url = serializers.SerializerMethodField()\n\n class Meta:\n model = Table\n fields = ['id', 'name', 'url']\n\n def get_url(self, obj):\n request = self.context['request']\n return request.build_absolute_uri(reverse('table-detail', kwargs={'pk': obj.pk}))\n\n\nclass ModelNameField(serializers.CharField):\n \"\"\"\n De-serializes the request field as a string, but serializes the response field as\n `model.name`. Required to support passing and returing a model name from the\n endpoint, while also storing the model as a related field.\n \"\"\"\n def to_representation(self, value):\n return value.name\n\n\nclass SchemaSerializer(serializers.HyperlinkedModelSerializer):\n tables = NestedTableSerializer(many=True, read_only=True)\n name = serializers.CharField()\n database = ModelNameField(max_length=128)\n\n class Meta:\n model = Schema\n fields = ['id', 'name', 'tables', 'database', 'has_dependencies']\n\n\nclass SimpleColumnSerializer(serializers.Serializer):\n name = serializers.CharField()\n type = serializers.CharField()\n\n\nclass ColumnSerializer(SimpleColumnSerializer):\n index = serializers.IntegerField(source='column_index', read_only=True)\n nullable = serializers.BooleanField(default=True)\n primary_key = serializers.BooleanField(default=False)\n valid_target_types = serializers.ListField(read_only=True)\n\n\nclass TableSerializer(serializers.ModelSerializer):\n columns = SimpleColumnSerializer(many=True, read_only=True, source='sa_columns')\n records = serializers.SerializerMethodField()\n name = serializers.CharField()\n data_files = serializers.PrimaryKeyRelatedField(required=False, many=True, queryset=DataFile.objects.all())\n\n class Meta:\n model = Table\n fields = ['id', 'name', 'schema', 'created_at', 'updated_at',\n 'columns', 'records', 'data_files', 'has_dependencies']\n\n def get_records(self, obj):\n if isinstance(obj, Table):\n # Only get records if we are serializing an existing table\n request = self.context['request']\n return request.build_absolute_uri(reverse('table-record-list', kwargs={'table_pk': obj.pk}))\n else:\n return None\n\n\nclass RecordSerializer(serializers.BaseSerializer):\n def to_representation(self, instance):\n return instance._asdict()\n\n\nclass RecordListParameterSerializer(serializers.Serializer):\n filters = serializers.JSONField(required=False, default=[])\n order_by = serializers.JSONField(required=False, default=[])\n group_count_by = serializers.JSONField(required=False, default=[])\n\n\nclass DatabaseSerializer(serializers.ModelSerializer):\n supported_types = serializers.ListField(child=serializers.CharField())\n\n class Meta:\n model = Database\n fields = ['id', 'name', 'deleted', 'supported_types']\n read_only_fields = ['id', 'name', 'deleted', 'supported_types']\n\n\nclass DataFileSerializer(serializers.ModelSerializer):\n user = serializers.PrimaryKeyRelatedField(\n default=serializers.CurrentUserDefault(), read_only=True\n )\n\n class Meta:\n model = DataFile\n fields = [\n 'id', 'file', 'table_imported_to', 'user', 'header', 'delimiter', 'escapechar', 'quotechar'\n ]\n extra_kwargs = {'delimiter': {'trim_whitespace': False},\n 'escapechar': {'trim_whitespace': False},\n 'quotechar': {'trim_whitespace': False},\n 'header': {'required': True}}\n # We only currently support importing to a new table, so setting a table via API is invalid.\n # User should be set automatically, not submitted via the API.\n read_only_fields = ['table_imported_to']\n\n def save(self, **kwargs):\n \"\"\"\n Set user to current user while saving the data file.\n \"\"\"\n current_user = self.fields['user'].get_default()\n if current_user.is_authenticated:\n kwargs['user'] = current_user\n return super().save(**kwargs)\n", "path": "mathesar/serializers.py"}]}
| 1,517 | 156 |
gh_patches_debug_4145
|
rasdani/github-patches
|
git_diff
|
benoitc__gunicorn-1414
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
gunicorn.pidfile.validate crashes gunicorn when PID exists but is from a different user
```
Traceback (most recent call last):
File "/opt/python2.7/bin/gunicorn", line 11, in <module>
sys.exit(run())
File "/opt/python2.7/lib/python2.7/site-packages/gunicorn/app/wsgiapp.py", line 74, in run
WSGIApplication("%(prog)s [OPTIONS] [APP_MODULE]").run()
File "/opt/python2.7/lib/python2.7/site-packages/gunicorn/app/base.py", line 189, in run
super(Application, self).run()
File "/opt/python2.7/lib/python2.7/site-packages/gunicorn/app/base.py", line 72, in run
Arbiter(self).run()
File "/opt/python2.7/lib/python2.7/site-packages/gunicorn/arbiter.py", line 171, in run
self.start()
File "/opt/python2.7/lib/python2.7/site-packages/gunicorn/arbiter.py", line 125, in start
self.pidfile.create(self.pid)
File "/opt/python2.7/lib/python2.7/site-packages/gunicorn/pidfile.py", line 23, in create
oldpid = self.validate()
File "/opt/python2.7/lib/python2.7/site-packages/gunicorn/pidfile.py", line 75, in validate
os.kill(wpid, 0)
OSError: [Errno 1] Operation not permitted
```
This happens because the process identified by the pid-file exists, but belongs to a different user than the one starting gunicorn.
(This is with gunicorn 19.3.0)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gunicorn/pidfile.py`
Content:
```
1 # -*- coding: utf-8 -
2 #
3 # This file is part of gunicorn released under the MIT license.
4 # See the NOTICE for more information.
5
6 import errno
7 import os
8 import tempfile
9
10
11 class Pidfile(object):
12 """\
13 Manage a PID file. If a specific name is provided
14 it and '"%s.oldpid" % name' will be used. Otherwise
15 we create a temp file using os.mkstemp.
16 """
17
18 def __init__(self, fname):
19 self.fname = fname
20 self.pid = None
21
22 def create(self, pid):
23 oldpid = self.validate()
24 if oldpid:
25 if oldpid == os.getpid():
26 return
27 msg = "Already running on PID %s (or pid file '%s' is stale)"
28 raise RuntimeError(msg % (oldpid, self.fname))
29
30 self.pid = pid
31
32 # Write pidfile
33 fdir = os.path.dirname(self.fname)
34 if fdir and not os.path.isdir(fdir):
35 raise RuntimeError("%s doesn't exist. Can't create pidfile." % fdir)
36 fd, fname = tempfile.mkstemp(dir=fdir)
37 os.write(fd, ("%s\n" % self.pid).encode('utf-8'))
38 if self.fname:
39 os.rename(fname, self.fname)
40 else:
41 self.fname = fname
42 os.close(fd)
43
44 # set permissions to -rw-r--r--
45 os.chmod(self.fname, 420)
46
47 def rename(self, path):
48 self.unlink()
49 self.fname = path
50 self.create(self.pid)
51
52 def unlink(self):
53 """ delete pidfile"""
54 try:
55 with open(self.fname, "r") as f:
56 pid1 = int(f.read() or 0)
57
58 if pid1 == self.pid:
59 os.unlink(self.fname)
60 except:
61 pass
62
63 def validate(self):
64 """ Validate pidfile and make it stale if needed"""
65 if not self.fname:
66 return
67 try:
68 with open(self.fname, "r") as f:
69 try:
70 wpid = int(f.read())
71 except ValueError:
72 return
73
74 try:
75 os.kill(wpid, 0)
76 return wpid
77 except OSError as e:
78 if e.args[0] == errno.ESRCH:
79 return
80 raise
81 except IOError as e:
82 if e.args[0] == errno.ENOENT:
83 return
84 raise
85
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gunicorn/pidfile.py b/gunicorn/pidfile.py
--- a/gunicorn/pidfile.py
+++ b/gunicorn/pidfile.py
@@ -75,6 +75,8 @@
os.kill(wpid, 0)
return wpid
except OSError as e:
+ if e.args[0] == errno.EPERM:
+ return wpid
if e.args[0] == errno.ESRCH:
return
raise
|
{"golden_diff": "diff --git a/gunicorn/pidfile.py b/gunicorn/pidfile.py\n--- a/gunicorn/pidfile.py\n+++ b/gunicorn/pidfile.py\n@@ -75,6 +75,8 @@\n os.kill(wpid, 0)\n return wpid\n except OSError as e:\n+ if e.args[0] == errno.EPERM:\n+ return wpid\n if e.args[0] == errno.ESRCH:\n return\n raise\n", "issue": "gunicorn.pidfile.validate crashes gunicorn when PID exists but is from a different user\n```\nTraceback (most recent call last):\n File \"/opt/python2.7/bin/gunicorn\", line 11, in <module>\n sys.exit(run())\n File \"/opt/python2.7/lib/python2.7/site-packages/gunicorn/app/wsgiapp.py\", line 74, in run\n WSGIApplication(\"%(prog)s [OPTIONS] [APP_MODULE]\").run()\n File \"/opt/python2.7/lib/python2.7/site-packages/gunicorn/app/base.py\", line 189, in run\n super(Application, self).run()\n File \"/opt/python2.7/lib/python2.7/site-packages/gunicorn/app/base.py\", line 72, in run\n Arbiter(self).run()\n File \"/opt/python2.7/lib/python2.7/site-packages/gunicorn/arbiter.py\", line 171, in run\n self.start()\n File \"/opt/python2.7/lib/python2.7/site-packages/gunicorn/arbiter.py\", line 125, in start\n self.pidfile.create(self.pid)\n File \"/opt/python2.7/lib/python2.7/site-packages/gunicorn/pidfile.py\", line 23, in create\n oldpid = self.validate()\n File \"/opt/python2.7/lib/python2.7/site-packages/gunicorn/pidfile.py\", line 75, in validate\n os.kill(wpid, 0)\nOSError: [Errno 1] Operation not permitted\n```\n\nThis happens because the process identified by the pid-file exists, but belongs to a different user than the one starting gunicorn.\n\n(This is with gunicorn 19.3.0)\n\n", "before_files": [{"content": "# -*- coding: utf-8 -\n#\n# This file is part of gunicorn released under the MIT license.\n# See the NOTICE for more information.\n\nimport errno\nimport os\nimport tempfile\n\n\nclass Pidfile(object):\n \"\"\"\\\n Manage a PID file. If a specific name is provided\n it and '\"%s.oldpid\" % name' will be used. Otherwise\n we create a temp file using os.mkstemp.\n \"\"\"\n\n def __init__(self, fname):\n self.fname = fname\n self.pid = None\n\n def create(self, pid):\n oldpid = self.validate()\n if oldpid:\n if oldpid == os.getpid():\n return\n msg = \"Already running on PID %s (or pid file '%s' is stale)\"\n raise RuntimeError(msg % (oldpid, self.fname))\n\n self.pid = pid\n\n # Write pidfile\n fdir = os.path.dirname(self.fname)\n if fdir and not os.path.isdir(fdir):\n raise RuntimeError(\"%s doesn't exist. Can't create pidfile.\" % fdir)\n fd, fname = tempfile.mkstemp(dir=fdir)\n os.write(fd, (\"%s\\n\" % self.pid).encode('utf-8'))\n if self.fname:\n os.rename(fname, self.fname)\n else:\n self.fname = fname\n os.close(fd)\n\n # set permissions to -rw-r--r--\n os.chmod(self.fname, 420)\n\n def rename(self, path):\n self.unlink()\n self.fname = path\n self.create(self.pid)\n\n def unlink(self):\n \"\"\" delete pidfile\"\"\"\n try:\n with open(self.fname, \"r\") as f:\n pid1 = int(f.read() or 0)\n\n if pid1 == self.pid:\n os.unlink(self.fname)\n except:\n pass\n\n def validate(self):\n \"\"\" Validate pidfile and make it stale if needed\"\"\"\n if not self.fname:\n return\n try:\n with open(self.fname, \"r\") as f:\n try:\n wpid = int(f.read())\n except ValueError:\n return\n\n try:\n os.kill(wpid, 0)\n return wpid\n except OSError as e:\n if e.args[0] == errno.ESRCH:\n return\n raise\n except IOError as e:\n if e.args[0] == errno.ENOENT:\n return\n raise\n", "path": "gunicorn/pidfile.py"}], "after_files": [{"content": "# -*- coding: utf-8 -\n#\n# This file is part of gunicorn released under the MIT license.\n# See the NOTICE for more information.\n\nimport errno\nimport os\nimport tempfile\n\n\nclass Pidfile(object):\n \"\"\"\\\n Manage a PID file. If a specific name is provided\n it and '\"%s.oldpid\" % name' will be used. Otherwise\n we create a temp file using os.mkstemp.\n \"\"\"\n\n def __init__(self, fname):\n self.fname = fname\n self.pid = None\n\n def create(self, pid):\n oldpid = self.validate()\n if oldpid:\n if oldpid == os.getpid():\n return\n msg = \"Already running on PID %s (or pid file '%s' is stale)\"\n raise RuntimeError(msg % (oldpid, self.fname))\n\n self.pid = pid\n\n # Write pidfile\n fdir = os.path.dirname(self.fname)\n if fdir and not os.path.isdir(fdir):\n raise RuntimeError(\"%s doesn't exist. Can't create pidfile.\" % fdir)\n fd, fname = tempfile.mkstemp(dir=fdir)\n os.write(fd, (\"%s\\n\" % self.pid).encode('utf-8'))\n if self.fname:\n os.rename(fname, self.fname)\n else:\n self.fname = fname\n os.close(fd)\n\n # set permissions to -rw-r--r--\n os.chmod(self.fname, 420)\n\n def rename(self, path):\n self.unlink()\n self.fname = path\n self.create(self.pid)\n\n def unlink(self):\n \"\"\" delete pidfile\"\"\"\n try:\n with open(self.fname, \"r\") as f:\n pid1 = int(f.read() or 0)\n\n if pid1 == self.pid:\n os.unlink(self.fname)\n except:\n pass\n\n def validate(self):\n \"\"\" Validate pidfile and make it stale if needed\"\"\"\n if not self.fname:\n return\n try:\n with open(self.fname, \"r\") as f:\n try:\n wpid = int(f.read())\n except ValueError:\n return\n\n try:\n os.kill(wpid, 0)\n return wpid\n except OSError as e:\n if e.args[0] == errno.EPERM:\n return wpid\n if e.args[0] == errno.ESRCH:\n return\n raise\n except IOError as e:\n if e.args[0] == errno.ENOENT:\n return\n raise\n", "path": "gunicorn/pidfile.py"}]}
| 1,335 | 108 |
gh_patches_debug_64391
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-5886
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
name=Bankomat should not be added for amenity=atm
It is like `name=ATM`
The same goes for `name=Wpłatomat` (for ATM accepting cash)
https://www.alltheplaces.xyz/map/#16.82/50.072257/20.036549

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `locations/spiders/santander_pl.py`
Content:
```
1 import chompjs
2 from scrapy import Spider
3
4 from locations.categories import Categories, apply_category, apply_yes_no
5 from locations.dict_parser import DictParser
6 from locations.hours import DAYS, OpeningHours
7 from locations.items import Feature
8
9
10 class SantanderPLSpider(Spider):
11 name = "santander_pl"
12 item_attributes = {"brand": "Santander", "brand_wikidata": "Q806653"}
13 # The "20000000000000" needs to be a valid date time, but it seems it's just there to stop the page being cached by
14 # the CDN. We always get the same data.
15 start_urls = ["https://www.santander.pl/_js_places/time20000000000000/places.js"]
16
17 def parse(self, response, **kwargs):
18 data = chompjs.parse_js_object(response.text)
19 for ref, branch in data["atm"].items():
20 yield self.parse_item(ref, branch, Categories.ATM)
21 for ref, branch in data["branch"].items():
22 yield self.parse_item(ref, branch, Categories.BANK)
23 for ref, branch in data["cashin"].items():
24 item = self.parse_item(ref, branch, Categories.ATM)
25 apply_yes_no("cash_in", item, True)
26 yield item
27
28 @staticmethod
29 def parse_item(ref: str, data: dict, category) -> Feature:
30 data["basicParameters"]["street_address"] = data["basicParameters"].pop("street")
31 item = DictParser.parse(data["basicParameters"])
32 item["ref"] = ref
33
34 if data["open_24h"]:
35 item["opening_hours"] = "24/7"
36 else:
37 item["opening_hours"] = OpeningHours()
38 for day, hours in data["basicParameters"]["opening_hours"].items():
39 start_time, end_time = hours.split("-")
40 item["opening_hours"].add_range(DAYS[int(day) - 2], start_time.strip(), end_time.strip())
41
42 apply_category(category, item)
43
44 return item
45
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/locations/spiders/santander_pl.py b/locations/spiders/santander_pl.py
--- a/locations/spiders/santander_pl.py
+++ b/locations/spiders/santander_pl.py
@@ -39,6 +39,9 @@
start_time, end_time = hours.split("-")
item["opening_hours"].add_range(DAYS[int(day) - 2], start_time.strip(), end_time.strip())
+ if category == Categories.ATM:
+ item["name"] = None
+
apply_category(category, item)
return item
|
{"golden_diff": "diff --git a/locations/spiders/santander_pl.py b/locations/spiders/santander_pl.py\n--- a/locations/spiders/santander_pl.py\n+++ b/locations/spiders/santander_pl.py\n@@ -39,6 +39,9 @@\n start_time, end_time = hours.split(\"-\")\n item[\"opening_hours\"].add_range(DAYS[int(day) - 2], start_time.strip(), end_time.strip())\n \n+ if category == Categories.ATM:\n+ item[\"name\"] = None\n+\n apply_category(category, item)\n \n return item\n", "issue": "name=Bankomat should not be added for amenity=atm\nIt is like `name=ATM`\r\n\r\nThe same goes for `name=Wp\u0142atomat` (for ATM accepting cash)\r\n\r\nhttps://www.alltheplaces.xyz/map/#16.82/50.072257/20.036549\r\n\r\n\r\n\n", "before_files": [{"content": "import chompjs\nfrom scrapy import Spider\n\nfrom locations.categories import Categories, apply_category, apply_yes_no\nfrom locations.dict_parser import DictParser\nfrom locations.hours import DAYS, OpeningHours\nfrom locations.items import Feature\n\n\nclass SantanderPLSpider(Spider):\n name = \"santander_pl\"\n item_attributes = {\"brand\": \"Santander\", \"brand_wikidata\": \"Q806653\"}\n # The \"20000000000000\" needs to be a valid date time, but it seems it's just there to stop the page being cached by\n # the CDN. We always get the same data.\n start_urls = [\"https://www.santander.pl/_js_places/time20000000000000/places.js\"]\n\n def parse(self, response, **kwargs):\n data = chompjs.parse_js_object(response.text)\n for ref, branch in data[\"atm\"].items():\n yield self.parse_item(ref, branch, Categories.ATM)\n for ref, branch in data[\"branch\"].items():\n yield self.parse_item(ref, branch, Categories.BANK)\n for ref, branch in data[\"cashin\"].items():\n item = self.parse_item(ref, branch, Categories.ATM)\n apply_yes_no(\"cash_in\", item, True)\n yield item\n\n @staticmethod\n def parse_item(ref: str, data: dict, category) -> Feature:\n data[\"basicParameters\"][\"street_address\"] = data[\"basicParameters\"].pop(\"street\")\n item = DictParser.parse(data[\"basicParameters\"])\n item[\"ref\"] = ref\n\n if data[\"open_24h\"]:\n item[\"opening_hours\"] = \"24/7\"\n else:\n item[\"opening_hours\"] = OpeningHours()\n for day, hours in data[\"basicParameters\"][\"opening_hours\"].items():\n start_time, end_time = hours.split(\"-\")\n item[\"opening_hours\"].add_range(DAYS[int(day) - 2], start_time.strip(), end_time.strip())\n\n apply_category(category, item)\n\n return item\n", "path": "locations/spiders/santander_pl.py"}], "after_files": [{"content": "import chompjs\nfrom scrapy import Spider\n\nfrom locations.categories import Categories, apply_category, apply_yes_no\nfrom locations.dict_parser import DictParser\nfrom locations.hours import DAYS, OpeningHours\nfrom locations.items import Feature\n\n\nclass SantanderPLSpider(Spider):\n name = \"santander_pl\"\n item_attributes = {\"brand\": \"Santander\", \"brand_wikidata\": \"Q806653\"}\n # The \"20000000000000\" needs to be a valid date time, but it seems it's just there to stop the page being cached by\n # the CDN. We always get the same data.\n start_urls = [\"https://www.santander.pl/_js_places/time20000000000000/places.js\"]\n\n def parse(self, response, **kwargs):\n data = chompjs.parse_js_object(response.text)\n for ref, branch in data[\"atm\"].items():\n yield self.parse_item(ref, branch, Categories.ATM)\n for ref, branch in data[\"branch\"].items():\n yield self.parse_item(ref, branch, Categories.BANK)\n for ref, branch in data[\"cashin\"].items():\n item = self.parse_item(ref, branch, Categories.ATM)\n apply_yes_no(\"cash_in\", item, True)\n yield item\n\n @staticmethod\n def parse_item(ref: str, data: dict, category) -> Feature:\n data[\"basicParameters\"][\"street_address\"] = data[\"basicParameters\"].pop(\"street\")\n item = DictParser.parse(data[\"basicParameters\"])\n item[\"ref\"] = ref\n\n if data[\"open_24h\"]:\n item[\"opening_hours\"] = \"24/7\"\n else:\n item[\"opening_hours\"] = OpeningHours()\n for day, hours in data[\"basicParameters\"][\"opening_hours\"].items():\n start_time, end_time = hours.split(\"-\")\n item[\"opening_hours\"].add_range(DAYS[int(day) - 2], start_time.strip(), end_time.strip())\n\n if category == Categories.ATM:\n item[\"name\"] = None\n\n apply_category(category, item)\n\n return item\n", "path": "locations/spiders/santander_pl.py"}]}
| 943 | 129 |
gh_patches_debug_20505
|
rasdani/github-patches
|
git_diff
|
deepchecks__deepchecks-499
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Suite output text - fix first part
1. Add explanation for the “!” (warning) 2. add link to docs where written (or remove wording), where it says:"Suites, checks and conditions can all be modified (see tutorial [link])."
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `deepchecks/base/display_suite.py`
Content:
```
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 """Handle display of suite result."""
12 from typing import List, Union
13
14 # pylint: disable=protected-access
15 import sys
16 import tqdm
17 import pandas as pd
18 from IPython.core.display import display_html
19 from IPython import get_ipython
20
21 from deepchecks import errors
22 from deepchecks.utils.ipython import is_widgets_enabled
23 from deepchecks.utils.strings import get_random_string
24 from deepchecks.base.check import CheckResult, CheckFailure
25 from deepchecks.base.display_pandas import dataframe_to_html, display_conditions_table
26
27
28 __all__ = ['display_suite_result', 'ProgressBar']
29
30
31 class ProgressBar:
32 """Progress bar for display while running suite."""
33
34 def __init__(self, name, length):
35 """Initialize progress bar."""
36 shared_args = {'total': length, 'desc': name, 'unit': ' Check', 'leave': False, 'file': sys.stdout}
37 if is_widgets_enabled():
38 self.pbar = tqdm.tqdm_notebook(**shared_args, colour='#9d60fb')
39 else:
40 # Normal tqdm with colour in notebooks produce bug that the cleanup doesn't remove all characters. so
41 # until bug fixed, doesn't add the colour to regular tqdm
42 self.pbar = tqdm.tqdm(**shared_args, bar_format=f'{{l_bar}}{{bar:{length}}}{{r_bar}}')
43
44 def set_text(self, text):
45 """Set current running check."""
46 self.pbar.set_postfix(Check=text)
47
48 def close(self):
49 """Close the progress bar."""
50 self.pbar.close()
51
52 def inc_progress(self):
53 """Increase progress bar value by 1."""
54 self.pbar.update(1)
55
56
57 def get_display_exists_icon(exists: bool):
58 if exists:
59 return '<div style="text-align: center">Yes</div>'
60 return '<div style="text-align: center">No</div>'
61
62
63 def display_suite_result(suite_name: str, results: List[Union[CheckResult, CheckFailure]]):
64 """Display results of suite in IPython."""
65 if len(results) == 0:
66 display_html(f"""<h1>{suite_name}</h1><p>Suite is empty.</p>""", raw=True)
67 return
68 if 'google.colab' in str(get_ipython()):
69 unique_id = ''
70 else:
71 unique_id = get_random_string()
72 checks_with_conditions = []
73 display_table: List[CheckResult] = []
74 others_table = []
75
76 for result in results:
77 if isinstance(result, CheckResult):
78 if result.have_conditions():
79 checks_with_conditions.append(result)
80 if result.have_display():
81 display_table.append(result)
82 else:
83 others_table.append([result.get_header(), 'Nothing found', 2])
84 elif isinstance(result, CheckFailure):
85 msg = result.exception.__class__.__name__ + ': ' + str(result.exception)
86 name = result.check.name()
87 others_table.append([name, msg, 1])
88 else:
89 # Should never reach here!
90 raise errors.DeepchecksValueError(
91 f"Expecting list of 'CheckResult'|'CheckFailure', but got {type(result)}."
92 )
93
94 display_table = sorted(display_table, key=lambda it: it.priority)
95
96 light_hr = '<hr style="background-color: #eee;border: 0 none;color: #eee;height: 1px;">'
97 bold_hr = '<hr style="background-color: black;border: 0 none;color: black;height: 1px;">'
98
99 icons = """
100 <span style="color: green;display:inline-block">\U00002713</span> /
101 <span style="color: red;display:inline-block">\U00002716</span> /
102 <span style="color: orange;font-weight:bold;display:inline-block">\U00000021</span>
103 """
104
105 check_names = list(set(it.check.name() for it in results))
106 prologue = (
107 f"The suite is composed of various checks such as: {', '.join(check_names[:3])}, etc..."
108 if len(check_names) > 3
109 else f"The suite is composed of the following checks: {', '.join(check_names)}."
110 )
111
112 display_html(
113 f"""
114 <h1 id="summary_{unique_id}">{suite_name}</h1>
115 <p>{prologue}<br>
116 Each check may contain conditions (which results in {icons}),
117 as well as other outputs such as plots or tables.<br>
118 Suites, checks and conditions can all be modified (see tutorial [link]).</p>
119 {bold_hr}<h2>Conditions Summary</h2>
120 """,
121 raw=True
122 )
123
124 if checks_with_conditions:
125 display_conditions_table(checks_with_conditions, unique_id)
126 else:
127 display_html('<p>No conditions defined on checks in the suite.</p>', raw=True)
128
129 display_html(f'{bold_hr}<h2>Additional Outputs</h2>', raw=True)
130 if display_table:
131 for i, r in enumerate(display_table):
132 r.show(show_conditions=False, unique_id=unique_id)
133 if i < len(display_table) - 1:
134 display_html(light_hr, raw=True)
135 else:
136 display_html('<p>No outputs to show.</p>', raw=True)
137
138 if others_table:
139 others_table = pd.DataFrame(data=others_table, columns=['Check', 'Reason', 'sort'])
140 others_table.sort_values(by=['sort'], inplace=True)
141 others_table.drop('sort', axis=1, inplace=True)
142 html = f"""{bold_hr}
143 <h2>Other Checks That Weren't Displayed</h2>
144 {dataframe_to_html(others_table.style.hide_index())}
145 """
146 display_html(html, raw=True)
147
148 display_html(f'<br><a href="#summary_{unique_id}" style="font-size: 14px">Go to top</a>', raw=True)
149
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/deepchecks/base/display_suite.py b/deepchecks/base/display_suite.py
--- a/deepchecks/base/display_suite.py
+++ b/deepchecks/base/display_suite.py
@@ -109,14 +109,20 @@
else f"The suite is composed of the following checks: {', '.join(check_names)}."
)
+ suite_creation_example_link = 'https://docs.deepchecks.com/en/stable/examples/guides/create_a_custom_suite.html'
+
display_html(
f"""
<h1 id="summary_{unique_id}">{suite_name}</h1>
- <p>{prologue}<br>
- Each check may contain conditions (which results in {icons}),
- as well as other outputs such as plots or tables.<br>
- Suites, checks and conditions can all be modified (see tutorial [link]).</p>
- {bold_hr}<h2>Conditions Summary</h2>
+ <p>
+ {prologue}<br>
+ Each check may contain conditions (which will result in pass / fail / warning, represented by {icons})
+ as well as other outputs such as plots or tables.<br>
+ Suites, checks and conditions can all be modified (see the
+ <a href={suite_creation_example_link}>Create a Custom Suite</a> tutorial).
+ </p>
+ {bold_hr}
+ <h2>Conditions Summary</h2>
""",
raw=True
)
|
{"golden_diff": "diff --git a/deepchecks/base/display_suite.py b/deepchecks/base/display_suite.py\n--- a/deepchecks/base/display_suite.py\n+++ b/deepchecks/base/display_suite.py\n@@ -109,14 +109,20 @@\n else f\"The suite is composed of the following checks: {', '.join(check_names)}.\"\n )\n \n+ suite_creation_example_link = 'https://docs.deepchecks.com/en/stable/examples/guides/create_a_custom_suite.html'\n+\n display_html(\n f\"\"\"\n <h1 id=\"summary_{unique_id}\">{suite_name}</h1>\n- <p>{prologue}<br>\n- Each check may contain conditions (which results in {icons}),\n- as well as other outputs such as plots or tables.<br>\n- Suites, checks and conditions can all be modified (see tutorial [link]).</p>\n- {bold_hr}<h2>Conditions Summary</h2>\n+ <p>\n+ {prologue}<br>\n+ Each check may contain conditions (which will result in pass / fail / warning, represented by {icons})\n+ as well as other outputs such as plots or tables.<br>\n+ Suites, checks and conditions can all be modified (see the\n+ <a href={suite_creation_example_link}>Create a Custom Suite</a> tutorial).\n+ </p>\n+ {bold_hr}\n+ <h2>Conditions Summary</h2>\n \"\"\",\n raw=True\n )\n", "issue": "Suite output text - fix first part\n1. Add explanation for the \u201c!\u201d (warning) 2. add link to docs where written (or remove wording), where it says:\"Suites, checks and conditions can all be modified (see tutorial [link]).\"\n", "before_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Handle display of suite result.\"\"\"\nfrom typing import List, Union\n\n# pylint: disable=protected-access\nimport sys\nimport tqdm\nimport pandas as pd\nfrom IPython.core.display import display_html\nfrom IPython import get_ipython\n\nfrom deepchecks import errors\nfrom deepchecks.utils.ipython import is_widgets_enabled\nfrom deepchecks.utils.strings import get_random_string\nfrom deepchecks.base.check import CheckResult, CheckFailure\nfrom deepchecks.base.display_pandas import dataframe_to_html, display_conditions_table\n\n\n__all__ = ['display_suite_result', 'ProgressBar']\n\n\nclass ProgressBar:\n \"\"\"Progress bar for display while running suite.\"\"\"\n\n def __init__(self, name, length):\n \"\"\"Initialize progress bar.\"\"\"\n shared_args = {'total': length, 'desc': name, 'unit': ' Check', 'leave': False, 'file': sys.stdout}\n if is_widgets_enabled():\n self.pbar = tqdm.tqdm_notebook(**shared_args, colour='#9d60fb')\n else:\n # Normal tqdm with colour in notebooks produce bug that the cleanup doesn't remove all characters. so\n # until bug fixed, doesn't add the colour to regular tqdm\n self.pbar = tqdm.tqdm(**shared_args, bar_format=f'{{l_bar}}{{bar:{length}}}{{r_bar}}')\n\n def set_text(self, text):\n \"\"\"Set current running check.\"\"\"\n self.pbar.set_postfix(Check=text)\n\n def close(self):\n \"\"\"Close the progress bar.\"\"\"\n self.pbar.close()\n\n def inc_progress(self):\n \"\"\"Increase progress bar value by 1.\"\"\"\n self.pbar.update(1)\n\n\ndef get_display_exists_icon(exists: bool):\n if exists:\n return '<div style=\"text-align: center\">Yes</div>'\n return '<div style=\"text-align: center\">No</div>'\n\n\ndef display_suite_result(suite_name: str, results: List[Union[CheckResult, CheckFailure]]):\n \"\"\"Display results of suite in IPython.\"\"\"\n if len(results) == 0:\n display_html(f\"\"\"<h1>{suite_name}</h1><p>Suite is empty.</p>\"\"\", raw=True)\n return\n if 'google.colab' in str(get_ipython()):\n unique_id = ''\n else:\n unique_id = get_random_string()\n checks_with_conditions = []\n display_table: List[CheckResult] = []\n others_table = []\n\n for result in results:\n if isinstance(result, CheckResult):\n if result.have_conditions():\n checks_with_conditions.append(result)\n if result.have_display():\n display_table.append(result)\n else:\n others_table.append([result.get_header(), 'Nothing found', 2])\n elif isinstance(result, CheckFailure):\n msg = result.exception.__class__.__name__ + ': ' + str(result.exception)\n name = result.check.name()\n others_table.append([name, msg, 1])\n else:\n # Should never reach here!\n raise errors.DeepchecksValueError(\n f\"Expecting list of 'CheckResult'|'CheckFailure', but got {type(result)}.\"\n )\n\n display_table = sorted(display_table, key=lambda it: it.priority)\n\n light_hr = '<hr style=\"background-color: #eee;border: 0 none;color: #eee;height: 1px;\">'\n bold_hr = '<hr style=\"background-color: black;border: 0 none;color: black;height: 1px;\">'\n\n icons = \"\"\"\n <span style=\"color: green;display:inline-block\">\\U00002713</span> /\n <span style=\"color: red;display:inline-block\">\\U00002716</span> /\n <span style=\"color: orange;font-weight:bold;display:inline-block\">\\U00000021</span>\n \"\"\"\n\n check_names = list(set(it.check.name() for it in results))\n prologue = (\n f\"The suite is composed of various checks such as: {', '.join(check_names[:3])}, etc...\"\n if len(check_names) > 3\n else f\"The suite is composed of the following checks: {', '.join(check_names)}.\"\n )\n\n display_html(\n f\"\"\"\n <h1 id=\"summary_{unique_id}\">{suite_name}</h1>\n <p>{prologue}<br>\n Each check may contain conditions (which results in {icons}),\n as well as other outputs such as plots or tables.<br>\n Suites, checks and conditions can all be modified (see tutorial [link]).</p>\n {bold_hr}<h2>Conditions Summary</h2>\n \"\"\",\n raw=True\n )\n\n if checks_with_conditions:\n display_conditions_table(checks_with_conditions, unique_id)\n else:\n display_html('<p>No conditions defined on checks in the suite.</p>', raw=True)\n\n display_html(f'{bold_hr}<h2>Additional Outputs</h2>', raw=True)\n if display_table:\n for i, r in enumerate(display_table):\n r.show(show_conditions=False, unique_id=unique_id)\n if i < len(display_table) - 1:\n display_html(light_hr, raw=True)\n else:\n display_html('<p>No outputs to show.</p>', raw=True)\n\n if others_table:\n others_table = pd.DataFrame(data=others_table, columns=['Check', 'Reason', 'sort'])\n others_table.sort_values(by=['sort'], inplace=True)\n others_table.drop('sort', axis=1, inplace=True)\n html = f\"\"\"{bold_hr}\n <h2>Other Checks That Weren't Displayed</h2>\n {dataframe_to_html(others_table.style.hide_index())}\n \"\"\"\n display_html(html, raw=True)\n\n display_html(f'<br><a href=\"#summary_{unique_id}\" style=\"font-size: 14px\">Go to top</a>', raw=True)\n", "path": "deepchecks/base/display_suite.py"}], "after_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Handle display of suite result.\"\"\"\nfrom typing import List, Union\n\n# pylint: disable=protected-access\nimport sys\nimport tqdm\nimport pandas as pd\nfrom IPython.core.display import display_html\nfrom IPython import get_ipython\n\nfrom deepchecks import errors\nfrom deepchecks.utils.ipython import is_widgets_enabled\nfrom deepchecks.utils.strings import get_random_string\nfrom deepchecks.base.check import CheckResult, CheckFailure\nfrom deepchecks.base.display_pandas import dataframe_to_html, display_conditions_table\n\n\n__all__ = ['display_suite_result', 'ProgressBar']\n\n\nclass ProgressBar:\n \"\"\"Progress bar for display while running suite.\"\"\"\n\n def __init__(self, name, length):\n \"\"\"Initialize progress bar.\"\"\"\n shared_args = {'total': length, 'desc': name, 'unit': ' Check', 'leave': False, 'file': sys.stdout}\n if is_widgets_enabled():\n self.pbar = tqdm.tqdm_notebook(**shared_args, colour='#9d60fb')\n else:\n # Normal tqdm with colour in notebooks produce bug that the cleanup doesn't remove all characters. so\n # until bug fixed, doesn't add the colour to regular tqdm\n self.pbar = tqdm.tqdm(**shared_args, bar_format=f'{{l_bar}}{{bar:{length}}}{{r_bar}}')\n\n def set_text(self, text):\n \"\"\"Set current running check.\"\"\"\n self.pbar.set_postfix(Check=text)\n\n def close(self):\n \"\"\"Close the progress bar.\"\"\"\n self.pbar.close()\n\n def inc_progress(self):\n \"\"\"Increase progress bar value by 1.\"\"\"\n self.pbar.update(1)\n\n\ndef get_display_exists_icon(exists: bool):\n if exists:\n return '<div style=\"text-align: center\">Yes</div>'\n return '<div style=\"text-align: center\">No</div>'\n\n\ndef display_suite_result(suite_name: str, results: List[Union[CheckResult, CheckFailure]]):\n \"\"\"Display results of suite in IPython.\"\"\"\n if len(results) == 0:\n display_html(f\"\"\"<h1>{suite_name}</h1><p>Suite is empty.</p>\"\"\", raw=True)\n return\n if 'google.colab' in str(get_ipython()):\n unique_id = ''\n else:\n unique_id = get_random_string()\n checks_with_conditions = []\n display_table: List[CheckResult] = []\n others_table = []\n\n for result in results:\n if isinstance(result, CheckResult):\n if result.have_conditions():\n checks_with_conditions.append(result)\n if result.have_display():\n display_table.append(result)\n else:\n others_table.append([result.get_header(), 'Nothing found', 2])\n elif isinstance(result, CheckFailure):\n msg = result.exception.__class__.__name__ + ': ' + str(result.exception)\n name = result.check.name()\n others_table.append([name, msg, 1])\n else:\n # Should never reach here!\n raise errors.DeepchecksValueError(\n f\"Expecting list of 'CheckResult'|'CheckFailure', but got {type(result)}.\"\n )\n\n display_table = sorted(display_table, key=lambda it: it.priority)\n\n light_hr = '<hr style=\"background-color: #eee;border: 0 none;color: #eee;height: 1px;\">'\n bold_hr = '<hr style=\"background-color: black;border: 0 none;color: black;height: 1px;\">'\n\n icons = \"\"\"\n <span style=\"color: green;display:inline-block\">\\U00002713</span> /\n <span style=\"color: red;display:inline-block\">\\U00002716</span> /\n <span style=\"color: orange;font-weight:bold;display:inline-block\">\\U00000021</span>\n \"\"\"\n\n check_names = list(set(it.check.name() for it in results))\n prologue = (\n f\"The suite is composed of various checks such as: {', '.join(check_names[:3])}, etc...\"\n if len(check_names) > 3\n else f\"The suite is composed of the following checks: {', '.join(check_names)}.\"\n )\n\n suite_creation_example_link = 'https://docs.deepchecks.com/en/stable/examples/guides/create_a_custom_suite.html'\n\n display_html(\n f\"\"\"\n <h1 id=\"summary_{unique_id}\">{suite_name}</h1>\n <p>\n {prologue}<br>\n Each check may contain conditions (which will result in pass / fail / warning, represented by {icons})\n as well as other outputs such as plots or tables.<br>\n Suites, checks and conditions can all be modified (see the\n <a href={suite_creation_example_link}>Create a Custom Suite</a> tutorial).\n </p>\n {bold_hr}\n <h2>Conditions Summary</h2>\n \"\"\",\n raw=True\n )\n\n if checks_with_conditions:\n display_conditions_table(checks_with_conditions, unique_id)\n else:\n display_html('<p>No conditions defined on checks in the suite.</p>', raw=True)\n\n display_html(f'{bold_hr}<h2>Additional Outputs</h2>', raw=True)\n if display_table:\n for i, r in enumerate(display_table):\n r.show(show_conditions=False, unique_id=unique_id)\n if i < len(display_table) - 1:\n display_html(light_hr, raw=True)\n else:\n display_html('<p>No outputs to show.</p>', raw=True)\n\n if others_table:\n others_table = pd.DataFrame(data=others_table, columns=['Check', 'Reason', 'sort'])\n others_table.sort_values(by=['sort'], inplace=True)\n others_table.drop('sort', axis=1, inplace=True)\n html = f\"\"\"{bold_hr}\n <h2>Other Checks That Weren't Displayed</h2>\n {dataframe_to_html(others_table.style.hide_index())}\n \"\"\"\n display_html(html, raw=True)\n\n display_html(f'<br><a href=\"#summary_{unique_id}\" style=\"font-size: 14px\">Go to top</a>', raw=True)\n", "path": "deepchecks/base/display_suite.py"}]}
| 2,023 | 324 |
gh_patches_debug_24114
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-5188
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Program PDF report returns an XLS report
# What were you doing?
Follow the steps in test "Download PDF Program overview".
# What should've happened?
A PDF report should've been received in the email, but an XLS report was delivered.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `akvo/rsr/views/py_reports/email_report.py`
Content:
```
1 import logging
2
3 from datetime import timedelta
4 from django.db.models import Q
5 from django.utils.timezone import now
6 from akvo.rsr.models import EmailReportJob
7
8 from . import (
9 program_overview_pdf_report,
10 program_overview_excel_report,
11 program_period_labels_overview_pdf_report,
12 results_indicators_with_map_pdf_reports,
13 nuffic_country_level_map_report,
14 )
15
16 TIMEOUT = timedelta(minutes=30)
17 MAX_ATTEMPTS = 3
18 HANDLER = {
19 program_overview_pdf_report.REPORT_NAME: program_overview_excel_report.handle_email_report,
20 program_overview_excel_report.REPORT_NAME: program_overview_excel_report.handle_email_report,
21 program_period_labels_overview_pdf_report.REPORT_NAME: program_period_labels_overview_pdf_report.handle_email_report,
22 results_indicators_with_map_pdf_reports.ORG_PROJECTS_REPORT_NAME: results_indicators_with_map_pdf_reports.handle_org_projects_email_report,
23 nuffic_country_level_map_report.REPORT_NAME: nuffic_country_level_map_report.handle_email_report,
24 }
25
26 logger = logging.getLogger(__name__)
27
28
29 def run_job():
30 pending_jobs = _get_pending_jobs()
31 if not pending_jobs.exists():
32 return
33 job = pending_jobs.first()
34 job.mark_started()
35 try:
36 handler = HANDLER.get(job.report, None)
37 if handler:
38 handler(job.payload, job.recipient)
39 job.mark_finished()
40 except Exception:
41 logger.exception(f'Failed to genereate report {job.report} for {job.recipient}')
42
43
44 def _get_pending_jobs():
45 started_timeout = now() - TIMEOUT
46 return EmailReportJob.objects\
47 .order_by('created_at')\
48 .filter(finished_at__isnull=True)\
49 .exclude(Q(attempts__gte=MAX_ATTEMPTS) | Q(started_at__gte=started_timeout))
50
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/akvo/rsr/views/py_reports/email_report.py b/akvo/rsr/views/py_reports/email_report.py
--- a/akvo/rsr/views/py_reports/email_report.py
+++ b/akvo/rsr/views/py_reports/email_report.py
@@ -16,7 +16,7 @@
TIMEOUT = timedelta(minutes=30)
MAX_ATTEMPTS = 3
HANDLER = {
- program_overview_pdf_report.REPORT_NAME: program_overview_excel_report.handle_email_report,
+ program_overview_pdf_report.REPORT_NAME: program_overview_pdf_report.handle_email_report,
program_overview_excel_report.REPORT_NAME: program_overview_excel_report.handle_email_report,
program_period_labels_overview_pdf_report.REPORT_NAME: program_period_labels_overview_pdf_report.handle_email_report,
results_indicators_with_map_pdf_reports.ORG_PROJECTS_REPORT_NAME: results_indicators_with_map_pdf_reports.handle_org_projects_email_report,
@@ -35,6 +35,7 @@
try:
handler = HANDLER.get(job.report, None)
if handler:
+ logger.info("Handling job %s for report %s with %s", job.id, job.report)
handler(job.payload, job.recipient)
job.mark_finished()
except Exception:
|
{"golden_diff": "diff --git a/akvo/rsr/views/py_reports/email_report.py b/akvo/rsr/views/py_reports/email_report.py\n--- a/akvo/rsr/views/py_reports/email_report.py\n+++ b/akvo/rsr/views/py_reports/email_report.py\n@@ -16,7 +16,7 @@\n TIMEOUT = timedelta(minutes=30)\n MAX_ATTEMPTS = 3\n HANDLER = {\n- program_overview_pdf_report.REPORT_NAME: program_overview_excel_report.handle_email_report,\n+ program_overview_pdf_report.REPORT_NAME: program_overview_pdf_report.handle_email_report,\n program_overview_excel_report.REPORT_NAME: program_overview_excel_report.handle_email_report,\n program_period_labels_overview_pdf_report.REPORT_NAME: program_period_labels_overview_pdf_report.handle_email_report,\n results_indicators_with_map_pdf_reports.ORG_PROJECTS_REPORT_NAME: results_indicators_with_map_pdf_reports.handle_org_projects_email_report,\n@@ -35,6 +35,7 @@\n try:\n handler = HANDLER.get(job.report, None)\n if handler:\n+ logger.info(\"Handling job %s for report %s with %s\", job.id, job.report)\n handler(job.payload, job.recipient)\n job.mark_finished()\n except Exception:\n", "issue": "Program PDF report returns an XLS report\n# What were you doing?\n\nFollow the steps in test \"Download PDF Program overview\".\n\n# What should've happened?\n\nA PDF report should've been received in the email, but an XLS report was delivered.\n", "before_files": [{"content": "import logging\n\nfrom datetime import timedelta\nfrom django.db.models import Q\nfrom django.utils.timezone import now\nfrom akvo.rsr.models import EmailReportJob\n\nfrom . import (\n program_overview_pdf_report,\n program_overview_excel_report,\n program_period_labels_overview_pdf_report,\n results_indicators_with_map_pdf_reports,\n nuffic_country_level_map_report,\n)\n\nTIMEOUT = timedelta(minutes=30)\nMAX_ATTEMPTS = 3\nHANDLER = {\n program_overview_pdf_report.REPORT_NAME: program_overview_excel_report.handle_email_report,\n program_overview_excel_report.REPORT_NAME: program_overview_excel_report.handle_email_report,\n program_period_labels_overview_pdf_report.REPORT_NAME: program_period_labels_overview_pdf_report.handle_email_report,\n results_indicators_with_map_pdf_reports.ORG_PROJECTS_REPORT_NAME: results_indicators_with_map_pdf_reports.handle_org_projects_email_report,\n nuffic_country_level_map_report.REPORT_NAME: nuffic_country_level_map_report.handle_email_report,\n}\n\nlogger = logging.getLogger(__name__)\n\n\ndef run_job():\n pending_jobs = _get_pending_jobs()\n if not pending_jobs.exists():\n return\n job = pending_jobs.first()\n job.mark_started()\n try:\n handler = HANDLER.get(job.report, None)\n if handler:\n handler(job.payload, job.recipient)\n job.mark_finished()\n except Exception:\n logger.exception(f'Failed to genereate report {job.report} for {job.recipient}')\n\n\ndef _get_pending_jobs():\n started_timeout = now() - TIMEOUT\n return EmailReportJob.objects\\\n .order_by('created_at')\\\n .filter(finished_at__isnull=True)\\\n .exclude(Q(attempts__gte=MAX_ATTEMPTS) | Q(started_at__gte=started_timeout))\n", "path": "akvo/rsr/views/py_reports/email_report.py"}], "after_files": [{"content": "import logging\n\nfrom datetime import timedelta\nfrom django.db.models import Q\nfrom django.utils.timezone import now\nfrom akvo.rsr.models import EmailReportJob\n\nfrom . import (\n program_overview_pdf_report,\n program_overview_excel_report,\n program_period_labels_overview_pdf_report,\n results_indicators_with_map_pdf_reports,\n nuffic_country_level_map_report,\n)\n\nTIMEOUT = timedelta(minutes=30)\nMAX_ATTEMPTS = 3\nHANDLER = {\n program_overview_pdf_report.REPORT_NAME: program_overview_pdf_report.handle_email_report,\n program_overview_excel_report.REPORT_NAME: program_overview_excel_report.handle_email_report,\n program_period_labels_overview_pdf_report.REPORT_NAME: program_period_labels_overview_pdf_report.handle_email_report,\n results_indicators_with_map_pdf_reports.ORG_PROJECTS_REPORT_NAME: results_indicators_with_map_pdf_reports.handle_org_projects_email_report,\n nuffic_country_level_map_report.REPORT_NAME: nuffic_country_level_map_report.handle_email_report,\n}\n\nlogger = logging.getLogger(__name__)\n\n\ndef run_job():\n pending_jobs = _get_pending_jobs()\n if not pending_jobs.exists():\n return\n job = pending_jobs.first()\n job.mark_started()\n try:\n handler = HANDLER.get(job.report, None)\n if handler:\n logger.info(\"Handling job %s for report %s with %s\", job.id, job.report)\n handler(job.payload, job.recipient)\n job.mark_finished()\n except Exception:\n logger.exception(f'Failed to genereate report {job.report} for {job.recipient}')\n\n\ndef _get_pending_jobs():\n started_timeout = now() - TIMEOUT\n return EmailReportJob.objects\\\n .order_by('created_at')\\\n .filter(finished_at__isnull=True)\\\n .exclude(Q(attempts__gte=MAX_ATTEMPTS) | Q(started_at__gte=started_timeout))\n", "path": "akvo/rsr/views/py_reports/email_report.py"}]}
| 792 | 269 |
gh_patches_debug_5510
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-3215
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
HKDF key-length inconsistency
For too small key sizes, `HKDF.derive()` outputs an empty array instead of a small key:
Program:
```python
#!/usr/bin/env python3.5
import cryptography
from cryptography.hazmat.primitives import hashes
from cryptography.hazmat.primitives.kdf.hkdf import HKDF
from cryptography.hazmat.backends import default_backend
print("cryptography.io:{}".format(cryptography.__version__))
hkdf = HKDF(algorithm=hashes.SHA256(), length=4, salt=b"salt",
info=b"some-test", backend=default_backend())
key = hkdf.derive(b"my secret passphrase")
print("Derived key: {}".format(key))
```
Output:
```
cryptography.io:1.5.2
Derived key: b''
```
Suggested fix:
I am not quite sure why the division by 8 in the snippet below was added. The cumulative size of the output array is always `self._algorithm.digest_size * len(output)` and thus we can stop after `self._algorithm.digest_size * len(output) >= self._length`. At first I thought this might be a clever trick taken from the paper, but I didn't find it there. I guess there was a mixup between bits and bytes at some point.
```python
# class HKDFExpand
def _expand(self, key_material):
output = [b""]
counter = 1
while (self._algorithm.digest_size // 8) * len(output) < self._length:
h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)
h.update(output[-1])
h.update(self._info)
h.update(six.int2byte(counter))
output.append(h.finalize())
counter += 1
return b"".join(output)[:self._length]
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cryptography/hazmat/primitives/kdf/hkdf.py`
Content:
```
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7 import six
8
9 from cryptography import utils
10 from cryptography.exceptions import (
11 AlreadyFinalized, InvalidKey, UnsupportedAlgorithm, _Reasons
12 )
13 from cryptography.hazmat.backends.interfaces import HMACBackend
14 from cryptography.hazmat.primitives import constant_time, hmac
15 from cryptography.hazmat.primitives.kdf import KeyDerivationFunction
16
17
18 @utils.register_interface(KeyDerivationFunction)
19 class HKDF(object):
20 def __init__(self, algorithm, length, salt, info, backend):
21 if not isinstance(backend, HMACBackend):
22 raise UnsupportedAlgorithm(
23 "Backend object does not implement HMACBackend.",
24 _Reasons.BACKEND_MISSING_INTERFACE
25 )
26
27 self._algorithm = algorithm
28
29 if not (salt is None or isinstance(salt, bytes)):
30 raise TypeError("salt must be bytes.")
31
32 if salt is None:
33 salt = b"\x00" * (self._algorithm.digest_size // 8)
34
35 self._salt = salt
36
37 self._backend = backend
38
39 self._hkdf_expand = HKDFExpand(self._algorithm, length, info, backend)
40
41 def _extract(self, key_material):
42 h = hmac.HMAC(self._salt, self._algorithm, backend=self._backend)
43 h.update(key_material)
44 return h.finalize()
45
46 def derive(self, key_material):
47 if not isinstance(key_material, bytes):
48 raise TypeError("key_material must be bytes.")
49
50 return self._hkdf_expand.derive(self._extract(key_material))
51
52 def verify(self, key_material, expected_key):
53 if not constant_time.bytes_eq(self.derive(key_material), expected_key):
54 raise InvalidKey
55
56
57 @utils.register_interface(KeyDerivationFunction)
58 class HKDFExpand(object):
59 def __init__(self, algorithm, length, info, backend):
60 if not isinstance(backend, HMACBackend):
61 raise UnsupportedAlgorithm(
62 "Backend object does not implement HMACBackend.",
63 _Reasons.BACKEND_MISSING_INTERFACE
64 )
65
66 self._algorithm = algorithm
67
68 self._backend = backend
69
70 max_length = 255 * (algorithm.digest_size // 8)
71
72 if length > max_length:
73 raise ValueError(
74 "Can not derive keys larger than {0} octets.".format(
75 max_length
76 ))
77
78 self._length = length
79
80 if not (info is None or isinstance(info, bytes)):
81 raise TypeError("info must be bytes.")
82
83 if info is None:
84 info = b""
85
86 self._info = info
87
88 self._used = False
89
90 def _expand(self, key_material):
91 output = [b""]
92 counter = 1
93
94 while (self._algorithm.digest_size // 8) * len(output) < self._length:
95 h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)
96 h.update(output[-1])
97 h.update(self._info)
98 h.update(six.int2byte(counter))
99 output.append(h.finalize())
100 counter += 1
101
102 return b"".join(output)[:self._length]
103
104 def derive(self, key_material):
105 if not isinstance(key_material, bytes):
106 raise TypeError("key_material must be bytes.")
107
108 if self._used:
109 raise AlreadyFinalized
110
111 self._used = True
112 return self._expand(key_material)
113
114 def verify(self, key_material, expected_key):
115 if not constant_time.bytes_eq(self.derive(key_material), expected_key):
116 raise InvalidKey
117
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cryptography/hazmat/primitives/kdf/hkdf.py b/src/cryptography/hazmat/primitives/kdf/hkdf.py
--- a/src/cryptography/hazmat/primitives/kdf/hkdf.py
+++ b/src/cryptography/hazmat/primitives/kdf/hkdf.py
@@ -91,7 +91,7 @@
output = [b""]
counter = 1
- while (self._algorithm.digest_size // 8) * len(output) < self._length:
+ while self._algorithm.digest_size * (len(output) - 1) < self._length:
h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)
h.update(output[-1])
h.update(self._info)
|
{"golden_diff": "diff --git a/src/cryptography/hazmat/primitives/kdf/hkdf.py b/src/cryptography/hazmat/primitives/kdf/hkdf.py\n--- a/src/cryptography/hazmat/primitives/kdf/hkdf.py\n+++ b/src/cryptography/hazmat/primitives/kdf/hkdf.py\n@@ -91,7 +91,7 @@\n output = [b\"\"]\n counter = 1\n \n- while (self._algorithm.digest_size // 8) * len(output) < self._length:\n+ while self._algorithm.digest_size * (len(output) - 1) < self._length:\n h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)\n h.update(output[-1])\n h.update(self._info)\n", "issue": "HKDF key-length inconsistency\nFor too small key sizes, `HKDF.derive()` outputs an empty array instead of a small key:\r\n\r\nProgram:\r\n```python\r\n#!/usr/bin/env python3.5\r\nimport cryptography\r\nfrom cryptography.hazmat.primitives import hashes\r\nfrom cryptography.hazmat.primitives.kdf.hkdf import HKDF\r\nfrom cryptography.hazmat.backends import default_backend\r\n\r\nprint(\"cryptography.io:{}\".format(cryptography.__version__))\r\n\r\nhkdf = HKDF(algorithm=hashes.SHA256(), length=4, salt=b\"salt\",\r\n info=b\"some-test\", backend=default_backend())\r\n\r\nkey = hkdf.derive(b\"my secret passphrase\")\r\nprint(\"Derived key: {}\".format(key))\r\n```\r\n\r\nOutput:\r\n```\r\ncryptography.io:1.5.2\r\nDerived key: b''\r\n```\r\n\r\nSuggested fix:\r\n\r\nI am not quite sure why the division by 8 in the snippet below was added. The cumulative size of the output array is always `self._algorithm.digest_size * len(output)` and thus we can stop after `self._algorithm.digest_size * len(output) >= self._length`. At first I thought this might be a clever trick taken from the paper, but I didn't find it there. I guess there was a mixup between bits and bytes at some point.\r\n\r\n```python\r\n# class HKDFExpand\r\ndef _expand(self, key_material):\r\n output = [b\"\"]\r\n counter = 1\r\n\r\n while (self._algorithm.digest_size // 8) * len(output) < self._length:\r\n h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)\r\n h.update(output[-1])\r\n h.update(self._info)\r\n h.update(six.int2byte(counter))\r\n output.append(h.finalize())\r\n counter += 1\r\n\r\n return b\"\".join(output)[:self._length]\r\n```\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport six\n\nfrom cryptography import utils\nfrom cryptography.exceptions import (\n AlreadyFinalized, InvalidKey, UnsupportedAlgorithm, _Reasons\n)\nfrom cryptography.hazmat.backends.interfaces import HMACBackend\nfrom cryptography.hazmat.primitives import constant_time, hmac\nfrom cryptography.hazmat.primitives.kdf import KeyDerivationFunction\n\n\n@utils.register_interface(KeyDerivationFunction)\nclass HKDF(object):\n def __init__(self, algorithm, length, salt, info, backend):\n if not isinstance(backend, HMACBackend):\n raise UnsupportedAlgorithm(\n \"Backend object does not implement HMACBackend.\",\n _Reasons.BACKEND_MISSING_INTERFACE\n )\n\n self._algorithm = algorithm\n\n if not (salt is None or isinstance(salt, bytes)):\n raise TypeError(\"salt must be bytes.\")\n\n if salt is None:\n salt = b\"\\x00\" * (self._algorithm.digest_size // 8)\n\n self._salt = salt\n\n self._backend = backend\n\n self._hkdf_expand = HKDFExpand(self._algorithm, length, info, backend)\n\n def _extract(self, key_material):\n h = hmac.HMAC(self._salt, self._algorithm, backend=self._backend)\n h.update(key_material)\n return h.finalize()\n\n def derive(self, key_material):\n if not isinstance(key_material, bytes):\n raise TypeError(\"key_material must be bytes.\")\n\n return self._hkdf_expand.derive(self._extract(key_material))\n\n def verify(self, key_material, expected_key):\n if not constant_time.bytes_eq(self.derive(key_material), expected_key):\n raise InvalidKey\n\n\n@utils.register_interface(KeyDerivationFunction)\nclass HKDFExpand(object):\n def __init__(self, algorithm, length, info, backend):\n if not isinstance(backend, HMACBackend):\n raise UnsupportedAlgorithm(\n \"Backend object does not implement HMACBackend.\",\n _Reasons.BACKEND_MISSING_INTERFACE\n )\n\n self._algorithm = algorithm\n\n self._backend = backend\n\n max_length = 255 * (algorithm.digest_size // 8)\n\n if length > max_length:\n raise ValueError(\n \"Can not derive keys larger than {0} octets.\".format(\n max_length\n ))\n\n self._length = length\n\n if not (info is None or isinstance(info, bytes)):\n raise TypeError(\"info must be bytes.\")\n\n if info is None:\n info = b\"\"\n\n self._info = info\n\n self._used = False\n\n def _expand(self, key_material):\n output = [b\"\"]\n counter = 1\n\n while (self._algorithm.digest_size // 8) * len(output) < self._length:\n h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)\n h.update(output[-1])\n h.update(self._info)\n h.update(six.int2byte(counter))\n output.append(h.finalize())\n counter += 1\n\n return b\"\".join(output)[:self._length]\n\n def derive(self, key_material):\n if not isinstance(key_material, bytes):\n raise TypeError(\"key_material must be bytes.\")\n\n if self._used:\n raise AlreadyFinalized\n\n self._used = True\n return self._expand(key_material)\n\n def verify(self, key_material, expected_key):\n if not constant_time.bytes_eq(self.derive(key_material), expected_key):\n raise InvalidKey\n", "path": "src/cryptography/hazmat/primitives/kdf/hkdf.py"}], "after_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport six\n\nfrom cryptography import utils\nfrom cryptography.exceptions import (\n AlreadyFinalized, InvalidKey, UnsupportedAlgorithm, _Reasons\n)\nfrom cryptography.hazmat.backends.interfaces import HMACBackend\nfrom cryptography.hazmat.primitives import constant_time, hmac\nfrom cryptography.hazmat.primitives.kdf import KeyDerivationFunction\n\n\n@utils.register_interface(KeyDerivationFunction)\nclass HKDF(object):\n def __init__(self, algorithm, length, salt, info, backend):\n if not isinstance(backend, HMACBackend):\n raise UnsupportedAlgorithm(\n \"Backend object does not implement HMACBackend.\",\n _Reasons.BACKEND_MISSING_INTERFACE\n )\n\n self._algorithm = algorithm\n\n if not (salt is None or isinstance(salt, bytes)):\n raise TypeError(\"salt must be bytes.\")\n\n if salt is None:\n salt = b\"\\x00\" * (self._algorithm.digest_size // 8)\n\n self._salt = salt\n\n self._backend = backend\n\n self._hkdf_expand = HKDFExpand(self._algorithm, length, info, backend)\n\n def _extract(self, key_material):\n h = hmac.HMAC(self._salt, self._algorithm, backend=self._backend)\n h.update(key_material)\n return h.finalize()\n\n def derive(self, key_material):\n if not isinstance(key_material, bytes):\n raise TypeError(\"key_material must be bytes.\")\n\n return self._hkdf_expand.derive(self._extract(key_material))\n\n def verify(self, key_material, expected_key):\n if not constant_time.bytes_eq(self.derive(key_material), expected_key):\n raise InvalidKey\n\n\n@utils.register_interface(KeyDerivationFunction)\nclass HKDFExpand(object):\n def __init__(self, algorithm, length, info, backend):\n if not isinstance(backend, HMACBackend):\n raise UnsupportedAlgorithm(\n \"Backend object does not implement HMACBackend.\",\n _Reasons.BACKEND_MISSING_INTERFACE\n )\n\n self._algorithm = algorithm\n\n self._backend = backend\n\n max_length = 255 * (algorithm.digest_size // 8)\n\n if length > max_length:\n raise ValueError(\n \"Can not derive keys larger than {0} octets.\".format(\n max_length\n ))\n\n self._length = length\n\n if not (info is None or isinstance(info, bytes)):\n raise TypeError(\"info must be bytes.\")\n\n if info is None:\n info = b\"\"\n\n self._info = info\n\n self._used = False\n\n def _expand(self, key_material):\n output = [b\"\"]\n counter = 1\n\n while self._algorithm.digest_size * (len(output) - 1) < self._length:\n h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)\n h.update(output[-1])\n h.update(self._info)\n h.update(six.int2byte(counter))\n output.append(h.finalize())\n counter += 1\n\n return b\"\".join(output)[:self._length]\n\n def derive(self, key_material):\n if not isinstance(key_material, bytes):\n raise TypeError(\"key_material must be bytes.\")\n\n if self._used:\n raise AlreadyFinalized\n\n self._used = True\n return self._expand(key_material)\n\n def verify(self, key_material, expected_key):\n if not constant_time.bytes_eq(self.derive(key_material), expected_key):\n raise InvalidKey\n", "path": "src/cryptography/hazmat/primitives/kdf/hkdf.py"}]}
| 1,713 | 169 |
gh_patches_debug_7796
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-1135
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Redis address parsing is done in init_app
This was added in #1107:
https://github.com/Mailu/Mailu/blob/f3f0c3190be9ab9b53a29c5b0326fc9a4602df46/core/admin/mailu/configuration.py#L11-L12
While, `REDIS_ADDRESS` is now only resolved in `init_app`. (#940). We took care of that in:
https://github.com/Mailu/Mailu/blob/f3f0c3190be9ab9b53a29c5b0326fc9a4602df46/core/admin/mailu/configuration.py#L116-L117
I believe DEFAULT_CONFIG should be like:
https://github.com/Mailu/Mailu/blob/4c25c83419be128fb12591721627a718ec23f69d/core/admin/mailu/configuration.py#L12-L13
We are now in the process of backporting #940 to 1.7. PR #1107 was not backported. Therefore 1.7 will look like the last snippet.
CC @mildred, @kaiyou
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/admin/mailu/configuration.py`
Content:
```
1 import os
2
3 from socrate import system
4
5 DEFAULT_CONFIG = {
6 # Specific to the admin UI
7 'DOCKER_SOCKET': 'unix:///var/run/docker.sock',
8 'BABEL_DEFAULT_LOCALE': 'en',
9 'BABEL_DEFAULT_TIMEZONE': 'UTC',
10 'BOOTSTRAP_SERVE_LOCAL': True,
11 'RATELIMIT_STORAGE_URL': 'redis://%s/2' % (os.getenv("REDIS_ADDRESS", "redis")),
12 'QUOTA_STORAGE_URL': 'redis://%s/1' % (os.getenv("REDIS_ADDRESS", "redis")),
13 'DEBUG': False,
14 'DOMAIN_REGISTRATION': False,
15 'TEMPLATES_AUTO_RELOAD': True,
16 # Database settings
17 'DB_FLAVOR': None,
18 'DB_USER': 'mailu',
19 'DB_PW': None,
20 'DB_HOST': 'database',
21 'DB_NAME': 'mailu',
22 'SQLITE_DATABASE_FILE':'data/main.db',
23 'SQLALCHEMY_DATABASE_URI': 'sqlite:////data/main.db',
24 'SQLALCHEMY_TRACK_MODIFICATIONS': False,
25 # Statistics management
26 'INSTANCE_ID_PATH': '/data/instance',
27 'STATS_ENDPOINT': '0.{}.stats.mailu.io',
28 # Common configuration variables
29 'SECRET_KEY': 'changeMe',
30 'DOMAIN': 'mailu.io',
31 'HOSTNAMES': 'mail.mailu.io,alternative.mailu.io,yetanother.mailu.io',
32 'POSTMASTER': 'postmaster',
33 'TLS_FLAVOR': 'cert',
34 'AUTH_RATELIMIT': '10/minute;1000/hour',
35 'DISABLE_STATISTICS': False,
36 # Mail settings
37 'DMARC_RUA': None,
38 'DMARC_RUF': None,
39 'WELCOME': False,
40 'WELCOME_SUBJECT': 'Dummy welcome topic',
41 'WELCOME_BODY': 'Dummy welcome body',
42 'DKIM_SELECTOR': 'dkim',
43 'DKIM_PATH': '/dkim/{domain}.{selector}.key',
44 'DEFAULT_QUOTA': 1000000000,
45 # Web settings
46 'SITENAME': 'Mailu',
47 'WEBSITE': 'https://mailu.io',
48 'WEB_ADMIN': '/admin',
49 'WEB_WEBMAIL': '/webmail',
50 'WEBMAIL': 'none',
51 'RECAPTCHA_PUBLIC_KEY': '',
52 'RECAPTCHA_PRIVATE_KEY': '',
53 # Advanced settings
54 'PASSWORD_SCHEME': 'BLF-CRYPT',
55 'LOG_LEVEL': 'WARNING',
56 # Host settings
57 'HOST_IMAP': 'imap',
58 'HOST_LMTP': 'imap:2525',
59 'HOST_POP3': 'imap',
60 'HOST_SMTP': 'smtp',
61 'HOST_AUTHSMTP': 'smtp',
62 'HOST_ADMIN': 'admin',
63 'HOST_ANTISPAM': 'antispam:11334',
64 'HOST_WEBMAIL': 'webmail',
65 'HOST_WEBDAV': 'webdav:5232',
66 'HOST_REDIS': 'redis',
67 'HOST_FRONT': 'front',
68 'SUBNET': '192.168.203.0/24',
69 'POD_ADDRESS_RANGE': None
70 }
71
72 class ConfigManager(dict):
73 """ Naive configuration manager that uses environment only
74 """
75
76 DB_TEMPLATES = {
77 'sqlite': 'sqlite:////{SQLITE_DATABASE_FILE}',
78 'postgresql': 'postgresql://{DB_USER}:{DB_PW}@{DB_HOST}/{DB_NAME}',
79 'mysql': 'mysql://{DB_USER}:{DB_PW}@{DB_HOST}/{DB_NAME}'
80 }
81
82 HOSTS = ('IMAP', 'POP3', 'AUTHSMTP', 'SMTP', 'REDIS')
83 OPTIONAL_HOSTS = ('WEBMAIL', 'ANTISPAM')
84
85 def __init__(self):
86 self.config = dict()
87
88 def resolve_host(self):
89 optional = [item for item in self.OPTIONAL_HOSTS if item in self.config and self.config[item] != "none"]
90 for item in list(self.HOSTS) + optional:
91 host = 'HOST_' + item
92 address = item + '_ADDRESS'
93 self.config[address] = system.resolve_address(self.config[host])
94
95 def __coerce_value(self, value):
96 if isinstance(value, str) and value.lower() in ('true','yes'):
97 return True
98 elif isinstance(value, str) and value.lower() in ('false', 'no'):
99 return False
100 return value
101
102 def init_app(self, app):
103 self.config.update(app.config)
104 # get environment variables
105 self.config.update({
106 key: self.__coerce_value(os.environ.get(key, value))
107 for key, value in DEFAULT_CONFIG.items()
108 })
109 self.resolve_host()
110
111 # automatically set the sqlalchemy string
112 if self.config['DB_FLAVOR']:
113 template = self.DB_TEMPLATES[self.config['DB_FLAVOR']]
114 self.config['SQLALCHEMY_DATABASE_URI'] = template.format(**self.config)
115
116 self.config['RATELIMIT_STORAGE_URL'] = 'redis://{0}/2'.format(self.config['REDIS_ADDRESS'])
117 self.config['QUOTA_STORAGE_URL'] = 'redis://{0}/1'.format(self.config['REDIS_ADDRESS'])
118 # update the app config itself
119 app.config = self
120
121 def setdefault(self, key, value):
122 if key not in self.config:
123 self.config[key] = value
124 return self.config[key]
125
126 def get(self, *args):
127 return self.config.get(*args)
128
129 def keys(self):
130 return self.config.keys()
131
132 def __getitem__(self, key):
133 return self.config.get(key)
134
135 def __setitem__(self, key, value):
136 self.config[key] = value
137
138 def __contains__(self, key):
139 return key in self.config
140
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/admin/mailu/configuration.py b/core/admin/mailu/configuration.py
--- a/core/admin/mailu/configuration.py
+++ b/core/admin/mailu/configuration.py
@@ -8,8 +8,8 @@
'BABEL_DEFAULT_LOCALE': 'en',
'BABEL_DEFAULT_TIMEZONE': 'UTC',
'BOOTSTRAP_SERVE_LOCAL': True,
- 'RATELIMIT_STORAGE_URL': 'redis://%s/2' % (os.getenv("REDIS_ADDRESS", "redis")),
- 'QUOTA_STORAGE_URL': 'redis://%s/1' % (os.getenv("REDIS_ADDRESS", "redis")),
+ 'RATELIMIT_STORAGE_URL': '',
+ 'QUOTA_STORAGE_URL': '',
'DEBUG': False,
'DOMAIN_REGISTRATION': False,
'TEMPLATES_AUTO_RELOAD': True,
|
{"golden_diff": "diff --git a/core/admin/mailu/configuration.py b/core/admin/mailu/configuration.py\n--- a/core/admin/mailu/configuration.py\n+++ b/core/admin/mailu/configuration.py\n@@ -8,8 +8,8 @@\n 'BABEL_DEFAULT_LOCALE': 'en',\n 'BABEL_DEFAULT_TIMEZONE': 'UTC',\n 'BOOTSTRAP_SERVE_LOCAL': True,\n- 'RATELIMIT_STORAGE_URL': 'redis://%s/2' % (os.getenv(\"REDIS_ADDRESS\", \"redis\")),\n- 'QUOTA_STORAGE_URL': 'redis://%s/1' % (os.getenv(\"REDIS_ADDRESS\", \"redis\")),\n+ 'RATELIMIT_STORAGE_URL': '',\n+ 'QUOTA_STORAGE_URL': '',\n 'DEBUG': False,\n 'DOMAIN_REGISTRATION': False,\n 'TEMPLATES_AUTO_RELOAD': True,\n", "issue": "Redis address parsing is done in init_app\nThis was added in #1107:\r\n\r\nhttps://github.com/Mailu/Mailu/blob/f3f0c3190be9ab9b53a29c5b0326fc9a4602df46/core/admin/mailu/configuration.py#L11-L12\r\n\r\nWhile, `REDIS_ADDRESS` is now only resolved in `init_app`. (#940). We took care of that in:\r\n\r\nhttps://github.com/Mailu/Mailu/blob/f3f0c3190be9ab9b53a29c5b0326fc9a4602df46/core/admin/mailu/configuration.py#L116-L117\r\n\r\nI believe DEFAULT_CONFIG should be like:\r\n\r\nhttps://github.com/Mailu/Mailu/blob/4c25c83419be128fb12591721627a718ec23f69d/core/admin/mailu/configuration.py#L12-L13\r\n\r\nWe are now in the process of backporting #940 to 1.7. PR #1107 was not backported. Therefore 1.7 will look like the last snippet.\r\n\r\nCC @mildred, @kaiyou \n", "before_files": [{"content": "import os\n\nfrom socrate import system\n\nDEFAULT_CONFIG = {\n # Specific to the admin UI\n 'DOCKER_SOCKET': 'unix:///var/run/docker.sock',\n 'BABEL_DEFAULT_LOCALE': 'en',\n 'BABEL_DEFAULT_TIMEZONE': 'UTC',\n 'BOOTSTRAP_SERVE_LOCAL': True,\n 'RATELIMIT_STORAGE_URL': 'redis://%s/2' % (os.getenv(\"REDIS_ADDRESS\", \"redis\")),\n 'QUOTA_STORAGE_URL': 'redis://%s/1' % (os.getenv(\"REDIS_ADDRESS\", \"redis\")),\n 'DEBUG': False,\n 'DOMAIN_REGISTRATION': False,\n 'TEMPLATES_AUTO_RELOAD': True,\n # Database settings\n 'DB_FLAVOR': None,\n 'DB_USER': 'mailu',\n 'DB_PW': None,\n 'DB_HOST': 'database',\n 'DB_NAME': 'mailu',\n 'SQLITE_DATABASE_FILE':'data/main.db',\n 'SQLALCHEMY_DATABASE_URI': 'sqlite:////data/main.db',\n 'SQLALCHEMY_TRACK_MODIFICATIONS': False,\n # Statistics management\n 'INSTANCE_ID_PATH': '/data/instance',\n 'STATS_ENDPOINT': '0.{}.stats.mailu.io',\n # Common configuration variables\n 'SECRET_KEY': 'changeMe',\n 'DOMAIN': 'mailu.io',\n 'HOSTNAMES': 'mail.mailu.io,alternative.mailu.io,yetanother.mailu.io',\n 'POSTMASTER': 'postmaster',\n 'TLS_FLAVOR': 'cert',\n 'AUTH_RATELIMIT': '10/minute;1000/hour',\n 'DISABLE_STATISTICS': False,\n # Mail settings\n 'DMARC_RUA': None,\n 'DMARC_RUF': None,\n 'WELCOME': False,\n 'WELCOME_SUBJECT': 'Dummy welcome topic',\n 'WELCOME_BODY': 'Dummy welcome body',\n 'DKIM_SELECTOR': 'dkim',\n 'DKIM_PATH': '/dkim/{domain}.{selector}.key',\n 'DEFAULT_QUOTA': 1000000000,\n # Web settings\n 'SITENAME': 'Mailu',\n 'WEBSITE': 'https://mailu.io',\n 'WEB_ADMIN': '/admin',\n 'WEB_WEBMAIL': '/webmail',\n 'WEBMAIL': 'none',\n 'RECAPTCHA_PUBLIC_KEY': '',\n 'RECAPTCHA_PRIVATE_KEY': '',\n # Advanced settings\n 'PASSWORD_SCHEME': 'BLF-CRYPT',\n 'LOG_LEVEL': 'WARNING',\n # Host settings\n 'HOST_IMAP': 'imap',\n 'HOST_LMTP': 'imap:2525',\n 'HOST_POP3': 'imap',\n 'HOST_SMTP': 'smtp',\n 'HOST_AUTHSMTP': 'smtp',\n 'HOST_ADMIN': 'admin',\n 'HOST_ANTISPAM': 'antispam:11334',\n 'HOST_WEBMAIL': 'webmail',\n 'HOST_WEBDAV': 'webdav:5232',\n 'HOST_REDIS': 'redis',\n 'HOST_FRONT': 'front',\n 'SUBNET': '192.168.203.0/24',\n 'POD_ADDRESS_RANGE': None\n}\n\nclass ConfigManager(dict):\n \"\"\" Naive configuration manager that uses environment only\n \"\"\"\n\n DB_TEMPLATES = {\n 'sqlite': 'sqlite:////{SQLITE_DATABASE_FILE}',\n 'postgresql': 'postgresql://{DB_USER}:{DB_PW}@{DB_HOST}/{DB_NAME}',\n 'mysql': 'mysql://{DB_USER}:{DB_PW}@{DB_HOST}/{DB_NAME}'\n }\n\n HOSTS = ('IMAP', 'POP3', 'AUTHSMTP', 'SMTP', 'REDIS')\n OPTIONAL_HOSTS = ('WEBMAIL', 'ANTISPAM')\n\n def __init__(self):\n self.config = dict()\n\n def resolve_host(self):\n optional = [item for item in self.OPTIONAL_HOSTS if item in self.config and self.config[item] != \"none\"]\n for item in list(self.HOSTS) + optional:\n host = 'HOST_' + item\n address = item + '_ADDRESS'\n self.config[address] = system.resolve_address(self.config[host])\n\n def __coerce_value(self, value):\n if isinstance(value, str) and value.lower() in ('true','yes'):\n return True\n elif isinstance(value, str) and value.lower() in ('false', 'no'):\n return False\n return value\n\n def init_app(self, app):\n self.config.update(app.config)\n # get environment variables\n self.config.update({\n key: self.__coerce_value(os.environ.get(key, value))\n for key, value in DEFAULT_CONFIG.items()\n })\n self.resolve_host()\n\n # automatically set the sqlalchemy string\n if self.config['DB_FLAVOR']:\n template = self.DB_TEMPLATES[self.config['DB_FLAVOR']]\n self.config['SQLALCHEMY_DATABASE_URI'] = template.format(**self.config)\n\n self.config['RATELIMIT_STORAGE_URL'] = 'redis://{0}/2'.format(self.config['REDIS_ADDRESS'])\n self.config['QUOTA_STORAGE_URL'] = 'redis://{0}/1'.format(self.config['REDIS_ADDRESS'])\n # update the app config itself\n app.config = self\n\n def setdefault(self, key, value):\n if key not in self.config:\n self.config[key] = value\n return self.config[key]\n\n def get(self, *args):\n return self.config.get(*args)\n\n def keys(self):\n return self.config.keys()\n\n def __getitem__(self, key):\n return self.config.get(key)\n\n def __setitem__(self, key, value):\n self.config[key] = value\n\n def __contains__(self, key):\n return key in self.config\n", "path": "core/admin/mailu/configuration.py"}], "after_files": [{"content": "import os\n\nfrom socrate import system\n\nDEFAULT_CONFIG = {\n # Specific to the admin UI\n 'DOCKER_SOCKET': 'unix:///var/run/docker.sock',\n 'BABEL_DEFAULT_LOCALE': 'en',\n 'BABEL_DEFAULT_TIMEZONE': 'UTC',\n 'BOOTSTRAP_SERVE_LOCAL': True,\n 'RATELIMIT_STORAGE_URL': '',\n 'QUOTA_STORAGE_URL': '',\n 'DEBUG': False,\n 'DOMAIN_REGISTRATION': False,\n 'TEMPLATES_AUTO_RELOAD': True,\n # Database settings\n 'DB_FLAVOR': None,\n 'DB_USER': 'mailu',\n 'DB_PW': None,\n 'DB_HOST': 'database',\n 'DB_NAME': 'mailu',\n 'SQLITE_DATABASE_FILE':'data/main.db',\n 'SQLALCHEMY_DATABASE_URI': 'sqlite:////data/main.db',\n 'SQLALCHEMY_TRACK_MODIFICATIONS': False,\n # Statistics management\n 'INSTANCE_ID_PATH': '/data/instance',\n 'STATS_ENDPOINT': '0.{}.stats.mailu.io',\n # Common configuration variables\n 'SECRET_KEY': 'changeMe',\n 'DOMAIN': 'mailu.io',\n 'HOSTNAMES': 'mail.mailu.io,alternative.mailu.io,yetanother.mailu.io',\n 'POSTMASTER': 'postmaster',\n 'TLS_FLAVOR': 'cert',\n 'AUTH_RATELIMIT': '10/minute;1000/hour',\n 'DISABLE_STATISTICS': False,\n # Mail settings\n 'DMARC_RUA': None,\n 'DMARC_RUF': None,\n 'WELCOME': False,\n 'WELCOME_SUBJECT': 'Dummy welcome topic',\n 'WELCOME_BODY': 'Dummy welcome body',\n 'DKIM_SELECTOR': 'dkim',\n 'DKIM_PATH': '/dkim/{domain}.{selector}.key',\n 'DEFAULT_QUOTA': 1000000000,\n # Web settings\n 'SITENAME': 'Mailu',\n 'WEBSITE': 'https://mailu.io',\n 'WEB_ADMIN': '/admin',\n 'WEB_WEBMAIL': '/webmail',\n 'WEBMAIL': 'none',\n 'RECAPTCHA_PUBLIC_KEY': '',\n 'RECAPTCHA_PRIVATE_KEY': '',\n # Advanced settings\n 'PASSWORD_SCHEME': 'BLF-CRYPT',\n 'LOG_LEVEL': 'WARNING',\n # Host settings\n 'HOST_IMAP': 'imap',\n 'HOST_LMTP': 'imap:2525',\n 'HOST_POP3': 'imap',\n 'HOST_SMTP': 'smtp',\n 'HOST_AUTHSMTP': 'smtp',\n 'HOST_ADMIN': 'admin',\n 'HOST_ANTISPAM': 'antispam:11334',\n 'HOST_WEBMAIL': 'webmail',\n 'HOST_WEBDAV': 'webdav:5232',\n 'HOST_REDIS': 'redis',\n 'HOST_FRONT': 'front',\n 'SUBNET': '192.168.203.0/24',\n 'POD_ADDRESS_RANGE': None\n}\n\nclass ConfigManager(dict):\n \"\"\" Naive configuration manager that uses environment only\n \"\"\"\n\n DB_TEMPLATES = {\n 'sqlite': 'sqlite:////{SQLITE_DATABASE_FILE}',\n 'postgresql': 'postgresql://{DB_USER}:{DB_PW}@{DB_HOST}/{DB_NAME}',\n 'mysql': 'mysql://{DB_USER}:{DB_PW}@{DB_HOST}/{DB_NAME}'\n }\n\n HOSTS = ('IMAP', 'POP3', 'AUTHSMTP', 'SMTP', 'REDIS')\n OPTIONAL_HOSTS = ('WEBMAIL', 'ANTISPAM')\n\n def __init__(self):\n self.config = dict()\n\n def resolve_host(self):\n optional = [item for item in self.OPTIONAL_HOSTS if item in self.config and self.config[item] != \"none\"]\n for item in list(self.HOSTS) + optional:\n host = 'HOST_' + item\n address = item + '_ADDRESS'\n self.config[address] = system.resolve_address(self.config[host])\n\n def __coerce_value(self, value):\n if isinstance(value, str) and value.lower() in ('true','yes'):\n return True\n elif isinstance(value, str) and value.lower() in ('false', 'no'):\n return False\n return value\n\n def init_app(self, app):\n self.config.update(app.config)\n # get environment variables\n self.config.update({\n key: self.__coerce_value(os.environ.get(key, value))\n for key, value in DEFAULT_CONFIG.items()\n })\n self.resolve_host()\n\n # automatically set the sqlalchemy string\n if self.config['DB_FLAVOR']:\n template = self.DB_TEMPLATES[self.config['DB_FLAVOR']]\n self.config['SQLALCHEMY_DATABASE_URI'] = template.format(**self.config)\n\n self.config['RATELIMIT_STORAGE_URL'] = 'redis://{0}/2'.format(self.config['REDIS_ADDRESS'])\n self.config['QUOTA_STORAGE_URL'] = 'redis://{0}/1'.format(self.config['REDIS_ADDRESS'])\n # update the app config itself\n app.config = self\n\n def setdefault(self, key, value):\n if key not in self.config:\n self.config[key] = value\n return self.config[key]\n\n def get(self, *args):\n return self.config.get(*args)\n\n def keys(self):\n return self.config.keys()\n\n def __getitem__(self, key):\n return self.config.get(key)\n\n def __setitem__(self, key, value):\n self.config[key] = value\n\n def __contains__(self, key):\n return key in self.config\n", "path": "core/admin/mailu/configuration.py"}]}
| 2,127 | 173 |
gh_patches_debug_11975
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-1394
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Compile and execute use a progress bar even if a single circuit is passed.
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues -->
### Informations
- **Qiskit Terra version**: master
- **Python version**: 3.7
- **Operating system**: OSX
### What is the current behavior?
The `compile` and `execute` functions make use of a progress bar for a single circuit.
### Steps to reproduce the problem
```
from qiskit import *
from qiskit.tools.jupyter import TextProgressBar
q = QuantumRegister(2)
c = ClassicalRegister(2)
qc = QuantumCircuit(q, c)
qc.h(q[0])
qc.cx(q[0], q[1])
qc.measure(q, c)
backend = Aer.get_backend('qasm_simulator')
TextProgressBar()
qobj = compile([qc], backend)
```
### What is the expected behavior?
A progress bar should not be used for a single circuit.
### Suggested solutions
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qiskit/transpiler/_parallel.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright 2018, IBM.
4 #
5 # This source code is licensed under the Apache License, Version 2.0 found in
6 # the LICENSE.txt file in the root directory of this source tree.
7
8 # This file is part of QuTiP: Quantum Toolbox in Python.
9 #
10 # Copyright (c) 2011 and later, Paul D. Nation and Robert J. Johansson.
11 # All rights reserved.
12 #
13 # Redistribution and use in source and binary forms, with or without
14 # modification, are permitted provided that the following conditions are
15 # met:
16 #
17 # 1. Redistributions of source code must retain the above copyright notice,
18 # this list of conditions and the following disclaimer.
19 #
20 # 2. Redistributions in binary form must reproduce the above copyright
21 # notice, this list of conditions and the following disclaimer in the
22 # documentation and/or other materials provided with the distribution.
23 #
24 # 3. Neither the name of the QuTiP: Quantum Toolbox in Python nor the names
25 # of its contributors may be used to endorse or promote products derived
26 # from this software without specific prior written permission.
27 #
28 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
29 # "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
30 # LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A
31 # PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
32 # HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
33 # SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
34 # LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
35 # DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
36 # THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
37 # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
38 # OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
39 ###############################################################################
40
41 """
42 Routines for running Python functions in parallel using process pools
43 from the multiprocessing library.
44 """
45
46 import os
47 import platform
48 from multiprocessing import Pool
49 from qiskit._qiskiterror import QISKitError
50 from qiskit._util import local_hardware_info
51 from qiskit._pubsub import Publisher
52
53 # Number of local physical cpus
54 CPU_COUNT = local_hardware_info()['cpus']
55
56
57 def parallel_map(task, values, task_args=tuple(), task_kwargs={}, # pylint: disable=W0102
58 num_processes=CPU_COUNT):
59 """
60 Parallel execution of a mapping of `values` to the function `task`. This
61 is functionally equivalent to::
62
63 result = [task(value, *task_args, **task_kwargs) for value in values]
64
65 On Windows this function defaults to a serial implementation to avoid the
66 overhead from spawning processes in Windows.
67
68 Args:
69 task (func): Function that is to be called for each value in ``task_vec``.
70 values (array_like): List or array of values for which the ``task``
71 function is to be evaluated.
72 task_args (list): Optional additional arguments to the ``task`` function.
73 task_kwargs (dict): Optional additional keyword argument to the ``task`` function.
74 num_processes (int): Number of processes to spawn.
75
76 Returns:
77 result: The result list contains the value of
78 ``task(value, *task_args, **task_kwargs)`` for
79 each value in ``values``.
80
81 Raises:
82 QISKitError: If user interrupts via keyboard.
83
84 Events:
85 terra.transpiler.parallel.start: The collection of parallel tasks are about to start.
86 terra.transpiler.parallel.update: One of the parallel task has finished.
87 terra.transpiler.parallel.finish: All the parallel tasks have finished.
88 """
89 Publisher().publish("terra.transpiler.parallel.start", len(values))
90 if len(values) == 1:
91 Publisher().publish("terra.transpiler.parallel.finish")
92 return [task(values[0], *task_args, **task_kwargs)]
93
94 nfinished = [0]
95
96 def _callback(_):
97 nfinished[0] += 1
98 Publisher().publish("terra.transpiler.parallel.done", nfinished[0])
99
100 # Run in parallel if not Win and not in parallel already
101 if platform.system() != 'Windows' and num_processes > 1 \
102 and os.getenv('QISKIT_IN_PARALLEL') == 'FALSE':
103 os.environ['QISKIT_IN_PARALLEL'] = 'TRUE'
104 try:
105 pool = Pool(processes=num_processes)
106
107 async_res = [pool.apply_async(task, (value,) + task_args, task_kwargs,
108 _callback) for value in values]
109
110 while not all([item.ready() for item in async_res]):
111 for item in async_res:
112 item.wait(timeout=0.1)
113
114 pool.terminate()
115 pool.join()
116
117 except KeyboardInterrupt:
118 pool.terminate()
119 pool.join()
120 Publisher().publish("terra.parallel.parallel.finish")
121 raise QISKitError('Keyboard interrupt in parallel_map.')
122
123 Publisher().publish("terra.transpiler.parallel.finish")
124 os.environ['QISKIT_IN_PARALLEL'] = 'FALSE'
125 return [ar.get() for ar in async_res]
126
127 # Cannot do parallel on Windows , if another parallel_map is running in parallel,
128 # or len(values) == 1.
129 results = []
130 for _, value in enumerate(values):
131 result = task(value, *task_args, **task_kwargs)
132 results.append(result)
133 _callback(0)
134 Publisher().publish("terra.transpiler.parallel.finish")
135 return results
136
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qiskit/transpiler/_parallel.py b/qiskit/transpiler/_parallel.py
--- a/qiskit/transpiler/_parallel.py
+++ b/qiskit/transpiler/_parallel.py
@@ -86,11 +86,10 @@
terra.transpiler.parallel.update: One of the parallel task has finished.
terra.transpiler.parallel.finish: All the parallel tasks have finished.
"""
- Publisher().publish("terra.transpiler.parallel.start", len(values))
if len(values) == 1:
- Publisher().publish("terra.transpiler.parallel.finish")
return [task(values[0], *task_args, **task_kwargs)]
+ Publisher().publish("terra.transpiler.parallel.start", len(values))
nfinished = [0]
def _callback(_):
|
{"golden_diff": "diff --git a/qiskit/transpiler/_parallel.py b/qiskit/transpiler/_parallel.py\n--- a/qiskit/transpiler/_parallel.py\n+++ b/qiskit/transpiler/_parallel.py\n@@ -86,11 +86,10 @@\n terra.transpiler.parallel.update: One of the parallel task has finished.\n terra.transpiler.parallel.finish: All the parallel tasks have finished.\n \"\"\"\n- Publisher().publish(\"terra.transpiler.parallel.start\", len(values))\n if len(values) == 1:\n- Publisher().publish(\"terra.transpiler.parallel.finish\")\n return [task(values[0], *task_args, **task_kwargs)]\n \n+ Publisher().publish(\"terra.transpiler.parallel.start\", len(values))\n nfinished = [0]\n \n def _callback(_):\n", "issue": "Compile and execute use a progress bar even if a single circuit is passed.\n<!-- \u26a0\ufe0f If you do not respect this template, your issue will be closed -->\r\n<!-- \u26a0\ufe0f Make sure to browse the opened and closed issues -->\r\n\r\n### Informations\r\n\r\n- **Qiskit Terra version**: master\r\n- **Python version**: 3.7\r\n- **Operating system**: OSX\r\n\r\n### What is the current behavior?\r\nThe `compile` and `execute` functions make use of a progress bar for a single circuit.\r\n\r\n### Steps to reproduce the problem\r\n```\r\nfrom qiskit import *\r\nfrom qiskit.tools.jupyter import TextProgressBar\r\n\r\nq = QuantumRegister(2)\r\nc = ClassicalRegister(2)\r\nqc = QuantumCircuit(q, c)\r\n\r\nqc.h(q[0])\r\nqc.cx(q[0], q[1])\r\nqc.measure(q, c)\r\n\r\nbackend = Aer.get_backend('qasm_simulator')\r\nTextProgressBar()\r\nqobj = compile([qc], backend)\r\n```\r\n\r\n\r\n### What is the expected behavior?\r\nA progress bar should not be used for a single circuit.\r\n\r\n### Suggested solutions\r\n\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright 2018, IBM.\n#\n# This source code is licensed under the Apache License, Version 2.0 found in\n# the LICENSE.txt file in the root directory of this source tree.\n\n# This file is part of QuTiP: Quantum Toolbox in Python.\n#\n# Copyright (c) 2011 and later, Paul D. Nation and Robert J. Johansson.\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are\n# met:\n#\n# 1. Redistributions of source code must retain the above copyright notice,\n# this list of conditions and the following disclaimer.\n#\n# 2. Redistributions in binary form must reproduce the above copyright\n# notice, this list of conditions and the following disclaimer in the\n# documentation and/or other materials provided with the distribution.\n#\n# 3. Neither the name of the QuTiP: Quantum Toolbox in Python nor the names\n# of its contributors may be used to endorse or promote products derived\n# from this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS\n# \"AS IS\" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT\n# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A\n# PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT\n# HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,\n# SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT\n# LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,\n# DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY\n# THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT\n# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n###############################################################################\n\n\"\"\"\nRoutines for running Python functions in parallel using process pools\nfrom the multiprocessing library.\n\"\"\"\n\nimport os\nimport platform\nfrom multiprocessing import Pool\nfrom qiskit._qiskiterror import QISKitError\nfrom qiskit._util import local_hardware_info\nfrom qiskit._pubsub import Publisher\n\n# Number of local physical cpus\nCPU_COUNT = local_hardware_info()['cpus']\n\n\ndef parallel_map(task, values, task_args=tuple(), task_kwargs={}, # pylint: disable=W0102\n num_processes=CPU_COUNT):\n \"\"\"\n Parallel execution of a mapping of `values` to the function `task`. This\n is functionally equivalent to::\n\n result = [task(value, *task_args, **task_kwargs) for value in values]\n\n On Windows this function defaults to a serial implementation to avoid the\n overhead from spawning processes in Windows.\n\n Args:\n task (func): Function that is to be called for each value in ``task_vec``.\n values (array_like): List or array of values for which the ``task``\n function is to be evaluated.\n task_args (list): Optional additional arguments to the ``task`` function.\n task_kwargs (dict): Optional additional keyword argument to the ``task`` function.\n num_processes (int): Number of processes to spawn.\n\n Returns:\n result: The result list contains the value of\n ``task(value, *task_args, **task_kwargs)`` for\n each value in ``values``.\n\n Raises:\n QISKitError: If user interrupts via keyboard.\n\n Events:\n terra.transpiler.parallel.start: The collection of parallel tasks are about to start.\n terra.transpiler.parallel.update: One of the parallel task has finished.\n terra.transpiler.parallel.finish: All the parallel tasks have finished.\n \"\"\"\n Publisher().publish(\"terra.transpiler.parallel.start\", len(values))\n if len(values) == 1:\n Publisher().publish(\"terra.transpiler.parallel.finish\")\n return [task(values[0], *task_args, **task_kwargs)]\n\n nfinished = [0]\n\n def _callback(_):\n nfinished[0] += 1\n Publisher().publish(\"terra.transpiler.parallel.done\", nfinished[0])\n\n # Run in parallel if not Win and not in parallel already\n if platform.system() != 'Windows' and num_processes > 1 \\\n and os.getenv('QISKIT_IN_PARALLEL') == 'FALSE':\n os.environ['QISKIT_IN_PARALLEL'] = 'TRUE'\n try:\n pool = Pool(processes=num_processes)\n\n async_res = [pool.apply_async(task, (value,) + task_args, task_kwargs,\n _callback) for value in values]\n\n while not all([item.ready() for item in async_res]):\n for item in async_res:\n item.wait(timeout=0.1)\n\n pool.terminate()\n pool.join()\n\n except KeyboardInterrupt:\n pool.terminate()\n pool.join()\n Publisher().publish(\"terra.parallel.parallel.finish\")\n raise QISKitError('Keyboard interrupt in parallel_map.')\n\n Publisher().publish(\"terra.transpiler.parallel.finish\")\n os.environ['QISKIT_IN_PARALLEL'] = 'FALSE'\n return [ar.get() for ar in async_res]\n\n # Cannot do parallel on Windows , if another parallel_map is running in parallel,\n # or len(values) == 1.\n results = []\n for _, value in enumerate(values):\n result = task(value, *task_args, **task_kwargs)\n results.append(result)\n _callback(0)\n Publisher().publish(\"terra.transpiler.parallel.finish\")\n return results\n", "path": "qiskit/transpiler/_parallel.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright 2018, IBM.\n#\n# This source code is licensed under the Apache License, Version 2.0 found in\n# the LICENSE.txt file in the root directory of this source tree.\n\n# This file is part of QuTiP: Quantum Toolbox in Python.\n#\n# Copyright (c) 2011 and later, Paul D. Nation and Robert J. Johansson.\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are\n# met:\n#\n# 1. Redistributions of source code must retain the above copyright notice,\n# this list of conditions and the following disclaimer.\n#\n# 2. Redistributions in binary form must reproduce the above copyright\n# notice, this list of conditions and the following disclaimer in the\n# documentation and/or other materials provided with the distribution.\n#\n# 3. Neither the name of the QuTiP: Quantum Toolbox in Python nor the names\n# of its contributors may be used to endorse or promote products derived\n# from this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS\n# \"AS IS\" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT\n# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A\n# PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT\n# HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,\n# SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT\n# LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,\n# DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY\n# THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT\n# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n###############################################################################\n\n\"\"\"\nRoutines for running Python functions in parallel using process pools\nfrom the multiprocessing library.\n\"\"\"\n\nimport os\nimport platform\nfrom multiprocessing import Pool\nfrom qiskit._qiskiterror import QISKitError\nfrom qiskit._util import local_hardware_info\nfrom qiskit._pubsub import Publisher\n\n# Number of local physical cpus\nCPU_COUNT = local_hardware_info()['cpus']\n\n\ndef parallel_map(task, values, task_args=tuple(), task_kwargs={}, # pylint: disable=W0102\n num_processes=CPU_COUNT):\n \"\"\"\n Parallel execution of a mapping of `values` to the function `task`. This\n is functionally equivalent to::\n\n result = [task(value, *task_args, **task_kwargs) for value in values]\n\n On Windows this function defaults to a serial implementation to avoid the\n overhead from spawning processes in Windows.\n\n Args:\n task (func): Function that is to be called for each value in ``task_vec``.\n values (array_like): List or array of values for which the ``task``\n function is to be evaluated.\n task_args (list): Optional additional arguments to the ``task`` function.\n task_kwargs (dict): Optional additional keyword argument to the ``task`` function.\n num_processes (int): Number of processes to spawn.\n\n Returns:\n result: The result list contains the value of\n ``task(value, *task_args, **task_kwargs)`` for\n each value in ``values``.\n\n Raises:\n QISKitError: If user interrupts via keyboard.\n\n Events:\n terra.transpiler.parallel.start: The collection of parallel tasks are about to start.\n terra.transpiler.parallel.update: One of the parallel task has finished.\n terra.transpiler.parallel.finish: All the parallel tasks have finished.\n \"\"\"\n if len(values) == 1:\n return [task(values[0], *task_args, **task_kwargs)]\n\n Publisher().publish(\"terra.transpiler.parallel.start\", len(values))\n nfinished = [0]\n\n def _callback(_):\n nfinished[0] += 1\n Publisher().publish(\"terra.transpiler.parallel.done\", nfinished[0])\n\n # Run in parallel if not Win and not in parallel already\n if platform.system() != 'Windows' and num_processes > 1 \\\n and os.getenv('QISKIT_IN_PARALLEL') == 'FALSE':\n os.environ['QISKIT_IN_PARALLEL'] = 'TRUE'\n try:\n pool = Pool(processes=num_processes)\n\n async_res = [pool.apply_async(task, (value,) + task_args, task_kwargs,\n _callback) for value in values]\n\n while not all([item.ready() for item in async_res]):\n for item in async_res:\n item.wait(timeout=0.1)\n\n pool.terminate()\n pool.join()\n\n except KeyboardInterrupt:\n pool.terminate()\n pool.join()\n Publisher().publish(\"terra.parallel.parallel.finish\")\n raise QISKitError('Keyboard interrupt in parallel_map.')\n\n Publisher().publish(\"terra.transpiler.parallel.finish\")\n os.environ['QISKIT_IN_PARALLEL'] = 'FALSE'\n return [ar.get() for ar in async_res]\n\n # Cannot do parallel on Windows , if another parallel_map is running in parallel,\n # or len(values) == 1.\n results = []\n for _, value in enumerate(values):\n result = task(value, *task_args, **task_kwargs)\n results.append(result)\n _callback(0)\n Publisher().publish(\"terra.transpiler.parallel.finish\")\n return results\n", "path": "qiskit/transpiler/_parallel.py"}]}
| 2,005 | 171 |
gh_patches_debug_37473
|
rasdani/github-patches
|
git_diff
|
OpenNMT__OpenNMT-py-1101
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Repeated check in code
https://github.com/OpenNMT/OpenNMT-py/blob/master/onmt/modules/multi_headed_attn.py#L133, why is the layer_cache is not None check required again? Similarly will this be ever called? https://github.com/OpenNMT/OpenNMT-py/blob/master/onmt/modules/multi_headed_attn.py#L158
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `onmt/modules/multi_headed_attn.py`
Content:
```
1 """ Multi-Head Attention module """
2 import math
3 import torch
4 import torch.nn as nn
5
6 # from onmt.utils.misc import aeq
7
8
9 class MultiHeadedAttention(nn.Module):
10 """
11 Multi-Head Attention module from
12 "Attention is All You Need"
13 :cite:`DBLP:journals/corr/VaswaniSPUJGKP17`.
14
15 Similar to standard `dot` attention but uses
16 multiple attention distributions simulataneously
17 to select relevant items.
18
19 .. mermaid::
20
21 graph BT
22 A[key]
23 B[value]
24 C[query]
25 O[output]
26 subgraph Attn
27 D[Attn 1]
28 E[Attn 2]
29 F[Attn N]
30 end
31 A --> D
32 C --> D
33 A --> E
34 C --> E
35 A --> F
36 C --> F
37 D --> O
38 E --> O
39 F --> O
40 B --> O
41
42 Also includes several additional tricks.
43
44 Args:
45 head_count (int): number of parallel heads
46 model_dim (int): the dimension of keys/values/queries,
47 must be divisible by head_count
48 dropout (float): dropout parameter
49 """
50
51 def __init__(self, head_count, model_dim, dropout=0.1):
52 assert model_dim % head_count == 0
53 self.dim_per_head = model_dim // head_count
54 self.model_dim = model_dim
55
56 super(MultiHeadedAttention, self).__init__()
57 self.head_count = head_count
58
59 self.linear_keys = nn.Linear(model_dim,
60 head_count * self.dim_per_head)
61 self.linear_values = nn.Linear(model_dim,
62 head_count * self.dim_per_head)
63 self.linear_query = nn.Linear(model_dim,
64 head_count * self.dim_per_head)
65 self.softmax = nn.Softmax(dim=-1)
66 self.dropout = nn.Dropout(dropout)
67 self.final_linear = nn.Linear(model_dim, model_dim)
68
69 def forward(self, key, value, query, mask=None,
70 layer_cache=None, type=None):
71 """
72 Compute the context vector and the attention vectors.
73
74 Args:
75 key (`FloatTensor`): set of `key_len`
76 key vectors `[batch, key_len, dim]`
77 value (`FloatTensor`): set of `key_len`
78 value vectors `[batch, key_len, dim]`
79 query (`FloatTensor`): set of `query_len`
80 query vectors `[batch, query_len, dim]`
81 mask: binary mask indicating which keys have
82 non-zero attention `[batch, query_len, key_len]`
83 Returns:
84 (`FloatTensor`, `FloatTensor`) :
85
86 * output context vectors `[batch, query_len, dim]`
87 * one of the attention vectors `[batch, query_len, key_len]`
88 """
89
90 # CHECKS
91 # batch, k_len, d = key.size()
92 # batch_, k_len_, d_ = value.size()
93 # aeq(batch, batch_)
94 # aeq(k_len, k_len_)
95 # aeq(d, d_)
96 # batch_, q_len, d_ = query.size()
97 # aeq(batch, batch_)
98 # aeq(d, d_)
99 # aeq(self.model_dim % 8, 0)
100 # if mask is not None:
101 # batch_, q_len_, k_len_ = mask.size()
102 # aeq(batch_, batch)
103 # aeq(k_len_, k_len)
104 # aeq(q_len_ == q_len)
105 # END CHECKS
106
107 batch_size = key.size(0)
108 dim_per_head = self.dim_per_head
109 head_count = self.head_count
110 key_len = key.size(1)
111 query_len = query.size(1)
112
113 def shape(x):
114 """ projection """
115 return x.view(batch_size, -1, head_count, dim_per_head) \
116 .transpose(1, 2)
117
118 def unshape(x):
119 """ compute context """
120 return x.transpose(1, 2).contiguous() \
121 .view(batch_size, -1, head_count * dim_per_head)
122
123 # 1) Project key, value, and query.
124 if layer_cache is not None:
125 if type == "self":
126 query, key, value = self.linear_query(query),\
127 self.linear_keys(query),\
128 self.linear_values(query)
129
130 key = shape(key)
131 value = shape(value)
132
133 if layer_cache is not None:
134 device = key.device
135 if layer_cache["self_keys"] is not None:
136 key = torch.cat(
137 (layer_cache["self_keys"].to(device), key),
138 dim=2)
139 if layer_cache["self_values"] is not None:
140 value = torch.cat(
141 (layer_cache["self_values"].to(device), value),
142 dim=2)
143 layer_cache["self_keys"] = key
144 layer_cache["self_values"] = value
145 elif type == "context":
146 query = self.linear_query(query)
147 if layer_cache is not None:
148 if layer_cache["memory_keys"] is None:
149 key, value = self.linear_keys(key),\
150 self.linear_values(value)
151 key = shape(key)
152 value = shape(value)
153 else:
154 key, value = layer_cache["memory_keys"],\
155 layer_cache["memory_values"]
156 layer_cache["memory_keys"] = key
157 layer_cache["memory_values"] = value
158 else:
159 key, value = self.linear_keys(key),\
160 self.linear_values(value)
161 key = shape(key)
162 value = shape(value)
163 else:
164 key = self.linear_keys(key)
165 value = self.linear_values(value)
166 query = self.linear_query(query)
167 key = shape(key)
168 value = shape(value)
169
170 query = shape(query)
171
172 key_len = key.size(2)
173 query_len = query.size(2)
174
175 # 2) Calculate and scale scores.
176 query = query / math.sqrt(dim_per_head)
177 scores = torch.matmul(query, key.transpose(2, 3))
178
179 if mask is not None:
180 mask = mask.unsqueeze(1) # [B, 1, 1, T_values]
181 scores = scores.masked_fill(mask, -1e18)
182
183 # 3) Apply attention dropout and compute context vectors.
184 attn = self.softmax(scores)
185 drop_attn = self.dropout(attn)
186 context = unshape(torch.matmul(drop_attn, value))
187
188 output = self.final_linear(context)
189 # CHECK
190 # batch_, q_len_, d_ = output.size()
191 # aeq(q_len, q_len_)
192 # aeq(batch, batch_)
193 # aeq(d, d_)
194
195 # Return one attn
196 top_attn = attn \
197 .view(batch_size, head_count,
198 query_len, key_len)[:, 0, :, :] \
199 .contiguous()
200
201 return output, top_attn
202
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/onmt/modules/multi_headed_attn.py b/onmt/modules/multi_headed_attn.py
--- a/onmt/modules/multi_headed_attn.py
+++ b/onmt/modules/multi_headed_attn.py
@@ -126,40 +126,31 @@
query, key, value = self.linear_query(query),\
self.linear_keys(query),\
self.linear_values(query)
-
key = shape(key)
value = shape(value)
-
- if layer_cache is not None:
- device = key.device
- if layer_cache["self_keys"] is not None:
- key = torch.cat(
- (layer_cache["self_keys"].to(device), key),
- dim=2)
- if layer_cache["self_values"] is not None:
- value = torch.cat(
- (layer_cache["self_values"].to(device), value),
- dim=2)
- layer_cache["self_keys"] = key
- layer_cache["self_values"] = value
+ device = key.device
+ if layer_cache["self_keys"] is not None:
+ key = torch.cat(
+ (layer_cache["self_keys"].to(device), key),
+ dim=2)
+ if layer_cache["self_values"] is not None:
+ value = torch.cat(
+ (layer_cache["self_values"].to(device), value),
+ dim=2)
+ layer_cache["self_keys"] = key
+ layer_cache["self_values"] = value
elif type == "context":
query = self.linear_query(query)
- if layer_cache is not None:
- if layer_cache["memory_keys"] is None:
- key, value = self.linear_keys(key),\
- self.linear_values(value)
- key = shape(key)
- value = shape(value)
- else:
- key, value = layer_cache["memory_keys"],\
- layer_cache["memory_values"]
- layer_cache["memory_keys"] = key
- layer_cache["memory_values"] = value
- else:
+ if layer_cache["memory_keys"] is None:
key, value = self.linear_keys(key),\
self.linear_values(value)
key = shape(key)
value = shape(value)
+ else:
+ key, value = layer_cache["memory_keys"],\
+ layer_cache["memory_values"]
+ layer_cache["memory_keys"] = key
+ layer_cache["memory_values"] = value
else:
key = self.linear_keys(key)
value = self.linear_values(value)
|
{"golden_diff": "diff --git a/onmt/modules/multi_headed_attn.py b/onmt/modules/multi_headed_attn.py\n--- a/onmt/modules/multi_headed_attn.py\n+++ b/onmt/modules/multi_headed_attn.py\n@@ -126,40 +126,31 @@\n query, key, value = self.linear_query(query),\\\n self.linear_keys(query),\\\n self.linear_values(query)\n-\n key = shape(key)\n value = shape(value)\n-\n- if layer_cache is not None:\n- device = key.device\n- if layer_cache[\"self_keys\"] is not None:\n- key = torch.cat(\n- (layer_cache[\"self_keys\"].to(device), key),\n- dim=2)\n- if layer_cache[\"self_values\"] is not None:\n- value = torch.cat(\n- (layer_cache[\"self_values\"].to(device), value),\n- dim=2)\n- layer_cache[\"self_keys\"] = key\n- layer_cache[\"self_values\"] = value\n+ device = key.device\n+ if layer_cache[\"self_keys\"] is not None:\n+ key = torch.cat(\n+ (layer_cache[\"self_keys\"].to(device), key),\n+ dim=2)\n+ if layer_cache[\"self_values\"] is not None:\n+ value = torch.cat(\n+ (layer_cache[\"self_values\"].to(device), value),\n+ dim=2)\n+ layer_cache[\"self_keys\"] = key\n+ layer_cache[\"self_values\"] = value\n elif type == \"context\":\n query = self.linear_query(query)\n- if layer_cache is not None:\n- if layer_cache[\"memory_keys\"] is None:\n- key, value = self.linear_keys(key),\\\n- self.linear_values(value)\n- key = shape(key)\n- value = shape(value)\n- else:\n- key, value = layer_cache[\"memory_keys\"],\\\n- layer_cache[\"memory_values\"]\n- layer_cache[\"memory_keys\"] = key\n- layer_cache[\"memory_values\"] = value\n- else:\n+ if layer_cache[\"memory_keys\"] is None:\n key, value = self.linear_keys(key),\\\n self.linear_values(value)\n key = shape(key)\n value = shape(value)\n+ else:\n+ key, value = layer_cache[\"memory_keys\"],\\\n+ layer_cache[\"memory_values\"]\n+ layer_cache[\"memory_keys\"] = key\n+ layer_cache[\"memory_values\"] = value\n else:\n key = self.linear_keys(key)\n value = self.linear_values(value)\n", "issue": "Repeated check in code\nhttps://github.com/OpenNMT/OpenNMT-py/blob/master/onmt/modules/multi_headed_attn.py#L133, why is the layer_cache is not None check required again? Similarly will this be ever called? https://github.com/OpenNMT/OpenNMT-py/blob/master/onmt/modules/multi_headed_attn.py#L158 \n", "before_files": [{"content": "\"\"\" Multi-Head Attention module \"\"\"\nimport math\nimport torch\nimport torch.nn as nn\n\n# from onmt.utils.misc import aeq\n\n\nclass MultiHeadedAttention(nn.Module):\n \"\"\"\n Multi-Head Attention module from\n \"Attention is All You Need\"\n :cite:`DBLP:journals/corr/VaswaniSPUJGKP17`.\n\n Similar to standard `dot` attention but uses\n multiple attention distributions simulataneously\n to select relevant items.\n\n .. mermaid::\n\n graph BT\n A[key]\n B[value]\n C[query]\n O[output]\n subgraph Attn\n D[Attn 1]\n E[Attn 2]\n F[Attn N]\n end\n A --> D\n C --> D\n A --> E\n C --> E\n A --> F\n C --> F\n D --> O\n E --> O\n F --> O\n B --> O\n\n Also includes several additional tricks.\n\n Args:\n head_count (int): number of parallel heads\n model_dim (int): the dimension of keys/values/queries,\n must be divisible by head_count\n dropout (float): dropout parameter\n \"\"\"\n\n def __init__(self, head_count, model_dim, dropout=0.1):\n assert model_dim % head_count == 0\n self.dim_per_head = model_dim // head_count\n self.model_dim = model_dim\n\n super(MultiHeadedAttention, self).__init__()\n self.head_count = head_count\n\n self.linear_keys = nn.Linear(model_dim,\n head_count * self.dim_per_head)\n self.linear_values = nn.Linear(model_dim,\n head_count * self.dim_per_head)\n self.linear_query = nn.Linear(model_dim,\n head_count * self.dim_per_head)\n self.softmax = nn.Softmax(dim=-1)\n self.dropout = nn.Dropout(dropout)\n self.final_linear = nn.Linear(model_dim, model_dim)\n\n def forward(self, key, value, query, mask=None,\n layer_cache=None, type=None):\n \"\"\"\n Compute the context vector and the attention vectors.\n\n Args:\n key (`FloatTensor`): set of `key_len`\n key vectors `[batch, key_len, dim]`\n value (`FloatTensor`): set of `key_len`\n value vectors `[batch, key_len, dim]`\n query (`FloatTensor`): set of `query_len`\n query vectors `[batch, query_len, dim]`\n mask: binary mask indicating which keys have\n non-zero attention `[batch, query_len, key_len]`\n Returns:\n (`FloatTensor`, `FloatTensor`) :\n\n * output context vectors `[batch, query_len, dim]`\n * one of the attention vectors `[batch, query_len, key_len]`\n \"\"\"\n\n # CHECKS\n # batch, k_len, d = key.size()\n # batch_, k_len_, d_ = value.size()\n # aeq(batch, batch_)\n # aeq(k_len, k_len_)\n # aeq(d, d_)\n # batch_, q_len, d_ = query.size()\n # aeq(batch, batch_)\n # aeq(d, d_)\n # aeq(self.model_dim % 8, 0)\n # if mask is not None:\n # batch_, q_len_, k_len_ = mask.size()\n # aeq(batch_, batch)\n # aeq(k_len_, k_len)\n # aeq(q_len_ == q_len)\n # END CHECKS\n\n batch_size = key.size(0)\n dim_per_head = self.dim_per_head\n head_count = self.head_count\n key_len = key.size(1)\n query_len = query.size(1)\n\n def shape(x):\n \"\"\" projection \"\"\"\n return x.view(batch_size, -1, head_count, dim_per_head) \\\n .transpose(1, 2)\n\n def unshape(x):\n \"\"\" compute context \"\"\"\n return x.transpose(1, 2).contiguous() \\\n .view(batch_size, -1, head_count * dim_per_head)\n\n # 1) Project key, value, and query.\n if layer_cache is not None:\n if type == \"self\":\n query, key, value = self.linear_query(query),\\\n self.linear_keys(query),\\\n self.linear_values(query)\n\n key = shape(key)\n value = shape(value)\n\n if layer_cache is not None:\n device = key.device\n if layer_cache[\"self_keys\"] is not None:\n key = torch.cat(\n (layer_cache[\"self_keys\"].to(device), key),\n dim=2)\n if layer_cache[\"self_values\"] is not None:\n value = torch.cat(\n (layer_cache[\"self_values\"].to(device), value),\n dim=2)\n layer_cache[\"self_keys\"] = key\n layer_cache[\"self_values\"] = value\n elif type == \"context\":\n query = self.linear_query(query)\n if layer_cache is not None:\n if layer_cache[\"memory_keys\"] is None:\n key, value = self.linear_keys(key),\\\n self.linear_values(value)\n key = shape(key)\n value = shape(value)\n else:\n key, value = layer_cache[\"memory_keys\"],\\\n layer_cache[\"memory_values\"]\n layer_cache[\"memory_keys\"] = key\n layer_cache[\"memory_values\"] = value\n else:\n key, value = self.linear_keys(key),\\\n self.linear_values(value)\n key = shape(key)\n value = shape(value)\n else:\n key = self.linear_keys(key)\n value = self.linear_values(value)\n query = self.linear_query(query)\n key = shape(key)\n value = shape(value)\n\n query = shape(query)\n\n key_len = key.size(2)\n query_len = query.size(2)\n\n # 2) Calculate and scale scores.\n query = query / math.sqrt(dim_per_head)\n scores = torch.matmul(query, key.transpose(2, 3))\n\n if mask is not None:\n mask = mask.unsqueeze(1) # [B, 1, 1, T_values]\n scores = scores.masked_fill(mask, -1e18)\n\n # 3) Apply attention dropout and compute context vectors.\n attn = self.softmax(scores)\n drop_attn = self.dropout(attn)\n context = unshape(torch.matmul(drop_attn, value))\n\n output = self.final_linear(context)\n # CHECK\n # batch_, q_len_, d_ = output.size()\n # aeq(q_len, q_len_)\n # aeq(batch, batch_)\n # aeq(d, d_)\n\n # Return one attn\n top_attn = attn \\\n .view(batch_size, head_count,\n query_len, key_len)[:, 0, :, :] \\\n .contiguous()\n\n return output, top_attn\n", "path": "onmt/modules/multi_headed_attn.py"}], "after_files": [{"content": "\"\"\" Multi-Head Attention module \"\"\"\nimport math\nimport torch\nimport torch.nn as nn\n\n# from onmt.utils.misc import aeq\n\n\nclass MultiHeadedAttention(nn.Module):\n \"\"\"\n Multi-Head Attention module from\n \"Attention is All You Need\"\n :cite:`DBLP:journals/corr/VaswaniSPUJGKP17`.\n\n Similar to standard `dot` attention but uses\n multiple attention distributions simulataneously\n to select relevant items.\n\n .. mermaid::\n\n graph BT\n A[key]\n B[value]\n C[query]\n O[output]\n subgraph Attn\n D[Attn 1]\n E[Attn 2]\n F[Attn N]\n end\n A --> D\n C --> D\n A --> E\n C --> E\n A --> F\n C --> F\n D --> O\n E --> O\n F --> O\n B --> O\n\n Also includes several additional tricks.\n\n Args:\n head_count (int): number of parallel heads\n model_dim (int): the dimension of keys/values/queries,\n must be divisible by head_count\n dropout (float): dropout parameter\n \"\"\"\n\n def __init__(self, head_count, model_dim, dropout=0.1):\n assert model_dim % head_count == 0\n self.dim_per_head = model_dim // head_count\n self.model_dim = model_dim\n\n super(MultiHeadedAttention, self).__init__()\n self.head_count = head_count\n\n self.linear_keys = nn.Linear(model_dim,\n head_count * self.dim_per_head)\n self.linear_values = nn.Linear(model_dim,\n head_count * self.dim_per_head)\n self.linear_query = nn.Linear(model_dim,\n head_count * self.dim_per_head)\n self.softmax = nn.Softmax(dim=-1)\n self.dropout = nn.Dropout(dropout)\n self.final_linear = nn.Linear(model_dim, model_dim)\n\n def forward(self, key, value, query, mask=None,\n layer_cache=None, type=None):\n \"\"\"\n Compute the context vector and the attention vectors.\n\n Args:\n key (`FloatTensor`): set of `key_len`\n key vectors `[batch, key_len, dim]`\n value (`FloatTensor`): set of `key_len`\n value vectors `[batch, key_len, dim]`\n query (`FloatTensor`): set of `query_len`\n query vectors `[batch, query_len, dim]`\n mask: binary mask indicating which keys have\n non-zero attention `[batch, query_len, key_len]`\n Returns:\n (`FloatTensor`, `FloatTensor`) :\n\n * output context vectors `[batch, query_len, dim]`\n * one of the attention vectors `[batch, query_len, key_len]`\n \"\"\"\n\n # CHECKS\n # batch, k_len, d = key.size()\n # batch_, k_len_, d_ = value.size()\n # aeq(batch, batch_)\n # aeq(k_len, k_len_)\n # aeq(d, d_)\n # batch_, q_len, d_ = query.size()\n # aeq(batch, batch_)\n # aeq(d, d_)\n # aeq(self.model_dim % 8, 0)\n # if mask is not None:\n # batch_, q_len_, k_len_ = mask.size()\n # aeq(batch_, batch)\n # aeq(k_len_, k_len)\n # aeq(q_len_ == q_len)\n # END CHECKS\n\n batch_size = key.size(0)\n dim_per_head = self.dim_per_head\n head_count = self.head_count\n key_len = key.size(1)\n query_len = query.size(1)\n\n def shape(x):\n \"\"\" projection \"\"\"\n return x.view(batch_size, -1, head_count, dim_per_head) \\\n .transpose(1, 2)\n\n def unshape(x):\n \"\"\" compute context \"\"\"\n return x.transpose(1, 2).contiguous() \\\n .view(batch_size, -1, head_count * dim_per_head)\n\n # 1) Project key, value, and query.\n if layer_cache is not None:\n if type == \"self\":\n query, key, value = self.linear_query(query),\\\n self.linear_keys(query),\\\n self.linear_values(query)\n key = shape(key)\n value = shape(value)\n device = key.device\n if layer_cache[\"self_keys\"] is not None:\n key = torch.cat(\n (layer_cache[\"self_keys\"].to(device), key),\n dim=2)\n if layer_cache[\"self_values\"] is not None:\n value = torch.cat(\n (layer_cache[\"self_values\"].to(device), value),\n dim=2)\n layer_cache[\"self_keys\"] = key\n layer_cache[\"self_values\"] = value\n elif type == \"context\":\n query = self.linear_query(query)\n if layer_cache[\"memory_keys\"] is None:\n key, value = self.linear_keys(key),\\\n self.linear_values(value)\n key = shape(key)\n value = shape(value)\n else:\n key, value = layer_cache[\"memory_keys\"],\\\n layer_cache[\"memory_values\"]\n layer_cache[\"memory_keys\"] = key\n layer_cache[\"memory_values\"] = value\n else:\n key = self.linear_keys(key)\n value = self.linear_values(value)\n query = self.linear_query(query)\n key = shape(key)\n value = shape(value)\n\n query = shape(query)\n\n key_len = key.size(2)\n query_len = query.size(2)\n\n # 2) Calculate and scale scores.\n query = query / math.sqrt(dim_per_head)\n scores = torch.matmul(query, key.transpose(2, 3))\n\n if mask is not None:\n mask = mask.unsqueeze(1) # [B, 1, 1, T_values]\n scores = scores.masked_fill(mask, -1e18)\n\n # 3) Apply attention dropout and compute context vectors.\n attn = self.softmax(scores)\n drop_attn = self.dropout(attn)\n context = unshape(torch.matmul(drop_attn, value))\n\n output = self.final_linear(context)\n # CHECK\n # batch_, q_len_, d_ = output.size()\n # aeq(q_len, q_len_)\n # aeq(batch, batch_)\n # aeq(d, d_)\n\n # Return one attn\n top_attn = attn \\\n .view(batch_size, head_count,\n query_len, key_len)[:, 0, :, :] \\\n .contiguous()\n\n return output, top_attn\n", "path": "onmt/modules/multi_headed_attn.py"}]}
| 2,362 | 562 |
gh_patches_debug_21739
|
rasdani/github-patches
|
git_diff
|
holoviz__holoviews-3810
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
UserWarning: Config option `use_jedi` not recognized by `IPCompleter`.
This error is show when I'm trying to import bokeh:
`hv.extension('bokeh')`
Product versions:
- numpy 1.16.4
- pandas 0.24.4
- bokeh 1.2.0
- holoviews 1.12.3
- hvplot 0.4.0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `holoviews/ipython/__init__.py`
Content:
```
1 import os
2 from unittest import SkipTest
3
4 import param
5 import holoviews
6 from pyviz_comms import nb_mime_js
7 from IPython import version_info
8 from param import ipython as param_ext
9 from IPython.display import HTML, publish_display_data
10
11 from ..core.dimension import LabelledData
12 from ..core.tree import AttrTree
13 from ..core.options import Store
14 from ..element.comparison import ComparisonTestCase
15 from ..util import extension
16 from ..plotting.renderer import Renderer, MIME_TYPES
17 from .magics import load_magics
18 from .display_hooks import display # noqa (API import)
19 from .display_hooks import pprint_display, png_display, svg_display
20
21
22 AttrTree._disabled_prefixes = ['_repr_','_ipython_canary_method_should_not_exist']
23
24 def show_traceback():
25 """
26 Display the full traceback after an abbreviated traceback has occurred.
27 """
28 from .display_hooks import FULL_TRACEBACK
29 print(FULL_TRACEBACK)
30
31
32 class IPTestCase(ComparisonTestCase):
33 """
34 This class extends ComparisonTestCase to handle IPython specific
35 objects and support the execution of cells and magic.
36 """
37
38 def setUp(self):
39 super(IPTestCase, self).setUp()
40 try:
41 import IPython
42 from IPython.display import HTML, SVG
43 self.ip = IPython.InteractiveShell()
44 if self.ip is None:
45 raise TypeError()
46 except Exception:
47 raise SkipTest("IPython could not be started")
48
49 self.addTypeEqualityFunc(HTML, self.skip_comparison)
50 self.addTypeEqualityFunc(SVG, self.skip_comparison)
51
52 def skip_comparison(self, obj1, obj2, msg): pass
53
54 def get_object(self, name):
55 obj = self.ip._object_find(name).obj
56 if obj is None:
57 raise self.failureException("Could not find object %s" % name)
58 return obj
59
60
61 def cell(self, line):
62 "Run an IPython cell"
63 self.ip.run_cell(line, silent=True)
64
65 def cell_magic(self, *args, **kwargs):
66 "Run an IPython cell magic"
67 self.ip.run_cell_magic(*args, **kwargs)
68
69
70 def line_magic(self, *args, **kwargs):
71 "Run an IPython line magic"
72 self.ip.run_line_magic(*args, **kwargs)
73
74
75 class notebook_extension(extension):
76 """
77 Notebook specific extension to hv.extension that offers options for
78 controlling the notebook environment.
79 """
80
81 css = param.String(default='', doc="Optional CSS rule set to apply to the notebook.")
82
83 logo = param.Boolean(default=True, doc="Toggles display of HoloViews logo")
84
85 inline = param.Boolean(default=True, doc="""
86 Whether to inline JS and CSS resources.
87 If disabled, resources are loaded from CDN if one is available.""")
88
89 width = param.Number(default=None, bounds=(0, 100), doc="""
90 Width of the notebook as a percentage of the browser screen window width.""")
91
92 display_formats = param.List(default=['html'], doc="""
93 A list of formats that are rendered to the notebook where
94 multiple formats may be selected at once (although only one
95 format will be displayed).
96
97 Although the 'html' format is supported across backends, other
98 formats supported by the current backend (e.g 'png' and 'svg'
99 using the matplotlib backend) may be used. This may be useful to
100 export figures to other formats such as PDF with nbconvert. """)
101
102 allow_jedi_completion = param.Boolean(default=False, doc="""
103 Whether to allow jedi tab-completion to be enabled in IPython.
104 Disabled by default because many HoloViews features rely on
105 tab-completion machinery not supported when using jedi.""")
106
107 case_sensitive_completion = param.Boolean(default=False, doc="""
108 Whether to monkey patch IPython to use the correct tab-completion
109 behavior. """)
110
111 _loaded = False
112
113 def __call__(self, *args, **params):
114 super(notebook_extension, self).__call__(*args, **params)
115 # Abort if IPython not found
116 try:
117 ip = params.pop('ip', None) or get_ipython() # noqa (get_ipython)
118 except:
119 return
120
121 # Notebook archive relies on display hooks being set to work.
122 try:
123 if version_info[0] >= 4:
124 import nbformat # noqa (ensures availability)
125 else:
126 from IPython import nbformat # noqa (ensures availability)
127 try:
128 from .archive import notebook_archive
129 holoviews.archive = notebook_archive
130 except AttributeError as e:
131 if str(e) != "module 'tornado.web' has no attribute 'asynchronous'":
132 raise
133
134 except ImportError:
135 pass
136
137 # Not quite right, should be set when switching backends
138 if 'matplotlib' in Store.renderers and not notebook_extension._loaded:
139 svg_exporter = Store.renderers['matplotlib'].instance(holomap=None,fig='svg')
140 holoviews.archive.exporters = [svg_exporter] + holoviews.archive.exporters
141
142 p = param.ParamOverrides(self, {k:v for k,v in params.items() if k!='config'})
143 if p.case_sensitive_completion:
144 from IPython.core import completer
145 completer.completions_sorting_key = self.completions_sorting_key
146 if not p.allow_jedi_completion:
147 ip.run_line_magic('config', 'IPCompleter.use_jedi = False')
148
149 resources = self._get_resources(args, params)
150
151 Store.display_formats = p.display_formats
152 if 'html' not in p.display_formats and len(p.display_formats) > 1:
153 msg = ('Output magic unable to control displayed format '
154 'as IPython notebook uses fixed precedence '
155 'between %r' % p.display_formats)
156 display(HTML('<b>Warning</b>: %s' % msg))
157
158 loaded = notebook_extension._loaded
159 if loaded == False:
160 param_ext.load_ipython_extension(ip, verbose=False)
161 load_magics(ip)
162 Store.output_settings.initialize(list(Store.renderers.keys()))
163 Store.set_display_hook('html+js', LabelledData, pprint_display)
164 Store.set_display_hook('png', LabelledData, png_display)
165 Store.set_display_hook('svg', LabelledData, svg_display)
166 notebook_extension._loaded = True
167
168 css = ''
169 if p.width is not None:
170 css += '<style>div.container { width: %s%% }</style>' % p.width
171 if p.css:
172 css += '<style>%s</style>' % p.css
173 if css:
174 display(HTML(css))
175
176 resources = list(resources)
177 if len(resources) == 0: return
178
179 Renderer.load_nb()
180 for r in [r for r in resources if r != 'holoviews']:
181 Store.renderers[r].load_nb(inline=p.inline)
182
183 if hasattr(ip, 'kernel') and not loaded:
184 Renderer.comm_manager.get_client_comm(notebook_extension._process_comm_msg,
185 "hv-extension-comm")
186
187 # Create a message for the logo (if shown)
188 self.load_hvjs(logo=p.logo,
189 bokeh_logo= p.logo and ('bokeh' in resources),
190 mpl_logo= p.logo and (('matplotlib' in resources)
191 or resources==['holoviews']),
192 plotly_logo= p.logo and ('plotly' in resources),
193 JS=('holoviews' in resources))
194
195 @classmethod
196 def completions_sorting_key(cls, word):
197 "Fixed version of IPyton.completer.completions_sorting_key"
198 prio1, prio2 = 0, 0
199 if word.startswith('__'): prio1 = 2
200 elif word.startswith('_'): prio1 = 1
201 if word.endswith('='): prio1 = -1
202 if word.startswith('%%'):
203 if not "%" in word[2:]:
204 word = word[2:]; prio2 = 2
205 elif word.startswith('%'):
206 if not "%" in word[1:]:
207 word = word[1:]; prio2 = 1
208 return prio1, word, prio2
209
210
211 def _get_resources(self, args, params):
212 """
213 Finds the list of resources from the keyword parameters and pops
214 them out of the params dictionary.
215 """
216 resources = []
217 disabled = []
218 for resource in ['holoviews'] + list(Store.renderers.keys()):
219 if resource in args:
220 resources.append(resource)
221
222 if resource in params:
223 setting = params.pop(resource)
224 if setting is True and resource != 'matplotlib':
225 if resource not in resources:
226 resources.append(resource)
227 if setting is False:
228 disabled.append(resource)
229
230 unmatched_args = set(args) - set(resources)
231 if unmatched_args:
232 display(HTML('<b>Warning:</b> Unrecognized resources %s'
233 % ', '.join(unmatched_args)))
234
235 resources = [r for r in resources if r not in disabled]
236 if ('holoviews' not in disabled) and ('holoviews' not in resources):
237 resources = ['holoviews'] + resources
238 return resources
239
240 @classmethod
241 def load_hvjs(cls, logo=False, bokeh_logo=False, mpl_logo=False, plotly_logo=False,
242 JS=True, message='HoloViewsJS successfully loaded.'):
243 """
244 Displays javascript and CSS to initialize HoloViews widgets.
245 """
246 import jinja2
247 # Evaluate load_notebook.html template with widgetjs code
248 if JS:
249 widgetjs, widgetcss = Renderer.html_assets(extras=False, backends=[], script=True)
250 else:
251 widgetjs, widgetcss = '', ''
252
253 # Add classic notebook MIME renderer
254 widgetjs += nb_mime_js
255
256 templateLoader = jinja2.FileSystemLoader(os.path.dirname(os.path.abspath(__file__)))
257 jinjaEnv = jinja2.Environment(loader=templateLoader)
258 template = jinjaEnv.get_template('load_notebook.html')
259 html = template.render({'widgetcss': widgetcss,
260 'logo': logo,
261 'bokeh_logo': bokeh_logo,
262 'mpl_logo': mpl_logo,
263 'plotly_logo': plotly_logo,
264 'message': message})
265 publish_display_data(data={'text/html': html})
266
267 # Vanilla JS mime type is only consumed by classic notebook
268 # Custom mime type is only consumed by JupyterLab
269 if JS:
270 mimebundle = {
271 MIME_TYPES['js'] : widgetjs,
272 MIME_TYPES['jlab-hv-load'] : widgetjs
273 }
274 publish_display_data(data=mimebundle)
275
276
277 @param.parameterized.bothmethod
278 def tab_completion_docstring(self_or_cls):
279 """
280 Generates a docstring that can be used to enable tab-completion
281 of resources.
282 """
283 elements = ['%s=Boolean' %k for k in list(Store.renderers.keys())]
284 for name, p in self_or_cls.param.objects().items():
285 param_type = p.__class__.__name__
286 elements.append("%s=%s" % (name, param_type))
287
288 return "params(%s)" % ', '.join(['holoviews=Boolean'] + elements)
289
290
291 notebook_extension.__doc__ = notebook_extension.tab_completion_docstring()
292 notebook_extension.add_delete_action(Renderer._delete_plot)
293
294
295 def load_ipython_extension(ip):
296 notebook_extension(ip=ip)
297
298 def unload_ipython_extension(ip):
299 notebook_extension._loaded = False
300
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/holoviews/ipython/__init__.py b/holoviews/ipython/__init__.py
--- a/holoviews/ipython/__init__.py
+++ b/holoviews/ipython/__init__.py
@@ -3,10 +3,12 @@
import param
import holoviews
-from pyviz_comms import nb_mime_js
+
from IPython import version_info
-from param import ipython as param_ext
+from IPython.core.completer import IPCompleter
from IPython.display import HTML, publish_display_data
+from param import ipython as param_ext
+from pyviz_comms import nb_mime_js
from ..core.dimension import LabelledData
from ..core.tree import AttrTree
@@ -143,7 +145,7 @@
if p.case_sensitive_completion:
from IPython.core import completer
completer.completions_sorting_key = self.completions_sorting_key
- if not p.allow_jedi_completion:
+ if not p.allow_jedi_completion and hasattr(IPCompleter, 'use_jedi'):
ip.run_line_magic('config', 'IPCompleter.use_jedi = False')
resources = self._get_resources(args, params)
|
{"golden_diff": "diff --git a/holoviews/ipython/__init__.py b/holoviews/ipython/__init__.py\n--- a/holoviews/ipython/__init__.py\n+++ b/holoviews/ipython/__init__.py\n@@ -3,10 +3,12 @@\n \n import param\n import holoviews\n-from pyviz_comms import nb_mime_js\n+\n from IPython import version_info\n-from param import ipython as param_ext\n+from IPython.core.completer import IPCompleter\n from IPython.display import HTML, publish_display_data\n+from param import ipython as param_ext\n+from pyviz_comms import nb_mime_js\n \n from ..core.dimension import LabelledData\n from ..core.tree import AttrTree\n@@ -143,7 +145,7 @@\n if p.case_sensitive_completion:\n from IPython.core import completer\n completer.completions_sorting_key = self.completions_sorting_key\n- if not p.allow_jedi_completion:\n+ if not p.allow_jedi_completion and hasattr(IPCompleter, 'use_jedi'):\n ip.run_line_magic('config', 'IPCompleter.use_jedi = False')\n \n resources = self._get_resources(args, params)\n", "issue": "UserWarning: Config option `use_jedi` not recognized by `IPCompleter`.\nThis error is show when I'm trying to import bokeh:\r\n`hv.extension('bokeh')`\r\n\r\nProduct versions:\r\n- numpy 1.16.4\r\n- pandas 0.24.4\r\n- bokeh 1.2.0\r\n- holoviews 1.12.3\r\n- hvplot 0.4.0\n", "before_files": [{"content": "import os\nfrom unittest import SkipTest\n\nimport param\nimport holoviews\nfrom pyviz_comms import nb_mime_js\nfrom IPython import version_info\nfrom param import ipython as param_ext\nfrom IPython.display import HTML, publish_display_data\n\nfrom ..core.dimension import LabelledData\nfrom ..core.tree import AttrTree\nfrom ..core.options import Store\nfrom ..element.comparison import ComparisonTestCase\nfrom ..util import extension\nfrom ..plotting.renderer import Renderer, MIME_TYPES\nfrom .magics import load_magics\nfrom .display_hooks import display # noqa (API import)\nfrom .display_hooks import pprint_display, png_display, svg_display\n\n\nAttrTree._disabled_prefixes = ['_repr_','_ipython_canary_method_should_not_exist']\n\ndef show_traceback():\n \"\"\"\n Display the full traceback after an abbreviated traceback has occurred.\n \"\"\"\n from .display_hooks import FULL_TRACEBACK\n print(FULL_TRACEBACK)\n\n\nclass IPTestCase(ComparisonTestCase):\n \"\"\"\n This class extends ComparisonTestCase to handle IPython specific\n objects and support the execution of cells and magic.\n \"\"\"\n\n def setUp(self):\n super(IPTestCase, self).setUp()\n try:\n import IPython\n from IPython.display import HTML, SVG\n self.ip = IPython.InteractiveShell()\n if self.ip is None:\n raise TypeError()\n except Exception:\n raise SkipTest(\"IPython could not be started\")\n\n self.addTypeEqualityFunc(HTML, self.skip_comparison)\n self.addTypeEqualityFunc(SVG, self.skip_comparison)\n\n def skip_comparison(self, obj1, obj2, msg): pass\n\n def get_object(self, name):\n obj = self.ip._object_find(name).obj\n if obj is None:\n raise self.failureException(\"Could not find object %s\" % name)\n return obj\n\n\n def cell(self, line):\n \"Run an IPython cell\"\n self.ip.run_cell(line, silent=True)\n\n def cell_magic(self, *args, **kwargs):\n \"Run an IPython cell magic\"\n self.ip.run_cell_magic(*args, **kwargs)\n\n\n def line_magic(self, *args, **kwargs):\n \"Run an IPython line magic\"\n self.ip.run_line_magic(*args, **kwargs)\n\n\nclass notebook_extension(extension):\n \"\"\"\n Notebook specific extension to hv.extension that offers options for\n controlling the notebook environment.\n \"\"\"\n\n css = param.String(default='', doc=\"Optional CSS rule set to apply to the notebook.\")\n\n logo = param.Boolean(default=True, doc=\"Toggles display of HoloViews logo\")\n\n inline = param.Boolean(default=True, doc=\"\"\"\n Whether to inline JS and CSS resources. \n If disabled, resources are loaded from CDN if one is available.\"\"\")\n\n width = param.Number(default=None, bounds=(0, 100), doc=\"\"\"\n Width of the notebook as a percentage of the browser screen window width.\"\"\")\n\n display_formats = param.List(default=['html'], doc=\"\"\"\n A list of formats that are rendered to the notebook where\n multiple formats may be selected at once (although only one\n format will be displayed).\n\n Although the 'html' format is supported across backends, other\n formats supported by the current backend (e.g 'png' and 'svg'\n using the matplotlib backend) may be used. This may be useful to\n export figures to other formats such as PDF with nbconvert. \"\"\")\n\n allow_jedi_completion = param.Boolean(default=False, doc=\"\"\"\n Whether to allow jedi tab-completion to be enabled in IPython.\n Disabled by default because many HoloViews features rely on\n tab-completion machinery not supported when using jedi.\"\"\")\n\n case_sensitive_completion = param.Boolean(default=False, doc=\"\"\"\n Whether to monkey patch IPython to use the correct tab-completion\n behavior. \"\"\")\n\n _loaded = False\n\n def __call__(self, *args, **params):\n super(notebook_extension, self).__call__(*args, **params)\n # Abort if IPython not found\n try:\n ip = params.pop('ip', None) or get_ipython() # noqa (get_ipython)\n except:\n return\n\n # Notebook archive relies on display hooks being set to work.\n try:\n if version_info[0] >= 4:\n import nbformat # noqa (ensures availability)\n else:\n from IPython import nbformat # noqa (ensures availability)\n try:\n from .archive import notebook_archive\n holoviews.archive = notebook_archive\n except AttributeError as e:\n if str(e) != \"module 'tornado.web' has no attribute 'asynchronous'\":\n raise\n\n except ImportError:\n pass\n\n # Not quite right, should be set when switching backends\n if 'matplotlib' in Store.renderers and not notebook_extension._loaded:\n svg_exporter = Store.renderers['matplotlib'].instance(holomap=None,fig='svg')\n holoviews.archive.exporters = [svg_exporter] + holoviews.archive.exporters\n\n p = param.ParamOverrides(self, {k:v for k,v in params.items() if k!='config'})\n if p.case_sensitive_completion:\n from IPython.core import completer\n completer.completions_sorting_key = self.completions_sorting_key\n if not p.allow_jedi_completion:\n ip.run_line_magic('config', 'IPCompleter.use_jedi = False')\n\n resources = self._get_resources(args, params)\n\n Store.display_formats = p.display_formats\n if 'html' not in p.display_formats and len(p.display_formats) > 1:\n msg = ('Output magic unable to control displayed format '\n 'as IPython notebook uses fixed precedence '\n 'between %r' % p.display_formats)\n display(HTML('<b>Warning</b>: %s' % msg))\n\n loaded = notebook_extension._loaded\n if loaded == False:\n param_ext.load_ipython_extension(ip, verbose=False)\n load_magics(ip)\n Store.output_settings.initialize(list(Store.renderers.keys()))\n Store.set_display_hook('html+js', LabelledData, pprint_display)\n Store.set_display_hook('png', LabelledData, png_display)\n Store.set_display_hook('svg', LabelledData, svg_display)\n notebook_extension._loaded = True\n\n css = ''\n if p.width is not None:\n css += '<style>div.container { width: %s%% }</style>' % p.width\n if p.css:\n css += '<style>%s</style>' % p.css\n if css:\n display(HTML(css))\n\n resources = list(resources)\n if len(resources) == 0: return\n\n Renderer.load_nb()\n for r in [r for r in resources if r != 'holoviews']:\n Store.renderers[r].load_nb(inline=p.inline)\n\n if hasattr(ip, 'kernel') and not loaded:\n Renderer.comm_manager.get_client_comm(notebook_extension._process_comm_msg,\n \"hv-extension-comm\")\n\n # Create a message for the logo (if shown)\n self.load_hvjs(logo=p.logo,\n bokeh_logo= p.logo and ('bokeh' in resources),\n mpl_logo= p.logo and (('matplotlib' in resources)\n or resources==['holoviews']),\n plotly_logo= p.logo and ('plotly' in resources),\n JS=('holoviews' in resources))\n\n @classmethod\n def completions_sorting_key(cls, word):\n \"Fixed version of IPyton.completer.completions_sorting_key\"\n prio1, prio2 = 0, 0\n if word.startswith('__'): prio1 = 2\n elif word.startswith('_'): prio1 = 1\n if word.endswith('='): prio1 = -1\n if word.startswith('%%'):\n if not \"%\" in word[2:]:\n word = word[2:]; prio2 = 2\n elif word.startswith('%'):\n if not \"%\" in word[1:]:\n word = word[1:]; prio2 = 1\n return prio1, word, prio2\n\n\n def _get_resources(self, args, params):\n \"\"\"\n Finds the list of resources from the keyword parameters and pops\n them out of the params dictionary.\n \"\"\"\n resources = []\n disabled = []\n for resource in ['holoviews'] + list(Store.renderers.keys()):\n if resource in args:\n resources.append(resource)\n\n if resource in params:\n setting = params.pop(resource)\n if setting is True and resource != 'matplotlib':\n if resource not in resources:\n resources.append(resource)\n if setting is False:\n disabled.append(resource)\n\n unmatched_args = set(args) - set(resources)\n if unmatched_args:\n display(HTML('<b>Warning:</b> Unrecognized resources %s'\n % ', '.join(unmatched_args)))\n\n resources = [r for r in resources if r not in disabled]\n if ('holoviews' not in disabled) and ('holoviews' not in resources):\n resources = ['holoviews'] + resources\n return resources\n\n @classmethod\n def load_hvjs(cls, logo=False, bokeh_logo=False, mpl_logo=False, plotly_logo=False,\n JS=True, message='HoloViewsJS successfully loaded.'):\n \"\"\"\n Displays javascript and CSS to initialize HoloViews widgets.\n \"\"\"\n import jinja2\n # Evaluate load_notebook.html template with widgetjs code\n if JS:\n widgetjs, widgetcss = Renderer.html_assets(extras=False, backends=[], script=True)\n else:\n widgetjs, widgetcss = '', ''\n\n # Add classic notebook MIME renderer\n widgetjs += nb_mime_js\n\n templateLoader = jinja2.FileSystemLoader(os.path.dirname(os.path.abspath(__file__)))\n jinjaEnv = jinja2.Environment(loader=templateLoader)\n template = jinjaEnv.get_template('load_notebook.html')\n html = template.render({'widgetcss': widgetcss,\n 'logo': logo,\n 'bokeh_logo': bokeh_logo,\n 'mpl_logo': mpl_logo,\n 'plotly_logo': plotly_logo,\n 'message': message})\n publish_display_data(data={'text/html': html})\n\n # Vanilla JS mime type is only consumed by classic notebook\n # Custom mime type is only consumed by JupyterLab\n if JS:\n mimebundle = {\n MIME_TYPES['js'] : widgetjs,\n MIME_TYPES['jlab-hv-load'] : widgetjs\n }\n publish_display_data(data=mimebundle)\n\n\n @param.parameterized.bothmethod\n def tab_completion_docstring(self_or_cls):\n \"\"\"\n Generates a docstring that can be used to enable tab-completion\n of resources.\n \"\"\"\n elements = ['%s=Boolean' %k for k in list(Store.renderers.keys())]\n for name, p in self_or_cls.param.objects().items():\n param_type = p.__class__.__name__\n elements.append(\"%s=%s\" % (name, param_type))\n\n return \"params(%s)\" % ', '.join(['holoviews=Boolean'] + elements)\n\n\nnotebook_extension.__doc__ = notebook_extension.tab_completion_docstring()\nnotebook_extension.add_delete_action(Renderer._delete_plot)\n\n\ndef load_ipython_extension(ip):\n notebook_extension(ip=ip)\n\ndef unload_ipython_extension(ip):\n notebook_extension._loaded = False\n", "path": "holoviews/ipython/__init__.py"}], "after_files": [{"content": "import os\nfrom unittest import SkipTest\n\nimport param\nimport holoviews\n\nfrom IPython import version_info\nfrom IPython.core.completer import IPCompleter\nfrom IPython.display import HTML, publish_display_data\nfrom param import ipython as param_ext\nfrom pyviz_comms import nb_mime_js\n\nfrom ..core.dimension import LabelledData\nfrom ..core.tree import AttrTree\nfrom ..core.options import Store\nfrom ..element.comparison import ComparisonTestCase\nfrom ..util import extension\nfrom ..plotting.renderer import Renderer, MIME_TYPES\nfrom .magics import load_magics\nfrom .display_hooks import display # noqa (API import)\nfrom .display_hooks import pprint_display, png_display, svg_display\n\n\nAttrTree._disabled_prefixes = ['_repr_','_ipython_canary_method_should_not_exist']\n\ndef show_traceback():\n \"\"\"\n Display the full traceback after an abbreviated traceback has occurred.\n \"\"\"\n from .display_hooks import FULL_TRACEBACK\n print(FULL_TRACEBACK)\n\n\nclass IPTestCase(ComparisonTestCase):\n \"\"\"\n This class extends ComparisonTestCase to handle IPython specific\n objects and support the execution of cells and magic.\n \"\"\"\n\n def setUp(self):\n super(IPTestCase, self).setUp()\n try:\n import IPython\n from IPython.display import HTML, SVG\n self.ip = IPython.InteractiveShell()\n if self.ip is None:\n raise TypeError()\n except Exception:\n raise SkipTest(\"IPython could not be started\")\n\n self.addTypeEqualityFunc(HTML, self.skip_comparison)\n self.addTypeEqualityFunc(SVG, self.skip_comparison)\n\n def skip_comparison(self, obj1, obj2, msg): pass\n\n def get_object(self, name):\n obj = self.ip._object_find(name).obj\n if obj is None:\n raise self.failureException(\"Could not find object %s\" % name)\n return obj\n\n\n def cell(self, line):\n \"Run an IPython cell\"\n self.ip.run_cell(line, silent=True)\n\n def cell_magic(self, *args, **kwargs):\n \"Run an IPython cell magic\"\n self.ip.run_cell_magic(*args, **kwargs)\n\n\n def line_magic(self, *args, **kwargs):\n \"Run an IPython line magic\"\n self.ip.run_line_magic(*args, **kwargs)\n\n\nclass notebook_extension(extension):\n \"\"\"\n Notebook specific extension to hv.extension that offers options for\n controlling the notebook environment.\n \"\"\"\n\n css = param.String(default='', doc=\"Optional CSS rule set to apply to the notebook.\")\n\n logo = param.Boolean(default=True, doc=\"Toggles display of HoloViews logo\")\n\n inline = param.Boolean(default=True, doc=\"\"\"\n Whether to inline JS and CSS resources. \n If disabled, resources are loaded from CDN if one is available.\"\"\")\n\n width = param.Number(default=None, bounds=(0, 100), doc=\"\"\"\n Width of the notebook as a percentage of the browser screen window width.\"\"\")\n\n display_formats = param.List(default=['html'], doc=\"\"\"\n A list of formats that are rendered to the notebook where\n multiple formats may be selected at once (although only one\n format will be displayed).\n\n Although the 'html' format is supported across backends, other\n formats supported by the current backend (e.g 'png' and 'svg'\n using the matplotlib backend) may be used. This may be useful to\n export figures to other formats such as PDF with nbconvert. \"\"\")\n\n allow_jedi_completion = param.Boolean(default=False, doc=\"\"\"\n Whether to allow jedi tab-completion to be enabled in IPython.\n Disabled by default because many HoloViews features rely on\n tab-completion machinery not supported when using jedi.\"\"\")\n\n case_sensitive_completion = param.Boolean(default=False, doc=\"\"\"\n Whether to monkey patch IPython to use the correct tab-completion\n behavior. \"\"\")\n\n _loaded = False\n\n def __call__(self, *args, **params):\n super(notebook_extension, self).__call__(*args, **params)\n # Abort if IPython not found\n try:\n ip = params.pop('ip', None) or get_ipython() # noqa (get_ipython)\n except:\n return\n\n # Notebook archive relies on display hooks being set to work.\n try:\n if version_info[0] >= 4:\n import nbformat # noqa (ensures availability)\n else:\n from IPython import nbformat # noqa (ensures availability)\n try:\n from .archive import notebook_archive\n holoviews.archive = notebook_archive\n except AttributeError as e:\n if str(e) != \"module 'tornado.web' has no attribute 'asynchronous'\":\n raise\n\n except ImportError:\n pass\n\n # Not quite right, should be set when switching backends\n if 'matplotlib' in Store.renderers and not notebook_extension._loaded:\n svg_exporter = Store.renderers['matplotlib'].instance(holomap=None,fig='svg')\n holoviews.archive.exporters = [svg_exporter] + holoviews.archive.exporters\n\n p = param.ParamOverrides(self, {k:v for k,v in params.items() if k!='config'})\n if p.case_sensitive_completion:\n from IPython.core import completer\n completer.completions_sorting_key = self.completions_sorting_key\n if not p.allow_jedi_completion and hasattr(IPCompleter, 'use_jedi'):\n ip.run_line_magic('config', 'IPCompleter.use_jedi = False')\n\n resources = self._get_resources(args, params)\n\n Store.display_formats = p.display_formats\n if 'html' not in p.display_formats and len(p.display_formats) > 1:\n msg = ('Output magic unable to control displayed format '\n 'as IPython notebook uses fixed precedence '\n 'between %r' % p.display_formats)\n display(HTML('<b>Warning</b>: %s' % msg))\n\n loaded = notebook_extension._loaded\n if loaded == False:\n param_ext.load_ipython_extension(ip, verbose=False)\n load_magics(ip)\n Store.output_settings.initialize(list(Store.renderers.keys()))\n Store.set_display_hook('html+js', LabelledData, pprint_display)\n Store.set_display_hook('png', LabelledData, png_display)\n Store.set_display_hook('svg', LabelledData, svg_display)\n notebook_extension._loaded = True\n\n css = ''\n if p.width is not None:\n css += '<style>div.container { width: %s%% }</style>' % p.width\n if p.css:\n css += '<style>%s</style>' % p.css\n if css:\n display(HTML(css))\n\n resources = list(resources)\n if len(resources) == 0: return\n\n Renderer.load_nb()\n for r in [r for r in resources if r != 'holoviews']:\n Store.renderers[r].load_nb(inline=p.inline)\n\n if hasattr(ip, 'kernel') and not loaded:\n Renderer.comm_manager.get_client_comm(notebook_extension._process_comm_msg,\n \"hv-extension-comm\")\n\n # Create a message for the logo (if shown)\n self.load_hvjs(logo=p.logo,\n bokeh_logo= p.logo and ('bokeh' in resources),\n mpl_logo= p.logo and (('matplotlib' in resources)\n or resources==['holoviews']),\n plotly_logo= p.logo and ('plotly' in resources),\n JS=('holoviews' in resources))\n\n @classmethod\n def completions_sorting_key(cls, word):\n \"Fixed version of IPyton.completer.completions_sorting_key\"\n prio1, prio2 = 0, 0\n if word.startswith('__'): prio1 = 2\n elif word.startswith('_'): prio1 = 1\n if word.endswith('='): prio1 = -1\n if word.startswith('%%'):\n if not \"%\" in word[2:]:\n word = word[2:]; prio2 = 2\n elif word.startswith('%'):\n if not \"%\" in word[1:]:\n word = word[1:]; prio2 = 1\n return prio1, word, prio2\n\n\n def _get_resources(self, args, params):\n \"\"\"\n Finds the list of resources from the keyword parameters and pops\n them out of the params dictionary.\n \"\"\"\n resources = []\n disabled = []\n for resource in ['holoviews'] + list(Store.renderers.keys()):\n if resource in args:\n resources.append(resource)\n\n if resource in params:\n setting = params.pop(resource)\n if setting is True and resource != 'matplotlib':\n if resource not in resources:\n resources.append(resource)\n if setting is False:\n disabled.append(resource)\n\n unmatched_args = set(args) - set(resources)\n if unmatched_args:\n display(HTML('<b>Warning:</b> Unrecognized resources %s'\n % ', '.join(unmatched_args)))\n\n resources = [r for r in resources if r not in disabled]\n if ('holoviews' not in disabled) and ('holoviews' not in resources):\n resources = ['holoviews'] + resources\n return resources\n\n @classmethod\n def load_hvjs(cls, logo=False, bokeh_logo=False, mpl_logo=False, plotly_logo=False,\n JS=True, message='HoloViewsJS successfully loaded.'):\n \"\"\"\n Displays javascript and CSS to initialize HoloViews widgets.\n \"\"\"\n import jinja2\n # Evaluate load_notebook.html template with widgetjs code\n if JS:\n widgetjs, widgetcss = Renderer.html_assets(extras=False, backends=[], script=True)\n else:\n widgetjs, widgetcss = '', ''\n\n # Add classic notebook MIME renderer\n widgetjs += nb_mime_js\n\n templateLoader = jinja2.FileSystemLoader(os.path.dirname(os.path.abspath(__file__)))\n jinjaEnv = jinja2.Environment(loader=templateLoader)\n template = jinjaEnv.get_template('load_notebook.html')\n html = template.render({'widgetcss': widgetcss,\n 'logo': logo,\n 'bokeh_logo': bokeh_logo,\n 'mpl_logo': mpl_logo,\n 'plotly_logo': plotly_logo,\n 'message': message})\n publish_display_data(data={'text/html': html})\n\n # Vanilla JS mime type is only consumed by classic notebook\n # Custom mime type is only consumed by JupyterLab\n if JS:\n mimebundle = {\n MIME_TYPES['js'] : widgetjs,\n MIME_TYPES['jlab-hv-load'] : widgetjs\n }\n publish_display_data(data=mimebundle)\n\n\n @param.parameterized.bothmethod\n def tab_completion_docstring(self_or_cls):\n \"\"\"\n Generates a docstring that can be used to enable tab-completion\n of resources.\n \"\"\"\n elements = ['%s=Boolean' %k for k in list(Store.renderers.keys())]\n for name, p in self_or_cls.param.objects().items():\n param_type = p.__class__.__name__\n elements.append(\"%s=%s\" % (name, param_type))\n\n return \"params(%s)\" % ', '.join(['holoviews=Boolean'] + elements)\n\n\nnotebook_extension.__doc__ = notebook_extension.tab_completion_docstring()\nnotebook_extension.add_delete_action(Renderer._delete_plot)\n\n\ndef load_ipython_extension(ip):\n notebook_extension(ip=ip)\n\ndef unload_ipython_extension(ip):\n notebook_extension._loaded = False\n", "path": "holoviews/ipython/__init__.py"}]}
| 3,666 | 279 |
gh_patches_debug_5996
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-2221
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
VA failing since at least 2018-03-21
VA has been failing since 2018-03-21
Based on automated runs it appears that VA has not run successfully in 3 days (2018-03-21).
```
00:06:18 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+062
00:06:20 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+068
00:06:21 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+063
00:06:23 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+064
00:06:24 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+026
00:06:26 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+065
00:06:27 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+lst+ALL
00:06:29 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+mbr+HB5001
00:06:30 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sum+HB5001
00:06:32 INFO pupa: save bill HB 5001 in 2018specialI as bill_f1ff8050-2e57-11e8-8346-0a58a9feac2a.json
00:06:32 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+mbr+HB5002
00:06:33 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sum+HB5002
00:06:35 INFO pupa: save bill HB 5002 in 2018specialI as bill_f3c89dd6-2e57-11e8-8346-0a58a9feac2a.json
00:06:35 INFO pupa: no session specified, using 2018specialI
00:06:35 INFO scrapelib: GET - http://lis.virginia.gov/182/mbr/MBR.HTM
00:06:35 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+mbr+S71
loaded Open States pupa settings...
va (scrape, import)
bills: {}
people: {}
Traceback (most recent call last):
File "/opt/openstates/venv-pupa//bin/pupa", line 11, in <module>
load_entry_point('pupa', 'console_scripts', 'pupa')()
File "/opt/openstates/venv-pupa/src/pupa/pupa/cli/__main__.py", line 68, in main
subcommands[args.subcommand].handle(args, other)
File "/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py", line 260, in handle
return self.do_handle(args, other, juris)
File "/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py", line 305, in do_handle
report['scrape'] = self.do_scrape(juris, args, scrapers)
File "/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py", line 173, in do_scrape
report[scraper_name] = scraper.do_scrape(**scrape_args)
File "/opt/openstates/venv-pupa/src/pupa/pupa/scrape/base.py", line 111, in do_scrape
for obj in self.scrape(**kwargs) or []:
File "/opt/openstates/openstates/openstates/va/people.py", line 194, in scrape
SenateList, session=session, url=url, committees=committees)
File "/opt/openstates/venv-pupa/lib/python3.5/site-packages/spatula/base.py", line 11, in scrape_page_items
yield from page_type(self, url=url, **kwargs).handle_page()
File "/opt/openstates/venv-pupa/lib/python3.5/site-packages/spatula/base.py", line 69, in handle_page
yield from processed
File "/opt/openstates/openstates/openstates/va/people.py", line 135, in handle_list_item
obj=leg,
File "/opt/openstates/venv-pupa/lib/python3.5/site-packages/spatula/base.py", line 66, in handle_page
processed = self.handle_list_item(item)
File "/opt/openstates/openstates/openstates/va/people.py", line 36, in handle_list_item
self.get_committees(item)
File "/opt/openstates/openstates/openstates/va/people.py", line 79, in get_committees
end_date=maybe_date(self.kwargs['session'].get('end_date')),
File "/opt/openstates/openstates/openstates/va/people.py", line 203, in maybe_date
date = datetime.datetime.strptime(text, '%Y-%d-%m')
TypeError: strptime() argument 1 must be str, not None
```
Visit http://bobsled.openstates.org for more info.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `openstates/va/people.py`
Content:
```
1 import re
2 import pytz
3 import datetime
4
5 import lxml.html
6 from pupa.scrape import Person
7 from pupa.scrape import Scraper
8 from pupa.scrape import Organization
9 from spatula import Page, Spatula
10
11 from .common import SESSION_SITE_IDS
12
13
14 CHAMBER_MOVES = {
15 "A. Benton \"Ben\" Chafin-Elect": "upper",
16 "A. Benton Chafin-Senate Elect": "upper",
17 }
18 PARTY_MAP = {
19 'R': 'Republican',
20 'D': 'Democratic',
21 'I': 'Independent',
22 }
23 TIMEZONE = pytz.timezone('US/Eastern')
24
25
26 class MemberDetail(Page):
27 list_xpath = '//body'
28
29 def handle_list_item(self, item):
30 party_district_text = item.xpath('//h3/font/text()')[0]
31 party, district = get_party_district(party_district_text)
32 self.obj.add_term(self.role, self.chamber, district=district)
33 self.obj.add_party(PARTY_MAP[party])
34
35 self.get_offices(item)
36 self.get_committees(item)
37
38 photo_url = self.get_photo_url()
39 if photo_url is not None:
40 self.obj.image = photo_url
41
42 def get_offices(self, item):
43 for ul in item.xpath('//ul[@class="linkNon" and normalize-space()]'):
44 address = []
45 phone = None
46 email = None
47 for li in ul.getchildren():
48 text = li.text_content()
49 if re.match('\(\d{3}\)', text):
50 phone = text.strip()
51 elif text.startswith('email:'):
52 email = text.strip('email: ').strip()
53 else:
54 address.append(text.strip())
55 office_type = ('Capitol Office' if 'Capitol Square' in address
56 else 'District Office')
57
58 self.obj.add_contact_detail(type='address', value='\n'.join(address), note=office_type)
59 if phone:
60 self.obj.add_contact_detail(type='voice', value=phone, note=office_type)
61 if email:
62 self.obj.add_contact_detail(type='email', value=email, note=office_type)
63
64 def get_committees(self, item):
65 for com in item.xpath('//ul[@class="linkSect"][1]/li/a/text()'):
66 key = (com, self.chamber)
67 if key not in self.kwargs['committees']:
68 org = Organization(
69 name=com,
70 chamber=self.chamber,
71 classification='committee',
72 )
73 org.add_source(self.url)
74 self.kwargs['committees'][key] = org
75
76 self.obj.add_membership(
77 self.kwargs['committees'][key],
78 start_date=maybe_date(self.kwargs['session'].get('start_date')),
79 end_date=maybe_date(self.kwargs['session'].get('end_date')),
80 )
81
82 def get_photo_url(self):
83 pass
84
85
86 class SenateDetail(MemberDetail):
87 role = 'Senator'
88 chamber = 'upper'
89
90 def get_photo_url(self):
91 lis_id = get_lis_id(self.chamber, self.url)
92 profile_url = 'http://apps.senate.virginia.gov/Senator/memberpage.php?id={}'.format(lis_id)
93 page = lxml.html.fromstring(self.scraper.get(profile_url).text)
94 src = page.xpath('.//img[@class="profile_pic"]/@src')
95 img = src[0] if src else None
96 if img.startswith('//'):
97 img = 'https:' + img
98 return img
99
100
101 class DelegateDetail(MemberDetail):
102 role = 'Delegate'
103 chamber = 'lower'
104
105 def get_photo_url(self):
106 lis_id = get_lis_id(self.chamber, self.url)
107 if lis_id:
108 lis_id = '{}{:04d}'.format(lis_id[0], int(lis_id[1:]))
109 return (
110 'http://memdata.virginiageneralassembly.gov'
111 '/images/display_image/{}'
112 ).format(lis_id)
113
114
115 class MemberList(Page):
116 def handle_list_item(self, item):
117 name = item.text
118
119 if 'resigned' in name.lower() or 'vacated' in name.lower():
120 return
121 if (name in CHAMBER_MOVES and(self.chamber != CHAMBER_MOVES[name])):
122 return
123
124 name, action, date = clean_name(name)
125
126 leg = Person(name=name)
127 leg.add_source(self.url)
128 leg.add_source(item.get('href'))
129 leg.add_link(item.get('href'))
130 yield from self.scrape_page(
131 self.detail_page,
132 item.get('href'),
133 session=self.kwargs['session'],
134 committees=self.kwargs['committees'],
135 obj=leg,
136 )
137 yield leg
138
139
140 party_district_pattern = re.compile(r'\((R|D|I)\) - (?:House|Senate) District\s+(\d+)')
141
142
143 def get_party_district(text):
144 return party_district_pattern.match(text).groups()
145
146
147 lis_id_patterns = {
148 'upper': re.compile(r'(S[0-9]+$)'),
149 'lower': re.compile(r'(H[0-9]+$)'),
150 }
151
152
153 def get_lis_id(chamber, url):
154 """Retrieve LIS ID of legislator from URL."""
155 match = re.search(lis_id_patterns[chamber], url)
156 if match.groups:
157 return match.group(1)
158
159
160 name_elect_pattern = re.compile(r'(- Elect)$')
161
162
163 def clean_name(name):
164 name = name_elect_pattern.sub('', name).strip()
165 action, date = (None, None)
166 match = re.search(r'-(Resigned|Member) (\d{1,2}/\d{1,2})?', name)
167 if match:
168 action, date = match.groups()
169 name = name.rsplit('-')[0]
170 return name, action, date
171
172
173 class SenateList(MemberList):
174 chamber = 'upper'
175 detail_page = SenateDetail
176 list_xpath = '//div[@class="lColRt"]/ul/li/a'
177
178
179 class DelegateList(MemberList):
180 chamber = 'lower'
181 detail_page = DelegateDetail
182 list_xpath = '//div[@class="lColLt"]/ul/li/a'
183
184
185 class VaPersonScraper(Scraper, Spatula):
186 def scrape(self, session=None):
187 if not session:
188 session = self.jurisdiction.legislative_sessions[-1]
189 self.info('no session specified, using %s', session['identifier'])
190 url = 'http://lis.virginia.gov/{}/mbr/MBR.HTM'.format(
191 SESSION_SITE_IDS[session['identifier']])
192 committees = {}
193 yield from self.scrape_page_items(
194 SenateList, session=session, url=url, committees=committees)
195 yield from self.scrape_page_items(
196 DelegateList, session=session, url=url, committees=committees)
197 for committee in committees.values():
198 yield committee
199
200
201 def maybe_date(text):
202 try:
203 date = datetime.datetime.strptime(text, '%Y-%d-%m')
204 return date.strftime('%Y-%m-%d')
205 except ValueError:
206 return ''
207
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/openstates/va/people.py b/openstates/va/people.py
--- a/openstates/va/people.py
+++ b/openstates/va/people.py
@@ -76,7 +76,7 @@
self.obj.add_membership(
self.kwargs['committees'][key],
start_date=maybe_date(self.kwargs['session'].get('start_date')),
- end_date=maybe_date(self.kwargs['session'].get('end_date')),
+ end_date=maybe_date(self.kwargs['session'].get('end_date', '')),
)
def get_photo_url(self):
|
{"golden_diff": "diff --git a/openstates/va/people.py b/openstates/va/people.py\n--- a/openstates/va/people.py\n+++ b/openstates/va/people.py\n@@ -76,7 +76,7 @@\n self.obj.add_membership(\n self.kwargs['committees'][key],\n start_date=maybe_date(self.kwargs['session'].get('start_date')),\n- end_date=maybe_date(self.kwargs['session'].get('end_date')),\n+ end_date=maybe_date(self.kwargs['session'].get('end_date', '')),\n )\n \n def get_photo_url(self):\n", "issue": "VA failing since at least 2018-03-21\nVA has been failing since 2018-03-21\n\nBased on automated runs it appears that VA has not run successfully in 3 days (2018-03-21).\n\n\n```\n 00:06:18 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+062\n00:06:20 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+068\n00:06:21 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+063\n00:06:23 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+064\n00:06:24 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+026\n00:06:26 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+065\n00:06:27 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+lst+ALL\n00:06:29 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+mbr+HB5001\n00:06:30 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sum+HB5001\n00:06:32 INFO pupa: save bill HB 5001 in 2018specialI as bill_f1ff8050-2e57-11e8-8346-0a58a9feac2a.json\n00:06:32 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+mbr+HB5002\n00:06:33 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sum+HB5002\n00:06:35 INFO pupa: save bill HB 5002 in 2018specialI as bill_f3c89dd6-2e57-11e8-8346-0a58a9feac2a.json\n00:06:35 INFO pupa: no session specified, using 2018specialI\n00:06:35 INFO scrapelib: GET - http://lis.virginia.gov/182/mbr/MBR.HTM\n00:06:35 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+mbr+S71\nloaded Open States pupa settings...\nva (scrape, import)\n bills: {}\n people: {}\nTraceback (most recent call last):\n File \"/opt/openstates/venv-pupa//bin/pupa\", line 11, in <module>\n load_entry_point('pupa', 'console_scripts', 'pupa')()\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/cli/__main__.py\", line 68, in main\n subcommands[args.subcommand].handle(args, other)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py\", line 260, in handle\n return self.do_handle(args, other, juris)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py\", line 305, in do_handle\n report['scrape'] = self.do_scrape(juris, args, scrapers)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py\", line 173, in do_scrape\n report[scraper_name] = scraper.do_scrape(**scrape_args)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/scrape/base.py\", line 111, in do_scrape\n for obj in self.scrape(**kwargs) or []:\n File \"/opt/openstates/openstates/openstates/va/people.py\", line 194, in scrape\n SenateList, session=session, url=url, committees=committees)\n File \"/opt/openstates/venv-pupa/lib/python3.5/site-packages/spatula/base.py\", line 11, in scrape_page_items\n yield from page_type(self, url=url, **kwargs).handle_page()\n File \"/opt/openstates/venv-pupa/lib/python3.5/site-packages/spatula/base.py\", line 69, in handle_page\n yield from processed\n File \"/opt/openstates/openstates/openstates/va/people.py\", line 135, in handle_list_item\n obj=leg,\n File \"/opt/openstates/venv-pupa/lib/python3.5/site-packages/spatula/base.py\", line 66, in handle_page\n processed = self.handle_list_item(item)\n File \"/opt/openstates/openstates/openstates/va/people.py\", line 36, in handle_list_item\n self.get_committees(item)\n File \"/opt/openstates/openstates/openstates/va/people.py\", line 79, in get_committees\n end_date=maybe_date(self.kwargs['session'].get('end_date')),\n File \"/opt/openstates/openstates/openstates/va/people.py\", line 203, in maybe_date\n date = datetime.datetime.strptime(text, '%Y-%d-%m')\nTypeError: strptime() argument 1 must be str, not None\n```\n\nVisit http://bobsled.openstates.org for more info.\n\n", "before_files": [{"content": "import re\nimport pytz\nimport datetime\n\nimport lxml.html\nfrom pupa.scrape import Person\nfrom pupa.scrape import Scraper\nfrom pupa.scrape import Organization\nfrom spatula import Page, Spatula\n\nfrom .common import SESSION_SITE_IDS\n\n\nCHAMBER_MOVES = {\n \"A. Benton \\\"Ben\\\" Chafin-Elect\": \"upper\",\n \"A. Benton Chafin-Senate Elect\": \"upper\",\n}\nPARTY_MAP = {\n 'R': 'Republican',\n 'D': 'Democratic',\n 'I': 'Independent',\n}\nTIMEZONE = pytz.timezone('US/Eastern')\n\n\nclass MemberDetail(Page):\n list_xpath = '//body'\n\n def handle_list_item(self, item):\n party_district_text = item.xpath('//h3/font/text()')[0]\n party, district = get_party_district(party_district_text)\n self.obj.add_term(self.role, self.chamber, district=district)\n self.obj.add_party(PARTY_MAP[party])\n\n self.get_offices(item)\n self.get_committees(item)\n\n photo_url = self.get_photo_url()\n if photo_url is not None:\n self.obj.image = photo_url\n\n def get_offices(self, item):\n for ul in item.xpath('//ul[@class=\"linkNon\" and normalize-space()]'):\n address = []\n phone = None\n email = None\n for li in ul.getchildren():\n text = li.text_content()\n if re.match('\\(\\d{3}\\)', text):\n phone = text.strip()\n elif text.startswith('email:'):\n email = text.strip('email: ').strip()\n else:\n address.append(text.strip())\n office_type = ('Capitol Office' if 'Capitol Square' in address\n else 'District Office')\n\n self.obj.add_contact_detail(type='address', value='\\n'.join(address), note=office_type)\n if phone:\n self.obj.add_contact_detail(type='voice', value=phone, note=office_type)\n if email:\n self.obj.add_contact_detail(type='email', value=email, note=office_type)\n\n def get_committees(self, item):\n for com in item.xpath('//ul[@class=\"linkSect\"][1]/li/a/text()'):\n key = (com, self.chamber)\n if key not in self.kwargs['committees']:\n org = Organization(\n name=com,\n chamber=self.chamber,\n classification='committee',\n )\n org.add_source(self.url)\n self.kwargs['committees'][key] = org\n\n self.obj.add_membership(\n self.kwargs['committees'][key],\n start_date=maybe_date(self.kwargs['session'].get('start_date')),\n end_date=maybe_date(self.kwargs['session'].get('end_date')),\n )\n\n def get_photo_url(self):\n pass\n\n\nclass SenateDetail(MemberDetail):\n role = 'Senator'\n chamber = 'upper'\n\n def get_photo_url(self):\n lis_id = get_lis_id(self.chamber, self.url)\n profile_url = 'http://apps.senate.virginia.gov/Senator/memberpage.php?id={}'.format(lis_id)\n page = lxml.html.fromstring(self.scraper.get(profile_url).text)\n src = page.xpath('.//img[@class=\"profile_pic\"]/@src')\n img = src[0] if src else None\n if img.startswith('//'):\n img = 'https:' + img\n return img\n\n\nclass DelegateDetail(MemberDetail):\n role = 'Delegate'\n chamber = 'lower'\n\n def get_photo_url(self):\n lis_id = get_lis_id(self.chamber, self.url)\n if lis_id:\n lis_id = '{}{:04d}'.format(lis_id[0], int(lis_id[1:]))\n return (\n 'http://memdata.virginiageneralassembly.gov'\n '/images/display_image/{}'\n ).format(lis_id)\n\n\nclass MemberList(Page):\n def handle_list_item(self, item):\n name = item.text\n\n if 'resigned' in name.lower() or 'vacated' in name.lower():\n return\n if (name in CHAMBER_MOVES and(self.chamber != CHAMBER_MOVES[name])):\n return\n\n name, action, date = clean_name(name)\n\n leg = Person(name=name)\n leg.add_source(self.url)\n leg.add_source(item.get('href'))\n leg.add_link(item.get('href'))\n yield from self.scrape_page(\n self.detail_page,\n item.get('href'),\n session=self.kwargs['session'],\n committees=self.kwargs['committees'],\n obj=leg,\n )\n yield leg\n\n\nparty_district_pattern = re.compile(r'\\((R|D|I)\\) - (?:House|Senate) District\\s+(\\d+)')\n\n\ndef get_party_district(text):\n return party_district_pattern.match(text).groups()\n\n\nlis_id_patterns = {\n 'upper': re.compile(r'(S[0-9]+$)'),\n 'lower': re.compile(r'(H[0-9]+$)'),\n}\n\n\ndef get_lis_id(chamber, url):\n \"\"\"Retrieve LIS ID of legislator from URL.\"\"\"\n match = re.search(lis_id_patterns[chamber], url)\n if match.groups:\n return match.group(1)\n\n\nname_elect_pattern = re.compile(r'(- Elect)$')\n\n\ndef clean_name(name):\n name = name_elect_pattern.sub('', name).strip()\n action, date = (None, None)\n match = re.search(r'-(Resigned|Member) (\\d{1,2}/\\d{1,2})?', name)\n if match:\n action, date = match.groups()\n name = name.rsplit('-')[0]\n return name, action, date\n\n\nclass SenateList(MemberList):\n chamber = 'upper'\n detail_page = SenateDetail\n list_xpath = '//div[@class=\"lColRt\"]/ul/li/a'\n\n\nclass DelegateList(MemberList):\n chamber = 'lower'\n detail_page = DelegateDetail\n list_xpath = '//div[@class=\"lColLt\"]/ul/li/a'\n\n\nclass VaPersonScraper(Scraper, Spatula):\n def scrape(self, session=None):\n if not session:\n session = self.jurisdiction.legislative_sessions[-1]\n self.info('no session specified, using %s', session['identifier'])\n url = 'http://lis.virginia.gov/{}/mbr/MBR.HTM'.format(\n SESSION_SITE_IDS[session['identifier']])\n committees = {}\n yield from self.scrape_page_items(\n SenateList, session=session, url=url, committees=committees)\n yield from self.scrape_page_items(\n DelegateList, session=session, url=url, committees=committees)\n for committee in committees.values():\n yield committee\n\n\ndef maybe_date(text):\n try:\n date = datetime.datetime.strptime(text, '%Y-%d-%m')\n return date.strftime('%Y-%m-%d')\n except ValueError:\n return ''\n", "path": "openstates/va/people.py"}], "after_files": [{"content": "import re\nimport pytz\nimport datetime\n\nimport lxml.html\nfrom pupa.scrape import Person\nfrom pupa.scrape import Scraper\nfrom pupa.scrape import Organization\nfrom spatula import Page, Spatula\n\nfrom .common import SESSION_SITE_IDS\n\n\nCHAMBER_MOVES = {\n \"A. Benton \\\"Ben\\\" Chafin-Elect\": \"upper\",\n \"A. Benton Chafin-Senate Elect\": \"upper\",\n}\nPARTY_MAP = {\n 'R': 'Republican',\n 'D': 'Democratic',\n 'I': 'Independent',\n}\nTIMEZONE = pytz.timezone('US/Eastern')\n\n\nclass MemberDetail(Page):\n list_xpath = '//body'\n\n def handle_list_item(self, item):\n party_district_text = item.xpath('//h3/font/text()')[0]\n party, district = get_party_district(party_district_text)\n self.obj.add_term(self.role, self.chamber, district=district)\n self.obj.add_party(PARTY_MAP[party])\n\n self.get_offices(item)\n self.get_committees(item)\n\n photo_url = self.get_photo_url()\n if photo_url is not None:\n self.obj.image = photo_url\n\n def get_offices(self, item):\n for ul in item.xpath('//ul[@class=\"linkNon\" and normalize-space()]'):\n address = []\n phone = None\n email = None\n for li in ul.getchildren():\n text = li.text_content()\n if re.match('\\(\\d{3}\\)', text):\n phone = text.strip()\n elif text.startswith('email:'):\n email = text.strip('email: ').strip()\n else:\n address.append(text.strip())\n office_type = ('Capitol Office' if 'Capitol Square' in address\n else 'District Office')\n\n self.obj.add_contact_detail(type='address', value='\\n'.join(address), note=office_type)\n if phone:\n self.obj.add_contact_detail(type='voice', value=phone, note=office_type)\n if email:\n self.obj.add_contact_detail(type='email', value=email, note=office_type)\n\n def get_committees(self, item):\n for com in item.xpath('//ul[@class=\"linkSect\"][1]/li/a/text()'):\n key = (com, self.chamber)\n if key not in self.kwargs['committees']:\n org = Organization(\n name=com,\n chamber=self.chamber,\n classification='committee',\n )\n org.add_source(self.url)\n self.kwargs['committees'][key] = org\n\n self.obj.add_membership(\n self.kwargs['committees'][key],\n start_date=maybe_date(self.kwargs['session'].get('start_date')),\n end_date=maybe_date(self.kwargs['session'].get('end_date', '')),\n )\n\n def get_photo_url(self):\n pass\n\n\nclass SenateDetail(MemberDetail):\n role = 'Senator'\n chamber = 'upper'\n\n def get_photo_url(self):\n lis_id = get_lis_id(self.chamber, self.url)\n profile_url = 'http://apps.senate.virginia.gov/Senator/memberpage.php?id={}'.format(lis_id)\n page = lxml.html.fromstring(self.scraper.get(profile_url).text)\n src = page.xpath('.//img[@class=\"profile_pic\"]/@src')\n img = src[0] if src else None\n if img.startswith('//'):\n img = 'https:' + img\n return img\n\n\nclass DelegateDetail(MemberDetail):\n role = 'Delegate'\n chamber = 'lower'\n\n def get_photo_url(self):\n lis_id = get_lis_id(self.chamber, self.url)\n if lis_id:\n lis_id = '{}{:04d}'.format(lis_id[0], int(lis_id[1:]))\n return (\n 'http://memdata.virginiageneralassembly.gov'\n '/images/display_image/{}'\n ).format(lis_id)\n\n\nclass MemberList(Page):\n def handle_list_item(self, item):\n name = item.text\n\n if 'resigned' in name.lower() or 'vacated' in name.lower():\n return\n if (name in CHAMBER_MOVES and(self.chamber != CHAMBER_MOVES[name])):\n return\n\n name, action, date = clean_name(name)\n\n leg = Person(name=name)\n leg.add_source(self.url)\n leg.add_source(item.get('href'))\n leg.add_link(item.get('href'))\n yield from self.scrape_page(\n self.detail_page,\n item.get('href'),\n session=self.kwargs['session'],\n committees=self.kwargs['committees'],\n obj=leg,\n )\n yield leg\n\n\nparty_district_pattern = re.compile(r'\\((R|D|I)\\) - (?:House|Senate) District\\s+(\\d+)')\n\n\ndef get_party_district(text):\n return party_district_pattern.match(text).groups()\n\n\nlis_id_patterns = {\n 'upper': re.compile(r'(S[0-9]+$)'),\n 'lower': re.compile(r'(H[0-9]+$)'),\n}\n\n\ndef get_lis_id(chamber, url):\n \"\"\"Retrieve LIS ID of legislator from URL.\"\"\"\n match = re.search(lis_id_patterns[chamber], url)\n if match.groups:\n return match.group(1)\n\n\nname_elect_pattern = re.compile(r'(- Elect)$')\n\n\ndef clean_name(name):\n name = name_elect_pattern.sub('', name).strip()\n action, date = (None, None)\n match = re.search(r'-(Resigned|Member) (\\d{1,2}/\\d{1,2})?', name)\n if match:\n action, date = match.groups()\n name = name.rsplit('-')[0]\n return name, action, date\n\n\nclass SenateList(MemberList):\n chamber = 'upper'\n detail_page = SenateDetail\n list_xpath = '//div[@class=\"lColRt\"]/ul/li/a'\n\n\nclass DelegateList(MemberList):\n chamber = 'lower'\n detail_page = DelegateDetail\n list_xpath = '//div[@class=\"lColLt\"]/ul/li/a'\n\n\nclass VaPersonScraper(Scraper, Spatula):\n def scrape(self, session=None):\n if not session:\n session = self.jurisdiction.legislative_sessions[-1]\n self.info('no session specified, using %s', session['identifier'])\n url = 'http://lis.virginia.gov/{}/mbr/MBR.HTM'.format(\n SESSION_SITE_IDS[session['identifier']])\n committees = {}\n yield from self.scrape_page_items(\n SenateList, session=session, url=url, committees=committees)\n yield from self.scrape_page_items(\n DelegateList, session=session, url=url, committees=committees)\n for committee in committees.values():\n yield committee\n\n\ndef maybe_date(text):\n try:\n date = datetime.datetime.strptime(text, '%Y-%d-%m')\n return date.strftime('%Y-%m-%d')\n except ValueError:\n return ''\n", "path": "openstates/va/people.py"}]}
| 3,720 | 125 |
gh_patches_debug_14774
|
rasdani/github-patches
|
git_diff
|
speechbrain__speechbrain-124
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Replicability Issue
Every time I run the same experiment (e.,g minimal_examples/neural_networks/autoencoder) on the same machine I got slightly different results. Since we set up the seed, this shouldn't happen.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/TIMIT/ASR_CTC/experiment.py`
Content:
```
1 #!/usr/bin/env python3
2 import os
3 import sys
4 import torch
5 import speechbrain as sb
6 import speechbrain.data_io.wer as wer_io
7 import speechbrain.utils.edit_distance as edit_distance
8 from speechbrain.data_io.data_io import convert_index_to_lab
9 from speechbrain.decoders.ctc import ctc_greedy_decode
10 from speechbrain.decoders.decoders import undo_padding
11 from speechbrain.utils.checkpoints import ckpt_recency
12 from speechbrain.utils.train_logger import summarize_error_rate
13
14 # This hack needed to import data preparation script from ..
15 current_dir = os.path.dirname(os.path.abspath(__file__))
16 sys.path.append(os.path.dirname(current_dir))
17 from timit_prepare import TIMITPreparer # noqa E402
18
19 # Load hyperparameters file with command-line overrides
20 params_file, overrides = sb.core.parse_arguments(sys.argv[1:])
21 if "seed" in overrides:
22 torch.manual_seed(overrides["seed"])
23 with open(params_file) as fin:
24 params = sb.yaml.load_extended_yaml(fin, overrides)
25
26 # Create experiment directory
27 sb.core.create_experiment_directory(
28 experiment_directory=params.output_folder,
29 params_to_save=params_file,
30 overrides=overrides,
31 )
32
33
34 # Define training procedure
35 class ASR(sb.core.Brain):
36 def compute_forward(self, x, train_mode=True, init_params=False):
37 ids, wavs, wav_lens = x
38 wavs, wav_lens = wavs.to(params.device), wav_lens.to(params.device)
39 if hasattr(params, "augmentation"):
40 wavs = params.augmentation(wavs, wav_lens, init_params)
41 feats = params.compute_features(wavs, init_params)
42 feats = params.normalize(feats, wav_lens)
43 out = params.model(feats, init_params)
44 out = params.output(out, init_params)
45 pout = params.log_softmax(out)
46 return pout, wav_lens
47
48 def compute_objectives(self, predictions, targets, train_mode=True):
49 pout, pout_lens = predictions
50 ids, phns, phn_lens = targets
51 phns, phn_lens = phns.to(params.device), phn_lens.to(params.device)
52 loss = params.compute_cost(pout, phns, [pout_lens, phn_lens])
53
54 if not train_mode:
55 ind2lab = params.train_loader.label_dict["phn"]["index2lab"]
56 sequence = ctc_greedy_decode(pout, pout_lens, blank_id=-1)
57 sequence = convert_index_to_lab(sequence, ind2lab)
58 phns = undo_padding(phns, phn_lens)
59 phns = convert_index_to_lab(phns, ind2lab)
60 stats = edit_distance.wer_details_for_batch(
61 ids, phns, sequence, compute_alignments=True
62 )
63 stats = {"PER": stats}
64 return loss, stats
65
66 return loss
67
68 def on_epoch_end(self, epoch, train_stats, valid_stats=None):
69 per = summarize_error_rate(valid_stats["PER"])
70 old_lr, new_lr = params.lr_annealing([params.optimizer], epoch, per)
71 epoch_stats = {"epoch": epoch, "lr": old_lr}
72 params.train_logger.log_stats(epoch_stats, train_stats, valid_stats)
73
74 params.checkpointer.save_and_keep_only(
75 meta={"PER": per},
76 importance_keys=[ckpt_recency, lambda c: -c.meta["PER"]],
77 )
78
79
80 # Prepare data
81 prepare = TIMITPreparer(
82 data_folder=params.data_folder,
83 splits=["train", "dev", "test"],
84 save_folder=params.data_folder,
85 )
86 prepare()
87 train_set = params.train_loader()
88 valid_set = params.valid_loader()
89 first_x, first_y = next(zip(*train_set))
90
91 # Modules are passed to optimizer and have train/eval called on them
92 modules = [params.model, params.output]
93 if hasattr(params, "augmentation"):
94 modules.append(params.augmentation)
95
96 # Create brain object for training
97 asr_brain = ASR(
98 modules=modules, optimizer=params.optimizer, first_inputs=[first_x],
99 )
100
101 # Load latest checkpoint to resume training
102 params.checkpointer.recover_if_possible()
103 asr_brain.fit(params.epoch_counter, train_set, valid_set)
104
105 # Load best checkpoint for evaluation
106 params.checkpointer.recover_if_possible(lambda c: -c.meta["PER"])
107 test_stats = asr_brain.evaluate(params.test_loader())
108 params.train_logger.log_stats(
109 stats_meta={"Epoch loaded": params.epoch_counter.current},
110 test_stats=test_stats,
111 )
112
113 # Write alignments to file
114 per_summary = edit_distance.wer_summary(test_stats["PER"])
115 with open(params.wer_file, "w") as fo:
116 wer_io.print_wer_summary(per_summary, fo)
117 wer_io.print_alignments(test_stats["PER"], fo)
118
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/recipes/TIMIT/ASR_CTC/experiment.py b/recipes/TIMIT/ASR_CTC/experiment.py
--- a/recipes/TIMIT/ASR_CTC/experiment.py
+++ b/recipes/TIMIT/ASR_CTC/experiment.py
@@ -1,7 +1,6 @@
#!/usr/bin/env python3
import os
import sys
-import torch
import speechbrain as sb
import speechbrain.data_io.wer as wer_io
import speechbrain.utils.edit_distance as edit_distance
@@ -18,8 +17,6 @@
# Load hyperparameters file with command-line overrides
params_file, overrides = sb.core.parse_arguments(sys.argv[1:])
-if "seed" in overrides:
- torch.manual_seed(overrides["seed"])
with open(params_file) as fin:
params = sb.yaml.load_extended_yaml(fin, overrides)
|
{"golden_diff": "diff --git a/recipes/TIMIT/ASR_CTC/experiment.py b/recipes/TIMIT/ASR_CTC/experiment.py\n--- a/recipes/TIMIT/ASR_CTC/experiment.py\n+++ b/recipes/TIMIT/ASR_CTC/experiment.py\n@@ -1,7 +1,6 @@\n #!/usr/bin/env python3\n import os\n import sys\n-import torch\n import speechbrain as sb\n import speechbrain.data_io.wer as wer_io\n import speechbrain.utils.edit_distance as edit_distance\n@@ -18,8 +17,6 @@\n \n # Load hyperparameters file with command-line overrides\n params_file, overrides = sb.core.parse_arguments(sys.argv[1:])\n-if \"seed\" in overrides:\n- torch.manual_seed(overrides[\"seed\"])\n with open(params_file) as fin:\n params = sb.yaml.load_extended_yaml(fin, overrides)\n", "issue": "Replicability Issue\nEvery time I run the same experiment (e.,g minimal_examples/neural_networks/autoencoder) on the same machine I got slightly different results. Since we set up the seed, this shouldn't happen. \n", "before_files": [{"content": "#!/usr/bin/env python3\nimport os\nimport sys\nimport torch\nimport speechbrain as sb\nimport speechbrain.data_io.wer as wer_io\nimport speechbrain.utils.edit_distance as edit_distance\nfrom speechbrain.data_io.data_io import convert_index_to_lab\nfrom speechbrain.decoders.ctc import ctc_greedy_decode\nfrom speechbrain.decoders.decoders import undo_padding\nfrom speechbrain.utils.checkpoints import ckpt_recency\nfrom speechbrain.utils.train_logger import summarize_error_rate\n\n# This hack needed to import data preparation script from ..\ncurrent_dir = os.path.dirname(os.path.abspath(__file__))\nsys.path.append(os.path.dirname(current_dir))\nfrom timit_prepare import TIMITPreparer # noqa E402\n\n# Load hyperparameters file with command-line overrides\nparams_file, overrides = sb.core.parse_arguments(sys.argv[1:])\nif \"seed\" in overrides:\n torch.manual_seed(overrides[\"seed\"])\nwith open(params_file) as fin:\n params = sb.yaml.load_extended_yaml(fin, overrides)\n\n# Create experiment directory\nsb.core.create_experiment_directory(\n experiment_directory=params.output_folder,\n params_to_save=params_file,\n overrides=overrides,\n)\n\n\n# Define training procedure\nclass ASR(sb.core.Brain):\n def compute_forward(self, x, train_mode=True, init_params=False):\n ids, wavs, wav_lens = x\n wavs, wav_lens = wavs.to(params.device), wav_lens.to(params.device)\n if hasattr(params, \"augmentation\"):\n wavs = params.augmentation(wavs, wav_lens, init_params)\n feats = params.compute_features(wavs, init_params)\n feats = params.normalize(feats, wav_lens)\n out = params.model(feats, init_params)\n out = params.output(out, init_params)\n pout = params.log_softmax(out)\n return pout, wav_lens\n\n def compute_objectives(self, predictions, targets, train_mode=True):\n pout, pout_lens = predictions\n ids, phns, phn_lens = targets\n phns, phn_lens = phns.to(params.device), phn_lens.to(params.device)\n loss = params.compute_cost(pout, phns, [pout_lens, phn_lens])\n\n if not train_mode:\n ind2lab = params.train_loader.label_dict[\"phn\"][\"index2lab\"]\n sequence = ctc_greedy_decode(pout, pout_lens, blank_id=-1)\n sequence = convert_index_to_lab(sequence, ind2lab)\n phns = undo_padding(phns, phn_lens)\n phns = convert_index_to_lab(phns, ind2lab)\n stats = edit_distance.wer_details_for_batch(\n ids, phns, sequence, compute_alignments=True\n )\n stats = {\"PER\": stats}\n return loss, stats\n\n return loss\n\n def on_epoch_end(self, epoch, train_stats, valid_stats=None):\n per = summarize_error_rate(valid_stats[\"PER\"])\n old_lr, new_lr = params.lr_annealing([params.optimizer], epoch, per)\n epoch_stats = {\"epoch\": epoch, \"lr\": old_lr}\n params.train_logger.log_stats(epoch_stats, train_stats, valid_stats)\n\n params.checkpointer.save_and_keep_only(\n meta={\"PER\": per},\n importance_keys=[ckpt_recency, lambda c: -c.meta[\"PER\"]],\n )\n\n\n# Prepare data\nprepare = TIMITPreparer(\n data_folder=params.data_folder,\n splits=[\"train\", \"dev\", \"test\"],\n save_folder=params.data_folder,\n)\nprepare()\ntrain_set = params.train_loader()\nvalid_set = params.valid_loader()\nfirst_x, first_y = next(zip(*train_set))\n\n# Modules are passed to optimizer and have train/eval called on them\nmodules = [params.model, params.output]\nif hasattr(params, \"augmentation\"):\n modules.append(params.augmentation)\n\n# Create brain object for training\nasr_brain = ASR(\n modules=modules, optimizer=params.optimizer, first_inputs=[first_x],\n)\n\n# Load latest checkpoint to resume training\nparams.checkpointer.recover_if_possible()\nasr_brain.fit(params.epoch_counter, train_set, valid_set)\n\n# Load best checkpoint for evaluation\nparams.checkpointer.recover_if_possible(lambda c: -c.meta[\"PER\"])\ntest_stats = asr_brain.evaluate(params.test_loader())\nparams.train_logger.log_stats(\n stats_meta={\"Epoch loaded\": params.epoch_counter.current},\n test_stats=test_stats,\n)\n\n# Write alignments to file\nper_summary = edit_distance.wer_summary(test_stats[\"PER\"])\nwith open(params.wer_file, \"w\") as fo:\n wer_io.print_wer_summary(per_summary, fo)\n wer_io.print_alignments(test_stats[\"PER\"], fo)\n", "path": "recipes/TIMIT/ASR_CTC/experiment.py"}], "after_files": [{"content": "#!/usr/bin/env python3\nimport os\nimport sys\nimport speechbrain as sb\nimport speechbrain.data_io.wer as wer_io\nimport speechbrain.utils.edit_distance as edit_distance\nfrom speechbrain.data_io.data_io import convert_index_to_lab\nfrom speechbrain.decoders.ctc import ctc_greedy_decode\nfrom speechbrain.decoders.decoders import undo_padding\nfrom speechbrain.utils.checkpoints import ckpt_recency\nfrom speechbrain.utils.train_logger import summarize_error_rate\n\n# This hack needed to import data preparation script from ..\ncurrent_dir = os.path.dirname(os.path.abspath(__file__))\nsys.path.append(os.path.dirname(current_dir))\nfrom timit_prepare import TIMITPreparer # noqa E402\n\n# Load hyperparameters file with command-line overrides\nparams_file, overrides = sb.core.parse_arguments(sys.argv[1:])\nwith open(params_file) as fin:\n params = sb.yaml.load_extended_yaml(fin, overrides)\n\n# Create experiment directory\nsb.core.create_experiment_directory(\n experiment_directory=params.output_folder,\n params_to_save=params_file,\n overrides=overrides,\n)\n\n\n# Define training procedure\nclass ASR(sb.core.Brain):\n def compute_forward(self, x, train_mode=True, init_params=False):\n ids, wavs, wav_lens = x\n wavs, wav_lens = wavs.to(params.device), wav_lens.to(params.device)\n if hasattr(params, \"augmentation\"):\n wavs = params.augmentation(wavs, wav_lens, init_params)\n feats = params.compute_features(wavs, init_params)\n feats = params.normalize(feats, wav_lens)\n out = params.model(feats, init_params)\n out = params.output(out, init_params)\n pout = params.log_softmax(out)\n return pout, wav_lens\n\n def compute_objectives(self, predictions, targets, train_mode=True):\n pout, pout_lens = predictions\n ids, phns, phn_lens = targets\n phns, phn_lens = phns.to(params.device), phn_lens.to(params.device)\n loss = params.compute_cost(pout, phns, [pout_lens, phn_lens])\n\n if not train_mode:\n ind2lab = params.train_loader.label_dict[\"phn\"][\"index2lab\"]\n sequence = ctc_greedy_decode(pout, pout_lens, blank_id=-1)\n sequence = convert_index_to_lab(sequence, ind2lab)\n phns = undo_padding(phns, phn_lens)\n phns = convert_index_to_lab(phns, ind2lab)\n stats = edit_distance.wer_details_for_batch(\n ids, phns, sequence, compute_alignments=True\n )\n stats = {\"PER\": stats}\n return loss, stats\n\n return loss\n\n def on_epoch_end(self, epoch, train_stats, valid_stats=None):\n per = summarize_error_rate(valid_stats[\"PER\"])\n old_lr, new_lr = params.lr_annealing([params.optimizer], epoch, per)\n epoch_stats = {\"epoch\": epoch, \"lr\": old_lr}\n params.train_logger.log_stats(epoch_stats, train_stats, valid_stats)\n\n params.checkpointer.save_and_keep_only(\n meta={\"PER\": per},\n importance_keys=[ckpt_recency, lambda c: -c.meta[\"PER\"]],\n )\n\n\n# Prepare data\nprepare = TIMITPreparer(\n data_folder=params.data_folder,\n splits=[\"train\", \"dev\", \"test\"],\n save_folder=params.data_folder,\n)\nprepare()\ntrain_set = params.train_loader()\nvalid_set = params.valid_loader()\nfirst_x, first_y = next(zip(*train_set))\n\n# Modules are passed to optimizer and have train/eval called on them\nmodules = [params.model, params.output]\nif hasattr(params, \"augmentation\"):\n modules.append(params.augmentation)\n\n# Create brain object for training\nasr_brain = ASR(\n modules=modules, optimizer=params.optimizer, first_inputs=[first_x],\n)\n\n# Load latest checkpoint to resume training\nparams.checkpointer.recover_if_possible()\nasr_brain.fit(params.epoch_counter, train_set, valid_set)\n\n# Load best checkpoint for evaluation\nparams.checkpointer.recover_if_possible(lambda c: -c.meta[\"PER\"])\ntest_stats = asr_brain.evaluate(params.test_loader())\nparams.train_logger.log_stats(\n stats_meta={\"Epoch loaded\": params.epoch_counter.current},\n test_stats=test_stats,\n)\n\n# Write alignments to file\nper_summary = edit_distance.wer_summary(test_stats[\"PER\"])\nwith open(params.wer_file, \"w\") as fo:\n wer_io.print_wer_summary(per_summary, fo)\n wer_io.print_alignments(test_stats[\"PER\"], fo)\n", "path": "recipes/TIMIT/ASR_CTC/experiment.py"}]}
| 1,576 | 188 |
gh_patches_debug_5694
|
rasdani/github-patches
|
git_diff
|
saulpw__visidata-1558
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[zo] Give feedback when a file or URL is not found in the cell value
New users (and me when I have a few z related `open-cell-XYZ` commands 🙃) may get confused at the purpose of `zo`, when it is usually `zENTER` they want.
I propose the change, whereby a status is given to the user to tell them that a `file` or `URL` wasn't found (and therefore nothing happens). Also maybe suggest they want `zENTER`?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `visidata/_open.py`
Content:
```
1 from visidata import *
2
3
4 vd.option('filetype', '', 'specify file type', replay=True)
5
6
7 @VisiData.api
8 def inputFilename(vd, prompt, *args, **kwargs):
9 return vd.input(prompt, type="filename", *args, completer=_completeFilename, **kwargs).strip()
10
11
12 @VisiData.api
13 def inputPath(vd, *args, **kwargs):
14 return Path(vd.inputFilename(*args, **kwargs))
15
16
17 def _completeFilename(val, state):
18 i = val.rfind('/')
19 if i < 0: # no /
20 base = ''
21 partial = val
22 elif i == 0: # root /
23 base = '/'
24 partial = val[1:]
25 else:
26 base = val[:i]
27 partial = val[i+1:]
28
29 files = []
30 for f in os.listdir(Path(base or '.')):
31 if f.startswith(partial):
32 files.append(os.path.join(base, f))
33
34 files.sort()
35 return files[state%len(files)]
36
37
38 @VisiData.api
39 def openPath(vd, p, filetype=None, create=False):
40 '''Call ``open_<filetype>(p)`` or ``openurl_<p.scheme>(p, filetype)``. Return constructed but unloaded sheet of appropriate type.
41 If True, *create* will return a new, blank **Sheet** if file does not exist.'''
42 if p.scheme and not p.has_fp():
43 schemes = p.scheme.split('+')
44 openfuncname = 'openurl_' + schemes[-1]
45
46 openfunc = getattr(vd, openfuncname, None) or vd.getGlobals().get(openfuncname, None)
47 if not openfunc:
48 vd.fail(f'no loader for url scheme: {p.scheme}')
49
50 return openfunc(p, filetype=filetype)
51
52 if not p.exists() and not create:
53 return None
54
55 if not filetype:
56 if p.is_dir():
57 filetype = 'dir'
58 else:
59 filetype = p.ext or options.filetype or 'txt'
60
61 filetype = filetype.lower()
62
63 if not p.exists():
64 if not create:
65 return None
66 newfunc = getattr(vd, 'new_' + filetype, vd.getGlobals().get('new_' + filetype))
67 if not newfunc:
68 vd.warning('%s does not exist, creating new sheet' % p)
69 return vd.newSheet(p.name, 1, source=p)
70
71 vd.status('creating blank %s' % (p.given))
72 return newfunc(p)
73
74 openfunc = getattr(vd, 'open_' + filetype, vd.getGlobals().get('open_' + filetype))
75 if not openfunc:
76 vd.warning('unknown "%s" filetype' % filetype)
77 filetype = 'txt'
78 openfunc = vd.open_txt
79
80 vd.status('opening %s as %s' % (p.given, filetype))
81
82 return openfunc(p)
83
84
85 @VisiData.api
86 def openSource(vd, p, filetype=None, create=False, **kwargs):
87 '''Return unloaded sheet object for *p* opened as the given *filetype* and with *kwargs* as option overrides. *p* can be a Path or a string (filename, url, or "-" for stdin).
88 when true, *create* will return a blank sheet, if file does not exist.'''
89 if not filetype:
90 filetype = options.getonly('filetype', 'global', '')
91
92 vs = None
93 if isinstance(p, str):
94 if '://' in p:
95 vs = vd.openPath(Path(p), filetype=filetype) # convert to Path and recurse
96 elif p == '-':
97 vs = vd.openPath(vd.stdinSource, filetype=filetype)
98 else:
99 vs = vd.openPath(Path(p), filetype=filetype, create=create) # convert to Path and recurse
100 else:
101 vs = vd.openPath(p, filetype=filetype, create=create)
102
103 for optname, optval in kwargs.items():
104 vs.options[optname] = optval
105
106 return vs
107
108
109 #### enable external addons
110 @VisiData.api
111 def open_txt(vd, p):
112 'Create sheet from `.txt` file at Path `p`, checking whether it is TSV.'
113 with p.open_text(encoding=vd.options.encoding) as fp:
114 try:
115 if options.delimiter in next(fp): # peek at the first line
116 return vd.open_tsv(p) # TSV often have .txt extension
117 except StopIteration:
118 return Sheet(p.name, columns=[SettableColumn()], source=p)
119 return TextSheet(p.name, source=p)
120
121
122 @VisiData.api
123 def loadInternalSheet(vd, cls, p, **kwargs):
124 'Load internal sheet of given class. Internal sheets are always tsv.'
125 vs = cls(p.name, source=p, **kwargs)
126 options._set('encoding', 'utf8', vs)
127 if p.exists():
128 vd.sheets.insert(0, vs)
129 vs.reload.__wrapped__(vs)
130 vd.sheets.pop(0)
131 return vs
132
133
134 BaseSheet.addCommand('o', 'open-file', 'vd.push(openSource(inputFilename("open: "), create=True))', 'Open file or URL')
135 TableSheet.addCommand('zo', 'open-cell-file', 'vd.push(openSource(cursorDisplay))', 'Open file or URL from path in current cell')
136
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/visidata/_open.py b/visidata/_open.py
--- a/visidata/_open.py
+++ b/visidata/_open.py
@@ -132,4 +132,4 @@
BaseSheet.addCommand('o', 'open-file', 'vd.push(openSource(inputFilename("open: "), create=True))', 'Open file or URL')
-TableSheet.addCommand('zo', 'open-cell-file', 'vd.push(openSource(cursorDisplay))', 'Open file or URL from path in current cell')
+TableSheet.addCommand('zo', 'open-cell-file', 'vd.push(openSource(cursorDisplay) or fail(f"file {cursorDisplay} does not exist"))', 'Open file or URL from path in current cell')
|
{"golden_diff": "diff --git a/visidata/_open.py b/visidata/_open.py\n--- a/visidata/_open.py\n+++ b/visidata/_open.py\n@@ -132,4 +132,4 @@\n \n \n BaseSheet.addCommand('o', 'open-file', 'vd.push(openSource(inputFilename(\"open: \"), create=True))', 'Open file or URL')\n-TableSheet.addCommand('zo', 'open-cell-file', 'vd.push(openSource(cursorDisplay))', 'Open file or URL from path in current cell')\n+TableSheet.addCommand('zo', 'open-cell-file', 'vd.push(openSource(cursorDisplay) or fail(f\"file {cursorDisplay} does not exist\"))', 'Open file or URL from path in current cell')\n", "issue": "[zo] Give feedback when a file or URL is not found in the cell value\nNew users (and me when I have a few z related `open-cell-XYZ` commands \ud83d\ude43) may get confused at the purpose of `zo`, when it is usually `zENTER` they want.\r\n\r\nI propose the change, whereby a status is given to the user to tell them that a `file` or `URL` wasn't found (and therefore nothing happens). Also maybe suggest they want `zENTER`?\n", "before_files": [{"content": "from visidata import *\n\n\nvd.option('filetype', '', 'specify file type', replay=True)\n\n\n@VisiData.api\ndef inputFilename(vd, prompt, *args, **kwargs):\n return vd.input(prompt, type=\"filename\", *args, completer=_completeFilename, **kwargs).strip()\n\n\n@VisiData.api\ndef inputPath(vd, *args, **kwargs):\n return Path(vd.inputFilename(*args, **kwargs))\n\n\ndef _completeFilename(val, state):\n i = val.rfind('/')\n if i < 0: # no /\n base = ''\n partial = val\n elif i == 0: # root /\n base = '/'\n partial = val[1:]\n else:\n base = val[:i]\n partial = val[i+1:]\n\n files = []\n for f in os.listdir(Path(base or '.')):\n if f.startswith(partial):\n files.append(os.path.join(base, f))\n\n files.sort()\n return files[state%len(files)]\n\n\n@VisiData.api\ndef openPath(vd, p, filetype=None, create=False):\n '''Call ``open_<filetype>(p)`` or ``openurl_<p.scheme>(p, filetype)``. Return constructed but unloaded sheet of appropriate type.\n If True, *create* will return a new, blank **Sheet** if file does not exist.'''\n if p.scheme and not p.has_fp():\n schemes = p.scheme.split('+')\n openfuncname = 'openurl_' + schemes[-1]\n\n openfunc = getattr(vd, openfuncname, None) or vd.getGlobals().get(openfuncname, None)\n if not openfunc:\n vd.fail(f'no loader for url scheme: {p.scheme}')\n\n return openfunc(p, filetype=filetype)\n\n if not p.exists() and not create:\n return None\n\n if not filetype:\n if p.is_dir():\n filetype = 'dir'\n else:\n filetype = p.ext or options.filetype or 'txt'\n\n filetype = filetype.lower()\n\n if not p.exists():\n if not create:\n return None\n newfunc = getattr(vd, 'new_' + filetype, vd.getGlobals().get('new_' + filetype))\n if not newfunc:\n vd.warning('%s does not exist, creating new sheet' % p)\n return vd.newSheet(p.name, 1, source=p)\n\n vd.status('creating blank %s' % (p.given))\n return newfunc(p)\n\n openfunc = getattr(vd, 'open_' + filetype, vd.getGlobals().get('open_' + filetype))\n if not openfunc:\n vd.warning('unknown \"%s\" filetype' % filetype)\n filetype = 'txt'\n openfunc = vd.open_txt\n\n vd.status('opening %s as %s' % (p.given, filetype))\n\n return openfunc(p)\n\n\n@VisiData.api\ndef openSource(vd, p, filetype=None, create=False, **kwargs):\n '''Return unloaded sheet object for *p* opened as the given *filetype* and with *kwargs* as option overrides. *p* can be a Path or a string (filename, url, or \"-\" for stdin).\n when true, *create* will return a blank sheet, if file does not exist.'''\n if not filetype:\n filetype = options.getonly('filetype', 'global', '')\n\n vs = None\n if isinstance(p, str):\n if '://' in p:\n vs = vd.openPath(Path(p), filetype=filetype) # convert to Path and recurse\n elif p == '-':\n vs = vd.openPath(vd.stdinSource, filetype=filetype)\n else:\n vs = vd.openPath(Path(p), filetype=filetype, create=create) # convert to Path and recurse\n else:\n vs = vd.openPath(p, filetype=filetype, create=create)\n\n for optname, optval in kwargs.items():\n vs.options[optname] = optval\n\n return vs\n\n\n#### enable external addons\n@VisiData.api\ndef open_txt(vd, p):\n 'Create sheet from `.txt` file at Path `p`, checking whether it is TSV.'\n with p.open_text(encoding=vd.options.encoding) as fp:\n try:\n if options.delimiter in next(fp): # peek at the first line\n return vd.open_tsv(p) # TSV often have .txt extension\n except StopIteration:\n return Sheet(p.name, columns=[SettableColumn()], source=p)\n return TextSheet(p.name, source=p)\n\n\n@VisiData.api\ndef loadInternalSheet(vd, cls, p, **kwargs):\n 'Load internal sheet of given class. Internal sheets are always tsv.'\n vs = cls(p.name, source=p, **kwargs)\n options._set('encoding', 'utf8', vs)\n if p.exists():\n vd.sheets.insert(0, vs)\n vs.reload.__wrapped__(vs)\n vd.sheets.pop(0)\n return vs\n\n\nBaseSheet.addCommand('o', 'open-file', 'vd.push(openSource(inputFilename(\"open: \"), create=True))', 'Open file or URL')\nTableSheet.addCommand('zo', 'open-cell-file', 'vd.push(openSource(cursorDisplay))', 'Open file or URL from path in current cell')\n", "path": "visidata/_open.py"}], "after_files": [{"content": "from visidata import *\n\n\nvd.option('filetype', '', 'specify file type', replay=True)\n\n\n@VisiData.api\ndef inputFilename(vd, prompt, *args, **kwargs):\n return vd.input(prompt, type=\"filename\", *args, completer=_completeFilename, **kwargs).strip()\n\n\n@VisiData.api\ndef inputPath(vd, *args, **kwargs):\n return Path(vd.inputFilename(*args, **kwargs))\n\n\ndef _completeFilename(val, state):\n i = val.rfind('/')\n if i < 0: # no /\n base = ''\n partial = val\n elif i == 0: # root /\n base = '/'\n partial = val[1:]\n else:\n base = val[:i]\n partial = val[i+1:]\n\n files = []\n for f in os.listdir(Path(base or '.')):\n if f.startswith(partial):\n files.append(os.path.join(base, f))\n\n files.sort()\n return files[state%len(files)]\n\n\n@VisiData.api\ndef openPath(vd, p, filetype=None, create=False):\n '''Call ``open_<filetype>(p)`` or ``openurl_<p.scheme>(p, filetype)``. Return constructed but unloaded sheet of appropriate type.\n If True, *create* will return a new, blank **Sheet** if file does not exist.'''\n if p.scheme and not p.has_fp():\n schemes = p.scheme.split('+')\n openfuncname = 'openurl_' + schemes[-1]\n\n openfunc = getattr(vd, openfuncname, None) or vd.getGlobals().get(openfuncname, None)\n if not openfunc:\n vd.fail(f'no loader for url scheme: {p.scheme}')\n\n return openfunc(p, filetype=filetype)\n\n if not p.exists() and not create:\n return None\n\n if not filetype:\n if p.is_dir():\n filetype = 'dir'\n else:\n filetype = p.ext or options.filetype or 'txt'\n\n filetype = filetype.lower()\n\n if not p.exists():\n if not create:\n return None\n newfunc = getattr(vd, 'new_' + filetype, vd.getGlobals().get('new_' + filetype))\n if not newfunc:\n vd.warning('%s does not exist, creating new sheet' % p)\n return vd.newSheet(p.name, 1, source=p)\n\n vd.status('creating blank %s' % (p.given))\n return newfunc(p)\n\n openfunc = getattr(vd, 'open_' + filetype, vd.getGlobals().get('open_' + filetype))\n if not openfunc:\n vd.warning('unknown \"%s\" filetype' % filetype)\n filetype = 'txt'\n openfunc = vd.open_txt\n\n vd.status('opening %s as %s' % (p.given, filetype))\n\n return openfunc(p)\n\n\n@VisiData.api\ndef openSource(vd, p, filetype=None, create=False, **kwargs):\n '''Return unloaded sheet object for *p* opened as the given *filetype* and with *kwargs* as option overrides. *p* can be a Path or a string (filename, url, or \"-\" for stdin).\n when true, *create* will return a blank sheet, if file does not exist.'''\n if not filetype:\n filetype = options.getonly('filetype', 'global', '')\n\n vs = None\n if isinstance(p, str):\n if '://' in p:\n vs = vd.openPath(Path(p), filetype=filetype) # convert to Path and recurse\n elif p == '-':\n vs = vd.openPath(vd.stdinSource, filetype=filetype)\n else:\n vs = vd.openPath(Path(p), filetype=filetype, create=create) # convert to Path and recurse\n else:\n vs = vd.openPath(p, filetype=filetype, create=create)\n\n for optname, optval in kwargs.items():\n vs.options[optname] = optval\n\n return vs\n\n\n#### enable external addons\n@VisiData.api\ndef open_txt(vd, p):\n 'Create sheet from `.txt` file at Path `p`, checking whether it is TSV.'\n with p.open_text(encoding=vd.options.encoding) as fp:\n try:\n if options.delimiter in next(fp): # peek at the first line\n return vd.open_tsv(p) # TSV often have .txt extension\n except StopIteration:\n return Sheet(p.name, columns=[SettableColumn()], source=p)\n return TextSheet(p.name, source=p)\n\n\n@VisiData.api\ndef loadInternalSheet(vd, cls, p, **kwargs):\n 'Load internal sheet of given class. Internal sheets are always tsv.'\n vs = cls(p.name, source=p, **kwargs)\n options._set('encoding', 'utf8', vs)\n if p.exists():\n vd.sheets.insert(0, vs)\n vs.reload.__wrapped__(vs)\n vd.sheets.pop(0)\n return vs\n\n\nBaseSheet.addCommand('o', 'open-file', 'vd.push(openSource(inputFilename(\"open: \"), create=True))', 'Open file or URL')\nTableSheet.addCommand('zo', 'open-cell-file', 'vd.push(openSource(cursorDisplay) or fail(f\"file {cursorDisplay} does not exist\"))', 'Open file or URL from path in current cell')\n", "path": "visidata/_open.py"}]}
| 1,835 | 162 |
gh_patches_debug_27186
|
rasdani/github-patches
|
git_diff
|
translate__pootle-3593
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Mitigate the risk of revision counter also being in 'default' Redis cache
The revision counter goes into the 'default' cache. This adds the risk of people clearing the default cache and also wiping out the revision counter — even if there's a way to restore it, we might want to prevent removal in the first place. This concern was raised in https://github.com/translate/pootle/issues/3500#issuecomment-73204160
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pootle/core/models.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 #
4 # Copyright 2013-2015 Evernote Corporation
5 #
6 # This file is part of Pootle.
7 #
8 # Pootle is free software; you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation; either version 2 of the License, or
11 # (at your option) any later version.
12 #
13 # translate is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with translate; if not, write to the Free Software
20 # Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
21
22
23 from .cache import get_cache
24 from .mixins import TreeItem
25
26
27 cache = get_cache()
28
29
30 class Revision(object):
31 """Wrapper around the revision counter stored in Redis."""
32
33 CACHE_KEY = 'pootle:revision'
34 INITIAL = 0
35
36 @classmethod
37 def initialize(cls, force=False):
38 """Initializes the revision with `cls.INITIAL`.
39
40 :param force: whether to overwrite the number if there's a
41 revision already set or not.
42 :return: `True` if the initial value was set, `False` otherwise.
43 """
44 if force:
45 return cls.set(cls.INITIAL)
46
47 return cls.add(cls.INITIAL)
48
49 @classmethod
50 def get(cls):
51 """Gets the current revision number.
52
53 :return: The current revision number, or the initial number if
54 there's no revision stored yet.
55 """
56 return cache.get(cls.CACHE_KEY, cls.INITIAL)
57
58 @classmethod
59 def set(cls, value):
60 """Sets the revision number to `value`, regardless of whether
61 there's a value previously set or not.
62
63 :return: `True` if the value was set, `False` otherwise.
64 """
65 return cache.set(cls.CACHE_KEY, value, None)
66
67 @classmethod
68 def add(cls, value):
69 """Sets the revision number to `value`, only if there's no
70 revision already set.
71
72 :return: `True` if the value was set, `False` otherwise.
73 """
74 return cache.add(cls.CACHE_KEY, value, None)
75
76 @classmethod
77 def incr(cls):
78 """Increments the revision number.
79
80 :return: the new revision number after incrementing it, or the
81 initial number if there's no revision stored yet.
82 """
83 try:
84 return cache.incr(cls.CACHE_KEY)
85 except ValueError:
86 return cls.INITIAL
87
88
89 class VirtualResource(TreeItem):
90 """An object representing a virtual resource.
91
92 A virtual resource doesn't live in the DB and has a unique
93 `pootle_path` of its own. It's a simple collection of actual
94 resources.
95
96 For instance, this can be used in projects to have cross-language
97 references.
98
99 Don't use this object as-is, rather subclass it and adapt the
100 implementation details for each context.
101 """
102 def __init__(self, resources, pootle_path, *args, **kwargs):
103 self.resources = resources #: Collection of underlying resources
104 self.pootle_path = pootle_path
105
106 super(VirtualResource, self).__init__(*args, **kwargs)
107
108 def __unicode__(self):
109 return self.pootle_path
110
111 ### TreeItem
112
113 def get_children(self):
114 return self.resources
115
116 def get_cachekey(self):
117 return self.pootle_path
118
119 ### /TreeItem
120
```
Path: `pootle/core/cache.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 #
4 # Copyright 2013-2015 Evernote Corporation
5 #
6 # This file is part of Pootle.
7 #
8 # Pootle is free software; you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation; either version 2 of the License, or
11 # (at your option) any later version.
12 #
13 # This program is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with this program; if not, see <http://www.gnu.org/licenses/>.
20
21
22 from django.core.cache import caches, cache as default_cache
23 from django.core.cache.backends.base import InvalidCacheBackendError
24
25
26 def make_method_key(model, method, key):
27 """Creates a cache key for model's `method` method.
28
29 :param model: A model instance
30 :param method: Method name to cache
31 :param key: a unique key to identify the object to be cached
32 """
33 prefix = 'method-cache'
34
35 if isinstance(model, basestring):
36 name = model
37 else:
38 name = (model.__name__ if hasattr(model, '__name__')
39 else model.__class__.__name__)
40
41 key = key if not isinstance(key, dict) else make_key(**key)
42 return u':'.join([prefix, name, method, key])
43
44
45 def make_key(*args, **kwargs):
46 """Creates a cache key with key-value pairs from a dict."""
47 return ':'.join([
48 '%s=%s' % (k, v) for k, v in sorted(kwargs.iteritems())
49 ])
50
51
52 def get_cache(cache=None):
53 """Return ``cache`` or the 'default' cache if ``cache`` is not specified or
54 ``cache`` is not configured.
55
56 :param cache: The name of the requested cache.
57 """
58 try:
59 return caches[cache]
60 except InvalidCacheBackendError:
61 return default_cache
62
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pootle/core/cache.py b/pootle/core/cache.py
--- a/pootle/core/cache.py
+++ b/pootle/core/cache.py
@@ -19,8 +19,13 @@
# along with this program; if not, see <http://www.gnu.org/licenses/>.
+from django.conf import settings
from django.core.cache import caches, cache as default_cache
from django.core.cache.backends.base import InvalidCacheBackendError
+from django.core.exceptions import ImproperlyConfigured
+
+
+PERSISTENT_STORES = ('redis', 'stats')
def make_method_key(model, method, key):
@@ -56,6 +61,17 @@
:param cache: The name of the requested cache.
"""
try:
+ # Check for proper Redis persistent backends
+ # FIXME: this logic needs to be a system sanity check
+ if (cache in PERSISTENT_STORES and
+ (cache not in settings.CACHES or
+ 'RedisCache' not in settings.CACHES[cache]['BACKEND'] or
+ settings.CACHES[cache].get('TIMEOUT', '') != None)):
+ raise ImproperlyConfigured(
+ 'Pootle requires a Redis-backed caching backend for %r '
+ 'with `TIMEOUT: None`. Please review your settings.' % cache
+ )
+
return caches[cache]
except InvalidCacheBackendError:
return default_cache
diff --git a/pootle/core/models.py b/pootle/core/models.py
--- a/pootle/core/models.py
+++ b/pootle/core/models.py
@@ -24,7 +24,7 @@
from .mixins import TreeItem
-cache = get_cache()
+cache = get_cache('redis')
class Revision(object):
|
{"golden_diff": "diff --git a/pootle/core/cache.py b/pootle/core/cache.py\n--- a/pootle/core/cache.py\n+++ b/pootle/core/cache.py\n@@ -19,8 +19,13 @@\n # along with this program; if not, see <http://www.gnu.org/licenses/>.\n \n \n+from django.conf import settings\n from django.core.cache import caches, cache as default_cache\n from django.core.cache.backends.base import InvalidCacheBackendError\n+from django.core.exceptions import ImproperlyConfigured\n+\n+\n+PERSISTENT_STORES = ('redis', 'stats')\n \n \n def make_method_key(model, method, key):\n@@ -56,6 +61,17 @@\n :param cache: The name of the requested cache.\n \"\"\"\n try:\n+ # Check for proper Redis persistent backends\n+ # FIXME: this logic needs to be a system sanity check\n+ if (cache in PERSISTENT_STORES and\n+ (cache not in settings.CACHES or\n+ 'RedisCache' not in settings.CACHES[cache]['BACKEND'] or\n+ settings.CACHES[cache].get('TIMEOUT', '') != None)):\n+ raise ImproperlyConfigured(\n+ 'Pootle requires a Redis-backed caching backend for %r '\n+ 'with `TIMEOUT: None`. Please review your settings.' % cache\n+ )\n+\n return caches[cache]\n except InvalidCacheBackendError:\n return default_cache\ndiff --git a/pootle/core/models.py b/pootle/core/models.py\n--- a/pootle/core/models.py\n+++ b/pootle/core/models.py\n@@ -24,7 +24,7 @@\n from .mixins import TreeItem\n \n \n-cache = get_cache()\n+cache = get_cache('redis')\n \n \n class Revision(object):\n", "issue": "Mitigate the risk of revision counter also being in 'default' Redis cache\nThe revision counter goes into the 'default' cache. This adds the risk of people clearing the default cache and also wiping out the revision counter \u2014 even if there's a way to restore it, we might want to prevent removal in the first place. This concern was raised in https://github.com/translate/pootle/issues/3500#issuecomment-73204160\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright 2013-2015 Evernote Corporation\n#\n# This file is part of Pootle.\n#\n# Pootle is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# translate is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with translate; if not, write to the Free Software\n# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA\n\n\nfrom .cache import get_cache\nfrom .mixins import TreeItem\n\n\ncache = get_cache()\n\n\nclass Revision(object):\n \"\"\"Wrapper around the revision counter stored in Redis.\"\"\"\n\n CACHE_KEY = 'pootle:revision'\n INITIAL = 0\n\n @classmethod\n def initialize(cls, force=False):\n \"\"\"Initializes the revision with `cls.INITIAL`.\n\n :param force: whether to overwrite the number if there's a\n revision already set or not.\n :return: `True` if the initial value was set, `False` otherwise.\n \"\"\"\n if force:\n return cls.set(cls.INITIAL)\n\n return cls.add(cls.INITIAL)\n\n @classmethod\n def get(cls):\n \"\"\"Gets the current revision number.\n\n :return: The current revision number, or the initial number if\n there's no revision stored yet.\n \"\"\"\n return cache.get(cls.CACHE_KEY, cls.INITIAL)\n\n @classmethod\n def set(cls, value):\n \"\"\"Sets the revision number to `value`, regardless of whether\n there's a value previously set or not.\n\n :return: `True` if the value was set, `False` otherwise.\n \"\"\"\n return cache.set(cls.CACHE_KEY, value, None)\n\n @classmethod\n def add(cls, value):\n \"\"\"Sets the revision number to `value`, only if there's no\n revision already set.\n\n :return: `True` if the value was set, `False` otherwise.\n \"\"\"\n return cache.add(cls.CACHE_KEY, value, None)\n\n @classmethod\n def incr(cls):\n \"\"\"Increments the revision number.\n\n :return: the new revision number after incrementing it, or the\n initial number if there's no revision stored yet.\n \"\"\"\n try:\n return cache.incr(cls.CACHE_KEY)\n except ValueError:\n return cls.INITIAL\n\n\nclass VirtualResource(TreeItem):\n \"\"\"An object representing a virtual resource.\n\n A virtual resource doesn't live in the DB and has a unique\n `pootle_path` of its own. It's a simple collection of actual\n resources.\n\n For instance, this can be used in projects to have cross-language\n references.\n\n Don't use this object as-is, rather subclass it and adapt the\n implementation details for each context.\n \"\"\"\n def __init__(self, resources, pootle_path, *args, **kwargs):\n self.resources = resources #: Collection of underlying resources\n self.pootle_path = pootle_path\n\n super(VirtualResource, self).__init__(*args, **kwargs)\n\n def __unicode__(self):\n return self.pootle_path\n\n ### TreeItem\n\n def get_children(self):\n return self.resources\n\n def get_cachekey(self):\n return self.pootle_path\n\n ### /TreeItem\n", "path": "pootle/core/models.py"}, {"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright 2013-2015 Evernote Corporation\n#\n# This file is part of Pootle.\n#\n# Pootle is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, see <http://www.gnu.org/licenses/>.\n\n\nfrom django.core.cache import caches, cache as default_cache\nfrom django.core.cache.backends.base import InvalidCacheBackendError\n\n\ndef make_method_key(model, method, key):\n \"\"\"Creates a cache key for model's `method` method.\n\n :param model: A model instance\n :param method: Method name to cache\n :param key: a unique key to identify the object to be cached\n \"\"\"\n prefix = 'method-cache'\n\n if isinstance(model, basestring):\n name = model\n else:\n name = (model.__name__ if hasattr(model, '__name__')\n else model.__class__.__name__)\n\n key = key if not isinstance(key, dict) else make_key(**key)\n return u':'.join([prefix, name, method, key])\n\n\ndef make_key(*args, **kwargs):\n \"\"\"Creates a cache key with key-value pairs from a dict.\"\"\"\n return ':'.join([\n '%s=%s' % (k, v) for k, v in sorted(kwargs.iteritems())\n ])\n\n\ndef get_cache(cache=None):\n \"\"\"Return ``cache`` or the 'default' cache if ``cache`` is not specified or\n ``cache`` is not configured.\n\n :param cache: The name of the requested cache.\n \"\"\"\n try:\n return caches[cache]\n except InvalidCacheBackendError:\n return default_cache\n", "path": "pootle/core/cache.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright 2013-2015 Evernote Corporation\n#\n# This file is part of Pootle.\n#\n# Pootle is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# translate is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with translate; if not, write to the Free Software\n# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA\n\n\nfrom .cache import get_cache\nfrom .mixins import TreeItem\n\n\ncache = get_cache('redis')\n\n\nclass Revision(object):\n \"\"\"Wrapper around the revision counter stored in Redis.\"\"\"\n\n CACHE_KEY = 'pootle:revision'\n INITIAL = 0\n\n @classmethod\n def initialize(cls, force=False):\n \"\"\"Initializes the revision with `cls.INITIAL`.\n\n :param force: whether to overwrite the number if there's a\n revision already set or not.\n :return: `True` if the initial value was set, `False` otherwise.\n \"\"\"\n if force:\n return cls.set(cls.INITIAL)\n\n return cls.add(cls.INITIAL)\n\n @classmethod\n def get(cls):\n \"\"\"Gets the current revision number.\n\n :return: The current revision number, or the initial number if\n there's no revision stored yet.\n \"\"\"\n return cache.get(cls.CACHE_KEY, cls.INITIAL)\n\n @classmethod\n def set(cls, value):\n \"\"\"Sets the revision number to `value`, regardless of whether\n there's a value previously set or not.\n\n :return: `True` if the value was set, `False` otherwise.\n \"\"\"\n return cache.set(cls.CACHE_KEY, value, None)\n\n @classmethod\n def add(cls, value):\n \"\"\"Sets the revision number to `value`, only if there's no\n revision already set.\n\n :return: `True` if the value was set, `False` otherwise.\n \"\"\"\n return cache.add(cls.CACHE_KEY, value, None)\n\n @classmethod\n def incr(cls):\n \"\"\"Increments the revision number.\n\n :return: the new revision number after incrementing it, or the\n initial number if there's no revision stored yet.\n \"\"\"\n try:\n return cache.incr(cls.CACHE_KEY)\n except ValueError:\n return cls.INITIAL\n\n\nclass VirtualResource(TreeItem):\n \"\"\"An object representing a virtual resource.\n\n A virtual resource doesn't live in the DB and has a unique\n `pootle_path` of its own. It's a simple collection of actual\n resources.\n\n For instance, this can be used in projects to have cross-language\n references.\n\n Don't use this object as-is, rather subclass it and adapt the\n implementation details for each context.\n \"\"\"\n def __init__(self, resources, pootle_path, *args, **kwargs):\n self.resources = resources #: Collection of underlying resources\n self.pootle_path = pootle_path\n\n super(VirtualResource, self).__init__(*args, **kwargs)\n\n def __unicode__(self):\n return self.pootle_path\n\n ### TreeItem\n\n def get_children(self):\n return self.resources\n\n def get_cachekey(self):\n return self.pootle_path\n\n ### /TreeItem\n", "path": "pootle/core/models.py"}, {"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright 2013-2015 Evernote Corporation\n#\n# This file is part of Pootle.\n#\n# Pootle is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, see <http://www.gnu.org/licenses/>.\n\n\nfrom django.conf import settings\nfrom django.core.cache import caches, cache as default_cache\nfrom django.core.cache.backends.base import InvalidCacheBackendError\nfrom django.core.exceptions import ImproperlyConfigured\n\n\nPERSISTENT_STORES = ('redis', 'stats')\n\n\ndef make_method_key(model, method, key):\n \"\"\"Creates a cache key for model's `method` method.\n\n :param model: A model instance\n :param method: Method name to cache\n :param key: a unique key to identify the object to be cached\n \"\"\"\n prefix = 'method-cache'\n\n if isinstance(model, basestring):\n name = model\n else:\n name = (model.__name__ if hasattr(model, '__name__')\n else model.__class__.__name__)\n\n key = key if not isinstance(key, dict) else make_key(**key)\n return u':'.join([prefix, name, method, key])\n\n\ndef make_key(*args, **kwargs):\n \"\"\"Creates a cache key with key-value pairs from a dict.\"\"\"\n return ':'.join([\n '%s=%s' % (k, v) for k, v in sorted(kwargs.iteritems())\n ])\n\n\ndef get_cache(cache=None):\n \"\"\"Return ``cache`` or the 'default' cache if ``cache`` is not specified or\n ``cache`` is not configured.\n\n :param cache: The name of the requested cache.\n \"\"\"\n try:\n # Check for proper Redis persistent backends\n # FIXME: this logic needs to be a system sanity check\n if (cache in PERSISTENT_STORES and\n (cache not in settings.CACHES or\n 'RedisCache' not in settings.CACHES[cache]['BACKEND'] or\n settings.CACHES[cache].get('TIMEOUT', '') != None)):\n raise ImproperlyConfigured(\n 'Pootle requires a Redis-backed caching backend for %r '\n 'with `TIMEOUT: None`. Please review your settings.' % cache\n )\n\n return caches[cache]\n except InvalidCacheBackendError:\n return default_cache\n", "path": "pootle/core/cache.py"}]}
| 2,076 | 396 |
gh_patches_debug_32284
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-1011
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
reST listings can’t number lines, while code-blocks do it incompatibly
1. One can’t do a `.. listing::` in Nikola with line numbers.
2. In `.. code-block::`s, one must use the reST `:number-lines:` option syntax. However, Sphinx wants `:linenos:` instead. (#770)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nikola/plugins/compile/rest/listing.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2014 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27
28 """ Define and register a listing directive using the existing CodeBlock """
29
30
31 from __future__ import unicode_literals
32 from codecs import open as codecs_open # for patching purposes
33 import os
34 try:
35 from urlparse import urlunsplit
36 except ImportError:
37 from urllib.parse import urlunsplit # NOQA
38
39 from docutils import core
40 from docutils import nodes
41 from docutils.parsers.rst import Directive, directives
42 from docutils.parsers.rst.directives.misc import Include
43 try:
44 from docutils.parsers.rst.directives.body import CodeBlock
45 except ImportError: # docutils < 0.9 (Debian Sid For The Loss)
46 class CodeBlock(Directive):
47 required_arguments = 1
48 has_content = True
49 CODE = '<pre>{0}</pre>'
50
51 def run(self):
52 """ Required by the Directive interface. Create docutils nodes """
53 return [nodes.raw('', self.CODE.format('\n'.join(self.content)), format='html')]
54 directives.register_directive('code', CodeBlock)
55
56
57 from nikola.plugin_categories import RestExtension
58
59
60 class Plugin(RestExtension):
61
62 name = "rest_listing"
63
64 def set_site(self, site):
65 self.site = site
66 # Even though listings don't use CodeBlock anymore, I am
67 # leaving these to make the code directive work with
68 # docutils < 0.9
69 directives.register_directive('code-block', CodeBlock)
70 directives.register_directive('sourcecode', CodeBlock)
71 directives.register_directive('listing', Listing)
72 return super(Plugin, self).set_site(site)
73
74
75 class Listing(Include):
76 """ listing directive: create a highlighted block of code from a file in listings/
77
78 Usage:
79
80 .. listing:: nikola.py python
81 :number-lines:
82
83 """
84 has_content = False
85 required_arguments = 1
86 optional_arguments = 1
87
88 def run(self):
89 fname = self.arguments.pop(0)
90 lang = self.arguments.pop(0)
91 fpath = os.path.join('listings', fname)
92 self.arguments.insert(0, fpath)
93 self.options['code'] = lang
94 with codecs_open(fpath, 'rb+', 'utf8') as fileobject:
95 self.content = fileobject.read().splitlines()
96 self.state.document.settings.record_dependencies.add(fpath)
97 target = urlunsplit(("link", 'listing', fname, '', ''))
98 generated_nodes = (
99 [core.publish_doctree('`{0} <{1}>`_'.format(fname, target))[0]])
100 generated_nodes += self.get_code_from_file(fileobject)
101 return generated_nodes
102
103 def get_code_from_file(self, data):
104 """ Create CodeBlock nodes from file object content """
105 return super(Listing, self).run()
106
107 def assert_has_content(self):
108 """ Listing has no content, override check from superclass """
109 pass
110
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/nikola/plugins/compile/rest/listing.py b/nikola/plugins/compile/rest/listing.py
--- a/nikola/plugins/compile/rest/listing.py
+++ b/nikola/plugins/compile/rest/listing.py
@@ -56,6 +56,18 @@
from nikola.plugin_categories import RestExtension
+# Add sphinx compatibility option
+CodeBlock.option_spec['linenos'] = directives.unchanged
+
+
+class FlexibleCodeBlock(CodeBlock):
+
+ def run(self):
+ if 'linenos' in self.options:
+ self.options['number-lines'] = self.options['linenos']
+ return super(FlexibleCodeBlock, self).run()
+CodeBlock = FlexibleCodeBlock
+
class Plugin(RestExtension):
@@ -71,6 +83,11 @@
directives.register_directive('listing', Listing)
return super(Plugin, self).set_site(site)
+# Add sphinx compatibility option
+listing_spec = Include.option_spec
+listing_spec['linenos'] = directives.unchanged
+print(listing_spec)
+
class Listing(Include):
""" listing directive: create a highlighted block of code from a file in listings/
@@ -84,6 +101,7 @@
has_content = False
required_arguments = 1
optional_arguments = 1
+ option_spec = listing_spec
def run(self):
fname = self.arguments.pop(0)
@@ -91,6 +109,8 @@
fpath = os.path.join('listings', fname)
self.arguments.insert(0, fpath)
self.options['code'] = lang
+ if 'linenos' in self.options:
+ self.options['number-lines'] = self.options['linenos']
with codecs_open(fpath, 'rb+', 'utf8') as fileobject:
self.content = fileobject.read().splitlines()
self.state.document.settings.record_dependencies.add(fpath)
|
{"golden_diff": "diff --git a/nikola/plugins/compile/rest/listing.py b/nikola/plugins/compile/rest/listing.py\n--- a/nikola/plugins/compile/rest/listing.py\n+++ b/nikola/plugins/compile/rest/listing.py\n@@ -56,6 +56,18 @@\n \n from nikola.plugin_categories import RestExtension\n \n+# Add sphinx compatibility option\n+CodeBlock.option_spec['linenos'] = directives.unchanged\n+\n+\n+class FlexibleCodeBlock(CodeBlock):\n+\n+ def run(self):\n+ if 'linenos' in self.options:\n+ self.options['number-lines'] = self.options['linenos']\n+ return super(FlexibleCodeBlock, self).run()\n+CodeBlock = FlexibleCodeBlock\n+\n \n class Plugin(RestExtension):\n \n@@ -71,6 +83,11 @@\n directives.register_directive('listing', Listing)\n return super(Plugin, self).set_site(site)\n \n+# Add sphinx compatibility option\n+listing_spec = Include.option_spec\n+listing_spec['linenos'] = directives.unchanged\n+print(listing_spec)\n+\n \n class Listing(Include):\n \"\"\" listing directive: create a highlighted block of code from a file in listings/\n@@ -84,6 +101,7 @@\n has_content = False\n required_arguments = 1\n optional_arguments = 1\n+ option_spec = listing_spec\n \n def run(self):\n fname = self.arguments.pop(0)\n@@ -91,6 +109,8 @@\n fpath = os.path.join('listings', fname)\n self.arguments.insert(0, fpath)\n self.options['code'] = lang\n+ if 'linenos' in self.options:\n+ self.options['number-lines'] = self.options['linenos']\n with codecs_open(fpath, 'rb+', 'utf8') as fileobject:\n self.content = fileobject.read().splitlines()\n self.state.document.settings.record_dependencies.add(fpath)\n", "issue": "reST listings can\u2019t number lines, while code-blocks do it incompatibly\n1. One can\u2019t do a `.. listing::` in Nikola with line numbers.\n2. In `.. code-block::`s, one must use the reST `:number-lines:` option syntax. However, Sphinx wants `:linenos:` instead. (#770)\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2014 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\n\"\"\" Define and register a listing directive using the existing CodeBlock \"\"\"\n\n\nfrom __future__ import unicode_literals\nfrom codecs import open as codecs_open # for patching purposes\nimport os\ntry:\n from urlparse import urlunsplit\nexcept ImportError:\n from urllib.parse import urlunsplit # NOQA\n\nfrom docutils import core\nfrom docutils import nodes\nfrom docutils.parsers.rst import Directive, directives\nfrom docutils.parsers.rst.directives.misc import Include\ntry:\n from docutils.parsers.rst.directives.body import CodeBlock\nexcept ImportError: # docutils < 0.9 (Debian Sid For The Loss)\n class CodeBlock(Directive):\n required_arguments = 1\n has_content = True\n CODE = '<pre>{0}</pre>'\n\n def run(self):\n \"\"\" Required by the Directive interface. Create docutils nodes \"\"\"\n return [nodes.raw('', self.CODE.format('\\n'.join(self.content)), format='html')]\n directives.register_directive('code', CodeBlock)\n\n\nfrom nikola.plugin_categories import RestExtension\n\n\nclass Plugin(RestExtension):\n\n name = \"rest_listing\"\n\n def set_site(self, site):\n self.site = site\n # Even though listings don't use CodeBlock anymore, I am\n # leaving these to make the code directive work with\n # docutils < 0.9\n directives.register_directive('code-block', CodeBlock)\n directives.register_directive('sourcecode', CodeBlock)\n directives.register_directive('listing', Listing)\n return super(Plugin, self).set_site(site)\n\n\nclass Listing(Include):\n \"\"\" listing directive: create a highlighted block of code from a file in listings/\n\n Usage:\n\n .. listing:: nikola.py python\n :number-lines:\n\n \"\"\"\n has_content = False\n required_arguments = 1\n optional_arguments = 1\n\n def run(self):\n fname = self.arguments.pop(0)\n lang = self.arguments.pop(0)\n fpath = os.path.join('listings', fname)\n self.arguments.insert(0, fpath)\n self.options['code'] = lang\n with codecs_open(fpath, 'rb+', 'utf8') as fileobject:\n self.content = fileobject.read().splitlines()\n self.state.document.settings.record_dependencies.add(fpath)\n target = urlunsplit((\"link\", 'listing', fname, '', ''))\n generated_nodes = (\n [core.publish_doctree('`{0} <{1}>`_'.format(fname, target))[0]])\n generated_nodes += self.get_code_from_file(fileobject)\n return generated_nodes\n\n def get_code_from_file(self, data):\n \"\"\" Create CodeBlock nodes from file object content \"\"\"\n return super(Listing, self).run()\n\n def assert_has_content(self):\n \"\"\" Listing has no content, override check from superclass \"\"\"\n pass\n", "path": "nikola/plugins/compile/rest/listing.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2014 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\n\"\"\" Define and register a listing directive using the existing CodeBlock \"\"\"\n\n\nfrom __future__ import unicode_literals\nfrom codecs import open as codecs_open # for patching purposes\nimport os\ntry:\n from urlparse import urlunsplit\nexcept ImportError:\n from urllib.parse import urlunsplit # NOQA\n\nfrom docutils import core\nfrom docutils import nodes\nfrom docutils.parsers.rst import Directive, directives\nfrom docutils.parsers.rst.directives.misc import Include\ntry:\n from docutils.parsers.rst.directives.body import CodeBlock\nexcept ImportError: # docutils < 0.9 (Debian Sid For The Loss)\n class CodeBlock(Directive):\n required_arguments = 1\n has_content = True\n CODE = '<pre>{0}</pre>'\n\n def run(self):\n \"\"\" Required by the Directive interface. Create docutils nodes \"\"\"\n return [nodes.raw('', self.CODE.format('\\n'.join(self.content)), format='html')]\n directives.register_directive('code', CodeBlock)\n\n\nfrom nikola.plugin_categories import RestExtension\n\n# Add sphinx compatibility option\nCodeBlock.option_spec['linenos'] = directives.unchanged\n\n\nclass FlexibleCodeBlock(CodeBlock):\n\n def run(self):\n if 'linenos' in self.options:\n self.options['number-lines'] = self.options['linenos']\n return super(FlexibleCodeBlock, self).run()\nCodeBlock = FlexibleCodeBlock\n\n\nclass Plugin(RestExtension):\n\n name = \"rest_listing\"\n\n def set_site(self, site):\n self.site = site\n # Even though listings don't use CodeBlock anymore, I am\n # leaving these to make the code directive work with\n # docutils < 0.9\n directives.register_directive('code-block', CodeBlock)\n directives.register_directive('sourcecode', CodeBlock)\n directives.register_directive('listing', Listing)\n return super(Plugin, self).set_site(site)\n\n# Add sphinx compatibility option\nlisting_spec = Include.option_spec\nlisting_spec['linenos'] = directives.unchanged\nprint(listing_spec)\n\n\nclass Listing(Include):\n \"\"\" listing directive: create a highlighted block of code from a file in listings/\n\n Usage:\n\n .. listing:: nikola.py python\n :number-lines:\n\n \"\"\"\n has_content = False\n required_arguments = 1\n optional_arguments = 1\n option_spec = listing_spec\n\n def run(self):\n fname = self.arguments.pop(0)\n lang = self.arguments.pop(0)\n fpath = os.path.join('listings', fname)\n self.arguments.insert(0, fpath)\n self.options['code'] = lang\n if 'linenos' in self.options:\n self.options['number-lines'] = self.options['linenos']\n with codecs_open(fpath, 'rb+', 'utf8') as fileobject:\n self.content = fileobject.read().splitlines()\n self.state.document.settings.record_dependencies.add(fpath)\n target = urlunsplit((\"link\", 'listing', fname, '', ''))\n generated_nodes = (\n [core.publish_doctree('`{0} <{1}>`_'.format(fname, target))[0]])\n generated_nodes += self.get_code_from_file(fileobject)\n return generated_nodes\n\n def get_code_from_file(self, data):\n \"\"\" Create CodeBlock nodes from file object content \"\"\"\n return super(Listing, self).run()\n\n def assert_has_content(self):\n \"\"\" Listing has no content, override check from superclass \"\"\"\n pass\n", "path": "nikola/plugins/compile/rest/listing.py"}]}
| 1,448 | 430 |
gh_patches_debug_32545
|
rasdani/github-patches
|
git_diff
|
deepchecks__deepchecks-395
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
BUG: Simple model comparison shows irrelevant labels
To reproduce:
https://www.kaggle.com/itay94/notebook05f499eb19

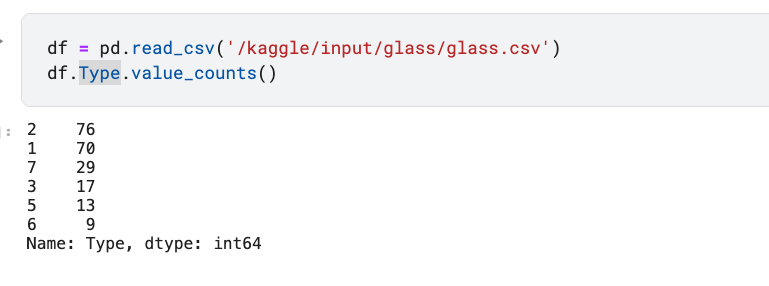
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `deepchecks/checks/performance/simple_model_comparison.py`
Content:
```
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 """Module containing simple comparison check."""
12 from typing import Callable, Dict, Hashable, List
13 import numpy as np
14 import pandas as pd
15 import plotly.express as px
16 from sklearn.dummy import DummyRegressor, DummyClassifier
17 from sklearn.pipeline import Pipeline
18 from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
19 from deepchecks.checks.distribution.preprocessing import ScaledNumerics
20 from deepchecks.utils.strings import format_number
21
22 from deepchecks import CheckResult, Dataset
23 from deepchecks.base.check import ConditionResult, TrainTestBaseCheck
24 from deepchecks.utils.metrics import task_type_check, ModelType, initialize_multi_scorers, \
25 get_scorers_list, get_scores_ratio, get_scorer_single
26 from deepchecks.utils.validation import validate_model
27 from deepchecks.errors import DeepchecksValueError
28
29
30 __all__ = ['SimpleModelComparison']
31
32
33 class SimpleModelComparison(TrainTestBaseCheck):
34 """Compare given model score to simple model score (according to given model type).
35
36 Args:
37 simple_model_type (str):
38 Type of the simple model ['random', 'constant', 'tree'].
39 + random - select one of the labels by random.
40 + constant - in regression is mean value, in classification the most common value.
41 + tree - runs a simple decision tree.
42 alternative_scorers (Dict[str, Callable], default None):
43 An optional dictionary of scorer name to scorer functions.
44 If none given, using default scorers
45 maximum_ratio (int):
46 the ratio can be up to infinity so choose maximum value to limit to.
47 max_depth (int):
48 the max depth of the tree (used only if simple model type is tree).
49 random_state (int):
50 the random state (used only if simple model type is tree or random).
51 """
52
53 def __init__(self, simple_model_type: str = 'constant', alternative_scorers: Dict[str, Callable] = None,
54 maximum_ratio: int = 50, max_depth: int = 3, random_state: int = 42):
55 super().__init__()
56 self.simple_model_type = simple_model_type
57 self.alternative_scorers = initialize_multi_scorers(alternative_scorers)
58 self.maximum_ratio = maximum_ratio
59 self.max_depth = max_depth
60 self.random_state = random_state
61
62 def run(self, train_dataset, test_dataset, model) -> CheckResult:
63 """Run check.
64
65 Args:
66 train_dataset (Dataset): The training dataset object. Must contain a label.
67 test_dataset (Dataset): The test dataset object. Must contain a label.
68 model (BaseEstimator): A scikit-learn-compatible fitted estimator instance.
69
70 Returns:
71 CheckResult: value is a Dict of: given_model_score, simple_model_score, ratio
72 ratio is given model / simple model (if the scorer returns negative values we divide 1 by it)
73 if ratio is infinite max_ratio is returned
74
75 Raises:
76 DeepchecksValueError: If the object is not a Dataset instance.
77 """
78 Dataset.validate_dataset(train_dataset)
79 Dataset.validate_dataset(test_dataset)
80 train_dataset.validate_label()
81 test_dataset.validate_label()
82 validate_model(test_dataset, model)
83
84 # If user defined scorers used them, else use a single scorer
85 if self.alternative_scorers:
86 scorers = get_scorers_list(model, train_dataset, self.alternative_scorers, multiclass_avg=False)
87 else:
88 scorers = [get_scorer_single(model, train_dataset, multiclass_avg=False)]
89
90 task_type = task_type_check(model, train_dataset)
91 simple_model = self._create_simple_model(train_dataset, task_type)
92
93 models = [
94 (f'{type(model).__name__} model', 'Origin', model),
95 (f'Simple model - {self.simple_model_type}', 'Simple', simple_model)
96 ]
97
98 # Multiclass have different return type from the scorer, list of score per class instead of single score
99 if task_type == ModelType.MULTICLASS:
100 results = []
101 for model_name, model_type, model_instance in models:
102 for scorer in scorers:
103 score_result: np.ndarray = scorer(model_instance, test_dataset)
104 # Multiclass scorers return numpy array of result per class
105 for class_i, class_score in enumerate(score_result):
106 # The proba returns in order of the sorted classes.
107 class_value = train_dataset.classes[class_i]
108 results.append([model_name, model_type, class_score, scorer.name, class_value])
109
110 results_df = pd.DataFrame(results, columns=['Model', 'Type', 'Value', 'Metric', 'Class'])
111
112 # Plot the metrics in a graph, grouping by the model and class
113 fig = px.bar(results_df, x=['Class', 'Model'], y='Value', color='Model', barmode='group',
114 facet_col='Metric', facet_col_spacing=0.05)
115 fig.update_xaxes(title=None, tickprefix='Class ', tickangle=60)
116 fig.update_yaxes(title=None, matches=None)
117 fig.for_each_annotation(lambda a: a.update(text=a.text.split('=')[-1]))
118 fig.for_each_yaxis(lambda yaxis: yaxis.update(showticklabels=True))
119 # Model is binary or regression
120 else:
121 results = []
122 for model_name, model_type, model_instance in models:
123 for scorer in scorers:
124 score_result: float = scorer(model_instance, test_dataset)
125 results.append([model_name, model_type, score_result, scorer.name])
126
127 results_df = pd.DataFrame(results, columns=['Model', 'Type', 'Value', 'Metric'])
128
129 # Plot the metrics in a graph, grouping by the model
130 fig = px.bar(results_df, x='Model', y='Value', color='Model', barmode='group',
131 facet_col='Metric', facet_col_spacing=0.05)
132 fig.update_xaxes(title=None)
133 fig.update_yaxes(title=None, matches=None)
134 fig.for_each_annotation(lambda a: a.update(text=a.text.split('=')[-1]))
135 fig.for_each_yaxis(lambda yaxis: yaxis.update(showticklabels=True))
136
137 return CheckResult({'scores': results_df, 'type': task_type}, display=fig)
138
139 def _create_simple_model(self, train_ds: Dataset, task_type: ModelType):
140 """Create a simple model of given type (random/constant/tree) to the given dataset.
141
142 Args:
143 train_ds (Dataset): The training dataset object.
144 task_type (ModelType): the model type.
145 Returns:
146 Classifier object.
147
148 Raises:
149 NotImplementedError: If the simple_model_type is not supported
150 """
151 np.random.seed(self.random_state)
152
153 if self.simple_model_type == 'random':
154 simple_model = RandomModel()
155
156 elif self.simple_model_type == 'constant':
157 if task_type == ModelType.REGRESSION:
158 simple_model = DummyRegressor(strategy='mean')
159 elif task_type in {ModelType.BINARY, ModelType.MULTICLASS}:
160 simple_model = DummyClassifier(strategy='most_frequent')
161 else:
162 raise DeepchecksValueError(f'Unknown task type - {task_type}')
163 elif self.simple_model_type == 'tree':
164 if task_type == ModelType.REGRESSION:
165 clf = DecisionTreeRegressor(
166 max_depth=self.max_depth,
167 random_state=self.random_state
168 )
169 elif task_type in {ModelType.BINARY, ModelType.MULTICLASS}:
170 clf = DecisionTreeClassifier(
171 max_depth=self.max_depth,
172 random_state=self.random_state,
173 class_weight='balanced'
174 )
175 else:
176 raise DeepchecksValueError(f'Unknown task type - {task_type}')
177
178 simple_model = Pipeline([('scaler', ScaledNumerics(train_ds.cat_features, max_num_categories=10)),
179 ('tree-model', clf)])
180 else:
181 raise DeepchecksValueError(
182 f'Unknown model type - {self.simple_model_type}, expected to be one of '
183 f"['random', 'constant', 'tree'] "
184 f"but instead got {self.simple_model_type}" # pylint: disable=inconsistent-quotes
185 )
186
187 simple_model.fit(train_ds.features_columns, train_ds.label_col)
188 return simple_model
189
190 def add_condition_ratio_not_less_than(self, min_allowed_ratio: float = 1.1, classes: List[Hashable] = None):
191 """Add condition - require min allowed ratio between the given and the simple model.
192
193 Args:
194 min_allowed_ratio (float): Min allowed ratio between the given and the simple model -
195 ratio is given model / simple model (if the scorer returns negative values we divide 1 by it)
196 classes (List[Hashable]): Used in multiclass models to limit condition only to given classes.
197 """
198 def condition(result: Dict, max_ratio=self.maximum_ratio, class_list=classes) -> ConditionResult:
199 scores_df = result['scores']
200 task_type = result['type']
201 metrics = scores_df['Metric'].unique()
202
203 def get_ratio(df):
204 simple_score = df[df['Type'] == 'Simple']['Value'].iloc[0]
205 origin_score = df[df['Type'] == 'Origin']['Value'].iloc[0]
206 return get_scores_ratio(simple_score, origin_score, max_ratio)
207
208 fails = []
209 if task_type == ModelType.MULTICLASS:
210 if class_list is None:
211 class_list = scores_df['Class'].unique()
212 for metric in metrics:
213 failed_classes = []
214 for clas in class_list:
215 score_rows = scores_df[(scores_df['Metric'] == metric) & (scores_df['Class'] == clas)]
216 ratio = get_ratio(score_rows)
217 if ratio < min_allowed_ratio:
218 failed_classes.append(str(clas))
219 if failed_classes:
220 fails.append(f'"{metric}" - Classes: {", ".join(failed_classes)}')
221 else:
222 for metric in metrics:
223 score_rows = scores_df[(scores_df['Metric'] == metric)]
224 ratio = get_ratio(score_rows)
225 if ratio < min_allowed_ratio:
226 fails.append(f'"{metric}"')
227
228 if fails:
229 msg = f'Metrics failed: {", ".join(sorted(fails))}'
230 return ConditionResult(False, msg)
231 else:
232 return ConditionResult(True)
233
234 return self.add_condition('$$\\frac{\\text{model score}}{\\text{simple model score}} >= '
235 f'{format_number(min_allowed_ratio)}$$', condition)
236
237
238 class RandomModel:
239 """Model used to randomly predict from given series of labels."""
240
241 def __init__(self):
242 self.labels = None
243
244 def fit(self, X, y): # pylint: disable=unused-argument,invalid-name
245 # The X is not used, but it is needed to be matching to sklearn `fit` signature
246 self.labels = y
247
248 def predict(self, X): # pylint: disable=invalid-name
249 return np.random.choice(self.labels, X.shape[0])
250
251 def predict_proba(self, X): # pylint: disable=invalid-name
252 classes = sorted(self.labels.unique().tolist())
253 predictions = self.predict(X)
254
255 def prediction_to_proba(y_pred):
256 proba = np.zeros(len(classes))
257 proba[classes.index(y_pred)] = 1
258 return proba
259 return np.apply_along_axis(prediction_to_proba, axis=1, arr=predictions)
260
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/deepchecks/checks/performance/simple_model_comparison.py b/deepchecks/checks/performance/simple_model_comparison.py
--- a/deepchecks/checks/performance/simple_model_comparison.py
+++ b/deepchecks/checks/performance/simple_model_comparison.py
@@ -101,10 +101,8 @@
for model_name, model_type, model_instance in models:
for scorer in scorers:
score_result: np.ndarray = scorer(model_instance, test_dataset)
- # Multiclass scorers return numpy array of result per class
- for class_i, class_score in enumerate(score_result):
- # The proba returns in order of the sorted classes.
- class_value = train_dataset.classes[class_i]
+ # Multiclass scorers return numpy array of result per class in order of sorted classes
+ for class_score, class_value in zip(score_result, test_dataset.classes):
results.append([model_name, model_type, class_score, scorer.name, class_value])
results_df = pd.DataFrame(results, columns=['Model', 'Type', 'Value', 'Metric', 'Class'])
@@ -112,7 +110,7 @@
# Plot the metrics in a graph, grouping by the model and class
fig = px.bar(results_df, x=['Class', 'Model'], y='Value', color='Model', barmode='group',
facet_col='Metric', facet_col_spacing=0.05)
- fig.update_xaxes(title=None, tickprefix='Class ', tickangle=60)
+ fig.update_xaxes(title=None, tickprefix='Class ', tickangle=60, type='category')
fig.update_yaxes(title=None, matches=None)
fig.for_each_annotation(lambda a: a.update(text=a.text.split('=')[-1]))
fig.for_each_yaxis(lambda yaxis: yaxis.update(showticklabels=True))
|
{"golden_diff": "diff --git a/deepchecks/checks/performance/simple_model_comparison.py b/deepchecks/checks/performance/simple_model_comparison.py\n--- a/deepchecks/checks/performance/simple_model_comparison.py\n+++ b/deepchecks/checks/performance/simple_model_comparison.py\n@@ -101,10 +101,8 @@\n for model_name, model_type, model_instance in models:\n for scorer in scorers:\n score_result: np.ndarray = scorer(model_instance, test_dataset)\n- # Multiclass scorers return numpy array of result per class\n- for class_i, class_score in enumerate(score_result):\n- # The proba returns in order of the sorted classes.\n- class_value = train_dataset.classes[class_i]\n+ # Multiclass scorers return numpy array of result per class in order of sorted classes\n+ for class_score, class_value in zip(score_result, test_dataset.classes):\n results.append([model_name, model_type, class_score, scorer.name, class_value])\n \n results_df = pd.DataFrame(results, columns=['Model', 'Type', 'Value', 'Metric', 'Class'])\n@@ -112,7 +110,7 @@\n # Plot the metrics in a graph, grouping by the model and class\n fig = px.bar(results_df, x=['Class', 'Model'], y='Value', color='Model', barmode='group',\n facet_col='Metric', facet_col_spacing=0.05)\n- fig.update_xaxes(title=None, tickprefix='Class ', tickangle=60)\n+ fig.update_xaxes(title=None, tickprefix='Class ', tickangle=60, type='category')\n fig.update_yaxes(title=None, matches=None)\n fig.for_each_annotation(lambda a: a.update(text=a.text.split('=')[-1]))\n fig.for_each_yaxis(lambda yaxis: yaxis.update(showticklabels=True))\n", "issue": "BUG: Simple model comparison shows irrelevant labels\nTo reproduce:\r\nhttps://www.kaggle.com/itay94/notebook05f499eb19\r\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Module containing simple comparison check.\"\"\"\nfrom typing import Callable, Dict, Hashable, List\nimport numpy as np\nimport pandas as pd\nimport plotly.express as px\nfrom sklearn.dummy import DummyRegressor, DummyClassifier\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor\nfrom deepchecks.checks.distribution.preprocessing import ScaledNumerics\nfrom deepchecks.utils.strings import format_number\n\nfrom deepchecks import CheckResult, Dataset\nfrom deepchecks.base.check import ConditionResult, TrainTestBaseCheck\nfrom deepchecks.utils.metrics import task_type_check, ModelType, initialize_multi_scorers, \\\n get_scorers_list, get_scores_ratio, get_scorer_single\nfrom deepchecks.utils.validation import validate_model\nfrom deepchecks.errors import DeepchecksValueError\n\n\n__all__ = ['SimpleModelComparison']\n\n\nclass SimpleModelComparison(TrainTestBaseCheck):\n \"\"\"Compare given model score to simple model score (according to given model type).\n\n Args:\n simple_model_type (str):\n Type of the simple model ['random', 'constant', 'tree'].\n + random - select one of the labels by random.\n + constant - in regression is mean value, in classification the most common value.\n + tree - runs a simple decision tree.\n alternative_scorers (Dict[str, Callable], default None):\n An optional dictionary of scorer name to scorer functions.\n If none given, using default scorers\n maximum_ratio (int):\n the ratio can be up to infinity so choose maximum value to limit to.\n max_depth (int):\n the max depth of the tree (used only if simple model type is tree).\n random_state (int):\n the random state (used only if simple model type is tree or random).\n \"\"\"\n\n def __init__(self, simple_model_type: str = 'constant', alternative_scorers: Dict[str, Callable] = None,\n maximum_ratio: int = 50, max_depth: int = 3, random_state: int = 42):\n super().__init__()\n self.simple_model_type = simple_model_type\n self.alternative_scorers = initialize_multi_scorers(alternative_scorers)\n self.maximum_ratio = maximum_ratio\n self.max_depth = max_depth\n self.random_state = random_state\n\n def run(self, train_dataset, test_dataset, model) -> CheckResult:\n \"\"\"Run check.\n\n Args:\n train_dataset (Dataset): The training dataset object. Must contain a label.\n test_dataset (Dataset): The test dataset object. Must contain a label.\n model (BaseEstimator): A scikit-learn-compatible fitted estimator instance.\n\n Returns:\n CheckResult: value is a Dict of: given_model_score, simple_model_score, ratio\n ratio is given model / simple model (if the scorer returns negative values we divide 1 by it)\n if ratio is infinite max_ratio is returned\n\n Raises:\n DeepchecksValueError: If the object is not a Dataset instance.\n \"\"\"\n Dataset.validate_dataset(train_dataset)\n Dataset.validate_dataset(test_dataset)\n train_dataset.validate_label()\n test_dataset.validate_label()\n validate_model(test_dataset, model)\n\n # If user defined scorers used them, else use a single scorer\n if self.alternative_scorers:\n scorers = get_scorers_list(model, train_dataset, self.alternative_scorers, multiclass_avg=False)\n else:\n scorers = [get_scorer_single(model, train_dataset, multiclass_avg=False)]\n\n task_type = task_type_check(model, train_dataset)\n simple_model = self._create_simple_model(train_dataset, task_type)\n\n models = [\n (f'{type(model).__name__} model', 'Origin', model),\n (f'Simple model - {self.simple_model_type}', 'Simple', simple_model)\n ]\n\n # Multiclass have different return type from the scorer, list of score per class instead of single score\n if task_type == ModelType.MULTICLASS:\n results = []\n for model_name, model_type, model_instance in models:\n for scorer in scorers:\n score_result: np.ndarray = scorer(model_instance, test_dataset)\n # Multiclass scorers return numpy array of result per class\n for class_i, class_score in enumerate(score_result):\n # The proba returns in order of the sorted classes.\n class_value = train_dataset.classes[class_i]\n results.append([model_name, model_type, class_score, scorer.name, class_value])\n\n results_df = pd.DataFrame(results, columns=['Model', 'Type', 'Value', 'Metric', 'Class'])\n\n # Plot the metrics in a graph, grouping by the model and class\n fig = px.bar(results_df, x=['Class', 'Model'], y='Value', color='Model', barmode='group',\n facet_col='Metric', facet_col_spacing=0.05)\n fig.update_xaxes(title=None, tickprefix='Class ', tickangle=60)\n fig.update_yaxes(title=None, matches=None)\n fig.for_each_annotation(lambda a: a.update(text=a.text.split('=')[-1]))\n fig.for_each_yaxis(lambda yaxis: yaxis.update(showticklabels=True))\n # Model is binary or regression\n else:\n results = []\n for model_name, model_type, model_instance in models:\n for scorer in scorers:\n score_result: float = scorer(model_instance, test_dataset)\n results.append([model_name, model_type, score_result, scorer.name])\n\n results_df = pd.DataFrame(results, columns=['Model', 'Type', 'Value', 'Metric'])\n\n # Plot the metrics in a graph, grouping by the model\n fig = px.bar(results_df, x='Model', y='Value', color='Model', barmode='group',\n facet_col='Metric', facet_col_spacing=0.05)\n fig.update_xaxes(title=None)\n fig.update_yaxes(title=None, matches=None)\n fig.for_each_annotation(lambda a: a.update(text=a.text.split('=')[-1]))\n fig.for_each_yaxis(lambda yaxis: yaxis.update(showticklabels=True))\n\n return CheckResult({'scores': results_df, 'type': task_type}, display=fig)\n\n def _create_simple_model(self, train_ds: Dataset, task_type: ModelType):\n \"\"\"Create a simple model of given type (random/constant/tree) to the given dataset.\n\n Args:\n train_ds (Dataset): The training dataset object.\n task_type (ModelType): the model type.\n Returns:\n Classifier object.\n\n Raises:\n NotImplementedError: If the simple_model_type is not supported\n \"\"\"\n np.random.seed(self.random_state)\n\n if self.simple_model_type == 'random':\n simple_model = RandomModel()\n\n elif self.simple_model_type == 'constant':\n if task_type == ModelType.REGRESSION:\n simple_model = DummyRegressor(strategy='mean')\n elif task_type in {ModelType.BINARY, ModelType.MULTICLASS}:\n simple_model = DummyClassifier(strategy='most_frequent')\n else:\n raise DeepchecksValueError(f'Unknown task type - {task_type}')\n elif self.simple_model_type == 'tree':\n if task_type == ModelType.REGRESSION:\n clf = DecisionTreeRegressor(\n max_depth=self.max_depth,\n random_state=self.random_state\n )\n elif task_type in {ModelType.BINARY, ModelType.MULTICLASS}:\n clf = DecisionTreeClassifier(\n max_depth=self.max_depth,\n random_state=self.random_state,\n class_weight='balanced'\n )\n else:\n raise DeepchecksValueError(f'Unknown task type - {task_type}')\n\n simple_model = Pipeline([('scaler', ScaledNumerics(train_ds.cat_features, max_num_categories=10)),\n ('tree-model', clf)])\n else:\n raise DeepchecksValueError(\n f'Unknown model type - {self.simple_model_type}, expected to be one of '\n f\"['random', 'constant', 'tree'] \"\n f\"but instead got {self.simple_model_type}\" # pylint: disable=inconsistent-quotes\n )\n\n simple_model.fit(train_ds.features_columns, train_ds.label_col)\n return simple_model\n\n def add_condition_ratio_not_less_than(self, min_allowed_ratio: float = 1.1, classes: List[Hashable] = None):\n \"\"\"Add condition - require min allowed ratio between the given and the simple model.\n\n Args:\n min_allowed_ratio (float): Min allowed ratio between the given and the simple model -\n ratio is given model / simple model (if the scorer returns negative values we divide 1 by it)\n classes (List[Hashable]): Used in multiclass models to limit condition only to given classes.\n \"\"\"\n def condition(result: Dict, max_ratio=self.maximum_ratio, class_list=classes) -> ConditionResult:\n scores_df = result['scores']\n task_type = result['type']\n metrics = scores_df['Metric'].unique()\n\n def get_ratio(df):\n simple_score = df[df['Type'] == 'Simple']['Value'].iloc[0]\n origin_score = df[df['Type'] == 'Origin']['Value'].iloc[0]\n return get_scores_ratio(simple_score, origin_score, max_ratio)\n\n fails = []\n if task_type == ModelType.MULTICLASS:\n if class_list is None:\n class_list = scores_df['Class'].unique()\n for metric in metrics:\n failed_classes = []\n for clas in class_list:\n score_rows = scores_df[(scores_df['Metric'] == metric) & (scores_df['Class'] == clas)]\n ratio = get_ratio(score_rows)\n if ratio < min_allowed_ratio:\n failed_classes.append(str(clas))\n if failed_classes:\n fails.append(f'\"{metric}\" - Classes: {\", \".join(failed_classes)}')\n else:\n for metric in metrics:\n score_rows = scores_df[(scores_df['Metric'] == metric)]\n ratio = get_ratio(score_rows)\n if ratio < min_allowed_ratio:\n fails.append(f'\"{metric}\"')\n\n if fails:\n msg = f'Metrics failed: {\", \".join(sorted(fails))}'\n return ConditionResult(False, msg)\n else:\n return ConditionResult(True)\n\n return self.add_condition('$$\\\\frac{\\\\text{model score}}{\\\\text{simple model score}} >= '\n f'{format_number(min_allowed_ratio)}$$', condition)\n\n\nclass RandomModel:\n \"\"\"Model used to randomly predict from given series of labels.\"\"\"\n\n def __init__(self):\n self.labels = None\n\n def fit(self, X, y): # pylint: disable=unused-argument,invalid-name\n # The X is not used, but it is needed to be matching to sklearn `fit` signature\n self.labels = y\n\n def predict(self, X): # pylint: disable=invalid-name\n return np.random.choice(self.labels, X.shape[0])\n\n def predict_proba(self, X): # pylint: disable=invalid-name\n classes = sorted(self.labels.unique().tolist())\n predictions = self.predict(X)\n\n def prediction_to_proba(y_pred):\n proba = np.zeros(len(classes))\n proba[classes.index(y_pred)] = 1\n return proba\n return np.apply_along_axis(prediction_to_proba, axis=1, arr=predictions)\n", "path": "deepchecks/checks/performance/simple_model_comparison.py"}], "after_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Module containing simple comparison check.\"\"\"\nfrom typing import Callable, Dict, Hashable, List\nimport numpy as np\nimport pandas as pd\nimport plotly.express as px\nfrom sklearn.dummy import DummyRegressor, DummyClassifier\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor\nfrom deepchecks.checks.distribution.preprocessing import ScaledNumerics\nfrom deepchecks.utils.strings import format_number\n\nfrom deepchecks import CheckResult, Dataset\nfrom deepchecks.base.check import ConditionResult, TrainTestBaseCheck\nfrom deepchecks.utils.metrics import task_type_check, ModelType, initialize_multi_scorers, \\\n get_scorers_list, get_scores_ratio, get_scorer_single\nfrom deepchecks.utils.validation import validate_model\nfrom deepchecks.errors import DeepchecksValueError\n\n\n__all__ = ['SimpleModelComparison']\n\n\nclass SimpleModelComparison(TrainTestBaseCheck):\n \"\"\"Compare given model score to simple model score (according to given model type).\n\n Args:\n simple_model_type (str):\n Type of the simple model ['random', 'constant', 'tree'].\n + random - select one of the labels by random.\n + constant - in regression is mean value, in classification the most common value.\n + tree - runs a simple decision tree.\n alternative_scorers (Dict[str, Callable], default None):\n An optional dictionary of scorer name to scorer functions.\n If none given, using default scorers\n maximum_ratio (int):\n the ratio can be up to infinity so choose maximum value to limit to.\n max_depth (int):\n the max depth of the tree (used only if simple model type is tree).\n random_state (int):\n the random state (used only if simple model type is tree or random).\n \"\"\"\n\n def __init__(self, simple_model_type: str = 'constant', alternative_scorers: Dict[str, Callable] = None,\n maximum_ratio: int = 50, max_depth: int = 3, random_state: int = 42):\n super().__init__()\n self.simple_model_type = simple_model_type\n self.alternative_scorers = initialize_multi_scorers(alternative_scorers)\n self.maximum_ratio = maximum_ratio\n self.max_depth = max_depth\n self.random_state = random_state\n\n def run(self, train_dataset, test_dataset, model) -> CheckResult:\n \"\"\"Run check.\n\n Args:\n train_dataset (Dataset): The training dataset object. Must contain a label.\n test_dataset (Dataset): The test dataset object. Must contain a label.\n model (BaseEstimator): A scikit-learn-compatible fitted estimator instance.\n\n Returns:\n CheckResult: value is a Dict of: given_model_score, simple_model_score, ratio\n ratio is given model / simple model (if the scorer returns negative values we divide 1 by it)\n if ratio is infinite max_ratio is returned\n\n Raises:\n DeepchecksValueError: If the object is not a Dataset instance.\n \"\"\"\n Dataset.validate_dataset(train_dataset)\n Dataset.validate_dataset(test_dataset)\n train_dataset.validate_label()\n test_dataset.validate_label()\n validate_model(test_dataset, model)\n\n # If user defined scorers used them, else use a single scorer\n if self.alternative_scorers:\n scorers = get_scorers_list(model, train_dataset, self.alternative_scorers, multiclass_avg=False)\n else:\n scorers = [get_scorer_single(model, train_dataset, multiclass_avg=False)]\n\n task_type = task_type_check(model, train_dataset)\n simple_model = self._create_simple_model(train_dataset, task_type)\n\n models = [\n (f'{type(model).__name__} model', 'Origin', model),\n (f'Simple model - {self.simple_model_type}', 'Simple', simple_model)\n ]\n\n # Multiclass have different return type from the scorer, list of score per class instead of single score\n if task_type == ModelType.MULTICLASS:\n results = []\n for model_name, model_type, model_instance in models:\n for scorer in scorers:\n score_result: np.ndarray = scorer(model_instance, test_dataset)\n # Multiclass scorers return numpy array of result per class in order of sorted classes\n for class_score, class_value in zip(score_result, test_dataset.classes):\n results.append([model_name, model_type, class_score, scorer.name, class_value])\n\n results_df = pd.DataFrame(results, columns=['Model', 'Type', 'Value', 'Metric', 'Class'])\n\n # Plot the metrics in a graph, grouping by the model and class\n fig = px.bar(results_df, x=['Class', 'Model'], y='Value', color='Model', barmode='group',\n facet_col='Metric', facet_col_spacing=0.05)\n fig.update_xaxes(title=None, tickprefix='Class ', tickangle=60, type='category')\n fig.update_yaxes(title=None, matches=None)\n fig.for_each_annotation(lambda a: a.update(text=a.text.split('=')[-1]))\n fig.for_each_yaxis(lambda yaxis: yaxis.update(showticklabels=True))\n # Model is binary or regression\n else:\n results = []\n for model_name, model_type, model_instance in models:\n for scorer in scorers:\n score_result: float = scorer(model_instance, test_dataset)\n results.append([model_name, model_type, score_result, scorer.name])\n\n results_df = pd.DataFrame(results, columns=['Model', 'Type', 'Value', 'Metric'])\n\n # Plot the metrics in a graph, grouping by the model\n fig = px.bar(results_df, x='Model', y='Value', color='Model', barmode='group',\n facet_col='Metric', facet_col_spacing=0.05)\n fig.update_xaxes(title=None)\n fig.update_yaxes(title=None, matches=None)\n fig.for_each_annotation(lambda a: a.update(text=a.text.split('=')[-1]))\n fig.for_each_yaxis(lambda yaxis: yaxis.update(showticklabels=True))\n\n return CheckResult({'scores': results_df, 'type': task_type}, display=fig)\n\n def _create_simple_model(self, train_ds: Dataset, task_type: ModelType):\n \"\"\"Create a simple model of given type (random/constant/tree) to the given dataset.\n\n Args:\n train_ds (Dataset): The training dataset object.\n task_type (ModelType): the model type.\n Returns:\n Classifier object.\n\n Raises:\n NotImplementedError: If the simple_model_type is not supported\n \"\"\"\n np.random.seed(self.random_state)\n\n if self.simple_model_type == 'random':\n simple_model = RandomModel()\n\n elif self.simple_model_type == 'constant':\n if task_type == ModelType.REGRESSION:\n simple_model = DummyRegressor(strategy='mean')\n elif task_type in {ModelType.BINARY, ModelType.MULTICLASS}:\n simple_model = DummyClassifier(strategy='most_frequent')\n else:\n raise DeepchecksValueError(f'Unknown task type - {task_type}')\n elif self.simple_model_type == 'tree':\n if task_type == ModelType.REGRESSION:\n clf = DecisionTreeRegressor(\n max_depth=self.max_depth,\n random_state=self.random_state\n )\n elif task_type in {ModelType.BINARY, ModelType.MULTICLASS}:\n clf = DecisionTreeClassifier(\n max_depth=self.max_depth,\n random_state=self.random_state,\n class_weight='balanced'\n )\n else:\n raise DeepchecksValueError(f'Unknown task type - {task_type}')\n\n simple_model = Pipeline([('scaler', ScaledNumerics(train_ds.cat_features, max_num_categories=10)),\n ('tree-model', clf)])\n else:\n raise DeepchecksValueError(\n f'Unknown model type - {self.simple_model_type}, expected to be one of '\n f\"['random', 'constant', 'tree'] \"\n f\"but instead got {self.simple_model_type}\" # pylint: disable=inconsistent-quotes\n )\n\n simple_model.fit(train_ds.features_columns, train_ds.label_col)\n return simple_model\n\n def add_condition_ratio_not_less_than(self, min_allowed_ratio: float = 1.1, classes: List[Hashable] = None):\n \"\"\"Add condition - require min allowed ratio between the given and the simple model.\n\n Args:\n min_allowed_ratio (float): Min allowed ratio between the given and the simple model -\n ratio is given model / simple model (if the scorer returns negative values we divide 1 by it)\n classes (List[Hashable]): Used in multiclass models to limit condition only to given classes.\n \"\"\"\n def condition(result: Dict, max_ratio=self.maximum_ratio, class_list=classes) -> ConditionResult:\n scores_df = result['scores']\n task_type = result['type']\n metrics = scores_df['Metric'].unique()\n\n def get_ratio(df):\n simple_score = df[df['Type'] == 'Simple']['Value'].iloc[0]\n origin_score = df[df['Type'] == 'Origin']['Value'].iloc[0]\n return get_scores_ratio(simple_score, origin_score, max_ratio)\n\n fails = []\n if task_type == ModelType.MULTICLASS:\n if class_list is None:\n class_list = scores_df['Class'].unique()\n for metric in metrics:\n failed_classes = []\n for clas in class_list:\n score_rows = scores_df[(scores_df['Metric'] == metric) & (scores_df['Class'] == clas)]\n ratio = get_ratio(score_rows)\n if ratio < min_allowed_ratio:\n failed_classes.append(str(clas))\n if failed_classes:\n fails.append(f'\"{metric}\" - Classes: {\", \".join(failed_classes)}')\n else:\n for metric in metrics:\n score_rows = scores_df[(scores_df['Metric'] == metric)]\n ratio = get_ratio(score_rows)\n if ratio < min_allowed_ratio:\n fails.append(f'\"{metric}\"')\n\n if fails:\n msg = f'Metrics failed: {\", \".join(sorted(fails))}'\n return ConditionResult(False, msg)\n else:\n return ConditionResult(True)\n\n return self.add_condition('$$\\\\frac{\\\\text{model score}}{\\\\text{simple model score}} >= '\n f'{format_number(min_allowed_ratio)}$$', condition)\n\n\nclass RandomModel:\n \"\"\"Model used to randomly predict from given series of labels.\"\"\"\n\n def __init__(self):\n self.labels = None\n\n def fit(self, X, y): # pylint: disable=unused-argument,invalid-name\n # The X is not used, but it is needed to be matching to sklearn `fit` signature\n self.labels = y\n\n def predict(self, X): # pylint: disable=invalid-name\n return np.random.choice(self.labels, X.shape[0])\n\n def predict_proba(self, X): # pylint: disable=invalid-name\n classes = sorted(self.labels.unique().tolist())\n predictions = self.predict(X)\n\n def prediction_to_proba(y_pred):\n proba = np.zeros(len(classes))\n proba[classes.index(y_pred)] = 1\n return proba\n return np.apply_along_axis(prediction_to_proba, axis=1, arr=predictions)\n", "path": "deepchecks/checks/performance/simple_model_comparison.py"}]}
| 3,647 | 405 |
gh_patches_debug_26336
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-13744
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Suggestion: 'undeprecate' extensions
I can't think of a single reason why it is deprecated. Python package management is really bad to rely on pip, packing small personal customization extensions is a massive overkill and can lead to potential pip conflicts in the future and publishing it is a horrendous waste of time (and might not even be possible in some cases). Extensions folder was perfect for very simple personal extensions and now using it constantly shows warnings that can't be disabled. Startup scripts aren't a good alternative because they clutter globals space and trying to do something without putting anything into globals leads to extremely ugly code in startup scripts.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `IPython/core/extensions.py`
Content:
```
1 # encoding: utf-8
2 """A class for managing IPython extensions."""
3
4 # Copyright (c) IPython Development Team.
5 # Distributed under the terms of the Modified BSD License.
6
7 import os
8 import os.path
9 import sys
10 from importlib import import_module, reload
11
12 from traitlets.config.configurable import Configurable
13 from IPython.utils.path import ensure_dir_exists, compress_user
14 from IPython.utils.decorators import undoc
15 from traitlets import Instance
16
17
18 #-----------------------------------------------------------------------------
19 # Main class
20 #-----------------------------------------------------------------------------
21
22 BUILTINS_EXTS = {"storemagic": False, "autoreload": False}
23
24
25 class ExtensionManager(Configurable):
26 """A class to manage IPython extensions.
27
28 An IPython extension is an importable Python module that has
29 a function with the signature::
30
31 def load_ipython_extension(ipython):
32 # Do things with ipython
33
34 This function is called after your extension is imported and the
35 currently active :class:`InteractiveShell` instance is passed as
36 the only argument. You can do anything you want with IPython at
37 that point, including defining new magic and aliases, adding new
38 components, etc.
39
40 You can also optionally define an :func:`unload_ipython_extension(ipython)`
41 function, which will be called if the user unloads or reloads the extension.
42 The extension manager will only call :func:`load_ipython_extension` again
43 if the extension is reloaded.
44
45 You can put your extension modules anywhere you want, as long as
46 they can be imported by Python's standard import mechanism. However,
47 to make it easy to write extensions, you can also put your extensions
48 in ``os.path.join(self.ipython_dir, 'extensions')``. This directory
49 is added to ``sys.path`` automatically.
50 """
51
52 shell = Instance('IPython.core.interactiveshell.InteractiveShellABC', allow_none=True)
53
54 def __init__(self, shell=None, **kwargs):
55 super(ExtensionManager, self).__init__(shell=shell, **kwargs)
56 self.shell.observe(
57 self._on_ipython_dir_changed, names=('ipython_dir',)
58 )
59 self.loaded = set()
60
61 @property
62 def ipython_extension_dir(self):
63 return os.path.join(self.shell.ipython_dir, u'extensions')
64
65 def _on_ipython_dir_changed(self, change):
66 ensure_dir_exists(self.ipython_extension_dir)
67
68 def load_extension(self, module_str: str):
69 """Load an IPython extension by its module name.
70
71 Returns the string "already loaded" if the extension is already loaded,
72 "no load function" if the module doesn't have a load_ipython_extension
73 function, or None if it succeeded.
74 """
75 try:
76 return self._load_extension(module_str)
77 except ModuleNotFoundError:
78 if module_str in BUILTINS_EXTS:
79 BUILTINS_EXTS[module_str] = True
80 return self._load_extension("IPython.extensions." + module_str)
81 raise
82
83 def _load_extension(self, module_str: str):
84 if module_str in self.loaded:
85 return "already loaded"
86
87 from IPython.utils.syspathcontext import prepended_to_syspath
88
89 with self.shell.builtin_trap:
90 if module_str not in sys.modules:
91 with prepended_to_syspath(self.ipython_extension_dir):
92 mod = import_module(module_str)
93 if mod.__file__.startswith(self.ipython_extension_dir):
94 print(("Loading extensions from {dir} is deprecated. "
95 "We recommend managing extensions like any "
96 "other Python packages, in site-packages.").format(
97 dir=compress_user(self.ipython_extension_dir)))
98 mod = sys.modules[module_str]
99 if self._call_load_ipython_extension(mod):
100 self.loaded.add(module_str)
101 else:
102 return "no load function"
103
104 def unload_extension(self, module_str: str):
105 """Unload an IPython extension by its module name.
106
107 This function looks up the extension's name in ``sys.modules`` and
108 simply calls ``mod.unload_ipython_extension(self)``.
109
110 Returns the string "no unload function" if the extension doesn't define
111 a function to unload itself, "not loaded" if the extension isn't loaded,
112 otherwise None.
113 """
114 if BUILTINS_EXTS.get(module_str, False) is True:
115 module_str = "IPython.extensions." + module_str
116 if module_str not in self.loaded:
117 return "not loaded"
118
119 if module_str in sys.modules:
120 mod = sys.modules[module_str]
121 if self._call_unload_ipython_extension(mod):
122 self.loaded.discard(module_str)
123 else:
124 return "no unload function"
125
126 def reload_extension(self, module_str: str):
127 """Reload an IPython extension by calling reload.
128
129 If the module has not been loaded before,
130 :meth:`InteractiveShell.load_extension` is called. Otherwise
131 :func:`reload` is called and then the :func:`load_ipython_extension`
132 function of the module, if it exists is called.
133 """
134 from IPython.utils.syspathcontext import prepended_to_syspath
135
136 if BUILTINS_EXTS.get(module_str, False) is True:
137 module_str = "IPython.extensions." + module_str
138
139 if (module_str in self.loaded) and (module_str in sys.modules):
140 self.unload_extension(module_str)
141 mod = sys.modules[module_str]
142 with prepended_to_syspath(self.ipython_extension_dir):
143 reload(mod)
144 if self._call_load_ipython_extension(mod):
145 self.loaded.add(module_str)
146 else:
147 self.load_extension(module_str)
148
149 def _call_load_ipython_extension(self, mod):
150 if hasattr(mod, 'load_ipython_extension'):
151 mod.load_ipython_extension(self.shell)
152 return True
153
154 def _call_unload_ipython_extension(self, mod):
155 if hasattr(mod, 'unload_ipython_extension'):
156 mod.unload_ipython_extension(self.shell)
157 return True
158
159 @undoc
160 def install_extension(self, url, filename=None):
161 """
162 Deprecated.
163 """
164 # Ensure the extension directory exists
165 raise DeprecationWarning(
166 '`install_extension` and the `install_ext` magic have been deprecated since IPython 4.0'
167 'Use pip or other package managers to manage ipython extensions.')
168
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/IPython/core/extensions.py b/IPython/core/extensions.py
--- a/IPython/core/extensions.py
+++ b/IPython/core/extensions.py
@@ -88,13 +88,7 @@
with self.shell.builtin_trap:
if module_str not in sys.modules:
- with prepended_to_syspath(self.ipython_extension_dir):
- mod = import_module(module_str)
- if mod.__file__.startswith(self.ipython_extension_dir):
- print(("Loading extensions from {dir} is deprecated. "
- "We recommend managing extensions like any "
- "other Python packages, in site-packages.").format(
- dir=compress_user(self.ipython_extension_dir)))
+ mod = import_module(module_str)
mod = sys.modules[module_str]
if self._call_load_ipython_extension(mod):
self.loaded.add(module_str)
@@ -155,13 +149,3 @@
if hasattr(mod, 'unload_ipython_extension'):
mod.unload_ipython_extension(self.shell)
return True
-
- @undoc
- def install_extension(self, url, filename=None):
- """
- Deprecated.
- """
- # Ensure the extension directory exists
- raise DeprecationWarning(
- '`install_extension` and the `install_ext` magic have been deprecated since IPython 4.0'
- 'Use pip or other package managers to manage ipython extensions.')
|
{"golden_diff": "diff --git a/IPython/core/extensions.py b/IPython/core/extensions.py\n--- a/IPython/core/extensions.py\n+++ b/IPython/core/extensions.py\n@@ -88,13 +88,7 @@\n \n with self.shell.builtin_trap:\n if module_str not in sys.modules:\n- with prepended_to_syspath(self.ipython_extension_dir):\n- mod = import_module(module_str)\n- if mod.__file__.startswith(self.ipython_extension_dir):\n- print((\"Loading extensions from {dir} is deprecated. \"\n- \"We recommend managing extensions like any \"\n- \"other Python packages, in site-packages.\").format(\n- dir=compress_user(self.ipython_extension_dir)))\n+ mod = import_module(module_str)\n mod = sys.modules[module_str]\n if self._call_load_ipython_extension(mod):\n self.loaded.add(module_str)\n@@ -155,13 +149,3 @@\n if hasattr(mod, 'unload_ipython_extension'):\n mod.unload_ipython_extension(self.shell)\n return True\n-\n- @undoc\n- def install_extension(self, url, filename=None):\n- \"\"\"\n- Deprecated.\n- \"\"\"\n- # Ensure the extension directory exists\n- raise DeprecationWarning(\n- '`install_extension` and the `install_ext` magic have been deprecated since IPython 4.0'\n- 'Use pip or other package managers to manage ipython extensions.')\n", "issue": "Suggestion: 'undeprecate' extensions\nI can't think of a single reason why it is deprecated. Python package management is really bad to rely on pip, packing small personal customization extensions is a massive overkill and can lead to potential pip conflicts in the future and publishing it is a horrendous waste of time (and might not even be possible in some cases). Extensions folder was perfect for very simple personal extensions and now using it constantly shows warnings that can't be disabled. Startup scripts aren't a good alternative because they clutter globals space and trying to do something without putting anything into globals leads to extremely ugly code in startup scripts.\n", "before_files": [{"content": "# encoding: utf-8\n\"\"\"A class for managing IPython extensions.\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nimport os\nimport os.path\nimport sys\nfrom importlib import import_module, reload\n\nfrom traitlets.config.configurable import Configurable\nfrom IPython.utils.path import ensure_dir_exists, compress_user\nfrom IPython.utils.decorators import undoc\nfrom traitlets import Instance\n\n\n#-----------------------------------------------------------------------------\n# Main class\n#-----------------------------------------------------------------------------\n\nBUILTINS_EXTS = {\"storemagic\": False, \"autoreload\": False}\n\n\nclass ExtensionManager(Configurable):\n \"\"\"A class to manage IPython extensions.\n\n An IPython extension is an importable Python module that has\n a function with the signature::\n\n def load_ipython_extension(ipython):\n # Do things with ipython\n\n This function is called after your extension is imported and the\n currently active :class:`InteractiveShell` instance is passed as\n the only argument. You can do anything you want with IPython at\n that point, including defining new magic and aliases, adding new\n components, etc.\n \n You can also optionally define an :func:`unload_ipython_extension(ipython)`\n function, which will be called if the user unloads or reloads the extension.\n The extension manager will only call :func:`load_ipython_extension` again\n if the extension is reloaded.\n\n You can put your extension modules anywhere you want, as long as\n they can be imported by Python's standard import mechanism. However,\n to make it easy to write extensions, you can also put your extensions\n in ``os.path.join(self.ipython_dir, 'extensions')``. This directory\n is added to ``sys.path`` automatically.\n \"\"\"\n\n shell = Instance('IPython.core.interactiveshell.InteractiveShellABC', allow_none=True)\n\n def __init__(self, shell=None, **kwargs):\n super(ExtensionManager, self).__init__(shell=shell, **kwargs)\n self.shell.observe(\n self._on_ipython_dir_changed, names=('ipython_dir',)\n )\n self.loaded = set()\n\n @property\n def ipython_extension_dir(self):\n return os.path.join(self.shell.ipython_dir, u'extensions')\n\n def _on_ipython_dir_changed(self, change):\n ensure_dir_exists(self.ipython_extension_dir)\n\n def load_extension(self, module_str: str):\n \"\"\"Load an IPython extension by its module name.\n\n Returns the string \"already loaded\" if the extension is already loaded,\n \"no load function\" if the module doesn't have a load_ipython_extension\n function, or None if it succeeded.\n \"\"\"\n try:\n return self._load_extension(module_str)\n except ModuleNotFoundError:\n if module_str in BUILTINS_EXTS:\n BUILTINS_EXTS[module_str] = True\n return self._load_extension(\"IPython.extensions.\" + module_str)\n raise\n\n def _load_extension(self, module_str: str):\n if module_str in self.loaded:\n return \"already loaded\"\n\n from IPython.utils.syspathcontext import prepended_to_syspath\n\n with self.shell.builtin_trap:\n if module_str not in sys.modules:\n with prepended_to_syspath(self.ipython_extension_dir):\n mod = import_module(module_str)\n if mod.__file__.startswith(self.ipython_extension_dir):\n print((\"Loading extensions from {dir} is deprecated. \"\n \"We recommend managing extensions like any \"\n \"other Python packages, in site-packages.\").format(\n dir=compress_user(self.ipython_extension_dir)))\n mod = sys.modules[module_str]\n if self._call_load_ipython_extension(mod):\n self.loaded.add(module_str)\n else:\n return \"no load function\"\n\n def unload_extension(self, module_str: str):\n \"\"\"Unload an IPython extension by its module name.\n\n This function looks up the extension's name in ``sys.modules`` and\n simply calls ``mod.unload_ipython_extension(self)``.\n\n Returns the string \"no unload function\" if the extension doesn't define\n a function to unload itself, \"not loaded\" if the extension isn't loaded,\n otherwise None.\n \"\"\"\n if BUILTINS_EXTS.get(module_str, False) is True:\n module_str = \"IPython.extensions.\" + module_str\n if module_str not in self.loaded:\n return \"not loaded\"\n\n if module_str in sys.modules:\n mod = sys.modules[module_str]\n if self._call_unload_ipython_extension(mod):\n self.loaded.discard(module_str)\n else:\n return \"no unload function\"\n\n def reload_extension(self, module_str: str):\n \"\"\"Reload an IPython extension by calling reload.\n\n If the module has not been loaded before,\n :meth:`InteractiveShell.load_extension` is called. Otherwise\n :func:`reload` is called and then the :func:`load_ipython_extension`\n function of the module, if it exists is called.\n \"\"\"\n from IPython.utils.syspathcontext import prepended_to_syspath\n\n if BUILTINS_EXTS.get(module_str, False) is True:\n module_str = \"IPython.extensions.\" + module_str\n\n if (module_str in self.loaded) and (module_str in sys.modules):\n self.unload_extension(module_str)\n mod = sys.modules[module_str]\n with prepended_to_syspath(self.ipython_extension_dir):\n reload(mod)\n if self._call_load_ipython_extension(mod):\n self.loaded.add(module_str)\n else:\n self.load_extension(module_str)\n\n def _call_load_ipython_extension(self, mod):\n if hasattr(mod, 'load_ipython_extension'):\n mod.load_ipython_extension(self.shell)\n return True\n\n def _call_unload_ipython_extension(self, mod):\n if hasattr(mod, 'unload_ipython_extension'):\n mod.unload_ipython_extension(self.shell)\n return True\n\n @undoc\n def install_extension(self, url, filename=None):\n \"\"\"\n Deprecated.\n \"\"\"\n # Ensure the extension directory exists\n raise DeprecationWarning(\n '`install_extension` and the `install_ext` magic have been deprecated since IPython 4.0'\n 'Use pip or other package managers to manage ipython extensions.')\n", "path": "IPython/core/extensions.py"}], "after_files": [{"content": "# encoding: utf-8\n\"\"\"A class for managing IPython extensions.\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nimport os\nimport os.path\nimport sys\nfrom importlib import import_module, reload\n\nfrom traitlets.config.configurable import Configurable\nfrom IPython.utils.path import ensure_dir_exists, compress_user\nfrom IPython.utils.decorators import undoc\nfrom traitlets import Instance\n\n\n#-----------------------------------------------------------------------------\n# Main class\n#-----------------------------------------------------------------------------\n\nBUILTINS_EXTS = {\"storemagic\": False, \"autoreload\": False}\n\n\nclass ExtensionManager(Configurable):\n \"\"\"A class to manage IPython extensions.\n\n An IPython extension is an importable Python module that has\n a function with the signature::\n\n def load_ipython_extension(ipython):\n # Do things with ipython\n\n This function is called after your extension is imported and the\n currently active :class:`InteractiveShell` instance is passed as\n the only argument. You can do anything you want with IPython at\n that point, including defining new magic and aliases, adding new\n components, etc.\n \n You can also optionally define an :func:`unload_ipython_extension(ipython)`\n function, which will be called if the user unloads or reloads the extension.\n The extension manager will only call :func:`load_ipython_extension` again\n if the extension is reloaded.\n\n You can put your extension modules anywhere you want, as long as\n they can be imported by Python's standard import mechanism. However,\n to make it easy to write extensions, you can also put your extensions\n in ``os.path.join(self.ipython_dir, 'extensions')``. This directory\n is added to ``sys.path`` automatically.\n \"\"\"\n\n shell = Instance('IPython.core.interactiveshell.InteractiveShellABC', allow_none=True)\n\n def __init__(self, shell=None, **kwargs):\n super(ExtensionManager, self).__init__(shell=shell, **kwargs)\n self.shell.observe(\n self._on_ipython_dir_changed, names=('ipython_dir',)\n )\n self.loaded = set()\n\n @property\n def ipython_extension_dir(self):\n return os.path.join(self.shell.ipython_dir, u'extensions')\n\n def _on_ipython_dir_changed(self, change):\n ensure_dir_exists(self.ipython_extension_dir)\n\n def load_extension(self, module_str: str):\n \"\"\"Load an IPython extension by its module name.\n\n Returns the string \"already loaded\" if the extension is already loaded,\n \"no load function\" if the module doesn't have a load_ipython_extension\n function, or None if it succeeded.\n \"\"\"\n try:\n return self._load_extension(module_str)\n except ModuleNotFoundError:\n if module_str in BUILTINS_EXTS:\n BUILTINS_EXTS[module_str] = True\n return self._load_extension(\"IPython.extensions.\" + module_str)\n raise\n\n def _load_extension(self, module_str: str):\n if module_str in self.loaded:\n return \"already loaded\"\n\n from IPython.utils.syspathcontext import prepended_to_syspath\n\n with self.shell.builtin_trap:\n if module_str not in sys.modules:\n mod = import_module(module_str)\n mod = sys.modules[module_str]\n if self._call_load_ipython_extension(mod):\n self.loaded.add(module_str)\n else:\n return \"no load function\"\n\n def unload_extension(self, module_str: str):\n \"\"\"Unload an IPython extension by its module name.\n\n This function looks up the extension's name in ``sys.modules`` and\n simply calls ``mod.unload_ipython_extension(self)``.\n\n Returns the string \"no unload function\" if the extension doesn't define\n a function to unload itself, \"not loaded\" if the extension isn't loaded,\n otherwise None.\n \"\"\"\n if BUILTINS_EXTS.get(module_str, False) is True:\n module_str = \"IPython.extensions.\" + module_str\n if module_str not in self.loaded:\n return \"not loaded\"\n\n if module_str in sys.modules:\n mod = sys.modules[module_str]\n if self._call_unload_ipython_extension(mod):\n self.loaded.discard(module_str)\n else:\n return \"no unload function\"\n\n def reload_extension(self, module_str: str):\n \"\"\"Reload an IPython extension by calling reload.\n\n If the module has not been loaded before,\n :meth:`InteractiveShell.load_extension` is called. Otherwise\n :func:`reload` is called and then the :func:`load_ipython_extension`\n function of the module, if it exists is called.\n \"\"\"\n from IPython.utils.syspathcontext import prepended_to_syspath\n\n if BUILTINS_EXTS.get(module_str, False) is True:\n module_str = \"IPython.extensions.\" + module_str\n\n if (module_str in self.loaded) and (module_str in sys.modules):\n self.unload_extension(module_str)\n mod = sys.modules[module_str]\n with prepended_to_syspath(self.ipython_extension_dir):\n reload(mod)\n if self._call_load_ipython_extension(mod):\n self.loaded.add(module_str)\n else:\n self.load_extension(module_str)\n\n def _call_load_ipython_extension(self, mod):\n if hasattr(mod, 'load_ipython_extension'):\n mod.load_ipython_extension(self.shell)\n return True\n\n def _call_unload_ipython_extension(self, mod):\n if hasattr(mod, 'unload_ipython_extension'):\n mod.unload_ipython_extension(self.shell)\n return True\n", "path": "IPython/core/extensions.py"}]}
| 2,169 | 313 |
gh_patches_debug_33107
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-6317
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[bug] authentication error is handled incorrectly in client.rest.uploader_downloader.FileDownloader
When installing a Conan package I've got this error message:
```
tools.get(**self.conan_data["sources"][self.version])
AttributeError: 'NoneType' object has no attribute 'token'
```
Obviously, the message isn't very helpful as it implies that there's a problem with the package recipe (there wasn't).
After some investigation I found out that the error ultimately happens in `client.rest.uploader_downloader.FileDownloader` when the download fails with a 403.
The method does the following check: `auth.token is None`. The issue is, `auth` is an optional parameter. Also it is effectively allowed to be a tuple according to documentation for `tools.get`. So, I assume the check should have been `not auth or not hasattr(auth, "token") or auth.token is None`.
Conan version: 1.21.0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conans/client/rest/uploader_downloader.py`
Content:
```
1 import os
2 import traceback
3 import time
4 from copy import copy
5
6 import six
7
8 from conans.util import progress_bar
9 from conans.client.rest import response_to_str
10 from conans.errors import AuthenticationException, ConanConnectionError, ConanException, \
11 NotFoundException, ForbiddenException, RequestErrorException
12 from conans.util.files import mkdir, sha1sum
13 from conans.util.log import logger
14 from conans.util.tracer import log_download
15
16
17 class FileUploader(object):
18
19 def __init__(self, requester, output, verify, chunk_size=1000):
20 self.chunk_size = chunk_size
21 self.output = output
22 self.requester = requester
23 self.verify = verify
24
25 def upload(self, url, abs_path, auth=None, dedup=False, retry=None, retry_wait=None,
26 headers=None):
27 retry = retry if retry is not None else self.requester.retry
28 retry = retry if retry is not None else 1
29 retry_wait = retry_wait if retry_wait is not None else self.requester.retry_wait
30 retry_wait = retry_wait if retry_wait is not None else 5
31
32 # Send always the header with the Sha1
33 headers = copy(headers) or {}
34 headers["X-Checksum-Sha1"] = sha1sum(abs_path)
35 if dedup:
36 dedup_headers = {"X-Checksum-Deploy": "true"}
37 if headers:
38 dedup_headers.update(headers)
39 response = self.requester.put(url, data="", verify=self.verify, headers=dedup_headers,
40 auth=auth)
41 if response.status_code == 400:
42 raise RequestErrorException(response_to_str(response))
43
44 if response.status_code == 401:
45 raise AuthenticationException(response_to_str(response))
46
47 if response.status_code == 403:
48 if auth.token is None:
49 raise AuthenticationException(response_to_str(response))
50 raise ForbiddenException(response_to_str(response))
51 if response.status_code == 201: # Artifactory returns 201 if the file is there
52 return response
53
54 ret = call_with_retry(self.output, retry, retry_wait, self._upload_file, url,
55 abs_path=abs_path, headers=headers, auth=auth)
56 return ret
57
58 def _upload_file(self, url, abs_path, headers, auth):
59
60 file_size = os.stat(abs_path).st_size
61 file_name = os.path.basename(abs_path)
62 description = "Uploading {}".format(file_name)
63
64 def load_in_chunks(_file, size):
65 """Lazy function (generator) to read a file piece by piece.
66 Default chunk size: 1k."""
67 while True:
68 chunk = _file.read(size)
69 if not chunk:
70 break
71 yield chunk
72
73 with open(abs_path, mode='rb') as file_handler:
74 progress = progress_bar.Progress(file_size, self.output, description, print_dot=True)
75 chunk_size = 1024
76 data = progress.update(load_in_chunks(file_handler, chunk_size), chunk_size)
77 iterable_to_file = IterableToFileAdapter(data, file_size)
78 try:
79 response = self.requester.put(url, data=iterable_to_file, verify=self.verify,
80 headers=headers, auth=auth)
81
82 if response.status_code == 400:
83 raise RequestErrorException(response_to_str(response))
84
85 if response.status_code == 401:
86 raise AuthenticationException(response_to_str(response))
87
88 if response.status_code == 403:
89 if auth.token is None:
90 raise AuthenticationException(response_to_str(response))
91 raise ForbiddenException(response_to_str(response))
92
93 response.raise_for_status() # Raise HTTPError for bad http response status
94
95 except ConanException:
96 raise
97 except Exception as exc:
98 raise ConanException(exc)
99
100 return response
101
102
103 class IterableToFileAdapter(object):
104 def __init__(self, iterable, total_size):
105 self.iterator = iter(iterable)
106 self.total_size = total_size
107
108 def read(self, size=-1): # @UnusedVariable
109 return next(self.iterator, b'')
110
111 def __len__(self):
112 return self.total_size
113
114 def __iter__(self):
115 return self.iterator.__iter__()
116
117
118 class FileDownloader(object):
119
120 def __init__(self, requester, output, verify, chunk_size=1000):
121 self.chunk_size = chunk_size
122 self.output = output
123 self.requester = requester
124 self.verify = verify
125
126 def download(self, url, file_path=None, auth=None, retry=None, retry_wait=None, overwrite=False,
127 headers=None):
128 retry = retry if retry is not None else self.requester.retry
129 retry = retry if retry is not None else 2
130 retry_wait = retry_wait if retry_wait is not None else self.requester.retry_wait
131 retry_wait = retry_wait if retry_wait is not None else 0
132
133 if file_path and not os.path.isabs(file_path):
134 file_path = os.path.abspath(file_path)
135
136 if file_path and os.path.exists(file_path):
137 if overwrite:
138 if self.output:
139 self.output.warn("file '%s' already exists, overwriting" % file_path)
140 else:
141 # Should not happen, better to raise, probably we had to remove
142 # the dest folder before
143 raise ConanException("Error, the file to download already exists: '%s'" % file_path)
144
145 return call_with_retry(self.output, retry, retry_wait, self._download_file, url, auth,
146 headers, file_path)
147
148 def _download_file(self, url, auth, headers, file_path):
149 t1 = time.time()
150 try:
151 response = self.requester.get(url, stream=True, verify=self.verify, auth=auth,
152 headers=headers)
153 except Exception as exc:
154 raise ConanException("Error downloading file %s: '%s'" % (url, exc))
155
156 if not response.ok:
157 if response.status_code == 404:
158 raise NotFoundException("Not found: %s" % url)
159 elif response.status_code == 403:
160 if auth.token is None:
161 raise AuthenticationException(response_to_str(response))
162 raise ForbiddenException(response_to_str(response))
163 elif response.status_code == 401:
164 raise AuthenticationException()
165 raise ConanException("Error %d downloading file %s" % (response.status_code, url))
166
167 def read_response(size):
168 for chunk in response.iter_content(size):
169 yield chunk
170
171 def write_chunks(chunks, path):
172 ret = None
173 downloaded_size = 0
174 if path:
175 mkdir(os.path.dirname(path))
176 with open(path, 'wb') as file_handler:
177 for chunk in chunks:
178 assert ((six.PY3 and isinstance(chunk, bytes)) or
179 (six.PY2 and isinstance(chunk, str)))
180 file_handler.write(chunk)
181 downloaded_size += len(chunk)
182 else:
183 ret_data = bytearray()
184 for chunk in chunks:
185 ret_data.extend(chunk)
186 downloaded_size += len(chunk)
187 ret = bytes(ret_data)
188 return ret, downloaded_size
189
190 try:
191 logger.debug("DOWNLOAD: %s" % url)
192 total_length = response.headers.get('content-length') or len(response.content)
193 total_length = int(total_length)
194 description = "Downloading {}".format(os.path.basename(file_path)) if file_path else None
195 progress = progress_bar.Progress(total_length, self.output, description, print_dot=False)
196
197 chunk_size = 1024 if not file_path else 1024 * 100
198 encoding = response.headers.get('content-encoding')
199 gzip = (encoding == "gzip")
200
201 written_chunks, total_downloaded_size = write_chunks(
202 progress.update(read_response(chunk_size), chunk_size),
203 file_path
204 )
205
206 response.close()
207 if total_downloaded_size != total_length and not gzip:
208 raise ConanException("Transfer interrupted before "
209 "complete: %s < %s" % (total_downloaded_size, total_length))
210
211 duration = time.time() - t1
212 log_download(url, duration)
213 return written_chunks
214
215 except Exception as e:
216 logger.debug(e.__class__)
217 logger.debug(traceback.format_exc())
218 # If this part failed, it means problems with the connection to server
219 raise ConanConnectionError("Download failed, check server, possibly try again\n%s"
220 % str(e))
221
222
223 def print_progress(output, units, progress=""):
224 if output.is_terminal:
225 output.rewrite_line("[%s%s] %s" % ('=' * units, ' ' * (50 - units), progress))
226
227
228 def call_with_retry(out, retry, retry_wait, method, *args, **kwargs):
229 for counter in range(retry + 1):
230 try:
231 return method(*args, **kwargs)
232 except (NotFoundException, ForbiddenException, AuthenticationException,
233 RequestErrorException):
234 raise
235 except ConanException as exc:
236 if counter == retry:
237 raise
238 else:
239 if out:
240 out.error(exc)
241 out.info("Waiting %d seconds to retry..." % retry_wait)
242 time.sleep(retry_wait)
243
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conans/client/rest/uploader_downloader.py b/conans/client/rest/uploader_downloader.py
--- a/conans/client/rest/uploader_downloader.py
+++ b/conans/client/rest/uploader_downloader.py
@@ -45,7 +45,7 @@
raise AuthenticationException(response_to_str(response))
if response.status_code == 403:
- if auth.token is None:
+ if auth is None or auth.token is None:
raise AuthenticationException(response_to_str(response))
raise ForbiddenException(response_to_str(response))
if response.status_code == 201: # Artifactory returns 201 if the file is there
@@ -86,7 +86,7 @@
raise AuthenticationException(response_to_str(response))
if response.status_code == 403:
- if auth.token is None:
+ if auth is None or auth.token is None:
raise AuthenticationException(response_to_str(response))
raise ForbiddenException(response_to_str(response))
@@ -157,7 +157,8 @@
if response.status_code == 404:
raise NotFoundException("Not found: %s" % url)
elif response.status_code == 403:
- if auth.token is None:
+ if auth is None or (hasattr(auth, "token") and auth.token is None):
+ # TODO: This is a bit weird, why this conversion? Need to investigate
raise AuthenticationException(response_to_str(response))
raise ForbiddenException(response_to_str(response))
elif response.status_code == 401:
|
{"golden_diff": "diff --git a/conans/client/rest/uploader_downloader.py b/conans/client/rest/uploader_downloader.py\n--- a/conans/client/rest/uploader_downloader.py\n+++ b/conans/client/rest/uploader_downloader.py\n@@ -45,7 +45,7 @@\n raise AuthenticationException(response_to_str(response))\n \n if response.status_code == 403:\n- if auth.token is None:\n+ if auth is None or auth.token is None:\n raise AuthenticationException(response_to_str(response))\n raise ForbiddenException(response_to_str(response))\n if response.status_code == 201: # Artifactory returns 201 if the file is there\n@@ -86,7 +86,7 @@\n raise AuthenticationException(response_to_str(response))\n \n if response.status_code == 403:\n- if auth.token is None:\n+ if auth is None or auth.token is None:\n raise AuthenticationException(response_to_str(response))\n raise ForbiddenException(response_to_str(response))\n \n@@ -157,7 +157,8 @@\n if response.status_code == 404:\n raise NotFoundException(\"Not found: %s\" % url)\n elif response.status_code == 403:\n- if auth.token is None:\n+ if auth is None or (hasattr(auth, \"token\") and auth.token is None):\n+ # TODO: This is a bit weird, why this conversion? Need to investigate\n raise AuthenticationException(response_to_str(response))\n raise ForbiddenException(response_to_str(response))\n elif response.status_code == 401:\n", "issue": "[bug] authentication error is handled incorrectly in client.rest.uploader_downloader.FileDownloader\nWhen installing a Conan package I've got this error message:\r\n```\r\ntools.get(**self.conan_data[\"sources\"][self.version])\r\nAttributeError: 'NoneType' object has no attribute 'token'\r\n```\r\nObviously, the message isn't very helpful as it implies that there's a problem with the package recipe (there wasn't).\r\n\r\nAfter some investigation I found out that the error ultimately happens in `client.rest.uploader_downloader.FileDownloader` when the download fails with a 403.\r\nThe method does the following check: `auth.token is None`. The issue is, `auth` is an optional parameter. Also it is effectively allowed to be a tuple according to documentation for `tools.get`. So, I assume the check should have been `not auth or not hasattr(auth, \"token\") or auth.token is None`.\r\n\r\nConan version: 1.21.0\r\n\n", "before_files": [{"content": "import os\nimport traceback\nimport time\nfrom copy import copy\n\nimport six\n\nfrom conans.util import progress_bar\nfrom conans.client.rest import response_to_str\nfrom conans.errors import AuthenticationException, ConanConnectionError, ConanException, \\\n NotFoundException, ForbiddenException, RequestErrorException\nfrom conans.util.files import mkdir, sha1sum\nfrom conans.util.log import logger\nfrom conans.util.tracer import log_download\n\n\nclass FileUploader(object):\n\n def __init__(self, requester, output, verify, chunk_size=1000):\n self.chunk_size = chunk_size\n self.output = output\n self.requester = requester\n self.verify = verify\n\n def upload(self, url, abs_path, auth=None, dedup=False, retry=None, retry_wait=None,\n headers=None):\n retry = retry if retry is not None else self.requester.retry\n retry = retry if retry is not None else 1\n retry_wait = retry_wait if retry_wait is not None else self.requester.retry_wait\n retry_wait = retry_wait if retry_wait is not None else 5\n\n # Send always the header with the Sha1\n headers = copy(headers) or {}\n headers[\"X-Checksum-Sha1\"] = sha1sum(abs_path)\n if dedup:\n dedup_headers = {\"X-Checksum-Deploy\": \"true\"}\n if headers:\n dedup_headers.update(headers)\n response = self.requester.put(url, data=\"\", verify=self.verify, headers=dedup_headers,\n auth=auth)\n if response.status_code == 400:\n raise RequestErrorException(response_to_str(response))\n\n if response.status_code == 401:\n raise AuthenticationException(response_to_str(response))\n\n if response.status_code == 403:\n if auth.token is None:\n raise AuthenticationException(response_to_str(response))\n raise ForbiddenException(response_to_str(response))\n if response.status_code == 201: # Artifactory returns 201 if the file is there\n return response\n\n ret = call_with_retry(self.output, retry, retry_wait, self._upload_file, url,\n abs_path=abs_path, headers=headers, auth=auth)\n return ret\n\n def _upload_file(self, url, abs_path, headers, auth):\n\n file_size = os.stat(abs_path).st_size\n file_name = os.path.basename(abs_path)\n description = \"Uploading {}\".format(file_name)\n\n def load_in_chunks(_file, size):\n \"\"\"Lazy function (generator) to read a file piece by piece.\n Default chunk size: 1k.\"\"\"\n while True:\n chunk = _file.read(size)\n if not chunk:\n break\n yield chunk\n\n with open(abs_path, mode='rb') as file_handler:\n progress = progress_bar.Progress(file_size, self.output, description, print_dot=True)\n chunk_size = 1024\n data = progress.update(load_in_chunks(file_handler, chunk_size), chunk_size)\n iterable_to_file = IterableToFileAdapter(data, file_size)\n try:\n response = self.requester.put(url, data=iterable_to_file, verify=self.verify,\n headers=headers, auth=auth)\n\n if response.status_code == 400:\n raise RequestErrorException(response_to_str(response))\n\n if response.status_code == 401:\n raise AuthenticationException(response_to_str(response))\n\n if response.status_code == 403:\n if auth.token is None:\n raise AuthenticationException(response_to_str(response))\n raise ForbiddenException(response_to_str(response))\n\n response.raise_for_status() # Raise HTTPError for bad http response status\n\n except ConanException:\n raise\n except Exception as exc:\n raise ConanException(exc)\n\n return response\n\n\nclass IterableToFileAdapter(object):\n def __init__(self, iterable, total_size):\n self.iterator = iter(iterable)\n self.total_size = total_size\n\n def read(self, size=-1): # @UnusedVariable\n return next(self.iterator, b'')\n\n def __len__(self):\n return self.total_size\n\n def __iter__(self):\n return self.iterator.__iter__()\n\n\nclass FileDownloader(object):\n\n def __init__(self, requester, output, verify, chunk_size=1000):\n self.chunk_size = chunk_size\n self.output = output\n self.requester = requester\n self.verify = verify\n\n def download(self, url, file_path=None, auth=None, retry=None, retry_wait=None, overwrite=False,\n headers=None):\n retry = retry if retry is not None else self.requester.retry\n retry = retry if retry is not None else 2\n retry_wait = retry_wait if retry_wait is not None else self.requester.retry_wait\n retry_wait = retry_wait if retry_wait is not None else 0\n\n if file_path and not os.path.isabs(file_path):\n file_path = os.path.abspath(file_path)\n\n if file_path and os.path.exists(file_path):\n if overwrite:\n if self.output:\n self.output.warn(\"file '%s' already exists, overwriting\" % file_path)\n else:\n # Should not happen, better to raise, probably we had to remove\n # the dest folder before\n raise ConanException(\"Error, the file to download already exists: '%s'\" % file_path)\n\n return call_with_retry(self.output, retry, retry_wait, self._download_file, url, auth,\n headers, file_path)\n\n def _download_file(self, url, auth, headers, file_path):\n t1 = time.time()\n try:\n response = self.requester.get(url, stream=True, verify=self.verify, auth=auth,\n headers=headers)\n except Exception as exc:\n raise ConanException(\"Error downloading file %s: '%s'\" % (url, exc))\n\n if not response.ok:\n if response.status_code == 404:\n raise NotFoundException(\"Not found: %s\" % url)\n elif response.status_code == 403:\n if auth.token is None:\n raise AuthenticationException(response_to_str(response))\n raise ForbiddenException(response_to_str(response))\n elif response.status_code == 401:\n raise AuthenticationException()\n raise ConanException(\"Error %d downloading file %s\" % (response.status_code, url))\n\n def read_response(size):\n for chunk in response.iter_content(size):\n yield chunk\n\n def write_chunks(chunks, path):\n ret = None\n downloaded_size = 0\n if path:\n mkdir(os.path.dirname(path))\n with open(path, 'wb') as file_handler:\n for chunk in chunks:\n assert ((six.PY3 and isinstance(chunk, bytes)) or\n (six.PY2 and isinstance(chunk, str)))\n file_handler.write(chunk)\n downloaded_size += len(chunk)\n else:\n ret_data = bytearray()\n for chunk in chunks:\n ret_data.extend(chunk)\n downloaded_size += len(chunk)\n ret = bytes(ret_data)\n return ret, downloaded_size\n\n try:\n logger.debug(\"DOWNLOAD: %s\" % url)\n total_length = response.headers.get('content-length') or len(response.content)\n total_length = int(total_length)\n description = \"Downloading {}\".format(os.path.basename(file_path)) if file_path else None\n progress = progress_bar.Progress(total_length, self.output, description, print_dot=False)\n\n chunk_size = 1024 if not file_path else 1024 * 100\n encoding = response.headers.get('content-encoding')\n gzip = (encoding == \"gzip\")\n\n written_chunks, total_downloaded_size = write_chunks(\n progress.update(read_response(chunk_size), chunk_size),\n file_path\n )\n\n response.close()\n if total_downloaded_size != total_length and not gzip:\n raise ConanException(\"Transfer interrupted before \"\n \"complete: %s < %s\" % (total_downloaded_size, total_length))\n\n duration = time.time() - t1\n log_download(url, duration)\n return written_chunks\n\n except Exception as e:\n logger.debug(e.__class__)\n logger.debug(traceback.format_exc())\n # If this part failed, it means problems with the connection to server\n raise ConanConnectionError(\"Download failed, check server, possibly try again\\n%s\"\n % str(e))\n\n\ndef print_progress(output, units, progress=\"\"):\n if output.is_terminal:\n output.rewrite_line(\"[%s%s] %s\" % ('=' * units, ' ' * (50 - units), progress))\n\n\ndef call_with_retry(out, retry, retry_wait, method, *args, **kwargs):\n for counter in range(retry + 1):\n try:\n return method(*args, **kwargs)\n except (NotFoundException, ForbiddenException, AuthenticationException,\n RequestErrorException):\n raise\n except ConanException as exc:\n if counter == retry:\n raise\n else:\n if out:\n out.error(exc)\n out.info(\"Waiting %d seconds to retry...\" % retry_wait)\n time.sleep(retry_wait)\n", "path": "conans/client/rest/uploader_downloader.py"}], "after_files": [{"content": "import os\nimport traceback\nimport time\nfrom copy import copy\n\nimport six\n\nfrom conans.util import progress_bar\nfrom conans.client.rest import response_to_str\nfrom conans.errors import AuthenticationException, ConanConnectionError, ConanException, \\\n NotFoundException, ForbiddenException, RequestErrorException\nfrom conans.util.files import mkdir, sha1sum\nfrom conans.util.log import logger\nfrom conans.util.tracer import log_download\n\n\nclass FileUploader(object):\n\n def __init__(self, requester, output, verify, chunk_size=1000):\n self.chunk_size = chunk_size\n self.output = output\n self.requester = requester\n self.verify = verify\n\n def upload(self, url, abs_path, auth=None, dedup=False, retry=None, retry_wait=None,\n headers=None):\n retry = retry if retry is not None else self.requester.retry\n retry = retry if retry is not None else 1\n retry_wait = retry_wait if retry_wait is not None else self.requester.retry_wait\n retry_wait = retry_wait if retry_wait is not None else 5\n\n # Send always the header with the Sha1\n headers = copy(headers) or {}\n headers[\"X-Checksum-Sha1\"] = sha1sum(abs_path)\n if dedup:\n dedup_headers = {\"X-Checksum-Deploy\": \"true\"}\n if headers:\n dedup_headers.update(headers)\n response = self.requester.put(url, data=\"\", verify=self.verify, headers=dedup_headers,\n auth=auth)\n if response.status_code == 400:\n raise RequestErrorException(response_to_str(response))\n\n if response.status_code == 401:\n raise AuthenticationException(response_to_str(response))\n\n if response.status_code == 403:\n if auth is None or auth.token is None:\n raise AuthenticationException(response_to_str(response))\n raise ForbiddenException(response_to_str(response))\n if response.status_code == 201: # Artifactory returns 201 if the file is there\n return response\n\n ret = call_with_retry(self.output, retry, retry_wait, self._upload_file, url,\n abs_path=abs_path, headers=headers, auth=auth)\n return ret\n\n def _upload_file(self, url, abs_path, headers, auth):\n\n file_size = os.stat(abs_path).st_size\n file_name = os.path.basename(abs_path)\n description = \"Uploading {}\".format(file_name)\n\n def load_in_chunks(_file, size):\n \"\"\"Lazy function (generator) to read a file piece by piece.\n Default chunk size: 1k.\"\"\"\n while True:\n chunk = _file.read(size)\n if not chunk:\n break\n yield chunk\n\n with open(abs_path, mode='rb') as file_handler:\n progress = progress_bar.Progress(file_size, self.output, description, print_dot=True)\n chunk_size = 1024\n data = progress.update(load_in_chunks(file_handler, chunk_size), chunk_size)\n iterable_to_file = IterableToFileAdapter(data, file_size)\n try:\n response = self.requester.put(url, data=iterable_to_file, verify=self.verify,\n headers=headers, auth=auth)\n\n if response.status_code == 400:\n raise RequestErrorException(response_to_str(response))\n\n if response.status_code == 401:\n raise AuthenticationException(response_to_str(response))\n\n if response.status_code == 403:\n if auth is None or auth.token is None:\n raise AuthenticationException(response_to_str(response))\n raise ForbiddenException(response_to_str(response))\n\n response.raise_for_status() # Raise HTTPError for bad http response status\n\n except ConanException:\n raise\n except Exception as exc:\n raise ConanException(exc)\n\n return response\n\n\nclass IterableToFileAdapter(object):\n def __init__(self, iterable, total_size):\n self.iterator = iter(iterable)\n self.total_size = total_size\n\n def read(self, size=-1): # @UnusedVariable\n return next(self.iterator, b'')\n\n def __len__(self):\n return self.total_size\n\n def __iter__(self):\n return self.iterator.__iter__()\n\n\nclass FileDownloader(object):\n\n def __init__(self, requester, output, verify, chunk_size=1000):\n self.chunk_size = chunk_size\n self.output = output\n self.requester = requester\n self.verify = verify\n\n def download(self, url, file_path=None, auth=None, retry=None, retry_wait=None, overwrite=False,\n headers=None):\n retry = retry if retry is not None else self.requester.retry\n retry = retry if retry is not None else 2\n retry_wait = retry_wait if retry_wait is not None else self.requester.retry_wait\n retry_wait = retry_wait if retry_wait is not None else 0\n\n if file_path and not os.path.isabs(file_path):\n file_path = os.path.abspath(file_path)\n\n if file_path and os.path.exists(file_path):\n if overwrite:\n if self.output:\n self.output.warn(\"file '%s' already exists, overwriting\" % file_path)\n else:\n # Should not happen, better to raise, probably we had to remove\n # the dest folder before\n raise ConanException(\"Error, the file to download already exists: '%s'\" % file_path)\n\n return call_with_retry(self.output, retry, retry_wait, self._download_file, url, auth,\n headers, file_path)\n\n def _download_file(self, url, auth, headers, file_path):\n t1 = time.time()\n try:\n response = self.requester.get(url, stream=True, verify=self.verify, auth=auth,\n headers=headers)\n except Exception as exc:\n raise ConanException(\"Error downloading file %s: '%s'\" % (url, exc))\n\n if not response.ok:\n if response.status_code == 404:\n raise NotFoundException(\"Not found: %s\" % url)\n elif response.status_code == 403:\n if auth is None or (hasattr(auth, \"token\") and auth.token is None):\n # TODO: This is a bit weird, why this conversion? Need to investigate\n raise AuthenticationException(response_to_str(response))\n raise ForbiddenException(response_to_str(response))\n elif response.status_code == 401:\n raise AuthenticationException()\n raise ConanException(\"Error %d downloading file %s\" % (response.status_code, url))\n\n def read_response(size):\n for chunk in response.iter_content(size):\n yield chunk\n\n def write_chunks(chunks, path):\n ret = None\n downloaded_size = 0\n if path:\n mkdir(os.path.dirname(path))\n with open(path, 'wb') as file_handler:\n for chunk in chunks:\n assert ((six.PY3 and isinstance(chunk, bytes)) or\n (six.PY2 and isinstance(chunk, str)))\n file_handler.write(chunk)\n downloaded_size += len(chunk)\n else:\n ret_data = bytearray()\n for chunk in chunks:\n ret_data.extend(chunk)\n downloaded_size += len(chunk)\n ret = bytes(ret_data)\n return ret, downloaded_size\n\n try:\n logger.debug(\"DOWNLOAD: %s\" % url)\n total_length = response.headers.get('content-length') or len(response.content)\n total_length = int(total_length)\n description = \"Downloading {}\".format(os.path.basename(file_path)) if file_path else None\n progress = progress_bar.Progress(total_length, self.output, description, print_dot=False)\n\n chunk_size = 1024 if not file_path else 1024 * 100\n encoding = response.headers.get('content-encoding')\n gzip = (encoding == \"gzip\")\n\n written_chunks, total_downloaded_size = write_chunks(\n progress.update(read_response(chunk_size), chunk_size),\n file_path\n )\n\n response.close()\n if total_downloaded_size != total_length and not gzip:\n raise ConanException(\"Transfer interrupted before \"\n \"complete: %s < %s\" % (total_downloaded_size, total_length))\n\n duration = time.time() - t1\n log_download(url, duration)\n return written_chunks\n\n except Exception as e:\n logger.debug(e.__class__)\n logger.debug(traceback.format_exc())\n # If this part failed, it means problems with the connection to server\n raise ConanConnectionError(\"Download failed, check server, possibly try again\\n%s\"\n % str(e))\n\n\ndef print_progress(output, units, progress=\"\"):\n if output.is_terminal:\n output.rewrite_line(\"[%s%s] %s\" % ('=' * units, ' ' * (50 - units), progress))\n\n\ndef call_with_retry(out, retry, retry_wait, method, *args, **kwargs):\n for counter in range(retry + 1):\n try:\n return method(*args, **kwargs)\n except (NotFoundException, ForbiddenException, AuthenticationException,\n RequestErrorException):\n raise\n except ConanException as exc:\n if counter == retry:\n raise\n else:\n if out:\n out.error(exc)\n out.info(\"Waiting %d seconds to retry...\" % retry_wait)\n time.sleep(retry_wait)\n", "path": "conans/client/rest/uploader_downloader.py"}]}
| 3,062 | 344 |
gh_patches_debug_31330
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-2324
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Upgrade websockets to 10.1 ?
* Version: 5.25.0
* Python: 3.8
* OS: osx
* `pip freeze` output
```
solana==0.19.0 (problem)
```
### What was wrong?
Currently in dependency hell trying to use solana-py and web3 in same service. solana-py requires websockets 10.1, web3 seems to not support that. Below is the changelog for 10.1 release of websockets, there are no incompatible changes. Any chance I could bother the team to consider upgrading support to 10.1?
Also, from my logs it seems web3 needs "websockets<10" but i think changes were made to support 10.0 (#2175) . May need to update requirements:
remote: The conflict is caused by:
remote: solana 0.19.0 depends on websockets<11.0 and >=10.1
remote: web3 5.25.0 depends on websockets<10 and >=9.1
https://websockets.readthedocs.io/en/latest/project/changelog.html#id3
Thanks!
### How can it be fixed?
Upgrade websockets support to 10.1
---
**Note:** We prefer to use issues to track our work. If you think you've encountered a bug in web3py or
have a feature request, you're in the right place. If you have implementation or usage questions,
please refer to our [documentation](https://web3py.readthedocs.io/en/latest/) and/or join the conversation
on [discord](https://discord.gg/GHryRvPB84).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 from setuptools import (
4 find_packages,
5 setup,
6 )
7
8 extras_require = {
9 'tester': [
10 "eth-tester[py-evm]==v0.6.0-beta.6",
11 "py-geth>=3.7.0,<4",
12 ],
13 'linter': [
14 "flake8==3.8.3",
15 "isort>=4.2.15,<4.3.5",
16 "mypy==0.910",
17 "types-setuptools>=57.4.4,<58",
18 "types-requests>=2.26.1,<3",
19 "types-protobuf>=3.18.2,<4",
20 ],
21 'docs': [
22 "mock",
23 "sphinx-better-theme>=0.1.4",
24 "click>=5.1",
25 "configparser==3.5.0",
26 "contextlib2>=0.5.4",
27 "py-geth>=3.6.0,<4",
28 "py-solc>=0.4.0",
29 "pytest>=4.4.0,<5.0.0",
30 "sphinx>=3.0,<4",
31 "sphinx_rtd_theme>=0.1.9",
32 "toposort>=1.4",
33 "towncrier==18.5.0",
34 "urllib3",
35 "wheel"
36 ],
37 'dev': [
38 "bumpversion",
39 "flaky>=3.7.0,<4",
40 "hypothesis>=3.31.2,<6",
41 "pytest>=4.4.0,<5.0.0",
42 "pytest-asyncio>=0.10.0,<0.11",
43 "pytest-mock>=1.10,<2",
44 "pytest-pythonpath>=0.3",
45 "pytest-watch>=4.2,<5",
46 "pytest-xdist>=1.29,<2",
47 "setuptools>=38.6.0",
48 "tox>=1.8.0",
49 "tqdm>4.32,<5",
50 "twine>=1.13,<2",
51 "pluggy==0.13.1",
52 "when-changed>=0.3.0,<0.4"
53 ]
54 }
55
56 extras_require['dev'] = (
57 extras_require['tester']
58 + extras_require['linter']
59 + extras_require['docs']
60 + extras_require['dev']
61 )
62
63 with open('./README.md') as readme:
64 long_description = readme.read()
65
66 setup(
67 name='web3',
68 # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.
69 version='5.28.0',
70 description="""Web3.py""",
71 long_description_content_type='text/markdown',
72 long_description=long_description,
73 author='Piper Merriam',
74 author_email='pipermerriam@gmail.com',
75 url='https://github.com/ethereum/web3.py',
76 include_package_data=True,
77 install_requires=[
78 "aiohttp>=3.7.4.post0,<4",
79 "eth-abi>=2.0.0b6,<3.0.0",
80 "eth-account>=0.5.7,<0.6.0",
81 "eth-hash[pycryptodome]>=0.2.0,<1.0.0",
82 "eth-typing>=2.0.0,<3.0.0",
83 "eth-utils>=1.9.5,<2.0.0",
84 "hexbytes>=0.1.0,<1.0.0",
85 "ipfshttpclient==0.8.0a2",
86 "jsonschema>=3.2.0,<4.0.0",
87 "lru-dict>=1.1.6,<2.0.0",
88 "protobuf>=3.10.0,<4",
89 "pywin32>=223;platform_system=='Windows'",
90 "requests>=2.16.0,<3.0.0",
91 # remove typing_extensions after python_requires>=3.8, see web3._utils.compat
92 "typing-extensions>=3.7.4.1,<5;python_version<'3.8'",
93 "websockets>=9.1,<10",
94 ],
95 python_requires='>=3.7,<3.10',
96 extras_require=extras_require,
97 py_modules=['web3', 'ens', 'ethpm'],
98 entry_points={"pytest11": ["pytest_ethereum = web3.tools.pytest_ethereum.plugins"]},
99 license="MIT",
100 zip_safe=False,
101 keywords='ethereum',
102 packages=find_packages(exclude=["tests", "tests.*"]),
103 package_data={"web3": ["py.typed"]},
104 classifiers=[
105 'Development Status :: 5 - Production/Stable',
106 'Intended Audience :: Developers',
107 'License :: OSI Approved :: MIT License',
108 'Natural Language :: English',
109 'Programming Language :: Python :: 3',
110 'Programming Language :: Python :: 3.7',
111 'Programming Language :: Python :: 3.8',
112 'Programming Language :: Python :: 3.9',
113 ],
114 )
115
```
Path: `web3/providers/websocket.py`
Content:
```
1 import asyncio
2 import json
3 import logging
4 import os
5 from threading import (
6 Thread,
7 )
8 from types import (
9 TracebackType,
10 )
11 from typing import (
12 Any,
13 Optional,
14 Type,
15 Union,
16 )
17
18 from eth_typing import (
19 URI,
20 )
21 from websockets.client import (
22 connect,
23 )
24 from websockets.legacy.client import (
25 WebSocketClientProtocol,
26 )
27
28 from web3.exceptions import (
29 ValidationError,
30 )
31 from web3.providers.base import (
32 JSONBaseProvider,
33 )
34 from web3.types import (
35 RPCEndpoint,
36 RPCResponse,
37 )
38
39 RESTRICTED_WEBSOCKET_KWARGS = {'uri', 'loop'}
40 DEFAULT_WEBSOCKET_TIMEOUT = 10
41
42
43 def _start_event_loop(loop: asyncio.AbstractEventLoop) -> None:
44 asyncio.set_event_loop(loop)
45 loop.run_forever()
46 loop.close()
47
48
49 def _get_threaded_loop() -> asyncio.AbstractEventLoop:
50 new_loop = asyncio.new_event_loop()
51 thread_loop = Thread(target=_start_event_loop, args=(new_loop,), daemon=True)
52 thread_loop.start()
53 return new_loop
54
55
56 def get_default_endpoint() -> URI:
57 return URI(os.environ.get('WEB3_WS_PROVIDER_URI', 'ws://127.0.0.1:8546'))
58
59
60 class PersistentWebSocket:
61
62 def __init__(
63 self, endpoint_uri: URI, loop: asyncio.AbstractEventLoop, websocket_kwargs: Any
64 ) -> None:
65 self.ws: WebSocketClientProtocol = None
66 self.endpoint_uri = endpoint_uri
67 self.loop = loop
68 self.websocket_kwargs = websocket_kwargs
69
70 async def __aenter__(self) -> WebSocketClientProtocol:
71 if self.ws is None:
72 self.ws = await connect(
73 uri=self.endpoint_uri, loop=self.loop, **self.websocket_kwargs
74 )
75 return self.ws
76
77 async def __aexit__(
78 self, exc_type: Type[BaseException], exc_val: BaseException, exc_tb: TracebackType
79 ) -> None:
80 if exc_val is not None:
81 try:
82 await self.ws.close()
83 except Exception:
84 pass
85 self.ws = None
86
87
88 class WebsocketProvider(JSONBaseProvider):
89 logger = logging.getLogger("web3.providers.WebsocketProvider")
90 _loop = None
91
92 def __init__(
93 self,
94 endpoint_uri: Optional[Union[URI, str]] = None,
95 websocket_kwargs: Optional[Any] = None,
96 websocket_timeout: int = DEFAULT_WEBSOCKET_TIMEOUT,
97 ) -> None:
98 self.endpoint_uri = URI(endpoint_uri)
99 self.websocket_timeout = websocket_timeout
100 if self.endpoint_uri is None:
101 self.endpoint_uri = get_default_endpoint()
102 if WebsocketProvider._loop is None:
103 WebsocketProvider._loop = _get_threaded_loop()
104 if websocket_kwargs is None:
105 websocket_kwargs = {}
106 else:
107 found_restricted_keys = set(websocket_kwargs.keys()).intersection(
108 RESTRICTED_WEBSOCKET_KWARGS
109 )
110 if found_restricted_keys:
111 raise ValidationError(
112 '{0} are not allowed in websocket_kwargs, '
113 'found: {1}'.format(RESTRICTED_WEBSOCKET_KWARGS, found_restricted_keys)
114 )
115 self.conn = PersistentWebSocket(
116 self.endpoint_uri, WebsocketProvider._loop, websocket_kwargs
117 )
118 super().__init__()
119
120 def __str__(self) -> str:
121 return "WS connection {0}".format(self.endpoint_uri)
122
123 async def coro_make_request(self, request_data: bytes) -> RPCResponse:
124 async with self.conn as conn:
125 await asyncio.wait_for(
126 conn.send(request_data),
127 timeout=self.websocket_timeout
128 )
129 return json.loads(
130 await asyncio.wait_for(
131 conn.recv(),
132 timeout=self.websocket_timeout
133 )
134 )
135
136 def make_request(self, method: RPCEndpoint, params: Any) -> RPCResponse:
137 self.logger.debug("Making request WebSocket. URI: %s, "
138 "Method: %s", self.endpoint_uri, method)
139 request_data = self.encode_rpc_request(method, params)
140 future = asyncio.run_coroutine_threadsafe(
141 self.coro_make_request(request_data),
142 WebsocketProvider._loop
143 )
144 return future.result()
145
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -90,7 +90,7 @@
"requests>=2.16.0,<3.0.0",
# remove typing_extensions after python_requires>=3.8, see web3._utils.compat
"typing-extensions>=3.7.4.1,<5;python_version<'3.8'",
- "websockets>=9.1,<10",
+ "websockets>=10.0.0,<11",
],
python_requires='>=3.7,<3.10',
extras_require=extras_require,
diff --git a/web3/providers/websocket.py b/web3/providers/websocket.py
--- a/web3/providers/websocket.py
+++ b/web3/providers/websocket.py
@@ -60,17 +60,16 @@
class PersistentWebSocket:
def __init__(
- self, endpoint_uri: URI, loop: asyncio.AbstractEventLoop, websocket_kwargs: Any
+ self, endpoint_uri: URI, websocket_kwargs: Any
) -> None:
self.ws: WebSocketClientProtocol = None
self.endpoint_uri = endpoint_uri
- self.loop = loop
self.websocket_kwargs = websocket_kwargs
async def __aenter__(self) -> WebSocketClientProtocol:
if self.ws is None:
self.ws = await connect(
- uri=self.endpoint_uri, loop=self.loop, **self.websocket_kwargs
+ uri=self.endpoint_uri, **self.websocket_kwargs
)
return self.ws
@@ -113,7 +112,7 @@
'found: {1}'.format(RESTRICTED_WEBSOCKET_KWARGS, found_restricted_keys)
)
self.conn = PersistentWebSocket(
- self.endpoint_uri, WebsocketProvider._loop, websocket_kwargs
+ self.endpoint_uri, websocket_kwargs
)
super().__init__()
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -90,7 +90,7 @@\n \"requests>=2.16.0,<3.0.0\",\n # remove typing_extensions after python_requires>=3.8, see web3._utils.compat\n \"typing-extensions>=3.7.4.1,<5;python_version<'3.8'\",\n- \"websockets>=9.1,<10\",\n+ \"websockets>=10.0.0,<11\",\n ],\n python_requires='>=3.7,<3.10',\n extras_require=extras_require,\ndiff --git a/web3/providers/websocket.py b/web3/providers/websocket.py\n--- a/web3/providers/websocket.py\n+++ b/web3/providers/websocket.py\n@@ -60,17 +60,16 @@\n class PersistentWebSocket:\n \n def __init__(\n- self, endpoint_uri: URI, loop: asyncio.AbstractEventLoop, websocket_kwargs: Any\n+ self, endpoint_uri: URI, websocket_kwargs: Any\n ) -> None:\n self.ws: WebSocketClientProtocol = None\n self.endpoint_uri = endpoint_uri\n- self.loop = loop\n self.websocket_kwargs = websocket_kwargs\n \n async def __aenter__(self) -> WebSocketClientProtocol:\n if self.ws is None:\n self.ws = await connect(\n- uri=self.endpoint_uri, loop=self.loop, **self.websocket_kwargs\n+ uri=self.endpoint_uri, **self.websocket_kwargs\n )\n return self.ws\n \n@@ -113,7 +112,7 @@\n 'found: {1}'.format(RESTRICTED_WEBSOCKET_KWARGS, found_restricted_keys)\n )\n self.conn = PersistentWebSocket(\n- self.endpoint_uri, WebsocketProvider._loop, websocket_kwargs\n+ self.endpoint_uri, websocket_kwargs\n )\n super().__init__()\n", "issue": "Upgrade websockets to 10.1 ?\n* Version: 5.25.0\r\n* Python: 3.8\r\n* OS: osx\r\n* `pip freeze` output\r\n\r\n```\r\nsolana==0.19.0 (problem)\r\n```\r\n\r\n\r\n### What was wrong?\r\n\r\nCurrently in dependency hell trying to use solana-py and web3 in same service. solana-py requires websockets 10.1, web3 seems to not support that. Below is the changelog for 10.1 release of websockets, there are no incompatible changes. Any chance I could bother the team to consider upgrading support to 10.1?\r\n\r\nAlso, from my logs it seems web3 needs \"websockets<10\" but i think changes were made to support 10.0 (#2175) . May need to update requirements:\r\n\r\nremote: The conflict is caused by:\r\nremote: solana 0.19.0 depends on websockets<11.0 and >=10.1\r\nremote: web3 5.25.0 depends on websockets<10 and >=9.1\r\n\r\nhttps://websockets.readthedocs.io/en/latest/project/changelog.html#id3\r\n\r\nThanks!\r\n\r\n\r\n### How can it be fixed?\r\n\r\nUpgrade websockets support to 10.1\r\n\r\n---\r\n**Note:** We prefer to use issues to track our work. If you think you've encountered a bug in web3py or \r\nhave a feature request, you're in the right place. If you have implementation or usage questions, \r\nplease refer to our [documentation](https://web3py.readthedocs.io/en/latest/) and/or join the conversation \r\non [discord](https://discord.gg/GHryRvPB84).\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom setuptools import (\n find_packages,\n setup,\n)\n\nextras_require = {\n 'tester': [\n \"eth-tester[py-evm]==v0.6.0-beta.6\",\n \"py-geth>=3.7.0,<4\",\n ],\n 'linter': [\n \"flake8==3.8.3\",\n \"isort>=4.2.15,<4.3.5\",\n \"mypy==0.910\",\n \"types-setuptools>=57.4.4,<58\",\n \"types-requests>=2.26.1,<3\",\n \"types-protobuf>=3.18.2,<4\",\n ],\n 'docs': [\n \"mock\",\n \"sphinx-better-theme>=0.1.4\",\n \"click>=5.1\",\n \"configparser==3.5.0\",\n \"contextlib2>=0.5.4\",\n \"py-geth>=3.6.0,<4\",\n \"py-solc>=0.4.0\",\n \"pytest>=4.4.0,<5.0.0\",\n \"sphinx>=3.0,<4\",\n \"sphinx_rtd_theme>=0.1.9\",\n \"toposort>=1.4\",\n \"towncrier==18.5.0\",\n \"urllib3\",\n \"wheel\"\n ],\n 'dev': [\n \"bumpversion\",\n \"flaky>=3.7.0,<4\",\n \"hypothesis>=3.31.2,<6\",\n \"pytest>=4.4.0,<5.0.0\",\n \"pytest-asyncio>=0.10.0,<0.11\",\n \"pytest-mock>=1.10,<2\",\n \"pytest-pythonpath>=0.3\",\n \"pytest-watch>=4.2,<5\",\n \"pytest-xdist>=1.29,<2\",\n \"setuptools>=38.6.0\",\n \"tox>=1.8.0\",\n \"tqdm>4.32,<5\",\n \"twine>=1.13,<2\",\n \"pluggy==0.13.1\",\n \"when-changed>=0.3.0,<0.4\"\n ]\n}\n\nextras_require['dev'] = (\n extras_require['tester']\n + extras_require['linter']\n + extras_require['docs']\n + extras_require['dev']\n)\n\nwith open('./README.md') as readme:\n long_description = readme.read()\n\nsetup(\n name='web3',\n # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.\n version='5.28.0',\n description=\"\"\"Web3.py\"\"\",\n long_description_content_type='text/markdown',\n long_description=long_description,\n author='Piper Merriam',\n author_email='pipermerriam@gmail.com',\n url='https://github.com/ethereum/web3.py',\n include_package_data=True,\n install_requires=[\n \"aiohttp>=3.7.4.post0,<4\",\n \"eth-abi>=2.0.0b6,<3.0.0\",\n \"eth-account>=0.5.7,<0.6.0\",\n \"eth-hash[pycryptodome]>=0.2.0,<1.0.0\",\n \"eth-typing>=2.0.0,<3.0.0\",\n \"eth-utils>=1.9.5,<2.0.0\",\n \"hexbytes>=0.1.0,<1.0.0\",\n \"ipfshttpclient==0.8.0a2\",\n \"jsonschema>=3.2.0,<4.0.0\",\n \"lru-dict>=1.1.6,<2.0.0\",\n \"protobuf>=3.10.0,<4\",\n \"pywin32>=223;platform_system=='Windows'\",\n \"requests>=2.16.0,<3.0.0\",\n # remove typing_extensions after python_requires>=3.8, see web3._utils.compat\n \"typing-extensions>=3.7.4.1,<5;python_version<'3.8'\",\n \"websockets>=9.1,<10\",\n ],\n python_requires='>=3.7,<3.10',\n extras_require=extras_require,\n py_modules=['web3', 'ens', 'ethpm'],\n entry_points={\"pytest11\": [\"pytest_ethereum = web3.tools.pytest_ethereum.plugins\"]},\n license=\"MIT\",\n zip_safe=False,\n keywords='ethereum',\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n package_data={\"web3\": [\"py.typed\"]},\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n ],\n)\n", "path": "setup.py"}, {"content": "import asyncio\nimport json\nimport logging\nimport os\nfrom threading import (\n Thread,\n)\nfrom types import (\n TracebackType,\n)\nfrom typing import (\n Any,\n Optional,\n Type,\n Union,\n)\n\nfrom eth_typing import (\n URI,\n)\nfrom websockets.client import (\n connect,\n)\nfrom websockets.legacy.client import (\n WebSocketClientProtocol,\n)\n\nfrom web3.exceptions import (\n ValidationError,\n)\nfrom web3.providers.base import (\n JSONBaseProvider,\n)\nfrom web3.types import (\n RPCEndpoint,\n RPCResponse,\n)\n\nRESTRICTED_WEBSOCKET_KWARGS = {'uri', 'loop'}\nDEFAULT_WEBSOCKET_TIMEOUT = 10\n\n\ndef _start_event_loop(loop: asyncio.AbstractEventLoop) -> None:\n asyncio.set_event_loop(loop)\n loop.run_forever()\n loop.close()\n\n\ndef _get_threaded_loop() -> asyncio.AbstractEventLoop:\n new_loop = asyncio.new_event_loop()\n thread_loop = Thread(target=_start_event_loop, args=(new_loop,), daemon=True)\n thread_loop.start()\n return new_loop\n\n\ndef get_default_endpoint() -> URI:\n return URI(os.environ.get('WEB3_WS_PROVIDER_URI', 'ws://127.0.0.1:8546'))\n\n\nclass PersistentWebSocket:\n\n def __init__(\n self, endpoint_uri: URI, loop: asyncio.AbstractEventLoop, websocket_kwargs: Any\n ) -> None:\n self.ws: WebSocketClientProtocol = None\n self.endpoint_uri = endpoint_uri\n self.loop = loop\n self.websocket_kwargs = websocket_kwargs\n\n async def __aenter__(self) -> WebSocketClientProtocol:\n if self.ws is None:\n self.ws = await connect(\n uri=self.endpoint_uri, loop=self.loop, **self.websocket_kwargs\n )\n return self.ws\n\n async def __aexit__(\n self, exc_type: Type[BaseException], exc_val: BaseException, exc_tb: TracebackType\n ) -> None:\n if exc_val is not None:\n try:\n await self.ws.close()\n except Exception:\n pass\n self.ws = None\n\n\nclass WebsocketProvider(JSONBaseProvider):\n logger = logging.getLogger(\"web3.providers.WebsocketProvider\")\n _loop = None\n\n def __init__(\n self,\n endpoint_uri: Optional[Union[URI, str]] = None,\n websocket_kwargs: Optional[Any] = None,\n websocket_timeout: int = DEFAULT_WEBSOCKET_TIMEOUT,\n ) -> None:\n self.endpoint_uri = URI(endpoint_uri)\n self.websocket_timeout = websocket_timeout\n if self.endpoint_uri is None:\n self.endpoint_uri = get_default_endpoint()\n if WebsocketProvider._loop is None:\n WebsocketProvider._loop = _get_threaded_loop()\n if websocket_kwargs is None:\n websocket_kwargs = {}\n else:\n found_restricted_keys = set(websocket_kwargs.keys()).intersection(\n RESTRICTED_WEBSOCKET_KWARGS\n )\n if found_restricted_keys:\n raise ValidationError(\n '{0} are not allowed in websocket_kwargs, '\n 'found: {1}'.format(RESTRICTED_WEBSOCKET_KWARGS, found_restricted_keys)\n )\n self.conn = PersistentWebSocket(\n self.endpoint_uri, WebsocketProvider._loop, websocket_kwargs\n )\n super().__init__()\n\n def __str__(self) -> str:\n return \"WS connection {0}\".format(self.endpoint_uri)\n\n async def coro_make_request(self, request_data: bytes) -> RPCResponse:\n async with self.conn as conn:\n await asyncio.wait_for(\n conn.send(request_data),\n timeout=self.websocket_timeout\n )\n return json.loads(\n await asyncio.wait_for(\n conn.recv(),\n timeout=self.websocket_timeout\n )\n )\n\n def make_request(self, method: RPCEndpoint, params: Any) -> RPCResponse:\n self.logger.debug(\"Making request WebSocket. URI: %s, \"\n \"Method: %s\", self.endpoint_uri, method)\n request_data = self.encode_rpc_request(method, params)\n future = asyncio.run_coroutine_threadsafe(\n self.coro_make_request(request_data),\n WebsocketProvider._loop\n )\n return future.result()\n", "path": "web3/providers/websocket.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom setuptools import (\n find_packages,\n setup,\n)\n\nextras_require = {\n 'tester': [\n \"eth-tester[py-evm]==v0.6.0-beta.6\",\n \"py-geth>=3.7.0,<4\",\n ],\n 'linter': [\n \"flake8==3.8.3\",\n \"isort>=4.2.15,<4.3.5\",\n \"mypy==0.910\",\n \"types-setuptools>=57.4.4,<58\",\n \"types-requests>=2.26.1,<3\",\n \"types-protobuf>=3.18.2,<4\",\n ],\n 'docs': [\n \"mock\",\n \"sphinx-better-theme>=0.1.4\",\n \"click>=5.1\",\n \"configparser==3.5.0\",\n \"contextlib2>=0.5.4\",\n \"py-geth>=3.6.0,<4\",\n \"py-solc>=0.4.0\",\n \"pytest>=4.4.0,<5.0.0\",\n \"sphinx>=3.0,<4\",\n \"sphinx_rtd_theme>=0.1.9\",\n \"toposort>=1.4\",\n \"towncrier==18.5.0\",\n \"urllib3\",\n \"wheel\"\n ],\n 'dev': [\n \"bumpversion\",\n \"flaky>=3.7.0,<4\",\n \"hypothesis>=3.31.2,<6\",\n \"pytest>=4.4.0,<5.0.0\",\n \"pytest-asyncio>=0.10.0,<0.11\",\n \"pytest-mock>=1.10,<2\",\n \"pytest-pythonpath>=0.3\",\n \"pytest-watch>=4.2,<5\",\n \"pytest-xdist>=1.29,<2\",\n \"setuptools>=38.6.0\",\n \"tox>=1.8.0\",\n \"tqdm>4.32,<5\",\n \"twine>=1.13,<2\",\n \"pluggy==0.13.1\",\n \"when-changed>=0.3.0,<0.4\"\n ]\n}\n\nextras_require['dev'] = (\n extras_require['tester']\n + extras_require['linter']\n + extras_require['docs']\n + extras_require['dev']\n)\n\nwith open('./README.md') as readme:\n long_description = readme.read()\n\nsetup(\n name='web3',\n # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.\n version='5.28.0',\n description=\"\"\"Web3.py\"\"\",\n long_description_content_type='text/markdown',\n long_description=long_description,\n author='Piper Merriam',\n author_email='pipermerriam@gmail.com',\n url='https://github.com/ethereum/web3.py',\n include_package_data=True,\n install_requires=[\n \"aiohttp>=3.7.4.post0,<4\",\n \"eth-abi>=2.0.0b6,<3.0.0\",\n \"eth-account>=0.5.7,<0.6.0\",\n \"eth-hash[pycryptodome]>=0.2.0,<1.0.0\",\n \"eth-typing>=2.0.0,<3.0.0\",\n \"eth-utils>=1.9.5,<2.0.0\",\n \"hexbytes>=0.1.0,<1.0.0\",\n \"ipfshttpclient==0.8.0a2\",\n \"jsonschema>=3.2.0,<4.0.0\",\n \"lru-dict>=1.1.6,<2.0.0\",\n \"protobuf>=3.10.0,<4\",\n \"pywin32>=223;platform_system=='Windows'\",\n \"requests>=2.16.0,<3.0.0\",\n # remove typing_extensions after python_requires>=3.8, see web3._utils.compat\n \"typing-extensions>=3.7.4.1,<5;python_version<'3.8'\",\n \"websockets>=10.0.0,<11\",\n ],\n python_requires='>=3.7,<3.10',\n extras_require=extras_require,\n py_modules=['web3', 'ens', 'ethpm'],\n entry_points={\"pytest11\": [\"pytest_ethereum = web3.tools.pytest_ethereum.plugins\"]},\n license=\"MIT\",\n zip_safe=False,\n keywords='ethereum',\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n package_data={\"web3\": [\"py.typed\"]},\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n ],\n)\n", "path": "setup.py"}, {"content": "import asyncio\nimport json\nimport logging\nimport os\nfrom threading import (\n Thread,\n)\nfrom types import (\n TracebackType,\n)\nfrom typing import (\n Any,\n Optional,\n Type,\n Union,\n)\n\nfrom eth_typing import (\n URI,\n)\nfrom websockets.client import (\n connect,\n)\nfrom websockets.legacy.client import (\n WebSocketClientProtocol,\n)\n\nfrom web3.exceptions import (\n ValidationError,\n)\nfrom web3.providers.base import (\n JSONBaseProvider,\n)\nfrom web3.types import (\n RPCEndpoint,\n RPCResponse,\n)\n\nRESTRICTED_WEBSOCKET_KWARGS = {'uri', 'loop'}\nDEFAULT_WEBSOCKET_TIMEOUT = 10\n\n\ndef _start_event_loop(loop: asyncio.AbstractEventLoop) -> None:\n asyncio.set_event_loop(loop)\n loop.run_forever()\n loop.close()\n\n\ndef _get_threaded_loop() -> asyncio.AbstractEventLoop:\n new_loop = asyncio.new_event_loop()\n thread_loop = Thread(target=_start_event_loop, args=(new_loop,), daemon=True)\n thread_loop.start()\n return new_loop\n\n\ndef get_default_endpoint() -> URI:\n return URI(os.environ.get('WEB3_WS_PROVIDER_URI', 'ws://127.0.0.1:8546'))\n\n\nclass PersistentWebSocket:\n\n def __init__(\n self, endpoint_uri: URI, websocket_kwargs: Any\n ) -> None:\n self.ws: WebSocketClientProtocol = None\n self.endpoint_uri = endpoint_uri\n self.websocket_kwargs = websocket_kwargs\n\n async def __aenter__(self) -> WebSocketClientProtocol:\n if self.ws is None:\n self.ws = await connect(\n uri=self.endpoint_uri, **self.websocket_kwargs\n )\n return self.ws\n\n async def __aexit__(\n self, exc_type: Type[BaseException], exc_val: BaseException, exc_tb: TracebackType\n ) -> None:\n if exc_val is not None:\n try:\n await self.ws.close()\n except Exception:\n pass\n self.ws = None\n\n\nclass WebsocketProvider(JSONBaseProvider):\n logger = logging.getLogger(\"web3.providers.WebsocketProvider\")\n _loop = None\n\n def __init__(\n self,\n endpoint_uri: Optional[Union[URI, str]] = None,\n websocket_kwargs: Optional[Any] = None,\n websocket_timeout: int = DEFAULT_WEBSOCKET_TIMEOUT,\n ) -> None:\n self.endpoint_uri = URI(endpoint_uri)\n self.websocket_timeout = websocket_timeout\n if self.endpoint_uri is None:\n self.endpoint_uri = get_default_endpoint()\n if WebsocketProvider._loop is None:\n WebsocketProvider._loop = _get_threaded_loop()\n if websocket_kwargs is None:\n websocket_kwargs = {}\n else:\n found_restricted_keys = set(websocket_kwargs.keys()).intersection(\n RESTRICTED_WEBSOCKET_KWARGS\n )\n if found_restricted_keys:\n raise ValidationError(\n '{0} are not allowed in websocket_kwargs, '\n 'found: {1}'.format(RESTRICTED_WEBSOCKET_KWARGS, found_restricted_keys)\n )\n self.conn = PersistentWebSocket(\n self.endpoint_uri, websocket_kwargs\n )\n super().__init__()\n\n def __str__(self) -> str:\n return \"WS connection {0}\".format(self.endpoint_uri)\n\n async def coro_make_request(self, request_data: bytes) -> RPCResponse:\n async with self.conn as conn:\n await asyncio.wait_for(\n conn.send(request_data),\n timeout=self.websocket_timeout\n )\n return json.loads(\n await asyncio.wait_for(\n conn.recv(),\n timeout=self.websocket_timeout\n )\n )\n\n def make_request(self, method: RPCEndpoint, params: Any) -> RPCResponse:\n self.logger.debug(\"Making request WebSocket. URI: %s, \"\n \"Method: %s\", self.endpoint_uri, method)\n request_data = self.encode_rpc_request(method, params)\n future = asyncio.run_coroutine_threadsafe(\n self.coro_make_request(request_data),\n WebsocketProvider._loop\n )\n return future.result()\n", "path": "web3/providers/websocket.py"}]}
| 3,288 | 418 |
gh_patches_debug_22585
|
rasdani/github-patches
|
git_diff
|
rasterio__rasterio-2656
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ENH: Add support for RFC 87: Signed int8 data type for raster
Cf https://github.com/OSGeo/gdal/pull/6634 "RFC 87: Signed int8 data type for raster" that will likely be implemented in GDAL 3.7
_Originally posted by @rouault in https://github.com/rasterio/rasterio/issues/1595#issuecomment-1307086052_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `rasterio/dtypes.py`
Content:
```
1 """Mapping of GDAL to Numpy data types.
2
3 Since 0.13 we are not importing numpy here and data types are strings.
4 Happily strings can be used throughout Numpy and so existing code will
5 not break.
6
7 """
8 import numpy
9
10 from rasterio.env import GDALVersion
11
12 _GDAL_AT_LEAST_35 = GDALVersion.runtime().at_least("3.5")
13
14 bool_ = 'bool'
15 ubyte = uint8 = 'uint8'
16 sbyte = int8 = 'int8'
17 uint16 = 'uint16'
18 int16 = 'int16'
19 uint32 = 'uint32'
20 int32 = 'int32'
21 uint64 = 'uint64'
22 int64 = 'int64'
23 float32 = 'float32'
24 float64 = 'float64'
25 complex_ = 'complex'
26 complex64 = 'complex64'
27 complex128 = 'complex128'
28
29 complex_int16 = "complex_int16"
30
31 dtype_fwd = {
32 0: None, # GDT_Unknown
33 1: ubyte, # GDT_Byte
34 2: uint16, # GDT_UInt16
35 3: int16, # GDT_Int16
36 4: uint32, # GDT_UInt32
37 5: int32, # GDT_Int32
38 6: float32, # GDT_Float32
39 7: float64, # GDT_Float64
40 8: complex_int16, # GDT_CInt16
41 9: complex64, # GDT_CInt32
42 10: complex64, # GDT_CFloat32
43 11: complex128, # GDT_CFloat64
44 }
45
46 if _GDAL_AT_LEAST_35:
47 dtype_fwd[12] = int64 # GDT_Int64
48 dtype_fwd[13] = uint64 # GDT_UInt64
49
50 dtype_rev = dict((v, k) for k, v in dtype_fwd.items())
51
52 dtype_rev["uint8"] = 1
53 dtype_rev["int8"] = 1
54 dtype_rev["complex"] = 11
55 dtype_rev["complex_int16"] = 8
56
57
58 def _get_gdal_dtype(type_name):
59 try:
60 return dtype_rev[type_name]
61 except KeyError:
62 raise TypeError(
63 f"Unsupported data type {type_name}. "
64 f"Allowed data types: {list(dtype_rev)}."
65 )
66
67 typename_fwd = {
68 0: 'Unknown',
69 1: 'Byte',
70 2: 'UInt16',
71 3: 'Int16',
72 4: 'UInt32',
73 5: 'Int32',
74 6: 'Float32',
75 7: 'Float64',
76 8: 'CInt16',
77 9: 'CInt32',
78 10: 'CFloat32',
79 11: 'CFloat64'}
80
81 if _GDAL_AT_LEAST_35:
82 typename_fwd[12] = 'Int64'
83 typename_fwd[13] = 'UInt64'
84
85 typename_rev = dict((v, k) for k, v in typename_fwd.items())
86
87 dtype_ranges = {
88 'int8': (-128, 127),
89 'uint8': (0, 255),
90 'uint16': (0, 65535),
91 'int16': (-32768, 32767),
92 'uint32': (0, 4294967295),
93 'int32': (-2147483648, 2147483647),
94 'float32': (-3.4028235e+38, 3.4028235e+38),
95 'float64': (-1.7976931348623157e+308, 1.7976931348623157e+308)}
96
97 if _GDAL_AT_LEAST_35:
98 dtype_ranges['int64'] = (-9223372036854775808, 9223372036854775807)
99 dtype_ranges['uint64'] = (0, 18446744073709551615)
100
101
102 def in_dtype_range(value, dtype):
103 """
104 Check if the value is within the dtype range
105 """
106 if numpy.dtype(dtype).kind == "f" and (numpy.isinf(value) or numpy.isnan(value)):
107 return True
108 range_min, range_max = dtype_ranges[dtype]
109 return range_min <= value <= range_max
110
111
112 def _gdal_typename(dt):
113 try:
114 return typename_fwd[dtype_rev[dt]]
115 except KeyError:
116 return typename_fwd[dtype_rev[dt().dtype.name]]
117
118
119 def check_dtype(dt):
120 """Check if dtype is a known dtype."""
121 if str(dt) in dtype_rev:
122 return True
123 elif callable(dt) and str(dt().dtype) in dtype_rev:
124 return True
125 return False
126
127
128 def get_minimum_dtype(values):
129 """Determine minimum type to represent values.
130
131 Uses range checking to determine the minimum integer or floating point
132 data type required to represent values.
133
134 Parameters
135 ----------
136 values: list-like
137
138
139 Returns
140 -------
141 rasterio dtype string
142 """
143 import numpy as np
144
145 if not is_ndarray(values):
146 values = np.array(values)
147
148 min_value = values.min()
149 max_value = values.max()
150
151 if values.dtype.kind in ('i', 'u'):
152 if min_value >= 0:
153 if max_value <= 255:
154 return uint8
155 elif max_value <= 65535:
156 return uint16
157 elif max_value <= 4294967295:
158 return uint32
159 if not _GDAL_AT_LEAST_35:
160 raise ValueError("Values out of range for supported dtypes")
161 return uint64
162 elif min_value >= -32768 and max_value <= 32767:
163 return int16
164 elif min_value >= -2147483648 and max_value <= 2147483647:
165 return int32
166 if not _GDAL_AT_LEAST_35:
167 raise ValueError("Values out of range for supported dtypes")
168 return int64
169
170 else:
171 if min_value >= -3.4028235e+38 and max_value <= 3.4028235e+38:
172 return float32
173 return float64
174
175
176 def is_ndarray(array):
177 """Check if array is a ndarray."""
178 import numpy as np
179
180 return isinstance(array, np.ndarray) or hasattr(array, '__array__')
181
182
183 def can_cast_dtype(values, dtype):
184 """Test if values can be cast to dtype without loss of information.
185
186 Parameters
187 ----------
188 values: list-like
189 dtype: numpy.dtype or string
190
191 Returns
192 -------
193 boolean
194 True if values can be cast to data type.
195 """
196 import numpy as np
197
198 if not is_ndarray(values):
199 values = np.array(values)
200
201 if values.dtype.name == _getnpdtype(dtype).name:
202 return True
203
204 elif values.dtype.kind == 'f':
205 return np.allclose(values, values.astype(dtype), equal_nan=True)
206
207 else:
208 return np.array_equal(values, values.astype(dtype))
209
210
211 def validate_dtype(values, valid_dtypes):
212 """Test if dtype of values is one of valid_dtypes.
213
214 Parameters
215 ----------
216 values: list-like
217 valid_dtypes: list-like
218 list of valid dtype strings, e.g., ('int16', 'int32')
219
220 Returns
221 -------
222 boolean:
223 True if dtype of values is one of valid_dtypes
224 """
225 import numpy as np
226
227 if not is_ndarray(values):
228 values = np.array(values)
229
230 return (values.dtype.name in valid_dtypes or
231 get_minimum_dtype(values) in valid_dtypes)
232
233
234 def _is_complex_int(dtype):
235 return isinstance(dtype, str) and dtype.startswith("complex_int")
236
237
238 def _getnpdtype(dtype):
239 import numpy as np
240 if _is_complex_int(dtype):
241 return np.dtype("complex64")
242 else:
243 return np.dtype(dtype)
244
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/rasterio/dtypes.py b/rasterio/dtypes.py
--- a/rasterio/dtypes.py
+++ b/rasterio/dtypes.py
@@ -10,6 +10,7 @@
from rasterio.env import GDALVersion
_GDAL_AT_LEAST_35 = GDALVersion.runtime().at_least("3.5")
+_GDAL_AT_LEAST_37 = GDALVersion.runtime().at_least("3.7")
bool_ = 'bool'
ubyte = uint8 = 'uint8'
@@ -47,10 +48,15 @@
dtype_fwd[12] = int64 # GDT_Int64
dtype_fwd[13] = uint64 # GDT_UInt64
+if _GDAL_AT_LEAST_37:
+ dtype_fwd[14] = sbyte # GDT_Int8
+
dtype_rev = dict((v, k) for k, v in dtype_fwd.items())
dtype_rev["uint8"] = 1
-dtype_rev["int8"] = 1
+if not _GDAL_AT_LEAST_37:
+ dtype_rev["int8"] = 1
+
dtype_rev["complex"] = 11
dtype_rev["complex_int16"] = 8
@@ -82,6 +88,9 @@
typename_fwd[12] = 'Int64'
typename_fwd[13] = 'UInt64'
+if _GDAL_AT_LEAST_37:
+ typename_fwd[14] = 'Int8'
+
typename_rev = dict((v, k) for k, v in typename_fwd.items())
dtype_ranges = {
|
{"golden_diff": "diff --git a/rasterio/dtypes.py b/rasterio/dtypes.py\n--- a/rasterio/dtypes.py\n+++ b/rasterio/dtypes.py\n@@ -10,6 +10,7 @@\n from rasterio.env import GDALVersion\n \n _GDAL_AT_LEAST_35 = GDALVersion.runtime().at_least(\"3.5\")\n+_GDAL_AT_LEAST_37 = GDALVersion.runtime().at_least(\"3.7\")\n \n bool_ = 'bool'\n ubyte = uint8 = 'uint8'\n@@ -47,10 +48,15 @@\n dtype_fwd[12] = int64 # GDT_Int64\n dtype_fwd[13] = uint64 # GDT_UInt64\n \n+if _GDAL_AT_LEAST_37:\n+ dtype_fwd[14] = sbyte # GDT_Int8\n+\n dtype_rev = dict((v, k) for k, v in dtype_fwd.items())\n \n dtype_rev[\"uint8\"] = 1\n-dtype_rev[\"int8\"] = 1\n+if not _GDAL_AT_LEAST_37:\n+ dtype_rev[\"int8\"] = 1\n+\n dtype_rev[\"complex\"] = 11\n dtype_rev[\"complex_int16\"] = 8\n \n@@ -82,6 +88,9 @@\n typename_fwd[12] = 'Int64'\n typename_fwd[13] = 'UInt64'\n \n+if _GDAL_AT_LEAST_37:\n+ typename_fwd[14] = 'Int8'\n+\n typename_rev = dict((v, k) for k, v in typename_fwd.items())\n \n dtype_ranges = {\n", "issue": "ENH: Add support for RFC 87: Signed int8 data type for raster\n Cf https://github.com/OSGeo/gdal/pull/6634 \"RFC 87: Signed int8 data type for raster\" that will likely be implemented in GDAL 3.7\r\n\r\n_Originally posted by @rouault in https://github.com/rasterio/rasterio/issues/1595#issuecomment-1307086052_\r\n \n", "before_files": [{"content": "\"\"\"Mapping of GDAL to Numpy data types.\n\nSince 0.13 we are not importing numpy here and data types are strings.\nHappily strings can be used throughout Numpy and so existing code will\nnot break.\n\n\"\"\"\nimport numpy\n\nfrom rasterio.env import GDALVersion\n\n_GDAL_AT_LEAST_35 = GDALVersion.runtime().at_least(\"3.5\")\n\nbool_ = 'bool'\nubyte = uint8 = 'uint8'\nsbyte = int8 = 'int8'\nuint16 = 'uint16'\nint16 = 'int16'\nuint32 = 'uint32'\nint32 = 'int32'\nuint64 = 'uint64'\nint64 = 'int64'\nfloat32 = 'float32'\nfloat64 = 'float64'\ncomplex_ = 'complex'\ncomplex64 = 'complex64'\ncomplex128 = 'complex128'\n\ncomplex_int16 = \"complex_int16\"\n\ndtype_fwd = {\n 0: None, # GDT_Unknown\n 1: ubyte, # GDT_Byte\n 2: uint16, # GDT_UInt16\n 3: int16, # GDT_Int16\n 4: uint32, # GDT_UInt32\n 5: int32, # GDT_Int32\n 6: float32, # GDT_Float32\n 7: float64, # GDT_Float64\n 8: complex_int16, # GDT_CInt16\n 9: complex64, # GDT_CInt32\n 10: complex64, # GDT_CFloat32\n 11: complex128, # GDT_CFloat64\n}\n\nif _GDAL_AT_LEAST_35:\n dtype_fwd[12] = int64 # GDT_Int64\n dtype_fwd[13] = uint64 # GDT_UInt64\n\ndtype_rev = dict((v, k) for k, v in dtype_fwd.items())\n\ndtype_rev[\"uint8\"] = 1\ndtype_rev[\"int8\"] = 1\ndtype_rev[\"complex\"] = 11\ndtype_rev[\"complex_int16\"] = 8\n\n\ndef _get_gdal_dtype(type_name):\n try:\n return dtype_rev[type_name]\n except KeyError:\n raise TypeError(\n f\"Unsupported data type {type_name}. \"\n f\"Allowed data types: {list(dtype_rev)}.\"\n )\n\ntypename_fwd = {\n 0: 'Unknown',\n 1: 'Byte',\n 2: 'UInt16',\n 3: 'Int16',\n 4: 'UInt32',\n 5: 'Int32',\n 6: 'Float32',\n 7: 'Float64',\n 8: 'CInt16',\n 9: 'CInt32',\n 10: 'CFloat32',\n 11: 'CFloat64'}\n\nif _GDAL_AT_LEAST_35:\n typename_fwd[12] = 'Int64'\n typename_fwd[13] = 'UInt64'\n\ntypename_rev = dict((v, k) for k, v in typename_fwd.items())\n\ndtype_ranges = {\n 'int8': (-128, 127),\n 'uint8': (0, 255),\n 'uint16': (0, 65535),\n 'int16': (-32768, 32767),\n 'uint32': (0, 4294967295),\n 'int32': (-2147483648, 2147483647),\n 'float32': (-3.4028235e+38, 3.4028235e+38),\n 'float64': (-1.7976931348623157e+308, 1.7976931348623157e+308)}\n\nif _GDAL_AT_LEAST_35:\n dtype_ranges['int64'] = (-9223372036854775808, 9223372036854775807)\n dtype_ranges['uint64'] = (0, 18446744073709551615)\n\n\ndef in_dtype_range(value, dtype):\n \"\"\"\n Check if the value is within the dtype range\n \"\"\"\n if numpy.dtype(dtype).kind == \"f\" and (numpy.isinf(value) or numpy.isnan(value)):\n return True\n range_min, range_max = dtype_ranges[dtype]\n return range_min <= value <= range_max\n\n\ndef _gdal_typename(dt):\n try:\n return typename_fwd[dtype_rev[dt]]\n except KeyError:\n return typename_fwd[dtype_rev[dt().dtype.name]]\n\n\ndef check_dtype(dt):\n \"\"\"Check if dtype is a known dtype.\"\"\"\n if str(dt) in dtype_rev:\n return True\n elif callable(dt) and str(dt().dtype) in dtype_rev:\n return True\n return False\n\n\ndef get_minimum_dtype(values):\n \"\"\"Determine minimum type to represent values.\n\n Uses range checking to determine the minimum integer or floating point\n data type required to represent values.\n\n Parameters\n ----------\n values: list-like\n\n\n Returns\n -------\n rasterio dtype string\n \"\"\"\n import numpy as np\n\n if not is_ndarray(values):\n values = np.array(values)\n\n min_value = values.min()\n max_value = values.max()\n\n if values.dtype.kind in ('i', 'u'):\n if min_value >= 0:\n if max_value <= 255:\n return uint8\n elif max_value <= 65535:\n return uint16\n elif max_value <= 4294967295:\n return uint32\n if not _GDAL_AT_LEAST_35:\n raise ValueError(\"Values out of range for supported dtypes\")\n return uint64\n elif min_value >= -32768 and max_value <= 32767:\n return int16\n elif min_value >= -2147483648 and max_value <= 2147483647:\n return int32\n if not _GDAL_AT_LEAST_35:\n raise ValueError(\"Values out of range for supported dtypes\")\n return int64\n\n else:\n if min_value >= -3.4028235e+38 and max_value <= 3.4028235e+38:\n return float32\n return float64\n\n\ndef is_ndarray(array):\n \"\"\"Check if array is a ndarray.\"\"\"\n import numpy as np\n\n return isinstance(array, np.ndarray) or hasattr(array, '__array__')\n\n\ndef can_cast_dtype(values, dtype):\n \"\"\"Test if values can be cast to dtype without loss of information.\n\n Parameters\n ----------\n values: list-like\n dtype: numpy.dtype or string\n\n Returns\n -------\n boolean\n True if values can be cast to data type.\n \"\"\"\n import numpy as np\n\n if not is_ndarray(values):\n values = np.array(values)\n\n if values.dtype.name == _getnpdtype(dtype).name:\n return True\n\n elif values.dtype.kind == 'f':\n return np.allclose(values, values.astype(dtype), equal_nan=True)\n\n else:\n return np.array_equal(values, values.astype(dtype))\n\n\ndef validate_dtype(values, valid_dtypes):\n \"\"\"Test if dtype of values is one of valid_dtypes.\n\n Parameters\n ----------\n values: list-like\n valid_dtypes: list-like\n list of valid dtype strings, e.g., ('int16', 'int32')\n\n Returns\n -------\n boolean:\n True if dtype of values is one of valid_dtypes\n \"\"\"\n import numpy as np\n\n if not is_ndarray(values):\n values = np.array(values)\n\n return (values.dtype.name in valid_dtypes or\n get_minimum_dtype(values) in valid_dtypes)\n\n\ndef _is_complex_int(dtype):\n return isinstance(dtype, str) and dtype.startswith(\"complex_int\")\n\n\ndef _getnpdtype(dtype):\n import numpy as np\n if _is_complex_int(dtype):\n return np.dtype(\"complex64\")\n else:\n return np.dtype(dtype)\n", "path": "rasterio/dtypes.py"}], "after_files": [{"content": "\"\"\"Mapping of GDAL to Numpy data types.\n\nSince 0.13 we are not importing numpy here and data types are strings.\nHappily strings can be used throughout Numpy and so existing code will\nnot break.\n\n\"\"\"\nimport numpy\n\nfrom rasterio.env import GDALVersion\n\n_GDAL_AT_LEAST_35 = GDALVersion.runtime().at_least(\"3.5\")\n_GDAL_AT_LEAST_37 = GDALVersion.runtime().at_least(\"3.7\")\n\nbool_ = 'bool'\nubyte = uint8 = 'uint8'\nsbyte = int8 = 'int8'\nuint16 = 'uint16'\nint16 = 'int16'\nuint32 = 'uint32'\nint32 = 'int32'\nuint64 = 'uint64'\nint64 = 'int64'\nfloat32 = 'float32'\nfloat64 = 'float64'\ncomplex_ = 'complex'\ncomplex64 = 'complex64'\ncomplex128 = 'complex128'\n\ncomplex_int16 = \"complex_int16\"\n\ndtype_fwd = {\n 0: None, # GDT_Unknown\n 1: ubyte, # GDT_Byte\n 2: uint16, # GDT_UInt16\n 3: int16, # GDT_Int16\n 4: uint32, # GDT_UInt32\n 5: int32, # GDT_Int32\n 6: float32, # GDT_Float32\n 7: float64, # GDT_Float64\n 8: complex_int16, # GDT_CInt16\n 9: complex64, # GDT_CInt32\n 10: complex64, # GDT_CFloat32\n 11: complex128, # GDT_CFloat64\n}\n\nif _GDAL_AT_LEAST_35:\n dtype_fwd[12] = int64 # GDT_Int64\n dtype_fwd[13] = uint64 # GDT_UInt64\n\nif _GDAL_AT_LEAST_37:\n dtype_fwd[14] = sbyte # GDT_Int8\n\ndtype_rev = dict((v, k) for k, v in dtype_fwd.items())\n\ndtype_rev[\"uint8\"] = 1\nif not _GDAL_AT_LEAST_37:\n dtype_rev[\"int8\"] = 1\n\ndtype_rev[\"complex\"] = 11\ndtype_rev[\"complex_int16\"] = 8\n\n\ndef _get_gdal_dtype(type_name):\n try:\n return dtype_rev[type_name]\n except KeyError:\n raise TypeError(\n f\"Unsupported data type {type_name}. \"\n f\"Allowed data types: {list(dtype_rev)}.\"\n )\n\ntypename_fwd = {\n 0: 'Unknown',\n 1: 'Byte',\n 2: 'UInt16',\n 3: 'Int16',\n 4: 'UInt32',\n 5: 'Int32',\n 6: 'Float32',\n 7: 'Float64',\n 8: 'CInt16',\n 9: 'CInt32',\n 10: 'CFloat32',\n 11: 'CFloat64'}\n\nif _GDAL_AT_LEAST_35:\n typename_fwd[12] = 'Int64'\n typename_fwd[13] = 'UInt64'\n\nif _GDAL_AT_LEAST_37:\n typename_fwd[14] = 'Int8'\n\ntypename_rev = dict((v, k) for k, v in typename_fwd.items())\n\ndtype_ranges = {\n 'int8': (-128, 127),\n 'uint8': (0, 255),\n 'uint16': (0, 65535),\n 'int16': (-32768, 32767),\n 'uint32': (0, 4294967295),\n 'int32': (-2147483648, 2147483647),\n 'float32': (-3.4028235e+38, 3.4028235e+38),\n 'float64': (-1.7976931348623157e+308, 1.7976931348623157e+308)}\n\nif _GDAL_AT_LEAST_35:\n dtype_ranges['int64'] = (-9223372036854775808, 9223372036854775807)\n dtype_ranges['uint64'] = (0, 18446744073709551615)\n\n\ndef in_dtype_range(value, dtype):\n \"\"\"\n Check if the value is within the dtype range\n \"\"\"\n if numpy.dtype(dtype).kind == \"f\" and (numpy.isinf(value) or numpy.isnan(value)):\n return True\n range_min, range_max = dtype_ranges[dtype]\n return range_min <= value <= range_max\n\n\ndef _gdal_typename(dt):\n try:\n return typename_fwd[dtype_rev[dt]]\n except KeyError:\n return typename_fwd[dtype_rev[dt().dtype.name]]\n\n\ndef check_dtype(dt):\n \"\"\"Check if dtype is a known dtype.\"\"\"\n if str(dt) in dtype_rev:\n return True\n elif callable(dt) and str(dt().dtype) in dtype_rev:\n return True\n return False\n\n\ndef get_minimum_dtype(values):\n \"\"\"Determine minimum type to represent values.\n\n Uses range checking to determine the minimum integer or floating point\n data type required to represent values.\n\n Parameters\n ----------\n values: list-like\n\n\n Returns\n -------\n rasterio dtype string\n \"\"\"\n import numpy as np\n\n if not is_ndarray(values):\n values = np.array(values)\n\n min_value = values.min()\n max_value = values.max()\n\n if values.dtype.kind in ('i', 'u'):\n if min_value >= 0:\n if max_value <= 255:\n return uint8\n elif max_value <= 65535:\n return uint16\n elif max_value <= 4294967295:\n return uint32\n if not _GDAL_AT_LEAST_35:\n raise ValueError(\"Values out of range for supported dtypes\")\n return uint64\n elif min_value >= -32768 and max_value <= 32767:\n return int16\n elif min_value >= -2147483648 and max_value <= 2147483647:\n return int32\n if not _GDAL_AT_LEAST_35:\n raise ValueError(\"Values out of range for supported dtypes\")\n return int64\n\n else:\n if min_value >= -3.4028235e+38 and max_value <= 3.4028235e+38:\n return float32\n return float64\n\n\ndef is_ndarray(array):\n \"\"\"Check if array is a ndarray.\"\"\"\n import numpy as np\n\n return isinstance(array, np.ndarray) or hasattr(array, '__array__')\n\n\ndef can_cast_dtype(values, dtype):\n \"\"\"Test if values can be cast to dtype without loss of information.\n\n Parameters\n ----------\n values: list-like\n dtype: numpy.dtype or string\n\n Returns\n -------\n boolean\n True if values can be cast to data type.\n \"\"\"\n import numpy as np\n\n if not is_ndarray(values):\n values = np.array(values)\n\n if values.dtype.name == _getnpdtype(dtype).name:\n return True\n\n elif values.dtype.kind == 'f':\n return np.allclose(values, values.astype(dtype), equal_nan=True)\n\n else:\n return np.array_equal(values, values.astype(dtype))\n\n\ndef validate_dtype(values, valid_dtypes):\n \"\"\"Test if dtype of values is one of valid_dtypes.\n\n Parameters\n ----------\n values: list-like\n valid_dtypes: list-like\n list of valid dtype strings, e.g., ('int16', 'int32')\n\n Returns\n -------\n boolean:\n True if dtype of values is one of valid_dtypes\n \"\"\"\n import numpy as np\n\n if not is_ndarray(values):\n values = np.array(values)\n\n return (values.dtype.name in valid_dtypes or\n get_minimum_dtype(values) in valid_dtypes)\n\n\ndef _is_complex_int(dtype):\n return isinstance(dtype, str) and dtype.startswith(\"complex_int\")\n\n\ndef _getnpdtype(dtype):\n import numpy as np\n if _is_complex_int(dtype):\n return np.dtype(\"complex64\")\n else:\n return np.dtype(dtype)\n", "path": "rasterio/dtypes.py"}]}
| 2,980 | 375 |
gh_patches_debug_4104
|
rasdani/github-patches
|
git_diff
|
google__TensorNetwork-250
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Python version requirement
Our current setup file is still happy with python>=3.5, whereas we stopped testing for it and it seems that Jax also discontinued support. Should we not be stricter in the setup especially if we move to Jax as default?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # Copyright 2019 The TensorNetwork Developers
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # https://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15
16 from setuptools import find_packages, setup
17
18 # This reads the __version__ variable from tensornetwork/version.py
19 with open('tensornetwork/version.py') as f:
20 exec(f.read(), globals())
21
22 description = ('A high level tensor network API for tensorflow.')
23
24 # Reading long Description from README.md file.
25 with open("README.md", "r") as fh:
26 long_description = fh.read()
27
28 # Read in requirements
29 requirements = [
30 requirement.strip() for requirement in open('requirements.txt').readlines()
31 ]
32
33 setup(
34 name='tensornetwork',
35 version=__version__,
36 url='http://github.com/google/TensorNetwork',
37 author='The TensorNetwork Developers',
38 author_email='chaseriley@google.com',
39 python_requires=('>=3.5.0'),
40 install_requires=requirements,
41 license='Apache 2.0',
42 description=description,
43 long_description=long_description,
44 long_description_content_type="text/markdown",
45 packages=find_packages(),
46 )
47
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -36,7 +36,7 @@
url='http://github.com/google/TensorNetwork',
author='The TensorNetwork Developers',
author_email='chaseriley@google.com',
- python_requires=('>=3.5.0'),
+ python_requires=('>=3.6.0'),
install_requires=requirements,
license='Apache 2.0',
description=description,
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -36,7 +36,7 @@\n url='http://github.com/google/TensorNetwork',\n author='The TensorNetwork Developers',\n author_email='chaseriley@google.com',\n- python_requires=('>=3.5.0'),\n+ python_requires=('>=3.6.0'),\n install_requires=requirements,\n license='Apache 2.0',\n description=description,\n", "issue": "Python version requirement\nOur current setup file is still happy with python>=3.5, whereas we stopped testing for it and it seems that Jax also discontinued support. Should we not be stricter in the setup especially if we move to Jax as default?\n", "before_files": [{"content": "#!/usr/bin/env python\n# Copyright 2019 The TensorNetwork Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom setuptools import find_packages, setup\n\n# This reads the __version__ variable from tensornetwork/version.py\nwith open('tensornetwork/version.py') as f:\n exec(f.read(), globals())\n\ndescription = ('A high level tensor network API for tensorflow.')\n\n# Reading long Description from README.md file.\nwith open(\"README.md\", \"r\") as fh:\n long_description = fh.read()\n\n# Read in requirements\nrequirements = [\n requirement.strip() for requirement in open('requirements.txt').readlines()\n]\n\nsetup(\n name='tensornetwork',\n version=__version__,\n url='http://github.com/google/TensorNetwork',\n author='The TensorNetwork Developers',\n author_email='chaseriley@google.com',\n python_requires=('>=3.5.0'),\n install_requires=requirements,\n license='Apache 2.0',\n description=description,\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n packages=find_packages(),\n)\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# Copyright 2019 The TensorNetwork Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom setuptools import find_packages, setup\n\n# This reads the __version__ variable from tensornetwork/version.py\nwith open('tensornetwork/version.py') as f:\n exec(f.read(), globals())\n\ndescription = ('A high level tensor network API for tensorflow.')\n\n# Reading long Description from README.md file.\nwith open(\"README.md\", \"r\") as fh:\n long_description = fh.read()\n\n# Read in requirements\nrequirements = [\n requirement.strip() for requirement in open('requirements.txt').readlines()\n]\n\nsetup(\n name='tensornetwork',\n version=__version__,\n url='http://github.com/google/TensorNetwork',\n author='The TensorNetwork Developers',\n author_email='chaseriley@google.com',\n python_requires=('>=3.6.0'),\n install_requires=requirements,\n license='Apache 2.0',\n description=description,\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n packages=find_packages(),\n)\n", "path": "setup.py"}]}
| 745 | 107 |
gh_patches_debug_1639
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-318
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Access to the Generator.random
It would be nice if one could gain access to the Generator.random variable so that one could save/set the state. I realize I can pass in the seed, but one currently has no way of gathering what the seed/state is if using the automatically generated seed. I don't want to use a fixed seed, but I do want to log/print the seed used _if_ the tests fail.
That is, I'd like to be able to do something like: `faker.generator.getstate()` (which gets the random state w/o exposing random) or `faker.generator.random.getstate()` (which gives access to the random variable)
For now, the workaround appears to be to create a Faker object with your own Generator.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `faker/generator.py`
Content:
```
1 # coding=utf-8
2
3 from __future__ import unicode_literals
4
5 import re
6 import random
7
8
9 _re_token = re.compile(r'\{\{(\s?)(\w+)(\s?)\}\}')
10 random = random.Random()
11
12
13 class Generator(object):
14
15 __config = {}
16
17 def __init__(self, **config):
18 self.providers = []
19 self.__config = dict(
20 list(self.__config.items()) + list(config.items()))
21
22 def add_provider(self, provider):
23
24 if type(provider) is type:
25 provider = provider(self)
26
27 self.providers.insert(0, provider)
28
29 for method_name in dir(provider):
30 # skip 'private' method
31 if method_name.startswith('_'):
32 continue
33
34 faker_function = getattr(provider, method_name)
35
36 if hasattr(faker_function, '__call__') or \
37 isinstance(faker_function, (classmethod, staticmethod)):
38 # add all faker method to generator
39 self.set_formatter(method_name, faker_function)
40
41 def provider(self, name):
42 try:
43 lst = [p for p in self.get_providers()
44 if p.__provider__ == name.lower()]
45 return lst[0]
46 except IndexError:
47 return None
48
49 def get_providers(self):
50 """Returns added providers."""
51 return self.providers
52
53 def seed(self, seed=None):
54 """Calls random.seed"""
55 random.seed(seed)
56
57 def format(self, formatter, *args, **kwargs):
58 """
59 This is a secure way to make a fake from another Provider.
60 """
61 # TODO: data export?
62 return self.get_formatter(formatter)(*args, **kwargs)
63
64 def get_formatter(self, formatter):
65 try:
66 return getattr(self, formatter)
67 except AttributeError:
68 raise AttributeError('Unknown formatter "{0}"'.format(formatter))
69
70 def set_formatter(self, name, method):
71 """
72 This method adds a provider method to generator.
73 Override this method to add some decoration or logging stuff.
74 """
75 setattr(self, name, method)
76
77 def parse(self, text):
78 """
79 Replaces tokens (like '{{ tokenName }}' or '{{tokenName}}')
80 with the result from the token method call.
81 """
82 return _re_token.sub(self.__format_token, text)
83
84 def __format_token(self, matches):
85 formatter = list(matches.groups())
86 formatter[1] = self.format(formatter[1])
87 return ''.join(formatter)
88
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/faker/generator.py b/faker/generator.py
--- a/faker/generator.py
+++ b/faker/generator.py
@@ -50,6 +50,10 @@
"""Returns added providers."""
return self.providers
+ @property
+ def random(self):
+ return random
+
def seed(self, seed=None):
"""Calls random.seed"""
random.seed(seed)
|
{"golden_diff": "diff --git a/faker/generator.py b/faker/generator.py\n--- a/faker/generator.py\n+++ b/faker/generator.py\n@@ -50,6 +50,10 @@\n \"\"\"Returns added providers.\"\"\"\n return self.providers\n \n+ @property\n+ def random(self):\n+ return random\n+\n def seed(self, seed=None):\n \"\"\"Calls random.seed\"\"\"\n random.seed(seed)\n", "issue": "Access to the Generator.random\nIt would be nice if one could gain access to the Generator.random variable so that one could save/set the state. I realize I can pass in the seed, but one currently has no way of gathering what the seed/state is if using the automatically generated seed. I don't want to use a fixed seed, but I do want to log/print the seed used _if_ the tests fail.\n\nThat is, I'd like to be able to do something like: `faker.generator.getstate()` (which gets the random state w/o exposing random) or `faker.generator.random.getstate()` (which gives access to the random variable)\n\nFor now, the workaround appears to be to create a Faker object with your own Generator.\n\n", "before_files": [{"content": "# coding=utf-8\n\nfrom __future__ import unicode_literals\n\nimport re\nimport random\n\n\n_re_token = re.compile(r'\\{\\{(\\s?)(\\w+)(\\s?)\\}\\}')\nrandom = random.Random()\n\n\nclass Generator(object):\n\n __config = {}\n\n def __init__(self, **config):\n self.providers = []\n self.__config = dict(\n list(self.__config.items()) + list(config.items()))\n\n def add_provider(self, provider):\n\n if type(provider) is type:\n provider = provider(self)\n\n self.providers.insert(0, provider)\n\n for method_name in dir(provider):\n # skip 'private' method\n if method_name.startswith('_'):\n continue\n\n faker_function = getattr(provider, method_name)\n\n if hasattr(faker_function, '__call__') or \\\n isinstance(faker_function, (classmethod, staticmethod)):\n # add all faker method to generator\n self.set_formatter(method_name, faker_function)\n\n def provider(self, name):\n try:\n lst = [p for p in self.get_providers()\n if p.__provider__ == name.lower()]\n return lst[0]\n except IndexError:\n return None\n\n def get_providers(self):\n \"\"\"Returns added providers.\"\"\"\n return self.providers\n\n def seed(self, seed=None):\n \"\"\"Calls random.seed\"\"\"\n random.seed(seed)\n\n def format(self, formatter, *args, **kwargs):\n \"\"\"\n This is a secure way to make a fake from another Provider.\n \"\"\"\n # TODO: data export?\n return self.get_formatter(formatter)(*args, **kwargs)\n\n def get_formatter(self, formatter):\n try:\n return getattr(self, formatter)\n except AttributeError:\n raise AttributeError('Unknown formatter \"{0}\"'.format(formatter))\n\n def set_formatter(self, name, method):\n \"\"\"\n This method adds a provider method to generator.\n Override this method to add some decoration or logging stuff.\n \"\"\"\n setattr(self, name, method)\n\n def parse(self, text):\n \"\"\"\n Replaces tokens (like '{{ tokenName }}' or '{{tokenName}}')\n with the result from the token method call.\n \"\"\"\n return _re_token.sub(self.__format_token, text)\n\n def __format_token(self, matches):\n formatter = list(matches.groups())\n formatter[1] = self.format(formatter[1])\n return ''.join(formatter)\n", "path": "faker/generator.py"}], "after_files": [{"content": "# coding=utf-8\n\nfrom __future__ import unicode_literals\n\nimport re\nimport random\n\n\n_re_token = re.compile(r'\\{\\{(\\s?)(\\w+)(\\s?)\\}\\}')\nrandom = random.Random()\n\n\nclass Generator(object):\n\n __config = {}\n\n def __init__(self, **config):\n self.providers = []\n self.__config = dict(\n list(self.__config.items()) + list(config.items()))\n\n def add_provider(self, provider):\n\n if type(provider) is type:\n provider = provider(self)\n\n self.providers.insert(0, provider)\n\n for method_name in dir(provider):\n # skip 'private' method\n if method_name.startswith('_'):\n continue\n\n faker_function = getattr(provider, method_name)\n\n if hasattr(faker_function, '__call__') or \\\n isinstance(faker_function, (classmethod, staticmethod)):\n # add all faker method to generator\n self.set_formatter(method_name, faker_function)\n\n def provider(self, name):\n try:\n lst = [p for p in self.get_providers()\n if p.__provider__ == name.lower()]\n return lst[0]\n except IndexError:\n return None\n\n def get_providers(self):\n \"\"\"Returns added providers.\"\"\"\n return self.providers\n\n @property\n def random(self):\n return random\n\n def seed(self, seed=None):\n \"\"\"Calls random.seed\"\"\"\n random.seed(seed)\n\n def format(self, formatter, *args, **kwargs):\n \"\"\"\n This is a secure way to make a fake from another Provider.\n \"\"\"\n # TODO: data export?\n return self.get_formatter(formatter)(*args, **kwargs)\n\n def get_formatter(self, formatter):\n try:\n return getattr(self, formatter)\n except AttributeError:\n raise AttributeError('Unknown formatter \"{0}\"'.format(formatter))\n\n def set_formatter(self, name, method):\n \"\"\"\n This method adds a provider method to generator.\n Override this method to add some decoration or logging stuff.\n \"\"\"\n setattr(self, name, method)\n\n def parse(self, text):\n \"\"\"\n Replaces tokens (like '{{ tokenName }}' or '{{tokenName}}')\n with the result from the token method call.\n \"\"\"\n return _re_token.sub(self.__format_token, text)\n\n def __format_token(self, matches):\n formatter = list(matches.groups())\n formatter[1] = self.format(formatter[1])\n return ''.join(formatter)\n", "path": "faker/generator.py"}]}
| 1,102 | 92 |
gh_patches_debug_12588
|
rasdani/github-patches
|
git_diff
|
goauthentik__authentik-9255
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
The SCIM JSON for User and Group schema attribute allows only one value
The SCIM JSON for User and Group schema attribute allows only one value. The schemas attribute check should only check for a minimum number of entries not for a maximum.
For example I would like to be able so support the following
"schemas": [
"urn:ietf:params:scim:schemas:extension:servicenow:2.0:User",
"urn:ietf:params:scim:schemas:core:2.0:User",
"urn:ietf:params:scim:schemas:extension:enterprise:2.0:User"
]
To Reproduce
Steps to reproduce the behavior:
Create Property mapping, add
return {
"schemas" : [
"urn:ietf:params:scim:schemas:core:2.0:User",
"urn:ietf:params:scim:schemas:extention:enterprise:2.0:User"
],
"userName": request.user.username,
"name": {
"formatted": request.user.name,
"givenName": givenName,
"familyName": familyName,
},
Expected behavior
JSON containing schemas attribute
Instead I get
Stopping sync due to error: Error 1 validation error for User schemas Tuple should have at most 1 item after validation, not 2 [type=too_long, input_value=['urn:ietf:params:scim:sc...on:enterprise:2.0:User'], input_type=list] For further information visit https://errors.pydantic.dev/2.4/v/too_long
Version and Deployment (please complete the following information):
authentik version: [2023.10.2]
Deployment: [docker-compose]
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `authentik/providers/scim/clients/schema.py`
Content:
```
1 """Custom SCIM schemas"""
2
3 from pydanticscim.group import Group as BaseGroup
4 from pydanticscim.responses import PatchRequest as BasePatchRequest
5 from pydanticscim.responses import SCIMError as BaseSCIMError
6 from pydanticscim.service_provider import Bulk, ChangePassword, Filter, Patch, Sort
7 from pydanticscim.service_provider import (
8 ServiceProviderConfiguration as BaseServiceProviderConfiguration,
9 )
10 from pydanticscim.user import User as BaseUser
11
12
13 class User(BaseUser):
14 """Modified User schema with added externalId field"""
15
16 schemas: tuple[str] = ("urn:ietf:params:scim:schemas:core:2.0:User",)
17 externalId: str | None = None
18
19
20 class Group(BaseGroup):
21 """Modified Group schema with added externalId field"""
22
23 schemas: tuple[str] = ("urn:ietf:params:scim:schemas:core:2.0:Group",)
24 externalId: str | None = None
25
26
27 class ServiceProviderConfiguration(BaseServiceProviderConfiguration):
28 """ServiceProviderConfig with fallback"""
29
30 _is_fallback: bool | None = False
31
32 @property
33 def is_fallback(self) -> bool:
34 """Check if this service provider config was retrieved from the API endpoint
35 or a fallback was used"""
36 return self._is_fallback
37
38 @staticmethod
39 def default() -> "ServiceProviderConfiguration":
40 """Get default configuration, which doesn't support any optional features as fallback"""
41 return ServiceProviderConfiguration(
42 patch=Patch(supported=False),
43 bulk=Bulk(supported=False),
44 filter=Filter(supported=False),
45 changePassword=ChangePassword(supported=False),
46 sort=Sort(supported=False),
47 authenticationSchemes=[],
48 _is_fallback=True,
49 )
50
51
52 class PatchRequest(BasePatchRequest):
53 """PatchRequest which correctly sets schemas"""
54
55 schemas: tuple[str] = ("urn:ietf:params:scim:api:messages:2.0:PatchOp",)
56
57
58 class SCIMError(BaseSCIMError):
59 """SCIM error with optional status code"""
60
61 status: int | None
62
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/authentik/providers/scim/clients/schema.py b/authentik/providers/scim/clients/schema.py
--- a/authentik/providers/scim/clients/schema.py
+++ b/authentik/providers/scim/clients/schema.py
@@ -13,14 +13,18 @@
class User(BaseUser):
"""Modified User schema with added externalId field"""
- schemas: tuple[str] = ("urn:ietf:params:scim:schemas:core:2.0:User",)
+ schemas: list[str] = [
+ "urn:ietf:params:scim:schemas:core:2.0:User",
+ ]
externalId: str | None = None
class Group(BaseGroup):
"""Modified Group schema with added externalId field"""
- schemas: tuple[str] = ("urn:ietf:params:scim:schemas:core:2.0:Group",)
+ schemas: list[str] = [
+ "urn:ietf:params:scim:schemas:core:2.0:Group",
+ ]
externalId: str | None = None
|
{"golden_diff": "diff --git a/authentik/providers/scim/clients/schema.py b/authentik/providers/scim/clients/schema.py\n--- a/authentik/providers/scim/clients/schema.py\n+++ b/authentik/providers/scim/clients/schema.py\n@@ -13,14 +13,18 @@\n class User(BaseUser):\n \"\"\"Modified User schema with added externalId field\"\"\"\n \n- schemas: tuple[str] = (\"urn:ietf:params:scim:schemas:core:2.0:User\",)\n+ schemas: list[str] = [\n+ \"urn:ietf:params:scim:schemas:core:2.0:User\",\n+ ]\n externalId: str | None = None\n \n \n class Group(BaseGroup):\n \"\"\"Modified Group schema with added externalId field\"\"\"\n \n- schemas: tuple[str] = (\"urn:ietf:params:scim:schemas:core:2.0:Group\",)\n+ schemas: list[str] = [\n+ \"urn:ietf:params:scim:schemas:core:2.0:Group\",\n+ ]\n externalId: str | None = None\n", "issue": "The SCIM JSON for User and Group schema attribute allows only one value\nThe SCIM JSON for User and Group schema attribute allows only one value. The schemas attribute check should only check for a minimum number of entries not for a maximum. \r\n\r\nFor example I would like to be able so support the following\r\n\r\n \"schemas\": [\r\n \"urn:ietf:params:scim:schemas:extension:servicenow:2.0:User\",\r\n \"urn:ietf:params:scim:schemas:core:2.0:User\",\r\n \"urn:ietf:params:scim:schemas:extension:enterprise:2.0:User\"\r\n ]\r\n\r\nTo Reproduce\r\nSteps to reproduce the behavior:\r\nCreate Property mapping, add\r\n\r\nreturn {\r\n \"schemas\" : [\r\n \"urn:ietf:params:scim:schemas:core:2.0:User\",\r\n \"urn:ietf:params:scim:schemas:extention:enterprise:2.0:User\"\r\n ],\r\n \"userName\": request.user.username,\r\n \"name\": {\r\n \"formatted\": request.user.name,\r\n \"givenName\": givenName,\r\n \"familyName\": familyName,\r\n },\r\n\r\nExpected behavior\r\nJSON containing schemas attribute \r\n\r\nInstead I get \r\nStopping sync due to error: Error 1 validation error for User schemas Tuple should have at most 1 item after validation, not 2 [type=too_long, input_value=['urn:ietf:params:scim:sc...on:enterprise:2.0:User'], input_type=list] For further information visit https://errors.pydantic.dev/2.4/v/too_long\r\n\r\nVersion and Deployment (please complete the following information):\r\n\r\nauthentik version: [2023.10.2]\r\nDeployment: [docker-compose]\n", "before_files": [{"content": "\"\"\"Custom SCIM schemas\"\"\"\n\nfrom pydanticscim.group import Group as BaseGroup\nfrom pydanticscim.responses import PatchRequest as BasePatchRequest\nfrom pydanticscim.responses import SCIMError as BaseSCIMError\nfrom pydanticscim.service_provider import Bulk, ChangePassword, Filter, Patch, Sort\nfrom pydanticscim.service_provider import (\n ServiceProviderConfiguration as BaseServiceProviderConfiguration,\n)\nfrom pydanticscim.user import User as BaseUser\n\n\nclass User(BaseUser):\n \"\"\"Modified User schema with added externalId field\"\"\"\n\n schemas: tuple[str] = (\"urn:ietf:params:scim:schemas:core:2.0:User\",)\n externalId: str | None = None\n\n\nclass Group(BaseGroup):\n \"\"\"Modified Group schema with added externalId field\"\"\"\n\n schemas: tuple[str] = (\"urn:ietf:params:scim:schemas:core:2.0:Group\",)\n externalId: str | None = None\n\n\nclass ServiceProviderConfiguration(BaseServiceProviderConfiguration):\n \"\"\"ServiceProviderConfig with fallback\"\"\"\n\n _is_fallback: bool | None = False\n\n @property\n def is_fallback(self) -> bool:\n \"\"\"Check if this service provider config was retrieved from the API endpoint\n or a fallback was used\"\"\"\n return self._is_fallback\n\n @staticmethod\n def default() -> \"ServiceProviderConfiguration\":\n \"\"\"Get default configuration, which doesn't support any optional features as fallback\"\"\"\n return ServiceProviderConfiguration(\n patch=Patch(supported=False),\n bulk=Bulk(supported=False),\n filter=Filter(supported=False),\n changePassword=ChangePassword(supported=False),\n sort=Sort(supported=False),\n authenticationSchemes=[],\n _is_fallback=True,\n )\n\n\nclass PatchRequest(BasePatchRequest):\n \"\"\"PatchRequest which correctly sets schemas\"\"\"\n\n schemas: tuple[str] = (\"urn:ietf:params:scim:api:messages:2.0:PatchOp\",)\n\n\nclass SCIMError(BaseSCIMError):\n \"\"\"SCIM error with optional status code\"\"\"\n\n status: int | None\n", "path": "authentik/providers/scim/clients/schema.py"}], "after_files": [{"content": "\"\"\"Custom SCIM schemas\"\"\"\n\nfrom pydanticscim.group import Group as BaseGroup\nfrom pydanticscim.responses import PatchRequest as BasePatchRequest\nfrom pydanticscim.responses import SCIMError as BaseSCIMError\nfrom pydanticscim.service_provider import Bulk, ChangePassword, Filter, Patch, Sort\nfrom pydanticscim.service_provider import (\n ServiceProviderConfiguration as BaseServiceProviderConfiguration,\n)\nfrom pydanticscim.user import User as BaseUser\n\n\nclass User(BaseUser):\n \"\"\"Modified User schema with added externalId field\"\"\"\n\n schemas: list[str] = [\n \"urn:ietf:params:scim:schemas:core:2.0:User\",\n ]\n externalId: str | None = None\n\n\nclass Group(BaseGroup):\n \"\"\"Modified Group schema with added externalId field\"\"\"\n\n schemas: list[str] = [\n \"urn:ietf:params:scim:schemas:core:2.0:Group\",\n ]\n externalId: str | None = None\n\n\nclass ServiceProviderConfiguration(BaseServiceProviderConfiguration):\n \"\"\"ServiceProviderConfig with fallback\"\"\"\n\n _is_fallback: bool | None = False\n\n @property\n def is_fallback(self) -> bool:\n \"\"\"Check if this service provider config was retrieved from the API endpoint\n or a fallback was used\"\"\"\n return self._is_fallback\n\n @staticmethod\n def default() -> \"ServiceProviderConfiguration\":\n \"\"\"Get default configuration, which doesn't support any optional features as fallback\"\"\"\n return ServiceProviderConfiguration(\n patch=Patch(supported=False),\n bulk=Bulk(supported=False),\n filter=Filter(supported=False),\n changePassword=ChangePassword(supported=False),\n sort=Sort(supported=False),\n authenticationSchemes=[],\n _is_fallback=True,\n )\n\n\nclass PatchRequest(BasePatchRequest):\n \"\"\"PatchRequest which correctly sets schemas\"\"\"\n\n schemas: tuple[str] = (\"urn:ietf:params:scim:api:messages:2.0:PatchOp\",)\n\n\nclass SCIMError(BaseSCIMError):\n \"\"\"SCIM error with optional status code\"\"\"\n\n status: int | None\n", "path": "authentik/providers/scim/clients/schema.py"}]}
| 1,207 | 243 |
gh_patches_debug_9851
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-1644
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cannot save phase update form without changing the title of the phase
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/grandchallenge/evaluation/forms.py`
Content:
```
1 from crispy_forms.bootstrap import Tab, TabHolder
2 from crispy_forms.helper import FormHelper
3 from crispy_forms.layout import ButtonHolder, Layout, Submit
4 from django import forms
5 from django.core.exceptions import ValidationError
6 from django.db.models.functions import Lower
7 from django.forms import ModelChoiceField
8 from django.utils.text import format_lazy
9 from django_summernote.widgets import SummernoteInplaceWidget
10 from guardian.shortcuts import get_objects_for_user
11
12 from grandchallenge.algorithms.models import Algorithm
13 from grandchallenge.core.forms import SaveFormInitMixin
14 from grandchallenge.core.validators import ExtensionValidator
15 from grandchallenge.core.widgets import JSONEditorWidget
16 from grandchallenge.evaluation.models import (
17 EXTRA_RESULT_COLUMNS_SCHEMA,
18 Method,
19 Phase,
20 Submission,
21 )
22 from grandchallenge.jqfileupload.widgets import uploader
23 from grandchallenge.jqfileupload.widgets.uploader import UploadedAjaxFileList
24 from grandchallenge.subdomains.utils import reverse_lazy
25
26 phase_options = ("title",)
27
28 submission_options = (
29 "submission_page_html",
30 "daily_submission_limit",
31 "allow_submission_comments",
32 "supplementary_file_choice",
33 "supplementary_file_label",
34 "supplementary_file_help_text",
35 "publication_url_choice",
36 )
37
38 scoring_options = (
39 "score_title",
40 "score_jsonpath",
41 "score_error_jsonpath",
42 "score_default_sort",
43 "score_decimal_places",
44 "extra_results_columns",
45 "scoring_method_choice",
46 "auto_publish_new_results",
47 "result_display_choice",
48 )
49
50 leaderboard_options = (
51 "display_submission_comments",
52 "show_supplementary_file_link",
53 "show_publication_url",
54 "evaluation_comparison_observable_url",
55 )
56
57 result_detail_options = (
58 "display_all_metrics",
59 "evaluation_detail_observable_url",
60 )
61
62
63 class PhaseTitleMixin:
64 def __init__(self, *args, challenge, **kwargs):
65 self.challenge = challenge
66 super().__init__(*args, **kwargs)
67
68 def clean_title(self):
69 title = self.cleaned_data["title"]
70
71 if self.challenge.phase_set.filter(title=title).exists():
72 raise ValidationError(
73 "This challenge already has a phase with this title"
74 )
75
76 return title
77
78
79 class PhaseCreateForm(PhaseTitleMixin, SaveFormInitMixin, forms.ModelForm):
80 class Meta:
81 model = Phase
82 fields = ("title",)
83
84
85 class PhaseUpdateForm(PhaseTitleMixin, forms.ModelForm):
86 def __init__(self, *args, **kwargs):
87 super().__init__(*args, **kwargs)
88 self.helper = FormHelper(self)
89 self.helper.layout = Layout(
90 TabHolder(
91 Tab("Phase", *phase_options),
92 Tab("Submission", *submission_options),
93 Tab("Scoring", *scoring_options),
94 Tab("Leaderboard", *leaderboard_options),
95 Tab("Result Detail", *result_detail_options),
96 ),
97 ButtonHolder(Submit("save", "Save")),
98 )
99
100 class Meta:
101 model = Phase
102 fields = (
103 *phase_options,
104 *submission_options,
105 *scoring_options,
106 *leaderboard_options,
107 *result_detail_options,
108 )
109 widgets = {
110 "submission_page_html": SummernoteInplaceWidget(),
111 "extra_results_columns": JSONEditorWidget(
112 schema=EXTRA_RESULT_COLUMNS_SCHEMA
113 ),
114 }
115
116
117 class MethodForm(SaveFormInitMixin, forms.ModelForm):
118 phase = ModelChoiceField(
119 queryset=None,
120 help_text="Which phase is this evaluation container for?",
121 )
122 chunked_upload = UploadedAjaxFileList(
123 widget=uploader.AjaxUploadWidget(multifile=False, auto_commit=False),
124 label="Evaluation Method Container",
125 validators=[
126 ExtensionValidator(allowed_extensions=(".tar", ".tar.gz"))
127 ],
128 help_text=(
129 ".tar.gz archive of the container image produced from the command "
130 "'docker save IMAGE | gzip -c > IMAGE.tar.gz'. See "
131 "https://docs.docker.com/engine/reference/commandline/save/"
132 ),
133 )
134
135 def __init__(self, *args, user, challenge, **kwargs):
136 super().__init__(*args, **kwargs)
137 self.fields["chunked_upload"].widget.user = user
138 self.fields["phase"].queryset = challenge.phase_set.all()
139
140 class Meta:
141 model = Method
142 fields = ["phase", "chunked_upload"]
143
144
145 submission_fields = (
146 "comment",
147 "supplementary_file",
148 "publication_url",
149 "chunked_upload",
150 )
151
152
153 class SubmissionForm(forms.ModelForm):
154 chunked_upload = UploadedAjaxFileList(
155 widget=uploader.AjaxUploadWidget(multifile=False, auto_commit=False),
156 label="Predictions File",
157 validators=[ExtensionValidator(allowed_extensions=(".zip", ".csv"))],
158 )
159 algorithm = ModelChoiceField(
160 queryset=None,
161 help_text=format_lazy(
162 "Select one of your algorithms to submit as a solution to this "
163 "challenge. If you have not created your algorithm yet you can "
164 "do so <a href={}>on this page</a>.",
165 reverse_lazy("algorithms:create"),
166 ),
167 )
168
169 def __init__(
170 self,
171 *args,
172 user,
173 algorithm_submission=False,
174 display_comment_field=False,
175 supplementary_file_choice=Phase.OFF,
176 supplementary_file_label="",
177 supplementary_file_help_text="",
178 publication_url_choice=Phase.OFF,
179 **kwargs,
180 ):
181 """
182 Conditionally render the comment field based on the
183 display_comment_field kwarg
184 """
185 super().__init__(*args, **kwargs)
186
187 if not display_comment_field:
188 del self.fields["comment"]
189
190 if supplementary_file_label:
191 self.fields["supplementary_file"].label = supplementary_file_label
192
193 if supplementary_file_help_text:
194 self.fields[
195 "supplementary_file"
196 ].help_text = supplementary_file_help_text
197
198 if supplementary_file_choice == Phase.REQUIRED:
199 self.fields["supplementary_file"].required = True
200 elif supplementary_file_choice == Phase.OFF:
201 del self.fields["supplementary_file"]
202
203 if publication_url_choice == Phase.REQUIRED:
204 self.fields["publication_url"].required = True
205 elif publication_url_choice == Phase.OFF:
206 del self.fields["publication_url"]
207
208 if algorithm_submission:
209 del self.fields["chunked_upload"]
210
211 self.fields["algorithm"].queryset = get_objects_for_user(
212 user,
213 f"{Algorithm._meta.app_label}.change_{Algorithm._meta.model_name}",
214 Algorithm,
215 ).order_by("title")
216 else:
217 del self.fields["algorithm"]
218
219 self.fields["chunked_upload"].widget.user = user
220
221 self.helper = FormHelper(self)
222 self.helper.layout.append(Submit("save", "Save"))
223
224 def clean_algorithm(self):
225 algorithm = self.cleaned_data["algorithm"]
226
227 if algorithm.latest_ready_image is None:
228 raise ValidationError(
229 "This algorithm does not have a usable container image. "
230 "Please add one and try again."
231 )
232
233 return algorithm
234
235 class Meta:
236 model = Submission
237 fields = submission_fields
238
239
240 class LegacySubmissionForm(SubmissionForm):
241 def __init__(self, *args, challenge, **kwargs):
242 super().__init__(*args, **kwargs)
243 self.fields[
244 "creator"
245 ].queryset = challenge.participants_group.user_set.all().order_by(
246 Lower("username")
247 )
248
249 class Meta:
250 model = Submission
251 fields = ("creator", *submission_fields)
252
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/app/grandchallenge/evaluation/forms.py b/app/grandchallenge/evaluation/forms.py
--- a/app/grandchallenge/evaluation/forms.py
+++ b/app/grandchallenge/evaluation/forms.py
@@ -66,9 +66,14 @@
super().__init__(*args, **kwargs)
def clean_title(self):
- title = self.cleaned_data["title"]
+ title = self.cleaned_data["title"].strip()
- if self.challenge.phase_set.filter(title=title).exists():
+ qs = self.challenge.phase_set.filter(title__iexact=title)
+
+ if self.instance:
+ qs = qs.exclude(pk=self.instance.pk)
+
+ if qs.exists():
raise ValidationError(
"This challenge already has a phase with this title"
)
|
{"golden_diff": "diff --git a/app/grandchallenge/evaluation/forms.py b/app/grandchallenge/evaluation/forms.py\n--- a/app/grandchallenge/evaluation/forms.py\n+++ b/app/grandchallenge/evaluation/forms.py\n@@ -66,9 +66,14 @@\n super().__init__(*args, **kwargs)\n \n def clean_title(self):\n- title = self.cleaned_data[\"title\"]\n+ title = self.cleaned_data[\"title\"].strip()\n \n- if self.challenge.phase_set.filter(title=title).exists():\n+ qs = self.challenge.phase_set.filter(title__iexact=title)\n+\n+ if self.instance:\n+ qs = qs.exclude(pk=self.instance.pk)\n+\n+ if qs.exists():\n raise ValidationError(\n \"This challenge already has a phase with this title\"\n )\n", "issue": "Cannot save phase update form without changing the title of the phase\n\r\n\n", "before_files": [{"content": "from crispy_forms.bootstrap import Tab, TabHolder\nfrom crispy_forms.helper import FormHelper\nfrom crispy_forms.layout import ButtonHolder, Layout, Submit\nfrom django import forms\nfrom django.core.exceptions import ValidationError\nfrom django.db.models.functions import Lower\nfrom django.forms import ModelChoiceField\nfrom django.utils.text import format_lazy\nfrom django_summernote.widgets import SummernoteInplaceWidget\nfrom guardian.shortcuts import get_objects_for_user\n\nfrom grandchallenge.algorithms.models import Algorithm\nfrom grandchallenge.core.forms import SaveFormInitMixin\nfrom grandchallenge.core.validators import ExtensionValidator\nfrom grandchallenge.core.widgets import JSONEditorWidget\nfrom grandchallenge.evaluation.models import (\n EXTRA_RESULT_COLUMNS_SCHEMA,\n Method,\n Phase,\n Submission,\n)\nfrom grandchallenge.jqfileupload.widgets import uploader\nfrom grandchallenge.jqfileupload.widgets.uploader import UploadedAjaxFileList\nfrom grandchallenge.subdomains.utils import reverse_lazy\n\nphase_options = (\"title\",)\n\nsubmission_options = (\n \"submission_page_html\",\n \"daily_submission_limit\",\n \"allow_submission_comments\",\n \"supplementary_file_choice\",\n \"supplementary_file_label\",\n \"supplementary_file_help_text\",\n \"publication_url_choice\",\n)\n\nscoring_options = (\n \"score_title\",\n \"score_jsonpath\",\n \"score_error_jsonpath\",\n \"score_default_sort\",\n \"score_decimal_places\",\n \"extra_results_columns\",\n \"scoring_method_choice\",\n \"auto_publish_new_results\",\n \"result_display_choice\",\n)\n\nleaderboard_options = (\n \"display_submission_comments\",\n \"show_supplementary_file_link\",\n \"show_publication_url\",\n \"evaluation_comparison_observable_url\",\n)\n\nresult_detail_options = (\n \"display_all_metrics\",\n \"evaluation_detail_observable_url\",\n)\n\n\nclass PhaseTitleMixin:\n def __init__(self, *args, challenge, **kwargs):\n self.challenge = challenge\n super().__init__(*args, **kwargs)\n\n def clean_title(self):\n title = self.cleaned_data[\"title\"]\n\n if self.challenge.phase_set.filter(title=title).exists():\n raise ValidationError(\n \"This challenge already has a phase with this title\"\n )\n\n return title\n\n\nclass PhaseCreateForm(PhaseTitleMixin, SaveFormInitMixin, forms.ModelForm):\n class Meta:\n model = Phase\n fields = (\"title\",)\n\n\nclass PhaseUpdateForm(PhaseTitleMixin, forms.ModelForm):\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.helper = FormHelper(self)\n self.helper.layout = Layout(\n TabHolder(\n Tab(\"Phase\", *phase_options),\n Tab(\"Submission\", *submission_options),\n Tab(\"Scoring\", *scoring_options),\n Tab(\"Leaderboard\", *leaderboard_options),\n Tab(\"Result Detail\", *result_detail_options),\n ),\n ButtonHolder(Submit(\"save\", \"Save\")),\n )\n\n class Meta:\n model = Phase\n fields = (\n *phase_options,\n *submission_options,\n *scoring_options,\n *leaderboard_options,\n *result_detail_options,\n )\n widgets = {\n \"submission_page_html\": SummernoteInplaceWidget(),\n \"extra_results_columns\": JSONEditorWidget(\n schema=EXTRA_RESULT_COLUMNS_SCHEMA\n ),\n }\n\n\nclass MethodForm(SaveFormInitMixin, forms.ModelForm):\n phase = ModelChoiceField(\n queryset=None,\n help_text=\"Which phase is this evaluation container for?\",\n )\n chunked_upload = UploadedAjaxFileList(\n widget=uploader.AjaxUploadWidget(multifile=False, auto_commit=False),\n label=\"Evaluation Method Container\",\n validators=[\n ExtensionValidator(allowed_extensions=(\".tar\", \".tar.gz\"))\n ],\n help_text=(\n \".tar.gz archive of the container image produced from the command \"\n \"'docker save IMAGE | gzip -c > IMAGE.tar.gz'. See \"\n \"https://docs.docker.com/engine/reference/commandline/save/\"\n ),\n )\n\n def __init__(self, *args, user, challenge, **kwargs):\n super().__init__(*args, **kwargs)\n self.fields[\"chunked_upload\"].widget.user = user\n self.fields[\"phase\"].queryset = challenge.phase_set.all()\n\n class Meta:\n model = Method\n fields = [\"phase\", \"chunked_upload\"]\n\n\nsubmission_fields = (\n \"comment\",\n \"supplementary_file\",\n \"publication_url\",\n \"chunked_upload\",\n)\n\n\nclass SubmissionForm(forms.ModelForm):\n chunked_upload = UploadedAjaxFileList(\n widget=uploader.AjaxUploadWidget(multifile=False, auto_commit=False),\n label=\"Predictions File\",\n validators=[ExtensionValidator(allowed_extensions=(\".zip\", \".csv\"))],\n )\n algorithm = ModelChoiceField(\n queryset=None,\n help_text=format_lazy(\n \"Select one of your algorithms to submit as a solution to this \"\n \"challenge. If you have not created your algorithm yet you can \"\n \"do so <a href={}>on this page</a>.\",\n reverse_lazy(\"algorithms:create\"),\n ),\n )\n\n def __init__(\n self,\n *args,\n user,\n algorithm_submission=False,\n display_comment_field=False,\n supplementary_file_choice=Phase.OFF,\n supplementary_file_label=\"\",\n supplementary_file_help_text=\"\",\n publication_url_choice=Phase.OFF,\n **kwargs,\n ):\n \"\"\"\n Conditionally render the comment field based on the\n display_comment_field kwarg\n \"\"\"\n super().__init__(*args, **kwargs)\n\n if not display_comment_field:\n del self.fields[\"comment\"]\n\n if supplementary_file_label:\n self.fields[\"supplementary_file\"].label = supplementary_file_label\n\n if supplementary_file_help_text:\n self.fields[\n \"supplementary_file\"\n ].help_text = supplementary_file_help_text\n\n if supplementary_file_choice == Phase.REQUIRED:\n self.fields[\"supplementary_file\"].required = True\n elif supplementary_file_choice == Phase.OFF:\n del self.fields[\"supplementary_file\"]\n\n if publication_url_choice == Phase.REQUIRED:\n self.fields[\"publication_url\"].required = True\n elif publication_url_choice == Phase.OFF:\n del self.fields[\"publication_url\"]\n\n if algorithm_submission:\n del self.fields[\"chunked_upload\"]\n\n self.fields[\"algorithm\"].queryset = get_objects_for_user(\n user,\n f\"{Algorithm._meta.app_label}.change_{Algorithm._meta.model_name}\",\n Algorithm,\n ).order_by(\"title\")\n else:\n del self.fields[\"algorithm\"]\n\n self.fields[\"chunked_upload\"].widget.user = user\n\n self.helper = FormHelper(self)\n self.helper.layout.append(Submit(\"save\", \"Save\"))\n\n def clean_algorithm(self):\n algorithm = self.cleaned_data[\"algorithm\"]\n\n if algorithm.latest_ready_image is None:\n raise ValidationError(\n \"This algorithm does not have a usable container image. \"\n \"Please add one and try again.\"\n )\n\n return algorithm\n\n class Meta:\n model = Submission\n fields = submission_fields\n\n\nclass LegacySubmissionForm(SubmissionForm):\n def __init__(self, *args, challenge, **kwargs):\n super().__init__(*args, **kwargs)\n self.fields[\n \"creator\"\n ].queryset = challenge.participants_group.user_set.all().order_by(\n Lower(\"username\")\n )\n\n class Meta:\n model = Submission\n fields = (\"creator\", *submission_fields)\n", "path": "app/grandchallenge/evaluation/forms.py"}], "after_files": [{"content": "from crispy_forms.bootstrap import Tab, TabHolder\nfrom crispy_forms.helper import FormHelper\nfrom crispy_forms.layout import ButtonHolder, Layout, Submit\nfrom django import forms\nfrom django.core.exceptions import ValidationError\nfrom django.db.models.functions import Lower\nfrom django.forms import ModelChoiceField\nfrom django.utils.text import format_lazy\nfrom django_summernote.widgets import SummernoteInplaceWidget\nfrom guardian.shortcuts import get_objects_for_user\n\nfrom grandchallenge.algorithms.models import Algorithm\nfrom grandchallenge.core.forms import SaveFormInitMixin\nfrom grandchallenge.core.validators import ExtensionValidator\nfrom grandchallenge.core.widgets import JSONEditorWidget\nfrom grandchallenge.evaluation.models import (\n EXTRA_RESULT_COLUMNS_SCHEMA,\n Method,\n Phase,\n Submission,\n)\nfrom grandchallenge.jqfileupload.widgets import uploader\nfrom grandchallenge.jqfileupload.widgets.uploader import UploadedAjaxFileList\nfrom grandchallenge.subdomains.utils import reverse_lazy\n\nphase_options = (\"title\",)\n\nsubmission_options = (\n \"submission_page_html\",\n \"daily_submission_limit\",\n \"allow_submission_comments\",\n \"supplementary_file_choice\",\n \"supplementary_file_label\",\n \"supplementary_file_help_text\",\n \"publication_url_choice\",\n)\n\nscoring_options = (\n \"score_title\",\n \"score_jsonpath\",\n \"score_error_jsonpath\",\n \"score_default_sort\",\n \"score_decimal_places\",\n \"extra_results_columns\",\n \"scoring_method_choice\",\n \"auto_publish_new_results\",\n \"result_display_choice\",\n)\n\nleaderboard_options = (\n \"display_submission_comments\",\n \"show_supplementary_file_link\",\n \"show_publication_url\",\n \"evaluation_comparison_observable_url\",\n)\n\nresult_detail_options = (\n \"display_all_metrics\",\n \"evaluation_detail_observable_url\",\n)\n\n\nclass PhaseTitleMixin:\n def __init__(self, *args, challenge, **kwargs):\n self.challenge = challenge\n super().__init__(*args, **kwargs)\n\n def clean_title(self):\n title = self.cleaned_data[\"title\"].strip()\n\n qs = self.challenge.phase_set.filter(title__iexact=title)\n\n if self.instance:\n qs = qs.exclude(pk=self.instance.pk)\n\n if qs.exists():\n raise ValidationError(\n \"This challenge already has a phase with this title\"\n )\n\n return title\n\n\nclass PhaseCreateForm(PhaseTitleMixin, SaveFormInitMixin, forms.ModelForm):\n class Meta:\n model = Phase\n fields = (\"title\",)\n\n\nclass PhaseUpdateForm(PhaseTitleMixin, forms.ModelForm):\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.helper = FormHelper(self)\n self.helper.layout = Layout(\n TabHolder(\n Tab(\"Phase\", *phase_options),\n Tab(\"Submission\", *submission_options),\n Tab(\"Scoring\", *scoring_options),\n Tab(\"Leaderboard\", *leaderboard_options),\n Tab(\"Result Detail\", *result_detail_options),\n ),\n ButtonHolder(Submit(\"save\", \"Save\")),\n )\n\n class Meta:\n model = Phase\n fields = (\n *phase_options,\n *submission_options,\n *scoring_options,\n *leaderboard_options,\n *result_detail_options,\n )\n widgets = {\n \"submission_page_html\": SummernoteInplaceWidget(),\n \"extra_results_columns\": JSONEditorWidget(\n schema=EXTRA_RESULT_COLUMNS_SCHEMA\n ),\n }\n\n\nclass MethodForm(SaveFormInitMixin, forms.ModelForm):\n phase = ModelChoiceField(\n queryset=None,\n help_text=\"Which phase is this evaluation container for?\",\n )\n chunked_upload = UploadedAjaxFileList(\n widget=uploader.AjaxUploadWidget(multifile=False, auto_commit=False),\n label=\"Evaluation Method Container\",\n validators=[\n ExtensionValidator(allowed_extensions=(\".tar\", \".tar.gz\"))\n ],\n help_text=(\n \".tar.gz archive of the container image produced from the command \"\n \"'docker save IMAGE | gzip -c > IMAGE.tar.gz'. See \"\n \"https://docs.docker.com/engine/reference/commandline/save/\"\n ),\n )\n\n def __init__(self, *args, user, challenge, **kwargs):\n super().__init__(*args, **kwargs)\n self.fields[\"chunked_upload\"].widget.user = user\n self.fields[\"phase\"].queryset = challenge.phase_set.all()\n\n class Meta:\n model = Method\n fields = [\"phase\", \"chunked_upload\"]\n\n\nsubmission_fields = (\n \"comment\",\n \"supplementary_file\",\n \"publication_url\",\n \"chunked_upload\",\n)\n\n\nclass SubmissionForm(forms.ModelForm):\n chunked_upload = UploadedAjaxFileList(\n widget=uploader.AjaxUploadWidget(multifile=False, auto_commit=False),\n label=\"Predictions File\",\n validators=[ExtensionValidator(allowed_extensions=(\".zip\", \".csv\"))],\n )\n algorithm = ModelChoiceField(\n queryset=None,\n help_text=format_lazy(\n \"Select one of your algorithms to submit as a solution to this \"\n \"challenge. If you have not created your algorithm yet you can \"\n \"do so <a href={}>on this page</a>.\",\n reverse_lazy(\"algorithms:create\"),\n ),\n )\n\n def __init__(\n self,\n *args,\n user,\n algorithm_submission=False,\n display_comment_field=False,\n supplementary_file_choice=Phase.OFF,\n supplementary_file_label=\"\",\n supplementary_file_help_text=\"\",\n publication_url_choice=Phase.OFF,\n **kwargs,\n ):\n \"\"\"\n Conditionally render the comment field based on the\n display_comment_field kwarg\n \"\"\"\n super().__init__(*args, **kwargs)\n\n if not display_comment_field:\n del self.fields[\"comment\"]\n\n if supplementary_file_label:\n self.fields[\"supplementary_file\"].label = supplementary_file_label\n\n if supplementary_file_help_text:\n self.fields[\n \"supplementary_file\"\n ].help_text = supplementary_file_help_text\n\n if supplementary_file_choice == Phase.REQUIRED:\n self.fields[\"supplementary_file\"].required = True\n elif supplementary_file_choice == Phase.OFF:\n del self.fields[\"supplementary_file\"]\n\n if publication_url_choice == Phase.REQUIRED:\n self.fields[\"publication_url\"].required = True\n elif publication_url_choice == Phase.OFF:\n del self.fields[\"publication_url\"]\n\n if algorithm_submission:\n del self.fields[\"chunked_upload\"]\n\n self.fields[\"algorithm\"].queryset = get_objects_for_user(\n user,\n f\"{Algorithm._meta.app_label}.change_{Algorithm._meta.model_name}\",\n Algorithm,\n ).order_by(\"title\")\n else:\n del self.fields[\"algorithm\"]\n\n self.fields[\"chunked_upload\"].widget.user = user\n\n self.helper = FormHelper(self)\n self.helper.layout.append(Submit(\"save\", \"Save\"))\n\n def clean_algorithm(self):\n algorithm = self.cleaned_data[\"algorithm\"]\n\n if algorithm.latest_ready_image is None:\n raise ValidationError(\n \"This algorithm does not have a usable container image. \"\n \"Please add one and try again.\"\n )\n\n return algorithm\n\n class Meta:\n model = Submission\n fields = submission_fields\n\n\nclass LegacySubmissionForm(SubmissionForm):\n def __init__(self, *args, challenge, **kwargs):\n super().__init__(*args, **kwargs)\n self.fields[\n \"creator\"\n ].queryset = challenge.participants_group.user_set.all().order_by(\n Lower(\"username\")\n )\n\n class Meta:\n model = Submission\n fields = (\"creator\", *submission_fields)\n", "path": "app/grandchallenge/evaluation/forms.py"}]}
| 2,519 | 170 |
gh_patches_debug_7517
|
rasdani/github-patches
|
git_diff
|
ranaroussi__yfinance-1807
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ImportError using yf.Ticker
Hello. Hope everyone is doing well. Getting an error after upgraded yfinance today (11/28/23) with the following code ```%pip install yfinance --upgrade --no-cache-dir --pre```.
I am using python version 3.10 and yfinance version 02.32
Error I am getting is as follows:
ImportError: cannot import name 'DO_NOT_CACHE' from 'requests_cache' (C:\Users\17147\anaconda3\envs\ib230729\Lib\site-packages\requests_cache\__init__.py)
Simple code that reproduces the problem:
session = requests_cache.CachedSession('yfinance.cache')
session.headers['User-agent'] = 'my-program/1.0'
msft = yf.Ticker('msft', session=session)
msft.actions
Traceback below:
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
Cell In[2], line 3
1 session = requests_cache.CachedSession('yfinance.cache')
2 session.headers['User-agent'] = 'my-program/1.0'
----> 3 msft = yf.Ticker('msft', session=session)
File ~\anaconda3\envs\ib230729\Lib\site-packages\yfinance\ticker.py:34, in Ticker.__init__(self, ticker, session)
33 def __init__(self, ticker, session=None):
---> 34 super(Ticker, self).__init__(ticker, session=session)
35 self._expirations = {}
36 self._underlying = {}
File ~\anaconda3\envs\ib230729\Lib\site-packages\yfinance\base.py:71, in TickerBase.__init__(self, ticker, session)
68 if utils.is_isin(self.ticker):
69 self.ticker = utils.get_ticker_by_isin(self.ticker, None, session)
---> 71 self._data: YfData = YfData(session=session)
73 self._analysis = Analysis(self._data, ticker)
74 self._holders = Holders(self._data, ticker)
File ~\anaconda3\envs\ib230729\Lib\site-packages\yfinance\data.py:47, in SingletonMeta.__call__(cls, *args, **kwargs)
45 with cls._lock:
46 if cls not in cls._instances:
---> 47 instance = super().__call__(*args, **kwargs)
48 cls._instances[cls] = instance
49 else:
File ~\anaconda3\envs\ib230729\Lib\site-packages\yfinance\data.py:75, in YfData.__init__(self, session)
70 else:
71 # Is caching. This is annoying.
72 # Can't simply use a non-caching session to fetch cookie & crumb,
73 # because then the caching-session won't have cookie.
74 self._session_is_caching = True
---> 75 from requests_cache import DO_NOT_CACHE
76 self._expire_after = DO_NOT_CACHE
77 self._crumb = None
ImportError: cannot import name 'DO_NOT_CACHE' from 'requests_cache' (C:\Users\17147\anaconda3\envs\ib230729\Lib\site-packages\requests_cache\__init__.py)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 #!/usr/bin/env python
2 # -*- coding: UTF-8 -*-
3 #
4 # yfinance - market data downloader
5 # https://github.com/ranaroussi/yfinance
6
7 """yfinance - market data downloader"""
8
9 from setuptools import setup, find_packages
10 # from codecs import open
11 import io
12 from os import path
13
14 # --- get version ---
15 version = "unknown"
16 with open("yfinance/version.py") as f:
17 line = f.read().strip()
18 version = line.replace("version = ", "").replace('"', '')
19 # --- /get version ---
20
21
22 here = path.abspath(path.dirname(__file__))
23
24 # Get the long description from the README file
25 with io.open(path.join(here, 'README.md'), encoding='utf-8') as f:
26 long_description = f.read()
27
28 setup(
29 name='yfinance',
30 version=version,
31 description='Download market data from Yahoo! Finance API',
32 long_description=long_description,
33 long_description_content_type='text/markdown',
34 url='https://github.com/ranaroussi/yfinance',
35 author='Ran Aroussi',
36 author_email='ran@aroussi.com',
37 license='Apache',
38 classifiers=[
39 'License :: OSI Approved :: Apache Software License',
40 # 'Development Status :: 3 - Alpha',
41 'Development Status :: 4 - Beta',
42 # 'Development Status :: 5 - Production/Stable',
43
44
45 'Operating System :: OS Independent',
46 'Intended Audience :: Developers',
47 'Topic :: Office/Business :: Financial',
48 'Topic :: Office/Business :: Financial :: Investment',
49 'Topic :: Scientific/Engineering :: Interface Engine/Protocol Translator',
50 'Topic :: Software Development :: Libraries',
51 'Topic :: Software Development :: Libraries :: Python Modules',
52
53 'Programming Language :: Python :: 3.6',
54 'Programming Language :: Python :: 3.7',
55 'Programming Language :: Python :: 3.8',
56 'Programming Language :: Python :: 3.9',
57 'Programming Language :: Python :: 3.10',
58 ],
59 platforms=['any'],
60 keywords='pandas, yahoo finance, pandas datareader',
61 packages=find_packages(exclude=['contrib', 'docs', 'tests', 'examples']),
62 install_requires=['pandas>=1.3.0', 'numpy>=1.16.5',
63 'requests>=2.31', 'multitasking>=0.0.7',
64 'lxml>=4.9.1', 'appdirs>=1.4.4', 'pytz>=2022.5',
65 'frozendict>=2.3.4', 'peewee>=3.16.2',
66 'beautifulsoup4>=4.11.1', 'html5lib>=1.1'],
67 extras_require={
68 'nospam': ['requests_cache>=1.1.1', 'requests_ratelimiter>=0.4.2'],
69 'repair': ['scipy>=1.6.3'],
70 },
71 # Note: Pandas.read_html() needs html5lib & beautifulsoup4
72 entry_points={
73 'console_scripts': [
74 'sample=sample:main',
75 ],
76 },
77 )
78
79 print("""
80 NOTE: yfinance is not affiliated, endorsed, or vetted by Yahoo, Inc.
81
82 You should refer to Yahoo!'s terms of use for details on your rights
83 to use the actual data downloaded.""")
84
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -65,7 +65,7 @@
'frozendict>=2.3.4', 'peewee>=3.16.2',
'beautifulsoup4>=4.11.1', 'html5lib>=1.1'],
extras_require={
- 'nospam': ['requests_cache>=1.1.1', 'requests_ratelimiter>=0.4.2'],
+ 'nospam': ['requests_cache>=1.0', 'requests_ratelimiter>=0.3.1'],
'repair': ['scipy>=1.6.3'],
},
# Note: Pandas.read_html() needs html5lib & beautifulsoup4
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -65,7 +65,7 @@\n 'frozendict>=2.3.4', 'peewee>=3.16.2',\n 'beautifulsoup4>=4.11.1', 'html5lib>=1.1'],\n extras_require={\n- 'nospam': ['requests_cache>=1.1.1', 'requests_ratelimiter>=0.4.2'],\n+ 'nospam': ['requests_cache>=1.0', 'requests_ratelimiter>=0.3.1'],\n 'repair': ['scipy>=1.6.3'],\n },\n # Note: Pandas.read_html() needs html5lib & beautifulsoup4\n", "issue": "ImportError using yf.Ticker\nHello. Hope everyone is doing well. Getting an error after upgraded yfinance today (11/28/23) with the following code ```%pip install yfinance --upgrade --no-cache-dir --pre```. \r\n\r\nI am using python version 3.10 and yfinance version 02.32\r\n\r\nError I am getting is as follows:\r\n\r\nImportError: cannot import name 'DO_NOT_CACHE' from 'requests_cache' (C:\\Users\\17147\\anaconda3\\envs\\ib230729\\Lib\\site-packages\\requests_cache\\__init__.py)\r\n\r\n\r\nSimple code that reproduces the problem:\r\nsession = requests_cache.CachedSession('yfinance.cache')\r\nsession.headers['User-agent'] = 'my-program/1.0'\r\nmsft = yf.Ticker('msft', session=session)\r\nmsft.actions\r\n\r\n\r\nTraceback below:\r\n---------------------------------------------------------------------------\r\nImportError Traceback (most recent call last)\r\nCell In[2], line 3\r\n 1 session = requests_cache.CachedSession('yfinance.cache')\r\n 2 session.headers['User-agent'] = 'my-program/1.0'\r\n----> 3 msft = yf.Ticker('msft', session=session)\r\n\r\nFile ~\\anaconda3\\envs\\ib230729\\Lib\\site-packages\\yfinance\\ticker.py:34, in Ticker.__init__(self, ticker, session)\r\n 33 def __init__(self, ticker, session=None):\r\n---> 34 super(Ticker, self).__init__(ticker, session=session)\r\n 35 self._expirations = {}\r\n 36 self._underlying = {}\r\n\r\nFile ~\\anaconda3\\envs\\ib230729\\Lib\\site-packages\\yfinance\\base.py:71, in TickerBase.__init__(self, ticker, session)\r\n 68 if utils.is_isin(self.ticker):\r\n 69 self.ticker = utils.get_ticker_by_isin(self.ticker, None, session)\r\n---> 71 self._data: YfData = YfData(session=session)\r\n 73 self._analysis = Analysis(self._data, ticker)\r\n 74 self._holders = Holders(self._data, ticker)\r\n\r\nFile ~\\anaconda3\\envs\\ib230729\\Lib\\site-packages\\yfinance\\data.py:47, in SingletonMeta.__call__(cls, *args, **kwargs)\r\n 45 with cls._lock:\r\n 46 if cls not in cls._instances:\r\n---> 47 instance = super().__call__(*args, **kwargs)\r\n 48 cls._instances[cls] = instance\r\n 49 else:\r\n\r\nFile ~\\anaconda3\\envs\\ib230729\\Lib\\site-packages\\yfinance\\data.py:75, in YfData.__init__(self, session)\r\n 70 else:\r\n 71 # Is caching. This is annoying. \r\n 72 # Can't simply use a non-caching session to fetch cookie & crumb, \r\n 73 # because then the caching-session won't have cookie.\r\n 74 self._session_is_caching = True\r\n---> 75 from requests_cache import DO_NOT_CACHE\r\n 76 self._expire_after = DO_NOT_CACHE\r\n 77 self._crumb = None\r\n\r\nImportError: cannot import name 'DO_NOT_CACHE' from 'requests_cache' (C:\\Users\\17147\\anaconda3\\envs\\ib230729\\Lib\\site-packages\\requests_cache\\__init__.py)\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: UTF-8 -*-\n#\n# yfinance - market data downloader\n# https://github.com/ranaroussi/yfinance\n\n\"\"\"yfinance - market data downloader\"\"\"\n\nfrom setuptools import setup, find_packages\n# from codecs import open\nimport io\nfrom os import path\n\n# --- get version ---\nversion = \"unknown\"\nwith open(\"yfinance/version.py\") as f:\n line = f.read().strip()\n version = line.replace(\"version = \", \"\").replace('\"', '')\n# --- /get version ---\n\n\nhere = path.abspath(path.dirname(__file__))\n\n# Get the long description from the README file\nwith io.open(path.join(here, 'README.md'), encoding='utf-8') as f:\n long_description = f.read()\n\nsetup(\n name='yfinance',\n version=version,\n description='Download market data from Yahoo! Finance API',\n long_description=long_description,\n long_description_content_type='text/markdown',\n url='https://github.com/ranaroussi/yfinance',\n author='Ran Aroussi',\n author_email='ran@aroussi.com',\n license='Apache',\n classifiers=[\n 'License :: OSI Approved :: Apache Software License',\n # 'Development Status :: 3 - Alpha',\n 'Development Status :: 4 - Beta',\n # 'Development Status :: 5 - Production/Stable',\n\n\n 'Operating System :: OS Independent',\n 'Intended Audience :: Developers',\n 'Topic :: Office/Business :: Financial',\n 'Topic :: Office/Business :: Financial :: Investment',\n 'Topic :: Scientific/Engineering :: Interface Engine/Protocol Translator',\n 'Topic :: Software Development :: Libraries',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Programming Language :: Python :: 3.10',\n ],\n platforms=['any'],\n keywords='pandas, yahoo finance, pandas datareader',\n packages=find_packages(exclude=['contrib', 'docs', 'tests', 'examples']),\n install_requires=['pandas>=1.3.0', 'numpy>=1.16.5',\n 'requests>=2.31', 'multitasking>=0.0.7',\n 'lxml>=4.9.1', 'appdirs>=1.4.4', 'pytz>=2022.5',\n 'frozendict>=2.3.4', 'peewee>=3.16.2',\n 'beautifulsoup4>=4.11.1', 'html5lib>=1.1'],\n extras_require={\n 'nospam': ['requests_cache>=1.1.1', 'requests_ratelimiter>=0.4.2'],\n 'repair': ['scipy>=1.6.3'],\n },\n # Note: Pandas.read_html() needs html5lib & beautifulsoup4\n entry_points={\n 'console_scripts': [\n 'sample=sample:main',\n ],\n },\n)\n\nprint(\"\"\"\nNOTE: yfinance is not affiliated, endorsed, or vetted by Yahoo, Inc.\n\nYou should refer to Yahoo!'s terms of use for details on your rights\nto use the actual data downloaded.\"\"\")\n", "path": "setup.py"}], "after_files": [{"content": "#!/usr/bin/env python\n# -*- coding: UTF-8 -*-\n#\n# yfinance - market data downloader\n# https://github.com/ranaroussi/yfinance\n\n\"\"\"yfinance - market data downloader\"\"\"\n\nfrom setuptools import setup, find_packages\n# from codecs import open\nimport io\nfrom os import path\n\n# --- get version ---\nversion = \"unknown\"\nwith open(\"yfinance/version.py\") as f:\n line = f.read().strip()\n version = line.replace(\"version = \", \"\").replace('\"', '')\n# --- /get version ---\n\n\nhere = path.abspath(path.dirname(__file__))\n\n# Get the long description from the README file\nwith io.open(path.join(here, 'README.md'), encoding='utf-8') as f:\n long_description = f.read()\n\nsetup(\n name='yfinance',\n version=version,\n description='Download market data from Yahoo! Finance API',\n long_description=long_description,\n long_description_content_type='text/markdown',\n url='https://github.com/ranaroussi/yfinance',\n author='Ran Aroussi',\n author_email='ran@aroussi.com',\n license='Apache',\n classifiers=[\n 'License :: OSI Approved :: Apache Software License',\n # 'Development Status :: 3 - Alpha',\n 'Development Status :: 4 - Beta',\n # 'Development Status :: 5 - Production/Stable',\n\n\n 'Operating System :: OS Independent',\n 'Intended Audience :: Developers',\n 'Topic :: Office/Business :: Financial',\n 'Topic :: Office/Business :: Financial :: Investment',\n 'Topic :: Scientific/Engineering :: Interface Engine/Protocol Translator',\n 'Topic :: Software Development :: Libraries',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Programming Language :: Python :: 3.10',\n ],\n platforms=['any'],\n keywords='pandas, yahoo finance, pandas datareader',\n packages=find_packages(exclude=['contrib', 'docs', 'tests', 'examples']),\n install_requires=['pandas>=1.3.0', 'numpy>=1.16.5',\n 'requests>=2.31', 'multitasking>=0.0.7',\n 'lxml>=4.9.1', 'appdirs>=1.4.4', 'pytz>=2022.5',\n 'frozendict>=2.3.4', 'peewee>=3.16.2',\n 'beautifulsoup4>=4.11.1', 'html5lib>=1.1'],\n extras_require={\n 'nospam': ['requests_cache>=1.0', 'requests_ratelimiter>=0.3.1'],\n 'repair': ['scipy>=1.6.3'],\n },\n # Note: Pandas.read_html() needs html5lib & beautifulsoup4\n entry_points={\n 'console_scripts': [\n 'sample=sample:main',\n ],\n },\n)\n\nprint(\"\"\"\nNOTE: yfinance is not affiliated, endorsed, or vetted by Yahoo, Inc.\n\nYou should refer to Yahoo!'s terms of use for details on your rights\nto use the actual data downloaded.\"\"\")\n", "path": "setup.py"}]}
| 1,961 | 173 |
gh_patches_debug_980
|
rasdani/github-patches
|
git_diff
|
docker__docker-py-1647
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
DockerClient.secrets is not a property
`DockerClient.secrets` is not decorated with `property` and so must be called rather than just accessed. This is inconsistent with the docs and similar collections on the client attribute (e.g. images, containers, etc.).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docker/client.py`
Content:
```
1 from .api.client import APIClient
2 from .models.containers import ContainerCollection
3 from .models.images import ImageCollection
4 from .models.networks import NetworkCollection
5 from .models.nodes import NodeCollection
6 from .models.plugins import PluginCollection
7 from .models.secrets import SecretCollection
8 from .models.services import ServiceCollection
9 from .models.swarm import Swarm
10 from .models.volumes import VolumeCollection
11 from .utils import kwargs_from_env
12
13
14 class DockerClient(object):
15 """
16 A client for communicating with a Docker server.
17
18 Example:
19
20 >>> import docker
21 >>> client = docker.DockerClient(base_url='unix://var/run/docker.sock')
22
23 Args:
24 base_url (str): URL to the Docker server. For example,
25 ``unix:///var/run/docker.sock`` or ``tcp://127.0.0.1:1234``.
26 version (str): The version of the API to use. Set to ``auto`` to
27 automatically detect the server's version. Default: ``1.26``
28 timeout (int): Default timeout for API calls, in seconds.
29 tls (bool or :py:class:`~docker.tls.TLSConfig`): Enable TLS. Pass
30 ``True`` to enable it with default options, or pass a
31 :py:class:`~docker.tls.TLSConfig` object to use custom
32 configuration.
33 user_agent (str): Set a custom user agent for requests to the server.
34 """
35 def __init__(self, *args, **kwargs):
36 self.api = APIClient(*args, **kwargs)
37
38 @classmethod
39 def from_env(cls, **kwargs):
40 """
41 Return a client configured from environment variables.
42
43 The environment variables used are the same as those used by the
44 Docker command-line client. They are:
45
46 .. envvar:: DOCKER_HOST
47
48 The URL to the Docker host.
49
50 .. envvar:: DOCKER_TLS_VERIFY
51
52 Verify the host against a CA certificate.
53
54 .. envvar:: DOCKER_CERT_PATH
55
56 A path to a directory containing TLS certificates to use when
57 connecting to the Docker host.
58
59 Args:
60 version (str): The version of the API to use. Set to ``auto`` to
61 automatically detect the server's version. Default: ``1.26``
62 timeout (int): Default timeout for API calls, in seconds.
63 ssl_version (int): A valid `SSL version`_.
64 assert_hostname (bool): Verify the hostname of the server.
65 environment (dict): The environment to read environment variables
66 from. Default: the value of ``os.environ``
67
68 Example:
69
70 >>> import docker
71 >>> client = docker.from_env()
72
73 .. _`SSL version`:
74 https://docs.python.org/3.5/library/ssl.html#ssl.PROTOCOL_TLSv1
75 """
76 timeout = kwargs.pop('timeout', None)
77 version = kwargs.pop('version', None)
78 return cls(timeout=timeout, version=version,
79 **kwargs_from_env(**kwargs))
80
81 # Resources
82 @property
83 def containers(self):
84 """
85 An object for managing containers on the server. See the
86 :doc:`containers documentation <containers>` for full details.
87 """
88 return ContainerCollection(client=self)
89
90 @property
91 def images(self):
92 """
93 An object for managing images on the server. See the
94 :doc:`images documentation <images>` for full details.
95 """
96 return ImageCollection(client=self)
97
98 @property
99 def networks(self):
100 """
101 An object for managing networks on the server. See the
102 :doc:`networks documentation <networks>` for full details.
103 """
104 return NetworkCollection(client=self)
105
106 @property
107 def nodes(self):
108 """
109 An object for managing nodes on the server. See the
110 :doc:`nodes documentation <nodes>` for full details.
111 """
112 return NodeCollection(client=self)
113
114 @property
115 def plugins(self):
116 """
117 An object for managing plugins on the server. See the
118 :doc:`plugins documentation <plugins>` for full details.
119 """
120 return PluginCollection(client=self)
121
122 def secrets(self):
123 """
124 An object for managing secrets on the server. See the
125 :doc:`secrets documentation <secrets>` for full details.
126 """
127 return SecretCollection(client=self)
128
129 @property
130 def services(self):
131 """
132 An object for managing services on the server. See the
133 :doc:`services documentation <services>` for full details.
134 """
135 return ServiceCollection(client=self)
136
137 @property
138 def swarm(self):
139 """
140 An object for managing a swarm on the server. See the
141 :doc:`swarm documentation <swarm>` for full details.
142 """
143 return Swarm(client=self)
144
145 @property
146 def volumes(self):
147 """
148 An object for managing volumes on the server. See the
149 :doc:`volumes documentation <volumes>` for full details.
150 """
151 return VolumeCollection(client=self)
152
153 # Top-level methods
154 def events(self, *args, **kwargs):
155 return self.api.events(*args, **kwargs)
156 events.__doc__ = APIClient.events.__doc__
157
158 def df(self):
159 return self.api.df()
160 df.__doc__ = APIClient.df.__doc__
161
162 def info(self, *args, **kwargs):
163 return self.api.info(*args, **kwargs)
164 info.__doc__ = APIClient.info.__doc__
165
166 def login(self, *args, **kwargs):
167 return self.api.login(*args, **kwargs)
168 login.__doc__ = APIClient.login.__doc__
169
170 def ping(self, *args, **kwargs):
171 return self.api.ping(*args, **kwargs)
172 ping.__doc__ = APIClient.ping.__doc__
173
174 def version(self, *args, **kwargs):
175 return self.api.version(*args, **kwargs)
176 version.__doc__ = APIClient.version.__doc__
177
178 def __getattr__(self, name):
179 s = ["'DockerClient' object has no attribute '{}'".format(name)]
180 # If a user calls a method on APIClient, they
181 if hasattr(APIClient, name):
182 s.append("In Docker SDK for Python 2.0, this method is now on the "
183 "object APIClient. See the low-level API section of the "
184 "documentation for more details.")
185 raise AttributeError(' '.join(s))
186
187
188 from_env = DockerClient.from_env
189
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docker/client.py b/docker/client.py
--- a/docker/client.py
+++ b/docker/client.py
@@ -119,6 +119,7 @@
"""
return PluginCollection(client=self)
+ @property
def secrets(self):
"""
An object for managing secrets on the server. See the
|
{"golden_diff": "diff --git a/docker/client.py b/docker/client.py\n--- a/docker/client.py\n+++ b/docker/client.py\n@@ -119,6 +119,7 @@\n \"\"\"\n return PluginCollection(client=self)\n \n+ @property\n def secrets(self):\n \"\"\"\n An object for managing secrets on the server. See the\n", "issue": "DockerClient.secrets is not a property\n`DockerClient.secrets` is not decorated with `property` and so must be called rather than just accessed. This is inconsistent with the docs and similar collections on the client attribute (e.g. images, containers, etc.).\n", "before_files": [{"content": "from .api.client import APIClient\nfrom .models.containers import ContainerCollection\nfrom .models.images import ImageCollection\nfrom .models.networks import NetworkCollection\nfrom .models.nodes import NodeCollection\nfrom .models.plugins import PluginCollection\nfrom .models.secrets import SecretCollection\nfrom .models.services import ServiceCollection\nfrom .models.swarm import Swarm\nfrom .models.volumes import VolumeCollection\nfrom .utils import kwargs_from_env\n\n\nclass DockerClient(object):\n \"\"\"\n A client for communicating with a Docker server.\n\n Example:\n\n >>> import docker\n >>> client = docker.DockerClient(base_url='unix://var/run/docker.sock')\n\n Args:\n base_url (str): URL to the Docker server. For example,\n ``unix:///var/run/docker.sock`` or ``tcp://127.0.0.1:1234``.\n version (str): The version of the API to use. Set to ``auto`` to\n automatically detect the server's version. Default: ``1.26``\n timeout (int): Default timeout for API calls, in seconds.\n tls (bool or :py:class:`~docker.tls.TLSConfig`): Enable TLS. Pass\n ``True`` to enable it with default options, or pass a\n :py:class:`~docker.tls.TLSConfig` object to use custom\n configuration.\n user_agent (str): Set a custom user agent for requests to the server.\n \"\"\"\n def __init__(self, *args, **kwargs):\n self.api = APIClient(*args, **kwargs)\n\n @classmethod\n def from_env(cls, **kwargs):\n \"\"\"\n Return a client configured from environment variables.\n\n The environment variables used are the same as those used by the\n Docker command-line client. They are:\n\n .. envvar:: DOCKER_HOST\n\n The URL to the Docker host.\n\n .. envvar:: DOCKER_TLS_VERIFY\n\n Verify the host against a CA certificate.\n\n .. envvar:: DOCKER_CERT_PATH\n\n A path to a directory containing TLS certificates to use when\n connecting to the Docker host.\n\n Args:\n version (str): The version of the API to use. Set to ``auto`` to\n automatically detect the server's version. Default: ``1.26``\n timeout (int): Default timeout for API calls, in seconds.\n ssl_version (int): A valid `SSL version`_.\n assert_hostname (bool): Verify the hostname of the server.\n environment (dict): The environment to read environment variables\n from. Default: the value of ``os.environ``\n\n Example:\n\n >>> import docker\n >>> client = docker.from_env()\n\n .. _`SSL version`:\n https://docs.python.org/3.5/library/ssl.html#ssl.PROTOCOL_TLSv1\n \"\"\"\n timeout = kwargs.pop('timeout', None)\n version = kwargs.pop('version', None)\n return cls(timeout=timeout, version=version,\n **kwargs_from_env(**kwargs))\n\n # Resources\n @property\n def containers(self):\n \"\"\"\n An object for managing containers on the server. See the\n :doc:`containers documentation <containers>` for full details.\n \"\"\"\n return ContainerCollection(client=self)\n\n @property\n def images(self):\n \"\"\"\n An object for managing images on the server. See the\n :doc:`images documentation <images>` for full details.\n \"\"\"\n return ImageCollection(client=self)\n\n @property\n def networks(self):\n \"\"\"\n An object for managing networks on the server. See the\n :doc:`networks documentation <networks>` for full details.\n \"\"\"\n return NetworkCollection(client=self)\n\n @property\n def nodes(self):\n \"\"\"\n An object for managing nodes on the server. See the\n :doc:`nodes documentation <nodes>` for full details.\n \"\"\"\n return NodeCollection(client=self)\n\n @property\n def plugins(self):\n \"\"\"\n An object for managing plugins on the server. See the\n :doc:`plugins documentation <plugins>` for full details.\n \"\"\"\n return PluginCollection(client=self)\n\n def secrets(self):\n \"\"\"\n An object for managing secrets on the server. See the\n :doc:`secrets documentation <secrets>` for full details.\n \"\"\"\n return SecretCollection(client=self)\n\n @property\n def services(self):\n \"\"\"\n An object for managing services on the server. See the\n :doc:`services documentation <services>` for full details.\n \"\"\"\n return ServiceCollection(client=self)\n\n @property\n def swarm(self):\n \"\"\"\n An object for managing a swarm on the server. See the\n :doc:`swarm documentation <swarm>` for full details.\n \"\"\"\n return Swarm(client=self)\n\n @property\n def volumes(self):\n \"\"\"\n An object for managing volumes on the server. See the\n :doc:`volumes documentation <volumes>` for full details.\n \"\"\"\n return VolumeCollection(client=self)\n\n # Top-level methods\n def events(self, *args, **kwargs):\n return self.api.events(*args, **kwargs)\n events.__doc__ = APIClient.events.__doc__\n\n def df(self):\n return self.api.df()\n df.__doc__ = APIClient.df.__doc__\n\n def info(self, *args, **kwargs):\n return self.api.info(*args, **kwargs)\n info.__doc__ = APIClient.info.__doc__\n\n def login(self, *args, **kwargs):\n return self.api.login(*args, **kwargs)\n login.__doc__ = APIClient.login.__doc__\n\n def ping(self, *args, **kwargs):\n return self.api.ping(*args, **kwargs)\n ping.__doc__ = APIClient.ping.__doc__\n\n def version(self, *args, **kwargs):\n return self.api.version(*args, **kwargs)\n version.__doc__ = APIClient.version.__doc__\n\n def __getattr__(self, name):\n s = [\"'DockerClient' object has no attribute '{}'\".format(name)]\n # If a user calls a method on APIClient, they\n if hasattr(APIClient, name):\n s.append(\"In Docker SDK for Python 2.0, this method is now on the \"\n \"object APIClient. See the low-level API section of the \"\n \"documentation for more details.\")\n raise AttributeError(' '.join(s))\n\n\nfrom_env = DockerClient.from_env\n", "path": "docker/client.py"}], "after_files": [{"content": "from .api.client import APIClient\nfrom .models.containers import ContainerCollection\nfrom .models.images import ImageCollection\nfrom .models.networks import NetworkCollection\nfrom .models.nodes import NodeCollection\nfrom .models.plugins import PluginCollection\nfrom .models.secrets import SecretCollection\nfrom .models.services import ServiceCollection\nfrom .models.swarm import Swarm\nfrom .models.volumes import VolumeCollection\nfrom .utils import kwargs_from_env\n\n\nclass DockerClient(object):\n \"\"\"\n A client for communicating with a Docker server.\n\n Example:\n\n >>> import docker\n >>> client = docker.DockerClient(base_url='unix://var/run/docker.sock')\n\n Args:\n base_url (str): URL to the Docker server. For example,\n ``unix:///var/run/docker.sock`` or ``tcp://127.0.0.1:1234``.\n version (str): The version of the API to use. Set to ``auto`` to\n automatically detect the server's version. Default: ``1.26``\n timeout (int): Default timeout for API calls, in seconds.\n tls (bool or :py:class:`~docker.tls.TLSConfig`): Enable TLS. Pass\n ``True`` to enable it with default options, or pass a\n :py:class:`~docker.tls.TLSConfig` object to use custom\n configuration.\n user_agent (str): Set a custom user agent for requests to the server.\n \"\"\"\n def __init__(self, *args, **kwargs):\n self.api = APIClient(*args, **kwargs)\n\n @classmethod\n def from_env(cls, **kwargs):\n \"\"\"\n Return a client configured from environment variables.\n\n The environment variables used are the same as those used by the\n Docker command-line client. They are:\n\n .. envvar:: DOCKER_HOST\n\n The URL to the Docker host.\n\n .. envvar:: DOCKER_TLS_VERIFY\n\n Verify the host against a CA certificate.\n\n .. envvar:: DOCKER_CERT_PATH\n\n A path to a directory containing TLS certificates to use when\n connecting to the Docker host.\n\n Args:\n version (str): The version of the API to use. Set to ``auto`` to\n automatically detect the server's version. Default: ``1.26``\n timeout (int): Default timeout for API calls, in seconds.\n ssl_version (int): A valid `SSL version`_.\n assert_hostname (bool): Verify the hostname of the server.\n environment (dict): The environment to read environment variables\n from. Default: the value of ``os.environ``\n\n Example:\n\n >>> import docker\n >>> client = docker.from_env()\n\n .. _`SSL version`:\n https://docs.python.org/3.5/library/ssl.html#ssl.PROTOCOL_TLSv1\n \"\"\"\n timeout = kwargs.pop('timeout', None)\n version = kwargs.pop('version', None)\n return cls(timeout=timeout, version=version,\n **kwargs_from_env(**kwargs))\n\n # Resources\n @property\n def containers(self):\n \"\"\"\n An object for managing containers on the server. See the\n :doc:`containers documentation <containers>` for full details.\n \"\"\"\n return ContainerCollection(client=self)\n\n @property\n def images(self):\n \"\"\"\n An object for managing images on the server. See the\n :doc:`images documentation <images>` for full details.\n \"\"\"\n return ImageCollection(client=self)\n\n @property\n def networks(self):\n \"\"\"\n An object for managing networks on the server. See the\n :doc:`networks documentation <networks>` for full details.\n \"\"\"\n return NetworkCollection(client=self)\n\n @property\n def nodes(self):\n \"\"\"\n An object for managing nodes on the server. See the\n :doc:`nodes documentation <nodes>` for full details.\n \"\"\"\n return NodeCollection(client=self)\n\n @property\n def plugins(self):\n \"\"\"\n An object for managing plugins on the server. See the\n :doc:`plugins documentation <plugins>` for full details.\n \"\"\"\n return PluginCollection(client=self)\n\n @property\n def secrets(self):\n \"\"\"\n An object for managing secrets on the server. See the\n :doc:`secrets documentation <secrets>` for full details.\n \"\"\"\n return SecretCollection(client=self)\n\n @property\n def services(self):\n \"\"\"\n An object for managing services on the server. See the\n :doc:`services documentation <services>` for full details.\n \"\"\"\n return ServiceCollection(client=self)\n\n @property\n def swarm(self):\n \"\"\"\n An object for managing a swarm on the server. See the\n :doc:`swarm documentation <swarm>` for full details.\n \"\"\"\n return Swarm(client=self)\n\n @property\n def volumes(self):\n \"\"\"\n An object for managing volumes on the server. See the\n :doc:`volumes documentation <volumes>` for full details.\n \"\"\"\n return VolumeCollection(client=self)\n\n # Top-level methods\n def events(self, *args, **kwargs):\n return self.api.events(*args, **kwargs)\n events.__doc__ = APIClient.events.__doc__\n\n def df(self):\n return self.api.df()\n df.__doc__ = APIClient.df.__doc__\n\n def info(self, *args, **kwargs):\n return self.api.info(*args, **kwargs)\n info.__doc__ = APIClient.info.__doc__\n\n def login(self, *args, **kwargs):\n return self.api.login(*args, **kwargs)\n login.__doc__ = APIClient.login.__doc__\n\n def ping(self, *args, **kwargs):\n return self.api.ping(*args, **kwargs)\n ping.__doc__ = APIClient.ping.__doc__\n\n def version(self, *args, **kwargs):\n return self.api.version(*args, **kwargs)\n version.__doc__ = APIClient.version.__doc__\n\n def __getattr__(self, name):\n s = [\"'DockerClient' object has no attribute '{}'\".format(name)]\n # If a user calls a method on APIClient, they\n if hasattr(APIClient, name):\n s.append(\"In Docker SDK for Python 2.0, this method is now on the \"\n \"object APIClient. See the low-level API section of the \"\n \"documentation for more details.\")\n raise AttributeError(' '.join(s))\n\n\nfrom_env = DockerClient.from_env\n", "path": "docker/client.py"}]}
| 2,174 | 73 |
gh_patches_debug_6569
|
rasdani/github-patches
|
git_diff
|
Lightning-Universe__lightning-bolts-230
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CPCv2-Resnet18 pretrained not available
Hi,
When I try to load a pretrained CPCv2-resnet18 model, I get an `urllib.error.HTTPError: HTTP Error 403: Forbidden` error. The code I use to load the pretrained model is
```
model = CPCV2(encoder='resnet18', pretrained=True)
x = torch.rand(1, 3, 224, 224)
feats = model.encoder(x)
```
The following URL doesn't seem to open on my browser (Chrome) too.
https://github.com/PyTorchLightning/pytorch-lightning-bolts/blob/32fb560a429532dfb40a5935ca7674990dae1f66/pl_bolts/utils/pretrained_weights.py#L6
Any help is much appreciated.
Thanks!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pl_bolts/utils/pretrained_weights.py`
Content:
```
1
2
3 vae_imagenet2012 = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/' \
4 'vae/imagenet_06_22_2019/checkpoints/epoch%3D63.ckpt'
5
6 cpcv2_resnet18 = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/' \
7 'cpc/resnet18_version_6/checkpoints/epoch%3D85.ckpt'
8 urls = {
9 'vae-imagenet2012': vae_imagenet2012,
10 'CPCV2-resnet18': cpcv2_resnet18
11 }
12
13
14 def load_pretrained(model, class_name=None): # pragma: no-cover
15 if class_name is None:
16 class_name = model.__class__.__name__
17 ckpt_url = urls[class_name]
18 weights_model = model.__class__.load_from_checkpoint(ckpt_url)
19 model.load_state_dict(weights_model.state_dict())
20
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pl_bolts/utils/pretrained_weights.py b/pl_bolts/utils/pretrained_weights.py
--- a/pl_bolts/utils/pretrained_weights.py
+++ b/pl_bolts/utils/pretrained_weights.py
@@ -4,7 +4,7 @@
'vae/imagenet_06_22_2019/checkpoints/epoch%3D63.ckpt'
cpcv2_resnet18 = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/' \
- 'cpc/resnet18_version_6/checkpoints/epoch%3D85.ckpt'
+ 'cpc/resnet18-v6/epoch%3D85.ckpt'
urls = {
'vae-imagenet2012': vae_imagenet2012,
'CPCV2-resnet18': cpcv2_resnet18
|
{"golden_diff": "diff --git a/pl_bolts/utils/pretrained_weights.py b/pl_bolts/utils/pretrained_weights.py\n--- a/pl_bolts/utils/pretrained_weights.py\n+++ b/pl_bolts/utils/pretrained_weights.py\n@@ -4,7 +4,7 @@\n 'vae/imagenet_06_22_2019/checkpoints/epoch%3D63.ckpt'\n \n cpcv2_resnet18 = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/' \\\n- 'cpc/resnet18_version_6/checkpoints/epoch%3D85.ckpt'\n+ 'cpc/resnet18-v6/epoch%3D85.ckpt'\n urls = {\n 'vae-imagenet2012': vae_imagenet2012,\n 'CPCV2-resnet18': cpcv2_resnet18\n", "issue": "CPCv2-Resnet18 pretrained not available\nHi, \r\nWhen I try to load a pretrained CPCv2-resnet18 model, I get an `urllib.error.HTTPError: HTTP Error 403: Forbidden` error. The code I use to load the pretrained model is \r\n```\r\nmodel = CPCV2(encoder='resnet18', pretrained=True)\r\nx = torch.rand(1, 3, 224, 224)\r\nfeats = model.encoder(x)\r\n```\r\nThe following URL doesn't seem to open on my browser (Chrome) too. \r\nhttps://github.com/PyTorchLightning/pytorch-lightning-bolts/blob/32fb560a429532dfb40a5935ca7674990dae1f66/pl_bolts/utils/pretrained_weights.py#L6\r\n\r\nAny help is much appreciated.\r\nThanks! \r\n\n", "before_files": [{"content": "\n\nvae_imagenet2012 = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/' \\\n 'vae/imagenet_06_22_2019/checkpoints/epoch%3D63.ckpt'\n\ncpcv2_resnet18 = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/' \\\n 'cpc/resnet18_version_6/checkpoints/epoch%3D85.ckpt'\nurls = {\n 'vae-imagenet2012': vae_imagenet2012,\n 'CPCV2-resnet18': cpcv2_resnet18\n}\n\n\ndef load_pretrained(model, class_name=None): # pragma: no-cover\n if class_name is None:\n class_name = model.__class__.__name__\n ckpt_url = urls[class_name]\n weights_model = model.__class__.load_from_checkpoint(ckpt_url)\n model.load_state_dict(weights_model.state_dict())\n", "path": "pl_bolts/utils/pretrained_weights.py"}], "after_files": [{"content": "\n\nvae_imagenet2012 = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/' \\\n 'vae/imagenet_06_22_2019/checkpoints/epoch%3D63.ckpt'\n\ncpcv2_resnet18 = 'https://pl-bolts-weights.s3.us-east-2.amazonaws.com/' \\\n 'cpc/resnet18-v6/epoch%3D85.ckpt'\nurls = {\n 'vae-imagenet2012': vae_imagenet2012,\n 'CPCV2-resnet18': cpcv2_resnet18\n}\n\n\ndef load_pretrained(model, class_name=None): # pragma: no-cover\n if class_name is None:\n class_name = model.__class__.__name__\n ckpt_url = urls[class_name]\n weights_model = model.__class__.load_from_checkpoint(ckpt_url)\n model.load_state_dict(weights_model.state_dict())\n", "path": "pl_bolts/utils/pretrained_weights.py"}]}
| 726 | 205 |
gh_patches_debug_31364
|
rasdani/github-patches
|
git_diff
|
cupy__cupy-4678
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add Windows support in cuTENSOR download tool
https://github.com/cupy/cupy/pull/4560#issuecomment-764422155
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cupyx/tools/install_library.py`
Content:
```
1 #!/usr/bin/env python
2
3 """
4 CUDA Library Installer
5
6 Installs the latest CUDA library supported by CuPy.
7 """
8
9 # This script will also be used as a standalone script when building wheels.
10 # Keep the script runnable without CuPy dependency.
11
12 import argparse
13 import json
14 import os
15 import platform
16 import shutil
17 import sys
18 import tempfile
19 import urllib.request
20
21
22 _cudnn_records = []
23 _cutensor_records = []
24 library_records = {}
25
26
27 def _make_cudnn_url(public_version, filename):
28 # https://developer.download.nvidia.com/compute/redist/cudnn/v8.0.2/cudnn-11.0-linux-x64-v8.0.2.39.tgz
29 return (
30 'https://developer.download.nvidia.com/compute/redist/cudnn' +
31 '/v{}/{}'.format(public_version, filename))
32
33
34 def _make_cudnn_record(
35 cuda_version, public_version, filename_linux, filename_windows):
36 major_version = public_version.split('.')[0]
37 return {
38 'cuda': cuda_version,
39 'cudnn': public_version,
40 'assets': {
41 'Linux': {
42 'url': _make_cudnn_url(public_version, filename_linux),
43 'filename': 'libcudnn.so.{}'.format(public_version),
44 },
45 'Windows': {
46 'url': _make_cudnn_url(public_version, filename_windows),
47 'filename': 'cudnn64_{}.dll'.format(major_version),
48 },
49 }
50 }
51
52
53 # Latest cuDNN versions: https://developer.nvidia.com/rdp/cudnn-download
54 _cudnn_records.append(_make_cudnn_record(
55 '11.1', '8.1.0',
56 'cudnn-11.2-linux-x64-v8.1.0.77.tgz',
57 'cudnn-11.2-windows-x64-v8.1.0.77.zip'))
58 _cudnn_records.append(_make_cudnn_record(
59 '11.0', '8.1.0',
60 'cudnn-11.2-linux-x64-v8.1.0.77.tgz',
61 'cudnn-11.2-windows-x64-v8.1.0.77.zip'))
62 _cudnn_records.append(_make_cudnn_record(
63 '10.2', '8.1.0',
64 'cudnn-10.2-linux-x64-v8.1.0.77.tgz',
65 'cudnn-10.2-windows10-x64-v8.1.0.77.zip'))
66 _cudnn_records.append(_make_cudnn_record(
67 '10.1', '8.0.5',
68 'cudnn-10.1-linux-x64-v8.0.5.39.tgz',
69 'cudnn-10.1-windows10-x64-v8.0.5.39.zip'))
70 _cudnn_records.append(_make_cudnn_record(
71 '10.0', '7.6.5',
72 'cudnn-10.0-linux-x64-v7.6.5.32.tgz',
73 'cudnn-10.0-windows10-x64-v7.6.5.32.zip'))
74 _cudnn_records.append(_make_cudnn_record(
75 '9.2', '7.6.5',
76 'cudnn-9.2-linux-x64-v7.6.5.32.tgz',
77 'cudnn-9.2-windows10-x64-v7.6.5.32.zip'))
78 library_records['cudnn'] = _cudnn_records
79
80
81 def _make_cutensor_url(public_version, filename):
82 # https://developer.download.nvidia.com/compute/cutensor/1.2.2/local_installers/libcutensor-linux-x86_64-1.2.2.5.tar.gz
83 return (
84 'https://developer.download.nvidia.com/compute/cutensor/' +
85 '{}/local_installers/{}'.format(public_version, filename))
86
87
88 def _make_cutensor_record(
89 cuda_version, public_version, filename_linux, filename_windows=''):
90 # TODO(leofang): Support Windows when a public link becomes available
91 return {
92 'cuda': cuda_version,
93 'cutensor': public_version,
94 'assets': {
95 'Linux': {
96 'url': _make_cutensor_url(public_version, filename_linux),
97 'filename': 'libcutensor.so.{}'.format(public_version),
98 },
99 }
100 }
101
102
103 _cutensor_records.append(_make_cutensor_record(
104 '11.1', '1.2.2',
105 'libcutensor-linux-x86_64-1.2.2.5.tar.gz', ''))
106 _cutensor_records.append(_make_cutensor_record(
107 '11.0', '1.2.2',
108 'libcutensor-linux-x86_64-1.2.2.5.tar.gz', ''))
109 _cutensor_records.append(_make_cutensor_record(
110 '10.2', '1.2.2',
111 'libcutensor-linux-x86_64-1.2.2.5.tar.gz', ''))
112 _cutensor_records.append(_make_cutensor_record(
113 '10.1', '1.2.2',
114 'libcutensor-linux-x86_64-1.2.2.5.tar.gz', ''))
115 library_records['cutensor'] = _cutensor_records
116
117
118 def install_lib(cuda, prefix, library):
119 record = None
120 lib_records = library_records
121 for record in lib_records[library]:
122 if record['cuda'] == cuda:
123 break
124 else:
125 raise RuntimeError('''
126 The CUDA version specified is not supported.
127 Should be one of {}.'''.format(str([x['cuda'] for x in lib_records[library]])))
128 if prefix is None:
129 prefix = os.path.expanduser('~/.cupy/cuda_lib')
130 destination = calculate_destination(prefix, cuda, library, record[library])
131
132 if os.path.exists(destination):
133 raise RuntimeError('''
134 The destination directory {} already exists.
135 Remove the directory first if you want to reinstall.'''.format(destination))
136 asset = record['assets'][platform.system()]
137
138 print('Installing {} {} for CUDA {} to: {}'.format(
139 library, record[library], record['cuda'], destination))
140
141 url = asset['url']
142 print('Downloading {}...'.format(url))
143 with tempfile.TemporaryDirectory() as tmpdir:
144 with open(os.path.join(tmpdir, os.path.basename(url)), 'wb') as f:
145 with urllib.request.urlopen(url) as response:
146 f.write(response.read())
147 print('Extracting...')
148 shutil.unpack_archive(f.name, tmpdir)
149 print('Installing...')
150 if library == 'cudnn':
151 shutil.move(os.path.join(tmpdir, 'cuda'), destination)
152 elif library == 'cutensor':
153 include = os.path.join(destination, 'include')
154 lib = os.path.join(destination, 'lib64')
155 shutil.move(os.path.join(tmpdir, 'libcutensor/include'), include)
156 if cuda.startswith('11'):
157 cuda = '11'
158 shutil.move(os.path.join(tmpdir, 'libcutensor/lib', cuda), lib)
159 print('Cleaning up...')
160 print('Done!')
161
162
163 def calculate_destination(prefix, cuda, lib, lib_ver):
164 """Calculates the installation directory.
165
166 ~/.cupy/cuda_lib/{cuda_version}/{library_name}/{library_version}
167 """
168 return os.path.join(prefix, cuda, lib, lib_ver)
169
170
171 def main(args):
172 parser = argparse.ArgumentParser()
173
174 # TODO(kmaehashi): support NCCL
175 parser.add_argument('--library',
176 choices=['cudnn', 'cutensor'],
177 required=True,
178 help='Library to install')
179 parser.add_argument('--cuda', type=str, required=True,
180 help='CUDA version')
181 parser.add_argument('--prefix', type=str, default=None,
182 help='Install destination')
183 parser.add_argument('--action', choices=['install', 'dump'],
184 default='install',
185 help='Action to perform')
186 params = parser.parse_args(args)
187
188 if params.prefix is not None:
189 params.prefix = os.path.abspath(params.prefix)
190
191 if params.library == 'cudnn':
192 if params.action == 'install':
193 install_lib(params.cuda, params.prefix, 'cudnn')
194 elif params.action == 'dump':
195 print(json.dumps(_cudnn_records, indent=4))
196 else:
197 assert False
198 elif params.library == 'cutensor':
199 if params.action == 'install':
200 install_lib(params.cuda, params.prefix, 'cutensor')
201 elif params.action == 'dump':
202 print(json.dumps(_cutensor_records, indent=4))
203 else:
204 assert False
205 else:
206 assert False
207
208
209 if __name__ == '__main__':
210 main(sys.argv[1:])
211
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cupyx/tools/install_library.py b/cupyx/tools/install_library.py
--- a/cupyx/tools/install_library.py
+++ b/cupyx/tools/install_library.py
@@ -86,8 +86,7 @@
def _make_cutensor_record(
- cuda_version, public_version, filename_linux, filename_windows=''):
- # TODO(leofang): Support Windows when a public link becomes available
+ cuda_version, public_version, filename_linux, filename_windows):
return {
'cuda': cuda_version,
'cutensor': public_version,
@@ -96,22 +95,30 @@
'url': _make_cutensor_url(public_version, filename_linux),
'filename': 'libcutensor.so.{}'.format(public_version),
},
+ 'Windows': {
+ 'url': _make_cutensor_url(public_version, filename_windows),
+ 'filename': 'cutensor.dll',
+ },
}
}
_cutensor_records.append(_make_cutensor_record(
'11.1', '1.2.2',
- 'libcutensor-linux-x86_64-1.2.2.5.tar.gz', ''))
+ 'libcutensor-linux-x86_64-1.2.2.5.tar.gz',
+ 'libcutensor-windows-x86_64-1.2.2.5.zip'))
_cutensor_records.append(_make_cutensor_record(
'11.0', '1.2.2',
- 'libcutensor-linux-x86_64-1.2.2.5.tar.gz', ''))
+ 'libcutensor-linux-x86_64-1.2.2.5.tar.gz',
+ 'libcutensor-windows-x86_64-1.2.2.5.zip'))
_cutensor_records.append(_make_cutensor_record(
'10.2', '1.2.2',
- 'libcutensor-linux-x86_64-1.2.2.5.tar.gz', ''))
+ 'libcutensor-linux-x86_64-1.2.2.5.tar.gz',
+ 'libcutensor-windows-x86_64-1.2.2.5.zip'))
_cutensor_records.append(_make_cutensor_record(
'10.1', '1.2.2',
- 'libcutensor-linux-x86_64-1.2.2.5.tar.gz', ''))
+ 'libcutensor-linux-x86_64-1.2.2.5.tar.gz',
+ 'libcutensor-windows-x86_64-1.2.2.5.zip'))
library_records['cutensor'] = _cutensor_records
|
{"golden_diff": "diff --git a/cupyx/tools/install_library.py b/cupyx/tools/install_library.py\n--- a/cupyx/tools/install_library.py\n+++ b/cupyx/tools/install_library.py\n@@ -86,8 +86,7 @@\n \n \n def _make_cutensor_record(\n- cuda_version, public_version, filename_linux, filename_windows=''):\n- # TODO(leofang): Support Windows when a public link becomes available\n+ cuda_version, public_version, filename_linux, filename_windows):\n return {\n 'cuda': cuda_version,\n 'cutensor': public_version,\n@@ -96,22 +95,30 @@\n 'url': _make_cutensor_url(public_version, filename_linux),\n 'filename': 'libcutensor.so.{}'.format(public_version),\n },\n+ 'Windows': {\n+ 'url': _make_cutensor_url(public_version, filename_windows),\n+ 'filename': 'cutensor.dll',\n+ },\n }\n }\n \n \n _cutensor_records.append(_make_cutensor_record(\n '11.1', '1.2.2',\n- 'libcutensor-linux-x86_64-1.2.2.5.tar.gz', ''))\n+ 'libcutensor-linux-x86_64-1.2.2.5.tar.gz',\n+ 'libcutensor-windows-x86_64-1.2.2.5.zip'))\n _cutensor_records.append(_make_cutensor_record(\n '11.0', '1.2.2',\n- 'libcutensor-linux-x86_64-1.2.2.5.tar.gz', ''))\n+ 'libcutensor-linux-x86_64-1.2.2.5.tar.gz',\n+ 'libcutensor-windows-x86_64-1.2.2.5.zip'))\n _cutensor_records.append(_make_cutensor_record(\n '10.2', '1.2.2',\n- 'libcutensor-linux-x86_64-1.2.2.5.tar.gz', ''))\n+ 'libcutensor-linux-x86_64-1.2.2.5.tar.gz',\n+ 'libcutensor-windows-x86_64-1.2.2.5.zip'))\n _cutensor_records.append(_make_cutensor_record(\n '10.1', '1.2.2',\n- 'libcutensor-linux-x86_64-1.2.2.5.tar.gz', ''))\n+ 'libcutensor-linux-x86_64-1.2.2.5.tar.gz',\n+ 'libcutensor-windows-x86_64-1.2.2.5.zip'))\n library_records['cutensor'] = _cutensor_records\n", "issue": "Add Windows support in cuTENSOR download tool\nhttps://github.com/cupy/cupy/pull/4560#issuecomment-764422155\n", "before_files": [{"content": "#!/usr/bin/env python\n\n\"\"\"\nCUDA Library Installer\n\nInstalls the latest CUDA library supported by CuPy.\n\"\"\"\n\n# This script will also be used as a standalone script when building wheels.\n# Keep the script runnable without CuPy dependency.\n\nimport argparse\nimport json\nimport os\nimport platform\nimport shutil\nimport sys\nimport tempfile\nimport urllib.request\n\n\n_cudnn_records = []\n_cutensor_records = []\nlibrary_records = {}\n\n\ndef _make_cudnn_url(public_version, filename):\n # https://developer.download.nvidia.com/compute/redist/cudnn/v8.0.2/cudnn-11.0-linux-x64-v8.0.2.39.tgz\n return (\n 'https://developer.download.nvidia.com/compute/redist/cudnn' +\n '/v{}/{}'.format(public_version, filename))\n\n\ndef _make_cudnn_record(\n cuda_version, public_version, filename_linux, filename_windows):\n major_version = public_version.split('.')[0]\n return {\n 'cuda': cuda_version,\n 'cudnn': public_version,\n 'assets': {\n 'Linux': {\n 'url': _make_cudnn_url(public_version, filename_linux),\n 'filename': 'libcudnn.so.{}'.format(public_version),\n },\n 'Windows': {\n 'url': _make_cudnn_url(public_version, filename_windows),\n 'filename': 'cudnn64_{}.dll'.format(major_version),\n },\n }\n }\n\n\n# Latest cuDNN versions: https://developer.nvidia.com/rdp/cudnn-download\n_cudnn_records.append(_make_cudnn_record(\n '11.1', '8.1.0',\n 'cudnn-11.2-linux-x64-v8.1.0.77.tgz',\n 'cudnn-11.2-windows-x64-v8.1.0.77.zip'))\n_cudnn_records.append(_make_cudnn_record(\n '11.0', '8.1.0',\n 'cudnn-11.2-linux-x64-v8.1.0.77.tgz',\n 'cudnn-11.2-windows-x64-v8.1.0.77.zip'))\n_cudnn_records.append(_make_cudnn_record(\n '10.2', '8.1.0',\n 'cudnn-10.2-linux-x64-v8.1.0.77.tgz',\n 'cudnn-10.2-windows10-x64-v8.1.0.77.zip'))\n_cudnn_records.append(_make_cudnn_record(\n '10.1', '8.0.5',\n 'cudnn-10.1-linux-x64-v8.0.5.39.tgz',\n 'cudnn-10.1-windows10-x64-v8.0.5.39.zip'))\n_cudnn_records.append(_make_cudnn_record(\n '10.0', '7.6.5',\n 'cudnn-10.0-linux-x64-v7.6.5.32.tgz',\n 'cudnn-10.0-windows10-x64-v7.6.5.32.zip'))\n_cudnn_records.append(_make_cudnn_record(\n '9.2', '7.6.5',\n 'cudnn-9.2-linux-x64-v7.6.5.32.tgz',\n 'cudnn-9.2-windows10-x64-v7.6.5.32.zip'))\nlibrary_records['cudnn'] = _cudnn_records\n\n\ndef _make_cutensor_url(public_version, filename):\n # https://developer.download.nvidia.com/compute/cutensor/1.2.2/local_installers/libcutensor-linux-x86_64-1.2.2.5.tar.gz\n return (\n 'https://developer.download.nvidia.com/compute/cutensor/' +\n '{}/local_installers/{}'.format(public_version, filename))\n\n\ndef _make_cutensor_record(\n cuda_version, public_version, filename_linux, filename_windows=''):\n # TODO(leofang): Support Windows when a public link becomes available\n return {\n 'cuda': cuda_version,\n 'cutensor': public_version,\n 'assets': {\n 'Linux': {\n 'url': _make_cutensor_url(public_version, filename_linux),\n 'filename': 'libcutensor.so.{}'.format(public_version),\n },\n }\n }\n\n\n_cutensor_records.append(_make_cutensor_record(\n '11.1', '1.2.2',\n 'libcutensor-linux-x86_64-1.2.2.5.tar.gz', ''))\n_cutensor_records.append(_make_cutensor_record(\n '11.0', '1.2.2',\n 'libcutensor-linux-x86_64-1.2.2.5.tar.gz', ''))\n_cutensor_records.append(_make_cutensor_record(\n '10.2', '1.2.2',\n 'libcutensor-linux-x86_64-1.2.2.5.tar.gz', ''))\n_cutensor_records.append(_make_cutensor_record(\n '10.1', '1.2.2',\n 'libcutensor-linux-x86_64-1.2.2.5.tar.gz', ''))\nlibrary_records['cutensor'] = _cutensor_records\n\n\ndef install_lib(cuda, prefix, library):\n record = None\n lib_records = library_records\n for record in lib_records[library]:\n if record['cuda'] == cuda:\n break\n else:\n raise RuntimeError('''\nThe CUDA version specified is not supported.\nShould be one of {}.'''.format(str([x['cuda'] for x in lib_records[library]])))\n if prefix is None:\n prefix = os.path.expanduser('~/.cupy/cuda_lib')\n destination = calculate_destination(prefix, cuda, library, record[library])\n\n if os.path.exists(destination):\n raise RuntimeError('''\nThe destination directory {} already exists.\nRemove the directory first if you want to reinstall.'''.format(destination))\n asset = record['assets'][platform.system()]\n\n print('Installing {} {} for CUDA {} to: {}'.format(\n library, record[library], record['cuda'], destination))\n\n url = asset['url']\n print('Downloading {}...'.format(url))\n with tempfile.TemporaryDirectory() as tmpdir:\n with open(os.path.join(tmpdir, os.path.basename(url)), 'wb') as f:\n with urllib.request.urlopen(url) as response:\n f.write(response.read())\n print('Extracting...')\n shutil.unpack_archive(f.name, tmpdir)\n print('Installing...')\n if library == 'cudnn':\n shutil.move(os.path.join(tmpdir, 'cuda'), destination)\n elif library == 'cutensor':\n include = os.path.join(destination, 'include')\n lib = os.path.join(destination, 'lib64')\n shutil.move(os.path.join(tmpdir, 'libcutensor/include'), include)\n if cuda.startswith('11'):\n cuda = '11'\n shutil.move(os.path.join(tmpdir, 'libcutensor/lib', cuda), lib)\n print('Cleaning up...')\n print('Done!')\n\n\ndef calculate_destination(prefix, cuda, lib, lib_ver):\n \"\"\"Calculates the installation directory.\n\n ~/.cupy/cuda_lib/{cuda_version}/{library_name}/{library_version}\n \"\"\"\n return os.path.join(prefix, cuda, lib, lib_ver)\n\n\ndef main(args):\n parser = argparse.ArgumentParser()\n\n # TODO(kmaehashi): support NCCL\n parser.add_argument('--library',\n choices=['cudnn', 'cutensor'],\n required=True,\n help='Library to install')\n parser.add_argument('--cuda', type=str, required=True,\n help='CUDA version')\n parser.add_argument('--prefix', type=str, default=None,\n help='Install destination')\n parser.add_argument('--action', choices=['install', 'dump'],\n default='install',\n help='Action to perform')\n params = parser.parse_args(args)\n\n if params.prefix is not None:\n params.prefix = os.path.abspath(params.prefix)\n\n if params.library == 'cudnn':\n if params.action == 'install':\n install_lib(params.cuda, params.prefix, 'cudnn')\n elif params.action == 'dump':\n print(json.dumps(_cudnn_records, indent=4))\n else:\n assert False\n elif params.library == 'cutensor':\n if params.action == 'install':\n install_lib(params.cuda, params.prefix, 'cutensor')\n elif params.action == 'dump':\n print(json.dumps(_cutensor_records, indent=4))\n else:\n assert False\n else:\n assert False\n\n\nif __name__ == '__main__':\n main(sys.argv[1:])\n", "path": "cupyx/tools/install_library.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\n\"\"\"\nCUDA Library Installer\n\nInstalls the latest CUDA library supported by CuPy.\n\"\"\"\n\n# This script will also be used as a standalone script when building wheels.\n# Keep the script runnable without CuPy dependency.\n\nimport argparse\nimport json\nimport os\nimport platform\nimport shutil\nimport sys\nimport tempfile\nimport urllib.request\n\n\n_cudnn_records = []\n_cutensor_records = []\nlibrary_records = {}\n\n\ndef _make_cudnn_url(public_version, filename):\n # https://developer.download.nvidia.com/compute/redist/cudnn/v8.0.2/cudnn-11.0-linux-x64-v8.0.2.39.tgz\n return (\n 'https://developer.download.nvidia.com/compute/redist/cudnn' +\n '/v{}/{}'.format(public_version, filename))\n\n\ndef _make_cudnn_record(\n cuda_version, public_version, filename_linux, filename_windows):\n major_version = public_version.split('.')[0]\n return {\n 'cuda': cuda_version,\n 'cudnn': public_version,\n 'assets': {\n 'Linux': {\n 'url': _make_cudnn_url(public_version, filename_linux),\n 'filename': 'libcudnn.so.{}'.format(public_version),\n },\n 'Windows': {\n 'url': _make_cudnn_url(public_version, filename_windows),\n 'filename': 'cudnn64_{}.dll'.format(major_version),\n },\n }\n }\n\n\n# Latest cuDNN versions: https://developer.nvidia.com/rdp/cudnn-download\n_cudnn_records.append(_make_cudnn_record(\n '11.1', '8.1.0',\n 'cudnn-11.2-linux-x64-v8.1.0.77.tgz',\n 'cudnn-11.2-windows-x64-v8.1.0.77.zip'))\n_cudnn_records.append(_make_cudnn_record(\n '11.0', '8.1.0',\n 'cudnn-11.2-linux-x64-v8.1.0.77.tgz',\n 'cudnn-11.2-windows-x64-v8.1.0.77.zip'))\n_cudnn_records.append(_make_cudnn_record(\n '10.2', '8.1.0',\n 'cudnn-10.2-linux-x64-v8.1.0.77.tgz',\n 'cudnn-10.2-windows10-x64-v8.1.0.77.zip'))\n_cudnn_records.append(_make_cudnn_record(\n '10.1', '8.0.5',\n 'cudnn-10.1-linux-x64-v8.0.5.39.tgz',\n 'cudnn-10.1-windows10-x64-v8.0.5.39.zip'))\n_cudnn_records.append(_make_cudnn_record(\n '10.0', '7.6.5',\n 'cudnn-10.0-linux-x64-v7.6.5.32.tgz',\n 'cudnn-10.0-windows10-x64-v7.6.5.32.zip'))\n_cudnn_records.append(_make_cudnn_record(\n '9.2', '7.6.5',\n 'cudnn-9.2-linux-x64-v7.6.5.32.tgz',\n 'cudnn-9.2-windows10-x64-v7.6.5.32.zip'))\nlibrary_records['cudnn'] = _cudnn_records\n\n\ndef _make_cutensor_url(public_version, filename):\n # https://developer.download.nvidia.com/compute/cutensor/1.2.2/local_installers/libcutensor-linux-x86_64-1.2.2.5.tar.gz\n return (\n 'https://developer.download.nvidia.com/compute/cutensor/' +\n '{}/local_installers/{}'.format(public_version, filename))\n\n\ndef _make_cutensor_record(\n cuda_version, public_version, filename_linux, filename_windows):\n return {\n 'cuda': cuda_version,\n 'cutensor': public_version,\n 'assets': {\n 'Linux': {\n 'url': _make_cutensor_url(public_version, filename_linux),\n 'filename': 'libcutensor.so.{}'.format(public_version),\n },\n 'Windows': {\n 'url': _make_cutensor_url(public_version, filename_windows),\n 'filename': 'cutensor.dll',\n },\n }\n }\n\n\n_cutensor_records.append(_make_cutensor_record(\n '11.1', '1.2.2',\n 'libcutensor-linux-x86_64-1.2.2.5.tar.gz',\n 'libcutensor-windows-x86_64-1.2.2.5.zip'))\n_cutensor_records.append(_make_cutensor_record(\n '11.0', '1.2.2',\n 'libcutensor-linux-x86_64-1.2.2.5.tar.gz',\n 'libcutensor-windows-x86_64-1.2.2.5.zip'))\n_cutensor_records.append(_make_cutensor_record(\n '10.2', '1.2.2',\n 'libcutensor-linux-x86_64-1.2.2.5.tar.gz',\n 'libcutensor-windows-x86_64-1.2.2.5.zip'))\n_cutensor_records.append(_make_cutensor_record(\n '10.1', '1.2.2',\n 'libcutensor-linux-x86_64-1.2.2.5.tar.gz',\n 'libcutensor-windows-x86_64-1.2.2.5.zip'))\nlibrary_records['cutensor'] = _cutensor_records\n\n\ndef install_lib(cuda, prefix, library):\n record = None\n lib_records = library_records\n for record in lib_records[library]:\n if record['cuda'] == cuda:\n break\n else:\n raise RuntimeError('''\nThe CUDA version specified is not supported.\nShould be one of {}.'''.format(str([x['cuda'] for x in lib_records[library]])))\n if prefix is None:\n prefix = os.path.expanduser('~/.cupy/cuda_lib')\n destination = calculate_destination(prefix, cuda, library, record[library])\n\n if os.path.exists(destination):\n raise RuntimeError('''\nThe destination directory {} already exists.\nRemove the directory first if you want to reinstall.'''.format(destination))\n asset = record['assets'][platform.system()]\n\n print('Installing {} {} for CUDA {} to: {}'.format(\n library, record[library], record['cuda'], destination))\n\n url = asset['url']\n print('Downloading {}...'.format(url))\n with tempfile.TemporaryDirectory() as tmpdir:\n with open(os.path.join(tmpdir, os.path.basename(url)), 'wb') as f:\n with urllib.request.urlopen(url) as response:\n f.write(response.read())\n print('Extracting...')\n shutil.unpack_archive(f.name, tmpdir)\n print('Installing...')\n if library == 'cudnn':\n shutil.move(os.path.join(tmpdir, 'cuda'), destination)\n elif library == 'cutensor':\n include = os.path.join(destination, 'include')\n lib = os.path.join(destination, 'lib64')\n shutil.move(os.path.join(tmpdir, 'libcutensor/include'), include)\n if cuda.startswith('11'):\n cuda = '11'\n shutil.move(os.path.join(tmpdir, 'libcutensor/lib', cuda), lib)\n print('Cleaning up...')\n print('Done!')\n\n\ndef calculate_destination(prefix, cuda, lib, lib_ver):\n \"\"\"Calculates the installation directory.\n\n ~/.cupy/cuda_lib/{cuda_version}/{library_name}/{library_version}\n \"\"\"\n return os.path.join(prefix, cuda, lib, lib_ver)\n\n\ndef main(args):\n parser = argparse.ArgumentParser()\n\n # TODO(kmaehashi): support NCCL\n parser.add_argument('--library',\n choices=['cudnn', 'cutensor'],\n required=True,\n help='Library to install')\n parser.add_argument('--cuda', type=str, required=True,\n help='CUDA version')\n parser.add_argument('--prefix', type=str, default=None,\n help='Install destination')\n parser.add_argument('--action', choices=['install', 'dump'],\n default='install',\n help='Action to perform')\n params = parser.parse_args(args)\n\n if params.prefix is not None:\n params.prefix = os.path.abspath(params.prefix)\n\n if params.library == 'cudnn':\n if params.action == 'install':\n install_lib(params.cuda, params.prefix, 'cudnn')\n elif params.action == 'dump':\n print(json.dumps(_cudnn_records, indent=4))\n else:\n assert False\n elif params.library == 'cutensor':\n if params.action == 'install':\n install_lib(params.cuda, params.prefix, 'cutensor')\n elif params.action == 'dump':\n print(json.dumps(_cutensor_records, indent=4))\n else:\n assert False\n else:\n assert False\n\n\nif __name__ == '__main__':\n main(sys.argv[1:])\n", "path": "cupyx/tools/install_library.py"}]}
| 2,810 | 613 |
gh_patches_debug_10656
|
rasdani/github-patches
|
git_diff
|
vacanza__python-holidays-555
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
October 25 is no longer holiday in Spain Prov=PV
I'm using the WORKDAY integration of Home Assistant to obtain a binary sensor for workdays.
AFAIK python-holidays is being used "under the hood" in this integration
Yesterday October 25th was wrongly marked as holiday.
It's not holiday since 2014.
More info (sorry, in spanish): [https://es.wikipedia.org/wiki/D%C3%ADa_del_Pa%C3%ADs_Vasco#Creaci%C3%B3n_y_desaparici%C3%B3n_de_la_festividad]
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `holidays/countries/spain.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # python-holidays
4 # ---------------
5 # A fast, efficient Python library for generating country, province and state
6 # specific sets of holidays on the fly. It aims to make determining whether a
7 # specific date is a holiday as fast and flexible as possible.
8 #
9 # Author: ryanss <ryanssdev@icloud.com> (c) 2014-2017
10 # dr-prodigy <maurizio.montel@gmail.com> (c) 2017-2021
11 # Website: https://github.com/dr-prodigy/python-holidays
12 # License: MIT (see LICENSE file)
13
14 from datetime import date
15
16 from dateutil.easter import easter
17 from dateutil.relativedelta import relativedelta as rd, TH, FR, MO
18 from holidays.constants import (
19 JAN,
20 FEB,
21 MAR,
22 APR,
23 MAY,
24 JUN,
25 JUL,
26 AUG,
27 SEP,
28 OCT,
29 NOV,
30 DEC,
31 )
32 from holidays.constants import SUN
33 from holidays.holiday_base import HolidayBase
34
35
36 class Spain(HolidayBase):
37 PROVINCES = [
38 "AN",
39 "AR",
40 "AS",
41 "CB",
42 "CM",
43 "CL",
44 "CT",
45 "VC",
46 "EX",
47 "GA",
48 "IB",
49 "CN",
50 "MD",
51 "MC",
52 "ML",
53 "NC",
54 "PV",
55 "RI",
56 ]
57
58 def __init__(self, **kwargs):
59 self.country = "ES"
60 self.prov = kwargs.pop("prov", kwargs.pop("state", ""))
61 HolidayBase.__init__(self, **kwargs)
62
63 def _is_observed(self, date_holiday, name_holiday):
64 if self.observed and date_holiday.weekday() == SUN:
65 self[date_holiday + rd(days=+1)] = name_holiday + " (Trasladado)"
66 else:
67 self[date_holiday] = name_holiday
68
69 def _populate(self, year):
70 self._is_observed(date(year, JAN, 1), "Año nuevo")
71 self._is_observed(date(year, JAN, 6), "Epifanía del Señor")
72
73 if (
74 year < 2015
75 and self.prov
76 and self.prov
77 in [
78 "AR",
79 "CL",
80 "CM",
81 "EX",
82 "GA",
83 "MD",
84 "ML",
85 "MC",
86 "NC",
87 "PV",
88 "VC",
89 ]
90 ):
91 self._is_observed(date(year, MAR, 19), "San José")
92 elif (
93 year == 2015
94 and self.prov
95 and self.prov in ["CM", "MD", "ML", "MC", "NC", "PV", "VC"]
96 ):
97 self._is_observed(date(year, MAR, 19), "San José")
98 elif (
99 year == 2016
100 and self.prov
101 and self.prov in ["ML", "MC", "PV", "VC"]
102 ):
103 self._is_observed(date(year, MAR, 19), "San José")
104 elif year == 2017 and self.prov and self.prov in ["PV"]:
105 self._is_observed(date(year, MAR, 19), "San José")
106 elif (
107 2018 <= year <= 2019
108 and self.prov
109 and self.prov in ["GA", "MC", "NC", "PV", "VC"]
110 ):
111 self._is_observed(date(year, MAR, 19), "San José")
112 elif (
113 2020 <= year <= 2025
114 and self.prov
115 and self.prov in ["CM", "GA", "MC", "NC", "PV", "VC"]
116 ):
117 self._is_observed(date(year, MAR, 19), "San José")
118 if self.prov and self.prov not in ["CT", "VC"]:
119 self[easter(year) + rd(weeks=-1, weekday=TH)] = "Jueves Santo"
120 self[easter(year) + rd(weeks=-1, weekday=FR)] = "Viernes Santo"
121 if self.prov and self.prov in ["CT", "PV", "NC", "VC", "IB", "CM"]:
122 self[easter(year) + rd(weekday=MO)] = "Lunes de Pascua"
123 self._is_observed(date(year, MAY, 1), "Día del Trabajador")
124 if self.prov and self.prov in ["CT", "GA", "VC"]:
125 self._is_observed(date(year, JUN, 24), "San Juan")
126 self._is_observed(date(year, AUG, 15), "Asunción de la Virgen")
127 self._is_observed(date(year, OCT, 12), "Día de la Hispanidad")
128 self._is_observed(date(year, NOV, 1), "Todos los Santos")
129 self._is_observed(
130 date(year, DEC, 6), "Día de la Constitución " "Española"
131 )
132 self._is_observed(date(year, DEC, 8), "La Inmaculada Concepción")
133 self._is_observed(date(year, DEC, 25), "Navidad")
134 if self.prov and self.prov in ["CT", "IB"]:
135 self._is_observed(date(year, DEC, 26), "San Esteban")
136 # Provinces festive day
137 if self.prov:
138 if self.prov == "AN":
139 self._is_observed(date(year, FEB, 28), "Día de Andalucia")
140 elif self.prov == "AR":
141 self._is_observed(date(year, APR, 23), "Día de San Jorge")
142 elif self.prov == "AS":
143 self._is_observed(date(year, SEP, 8), "Día de Asturias")
144 elif self.prov == "CB":
145 self._is_observed(
146 date(year, JUL, 28),
147 "Día de las Instituci" "ones de Cantabria",
148 )
149 elif self.prov == "CM":
150 self._is_observed(
151 date(year, MAY, 31), "Día de Castilla " "La Mancha"
152 )
153 elif self.prov == "CL":
154 self._is_observed(
155 date(year, APR, 23), "Día de Castilla y " "Leon"
156 )
157 elif self.prov == "CT":
158 self._is_observed(
159 date(year, SEP, 11), "Día Nacional de " "Catalunya"
160 )
161 elif self.prov == "VC":
162 self._is_observed(
163 date(year, OCT, 9), "Día de la Comunidad " "Valenciana"
164 )
165 elif self.prov == "EX":
166 self._is_observed(date(year, SEP, 8), "Día de Extremadura")
167 elif self.prov == "GA":
168 self._is_observed(
169 date(year, JUL, 25), "Día Nacional de " "Galicia"
170 )
171 elif self.prov == "IB":
172 self._is_observed(
173 date(year, MAR, 1), "Día de las Islas " "Baleares"
174 )
175 elif self.prov == "CN":
176 self._is_observed(date(year, MAY, 30), "Día de Canarias")
177 elif self.prov == "MD":
178 self._is_observed(
179 date(year, MAY, 2), "Día de Comunidad de " "Madrid"
180 )
181 elif self.prov == "MC":
182 self._is_observed(
183 date(year, JUN, 9), "Día de la Región de " "Murcia"
184 )
185 elif self.prov == "NC":
186 self._is_observed(date(year, SEP, 27), "Día de Navarra")
187 elif self.prov == "PV":
188 self._is_observed(date(year, OCT, 25), "Día del Páis Vasco")
189 elif self.prov == "RI":
190 self._is_observed(date(year, JUN, 9), "Día de La Rioja")
191
192
193 class ES(Spain):
194 pass
195
196
197 class ESP(Spain):
198 pass
199
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/holidays/countries/spain.py b/holidays/countries/spain.py
--- a/holidays/countries/spain.py
+++ b/holidays/countries/spain.py
@@ -185,7 +185,10 @@
elif self.prov == "NC":
self._is_observed(date(year, SEP, 27), "Día de Navarra")
elif self.prov == "PV":
- self._is_observed(date(year, OCT, 25), "Día del Páis Vasco")
+ if 2011 <= year <= 2013:
+ self._is_observed(
+ date(year, OCT, 25), "Día del Páis Vasco"
+ )
elif self.prov == "RI":
self._is_observed(date(year, JUN, 9), "Día de La Rioja")
|
{"golden_diff": "diff --git a/holidays/countries/spain.py b/holidays/countries/spain.py\n--- a/holidays/countries/spain.py\n+++ b/holidays/countries/spain.py\n@@ -185,7 +185,10 @@\n elif self.prov == \"NC\":\n self._is_observed(date(year, SEP, 27), \"D\u00eda de Navarra\")\n elif self.prov == \"PV\":\n- self._is_observed(date(year, OCT, 25), \"D\u00eda del P\u00e1is Vasco\")\n+ if 2011 <= year <= 2013:\n+ self._is_observed(\n+ date(year, OCT, 25), \"D\u00eda del P\u00e1is Vasco\"\n+ )\n elif self.prov == \"RI\":\n self._is_observed(date(year, JUN, 9), \"D\u00eda de La Rioja\")\n", "issue": "October 25 is no longer holiday in Spain Prov=PV\nI'm using the WORKDAY integration of Home Assistant to obtain a binary sensor for workdays.\r\nAFAIK python-holidays is being used \"under the hood\" in this integration\r\nYesterday October 25th was wrongly marked as holiday.\r\nIt's not holiday since 2014.\r\n\r\nMore info (sorry, in spanish): [https://es.wikipedia.org/wiki/D%C3%ADa_del_Pa%C3%ADs_Vasco#Creaci%C3%B3n_y_desaparici%C3%B3n_de_la_festividad]\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# python-holidays\n# ---------------\n# A fast, efficient Python library for generating country, province and state\n# specific sets of holidays on the fly. It aims to make determining whether a\n# specific date is a holiday as fast and flexible as possible.\n#\n# Author: ryanss <ryanssdev@icloud.com> (c) 2014-2017\n# dr-prodigy <maurizio.montel@gmail.com> (c) 2017-2021\n# Website: https://github.com/dr-prodigy/python-holidays\n# License: MIT (see LICENSE file)\n\nfrom datetime import date\n\nfrom dateutil.easter import easter\nfrom dateutil.relativedelta import relativedelta as rd, TH, FR, MO\nfrom holidays.constants import (\n JAN,\n FEB,\n MAR,\n APR,\n MAY,\n JUN,\n JUL,\n AUG,\n SEP,\n OCT,\n NOV,\n DEC,\n)\nfrom holidays.constants import SUN\nfrom holidays.holiday_base import HolidayBase\n\n\nclass Spain(HolidayBase):\n PROVINCES = [\n \"AN\",\n \"AR\",\n \"AS\",\n \"CB\",\n \"CM\",\n \"CL\",\n \"CT\",\n \"VC\",\n \"EX\",\n \"GA\",\n \"IB\",\n \"CN\",\n \"MD\",\n \"MC\",\n \"ML\",\n \"NC\",\n \"PV\",\n \"RI\",\n ]\n\n def __init__(self, **kwargs):\n self.country = \"ES\"\n self.prov = kwargs.pop(\"prov\", kwargs.pop(\"state\", \"\"))\n HolidayBase.__init__(self, **kwargs)\n\n def _is_observed(self, date_holiday, name_holiday):\n if self.observed and date_holiday.weekday() == SUN:\n self[date_holiday + rd(days=+1)] = name_holiday + \" (Trasladado)\"\n else:\n self[date_holiday] = name_holiday\n\n def _populate(self, year):\n self._is_observed(date(year, JAN, 1), \"A\u00f1o nuevo\")\n self._is_observed(date(year, JAN, 6), \"Epifan\u00eda del Se\u00f1or\")\n\n if (\n year < 2015\n and self.prov\n and self.prov\n in [\n \"AR\",\n \"CL\",\n \"CM\",\n \"EX\",\n \"GA\",\n \"MD\",\n \"ML\",\n \"MC\",\n \"NC\",\n \"PV\",\n \"VC\",\n ]\n ):\n self._is_observed(date(year, MAR, 19), \"San Jos\u00e9\")\n elif (\n year == 2015\n and self.prov\n and self.prov in [\"CM\", \"MD\", \"ML\", \"MC\", \"NC\", \"PV\", \"VC\"]\n ):\n self._is_observed(date(year, MAR, 19), \"San Jos\u00e9\")\n elif (\n year == 2016\n and self.prov\n and self.prov in [\"ML\", \"MC\", \"PV\", \"VC\"]\n ):\n self._is_observed(date(year, MAR, 19), \"San Jos\u00e9\")\n elif year == 2017 and self.prov and self.prov in [\"PV\"]:\n self._is_observed(date(year, MAR, 19), \"San Jos\u00e9\")\n elif (\n 2018 <= year <= 2019\n and self.prov\n and self.prov in [\"GA\", \"MC\", \"NC\", \"PV\", \"VC\"]\n ):\n self._is_observed(date(year, MAR, 19), \"San Jos\u00e9\")\n elif (\n 2020 <= year <= 2025\n and self.prov\n and self.prov in [\"CM\", \"GA\", \"MC\", \"NC\", \"PV\", \"VC\"]\n ):\n self._is_observed(date(year, MAR, 19), \"San Jos\u00e9\")\n if self.prov and self.prov not in [\"CT\", \"VC\"]:\n self[easter(year) + rd(weeks=-1, weekday=TH)] = \"Jueves Santo\"\n self[easter(year) + rd(weeks=-1, weekday=FR)] = \"Viernes Santo\"\n if self.prov and self.prov in [\"CT\", \"PV\", \"NC\", \"VC\", \"IB\", \"CM\"]:\n self[easter(year) + rd(weekday=MO)] = \"Lunes de Pascua\"\n self._is_observed(date(year, MAY, 1), \"D\u00eda del Trabajador\")\n if self.prov and self.prov in [\"CT\", \"GA\", \"VC\"]:\n self._is_observed(date(year, JUN, 24), \"San Juan\")\n self._is_observed(date(year, AUG, 15), \"Asunci\u00f3n de la Virgen\")\n self._is_observed(date(year, OCT, 12), \"D\u00eda de la Hispanidad\")\n self._is_observed(date(year, NOV, 1), \"Todos los Santos\")\n self._is_observed(\n date(year, DEC, 6), \"D\u00eda de la Constituci\u00f3n \" \"Espa\u00f1ola\"\n )\n self._is_observed(date(year, DEC, 8), \"La Inmaculada Concepci\u00f3n\")\n self._is_observed(date(year, DEC, 25), \"Navidad\")\n if self.prov and self.prov in [\"CT\", \"IB\"]:\n self._is_observed(date(year, DEC, 26), \"San Esteban\")\n # Provinces festive day\n if self.prov:\n if self.prov == \"AN\":\n self._is_observed(date(year, FEB, 28), \"D\u00eda de Andalucia\")\n elif self.prov == \"AR\":\n self._is_observed(date(year, APR, 23), \"D\u00eda de San Jorge\")\n elif self.prov == \"AS\":\n self._is_observed(date(year, SEP, 8), \"D\u00eda de Asturias\")\n elif self.prov == \"CB\":\n self._is_observed(\n date(year, JUL, 28),\n \"D\u00eda de las Instituci\" \"ones de Cantabria\",\n )\n elif self.prov == \"CM\":\n self._is_observed(\n date(year, MAY, 31), \"D\u00eda de Castilla \" \"La Mancha\"\n )\n elif self.prov == \"CL\":\n self._is_observed(\n date(year, APR, 23), \"D\u00eda de Castilla y \" \"Leon\"\n )\n elif self.prov == \"CT\":\n self._is_observed(\n date(year, SEP, 11), \"D\u00eda Nacional de \" \"Catalunya\"\n )\n elif self.prov == \"VC\":\n self._is_observed(\n date(year, OCT, 9), \"D\u00eda de la Comunidad \" \"Valenciana\"\n )\n elif self.prov == \"EX\":\n self._is_observed(date(year, SEP, 8), \"D\u00eda de Extremadura\")\n elif self.prov == \"GA\":\n self._is_observed(\n date(year, JUL, 25), \"D\u00eda Nacional de \" \"Galicia\"\n )\n elif self.prov == \"IB\":\n self._is_observed(\n date(year, MAR, 1), \"D\u00eda de las Islas \" \"Baleares\"\n )\n elif self.prov == \"CN\":\n self._is_observed(date(year, MAY, 30), \"D\u00eda de Canarias\")\n elif self.prov == \"MD\":\n self._is_observed(\n date(year, MAY, 2), \"D\u00eda de Comunidad de \" \"Madrid\"\n )\n elif self.prov == \"MC\":\n self._is_observed(\n date(year, JUN, 9), \"D\u00eda de la Regi\u00f3n de \" \"Murcia\"\n )\n elif self.prov == \"NC\":\n self._is_observed(date(year, SEP, 27), \"D\u00eda de Navarra\")\n elif self.prov == \"PV\":\n self._is_observed(date(year, OCT, 25), \"D\u00eda del P\u00e1is Vasco\")\n elif self.prov == \"RI\":\n self._is_observed(date(year, JUN, 9), \"D\u00eda de La Rioja\")\n\n\nclass ES(Spain):\n pass\n\n\nclass ESP(Spain):\n pass\n", "path": "holidays/countries/spain.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# python-holidays\n# ---------------\n# A fast, efficient Python library for generating country, province and state\n# specific sets of holidays on the fly. It aims to make determining whether a\n# specific date is a holiday as fast and flexible as possible.\n#\n# Author: ryanss <ryanssdev@icloud.com> (c) 2014-2017\n# dr-prodigy <maurizio.montel@gmail.com> (c) 2017-2021\n# Website: https://github.com/dr-prodigy/python-holidays\n# License: MIT (see LICENSE file)\n\nfrom datetime import date\n\nfrom dateutil.easter import easter\nfrom dateutil.relativedelta import relativedelta as rd, TH, FR, MO\nfrom holidays.constants import (\n JAN,\n FEB,\n MAR,\n APR,\n MAY,\n JUN,\n JUL,\n AUG,\n SEP,\n OCT,\n NOV,\n DEC,\n)\nfrom holidays.constants import SUN\nfrom holidays.holiday_base import HolidayBase\n\n\nclass Spain(HolidayBase):\n PROVINCES = [\n \"AN\",\n \"AR\",\n \"AS\",\n \"CB\",\n \"CM\",\n \"CL\",\n \"CT\",\n \"VC\",\n \"EX\",\n \"GA\",\n \"IB\",\n \"CN\",\n \"MD\",\n \"MC\",\n \"ML\",\n \"NC\",\n \"PV\",\n \"RI\",\n ]\n\n def __init__(self, **kwargs):\n self.country = \"ES\"\n self.prov = kwargs.pop(\"prov\", kwargs.pop(\"state\", \"\"))\n HolidayBase.__init__(self, **kwargs)\n\n def _is_observed(self, date_holiday, name_holiday):\n if self.observed and date_holiday.weekday() == SUN:\n self[date_holiday + rd(days=+1)] = name_holiday + \" (Trasladado)\"\n else:\n self[date_holiday] = name_holiday\n\n def _populate(self, year):\n self._is_observed(date(year, JAN, 1), \"A\u00f1o nuevo\")\n self._is_observed(date(year, JAN, 6), \"Epifan\u00eda del Se\u00f1or\")\n\n if (\n year < 2015\n and self.prov\n and self.prov\n in [\n \"AR\",\n \"CL\",\n \"CM\",\n \"EX\",\n \"GA\",\n \"MD\",\n \"ML\",\n \"MC\",\n \"NC\",\n \"PV\",\n \"VC\",\n ]\n ):\n self._is_observed(date(year, MAR, 19), \"San Jos\u00e9\")\n elif (\n year == 2015\n and self.prov\n and self.prov in [\"CM\", \"MD\", \"ML\", \"MC\", \"NC\", \"PV\", \"VC\"]\n ):\n self._is_observed(date(year, MAR, 19), \"San Jos\u00e9\")\n elif (\n year == 2016\n and self.prov\n and self.prov in [\"ML\", \"MC\", \"PV\", \"VC\"]\n ):\n self._is_observed(date(year, MAR, 19), \"San Jos\u00e9\")\n elif year == 2017 and self.prov and self.prov in [\"PV\"]:\n self._is_observed(date(year, MAR, 19), \"San Jos\u00e9\")\n elif (\n 2018 <= year <= 2019\n and self.prov\n and self.prov in [\"GA\", \"MC\", \"NC\", \"PV\", \"VC\"]\n ):\n self._is_observed(date(year, MAR, 19), \"San Jos\u00e9\")\n elif (\n 2020 <= year <= 2025\n and self.prov\n and self.prov in [\"CM\", \"GA\", \"MC\", \"NC\", \"PV\", \"VC\"]\n ):\n self._is_observed(date(year, MAR, 19), \"San Jos\u00e9\")\n if self.prov and self.prov not in [\"CT\", \"VC\"]:\n self[easter(year) + rd(weeks=-1, weekday=TH)] = \"Jueves Santo\"\n self[easter(year) + rd(weeks=-1, weekday=FR)] = \"Viernes Santo\"\n if self.prov and self.prov in [\"CT\", \"PV\", \"NC\", \"VC\", \"IB\", \"CM\"]:\n self[easter(year) + rd(weekday=MO)] = \"Lunes de Pascua\"\n self._is_observed(date(year, MAY, 1), \"D\u00eda del Trabajador\")\n if self.prov and self.prov in [\"CT\", \"GA\", \"VC\"]:\n self._is_observed(date(year, JUN, 24), \"San Juan\")\n self._is_observed(date(year, AUG, 15), \"Asunci\u00f3n de la Virgen\")\n self._is_observed(date(year, OCT, 12), \"D\u00eda de la Hispanidad\")\n self._is_observed(date(year, NOV, 1), \"Todos los Santos\")\n self._is_observed(\n date(year, DEC, 6), \"D\u00eda de la Constituci\u00f3n \" \"Espa\u00f1ola\"\n )\n self._is_observed(date(year, DEC, 8), \"La Inmaculada Concepci\u00f3n\")\n self._is_observed(date(year, DEC, 25), \"Navidad\")\n if self.prov and self.prov in [\"CT\", \"IB\"]:\n self._is_observed(date(year, DEC, 26), \"San Esteban\")\n # Provinces festive day\n if self.prov:\n if self.prov == \"AN\":\n self._is_observed(date(year, FEB, 28), \"D\u00eda de Andalucia\")\n elif self.prov == \"AR\":\n self._is_observed(date(year, APR, 23), \"D\u00eda de San Jorge\")\n elif self.prov == \"AS\":\n self._is_observed(date(year, SEP, 8), \"D\u00eda de Asturias\")\n elif self.prov == \"CB\":\n self._is_observed(\n date(year, JUL, 28),\n \"D\u00eda de las Instituci\" \"ones de Cantabria\",\n )\n elif self.prov == \"CM\":\n self._is_observed(\n date(year, MAY, 31), \"D\u00eda de Castilla \" \"La Mancha\"\n )\n elif self.prov == \"CL\":\n self._is_observed(\n date(year, APR, 23), \"D\u00eda de Castilla y \" \"Leon\"\n )\n elif self.prov == \"CT\":\n self._is_observed(\n date(year, SEP, 11), \"D\u00eda Nacional de \" \"Catalunya\"\n )\n elif self.prov == \"VC\":\n self._is_observed(\n date(year, OCT, 9), \"D\u00eda de la Comunidad \" \"Valenciana\"\n )\n elif self.prov == \"EX\":\n self._is_observed(date(year, SEP, 8), \"D\u00eda de Extremadura\")\n elif self.prov == \"GA\":\n self._is_observed(\n date(year, JUL, 25), \"D\u00eda Nacional de \" \"Galicia\"\n )\n elif self.prov == \"IB\":\n self._is_observed(\n date(year, MAR, 1), \"D\u00eda de las Islas \" \"Baleares\"\n )\n elif self.prov == \"CN\":\n self._is_observed(date(year, MAY, 30), \"D\u00eda de Canarias\")\n elif self.prov == \"MD\":\n self._is_observed(\n date(year, MAY, 2), \"D\u00eda de Comunidad de \" \"Madrid\"\n )\n elif self.prov == \"MC\":\n self._is_observed(\n date(year, JUN, 9), \"D\u00eda de la Regi\u00f3n de \" \"Murcia\"\n )\n elif self.prov == \"NC\":\n self._is_observed(date(year, SEP, 27), \"D\u00eda de Navarra\")\n elif self.prov == \"PV\":\n if 2011 <= year <= 2013:\n self._is_observed(\n date(year, OCT, 25), \"D\u00eda del P\u00e1is Vasco\"\n )\n elif self.prov == \"RI\":\n self._is_observed(date(year, JUN, 9), \"D\u00eda de La Rioja\")\n\n\nclass ES(Spain):\n pass\n\n\nclass ESP(Spain):\n pass\n", "path": "holidays/countries/spain.py"}]}
| 2,780 | 202 |
gh_patches_debug_35515
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-460
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Hooks pre-fetching
Hi,
I want to suggest introducing a command for downloading all required hooks forcefully. The use case is simple:
1. I pack everything needed for testing into container
2. I deploy that into CI
3. It gets built and tests are ran
I'd like to separate fetching of the hooks and pre-installing them into a build step. This would allow me use caching for containers, saving time for tests.
P.S. Perhaps it's needed to add some argument to `run` command, so that it won't try downloading stuff when executing tests.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pre_commit/commands/install_uninstall.py`
Content:
```
1 from __future__ import print_function
2 from __future__ import unicode_literals
3
4 import io
5 import os.path
6 import sys
7
8 from pre_commit import output
9 from pre_commit.util import make_executable
10 from pre_commit.util import mkdirp
11 from pre_commit.util import resource_filename
12
13
14 # This is used to identify the hook file we install
15 PREVIOUS_IDENTIFYING_HASHES = (
16 '4d9958c90bc262f47553e2c073f14cfe',
17 'd8ee923c46731b42cd95cc869add4062',
18 '49fd668cb42069aa1b6048464be5d395',
19 '79f09a650522a87b0da915d0d983b2de',
20 'e358c9dae00eac5d06b38dfdb1e33a8c',
21 )
22
23
24 IDENTIFYING_HASH = '138fd403232d2ddd5efb44317e38bf03'
25
26
27 def is_our_pre_commit(filename):
28 if not os.path.exists(filename):
29 return False
30 return IDENTIFYING_HASH in io.open(filename).read()
31
32
33 def is_previous_pre_commit(filename):
34 if not os.path.exists(filename):
35 return False
36 contents = io.open(filename).read()
37 return any(hash in contents for hash in PREVIOUS_IDENTIFYING_HASHES)
38
39
40 def install(runner, overwrite=False, hooks=False, hook_type='pre-commit'):
41 """Install the pre-commit hooks."""
42 hook_path = runner.get_hook_path(hook_type)
43 legacy_path = hook_path + '.legacy'
44
45 mkdirp(os.path.dirname(hook_path))
46
47 # If we have an existing hook, move it to pre-commit.legacy
48 if (
49 os.path.lexists(hook_path) and
50 not is_our_pre_commit(hook_path) and
51 not is_previous_pre_commit(hook_path)
52 ):
53 os.rename(hook_path, legacy_path)
54
55 # If we specify overwrite, we simply delete the legacy file
56 if overwrite and os.path.exists(legacy_path):
57 os.remove(legacy_path)
58 elif os.path.exists(legacy_path):
59 output.write_line(
60 'Running in migration mode with existing hooks at {}\n'
61 'Use -f to use only pre-commit.'.format(
62 legacy_path,
63 )
64 )
65
66 with io.open(hook_path, 'w') as pre_commit_file_obj:
67 if hook_type == 'pre-push':
68 with io.open(resource_filename('pre-push-tmpl')) as fp:
69 pre_push_contents = fp.read()
70 else:
71 pre_push_contents = ''
72
73 contents = io.open(resource_filename('hook-tmpl')).read().format(
74 sys_executable=sys.executable,
75 hook_type=hook_type,
76 pre_push=pre_push_contents,
77 )
78 pre_commit_file_obj.write(contents)
79 make_executable(hook_path)
80
81 output.write_line('pre-commit installed at {}'.format(hook_path))
82
83 # If they requested we install all of the hooks, do so.
84 if hooks:
85 for repository in runner.repositories:
86 repository.require_installed()
87
88 return 0
89
90
91 def uninstall(runner, hook_type='pre-commit'):
92 """Uninstall the pre-commit hooks."""
93 hook_path = runner.get_hook_path(hook_type)
94 legacy_path = hook_path + '.legacy'
95 # If our file doesn't exist or it isn't ours, gtfo.
96 if (
97 not os.path.exists(hook_path) or (
98 not is_our_pre_commit(hook_path) and
99 not is_previous_pre_commit(hook_path)
100 )
101 ):
102 return 0
103
104 os.remove(hook_path)
105 output.write_line('{} uninstalled'.format(hook_type))
106
107 if os.path.exists(legacy_path):
108 os.rename(legacy_path, hook_path)
109 output.write_line('Restored previous hooks to {}'.format(hook_path))
110
111 return 0
112
```
Path: `pre_commit/main.py`
Content:
```
1 from __future__ import unicode_literals
2
3 import argparse
4 import os
5 import sys
6
7 import pkg_resources
8
9 from pre_commit import color
10 from pre_commit import five
11 from pre_commit import git
12 from pre_commit.commands.autoupdate import autoupdate
13 from pre_commit.commands.clean import clean
14 from pre_commit.commands.install_uninstall import install
15 from pre_commit.commands.install_uninstall import uninstall
16 from pre_commit.commands.run import run
17 from pre_commit.error_handler import error_handler
18 from pre_commit.logging_handler import add_logging_handler
19 from pre_commit.runner import Runner
20
21
22 # https://github.com/pre-commit/pre-commit/issues/217
23 # On OSX, making a virtualenv using pyvenv at . causes `virtualenv` and `pip`
24 # to install packages to the wrong place. We don't want anything to deal with
25 # pyvenv
26 os.environ.pop('__PYVENV_LAUNCHER__', None)
27
28
29 def _add_color_option(parser):
30 parser.add_argument(
31 '--color', default='auto', type=color.use_color,
32 metavar='{' + ','.join(color.COLOR_CHOICES) + '}',
33 help='Whether to use color in output. Defaults to `%(default)s`.',
34 )
35
36
37 def _add_config_option(parser):
38 parser.add_argument(
39 '-c', '--config', default='.pre-commit-config.yaml',
40 help='Path to alternate config file'
41 )
42
43
44 def main(argv=None):
45 argv = argv if argv is not None else sys.argv[1:]
46 argv = [five.to_text(arg) for arg in argv]
47 parser = argparse.ArgumentParser()
48
49 # http://stackoverflow.com/a/8521644/812183
50 parser.add_argument(
51 '-V', '--version',
52 action='version',
53 version='%(prog)s {}'.format(
54 pkg_resources.get_distribution('pre-commit').version
55 )
56 )
57
58 subparsers = parser.add_subparsers(dest='command')
59
60 install_parser = subparsers.add_parser(
61 'install', help='Install the pre-commit script.',
62 )
63 _add_color_option(install_parser)
64 _add_config_option(install_parser)
65 install_parser.add_argument(
66 '-f', '--overwrite', action='store_true',
67 help='Overwrite existing hooks / remove migration mode.',
68 )
69 install_parser.add_argument(
70 '--install-hooks', action='store_true',
71 help=(
72 'Whether to install hook environments for all environments '
73 'in the config file.'
74 ),
75 )
76 install_parser.add_argument(
77 '-t', '--hook-type', choices=('pre-commit', 'pre-push'),
78 default='pre-commit',
79 )
80
81 uninstall_parser = subparsers.add_parser(
82 'uninstall', help='Uninstall the pre-commit script.',
83 )
84 _add_color_option(uninstall_parser)
85 _add_config_option(uninstall_parser)
86 uninstall_parser.add_argument(
87 '-t', '--hook-type', choices=('pre-commit', 'pre-push'),
88 default='pre-commit',
89 )
90
91 clean_parser = subparsers.add_parser(
92 'clean', help='Clean out pre-commit files.',
93 )
94 _add_color_option(clean_parser)
95 _add_config_option(clean_parser)
96 autoupdate_parser = subparsers.add_parser(
97 'autoupdate',
98 help="Auto-update pre-commit config to the latest repos' versions.",
99 )
100 _add_color_option(autoupdate_parser)
101 _add_config_option(autoupdate_parser)
102
103 run_parser = subparsers.add_parser('run', help='Run hooks.')
104 _add_color_option(run_parser)
105 _add_config_option(run_parser)
106 run_parser.add_argument('hook', nargs='?', help='A single hook-id to run')
107 run_parser.add_argument(
108 '--no-stash', default=False, action='store_true',
109 help='Use this option to prevent auto stashing of unstaged files.',
110 )
111 run_parser.add_argument(
112 '--verbose', '-v', action='store_true', default=False,
113 )
114 run_parser.add_argument(
115 '--origin', '-o',
116 help="The origin branch's commit_id when using `git push`.",
117 )
118 run_parser.add_argument(
119 '--source', '-s',
120 help="The remote branch's commit_id when using `git push`.",
121 )
122 run_parser.add_argument(
123 '--allow-unstaged-config', default=False, action='store_true',
124 help=(
125 'Allow an unstaged config to be present. Note that this will '
126 'be stashed before parsing unless --no-stash is specified.'
127 ),
128 )
129 run_parser.add_argument(
130 '--hook-stage', choices=('commit', 'push'), default='commit',
131 help='The stage during which the hook is fired e.g. commit or push.',
132 )
133 run_mutex_group = run_parser.add_mutually_exclusive_group(required=False)
134 run_mutex_group.add_argument(
135 '--all-files', '-a', action='store_true', default=False,
136 help='Run on all the files in the repo. Implies --no-stash.',
137 )
138 run_mutex_group.add_argument(
139 '--files', nargs='*', default=[],
140 help='Specific filenames to run hooks on.',
141 )
142
143 help = subparsers.add_parser(
144 'help', help='Show help for a specific command.',
145 )
146 help.add_argument('help_cmd', nargs='?', help='Command to show help for.')
147
148 # Argparse doesn't really provide a way to use a `default` subparser
149 if len(argv) == 0:
150 argv = ['run']
151 args = parser.parse_args(argv)
152 if args.command == 'run':
153 args.files = [
154 os.path.relpath(os.path.abspath(filename), git.get_root())
155 for filename in args.files
156 ]
157
158 if args.command == 'help':
159 if args.help_cmd:
160 parser.parse_args([args.help_cmd, '--help'])
161 else:
162 parser.parse_args(['--help'])
163
164 with error_handler():
165 add_logging_handler(args.color)
166 runner = Runner.create(args.config)
167 git.check_for_cygwin_mismatch()
168
169 if args.command == 'install':
170 return install(
171 runner, overwrite=args.overwrite, hooks=args.install_hooks,
172 hook_type=args.hook_type,
173 )
174 elif args.command == 'uninstall':
175 return uninstall(runner, hook_type=args.hook_type)
176 elif args.command == 'clean':
177 return clean(runner)
178 elif args.command == 'autoupdate':
179 return autoupdate(runner)
180 elif args.command == 'run':
181 return run(runner, args)
182 else:
183 raise NotImplementedError(
184 'Command {} not implemented.'.format(args.command)
185 )
186
187 raise AssertionError(
188 'Command {} failed to exit with a returncode'.format(args.command)
189 )
190
191
192 if __name__ == '__main__':
193 exit(main())
194
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pre_commit/commands/install_uninstall.py b/pre_commit/commands/install_uninstall.py
--- a/pre_commit/commands/install_uninstall.py
+++ b/pre_commit/commands/install_uninstall.py
@@ -82,12 +82,16 @@
# If they requested we install all of the hooks, do so.
if hooks:
- for repository in runner.repositories:
- repository.require_installed()
+ install_hooks(runner)
return 0
+def install_hooks(runner):
+ for repository in runner.repositories:
+ repository.require_installed()
+
+
def uninstall(runner, hook_type='pre-commit'):
"""Uninstall the pre-commit hooks."""
hook_path = runner.get_hook_path(hook_type)
diff --git a/pre_commit/main.py b/pre_commit/main.py
--- a/pre_commit/main.py
+++ b/pre_commit/main.py
@@ -12,6 +12,7 @@
from pre_commit.commands.autoupdate import autoupdate
from pre_commit.commands.clean import clean
from pre_commit.commands.install_uninstall import install
+from pre_commit.commands.install_uninstall import install_hooks
from pre_commit.commands.install_uninstall import uninstall
from pre_commit.commands.run import run
from pre_commit.error_handler import error_handler
@@ -78,6 +79,17 @@
default='pre-commit',
)
+ install_hooks_parser = subparsers.add_parser(
+ 'install-hooks',
+ help=(
+ 'Install hook environemnts for all environemnts in the config '
+ 'file. You may find `pre-commit install --install-hooks` more '
+ 'useful.'
+ ),
+ )
+ _add_color_option(install_hooks_parser)
+ _add_config_option(install_hooks_parser)
+
uninstall_parser = subparsers.add_parser(
'uninstall', help='Uninstall the pre-commit script.',
)
@@ -171,6 +183,8 @@
runner, overwrite=args.overwrite, hooks=args.install_hooks,
hook_type=args.hook_type,
)
+ elif args.command == 'install-hooks':
+ return install_hooks(runner)
elif args.command == 'uninstall':
return uninstall(runner, hook_type=args.hook_type)
elif args.command == 'clean':
|
{"golden_diff": "diff --git a/pre_commit/commands/install_uninstall.py b/pre_commit/commands/install_uninstall.py\n--- a/pre_commit/commands/install_uninstall.py\n+++ b/pre_commit/commands/install_uninstall.py\n@@ -82,12 +82,16 @@\n \n # If they requested we install all of the hooks, do so.\n if hooks:\n- for repository in runner.repositories:\n- repository.require_installed()\n+ install_hooks(runner)\n \n return 0\n \n \n+def install_hooks(runner):\n+ for repository in runner.repositories:\n+ repository.require_installed()\n+\n+\n def uninstall(runner, hook_type='pre-commit'):\n \"\"\"Uninstall the pre-commit hooks.\"\"\"\n hook_path = runner.get_hook_path(hook_type)\ndiff --git a/pre_commit/main.py b/pre_commit/main.py\n--- a/pre_commit/main.py\n+++ b/pre_commit/main.py\n@@ -12,6 +12,7 @@\n from pre_commit.commands.autoupdate import autoupdate\n from pre_commit.commands.clean import clean\n from pre_commit.commands.install_uninstall import install\n+from pre_commit.commands.install_uninstall import install_hooks\n from pre_commit.commands.install_uninstall import uninstall\n from pre_commit.commands.run import run\n from pre_commit.error_handler import error_handler\n@@ -78,6 +79,17 @@\n default='pre-commit',\n )\n \n+ install_hooks_parser = subparsers.add_parser(\n+ 'install-hooks',\n+ help=(\n+ 'Install hook environemnts for all environemnts in the config '\n+ 'file. You may find `pre-commit install --install-hooks` more '\n+ 'useful.'\n+ ),\n+ )\n+ _add_color_option(install_hooks_parser)\n+ _add_config_option(install_hooks_parser)\n+\n uninstall_parser = subparsers.add_parser(\n 'uninstall', help='Uninstall the pre-commit script.',\n )\n@@ -171,6 +183,8 @@\n runner, overwrite=args.overwrite, hooks=args.install_hooks,\n hook_type=args.hook_type,\n )\n+ elif args.command == 'install-hooks':\n+ return install_hooks(runner)\n elif args.command == 'uninstall':\n return uninstall(runner, hook_type=args.hook_type)\n elif args.command == 'clean':\n", "issue": "Hooks pre-fetching\nHi,\r\n\r\nI want to suggest introducing a command for downloading all required hooks forcefully. The use case is simple:\r\n1. I pack everything needed for testing into container\r\n2. I deploy that into CI\r\n3. It gets built and tests are ran\r\n\r\nI'd like to separate fetching of the hooks and pre-installing them into a build step. This would allow me use caching for containers, saving time for tests.\r\n\r\nP.S. Perhaps it's needed to add some argument to `run` command, so that it won't try downloading stuff when executing tests.\n", "before_files": [{"content": "from __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport io\nimport os.path\nimport sys\n\nfrom pre_commit import output\nfrom pre_commit.util import make_executable\nfrom pre_commit.util import mkdirp\nfrom pre_commit.util import resource_filename\n\n\n# This is used to identify the hook file we install\nPREVIOUS_IDENTIFYING_HASHES = (\n '4d9958c90bc262f47553e2c073f14cfe',\n 'd8ee923c46731b42cd95cc869add4062',\n '49fd668cb42069aa1b6048464be5d395',\n '79f09a650522a87b0da915d0d983b2de',\n 'e358c9dae00eac5d06b38dfdb1e33a8c',\n)\n\n\nIDENTIFYING_HASH = '138fd403232d2ddd5efb44317e38bf03'\n\n\ndef is_our_pre_commit(filename):\n if not os.path.exists(filename):\n return False\n return IDENTIFYING_HASH in io.open(filename).read()\n\n\ndef is_previous_pre_commit(filename):\n if not os.path.exists(filename):\n return False\n contents = io.open(filename).read()\n return any(hash in contents for hash in PREVIOUS_IDENTIFYING_HASHES)\n\n\ndef install(runner, overwrite=False, hooks=False, hook_type='pre-commit'):\n \"\"\"Install the pre-commit hooks.\"\"\"\n hook_path = runner.get_hook_path(hook_type)\n legacy_path = hook_path + '.legacy'\n\n mkdirp(os.path.dirname(hook_path))\n\n # If we have an existing hook, move it to pre-commit.legacy\n if (\n os.path.lexists(hook_path) and\n not is_our_pre_commit(hook_path) and\n not is_previous_pre_commit(hook_path)\n ):\n os.rename(hook_path, legacy_path)\n\n # If we specify overwrite, we simply delete the legacy file\n if overwrite and os.path.exists(legacy_path):\n os.remove(legacy_path)\n elif os.path.exists(legacy_path):\n output.write_line(\n 'Running in migration mode with existing hooks at {}\\n'\n 'Use -f to use only pre-commit.'.format(\n legacy_path,\n )\n )\n\n with io.open(hook_path, 'w') as pre_commit_file_obj:\n if hook_type == 'pre-push':\n with io.open(resource_filename('pre-push-tmpl')) as fp:\n pre_push_contents = fp.read()\n else:\n pre_push_contents = ''\n\n contents = io.open(resource_filename('hook-tmpl')).read().format(\n sys_executable=sys.executable,\n hook_type=hook_type,\n pre_push=pre_push_contents,\n )\n pre_commit_file_obj.write(contents)\n make_executable(hook_path)\n\n output.write_line('pre-commit installed at {}'.format(hook_path))\n\n # If they requested we install all of the hooks, do so.\n if hooks:\n for repository in runner.repositories:\n repository.require_installed()\n\n return 0\n\n\ndef uninstall(runner, hook_type='pre-commit'):\n \"\"\"Uninstall the pre-commit hooks.\"\"\"\n hook_path = runner.get_hook_path(hook_type)\n legacy_path = hook_path + '.legacy'\n # If our file doesn't exist or it isn't ours, gtfo.\n if (\n not os.path.exists(hook_path) or (\n not is_our_pre_commit(hook_path) and\n not is_previous_pre_commit(hook_path)\n )\n ):\n return 0\n\n os.remove(hook_path)\n output.write_line('{} uninstalled'.format(hook_type))\n\n if os.path.exists(legacy_path):\n os.rename(legacy_path, hook_path)\n output.write_line('Restored previous hooks to {}'.format(hook_path))\n\n return 0\n", "path": "pre_commit/commands/install_uninstall.py"}, {"content": "from __future__ import unicode_literals\n\nimport argparse\nimport os\nimport sys\n\nimport pkg_resources\n\nfrom pre_commit import color\nfrom pre_commit import five\nfrom pre_commit import git\nfrom pre_commit.commands.autoupdate import autoupdate\nfrom pre_commit.commands.clean import clean\nfrom pre_commit.commands.install_uninstall import install\nfrom pre_commit.commands.install_uninstall import uninstall\nfrom pre_commit.commands.run import run\nfrom pre_commit.error_handler import error_handler\nfrom pre_commit.logging_handler import add_logging_handler\nfrom pre_commit.runner import Runner\n\n\n# https://github.com/pre-commit/pre-commit/issues/217\n# On OSX, making a virtualenv using pyvenv at . causes `virtualenv` and `pip`\n# to install packages to the wrong place. We don't want anything to deal with\n# pyvenv\nos.environ.pop('__PYVENV_LAUNCHER__', None)\n\n\ndef _add_color_option(parser):\n parser.add_argument(\n '--color', default='auto', type=color.use_color,\n metavar='{' + ','.join(color.COLOR_CHOICES) + '}',\n help='Whether to use color in output. Defaults to `%(default)s`.',\n )\n\n\ndef _add_config_option(parser):\n parser.add_argument(\n '-c', '--config', default='.pre-commit-config.yaml',\n help='Path to alternate config file'\n )\n\n\ndef main(argv=None):\n argv = argv if argv is not None else sys.argv[1:]\n argv = [five.to_text(arg) for arg in argv]\n parser = argparse.ArgumentParser()\n\n # http://stackoverflow.com/a/8521644/812183\n parser.add_argument(\n '-V', '--version',\n action='version',\n version='%(prog)s {}'.format(\n pkg_resources.get_distribution('pre-commit').version\n )\n )\n\n subparsers = parser.add_subparsers(dest='command')\n\n install_parser = subparsers.add_parser(\n 'install', help='Install the pre-commit script.',\n )\n _add_color_option(install_parser)\n _add_config_option(install_parser)\n install_parser.add_argument(\n '-f', '--overwrite', action='store_true',\n help='Overwrite existing hooks / remove migration mode.',\n )\n install_parser.add_argument(\n '--install-hooks', action='store_true',\n help=(\n 'Whether to install hook environments for all environments '\n 'in the config file.'\n ),\n )\n install_parser.add_argument(\n '-t', '--hook-type', choices=('pre-commit', 'pre-push'),\n default='pre-commit',\n )\n\n uninstall_parser = subparsers.add_parser(\n 'uninstall', help='Uninstall the pre-commit script.',\n )\n _add_color_option(uninstall_parser)\n _add_config_option(uninstall_parser)\n uninstall_parser.add_argument(\n '-t', '--hook-type', choices=('pre-commit', 'pre-push'),\n default='pre-commit',\n )\n\n clean_parser = subparsers.add_parser(\n 'clean', help='Clean out pre-commit files.',\n )\n _add_color_option(clean_parser)\n _add_config_option(clean_parser)\n autoupdate_parser = subparsers.add_parser(\n 'autoupdate',\n help=\"Auto-update pre-commit config to the latest repos' versions.\",\n )\n _add_color_option(autoupdate_parser)\n _add_config_option(autoupdate_parser)\n\n run_parser = subparsers.add_parser('run', help='Run hooks.')\n _add_color_option(run_parser)\n _add_config_option(run_parser)\n run_parser.add_argument('hook', nargs='?', help='A single hook-id to run')\n run_parser.add_argument(\n '--no-stash', default=False, action='store_true',\n help='Use this option to prevent auto stashing of unstaged files.',\n )\n run_parser.add_argument(\n '--verbose', '-v', action='store_true', default=False,\n )\n run_parser.add_argument(\n '--origin', '-o',\n help=\"The origin branch's commit_id when using `git push`.\",\n )\n run_parser.add_argument(\n '--source', '-s',\n help=\"The remote branch's commit_id when using `git push`.\",\n )\n run_parser.add_argument(\n '--allow-unstaged-config', default=False, action='store_true',\n help=(\n 'Allow an unstaged config to be present. Note that this will '\n 'be stashed before parsing unless --no-stash is specified.'\n ),\n )\n run_parser.add_argument(\n '--hook-stage', choices=('commit', 'push'), default='commit',\n help='The stage during which the hook is fired e.g. commit or push.',\n )\n run_mutex_group = run_parser.add_mutually_exclusive_group(required=False)\n run_mutex_group.add_argument(\n '--all-files', '-a', action='store_true', default=False,\n help='Run on all the files in the repo. Implies --no-stash.',\n )\n run_mutex_group.add_argument(\n '--files', nargs='*', default=[],\n help='Specific filenames to run hooks on.',\n )\n\n help = subparsers.add_parser(\n 'help', help='Show help for a specific command.',\n )\n help.add_argument('help_cmd', nargs='?', help='Command to show help for.')\n\n # Argparse doesn't really provide a way to use a `default` subparser\n if len(argv) == 0:\n argv = ['run']\n args = parser.parse_args(argv)\n if args.command == 'run':\n args.files = [\n os.path.relpath(os.path.abspath(filename), git.get_root())\n for filename in args.files\n ]\n\n if args.command == 'help':\n if args.help_cmd:\n parser.parse_args([args.help_cmd, '--help'])\n else:\n parser.parse_args(['--help'])\n\n with error_handler():\n add_logging_handler(args.color)\n runner = Runner.create(args.config)\n git.check_for_cygwin_mismatch()\n\n if args.command == 'install':\n return install(\n runner, overwrite=args.overwrite, hooks=args.install_hooks,\n hook_type=args.hook_type,\n )\n elif args.command == 'uninstall':\n return uninstall(runner, hook_type=args.hook_type)\n elif args.command == 'clean':\n return clean(runner)\n elif args.command == 'autoupdate':\n return autoupdate(runner)\n elif args.command == 'run':\n return run(runner, args)\n else:\n raise NotImplementedError(\n 'Command {} not implemented.'.format(args.command)\n )\n\n raise AssertionError(\n 'Command {} failed to exit with a returncode'.format(args.command)\n )\n\n\nif __name__ == '__main__':\n exit(main())\n", "path": "pre_commit/main.py"}], "after_files": [{"content": "from __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport io\nimport os.path\nimport sys\n\nfrom pre_commit import output\nfrom pre_commit.util import make_executable\nfrom pre_commit.util import mkdirp\nfrom pre_commit.util import resource_filename\n\n\n# This is used to identify the hook file we install\nPREVIOUS_IDENTIFYING_HASHES = (\n '4d9958c90bc262f47553e2c073f14cfe',\n 'd8ee923c46731b42cd95cc869add4062',\n '49fd668cb42069aa1b6048464be5d395',\n '79f09a650522a87b0da915d0d983b2de',\n 'e358c9dae00eac5d06b38dfdb1e33a8c',\n)\n\n\nIDENTIFYING_HASH = '138fd403232d2ddd5efb44317e38bf03'\n\n\ndef is_our_pre_commit(filename):\n if not os.path.exists(filename):\n return False\n return IDENTIFYING_HASH in io.open(filename).read()\n\n\ndef is_previous_pre_commit(filename):\n if not os.path.exists(filename):\n return False\n contents = io.open(filename).read()\n return any(hash in contents for hash in PREVIOUS_IDENTIFYING_HASHES)\n\n\ndef install(runner, overwrite=False, hooks=False, hook_type='pre-commit'):\n \"\"\"Install the pre-commit hooks.\"\"\"\n hook_path = runner.get_hook_path(hook_type)\n legacy_path = hook_path + '.legacy'\n\n mkdirp(os.path.dirname(hook_path))\n\n # If we have an existing hook, move it to pre-commit.legacy\n if (\n os.path.lexists(hook_path) and\n not is_our_pre_commit(hook_path) and\n not is_previous_pre_commit(hook_path)\n ):\n os.rename(hook_path, legacy_path)\n\n # If we specify overwrite, we simply delete the legacy file\n if overwrite and os.path.exists(legacy_path):\n os.remove(legacy_path)\n elif os.path.exists(legacy_path):\n output.write_line(\n 'Running in migration mode with existing hooks at {}\\n'\n 'Use -f to use only pre-commit.'.format(\n legacy_path,\n )\n )\n\n with io.open(hook_path, 'w') as pre_commit_file_obj:\n if hook_type == 'pre-push':\n with io.open(resource_filename('pre-push-tmpl')) as fp:\n pre_push_contents = fp.read()\n else:\n pre_push_contents = ''\n\n contents = io.open(resource_filename('hook-tmpl')).read().format(\n sys_executable=sys.executable,\n hook_type=hook_type,\n pre_push=pre_push_contents,\n )\n pre_commit_file_obj.write(contents)\n make_executable(hook_path)\n\n output.write_line('pre-commit installed at {}'.format(hook_path))\n\n # If they requested we install all of the hooks, do so.\n if hooks:\n install_hooks(runner)\n\n return 0\n\n\ndef install_hooks(runner):\n for repository in runner.repositories:\n repository.require_installed()\n\n\ndef uninstall(runner, hook_type='pre-commit'):\n \"\"\"Uninstall the pre-commit hooks.\"\"\"\n hook_path = runner.get_hook_path(hook_type)\n legacy_path = hook_path + '.legacy'\n # If our file doesn't exist or it isn't ours, gtfo.\n if (\n not os.path.exists(hook_path) or (\n not is_our_pre_commit(hook_path) and\n not is_previous_pre_commit(hook_path)\n )\n ):\n return 0\n\n os.remove(hook_path)\n output.write_line('{} uninstalled'.format(hook_type))\n\n if os.path.exists(legacy_path):\n os.rename(legacy_path, hook_path)\n output.write_line('Restored previous hooks to {}'.format(hook_path))\n\n return 0\n", "path": "pre_commit/commands/install_uninstall.py"}, {"content": "from __future__ import unicode_literals\n\nimport argparse\nimport os\nimport sys\n\nimport pkg_resources\n\nfrom pre_commit import color\nfrom pre_commit import five\nfrom pre_commit import git\nfrom pre_commit.commands.autoupdate import autoupdate\nfrom pre_commit.commands.clean import clean\nfrom pre_commit.commands.install_uninstall import install\nfrom pre_commit.commands.install_uninstall import install_hooks\nfrom pre_commit.commands.install_uninstall import uninstall\nfrom pre_commit.commands.run import run\nfrom pre_commit.error_handler import error_handler\nfrom pre_commit.logging_handler import add_logging_handler\nfrom pre_commit.runner import Runner\n\n\n# https://github.com/pre-commit/pre-commit/issues/217\n# On OSX, making a virtualenv using pyvenv at . causes `virtualenv` and `pip`\n# to install packages to the wrong place. We don't want anything to deal with\n# pyvenv\nos.environ.pop('__PYVENV_LAUNCHER__', None)\n\n\ndef _add_color_option(parser):\n parser.add_argument(\n '--color', default='auto', type=color.use_color,\n metavar='{' + ','.join(color.COLOR_CHOICES) + '}',\n help='Whether to use color in output. Defaults to `%(default)s`.',\n )\n\n\ndef _add_config_option(parser):\n parser.add_argument(\n '-c', '--config', default='.pre-commit-config.yaml',\n help='Path to alternate config file'\n )\n\n\ndef main(argv=None):\n argv = argv if argv is not None else sys.argv[1:]\n argv = [five.to_text(arg) for arg in argv]\n parser = argparse.ArgumentParser()\n\n # http://stackoverflow.com/a/8521644/812183\n parser.add_argument(\n '-V', '--version',\n action='version',\n version='%(prog)s {}'.format(\n pkg_resources.get_distribution('pre-commit').version\n )\n )\n\n subparsers = parser.add_subparsers(dest='command')\n\n install_parser = subparsers.add_parser(\n 'install', help='Install the pre-commit script.',\n )\n _add_color_option(install_parser)\n _add_config_option(install_parser)\n install_parser.add_argument(\n '-f', '--overwrite', action='store_true',\n help='Overwrite existing hooks / remove migration mode.',\n )\n install_parser.add_argument(\n '--install-hooks', action='store_true',\n help=(\n 'Whether to install hook environments for all environments '\n 'in the config file.'\n ),\n )\n install_parser.add_argument(\n '-t', '--hook-type', choices=('pre-commit', 'pre-push'),\n default='pre-commit',\n )\n\n install_hooks_parser = subparsers.add_parser(\n 'install-hooks',\n help=(\n 'Install hook environemnts for all environemnts in the config '\n 'file. You may find `pre-commit install --install-hooks` more '\n 'useful.'\n ),\n )\n _add_color_option(install_hooks_parser)\n _add_config_option(install_hooks_parser)\n\n uninstall_parser = subparsers.add_parser(\n 'uninstall', help='Uninstall the pre-commit script.',\n )\n _add_color_option(uninstall_parser)\n _add_config_option(uninstall_parser)\n uninstall_parser.add_argument(\n '-t', '--hook-type', choices=('pre-commit', 'pre-push'),\n default='pre-commit',\n )\n\n clean_parser = subparsers.add_parser(\n 'clean', help='Clean out pre-commit files.',\n )\n _add_color_option(clean_parser)\n _add_config_option(clean_parser)\n autoupdate_parser = subparsers.add_parser(\n 'autoupdate',\n help=\"Auto-update pre-commit config to the latest repos' versions.\",\n )\n _add_color_option(autoupdate_parser)\n _add_config_option(autoupdate_parser)\n\n run_parser = subparsers.add_parser('run', help='Run hooks.')\n _add_color_option(run_parser)\n _add_config_option(run_parser)\n run_parser.add_argument('hook', nargs='?', help='A single hook-id to run')\n run_parser.add_argument(\n '--no-stash', default=False, action='store_true',\n help='Use this option to prevent auto stashing of unstaged files.',\n )\n run_parser.add_argument(\n '--verbose', '-v', action='store_true', default=False,\n )\n run_parser.add_argument(\n '--origin', '-o',\n help=\"The origin branch's commit_id when using `git push`.\",\n )\n run_parser.add_argument(\n '--source', '-s',\n help=\"The remote branch's commit_id when using `git push`.\",\n )\n run_parser.add_argument(\n '--allow-unstaged-config', default=False, action='store_true',\n help=(\n 'Allow an unstaged config to be present. Note that this will '\n 'be stashed before parsing unless --no-stash is specified.'\n ),\n )\n run_parser.add_argument(\n '--hook-stage', choices=('commit', 'push'), default='commit',\n help='The stage during which the hook is fired e.g. commit or push.',\n )\n run_mutex_group = run_parser.add_mutually_exclusive_group(required=False)\n run_mutex_group.add_argument(\n '--all-files', '-a', action='store_true', default=False,\n help='Run on all the files in the repo. Implies --no-stash.',\n )\n run_mutex_group.add_argument(\n '--files', nargs='*', default=[],\n help='Specific filenames to run hooks on.',\n )\n\n help = subparsers.add_parser(\n 'help', help='Show help for a specific command.',\n )\n help.add_argument('help_cmd', nargs='?', help='Command to show help for.')\n\n # Argparse doesn't really provide a way to use a `default` subparser\n if len(argv) == 0:\n argv = ['run']\n args = parser.parse_args(argv)\n if args.command == 'run':\n args.files = [\n os.path.relpath(os.path.abspath(filename), git.get_root())\n for filename in args.files\n ]\n\n if args.command == 'help':\n if args.help_cmd:\n parser.parse_args([args.help_cmd, '--help'])\n else:\n parser.parse_args(['--help'])\n\n with error_handler():\n add_logging_handler(args.color)\n runner = Runner.create(args.config)\n git.check_for_cygwin_mismatch()\n\n if args.command == 'install':\n return install(\n runner, overwrite=args.overwrite, hooks=args.install_hooks,\n hook_type=args.hook_type,\n )\n elif args.command == 'install-hooks':\n return install_hooks(runner)\n elif args.command == 'uninstall':\n return uninstall(runner, hook_type=args.hook_type)\n elif args.command == 'clean':\n return clean(runner)\n elif args.command == 'autoupdate':\n return autoupdate(runner)\n elif args.command == 'run':\n return run(runner, args)\n else:\n raise NotImplementedError(\n 'Command {} not implemented.'.format(args.command)\n )\n\n raise AssertionError(\n 'Command {} failed to exit with a returncode'.format(args.command)\n )\n\n\nif __name__ == '__main__':\n exit(main())\n", "path": "pre_commit/main.py"}]}
| 3,458 | 494 |
gh_patches_debug_20599
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-1650
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Error when serving images through the URL generator
I posted a comment on https://github.com/torchbox/wagtail/issues/983 but probably better to open a new issue. Looks like the same problem to me though.
Hi guys, I think I'm having the same problem but when serving images using the URL generator. It does work if I'm logged-in in the site (cache not working) but doesn't when I'm not (cache full on).
Cheers,
Jordi
Internal Server Error: /images/2dMQIUOPwS5DlZuprp_E_WFdfhw=/47/width-75/
Traceback (most recent call last):
File "/var/www/buildability/venvs/buildability.co.nz/local/lib/python2.7/site-packages/django/core/handlers/base.py", line 204, in get_response
response = middleware_method(request, response)
File "/var/www/buildability/venvs/buildability.co.nz/local/lib/python2.7/site-packages/django/middleware/cache.py", line 121, in process_response
self.cache.set(cache_key, response, timeout)
File "/var/www/buildability/venvs/buildability.co.nz/local/lib/python2.7/site-packages/redis_cache/cache.py", line 239, in set
result = self._set(key, pickle.dumps(value), timeout, client, _add_only)
File "/var/www/buildability/venvs/buildability.co.nz/lib/python2.7/copy_reg.py", line 70, in _reduce_ex
raise TypeError, "can't pickle %s objects" % base.__name__
TypeError: can't pickle instancemethod objects
Request repr():
<WSGIRequest
path:/images/2dMQIUOPwS5DlZuprp_E_WFdfhw=/47/width-75/,
GET:<QueryDict: {}>,
POST:<QueryDict: {}>,
COOKIES:{'_ga': 'GA1.3.1219121887.1434427204',
'csrftoken': 'GNhfTEGBu40y8wRAFPa15lQTV66F9WCs'},
META:{'CONTENT_LENGTH': '',
'CONTENT_TYPE': '',
u'CSRF_COOKIE': u'GNhfTEGBu40y8wRAFPa15lQTV66F9WCs',
'DOCUMENT_ROOT': '/usr/share/nginx/html',
'HTTP_ACCEPT': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,_/_;q=0.8',
'HTTP_ACCEPT_ENCODING': 'gzip, deflate, sdch',
'HTTP_ACCEPT_LANGUAGE': 'en-US,en;q=0.8',
'HTTP_CACHE_CONTROL': 'max-age=0',
'HTTP_CONNECTION': 'keep-alive',
'HTTP_COOKIE': '_ga=GA1.3.1219121887.1434427204; csrftoken=GNhfTEGBu40y8wRAFPa15lQTV66F9WCs',
'HTTP_HOST': 'www.buildability.co.nz',
'HTTP_UPGRADE_INSECURE_REQUESTS': '1',
'HTTP_USER_AGENT': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36',
'PATH_INFO': u'/images/2dMQIUOPwS5DlZuprp_E_WFdfhw=/47/width-75/',
'QUERY_STRING': '',
'REMOTE_ADDR': '131.203.137.142',
'REMOTE_PORT': '51455',
'REQUEST_METHOD': 'GET',
'REQUEST_URI': '/images/2dMQIUOPwS5DlZuprp_E_WFdfhw%3D/47/width-75/',
u'SCRIPT_NAME': u'',
'SERVER_NAME': 'www.buildability.co.nz',
'SERVER_PORT': '80',
'SERVER_PROTOCOL': 'HTTP/1.1',
'UWSGI_SCHEME': 'http',
'uwsgi.core': 7,
'uwsgi.node': 'avinton',
'uwsgi.version': '1.9.17.1-debian',
'wsgi.errors': <open file 'wsgi_errors', mode 'w' at 0x7f0548a548a0>,
'wsgi.file_wrapper': <built-in function uwsgi_sendfile>,
'wsgi.input': <uwsgi._Input object at 0x7f0548a20a08>,
'wsgi.multiprocess': True,
'wsgi.multithread': True,
'wsgi.run_once': False,
'wsgi.url_scheme': 'http',
'wsgi.version': (1, 0)}>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `wagtail/wagtailimages/views/frontend.py`
Content:
```
1 from wsgiref.util import FileWrapper
2 import imghdr
3
4 from django.shortcuts import get_object_or_404
5 from django.http import HttpResponse
6 from django.core.exceptions import PermissionDenied
7
8 from wagtail.wagtailimages.models import get_image_model
9 from wagtail.wagtailimages.utils import verify_signature
10 from wagtail.wagtailimages.exceptions import InvalidFilterSpecError
11
12
13 def serve(request, signature, image_id, filter_spec):
14 image = get_object_or_404(get_image_model(), id=image_id)
15
16 if not verify_signature(signature.encode(), image_id, filter_spec):
17 raise PermissionDenied
18
19 try:
20 rendition = image.get_rendition(filter_spec)
21 rendition.file.open('rb')
22 image_format = imghdr.what(rendition.file)
23 return HttpResponse(FileWrapper(rendition.file), content_type='image/' + image_format)
24 except InvalidFilterSpecError:
25 return HttpResponse("Invalid filter spec: " + filter_spec, content_type='text/plain', status=400)
26
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/wagtail/wagtailimages/views/frontend.py b/wagtail/wagtailimages/views/frontend.py
--- a/wagtail/wagtailimages/views/frontend.py
+++ b/wagtail/wagtailimages/views/frontend.py
@@ -2,7 +2,7 @@
import imghdr
from django.shortcuts import get_object_or_404
-from django.http import HttpResponse
+from django.http import HttpResponse, StreamingHttpResponse
from django.core.exceptions import PermissionDenied
from wagtail.wagtailimages.models import get_image_model
@@ -20,6 +20,6 @@
rendition = image.get_rendition(filter_spec)
rendition.file.open('rb')
image_format = imghdr.what(rendition.file)
- return HttpResponse(FileWrapper(rendition.file), content_type='image/' + image_format)
+ return StreamingHttpResponse(FileWrapper(rendition.file), content_type='image/' + image_format)
except InvalidFilterSpecError:
return HttpResponse("Invalid filter spec: " + filter_spec, content_type='text/plain', status=400)
|
{"golden_diff": "diff --git a/wagtail/wagtailimages/views/frontend.py b/wagtail/wagtailimages/views/frontend.py\n--- a/wagtail/wagtailimages/views/frontend.py\n+++ b/wagtail/wagtailimages/views/frontend.py\n@@ -2,7 +2,7 @@\n import imghdr\n \n from django.shortcuts import get_object_or_404\n-from django.http import HttpResponse\n+from django.http import HttpResponse, StreamingHttpResponse\n from django.core.exceptions import PermissionDenied\n \n from wagtail.wagtailimages.models import get_image_model\n@@ -20,6 +20,6 @@\n rendition = image.get_rendition(filter_spec)\n rendition.file.open('rb')\n image_format = imghdr.what(rendition.file)\n- return HttpResponse(FileWrapper(rendition.file), content_type='image/' + image_format)\n+ return StreamingHttpResponse(FileWrapper(rendition.file), content_type='image/' + image_format)\n except InvalidFilterSpecError:\n return HttpResponse(\"Invalid filter spec: \" + filter_spec, content_type='text/plain', status=400)\n", "issue": "Error when serving images through the URL generator\nI posted a comment on https://github.com/torchbox/wagtail/issues/983 but probably better to open a new issue. Looks like the same problem to me though.\n\nHi guys, I think I'm having the same problem but when serving images using the URL generator. It does work if I'm logged-in in the site (cache not working) but doesn't when I'm not (cache full on).\n\nCheers,\nJordi\n\nInternal Server Error: /images/2dMQIUOPwS5DlZuprp_E_WFdfhw=/47/width-75/\nTraceback (most recent call last):\n File \"/var/www/buildability/venvs/buildability.co.nz/local/lib/python2.7/site-packages/django/core/handlers/base.py\", line 204, in get_response\n response = middleware_method(request, response)\n File \"/var/www/buildability/venvs/buildability.co.nz/local/lib/python2.7/site-packages/django/middleware/cache.py\", line 121, in process_response\n self.cache.set(cache_key, response, timeout)\n File \"/var/www/buildability/venvs/buildability.co.nz/local/lib/python2.7/site-packages/redis_cache/cache.py\", line 239, in set\n result = self._set(key, pickle.dumps(value), timeout, client, _add_only)\n File \"/var/www/buildability/venvs/buildability.co.nz/lib/python2.7/copy_reg.py\", line 70, in _reduce_ex\n raise TypeError, \"can't pickle %s objects\" % base.__name__\nTypeError: can't pickle instancemethod objects\n\nRequest repr(): \n<WSGIRequest\npath:/images/2dMQIUOPwS5DlZuprp_E_WFdfhw=/47/width-75/,\nGET:<QueryDict: {}>,\nPOST:<QueryDict: {}>,\nCOOKIES:{'_ga': 'GA1.3.1219121887.1434427204',\n 'csrftoken': 'GNhfTEGBu40y8wRAFPa15lQTV66F9WCs'},\nMETA:{'CONTENT_LENGTH': '',\n 'CONTENT_TYPE': '',\n u'CSRF_COOKIE': u'GNhfTEGBu40y8wRAFPa15lQTV66F9WCs',\n 'DOCUMENT_ROOT': '/usr/share/nginx/html',\n 'HTTP_ACCEPT': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,_/_;q=0.8',\n 'HTTP_ACCEPT_ENCODING': 'gzip, deflate, sdch',\n 'HTTP_ACCEPT_LANGUAGE': 'en-US,en;q=0.8',\n 'HTTP_CACHE_CONTROL': 'max-age=0',\n 'HTTP_CONNECTION': 'keep-alive',\n 'HTTP_COOKIE': '_ga=GA1.3.1219121887.1434427204; csrftoken=GNhfTEGBu40y8wRAFPa15lQTV66F9WCs',\n 'HTTP_HOST': 'www.buildability.co.nz',\n 'HTTP_UPGRADE_INSECURE_REQUESTS': '1',\n 'HTTP_USER_AGENT': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36',\n 'PATH_INFO': u'/images/2dMQIUOPwS5DlZuprp_E_WFdfhw=/47/width-75/',\n 'QUERY_STRING': '',\n 'REMOTE_ADDR': '131.203.137.142',\n 'REMOTE_PORT': '51455',\n 'REQUEST_METHOD': 'GET',\n 'REQUEST_URI': '/images/2dMQIUOPwS5DlZuprp_E_WFdfhw%3D/47/width-75/',\n u'SCRIPT_NAME': u'',\n 'SERVER_NAME': 'www.buildability.co.nz',\n 'SERVER_PORT': '80',\n 'SERVER_PROTOCOL': 'HTTP/1.1',\n 'UWSGI_SCHEME': 'http',\n 'uwsgi.core': 7,\n 'uwsgi.node': 'avinton',\n 'uwsgi.version': '1.9.17.1-debian',\n 'wsgi.errors': <open file 'wsgi_errors', mode 'w' at 0x7f0548a548a0>,\n 'wsgi.file_wrapper': <built-in function uwsgi_sendfile>,\n 'wsgi.input': <uwsgi._Input object at 0x7f0548a20a08>,\n 'wsgi.multiprocess': True,\n 'wsgi.multithread': True,\n 'wsgi.run_once': False,\n 'wsgi.url_scheme': 'http',\n 'wsgi.version': (1, 0)}>\n\n", "before_files": [{"content": "from wsgiref.util import FileWrapper\nimport imghdr\n\nfrom django.shortcuts import get_object_or_404\nfrom django.http import HttpResponse\nfrom django.core.exceptions import PermissionDenied\n\nfrom wagtail.wagtailimages.models import get_image_model\nfrom wagtail.wagtailimages.utils import verify_signature\nfrom wagtail.wagtailimages.exceptions import InvalidFilterSpecError\n\n\ndef serve(request, signature, image_id, filter_spec):\n image = get_object_or_404(get_image_model(), id=image_id)\n\n if not verify_signature(signature.encode(), image_id, filter_spec):\n raise PermissionDenied\n\n try:\n rendition = image.get_rendition(filter_spec)\n rendition.file.open('rb')\n image_format = imghdr.what(rendition.file)\n return HttpResponse(FileWrapper(rendition.file), content_type='image/' + image_format)\n except InvalidFilterSpecError:\n return HttpResponse(\"Invalid filter spec: \" + filter_spec, content_type='text/plain', status=400)\n", "path": "wagtail/wagtailimages/views/frontend.py"}], "after_files": [{"content": "from wsgiref.util import FileWrapper\nimport imghdr\n\nfrom django.shortcuts import get_object_or_404\nfrom django.http import HttpResponse, StreamingHttpResponse\nfrom django.core.exceptions import PermissionDenied\n\nfrom wagtail.wagtailimages.models import get_image_model\nfrom wagtail.wagtailimages.utils import verify_signature\nfrom wagtail.wagtailimages.exceptions import InvalidFilterSpecError\n\n\ndef serve(request, signature, image_id, filter_spec):\n image = get_object_or_404(get_image_model(), id=image_id)\n\n if not verify_signature(signature.encode(), image_id, filter_spec):\n raise PermissionDenied\n\n try:\n rendition = image.get_rendition(filter_spec)\n rendition.file.open('rb')\n image_format = imghdr.what(rendition.file)\n return StreamingHttpResponse(FileWrapper(rendition.file), content_type='image/' + image_format)\n except InvalidFilterSpecError:\n return HttpResponse(\"Invalid filter spec: \" + filter_spec, content_type='text/plain', status=400)\n", "path": "wagtail/wagtailimages/views/frontend.py"}]}
| 1,617 | 232 |
gh_patches_debug_13497
|
rasdani/github-patches
|
git_diff
|
ray-project__ray-8493
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
import error
ray 0.8.5,when I try to use ray, it occurs Ray must be imported before pickle5 because Ray requires a specific version of pickle5 (which is packaged along with Ray.
I want to know it must import pickle5 before import ray, Right?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/ray/__init__.py`
Content:
```
1 import os
2 import logging
3 from os.path import dirname
4 import sys
5
6 logger = logging.getLogger(__name__)
7
8 # MUST add pickle5 to the import path because it will be imported by some
9 # raylet modules.
10
11 if "pickle5" in sys.modules:
12 raise ImportError("Ray must be imported before pickle5 because Ray "
13 "requires a specific version of pickle5 (which is "
14 "packaged along with Ray).")
15
16 if "OMP_NUM_THREADS" not in os.environ:
17 logger.debug("[ray] Forcing OMP_NUM_THREADS=1 to avoid performance "
18 "degradation with many workers (issue #6998). You can "
19 "override this by explicitly setting OMP_NUM_THREADS.")
20 os.environ["OMP_NUM_THREADS"] = "1"
21
22 # Add the directory containing pickle5 to the Python path so that we find the
23 # pickle5 version packaged with ray and not a pre-existing pickle5.
24 pickle5_path = os.path.join(
25 os.path.abspath(os.path.dirname(__file__)), "pickle5_files")
26 sys.path.insert(0, pickle5_path)
27
28 # Importing psutil & setproctitle. Must be before ray._raylet is initialized.
29 thirdparty_files = os.path.join(
30 os.path.abspath(os.path.dirname(__file__)), "thirdparty_files")
31 sys.path.insert(0, thirdparty_files)
32
33 if sys.platform == "win32":
34 import ray.compat # noqa: E402
35 ray.compat.patch_redis_empty_recv()
36
37 # Expose ray ABI symbols which may be dependent by other shared
38 # libraries such as _streaming.so. See BUILD.bazel:_raylet
39 python_shared_lib_suffix = ".so" if sys.platform != "win32" else ".pyd"
40 so_path = os.path.join(dirname(__file__), "_raylet" + python_shared_lib_suffix)
41 if os.path.exists(so_path):
42 import ctypes
43 from ctypes import CDLL
44 CDLL(so_path, ctypes.RTLD_GLOBAL)
45
46 import ray._raylet # noqa: E402
47
48 from ray._raylet import (
49 ActorCheckpointID,
50 ActorClassID,
51 ActorID,
52 ClientID,
53 Config as _Config,
54 JobID,
55 WorkerID,
56 FunctionID,
57 ObjectID,
58 TaskID,
59 UniqueID,
60 Language,
61 ) # noqa: E402
62
63 _config = _Config()
64
65 from ray.profiling import profile # noqa: E402
66 from ray.state import (jobs, nodes, actors, objects, timeline,
67 object_transfer_timeline, cluster_resources,
68 available_resources, errors) # noqa: E402
69 from ray.worker import (
70 LOCAL_MODE,
71 SCRIPT_MODE,
72 WORKER_MODE,
73 cancel,
74 connect,
75 disconnect,
76 get,
77 get_gpu_ids,
78 get_resource_ids,
79 get_webui_url,
80 init,
81 is_initialized,
82 put,
83 kill,
84 register_custom_serializer,
85 remote,
86 shutdown,
87 show_in_webui,
88 wait,
89 ) # noqa: E402
90 import ray.internal # noqa: E402
91 import ray.projects # noqa: E402
92 # We import ray.actor because some code is run in actor.py which initializes
93 # some functions in the worker.
94 import ray.actor # noqa: F401
95 from ray.actor import method # noqa: E402
96 from ray.cross_language import java_function, java_actor_class # noqa: E402
97 from ray import util # noqa: E402
98
99 # Replaced with the current commit when building the wheels.
100 __commit__ = "{{RAY_COMMIT_SHA}}"
101 __version__ = "0.9.0.dev0"
102
103 __all__ = [
104 "jobs",
105 "nodes",
106 "actors",
107 "objects",
108 "timeline",
109 "object_transfer_timeline",
110 "cluster_resources",
111 "available_resources",
112 "errors",
113 "LOCAL_MODE",
114 "PYTHON_MODE",
115 "SCRIPT_MODE",
116 "WORKER_MODE",
117 "__version__",
118 "_config",
119 "_get_runtime_context",
120 "actor",
121 "cancel",
122 "connect",
123 "disconnect",
124 "get",
125 "get_gpu_ids",
126 "get_resource_ids",
127 "get_webui_url",
128 "init",
129 "internal",
130 "is_initialized",
131 "method",
132 "profile",
133 "projects",
134 "put",
135 "kill",
136 "register_custom_serializer",
137 "remote",
138 "shutdown",
139 "show_in_webui",
140 "wait",
141 "Language",
142 "java_function",
143 "java_actor_class",
144 "util",
145 ]
146
147 # ID types
148 __all__ += [
149 "ActorCheckpointID",
150 "ActorClassID",
151 "ActorID",
152 "ClientID",
153 "JobID",
154 "WorkerID",
155 "FunctionID",
156 "ObjectID",
157 "TaskID",
158 "UniqueID",
159 ]
160
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/python/ray/__init__.py b/python/ray/__init__.py
--- a/python/ray/__init__.py
+++ b/python/ray/__init__.py
@@ -9,9 +9,13 @@
# raylet modules.
if "pickle5" in sys.modules:
- raise ImportError("Ray must be imported before pickle5 because Ray "
- "requires a specific version of pickle5 (which is "
- "packaged along with Ray).")
+ import pkg_resources
+ version_info = pkg_resources.require("pickle5")
+ version = tuple(int(n) for n in version_info[0].version.split("."))
+ if version < (0, 0, 10):
+ raise ImportError("You are using an old version of pickle5 that "
+ "leaks memory, please run 'pip install pickle5 -U' "
+ "to upgrade")
if "OMP_NUM_THREADS" not in os.environ:
logger.debug("[ray] Forcing OMP_NUM_THREADS=1 to avoid performance "
|
{"golden_diff": "diff --git a/python/ray/__init__.py b/python/ray/__init__.py\n--- a/python/ray/__init__.py\n+++ b/python/ray/__init__.py\n@@ -9,9 +9,13 @@\n # raylet modules.\n \n if \"pickle5\" in sys.modules:\n- raise ImportError(\"Ray must be imported before pickle5 because Ray \"\n- \"requires a specific version of pickle5 (which is \"\n- \"packaged along with Ray).\")\n+ import pkg_resources\n+ version_info = pkg_resources.require(\"pickle5\")\n+ version = tuple(int(n) for n in version_info[0].version.split(\".\"))\n+ if version < (0, 0, 10):\n+ raise ImportError(\"You are using an old version of pickle5 that \"\n+ \"leaks memory, please run 'pip install pickle5 -U' \"\n+ \"to upgrade\")\n \n if \"OMP_NUM_THREADS\" not in os.environ:\n logger.debug(\"[ray] Forcing OMP_NUM_THREADS=1 to avoid performance \"\n", "issue": "import error\nray 0.8.5,when I try to use ray\uff0c it occurs Ray must be imported before pickle5 because Ray requires a specific version of pickle5 (which is packaged along with Ray.\r\n\r\nI want to know it must import pickle5 before import ray, Right?\n", "before_files": [{"content": "import os\nimport logging\nfrom os.path import dirname\nimport sys\n\nlogger = logging.getLogger(__name__)\n\n# MUST add pickle5 to the import path because it will be imported by some\n# raylet modules.\n\nif \"pickle5\" in sys.modules:\n raise ImportError(\"Ray must be imported before pickle5 because Ray \"\n \"requires a specific version of pickle5 (which is \"\n \"packaged along with Ray).\")\n\nif \"OMP_NUM_THREADS\" not in os.environ:\n logger.debug(\"[ray] Forcing OMP_NUM_THREADS=1 to avoid performance \"\n \"degradation with many workers (issue #6998). You can \"\n \"override this by explicitly setting OMP_NUM_THREADS.\")\n os.environ[\"OMP_NUM_THREADS\"] = \"1\"\n\n# Add the directory containing pickle5 to the Python path so that we find the\n# pickle5 version packaged with ray and not a pre-existing pickle5.\npickle5_path = os.path.join(\n os.path.abspath(os.path.dirname(__file__)), \"pickle5_files\")\nsys.path.insert(0, pickle5_path)\n\n# Importing psutil & setproctitle. Must be before ray._raylet is initialized.\nthirdparty_files = os.path.join(\n os.path.abspath(os.path.dirname(__file__)), \"thirdparty_files\")\nsys.path.insert(0, thirdparty_files)\n\nif sys.platform == \"win32\":\n import ray.compat # noqa: E402\n ray.compat.patch_redis_empty_recv()\n\n# Expose ray ABI symbols which may be dependent by other shared\n# libraries such as _streaming.so. See BUILD.bazel:_raylet\npython_shared_lib_suffix = \".so\" if sys.platform != \"win32\" else \".pyd\"\nso_path = os.path.join(dirname(__file__), \"_raylet\" + python_shared_lib_suffix)\nif os.path.exists(so_path):\n import ctypes\n from ctypes import CDLL\n CDLL(so_path, ctypes.RTLD_GLOBAL)\n\nimport ray._raylet # noqa: E402\n\nfrom ray._raylet import (\n ActorCheckpointID,\n ActorClassID,\n ActorID,\n ClientID,\n Config as _Config,\n JobID,\n WorkerID,\n FunctionID,\n ObjectID,\n TaskID,\n UniqueID,\n Language,\n) # noqa: E402\n\n_config = _Config()\n\nfrom ray.profiling import profile # noqa: E402\nfrom ray.state import (jobs, nodes, actors, objects, timeline,\n object_transfer_timeline, cluster_resources,\n available_resources, errors) # noqa: E402\nfrom ray.worker import (\n LOCAL_MODE,\n SCRIPT_MODE,\n WORKER_MODE,\n cancel,\n connect,\n disconnect,\n get,\n get_gpu_ids,\n get_resource_ids,\n get_webui_url,\n init,\n is_initialized,\n put,\n kill,\n register_custom_serializer,\n remote,\n shutdown,\n show_in_webui,\n wait,\n) # noqa: E402\nimport ray.internal # noqa: E402\nimport ray.projects # noqa: E402\n# We import ray.actor because some code is run in actor.py which initializes\n# some functions in the worker.\nimport ray.actor # noqa: F401\nfrom ray.actor import method # noqa: E402\nfrom ray.cross_language import java_function, java_actor_class # noqa: E402\nfrom ray import util # noqa: E402\n\n# Replaced with the current commit when building the wheels.\n__commit__ = \"{{RAY_COMMIT_SHA}}\"\n__version__ = \"0.9.0.dev0\"\n\n__all__ = [\n \"jobs\",\n \"nodes\",\n \"actors\",\n \"objects\",\n \"timeline\",\n \"object_transfer_timeline\",\n \"cluster_resources\",\n \"available_resources\",\n \"errors\",\n \"LOCAL_MODE\",\n \"PYTHON_MODE\",\n \"SCRIPT_MODE\",\n \"WORKER_MODE\",\n \"__version__\",\n \"_config\",\n \"_get_runtime_context\",\n \"actor\",\n \"cancel\",\n \"connect\",\n \"disconnect\",\n \"get\",\n \"get_gpu_ids\",\n \"get_resource_ids\",\n \"get_webui_url\",\n \"init\",\n \"internal\",\n \"is_initialized\",\n \"method\",\n \"profile\",\n \"projects\",\n \"put\",\n \"kill\",\n \"register_custom_serializer\",\n \"remote\",\n \"shutdown\",\n \"show_in_webui\",\n \"wait\",\n \"Language\",\n \"java_function\",\n \"java_actor_class\",\n \"util\",\n]\n\n# ID types\n__all__ += [\n \"ActorCheckpointID\",\n \"ActorClassID\",\n \"ActorID\",\n \"ClientID\",\n \"JobID\",\n \"WorkerID\",\n \"FunctionID\",\n \"ObjectID\",\n \"TaskID\",\n \"UniqueID\",\n]\n", "path": "python/ray/__init__.py"}], "after_files": [{"content": "import os\nimport logging\nfrom os.path import dirname\nimport sys\n\nlogger = logging.getLogger(__name__)\n\n# MUST add pickle5 to the import path because it will be imported by some\n# raylet modules.\n\nif \"pickle5\" in sys.modules:\n import pkg_resources\n version_info = pkg_resources.require(\"pickle5\")\n version = tuple(int(n) for n in version_info[0].version.split(\".\"))\n if version < (0, 0, 10):\n raise ImportError(\"You are using an old version of pickle5 that \"\n \"leaks memory, please run 'pip install pickle5 -U' \"\n \"to upgrade\")\n\nif \"OMP_NUM_THREADS\" not in os.environ:\n logger.debug(\"[ray] Forcing OMP_NUM_THREADS=1 to avoid performance \"\n \"degradation with many workers (issue #6998). You can \"\n \"override this by explicitly setting OMP_NUM_THREADS.\")\n os.environ[\"OMP_NUM_THREADS\"] = \"1\"\n\n# Add the directory containing pickle5 to the Python path so that we find the\n# pickle5 version packaged with ray and not a pre-existing pickle5.\npickle5_path = os.path.join(\n os.path.abspath(os.path.dirname(__file__)), \"pickle5_files\")\nsys.path.insert(0, pickle5_path)\n\n# Importing psutil & setproctitle. Must be before ray._raylet is initialized.\nthirdparty_files = os.path.join(\n os.path.abspath(os.path.dirname(__file__)), \"thirdparty_files\")\nsys.path.insert(0, thirdparty_files)\n\nif sys.platform == \"win32\":\n import ray.compat # noqa: E402\n ray.compat.patch_redis_empty_recv()\n\n# Expose ray ABI symbols which may be dependent by other shared\n# libraries such as _streaming.so. See BUILD.bazel:_raylet\npython_shared_lib_suffix = \".so\" if sys.platform != \"win32\" else \".pyd\"\nso_path = os.path.join(dirname(__file__), \"_raylet\" + python_shared_lib_suffix)\nif os.path.exists(so_path):\n import ctypes\n from ctypes import CDLL\n CDLL(so_path, ctypes.RTLD_GLOBAL)\n\nimport ray._raylet # noqa: E402\n\nfrom ray._raylet import (\n ActorCheckpointID,\n ActorClassID,\n ActorID,\n ClientID,\n Config as _Config,\n JobID,\n WorkerID,\n FunctionID,\n ObjectID,\n TaskID,\n UniqueID,\n Language,\n) # noqa: E402\n\n_config = _Config()\n\nfrom ray.profiling import profile # noqa: E402\nfrom ray.state import (jobs, nodes, actors, objects, timeline,\n object_transfer_timeline, cluster_resources,\n available_resources, errors) # noqa: E402\nfrom ray.worker import (\n LOCAL_MODE,\n SCRIPT_MODE,\n WORKER_MODE,\n cancel,\n connect,\n disconnect,\n get,\n get_gpu_ids,\n get_resource_ids,\n get_webui_url,\n init,\n is_initialized,\n put,\n kill,\n register_custom_serializer,\n remote,\n shutdown,\n show_in_webui,\n wait,\n) # noqa: E402\nimport ray.internal # noqa: E402\nimport ray.projects # noqa: E402\n# We import ray.actor because some code is run in actor.py which initializes\n# some functions in the worker.\nimport ray.actor # noqa: F401\nfrom ray.actor import method # noqa: E402\nfrom ray.cross_language import java_function, java_actor_class # noqa: E402\nfrom ray import util # noqa: E402\n\n# Replaced with the current commit when building the wheels.\n__commit__ = \"{{RAY_COMMIT_SHA}}\"\n__version__ = \"0.9.0.dev0\"\n\n__all__ = [\n \"jobs\",\n \"nodes\",\n \"actors\",\n \"objects\",\n \"timeline\",\n \"object_transfer_timeline\",\n \"cluster_resources\",\n \"available_resources\",\n \"errors\",\n \"LOCAL_MODE\",\n \"PYTHON_MODE\",\n \"SCRIPT_MODE\",\n \"WORKER_MODE\",\n \"__version__\",\n \"_config\",\n \"_get_runtime_context\",\n \"actor\",\n \"cancel\",\n \"connect\",\n \"disconnect\",\n \"get\",\n \"get_gpu_ids\",\n \"get_resource_ids\",\n \"get_webui_url\",\n \"init\",\n \"internal\",\n \"is_initialized\",\n \"method\",\n \"profile\",\n \"projects\",\n \"put\",\n \"kill\",\n \"register_custom_serializer\",\n \"remote\",\n \"shutdown\",\n \"show_in_webui\",\n \"wait\",\n \"Language\",\n \"java_function\",\n \"java_actor_class\",\n \"util\",\n]\n\n# ID types\n__all__ += [\n \"ActorCheckpointID\",\n \"ActorClassID\",\n \"ActorID\",\n \"ClientID\",\n \"JobID\",\n \"WorkerID\",\n \"FunctionID\",\n \"ObjectID\",\n \"TaskID\",\n \"UniqueID\",\n]\n", "path": "python/ray/__init__.py"}]}
| 1,754 | 228 |
gh_patches_debug_16437
|
rasdani/github-patches
|
git_diff
|
google__pytype-773
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Automatically added git ignore file to sub directory
This PR automatically creates a .gitignore file to the output directory of pytype/tools/analyze_project/main.py
Issue #759
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pytype/tools/analyze_project/main.py`
Content:
```
1 """Analyze an entire project using pytype."""
2
3 import logging
4 import sys
5 import tempfile
6
7 import importlab.environment
8 import importlab.fs
9 import importlab.graph
10 import importlab.output
11
12 from pytype import io
13 from pytype.tools import environment
14 from pytype.tools import tool_utils
15 from pytype.tools.analyze_project import config
16 from pytype.tools.analyze_project import environment as analyze_project_env
17 from pytype.tools.analyze_project import parse_args
18 from pytype.tools.analyze_project import pytype_runner
19
20
21 def main():
22 parser = parse_args.make_parser()
23 args = parser.parse_args(sys.argv[1:])
24
25 if args.version:
26 print(io.get_pytype_version())
27 sys.exit(0)
28
29 tool_utils.setup_logging_or_die(args.verbosity)
30
31 if args.generate_config:
32 config.generate_sample_config_or_die(args.generate_config,
33 parser.pytype_single_args)
34 sys.exit(0)
35
36 conf = parser.config_from_defaults()
37 # File options overwrite defaults.
38 file_config = config.read_config_file_or_die(args.config)
39 parser.postprocess(file_config, from_strings=True)
40 conf.populate_from(file_config)
41 # Command line arguments overwrite file options.
42 conf.populate_from(args)
43 conf.inputs -= conf.exclude
44 if args.no_cache:
45 conf.output = tempfile.mkdtemp()
46 if not conf.pythonpath:
47 conf.pythonpath = environment.compute_pythonpath(conf.inputs)
48 logging.info('\n '.join(['Configuration:'] + str(conf).split('\n')))
49
50 if not conf.inputs:
51 parser.parser.error('Need an input.')
52
53 # Importlab needs the python exe, so we check it as early as possible.
54 environment.check_python_exe_or_die(conf.python_version)
55
56 typeshed = environment.initialize_typeshed_or_die()
57 env = analyze_project_env.create_importlab_environment(conf, typeshed)
58 print('Computing dependencies')
59 import_graph = importlab.graph.ImportGraph.create(env, conf.inputs, trim=True)
60
61 if args.tree:
62 print('Source tree:')
63 importlab.output.print_tree(import_graph)
64 sys.exit(0)
65
66 if args.unresolved:
67 print('Unresolved dependencies:')
68 for imp in sorted(import_graph.get_all_unresolved()):
69 print(' ', imp.name)
70 sys.exit(0)
71
72 # Main usage mode: analyze the project file by file in dependency order.
73
74 logging.info('Source tree:\n%s',
75 importlab.output.formatted_deps_list(import_graph))
76 tool_utils.makedirs_or_die(conf.output, 'Could not create output directory')
77 deps = pytype_runner.deps_from_import_graph(import_graph)
78 runner = pytype_runner.PytypeRunner(conf, deps)
79 return runner.run()
80
81
82 if __name__ == '__main__':
83 sys.exit(main())
84
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pytype/tools/analyze_project/main.py b/pytype/tools/analyze_project/main.py
--- a/pytype/tools/analyze_project/main.py
+++ b/pytype/tools/analyze_project/main.py
@@ -1,6 +1,7 @@
"""Analyze an entire project using pytype."""
import logging
+import os
import sys
import tempfile
@@ -74,6 +75,8 @@
logging.info('Source tree:\n%s',
importlab.output.formatted_deps_list(import_graph))
tool_utils.makedirs_or_die(conf.output, 'Could not create output directory')
+ with open(os.path.join(conf.output, '.gitignore'), 'w') as f:
+ f.write('# Automatically created by pytype\n*')
deps = pytype_runner.deps_from_import_graph(import_graph)
runner = pytype_runner.PytypeRunner(conf, deps)
return runner.run()
|
{"golden_diff": "diff --git a/pytype/tools/analyze_project/main.py b/pytype/tools/analyze_project/main.py\n--- a/pytype/tools/analyze_project/main.py\n+++ b/pytype/tools/analyze_project/main.py\n@@ -1,6 +1,7 @@\n \"\"\"Analyze an entire project using pytype.\"\"\"\n \n import logging\n+import os\n import sys\n import tempfile\n \n@@ -74,6 +75,8 @@\n logging.info('Source tree:\\n%s',\n importlab.output.formatted_deps_list(import_graph))\n tool_utils.makedirs_or_die(conf.output, 'Could not create output directory')\n+ with open(os.path.join(conf.output, '.gitignore'), 'w') as f:\n+ f.write('# Automatically created by pytype\\n*')\n deps = pytype_runner.deps_from_import_graph(import_graph)\n runner = pytype_runner.PytypeRunner(conf, deps)\n return runner.run()\n", "issue": "Automatically added git ignore file to sub directory\nThis PR automatically creates a .gitignore file to the output directory of pytype/tools/analyze_project/main.py\r\n\r\nIssue #759 \n", "before_files": [{"content": "\"\"\"Analyze an entire project using pytype.\"\"\"\n\nimport logging\nimport sys\nimport tempfile\n\nimport importlab.environment\nimport importlab.fs\nimport importlab.graph\nimport importlab.output\n\nfrom pytype import io\nfrom pytype.tools import environment\nfrom pytype.tools import tool_utils\nfrom pytype.tools.analyze_project import config\nfrom pytype.tools.analyze_project import environment as analyze_project_env\nfrom pytype.tools.analyze_project import parse_args\nfrom pytype.tools.analyze_project import pytype_runner\n\n\ndef main():\n parser = parse_args.make_parser()\n args = parser.parse_args(sys.argv[1:])\n\n if args.version:\n print(io.get_pytype_version())\n sys.exit(0)\n\n tool_utils.setup_logging_or_die(args.verbosity)\n\n if args.generate_config:\n config.generate_sample_config_or_die(args.generate_config,\n parser.pytype_single_args)\n sys.exit(0)\n\n conf = parser.config_from_defaults()\n # File options overwrite defaults.\n file_config = config.read_config_file_or_die(args.config)\n parser.postprocess(file_config, from_strings=True)\n conf.populate_from(file_config)\n # Command line arguments overwrite file options.\n conf.populate_from(args)\n conf.inputs -= conf.exclude\n if args.no_cache:\n conf.output = tempfile.mkdtemp()\n if not conf.pythonpath:\n conf.pythonpath = environment.compute_pythonpath(conf.inputs)\n logging.info('\\n '.join(['Configuration:'] + str(conf).split('\\n')))\n\n if not conf.inputs:\n parser.parser.error('Need an input.')\n\n # Importlab needs the python exe, so we check it as early as possible.\n environment.check_python_exe_or_die(conf.python_version)\n\n typeshed = environment.initialize_typeshed_or_die()\n env = analyze_project_env.create_importlab_environment(conf, typeshed)\n print('Computing dependencies')\n import_graph = importlab.graph.ImportGraph.create(env, conf.inputs, trim=True)\n\n if args.tree:\n print('Source tree:')\n importlab.output.print_tree(import_graph)\n sys.exit(0)\n\n if args.unresolved:\n print('Unresolved dependencies:')\n for imp in sorted(import_graph.get_all_unresolved()):\n print(' ', imp.name)\n sys.exit(0)\n\n # Main usage mode: analyze the project file by file in dependency order.\n\n logging.info('Source tree:\\n%s',\n importlab.output.formatted_deps_list(import_graph))\n tool_utils.makedirs_or_die(conf.output, 'Could not create output directory')\n deps = pytype_runner.deps_from_import_graph(import_graph)\n runner = pytype_runner.PytypeRunner(conf, deps)\n return runner.run()\n\n\nif __name__ == '__main__':\n sys.exit(main())\n", "path": "pytype/tools/analyze_project/main.py"}], "after_files": [{"content": "\"\"\"Analyze an entire project using pytype.\"\"\"\n\nimport logging\nimport os\nimport sys\nimport tempfile\n\nimport importlab.environment\nimport importlab.fs\nimport importlab.graph\nimport importlab.output\n\nfrom pytype import io\nfrom pytype.tools import environment\nfrom pytype.tools import tool_utils\nfrom pytype.tools.analyze_project import config\nfrom pytype.tools.analyze_project import environment as analyze_project_env\nfrom pytype.tools.analyze_project import parse_args\nfrom pytype.tools.analyze_project import pytype_runner\n\n\ndef main():\n parser = parse_args.make_parser()\n args = parser.parse_args(sys.argv[1:])\n\n if args.version:\n print(io.get_pytype_version())\n sys.exit(0)\n\n tool_utils.setup_logging_or_die(args.verbosity)\n\n if args.generate_config:\n config.generate_sample_config_or_die(args.generate_config,\n parser.pytype_single_args)\n sys.exit(0)\n\n conf = parser.config_from_defaults()\n # File options overwrite defaults.\n file_config = config.read_config_file_or_die(args.config)\n parser.postprocess(file_config, from_strings=True)\n conf.populate_from(file_config)\n # Command line arguments overwrite file options.\n conf.populate_from(args)\n conf.inputs -= conf.exclude\n if args.no_cache:\n conf.output = tempfile.mkdtemp()\n if not conf.pythonpath:\n conf.pythonpath = environment.compute_pythonpath(conf.inputs)\n logging.info('\\n '.join(['Configuration:'] + str(conf).split('\\n')))\n\n if not conf.inputs:\n parser.parser.error('Need an input.')\n\n # Importlab needs the python exe, so we check it as early as possible.\n environment.check_python_exe_or_die(conf.python_version)\n\n typeshed = environment.initialize_typeshed_or_die()\n env = analyze_project_env.create_importlab_environment(conf, typeshed)\n print('Computing dependencies')\n import_graph = importlab.graph.ImportGraph.create(env, conf.inputs, trim=True)\n\n if args.tree:\n print('Source tree:')\n importlab.output.print_tree(import_graph)\n sys.exit(0)\n\n if args.unresolved:\n print('Unresolved dependencies:')\n for imp in sorted(import_graph.get_all_unresolved()):\n print(' ', imp.name)\n sys.exit(0)\n\n # Main usage mode: analyze the project file by file in dependency order.\n\n logging.info('Source tree:\\n%s',\n importlab.output.formatted_deps_list(import_graph))\n tool_utils.makedirs_or_die(conf.output, 'Could not create output directory')\n with open(os.path.join(conf.output, '.gitignore'), 'w') as f:\n f.write('# Automatically created by pytype\\n*')\n deps = pytype_runner.deps_from_import_graph(import_graph)\n runner = pytype_runner.PytypeRunner(conf, deps)\n return runner.run()\n\n\nif __name__ == '__main__':\n sys.exit(main())\n", "path": "pytype/tools/analyze_project/main.py"}]}
| 1,047 | 193 |
gh_patches_debug_26916
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-3160
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`CKV_AZURE_4` cannot work with AzureRM 3.0 provider
**Describe the issue**
Scan an aks resource with AzrueRM 3.0 provider will get the following false error:
```text
terraform scan results:
Passed checks: 0, Failed checks: 1, Skipped checks: 0
Check: CKV_AZURE_4: "Ensure AKS logging to Azure Monitoring is Configured"
FAILED for resource: azurerm_kubernetes_cluster.example
File: /main.tf:35-58
Guide: https://docs.bridgecrew.io/docs/bc_azr_kubernetes_1
35 | resource "azurerm_kubernetes_cluster" "example" {
36 | name = "example-aks1"
37 | location = azurerm_resource_group.example.location
38 | resource_group_name = azurerm_resource_group.example.name
39 | dns_prefix = "exampleaks1"
40 |
41 | default_node_pool {
42 | name = "default"
43 | node_count = 1
44 | vm_size = "Standard_D2_v2"
45 | }
46 |
47 | oms_agent {
48 | log_analytics_workspace_id = azurerm_log_analytics_workspace.main.id
49 | }
50 |
51 | identity {
52 | type = "SystemAssigned"
53 | }
54 |
55 | tags = {
56 | Environment = "Production"
57 | }
58 | }
```
**Examples**
```hcl
variable "admin_user" {
default = null
}
provider "azurerm" {
features {}
}
resource "azurerm_resource_group" "example" {
location = "eastus"
name = "checkov-dynamic"
}
resource "azurerm_log_analytics_workspace" "main" {
name = "workspace"
location = azurerm_resource_group.example.location
resource_group_name = azurerm_resource_group.example.name
sku = "PerGB2018"
retention_in_days = 7
}
resource "azurerm_log_analytics_solution" "main" {
solution_name = "ContainerInsights"
location = azurerm_resource_group.example.location
resource_group_name = azurerm_resource_group.example.name
workspace_resource_id = azurerm_log_analytics_workspace.main[0].id
workspace_name = azurerm_log_analytics_workspace.main[0].name
plan {
publisher = "Microsoft"
product = "OMSGallery/ContainerInsights"
}
}
resource "azurerm_kubernetes_cluster" "example" {
name = "example-aks1"
location = azurerm_resource_group.example.location
resource_group_name = azurerm_resource_group.example.name
dns_prefix = "exampleaks1"
default_node_pool {
name = "default"
node_count = 1
vm_size = "Standard_D2_v2"
}
oms_agent {
log_analytics_workspace_id = azurerm_log_analytics_workspace.main.id
}
identity {
type = "SystemAssigned"
}
tags = {
Environment = "Production"
}
}
```
**Version (please complete the following information):**
- 2.1.20
**Additional context**
The [current implemention](https://github.com/bridgecrewio/checkov/blob/master/checkov/terraform/checks/resource/azure/AKSLoggingEnabled.py#L13-L14) are based on 2.x and not work for 3.x.
`CKV_AZURE_4` cannot work with AzureRM 3.0 provider
**Describe the issue**
Scan an aks resource with AzrueRM 3.0 provider will get the following false error:
```text
terraform scan results:
Passed checks: 0, Failed checks: 1, Skipped checks: 0
Check: CKV_AZURE_4: "Ensure AKS logging to Azure Monitoring is Configured"
FAILED for resource: azurerm_kubernetes_cluster.example
File: /main.tf:35-58
Guide: https://docs.bridgecrew.io/docs/bc_azr_kubernetes_1
35 | resource "azurerm_kubernetes_cluster" "example" {
36 | name = "example-aks1"
37 | location = azurerm_resource_group.example.location
38 | resource_group_name = azurerm_resource_group.example.name
39 | dns_prefix = "exampleaks1"
40 |
41 | default_node_pool {
42 | name = "default"
43 | node_count = 1
44 | vm_size = "Standard_D2_v2"
45 | }
46 |
47 | oms_agent {
48 | log_analytics_workspace_id = azurerm_log_analytics_workspace.main.id
49 | }
50 |
51 | identity {
52 | type = "SystemAssigned"
53 | }
54 |
55 | tags = {
56 | Environment = "Production"
57 | }
58 | }
```
**Examples**
```hcl
variable "admin_user" {
default = null
}
provider "azurerm" {
features {}
}
resource "azurerm_resource_group" "example" {
location = "eastus"
name = "checkov-dynamic"
}
resource "azurerm_log_analytics_workspace" "main" {
name = "workspace"
location = azurerm_resource_group.example.location
resource_group_name = azurerm_resource_group.example.name
sku = "PerGB2018"
retention_in_days = 7
}
resource "azurerm_log_analytics_solution" "main" {
solution_name = "ContainerInsights"
location = azurerm_resource_group.example.location
resource_group_name = azurerm_resource_group.example.name
workspace_resource_id = azurerm_log_analytics_workspace.main[0].id
workspace_name = azurerm_log_analytics_workspace.main[0].name
plan {
publisher = "Microsoft"
product = "OMSGallery/ContainerInsights"
}
}
resource "azurerm_kubernetes_cluster" "example" {
name = "example-aks1"
location = azurerm_resource_group.example.location
resource_group_name = azurerm_resource_group.example.name
dns_prefix = "exampleaks1"
default_node_pool {
name = "default"
node_count = 1
vm_size = "Standard_D2_v2"
}
oms_agent {
log_analytics_workspace_id = azurerm_log_analytics_workspace.main.id
}
identity {
type = "SystemAssigned"
}
tags = {
Environment = "Production"
}
}
```
**Version (please complete the following information):**
- 2.1.20
**Additional context**
The [current implemention](https://github.com/bridgecrewio/checkov/blob/master/checkov/terraform/checks/resource/azure/AKSLoggingEnabled.py#L13-L14) are based on 2.x and not work for 3.x.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/terraform/checks/resource/azure/AKSLoggingEnabled.py`
Content:
```
1 from checkov.common.models.enums import CheckCategories
2 from checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck
3
4
5 class AKSLoggingEnabled(BaseResourceValueCheck):
6 def __init__(self):
7 name = "Ensure AKS logging to Azure Monitoring is Configured"
8 id = "CKV_AZURE_4"
9 supported_resources = ['azurerm_kubernetes_cluster']
10 categories = [CheckCategories.KUBERNETES]
11 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
12
13 def get_inspected_key(self):
14 return "addon_profile/[0]/oms_agent/[0]/enabled"
15
16
17 check = AKSLoggingEnabled()
18
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/checkov/terraform/checks/resource/azure/AKSLoggingEnabled.py b/checkov/terraform/checks/resource/azure/AKSLoggingEnabled.py
--- a/checkov/terraform/checks/resource/azure/AKSLoggingEnabled.py
+++ b/checkov/terraform/checks/resource/azure/AKSLoggingEnabled.py
@@ -1,8 +1,10 @@
-from checkov.common.models.enums import CheckCategories
-from checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck
+import dpath
+from checkov.common.models.enums import CheckCategories, CheckResult
+from checkov.terraform.checks.resource.base_resource_value_check import BaseResourceCheck
-class AKSLoggingEnabled(BaseResourceValueCheck):
+
+class AKSLoggingEnabled(BaseResourceCheck):
def __init__(self):
name = "Ensure AKS logging to Azure Monitoring is Configured"
id = "CKV_AZURE_4"
@@ -10,8 +12,17 @@
categories = [CheckCategories.KUBERNETES]
super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
- def get_inspected_key(self):
- return "addon_profile/[0]/oms_agent/[0]/enabled"
+ def scan_resource_conf(self, conf):
+ provider_version_2_path = "addon_profile/[0]/oms_agent/[0]/enabled"
+ provider_version_3_path = "oms_agent/[0]"
+ if dpath.search(conf, provider_version_2_path) and dpath.get(conf, provider_version_2_path)[0]:
+ self.evaluated_keys = [provider_version_2_path]
+ return CheckResult.PASSED
+ elif dpath.search(conf, provider_version_3_path):
+ self.evaluated_keys = [provider_version_3_path]
+ return CheckResult.PASSED
+
+ return CheckResult.FAILED
check = AKSLoggingEnabled()
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/azure/AKSLoggingEnabled.py b/checkov/terraform/checks/resource/azure/AKSLoggingEnabled.py\n--- a/checkov/terraform/checks/resource/azure/AKSLoggingEnabled.py\n+++ b/checkov/terraform/checks/resource/azure/AKSLoggingEnabled.py\n@@ -1,8 +1,10 @@\n-from checkov.common.models.enums import CheckCategories\n-from checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck\n+import dpath\n \n+from checkov.common.models.enums import CheckCategories, CheckResult\n+from checkov.terraform.checks.resource.base_resource_value_check import BaseResourceCheck\n \n-class AKSLoggingEnabled(BaseResourceValueCheck):\n+\n+class AKSLoggingEnabled(BaseResourceCheck):\n def __init__(self):\n name = \"Ensure AKS logging to Azure Monitoring is Configured\"\n id = \"CKV_AZURE_4\"\n@@ -10,8 +12,17 @@\n categories = [CheckCategories.KUBERNETES]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n \n- def get_inspected_key(self):\n- return \"addon_profile/[0]/oms_agent/[0]/enabled\"\n+ def scan_resource_conf(self, conf):\n+ provider_version_2_path = \"addon_profile/[0]/oms_agent/[0]/enabled\"\n+ provider_version_3_path = \"oms_agent/[0]\"\n+ if dpath.search(conf, provider_version_2_path) and dpath.get(conf, provider_version_2_path)[0]:\n+ self.evaluated_keys = [provider_version_2_path]\n+ return CheckResult.PASSED\n+ elif dpath.search(conf, provider_version_3_path):\n+ self.evaluated_keys = [provider_version_3_path]\n+ return CheckResult.PASSED\n+\n+ return CheckResult.FAILED\n \n \n check = AKSLoggingEnabled()\n", "issue": "`CKV_AZURE_4` cannot work with AzureRM 3.0 provider\n**Describe the issue**\r\n\r\nScan an aks resource with AzrueRM 3.0 provider will get the following false error:\r\n\r\n```text\r\nterraform scan results:\r\n\r\nPassed checks: 0, Failed checks: 1, Skipped checks: 0\r\n\r\nCheck: CKV_AZURE_4: \"Ensure AKS logging to Azure Monitoring is Configured\"\r\n FAILED for resource: azurerm_kubernetes_cluster.example\r\n File: /main.tf:35-58\r\n Guide: https://docs.bridgecrew.io/docs/bc_azr_kubernetes_1\r\n\r\n 35 | resource \"azurerm_kubernetes_cluster\" \"example\" {\r\n 36 | name = \"example-aks1\"\r\n 37 | location = azurerm_resource_group.example.location\r\n 38 | resource_group_name = azurerm_resource_group.example.name\r\n 39 | dns_prefix = \"exampleaks1\"\r\n 40 |\r\n 41 | default_node_pool {\r\n 42 | name = \"default\"\r\n 43 | node_count = 1\r\n 44 | vm_size = \"Standard_D2_v2\"\r\n 45 | }\r\n 46 |\r\n 47 | oms_agent {\r\n 48 | log_analytics_workspace_id = azurerm_log_analytics_workspace.main.id\r\n 49 | }\r\n 50 |\r\n 51 | identity {\r\n 52 | type = \"SystemAssigned\"\r\n 53 | }\r\n 54 |\r\n 55 | tags = {\r\n 56 | Environment = \"Production\"\r\n 57 | }\r\n 58 | }\r\n```\r\n\r\n**Examples**\r\n```hcl\r\nvariable \"admin_user\" {\r\n default = null\r\n}\r\n\r\nprovider \"azurerm\" {\r\n features {}\r\n}\r\n\r\nresource \"azurerm_resource_group\" \"example\" {\r\n location = \"eastus\"\r\n name = \"checkov-dynamic\"\r\n}\r\n\r\nresource \"azurerm_log_analytics_workspace\" \"main\" {\r\n name = \"workspace\"\r\n location = azurerm_resource_group.example.location\r\n resource_group_name = azurerm_resource_group.example.name\r\n sku = \"PerGB2018\"\r\n retention_in_days = 7\r\n}\r\n\r\nresource \"azurerm_log_analytics_solution\" \"main\" {\r\n solution_name = \"ContainerInsights\"\r\n location = azurerm_resource_group.example.location\r\n resource_group_name = azurerm_resource_group.example.name\r\n workspace_resource_id = azurerm_log_analytics_workspace.main[0].id\r\n workspace_name = azurerm_log_analytics_workspace.main[0].name\r\n\r\n plan {\r\n publisher = \"Microsoft\"\r\n product = \"OMSGallery/ContainerInsights\"\r\n }\r\n}\r\n\r\nresource \"azurerm_kubernetes_cluster\" \"example\" {\r\n name = \"example-aks1\"\r\n location = azurerm_resource_group.example.location\r\n resource_group_name = azurerm_resource_group.example.name\r\n dns_prefix = \"exampleaks1\"\r\n\r\n default_node_pool {\r\n name = \"default\"\r\n node_count = 1\r\n vm_size = \"Standard_D2_v2\"\r\n }\r\n\r\n oms_agent {\r\n log_analytics_workspace_id = azurerm_log_analytics_workspace.main.id\r\n }\r\n\r\n identity {\r\n type = \"SystemAssigned\"\r\n }\r\n\r\n tags = {\r\n Environment = \"Production\"\r\n }\r\n}\r\n```\r\n\r\n**Version (please complete the following information):**\r\n - 2.1.20\r\n\r\n**Additional context**\r\n\r\nThe [current implemention](https://github.com/bridgecrewio/checkov/blob/master/checkov/terraform/checks/resource/azure/AKSLoggingEnabled.py#L13-L14) are based on 2.x and not work for 3.x.\r\n\n`CKV_AZURE_4` cannot work with AzureRM 3.0 provider\n**Describe the issue**\r\n\r\nScan an aks resource with AzrueRM 3.0 provider will get the following false error:\r\n\r\n```text\r\nterraform scan results:\r\n\r\nPassed checks: 0, Failed checks: 1, Skipped checks: 0\r\n\r\nCheck: CKV_AZURE_4: \"Ensure AKS logging to Azure Monitoring is Configured\"\r\n FAILED for resource: azurerm_kubernetes_cluster.example\r\n File: /main.tf:35-58\r\n Guide: https://docs.bridgecrew.io/docs/bc_azr_kubernetes_1\r\n\r\n 35 | resource \"azurerm_kubernetes_cluster\" \"example\" {\r\n 36 | name = \"example-aks1\"\r\n 37 | location = azurerm_resource_group.example.location\r\n 38 | resource_group_name = azurerm_resource_group.example.name\r\n 39 | dns_prefix = \"exampleaks1\"\r\n 40 |\r\n 41 | default_node_pool {\r\n 42 | name = \"default\"\r\n 43 | node_count = 1\r\n 44 | vm_size = \"Standard_D2_v2\"\r\n 45 | }\r\n 46 |\r\n 47 | oms_agent {\r\n 48 | log_analytics_workspace_id = azurerm_log_analytics_workspace.main.id\r\n 49 | }\r\n 50 |\r\n 51 | identity {\r\n 52 | type = \"SystemAssigned\"\r\n 53 | }\r\n 54 |\r\n 55 | tags = {\r\n 56 | Environment = \"Production\"\r\n 57 | }\r\n 58 | }\r\n```\r\n\r\n**Examples**\r\n```hcl\r\nvariable \"admin_user\" {\r\n default = null\r\n}\r\n\r\nprovider \"azurerm\" {\r\n features {}\r\n}\r\n\r\nresource \"azurerm_resource_group\" \"example\" {\r\n location = \"eastus\"\r\n name = \"checkov-dynamic\"\r\n}\r\n\r\nresource \"azurerm_log_analytics_workspace\" \"main\" {\r\n name = \"workspace\"\r\n location = azurerm_resource_group.example.location\r\n resource_group_name = azurerm_resource_group.example.name\r\n sku = \"PerGB2018\"\r\n retention_in_days = 7\r\n}\r\n\r\nresource \"azurerm_log_analytics_solution\" \"main\" {\r\n solution_name = \"ContainerInsights\"\r\n location = azurerm_resource_group.example.location\r\n resource_group_name = azurerm_resource_group.example.name\r\n workspace_resource_id = azurerm_log_analytics_workspace.main[0].id\r\n workspace_name = azurerm_log_analytics_workspace.main[0].name\r\n\r\n plan {\r\n publisher = \"Microsoft\"\r\n product = \"OMSGallery/ContainerInsights\"\r\n }\r\n}\r\n\r\nresource \"azurerm_kubernetes_cluster\" \"example\" {\r\n name = \"example-aks1\"\r\n location = azurerm_resource_group.example.location\r\n resource_group_name = azurerm_resource_group.example.name\r\n dns_prefix = \"exampleaks1\"\r\n\r\n default_node_pool {\r\n name = \"default\"\r\n node_count = 1\r\n vm_size = \"Standard_D2_v2\"\r\n }\r\n\r\n oms_agent {\r\n log_analytics_workspace_id = azurerm_log_analytics_workspace.main.id\r\n }\r\n\r\n identity {\r\n type = \"SystemAssigned\"\r\n }\r\n\r\n tags = {\r\n Environment = \"Production\"\r\n }\r\n}\r\n```\r\n\r\n**Version (please complete the following information):**\r\n - 2.1.20\r\n\r\n**Additional context**\r\n\r\nThe [current implemention](https://github.com/bridgecrewio/checkov/blob/master/checkov/terraform/checks/resource/azure/AKSLoggingEnabled.py#L13-L14) are based on 2.x and not work for 3.x.\r\n\n", "before_files": [{"content": "from checkov.common.models.enums import CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck\n\n\nclass AKSLoggingEnabled(BaseResourceValueCheck):\n def __init__(self):\n name = \"Ensure AKS logging to Azure Monitoring is Configured\"\n id = \"CKV_AZURE_4\"\n supported_resources = ['azurerm_kubernetes_cluster']\n categories = [CheckCategories.KUBERNETES]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def get_inspected_key(self):\n return \"addon_profile/[0]/oms_agent/[0]/enabled\"\n\n\ncheck = AKSLoggingEnabled()\n", "path": "checkov/terraform/checks/resource/azure/AKSLoggingEnabled.py"}], "after_files": [{"content": "import dpath\n\nfrom checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.terraform.checks.resource.base_resource_value_check import BaseResourceCheck\n\n\nclass AKSLoggingEnabled(BaseResourceCheck):\n def __init__(self):\n name = \"Ensure AKS logging to Azure Monitoring is Configured\"\n id = \"CKV_AZURE_4\"\n supported_resources = ['azurerm_kubernetes_cluster']\n categories = [CheckCategories.KUBERNETES]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n provider_version_2_path = \"addon_profile/[0]/oms_agent/[0]/enabled\"\n provider_version_3_path = \"oms_agent/[0]\"\n if dpath.search(conf, provider_version_2_path) and dpath.get(conf, provider_version_2_path)[0]:\n self.evaluated_keys = [provider_version_2_path]\n return CheckResult.PASSED\n elif dpath.search(conf, provider_version_3_path):\n self.evaluated_keys = [provider_version_3_path]\n return CheckResult.PASSED\n\n return CheckResult.FAILED\n\n\ncheck = AKSLoggingEnabled()\n", "path": "checkov/terraform/checks/resource/azure/AKSLoggingEnabled.py"}]}
| 2,172 | 422 |
gh_patches_debug_32140
|
rasdani/github-patches
|
git_diff
|
pypa__cibuildwheel-263
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
remove .so files when copying source into the container
Trying to build wheels on travis and I'm getting the following error:
```
auditwheel: error: cannot repair "/tmp/built_wheel/pydantic-0.27a1-cp37-cp37m-linux_x86_64.whl" to "manylinux1_x86_64" ABI because of the presence of too-recent versioned symbols. You'll need to compile the wheel on an older toolchain.
```
See [this build](https://travis-ci.org/samuelcolvin/pydantic/jobs/537258176) for details.
I don't get this error when building locally with `cibuildwheel --platform linux --output-dir dist`.
Any idea what I'm doing wrong?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cibuildwheel/linux.py`
Content:
```
1 from __future__ import print_function
2 import os, subprocess, sys, uuid
3 from collections import namedtuple
4 from .util import prepare_command, get_build_verbosity_extra_flags
5
6 try:
7 from shlex import quote as shlex_quote
8 except ImportError:
9 from pipes import quote as shlex_quote
10
11
12 def get_python_configurations(build_selector):
13 PythonConfiguration = namedtuple('PythonConfiguration', ['identifier', 'path'])
14 python_configurations = [
15 PythonConfiguration(identifier='cp27-manylinux_x86_64', path='/opt/python/cp27-cp27m'),
16 PythonConfiguration(identifier='cp27-manylinux_x86_64', path='/opt/python/cp27-cp27mu'),
17 PythonConfiguration(identifier='cp35-manylinux_x86_64', path='/opt/python/cp35-cp35m'),
18 PythonConfiguration(identifier='cp36-manylinux_x86_64', path='/opt/python/cp36-cp36m'),
19 PythonConfiguration(identifier='cp37-manylinux_x86_64', path='/opt/python/cp37-cp37m'),
20 PythonConfiguration(identifier='cp38-manylinux_x86_64', path='/opt/python/cp38-cp38'),
21 PythonConfiguration(identifier='cp27-manylinux_i686', path='/opt/python/cp27-cp27m'),
22 PythonConfiguration(identifier='cp27-manylinux_i686', path='/opt/python/cp27-cp27mu'),
23 PythonConfiguration(identifier='cp35-manylinux_i686', path='/opt/python/cp35-cp35m'),
24 PythonConfiguration(identifier='cp36-manylinux_i686', path='/opt/python/cp36-cp36m'),
25 PythonConfiguration(identifier='cp37-manylinux_i686', path='/opt/python/cp37-cp37m'),
26 PythonConfiguration(identifier='cp38-manylinux_i686', path='/opt/python/cp38-cp38'),
27 ]
28
29 # skip builds as required
30 return [c for c in python_configurations if build_selector(c.identifier)]
31
32
33 def build(project_dir, output_dir, test_command, test_requires, test_extras, before_build, build_verbosity, build_selector, repair_command, environment, manylinux_images):
34 try:
35 subprocess.check_call(['docker', '--version'])
36 except:
37 print('cibuildwheel: Docker not found. Docker is required to run Linux builds. '
38 'If you\'re building on Travis CI, add `services: [docker]` to your .travis.yml.'
39 'If you\'re building on Circle CI in Linux, add a `setup_remote_docker` step to your .circleci/config.yml',
40 file=sys.stderr)
41 exit(2)
42
43 python_configurations = get_python_configurations(build_selector)
44 platforms = [
45 ('manylinux_x86_64', manylinux_images['x86_64']),
46 ('manylinux_i686', manylinux_images['i686']),
47 ]
48
49 for platform_tag, docker_image in platforms:
50 platform_configs = [c for c in python_configurations if c.identifier.endswith(platform_tag)]
51 if not platform_configs:
52 continue
53
54 bash_script = '''
55 set -o errexit
56 set -o xtrace
57 mkdir /output
58 cd /project
59
60 {environment_exports}
61
62 for PYBIN in {pybin_paths}; do
63 if [ ! -z {before_build} ]; then
64 PATH="$PYBIN:$PATH" sh -c {before_build}
65 fi
66
67 # Build the wheel
68 rm -rf /tmp/built_wheel
69 mkdir /tmp/built_wheel
70 PATH="$PYBIN:$PATH" "$PYBIN/pip" wheel . -w /tmp/built_wheel --no-deps {build_verbosity_flag}
71 built_wheel=(/tmp/built_wheel/*.whl)
72
73 # repair the wheel
74 rm -rf /tmp/repaired_wheels
75 mkdir /tmp/repaired_wheels
76 # NOTE: 'built_wheel' here is a bash array of glob matches; "$built_wheel" returns
77 # the first element
78 if [[ "$built_wheel" == *none-any.whl ]] || [ -z {repair_command} ]; then
79 # pure Python wheel or empty repair command
80 mv "$built_wheel" /tmp/repaired_wheels
81 else
82 sh -c {repair_command} repair_command "$built_wheel"
83 fi
84 repaired_wheels=(/tmp/repaired_wheels/*.whl)
85
86 if [ ! -z {test_command} ]; then
87 # Set up a virtual environment to install and test from, to make sure
88 # there are no dependencies that were pulled in at build time.
89 "$PYBIN/pip" install virtualenv
90 venv_dir=`mktemp -d`/venv
91 "$PYBIN/python" -m virtualenv "$venv_dir"
92
93 # run the tests in a subshell to keep that `activate`
94 # script from polluting the env
95 (
96 source "$venv_dir/bin/activate"
97
98 echo "Running tests using `which python`"
99
100 # Install the wheel we just built
101 # Note: If auditwheel produced two wheels, it's because the earlier produced wheel
102 # conforms to multiple manylinux standards. These multiple versions of the wheel are
103 # functionally the same, differing only in name, wheel metadata, and possibly include
104 # different external shared libraries. so it doesn't matter which one we run the tests on.
105 # Let's just pick the first one.
106 pip install "${{repaired_wheels[0]}}"{test_extras}
107
108 # Install any requirements to run the tests
109 if [ ! -z "{test_requires}" ]; then
110 pip install {test_requires}
111 fi
112
113 # Run the tests from a different directory
114 pushd $HOME
115 sh -c {test_command}
116 popd
117 )
118 # exit if tests failed (needed for older bash versions)
119 if [ $? -ne 0 ]; then
120 exit 1;
121 fi
122
123 # clean up
124 rm -rf "$venv_dir"
125 fi
126
127 # we're all done here; move it to output
128 mv "${{repaired_wheels[@]}}" /output
129 for repaired_wheel in "${{repaired_wheels[@]}}"; do chown {uid}:{gid} "/output/$(basename "$repaired_wheel")"; done
130 done
131 '''.format(
132 pybin_paths=' '.join(c.path+'/bin' for c in platform_configs),
133 test_requires=' '.join(test_requires),
134 test_extras=test_extras,
135 test_command=shlex_quote(
136 prepare_command(test_command, project='/project') if test_command else ''
137 ),
138 before_build=shlex_quote(
139 prepare_command(before_build, project='/project') if before_build else ''
140 ),
141 build_verbosity_flag=' '.join(get_build_verbosity_extra_flags(build_verbosity)),
142 repair_command=shlex_quote(
143 prepare_command(repair_command, wheel='"$1"', dest_dir='/tmp/repaired_wheels') if repair_command else ''
144 ),
145 environment_exports='\n'.join(environment.as_shell_commands()),
146 uid=os.getuid(),
147 gid=os.getgid(),
148 )
149
150 def run_docker(command, stdin_str=None):
151 print('docker command: docker {}'.format(' '.join(map(shlex_quote, command))))
152 if stdin_str is None:
153 subprocess.check_call(['docker'] + command)
154 else:
155 args = ['docker'] + command
156 process = subprocess.Popen(args, stdin=subprocess.PIPE, universal_newlines=True)
157 try:
158 process.communicate(stdin_str)
159 except KeyboardInterrupt:
160 process.kill()
161 process.wait()
162 if process.returncode != 0:
163 raise subprocess.CalledProcessError(process.returncode, args)
164
165 container_name = 'cibuildwheel-{}'.format(uuid.uuid4())
166 try:
167 run_docker(['create',
168 '--env', 'CIBUILDWHEEL',
169 '--name', container_name,
170 '-i',
171 '-v', '/:/host', # ignored on Circle
172 docker_image, '/bin/bash'])
173 run_docker(['cp', os.path.abspath(project_dir) + '/.', container_name + ':/project'])
174 run_docker(['start', '-i', '-a', container_name], stdin_str=bash_script)
175 run_docker(['cp', container_name + ':/output/.', os.path.abspath(output_dir)])
176 except subprocess.CalledProcessError:
177 exit(1)
178 finally:
179 # Still gets executed, even when 'exit(1)' gets called
180 run_docker(['rm', '--force', '-v', container_name])
181
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cibuildwheel/linux.py b/cibuildwheel/linux.py
--- a/cibuildwheel/linux.py
+++ b/cibuildwheel/linux.py
@@ -1,5 +1,5 @@
from __future__ import print_function
-import os, subprocess, sys, uuid
+import os, subprocess, sys, uuid, textwrap
from collections import namedtuple
from .util import prepare_command, get_build_verbosity_extra_flags
@@ -173,8 +173,36 @@
run_docker(['cp', os.path.abspath(project_dir) + '/.', container_name + ':/project'])
run_docker(['start', '-i', '-a', container_name], stdin_str=bash_script)
run_docker(['cp', container_name + ':/output/.', os.path.abspath(output_dir)])
- except subprocess.CalledProcessError:
+ except subprocess.CalledProcessError as error:
+ troubleshoot(project_dir, error)
exit(1)
finally:
# Still gets executed, even when 'exit(1)' gets called
run_docker(['rm', '--force', '-v', container_name])
+
+
+def troubleshoot(project_dir, error):
+ if (isinstance(error, subprocess.CalledProcessError) and 'start' in error.cmd):
+ # the bash script failed
+ print('Checking for common errors...')
+ so_files = []
+ for root, dirs, files in os.walk(project_dir):
+ for name in files:
+ _, ext = os.path.splitext(name)
+ if ext == '.so':
+ so_files.append(os.path.join(root, name))
+
+ if so_files:
+ print(textwrap.dedent('''
+ NOTE: Shared object (.so) files found in this project.
+
+ These files might be built against the wrong OS, causing problems with
+ auditwheel.
+
+ If you're using Cython and have previously done an in-place build,
+ remove those build files (*.so and *.c) before starting cibuildwheel.
+ '''))
+
+ print(' Files detected:')
+ print('\n'.join([' '+f for f in so_files]))
+ print('')
|
{"golden_diff": "diff --git a/cibuildwheel/linux.py b/cibuildwheel/linux.py\n--- a/cibuildwheel/linux.py\n+++ b/cibuildwheel/linux.py\n@@ -1,5 +1,5 @@\n from __future__ import print_function\n-import os, subprocess, sys, uuid\n+import os, subprocess, sys, uuid, textwrap\n from collections import namedtuple\n from .util import prepare_command, get_build_verbosity_extra_flags\n \n@@ -173,8 +173,36 @@\n run_docker(['cp', os.path.abspath(project_dir) + '/.', container_name + ':/project'])\n run_docker(['start', '-i', '-a', container_name], stdin_str=bash_script)\n run_docker(['cp', container_name + ':/output/.', os.path.abspath(output_dir)])\n- except subprocess.CalledProcessError:\n+ except subprocess.CalledProcessError as error:\n+ troubleshoot(project_dir, error)\n exit(1)\n finally:\n # Still gets executed, even when 'exit(1)' gets called\n run_docker(['rm', '--force', '-v', container_name])\n+\n+\n+def troubleshoot(project_dir, error):\n+ if (isinstance(error, subprocess.CalledProcessError) and 'start' in error.cmd):\n+ # the bash script failed\n+ print('Checking for common errors...')\n+ so_files = []\n+ for root, dirs, files in os.walk(project_dir):\n+ for name in files:\n+ _, ext = os.path.splitext(name)\n+ if ext == '.so':\n+ so_files.append(os.path.join(root, name))\n+\n+ if so_files:\n+ print(textwrap.dedent('''\n+ NOTE: Shared object (.so) files found in this project.\n+\n+ These files might be built against the wrong OS, causing problems with\n+ auditwheel.\n+\n+ If you're using Cython and have previously done an in-place build,\n+ remove those build files (*.so and *.c) before starting cibuildwheel.\n+ '''))\n+\n+ print(' Files detected:')\n+ print('\\n'.join([' '+f for f in so_files]))\n+ print('')\n", "issue": "remove .so files when copying source into the container\nTrying to build wheels on travis and I'm getting the following error:\r\n\r\n```\r\nauditwheel: error: cannot repair \"/tmp/built_wheel/pydantic-0.27a1-cp37-cp37m-linux_x86_64.whl\" to \"manylinux1_x86_64\" ABI because of the presence of too-recent versioned symbols. You'll need to compile the wheel on an older toolchain.\r\n```\r\n\r\nSee [this build](https://travis-ci.org/samuelcolvin/pydantic/jobs/537258176) for details.\r\n\r\nI don't get this error when building locally with `cibuildwheel --platform linux --output-dir dist`.\r\n\r\nAny idea what I'm doing wrong?\n", "before_files": [{"content": "from __future__ import print_function\nimport os, subprocess, sys, uuid\nfrom collections import namedtuple\nfrom .util import prepare_command, get_build_verbosity_extra_flags\n\ntry:\n from shlex import quote as shlex_quote\nexcept ImportError:\n from pipes import quote as shlex_quote\n\n\ndef get_python_configurations(build_selector):\n PythonConfiguration = namedtuple('PythonConfiguration', ['identifier', 'path'])\n python_configurations = [\n PythonConfiguration(identifier='cp27-manylinux_x86_64', path='/opt/python/cp27-cp27m'),\n PythonConfiguration(identifier='cp27-manylinux_x86_64', path='/opt/python/cp27-cp27mu'),\n PythonConfiguration(identifier='cp35-manylinux_x86_64', path='/opt/python/cp35-cp35m'),\n PythonConfiguration(identifier='cp36-manylinux_x86_64', path='/opt/python/cp36-cp36m'),\n PythonConfiguration(identifier='cp37-manylinux_x86_64', path='/opt/python/cp37-cp37m'),\n PythonConfiguration(identifier='cp38-manylinux_x86_64', path='/opt/python/cp38-cp38'),\n PythonConfiguration(identifier='cp27-manylinux_i686', path='/opt/python/cp27-cp27m'),\n PythonConfiguration(identifier='cp27-manylinux_i686', path='/opt/python/cp27-cp27mu'),\n PythonConfiguration(identifier='cp35-manylinux_i686', path='/opt/python/cp35-cp35m'),\n PythonConfiguration(identifier='cp36-manylinux_i686', path='/opt/python/cp36-cp36m'),\n PythonConfiguration(identifier='cp37-manylinux_i686', path='/opt/python/cp37-cp37m'),\n PythonConfiguration(identifier='cp38-manylinux_i686', path='/opt/python/cp38-cp38'),\n ]\n\n # skip builds as required\n return [c for c in python_configurations if build_selector(c.identifier)]\n\n\ndef build(project_dir, output_dir, test_command, test_requires, test_extras, before_build, build_verbosity, build_selector, repair_command, environment, manylinux_images):\n try:\n subprocess.check_call(['docker', '--version'])\n except:\n print('cibuildwheel: Docker not found. Docker is required to run Linux builds. '\n 'If you\\'re building on Travis CI, add `services: [docker]` to your .travis.yml.'\n 'If you\\'re building on Circle CI in Linux, add a `setup_remote_docker` step to your .circleci/config.yml',\n file=sys.stderr)\n exit(2)\n\n python_configurations = get_python_configurations(build_selector)\n platforms = [\n ('manylinux_x86_64', manylinux_images['x86_64']),\n ('manylinux_i686', manylinux_images['i686']),\n ]\n\n for platform_tag, docker_image in platforms:\n platform_configs = [c for c in python_configurations if c.identifier.endswith(platform_tag)]\n if not platform_configs:\n continue\n\n bash_script = '''\n set -o errexit\n set -o xtrace\n mkdir /output\n cd /project\n\n {environment_exports}\n\n for PYBIN in {pybin_paths}; do\n if [ ! -z {before_build} ]; then\n PATH=\"$PYBIN:$PATH\" sh -c {before_build}\n fi\n\n # Build the wheel\n rm -rf /tmp/built_wheel\n mkdir /tmp/built_wheel\n PATH=\"$PYBIN:$PATH\" \"$PYBIN/pip\" wheel . -w /tmp/built_wheel --no-deps {build_verbosity_flag}\n built_wheel=(/tmp/built_wheel/*.whl)\n\n # repair the wheel\n rm -rf /tmp/repaired_wheels\n mkdir /tmp/repaired_wheels\n # NOTE: 'built_wheel' here is a bash array of glob matches; \"$built_wheel\" returns\n # the first element\n if [[ \"$built_wheel\" == *none-any.whl ]] || [ -z {repair_command} ]; then\n # pure Python wheel or empty repair command\n mv \"$built_wheel\" /tmp/repaired_wheels\n else\n sh -c {repair_command} repair_command \"$built_wheel\"\n fi\n repaired_wheels=(/tmp/repaired_wheels/*.whl)\n\n if [ ! -z {test_command} ]; then\n # Set up a virtual environment to install and test from, to make sure\n # there are no dependencies that were pulled in at build time.\n \"$PYBIN/pip\" install virtualenv\n venv_dir=`mktemp -d`/venv\n \"$PYBIN/python\" -m virtualenv \"$venv_dir\"\n\n # run the tests in a subshell to keep that `activate`\n # script from polluting the env\n (\n source \"$venv_dir/bin/activate\"\n\n echo \"Running tests using `which python`\"\n\n # Install the wheel we just built\n # Note: If auditwheel produced two wheels, it's because the earlier produced wheel\n # conforms to multiple manylinux standards. These multiple versions of the wheel are\n # functionally the same, differing only in name, wheel metadata, and possibly include\n # different external shared libraries. so it doesn't matter which one we run the tests on.\n # Let's just pick the first one.\n pip install \"${{repaired_wheels[0]}}\"{test_extras}\n\n # Install any requirements to run the tests\n if [ ! -z \"{test_requires}\" ]; then\n pip install {test_requires}\n fi\n\n # Run the tests from a different directory\n pushd $HOME\n sh -c {test_command}\n popd\n )\n # exit if tests failed (needed for older bash versions)\n if [ $? -ne 0 ]; then\n exit 1;\n fi\n\n # clean up\n rm -rf \"$venv_dir\"\n fi\n\n # we're all done here; move it to output\n mv \"${{repaired_wheels[@]}}\" /output\n for repaired_wheel in \"${{repaired_wheels[@]}}\"; do chown {uid}:{gid} \"/output/$(basename \"$repaired_wheel\")\"; done\n done\n '''.format(\n pybin_paths=' '.join(c.path+'/bin' for c in platform_configs),\n test_requires=' '.join(test_requires),\n test_extras=test_extras,\n test_command=shlex_quote(\n prepare_command(test_command, project='/project') if test_command else ''\n ),\n before_build=shlex_quote(\n prepare_command(before_build, project='/project') if before_build else ''\n ),\n build_verbosity_flag=' '.join(get_build_verbosity_extra_flags(build_verbosity)),\n repair_command=shlex_quote(\n prepare_command(repair_command, wheel='\"$1\"', dest_dir='/tmp/repaired_wheels') if repair_command else ''\n ),\n environment_exports='\\n'.join(environment.as_shell_commands()),\n uid=os.getuid(),\n gid=os.getgid(),\n )\n\n def run_docker(command, stdin_str=None):\n print('docker command: docker {}'.format(' '.join(map(shlex_quote, command))))\n if stdin_str is None:\n subprocess.check_call(['docker'] + command)\n else:\n args = ['docker'] + command\n process = subprocess.Popen(args, stdin=subprocess.PIPE, universal_newlines=True)\n try:\n process.communicate(stdin_str)\n except KeyboardInterrupt:\n process.kill()\n process.wait()\n if process.returncode != 0:\n raise subprocess.CalledProcessError(process.returncode, args)\n\n container_name = 'cibuildwheel-{}'.format(uuid.uuid4())\n try:\n run_docker(['create',\n '--env', 'CIBUILDWHEEL',\n '--name', container_name,\n '-i',\n '-v', '/:/host', # ignored on Circle\n docker_image, '/bin/bash'])\n run_docker(['cp', os.path.abspath(project_dir) + '/.', container_name + ':/project'])\n run_docker(['start', '-i', '-a', container_name], stdin_str=bash_script)\n run_docker(['cp', container_name + ':/output/.', os.path.abspath(output_dir)])\n except subprocess.CalledProcessError:\n exit(1)\n finally:\n # Still gets executed, even when 'exit(1)' gets called\n run_docker(['rm', '--force', '-v', container_name])\n", "path": "cibuildwheel/linux.py"}], "after_files": [{"content": "from __future__ import print_function\nimport os, subprocess, sys, uuid, textwrap\nfrom collections import namedtuple\nfrom .util import prepare_command, get_build_verbosity_extra_flags\n\ntry:\n from shlex import quote as shlex_quote\nexcept ImportError:\n from pipes import quote as shlex_quote\n\n\ndef get_python_configurations(build_selector):\n PythonConfiguration = namedtuple('PythonConfiguration', ['identifier', 'path'])\n python_configurations = [\n PythonConfiguration(identifier='cp27-manylinux_x86_64', path='/opt/python/cp27-cp27m'),\n PythonConfiguration(identifier='cp27-manylinux_x86_64', path='/opt/python/cp27-cp27mu'),\n PythonConfiguration(identifier='cp35-manylinux_x86_64', path='/opt/python/cp35-cp35m'),\n PythonConfiguration(identifier='cp36-manylinux_x86_64', path='/opt/python/cp36-cp36m'),\n PythonConfiguration(identifier='cp37-manylinux_x86_64', path='/opt/python/cp37-cp37m'),\n PythonConfiguration(identifier='cp38-manylinux_x86_64', path='/opt/python/cp38-cp38'),\n PythonConfiguration(identifier='cp27-manylinux_i686', path='/opt/python/cp27-cp27m'),\n PythonConfiguration(identifier='cp27-manylinux_i686', path='/opt/python/cp27-cp27mu'),\n PythonConfiguration(identifier='cp35-manylinux_i686', path='/opt/python/cp35-cp35m'),\n PythonConfiguration(identifier='cp36-manylinux_i686', path='/opt/python/cp36-cp36m'),\n PythonConfiguration(identifier='cp37-manylinux_i686', path='/opt/python/cp37-cp37m'),\n PythonConfiguration(identifier='cp38-manylinux_i686', path='/opt/python/cp38-cp38'),\n ]\n\n # skip builds as required\n return [c for c in python_configurations if build_selector(c.identifier)]\n\n\ndef build(project_dir, output_dir, test_command, test_requires, test_extras, before_build, build_verbosity, build_selector, repair_command, environment, manylinux_images):\n try:\n subprocess.check_call(['docker', '--version'])\n except:\n print('cibuildwheel: Docker not found. Docker is required to run Linux builds. '\n 'If you\\'re building on Travis CI, add `services: [docker]` to your .travis.yml.'\n 'If you\\'re building on Circle CI in Linux, add a `setup_remote_docker` step to your .circleci/config.yml',\n file=sys.stderr)\n exit(2)\n\n python_configurations = get_python_configurations(build_selector)\n platforms = [\n ('manylinux_x86_64', manylinux_images['x86_64']),\n ('manylinux_i686', manylinux_images['i686']),\n ]\n\n for platform_tag, docker_image in platforms:\n platform_configs = [c for c in python_configurations if c.identifier.endswith(platform_tag)]\n if not platform_configs:\n continue\n\n bash_script = '''\n set -o errexit\n set -o xtrace\n mkdir /output\n cd /project\n\n {environment_exports}\n\n for PYBIN in {pybin_paths}; do\n if [ ! -z {before_build} ]; then\n PATH=\"$PYBIN:$PATH\" sh -c {before_build}\n fi\n\n # Build the wheel\n rm -rf /tmp/built_wheel\n mkdir /tmp/built_wheel\n PATH=\"$PYBIN:$PATH\" \"$PYBIN/pip\" wheel . -w /tmp/built_wheel --no-deps {build_verbosity_flag}\n built_wheel=(/tmp/built_wheel/*.whl)\n\n # repair the wheel\n rm -rf /tmp/repaired_wheels\n mkdir /tmp/repaired_wheels\n # NOTE: 'built_wheel' here is a bash array of glob matches; \"$built_wheel\" returns\n # the first element\n if [[ \"$built_wheel\" == *none-any.whl ]] || [ -z {repair_command} ]; then\n # pure Python wheel or empty repair command\n mv \"$built_wheel\" /tmp/repaired_wheels\n else\n sh -c {repair_command} repair_command \"$built_wheel\"\n fi\n repaired_wheels=(/tmp/repaired_wheels/*.whl)\n\n if [ ! -z {test_command} ]; then\n # Set up a virtual environment to install and test from, to make sure\n # there are no dependencies that were pulled in at build time.\n \"$PYBIN/pip\" install virtualenv\n venv_dir=`mktemp -d`/venv\n \"$PYBIN/python\" -m virtualenv \"$venv_dir\"\n\n # run the tests in a subshell to keep that `activate`\n # script from polluting the env\n (\n source \"$venv_dir/bin/activate\"\n\n echo \"Running tests using `which python`\"\n\n # Install the wheel we just built\n # Note: If auditwheel produced two wheels, it's because the earlier produced wheel\n # conforms to multiple manylinux standards. These multiple versions of the wheel are\n # functionally the same, differing only in name, wheel metadata, and possibly include\n # different external shared libraries. so it doesn't matter which one we run the tests on.\n # Let's just pick the first one.\n pip install \"${{repaired_wheels[0]}}\"{test_extras}\n\n # Install any requirements to run the tests\n if [ ! -z \"{test_requires}\" ]; then\n pip install {test_requires}\n fi\n\n # Run the tests from a different directory\n pushd $HOME\n sh -c {test_command}\n popd\n )\n # exit if tests failed (needed for older bash versions)\n if [ $? -ne 0 ]; then\n exit 1;\n fi\n\n # clean up\n rm -rf \"$venv_dir\"\n fi\n\n # we're all done here; move it to output\n mv \"${{repaired_wheels[@]}}\" /output\n for repaired_wheel in \"${{repaired_wheels[@]}}\"; do chown {uid}:{gid} \"/output/$(basename \"$repaired_wheel\")\"; done\n done\n '''.format(\n pybin_paths=' '.join(c.path+'/bin' for c in platform_configs),\n test_requires=' '.join(test_requires),\n test_extras=test_extras,\n test_command=shlex_quote(\n prepare_command(test_command, project='/project') if test_command else ''\n ),\n before_build=shlex_quote(\n prepare_command(before_build, project='/project') if before_build else ''\n ),\n build_verbosity_flag=' '.join(get_build_verbosity_extra_flags(build_verbosity)),\n repair_command=shlex_quote(\n prepare_command(repair_command, wheel='\"$1\"', dest_dir='/tmp/repaired_wheels') if repair_command else ''\n ),\n environment_exports='\\n'.join(environment.as_shell_commands()),\n uid=os.getuid(),\n gid=os.getgid(),\n )\n\n def run_docker(command, stdin_str=None):\n print('docker command: docker {}'.format(' '.join(map(shlex_quote, command))))\n if stdin_str is None:\n subprocess.check_call(['docker'] + command)\n else:\n args = ['docker'] + command\n process = subprocess.Popen(args, stdin=subprocess.PIPE, universal_newlines=True)\n try:\n process.communicate(stdin_str)\n except KeyboardInterrupt:\n process.kill()\n process.wait()\n if process.returncode != 0:\n raise subprocess.CalledProcessError(process.returncode, args)\n\n container_name = 'cibuildwheel-{}'.format(uuid.uuid4())\n try:\n run_docker(['create',\n '--env', 'CIBUILDWHEEL',\n '--name', container_name,\n '-i',\n '-v', '/:/host', # ignored on Circle\n docker_image, '/bin/bash'])\n run_docker(['cp', os.path.abspath(project_dir) + '/.', container_name + ':/project'])\n run_docker(['start', '-i', '-a', container_name], stdin_str=bash_script)\n run_docker(['cp', container_name + ':/output/.', os.path.abspath(output_dir)])\n except subprocess.CalledProcessError as error:\n troubleshoot(project_dir, error)\n exit(1)\n finally:\n # Still gets executed, even when 'exit(1)' gets called\n run_docker(['rm', '--force', '-v', container_name])\n\n\ndef troubleshoot(project_dir, error):\n if (isinstance(error, subprocess.CalledProcessError) and 'start' in error.cmd):\n # the bash script failed\n print('Checking for common errors...')\n so_files = []\n for root, dirs, files in os.walk(project_dir):\n for name in files:\n _, ext = os.path.splitext(name)\n if ext == '.so':\n so_files.append(os.path.join(root, name))\n\n if so_files:\n print(textwrap.dedent('''\n NOTE: Shared object (.so) files found in this project.\n\n These files might be built against the wrong OS, causing problems with\n auditwheel.\n\n If you're using Cython and have previously done an in-place build,\n remove those build files (*.so and *.c) before starting cibuildwheel.\n '''))\n\n print(' Files detected:')\n print('\\n'.join([' '+f for f in so_files]))\n print('')\n", "path": "cibuildwheel/linux.py"}]}
| 2,782 | 477 |
gh_patches_debug_15680
|
rasdani/github-patches
|
git_diff
|
liqd__a4-product-837
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
#2151 contact form field labels
In EN:
It should say „Your name“ instead of „your first and last name“
It should say „I want to receive a copy of my message“ instead of „
I want to receicve a copy of my message as email“
in DE:
It should say „Ihr Name” instead of „Ihr Vor- und Nachname“
It should say „Eine Kopie der Nachricht an mich senden“ instead of „Eine Kopie der Anfrage an mich senden“
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `apps/cms/contacts/models.py`
Content:
```
1 import json
2
3 from django.contrib import messages
4 from django.core.serializers.json import DjangoJSONEncoder
5 from django.db import models
6 from django.shortcuts import redirect
7 from django.utils.translation import ugettext_lazy as _
8 from modelcluster.fields import ParentalKey
9 from wagtail.admin.edit_handlers import FieldPanel
10 from wagtail.admin.edit_handlers import FieldRowPanel
11 from wagtail.admin.edit_handlers import MultiFieldPanel
12 from wagtail.admin.edit_handlers import ObjectList
13 from wagtail.admin.edit_handlers import TabbedInterface
14 from wagtail.contrib.forms.models import AbstractEmailForm
15 from wagtail.contrib.forms.models import AbstractFormField
16 from wagtail.contrib.forms.models import AbstractFormSubmission
17 from wagtail.core.fields import RichTextField
18 from wagtail.images.edit_handlers import ImageChooserPanel
19
20 from apps.cms.emails import AnswerToContactFormEmail
21 from apps.contrib.translations import TranslatedField
22
23
24 class FormField(AbstractFormField):
25 page = ParentalKey('FormPage',
26 on_delete=models.CASCADE,
27 related_name='form_fields')
28
29
30 class CustomFormSubmission(AbstractFormSubmission):
31 email = models.EmailField()
32 message = models.TextField()
33 telephone_number = models.CharField(max_length=100, blank=True)
34 name = models.CharField(max_length=100, blank=True)
35
36 def get_data(self):
37 form_data = super().get_data()
38 form_data.update({
39 'email': self.email,
40 'message': self.message,
41 'telephone_number': self.telephone_number,
42 'name': self.name
43 })
44
45 return form_data
46
47
48 class FormPage(AbstractEmailForm):
49 header_de = models.CharField(
50 max_length=500, blank=True, verbose_name="Header")
51 header_en = models.CharField(
52 max_length=500, blank=True, verbose_name="Header")
53
54 intro_en = RichTextField(blank=True)
55 intro_de = RichTextField(blank=True)
56
57 thank_you_text_en = models.TextField(blank=True)
58 thank_you_text_de = models.TextField(blank=True)
59
60 contact_person_name = models.CharField(max_length=100, blank=True)
61 contact_person_image = models.ForeignKey(
62 'wagtailimages.Image',
63 null=True,
64 blank=True,
65 on_delete=models.SET_NULL,
66 related_name='+',
67 verbose_name="Image of contact person",
68 help_text="The Image will be shown "
69 "besides the name of the contact person"
70 )
71
72 header = TranslatedField(
73 'header_de',
74 'header_en'
75 )
76
77 intro = TranslatedField(
78 'intro_de',
79 'intro_en'
80 )
81
82 thank_you_text = TranslatedField(
83 'thank_you_text_de',
84 'thank_you_text_en'
85 )
86
87 def get_submission_class(self):
88 return CustomFormSubmission
89
90 def process_form_submission(self, form):
91 data = form.cleaned_data
92 submission = self.get_submission_class().objects.create(
93 form_data=json.dumps(form.cleaned_data, cls=DjangoJSONEncoder),
94 page=self, email=data['email'], message=data['message'],
95 telephone_number=data['telephone_number'], name=data['name']
96 )
97 if self.to_address:
98 self.send_mail(form)
99 if form.cleaned_data['receive_copy']:
100 AnswerToContactFormEmail.send(submission)
101 return submission
102
103 def render_landing_page(
104 self, request, form_submission=None, *args, **kwargs):
105 if 'HTTP_REFERER' in request.META \
106 and request.META.get('HTTP_REFERER'):
107 messages.add_message(request, messages.SUCCESS,
108 self.thank_you_text)
109 return redirect(request.META['HTTP_REFERER'])
110 return super().render_landing_page(
111 request, form_submission, *args, **kwargs)
112
113 def get_form_fields(self):
114 fields = list(super().get_form_fields())
115 fields.insert(0, FormField(
116 label='receive_copy',
117 field_type='checkbox',
118 help_text=_('I want to receicve a copy of my message as email'),
119 required=False))
120
121 fields.insert(0, FormField(
122 label='message',
123 help_text=_('Your message'),
124 field_type='multiline',
125 required=True))
126
127 fields.insert(0, FormField(
128 label='email',
129 help_text=_('Your email address'),
130 field_type='email',
131 required=True))
132
133 fields.insert(0, FormField(
134 label='telephone_number',
135 help_text=_('Your telephone number'),
136 field_type='singleline',
137 required=False))
138
139 fields.insert(0, FormField(
140 label='name',
141 help_text=_('Your first and last name'),
142 field_type='singleline',
143 required=False))
144 return fields
145
146 en_content_panels = [
147 FieldPanel('header_en'),
148 FieldPanel('intro_en'),
149 FieldPanel('thank_you_text_en'),
150 ]
151
152 de_content_panels = [
153 FieldPanel('header_de'),
154 FieldPanel('intro_de'),
155 FieldPanel('thank_you_text_de'),
156 ]
157
158 common_panels = [
159 FieldPanel('title'),
160 FieldPanel('slug'),
161 MultiFieldPanel([
162 FieldRowPanel([
163 FieldPanel('from_address', classname="col6"),
164 FieldPanel('to_address', classname="col6"),
165 ]),
166 FieldPanel('subject'),
167 ], "Email"),
168 MultiFieldPanel([
169 FieldRowPanel([
170 FieldPanel('contact_person_name', classname="col6"),
171 ImageChooserPanel('contact_person_image', classname="col6"),
172 ]),
173 ], "Contact Person"),
174
175 ]
176
177 edit_handler = TabbedInterface([
178 ObjectList(common_panels, heading='Common'),
179 ObjectList(en_content_panels, heading='English'),
180 ObjectList(de_content_panels, heading='German')
181 ])
182
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/apps/cms/contacts/models.py b/apps/cms/contacts/models.py
--- a/apps/cms/contacts/models.py
+++ b/apps/cms/contacts/models.py
@@ -115,7 +115,7 @@
fields.insert(0, FormField(
label='receive_copy',
field_type='checkbox',
- help_text=_('I want to receicve a copy of my message as email'),
+ help_text=_('I want to receive a copy of my message'),
required=False))
fields.insert(0, FormField(
@@ -138,7 +138,7 @@
fields.insert(0, FormField(
label='name',
- help_text=_('Your first and last name'),
+ help_text=_('Your name'),
field_type='singleline',
required=False))
return fields
|
{"golden_diff": "diff --git a/apps/cms/contacts/models.py b/apps/cms/contacts/models.py\n--- a/apps/cms/contacts/models.py\n+++ b/apps/cms/contacts/models.py\n@@ -115,7 +115,7 @@\n fields.insert(0, FormField(\n label='receive_copy',\n field_type='checkbox',\n- help_text=_('I want to receicve a copy of my message as email'),\n+ help_text=_('I want to receive a copy of my message'),\n required=False))\n \n fields.insert(0, FormField(\n@@ -138,7 +138,7 @@\n \n fields.insert(0, FormField(\n label='name',\n- help_text=_('Your first and last name'),\n+ help_text=_('Your name'),\n field_type='singleline',\n required=False))\n return fields\n", "issue": "#2151 contact form field labels\nIn EN: \r\n\r\nIt should say \u201eYour name\u201c instead of \u201eyour first and last name\u201c\r\nIt should say \u201eI want to receive a copy of my message\u201c instead of \u201e\r\nI want to receicve a copy of my message as email\u201c\r\n\r\nin DE:\r\n\r\nIt should say \u201eIhr Name\u201d instead of \u201eIhr Vor- und Nachname\u201c\r\n\r\nIt should say \u201eEine Kopie der Nachricht an mich senden\u201c instead of \u201eEine Kopie der Anfrage an mich senden\u201c\r\n\n", "before_files": [{"content": "import json\n\nfrom django.contrib import messages\nfrom django.core.serializers.json import DjangoJSONEncoder\nfrom django.db import models\nfrom django.shortcuts import redirect\nfrom django.utils.translation import ugettext_lazy as _\nfrom modelcluster.fields import ParentalKey\nfrom wagtail.admin.edit_handlers import FieldPanel\nfrom wagtail.admin.edit_handlers import FieldRowPanel\nfrom wagtail.admin.edit_handlers import MultiFieldPanel\nfrom wagtail.admin.edit_handlers import ObjectList\nfrom wagtail.admin.edit_handlers import TabbedInterface\nfrom wagtail.contrib.forms.models import AbstractEmailForm\nfrom wagtail.contrib.forms.models import AbstractFormField\nfrom wagtail.contrib.forms.models import AbstractFormSubmission\nfrom wagtail.core.fields import RichTextField\nfrom wagtail.images.edit_handlers import ImageChooserPanel\n\nfrom apps.cms.emails import AnswerToContactFormEmail\nfrom apps.contrib.translations import TranslatedField\n\n\nclass FormField(AbstractFormField):\n page = ParentalKey('FormPage',\n on_delete=models.CASCADE,\n related_name='form_fields')\n\n\nclass CustomFormSubmission(AbstractFormSubmission):\n email = models.EmailField()\n message = models.TextField()\n telephone_number = models.CharField(max_length=100, blank=True)\n name = models.CharField(max_length=100, blank=True)\n\n def get_data(self):\n form_data = super().get_data()\n form_data.update({\n 'email': self.email,\n 'message': self.message,\n 'telephone_number': self.telephone_number,\n 'name': self.name\n })\n\n return form_data\n\n\nclass FormPage(AbstractEmailForm):\n header_de = models.CharField(\n max_length=500, blank=True, verbose_name=\"Header\")\n header_en = models.CharField(\n max_length=500, blank=True, verbose_name=\"Header\")\n\n intro_en = RichTextField(blank=True)\n intro_de = RichTextField(blank=True)\n\n thank_you_text_en = models.TextField(blank=True)\n thank_you_text_de = models.TextField(blank=True)\n\n contact_person_name = models.CharField(max_length=100, blank=True)\n contact_person_image = models.ForeignKey(\n 'wagtailimages.Image',\n null=True,\n blank=True,\n on_delete=models.SET_NULL,\n related_name='+',\n verbose_name=\"Image of contact person\",\n help_text=\"The Image will be shown \"\n \"besides the name of the contact person\"\n )\n\n header = TranslatedField(\n 'header_de',\n 'header_en'\n )\n\n intro = TranslatedField(\n 'intro_de',\n 'intro_en'\n )\n\n thank_you_text = TranslatedField(\n 'thank_you_text_de',\n 'thank_you_text_en'\n )\n\n def get_submission_class(self):\n return CustomFormSubmission\n\n def process_form_submission(self, form):\n data = form.cleaned_data\n submission = self.get_submission_class().objects.create(\n form_data=json.dumps(form.cleaned_data, cls=DjangoJSONEncoder),\n page=self, email=data['email'], message=data['message'],\n telephone_number=data['telephone_number'], name=data['name']\n )\n if self.to_address:\n self.send_mail(form)\n if form.cleaned_data['receive_copy']:\n AnswerToContactFormEmail.send(submission)\n return submission\n\n def render_landing_page(\n self, request, form_submission=None, *args, **kwargs):\n if 'HTTP_REFERER' in request.META \\\n and request.META.get('HTTP_REFERER'):\n messages.add_message(request, messages.SUCCESS,\n self.thank_you_text)\n return redirect(request.META['HTTP_REFERER'])\n return super().render_landing_page(\n request, form_submission, *args, **kwargs)\n\n def get_form_fields(self):\n fields = list(super().get_form_fields())\n fields.insert(0, FormField(\n label='receive_copy',\n field_type='checkbox',\n help_text=_('I want to receicve a copy of my message as email'),\n required=False))\n\n fields.insert(0, FormField(\n label='message',\n help_text=_('Your message'),\n field_type='multiline',\n required=True))\n\n fields.insert(0, FormField(\n label='email',\n help_text=_('Your email address'),\n field_type='email',\n required=True))\n\n fields.insert(0, FormField(\n label='telephone_number',\n help_text=_('Your telephone number'),\n field_type='singleline',\n required=False))\n\n fields.insert(0, FormField(\n label='name',\n help_text=_('Your first and last name'),\n field_type='singleline',\n required=False))\n return fields\n\n en_content_panels = [\n FieldPanel('header_en'),\n FieldPanel('intro_en'),\n FieldPanel('thank_you_text_en'),\n ]\n\n de_content_panels = [\n FieldPanel('header_de'),\n FieldPanel('intro_de'),\n FieldPanel('thank_you_text_de'),\n ]\n\n common_panels = [\n FieldPanel('title'),\n FieldPanel('slug'),\n MultiFieldPanel([\n FieldRowPanel([\n FieldPanel('from_address', classname=\"col6\"),\n FieldPanel('to_address', classname=\"col6\"),\n ]),\n FieldPanel('subject'),\n ], \"Email\"),\n MultiFieldPanel([\n FieldRowPanel([\n FieldPanel('contact_person_name', classname=\"col6\"),\n ImageChooserPanel('contact_person_image', classname=\"col6\"),\n ]),\n ], \"Contact Person\"),\n\n ]\n\n edit_handler = TabbedInterface([\n ObjectList(common_panels, heading='Common'),\n ObjectList(en_content_panels, heading='English'),\n ObjectList(de_content_panels, heading='German')\n ])\n", "path": "apps/cms/contacts/models.py"}], "after_files": [{"content": "import json\n\nfrom django.contrib import messages\nfrom django.core.serializers.json import DjangoJSONEncoder\nfrom django.db import models\nfrom django.shortcuts import redirect\nfrom django.utils.translation import ugettext_lazy as _\nfrom modelcluster.fields import ParentalKey\nfrom wagtail.admin.edit_handlers import FieldPanel\nfrom wagtail.admin.edit_handlers import FieldRowPanel\nfrom wagtail.admin.edit_handlers import MultiFieldPanel\nfrom wagtail.admin.edit_handlers import ObjectList\nfrom wagtail.admin.edit_handlers import TabbedInterface\nfrom wagtail.contrib.forms.models import AbstractEmailForm\nfrom wagtail.contrib.forms.models import AbstractFormField\nfrom wagtail.contrib.forms.models import AbstractFormSubmission\nfrom wagtail.core.fields import RichTextField\nfrom wagtail.images.edit_handlers import ImageChooserPanel\n\nfrom apps.cms.emails import AnswerToContactFormEmail\nfrom apps.contrib.translations import TranslatedField\n\n\nclass FormField(AbstractFormField):\n page = ParentalKey('FormPage',\n on_delete=models.CASCADE,\n related_name='form_fields')\n\n\nclass CustomFormSubmission(AbstractFormSubmission):\n email = models.EmailField()\n message = models.TextField()\n telephone_number = models.CharField(max_length=100, blank=True)\n name = models.CharField(max_length=100, blank=True)\n\n def get_data(self):\n form_data = super().get_data()\n form_data.update({\n 'email': self.email,\n 'message': self.message,\n 'telephone_number': self.telephone_number,\n 'name': self.name\n })\n\n return form_data\n\n\nclass FormPage(AbstractEmailForm):\n header_de = models.CharField(\n max_length=500, blank=True, verbose_name=\"Header\")\n header_en = models.CharField(\n max_length=500, blank=True, verbose_name=\"Header\")\n\n intro_en = RichTextField(blank=True)\n intro_de = RichTextField(blank=True)\n\n thank_you_text_en = models.TextField(blank=True)\n thank_you_text_de = models.TextField(blank=True)\n\n contact_person_name = models.CharField(max_length=100, blank=True)\n contact_person_image = models.ForeignKey(\n 'wagtailimages.Image',\n null=True,\n blank=True,\n on_delete=models.SET_NULL,\n related_name='+',\n verbose_name=\"Image of contact person\",\n help_text=\"The Image will be shown \"\n \"besides the name of the contact person\"\n )\n\n header = TranslatedField(\n 'header_de',\n 'header_en'\n )\n\n intro = TranslatedField(\n 'intro_de',\n 'intro_en'\n )\n\n thank_you_text = TranslatedField(\n 'thank_you_text_de',\n 'thank_you_text_en'\n )\n\n def get_submission_class(self):\n return CustomFormSubmission\n\n def process_form_submission(self, form):\n data = form.cleaned_data\n submission = self.get_submission_class().objects.create(\n form_data=json.dumps(form.cleaned_data, cls=DjangoJSONEncoder),\n page=self, email=data['email'], message=data['message'],\n telephone_number=data['telephone_number'], name=data['name']\n )\n if self.to_address:\n self.send_mail(form)\n if form.cleaned_data['receive_copy']:\n AnswerToContactFormEmail.send(submission)\n return submission\n\n def render_landing_page(\n self, request, form_submission=None, *args, **kwargs):\n if 'HTTP_REFERER' in request.META \\\n and request.META.get('HTTP_REFERER'):\n messages.add_message(request, messages.SUCCESS,\n self.thank_you_text)\n return redirect(request.META['HTTP_REFERER'])\n return super().render_landing_page(\n request, form_submission, *args, **kwargs)\n\n def get_form_fields(self):\n fields = list(super().get_form_fields())\n fields.insert(0, FormField(\n label='receive_copy',\n field_type='checkbox',\n help_text=_('I want to receive a copy of my message'),\n required=False))\n\n fields.insert(0, FormField(\n label='message',\n help_text=_('Your message'),\n field_type='multiline',\n required=True))\n\n fields.insert(0, FormField(\n label='email',\n help_text=_('Your email address'),\n field_type='email',\n required=True))\n\n fields.insert(0, FormField(\n label='telephone_number',\n help_text=_('Your telephone number'),\n field_type='singleline',\n required=False))\n\n fields.insert(0, FormField(\n label='name',\n help_text=_('Your name'),\n field_type='singleline',\n required=False))\n return fields\n\n en_content_panels = [\n FieldPanel('header_en'),\n FieldPanel('intro_en'),\n FieldPanel('thank_you_text_en'),\n ]\n\n de_content_panels = [\n FieldPanel('header_de'),\n FieldPanel('intro_de'),\n FieldPanel('thank_you_text_de'),\n ]\n\n common_panels = [\n FieldPanel('title'),\n FieldPanel('slug'),\n MultiFieldPanel([\n FieldRowPanel([\n FieldPanel('from_address', classname=\"col6\"),\n FieldPanel('to_address', classname=\"col6\"),\n ]),\n FieldPanel('subject'),\n ], \"Email\"),\n MultiFieldPanel([\n FieldRowPanel([\n FieldPanel('contact_person_name', classname=\"col6\"),\n ImageChooserPanel('contact_person_image', classname=\"col6\"),\n ]),\n ], \"Contact Person\"),\n\n ]\n\n edit_handler = TabbedInterface([\n ObjectList(common_panels, heading='Common'),\n ObjectList(en_content_panels, heading='English'),\n ObjectList(de_content_panels, heading='German')\n ])\n", "path": "apps/cms/contacts/models.py"}]}
| 2,028 | 182 |
gh_patches_debug_63373
|
rasdani/github-patches
|
git_diff
|
google__flax-107
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
VAE example uses deprecated `optimizer.optimize()`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/vae/main.py`
Content:
```
1 # Copyright 2020 The Flax Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from absl import app
16 from absl import flags
17
18 import jax.numpy as jnp
19 import numpy as np
20
21 import jax
22 from jax import random
23
24 from flax import nn
25 from flax import optim
26
27 import tensorflow_datasets as tfds
28
29 from utils import save_image
30
31
32 FLAGS = flags.FLAGS
33
34 flags.DEFINE_float(
35 'learning_rate', default=1e-3,
36 help=('The leanring rate for the Adam optimizer')
37 )
38
39 flags.DEFINE_integer(
40 'batch_size', default=128,
41 help=('Batch size for training')
42 )
43
44 flags.DEFINE_integer(
45 'num_epochs', default=10,
46 help=('Number of training epochs')
47 )
48
49
50 class Encoder(nn.Module):
51 def apply(self, x):
52 x = nn.Dense(x, 400, name='enc_fc1')
53 x = nn.relu(x)
54 mean_x = nn.Dense(x, 20, name='enc_fc21')
55 logvar_x = nn.Dense(x, 20, name='enc_fc22')
56 return mean_x, logvar_x
57
58
59 class Decoder(nn.Module):
60 def apply(self, z):
61 z = nn.Dense(z, 400, name='dec_fc1')
62 z = nn.relu(z)
63 z = nn.Dense(z, 784, name='dec_fc2')
64 return z
65
66
67 class VAE(nn.Module):
68 def apply(self, x):
69 mean, logvar = Encoder(x, name='encoder')
70 z = reparameterize(mean, logvar)
71 recon_x = self._created_decoder()(z)
72 return recon_x, mean, logvar
73
74 @nn.module_method
75 def generate(self, z):
76 params = self.get_param('decoder')
77 return nn.sigmoid(Decoder.call(params, z))
78
79 @nn.module_method
80 def generate_one_liner(self, z):
81 return nn.sigmoid(Decoder(z, name='decoder'))
82
83 @nn.module_method
84 def generate_shared(self, z):
85 return nn.sigmoid(self._created_decoder()(z))
86
87 def _created_decoder(self):
88 return Decoder.shared(name='decoder')
89
90
91 def reparameterize(mean, logvar):
92 std = jnp.exp(0.5 * logvar)
93 eps = np.random.normal(size=logvar.shape)
94 return mean + eps * std
95
96
97 @jax.vmap
98 def kl_divergence(mean, logvar):
99 return - 0.5 * jnp.sum(1 + logvar - jnp.power(mean, 2) - jnp.exp(logvar))
100
101
102 @jax.vmap
103 def binary_cross_entropy_with_logits(logits, labels):
104 return - jnp.sum(labels * nn.log_sigmoid(logits) + (1 - labels) * (nn.log_sigmoid(logits) - logits))
105
106
107 def compute_metrics(recon_x, x, mean, logvar):
108 bce_loss = binary_cross_entropy_with_logits(recon_x, x)
109 kld_loss = kl_divergence(mean, logvar)
110 return {'bce': jnp.mean(bce_loss), 'kld': jnp.mean(kld_loss), 'loss': jnp.mean(bce_loss + kld_loss)}
111
112
113 @jax.jit
114 def train_step(optimizer, batch):
115 def loss_fn(model):
116 x = batch['image']
117 recon_x, mean, logvar = model(x)
118
119 bce_loss = binary_cross_entropy_with_logits(recon_x, x)
120 kld_loss = kl_divergence(mean, logvar)
121 loss = jnp.mean(bce_loss + kld_loss)
122 return loss, recon_x
123 optimizer, _, _ = optimizer.optimize(loss_fn)
124 return optimizer
125
126
127 @jax.jit
128 def eval(model, eval_ds, z):
129 xs = eval_ds['image'] / 255.0
130 xs = xs.reshape(-1, 784)
131 recon_xs, mean, logvar = model(xs)
132
133 comparison = jnp.concatenate([xs[:8].reshape(-1, 28, 28, 1),
134 recon_xs[:8].reshape(-1, 28, 28, 1)])
135
136 generate_xs = model.generate(z)
137 generate_xs = generate_xs.reshape(-1, 28, 28, 1)
138
139 return compute_metrics(recon_xs, xs, mean, logvar), comparison, generate_xs
140
141
142 def main(argv):
143 key = random.PRNGKey(0)
144 train_ds = tfds.load('mnist', split=tfds.Split.TRAIN)
145 train_ds = train_ds.cache().shuffle(1000).batch(FLAGS.batch_size)
146 test_ds = tfds.as_numpy(tfds.load('mnist', split=tfds.Split.TEST, batch_size=-1))
147
148 _, params = VAE.init_by_shape(key, [((1, 784), jnp.float32)])
149 vae = nn.Model(VAE, params)
150
151 optimizer = optim.Adam(learning_rate=FLAGS.learning_rate).create(vae)
152
153 for epoch in range(FLAGS.num_epochs):
154 for batch in tfds.as_numpy(train_ds):
155 batch['image'] = batch['image'].reshape(-1, 784) / 255.0
156 optimizer = train_step(optimizer, batch)
157
158 z = np.random.normal(size=(64, 20))
159 metrics, comparison, sample = eval(optimizer.target, test_ds, z)
160 save_image(comparison, 'results/reconstruction_' + str(epoch) + '.png', nrow=8)
161 save_image(sample, 'results/sample_' + str(epoch) + '.png', nrow=8)
162
163 print("eval epoch: {}, loss: {:.4f}, BCE: {:.4f}, KLD: {:.4f}".format(
164 epoch + 1, metrics['loss'], metrics['bce'], metrics['kld']
165 ))
166
167
168 if __name__ == '__main__':
169 app.run(main)
170
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/vae/main.py b/examples/vae/main.py
--- a/examples/vae/main.py
+++ b/examples/vae/main.py
@@ -120,7 +120,9 @@
kld_loss = kl_divergence(mean, logvar)
loss = jnp.mean(bce_loss + kld_loss)
return loss, recon_x
- optimizer, _, _ = optimizer.optimize(loss_fn)
+ grad_fn = jax.value_and_grad(loss_fn, has_aux=True)
+ _, grad = grad_fn(optimizer.target)
+ optimizer = optimizer.apply_gradient(grad)
return optimizer
|
{"golden_diff": "diff --git a/examples/vae/main.py b/examples/vae/main.py\n--- a/examples/vae/main.py\n+++ b/examples/vae/main.py\n@@ -120,7 +120,9 @@\n kld_loss = kl_divergence(mean, logvar)\n loss = jnp.mean(bce_loss + kld_loss)\n return loss, recon_x\n- optimizer, _, _ = optimizer.optimize(loss_fn)\n+ grad_fn = jax.value_and_grad(loss_fn, has_aux=True)\n+ _, grad = grad_fn(optimizer.target)\n+ optimizer = optimizer.apply_gradient(grad)\n return optimizer\n", "issue": "VAE example uses deprecated `optimizer.optimize()`\n\n", "before_files": [{"content": "# Copyright 2020 The Flax Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom absl import app\nfrom absl import flags\n\nimport jax.numpy as jnp\nimport numpy as np\n\nimport jax\nfrom jax import random\n\nfrom flax import nn\nfrom flax import optim\n\nimport tensorflow_datasets as tfds\n\nfrom utils import save_image\n\n\nFLAGS = flags.FLAGS\n\nflags.DEFINE_float(\n 'learning_rate', default=1e-3,\n help=('The leanring rate for the Adam optimizer')\n)\n\nflags.DEFINE_integer(\n 'batch_size', default=128,\n help=('Batch size for training')\n)\n\nflags.DEFINE_integer(\n 'num_epochs', default=10,\n help=('Number of training epochs')\n)\n\n\nclass Encoder(nn.Module):\n def apply(self, x):\n x = nn.Dense(x, 400, name='enc_fc1')\n x = nn.relu(x)\n mean_x = nn.Dense(x, 20, name='enc_fc21')\n logvar_x = nn.Dense(x, 20, name='enc_fc22')\n return mean_x, logvar_x\n\n\nclass Decoder(nn.Module):\n def apply(self, z):\n z = nn.Dense(z, 400, name='dec_fc1')\n z = nn.relu(z)\n z = nn.Dense(z, 784, name='dec_fc2')\n return z\n\n\nclass VAE(nn.Module):\n def apply(self, x):\n mean, logvar = Encoder(x, name='encoder')\n z = reparameterize(mean, logvar)\n recon_x = self._created_decoder()(z)\n return recon_x, mean, logvar\n\n @nn.module_method\n def generate(self, z):\n params = self.get_param('decoder')\n return nn.sigmoid(Decoder.call(params, z))\n\n @nn.module_method\n def generate_one_liner(self, z):\n return nn.sigmoid(Decoder(z, name='decoder'))\n\n @nn.module_method\n def generate_shared(self, z):\n return nn.sigmoid(self._created_decoder()(z))\n\n def _created_decoder(self):\n return Decoder.shared(name='decoder')\n\n\ndef reparameterize(mean, logvar):\n std = jnp.exp(0.5 * logvar)\n eps = np.random.normal(size=logvar.shape)\n return mean + eps * std\n\n\n@jax.vmap\ndef kl_divergence(mean, logvar):\n return - 0.5 * jnp.sum(1 + logvar - jnp.power(mean, 2) - jnp.exp(logvar))\n\n\n@jax.vmap\ndef binary_cross_entropy_with_logits(logits, labels):\n return - jnp.sum(labels * nn.log_sigmoid(logits) + (1 - labels) * (nn.log_sigmoid(logits) - logits))\n\n\ndef compute_metrics(recon_x, x, mean, logvar):\n bce_loss = binary_cross_entropy_with_logits(recon_x, x)\n kld_loss = kl_divergence(mean, logvar)\n return {'bce': jnp.mean(bce_loss), 'kld': jnp.mean(kld_loss), 'loss': jnp.mean(bce_loss + kld_loss)}\n\n\n@jax.jit\ndef train_step(optimizer, batch):\n def loss_fn(model):\n x = batch['image']\n recon_x, mean, logvar = model(x)\n\n bce_loss = binary_cross_entropy_with_logits(recon_x, x)\n kld_loss = kl_divergence(mean, logvar)\n loss = jnp.mean(bce_loss + kld_loss)\n return loss, recon_x\n optimizer, _, _ = optimizer.optimize(loss_fn)\n return optimizer\n\n\n@jax.jit\ndef eval(model, eval_ds, z):\n xs = eval_ds['image'] / 255.0\n xs = xs.reshape(-1, 784)\n recon_xs, mean, logvar = model(xs)\n\n comparison = jnp.concatenate([xs[:8].reshape(-1, 28, 28, 1),\n recon_xs[:8].reshape(-1, 28, 28, 1)])\n\n generate_xs = model.generate(z)\n generate_xs = generate_xs.reshape(-1, 28, 28, 1)\n\n return compute_metrics(recon_xs, xs, mean, logvar), comparison, generate_xs\n\n\ndef main(argv):\n key = random.PRNGKey(0)\n train_ds = tfds.load('mnist', split=tfds.Split.TRAIN)\n train_ds = train_ds.cache().shuffle(1000).batch(FLAGS.batch_size)\n test_ds = tfds.as_numpy(tfds.load('mnist', split=tfds.Split.TEST, batch_size=-1))\n\n _, params = VAE.init_by_shape(key, [((1, 784), jnp.float32)])\n vae = nn.Model(VAE, params)\n\n optimizer = optim.Adam(learning_rate=FLAGS.learning_rate).create(vae)\n\n for epoch in range(FLAGS.num_epochs):\n for batch in tfds.as_numpy(train_ds):\n batch['image'] = batch['image'].reshape(-1, 784) / 255.0\n optimizer = train_step(optimizer, batch)\n\n z = np.random.normal(size=(64, 20))\n metrics, comparison, sample = eval(optimizer.target, test_ds, z)\n save_image(comparison, 'results/reconstruction_' + str(epoch) + '.png', nrow=8)\n save_image(sample, 'results/sample_' + str(epoch) + '.png', nrow=8)\n\n print(\"eval epoch: {}, loss: {:.4f}, BCE: {:.4f}, KLD: {:.4f}\".format(\n epoch + 1, metrics['loss'], metrics['bce'], metrics['kld']\n ))\n\n\nif __name__ == '__main__':\n app.run(main)\n", "path": "examples/vae/main.py"}], "after_files": [{"content": "# Copyright 2020 The Flax Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom absl import app\nfrom absl import flags\n\nimport jax.numpy as jnp\nimport numpy as np\n\nimport jax\nfrom jax import random\n\nfrom flax import nn\nfrom flax import optim\n\nimport tensorflow_datasets as tfds\n\nfrom utils import save_image\n\n\nFLAGS = flags.FLAGS\n\nflags.DEFINE_float(\n 'learning_rate', default=1e-3,\n help=('The leanring rate for the Adam optimizer')\n)\n\nflags.DEFINE_integer(\n 'batch_size', default=128,\n help=('Batch size for training')\n)\n\nflags.DEFINE_integer(\n 'num_epochs', default=10,\n help=('Number of training epochs')\n)\n\n\nclass Encoder(nn.Module):\n def apply(self, x):\n x = nn.Dense(x, 400, name='enc_fc1')\n x = nn.relu(x)\n mean_x = nn.Dense(x, 20, name='enc_fc21')\n logvar_x = nn.Dense(x, 20, name='enc_fc22')\n return mean_x, logvar_x\n\n\nclass Decoder(nn.Module):\n def apply(self, z):\n z = nn.Dense(z, 400, name='dec_fc1')\n z = nn.relu(z)\n z = nn.Dense(z, 784, name='dec_fc2')\n return z\n\n\nclass VAE(nn.Module):\n def apply(self, x):\n mean, logvar = Encoder(x, name='encoder')\n z = reparameterize(mean, logvar)\n recon_x = self._created_decoder()(z)\n return recon_x, mean, logvar\n\n @nn.module_method\n def generate(self, z):\n params = self.get_param('decoder')\n return nn.sigmoid(Decoder.call(params, z))\n\n @nn.module_method\n def generate_one_liner(self, z):\n return nn.sigmoid(Decoder(z, name='decoder'))\n\n @nn.module_method\n def generate_shared(self, z):\n return nn.sigmoid(self._created_decoder()(z))\n\n def _created_decoder(self):\n return Decoder.shared(name='decoder')\n\n\ndef reparameterize(mean, logvar):\n std = jnp.exp(0.5 * logvar)\n eps = np.random.normal(size=logvar.shape)\n return mean + eps * std\n\n\n@jax.vmap\ndef kl_divergence(mean, logvar):\n return - 0.5 * jnp.sum(1 + logvar - jnp.power(mean, 2) - jnp.exp(logvar))\n\n\n@jax.vmap\ndef binary_cross_entropy_with_logits(logits, labels):\n return - jnp.sum(labels * nn.log_sigmoid(logits) + (1 - labels) * (nn.log_sigmoid(logits) - logits))\n\n\ndef compute_metrics(recon_x, x, mean, logvar):\n bce_loss = binary_cross_entropy_with_logits(recon_x, x)\n kld_loss = kl_divergence(mean, logvar)\n return {'bce': jnp.mean(bce_loss), 'kld': jnp.mean(kld_loss), 'loss': jnp.mean(bce_loss + kld_loss)}\n\n\n@jax.jit\ndef train_step(optimizer, batch):\n def loss_fn(model):\n x = batch['image']\n recon_x, mean, logvar = model(x)\n\n bce_loss = binary_cross_entropy_with_logits(recon_x, x)\n kld_loss = kl_divergence(mean, logvar)\n loss = jnp.mean(bce_loss + kld_loss)\n return loss, recon_x\n grad_fn = jax.value_and_grad(loss_fn, has_aux=True)\n _, grad = grad_fn(optimizer.target)\n optimizer = optimizer.apply_gradient(grad)\n return optimizer\n\n\n@jax.jit\ndef eval(model, eval_ds, z):\n xs = eval_ds['image'] / 255.0\n xs = xs.reshape(-1, 784)\n recon_xs, mean, logvar = model(xs)\n\n comparison = jnp.concatenate([xs[:8].reshape(-1, 28, 28, 1),\n recon_xs[:8].reshape(-1, 28, 28, 1)])\n\n generate_xs = model.generate(z)\n generate_xs = generate_xs.reshape(-1, 28, 28, 1)\n\n return compute_metrics(recon_xs, xs, mean, logvar), comparison, generate_xs\n\n\ndef main(argv):\n key = random.PRNGKey(0)\n train_ds = tfds.load('mnist', split=tfds.Split.TRAIN)\n train_ds = train_ds.cache().shuffle(1000).batch(FLAGS.batch_size)\n test_ds = tfds.as_numpy(tfds.load('mnist', split=tfds.Split.TEST, batch_size=-1))\n\n _, params = VAE.init_by_shape(key, [((1, 784), jnp.float32)])\n vae = nn.Model(VAE, params)\n\n optimizer = optim.Adam(learning_rate=FLAGS.learning_rate).create(vae)\n\n for epoch in range(FLAGS.num_epochs):\n for batch in tfds.as_numpy(train_ds):\n batch['image'] = batch['image'].reshape(-1, 784) / 255.0\n optimizer = train_step(optimizer, batch)\n\n z = np.random.normal(size=(64, 20))\n metrics, comparison, sample = eval(optimizer.target, test_ds, z)\n save_image(comparison, 'results/reconstruction_' + str(epoch) + '.png', nrow=8)\n save_image(sample, 'results/sample_' + str(epoch) + '.png', nrow=8)\n\n print(\"eval epoch: {}, loss: {:.4f}, BCE: {:.4f}, KLD: {:.4f}\".format(\n epoch + 1, metrics['loss'], metrics['bce'], metrics['kld']\n ))\n\n\nif __name__ == '__main__':\n app.run(main)\n", "path": "examples/vae/main.py"}]}
| 2,091 | 133 |
gh_patches_debug_10989
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-3323
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Culprit not shown for iOS
For some iOS events the culprit is not shown in the UI.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/sentry/lang/native/plugin.py`
Content:
```
1 from __future__ import absolute_import, print_function
2
3 import logging
4 import posixpath
5
6 from sentry.models import Project, EventError
7 from sentry.plugins import Plugin2
8 from sentry.lang.native.symbolizer import Symbolizer, have_symsynd
9 from sentry.models.dsymfile import SDK_MAPPING
10
11
12 logger = logging.getLogger(__name__)
13
14
15 def append_error(data, err):
16 data.setdefault('errors', []).append(err)
17
18
19 def exception_from_apple_error_or_diagnosis(error, diagnosis=None):
20 error = error or {}
21
22 if error:
23 nsexception = error.get('nsexception')
24 if nsexception:
25 return {
26 'type': nsexception['name'],
27 'value': error['reason'],
28 }
29
30 if diagnosis:
31 return {
32 'type': 'Error',
33 'value': diagnosis
34 }
35
36
37 def inject_apple_backtrace(data, frames, diagnosis=None, error=None,
38 system=None):
39 # TODO:
40 # user report stacktraces from unity
41
42 app_uuid = None
43 if system:
44 app_uuid = system.get('app_uuid')
45 if app_uuid is not None:
46 app_uuid = app_uuid.lower()
47
48 converted_frames = []
49 longest_addr = 0
50 for frame in reversed(frames):
51 fn = frame.get('filename')
52 in_app = False
53
54 if app_uuid is not None:
55 frame_uuid = frame.get('uuid')
56 if frame_uuid == app_uuid:
57 in_app = True
58
59 # We only record the offset if we found a symbol but we did not
60 # find a line number. In that case it's the offset in bytes from
61 # the beginning of the symbol.
62 function = frame['symbol_name'] or '<unknown>'
63 lineno = frame.get('line')
64 offset = None
65 if not lineno:
66 offset = frame['instruction_addr'] - frame['symbol_addr']
67
68 cframe = {
69 'in_app': in_app,
70 'abs_path': fn,
71 'filename': fn and posixpath.basename(fn) or None,
72 # This can come back as `None` from the symbolizer, in which
73 # case we need to fill something else in or we will fail
74 # later fulfill the interface requirements which say that a
75 # function needs to be provided.
76 'function': function,
77 'package': frame['object_name'],
78 'symbol_addr': '%x' % frame['symbol_addr'],
79 'instruction_addr': '%x' % frame['instruction_addr'],
80 'instruction_offset': offset,
81 'lineno': lineno,
82 }
83 converted_frames.append(cframe)
84 longest_addr = max(longest_addr, len(cframe['symbol_addr']),
85 len(cframe['instruction_addr']))
86
87 # Pad out addresses to be of the same length and add prefix
88 for frame in converted_frames:
89 for key in 'symbol_addr', 'instruction_addr':
90 frame[key] = '0x' + frame[key][2:].rjust(longest_addr, '0')
91
92 stacktrace = {'frames': converted_frames}
93
94 if error or diagnosis:
95 error = error or {}
96 exc = exception_from_apple_error_or_diagnosis(error, diagnosis)
97 if exc is not None:
98 exc['stacktrace'] = stacktrace
99 data['sentry.interfaces.Exception'] = exc
100 return
101
102 data['sentry.interfaces.Stacktrace'] = stacktrace
103
104
105 def inject_apple_device_data(data, system):
106 container = data.setdefault('device', {})
107 try:
108 container['name'] = SDK_MAPPING[system['system_name']]
109 except LookupError:
110 container['name'] = system.get('system_name') or 'Generic Apple'
111
112 if 'system_version' in system:
113 container['version'] = system['system_version']
114 if 'os_version' in system:
115 container['build'] = system['os_version']
116
117 extra = container.setdefault('data', {})
118 if 'cpu_arch' in system:
119 extra['cpu_arch'] = system['cpu_arch']
120 if 'model' in system:
121 extra['device_model_id'] = system['model']
122 if 'machine' in system:
123 extra['device_model'] = system['machine']
124 if 'kernel_version' in system:
125 extra['kernel_version'] = system['kernel_version']
126
127
128 def preprocess_apple_crash_event(data):
129 crash_report = data.get('sentry.interfaces.AppleCrashReport')
130 if crash_report is None:
131 return
132
133 project = Project.objects.get_from_cache(
134 id=data['project'],
135 )
136
137 crash = crash_report['crash']
138 crashed_thread = None
139 for thread in crash['threads']:
140 if thread['crashed']:
141 crashed_thread = thread
142 if crashed_thread is None:
143 append_error(data, {
144 'type': EventError.NATIVE_NO_CRASHED_THREAD,
145 })
146
147 else:
148 system = crash_report.get('system')
149 try:
150 sym = Symbolizer(project, crash_report['binary_images'],
151 threads=[crashed_thread])
152 with sym:
153 bt = sym.symbolize_backtrace(
154 crashed_thread['backtrace']['contents'], system)
155 inject_apple_backtrace(data, bt, crash.get('diagnosis'),
156 crash.get('error'), system)
157 except Exception as e:
158 logger.exception('Failed to symbolicate')
159 append_error(data, {
160 'type': EventError.NATIVE_INTERNAL_FAILURE,
161 'error': '%s: %s' % (e.__class__.__name__, str(e)),
162 })
163 return
164
165 if system:
166 inject_apple_device_data(data, system)
167
168 return data
169
170
171 class NativePlugin(Plugin2):
172 can_disable = False
173
174 def get_event_preprocessors(self, **kwargs):
175 if not have_symsynd:
176 return []
177 return [preprocess_apple_crash_event]
178
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/sentry/lang/native/plugin.py b/src/sentry/lang/native/plugin.py
--- a/src/sentry/lang/native/plugin.py
+++ b/src/sentry/lang/native/plugin.py
@@ -96,7 +96,11 @@
exc = exception_from_apple_error_or_diagnosis(error, diagnosis)
if exc is not None:
exc['stacktrace'] = stacktrace
- data['sentry.interfaces.Exception'] = exc
+ data['sentry.interfaces.Exception'] = {'values': [exc]}
+ # Since we inject the exception late we need to make sure that
+ # we set the event type to error as it would be set to
+ # 'default' otherwise.
+ data['type'] = 'error'
return
data['sentry.interfaces.Stacktrace'] = stacktrace
|
{"golden_diff": "diff --git a/src/sentry/lang/native/plugin.py b/src/sentry/lang/native/plugin.py\n--- a/src/sentry/lang/native/plugin.py\n+++ b/src/sentry/lang/native/plugin.py\n@@ -96,7 +96,11 @@\n exc = exception_from_apple_error_or_diagnosis(error, diagnosis)\n if exc is not None:\n exc['stacktrace'] = stacktrace\n- data['sentry.interfaces.Exception'] = exc\n+ data['sentry.interfaces.Exception'] = {'values': [exc]}\n+ # Since we inject the exception late we need to make sure that\n+ # we set the event type to error as it would be set to\n+ # 'default' otherwise.\n+ data['type'] = 'error'\n return\n \n data['sentry.interfaces.Stacktrace'] = stacktrace\n", "issue": "Culprit not shown for iOS\nFor some iOS events the culprit is not shown in the UI.\n\n", "before_files": [{"content": "from __future__ import absolute_import, print_function\n\nimport logging\nimport posixpath\n\nfrom sentry.models import Project, EventError\nfrom sentry.plugins import Plugin2\nfrom sentry.lang.native.symbolizer import Symbolizer, have_symsynd\nfrom sentry.models.dsymfile import SDK_MAPPING\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef append_error(data, err):\n data.setdefault('errors', []).append(err)\n\n\ndef exception_from_apple_error_or_diagnosis(error, diagnosis=None):\n error = error or {}\n\n if error:\n nsexception = error.get('nsexception')\n if nsexception:\n return {\n 'type': nsexception['name'],\n 'value': error['reason'],\n }\n\n if diagnosis:\n return {\n 'type': 'Error',\n 'value': diagnosis\n }\n\n\ndef inject_apple_backtrace(data, frames, diagnosis=None, error=None,\n system=None):\n # TODO:\n # user report stacktraces from unity\n\n app_uuid = None\n if system:\n app_uuid = system.get('app_uuid')\n if app_uuid is not None:\n app_uuid = app_uuid.lower()\n\n converted_frames = []\n longest_addr = 0\n for frame in reversed(frames):\n fn = frame.get('filename')\n in_app = False\n\n if app_uuid is not None:\n frame_uuid = frame.get('uuid')\n if frame_uuid == app_uuid:\n in_app = True\n\n # We only record the offset if we found a symbol but we did not\n # find a line number. In that case it's the offset in bytes from\n # the beginning of the symbol.\n function = frame['symbol_name'] or '<unknown>'\n lineno = frame.get('line')\n offset = None\n if not lineno:\n offset = frame['instruction_addr'] - frame['symbol_addr']\n\n cframe = {\n 'in_app': in_app,\n 'abs_path': fn,\n 'filename': fn and posixpath.basename(fn) or None,\n # This can come back as `None` from the symbolizer, in which\n # case we need to fill something else in or we will fail\n # later fulfill the interface requirements which say that a\n # function needs to be provided.\n 'function': function,\n 'package': frame['object_name'],\n 'symbol_addr': '%x' % frame['symbol_addr'],\n 'instruction_addr': '%x' % frame['instruction_addr'],\n 'instruction_offset': offset,\n 'lineno': lineno,\n }\n converted_frames.append(cframe)\n longest_addr = max(longest_addr, len(cframe['symbol_addr']),\n len(cframe['instruction_addr']))\n\n # Pad out addresses to be of the same length and add prefix\n for frame in converted_frames:\n for key in 'symbol_addr', 'instruction_addr':\n frame[key] = '0x' + frame[key][2:].rjust(longest_addr, '0')\n\n stacktrace = {'frames': converted_frames}\n\n if error or diagnosis:\n error = error or {}\n exc = exception_from_apple_error_or_diagnosis(error, diagnosis)\n if exc is not None:\n exc['stacktrace'] = stacktrace\n data['sentry.interfaces.Exception'] = exc\n return\n\n data['sentry.interfaces.Stacktrace'] = stacktrace\n\n\ndef inject_apple_device_data(data, system):\n container = data.setdefault('device', {})\n try:\n container['name'] = SDK_MAPPING[system['system_name']]\n except LookupError:\n container['name'] = system.get('system_name') or 'Generic Apple'\n\n if 'system_version' in system:\n container['version'] = system['system_version']\n if 'os_version' in system:\n container['build'] = system['os_version']\n\n extra = container.setdefault('data', {})\n if 'cpu_arch' in system:\n extra['cpu_arch'] = system['cpu_arch']\n if 'model' in system:\n extra['device_model_id'] = system['model']\n if 'machine' in system:\n extra['device_model'] = system['machine']\n if 'kernel_version' in system:\n extra['kernel_version'] = system['kernel_version']\n\n\ndef preprocess_apple_crash_event(data):\n crash_report = data.get('sentry.interfaces.AppleCrashReport')\n if crash_report is None:\n return\n\n project = Project.objects.get_from_cache(\n id=data['project'],\n )\n\n crash = crash_report['crash']\n crashed_thread = None\n for thread in crash['threads']:\n if thread['crashed']:\n crashed_thread = thread\n if crashed_thread is None:\n append_error(data, {\n 'type': EventError.NATIVE_NO_CRASHED_THREAD,\n })\n\n else:\n system = crash_report.get('system')\n try:\n sym = Symbolizer(project, crash_report['binary_images'],\n threads=[crashed_thread])\n with sym:\n bt = sym.symbolize_backtrace(\n crashed_thread['backtrace']['contents'], system)\n inject_apple_backtrace(data, bt, crash.get('diagnosis'),\n crash.get('error'), system)\n except Exception as e:\n logger.exception('Failed to symbolicate')\n append_error(data, {\n 'type': EventError.NATIVE_INTERNAL_FAILURE,\n 'error': '%s: %s' % (e.__class__.__name__, str(e)),\n })\n return\n\n if system:\n inject_apple_device_data(data, system)\n\n return data\n\n\nclass NativePlugin(Plugin2):\n can_disable = False\n\n def get_event_preprocessors(self, **kwargs):\n if not have_symsynd:\n return []\n return [preprocess_apple_crash_event]\n", "path": "src/sentry/lang/native/plugin.py"}], "after_files": [{"content": "from __future__ import absolute_import, print_function\n\nimport logging\nimport posixpath\n\nfrom sentry.models import Project, EventError\nfrom sentry.plugins import Plugin2\nfrom sentry.lang.native.symbolizer import Symbolizer, have_symsynd\nfrom sentry.models.dsymfile import SDK_MAPPING\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef append_error(data, err):\n data.setdefault('errors', []).append(err)\n\n\ndef exception_from_apple_error_or_diagnosis(error, diagnosis=None):\n error = error or {}\n\n if error:\n nsexception = error.get('nsexception')\n if nsexception:\n return {\n 'type': nsexception['name'],\n 'value': error['reason'],\n }\n\n if diagnosis:\n return {\n 'type': 'Error',\n 'value': diagnosis\n }\n\n\ndef inject_apple_backtrace(data, frames, diagnosis=None, error=None,\n system=None):\n # TODO:\n # user report stacktraces from unity\n\n app_uuid = None\n if system:\n app_uuid = system.get('app_uuid')\n if app_uuid is not None:\n app_uuid = app_uuid.lower()\n\n converted_frames = []\n longest_addr = 0\n for frame in reversed(frames):\n fn = frame.get('filename')\n in_app = False\n\n if app_uuid is not None:\n frame_uuid = frame.get('uuid')\n if frame_uuid == app_uuid:\n in_app = True\n\n # We only record the offset if we found a symbol but we did not\n # find a line number. In that case it's the offset in bytes from\n # the beginning of the symbol.\n function = frame['symbol_name'] or '<unknown>'\n lineno = frame.get('line')\n offset = None\n if not lineno:\n offset = frame['instruction_addr'] - frame['symbol_addr']\n\n cframe = {\n 'in_app': in_app,\n 'abs_path': fn,\n 'filename': fn and posixpath.basename(fn) or None,\n # This can come back as `None` from the symbolizer, in which\n # case we need to fill something else in or we will fail\n # later fulfill the interface requirements which say that a\n # function needs to be provided.\n 'function': function,\n 'package': frame['object_name'],\n 'symbol_addr': '%x' % frame['symbol_addr'],\n 'instruction_addr': '%x' % frame['instruction_addr'],\n 'instruction_offset': offset,\n 'lineno': lineno,\n }\n converted_frames.append(cframe)\n longest_addr = max(longest_addr, len(cframe['symbol_addr']),\n len(cframe['instruction_addr']))\n\n # Pad out addresses to be of the same length and add prefix\n for frame in converted_frames:\n for key in 'symbol_addr', 'instruction_addr':\n frame[key] = '0x' + frame[key][2:].rjust(longest_addr, '0')\n\n stacktrace = {'frames': converted_frames}\n\n if error or diagnosis:\n error = error or {}\n exc = exception_from_apple_error_or_diagnosis(error, diagnosis)\n if exc is not None:\n exc['stacktrace'] = stacktrace\n data['sentry.interfaces.Exception'] = {'values': [exc]}\n # Since we inject the exception late we need to make sure that\n # we set the event type to error as it would be set to\n # 'default' otherwise.\n data['type'] = 'error'\n return\n\n data['sentry.interfaces.Stacktrace'] = stacktrace\n\n\ndef inject_apple_device_data(data, system):\n container = data.setdefault('device', {})\n try:\n container['name'] = SDK_MAPPING[system['system_name']]\n except LookupError:\n container['name'] = system.get('system_name') or 'Generic Apple'\n\n if 'system_version' in system:\n container['version'] = system['system_version']\n if 'os_version' in system:\n container['build'] = system['os_version']\n\n extra = container.setdefault('data', {})\n if 'cpu_arch' in system:\n extra['cpu_arch'] = system['cpu_arch']\n if 'model' in system:\n extra['device_model_id'] = system['model']\n if 'machine' in system:\n extra['device_model'] = system['machine']\n if 'kernel_version' in system:\n extra['kernel_version'] = system['kernel_version']\n\n\ndef preprocess_apple_crash_event(data):\n crash_report = data.get('sentry.interfaces.AppleCrashReport')\n if crash_report is None:\n return\n\n project = Project.objects.get_from_cache(\n id=data['project'],\n )\n\n crash = crash_report['crash']\n crashed_thread = None\n for thread in crash['threads']:\n if thread['crashed']:\n crashed_thread = thread\n if crashed_thread is None:\n append_error(data, {\n 'type': EventError.NATIVE_NO_CRASHED_THREAD,\n })\n\n else:\n system = crash_report.get('system')\n try:\n sym = Symbolizer(project, crash_report['binary_images'],\n threads=[crashed_thread])\n with sym:\n bt = sym.symbolize_backtrace(\n crashed_thread['backtrace']['contents'], system)\n inject_apple_backtrace(data, bt, crash.get('diagnosis'),\n crash.get('error'), system)\n except Exception as e:\n logger.exception('Failed to symbolicate')\n append_error(data, {\n 'type': EventError.NATIVE_INTERNAL_FAILURE,\n 'error': '%s: %s' % (e.__class__.__name__, str(e)),\n })\n return\n\n if system:\n inject_apple_device_data(data, system)\n\n return data\n\n\nclass NativePlugin(Plugin2):\n can_disable = False\n\n def get_event_preprocessors(self, **kwargs):\n if not have_symsynd:\n return []\n return [preprocess_apple_crash_event]\n", "path": "src/sentry/lang/native/plugin.py"}]}
| 1,967 | 180 |
gh_patches_debug_2205
|
rasdani/github-patches
|
git_diff
|
zigpy__zha-device-handlers-891
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Device Support Request] Lidl _TZ3000_oh7jddmx TS0502A
**Is your feature request related to a problem? Please describe.**
Very similar to #808 I have a LIDL ceiling light panel, which only supports CCT but is incorrectly reported to HA.
**Describe the solution you'd like**
Only exposing the color temperature.
**Device signature**
```
{
"node_descriptor": "NodeDescriptor(byte1=1, byte2=64, mac_capability_flags=142, manufacturer_code=4098, maximum_buffer_size=82, maximum_incoming_transfer_size=82, server_mask=11264, maximum_outgoing_transfer_size=82, descriptor_capability_field=0, *allocate_address=True, *complex_descriptor_available=False, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False, *is_valid=True, *logical_type=<LogicalType.Router: 1>, *user_descriptor_available=False)",
"endpoints": {
"1": {
"profile_id": 260,
"device_type": "0x010c",
"in_clusters": [
"0x0000",
"0x0003",
"0x0004",
"0x0005",
"0x0006",
"0x0008",
"0x0300",
"0x1000"
],
"out_clusters": [
"0x000a",
"0x0019"
]
},
"242": {
"profile_id": 41440,
"device_type": "0x0061",
"in_clusters": [],
"out_clusters": [
"0x0021"
]
}
},
"manufacturer": "_TZ3000_oh7jddmx",
"model": "TS0502A",
"class": "zigpy.device.Device"
}
```
**Additional context**
I'm assuming adding the signature into
https://github.com/zigpy/zha-device-handlers/blob/b180e4f7ab4a096688f4d4ad9b47ac1b3efa9fe2/zhaquirks/lidl/cct.py#L40-L46
will fix this. ~~I'll test it and open a PR if I find time for it.~~
Update: Successfully tested. PR opened.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zhaquirks/lidl/cct.py`
Content:
```
1 """Quirk for LIDL CCT bulb."""
2 from zigpy.profiles import zha
3 from zigpy.quirks import CustomCluster, CustomDevice
4 from zigpy.zcl.clusters.general import (
5 Basic,
6 GreenPowerProxy,
7 Groups,
8 Identify,
9 LevelControl,
10 OnOff,
11 Ota,
12 Scenes,
13 Time,
14 )
15 from zigpy.zcl.clusters.lighting import Color
16 from zigpy.zcl.clusters.lightlink import LightLink
17
18 from zhaquirks.const import (
19 DEVICE_TYPE,
20 ENDPOINTS,
21 INPUT_CLUSTERS,
22 MODELS_INFO,
23 OUTPUT_CLUSTERS,
24 PROFILE_ID,
25 )
26
27
28 class LidlCCTColorCluster(CustomCluster, Color):
29 """Lidl CCT Lighting custom cluster."""
30
31 # Remove RGB color wheel for CCT Lighting: only expose color temperature
32 # LIDL bulbs do not correctly report this attribute (comes back as None in Home Assistant)
33 _CONSTANT_ATTRIBUTES = {0x400A: 16}
34
35
36 class CCTLight(CustomDevice):
37 """Lidl CCT Lighting device."""
38
39 signature = {
40 MODELS_INFO: [
41 ("_TZ3000_49qchf10", "TS0502A"),
42 ("_TZ3000_oborybow", "TS0502A"),
43 ("_TZ3000_9evm3otq", "TS0502A"),
44 ("_TZ3000_rylaozuc", "TS0502A"),
45 ("_TZ3000_el5kt5im", "TS0502A"),
46 ],
47 ENDPOINTS: {
48 1: {
49 # <SimpleDescriptor endpoint=1 profile=260 device_type=268
50 # device_version=1
51 # input_clusters=[0, 3, 4, 5, 6, 8, 768, 4096]
52 # output_clusters=[10, 25]
53 PROFILE_ID: zha.PROFILE_ID,
54 DEVICE_TYPE: zha.DeviceType.COLOR_TEMPERATURE_LIGHT,
55 INPUT_CLUSTERS: [
56 Basic.cluster_id,
57 Identify.cluster_id,
58 Groups.cluster_id,
59 Scenes.cluster_id,
60 OnOff.cluster_id,
61 LevelControl.cluster_id,
62 Color.cluster_id,
63 LightLink.cluster_id,
64 ],
65 OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],
66 },
67 242: {
68 # <SimpleDescriptor endpoint=242 profile=41440 device_type=97
69 # device_version=0
70 # input_clusters=[]
71 # output_clusters=[33]
72 PROFILE_ID: 41440,
73 DEVICE_TYPE: 97,
74 INPUT_CLUSTERS: [],
75 OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],
76 },
77 },
78 }
79
80 replacement = {
81 ENDPOINTS: {
82 1: {
83 PROFILE_ID: zha.PROFILE_ID,
84 DEVICE_TYPE: zha.DeviceType.COLOR_TEMPERATURE_LIGHT,
85 INPUT_CLUSTERS: [
86 Basic.cluster_id,
87 Identify.cluster_id,
88 Groups.cluster_id,
89 Scenes.cluster_id,
90 OnOff.cluster_id,
91 LevelControl.cluster_id,
92 LidlCCTColorCluster,
93 LightLink.cluster_id,
94 ],
95 OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],
96 },
97 242: {
98 PROFILE_ID: 41440,
99 DEVICE_TYPE: 97,
100 INPUT_CLUSTERS: [],
101 OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],
102 },
103 }
104 }
105
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zhaquirks/lidl/cct.py b/zhaquirks/lidl/cct.py
--- a/zhaquirks/lidl/cct.py
+++ b/zhaquirks/lidl/cct.py
@@ -43,6 +43,7 @@
("_TZ3000_9evm3otq", "TS0502A"),
("_TZ3000_rylaozuc", "TS0502A"),
("_TZ3000_el5kt5im", "TS0502A"),
+ ("_TZ3000_oh7jddmx", "TS0502A"),
],
ENDPOINTS: {
1: {
|
{"golden_diff": "diff --git a/zhaquirks/lidl/cct.py b/zhaquirks/lidl/cct.py\n--- a/zhaquirks/lidl/cct.py\n+++ b/zhaquirks/lidl/cct.py\n@@ -43,6 +43,7 @@\n (\"_TZ3000_9evm3otq\", \"TS0502A\"),\n (\"_TZ3000_rylaozuc\", \"TS0502A\"),\n (\"_TZ3000_el5kt5im\", \"TS0502A\"),\n+ (\"_TZ3000_oh7jddmx\", \"TS0502A\"),\n ],\n ENDPOINTS: {\n 1: {\n", "issue": "[Device Support Request] Lidl _TZ3000_oh7jddmx TS0502A\n**Is your feature request related to a problem? Please describe.**\r\nVery similar to #808 I have a LIDL ceiling light panel, which only supports CCT but is incorrectly reported to HA.\r\n\r\n**Describe the solution you'd like**\r\nOnly exposing the color temperature.\r\n\r\n**Device signature**\r\n```\r\n{\r\n \"node_descriptor\": \"NodeDescriptor(byte1=1, byte2=64, mac_capability_flags=142, manufacturer_code=4098, maximum_buffer_size=82, maximum_incoming_transfer_size=82, server_mask=11264, maximum_outgoing_transfer_size=82, descriptor_capability_field=0, *allocate_address=True, *complex_descriptor_available=False, *is_alternate_pan_coordinator=False, *is_coordinator=False, *is_end_device=False, *is_full_function_device=True, *is_mains_powered=True, *is_receiver_on_when_idle=True, *is_router=True, *is_security_capable=False, *is_valid=True, *logical_type=<LogicalType.Router: 1>, *user_descriptor_available=False)\",\r\n \"endpoints\": {\r\n \"1\": {\r\n \"profile_id\": 260,\r\n \"device_type\": \"0x010c\",\r\n \"in_clusters\": [\r\n \"0x0000\",\r\n \"0x0003\",\r\n \"0x0004\",\r\n \"0x0005\",\r\n \"0x0006\",\r\n \"0x0008\",\r\n \"0x0300\",\r\n \"0x1000\"\r\n ],\r\n \"out_clusters\": [\r\n \"0x000a\",\r\n \"0x0019\"\r\n ]\r\n },\r\n \"242\": {\r\n \"profile_id\": 41440,\r\n \"device_type\": \"0x0061\",\r\n \"in_clusters\": [],\r\n \"out_clusters\": [\r\n \"0x0021\"\r\n ]\r\n }\r\n },\r\n \"manufacturer\": \"_TZ3000_oh7jddmx\",\r\n \"model\": \"TS0502A\",\r\n \"class\": \"zigpy.device.Device\"\r\n}\r\n```\r\n\r\n**Additional context**\r\nI'm assuming adding the signature into\r\nhttps://github.com/zigpy/zha-device-handlers/blob/b180e4f7ab4a096688f4d4ad9b47ac1b3efa9fe2/zhaquirks/lidl/cct.py#L40-L46\r\nwill fix this. ~~I'll test it and open a PR if I find time for it.~~\r\nUpdate: Successfully tested. PR opened.\n", "before_files": [{"content": "\"\"\"Quirk for LIDL CCT bulb.\"\"\"\nfrom zigpy.profiles import zha\nfrom zigpy.quirks import CustomCluster, CustomDevice\nfrom zigpy.zcl.clusters.general import (\n Basic,\n GreenPowerProxy,\n Groups,\n Identify,\n LevelControl,\n OnOff,\n Ota,\n Scenes,\n Time,\n)\nfrom zigpy.zcl.clusters.lighting import Color\nfrom zigpy.zcl.clusters.lightlink import LightLink\n\nfrom zhaquirks.const import (\n DEVICE_TYPE,\n ENDPOINTS,\n INPUT_CLUSTERS,\n MODELS_INFO,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n)\n\n\nclass LidlCCTColorCluster(CustomCluster, Color):\n \"\"\"Lidl CCT Lighting custom cluster.\"\"\"\n\n # Remove RGB color wheel for CCT Lighting: only expose color temperature\n # LIDL bulbs do not correctly report this attribute (comes back as None in Home Assistant)\n _CONSTANT_ATTRIBUTES = {0x400A: 16}\n\n\nclass CCTLight(CustomDevice):\n \"\"\"Lidl CCT Lighting device.\"\"\"\n\n signature = {\n MODELS_INFO: [\n (\"_TZ3000_49qchf10\", \"TS0502A\"),\n (\"_TZ3000_oborybow\", \"TS0502A\"),\n (\"_TZ3000_9evm3otq\", \"TS0502A\"),\n (\"_TZ3000_rylaozuc\", \"TS0502A\"),\n (\"_TZ3000_el5kt5im\", \"TS0502A\"),\n ],\n ENDPOINTS: {\n 1: {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=268\n # device_version=1\n # input_clusters=[0, 3, 4, 5, 6, 8, 768, 4096]\n # output_clusters=[10, 25]\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.COLOR_TEMPERATURE_LIGHT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n Color.cluster_id,\n LightLink.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n },\n 242: {\n # <SimpleDescriptor endpoint=242 profile=41440 device_type=97\n # device_version=0\n # input_clusters=[]\n # output_clusters=[33]\n PROFILE_ID: 41440,\n DEVICE_TYPE: 97,\n INPUT_CLUSTERS: [],\n OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n },\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.COLOR_TEMPERATURE_LIGHT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n LidlCCTColorCluster,\n LightLink.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n },\n 242: {\n PROFILE_ID: 41440,\n DEVICE_TYPE: 97,\n INPUT_CLUSTERS: [],\n OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n },\n }\n }\n", "path": "zhaquirks/lidl/cct.py"}], "after_files": [{"content": "\"\"\"Quirk for LIDL CCT bulb.\"\"\"\nfrom zigpy.profiles import zha\nfrom zigpy.quirks import CustomCluster, CustomDevice\nfrom zigpy.zcl.clusters.general import (\n Basic,\n GreenPowerProxy,\n Groups,\n Identify,\n LevelControl,\n OnOff,\n Ota,\n Scenes,\n Time,\n)\nfrom zigpy.zcl.clusters.lighting import Color\nfrom zigpy.zcl.clusters.lightlink import LightLink\n\nfrom zhaquirks.const import (\n DEVICE_TYPE,\n ENDPOINTS,\n INPUT_CLUSTERS,\n MODELS_INFO,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n)\n\n\nclass LidlCCTColorCluster(CustomCluster, Color):\n \"\"\"Lidl CCT Lighting custom cluster.\"\"\"\n\n # Remove RGB color wheel for CCT Lighting: only expose color temperature\n # LIDL bulbs do not correctly report this attribute (comes back as None in Home Assistant)\n _CONSTANT_ATTRIBUTES = {0x400A: 16}\n\n\nclass CCTLight(CustomDevice):\n \"\"\"Lidl CCT Lighting device.\"\"\"\n\n signature = {\n MODELS_INFO: [\n (\"_TZ3000_49qchf10\", \"TS0502A\"),\n (\"_TZ3000_oborybow\", \"TS0502A\"),\n (\"_TZ3000_9evm3otq\", \"TS0502A\"),\n (\"_TZ3000_rylaozuc\", \"TS0502A\"),\n (\"_TZ3000_el5kt5im\", \"TS0502A\"),\n (\"_TZ3000_oh7jddmx\", \"TS0502A\"),\n ],\n ENDPOINTS: {\n 1: {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=268\n # device_version=1\n # input_clusters=[0, 3, 4, 5, 6, 8, 768, 4096]\n # output_clusters=[10, 25]\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.COLOR_TEMPERATURE_LIGHT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n Color.cluster_id,\n LightLink.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n },\n 242: {\n # <SimpleDescriptor endpoint=242 profile=41440 device_type=97\n # device_version=0\n # input_clusters=[]\n # output_clusters=[33]\n PROFILE_ID: 41440,\n DEVICE_TYPE: 97,\n INPUT_CLUSTERS: [],\n OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n },\n },\n }\n\n replacement = {\n ENDPOINTS: {\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.COLOR_TEMPERATURE_LIGHT,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n LidlCCTColorCluster,\n LightLink.cluster_id,\n ],\n OUTPUT_CLUSTERS: [Time.cluster_id, Ota.cluster_id],\n },\n 242: {\n PROFILE_ID: 41440,\n DEVICE_TYPE: 97,\n INPUT_CLUSTERS: [],\n OUTPUT_CLUSTERS: [GreenPowerProxy.cluster_id],\n },\n }\n }\n", "path": "zhaquirks/lidl/cct.py"}]}
| 1,864 | 165 |
gh_patches_debug_40539
|
rasdani/github-patches
|
git_diff
|
apache__airflow-21551
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Allow to set statement behavior for PostgresOperator
### Body
Add the ability to pass parameters like `statement_timeout` from PostgresOperator.
https://www.postgresql.org/docs/14/runtime-config-client.html#GUC-STATEMENT-TIMEOUT
The goal is to allow to control over specific query rather than setting the parameters on the connection level.
### Committer
- [X] I acknowledge that I am a maintainer/committer of the Apache Airflow project.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `airflow/providers/postgres/example_dags/example_postgres.py`
Content:
```
1 # Licensed to the Apache Software Foundation (ASF) under one
2 # or more contributor license agreements. See the NOTICE file
3 # distributed with this work for additional information
4 # regarding copyright ownership. The ASF licenses this file
5 # to you under the Apache License, Version 2.0 (the
6 # "License"); you may not use this file except in compliance
7 # with the License. You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing,
12 # software distributed under the License is distributed on an
13 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
14 # KIND, either express or implied. See the License for the
15 # specific language governing permissions and limitations
16 # under the License.
17
18 # [START postgres_operator_howto_guide]
19 import datetime
20
21 from airflow import DAG
22 from airflow.providers.postgres.operators.postgres import PostgresOperator
23
24 # create_pet_table, populate_pet_table, get_all_pets, and get_birth_date are examples of tasks created by
25 # instantiating the Postgres Operator
26
27 with DAG(
28 dag_id="postgres_operator_dag",
29 start_date=datetime.datetime(2020, 2, 2),
30 schedule_interval="@once",
31 catchup=False,
32 ) as dag:
33 # [START postgres_operator_howto_guide_create_pet_table]
34 create_pet_table = PostgresOperator(
35 task_id="create_pet_table",
36 sql="""
37 CREATE TABLE IF NOT EXISTS pet (
38 pet_id SERIAL PRIMARY KEY,
39 name VARCHAR NOT NULL,
40 pet_type VARCHAR NOT NULL,
41 birth_date DATE NOT NULL,
42 OWNER VARCHAR NOT NULL);
43 """,
44 )
45 # [END postgres_operator_howto_guide_create_pet_table]
46 # [START postgres_operator_howto_guide_populate_pet_table]
47 populate_pet_table = PostgresOperator(
48 task_id="populate_pet_table",
49 sql="""
50 INSERT INTO pet (name, pet_type, birth_date, OWNER)
51 VALUES ( 'Max', 'Dog', '2018-07-05', 'Jane');
52 INSERT INTO pet (name, pet_type, birth_date, OWNER)
53 VALUES ( 'Susie', 'Cat', '2019-05-01', 'Phil');
54 INSERT INTO pet (name, pet_type, birth_date, OWNER)
55 VALUES ( 'Lester', 'Hamster', '2020-06-23', 'Lily');
56 INSERT INTO pet (name, pet_type, birth_date, OWNER)
57 VALUES ( 'Quincy', 'Parrot', '2013-08-11', 'Anne');
58 """,
59 )
60 # [END postgres_operator_howto_guide_populate_pet_table]
61 # [START postgres_operator_howto_guide_get_all_pets]
62 get_all_pets = PostgresOperator(task_id="get_all_pets", sql="SELECT * FROM pet;")
63 # [END postgres_operator_howto_guide_get_all_pets]
64 # [START postgres_operator_howto_guide_get_birth_date]
65 get_birth_date = PostgresOperator(
66 task_id="get_birth_date",
67 sql="""
68 SELECT * FROM pet
69 WHERE birth_date
70 BETWEEN SYMMETRIC DATE '{{ params.begin_date }}' AND DATE '{{ params.end_date }}';
71 """,
72 params={'begin_date': '2020-01-01', 'end_date': '2020-12-31'},
73 )
74 # [START postgres_operator_howto_guide_get_birth_date]
75
76 create_pet_table >> populate_pet_table >> get_all_pets >> get_birth_date
77 # [END postgres_operator_howto_guide]
78
```
Path: `airflow/providers/postgres/operators/postgres.py`
Content:
```
1 #
2 # Licensed to the Apache Software Foundation (ASF) under one
3 # or more contributor license agreements. See the NOTICE file
4 # distributed with this work for additional information
5 # regarding copyright ownership. The ASF licenses this file
6 # to you under the Apache License, Version 2.0 (the
7 # "License"); you may not use this file except in compliance
8 # with the License. You may obtain a copy of the License at
9 #
10 # http://www.apache.org/licenses/LICENSE-2.0
11 #
12 # Unless required by applicable law or agreed to in writing,
13 # software distributed under the License is distributed on an
14 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
15 # KIND, either express or implied. See the License for the
16 # specific language governing permissions and limitations
17 # under the License.
18 from typing import TYPE_CHECKING, Iterable, List, Mapping, Optional, Sequence, Union
19
20 from airflow.models import BaseOperator
21 from airflow.providers.postgres.hooks.postgres import PostgresHook
22 from airflow.www import utils as wwwutils
23
24 if TYPE_CHECKING:
25 from airflow.utils.context import Context
26
27
28 class PostgresOperator(BaseOperator):
29 """
30 Executes sql code in a specific Postgres database
31
32 :param sql: the SQL code to be executed as a single string, or
33 a list of str (sql statements), or a reference to a template file.
34 Template references are recognized by str ending in '.sql'
35 :param postgres_conn_id: The :ref:`postgres conn id <howto/connection:postgres>`
36 reference to a specific postgres database.
37 :param autocommit: if True, each command is automatically committed.
38 (default value: False)
39 :param parameters: (optional) the parameters to render the SQL query with.
40 :param database: name of database which overwrite defined one in connection
41 """
42
43 template_fields: Sequence[str] = ('sql',)
44 # TODO: Remove renderer check when the provider has an Airflow 2.3+ requirement.
45 template_fields_renderers = {
46 'sql': 'postgresql' if 'postgresql' in wwwutils.get_attr_renderer() else 'sql'
47 }
48 template_ext: Sequence[str] = ('.sql',)
49 ui_color = '#ededed'
50
51 def __init__(
52 self,
53 *,
54 sql: Union[str, List[str]],
55 postgres_conn_id: str = 'postgres_default',
56 autocommit: bool = False,
57 parameters: Optional[Union[Mapping, Iterable]] = None,
58 database: Optional[str] = None,
59 **kwargs,
60 ) -> None:
61 super().__init__(**kwargs)
62 self.sql = sql
63 self.postgres_conn_id = postgres_conn_id
64 self.autocommit = autocommit
65 self.parameters = parameters
66 self.database = database
67 self.hook: Optional[PostgresHook] = None
68
69 def execute(self, context: 'Context'):
70 self.hook = PostgresHook(postgres_conn_id=self.postgres_conn_id, schema=self.database)
71 self.hook.run(self.sql, self.autocommit, parameters=self.parameters)
72 for output in self.hook.conn.notices:
73 self.log.info(output)
74
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/airflow/providers/postgres/example_dags/example_postgres.py b/airflow/providers/postgres/example_dags/example_postgres.py
--- a/airflow/providers/postgres/example_dags/example_postgres.py
+++ b/airflow/providers/postgres/example_dags/example_postgres.py
@@ -64,14 +64,11 @@
# [START postgres_operator_howto_guide_get_birth_date]
get_birth_date = PostgresOperator(
task_id="get_birth_date",
- sql="""
- SELECT * FROM pet
- WHERE birth_date
- BETWEEN SYMMETRIC DATE '{{ params.begin_date }}' AND DATE '{{ params.end_date }}';
- """,
- params={'begin_date': '2020-01-01', 'end_date': '2020-12-31'},
+ sql="SELECT * FROM pet WHERE birth_date BETWEEN SYMMETRIC %(begin_date)s AND %(end_date)s",
+ parameters={"begin_date": "2020-01-01", "end_date": "2020-12-31"},
+ runtime_parameters={'statement_timeout': '3000ms'},
)
- # [START postgres_operator_howto_guide_get_birth_date]
+ # [END postgres_operator_howto_guide_get_birth_date]
create_pet_table >> populate_pet_table >> get_all_pets >> get_birth_date
# [END postgres_operator_howto_guide]
diff --git a/airflow/providers/postgres/operators/postgres.py b/airflow/providers/postgres/operators/postgres.py
--- a/airflow/providers/postgres/operators/postgres.py
+++ b/airflow/providers/postgres/operators/postgres.py
@@ -17,6 +17,8 @@
# under the License.
from typing import TYPE_CHECKING, Iterable, List, Mapping, Optional, Sequence, Union
+from psycopg2.sql import SQL, Identifier
+
from airflow.models import BaseOperator
from airflow.providers.postgres.hooks.postgres import PostgresHook
@@ -52,6 +54,7 @@
autocommit: bool = False,
parameters: Optional[Union[Mapping, Iterable]] = None,
database: Optional[str] = None,
+ runtime_parameters: Optional[Mapping] = None,
**kwargs,
) -> None:
super().__init__(**kwargs)
@@ -60,10 +63,28 @@
self.autocommit = autocommit
self.parameters = parameters
self.database = database
+ self.runtime_parameters = runtime_parameters
self.hook: Optional[PostgresHook] = None
def execute(self, context: 'Context'):
self.hook = PostgresHook(postgres_conn_id=self.postgres_conn_id, schema=self.database)
- self.hook.run(self.sql, self.autocommit, parameters=self.parameters)
+ if self.runtime_parameters:
+ final_sql = []
+ sql_param = {}
+ for param in self.runtime_parameters:
+ set_param_sql = f"SET {{}} TO %({param})s;"
+ dynamic_sql = SQL(set_param_sql).format(Identifier(f"{param}"))
+ final_sql.append(dynamic_sql)
+ for param, val in self.runtime_parameters.items():
+ sql_param.update({f"{param}": f"{val}"})
+ if self.parameters:
+ sql_param.update(self.parameters)
+ if isinstance(self.sql, str):
+ final_sql.append(SQL(self.sql))
+ else:
+ final_sql.extend(list(map(SQL, self.sql)))
+ self.hook.run(final_sql, self.autocommit, parameters=sql_param)
+ else:
+ self.hook.run(self.sql, self.autocommit, parameters=self.parameters)
for output in self.hook.conn.notices:
self.log.info(output)
|
{"golden_diff": "diff --git a/airflow/providers/postgres/example_dags/example_postgres.py b/airflow/providers/postgres/example_dags/example_postgres.py\n--- a/airflow/providers/postgres/example_dags/example_postgres.py\n+++ b/airflow/providers/postgres/example_dags/example_postgres.py\n@@ -64,14 +64,11 @@\n # [START postgres_operator_howto_guide_get_birth_date]\n get_birth_date = PostgresOperator(\n task_id=\"get_birth_date\",\n- sql=\"\"\"\n- SELECT * FROM pet\n- WHERE birth_date\n- BETWEEN SYMMETRIC DATE '{{ params.begin_date }}' AND DATE '{{ params.end_date }}';\n- \"\"\",\n- params={'begin_date': '2020-01-01', 'end_date': '2020-12-31'},\n+ sql=\"SELECT * FROM pet WHERE birth_date BETWEEN SYMMETRIC %(begin_date)s AND %(end_date)s\",\n+ parameters={\"begin_date\": \"2020-01-01\", \"end_date\": \"2020-12-31\"},\n+ runtime_parameters={'statement_timeout': '3000ms'},\n )\n- # [START postgres_operator_howto_guide_get_birth_date]\n+ # [END postgres_operator_howto_guide_get_birth_date]\n \n create_pet_table >> populate_pet_table >> get_all_pets >> get_birth_date\n # [END postgres_operator_howto_guide]\ndiff --git a/airflow/providers/postgres/operators/postgres.py b/airflow/providers/postgres/operators/postgres.py\n--- a/airflow/providers/postgres/operators/postgres.py\n+++ b/airflow/providers/postgres/operators/postgres.py\n@@ -17,6 +17,8 @@\n # under the License.\n from typing import TYPE_CHECKING, Iterable, List, Mapping, Optional, Sequence, Union\n \n+from psycopg2.sql import SQL, Identifier\n+\n from airflow.models import BaseOperator\n from airflow.providers.postgres.hooks.postgres import PostgresHook\n \n@@ -52,6 +54,7 @@\n autocommit: bool = False,\n parameters: Optional[Union[Mapping, Iterable]] = None,\n database: Optional[str] = None,\n+ runtime_parameters: Optional[Mapping] = None,\n **kwargs,\n ) -> None:\n super().__init__(**kwargs)\n@@ -60,10 +63,28 @@\n self.autocommit = autocommit\n self.parameters = parameters\n self.database = database\n+ self.runtime_parameters = runtime_parameters\n self.hook: Optional[PostgresHook] = None\n \n def execute(self, context: 'Context'):\n self.hook = PostgresHook(postgres_conn_id=self.postgres_conn_id, schema=self.database)\n- self.hook.run(self.sql, self.autocommit, parameters=self.parameters)\n+ if self.runtime_parameters:\n+ final_sql = []\n+ sql_param = {}\n+ for param in self.runtime_parameters:\n+ set_param_sql = f\"SET {{}} TO %({param})s;\"\n+ dynamic_sql = SQL(set_param_sql).format(Identifier(f\"{param}\"))\n+ final_sql.append(dynamic_sql)\n+ for param, val in self.runtime_parameters.items():\n+ sql_param.update({f\"{param}\": f\"{val}\"})\n+ if self.parameters:\n+ sql_param.update(self.parameters)\n+ if isinstance(self.sql, str):\n+ final_sql.append(SQL(self.sql))\n+ else:\n+ final_sql.extend(list(map(SQL, self.sql)))\n+ self.hook.run(final_sql, self.autocommit, parameters=sql_param)\n+ else:\n+ self.hook.run(self.sql, self.autocommit, parameters=self.parameters)\n for output in self.hook.conn.notices:\n self.log.info(output)\n", "issue": "Allow to set statement behavior for PostgresOperator\n### Body\n\nAdd the ability to pass parameters like `statement_timeout` from PostgresOperator.\r\nhttps://www.postgresql.org/docs/14/runtime-config-client.html#GUC-STATEMENT-TIMEOUT\r\n\r\nThe goal is to allow to control over specific query rather than setting the parameters on the connection level.\n\n### Committer\n\n- [X] I acknowledge that I am a maintainer/committer of the Apache Airflow project.\n", "before_files": [{"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\n# [START postgres_operator_howto_guide]\nimport datetime\n\nfrom airflow import DAG\nfrom airflow.providers.postgres.operators.postgres import PostgresOperator\n\n# create_pet_table, populate_pet_table, get_all_pets, and get_birth_date are examples of tasks created by\n# instantiating the Postgres Operator\n\nwith DAG(\n dag_id=\"postgres_operator_dag\",\n start_date=datetime.datetime(2020, 2, 2),\n schedule_interval=\"@once\",\n catchup=False,\n) as dag:\n # [START postgres_operator_howto_guide_create_pet_table]\n create_pet_table = PostgresOperator(\n task_id=\"create_pet_table\",\n sql=\"\"\"\n CREATE TABLE IF NOT EXISTS pet (\n pet_id SERIAL PRIMARY KEY,\n name VARCHAR NOT NULL,\n pet_type VARCHAR NOT NULL,\n birth_date DATE NOT NULL,\n OWNER VARCHAR NOT NULL);\n \"\"\",\n )\n # [END postgres_operator_howto_guide_create_pet_table]\n # [START postgres_operator_howto_guide_populate_pet_table]\n populate_pet_table = PostgresOperator(\n task_id=\"populate_pet_table\",\n sql=\"\"\"\n INSERT INTO pet (name, pet_type, birth_date, OWNER)\n VALUES ( 'Max', 'Dog', '2018-07-05', 'Jane');\n INSERT INTO pet (name, pet_type, birth_date, OWNER)\n VALUES ( 'Susie', 'Cat', '2019-05-01', 'Phil');\n INSERT INTO pet (name, pet_type, birth_date, OWNER)\n VALUES ( 'Lester', 'Hamster', '2020-06-23', 'Lily');\n INSERT INTO pet (name, pet_type, birth_date, OWNER)\n VALUES ( 'Quincy', 'Parrot', '2013-08-11', 'Anne');\n \"\"\",\n )\n # [END postgres_operator_howto_guide_populate_pet_table]\n # [START postgres_operator_howto_guide_get_all_pets]\n get_all_pets = PostgresOperator(task_id=\"get_all_pets\", sql=\"SELECT * FROM pet;\")\n # [END postgres_operator_howto_guide_get_all_pets]\n # [START postgres_operator_howto_guide_get_birth_date]\n get_birth_date = PostgresOperator(\n task_id=\"get_birth_date\",\n sql=\"\"\"\n SELECT * FROM pet\n WHERE birth_date\n BETWEEN SYMMETRIC DATE '{{ params.begin_date }}' AND DATE '{{ params.end_date }}';\n \"\"\",\n params={'begin_date': '2020-01-01', 'end_date': '2020-12-31'},\n )\n # [START postgres_operator_howto_guide_get_birth_date]\n\n create_pet_table >> populate_pet_table >> get_all_pets >> get_birth_date\n # [END postgres_operator_howto_guide]\n", "path": "airflow/providers/postgres/example_dags/example_postgres.py"}, {"content": "#\n# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\nfrom typing import TYPE_CHECKING, Iterable, List, Mapping, Optional, Sequence, Union\n\nfrom airflow.models import BaseOperator\nfrom airflow.providers.postgres.hooks.postgres import PostgresHook\nfrom airflow.www import utils as wwwutils\n\nif TYPE_CHECKING:\n from airflow.utils.context import Context\n\n\nclass PostgresOperator(BaseOperator):\n \"\"\"\n Executes sql code in a specific Postgres database\n\n :param sql: the SQL code to be executed as a single string, or\n a list of str (sql statements), or a reference to a template file.\n Template references are recognized by str ending in '.sql'\n :param postgres_conn_id: The :ref:`postgres conn id <howto/connection:postgres>`\n reference to a specific postgres database.\n :param autocommit: if True, each command is automatically committed.\n (default value: False)\n :param parameters: (optional) the parameters to render the SQL query with.\n :param database: name of database which overwrite defined one in connection\n \"\"\"\n\n template_fields: Sequence[str] = ('sql',)\n # TODO: Remove renderer check when the provider has an Airflow 2.3+ requirement.\n template_fields_renderers = {\n 'sql': 'postgresql' if 'postgresql' in wwwutils.get_attr_renderer() else 'sql'\n }\n template_ext: Sequence[str] = ('.sql',)\n ui_color = '#ededed'\n\n def __init__(\n self,\n *,\n sql: Union[str, List[str]],\n postgres_conn_id: str = 'postgres_default',\n autocommit: bool = False,\n parameters: Optional[Union[Mapping, Iterable]] = None,\n database: Optional[str] = None,\n **kwargs,\n ) -> None:\n super().__init__(**kwargs)\n self.sql = sql\n self.postgres_conn_id = postgres_conn_id\n self.autocommit = autocommit\n self.parameters = parameters\n self.database = database\n self.hook: Optional[PostgresHook] = None\n\n def execute(self, context: 'Context'):\n self.hook = PostgresHook(postgres_conn_id=self.postgres_conn_id, schema=self.database)\n self.hook.run(self.sql, self.autocommit, parameters=self.parameters)\n for output in self.hook.conn.notices:\n self.log.info(output)\n", "path": "airflow/providers/postgres/operators/postgres.py"}], "after_files": [{"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\n# [START postgres_operator_howto_guide]\nimport datetime\n\nfrom airflow import DAG\nfrom airflow.providers.postgres.operators.postgres import PostgresOperator\n\n# create_pet_table, populate_pet_table, get_all_pets, and get_birth_date are examples of tasks created by\n# instantiating the Postgres Operator\n\nwith DAG(\n dag_id=\"postgres_operator_dag\",\n start_date=datetime.datetime(2020, 2, 2),\n schedule_interval=\"@once\",\n catchup=False,\n) as dag:\n # [START postgres_operator_howto_guide_create_pet_table]\n create_pet_table = PostgresOperator(\n task_id=\"create_pet_table\",\n sql=\"\"\"\n CREATE TABLE IF NOT EXISTS pet (\n pet_id SERIAL PRIMARY KEY,\n name VARCHAR NOT NULL,\n pet_type VARCHAR NOT NULL,\n birth_date DATE NOT NULL,\n OWNER VARCHAR NOT NULL);\n \"\"\",\n )\n # [END postgres_operator_howto_guide_create_pet_table]\n # [START postgres_operator_howto_guide_populate_pet_table]\n populate_pet_table = PostgresOperator(\n task_id=\"populate_pet_table\",\n sql=\"\"\"\n INSERT INTO pet (name, pet_type, birth_date, OWNER)\n VALUES ( 'Max', 'Dog', '2018-07-05', 'Jane');\n INSERT INTO pet (name, pet_type, birth_date, OWNER)\n VALUES ( 'Susie', 'Cat', '2019-05-01', 'Phil');\n INSERT INTO pet (name, pet_type, birth_date, OWNER)\n VALUES ( 'Lester', 'Hamster', '2020-06-23', 'Lily');\n INSERT INTO pet (name, pet_type, birth_date, OWNER)\n VALUES ( 'Quincy', 'Parrot', '2013-08-11', 'Anne');\n \"\"\",\n )\n # [END postgres_operator_howto_guide_populate_pet_table]\n # [START postgres_operator_howto_guide_get_all_pets]\n get_all_pets = PostgresOperator(task_id=\"get_all_pets\", sql=\"SELECT * FROM pet;\")\n # [END postgres_operator_howto_guide_get_all_pets]\n # [START postgres_operator_howto_guide_get_birth_date]\n get_birth_date = PostgresOperator(\n task_id=\"get_birth_date\",\n sql=\"SELECT * FROM pet WHERE birth_date BETWEEN SYMMETRIC %(begin_date)s AND %(end_date)s\",\n parameters={\"begin_date\": \"2020-01-01\", \"end_date\": \"2020-12-31\"},\n runtime_parameters={'statement_timeout': '3000ms'},\n )\n # [END postgres_operator_howto_guide_get_birth_date]\n\n create_pet_table >> populate_pet_table >> get_all_pets >> get_birth_date\n # [END postgres_operator_howto_guide]\n", "path": "airflow/providers/postgres/example_dags/example_postgres.py"}, {"content": "#\n# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\nfrom typing import TYPE_CHECKING, Iterable, List, Mapping, Optional, Sequence, Union\n\nfrom psycopg2.sql import SQL, Identifier\n\nfrom airflow.models import BaseOperator\nfrom airflow.providers.postgres.hooks.postgres import PostgresHook\n\nif TYPE_CHECKING:\n from airflow.utils.context import Context\n\n\nclass PostgresOperator(BaseOperator):\n \"\"\"\n Executes sql code in a specific Postgres database\n\n :param sql: the SQL code to be executed as a single string, or\n a list of str (sql statements), or a reference to a template file.\n Template references are recognized by str ending in '.sql'\n :param postgres_conn_id: The :ref:`postgres conn id <howto/connection:postgres>`\n reference to a specific postgres database.\n :param autocommit: if True, each command is automatically committed.\n (default value: False)\n :param parameters: (optional) the parameters to render the SQL query with.\n :param database: name of database which overwrite defined one in connection\n \"\"\"\n\n template_fields: Sequence[str] = ('sql',)\n template_fields_renderers = {'sql': 'sql'}\n template_ext: Sequence[str] = ('.sql',)\n ui_color = '#ededed'\n\n def __init__(\n self,\n *,\n sql: Union[str, List[str]],\n postgres_conn_id: str = 'postgres_default',\n autocommit: bool = False,\n parameters: Optional[Union[Mapping, Iterable]] = None,\n database: Optional[str] = None,\n runtime_parameters: Optional[Mapping] = None,\n **kwargs,\n ) -> None:\n super().__init__(**kwargs)\n self.sql = sql\n self.postgres_conn_id = postgres_conn_id\n self.autocommit = autocommit\n self.parameters = parameters\n self.database = database\n self.runtime_parameters = runtime_parameters\n self.hook: Optional[PostgresHook] = None\n\n def execute(self, context: 'Context'):\n self.hook = PostgresHook(postgres_conn_id=self.postgres_conn_id, schema=self.database)\n if self.runtime_parameters:\n final_sql = []\n sql_param = {}\n for param in self.runtime_parameters:\n set_param_sql = f\"SET {{}} TO %({param})s;\"\n dynamic_sql = SQL(set_param_sql).format(Identifier(f\"{param}\"))\n final_sql.append(dynamic_sql)\n for param, val in self.runtime_parameters.items():\n sql_param.update({f\"{param}\": f\"{val}\"})\n if self.parameters:\n sql_param.update(self.parameters)\n if isinstance(self.sql, str):\n final_sql.append(SQL(self.sql))\n else:\n final_sql.extend(list(map(SQL, self.sql)))\n self.hook.run(final_sql, self.autocommit, parameters=sql_param)\n else:\n self.hook.run(self.sql, self.autocommit, parameters=self.parameters)\n for output in self.hook.conn.notices:\n self.log.info(output)\n", "path": "airflow/providers/postgres/operators/postgres.py"}]}
| 2,153 | 834 |
gh_patches_debug_31834
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__pytorch-lightning-881
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix segmentation example
# Before submitting
- [x] Was this discussed/approved via a Github issue? (no need for typos, doc improvements)
- [x] Did you read the [contributor guideline](https://github.com/PyTorchLightning/pytorch-lightning/blob/master/.github/CONTRIBUTING.md)?
- [x] Did you make sure to update the docs?
- [ ] Did you write any new necessary tests?
## What does this PR do?
Fixes #874 (issue).
## PR review
Anyone in the community is free to review the PR once the tests have passed.
## Some comments
I have added a custom model (UNet) instead of the previous torchvision segmentation model as it was causing tests to fail (mostly because those torchvision models were introduced in version 0.3 and it will fail for previous versions).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pl_examples/full_examples/semantic_segmentation/models/unet/model.py`
Content:
```
1 import torch
2 import torch.nn as nn
3 import torch.nn.functional as F
4
5 from parts import DoubleConv, Down, Up
6
7
8 class UNet(nn.Module):
9 '''
10 Architecture based on U-Net: Convolutional Networks for Biomedical Image Segmentation
11 Link - https://arxiv.org/abs/1505.04597
12 '''
13 def __init__(self, num_classes=19, bilinear=False):
14 super().__init__()
15 self.bilinear = bilinear
16 self.num_classes = num_classes
17 self.layer1 = DoubleConv(3, 64)
18 self.layer2 = Down(64, 128)
19 self.layer3 = Down(128, 256)
20 self.layer4 = Down(256, 512)
21 self.layer5 = Down(512, 1024)
22
23 self.layer6 = Up(1024, 512, bilinear=self.bilinear)
24 self.layer7 = Up(512, 256, bilinear=self.bilinear)
25 self.layer8 = Up(256, 128, bilinear=self.bilinear)
26 self.layer9 = Up(128, 64, bilinear=self.bilinear)
27
28 self.layer10 = nn.Conv2d(64, self.num_classes, kernel_size=1)
29
30 def forward(self, x):
31 x1 = self.layer1(x)
32 x2 = self.layer2(x1)
33 x3 = self.layer3(x2)
34 x4 = self.layer4(x3)
35 x5 = self.layer5(x4)
36
37 x6 = self.layer6(x5, x4)
38 x6 = self.layer7(x6, x3)
39 x6 = self.layer8(x6, x2)
40 x6 = self.layer9(x6, x1)
41
42 return self.layer10(x6)
43
```
Path: `pl_examples/full_examples/semantic_segmentation/models/unet/__init__.py`
Content:
```
1 # For relative imports to work in Python 3.6
2 import os
3 import sys
4 sys.path.append(os.path.dirname(os.path.realpath(__file__)))
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pl_examples/full_examples/semantic_segmentation/models/unet/__init__.py b/pl_examples/full_examples/semantic_segmentation/models/unet/__init__.py
deleted file mode 100644
--- a/pl_examples/full_examples/semantic_segmentation/models/unet/__init__.py
+++ /dev/null
@@ -1,4 +0,0 @@
-# For relative imports to work in Python 3.6
-import os
-import sys
-sys.path.append(os.path.dirname(os.path.realpath(__file__)))
diff --git a/pl_examples/full_examples/semantic_segmentation/models/unet/model.py b/pl_examples/full_examples/semantic_segmentation/models/unet/model.py
--- a/pl_examples/full_examples/semantic_segmentation/models/unet/model.py
+++ b/pl_examples/full_examples/semantic_segmentation/models/unet/model.py
@@ -2,30 +2,33 @@
import torch.nn as nn
import torch.nn.functional as F
-from parts import DoubleConv, Down, Up
+from models.unet.parts import DoubleConv, Down, Up
class UNet(nn.Module):
'''
Architecture based on U-Net: Convolutional Networks for Biomedical Image Segmentation
Link - https://arxiv.org/abs/1505.04597
+
+ Parameters:
+ num_classes (int) - Number of output classes required (default 19 for KITTI dataset)
+ bilinear (bool) - Whether to use bilinear interpolation or transposed
+ convolutions for upsampling.
'''
def __init__(self, num_classes=19, bilinear=False):
super().__init__()
- self.bilinear = bilinear
- self.num_classes = num_classes
self.layer1 = DoubleConv(3, 64)
self.layer2 = Down(64, 128)
self.layer3 = Down(128, 256)
self.layer4 = Down(256, 512)
self.layer5 = Down(512, 1024)
- self.layer6 = Up(1024, 512, bilinear=self.bilinear)
- self.layer7 = Up(512, 256, bilinear=self.bilinear)
- self.layer8 = Up(256, 128, bilinear=self.bilinear)
- self.layer9 = Up(128, 64, bilinear=self.bilinear)
+ self.layer6 = Up(1024, 512, bilinear=bilinear)
+ self.layer7 = Up(512, 256, bilinear=bilinear)
+ self.layer8 = Up(256, 128, bilinear=bilinear)
+ self.layer9 = Up(128, 64, bilinear=bilinear)
- self.layer10 = nn.Conv2d(64, self.num_classes, kernel_size=1)
+ self.layer10 = nn.Conv2d(64, num_classes, kernel_size=1)
def forward(self, x):
x1 = self.layer1(x)
|
{"golden_diff": "diff --git a/pl_examples/full_examples/semantic_segmentation/models/unet/__init__.py b/pl_examples/full_examples/semantic_segmentation/models/unet/__init__.py\ndeleted file mode 100644\n--- a/pl_examples/full_examples/semantic_segmentation/models/unet/__init__.py\n+++ /dev/null\n@@ -1,4 +0,0 @@\n-# For relative imports to work in Python 3.6\n-import os\n-import sys\n-sys.path.append(os.path.dirname(os.path.realpath(__file__)))\ndiff --git a/pl_examples/full_examples/semantic_segmentation/models/unet/model.py b/pl_examples/full_examples/semantic_segmentation/models/unet/model.py\n--- a/pl_examples/full_examples/semantic_segmentation/models/unet/model.py\n+++ b/pl_examples/full_examples/semantic_segmentation/models/unet/model.py\n@@ -2,30 +2,33 @@\n import torch.nn as nn\n import torch.nn.functional as F\n \n-from parts import DoubleConv, Down, Up\n+from models.unet.parts import DoubleConv, Down, Up\n \n \n class UNet(nn.Module):\n '''\n Architecture based on U-Net: Convolutional Networks for Biomedical Image Segmentation\n Link - https://arxiv.org/abs/1505.04597\n+\n+ Parameters:\n+ num_classes (int) - Number of output classes required (default 19 for KITTI dataset)\n+ bilinear (bool) - Whether to use bilinear interpolation or transposed\n+ convolutions for upsampling.\n '''\n def __init__(self, num_classes=19, bilinear=False):\n super().__init__()\n- self.bilinear = bilinear\n- self.num_classes = num_classes\n self.layer1 = DoubleConv(3, 64)\n self.layer2 = Down(64, 128)\n self.layer3 = Down(128, 256)\n self.layer4 = Down(256, 512)\n self.layer5 = Down(512, 1024)\n \n- self.layer6 = Up(1024, 512, bilinear=self.bilinear)\n- self.layer7 = Up(512, 256, bilinear=self.bilinear)\n- self.layer8 = Up(256, 128, bilinear=self.bilinear)\n- self.layer9 = Up(128, 64, bilinear=self.bilinear)\n+ self.layer6 = Up(1024, 512, bilinear=bilinear)\n+ self.layer7 = Up(512, 256, bilinear=bilinear)\n+ self.layer8 = Up(256, 128, bilinear=bilinear)\n+ self.layer9 = Up(128, 64, bilinear=bilinear)\n \n- self.layer10 = nn.Conv2d(64, self.num_classes, kernel_size=1)\n+ self.layer10 = nn.Conv2d(64, num_classes, kernel_size=1)\n \n def forward(self, x):\n x1 = self.layer1(x)\n", "issue": "Fix segmentation example\n# Before submitting\r\n\r\n- [x] Was this discussed/approved via a Github issue? (no need for typos, doc improvements)\r\n- [x] Did you read the [contributor guideline](https://github.com/PyTorchLightning/pytorch-lightning/blob/master/.github/CONTRIBUTING.md)?\r\n- [x] Did you make sure to update the docs? \r\n- [ ] Did you write any new necessary tests? \r\n\r\n## What does this PR do?\r\nFixes #874 (issue).\r\n\r\n## PR review \r\nAnyone in the community is free to review the PR once the tests have passed. \r\n\r\n## Some comments\r\nI have added a custom model (UNet) instead of the previous torchvision segmentation model as it was causing tests to fail (mostly because those torchvision models were introduced in version 0.3 and it will fail for previous versions).\n", "before_files": [{"content": "import torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nfrom parts import DoubleConv, Down, Up\n\n\nclass UNet(nn.Module):\n '''\n Architecture based on U-Net: Convolutional Networks for Biomedical Image Segmentation\n Link - https://arxiv.org/abs/1505.04597\n '''\n def __init__(self, num_classes=19, bilinear=False):\n super().__init__()\n self.bilinear = bilinear\n self.num_classes = num_classes\n self.layer1 = DoubleConv(3, 64)\n self.layer2 = Down(64, 128)\n self.layer3 = Down(128, 256)\n self.layer4 = Down(256, 512)\n self.layer5 = Down(512, 1024)\n\n self.layer6 = Up(1024, 512, bilinear=self.bilinear)\n self.layer7 = Up(512, 256, bilinear=self.bilinear)\n self.layer8 = Up(256, 128, bilinear=self.bilinear)\n self.layer9 = Up(128, 64, bilinear=self.bilinear)\n\n self.layer10 = nn.Conv2d(64, self.num_classes, kernel_size=1)\n\n def forward(self, x):\n x1 = self.layer1(x)\n x2 = self.layer2(x1)\n x3 = self.layer3(x2)\n x4 = self.layer4(x3)\n x5 = self.layer5(x4)\n\n x6 = self.layer6(x5, x4)\n x6 = self.layer7(x6, x3)\n x6 = self.layer8(x6, x2)\n x6 = self.layer9(x6, x1)\n\n return self.layer10(x6)\n", "path": "pl_examples/full_examples/semantic_segmentation/models/unet/model.py"}, {"content": "# For relative imports to work in Python 3.6\nimport os\nimport sys\nsys.path.append(os.path.dirname(os.path.realpath(__file__)))\n", "path": "pl_examples/full_examples/semantic_segmentation/models/unet/__init__.py"}], "after_files": [{"content": "import torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nfrom models.unet.parts import DoubleConv, Down, Up\n\n\nclass UNet(nn.Module):\n '''\n Architecture based on U-Net: Convolutional Networks for Biomedical Image Segmentation\n Link - https://arxiv.org/abs/1505.04597\n\n Parameters:\n num_classes (int) - Number of output classes required (default 19 for KITTI dataset)\n bilinear (bool) - Whether to use bilinear interpolation or transposed\n convolutions for upsampling.\n '''\n def __init__(self, num_classes=19, bilinear=False):\n super().__init__()\n self.layer1 = DoubleConv(3, 64)\n self.layer2 = Down(64, 128)\n self.layer3 = Down(128, 256)\n self.layer4 = Down(256, 512)\n self.layer5 = Down(512, 1024)\n\n self.layer6 = Up(1024, 512, bilinear=bilinear)\n self.layer7 = Up(512, 256, bilinear=bilinear)\n self.layer8 = Up(256, 128, bilinear=bilinear)\n self.layer9 = Up(128, 64, bilinear=bilinear)\n\n self.layer10 = nn.Conv2d(64, num_classes, kernel_size=1)\n\n def forward(self, x):\n x1 = self.layer1(x)\n x2 = self.layer2(x1)\n x3 = self.layer3(x2)\n x4 = self.layer4(x3)\n x5 = self.layer5(x4)\n\n x6 = self.layer6(x5, x4)\n x6 = self.layer7(x6, x3)\n x6 = self.layer8(x6, x2)\n x6 = self.layer9(x6, x1)\n\n return self.layer10(x6)\n", "path": "pl_examples/full_examples/semantic_segmentation/models/unet/model.py"}, {"content": null, "path": "pl_examples/full_examples/semantic_segmentation/models/unet/__init__.py"}]}
| 1,022 | 698 |
gh_patches_debug_40076
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-287
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Match core API in contrib TBPTT trainer
I propose the following change so that tbptt trainer behaves like the supervised trainer:
- [ ] Replace `convert_tensor` by `prepare_batch` ([line](https://github.com/pytorch/ignite/blob/d3d7b146d56efb5b497f3cf4b22caab976774e7e/ignite/contrib/engines/tbptt.py#L29))
- [ ] Call `prepare_batch` on time chunks (the quantity used to compute gradients) rather that whole time series mini bactch
- [ ] Add `prepare_batch` function in the arguments
- [ ] Add `non_blocking` in the arguments
Match core API in contrib TBPTT trainer
I propose the following change so that tbptt trainer behaves like the supervised trainer:
- [ ] Replace `convert_tensor` by `prepare_batch` ([line](https://github.com/pytorch/ignite/blob/d3d7b146d56efb5b497f3cf4b22caab976774e7e/ignite/contrib/engines/tbptt.py#L29))
- [ ] Call `prepare_batch` on time chunks (the quantity used to compute gradients) rather that whole time series mini bactch
- [ ] Add `prepare_batch` function in the arguments
- [ ] Add `non_blocking` in the arguments
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ignite/engine/__init__.py`
Content:
```
1 import torch
2
3 from ignite.engine.engine import Engine, State, Events
4 from ignite._utils import convert_tensor
5
6
7 def _prepare_batch(batch, device=None, non_blocking=False):
8 x, y = batch
9 return (convert_tensor(x, device=device, non_blocking=non_blocking),
10 convert_tensor(y, device=device, non_blocking=non_blocking))
11
12
13 def create_supervised_trainer(model, optimizer, loss_fn,
14 device=None, non_blocking=False,
15 prepare_batch=_prepare_batch):
16 """
17 Factory function for creating a trainer for supervised models
18
19 Args:
20 model (`torch.nn.Module`): the model to train
21 optimizer (`torch.optim.Optimizer`): the optimizer to use
22 loss_fn (torch.nn loss function): the loss function to use
23 device (str, optional): device type specification (default: None).
24 Applies to both model and batches.
25 non_blocking (bool, optional): if True and this copy is between CPU and GPU, the copy may occur asynchronously
26 with respect to the host. For other cases, this argument has no effect.
27 prepare_batch (Callable, optional): function that receives `batch`, `device`, `non_blocking` and outputs
28 tuple of tensors `(batch_x, batch_y)`.
29
30 Returns:
31 Engine: a trainer engine with supervised update function
32 """
33 if device:
34 model.to(device)
35
36 def _update(engine, batch):
37 model.train()
38 optimizer.zero_grad()
39 x, y = prepare_batch(batch, device=device, non_blocking=non_blocking)
40 y_pred = model(x)
41 loss = loss_fn(y_pred, y)
42 loss.backward()
43 optimizer.step()
44 return loss.item()
45
46 return Engine(_update)
47
48
49 def create_supervised_evaluator(model, metrics={},
50 device=None, non_blocking=False,
51 prepare_batch=_prepare_batch):
52 """
53 Factory function for creating an evaluator for supervised models
54
55 Args:
56 model (`torch.nn.Module`): the model to train
57 metrics (dict of str - :class:`ignite.metrics.Metric`): a map of metric names to Metrics
58 device (str, optional): device type specification (default: None).
59 Applies to both model and batches.
60 non_blocking (bool, optional): if True and this copy is between CPU and GPU, the copy may occur asynchronously
61 with respect to the host. For other cases, this argument has no effect.
62 prepare_batch (Callable, optional): function that receives `batch`, `device`, `non_blocking` and outputs
63 tuple of tensors `(batch_x, batch_y)`.
64
65 Returns:
66 Engine: an evaluator engine with supervised inference function
67 """
68 if device:
69 model.to(device)
70
71 def _inference(engine, batch):
72 model.eval()
73 with torch.no_grad():
74 x, y = prepare_batch(batch, device=device, non_blocking=non_blocking)
75 y_pred = model(x)
76 return y_pred, y
77
78 engine = Engine(_inference)
79
80 for name, metric in metrics.items():
81 metric.attach(engine, name)
82
83 return engine
84
```
Path: `ignite/contrib/engines/tbptt.py`
Content:
```
1 # coding: utf-8
2
3 from enum import Enum
4
5 import torch
6
7 from ignite._utils import convert_tensor, apply_to_tensor
8 from ignite.engine import Engine
9
10
11 class Tbptt_Events(Enum):
12 """Aditional tbptt events.
13
14 Additional events for truncated backpropagation throught time dedicated
15 trainer.
16 """
17
18 TIME_ITERATION_STARTED = "time_iteration_started"
19 TIME_ITERATION_COMPLETED = "time_iteration_completed"
20
21
22 def _prepare_tbptt_batch(batch, tbptt_step, dim=0, device=None):
23 """Prepare batch for tbptt trainer.
24
25 Batch come from the dataloader. It is split in chunks along the time
26 dimension and fed to the truncated backpropagation throught time trainer.
27 """
28 x, y = batch
29 x = convert_tensor(x, device=device)
30 y = convert_tensor(y, device=device)
31 return zip(x.split(tbptt_step, dim=dim), y.split(tbptt_step, dim=dim))
32
33
34 def _detach_hidden(hidden):
35 """Cut backpropagation graph.
36
37 Auxillary function to cut the backpropagation graph by detaching the hidden
38 vector.
39 """
40 return apply_to_tensor(hidden, torch.Tensor.detach)
41
42
43 def create_supervised_tbptt_trainer(
44 model,
45 optimizer,
46 loss_fn,
47 tbtt_step,
48 dim=0,
49 device=None
50 ):
51 """Create a trainer for truncated backprop through time supervised models.
52
53 Training recurrent model on long sequences is computationally intensive as
54 it requires to process the whole sequence before getting a gradient.
55 However, when the training loss is computed over many outputs
56 (`X to many <https://karpathy.github.io/2015/05/21/rnn-effectiveness/>`_),
57 there is an opportunity to compute a gradient over a subsequence. This is
58 known as
59 `truncated backpropagation through time <https://machinelearningmastery.com/
60 gentle-introduction-backpropagation-time/>`_.
61 This supervised trainer apply gradient optimization step every `tbtt_step`
62 time steps of the sequence, while backpropagating through the same
63 `tbtt_step` time steps.
64
65 Args:
66 model (`torch.nn.Module`): the model to train
67 optimizer (`torch.optim.Optimizer`): the optimizer to use
68 loss_fn (torch.nn loss function): the loss function to use
69 tbtt_step (int): the length of time chunks (last one may be smaller)
70 dim (int): axis representing the time dimension
71 device (str, optional): device type specification (default: None).
72 Applies to both model and batches.
73
74 Returns:
75 Engine: a trainer engine with supervised update function
76
77 """
78 if device:
79 model.to(device)
80
81 def _update(engine, batch):
82 loss_list = []
83 hidden = None
84
85 # Batches split in time chunks
86 batch_splits = _prepare_tbptt_batch(
87 batch, tbtt_step, dim=dim, device=device
88 )
89 for x_t, y_t in batch_splits:
90 # Fire event for start of iteration
91 engine.fire_event(Tbptt_Events.TIME_ITERATION_STARTED)
92 # Forward, backward and
93 model.train()
94 optimizer.zero_grad()
95 if hidden is None:
96 y_pred_t, hidden = model(x_t)
97 else:
98 hidden = _detach_hidden(hidden)
99 y_pred_t, hidden = model(x_t, hidden)
100 loss_t = loss_fn(y_pred_t, y_t)
101 loss_t.backward()
102 optimizer.step()
103
104 # Setting state of engine for consistent behaviour
105 engine.state.output = loss_t.item()
106 loss_list.append(loss_t.item())
107
108 # Fire event for end of iteration
109 engine.fire_event(Tbptt_Events.TIME_ITERATION_COMPLETED)
110
111 # return average loss over the time splits
112 return sum(loss_list) / len(loss_list)
113
114 engine = Engine(_update)
115 engine.register_events(*Tbptt_Events)
116 return engine
117
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ignite/contrib/engines/tbptt.py b/ignite/contrib/engines/tbptt.py
--- a/ignite/contrib/engines/tbptt.py
+++ b/ignite/contrib/engines/tbptt.py
@@ -4,8 +4,8 @@
import torch
-from ignite._utils import convert_tensor, apply_to_tensor
-from ignite.engine import Engine
+from ignite._utils import apply_to_tensor
+from ignite.engine import Engine, _prepare_batch
class Tbptt_Events(Enum):
@@ -19,18 +19,6 @@
TIME_ITERATION_COMPLETED = "time_iteration_completed"
-def _prepare_tbptt_batch(batch, tbptt_step, dim=0, device=None):
- """Prepare batch for tbptt trainer.
-
- Batch come from the dataloader. It is split in chunks along the time
- dimension and fed to the truncated backpropagation throught time trainer.
- """
- x, y = batch
- x = convert_tensor(x, device=device)
- y = convert_tensor(y, device=device)
- return zip(x.split(tbptt_step, dim=dim), y.split(tbptt_step, dim=dim))
-
-
def _detach_hidden(hidden):
"""Cut backpropagation graph.
@@ -46,7 +34,9 @@
loss_fn,
tbtt_step,
dim=0,
- device=None
+ device=None,
+ non_blocking=False,
+ prepare_batch=_prepare_batch
):
"""Create a trainer for truncated backprop through time supervised models.
@@ -70,6 +60,11 @@
dim (int): axis representing the time dimension
device (str, optional): device type specification (default: None).
Applies to both model and batches.
+ non_blocking (bool, optional): if True and this copy is between CPU and GPU,
+ the copy may occur asynchronously with respect to the host. For other cases,
+ this argument has no effect.
+ prepare_batch (Callable, optional): function that receives `batch`, `device`,
+ `non_blocking` and outputs tuple of tensors `(batch_x, batch_y)`.
Returns:
Engine: a trainer engine with supervised update function
@@ -82,11 +77,9 @@
loss_list = []
hidden = None
- # Batches split in time chunks
- batch_splits = _prepare_tbptt_batch(
- batch, tbtt_step, dim=dim, device=device
- )
- for x_t, y_t in batch_splits:
+ x, y = batch
+ for batch_t in zip(x.split(tbtt_step, dim=dim), y.split(tbtt_step, dim=dim)):
+ x_t, y_t = prepare_batch(batch_t, device=device, non_blocking=non_blocking)
# Fire event for start of iteration
engine.fire_event(Tbptt_Events.TIME_ITERATION_STARTED)
# Forward, backward and
diff --git a/ignite/engine/__init__.py b/ignite/engine/__init__.py
--- a/ignite/engine/__init__.py
+++ b/ignite/engine/__init__.py
@@ -5,6 +5,9 @@
def _prepare_batch(batch, device=None, non_blocking=False):
+ """Prepare batch for training: pass to a device with options
+
+ """
x, y = batch
return (convert_tensor(x, device=device, non_blocking=non_blocking),
convert_tensor(y, device=device, non_blocking=non_blocking))
|
{"golden_diff": "diff --git a/ignite/contrib/engines/tbptt.py b/ignite/contrib/engines/tbptt.py\n--- a/ignite/contrib/engines/tbptt.py\n+++ b/ignite/contrib/engines/tbptt.py\n@@ -4,8 +4,8 @@\n \n import torch\n \n-from ignite._utils import convert_tensor, apply_to_tensor\n-from ignite.engine import Engine\n+from ignite._utils import apply_to_tensor\n+from ignite.engine import Engine, _prepare_batch\n \n \n class Tbptt_Events(Enum):\n@@ -19,18 +19,6 @@\n TIME_ITERATION_COMPLETED = \"time_iteration_completed\"\n \n \n-def _prepare_tbptt_batch(batch, tbptt_step, dim=0, device=None):\n- \"\"\"Prepare batch for tbptt trainer.\n-\n- Batch come from the dataloader. It is split in chunks along the time\n- dimension and fed to the truncated backpropagation throught time trainer.\n- \"\"\"\n- x, y = batch\n- x = convert_tensor(x, device=device)\n- y = convert_tensor(y, device=device)\n- return zip(x.split(tbptt_step, dim=dim), y.split(tbptt_step, dim=dim))\n-\n-\n def _detach_hidden(hidden):\n \"\"\"Cut backpropagation graph.\n \n@@ -46,7 +34,9 @@\n loss_fn,\n tbtt_step,\n dim=0,\n- device=None\n+ device=None,\n+ non_blocking=False,\n+ prepare_batch=_prepare_batch\n ):\n \"\"\"Create a trainer for truncated backprop through time supervised models.\n \n@@ -70,6 +60,11 @@\n dim (int): axis representing the time dimension\n device (str, optional): device type specification (default: None).\n Applies to both model and batches.\n+ non_blocking (bool, optional): if True and this copy is between CPU and GPU,\n+ the copy may occur asynchronously with respect to the host. For other cases,\n+ this argument has no effect.\n+ prepare_batch (Callable, optional): function that receives `batch`, `device`,\n+ `non_blocking` and outputs tuple of tensors `(batch_x, batch_y)`.\n \n Returns:\n Engine: a trainer engine with supervised update function\n@@ -82,11 +77,9 @@\n loss_list = []\n hidden = None\n \n- # Batches split in time chunks\n- batch_splits = _prepare_tbptt_batch(\n- batch, tbtt_step, dim=dim, device=device\n- )\n- for x_t, y_t in batch_splits:\n+ x, y = batch\n+ for batch_t in zip(x.split(tbtt_step, dim=dim), y.split(tbtt_step, dim=dim)):\n+ x_t, y_t = prepare_batch(batch_t, device=device, non_blocking=non_blocking)\n # Fire event for start of iteration\n engine.fire_event(Tbptt_Events.TIME_ITERATION_STARTED)\n # Forward, backward and\ndiff --git a/ignite/engine/__init__.py b/ignite/engine/__init__.py\n--- a/ignite/engine/__init__.py\n+++ b/ignite/engine/__init__.py\n@@ -5,6 +5,9 @@\n \n \n def _prepare_batch(batch, device=None, non_blocking=False):\n+ \"\"\"Prepare batch for training: pass to a device with options\n+\n+ \"\"\"\n x, y = batch\n return (convert_tensor(x, device=device, non_blocking=non_blocking),\n convert_tensor(y, device=device, non_blocking=non_blocking))\n", "issue": "Match core API in contrib TBPTT trainer\nI propose the following change so that tbptt trainer behaves like the supervised trainer:\r\n\r\n- [ ] Replace `convert_tensor` by `prepare_batch` ([line](https://github.com/pytorch/ignite/blob/d3d7b146d56efb5b497f3cf4b22caab976774e7e/ignite/contrib/engines/tbptt.py#L29))\r\n- [ ] Call `prepare_batch` on time chunks (the quantity used to compute gradients) rather that whole time series mini bactch\r\n- [ ] Add `prepare_batch` function in the arguments\r\n- [ ] Add `non_blocking` in the arguments\nMatch core API in contrib TBPTT trainer\nI propose the following change so that tbptt trainer behaves like the supervised trainer:\r\n\r\n- [ ] Replace `convert_tensor` by `prepare_batch` ([line](https://github.com/pytorch/ignite/blob/d3d7b146d56efb5b497f3cf4b22caab976774e7e/ignite/contrib/engines/tbptt.py#L29))\r\n- [ ] Call `prepare_batch` on time chunks (the quantity used to compute gradients) rather that whole time series mini bactch\r\n- [ ] Add `prepare_batch` function in the arguments\r\n- [ ] Add `non_blocking` in the arguments\n", "before_files": [{"content": "import torch\n\nfrom ignite.engine.engine import Engine, State, Events\nfrom ignite._utils import convert_tensor\n\n\ndef _prepare_batch(batch, device=None, non_blocking=False):\n x, y = batch\n return (convert_tensor(x, device=device, non_blocking=non_blocking),\n convert_tensor(y, device=device, non_blocking=non_blocking))\n\n\ndef create_supervised_trainer(model, optimizer, loss_fn,\n device=None, non_blocking=False,\n prepare_batch=_prepare_batch):\n \"\"\"\n Factory function for creating a trainer for supervised models\n\n Args:\n model (`torch.nn.Module`): the model to train\n optimizer (`torch.optim.Optimizer`): the optimizer to use\n loss_fn (torch.nn loss function): the loss function to use\n device (str, optional): device type specification (default: None).\n Applies to both model and batches.\n non_blocking (bool, optional): if True and this copy is between CPU and GPU, the copy may occur asynchronously\n with respect to the host. For other cases, this argument has no effect.\n prepare_batch (Callable, optional): function that receives `batch`, `device`, `non_blocking` and outputs\n tuple of tensors `(batch_x, batch_y)`.\n\n Returns:\n Engine: a trainer engine with supervised update function\n \"\"\"\n if device:\n model.to(device)\n\n def _update(engine, batch):\n model.train()\n optimizer.zero_grad()\n x, y = prepare_batch(batch, device=device, non_blocking=non_blocking)\n y_pred = model(x)\n loss = loss_fn(y_pred, y)\n loss.backward()\n optimizer.step()\n return loss.item()\n\n return Engine(_update)\n\n\ndef create_supervised_evaluator(model, metrics={},\n device=None, non_blocking=False,\n prepare_batch=_prepare_batch):\n \"\"\"\n Factory function for creating an evaluator for supervised models\n\n Args:\n model (`torch.nn.Module`): the model to train\n metrics (dict of str - :class:`ignite.metrics.Metric`): a map of metric names to Metrics\n device (str, optional): device type specification (default: None).\n Applies to both model and batches.\n non_blocking (bool, optional): if True and this copy is between CPU and GPU, the copy may occur asynchronously\n with respect to the host. For other cases, this argument has no effect.\n prepare_batch (Callable, optional): function that receives `batch`, `device`, `non_blocking` and outputs\n tuple of tensors `(batch_x, batch_y)`.\n\n Returns:\n Engine: an evaluator engine with supervised inference function\n \"\"\"\n if device:\n model.to(device)\n\n def _inference(engine, batch):\n model.eval()\n with torch.no_grad():\n x, y = prepare_batch(batch, device=device, non_blocking=non_blocking)\n y_pred = model(x)\n return y_pred, y\n\n engine = Engine(_inference)\n\n for name, metric in metrics.items():\n metric.attach(engine, name)\n\n return engine\n", "path": "ignite/engine/__init__.py"}, {"content": "# coding: utf-8\n\nfrom enum import Enum\n\nimport torch\n\nfrom ignite._utils import convert_tensor, apply_to_tensor\nfrom ignite.engine import Engine\n\n\nclass Tbptt_Events(Enum):\n \"\"\"Aditional tbptt events.\n\n Additional events for truncated backpropagation throught time dedicated\n trainer.\n \"\"\"\n\n TIME_ITERATION_STARTED = \"time_iteration_started\"\n TIME_ITERATION_COMPLETED = \"time_iteration_completed\"\n\n\ndef _prepare_tbptt_batch(batch, tbptt_step, dim=0, device=None):\n \"\"\"Prepare batch for tbptt trainer.\n\n Batch come from the dataloader. It is split in chunks along the time\n dimension and fed to the truncated backpropagation throught time trainer.\n \"\"\"\n x, y = batch\n x = convert_tensor(x, device=device)\n y = convert_tensor(y, device=device)\n return zip(x.split(tbptt_step, dim=dim), y.split(tbptt_step, dim=dim))\n\n\ndef _detach_hidden(hidden):\n \"\"\"Cut backpropagation graph.\n\n Auxillary function to cut the backpropagation graph by detaching the hidden\n vector.\n \"\"\"\n return apply_to_tensor(hidden, torch.Tensor.detach)\n\n\ndef create_supervised_tbptt_trainer(\n model,\n optimizer,\n loss_fn,\n tbtt_step,\n dim=0,\n device=None\n):\n \"\"\"Create a trainer for truncated backprop through time supervised models.\n\n Training recurrent model on long sequences is computationally intensive as\n it requires to process the whole sequence before getting a gradient.\n However, when the training loss is computed over many outputs\n (`X to many <https://karpathy.github.io/2015/05/21/rnn-effectiveness/>`_),\n there is an opportunity to compute a gradient over a subsequence. This is\n known as\n `truncated backpropagation through time <https://machinelearningmastery.com/\n gentle-introduction-backpropagation-time/>`_.\n This supervised trainer apply gradient optimization step every `tbtt_step`\n time steps of the sequence, while backpropagating through the same\n `tbtt_step` time steps.\n\n Args:\n model (`torch.nn.Module`): the model to train\n optimizer (`torch.optim.Optimizer`): the optimizer to use\n loss_fn (torch.nn loss function): the loss function to use\n tbtt_step (int): the length of time chunks (last one may be smaller)\n dim (int): axis representing the time dimension\n device (str, optional): device type specification (default: None).\n Applies to both model and batches.\n\n Returns:\n Engine: a trainer engine with supervised update function\n\n \"\"\"\n if device:\n model.to(device)\n\n def _update(engine, batch):\n loss_list = []\n hidden = None\n\n # Batches split in time chunks\n batch_splits = _prepare_tbptt_batch(\n batch, tbtt_step, dim=dim, device=device\n )\n for x_t, y_t in batch_splits:\n # Fire event for start of iteration\n engine.fire_event(Tbptt_Events.TIME_ITERATION_STARTED)\n # Forward, backward and\n model.train()\n optimizer.zero_grad()\n if hidden is None:\n y_pred_t, hidden = model(x_t)\n else:\n hidden = _detach_hidden(hidden)\n y_pred_t, hidden = model(x_t, hidden)\n loss_t = loss_fn(y_pred_t, y_t)\n loss_t.backward()\n optimizer.step()\n\n # Setting state of engine for consistent behaviour\n engine.state.output = loss_t.item()\n loss_list.append(loss_t.item())\n\n # Fire event for end of iteration\n engine.fire_event(Tbptt_Events.TIME_ITERATION_COMPLETED)\n\n # return average loss over the time splits\n return sum(loss_list) / len(loss_list)\n\n engine = Engine(_update)\n engine.register_events(*Tbptt_Events)\n return engine\n", "path": "ignite/contrib/engines/tbptt.py"}], "after_files": [{"content": "import torch\n\nfrom ignite.engine.engine import Engine, State, Events\nfrom ignite._utils import convert_tensor\n\n\ndef _prepare_batch(batch, device=None, non_blocking=False):\n \"\"\"Prepare batch for training: pass to a device with options\n\n \"\"\"\n x, y = batch\n return (convert_tensor(x, device=device, non_blocking=non_blocking),\n convert_tensor(y, device=device, non_blocking=non_blocking))\n\n\ndef create_supervised_trainer(model, optimizer, loss_fn,\n device=None, non_blocking=False,\n prepare_batch=_prepare_batch):\n \"\"\"\n Factory function for creating a trainer for supervised models\n\n Args:\n model (`torch.nn.Module`): the model to train\n optimizer (`torch.optim.Optimizer`): the optimizer to use\n loss_fn (torch.nn loss function): the loss function to use\n device (str, optional): device type specification (default: None).\n Applies to both model and batches.\n non_blocking (bool, optional): if True and this copy is between CPU and GPU, the copy may occur asynchronously\n with respect to the host. For other cases, this argument has no effect.\n prepare_batch (Callable, optional): function that receives `batch`, `device`, `non_blocking` and outputs\n tuple of tensors `(batch_x, batch_y)`.\n\n Returns:\n Engine: a trainer engine with supervised update function\n \"\"\"\n if device:\n model.to(device)\n\n def _update(engine, batch):\n model.train()\n optimizer.zero_grad()\n x, y = prepare_batch(batch, device=device, non_blocking=non_blocking)\n y_pred = model(x)\n loss = loss_fn(y_pred, y)\n loss.backward()\n optimizer.step()\n return loss.item()\n\n return Engine(_update)\n\n\ndef create_supervised_evaluator(model, metrics={},\n device=None, non_blocking=False,\n prepare_batch=_prepare_batch):\n \"\"\"\n Factory function for creating an evaluator for supervised models\n\n Args:\n model (`torch.nn.Module`): the model to train\n metrics (dict of str - :class:`ignite.metrics.Metric`): a map of metric names to Metrics\n device (str, optional): device type specification (default: None).\n Applies to both model and batches.\n non_blocking (bool, optional): if True and this copy is between CPU and GPU, the copy may occur asynchronously\n with respect to the host. For other cases, this argument has no effect.\n prepare_batch (Callable, optional): function that receives `batch`, `device`, `non_blocking` and outputs\n tuple of tensors `(batch_x, batch_y)`.\n\n Returns:\n Engine: an evaluator engine with supervised inference function\n \"\"\"\n if device:\n model.to(device)\n\n def _inference(engine, batch):\n model.eval()\n with torch.no_grad():\n x, y = prepare_batch(batch, device=device, non_blocking=non_blocking)\n y_pred = model(x)\n return y_pred, y\n\n engine = Engine(_inference)\n\n for name, metric in metrics.items():\n metric.attach(engine, name)\n\n return engine\n", "path": "ignite/engine/__init__.py"}, {"content": "# coding: utf-8\n\nfrom enum import Enum\n\nimport torch\n\nfrom ignite._utils import apply_to_tensor\nfrom ignite.engine import Engine, _prepare_batch\n\n\nclass Tbptt_Events(Enum):\n \"\"\"Aditional tbptt events.\n\n Additional events for truncated backpropagation throught time dedicated\n trainer.\n \"\"\"\n\n TIME_ITERATION_STARTED = \"time_iteration_started\"\n TIME_ITERATION_COMPLETED = \"time_iteration_completed\"\n\n\ndef _detach_hidden(hidden):\n \"\"\"Cut backpropagation graph.\n\n Auxillary function to cut the backpropagation graph by detaching the hidden\n vector.\n \"\"\"\n return apply_to_tensor(hidden, torch.Tensor.detach)\n\n\ndef create_supervised_tbptt_trainer(\n model,\n optimizer,\n loss_fn,\n tbtt_step,\n dim=0,\n device=None,\n non_blocking=False,\n prepare_batch=_prepare_batch\n):\n \"\"\"Create a trainer for truncated backprop through time supervised models.\n\n Training recurrent model on long sequences is computationally intensive as\n it requires to process the whole sequence before getting a gradient.\n However, when the training loss is computed over many outputs\n (`X to many <https://karpathy.github.io/2015/05/21/rnn-effectiveness/>`_),\n there is an opportunity to compute a gradient over a subsequence. This is\n known as\n `truncated backpropagation through time <https://machinelearningmastery.com/\n gentle-introduction-backpropagation-time/>`_.\n This supervised trainer apply gradient optimization step every `tbtt_step`\n time steps of the sequence, while backpropagating through the same\n `tbtt_step` time steps.\n\n Args:\n model (`torch.nn.Module`): the model to train\n optimizer (`torch.optim.Optimizer`): the optimizer to use\n loss_fn (torch.nn loss function): the loss function to use\n tbtt_step (int): the length of time chunks (last one may be smaller)\n dim (int): axis representing the time dimension\n device (str, optional): device type specification (default: None).\n Applies to both model and batches.\n non_blocking (bool, optional): if True and this copy is between CPU and GPU,\n the copy may occur asynchronously with respect to the host. For other cases,\n this argument has no effect.\n prepare_batch (Callable, optional): function that receives `batch`, `device`,\n `non_blocking` and outputs tuple of tensors `(batch_x, batch_y)`.\n\n Returns:\n Engine: a trainer engine with supervised update function\n\n \"\"\"\n if device:\n model.to(device)\n\n def _update(engine, batch):\n loss_list = []\n hidden = None\n\n x, y = batch\n for batch_t in zip(x.split(tbtt_step, dim=dim), y.split(tbtt_step, dim=dim)):\n x_t, y_t = prepare_batch(batch_t, device=device, non_blocking=non_blocking)\n # Fire event for start of iteration\n engine.fire_event(Tbptt_Events.TIME_ITERATION_STARTED)\n # Forward, backward and\n model.train()\n optimizer.zero_grad()\n if hidden is None:\n y_pred_t, hidden = model(x_t)\n else:\n hidden = _detach_hidden(hidden)\n y_pred_t, hidden = model(x_t, hidden)\n loss_t = loss_fn(y_pred_t, y_t)\n loss_t.backward()\n optimizer.step()\n\n # Setting state of engine for consistent behaviour\n engine.state.output = loss_t.item()\n loss_list.append(loss_t.item())\n\n # Fire event for end of iteration\n engine.fire_event(Tbptt_Events.TIME_ITERATION_COMPLETED)\n\n # return average loss over the time splits\n return sum(loss_list) / len(loss_list)\n\n engine = Engine(_update)\n engine.register_events(*Tbptt_Events)\n return engine\n", "path": "ignite/contrib/engines/tbptt.py"}]}
| 2,537 | 784 |
gh_patches_debug_42133
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-4036
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ItemLoaders can break if instantiated with pre-populated items
Before I start, I know item loaders have been a big source of discussion for a long time; I'm only opening this issue because the latest release breaks some of our spiders.
In one of our projects, our [Autounit](https://github.com/scrapinghub/scrapy-autounit) tests fail under 1.7.1 due to some item loaders which are created from partially populated items. I suspect the relevant change is #3819 (which BTW I think inadvertently closes #3046).
Personally I think a better approach here would be something _closer_ to the solution proposed in #3149, although not exactly the same.
Consider the following:
```python
In [1]: import scrapy
In [2]: scrapy.__version__
Out[2]: '1.6.0'
In [3]: from scrapy.loader import ItemLoader
...: lo = ItemLoader(item={'key': 'value'})
...: lo.add_value('key', 'other value')
...: print(lo.load_item())
{'key': ['other value']}
```
```python
In [1]: import scrapy
In [2]: scrapy.__version__
Out[2]: '1.7.1'
In [3]: from scrapy.loader import ItemLoader
...: lo = ItemLoader(item={'key': 'value'})
...: lo.add_value('key', 'other value')
...: print(lo.load_item())
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-3-6aa64a41edb1> in <module>
1 from scrapy.loader import ItemLoader
2 lo = ItemLoader(item={'key': 'value'})
----> 3 lo.add_value('key', 'other value')
4 print(lo.load_item())
~/venv-temporal/lib/python3.6/site-packages/scrapy/loader/__init__.py in add_value(self, field_name, value, *processors, **kw)
77 self._add_value(k, v)
78 else:
---> 79 self._add_value(field_name, value)
80
81 def replace_value(self, field_name, value, *processors, **kw):
~/venv-temporal/lib/python3.6/site-packages/scrapy/loader/__init__.py in _add_value(self, field_name, value)
93 processed_value = self._process_input_value(field_name, value)
94 if processed_value:
---> 95 self._values[field_name] += arg_to_iter(processed_value)
96
97 def _replace_value(self, field_name, value):
TypeError: must be str, not list
```
I'm not directly opening a PR because I think this needs discussion. What if we changed
```python
for field_name, value in item.items():
self._values[field_name] = self._process_input_value(field_name, value)
```
to
```python
for field_name, value in item.items():
self._add_value(field_name, value)
```
which calls `arg_to_iter` internally?
With that change, the following happens which is more reasonable IMHO:
```python
In [3]: from scrapy.loader import ItemLoader
...: lo = ItemLoader(item={'key': 'value'})
...: lo.add_value('key', 'other value')
...: print(lo.load_item())
{'key': ['value', 'other value']}
```
Looking forward to reading your thoughts on the matter
/cc @Gallaecio @kmike @andrewbaxter @fcanobrash @sortafreel
`ItemLoader` fields initialized from `item` are reprocessed
### Description
#3804 introduced a bug where `ItemLoader` fields are reprocessed.
Related #3897.
### Steps to Reproduce
```python
from pprint import pprint
from scrapy import Field, Item
from scrapy.loader import ItemLoader
from scrapy.loader.processors import TakeFirst
class X(Item):
x = Field(output_processor=TakeFirst())
loader = ItemLoader(X())
loader.add_value("x", ["value1", "value2"])
x = loader.load_item()
pprint(x)
# {'x': 'value1'}
pprint(ItemLoader(x).load_item())
# {'x': 'v'}
```
**Expected behavior:** `ItemLoader` initialized from the `x` item does not reprocess its fields and loads `{'x': 'value1'}`.
**Actual behavior:** `ItemLoader` initialized from the `x` item reprocesses its fields and loads `{'x': 'v'}`.
### Versions
```
Scrapy : 1.7.3
lxml : 4.4.1.0
libxml2 : 2.9.9
cssselect : 1.1.0
parsel : 1.5.2
w3lib : 1.21.0
Twisted : 19.7.0
Python : 3.6.5 (default, May 3 2018, 10:08:28) - [GCC 5.4.0 20160609]
pyOpenSSL : 19.0.0 (OpenSSL 1.1.1c 28 May 2019)
cryptography : 2.7
Platform : Linux-4.4.0-127-generic-x86_64-with-LinuxMint-18.1-serena
```
### Additional context
Here's the behavior of the previous version:
```
Scrapy : 1.6.0
lxml : 4.4.0.0
libxml2 : 2.9.9
cssselect : 1.0.3
parsel : 1.5.1
w3lib : 1.20.0
Twisted : 19.7.0
Python : 3.6.5 (default, May 3 2018, 10:08:28) - [GCC 5.4.0 20160609]
pyOpenSSL : 19.0.0 (OpenSSL 1.1.1c 28 May 2019)
cryptography : 2.7
Platform : Linux-4.4.0-127-generic-x86_64-with-LinuxMint-18.1-serena
```
```python
# {'x': 'value1'}
# {'x': 'value1'}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scrapy/loader/__init__.py`
Content:
```
1 """Item Loader
2
3 See documentation in docs/topics/loaders.rst
4
5 """
6 from collections import defaultdict
7 import six
8
9 from scrapy.item import Item
10 from scrapy.selector import Selector
11 from scrapy.utils.misc import arg_to_iter, extract_regex
12 from scrapy.utils.python import flatten
13
14 from .common import wrap_loader_context
15 from .processors import Identity
16
17
18 class ItemLoader(object):
19
20 default_item_class = Item
21 default_input_processor = Identity()
22 default_output_processor = Identity()
23 default_selector_class = Selector
24
25 def __init__(self, item=None, selector=None, response=None, parent=None, **context):
26 if selector is None and response is not None:
27 selector = self.default_selector_class(response)
28 self.selector = selector
29 context.update(selector=selector, response=response)
30 if item is None:
31 item = self.default_item_class()
32 self.context = context
33 self.parent = parent
34 self._local_item = context['item'] = item
35 self._local_values = defaultdict(list)
36 # Preprocess values if item built from dict
37 # Values need to be added to item._values if added them from dict (not with add_values)
38 for field_name, value in item.items():
39 self._values[field_name] = self._process_input_value(field_name, value)
40
41 @property
42 def _values(self):
43 if self.parent is not None:
44 return self.parent._values
45 else:
46 return self._local_values
47
48 @property
49 def item(self):
50 if self.parent is not None:
51 return self.parent.item
52 else:
53 return self._local_item
54
55 def nested_xpath(self, xpath, **context):
56 selector = self.selector.xpath(xpath)
57 context.update(selector=selector)
58 subloader = self.__class__(
59 item=self.item, parent=self, **context
60 )
61 return subloader
62
63 def nested_css(self, css, **context):
64 selector = self.selector.css(css)
65 context.update(selector=selector)
66 subloader = self.__class__(
67 item=self.item, parent=self, **context
68 )
69 return subloader
70
71 def add_value(self, field_name, value, *processors, **kw):
72 value = self.get_value(value, *processors, **kw)
73 if value is None:
74 return
75 if not field_name:
76 for k, v in six.iteritems(value):
77 self._add_value(k, v)
78 else:
79 self._add_value(field_name, value)
80
81 def replace_value(self, field_name, value, *processors, **kw):
82 value = self.get_value(value, *processors, **kw)
83 if value is None:
84 return
85 if not field_name:
86 for k, v in six.iteritems(value):
87 self._replace_value(k, v)
88 else:
89 self._replace_value(field_name, value)
90
91 def _add_value(self, field_name, value):
92 value = arg_to_iter(value)
93 processed_value = self._process_input_value(field_name, value)
94 if processed_value:
95 self._values[field_name] += arg_to_iter(processed_value)
96
97 def _replace_value(self, field_name, value):
98 self._values.pop(field_name, None)
99 self._add_value(field_name, value)
100
101 def get_value(self, value, *processors, **kw):
102 regex = kw.get('re', None)
103 if regex:
104 value = arg_to_iter(value)
105 value = flatten(extract_regex(regex, x) for x in value)
106
107 for proc in processors:
108 if value is None:
109 break
110 _proc = proc
111 proc = wrap_loader_context(proc, self.context)
112 try:
113 value = proc(value)
114 except Exception as e:
115 raise ValueError("Error with processor %s value=%r error='%s: %s'" %
116 (_proc.__class__.__name__, value,
117 type(e).__name__, str(e)))
118 return value
119
120 def load_item(self):
121 item = self.item
122 for field_name in tuple(self._values):
123 value = self.get_output_value(field_name)
124 if value is not None:
125 item[field_name] = value
126
127 return item
128
129 def get_output_value(self, field_name):
130 proc = self.get_output_processor(field_name)
131 proc = wrap_loader_context(proc, self.context)
132 try:
133 return proc(self._values[field_name])
134 except Exception as e:
135 raise ValueError("Error with output processor: field=%r value=%r error='%s: %s'" % \
136 (field_name, self._values[field_name], type(e).__name__, str(e)))
137
138 def get_collected_values(self, field_name):
139 return self._values[field_name]
140
141 def get_input_processor(self, field_name):
142 proc = getattr(self, '%s_in' % field_name, None)
143 if not proc:
144 proc = self._get_item_field_attr(field_name, 'input_processor', \
145 self.default_input_processor)
146 return proc
147
148 def get_output_processor(self, field_name):
149 proc = getattr(self, '%s_out' % field_name, None)
150 if not proc:
151 proc = self._get_item_field_attr(field_name, 'output_processor', \
152 self.default_output_processor)
153 return proc
154
155 def _process_input_value(self, field_name, value):
156 proc = self.get_input_processor(field_name)
157 _proc = proc
158 proc = wrap_loader_context(proc, self.context)
159 try:
160 return proc(value)
161 except Exception as e:
162 raise ValueError(
163 "Error with input processor %s: field=%r value=%r "
164 "error='%s: %s'" % (_proc.__class__.__name__, field_name,
165 value, type(e).__name__, str(e)))
166
167 def _get_item_field_attr(self, field_name, key, default=None):
168 if isinstance(self.item, Item):
169 value = self.item.fields[field_name].get(key, default)
170 else:
171 value = default
172 return value
173
174 def _check_selector_method(self):
175 if self.selector is None:
176 raise RuntimeError("To use XPath or CSS selectors, "
177 "%s must be instantiated with a selector "
178 "or a response" % self.__class__.__name__)
179
180 def add_xpath(self, field_name, xpath, *processors, **kw):
181 values = self._get_xpathvalues(xpath, **kw)
182 self.add_value(field_name, values, *processors, **kw)
183
184 def replace_xpath(self, field_name, xpath, *processors, **kw):
185 values = self._get_xpathvalues(xpath, **kw)
186 self.replace_value(field_name, values, *processors, **kw)
187
188 def get_xpath(self, xpath, *processors, **kw):
189 values = self._get_xpathvalues(xpath, **kw)
190 return self.get_value(values, *processors, **kw)
191
192 def _get_xpathvalues(self, xpaths, **kw):
193 self._check_selector_method()
194 xpaths = arg_to_iter(xpaths)
195 return flatten(self.selector.xpath(xpath).getall() for xpath in xpaths)
196
197 def add_css(self, field_name, css, *processors, **kw):
198 values = self._get_cssvalues(css, **kw)
199 self.add_value(field_name, values, *processors, **kw)
200
201 def replace_css(self, field_name, css, *processors, **kw):
202 values = self._get_cssvalues(css, **kw)
203 self.replace_value(field_name, values, *processors, **kw)
204
205 def get_css(self, css, *processors, **kw):
206 values = self._get_cssvalues(css, **kw)
207 return self.get_value(values, *processors, **kw)
208
209 def _get_cssvalues(self, csss, **kw):
210 self._check_selector_method()
211 csss = arg_to_iter(csss)
212 return flatten(self.selector.css(css).getall() for css in csss)
213
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/scrapy/loader/__init__.py b/scrapy/loader/__init__.py
--- a/scrapy/loader/__init__.py
+++ b/scrapy/loader/__init__.py
@@ -1,19 +1,19 @@
-"""Item Loader
+"""
+Item Loader
See documentation in docs/topics/loaders.rst
-
"""
from collections import defaultdict
+
import six
from scrapy.item import Item
+from scrapy.loader.common import wrap_loader_context
+from scrapy.loader.processors import Identity
from scrapy.selector import Selector
from scrapy.utils.misc import arg_to_iter, extract_regex
from scrapy.utils.python import flatten
-from .common import wrap_loader_context
-from .processors import Identity
-
class ItemLoader(object):
@@ -33,10 +33,9 @@
self.parent = parent
self._local_item = context['item'] = item
self._local_values = defaultdict(list)
- # Preprocess values if item built from dict
- # Values need to be added to item._values if added them from dict (not with add_values)
+ # values from initial item
for field_name, value in item.items():
- self._values[field_name] = self._process_input_value(field_name, value)
+ self._values[field_name] += arg_to_iter(value)
@property
def _values(self):
@@ -132,8 +131,8 @@
try:
return proc(self._values[field_name])
except Exception as e:
- raise ValueError("Error with output processor: field=%r value=%r error='%s: %s'" % \
- (field_name, self._values[field_name], type(e).__name__, str(e)))
+ raise ValueError("Error with output processor: field=%r value=%r error='%s: %s'" %
+ (field_name, self._values[field_name], type(e).__name__, str(e)))
def get_collected_values(self, field_name):
return self._values[field_name]
@@ -141,15 +140,15 @@
def get_input_processor(self, field_name):
proc = getattr(self, '%s_in' % field_name, None)
if not proc:
- proc = self._get_item_field_attr(field_name, 'input_processor', \
- self.default_input_processor)
+ proc = self._get_item_field_attr(field_name, 'input_processor',
+ self.default_input_processor)
return proc
def get_output_processor(self, field_name):
proc = getattr(self, '%s_out' % field_name, None)
if not proc:
- proc = self._get_item_field_attr(field_name, 'output_processor', \
- self.default_output_processor)
+ proc = self._get_item_field_attr(field_name, 'output_processor',
+ self.default_output_processor)
return proc
def _process_input_value(self, field_name, value):
@@ -174,8 +173,8 @@
def _check_selector_method(self):
if self.selector is None:
raise RuntimeError("To use XPath or CSS selectors, "
- "%s must be instantiated with a selector "
- "or a response" % self.__class__.__name__)
+ "%s must be instantiated with a selector "
+ "or a response" % self.__class__.__name__)
def add_xpath(self, field_name, xpath, *processors, **kw):
values = self._get_xpathvalues(xpath, **kw)
|
{"golden_diff": "diff --git a/scrapy/loader/__init__.py b/scrapy/loader/__init__.py\n--- a/scrapy/loader/__init__.py\n+++ b/scrapy/loader/__init__.py\n@@ -1,19 +1,19 @@\n-\"\"\"Item Loader\n+\"\"\"\n+Item Loader\n \n See documentation in docs/topics/loaders.rst\n-\n \"\"\"\n from collections import defaultdict\n+\n import six\n \n from scrapy.item import Item\n+from scrapy.loader.common import wrap_loader_context\n+from scrapy.loader.processors import Identity\n from scrapy.selector import Selector\n from scrapy.utils.misc import arg_to_iter, extract_regex\n from scrapy.utils.python import flatten\n \n-from .common import wrap_loader_context\n-from .processors import Identity\n-\n \n class ItemLoader(object):\n \n@@ -33,10 +33,9 @@\n self.parent = parent\n self._local_item = context['item'] = item\n self._local_values = defaultdict(list)\n- # Preprocess values if item built from dict\n- # Values need to be added to item._values if added them from dict (not with add_values)\n+ # values from initial item\n for field_name, value in item.items():\n- self._values[field_name] = self._process_input_value(field_name, value)\n+ self._values[field_name] += arg_to_iter(value)\n \n @property\n def _values(self):\n@@ -132,8 +131,8 @@\n try:\n return proc(self._values[field_name])\n except Exception as e:\n- raise ValueError(\"Error with output processor: field=%r value=%r error='%s: %s'\" % \\\n- (field_name, self._values[field_name], type(e).__name__, str(e)))\n+ raise ValueError(\"Error with output processor: field=%r value=%r error='%s: %s'\" %\n+ (field_name, self._values[field_name], type(e).__name__, str(e)))\n \n def get_collected_values(self, field_name):\n return self._values[field_name]\n@@ -141,15 +140,15 @@\n def get_input_processor(self, field_name):\n proc = getattr(self, '%s_in' % field_name, None)\n if not proc:\n- proc = self._get_item_field_attr(field_name, 'input_processor', \\\n- self.default_input_processor)\n+ proc = self._get_item_field_attr(field_name, 'input_processor',\n+ self.default_input_processor)\n return proc\n \n def get_output_processor(self, field_name):\n proc = getattr(self, '%s_out' % field_name, None)\n if not proc:\n- proc = self._get_item_field_attr(field_name, 'output_processor', \\\n- self.default_output_processor)\n+ proc = self._get_item_field_attr(field_name, 'output_processor',\n+ self.default_output_processor)\n return proc\n \n def _process_input_value(self, field_name, value):\n@@ -174,8 +173,8 @@\n def _check_selector_method(self):\n if self.selector is None:\n raise RuntimeError(\"To use XPath or CSS selectors, \"\n- \"%s must be instantiated with a selector \"\n- \"or a response\" % self.__class__.__name__)\n+ \"%s must be instantiated with a selector \"\n+ \"or a response\" % self.__class__.__name__)\n \n def add_xpath(self, field_name, xpath, *processors, **kw):\n values = self._get_xpathvalues(xpath, **kw)\n", "issue": "ItemLoaders can break if instantiated with pre-populated items\nBefore I start, I know item loaders have been a big source of discussion for a long time; I'm only opening this issue because the latest release breaks some of our spiders.\r\n\r\nIn one of our projects, our [Autounit](https://github.com/scrapinghub/scrapy-autounit) tests fail under 1.7.1 due to some item loaders which are created from partially populated items. I suspect the relevant change is #3819 (which BTW I think inadvertently closes #3046).\r\nPersonally I think a better approach here would be something _closer_ to the solution proposed in #3149, although not exactly the same.\r\n\r\nConsider the following:\r\n\r\n```python\r\nIn [1]: import scrapy\r\n\r\nIn [2]: scrapy.__version__\r\nOut[2]: '1.6.0'\r\n\r\nIn [3]: from scrapy.loader import ItemLoader\r\n ...: lo = ItemLoader(item={'key': 'value'})\r\n ...: lo.add_value('key', 'other value')\r\n ...: print(lo.load_item())\r\n{'key': ['other value']}\r\n```\r\n\r\n```python\r\nIn [1]: import scrapy\r\n\r\nIn [2]: scrapy.__version__\r\nOut[2]: '1.7.1'\r\n\r\nIn [3]: from scrapy.loader import ItemLoader\r\n ...: lo = ItemLoader(item={'key': 'value'})\r\n ...: lo.add_value('key', 'other value')\r\n ...: print(lo.load_item())\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-3-6aa64a41edb1> in <module>\r\n 1 from scrapy.loader import ItemLoader\r\n 2 lo = ItemLoader(item={'key': 'value'})\r\n----> 3 lo.add_value('key', 'other value')\r\n 4 print(lo.load_item())\r\n\r\n~/venv-temporal/lib/python3.6/site-packages/scrapy/loader/__init__.py in add_value(self, field_name, value, *processors, **kw)\r\n 77 self._add_value(k, v)\r\n 78 else:\r\n---> 79 self._add_value(field_name, value)\r\n 80\r\n 81 def replace_value(self, field_name, value, *processors, **kw):\r\n\r\n~/venv-temporal/lib/python3.6/site-packages/scrapy/loader/__init__.py in _add_value(self, field_name, value)\r\n 93 processed_value = self._process_input_value(field_name, value)\r\n 94 if processed_value:\r\n---> 95 self._values[field_name] += arg_to_iter(processed_value)\r\n 96\r\n 97 def _replace_value(self, field_name, value):\r\n\r\nTypeError: must be str, not list\r\n```\r\nI'm not directly opening a PR because I think this needs discussion. What if we changed\r\n```python\r\nfor field_name, value in item.items():\r\n self._values[field_name] = self._process_input_value(field_name, value)\r\n```\r\n\r\nto\r\n\r\n```python\r\nfor field_name, value in item.items():\r\n self._add_value(field_name, value)\r\n```\r\n\r\nwhich calls `arg_to_iter` internally?\r\n\r\nWith that change, the following happens which is more reasonable IMHO:\r\n```python\r\nIn [3]: from scrapy.loader import ItemLoader \r\n ...: lo = ItemLoader(item={'key': 'value'}) \r\n ...: lo.add_value('key', 'other value') \r\n ...: print(lo.load_item()) \r\n{'key': ['value', 'other value']}\r\n```\r\n\r\nLooking forward to reading your thoughts on the matter\r\n\r\n/cc @Gallaecio @kmike @andrewbaxter @fcanobrash @sortafreel\n`ItemLoader` fields initialized from `item` are reprocessed\n### Description\r\n\r\n#3804 introduced a bug where `ItemLoader` fields are reprocessed.\r\nRelated #3897.\r\n\r\n### Steps to Reproduce\r\n\r\n```python\r\nfrom pprint import pprint\r\n\r\nfrom scrapy import Field, Item\r\nfrom scrapy.loader import ItemLoader\r\nfrom scrapy.loader.processors import TakeFirst\r\n\r\n\r\nclass X(Item):\r\n x = Field(output_processor=TakeFirst())\r\n\r\n\r\nloader = ItemLoader(X())\r\nloader.add_value(\"x\", [\"value1\", \"value2\"])\r\nx = loader.load_item()\r\npprint(x)\r\n# {'x': 'value1'}\r\n\r\npprint(ItemLoader(x).load_item())\r\n# {'x': 'v'}\r\n```\r\n\r\n**Expected behavior:** `ItemLoader` initialized from the `x` item does not reprocess its fields and loads `{'x': 'value1'}`.\r\n\r\n**Actual behavior:** `ItemLoader` initialized from the `x` item reprocesses its fields and loads `{'x': 'v'}`.\r\n\r\n### Versions\r\n\r\n```\r\nScrapy : 1.7.3\r\nlxml : 4.4.1.0\r\nlibxml2 : 2.9.9\r\ncssselect : 1.1.0\r\nparsel : 1.5.2\r\nw3lib : 1.21.0\r\nTwisted : 19.7.0\r\nPython : 3.6.5 (default, May 3 2018, 10:08:28) - [GCC 5.4.0 20160609]\r\npyOpenSSL : 19.0.0 (OpenSSL 1.1.1c 28 May 2019)\r\ncryptography : 2.7\r\nPlatform : Linux-4.4.0-127-generic-x86_64-with-LinuxMint-18.1-serena\r\n```\r\n\r\n### Additional context\r\n\r\nHere's the behavior of the previous version:\r\n\r\n```\r\nScrapy : 1.6.0\r\nlxml : 4.4.0.0\r\nlibxml2 : 2.9.9\r\ncssselect : 1.0.3\r\nparsel : 1.5.1\r\nw3lib : 1.20.0\r\nTwisted : 19.7.0\r\nPython : 3.6.5 (default, May 3 2018, 10:08:28) - [GCC 5.4.0 20160609]\r\npyOpenSSL : 19.0.0 (OpenSSL 1.1.1c 28 May 2019)\r\ncryptography : 2.7\r\nPlatform : Linux-4.4.0-127-generic-x86_64-with-LinuxMint-18.1-serena\r\n```\r\n\r\n```python\r\n# {'x': 'value1'}\r\n# {'x': 'value1'}\r\n```\n", "before_files": [{"content": "\"\"\"Item Loader\n\nSee documentation in docs/topics/loaders.rst\n\n\"\"\"\nfrom collections import defaultdict\nimport six\n\nfrom scrapy.item import Item\nfrom scrapy.selector import Selector\nfrom scrapy.utils.misc import arg_to_iter, extract_regex\nfrom scrapy.utils.python import flatten\n\nfrom .common import wrap_loader_context\nfrom .processors import Identity\n\n\nclass ItemLoader(object):\n\n default_item_class = Item\n default_input_processor = Identity()\n default_output_processor = Identity()\n default_selector_class = Selector\n\n def __init__(self, item=None, selector=None, response=None, parent=None, **context):\n if selector is None and response is not None:\n selector = self.default_selector_class(response)\n self.selector = selector\n context.update(selector=selector, response=response)\n if item is None:\n item = self.default_item_class()\n self.context = context\n self.parent = parent\n self._local_item = context['item'] = item\n self._local_values = defaultdict(list)\n # Preprocess values if item built from dict\n # Values need to be added to item._values if added them from dict (not with add_values)\n for field_name, value in item.items():\n self._values[field_name] = self._process_input_value(field_name, value)\n\n @property\n def _values(self):\n if self.parent is not None:\n return self.parent._values\n else:\n return self._local_values\n\n @property\n def item(self):\n if self.parent is not None:\n return self.parent.item\n else:\n return self._local_item\n\n def nested_xpath(self, xpath, **context):\n selector = self.selector.xpath(xpath)\n context.update(selector=selector)\n subloader = self.__class__(\n item=self.item, parent=self, **context\n )\n return subloader\n\n def nested_css(self, css, **context):\n selector = self.selector.css(css)\n context.update(selector=selector)\n subloader = self.__class__(\n item=self.item, parent=self, **context\n )\n return subloader\n\n def add_value(self, field_name, value, *processors, **kw):\n value = self.get_value(value, *processors, **kw)\n if value is None:\n return\n if not field_name:\n for k, v in six.iteritems(value):\n self._add_value(k, v)\n else:\n self._add_value(field_name, value)\n\n def replace_value(self, field_name, value, *processors, **kw):\n value = self.get_value(value, *processors, **kw)\n if value is None:\n return\n if not field_name:\n for k, v in six.iteritems(value):\n self._replace_value(k, v)\n else:\n self._replace_value(field_name, value)\n\n def _add_value(self, field_name, value):\n value = arg_to_iter(value)\n processed_value = self._process_input_value(field_name, value)\n if processed_value:\n self._values[field_name] += arg_to_iter(processed_value)\n\n def _replace_value(self, field_name, value):\n self._values.pop(field_name, None)\n self._add_value(field_name, value)\n\n def get_value(self, value, *processors, **kw):\n regex = kw.get('re', None)\n if regex:\n value = arg_to_iter(value)\n value = flatten(extract_regex(regex, x) for x in value)\n\n for proc in processors:\n if value is None:\n break\n _proc = proc\n proc = wrap_loader_context(proc, self.context)\n try:\n value = proc(value)\n except Exception as e:\n raise ValueError(\"Error with processor %s value=%r error='%s: %s'\" %\n (_proc.__class__.__name__, value,\n type(e).__name__, str(e)))\n return value\n\n def load_item(self):\n item = self.item\n for field_name in tuple(self._values):\n value = self.get_output_value(field_name)\n if value is not None:\n item[field_name] = value\n\n return item\n\n def get_output_value(self, field_name):\n proc = self.get_output_processor(field_name)\n proc = wrap_loader_context(proc, self.context)\n try:\n return proc(self._values[field_name])\n except Exception as e:\n raise ValueError(\"Error with output processor: field=%r value=%r error='%s: %s'\" % \\\n (field_name, self._values[field_name], type(e).__name__, str(e)))\n\n def get_collected_values(self, field_name):\n return self._values[field_name]\n\n def get_input_processor(self, field_name):\n proc = getattr(self, '%s_in' % field_name, None)\n if not proc:\n proc = self._get_item_field_attr(field_name, 'input_processor', \\\n self.default_input_processor)\n return proc\n\n def get_output_processor(self, field_name):\n proc = getattr(self, '%s_out' % field_name, None)\n if not proc:\n proc = self._get_item_field_attr(field_name, 'output_processor', \\\n self.default_output_processor)\n return proc\n\n def _process_input_value(self, field_name, value):\n proc = self.get_input_processor(field_name)\n _proc = proc\n proc = wrap_loader_context(proc, self.context)\n try:\n return proc(value)\n except Exception as e:\n raise ValueError(\n \"Error with input processor %s: field=%r value=%r \"\n \"error='%s: %s'\" % (_proc.__class__.__name__, field_name,\n value, type(e).__name__, str(e)))\n\n def _get_item_field_attr(self, field_name, key, default=None):\n if isinstance(self.item, Item):\n value = self.item.fields[field_name].get(key, default)\n else:\n value = default\n return value\n\n def _check_selector_method(self):\n if self.selector is None:\n raise RuntimeError(\"To use XPath or CSS selectors, \"\n \"%s must be instantiated with a selector \"\n \"or a response\" % self.__class__.__name__)\n\n def add_xpath(self, field_name, xpath, *processors, **kw):\n values = self._get_xpathvalues(xpath, **kw)\n self.add_value(field_name, values, *processors, **kw)\n\n def replace_xpath(self, field_name, xpath, *processors, **kw):\n values = self._get_xpathvalues(xpath, **kw)\n self.replace_value(field_name, values, *processors, **kw)\n\n def get_xpath(self, xpath, *processors, **kw):\n values = self._get_xpathvalues(xpath, **kw)\n return self.get_value(values, *processors, **kw)\n\n def _get_xpathvalues(self, xpaths, **kw):\n self._check_selector_method()\n xpaths = arg_to_iter(xpaths)\n return flatten(self.selector.xpath(xpath).getall() for xpath in xpaths)\n\n def add_css(self, field_name, css, *processors, **kw):\n values = self._get_cssvalues(css, **kw)\n self.add_value(field_name, values, *processors, **kw)\n\n def replace_css(self, field_name, css, *processors, **kw):\n values = self._get_cssvalues(css, **kw)\n self.replace_value(field_name, values, *processors, **kw)\n\n def get_css(self, css, *processors, **kw):\n values = self._get_cssvalues(css, **kw)\n return self.get_value(values, *processors, **kw)\n\n def _get_cssvalues(self, csss, **kw):\n self._check_selector_method()\n csss = arg_to_iter(csss)\n return flatten(self.selector.css(css).getall() for css in csss)\n", "path": "scrapy/loader/__init__.py"}], "after_files": [{"content": "\"\"\"\nItem Loader\n\nSee documentation in docs/topics/loaders.rst\n\"\"\"\nfrom collections import defaultdict\n\nimport six\n\nfrom scrapy.item import Item\nfrom scrapy.loader.common import wrap_loader_context\nfrom scrapy.loader.processors import Identity\nfrom scrapy.selector import Selector\nfrom scrapy.utils.misc import arg_to_iter, extract_regex\nfrom scrapy.utils.python import flatten\n\n\nclass ItemLoader(object):\n\n default_item_class = Item\n default_input_processor = Identity()\n default_output_processor = Identity()\n default_selector_class = Selector\n\n def __init__(self, item=None, selector=None, response=None, parent=None, **context):\n if selector is None and response is not None:\n selector = self.default_selector_class(response)\n self.selector = selector\n context.update(selector=selector, response=response)\n if item is None:\n item = self.default_item_class()\n self.context = context\n self.parent = parent\n self._local_item = context['item'] = item\n self._local_values = defaultdict(list)\n # values from initial item\n for field_name, value in item.items():\n self._values[field_name] += arg_to_iter(value)\n\n @property\n def _values(self):\n if self.parent is not None:\n return self.parent._values\n else:\n return self._local_values\n\n @property\n def item(self):\n if self.parent is not None:\n return self.parent.item\n else:\n return self._local_item\n\n def nested_xpath(self, xpath, **context):\n selector = self.selector.xpath(xpath)\n context.update(selector=selector)\n subloader = self.__class__(\n item=self.item, parent=self, **context\n )\n return subloader\n\n def nested_css(self, css, **context):\n selector = self.selector.css(css)\n context.update(selector=selector)\n subloader = self.__class__(\n item=self.item, parent=self, **context\n )\n return subloader\n\n def add_value(self, field_name, value, *processors, **kw):\n value = self.get_value(value, *processors, **kw)\n if value is None:\n return\n if not field_name:\n for k, v in six.iteritems(value):\n self._add_value(k, v)\n else:\n self._add_value(field_name, value)\n\n def replace_value(self, field_name, value, *processors, **kw):\n value = self.get_value(value, *processors, **kw)\n if value is None:\n return\n if not field_name:\n for k, v in six.iteritems(value):\n self._replace_value(k, v)\n else:\n self._replace_value(field_name, value)\n\n def _add_value(self, field_name, value):\n value = arg_to_iter(value)\n processed_value = self._process_input_value(field_name, value)\n if processed_value:\n self._values[field_name] += arg_to_iter(processed_value)\n\n def _replace_value(self, field_name, value):\n self._values.pop(field_name, None)\n self._add_value(field_name, value)\n\n def get_value(self, value, *processors, **kw):\n regex = kw.get('re', None)\n if regex:\n value = arg_to_iter(value)\n value = flatten(extract_regex(regex, x) for x in value)\n\n for proc in processors:\n if value is None:\n break\n _proc = proc\n proc = wrap_loader_context(proc, self.context)\n try:\n value = proc(value)\n except Exception as e:\n raise ValueError(\"Error with processor %s value=%r error='%s: %s'\" %\n (_proc.__class__.__name__, value,\n type(e).__name__, str(e)))\n return value\n\n def load_item(self):\n item = self.item\n for field_name in tuple(self._values):\n value = self.get_output_value(field_name)\n if value is not None:\n item[field_name] = value\n\n return item\n\n def get_output_value(self, field_name):\n proc = self.get_output_processor(field_name)\n proc = wrap_loader_context(proc, self.context)\n try:\n return proc(self._values[field_name])\n except Exception as e:\n raise ValueError(\"Error with output processor: field=%r value=%r error='%s: %s'\" %\n (field_name, self._values[field_name], type(e).__name__, str(e)))\n\n def get_collected_values(self, field_name):\n return self._values[field_name]\n\n def get_input_processor(self, field_name):\n proc = getattr(self, '%s_in' % field_name, None)\n if not proc:\n proc = self._get_item_field_attr(field_name, 'input_processor',\n self.default_input_processor)\n return proc\n\n def get_output_processor(self, field_name):\n proc = getattr(self, '%s_out' % field_name, None)\n if not proc:\n proc = self._get_item_field_attr(field_name, 'output_processor',\n self.default_output_processor)\n return proc\n\n def _process_input_value(self, field_name, value):\n proc = self.get_input_processor(field_name)\n _proc = proc\n proc = wrap_loader_context(proc, self.context)\n try:\n return proc(value)\n except Exception as e:\n raise ValueError(\n \"Error with input processor %s: field=%r value=%r \"\n \"error='%s: %s'\" % (_proc.__class__.__name__, field_name,\n value, type(e).__name__, str(e)))\n\n def _get_item_field_attr(self, field_name, key, default=None):\n if isinstance(self.item, Item):\n value = self.item.fields[field_name].get(key, default)\n else:\n value = default\n return value\n\n def _check_selector_method(self):\n if self.selector is None:\n raise RuntimeError(\"To use XPath or CSS selectors, \"\n \"%s must be instantiated with a selector \"\n \"or a response\" % self.__class__.__name__)\n\n def add_xpath(self, field_name, xpath, *processors, **kw):\n values = self._get_xpathvalues(xpath, **kw)\n self.add_value(field_name, values, *processors, **kw)\n\n def replace_xpath(self, field_name, xpath, *processors, **kw):\n values = self._get_xpathvalues(xpath, **kw)\n self.replace_value(field_name, values, *processors, **kw)\n\n def get_xpath(self, xpath, *processors, **kw):\n values = self._get_xpathvalues(xpath, **kw)\n return self.get_value(values, *processors, **kw)\n\n def _get_xpathvalues(self, xpaths, **kw):\n self._check_selector_method()\n xpaths = arg_to_iter(xpaths)\n return flatten(self.selector.xpath(xpath).getall() for xpath in xpaths)\n\n def add_css(self, field_name, css, *processors, **kw):\n values = self._get_cssvalues(css, **kw)\n self.add_value(field_name, values, *processors, **kw)\n\n def replace_css(self, field_name, css, *processors, **kw):\n values = self._get_cssvalues(css, **kw)\n self.replace_value(field_name, values, *processors, **kw)\n\n def get_css(self, css, *processors, **kw):\n values = self._get_cssvalues(css, **kw)\n return self.get_value(values, *processors, **kw)\n\n def _get_cssvalues(self, csss, **kw):\n self._check_selector_method()\n csss = arg_to_iter(csss)\n return flatten(self.selector.css(css).getall() for css in csss)\n", "path": "scrapy/loader/__init__.py"}]}
| 3,982 | 754 |
gh_patches_debug_18383
|
rasdani/github-patches
|
git_diff
|
scoutapp__scout_apm_python-430
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Switch to importlib.metadata for package versions
Python 3.8 comes with the new standard library [module `importlib.metadata`](https://docs.python.org/3.8/library/importlib.metadata.html). This is the new de-facto way of discovering installed package versions.
For older versions there's the [`importlib-metadata` backport](https://importlib-metadata.readthedocs.io/en/latest/).
We currently use `pkg_resources` to do this, we'd be better off long term switching to the backport and standard library module. The backport supports down to Python 2.7 so it'll work for everything we do.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/scout_apm/core/metadata.py`
Content:
```
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import datetime as dt
5 import sys
6 from os import getpid
7
8 from scout_apm.core.commands import ApplicationEvent
9 from scout_apm.core.config import scout_config
10 from scout_apm.core.socket import CoreAgentSocket
11
12
13 def report_app_metadata():
14 CoreAgentSocket.instance().send(
15 ApplicationEvent(
16 event_type="scout.metadata",
17 event_value=get_metadata(),
18 source="Pid: " + str(getpid()),
19 timestamp=dt.datetime.utcnow(),
20 )
21 )
22
23
24 def get_metadata():
25 data = {
26 "language": "python",
27 "language_version": "{}.{}.{}".format(*sys.version_info[:3]),
28 "server_time": dt.datetime.utcnow().isoformat() + "Z",
29 "framework": scout_config.value("framework"),
30 "framework_version": scout_config.value("framework_version"),
31 "environment": "",
32 "app_server": scout_config.value("app_server"),
33 "hostname": scout_config.value("hostname"),
34 "database_engine": "",
35 "database_adapter": "",
36 "application_name": "",
37 "libraries": get_python_packages_versions(),
38 "paas": "",
39 "application_root": scout_config.value("application_root"),
40 "scm_subdirectory": scout_config.value("scm_subdirectory"),
41 "git_sha": scout_config.value("revision_sha"),
42 }
43 # Deprecated - see #327:
44 data["version"] = data["language_version"]
45 return data
46
47
48 def get_python_packages_versions():
49 try:
50 import pkg_resources
51 except ImportError:
52 return []
53
54 return sorted(
55 (distribution.project_name, distribution.version)
56 for distribution in pkg_resources.working_set
57 )
58
```
Path: `setup.py`
Content:
```
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 import sys
5
6 from setuptools import Extension, find_packages, setup
7
8 with open("README.md", "r") as fp:
9 long_description = fp.read()
10
11 packages = find_packages("src")
12 if sys.version_info < (3, 6):
13 packages = [p for p in packages if not p.startswith("scout_apm.async_")]
14
15 compile_extensions = (
16 # Python 3+
17 sys.version_info >= (3,)
18 # Not Jython
19 and not sys.platform.startswith("java")
20 # Not PyPy
21 and "__pypy__" not in sys.builtin_module_names
22 )
23 if compile_extensions:
24 ext_modules = [
25 Extension(
26 str("scout_apm.core._objtrace"), [str("src/scout_apm/core/_objtrace.c")]
27 )
28 ]
29 else:
30 ext_modules = []
31
32 setup(
33 name="scout_apm",
34 version="2.9.1",
35 description="Scout Application Performance Monitoring Agent",
36 long_description=long_description,
37 long_description_content_type="text/markdown",
38 url="https://github.com/scoutapp/scout_apm_python",
39 project_urls={
40 "Documentation": "https://docs.scoutapm.com/#python-agent",
41 "Changelog": (
42 "https://github.com/scoutapp/scout_apm_python/blob/master/CHANGELOG.md"
43 ),
44 },
45 author="Scout",
46 author_email="support@scoutapm.com",
47 license="MIT",
48 zip_safe=False,
49 python_requires=">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, <4",
50 packages=packages,
51 package_dir={str(""): str("src")},
52 ext_modules=ext_modules,
53 entry_points={
54 "console_scripts": [
55 "core-agent-manager = scout_apm.core.cli.core_agent_manager:main"
56 ]
57 },
58 install_requires=[
59 'asgiref ; python_version >= "3.5"',
60 "psutil>=5,<6",
61 "requests>=2,<3",
62 "wrapt>=1.10,<2.0",
63 ],
64 keywords="apm performance monitoring development",
65 classifiers=[
66 "Development Status :: 5 - Production/Stable",
67 "Framework :: Bottle",
68 "Framework :: Django",
69 "Framework :: Django :: 1.8",
70 "Framework :: Django :: 1.9",
71 "Framework :: Django :: 1.10",
72 "Framework :: Django :: 1.11",
73 "Framework :: Django :: 2.0",
74 "Framework :: Django :: 2.1",
75 "Framework :: Django :: 2.2",
76 "Framework :: Django :: 3.0",
77 "Framework :: Flask",
78 "Framework :: Pyramid",
79 "Intended Audience :: Developers",
80 "Topic :: System :: Monitoring",
81 "License :: OSI Approved :: MIT License",
82 "Operating System :: MacOS",
83 "Operating System :: POSIX",
84 "Operating System :: POSIX :: Linux",
85 "Programming Language :: Python :: 2",
86 "Programming Language :: Python :: 2.7",
87 "Programming Language :: Python :: 3",
88 "Programming Language :: Python :: 3.4",
89 "Programming Language :: Python :: 3.5",
90 "Programming Language :: Python :: 3.6",
91 "Programming Language :: Python :: 3.7",
92 "Programming Language :: Python :: 3.8",
93 ],
94 )
95
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -57,6 +57,7 @@
},
install_requires=[
'asgiref ; python_version >= "3.5"',
+ 'importlib-metadata ; python_version < "3.8"',
"psutil>=5,<6",
"requests>=2,<3",
"wrapt>=1.10,<2.0",
diff --git a/src/scout_apm/core/metadata.py b/src/scout_apm/core/metadata.py
--- a/src/scout_apm/core/metadata.py
+++ b/src/scout_apm/core/metadata.py
@@ -47,11 +47,15 @@
def get_python_packages_versions():
try:
- import pkg_resources
+ if sys.version_info >= (3, 8):
+ from importlib.metadata import distributions
+ else:
+ from importlib_metadata import distributions
except ImportError:
+ # For some reason it is unavailable
return []
return sorted(
- (distribution.project_name, distribution.version)
- for distribution in pkg_resources.working_set
+ (distribution.metadata["Name"], distribution.metadata["Version"])
+ for distribution in distributions()
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -57,6 +57,7 @@\n },\n install_requires=[\n 'asgiref ; python_version >= \"3.5\"',\n+ 'importlib-metadata ; python_version < \"3.8\"',\n \"psutil>=5,<6\",\n \"requests>=2,<3\",\n \"wrapt>=1.10,<2.0\",\ndiff --git a/src/scout_apm/core/metadata.py b/src/scout_apm/core/metadata.py\n--- a/src/scout_apm/core/metadata.py\n+++ b/src/scout_apm/core/metadata.py\n@@ -47,11 +47,15 @@\n \n def get_python_packages_versions():\n try:\n- import pkg_resources\n+ if sys.version_info >= (3, 8):\n+ from importlib.metadata import distributions\n+ else:\n+ from importlib_metadata import distributions\n except ImportError:\n+ # For some reason it is unavailable\n return []\n \n return sorted(\n- (distribution.project_name, distribution.version)\n- for distribution in pkg_resources.working_set\n+ (distribution.metadata[\"Name\"], distribution.metadata[\"Version\"])\n+ for distribution in distributions()\n )\n", "issue": "Switch to importlib.metadata for package versions\nPython 3.8 comes with the new standard library [module `importlib.metadata`](https://docs.python.org/3.8/library/importlib.metadata.html). This is the new de-facto way of discovering installed package versions.\r\n\r\nFor older versions there's the [`importlib-metadata` backport](https://importlib-metadata.readthedocs.io/en/latest/).\r\n\r\nWe currently use `pkg_resources` to do this, we'd be better off long term switching to the backport and standard library module. The backport supports down to Python 2.7 so it'll work for everything we do.\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport datetime as dt\nimport sys\nfrom os import getpid\n\nfrom scout_apm.core.commands import ApplicationEvent\nfrom scout_apm.core.config import scout_config\nfrom scout_apm.core.socket import CoreAgentSocket\n\n\ndef report_app_metadata():\n CoreAgentSocket.instance().send(\n ApplicationEvent(\n event_type=\"scout.metadata\",\n event_value=get_metadata(),\n source=\"Pid: \" + str(getpid()),\n timestamp=dt.datetime.utcnow(),\n )\n )\n\n\ndef get_metadata():\n data = {\n \"language\": \"python\",\n \"language_version\": \"{}.{}.{}\".format(*sys.version_info[:3]),\n \"server_time\": dt.datetime.utcnow().isoformat() + \"Z\",\n \"framework\": scout_config.value(\"framework\"),\n \"framework_version\": scout_config.value(\"framework_version\"),\n \"environment\": \"\",\n \"app_server\": scout_config.value(\"app_server\"),\n \"hostname\": scout_config.value(\"hostname\"),\n \"database_engine\": \"\",\n \"database_adapter\": \"\",\n \"application_name\": \"\",\n \"libraries\": get_python_packages_versions(),\n \"paas\": \"\",\n \"application_root\": scout_config.value(\"application_root\"),\n \"scm_subdirectory\": scout_config.value(\"scm_subdirectory\"),\n \"git_sha\": scout_config.value(\"revision_sha\"),\n }\n # Deprecated - see #327:\n data[\"version\"] = data[\"language_version\"]\n return data\n\n\ndef get_python_packages_versions():\n try:\n import pkg_resources\n except ImportError:\n return []\n\n return sorted(\n (distribution.project_name, distribution.version)\n for distribution in pkg_resources.working_set\n )\n", "path": "src/scout_apm/core/metadata.py"}, {"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport sys\n\nfrom setuptools import Extension, find_packages, setup\n\nwith open(\"README.md\", \"r\") as fp:\n long_description = fp.read()\n\npackages = find_packages(\"src\")\nif sys.version_info < (3, 6):\n packages = [p for p in packages if not p.startswith(\"scout_apm.async_\")]\n\ncompile_extensions = (\n # Python 3+\n sys.version_info >= (3,)\n # Not Jython\n and not sys.platform.startswith(\"java\")\n # Not PyPy\n and \"__pypy__\" not in sys.builtin_module_names\n)\nif compile_extensions:\n ext_modules = [\n Extension(\n str(\"scout_apm.core._objtrace\"), [str(\"src/scout_apm/core/_objtrace.c\")]\n )\n ]\nelse:\n ext_modules = []\n\nsetup(\n name=\"scout_apm\",\n version=\"2.9.1\",\n description=\"Scout Application Performance Monitoring Agent\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/scoutapp/scout_apm_python\",\n project_urls={\n \"Documentation\": \"https://docs.scoutapm.com/#python-agent\",\n \"Changelog\": (\n \"https://github.com/scoutapp/scout_apm_python/blob/master/CHANGELOG.md\"\n ),\n },\n author=\"Scout\",\n author_email=\"support@scoutapm.com\",\n license=\"MIT\",\n zip_safe=False,\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, <4\",\n packages=packages,\n package_dir={str(\"\"): str(\"src\")},\n ext_modules=ext_modules,\n entry_points={\n \"console_scripts\": [\n \"core-agent-manager = scout_apm.core.cli.core_agent_manager:main\"\n ]\n },\n install_requires=[\n 'asgiref ; python_version >= \"3.5\"',\n \"psutil>=5,<6\",\n \"requests>=2,<3\",\n \"wrapt>=1.10,<2.0\",\n ],\n keywords=\"apm performance monitoring development\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Framework :: Bottle\",\n \"Framework :: Django\",\n \"Framework :: Django :: 1.8\",\n \"Framework :: Django :: 1.9\",\n \"Framework :: Django :: 1.10\",\n \"Framework :: Django :: 1.11\",\n \"Framework :: Django :: 2.0\",\n \"Framework :: Django :: 2.1\",\n \"Framework :: Django :: 2.2\",\n \"Framework :: Django :: 3.0\",\n \"Framework :: Flask\",\n \"Framework :: Pyramid\",\n \"Intended Audience :: Developers\",\n \"Topic :: System :: Monitoring\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: MacOS\",\n \"Operating System :: POSIX\",\n \"Operating System :: POSIX :: Linux\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n ],\n)\n", "path": "setup.py"}], "after_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport datetime as dt\nimport sys\nfrom os import getpid\n\nfrom scout_apm.core.commands import ApplicationEvent\nfrom scout_apm.core.config import scout_config\nfrom scout_apm.core.socket import CoreAgentSocket\n\n\ndef report_app_metadata():\n CoreAgentSocket.instance().send(\n ApplicationEvent(\n event_type=\"scout.metadata\",\n event_value=get_metadata(),\n source=\"Pid: \" + str(getpid()),\n timestamp=dt.datetime.utcnow(),\n )\n )\n\n\ndef get_metadata():\n data = {\n \"language\": \"python\",\n \"language_version\": \"{}.{}.{}\".format(*sys.version_info[:3]),\n \"server_time\": dt.datetime.utcnow().isoformat() + \"Z\",\n \"framework\": scout_config.value(\"framework\"),\n \"framework_version\": scout_config.value(\"framework_version\"),\n \"environment\": \"\",\n \"app_server\": scout_config.value(\"app_server\"),\n \"hostname\": scout_config.value(\"hostname\"),\n \"database_engine\": \"\",\n \"database_adapter\": \"\",\n \"application_name\": \"\",\n \"libraries\": get_python_packages_versions(),\n \"paas\": \"\",\n \"application_root\": scout_config.value(\"application_root\"),\n \"scm_subdirectory\": scout_config.value(\"scm_subdirectory\"),\n \"git_sha\": scout_config.value(\"revision_sha\"),\n }\n # Deprecated - see #327:\n data[\"version\"] = data[\"language_version\"]\n return data\n\n\ndef get_python_packages_versions():\n try:\n if sys.version_info >= (3, 8):\n from importlib.metadata import distributions\n else:\n from importlib_metadata import distributions\n except ImportError:\n # For some reason it is unavailable\n return []\n\n return sorted(\n (distribution.metadata[\"Name\"], distribution.metadata[\"Version\"])\n for distribution in distributions()\n )\n", "path": "src/scout_apm/core/metadata.py"}, {"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport sys\n\nfrom setuptools import Extension, find_packages, setup\n\nwith open(\"README.md\", \"r\") as fp:\n long_description = fp.read()\n\npackages = find_packages(\"src\")\nif sys.version_info < (3, 6):\n packages = [p for p in packages if not p.startswith(\"scout_apm.async_\")]\n\ncompile_extensions = (\n # Python 3+\n sys.version_info >= (3,)\n # Not Jython\n and not sys.platform.startswith(\"java\")\n # Not PyPy\n and \"__pypy__\" not in sys.builtin_module_names\n)\nif compile_extensions:\n ext_modules = [\n Extension(\n str(\"scout_apm.core._objtrace\"), [str(\"src/scout_apm/core/_objtrace.c\")]\n )\n ]\nelse:\n ext_modules = []\n\nsetup(\n name=\"scout_apm\",\n version=\"2.9.1\",\n description=\"Scout Application Performance Monitoring Agent\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/scoutapp/scout_apm_python\",\n project_urls={\n \"Documentation\": \"https://docs.scoutapm.com/#python-agent\",\n \"Changelog\": (\n \"https://github.com/scoutapp/scout_apm_python/blob/master/CHANGELOG.md\"\n ),\n },\n author=\"Scout\",\n author_email=\"support@scoutapm.com\",\n license=\"MIT\",\n zip_safe=False,\n python_requires=\">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, <4\",\n packages=packages,\n package_dir={str(\"\"): str(\"src\")},\n ext_modules=ext_modules,\n entry_points={\n \"console_scripts\": [\n \"core-agent-manager = scout_apm.core.cli.core_agent_manager:main\"\n ]\n },\n install_requires=[\n 'asgiref ; python_version >= \"3.5\"',\n 'importlib-metadata ; python_version < \"3.8\"',\n \"psutil>=5,<6\",\n \"requests>=2,<3\",\n \"wrapt>=1.10,<2.0\",\n ],\n keywords=\"apm performance monitoring development\",\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Framework :: Bottle\",\n \"Framework :: Django\",\n \"Framework :: Django :: 1.8\",\n \"Framework :: Django :: 1.9\",\n \"Framework :: Django :: 1.10\",\n \"Framework :: Django :: 1.11\",\n \"Framework :: Django :: 2.0\",\n \"Framework :: Django :: 2.1\",\n \"Framework :: Django :: 2.2\",\n \"Framework :: Django :: 3.0\",\n \"Framework :: Flask\",\n \"Framework :: Pyramid\",\n \"Intended Audience :: Developers\",\n \"Topic :: System :: Monitoring\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: MacOS\",\n \"Operating System :: POSIX\",\n \"Operating System :: POSIX :: Linux\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n ],\n)\n", "path": "setup.py"}]}
| 1,833 | 277 |
gh_patches_debug_65526
|
rasdani/github-patches
|
git_diff
|
localstack__localstack-4849
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
bug: Java 11 Lambda incorrect handler specification
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
Up to localstack 0.12.15 (I haven't checked with 0.12.16), Java 11 Lambda function handler was correctly specified according to [AWS docs](https://docs.aws.amazon.com/lambda/latest/dg/lambda-java.html) e.g.
```
example.Hello::handleRequest
```
With 0.12.17, instead, such specification leads to error during Lambda execution, with stacktrace:
```
2021-08-30T14:08:01:INFO:localstack.utils.run: Thread run method <function LambdaExecutor.execute.<locals>.do_execute at 0x7fc385d26560>(None) failed: Lambda process returned error status code: 1. Result: . Output:
Exception in thread "main" java.lang.ClassNotFoundException: example.Hello::handleRequest
at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(Unknown Source)
at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(Unknown Source)
at java.base/java.lang.ClassLoader.loadClass(Unknown Source)
at java.base/java.lang.Class.forName0(Native Method)
at java.base/java.lang.Class.forName(Unknown Source)
at cloud.localstack.LambdaExecutor.getHandler(LambdaExecutor.java:142)
at cloud.localstack.LambdaExecutor.main(LambdaExecutor.java:69) Traceback (most recent call last):
File "/opt/code/localstack/localstack/utils/run.py", line 138, in run
result = self.func(self.params, **kwargs)
File "/opt/code/localstack/localstack/services/awslambda/lambda_executors.py", line 326, in do_execute
return _run(func_arn=func_arn)
File "/opt/code/localstack/localstack/utils/cloudwatch/cloudwatch_util.py", line 157, in wrapped
raise e
File "/opt/code/localstack/localstack/utils/cloudwatch/cloudwatch_util.py", line 153, in wrapped
result = func(*args, **kwargs)
File "/opt/code/localstack/localstack/services/awslambda/lambda_executors.py", line 313, in _run
raise e
File "/opt/code/localstack/localstack/services/awslambda/lambda_executors.py", line 299, in _run
result = self._execute(func_arn, func_details, event, context, version)
File "/opt/code/localstack/localstack/services/awslambda/lambda_executors.py", line 1101, in _execute
raise InvocationException(result, log_output)
localstack.services.awslambda.lambda_executors.InvocationException: Lambda process returned error status code: 1. Result: . Output:
Exception in thread "main" java.lang.ClassNotFoundException: example.Hello::handleRequest
at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(Unknown Source)
at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(Unknown Source)
at java.base/java.lang.ClassLoader.loadClass(Unknown Source)
at java.base/java.lang.Class.forName0(Native Method)
at java.base/java.lang.Class.forName(Unknown Source)
at cloud.localstack.LambdaExecutor.getHandler(LambdaExecutor.java:142)
at cloud.localstack.LambdaExecutor.main(LambdaExecutor.java:69)
```
I would say that this line in the test case is incorrect: https://github.com/localstack/localstack/blob/master/tests/integration/test_lambda.py#L1711
### Expected Behavior
I would expect to specify Java 11 Lambda handlers as it used to be at least until localstack 0.12.15 and according to AWS docs.
### How are you starting LocalStack?
With a docker-compose file
### Steps To Reproduce
#### How are you starting localstack (e.g., `bin/localstack` command, arguments, or `docker-compose.yml`)
docker run localstack/localstack
#### Client commands (e.g., AWS SDK code snippet, or sequence of "awslocal" commands)
awslocal s3 mb s3://mybucket
### Environment
```markdown
- OS: Ubuntu 20.04
- LocalStack: 0.12.17
```
### Anything else?
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `localstack/constants.py`
Content:
```
1 import os
2
3 import localstack_client.config
4
5 import localstack
6
7 # LocalStack version
8 VERSION = localstack.__version__
9
10 # constant to represent the "local" region, i.e., local machine
11 REGION_LOCAL = "local"
12
13 # dev environment
14 ENV_DEV = "dev"
15
16 # HTTP headers used to forward proxy request URLs
17 HEADER_LOCALSTACK_EDGE_URL = "x-localstack-edge"
18 HEADER_LOCALSTACK_REQUEST_URL = "x-localstack-request-url"
19 HEADER_LOCALSTACK_TARGET = "x-localstack-target"
20 HEADER_AMZN_ERROR_TYPE = "X-Amzn-Errortype"
21
22 # backend service ports, for services that are behind a proxy (counting down from 4566)
23 DEFAULT_PORT_EDGE = 4566
24
25 # host name for localhost
26 LOCALHOST = "localhost"
27 LOCALHOST_IP = "127.0.0.1"
28 LOCALHOST_HOSTNAME = "localhost.localstack.cloud"
29
30 # version of the Maven dependency with Java utility code
31 LOCALSTACK_MAVEN_VERSION = "0.2.16"
32
33 # map of default service APIs and ports to be spun up (fetch map from localstack_client)
34 DEFAULT_SERVICE_PORTS = localstack_client.config.get_service_ports()
35
36 # host to bind to when starting the services
37 BIND_HOST = "0.0.0.0"
38
39 # AWS user account ID used for tests
40 if "TEST_AWS_ACCOUNT_ID" not in os.environ:
41 os.environ["TEST_AWS_ACCOUNT_ID"] = "000000000000"
42 TEST_AWS_ACCOUNT_ID = os.environ["TEST_AWS_ACCOUNT_ID"]
43
44 # root code folder
45 MODULE_MAIN_PATH = os.path.dirname(os.path.realpath(__file__))
46 # TODO rename to "ROOT_FOLDER"!
47 LOCALSTACK_ROOT_FOLDER = os.path.realpath(os.path.join(MODULE_MAIN_PATH, ".."))
48 INSTALL_DIR_INFRA = os.path.join(MODULE_MAIN_PATH, "infra")
49
50 # virtualenv folder
51 LOCALSTACK_VENV_FOLDER = os.path.join(LOCALSTACK_ROOT_FOLDER, ".venv")
52 if not os.path.isdir(LOCALSTACK_VENV_FOLDER):
53 # assuming this package lives here: <python>/lib/pythonX.X/site-packages/localstack/
54 LOCALSTACK_VENV_FOLDER = os.path.realpath(
55 os.path.join(LOCALSTACK_ROOT_FOLDER, "..", "..", "..")
56 )
57
58 # API Gateway path to indicate a user request sent to the gateway
59 PATH_USER_REQUEST = "_user_request_"
60
61 # name of LocalStack Docker image
62 DOCKER_IMAGE_NAME = "localstack/localstack"
63 DOCKER_IMAGE_NAME_FULL = "localstack/localstack-full"
64
65 # backdoor API path used to retrieve or update config variables
66 CONFIG_UPDATE_PATH = "/?_config_"
67
68 # environment variable name to tag local test runs
69 ENV_INTERNAL_TEST_RUN = "LOCALSTACK_INTERNAL_TEST_RUN"
70
71 # environment variable that flags whether pro was activated. do not use for security purposes!
72 ENV_PRO_ACTIVATED = "PRO_ACTIVATED"
73
74 # content types
75 HEADER_CONTENT_TYPE = "Content-Type"
76 APPLICATION_AMZ_JSON_1_0 = "application/x-amz-json-1.0"
77 APPLICATION_AMZ_JSON_1_1 = "application/x-amz-json-1.1"
78 APPLICATION_AMZ_CBOR_1_1 = "application/x-amz-cbor-1.1"
79 APPLICATION_CBOR = "application/cbor"
80 APPLICATION_JSON = "application/json"
81 APPLICATION_XML = "application/xml"
82 APPLICATION_OCTET_STREAM = "application/octet-stream"
83 APPLICATION_X_WWW_FORM_URLENCODED = "application/x-www-form-urlencoded"
84
85 # strings to indicate truthy/falsy values
86 TRUE_STRINGS = ("1", "true", "True")
87 FALSE_STRINGS = ("0", "false", "False")
88 # strings with valid log levels for LS_LOG
89 LOG_LEVELS = ("trace-internal", "trace", "debug", "info", "warn", "error", "warning")
90
91 # Lambda defaults
92 LAMBDA_TEST_ROLE = "arn:aws:iam::%s:role/lambda-test-role" % TEST_AWS_ACCOUNT_ID
93
94 # installation constants
95 ELASTICSEARCH_URLS = {
96 "7.10.0": "https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.10.0-linux-x86_64.tar.gz",
97 "7.7.0": "https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.7.0-linux-x86_64.tar.gz",
98 "7.4.0": "https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.0-linux-x86_64.tar.gz",
99 "7.1.0": "https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.1.0-linux-x86_64.tar.gz",
100 "6.7.0": "https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.7.0.zip",
101 }
102 ELASTICSEARCH_DEFAULT_VERSION = "7.10.0"
103 # See https://docs.aws.amazon.com/ja_jp/elasticsearch-service/latest/developerguide/aes-supported-plugins.html
104 ELASTICSEARCH_PLUGIN_LIST = [
105 "analysis-icu",
106 "ingest-attachment",
107 "analysis-kuromoji",
108 "mapper-murmur3",
109 "mapper-size",
110 "analysis-phonetic",
111 "analysis-smartcn",
112 "analysis-stempel",
113 "analysis-ukrainian",
114 ]
115 # Default ES modules to exclude (save apprx 66MB in the final image)
116 ELASTICSEARCH_DELETE_MODULES = ["ingest-geoip"]
117 ELASTICMQ_JAR_URL = (
118 "https://s3-eu-west-1.amazonaws.com/softwaremill-public/elasticmq-server-1.1.0.jar"
119 )
120 STS_JAR_URL = "https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-sts/1.11.14/aws-java-sdk-sts-1.11.14.jar"
121 STEPFUNCTIONS_ZIP_URL = "https://s3.amazonaws.com/stepfunctionslocal/StepFunctionsLocal.zip"
122 KMS_URL_PATTERN = "https://s3-eu-west-2.amazonaws.com/local-kms/localstack/v3/local-kms.<arch>.bin"
123
124 # TODO: Temporarily using a fixed version of DDB in Alpine, as we're hitting a SIGSEGV JVM crash with latest
125 DYNAMODB_JAR_URL_ALPINE = "https://github.com/localstack/localstack-artifacts/raw/master/dynamodb-local-patch/etc/DynamoDBLocal.zip"
126 DYNAMODB_JAR_URL = "https://s3-us-west-2.amazonaws.com/dynamodb-local/dynamodb_local_latest.zip"
127
128 # API endpoint for analytics events
129 API_ENDPOINT = os.environ.get("API_ENDPOINT") or "https://api.localstack.cloud/v1"
130 # new analytics API endpoint
131 ANALYTICS_API = os.environ.get("ANALYTICS_API") or "https://analytics.localstack.cloud/v0"
132
133 # environment variable to indicates that this process is running the Web UI
134 LOCALSTACK_WEB_PROCESS = "LOCALSTACK_WEB_PROCESS"
135 LOCALSTACK_INFRA_PROCESS = "LOCALSTACK_INFRA_PROCESS"
136
137 # hardcoded AWS account ID used by moto
138 MOTO_ACCOUNT_ID = TEST_AWS_ACCOUNT_ID
139 # fix moto account ID - note: keep this at the top level here
140 try:
141 from moto import core as moto_core
142 from moto.core import models as moto_core_models
143
144 moto_core.ACCOUNT_ID = moto_core_models.ACCOUNT_ID = MOTO_ACCOUNT_ID
145 except Exception:
146 # ignore import errors
147 pass
148
149 # default AWS region us-east-1
150 AWS_REGION_US_EAST_1 = "us-east-1"
151
152 # default lambda registry
153 DEFAULT_LAMBDA_CONTAINER_REGISTRY = "lambci/lambda"
154
155 # environment variable to override max pool connections
156 try:
157 MAX_POOL_CONNECTIONS = int(os.environ["MAX_POOL_CONNECTIONS"])
158 except Exception:
159 MAX_POOL_CONNECTIONS = 150
160
161 # test credentials used for generating signature for S3 presigned URLs (to be used by external clients)
162 TEST_AWS_ACCESS_KEY_ID = "test"
163 TEST_AWS_SECRET_ACCESS_KEY = "test"
164
165 # credentials being used for internal calls
166 INTERNAL_AWS_ACCESS_KEY_ID = "__internal_call__"
167 INTERNAL_AWS_SECRET_ACCESS_KEY = "__internal_call__"
168
169 # trace log levels (excluding/including internal API calls), configurable via $LS_LOG
170 LS_LOG_TRACE = "trace"
171 LS_LOG_TRACE_INTERNAL = "trace-internal"
172 TRACE_LOG_LEVELS = [LS_LOG_TRACE, LS_LOG_TRACE_INTERNAL]
173
174 # list of official docker images
175 OFFICIAL_IMAGES = [
176 "localstack/localstack",
177 "localstack/localstack-light",
178 "localstack/localstack-full",
179 ]
180
181 # s3 virtual host name
182 S3_VIRTUAL_HOSTNAME = "s3.%s" % LOCALHOST_HOSTNAME
183 S3_STATIC_WEBSITE_HOSTNAME = "s3-website.%s" % LOCALHOST_HOSTNAME
184
185 # port for debug py
186 DEFAULT_DEVELOP_PORT = 5678
187
188 # Default bucket name of the s3 bucket used for local lambda development
189 DEFAULT_BUCKET_MARKER_LOCAL = "__local__"
190
191 # user that starts the elasticsearch process if the current user is root
192 OS_USER_ELASTICSEARCH = "localstack"
193
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/localstack/constants.py b/localstack/constants.py
--- a/localstack/constants.py
+++ b/localstack/constants.py
@@ -28,7 +28,7 @@
LOCALHOST_HOSTNAME = "localhost.localstack.cloud"
# version of the Maven dependency with Java utility code
-LOCALSTACK_MAVEN_VERSION = "0.2.16"
+LOCALSTACK_MAVEN_VERSION = "0.2.17"
# map of default service APIs and ports to be spun up (fetch map from localstack_client)
DEFAULT_SERVICE_PORTS = localstack_client.config.get_service_ports()
|
{"golden_diff": "diff --git a/localstack/constants.py b/localstack/constants.py\n--- a/localstack/constants.py\n+++ b/localstack/constants.py\n@@ -28,7 +28,7 @@\n LOCALHOST_HOSTNAME = \"localhost.localstack.cloud\"\n \n # version of the Maven dependency with Java utility code\n-LOCALSTACK_MAVEN_VERSION = \"0.2.16\"\n+LOCALSTACK_MAVEN_VERSION = \"0.2.17\"\n \n # map of default service APIs and ports to be spun up (fetch map from localstack_client)\n DEFAULT_SERVICE_PORTS = localstack_client.config.get_service_ports()\n", "issue": "bug: Java 11 Lambda incorrect handler specification\n### Is there an existing issue for this?\n\n- [X] I have searched the existing issues\n\n### Current Behavior\n\nUp to localstack 0.12.15 (I haven't checked with 0.12.16), Java 11 Lambda function handler was correctly specified according to [AWS docs](https://docs.aws.amazon.com/lambda/latest/dg/lambda-java.html) e.g.\r\n\r\n```\r\nexample.Hello::handleRequest\r\n```\r\n\r\nWith 0.12.17, instead, such specification leads to error during Lambda execution, with stacktrace:\r\n\r\n```\r\n2021-08-30T14:08:01:INFO:localstack.utils.run: Thread run method <function LambdaExecutor.execute.<locals>.do_execute at 0x7fc385d26560>(None) failed: Lambda process returned error status code: 1. Result: . Output:\r\nException in thread \"main\" java.lang.ClassNotFoundException: example.Hello::handleRequest\r\n at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(Unknown Source)\r\n at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(Unknown Source)\r\n at java.base/java.lang.ClassLoader.loadClass(Unknown Source)\r\n at java.base/java.lang.Class.forName0(Native Method)\r\n at java.base/java.lang.Class.forName(Unknown Source)\r\n at cloud.localstack.LambdaExecutor.getHandler(LambdaExecutor.java:142)\r\n at cloud.localstack.LambdaExecutor.main(LambdaExecutor.java:69) Traceback (most recent call last):\r\n File \"/opt/code/localstack/localstack/utils/run.py\", line 138, in run\r\n result = self.func(self.params, **kwargs)\r\n File \"/opt/code/localstack/localstack/services/awslambda/lambda_executors.py\", line 326, in do_execute\r\n return _run(func_arn=func_arn)\r\n File \"/opt/code/localstack/localstack/utils/cloudwatch/cloudwatch_util.py\", line 157, in wrapped\r\n raise e\r\n File \"/opt/code/localstack/localstack/utils/cloudwatch/cloudwatch_util.py\", line 153, in wrapped\r\n result = func(*args, **kwargs)\r\n File \"/opt/code/localstack/localstack/services/awslambda/lambda_executors.py\", line 313, in _run\r\n raise e\r\n File \"/opt/code/localstack/localstack/services/awslambda/lambda_executors.py\", line 299, in _run\r\n result = self._execute(func_arn, func_details, event, context, version)\r\n File \"/opt/code/localstack/localstack/services/awslambda/lambda_executors.py\", line 1101, in _execute\r\n raise InvocationException(result, log_output)\r\nlocalstack.services.awslambda.lambda_executors.InvocationException: Lambda process returned error status code: 1. Result: . Output:\r\nException in thread \"main\" java.lang.ClassNotFoundException: example.Hello::handleRequest\r\n at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(Unknown Source)\r\n at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(Unknown Source)\r\n at java.base/java.lang.ClassLoader.loadClass(Unknown Source)\r\n at java.base/java.lang.Class.forName0(Native Method)\r\n at java.base/java.lang.Class.forName(Unknown Source)\r\n at cloud.localstack.LambdaExecutor.getHandler(LambdaExecutor.java:142)\r\n at cloud.localstack.LambdaExecutor.main(LambdaExecutor.java:69)\r\n```\r\n\r\nI would say that this line in the test case is incorrect: https://github.com/localstack/localstack/blob/master/tests/integration/test_lambda.py#L1711\n\n### Expected Behavior\n\nI would expect to specify Java 11 Lambda handlers as it used to be at least until localstack 0.12.15 and according to AWS docs.\n\n### How are you starting LocalStack?\n\nWith a docker-compose file\n\n### Steps To Reproduce\n\n#### How are you starting localstack (e.g., `bin/localstack` command, arguments, or `docker-compose.yml`)\r\n\r\n docker run localstack/localstack\r\n\r\n#### Client commands (e.g., AWS SDK code snippet, or sequence of \"awslocal\" commands)\r\n\r\n awslocal s3 mb s3://mybucket\r\n\n\n### Environment\n\n```markdown\n- OS: Ubuntu 20.04\r\n- LocalStack: 0.12.17\n```\n\n\n### Anything else?\n\n_No response_\n", "before_files": [{"content": "import os\n\nimport localstack_client.config\n\nimport localstack\n\n# LocalStack version\nVERSION = localstack.__version__\n\n# constant to represent the \"local\" region, i.e., local machine\nREGION_LOCAL = \"local\"\n\n# dev environment\nENV_DEV = \"dev\"\n\n# HTTP headers used to forward proxy request URLs\nHEADER_LOCALSTACK_EDGE_URL = \"x-localstack-edge\"\nHEADER_LOCALSTACK_REQUEST_URL = \"x-localstack-request-url\"\nHEADER_LOCALSTACK_TARGET = \"x-localstack-target\"\nHEADER_AMZN_ERROR_TYPE = \"X-Amzn-Errortype\"\n\n# backend service ports, for services that are behind a proxy (counting down from 4566)\nDEFAULT_PORT_EDGE = 4566\n\n# host name for localhost\nLOCALHOST = \"localhost\"\nLOCALHOST_IP = \"127.0.0.1\"\nLOCALHOST_HOSTNAME = \"localhost.localstack.cloud\"\n\n# version of the Maven dependency with Java utility code\nLOCALSTACK_MAVEN_VERSION = \"0.2.16\"\n\n# map of default service APIs and ports to be spun up (fetch map from localstack_client)\nDEFAULT_SERVICE_PORTS = localstack_client.config.get_service_ports()\n\n# host to bind to when starting the services\nBIND_HOST = \"0.0.0.0\"\n\n# AWS user account ID used for tests\nif \"TEST_AWS_ACCOUNT_ID\" not in os.environ:\n os.environ[\"TEST_AWS_ACCOUNT_ID\"] = \"000000000000\"\nTEST_AWS_ACCOUNT_ID = os.environ[\"TEST_AWS_ACCOUNT_ID\"]\n\n# root code folder\nMODULE_MAIN_PATH = os.path.dirname(os.path.realpath(__file__))\n# TODO rename to \"ROOT_FOLDER\"!\nLOCALSTACK_ROOT_FOLDER = os.path.realpath(os.path.join(MODULE_MAIN_PATH, \"..\"))\nINSTALL_DIR_INFRA = os.path.join(MODULE_MAIN_PATH, \"infra\")\n\n# virtualenv folder\nLOCALSTACK_VENV_FOLDER = os.path.join(LOCALSTACK_ROOT_FOLDER, \".venv\")\nif not os.path.isdir(LOCALSTACK_VENV_FOLDER):\n # assuming this package lives here: <python>/lib/pythonX.X/site-packages/localstack/\n LOCALSTACK_VENV_FOLDER = os.path.realpath(\n os.path.join(LOCALSTACK_ROOT_FOLDER, \"..\", \"..\", \"..\")\n )\n\n# API Gateway path to indicate a user request sent to the gateway\nPATH_USER_REQUEST = \"_user_request_\"\n\n# name of LocalStack Docker image\nDOCKER_IMAGE_NAME = \"localstack/localstack\"\nDOCKER_IMAGE_NAME_FULL = \"localstack/localstack-full\"\n\n# backdoor API path used to retrieve or update config variables\nCONFIG_UPDATE_PATH = \"/?_config_\"\n\n# environment variable name to tag local test runs\nENV_INTERNAL_TEST_RUN = \"LOCALSTACK_INTERNAL_TEST_RUN\"\n\n# environment variable that flags whether pro was activated. do not use for security purposes!\nENV_PRO_ACTIVATED = \"PRO_ACTIVATED\"\n\n# content types\nHEADER_CONTENT_TYPE = \"Content-Type\"\nAPPLICATION_AMZ_JSON_1_0 = \"application/x-amz-json-1.0\"\nAPPLICATION_AMZ_JSON_1_1 = \"application/x-amz-json-1.1\"\nAPPLICATION_AMZ_CBOR_1_1 = \"application/x-amz-cbor-1.1\"\nAPPLICATION_CBOR = \"application/cbor\"\nAPPLICATION_JSON = \"application/json\"\nAPPLICATION_XML = \"application/xml\"\nAPPLICATION_OCTET_STREAM = \"application/octet-stream\"\nAPPLICATION_X_WWW_FORM_URLENCODED = \"application/x-www-form-urlencoded\"\n\n# strings to indicate truthy/falsy values\nTRUE_STRINGS = (\"1\", \"true\", \"True\")\nFALSE_STRINGS = (\"0\", \"false\", \"False\")\n# strings with valid log levels for LS_LOG\nLOG_LEVELS = (\"trace-internal\", \"trace\", \"debug\", \"info\", \"warn\", \"error\", \"warning\")\n\n# Lambda defaults\nLAMBDA_TEST_ROLE = \"arn:aws:iam::%s:role/lambda-test-role\" % TEST_AWS_ACCOUNT_ID\n\n# installation constants\nELASTICSEARCH_URLS = {\n \"7.10.0\": \"https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.10.0-linux-x86_64.tar.gz\",\n \"7.7.0\": \"https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.7.0-linux-x86_64.tar.gz\",\n \"7.4.0\": \"https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.0-linux-x86_64.tar.gz\",\n \"7.1.0\": \"https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.1.0-linux-x86_64.tar.gz\",\n \"6.7.0\": \"https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.7.0.zip\",\n}\nELASTICSEARCH_DEFAULT_VERSION = \"7.10.0\"\n# See https://docs.aws.amazon.com/ja_jp/elasticsearch-service/latest/developerguide/aes-supported-plugins.html\nELASTICSEARCH_PLUGIN_LIST = [\n \"analysis-icu\",\n \"ingest-attachment\",\n \"analysis-kuromoji\",\n \"mapper-murmur3\",\n \"mapper-size\",\n \"analysis-phonetic\",\n \"analysis-smartcn\",\n \"analysis-stempel\",\n \"analysis-ukrainian\",\n]\n# Default ES modules to exclude (save apprx 66MB in the final image)\nELASTICSEARCH_DELETE_MODULES = [\"ingest-geoip\"]\nELASTICMQ_JAR_URL = (\n \"https://s3-eu-west-1.amazonaws.com/softwaremill-public/elasticmq-server-1.1.0.jar\"\n)\nSTS_JAR_URL = \"https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-sts/1.11.14/aws-java-sdk-sts-1.11.14.jar\"\nSTEPFUNCTIONS_ZIP_URL = \"https://s3.amazonaws.com/stepfunctionslocal/StepFunctionsLocal.zip\"\nKMS_URL_PATTERN = \"https://s3-eu-west-2.amazonaws.com/local-kms/localstack/v3/local-kms.<arch>.bin\"\n\n# TODO: Temporarily using a fixed version of DDB in Alpine, as we're hitting a SIGSEGV JVM crash with latest\nDYNAMODB_JAR_URL_ALPINE = \"https://github.com/localstack/localstack-artifacts/raw/master/dynamodb-local-patch/etc/DynamoDBLocal.zip\"\nDYNAMODB_JAR_URL = \"https://s3-us-west-2.amazonaws.com/dynamodb-local/dynamodb_local_latest.zip\"\n\n# API endpoint for analytics events\nAPI_ENDPOINT = os.environ.get(\"API_ENDPOINT\") or \"https://api.localstack.cloud/v1\"\n# new analytics API endpoint\nANALYTICS_API = os.environ.get(\"ANALYTICS_API\") or \"https://analytics.localstack.cloud/v0\"\n\n# environment variable to indicates that this process is running the Web UI\nLOCALSTACK_WEB_PROCESS = \"LOCALSTACK_WEB_PROCESS\"\nLOCALSTACK_INFRA_PROCESS = \"LOCALSTACK_INFRA_PROCESS\"\n\n# hardcoded AWS account ID used by moto\nMOTO_ACCOUNT_ID = TEST_AWS_ACCOUNT_ID\n# fix moto account ID - note: keep this at the top level here\ntry:\n from moto import core as moto_core\n from moto.core import models as moto_core_models\n\n moto_core.ACCOUNT_ID = moto_core_models.ACCOUNT_ID = MOTO_ACCOUNT_ID\nexcept Exception:\n # ignore import errors\n pass\n\n# default AWS region us-east-1\nAWS_REGION_US_EAST_1 = \"us-east-1\"\n\n# default lambda registry\nDEFAULT_LAMBDA_CONTAINER_REGISTRY = \"lambci/lambda\"\n\n# environment variable to override max pool connections\ntry:\n MAX_POOL_CONNECTIONS = int(os.environ[\"MAX_POOL_CONNECTIONS\"])\nexcept Exception:\n MAX_POOL_CONNECTIONS = 150\n\n# test credentials used for generating signature for S3 presigned URLs (to be used by external clients)\nTEST_AWS_ACCESS_KEY_ID = \"test\"\nTEST_AWS_SECRET_ACCESS_KEY = \"test\"\n\n# credentials being used for internal calls\nINTERNAL_AWS_ACCESS_KEY_ID = \"__internal_call__\"\nINTERNAL_AWS_SECRET_ACCESS_KEY = \"__internal_call__\"\n\n# trace log levels (excluding/including internal API calls), configurable via $LS_LOG\nLS_LOG_TRACE = \"trace\"\nLS_LOG_TRACE_INTERNAL = \"trace-internal\"\nTRACE_LOG_LEVELS = [LS_LOG_TRACE, LS_LOG_TRACE_INTERNAL]\n\n# list of official docker images\nOFFICIAL_IMAGES = [\n \"localstack/localstack\",\n \"localstack/localstack-light\",\n \"localstack/localstack-full\",\n]\n\n# s3 virtual host name\nS3_VIRTUAL_HOSTNAME = \"s3.%s\" % LOCALHOST_HOSTNAME\nS3_STATIC_WEBSITE_HOSTNAME = \"s3-website.%s\" % LOCALHOST_HOSTNAME\n\n# port for debug py\nDEFAULT_DEVELOP_PORT = 5678\n\n# Default bucket name of the s3 bucket used for local lambda development\nDEFAULT_BUCKET_MARKER_LOCAL = \"__local__\"\n\n# user that starts the elasticsearch process if the current user is root\nOS_USER_ELASTICSEARCH = \"localstack\"\n", "path": "localstack/constants.py"}], "after_files": [{"content": "import os\n\nimport localstack_client.config\n\nimport localstack\n\n# LocalStack version\nVERSION = localstack.__version__\n\n# constant to represent the \"local\" region, i.e., local machine\nREGION_LOCAL = \"local\"\n\n# dev environment\nENV_DEV = \"dev\"\n\n# HTTP headers used to forward proxy request URLs\nHEADER_LOCALSTACK_EDGE_URL = \"x-localstack-edge\"\nHEADER_LOCALSTACK_REQUEST_URL = \"x-localstack-request-url\"\nHEADER_LOCALSTACK_TARGET = \"x-localstack-target\"\nHEADER_AMZN_ERROR_TYPE = \"X-Amzn-Errortype\"\n\n# backend service ports, for services that are behind a proxy (counting down from 4566)\nDEFAULT_PORT_EDGE = 4566\n\n# host name for localhost\nLOCALHOST = \"localhost\"\nLOCALHOST_IP = \"127.0.0.1\"\nLOCALHOST_HOSTNAME = \"localhost.localstack.cloud\"\n\n# version of the Maven dependency with Java utility code\nLOCALSTACK_MAVEN_VERSION = \"0.2.17\"\n\n# map of default service APIs and ports to be spun up (fetch map from localstack_client)\nDEFAULT_SERVICE_PORTS = localstack_client.config.get_service_ports()\n\n# host to bind to when starting the services\nBIND_HOST = \"0.0.0.0\"\n\n# AWS user account ID used for tests\nif \"TEST_AWS_ACCOUNT_ID\" not in os.environ:\n os.environ[\"TEST_AWS_ACCOUNT_ID\"] = \"000000000000\"\nTEST_AWS_ACCOUNT_ID = os.environ[\"TEST_AWS_ACCOUNT_ID\"]\n\n# root code folder\nMODULE_MAIN_PATH = os.path.dirname(os.path.realpath(__file__))\n# TODO rename to \"ROOT_FOLDER\"!\nLOCALSTACK_ROOT_FOLDER = os.path.realpath(os.path.join(MODULE_MAIN_PATH, \"..\"))\nINSTALL_DIR_INFRA = os.path.join(MODULE_MAIN_PATH, \"infra\")\n\n# virtualenv folder\nLOCALSTACK_VENV_FOLDER = os.path.join(LOCALSTACK_ROOT_FOLDER, \".venv\")\nif not os.path.isdir(LOCALSTACK_VENV_FOLDER):\n # assuming this package lives here: <python>/lib/pythonX.X/site-packages/localstack/\n LOCALSTACK_VENV_FOLDER = os.path.realpath(\n os.path.join(LOCALSTACK_ROOT_FOLDER, \"..\", \"..\", \"..\")\n )\n\n# API Gateway path to indicate a user request sent to the gateway\nPATH_USER_REQUEST = \"_user_request_\"\n\n# name of LocalStack Docker image\nDOCKER_IMAGE_NAME = \"localstack/localstack\"\nDOCKER_IMAGE_NAME_FULL = \"localstack/localstack-full\"\n\n# backdoor API path used to retrieve or update config variables\nCONFIG_UPDATE_PATH = \"/?_config_\"\n\n# environment variable name to tag local test runs\nENV_INTERNAL_TEST_RUN = \"LOCALSTACK_INTERNAL_TEST_RUN\"\n\n# environment variable that flags whether pro was activated. do not use for security purposes!\nENV_PRO_ACTIVATED = \"PRO_ACTIVATED\"\n\n# content types\nHEADER_CONTENT_TYPE = \"Content-Type\"\nAPPLICATION_AMZ_JSON_1_0 = \"application/x-amz-json-1.0\"\nAPPLICATION_AMZ_JSON_1_1 = \"application/x-amz-json-1.1\"\nAPPLICATION_AMZ_CBOR_1_1 = \"application/x-amz-cbor-1.1\"\nAPPLICATION_CBOR = \"application/cbor\"\nAPPLICATION_JSON = \"application/json\"\nAPPLICATION_XML = \"application/xml\"\nAPPLICATION_OCTET_STREAM = \"application/octet-stream\"\nAPPLICATION_X_WWW_FORM_URLENCODED = \"application/x-www-form-urlencoded\"\n\n# strings to indicate truthy/falsy values\nTRUE_STRINGS = (\"1\", \"true\", \"True\")\nFALSE_STRINGS = (\"0\", \"false\", \"False\")\n# strings with valid log levels for LS_LOG\nLOG_LEVELS = (\"trace-internal\", \"trace\", \"debug\", \"info\", \"warn\", \"error\", \"warning\")\n\n# Lambda defaults\nLAMBDA_TEST_ROLE = \"arn:aws:iam::%s:role/lambda-test-role\" % TEST_AWS_ACCOUNT_ID\n\n# installation constants\nELASTICSEARCH_URLS = {\n \"7.10.0\": \"https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.10.0-linux-x86_64.tar.gz\",\n \"7.7.0\": \"https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.7.0-linux-x86_64.tar.gz\",\n \"7.4.0\": \"https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.0-linux-x86_64.tar.gz\",\n \"7.1.0\": \"https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.1.0-linux-x86_64.tar.gz\",\n \"6.7.0\": \"https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.7.0.zip\",\n}\nELASTICSEARCH_DEFAULT_VERSION = \"7.10.0\"\n# See https://docs.aws.amazon.com/ja_jp/elasticsearch-service/latest/developerguide/aes-supported-plugins.html\nELASTICSEARCH_PLUGIN_LIST = [\n \"analysis-icu\",\n \"ingest-attachment\",\n \"analysis-kuromoji\",\n \"mapper-murmur3\",\n \"mapper-size\",\n \"analysis-phonetic\",\n \"analysis-smartcn\",\n \"analysis-stempel\",\n \"analysis-ukrainian\",\n]\n# Default ES modules to exclude (save apprx 66MB in the final image)\nELASTICSEARCH_DELETE_MODULES = [\"ingest-geoip\"]\nELASTICMQ_JAR_URL = (\n \"https://s3-eu-west-1.amazonaws.com/softwaremill-public/elasticmq-server-1.1.0.jar\"\n)\nSTS_JAR_URL = \"https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-sts/1.11.14/aws-java-sdk-sts-1.11.14.jar\"\nSTEPFUNCTIONS_ZIP_URL = \"https://s3.amazonaws.com/stepfunctionslocal/StepFunctionsLocal.zip\"\nKMS_URL_PATTERN = \"https://s3-eu-west-2.amazonaws.com/local-kms/localstack/v3/local-kms.<arch>.bin\"\n\n# TODO: Temporarily using a fixed version of DDB in Alpine, as we're hitting a SIGSEGV JVM crash with latest\nDYNAMODB_JAR_URL_ALPINE = \"https://github.com/localstack/localstack-artifacts/raw/master/dynamodb-local-patch/etc/DynamoDBLocal.zip\"\nDYNAMODB_JAR_URL = \"https://s3-us-west-2.amazonaws.com/dynamodb-local/dynamodb_local_latest.zip\"\n\n# API endpoint for analytics events\nAPI_ENDPOINT = os.environ.get(\"API_ENDPOINT\") or \"https://api.localstack.cloud/v1\"\n# new analytics API endpoint\nANALYTICS_API = os.environ.get(\"ANALYTICS_API\") or \"https://analytics.localstack.cloud/v0\"\n\n# environment variable to indicates that this process is running the Web UI\nLOCALSTACK_WEB_PROCESS = \"LOCALSTACK_WEB_PROCESS\"\nLOCALSTACK_INFRA_PROCESS = \"LOCALSTACK_INFRA_PROCESS\"\n\n# hardcoded AWS account ID used by moto\nMOTO_ACCOUNT_ID = TEST_AWS_ACCOUNT_ID\n# fix moto account ID - note: keep this at the top level here\ntry:\n from moto import core as moto_core\n from moto.core import models as moto_core_models\n\n moto_core.ACCOUNT_ID = moto_core_models.ACCOUNT_ID = MOTO_ACCOUNT_ID\nexcept Exception:\n # ignore import errors\n pass\n\n# default AWS region us-east-1\nAWS_REGION_US_EAST_1 = \"us-east-1\"\n\n# default lambda registry\nDEFAULT_LAMBDA_CONTAINER_REGISTRY = \"lambci/lambda\"\n\n# environment variable to override max pool connections\ntry:\n MAX_POOL_CONNECTIONS = int(os.environ[\"MAX_POOL_CONNECTIONS\"])\nexcept Exception:\n MAX_POOL_CONNECTIONS = 150\n\n# test credentials used for generating signature for S3 presigned URLs (to be used by external clients)\nTEST_AWS_ACCESS_KEY_ID = \"test\"\nTEST_AWS_SECRET_ACCESS_KEY = \"test\"\n\n# credentials being used for internal calls\nINTERNAL_AWS_ACCESS_KEY_ID = \"__internal_call__\"\nINTERNAL_AWS_SECRET_ACCESS_KEY = \"__internal_call__\"\n\n# trace log levels (excluding/including internal API calls), configurable via $LS_LOG\nLS_LOG_TRACE = \"trace\"\nLS_LOG_TRACE_INTERNAL = \"trace-internal\"\nTRACE_LOG_LEVELS = [LS_LOG_TRACE, LS_LOG_TRACE_INTERNAL]\n\n# list of official docker images\nOFFICIAL_IMAGES = [\n \"localstack/localstack\",\n \"localstack/localstack-light\",\n \"localstack/localstack-full\",\n]\n\n# s3 virtual host name\nS3_VIRTUAL_HOSTNAME = \"s3.%s\" % LOCALHOST_HOSTNAME\nS3_STATIC_WEBSITE_HOSTNAME = \"s3-website.%s\" % LOCALHOST_HOSTNAME\n\n# port for debug py\nDEFAULT_DEVELOP_PORT = 5678\n\n# Default bucket name of the s3 bucket used for local lambda development\nDEFAULT_BUCKET_MARKER_LOCAL = \"__local__\"\n\n# user that starts the elasticsearch process if the current user is root\nOS_USER_ELASTICSEARCH = \"localstack\"\n", "path": "localstack/constants.py"}]}
| 3,685 | 128 |
gh_patches_debug_41360
|
rasdani/github-patches
|
git_diff
|
cisagov__manage.get.gov-1860
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
The meta data report is not able to download on stable
### Current Behavior
The meta data report is not able to download on stable and results in an error
### Expected Behavior
The meta data report should download
### Steps to Reproduce
1.go to manage.get.gov/admin/registrar/domain
2. click the meta data report
3. see it takes for ever to load and throws an error
### Environment
stable
works fine on others
### Additional Context
Adding additional columns on the meta data report has resulted in a lot more computation time when it comes to our full data set. Look at the logic around columns and you will see some duplication that could be reduced.
### Issue Links
Relates to #1840 and #1556
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/registrar/utility/csv_export.py`
Content:
```
1 import csv
2 import logging
3 from datetime import datetime
4 from registrar.models.domain import Domain
5 from registrar.models.domain_information import DomainInformation
6 from django.utils import timezone
7 from django.core.paginator import Paginator
8 from django.db.models import F, Value, CharField
9 from django.db.models.functions import Concat, Coalesce
10
11 from registrar.models.public_contact import PublicContact
12 from registrar.utility.enums import DefaultEmail
13
14 logger = logging.getLogger(__name__)
15
16
17 def write_header(writer, columns):
18 """
19 Receives params from the parent methods and outputs a CSV with a header row.
20 Works with write_header as long as the same writer object is passed.
21 """
22
23 writer.writerow(columns)
24
25
26 def get_domain_infos(filter_condition, sort_fields):
27 domain_infos = (
28 DomainInformation.objects.select_related("domain", "authorizing_official")
29 .filter(**filter_condition)
30 .order_by(*sort_fields)
31 )
32
33 # Do a mass concat of the first and last name fields for authorizing_official.
34 # The old operation was computationally heavy for some reason, so if we precompute
35 # this here, it is vastly more efficient.
36 domain_infos_cleaned = domain_infos.annotate(
37 ao=Concat(
38 Coalesce(F("authorizing_official__first_name"), Value("")),
39 Value(" "),
40 Coalesce(F("authorizing_official__last_name"), Value("")),
41 output_field=CharField(),
42 )
43 )
44 return domain_infos_cleaned
45
46
47 def parse_row(columns, domain_info: DomainInformation, security_emails_dict=None, get_domain_managers=False):
48 """Given a set of columns, generate a new row from cleaned column data"""
49
50 # Domain should never be none when parsing this information
51 if domain_info.domain is None:
52 raise ValueError("Domain is none")
53
54 domain = domain_info.domain # type: ignore
55
56 # Grab the security email from a preset dictionary.
57 # If nothing exists in the dictionary, grab from .contacts.
58 if security_emails_dict is not None and domain.name in security_emails_dict:
59 _email = security_emails_dict.get(domain.name)
60 security_email = _email if _email is not None else " "
61 else:
62 # If the dictionary doesn't contain that data, lets filter for it manually.
63 # This is a last resort as this is a more expensive operation.
64 security_contacts = domain.contacts.filter(contact_type=PublicContact.ContactTypeChoices.SECURITY)
65 _email = security_contacts[0].email if security_contacts else None
66 security_email = _email if _email is not None else " "
67
68 # These are default emails that should not be displayed in the csv report
69 invalid_emails = {DefaultEmail.LEGACY_DEFAULT.value, DefaultEmail.PUBLIC_CONTACT_DEFAULT.value}
70 if security_email.lower() in invalid_emails:
71 security_email = "(blank)"
72
73 if domain_info.federal_type:
74 domain_type = f"{domain_info.get_organization_type_display()} - {domain_info.get_federal_type_display()}"
75 else:
76 domain_type = domain_info.get_organization_type_display()
77
78 # create a dictionary of fields which can be included in output
79 FIELDS = {
80 "Domain name": domain.name,
81 "Status": domain.get_state_display(),
82 "Expiration date": domain.expiration_date,
83 "Domain type": domain_type,
84 "Agency": domain_info.federal_agency,
85 "Organization name": domain_info.organization_name,
86 "City": domain_info.city,
87 "State": domain_info.state_territory,
88 "AO": domain_info.ao, # type: ignore
89 "AO email": domain_info.authorizing_official.email if domain_info.authorizing_official else " ",
90 "Security contact email": security_email,
91 "Created at": domain.created_at,
92 "First ready": domain.first_ready,
93 "Deleted": domain.deleted,
94 }
95
96 if get_domain_managers:
97 # Get each domain managers email and add to list
98 dm_emails = [dm.user.email for dm in domain.permissions.all()]
99
100 # Set up the "matching header" + row field data
101 for i, dm_email in enumerate(dm_emails, start=1):
102 FIELDS[f"Domain manager email {i}"] = dm_email
103
104 row = [FIELDS.get(column, "") for column in columns]
105 return row
106
107
108 def _get_security_emails(sec_contact_ids):
109 """
110 Retrieve security contact emails for the given security contact IDs.
111 """
112 security_emails_dict = {}
113 public_contacts = (
114 PublicContact.objects.only("email", "domain__name")
115 .select_related("domain")
116 .filter(registry_id__in=sec_contact_ids)
117 )
118
119 # Populate a dictionary of domain names and their security contacts
120 for contact in public_contacts:
121 domain: Domain = contact.domain
122 if domain is not None and domain.name not in security_emails_dict:
123 security_emails_dict[domain.name] = contact.email
124 else:
125 logger.warning("csv_export -> Domain was none for PublicContact")
126
127 return security_emails_dict
128
129
130 def update_columns_with_domain_managers(columns, max_dm_count):
131 """
132 Update the columns list to include "Domain manager email {#}" headers
133 based on the maximum domain manager count.
134 """
135 for i in range(1, max_dm_count + 1):
136 columns.append(f"Domain manager email {i}")
137
138
139 def write_csv(
140 writer,
141 columns,
142 sort_fields,
143 filter_condition,
144 get_domain_managers=False,
145 should_write_header=True,
146 ):
147 """
148 Receives params from the parent methods and outputs a CSV with fltered and sorted domains.
149 Works with write_header as longas the same writer object is passed.
150 get_domain_managers: Conditional bc we only use domain manager info for export_data_full_to_csv
151 should_write_header: Conditional bc export_data_growth_to_csv calls write_body twice
152 """
153
154 all_domain_infos = get_domain_infos(filter_condition, sort_fields)
155
156 # Store all security emails to avoid epp calls or excessive filters
157 sec_contact_ids = all_domain_infos.values_list("domain__security_contact_registry_id", flat=True)
158
159 security_emails_dict = _get_security_emails(sec_contact_ids)
160
161 # Reduce the memory overhead when performing the write operation
162 paginator = Paginator(all_domain_infos, 1000)
163
164 if get_domain_managers and len(all_domain_infos) > 0:
165 # We want to get the max amont of domain managers an
166 # account has to set the column header dynamically
167 max_dm_count = max(len(domain_info.domain.permissions.all()) for domain_info in all_domain_infos)
168 update_columns_with_domain_managers(columns, max_dm_count)
169
170 if should_write_header:
171 write_header(writer, columns)
172
173 for page_num in paginator.page_range:
174 rows = []
175 page = paginator.page(page_num)
176 for domain_info in page.object_list:
177 try:
178 row = parse_row(columns, domain_info, security_emails_dict, get_domain_managers)
179 rows.append(row)
180 except ValueError:
181 # This should not happen. If it does, just skip this row.
182 # It indicates that DomainInformation.domain is None.
183 logger.error("csv_export -> Error when parsing row, domain was None")
184 continue
185
186 writer.writerows(rows)
187
188
189 def export_data_type_to_csv(csv_file):
190 """All domains report with extra columns"""
191
192 writer = csv.writer(csv_file)
193 # define columns to include in export
194 columns = [
195 "Domain name",
196 "Status",
197 "Expiration date",
198 "Domain type",
199 "Agency",
200 "Organization name",
201 "City",
202 "State",
203 "AO",
204 "AO email",
205 "Security contact email",
206 # For domain manager we are pass it in as a parameter below in write_body
207 ]
208
209 # Coalesce is used to replace federal_type of None with ZZZZZ
210 sort_fields = [
211 "organization_type",
212 Coalesce("federal_type", Value("ZZZZZ")),
213 "federal_agency",
214 "domain__name",
215 ]
216 filter_condition = {
217 "domain__state__in": [
218 Domain.State.READY,
219 Domain.State.DNS_NEEDED,
220 Domain.State.ON_HOLD,
221 ],
222 }
223 write_csv(writer, columns, sort_fields, filter_condition, get_domain_managers=True, should_write_header=True)
224
225
226 def export_data_full_to_csv(csv_file):
227 """All domains report"""
228
229 writer = csv.writer(csv_file)
230 # define columns to include in export
231 columns = [
232 "Domain name",
233 "Domain type",
234 "Agency",
235 "Organization name",
236 "City",
237 "State",
238 "Security contact email",
239 ]
240 # Coalesce is used to replace federal_type of None with ZZZZZ
241 sort_fields = [
242 "organization_type",
243 Coalesce("federal_type", Value("ZZZZZ")),
244 "federal_agency",
245 "domain__name",
246 ]
247 filter_condition = {
248 "domain__state__in": [
249 Domain.State.READY,
250 Domain.State.DNS_NEEDED,
251 Domain.State.ON_HOLD,
252 ],
253 }
254 write_csv(writer, columns, sort_fields, filter_condition, get_domain_managers=False, should_write_header=True)
255
256
257 def export_data_federal_to_csv(csv_file):
258 """Federal domains report"""
259
260 writer = csv.writer(csv_file)
261 # define columns to include in export
262 columns = [
263 "Domain name",
264 "Domain type",
265 "Agency",
266 "Organization name",
267 "City",
268 "State",
269 "Security contact email",
270 ]
271 # Coalesce is used to replace federal_type of None with ZZZZZ
272 sort_fields = [
273 "organization_type",
274 Coalesce("federal_type", Value("ZZZZZ")),
275 "federal_agency",
276 "domain__name",
277 ]
278 filter_condition = {
279 "organization_type__icontains": "federal",
280 "domain__state__in": [
281 Domain.State.READY,
282 Domain.State.DNS_NEEDED,
283 Domain.State.ON_HOLD,
284 ],
285 }
286 write_csv(writer, columns, sort_fields, filter_condition, get_domain_managers=False, should_write_header=True)
287
288
289 def get_default_start_date():
290 # Default to a date that's prior to our first deployment
291 return timezone.make_aware(datetime(2023, 11, 1))
292
293
294 def get_default_end_date():
295 # Default to now()
296 return timezone.now()
297
298
299 def export_data_growth_to_csv(csv_file, start_date, end_date):
300 """
301 Growth report:
302 Receive start and end dates from the view, parse them.
303 Request from write_body READY domains that are created between
304 the start and end dates, as well as DELETED domains that are deleted between
305 the start and end dates. Specify sort params for both lists.
306 """
307
308 start_date_formatted = (
309 timezone.make_aware(datetime.strptime(start_date, "%Y-%m-%d")) if start_date else get_default_start_date()
310 )
311
312 end_date_formatted = (
313 timezone.make_aware(datetime.strptime(end_date, "%Y-%m-%d")) if end_date else get_default_end_date()
314 )
315
316 writer = csv.writer(csv_file)
317
318 # define columns to include in export
319 columns = [
320 "Domain name",
321 "Domain type",
322 "Agency",
323 "Organization name",
324 "City",
325 "State",
326 "Status",
327 "Expiration date",
328 "Created at",
329 "First ready",
330 "Deleted",
331 ]
332 sort_fields = [
333 "domain__first_ready",
334 "domain__name",
335 ]
336 filter_condition = {
337 "domain__state__in": [Domain.State.READY],
338 "domain__first_ready__lte": end_date_formatted,
339 "domain__first_ready__gte": start_date_formatted,
340 }
341
342 # We also want domains deleted between sar and end dates, sorted
343 sort_fields_for_deleted_domains = [
344 "domain__deleted",
345 "domain__name",
346 ]
347 filter_condition_for_deleted_domains = {
348 "domain__state__in": [Domain.State.DELETED],
349 "domain__deleted__lte": end_date_formatted,
350 "domain__deleted__gte": start_date_formatted,
351 }
352
353 write_csv(writer, columns, sort_fields, filter_condition, get_domain_managers=False, should_write_header=True)
354 write_csv(
355 writer,
356 columns,
357 sort_fields_for_deleted_domains,
358 filter_condition_for_deleted_domains,
359 get_domain_managers=False,
360 should_write_header=False,
361 )
362
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/registrar/utility/csv_export.py b/src/registrar/utility/csv_export.py
--- a/src/registrar/utility/csv_export.py
+++ b/src/registrar/utility/csv_export.py
@@ -26,6 +26,7 @@
def get_domain_infos(filter_condition, sort_fields):
domain_infos = (
DomainInformation.objects.select_related("domain", "authorizing_official")
+ .prefetch_related("domain__permissions")
.filter(**filter_condition)
.order_by(*sort_fields)
)
@@ -49,6 +50,7 @@
# Domain should never be none when parsing this information
if domain_info.domain is None:
+ logger.error("Attemting to parse row for csv exports but Domain is none in a DomainInfo")
raise ValueError("Domain is none")
domain = domain_info.domain # type: ignore
@@ -127,15 +129,6 @@
return security_emails_dict
-def update_columns_with_domain_managers(columns, max_dm_count):
- """
- Update the columns list to include "Domain manager email {#}" headers
- based on the maximum domain manager count.
- """
- for i in range(1, max_dm_count + 1):
- columns.append(f"Domain manager email {i}")
-
-
def write_csv(
writer,
columns,
@@ -161,19 +154,26 @@
# Reduce the memory overhead when performing the write operation
paginator = Paginator(all_domain_infos, 1000)
- if get_domain_managers and len(all_domain_infos) > 0:
- # We want to get the max amont of domain managers an
- # account has to set the column header dynamically
- max_dm_count = max(len(domain_info.domain.permissions.all()) for domain_info in all_domain_infos)
- update_columns_with_domain_managers(columns, max_dm_count)
-
- if should_write_header:
- write_header(writer, columns)
+ # The maximum amount of domain managers an account has
+ # We get the max so we can set the column header accurately
+ max_dm_count = 0
+ total_body_rows = []
for page_num in paginator.page_range:
rows = []
page = paginator.page(page_num)
for domain_info in page.object_list:
+
+ # Get count of all the domain managers for an account
+ if get_domain_managers:
+ dm_count = domain_info.domain.permissions.count()
+ if dm_count > max_dm_count:
+ max_dm_count = dm_count
+ for i in range(1, max_dm_count + 1):
+ column_name = f"Domain manager email {i}"
+ if column_name not in columns:
+ columns.append(column_name)
+
try:
row = parse_row(columns, domain_info, security_emails_dict, get_domain_managers)
rows.append(row)
@@ -182,8 +182,11 @@
# It indicates that DomainInformation.domain is None.
logger.error("csv_export -> Error when parsing row, domain was None")
continue
+ total_body_rows.extend(rows)
- writer.writerows(rows)
+ if should_write_header:
+ write_header(writer, columns)
+ writer.writerows(total_body_rows)
def export_data_type_to_csv(csv_file):
|
{"golden_diff": "diff --git a/src/registrar/utility/csv_export.py b/src/registrar/utility/csv_export.py\n--- a/src/registrar/utility/csv_export.py\n+++ b/src/registrar/utility/csv_export.py\n@@ -26,6 +26,7 @@\n def get_domain_infos(filter_condition, sort_fields):\n domain_infos = (\n DomainInformation.objects.select_related(\"domain\", \"authorizing_official\")\n+ .prefetch_related(\"domain__permissions\")\n .filter(**filter_condition)\n .order_by(*sort_fields)\n )\n@@ -49,6 +50,7 @@\n \n # Domain should never be none when parsing this information\n if domain_info.domain is None:\n+ logger.error(\"Attemting to parse row for csv exports but Domain is none in a DomainInfo\")\n raise ValueError(\"Domain is none\")\n \n domain = domain_info.domain # type: ignore\n@@ -127,15 +129,6 @@\n return security_emails_dict\n \n \n-def update_columns_with_domain_managers(columns, max_dm_count):\n- \"\"\"\n- Update the columns list to include \"Domain manager email {#}\" headers\n- based on the maximum domain manager count.\n- \"\"\"\n- for i in range(1, max_dm_count + 1):\n- columns.append(f\"Domain manager email {i}\")\n-\n-\n def write_csv(\n writer,\n columns,\n@@ -161,19 +154,26 @@\n # Reduce the memory overhead when performing the write operation\n paginator = Paginator(all_domain_infos, 1000)\n \n- if get_domain_managers and len(all_domain_infos) > 0:\n- # We want to get the max amont of domain managers an\n- # account has to set the column header dynamically\n- max_dm_count = max(len(domain_info.domain.permissions.all()) for domain_info in all_domain_infos)\n- update_columns_with_domain_managers(columns, max_dm_count)\n-\n- if should_write_header:\n- write_header(writer, columns)\n+ # The maximum amount of domain managers an account has\n+ # We get the max so we can set the column header accurately\n+ max_dm_count = 0\n+ total_body_rows = []\n \n for page_num in paginator.page_range:\n rows = []\n page = paginator.page(page_num)\n for domain_info in page.object_list:\n+\n+ # Get count of all the domain managers for an account\n+ if get_domain_managers:\n+ dm_count = domain_info.domain.permissions.count()\n+ if dm_count > max_dm_count:\n+ max_dm_count = dm_count\n+ for i in range(1, max_dm_count + 1):\n+ column_name = f\"Domain manager email {i}\"\n+ if column_name not in columns:\n+ columns.append(column_name)\n+\n try:\n row = parse_row(columns, domain_info, security_emails_dict, get_domain_managers)\n rows.append(row)\n@@ -182,8 +182,11 @@\n # It indicates that DomainInformation.domain is None.\n logger.error(\"csv_export -> Error when parsing row, domain was None\")\n continue\n+ total_body_rows.extend(rows)\n \n- writer.writerows(rows)\n+ if should_write_header:\n+ write_header(writer, columns)\n+ writer.writerows(total_body_rows)\n \n \n def export_data_type_to_csv(csv_file):\n", "issue": "The meta data report is not able to download on stable\n### Current Behavior\n\nThe meta data report is not able to download on stable and results in an error\n\n### Expected Behavior\n\nThe meta data report should download\n\n### Steps to Reproduce\n\n1.go to manage.get.gov/admin/registrar/domain\r\n2. click the meta data report\r\n3. see it takes for ever to load and throws an error\r\n\n\n### Environment\n\nstable\r\n\r\nworks fine on others\n\n### Additional Context\n\nAdding additional columns on the meta data report has resulted in a lot more computation time when it comes to our full data set. Look at the logic around columns and you will see some duplication that could be reduced. \n\n### Issue Links\n\nRelates to #1840 and #1556 \n", "before_files": [{"content": "import csv\nimport logging\nfrom datetime import datetime\nfrom registrar.models.domain import Domain\nfrom registrar.models.domain_information import DomainInformation\nfrom django.utils import timezone\nfrom django.core.paginator import Paginator\nfrom django.db.models import F, Value, CharField\nfrom django.db.models.functions import Concat, Coalesce\n\nfrom registrar.models.public_contact import PublicContact\nfrom registrar.utility.enums import DefaultEmail\n\nlogger = logging.getLogger(__name__)\n\n\ndef write_header(writer, columns):\n \"\"\"\n Receives params from the parent methods and outputs a CSV with a header row.\n Works with write_header as long as the same writer object is passed.\n \"\"\"\n\n writer.writerow(columns)\n\n\ndef get_domain_infos(filter_condition, sort_fields):\n domain_infos = (\n DomainInformation.objects.select_related(\"domain\", \"authorizing_official\")\n .filter(**filter_condition)\n .order_by(*sort_fields)\n )\n\n # Do a mass concat of the first and last name fields for authorizing_official.\n # The old operation was computationally heavy for some reason, so if we precompute\n # this here, it is vastly more efficient.\n domain_infos_cleaned = domain_infos.annotate(\n ao=Concat(\n Coalesce(F(\"authorizing_official__first_name\"), Value(\"\")),\n Value(\" \"),\n Coalesce(F(\"authorizing_official__last_name\"), Value(\"\")),\n output_field=CharField(),\n )\n )\n return domain_infos_cleaned\n\n\ndef parse_row(columns, domain_info: DomainInformation, security_emails_dict=None, get_domain_managers=False):\n \"\"\"Given a set of columns, generate a new row from cleaned column data\"\"\"\n\n # Domain should never be none when parsing this information\n if domain_info.domain is None:\n raise ValueError(\"Domain is none\")\n\n domain = domain_info.domain # type: ignore\n\n # Grab the security email from a preset dictionary.\n # If nothing exists in the dictionary, grab from .contacts.\n if security_emails_dict is not None and domain.name in security_emails_dict:\n _email = security_emails_dict.get(domain.name)\n security_email = _email if _email is not None else \" \"\n else:\n # If the dictionary doesn't contain that data, lets filter for it manually.\n # This is a last resort as this is a more expensive operation.\n security_contacts = domain.contacts.filter(contact_type=PublicContact.ContactTypeChoices.SECURITY)\n _email = security_contacts[0].email if security_contacts else None\n security_email = _email if _email is not None else \" \"\n\n # These are default emails that should not be displayed in the csv report\n invalid_emails = {DefaultEmail.LEGACY_DEFAULT.value, DefaultEmail.PUBLIC_CONTACT_DEFAULT.value}\n if security_email.lower() in invalid_emails:\n security_email = \"(blank)\"\n\n if domain_info.federal_type:\n domain_type = f\"{domain_info.get_organization_type_display()} - {domain_info.get_federal_type_display()}\"\n else:\n domain_type = domain_info.get_organization_type_display()\n\n # create a dictionary of fields which can be included in output\n FIELDS = {\n \"Domain name\": domain.name,\n \"Status\": domain.get_state_display(),\n \"Expiration date\": domain.expiration_date,\n \"Domain type\": domain_type,\n \"Agency\": domain_info.federal_agency,\n \"Organization name\": domain_info.organization_name,\n \"City\": domain_info.city,\n \"State\": domain_info.state_territory,\n \"AO\": domain_info.ao, # type: ignore\n \"AO email\": domain_info.authorizing_official.email if domain_info.authorizing_official else \" \",\n \"Security contact email\": security_email,\n \"Created at\": domain.created_at,\n \"First ready\": domain.first_ready,\n \"Deleted\": domain.deleted,\n }\n\n if get_domain_managers:\n # Get each domain managers email and add to list\n dm_emails = [dm.user.email for dm in domain.permissions.all()]\n\n # Set up the \"matching header\" + row field data\n for i, dm_email in enumerate(dm_emails, start=1):\n FIELDS[f\"Domain manager email {i}\"] = dm_email\n\n row = [FIELDS.get(column, \"\") for column in columns]\n return row\n\n\ndef _get_security_emails(sec_contact_ids):\n \"\"\"\n Retrieve security contact emails for the given security contact IDs.\n \"\"\"\n security_emails_dict = {}\n public_contacts = (\n PublicContact.objects.only(\"email\", \"domain__name\")\n .select_related(\"domain\")\n .filter(registry_id__in=sec_contact_ids)\n )\n\n # Populate a dictionary of domain names and their security contacts\n for contact in public_contacts:\n domain: Domain = contact.domain\n if domain is not None and domain.name not in security_emails_dict:\n security_emails_dict[domain.name] = contact.email\n else:\n logger.warning(\"csv_export -> Domain was none for PublicContact\")\n\n return security_emails_dict\n\n\ndef update_columns_with_domain_managers(columns, max_dm_count):\n \"\"\"\n Update the columns list to include \"Domain manager email {#}\" headers\n based on the maximum domain manager count.\n \"\"\"\n for i in range(1, max_dm_count + 1):\n columns.append(f\"Domain manager email {i}\")\n\n\ndef write_csv(\n writer,\n columns,\n sort_fields,\n filter_condition,\n get_domain_managers=False,\n should_write_header=True,\n):\n \"\"\"\n Receives params from the parent methods and outputs a CSV with fltered and sorted domains.\n Works with write_header as longas the same writer object is passed.\n get_domain_managers: Conditional bc we only use domain manager info for export_data_full_to_csv\n should_write_header: Conditional bc export_data_growth_to_csv calls write_body twice\n \"\"\"\n\n all_domain_infos = get_domain_infos(filter_condition, sort_fields)\n\n # Store all security emails to avoid epp calls or excessive filters\n sec_contact_ids = all_domain_infos.values_list(\"domain__security_contact_registry_id\", flat=True)\n\n security_emails_dict = _get_security_emails(sec_contact_ids)\n\n # Reduce the memory overhead when performing the write operation\n paginator = Paginator(all_domain_infos, 1000)\n\n if get_domain_managers and len(all_domain_infos) > 0:\n # We want to get the max amont of domain managers an\n # account has to set the column header dynamically\n max_dm_count = max(len(domain_info.domain.permissions.all()) for domain_info in all_domain_infos)\n update_columns_with_domain_managers(columns, max_dm_count)\n\n if should_write_header:\n write_header(writer, columns)\n\n for page_num in paginator.page_range:\n rows = []\n page = paginator.page(page_num)\n for domain_info in page.object_list:\n try:\n row = parse_row(columns, domain_info, security_emails_dict, get_domain_managers)\n rows.append(row)\n except ValueError:\n # This should not happen. If it does, just skip this row.\n # It indicates that DomainInformation.domain is None.\n logger.error(\"csv_export -> Error when parsing row, domain was None\")\n continue\n\n writer.writerows(rows)\n\n\ndef export_data_type_to_csv(csv_file):\n \"\"\"All domains report with extra columns\"\"\"\n\n writer = csv.writer(csv_file)\n # define columns to include in export\n columns = [\n \"Domain name\",\n \"Status\",\n \"Expiration date\",\n \"Domain type\",\n \"Agency\",\n \"Organization name\",\n \"City\",\n \"State\",\n \"AO\",\n \"AO email\",\n \"Security contact email\",\n # For domain manager we are pass it in as a parameter below in write_body\n ]\n\n # Coalesce is used to replace federal_type of None with ZZZZZ\n sort_fields = [\n \"organization_type\",\n Coalesce(\"federal_type\", Value(\"ZZZZZ\")),\n \"federal_agency\",\n \"domain__name\",\n ]\n filter_condition = {\n \"domain__state__in\": [\n Domain.State.READY,\n Domain.State.DNS_NEEDED,\n Domain.State.ON_HOLD,\n ],\n }\n write_csv(writer, columns, sort_fields, filter_condition, get_domain_managers=True, should_write_header=True)\n\n\ndef export_data_full_to_csv(csv_file):\n \"\"\"All domains report\"\"\"\n\n writer = csv.writer(csv_file)\n # define columns to include in export\n columns = [\n \"Domain name\",\n \"Domain type\",\n \"Agency\",\n \"Organization name\",\n \"City\",\n \"State\",\n \"Security contact email\",\n ]\n # Coalesce is used to replace federal_type of None with ZZZZZ\n sort_fields = [\n \"organization_type\",\n Coalesce(\"federal_type\", Value(\"ZZZZZ\")),\n \"federal_agency\",\n \"domain__name\",\n ]\n filter_condition = {\n \"domain__state__in\": [\n Domain.State.READY,\n Domain.State.DNS_NEEDED,\n Domain.State.ON_HOLD,\n ],\n }\n write_csv(writer, columns, sort_fields, filter_condition, get_domain_managers=False, should_write_header=True)\n\n\ndef export_data_federal_to_csv(csv_file):\n \"\"\"Federal domains report\"\"\"\n\n writer = csv.writer(csv_file)\n # define columns to include in export\n columns = [\n \"Domain name\",\n \"Domain type\",\n \"Agency\",\n \"Organization name\",\n \"City\",\n \"State\",\n \"Security contact email\",\n ]\n # Coalesce is used to replace federal_type of None with ZZZZZ\n sort_fields = [\n \"organization_type\",\n Coalesce(\"federal_type\", Value(\"ZZZZZ\")),\n \"federal_agency\",\n \"domain__name\",\n ]\n filter_condition = {\n \"organization_type__icontains\": \"federal\",\n \"domain__state__in\": [\n Domain.State.READY,\n Domain.State.DNS_NEEDED,\n Domain.State.ON_HOLD,\n ],\n }\n write_csv(writer, columns, sort_fields, filter_condition, get_domain_managers=False, should_write_header=True)\n\n\ndef get_default_start_date():\n # Default to a date that's prior to our first deployment\n return timezone.make_aware(datetime(2023, 11, 1))\n\n\ndef get_default_end_date():\n # Default to now()\n return timezone.now()\n\n\ndef export_data_growth_to_csv(csv_file, start_date, end_date):\n \"\"\"\n Growth report:\n Receive start and end dates from the view, parse them.\n Request from write_body READY domains that are created between\n the start and end dates, as well as DELETED domains that are deleted between\n the start and end dates. Specify sort params for both lists.\n \"\"\"\n\n start_date_formatted = (\n timezone.make_aware(datetime.strptime(start_date, \"%Y-%m-%d\")) if start_date else get_default_start_date()\n )\n\n end_date_formatted = (\n timezone.make_aware(datetime.strptime(end_date, \"%Y-%m-%d\")) if end_date else get_default_end_date()\n )\n\n writer = csv.writer(csv_file)\n\n # define columns to include in export\n columns = [\n \"Domain name\",\n \"Domain type\",\n \"Agency\",\n \"Organization name\",\n \"City\",\n \"State\",\n \"Status\",\n \"Expiration date\",\n \"Created at\",\n \"First ready\",\n \"Deleted\",\n ]\n sort_fields = [\n \"domain__first_ready\",\n \"domain__name\",\n ]\n filter_condition = {\n \"domain__state__in\": [Domain.State.READY],\n \"domain__first_ready__lte\": end_date_formatted,\n \"domain__first_ready__gte\": start_date_formatted,\n }\n\n # We also want domains deleted between sar and end dates, sorted\n sort_fields_for_deleted_domains = [\n \"domain__deleted\",\n \"domain__name\",\n ]\n filter_condition_for_deleted_domains = {\n \"domain__state__in\": [Domain.State.DELETED],\n \"domain__deleted__lte\": end_date_formatted,\n \"domain__deleted__gte\": start_date_formatted,\n }\n\n write_csv(writer, columns, sort_fields, filter_condition, get_domain_managers=False, should_write_header=True)\n write_csv(\n writer,\n columns,\n sort_fields_for_deleted_domains,\n filter_condition_for_deleted_domains,\n get_domain_managers=False,\n should_write_header=False,\n )\n", "path": "src/registrar/utility/csv_export.py"}], "after_files": [{"content": "import csv\nimport logging\nfrom datetime import datetime\nfrom registrar.models.domain import Domain\nfrom registrar.models.domain_information import DomainInformation\nfrom django.utils import timezone\nfrom django.core.paginator import Paginator\nfrom django.db.models import F, Value, CharField\nfrom django.db.models.functions import Concat, Coalesce\n\nfrom registrar.models.public_contact import PublicContact\nfrom registrar.utility.enums import DefaultEmail\n\nlogger = logging.getLogger(__name__)\n\n\ndef write_header(writer, columns):\n \"\"\"\n Receives params from the parent methods and outputs a CSV with a header row.\n Works with write_header as long as the same writer object is passed.\n \"\"\"\n\n writer.writerow(columns)\n\n\ndef get_domain_infos(filter_condition, sort_fields):\n domain_infos = (\n DomainInformation.objects.select_related(\"domain\", \"authorizing_official\")\n .prefetch_related(\"domain__permissions\")\n .filter(**filter_condition)\n .order_by(*sort_fields)\n )\n\n # Do a mass concat of the first and last name fields for authorizing_official.\n # The old operation was computationally heavy for some reason, so if we precompute\n # this here, it is vastly more efficient.\n domain_infos_cleaned = domain_infos.annotate(\n ao=Concat(\n Coalesce(F(\"authorizing_official__first_name\"), Value(\"\")),\n Value(\" \"),\n Coalesce(F(\"authorizing_official__last_name\"), Value(\"\")),\n output_field=CharField(),\n )\n )\n return domain_infos_cleaned\n\n\ndef parse_row(columns, domain_info: DomainInformation, security_emails_dict=None, get_domain_managers=False):\n \"\"\"Given a set of columns, generate a new row from cleaned column data\"\"\"\n\n # Domain should never be none when parsing this information\n if domain_info.domain is None:\n logger.error(\"Attemting to parse row for csv exports but Domain is none in a DomainInfo\")\n raise ValueError(\"Domain is none\")\n\n domain = domain_info.domain # type: ignore\n\n # Grab the security email from a preset dictionary.\n # If nothing exists in the dictionary, grab from .contacts.\n if security_emails_dict is not None and domain.name in security_emails_dict:\n _email = security_emails_dict.get(domain.name)\n security_email = _email if _email is not None else \" \"\n else:\n # If the dictionary doesn't contain that data, lets filter for it manually.\n # This is a last resort as this is a more expensive operation.\n security_contacts = domain.contacts.filter(contact_type=PublicContact.ContactTypeChoices.SECURITY)\n _email = security_contacts[0].email if security_contacts else None\n security_email = _email if _email is not None else \" \"\n\n # These are default emails that should not be displayed in the csv report\n invalid_emails = {DefaultEmail.LEGACY_DEFAULT.value, DefaultEmail.PUBLIC_CONTACT_DEFAULT.value}\n if security_email.lower() in invalid_emails:\n security_email = \"(blank)\"\n\n if domain_info.federal_type:\n domain_type = f\"{domain_info.get_organization_type_display()} - {domain_info.get_federal_type_display()}\"\n else:\n domain_type = domain_info.get_organization_type_display()\n\n # create a dictionary of fields which can be included in output\n FIELDS = {\n \"Domain name\": domain.name,\n \"Status\": domain.get_state_display(),\n \"Expiration date\": domain.expiration_date,\n \"Domain type\": domain_type,\n \"Agency\": domain_info.federal_agency,\n \"Organization name\": domain_info.organization_name,\n \"City\": domain_info.city,\n \"State\": domain_info.state_territory,\n \"AO\": domain_info.ao, # type: ignore\n \"AO email\": domain_info.authorizing_official.email if domain_info.authorizing_official else \" \",\n \"Security contact email\": security_email,\n \"Created at\": domain.created_at,\n \"First ready\": domain.first_ready,\n \"Deleted\": domain.deleted,\n }\n\n if get_domain_managers:\n # Get each domain managers email and add to list\n dm_emails = [dm.user.email for dm in domain.permissions.all()]\n\n # Set up the \"matching header\" + row field data\n for i, dm_email in enumerate(dm_emails, start=1):\n FIELDS[f\"Domain manager email {i}\"] = dm_email\n\n row = [FIELDS.get(column, \"\") for column in columns]\n return row\n\n\ndef _get_security_emails(sec_contact_ids):\n \"\"\"\n Retrieve security contact emails for the given security contact IDs.\n \"\"\"\n security_emails_dict = {}\n public_contacts = (\n PublicContact.objects.only(\"email\", \"domain__name\")\n .select_related(\"domain\")\n .filter(registry_id__in=sec_contact_ids)\n )\n\n # Populate a dictionary of domain names and their security contacts\n for contact in public_contacts:\n domain: Domain = contact.domain\n if domain is not None and domain.name not in security_emails_dict:\n security_emails_dict[domain.name] = contact.email\n else:\n logger.warning(\"csv_export -> Domain was none for PublicContact\")\n\n return security_emails_dict\n\n\ndef write_csv(\n writer,\n columns,\n sort_fields,\n filter_condition,\n get_domain_managers=False,\n should_write_header=True,\n):\n \"\"\"\n Receives params from the parent methods and outputs a CSV with fltered and sorted domains.\n Works with write_header as longas the same writer object is passed.\n get_domain_managers: Conditional bc we only use domain manager info for export_data_full_to_csv\n should_write_header: Conditional bc export_data_growth_to_csv calls write_body twice\n \"\"\"\n\n all_domain_infos = get_domain_infos(filter_condition, sort_fields)\n\n # Store all security emails to avoid epp calls or excessive filters\n sec_contact_ids = all_domain_infos.values_list(\"domain__security_contact_registry_id\", flat=True)\n\n security_emails_dict = _get_security_emails(sec_contact_ids)\n\n # Reduce the memory overhead when performing the write operation\n paginator = Paginator(all_domain_infos, 1000)\n\n # The maximum amount of domain managers an account has\n # We get the max so we can set the column header accurately\n max_dm_count = 0\n total_body_rows = []\n\n for page_num in paginator.page_range:\n rows = []\n page = paginator.page(page_num)\n for domain_info in page.object_list:\n\n # Get count of all the domain managers for an account\n if get_domain_managers:\n dm_count = domain_info.domain.permissions.count()\n if dm_count > max_dm_count:\n max_dm_count = dm_count\n for i in range(1, max_dm_count + 1):\n column_name = f\"Domain manager email {i}\"\n if column_name not in columns:\n columns.append(column_name)\n\n try:\n row = parse_row(columns, domain_info, security_emails_dict, get_domain_managers)\n rows.append(row)\n except ValueError:\n # This should not happen. If it does, just skip this row.\n # It indicates that DomainInformation.domain is None.\n logger.error(\"csv_export -> Error when parsing row, domain was None\")\n continue\n total_body_rows.extend(rows)\n\n if should_write_header:\n write_header(writer, columns)\n writer.writerows(total_body_rows)\n\n\ndef export_data_type_to_csv(csv_file):\n \"\"\"All domains report with extra columns\"\"\"\n\n writer = csv.writer(csv_file)\n # define columns to include in export\n columns = [\n \"Domain name\",\n \"Status\",\n \"Expiration date\",\n \"Domain type\",\n \"Agency\",\n \"Organization name\",\n \"City\",\n \"State\",\n \"AO\",\n \"AO email\",\n \"Security contact email\",\n # For domain manager we are pass it in as a parameter below in write_body\n ]\n\n # Coalesce is used to replace federal_type of None with ZZZZZ\n sort_fields = [\n \"organization_type\",\n Coalesce(\"federal_type\", Value(\"ZZZZZ\")),\n \"federal_agency\",\n \"domain__name\",\n ]\n filter_condition = {\n \"domain__state__in\": [\n Domain.State.READY,\n Domain.State.DNS_NEEDED,\n Domain.State.ON_HOLD,\n ],\n }\n write_csv(writer, columns, sort_fields, filter_condition, get_domain_managers=True, should_write_header=True)\n\n\ndef export_data_full_to_csv(csv_file):\n \"\"\"All domains report\"\"\"\n\n writer = csv.writer(csv_file)\n # define columns to include in export\n columns = [\n \"Domain name\",\n \"Domain type\",\n \"Agency\",\n \"Organization name\",\n \"City\",\n \"State\",\n \"Security contact email\",\n ]\n # Coalesce is used to replace federal_type of None with ZZZZZ\n sort_fields = [\n \"organization_type\",\n Coalesce(\"federal_type\", Value(\"ZZZZZ\")),\n \"federal_agency\",\n \"domain__name\",\n ]\n filter_condition = {\n \"domain__state__in\": [\n Domain.State.READY,\n Domain.State.DNS_NEEDED,\n Domain.State.ON_HOLD,\n ],\n }\n write_csv(writer, columns, sort_fields, filter_condition, get_domain_managers=False, should_write_header=True)\n\n\ndef export_data_federal_to_csv(csv_file):\n \"\"\"Federal domains report\"\"\"\n\n writer = csv.writer(csv_file)\n # define columns to include in export\n columns = [\n \"Domain name\",\n \"Domain type\",\n \"Agency\",\n \"Organization name\",\n \"City\",\n \"State\",\n \"Security contact email\",\n ]\n # Coalesce is used to replace federal_type of None with ZZZZZ\n sort_fields = [\n \"organization_type\",\n Coalesce(\"federal_type\", Value(\"ZZZZZ\")),\n \"federal_agency\",\n \"domain__name\",\n ]\n filter_condition = {\n \"organization_type__icontains\": \"federal\",\n \"domain__state__in\": [\n Domain.State.READY,\n Domain.State.DNS_NEEDED,\n Domain.State.ON_HOLD,\n ],\n }\n write_csv(writer, columns, sort_fields, filter_condition, get_domain_managers=False, should_write_header=True)\n\n\ndef get_default_start_date():\n # Default to a date that's prior to our first deployment\n return timezone.make_aware(datetime(2023, 11, 1))\n\n\ndef get_default_end_date():\n # Default to now()\n return timezone.now()\n\n\ndef export_data_growth_to_csv(csv_file, start_date, end_date):\n \"\"\"\n Growth report:\n Receive start and end dates from the view, parse them.\n Request from write_body READY domains that are created between\n the start and end dates, as well as DELETED domains that are deleted between\n the start and end dates. Specify sort params for both lists.\n \"\"\"\n\n start_date_formatted = (\n timezone.make_aware(datetime.strptime(start_date, \"%Y-%m-%d\")) if start_date else get_default_start_date()\n )\n\n end_date_formatted = (\n timezone.make_aware(datetime.strptime(end_date, \"%Y-%m-%d\")) if end_date else get_default_end_date()\n )\n\n writer = csv.writer(csv_file)\n\n # define columns to include in export\n columns = [\n \"Domain name\",\n \"Domain type\",\n \"Agency\",\n \"Organization name\",\n \"City\",\n \"State\",\n \"Status\",\n \"Expiration date\",\n \"Created at\",\n \"First ready\",\n \"Deleted\",\n ]\n sort_fields = [\n \"domain__first_ready\",\n \"domain__name\",\n ]\n filter_condition = {\n \"domain__state__in\": [Domain.State.READY],\n \"domain__first_ready__lte\": end_date_formatted,\n \"domain__first_ready__gte\": start_date_formatted,\n }\n\n # We also want domains deleted between sar and end dates, sorted\n sort_fields_for_deleted_domains = [\n \"domain__deleted\",\n \"domain__name\",\n ]\n filter_condition_for_deleted_domains = {\n \"domain__state__in\": [Domain.State.DELETED],\n \"domain__deleted__lte\": end_date_formatted,\n \"domain__deleted__gte\": start_date_formatted,\n }\n\n write_csv(writer, columns, sort_fields, filter_condition, get_domain_managers=False, should_write_header=True)\n write_csv(\n writer,\n columns,\n sort_fields_for_deleted_domains,\n filter_condition_for_deleted_domains,\n get_domain_managers=False,\n should_write_header=False,\n )\n", "path": "src/registrar/utility/csv_export.py"}]}
| 4,078 | 732 |
gh_patches_debug_33264
|
rasdani/github-patches
|
git_diff
|
ansible-collections__community.vmware-427
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
vmware_object_role_permission: Missing required parameters in examples
##### SUMMARY
Examples missing required fields of hostname, username, and password, while other module examples include these.
##### ISSUE TYPE
- Documentation Report
##### COMPONENT NAME
vmware_object_role_permission
##### ADDITIONAL INFORMATION
PR #422
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `plugins/modules/vmware_object_role_permission.py`
Content:
```
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3 #
4 # Copyright: (c) 2018, Derek Rushing <derek.rushing@geekops.com>
5 # Copyright: (c) 2018, VMware, Inc.
6 # SPDX-License-Identifier: GPL-3.0-or-later
7 # GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)
8
9 from __future__ import absolute_import, division, print_function
10
11 __metaclass__ = type
12
13
14 DOCUMENTATION = '''
15 ---
16 module: vmware_object_role_permission
17 short_description: Manage local roles on an ESXi host
18 description: This module can be used to manage object permissions on the given host.
19 author:
20 - Derek Rushing (@kryptsi)
21 - Joseph Andreatta (@vmwjoseph)
22 notes:
23 - Tested on ESXi 6.5, vSphere 6.7
24 - The ESXi login user must have the appropriate rights to administer permissions.
25 - Permissions for a distributed switch must be defined and managed on either the datacenter or a folder containing the switch.
26 requirements:
27 - "python >= 2.7"
28 - PyVmomi
29 options:
30 role:
31 description:
32 - The role to be assigned permission.
33 required: True
34 type: str
35 principal:
36 description:
37 - The user to be assigned permission.
38 - Required if C(group) is not specified.
39 type: str
40 group:
41 description:
42 - The group to be assigned permission.
43 - Required if C(principal) is not specified.
44 type: str
45 object_name:
46 description:
47 - The object name to assigned permission.
48 type: str
49 required: True
50 object_type:
51 description:
52 - The object type being targeted.
53 default: 'Folder'
54 choices: ['Folder', 'VirtualMachine', 'Datacenter', 'ResourcePool',
55 'Datastore', 'Network', 'HostSystem', 'ComputeResource',
56 'ClusterComputeResource', 'DistributedVirtualSwitch']
57 type: str
58 recursive:
59 description:
60 - Should the permissions be recursively applied.
61 default: True
62 type: bool
63 state:
64 description:
65 - Indicate desired state of the object's permission.
66 - When C(state=present), the permission will be added if it doesn't already exist.
67 - When C(state=absent), the permission is removed if it exists.
68 choices: ['present', 'absent']
69 default: present
70 type: str
71 extends_documentation_fragment:
72 - community.vmware.vmware.documentation
73
74 '''
75
76 EXAMPLES = '''
77 - name: Assign user to VM folder
78 community.vmware.vmware_object_role_permission:
79 role: Admin
80 principal: user_bob
81 object_name: services
82 state: present
83 delegate_to: localhost
84
85 - name: Remove user from VM folder
86 community.vmware.vmware_object_role_permission:
87 role: Admin
88 principal: user_bob
89 object_name: services
90 state: absent
91 delegate_to: localhost
92
93 - name: Assign finance group to VM folder
94 community.vmware.vmware_object_role_permission:
95 role: Limited Users
96 group: finance
97 object_name: Accounts
98 state: present
99 delegate_to: localhost
100
101 - name: Assign view_user Read Only permission at root folder
102 community.vmware.vmware_object_role_permission:
103 role: ReadOnly
104 principal: view_user
105 object_name: rootFolder
106 state: present
107 delegate_to: localhost
108 '''
109
110 RETURN = r'''
111 changed:
112 description: whether or not a change was made to the object's role
113 returned: always
114 type: bool
115 '''
116
117 try:
118 from pyVmomi import vim, vmodl
119 except ImportError:
120 pass
121
122 from ansible.module_utils.basic import AnsibleModule
123 from ansible.module_utils._text import to_native
124 from ansible_collections.community.vmware.plugins.module_utils.vmware import PyVmomi, vmware_argument_spec, find_obj
125
126
127 class VMwareObjectRolePermission(PyVmomi):
128 def __init__(self, module):
129 super(VMwareObjectRolePermission, self).__init__(module)
130 self.module = module
131 self.params = module.params
132 self.is_group = False
133
134 if self.params.get('principal', None) is not None:
135 self.applied_to = self.params['principal']
136 elif self.params.get('group', None) is not None:
137 self.applied_to = self.params['group']
138 self.is_group = True
139
140 self.get_role()
141 self.get_object()
142 self.get_perms()
143 self.perm = self.setup_permission()
144 self.state = self.params['state']
145
146 def get_perms(self):
147 self.current_perms = self.content.authorizationManager.RetrieveEntityPermissions(self.current_obj, False)
148
149 def same_permission(self, perm_one, perm_two):
150 return perm_one.principal.lower() == perm_two.principal.lower() \
151 and perm_one.roleId == perm_two.roleId
152
153 def get_state(self):
154 for perm in self.current_perms:
155 if self.same_permission(self.perm, perm):
156 return 'present'
157 return 'absent'
158
159 def process_state(self):
160 local_permission_states = {
161 'absent': {
162 'present': self.remove_permission,
163 'absent': self.state_exit_unchanged,
164 },
165 'present': {
166 'present': self.state_exit_unchanged,
167 'absent': self.add_permission,
168 }
169 }
170 try:
171 local_permission_states[self.state][self.get_state()]()
172 except vmodl.RuntimeFault as runtime_fault:
173 self.module.fail_json(msg=to_native(runtime_fault.msg))
174 except vmodl.MethodFault as method_fault:
175 self.module.fail_json(msg=to_native(method_fault.msg))
176 except Exception as e:
177 self.module.fail_json(msg=to_native(e))
178
179 def state_exit_unchanged(self):
180 self.module.exit_json(changed=False)
181
182 def setup_permission(self):
183 perm = vim.AuthorizationManager.Permission()
184 perm.entity = self.current_obj
185 perm.group = self.is_group
186 perm.principal = self.applied_to
187 perm.roleId = self.role.roleId
188 perm.propagate = self.params['recursive']
189 return perm
190
191 def add_permission(self):
192 if not self.module.check_mode:
193 self.content.authorizationManager.SetEntityPermissions(self.current_obj, [self.perm])
194 self.module.exit_json(changed=True)
195
196 def remove_permission(self):
197 if not self.module.check_mode:
198 self.content.authorizationManager.RemoveEntityPermission(self.current_obj, self.applied_to, self.is_group)
199 self.module.exit_json(changed=True)
200
201 def get_role(self):
202 for role in self.content.authorizationManager.roleList:
203 if role.name == self.params['role']:
204 self.role = role
205 return
206 self.module.fail_json(msg="Specified role (%s) was not found" % self.params['role'])
207
208 def get_object(self):
209 # find_obj doesn't include rootFolder
210 if self.params['object_type'] == 'Folder' and self.params['object_name'] == 'rootFolder':
211 self.current_obj = self.content.rootFolder
212 return
213 try:
214 getattr(vim, self.params['object_type'])
215 except AttributeError:
216 self.module.fail_json(msg="Object type %s is not valid." % self.params['object_type'])
217 self.current_obj = find_obj(content=self.content,
218 vimtype=[getattr(vim, self.params['object_type'])],
219 name=self.params['object_name'])
220
221 if self.current_obj is None:
222 self.module.fail_json(
223 msg="Specified object %s of type %s was not found."
224 % (self.params['object_name'], self.params['object_type'])
225 )
226 if self.params['object_type'] == 'DistributedVirtualSwitch':
227 msg = "You are applying permissions to a Distributed vSwitch. " \
228 "This will probably fail, since Distributed vSwitches inherits permissions " \
229 "from the datacenter or a folder level. " \
230 "Define permissions on the datacenter or the folder containing the switch."
231 self.module.warn(msg)
232
233
234 def main():
235 argument_spec = vmware_argument_spec()
236 argument_spec.update(
237 dict(
238 role=dict(required=True, type='str'),
239 object_name=dict(required=True, type='str'),
240 object_type=dict(
241 type='str',
242 default='Folder',
243 choices=[
244 'Folder',
245 'VirtualMachine',
246 'Datacenter',
247 'ResourcePool',
248 'Datastore',
249 'Network',
250 'HostSystem',
251 'ComputeResource',
252 'ClusterComputeResource',
253 'DistributedVirtualSwitch',
254 ],
255 ),
256 principal=dict(type='str'),
257 group=dict(type='str'),
258 recursive=dict(type='bool', default=True),
259 state=dict(default='present', choices=['present', 'absent'], type='str'),
260 )
261 )
262
263 module = AnsibleModule(
264 argument_spec=argument_spec,
265 supports_check_mode=True,
266 mutually_exclusive=[['principal', 'group']],
267 required_one_of=[['principal', 'group']],
268 )
269
270 vmware_object_permission = VMwareObjectRolePermission(module)
271 vmware_object_permission.process_state()
272
273
274 if __name__ == '__main__':
275 main()
276
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/plugins/modules/vmware_object_role_permission.py b/plugins/modules/vmware_object_role_permission.py
--- a/plugins/modules/vmware_object_role_permission.py
+++ b/plugins/modules/vmware_object_role_permission.py
@@ -11,7 +11,7 @@
__metaclass__ = type
-DOCUMENTATION = '''
+DOCUMENTATION = r'''
---
module: vmware_object_role_permission
short_description: Manage local roles on an ESXi host
@@ -73,9 +73,12 @@
'''
-EXAMPLES = '''
+EXAMPLES = r'''
- name: Assign user to VM folder
community.vmware.vmware_object_role_permission:
+ hostname: '{{ esxi_hostname }}'
+ username: '{{ esxi_username }}'
+ password: '{{ esxi_password }}'
role: Admin
principal: user_bob
object_name: services
@@ -84,6 +87,9 @@
- name: Remove user from VM folder
community.vmware.vmware_object_role_permission:
+ hostname: '{{ esxi_hostname }}'
+ username: '{{ esxi_username }}'
+ password: '{{ esxi_password }}'
role: Admin
principal: user_bob
object_name: services
@@ -92,6 +98,9 @@
- name: Assign finance group to VM folder
community.vmware.vmware_object_role_permission:
+ hostname: '{{ esxi_hostname }}'
+ username: '{{ esxi_username }}'
+ password: '{{ esxi_password }}'
role: Limited Users
group: finance
object_name: Accounts
@@ -100,6 +109,9 @@
- name: Assign view_user Read Only permission at root folder
community.vmware.vmware_object_role_permission:
+ hostname: '{{ esxi_hostname }}'
+ username: '{{ esxi_username }}'
+ password: '{{ esxi_password }}'
role: ReadOnly
principal: view_user
object_name: rootFolder
|
{"golden_diff": "diff --git a/plugins/modules/vmware_object_role_permission.py b/plugins/modules/vmware_object_role_permission.py\n--- a/plugins/modules/vmware_object_role_permission.py\n+++ b/plugins/modules/vmware_object_role_permission.py\n@@ -11,7 +11,7 @@\n __metaclass__ = type\n \n \n-DOCUMENTATION = '''\n+DOCUMENTATION = r'''\n ---\n module: vmware_object_role_permission\n short_description: Manage local roles on an ESXi host\n@@ -73,9 +73,12 @@\n \n '''\n \n-EXAMPLES = '''\n+EXAMPLES = r'''\n - name: Assign user to VM folder\n community.vmware.vmware_object_role_permission:\n+ hostname: '{{ esxi_hostname }}'\n+ username: '{{ esxi_username }}'\n+ password: '{{ esxi_password }}'\n role: Admin\n principal: user_bob\n object_name: services\n@@ -84,6 +87,9 @@\n \n - name: Remove user from VM folder\n community.vmware.vmware_object_role_permission:\n+ hostname: '{{ esxi_hostname }}'\n+ username: '{{ esxi_username }}'\n+ password: '{{ esxi_password }}'\n role: Admin\n principal: user_bob\n object_name: services\n@@ -92,6 +98,9 @@\n \n - name: Assign finance group to VM folder\n community.vmware.vmware_object_role_permission:\n+ hostname: '{{ esxi_hostname }}'\n+ username: '{{ esxi_username }}'\n+ password: '{{ esxi_password }}'\n role: Limited Users\n group: finance\n object_name: Accounts\n@@ -100,6 +109,9 @@\n \n - name: Assign view_user Read Only permission at root folder\n community.vmware.vmware_object_role_permission:\n+ hostname: '{{ esxi_hostname }}'\n+ username: '{{ esxi_username }}'\n+ password: '{{ esxi_password }}'\n role: ReadOnly\n principal: view_user\n object_name: rootFolder\n", "issue": "vmware_object_role_permission: Missing required parameters in examples\n##### SUMMARY\r\nExamples missing required fields of hostname, username, and password, while other module examples include these.\r\n\r\n##### ISSUE TYPE\r\n- Documentation Report\r\n\r\n##### COMPONENT NAME\r\nvmware_object_role_permission\r\n\r\n##### ADDITIONAL INFORMATION\r\nPR #422 \n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n#\n# Copyright: (c) 2018, Derek Rushing <derek.rushing@geekops.com>\n# Copyright: (c) 2018, VMware, Inc.\n# SPDX-License-Identifier: GPL-3.0-or-later\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n\n__metaclass__ = type\n\n\nDOCUMENTATION = '''\n---\nmodule: vmware_object_role_permission\nshort_description: Manage local roles on an ESXi host\ndescription: This module can be used to manage object permissions on the given host.\nauthor:\n- Derek Rushing (@kryptsi)\n- Joseph Andreatta (@vmwjoseph)\nnotes:\n - Tested on ESXi 6.5, vSphere 6.7\n - The ESXi login user must have the appropriate rights to administer permissions.\n - Permissions for a distributed switch must be defined and managed on either the datacenter or a folder containing the switch.\nrequirements:\n - \"python >= 2.7\"\n - PyVmomi\noptions:\n role:\n description:\n - The role to be assigned permission.\n required: True\n type: str\n principal:\n description:\n - The user to be assigned permission.\n - Required if C(group) is not specified.\n type: str\n group:\n description:\n - The group to be assigned permission.\n - Required if C(principal) is not specified.\n type: str\n object_name:\n description:\n - The object name to assigned permission.\n type: str\n required: True\n object_type:\n description:\n - The object type being targeted.\n default: 'Folder'\n choices: ['Folder', 'VirtualMachine', 'Datacenter', 'ResourcePool',\n 'Datastore', 'Network', 'HostSystem', 'ComputeResource',\n 'ClusterComputeResource', 'DistributedVirtualSwitch']\n type: str\n recursive:\n description:\n - Should the permissions be recursively applied.\n default: True\n type: bool\n state:\n description:\n - Indicate desired state of the object's permission.\n - When C(state=present), the permission will be added if it doesn't already exist.\n - When C(state=absent), the permission is removed if it exists.\n choices: ['present', 'absent']\n default: present\n type: str\nextends_documentation_fragment:\n- community.vmware.vmware.documentation\n\n'''\n\nEXAMPLES = '''\n- name: Assign user to VM folder\n community.vmware.vmware_object_role_permission:\n role: Admin\n principal: user_bob\n object_name: services\n state: present\n delegate_to: localhost\n\n- name: Remove user from VM folder\n community.vmware.vmware_object_role_permission:\n role: Admin\n principal: user_bob\n object_name: services\n state: absent\n delegate_to: localhost\n\n- name: Assign finance group to VM folder\n community.vmware.vmware_object_role_permission:\n role: Limited Users\n group: finance\n object_name: Accounts\n state: present\n delegate_to: localhost\n\n- name: Assign view_user Read Only permission at root folder\n community.vmware.vmware_object_role_permission:\n role: ReadOnly\n principal: view_user\n object_name: rootFolder\n state: present\n delegate_to: localhost\n'''\n\nRETURN = r'''\nchanged:\n description: whether or not a change was made to the object's role\n returned: always\n type: bool\n'''\n\ntry:\n from pyVmomi import vim, vmodl\nexcept ImportError:\n pass\n\nfrom ansible.module_utils.basic import AnsibleModule\nfrom ansible.module_utils._text import to_native\nfrom ansible_collections.community.vmware.plugins.module_utils.vmware import PyVmomi, vmware_argument_spec, find_obj\n\n\nclass VMwareObjectRolePermission(PyVmomi):\n def __init__(self, module):\n super(VMwareObjectRolePermission, self).__init__(module)\n self.module = module\n self.params = module.params\n self.is_group = False\n\n if self.params.get('principal', None) is not None:\n self.applied_to = self.params['principal']\n elif self.params.get('group', None) is not None:\n self.applied_to = self.params['group']\n self.is_group = True\n\n self.get_role()\n self.get_object()\n self.get_perms()\n self.perm = self.setup_permission()\n self.state = self.params['state']\n\n def get_perms(self):\n self.current_perms = self.content.authorizationManager.RetrieveEntityPermissions(self.current_obj, False)\n\n def same_permission(self, perm_one, perm_two):\n return perm_one.principal.lower() == perm_two.principal.lower() \\\n and perm_one.roleId == perm_two.roleId\n\n def get_state(self):\n for perm in self.current_perms:\n if self.same_permission(self.perm, perm):\n return 'present'\n return 'absent'\n\n def process_state(self):\n local_permission_states = {\n 'absent': {\n 'present': self.remove_permission,\n 'absent': self.state_exit_unchanged,\n },\n 'present': {\n 'present': self.state_exit_unchanged,\n 'absent': self.add_permission,\n }\n }\n try:\n local_permission_states[self.state][self.get_state()]()\n except vmodl.RuntimeFault as runtime_fault:\n self.module.fail_json(msg=to_native(runtime_fault.msg))\n except vmodl.MethodFault as method_fault:\n self.module.fail_json(msg=to_native(method_fault.msg))\n except Exception as e:\n self.module.fail_json(msg=to_native(e))\n\n def state_exit_unchanged(self):\n self.module.exit_json(changed=False)\n\n def setup_permission(self):\n perm = vim.AuthorizationManager.Permission()\n perm.entity = self.current_obj\n perm.group = self.is_group\n perm.principal = self.applied_to\n perm.roleId = self.role.roleId\n perm.propagate = self.params['recursive']\n return perm\n\n def add_permission(self):\n if not self.module.check_mode:\n self.content.authorizationManager.SetEntityPermissions(self.current_obj, [self.perm])\n self.module.exit_json(changed=True)\n\n def remove_permission(self):\n if not self.module.check_mode:\n self.content.authorizationManager.RemoveEntityPermission(self.current_obj, self.applied_to, self.is_group)\n self.module.exit_json(changed=True)\n\n def get_role(self):\n for role in self.content.authorizationManager.roleList:\n if role.name == self.params['role']:\n self.role = role\n return\n self.module.fail_json(msg=\"Specified role (%s) was not found\" % self.params['role'])\n\n def get_object(self):\n # find_obj doesn't include rootFolder\n if self.params['object_type'] == 'Folder' and self.params['object_name'] == 'rootFolder':\n self.current_obj = self.content.rootFolder\n return\n try:\n getattr(vim, self.params['object_type'])\n except AttributeError:\n self.module.fail_json(msg=\"Object type %s is not valid.\" % self.params['object_type'])\n self.current_obj = find_obj(content=self.content,\n vimtype=[getattr(vim, self.params['object_type'])],\n name=self.params['object_name'])\n\n if self.current_obj is None:\n self.module.fail_json(\n msg=\"Specified object %s of type %s was not found.\"\n % (self.params['object_name'], self.params['object_type'])\n )\n if self.params['object_type'] == 'DistributedVirtualSwitch':\n msg = \"You are applying permissions to a Distributed vSwitch. \" \\\n \"This will probably fail, since Distributed vSwitches inherits permissions \" \\\n \"from the datacenter or a folder level. \" \\\n \"Define permissions on the datacenter or the folder containing the switch.\"\n self.module.warn(msg)\n\n\ndef main():\n argument_spec = vmware_argument_spec()\n argument_spec.update(\n dict(\n role=dict(required=True, type='str'),\n object_name=dict(required=True, type='str'),\n object_type=dict(\n type='str',\n default='Folder',\n choices=[\n 'Folder',\n 'VirtualMachine',\n 'Datacenter',\n 'ResourcePool',\n 'Datastore',\n 'Network',\n 'HostSystem',\n 'ComputeResource',\n 'ClusterComputeResource',\n 'DistributedVirtualSwitch',\n ],\n ),\n principal=dict(type='str'),\n group=dict(type='str'),\n recursive=dict(type='bool', default=True),\n state=dict(default='present', choices=['present', 'absent'], type='str'),\n )\n )\n\n module = AnsibleModule(\n argument_spec=argument_spec,\n supports_check_mode=True,\n mutually_exclusive=[['principal', 'group']],\n required_one_of=[['principal', 'group']],\n )\n\n vmware_object_permission = VMwareObjectRolePermission(module)\n vmware_object_permission.process_state()\n\n\nif __name__ == '__main__':\n main()\n", "path": "plugins/modules/vmware_object_role_permission.py"}], "after_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n#\n# Copyright: (c) 2018, Derek Rushing <derek.rushing@geekops.com>\n# Copyright: (c) 2018, VMware, Inc.\n# SPDX-License-Identifier: GPL-3.0-or-later\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n\n__metaclass__ = type\n\n\nDOCUMENTATION = r'''\n---\nmodule: vmware_object_role_permission\nshort_description: Manage local roles on an ESXi host\ndescription: This module can be used to manage object permissions on the given host.\nauthor:\n- Derek Rushing (@kryptsi)\n- Joseph Andreatta (@vmwjoseph)\nnotes:\n - Tested on ESXi 6.5, vSphere 6.7\n - The ESXi login user must have the appropriate rights to administer permissions.\n - Permissions for a distributed switch must be defined and managed on either the datacenter or a folder containing the switch.\nrequirements:\n - \"python >= 2.7\"\n - PyVmomi\noptions:\n role:\n description:\n - The role to be assigned permission.\n required: True\n type: str\n principal:\n description:\n - The user to be assigned permission.\n - Required if C(group) is not specified.\n type: str\n group:\n description:\n - The group to be assigned permission.\n - Required if C(principal) is not specified.\n type: str\n object_name:\n description:\n - The object name to assigned permission.\n type: str\n required: True\n object_type:\n description:\n - The object type being targeted.\n default: 'Folder'\n choices: ['Folder', 'VirtualMachine', 'Datacenter', 'ResourcePool',\n 'Datastore', 'Network', 'HostSystem', 'ComputeResource',\n 'ClusterComputeResource', 'DistributedVirtualSwitch']\n type: str\n recursive:\n description:\n - Should the permissions be recursively applied.\n default: True\n type: bool\n state:\n description:\n - Indicate desired state of the object's permission.\n - When C(state=present), the permission will be added if it doesn't already exist.\n - When C(state=absent), the permission is removed if it exists.\n choices: ['present', 'absent']\n default: present\n type: str\nextends_documentation_fragment:\n- community.vmware.vmware.documentation\n\n'''\n\nEXAMPLES = r'''\n- name: Assign user to VM folder\n community.vmware.vmware_object_role_permission:\n hostname: '{{ esxi_hostname }}'\n username: '{{ esxi_username }}'\n password: '{{ esxi_password }}'\n role: Admin\n principal: user_bob\n object_name: services\n state: present\n delegate_to: localhost\n\n- name: Remove user from VM folder\n community.vmware.vmware_object_role_permission:\n hostname: '{{ esxi_hostname }}'\n username: '{{ esxi_username }}'\n password: '{{ esxi_password }}'\n role: Admin\n principal: user_bob\n object_name: services\n state: absent\n delegate_to: localhost\n\n- name: Assign finance group to VM folder\n community.vmware.vmware_object_role_permission:\n hostname: '{{ esxi_hostname }}'\n username: '{{ esxi_username }}'\n password: '{{ esxi_password }}'\n role: Limited Users\n group: finance\n object_name: Accounts\n state: present\n delegate_to: localhost\n\n- name: Assign view_user Read Only permission at root folder\n community.vmware.vmware_object_role_permission:\n hostname: '{{ esxi_hostname }}'\n username: '{{ esxi_username }}'\n password: '{{ esxi_password }}'\n role: ReadOnly\n principal: view_user\n object_name: rootFolder\n state: present\n delegate_to: localhost\n'''\n\nRETURN = r'''\nchanged:\n description: whether or not a change was made to the object's role\n returned: always\n type: bool\n'''\n\ntry:\n from pyVmomi import vim, vmodl\nexcept ImportError:\n pass\n\nfrom ansible.module_utils.basic import AnsibleModule\nfrom ansible.module_utils._text import to_native\nfrom ansible_collections.community.vmware.plugins.module_utils.vmware import PyVmomi, vmware_argument_spec, find_obj\n\n\nclass VMwareObjectRolePermission(PyVmomi):\n def __init__(self, module):\n super(VMwareObjectRolePermission, self).__init__(module)\n self.module = module\n self.params = module.params\n self.is_group = False\n\n if self.params.get('principal', None) is not None:\n self.applied_to = self.params['principal']\n elif self.params.get('group', None) is not None:\n self.applied_to = self.params['group']\n self.is_group = True\n\n self.get_role()\n self.get_object()\n self.get_perms()\n self.perm = self.setup_permission()\n self.state = self.params['state']\n\n def get_perms(self):\n self.current_perms = self.content.authorizationManager.RetrieveEntityPermissions(self.current_obj, False)\n\n def same_permission(self, perm_one, perm_two):\n return perm_one.principal.lower() == perm_two.principal.lower() \\\n and perm_one.roleId == perm_two.roleId\n\n def get_state(self):\n for perm in self.current_perms:\n if self.same_permission(self.perm, perm):\n return 'present'\n return 'absent'\n\n def process_state(self):\n local_permission_states = {\n 'absent': {\n 'present': self.remove_permission,\n 'absent': self.state_exit_unchanged,\n },\n 'present': {\n 'present': self.state_exit_unchanged,\n 'absent': self.add_permission,\n }\n }\n try:\n local_permission_states[self.state][self.get_state()]()\n except vmodl.RuntimeFault as runtime_fault:\n self.module.fail_json(msg=to_native(runtime_fault.msg))\n except vmodl.MethodFault as method_fault:\n self.module.fail_json(msg=to_native(method_fault.msg))\n except Exception as e:\n self.module.fail_json(msg=to_native(e))\n\n def state_exit_unchanged(self):\n self.module.exit_json(changed=False)\n\n def setup_permission(self):\n perm = vim.AuthorizationManager.Permission()\n perm.entity = self.current_obj\n perm.group = self.is_group\n perm.principal = self.applied_to\n perm.roleId = self.role.roleId\n perm.propagate = self.params['recursive']\n return perm\n\n def add_permission(self):\n if not self.module.check_mode:\n self.content.authorizationManager.SetEntityPermissions(self.current_obj, [self.perm])\n self.module.exit_json(changed=True)\n\n def remove_permission(self):\n if not self.module.check_mode:\n self.content.authorizationManager.RemoveEntityPermission(self.current_obj, self.applied_to, self.is_group)\n self.module.exit_json(changed=True)\n\n def get_role(self):\n for role in self.content.authorizationManager.roleList:\n if role.name == self.params['role']:\n self.role = role\n return\n self.module.fail_json(msg=\"Specified role (%s) was not found\" % self.params['role'])\n\n def get_object(self):\n # find_obj doesn't include rootFolder\n if self.params['object_type'] == 'Folder' and self.params['object_name'] == 'rootFolder':\n self.current_obj = self.content.rootFolder\n return\n try:\n getattr(vim, self.params['object_type'])\n except AttributeError:\n self.module.fail_json(msg=\"Object type %s is not valid.\" % self.params['object_type'])\n self.current_obj = find_obj(content=self.content,\n vimtype=[getattr(vim, self.params['object_type'])],\n name=self.params['object_name'])\n\n if self.current_obj is None:\n self.module.fail_json(\n msg=\"Specified object %s of type %s was not found.\"\n % (self.params['object_name'], self.params['object_type'])\n )\n if self.params['object_type'] == 'DistributedVirtualSwitch':\n msg = \"You are applying permissions to a Distributed vSwitch. \" \\\n \"This will probably fail, since Distributed vSwitches inherits permissions \" \\\n \"from the datacenter or a folder level. \" \\\n \"Define permissions on the datacenter or the folder containing the switch.\"\n self.module.warn(msg)\n\n\ndef main():\n argument_spec = vmware_argument_spec()\n argument_spec.update(\n dict(\n role=dict(required=True, type='str'),\n object_name=dict(required=True, type='str'),\n object_type=dict(\n type='str',\n default='Folder',\n choices=[\n 'Folder',\n 'VirtualMachine',\n 'Datacenter',\n 'ResourcePool',\n 'Datastore',\n 'Network',\n 'HostSystem',\n 'ComputeResource',\n 'ClusterComputeResource',\n 'DistributedVirtualSwitch',\n ],\n ),\n principal=dict(type='str'),\n group=dict(type='str'),\n recursive=dict(type='bool', default=True),\n state=dict(default='present', choices=['present', 'absent'], type='str'),\n )\n )\n\n module = AnsibleModule(\n argument_spec=argument_spec,\n supports_check_mode=True,\n mutually_exclusive=[['principal', 'group']],\n required_one_of=[['principal', 'group']],\n )\n\n vmware_object_permission = VMwareObjectRolePermission(module)\n vmware_object_permission.process_state()\n\n\nif __name__ == '__main__':\n main()\n", "path": "plugins/modules/vmware_object_role_permission.py"}]}
| 3,044 | 440 |
gh_patches_debug_35203
|
rasdani/github-patches
|
git_diff
|
acl-org__acl-anthology-255
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
How to annotate first initials in XML
@mjpost and I have been discussing offline: When an author's name is written using a first initial on the paper itself, but the complete first name is known (at least probably), how should it be written in the XML? Some ideas (others are possible):
```
a) <author><first>Matt</first><last>Post</last></author>
b) <author><first>M[att]</first><last>Post</last></author>
c) <author><first complete="Matt">M.</first><last>Post</last></author>
d) <author><first initials="M.">Matt</first><last>Post</last></author>
e) <author><first>M<completion>att</completion></first><last>Post</last></author>
```
We have a big influx of these, thanks to the hard work of the LREC organizers supplying complete first names, so if the answer is anything other than (a), it would be nice to decide before merging in the new ones.
JATS uses (d) but without the period (https://jats.nlm.nih.gov/archiving/tag-library/1.1d1/n-zu82.html).
Some special cases to consider:
- Initials are not always initials: `Wm.` to `William`, `R.` to `Bob`
- Middle initials, double first names, second last names, etc. can be expanded from initials as well.
- ADDED: Possibly related, possibly a can of worms: There are some (but not many) papers where the author's name is written _only_ in a non-Latin script (e.g., https://www.aclweb.org/anthology/O00-1008), so the editor has filled in a transliteration.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bin/check_name_variants.py`
Content:
```
1 import yaml
2 import sys
3 import lxml.etree as etree
4
5 person_fields = {'canonical', 'variants', 'comment'}
6 name_fields = {'first', 'last', 'papers'}
7
8 def text(node):
9 """Extract text from an XML node."""
10 if node is None: return ''
11 s = ''.join(node.itertext())
12 return ' '.join(s.split())
13
14 def name(d):
15 return (d['first'], d['last'])
16
17 if len(sys.argv) > 2:
18 names = set()
19 for xmlfilename in sys.argv[2:]:
20 try:
21 tree = etree.parse(xmlfilename)
22 except:
23 print(xmlfilename)
24 raise
25 for paper in tree.getroot().findall('paper'):
26 for person in paper.xpath('./author|./editor'):
27 first = text(person.find('first'))
28 last = text(person.find('last'))
29 names.add((first,last))
30 else:
31 names = None
32
33 doc = yaml.load(open(sys.argv[1]))
34
35 assert isinstance(doc, list)
36 for person in doc:
37 assert isinstance(person, dict), person
38 assert set(person.keys()).issubset(person_fields), person
39 assert 'canonical' in person, person
40 assert isinstance(person['canonical'], dict), person
41 assert set(person['canonical']).issubset(name_fields), person
42 if names is not None and name(person['canonical']) not in names:
43 print('unused name', person['canonical'])
44 dupes = {name(person['canonical'])}
45 assert 'variants' in person, person
46 assert isinstance(person['variants'], list), person
47 for variant in person['variants']:
48 assert set(variant).issubset(name_fields), person
49 if names is not None and name(variant) not in names:
50 print('unused name', variant)
51 assert name(variant) not in dupes, variant
52 dupes.add(name(variant))
53
54
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/bin/check_name_variants.py b/bin/check_name_variants.py
--- a/bin/check_name_variants.py
+++ b/bin/check_name_variants.py
@@ -1,14 +1,19 @@
import yaml
import sys
import lxml.etree as etree
+import logging
person_fields = {'canonical', 'variants', 'comment'}
name_fields = {'first', 'last', 'papers'}
def text(node):
"""Extract text from an XML node."""
- if node is None: return ''
- s = ''.join(node.itertext())
+ if node is None:
+ return ''
+ if 'complete' in node.attrib:
+ s = node.attrib['complete']
+ else:
+ s = ''.join(node.itertext())
return ' '.join(s.split())
def name(d):
@@ -20,7 +25,7 @@
try:
tree = etree.parse(xmlfilename)
except:
- print(xmlfilename)
+ logging.error("couldn't parse {}".format(xmlfilename))
raise
for paper in tree.getroot().findall('paper'):
for person in paper.xpath('./author|./editor'):
@@ -40,14 +45,15 @@
assert isinstance(person['canonical'], dict), person
assert set(person['canonical']).issubset(name_fields), person
if names is not None and name(person['canonical']) not in names:
- print('unused name', person['canonical'])
+ logging.warning('unused name: {}'.format(person['canonical']))
dupes = {name(person['canonical'])}
assert 'variants' in person, person
assert isinstance(person['variants'], list), person
for variant in person['variants']:
assert set(variant).issubset(name_fields), person
if names is not None and name(variant) not in names:
- print('unused name', variant)
+ logging.warning('unused name: {}'.format(variant))
assert name(variant) not in dupes, variant
dupes.add(name(variant))
+print(yaml.dump(doc, allow_unicode=True))
|
{"golden_diff": "diff --git a/bin/check_name_variants.py b/bin/check_name_variants.py\n--- a/bin/check_name_variants.py\n+++ b/bin/check_name_variants.py\n@@ -1,14 +1,19 @@\n import yaml\n import sys\n import lxml.etree as etree\n+import logging\n \n person_fields = {'canonical', 'variants', 'comment'}\n name_fields = {'first', 'last', 'papers'}\n \n def text(node):\n \"\"\"Extract text from an XML node.\"\"\"\n- if node is None: return ''\n- s = ''.join(node.itertext())\n+ if node is None:\n+ return ''\n+ if 'complete' in node.attrib:\n+ s = node.attrib['complete']\n+ else:\n+ s = ''.join(node.itertext())\n return ' '.join(s.split())\n \n def name(d):\n@@ -20,7 +25,7 @@\n try:\n tree = etree.parse(xmlfilename)\n except:\n- print(xmlfilename)\n+ logging.error(\"couldn't parse {}\".format(xmlfilename))\n raise\n for paper in tree.getroot().findall('paper'):\n for person in paper.xpath('./author|./editor'):\n@@ -40,14 +45,15 @@\n assert isinstance(person['canonical'], dict), person\n assert set(person['canonical']).issubset(name_fields), person\n if names is not None and name(person['canonical']) not in names:\n- print('unused name', person['canonical'])\n+ logging.warning('unused name: {}'.format(person['canonical']))\n dupes = {name(person['canonical'])}\n assert 'variants' in person, person\n assert isinstance(person['variants'], list), person\n for variant in person['variants']:\n assert set(variant).issubset(name_fields), person\n if names is not None and name(variant) not in names:\n- print('unused name', variant)\n+ logging.warning('unused name: {}'.format(variant))\n assert name(variant) not in dupes, variant\n dupes.add(name(variant))\n \n+print(yaml.dump(doc, allow_unicode=True))\n", "issue": "How to annotate first initials in XML\n@mjpost and I have been discussing offline: When an author's name is written using a first initial on the paper itself, but the complete first name is known (at least probably), how should it be written in the XML? Some ideas (others are possible):\r\n\r\n```\r\na) <author><first>Matt</first><last>Post</last></author>\r\nb) <author><first>M[att]</first><last>Post</last></author>\r\nc) <author><first complete=\"Matt\">M.</first><last>Post</last></author>\r\nd) <author><first initials=\"M.\">Matt</first><last>Post</last></author>\r\ne) <author><first>M<completion>att</completion></first><last>Post</last></author>\r\n```\r\n\r\nWe have a big influx of these, thanks to the hard work of the LREC organizers supplying complete first names, so if the answer is anything other than (a), it would be nice to decide before merging in the new ones.\r\n\r\nJATS uses (d) but without the period (https://jats.nlm.nih.gov/archiving/tag-library/1.1d1/n-zu82.html).\r\n\r\nSome special cases to consider:\r\n\r\n- Initials are not always initials: `Wm.` to `William`, `R.` to `Bob`\r\n- Middle initials, double first names, second last names, etc. can be expanded from initials as well.\r\n- ADDED: Possibly related, possibly a can of worms: There are some (but not many) papers where the author's name is written _only_ in a non-Latin script (e.g., https://www.aclweb.org/anthology/O00-1008), so the editor has filled in a transliteration.\n", "before_files": [{"content": "import yaml\nimport sys\nimport lxml.etree as etree\n\nperson_fields = {'canonical', 'variants', 'comment'}\nname_fields = {'first', 'last', 'papers'}\n\ndef text(node):\n \"\"\"Extract text from an XML node.\"\"\"\n if node is None: return ''\n s = ''.join(node.itertext())\n return ' '.join(s.split())\n\ndef name(d):\n return (d['first'], d['last'])\n\nif len(sys.argv) > 2:\n names = set()\n for xmlfilename in sys.argv[2:]:\n try:\n tree = etree.parse(xmlfilename)\n except:\n print(xmlfilename)\n raise\n for paper in tree.getroot().findall('paper'):\n for person in paper.xpath('./author|./editor'):\n first = text(person.find('first'))\n last = text(person.find('last'))\n names.add((first,last))\nelse:\n names = None\n\ndoc = yaml.load(open(sys.argv[1]))\n\nassert isinstance(doc, list)\nfor person in doc:\n assert isinstance(person, dict), person\n assert set(person.keys()).issubset(person_fields), person\n assert 'canonical' in person, person\n assert isinstance(person['canonical'], dict), person\n assert set(person['canonical']).issubset(name_fields), person\n if names is not None and name(person['canonical']) not in names:\n print('unused name', person['canonical'])\n dupes = {name(person['canonical'])}\n assert 'variants' in person, person\n assert isinstance(person['variants'], list), person\n for variant in person['variants']:\n assert set(variant).issubset(name_fields), person\n if names is not None and name(variant) not in names:\n print('unused name', variant)\n assert name(variant) not in dupes, variant\n dupes.add(name(variant))\n \n", "path": "bin/check_name_variants.py"}], "after_files": [{"content": "import yaml\nimport sys\nimport lxml.etree as etree\nimport logging\n\nperson_fields = {'canonical', 'variants', 'comment'}\nname_fields = {'first', 'last', 'papers'}\n\ndef text(node):\n \"\"\"Extract text from an XML node.\"\"\"\n if node is None:\n return ''\n if 'complete' in node.attrib:\n s = node.attrib['complete']\n else:\n s = ''.join(node.itertext())\n return ' '.join(s.split())\n\ndef name(d):\n return (d['first'], d['last'])\n\nif len(sys.argv) > 2:\n names = set()\n for xmlfilename in sys.argv[2:]:\n try:\n tree = etree.parse(xmlfilename)\n except:\n logging.error(\"couldn't parse {}\".format(xmlfilename))\n raise\n for paper in tree.getroot().findall('paper'):\n for person in paper.xpath('./author|./editor'):\n first = text(person.find('first'))\n last = text(person.find('last'))\n names.add((first,last))\nelse:\n names = None\n\ndoc = yaml.load(open(sys.argv[1]))\n\nassert isinstance(doc, list)\nfor person in doc:\n assert isinstance(person, dict), person\n assert set(person.keys()).issubset(person_fields), person\n assert 'canonical' in person, person\n assert isinstance(person['canonical'], dict), person\n assert set(person['canonical']).issubset(name_fields), person\n if names is not None and name(person['canonical']) not in names:\n logging.warning('unused name: {}'.format(person['canonical']))\n dupes = {name(person['canonical'])}\n assert 'variants' in person, person\n assert isinstance(person['variants'], list), person\n for variant in person['variants']:\n assert set(variant).issubset(name_fields), person\n if names is not None and name(variant) not in names:\n logging.warning('unused name: {}'.format(variant))\n assert name(variant) not in dupes, variant\n dupes.add(name(variant))\n \nprint(yaml.dump(doc, allow_unicode=True))\n", "path": "bin/check_name_variants.py"}]}
| 1,142 | 457 |
gh_patches_debug_10203
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-746
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Set up integration testing environment
## Problem
We need to setup an integration test environment for Mathesar, to test all user action scenarios.
## Proposed solution
Based on the discussions we've had previously (#89), the most suitable choice for us is [Playwright](https://playwright.dev/).
Integ tests require a complete mathesar setup, including a database. We should be able to test `user action -> api calls -> changes in db`.
## Additional context
- #89
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `install.py`
Content:
```
1 """
2 This script installs functions and types for Mathesar onto the configured DB.
3 """
4 from config.settings import DATABASES
5 from db import install
6 import sys
7 import getopt
8
9
10 def main():
11 skip_confirm = False
12 (opts, _) = getopt.getopt(sys.argv[1:], ":s", ["skip-confirm"])
13 for (opt, value) in opts:
14 if (opt == "-s") or (opt == "--skip-confirm"):
15 skip_confirm = True
16 for database_key in [key for key in DATABASES if key != "default"]:
17 install_on_db_with_key(database_key, skip_confirm)
18
19
20 def install_on_db_with_key(database_key, skip_confirm):
21 if DATABASES[database_key]["HOST"] == "mathesar_db":
22 # if we're going to install on the docker-created Postgres, we'll
23 # create the DB
24 print("Creating Mathesar DB on docker-created PostgreSQL instance")
25 install.create_mathesar_database(
26 DATABASES[database_key]["NAME"],
27 DATABASES["default"]["USER"],
28 DATABASES["default"]["PASSWORD"],
29 DATABASES["default"]["HOST"],
30 DATABASES["default"]["NAME"],
31 DATABASES["default"]["PORT"],
32 )
33 print(f"Created DB is {DATABASES['mathesar_tables']['NAME']}")
34 else:
35 # if we're installing anywhere else, we require the DB to exist in
36 # advance.
37 username = DATABASES[database_key]["USER"]
38 password = DATABASES[database_key]["PASSWORD"]
39 host = DATABASES[database_key]["HOST"]
40 db_name = DATABASES[database_key]["NAME"]
41 port = DATABASES[database_key]["PORT"]
42 print("Installing Mathesar DB on preexisting PostgreSQL instance...")
43 if skip_confirm is False:
44 confirmation = input(
45 f"Mathesar will be installed on DB {db_name} at host {host}."
46 "Confirm? (y/n) > "
47 )
48 if (confirmation.lower() in ["y", "yes"]) or (skip_confirm is True):
49 print("Installing...")
50 install.install_mathesar_on_preexisting_database(
51 username,
52 password,
53 host,
54 db_name,
55 port,
56 )
57 else:
58 print("Skipping DB with key {database_key}.")
59
60
61 if __name__ == "__main__":
62 main()
63
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/install.py b/install.py
--- a/install.py
+++ b/install.py
@@ -39,7 +39,7 @@
host = DATABASES[database_key]["HOST"]
db_name = DATABASES[database_key]["NAME"]
port = DATABASES[database_key]["PORT"]
- print("Installing Mathesar DB on preexisting PostgreSQL instance...")
+ print(f"Installing Mathesar DB {db_name} on preexisting PostgreSQL instance at host {host}...")
if skip_confirm is False:
confirmation = input(
f"Mathesar will be installed on DB {db_name} at host {host}."
|
{"golden_diff": "diff --git a/install.py b/install.py\n--- a/install.py\n+++ b/install.py\n@@ -39,7 +39,7 @@\n host = DATABASES[database_key][\"HOST\"]\n db_name = DATABASES[database_key][\"NAME\"]\n port = DATABASES[database_key][\"PORT\"]\n- print(\"Installing Mathesar DB on preexisting PostgreSQL instance...\")\n+ print(f\"Installing Mathesar DB {db_name} on preexisting PostgreSQL instance at host {host}...\")\n if skip_confirm is False:\n confirmation = input(\n f\"Mathesar will be installed on DB {db_name} at host {host}.\"\n", "issue": "Set up integration testing environment\n## Problem\r\nWe need to setup an integration test environment for Mathesar, to test all user action scenarios.\r\n\r\n## Proposed solution\r\nBased on the discussions we've had previously (#89), the most suitable choice for us is [Playwright](https://playwright.dev/).\r\n\r\nInteg tests require a complete mathesar setup, including a database. We should be able to test `user action -> api calls -> changes in db`.\r\n\r\n## Additional context\r\n- #89 \n", "before_files": [{"content": "\"\"\"\nThis script installs functions and types for Mathesar onto the configured DB.\n\"\"\"\nfrom config.settings import DATABASES\nfrom db import install\nimport sys\nimport getopt\n\n\ndef main():\n skip_confirm = False\n (opts, _) = getopt.getopt(sys.argv[1:], \":s\", [\"skip-confirm\"])\n for (opt, value) in opts:\n if (opt == \"-s\") or (opt == \"--skip-confirm\"):\n skip_confirm = True\n for database_key in [key for key in DATABASES if key != \"default\"]:\n install_on_db_with_key(database_key, skip_confirm)\n\n\ndef install_on_db_with_key(database_key, skip_confirm):\n if DATABASES[database_key][\"HOST\"] == \"mathesar_db\":\n # if we're going to install on the docker-created Postgres, we'll\n # create the DB\n print(\"Creating Mathesar DB on docker-created PostgreSQL instance\")\n install.create_mathesar_database(\n DATABASES[database_key][\"NAME\"],\n DATABASES[\"default\"][\"USER\"],\n DATABASES[\"default\"][\"PASSWORD\"],\n DATABASES[\"default\"][\"HOST\"],\n DATABASES[\"default\"][\"NAME\"],\n DATABASES[\"default\"][\"PORT\"],\n )\n print(f\"Created DB is {DATABASES['mathesar_tables']['NAME']}\")\n else:\n # if we're installing anywhere else, we require the DB to exist in\n # advance.\n username = DATABASES[database_key][\"USER\"]\n password = DATABASES[database_key][\"PASSWORD\"]\n host = DATABASES[database_key][\"HOST\"]\n db_name = DATABASES[database_key][\"NAME\"]\n port = DATABASES[database_key][\"PORT\"]\n print(\"Installing Mathesar DB on preexisting PostgreSQL instance...\")\n if skip_confirm is False:\n confirmation = input(\n f\"Mathesar will be installed on DB {db_name} at host {host}.\"\n \"Confirm? (y/n) > \"\n )\n if (confirmation.lower() in [\"y\", \"yes\"]) or (skip_confirm is True):\n print(\"Installing...\")\n install.install_mathesar_on_preexisting_database(\n username,\n password,\n host,\n db_name,\n port,\n )\n else:\n print(\"Skipping DB with key {database_key}.\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "install.py"}], "after_files": [{"content": "\"\"\"\nThis script installs functions and types for Mathesar onto the configured DB.\n\"\"\"\nfrom config.settings import DATABASES\nfrom db import install\nimport sys\nimport getopt\n\n\ndef main():\n skip_confirm = False\n (opts, _) = getopt.getopt(sys.argv[1:], \":s\", [\"skip-confirm\"])\n for (opt, value) in opts:\n if (opt == \"-s\") or (opt == \"--skip-confirm\"):\n skip_confirm = True\n for database_key in [key for key in DATABASES if key != \"default\"]:\n install_on_db_with_key(database_key, skip_confirm)\n\n\ndef install_on_db_with_key(database_key, skip_confirm):\n if DATABASES[database_key][\"HOST\"] == \"mathesar_db\":\n # if we're going to install on the docker-created Postgres, we'll\n # create the DB\n print(\"Creating Mathesar DB on docker-created PostgreSQL instance\")\n install.create_mathesar_database(\n DATABASES[database_key][\"NAME\"],\n DATABASES[\"default\"][\"USER\"],\n DATABASES[\"default\"][\"PASSWORD\"],\n DATABASES[\"default\"][\"HOST\"],\n DATABASES[\"default\"][\"NAME\"],\n DATABASES[\"default\"][\"PORT\"],\n )\n print(f\"Created DB is {DATABASES['mathesar_tables']['NAME']}\")\n else:\n # if we're installing anywhere else, we require the DB to exist in\n # advance.\n username = DATABASES[database_key][\"USER\"]\n password = DATABASES[database_key][\"PASSWORD\"]\n host = DATABASES[database_key][\"HOST\"]\n db_name = DATABASES[database_key][\"NAME\"]\n port = DATABASES[database_key][\"PORT\"]\n print(f\"Installing Mathesar DB {db_name} on preexisting PostgreSQL instance at host {host}...\")\n if skip_confirm is False:\n confirmation = input(\n f\"Mathesar will be installed on DB {db_name} at host {host}.\"\n \"Confirm? (y/n) > \"\n )\n if (confirmation.lower() in [\"y\", \"yes\"]) or (skip_confirm is True):\n print(\"Installing...\")\n install.install_mathesar_on_preexisting_database(\n username,\n password,\n host,\n db_name,\n port,\n )\n else:\n print(\"Skipping DB with key {database_key}.\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "install.py"}]}
| 967 | 136 |
gh_patches_debug_29514
|
rasdani/github-patches
|
git_diff
|
liqd__a4-opin-250
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
No warning/help text when password entered incorrectly
When I try to log in with the wrong log in details, I don't get a message informing me what didn't work - i.e. wrong password/log in (Firefox, 47 on Mac).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `euth/user_management/forms.py`
Content:
```
1 from django import forms
2 from django.contrib.auth import authenticate, get_user_model
3 from django.contrib.auth.hashers import make_password
4 from django.core.exceptions import ValidationError
5 from django.utils.translation import ugettext as _
6
7 from .models import Registration, Reset
8
9 User = get_user_model()
10
11
12 class LoginForm(forms.Form):
13 email = forms.EmailField(max_length=255, required=True)
14 password = forms.CharField(widget=forms.PasswordInput, required=True)
15
16 def clean(self):
17 email = self.cleaned_data.get('email')
18 password = self.cleaned_data.get('password')
19 user = authenticate(username=email, password=password)
20 if not user or not user.is_active:
21 raise ValidationError(_('password mismatch'))
22 return self.cleaned_data
23
24 def login(self, request):
25 email = self.cleaned_data.get('email')
26 password = self.cleaned_data.get('password')
27 user = authenticate(username=email, password=password)
28 return user
29
30
31 class RegisterForm(forms.Form):
32 email = forms.EmailField(max_length=255, required=True)
33 username = forms.CharField(max_length=255, required=True)
34 password = forms.CharField(
35 widget=forms.PasswordInput,
36 min_length=8,
37 required=True)
38 password_repeat = forms.CharField(
39 widget=forms.PasswordInput, required=True)
40
41 def clean_password_repeat(self):
42 password1 = self.cleaned_data.get('password')
43 password2 = self.cleaned_data.get('password_repeat')
44 if password1 != password2:
45 raise ValidationError(_('passwords dont match'))
46 return password2
47
48 def clean_username(self):
49 username = self.cleaned_data.get('username')
50 user_exists = User.objects.filter(
51 username=username).first() is not None
52 register_exits = Registration.objects.filter(
53 username=username).first() is not None
54
55 if user_exists or register_exits:
56 raise ValidationError(_('username taken'))
57 return username
58
59 def clean_email(self):
60 email = self.cleaned_data.get('email')
61 user_exists = User.objects.filter(email=email).first()
62 register_exists = Registration.objects.filter(email=email).first()
63 if user_exists or register_exists:
64 raise ValidationError(_('email in use'))
65 return email
66
67 def register(self, request):
68 username = self.cleaned_data.get('username')
69 password = self.cleaned_data.get('password')
70 email = self.cleaned_data.get('email')
71 registration = Registration(username=username,
72 email=email,
73 password=make_password(password))
74 return registration
75
76
77 class ActivateForm(forms.Form):
78 token = forms.UUIDField(widget=forms.HiddenInput(), required=True)
79
80 def clean_token(self):
81 token = self.cleaned_data.get('token')
82 registration = Registration.objects.filter(token=token).first()
83 if not registration:
84 raise ValidationError(_('invalid token'))
85 else:
86 self.cleaned_data['registration'] = registration
87 return token
88
89 def activate(self, request):
90 registration = self.cleaned_data.get('registration')
91 user = User(username=registration.username,
92 email=registration.email,
93 password=registration.password)
94 return user, registration
95
96
97 class RequestResetForm(forms.Form):
98 username_or_email = forms.CharField(max_length=255)
99
100 def clean_username_or_email(self):
101 username_or_email = self.cleaned_data.get('username_or_email')
102 user = (User.objects.filter(username=username_or_email).first() or
103 User.objects.filter(email=username_or_email).first())
104 if not user:
105 raise ValidationError(_('unkown user'))
106 else:
107 self.cleaned_data['user'] = user
108 return username_or_email
109
110 def request_reset(self, request):
111 user = self.cleaned_data.get('user')
112 return Reset(user=user)
113
114
115 class ResetForm(forms.Form):
116 token = forms.UUIDField(widget=forms.HiddenInput(), required=True)
117 password = forms.CharField(
118 widget=forms.PasswordInput,
119 min_length=8,
120 required=True)
121 password_repeat = forms.CharField(
122 widget=forms.PasswordInput,
123 required=True)
124
125 def clean_token(self):
126 token = self.cleaned_data.get('token')
127 reset = Reset.objects.filter(token=token).first()
128 if not reset:
129 ValidationError(_('invalid token'))
130 else:
131 self.cleaned_data['reset'] = reset
132 return token
133
134 def clean_password_repeat(self):
135 password1 = self.cleaned_data.get('password')
136 password2 = self.cleaned_data.get('password_repeat')
137 if password1 != password2:
138 raise ValidationError(_('passwords dont match'))
139 return password2
140
141 def reset_password(self, request):
142 reset = self.cleaned_data.get('reset')
143 password = self.cleaned_data.get('password')
144 user = reset.user
145 user.password = make_password(password)
146 return user, reset
147
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/euth/user_management/forms.py b/euth/user_management/forms.py
--- a/euth/user_management/forms.py
+++ b/euth/user_management/forms.py
@@ -15,6 +15,12 @@
def clean(self):
email = self.cleaned_data.get('email')
+ if email and not User.objects.filter(email=email):
+ if Registration.objects.filter(email=email):
+ raise ValidationError(_('account not activated'))
+ else:
+ raise ValidationError(_('account doesn\'t exist'))
+
password = self.cleaned_data.get('password')
user = authenticate(username=email, password=password)
if not user or not user.is_active:
@@ -42,7 +48,7 @@
password1 = self.cleaned_data.get('password')
password2 = self.cleaned_data.get('password_repeat')
if password1 != password2:
- raise ValidationError(_('passwords dont match'))
+ raise ValidationError(_('passwords don\'t match'))
return password2
def clean_username(self):
@@ -134,8 +140,8 @@
def clean_password_repeat(self):
password1 = self.cleaned_data.get('password')
password2 = self.cleaned_data.get('password_repeat')
- if password1 != password2:
- raise ValidationError(_('passwords dont match'))
+ if password1 and password1 != password2:
+ raise ValidationError(_('passwords don\'t match'))
return password2
def reset_password(self, request):
|
{"golden_diff": "diff --git a/euth/user_management/forms.py b/euth/user_management/forms.py\n--- a/euth/user_management/forms.py\n+++ b/euth/user_management/forms.py\n@@ -15,6 +15,12 @@\n \n def clean(self):\n email = self.cleaned_data.get('email')\n+ if email and not User.objects.filter(email=email):\n+ if Registration.objects.filter(email=email):\n+ raise ValidationError(_('account not activated'))\n+ else:\n+ raise ValidationError(_('account doesn\\'t exist'))\n+\n password = self.cleaned_data.get('password')\n user = authenticate(username=email, password=password)\n if not user or not user.is_active:\n@@ -42,7 +48,7 @@\n password1 = self.cleaned_data.get('password')\n password2 = self.cleaned_data.get('password_repeat')\n if password1 != password2:\n- raise ValidationError(_('passwords dont match'))\n+ raise ValidationError(_('passwords don\\'t match'))\n return password2\n \n def clean_username(self):\n@@ -134,8 +140,8 @@\n def clean_password_repeat(self):\n password1 = self.cleaned_data.get('password')\n password2 = self.cleaned_data.get('password_repeat')\n- if password1 != password2:\n- raise ValidationError(_('passwords dont match'))\n+ if password1 and password1 != password2:\n+ raise ValidationError(_('passwords don\\'t match'))\n return password2\n \n def reset_password(self, request):\n", "issue": "No warning/help text when password entered incorrectly\nWhen I try to log in with the wrong log in details, I don't get a message informing me what didn't work - i.e. wrong password/log in (Firefox, 47 on Mac).\n\n", "before_files": [{"content": "from django import forms\nfrom django.contrib.auth import authenticate, get_user_model\nfrom django.contrib.auth.hashers import make_password\nfrom django.core.exceptions import ValidationError\nfrom django.utils.translation import ugettext as _\n\nfrom .models import Registration, Reset\n\nUser = get_user_model()\n\n\nclass LoginForm(forms.Form):\n email = forms.EmailField(max_length=255, required=True)\n password = forms.CharField(widget=forms.PasswordInput, required=True)\n\n def clean(self):\n email = self.cleaned_data.get('email')\n password = self.cleaned_data.get('password')\n user = authenticate(username=email, password=password)\n if not user or not user.is_active:\n raise ValidationError(_('password mismatch'))\n return self.cleaned_data\n\n def login(self, request):\n email = self.cleaned_data.get('email')\n password = self.cleaned_data.get('password')\n user = authenticate(username=email, password=password)\n return user\n\n\nclass RegisterForm(forms.Form):\n email = forms.EmailField(max_length=255, required=True)\n username = forms.CharField(max_length=255, required=True)\n password = forms.CharField(\n widget=forms.PasswordInput,\n min_length=8,\n required=True)\n password_repeat = forms.CharField(\n widget=forms.PasswordInput, required=True)\n\n def clean_password_repeat(self):\n password1 = self.cleaned_data.get('password')\n password2 = self.cleaned_data.get('password_repeat')\n if password1 != password2:\n raise ValidationError(_('passwords dont match'))\n return password2\n\n def clean_username(self):\n username = self.cleaned_data.get('username')\n user_exists = User.objects.filter(\n username=username).first() is not None\n register_exits = Registration.objects.filter(\n username=username).first() is not None\n\n if user_exists or register_exits:\n raise ValidationError(_('username taken'))\n return username\n\n def clean_email(self):\n email = self.cleaned_data.get('email')\n user_exists = User.objects.filter(email=email).first()\n register_exists = Registration.objects.filter(email=email).first()\n if user_exists or register_exists:\n raise ValidationError(_('email in use'))\n return email\n\n def register(self, request):\n username = self.cleaned_data.get('username')\n password = self.cleaned_data.get('password')\n email = self.cleaned_data.get('email')\n registration = Registration(username=username,\n email=email,\n password=make_password(password))\n return registration\n\n\nclass ActivateForm(forms.Form):\n token = forms.UUIDField(widget=forms.HiddenInput(), required=True)\n\n def clean_token(self):\n token = self.cleaned_data.get('token')\n registration = Registration.objects.filter(token=token).first()\n if not registration:\n raise ValidationError(_('invalid token'))\n else:\n self.cleaned_data['registration'] = registration\n return token\n\n def activate(self, request):\n registration = self.cleaned_data.get('registration')\n user = User(username=registration.username,\n email=registration.email,\n password=registration.password)\n return user, registration\n\n\nclass RequestResetForm(forms.Form):\n username_or_email = forms.CharField(max_length=255)\n\n def clean_username_or_email(self):\n username_or_email = self.cleaned_data.get('username_or_email')\n user = (User.objects.filter(username=username_or_email).first() or\n User.objects.filter(email=username_or_email).first())\n if not user:\n raise ValidationError(_('unkown user'))\n else:\n self.cleaned_data['user'] = user\n return username_or_email\n\n def request_reset(self, request):\n user = self.cleaned_data.get('user')\n return Reset(user=user)\n\n\nclass ResetForm(forms.Form):\n token = forms.UUIDField(widget=forms.HiddenInput(), required=True)\n password = forms.CharField(\n widget=forms.PasswordInput,\n min_length=8,\n required=True)\n password_repeat = forms.CharField(\n widget=forms.PasswordInput,\n required=True)\n\n def clean_token(self):\n token = self.cleaned_data.get('token')\n reset = Reset.objects.filter(token=token).first()\n if not reset:\n ValidationError(_('invalid token'))\n else:\n self.cleaned_data['reset'] = reset\n return token\n\n def clean_password_repeat(self):\n password1 = self.cleaned_data.get('password')\n password2 = self.cleaned_data.get('password_repeat')\n if password1 != password2:\n raise ValidationError(_('passwords dont match'))\n return password2\n\n def reset_password(self, request):\n reset = self.cleaned_data.get('reset')\n password = self.cleaned_data.get('password')\n user = reset.user\n user.password = make_password(password)\n return user, reset\n", "path": "euth/user_management/forms.py"}], "after_files": [{"content": "from django import forms\nfrom django.contrib.auth import authenticate, get_user_model\nfrom django.contrib.auth.hashers import make_password\nfrom django.core.exceptions import ValidationError\nfrom django.utils.translation import ugettext as _\n\nfrom .models import Registration, Reset\n\nUser = get_user_model()\n\n\nclass LoginForm(forms.Form):\n email = forms.EmailField(max_length=255, required=True)\n password = forms.CharField(widget=forms.PasswordInput, required=True)\n\n def clean(self):\n email = self.cleaned_data.get('email')\n if email and not User.objects.filter(email=email):\n if Registration.objects.filter(email=email):\n raise ValidationError(_('account not activated'))\n else:\n raise ValidationError(_('account doesn\\'t exist'))\n\n password = self.cleaned_data.get('password')\n user = authenticate(username=email, password=password)\n if not user or not user.is_active:\n raise ValidationError(_('password mismatch'))\n return self.cleaned_data\n\n def login(self, request):\n email = self.cleaned_data.get('email')\n password = self.cleaned_data.get('password')\n user = authenticate(username=email, password=password)\n return user\n\n\nclass RegisterForm(forms.Form):\n email = forms.EmailField(max_length=255, required=True)\n username = forms.CharField(max_length=255, required=True)\n password = forms.CharField(\n widget=forms.PasswordInput,\n min_length=8,\n required=True)\n password_repeat = forms.CharField(\n widget=forms.PasswordInput, required=True)\n\n def clean_password_repeat(self):\n password1 = self.cleaned_data.get('password')\n password2 = self.cleaned_data.get('password_repeat')\n if password1 != password2:\n raise ValidationError(_('passwords don\\'t match'))\n return password2\n\n def clean_username(self):\n username = self.cleaned_data.get('username')\n user_exists = User.objects.filter(\n username=username).first() is not None\n register_exits = Registration.objects.filter(\n username=username).first() is not None\n\n if user_exists or register_exits:\n raise ValidationError(_('username taken'))\n return username\n\n def clean_email(self):\n email = self.cleaned_data.get('email')\n user_exists = User.objects.filter(email=email).first()\n register_exists = Registration.objects.filter(email=email).first()\n if user_exists or register_exists:\n raise ValidationError(_('email in use'))\n return email\n\n def register(self, request):\n username = self.cleaned_data.get('username')\n password = self.cleaned_data.get('password')\n email = self.cleaned_data.get('email')\n registration = Registration(username=username,\n email=email,\n password=make_password(password))\n return registration\n\n\nclass ActivateForm(forms.Form):\n token = forms.UUIDField(widget=forms.HiddenInput(), required=True)\n\n def clean_token(self):\n token = self.cleaned_data.get('token')\n registration = Registration.objects.filter(token=token).first()\n if not registration:\n raise ValidationError(_('invalid token'))\n else:\n self.cleaned_data['registration'] = registration\n return token\n\n def activate(self, request):\n registration = self.cleaned_data.get('registration')\n user = User(username=registration.username,\n email=registration.email,\n password=registration.password)\n return user, registration\n\n\nclass RequestResetForm(forms.Form):\n username_or_email = forms.CharField(max_length=255)\n\n def clean_username_or_email(self):\n username_or_email = self.cleaned_data.get('username_or_email')\n user = (User.objects.filter(username=username_or_email).first() or\n User.objects.filter(email=username_or_email).first())\n if not user:\n raise ValidationError(_('unkown user'))\n else:\n self.cleaned_data['user'] = user\n return username_or_email\n\n def request_reset(self, request):\n user = self.cleaned_data.get('user')\n return Reset(user=user)\n\n\nclass ResetForm(forms.Form):\n token = forms.UUIDField(widget=forms.HiddenInput(), required=True)\n password = forms.CharField(\n widget=forms.PasswordInput,\n min_length=8,\n required=True)\n password_repeat = forms.CharField(\n widget=forms.PasswordInput,\n required=True)\n\n def clean_token(self):\n token = self.cleaned_data.get('token')\n reset = Reset.objects.filter(token=token).first()\n if not reset:\n ValidationError(_('invalid token'))\n else:\n self.cleaned_data['reset'] = reset\n return token\n\n def clean_password_repeat(self):\n password1 = self.cleaned_data.get('password')\n password2 = self.cleaned_data.get('password_repeat')\n if password1 and password1 != password2:\n raise ValidationError(_('passwords don\\'t match'))\n return password2\n\n def reset_password(self, request):\n reset = self.cleaned_data.get('reset')\n password = self.cleaned_data.get('password')\n user = reset.user\n user.password = make_password(password)\n return user, reset\n", "path": "euth/user_management/forms.py"}]}
| 1,640 | 317 |
gh_patches_debug_17776
|
rasdani/github-patches
|
git_diff
|
zulip__zulip-26842
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Don't activate zulip_py3_venv at the launch of shell on direct system dev setups.
As a part of `./tools/provision` we add `"source " + os.path.join(VENV_PATH, "bin", "activate")` to the bash profile of the user which is responsible for automatic activation of the zulip's virtualenv when a new shell is launched.
While this is handy for Vagrant/Docker/Droplet setups, which are dedicated machines for running Zulip, this is not a desired behaviour in other setups like [Direct Installation on systems](https://zulip.readthedocs.io/en/latest/development/setup-advanced.html#installing-directly-on-ubuntu-debian-centos-or-fedora).
Solution would be to extract the script which writes the venv activation to bash profile and call it via Vagrantfile/Dockerfile/Droplet setup script.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tools/lib/provision_inner.py`
Content:
```
1 #!/usr/bin/env python3
2 import argparse
3 import glob
4 import os
5 import shutil
6 import sys
7 from typing import List
8
9 ZULIP_PATH = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
10
11 sys.path.append(ZULIP_PATH)
12 import pygments
13
14 from scripts.lib import clean_unused_caches
15 from scripts.lib.zulip_tools import (
16 ENDC,
17 OKBLUE,
18 get_dev_uuid_var_path,
19 get_tzdata_zi,
20 is_digest_obsolete,
21 run,
22 run_as_root,
23 write_new_digest,
24 )
25 from tools.setup.generate_zulip_bots_static_files import generate_zulip_bots_static_files
26 from version import PROVISION_VERSION
27
28 VENV_PATH = "/srv/zulip-py3-venv"
29 UUID_VAR_PATH = get_dev_uuid_var_path()
30
31 with get_tzdata_zi() as f:
32 line = f.readline()
33 assert line.startswith("# version ")
34 timezones_version = line[len("# version ") :]
35
36
37 def create_var_directories() -> None:
38 # create var/coverage, var/log, etc.
39 var_dir = os.path.join(ZULIP_PATH, "var")
40 sub_dirs = [
41 "coverage",
42 "log",
43 "node-coverage",
44 "test_uploads",
45 "uploads",
46 "xunit-test-results",
47 ]
48 for sub_dir in sub_dirs:
49 path = os.path.join(var_dir, sub_dir)
50 os.makedirs(path, exist_ok=True)
51
52
53 def build_pygments_data_paths() -> List[str]:
54 paths = [
55 "tools/setup/build_pygments_data",
56 "tools/setup/lang.json",
57 ]
58 return paths
59
60
61 def build_timezones_data_paths() -> List[str]:
62 paths = [
63 "tools/setup/build_timezone_values",
64 ]
65 return paths
66
67
68 def compilemessages_paths() -> List[str]:
69 paths = ["zerver/management/commands/compilemessages.py"]
70 paths += glob.glob("locale/*/LC_MESSAGES/*.po")
71 paths += glob.glob("locale/*/translations.json")
72 return paths
73
74
75 def configure_rabbitmq_paths() -> List[str]:
76 paths = [
77 "scripts/setup/configure-rabbitmq",
78 ]
79 return paths
80
81
82 def setup_shell_profile(shell_profile: str) -> None:
83 shell_profile_path = os.path.expanduser(shell_profile)
84
85 def write_command(command: str) -> None:
86 if os.path.exists(shell_profile_path):
87 with open(shell_profile_path) as shell_profile_file:
88 lines = [line.strip() for line in shell_profile_file.readlines()]
89 if command not in lines:
90 with open(shell_profile_path, "a+") as shell_profile_file:
91 shell_profile_file.writelines(command + "\n")
92 else:
93 with open(shell_profile_path, "w") as shell_profile_file:
94 shell_profile_file.writelines(command + "\n")
95
96 source_activate_command = "source " + os.path.join(VENV_PATH, "bin", "activate")
97 write_command(source_activate_command)
98 if os.path.exists("/srv/zulip"):
99 write_command("cd /srv/zulip")
100
101
102 def setup_bash_profile() -> None:
103 """Select a bash profile file to add setup code to."""
104
105 BASH_PROFILES = [
106 os.path.expanduser(p) for p in ("~/.bash_profile", "~/.bash_login", "~/.profile")
107 ]
108
109 def clear_old_profile() -> None:
110 # An earlier version of this script would output a fresh .bash_profile
111 # even though a .profile existed in the image used. As a convenience to
112 # existing developers (and, perhaps, future developers git-bisecting the
113 # provisioning scripts), check for this situation, and blow away the
114 # created .bash_profile if one is found.
115
116 BASH_PROFILE = BASH_PROFILES[0]
117 DOT_PROFILE = BASH_PROFILES[2]
118 OLD_PROFILE_TEXT = "source /srv/zulip-py3-venv/bin/activate\ncd /srv/zulip\n"
119
120 if os.path.exists(DOT_PROFILE):
121 try:
122 with open(BASH_PROFILE) as f:
123 profile_contents = f.read()
124 if profile_contents == OLD_PROFILE_TEXT:
125 os.unlink(BASH_PROFILE)
126 except FileNotFoundError:
127 pass
128
129 clear_old_profile()
130
131 for candidate_profile in BASH_PROFILES:
132 if os.path.exists(candidate_profile):
133 setup_shell_profile(candidate_profile)
134 break
135 else:
136 # no existing bash profile found; claim .bash_profile
137 setup_shell_profile(BASH_PROFILES[0])
138
139
140 def need_to_run_build_pygments_data() -> bool:
141 if not os.path.exists("web/generated/pygments_data.json"):
142 return True
143
144 return is_digest_obsolete(
145 "build_pygments_data_hash",
146 build_pygments_data_paths(),
147 [pygments.__version__],
148 )
149
150
151 def need_to_run_build_timezone_data() -> bool:
152 if not os.path.exists("web/generated/timezones.json"):
153 return True
154
155 return is_digest_obsolete(
156 "build_timezones_data_hash",
157 build_timezones_data_paths(),
158 [timezones_version],
159 )
160
161
162 def need_to_run_compilemessages() -> bool:
163 if not os.path.exists("locale/language_name_map.json"):
164 # User may have cleaned their Git checkout.
165 print("Need to run compilemessages due to missing language_name_map.json")
166 return True
167
168 return is_digest_obsolete(
169 "last_compilemessages_hash",
170 compilemessages_paths(),
171 )
172
173
174 def need_to_run_configure_rabbitmq(settings_list: List[str]) -> bool:
175 obsolete = is_digest_obsolete(
176 "last_configure_rabbitmq_hash",
177 configure_rabbitmq_paths(),
178 settings_list,
179 )
180
181 if obsolete:
182 return True
183
184 try:
185 from zerver.lib.queue import SimpleQueueClient
186
187 SimpleQueueClient()
188 return False
189 except Exception:
190 return True
191
192
193 def main(options: argparse.Namespace) -> int:
194 setup_bash_profile()
195 setup_shell_profile("~/.zprofile")
196
197 # This needs to happen before anything that imports zproject.settings.
198 run(["scripts/setup/generate_secrets.py", "--development"])
199
200 create_var_directories()
201
202 # The `build_emoji` script requires `emoji-datasource` package
203 # which we install via npm; thus this step is after installing npm
204 # packages.
205 run(["tools/setup/emoji/build_emoji"])
206
207 # copy over static files from the zulip_bots package
208 generate_zulip_bots_static_files()
209
210 if options.is_force or need_to_run_build_pygments_data():
211 run(["tools/setup/build_pygments_data"])
212 write_new_digest(
213 "build_pygments_data_hash",
214 build_pygments_data_paths(),
215 [pygments.__version__],
216 )
217 else:
218 print("No need to run `tools/setup/build_pygments_data`.")
219
220 if options.is_force or need_to_run_build_timezone_data():
221 run(["tools/setup/build_timezone_values"])
222 write_new_digest(
223 "build_timezones_data_hash",
224 build_timezones_data_paths(),
225 [timezones_version],
226 )
227 else:
228 print("No need to run `tools/setup/build_timezone_values`.")
229
230 if not options.is_build_release_tarball_only:
231 # The following block is skipped when we just need the development
232 # environment to build a release tarball.
233
234 # Need to set up Django before using template_status
235 os.environ.setdefault("DJANGO_SETTINGS_MODULE", "zproject.settings")
236 import django
237
238 django.setup()
239
240 from django.conf import settings
241
242 from zerver.lib.test_fixtures import (
243 DEV_DATABASE,
244 TEST_DATABASE,
245 destroy_leaked_test_databases,
246 )
247
248 assert settings.RABBITMQ_PASSWORD is not None
249 if options.is_force or need_to_run_configure_rabbitmq([settings.RABBITMQ_PASSWORD]):
250 run_as_root(["scripts/setup/configure-rabbitmq"])
251 write_new_digest(
252 "last_configure_rabbitmq_hash",
253 configure_rabbitmq_paths(),
254 [settings.RABBITMQ_PASSWORD],
255 )
256 else:
257 print("No need to run `scripts/setup/configure-rabbitmq.")
258
259 dev_template_db_status = DEV_DATABASE.template_status()
260 if options.is_force or dev_template_db_status == "needs_rebuild":
261 run(["tools/setup/postgresql-init-dev-db"])
262 if options.skip_dev_db_build:
263 # We don't need to build the manual development
264 # database on continuous integration for running tests, so we can
265 # just leave it as a template db and save a minute.
266 #
267 # Important: We don't write a digest as that would
268 # incorrectly claim that we ran migrations.
269 pass
270 else:
271 run(["tools/rebuild-dev-database"])
272 DEV_DATABASE.write_new_db_digest()
273 elif dev_template_db_status == "run_migrations":
274 DEV_DATABASE.run_db_migrations()
275 elif dev_template_db_status == "current":
276 print("No need to regenerate the dev DB.")
277
278 test_template_db_status = TEST_DATABASE.template_status()
279 if options.is_force or test_template_db_status == "needs_rebuild":
280 run(["tools/setup/postgresql-init-test-db"])
281 run(["tools/rebuild-test-database"])
282 TEST_DATABASE.write_new_db_digest()
283 elif test_template_db_status == "run_migrations":
284 TEST_DATABASE.run_db_migrations()
285 elif test_template_db_status == "current":
286 print("No need to regenerate the test DB.")
287
288 if options.is_force or need_to_run_compilemessages():
289 run(["./manage.py", "compilemessages", "--ignore=*"])
290 write_new_digest(
291 "last_compilemessages_hash",
292 compilemessages_paths(),
293 )
294 else:
295 print("No need to run `manage.py compilemessages`.")
296
297 destroyed = destroy_leaked_test_databases()
298 if destroyed:
299 print(f"Dropped {destroyed} stale test databases!")
300
301 clean_unused_caches.main(
302 argparse.Namespace(
303 threshold_days=6,
304 # The defaults here should match parse_cache_script_args in zulip_tools.py
305 dry_run=False,
306 verbose=False,
307 no_headings=True,
308 )
309 )
310
311 # Keeping this cache file around can cause eslint to throw
312 # random TypeErrors when new/updated dependencies are added
313 if os.path.isfile(".eslintcache"):
314 # Remove this block when
315 # https://github.com/eslint/eslint/issues/11639 is fixed
316 # upstream.
317 os.remove(".eslintcache")
318
319 # Clean up the root of the `var/` directory for various
320 # testing-related files that we have migrated to
321 # `var/<uuid>/test-backend`.
322 print("Cleaning var/ directory files...")
323 var_paths = glob.glob("var/test*")
324 var_paths.append("var/bot_avatar")
325 for path in var_paths:
326 try:
327 if os.path.isdir(path):
328 shutil.rmtree(path)
329 else:
330 os.remove(path)
331 except FileNotFoundError:
332 pass
333
334 version_file = os.path.join(UUID_VAR_PATH, "provision_version")
335 print(f"writing to {version_file}\n")
336 with open(version_file, "w") as f:
337 f.write(".".join(map(str, PROVISION_VERSION)) + "\n")
338
339 print()
340 print(OKBLUE + "Zulip development environment setup succeeded!" + ENDC)
341 return 0
342
343
344 if __name__ == "__main__":
345 parser = argparse.ArgumentParser()
346 parser.add_argument(
347 "--force",
348 action="store_true",
349 dest="is_force",
350 help="Ignore all provisioning optimizations.",
351 )
352
353 parser.add_argument(
354 "--build-release-tarball-only",
355 action="store_true",
356 dest="is_build_release_tarball_only",
357 help="Provision for test suite with production settings.",
358 )
359
360 parser.add_argument(
361 "--skip-dev-db-build", action="store_true", help="Don't run migrations on dev database."
362 )
363
364 options = parser.parse_args()
365 sys.exit(main(options))
366
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/tools/lib/provision_inner.py b/tools/lib/provision_inner.py
--- a/tools/lib/provision_inner.py
+++ b/tools/lib/provision_inner.py
@@ -93,8 +93,16 @@
with open(shell_profile_path, "w") as shell_profile_file:
shell_profile_file.writelines(command + "\n")
- source_activate_command = "source " + os.path.join(VENV_PATH, "bin", "activate")
- write_command(source_activate_command)
+ # Check if the environment is one of the dedicated containers: Vagrant, Docker, Droplet or WSL2
+ WSL = os.path.exists("/proc/sys/fs/binfmt_misc/WSLInterop")
+ vagrant = os.path.exists("/vagrant")
+ docker = os.path.exists("/var/run/docker.sock")
+ droplet = os.path.exists("/etc/digitalocean")
+ # If the environment matches one of the containers, write the activation command to the user's bash profile
+ if WSL or vagrant or docker or droplet:
+ source_activate_command = "source " + os.path.join(VENV_PATH, "bin", "activate")
+ write_command(source_activate_command)
+
if os.path.exists("/srv/zulip"):
write_command("cd /srv/zulip")
|
{"golden_diff": "diff --git a/tools/lib/provision_inner.py b/tools/lib/provision_inner.py\n--- a/tools/lib/provision_inner.py\n+++ b/tools/lib/provision_inner.py\n@@ -93,8 +93,16 @@\n with open(shell_profile_path, \"w\") as shell_profile_file:\n shell_profile_file.writelines(command + \"\\n\")\n \n- source_activate_command = \"source \" + os.path.join(VENV_PATH, \"bin\", \"activate\")\n- write_command(source_activate_command)\n+ # Check if the environment is one of the dedicated containers: Vagrant, Docker, Droplet or WSL2\n+ WSL = os.path.exists(\"/proc/sys/fs/binfmt_misc/WSLInterop\")\n+ vagrant = os.path.exists(\"/vagrant\")\n+ docker = os.path.exists(\"/var/run/docker.sock\")\n+ droplet = os.path.exists(\"/etc/digitalocean\")\n+ # If the environment matches one of the containers, write the activation command to the user's bash profile\n+ if WSL or vagrant or docker or droplet:\n+ source_activate_command = \"source \" + os.path.join(VENV_PATH, \"bin\", \"activate\")\n+ write_command(source_activate_command)\n+\n if os.path.exists(\"/srv/zulip\"):\n write_command(\"cd /srv/zulip\")\n", "issue": "Don't activate zulip_py3_venv at the launch of shell on direct system dev setups.\nAs a part of `./tools/provision` we add `\"source \" + os.path.join(VENV_PATH, \"bin\", \"activate\")` to the bash profile of the user which is responsible for automatic activation of the zulip's virtualenv when a new shell is launched.\r\n\r\nWhile this is handy for Vagrant/Docker/Droplet setups, which are dedicated machines for running Zulip, this is not a desired behaviour in other setups like [Direct Installation on systems](https://zulip.readthedocs.io/en/latest/development/setup-advanced.html#installing-directly-on-ubuntu-debian-centos-or-fedora).\r\n\r\nSolution would be to extract the script which writes the venv activation to bash profile and call it via Vagrantfile/Dockerfile/Droplet setup script.\n", "before_files": [{"content": "#!/usr/bin/env python3\nimport argparse\nimport glob\nimport os\nimport shutil\nimport sys\nfrom typing import List\n\nZULIP_PATH = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))\n\nsys.path.append(ZULIP_PATH)\nimport pygments\n\nfrom scripts.lib import clean_unused_caches\nfrom scripts.lib.zulip_tools import (\n ENDC,\n OKBLUE,\n get_dev_uuid_var_path,\n get_tzdata_zi,\n is_digest_obsolete,\n run,\n run_as_root,\n write_new_digest,\n)\nfrom tools.setup.generate_zulip_bots_static_files import generate_zulip_bots_static_files\nfrom version import PROVISION_VERSION\n\nVENV_PATH = \"/srv/zulip-py3-venv\"\nUUID_VAR_PATH = get_dev_uuid_var_path()\n\nwith get_tzdata_zi() as f:\n line = f.readline()\n assert line.startswith(\"# version \")\n timezones_version = line[len(\"# version \") :]\n\n\ndef create_var_directories() -> None:\n # create var/coverage, var/log, etc.\n var_dir = os.path.join(ZULIP_PATH, \"var\")\n sub_dirs = [\n \"coverage\",\n \"log\",\n \"node-coverage\",\n \"test_uploads\",\n \"uploads\",\n \"xunit-test-results\",\n ]\n for sub_dir in sub_dirs:\n path = os.path.join(var_dir, sub_dir)\n os.makedirs(path, exist_ok=True)\n\n\ndef build_pygments_data_paths() -> List[str]:\n paths = [\n \"tools/setup/build_pygments_data\",\n \"tools/setup/lang.json\",\n ]\n return paths\n\n\ndef build_timezones_data_paths() -> List[str]:\n paths = [\n \"tools/setup/build_timezone_values\",\n ]\n return paths\n\n\ndef compilemessages_paths() -> List[str]:\n paths = [\"zerver/management/commands/compilemessages.py\"]\n paths += glob.glob(\"locale/*/LC_MESSAGES/*.po\")\n paths += glob.glob(\"locale/*/translations.json\")\n return paths\n\n\ndef configure_rabbitmq_paths() -> List[str]:\n paths = [\n \"scripts/setup/configure-rabbitmq\",\n ]\n return paths\n\n\ndef setup_shell_profile(shell_profile: str) -> None:\n shell_profile_path = os.path.expanduser(shell_profile)\n\n def write_command(command: str) -> None:\n if os.path.exists(shell_profile_path):\n with open(shell_profile_path) as shell_profile_file:\n lines = [line.strip() for line in shell_profile_file.readlines()]\n if command not in lines:\n with open(shell_profile_path, \"a+\") as shell_profile_file:\n shell_profile_file.writelines(command + \"\\n\")\n else:\n with open(shell_profile_path, \"w\") as shell_profile_file:\n shell_profile_file.writelines(command + \"\\n\")\n\n source_activate_command = \"source \" + os.path.join(VENV_PATH, \"bin\", \"activate\")\n write_command(source_activate_command)\n if os.path.exists(\"/srv/zulip\"):\n write_command(\"cd /srv/zulip\")\n\n\ndef setup_bash_profile() -> None:\n \"\"\"Select a bash profile file to add setup code to.\"\"\"\n\n BASH_PROFILES = [\n os.path.expanduser(p) for p in (\"~/.bash_profile\", \"~/.bash_login\", \"~/.profile\")\n ]\n\n def clear_old_profile() -> None:\n # An earlier version of this script would output a fresh .bash_profile\n # even though a .profile existed in the image used. As a convenience to\n # existing developers (and, perhaps, future developers git-bisecting the\n # provisioning scripts), check for this situation, and blow away the\n # created .bash_profile if one is found.\n\n BASH_PROFILE = BASH_PROFILES[0]\n DOT_PROFILE = BASH_PROFILES[2]\n OLD_PROFILE_TEXT = \"source /srv/zulip-py3-venv/bin/activate\\ncd /srv/zulip\\n\"\n\n if os.path.exists(DOT_PROFILE):\n try:\n with open(BASH_PROFILE) as f:\n profile_contents = f.read()\n if profile_contents == OLD_PROFILE_TEXT:\n os.unlink(BASH_PROFILE)\n except FileNotFoundError:\n pass\n\n clear_old_profile()\n\n for candidate_profile in BASH_PROFILES:\n if os.path.exists(candidate_profile):\n setup_shell_profile(candidate_profile)\n break\n else:\n # no existing bash profile found; claim .bash_profile\n setup_shell_profile(BASH_PROFILES[0])\n\n\ndef need_to_run_build_pygments_data() -> bool:\n if not os.path.exists(\"web/generated/pygments_data.json\"):\n return True\n\n return is_digest_obsolete(\n \"build_pygments_data_hash\",\n build_pygments_data_paths(),\n [pygments.__version__],\n )\n\n\ndef need_to_run_build_timezone_data() -> bool:\n if not os.path.exists(\"web/generated/timezones.json\"):\n return True\n\n return is_digest_obsolete(\n \"build_timezones_data_hash\",\n build_timezones_data_paths(),\n [timezones_version],\n )\n\n\ndef need_to_run_compilemessages() -> bool:\n if not os.path.exists(\"locale/language_name_map.json\"):\n # User may have cleaned their Git checkout.\n print(\"Need to run compilemessages due to missing language_name_map.json\")\n return True\n\n return is_digest_obsolete(\n \"last_compilemessages_hash\",\n compilemessages_paths(),\n )\n\n\ndef need_to_run_configure_rabbitmq(settings_list: List[str]) -> bool:\n obsolete = is_digest_obsolete(\n \"last_configure_rabbitmq_hash\",\n configure_rabbitmq_paths(),\n settings_list,\n )\n\n if obsolete:\n return True\n\n try:\n from zerver.lib.queue import SimpleQueueClient\n\n SimpleQueueClient()\n return False\n except Exception:\n return True\n\n\ndef main(options: argparse.Namespace) -> int:\n setup_bash_profile()\n setup_shell_profile(\"~/.zprofile\")\n\n # This needs to happen before anything that imports zproject.settings.\n run([\"scripts/setup/generate_secrets.py\", \"--development\"])\n\n create_var_directories()\n\n # The `build_emoji` script requires `emoji-datasource` package\n # which we install via npm; thus this step is after installing npm\n # packages.\n run([\"tools/setup/emoji/build_emoji\"])\n\n # copy over static files from the zulip_bots package\n generate_zulip_bots_static_files()\n\n if options.is_force or need_to_run_build_pygments_data():\n run([\"tools/setup/build_pygments_data\"])\n write_new_digest(\n \"build_pygments_data_hash\",\n build_pygments_data_paths(),\n [pygments.__version__],\n )\n else:\n print(\"No need to run `tools/setup/build_pygments_data`.\")\n\n if options.is_force or need_to_run_build_timezone_data():\n run([\"tools/setup/build_timezone_values\"])\n write_new_digest(\n \"build_timezones_data_hash\",\n build_timezones_data_paths(),\n [timezones_version],\n )\n else:\n print(\"No need to run `tools/setup/build_timezone_values`.\")\n\n if not options.is_build_release_tarball_only:\n # The following block is skipped when we just need the development\n # environment to build a release tarball.\n\n # Need to set up Django before using template_status\n os.environ.setdefault(\"DJANGO_SETTINGS_MODULE\", \"zproject.settings\")\n import django\n\n django.setup()\n\n from django.conf import settings\n\n from zerver.lib.test_fixtures import (\n DEV_DATABASE,\n TEST_DATABASE,\n destroy_leaked_test_databases,\n )\n\n assert settings.RABBITMQ_PASSWORD is not None\n if options.is_force or need_to_run_configure_rabbitmq([settings.RABBITMQ_PASSWORD]):\n run_as_root([\"scripts/setup/configure-rabbitmq\"])\n write_new_digest(\n \"last_configure_rabbitmq_hash\",\n configure_rabbitmq_paths(),\n [settings.RABBITMQ_PASSWORD],\n )\n else:\n print(\"No need to run `scripts/setup/configure-rabbitmq.\")\n\n dev_template_db_status = DEV_DATABASE.template_status()\n if options.is_force or dev_template_db_status == \"needs_rebuild\":\n run([\"tools/setup/postgresql-init-dev-db\"])\n if options.skip_dev_db_build:\n # We don't need to build the manual development\n # database on continuous integration for running tests, so we can\n # just leave it as a template db and save a minute.\n #\n # Important: We don't write a digest as that would\n # incorrectly claim that we ran migrations.\n pass\n else:\n run([\"tools/rebuild-dev-database\"])\n DEV_DATABASE.write_new_db_digest()\n elif dev_template_db_status == \"run_migrations\":\n DEV_DATABASE.run_db_migrations()\n elif dev_template_db_status == \"current\":\n print(\"No need to regenerate the dev DB.\")\n\n test_template_db_status = TEST_DATABASE.template_status()\n if options.is_force or test_template_db_status == \"needs_rebuild\":\n run([\"tools/setup/postgresql-init-test-db\"])\n run([\"tools/rebuild-test-database\"])\n TEST_DATABASE.write_new_db_digest()\n elif test_template_db_status == \"run_migrations\":\n TEST_DATABASE.run_db_migrations()\n elif test_template_db_status == \"current\":\n print(\"No need to regenerate the test DB.\")\n\n if options.is_force or need_to_run_compilemessages():\n run([\"./manage.py\", \"compilemessages\", \"--ignore=*\"])\n write_new_digest(\n \"last_compilemessages_hash\",\n compilemessages_paths(),\n )\n else:\n print(\"No need to run `manage.py compilemessages`.\")\n\n destroyed = destroy_leaked_test_databases()\n if destroyed:\n print(f\"Dropped {destroyed} stale test databases!\")\n\n clean_unused_caches.main(\n argparse.Namespace(\n threshold_days=6,\n # The defaults here should match parse_cache_script_args in zulip_tools.py\n dry_run=False,\n verbose=False,\n no_headings=True,\n )\n )\n\n # Keeping this cache file around can cause eslint to throw\n # random TypeErrors when new/updated dependencies are added\n if os.path.isfile(\".eslintcache\"):\n # Remove this block when\n # https://github.com/eslint/eslint/issues/11639 is fixed\n # upstream.\n os.remove(\".eslintcache\")\n\n # Clean up the root of the `var/` directory for various\n # testing-related files that we have migrated to\n # `var/<uuid>/test-backend`.\n print(\"Cleaning var/ directory files...\")\n var_paths = glob.glob(\"var/test*\")\n var_paths.append(\"var/bot_avatar\")\n for path in var_paths:\n try:\n if os.path.isdir(path):\n shutil.rmtree(path)\n else:\n os.remove(path)\n except FileNotFoundError:\n pass\n\n version_file = os.path.join(UUID_VAR_PATH, \"provision_version\")\n print(f\"writing to {version_file}\\n\")\n with open(version_file, \"w\") as f:\n f.write(\".\".join(map(str, PROVISION_VERSION)) + \"\\n\")\n\n print()\n print(OKBLUE + \"Zulip development environment setup succeeded!\" + ENDC)\n return 0\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument(\n \"--force\",\n action=\"store_true\",\n dest=\"is_force\",\n help=\"Ignore all provisioning optimizations.\",\n )\n\n parser.add_argument(\n \"--build-release-tarball-only\",\n action=\"store_true\",\n dest=\"is_build_release_tarball_only\",\n help=\"Provision for test suite with production settings.\",\n )\n\n parser.add_argument(\n \"--skip-dev-db-build\", action=\"store_true\", help=\"Don't run migrations on dev database.\"\n )\n\n options = parser.parse_args()\n sys.exit(main(options))\n", "path": "tools/lib/provision_inner.py"}], "after_files": [{"content": "#!/usr/bin/env python3\nimport argparse\nimport glob\nimport os\nimport shutil\nimport sys\nfrom typing import List\n\nZULIP_PATH = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))\n\nsys.path.append(ZULIP_PATH)\nimport pygments\n\nfrom scripts.lib import clean_unused_caches\nfrom scripts.lib.zulip_tools import (\n ENDC,\n OKBLUE,\n get_dev_uuid_var_path,\n get_tzdata_zi,\n is_digest_obsolete,\n run,\n run_as_root,\n write_new_digest,\n)\nfrom tools.setup.generate_zulip_bots_static_files import generate_zulip_bots_static_files\nfrom version import PROVISION_VERSION\n\nVENV_PATH = \"/srv/zulip-py3-venv\"\nUUID_VAR_PATH = get_dev_uuid_var_path()\n\nwith get_tzdata_zi() as f:\n line = f.readline()\n assert line.startswith(\"# version \")\n timezones_version = line[len(\"# version \") :]\n\n\ndef create_var_directories() -> None:\n # create var/coverage, var/log, etc.\n var_dir = os.path.join(ZULIP_PATH, \"var\")\n sub_dirs = [\n \"coverage\",\n \"log\",\n \"node-coverage\",\n \"test_uploads\",\n \"uploads\",\n \"xunit-test-results\",\n ]\n for sub_dir in sub_dirs:\n path = os.path.join(var_dir, sub_dir)\n os.makedirs(path, exist_ok=True)\n\n\ndef build_pygments_data_paths() -> List[str]:\n paths = [\n \"tools/setup/build_pygments_data\",\n \"tools/setup/lang.json\",\n ]\n return paths\n\n\ndef build_timezones_data_paths() -> List[str]:\n paths = [\n \"tools/setup/build_timezone_values\",\n ]\n return paths\n\n\ndef compilemessages_paths() -> List[str]:\n paths = [\"zerver/management/commands/compilemessages.py\"]\n paths += glob.glob(\"locale/*/LC_MESSAGES/*.po\")\n paths += glob.glob(\"locale/*/translations.json\")\n return paths\n\n\ndef configure_rabbitmq_paths() -> List[str]:\n paths = [\n \"scripts/setup/configure-rabbitmq\",\n ]\n return paths\n\n\ndef setup_shell_profile(shell_profile: str) -> None:\n shell_profile_path = os.path.expanduser(shell_profile)\n\n def write_command(command: str) -> None:\n if os.path.exists(shell_profile_path):\n with open(shell_profile_path) as shell_profile_file:\n lines = [line.strip() for line in shell_profile_file.readlines()]\n if command not in lines:\n with open(shell_profile_path, \"a+\") as shell_profile_file:\n shell_profile_file.writelines(command + \"\\n\")\n else:\n with open(shell_profile_path, \"w\") as shell_profile_file:\n shell_profile_file.writelines(command + \"\\n\")\n\n # Check if the environment is one of the dedicated containers: Vagrant, Docker, Droplet or WSL2\n WSL = os.path.exists(\"/proc/sys/fs/binfmt_misc/WSLInterop\")\n vagrant = os.path.exists(\"/vagrant\")\n docker = os.path.exists(\"/var/run/docker.sock\")\n droplet = os.path.exists(\"/etc/digitalocean\")\n # If the environment matches one of the containers, write the activation command to the user's bash profile\n if WSL or vagrant or docker or droplet:\n source_activate_command = \"source \" + os.path.join(VENV_PATH, \"bin\", \"activate\")\n write_command(source_activate_command)\n\n if os.path.exists(\"/srv/zulip\"):\n write_command(\"cd /srv/zulip\")\n\n\ndef setup_bash_profile() -> None:\n \"\"\"Select a bash profile file to add setup code to.\"\"\"\n\n BASH_PROFILES = [\n os.path.expanduser(p) for p in (\"~/.bash_profile\", \"~/.bash_login\", \"~/.profile\")\n ]\n\n def clear_old_profile() -> None:\n # An earlier version of this script would output a fresh .bash_profile\n # even though a .profile existed in the image used. As a convenience to\n # existing developers (and, perhaps, future developers git-bisecting the\n # provisioning scripts), check for this situation, and blow away the\n # created .bash_profile if one is found.\n\n BASH_PROFILE = BASH_PROFILES[0]\n DOT_PROFILE = BASH_PROFILES[2]\n OLD_PROFILE_TEXT = \"source /srv/zulip-py3-venv/bin/activate\\ncd /srv/zulip\\n\"\n\n if os.path.exists(DOT_PROFILE):\n try:\n with open(BASH_PROFILE) as f:\n profile_contents = f.read()\n if profile_contents == OLD_PROFILE_TEXT:\n os.unlink(BASH_PROFILE)\n except FileNotFoundError:\n pass\n\n clear_old_profile()\n\n for candidate_profile in BASH_PROFILES:\n if os.path.exists(candidate_profile):\n setup_shell_profile(candidate_profile)\n break\n else:\n # no existing bash profile found; claim .bash_profile\n setup_shell_profile(BASH_PROFILES[0])\n\n\ndef need_to_run_build_pygments_data() -> bool:\n if not os.path.exists(\"web/generated/pygments_data.json\"):\n return True\n\n return is_digest_obsolete(\n \"build_pygments_data_hash\",\n build_pygments_data_paths(),\n [pygments.__version__],\n )\n\n\ndef need_to_run_build_timezone_data() -> bool:\n if not os.path.exists(\"web/generated/timezones.json\"):\n return True\n\n return is_digest_obsolete(\n \"build_timezones_data_hash\",\n build_timezones_data_paths(),\n [timezones_version],\n )\n\n\ndef need_to_run_compilemessages() -> bool:\n if not os.path.exists(\"locale/language_name_map.json\"):\n # User may have cleaned their Git checkout.\n print(\"Need to run compilemessages due to missing language_name_map.json\")\n return True\n\n return is_digest_obsolete(\n \"last_compilemessages_hash\",\n compilemessages_paths(),\n )\n\n\ndef need_to_run_configure_rabbitmq(settings_list: List[str]) -> bool:\n obsolete = is_digest_obsolete(\n \"last_configure_rabbitmq_hash\",\n configure_rabbitmq_paths(),\n settings_list,\n )\n\n if obsolete:\n return True\n\n try:\n from zerver.lib.queue import SimpleQueueClient\n\n SimpleQueueClient()\n return False\n except Exception:\n return True\n\n\ndef main(options: argparse.Namespace) -> int:\n setup_bash_profile()\n setup_shell_profile(\"~/.zprofile\")\n\n # This needs to happen before anything that imports zproject.settings.\n run([\"scripts/setup/generate_secrets.py\", \"--development\"])\n\n create_var_directories()\n\n # The `build_emoji` script requires `emoji-datasource` package\n # which we install via npm; thus this step is after installing npm\n # packages.\n run([\"tools/setup/emoji/build_emoji\"])\n\n # copy over static files from the zulip_bots package\n generate_zulip_bots_static_files()\n\n if options.is_force or need_to_run_build_pygments_data():\n run([\"tools/setup/build_pygments_data\"])\n write_new_digest(\n \"build_pygments_data_hash\",\n build_pygments_data_paths(),\n [pygments.__version__],\n )\n else:\n print(\"No need to run `tools/setup/build_pygments_data`.\")\n\n if options.is_force or need_to_run_build_timezone_data():\n run([\"tools/setup/build_timezone_values\"])\n write_new_digest(\n \"build_timezones_data_hash\",\n build_timezones_data_paths(),\n [timezones_version],\n )\n else:\n print(\"No need to run `tools/setup/build_timezone_values`.\")\n\n if not options.is_build_release_tarball_only:\n # The following block is skipped when we just need the development\n # environment to build a release tarball.\n\n # Need to set up Django before using template_status\n os.environ.setdefault(\"DJANGO_SETTINGS_MODULE\", \"zproject.settings\")\n import django\n\n django.setup()\n\n from django.conf import settings\n\n from zerver.lib.test_fixtures import (\n DEV_DATABASE,\n TEST_DATABASE,\n destroy_leaked_test_databases,\n )\n\n assert settings.RABBITMQ_PASSWORD is not None\n if options.is_force or need_to_run_configure_rabbitmq([settings.RABBITMQ_PASSWORD]):\n run_as_root([\"scripts/setup/configure-rabbitmq\"])\n write_new_digest(\n \"last_configure_rabbitmq_hash\",\n configure_rabbitmq_paths(),\n [settings.RABBITMQ_PASSWORD],\n )\n else:\n print(\"No need to run `scripts/setup/configure-rabbitmq.\")\n\n dev_template_db_status = DEV_DATABASE.template_status()\n if options.is_force or dev_template_db_status == \"needs_rebuild\":\n run([\"tools/setup/postgresql-init-dev-db\"])\n if options.skip_dev_db_build:\n # We don't need to build the manual development\n # database on continuous integration for running tests, so we can\n # just leave it as a template db and save a minute.\n #\n # Important: We don't write a digest as that would\n # incorrectly claim that we ran migrations.\n pass\n else:\n run([\"tools/rebuild-dev-database\"])\n DEV_DATABASE.write_new_db_digest()\n elif dev_template_db_status == \"run_migrations\":\n DEV_DATABASE.run_db_migrations()\n elif dev_template_db_status == \"current\":\n print(\"No need to regenerate the dev DB.\")\n\n test_template_db_status = TEST_DATABASE.template_status()\n if options.is_force or test_template_db_status == \"needs_rebuild\":\n run([\"tools/setup/postgresql-init-test-db\"])\n run([\"tools/rebuild-test-database\"])\n TEST_DATABASE.write_new_db_digest()\n elif test_template_db_status == \"run_migrations\":\n TEST_DATABASE.run_db_migrations()\n elif test_template_db_status == \"current\":\n print(\"No need to regenerate the test DB.\")\n\n if options.is_force or need_to_run_compilemessages():\n run([\"./manage.py\", \"compilemessages\", \"--ignore=*\"])\n write_new_digest(\n \"last_compilemessages_hash\",\n compilemessages_paths(),\n )\n else:\n print(\"No need to run `manage.py compilemessages`.\")\n\n destroyed = destroy_leaked_test_databases()\n if destroyed:\n print(f\"Dropped {destroyed} stale test databases!\")\n\n clean_unused_caches.main(\n argparse.Namespace(\n threshold_days=6,\n # The defaults here should match parse_cache_script_args in zulip_tools.py\n dry_run=False,\n verbose=False,\n no_headings=True,\n )\n )\n\n # Keeping this cache file around can cause eslint to throw\n # random TypeErrors when new/updated dependencies are added\n if os.path.isfile(\".eslintcache\"):\n # Remove this block when\n # https://github.com/eslint/eslint/issues/11639 is fixed\n # upstream.\n os.remove(\".eslintcache\")\n\n # Clean up the root of the `var/` directory for various\n # testing-related files that we have migrated to\n # `var/<uuid>/test-backend`.\n print(\"Cleaning var/ directory files...\")\n var_paths = glob.glob(\"var/test*\")\n var_paths.append(\"var/bot_avatar\")\n for path in var_paths:\n try:\n if os.path.isdir(path):\n shutil.rmtree(path)\n else:\n os.remove(path)\n except FileNotFoundError:\n pass\n\n version_file = os.path.join(UUID_VAR_PATH, \"provision_version\")\n print(f\"writing to {version_file}\\n\")\n with open(version_file, \"w\") as f:\n f.write(\".\".join(map(str, PROVISION_VERSION)) + \"\\n\")\n\n print()\n print(OKBLUE + \"Zulip development environment setup succeeded!\" + ENDC)\n return 0\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument(\n \"--force\",\n action=\"store_true\",\n dest=\"is_force\",\n help=\"Ignore all provisioning optimizations.\",\n )\n\n parser.add_argument(\n \"--build-release-tarball-only\",\n action=\"store_true\",\n dest=\"is_build_release_tarball_only\",\n help=\"Provision for test suite with production settings.\",\n )\n\n parser.add_argument(\n \"--skip-dev-db-build\", action=\"store_true\", help=\"Don't run migrations on dev database.\"\n )\n\n options = parser.parse_args()\n sys.exit(main(options))\n", "path": "tools/lib/provision_inner.py"}]}
| 4,026 | 284 |
gh_patches_debug_17
|
rasdani/github-patches
|
git_diff
|
OCHA-DAP__hdx-ckan-2071
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Update data on the Ebola map
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ckanext-hdx_theme/ckanext/hdx_theme/version.py`
Content:
```
1 hdx_version = 'v0.5.13'
2
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ckanext-hdx_theme/ckanext/hdx_theme/version.py b/ckanext-hdx_theme/ckanext/hdx_theme/version.py
--- a/ckanext-hdx_theme/ckanext/hdx_theme/version.py
+++ b/ckanext-hdx_theme/ckanext/hdx_theme/version.py
@@ -1 +1 @@
-hdx_version = 'v0.5.13'
+hdx_version = 'v0.5.14'
|
{"golden_diff": "diff --git a/ckanext-hdx_theme/ckanext/hdx_theme/version.py b/ckanext-hdx_theme/ckanext/hdx_theme/version.py\n--- a/ckanext-hdx_theme/ckanext/hdx_theme/version.py\n+++ b/ckanext-hdx_theme/ckanext/hdx_theme/version.py\n@@ -1 +1 @@\n-hdx_version = 'v0.5.13'\n+hdx_version = 'v0.5.14'\n", "issue": "Update data on the Ebola map\n\n", "before_files": [{"content": "hdx_version = 'v0.5.13'\n", "path": "ckanext-hdx_theme/ckanext/hdx_theme/version.py"}], "after_files": [{"content": "hdx_version = 'v0.5.14'\n", "path": "ckanext-hdx_theme/ckanext/hdx_theme/version.py"}]}
| 291 | 108 |
gh_patches_debug_21439
|
rasdani/github-patches
|
git_diff
|
Parsl__parsl-1561
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
GridEngine provider mis-parses wall times, treating minutes as seconds
**Describe the bug**
The GridEngine system expects walltime in seconds, but parsl provides `10`, which leads to difficult-to-recognize errors relating to walltime errors.
**To Reproduce**
Steps to reproduce the behavior, for e.g:
1. Setup Parsl 0.9.0 with Python 3.6 on cluster
2. Run a sleep job with GridEngine provider
3. Watch the `qstat`, where you will see jobs disappear
**Expected behavior**
10 minute default walltime
**Environment**
- OS: CentOS 7
- Python version 3.6
- Parsl version 0.9
**Distributed Environment**
- Where are you running the Parsl script from ? Login node
- Where do you need the workers to run ?Worker nodes on same network as login node
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `parsl/providers/grid_engine/grid_engine.py`
Content:
```
1 import logging
2 import os
3 import time
4
5 from parsl.channels import LocalChannel
6 from parsl.providers.cluster_provider import ClusterProvider
7 from parsl.providers.grid_engine.template import template_string
8 from parsl.launchers import SingleNodeLauncher
9 from parsl.providers.provider_base import JobState, JobStatus
10 from parsl.utils import RepresentationMixin, wtime_to_minutes
11
12 logger = logging.getLogger(__name__)
13
14 translate_table = {
15 'qw': JobState.PENDING,
16 'hqw': JobState.PENDING,
17 'hrwq': JobState.PENDING,
18 'r': JobState.RUNNING,
19 's': JobState.FAILED, # obsuspended
20 'ts': JobState.FAILED,
21 't': JobState.FAILED, # Suspended by alarm
22 'eqw': JobState.FAILED, # Error states
23 'ehqw': JobState.FAILED, # ..
24 'ehrqw': JobState.FAILED, # ..
25 'd': JobState.COMPLETED,
26 'dr': JobState.COMPLETED,
27 'dt': JobState.COMPLETED,
28 'drt': JobState.COMPLETED,
29 'ds': JobState.COMPLETED,
30 'drs': JobState.COMPLETED,
31 }
32
33
34 class GridEngineProvider(ClusterProvider, RepresentationMixin):
35 """A provider for the Grid Engine scheduler.
36
37 Parameters
38 ----------
39 channel : Channel
40 Channel for accessing this provider. Possible channels include
41 :class:`~parsl.channels.LocalChannel` (the default),
42 :class:`~parsl.channels.SSHChannel`, or
43 :class:`~parsl.channels.SSHInteractiveLoginChannel`.
44 nodes_per_block : int
45 Nodes to provision per block.
46 min_blocks : int
47 Minimum number of blocks to maintain.
48 max_blocks : int
49 Maximum number of blocks to maintain.
50 parallelism : float
51 Ratio of provisioned task slots to active tasks. A parallelism value of 1 represents aggressive
52 scaling where as many resources as possible are used; parallelism close to 0 represents
53 the opposite situation in which as few resources as possible (i.e., min_blocks) are used.
54 walltime : str
55 Walltime requested per block in HH:MM:SS.
56 scheduler_options : str
57 String to prepend to the #$$ blocks in the submit script to the scheduler.
58 worker_init : str
59 Command to be run before starting a worker, such as 'module load Anaconda; source activate env'.
60 launcher : Launcher
61 Launcher for this provider. Possible launchers include
62 :class:`~parsl.launchers.SingleNodeLauncher` (the default),
63 """
64
65 def __init__(self,
66 channel=LocalChannel(),
67 nodes_per_block=1,
68 init_blocks=1,
69 min_blocks=0,
70 max_blocks=10,
71 parallelism=1,
72 walltime="00:10:00",
73 scheduler_options='',
74 worker_init='',
75 launcher=SingleNodeLauncher()):
76 label = 'grid_engine'
77 super().__init__(label,
78 channel,
79 nodes_per_block,
80 init_blocks,
81 min_blocks,
82 max_blocks,
83 parallelism,
84 walltime,
85 launcher)
86 self.scheduler_options = scheduler_options
87 self.worker_init = worker_init
88
89 if launcher in ['srun', 'srun_mpi']:
90 logger.warning("Use of {} launcher is usually appropriate for Slurm providers. "
91 "Recommended options include 'single_node' or 'aprun'.".format(launcher))
92
93 def get_configs(self, command, tasks_per_node):
94 """Compose a dictionary with information for writing the submit script."""
95
96 logger.debug("Requesting one block with {} nodes per block and {} tasks per node".format(
97 self.nodes_per_block, tasks_per_node))
98
99 job_config = {}
100 job_config["submit_script_dir"] = self.channel.script_dir
101 job_config["nodes"] = self.nodes_per_block
102 job_config["walltime"] = wtime_to_minutes(self.walltime)
103 job_config["scheduler_options"] = self.scheduler_options
104 job_config["worker_init"] = self.worker_init
105 job_config["user_script"] = command
106
107 job_config["user_script"] = self.launcher(command,
108 tasks_per_node,
109 self.nodes_per_block)
110 return job_config
111
112 def submit(self, command, tasks_per_node, job_name="parsl.sge"):
113 ''' The submit method takes the command string to be executed upon
114 instantiation of a resource most often to start a pilot (such as IPP engine
115 or even Swift-T engines).
116
117 Args :
118 - command (str) : The bash command string to be executed.
119 - tasks_per_node (int) : command invocations to be launched per node
120
121 KWargs:
122 - job_name (str) : Human friendly name to be assigned to the job request
123
124 Returns:
125 - A job identifier, this could be an integer, string etc
126
127 Raises:
128 - ExecutionProviderException or its subclasses
129 '''
130
131 # Set job name
132 job_name = "{0}.{1}".format(job_name, time.time())
133
134 # Set script path
135 script_path = "{0}/{1}.submit".format(self.script_dir, job_name)
136 script_path = os.path.abspath(script_path)
137
138 job_config = self.get_configs(command, tasks_per_node)
139
140 logger.debug("Writing submit script")
141 self._write_submit_script(template_string, script_path, job_name, job_config)
142
143 channel_script_path = self.channel.push_file(script_path, self.channel.script_dir)
144 cmd = "qsub -terse {0}".format(channel_script_path)
145 retcode, stdout, stderr = self.execute_wait(cmd, 10)
146
147 if retcode == 0:
148 for line in stdout.split('\n'):
149 job_id = line.strip()
150 if not job_id:
151 continue
152 self.resources[job_id] = {'job_id': job_id, 'status': JobStatus(JobState.PENDING)}
153 return job_id
154 else:
155 print("[WARNING!!] Submission of command to scale_out failed")
156 logger.error("Retcode:%s STDOUT:%s STDERR:%s", retcode, stdout.strip(), stderr.strip())
157
158 def _status(self):
159 ''' Get the status of a list of jobs identified by the job identifiers
160 returned from the submit request.
161
162 Returns:
163 - A list of JobStatus objects corresponding to each job_id in the job_ids list.
164
165 Raises:
166 - ExecutionProviderException or its subclasses
167
168 '''
169
170 cmd = "qstat"
171
172 retcode, stdout, stderr = self.execute_wait(cmd)
173
174 # Execute_wait failed. Do no update
175 if retcode != 0:
176 return
177
178 jobs_missing = list(self.resources.keys())
179 for line in stdout.split('\n'):
180 parts = line.split()
181 if parts and parts[0].lower().lower() != 'job-id' \
182 and not parts[0].startswith('----'):
183 job_id = parts[0]
184 status = translate_table.get(parts[4].lower(), JobState.UNKNOWN)
185 if job_id in self.resources:
186 self.resources[job_id]['status'] = status
187 jobs_missing.remove(job_id)
188
189 # Filling in missing blanks for jobs that might have gone missing
190 # we might lose some information about why the jobs failed.
191 for missing_job in jobs_missing:
192 self.resources[missing_job]['status'] = JobStatus(JobState.COMPLETED)
193
194 def cancel(self, job_ids):
195 ''' Cancels the resources identified by the job_ids provided by the user.
196
197 Args:
198 - job_ids (list): A list of job identifiers
199
200 Returns:
201 - A list of status from cancelling the job which can be True, False
202
203 Raises:
204 - ExecutionProviderException or its subclasses
205 '''
206
207 job_id_list = ' '.join(job_ids)
208 cmd = "qdel {}".format(job_id_list)
209 retcode, stdout, stderr = self.execute_wait(cmd, 3)
210
211 rets = None
212 if retcode == 0:
213 for jid in job_ids:
214 self.resources[jid]['status'] = JobStatus(JobState.COMPLETED)
215 rets = [True for i in job_ids]
216 else:
217 rets = [False for i in job_ids]
218
219 return rets
220
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/parsl/providers/grid_engine/grid_engine.py b/parsl/providers/grid_engine/grid_engine.py
--- a/parsl/providers/grid_engine/grid_engine.py
+++ b/parsl/providers/grid_engine/grid_engine.py
@@ -7,7 +7,7 @@
from parsl.providers.grid_engine.template import template_string
from parsl.launchers import SingleNodeLauncher
from parsl.providers.provider_base import JobState, JobStatus
-from parsl.utils import RepresentationMixin, wtime_to_minutes
+from parsl.utils import RepresentationMixin
logger = logging.getLogger(__name__)
@@ -99,7 +99,7 @@
job_config = {}
job_config["submit_script_dir"] = self.channel.script_dir
job_config["nodes"] = self.nodes_per_block
- job_config["walltime"] = wtime_to_minutes(self.walltime)
+ job_config["walltime"] = self.walltime
job_config["scheduler_options"] = self.scheduler_options
job_config["worker_init"] = self.worker_init
job_config["user_script"] = command
|
{"golden_diff": "diff --git a/parsl/providers/grid_engine/grid_engine.py b/parsl/providers/grid_engine/grid_engine.py\n--- a/parsl/providers/grid_engine/grid_engine.py\n+++ b/parsl/providers/grid_engine/grid_engine.py\n@@ -7,7 +7,7 @@\n from parsl.providers.grid_engine.template import template_string\n from parsl.launchers import SingleNodeLauncher\n from parsl.providers.provider_base import JobState, JobStatus\n-from parsl.utils import RepresentationMixin, wtime_to_minutes\n+from parsl.utils import RepresentationMixin\n \n logger = logging.getLogger(__name__)\n \n@@ -99,7 +99,7 @@\n job_config = {}\n job_config[\"submit_script_dir\"] = self.channel.script_dir\n job_config[\"nodes\"] = self.nodes_per_block\n- job_config[\"walltime\"] = wtime_to_minutes(self.walltime)\n+ job_config[\"walltime\"] = self.walltime\n job_config[\"scheduler_options\"] = self.scheduler_options\n job_config[\"worker_init\"] = self.worker_init\n job_config[\"user_script\"] = command\n", "issue": "GridEngine provider mis-parses wall times, treating minutes as seconds\n**Describe the bug**\r\nThe GridEngine system expects walltime in seconds, but parsl provides `10`, which leads to difficult-to-recognize errors relating to walltime errors.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior, for e.g:\r\n1. Setup Parsl 0.9.0 with Python 3.6 on cluster\r\n2. Run a sleep job with GridEngine provider\r\n3. Watch the `qstat`, where you will see jobs disappear\r\n\r\n**Expected behavior**\r\n10 minute default walltime\r\n\r\n**Environment**\r\n - OS: CentOS 7\r\n - Python version 3.6\r\n - Parsl version 0.9\r\n\r\n**Distributed Environment**\r\n- Where are you running the Parsl script from ? Login node\r\n\r\n- Where do you need the workers to run ?Worker nodes on same network as login node\n", "before_files": [{"content": "import logging\nimport os\nimport time\n\nfrom parsl.channels import LocalChannel\nfrom parsl.providers.cluster_provider import ClusterProvider\nfrom parsl.providers.grid_engine.template import template_string\nfrom parsl.launchers import SingleNodeLauncher\nfrom parsl.providers.provider_base import JobState, JobStatus\nfrom parsl.utils import RepresentationMixin, wtime_to_minutes\n\nlogger = logging.getLogger(__name__)\n\ntranslate_table = {\n 'qw': JobState.PENDING,\n 'hqw': JobState.PENDING,\n 'hrwq': JobState.PENDING,\n 'r': JobState.RUNNING,\n 's': JobState.FAILED, # obsuspended\n 'ts': JobState.FAILED,\n 't': JobState.FAILED, # Suspended by alarm\n 'eqw': JobState.FAILED, # Error states\n 'ehqw': JobState.FAILED, # ..\n 'ehrqw': JobState.FAILED, # ..\n 'd': JobState.COMPLETED,\n 'dr': JobState.COMPLETED,\n 'dt': JobState.COMPLETED,\n 'drt': JobState.COMPLETED,\n 'ds': JobState.COMPLETED,\n 'drs': JobState.COMPLETED,\n}\n\n\nclass GridEngineProvider(ClusterProvider, RepresentationMixin):\n \"\"\"A provider for the Grid Engine scheduler.\n\n Parameters\n ----------\n channel : Channel\n Channel for accessing this provider. Possible channels include\n :class:`~parsl.channels.LocalChannel` (the default),\n :class:`~parsl.channels.SSHChannel`, or\n :class:`~parsl.channels.SSHInteractiveLoginChannel`.\n nodes_per_block : int\n Nodes to provision per block.\n min_blocks : int\n Minimum number of blocks to maintain.\n max_blocks : int\n Maximum number of blocks to maintain.\n parallelism : float\n Ratio of provisioned task slots to active tasks. A parallelism value of 1 represents aggressive\n scaling where as many resources as possible are used; parallelism close to 0 represents\n the opposite situation in which as few resources as possible (i.e., min_blocks) are used.\n walltime : str\n Walltime requested per block in HH:MM:SS.\n scheduler_options : str\n String to prepend to the #$$ blocks in the submit script to the scheduler.\n worker_init : str\n Command to be run before starting a worker, such as 'module load Anaconda; source activate env'.\n launcher : Launcher\n Launcher for this provider. Possible launchers include\n :class:`~parsl.launchers.SingleNodeLauncher` (the default),\n \"\"\"\n\n def __init__(self,\n channel=LocalChannel(),\n nodes_per_block=1,\n init_blocks=1,\n min_blocks=0,\n max_blocks=10,\n parallelism=1,\n walltime=\"00:10:00\",\n scheduler_options='',\n worker_init='',\n launcher=SingleNodeLauncher()):\n label = 'grid_engine'\n super().__init__(label,\n channel,\n nodes_per_block,\n init_blocks,\n min_blocks,\n max_blocks,\n parallelism,\n walltime,\n launcher)\n self.scheduler_options = scheduler_options\n self.worker_init = worker_init\n\n if launcher in ['srun', 'srun_mpi']:\n logger.warning(\"Use of {} launcher is usually appropriate for Slurm providers. \"\n \"Recommended options include 'single_node' or 'aprun'.\".format(launcher))\n\n def get_configs(self, command, tasks_per_node):\n \"\"\"Compose a dictionary with information for writing the submit script.\"\"\"\n\n logger.debug(\"Requesting one block with {} nodes per block and {} tasks per node\".format(\n self.nodes_per_block, tasks_per_node))\n\n job_config = {}\n job_config[\"submit_script_dir\"] = self.channel.script_dir\n job_config[\"nodes\"] = self.nodes_per_block\n job_config[\"walltime\"] = wtime_to_minutes(self.walltime)\n job_config[\"scheduler_options\"] = self.scheduler_options\n job_config[\"worker_init\"] = self.worker_init\n job_config[\"user_script\"] = command\n\n job_config[\"user_script\"] = self.launcher(command,\n tasks_per_node,\n self.nodes_per_block)\n return job_config\n\n def submit(self, command, tasks_per_node, job_name=\"parsl.sge\"):\n ''' The submit method takes the command string to be executed upon\n instantiation of a resource most often to start a pilot (such as IPP engine\n or even Swift-T engines).\n\n Args :\n - command (str) : The bash command string to be executed.\n - tasks_per_node (int) : command invocations to be launched per node\n\n KWargs:\n - job_name (str) : Human friendly name to be assigned to the job request\n\n Returns:\n - A job identifier, this could be an integer, string etc\n\n Raises:\n - ExecutionProviderException or its subclasses\n '''\n\n # Set job name\n job_name = \"{0}.{1}\".format(job_name, time.time())\n\n # Set script path\n script_path = \"{0}/{1}.submit\".format(self.script_dir, job_name)\n script_path = os.path.abspath(script_path)\n\n job_config = self.get_configs(command, tasks_per_node)\n\n logger.debug(\"Writing submit script\")\n self._write_submit_script(template_string, script_path, job_name, job_config)\n\n channel_script_path = self.channel.push_file(script_path, self.channel.script_dir)\n cmd = \"qsub -terse {0}\".format(channel_script_path)\n retcode, stdout, stderr = self.execute_wait(cmd, 10)\n\n if retcode == 0:\n for line in stdout.split('\\n'):\n job_id = line.strip()\n if not job_id:\n continue\n self.resources[job_id] = {'job_id': job_id, 'status': JobStatus(JobState.PENDING)}\n return job_id\n else:\n print(\"[WARNING!!] Submission of command to scale_out failed\")\n logger.error(\"Retcode:%s STDOUT:%s STDERR:%s\", retcode, stdout.strip(), stderr.strip())\n\n def _status(self):\n ''' Get the status of a list of jobs identified by the job identifiers\n returned from the submit request.\n\n Returns:\n - A list of JobStatus objects corresponding to each job_id in the job_ids list.\n\n Raises:\n - ExecutionProviderException or its subclasses\n\n '''\n\n cmd = \"qstat\"\n\n retcode, stdout, stderr = self.execute_wait(cmd)\n\n # Execute_wait failed. Do no update\n if retcode != 0:\n return\n\n jobs_missing = list(self.resources.keys())\n for line in stdout.split('\\n'):\n parts = line.split()\n if parts and parts[0].lower().lower() != 'job-id' \\\n and not parts[0].startswith('----'):\n job_id = parts[0]\n status = translate_table.get(parts[4].lower(), JobState.UNKNOWN)\n if job_id in self.resources:\n self.resources[job_id]['status'] = status\n jobs_missing.remove(job_id)\n\n # Filling in missing blanks for jobs that might have gone missing\n # we might lose some information about why the jobs failed.\n for missing_job in jobs_missing:\n self.resources[missing_job]['status'] = JobStatus(JobState.COMPLETED)\n\n def cancel(self, job_ids):\n ''' Cancels the resources identified by the job_ids provided by the user.\n\n Args:\n - job_ids (list): A list of job identifiers\n\n Returns:\n - A list of status from cancelling the job which can be True, False\n\n Raises:\n - ExecutionProviderException or its subclasses\n '''\n\n job_id_list = ' '.join(job_ids)\n cmd = \"qdel {}\".format(job_id_list)\n retcode, stdout, stderr = self.execute_wait(cmd, 3)\n\n rets = None\n if retcode == 0:\n for jid in job_ids:\n self.resources[jid]['status'] = JobStatus(JobState.COMPLETED)\n rets = [True for i in job_ids]\n else:\n rets = [False for i in job_ids]\n\n return rets\n", "path": "parsl/providers/grid_engine/grid_engine.py"}], "after_files": [{"content": "import logging\nimport os\nimport time\n\nfrom parsl.channels import LocalChannel\nfrom parsl.providers.cluster_provider import ClusterProvider\nfrom parsl.providers.grid_engine.template import template_string\nfrom parsl.launchers import SingleNodeLauncher\nfrom parsl.providers.provider_base import JobState, JobStatus\nfrom parsl.utils import RepresentationMixin\n\nlogger = logging.getLogger(__name__)\n\ntranslate_table = {\n 'qw': JobState.PENDING,\n 'hqw': JobState.PENDING,\n 'hrwq': JobState.PENDING,\n 'r': JobState.RUNNING,\n 's': JobState.FAILED, # obsuspended\n 'ts': JobState.FAILED,\n 't': JobState.FAILED, # Suspended by alarm\n 'eqw': JobState.FAILED, # Error states\n 'ehqw': JobState.FAILED, # ..\n 'ehrqw': JobState.FAILED, # ..\n 'd': JobState.COMPLETED,\n 'dr': JobState.COMPLETED,\n 'dt': JobState.COMPLETED,\n 'drt': JobState.COMPLETED,\n 'ds': JobState.COMPLETED,\n 'drs': JobState.COMPLETED,\n}\n\n\nclass GridEngineProvider(ClusterProvider, RepresentationMixin):\n \"\"\"A provider for the Grid Engine scheduler.\n\n Parameters\n ----------\n channel : Channel\n Channel for accessing this provider. Possible channels include\n :class:`~parsl.channels.LocalChannel` (the default),\n :class:`~parsl.channels.SSHChannel`, or\n :class:`~parsl.channels.SSHInteractiveLoginChannel`.\n nodes_per_block : int\n Nodes to provision per block.\n min_blocks : int\n Minimum number of blocks to maintain.\n max_blocks : int\n Maximum number of blocks to maintain.\n parallelism : float\n Ratio of provisioned task slots to active tasks. A parallelism value of 1 represents aggressive\n scaling where as many resources as possible are used; parallelism close to 0 represents\n the opposite situation in which as few resources as possible (i.e., min_blocks) are used.\n walltime : str\n Walltime requested per block in HH:MM:SS.\n scheduler_options : str\n String to prepend to the #$$ blocks in the submit script to the scheduler.\n worker_init : str\n Command to be run before starting a worker, such as 'module load Anaconda; source activate env'.\n launcher : Launcher\n Launcher for this provider. Possible launchers include\n :class:`~parsl.launchers.SingleNodeLauncher` (the default),\n \"\"\"\n\n def __init__(self,\n channel=LocalChannel(),\n nodes_per_block=1,\n init_blocks=1,\n min_blocks=0,\n max_blocks=10,\n parallelism=1,\n walltime=\"00:10:00\",\n scheduler_options='',\n worker_init='',\n launcher=SingleNodeLauncher()):\n label = 'grid_engine'\n super().__init__(label,\n channel,\n nodes_per_block,\n init_blocks,\n min_blocks,\n max_blocks,\n parallelism,\n walltime,\n launcher)\n self.scheduler_options = scheduler_options\n self.worker_init = worker_init\n\n if launcher in ['srun', 'srun_mpi']:\n logger.warning(\"Use of {} launcher is usually appropriate for Slurm providers. \"\n \"Recommended options include 'single_node' or 'aprun'.\".format(launcher))\n\n def get_configs(self, command, tasks_per_node):\n \"\"\"Compose a dictionary with information for writing the submit script.\"\"\"\n\n logger.debug(\"Requesting one block with {} nodes per block and {} tasks per node\".format(\n self.nodes_per_block, tasks_per_node))\n\n job_config = {}\n job_config[\"submit_script_dir\"] = self.channel.script_dir\n job_config[\"nodes\"] = self.nodes_per_block\n job_config[\"walltime\"] = self.walltime\n job_config[\"scheduler_options\"] = self.scheduler_options\n job_config[\"worker_init\"] = self.worker_init\n job_config[\"user_script\"] = command\n\n job_config[\"user_script\"] = self.launcher(command,\n tasks_per_node,\n self.nodes_per_block)\n return job_config\n\n def submit(self, command, tasks_per_node, job_name=\"parsl.sge\"):\n ''' The submit method takes the command string to be executed upon\n instantiation of a resource most often to start a pilot (such as IPP engine\n or even Swift-T engines).\n\n Args :\n - command (str) : The bash command string to be executed.\n - tasks_per_node (int) : command invocations to be launched per node\n\n KWargs:\n - job_name (str) : Human friendly name to be assigned to the job request\n\n Returns:\n - A job identifier, this could be an integer, string etc\n\n Raises:\n - ExecutionProviderException or its subclasses\n '''\n\n # Set job name\n job_name = \"{0}.{1}\".format(job_name, time.time())\n\n # Set script path\n script_path = \"{0}/{1}.submit\".format(self.script_dir, job_name)\n script_path = os.path.abspath(script_path)\n\n job_config = self.get_configs(command, tasks_per_node)\n\n logger.debug(\"Writing submit script\")\n self._write_submit_script(template_string, script_path, job_name, job_config)\n\n channel_script_path = self.channel.push_file(script_path, self.channel.script_dir)\n cmd = \"qsub -terse {0}\".format(channel_script_path)\n retcode, stdout, stderr = self.execute_wait(cmd, 10)\n\n if retcode == 0:\n for line in stdout.split('\\n'):\n job_id = line.strip()\n if not job_id:\n continue\n self.resources[job_id] = {'job_id': job_id, 'status': JobStatus(JobState.PENDING)}\n return job_id\n else:\n print(\"[WARNING!!] Submission of command to scale_out failed\")\n logger.error(\"Retcode:%s STDOUT:%s STDERR:%s\", retcode, stdout.strip(), stderr.strip())\n\n def _status(self):\n ''' Get the status of a list of jobs identified by the job identifiers\n returned from the submit request.\n\n Returns:\n - A list of JobStatus objects corresponding to each job_id in the job_ids list.\n\n Raises:\n - ExecutionProviderException or its subclasses\n\n '''\n\n cmd = \"qstat\"\n\n retcode, stdout, stderr = self.execute_wait(cmd)\n\n # Execute_wait failed. Do no update\n if retcode != 0:\n return\n\n jobs_missing = list(self.resources.keys())\n for line in stdout.split('\\n'):\n parts = line.split()\n if parts and parts[0].lower().lower() != 'job-id' \\\n and not parts[0].startswith('----'):\n job_id = parts[0]\n status = translate_table.get(parts[4].lower(), JobState.UNKNOWN)\n if job_id in self.resources:\n self.resources[job_id]['status'] = status\n jobs_missing.remove(job_id)\n\n # Filling in missing blanks for jobs that might have gone missing\n # we might lose some information about why the jobs failed.\n for missing_job in jobs_missing:\n self.resources[missing_job]['status'] = JobStatus(JobState.COMPLETED)\n\n def cancel(self, job_ids):\n ''' Cancels the resources identified by the job_ids provided by the user.\n\n Args:\n - job_ids (list): A list of job identifiers\n\n Returns:\n - A list of status from cancelling the job which can be True, False\n\n Raises:\n - ExecutionProviderException or its subclasses\n '''\n\n job_id_list = ' '.join(job_ids)\n cmd = \"qdel {}\".format(job_id_list)\n retcode, stdout, stderr = self.execute_wait(cmd, 3)\n\n rets = None\n if retcode == 0:\n for jid in job_ids:\n self.resources[jid]['status'] = JobStatus(JobState.COMPLETED)\n rets = [True for i in job_ids]\n else:\n rets = [False for i in job_ids]\n\n return rets\n", "path": "parsl/providers/grid_engine/grid_engine.py"}]}
| 2,799 | 229 |
gh_patches_debug_3433
|
rasdani/github-patches
|
git_diff
|
facebookresearch__mmf-74
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ERROR: 'BaseTrainer' object has no attribute 'args'
I followed the instructions on the https://learnpythia.readthedocs.io/ to setup. I seem to have everything installed, and I could run the collab notebook locally.
However, when I am trying to run the below command to try out inferences:
python tools/run.py --tasks vqa --datasets textvqa --model lorra --config configs/vqa/textvqa/lorra.yml \
--run_type val --evalai_inference 1 --resume_file data/models/lorra_best.pth
I am getting below error:
}
2019-05-29T20:25:41 INFO: Loading tasks and data
2019-05-29T20:25:44 INFO: CUDA Device 0 is: GeForce GTX 1080 Ti
2019-05-29T20:25:46 INFO: Torch version is: 1.0.0
2019-05-29T20:25:46 ERROR: 'BaseTrainer' object has no attribute 'args'
Traceback (most recent call last):
File "tools/run.py", line 94, in <module>
run()
File "tools/run.py", line 82, in run
trainer.load()
File "/root/pythia/pythia/trainers/base_trainer.py", line 46, in load
self.load_extras()
File "/root/pythia/pythia/trainers/base_trainer.py", line 139, in load_extras
self.checkpoint = Checkpoint(self)
File "/root/pythia/pythia/utils/checkpoint.py", line 28, in __init__
self.ckpt_foldername += foldername_from_config_override(self.trainer.args)
AttributeError: 'BaseTrainer' object has no attribute 'args'
I seem to be doing something wrong, any help would be great. I didn't change any code or config yet.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pythia/utils/build_utils.py`
Content:
```
1 # Copyright (c) Facebook, Inc. and its affiliates.
2 import torch
3 import warnings
4
5 from pythia.utils.configuration import Configuration
6 from pythia.common.registry import registry
7 from pythia.utils.general import get_optimizer_parameters
8
9
10 def build_trainer(args, *rest, **kwargs):
11 configuration = Configuration(args.config)
12
13 # Update with the config override if passed
14 configuration.override_with_cmd_config(args.config_override)
15
16 # Now, update with opts args that were passed
17 configuration.override_with_cmd_opts(args.opts)
18
19 # Finally, update with args that were specifically passed
20 # as arguments
21 configuration.update_with_args(args)
22 configuration.freeze()
23
24 config = configuration.get_config()
25 registry.register("config", config)
26 registry.register("configuration", configuration)
27
28 trainer_type = config.training_parameters.trainer
29 trainer_cls = registry.get_trainer_class(trainer_type)
30 return trainer_cls(config)
31
32
33 def build_model(config):
34 model_name = config.model
35
36 model_class = registry.get_model_class(model_name)
37
38 if model_class is None:
39 registry.get("writer").write("No model registered for name: %s" % model_name)
40 model = model_class(config)
41
42 if hasattr(model, "build"):
43 model.build()
44 model.init_losses_and_metrics()
45
46 return model
47
48
49 def build_optimizer(model, config):
50 optimizer_config = config.optimizer_attributes
51 if not hasattr(optimizer_config, "type"):
52 raise ValueError(
53 "Optimizer attributes must have a 'type' key "
54 "specifying the type of optimizer. "
55 "(Custom or PyTorch)"
56 )
57 optimizer_type = optimizer_config.type
58
59 if not hasattr(optimizer_config, "params"):
60 warnings.warn(
61 "optimizer attributes has no params defined, defaulting to {}."
62 )
63
64 params = getattr(optimizer_config, "params", {})
65
66 if hasattr(torch.optim, optimizer_type):
67 optimizer_class = getattr(torch.optim, optimizer_type)
68 else:
69 optimizer_class = registry.get_optimizer_class(optimizer_type)
70 if optimizer_class is None:
71 raise ValueError(
72 "No optimizer class of type {} present in "
73 "either torch or registered to registry"
74 )
75
76 parameters = get_optimizer_parameters(model, config)
77 optimizer = optimizer_class(parameters, **params)
78 return optimizer
79
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pythia/utils/build_utils.py b/pythia/utils/build_utils.py
--- a/pythia/utils/build_utils.py
+++ b/pythia/utils/build_utils.py
@@ -27,7 +27,12 @@
trainer_type = config.training_parameters.trainer
trainer_cls = registry.get_trainer_class(trainer_type)
- return trainer_cls(config)
+ trainer_obj = trainer_cls(config)
+
+ # Set args as an attribute for future use
+ setattr(trainer_obj, 'args', args)
+
+ return trainer_obj
def build_model(config):
|
{"golden_diff": "diff --git a/pythia/utils/build_utils.py b/pythia/utils/build_utils.py\n--- a/pythia/utils/build_utils.py\n+++ b/pythia/utils/build_utils.py\n@@ -27,7 +27,12 @@\n \n trainer_type = config.training_parameters.trainer\n trainer_cls = registry.get_trainer_class(trainer_type)\n- return trainer_cls(config)\n+ trainer_obj = trainer_cls(config)\n+\n+ # Set args as an attribute for future use\n+ setattr(trainer_obj, 'args', args)\n+\n+ return trainer_obj\n \n \n def build_model(config):\n", "issue": "ERROR: 'BaseTrainer' object has no attribute 'args'\nI followed the instructions on the https://learnpythia.readthedocs.io/ to setup. I seem to have everything installed, and I could run the collab notebook locally. \r\n\r\nHowever, when I am trying to run the below command to try out inferences:\r\n\r\npython tools/run.py --tasks vqa --datasets textvqa --model lorra --config configs/vqa/textvqa/lorra.yml \\\r\n--run_type val --evalai_inference 1 --resume_file data/models/lorra_best.pth\r\n\r\nI am getting below error:\r\n\r\n\r\n}\r\n2019-05-29T20:25:41 INFO: Loading tasks and data\r\n2019-05-29T20:25:44 INFO: CUDA Device 0 is: GeForce GTX 1080 Ti\r\n2019-05-29T20:25:46 INFO: Torch version is: 1.0.0\r\n2019-05-29T20:25:46 ERROR: 'BaseTrainer' object has no attribute 'args'\r\nTraceback (most recent call last):\r\n File \"tools/run.py\", line 94, in <module>\r\n run()\r\n File \"tools/run.py\", line 82, in run\r\n trainer.load()\r\n File \"/root/pythia/pythia/trainers/base_trainer.py\", line 46, in load\r\n self.load_extras()\r\n File \"/root/pythia/pythia/trainers/base_trainer.py\", line 139, in load_extras\r\n self.checkpoint = Checkpoint(self)\r\n File \"/root/pythia/pythia/utils/checkpoint.py\", line 28, in __init__\r\n self.ckpt_foldername += foldername_from_config_override(self.trainer.args)\r\nAttributeError: 'BaseTrainer' object has no attribute 'args'\r\n\r\n\r\nI seem to be doing something wrong, any help would be great. I didn't change any code or config yet.\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates.\nimport torch\nimport warnings\n\nfrom pythia.utils.configuration import Configuration\nfrom pythia.common.registry import registry\nfrom pythia.utils.general import get_optimizer_parameters\n\n\ndef build_trainer(args, *rest, **kwargs):\n configuration = Configuration(args.config)\n\n # Update with the config override if passed\n configuration.override_with_cmd_config(args.config_override)\n\n # Now, update with opts args that were passed\n configuration.override_with_cmd_opts(args.opts)\n\n # Finally, update with args that were specifically passed\n # as arguments\n configuration.update_with_args(args)\n configuration.freeze()\n\n config = configuration.get_config()\n registry.register(\"config\", config)\n registry.register(\"configuration\", configuration)\n\n trainer_type = config.training_parameters.trainer\n trainer_cls = registry.get_trainer_class(trainer_type)\n return trainer_cls(config)\n\n\ndef build_model(config):\n model_name = config.model\n\n model_class = registry.get_model_class(model_name)\n\n if model_class is None:\n registry.get(\"writer\").write(\"No model registered for name: %s\" % model_name)\n model = model_class(config)\n\n if hasattr(model, \"build\"):\n model.build()\n model.init_losses_and_metrics()\n\n return model\n\n\ndef build_optimizer(model, config):\n optimizer_config = config.optimizer_attributes\n if not hasattr(optimizer_config, \"type\"):\n raise ValueError(\n \"Optimizer attributes must have a 'type' key \"\n \"specifying the type of optimizer. \"\n \"(Custom or PyTorch)\"\n )\n optimizer_type = optimizer_config.type\n\n if not hasattr(optimizer_config, \"params\"):\n warnings.warn(\n \"optimizer attributes has no params defined, defaulting to {}.\"\n )\n\n params = getattr(optimizer_config, \"params\", {})\n\n if hasattr(torch.optim, optimizer_type):\n optimizer_class = getattr(torch.optim, optimizer_type)\n else:\n optimizer_class = registry.get_optimizer_class(optimizer_type)\n if optimizer_class is None:\n raise ValueError(\n \"No optimizer class of type {} present in \"\n \"either torch or registered to registry\"\n )\n\n parameters = get_optimizer_parameters(model, config)\n optimizer = optimizer_class(parameters, **params)\n return optimizer\n", "path": "pythia/utils/build_utils.py"}], "after_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates.\nimport torch\nimport warnings\n\nfrom pythia.utils.configuration import Configuration\nfrom pythia.common.registry import registry\nfrom pythia.utils.general import get_optimizer_parameters\n\n\ndef build_trainer(args, *rest, **kwargs):\n configuration = Configuration(args.config)\n\n # Update with the config override if passed\n configuration.override_with_cmd_config(args.config_override)\n\n # Now, update with opts args that were passed\n configuration.override_with_cmd_opts(args.opts)\n\n # Finally, update with args that were specifically passed\n # as arguments\n configuration.update_with_args(args)\n configuration.freeze()\n\n config = configuration.get_config()\n registry.register(\"config\", config)\n registry.register(\"configuration\", configuration)\n\n trainer_type = config.training_parameters.trainer\n trainer_cls = registry.get_trainer_class(trainer_type)\n trainer_obj = trainer_cls(config)\n\n # Set args as an attribute for future use\n setattr(trainer_obj, 'args', args)\n\n return trainer_obj\n\n\ndef build_model(config):\n model_name = config.model\n\n model_class = registry.get_model_class(model_name)\n\n if model_class is None:\n registry.get(\"writer\").write(\"No model registered for name: %s\" % model_name)\n model = model_class(config)\n\n if hasattr(model, \"build\"):\n model.build()\n model.init_losses_and_metrics()\n\n return model\n\n\ndef build_optimizer(model, config):\n optimizer_config = config.optimizer_attributes\n if not hasattr(optimizer_config, \"type\"):\n raise ValueError(\n \"Optimizer attributes must have a 'type' key \"\n \"specifying the type of optimizer. \"\n \"(Custom or PyTorch)\"\n )\n optimizer_type = optimizer_config.type\n\n if not hasattr(optimizer_config, \"params\"):\n warnings.warn(\n \"optimizer attributes has no params defined, defaulting to {}.\"\n )\n\n params = getattr(optimizer_config, \"params\", {})\n\n if hasattr(torch.optim, optimizer_type):\n optimizer_class = getattr(torch.optim, optimizer_type)\n else:\n optimizer_class = registry.get_optimizer_class(optimizer_type)\n if optimizer_class is None:\n raise ValueError(\n \"No optimizer class of type {} present in \"\n \"either torch or registered to registry\"\n )\n\n parameters = get_optimizer_parameters(model, config)\n optimizer = optimizer_class(parameters, **params)\n return optimizer\n", "path": "pythia/utils/build_utils.py"}]}
| 1,351 | 131 |
gh_patches_debug_3708
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-163
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Hasher.hexdigest() is documented as returning a str, but returns unicode under python2
It should return a native string under boht py2 and py3
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cryptography/primitives/hashes.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
10 # implied.
11 # See the License for the specific language governing permissions and
12 # limitations under the License.
13
14 from __future__ import absolute_import, division, print_function
15
16 import abc
17
18 import binascii
19
20 import six
21
22 from cryptography.bindings import _default_api
23
24
25 class BaseHash(six.with_metaclass(abc.ABCMeta)):
26 def __init__(self, data=None, api=None, ctx=None):
27 if api is None:
28 api = _default_api
29 self._api = api
30 self._ctx = self._api.create_hash_context(self) if ctx is None else ctx
31 if data is not None:
32 self.update(data)
33
34 def update(self, data):
35 if isinstance(data, six.text_type):
36 raise TypeError("Unicode-objects must be encoded before hashing")
37 self._api.update_hash_context(self._ctx, data)
38
39 def copy(self):
40 return self.__class__(ctx=self._copy_ctx())
41
42 def digest(self):
43 return self._api.finalize_hash_context(self._copy_ctx(),
44 self.digest_size)
45
46 def hexdigest(self):
47 return binascii.hexlify(self.digest()).decode("ascii")
48
49 def _copy_ctx(self):
50 return self._api.copy_hash_context(self._ctx)
51
52
53 class SHA1(BaseHash):
54 name = "sha1"
55 digest_size = 20
56 block_size = 64
57
58
59 class SHA224(BaseHash):
60 name = "sha224"
61 digest_size = 28
62 block_size = 64
63
64
65 class SHA256(BaseHash):
66 name = "sha256"
67 digest_size = 32
68 block_size = 64
69
70
71 class SHA384(BaseHash):
72 name = "sha384"
73 digest_size = 48
74 block_size = 128
75
76
77 class SHA512(BaseHash):
78 name = "sha512"
79 digest_size = 64
80 block_size = 128
81
82
83 class RIPEMD160(BaseHash):
84 name = "ripemd160"
85 digest_size = 20
86 block_size = 64
87
88
89 class Whirlpool(BaseHash):
90 name = "whirlpool"
91 digest_size = 64
92 block_size = 64
93
94
95 class MD5(BaseHash):
96 name = "md5"
97 digest_size = 16
98 block_size = 64
99
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/cryptography/primitives/hashes.py b/cryptography/primitives/hashes.py
--- a/cryptography/primitives/hashes.py
+++ b/cryptography/primitives/hashes.py
@@ -44,7 +44,7 @@
self.digest_size)
def hexdigest(self):
- return binascii.hexlify(self.digest()).decode("ascii")
+ return str(binascii.hexlify(self.digest()).decode("ascii"))
def _copy_ctx(self):
return self._api.copy_hash_context(self._ctx)
|
{"golden_diff": "diff --git a/cryptography/primitives/hashes.py b/cryptography/primitives/hashes.py\n--- a/cryptography/primitives/hashes.py\n+++ b/cryptography/primitives/hashes.py\n@@ -44,7 +44,7 @@\n self.digest_size)\n \n def hexdigest(self):\n- return binascii.hexlify(self.digest()).decode(\"ascii\")\n+ return str(binascii.hexlify(self.digest()).decode(\"ascii\"))\n \n def _copy_ctx(self):\n return self._api.copy_hash_context(self._ctx)\n", "issue": "Hasher.hexdigest() is documented as returning a str, but returns unicode under python2\nIt should return a native string under boht py2 and py3\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or\n# implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport abc\n\nimport binascii\n\nimport six\n\nfrom cryptography.bindings import _default_api\n\n\nclass BaseHash(six.with_metaclass(abc.ABCMeta)):\n def __init__(self, data=None, api=None, ctx=None):\n if api is None:\n api = _default_api\n self._api = api\n self._ctx = self._api.create_hash_context(self) if ctx is None else ctx\n if data is not None:\n self.update(data)\n\n def update(self, data):\n if isinstance(data, six.text_type):\n raise TypeError(\"Unicode-objects must be encoded before hashing\")\n self._api.update_hash_context(self._ctx, data)\n\n def copy(self):\n return self.__class__(ctx=self._copy_ctx())\n\n def digest(self):\n return self._api.finalize_hash_context(self._copy_ctx(),\n self.digest_size)\n\n def hexdigest(self):\n return binascii.hexlify(self.digest()).decode(\"ascii\")\n\n def _copy_ctx(self):\n return self._api.copy_hash_context(self._ctx)\n\n\nclass SHA1(BaseHash):\n name = \"sha1\"\n digest_size = 20\n block_size = 64\n\n\nclass SHA224(BaseHash):\n name = \"sha224\"\n digest_size = 28\n block_size = 64\n\n\nclass SHA256(BaseHash):\n name = \"sha256\"\n digest_size = 32\n block_size = 64\n\n\nclass SHA384(BaseHash):\n name = \"sha384\"\n digest_size = 48\n block_size = 128\n\n\nclass SHA512(BaseHash):\n name = \"sha512\"\n digest_size = 64\n block_size = 128\n\n\nclass RIPEMD160(BaseHash):\n name = \"ripemd160\"\n digest_size = 20\n block_size = 64\n\n\nclass Whirlpool(BaseHash):\n name = \"whirlpool\"\n digest_size = 64\n block_size = 64\n\n\nclass MD5(BaseHash):\n name = \"md5\"\n digest_size = 16\n block_size = 64\n", "path": "cryptography/primitives/hashes.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or\n# implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport abc\n\nimport binascii\n\nimport six\n\nfrom cryptography.bindings import _default_api\n\n\nclass BaseHash(six.with_metaclass(abc.ABCMeta)):\n def __init__(self, data=None, api=None, ctx=None):\n if api is None:\n api = _default_api\n self._api = api\n self._ctx = self._api.create_hash_context(self) if ctx is None else ctx\n if data is not None:\n self.update(data)\n\n def update(self, data):\n if isinstance(data, six.text_type):\n raise TypeError(\"Unicode-objects must be encoded before hashing\")\n self._api.update_hash_context(self._ctx, data)\n\n def copy(self):\n return self.__class__(ctx=self._copy_ctx())\n\n def digest(self):\n return self._api.finalize_hash_context(self._copy_ctx(),\n self.digest_size)\n\n def hexdigest(self):\n return str(binascii.hexlify(self.digest()).decode(\"ascii\"))\n\n def _copy_ctx(self):\n return self._api.copy_hash_context(self._ctx)\n\n\nclass SHA1(BaseHash):\n name = \"sha1\"\n digest_size = 20\n block_size = 64\n\n\nclass SHA224(BaseHash):\n name = \"sha224\"\n digest_size = 28\n block_size = 64\n\n\nclass SHA256(BaseHash):\n name = \"sha256\"\n digest_size = 32\n block_size = 64\n\n\nclass SHA384(BaseHash):\n name = \"sha384\"\n digest_size = 48\n block_size = 128\n\n\nclass SHA512(BaseHash):\n name = \"sha512\"\n digest_size = 64\n block_size = 128\n\n\nclass RIPEMD160(BaseHash):\n name = \"ripemd160\"\n digest_size = 20\n block_size = 64\n\n\nclass Whirlpool(BaseHash):\n name = \"whirlpool\"\n digest_size = 64\n block_size = 64\n\n\nclass MD5(BaseHash):\n name = \"md5\"\n digest_size = 16\n block_size = 64\n", "path": "cryptography/primitives/hashes.py"}]}
| 1,127 | 113 |
gh_patches_debug_3139
|
rasdani/github-patches
|
git_diff
|
UTNkar__moore-53
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Confirmation e-mails are not sent
For some reason the confirmation e-mails are no longer being send.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `website/members/signals.py`
Content:
```
1 import datetime
2 from django.conf import settings
3 from django.core.mail import EmailMultiAlternatives
4 from django.db.models.signals import pre_save
5 from django.dispatch import receiver
6 from django.template import loader
7 from django.utils import timezone
8 from simple_email_confirmation import unconfirmed_email_created
9
10 from members.models import Member
11
12
13 @receiver(unconfirmed_email_created, dispatch_uid='send_email_confirmation')
14 def send_confirmation_email(sender, email, user=None, **kwargs):
15 if user is not None:
16 context = {
17 'email': email,
18 'domain': settings.BASE_URL,
19 'site_name': settings.WAGTAIL_SITE_NAME,
20 'token': user.get_confirmation_key(email),
21 }
22
23 subject = loader.render_to_string(
24 'members/email_change_subject.txt', context)
25 # Email subject *must not* contain newlines
26 subject = ''.join(subject.splitlines())
27 body = loader.render_to_string('members/email_change_email.html',
28 context)
29
30 email_message = EmailMultiAlternatives(subject, body, None, [email])
31 email_message.send()
32
33
34 @receiver(pre_save, sender=Member, dispatch_uid='member_check_membership')
35 def check_membership(sender, instance, **kwargs):
36 if timezone.now() - instance.status_changed > datetime.timedelta(1):
37 instance.update_status()
38
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/website/members/signals.py b/website/members/signals.py
--- a/website/members/signals.py
+++ b/website/members/signals.py
@@ -12,6 +12,7 @@
@receiver(unconfirmed_email_created, dispatch_uid='send_email_confirmation')
def send_confirmation_email(sender, email, user=None, **kwargs):
+ user = user or sender
if user is not None:
context = {
'email': email,
|
{"golden_diff": "diff --git a/website/members/signals.py b/website/members/signals.py\n--- a/website/members/signals.py\n+++ b/website/members/signals.py\n@@ -12,6 +12,7 @@\n \n @receiver(unconfirmed_email_created, dispatch_uid='send_email_confirmation')\n def send_confirmation_email(sender, email, user=None, **kwargs):\n+ user = user or sender\n if user is not None:\n context = {\n 'email': email,\n", "issue": "Confirmation e-mails are not sent\nFor some reason the confirmation e-mails are no longer being send.\n", "before_files": [{"content": "import datetime\nfrom django.conf import settings\nfrom django.core.mail import EmailMultiAlternatives\nfrom django.db.models.signals import pre_save\nfrom django.dispatch import receiver\nfrom django.template import loader\nfrom django.utils import timezone\nfrom simple_email_confirmation import unconfirmed_email_created\n\nfrom members.models import Member\n\n\n@receiver(unconfirmed_email_created, dispatch_uid='send_email_confirmation')\ndef send_confirmation_email(sender, email, user=None, **kwargs):\n if user is not None:\n context = {\n 'email': email,\n 'domain': settings.BASE_URL,\n 'site_name': settings.WAGTAIL_SITE_NAME,\n 'token': user.get_confirmation_key(email),\n }\n\n subject = loader.render_to_string(\n 'members/email_change_subject.txt', context)\n # Email subject *must not* contain newlines\n subject = ''.join(subject.splitlines())\n body = loader.render_to_string('members/email_change_email.html',\n context)\n\n email_message = EmailMultiAlternatives(subject, body, None, [email])\n email_message.send()\n\n\n@receiver(pre_save, sender=Member, dispatch_uid='member_check_membership')\ndef check_membership(sender, instance, **kwargs):\n if timezone.now() - instance.status_changed > datetime.timedelta(1):\n instance.update_status()\n", "path": "website/members/signals.py"}], "after_files": [{"content": "import datetime\nfrom django.conf import settings\nfrom django.core.mail import EmailMultiAlternatives\nfrom django.db.models.signals import pre_save\nfrom django.dispatch import receiver\nfrom django.template import loader\nfrom django.utils import timezone\nfrom simple_email_confirmation import unconfirmed_email_created\n\nfrom members.models import Member\n\n\n@receiver(unconfirmed_email_created, dispatch_uid='send_email_confirmation')\ndef send_confirmation_email(sender, email, user=None, **kwargs):\n user = user or sender\n if user is not None:\n context = {\n 'email': email,\n 'domain': settings.BASE_URL,\n 'site_name': settings.WAGTAIL_SITE_NAME,\n 'token': user.get_confirmation_key(email),\n }\n\n subject = loader.render_to_string(\n 'members/email_change_subject.txt', context)\n # Email subject *must not* contain newlines\n subject = ''.join(subject.splitlines())\n body = loader.render_to_string('members/email_change_email.html',\n context)\n\n email_message = EmailMultiAlternatives(subject, body, None, [email])\n email_message.send()\n\n\n@receiver(pre_save, sender=Member, dispatch_uid='member_check_membership')\ndef check_membership(sender, instance, **kwargs):\n if timezone.now() - instance.status_changed > datetime.timedelta(1):\n instance.update_status()\n", "path": "website/members/signals.py"}]}
| 617 | 106 |
gh_patches_debug_21111
|
rasdani/github-patches
|
git_diff
|
gammapy__gammapy-4314
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Bad rendering of Super Exponential Cutoff Power Law Model used for 4FGL-DR3 equations in docs
**Gammapy version**
dev
**Bug description**
The latex rendering of equations in the following doc page is broken.
https://docs.gammapy.org/dev/user-guide/model-gallery/spectral/plot_super_exp_cutoff_powerlaw_4fgl.html
I think that it is due to the `\a`that appears multiple times in `\frac`, but I am not really sure as I don't understand HTML.
Bad rendering of Super Exponential Cutoff Power Law Model used for 4FGL-DR3 equations in docs
**Gammapy version**
dev
**Bug description**
The latex rendering of equations in the following doc page is broken.
https://docs.gammapy.org/dev/user-guide/model-gallery/spectral/plot_super_exp_cutoff_powerlaw_4fgl.html
I think that it is due to the `\a`that appears multiple times in `\frac`, but I am not really sure as I don't understand HTML.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/models/spectral/plot_super_exp_cutoff_powerlaw_4fgl.py`
Content:
```
1 r"""
2 .. _super-exp-cutoff-powerlaw-4fgl-dr3-spectral-model:
3
4 Super Exponential Cutoff Power Law Model used for 4FGL-DR3
5 ==========================================================
6
7 This model parametrises super exponential cutoff power-law model spectrum used for 4FGL.
8
9 It is defined by the following equation:
10
11 .. math::
12
13
14 \phi(e) =
15 \begin{cases}
16 \phi_0 \cdot \left(\frac{E}{E_0}\right)^{\frac{\a}{\Gamma_2} -\Gamma_1} \cdot \exp \left(
17 \frac{\a}{\Gamma_2^2} \left( 1 - \left(\frac{E}{E_0}\right)^{\frac{\a}{\Gamma_2} \right)
18 \right)&
19 \\
20 \phi_0 \cdot \left(\frac{E}{E_0}\right)^{ -\Gamma_1 - \frac{\a}{2} \ln \frac{E}{E_0} - \frac{\a \Gamma_2}{6} \ln^2 \frac{E}{E_0} - \frac{\a \Gamma_2^2}{24} \ln^3 \frac{E}{E_0}}\\
21 0 & \text{for } \left| \Gamma_2 \ln \frac{E}{E_0} \right|
22 \end{cases}
23
24 See Equation (2) and (3) in https://arxiv.org/pdf/2201.11184.pdf
25 """
26
27 # %%
28 # Example plot
29 # ------------
30 # Here is an example plot of the model:
31
32 from astropy import units as u
33 import matplotlib.pyplot as plt
34 from gammapy.modeling.models import (
35 Models,
36 SkyModel,
37 SuperExpCutoffPowerLaw4FGLDR3SpectralModel,
38 )
39
40 energy_range = [0.1, 100] * u.TeV
41 model = SuperExpCutoffPowerLaw4FGLDR3SpectralModel(
42 index_1=1,
43 index_2=2,
44 amplitude="1e-12 TeV-1 cm-2 s-1",
45 reference="1 TeV",
46 expfactor=1e-2,
47 )
48 model.plot(energy_range)
49 plt.grid(which="both")
50 plt.ylim(1e-24, 1e-10)
51
52 # %%
53 # YAML representation
54 # -------------------
55 # Here is an example YAML file using the model:
56
57 model = SkyModel(spectral_model=model, name="super-exp-cutoff-power-law-4fgl-dr3-model")
58 models = Models([model])
59
60 print(models.to_yaml())
61
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/models/spectral/plot_super_exp_cutoff_powerlaw_4fgl.py b/examples/models/spectral/plot_super_exp_cutoff_powerlaw_4fgl.py
--- a/examples/models/spectral/plot_super_exp_cutoff_powerlaw_4fgl.py
+++ b/examples/models/spectral/plot_super_exp_cutoff_powerlaw_4fgl.py
@@ -10,16 +10,7 @@
.. math::
-
- \phi(e) =
- \begin{cases}
- \phi_0 \cdot \left(\frac{E}{E_0}\right)^{\frac{\a}{\Gamma_2} -\Gamma_1} \cdot \exp \left(
- \frac{\a}{\Gamma_2^2} \left( 1 - \left(\frac{E}{E_0}\right)^{\frac{\a}{\Gamma_2} \right)
- \right)&
- \\
- \phi_0 \cdot \left(\frac{E}{E_0}\right)^{ -\Gamma_1 - \frac{\a}{2} \ln \frac{E}{E_0} - \frac{\a \Gamma_2}{6} \ln^2 \frac{E}{E_0} - \frac{\a \Gamma_2^2}{24} \ln^3 \frac{E}{E_0}}\\
- 0 & \text{for } \left| \Gamma_2 \ln \frac{E}{E_0} \right|
- \end{cases}
+\phi(E) = \begin{cases} \phi_0 \cdot \left(\frac{E}{E_0}\right)^{\frac{a}{\Gamma_2} -\Gamma_1} \cdot \exp \left( \frac{a}{\Gamma_2^2}\left( 1 - \left(\frac{E}{E_0}\right)^{\Gamma_2} \right) \right) \\ \phi_0 \cdot \left(\frac{E}{E_0}\right)^{ -\Gamma_1 - \frac{a}{2} \ln \frac{E}{E_0} - \frac{a \Gamma_2}{6} \ln^2 \frac{E}{E_0} - \frac{a \Gamma_2^2}{24} \ln^3 \frac{E}{E_0}} & \text{for } \left| \Gamma_2 \ln \frac{E}{E_0} \right| < 10^{-2} \end{cases}
See Equation (2) and (3) in https://arxiv.org/pdf/2201.11184.pdf
"""
|
{"golden_diff": "diff --git a/examples/models/spectral/plot_super_exp_cutoff_powerlaw_4fgl.py b/examples/models/spectral/plot_super_exp_cutoff_powerlaw_4fgl.py\n--- a/examples/models/spectral/plot_super_exp_cutoff_powerlaw_4fgl.py\n+++ b/examples/models/spectral/plot_super_exp_cutoff_powerlaw_4fgl.py\n@@ -10,16 +10,7 @@\n \n .. math::\n \n-\n- \\phi(e) =\n- \\begin{cases}\n- \\phi_0 \\cdot \\left(\\frac{E}{E_0}\\right)^{\\frac{\\a}{\\Gamma_2} -\\Gamma_1} \\cdot \\exp \\left(\n- \\frac{\\a}{\\Gamma_2^2} \\left( 1 - \\left(\\frac{E}{E_0}\\right)^{\\frac{\\a}{\\Gamma_2} \\right)\n- \\right)&\n- \\\\\n- \\phi_0 \\cdot \\left(\\frac{E}{E_0}\\right)^{ -\\Gamma_1 - \\frac{\\a}{2} \\ln \\frac{E}{E_0} - \\frac{\\a \\Gamma_2}{6} \\ln^2 \\frac{E}{E_0} - \\frac{\\a \\Gamma_2^2}{24} \\ln^3 \\frac{E}{E_0}}\\\\\n- 0 & \\text{for } \\left| \\Gamma_2 \\ln \\frac{E}{E_0} \\right|\n- \\end{cases}\n+\\phi(E) = \\begin{cases} \\phi_0 \\cdot \\left(\\frac{E}{E_0}\\right)^{\\frac{a}{\\Gamma_2} -\\Gamma_1} \\cdot \\exp \\left( \\frac{a}{\\Gamma_2^2}\\left( 1 - \\left(\\frac{E}{E_0}\\right)^{\\Gamma_2} \\right) \\right) \\\\ \\phi_0 \\cdot \\left(\\frac{E}{E_0}\\right)^{ -\\Gamma_1 - \\frac{a}{2} \\ln \\frac{E}{E_0} - \\frac{a \\Gamma_2}{6} \\ln^2 \\frac{E}{E_0} - \\frac{a \\Gamma_2^2}{24} \\ln^3 \\frac{E}{E_0}} & \\text{for } \\left| \\Gamma_2 \\ln \\frac{E}{E_0} \\right| < 10^{-2} \\end{cases}\n \n See Equation (2) and (3) in https://arxiv.org/pdf/2201.11184.pdf\n \"\"\"\n", "issue": "Bad rendering of Super Exponential Cutoff Power Law Model used for 4FGL-DR3 equations in docs\n**Gammapy version**\r\ndev\r\n\r\n**Bug description**\r\n\r\nThe latex rendering of equations in the following doc page is broken. \r\nhttps://docs.gammapy.org/dev/user-guide/model-gallery/spectral/plot_super_exp_cutoff_powerlaw_4fgl.html\r\n\r\nI think that it is due to the `\\a`that appears multiple times in `\\frac`, but I am not really sure as I don't understand HTML.\r\n\nBad rendering of Super Exponential Cutoff Power Law Model used for 4FGL-DR3 equations in docs\n**Gammapy version**\r\ndev\r\n\r\n**Bug description**\r\n\r\nThe latex rendering of equations in the following doc page is broken. \r\nhttps://docs.gammapy.org/dev/user-guide/model-gallery/spectral/plot_super_exp_cutoff_powerlaw_4fgl.html\r\n\r\nI think that it is due to the `\\a`that appears multiple times in `\\frac`, but I am not really sure as I don't understand HTML.\r\n\n", "before_files": [{"content": "r\"\"\"\n.. _super-exp-cutoff-powerlaw-4fgl-dr3-spectral-model:\n\nSuper Exponential Cutoff Power Law Model used for 4FGL-DR3\n==========================================================\n\nThis model parametrises super exponential cutoff power-law model spectrum used for 4FGL.\n\nIt is defined by the following equation:\n\n.. math::\n\n\n \\phi(e) =\n \\begin{cases}\n \\phi_0 \\cdot \\left(\\frac{E}{E_0}\\right)^{\\frac{\\a}{\\Gamma_2} -\\Gamma_1} \\cdot \\exp \\left(\n \\frac{\\a}{\\Gamma_2^2} \\left( 1 - \\left(\\frac{E}{E_0}\\right)^{\\frac{\\a}{\\Gamma_2} \\right)\n \\right)&\n \\\\\n \\phi_0 \\cdot \\left(\\frac{E}{E_0}\\right)^{ -\\Gamma_1 - \\frac{\\a}{2} \\ln \\frac{E}{E_0} - \\frac{\\a \\Gamma_2}{6} \\ln^2 \\frac{E}{E_0} - \\frac{\\a \\Gamma_2^2}{24} \\ln^3 \\frac{E}{E_0}}\\\\\n 0 & \\text{for } \\left| \\Gamma_2 \\ln \\frac{E}{E_0} \\right|\n \\end{cases}\n\nSee Equation (2) and (3) in https://arxiv.org/pdf/2201.11184.pdf\n\"\"\"\n\n# %%\n# Example plot\n# ------------\n# Here is an example plot of the model:\n\nfrom astropy import units as u\nimport matplotlib.pyplot as plt\nfrom gammapy.modeling.models import (\n Models,\n SkyModel,\n SuperExpCutoffPowerLaw4FGLDR3SpectralModel,\n)\n\nenergy_range = [0.1, 100] * u.TeV\nmodel = SuperExpCutoffPowerLaw4FGLDR3SpectralModel(\n index_1=1,\n index_2=2,\n amplitude=\"1e-12 TeV-1 cm-2 s-1\",\n reference=\"1 TeV\",\n expfactor=1e-2,\n)\nmodel.plot(energy_range)\nplt.grid(which=\"both\")\nplt.ylim(1e-24, 1e-10)\n\n# %%\n# YAML representation\n# -------------------\n# Here is an example YAML file using the model:\n\nmodel = SkyModel(spectral_model=model, name=\"super-exp-cutoff-power-law-4fgl-dr3-model\")\nmodels = Models([model])\n\nprint(models.to_yaml())\n", "path": "examples/models/spectral/plot_super_exp_cutoff_powerlaw_4fgl.py"}], "after_files": [{"content": "r\"\"\"\n.. _super-exp-cutoff-powerlaw-4fgl-dr3-spectral-model:\n\nSuper Exponential Cutoff Power Law Model used for 4FGL-DR3\n==========================================================\n\nThis model parametrises super exponential cutoff power-law model spectrum used for 4FGL.\n\nIt is defined by the following equation:\n\n.. math::\n\n\\phi(E) = \\begin{cases} \\phi_0 \\cdot \\left(\\frac{E}{E_0}\\right)^{\\frac{a}{\\Gamma_2} -\\Gamma_1} \\cdot \\exp \\left( \\frac{a}{\\Gamma_2^2}\\left( 1 - \\left(\\frac{E}{E_0}\\right)^{\\Gamma_2} \\right) \\right) \\\\ \\phi_0 \\cdot \\left(\\frac{E}{E_0}\\right)^{ -\\Gamma_1 - \\frac{a}{2} \\ln \\frac{E}{E_0} - \\frac{a \\Gamma_2}{6} \\ln^2 \\frac{E}{E_0} - \\frac{a \\Gamma_2^2}{24} \\ln^3 \\frac{E}{E_0}} & \\text{for } \\left| \\Gamma_2 \\ln \\frac{E}{E_0} \\right| < 10^{-2} \\end{cases}\n\nSee Equation (2) and (3) in https://arxiv.org/pdf/2201.11184.pdf\n\"\"\"\n\n# %%\n# Example plot\n# ------------\n# Here is an example plot of the model:\n\nfrom astropy import units as u\nimport matplotlib.pyplot as plt\nfrom gammapy.modeling.models import (\n Models,\n SkyModel,\n SuperExpCutoffPowerLaw4FGLDR3SpectralModel,\n)\n\nenergy_range = [0.1, 100] * u.TeV\nmodel = SuperExpCutoffPowerLaw4FGLDR3SpectralModel(\n index_1=1,\n index_2=2,\n amplitude=\"1e-12 TeV-1 cm-2 s-1\",\n reference=\"1 TeV\",\n expfactor=1e-2,\n)\nmodel.plot(energy_range)\nplt.grid(which=\"both\")\nplt.ylim(1e-24, 1e-10)\n\n# %%\n# YAML representation\n# -------------------\n# Here is an example YAML file using the model:\n\nmodel = SkyModel(spectral_model=model, name=\"super-exp-cutoff-power-law-4fgl-dr3-model\")\nmodels = Models([model])\n\nprint(models.to_yaml())\n", "path": "examples/models/spectral/plot_super_exp_cutoff_powerlaw_4fgl.py"}]}
| 1,200 | 609 |
gh_patches_debug_4745
|
rasdani/github-patches
|
git_diff
|
medtagger__MedTagger-409
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Sending Label with Brush Selection doesn't work
## Current Behavior
Sending Label with Brush Selection doesn't work.
## Expected Behavior
Label with Brush Selection should be sent correctly.
## Steps to Reproduce the Problem
1. Go to labeling page and use Brush Tool
2. Send label
3. "Can't send scan" appeared
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `backend/medtagger/api/scans/business.py`
Content:
```
1 """Module responsible for business logic in all Scans endpoints."""
2 import io
3 import logging
4 from typing import Callable, Iterable, Dict, List, Tuple, Any
5
6 from cassandra import WriteTimeout
7 from sqlalchemy.exc import IntegrityError
8 from sqlalchemy.orm.exc import NoResultFound
9 from PIL import Image
10
11 from medtagger.exceptions import InternalErrorException
12 from medtagger.api.exceptions import NotFoundException, InvalidArgumentsException
13 from medtagger.types import ScanID, LabelPosition, LabelShape, LabelingTime, LabelID, Point
14 from medtagger.database.models import Dataset, Scan, Slice, Label, LabelTag, SliceOrientation
15 from medtagger.definitions import LabelTool
16 from medtagger.repositories import (
17 labels as LabelsRepository,
18 label_tags as LabelTagsRepository,
19 slices as SlicesRepository,
20 scans as ScansRepository,
21 datasets as DatasetsRepository,
22 tasks as TasksRepository,
23 )
24 from medtagger.workers.storage import parse_dicom_and_update_slice
25 from medtagger.api.utils import get_current_user
26
27 logger = logging.getLogger(__name__)
28
29 LabelElementHandler = Callable[[Dict[str, Any], LabelID, Dict[str, bytes]], None]
30
31
32 def get_available_datasets() -> List[Dataset]:
33 """Fetch list of all available Datasets.
34
35 :return: list of Datasets
36 """
37 return DatasetsRepository.get_all_datasets()
38
39
40 def dataset_is_valid(dataset_key: str) -> bool:
41 """Check if Dataset for such key exists.
42
43 :param dataset_key: key representing Dataset
44 :return: boolean information if Dataset key is valid
45 """
46 try:
47 DatasetsRepository.get_dataset_by_key(dataset_key)
48 return True
49 except NoResultFound:
50 return False
51
52
53 def create_dataset(key: str, name: str) -> Dataset:
54 """Create new Dataset.
55
56 :param key: unique key representing Dataset
57 :param name: name which describes this Dataset
58 :return: Dataset object
59 """
60 return DatasetsRepository.add_new_dataset(key, name)
61
62
63 def create_empty_scan(dataset_key: str, declared_number_of_slices: int) -> Scan:
64 """Create new empty scan.
65
66 :param dataset_key: string with dataset key
67 :param declared_number_of_slices: number of Slices that will be uploaded
68 :return: Newly created Scan object
69 """
70 user = get_current_user()
71 dataset = DatasetsRepository.get_dataset_by_key(dataset_key)
72 return ScansRepository.add_new_scan(dataset, declared_number_of_slices, user)
73
74
75 def get_random_scan(task_key: str) -> Scan:
76 """Fetch random scan from specified Task for labeling.
77
78 :param task_key: unique key identifying task
79 :return: Scan Metadata object
80 """
81 user = get_current_user()
82 task = TasksRepository.get_task_by_key(task_key)
83 if not task:
84 raise InvalidArgumentsException('Task key {} is invalid!'.format(task_key))
85 scan = ScansRepository.get_random_scan(task, user)
86 if not scan:
87 raise NotFoundException('Could not find any Scan for this task!')
88 return scan
89
90
91 def get_slices_for_scan(scan_id: ScanID, begin: int, count: int,
92 orientation: SliceOrientation = SliceOrientation.Z) -> Iterable[Tuple[Slice, bytes]]:
93 """Fetch multiple slices for given scan.
94
95 :param scan_id: ID of a given scan
96 :param begin: first slice index (included)
97 :param count: number of slices that will be returned
98 :param orientation: orientation for Slices (by default set to Z axis)
99 :return: generator for Slices
100 """
101 slices = SlicesRepository.get_slices_by_scan_id(scan_id, orientation=orientation)
102 for _slice in slices[begin:begin + count]:
103 image = SlicesRepository.get_slice_converted_image(_slice.id)
104 yield _slice, image
105
106
107 def validate_label_payload(elements: List[Dict], files: Dict[str, bytes]) -> None:
108 """Validate and raise an Exception for sent payload.
109
110 :param elements: List of JSONs describing elements for a single label
111 :param files: mapping of uploaded files (name and content)
112 """
113 _validate_files(files)
114 _validate_label_elements(elements, files)
115 _validate_tool(elements)
116
117
118 def _validate_tool(elements: List[Dict]) -> None:
119 """Validate if the tool for given Label Element is available for given tag."""
120 for label_element in elements:
121 tag = _get_label_tag(label_element['tag'])
122 if label_element['tool'] not in {tool.name for tool in tag.tools}:
123 raise InvalidArgumentsException('{} tool is not available for {} tag'.format(
124 label_element['tool'], tag.name))
125
126
127 def _validate_files(files: Dict[str, bytes]) -> None:
128 """Validate files and make sure that images are PNGs."""
129 for file_name, file_data in files.items():
130 try:
131 image = Image.open(io.BytesIO(file_data))
132 image.verify()
133 assert image.format == 'PNG'
134 except Exception:
135 raise InvalidArgumentsException('Type of file "{}" is not supported!'.format(file_name))
136
137
138 def _validate_label_elements(elements: List[Dict], files: Dict[str, bytes]) -> None:
139 """Validate Label Elements and make sure that all Brush Elements have images."""
140 for label_element in elements:
141 # Each Brush Label Element should have its own image attached
142 if label_element['tool'] == LabelTool.BRUSH.value:
143 try:
144 files[label_element['image_key']]
145 except KeyError:
146 message = 'Request does not have field named {} that could contain the image!'
147 raise InvalidArgumentsException(message.format(label_element['image_key']))
148
149
150 def add_label(scan_id: ScanID, task_key: str, elements: List[Dict], # pylint: disable-msg=too-many-arguments
151 files: Dict[str, bytes], labeling_time: LabelingTime, comment: str = None) -> Label:
152 """Add label to given scan.
153
154 :param scan_id: ID of a given scan
155 :param task_key: Key of Task
156 :param elements: List of JSONs describing elements for a single label
157 :param files: mapping of uploaded files (name and content)
158 :param labeling_time: time in seconds that user spent on labeling
159 :param comment: (optional) comment describing a label
160 :return: Label object
161 """
162 user = get_current_user()
163 try:
164 label = LabelsRepository.add_new_label(scan_id, task_key, user, labeling_time, comment)
165 except IntegrityError:
166 raise NotFoundException('Could not find Scan for that id!')
167 for element in elements:
168 add_label_element(element, label.id, files)
169 return label
170
171
172 def add_label_element(element: Dict[str, Any], label_id: LabelID, files: Dict[str, bytes]) -> None:
173 """Add new Label Element for given Label.
174
175 :param element: JSON describing single element
176 :param label_id: ID of a given Label that the element should be added to
177 :param files: mapping of uploaded files (name and content)
178 """
179 tool = element['tool']
180 handlers: Dict[str, LabelElementHandler] = {
181 LabelTool.RECTANGLE.value: _add_rectangle_element,
182 LabelTool.BRUSH.value: _add_brush_element,
183 LabelTool.POINT.value: _add_point_element,
184 LabelTool.CHAIN.value: _add_chain_element,
185 }
186 handler = handlers[tool]
187 handler(element, label_id, files)
188
189
190 def _add_rectangle_element(element: Dict[str, Any], label_id: LabelID, *_: Any) -> None:
191 """Add new Rectangular Label Element for given Label.
192
193 :param element: JSON describing single element
194 :param label_id: ID of a given Label that the element should be added to
195 """
196 position = LabelPosition(x=element['x'], y=element['y'], slice_index=element['slice_index'])
197 shape = LabelShape(width=element['width'], height=element['height'])
198 label_tag = _get_label_tag(element['tag'])
199 LabelsRepository.add_new_rectangular_label_element(label_id, position, shape, label_tag)
200
201
202 def _add_brush_element(element: Dict[str, Any], label_id: LabelID, files: Dict[str, bytes]) -> None:
203 """Add new Brush Label Element for given Label.
204
205 :param element: JSON describing single element
206 :param label_id: ID of a given Label that the element should be added to
207 :param files: mapping of uploaded files (name and content)
208 """
209 width = element['width']
210 height = element['height']
211 label_tag = _get_label_tag(element['tag'])
212 slice_index = element['slice_index']
213 image = files[element['image_key']]
214 LabelsRepository.add_new_brush_label_element(label_id, slice_index, width, height, image, label_tag)
215
216
217 def _add_point_element(element: Dict[str, Any], label_id: LabelID, *_: Any) -> None:
218 """Add new Point Label Element for given Label.
219
220 :param element: JSON describing single element
221 :param label_id: ID of a given Label that the element should be added to
222 """
223 position = LabelPosition(x=element['x'], y=element['y'], slice_index=element['slice_index'])
224 label_tag = _get_label_tag(element['tag'])
225 LabelsRepository.add_new_point_label_element(label_id, position, label_tag)
226
227
228 def _add_chain_element(element: Dict[str, Any], label_id: LabelID, *_: Any) -> None:
229 """Add new Chain Label Element for given Label.
230
231 :param element: JSON describing single element
232 :param label_id: ID of a given Label that the element should be added to
233 """
234 label_tag = _get_label_tag(element['tag'])
235 points = [Point(p['x'], p['y']) for p in element['points']]
236 slice_index = element['slice_index']
237 loop = element['loop']
238 LabelsRepository.add_new_chain_label_element(label_id, slice_index, label_tag, points, loop)
239
240
241 def _get_label_tag(tag_key: str) -> LabelTag:
242 """Return Label Tag based on Tag's key or raise an exception in case if not found."""
243 try:
244 return LabelTagsRepository.get_label_tag_by_key(tag_key)
245 except NoResultFound:
246 raise NotFoundException('Could not find any Label Tag for that key!')
247
248
249 def add_new_slice(scan_id: ScanID, image: bytes) -> Slice:
250 """Add new Slice for given Scan.
251
252 :param scan_id: ID of a Scan for which it should add new slice
253 :param image: bytes representing DICOM image
254 :return: Slice object
255 """
256 scan = ScansRepository.get_scan_by_id(scan_id)
257 _slice = scan.add_slice()
258 try:
259 SlicesRepository.store_original_image(_slice.id, image)
260 except WriteTimeout:
261 SlicesRepository.delete_slice(_slice)
262 raise InternalErrorException('Timeout during saving original image to the Storage.')
263 parse_dicom_and_update_slice.delay(_slice.id)
264 return _slice
265
266
267 def get_scan(scan_id: ScanID) -> Scan:
268 """Return Scan for given scan_id.
269
270 :param scan_id: ID of a Scan which should be returned
271 :return: Scan object
272 """
273 try:
274 return ScansRepository.get_scan_by_id(scan_id)
275 except NoResultFound:
276 raise NotFoundException('Scan "{}" not found.'.format(scan_id))
277
278
279 def skip_scan(scan_id: ScanID) -> bool:
280 """Increases skip count of Scan with given scan_id.
281
282 :param scan_id: ID of a Scan which should be returned
283 :return: boolean information whether the Scan was skipped or not
284 """
285 if not ScansRepository.increase_skip_count_of_a_scan(scan_id):
286 raise NotFoundException('Scan "{}" not found.'.format(scan_id))
287 return True
288
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/backend/medtagger/api/scans/business.py b/backend/medtagger/api/scans/business.py
--- a/backend/medtagger/api/scans/business.py
+++ b/backend/medtagger/api/scans/business.py
@@ -110,8 +110,8 @@
:param elements: List of JSONs describing elements for a single label
:param files: mapping of uploaded files (name and content)
"""
- _validate_files(files)
_validate_label_elements(elements, files)
+ _validate_files(files)
_validate_tool(elements)
|
{"golden_diff": "diff --git a/backend/medtagger/api/scans/business.py b/backend/medtagger/api/scans/business.py\n--- a/backend/medtagger/api/scans/business.py\n+++ b/backend/medtagger/api/scans/business.py\n@@ -110,8 +110,8 @@\n :param elements: List of JSONs describing elements for a single label\n :param files: mapping of uploaded files (name and content)\n \"\"\"\n- _validate_files(files)\n _validate_label_elements(elements, files)\n+ _validate_files(files)\n _validate_tool(elements)\n", "issue": "Sending Label with Brush Selection doesn't work \n## Current Behavior\r\n\r\nSending Label with Brush Selection doesn't work.\r\n\r\n## Expected Behavior\r\n\r\nLabel with Brush Selection should be sent correctly.\r\n\r\n## Steps to Reproduce the Problem\r\n\r\n 1. Go to labeling page and use Brush Tool\r\n 2. Send label\r\n 3. \"Can't send scan\" appeared\r\n\r\n\n", "before_files": [{"content": "\"\"\"Module responsible for business logic in all Scans endpoints.\"\"\"\nimport io\nimport logging\nfrom typing import Callable, Iterable, Dict, List, Tuple, Any\n\nfrom cassandra import WriteTimeout\nfrom sqlalchemy.exc import IntegrityError\nfrom sqlalchemy.orm.exc import NoResultFound\nfrom PIL import Image\n\nfrom medtagger.exceptions import InternalErrorException\nfrom medtagger.api.exceptions import NotFoundException, InvalidArgumentsException\nfrom medtagger.types import ScanID, LabelPosition, LabelShape, LabelingTime, LabelID, Point\nfrom medtagger.database.models import Dataset, Scan, Slice, Label, LabelTag, SliceOrientation\nfrom medtagger.definitions import LabelTool\nfrom medtagger.repositories import (\n labels as LabelsRepository,\n label_tags as LabelTagsRepository,\n slices as SlicesRepository,\n scans as ScansRepository,\n datasets as DatasetsRepository,\n tasks as TasksRepository,\n)\nfrom medtagger.workers.storage import parse_dicom_and_update_slice\nfrom medtagger.api.utils import get_current_user\n\nlogger = logging.getLogger(__name__)\n\nLabelElementHandler = Callable[[Dict[str, Any], LabelID, Dict[str, bytes]], None]\n\n\ndef get_available_datasets() -> List[Dataset]:\n \"\"\"Fetch list of all available Datasets.\n\n :return: list of Datasets\n \"\"\"\n return DatasetsRepository.get_all_datasets()\n\n\ndef dataset_is_valid(dataset_key: str) -> bool:\n \"\"\"Check if Dataset for such key exists.\n\n :param dataset_key: key representing Dataset\n :return: boolean information if Dataset key is valid\n \"\"\"\n try:\n DatasetsRepository.get_dataset_by_key(dataset_key)\n return True\n except NoResultFound:\n return False\n\n\ndef create_dataset(key: str, name: str) -> Dataset:\n \"\"\"Create new Dataset.\n\n :param key: unique key representing Dataset\n :param name: name which describes this Dataset\n :return: Dataset object\n \"\"\"\n return DatasetsRepository.add_new_dataset(key, name)\n\n\ndef create_empty_scan(dataset_key: str, declared_number_of_slices: int) -> Scan:\n \"\"\"Create new empty scan.\n\n :param dataset_key: string with dataset key\n :param declared_number_of_slices: number of Slices that will be uploaded\n :return: Newly created Scan object\n \"\"\"\n user = get_current_user()\n dataset = DatasetsRepository.get_dataset_by_key(dataset_key)\n return ScansRepository.add_new_scan(dataset, declared_number_of_slices, user)\n\n\ndef get_random_scan(task_key: str) -> Scan:\n \"\"\"Fetch random scan from specified Task for labeling.\n\n :param task_key: unique key identifying task\n :return: Scan Metadata object\n \"\"\"\n user = get_current_user()\n task = TasksRepository.get_task_by_key(task_key)\n if not task:\n raise InvalidArgumentsException('Task key {} is invalid!'.format(task_key))\n scan = ScansRepository.get_random_scan(task, user)\n if not scan:\n raise NotFoundException('Could not find any Scan for this task!')\n return scan\n\n\ndef get_slices_for_scan(scan_id: ScanID, begin: int, count: int,\n orientation: SliceOrientation = SliceOrientation.Z) -> Iterable[Tuple[Slice, bytes]]:\n \"\"\"Fetch multiple slices for given scan.\n\n :param scan_id: ID of a given scan\n :param begin: first slice index (included)\n :param count: number of slices that will be returned\n :param orientation: orientation for Slices (by default set to Z axis)\n :return: generator for Slices\n \"\"\"\n slices = SlicesRepository.get_slices_by_scan_id(scan_id, orientation=orientation)\n for _slice in slices[begin:begin + count]:\n image = SlicesRepository.get_slice_converted_image(_slice.id)\n yield _slice, image\n\n\ndef validate_label_payload(elements: List[Dict], files: Dict[str, bytes]) -> None:\n \"\"\"Validate and raise an Exception for sent payload.\n\n :param elements: List of JSONs describing elements for a single label\n :param files: mapping of uploaded files (name and content)\n \"\"\"\n _validate_files(files)\n _validate_label_elements(elements, files)\n _validate_tool(elements)\n\n\ndef _validate_tool(elements: List[Dict]) -> None:\n \"\"\"Validate if the tool for given Label Element is available for given tag.\"\"\"\n for label_element in elements:\n tag = _get_label_tag(label_element['tag'])\n if label_element['tool'] not in {tool.name for tool in tag.tools}:\n raise InvalidArgumentsException('{} tool is not available for {} tag'.format(\n label_element['tool'], tag.name))\n\n\ndef _validate_files(files: Dict[str, bytes]) -> None:\n \"\"\"Validate files and make sure that images are PNGs.\"\"\"\n for file_name, file_data in files.items():\n try:\n image = Image.open(io.BytesIO(file_data))\n image.verify()\n assert image.format == 'PNG'\n except Exception:\n raise InvalidArgumentsException('Type of file \"{}\" is not supported!'.format(file_name))\n\n\ndef _validate_label_elements(elements: List[Dict], files: Dict[str, bytes]) -> None:\n \"\"\"Validate Label Elements and make sure that all Brush Elements have images.\"\"\"\n for label_element in elements:\n # Each Brush Label Element should have its own image attached\n if label_element['tool'] == LabelTool.BRUSH.value:\n try:\n files[label_element['image_key']]\n except KeyError:\n message = 'Request does not have field named {} that could contain the image!'\n raise InvalidArgumentsException(message.format(label_element['image_key']))\n\n\ndef add_label(scan_id: ScanID, task_key: str, elements: List[Dict], # pylint: disable-msg=too-many-arguments\n files: Dict[str, bytes], labeling_time: LabelingTime, comment: str = None) -> Label:\n \"\"\"Add label to given scan.\n\n :param scan_id: ID of a given scan\n :param task_key: Key of Task\n :param elements: List of JSONs describing elements for a single label\n :param files: mapping of uploaded files (name and content)\n :param labeling_time: time in seconds that user spent on labeling\n :param comment: (optional) comment describing a label\n :return: Label object\n \"\"\"\n user = get_current_user()\n try:\n label = LabelsRepository.add_new_label(scan_id, task_key, user, labeling_time, comment)\n except IntegrityError:\n raise NotFoundException('Could not find Scan for that id!')\n for element in elements:\n add_label_element(element, label.id, files)\n return label\n\n\ndef add_label_element(element: Dict[str, Any], label_id: LabelID, files: Dict[str, bytes]) -> None:\n \"\"\"Add new Label Element for given Label.\n\n :param element: JSON describing single element\n :param label_id: ID of a given Label that the element should be added to\n :param files: mapping of uploaded files (name and content)\n \"\"\"\n tool = element['tool']\n handlers: Dict[str, LabelElementHandler] = {\n LabelTool.RECTANGLE.value: _add_rectangle_element,\n LabelTool.BRUSH.value: _add_brush_element,\n LabelTool.POINT.value: _add_point_element,\n LabelTool.CHAIN.value: _add_chain_element,\n }\n handler = handlers[tool]\n handler(element, label_id, files)\n\n\ndef _add_rectangle_element(element: Dict[str, Any], label_id: LabelID, *_: Any) -> None:\n \"\"\"Add new Rectangular Label Element for given Label.\n\n :param element: JSON describing single element\n :param label_id: ID of a given Label that the element should be added to\n \"\"\"\n position = LabelPosition(x=element['x'], y=element['y'], slice_index=element['slice_index'])\n shape = LabelShape(width=element['width'], height=element['height'])\n label_tag = _get_label_tag(element['tag'])\n LabelsRepository.add_new_rectangular_label_element(label_id, position, shape, label_tag)\n\n\ndef _add_brush_element(element: Dict[str, Any], label_id: LabelID, files: Dict[str, bytes]) -> None:\n \"\"\"Add new Brush Label Element for given Label.\n\n :param element: JSON describing single element\n :param label_id: ID of a given Label that the element should be added to\n :param files: mapping of uploaded files (name and content)\n \"\"\"\n width = element['width']\n height = element['height']\n label_tag = _get_label_tag(element['tag'])\n slice_index = element['slice_index']\n image = files[element['image_key']]\n LabelsRepository.add_new_brush_label_element(label_id, slice_index, width, height, image, label_tag)\n\n\ndef _add_point_element(element: Dict[str, Any], label_id: LabelID, *_: Any) -> None:\n \"\"\"Add new Point Label Element for given Label.\n\n :param element: JSON describing single element\n :param label_id: ID of a given Label that the element should be added to\n \"\"\"\n position = LabelPosition(x=element['x'], y=element['y'], slice_index=element['slice_index'])\n label_tag = _get_label_tag(element['tag'])\n LabelsRepository.add_new_point_label_element(label_id, position, label_tag)\n\n\ndef _add_chain_element(element: Dict[str, Any], label_id: LabelID, *_: Any) -> None:\n \"\"\"Add new Chain Label Element for given Label.\n\n :param element: JSON describing single element\n :param label_id: ID of a given Label that the element should be added to\n \"\"\"\n label_tag = _get_label_tag(element['tag'])\n points = [Point(p['x'], p['y']) for p in element['points']]\n slice_index = element['slice_index']\n loop = element['loop']\n LabelsRepository.add_new_chain_label_element(label_id, slice_index, label_tag, points, loop)\n\n\ndef _get_label_tag(tag_key: str) -> LabelTag:\n \"\"\"Return Label Tag based on Tag's key or raise an exception in case if not found.\"\"\"\n try:\n return LabelTagsRepository.get_label_tag_by_key(tag_key)\n except NoResultFound:\n raise NotFoundException('Could not find any Label Tag for that key!')\n\n\ndef add_new_slice(scan_id: ScanID, image: bytes) -> Slice:\n \"\"\"Add new Slice for given Scan.\n\n :param scan_id: ID of a Scan for which it should add new slice\n :param image: bytes representing DICOM image\n :return: Slice object\n \"\"\"\n scan = ScansRepository.get_scan_by_id(scan_id)\n _slice = scan.add_slice()\n try:\n SlicesRepository.store_original_image(_slice.id, image)\n except WriteTimeout:\n SlicesRepository.delete_slice(_slice)\n raise InternalErrorException('Timeout during saving original image to the Storage.')\n parse_dicom_and_update_slice.delay(_slice.id)\n return _slice\n\n\ndef get_scan(scan_id: ScanID) -> Scan:\n \"\"\"Return Scan for given scan_id.\n\n :param scan_id: ID of a Scan which should be returned\n :return: Scan object\n \"\"\"\n try:\n return ScansRepository.get_scan_by_id(scan_id)\n except NoResultFound:\n raise NotFoundException('Scan \"{}\" not found.'.format(scan_id))\n\n\ndef skip_scan(scan_id: ScanID) -> bool:\n \"\"\"Increases skip count of Scan with given scan_id.\n\n :param scan_id: ID of a Scan which should be returned\n :return: boolean information whether the Scan was skipped or not\n \"\"\"\n if not ScansRepository.increase_skip_count_of_a_scan(scan_id):\n raise NotFoundException('Scan \"{}\" not found.'.format(scan_id))\n return True\n", "path": "backend/medtagger/api/scans/business.py"}], "after_files": [{"content": "\"\"\"Module responsible for business logic in all Scans endpoints.\"\"\"\nimport io\nimport logging\nfrom typing import Callable, Iterable, Dict, List, Tuple, Any\n\nfrom cassandra import WriteTimeout\nfrom sqlalchemy.exc import IntegrityError\nfrom sqlalchemy.orm.exc import NoResultFound\nfrom PIL import Image\n\nfrom medtagger.exceptions import InternalErrorException\nfrom medtagger.api.exceptions import NotFoundException, InvalidArgumentsException\nfrom medtagger.types import ScanID, LabelPosition, LabelShape, LabelingTime, LabelID, Point\nfrom medtagger.database.models import Dataset, Scan, Slice, Label, LabelTag, SliceOrientation\nfrom medtagger.definitions import LabelTool\nfrom medtagger.repositories import (\n labels as LabelsRepository,\n label_tags as LabelTagsRepository,\n slices as SlicesRepository,\n scans as ScansRepository,\n datasets as DatasetsRepository,\n tasks as TasksRepository,\n)\nfrom medtagger.workers.storage import parse_dicom_and_update_slice\nfrom medtagger.api.utils import get_current_user\n\nlogger = logging.getLogger(__name__)\n\nLabelElementHandler = Callable[[Dict[str, Any], LabelID, Dict[str, bytes]], None]\n\n\ndef get_available_datasets() -> List[Dataset]:\n \"\"\"Fetch list of all available Datasets.\n\n :return: list of Datasets\n \"\"\"\n return DatasetsRepository.get_all_datasets()\n\n\ndef dataset_is_valid(dataset_key: str) -> bool:\n \"\"\"Check if Dataset for such key exists.\n\n :param dataset_key: key representing Dataset\n :return: boolean information if Dataset key is valid\n \"\"\"\n try:\n DatasetsRepository.get_dataset_by_key(dataset_key)\n return True\n except NoResultFound:\n return False\n\n\ndef create_dataset(key: str, name: str) -> Dataset:\n \"\"\"Create new Dataset.\n\n :param key: unique key representing Dataset\n :param name: name which describes this Dataset\n :return: Dataset object\n \"\"\"\n return DatasetsRepository.add_new_dataset(key, name)\n\n\ndef create_empty_scan(dataset_key: str, declared_number_of_slices: int) -> Scan:\n \"\"\"Create new empty scan.\n\n :param dataset_key: string with dataset key\n :param declared_number_of_slices: number of Slices that will be uploaded\n :return: Newly created Scan object\n \"\"\"\n user = get_current_user()\n dataset = DatasetsRepository.get_dataset_by_key(dataset_key)\n return ScansRepository.add_new_scan(dataset, declared_number_of_slices, user)\n\n\ndef get_random_scan(task_key: str) -> Scan:\n \"\"\"Fetch random scan from specified Task for labeling.\n\n :param task_key: unique key identifying task\n :return: Scan Metadata object\n \"\"\"\n user = get_current_user()\n task = TasksRepository.get_task_by_key(task_key)\n if not task:\n raise InvalidArgumentsException('Task key {} is invalid!'.format(task_key))\n scan = ScansRepository.get_random_scan(task, user)\n if not scan:\n raise NotFoundException('Could not find any Scan for this task!')\n return scan\n\n\ndef get_slices_for_scan(scan_id: ScanID, begin: int, count: int,\n orientation: SliceOrientation = SliceOrientation.Z) -> Iterable[Tuple[Slice, bytes]]:\n \"\"\"Fetch multiple slices for given scan.\n\n :param scan_id: ID of a given scan\n :param begin: first slice index (included)\n :param count: number of slices that will be returned\n :param orientation: orientation for Slices (by default set to Z axis)\n :return: generator for Slices\n \"\"\"\n slices = SlicesRepository.get_slices_by_scan_id(scan_id, orientation=orientation)\n for _slice in slices[begin:begin + count]:\n image = SlicesRepository.get_slice_converted_image(_slice.id)\n yield _slice, image\n\n\ndef validate_label_payload(elements: List[Dict], files: Dict[str, bytes]) -> None:\n \"\"\"Validate and raise an Exception for sent payload.\n\n :param elements: List of JSONs describing elements for a single label\n :param files: mapping of uploaded files (name and content)\n \"\"\"\n _validate_label_elements(elements, files)\n _validate_files(files)\n _validate_tool(elements)\n\n\ndef _validate_tool(elements: List[Dict]) -> None:\n \"\"\"Validate if the tool for given Label Element is available for given tag.\"\"\"\n for label_element in elements:\n tag = _get_label_tag(label_element['tag'])\n if label_element['tool'] not in {tool.name for tool in tag.tools}:\n raise InvalidArgumentsException('{} tool is not available for {} tag'.format(\n label_element['tool'], tag.name))\n\n\ndef _validate_files(files: Dict[str, bytes]) -> None:\n \"\"\"Validate files and make sure that images are PNGs.\"\"\"\n for file_name, file_data in files.items():\n try:\n image = Image.open(io.BytesIO(file_data))\n image.verify()\n assert image.format == 'PNG'\n except Exception:\n raise InvalidArgumentsException('Type of file \"{}\" is not supported!'.format(file_name))\n\n\ndef _validate_label_elements(elements: List[Dict], files: Dict[str, bytes]) -> None:\n \"\"\"Validate Label Elements and make sure that all Brush Elements have images.\"\"\"\n for label_element in elements:\n # Each Brush Label Element should have its own image attached\n if label_element['tool'] == LabelTool.BRUSH.value:\n try:\n files[label_element['image_key']]\n except KeyError:\n message = 'Request does not have field named {} that could contain the image!'\n raise InvalidArgumentsException(message.format(label_element['image_key']))\n\n\ndef add_label(scan_id: ScanID, task_key: str, elements: List[Dict], # pylint: disable-msg=too-many-arguments\n files: Dict[str, bytes], labeling_time: LabelingTime, comment: str = None) -> Label:\n \"\"\"Add label to given scan.\n\n :param scan_id: ID of a given scan\n :param task_key: Key of Task\n :param elements: List of JSONs describing elements for a single label\n :param files: mapping of uploaded files (name and content)\n :param labeling_time: time in seconds that user spent on labeling\n :param comment: (optional) comment describing a label\n :return: Label object\n \"\"\"\n user = get_current_user()\n try:\n label = LabelsRepository.add_new_label(scan_id, task_key, user, labeling_time, comment)\n except IntegrityError:\n raise NotFoundException('Could not find Scan for that id!')\n for element in elements:\n add_label_element(element, label.id, files)\n return label\n\n\ndef add_label_element(element: Dict[str, Any], label_id: LabelID, files: Dict[str, bytes]) -> None:\n \"\"\"Add new Label Element for given Label.\n\n :param element: JSON describing single element\n :param label_id: ID of a given Label that the element should be added to\n :param files: mapping of uploaded files (name and content)\n \"\"\"\n tool = element['tool']\n handlers: Dict[str, LabelElementHandler] = {\n LabelTool.RECTANGLE.value: _add_rectangle_element,\n LabelTool.BRUSH.value: _add_brush_element,\n LabelTool.POINT.value: _add_point_element,\n LabelTool.CHAIN.value: _add_chain_element,\n }\n handler = handlers[tool]\n handler(element, label_id, files)\n\n\ndef _add_rectangle_element(element: Dict[str, Any], label_id: LabelID, *_: Any) -> None:\n \"\"\"Add new Rectangular Label Element for given Label.\n\n :param element: JSON describing single element\n :param label_id: ID of a given Label that the element should be added to\n \"\"\"\n position = LabelPosition(x=element['x'], y=element['y'], slice_index=element['slice_index'])\n shape = LabelShape(width=element['width'], height=element['height'])\n label_tag = _get_label_tag(element['tag'])\n LabelsRepository.add_new_rectangular_label_element(label_id, position, shape, label_tag)\n\n\ndef _add_brush_element(element: Dict[str, Any], label_id: LabelID, files: Dict[str, bytes]) -> None:\n \"\"\"Add new Brush Label Element for given Label.\n\n :param element: JSON describing single element\n :param label_id: ID of a given Label that the element should be added to\n :param files: mapping of uploaded files (name and content)\n \"\"\"\n width = element['width']\n height = element['height']\n label_tag = _get_label_tag(element['tag'])\n slice_index = element['slice_index']\n image = files[element['image_key']]\n LabelsRepository.add_new_brush_label_element(label_id, slice_index, width, height, image, label_tag)\n\n\ndef _add_point_element(element: Dict[str, Any], label_id: LabelID, *_: Any) -> None:\n \"\"\"Add new Point Label Element for given Label.\n\n :param element: JSON describing single element\n :param label_id: ID of a given Label that the element should be added to\n \"\"\"\n position = LabelPosition(x=element['x'], y=element['y'], slice_index=element['slice_index'])\n label_tag = _get_label_tag(element['tag'])\n LabelsRepository.add_new_point_label_element(label_id, position, label_tag)\n\n\ndef _add_chain_element(element: Dict[str, Any], label_id: LabelID, *_: Any) -> None:\n \"\"\"Add new Chain Label Element for given Label.\n\n :param element: JSON describing single element\n :param label_id: ID of a given Label that the element should be added to\n \"\"\"\n label_tag = _get_label_tag(element['tag'])\n points = [Point(p['x'], p['y']) for p in element['points']]\n slice_index = element['slice_index']\n loop = element['loop']\n LabelsRepository.add_new_chain_label_element(label_id, slice_index, label_tag, points, loop)\n\n\ndef _get_label_tag(tag_key: str) -> LabelTag:\n \"\"\"Return Label Tag based on Tag's key or raise an exception in case if not found.\"\"\"\n try:\n return LabelTagsRepository.get_label_tag_by_key(tag_key)\n except NoResultFound:\n raise NotFoundException('Could not find any Label Tag for that key!')\n\n\ndef add_new_slice(scan_id: ScanID, image: bytes) -> Slice:\n \"\"\"Add new Slice for given Scan.\n\n :param scan_id: ID of a Scan for which it should add new slice\n :param image: bytes representing DICOM image\n :return: Slice object\n \"\"\"\n scan = ScansRepository.get_scan_by_id(scan_id)\n _slice = scan.add_slice()\n try:\n SlicesRepository.store_original_image(_slice.id, image)\n except WriteTimeout:\n SlicesRepository.delete_slice(_slice)\n raise InternalErrorException('Timeout during saving original image to the Storage.')\n parse_dicom_and_update_slice.delay(_slice.id)\n return _slice\n\n\ndef get_scan(scan_id: ScanID) -> Scan:\n \"\"\"Return Scan for given scan_id.\n\n :param scan_id: ID of a Scan which should be returned\n :return: Scan object\n \"\"\"\n try:\n return ScansRepository.get_scan_by_id(scan_id)\n except NoResultFound:\n raise NotFoundException('Scan \"{}\" not found.'.format(scan_id))\n\n\ndef skip_scan(scan_id: ScanID) -> bool:\n \"\"\"Increases skip count of Scan with given scan_id.\n\n :param scan_id: ID of a Scan which should be returned\n :return: boolean information whether the Scan was skipped or not\n \"\"\"\n if not ScansRepository.increase_skip_count_of_a_scan(scan_id):\n raise NotFoundException('Scan \"{}\" not found.'.format(scan_id))\n return True\n", "path": "backend/medtagger/api/scans/business.py"}]}
| 3,667 | 127 |
gh_patches_debug_7302
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-9411
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
JSON endpoint for project is 404 if only yanked releases are available
From https://github.com/pypa/warehouse/issues/3709#issuecomment-754973958, it appears that the JSON API for a project is 404 if the only releases available are yanked releases.
E.g. https://pypi.org/pypi/django-twilio2/json should probably look like https://pypi.org/pypi/django-twilio2/0.9.0/json instead of being 404.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `warehouse/legacy/api/json.py`
Content:
```
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 from collections import OrderedDict
14
15 from pyramid.httpexceptions import HTTPMovedPermanently, HTTPNotFound
16 from pyramid.view import view_config
17 from sqlalchemy.orm import Load
18 from sqlalchemy.orm.exc import NoResultFound
19
20 from warehouse.cache.http import cache_control
21 from warehouse.cache.origin import origin_cache
22 from warehouse.packaging.models import File, Project, Release
23
24 # Generate appropriate CORS headers for the JSON endpoint.
25 # We want to allow Cross-Origin requests here so that users can interact
26 # with these endpoints via XHR/Fetch APIs in the browser.
27 _CORS_HEADERS = {
28 "Access-Control-Allow-Origin": "*",
29 "Access-Control-Allow-Headers": ", ".join(
30 [
31 "Content-Type",
32 "If-Match",
33 "If-Modified-Since",
34 "If-None-Match",
35 "If-Unmodified-Since",
36 ]
37 ),
38 "Access-Control-Allow-Methods": "GET",
39 "Access-Control-Max-Age": "86400", # 1 day.
40 "Access-Control-Expose-Headers": ", ".join(["X-PyPI-Last-Serial"]),
41 }
42
43 _CACHE_DECORATOR = [
44 cache_control(15 * 60), # 15 minutes
45 origin_cache(
46 1 * 24 * 60 * 60, # 1 day
47 stale_while_revalidate=5 * 60, # 5 minutes
48 stale_if_error=1 * 24 * 60 * 60, # 1 day
49 ),
50 ]
51
52
53 @view_config(
54 route_name="legacy.api.json.project",
55 context=Project,
56 renderer="json",
57 decorator=_CACHE_DECORATOR,
58 )
59 def json_project(project, request):
60 if project.name != request.matchdict.get("name", project.name):
61 return HTTPMovedPermanently(
62 request.current_route_path(name=project.name), headers=_CORS_HEADERS
63 )
64
65 try:
66 release = (
67 request.db.query(Release)
68 .filter(Release.project == project, Release.yanked.is_(False))
69 .order_by(Release.is_prerelease.nullslast(), Release._pypi_ordering.desc())
70 .limit(1)
71 .one()
72 )
73 except NoResultFound:
74 return HTTPNotFound(headers=_CORS_HEADERS)
75
76 return json_release(release, request)
77
78
79 @view_config(
80 route_name="legacy.api.json.project_slash",
81 context=Project,
82 decorator=_CACHE_DECORATOR,
83 )
84 def json_project_slash(project, request):
85 return HTTPMovedPermanently(
86 # Respond with redirect to url without trailing slash
87 request.route_path("legacy.api.json.project", name=project.name),
88 headers=_CORS_HEADERS,
89 )
90
91
92 @view_config(
93 route_name="legacy.api.json.release",
94 context=Release,
95 renderer="json",
96 decorator=_CACHE_DECORATOR,
97 )
98 def json_release(release, request):
99 project = release.project
100
101 if project.name != request.matchdict.get("name", project.name):
102 return HTTPMovedPermanently(
103 request.current_route_path(name=project.name), headers=_CORS_HEADERS
104 )
105
106 # Apply CORS headers.
107 request.response.headers.update(_CORS_HEADERS)
108
109 # Get the latest serial number for this project.
110 request.response.headers["X-PyPI-Last-Serial"] = str(project.last_serial)
111
112 # Get all of the releases and files for this project.
113 release_files = (
114 request.db.query(Release, File)
115 .options(
116 Load(Release).load_only(
117 "version", "requires_python", "yanked", "yanked_reason"
118 )
119 )
120 .outerjoin(File)
121 .filter(Release.project == project)
122 .order_by(Release._pypi_ordering.desc(), File.filename)
123 .all()
124 )
125
126 # Map our releases + files into a dictionary that maps each release to a
127 # list of all its files.
128 releases = {}
129 for r, file_ in release_files:
130 files = releases.setdefault(r, [])
131 if file_ is not None:
132 files.append(file_)
133
134 # Serialize our database objects to match the way that PyPI legacy
135 # presented this data.
136 releases = {
137 r.version: [
138 {
139 "filename": f.filename,
140 "packagetype": f.packagetype,
141 "python_version": f.python_version,
142 "has_sig": f.has_signature,
143 "comment_text": f.comment_text,
144 "md5_digest": f.md5_digest,
145 "digests": {"md5": f.md5_digest, "sha256": f.sha256_digest},
146 "size": f.size,
147 # TODO: Remove this once we've had a long enough time with it
148 # here to consider it no longer in use.
149 "downloads": -1,
150 "upload_time": f.upload_time.strftime("%Y-%m-%dT%H:%M:%S"),
151 "upload_time_iso_8601": f.upload_time.isoformat() + "Z",
152 "url": request.route_url("packaging.file", path=f.path),
153 "requires_python": r.requires_python if r.requires_python else None,
154 "yanked": r.yanked,
155 "yanked_reason": r.yanked_reason or None,
156 }
157 for f in fs
158 ]
159 for r, fs in releases.items()
160 }
161
162 return {
163 "info": {
164 "name": project.name,
165 "version": release.version,
166 "summary": release.summary,
167 "description_content_type": release.description.content_type,
168 "description": release.description.raw,
169 "keywords": release.keywords,
170 "license": release.license,
171 "classifiers": list(release.classifiers),
172 "author": release.author,
173 "author_email": release.author_email,
174 "maintainer": release.maintainer,
175 "maintainer_email": release.maintainer_email,
176 "requires_python": release.requires_python,
177 "platform": release.platform,
178 "downloads": {"last_day": -1, "last_week": -1, "last_month": -1},
179 "package_url": request.route_url("packaging.project", name=project.name),
180 "project_url": request.route_url("packaging.project", name=project.name),
181 "project_urls": OrderedDict(release.urls) if release.urls else None,
182 "release_url": request.route_url(
183 "packaging.release", name=project.name, version=release.version
184 ),
185 "requires_dist": (
186 list(release.requires_dist) if release.requires_dist else None
187 ),
188 "docs_url": project.documentation_url,
189 "bugtrack_url": None,
190 "home_page": release.home_page,
191 "download_url": release.download_url,
192 "yanked": release.yanked,
193 "yanked_reason": release.yanked_reason or None,
194 },
195 "urls": releases[release.version],
196 "releases": releases,
197 "last_serial": project.last_serial,
198 }
199
200
201 @view_config(
202 route_name="legacy.api.json.release_slash",
203 context=Release,
204 decorator=_CACHE_DECORATOR,
205 )
206 def json_release_slash(release, request):
207 return HTTPMovedPermanently(
208 # Respond with redirect to url without trailing slash
209 request.route_path(
210 "legacy.api.json.release",
211 name=release.project.name,
212 version=release.version,
213 ),
214 headers=_CORS_HEADERS,
215 )
216
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/warehouse/legacy/api/json.py b/warehouse/legacy/api/json.py
--- a/warehouse/legacy/api/json.py
+++ b/warehouse/legacy/api/json.py
@@ -65,8 +65,12 @@
try:
release = (
request.db.query(Release)
- .filter(Release.project == project, Release.yanked.is_(False))
- .order_by(Release.is_prerelease.nullslast(), Release._pypi_ordering.desc())
+ .filter(Release.project == project)
+ .order_by(
+ Release.yanked.asc(),
+ Release.is_prerelease.nullslast(),
+ Release._pypi_ordering.desc(),
+ )
.limit(1)
.one()
)
|
{"golden_diff": "diff --git a/warehouse/legacy/api/json.py b/warehouse/legacy/api/json.py\n--- a/warehouse/legacy/api/json.py\n+++ b/warehouse/legacy/api/json.py\n@@ -65,8 +65,12 @@\n try:\n release = (\n request.db.query(Release)\n- .filter(Release.project == project, Release.yanked.is_(False))\n- .order_by(Release.is_prerelease.nullslast(), Release._pypi_ordering.desc())\n+ .filter(Release.project == project)\n+ .order_by(\n+ Release.yanked.asc(),\n+ Release.is_prerelease.nullslast(),\n+ Release._pypi_ordering.desc(),\n+ )\n .limit(1)\n .one()\n )\n", "issue": "JSON endpoint for project is 404 if only yanked releases are available\nFrom https://github.com/pypa/warehouse/issues/3709#issuecomment-754973958, it appears that the JSON API for a project is 404 if the only releases available are yanked releases.\r\n\r\nE.g. https://pypi.org/pypi/django-twilio2/json should probably look like https://pypi.org/pypi/django-twilio2/0.9.0/json instead of being 404.\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom collections import OrderedDict\n\nfrom pyramid.httpexceptions import HTTPMovedPermanently, HTTPNotFound\nfrom pyramid.view import view_config\nfrom sqlalchemy.orm import Load\nfrom sqlalchemy.orm.exc import NoResultFound\n\nfrom warehouse.cache.http import cache_control\nfrom warehouse.cache.origin import origin_cache\nfrom warehouse.packaging.models import File, Project, Release\n\n# Generate appropriate CORS headers for the JSON endpoint.\n# We want to allow Cross-Origin requests here so that users can interact\n# with these endpoints via XHR/Fetch APIs in the browser.\n_CORS_HEADERS = {\n \"Access-Control-Allow-Origin\": \"*\",\n \"Access-Control-Allow-Headers\": \", \".join(\n [\n \"Content-Type\",\n \"If-Match\",\n \"If-Modified-Since\",\n \"If-None-Match\",\n \"If-Unmodified-Since\",\n ]\n ),\n \"Access-Control-Allow-Methods\": \"GET\",\n \"Access-Control-Max-Age\": \"86400\", # 1 day.\n \"Access-Control-Expose-Headers\": \", \".join([\"X-PyPI-Last-Serial\"]),\n}\n\n_CACHE_DECORATOR = [\n cache_control(15 * 60), # 15 minutes\n origin_cache(\n 1 * 24 * 60 * 60, # 1 day\n stale_while_revalidate=5 * 60, # 5 minutes\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n ),\n]\n\n\n@view_config(\n route_name=\"legacy.api.json.project\",\n context=Project,\n renderer=\"json\",\n decorator=_CACHE_DECORATOR,\n)\ndef json_project(project, request):\n if project.name != request.matchdict.get(\"name\", project.name):\n return HTTPMovedPermanently(\n request.current_route_path(name=project.name), headers=_CORS_HEADERS\n )\n\n try:\n release = (\n request.db.query(Release)\n .filter(Release.project == project, Release.yanked.is_(False))\n .order_by(Release.is_prerelease.nullslast(), Release._pypi_ordering.desc())\n .limit(1)\n .one()\n )\n except NoResultFound:\n return HTTPNotFound(headers=_CORS_HEADERS)\n\n return json_release(release, request)\n\n\n@view_config(\n route_name=\"legacy.api.json.project_slash\",\n context=Project,\n decorator=_CACHE_DECORATOR,\n)\ndef json_project_slash(project, request):\n return HTTPMovedPermanently(\n # Respond with redirect to url without trailing slash\n request.route_path(\"legacy.api.json.project\", name=project.name),\n headers=_CORS_HEADERS,\n )\n\n\n@view_config(\n route_name=\"legacy.api.json.release\",\n context=Release,\n renderer=\"json\",\n decorator=_CACHE_DECORATOR,\n)\ndef json_release(release, request):\n project = release.project\n\n if project.name != request.matchdict.get(\"name\", project.name):\n return HTTPMovedPermanently(\n request.current_route_path(name=project.name), headers=_CORS_HEADERS\n )\n\n # Apply CORS headers.\n request.response.headers.update(_CORS_HEADERS)\n\n # Get the latest serial number for this project.\n request.response.headers[\"X-PyPI-Last-Serial\"] = str(project.last_serial)\n\n # Get all of the releases and files for this project.\n release_files = (\n request.db.query(Release, File)\n .options(\n Load(Release).load_only(\n \"version\", \"requires_python\", \"yanked\", \"yanked_reason\"\n )\n )\n .outerjoin(File)\n .filter(Release.project == project)\n .order_by(Release._pypi_ordering.desc(), File.filename)\n .all()\n )\n\n # Map our releases + files into a dictionary that maps each release to a\n # list of all its files.\n releases = {}\n for r, file_ in release_files:\n files = releases.setdefault(r, [])\n if file_ is not None:\n files.append(file_)\n\n # Serialize our database objects to match the way that PyPI legacy\n # presented this data.\n releases = {\n r.version: [\n {\n \"filename\": f.filename,\n \"packagetype\": f.packagetype,\n \"python_version\": f.python_version,\n \"has_sig\": f.has_signature,\n \"comment_text\": f.comment_text,\n \"md5_digest\": f.md5_digest,\n \"digests\": {\"md5\": f.md5_digest, \"sha256\": f.sha256_digest},\n \"size\": f.size,\n # TODO: Remove this once we've had a long enough time with it\n # here to consider it no longer in use.\n \"downloads\": -1,\n \"upload_time\": f.upload_time.strftime(\"%Y-%m-%dT%H:%M:%S\"),\n \"upload_time_iso_8601\": f.upload_time.isoformat() + \"Z\",\n \"url\": request.route_url(\"packaging.file\", path=f.path),\n \"requires_python\": r.requires_python if r.requires_python else None,\n \"yanked\": r.yanked,\n \"yanked_reason\": r.yanked_reason or None,\n }\n for f in fs\n ]\n for r, fs in releases.items()\n }\n\n return {\n \"info\": {\n \"name\": project.name,\n \"version\": release.version,\n \"summary\": release.summary,\n \"description_content_type\": release.description.content_type,\n \"description\": release.description.raw,\n \"keywords\": release.keywords,\n \"license\": release.license,\n \"classifiers\": list(release.classifiers),\n \"author\": release.author,\n \"author_email\": release.author_email,\n \"maintainer\": release.maintainer,\n \"maintainer_email\": release.maintainer_email,\n \"requires_python\": release.requires_python,\n \"platform\": release.platform,\n \"downloads\": {\"last_day\": -1, \"last_week\": -1, \"last_month\": -1},\n \"package_url\": request.route_url(\"packaging.project\", name=project.name),\n \"project_url\": request.route_url(\"packaging.project\", name=project.name),\n \"project_urls\": OrderedDict(release.urls) if release.urls else None,\n \"release_url\": request.route_url(\n \"packaging.release\", name=project.name, version=release.version\n ),\n \"requires_dist\": (\n list(release.requires_dist) if release.requires_dist else None\n ),\n \"docs_url\": project.documentation_url,\n \"bugtrack_url\": None,\n \"home_page\": release.home_page,\n \"download_url\": release.download_url,\n \"yanked\": release.yanked,\n \"yanked_reason\": release.yanked_reason or None,\n },\n \"urls\": releases[release.version],\n \"releases\": releases,\n \"last_serial\": project.last_serial,\n }\n\n\n@view_config(\n route_name=\"legacy.api.json.release_slash\",\n context=Release,\n decorator=_CACHE_DECORATOR,\n)\ndef json_release_slash(release, request):\n return HTTPMovedPermanently(\n # Respond with redirect to url without trailing slash\n request.route_path(\n \"legacy.api.json.release\",\n name=release.project.name,\n version=release.version,\n ),\n headers=_CORS_HEADERS,\n )\n", "path": "warehouse/legacy/api/json.py"}], "after_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom collections import OrderedDict\n\nfrom pyramid.httpexceptions import HTTPMovedPermanently, HTTPNotFound\nfrom pyramid.view import view_config\nfrom sqlalchemy.orm import Load\nfrom sqlalchemy.orm.exc import NoResultFound\n\nfrom warehouse.cache.http import cache_control\nfrom warehouse.cache.origin import origin_cache\nfrom warehouse.packaging.models import File, Project, Release\n\n# Generate appropriate CORS headers for the JSON endpoint.\n# We want to allow Cross-Origin requests here so that users can interact\n# with these endpoints via XHR/Fetch APIs in the browser.\n_CORS_HEADERS = {\n \"Access-Control-Allow-Origin\": \"*\",\n \"Access-Control-Allow-Headers\": \", \".join(\n [\n \"Content-Type\",\n \"If-Match\",\n \"If-Modified-Since\",\n \"If-None-Match\",\n \"If-Unmodified-Since\",\n ]\n ),\n \"Access-Control-Allow-Methods\": \"GET\",\n \"Access-Control-Max-Age\": \"86400\", # 1 day.\n \"Access-Control-Expose-Headers\": \", \".join([\"X-PyPI-Last-Serial\"]),\n}\n\n_CACHE_DECORATOR = [\n cache_control(15 * 60), # 15 minutes\n origin_cache(\n 1 * 24 * 60 * 60, # 1 day\n stale_while_revalidate=5 * 60, # 5 minutes\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n ),\n]\n\n\n@view_config(\n route_name=\"legacy.api.json.project\",\n context=Project,\n renderer=\"json\",\n decorator=_CACHE_DECORATOR,\n)\ndef json_project(project, request):\n if project.name != request.matchdict.get(\"name\", project.name):\n return HTTPMovedPermanently(\n request.current_route_path(name=project.name), headers=_CORS_HEADERS\n )\n\n try:\n release = (\n request.db.query(Release)\n .filter(Release.project == project)\n .order_by(\n Release.yanked.asc(),\n Release.is_prerelease.nullslast(),\n Release._pypi_ordering.desc(),\n )\n .limit(1)\n .one()\n )\n except NoResultFound:\n return HTTPNotFound(headers=_CORS_HEADERS)\n\n return json_release(release, request)\n\n\n@view_config(\n route_name=\"legacy.api.json.project_slash\",\n context=Project,\n decorator=_CACHE_DECORATOR,\n)\ndef json_project_slash(project, request):\n return HTTPMovedPermanently(\n # Respond with redirect to url without trailing slash\n request.route_path(\"legacy.api.json.project\", name=project.name),\n headers=_CORS_HEADERS,\n )\n\n\n@view_config(\n route_name=\"legacy.api.json.release\",\n context=Release,\n renderer=\"json\",\n decorator=_CACHE_DECORATOR,\n)\ndef json_release(release, request):\n project = release.project\n\n if project.name != request.matchdict.get(\"name\", project.name):\n return HTTPMovedPermanently(\n request.current_route_path(name=project.name), headers=_CORS_HEADERS\n )\n\n # Apply CORS headers.\n request.response.headers.update(_CORS_HEADERS)\n\n # Get the latest serial number for this project.\n request.response.headers[\"X-PyPI-Last-Serial\"] = str(project.last_serial)\n\n # Get all of the releases and files for this project.\n release_files = (\n request.db.query(Release, File)\n .options(\n Load(Release).load_only(\n \"version\", \"requires_python\", \"yanked\", \"yanked_reason\"\n )\n )\n .outerjoin(File)\n .filter(Release.project == project)\n .order_by(Release._pypi_ordering.desc(), File.filename)\n .all()\n )\n\n # Map our releases + files into a dictionary that maps each release to a\n # list of all its files.\n releases = {}\n for r, file_ in release_files:\n files = releases.setdefault(r, [])\n if file_ is not None:\n files.append(file_)\n\n # Serialize our database objects to match the way that PyPI legacy\n # presented this data.\n releases = {\n r.version: [\n {\n \"filename\": f.filename,\n \"packagetype\": f.packagetype,\n \"python_version\": f.python_version,\n \"has_sig\": f.has_signature,\n \"comment_text\": f.comment_text,\n \"md5_digest\": f.md5_digest,\n \"digests\": {\"md5\": f.md5_digest, \"sha256\": f.sha256_digest},\n \"size\": f.size,\n # TODO: Remove this once we've had a long enough time with it\n # here to consider it no longer in use.\n \"downloads\": -1,\n \"upload_time\": f.upload_time.strftime(\"%Y-%m-%dT%H:%M:%S\"),\n \"upload_time_iso_8601\": f.upload_time.isoformat() + \"Z\",\n \"url\": request.route_url(\"packaging.file\", path=f.path),\n \"requires_python\": r.requires_python if r.requires_python else None,\n \"yanked\": r.yanked,\n \"yanked_reason\": r.yanked_reason or None,\n }\n for f in fs\n ]\n for r, fs in releases.items()\n }\n\n return {\n \"info\": {\n \"name\": project.name,\n \"version\": release.version,\n \"summary\": release.summary,\n \"description_content_type\": release.description.content_type,\n \"description\": release.description.raw,\n \"keywords\": release.keywords,\n \"license\": release.license,\n \"classifiers\": list(release.classifiers),\n \"author\": release.author,\n \"author_email\": release.author_email,\n \"maintainer\": release.maintainer,\n \"maintainer_email\": release.maintainer_email,\n \"requires_python\": release.requires_python,\n \"platform\": release.platform,\n \"downloads\": {\"last_day\": -1, \"last_week\": -1, \"last_month\": -1},\n \"package_url\": request.route_url(\"packaging.project\", name=project.name),\n \"project_url\": request.route_url(\"packaging.project\", name=project.name),\n \"project_urls\": OrderedDict(release.urls) if release.urls else None,\n \"release_url\": request.route_url(\n \"packaging.release\", name=project.name, version=release.version\n ),\n \"requires_dist\": (\n list(release.requires_dist) if release.requires_dist else None\n ),\n \"docs_url\": project.documentation_url,\n \"bugtrack_url\": None,\n \"home_page\": release.home_page,\n \"download_url\": release.download_url,\n \"yanked\": release.yanked,\n \"yanked_reason\": release.yanked_reason or None,\n },\n \"urls\": releases[release.version],\n \"releases\": releases,\n \"last_serial\": project.last_serial,\n }\n\n\n@view_config(\n route_name=\"legacy.api.json.release_slash\",\n context=Release,\n decorator=_CACHE_DECORATOR,\n)\ndef json_release_slash(release, request):\n return HTTPMovedPermanently(\n # Respond with redirect to url without trailing slash\n request.route_path(\n \"legacy.api.json.release\",\n name=release.project.name,\n version=release.version,\n ),\n headers=_CORS_HEADERS,\n )\n", "path": "warehouse/legacy/api/json.py"}]}
| 2,633 | 166 |
gh_patches_debug_60369
|
rasdani/github-patches
|
git_diff
|
Lightning-Universe__lightning-flash-1426
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix Flash CI (special examples failing)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `flash_examples/integrations/learn2learn/image_classification_imagenette_mini.py`
Content:
```
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 # adapted from https://github.com/learnables/learn2learn/blob/master/examples/vision/protonet_miniimagenet.py#L154
16
17 """## Train file https://www.dropbox.com/s/9g8c6w345s2ek03/mini-imagenet-cache-train.pkl?dl=1
18
19 ## Validation File
20 https://www.dropbox.com/s/ip1b7se3gij3r1b/mini-imagenet-cache-validation.pkl?dl=1
21
22 Followed by renaming the pickle files
23 cp './mini-imagenet-cache-train.pkl?dl=1' './mini-imagenet-cache-train.pkl'
24 cp './mini-imagenet-cache-validation.pkl?dl=1' './mini-imagenet-cache-validation.pkl'
25 """
26
27 import warnings
28 from dataclasses import dataclass
29 from typing import Tuple, Union
30
31 import kornia.augmentation as Ka
32 import kornia.geometry as Kg
33 import learn2learn as l2l
34 import torch
35 import torchvision.transforms as T
36
37 import flash
38 from flash.core.data.io.input import DataKeys
39 from flash.core.data.io.input_transform import InputTransform
40 from flash.core.data.transforms import ApplyToKeys, kornia_collate
41 from flash.image import ImageClassificationData, ImageClassifier
42
43 warnings.simplefilter("ignore")
44
45 # download MiniImagenet
46 train_dataset = l2l.vision.datasets.MiniImagenet(root="./", mode="train", download=False)
47 val_dataset = l2l.vision.datasets.MiniImagenet(root="./", mode="validation", download=False)
48
49
50 @dataclass
51 class ImageClassificationInputTransform(InputTransform):
52
53 image_size: Tuple[int, int] = (196, 196)
54 mean: Union[float, Tuple[float, float, float]] = (0.485, 0.456, 0.406)
55 std: Union[float, Tuple[float, float, float]] = (0.229, 0.224, 0.225)
56
57 def per_sample_transform(self):
58 return T.Compose(
59 [
60 ApplyToKeys(
61 DataKeys.INPUT,
62 T.Compose(
63 [
64 T.ToTensor(),
65 Kg.Resize((196, 196)),
66 # SPATIAL
67 Ka.RandomHorizontalFlip(p=0.25),
68 Ka.RandomRotation(degrees=90.0, p=0.25),
69 Ka.RandomAffine(degrees=1 * 5.0, shear=1 / 5, translate=1 / 20, p=0.25),
70 Ka.RandomPerspective(distortion_scale=1 / 25, p=0.25),
71 # PIXEL-LEVEL
72 Ka.ColorJitter(brightness=1 / 30, p=0.25), # brightness
73 Ka.ColorJitter(saturation=1 / 30, p=0.25), # saturation
74 Ka.ColorJitter(contrast=1 / 30, p=0.25), # contrast
75 Ka.ColorJitter(hue=1 / 30, p=0.25), # hue
76 Ka.RandomMotionBlur(kernel_size=2 * (4 // 3) + 1, angle=1, direction=1.0, p=0.25),
77 Ka.RandomErasing(scale=(1 / 100, 1 / 50), ratio=(1 / 20, 1), p=0.25),
78 ]
79 ),
80 ),
81 ApplyToKeys(DataKeys.TARGET, torch.as_tensor),
82 ]
83 )
84
85 def train_per_sample_transform(self):
86 return T.Compose(
87 [
88 ApplyToKeys(
89 DataKeys.INPUT,
90 T.Compose(
91 [
92 T.ToTensor(),
93 T.Resize(self.image_size),
94 T.Normalize(self.mean, self.std),
95 T.RandomHorizontalFlip(),
96 T.ColorJitter(),
97 T.RandomAutocontrast(),
98 T.RandomPerspective(),
99 ]
100 ),
101 ),
102 ApplyToKeys("target", torch.as_tensor),
103 ]
104 )
105
106 def per_batch_transform_on_device(self):
107 return ApplyToKeys(
108 DataKeys.INPUT,
109 Ka.RandomHorizontalFlip(p=0.25),
110 )
111
112 def collate(self):
113 return kornia_collate
114
115
116 # construct datamodule
117
118 datamodule = ImageClassificationData.from_tensors(
119 train_data=train_dataset.x,
120 train_targets=torch.from_numpy(train_dataset.y.astype(int)),
121 val_data=val_dataset.x,
122 val_targets=torch.from_numpy(val_dataset.y.astype(int)),
123 train_transform=ImageClassificationInputTransform,
124 val_transform=ImageClassificationInputTransform,
125 batch_size=1,
126 )
127
128 model = ImageClassifier(
129 backbone="resnet18",
130 training_strategy="prototypicalnetworks",
131 training_strategy_kwargs={
132 "epoch_length": 10 * 16,
133 "meta_batch_size": 1,
134 "num_tasks": 200,
135 "test_num_tasks": 2000,
136 "ways": datamodule.num_classes,
137 "shots": 1,
138 "test_ways": 5,
139 "test_shots": 1,
140 "test_queries": 15,
141 },
142 optimizer=torch.optim.Adam,
143 learning_rate=0.001,
144 )
145
146 trainer = flash.Trainer(
147 max_epochs=1,
148 gpus=1,
149 precision=16,
150 )
151
152 trainer.finetune(model, datamodule=datamodule, strategy="no_freeze")
153
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/flash_examples/integrations/learn2learn/image_classification_imagenette_mini.py b/flash_examples/integrations/learn2learn/image_classification_imagenette_mini.py
--- a/flash_examples/integrations/learn2learn/image_classification_imagenette_mini.py
+++ b/flash_examples/integrations/learn2learn/image_classification_imagenette_mini.py
@@ -146,6 +146,7 @@
trainer = flash.Trainer(
max_epochs=1,
gpus=1,
+ accelerator="gpu",
precision=16,
)
|
{"golden_diff": "diff --git a/flash_examples/integrations/learn2learn/image_classification_imagenette_mini.py b/flash_examples/integrations/learn2learn/image_classification_imagenette_mini.py\n--- a/flash_examples/integrations/learn2learn/image_classification_imagenette_mini.py\n+++ b/flash_examples/integrations/learn2learn/image_classification_imagenette_mini.py\n@@ -146,6 +146,7 @@\n trainer = flash.Trainer(\n max_epochs=1,\n gpus=1,\n+ accelerator=\"gpu\",\n precision=16,\n )\n", "issue": "Fix Flash CI (special examples failing)\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# adapted from https://github.com/learnables/learn2learn/blob/master/examples/vision/protonet_miniimagenet.py#L154\n\n\"\"\"## Train file https://www.dropbox.com/s/9g8c6w345s2ek03/mini-imagenet-cache-train.pkl?dl=1\n\n## Validation File\nhttps://www.dropbox.com/s/ip1b7se3gij3r1b/mini-imagenet-cache-validation.pkl?dl=1\n\nFollowed by renaming the pickle files\ncp './mini-imagenet-cache-train.pkl?dl=1' './mini-imagenet-cache-train.pkl'\ncp './mini-imagenet-cache-validation.pkl?dl=1' './mini-imagenet-cache-validation.pkl'\n\"\"\"\n\nimport warnings\nfrom dataclasses import dataclass\nfrom typing import Tuple, Union\n\nimport kornia.augmentation as Ka\nimport kornia.geometry as Kg\nimport learn2learn as l2l\nimport torch\nimport torchvision.transforms as T\n\nimport flash\nfrom flash.core.data.io.input import DataKeys\nfrom flash.core.data.io.input_transform import InputTransform\nfrom flash.core.data.transforms import ApplyToKeys, kornia_collate\nfrom flash.image import ImageClassificationData, ImageClassifier\n\nwarnings.simplefilter(\"ignore\")\n\n# download MiniImagenet\ntrain_dataset = l2l.vision.datasets.MiniImagenet(root=\"./\", mode=\"train\", download=False)\nval_dataset = l2l.vision.datasets.MiniImagenet(root=\"./\", mode=\"validation\", download=False)\n\n\n@dataclass\nclass ImageClassificationInputTransform(InputTransform):\n\n image_size: Tuple[int, int] = (196, 196)\n mean: Union[float, Tuple[float, float, float]] = (0.485, 0.456, 0.406)\n std: Union[float, Tuple[float, float, float]] = (0.229, 0.224, 0.225)\n\n def per_sample_transform(self):\n return T.Compose(\n [\n ApplyToKeys(\n DataKeys.INPUT,\n T.Compose(\n [\n T.ToTensor(),\n Kg.Resize((196, 196)),\n # SPATIAL\n Ka.RandomHorizontalFlip(p=0.25),\n Ka.RandomRotation(degrees=90.0, p=0.25),\n Ka.RandomAffine(degrees=1 * 5.0, shear=1 / 5, translate=1 / 20, p=0.25),\n Ka.RandomPerspective(distortion_scale=1 / 25, p=0.25),\n # PIXEL-LEVEL\n Ka.ColorJitter(brightness=1 / 30, p=0.25), # brightness\n Ka.ColorJitter(saturation=1 / 30, p=0.25), # saturation\n Ka.ColorJitter(contrast=1 / 30, p=0.25), # contrast\n Ka.ColorJitter(hue=1 / 30, p=0.25), # hue\n Ka.RandomMotionBlur(kernel_size=2 * (4 // 3) + 1, angle=1, direction=1.0, p=0.25),\n Ka.RandomErasing(scale=(1 / 100, 1 / 50), ratio=(1 / 20, 1), p=0.25),\n ]\n ),\n ),\n ApplyToKeys(DataKeys.TARGET, torch.as_tensor),\n ]\n )\n\n def train_per_sample_transform(self):\n return T.Compose(\n [\n ApplyToKeys(\n DataKeys.INPUT,\n T.Compose(\n [\n T.ToTensor(),\n T.Resize(self.image_size),\n T.Normalize(self.mean, self.std),\n T.RandomHorizontalFlip(),\n T.ColorJitter(),\n T.RandomAutocontrast(),\n T.RandomPerspective(),\n ]\n ),\n ),\n ApplyToKeys(\"target\", torch.as_tensor),\n ]\n )\n\n def per_batch_transform_on_device(self):\n return ApplyToKeys(\n DataKeys.INPUT,\n Ka.RandomHorizontalFlip(p=0.25),\n )\n\n def collate(self):\n return kornia_collate\n\n\n# construct datamodule\n\ndatamodule = ImageClassificationData.from_tensors(\n train_data=train_dataset.x,\n train_targets=torch.from_numpy(train_dataset.y.astype(int)),\n val_data=val_dataset.x,\n val_targets=torch.from_numpy(val_dataset.y.astype(int)),\n train_transform=ImageClassificationInputTransform,\n val_transform=ImageClassificationInputTransform,\n batch_size=1,\n)\n\nmodel = ImageClassifier(\n backbone=\"resnet18\",\n training_strategy=\"prototypicalnetworks\",\n training_strategy_kwargs={\n \"epoch_length\": 10 * 16,\n \"meta_batch_size\": 1,\n \"num_tasks\": 200,\n \"test_num_tasks\": 2000,\n \"ways\": datamodule.num_classes,\n \"shots\": 1,\n \"test_ways\": 5,\n \"test_shots\": 1,\n \"test_queries\": 15,\n },\n optimizer=torch.optim.Adam,\n learning_rate=0.001,\n)\n\ntrainer = flash.Trainer(\n max_epochs=1,\n gpus=1,\n precision=16,\n)\n\ntrainer.finetune(model, datamodule=datamodule, strategy=\"no_freeze\")\n", "path": "flash_examples/integrations/learn2learn/image_classification_imagenette_mini.py"}], "after_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n# adapted from https://github.com/learnables/learn2learn/blob/master/examples/vision/protonet_miniimagenet.py#L154\n\n\"\"\"## Train file https://www.dropbox.com/s/9g8c6w345s2ek03/mini-imagenet-cache-train.pkl?dl=1\n\n## Validation File\nhttps://www.dropbox.com/s/ip1b7se3gij3r1b/mini-imagenet-cache-validation.pkl?dl=1\n\nFollowed by renaming the pickle files\ncp './mini-imagenet-cache-train.pkl?dl=1' './mini-imagenet-cache-train.pkl'\ncp './mini-imagenet-cache-validation.pkl?dl=1' './mini-imagenet-cache-validation.pkl'\n\"\"\"\n\nimport warnings\nfrom dataclasses import dataclass\nfrom typing import Tuple, Union\n\nimport kornia.augmentation as Ka\nimport kornia.geometry as Kg\nimport learn2learn as l2l\nimport torch\nimport torchvision.transforms as T\n\nimport flash\nfrom flash.core.data.io.input import DataKeys\nfrom flash.core.data.io.input_transform import InputTransform\nfrom flash.core.data.transforms import ApplyToKeys, kornia_collate\nfrom flash.image import ImageClassificationData, ImageClassifier\n\nwarnings.simplefilter(\"ignore\")\n\n# download MiniImagenet\ntrain_dataset = l2l.vision.datasets.MiniImagenet(root=\"./\", mode=\"train\", download=False)\nval_dataset = l2l.vision.datasets.MiniImagenet(root=\"./\", mode=\"validation\", download=False)\n\n\n@dataclass\nclass ImageClassificationInputTransform(InputTransform):\n\n image_size: Tuple[int, int] = (196, 196)\n mean: Union[float, Tuple[float, float, float]] = (0.485, 0.456, 0.406)\n std: Union[float, Tuple[float, float, float]] = (0.229, 0.224, 0.225)\n\n def per_sample_transform(self):\n return T.Compose(\n [\n ApplyToKeys(\n DataKeys.INPUT,\n T.Compose(\n [\n T.ToTensor(),\n Kg.Resize((196, 196)),\n # SPATIAL\n Ka.RandomHorizontalFlip(p=0.25),\n Ka.RandomRotation(degrees=90.0, p=0.25),\n Ka.RandomAffine(degrees=1 * 5.0, shear=1 / 5, translate=1 / 20, p=0.25),\n Ka.RandomPerspective(distortion_scale=1 / 25, p=0.25),\n # PIXEL-LEVEL\n Ka.ColorJitter(brightness=1 / 30, p=0.25), # brightness\n Ka.ColorJitter(saturation=1 / 30, p=0.25), # saturation\n Ka.ColorJitter(contrast=1 / 30, p=0.25), # contrast\n Ka.ColorJitter(hue=1 / 30, p=0.25), # hue\n Ka.RandomMotionBlur(kernel_size=2 * (4 // 3) + 1, angle=1, direction=1.0, p=0.25),\n Ka.RandomErasing(scale=(1 / 100, 1 / 50), ratio=(1 / 20, 1), p=0.25),\n ]\n ),\n ),\n ApplyToKeys(DataKeys.TARGET, torch.as_tensor),\n ]\n )\n\n def train_per_sample_transform(self):\n return T.Compose(\n [\n ApplyToKeys(\n DataKeys.INPUT,\n T.Compose(\n [\n T.ToTensor(),\n T.Resize(self.image_size),\n T.Normalize(self.mean, self.std),\n T.RandomHorizontalFlip(),\n T.ColorJitter(),\n T.RandomAutocontrast(),\n T.RandomPerspective(),\n ]\n ),\n ),\n ApplyToKeys(\"target\", torch.as_tensor),\n ]\n )\n\n def per_batch_transform_on_device(self):\n return ApplyToKeys(\n DataKeys.INPUT,\n Ka.RandomHorizontalFlip(p=0.25),\n )\n\n def collate(self):\n return kornia_collate\n\n\n# construct datamodule\n\ndatamodule = ImageClassificationData.from_tensors(\n train_data=train_dataset.x,\n train_targets=torch.from_numpy(train_dataset.y.astype(int)),\n val_data=val_dataset.x,\n val_targets=torch.from_numpy(val_dataset.y.astype(int)),\n train_transform=ImageClassificationInputTransform,\n val_transform=ImageClassificationInputTransform,\n batch_size=1,\n)\n\nmodel = ImageClassifier(\n backbone=\"resnet18\",\n training_strategy=\"prototypicalnetworks\",\n training_strategy_kwargs={\n \"epoch_length\": 10 * 16,\n \"meta_batch_size\": 1,\n \"num_tasks\": 200,\n \"test_num_tasks\": 2000,\n \"ways\": datamodule.num_classes,\n \"shots\": 1,\n \"test_ways\": 5,\n \"test_shots\": 1,\n \"test_queries\": 15,\n },\n optimizer=torch.optim.Adam,\n learning_rate=0.001,\n)\n\ntrainer = flash.Trainer(\n max_epochs=1,\n gpus=1,\n accelerator=\"gpu\",\n precision=16,\n)\n\ntrainer.finetune(model, datamodule=datamodule, strategy=\"no_freeze\")\n", "path": "flash_examples/integrations/learn2learn/image_classification_imagenette_mini.py"}]}
| 1,962 | 125 |
gh_patches_debug_3197
|
rasdani/github-patches
|
git_diff
|
huggingface__accelerate-227
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Should `get_linear_schedule_with_warmup` consider `gradient_accumulation_steps`?
I think `num_training_steps` should be `len(train_dataloader) * num_epochs // gradient_accumulation_steps`
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/nlp_example.py`
Content:
```
1 # coding=utf-8
2 # Copyright 2021 The HuggingFace Inc. team. All rights reserved.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 import argparse
16
17 import torch
18 from torch.utils.data import DataLoader
19
20 from accelerate import Accelerator, DistributedType
21 from datasets import load_dataset, load_metric
22 from transformers import (
23 AdamW,
24 AutoModelForSequenceClassification,
25 AutoTokenizer,
26 get_linear_schedule_with_warmup,
27 set_seed,
28 )
29
30
31 ########################################################################
32 # This is a fully working simple example to use Accelerate
33 #
34 # This example trains a Bert base model on GLUE MRPC
35 # in any of the following settings (with the same script):
36 # - single CPU or single GPU
37 # - multi GPUS (using PyTorch distributed mode)
38 # - (multi) TPUs
39 # - fp16 (mixed-precision) or fp32 (normal precision)
40 #
41 # To run it in each of these various modes, follow the instructions
42 # in the readme for examples:
43 # https://github.com/huggingface/accelerate/tree/main/examples
44 #
45 ########################################################################
46
47
48 MAX_GPU_BATCH_SIZE = 16
49 EVAL_BATCH_SIZE = 32
50
51
52 def training_function(config, args):
53 # Initialize accelerator
54 accelerator = Accelerator(fp16=args.fp16, cpu=args.cpu)
55
56 # Sample hyper-parameters for learning rate, batch size, seed and a few other HPs
57 lr = config["lr"]
58 num_epochs = int(config["num_epochs"])
59 correct_bias = config["correct_bias"]
60 seed = int(config["seed"])
61 batch_size = int(config["batch_size"])
62
63 tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
64 datasets = load_dataset("glue", "mrpc")
65 metric = load_metric("glue", "mrpc")
66
67 def tokenize_function(examples):
68 # max_length=None => use the model max length (it's actually the default)
69 outputs = tokenizer(examples["sentence1"], examples["sentence2"], truncation=True, max_length=None)
70 return outputs
71
72 # Apply the method we just defined to all the examples in all the splits of the dataset
73 tokenized_datasets = datasets.map(
74 tokenize_function,
75 batched=True,
76 remove_columns=["idx", "sentence1", "sentence2"],
77 )
78
79 # We also rename the 'label' column to 'labels' which is the expected name for labels by the models of the
80 # transformers library
81 tokenized_datasets.rename_column_("label", "labels")
82
83 # If the batch size is too big we use gradient accumulation
84 gradient_accumulation_steps = 1
85 if batch_size > MAX_GPU_BATCH_SIZE:
86 gradient_accumulation_steps = batch_size // MAX_GPU_BATCH_SIZE
87 batch_size = MAX_GPU_BATCH_SIZE
88
89 def collate_fn(examples):
90 # On TPU it's best to pad everything to the same length or training will be very slow.
91 if accelerator.distributed_type == DistributedType.TPU:
92 return tokenizer.pad(examples, padding="max_length", max_length=128, return_tensors="pt")
93 return tokenizer.pad(examples, padding="longest", return_tensors="pt")
94
95 # Instantiate dataloaders.
96 train_dataloader = DataLoader(
97 tokenized_datasets["train"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size
98 )
99 eval_dataloader = DataLoader(
100 tokenized_datasets["validation"], shuffle=False, collate_fn=collate_fn, batch_size=EVAL_BATCH_SIZE
101 )
102
103 set_seed(seed)
104
105 # Instantiate the model (we build the model here so that the seed also control new weights initialization)
106 model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", return_dict=True)
107
108 # We could avoid this line since the accelerator is set with `device_placement=True` (default value).
109 # Note that if you are placing tensors on devices manually, this line absolutely needs to be before the optimizer
110 # creation otherwise training will not work on TPU (`accelerate` will kindly throw an error to make us aware of that).
111 model = model.to(accelerator.device)
112
113 # Instantiate optimizer
114 optimizer = AdamW(params=model.parameters(), lr=lr, correct_bias=correct_bias)
115
116 # Prepare everything
117 # There is no specific order to remember, we just need to unpack the objects in the same order we gave them to the
118 # prepare method.
119 model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
120 model, optimizer, train_dataloader, eval_dataloader
121 )
122
123 # Instantiate learning rate scheduler after preparing the training dataloader as the prepare method
124 # may change its length.
125 lr_scheduler = get_linear_schedule_with_warmup(
126 optimizer=optimizer,
127 num_warmup_steps=100,
128 num_training_steps=len(train_dataloader) * num_epochs,
129 )
130
131 # Now we train the model
132 for epoch in range(num_epochs):
133 model.train()
134 for step, batch in enumerate(train_dataloader):
135 # We could avoid this line since we set the accelerator with `device_placement=True`.
136 batch.to(accelerator.device)
137 outputs = model(**batch)
138 loss = outputs.loss
139 loss = loss / gradient_accumulation_steps
140 accelerator.backward(loss)
141 if step % gradient_accumulation_steps == 0:
142 optimizer.step()
143 lr_scheduler.step()
144 optimizer.zero_grad()
145
146 model.eval()
147 for step, batch in enumerate(eval_dataloader):
148 # We could avoid this line since we set the accelerator with `device_placement=True`.
149 batch.to(accelerator.device)
150 with torch.no_grad():
151 outputs = model(**batch)
152 predictions = outputs.logits.argmax(dim=-1)
153 metric.add_batch(
154 predictions=accelerator.gather(predictions),
155 references=accelerator.gather(batch["labels"]),
156 )
157
158 eval_metric = metric.compute()
159 # Use accelerator.print to print only on the main process.
160 accelerator.print(f"epoch {epoch}:", eval_metric)
161
162
163 def main():
164 parser = argparse.ArgumentParser(description="Simple example of training script.")
165 parser.add_argument("--fp16", action="store_true", help="If passed, will use FP16 training.")
166 parser.add_argument("--cpu", action="store_true", help="If passed, will train on the CPU.")
167 args = parser.parse_args()
168 config = {"lr": 2e-5, "num_epochs": 3, "correct_bias": True, "seed": 42, "batch_size": 16}
169 training_function(config, args)
170
171
172 if __name__ == "__main__":
173 main()
174
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/examples/nlp_example.py b/examples/nlp_example.py
--- a/examples/nlp_example.py
+++ b/examples/nlp_example.py
@@ -125,7 +125,7 @@
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=100,
- num_training_steps=len(train_dataloader) * num_epochs,
+ num_training_steps=(len(train_dataloader) * num_epochs) // gradient_accumulation_steps,
)
# Now we train the model
|
{"golden_diff": "diff --git a/examples/nlp_example.py b/examples/nlp_example.py\n--- a/examples/nlp_example.py\n+++ b/examples/nlp_example.py\n@@ -125,7 +125,7 @@\n lr_scheduler = get_linear_schedule_with_warmup(\n optimizer=optimizer,\n num_warmup_steps=100,\n- num_training_steps=len(train_dataloader) * num_epochs,\n+ num_training_steps=(len(train_dataloader) * num_epochs) // gradient_accumulation_steps,\n )\n \n # Now we train the model\n", "issue": "Should `get_linear_schedule_with_warmup` consider `gradient_accumulation_steps`?\nI think `num_training_steps` should be `len(train_dataloader) * num_epochs // gradient_accumulation_steps`\n", "before_files": [{"content": "# coding=utf-8\n# Copyright 2021 The HuggingFace Inc. team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport argparse\n\nimport torch\nfrom torch.utils.data import DataLoader\n\nfrom accelerate import Accelerator, DistributedType\nfrom datasets import load_dataset, load_metric\nfrom transformers import (\n AdamW,\n AutoModelForSequenceClassification,\n AutoTokenizer,\n get_linear_schedule_with_warmup,\n set_seed,\n)\n\n\n########################################################################\n# This is a fully working simple example to use Accelerate\n#\n# This example trains a Bert base model on GLUE MRPC\n# in any of the following settings (with the same script):\n# - single CPU or single GPU\n# - multi GPUS (using PyTorch distributed mode)\n# - (multi) TPUs\n# - fp16 (mixed-precision) or fp32 (normal precision)\n#\n# To run it in each of these various modes, follow the instructions\n# in the readme for examples:\n# https://github.com/huggingface/accelerate/tree/main/examples\n#\n########################################################################\n\n\nMAX_GPU_BATCH_SIZE = 16\nEVAL_BATCH_SIZE = 32\n\n\ndef training_function(config, args):\n # Initialize accelerator\n accelerator = Accelerator(fp16=args.fp16, cpu=args.cpu)\n\n # Sample hyper-parameters for learning rate, batch size, seed and a few other HPs\n lr = config[\"lr\"]\n num_epochs = int(config[\"num_epochs\"])\n correct_bias = config[\"correct_bias\"]\n seed = int(config[\"seed\"])\n batch_size = int(config[\"batch_size\"])\n\n tokenizer = AutoTokenizer.from_pretrained(\"bert-base-cased\")\n datasets = load_dataset(\"glue\", \"mrpc\")\n metric = load_metric(\"glue\", \"mrpc\")\n\n def tokenize_function(examples):\n # max_length=None => use the model max length (it's actually the default)\n outputs = tokenizer(examples[\"sentence1\"], examples[\"sentence2\"], truncation=True, max_length=None)\n return outputs\n\n # Apply the method we just defined to all the examples in all the splits of the dataset\n tokenized_datasets = datasets.map(\n tokenize_function,\n batched=True,\n remove_columns=[\"idx\", \"sentence1\", \"sentence2\"],\n )\n\n # We also rename the 'label' column to 'labels' which is the expected name for labels by the models of the\n # transformers library\n tokenized_datasets.rename_column_(\"label\", \"labels\")\n\n # If the batch size is too big we use gradient accumulation\n gradient_accumulation_steps = 1\n if batch_size > MAX_GPU_BATCH_SIZE:\n gradient_accumulation_steps = batch_size // MAX_GPU_BATCH_SIZE\n batch_size = MAX_GPU_BATCH_SIZE\n\n def collate_fn(examples):\n # On TPU it's best to pad everything to the same length or training will be very slow.\n if accelerator.distributed_type == DistributedType.TPU:\n return tokenizer.pad(examples, padding=\"max_length\", max_length=128, return_tensors=\"pt\")\n return tokenizer.pad(examples, padding=\"longest\", return_tensors=\"pt\")\n\n # Instantiate dataloaders.\n train_dataloader = DataLoader(\n tokenized_datasets[\"train\"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size\n )\n eval_dataloader = DataLoader(\n tokenized_datasets[\"validation\"], shuffle=False, collate_fn=collate_fn, batch_size=EVAL_BATCH_SIZE\n )\n\n set_seed(seed)\n\n # Instantiate the model (we build the model here so that the seed also control new weights initialization)\n model = AutoModelForSequenceClassification.from_pretrained(\"bert-base-cased\", return_dict=True)\n\n # We could avoid this line since the accelerator is set with `device_placement=True` (default value).\n # Note that if you are placing tensors on devices manually, this line absolutely needs to be before the optimizer\n # creation otherwise training will not work on TPU (`accelerate` will kindly throw an error to make us aware of that).\n model = model.to(accelerator.device)\n\n # Instantiate optimizer\n optimizer = AdamW(params=model.parameters(), lr=lr, correct_bias=correct_bias)\n\n # Prepare everything\n # There is no specific order to remember, we just need to unpack the objects in the same order we gave them to the\n # prepare method.\n model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(\n model, optimizer, train_dataloader, eval_dataloader\n )\n\n # Instantiate learning rate scheduler after preparing the training dataloader as the prepare method\n # may change its length.\n lr_scheduler = get_linear_schedule_with_warmup(\n optimizer=optimizer,\n num_warmup_steps=100,\n num_training_steps=len(train_dataloader) * num_epochs,\n )\n\n # Now we train the model\n for epoch in range(num_epochs):\n model.train()\n for step, batch in enumerate(train_dataloader):\n # We could avoid this line since we set the accelerator with `device_placement=True`.\n batch.to(accelerator.device)\n outputs = model(**batch)\n loss = outputs.loss\n loss = loss / gradient_accumulation_steps\n accelerator.backward(loss)\n if step % gradient_accumulation_steps == 0:\n optimizer.step()\n lr_scheduler.step()\n optimizer.zero_grad()\n\n model.eval()\n for step, batch in enumerate(eval_dataloader):\n # We could avoid this line since we set the accelerator with `device_placement=True`.\n batch.to(accelerator.device)\n with torch.no_grad():\n outputs = model(**batch)\n predictions = outputs.logits.argmax(dim=-1)\n metric.add_batch(\n predictions=accelerator.gather(predictions),\n references=accelerator.gather(batch[\"labels\"]),\n )\n\n eval_metric = metric.compute()\n # Use accelerator.print to print only on the main process.\n accelerator.print(f\"epoch {epoch}:\", eval_metric)\n\n\ndef main():\n parser = argparse.ArgumentParser(description=\"Simple example of training script.\")\n parser.add_argument(\"--fp16\", action=\"store_true\", help=\"If passed, will use FP16 training.\")\n parser.add_argument(\"--cpu\", action=\"store_true\", help=\"If passed, will train on the CPU.\")\n args = parser.parse_args()\n config = {\"lr\": 2e-5, \"num_epochs\": 3, \"correct_bias\": True, \"seed\": 42, \"batch_size\": 16}\n training_function(config, args)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "examples/nlp_example.py"}], "after_files": [{"content": "# coding=utf-8\n# Copyright 2021 The HuggingFace Inc. team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport argparse\n\nimport torch\nfrom torch.utils.data import DataLoader\n\nfrom accelerate import Accelerator, DistributedType\nfrom datasets import load_dataset, load_metric\nfrom transformers import (\n AdamW,\n AutoModelForSequenceClassification,\n AutoTokenizer,\n get_linear_schedule_with_warmup,\n set_seed,\n)\n\n\n########################################################################\n# This is a fully working simple example to use Accelerate\n#\n# This example trains a Bert base model on GLUE MRPC\n# in any of the following settings (with the same script):\n# - single CPU or single GPU\n# - multi GPUS (using PyTorch distributed mode)\n# - (multi) TPUs\n# - fp16 (mixed-precision) or fp32 (normal precision)\n#\n# To run it in each of these various modes, follow the instructions\n# in the readme for examples:\n# https://github.com/huggingface/accelerate/tree/main/examples\n#\n########################################################################\n\n\nMAX_GPU_BATCH_SIZE = 16\nEVAL_BATCH_SIZE = 32\n\n\ndef training_function(config, args):\n # Initialize accelerator\n accelerator = Accelerator(fp16=args.fp16, cpu=args.cpu)\n\n # Sample hyper-parameters for learning rate, batch size, seed and a few other HPs\n lr = config[\"lr\"]\n num_epochs = int(config[\"num_epochs\"])\n correct_bias = config[\"correct_bias\"]\n seed = int(config[\"seed\"])\n batch_size = int(config[\"batch_size\"])\n\n tokenizer = AutoTokenizer.from_pretrained(\"bert-base-cased\")\n datasets = load_dataset(\"glue\", \"mrpc\")\n metric = load_metric(\"glue\", \"mrpc\")\n\n def tokenize_function(examples):\n # max_length=None => use the model max length (it's actually the default)\n outputs = tokenizer(examples[\"sentence1\"], examples[\"sentence2\"], truncation=True, max_length=None)\n return outputs\n\n # Apply the method we just defined to all the examples in all the splits of the dataset\n tokenized_datasets = datasets.map(\n tokenize_function,\n batched=True,\n remove_columns=[\"idx\", \"sentence1\", \"sentence2\"],\n )\n\n # We also rename the 'label' column to 'labels' which is the expected name for labels by the models of the\n # transformers library\n tokenized_datasets.rename_column_(\"label\", \"labels\")\n\n # If the batch size is too big we use gradient accumulation\n gradient_accumulation_steps = 1\n if batch_size > MAX_GPU_BATCH_SIZE:\n gradient_accumulation_steps = batch_size // MAX_GPU_BATCH_SIZE\n batch_size = MAX_GPU_BATCH_SIZE\n\n def collate_fn(examples):\n # On TPU it's best to pad everything to the same length or training will be very slow.\n if accelerator.distributed_type == DistributedType.TPU:\n return tokenizer.pad(examples, padding=\"max_length\", max_length=128, return_tensors=\"pt\")\n return tokenizer.pad(examples, padding=\"longest\", return_tensors=\"pt\")\n\n # Instantiate dataloaders.\n train_dataloader = DataLoader(\n tokenized_datasets[\"train\"], shuffle=True, collate_fn=collate_fn, batch_size=batch_size\n )\n eval_dataloader = DataLoader(\n tokenized_datasets[\"validation\"], shuffle=False, collate_fn=collate_fn, batch_size=EVAL_BATCH_SIZE\n )\n\n set_seed(seed)\n\n # Instantiate the model (we build the model here so that the seed also control new weights initialization)\n model = AutoModelForSequenceClassification.from_pretrained(\"bert-base-cased\", return_dict=True)\n\n # We could avoid this line since the accelerator is set with `device_placement=True` (default value).\n # Note that if you are placing tensors on devices manually, this line absolutely needs to be before the optimizer\n # creation otherwise training will not work on TPU (`accelerate` will kindly throw an error to make us aware of that).\n model = model.to(accelerator.device)\n\n # Instantiate optimizer\n optimizer = AdamW(params=model.parameters(), lr=lr, correct_bias=correct_bias)\n\n # Prepare everything\n # There is no specific order to remember, we just need to unpack the objects in the same order we gave them to the\n # prepare method.\n model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(\n model, optimizer, train_dataloader, eval_dataloader\n )\n\n # Instantiate learning rate scheduler after preparing the training dataloader as the prepare method\n # may change its length.\n lr_scheduler = get_linear_schedule_with_warmup(\n optimizer=optimizer,\n num_warmup_steps=100,\n num_training_steps=(len(train_dataloader) * num_epochs) // gradient_accumulation_steps,\n )\n\n # Now we train the model\n for epoch in range(num_epochs):\n model.train()\n for step, batch in enumerate(train_dataloader):\n # We could avoid this line since we set the accelerator with `device_placement=True`.\n batch.to(accelerator.device)\n outputs = model(**batch)\n loss = outputs.loss\n loss = loss / gradient_accumulation_steps\n accelerator.backward(loss)\n if step % gradient_accumulation_steps == 0:\n optimizer.step()\n lr_scheduler.step()\n optimizer.zero_grad()\n\n model.eval()\n for step, batch in enumerate(eval_dataloader):\n # We could avoid this line since we set the accelerator with `device_placement=True`.\n batch.to(accelerator.device)\n with torch.no_grad():\n outputs = model(**batch)\n predictions = outputs.logits.argmax(dim=-1)\n metric.add_batch(\n predictions=accelerator.gather(predictions),\n references=accelerator.gather(batch[\"labels\"]),\n )\n\n eval_metric = metric.compute()\n # Use accelerator.print to print only on the main process.\n accelerator.print(f\"epoch {epoch}:\", eval_metric)\n\n\ndef main():\n parser = argparse.ArgumentParser(description=\"Simple example of training script.\")\n parser.add_argument(\"--fp16\", action=\"store_true\", help=\"If passed, will use FP16 training.\")\n parser.add_argument(\"--cpu\", action=\"store_true\", help=\"If passed, will train on the CPU.\")\n args = parser.parse_args()\n config = {\"lr\": 2e-5, \"num_epochs\": 3, \"correct_bias\": True, \"seed\": 42, \"batch_size\": 16}\n training_function(config, args)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "examples/nlp_example.py"}]}
| 2,255 | 120 |
gh_patches_debug_20931
|
rasdani/github-patches
|
git_diff
|
beeware__toga-2591
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add API to replace children
### What is the problem or limitation you are having?
Currently, if I use a multi-pages design and create multiple pages (multiple boxes containing multiple widgets), and I want to switch between these pages — between page1_box and page2_box, for example — I need to:
```
main_box.remove(page1_box)
main_box.insert(pos, page2_box)
```
So, not only it's 2 steps to do 1 thing (swap out/replace a child), but I also need to know the right index for the insert, which seems cumbersome to keep track of if I plan on adding/removing a few widgets during runtime.
### Describe the solution you'd like
Add a `.replace()` method to nodes, that will join the likes of `.remove()` .`add()` and `.insert()`, so that we can:
1. Replace a child node in one step;
2. Not have to worry about index numbers.
Example:
`main_box.replace(page1_box, page2_box)`
In other words:
`Box.replace(old_child, new_child)`
This pattern follows the way Python's string replace works — `str.replace(old, new)`.
### Describe alternatives you've considered
Add method to replace its calling node.
`page1_box.replace(page2_box)`
In other words:
`old_child.replace(new_child)`
But this seems to break the existing convention with add, remove and insert.
### Additional context
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/src/toga/widgets/base.py`
Content:
```
1 from __future__ import annotations
2
3 from builtins import id as identifier
4 from typing import TYPE_CHECKING
5
6 from travertino.node import Node
7
8 from toga.platform import get_platform_factory
9 from toga.style import Pack, TogaApplicator
10
11 if TYPE_CHECKING:
12 from toga.app import App
13 from toga.window import Window
14
15
16 class Widget(Node):
17 _MIN_WIDTH = 100
18 _MIN_HEIGHT = 100
19
20 def __init__(
21 self,
22 id: str | None = None,
23 style=None,
24 ):
25 """Create a base Toga widget.
26
27 This is an abstract base class; it cannot be instantiated.
28
29 :param id: The ID for the widget.
30 :param style: A style object. If no style is provided, a default style
31 will be applied to the widget.
32 """
33 super().__init__(
34 style=style if style else Pack(),
35 applicator=TogaApplicator(self),
36 )
37
38 self._id = str(id if id else identifier(self))
39 self._window = None
40 self._app = None
41 self._impl = None
42
43 self.factory = get_platform_factory()
44
45 def __repr__(self) -> str:
46 return f"<{self.__class__.__name__}:0x{identifier(self):x}>"
47
48 def __lt__(self, other) -> bool:
49 return self.id < other.id
50
51 @property
52 def id(self) -> str:
53 """The DOM identifier for the widget.
54
55 This id can be used to target CSS directives.
56 """
57 return self._id
58
59 @property
60 def tab_index(self) -> int | None:
61 """The position of the widget in the focus chain for the window.
62
63 .. note::
64
65 This is a beta feature. The ``tab_index`` API may change in
66 the future.
67 """
68 return self._impl.get_tab_index()
69
70 @tab_index.setter
71 def tab_index(self, tab_index: int) -> None:
72 self._impl.set_tab_index(tab_index)
73
74 def _assert_can_have_children(self):
75 if not self.can_have_children:
76 raise ValueError(f"{type(self).__name__} cannot have children")
77
78 def add(self, *children: Widget) -> None:
79 """Add the provided widgets as children of this widget.
80
81 If a child widget already has a parent, it will be re-parented as a
82 child of this widget. If the child widget is already a child of this
83 widget, there is no change.
84
85 :param children: The widgets to add as children of this widget.
86 :raises ValueError: If this widget cannot have children.
87 """
88 self._assert_can_have_children()
89 for child in children:
90 if child.parent is not self:
91 # remove from old parent
92 if child.parent:
93 child.parent.remove(child)
94
95 # Set app and window. This is done *before* changing any parenting
96 # relationships, so that the widget registry can verify the widget ID is
97 # unique. App must be set before window to ensure the widget registry
98 # can be found.
99 child.app = self.app
100 child.window = self.window
101
102 # add to new parent
103 super().add(child)
104
105 self._impl.add_child(child._impl)
106
107 # Whatever layout we're a part of needs to be refreshed
108 self.refresh()
109
110 def insert(self, index: int, child: Widget) -> None:
111 """Insert a widget as a child of this widget.
112
113 If a child widget already has a parent, it will be re-parented as a
114 child of this widget. If the child widget is already a child of this
115 widget, there is no change.
116
117 :param index: The position in the list of children where the new widget
118 should be added.
119 :param child: The child to insert as a child of this node.
120 :raises ValueError: If this widget cannot have children.
121 """
122 self._assert_can_have_children()
123 if child.parent is not self:
124 # remove from old parent
125 if child.parent:
126 child.parent.remove(child)
127
128 # Set app and window. This is done *before* changing any parenting
129 # relationships, so that the widget registry can verify the widget ID is
130 # unique. App must be set before window to ensure the widget registry
131 # can be found.
132 child.app = self.app
133 child.window = self.window
134
135 # add to new parent
136 super().insert(index, child)
137
138 self._impl.insert_child(index, child._impl)
139
140 # Whatever layout we're a part of needs to be refreshed
141 self.refresh()
142
143 def remove(self, *children: Widget) -> None:
144 """Remove the provided widgets as children of this node.
145
146 Any nominated child widget that is not a child of this widget will
147 not have any change in parentage.
148
149 Refreshes the widget after removal if any children were removed.
150
151 :param children: The child nodes to remove.
152 :raises ValueError: If this widget cannot have children.
153 """
154 self._assert_can_have_children()
155
156 removed = False
157 for child in children:
158 if child.parent is self:
159 removed = True
160 super().remove(child)
161
162 # Remove from the window before removing from the app
163 # so that the widget can be removed from the app-level registry.
164 child.window = None
165 child.app = None
166
167 self._impl.remove_child(child._impl)
168
169 # If we removed something, whatever layout we're a part of needs to be refreshed
170 if removed:
171 self.refresh()
172
173 def clear(self) -> None:
174 """Remove all child widgets of this node.
175
176 Refreshes the widget after removal if any children were removed.
177
178 :raises ValueError: If this widget cannot have children.
179 """
180 self._assert_can_have_children()
181 self.remove(*self.children)
182
183 @property
184 def app(self) -> App | None:
185 """The App to which this widget belongs.
186
187 When setting the app for a widget, all children of this widget will be
188 recursively assigned to the same app.
189
190 :raises ValueError: If this widget is already associated with another app.
191 """
192 return self._app
193
194 @app.setter
195 def app(self, app: App | None) -> None:
196 # If the widget is already assigned to an app
197 if self._app:
198 if self._app == app:
199 # If app is the same as the previous app, return
200 return
201
202 self._app = app
203 self._impl.set_app(app)
204 for child in self.children:
205 child.app = app
206
207 @property
208 def window(self) -> Window | None:
209 """The window to which this widget belongs.
210
211 When setting the window for a widget, all children of this widget will be
212 recursively assigned to the same window.
213
214 If the widget has a value for :any:`window`, it *must* also have a value for
215 :any:`app`.
216 """
217 return self._window
218
219 @window.setter
220 def window(self, window: Window | None) -> None:
221 if self.window is not None and window is None:
222 # If the widget is currently in the registry, but is being removed from a
223 # window, remove the widget from the widget registry
224 self.window.app.widgets._remove(self.id)
225 elif self.window is None and window is not None:
226 # If the widget is being assigned to a window for the first time, add it to the widget registry
227 window.app.widgets._add(self)
228
229 self._window = window
230 self._impl.set_window(window)
231
232 for child in self.children:
233 child.window = window
234
235 @property
236 def enabled(self) -> bool:
237 """Is the widget currently enabled? i.e., can the user interact with the widget?"""
238 return self._impl.get_enabled()
239
240 @enabled.setter
241 def enabled(self, value: bool) -> None:
242 self._impl.set_enabled(bool(value))
243
244 def refresh(self) -> None:
245 self._impl.refresh()
246
247 # Refresh the layout
248 if self._root:
249 # We're not the root of the node hierarchy;
250 # defer the refresh call to the root node.
251 self._root.refresh()
252 else:
253 # We can't compute a layout until we have a container
254 if self._impl.container:
255 super().refresh(self._impl.container)
256 self._impl.container.refreshed()
257
258 def focus(self) -> None:
259 """Give this widget the input focus.
260
261 This method is a no-op if the widget can't accept focus. The ability of a widget
262 to accept focus is platform-dependent. In general, on desktop platforms you can
263 focus any widget that can accept user input, while on mobile platforms focus is
264 limited to widgets that accept text input (i.e., widgets that cause the virtual
265 keyboard to appear).
266 """
267 self._impl.focus()
268
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/core/src/toga/widgets/base.py b/core/src/toga/widgets/base.py
--- a/core/src/toga/widgets/base.py
+++ b/core/src/toga/widgets/base.py
@@ -140,6 +140,30 @@
# Whatever layout we're a part of needs to be refreshed
self.refresh()
+ def index(self, child: Widget) -> int:
+ """Get the index of a widget in the list of children of this widget.
+
+ :param child: The child widget of interest.
+ :raises ValueError: If the specified child widget is not found in the
+ list of children.
+
+ :returns: Index of specified child widget in children list.
+ """
+ for _ind, _child in enumerate(self._children):
+ if child == _child:
+ return _ind
+ raise ValueError(f"{type(child).__name__} not found")
+
+ def replace(self, old_child: Widget, new_child: Widget) -> None:
+ """Replace an existing child widget with a new child widget.
+
+ :param old_child: The existing child widget to be replaced.
+ :param new_child: The new child widget to be included.
+ """
+ old_child_index = self.index(old_child)
+ self.remove(old_child)
+ self.insert(old_child_index, new_child)
+
def remove(self, *children: Widget) -> None:
"""Remove the provided widgets as children of this node.
|
{"golden_diff": "diff --git a/core/src/toga/widgets/base.py b/core/src/toga/widgets/base.py\n--- a/core/src/toga/widgets/base.py\n+++ b/core/src/toga/widgets/base.py\n@@ -140,6 +140,30 @@\n # Whatever layout we're a part of needs to be refreshed\n self.refresh()\n \n+ def index(self, child: Widget) -> int:\n+ \"\"\"Get the index of a widget in the list of children of this widget.\n+\n+ :param child: The child widget of interest.\n+ :raises ValueError: If the specified child widget is not found in the\n+ list of children.\n+\n+ :returns: Index of specified child widget in children list.\n+ \"\"\"\n+ for _ind, _child in enumerate(self._children):\n+ if child == _child:\n+ return _ind\n+ raise ValueError(f\"{type(child).__name__} not found\")\n+\n+ def replace(self, old_child: Widget, new_child: Widget) -> None:\n+ \"\"\"Replace an existing child widget with a new child widget.\n+\n+ :param old_child: The existing child widget to be replaced.\n+ :param new_child: The new child widget to be included.\n+ \"\"\"\n+ old_child_index = self.index(old_child)\n+ self.remove(old_child)\n+ self.insert(old_child_index, new_child)\n+\n def remove(self, *children: Widget) -> None:\n \"\"\"Remove the provided widgets as children of this node.\n", "issue": "Add API to replace children\n### What is the problem or limitation you are having?\r\n\r\nCurrently, if I use a multi-pages design and create multiple pages (multiple boxes containing multiple widgets), and I want to switch between these pages \u2014 between page1_box and page2_box, for example \u2014 I need to:\r\n```\r\nmain_box.remove(page1_box)\r\nmain_box.insert(pos, page2_box)\r\n```\r\n\r\nSo, not only it's 2 steps to do 1 thing (swap out/replace a child), but I also need to know the right index for the insert, which seems cumbersome to keep track of if I plan on adding/removing a few widgets during runtime.\r\n\r\n### Describe the solution you'd like\r\n\r\nAdd a `.replace()` method to nodes, that will join the likes of `.remove()` .`add()` and `.insert()`, so that we can:\r\n1. Replace a child node in one step;\r\n2. Not have to worry about index numbers.\r\n\r\nExample:\r\n`main_box.replace(page1_box, page2_box)`\r\n\r\nIn other words:\r\n`Box.replace(old_child, new_child)`\r\n\r\nThis pattern follows the way Python's string replace works \u2014 `str.replace(old, new)`.\r\n\r\n### Describe alternatives you've considered\r\n\r\nAdd method to replace its calling node.\r\n`page1_box.replace(page2_box)`\r\n\r\nIn other words:\r\n`old_child.replace(new_child)`\r\n\r\nBut this seems to break the existing convention with add, remove and insert.\r\n\r\n### Additional context\r\n\r\n_No response_\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom builtins import id as identifier\nfrom typing import TYPE_CHECKING\n\nfrom travertino.node import Node\n\nfrom toga.platform import get_platform_factory\nfrom toga.style import Pack, TogaApplicator\n\nif TYPE_CHECKING:\n from toga.app import App\n from toga.window import Window\n\n\nclass Widget(Node):\n _MIN_WIDTH = 100\n _MIN_HEIGHT = 100\n\n def __init__(\n self,\n id: str | None = None,\n style=None,\n ):\n \"\"\"Create a base Toga widget.\n\n This is an abstract base class; it cannot be instantiated.\n\n :param id: The ID for the widget.\n :param style: A style object. If no style is provided, a default style\n will be applied to the widget.\n \"\"\"\n super().__init__(\n style=style if style else Pack(),\n applicator=TogaApplicator(self),\n )\n\n self._id = str(id if id else identifier(self))\n self._window = None\n self._app = None\n self._impl = None\n\n self.factory = get_platform_factory()\n\n def __repr__(self) -> str:\n return f\"<{self.__class__.__name__}:0x{identifier(self):x}>\"\n\n def __lt__(self, other) -> bool:\n return self.id < other.id\n\n @property\n def id(self) -> str:\n \"\"\"The DOM identifier for the widget.\n\n This id can be used to target CSS directives.\n \"\"\"\n return self._id\n\n @property\n def tab_index(self) -> int | None:\n \"\"\"The position of the widget in the focus chain for the window.\n\n .. note::\n\n This is a beta feature. The ``tab_index`` API may change in\n the future.\n \"\"\"\n return self._impl.get_tab_index()\n\n @tab_index.setter\n def tab_index(self, tab_index: int) -> None:\n self._impl.set_tab_index(tab_index)\n\n def _assert_can_have_children(self):\n if not self.can_have_children:\n raise ValueError(f\"{type(self).__name__} cannot have children\")\n\n def add(self, *children: Widget) -> None:\n \"\"\"Add the provided widgets as children of this widget.\n\n If a child widget already has a parent, it will be re-parented as a\n child of this widget. If the child widget is already a child of this\n widget, there is no change.\n\n :param children: The widgets to add as children of this widget.\n :raises ValueError: If this widget cannot have children.\n \"\"\"\n self._assert_can_have_children()\n for child in children:\n if child.parent is not self:\n # remove from old parent\n if child.parent:\n child.parent.remove(child)\n\n # Set app and window. This is done *before* changing any parenting\n # relationships, so that the widget registry can verify the widget ID is\n # unique. App must be set before window to ensure the widget registry\n # can be found.\n child.app = self.app\n child.window = self.window\n\n # add to new parent\n super().add(child)\n\n self._impl.add_child(child._impl)\n\n # Whatever layout we're a part of needs to be refreshed\n self.refresh()\n\n def insert(self, index: int, child: Widget) -> None:\n \"\"\"Insert a widget as a child of this widget.\n\n If a child widget already has a parent, it will be re-parented as a\n child of this widget. If the child widget is already a child of this\n widget, there is no change.\n\n :param index: The position in the list of children where the new widget\n should be added.\n :param child: The child to insert as a child of this node.\n :raises ValueError: If this widget cannot have children.\n \"\"\"\n self._assert_can_have_children()\n if child.parent is not self:\n # remove from old parent\n if child.parent:\n child.parent.remove(child)\n\n # Set app and window. This is done *before* changing any parenting\n # relationships, so that the widget registry can verify the widget ID is\n # unique. App must be set before window to ensure the widget registry\n # can be found.\n child.app = self.app\n child.window = self.window\n\n # add to new parent\n super().insert(index, child)\n\n self._impl.insert_child(index, child._impl)\n\n # Whatever layout we're a part of needs to be refreshed\n self.refresh()\n\n def remove(self, *children: Widget) -> None:\n \"\"\"Remove the provided widgets as children of this node.\n\n Any nominated child widget that is not a child of this widget will\n not have any change in parentage.\n\n Refreshes the widget after removal if any children were removed.\n\n :param children: The child nodes to remove.\n :raises ValueError: If this widget cannot have children.\n \"\"\"\n self._assert_can_have_children()\n\n removed = False\n for child in children:\n if child.parent is self:\n removed = True\n super().remove(child)\n\n # Remove from the window before removing from the app\n # so that the widget can be removed from the app-level registry.\n child.window = None\n child.app = None\n\n self._impl.remove_child(child._impl)\n\n # If we removed something, whatever layout we're a part of needs to be refreshed\n if removed:\n self.refresh()\n\n def clear(self) -> None:\n \"\"\"Remove all child widgets of this node.\n\n Refreshes the widget after removal if any children were removed.\n\n :raises ValueError: If this widget cannot have children.\n \"\"\"\n self._assert_can_have_children()\n self.remove(*self.children)\n\n @property\n def app(self) -> App | None:\n \"\"\"The App to which this widget belongs.\n\n When setting the app for a widget, all children of this widget will be\n recursively assigned to the same app.\n\n :raises ValueError: If this widget is already associated with another app.\n \"\"\"\n return self._app\n\n @app.setter\n def app(self, app: App | None) -> None:\n # If the widget is already assigned to an app\n if self._app:\n if self._app == app:\n # If app is the same as the previous app, return\n return\n\n self._app = app\n self._impl.set_app(app)\n for child in self.children:\n child.app = app\n\n @property\n def window(self) -> Window | None:\n \"\"\"The window to which this widget belongs.\n\n When setting the window for a widget, all children of this widget will be\n recursively assigned to the same window.\n\n If the widget has a value for :any:`window`, it *must* also have a value for\n :any:`app`.\n \"\"\"\n return self._window\n\n @window.setter\n def window(self, window: Window | None) -> None:\n if self.window is not None and window is None:\n # If the widget is currently in the registry, but is being removed from a\n # window, remove the widget from the widget registry\n self.window.app.widgets._remove(self.id)\n elif self.window is None and window is not None:\n # If the widget is being assigned to a window for the first time, add it to the widget registry\n window.app.widgets._add(self)\n\n self._window = window\n self._impl.set_window(window)\n\n for child in self.children:\n child.window = window\n\n @property\n def enabled(self) -> bool:\n \"\"\"Is the widget currently enabled? i.e., can the user interact with the widget?\"\"\"\n return self._impl.get_enabled()\n\n @enabled.setter\n def enabled(self, value: bool) -> None:\n self._impl.set_enabled(bool(value))\n\n def refresh(self) -> None:\n self._impl.refresh()\n\n # Refresh the layout\n if self._root:\n # We're not the root of the node hierarchy;\n # defer the refresh call to the root node.\n self._root.refresh()\n else:\n # We can't compute a layout until we have a container\n if self._impl.container:\n super().refresh(self._impl.container)\n self._impl.container.refreshed()\n\n def focus(self) -> None:\n \"\"\"Give this widget the input focus.\n\n This method is a no-op if the widget can't accept focus. The ability of a widget\n to accept focus is platform-dependent. In general, on desktop platforms you can\n focus any widget that can accept user input, while on mobile platforms focus is\n limited to widgets that accept text input (i.e., widgets that cause the virtual\n keyboard to appear).\n \"\"\"\n self._impl.focus()\n", "path": "core/src/toga/widgets/base.py"}], "after_files": [{"content": "from __future__ import annotations\n\nfrom builtins import id as identifier\nfrom typing import TYPE_CHECKING\n\nfrom travertino.node import Node\n\nfrom toga.platform import get_platform_factory\nfrom toga.style import Pack, TogaApplicator\n\nif TYPE_CHECKING:\n from toga.app import App\n from toga.window import Window\n\n\nclass Widget(Node):\n _MIN_WIDTH = 100\n _MIN_HEIGHT = 100\n\n def __init__(\n self,\n id: str | None = None,\n style=None,\n ):\n \"\"\"Create a base Toga widget.\n\n This is an abstract base class; it cannot be instantiated.\n\n :param id: The ID for the widget.\n :param style: A style object. If no style is provided, a default style\n will be applied to the widget.\n \"\"\"\n super().__init__(\n style=style if style else Pack(),\n applicator=TogaApplicator(self),\n )\n\n self._id = str(id if id else identifier(self))\n self._window = None\n self._app = None\n self._impl = None\n\n self.factory = get_platform_factory()\n\n def __repr__(self) -> str:\n return f\"<{self.__class__.__name__}:0x{identifier(self):x}>\"\n\n def __lt__(self, other) -> bool:\n return self.id < other.id\n\n @property\n def id(self) -> str:\n \"\"\"The DOM identifier for the widget.\n\n This id can be used to target CSS directives.\n \"\"\"\n return self._id\n\n @property\n def tab_index(self) -> int | None:\n \"\"\"The position of the widget in the focus chain for the window.\n\n .. note::\n\n This is a beta feature. The ``tab_index`` API may change in\n the future.\n \"\"\"\n return self._impl.get_tab_index()\n\n @tab_index.setter\n def tab_index(self, tab_index: int) -> None:\n self._impl.set_tab_index(tab_index)\n\n def _assert_can_have_children(self):\n if not self.can_have_children:\n raise ValueError(f\"{type(self).__name__} cannot have children\")\n\n def add(self, *children: Widget) -> None:\n \"\"\"Add the provided widgets as children of this widget.\n\n If a child widget already has a parent, it will be re-parented as a\n child of this widget. If the child widget is already a child of this\n widget, there is no change.\n\n :param children: The widgets to add as children of this widget.\n :raises ValueError: If this widget cannot have children.\n \"\"\"\n self._assert_can_have_children()\n for child in children:\n if child.parent is not self:\n # remove from old parent\n if child.parent:\n child.parent.remove(child)\n\n # Set app and window. This is done *before* changing any parenting\n # relationships, so that the widget registry can verify the widget ID is\n # unique. App must be set before window to ensure the widget registry\n # can be found.\n child.app = self.app\n child.window = self.window\n\n # add to new parent\n super().add(child)\n\n self._impl.add_child(child._impl)\n\n # Whatever layout we're a part of needs to be refreshed\n self.refresh()\n\n def insert(self, index: int, child: Widget) -> None:\n \"\"\"Insert a widget as a child of this widget.\n\n If a child widget already has a parent, it will be re-parented as a\n child of this widget. If the child widget is already a child of this\n widget, there is no change.\n\n :param index: The position in the list of children where the new widget\n should be added.\n :param child: The child to insert as a child of this node.\n :raises ValueError: If this widget cannot have children.\n \"\"\"\n self._assert_can_have_children()\n if child.parent is not self:\n # remove from old parent\n if child.parent:\n child.parent.remove(child)\n\n # Set app and window. This is done *before* changing any parenting\n # relationships, so that the widget registry can verify the widget ID is\n # unique. App must be set before window to ensure the widget registry\n # can be found.\n child.app = self.app\n child.window = self.window\n\n # add to new parent\n super().insert(index, child)\n\n self._impl.insert_child(index, child._impl)\n\n # Whatever layout we're a part of needs to be refreshed\n self.refresh()\n\n def index(self, child: Widget) -> int:\n \"\"\"Get the index of a widget in the list of children of this widget.\n\n :param child: The child widget of interest.\n :raises ValueError: If the specified child widget is not found in the\n list of children.\n\n :returns: Index of specified child widget in children list.\n \"\"\"\n for _ind, _child in enumerate(self._children):\n if child == _child:\n return _ind\n raise ValueError(f\"{type(child).__name__} not found\")\n\n def replace(self, old_child: Widget, new_child: Widget) -> None:\n \"\"\"Replace an existing child widget with a new child widget.\n\n :param old_child: The existing child widget to be replaced.\n :param new_child: The new child widget to be included.\n \"\"\"\n old_child_index = self.index(old_child)\n self.remove(old_child)\n self.insert(old_child_index, new_child)\n\n def remove(self, *children: Widget) -> None:\n \"\"\"Remove the provided widgets as children of this node.\n\n Any nominated child widget that is not a child of this widget will\n not have any change in parentage.\n\n Refreshes the widget after removal if any children were removed.\n\n :param children: The child nodes to remove.\n :raises ValueError: If this widget cannot have children.\n \"\"\"\n self._assert_can_have_children()\n\n removed = False\n for child in children:\n if child.parent is self:\n removed = True\n super().remove(child)\n\n # Remove from the window before removing from the app\n # so that the widget can be removed from the app-level registry.\n child.window = None\n child.app = None\n\n self._impl.remove_child(child._impl)\n\n # If we removed something, whatever layout we're a part of needs to be refreshed\n if removed:\n self.refresh()\n\n def clear(self) -> None:\n \"\"\"Remove all child widgets of this node.\n\n Refreshes the widget after removal if any children were removed.\n\n :raises ValueError: If this widget cannot have children.\n \"\"\"\n self._assert_can_have_children()\n self.remove(*self.children)\n\n @property\n def app(self) -> App | None:\n \"\"\"The App to which this widget belongs.\n\n When setting the app for a widget, all children of this widget will be\n recursively assigned to the same app.\n\n :raises ValueError: If this widget is already associated with another app.\n \"\"\"\n return self._app\n\n @app.setter\n def app(self, app: App | None) -> None:\n # If the widget is already assigned to an app\n if self._app:\n if self._app == app:\n # If app is the same as the previous app, return\n return\n\n self._app = app\n self._impl.set_app(app)\n for child in self.children:\n child.app = app\n\n @property\n def window(self) -> Window | None:\n \"\"\"The window to which this widget belongs.\n\n When setting the window for a widget, all children of this widget will be\n recursively assigned to the same window.\n\n If the widget has a value for :any:`window`, it *must* also have a value for\n :any:`app`.\n \"\"\"\n return self._window\n\n @window.setter\n def window(self, window: Window | None) -> None:\n if self.window is not None and window is None:\n # If the widget is currently in the registry, but is being removed from a\n # window, remove the widget from the widget registry\n self.window.app.widgets._remove(self.id)\n elif self.window is None and window is not None:\n # If the widget is being assigned to a window for the first time, add it to the widget registry\n window.app.widgets._add(self)\n\n self._window = window\n self._impl.set_window(window)\n\n for child in self.children:\n child.window = window\n\n @property\n def enabled(self) -> bool:\n \"\"\"Is the widget currently enabled? i.e., can the user interact with the widget?\"\"\"\n return self._impl.get_enabled()\n\n @enabled.setter\n def enabled(self, value: bool) -> None:\n self._impl.set_enabled(bool(value))\n\n def refresh(self) -> None:\n self._impl.refresh()\n\n # Refresh the layout\n if self._root:\n # We're not the root of the node hierarchy;\n # defer the refresh call to the root node.\n self._root.refresh()\n else:\n # We can't compute a layout until we have a container\n if self._impl.container:\n super().refresh(self._impl.container)\n self._impl.container.refreshed()\n\n def focus(self) -> None:\n \"\"\"Give this widget the input focus.\n\n This method is a no-op if the widget can't accept focus. The ability of a widget\n to accept focus is platform-dependent. In general, on desktop platforms you can\n focus any widget that can accept user input, while on mobile platforms focus is\n limited to widgets that accept text input (i.e., widgets that cause the virtual\n keyboard to appear).\n \"\"\"\n self._impl.focus()\n", "path": "core/src/toga/widgets/base.py"}]}
| 3,227 | 325 |
gh_patches_debug_13332
|
rasdani/github-patches
|
git_diff
|
Azure__azure-cli-extensions-444
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
add timeout support in image copy command
- If the issue is to do with Azure CLI 2.0 in-particular, create an issue here at [Azure/azure-cli](https://github.com/Azure/azure-cli/issues)
### Extension name (the extension in question)
image-copy-extension
### Description of issue (in as much detail as possible)
src/image-copy/azext_imagecopy/create_target.py
at line 50:
https://github.com/Azure/azure-cli-extensions/blob/master/src/image-copy/azext_imagecopy/create_target.py#L50
we are using hardcoded SAS expiration time 1 hour
expiry = datetime.datetime.utcnow() + datetime.timedelta(hours=1)
This could cause problem as some times the copy take longer than 1 hour. Please consider to add a parameter to the image copy command to add a timeout parameter and use the specified timeout(maybe +5min) to generate the SAS token.
-----
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/image-copy/azext_imagecopy/create_target.py`
Content:
```
1 # --------------------------------------------------------------------------------------------
2 # Copyright (c) Microsoft Corporation. All rights reserved.
3 # Licensed under the MIT License. See License.txt in the project root for license information.
4 # --------------------------------------------------------------------------------------------
5
6 import datetime
7 import time
8 from azext_imagecopy.cli_utils import run_cli_command, prepare_cli_command
9 from knack.util import CLIError
10
11 from knack.log import get_logger
12 logger = get_logger(__name__)
13
14 STORAGE_ACCOUNT_NAME_LENGTH = 24
15
16
17 # pylint: disable=too-many-locals
18 def create_target_image(location, transient_resource_group_name, source_type, source_object_name,
19 source_os_disk_snapshot_name, source_os_disk_snapshot_url, source_os_type,
20 target_resource_group_name, azure_pool_frequency, tags, target_name, target_subscription,
21 timeout):
22
23 random_string = get_random_string(STORAGE_ACCOUNT_NAME_LENGTH - len(location))
24
25 # create the target storage account. storage account name must be lowercase.
26 logger.warn(
27 "%s - Creating target storage account (can be slow sometimes)", location)
28 target_storage_account_name = location.lower() + random_string
29 cli_cmd = prepare_cli_command(['storage', 'account', 'create',
30 '--name', target_storage_account_name,
31 '--resource-group', transient_resource_group_name,
32 '--location', location,
33 '--sku', 'Standard_LRS'],
34 subscription=target_subscription)
35
36 json_output = run_cli_command(cli_cmd, return_as_json=True)
37 target_blob_endpoint = json_output['primaryEndpoints']['blob']
38
39 # Setup the target storage account
40 cli_cmd = prepare_cli_command(['storage', 'account', 'keys', 'list',
41 '--account-name', target_storage_account_name,
42 '--resource-group', transient_resource_group_name],
43 subscription=target_subscription)
44
45 json_output = run_cli_command(cli_cmd, return_as_json=True)
46
47 target_storage_account_key = json_output[0]['value']
48 logger.debug("storage account key: %s", target_storage_account_key)
49
50 expiry_format = "%Y-%m-%dT%H:%MZ"
51 expiry = datetime.datetime.utcnow() + datetime.timedelta(seconds=timeout)
52 logger.debug("create target storage sas using timeout seconds: %d", timeout)
53
54 cli_cmd = prepare_cli_command(['storage', 'account', 'generate-sas',
55 '--account-name', target_storage_account_name,
56 '--account-key', target_storage_account_key,
57 '--expiry', expiry.strftime(expiry_format),
58 '--permissions', 'aclrpuw', '--resource-types',
59 'sco', '--services', 'b', '--https-only'],
60 output_as_json=False,
61 subscription=target_subscription)
62
63 sas_token = run_cli_command(cli_cmd)
64 sas_token = sas_token.rstrip("\n\r") # STRANGE
65 logger.debug("sas token: %s", sas_token)
66
67 # create a container in the target blob storage account
68 logger.warn(
69 "%s - Creating container in the target storage account", location)
70 target_container_name = 'snapshots'
71 cli_cmd = prepare_cli_command(['storage', 'container', 'create',
72 '--name', target_container_name,
73 '--account-name', target_storage_account_name],
74 subscription=target_subscription)
75
76 run_cli_command(cli_cmd)
77
78 # Copy the snapshot to the target region using the SAS URL
79 blob_name = source_os_disk_snapshot_name + '.vhd'
80 logger.warn(
81 "%s - Copying blob to target storage account", location)
82 cli_cmd = prepare_cli_command(['storage', 'blob', 'copy', 'start',
83 '--source-uri', source_os_disk_snapshot_url,
84 '--destination-blob', blob_name,
85 '--destination-container', target_container_name,
86 '--account-name', target_storage_account_name,
87 '--sas-token', sas_token],
88 subscription=target_subscription)
89
90 run_cli_command(cli_cmd)
91
92 # Wait for the copy to complete
93 start_datetime = datetime.datetime.now()
94 wait_for_blob_copy_operation(blob_name, target_container_name, target_storage_account_name,
95 azure_pool_frequency, location, target_subscription)
96 msg = "{0} - Copy time: {1}".format(
97 location, datetime.datetime.now() - start_datetime)
98 logger.warn(msg)
99
100 # Create the snapshot in the target region from the copied blob
101 logger.warn(
102 "%s - Creating snapshot in target region from the copied blob", location)
103 target_blob_path = target_blob_endpoint + \
104 target_container_name + '/' + blob_name
105 target_snapshot_name = source_os_disk_snapshot_name + '-' + location
106 cli_cmd = prepare_cli_command(['snapshot', 'create',
107 '--resource-group', transient_resource_group_name,
108 '--name', target_snapshot_name,
109 '--location', location,
110 '--source', target_blob_path],
111 subscription=target_subscription)
112
113 json_output = run_cli_command(cli_cmd, return_as_json=True)
114 target_snapshot_id = json_output['id']
115
116 # Create the final image
117 logger.warn("%s - Creating final image", location)
118 if target_name is None:
119 target_image_name = source_object_name
120 if source_type != 'image':
121 target_image_name += '-image'
122 target_image_name += '-' + location
123 else:
124 target_image_name = target_name
125
126 cli_cmd = prepare_cli_command(['image', 'create',
127 '--resource-group', target_resource_group_name,
128 '--name', target_image_name,
129 '--location', location,
130 '--source', target_blob_path,
131 '--os-type', source_os_type,
132 '--source', target_snapshot_id],
133 tags=tags,
134 subscription=target_subscription)
135
136 run_cli_command(cli_cmd)
137
138
139 def wait_for_blob_copy_operation(blob_name, target_container_name, target_storage_account_name,
140 azure_pool_frequency, location, subscription):
141 copy_status = "pending"
142 prev_progress = -1
143 while copy_status == "pending":
144 cli_cmd = prepare_cli_command(['storage', 'blob', 'show',
145 '--name', blob_name,
146 '--container-name', target_container_name,
147 '--account-name', target_storage_account_name],
148 subscription=subscription)
149
150 json_output = run_cli_command(cli_cmd, return_as_json=True)
151 copy_status = json_output["properties"]["copy"]["status"]
152 copy_progress_1, copy_progress_2 = json_output["properties"]["copy"]["progress"].split(
153 "/")
154 current_progress = int(
155 int(copy_progress_1) / int(copy_progress_2) * 100)
156
157 if current_progress != prev_progress:
158 msg = "{0} - Copy progress: {1}%"\
159 .format(location, str(current_progress))
160 logger.warn(msg)
161
162 prev_progress = current_progress
163
164 try:
165 time.sleep(azure_pool_frequency)
166 except KeyboardInterrupt:
167 return
168
169 if copy_status != 'success':
170 logger.error("The copy operation didn't succeed. Last status: %s", copy_status)
171 raise CLIError('Blob copy failed')
172
173
174 def get_random_string(length):
175 import string
176 import random
177 chars = string.ascii_lowercase + string.digits
178 return ''.join(random.choice(chars) for _ in range(length))
179
```
Path: `src/image-copy/setup.py`
Content:
```
1 #!/usr/bin/env python
2
3 # --------------------------------------------------------------------------------------------
4 # Copyright (c) Microsoft Corporation. All rights reserved.
5 # Licensed under the MIT License. See License.txt in the project root for license information.
6 # --------------------------------------------------------------------------------------------
7
8 from codecs import open
9 from setuptools import setup, find_packages
10
11 VERSION = "0.0.8"
12
13 CLASSIFIERS = [
14 'Development Status :: 4 - Beta',
15 'Intended Audience :: Developers',
16 'Intended Audience :: System Administrators',
17 'Programming Language :: Python',
18 'Programming Language :: Python :: 2',
19 'Programming Language :: Python :: 2.7',
20 'Programming Language :: Python :: 3',
21 'Programming Language :: Python :: 3.4',
22 'Programming Language :: Python :: 3.5',
23 'Programming Language :: Python :: 3.6',
24 'License :: OSI Approved :: MIT License',
25 ]
26
27 DEPENDENCIES = []
28
29 setup(
30 name='image-copy-extension',
31 version=VERSION,
32 description='Support for copying managed vm images between regions',
33 long_description='Support for copying managed vm images between regions',
34 license='MIT',
35 author='Tamir Kamara',
36 author_email='tamir.kamara@microsoft.com',
37 url='https://github.com/Azure/azure-cli-extensions',
38 classifiers=CLASSIFIERS,
39 package_data={'azext_imagecopy': ['azext_metadata.json']},
40 packages=find_packages(),
41 install_requires=DEPENDENCIES
42 )
43
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/image-copy/azext_imagecopy/create_target.py b/src/image-copy/azext_imagecopy/create_target.py
--- a/src/image-copy/azext_imagecopy/create_target.py
+++ b/src/image-copy/azext_imagecopy/create_target.py
@@ -168,6 +168,9 @@
if copy_status != 'success':
logger.error("The copy operation didn't succeed. Last status: %s", copy_status)
+ logger.error("Command run: %s", cli_cmd)
+ logger.error("Command output: %s", json_output)
+
raise CLIError('Blob copy failed')
diff --git a/src/image-copy/setup.py b/src/image-copy/setup.py
--- a/src/image-copy/setup.py
+++ b/src/image-copy/setup.py
@@ -8,7 +8,7 @@
from codecs import open
from setuptools import setup, find_packages
-VERSION = "0.0.8"
+VERSION = "0.0.9"
CLASSIFIERS = [
'Development Status :: 4 - Beta',
|
{"golden_diff": "diff --git a/src/image-copy/azext_imagecopy/create_target.py b/src/image-copy/azext_imagecopy/create_target.py\n--- a/src/image-copy/azext_imagecopy/create_target.py\n+++ b/src/image-copy/azext_imagecopy/create_target.py\n@@ -168,6 +168,9 @@\n \n if copy_status != 'success':\n logger.error(\"The copy operation didn't succeed. Last status: %s\", copy_status)\n+ logger.error(\"Command run: %s\", cli_cmd)\n+ logger.error(\"Command output: %s\", json_output)\n+\n raise CLIError('Blob copy failed')\n \n \ndiff --git a/src/image-copy/setup.py b/src/image-copy/setup.py\n--- a/src/image-copy/setup.py\n+++ b/src/image-copy/setup.py\n@@ -8,7 +8,7 @@\n from codecs import open\n from setuptools import setup, find_packages\n \n-VERSION = \"0.0.8\"\n+VERSION = \"0.0.9\"\n \n CLASSIFIERS = [\n 'Development Status :: 4 - Beta',\n", "issue": "add timeout support in image copy command\n- If the issue is to do with Azure CLI 2.0 in-particular, create an issue here at [Azure/azure-cli](https://github.com/Azure/azure-cli/issues)\r\n\r\n### Extension name (the extension in question)\r\nimage-copy-extension\r\n\r\n### Description of issue (in as much detail as possible)\r\nsrc/image-copy/azext_imagecopy/create_target.py\r\n\r\nat line 50:\r\nhttps://github.com/Azure/azure-cli-extensions/blob/master/src/image-copy/azext_imagecopy/create_target.py#L50\r\n\r\nwe are using hardcoded SAS expiration time 1 hour\r\nexpiry = datetime.datetime.utcnow() + datetime.timedelta(hours=1)\r\n\r\nThis could cause problem as some times the copy take longer than 1 hour. Please consider to add a parameter to the image copy command to add a timeout parameter and use the specified timeout(maybe +5min) to generate the SAS token.\r\n-----\r\n\r\n\n", "before_files": [{"content": "# --------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See License.txt in the project root for license information.\n# --------------------------------------------------------------------------------------------\n\nimport datetime\nimport time\nfrom azext_imagecopy.cli_utils import run_cli_command, prepare_cli_command\nfrom knack.util import CLIError\n\nfrom knack.log import get_logger\nlogger = get_logger(__name__)\n\nSTORAGE_ACCOUNT_NAME_LENGTH = 24\n\n\n# pylint: disable=too-many-locals\ndef create_target_image(location, transient_resource_group_name, source_type, source_object_name,\n source_os_disk_snapshot_name, source_os_disk_snapshot_url, source_os_type,\n target_resource_group_name, azure_pool_frequency, tags, target_name, target_subscription,\n timeout):\n\n random_string = get_random_string(STORAGE_ACCOUNT_NAME_LENGTH - len(location))\n\n # create the target storage account. storage account name must be lowercase.\n logger.warn(\n \"%s - Creating target storage account (can be slow sometimes)\", location)\n target_storage_account_name = location.lower() + random_string\n cli_cmd = prepare_cli_command(['storage', 'account', 'create',\n '--name', target_storage_account_name,\n '--resource-group', transient_resource_group_name,\n '--location', location,\n '--sku', 'Standard_LRS'],\n subscription=target_subscription)\n\n json_output = run_cli_command(cli_cmd, return_as_json=True)\n target_blob_endpoint = json_output['primaryEndpoints']['blob']\n\n # Setup the target storage account\n cli_cmd = prepare_cli_command(['storage', 'account', 'keys', 'list',\n '--account-name', target_storage_account_name,\n '--resource-group', transient_resource_group_name],\n subscription=target_subscription)\n\n json_output = run_cli_command(cli_cmd, return_as_json=True)\n\n target_storage_account_key = json_output[0]['value']\n logger.debug(\"storage account key: %s\", target_storage_account_key)\n\n expiry_format = \"%Y-%m-%dT%H:%MZ\"\n expiry = datetime.datetime.utcnow() + datetime.timedelta(seconds=timeout)\n logger.debug(\"create target storage sas using timeout seconds: %d\", timeout)\n\n cli_cmd = prepare_cli_command(['storage', 'account', 'generate-sas',\n '--account-name', target_storage_account_name,\n '--account-key', target_storage_account_key,\n '--expiry', expiry.strftime(expiry_format),\n '--permissions', 'aclrpuw', '--resource-types',\n 'sco', '--services', 'b', '--https-only'],\n output_as_json=False,\n subscription=target_subscription)\n\n sas_token = run_cli_command(cli_cmd)\n sas_token = sas_token.rstrip(\"\\n\\r\") # STRANGE\n logger.debug(\"sas token: %s\", sas_token)\n\n # create a container in the target blob storage account\n logger.warn(\n \"%s - Creating container in the target storage account\", location)\n target_container_name = 'snapshots'\n cli_cmd = prepare_cli_command(['storage', 'container', 'create',\n '--name', target_container_name,\n '--account-name', target_storage_account_name],\n subscription=target_subscription)\n\n run_cli_command(cli_cmd)\n\n # Copy the snapshot to the target region using the SAS URL\n blob_name = source_os_disk_snapshot_name + '.vhd'\n logger.warn(\n \"%s - Copying blob to target storage account\", location)\n cli_cmd = prepare_cli_command(['storage', 'blob', 'copy', 'start',\n '--source-uri', source_os_disk_snapshot_url,\n '--destination-blob', blob_name,\n '--destination-container', target_container_name,\n '--account-name', target_storage_account_name,\n '--sas-token', sas_token],\n subscription=target_subscription)\n\n run_cli_command(cli_cmd)\n\n # Wait for the copy to complete\n start_datetime = datetime.datetime.now()\n wait_for_blob_copy_operation(blob_name, target_container_name, target_storage_account_name,\n azure_pool_frequency, location, target_subscription)\n msg = \"{0} - Copy time: {1}\".format(\n location, datetime.datetime.now() - start_datetime)\n logger.warn(msg)\n\n # Create the snapshot in the target region from the copied blob\n logger.warn(\n \"%s - Creating snapshot in target region from the copied blob\", location)\n target_blob_path = target_blob_endpoint + \\\n target_container_name + '/' + blob_name\n target_snapshot_name = source_os_disk_snapshot_name + '-' + location\n cli_cmd = prepare_cli_command(['snapshot', 'create',\n '--resource-group', transient_resource_group_name,\n '--name', target_snapshot_name,\n '--location', location,\n '--source', target_blob_path],\n subscription=target_subscription)\n\n json_output = run_cli_command(cli_cmd, return_as_json=True)\n target_snapshot_id = json_output['id']\n\n # Create the final image\n logger.warn(\"%s - Creating final image\", location)\n if target_name is None:\n target_image_name = source_object_name\n if source_type != 'image':\n target_image_name += '-image'\n target_image_name += '-' + location\n else:\n target_image_name = target_name\n\n cli_cmd = prepare_cli_command(['image', 'create',\n '--resource-group', target_resource_group_name,\n '--name', target_image_name,\n '--location', location,\n '--source', target_blob_path,\n '--os-type', source_os_type,\n '--source', target_snapshot_id],\n tags=tags,\n subscription=target_subscription)\n\n run_cli_command(cli_cmd)\n\n\ndef wait_for_blob_copy_operation(blob_name, target_container_name, target_storage_account_name,\n azure_pool_frequency, location, subscription):\n copy_status = \"pending\"\n prev_progress = -1\n while copy_status == \"pending\":\n cli_cmd = prepare_cli_command(['storage', 'blob', 'show',\n '--name', blob_name,\n '--container-name', target_container_name,\n '--account-name', target_storage_account_name],\n subscription=subscription)\n\n json_output = run_cli_command(cli_cmd, return_as_json=True)\n copy_status = json_output[\"properties\"][\"copy\"][\"status\"]\n copy_progress_1, copy_progress_2 = json_output[\"properties\"][\"copy\"][\"progress\"].split(\n \"/\")\n current_progress = int(\n int(copy_progress_1) / int(copy_progress_2) * 100)\n\n if current_progress != prev_progress:\n msg = \"{0} - Copy progress: {1}%\"\\\n .format(location, str(current_progress))\n logger.warn(msg)\n\n prev_progress = current_progress\n\n try:\n time.sleep(azure_pool_frequency)\n except KeyboardInterrupt:\n return\n\n if copy_status != 'success':\n logger.error(\"The copy operation didn't succeed. Last status: %s\", copy_status)\n raise CLIError('Blob copy failed')\n\n\ndef get_random_string(length):\n import string\n import random\n chars = string.ascii_lowercase + string.digits\n return ''.join(random.choice(chars) for _ in range(length))\n", "path": "src/image-copy/azext_imagecopy/create_target.py"}, {"content": "#!/usr/bin/env python\n\n# --------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See License.txt in the project root for license information.\n# --------------------------------------------------------------------------------------------\n\nfrom codecs import open\nfrom setuptools import setup, find_packages\n\nVERSION = \"0.0.8\"\n\nCLASSIFIERS = [\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: System Administrators',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'License :: OSI Approved :: MIT License',\n]\n\nDEPENDENCIES = []\n\nsetup(\n name='image-copy-extension',\n version=VERSION,\n description='Support for copying managed vm images between regions',\n long_description='Support for copying managed vm images between regions',\n license='MIT',\n author='Tamir Kamara',\n author_email='tamir.kamara@microsoft.com',\n url='https://github.com/Azure/azure-cli-extensions',\n classifiers=CLASSIFIERS,\n package_data={'azext_imagecopy': ['azext_metadata.json']},\n packages=find_packages(),\n install_requires=DEPENDENCIES\n)\n", "path": "src/image-copy/setup.py"}], "after_files": [{"content": "# --------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See License.txt in the project root for license information.\n# --------------------------------------------------------------------------------------------\n\nimport datetime\nimport time\nfrom azext_imagecopy.cli_utils import run_cli_command, prepare_cli_command\nfrom knack.util import CLIError\n\nfrom knack.log import get_logger\nlogger = get_logger(__name__)\n\nSTORAGE_ACCOUNT_NAME_LENGTH = 24\n\n\n# pylint: disable=too-many-locals\ndef create_target_image(location, transient_resource_group_name, source_type, source_object_name,\n source_os_disk_snapshot_name, source_os_disk_snapshot_url, source_os_type,\n target_resource_group_name, azure_pool_frequency, tags, target_name, target_subscription,\n timeout):\n\n random_string = get_random_string(STORAGE_ACCOUNT_NAME_LENGTH - len(location))\n\n # create the target storage account. storage account name must be lowercase.\n logger.warn(\n \"%s - Creating target storage account (can be slow sometimes)\", location)\n target_storage_account_name = location.lower() + random_string\n cli_cmd = prepare_cli_command(['storage', 'account', 'create',\n '--name', target_storage_account_name,\n '--resource-group', transient_resource_group_name,\n '--location', location,\n '--sku', 'Standard_LRS'],\n subscription=target_subscription)\n\n json_output = run_cli_command(cli_cmd, return_as_json=True)\n target_blob_endpoint = json_output['primaryEndpoints']['blob']\n\n # Setup the target storage account\n cli_cmd = prepare_cli_command(['storage', 'account', 'keys', 'list',\n '--account-name', target_storage_account_name,\n '--resource-group', transient_resource_group_name],\n subscription=target_subscription)\n\n json_output = run_cli_command(cli_cmd, return_as_json=True)\n\n target_storage_account_key = json_output[0]['value']\n logger.debug(\"storage account key: %s\", target_storage_account_key)\n\n expiry_format = \"%Y-%m-%dT%H:%MZ\"\n expiry = datetime.datetime.utcnow() + datetime.timedelta(seconds=timeout)\n logger.debug(\"create target storage sas using timeout seconds: %d\", timeout)\n\n cli_cmd = prepare_cli_command(['storage', 'account', 'generate-sas',\n '--account-name', target_storage_account_name,\n '--account-key', target_storage_account_key,\n '--expiry', expiry.strftime(expiry_format),\n '--permissions', 'aclrpuw', '--resource-types',\n 'sco', '--services', 'b', '--https-only'],\n output_as_json=False,\n subscription=target_subscription)\n\n sas_token = run_cli_command(cli_cmd)\n sas_token = sas_token.rstrip(\"\\n\\r\") # STRANGE\n logger.debug(\"sas token: %s\", sas_token)\n\n # create a container in the target blob storage account\n logger.warn(\n \"%s - Creating container in the target storage account\", location)\n target_container_name = 'snapshots'\n cli_cmd = prepare_cli_command(['storage', 'container', 'create',\n '--name', target_container_name,\n '--account-name', target_storage_account_name],\n subscription=target_subscription)\n\n run_cli_command(cli_cmd)\n\n # Copy the snapshot to the target region using the SAS URL\n blob_name = source_os_disk_snapshot_name + '.vhd'\n logger.warn(\n \"%s - Copying blob to target storage account\", location)\n cli_cmd = prepare_cli_command(['storage', 'blob', 'copy', 'start',\n '--source-uri', source_os_disk_snapshot_url,\n '--destination-blob', blob_name,\n '--destination-container', target_container_name,\n '--account-name', target_storage_account_name,\n '--sas-token', sas_token],\n subscription=target_subscription)\n\n run_cli_command(cli_cmd)\n\n # Wait for the copy to complete\n start_datetime = datetime.datetime.now()\n wait_for_blob_copy_operation(blob_name, target_container_name, target_storage_account_name,\n azure_pool_frequency, location, target_subscription)\n msg = \"{0} - Copy time: {1}\".format(\n location, datetime.datetime.now() - start_datetime)\n logger.warn(msg)\n\n # Create the snapshot in the target region from the copied blob\n logger.warn(\n \"%s - Creating snapshot in target region from the copied blob\", location)\n target_blob_path = target_blob_endpoint + \\\n target_container_name + '/' + blob_name\n target_snapshot_name = source_os_disk_snapshot_name + '-' + location\n cli_cmd = prepare_cli_command(['snapshot', 'create',\n '--resource-group', transient_resource_group_name,\n '--name', target_snapshot_name,\n '--location', location,\n '--source', target_blob_path],\n subscription=target_subscription)\n\n json_output = run_cli_command(cli_cmd, return_as_json=True)\n target_snapshot_id = json_output['id']\n\n # Create the final image\n logger.warn(\"%s - Creating final image\", location)\n if target_name is None:\n target_image_name = source_object_name\n if source_type != 'image':\n target_image_name += '-image'\n target_image_name += '-' + location\n else:\n target_image_name = target_name\n\n cli_cmd = prepare_cli_command(['image', 'create',\n '--resource-group', target_resource_group_name,\n '--name', target_image_name,\n '--location', location,\n '--source', target_blob_path,\n '--os-type', source_os_type,\n '--source', target_snapshot_id],\n tags=tags,\n subscription=target_subscription)\n\n run_cli_command(cli_cmd)\n\n\ndef wait_for_blob_copy_operation(blob_name, target_container_name, target_storage_account_name,\n azure_pool_frequency, location, subscription):\n copy_status = \"pending\"\n prev_progress = -1\n while copy_status == \"pending\":\n cli_cmd = prepare_cli_command(['storage', 'blob', 'show',\n '--name', blob_name,\n '--container-name', target_container_name,\n '--account-name', target_storage_account_name],\n subscription=subscription)\n\n json_output = run_cli_command(cli_cmd, return_as_json=True)\n copy_status = json_output[\"properties\"][\"copy\"][\"status\"]\n copy_progress_1, copy_progress_2 = json_output[\"properties\"][\"copy\"][\"progress\"].split(\n \"/\")\n current_progress = int(\n int(copy_progress_1) / int(copy_progress_2) * 100)\n\n if current_progress != prev_progress:\n msg = \"{0} - Copy progress: {1}%\"\\\n .format(location, str(current_progress))\n logger.warn(msg)\n\n prev_progress = current_progress\n\n try:\n time.sleep(azure_pool_frequency)\n except KeyboardInterrupt:\n return\n\n if copy_status != 'success':\n logger.error(\"The copy operation didn't succeed. Last status: %s\", copy_status)\n logger.error(\"Command run: %s\", cli_cmd)\n logger.error(\"Command output: %s\", json_output)\n\n raise CLIError('Blob copy failed')\n\n\ndef get_random_string(length):\n import string\n import random\n chars = string.ascii_lowercase + string.digits\n return ''.join(random.choice(chars) for _ in range(length))\n", "path": "src/image-copy/azext_imagecopy/create_target.py"}, {"content": "#!/usr/bin/env python\n\n# --------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See License.txt in the project root for license information.\n# --------------------------------------------------------------------------------------------\n\nfrom codecs import open\nfrom setuptools import setup, find_packages\n\nVERSION = \"0.0.9\"\n\nCLASSIFIERS = [\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: System Administrators',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'License :: OSI Approved :: MIT License',\n]\n\nDEPENDENCIES = []\n\nsetup(\n name='image-copy-extension',\n version=VERSION,\n description='Support for copying managed vm images between regions',\n long_description='Support for copying managed vm images between regions',\n license='MIT',\n author='Tamir Kamara',\n author_email='tamir.kamara@microsoft.com',\n url='https://github.com/Azure/azure-cli-extensions',\n classifiers=CLASSIFIERS,\n package_data={'azext_imagecopy': ['azext_metadata.json']},\n packages=find_packages(),\n install_requires=DEPENDENCIES\n)\n", "path": "src/image-copy/setup.py"}]}
| 2,800 | 229 |
gh_patches_debug_13125
|
rasdani/github-patches
|
git_diff
|
microsoft__hi-ml-812
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Links to BioViL paper need to be updated
We are still using the arXiv preprint. But this should be solved first:
- https://github.com/microsoft/hi-ml/pull/730#issuecomment-1419298653
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hi-ml-multimodal/src/health_multimodal/text/model/modelling_cxrbert.py`
Content:
```
1 # ------------------------------------------------------------------------------------------
2 # Copyright (c) Microsoft Corporation. All rights reserved.
3 # Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.
4 # ------------------------------------------------------------------------------------------
5
6 from typing import Any, Optional, Tuple, Union
7
8 import torch
9 import torch.nn.functional as F
10 from torch import nn
11 from torch import Tensor as T
12 from transformers import BertForMaskedLM
13 from transformers.modeling_outputs import ModelOutput
14
15 from health_multimodal.text.model.configuration_cxrbert import CXRBertConfig
16
17 BERTTupleOutput = Tuple[T, T, T, T, T]
18
19
20 class CXRBertOutput(ModelOutput):
21 last_hidden_state: torch.FloatTensor
22 logits: torch.FloatTensor
23 cls_projected_embedding: Optional[torch.FloatTensor] = None
24 hidden_states: Optional[Tuple[torch.FloatTensor]] = None
25 attentions: Optional[Tuple[torch.FloatTensor]] = None
26
27
28 class BertProjectionHead(nn.Module):
29 """Projection head to be used with BERT CLS token.
30
31 This is similar to ``BertPredictionHeadTransform`` in HuggingFace.
32
33 :param config: Configuration for BERT.
34 """
35
36 def __init__(self, config: CXRBertConfig) -> None:
37 super().__init__()
38 self.dense_to_hidden = nn.Linear(config.hidden_size, config.projection_size)
39 self.transform_act_fn = nn.functional.gelu
40 self.LayerNorm = nn.LayerNorm(config.projection_size, eps=1e-12)
41 self.dense_to_output = nn.Linear(config.projection_size, config.projection_size)
42
43 def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
44 hidden_states = self.dense_to_hidden(hidden_states)
45 hidden_states = self.transform_act_fn(hidden_states)
46 hidden_states = self.LayerNorm(hidden_states)
47 hidden_states = self.dense_to_output(hidden_states)
48
49 return hidden_states
50
51
52 class CXRBertModel(BertForMaskedLM):
53 """
54 Implements the CXR-BERT model outlined in the manuscript:
55 Boecking et al. "Making the Most of Text Semantics to Improve Biomedical Vision-Language Processing", 2022
56 https://arxiv.org/abs/2204.09817
57
58 Extends the HuggingFace BertForMaskedLM model by adding a separate projection head. The projection "[CLS]" token is
59 used to align the latent vectors of image and text modalities.
60 """
61
62 config_class = CXRBertConfig # type: ignore
63
64 def __init__(self, config: CXRBertConfig):
65 super().__init__(config)
66
67 self.cls_projection_head = BertProjectionHead(config)
68 self.init_weights()
69
70 def forward(
71 self,
72 input_ids: torch.Tensor,
73 attention_mask: torch.Tensor,
74 token_type_ids: Optional[torch.Tensor] = None,
75 position_ids: Optional[torch.Tensor] = None,
76 head_mask: Optional[torch.Tensor] = None,
77 inputs_embeds: Optional[torch.Tensor] = None,
78 output_attentions: Optional[bool] = None,
79 output_hidden_states: Optional[bool] = None,
80 output_cls_projected_embedding: Optional[bool] = None,
81 return_dict: Optional[bool] = None,
82 **kwargs: Any
83 ) -> Union[BERTTupleOutput, CXRBertOutput]:
84
85 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
86
87 bert_for_masked_lm_output = super().forward(input_ids=input_ids,
88 attention_mask=attention_mask,
89 token_type_ids=token_type_ids,
90 position_ids=position_ids,
91 head_mask=head_mask,
92 inputs_embeds=inputs_embeds,
93 output_attentions=output_attentions,
94 output_hidden_states=True,
95 return_dict=True)
96
97 last_hidden_state = bert_for_masked_lm_output.hidden_states[-1]
98 cls_projected_embedding = self.cls_projection_head(
99 last_hidden_state[:, 0, :]) if output_cls_projected_embedding else None
100
101 if return_dict:
102 return CXRBertOutput(
103 last_hidden_state=last_hidden_state,
104 logits=bert_for_masked_lm_output.logits,
105 cls_projected_embedding=cls_projected_embedding,
106 hidden_states=bert_for_masked_lm_output.hidden_states if output_hidden_states else None,
107 attentions=bert_for_masked_lm_output.attentions,
108 )
109 else:
110 return (
111 last_hidden_state,
112 bert_for_masked_lm_output.logits,
113 cls_projected_embedding,
114 bert_for_masked_lm_output.hidden_states,
115 bert_for_masked_lm_output.attentions,)
116
117 def get_projected_text_embeddings(self,
118 input_ids: torch.Tensor,
119 attention_mask: torch.Tensor,
120 normalize_embeddings: bool = True) -> torch.Tensor:
121 """
122 Returns l2-normalised projected cls token embeddings for the given input token ids and attention mask.
123 The joint latent space is trained using a contrastive objective between image and text data modalities.
124
125 :param input_ids: (batch_size, sequence_length)
126 :param attention_mask: (batch_size, sequence_length)
127 :param normalize_embeddings: Whether to l2-normalise the embeddings.
128 :return: (batch_size, projection_size)
129 """
130
131 outputs = self.forward(input_ids=input_ids, attention_mask=attention_mask,
132 output_cls_projected_embedding=True, return_dict=True)
133 assert isinstance(outputs, CXRBertOutput)
134
135 cls_projected_embedding = outputs.cls_projected_embedding
136 assert cls_projected_embedding is not None
137
138 if normalize_embeddings:
139 return F.normalize(cls_projected_embedding, dim=1)
140
141 return cls_projected_embedding
142
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/hi-ml-multimodal/src/health_multimodal/text/model/modelling_cxrbert.py b/hi-ml-multimodal/src/health_multimodal/text/model/modelling_cxrbert.py
--- a/hi-ml-multimodal/src/health_multimodal/text/model/modelling_cxrbert.py
+++ b/hi-ml-multimodal/src/health_multimodal/text/model/modelling_cxrbert.py
@@ -53,7 +53,7 @@
"""
Implements the CXR-BERT model outlined in the manuscript:
Boecking et al. "Making the Most of Text Semantics to Improve Biomedical Vision-Language Processing", 2022
- https://arxiv.org/abs/2204.09817
+ https://link.springer.com/chapter/10.1007/978-3-031-20059-5_1
Extends the HuggingFace BertForMaskedLM model by adding a separate projection head. The projection "[CLS]" token is
used to align the latent vectors of image and text modalities.
|
{"golden_diff": "diff --git a/hi-ml-multimodal/src/health_multimodal/text/model/modelling_cxrbert.py b/hi-ml-multimodal/src/health_multimodal/text/model/modelling_cxrbert.py\n--- a/hi-ml-multimodal/src/health_multimodal/text/model/modelling_cxrbert.py\n+++ b/hi-ml-multimodal/src/health_multimodal/text/model/modelling_cxrbert.py\n@@ -53,7 +53,7 @@\n \"\"\"\n Implements the CXR-BERT model outlined in the manuscript:\n Boecking et al. \"Making the Most of Text Semantics to Improve Biomedical Vision-Language Processing\", 2022\n- https://arxiv.org/abs/2204.09817\n+ https://link.springer.com/chapter/10.1007/978-3-031-20059-5_1\n \n Extends the HuggingFace BertForMaskedLM model by adding a separate projection head. The projection \"[CLS]\" token is\n used to align the latent vectors of image and text modalities.\n", "issue": "Links to BioViL paper need to be updated\nWe are still using the arXiv preprint. But this should be solved first:\r\n- https://github.com/microsoft/hi-ml/pull/730#issuecomment-1419298653\n", "before_files": [{"content": "# ------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.\n# ------------------------------------------------------------------------------------------\n\nfrom typing import Any, Optional, Tuple, Union\n\nimport torch\nimport torch.nn.functional as F\nfrom torch import nn\nfrom torch import Tensor as T\nfrom transformers import BertForMaskedLM\nfrom transformers.modeling_outputs import ModelOutput\n\nfrom health_multimodal.text.model.configuration_cxrbert import CXRBertConfig\n\nBERTTupleOutput = Tuple[T, T, T, T, T]\n\n\nclass CXRBertOutput(ModelOutput):\n last_hidden_state: torch.FloatTensor\n logits: torch.FloatTensor\n cls_projected_embedding: Optional[torch.FloatTensor] = None\n hidden_states: Optional[Tuple[torch.FloatTensor]] = None\n attentions: Optional[Tuple[torch.FloatTensor]] = None\n\n\nclass BertProjectionHead(nn.Module):\n \"\"\"Projection head to be used with BERT CLS token.\n\n This is similar to ``BertPredictionHeadTransform`` in HuggingFace.\n\n :param config: Configuration for BERT.\n \"\"\"\n\n def __init__(self, config: CXRBertConfig) -> None:\n super().__init__()\n self.dense_to_hidden = nn.Linear(config.hidden_size, config.projection_size)\n self.transform_act_fn = nn.functional.gelu\n self.LayerNorm = nn.LayerNorm(config.projection_size, eps=1e-12)\n self.dense_to_output = nn.Linear(config.projection_size, config.projection_size)\n\n def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:\n hidden_states = self.dense_to_hidden(hidden_states)\n hidden_states = self.transform_act_fn(hidden_states)\n hidden_states = self.LayerNorm(hidden_states)\n hidden_states = self.dense_to_output(hidden_states)\n\n return hidden_states\n\n\nclass CXRBertModel(BertForMaskedLM):\n \"\"\"\n Implements the CXR-BERT model outlined in the manuscript:\n Boecking et al. \"Making the Most of Text Semantics to Improve Biomedical Vision-Language Processing\", 2022\n https://arxiv.org/abs/2204.09817\n\n Extends the HuggingFace BertForMaskedLM model by adding a separate projection head. The projection \"[CLS]\" token is\n used to align the latent vectors of image and text modalities.\n \"\"\"\n\n config_class = CXRBertConfig # type: ignore\n\n def __init__(self, config: CXRBertConfig):\n super().__init__(config)\n\n self.cls_projection_head = BertProjectionHead(config)\n self.init_weights()\n\n def forward(\n self,\n input_ids: torch.Tensor,\n attention_mask: torch.Tensor,\n token_type_ids: Optional[torch.Tensor] = None,\n position_ids: Optional[torch.Tensor] = None,\n head_mask: Optional[torch.Tensor] = None,\n inputs_embeds: Optional[torch.Tensor] = None,\n output_attentions: Optional[bool] = None,\n output_hidden_states: Optional[bool] = None,\n output_cls_projected_embedding: Optional[bool] = None,\n return_dict: Optional[bool] = None,\n **kwargs: Any\n ) -> Union[BERTTupleOutput, CXRBertOutput]:\n\n return_dict = return_dict if return_dict is not None else self.config.use_return_dict\n\n bert_for_masked_lm_output = super().forward(input_ids=input_ids,\n attention_mask=attention_mask,\n token_type_ids=token_type_ids,\n position_ids=position_ids,\n head_mask=head_mask,\n inputs_embeds=inputs_embeds,\n output_attentions=output_attentions,\n output_hidden_states=True,\n return_dict=True)\n\n last_hidden_state = bert_for_masked_lm_output.hidden_states[-1]\n cls_projected_embedding = self.cls_projection_head(\n last_hidden_state[:, 0, :]) if output_cls_projected_embedding else None\n\n if return_dict:\n return CXRBertOutput(\n last_hidden_state=last_hidden_state,\n logits=bert_for_masked_lm_output.logits,\n cls_projected_embedding=cls_projected_embedding,\n hidden_states=bert_for_masked_lm_output.hidden_states if output_hidden_states else None,\n attentions=bert_for_masked_lm_output.attentions,\n )\n else:\n return (\n last_hidden_state,\n bert_for_masked_lm_output.logits,\n cls_projected_embedding,\n bert_for_masked_lm_output.hidden_states,\n bert_for_masked_lm_output.attentions,)\n\n def get_projected_text_embeddings(self,\n input_ids: torch.Tensor,\n attention_mask: torch.Tensor,\n normalize_embeddings: bool = True) -> torch.Tensor:\n \"\"\"\n Returns l2-normalised projected cls token embeddings for the given input token ids and attention mask.\n The joint latent space is trained using a contrastive objective between image and text data modalities.\n\n :param input_ids: (batch_size, sequence_length)\n :param attention_mask: (batch_size, sequence_length)\n :param normalize_embeddings: Whether to l2-normalise the embeddings.\n :return: (batch_size, projection_size)\n \"\"\"\n\n outputs = self.forward(input_ids=input_ids, attention_mask=attention_mask,\n output_cls_projected_embedding=True, return_dict=True)\n assert isinstance(outputs, CXRBertOutput)\n\n cls_projected_embedding = outputs.cls_projected_embedding\n assert cls_projected_embedding is not None\n\n if normalize_embeddings:\n return F.normalize(cls_projected_embedding, dim=1)\n\n return cls_projected_embedding\n", "path": "hi-ml-multimodal/src/health_multimodal/text/model/modelling_cxrbert.py"}], "after_files": [{"content": "# ------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.\n# ------------------------------------------------------------------------------------------\n\nfrom typing import Any, Optional, Tuple, Union\n\nimport torch\nimport torch.nn.functional as F\nfrom torch import nn\nfrom torch import Tensor as T\nfrom transformers import BertForMaskedLM\nfrom transformers.modeling_outputs import ModelOutput\n\nfrom health_multimodal.text.model.configuration_cxrbert import CXRBertConfig\n\nBERTTupleOutput = Tuple[T, T, T, T, T]\n\n\nclass CXRBertOutput(ModelOutput):\n last_hidden_state: torch.FloatTensor\n logits: torch.FloatTensor\n cls_projected_embedding: Optional[torch.FloatTensor] = None\n hidden_states: Optional[Tuple[torch.FloatTensor]] = None\n attentions: Optional[Tuple[torch.FloatTensor]] = None\n\n\nclass BertProjectionHead(nn.Module):\n \"\"\"Projection head to be used with BERT CLS token.\n\n This is similar to ``BertPredictionHeadTransform`` in HuggingFace.\n\n :param config: Configuration for BERT.\n \"\"\"\n\n def __init__(self, config: CXRBertConfig) -> None:\n super().__init__()\n self.dense_to_hidden = nn.Linear(config.hidden_size, config.projection_size)\n self.transform_act_fn = nn.functional.gelu\n self.LayerNorm = nn.LayerNorm(config.projection_size, eps=1e-12)\n self.dense_to_output = nn.Linear(config.projection_size, config.projection_size)\n\n def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:\n hidden_states = self.dense_to_hidden(hidden_states)\n hidden_states = self.transform_act_fn(hidden_states)\n hidden_states = self.LayerNorm(hidden_states)\n hidden_states = self.dense_to_output(hidden_states)\n\n return hidden_states\n\n\nclass CXRBertModel(BertForMaskedLM):\n \"\"\"\n Implements the CXR-BERT model outlined in the manuscript:\n Boecking et al. \"Making the Most of Text Semantics to Improve Biomedical Vision-Language Processing\", 2022\n https://link.springer.com/chapter/10.1007/978-3-031-20059-5_1\n\n Extends the HuggingFace BertForMaskedLM model by adding a separate projection head. The projection \"[CLS]\" token is\n used to align the latent vectors of image and text modalities.\n \"\"\"\n\n config_class = CXRBertConfig # type: ignore\n\n def __init__(self, config: CXRBertConfig):\n super().__init__(config)\n\n self.cls_projection_head = BertProjectionHead(config)\n self.init_weights()\n\n def forward(\n self,\n input_ids: torch.Tensor,\n attention_mask: torch.Tensor,\n token_type_ids: Optional[torch.Tensor] = None,\n position_ids: Optional[torch.Tensor] = None,\n head_mask: Optional[torch.Tensor] = None,\n inputs_embeds: Optional[torch.Tensor] = None,\n output_attentions: Optional[bool] = None,\n output_hidden_states: Optional[bool] = None,\n output_cls_projected_embedding: Optional[bool] = None,\n return_dict: Optional[bool] = None,\n **kwargs: Any\n ) -> Union[BERTTupleOutput, CXRBertOutput]:\n\n return_dict = return_dict if return_dict is not None else self.config.use_return_dict\n\n bert_for_masked_lm_output = super().forward(input_ids=input_ids,\n attention_mask=attention_mask,\n token_type_ids=token_type_ids,\n position_ids=position_ids,\n head_mask=head_mask,\n inputs_embeds=inputs_embeds,\n output_attentions=output_attentions,\n output_hidden_states=True,\n return_dict=True)\n\n last_hidden_state = bert_for_masked_lm_output.hidden_states[-1]\n cls_projected_embedding = self.cls_projection_head(\n last_hidden_state[:, 0, :]) if output_cls_projected_embedding else None\n\n if return_dict:\n return CXRBertOutput(\n last_hidden_state=last_hidden_state,\n logits=bert_for_masked_lm_output.logits,\n cls_projected_embedding=cls_projected_embedding,\n hidden_states=bert_for_masked_lm_output.hidden_states if output_hidden_states else None,\n attentions=bert_for_masked_lm_output.attentions,\n )\n else:\n return (\n last_hidden_state,\n bert_for_masked_lm_output.logits,\n cls_projected_embedding,\n bert_for_masked_lm_output.hidden_states,\n bert_for_masked_lm_output.attentions,)\n\n def get_projected_text_embeddings(self,\n input_ids: torch.Tensor,\n attention_mask: torch.Tensor,\n normalize_embeddings: bool = True) -> torch.Tensor:\n \"\"\"\n Returns l2-normalised projected cls token embeddings for the given input token ids and attention mask.\n The joint latent space is trained using a contrastive objective between image and text data modalities.\n\n :param input_ids: (batch_size, sequence_length)\n :param attention_mask: (batch_size, sequence_length)\n :param normalize_embeddings: Whether to l2-normalise the embeddings.\n :return: (batch_size, projection_size)\n \"\"\"\n\n outputs = self.forward(input_ids=input_ids, attention_mask=attention_mask,\n output_cls_projected_embedding=True, return_dict=True)\n assert isinstance(outputs, CXRBertOutput)\n\n cls_projected_embedding = outputs.cls_projected_embedding\n assert cls_projected_embedding is not None\n\n if normalize_embeddings:\n return F.normalize(cls_projected_embedding, dim=1)\n\n return cls_projected_embedding\n", "path": "hi-ml-multimodal/src/health_multimodal/text/model/modelling_cxrbert.py"}]}
| 1,865 | 255 |
gh_patches_debug_40752
|
rasdani/github-patches
|
git_diff
|
SeldonIO__MLServer-1058
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
merging the huggingface and mlserver batch variable
As per https://github.com/SeldonIO/MLServer/pull/740#discussion_r981259626 it would be possible to just merge both huggingface batch variable into the mlserver batch variable for less redundancy in the `model-settings.json` file.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `runtimes/huggingface/mlserver_huggingface/common.py`
Content:
```
1 import os
2 import json
3 from typing import Optional, Dict
4 from distutils.util import strtobool
5
6 import numpy as np
7 from pydantic import BaseSettings
8 from mlserver.errors import MLServerError
9
10 from transformers.pipelines import pipeline
11 from transformers.pipelines.base import Pipeline
12 from transformers.models.auto.tokenization_auto import AutoTokenizer
13
14 try:
15 # Optimum 1.7 changed the import name from `SUPPORTED_TASKS` to
16 # `ORT_SUPPORTED_TASKS`.
17 # We'll try to import the more recent one, falling back to the previous
18 # import name if not present.
19 # https://github.com/huggingface/optimum/blob/987b02e4f6e2a1c9325b364ff764da2e57e89902/optimum/pipelines/__init__.py#L18
20 from optimum.pipelines import ORT_SUPPORTED_TASKS as SUPPORTED_OPTIMUM_TASKS
21 except ImportError:
22 from optimum.pipelines import SUPPORTED_TASKS as SUPPORTED_OPTIMUM_TASKS
23
24
25 HUGGINGFACE_TASK_TAG = "task"
26
27 ENV_PREFIX_HUGGINGFACE_SETTINGS = "MLSERVER_MODEL_HUGGINGFACE_"
28 HUGGINGFACE_PARAMETERS_TAG = "huggingface_parameters"
29 PARAMETERS_ENV_NAME = "PREDICTIVE_UNIT_PARAMETERS"
30
31
32 class InvalidTranformerInitialisation(MLServerError):
33 def __init__(self, code: int, reason: str):
34 super().__init__(
35 f"Huggingface server failed with {code}, {reason}",
36 status_code=code,
37 )
38
39
40 class HuggingFaceSettings(BaseSettings):
41 """
42 Parameters that apply only to alibi huggingface models
43 """
44
45 class Config:
46 env_prefix = ENV_PREFIX_HUGGINGFACE_SETTINGS
47
48 task: str = ""
49 # Why need this filed?
50 # for translation task, required a suffix to specify source and target
51 # related issue: https://github.com/SeldonIO/MLServer/issues/947
52 task_suffix: str = ""
53 pretrained_model: Optional[str] = None
54 pretrained_tokenizer: Optional[str] = None
55 optimum_model: bool = False
56 device: int = -1
57 batch_size: Optional[int] = None
58
59 @property
60 def task_name(self):
61 if self.task == "translation":
62 return f"{self.task}{self.task_suffix}"
63 return self.task
64
65
66 def parse_parameters_from_env() -> Dict:
67 """
68 TODO
69 """
70 parameters = json.loads(os.environ.get(PARAMETERS_ENV_NAME, "[]"))
71
72 type_dict = {
73 "INT": int,
74 "FLOAT": float,
75 "DOUBLE": float,
76 "STRING": str,
77 "BOOL": bool,
78 }
79
80 parsed_parameters = {}
81 for param in parameters:
82 name = param.get("name")
83 value = param.get("value")
84 type_ = param.get("type")
85 if type_ == "BOOL":
86 parsed_parameters[name] = bool(strtobool(value))
87 else:
88 try:
89 parsed_parameters[name] = type_dict[type_](value)
90 except ValueError:
91 raise InvalidTranformerInitialisation(
92 "Bad model parameter: "
93 + name
94 + " with value "
95 + value
96 + " can't be parsed as a "
97 + type_,
98 reason="MICROSERVICE_BAD_PARAMETER",
99 )
100 except KeyError:
101 raise InvalidTranformerInitialisation(
102 "Bad model parameter type: "
103 + type_
104 + " valid are INT, FLOAT, DOUBLE, STRING, BOOL",
105 reason="MICROSERVICE_BAD_PARAMETER",
106 )
107 return parsed_parameters
108
109
110 def load_pipeline_from_settings(hf_settings: HuggingFaceSettings) -> Pipeline:
111 """
112 TODO
113 """
114 # TODO: Support URI for locally downloaded artifacts
115 # uri = model_parameters.uri
116 model = hf_settings.pretrained_model
117 tokenizer = hf_settings.pretrained_tokenizer
118 device = hf_settings.device
119
120 if model and not tokenizer:
121 tokenizer = model
122
123 if hf_settings.optimum_model:
124 optimum_class = SUPPORTED_OPTIMUM_TASKS[hf_settings.task]["class"][0]
125 model = optimum_class.from_pretrained(
126 hf_settings.pretrained_model,
127 from_transformers=True,
128 )
129 tokenizer = AutoTokenizer.from_pretrained(tokenizer)
130 # Device needs to be set to -1 due to known issue
131 # https://github.com/huggingface/optimum/issues/191
132 device = -1
133
134 pp = pipeline(
135 hf_settings.task_name,
136 model=model,
137 tokenizer=tokenizer,
138 device=device,
139 batch_size=hf_settings.batch_size,
140 )
141
142 # If batch_size > 0 we need to ensure tokens are padded
143 if hf_settings.batch_size:
144 pp.tokenizer.pad_token_id = [str(pp.model.config.eos_token_id)] # type: ignore
145
146 return pp
147
148
149 class NumpyEncoder(json.JSONEncoder):
150 def default(self, obj):
151 if isinstance(obj, np.ndarray):
152 return obj.tolist()
153 return json.JSONEncoder.default(self, obj)
154
```
Path: `runtimes/huggingface/mlserver_huggingface/runtime.py`
Content:
```
1 import asyncio
2 from mlserver.model import MLModel
3 from mlserver.settings import ModelSettings
4 from mlserver.types import (
5 InferenceRequest,
6 InferenceResponse,
7 )
8 from transformers.pipelines import SUPPORTED_TASKS
9
10 from mlserver.logging import logger
11
12 from .common import (
13 HuggingFaceSettings,
14 parse_parameters_from_env,
15 InvalidTranformerInitialisation,
16 load_pipeline_from_settings,
17 SUPPORTED_OPTIMUM_TASKS,
18 )
19 from .codecs import HuggingfaceRequestCodec
20 from .metadata import METADATA
21
22
23 class HuggingFaceRuntime(MLModel):
24 """Runtime class for specific Huggingface models"""
25
26 def __init__(self, settings: ModelSettings):
27 env_params = parse_parameters_from_env()
28 if not env_params and (
29 not settings.parameters or not settings.parameters.extra
30 ):
31 raise InvalidTranformerInitialisation(
32 500,
33 "Settings parameters not provided via config file nor env variables",
34 )
35
36 extra = env_params or settings.parameters.extra # type: ignore
37 self.hf_settings = HuggingFaceSettings(**extra) # type: ignore
38
39 if self.hf_settings.task not in SUPPORTED_TASKS:
40 raise InvalidTranformerInitialisation(
41 500,
42 (
43 f"Invalid transformer task: {self.hf_settings.task}."
44 f" Available tasks: {SUPPORTED_TASKS.keys()}"
45 ),
46 )
47
48 if self.hf_settings.optimum_model:
49 if self.hf_settings.task not in SUPPORTED_OPTIMUM_TASKS:
50 raise InvalidTranformerInitialisation(
51 500,
52 (
53 f"Invalid transformer task for "
54 f"OPTIMUM model: {self.hf_settings.task}. "
55 f"Supported Optimum tasks: {SUPPORTED_OPTIMUM_TASKS.keys()}"
56 ),
57 )
58
59 if settings.max_batch_size != self.hf_settings.batch_size:
60 logger.warning(
61 f"hf batch_size: {self.hf_settings.batch_size} is different "
62 f"from MLServer max_batch_size: {settings.max_batch_size}"
63 )
64
65 super().__init__(settings)
66
67 async def load(self) -> bool:
68 # Loading & caching pipeline in asyncio loop to avoid blocking
69 print("=" * 80)
70 print(self.hf_settings.task_name)
71 print("loading model...")
72 await asyncio.get_running_loop().run_in_executor(
73 None, load_pipeline_from_settings, self.hf_settings
74 )
75 print("(re)loading model...")
76 # Now we load the cached model which should not block asyncio
77 self._model = load_pipeline_from_settings(self.hf_settings)
78 self._merge_metadata()
79 print("model has been loaded!")
80 self.ready = True
81 return self.ready
82
83 async def predict(self, payload: InferenceRequest) -> InferenceResponse:
84 """
85 TODO
86 """
87
88 # Adding some logging as hard to debug given the many types of input accepted
89 logger.debug("Payload %s", payload)
90
91 # TODO: convert and validate?
92 kwargs = self.decode_request(payload, default_codec=HuggingfaceRequestCodec)
93 args = kwargs.pop("args", [])
94
95 array_inputs = kwargs.pop("array_inputs", [])
96 if array_inputs:
97 args = [list(array_inputs)] + args
98 prediction = self._model(*args, **kwargs)
99
100 logger.debug("Prediction %s", prediction)
101
102 return self.encode_response(
103 payload=prediction, default_codec=HuggingfaceRequestCodec
104 )
105
106 def _merge_metadata(self) -> None:
107 meta = METADATA.get(self.hf_settings.task)
108 if meta:
109 self.inputs += meta.get("inputs", []) # type: ignore
110 self.outputs += meta.get("outputs", []) # type: ignore
111
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/runtimes/huggingface/mlserver_huggingface/common.py b/runtimes/huggingface/mlserver_huggingface/common.py
--- a/runtimes/huggingface/mlserver_huggingface/common.py
+++ b/runtimes/huggingface/mlserver_huggingface/common.py
@@ -6,6 +6,7 @@
import numpy as np
from pydantic import BaseSettings
from mlserver.errors import MLServerError
+from mlserver.settings import ModelSettings
from transformers.pipelines import pipeline
from transformers.pipelines.base import Pipeline
@@ -54,7 +55,6 @@
pretrained_tokenizer: Optional[str] = None
optimum_model: bool = False
device: int = -1
- batch_size: Optional[int] = None
@property
def task_name(self):
@@ -107,7 +107,9 @@
return parsed_parameters
-def load_pipeline_from_settings(hf_settings: HuggingFaceSettings) -> Pipeline:
+def load_pipeline_from_settings(
+ hf_settings: HuggingFaceSettings, settings: ModelSettings
+) -> Pipeline:
"""
TODO
"""
@@ -131,16 +133,17 @@
# https://github.com/huggingface/optimum/issues/191
device = -1
+ batch_size = 1 if settings.max_batch_size == 0 else settings.max_batch_size
pp = pipeline(
hf_settings.task_name,
model=model,
tokenizer=tokenizer,
device=device,
- batch_size=hf_settings.batch_size,
+ batch_size=batch_size,
)
- # If batch_size > 0 we need to ensure tokens are padded
- if hf_settings.batch_size:
+ # If max_batch_size > 0 we need to ensure tokens are padded
+ if settings.max_batch_size:
pp.tokenizer.pad_token_id = [str(pp.model.config.eos_token_id)] # type: ignore
return pp
diff --git a/runtimes/huggingface/mlserver_huggingface/runtime.py b/runtimes/huggingface/mlserver_huggingface/runtime.py
--- a/runtimes/huggingface/mlserver_huggingface/runtime.py
+++ b/runtimes/huggingface/mlserver_huggingface/runtime.py
@@ -56,12 +56,6 @@
),
)
- if settings.max_batch_size != self.hf_settings.batch_size:
- logger.warning(
- f"hf batch_size: {self.hf_settings.batch_size} is different "
- f"from MLServer max_batch_size: {settings.max_batch_size}"
- )
-
super().__init__(settings)
async def load(self) -> bool:
@@ -70,11 +64,14 @@
print(self.hf_settings.task_name)
print("loading model...")
await asyncio.get_running_loop().run_in_executor(
- None, load_pipeline_from_settings, self.hf_settings
+ None,
+ load_pipeline_from_settings,
+ self.hf_settings,
+ self.settings,
)
print("(re)loading model...")
# Now we load the cached model which should not block asyncio
- self._model = load_pipeline_from_settings(self.hf_settings)
+ self._model = load_pipeline_from_settings(self.hf_settings, self.settings)
self._merge_metadata()
print("model has been loaded!")
self.ready = True
|
{"golden_diff": "diff --git a/runtimes/huggingface/mlserver_huggingface/common.py b/runtimes/huggingface/mlserver_huggingface/common.py\n--- a/runtimes/huggingface/mlserver_huggingface/common.py\n+++ b/runtimes/huggingface/mlserver_huggingface/common.py\n@@ -6,6 +6,7 @@\n import numpy as np\n from pydantic import BaseSettings\n from mlserver.errors import MLServerError\n+from mlserver.settings import ModelSettings\n \n from transformers.pipelines import pipeline\n from transformers.pipelines.base import Pipeline\n@@ -54,7 +55,6 @@\n pretrained_tokenizer: Optional[str] = None\n optimum_model: bool = False\n device: int = -1\n- batch_size: Optional[int] = None\n \n @property\n def task_name(self):\n@@ -107,7 +107,9 @@\n return parsed_parameters\n \n \n-def load_pipeline_from_settings(hf_settings: HuggingFaceSettings) -> Pipeline:\n+def load_pipeline_from_settings(\n+ hf_settings: HuggingFaceSettings, settings: ModelSettings\n+) -> Pipeline:\n \"\"\"\n TODO\n \"\"\"\n@@ -131,16 +133,17 @@\n # https://github.com/huggingface/optimum/issues/191\n device = -1\n \n+ batch_size = 1 if settings.max_batch_size == 0 else settings.max_batch_size\n pp = pipeline(\n hf_settings.task_name,\n model=model,\n tokenizer=tokenizer,\n device=device,\n- batch_size=hf_settings.batch_size,\n+ batch_size=batch_size,\n )\n \n- # If batch_size > 0 we need to ensure tokens are padded\n- if hf_settings.batch_size:\n+ # If max_batch_size > 0 we need to ensure tokens are padded\n+ if settings.max_batch_size:\n pp.tokenizer.pad_token_id = [str(pp.model.config.eos_token_id)] # type: ignore\n \n return pp\ndiff --git a/runtimes/huggingface/mlserver_huggingface/runtime.py b/runtimes/huggingface/mlserver_huggingface/runtime.py\n--- a/runtimes/huggingface/mlserver_huggingface/runtime.py\n+++ b/runtimes/huggingface/mlserver_huggingface/runtime.py\n@@ -56,12 +56,6 @@\n ),\n )\n \n- if settings.max_batch_size != self.hf_settings.batch_size:\n- logger.warning(\n- f\"hf batch_size: {self.hf_settings.batch_size} is different \"\n- f\"from MLServer max_batch_size: {settings.max_batch_size}\"\n- )\n-\n super().__init__(settings)\n \n async def load(self) -> bool:\n@@ -70,11 +64,14 @@\n print(self.hf_settings.task_name)\n print(\"loading model...\")\n await asyncio.get_running_loop().run_in_executor(\n- None, load_pipeline_from_settings, self.hf_settings\n+ None,\n+ load_pipeline_from_settings,\n+ self.hf_settings,\n+ self.settings,\n )\n print(\"(re)loading model...\")\n # Now we load the cached model which should not block asyncio\n- self._model = load_pipeline_from_settings(self.hf_settings)\n+ self._model = load_pipeline_from_settings(self.hf_settings, self.settings)\n self._merge_metadata()\n print(\"model has been loaded!\")\n self.ready = True\n", "issue": "merging the huggingface and mlserver batch variable\nAs per https://github.com/SeldonIO/MLServer/pull/740#discussion_r981259626 it would be possible to just merge both huggingface batch variable into the mlserver batch variable for less redundancy in the `model-settings.json` file.\n", "before_files": [{"content": "import os\nimport json\nfrom typing import Optional, Dict\nfrom distutils.util import strtobool\n\nimport numpy as np\nfrom pydantic import BaseSettings\nfrom mlserver.errors import MLServerError\n\nfrom transformers.pipelines import pipeline\nfrom transformers.pipelines.base import Pipeline\nfrom transformers.models.auto.tokenization_auto import AutoTokenizer\n\ntry:\n # Optimum 1.7 changed the import name from `SUPPORTED_TASKS` to\n # `ORT_SUPPORTED_TASKS`.\n # We'll try to import the more recent one, falling back to the previous\n # import name if not present.\n # https://github.com/huggingface/optimum/blob/987b02e4f6e2a1c9325b364ff764da2e57e89902/optimum/pipelines/__init__.py#L18\n from optimum.pipelines import ORT_SUPPORTED_TASKS as SUPPORTED_OPTIMUM_TASKS\nexcept ImportError:\n from optimum.pipelines import SUPPORTED_TASKS as SUPPORTED_OPTIMUM_TASKS\n\n\nHUGGINGFACE_TASK_TAG = \"task\"\n\nENV_PREFIX_HUGGINGFACE_SETTINGS = \"MLSERVER_MODEL_HUGGINGFACE_\"\nHUGGINGFACE_PARAMETERS_TAG = \"huggingface_parameters\"\nPARAMETERS_ENV_NAME = \"PREDICTIVE_UNIT_PARAMETERS\"\n\n\nclass InvalidTranformerInitialisation(MLServerError):\n def __init__(self, code: int, reason: str):\n super().__init__(\n f\"Huggingface server failed with {code}, {reason}\",\n status_code=code,\n )\n\n\nclass HuggingFaceSettings(BaseSettings):\n \"\"\"\n Parameters that apply only to alibi huggingface models\n \"\"\"\n\n class Config:\n env_prefix = ENV_PREFIX_HUGGINGFACE_SETTINGS\n\n task: str = \"\"\n # Why need this filed?\n # for translation task, required a suffix to specify source and target\n # related issue: https://github.com/SeldonIO/MLServer/issues/947\n task_suffix: str = \"\"\n pretrained_model: Optional[str] = None\n pretrained_tokenizer: Optional[str] = None\n optimum_model: bool = False\n device: int = -1\n batch_size: Optional[int] = None\n\n @property\n def task_name(self):\n if self.task == \"translation\":\n return f\"{self.task}{self.task_suffix}\"\n return self.task\n\n\ndef parse_parameters_from_env() -> Dict:\n \"\"\"\n TODO\n \"\"\"\n parameters = json.loads(os.environ.get(PARAMETERS_ENV_NAME, \"[]\"))\n\n type_dict = {\n \"INT\": int,\n \"FLOAT\": float,\n \"DOUBLE\": float,\n \"STRING\": str,\n \"BOOL\": bool,\n }\n\n parsed_parameters = {}\n for param in parameters:\n name = param.get(\"name\")\n value = param.get(\"value\")\n type_ = param.get(\"type\")\n if type_ == \"BOOL\":\n parsed_parameters[name] = bool(strtobool(value))\n else:\n try:\n parsed_parameters[name] = type_dict[type_](value)\n except ValueError:\n raise InvalidTranformerInitialisation(\n \"Bad model parameter: \"\n + name\n + \" with value \"\n + value\n + \" can't be parsed as a \"\n + type_,\n reason=\"MICROSERVICE_BAD_PARAMETER\",\n )\n except KeyError:\n raise InvalidTranformerInitialisation(\n \"Bad model parameter type: \"\n + type_\n + \" valid are INT, FLOAT, DOUBLE, STRING, BOOL\",\n reason=\"MICROSERVICE_BAD_PARAMETER\",\n )\n return parsed_parameters\n\n\ndef load_pipeline_from_settings(hf_settings: HuggingFaceSettings) -> Pipeline:\n \"\"\"\n TODO\n \"\"\"\n # TODO: Support URI for locally downloaded artifacts\n # uri = model_parameters.uri\n model = hf_settings.pretrained_model\n tokenizer = hf_settings.pretrained_tokenizer\n device = hf_settings.device\n\n if model and not tokenizer:\n tokenizer = model\n\n if hf_settings.optimum_model:\n optimum_class = SUPPORTED_OPTIMUM_TASKS[hf_settings.task][\"class\"][0]\n model = optimum_class.from_pretrained(\n hf_settings.pretrained_model,\n from_transformers=True,\n )\n tokenizer = AutoTokenizer.from_pretrained(tokenizer)\n # Device needs to be set to -1 due to known issue\n # https://github.com/huggingface/optimum/issues/191\n device = -1\n\n pp = pipeline(\n hf_settings.task_name,\n model=model,\n tokenizer=tokenizer,\n device=device,\n batch_size=hf_settings.batch_size,\n )\n\n # If batch_size > 0 we need to ensure tokens are padded\n if hf_settings.batch_size:\n pp.tokenizer.pad_token_id = [str(pp.model.config.eos_token_id)] # type: ignore\n\n return pp\n\n\nclass NumpyEncoder(json.JSONEncoder):\n def default(self, obj):\n if isinstance(obj, np.ndarray):\n return obj.tolist()\n return json.JSONEncoder.default(self, obj)\n", "path": "runtimes/huggingface/mlserver_huggingface/common.py"}, {"content": "import asyncio\nfrom mlserver.model import MLModel\nfrom mlserver.settings import ModelSettings\nfrom mlserver.types import (\n InferenceRequest,\n InferenceResponse,\n)\nfrom transformers.pipelines import SUPPORTED_TASKS\n\nfrom mlserver.logging import logger\n\nfrom .common import (\n HuggingFaceSettings,\n parse_parameters_from_env,\n InvalidTranformerInitialisation,\n load_pipeline_from_settings,\n SUPPORTED_OPTIMUM_TASKS,\n)\nfrom .codecs import HuggingfaceRequestCodec\nfrom .metadata import METADATA\n\n\nclass HuggingFaceRuntime(MLModel):\n \"\"\"Runtime class for specific Huggingface models\"\"\"\n\n def __init__(self, settings: ModelSettings):\n env_params = parse_parameters_from_env()\n if not env_params and (\n not settings.parameters or not settings.parameters.extra\n ):\n raise InvalidTranformerInitialisation(\n 500,\n \"Settings parameters not provided via config file nor env variables\",\n )\n\n extra = env_params or settings.parameters.extra # type: ignore\n self.hf_settings = HuggingFaceSettings(**extra) # type: ignore\n\n if self.hf_settings.task not in SUPPORTED_TASKS:\n raise InvalidTranformerInitialisation(\n 500,\n (\n f\"Invalid transformer task: {self.hf_settings.task}.\"\n f\" Available tasks: {SUPPORTED_TASKS.keys()}\"\n ),\n )\n\n if self.hf_settings.optimum_model:\n if self.hf_settings.task not in SUPPORTED_OPTIMUM_TASKS:\n raise InvalidTranformerInitialisation(\n 500,\n (\n f\"Invalid transformer task for \"\n f\"OPTIMUM model: {self.hf_settings.task}. \"\n f\"Supported Optimum tasks: {SUPPORTED_OPTIMUM_TASKS.keys()}\"\n ),\n )\n\n if settings.max_batch_size != self.hf_settings.batch_size:\n logger.warning(\n f\"hf batch_size: {self.hf_settings.batch_size} is different \"\n f\"from MLServer max_batch_size: {settings.max_batch_size}\"\n )\n\n super().__init__(settings)\n\n async def load(self) -> bool:\n # Loading & caching pipeline in asyncio loop to avoid blocking\n print(\"=\" * 80)\n print(self.hf_settings.task_name)\n print(\"loading model...\")\n await asyncio.get_running_loop().run_in_executor(\n None, load_pipeline_from_settings, self.hf_settings\n )\n print(\"(re)loading model...\")\n # Now we load the cached model which should not block asyncio\n self._model = load_pipeline_from_settings(self.hf_settings)\n self._merge_metadata()\n print(\"model has been loaded!\")\n self.ready = True\n return self.ready\n\n async def predict(self, payload: InferenceRequest) -> InferenceResponse:\n \"\"\"\n TODO\n \"\"\"\n\n # Adding some logging as hard to debug given the many types of input accepted\n logger.debug(\"Payload %s\", payload)\n\n # TODO: convert and validate?\n kwargs = self.decode_request(payload, default_codec=HuggingfaceRequestCodec)\n args = kwargs.pop(\"args\", [])\n\n array_inputs = kwargs.pop(\"array_inputs\", [])\n if array_inputs:\n args = [list(array_inputs)] + args\n prediction = self._model(*args, **kwargs)\n\n logger.debug(\"Prediction %s\", prediction)\n\n return self.encode_response(\n payload=prediction, default_codec=HuggingfaceRequestCodec\n )\n\n def _merge_metadata(self) -> None:\n meta = METADATA.get(self.hf_settings.task)\n if meta:\n self.inputs += meta.get(\"inputs\", []) # type: ignore\n self.outputs += meta.get(\"outputs\", []) # type: ignore\n", "path": "runtimes/huggingface/mlserver_huggingface/runtime.py"}], "after_files": [{"content": "import os\nimport json\nfrom typing import Optional, Dict\nfrom distutils.util import strtobool\n\nimport numpy as np\nfrom pydantic import BaseSettings\nfrom mlserver.errors import MLServerError\nfrom mlserver.settings import ModelSettings\n\nfrom transformers.pipelines import pipeline\nfrom transformers.pipelines.base import Pipeline\nfrom transformers.models.auto.tokenization_auto import AutoTokenizer\n\ntry:\n # Optimum 1.7 changed the import name from `SUPPORTED_TASKS` to\n # `ORT_SUPPORTED_TASKS`.\n # We'll try to import the more recent one, falling back to the previous\n # import name if not present.\n # https://github.com/huggingface/optimum/blob/987b02e4f6e2a1c9325b364ff764da2e57e89902/optimum/pipelines/__init__.py#L18\n from optimum.pipelines import ORT_SUPPORTED_TASKS as SUPPORTED_OPTIMUM_TASKS\nexcept ImportError:\n from optimum.pipelines import SUPPORTED_TASKS as SUPPORTED_OPTIMUM_TASKS\n\n\nHUGGINGFACE_TASK_TAG = \"task\"\n\nENV_PREFIX_HUGGINGFACE_SETTINGS = \"MLSERVER_MODEL_HUGGINGFACE_\"\nHUGGINGFACE_PARAMETERS_TAG = \"huggingface_parameters\"\nPARAMETERS_ENV_NAME = \"PREDICTIVE_UNIT_PARAMETERS\"\n\n\nclass InvalidTranformerInitialisation(MLServerError):\n def __init__(self, code: int, reason: str):\n super().__init__(\n f\"Huggingface server failed with {code}, {reason}\",\n status_code=code,\n )\n\n\nclass HuggingFaceSettings(BaseSettings):\n \"\"\"\n Parameters that apply only to alibi huggingface models\n \"\"\"\n\n class Config:\n env_prefix = ENV_PREFIX_HUGGINGFACE_SETTINGS\n\n task: str = \"\"\n # Why need this filed?\n # for translation task, required a suffix to specify source and target\n # related issue: https://github.com/SeldonIO/MLServer/issues/947\n task_suffix: str = \"\"\n pretrained_model: Optional[str] = None\n pretrained_tokenizer: Optional[str] = None\n optimum_model: bool = False\n device: int = -1\n\n @property\n def task_name(self):\n if self.task == \"translation\":\n return f\"{self.task}{self.task_suffix}\"\n return self.task\n\n\ndef parse_parameters_from_env() -> Dict:\n \"\"\"\n TODO\n \"\"\"\n parameters = json.loads(os.environ.get(PARAMETERS_ENV_NAME, \"[]\"))\n\n type_dict = {\n \"INT\": int,\n \"FLOAT\": float,\n \"DOUBLE\": float,\n \"STRING\": str,\n \"BOOL\": bool,\n }\n\n parsed_parameters = {}\n for param in parameters:\n name = param.get(\"name\")\n value = param.get(\"value\")\n type_ = param.get(\"type\")\n if type_ == \"BOOL\":\n parsed_parameters[name] = bool(strtobool(value))\n else:\n try:\n parsed_parameters[name] = type_dict[type_](value)\n except ValueError:\n raise InvalidTranformerInitialisation(\n \"Bad model parameter: \"\n + name\n + \" with value \"\n + value\n + \" can't be parsed as a \"\n + type_,\n reason=\"MICROSERVICE_BAD_PARAMETER\",\n )\n except KeyError:\n raise InvalidTranformerInitialisation(\n \"Bad model parameter type: \"\n + type_\n + \" valid are INT, FLOAT, DOUBLE, STRING, BOOL\",\n reason=\"MICROSERVICE_BAD_PARAMETER\",\n )\n return parsed_parameters\n\n\ndef load_pipeline_from_settings(\n hf_settings: HuggingFaceSettings, settings: ModelSettings\n) -> Pipeline:\n \"\"\"\n TODO\n \"\"\"\n # TODO: Support URI for locally downloaded artifacts\n # uri = model_parameters.uri\n model = hf_settings.pretrained_model\n tokenizer = hf_settings.pretrained_tokenizer\n device = hf_settings.device\n\n if model and not tokenizer:\n tokenizer = model\n\n if hf_settings.optimum_model:\n optimum_class = SUPPORTED_OPTIMUM_TASKS[hf_settings.task][\"class\"][0]\n model = optimum_class.from_pretrained(\n hf_settings.pretrained_model,\n from_transformers=True,\n )\n tokenizer = AutoTokenizer.from_pretrained(tokenizer)\n # Device needs to be set to -1 due to known issue\n # https://github.com/huggingface/optimum/issues/191\n device = -1\n\n batch_size = 1 if settings.max_batch_size == 0 else settings.max_batch_size\n pp = pipeline(\n hf_settings.task_name,\n model=model,\n tokenizer=tokenizer,\n device=device,\n batch_size=batch_size,\n )\n\n # If max_batch_size > 0 we need to ensure tokens are padded\n if settings.max_batch_size:\n pp.tokenizer.pad_token_id = [str(pp.model.config.eos_token_id)] # type: ignore\n\n return pp\n\n\nclass NumpyEncoder(json.JSONEncoder):\n def default(self, obj):\n if isinstance(obj, np.ndarray):\n return obj.tolist()\n return json.JSONEncoder.default(self, obj)\n", "path": "runtimes/huggingface/mlserver_huggingface/common.py"}, {"content": "import asyncio\nfrom mlserver.model import MLModel\nfrom mlserver.settings import ModelSettings\nfrom mlserver.types import (\n InferenceRequest,\n InferenceResponse,\n)\nfrom transformers.pipelines import SUPPORTED_TASKS\n\nfrom mlserver.logging import logger\n\nfrom .common import (\n HuggingFaceSettings,\n parse_parameters_from_env,\n InvalidTranformerInitialisation,\n load_pipeline_from_settings,\n SUPPORTED_OPTIMUM_TASKS,\n)\nfrom .codecs import HuggingfaceRequestCodec\nfrom .metadata import METADATA\n\n\nclass HuggingFaceRuntime(MLModel):\n \"\"\"Runtime class for specific Huggingface models\"\"\"\n\n def __init__(self, settings: ModelSettings):\n env_params = parse_parameters_from_env()\n if not env_params and (\n not settings.parameters or not settings.parameters.extra\n ):\n raise InvalidTranformerInitialisation(\n 500,\n \"Settings parameters not provided via config file nor env variables\",\n )\n\n extra = env_params or settings.parameters.extra # type: ignore\n self.hf_settings = HuggingFaceSettings(**extra) # type: ignore\n\n if self.hf_settings.task not in SUPPORTED_TASKS:\n raise InvalidTranformerInitialisation(\n 500,\n (\n f\"Invalid transformer task: {self.hf_settings.task}.\"\n f\" Available tasks: {SUPPORTED_TASKS.keys()}\"\n ),\n )\n\n if self.hf_settings.optimum_model:\n if self.hf_settings.task not in SUPPORTED_OPTIMUM_TASKS:\n raise InvalidTranformerInitialisation(\n 500,\n (\n f\"Invalid transformer task for \"\n f\"OPTIMUM model: {self.hf_settings.task}. \"\n f\"Supported Optimum tasks: {SUPPORTED_OPTIMUM_TASKS.keys()}\"\n ),\n )\n\n super().__init__(settings)\n\n async def load(self) -> bool:\n # Loading & caching pipeline in asyncio loop to avoid blocking\n print(\"=\" * 80)\n print(self.hf_settings.task_name)\n print(\"loading model...\")\n await asyncio.get_running_loop().run_in_executor(\n None,\n load_pipeline_from_settings,\n self.hf_settings,\n self.settings,\n )\n print(\"(re)loading model...\")\n # Now we load the cached model which should not block asyncio\n self._model = load_pipeline_from_settings(self.hf_settings, self.settings)\n self._merge_metadata()\n print(\"model has been loaded!\")\n self.ready = True\n return self.ready\n\n async def predict(self, payload: InferenceRequest) -> InferenceResponse:\n \"\"\"\n TODO\n \"\"\"\n\n # Adding some logging as hard to debug given the many types of input accepted\n logger.debug(\"Payload %s\", payload)\n\n # TODO: convert and validate?\n kwargs = self.decode_request(payload, default_codec=HuggingfaceRequestCodec)\n args = kwargs.pop(\"args\", [])\n\n array_inputs = kwargs.pop(\"array_inputs\", [])\n if array_inputs:\n args = [list(array_inputs)] + args\n prediction = self._model(*args, **kwargs)\n\n logger.debug(\"Prediction %s\", prediction)\n\n return self.encode_response(\n payload=prediction, default_codec=HuggingfaceRequestCodec\n )\n\n def _merge_metadata(self) -> None:\n meta = METADATA.get(self.hf_settings.task)\n if meta:\n self.inputs += meta.get(\"inputs\", []) # type: ignore\n self.outputs += meta.get(\"outputs\", []) # type: ignore\n", "path": "runtimes/huggingface/mlserver_huggingface/runtime.py"}]}
| 2,861 | 745 |
gh_patches_debug_32493
|
rasdani/github-patches
|
git_diff
|
avocado-framework__avocado-4831
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
assets fetch: handshake timeout it is not being caught
During investigation of #4824 I found a problem with timeout during handshake.
```
Process Process-1:
Traceback (most recent call last):
File "/usr/lib64/python3.7/urllib/request.py", line 1350, in do_open
encode_chunked=req.has_header('Transfer-encoding'))
File "/usr/lib64/python3.7/http/client.py", line 1277, in request
self._send_request(method, url, body, headers, encode_chunked)
File "/usr/lib64/python3.7/http/client.py", line 1323, in _send_request
self.endheaders(body, encode_chunked=encode_chunked)
File "/usr/lib64/python3.7/http/client.py", line 1272, in endheaders
self._send_output(message_body, encode_chunked=encode_chunked)
File "/usr/lib64/python3.7/http/client.py", line 1032, in _send_output
self.send(msg)
File "/usr/lib64/python3.7/http/client.py", line 972, in send
self.connect()
File "/usr/lib64/python3.7/http/client.py", line 1447, in connect
server_hostname=server_hostname)
File "/usr/lib64/python3.7/ssl.py", line 423, in wrap_socket
session=session
File "/usr/lib64/python3.7/ssl.py", line 870, in _create
self.do_handshake()
File "/usr/lib64/python3.7/ssl.py", line 1139, in do_handshake
self._sslobj.do_handshake()
socket.timeout: _ssl.c:1074: The handshake operation timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/lib64/python3.7/multiprocessing/process.py", line 297, in _bootstrap
self.run()
File "/usr/lib64/python3.7/multiprocessing/process.py", line 99, in run
self._target(*self._args, **self._kwargs)
File "/home/local/src/beraldo/avocado/avocado/utils/download.py", line 69, in download
src_file = url_open(url, data=data)
File "/home/local/src/beraldo/avocado/avocado/utils/download.py", line 46, in url_open
result = urlopen(url, data=data, timeout=timeout)
File "/usr/lib64/python3.7/urllib/request.py", line 222, in urlopen
return opener.open(url, data, timeout)
File "/usr/lib64/python3.7/urllib/request.py", line 525, in open
response = self._open(req, data)
File "/usr/lib64/python3.7/urllib/request.py", line 543, in _open
'_open', req)
File "/usr/lib64/python3.7/urllib/request.py", line 503, in _call_chain
result = func(*args)
File "/usr/lib64/python3.7/urllib/request.py", line 1393, in https_open
context=self._context, check_hostname=self._check_hostname)
File "/usr/lib64/python3.7/urllib/request.py", line 1352, in do_open
raise URLError(err)
urllib.error.URLError: <urlopen error _ssl.c:1074: The handshake operation timed out>
Failed to fetch download ([Errno 2] No such file or directory: '/home/local/avocado/data/cache/by_location/4135b9170bbc2afc3ec7f79c169bf722b4d2afe7/download.cd7fe814-e6c0-4b10-82cd-e390d92fa099').
(avocado-py3.7) [local@laptop avocado]$
```
Probably this is related to 9b75f9d62faf53248fc687bd6e4dde85bb705b56, but I'm still investigating.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `avocado/utils/download.py`
Content:
```
1 # This program is free software; you can redistribute it and/or modify
2 # it under the terms of the GNU General Public License as published by
3 # the Free Software Foundation; specifically version 2 of the License.
4 #
5 # This program is distributed in the hope that it will be useful,
6 # but WITHOUT ANY WARRANTY; without even the implied warranty of
7 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
8 #
9 # See LICENSE for more details.
10 #
11 # This code was inspired in the autotest project,
12 # client/shared/utils.py
13 # Authors: Martin J Bligh <mbligh@google.com>, Andy Whitcroft <apw@shadowen.org>
14
15
16 """
17 Methods to download URLs and regular files.
18 """
19
20 import logging
21 import os
22 import shutil
23 from multiprocessing import Process
24 from urllib.request import urlopen
25
26 from . import aurl, crypto, output
27
28 log = logging.getLogger('avocado.test')
29
30
31 def url_open(url, data=None, timeout=5):
32 """
33 Wrapper to :func:`urllib2.urlopen` with timeout addition.
34
35 :param url: URL to open.
36 :param data: (optional) data to post.
37 :param timeout: (optional) default timeout in seconds. Please, be aware
38 that timeout here is just for blocking operations during
39 the connection setup, since this method doesn't read the
40 file from the url.
41 :return: file-like object.
42 :raises: `URLError`.
43 """
44 result = urlopen(url, data=data, timeout=timeout)
45 msg = ('Retrieved URL "%s": content-length %s, date: "%s", '
46 'last-modified: "%s"')
47 log.debug(msg, url,
48 result.headers.get('Content-Length', 'UNKNOWN'),
49 result.headers.get('Date', 'UNKNOWN'),
50 result.headers.get('Last-Modified', 'UNKNOWN'))
51 return result
52
53
54 def url_download(url, filename, data=None, timeout=300):
55 """
56 Retrieve a file from given url.
57
58 :param url: source URL.
59 :param filename: destination path.
60 :param data: (optional) data to post.
61 :param timeout: (optional) default timeout in seconds.
62 :return: `None`.
63 """
64 def download():
65 log.info('Fetching %s -> %s', url, filename)
66
67 src_file = url_open(url, data=data)
68 try:
69 with open(filename, 'wb') as dest_file:
70 shutil.copyfileobj(src_file, dest_file)
71 finally:
72 src_file.close()
73
74 process = Process(target=download)
75 process.start()
76 process.join(timeout)
77 if process.is_alive():
78 process.terminate()
79 process.join()
80 raise OSError("Aborting downloading. Timeout was reach.")
81
82
83 def url_download_interactive(url, output_file, title='', chunk_size=102400):
84 """
85 Interactively downloads a given file url to a given output file.
86
87 :type url: string
88 :param url: URL for the file to be download
89 :type output_file: string
90 :param output_file: file name or absolute path on which to save the file to
91 :type title: string
92 :param title: optional title to go along the progress bar
93 :type chunk_size: integer
94 :param chunk_size: amount of data to read at a time
95 """
96 output_dir = os.path.dirname(output_file)
97 with open(output_file, 'w+b') as open_output_file:
98 input_file = urlopen(url)
99
100 try:
101 file_size = int(input_file.headers['Content-Length'])
102 except KeyError:
103 raise ValueError('Could not find file size in HTTP headers')
104
105 log.info('Downloading %s, %s to %s', os.path.basename(url),
106 output.display_data_size(file_size), output_dir)
107
108 progress_bar = output.ProgressBar(maximum=file_size, title=title)
109
110 # Download the file, while interactively updating the progress
111 progress_bar.draw()
112 while True:
113 data = input_file.read(chunk_size)
114 if data:
115 progress_bar.append_amount(len(data))
116 open_output_file.write(data)
117 else:
118 progress_bar.update_amount(file_size)
119 break
120
121
122 def _get_file(src, dst, permissions=None):
123 if src == dst:
124 return
125
126 if aurl.is_url(src):
127 url_download(src, dst)
128 else:
129 shutil.copyfile(src, dst)
130
131 if permissions:
132 os.chmod(dst, permissions)
133 return dst
134
135
136 def get_file(src, dst, permissions=None, hash_expected=None,
137 hash_algorithm="md5", download_retries=1):
138 """
139 Gets a file from a source location, optionally using caching.
140
141 If no hash_expected is provided, simply download the file. Else,
142 keep trying to download the file until download_failures exceeds
143 download_retries or the hashes match.
144
145 If the hashes match, return dst. If download_failures exceeds
146 download_retries, raise an EnvironmentError.
147
148 :param src: source path or URL. May be local or a remote file.
149 :param dst: destination path.
150 :param permissions: (optional) set access permissions.
151 :param hash_expected: Hash string that we expect the file downloaded to
152 have.
153 :param hash_algorithm: Algorithm used to calculate the hash string
154 (md5, sha1).
155 :param download_retries: Number of times we are going to retry a failed
156 download.
157 :raise: EnvironmentError.
158 :return: destination path.
159 """
160 def _verify_hash(filename):
161 if os.path.isfile(filename):
162 return crypto.hash_file(filename, algorithm=hash_algorithm)
163 return None
164
165 if hash_expected is None:
166 return _get_file(src, dst, permissions)
167
168 download_failures = 0
169 hash_file = _verify_hash(dst)
170
171 while not hash_file == hash_expected:
172 hash_file = _verify_hash(_get_file(src, dst, permissions))
173 if hash_file != hash_expected:
174 log.error("It seems that dst %s is corrupted", dst)
175 download_failures += 1
176 if download_failures > download_retries:
177 raise EnvironmentError("Failed to retrieve %s. "
178 "Possible reasons - Network connectivity "
179 "problems or incorrect hash_expected "
180 "provided -> '%s'" %
181 (src, hash_expected))
182 else:
183 log.error("Retrying download of src %s", src)
184
185 return dst
186
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/avocado/utils/download.py b/avocado/utils/download.py
--- a/avocado/utils/download.py
+++ b/avocado/utils/download.py
@@ -20,12 +20,14 @@
import logging
import os
import shutil
+import socket
+import sys
from multiprocessing import Process
from urllib.request import urlopen
from . import aurl, crypto, output
-log = logging.getLogger('avocado.test')
+log = logging.getLogger('avocado.utils.download')
def url_open(url, data=None, timeout=5):
@@ -41,7 +43,13 @@
:return: file-like object.
:raises: `URLError`.
"""
- result = urlopen(url, data=data, timeout=timeout)
+ try:
+ result = urlopen(url, data=data, timeout=timeout)
+ except socket.timeout as ex:
+ msg = "Timeout was reach: {}".format(str(ex))
+ log.error(msg)
+ return None
+
msg = ('Retrieved URL "%s": content-length %s, date: "%s", '
'last-modified: "%s"')
log.debug(msg, url,
@@ -62,9 +70,13 @@
:return: `None`.
"""
def download():
- log.info('Fetching %s -> %s', url, filename)
-
src_file = url_open(url, data=data)
+ if not src_file:
+ msg = ("Failed to get file. Probably timeout was reach when "
+ "connecting to the server.\n")
+ sys.stderr.write(msg)
+ sys.exit(1)
+
try:
with open(filename, 'wb') as dest_file:
shutil.copyfileobj(src_file, dest_file)
@@ -72,6 +84,7 @@
src_file.close()
process = Process(target=download)
+ log.info('Fetching %s -> %s', url, filename)
process.start()
process.join(timeout)
if process.is_alive():
|
{"golden_diff": "diff --git a/avocado/utils/download.py b/avocado/utils/download.py\n--- a/avocado/utils/download.py\n+++ b/avocado/utils/download.py\n@@ -20,12 +20,14 @@\n import logging\n import os\n import shutil\n+import socket\n+import sys\n from multiprocessing import Process\n from urllib.request import urlopen\n \n from . import aurl, crypto, output\n \n-log = logging.getLogger('avocado.test')\n+log = logging.getLogger('avocado.utils.download')\n \n \n def url_open(url, data=None, timeout=5):\n@@ -41,7 +43,13 @@\n :return: file-like object.\n :raises: `URLError`.\n \"\"\"\n- result = urlopen(url, data=data, timeout=timeout)\n+ try:\n+ result = urlopen(url, data=data, timeout=timeout)\n+ except socket.timeout as ex:\n+ msg = \"Timeout was reach: {}\".format(str(ex))\n+ log.error(msg)\n+ return None\n+\n msg = ('Retrieved URL \"%s\": content-length %s, date: \"%s\", '\n 'last-modified: \"%s\"')\n log.debug(msg, url,\n@@ -62,9 +70,13 @@\n :return: `None`.\n \"\"\"\n def download():\n- log.info('Fetching %s -> %s', url, filename)\n-\n src_file = url_open(url, data=data)\n+ if not src_file:\n+ msg = (\"Failed to get file. Probably timeout was reach when \"\n+ \"connecting to the server.\\n\")\n+ sys.stderr.write(msg)\n+ sys.exit(1)\n+\n try:\n with open(filename, 'wb') as dest_file:\n shutil.copyfileobj(src_file, dest_file)\n@@ -72,6 +84,7 @@\n src_file.close()\n \n process = Process(target=download)\n+ log.info('Fetching %s -> %s', url, filename)\n process.start()\n process.join(timeout)\n if process.is_alive():\n", "issue": "assets fetch: handshake timeout it is not being caught\nDuring investigation of #4824 I found a problem with timeout during handshake.\r\n\r\n\r\n```\r\nProcess Process-1:\r\nTraceback (most recent call last):\r\n File \"/usr/lib64/python3.7/urllib/request.py\", line 1350, in do_open\r\n encode_chunked=req.has_header('Transfer-encoding'))\r\n File \"/usr/lib64/python3.7/http/client.py\", line 1277, in request\r\n self._send_request(method, url, body, headers, encode_chunked)\r\n File \"/usr/lib64/python3.7/http/client.py\", line 1323, in _send_request\r\n self.endheaders(body, encode_chunked=encode_chunked)\r\n File \"/usr/lib64/python3.7/http/client.py\", line 1272, in endheaders\r\n self._send_output(message_body, encode_chunked=encode_chunked)\r\n File \"/usr/lib64/python3.7/http/client.py\", line 1032, in _send_output\r\n self.send(msg)\r\n File \"/usr/lib64/python3.7/http/client.py\", line 972, in send\r\n self.connect()\r\n File \"/usr/lib64/python3.7/http/client.py\", line 1447, in connect\r\n server_hostname=server_hostname)\r\n File \"/usr/lib64/python3.7/ssl.py\", line 423, in wrap_socket\r\n session=session\r\n File \"/usr/lib64/python3.7/ssl.py\", line 870, in _create\r\n self.do_handshake()\r\n File \"/usr/lib64/python3.7/ssl.py\", line 1139, in do_handshake\r\n self._sslobj.do_handshake()\r\nsocket.timeout: _ssl.c:1074: The handshake operation timed out\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/usr/lib64/python3.7/multiprocessing/process.py\", line 297, in _bootstrap\r\n self.run()\r\n File \"/usr/lib64/python3.7/multiprocessing/process.py\", line 99, in run\r\n self._target(*self._args, **self._kwargs)\r\n File \"/home/local/src/beraldo/avocado/avocado/utils/download.py\", line 69, in download\r\n src_file = url_open(url, data=data)\r\n File \"/home/local/src/beraldo/avocado/avocado/utils/download.py\", line 46, in url_open\r\n result = urlopen(url, data=data, timeout=timeout)\r\n File \"/usr/lib64/python3.7/urllib/request.py\", line 222, in urlopen\r\n return opener.open(url, data, timeout)\r\n File \"/usr/lib64/python3.7/urllib/request.py\", line 525, in open\r\n response = self._open(req, data)\r\n File \"/usr/lib64/python3.7/urllib/request.py\", line 543, in _open\r\n '_open', req)\r\n File \"/usr/lib64/python3.7/urllib/request.py\", line 503, in _call_chain\r\n result = func(*args)\r\n File \"/usr/lib64/python3.7/urllib/request.py\", line 1393, in https_open\r\n context=self._context, check_hostname=self._check_hostname)\r\n File \"/usr/lib64/python3.7/urllib/request.py\", line 1352, in do_open\r\n raise URLError(err)\r\nurllib.error.URLError: <urlopen error _ssl.c:1074: The handshake operation timed out>\r\nFailed to fetch download ([Errno 2] No such file or directory: '/home/local/avocado/data/cache/by_location/4135b9170bbc2afc3ec7f79c169bf722b4d2afe7/download.cd7fe814-e6c0-4b10-82cd-e390d92fa099').\r\n(avocado-py3.7) [local@laptop avocado]$ \r\n```\r\n\r\nProbably this is related to 9b75f9d62faf53248fc687bd6e4dde85bb705b56, but I'm still investigating.\n", "before_files": [{"content": "# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; specifically version 2 of the License.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.\n#\n# See LICENSE for more details.\n#\n# This code was inspired in the autotest project,\n# client/shared/utils.py\n# Authors: Martin J Bligh <mbligh@google.com>, Andy Whitcroft <apw@shadowen.org>\n\n\n\"\"\"\nMethods to download URLs and regular files.\n\"\"\"\n\nimport logging\nimport os\nimport shutil\nfrom multiprocessing import Process\nfrom urllib.request import urlopen\n\nfrom . import aurl, crypto, output\n\nlog = logging.getLogger('avocado.test')\n\n\ndef url_open(url, data=None, timeout=5):\n \"\"\"\n Wrapper to :func:`urllib2.urlopen` with timeout addition.\n\n :param url: URL to open.\n :param data: (optional) data to post.\n :param timeout: (optional) default timeout in seconds. Please, be aware\n that timeout here is just for blocking operations during\n the connection setup, since this method doesn't read the\n file from the url.\n :return: file-like object.\n :raises: `URLError`.\n \"\"\"\n result = urlopen(url, data=data, timeout=timeout)\n msg = ('Retrieved URL \"%s\": content-length %s, date: \"%s\", '\n 'last-modified: \"%s\"')\n log.debug(msg, url,\n result.headers.get('Content-Length', 'UNKNOWN'),\n result.headers.get('Date', 'UNKNOWN'),\n result.headers.get('Last-Modified', 'UNKNOWN'))\n return result\n\n\ndef url_download(url, filename, data=None, timeout=300):\n \"\"\"\n Retrieve a file from given url.\n\n :param url: source URL.\n :param filename: destination path.\n :param data: (optional) data to post.\n :param timeout: (optional) default timeout in seconds.\n :return: `None`.\n \"\"\"\n def download():\n log.info('Fetching %s -> %s', url, filename)\n\n src_file = url_open(url, data=data)\n try:\n with open(filename, 'wb') as dest_file:\n shutil.copyfileobj(src_file, dest_file)\n finally:\n src_file.close()\n\n process = Process(target=download)\n process.start()\n process.join(timeout)\n if process.is_alive():\n process.terminate()\n process.join()\n raise OSError(\"Aborting downloading. Timeout was reach.\")\n\n\ndef url_download_interactive(url, output_file, title='', chunk_size=102400):\n \"\"\"\n Interactively downloads a given file url to a given output file.\n\n :type url: string\n :param url: URL for the file to be download\n :type output_file: string\n :param output_file: file name or absolute path on which to save the file to\n :type title: string\n :param title: optional title to go along the progress bar\n :type chunk_size: integer\n :param chunk_size: amount of data to read at a time\n \"\"\"\n output_dir = os.path.dirname(output_file)\n with open(output_file, 'w+b') as open_output_file:\n input_file = urlopen(url)\n\n try:\n file_size = int(input_file.headers['Content-Length'])\n except KeyError:\n raise ValueError('Could not find file size in HTTP headers')\n\n log.info('Downloading %s, %s to %s', os.path.basename(url),\n output.display_data_size(file_size), output_dir)\n\n progress_bar = output.ProgressBar(maximum=file_size, title=title)\n\n # Download the file, while interactively updating the progress\n progress_bar.draw()\n while True:\n data = input_file.read(chunk_size)\n if data:\n progress_bar.append_amount(len(data))\n open_output_file.write(data)\n else:\n progress_bar.update_amount(file_size)\n break\n\n\ndef _get_file(src, dst, permissions=None):\n if src == dst:\n return\n\n if aurl.is_url(src):\n url_download(src, dst)\n else:\n shutil.copyfile(src, dst)\n\n if permissions:\n os.chmod(dst, permissions)\n return dst\n\n\ndef get_file(src, dst, permissions=None, hash_expected=None,\n hash_algorithm=\"md5\", download_retries=1):\n \"\"\"\n Gets a file from a source location, optionally using caching.\n\n If no hash_expected is provided, simply download the file. Else,\n keep trying to download the file until download_failures exceeds\n download_retries or the hashes match.\n\n If the hashes match, return dst. If download_failures exceeds\n download_retries, raise an EnvironmentError.\n\n :param src: source path or URL. May be local or a remote file.\n :param dst: destination path.\n :param permissions: (optional) set access permissions.\n :param hash_expected: Hash string that we expect the file downloaded to\n have.\n :param hash_algorithm: Algorithm used to calculate the hash string\n (md5, sha1).\n :param download_retries: Number of times we are going to retry a failed\n download.\n :raise: EnvironmentError.\n :return: destination path.\n \"\"\"\n def _verify_hash(filename):\n if os.path.isfile(filename):\n return crypto.hash_file(filename, algorithm=hash_algorithm)\n return None\n\n if hash_expected is None:\n return _get_file(src, dst, permissions)\n\n download_failures = 0\n hash_file = _verify_hash(dst)\n\n while not hash_file == hash_expected:\n hash_file = _verify_hash(_get_file(src, dst, permissions))\n if hash_file != hash_expected:\n log.error(\"It seems that dst %s is corrupted\", dst)\n download_failures += 1\n if download_failures > download_retries:\n raise EnvironmentError(\"Failed to retrieve %s. \"\n \"Possible reasons - Network connectivity \"\n \"problems or incorrect hash_expected \"\n \"provided -> '%s'\" %\n (src, hash_expected))\n else:\n log.error(\"Retrying download of src %s\", src)\n\n return dst\n", "path": "avocado/utils/download.py"}], "after_files": [{"content": "# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; specifically version 2 of the License.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.\n#\n# See LICENSE for more details.\n#\n# This code was inspired in the autotest project,\n# client/shared/utils.py\n# Authors: Martin J Bligh <mbligh@google.com>, Andy Whitcroft <apw@shadowen.org>\n\n\n\"\"\"\nMethods to download URLs and regular files.\n\"\"\"\n\nimport logging\nimport os\nimport shutil\nimport socket\nimport sys\nfrom multiprocessing import Process\nfrom urllib.request import urlopen\n\nfrom . import aurl, crypto, output\n\nlog = logging.getLogger('avocado.utils.download')\n\n\ndef url_open(url, data=None, timeout=5):\n \"\"\"\n Wrapper to :func:`urllib2.urlopen` with timeout addition.\n\n :param url: URL to open.\n :param data: (optional) data to post.\n :param timeout: (optional) default timeout in seconds. Please, be aware\n that timeout here is just for blocking operations during\n the connection setup, since this method doesn't read the\n file from the url.\n :return: file-like object.\n :raises: `URLError`.\n \"\"\"\n try:\n result = urlopen(url, data=data, timeout=timeout)\n except socket.timeout as ex:\n msg = \"Timeout was reach: {}\".format(str(ex))\n log.error(msg)\n return None\n\n msg = ('Retrieved URL \"%s\": content-length %s, date: \"%s\", '\n 'last-modified: \"%s\"')\n log.debug(msg, url,\n result.headers.get('Content-Length', 'UNKNOWN'),\n result.headers.get('Date', 'UNKNOWN'),\n result.headers.get('Last-Modified', 'UNKNOWN'))\n return result\n\n\ndef url_download(url, filename, data=None, timeout=300):\n \"\"\"\n Retrieve a file from given url.\n\n :param url: source URL.\n :param filename: destination path.\n :param data: (optional) data to post.\n :param timeout: (optional) default timeout in seconds.\n :return: `None`.\n \"\"\"\n def download():\n src_file = url_open(url, data=data)\n if not src_file:\n msg = (\"Failed to get file. Probably timeout was reach when \"\n \"connecting to the server.\\n\")\n sys.stderr.write(msg)\n sys.exit(1)\n\n try:\n with open(filename, 'wb') as dest_file:\n shutil.copyfileobj(src_file, dest_file)\n finally:\n src_file.close()\n\n process = Process(target=download)\n log.info('Fetching %s -> %s', url, filename)\n process.start()\n process.join(timeout)\n if process.is_alive():\n process.terminate()\n process.join()\n raise OSError(\"Aborting downloading. Timeout was reach.\")\n\n\ndef url_download_interactive(url, output_file, title='', chunk_size=102400):\n \"\"\"\n Interactively downloads a given file url to a given output file.\n\n :type url: string\n :param url: URL for the file to be download\n :type output_file: string\n :param output_file: file name or absolute path on which to save the file to\n :type title: string\n :param title: optional title to go along the progress bar\n :type chunk_size: integer\n :param chunk_size: amount of data to read at a time\n \"\"\"\n output_dir = os.path.dirname(output_file)\n with open(output_file, 'w+b') as open_output_file:\n input_file = urlopen(url)\n\n try:\n file_size = int(input_file.headers['Content-Length'])\n except KeyError:\n raise ValueError('Could not find file size in HTTP headers')\n\n log.info('Downloading %s, %s to %s', os.path.basename(url),\n output.display_data_size(file_size), output_dir)\n\n progress_bar = output.ProgressBar(maximum=file_size, title=title)\n\n # Download the file, while interactively updating the progress\n progress_bar.draw()\n while True:\n data = input_file.read(chunk_size)\n if data:\n progress_bar.append_amount(len(data))\n open_output_file.write(data)\n else:\n progress_bar.update_amount(file_size)\n break\n\n\ndef _get_file(src, dst, permissions=None):\n if src == dst:\n return\n\n if aurl.is_url(src):\n url_download(src, dst)\n else:\n shutil.copyfile(src, dst)\n\n if permissions:\n os.chmod(dst, permissions)\n return dst\n\n\ndef get_file(src, dst, permissions=None, hash_expected=None,\n hash_algorithm=\"md5\", download_retries=1):\n \"\"\"\n Gets a file from a source location, optionally using caching.\n\n If no hash_expected is provided, simply download the file. Else,\n keep trying to download the file until download_failures exceeds\n download_retries or the hashes match.\n\n If the hashes match, return dst. If download_failures exceeds\n download_retries, raise an EnvironmentError.\n\n :param src: source path or URL. May be local or a remote file.\n :param dst: destination path.\n :param permissions: (optional) set access permissions.\n :param hash_expected: Hash string that we expect the file downloaded to\n have.\n :param hash_algorithm: Algorithm used to calculate the hash string\n (md5, sha1).\n :param download_retries: Number of times we are going to retry a failed\n download.\n :raise: EnvironmentError.\n :return: destination path.\n \"\"\"\n def _verify_hash(filename):\n if os.path.isfile(filename):\n return crypto.hash_file(filename, algorithm=hash_algorithm)\n return None\n\n if hash_expected is None:\n return _get_file(src, dst, permissions)\n\n download_failures = 0\n hash_file = _verify_hash(dst)\n\n while not hash_file == hash_expected:\n hash_file = _verify_hash(_get_file(src, dst, permissions))\n if hash_file != hash_expected:\n log.error(\"It seems that dst %s is corrupted\", dst)\n download_failures += 1\n if download_failures > download_retries:\n raise EnvironmentError(\"Failed to retrieve %s. \"\n \"Possible reasons - Network connectivity \"\n \"problems or incorrect hash_expected \"\n \"provided -> '%s'\" %\n (src, hash_expected))\n else:\n log.error(\"Retrying download of src %s\", src)\n\n return dst\n", "path": "avocado/utils/download.py"}]}
| 3,077 | 444 |
gh_patches_debug_11011
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-2996
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
TypeError: Cannot convert None of type <class 'NoneType'> to bytes (in formatting middleware?)
* Version: 5.24.0
* Python: 3.8
* OS: linux
* `pip freeze` output
```
aiohttp==3.8.1
aiosignal==1.2.0
astroid==2.11.5
async-timeout==4.0.2
attrs==21.4.0
base58==2.1.1
bitarray==1.2.2
black==21.12b0
blinker==1.4
boto3==1.23.0
boto3-stubs==1.23.0
botocore==1.26.0
botocore-stubs==1.26.0.post1
CacheControl==0.12.11
cachy==0.3.0
certifi==2021.10.8
cffi==1.15.0
charset-normalizer==2.0.12
cleo==0.8.1
click==8.0.4
clickclick==20.10.2
clikit==0.6.2
common==0.1.0
connexion==2.13.1
crashtest==0.3.1
cryptography==37.0.2
cytoolz==0.11.2
dill==0.3.4
distlib==0.3.4
ecdsa==0.17.0
eth-abi==2.1.1
eth-account==0.5.7
eth-hash==0.3.2
eth-keyfile==0.5.1
eth-keys==0.3.4
eth-rlp==0.2.1
eth-typing==2.3.0
eth-utils==1.10.0
filelock==3.7.0
flasgger==0.9.5
Flask==2.1.2
Flask-Pydantic==0.9.0
frozenlist==1.3.0
hexbytes==0.2.2
html5lib==1.1
idna==3.3
importlib-metadata==4.11.3
importlib-resources==5.6.0
inflection==0.5.1
iniconfig==1.1.1
ipfshttpclient==0.8.0a2
isort==5.10.1
itsdangerous==2.1.2
jeepney==0.8.0
Jinja2==3.1.2
jmespath==1.0.0
jsonschema==3.2.0
keyring==23.5.0
lazy-object-proxy==1.7.1
lockfile==0.12.2
lru-dict==1.1.7
MarkupSafe==2.1.1
mccabe==0.7.0
mistune==2.0.2
msgpack==1.0.3
multiaddr==0.0.9
multidict==6.0.2
mypy==0.910
mypy-extensions==0.4.3
netaddr==0.8.0
openapi-schema-validator==0.2.3
openapi-spec-validator==0.3.1
packaging==20.9
parsimonious==0.8.1
pastel==0.2.1
pathspec==0.9.0
pendulum==2.1.2
pexpect==4.8.0
pip==22.0.4
pkginfo==1.8.2
platformdirs==2.5.2
pluggy==1.0.0
poetry==1.1.13
poetry-core==1.0.8
protobuf==3.20.1
ptyprocess==0.7.0
py==1.11.0
pyasn1==0.4.8
pycparser==2.21
pycryptodome==3.14.1
pydantic==1.9.0
pylev==1.4.0
pylint==2.13.9
pyparsing==3.0.9
pyrsistent==0.16.1
pytest==7.1.2
python-dateutil==2.8.2
python-dotenv==0.19.2
python-jose==3.3.0
pytzdata==2020.1
PyYAML==5.4.1
requests==2.27.1
requests-toolbelt==0.9.1
rlp==2.0.1
rsa==4.8
s3transfer==0.5.2
SecretStorage==3.3.2
sentry-sdk==1.5.12
setuptools==62.1.0
shellingham==1.4.0
six==1.16.0
swagger-ui-bundle==0.0.9
toml==0.10.2
tomli==1.2.3
tomlkit==0.10.2
toolz==0.11.2
types-boto3==1.0.2
types-requests==2.27.25
types-urllib3==1.26.14
typing_extensions==4.2.0
urllib3==1.26.9
varint==1.0.2
virtualenv==20.14.1
web3==5.24.0
webencodings==0.5.1
websockets==9.1
Werkzeug==2.1.2
wheel==0.37.1
wrapt==1.14.1
yarl==1.7.2
zipp==3.8.0
```
### What was wrong?
on a company project we're getting the following error once every few moons
```
Traceback (most recent call last):
.... (company code that calls contract.functions.functionName().call())
File "/usr/local/lib/python3.8/site-packages/web3/contract.py", line 959, in call
return call_contract_function(
File "/usr/local/lib/python3.8/site-packages/web3/contract.py", line 1503, in call_contract_function
return_data = web3.eth.call(
File "/usr/local/lib/python3.8/site-packages/web3/module.py", line 57, in caller
result = w3.manager.request_blocking(method_str,
File "/usr/local/lib/python3.8/site-packages/web3/manager.py", line 186, in request_blocking
response = self._make_request(method, params)
File "/usr/local/lib/python3.8/site-packages/web3/manager.py", line 147, in _make_request
return request_func(method, params)
File "cytoolz/functoolz.pyx", line 254, in cytoolz.functoolz.curry.__call__
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/usr/local/lib/python3.8/site-packages/web3/middleware/formatting.py", line 76, in apply_formatters
response = make_request(method, params)
File "/usr/local/lib/python3.8/site-packages/web3/middleware/gas_price_strategy.py", line 90, in middleware
return make_request(method, params)
File "cytoolz/functoolz.pyx", line 254, in cytoolz.functoolz.curry.__call__
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/usr/local/lib/python3.8/site-packages/web3/middleware/formatting.py", line 74, in apply_formatters
response = make_request(method, formatted_params)
File "/usr/local/lib/python3.8/site-packages/web3/middleware/attrdict.py", line 33, in middleware
response = make_request(method, params)
File "cytoolz/functoolz.pyx", line 254, in cytoolz.functoolz.curry.__call__
File "cytoolz/functoolz.pyx", line 250, in cytoolz.functoolz.curry.__call__
File "/usr/local/lib/python3.8/site-packages/web3/middleware/formatting.py", line 83, in apply_formatters
formatter(response["result"]),
File "/usr/local/lib/python3.8/site-packages/hexbytes/main.py", line 23, in __new__
bytesval = to_bytes(val)
File "/usr/local/lib/python3.8/site-packages/hexbytes/_utils.py", line 30, in to_bytes
raise TypeError(f"Cannot convert {val!r} of type {type(val)} to bytes")
TypeError: Cannot convert None of type <class 'NoneType'> to bytes
```
unfortunately we haven't managed to find code to reproduce this issue consistently, it just happens sometimes on a pretty standard `call` that we issue quite often and that almost always succeeds. any pointers would be appreciated !
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `web3/middleware/formatting.py`
Content:
```
1 from typing import (
2 TYPE_CHECKING,
3 Any,
4 Callable,
5 Coroutine,
6 Optional,
7 )
8
9 from eth_utils.toolz import (
10 assoc,
11 merge,
12 )
13
14 from web3.types import (
15 AsyncMiddleware,
16 AsyncMiddlewareCoroutine,
17 Formatters,
18 FormattersDict,
19 Literal,
20 Middleware,
21 RPCEndpoint,
22 RPCResponse,
23 )
24
25 if TYPE_CHECKING:
26 from web3 import ( # noqa: F401
27 AsyncWeb3,
28 Web3,
29 )
30
31 FORMATTER_DEFAULTS: FormattersDict = {
32 "request_formatters": {},
33 "result_formatters": {},
34 "error_formatters": {},
35 }
36
37
38 def _apply_response_formatters(
39 method: RPCEndpoint,
40 response: RPCResponse,
41 result_formatters: Formatters,
42 error_formatters: Formatters,
43 ) -> RPCResponse:
44 def _format_response(
45 response_type: Literal["result", "error"],
46 method_response_formatter: Callable[..., Any],
47 ) -> RPCResponse:
48 appropriate_response = response[response_type]
49 return assoc(
50 response, response_type, method_response_formatter(appropriate_response)
51 )
52
53 if "result" in response and method in result_formatters:
54 return _format_response("result", result_formatters[method])
55 elif "error" in response and method in error_formatters:
56 return _format_response("error", error_formatters[method])
57 else:
58 return response
59
60
61 # --- sync -- #
62
63
64 def construct_formatting_middleware(
65 request_formatters: Optional[Formatters] = None,
66 result_formatters: Optional[Formatters] = None,
67 error_formatters: Optional[Formatters] = None,
68 ) -> Middleware:
69 def ignore_web3_in_standard_formatters(
70 _w3: "Web3",
71 _method: RPCEndpoint,
72 ) -> FormattersDict:
73 return dict(
74 request_formatters=request_formatters or {},
75 result_formatters=result_formatters or {},
76 error_formatters=error_formatters or {},
77 )
78
79 return construct_web3_formatting_middleware(ignore_web3_in_standard_formatters)
80
81
82 def construct_web3_formatting_middleware(
83 web3_formatters_builder: Callable[["Web3", RPCEndpoint], FormattersDict],
84 ) -> Middleware:
85 def formatter_middleware(
86 make_request: Callable[[RPCEndpoint, Any], Any],
87 w3: "Web3",
88 ) -> Callable[[RPCEndpoint, Any], RPCResponse]:
89 def middleware(method: RPCEndpoint, params: Any) -> RPCResponse:
90 formatters = merge(
91 FORMATTER_DEFAULTS,
92 web3_formatters_builder(w3, method),
93 )
94 request_formatters = formatters.pop("request_formatters")
95
96 if method in request_formatters:
97 formatter = request_formatters[method]
98 params = formatter(params)
99 response = make_request(method, params)
100
101 return _apply_response_formatters(
102 method=method, response=response, **formatters
103 )
104
105 return middleware
106
107 return formatter_middleware
108
109
110 # --- async --- #
111
112
113 async def async_construct_formatting_middleware(
114 request_formatters: Optional[Formatters] = None,
115 result_formatters: Optional[Formatters] = None,
116 error_formatters: Optional[Formatters] = None,
117 ) -> AsyncMiddleware:
118 async def ignore_web3_in_standard_formatters(
119 _async_w3: "AsyncWeb3",
120 _method: RPCEndpoint,
121 ) -> FormattersDict:
122 return dict(
123 request_formatters=request_formatters or {},
124 result_formatters=result_formatters or {},
125 error_formatters=error_formatters or {},
126 )
127
128 return await async_construct_web3_formatting_middleware(
129 ignore_web3_in_standard_formatters
130 )
131
132
133 async def async_construct_web3_formatting_middleware(
134 async_web3_formatters_builder: Callable[
135 ["AsyncWeb3", RPCEndpoint], Coroutine[Any, Any, FormattersDict]
136 ]
137 ) -> Callable[
138 [Callable[[RPCEndpoint, Any], Any], "AsyncWeb3"],
139 Coroutine[Any, Any, AsyncMiddlewareCoroutine],
140 ]:
141 async def formatter_middleware(
142 make_request: Callable[[RPCEndpoint, Any], Any],
143 w3: "AsyncWeb3",
144 ) -> AsyncMiddlewareCoroutine:
145 async def middleware(method: RPCEndpoint, params: Any) -> RPCResponse:
146 formatters = merge(
147 FORMATTER_DEFAULTS,
148 await async_web3_formatters_builder(w3, method),
149 )
150 request_formatters = formatters.pop("request_formatters")
151
152 if method in request_formatters:
153 formatter = request_formatters[method]
154 params = formatter(params)
155 response = await make_request(method, params)
156
157 return _apply_response_formatters(
158 method=method, response=response, **formatters
159 )
160
161 return middleware
162
163 return formatter_middleware
164
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/web3/middleware/formatting.py b/web3/middleware/formatting.py
--- a/web3/middleware/formatting.py
+++ b/web3/middleware/formatting.py
@@ -50,7 +50,11 @@
response, response_type, method_response_formatter(appropriate_response)
)
- if "result" in response and method in result_formatters:
+ if (
+ "result" in response
+ and response["result"] is not None
+ and method in result_formatters
+ ):
return _format_response("result", result_formatters[method])
elif "error" in response and method in error_formatters:
return _format_response("error", error_formatters[method])
|
{"golden_diff": "diff --git a/web3/middleware/formatting.py b/web3/middleware/formatting.py\n--- a/web3/middleware/formatting.py\n+++ b/web3/middleware/formatting.py\n@@ -50,7 +50,11 @@\n response, response_type, method_response_formatter(appropriate_response)\n )\n \n- if \"result\" in response and method in result_formatters:\n+ if (\n+ \"result\" in response\n+ and response[\"result\"] is not None\n+ and method in result_formatters\n+ ):\n return _format_response(\"result\", result_formatters[method])\n elif \"error\" in response and method in error_formatters:\n return _format_response(\"error\", error_formatters[method])\n", "issue": "TypeError: Cannot convert None of type <class 'NoneType'> to bytes (in formatting middleware?)\n* Version: 5.24.0\r\n* Python: 3.8\r\n* OS: linux\r\n* `pip freeze` output\r\n\r\n```\r\naiohttp==3.8.1\r\naiosignal==1.2.0\r\nastroid==2.11.5\r\nasync-timeout==4.0.2\r\nattrs==21.4.0\r\nbase58==2.1.1\r\nbitarray==1.2.2\r\nblack==21.12b0\r\nblinker==1.4\r\nboto3==1.23.0\r\nboto3-stubs==1.23.0\r\nbotocore==1.26.0\r\nbotocore-stubs==1.26.0.post1\r\nCacheControl==0.12.11\r\ncachy==0.3.0\r\ncertifi==2021.10.8\r\ncffi==1.15.0\r\ncharset-normalizer==2.0.12\r\ncleo==0.8.1\r\nclick==8.0.4\r\nclickclick==20.10.2\r\nclikit==0.6.2\r\ncommon==0.1.0\r\nconnexion==2.13.1\r\ncrashtest==0.3.1\r\ncryptography==37.0.2\r\ncytoolz==0.11.2\r\ndill==0.3.4\r\ndistlib==0.3.4\r\necdsa==0.17.0\r\neth-abi==2.1.1\r\neth-account==0.5.7\r\neth-hash==0.3.2\r\neth-keyfile==0.5.1\r\neth-keys==0.3.4\r\neth-rlp==0.2.1\r\neth-typing==2.3.0\r\neth-utils==1.10.0\r\nfilelock==3.7.0\r\nflasgger==0.9.5\r\nFlask==2.1.2\r\nFlask-Pydantic==0.9.0\r\nfrozenlist==1.3.0\r\nhexbytes==0.2.2\r\nhtml5lib==1.1\r\nidna==3.3\r\nimportlib-metadata==4.11.3\r\nimportlib-resources==5.6.0\r\ninflection==0.5.1\r\niniconfig==1.1.1\r\nipfshttpclient==0.8.0a2\r\nisort==5.10.1\r\nitsdangerous==2.1.2\r\njeepney==0.8.0\r\nJinja2==3.1.2\r\njmespath==1.0.0\r\njsonschema==3.2.0\r\nkeyring==23.5.0\r\nlazy-object-proxy==1.7.1\r\nlockfile==0.12.2\r\nlru-dict==1.1.7\r\nMarkupSafe==2.1.1\r\nmccabe==0.7.0\r\nmistune==2.0.2\r\nmsgpack==1.0.3\r\nmultiaddr==0.0.9\r\nmultidict==6.0.2\r\nmypy==0.910\r\nmypy-extensions==0.4.3\r\nnetaddr==0.8.0\r\nopenapi-schema-validator==0.2.3\r\nopenapi-spec-validator==0.3.1\r\npackaging==20.9\r\nparsimonious==0.8.1\r\npastel==0.2.1\r\npathspec==0.9.0\r\npendulum==2.1.2\r\npexpect==4.8.0\r\npip==22.0.4\r\npkginfo==1.8.2\r\nplatformdirs==2.5.2\r\npluggy==1.0.0\r\npoetry==1.1.13\r\npoetry-core==1.0.8\r\nprotobuf==3.20.1\r\nptyprocess==0.7.0\r\npy==1.11.0\r\npyasn1==0.4.8\r\npycparser==2.21\r\npycryptodome==3.14.1\r\npydantic==1.9.0\r\npylev==1.4.0\r\npylint==2.13.9\r\npyparsing==3.0.9\r\npyrsistent==0.16.1\r\npytest==7.1.2\r\npython-dateutil==2.8.2\r\npython-dotenv==0.19.2\r\npython-jose==3.3.0\r\npytzdata==2020.1\r\nPyYAML==5.4.1\r\nrequests==2.27.1\r\nrequests-toolbelt==0.9.1\r\nrlp==2.0.1\r\nrsa==4.8\r\ns3transfer==0.5.2\r\nSecretStorage==3.3.2\r\nsentry-sdk==1.5.12\r\nsetuptools==62.1.0\r\nshellingham==1.4.0\r\nsix==1.16.0\r\nswagger-ui-bundle==0.0.9\r\ntoml==0.10.2\r\ntomli==1.2.3\r\ntomlkit==0.10.2\r\ntoolz==0.11.2\r\ntypes-boto3==1.0.2\r\ntypes-requests==2.27.25\r\ntypes-urllib3==1.26.14\r\ntyping_extensions==4.2.0\r\nurllib3==1.26.9\r\nvarint==1.0.2\r\nvirtualenv==20.14.1\r\nweb3==5.24.0\r\nwebencodings==0.5.1\r\nwebsockets==9.1\r\nWerkzeug==2.1.2\r\nwheel==0.37.1\r\nwrapt==1.14.1\r\nyarl==1.7.2\r\nzipp==3.8.0\r\n```\r\n\r\n\r\n### What was wrong?\r\n\r\non a company project we're getting the following error once every few moons\r\n```\r\nTraceback (most recent call last):\r\n .... (company code that calls contract.functions.functionName().call())\r\n File \"/usr/local/lib/python3.8/site-packages/web3/contract.py\", line 959, in call\r\n return call_contract_function(\r\n File \"/usr/local/lib/python3.8/site-packages/web3/contract.py\", line 1503, in call_contract_function\r\n return_data = web3.eth.call(\r\n File \"/usr/local/lib/python3.8/site-packages/web3/module.py\", line 57, in caller\r\n result = w3.manager.request_blocking(method_str,\r\n File \"/usr/local/lib/python3.8/site-packages/web3/manager.py\", line 186, in request_blocking\r\n response = self._make_request(method, params)\r\n File \"/usr/local/lib/python3.8/site-packages/web3/manager.py\", line 147, in _make_request\r\n return request_func(method, params)\r\n File \"cytoolz/functoolz.pyx\", line 254, in cytoolz.functoolz.curry.__call__\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/usr/local/lib/python3.8/site-packages/web3/middleware/formatting.py\", line 76, in apply_formatters\r\n response = make_request(method, params)\r\n File \"/usr/local/lib/python3.8/site-packages/web3/middleware/gas_price_strategy.py\", line 90, in middleware\r\n return make_request(method, params)\r\n File \"cytoolz/functoolz.pyx\", line 254, in cytoolz.functoolz.curry.__call__\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/usr/local/lib/python3.8/site-packages/web3/middleware/formatting.py\", line 74, in apply_formatters\r\n response = make_request(method, formatted_params)\r\n File \"/usr/local/lib/python3.8/site-packages/web3/middleware/attrdict.py\", line 33, in middleware\r\n response = make_request(method, params)\r\n File \"cytoolz/functoolz.pyx\", line 254, in cytoolz.functoolz.curry.__call__\r\n File \"cytoolz/functoolz.pyx\", line 250, in cytoolz.functoolz.curry.__call__\r\n File \"/usr/local/lib/python3.8/site-packages/web3/middleware/formatting.py\", line 83, in apply_formatters\r\n formatter(response[\"result\"]),\r\n File \"/usr/local/lib/python3.8/site-packages/hexbytes/main.py\", line 23, in __new__\r\n bytesval = to_bytes(val)\r\n File \"/usr/local/lib/python3.8/site-packages/hexbytes/_utils.py\", line 30, in to_bytes\r\n raise TypeError(f\"Cannot convert {val!r} of type {type(val)} to bytes\")\r\nTypeError: Cannot convert None of type <class 'NoneType'> to bytes\r\n```\r\n\r\nunfortunately we haven't managed to find code to reproduce this issue consistently, it just happens sometimes on a pretty standard `call` that we issue quite often and that almost always succeeds. any pointers would be appreciated !\r\n\n", "before_files": [{"content": "from typing import (\n TYPE_CHECKING,\n Any,\n Callable,\n Coroutine,\n Optional,\n)\n\nfrom eth_utils.toolz import (\n assoc,\n merge,\n)\n\nfrom web3.types import (\n AsyncMiddleware,\n AsyncMiddlewareCoroutine,\n Formatters,\n FormattersDict,\n Literal,\n Middleware,\n RPCEndpoint,\n RPCResponse,\n)\n\nif TYPE_CHECKING:\n from web3 import ( # noqa: F401\n AsyncWeb3,\n Web3,\n )\n\nFORMATTER_DEFAULTS: FormattersDict = {\n \"request_formatters\": {},\n \"result_formatters\": {},\n \"error_formatters\": {},\n}\n\n\ndef _apply_response_formatters(\n method: RPCEndpoint,\n response: RPCResponse,\n result_formatters: Formatters,\n error_formatters: Formatters,\n) -> RPCResponse:\n def _format_response(\n response_type: Literal[\"result\", \"error\"],\n method_response_formatter: Callable[..., Any],\n ) -> RPCResponse:\n appropriate_response = response[response_type]\n return assoc(\n response, response_type, method_response_formatter(appropriate_response)\n )\n\n if \"result\" in response and method in result_formatters:\n return _format_response(\"result\", result_formatters[method])\n elif \"error\" in response and method in error_formatters:\n return _format_response(\"error\", error_formatters[method])\n else:\n return response\n\n\n# --- sync -- #\n\n\ndef construct_formatting_middleware(\n request_formatters: Optional[Formatters] = None,\n result_formatters: Optional[Formatters] = None,\n error_formatters: Optional[Formatters] = None,\n) -> Middleware:\n def ignore_web3_in_standard_formatters(\n _w3: \"Web3\",\n _method: RPCEndpoint,\n ) -> FormattersDict:\n return dict(\n request_formatters=request_formatters or {},\n result_formatters=result_formatters or {},\n error_formatters=error_formatters or {},\n )\n\n return construct_web3_formatting_middleware(ignore_web3_in_standard_formatters)\n\n\ndef construct_web3_formatting_middleware(\n web3_formatters_builder: Callable[[\"Web3\", RPCEndpoint], FormattersDict],\n) -> Middleware:\n def formatter_middleware(\n make_request: Callable[[RPCEndpoint, Any], Any],\n w3: \"Web3\",\n ) -> Callable[[RPCEndpoint, Any], RPCResponse]:\n def middleware(method: RPCEndpoint, params: Any) -> RPCResponse:\n formatters = merge(\n FORMATTER_DEFAULTS,\n web3_formatters_builder(w3, method),\n )\n request_formatters = formatters.pop(\"request_formatters\")\n\n if method in request_formatters:\n formatter = request_formatters[method]\n params = formatter(params)\n response = make_request(method, params)\n\n return _apply_response_formatters(\n method=method, response=response, **formatters\n )\n\n return middleware\n\n return formatter_middleware\n\n\n# --- async --- #\n\n\nasync def async_construct_formatting_middleware(\n request_formatters: Optional[Formatters] = None,\n result_formatters: Optional[Formatters] = None,\n error_formatters: Optional[Formatters] = None,\n) -> AsyncMiddleware:\n async def ignore_web3_in_standard_formatters(\n _async_w3: \"AsyncWeb3\",\n _method: RPCEndpoint,\n ) -> FormattersDict:\n return dict(\n request_formatters=request_formatters or {},\n result_formatters=result_formatters or {},\n error_formatters=error_formatters or {},\n )\n\n return await async_construct_web3_formatting_middleware(\n ignore_web3_in_standard_formatters\n )\n\n\nasync def async_construct_web3_formatting_middleware(\n async_web3_formatters_builder: Callable[\n [\"AsyncWeb3\", RPCEndpoint], Coroutine[Any, Any, FormattersDict]\n ]\n) -> Callable[\n [Callable[[RPCEndpoint, Any], Any], \"AsyncWeb3\"],\n Coroutine[Any, Any, AsyncMiddlewareCoroutine],\n]:\n async def formatter_middleware(\n make_request: Callable[[RPCEndpoint, Any], Any],\n w3: \"AsyncWeb3\",\n ) -> AsyncMiddlewareCoroutine:\n async def middleware(method: RPCEndpoint, params: Any) -> RPCResponse:\n formatters = merge(\n FORMATTER_DEFAULTS,\n await async_web3_formatters_builder(w3, method),\n )\n request_formatters = formatters.pop(\"request_formatters\")\n\n if method in request_formatters:\n formatter = request_formatters[method]\n params = formatter(params)\n response = await make_request(method, params)\n\n return _apply_response_formatters(\n method=method, response=response, **formatters\n )\n\n return middleware\n\n return formatter_middleware\n", "path": "web3/middleware/formatting.py"}], "after_files": [{"content": "from typing import (\n TYPE_CHECKING,\n Any,\n Callable,\n Coroutine,\n Optional,\n)\n\nfrom eth_utils.toolz import (\n assoc,\n merge,\n)\n\nfrom web3.types import (\n AsyncMiddleware,\n AsyncMiddlewareCoroutine,\n Formatters,\n FormattersDict,\n Literal,\n Middleware,\n RPCEndpoint,\n RPCResponse,\n)\n\nif TYPE_CHECKING:\n from web3 import ( # noqa: F401\n AsyncWeb3,\n Web3,\n )\n\nFORMATTER_DEFAULTS: FormattersDict = {\n \"request_formatters\": {},\n \"result_formatters\": {},\n \"error_formatters\": {},\n}\n\n\ndef _apply_response_formatters(\n method: RPCEndpoint,\n response: RPCResponse,\n result_formatters: Formatters,\n error_formatters: Formatters,\n) -> RPCResponse:\n def _format_response(\n response_type: Literal[\"result\", \"error\"],\n method_response_formatter: Callable[..., Any],\n ) -> RPCResponse:\n appropriate_response = response[response_type]\n return assoc(\n response, response_type, method_response_formatter(appropriate_response)\n )\n\n if (\n \"result\" in response\n and response[\"result\"] is not None\n and method in result_formatters\n ):\n return _format_response(\"result\", result_formatters[method])\n elif \"error\" in response and method in error_formatters:\n return _format_response(\"error\", error_formatters[method])\n else:\n return response\n\n\n# --- sync -- #\n\n\ndef construct_formatting_middleware(\n request_formatters: Optional[Formatters] = None,\n result_formatters: Optional[Formatters] = None,\n error_formatters: Optional[Formatters] = None,\n) -> Middleware:\n def ignore_web3_in_standard_formatters(\n _w3: \"Web3\",\n _method: RPCEndpoint,\n ) -> FormattersDict:\n return dict(\n request_formatters=request_formatters or {},\n result_formatters=result_formatters or {},\n error_formatters=error_formatters or {},\n )\n\n return construct_web3_formatting_middleware(ignore_web3_in_standard_formatters)\n\n\ndef construct_web3_formatting_middleware(\n web3_formatters_builder: Callable[[\"Web3\", RPCEndpoint], FormattersDict],\n) -> Middleware:\n def formatter_middleware(\n make_request: Callable[[RPCEndpoint, Any], Any],\n w3: \"Web3\",\n ) -> Callable[[RPCEndpoint, Any], RPCResponse]:\n def middleware(method: RPCEndpoint, params: Any) -> RPCResponse:\n formatters = merge(\n FORMATTER_DEFAULTS,\n web3_formatters_builder(w3, method),\n )\n request_formatters = formatters.pop(\"request_formatters\")\n\n if method in request_formatters:\n formatter = request_formatters[method]\n params = formatter(params)\n response = make_request(method, params)\n\n return _apply_response_formatters(\n method=method, response=response, **formatters\n )\n\n return middleware\n\n return formatter_middleware\n\n\n# --- async --- #\n\n\nasync def async_construct_formatting_middleware(\n request_formatters: Optional[Formatters] = None,\n result_formatters: Optional[Formatters] = None,\n error_formatters: Optional[Formatters] = None,\n) -> AsyncMiddleware:\n async def ignore_web3_in_standard_formatters(\n _async_w3: \"AsyncWeb3\",\n _method: RPCEndpoint,\n ) -> FormattersDict:\n return dict(\n request_formatters=request_formatters or {},\n result_formatters=result_formatters or {},\n error_formatters=error_formatters or {},\n )\n\n return await async_construct_web3_formatting_middleware(\n ignore_web3_in_standard_formatters\n )\n\n\nasync def async_construct_web3_formatting_middleware(\n async_web3_formatters_builder: Callable[\n [\"AsyncWeb3\", RPCEndpoint], Coroutine[Any, Any, FormattersDict]\n ]\n) -> Callable[\n [Callable[[RPCEndpoint, Any], Any], \"AsyncWeb3\"],\n Coroutine[Any, Any, AsyncMiddlewareCoroutine],\n]:\n async def formatter_middleware(\n make_request: Callable[[RPCEndpoint, Any], Any],\n w3: \"AsyncWeb3\",\n ) -> AsyncMiddlewareCoroutine:\n async def middleware(method: RPCEndpoint, params: Any) -> RPCResponse:\n formatters = merge(\n FORMATTER_DEFAULTS,\n await async_web3_formatters_builder(w3, method),\n )\n request_formatters = formatters.pop(\"request_formatters\")\n\n if method in request_formatters:\n formatter = request_formatters[method]\n params = formatter(params)\n response = await make_request(method, params)\n\n return _apply_response_formatters(\n method=method, response=response, **formatters\n )\n\n return middleware\n\n return formatter_middleware\n", "path": "web3/middleware/formatting.py"}]}
| 3,813 | 159 |
gh_patches_debug_15716
|
rasdani/github-patches
|
git_diff
|
beeware__toga-1198
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
WebView in MacOS not accepting keyboard input
**Describe the bug**
I am unable to type text in HTML input fields within a Toga WebView on Mac OS.
**To Reproduce**
Steps to reproduce the behavior:
1. Follow the tutorial at https://docs.beeware.org/en/latest/tutorial/tutorial-1.html until you are able to run `briefcase dev` successfully.
2. Modify the `startup` function so that its body is:
```main_box = toga.Box()
self.main_window = toga.MainWindow(title=self.formal_name)
self.main_window.content = toga.WebView(style=Pack(flex=1))
self.main_window.content.url = 'https://www.google.ca/'
self.main_window.show()
```
3. Attempt to search for something in the Google search input.
4. When I try, I am unable to type characters. Nothing happens with my key presses. Note that specified command shortcuts do seem to work.
**Expected behavior**
I expect to be able to enter text into text boxes in a WebView in Toga.
**Environment:**
- Operating System: Mac OS 10.15.6
- Python version: 3.6.5
- Software versions:
- Briefcase: 0.3.0
- Toga: 0.3.0.dev26
**Additional context**
I discovered that If I just comment out the `keyDown_` method in toga_cocoa [here](https://github.com/beeware/toga/blob/master/src/cocoa/toga_cocoa/widgets/webview.py#L23-L27) then I am able to enter text in a WebView.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cocoa/toga_cocoa/widgets/webview.py`
Content:
```
1 from asyncio import get_event_loop
2
3 from travertino.size import at_least
4
5 from toga_cocoa.keys import toga_key
6 from toga_cocoa.libs import NSURL, NSURLRequest, WKWebView
7 from rubicon.objc import objc_method, py_from_ns
8 from rubicon.objc.runtime import objc_id
9
10 from .base import Widget
11
12
13 class TogaWebView(WKWebView):
14 @objc_method
15 def webView_didFinish_navigation_(self, sender, wkNavigation) -> None:
16 if self.interface.on_webview_load:
17 self.interface.on_webview_load(self.interface)
18
19 @objc_method
20 def acceptsFirstResponder(self) -> bool:
21 return True
22
23 @objc_method
24 def keyDown_(self, event) -> None:
25 if self.interface.on_key_down:
26 self.interface.on_key_down(self.interface, **toga_key(event))
27
28 @objc_method
29 def touchBar(self):
30 # Disable the touchbar.
31 return None
32
33
34 class WebView(Widget):
35 def create(self):
36 self.native = TogaWebView.alloc().init()
37 self.native.interface = self.interface
38
39 self.native.downloadDelegate = self.native
40 self.native.frameLoadDelegate = self.native
41 self.native.policyDelegate = self.native
42 self.native.resourceLoadDelegate = self.native
43 self.native.uIDelegate = self.native
44
45 # Add the layout constraints
46 self.add_constraints()
47
48 def set_on_key_down(self, handler):
49 pass
50
51 def set_on_webview_load(self, handler):
52 pass
53
54 def get_dom(self):
55 # Utilises Step 2) of:
56 # https://developer.apple.com/library/content/documentation/
57 # Cocoa/Conceptual/DisplayWebContent/Tasks/SaveAndLoad.html
58 html = self.native.mainframe.DOMDocument.documentElement.outerHTML
59 return html
60
61 def set_url(self, value):
62 if value:
63 request = NSURLRequest.requestWithURL(NSURL.URLWithString(self.interface.url))
64 self.native.loadRequest(request)
65
66 def set_content(self, root_url, content):
67 self.native.loadHTMLString(content, baseURL=NSURL.URLWithString(root_url))
68
69 def set_user_agent(self, value):
70 user_agent = value if value else "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8" # NOQA
71 self.native.customUserAgent = user_agent
72
73 async def evaluate_javascript(self, javascript):
74 """
75 Evaluate a JavaScript expression.
76
77 **This method is asynchronous**. It will return when the expression has been
78 evaluated and a result is available.
79
80 :param javascript: The javascript expression to evaluate
81 :type javascript: ``str``
82 """
83
84 loop = get_event_loop()
85 future = loop.create_future()
86
87 def completion_handler(res: objc_id, error: objc_id) -> None:
88
89 if error:
90 error = py_from_ns(error)
91 exc = RuntimeError(str(error))
92 future.set_exception(exc)
93 else:
94 future.set_result(py_from_ns(res))
95
96 self.native.evaluateJavaScript(javascript, completionHandler=completion_handler)
97
98 return await future
99
100 def invoke_javascript(self, javascript):
101 """
102 Invoke a block of javascript.
103
104 :param javascript: The javascript expression to invoke
105 """
106 self.native.evaluateJavaScript(javascript, completionHandler=None)
107
108 def rehint(self):
109 self.interface.intrinsic.width = at_least(self.interface.MIN_WIDTH)
110 self.interface.intrinsic.height = at_least(self.interface.MIN_HEIGHT)
111
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/cocoa/toga_cocoa/widgets/webview.py b/src/cocoa/toga_cocoa/widgets/webview.py
--- a/src/cocoa/toga_cocoa/widgets/webview.py
+++ b/src/cocoa/toga_cocoa/widgets/webview.py
@@ -4,7 +4,7 @@
from toga_cocoa.keys import toga_key
from toga_cocoa.libs import NSURL, NSURLRequest, WKWebView
-from rubicon.objc import objc_method, py_from_ns
+from rubicon.objc import objc_method, py_from_ns, send_super
from rubicon.objc.runtime import objc_id
from .base import Widget
@@ -24,6 +24,7 @@
def keyDown_(self, event) -> None:
if self.interface.on_key_down:
self.interface.on_key_down(self.interface, **toga_key(event))
+ send_super(__class__, self, 'keyDown:', event)
@objc_method
def touchBar(self):
|
{"golden_diff": "diff --git a/src/cocoa/toga_cocoa/widgets/webview.py b/src/cocoa/toga_cocoa/widgets/webview.py\n--- a/src/cocoa/toga_cocoa/widgets/webview.py\n+++ b/src/cocoa/toga_cocoa/widgets/webview.py\n@@ -4,7 +4,7 @@\n \n from toga_cocoa.keys import toga_key\n from toga_cocoa.libs import NSURL, NSURLRequest, WKWebView\n-from rubicon.objc import objc_method, py_from_ns\n+from rubicon.objc import objc_method, py_from_ns, send_super\n from rubicon.objc.runtime import objc_id\n \n from .base import Widget\n@@ -24,6 +24,7 @@\n def keyDown_(self, event) -> None:\n if self.interface.on_key_down:\n self.interface.on_key_down(self.interface, **toga_key(event))\n+ send_super(__class__, self, 'keyDown:', event)\n \n @objc_method\n def touchBar(self):\n", "issue": "WebView in MacOS not accepting keyboard input\n**Describe the bug**\r\n\r\nI am unable to type text in HTML input fields within a Toga WebView on Mac OS.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Follow the tutorial at https://docs.beeware.org/en/latest/tutorial/tutorial-1.html until you are able to run `briefcase dev` successfully.\r\n2. Modify the `startup` function so that its body is:\r\n ```main_box = toga.Box()\r\n self.main_window = toga.MainWindow(title=self.formal_name)\r\n self.main_window.content = toga.WebView(style=Pack(flex=1))\r\n self.main_window.content.url = 'https://www.google.ca/'\r\n self.main_window.show()\r\n ```\r\n3. Attempt to search for something in the Google search input.\r\n4. When I try, I am unable to type characters. Nothing happens with my key presses. Note that specified command shortcuts do seem to work.\r\n\r\n**Expected behavior**\r\nI expect to be able to enter text into text boxes in a WebView in Toga.\r\n\r\n**Environment:**\r\n - Operating System: Mac OS 10.15.6\r\n - Python version: 3.6.5\r\n - Software versions:\r\n - Briefcase: 0.3.0\r\n - Toga: 0.3.0.dev26\r\n\r\n**Additional context**\r\nI discovered that If I just comment out the `keyDown_` method in toga_cocoa [here](https://github.com/beeware/toga/blob/master/src/cocoa/toga_cocoa/widgets/webview.py#L23-L27) then I am able to enter text in a WebView.\n", "before_files": [{"content": "from asyncio import get_event_loop\n\nfrom travertino.size import at_least\n\nfrom toga_cocoa.keys import toga_key\nfrom toga_cocoa.libs import NSURL, NSURLRequest, WKWebView\nfrom rubicon.objc import objc_method, py_from_ns\nfrom rubicon.objc.runtime import objc_id\n\nfrom .base import Widget\n\n\nclass TogaWebView(WKWebView):\n @objc_method\n def webView_didFinish_navigation_(self, sender, wkNavigation) -> None:\n if self.interface.on_webview_load:\n self.interface.on_webview_load(self.interface)\n\n @objc_method\n def acceptsFirstResponder(self) -> bool:\n return True\n\n @objc_method\n def keyDown_(self, event) -> None:\n if self.interface.on_key_down:\n self.interface.on_key_down(self.interface, **toga_key(event))\n\n @objc_method\n def touchBar(self):\n # Disable the touchbar.\n return None\n\n\nclass WebView(Widget):\n def create(self):\n self.native = TogaWebView.alloc().init()\n self.native.interface = self.interface\n\n self.native.downloadDelegate = self.native\n self.native.frameLoadDelegate = self.native\n self.native.policyDelegate = self.native\n self.native.resourceLoadDelegate = self.native\n self.native.uIDelegate = self.native\n\n # Add the layout constraints\n self.add_constraints()\n\n def set_on_key_down(self, handler):\n pass\n\n def set_on_webview_load(self, handler):\n pass\n\n def get_dom(self):\n # Utilises Step 2) of:\n # https://developer.apple.com/library/content/documentation/\n # Cocoa/Conceptual/DisplayWebContent/Tasks/SaveAndLoad.html\n html = self.native.mainframe.DOMDocument.documentElement.outerHTML\n return html\n\n def set_url(self, value):\n if value:\n request = NSURLRequest.requestWithURL(NSURL.URLWithString(self.interface.url))\n self.native.loadRequest(request)\n\n def set_content(self, root_url, content):\n self.native.loadHTMLString(content, baseURL=NSURL.URLWithString(root_url))\n\n def set_user_agent(self, value):\n user_agent = value if value else \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8\" # NOQA\n self.native.customUserAgent = user_agent\n\n async def evaluate_javascript(self, javascript):\n \"\"\"\n Evaluate a JavaScript expression.\n\n **This method is asynchronous**. It will return when the expression has been\n evaluated and a result is available.\n\n :param javascript: The javascript expression to evaluate\n :type javascript: ``str``\n \"\"\"\n\n loop = get_event_loop()\n future = loop.create_future()\n\n def completion_handler(res: objc_id, error: objc_id) -> None:\n\n if error:\n error = py_from_ns(error)\n exc = RuntimeError(str(error))\n future.set_exception(exc)\n else:\n future.set_result(py_from_ns(res))\n\n self.native.evaluateJavaScript(javascript, completionHandler=completion_handler)\n\n return await future\n\n def invoke_javascript(self, javascript):\n \"\"\"\n Invoke a block of javascript.\n\n :param javascript: The javascript expression to invoke\n \"\"\"\n self.native.evaluateJavaScript(javascript, completionHandler=None)\n\n def rehint(self):\n self.interface.intrinsic.width = at_least(self.interface.MIN_WIDTH)\n self.interface.intrinsic.height = at_least(self.interface.MIN_HEIGHT)\n", "path": "src/cocoa/toga_cocoa/widgets/webview.py"}], "after_files": [{"content": "from asyncio import get_event_loop\n\nfrom travertino.size import at_least\n\nfrom toga_cocoa.keys import toga_key\nfrom toga_cocoa.libs import NSURL, NSURLRequest, WKWebView\nfrom rubicon.objc import objc_method, py_from_ns, send_super\nfrom rubicon.objc.runtime import objc_id\n\nfrom .base import Widget\n\n\nclass TogaWebView(WKWebView):\n @objc_method\n def webView_didFinish_navigation_(self, sender, wkNavigation) -> None:\n if self.interface.on_webview_load:\n self.interface.on_webview_load(self.interface)\n\n @objc_method\n def acceptsFirstResponder(self) -> bool:\n return True\n\n @objc_method\n def keyDown_(self, event) -> None:\n if self.interface.on_key_down:\n self.interface.on_key_down(self.interface, **toga_key(event))\n send_super(__class__, self, 'keyDown:', event)\n\n @objc_method\n def touchBar(self):\n # Disable the touchbar.\n return None\n\n\nclass WebView(Widget):\n def create(self):\n self.native = TogaWebView.alloc().init()\n self.native.interface = self.interface\n\n self.native.downloadDelegate = self.native\n self.native.frameLoadDelegate = self.native\n self.native.policyDelegate = self.native\n self.native.resourceLoadDelegate = self.native\n self.native.uIDelegate = self.native\n\n # Add the layout constraints\n self.add_constraints()\n\n def set_on_key_down(self, handler):\n pass\n\n def set_on_webview_load(self, handler):\n pass\n\n def get_dom(self):\n # Utilises Step 2) of:\n # https://developer.apple.com/library/content/documentation/\n # Cocoa/Conceptual/DisplayWebContent/Tasks/SaveAndLoad.html\n html = self.native.mainframe.DOMDocument.documentElement.outerHTML\n return html\n\n def set_url(self, value):\n if value:\n request = NSURLRequest.requestWithURL(NSURL.URLWithString(self.interface.url))\n self.native.loadRequest(request)\n\n def set_content(self, root_url, content):\n self.native.loadHTMLString(content, baseURL=NSURL.URLWithString(root_url))\n\n def set_user_agent(self, value):\n user_agent = value if value else \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/603.3.8 (KHTML, like Gecko) Version/10.1.2 Safari/603.3.8\" # NOQA\n self.native.customUserAgent = user_agent\n\n async def evaluate_javascript(self, javascript):\n \"\"\"\n Evaluate a JavaScript expression.\n\n **This method is asynchronous**. It will return when the expression has been\n evaluated and a result is available.\n\n :param javascript: The javascript expression to evaluate\n :type javascript: ``str``\n \"\"\"\n\n loop = get_event_loop()\n future = loop.create_future()\n\n def completion_handler(res: objc_id, error: objc_id) -> None:\n\n if error:\n error = py_from_ns(error)\n exc = RuntimeError(str(error))\n future.set_exception(exc)\n else:\n future.set_result(py_from_ns(res))\n\n self.native.evaluateJavaScript(javascript, completionHandler=completion_handler)\n\n return await future\n\n def invoke_javascript(self, javascript):\n \"\"\"\n Invoke a block of javascript.\n\n :param javascript: The javascript expression to invoke\n \"\"\"\n self.native.evaluateJavaScript(javascript, completionHandler=None)\n\n def rehint(self):\n self.interface.intrinsic.width = at_least(self.interface.MIN_WIDTH)\n self.interface.intrinsic.height = at_least(self.interface.MIN_HEIGHT)\n", "path": "src/cocoa/toga_cocoa/widgets/webview.py"}]}
| 1,624 | 213 |
gh_patches_debug_1943
|
rasdani/github-patches
|
git_diff
|
openfun__marsha-2577
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Sending a xAPI statement to a LRS not working anymore
## Bug Report
**Problematic Behavior**
When a LRS is configured in a consumer site, sending a xapi statement is failing
https://gip-fun-mooc.sentry.io/share/issue/081e7857e01544d3bd5b5f93d573c428/
**Expected behavior/code**
When a LRS is correctly configured for a given consumer site, the statement should be sent to the LRS.
**Steps to Reproduce**
1. Configure a LRS in a consumer site
2. Navigate on an existing video
3. And then the bug happens!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/backend/marsha/core/xapi.py`
Content:
```
1 """XAPI module."""
2
3 import re
4 import uuid
5
6 from django.conf import settings
7 from django.utils import timezone
8 from django.utils.translation import to_locale
9
10 import requests
11
12
13 def get_xapi_statement(resource):
14 """Return the xapi object statement based on the required resource type."""
15 if resource == "video":
16 return XAPIVideoStatement()
17
18 if resource == "document":
19 return XAPIDocumentStatement()
20
21 raise NotImplementedError
22
23
24 class XAPIStatementMixin:
25 """Mixin used by xapi statements."""
26
27 @staticmethod
28 def get_user_id(jwt_token):
29 """Return the user id if present in the JWT token or the session_is otherwise."""
30 return (
31 jwt_token.payload["user"].get("id")
32 if jwt_token.payload.get("user")
33 else jwt_token.payload["session_id"]
34 )
35
36 @staticmethod
37 def get_homepage(resource):
38 """Return the domain associated to the playlist consumer site."""
39 return resource.playlist.consumer_site.domain
40
41 def get_locale(self):
42 """Return the locale formatted with a - instead of _"""
43
44 return to_locale(settings.LANGUAGE_CODE).replace("_", "-")
45
46 def get_actor_from_website(self, homepage, user):
47 """Return the actor property from a website context"""
48 return {
49 "objectType": "Agent",
50 "account": {
51 "homePage": homepage,
52 "mbox": f"mailto:{user.email}",
53 "name": str(user.id),
54 },
55 }
56
57 def get_actor_from_lti(self, homepage, user_id):
58 """Return the actor property from a LTI context"""
59 return {
60 "objectType": "Agent",
61 "account": {"name": user_id, "homePage": homepage},
62 }
63
64 def build_common_statement_properties(
65 self, statement, homepage, user=None, user_id=None
66 ):
67 """build statement properties common to all resources."""
68 if "id" not in statement:
69 statement["id"] = str(uuid.uuid4())
70
71 statement["timestamp"] = timezone.now().isoformat()
72
73 statement["actor"] = (
74 self.get_actor_from_website(homepage, user)
75 if user
76 else self.get_actor_from_lti(homepage, user_id)
77 )
78
79 return statement
80
81
82 class XAPIDocumentStatement(XAPIStatementMixin):
83 """Object managing statement for document objects."""
84
85 # pylint: disable=too-many-arguments
86 def _build_statement(self, document, statement, homepage, user=None, user_id=None):
87 """Build all common properties for a document."""
88
89 if re.match(r"^http(s?):\/\/.*", homepage) is None:
90 homepage = f"http://{homepage}"
91
92 statement = self.build_common_statement_properties(
93 statement, homepage, user=user, user_id=user_id
94 )
95
96 statement["context"].update(
97 {"contextActivities": {"category": [{"id": "https://w3id.org/xapi/lms"}]}}
98 )
99
100 statement["object"] = {
101 "definition": {
102 "type": "http://id.tincanapi.com/activitytype/document",
103 "name": {self.get_locale(): document.title},
104 },
105 "id": f"uuid://{document.id}",
106 "objectType": "Activity",
107 }
108
109 return statement
110
111 def from_website(self, document, statement, current_site, user):
112 """Compute a valid xapi statement in a website context.
113
114 Parameters
115 ----------
116 document : Type[marsha.core.models.Document]
117 The document object used in the xAPI statement
118
119 statement : dictionary
120 Statement containing base information to send to the LRS
121 An example of expected statement:
122 {
123 "verb": {
124 "id": "http://adlnet.gov/expapi/verbs/initialized",
125 "display": {
126 "en-US": "initialized"
127 }
128 },
129 }
130
131 current_site : Type[django.contrib.sites.models.Site]
132 The current site used to send the XAPI request
133
134 user: Type[marsha.core.models.User]
135 The connected user who sent the XAPI request
136
137 """
138
139 return self._build_statement(
140 document, statement, homepage=current_site.domain, user=user
141 )
142
143 def from_lti(self, document, statement, jwt_token):
144 """Compute a valid xapi download activity statement."""
145
146 statement = self._build_statement(
147 document,
148 statement,
149 homepage=self.get_homepage(document),
150 user_id=self.get_user_id(jwt_token),
151 )
152
153 if jwt_token.payload.get("context_id"):
154 statement["context"]["contextActivities"].update(
155 {
156 "parent": [
157 {
158 "id": jwt_token.payload["context_id"],
159 "objectType": "Activity",
160 "definition": {
161 "type": "http://adlnet.gov/expapi/activities/course"
162 },
163 }
164 ]
165 }
166 )
167
168 return statement
169
170
171 class XAPIVideoStatement(XAPIStatementMixin):
172 """Object managing statement for video objects."""
173
174 def _get_activity_type(self, video):
175 """Return the activity type for a given video"""
176
177 activity_type = "https://w3id.org/xapi/video/activity-type/video"
178
179 # When the video is a live we change the activity to webinar
180 if video.is_live:
181 activity_type = "http://id.tincanapi.com/activitytype/webinar"
182
183 return activity_type
184
185 # pylint: disable=too-many-arguments
186 def _build_statement(self, video, statement, homepage, user=None, user_id=None):
187 """Build all common properties for a video."""
188 if re.match(r"^http(s?):\/\/.*", homepage) is None:
189 homepage = f"http://{homepage}"
190
191 statement = self.build_common_statement_properties(
192 statement, homepage, user=user, user_id=user_id
193 )
194
195 category_id = (
196 "https://w3id.org/xapi/lms"
197 if statement["verb"]["id"] == "http://id.tincanapi.com/verb/downloaded"
198 else "https://w3id.org/xapi/video"
199 )
200
201 statement["context"].update(
202 {"contextActivities": {"category": [{"id": category_id}]}}
203 )
204
205 statement["object"] = {
206 "definition": {
207 "type": self._get_activity_type(video),
208 "name": {self.get_locale(): video.title},
209 },
210 "id": f"uuid://{video.id}",
211 "objectType": "Activity",
212 }
213
214 return statement
215
216 def from_website(self, video, statement, current_site, user):
217 """Compute a valid xapi statement in a website context.
218
219 Parameters
220 ----------
221 video : Type[.models/videos]
222 The video object used in the xAPI statement
223
224 statement : dictionary
225 Statement containing base information to send to the LRS
226 An example of expected statement:
227 {
228 "verb": {
229 "id": "http://adlnet.gov/expapi/verbs/initialized",
230 "display": {
231 "en-US": "initialized"
232 }
233 },
234 "context": {
235 "extensions": {
236 "https://w3id.org/xapi/video/extensions/volume": 1,
237 "https://w3id.org/xapi/video/extensions/video-playback-size": "640x264",
238 }
239 }
240 }
241
242 current_site : Type[django.contrib.sites.models.Site]
243 The current site used to send the XAPI request
244
245 user: Type[marsha.core.models.User]
246 The connected user who sent the XAPI request
247
248 """
249
250 return self._build_statement(
251 video, statement, homepage=current_site.domain, user=user
252 )
253
254 def from_lti(self, video, statement, jwt_token):
255 """Compute a valid xapi statement in an LTI context.
256
257 Parameters
258 ----------
259 video : Type[.models/videos]
260 The video object used in the xAPI statement
261
262 statement : dictionary
263 Statement containing base information to send to the LRS
264 An example of expected statement:
265 {
266 "verb": {
267 "id": "http://adlnet.gov/expapi/verbs/initialized",
268 "display": {
269 "en-US": "initialized"
270 }
271 },
272 "context": {
273 "extensions": {
274 "https://w3id.org/xapi/video/extensions/volume": 1,
275 "https://w3id.org/xapi/video/extensions/video-playback-size": "640x264",
276 }
277 }
278 }
279
280 jwt_token : Type[rest_framework_simplejwt.tokens.AccessToken]
281 A jwt token containing the context used to enrich the xapi statement
282
283 """
284 statement = self._build_statement(
285 video,
286 statement,
287 homepage=self.get_homepage(video),
288 user_id=self.get_user_id(jwt_token),
289 )
290
291 if jwt_token.payload.get("context_id"):
292 statement["context"]["contextActivities"].update(
293 {
294 "parent": [
295 {
296 "id": jwt_token.payload["context_id"],
297 "objectType": "Activity",
298 "definition": {
299 "type": "http://adlnet.gov/expapi/activities/course"
300 },
301 }
302 ]
303 }
304 )
305
306 return statement
307
308
309 class XAPI:
310 """The XAPI object compute statements and send them to a LRS."""
311
312 def __init__(self, url, auth_token, xapi_version="1.0.3"):
313 """Initialize the XAPI module.
314
315 Parameters
316 ----------
317 url: string
318 The LRS endpoint to fetch
319
320 auth_token: string
321 The basic_auth token used to authenticate on the LRS
322
323 xapi_version: string
324 The xAPI version used.
325
326 """
327 self.url = url
328 self.auth_token = auth_token
329 self.xapi_version = xapi_version
330
331 def send(self, xapi_statement):
332 """Send the statement to a LRS.
333
334 Parameters
335 ----------
336 statement : Type[.XAPIStatement]
337
338 """
339 headers = {
340 "Authorization": self.auth_token,
341 "Content-Type": "application/json",
342 "X-Experience-API-Version": self.xapi_version,
343 }
344
345 response = requests.post(
346 self.url,
347 json=xapi_statement.get_statement(),
348 headers=headers,
349 timeout=settings.STAT_BACKEND_TIMEOUT,
350 )
351
352 response.raise_for_status()
353
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/backend/marsha/core/xapi.py b/src/backend/marsha/core/xapi.py
--- a/src/backend/marsha/core/xapi.py
+++ b/src/backend/marsha/core/xapi.py
@@ -344,7 +344,7 @@
response = requests.post(
self.url,
- json=xapi_statement.get_statement(),
+ json=xapi_statement,
headers=headers,
timeout=settings.STAT_BACKEND_TIMEOUT,
)
|
{"golden_diff": "diff --git a/src/backend/marsha/core/xapi.py b/src/backend/marsha/core/xapi.py\n--- a/src/backend/marsha/core/xapi.py\n+++ b/src/backend/marsha/core/xapi.py\n@@ -344,7 +344,7 @@\n \n response = requests.post(\n self.url,\n- json=xapi_statement.get_statement(),\n+ json=xapi_statement,\n headers=headers,\n timeout=settings.STAT_BACKEND_TIMEOUT,\n )\n", "issue": "Sending a xAPI statement to a LRS not working anymore\n## Bug Report\r\n\r\n**Problematic Behavior**\r\n\r\nWhen a LRS is configured in a consumer site, sending a xapi statement is failing\r\n\r\nhttps://gip-fun-mooc.sentry.io/share/issue/081e7857e01544d3bd5b5f93d573c428/\r\n\r\n**Expected behavior/code**\r\n\r\nWhen a LRS is correctly configured for a given consumer site, the statement should be sent to the LRS.\r\n\r\n**Steps to Reproduce**\r\n1. Configure a LRS in a consumer site\r\n2. Navigate on an existing video\r\n3. And then the bug happens!\r\n\n", "before_files": [{"content": "\"\"\"XAPI module.\"\"\"\n\nimport re\nimport uuid\n\nfrom django.conf import settings\nfrom django.utils import timezone\nfrom django.utils.translation import to_locale\n\nimport requests\n\n\ndef get_xapi_statement(resource):\n \"\"\"Return the xapi object statement based on the required resource type.\"\"\"\n if resource == \"video\":\n return XAPIVideoStatement()\n\n if resource == \"document\":\n return XAPIDocumentStatement()\n\n raise NotImplementedError\n\n\nclass XAPIStatementMixin:\n \"\"\"Mixin used by xapi statements.\"\"\"\n\n @staticmethod\n def get_user_id(jwt_token):\n \"\"\"Return the user id if present in the JWT token or the session_is otherwise.\"\"\"\n return (\n jwt_token.payload[\"user\"].get(\"id\")\n if jwt_token.payload.get(\"user\")\n else jwt_token.payload[\"session_id\"]\n )\n\n @staticmethod\n def get_homepage(resource):\n \"\"\"Return the domain associated to the playlist consumer site.\"\"\"\n return resource.playlist.consumer_site.domain\n\n def get_locale(self):\n \"\"\"Return the locale formatted with a - instead of _\"\"\"\n\n return to_locale(settings.LANGUAGE_CODE).replace(\"_\", \"-\")\n\n def get_actor_from_website(self, homepage, user):\n \"\"\"Return the actor property from a website context\"\"\"\n return {\n \"objectType\": \"Agent\",\n \"account\": {\n \"homePage\": homepage,\n \"mbox\": f\"mailto:{user.email}\",\n \"name\": str(user.id),\n },\n }\n\n def get_actor_from_lti(self, homepage, user_id):\n \"\"\"Return the actor property from a LTI context\"\"\"\n return {\n \"objectType\": \"Agent\",\n \"account\": {\"name\": user_id, \"homePage\": homepage},\n }\n\n def build_common_statement_properties(\n self, statement, homepage, user=None, user_id=None\n ):\n \"\"\"build statement properties common to all resources.\"\"\"\n if \"id\" not in statement:\n statement[\"id\"] = str(uuid.uuid4())\n\n statement[\"timestamp\"] = timezone.now().isoformat()\n\n statement[\"actor\"] = (\n self.get_actor_from_website(homepage, user)\n if user\n else self.get_actor_from_lti(homepage, user_id)\n )\n\n return statement\n\n\nclass XAPIDocumentStatement(XAPIStatementMixin):\n \"\"\"Object managing statement for document objects.\"\"\"\n\n # pylint: disable=too-many-arguments\n def _build_statement(self, document, statement, homepage, user=None, user_id=None):\n \"\"\"Build all common properties for a document.\"\"\"\n\n if re.match(r\"^http(s?):\\/\\/.*\", homepage) is None:\n homepage = f\"http://{homepage}\"\n\n statement = self.build_common_statement_properties(\n statement, homepage, user=user, user_id=user_id\n )\n\n statement[\"context\"].update(\n {\"contextActivities\": {\"category\": [{\"id\": \"https://w3id.org/xapi/lms\"}]}}\n )\n\n statement[\"object\"] = {\n \"definition\": {\n \"type\": \"http://id.tincanapi.com/activitytype/document\",\n \"name\": {self.get_locale(): document.title},\n },\n \"id\": f\"uuid://{document.id}\",\n \"objectType\": \"Activity\",\n }\n\n return statement\n\n def from_website(self, document, statement, current_site, user):\n \"\"\"Compute a valid xapi statement in a website context.\n\n Parameters\n ----------\n document : Type[marsha.core.models.Document]\n The document object used in the xAPI statement\n\n statement : dictionary\n Statement containing base information to send to the LRS\n An example of expected statement:\n {\n \"verb\": {\n \"id\": \"http://adlnet.gov/expapi/verbs/initialized\",\n \"display\": {\n \"en-US\": \"initialized\"\n }\n },\n }\n\n current_site : Type[django.contrib.sites.models.Site]\n The current site used to send the XAPI request\n\n user: Type[marsha.core.models.User]\n The connected user who sent the XAPI request\n\n \"\"\"\n\n return self._build_statement(\n document, statement, homepage=current_site.domain, user=user\n )\n\n def from_lti(self, document, statement, jwt_token):\n \"\"\"Compute a valid xapi download activity statement.\"\"\"\n\n statement = self._build_statement(\n document,\n statement,\n homepage=self.get_homepage(document),\n user_id=self.get_user_id(jwt_token),\n )\n\n if jwt_token.payload.get(\"context_id\"):\n statement[\"context\"][\"contextActivities\"].update(\n {\n \"parent\": [\n {\n \"id\": jwt_token.payload[\"context_id\"],\n \"objectType\": \"Activity\",\n \"definition\": {\n \"type\": \"http://adlnet.gov/expapi/activities/course\"\n },\n }\n ]\n }\n )\n\n return statement\n\n\nclass XAPIVideoStatement(XAPIStatementMixin):\n \"\"\"Object managing statement for video objects.\"\"\"\n\n def _get_activity_type(self, video):\n \"\"\"Return the activity type for a given video\"\"\"\n\n activity_type = \"https://w3id.org/xapi/video/activity-type/video\"\n\n # When the video is a live we change the activity to webinar\n if video.is_live:\n activity_type = \"http://id.tincanapi.com/activitytype/webinar\"\n\n return activity_type\n\n # pylint: disable=too-many-arguments\n def _build_statement(self, video, statement, homepage, user=None, user_id=None):\n \"\"\"Build all common properties for a video.\"\"\"\n if re.match(r\"^http(s?):\\/\\/.*\", homepage) is None:\n homepage = f\"http://{homepage}\"\n\n statement = self.build_common_statement_properties(\n statement, homepage, user=user, user_id=user_id\n )\n\n category_id = (\n \"https://w3id.org/xapi/lms\"\n if statement[\"verb\"][\"id\"] == \"http://id.tincanapi.com/verb/downloaded\"\n else \"https://w3id.org/xapi/video\"\n )\n\n statement[\"context\"].update(\n {\"contextActivities\": {\"category\": [{\"id\": category_id}]}}\n )\n\n statement[\"object\"] = {\n \"definition\": {\n \"type\": self._get_activity_type(video),\n \"name\": {self.get_locale(): video.title},\n },\n \"id\": f\"uuid://{video.id}\",\n \"objectType\": \"Activity\",\n }\n\n return statement\n\n def from_website(self, video, statement, current_site, user):\n \"\"\"Compute a valid xapi statement in a website context.\n\n Parameters\n ----------\n video : Type[.models/videos]\n The video object used in the xAPI statement\n\n statement : dictionary\n Statement containing base information to send to the LRS\n An example of expected statement:\n {\n \"verb\": {\n \"id\": \"http://adlnet.gov/expapi/verbs/initialized\",\n \"display\": {\n \"en-US\": \"initialized\"\n }\n },\n \"context\": {\n \"extensions\": {\n \"https://w3id.org/xapi/video/extensions/volume\": 1,\n \"https://w3id.org/xapi/video/extensions/video-playback-size\": \"640x264\",\n }\n }\n }\n\n current_site : Type[django.contrib.sites.models.Site]\n The current site used to send the XAPI request\n\n user: Type[marsha.core.models.User]\n The connected user who sent the XAPI request\n\n \"\"\"\n\n return self._build_statement(\n video, statement, homepage=current_site.domain, user=user\n )\n\n def from_lti(self, video, statement, jwt_token):\n \"\"\"Compute a valid xapi statement in an LTI context.\n\n Parameters\n ----------\n video : Type[.models/videos]\n The video object used in the xAPI statement\n\n statement : dictionary\n Statement containing base information to send to the LRS\n An example of expected statement:\n {\n \"verb\": {\n \"id\": \"http://adlnet.gov/expapi/verbs/initialized\",\n \"display\": {\n \"en-US\": \"initialized\"\n }\n },\n \"context\": {\n \"extensions\": {\n \"https://w3id.org/xapi/video/extensions/volume\": 1,\n \"https://w3id.org/xapi/video/extensions/video-playback-size\": \"640x264\",\n }\n }\n }\n\n jwt_token : Type[rest_framework_simplejwt.tokens.AccessToken]\n A jwt token containing the context used to enrich the xapi statement\n\n \"\"\"\n statement = self._build_statement(\n video,\n statement,\n homepage=self.get_homepage(video),\n user_id=self.get_user_id(jwt_token),\n )\n\n if jwt_token.payload.get(\"context_id\"):\n statement[\"context\"][\"contextActivities\"].update(\n {\n \"parent\": [\n {\n \"id\": jwt_token.payload[\"context_id\"],\n \"objectType\": \"Activity\",\n \"definition\": {\n \"type\": \"http://adlnet.gov/expapi/activities/course\"\n },\n }\n ]\n }\n )\n\n return statement\n\n\nclass XAPI:\n \"\"\"The XAPI object compute statements and send them to a LRS.\"\"\"\n\n def __init__(self, url, auth_token, xapi_version=\"1.0.3\"):\n \"\"\"Initialize the XAPI module.\n\n Parameters\n ----------\n url: string\n The LRS endpoint to fetch\n\n auth_token: string\n The basic_auth token used to authenticate on the LRS\n\n xapi_version: string\n The xAPI version used.\n\n \"\"\"\n self.url = url\n self.auth_token = auth_token\n self.xapi_version = xapi_version\n\n def send(self, xapi_statement):\n \"\"\"Send the statement to a LRS.\n\n Parameters\n ----------\n statement : Type[.XAPIStatement]\n\n \"\"\"\n headers = {\n \"Authorization\": self.auth_token,\n \"Content-Type\": \"application/json\",\n \"X-Experience-API-Version\": self.xapi_version,\n }\n\n response = requests.post(\n self.url,\n json=xapi_statement.get_statement(),\n headers=headers,\n timeout=settings.STAT_BACKEND_TIMEOUT,\n )\n\n response.raise_for_status()\n", "path": "src/backend/marsha/core/xapi.py"}], "after_files": [{"content": "\"\"\"XAPI module.\"\"\"\n\nimport re\nimport uuid\n\nfrom django.conf import settings\nfrom django.utils import timezone\nfrom django.utils.translation import to_locale\n\nimport requests\n\n\ndef get_xapi_statement(resource):\n \"\"\"Return the xapi object statement based on the required resource type.\"\"\"\n if resource == \"video\":\n return XAPIVideoStatement()\n\n if resource == \"document\":\n return XAPIDocumentStatement()\n\n raise NotImplementedError\n\n\nclass XAPIStatementMixin:\n \"\"\"Mixin used by xapi statements.\"\"\"\n\n @staticmethod\n def get_user_id(jwt_token):\n \"\"\"Return the user id if present in the JWT token or the session_is otherwise.\"\"\"\n return (\n jwt_token.payload[\"user\"].get(\"id\")\n if jwt_token.payload.get(\"user\")\n else jwt_token.payload[\"session_id\"]\n )\n\n @staticmethod\n def get_homepage(resource):\n \"\"\"Return the domain associated to the playlist consumer site.\"\"\"\n return resource.playlist.consumer_site.domain\n\n def get_locale(self):\n \"\"\"Return the locale formatted with a - instead of _\"\"\"\n\n return to_locale(settings.LANGUAGE_CODE).replace(\"_\", \"-\")\n\n def get_actor_from_website(self, homepage, user):\n \"\"\"Return the actor property from a website context\"\"\"\n return {\n \"objectType\": \"Agent\",\n \"account\": {\n \"homePage\": homepage,\n \"mbox\": f\"mailto:{user.email}\",\n \"name\": str(user.id),\n },\n }\n\n def get_actor_from_lti(self, homepage, user_id):\n \"\"\"Return the actor property from a LTI context\"\"\"\n return {\n \"objectType\": \"Agent\",\n \"account\": {\"name\": user_id, \"homePage\": homepage},\n }\n\n def build_common_statement_properties(\n self, statement, homepage, user=None, user_id=None\n ):\n \"\"\"build statement properties common to all resources.\"\"\"\n if \"id\" not in statement:\n statement[\"id\"] = str(uuid.uuid4())\n\n statement[\"timestamp\"] = timezone.now().isoformat()\n\n statement[\"actor\"] = (\n self.get_actor_from_website(homepage, user)\n if user\n else self.get_actor_from_lti(homepage, user_id)\n )\n\n return statement\n\n\nclass XAPIDocumentStatement(XAPIStatementMixin):\n \"\"\"Object managing statement for document objects.\"\"\"\n\n # pylint: disable=too-many-arguments\n def _build_statement(self, document, statement, homepage, user=None, user_id=None):\n \"\"\"Build all common properties for a document.\"\"\"\n\n if re.match(r\"^http(s?):\\/\\/.*\", homepage) is None:\n homepage = f\"http://{homepage}\"\n\n statement = self.build_common_statement_properties(\n statement, homepage, user=user, user_id=user_id\n )\n\n statement[\"context\"].update(\n {\"contextActivities\": {\"category\": [{\"id\": \"https://w3id.org/xapi/lms\"}]}}\n )\n\n statement[\"object\"] = {\n \"definition\": {\n \"type\": \"http://id.tincanapi.com/activitytype/document\",\n \"name\": {self.get_locale(): document.title},\n },\n \"id\": f\"uuid://{document.id}\",\n \"objectType\": \"Activity\",\n }\n\n return statement\n\n def from_website(self, document, statement, current_site, user):\n \"\"\"Compute a valid xapi statement in a website context.\n\n Parameters\n ----------\n document : Type[marsha.core.models.Document]\n The document object used in the xAPI statement\n\n statement : dictionary\n Statement containing base information to send to the LRS\n An example of expected statement:\n {\n \"verb\": {\n \"id\": \"http://adlnet.gov/expapi/verbs/initialized\",\n \"display\": {\n \"en-US\": \"initialized\"\n }\n },\n }\n\n current_site : Type[django.contrib.sites.models.Site]\n The current site used to send the XAPI request\n\n user: Type[marsha.core.models.User]\n The connected user who sent the XAPI request\n\n \"\"\"\n\n return self._build_statement(\n document, statement, homepage=current_site.domain, user=user\n )\n\n def from_lti(self, document, statement, jwt_token):\n \"\"\"Compute a valid xapi download activity statement.\"\"\"\n\n statement = self._build_statement(\n document,\n statement,\n homepage=self.get_homepage(document),\n user_id=self.get_user_id(jwt_token),\n )\n\n if jwt_token.payload.get(\"context_id\"):\n statement[\"context\"][\"contextActivities\"].update(\n {\n \"parent\": [\n {\n \"id\": jwt_token.payload[\"context_id\"],\n \"objectType\": \"Activity\",\n \"definition\": {\n \"type\": \"http://adlnet.gov/expapi/activities/course\"\n },\n }\n ]\n }\n )\n\n return statement\n\n\nclass XAPIVideoStatement(XAPIStatementMixin):\n \"\"\"Object managing statement for video objects.\"\"\"\n\n def _get_activity_type(self, video):\n \"\"\"Return the activity type for a given video\"\"\"\n\n activity_type = \"https://w3id.org/xapi/video/activity-type/video\"\n\n # When the video is a live we change the activity to webinar\n if video.is_live:\n activity_type = \"http://id.tincanapi.com/activitytype/webinar\"\n\n return activity_type\n\n # pylint: disable=too-many-arguments\n def _build_statement(self, video, statement, homepage, user=None, user_id=None):\n \"\"\"Build all common properties for a video.\"\"\"\n if re.match(r\"^http(s?):\\/\\/.*\", homepage) is None:\n homepage = f\"http://{homepage}\"\n\n statement = self.build_common_statement_properties(\n statement, homepage, user=user, user_id=user_id\n )\n\n category_id = (\n \"https://w3id.org/xapi/lms\"\n if statement[\"verb\"][\"id\"] == \"http://id.tincanapi.com/verb/downloaded\"\n else \"https://w3id.org/xapi/video\"\n )\n\n statement[\"context\"].update(\n {\"contextActivities\": {\"category\": [{\"id\": category_id}]}}\n )\n\n statement[\"object\"] = {\n \"definition\": {\n \"type\": self._get_activity_type(video),\n \"name\": {self.get_locale(): video.title},\n },\n \"id\": f\"uuid://{video.id}\",\n \"objectType\": \"Activity\",\n }\n\n return statement\n\n def from_website(self, video, statement, current_site, user):\n \"\"\"Compute a valid xapi statement in a website context.\n\n Parameters\n ----------\n video : Type[.models/videos]\n The video object used in the xAPI statement\n\n statement : dictionary\n Statement containing base information to send to the LRS\n An example of expected statement:\n {\n \"verb\": {\n \"id\": \"http://adlnet.gov/expapi/verbs/initialized\",\n \"display\": {\n \"en-US\": \"initialized\"\n }\n },\n \"context\": {\n \"extensions\": {\n \"https://w3id.org/xapi/video/extensions/volume\": 1,\n \"https://w3id.org/xapi/video/extensions/video-playback-size\": \"640x264\",\n }\n }\n }\n\n current_site : Type[django.contrib.sites.models.Site]\n The current site used to send the XAPI request\n\n user: Type[marsha.core.models.User]\n The connected user who sent the XAPI request\n\n \"\"\"\n\n return self._build_statement(\n video, statement, homepage=current_site.domain, user=user\n )\n\n def from_lti(self, video, statement, jwt_token):\n \"\"\"Compute a valid xapi statement in an LTI context.\n\n Parameters\n ----------\n video : Type[.models/videos]\n The video object used in the xAPI statement\n\n statement : dictionary\n Statement containing base information to send to the LRS\n An example of expected statement:\n {\n \"verb\": {\n \"id\": \"http://adlnet.gov/expapi/verbs/initialized\",\n \"display\": {\n \"en-US\": \"initialized\"\n }\n },\n \"context\": {\n \"extensions\": {\n \"https://w3id.org/xapi/video/extensions/volume\": 1,\n \"https://w3id.org/xapi/video/extensions/video-playback-size\": \"640x264\",\n }\n }\n }\n\n jwt_token : Type[rest_framework_simplejwt.tokens.AccessToken]\n A jwt token containing the context used to enrich the xapi statement\n\n \"\"\"\n statement = self._build_statement(\n video,\n statement,\n homepage=self.get_homepage(video),\n user_id=self.get_user_id(jwt_token),\n )\n\n if jwt_token.payload.get(\"context_id\"):\n statement[\"context\"][\"contextActivities\"].update(\n {\n \"parent\": [\n {\n \"id\": jwt_token.payload[\"context_id\"],\n \"objectType\": \"Activity\",\n \"definition\": {\n \"type\": \"http://adlnet.gov/expapi/activities/course\"\n },\n }\n ]\n }\n )\n\n return statement\n\n\nclass XAPI:\n \"\"\"The XAPI object compute statements and send them to a LRS.\"\"\"\n\n def __init__(self, url, auth_token, xapi_version=\"1.0.3\"):\n \"\"\"Initialize the XAPI module.\n\n Parameters\n ----------\n url: string\n The LRS endpoint to fetch\n\n auth_token: string\n The basic_auth token used to authenticate on the LRS\n\n xapi_version: string\n The xAPI version used.\n\n \"\"\"\n self.url = url\n self.auth_token = auth_token\n self.xapi_version = xapi_version\n\n def send(self, xapi_statement):\n \"\"\"Send the statement to a LRS.\n\n Parameters\n ----------\n statement : Type[.XAPIStatement]\n\n \"\"\"\n headers = {\n \"Authorization\": self.auth_token,\n \"Content-Type\": \"application/json\",\n \"X-Experience-API-Version\": self.xapi_version,\n }\n\n response = requests.post(\n self.url,\n json=xapi_statement,\n headers=headers,\n timeout=settings.STAT_BACKEND_TIMEOUT,\n )\n\n response.raise_for_status()\n", "path": "src/backend/marsha/core/xapi.py"}]}
| 3,609 | 103 |
gh_patches_debug_15799
|
rasdani/github-patches
|
git_diff
|
pytorch__vision-3453
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
What is expected Kinetics400 dataset directory structure?
Given that the dataset does not come with official downloader scripts and that most roll their own or hack some third-party scripts, it would be much clearer if https://pytorch.org/docs/stable/torchvision/datasets.html#kinetics-400 explained what directory structure is expected by `torchvision.datasets.Kinetics400`
What is the expected dataset size? and the video file extensions?
Thanks!
cc @pmeier
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torchvision/datasets/kinetics.py`
Content:
```
1 from .utils import list_dir
2 from .folder import make_dataset
3 from .video_utils import VideoClips
4 from .vision import VisionDataset
5
6
7 class Kinetics400(VisionDataset):
8 """
9 `Kinetics-400 <https://deepmind.com/research/open-source/open-source-datasets/kinetics/>`_
10 dataset.
11
12 Kinetics-400 is an action recognition video dataset.
13 This dataset consider every video as a collection of video clips of fixed size, specified
14 by ``frames_per_clip``, where the step in frames between each clip is given by
15 ``step_between_clips``.
16
17 To give an example, for 2 videos with 10 and 15 frames respectively, if ``frames_per_clip=5``
18 and ``step_between_clips=5``, the dataset size will be (2 + 3) = 5, where the first two
19 elements will come from video 1, and the next three elements from video 2.
20 Note that we drop clips which do not have exactly ``frames_per_clip`` elements, so not all
21 frames in a video might be present.
22
23 Internally, it uses a VideoClips object to handle clip creation.
24
25 Args:
26 root (string): Root directory of the Kinetics-400 Dataset.
27 frames_per_clip (int): number of frames in a clip
28 step_between_clips (int): number of frames between each clip
29 transform (callable, optional): A function/transform that takes in a TxHxWxC video
30 and returns a transformed version.
31
32 Returns:
33 tuple: A 3-tuple with the following entries:
34
35 - video (Tensor[T, H, W, C]): the `T` video frames
36 - audio(Tensor[K, L]): the audio frames, where `K` is the number of channels
37 and `L` is the number of points
38 - label (int): class of the video clip
39 """
40
41 def __init__(self, root, frames_per_clip, step_between_clips=1, frame_rate=None,
42 extensions=('avi',), transform=None, _precomputed_metadata=None,
43 num_workers=1, _video_width=0, _video_height=0,
44 _video_min_dimension=0, _audio_samples=0, _audio_channels=0):
45 super(Kinetics400, self).__init__(root)
46
47 classes = list(sorted(list_dir(root)))
48 class_to_idx = {classes[i]: i for i in range(len(classes))}
49 self.samples = make_dataset(self.root, class_to_idx, extensions, is_valid_file=None)
50 self.classes = classes
51 video_list = [x[0] for x in self.samples]
52 self.video_clips = VideoClips(
53 video_list,
54 frames_per_clip,
55 step_between_clips,
56 frame_rate,
57 _precomputed_metadata,
58 num_workers=num_workers,
59 _video_width=_video_width,
60 _video_height=_video_height,
61 _video_min_dimension=_video_min_dimension,
62 _audio_samples=_audio_samples,
63 _audio_channels=_audio_channels,
64 )
65 self.transform = transform
66
67 @property
68 def metadata(self):
69 return self.video_clips.metadata
70
71 def __len__(self):
72 return self.video_clips.num_clips()
73
74 def __getitem__(self, idx):
75 video, audio, info, video_idx = self.video_clips.get_clip(idx)
76 label = self.samples[video_idx][1]
77
78 if self.transform is not None:
79 video = self.transform(video)
80
81 return video, audio, label
82
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/torchvision/datasets/kinetics.py b/torchvision/datasets/kinetics.py
--- a/torchvision/datasets/kinetics.py
+++ b/torchvision/datasets/kinetics.py
@@ -23,7 +23,18 @@
Internally, it uses a VideoClips object to handle clip creation.
Args:
- root (string): Root directory of the Kinetics-400 Dataset.
+ root (string): Root directory of the Kinetics-400 Dataset. Should be structured as follows:
+ .. code::
+
+ root/
+ ├── class1
+ │ ├── clip1.avi
+ │ ├── clip2.avi
+ │ └── ...
+ └── class2
+ ├── clipx.avi
+ └── ...
+
frames_per_clip (int): number of frames in a clip
step_between_clips (int): number of frames between each clip
transform (callable, optional): A function/transform that takes in a TxHxWxC video
|
{"golden_diff": "diff --git a/torchvision/datasets/kinetics.py b/torchvision/datasets/kinetics.py\n--- a/torchvision/datasets/kinetics.py\n+++ b/torchvision/datasets/kinetics.py\n@@ -23,7 +23,18 @@\n Internally, it uses a VideoClips object to handle clip creation.\n \n Args:\n- root (string): Root directory of the Kinetics-400 Dataset.\n+ root (string): Root directory of the Kinetics-400 Dataset. Should be structured as follows:\n+ .. code::\n+\n+ root/\n+ \u251c\u2500\u2500 class1\n+ \u2502 \u251c\u2500\u2500 clip1.avi\n+ \u2502 \u251c\u2500\u2500 clip2.avi\n+ \u2502 \u2514\u2500\u2500 ...\n+ \u2514\u2500\u2500 class2\n+ \u251c\u2500\u2500 clipx.avi\n+ \u2514\u2500\u2500 ...\n+\n frames_per_clip (int): number of frames in a clip\n step_between_clips (int): number of frames between each clip\n transform (callable, optional): A function/transform that takes in a TxHxWxC video\n", "issue": "What is expected Kinetics400 dataset directory structure?\nGiven that the dataset does not come with official downloader scripts and that most roll their own or hack some third-party scripts, it would be much clearer if https://pytorch.org/docs/stable/torchvision/datasets.html#kinetics-400 explained what directory structure is expected by `torchvision.datasets.Kinetics400`\r\n\r\nWhat is the expected dataset size? and the video file extensions?\r\n\r\nThanks!\n\ncc @pmeier\n", "before_files": [{"content": "from .utils import list_dir\nfrom .folder import make_dataset\nfrom .video_utils import VideoClips\nfrom .vision import VisionDataset\n\n\nclass Kinetics400(VisionDataset):\n \"\"\"\n `Kinetics-400 <https://deepmind.com/research/open-source/open-source-datasets/kinetics/>`_\n dataset.\n\n Kinetics-400 is an action recognition video dataset.\n This dataset consider every video as a collection of video clips of fixed size, specified\n by ``frames_per_clip``, where the step in frames between each clip is given by\n ``step_between_clips``.\n\n To give an example, for 2 videos with 10 and 15 frames respectively, if ``frames_per_clip=5``\n and ``step_between_clips=5``, the dataset size will be (2 + 3) = 5, where the first two\n elements will come from video 1, and the next three elements from video 2.\n Note that we drop clips which do not have exactly ``frames_per_clip`` elements, so not all\n frames in a video might be present.\n\n Internally, it uses a VideoClips object to handle clip creation.\n\n Args:\n root (string): Root directory of the Kinetics-400 Dataset.\n frames_per_clip (int): number of frames in a clip\n step_between_clips (int): number of frames between each clip\n transform (callable, optional): A function/transform that takes in a TxHxWxC video\n and returns a transformed version.\n\n Returns:\n tuple: A 3-tuple with the following entries:\n\n - video (Tensor[T, H, W, C]): the `T` video frames\n - audio(Tensor[K, L]): the audio frames, where `K` is the number of channels\n and `L` is the number of points\n - label (int): class of the video clip\n \"\"\"\n\n def __init__(self, root, frames_per_clip, step_between_clips=1, frame_rate=None,\n extensions=('avi',), transform=None, _precomputed_metadata=None,\n num_workers=1, _video_width=0, _video_height=0,\n _video_min_dimension=0, _audio_samples=0, _audio_channels=0):\n super(Kinetics400, self).__init__(root)\n\n classes = list(sorted(list_dir(root)))\n class_to_idx = {classes[i]: i for i in range(len(classes))}\n self.samples = make_dataset(self.root, class_to_idx, extensions, is_valid_file=None)\n self.classes = classes\n video_list = [x[0] for x in self.samples]\n self.video_clips = VideoClips(\n video_list,\n frames_per_clip,\n step_between_clips,\n frame_rate,\n _precomputed_metadata,\n num_workers=num_workers,\n _video_width=_video_width,\n _video_height=_video_height,\n _video_min_dimension=_video_min_dimension,\n _audio_samples=_audio_samples,\n _audio_channels=_audio_channels,\n )\n self.transform = transform\n\n @property\n def metadata(self):\n return self.video_clips.metadata\n\n def __len__(self):\n return self.video_clips.num_clips()\n\n def __getitem__(self, idx):\n video, audio, info, video_idx = self.video_clips.get_clip(idx)\n label = self.samples[video_idx][1]\n\n if self.transform is not None:\n video = self.transform(video)\n\n return video, audio, label\n", "path": "torchvision/datasets/kinetics.py"}], "after_files": [{"content": "from .utils import list_dir\nfrom .folder import make_dataset\nfrom .video_utils import VideoClips\nfrom .vision import VisionDataset\n\n\nclass Kinetics400(VisionDataset):\n \"\"\"\n `Kinetics-400 <https://deepmind.com/research/open-source/open-source-datasets/kinetics/>`_\n dataset.\n\n Kinetics-400 is an action recognition video dataset.\n This dataset consider every video as a collection of video clips of fixed size, specified\n by ``frames_per_clip``, where the step in frames between each clip is given by\n ``step_between_clips``.\n\n To give an example, for 2 videos with 10 and 15 frames respectively, if ``frames_per_clip=5``\n and ``step_between_clips=5``, the dataset size will be (2 + 3) = 5, where the first two\n elements will come from video 1, and the next three elements from video 2.\n Note that we drop clips which do not have exactly ``frames_per_clip`` elements, so not all\n frames in a video might be present.\n\n Internally, it uses a VideoClips object to handle clip creation.\n\n Args:\n root (string): Root directory of the Kinetics-400 Dataset. Should be structured as follows:\n .. code::\n\n root/\n \u251c\u2500\u2500 class1\n \u2502 \u251c\u2500\u2500 clip1.avi\n \u2502 \u251c\u2500\u2500 clip2.avi\n \u2502 \u2514\u2500\u2500 ...\n \u2514\u2500\u2500 class2\n \u251c\u2500\u2500 clipx.avi\n \u2514\u2500\u2500 ...\n\n frames_per_clip (int): number of frames in a clip\n step_between_clips (int): number of frames between each clip\n transform (callable, optional): A function/transform that takes in a TxHxWxC video\n and returns a transformed version.\n\n Returns:\n tuple: A 3-tuple with the following entries:\n\n - video (Tensor[T, H, W, C]): the `T` video frames\n - audio(Tensor[K, L]): the audio frames, where `K` is the number of channels\n and `L` is the number of points\n - label (int): class of the video clip\n \"\"\"\n\n def __init__(self, root, frames_per_clip, step_between_clips=1, frame_rate=None,\n extensions=('avi',), transform=None, _precomputed_metadata=None,\n num_workers=1, _video_width=0, _video_height=0,\n _video_min_dimension=0, _audio_samples=0, _audio_channels=0):\n super(Kinetics400, self).__init__(root)\n\n classes = list(sorted(list_dir(root)))\n class_to_idx = {classes[i]: i for i in range(len(classes))}\n self.samples = make_dataset(self.root, class_to_idx, extensions, is_valid_file=None)\n self.classes = classes\n video_list = [x[0] for x in self.samples]\n self.video_clips = VideoClips(\n video_list,\n frames_per_clip,\n step_between_clips,\n frame_rate,\n _precomputed_metadata,\n num_workers=num_workers,\n _video_width=_video_width,\n _video_height=_video_height,\n _video_min_dimension=_video_min_dimension,\n _audio_samples=_audio_samples,\n _audio_channels=_audio_channels,\n )\n self.transform = transform\n\n @property\n def metadata(self):\n return self.video_clips.metadata\n\n def __len__(self):\n return self.video_clips.num_clips()\n\n def __getitem__(self, idx):\n video, audio, info, video_idx = self.video_clips.get_clip(idx)\n label = self.samples[video_idx][1]\n\n if self.transform is not None:\n video = self.transform(video)\n\n return video, audio, label\n", "path": "torchvision/datasets/kinetics.py"}]}
| 1,301 | 239 |
gh_patches_debug_2843
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-1371
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Revise the documentation TOC subsection handling
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. -->
### What is the expected enhancement?
An issue raised during #1254:
> Also Is it possible in the template to show the subsection when that section is viewed.
The new fancy design currently does not show subsections in the left-side TOC pane (except for the autodocs). Ideally it should show the subsections, allowing collapsing with sensible defaults and usability.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `doc/conf.py`
Content:
```
1 #!/usr/bin/env python3
2 # -*- coding: utf-8 -*-
3 #
4 # Qiskit documentation build configuration file, created by
5 # sphinx-quickstart on Tue Jul 25 18:13:28 2017.
6 #
7 # This file is execfile()d with the current directory set to its
8 # containing dir.
9 #
10 # Note that not all possible configuration values are present in this
11 # autogenerated file.
12 #
13 # All configuration values have a default; values that are commented out
14 # serve to show the default.
15
16 # If extensions (or modules to document with autodoc) are in another directory,
17 # add these directories to sys.path here. If the directory is relative to the
18 # documentation root, use os.path.abspath to make it absolute, like shown here.
19 #
20 import os
21 import sys
22 from qiskit import __version__
23 sys.path.insert(0, os.path.abspath('.'))
24
25 # Imported manually, as otherwise it will not be fully imported.
26 import qiskit.extensions.simulator
27
28 # -- General configuration ------------------------------------------------
29
30 # If your documentation needs a minimal Sphinx version, state it here.
31 #
32 # needs_sphinx = '1.0'
33
34 # Add any Sphinx extension module names here, as strings. They can be
35 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
36 # ones.
37 extensions = ['sphinx.ext.autodoc',
38 'sphinx.ext.autosummary',
39 'sphinx.ext.napoleon',
40 'sphinx.ext.doctest',
41 'sphinx.ext.coverage',
42 'sphinx.ext.mathjax',
43 'sphinx.ext.viewcode',
44 'sphinx.ext.githubpages']
45 # Napoleon settings
46 napoleon_google_docstring = True
47 napoleon_numpy_docstring = False
48 napoleon_include_init_with_doc = True
49 napoleon_include_private_with_doc = False
50 napoleon_include_special_with_doc = False
51 napoleon_use_admonition_for_examples = False
52 napoleon_use_admonition_for_notes = False
53 napoleon_use_admonition_for_references = False
54 napoleon_use_ivar = False
55 napoleon_use_param = True
56 napoleon_use_rtype = True
57
58 autoclass_content = 'both'
59
60 # Add any paths that contain templates here, relative to this directory.
61 templates_path = ['_templates']
62
63 # The suffix(es) of source filenames.
64 # You can specify multiple suffix as a list of string:
65 #
66 # source_suffix = ['.rst', '.md']
67 source_suffix = '.rst'
68
69 # The master toctree document.
70 master_doc = 'index'
71
72 # General information about the project.
73 project = 'Qiskit Terra'
74 copyright = '2017-2018 IBM'
75 author = 'IBM'
76
77 # Add description
78 html_context = {
79 'description': 'Qiskit Terra'
80 }
81
82 # The version info for the project you're documenting, acts as replacement for
83 # |version| and |release|, also used in various other places throughout the
84 # built documents.
85 #
86 # The short X.Y version.
87 version = __version__
88 # The full version, including alpha/beta/rc tags.
89 release = version
90
91 # The language for content autogenerated by Sphinx. Refer to documentation
92 # for a list of supported languages.
93 #
94 # This is also used if you do content translation via gettext catalogs.
95 # Usually you set "language" from the command line for these cases.
96 language = None
97
98 # List of patterns, relative to source directory, that match files and
99 # directories to ignore when looking for source files.
100 # This patterns also effect to html_static_path and html_extra_path
101 exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store',
102 '_autodoc/modules.rst', 'de', 'ja']
103
104 # The name of the Pygments (syntax highlighting) style to use.
105 pygments_style = 'sphinx'
106
107 # If true, `todo` and `todoList` produce output, else they produce nothing.
108 todo_include_todos = False
109
110
111 # -- Options for HTML output ----------------------------------------------
112
113 # The theme to use for HTML and HTML Help pages. See the documentation for
114 # a list of builtin themes.
115 #
116 # html_theme = 'alabaster'
117 # html_theme = 'bizstyle'
118 # html_theme = agogo
119
120 html_theme = 'sphinx_materialdesign_theme' # use the theme in subdir 'theme'
121 html_theme_path = ['./'] # make sphinx search for themes in current dir
122
123
124 # Theme options are theme-specific and customize the look and feel of a theme
125 # further. For a list of options available for each theme, see the
126 # documentation.
127 #
128 html_theme_options = {
129 # Specify a list of menu in Header.
130 # Tuples forms:
131 # ('Name', 'external url or path of pages in the document', boolean, 'icon name')
132 #
133 # Third argument:
134 # True indicates an external link.
135 # False indicates path of pages in the document.
136 #
137 # Fourth argument:
138 # Specify the icon name.
139 # For details see link.
140 # https://material.io/icons/
141 'header_links' : [
142 ('Home', 'index', False, 'home'),
143 ("ExternalLink", "http://example.com", True, 'launch'),
144 ("NoIconLink", "http://example.com", True, ''),
145 ("GitHub", "https://github.com/myyasuda/sphinx_materialdesign_theme", True, 'link')
146 ],
147
148 # Customize css colors.
149 # For details see link.
150 # https://getmdl.io/customize/index.html
151 #
152 # Values: amber, blue, brown, cyan deep_orange, deep_purple, green, grey, indigo, light_blue,
153 # light_green, lime, orange, pink, purple, red, teal, yellow(Default: indigo)
154 'primary_color': 'blue',
155 # Values: Same as primary_color. (Default: pink)
156 'accent_color': 'indigo',
157
158 # Customize layout.
159 # For details see link.
160 # https://getmdl.io/components/index.html#layout-section
161 'fixed_drawer': True,
162 'fixed_header': False,
163 'header_waterfall': True,
164 'header_scroll': False,
165
166 # Render title in header.
167 # Values: True, False (Default: False)
168 'show_header_title': False,
169 # Render title in drawer.
170 # Values: True, False (Default: True)
171 'show_drawer_title': True,
172 # Render footer.
173 }
174 # Add any paths that contain custom static files (such as style sheets) here,
175 # relative to this directory. They are copied after the builtin static files,
176 # so a file named "default.css" will overwrite the builtin "default.css".
177 html_static_path = ['./theme/static/']
178
179 # The name of an image file (relative to this directory) to place at the top
180 # of the sidebar.
181 html_logo = 'theme/static/qiskit-terra-logo.png'
182
183 html_favicon = 'theme/static/favicon.ico'
184
185 html_last_updated_fmt = '%Y/%m/%d'
186
187 # -- Options for HTMLHelp output ------------------------------------------
188
189 # Output file base name for HTML help builder.
190 htmlhelp_basename = 'Qiskitdoc'
191
192
193 # -- Options for LaTeX output ---------------------------------------------
194
195 latex_elements = {
196 # The paper size ('letterpaper' or 'a4paper').
197 #
198 # 'papersize': 'letterpaper',
199
200 # The font size ('10pt', '11pt' or '12pt').
201 #
202 # 'pointsize': '10pt',
203
204 # Additional stuff for the LaTeX preamble.
205 #
206 # 'preamble': '',
207
208 # Latex figure (float) alignment
209 #
210 # 'figure_align': 'htbp',
211 }
212
213 # Grouping the document tree into LaTeX files. List of tuples
214 # (source start file, target name, title,
215 # author, documentclass [howto, manual, or own class]).
216 latex_documents = [
217 (master_doc, 'Qiskit.tex', 'Qiskit Documentation',
218 '''Jim Challenger, Andrew Cross, Ismael Faro, Jay Gambetta''', 'manual'),
219 ]
220
221
222 # -- Options for manual page output ---------------------------------------
223
224 # One entry per manual page. List of tuples
225 # (source start file, name, description, authors, manual section).
226 man_pages = [
227 (master_doc, 'qiskit', 'Qiskit Documentation',
228 [author], 1)
229 ]
230
231
232 # -- Options for Texinfo output -------------------------------------------
233
234 # Grouping the document tree into Texinfo files. List of tuples
235 # (source start file, target name, title, author,
236 # dir menu entry, description, category)
237 texinfo_documents = [
238 (master_doc, 'Qiskit Terra', 'Qiskit Terra Documentation',
239 author, 'Qiskit', 'One line description of project.',
240 'Miscellaneous'),
241 ]
242
243
244 # Avoid a warning and treat the docstrings of the QasmLexer tokens as verbatim,
245 # as PLY uses docstring as a way to define the patterns the token matches.
246 def remove_module_docstring(app, what, name, obj, options, lines):
247 if name.startswith('qiskit.qasm._qasmlexer.QasmLexer.t_') and lines:
248 lines[0] = u'Token matching: ``%s``' % lines[0]
249
250
251 def setup(app):
252 app.connect('autodoc-process-docstring', remove_module_docstring)
253
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/doc/conf.py b/doc/conf.py
--- a/doc/conf.py
+++ b/doc/conf.py
@@ -117,6 +117,11 @@
# html_theme = 'bizstyle'
# html_theme = agogo
+html_sidebars = {
+ '**': ['globaltoc.html']
+}
+
+
html_theme = 'sphinx_materialdesign_theme' # use the theme in subdir 'theme'
html_theme_path = ['./'] # make sphinx search for themes in current dir
|
{"golden_diff": "diff --git a/doc/conf.py b/doc/conf.py\n--- a/doc/conf.py\n+++ b/doc/conf.py\n@@ -117,6 +117,11 @@\n # html_theme = 'bizstyle'\n # html_theme = agogo\n \n+html_sidebars = {\n+ '**': ['globaltoc.html']\n+}\n+\n+\n html_theme = 'sphinx_materialdesign_theme' # use the theme in subdir 'theme'\n html_theme_path = ['./'] # make sphinx search for themes in current dir\n", "issue": "Revise the documentation TOC subsection handling\n<!-- \u26a0\ufe0f If you do not respect this template, your issue will be closed -->\r\n<!-- \u26a0\ufe0f Make sure to browse the opened and closed issues to confirm this idea does not exist. -->\r\n\r\n### What is the expected enhancement?\r\n\r\nAn issue raised during #1254:\r\n\r\n> Also Is it possible in the template to show the subsection when that section is viewed.\r\n\r\nThe new fancy design currently does not show subsections in the left-side TOC pane (except for the autodocs). Ideally it should show the subsections, allowing collapsing with sensible defaults and usability.\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n#\n# Qiskit documentation build configuration file, created by\n# sphinx-quickstart on Tue Jul 25 18:13:28 2017.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nfrom qiskit import __version__\nsys.path.insert(0, os.path.abspath('.'))\n\n# Imported manually, as otherwise it will not be fully imported.\nimport qiskit.extensions.simulator\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = ['sphinx.ext.autodoc',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.napoleon',\n 'sphinx.ext.doctest',\n 'sphinx.ext.coverage',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.viewcode',\n 'sphinx.ext.githubpages']\n# Napoleon settings\nnapoleon_google_docstring = True\nnapoleon_numpy_docstring = False\nnapoleon_include_init_with_doc = True\nnapoleon_include_private_with_doc = False\nnapoleon_include_special_with_doc = False\nnapoleon_use_admonition_for_examples = False\nnapoleon_use_admonition_for_notes = False\nnapoleon_use_admonition_for_references = False\nnapoleon_use_ivar = False\nnapoleon_use_param = True\nnapoleon_use_rtype = True\n\nautoclass_content = 'both'\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = 'Qiskit Terra'\ncopyright = '2017-2018 IBM'\nauthor = 'IBM'\n\n# Add description\nhtml_context = {\n 'description': 'Qiskit Terra'\n}\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = __version__\n# The full version, including alpha/beta/rc tags.\nrelease = version\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store',\n '_autodoc/modules.rst', 'de', 'ja']\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\n# html_theme = 'alabaster'\n# html_theme = 'bizstyle'\n# html_theme = agogo\n\nhtml_theme = 'sphinx_materialdesign_theme' # use the theme in subdir 'theme'\nhtml_theme_path = ['./'] # make sphinx search for themes in current dir\n\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\nhtml_theme_options = {\n # Specify a list of menu in Header.\n # Tuples forms:\n # ('Name', 'external url or path of pages in the document', boolean, 'icon name')\n #\n # Third argument:\n # True indicates an external link.\n # False indicates path of pages in the document.\n #\n # Fourth argument:\n # Specify the icon name.\n # For details see link.\n # https://material.io/icons/\n 'header_links' : [\n ('Home', 'index', False, 'home'),\n (\"ExternalLink\", \"http://example.com\", True, 'launch'),\n (\"NoIconLink\", \"http://example.com\", True, ''),\n (\"GitHub\", \"https://github.com/myyasuda/sphinx_materialdesign_theme\", True, 'link')\n ],\n\n # Customize css colors.\n # For details see link.\n # https://getmdl.io/customize/index.html\n #\n # Values: amber, blue, brown, cyan deep_orange, deep_purple, green, grey, indigo, light_blue,\n # light_green, lime, orange, pink, purple, red, teal, yellow(Default: indigo)\n 'primary_color': 'blue',\n # Values: Same as primary_color. (Default: pink)\n 'accent_color': 'indigo',\n\n # Customize layout.\n # For details see link.\n # https://getmdl.io/components/index.html#layout-section\n 'fixed_drawer': True,\n 'fixed_header': False,\n 'header_waterfall': True,\n 'header_scroll': False,\n\n # Render title in header.\n # Values: True, False (Default: False)\n 'show_header_title': False,\n # Render title in drawer.\n # Values: True, False (Default: True)\n 'show_drawer_title': True,\n # Render footer.\n}\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['./theme/static/']\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\nhtml_logo = 'theme/static/qiskit-terra-logo.png'\n\nhtml_favicon = 'theme/static/favicon.ico'\n\nhtml_last_updated_fmt = '%Y/%m/%d'\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Qiskitdoc'\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'Qiskit.tex', 'Qiskit Documentation',\n '''Jim Challenger, Andrew Cross, Ismael Faro, Jay Gambetta''', 'manual'),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'qiskit', 'Qiskit Documentation',\n [author], 1)\n]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'Qiskit Terra', 'Qiskit Terra Documentation',\n author, 'Qiskit', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n\n# Avoid a warning and treat the docstrings of the QasmLexer tokens as verbatim,\n# as PLY uses docstring as a way to define the patterns the token matches.\ndef remove_module_docstring(app, what, name, obj, options, lines):\n if name.startswith('qiskit.qasm._qasmlexer.QasmLexer.t_') and lines:\n lines[0] = u'Token matching: ``%s``' % lines[0]\n\n\ndef setup(app):\n app.connect('autodoc-process-docstring', remove_module_docstring)\n", "path": "doc/conf.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n#\n# Qiskit documentation build configuration file, created by\n# sphinx-quickstart on Tue Jul 25 18:13:28 2017.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nfrom qiskit import __version__\nsys.path.insert(0, os.path.abspath('.'))\n\n# Imported manually, as otherwise it will not be fully imported.\nimport qiskit.extensions.simulator\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = ['sphinx.ext.autodoc',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.napoleon',\n 'sphinx.ext.doctest',\n 'sphinx.ext.coverage',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.viewcode',\n 'sphinx.ext.githubpages']\n# Napoleon settings\nnapoleon_google_docstring = True\nnapoleon_numpy_docstring = False\nnapoleon_include_init_with_doc = True\nnapoleon_include_private_with_doc = False\nnapoleon_include_special_with_doc = False\nnapoleon_use_admonition_for_examples = False\nnapoleon_use_admonition_for_notes = False\nnapoleon_use_admonition_for_references = False\nnapoleon_use_ivar = False\nnapoleon_use_param = True\nnapoleon_use_rtype = True\n\nautoclass_content = 'both'\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = 'Qiskit Terra'\ncopyright = '2017-2018 IBM'\nauthor = 'IBM'\n\n# Add description\nhtml_context = {\n 'description': 'Qiskit Terra'\n}\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = __version__\n# The full version, including alpha/beta/rc tags.\nrelease = version\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store',\n '_autodoc/modules.rst', 'de', 'ja']\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\n# html_theme = 'alabaster'\n# html_theme = 'bizstyle'\n# html_theme = agogo\n\nhtml_sidebars = {\n '**': ['globaltoc.html']\n}\n\n\nhtml_theme = 'sphinx_materialdesign_theme' # use the theme in subdir 'theme'\nhtml_theme_path = ['./'] # make sphinx search for themes in current dir\n\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\nhtml_theme_options = {\n # Specify a list of menu in Header.\n # Tuples forms:\n # ('Name', 'external url or path of pages in the document', boolean, 'icon name')\n #\n # Third argument:\n # True indicates an external link.\n # False indicates path of pages in the document.\n #\n # Fourth argument:\n # Specify the icon name.\n # For details see link.\n # https://material.io/icons/\n 'header_links' : [\n ('Home', 'index', False, 'home'),\n (\"ExternalLink\", \"http://example.com\", True, 'launch'),\n (\"NoIconLink\", \"http://example.com\", True, ''),\n (\"GitHub\", \"https://github.com/myyasuda/sphinx_materialdesign_theme\", True, 'link')\n ],\n\n # Customize css colors.\n # For details see link.\n # https://getmdl.io/customize/index.html\n #\n # Values: amber, blue, brown, cyan deep_orange, deep_purple, green, grey, indigo, light_blue,\n # light_green, lime, orange, pink, purple, red, teal, yellow(Default: indigo)\n 'primary_color': 'blue',\n # Values: Same as primary_color. (Default: pink)\n 'accent_color': 'indigo',\n\n # Customize layout.\n # For details see link.\n # https://getmdl.io/components/index.html#layout-section\n 'fixed_drawer': True,\n 'fixed_header': False,\n 'header_waterfall': True,\n 'header_scroll': False,\n\n # Render title in header.\n # Values: True, False (Default: False)\n 'show_header_title': False,\n # Render title in drawer.\n # Values: True, False (Default: True)\n 'show_drawer_title': True,\n # Render footer.\n}\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['./theme/static/']\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\nhtml_logo = 'theme/static/qiskit-terra-logo.png'\n\nhtml_favicon = 'theme/static/favicon.ico'\n\nhtml_last_updated_fmt = '%Y/%m/%d'\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Qiskitdoc'\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'Qiskit.tex', 'Qiskit Documentation',\n '''Jim Challenger, Andrew Cross, Ismael Faro, Jay Gambetta''', 'manual'),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'qiskit', 'Qiskit Documentation',\n [author], 1)\n]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'Qiskit Terra', 'Qiskit Terra Documentation',\n author, 'Qiskit', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n\n# Avoid a warning and treat the docstrings of the QasmLexer tokens as verbatim,\n# as PLY uses docstring as a way to define the patterns the token matches.\ndef remove_module_docstring(app, what, name, obj, options, lines):\n if name.startswith('qiskit.qasm._qasmlexer.QasmLexer.t_') and lines:\n lines[0] = u'Token matching: ``%s``' % lines[0]\n\n\ndef setup(app):\n app.connect('autodoc-process-docstring', remove_module_docstring)\n", "path": "doc/conf.py"}]}
| 3,065 | 110 |
gh_patches_debug_40895
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-4414
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
'Completed' attribute missing from order-statistics API
**I'm submitting a ...** (check one with "x")
- [x] bug report
- [ ] feature request
- [ ] support request => Please do not submit support requests here, instead ask your query in out Gitter channel at https://gitter.im/fossasia/open-event-orga-server
**Current behavior:**
Right now the response contains the following fields
```
"placed": 0,
"draft": 0,
"cancelled": 0,
"total": 0,
"expired": 0,
"pending": 0
```
The attribute `completed` is missing from the response.
Image for reference : https://user-images.githubusercontent.com/13910561/29230756-f5dabe20-7f01-11e7-8c5f-58ee69c38e65.png
**Expected behavior:**
`completed` attribute should be there.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/api/order_statistics/tickets.py`
Content:
```
1 from flask_rest_jsonapi import ResourceDetail
2 from marshmallow_jsonapi.flask import Schema
3 from marshmallow_jsonapi import fields
4 from sqlalchemy import func
5
6 from app.api.helpers.utilities import dasherize
7 from app.api.bootstrap import api
8 from app.models import db
9 from app.models.order import Order, OrderTicket
10 from app.models.ticket import Ticket
11 from app.api.helpers.db import get_count
12
13
14 class OrderStatisticsTicketSchema(Schema):
15 """
16 Api schema
17 """
18
19 class Meta:
20 """
21 Meta class
22 """
23 type_ = 'order-statistics-ticket'
24 self_view = 'v1.order_statistics_ticket_detail'
25 self_view_kwargs = {'id': '<id>'}
26 inflect = dasherize
27
28 id = fields.Str()
29 identifier = fields.Str()
30 tickets = fields.Method("tickets_count")
31 orders = fields.Method("orders_count")
32 sales = fields.Method("sales_count")
33
34 def tickets_count(self, obj):
35 obj_id = obj.id
36 total = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(
37 OrderTicket.ticket_id == obj_id).scalar()
38 draft = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(
39 OrderTicket.ticket_id == obj_id, Order.status == 'draft').scalar()
40 cancelled = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(
41 OrderTicket.ticket_id == obj_id, Order.status == 'cancelled').scalar()
42 pending = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(
43 OrderTicket.ticket_id == obj_id, Order.status == 'pending').scalar()
44 expired = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(
45 OrderTicket.ticket_id == obj_id, Order.status == 'expired').scalar()
46 placed = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(
47 OrderTicket.ticket_id == obj_id, Order.status == 'placed').scalar()
48 result = {
49 'total': total or 0,
50 'draft': draft or 0,
51 'cancelled': cancelled or 0,
52 'pending': pending or 0,
53 'expired': expired or 0,
54 'placed': placed or 0
55 }
56 return result
57
58 def orders_count(self, obj):
59 obj_id = obj.id
60 total = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id))
61 draft = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,
62 Order.status == 'draft'))
63 cancelled = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,
64 Order.status == 'cancelled'))
65 pending = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,
66 Order.status == 'pending'))
67 expired = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,
68 Order.status == 'expired'))
69 placed = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,
70 Order.status == 'placed'))
71 result = {
72 'total': total or 0,
73 'draft': draft or 0,
74 'cancelled': cancelled or 0,
75 'pending': pending or 0,
76 'expired': expired or 0,
77 'placed': placed or 0
78 }
79 return result
80
81 def sales_count(self, obj):
82 obj_id = obj.id
83 total = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(
84 OrderTicket.ticket_id == obj_id).scalar()
85 draft = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(
86 OrderTicket.ticket_id == obj_id, Order.status == 'draft').scalar()
87 cancelled = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(
88 OrderTicket.ticket_id == obj_id, Order.status == 'cancelled').scalar()
89 pending = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(
90 OrderTicket.ticket_id == obj_id, Order.status == 'pending').scalar()
91 expired = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(
92 OrderTicket.ticket_id == obj_id, Order.status == 'expired').scalar()
93 placed = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(
94 OrderTicket.ticket_id == obj_id, Order.status == 'placed').scalar()
95 result = {
96 'total': total or 0,
97 'draft': draft or 0,
98 'cancelled': cancelled or 0,
99 'pending': pending or 0,
100 'expired': expired or 0,
101 'placed': placed or 0
102 }
103 return result
104
105
106 class OrderStatisticsTicketDetail(ResourceDetail):
107 """
108 detail by id
109 """
110 methods = ['GET']
111 decorators = (api.has_permission('is_coorganizer', fetch="event_id", fetch_as="event_id", model=Ticket),)
112 schema = OrderStatisticsTicketSchema
113 data_layer = {'session': db.session,
114 'model': Ticket}
115
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/app/api/order_statistics/tickets.py b/app/api/order_statistics/tickets.py
--- a/app/api/order_statistics/tickets.py
+++ b/app/api/order_statistics/tickets.py
@@ -45,13 +45,16 @@
OrderTicket.ticket_id == obj_id, Order.status == 'expired').scalar()
placed = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(
OrderTicket.ticket_id == obj_id, Order.status == 'placed').scalar()
+ completed = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(
+ OrderTicket.ticket_id == obj_id, Order.status == 'completed').scalar()
result = {
'total': total or 0,
'draft': draft or 0,
'cancelled': cancelled or 0,
'pending': pending or 0,
'expired': expired or 0,
- 'placed': placed or 0
+ 'placed': placed or 0,
+ 'completed': completed or 0
}
return result
@@ -68,13 +71,16 @@
Order.status == 'expired'))
placed = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,
Order.status == 'placed'))
+ completed = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,
+ Order.status == 'completed'))
result = {
'total': total or 0,
'draft': draft or 0,
'cancelled': cancelled or 0,
'pending': pending or 0,
'expired': expired or 0,
- 'placed': placed or 0
+ 'placed': placed or 0,
+ 'completed': completed or 0
}
return result
@@ -92,13 +98,16 @@
OrderTicket.ticket_id == obj_id, Order.status == 'expired').scalar()
placed = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(
OrderTicket.ticket_id == obj_id, Order.status == 'placed').scalar()
+ completed = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(
+ OrderTicket.ticket_id == obj_id, Order.status == 'completed').scalar()
result = {
'total': total or 0,
'draft': draft or 0,
'cancelled': cancelled or 0,
'pending': pending or 0,
'expired': expired or 0,
- 'placed': placed or 0
+ 'placed': placed or 0,
+ 'completed': completed or 0
}
return result
|
{"golden_diff": "diff --git a/app/api/order_statistics/tickets.py b/app/api/order_statistics/tickets.py\n--- a/app/api/order_statistics/tickets.py\n+++ b/app/api/order_statistics/tickets.py\n@@ -45,13 +45,16 @@\n OrderTicket.ticket_id == obj_id, Order.status == 'expired').scalar()\n placed = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'placed').scalar()\n+ completed = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(\n+ OrderTicket.ticket_id == obj_id, Order.status == 'completed').scalar()\n result = {\n 'total': total or 0,\n 'draft': draft or 0,\n 'cancelled': cancelled or 0,\n 'pending': pending or 0,\n 'expired': expired or 0,\n- 'placed': placed or 0\n+ 'placed': placed or 0,\n+ 'completed': completed or 0\n }\n return result\n \n@@ -68,13 +71,16 @@\n Order.status == 'expired'))\n placed = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,\n Order.status == 'placed'))\n+ completed = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,\n+ Order.status == 'completed'))\n result = {\n 'total': total or 0,\n 'draft': draft or 0,\n 'cancelled': cancelled or 0,\n 'pending': pending or 0,\n 'expired': expired or 0,\n- 'placed': placed or 0\n+ 'placed': placed or 0,\n+ 'completed': completed or 0\n }\n return result\n \n@@ -92,13 +98,16 @@\n OrderTicket.ticket_id == obj_id, Order.status == 'expired').scalar()\n placed = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'placed').scalar()\n+ completed = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(\n+ OrderTicket.ticket_id == obj_id, Order.status == 'completed').scalar()\n result = {\n 'total': total or 0,\n 'draft': draft or 0,\n 'cancelled': cancelled or 0,\n 'pending': pending or 0,\n 'expired': expired or 0,\n- 'placed': placed or 0\n+ 'placed': placed or 0,\n+ 'completed': completed or 0\n }\n return result\n", "issue": "'Completed' attribute missing from order-statistics API\n**I'm submitting a ...** (check one with \"x\")\r\n- [x] bug report\r\n- [ ] feature request\r\n- [ ] support request => Please do not submit support requests here, instead ask your query in out Gitter channel at https://gitter.im/fossasia/open-event-orga-server\r\n\r\n**Current behavior:**\r\nRight now the response contains the following fields\r\n ```\r\n \"placed\": 0,\r\n \"draft\": 0,\r\n \"cancelled\": 0,\r\n \"total\": 0,\r\n \"expired\": 0,\r\n \"pending\": 0\r\n```\r\nThe attribute `completed` is missing from the response. \r\nImage for reference : https://user-images.githubusercontent.com/13910561/29230756-f5dabe20-7f01-11e7-8c5f-58ee69c38e65.png\r\n\r\n**Expected behavior:**\r\n`completed` attribute should be there.\n", "before_files": [{"content": "from flask_rest_jsonapi import ResourceDetail\nfrom marshmallow_jsonapi.flask import Schema\nfrom marshmallow_jsonapi import fields\nfrom sqlalchemy import func\n\nfrom app.api.helpers.utilities import dasherize\nfrom app.api.bootstrap import api\nfrom app.models import db\nfrom app.models.order import Order, OrderTicket\nfrom app.models.ticket import Ticket\nfrom app.api.helpers.db import get_count\n\n\nclass OrderStatisticsTicketSchema(Schema):\n \"\"\"\n Api schema\n \"\"\"\n\n class Meta:\n \"\"\"\n Meta class\n \"\"\"\n type_ = 'order-statistics-ticket'\n self_view = 'v1.order_statistics_ticket_detail'\n self_view_kwargs = {'id': '<id>'}\n inflect = dasherize\n\n id = fields.Str()\n identifier = fields.Str()\n tickets = fields.Method(\"tickets_count\")\n orders = fields.Method(\"orders_count\")\n sales = fields.Method(\"sales_count\")\n\n def tickets_count(self, obj):\n obj_id = obj.id\n total = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id).scalar()\n draft = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'draft').scalar()\n cancelled = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'cancelled').scalar()\n pending = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'pending').scalar()\n expired = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'expired').scalar()\n placed = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'placed').scalar()\n result = {\n 'total': total or 0,\n 'draft': draft or 0,\n 'cancelled': cancelled or 0,\n 'pending': pending or 0,\n 'expired': expired or 0,\n 'placed': placed or 0\n }\n return result\n\n def orders_count(self, obj):\n obj_id = obj.id\n total = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id))\n draft = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,\n Order.status == 'draft'))\n cancelled = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,\n Order.status == 'cancelled'))\n pending = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,\n Order.status == 'pending'))\n expired = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,\n Order.status == 'expired'))\n placed = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,\n Order.status == 'placed'))\n result = {\n 'total': total or 0,\n 'draft': draft or 0,\n 'cancelled': cancelled or 0,\n 'pending': pending or 0,\n 'expired': expired or 0,\n 'placed': placed or 0\n }\n return result\n\n def sales_count(self, obj):\n obj_id = obj.id\n total = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id).scalar()\n draft = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'draft').scalar()\n cancelled = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'cancelled').scalar()\n pending = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'pending').scalar()\n expired = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'expired').scalar()\n placed = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'placed').scalar()\n result = {\n 'total': total or 0,\n 'draft': draft or 0,\n 'cancelled': cancelled or 0,\n 'pending': pending or 0,\n 'expired': expired or 0,\n 'placed': placed or 0\n }\n return result\n\n\nclass OrderStatisticsTicketDetail(ResourceDetail):\n \"\"\"\n detail by id\n \"\"\"\n methods = ['GET']\n decorators = (api.has_permission('is_coorganizer', fetch=\"event_id\", fetch_as=\"event_id\", model=Ticket),)\n schema = OrderStatisticsTicketSchema\n data_layer = {'session': db.session,\n 'model': Ticket}\n", "path": "app/api/order_statistics/tickets.py"}], "after_files": [{"content": "from flask_rest_jsonapi import ResourceDetail\nfrom marshmallow_jsonapi.flask import Schema\nfrom marshmallow_jsonapi import fields\nfrom sqlalchemy import func\n\nfrom app.api.helpers.utilities import dasherize\nfrom app.api.bootstrap import api\nfrom app.models import db\nfrom app.models.order import Order, OrderTicket\nfrom app.models.ticket import Ticket\nfrom app.api.helpers.db import get_count\n\n\nclass OrderStatisticsTicketSchema(Schema):\n \"\"\"\n Api schema\n \"\"\"\n\n class Meta:\n \"\"\"\n Meta class\n \"\"\"\n type_ = 'order-statistics-ticket'\n self_view = 'v1.order_statistics_ticket_detail'\n self_view_kwargs = {'id': '<id>'}\n inflect = dasherize\n\n id = fields.Str()\n identifier = fields.Str()\n tickets = fields.Method(\"tickets_count\")\n orders = fields.Method(\"orders_count\")\n sales = fields.Method(\"sales_count\")\n\n def tickets_count(self, obj):\n obj_id = obj.id\n total = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id).scalar()\n draft = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'draft').scalar()\n cancelled = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'cancelled').scalar()\n pending = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'pending').scalar()\n expired = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'expired').scalar()\n placed = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'placed').scalar()\n completed = db.session.query(func.sum(OrderTicket.quantity.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'completed').scalar()\n result = {\n 'total': total or 0,\n 'draft': draft or 0,\n 'cancelled': cancelled or 0,\n 'pending': pending or 0,\n 'expired': expired or 0,\n 'placed': placed or 0,\n 'completed': completed or 0\n }\n return result\n\n def orders_count(self, obj):\n obj_id = obj.id\n total = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id))\n draft = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,\n Order.status == 'draft'))\n cancelled = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,\n Order.status == 'cancelled'))\n pending = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,\n Order.status == 'pending'))\n expired = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,\n Order.status == 'expired'))\n placed = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,\n Order.status == 'placed'))\n completed = get_count(db.session.query(Order).join(Order.order_tickets).filter(OrderTicket.ticket_id == obj_id,\n Order.status == 'completed'))\n result = {\n 'total': total or 0,\n 'draft': draft or 0,\n 'cancelled': cancelled or 0,\n 'pending': pending or 0,\n 'expired': expired or 0,\n 'placed': placed or 0,\n 'completed': completed or 0\n }\n return result\n\n def sales_count(self, obj):\n obj_id = obj.id\n total = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id).scalar()\n draft = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'draft').scalar()\n cancelled = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'cancelled').scalar()\n pending = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'pending').scalar()\n expired = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'expired').scalar()\n placed = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'placed').scalar()\n completed = db.session.query(func.sum(Order.amount.label('sum'))).join(Order.order_tickets).filter(\n OrderTicket.ticket_id == obj_id, Order.status == 'completed').scalar()\n result = {\n 'total': total or 0,\n 'draft': draft or 0,\n 'cancelled': cancelled or 0,\n 'pending': pending or 0,\n 'expired': expired or 0,\n 'placed': placed or 0,\n 'completed': completed or 0\n }\n return result\n\n\nclass OrderStatisticsTicketDetail(ResourceDetail):\n \"\"\"\n detail by id\n \"\"\"\n methods = ['GET']\n decorators = (api.has_permission('is_coorganizer', fetch=\"event_id\", fetch_as=\"event_id\", model=Ticket),)\n schema = OrderStatisticsTicketSchema\n data_layer = {'session': db.session,\n 'model': Ticket}\n", "path": "app/api/order_statistics/tickets.py"}]}
| 1,880 | 607 |
gh_patches_debug_38512
|
rasdani/github-patches
|
git_diff
|
apache__airflow-9740
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
API Endpoint - CRUD - DAG
Hello
We need to create several endpoints that perform basic CRUD operations on **DAG**. We need the following endpoints:
- PATCH /dags/{dag_id}
It depends on https://github.com/apache/airflow/issues/8128
Detailed information is available in the issue:
https://github.com/apache/airflow/issues/8118
LOVE,
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `airflow/api_connexion/schemas/dag_schema.py`
Content:
```
1 # Licensed to the Apache Software Foundation (ASF) under one
2 # or more contributor license agreements. See the NOTICE file
3 # distributed with this work for additional information
4 # regarding copyright ownership. The ASF licenses this file
5 # to you under the Apache License, Version 2.0 (the
6 # "License"); you may not use this file except in compliance
7 # with the License. You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing,
12 # software distributed under the License is distributed on an
13 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
14 # KIND, either express or implied. See the License for the
15 # specific language governing permissions and limitations
16 # under the License.
17
18 from typing import List, NamedTuple
19
20 from marshmallow import Schema, fields
21 from marshmallow_sqlalchemy import SQLAlchemySchema, auto_field
22
23 from airflow.api_connexion.schemas.common_schema import ScheduleIntervalSchema, TimeDeltaSchema, TimezoneField
24 from airflow.models.dag import DagModel, DagTag
25
26
27 class DagTagSchema(SQLAlchemySchema):
28 """Dag Tag schema"""
29 class Meta:
30 """Meta"""
31
32 model = DagTag
33
34 name = auto_field()
35
36
37 class DAGSchema(SQLAlchemySchema):
38 """DAG schema"""
39
40 class Meta:
41 """Meta"""
42 model = DagModel
43
44 dag_id = auto_field(dump_only=True)
45 root_dag_id = auto_field(dump_only=True)
46 is_paused = auto_field(dump_only=True)
47 is_subdag = auto_field(dump_only=True)
48 fileloc = auto_field(dump_only=True)
49 owners = fields.Method("get_owners", dump_only=True)
50 description = auto_field(dump_only=True)
51 schedule_interval = fields.Nested(ScheduleIntervalSchema, dump_only=True)
52 tags = fields.List(fields.Nested(DagTagSchema), dump_only=True)
53
54 @staticmethod
55 def get_owners(obj: DagModel):
56 """Convert owners attribute to DAG representation"""
57
58 if not getattr(obj, 'owners', None):
59 return []
60 return obj.owners.split(",")
61
62
63 class DAGDetailSchema(DAGSchema):
64 """DAG details"""
65
66 timezone = TimezoneField(dump_only=True)
67 catchup = fields.Boolean(dump_only=True)
68 orientation = fields.String(dump_only=True)
69 concurrency = fields.Integer(dump_only=True)
70 start_date = fields.DateTime(dump_only=True)
71 dag_run_timeout = fields.Nested(TimeDeltaSchema, dump_only=True, attribute="dagrun_timeout")
72 doc_md = fields.String(dump_only=True)
73 default_view = fields.String(dump_only=True)
74
75
76 class DAGCollection(NamedTuple):
77 """List of DAGs with metadata"""
78
79 dags: List[DagModel]
80 total_entries: int
81
82
83 class DAGCollectionSchema(Schema):
84 """DAG Collection schema"""
85
86 dags = fields.List(fields.Nested(DAGSchema))
87 total_entries = fields.Int()
88
89
90 dags_collection_schema = DAGCollectionSchema()
91 dag_schema = DAGSchema()
92
93 dag_detail_schema = DAGDetailSchema()
94
```
Path: `airflow/api_connexion/schemas/common_schema.py`
Content:
```
1 # Licensed to the Apache Software Foundation (ASF) under one
2 # or more contributor license agreements. See the NOTICE file
3 # distributed with this work for additional information
4 # regarding copyright ownership. The ASF licenses this file
5 # to you under the Apache License, Version 2.0 (the
6 # "License"); you may not use this file except in compliance
7 # with the License. You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing,
12 # software distributed under the License is distributed on an
13 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
14 # KIND, either express or implied. See the License for the
15 # specific language governing permissions and limitations
16 # under the License.
17
18 import datetime
19 import inspect
20 import typing
21
22 import marshmallow
23 from dateutil import relativedelta
24 from marshmallow import Schema, fields, validate
25 from marshmallow_oneofschema import OneOfSchema
26
27 from airflow.serialization.serialized_objects import SerializedBaseOperator
28 from airflow.utils.weight_rule import WeightRule
29
30
31 class CronExpression(typing.NamedTuple):
32 """Cron expression schema"""
33 value: str
34
35
36 class TimeDeltaSchema(Schema):
37 """Time delta schema"""
38
39 objectType = fields.Constant("TimeDelta", data_key="__type")
40 days = fields.Integer()
41 seconds = fields.Integer()
42 microseconds = fields.Integer()
43
44 @marshmallow.post_load
45 def make_time_delta(self, data, **kwargs):
46 """Create time delta based on data"""
47
48 if "objectType" in data:
49 del data["objectType"]
50 return datetime.timedelta(**data)
51
52
53 class RelativeDeltaSchema(Schema):
54 """Relative delta schema"""
55
56 objectType = fields.Constant("RelativeDelta", data_key="__type")
57 years = fields.Integer()
58 months = fields.Integer()
59 days = fields.Integer()
60 leapdays = fields.Integer()
61 hours = fields.Integer()
62 minutes = fields.Integer()
63 seconds = fields.Integer()
64 microseconds = fields.Integer()
65 year = fields.Integer()
66 month = fields.Integer()
67 day = fields.Integer()
68 hour = fields.Integer()
69 minute = fields.Integer()
70 second = fields.Integer()
71 microsecond = fields.Integer()
72
73 @marshmallow.post_load
74 def make_relative_delta(self, data, **kwargs):
75 """Create relative delta based on data"""
76
77 if "objectType" in data:
78 del data["objectType"]
79
80 return relativedelta.relativedelta(**data)
81
82
83 class CronExpressionSchema(Schema):
84 """Cron expression schema"""
85
86 objectType = fields.Constant("CronExpression", data_key="__type", required=True)
87 value = fields.String(required=True)
88
89 @marshmallow.post_load
90 def make_cron_expression(self, data, **kwargs):
91 """Create cron expression based on data"""
92 return CronExpression(data["value"])
93
94
95 class ScheduleIntervalSchema(OneOfSchema):
96 """
97 Schedule interval.
98
99 It supports the following types:
100
101 * TimeDelta
102 * RelativeDelta
103 * CronExpression
104 """
105 type_field = "__type"
106 type_schemas = {
107 "TimeDelta": TimeDeltaSchema,
108 "RelativeDelta": RelativeDeltaSchema,
109 "CronExpression": CronExpressionSchema,
110 }
111
112 def _dump(self, obj, update_fields=True, **kwargs):
113 if isinstance(obj, str):
114 obj = CronExpression(obj)
115
116 return super()._dump(obj, update_fields=update_fields, **kwargs)
117
118 def get_obj_type(self, obj):
119 """Select schema based on object type"""
120 if isinstance(obj, datetime.timedelta):
121 return "TimeDelta"
122 elif isinstance(obj, relativedelta.relativedelta):
123 return "RelativeDelta"
124 elif isinstance(obj, CronExpression):
125 return "CronExpression"
126 else:
127 raise Exception("Unknown object type: {}".format(obj.__class__.__name__))
128
129
130 class ColorField(fields.String):
131 """Schema for color property"""
132 def __init__(self, **metadata):
133 super().__init__(**metadata)
134 self.validators = (
135 [validate.Regexp("^#[a-fA-F0-9]{3,6}$")] + list(self.validators)
136 )
137
138
139 class WeightRuleField(fields.String):
140 """Schema for WeightRule"""
141 def __init__(self, **metadata):
142 super().__init__(**metadata)
143 self.validators = (
144 [validate.OneOf(WeightRule.all_weight_rules())] + list(self.validators)
145 )
146
147
148 class TimezoneField(fields.String):
149 """Schema for timezone"""
150
151
152 class ClassReferenceSchema(Schema):
153 """
154 Class reference schema.
155 """
156 module_path = fields.Method("_get_module", required=True)
157 class_name = fields.Method("_get_class_name", required=True)
158
159 def _get_module(self, obj):
160 if isinstance(obj, SerializedBaseOperator):
161 return obj._task_module # pylint: disable=protected-access
162 return inspect.getmodule(obj).__name__
163
164 def _get_class_name(self, obj):
165 if isinstance(obj, SerializedBaseOperator):
166 return obj._task_type # pylint: disable=protected-access
167 if isinstance(obj, type):
168 return obj.__name__
169 return type(obj).__name__
170
```
Path: `airflow/api_connexion/endpoints/dag_endpoint.py`
Content:
```
1 # Licensed to the Apache Software Foundation (ASF) under one
2 # or more contributor license agreements. See the NOTICE file
3 # distributed with this work for additional information
4 # regarding copyright ownership. The ASF licenses this file
5 # to you under the Apache License, Version 2.0 (the
6 # "License"); you may not use this file except in compliance
7 # with the License. You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing,
12 # software distributed under the License is distributed on an
13 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
14 # KIND, either express or implied. See the License for the
15 # specific language governing permissions and limitations
16 # under the License.
17 from flask import current_app
18 from sqlalchemy import func
19
20 from airflow import DAG
21 from airflow.api_connexion import security
22 from airflow.api_connexion.exceptions import NotFound
23 from airflow.api_connexion.parameters import check_limit, format_parameters
24 from airflow.api_connexion.schemas.dag_schema import (
25 DAGCollection, dag_detail_schema, dag_schema, dags_collection_schema,
26 )
27 from airflow.models.dag import DagModel
28 from airflow.utils.session import provide_session
29
30
31 @security.requires_authentication
32 @provide_session
33 def get_dag(dag_id, session):
34 """
35 Get basic information about a DAG.
36 """
37 dag = session.query(DagModel).filter(DagModel.dag_id == dag_id).one_or_none()
38
39 if dag is None:
40 raise NotFound("DAG not found")
41
42 return dag_schema.dump(dag)
43
44
45 @security.requires_authentication
46 def get_dag_details(dag_id):
47 """
48 Get details of DAG.
49 """
50 dag: DAG = current_app.dag_bag.get_dag(dag_id)
51 if not dag:
52 raise NotFound("DAG not found")
53 return dag_detail_schema.dump(dag)
54
55
56 @security.requires_authentication
57 @format_parameters({
58 'limit': check_limit
59 })
60 @provide_session
61 def get_dags(session, limit, offset=0):
62 """
63 Get all DAGs.
64 """
65 dags = session.query(DagModel).order_by(DagModel.dag_id).offset(offset).limit(limit).all()
66
67 total_entries = session.query(func.count(DagModel.dag_id)).scalar()
68
69 return dags_collection_schema.dump(DAGCollection(dags=dags, total_entries=total_entries))
70
71
72 @security.requires_authentication
73 def patch_dag():
74 """
75 Update the specific DAG
76 """
77 raise NotImplementedError("Not implemented yet.")
78
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/airflow/api_connexion/endpoints/dag_endpoint.py b/airflow/api_connexion/endpoints/dag_endpoint.py
--- a/airflow/api_connexion/endpoints/dag_endpoint.py
+++ b/airflow/api_connexion/endpoints/dag_endpoint.py
@@ -14,12 +14,13 @@
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
-from flask import current_app
+from flask import current_app, request
+from marshmallow import ValidationError
from sqlalchemy import func
from airflow import DAG
from airflow.api_connexion import security
-from airflow.api_connexion.exceptions import NotFound
+from airflow.api_connexion.exceptions import BadRequest, NotFound
from airflow.api_connexion.parameters import check_limit, format_parameters
from airflow.api_connexion.schemas.dag_schema import (
DAGCollection, dag_detail_schema, dag_schema, dags_collection_schema,
@@ -70,8 +71,19 @@
@security.requires_authentication
-def patch_dag():
+@provide_session
+def patch_dag(session, dag_id):
"""
Update the specific DAG
"""
- raise NotImplementedError("Not implemented yet.")
+ dag = session.query(DagModel).filter(DagModel.dag_id == dag_id).one_or_none()
+ if not dag:
+ raise NotFound(f"Dag with id: '{dag_id}' not found")
+ try:
+ patch_body = dag_schema.load(request.json, session=session)
+ except ValidationError as err:
+ raise BadRequest("Invalid Dag schema", detail=str(err.messages))
+ for key, value in patch_body.items():
+ setattr(dag, key, value)
+ session.commit()
+ return dag_schema.dump(dag)
diff --git a/airflow/api_connexion/schemas/common_schema.py b/airflow/api_connexion/schemas/common_schema.py
--- a/airflow/api_connexion/schemas/common_schema.py
+++ b/airflow/api_connexion/schemas/common_schema.py
@@ -83,7 +83,7 @@
class CronExpressionSchema(Schema):
"""Cron expression schema"""
- objectType = fields.Constant("CronExpression", data_key="__type", required=True)
+ objectType = fields.Constant("CronExpression", data_key="__type")
value = fields.String(required=True)
@marshmallow.post_load
diff --git a/airflow/api_connexion/schemas/dag_schema.py b/airflow/api_connexion/schemas/dag_schema.py
--- a/airflow/api_connexion/schemas/dag_schema.py
+++ b/airflow/api_connexion/schemas/dag_schema.py
@@ -43,12 +43,12 @@
dag_id = auto_field(dump_only=True)
root_dag_id = auto_field(dump_only=True)
- is_paused = auto_field(dump_only=True)
+ is_paused = auto_field()
is_subdag = auto_field(dump_only=True)
fileloc = auto_field(dump_only=True)
owners = fields.Method("get_owners", dump_only=True)
description = auto_field(dump_only=True)
- schedule_interval = fields.Nested(ScheduleIntervalSchema, dump_only=True)
+ schedule_interval = fields.Nested(ScheduleIntervalSchema)
tags = fields.List(fields.Nested(DagTagSchema), dump_only=True)
@staticmethod
|
{"golden_diff": "diff --git a/airflow/api_connexion/endpoints/dag_endpoint.py b/airflow/api_connexion/endpoints/dag_endpoint.py\n--- a/airflow/api_connexion/endpoints/dag_endpoint.py\n+++ b/airflow/api_connexion/endpoints/dag_endpoint.py\n@@ -14,12 +14,13 @@\n # KIND, either express or implied. See the License for the\n # specific language governing permissions and limitations\n # under the License.\n-from flask import current_app\n+from flask import current_app, request\n+from marshmallow import ValidationError\n from sqlalchemy import func\n \n from airflow import DAG\n from airflow.api_connexion import security\n-from airflow.api_connexion.exceptions import NotFound\n+from airflow.api_connexion.exceptions import BadRequest, NotFound\n from airflow.api_connexion.parameters import check_limit, format_parameters\n from airflow.api_connexion.schemas.dag_schema import (\n DAGCollection, dag_detail_schema, dag_schema, dags_collection_schema,\n@@ -70,8 +71,19 @@\n \n \n @security.requires_authentication\n-def patch_dag():\n+@provide_session\n+def patch_dag(session, dag_id):\n \"\"\"\n Update the specific DAG\n \"\"\"\n- raise NotImplementedError(\"Not implemented yet.\")\n+ dag = session.query(DagModel).filter(DagModel.dag_id == dag_id).one_or_none()\n+ if not dag:\n+ raise NotFound(f\"Dag with id: '{dag_id}' not found\")\n+ try:\n+ patch_body = dag_schema.load(request.json, session=session)\n+ except ValidationError as err:\n+ raise BadRequest(\"Invalid Dag schema\", detail=str(err.messages))\n+ for key, value in patch_body.items():\n+ setattr(dag, key, value)\n+ session.commit()\n+ return dag_schema.dump(dag)\ndiff --git a/airflow/api_connexion/schemas/common_schema.py b/airflow/api_connexion/schemas/common_schema.py\n--- a/airflow/api_connexion/schemas/common_schema.py\n+++ b/airflow/api_connexion/schemas/common_schema.py\n@@ -83,7 +83,7 @@\n class CronExpressionSchema(Schema):\n \"\"\"Cron expression schema\"\"\"\n \n- objectType = fields.Constant(\"CronExpression\", data_key=\"__type\", required=True)\n+ objectType = fields.Constant(\"CronExpression\", data_key=\"__type\")\n value = fields.String(required=True)\n \n @marshmallow.post_load\ndiff --git a/airflow/api_connexion/schemas/dag_schema.py b/airflow/api_connexion/schemas/dag_schema.py\n--- a/airflow/api_connexion/schemas/dag_schema.py\n+++ b/airflow/api_connexion/schemas/dag_schema.py\n@@ -43,12 +43,12 @@\n \n dag_id = auto_field(dump_only=True)\n root_dag_id = auto_field(dump_only=True)\n- is_paused = auto_field(dump_only=True)\n+ is_paused = auto_field()\n is_subdag = auto_field(dump_only=True)\n fileloc = auto_field(dump_only=True)\n owners = fields.Method(\"get_owners\", dump_only=True)\n description = auto_field(dump_only=True)\n- schedule_interval = fields.Nested(ScheduleIntervalSchema, dump_only=True)\n+ schedule_interval = fields.Nested(ScheduleIntervalSchema)\n tags = fields.List(fields.Nested(DagTagSchema), dump_only=True)\n \n @staticmethod\n", "issue": "API Endpoint - CRUD - DAG\nHello \r\n\r\nWe need to create several endpoints that perform basic CRUD operations on **DAG**. We need the following endpoints:\r\n\r\n- PATCH /dags/{dag_id}\r\n\r\nIt depends on https://github.com/apache/airflow/issues/8128\r\n\r\nDetailed information is available in the issue:\r\nhttps://github.com/apache/airflow/issues/8118\r\n\r\nLOVE,\n", "before_files": [{"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\nfrom typing import List, NamedTuple\n\nfrom marshmallow import Schema, fields\nfrom marshmallow_sqlalchemy import SQLAlchemySchema, auto_field\n\nfrom airflow.api_connexion.schemas.common_schema import ScheduleIntervalSchema, TimeDeltaSchema, TimezoneField\nfrom airflow.models.dag import DagModel, DagTag\n\n\nclass DagTagSchema(SQLAlchemySchema):\n \"\"\"Dag Tag schema\"\"\"\n class Meta:\n \"\"\"Meta\"\"\"\n\n model = DagTag\n\n name = auto_field()\n\n\nclass DAGSchema(SQLAlchemySchema):\n \"\"\"DAG schema\"\"\"\n\n class Meta:\n \"\"\"Meta\"\"\"\n model = DagModel\n\n dag_id = auto_field(dump_only=True)\n root_dag_id = auto_field(dump_only=True)\n is_paused = auto_field(dump_only=True)\n is_subdag = auto_field(dump_only=True)\n fileloc = auto_field(dump_only=True)\n owners = fields.Method(\"get_owners\", dump_only=True)\n description = auto_field(dump_only=True)\n schedule_interval = fields.Nested(ScheduleIntervalSchema, dump_only=True)\n tags = fields.List(fields.Nested(DagTagSchema), dump_only=True)\n\n @staticmethod\n def get_owners(obj: DagModel):\n \"\"\"Convert owners attribute to DAG representation\"\"\"\n\n if not getattr(obj, 'owners', None):\n return []\n return obj.owners.split(\",\")\n\n\nclass DAGDetailSchema(DAGSchema):\n \"\"\"DAG details\"\"\"\n\n timezone = TimezoneField(dump_only=True)\n catchup = fields.Boolean(dump_only=True)\n orientation = fields.String(dump_only=True)\n concurrency = fields.Integer(dump_only=True)\n start_date = fields.DateTime(dump_only=True)\n dag_run_timeout = fields.Nested(TimeDeltaSchema, dump_only=True, attribute=\"dagrun_timeout\")\n doc_md = fields.String(dump_only=True)\n default_view = fields.String(dump_only=True)\n\n\nclass DAGCollection(NamedTuple):\n \"\"\"List of DAGs with metadata\"\"\"\n\n dags: List[DagModel]\n total_entries: int\n\n\nclass DAGCollectionSchema(Schema):\n \"\"\"DAG Collection schema\"\"\"\n\n dags = fields.List(fields.Nested(DAGSchema))\n total_entries = fields.Int()\n\n\ndags_collection_schema = DAGCollectionSchema()\ndag_schema = DAGSchema()\n\ndag_detail_schema = DAGDetailSchema()\n", "path": "airflow/api_connexion/schemas/dag_schema.py"}, {"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\nimport datetime\nimport inspect\nimport typing\n\nimport marshmallow\nfrom dateutil import relativedelta\nfrom marshmallow import Schema, fields, validate\nfrom marshmallow_oneofschema import OneOfSchema\n\nfrom airflow.serialization.serialized_objects import SerializedBaseOperator\nfrom airflow.utils.weight_rule import WeightRule\n\n\nclass CronExpression(typing.NamedTuple):\n \"\"\"Cron expression schema\"\"\"\n value: str\n\n\nclass TimeDeltaSchema(Schema):\n \"\"\"Time delta schema\"\"\"\n\n objectType = fields.Constant(\"TimeDelta\", data_key=\"__type\")\n days = fields.Integer()\n seconds = fields.Integer()\n microseconds = fields.Integer()\n\n @marshmallow.post_load\n def make_time_delta(self, data, **kwargs):\n \"\"\"Create time delta based on data\"\"\"\n\n if \"objectType\" in data:\n del data[\"objectType\"]\n return datetime.timedelta(**data)\n\n\nclass RelativeDeltaSchema(Schema):\n \"\"\"Relative delta schema\"\"\"\n\n objectType = fields.Constant(\"RelativeDelta\", data_key=\"__type\")\n years = fields.Integer()\n months = fields.Integer()\n days = fields.Integer()\n leapdays = fields.Integer()\n hours = fields.Integer()\n minutes = fields.Integer()\n seconds = fields.Integer()\n microseconds = fields.Integer()\n year = fields.Integer()\n month = fields.Integer()\n day = fields.Integer()\n hour = fields.Integer()\n minute = fields.Integer()\n second = fields.Integer()\n microsecond = fields.Integer()\n\n @marshmallow.post_load\n def make_relative_delta(self, data, **kwargs):\n \"\"\"Create relative delta based on data\"\"\"\n\n if \"objectType\" in data:\n del data[\"objectType\"]\n\n return relativedelta.relativedelta(**data)\n\n\nclass CronExpressionSchema(Schema):\n \"\"\"Cron expression schema\"\"\"\n\n objectType = fields.Constant(\"CronExpression\", data_key=\"__type\", required=True)\n value = fields.String(required=True)\n\n @marshmallow.post_load\n def make_cron_expression(self, data, **kwargs):\n \"\"\"Create cron expression based on data\"\"\"\n return CronExpression(data[\"value\"])\n\n\nclass ScheduleIntervalSchema(OneOfSchema):\n \"\"\"\n Schedule interval.\n\n It supports the following types:\n\n * TimeDelta\n * RelativeDelta\n * CronExpression\n \"\"\"\n type_field = \"__type\"\n type_schemas = {\n \"TimeDelta\": TimeDeltaSchema,\n \"RelativeDelta\": RelativeDeltaSchema,\n \"CronExpression\": CronExpressionSchema,\n }\n\n def _dump(self, obj, update_fields=True, **kwargs):\n if isinstance(obj, str):\n obj = CronExpression(obj)\n\n return super()._dump(obj, update_fields=update_fields, **kwargs)\n\n def get_obj_type(self, obj):\n \"\"\"Select schema based on object type\"\"\"\n if isinstance(obj, datetime.timedelta):\n return \"TimeDelta\"\n elif isinstance(obj, relativedelta.relativedelta):\n return \"RelativeDelta\"\n elif isinstance(obj, CronExpression):\n return \"CronExpression\"\n else:\n raise Exception(\"Unknown object type: {}\".format(obj.__class__.__name__))\n\n\nclass ColorField(fields.String):\n \"\"\"Schema for color property\"\"\"\n def __init__(self, **metadata):\n super().__init__(**metadata)\n self.validators = (\n [validate.Regexp(\"^#[a-fA-F0-9]{3,6}$\")] + list(self.validators)\n )\n\n\nclass WeightRuleField(fields.String):\n \"\"\"Schema for WeightRule\"\"\"\n def __init__(self, **metadata):\n super().__init__(**metadata)\n self.validators = (\n [validate.OneOf(WeightRule.all_weight_rules())] + list(self.validators)\n )\n\n\nclass TimezoneField(fields.String):\n \"\"\"Schema for timezone\"\"\"\n\n\nclass ClassReferenceSchema(Schema):\n \"\"\"\n Class reference schema.\n \"\"\"\n module_path = fields.Method(\"_get_module\", required=True)\n class_name = fields.Method(\"_get_class_name\", required=True)\n\n def _get_module(self, obj):\n if isinstance(obj, SerializedBaseOperator):\n return obj._task_module # pylint: disable=protected-access\n return inspect.getmodule(obj).__name__\n\n def _get_class_name(self, obj):\n if isinstance(obj, SerializedBaseOperator):\n return obj._task_type # pylint: disable=protected-access\n if isinstance(obj, type):\n return obj.__name__\n return type(obj).__name__\n", "path": "airflow/api_connexion/schemas/common_schema.py"}, {"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\nfrom flask import current_app\nfrom sqlalchemy import func\n\nfrom airflow import DAG\nfrom airflow.api_connexion import security\nfrom airflow.api_connexion.exceptions import NotFound\nfrom airflow.api_connexion.parameters import check_limit, format_parameters\nfrom airflow.api_connexion.schemas.dag_schema import (\n DAGCollection, dag_detail_schema, dag_schema, dags_collection_schema,\n)\nfrom airflow.models.dag import DagModel\nfrom airflow.utils.session import provide_session\n\n\n@security.requires_authentication\n@provide_session\ndef get_dag(dag_id, session):\n \"\"\"\n Get basic information about a DAG.\n \"\"\"\n dag = session.query(DagModel).filter(DagModel.dag_id == dag_id).one_or_none()\n\n if dag is None:\n raise NotFound(\"DAG not found\")\n\n return dag_schema.dump(dag)\n\n\n@security.requires_authentication\ndef get_dag_details(dag_id):\n \"\"\"\n Get details of DAG.\n \"\"\"\n dag: DAG = current_app.dag_bag.get_dag(dag_id)\n if not dag:\n raise NotFound(\"DAG not found\")\n return dag_detail_schema.dump(dag)\n\n\n@security.requires_authentication\n@format_parameters({\n 'limit': check_limit\n})\n@provide_session\ndef get_dags(session, limit, offset=0):\n \"\"\"\n Get all DAGs.\n \"\"\"\n dags = session.query(DagModel).order_by(DagModel.dag_id).offset(offset).limit(limit).all()\n\n total_entries = session.query(func.count(DagModel.dag_id)).scalar()\n\n return dags_collection_schema.dump(DAGCollection(dags=dags, total_entries=total_entries))\n\n\n@security.requires_authentication\ndef patch_dag():\n \"\"\"\n Update the specific DAG\n \"\"\"\n raise NotImplementedError(\"Not implemented yet.\")\n", "path": "airflow/api_connexion/endpoints/dag_endpoint.py"}], "after_files": [{"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\nfrom typing import List, NamedTuple\n\nfrom marshmallow import Schema, fields\nfrom marshmallow_sqlalchemy import SQLAlchemySchema, auto_field\n\nfrom airflow.api_connexion.schemas.common_schema import ScheduleIntervalSchema, TimeDeltaSchema, TimezoneField\nfrom airflow.models.dag import DagModel, DagTag\n\n\nclass DagTagSchema(SQLAlchemySchema):\n \"\"\"Dag Tag schema\"\"\"\n class Meta:\n \"\"\"Meta\"\"\"\n\n model = DagTag\n\n name = auto_field()\n\n\nclass DAGSchema(SQLAlchemySchema):\n \"\"\"DAG schema\"\"\"\n\n class Meta:\n \"\"\"Meta\"\"\"\n model = DagModel\n\n dag_id = auto_field(dump_only=True)\n root_dag_id = auto_field(dump_only=True)\n is_paused = auto_field()\n is_subdag = auto_field(dump_only=True)\n fileloc = auto_field(dump_only=True)\n owners = fields.Method(\"get_owners\", dump_only=True)\n description = auto_field(dump_only=True)\n schedule_interval = fields.Nested(ScheduleIntervalSchema)\n tags = fields.List(fields.Nested(DagTagSchema), dump_only=True)\n\n @staticmethod\n def get_owners(obj: DagModel):\n \"\"\"Convert owners attribute to DAG representation\"\"\"\n\n if not getattr(obj, 'owners', None):\n return []\n return obj.owners.split(\",\")\n\n\nclass DAGDetailSchema(DAGSchema):\n \"\"\"DAG details\"\"\"\n\n timezone = TimezoneField(dump_only=True)\n catchup = fields.Boolean(dump_only=True)\n orientation = fields.String(dump_only=True)\n concurrency = fields.Integer(dump_only=True)\n start_date = fields.DateTime(dump_only=True)\n dag_run_timeout = fields.Nested(TimeDeltaSchema, dump_only=True, attribute=\"dagrun_timeout\")\n doc_md = fields.String(dump_only=True)\n default_view = fields.String(dump_only=True)\n\n\nclass DAGCollection(NamedTuple):\n \"\"\"List of DAGs with metadata\"\"\"\n\n dags: List[DagModel]\n total_entries: int\n\n\nclass DAGCollectionSchema(Schema):\n \"\"\"DAG Collection schema\"\"\"\n\n dags = fields.List(fields.Nested(DAGSchema))\n total_entries = fields.Int()\n\n\ndags_collection_schema = DAGCollectionSchema()\ndag_schema = DAGSchema()\n\ndag_detail_schema = DAGDetailSchema()\n", "path": "airflow/api_connexion/schemas/dag_schema.py"}, {"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\nimport datetime\nimport inspect\nimport typing\n\nimport marshmallow\nfrom dateutil import relativedelta\nfrom marshmallow import Schema, fields, validate\nfrom marshmallow_oneofschema import OneOfSchema\n\nfrom airflow.serialization.serialized_objects import SerializedBaseOperator\nfrom airflow.utils.weight_rule import WeightRule\n\n\nclass CronExpression(typing.NamedTuple):\n \"\"\"Cron expression schema\"\"\"\n value: str\n\n\nclass TimeDeltaSchema(Schema):\n \"\"\"Time delta schema\"\"\"\n\n objectType = fields.Constant(\"TimeDelta\", data_key=\"__type\")\n days = fields.Integer()\n seconds = fields.Integer()\n microseconds = fields.Integer()\n\n @marshmallow.post_load\n def make_time_delta(self, data, **kwargs):\n \"\"\"Create time delta based on data\"\"\"\n\n if \"objectType\" in data:\n del data[\"objectType\"]\n return datetime.timedelta(**data)\n\n\nclass RelativeDeltaSchema(Schema):\n \"\"\"Relative delta schema\"\"\"\n\n objectType = fields.Constant(\"RelativeDelta\", data_key=\"__type\")\n years = fields.Integer()\n months = fields.Integer()\n days = fields.Integer()\n leapdays = fields.Integer()\n hours = fields.Integer()\n minutes = fields.Integer()\n seconds = fields.Integer()\n microseconds = fields.Integer()\n year = fields.Integer()\n month = fields.Integer()\n day = fields.Integer()\n hour = fields.Integer()\n minute = fields.Integer()\n second = fields.Integer()\n microsecond = fields.Integer()\n\n @marshmallow.post_load\n def make_relative_delta(self, data, **kwargs):\n \"\"\"Create relative delta based on data\"\"\"\n\n if \"objectType\" in data:\n del data[\"objectType\"]\n\n return relativedelta.relativedelta(**data)\n\n\nclass CronExpressionSchema(Schema):\n \"\"\"Cron expression schema\"\"\"\n\n objectType = fields.Constant(\"CronExpression\", data_key=\"__type\")\n value = fields.String(required=True)\n\n @marshmallow.post_load\n def make_cron_expression(self, data, **kwargs):\n \"\"\"Create cron expression based on data\"\"\"\n return CronExpression(data[\"value\"])\n\n\nclass ScheduleIntervalSchema(OneOfSchema):\n \"\"\"\n Schedule interval.\n\n It supports the following types:\n\n * TimeDelta\n * RelativeDelta\n * CronExpression\n \"\"\"\n type_field = \"__type\"\n type_schemas = {\n \"TimeDelta\": TimeDeltaSchema,\n \"RelativeDelta\": RelativeDeltaSchema,\n \"CronExpression\": CronExpressionSchema,\n }\n\n def _dump(self, obj, update_fields=True, **kwargs):\n if isinstance(obj, str):\n obj = CronExpression(obj)\n\n return super()._dump(obj, update_fields=update_fields, **kwargs)\n\n def get_obj_type(self, obj):\n \"\"\"Select schema based on object type\"\"\"\n if isinstance(obj, datetime.timedelta):\n return \"TimeDelta\"\n elif isinstance(obj, relativedelta.relativedelta):\n return \"RelativeDelta\"\n elif isinstance(obj, CronExpression):\n return \"CronExpression\"\n else:\n raise Exception(\"Unknown object type: {}\".format(obj.__class__.__name__))\n\n\nclass ColorField(fields.String):\n \"\"\"Schema for color property\"\"\"\n def __init__(self, **metadata):\n super().__init__(**metadata)\n self.validators = (\n [validate.Regexp(\"^#[a-fA-F0-9]{3,6}$\")] + list(self.validators)\n )\n\n\nclass WeightRuleField(fields.String):\n \"\"\"Schema for WeightRule\"\"\"\n def __init__(self, **metadata):\n super().__init__(**metadata)\n self.validators = (\n [validate.OneOf(WeightRule.all_weight_rules())] + list(self.validators)\n )\n\n\nclass TimezoneField(fields.String):\n \"\"\"Schema for timezone\"\"\"\n\n\nclass ClassReferenceSchema(Schema):\n \"\"\"\n Class reference schema.\n \"\"\"\n module_path = fields.Method(\"_get_module\", required=True)\n class_name = fields.Method(\"_get_class_name\", required=True)\n\n def _get_module(self, obj):\n if isinstance(obj, SerializedBaseOperator):\n return obj._task_module # pylint: disable=protected-access\n return inspect.getmodule(obj).__name__\n\n def _get_class_name(self, obj):\n if isinstance(obj, SerializedBaseOperator):\n return obj._task_type # pylint: disable=protected-access\n if isinstance(obj, type):\n return obj.__name__\n return type(obj).__name__\n", "path": "airflow/api_connexion/schemas/common_schema.py"}, {"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\nfrom flask import current_app, request\nfrom marshmallow import ValidationError\nfrom sqlalchemy import func\n\nfrom airflow import DAG\nfrom airflow.api_connexion import security\nfrom airflow.api_connexion.exceptions import BadRequest, NotFound\nfrom airflow.api_connexion.parameters import check_limit, format_parameters\nfrom airflow.api_connexion.schemas.dag_schema import (\n DAGCollection, dag_detail_schema, dag_schema, dags_collection_schema,\n)\nfrom airflow.models.dag import DagModel\nfrom airflow.utils.session import provide_session\n\n\n@security.requires_authentication\n@provide_session\ndef get_dag(dag_id, session):\n \"\"\"\n Get basic information about a DAG.\n \"\"\"\n dag = session.query(DagModel).filter(DagModel.dag_id == dag_id).one_or_none()\n\n if dag is None:\n raise NotFound(\"DAG not found\")\n\n return dag_schema.dump(dag)\n\n\n@security.requires_authentication\ndef get_dag_details(dag_id):\n \"\"\"\n Get details of DAG.\n \"\"\"\n dag: DAG = current_app.dag_bag.get_dag(dag_id)\n if not dag:\n raise NotFound(\"DAG not found\")\n return dag_detail_schema.dump(dag)\n\n\n@security.requires_authentication\n@format_parameters({\n 'limit': check_limit\n})\n@provide_session\ndef get_dags(session, limit, offset=0):\n \"\"\"\n Get all DAGs.\n \"\"\"\n dags = session.query(DagModel).order_by(DagModel.dag_id).offset(offset).limit(limit).all()\n\n total_entries = session.query(func.count(DagModel.dag_id)).scalar()\n\n return dags_collection_schema.dump(DAGCollection(dags=dags, total_entries=total_entries))\n\n\n@security.requires_authentication\n@provide_session\ndef patch_dag(session, dag_id):\n \"\"\"\n Update the specific DAG\n \"\"\"\n dag = session.query(DagModel).filter(DagModel.dag_id == dag_id).one_or_none()\n if not dag:\n raise NotFound(f\"Dag with id: '{dag_id}' not found\")\n try:\n patch_body = dag_schema.load(request.json, session=session)\n except ValidationError as err:\n raise BadRequest(\"Invalid Dag schema\", detail=str(err.messages))\n for key, value in patch_body.items():\n setattr(dag, key, value)\n session.commit()\n return dag_schema.dump(dag)\n", "path": "airflow/api_connexion/endpoints/dag_endpoint.py"}]}
| 3,485 | 738 |
gh_patches_debug_2451
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-17429
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
empty_like
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ivy/functional/frontends/paddle/tensor/creation.py`
Content:
```
1 # global
2 import ivy
3 from ivy.func_wrapper import with_unsupported_dtypes
4 from .tensor import Tensor
5 from ivy.functional.frontends.paddle.func_wrapper import (
6 to_ivy_arrays_and_back,
7 )
8
9
10 @to_ivy_arrays_and_back
11 def to_tensor(data, /, *, dtype=None, place=None, stop_gradient=True):
12 array = ivy.array(data, dtype=dtype, device=place)
13 return Tensor(array, dtype=dtype, place=place)
14
15
16 @with_unsupported_dtypes({"2.4.2 and below": "int8"}, "paddle")
17 @to_ivy_arrays_and_back
18 def ones(shape, /, *, dtype=None, name=None):
19 dtype = "float32" if dtype is None else dtype
20 return ivy.ones(shape, dtype=dtype)
21
22
23 @with_unsupported_dtypes(
24 {"2.4.2 and below": ("uint8", "int8", "complex64", "complex128")}, "paddle"
25 )
26 @to_ivy_arrays_and_back
27 def ones_like(x, /, *, dtype=None, name=None):
28 dtype = x.dtype if dtype is None else dtype
29 return ivy.ones_like(x, dtype=dtype)
30
31
32 @with_unsupported_dtypes({"2.4.2 and below": "int8"}, "paddle")
33 @to_ivy_arrays_and_back
34 def zeros(shape, /, *, dtype=None, name=None):
35 dtype = "float32" if dtype is None else dtype
36 return ivy.zeros(shape, dtype=dtype)
37
38
39 @with_unsupported_dtypes(
40 {"2.4.2 and below": ("uint8", "int8", "complex64", "complex128")}, "paddle"
41 )
42 @to_ivy_arrays_and_back
43 def zeros_like(x, /, *, dtype=None, name=None):
44 dtype = x.dtype if dtype is None else dtype
45 return ivy.zeros_like(x, dtype=dtype)
46
47
48 @to_ivy_arrays_and_back
49 def full(shape, fill_value, /, *, dtype=None, name=None):
50 dtype = "float32" if dtype is None else dtype
51 return ivy.full(shape, fill_value, dtype=dtype)
52
53
54 @to_ivy_arrays_and_back
55 def full_like(x, fill_value, /, *, dtype=None, name=None):
56 dtype = x.dtype if dtype is None else dtype
57 return ivy.full_like(x, fill_value, dtype=dtype)
58
59
60 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
61 @to_ivy_arrays_and_back
62 def arange(start, end=None, step=1, dtype=None, name=None):
63 return ivy.arange(start, end, step=step, dtype=dtype)
64
65
66 @to_ivy_arrays_and_back
67 def empty(shape, dtype=None):
68 return ivy.empty(shape=shape, dtype=dtype)
69
70
71 @to_ivy_arrays_and_back
72 def eye(num_rows, num_columns=None, dtype=None, name=None):
73 return ivy.eye(num_rows, num_columns, dtype=dtype)
74
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/ivy/functional/frontends/paddle/tensor/creation.py b/ivy/functional/frontends/paddle/tensor/creation.py
--- a/ivy/functional/frontends/paddle/tensor/creation.py
+++ b/ivy/functional/frontends/paddle/tensor/creation.py
@@ -71,3 +71,8 @@
@to_ivy_arrays_and_back
def eye(num_rows, num_columns=None, dtype=None, name=None):
return ivy.eye(num_rows, num_columns, dtype=dtype)
+
+
+@to_ivy_arrays_and_back
+def empty_like(x, dtype=None, name=None):
+ return ivy.empty_like(x, dtype=dtype)
|
{"golden_diff": "diff --git a/ivy/functional/frontends/paddle/tensor/creation.py b/ivy/functional/frontends/paddle/tensor/creation.py\n--- a/ivy/functional/frontends/paddle/tensor/creation.py\n+++ b/ivy/functional/frontends/paddle/tensor/creation.py\n@@ -71,3 +71,8 @@\n @to_ivy_arrays_and_back\r\n def eye(num_rows, num_columns=None, dtype=None, name=None):\r\n return ivy.eye(num_rows, num_columns, dtype=dtype)\r\n+\r\n+\r\n+@to_ivy_arrays_and_back\r\n+def empty_like(x, dtype=None, name=None):\r\n+ return ivy.empty_like(x, dtype=dtype)\n", "issue": "empty_like\n\n", "before_files": [{"content": "# global\r\nimport ivy\r\nfrom ivy.func_wrapper import with_unsupported_dtypes\r\nfrom .tensor import Tensor\r\nfrom ivy.functional.frontends.paddle.func_wrapper import (\r\n to_ivy_arrays_and_back,\r\n)\r\n\r\n\r\n@to_ivy_arrays_and_back\r\ndef to_tensor(data, /, *, dtype=None, place=None, stop_gradient=True):\r\n array = ivy.array(data, dtype=dtype, device=place)\r\n return Tensor(array, dtype=dtype, place=place)\r\n\r\n\r\n@with_unsupported_dtypes({\"2.4.2 and below\": \"int8\"}, \"paddle\")\r\n@to_ivy_arrays_and_back\r\ndef ones(shape, /, *, dtype=None, name=None):\r\n dtype = \"float32\" if dtype is None else dtype\r\n return ivy.ones(shape, dtype=dtype)\r\n\r\n\r\n@with_unsupported_dtypes(\r\n {\"2.4.2 and below\": (\"uint8\", \"int8\", \"complex64\", \"complex128\")}, \"paddle\"\r\n)\r\n@to_ivy_arrays_and_back\r\ndef ones_like(x, /, *, dtype=None, name=None):\r\n dtype = x.dtype if dtype is None else dtype\r\n return ivy.ones_like(x, dtype=dtype)\r\n\r\n\r\n@with_unsupported_dtypes({\"2.4.2 and below\": \"int8\"}, \"paddle\")\r\n@to_ivy_arrays_and_back\r\ndef zeros(shape, /, *, dtype=None, name=None):\r\n dtype = \"float32\" if dtype is None else dtype\r\n return ivy.zeros(shape, dtype=dtype)\r\n\r\n\r\n@with_unsupported_dtypes(\r\n {\"2.4.2 and below\": (\"uint8\", \"int8\", \"complex64\", \"complex128\")}, \"paddle\"\r\n)\r\n@to_ivy_arrays_and_back\r\ndef zeros_like(x, /, *, dtype=None, name=None):\r\n dtype = x.dtype if dtype is None else dtype\r\n return ivy.zeros_like(x, dtype=dtype)\r\n\r\n\r\n@to_ivy_arrays_and_back\r\ndef full(shape, fill_value, /, *, dtype=None, name=None):\r\n dtype = \"float32\" if dtype is None else dtype\r\n return ivy.full(shape, fill_value, dtype=dtype)\r\n\r\n\r\n@to_ivy_arrays_and_back\r\ndef full_like(x, fill_value, /, *, dtype=None, name=None):\r\n dtype = x.dtype if dtype is None else dtype\r\n return ivy.full_like(x, fill_value, dtype=dtype)\r\n\r\n\r\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n@to_ivy_arrays_and_back\r\ndef arange(start, end=None, step=1, dtype=None, name=None):\r\n return ivy.arange(start, end, step=step, dtype=dtype)\r\n\r\n\r\n@to_ivy_arrays_and_back\r\ndef empty(shape, dtype=None):\r\n return ivy.empty(shape=shape, dtype=dtype)\r\n\r\n\r\n@to_ivy_arrays_and_back\r\ndef eye(num_rows, num_columns=None, dtype=None, name=None):\r\n return ivy.eye(num_rows, num_columns, dtype=dtype)\r\n", "path": "ivy/functional/frontends/paddle/tensor/creation.py"}], "after_files": [{"content": "# global\r\nimport ivy\r\nfrom ivy.func_wrapper import with_unsupported_dtypes\r\nfrom .tensor import Tensor\r\nfrom ivy.functional.frontends.paddle.func_wrapper import (\r\n to_ivy_arrays_and_back,\r\n)\r\n\r\n\r\n@to_ivy_arrays_and_back\r\ndef to_tensor(data, /, *, dtype=None, place=None, stop_gradient=True):\r\n array = ivy.array(data, dtype=dtype, device=place)\r\n return Tensor(array, dtype=dtype, place=place)\r\n\r\n\r\n@with_unsupported_dtypes({\"2.4.2 and below\": \"int8\"}, \"paddle\")\r\n@to_ivy_arrays_and_back\r\ndef ones(shape, /, *, dtype=None, name=None):\r\n dtype = \"float32\" if dtype is None else dtype\r\n return ivy.ones(shape, dtype=dtype)\r\n\r\n\r\n@with_unsupported_dtypes(\r\n {\"2.4.2 and below\": (\"uint8\", \"int8\", \"complex64\", \"complex128\")}, \"paddle\"\r\n)\r\n@to_ivy_arrays_and_back\r\ndef ones_like(x, /, *, dtype=None, name=None):\r\n dtype = x.dtype if dtype is None else dtype\r\n return ivy.ones_like(x, dtype=dtype)\r\n\r\n\r\n@with_unsupported_dtypes({\"2.4.2 and below\": \"int8\"}, \"paddle\")\r\n@to_ivy_arrays_and_back\r\ndef zeros(shape, /, *, dtype=None, name=None):\r\n dtype = \"float32\" if dtype is None else dtype\r\n return ivy.zeros(shape, dtype=dtype)\r\n\r\n\r\n@with_unsupported_dtypes(\r\n {\"2.4.2 and below\": (\"uint8\", \"int8\", \"complex64\", \"complex128\")}, \"paddle\"\r\n)\r\n@to_ivy_arrays_and_back\r\ndef zeros_like(x, /, *, dtype=None, name=None):\r\n dtype = x.dtype if dtype is None else dtype\r\n return ivy.zeros_like(x, dtype=dtype)\r\n\r\n\r\n@to_ivy_arrays_and_back\r\ndef full(shape, fill_value, /, *, dtype=None, name=None):\r\n dtype = \"float32\" if dtype is None else dtype\r\n return ivy.full(shape, fill_value, dtype=dtype)\r\n\r\n\r\n@to_ivy_arrays_and_back\r\ndef full_like(x, fill_value, /, *, dtype=None, name=None):\r\n dtype = x.dtype if dtype is None else dtype\r\n return ivy.full_like(x, fill_value, dtype=dtype)\r\n\r\n\r\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\r\n@to_ivy_arrays_and_back\r\ndef arange(start, end=None, step=1, dtype=None, name=None):\r\n return ivy.arange(start, end, step=step, dtype=dtype)\r\n\r\n\r\n@to_ivy_arrays_and_back\r\ndef empty(shape, dtype=None):\r\n return ivy.empty(shape=shape, dtype=dtype)\r\n\r\n\r\n@to_ivy_arrays_and_back\r\ndef eye(num_rows, num_columns=None, dtype=None, name=None):\r\n return ivy.eye(num_rows, num_columns, dtype=dtype)\r\n\r\n\r\n@to_ivy_arrays_and_back\r\ndef empty_like(x, dtype=None, name=None):\r\n return ivy.empty_like(x, dtype=dtype)\r\n", "path": "ivy/functional/frontends/paddle/tensor/creation.py"}]}
| 1,090 | 152 |
gh_patches_debug_57065
|
rasdani/github-patches
|
git_diff
|
gratipay__gratipay.com-302
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Show how many total fundees and the donation amount they're in for.
As a reciever of money I'd like to know how diversified my $13/wk is so that I know how volatile my income is likely to be.
How I see this working is a Histogram similar to:
$1 [---] 1
$3 []
$6 []
$12 [---] 1
$24 []
which shows that I have 2 funders, one in for $1 and one in for $12.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gittip/__init__.py`
Content:
```
1 import datetime
2 import locale
3 import os
4 from decimal import Decimal
5
6
7 try: # XXX This can't be right.
8 locale.setlocale(locale.LC_ALL, "en_US.utf8")
9 except locale.Error:
10 locale.setlocale(locale.LC_ALL, "en_US.UTF-8")
11
12
13 BIRTHDAY = datetime.date(2012, 6, 1)
14 CARDINALS = ['zero', 'one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine']
15 MONTHS = [None, 'January', 'February', 'March', 'April', 'May', 'June', 'July',
16 'August', 'September', 'October', 'November', 'December']
17
18 def age():
19 today = datetime.date.today()
20 nmonths = today.month - BIRTHDAY.month
21 plural = 's' if nmonths != 1 else ''
22 if nmonths < 10:
23 nmonths = CARDINALS[nmonths]
24 else:
25 nmonths = str(nmonths)
26 return "%s month%s" % (nmonths, plural)
27
28
29 db = None # This global is wired in wireup. It's an instance of
30 # gittip.postgres.PostgresManager.
31
32 # Not sure we won't want this for something yet. Prune if you don't find it in
33 # the codebase in a month.
34 OLD_OLD_AMOUNTS= [Decimal(a) for a in ('0.00', '0.08', '0.16', '0.32', '0.64', '1.28')]
35 OLD_AMOUNTS= [Decimal(a) for a in ('0.25',)]
36
37 AMOUNTS= [Decimal(a) for a in ('0.00', '1.00', '3.00', '6.00', '12.00', '24.00')]
38
39
40 __version__ = "~~VERSION~~"
41
42
43 def get_tip(tipper, tippee):
44 """Given two user ids, return a Decimal.
45 """
46 TIP = """\
47
48 SELECT amount
49 FROM tips
50 WHERE tipper=%s
51 AND tippee=%s
52 ORDER BY mtime DESC
53 LIMIT 1
54
55 """
56 rec = db.fetchone(TIP, (tipper, tippee))
57 if rec is None:
58 tip = Decimal(0.00)
59 else:
60 tip = rec['amount']
61 return tip
62
63
64 def get_backed_amount(participant_id):
65 """Given a unicode, return a Decimal.
66 """
67
68 BACKED = """\
69
70 SELECT sum(amount) AS backed
71 FROM ( SELECT DISTINCT ON (tipper)
72 amount
73 , tipper
74 FROM tips
75 JOIN participants p ON p.id = tipper
76 WHERE tippee=%s
77 AND last_bill_result = ''
78 ORDER BY tipper
79 , mtime DESC
80 ) AS foo
81
82 """
83 rec = db.fetchone(BACKED, (participant_id,))
84 if rec is None:
85 amount = None
86 else:
87 amount = rec['backed'] # might be None
88
89 if amount is None:
90 amount = Decimal(0.00)
91
92 return amount
93
94
95 def get_number_of_backers(participant_id):
96 """Given a unicode, return an int.
97 """
98
99 BACKED = """\
100
101 SELECT count(amount) AS nbackers
102 FROM ( SELECT DISTINCT ON (tipper)
103 amount
104 , tipper
105 FROM tips
106 JOIN participants p ON p.id = tipper
107 WHERE tippee=%s
108 AND last_bill_result = ''
109 ORDER BY tipper
110 , mtime DESC
111 ) AS foo
112 WHERE amount > 0
113
114 """
115 rec = db.fetchone(BACKED, (participant_id,))
116 if rec is None:
117 nbackers = None
118 else:
119 nbackers = rec['nbackers'] # might be None
120
121 if nbackers is None:
122 nbackers = 0
123
124 return nbackers
125
126
127 def get_tips_and_total(tipper, for_payday=False, db=None):
128 """Given a participant id and a date, return a list and a Decimal.
129
130 This function is used to populate a participant's page for their own
131 viewing pleasure, and also by the payday function. If for_payday is not
132 False it must be a date object.
133
134 A half-injected dependency, that's what db is.
135
136 """
137 if db is None:
138 from gittip import db
139
140 if for_payday:
141
142 # For payday we want the oldest relationship to be paid first.
143 order_by = "ctime ASC"
144
145
146 # This is where it gets crash-proof.
147 # ==================================
148 # We need to account for the fact that we may have crashed during
149 # Payday and we're re-running that function. We only want to select
150 # tips that existed before Payday started, but haven't been processed
151 # as part of this Payday yet.
152 #
153 # It's a bug if the paydays subselect returns > 1 rows.
154 #
155 # XXX If we crash during Payday and we rerun it after a timezone
156 # change, will we get burned? How?
157
158 ts_filter = """\
159
160 AND mtime < %s
161 AND ( SELECT id
162 FROM transfers
163 WHERE tipper=t.tipper
164 AND tippee=t.tippee
165 AND timestamp >= %s
166 ) IS NULL
167
168 """
169 args = (tipper, for_payday, for_payday)
170 else:
171 order_by = "amount DESC"
172 ts_filter = ""
173 args = (tipper,)
174
175 TIPS = """\
176
177 SELECT * FROM (
178 SELECT DISTINCT ON (tippee)
179 amount
180 , tippee
181 , t.ctime
182 , p.claimed_time
183 FROM tips t
184 JOIN participants p ON p.id = t.tippee
185 WHERE tipper = %%s
186 %s
187 ORDER BY tippee
188 , t.mtime DESC
189 ) AS foo
190 ORDER BY %s
191 , tippee
192
193 """ % (ts_filter, order_by) # XXX, No injections here, right?!
194 tips = list(db.fetchall(TIPS, args))
195
196
197 # Compute the total.
198 # ==================
199 # For payday we only want to process payments to tippees who have
200 # themselves opted into Gittip. For the tipper's profile page we want to
201 # show the total amount they've pledged (so they're not surprised when
202 # someone *does* start accepting tips and all of a sudden they're hit with
203 # bigger charges.
204
205 if for_payday:
206 to_total = [t for t in tips if t['claimed_time'] is not None]
207 else:
208 to_total = tips
209 total = sum([t['amount'] for t in to_total])
210
211 if not total:
212 # If to_total is an empty list then total is int 0. We want a Decimal.
213 total = Decimal('0.00')
214
215 return tips, total
216
217
218 # canonizer
219 # =========
220 # This is an Aspen hook to ensure that requests are served on a certain root
221 # URL, even if multiple domains point to the application.
222
223 class X: pass
224 canonical_scheme = None
225 canonical_host = None
226
227 def canonize(request):
228 """Enforce a certain scheme and hostname. Store these on request as well.
229 """
230 scheme = request.headers.get('X-Forwarded-Proto', 'http') # per Heroku
231 host = request.headers['Host']
232 bad_scheme = scheme != canonical_scheme
233 bad_host = bool(canonical_host) and (host != canonical_host)
234 # '' and False => ''
235 if bad_scheme or bad_host:
236 url = '%s://%s' % (canonical_scheme, canonical_host)
237 if request.line.method in ('GET', 'HEAD', 'OPTIONS', 'TRACE'):
238 # Redirect to a particular path for idempotent methods.
239 url += request.line.uri.path.raw
240 if request.line.uri.querystring:
241 url += '?' + request.line.uri.querystring.raw
242 else:
243 # For non-idempotent methods, redirect to homepage.
244 url += '/'
245 request.redirect(url, permanent=True)
246
247
248 def configure_payments(request):
249 # Work-around for https://github.com/balanced/balanced-python/issues/5
250 import balanced
251 balanced.configure(os.environ['BALANCED_API_SECRET'])
252
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gittip/__init__.py b/gittip/__init__.py
--- a/gittip/__init__.py
+++ b/gittip/__init__.py
@@ -215,6 +215,17 @@
return tips, total
+def get_histogram_of_giving(user):
+ SQL = """
+ SELECT amount, count(amount) num_contributing FROM tips t WHERE
+ tippee=%s GROUP BY (amount)
+ """
+ results = dict()
+ for amount_dict in db.fetchall(SQL, (user,)):
+ results[amount_dict['amount']] = amount_dict['num_contributing']
+ return results
+
+
# canonizer
# =========
# This is an Aspen hook to ensure that requests are served on a certain root
|
{"golden_diff": "diff --git a/gittip/__init__.py b/gittip/__init__.py\n--- a/gittip/__init__.py\n+++ b/gittip/__init__.py\n@@ -215,6 +215,17 @@\n return tips, total\n \n \n+def get_histogram_of_giving(user):\n+ SQL = \"\"\"\n+ SELECT amount, count(amount) num_contributing FROM tips t WHERE\n+ tippee=%s GROUP BY (amount)\n+ \"\"\"\n+ results = dict()\n+ for amount_dict in db.fetchall(SQL, (user,)):\n+ results[amount_dict['amount']] = amount_dict['num_contributing']\n+ return results\n+\n+\n # canonizer\n # =========\n # This is an Aspen hook to ensure that requests are served on a certain root\n", "issue": "Show how many total fundees and the donation amount they're in for.\nAs a reciever of money I'd like to know how diversified my $13/wk is so that I know how volatile my income is likely to be.\n\nHow I see this working is a Histogram similar to:\n\n $1 [---] 1\n $3 []\n $6 []\n$12 [---] 1\n$24 []\n\nwhich shows that I have 2 funders, one in for $1 and one in for $12.\n\n", "before_files": [{"content": "import datetime\nimport locale\nimport os\nfrom decimal import Decimal\n\n\ntry: # XXX This can't be right.\n locale.setlocale(locale.LC_ALL, \"en_US.utf8\")\nexcept locale.Error:\n locale.setlocale(locale.LC_ALL, \"en_US.UTF-8\")\n\n\nBIRTHDAY = datetime.date(2012, 6, 1)\nCARDINALS = ['zero', 'one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine']\nMONTHS = [None, 'January', 'February', 'March', 'April', 'May', 'June', 'July',\n 'August', 'September', 'October', 'November', 'December']\n\ndef age():\n today = datetime.date.today()\n nmonths = today.month - BIRTHDAY.month\n plural = 's' if nmonths != 1 else ''\n if nmonths < 10:\n nmonths = CARDINALS[nmonths]\n else:\n nmonths = str(nmonths)\n return \"%s month%s\" % (nmonths, plural)\n\n\ndb = None # This global is wired in wireup. It's an instance of\n # gittip.postgres.PostgresManager.\n\n# Not sure we won't want this for something yet. Prune if you don't find it in\n# the codebase in a month.\nOLD_OLD_AMOUNTS= [Decimal(a) for a in ('0.00', '0.08', '0.16', '0.32', '0.64', '1.28')]\nOLD_AMOUNTS= [Decimal(a) for a in ('0.25',)]\n\nAMOUNTS= [Decimal(a) for a in ('0.00', '1.00', '3.00', '6.00', '12.00', '24.00')]\n\n\n__version__ = \"~~VERSION~~\"\n\n\ndef get_tip(tipper, tippee):\n \"\"\"Given two user ids, return a Decimal.\n \"\"\"\n TIP = \"\"\"\\\n\n SELECT amount\n FROM tips\n WHERE tipper=%s\n AND tippee=%s\n ORDER BY mtime DESC\n LIMIT 1\n\n \"\"\"\n rec = db.fetchone(TIP, (tipper, tippee))\n if rec is None:\n tip = Decimal(0.00)\n else:\n tip = rec['amount']\n return tip\n\n\ndef get_backed_amount(participant_id):\n \"\"\"Given a unicode, return a Decimal.\n \"\"\"\n\n BACKED = \"\"\"\\\n\n SELECT sum(amount) AS backed\n FROM ( SELECT DISTINCT ON (tipper)\n amount\n , tipper\n FROM tips\n JOIN participants p ON p.id = tipper\n WHERE tippee=%s\n AND last_bill_result = ''\n ORDER BY tipper\n , mtime DESC\n ) AS foo\n\n \"\"\"\n rec = db.fetchone(BACKED, (participant_id,))\n if rec is None:\n amount = None\n else:\n amount = rec['backed'] # might be None\n\n if amount is None:\n amount = Decimal(0.00)\n\n return amount\n\n\ndef get_number_of_backers(participant_id):\n \"\"\"Given a unicode, return an int.\n \"\"\"\n\n BACKED = \"\"\"\\\n\n SELECT count(amount) AS nbackers\n FROM ( SELECT DISTINCT ON (tipper)\n amount\n , tipper\n FROM tips\n JOIN participants p ON p.id = tipper\n WHERE tippee=%s\n AND last_bill_result = ''\n ORDER BY tipper\n , mtime DESC\n ) AS foo\n WHERE amount > 0\n\n \"\"\"\n rec = db.fetchone(BACKED, (participant_id,))\n if rec is None:\n nbackers = None\n else:\n nbackers = rec['nbackers'] # might be None\n\n if nbackers is None:\n nbackers = 0\n\n return nbackers\n\n\ndef get_tips_and_total(tipper, for_payday=False, db=None):\n \"\"\"Given a participant id and a date, return a list and a Decimal.\n\n This function is used to populate a participant's page for their own\n viewing pleasure, and also by the payday function. If for_payday is not\n False it must be a date object.\n\n A half-injected dependency, that's what db is.\n\n \"\"\"\n if db is None:\n from gittip import db\n\n if for_payday:\n\n # For payday we want the oldest relationship to be paid first.\n order_by = \"ctime ASC\"\n\n\n # This is where it gets crash-proof.\n # ==================================\n # We need to account for the fact that we may have crashed during\n # Payday and we're re-running that function. We only want to select\n # tips that existed before Payday started, but haven't been processed\n # as part of this Payday yet.\n #\n # It's a bug if the paydays subselect returns > 1 rows.\n #\n # XXX If we crash during Payday and we rerun it after a timezone\n # change, will we get burned? How?\n\n ts_filter = \"\"\"\\\n\n AND mtime < %s\n AND ( SELECT id\n FROM transfers\n WHERE tipper=t.tipper\n AND tippee=t.tippee\n AND timestamp >= %s\n ) IS NULL\n\n \"\"\"\n args = (tipper, for_payday, for_payday)\n else:\n order_by = \"amount DESC\"\n ts_filter = \"\"\n args = (tipper,)\n\n TIPS = \"\"\"\\\n\n SELECT * FROM (\n SELECT DISTINCT ON (tippee)\n amount\n , tippee\n , t.ctime\n , p.claimed_time\n FROM tips t\n JOIN participants p ON p.id = t.tippee\n WHERE tipper = %%s\n %s\n ORDER BY tippee\n , t.mtime DESC\n ) AS foo\n ORDER BY %s\n , tippee\n\n \"\"\" % (ts_filter, order_by) # XXX, No injections here, right?!\n tips = list(db.fetchall(TIPS, args))\n\n\n # Compute the total.\n # ==================\n # For payday we only want to process payments to tippees who have\n # themselves opted into Gittip. For the tipper's profile page we want to\n # show the total amount they've pledged (so they're not surprised when\n # someone *does* start accepting tips and all of a sudden they're hit with\n # bigger charges.\n\n if for_payday:\n to_total = [t for t in tips if t['claimed_time'] is not None]\n else:\n to_total = tips\n total = sum([t['amount'] for t in to_total])\n\n if not total:\n # If to_total is an empty list then total is int 0. We want a Decimal.\n total = Decimal('0.00')\n\n return tips, total\n\n\n# canonizer\n# =========\n# This is an Aspen hook to ensure that requests are served on a certain root\n# URL, even if multiple domains point to the application.\n\nclass X: pass\ncanonical_scheme = None\ncanonical_host = None\n\ndef canonize(request):\n \"\"\"Enforce a certain scheme and hostname. Store these on request as well.\n \"\"\"\n scheme = request.headers.get('X-Forwarded-Proto', 'http') # per Heroku\n host = request.headers['Host']\n bad_scheme = scheme != canonical_scheme\n bad_host = bool(canonical_host) and (host != canonical_host)\n # '' and False => ''\n if bad_scheme or bad_host:\n url = '%s://%s' % (canonical_scheme, canonical_host)\n if request.line.method in ('GET', 'HEAD', 'OPTIONS', 'TRACE'):\n # Redirect to a particular path for idempotent methods.\n url += request.line.uri.path.raw\n if request.line.uri.querystring:\n url += '?' + request.line.uri.querystring.raw\n else:\n # For non-idempotent methods, redirect to homepage.\n url += '/'\n request.redirect(url, permanent=True)\n\n\ndef configure_payments(request):\n # Work-around for https://github.com/balanced/balanced-python/issues/5\n import balanced\n balanced.configure(os.environ['BALANCED_API_SECRET'])\n", "path": "gittip/__init__.py"}], "after_files": [{"content": "import datetime\nimport locale\nimport os\nfrom decimal import Decimal\n\n\ntry: # XXX This can't be right.\n locale.setlocale(locale.LC_ALL, \"en_US.utf8\")\nexcept locale.Error:\n locale.setlocale(locale.LC_ALL, \"en_US.UTF-8\")\n\n\nBIRTHDAY = datetime.date(2012, 6, 1)\nCARDINALS = ['zero', 'one', 'two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine']\nMONTHS = [None, 'January', 'February', 'March', 'April', 'May', 'June', 'July',\n 'August', 'September', 'October', 'November', 'December']\n\ndef age():\n today = datetime.date.today()\n nmonths = today.month - BIRTHDAY.month\n plural = 's' if nmonths != 1 else ''\n if nmonths < 10:\n nmonths = CARDINALS[nmonths]\n else:\n nmonths = str(nmonths)\n return \"%s month%s\" % (nmonths, plural)\n\n\ndb = None # This global is wired in wireup. It's an instance of\n # gittip.postgres.PostgresManager.\n\n# Not sure we won't want this for something yet. Prune if you don't find it in\n# the codebase in a month.\nOLD_OLD_AMOUNTS= [Decimal(a) for a in ('0.00', '0.08', '0.16', '0.32', '0.64', '1.28')]\nOLD_AMOUNTS= [Decimal(a) for a in ('0.25',)]\n\nAMOUNTS= [Decimal(a) for a in ('0.00', '1.00', '3.00', '6.00', '12.00', '24.00')]\n\n\n__version__ = \"~~VERSION~~\"\n\n\ndef get_tip(tipper, tippee):\n \"\"\"Given two user ids, return a Decimal.\n \"\"\"\n TIP = \"\"\"\\\n\n SELECT amount\n FROM tips\n WHERE tipper=%s\n AND tippee=%s\n ORDER BY mtime DESC\n LIMIT 1\n\n \"\"\"\n rec = db.fetchone(TIP, (tipper, tippee))\n if rec is None:\n tip = Decimal(0.00)\n else:\n tip = rec['amount']\n return tip\n\n\ndef get_backed_amount(participant_id):\n \"\"\"Given a unicode, return a Decimal.\n \"\"\"\n\n BACKED = \"\"\"\\\n\n SELECT sum(amount) AS backed\n FROM ( SELECT DISTINCT ON (tipper)\n amount\n , tipper\n FROM tips\n JOIN participants p ON p.id = tipper\n WHERE tippee=%s\n AND last_bill_result = ''\n ORDER BY tipper\n , mtime DESC\n ) AS foo\n\n \"\"\"\n rec = db.fetchone(BACKED, (participant_id,))\n if rec is None:\n amount = None\n else:\n amount = rec['backed'] # might be None\n\n if amount is None:\n amount = Decimal(0.00)\n\n return amount\n\n\ndef get_number_of_backers(participant_id):\n \"\"\"Given a unicode, return an int.\n \"\"\"\n\n BACKED = \"\"\"\\\n\n SELECT count(amount) AS nbackers\n FROM ( SELECT DISTINCT ON (tipper)\n amount\n , tipper\n FROM tips\n JOIN participants p ON p.id = tipper\n WHERE tippee=%s\n AND last_bill_result = ''\n ORDER BY tipper\n , mtime DESC\n ) AS foo\n WHERE amount > 0\n\n \"\"\"\n rec = db.fetchone(BACKED, (participant_id,))\n if rec is None:\n nbackers = None\n else:\n nbackers = rec['nbackers'] # might be None\n\n if nbackers is None:\n nbackers = 0\n\n return nbackers\n\n\ndef get_tips_and_total(tipper, for_payday=False, db=None):\n \"\"\"Given a participant id and a date, return a list and a Decimal.\n\n This function is used to populate a participant's page for their own\n viewing pleasure, and also by the payday function. If for_payday is not\n False it must be a date object.\n\n A half-injected dependency, that's what db is.\n\n \"\"\"\n if db is None:\n from gittip import db\n\n if for_payday:\n\n # For payday we want the oldest relationship to be paid first.\n order_by = \"ctime ASC\"\n\n\n # This is where it gets crash-proof.\n # ==================================\n # We need to account for the fact that we may have crashed during\n # Payday and we're re-running that function. We only want to select\n # tips that existed before Payday started, but haven't been processed\n # as part of this Payday yet.\n #\n # It's a bug if the paydays subselect returns > 1 rows.\n #\n # XXX If we crash during Payday and we rerun it after a timezone\n # change, will we get burned? How?\n\n ts_filter = \"\"\"\\\n\n AND mtime < %s\n AND ( SELECT id\n FROM transfers\n WHERE tipper=t.tipper\n AND tippee=t.tippee\n AND timestamp >= %s\n ) IS NULL\n\n \"\"\"\n args = (tipper, for_payday, for_payday)\n else:\n order_by = \"amount DESC\"\n ts_filter = \"\"\n args = (tipper,)\n\n TIPS = \"\"\"\\\n\n SELECT * FROM (\n SELECT DISTINCT ON (tippee)\n amount\n , tippee\n , t.ctime\n , p.claimed_time\n FROM tips t\n JOIN participants p ON p.id = t.tippee\n WHERE tipper = %%s\n %s\n ORDER BY tippee\n , t.mtime DESC\n ) AS foo\n ORDER BY %s\n , tippee\n\n \"\"\" % (ts_filter, order_by) # XXX, No injections here, right?!\n tips = list(db.fetchall(TIPS, args))\n\n\n # Compute the total.\n # ==================\n # For payday we only want to process payments to tippees who have\n # themselves opted into Gittip. For the tipper's profile page we want to\n # show the total amount they've pledged (so they're not surprised when\n # someone *does* start accepting tips and all of a sudden they're hit with\n # bigger charges.\n\n if for_payday:\n to_total = [t for t in tips if t['claimed_time'] is not None]\n else:\n to_total = tips\n total = sum([t['amount'] for t in to_total])\n\n if not total:\n # If to_total is an empty list then total is int 0. We want a Decimal.\n total = Decimal('0.00')\n\n return tips, total\n\n\ndef get_histogram_of_giving(user):\n SQL = \"\"\"\n SELECT amount, count(amount) num_contributing FROM tips t WHERE\n tippee=%s GROUP BY (amount)\n \"\"\"\n results = dict()\n for amount_dict in db.fetchall(SQL, (user,)):\n results[amount_dict['amount']] = amount_dict['num_contributing']\n return results\n\n\n# canonizer\n# =========\n# This is an Aspen hook to ensure that requests are served on a certain root\n# URL, even if multiple domains point to the application.\n\nclass X: pass\ncanonical_scheme = None\ncanonical_host = None\n\ndef canonize(request):\n \"\"\"Enforce a certain scheme and hostname. Store these on request as well.\n \"\"\"\n scheme = request.headers.get('X-Forwarded-Proto', 'http') # per Heroku\n host = request.headers['Host']\n bad_scheme = scheme != canonical_scheme\n bad_host = bool(canonical_host) and (host != canonical_host)\n # '' and False => ''\n if bad_scheme or bad_host:\n url = '%s://%s' % (canonical_scheme, canonical_host)\n if request.line.method in ('GET', 'HEAD', 'OPTIONS', 'TRACE'):\n # Redirect to a particular path for idempotent methods.\n url += request.line.uri.path.raw\n if request.line.uri.querystring:\n url += '?' + request.line.uri.querystring.raw\n else:\n # For non-idempotent methods, redirect to homepage.\n url += '/'\n request.redirect(url, permanent=True)\n\n\ndef configure_payments(request):\n # Work-around for https://github.com/balanced/balanced-python/issues/5\n import balanced\n balanced.configure(os.environ['BALANCED_API_SECRET'])\n", "path": "gittip/__init__.py"}]}
| 2,894 | 174 |
gh_patches_debug_19096
|
rasdani/github-patches
|
git_diff
|
spack__spack-28354
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Setting LD_LIBRARY_PATH to be "helpful" considered harmful
(with apologies to Djikstra and everyone else who's recycled that title meme)
**TL;DR**: the library that one of my spack binaries uses depends on what other spack packages I've `module load`-ed. **YIKES**. See also #3926.
I was trying to understand why @JusticeForMikeBrown was having trouble building bowtie2 (see #3950) when I've built it successfully with `gcc@4.x.y`.
His problem with `gcc@4.x.y` was zlib related; I checked the package and noticed that it doesn't have a dependency on zlib. Perhaps it should, I thought. Wonder what zlib my "production" copy was linked against?
```
$ ldd bowtie2-align-l | grep libz
libz.so.1 => /blah/spack/v0.0.8/opt/spack/linux-centos7-x86_64/gcc-5.4.0/zlib-1.2.11-ec535e2ikkpl7hd4y454t3yydjqorja6/lib/libz.so.1 (0x00002aaaaaf32000)
```
That surprised me, because there's no zlib dependency in the package.
Sure enough, it's because I have something else `module load`-ed that has the side effect of adding zlib's directory to `LD_LIBRARY_PATH`.
```
$ (unset LD_LIBRARY_PATH; ldd bowtie2-align-l) | grep libz
libz.so.1 => /lib64/libz.so.1 (0x00002aaaaaf2f000)
```
My "newer" version of CentOS has a `/lib64/libz.so.1` that includes gzbuffer (`nm` didn't help, library's stripped...):
```
$ strings /lib64/libz.so.1 | grep buffer
gzbuffer
buffer error
```
so it (probably) works for me either way.
But imagine if there were two versions of a library (perhaps something mathematical) that give different results. Now you have a program giving different results depending on what other Spack applications are also loaded.
**THAT** would be fun to track down (assuming you even noticed...).
W.R.T. the main problem, bowtie2 should probably have a dependency on a new-ish version of zlib, but stuff like this is why LD_LIBRARY_PATH is a slippery tool to reach for.
I'll argue that this kind of unpredictability is a bigger negative than being helpful and always setting `LD_LIBRARY_PATH`. This comment in the docs isn't actually correct:
> Spack avoids library misconfiguration by using RPATH to link dependencies. When a user links a library or runs a program, it is tied to the dependencies it was built with, so there is no need to manipulate LD_LIBRARY_PATH at runtime.
>
> [clipped from here](http://spack.readthedocs.io/en/latest/features.html?highlight=RPATH#packages-can-peacefully-coexist)
What would happen if `LD_LIBRARY_PATH` became *opt-in*, packages that need it specify it in their package definitions?
Looking at [the list of cases where RPATH support doesn't work](http://spack.readthedocs.io/en/latest/workflows.html?highlight=LD_LIBRARY_PATH#transitive-dependencies), it seems like 1) is not relevant (I think it's referring to `PERL5LIB`, etc...) and 3) are simply bugs. That leaves 2), python extensions. Is `RPATH` unworkable there or just not yet working?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/spack/spack/user_environment.py`
Content:
```
1 # Copyright 2013-2022 Lawrence Livermore National Security, LLC and other
2 # Spack Project Developers. See the top-level COPYRIGHT file for details.
3 #
4 # SPDX-License-Identifier: (Apache-2.0 OR MIT)
5 import os
6 import sys
7
8 import spack.build_environment
9 import spack.config
10 import spack.util.environment as environment
11 import spack.util.prefix as prefix
12
13 #: Environment variable name Spack uses to track individually loaded packages
14 spack_loaded_hashes_var = "SPACK_LOADED_HASHES"
15
16
17 def prefix_inspections(platform):
18 """Get list of prefix inspections for platform
19
20 Arguments:
21 platform (str): the name of the platform to consider. The platform
22 determines what environment variables Spack will use for some
23 inspections.
24
25 Returns:
26 A dictionary mapping subdirectory names to lists of environment
27 variables to modify with that directory if it exists.
28 """
29 inspections = spack.config.get("modules:prefix_inspections", {})
30 if inspections:
31 return inspections
32
33 inspections = {
34 "bin": ["PATH"],
35 "lib": ["LD_LIBRARY_PATH", "LIBRARY_PATH"],
36 "lib64": ["LD_LIBRARY_PATH", "LIBRARY_PATH"],
37 "man": ["MANPATH"],
38 "share/man": ["MANPATH"],
39 "share/aclocal": ["ACLOCAL_PATH"],
40 "include": ["CPATH"],
41 "lib/pkgconfig": ["PKG_CONFIG_PATH"],
42 "lib64/pkgconfig": ["PKG_CONFIG_PATH"],
43 "share/pkgconfig": ["PKG_CONFIG_PATH"],
44 "": ["CMAKE_PREFIX_PATH"],
45 }
46
47 if platform == "darwin":
48 for subdir in ("lib", "lib64"):
49 inspections[subdir].append("DYLD_FALLBACK_LIBRARY_PATH")
50
51 return inspections
52
53
54 def unconditional_environment_modifications(view):
55 """List of environment (shell) modifications to be processed for view.
56
57 This list does not depend on the specs in this environment"""
58 env = environment.EnvironmentModifications()
59
60 for subdir, vars in prefix_inspections(sys.platform).items():
61 full_subdir = os.path.join(view.root, subdir)
62 for var in vars:
63 env.prepend_path(var, full_subdir)
64
65 return env
66
67
68 def environment_modifications_for_spec(spec, view=None, set_package_py_globals=True):
69 """List of environment (shell) modifications to be processed for spec.
70
71 This list is specific to the location of the spec or its projection in
72 the view.
73
74 Args:
75 spec (spack.spec.Spec): spec for which to list the environment modifications
76 view: view associated with the spec passed as first argument
77 set_package_py_globals (bool): whether or not to set the global variables in the
78 package.py files (this may be problematic when using buildcaches that have
79 been built on a different but compatible OS)
80 """
81 spec = spec.copy()
82 if view and not spec.external:
83 spec.prefix = prefix.Prefix(view.get_projection_for_spec(spec))
84
85 # generic environment modifications determined by inspecting the spec
86 # prefix
87 env = environment.inspect_path(
88 spec.prefix, prefix_inspections(spec.platform), exclude=environment.is_system_path
89 )
90
91 # Let the extendee/dependency modify their extensions/dependents
92 # before asking for package-specific modifications
93 env.extend(
94 spack.build_environment.modifications_from_dependencies(
95 spec, context="run", set_package_py_globals=set_package_py_globals
96 )
97 )
98
99 if set_package_py_globals:
100 spack.build_environment.set_module_variables_for_package(spec.package)
101
102 spec.package.setup_run_environment(env)
103
104 return env
105
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/lib/spack/spack/user_environment.py b/lib/spack/spack/user_environment.py
--- a/lib/spack/spack/user_environment.py
+++ b/lib/spack/spack/user_environment.py
@@ -32,12 +32,9 @@
inspections = {
"bin": ["PATH"],
- "lib": ["LD_LIBRARY_PATH", "LIBRARY_PATH"],
- "lib64": ["LD_LIBRARY_PATH", "LIBRARY_PATH"],
"man": ["MANPATH"],
"share/man": ["MANPATH"],
"share/aclocal": ["ACLOCAL_PATH"],
- "include": ["CPATH"],
"lib/pkgconfig": ["PKG_CONFIG_PATH"],
"lib64/pkgconfig": ["PKG_CONFIG_PATH"],
"share/pkgconfig": ["PKG_CONFIG_PATH"],
@@ -45,8 +42,8 @@
}
if platform == "darwin":
- for subdir in ("lib", "lib64"):
- inspections[subdir].append("DYLD_FALLBACK_LIBRARY_PATH")
+ inspections["lib"] = ["DYLD_FALLBACK_LIBRARY_PATH"]
+ inspections["lib64"] = ["DYLD_FALLBACK_LIBRARY_PATH"]
return inspections
|
{"golden_diff": "diff --git a/lib/spack/spack/user_environment.py b/lib/spack/spack/user_environment.py\n--- a/lib/spack/spack/user_environment.py\n+++ b/lib/spack/spack/user_environment.py\n@@ -32,12 +32,9 @@\n \n inspections = {\n \"bin\": [\"PATH\"],\n- \"lib\": [\"LD_LIBRARY_PATH\", \"LIBRARY_PATH\"],\n- \"lib64\": [\"LD_LIBRARY_PATH\", \"LIBRARY_PATH\"],\n \"man\": [\"MANPATH\"],\n \"share/man\": [\"MANPATH\"],\n \"share/aclocal\": [\"ACLOCAL_PATH\"],\n- \"include\": [\"CPATH\"],\n \"lib/pkgconfig\": [\"PKG_CONFIG_PATH\"],\n \"lib64/pkgconfig\": [\"PKG_CONFIG_PATH\"],\n \"share/pkgconfig\": [\"PKG_CONFIG_PATH\"],\n@@ -45,8 +42,8 @@\n }\n \n if platform == \"darwin\":\n- for subdir in (\"lib\", \"lib64\"):\n- inspections[subdir].append(\"DYLD_FALLBACK_LIBRARY_PATH\")\n+ inspections[\"lib\"] = [\"DYLD_FALLBACK_LIBRARY_PATH\"]\n+ inspections[\"lib64\"] = [\"DYLD_FALLBACK_LIBRARY_PATH\"]\n \n return inspections\n", "issue": "Setting LD_LIBRARY_PATH to be \"helpful\" considered harmful\n(with apologies to Djikstra and everyone else who's recycled that title meme)\r\n\r\n**TL;DR**: the library that one of my spack binaries uses depends on what other spack packages I've `module load`-ed. **YIKES**. See also #3926.\r\n\r\nI was trying to understand why @JusticeForMikeBrown was having trouble building bowtie2 (see #3950) when I've built it successfully with `gcc@4.x.y`.\r\n\r\nHis problem with `gcc@4.x.y` was zlib related; I checked the package and noticed that it doesn't have a dependency on zlib. Perhaps it should, I thought. Wonder what zlib my \"production\" copy was linked against?\r\n\r\n```\r\n$ ldd bowtie2-align-l | grep libz\r\n\tlibz.so.1 => /blah/spack/v0.0.8/opt/spack/linux-centos7-x86_64/gcc-5.4.0/zlib-1.2.11-ec535e2ikkpl7hd4y454t3yydjqorja6/lib/libz.so.1 (0x00002aaaaaf32000)\r\n```\r\n\r\nThat surprised me, because there's no zlib dependency in the package.\r\n\r\nSure enough, it's because I have something else `module load`-ed that has the side effect of adding zlib's directory to `LD_LIBRARY_PATH`.\r\n\r\n```\r\n$ (unset LD_LIBRARY_PATH; ldd bowtie2-align-l) | grep libz\r\n\tlibz.so.1 => /lib64/libz.so.1 (0x00002aaaaaf2f000)\r\n```\r\n\r\nMy \"newer\" version of CentOS has a `/lib64/libz.so.1` that includes gzbuffer (`nm` didn't help, library's stripped...):\r\n\r\n```\r\n$ strings /lib64/libz.so.1 | grep buffer\r\ngzbuffer\r\nbuffer error\r\n```\r\n\r\nso it (probably) works for me either way.\r\n\r\nBut imagine if there were two versions of a library (perhaps something mathematical) that give different results. Now you have a program giving different results depending on what other Spack applications are also loaded. \r\n\r\n**THAT** would be fun to track down (assuming you even noticed...).\r\n\r\nW.R.T. the main problem, bowtie2 should probably have a dependency on a new-ish version of zlib, but stuff like this is why LD_LIBRARY_PATH is a slippery tool to reach for.\r\n\r\nI'll argue that this kind of unpredictability is a bigger negative than being helpful and always setting `LD_LIBRARY_PATH`. This comment in the docs isn't actually correct:\r\n\r\n> Spack avoids library misconfiguration by using RPATH to link dependencies. When a user links a library or runs a program, it is tied to the dependencies it was built with, so there is no need to manipulate LD_LIBRARY_PATH at runtime.\r\n>\r\n> [clipped from here](http://spack.readthedocs.io/en/latest/features.html?highlight=RPATH#packages-can-peacefully-coexist)\r\n\r\nWhat would happen if `LD_LIBRARY_PATH` became *opt-in*, packages that need it specify it in their package definitions?\r\n\r\nLooking at [the list of cases where RPATH support doesn't work](http://spack.readthedocs.io/en/latest/workflows.html?highlight=LD_LIBRARY_PATH#transitive-dependencies), it seems like 1) is not relevant (I think it's referring to `PERL5LIB`, etc...) and 3) are simply bugs. That leaves 2), python extensions. Is `RPATH` unworkable there or just not yet working?\n", "before_files": [{"content": "# Copyright 2013-2022 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\nimport os\nimport sys\n\nimport spack.build_environment\nimport spack.config\nimport spack.util.environment as environment\nimport spack.util.prefix as prefix\n\n#: Environment variable name Spack uses to track individually loaded packages\nspack_loaded_hashes_var = \"SPACK_LOADED_HASHES\"\n\n\ndef prefix_inspections(platform):\n \"\"\"Get list of prefix inspections for platform\n\n Arguments:\n platform (str): the name of the platform to consider. The platform\n determines what environment variables Spack will use for some\n inspections.\n\n Returns:\n A dictionary mapping subdirectory names to lists of environment\n variables to modify with that directory if it exists.\n \"\"\"\n inspections = spack.config.get(\"modules:prefix_inspections\", {})\n if inspections:\n return inspections\n\n inspections = {\n \"bin\": [\"PATH\"],\n \"lib\": [\"LD_LIBRARY_PATH\", \"LIBRARY_PATH\"],\n \"lib64\": [\"LD_LIBRARY_PATH\", \"LIBRARY_PATH\"],\n \"man\": [\"MANPATH\"],\n \"share/man\": [\"MANPATH\"],\n \"share/aclocal\": [\"ACLOCAL_PATH\"],\n \"include\": [\"CPATH\"],\n \"lib/pkgconfig\": [\"PKG_CONFIG_PATH\"],\n \"lib64/pkgconfig\": [\"PKG_CONFIG_PATH\"],\n \"share/pkgconfig\": [\"PKG_CONFIG_PATH\"],\n \"\": [\"CMAKE_PREFIX_PATH\"],\n }\n\n if platform == \"darwin\":\n for subdir in (\"lib\", \"lib64\"):\n inspections[subdir].append(\"DYLD_FALLBACK_LIBRARY_PATH\")\n\n return inspections\n\n\ndef unconditional_environment_modifications(view):\n \"\"\"List of environment (shell) modifications to be processed for view.\n\n This list does not depend on the specs in this environment\"\"\"\n env = environment.EnvironmentModifications()\n\n for subdir, vars in prefix_inspections(sys.platform).items():\n full_subdir = os.path.join(view.root, subdir)\n for var in vars:\n env.prepend_path(var, full_subdir)\n\n return env\n\n\ndef environment_modifications_for_spec(spec, view=None, set_package_py_globals=True):\n \"\"\"List of environment (shell) modifications to be processed for spec.\n\n This list is specific to the location of the spec or its projection in\n the view.\n\n Args:\n spec (spack.spec.Spec): spec for which to list the environment modifications\n view: view associated with the spec passed as first argument\n set_package_py_globals (bool): whether or not to set the global variables in the\n package.py files (this may be problematic when using buildcaches that have\n been built on a different but compatible OS)\n \"\"\"\n spec = spec.copy()\n if view and not spec.external:\n spec.prefix = prefix.Prefix(view.get_projection_for_spec(spec))\n\n # generic environment modifications determined by inspecting the spec\n # prefix\n env = environment.inspect_path(\n spec.prefix, prefix_inspections(spec.platform), exclude=environment.is_system_path\n )\n\n # Let the extendee/dependency modify their extensions/dependents\n # before asking for package-specific modifications\n env.extend(\n spack.build_environment.modifications_from_dependencies(\n spec, context=\"run\", set_package_py_globals=set_package_py_globals\n )\n )\n\n if set_package_py_globals:\n spack.build_environment.set_module_variables_for_package(spec.package)\n\n spec.package.setup_run_environment(env)\n\n return env\n", "path": "lib/spack/spack/user_environment.py"}], "after_files": [{"content": "# Copyright 2013-2022 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\nimport os\nimport sys\n\nimport spack.build_environment\nimport spack.config\nimport spack.util.environment as environment\nimport spack.util.prefix as prefix\n\n#: Environment variable name Spack uses to track individually loaded packages\nspack_loaded_hashes_var = \"SPACK_LOADED_HASHES\"\n\n\ndef prefix_inspections(platform):\n \"\"\"Get list of prefix inspections for platform\n\n Arguments:\n platform (str): the name of the platform to consider. The platform\n determines what environment variables Spack will use for some\n inspections.\n\n Returns:\n A dictionary mapping subdirectory names to lists of environment\n variables to modify with that directory if it exists.\n \"\"\"\n inspections = spack.config.get(\"modules:prefix_inspections\", {})\n if inspections:\n return inspections\n\n inspections = {\n \"bin\": [\"PATH\"],\n \"man\": [\"MANPATH\"],\n \"share/man\": [\"MANPATH\"],\n \"share/aclocal\": [\"ACLOCAL_PATH\"],\n \"lib/pkgconfig\": [\"PKG_CONFIG_PATH\"],\n \"lib64/pkgconfig\": [\"PKG_CONFIG_PATH\"],\n \"share/pkgconfig\": [\"PKG_CONFIG_PATH\"],\n \"\": [\"CMAKE_PREFIX_PATH\"],\n }\n\n if platform == \"darwin\":\n inspections[\"lib\"] = [\"DYLD_FALLBACK_LIBRARY_PATH\"]\n inspections[\"lib64\"] = [\"DYLD_FALLBACK_LIBRARY_PATH\"]\n\n return inspections\n\n\ndef unconditional_environment_modifications(view):\n \"\"\"List of environment (shell) modifications to be processed for view.\n\n This list does not depend on the specs in this environment\"\"\"\n env = environment.EnvironmentModifications()\n\n for subdir, vars in prefix_inspections(sys.platform).items():\n full_subdir = os.path.join(view.root, subdir)\n for var in vars:\n env.prepend_path(var, full_subdir)\n\n return env\n\n\ndef environment_modifications_for_spec(spec, view=None, set_package_py_globals=True):\n \"\"\"List of environment (shell) modifications to be processed for spec.\n\n This list is specific to the location of the spec or its projection in\n the view.\n\n Args:\n spec (spack.spec.Spec): spec for which to list the environment modifications\n view: view associated with the spec passed as first argument\n set_package_py_globals (bool): whether or not to set the global variables in the\n package.py files (this may be problematic when using buildcaches that have\n been built on a different but compatible OS)\n \"\"\"\n spec = spec.copy()\n if view and not spec.external:\n spec.prefix = prefix.Prefix(view.get_projection_for_spec(spec))\n\n # generic environment modifications determined by inspecting the spec\n # prefix\n env = environment.inspect_path(\n spec.prefix, prefix_inspections(spec.platform), exclude=environment.is_system_path\n )\n\n # Let the extendee/dependency modify their extensions/dependents\n # before asking for package-specific modifications\n env.extend(\n spack.build_environment.modifications_from_dependencies(\n spec, context=\"run\", set_package_py_globals=set_package_py_globals\n )\n )\n\n if set_package_py_globals:\n spack.build_environment.set_module_variables_for_package(spec.package)\n\n spec.package.setup_run_environment(env)\n\n return env\n", "path": "lib/spack/spack/user_environment.py"}]}
| 2,044 | 260 |
gh_patches_debug_38152
|
rasdani/github-patches
|
git_diff
|
pyinstaller__pyinstaller-1176
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
_tkinter.TclError Possible regression from ticket 540
**Original date**: 2012/10/26
**Original reporter**: _Lynn Oliver <raycores AND gmail DOT COOM >_
When I build with pyinstaller-2.0 on OSX 10.8.2, I can run the resulting binary on the build machine without any issues. When I run the binary on a fresh install of OSX 10.8.2, I get a _tkinter.TclError (traceback below). I believe this is similar to the error that I reported on ticket 540.
I'm able to build successfully with a pre-2.0 dev version of pyinstaller. I don't know of any way to identify the exact build I am using, but the files are dated 5/4/2012 at 10:20 AM (PDT).
```
Traceback (most recent call last):
File "<string>", line 149, in <module>
File "../axeomatic2/normal/build/pyi.darwin/aomDSP/out00-PYZ.pyz/Tkinter", line 1685, in __init__
_tkinter.TclError: Can't find a usable init.tcl in the following directories:
/var/folders/wr/ngmkb4s56cj4d2n1gxll358r0000gn/T/_MEIzgaAGB/_MEI/tcl /var/folders/wr/ngmkb4s56cj4d2n1gxll358r0000gn/T/_MEIzgaAGB/_MEI/tcl8.5 /Library/Frameworks/Tcl.framework/Versions/8.5/Resources/Scripts /Applications/aomDSP.app/Contents/lib/tcl8.5 /Applications/aomDSP.app/lib/tcl8.5 /Applications/aomDSP.app/Contents/library /Applications/aomDSP.app/library /Applications/aomDSP.app/tcl8.5.11/library /Applications/tcl8.5.11/library
/var/folders/wr/ngmkb4s56cj4d2n1gxll358r0000gn/T/_MEIzgaAGB/_MEI/tcl/init.tcl: can't find package activestate::teapot::link
can't find package activestate::teapot::link
while executing
"package require activestate::teapot::link"
invoked from within
"if {![interp issafe] && ![catch {package require platform}]} {
package require activestate::teapot::link
::activestate::teapot::link::setup
..."
(file "/var/folders/wr/ngmkb4s56cj4d2n1gxll358r0000gn/T/_MEIzgaAGB/_MEI/tcl/init.tcl" line 873)
invoked from within
"source /var/folders/wr/ngmkb4s56cj4d2n1gxll358r0000gn/T/_MEIzgaAGB/_MEI/tcl/init.tcl"
("uplevel" body line 1)
invoked from within
"uplevel #0 [list source $tclfile]"
This probably means that Tcl wasn't installed properly.
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `PyInstaller/hooks/hook-_tkinter.py`
Content:
```
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2013, PyInstaller Development Team.
3 #
4 # Distributed under the terms of the GNU General Public License with exception
5 # for distributing bootloader.
6 #
7 # The full license is in the file COPYING.txt, distributed with this software.
8 #-----------------------------------------------------------------------------
9
10
11 import os
12 import sys
13
14 import PyInstaller.bindepend
15
16 from PyInstaller.compat import is_win, is_darwin, is_unix, is_virtualenv, venv_real_prefix
17 from PyInstaller.build import Tree
18 from PyInstaller.hooks.hookutils import exec_statement, logger
19
20
21 def _handle_broken_tk():
22 """
23 Workaround for broken Tcl/Tk detection in virtualenv on Windows.
24
25 There is a bug in older versions of virtualenv in setting paths
26 to Tcl/Tk properly. PyInstaller running in virtualenv is then
27 not able to find Tcl/Tk.
28
29 This issue has been experienced in virtualenv with Python 2.4 on Win7.
30
31 https://github.com/pypa/virtualenv/issues/93
32 """
33 if is_win and is_virtualenv:
34 basedir = os.path.join(venv_real_prefix, 'tcl')
35 files = os.listdir(basedir)
36 v = os.environ
37 # Detect Tcl/Tk paths.
38 for f in files:
39 abs_path = os.path.join(basedir, f)
40 if f.startswith('tcl') and os.path.isdir(abs_path):
41 v['TCL_LIBRARY'] = abs_path
42 if f.startswith('tk') and os.path.isdir(abs_path):
43 v['TK_LIBRARY'] = abs_path
44 if f.startswith('tix') and os.path.isdir(abs_path):
45 v['TIX_LIBRARY'] = abs_path
46
47
48 def _find_tk_darwin_frameworks(binaries):
49 """
50 Tcl and Tk are installed as Mac OS X Frameworks.
51 """
52 tcl_root = tk_root = None
53 for nm, fnm in binaries:
54 if nm == 'Tcl':
55 tcl_root = os.path.join(os.path.dirname(fnm), 'Resources/Scripts')
56 if nm == 'Tk':
57 tk_root = os.path.join(os.path.dirname(fnm), 'Resources/Scripts')
58 return tcl_root, tk_root
59
60
61 def _find_tk_tclshell():
62 """
63 Get paths to Tcl/Tk from the Tcl shell command 'info library'.
64
65 This command will return path to TCL_LIBRARY.
66 On most systems are Tcl and Tk libraries installed
67 in the same prefix.
68 """
69 tcl_root = tk_root = None
70
71 # Python code to get path to TCL_LIBRARY.
72 code = 'from Tkinter import Tcl; t = Tcl(); print(t.eval("info library"))'
73
74 tcl_root = exec_statement(code)
75 tk_version = exec_statement('from _tkinter import TK_VERSION as v; print(v)')
76 # TK_LIBRARY is in the same prefix as Tcl.
77 tk_root = os.path.join(os.path.dirname(tcl_root), 'tk%s' % tk_version)
78 return tcl_root, tk_root
79
80
81 def _find_tk(mod):
82 """
83 Find paths with Tcl and Tk data files to be bundled by PyInstaller.
84
85 Return:
86 tcl_root path to Tcl data files.
87 tk_root path to Tk data files.
88 """
89 bins = PyInstaller.bindepend.selectImports(mod.__file__)
90
91 if is_darwin:
92 # _tkinter depends on system Tcl/Tk frameworks.
93 if not bins:
94 # 'mod.pyinstaller_binaries' can't be used because on Mac OS X _tkinter.so
95 # might depend on system Tcl/Tk frameworks and these are not
96 # included in 'mod.pyinstaller_binaries'.
97 bins = PyInstaller.bindepend.getImports(mod.__file__)
98 # Reformat data structure from
99 # set(['lib1', 'lib2', 'lib3'])
100 # to
101 # [('Tcl', '/path/to/Tcl'), ('Tk', '/path/to/Tk')]
102 mapping = {}
103 for l in bins:
104 mapping[os.path.basename(l)] = l
105 bins = [
106 ('Tcl', mapping['Tcl']),
107 ('Tk', mapping['Tk']),
108 ]
109
110 # _tkinter depends on Tcl/Tk compiled as frameworks.
111 path_to_tcl = bins[0][1]
112 if 'Library/Frameworks' in path_to_tcl:
113 tcl_tk = _find_tk_darwin_frameworks(bins)
114 # Tcl/Tk compiled as on Linux other Unices.
115 # For example this is the case of Tcl/Tk from macports.
116 else:
117 tcl_tk = _find_tk_tclshell()
118
119 else:
120 tcl_tk = _find_tk_tclshell()
121
122 return tcl_tk
123
124
125 def _collect_tkfiles(mod):
126 # Workaround for broken Tcl/Tk detection in virtualenv on Windows.
127 _handle_broken_tk()
128
129 tcl_root, tk_root = _find_tk(mod)
130
131 if not tcl_root:
132 logger.error("TCL/TK seams to be not properly installed on this system")
133 return []
134
135 tcldir = "tcl"
136 tkdir = "tk"
137
138 tcltree = Tree(tcl_root, os.path.join('_MEI', tcldir),
139 excludes=['demos', '*.lib', 'tclConfig.sh'])
140 tktree = Tree(tk_root, os.path.join('_MEI', tkdir),
141 excludes=['demos', '*.lib', 'tkConfig.sh'])
142 return (tcltree + tktree)
143
144
145 def hook(mod):
146 # If not supported platform, skip TCL/TK detection.
147 if not (is_win or is_darwin or is_unix):
148 logger.info("... skipping TCL/TK detection on this platform (%s)",
149 sys.platform)
150 return mod
151
152 # Get the Tcl/Tk data files for bundling with executable.
153 #try:
154 tk_files = _collect_tkfiles(mod)
155 mod.pyinstaller_datas.extend(tk_files)
156 #except:
157 #logger.error("could not find TCL/TK")
158
159 return mod
160
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/PyInstaller/hooks/hook-_tkinter.py b/PyInstaller/hooks/hook-_tkinter.py
--- a/PyInstaller/hooks/hook-_tkinter.py
+++ b/PyInstaller/hooks/hook-_tkinter.py
@@ -45,6 +45,58 @@
v['TIX_LIBRARY'] = abs_path
+def _warn_if_actvivetcl_or_teapot_install(tcl_root, tcltree):
+ """
+ Workaround ActiveTcl on OS X
+
+ PyInstaller does not package all requirements of ActiveTcl
+ (most notably teapot, which is not typically required). This
+ means packages built against ActiveTcl usually won't run on
+ non-host systems.
+
+ This method checks if ActiveTcl is being used, and if so logs
+ a warning if the problematic code is not commented out.
+
+ https://github.com/pyinstaller/pyinstaller/issues/621
+ """
+
+ from PyInstaller.lib.macholib import util
+ if util.in_system_path(tcl_root):
+ # system libraries do not experience this problem
+ return
+
+ # get the path to the 'init.tcl' script
+ try:
+ init_resource = [r[1] for r in tcltree if r[1].endswith('init.tcl')][0]
+ except IndexError:
+ # couldn't find the init script, return
+ return
+
+ mentions_activetcl = False
+ mentions_teapot = False
+ with open(init_resource, 'r') as init_file:
+ for line in init_file.readlines():
+ line = line.strip().lower()
+ if line.startswith('#'):
+ continue
+ if 'activetcl' in line:
+ mentions_activetcl = True
+ if 'teapot' in line:
+ mentions_teapot = True
+ if mentions_activetcl and mentions_teapot:
+ break
+
+ if mentions_activetcl and mentions_teapot:
+ logger.warning("""It seems you are using an ActiveTcl build of Tcl/Tk.\
+ This may not package correctly with PyInstaller.
+To fix the problem, please try commenting out all mentions of 'teapot' in:
+
+ %s
+
+See https://github.com/pyinstaller/pyinstaller/issues/621 for more information"""
+ % init_resource)
+
+
def _find_tk_darwin_frameworks(binaries):
"""
Tcl and Tk are installed as Mac OS X Frameworks.
@@ -137,6 +189,11 @@
tcltree = Tree(tcl_root, os.path.join('_MEI', tcldir),
excludes=['demos', '*.lib', 'tclConfig.sh'])
+
+ if is_darwin:
+ # handle workaround for ActiveTcl on OS X
+ _warn_if_actvivetcl_or_teapot_install(tcl_root, tcltree)
+
tktree = Tree(tk_root, os.path.join('_MEI', tkdir),
excludes=['demos', '*.lib', 'tkConfig.sh'])
return (tcltree + tktree)
@@ -146,7 +203,7 @@
# If not supported platform, skip TCL/TK detection.
if not (is_win or is_darwin or is_unix):
logger.info("... skipping TCL/TK detection on this platform (%s)",
- sys.platform)
+ sys.platform)
return mod
# Get the Tcl/Tk data files for bundling with executable.
|
{"golden_diff": "diff --git a/PyInstaller/hooks/hook-_tkinter.py b/PyInstaller/hooks/hook-_tkinter.py\n--- a/PyInstaller/hooks/hook-_tkinter.py\n+++ b/PyInstaller/hooks/hook-_tkinter.py\n@@ -45,6 +45,58 @@\n v['TIX_LIBRARY'] = abs_path\n \n \n+def _warn_if_actvivetcl_or_teapot_install(tcl_root, tcltree):\n+ \"\"\"\n+ Workaround ActiveTcl on OS X\n+\n+ PyInstaller does not package all requirements of ActiveTcl\n+ (most notably teapot, which is not typically required). This\n+ means packages built against ActiveTcl usually won't run on\n+ non-host systems.\n+\n+ This method checks if ActiveTcl is being used, and if so logs\n+ a warning if the problematic code is not commented out.\n+\n+ https://github.com/pyinstaller/pyinstaller/issues/621\n+ \"\"\"\n+\n+ from PyInstaller.lib.macholib import util\n+ if util.in_system_path(tcl_root):\n+ # system libraries do not experience this problem\n+ return\n+\n+ # get the path to the 'init.tcl' script\n+ try:\n+ init_resource = [r[1] for r in tcltree if r[1].endswith('init.tcl')][0]\n+ except IndexError:\n+ # couldn't find the init script, return\n+ return\n+\n+ mentions_activetcl = False\n+ mentions_teapot = False\n+ with open(init_resource, 'r') as init_file:\n+ for line in init_file.readlines():\n+ line = line.strip().lower()\n+ if line.startswith('#'):\n+ continue\n+ if 'activetcl' in line:\n+ mentions_activetcl = True\n+ if 'teapot' in line:\n+ mentions_teapot = True\n+ if mentions_activetcl and mentions_teapot:\n+ break\n+\n+ if mentions_activetcl and mentions_teapot:\n+ logger.warning(\"\"\"It seems you are using an ActiveTcl build of Tcl/Tk.\\\n+ This may not package correctly with PyInstaller.\n+To fix the problem, please try commenting out all mentions of 'teapot' in:\n+\n+ %s\n+\n+See https://github.com/pyinstaller/pyinstaller/issues/621 for more information\"\"\"\n+ % init_resource)\n+\n+\n def _find_tk_darwin_frameworks(binaries):\n \"\"\"\n Tcl and Tk are installed as Mac OS X Frameworks.\n@@ -137,6 +189,11 @@\n \n tcltree = Tree(tcl_root, os.path.join('_MEI', tcldir),\n excludes=['demos', '*.lib', 'tclConfig.sh'])\n+\n+ if is_darwin:\n+ # handle workaround for ActiveTcl on OS X\n+ _warn_if_actvivetcl_or_teapot_install(tcl_root, tcltree)\n+\n tktree = Tree(tk_root, os.path.join('_MEI', tkdir),\n excludes=['demos', '*.lib', 'tkConfig.sh'])\n return (tcltree + tktree)\n@@ -146,7 +203,7 @@\n # If not supported platform, skip TCL/TK detection.\n if not (is_win or is_darwin or is_unix):\n logger.info(\"... skipping TCL/TK detection on this platform (%s)\",\n- sys.platform)\n+ sys.platform)\n return mod\n \n # Get the Tcl/Tk data files for bundling with executable.\n", "issue": "_tkinter.TclError Possible regression from ticket 540\n**Original date**: 2012/10/26\n**Original reporter**: _Lynn Oliver <raycores AND gmail DOT COOM >_\n\nWhen I build with pyinstaller-2.0 on OSX 10.8.2, I can run the resulting binary on the build machine without any issues. When I run the binary on a fresh install of OSX 10.8.2, I get a _tkinter.TclError (traceback below). I believe this is similar to the error that I reported on ticket 540.\n\nI'm able to build successfully with a pre-2.0 dev version of pyinstaller. I don't know of any way to identify the exact build I am using, but the files are dated 5/4/2012 at 10:20 AM (PDT).\n\n```\nTraceback (most recent call last):\n File \"<string>\", line 149, in <module>\n File \"../axeomatic2/normal/build/pyi.darwin/aomDSP/out00-PYZ.pyz/Tkinter\", line 1685, in __init__\n_tkinter.TclError: Can't find a usable init.tcl in the following directories: \n /var/folders/wr/ngmkb4s56cj4d2n1gxll358r0000gn/T/_MEIzgaAGB/_MEI/tcl /var/folders/wr/ngmkb4s56cj4d2n1gxll358r0000gn/T/_MEIzgaAGB/_MEI/tcl8.5 /Library/Frameworks/Tcl.framework/Versions/8.5/Resources/Scripts /Applications/aomDSP.app/Contents/lib/tcl8.5 /Applications/aomDSP.app/lib/tcl8.5 /Applications/aomDSP.app/Contents/library /Applications/aomDSP.app/library /Applications/aomDSP.app/tcl8.5.11/library /Applications/tcl8.5.11/library\n\n/var/folders/wr/ngmkb4s56cj4d2n1gxll358r0000gn/T/_MEIzgaAGB/_MEI/tcl/init.tcl: can't find package activestate::teapot::link\ncan't find package activestate::teapot::link\n while executing\n\"package require activestate::teapot::link\"\n invoked from within\n\"if {![interp issafe] && ![catch {package require platform}]} {\n package require activestate::teapot::link\n ::activestate::teapot::link::setup\n...\"\n (file \"/var/folders/wr/ngmkb4s56cj4d2n1gxll358r0000gn/T/_MEIzgaAGB/_MEI/tcl/init.tcl\" line 873)\n invoked from within\n\"source /var/folders/wr/ngmkb4s56cj4d2n1gxll358r0000gn/T/_MEIzgaAGB/_MEI/tcl/init.tcl\"\n (\"uplevel\" body line 1)\n invoked from within\n\"uplevel #0 [list source $tclfile]\"\n\n\nThis probably means that Tcl wasn't installed properly.\n```\n\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2013, PyInstaller Development Team.\n#\n# Distributed under the terms of the GNU General Public License with exception\n# for distributing bootloader.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n\n\nimport os\nimport sys\n\nimport PyInstaller.bindepend\n\nfrom PyInstaller.compat import is_win, is_darwin, is_unix, is_virtualenv, venv_real_prefix\nfrom PyInstaller.build import Tree\nfrom PyInstaller.hooks.hookutils import exec_statement, logger\n\n\ndef _handle_broken_tk():\n \"\"\"\n Workaround for broken Tcl/Tk detection in virtualenv on Windows.\n\n There is a bug in older versions of virtualenv in setting paths\n to Tcl/Tk properly. PyInstaller running in virtualenv is then\n not able to find Tcl/Tk.\n\n This issue has been experienced in virtualenv with Python 2.4 on Win7.\n\n https://github.com/pypa/virtualenv/issues/93\n \"\"\"\n if is_win and is_virtualenv:\n basedir = os.path.join(venv_real_prefix, 'tcl')\n files = os.listdir(basedir)\n v = os.environ\n # Detect Tcl/Tk paths.\n for f in files:\n abs_path = os.path.join(basedir, f)\n if f.startswith('tcl') and os.path.isdir(abs_path):\n v['TCL_LIBRARY'] = abs_path\n if f.startswith('tk') and os.path.isdir(abs_path):\n v['TK_LIBRARY'] = abs_path\n if f.startswith('tix') and os.path.isdir(abs_path):\n v['TIX_LIBRARY'] = abs_path\n\n\ndef _find_tk_darwin_frameworks(binaries):\n \"\"\"\n Tcl and Tk are installed as Mac OS X Frameworks.\n \"\"\"\n tcl_root = tk_root = None\n for nm, fnm in binaries:\n if nm == 'Tcl':\n tcl_root = os.path.join(os.path.dirname(fnm), 'Resources/Scripts')\n if nm == 'Tk':\n tk_root = os.path.join(os.path.dirname(fnm), 'Resources/Scripts')\n return tcl_root, tk_root\n\n\ndef _find_tk_tclshell():\n \"\"\"\n Get paths to Tcl/Tk from the Tcl shell command 'info library'.\n\n This command will return path to TCL_LIBRARY.\n On most systems are Tcl and Tk libraries installed\n in the same prefix.\n \"\"\"\n tcl_root = tk_root = None\n\n # Python code to get path to TCL_LIBRARY.\n code = 'from Tkinter import Tcl; t = Tcl(); print(t.eval(\"info library\"))'\n\n tcl_root = exec_statement(code)\n tk_version = exec_statement('from _tkinter import TK_VERSION as v; print(v)')\n # TK_LIBRARY is in the same prefix as Tcl.\n tk_root = os.path.join(os.path.dirname(tcl_root), 'tk%s' % tk_version)\n return tcl_root, tk_root\n\n\ndef _find_tk(mod):\n \"\"\"\n Find paths with Tcl and Tk data files to be bundled by PyInstaller.\n\n Return:\n tcl_root path to Tcl data files.\n tk_root path to Tk data files.\n \"\"\"\n bins = PyInstaller.bindepend.selectImports(mod.__file__)\n\n if is_darwin:\n # _tkinter depends on system Tcl/Tk frameworks.\n if not bins:\n # 'mod.pyinstaller_binaries' can't be used because on Mac OS X _tkinter.so\n # might depend on system Tcl/Tk frameworks and these are not\n # included in 'mod.pyinstaller_binaries'.\n bins = PyInstaller.bindepend.getImports(mod.__file__)\n # Reformat data structure from\n # set(['lib1', 'lib2', 'lib3'])\n # to\n # [('Tcl', '/path/to/Tcl'), ('Tk', '/path/to/Tk')]\n mapping = {}\n for l in bins:\n mapping[os.path.basename(l)] = l\n bins = [\n ('Tcl', mapping['Tcl']),\n ('Tk', mapping['Tk']),\n ]\n\n # _tkinter depends on Tcl/Tk compiled as frameworks.\n path_to_tcl = bins[0][1]\n if 'Library/Frameworks' in path_to_tcl:\n tcl_tk = _find_tk_darwin_frameworks(bins)\n # Tcl/Tk compiled as on Linux other Unices.\n # For example this is the case of Tcl/Tk from macports.\n else:\n tcl_tk = _find_tk_tclshell()\n\n else:\n tcl_tk = _find_tk_tclshell()\n\n return tcl_tk\n\n\ndef _collect_tkfiles(mod):\n # Workaround for broken Tcl/Tk detection in virtualenv on Windows.\n _handle_broken_tk()\n\n tcl_root, tk_root = _find_tk(mod)\n\n if not tcl_root:\n logger.error(\"TCL/TK seams to be not properly installed on this system\")\n return []\n\n tcldir = \"tcl\"\n tkdir = \"tk\"\n\n tcltree = Tree(tcl_root, os.path.join('_MEI', tcldir),\n excludes=['demos', '*.lib', 'tclConfig.sh'])\n tktree = Tree(tk_root, os.path.join('_MEI', tkdir),\n excludes=['demos', '*.lib', 'tkConfig.sh'])\n return (tcltree + tktree)\n\n\ndef hook(mod):\n # If not supported platform, skip TCL/TK detection.\n if not (is_win or is_darwin or is_unix):\n logger.info(\"... skipping TCL/TK detection on this platform (%s)\",\n sys.platform)\n return mod\n\n # Get the Tcl/Tk data files for bundling with executable.\n #try:\n tk_files = _collect_tkfiles(mod)\n mod.pyinstaller_datas.extend(tk_files)\n #except:\n #logger.error(\"could not find TCL/TK\")\n\n return mod\n", "path": "PyInstaller/hooks/hook-_tkinter.py"}], "after_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2013, PyInstaller Development Team.\n#\n# Distributed under the terms of the GNU General Public License with exception\n# for distributing bootloader.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n\n\nimport os\nimport sys\n\nimport PyInstaller.bindepend\n\nfrom PyInstaller.compat import is_win, is_darwin, is_unix, is_virtualenv, venv_real_prefix\nfrom PyInstaller.build import Tree\nfrom PyInstaller.hooks.hookutils import exec_statement, logger\n\n\ndef _handle_broken_tk():\n \"\"\"\n Workaround for broken Tcl/Tk detection in virtualenv on Windows.\n\n There is a bug in older versions of virtualenv in setting paths\n to Tcl/Tk properly. PyInstaller running in virtualenv is then\n not able to find Tcl/Tk.\n\n This issue has been experienced in virtualenv with Python 2.4 on Win7.\n\n https://github.com/pypa/virtualenv/issues/93\n \"\"\"\n if is_win and is_virtualenv:\n basedir = os.path.join(venv_real_prefix, 'tcl')\n files = os.listdir(basedir)\n v = os.environ\n # Detect Tcl/Tk paths.\n for f in files:\n abs_path = os.path.join(basedir, f)\n if f.startswith('tcl') and os.path.isdir(abs_path):\n v['TCL_LIBRARY'] = abs_path\n if f.startswith('tk') and os.path.isdir(abs_path):\n v['TK_LIBRARY'] = abs_path\n if f.startswith('tix') and os.path.isdir(abs_path):\n v['TIX_LIBRARY'] = abs_path\n\n\ndef _warn_if_actvivetcl_or_teapot_install(tcl_root, tcltree):\n \"\"\"\n Workaround ActiveTcl on OS X\n\n PyInstaller does not package all requirements of ActiveTcl\n (most notably teapot, which is not typically required). This\n means packages built against ActiveTcl usually won't run on\n non-host systems.\n\n This method checks if ActiveTcl is being used, and if so logs\n a warning if the problematic code is not commented out.\n\n https://github.com/pyinstaller/pyinstaller/issues/621\n \"\"\"\n\n from PyInstaller.lib.macholib import util\n if util.in_system_path(tcl_root):\n # system libraries do not experience this problem\n return\n\n # get the path to the 'init.tcl' script\n try:\n init_resource = [r[1] for r in tcltree if r[1].endswith('init.tcl')][0]\n except IndexError:\n # couldn't find the init script, return\n return\n\n mentions_activetcl = False\n mentions_teapot = False\n with open(init_resource, 'r') as init_file:\n for line in init_file.readlines():\n line = line.strip().lower()\n if line.startswith('#'):\n continue\n if 'activetcl' in line:\n mentions_activetcl = True\n if 'teapot' in line:\n mentions_teapot = True\n if mentions_activetcl and mentions_teapot:\n break\n\n if mentions_activetcl and mentions_teapot:\n logger.warning(\"\"\"It seems you are using an ActiveTcl build of Tcl/Tk.\\\n This may not package correctly with PyInstaller.\nTo fix the problem, please try commenting out all mentions of 'teapot' in:\n\n %s\n\nSee https://github.com/pyinstaller/pyinstaller/issues/621 for more information\"\"\"\n % init_resource)\n\n\ndef _find_tk_darwin_frameworks(binaries):\n \"\"\"\n Tcl and Tk are installed as Mac OS X Frameworks.\n \"\"\"\n tcl_root = tk_root = None\n for nm, fnm in binaries:\n if nm == 'Tcl':\n tcl_root = os.path.join(os.path.dirname(fnm), 'Resources/Scripts')\n if nm == 'Tk':\n tk_root = os.path.join(os.path.dirname(fnm), 'Resources/Scripts')\n return tcl_root, tk_root\n\n\ndef _find_tk_tclshell():\n \"\"\"\n Get paths to Tcl/Tk from the Tcl shell command 'info library'.\n\n This command will return path to TCL_LIBRARY.\n On most systems are Tcl and Tk libraries installed\n in the same prefix.\n \"\"\"\n tcl_root = tk_root = None\n\n # Python code to get path to TCL_LIBRARY.\n code = 'from Tkinter import Tcl; t = Tcl(); print(t.eval(\"info library\"))'\n\n tcl_root = exec_statement(code)\n tk_version = exec_statement('from _tkinter import TK_VERSION as v; print(v)')\n # TK_LIBRARY is in the same prefix as Tcl.\n tk_root = os.path.join(os.path.dirname(tcl_root), 'tk%s' % tk_version)\n return tcl_root, tk_root\n\n\ndef _find_tk(mod):\n \"\"\"\n Find paths with Tcl and Tk data files to be bundled by PyInstaller.\n\n Return:\n tcl_root path to Tcl data files.\n tk_root path to Tk data files.\n \"\"\"\n bins = PyInstaller.bindepend.selectImports(mod.__file__)\n\n if is_darwin:\n # _tkinter depends on system Tcl/Tk frameworks.\n if not bins:\n # 'mod.pyinstaller_binaries' can't be used because on Mac OS X _tkinter.so\n # might depend on system Tcl/Tk frameworks and these are not\n # included in 'mod.pyinstaller_binaries'.\n bins = PyInstaller.bindepend.getImports(mod.__file__)\n # Reformat data structure from\n # set(['lib1', 'lib2', 'lib3'])\n # to\n # [('Tcl', '/path/to/Tcl'), ('Tk', '/path/to/Tk')]\n mapping = {}\n for l in bins:\n mapping[os.path.basename(l)] = l\n bins = [\n ('Tcl', mapping['Tcl']),\n ('Tk', mapping['Tk']),\n ]\n\n # _tkinter depends on Tcl/Tk compiled as frameworks.\n path_to_tcl = bins[0][1]\n if 'Library/Frameworks' in path_to_tcl:\n tcl_tk = _find_tk_darwin_frameworks(bins)\n # Tcl/Tk compiled as on Linux other Unices.\n # For example this is the case of Tcl/Tk from macports.\n else:\n tcl_tk = _find_tk_tclshell()\n\n else:\n tcl_tk = _find_tk_tclshell()\n\n return tcl_tk\n\n\ndef _collect_tkfiles(mod):\n # Workaround for broken Tcl/Tk detection in virtualenv on Windows.\n _handle_broken_tk()\n\n tcl_root, tk_root = _find_tk(mod)\n\n if not tcl_root:\n logger.error(\"TCL/TK seams to be not properly installed on this system\")\n return []\n\n tcldir = \"tcl\"\n tkdir = \"tk\"\n\n tcltree = Tree(tcl_root, os.path.join('_MEI', tcldir),\n excludes=['demos', '*.lib', 'tclConfig.sh'])\n\n if is_darwin:\n # handle workaround for ActiveTcl on OS X\n _warn_if_actvivetcl_or_teapot_install(tcl_root, tcltree)\n\n tktree = Tree(tk_root, os.path.join('_MEI', tkdir),\n excludes=['demos', '*.lib', 'tkConfig.sh'])\n return (tcltree + tktree)\n\n\ndef hook(mod):\n # If not supported platform, skip TCL/TK detection.\n if not (is_win or is_darwin or is_unix):\n logger.info(\"... skipping TCL/TK detection on this platform (%s)\",\n sys.platform)\n return mod\n\n # Get the Tcl/Tk data files for bundling with executable.\n #try:\n tk_files = _collect_tkfiles(mod)\n mod.pyinstaller_datas.extend(tk_files)\n #except:\n #logger.error(\"could not find TCL/TK\")\n\n return mod\n", "path": "PyInstaller/hooks/hook-_tkinter.py"}]}
| 2,713 | 794 |
gh_patches_debug_561
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-822
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Release 2.0.3
On the docket:
+ [x] Pex should trust any host passed via `--index` or `--find-links`. #812
+ [x] A cache should always be used by `pex.resolver.resolve`. #809
+ [x] Use the resolve cache to skip installs. #815
+ [x] Parallelize resolve. #818
+ [x] Cache sdist & local project builds #817
+ [x] Unify resolve and runtime wheel caches. #820
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pex/version.py`
Content:
```
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = '2.0.2'
5
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = '2.0.2'
+__version__ = '2.0.3'
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = '2.0.2'\n+__version__ = '2.0.3'\n", "issue": "Release 2.0.3\nOn the docket:\r\n\r\n+ [x] Pex should trust any host passed via `--index` or `--find-links`. #812\r\n+ [x] A cache should always be used by `pex.resolver.resolve`. #809\r\n+ [x] Use the resolve cache to skip installs. #815\r\n+ [x] Parallelize resolve. #818\r\n+ [x] Cache sdist & local project builds #817\r\n+ [x] Unify resolve and runtime wheel caches. #820\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = '2.0.2'\n", "path": "pex/version.py"}], "after_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = '2.0.3'\n", "path": "pex/version.py"}]}
| 432 | 94 |
gh_patches_debug_38338
|
rasdani/github-patches
|
git_diff
|
CTFd__CTFd-470
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Feature] Admin Team List - New Team
Admins should be able to create teams quickly for the admin team list page.
**TODO:**
- [x] MVP https://github.com/deckar01/CTFd/commit/c5df9994cbe61bc4815d71247eaa21ee5ed54d3c
- [ ] Fix inline style issue
- [ ] Add tests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `CTFd/admin/teams.py`
Content:
```
1 from flask import current_app as app, render_template, request, redirect, jsonify, url_for, Blueprint
2 from CTFd.utils import admins_only, is_admin, cache
3 from CTFd.models import db, Teams, Solves, Awards, Unlocks, Challenges, WrongKeys, Keys, Tags, Files, Tracking, Pages, Config, DatabaseError
4 from passlib.hash import bcrypt_sha256
5 from sqlalchemy.sql import not_
6
7 from CTFd import utils
8
9 admin_teams = Blueprint('admin_teams', __name__)
10
11
12 @admin_teams.route('/admin/teams', defaults={'page': '1'})
13 @admin_teams.route('/admin/teams/<int:page>')
14 @admins_only
15 def admin_teams_view(page):
16 q = request.args.get('q')
17 if q:
18 field = request.args.get('field')
19 teams = []
20 errors = []
21 if field == 'id':
22 if q.isnumeric():
23 teams = Teams.query.filter(Teams.id == q).order_by(Teams.id.asc()).all()
24 else:
25 teams = []
26 errors.append('Your ID search term is not numeric')
27 elif field == 'name':
28 teams = Teams.query.filter(Teams.name.like('%{}%'.format(q))).order_by(Teams.id.asc()).all()
29 elif field == 'email':
30 teams = Teams.query.filter(Teams.email.like('%{}%'.format(q))).order_by(Teams.id.asc()).all()
31 elif field == 'affiliation':
32 teams = Teams.query.filter(Teams.affiliation.like('%{}%'.format(q))).order_by(Teams.id.asc()).all()
33 elif field == 'country':
34 teams = Teams.query.filter(Teams.country.like('%{}%'.format(q))).order_by(Teams.id.asc()).all()
35 return render_template('admin/teams.html', teams=teams, pages=None, curr_page=None, q=q, field=field)
36
37 page = abs(int(page))
38 results_per_page = 50
39 page_start = results_per_page * (page - 1)
40 page_end = results_per_page * (page - 1) + results_per_page
41
42 teams = Teams.query.order_by(Teams.id.asc()).slice(page_start, page_end).all()
43 count = db.session.query(db.func.count(Teams.id)).first()[0]
44 pages = int(count / results_per_page) + (count % results_per_page > 0)
45 return render_template('admin/teams.html', teams=teams, pages=pages, curr_page=page)
46
47
48 @admin_teams.route('/admin/team/<int:teamid>', methods=['GET', 'POST'])
49 @admins_only
50 def admin_team(teamid):
51 user = Teams.query.filter_by(id=teamid).first_or_404()
52
53 if request.method == 'GET':
54 solves = Solves.query.filter_by(teamid=teamid).all()
55 solve_ids = [s.chalid for s in solves]
56 missing = Challenges.query.filter(not_(Challenges.id.in_(solve_ids))).all()
57 last_seen = db.func.max(Tracking.date).label('last_seen')
58 addrs = db.session.query(Tracking.ip, last_seen) \
59 .filter_by(team=teamid) \
60 .group_by(Tracking.ip) \
61 .order_by(last_seen.desc()).all()
62 wrong_keys = WrongKeys.query.filter_by(teamid=teamid).order_by(WrongKeys.date.asc()).all()
63 awards = Awards.query.filter_by(teamid=teamid).order_by(Awards.date.asc()).all()
64 score = user.score(admin=True)
65 place = user.place(admin=True)
66 return render_template('admin/team.html', solves=solves, team=user, addrs=addrs, score=score, missing=missing,
67 place=place, wrong_keys=wrong_keys, awards=awards)
68 elif request.method == 'POST':
69 admin_user = request.form.get('admin', None)
70 if admin_user:
71 admin_user = True if admin_user == 'true' else False
72 user.admin = admin_user
73 # Set user.banned to hide admins from scoreboard
74 user.banned = admin_user
75 db.session.commit()
76 db.session.close()
77 return jsonify({'data': ['success']})
78
79 verified = request.form.get('verified', None)
80 if verified:
81 verified = True if verified == 'true' else False
82 user.verified = verified
83 db.session.commit()
84 db.session.close()
85 return jsonify({'data': ['success']})
86
87 name = request.form.get('name', None)
88 password = request.form.get('password', None)
89 email = request.form.get('email', None)
90 website = request.form.get('website', None)
91 affiliation = request.form.get('affiliation', None)
92 country = request.form.get('country', None)
93
94 errors = []
95
96 name_used = Teams.query.filter(Teams.name == name).first()
97 if name_used and int(name_used.id) != int(teamid):
98 errors.append('That name is taken')
99
100 email_used = Teams.query.filter(Teams.email == email).first()
101 if email_used and int(email_used.id) != int(teamid):
102 errors.append('That email is taken')
103
104 if errors:
105 db.session.close()
106 return jsonify({'data': errors})
107 else:
108 user.name = name
109 if email:
110 user.email = email
111 if password:
112 user.password = bcrypt_sha256.encrypt(password)
113 user.website = website
114 user.affiliation = affiliation
115 user.country = country
116 db.session.commit()
117 db.session.close()
118 return jsonify({'data': ['success']})
119
120
121 @admin_teams.route('/admin/team/<int:teamid>/mail', methods=['POST'])
122 @admins_only
123 def email_user(teamid):
124 message = request.form.get('msg', None)
125 team = Teams.query.filter(Teams.id == teamid).first()
126 if message and team:
127 if utils.sendmail(team.email, message):
128 return '1'
129 return '0'
130
131
132 @admin_teams.route('/admin/team/<int:teamid>/ban', methods=['POST'])
133 @admins_only
134 def ban(teamid):
135 user = Teams.query.filter_by(id=teamid).first_or_404()
136 user.banned = True
137 db.session.commit()
138 db.session.close()
139 return redirect(url_for('admin_scoreboard.admin_scoreboard_view'))
140
141
142 @admin_teams.route('/admin/team/<int:teamid>/unban', methods=['POST'])
143 @admins_only
144 def unban(teamid):
145 user = Teams.query.filter_by(id=teamid).first_or_404()
146 user.banned = False
147 db.session.commit()
148 db.session.close()
149 return redirect(url_for('admin_scoreboard.admin_scoreboard_view'))
150
151
152 @admin_teams.route('/admin/team/<int:teamid>/delete', methods=['POST'])
153 @admins_only
154 def delete_team(teamid):
155 try:
156 Unlocks.query.filter_by(teamid=teamid).delete()
157 Awards.query.filter_by(teamid=teamid).delete()
158 WrongKeys.query.filter_by(teamid=teamid).delete()
159 Solves.query.filter_by(teamid=teamid).delete()
160 Tracking.query.filter_by(team=teamid).delete()
161 Teams.query.filter_by(id=teamid).delete()
162 db.session.commit()
163 db.session.close()
164 except DatabaseError:
165 return '0'
166 else:
167 return '1'
168
169
170 @admin_teams.route('/admin/solves/<teamid>', methods=['GET'])
171 @admins_only
172 def admin_solves(teamid="all"):
173 if teamid == "all":
174 solves = Solves.query.all()
175 else:
176 solves = Solves.query.filter_by(teamid=teamid).all()
177 awards = Awards.query.filter_by(teamid=teamid).all()
178 db.session.close()
179 json_data = {'solves': []}
180 for x in solves:
181 json_data['solves'].append({
182 'id': x.id,
183 'chal': x.chal.name,
184 'chalid': x.chalid,
185 'team': x.teamid,
186 'value': x.chal.value,
187 'category': x.chal.category,
188 'time': utils.unix_time(x.date)
189 })
190 for award in awards:
191 json_data['solves'].append({
192 'chal': award.name,
193 'chalid': None,
194 'team': award.teamid,
195 'value': award.value,
196 'category': award.category or "Award",
197 'time': utils.unix_time(award.date)
198 })
199 json_data['solves'].sort(key=lambda k: k['time'])
200 return jsonify(json_data)
201
202
203 @admin_teams.route('/admin/fails/all', defaults={'teamid': 'all'}, methods=['GET'])
204 @admin_teams.route('/admin/fails/<int:teamid>', methods=['GET'])
205 @admins_only
206 def admin_fails(teamid):
207 if teamid == "all":
208 fails = WrongKeys.query.join(Teams, WrongKeys.teamid == Teams.id).filter(Teams.banned == False).count()
209 solves = Solves.query.join(Teams, Solves.teamid == Teams.id).filter(Teams.banned == False).count()
210 db.session.close()
211 json_data = {'fails': str(fails), 'solves': str(solves)}
212 return jsonify(json_data)
213 else:
214 fails = WrongKeys.query.filter_by(teamid=teamid).count()
215 solves = Solves.query.filter_by(teamid=teamid).count()
216 db.session.close()
217 json_data = {'fails': str(fails), 'solves': str(solves)}
218 return jsonify(json_data)
219
220
221 @admin_teams.route('/admin/solves/<int:teamid>/<int:chalid>/solve', methods=['POST'])
222 @admins_only
223 def create_solve(teamid, chalid):
224 solve = Solves(teamid=teamid, chalid=chalid, ip='127.0.0.1', flag='MARKED_AS_SOLVED_BY_ADMIN')
225 db.session.add(solve)
226 db.session.commit()
227 db.session.close()
228 return '1'
229
230
231 @admin_teams.route('/admin/solves/<int:keyid>/delete', methods=['POST'])
232 @admins_only
233 def delete_solve(keyid):
234 solve = Solves.query.filter_by(id=keyid).first_or_404()
235 db.session.delete(solve)
236 db.session.commit()
237 db.session.close()
238 return '1'
239
240
241 @admin_teams.route('/admin/wrong_keys/<int:keyid>/delete', methods=['POST'])
242 @admins_only
243 def delete_wrong_key(keyid):
244 wrong_key = WrongKeys.query.filter_by(id=keyid).first_or_404()
245 db.session.delete(wrong_key)
246 db.session.commit()
247 db.session.close()
248 return '1'
249
250
251 @admin_teams.route('/admin/awards/<int:award_id>/delete', methods=['POST'])
252 @admins_only
253 def delete_award(award_id):
254 award = Awards.query.filter_by(id=award_id).first_or_404()
255 db.session.delete(award)
256 db.session.commit()
257 db.session.close()
258 return '1'
259
260
261 @admin_teams.route('/admin/teams/<int:teamid>/awards', methods=['GET'])
262 @admins_only
263 def admin_awards(teamid):
264 awards = Awards.query.filter_by(teamid=teamid).all()
265
266 awards_list = []
267 for award in awards:
268 awards_list.append({
269 'id': award.id,
270 'name': award.name,
271 'description': award.description,
272 'date': award.date,
273 'value': award.value,
274 'category': award.category,
275 'icon': award.icon
276 })
277 json_data = {'awards': awards_list}
278 return jsonify(json_data)
279
280
281 @admin_teams.route('/admin/awards/add', methods=['POST'])
282 @admins_only
283 def create_award():
284 try:
285 teamid = request.form['teamid']
286 name = request.form.get('name', 'Award')
287 value = request.form.get('value', 0)
288 award = Awards(teamid, name, value)
289 award.description = request.form.get('description')
290 award.category = request.form.get('category')
291 db.session.add(award)
292 db.session.commit()
293 db.session.close()
294 return '1'
295 except Exception as e:
296 print(e)
297 return '0'
298
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/CTFd/admin/teams.py b/CTFd/admin/teams.py
--- a/CTFd/admin/teams.py
+++ b/CTFd/admin/teams.py
@@ -6,6 +6,8 @@
from CTFd import utils
+import re
+
admin_teams = Blueprint('admin_teams', __name__)
@@ -45,6 +47,54 @@
return render_template('admin/teams.html', teams=teams, pages=pages, curr_page=page)
+@admin_teams.route('/admin/team/new', methods=['POST'])
+@admins_only
+def admin_create_team():
+ name = request.form.get('name', None)
+ password = request.form.get('password', None)
+ email = request.form.get('email', None)
+ website = request.form.get('website', None)
+ affiliation = request.form.get('affiliation', None)
+ country = request.form.get('country', None)
+
+ errors = []
+
+ if not name:
+ errors.append('The team requires a name')
+ elif Teams.query.filter(Teams.name == name).first():
+ errors.append('That name is taken')
+
+ if not email:
+ errors.append('The team requires an email')
+ elif Teams.query.filter(Teams.email == email).first():
+ errors.append('That email is taken')
+
+ if email:
+ valid_email = re.match(r"(^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$)", email)
+ if not valid_email:
+ errors.append("That email address is invalid")
+
+ if not password:
+ errors.append('The team requires a password')
+
+ if website and (website.startswith('http://') or website.startswith('https://')) is False:
+ errors.append('Websites must start with http:// or https://')
+
+ if errors:
+ db.session.close()
+ return jsonify({'data': errors})
+
+ team = Teams(name, email, password)
+ team.website = website
+ team.affiliation = affiliation
+ team.country = country
+
+ db.session.add(team)
+ db.session.commit()
+ db.session.close()
+ return jsonify({'data': ['success']})
+
+
@admin_teams.route('/admin/team/<int:teamid>', methods=['GET', 'POST'])
@admins_only
def admin_team(teamid):
@@ -93,6 +143,11 @@
errors = []
+ if email:
+ valid_email = re.match(r"(^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$)", email)
+ if not valid_email:
+ errors.append("That email address is invalid")
+
name_used = Teams.query.filter(Teams.name == name).first()
if name_used and int(name_used.id) != int(teamid):
errors.append('That name is taken')
@@ -101,6 +156,9 @@
if email_used and int(email_used.id) != int(teamid):
errors.append('That email is taken')
+ if website and (website.startswith('http://') or website.startswith('https://')) is False:
+ errors.append('Websites must start with http:// or https://')
+
if errors:
db.session.close()
return jsonify({'data': errors})
|
{"golden_diff": "diff --git a/CTFd/admin/teams.py b/CTFd/admin/teams.py\n--- a/CTFd/admin/teams.py\n+++ b/CTFd/admin/teams.py\n@@ -6,6 +6,8 @@\n \n from CTFd import utils\n \n+import re\n+\n admin_teams = Blueprint('admin_teams', __name__)\n \n \n@@ -45,6 +47,54 @@\n return render_template('admin/teams.html', teams=teams, pages=pages, curr_page=page)\n \n \n+@admin_teams.route('/admin/team/new', methods=['POST'])\n+@admins_only\n+def admin_create_team():\n+ name = request.form.get('name', None)\n+ password = request.form.get('password', None)\n+ email = request.form.get('email', None)\n+ website = request.form.get('website', None)\n+ affiliation = request.form.get('affiliation', None)\n+ country = request.form.get('country', None)\n+\n+ errors = []\n+\n+ if not name:\n+ errors.append('The team requires a name')\n+ elif Teams.query.filter(Teams.name == name).first():\n+ errors.append('That name is taken')\n+\n+ if not email:\n+ errors.append('The team requires an email')\n+ elif Teams.query.filter(Teams.email == email).first():\n+ errors.append('That email is taken')\n+\n+ if email:\n+ valid_email = re.match(r\"(^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\\.[a-zA-Z0-9-.]+$)\", email)\n+ if not valid_email:\n+ errors.append(\"That email address is invalid\")\n+\n+ if not password:\n+ errors.append('The team requires a password')\n+\n+ if website and (website.startswith('http://') or website.startswith('https://')) is False:\n+ errors.append('Websites must start with http:// or https://')\n+\n+ if errors:\n+ db.session.close()\n+ return jsonify({'data': errors})\n+\n+ team = Teams(name, email, password)\n+ team.website = website\n+ team.affiliation = affiliation\n+ team.country = country\n+\n+ db.session.add(team)\n+ db.session.commit()\n+ db.session.close()\n+ return jsonify({'data': ['success']})\n+\n+\n @admin_teams.route('/admin/team/<int:teamid>', methods=['GET', 'POST'])\n @admins_only\n def admin_team(teamid):\n@@ -93,6 +143,11 @@\n \n errors = []\n \n+ if email:\n+ valid_email = re.match(r\"(^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\\.[a-zA-Z0-9-.]+$)\", email)\n+ if not valid_email:\n+ errors.append(\"That email address is invalid\")\n+\n name_used = Teams.query.filter(Teams.name == name).first()\n if name_used and int(name_used.id) != int(teamid):\n errors.append('That name is taken')\n@@ -101,6 +156,9 @@\n if email_used and int(email_used.id) != int(teamid):\n errors.append('That email is taken')\n \n+ if website and (website.startswith('http://') or website.startswith('https://')) is False:\n+ errors.append('Websites must start with http:// or https://')\n+\n if errors:\n db.session.close()\n return jsonify({'data': errors})\n", "issue": "[Feature] Admin Team List - New Team\nAdmins should be able to create teams quickly for the admin team list page.\r\n\r\n**TODO:**\r\n- [x] MVP https://github.com/deckar01/CTFd/commit/c5df9994cbe61bc4815d71247eaa21ee5ed54d3c\r\n- [ ] Fix inline style issue\r\n- [ ] Add tests\r\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "from flask import current_app as app, render_template, request, redirect, jsonify, url_for, Blueprint\nfrom CTFd.utils import admins_only, is_admin, cache\nfrom CTFd.models import db, Teams, Solves, Awards, Unlocks, Challenges, WrongKeys, Keys, Tags, Files, Tracking, Pages, Config, DatabaseError\nfrom passlib.hash import bcrypt_sha256\nfrom sqlalchemy.sql import not_\n\nfrom CTFd import utils\n\nadmin_teams = Blueprint('admin_teams', __name__)\n\n\n@admin_teams.route('/admin/teams', defaults={'page': '1'})\n@admin_teams.route('/admin/teams/<int:page>')\n@admins_only\ndef admin_teams_view(page):\n q = request.args.get('q')\n if q:\n field = request.args.get('field')\n teams = []\n errors = []\n if field == 'id':\n if q.isnumeric():\n teams = Teams.query.filter(Teams.id == q).order_by(Teams.id.asc()).all()\n else:\n teams = []\n errors.append('Your ID search term is not numeric')\n elif field == 'name':\n teams = Teams.query.filter(Teams.name.like('%{}%'.format(q))).order_by(Teams.id.asc()).all()\n elif field == 'email':\n teams = Teams.query.filter(Teams.email.like('%{}%'.format(q))).order_by(Teams.id.asc()).all()\n elif field == 'affiliation':\n teams = Teams.query.filter(Teams.affiliation.like('%{}%'.format(q))).order_by(Teams.id.asc()).all()\n elif field == 'country':\n teams = Teams.query.filter(Teams.country.like('%{}%'.format(q))).order_by(Teams.id.asc()).all()\n return render_template('admin/teams.html', teams=teams, pages=None, curr_page=None, q=q, field=field)\n\n page = abs(int(page))\n results_per_page = 50\n page_start = results_per_page * (page - 1)\n page_end = results_per_page * (page - 1) + results_per_page\n\n teams = Teams.query.order_by(Teams.id.asc()).slice(page_start, page_end).all()\n count = db.session.query(db.func.count(Teams.id)).first()[0]\n pages = int(count / results_per_page) + (count % results_per_page > 0)\n return render_template('admin/teams.html', teams=teams, pages=pages, curr_page=page)\n\n\n@admin_teams.route('/admin/team/<int:teamid>', methods=['GET', 'POST'])\n@admins_only\ndef admin_team(teamid):\n user = Teams.query.filter_by(id=teamid).first_or_404()\n\n if request.method == 'GET':\n solves = Solves.query.filter_by(teamid=teamid).all()\n solve_ids = [s.chalid for s in solves]\n missing = Challenges.query.filter(not_(Challenges.id.in_(solve_ids))).all()\n last_seen = db.func.max(Tracking.date).label('last_seen')\n addrs = db.session.query(Tracking.ip, last_seen) \\\n .filter_by(team=teamid) \\\n .group_by(Tracking.ip) \\\n .order_by(last_seen.desc()).all()\n wrong_keys = WrongKeys.query.filter_by(teamid=teamid).order_by(WrongKeys.date.asc()).all()\n awards = Awards.query.filter_by(teamid=teamid).order_by(Awards.date.asc()).all()\n score = user.score(admin=True)\n place = user.place(admin=True)\n return render_template('admin/team.html', solves=solves, team=user, addrs=addrs, score=score, missing=missing,\n place=place, wrong_keys=wrong_keys, awards=awards)\n elif request.method == 'POST':\n admin_user = request.form.get('admin', None)\n if admin_user:\n admin_user = True if admin_user == 'true' else False\n user.admin = admin_user\n # Set user.banned to hide admins from scoreboard\n user.banned = admin_user\n db.session.commit()\n db.session.close()\n return jsonify({'data': ['success']})\n\n verified = request.form.get('verified', None)\n if verified:\n verified = True if verified == 'true' else False\n user.verified = verified\n db.session.commit()\n db.session.close()\n return jsonify({'data': ['success']})\n\n name = request.form.get('name', None)\n password = request.form.get('password', None)\n email = request.form.get('email', None)\n website = request.form.get('website', None)\n affiliation = request.form.get('affiliation', None)\n country = request.form.get('country', None)\n\n errors = []\n\n name_used = Teams.query.filter(Teams.name == name).first()\n if name_used and int(name_used.id) != int(teamid):\n errors.append('That name is taken')\n\n email_used = Teams.query.filter(Teams.email == email).first()\n if email_used and int(email_used.id) != int(teamid):\n errors.append('That email is taken')\n\n if errors:\n db.session.close()\n return jsonify({'data': errors})\n else:\n user.name = name\n if email:\n user.email = email\n if password:\n user.password = bcrypt_sha256.encrypt(password)\n user.website = website\n user.affiliation = affiliation\n user.country = country\n db.session.commit()\n db.session.close()\n return jsonify({'data': ['success']})\n\n\n@admin_teams.route('/admin/team/<int:teamid>/mail', methods=['POST'])\n@admins_only\ndef email_user(teamid):\n message = request.form.get('msg', None)\n team = Teams.query.filter(Teams.id == teamid).first()\n if message and team:\n if utils.sendmail(team.email, message):\n return '1'\n return '0'\n\n\n@admin_teams.route('/admin/team/<int:teamid>/ban', methods=['POST'])\n@admins_only\ndef ban(teamid):\n user = Teams.query.filter_by(id=teamid).first_or_404()\n user.banned = True\n db.session.commit()\n db.session.close()\n return redirect(url_for('admin_scoreboard.admin_scoreboard_view'))\n\n\n@admin_teams.route('/admin/team/<int:teamid>/unban', methods=['POST'])\n@admins_only\ndef unban(teamid):\n user = Teams.query.filter_by(id=teamid).first_or_404()\n user.banned = False\n db.session.commit()\n db.session.close()\n return redirect(url_for('admin_scoreboard.admin_scoreboard_view'))\n\n\n@admin_teams.route('/admin/team/<int:teamid>/delete', methods=['POST'])\n@admins_only\ndef delete_team(teamid):\n try:\n Unlocks.query.filter_by(teamid=teamid).delete()\n Awards.query.filter_by(teamid=teamid).delete()\n WrongKeys.query.filter_by(teamid=teamid).delete()\n Solves.query.filter_by(teamid=teamid).delete()\n Tracking.query.filter_by(team=teamid).delete()\n Teams.query.filter_by(id=teamid).delete()\n db.session.commit()\n db.session.close()\n except DatabaseError:\n return '0'\n else:\n return '1'\n\n\n@admin_teams.route('/admin/solves/<teamid>', methods=['GET'])\n@admins_only\ndef admin_solves(teamid=\"all\"):\n if teamid == \"all\":\n solves = Solves.query.all()\n else:\n solves = Solves.query.filter_by(teamid=teamid).all()\n awards = Awards.query.filter_by(teamid=teamid).all()\n db.session.close()\n json_data = {'solves': []}\n for x in solves:\n json_data['solves'].append({\n 'id': x.id,\n 'chal': x.chal.name,\n 'chalid': x.chalid,\n 'team': x.teamid,\n 'value': x.chal.value,\n 'category': x.chal.category,\n 'time': utils.unix_time(x.date)\n })\n for award in awards:\n json_data['solves'].append({\n 'chal': award.name,\n 'chalid': None,\n 'team': award.teamid,\n 'value': award.value,\n 'category': award.category or \"Award\",\n 'time': utils.unix_time(award.date)\n })\n json_data['solves'].sort(key=lambda k: k['time'])\n return jsonify(json_data)\n\n\n@admin_teams.route('/admin/fails/all', defaults={'teamid': 'all'}, methods=['GET'])\n@admin_teams.route('/admin/fails/<int:teamid>', methods=['GET'])\n@admins_only\ndef admin_fails(teamid):\n if teamid == \"all\":\n fails = WrongKeys.query.join(Teams, WrongKeys.teamid == Teams.id).filter(Teams.banned == False).count()\n solves = Solves.query.join(Teams, Solves.teamid == Teams.id).filter(Teams.banned == False).count()\n db.session.close()\n json_data = {'fails': str(fails), 'solves': str(solves)}\n return jsonify(json_data)\n else:\n fails = WrongKeys.query.filter_by(teamid=teamid).count()\n solves = Solves.query.filter_by(teamid=teamid).count()\n db.session.close()\n json_data = {'fails': str(fails), 'solves': str(solves)}\n return jsonify(json_data)\n\n\n@admin_teams.route('/admin/solves/<int:teamid>/<int:chalid>/solve', methods=['POST'])\n@admins_only\ndef create_solve(teamid, chalid):\n solve = Solves(teamid=teamid, chalid=chalid, ip='127.0.0.1', flag='MARKED_AS_SOLVED_BY_ADMIN')\n db.session.add(solve)\n db.session.commit()\n db.session.close()\n return '1'\n\n\n@admin_teams.route('/admin/solves/<int:keyid>/delete', methods=['POST'])\n@admins_only\ndef delete_solve(keyid):\n solve = Solves.query.filter_by(id=keyid).first_or_404()\n db.session.delete(solve)\n db.session.commit()\n db.session.close()\n return '1'\n\n\n@admin_teams.route('/admin/wrong_keys/<int:keyid>/delete', methods=['POST'])\n@admins_only\ndef delete_wrong_key(keyid):\n wrong_key = WrongKeys.query.filter_by(id=keyid).first_or_404()\n db.session.delete(wrong_key)\n db.session.commit()\n db.session.close()\n return '1'\n\n\n@admin_teams.route('/admin/awards/<int:award_id>/delete', methods=['POST'])\n@admins_only\ndef delete_award(award_id):\n award = Awards.query.filter_by(id=award_id).first_or_404()\n db.session.delete(award)\n db.session.commit()\n db.session.close()\n return '1'\n\n\n@admin_teams.route('/admin/teams/<int:teamid>/awards', methods=['GET'])\n@admins_only\ndef admin_awards(teamid):\n awards = Awards.query.filter_by(teamid=teamid).all()\n\n awards_list = []\n for award in awards:\n awards_list.append({\n 'id': award.id,\n 'name': award.name,\n 'description': award.description,\n 'date': award.date,\n 'value': award.value,\n 'category': award.category,\n 'icon': award.icon\n })\n json_data = {'awards': awards_list}\n return jsonify(json_data)\n\n\n@admin_teams.route('/admin/awards/add', methods=['POST'])\n@admins_only\ndef create_award():\n try:\n teamid = request.form['teamid']\n name = request.form.get('name', 'Award')\n value = request.form.get('value', 0)\n award = Awards(teamid, name, value)\n award.description = request.form.get('description')\n award.category = request.form.get('category')\n db.session.add(award)\n db.session.commit()\n db.session.close()\n return '1'\n except Exception as e:\n print(e)\n return '0'\n", "path": "CTFd/admin/teams.py"}], "after_files": [{"content": "from flask import current_app as app, render_template, request, redirect, jsonify, url_for, Blueprint\nfrom CTFd.utils import admins_only, is_admin, cache\nfrom CTFd.models import db, Teams, Solves, Awards, Unlocks, Challenges, WrongKeys, Keys, Tags, Files, Tracking, Pages, Config, DatabaseError\nfrom passlib.hash import bcrypt_sha256\nfrom sqlalchemy.sql import not_\n\nfrom CTFd import utils\n\nimport re\n\nadmin_teams = Blueprint('admin_teams', __name__)\n\n\n@admin_teams.route('/admin/teams', defaults={'page': '1'})\n@admin_teams.route('/admin/teams/<int:page>')\n@admins_only\ndef admin_teams_view(page):\n q = request.args.get('q')\n if q:\n field = request.args.get('field')\n teams = []\n errors = []\n if field == 'id':\n if q.isnumeric():\n teams = Teams.query.filter(Teams.id == q).order_by(Teams.id.asc()).all()\n else:\n teams = []\n errors.append('Your ID search term is not numeric')\n elif field == 'name':\n teams = Teams.query.filter(Teams.name.like('%{}%'.format(q))).order_by(Teams.id.asc()).all()\n elif field == 'email':\n teams = Teams.query.filter(Teams.email.like('%{}%'.format(q))).order_by(Teams.id.asc()).all()\n elif field == 'affiliation':\n teams = Teams.query.filter(Teams.affiliation.like('%{}%'.format(q))).order_by(Teams.id.asc()).all()\n elif field == 'country':\n teams = Teams.query.filter(Teams.country.like('%{}%'.format(q))).order_by(Teams.id.asc()).all()\n return render_template('admin/teams.html', teams=teams, pages=None, curr_page=None, q=q, field=field)\n\n page = abs(int(page))\n results_per_page = 50\n page_start = results_per_page * (page - 1)\n page_end = results_per_page * (page - 1) + results_per_page\n\n teams = Teams.query.order_by(Teams.id.asc()).slice(page_start, page_end).all()\n count = db.session.query(db.func.count(Teams.id)).first()[0]\n pages = int(count / results_per_page) + (count % results_per_page > 0)\n return render_template('admin/teams.html', teams=teams, pages=pages, curr_page=page)\n\n\n@admin_teams.route('/admin/team/new', methods=['POST'])\n@admins_only\ndef admin_create_team():\n name = request.form.get('name', None)\n password = request.form.get('password', None)\n email = request.form.get('email', None)\n website = request.form.get('website', None)\n affiliation = request.form.get('affiliation', None)\n country = request.form.get('country', None)\n\n errors = []\n\n if not name:\n errors.append('The team requires a name')\n elif Teams.query.filter(Teams.name == name).first():\n errors.append('That name is taken')\n\n if not email:\n errors.append('The team requires an email')\n elif Teams.query.filter(Teams.email == email).first():\n errors.append('That email is taken')\n\n if email:\n valid_email = re.match(r\"(^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\\.[a-zA-Z0-9-.]+$)\", email)\n if not valid_email:\n errors.append(\"That email address is invalid\")\n\n if not password:\n errors.append('The team requires a password')\n\n if website and (website.startswith('http://') or website.startswith('https://')) is False:\n errors.append('Websites must start with http:// or https://')\n\n if errors:\n db.session.close()\n return jsonify({'data': errors})\n\n team = Teams(name, email, password)\n team.website = website\n team.affiliation = affiliation\n team.country = country\n\n db.session.add(team)\n db.session.commit()\n db.session.close()\n return jsonify({'data': ['success']})\n\n\n@admin_teams.route('/admin/team/<int:teamid>', methods=['GET', 'POST'])\n@admins_only\ndef admin_team(teamid):\n user = Teams.query.filter_by(id=teamid).first_or_404()\n\n if request.method == 'GET':\n solves = Solves.query.filter_by(teamid=teamid).all()\n solve_ids = [s.chalid for s in solves]\n missing = Challenges.query.filter(not_(Challenges.id.in_(solve_ids))).all()\n last_seen = db.func.max(Tracking.date).label('last_seen')\n addrs = db.session.query(Tracking.ip, last_seen) \\\n .filter_by(team=teamid) \\\n .group_by(Tracking.ip) \\\n .order_by(last_seen.desc()).all()\n wrong_keys = WrongKeys.query.filter_by(teamid=teamid).order_by(WrongKeys.date.asc()).all()\n awards = Awards.query.filter_by(teamid=teamid).order_by(Awards.date.asc()).all()\n score = user.score(admin=True)\n place = user.place(admin=True)\n return render_template('admin/team.html', solves=solves, team=user, addrs=addrs, score=score, missing=missing,\n place=place, wrong_keys=wrong_keys, awards=awards)\n elif request.method == 'POST':\n admin_user = request.form.get('admin', None)\n if admin_user:\n admin_user = True if admin_user == 'true' else False\n user.admin = admin_user\n # Set user.banned to hide admins from scoreboard\n user.banned = admin_user\n db.session.commit()\n db.session.close()\n return jsonify({'data': ['success']})\n\n verified = request.form.get('verified', None)\n if verified:\n verified = True if verified == 'true' else False\n user.verified = verified\n db.session.commit()\n db.session.close()\n return jsonify({'data': ['success']})\n\n name = request.form.get('name', None)\n password = request.form.get('password', None)\n email = request.form.get('email', None)\n website = request.form.get('website', None)\n affiliation = request.form.get('affiliation', None)\n country = request.form.get('country', None)\n\n errors = []\n\n if email:\n valid_email = re.match(r\"(^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\\.[a-zA-Z0-9-.]+$)\", email)\n if not valid_email:\n errors.append(\"That email address is invalid\")\n\n name_used = Teams.query.filter(Teams.name == name).first()\n if name_used and int(name_used.id) != int(teamid):\n errors.append('That name is taken')\n\n email_used = Teams.query.filter(Teams.email == email).first()\n if email_used and int(email_used.id) != int(teamid):\n errors.append('That email is taken')\n\n if website and (website.startswith('http://') or website.startswith('https://')) is False:\n errors.append('Websites must start with http:// or https://')\n\n if errors:\n db.session.close()\n return jsonify({'data': errors})\n else:\n user.name = name\n if email:\n user.email = email\n if password:\n user.password = bcrypt_sha256.encrypt(password)\n user.website = website\n user.affiliation = affiliation\n user.country = country\n db.session.commit()\n db.session.close()\n return jsonify({'data': ['success']})\n\n\n@admin_teams.route('/admin/team/<int:teamid>/mail', methods=['POST'])\n@admins_only\ndef email_user(teamid):\n message = request.form.get('msg', None)\n team = Teams.query.filter(Teams.id == teamid).first()\n if message and team:\n if utils.sendmail(team.email, message):\n return '1'\n return '0'\n\n\n@admin_teams.route('/admin/team/<int:teamid>/ban', methods=['POST'])\n@admins_only\ndef ban(teamid):\n user = Teams.query.filter_by(id=teamid).first_or_404()\n user.banned = True\n db.session.commit()\n db.session.close()\n return redirect(url_for('admin_scoreboard.admin_scoreboard_view'))\n\n\n@admin_teams.route('/admin/team/<int:teamid>/unban', methods=['POST'])\n@admins_only\ndef unban(teamid):\n user = Teams.query.filter_by(id=teamid).first_or_404()\n user.banned = False\n db.session.commit()\n db.session.close()\n return redirect(url_for('admin_scoreboard.admin_scoreboard_view'))\n\n\n@admin_teams.route('/admin/team/<int:teamid>/delete', methods=['POST'])\n@admins_only\ndef delete_team(teamid):\n try:\n Unlocks.query.filter_by(teamid=teamid).delete()\n Awards.query.filter_by(teamid=teamid).delete()\n WrongKeys.query.filter_by(teamid=teamid).delete()\n Solves.query.filter_by(teamid=teamid).delete()\n Tracking.query.filter_by(team=teamid).delete()\n Teams.query.filter_by(id=teamid).delete()\n db.session.commit()\n db.session.close()\n except DatabaseError:\n return '0'\n else:\n return '1'\n\n\n@admin_teams.route('/admin/solves/<teamid>', methods=['GET'])\n@admins_only\ndef admin_solves(teamid=\"all\"):\n if teamid == \"all\":\n solves = Solves.query.all()\n else:\n solves = Solves.query.filter_by(teamid=teamid).all()\n awards = Awards.query.filter_by(teamid=teamid).all()\n db.session.close()\n json_data = {'solves': []}\n for x in solves:\n json_data['solves'].append({\n 'id': x.id,\n 'chal': x.chal.name,\n 'chalid': x.chalid,\n 'team': x.teamid,\n 'value': x.chal.value,\n 'category': x.chal.category,\n 'time': utils.unix_time(x.date)\n })\n for award in awards:\n json_data['solves'].append({\n 'chal': award.name,\n 'chalid': None,\n 'team': award.teamid,\n 'value': award.value,\n 'category': award.category or \"Award\",\n 'time': utils.unix_time(award.date)\n })\n json_data['solves'].sort(key=lambda k: k['time'])\n return jsonify(json_data)\n\n\n@admin_teams.route('/admin/fails/all', defaults={'teamid': 'all'}, methods=['GET'])\n@admin_teams.route('/admin/fails/<int:teamid>', methods=['GET'])\n@admins_only\ndef admin_fails(teamid):\n if teamid == \"all\":\n fails = WrongKeys.query.join(Teams, WrongKeys.teamid == Teams.id).filter(Teams.banned == False).count()\n solves = Solves.query.join(Teams, Solves.teamid == Teams.id).filter(Teams.banned == False).count()\n db.session.close()\n json_data = {'fails': str(fails), 'solves': str(solves)}\n return jsonify(json_data)\n else:\n fails = WrongKeys.query.filter_by(teamid=teamid).count()\n solves = Solves.query.filter_by(teamid=teamid).count()\n db.session.close()\n json_data = {'fails': str(fails), 'solves': str(solves)}\n return jsonify(json_data)\n\n\n@admin_teams.route('/admin/solves/<int:teamid>/<int:chalid>/solve', methods=['POST'])\n@admins_only\ndef create_solve(teamid, chalid):\n solve = Solves(teamid=teamid, chalid=chalid, ip='127.0.0.1', flag='MARKED_AS_SOLVED_BY_ADMIN')\n db.session.add(solve)\n db.session.commit()\n db.session.close()\n return '1'\n\n\n@admin_teams.route('/admin/solves/<int:keyid>/delete', methods=['POST'])\n@admins_only\ndef delete_solve(keyid):\n solve = Solves.query.filter_by(id=keyid).first_or_404()\n db.session.delete(solve)\n db.session.commit()\n db.session.close()\n return '1'\n\n\n@admin_teams.route('/admin/wrong_keys/<int:keyid>/delete', methods=['POST'])\n@admins_only\ndef delete_wrong_key(keyid):\n wrong_key = WrongKeys.query.filter_by(id=keyid).first_or_404()\n db.session.delete(wrong_key)\n db.session.commit()\n db.session.close()\n return '1'\n\n\n@admin_teams.route('/admin/awards/<int:award_id>/delete', methods=['POST'])\n@admins_only\ndef delete_award(award_id):\n award = Awards.query.filter_by(id=award_id).first_or_404()\n db.session.delete(award)\n db.session.commit()\n db.session.close()\n return '1'\n\n\n@admin_teams.route('/admin/teams/<int:teamid>/awards', methods=['GET'])\n@admins_only\ndef admin_awards(teamid):\n awards = Awards.query.filter_by(teamid=teamid).all()\n\n awards_list = []\n for award in awards:\n awards_list.append({\n 'id': award.id,\n 'name': award.name,\n 'description': award.description,\n 'date': award.date,\n 'value': award.value,\n 'category': award.category,\n 'icon': award.icon\n })\n json_data = {'awards': awards_list}\n return jsonify(json_data)\n\n\n@admin_teams.route('/admin/awards/add', methods=['POST'])\n@admins_only\ndef create_award():\n try:\n teamid = request.form['teamid']\n name = request.form.get('name', 'Award')\n value = request.form.get('value', 0)\n award = Awards(teamid, name, value)\n award.description = request.form.get('description')\n award.category = request.form.get('category')\n db.session.add(award)\n db.session.commit()\n db.session.close()\n return '1'\n except Exception as e:\n print(e)\n return '0'\n", "path": "CTFd/admin/teams.py"}]}
| 3,978 | 761 |
gh_patches_debug_1738
|
rasdani/github-patches
|
git_diff
|
googleapis__google-cloud-python-94
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
AttributeError: url on Storage Exception when key not found
When attempting to get a key that does not exist the exception for the `NotFoundError` is trying to reference `request.url` which does not exist.
``` py
Traceback (most recent call last):
[...]
file_key = self.bucket.get_key(path)
File "gcloud/storage/bucket.py", line 83, in get_key
response = self.connection.api_request(method='GET', path=key.path)
File "gcloud/storage/connection.py", line 212, in api_request
raise exceptions.NotFoundError(response, content)
File "gcloud/storage/exceptions.py", line 17, in __init__
self.message = 'GET %s returned a 404.' % (response.url)
File "httplib2/__init__.py", line 1680, in __getattr__
raise AttributeError, name
AttributeError: url
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gcloud/storage/exceptions.py`
Content:
```
1 # TODO: Make these super useful.
2
3 class StorageError(Exception):
4 pass
5
6
7 class ConnectionError(StorageError):
8
9 def __init__(self, response, content):
10 message = str(response) + content
11 super(ConnectionError, self).__init__(message)
12
13
14 class NotFoundError(ConnectionError):
15
16 def __init__(self, response, content):
17 self.message = 'GET %s returned a 404.' % (response.url)
18
19
20 class StorageDataError(StorageError):
21 pass
22
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/gcloud/storage/exceptions.py b/gcloud/storage/exceptions.py
--- a/gcloud/storage/exceptions.py
+++ b/gcloud/storage/exceptions.py
@@ -14,7 +14,7 @@
class NotFoundError(ConnectionError):
def __init__(self, response, content):
- self.message = 'GET %s returned a 404.' % (response.url)
+ self.message = 'Request returned a 404. Headers: %s' % (response)
class StorageDataError(StorageError):
|
{"golden_diff": "diff --git a/gcloud/storage/exceptions.py b/gcloud/storage/exceptions.py\n--- a/gcloud/storage/exceptions.py\n+++ b/gcloud/storage/exceptions.py\n@@ -14,7 +14,7 @@\n class NotFoundError(ConnectionError):\n \n def __init__(self, response, content):\n- self.message = 'GET %s returned a 404.' % (response.url)\n+ self.message = 'Request returned a 404. Headers: %s' % (response)\n \n \n class StorageDataError(StorageError):\n", "issue": "AttributeError: url on Storage Exception when key not found\nWhen attempting to get a key that does not exist the exception for the `NotFoundError` is trying to reference `request.url` which does not exist.\n\n``` py\nTraceback (most recent call last):\n [...]\n file_key = self.bucket.get_key(path)\n File \"gcloud/storage/bucket.py\", line 83, in get_key\n response = self.connection.api_request(method='GET', path=key.path)\n File \"gcloud/storage/connection.py\", line 212, in api_request\n raise exceptions.NotFoundError(response, content)\n File \"gcloud/storage/exceptions.py\", line 17, in __init__\n self.message = 'GET %s returned a 404.' % (response.url)\n File \"httplib2/__init__.py\", line 1680, in __getattr__\n raise AttributeError, name\nAttributeError: url\n```\n\n", "before_files": [{"content": "# TODO: Make these super useful.\n\nclass StorageError(Exception):\n pass\n\n\nclass ConnectionError(StorageError):\n\n def __init__(self, response, content):\n message = str(response) + content\n super(ConnectionError, self).__init__(message)\n\n\nclass NotFoundError(ConnectionError):\n\n def __init__(self, response, content):\n self.message = 'GET %s returned a 404.' % (response.url)\n\n\nclass StorageDataError(StorageError):\n pass\n", "path": "gcloud/storage/exceptions.py"}], "after_files": [{"content": "# TODO: Make these super useful.\n\nclass StorageError(Exception):\n pass\n\n\nclass ConnectionError(StorageError):\n\n def __init__(self, response, content):\n message = str(response) + content\n super(ConnectionError, self).__init__(message)\n\n\nclass NotFoundError(ConnectionError):\n\n def __init__(self, response, content):\n self.message = 'Request returned a 404. Headers: %s' % (response)\n\n\nclass StorageDataError(StorageError):\n pass\n", "path": "gcloud/storage/exceptions.py"}]}
| 608 | 119 |
gh_patches_debug_2712
|
rasdani/github-patches
|
git_diff
|
ManimCommunity__manim-1335
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add import statements to examples in documentation
See title.
The examples in the documentation should also include the `from manim import *` at the very least, and actually we could provide best-practice examples where we dont do a *-import, but rather import classes/functions separately.
This can of course be an iterative process: start with adding `from manim import *` first, and become more specific later.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/source/manim_directive.py`
Content:
```
1 r"""
2 A directive for including Manim videos in a Sphinx document
3 ===========================================================
4
5 When rendering the HTML documentation, the ``.. manim::`` directive
6 implemented here allows to include rendered videos.
7
8 Its basic usage that allows processing **inline content**
9 looks as follows::
10
11 .. manim:: MyScene
12
13 class MyScene(Scene):
14 def construct(self):
15 ...
16
17 It is required to pass the name of the class representing the
18 scene to be rendered to the directive.
19
20 As a second application, the directive can also be used to
21 render scenes that are defined within doctests, for example::
22
23 .. manim:: DirectiveDoctestExample
24 :ref_classes: Dot
25
26 >>> dot = Dot(color=RED)
27 >>> dot.color
28 <Color #fc6255>
29 >>> class DirectiveDoctestExample(Scene):
30 ... def construct(self):
31 ... self.play(Create(dot))
32
33
34 Options
35 -------
36
37 Options can be passed as follows::
38
39 .. manim:: <Class name>
40 :<option name>: <value>
41
42 The following configuration options are supported by the
43 directive:
44
45 hide_source
46 If this flag is present without argument,
47 the source code is not displayed above the rendered video.
48
49 quality : {'low', 'medium', 'high', 'fourk'}
50 Controls render quality of the video, in analogy to
51 the corresponding command line flags.
52
53 save_as_gif
54 If this flag is present without argument,
55 the scene is rendered as a gif.
56
57 save_last_frame
58 If this flag is present without argument,
59 an image representing the last frame of the scene will
60 be rendered and displayed, instead of a video.
61
62 ref_classes
63 A list of classes, separated by spaces, that is
64 rendered in a reference block after the source code.
65
66 ref_functions
67 A list of functions, separated by spaces,
68 that is rendered in a reference block after the source code.
69
70 ref_methods
71 A list of methods, separated by spaces,
72 that is rendered in a reference block after the source code.
73
74 """
75 import os
76 import shutil
77 from os.path import relpath
78 from pathlib import Path
79 from typing import List
80
81 import jinja2
82 from docutils import nodes
83 from docutils.parsers.rst import Directive, directives
84 from docutils.statemachine import StringList
85
86 from manim import QUALITIES
87
88 classnamedict = {}
89
90
91 class skip_manim_node(nodes.Admonition, nodes.Element):
92 pass
93
94
95 def visit(self, node, name=""):
96 self.visit_admonition(node, name)
97
98
99 def depart(self, node):
100 self.depart_admonition(node)
101
102
103 def process_name_list(option_input: str, reference_type: str) -> List[str]:
104 r"""Reformats a string of space separated class names
105 as a list of strings containing valid Sphinx references.
106
107 Tests
108 -----
109
110 ::
111
112 >>> process_name_list("Tex TexTemplate", "class")
113 [":class:`~.Tex`", ":class:`~.TexTemplate`"]
114 >>> process_name_list("Scene.play Mobject.rotate", "func")
115 [":func:`~.Scene.play`", ":func:`~.Mobject.rotate`"]
116 """
117 return [f":{reference_type}:`~.{name}`" for name in option_input.split()]
118
119
120 class ManimDirective(Directive):
121 r"""The manim directive, rendering videos while building
122 the documentation.
123
124 See the module docstring for documentation.
125 """
126 has_content = True
127 required_arguments = 1
128 optional_arguments = 0
129 option_spec = {
130 "hide_source": bool,
131 "quality": lambda arg: directives.choice(
132 arg, ("low", "medium", "high", "fourk")
133 ),
134 "save_as_gif": bool,
135 "save_last_frame": bool,
136 "ref_modules": lambda arg: process_name_list(arg, "mod"),
137 "ref_classes": lambda arg: process_name_list(arg, "class"),
138 "ref_functions": lambda arg: process_name_list(arg, "func"),
139 "ref_methods": lambda arg: process_name_list(arg, "meth"),
140 }
141 final_argument_whitespace = True
142
143 def run(self):
144 if "skip-manim" in self.state.document.settings.env.app.builder.tags.tags:
145 node = skip_manim_node()
146 self.state.nested_parse(
147 StringList(self.content[0]), self.content_offset, node
148 )
149 return [node]
150
151 from manim import config
152
153 global classnamedict
154
155 clsname = self.arguments[0]
156 if clsname not in classnamedict:
157 classnamedict[clsname] = 1
158 else:
159 classnamedict[clsname] += 1
160
161 hide_source = "hide_source" in self.options
162 save_as_gif = "save_as_gif" in self.options
163 save_last_frame = "save_last_frame" in self.options
164 assert not (save_as_gif and save_last_frame)
165
166 ref_content = (
167 self.options.get("ref_modules", [])
168 + self.options.get("ref_classes", [])
169 + self.options.get("ref_functions", [])
170 + self.options.get("ref_methods", [])
171 )
172 if ref_content:
173 ref_block = "References: " + " ".join(ref_content)
174
175 else:
176 ref_block = ""
177
178 if "quality" in self.options:
179 quality = f'{self.options["quality"]}_quality'
180 else:
181 quality = "example_quality"
182 frame_rate = QUALITIES[quality]["frame_rate"]
183 pixel_height = QUALITIES[quality]["pixel_height"]
184 pixel_width = QUALITIES[quality]["pixel_width"]
185 qualitydir = f"{pixel_height}p{frame_rate}"
186
187 state_machine = self.state_machine
188 document = state_machine.document
189
190 source_file_name = document.attributes["source"]
191 source_rel_name = relpath(source_file_name, setup.confdir)
192 source_rel_dir = os.path.dirname(source_rel_name)
193 while source_rel_dir.startswith(os.path.sep):
194 source_rel_dir = source_rel_dir[1:]
195
196 dest_dir = os.path.abspath(
197 os.path.join(setup.app.builder.outdir, source_rel_dir)
198 )
199 if not os.path.exists(dest_dir):
200 os.makedirs(dest_dir)
201
202 source_block = [
203 ".. code-block:: python",
204 "",
205 *[" " + line for line in self.content],
206 ]
207 source_block = "\n".join(source_block)
208
209 config.media_dir = Path(setup.confdir) / "media"
210 config.images_dir = "{media_dir}/images"
211 config.video_dir = "{media_dir}/videos/{quality}"
212 output_file = f"{clsname}-{classnamedict[clsname]}"
213 config.assets_dir = Path("_static")
214
215 config_code = [
216 f'config["frame_rate"] = {frame_rate}',
217 f'config["pixel_height"] = {pixel_height}',
218 f'config["pixel_width"] = {pixel_width}',
219 f'config["save_last_frame"] = {save_last_frame}',
220 f'config["save_as_gif"] = {save_as_gif}',
221 f'config["write_to_movie"] = {not save_last_frame}',
222 f'config["output_file"] = r"{output_file}"',
223 ]
224
225 user_code = self.content
226 if user_code[0].startswith(">>> "): # check whether block comes from doctest
227 user_code = [
228 line[4:] for line in user_code if line.startswith((">>> ", "... "))
229 ]
230
231 code = [
232 "from manim import *",
233 *config_code,
234 *user_code,
235 f"{clsname}().render()",
236 ]
237 exec("\n".join(code), globals())
238
239 # copy video file to output directory
240 if not (save_as_gif or save_last_frame):
241 filename = f"{output_file}.mp4"
242 filesrc = config.get_dir("video_dir") / filename
243 destfile = os.path.join(dest_dir, filename)
244 shutil.copyfile(filesrc, destfile)
245 elif save_as_gif:
246 filename = f"{output_file}.gif"
247 filesrc = config.get_dir("video_dir") / filename
248 elif save_last_frame:
249 filename = f"{output_file}.png"
250 filesrc = config.get_dir("images_dir") / filename
251 else:
252 raise ValueError("Invalid combination of render flags received.")
253
254 rendered_template = jinja2.Template(TEMPLATE).render(
255 clsname=clsname,
256 clsname_lowercase=clsname.lower(),
257 hide_source=hide_source,
258 filesrc_rel=os.path.relpath(filesrc, setup.confdir),
259 output_file=output_file,
260 save_last_frame=save_last_frame,
261 save_as_gif=save_as_gif,
262 source_block=source_block,
263 ref_block=ref_block,
264 )
265 state_machine.insert_input(
266 rendered_template.split("\n"), source=document.attributes["source"]
267 )
268
269 return []
270
271
272 def setup(app):
273 import manim
274
275 app.add_node(skip_manim_node, html=(visit, depart))
276
277 setup.app = app
278 setup.config = app.config
279 setup.confdir = app.confdir
280
281 app.add_directive("manim", ManimDirective)
282
283 metadata = {"parallel_read_safe": False, "parallel_write_safe": True}
284 return metadata
285
286
287 TEMPLATE = r"""
288 {% if not hide_source %}
289 .. raw:: html
290
291 <div id="{{ clsname_lowercase }}" class="admonition admonition-manim-example">
292 <p class="admonition-title">Example: {{ clsname }} <a class="headerlink" href="#{{ clsname_lowercase }}">¶</a></p>
293
294 {% endif %}
295
296 {% if not (save_as_gif or save_last_frame) %}
297 .. raw:: html
298
299 <video class="manim-video" controls loop autoplay src="./{{ output_file }}.mp4"></video>
300
301 {% elif save_as_gif %}
302 .. image:: /{{ filesrc_rel }}
303 :align: center
304
305 {% elif save_last_frame %}
306 .. image:: /{{ filesrc_rel }}
307 :align: center
308
309 {% endif %}
310 {% if not hide_source %}
311 {{ source_block }}
312
313 {{ ref_block }}
314
315 {% endif %}
316
317 .. raw:: html
318
319 </div>
320 """
321
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/docs/source/manim_directive.py b/docs/source/manim_directive.py
--- a/docs/source/manim_directive.py
+++ b/docs/source/manim_directive.py
@@ -202,6 +202,7 @@
source_block = [
".. code-block:: python",
"",
+ " from manim import *\n",
*[" " + line for line in self.content],
]
source_block = "\n".join(source_block)
|
{"golden_diff": "diff --git a/docs/source/manim_directive.py b/docs/source/manim_directive.py\n--- a/docs/source/manim_directive.py\n+++ b/docs/source/manim_directive.py\n@@ -202,6 +202,7 @@\n source_block = [\n \".. code-block:: python\",\n \"\",\n+ \" from manim import *\\n\",\n *[\" \" + line for line in self.content],\n ]\n source_block = \"\\n\".join(source_block)\n", "issue": "Add import statements to examples in documentation\nSee title.\r\n\r\nThe examples in the documentation should also include the `from manim import *` at the very least, and actually we could provide best-practice examples where we dont do a *-import, but rather import classes/functions separately.\r\n\r\nThis can of course be an iterative process: start with adding `from manim import *` first, and become more specific later.\n", "before_files": [{"content": "r\"\"\"\nA directive for including Manim videos in a Sphinx document\n===========================================================\n\nWhen rendering the HTML documentation, the ``.. manim::`` directive\nimplemented here allows to include rendered videos.\n\nIts basic usage that allows processing **inline content**\nlooks as follows::\n\n .. manim:: MyScene\n\n class MyScene(Scene):\n def construct(self):\n ...\n\nIt is required to pass the name of the class representing the\nscene to be rendered to the directive.\n\nAs a second application, the directive can also be used to\nrender scenes that are defined within doctests, for example::\n\n .. manim:: DirectiveDoctestExample\n :ref_classes: Dot\n\n >>> dot = Dot(color=RED)\n >>> dot.color\n <Color #fc6255>\n >>> class DirectiveDoctestExample(Scene):\n ... def construct(self):\n ... self.play(Create(dot))\n\n\nOptions\n-------\n\nOptions can be passed as follows::\n\n .. manim:: <Class name>\n :<option name>: <value>\n\nThe following configuration options are supported by the\ndirective:\n\n hide_source\n If this flag is present without argument,\n the source code is not displayed above the rendered video.\n\n quality : {'low', 'medium', 'high', 'fourk'}\n Controls render quality of the video, in analogy to\n the corresponding command line flags.\n\n save_as_gif\n If this flag is present without argument,\n the scene is rendered as a gif.\n\n save_last_frame\n If this flag is present without argument,\n an image representing the last frame of the scene will\n be rendered and displayed, instead of a video.\n\n ref_classes\n A list of classes, separated by spaces, that is\n rendered in a reference block after the source code.\n\n ref_functions\n A list of functions, separated by spaces,\n that is rendered in a reference block after the source code.\n\n ref_methods\n A list of methods, separated by spaces,\n that is rendered in a reference block after the source code.\n\n\"\"\"\nimport os\nimport shutil\nfrom os.path import relpath\nfrom pathlib import Path\nfrom typing import List\n\nimport jinja2\nfrom docutils import nodes\nfrom docutils.parsers.rst import Directive, directives\nfrom docutils.statemachine import StringList\n\nfrom manim import QUALITIES\n\nclassnamedict = {}\n\n\nclass skip_manim_node(nodes.Admonition, nodes.Element):\n pass\n\n\ndef visit(self, node, name=\"\"):\n self.visit_admonition(node, name)\n\n\ndef depart(self, node):\n self.depart_admonition(node)\n\n\ndef process_name_list(option_input: str, reference_type: str) -> List[str]:\n r\"\"\"Reformats a string of space separated class names\n as a list of strings containing valid Sphinx references.\n\n Tests\n -----\n\n ::\n\n >>> process_name_list(\"Tex TexTemplate\", \"class\")\n [\":class:`~.Tex`\", \":class:`~.TexTemplate`\"]\n >>> process_name_list(\"Scene.play Mobject.rotate\", \"func\")\n [\":func:`~.Scene.play`\", \":func:`~.Mobject.rotate`\"]\n \"\"\"\n return [f\":{reference_type}:`~.{name}`\" for name in option_input.split()]\n\n\nclass ManimDirective(Directive):\n r\"\"\"The manim directive, rendering videos while building\n the documentation.\n\n See the module docstring for documentation.\n \"\"\"\n has_content = True\n required_arguments = 1\n optional_arguments = 0\n option_spec = {\n \"hide_source\": bool,\n \"quality\": lambda arg: directives.choice(\n arg, (\"low\", \"medium\", \"high\", \"fourk\")\n ),\n \"save_as_gif\": bool,\n \"save_last_frame\": bool,\n \"ref_modules\": lambda arg: process_name_list(arg, \"mod\"),\n \"ref_classes\": lambda arg: process_name_list(arg, \"class\"),\n \"ref_functions\": lambda arg: process_name_list(arg, \"func\"),\n \"ref_methods\": lambda arg: process_name_list(arg, \"meth\"),\n }\n final_argument_whitespace = True\n\n def run(self):\n if \"skip-manim\" in self.state.document.settings.env.app.builder.tags.tags:\n node = skip_manim_node()\n self.state.nested_parse(\n StringList(self.content[0]), self.content_offset, node\n )\n return [node]\n\n from manim import config\n\n global classnamedict\n\n clsname = self.arguments[0]\n if clsname not in classnamedict:\n classnamedict[clsname] = 1\n else:\n classnamedict[clsname] += 1\n\n hide_source = \"hide_source\" in self.options\n save_as_gif = \"save_as_gif\" in self.options\n save_last_frame = \"save_last_frame\" in self.options\n assert not (save_as_gif and save_last_frame)\n\n ref_content = (\n self.options.get(\"ref_modules\", [])\n + self.options.get(\"ref_classes\", [])\n + self.options.get(\"ref_functions\", [])\n + self.options.get(\"ref_methods\", [])\n )\n if ref_content:\n ref_block = \"References: \" + \" \".join(ref_content)\n\n else:\n ref_block = \"\"\n\n if \"quality\" in self.options:\n quality = f'{self.options[\"quality\"]}_quality'\n else:\n quality = \"example_quality\"\n frame_rate = QUALITIES[quality][\"frame_rate\"]\n pixel_height = QUALITIES[quality][\"pixel_height\"]\n pixel_width = QUALITIES[quality][\"pixel_width\"]\n qualitydir = f\"{pixel_height}p{frame_rate}\"\n\n state_machine = self.state_machine\n document = state_machine.document\n\n source_file_name = document.attributes[\"source\"]\n source_rel_name = relpath(source_file_name, setup.confdir)\n source_rel_dir = os.path.dirname(source_rel_name)\n while source_rel_dir.startswith(os.path.sep):\n source_rel_dir = source_rel_dir[1:]\n\n dest_dir = os.path.abspath(\n os.path.join(setup.app.builder.outdir, source_rel_dir)\n )\n if not os.path.exists(dest_dir):\n os.makedirs(dest_dir)\n\n source_block = [\n \".. code-block:: python\",\n \"\",\n *[\" \" + line for line in self.content],\n ]\n source_block = \"\\n\".join(source_block)\n\n config.media_dir = Path(setup.confdir) / \"media\"\n config.images_dir = \"{media_dir}/images\"\n config.video_dir = \"{media_dir}/videos/{quality}\"\n output_file = f\"{clsname}-{classnamedict[clsname]}\"\n config.assets_dir = Path(\"_static\")\n\n config_code = [\n f'config[\"frame_rate\"] = {frame_rate}',\n f'config[\"pixel_height\"] = {pixel_height}',\n f'config[\"pixel_width\"] = {pixel_width}',\n f'config[\"save_last_frame\"] = {save_last_frame}',\n f'config[\"save_as_gif\"] = {save_as_gif}',\n f'config[\"write_to_movie\"] = {not save_last_frame}',\n f'config[\"output_file\"] = r\"{output_file}\"',\n ]\n\n user_code = self.content\n if user_code[0].startswith(\">>> \"): # check whether block comes from doctest\n user_code = [\n line[4:] for line in user_code if line.startswith((\">>> \", \"... \"))\n ]\n\n code = [\n \"from manim import *\",\n *config_code,\n *user_code,\n f\"{clsname}().render()\",\n ]\n exec(\"\\n\".join(code), globals())\n\n # copy video file to output directory\n if not (save_as_gif or save_last_frame):\n filename = f\"{output_file}.mp4\"\n filesrc = config.get_dir(\"video_dir\") / filename\n destfile = os.path.join(dest_dir, filename)\n shutil.copyfile(filesrc, destfile)\n elif save_as_gif:\n filename = f\"{output_file}.gif\"\n filesrc = config.get_dir(\"video_dir\") / filename\n elif save_last_frame:\n filename = f\"{output_file}.png\"\n filesrc = config.get_dir(\"images_dir\") / filename\n else:\n raise ValueError(\"Invalid combination of render flags received.\")\n\n rendered_template = jinja2.Template(TEMPLATE).render(\n clsname=clsname,\n clsname_lowercase=clsname.lower(),\n hide_source=hide_source,\n filesrc_rel=os.path.relpath(filesrc, setup.confdir),\n output_file=output_file,\n save_last_frame=save_last_frame,\n save_as_gif=save_as_gif,\n source_block=source_block,\n ref_block=ref_block,\n )\n state_machine.insert_input(\n rendered_template.split(\"\\n\"), source=document.attributes[\"source\"]\n )\n\n return []\n\n\ndef setup(app):\n import manim\n\n app.add_node(skip_manim_node, html=(visit, depart))\n\n setup.app = app\n setup.config = app.config\n setup.confdir = app.confdir\n\n app.add_directive(\"manim\", ManimDirective)\n\n metadata = {\"parallel_read_safe\": False, \"parallel_write_safe\": True}\n return metadata\n\n\nTEMPLATE = r\"\"\"\n{% if not hide_source %}\n.. raw:: html\n\n <div id=\"{{ clsname_lowercase }}\" class=\"admonition admonition-manim-example\">\n <p class=\"admonition-title\">Example: {{ clsname }} <a class=\"headerlink\" href=\"#{{ clsname_lowercase }}\">\u00b6</a></p>\n\n{% endif %}\n\n{% if not (save_as_gif or save_last_frame) %}\n.. raw:: html\n\n <video class=\"manim-video\" controls loop autoplay src=\"./{{ output_file }}.mp4\"></video>\n\n{% elif save_as_gif %}\n.. image:: /{{ filesrc_rel }}\n :align: center\n\n{% elif save_last_frame %}\n.. image:: /{{ filesrc_rel }}\n :align: center\n\n{% endif %}\n{% if not hide_source %}\n{{ source_block }}\n\n{{ ref_block }}\n\n{% endif %}\n\n.. raw:: html\n\n </div>\n\"\"\"\n", "path": "docs/source/manim_directive.py"}], "after_files": [{"content": "r\"\"\"\nA directive for including Manim videos in a Sphinx document\n===========================================================\n\nWhen rendering the HTML documentation, the ``.. manim::`` directive\nimplemented here allows to include rendered videos.\n\nIts basic usage that allows processing **inline content**\nlooks as follows::\n\n .. manim:: MyScene\n\n class MyScene(Scene):\n def construct(self):\n ...\n\nIt is required to pass the name of the class representing the\nscene to be rendered to the directive.\n\nAs a second application, the directive can also be used to\nrender scenes that are defined within doctests, for example::\n\n .. manim:: DirectiveDoctestExample\n :ref_classes: Dot\n\n >>> dot = Dot(color=RED)\n >>> dot.color\n <Color #fc6255>\n >>> class DirectiveDoctestExample(Scene):\n ... def construct(self):\n ... self.play(Create(dot))\n\n\nOptions\n-------\n\nOptions can be passed as follows::\n\n .. manim:: <Class name>\n :<option name>: <value>\n\nThe following configuration options are supported by the\ndirective:\n\n hide_source\n If this flag is present without argument,\n the source code is not displayed above the rendered video.\n\n quality : {'low', 'medium', 'high', 'fourk'}\n Controls render quality of the video, in analogy to\n the corresponding command line flags.\n\n save_as_gif\n If this flag is present without argument,\n the scene is rendered as a gif.\n\n save_last_frame\n If this flag is present without argument,\n an image representing the last frame of the scene will\n be rendered and displayed, instead of a video.\n\n ref_classes\n A list of classes, separated by spaces, that is\n rendered in a reference block after the source code.\n\n ref_functions\n A list of functions, separated by spaces,\n that is rendered in a reference block after the source code.\n\n ref_methods\n A list of methods, separated by spaces,\n that is rendered in a reference block after the source code.\n\n\"\"\"\nimport os\nimport shutil\nfrom os.path import relpath\nfrom pathlib import Path\nfrom typing import List\n\nimport jinja2\nfrom docutils import nodes\nfrom docutils.parsers.rst import Directive, directives\nfrom docutils.statemachine import StringList\n\nfrom manim import QUALITIES\n\nclassnamedict = {}\n\n\nclass skip_manim_node(nodes.Admonition, nodes.Element):\n pass\n\n\ndef visit(self, node, name=\"\"):\n self.visit_admonition(node, name)\n\n\ndef depart(self, node):\n self.depart_admonition(node)\n\n\ndef process_name_list(option_input: str, reference_type: str) -> List[str]:\n r\"\"\"Reformats a string of space separated class names\n as a list of strings containing valid Sphinx references.\n\n Tests\n -----\n\n ::\n\n >>> process_name_list(\"Tex TexTemplate\", \"class\")\n [\":class:`~.Tex`\", \":class:`~.TexTemplate`\"]\n >>> process_name_list(\"Scene.play Mobject.rotate\", \"func\")\n [\":func:`~.Scene.play`\", \":func:`~.Mobject.rotate`\"]\n \"\"\"\n return [f\":{reference_type}:`~.{name}`\" for name in option_input.split()]\n\n\nclass ManimDirective(Directive):\n r\"\"\"The manim directive, rendering videos while building\n the documentation.\n\n See the module docstring for documentation.\n \"\"\"\n has_content = True\n required_arguments = 1\n optional_arguments = 0\n option_spec = {\n \"hide_source\": bool,\n \"quality\": lambda arg: directives.choice(\n arg, (\"low\", \"medium\", \"high\", \"fourk\")\n ),\n \"save_as_gif\": bool,\n \"save_last_frame\": bool,\n \"ref_modules\": lambda arg: process_name_list(arg, \"mod\"),\n \"ref_classes\": lambda arg: process_name_list(arg, \"class\"),\n \"ref_functions\": lambda arg: process_name_list(arg, \"func\"),\n \"ref_methods\": lambda arg: process_name_list(arg, \"meth\"),\n }\n final_argument_whitespace = True\n\n def run(self):\n if \"skip-manim\" in self.state.document.settings.env.app.builder.tags.tags:\n node = skip_manim_node()\n self.state.nested_parse(\n StringList(self.content[0]), self.content_offset, node\n )\n return [node]\n\n from manim import config\n\n global classnamedict\n\n clsname = self.arguments[0]\n if clsname not in classnamedict:\n classnamedict[clsname] = 1\n else:\n classnamedict[clsname] += 1\n\n hide_source = \"hide_source\" in self.options\n save_as_gif = \"save_as_gif\" in self.options\n save_last_frame = \"save_last_frame\" in self.options\n assert not (save_as_gif and save_last_frame)\n\n ref_content = (\n self.options.get(\"ref_modules\", [])\n + self.options.get(\"ref_classes\", [])\n + self.options.get(\"ref_functions\", [])\n + self.options.get(\"ref_methods\", [])\n )\n if ref_content:\n ref_block = \"References: \" + \" \".join(ref_content)\n\n else:\n ref_block = \"\"\n\n if \"quality\" in self.options:\n quality = f'{self.options[\"quality\"]}_quality'\n else:\n quality = \"example_quality\"\n frame_rate = QUALITIES[quality][\"frame_rate\"]\n pixel_height = QUALITIES[quality][\"pixel_height\"]\n pixel_width = QUALITIES[quality][\"pixel_width\"]\n qualitydir = f\"{pixel_height}p{frame_rate}\"\n\n state_machine = self.state_machine\n document = state_machine.document\n\n source_file_name = document.attributes[\"source\"]\n source_rel_name = relpath(source_file_name, setup.confdir)\n source_rel_dir = os.path.dirname(source_rel_name)\n while source_rel_dir.startswith(os.path.sep):\n source_rel_dir = source_rel_dir[1:]\n\n dest_dir = os.path.abspath(\n os.path.join(setup.app.builder.outdir, source_rel_dir)\n )\n if not os.path.exists(dest_dir):\n os.makedirs(dest_dir)\n\n source_block = [\n \".. code-block:: python\",\n \"\",\n \" from manim import *\\n\",\n *[\" \" + line for line in self.content],\n ]\n source_block = \"\\n\".join(source_block)\n\n config.media_dir = Path(setup.confdir) / \"media\"\n config.images_dir = \"{media_dir}/images\"\n config.video_dir = \"{media_dir}/videos/{quality}\"\n output_file = f\"{clsname}-{classnamedict[clsname]}\"\n config.assets_dir = Path(\"_static\")\n\n config_code = [\n f'config[\"frame_rate\"] = {frame_rate}',\n f'config[\"pixel_height\"] = {pixel_height}',\n f'config[\"pixel_width\"] = {pixel_width}',\n f'config[\"save_last_frame\"] = {save_last_frame}',\n f'config[\"save_as_gif\"] = {save_as_gif}',\n f'config[\"write_to_movie\"] = {not save_last_frame}',\n f'config[\"output_file\"] = r\"{output_file}\"',\n ]\n\n user_code = self.content\n if user_code[0].startswith(\">>> \"): # check whether block comes from doctest\n user_code = [\n line[4:] for line in user_code if line.startswith((\">>> \", \"... \"))\n ]\n\n code = [\n \"from manim import *\",\n *config_code,\n *user_code,\n f\"{clsname}().render()\",\n ]\n exec(\"\\n\".join(code), globals())\n\n # copy video file to output directory\n if not (save_as_gif or save_last_frame):\n filename = f\"{output_file}.mp4\"\n filesrc = config.get_dir(\"video_dir\") / filename\n destfile = os.path.join(dest_dir, filename)\n shutil.copyfile(filesrc, destfile)\n elif save_as_gif:\n filename = f\"{output_file}.gif\"\n filesrc = config.get_dir(\"video_dir\") / filename\n elif save_last_frame:\n filename = f\"{output_file}.png\"\n filesrc = config.get_dir(\"images_dir\") / filename\n else:\n raise ValueError(\"Invalid combination of render flags received.\")\n\n rendered_template = jinja2.Template(TEMPLATE).render(\n clsname=clsname,\n clsname_lowercase=clsname.lower(),\n hide_source=hide_source,\n filesrc_rel=os.path.relpath(filesrc, setup.confdir),\n output_file=output_file,\n save_last_frame=save_last_frame,\n save_as_gif=save_as_gif,\n source_block=source_block,\n ref_block=ref_block,\n )\n state_machine.insert_input(\n rendered_template.split(\"\\n\"), source=document.attributes[\"source\"]\n )\n\n return []\n\n\ndef setup(app):\n import manim\n\n app.add_node(skip_manim_node, html=(visit, depart))\n\n setup.app = app\n setup.config = app.config\n setup.confdir = app.confdir\n\n app.add_directive(\"manim\", ManimDirective)\n\n metadata = {\"parallel_read_safe\": False, \"parallel_write_safe\": True}\n return metadata\n\n\nTEMPLATE = r\"\"\"\n{% if not hide_source %}\n.. raw:: html\n\n <div id=\"{{ clsname_lowercase }}\" class=\"admonition admonition-manim-example\">\n <p class=\"admonition-title\">Example: {{ clsname }} <a class=\"headerlink\" href=\"#{{ clsname_lowercase }}\">\u00b6</a></p>\n\n{% endif %}\n\n{% if not (save_as_gif or save_last_frame) %}\n.. raw:: html\n\n <video class=\"manim-video\" controls loop autoplay src=\"./{{ output_file }}.mp4\"></video>\n\n{% elif save_as_gif %}\n.. image:: /{{ filesrc_rel }}\n :align: center\n\n{% elif save_last_frame %}\n.. image:: /{{ filesrc_rel }}\n :align: center\n\n{% endif %}\n{% if not hide_source %}\n{{ source_block }}\n\n{{ ref_block }}\n\n{% endif %}\n\n.. raw:: html\n\n </div>\n\"\"\"\n", "path": "docs/source/manim_directive.py"}]}
| 3,425 | 105 |
gh_patches_debug_39593
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-4735
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
New submission cleanup could delete valid files of replies
## Description
In `securedrop/management/submissions.py`, the `find_disconnected_fs_submissions` returns any file found in the store that is not associated with a `Submission` record in the database. It should only return files that have neither a `Submission` nor `Reply` record, to avoid warning admins about and possibly deleting replies.
## Steps to Reproduce
- Run `make dev`
- In another shell:
- Run `docker container ls` to get the dev container's ID
- Run `docker exec -it "container-id" bash`
- Run `./manage.py list-disconnected-fs-submissions`
## Expected Behavior
With a consistent database and filesystem, no disconnects should be reported.
## Actual Behavior
The files of all replies in the database are reported as candidates for cleanup.
## Comments
The function simply needs to build a list of reply files as it does for submissions, and check the files under the store against the complete set of valid files.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `securedrop/management/submissions.py`
Content:
```
1 from __future__ import print_function
2
3 import datetime
4 import os
5 import sys
6 import time
7
8 from six.moves import input
9
10 from db import db
11 from rm import secure_delete
12 from models import Source, Submission
13 from management import app_context
14
15
16 def find_disconnected_db_submissions(path):
17 submissions = db.session.query(Submission).order_by(Submission.id, Submission.filename).all()
18
19 files_in_fs = {}
20 for directory, subdirs, files in os.walk(path):
21 for f in files:
22 files_in_fs[f] = os.path.abspath(os.path.join(directory, f))
23
24 disconnected_submissions = [s for s in submissions if s.filename not in files_in_fs]
25
26 return disconnected_submissions
27
28
29 def check_for_disconnected_db_submissions(args):
30 """
31 Check for Submission records whose files are missing.
32 """
33 with app_context():
34 disconnected = find_disconnected_db_submissions(args.store_dir)
35 if disconnected:
36 print(
37 "There are submissions in the database with no corresponding files. "
38 'Run "manage.py list-disconnected-db-submissions" for details.'
39 )
40 else:
41 print("No problems were found. All submissions' files are present.")
42
43
44 def list_disconnected_db_submissions(args):
45 """
46 List the IDs of Submission records whose files are missing.
47 """
48 with app_context():
49 disconnected_submissions = find_disconnected_db_submissions(args.store_dir)
50 if disconnected_submissions:
51 print(
52 'Run "manage.py delete-disconnected-db-submissions" to delete these records.',
53 file=sys.stderr
54 )
55 for s in disconnected_submissions:
56 print(s.id)
57
58
59 def delete_disconnected_db_submissions(args):
60 """
61 Delete Submission records whose files are missing.
62 """
63 with app_context():
64 disconnected_submissions = find_disconnected_db_submissions(args.store_dir)
65 ids = [s.id for s in disconnected_submissions]
66
67 remove = args.force
68 if not args.force:
69 remove = input("Enter 'y' to delete all submissions missing files: ") == "y"
70 if remove:
71 print("Removing submission IDs {}...".format(ids))
72 db.session.query(Submission).filter(Submission.id.in_(ids)).delete(
73 synchronize_session="fetch"
74 )
75 db.session.commit()
76 else:
77 print("Not removing disconnected submissions in database.")
78
79
80 def find_disconnected_fs_submissions(path):
81 submissions = Submission.query.order_by(Submission.id, Submission.filename).all()
82 files_in_db = {s.filename: s for s in submissions}
83
84 files_in_fs = {}
85 for directory, subdirs, files in os.walk(path):
86 for f in files:
87 files_in_fs[f] = os.path.abspath(os.path.join(directory, f))
88
89 disconnected_files = []
90 for f, p in files_in_fs.items():
91 if f not in files_in_db:
92 filesize = os.stat(p).st_size
93 disconnected_files.append((p, filesize))
94
95 disconnected_files = [t[0] for t in sorted(disconnected_files, key=lambda t: t[1])]
96
97 return disconnected_files
98
99
100 def check_for_disconnected_fs_submissions(args):
101 """
102 Check for files without a corresponding Submission record in the database.
103 """
104 with app_context():
105 disconnected = find_disconnected_fs_submissions(args.store_dir)
106 if disconnected:
107 print(
108 "There are files in the submission area with no corresponding records in the "
109 'database. Run "manage.py list-disconnected-fs-submissions" for details.'
110 )
111 else:
112 print("No unexpected files were found in the store.")
113
114
115 def list_disconnected_fs_submissions(args):
116 """
117 List files without a corresponding Submission record in the database.
118 """
119 with app_context():
120 disconnected_files = find_disconnected_fs_submissions(args.store_dir)
121 if disconnected_files:
122 print(
123 'Run "manage.py delete-disconnected-fs-submissions" to delete these files.',
124 file=sys.stderr
125 )
126 for f in disconnected_files:
127 print(f)
128
129
130 def delete_disconnected_fs_submissions(args):
131 """
132 Delete files without a corresponding Submission record in the database.
133 """
134 with app_context():
135 disconnected_files = find_disconnected_fs_submissions(args.store_dir)
136 bytes_deleted = 0
137 time_elapsed = 0.0
138 rate = 1.0
139 filecount = len(disconnected_files)
140 eta = 1.0
141 eta_msg = ""
142 for i, f in enumerate(disconnected_files, 1):
143 remove = args.force
144 if not args.force:
145 remove = input("Enter 'y' to delete {}: ".format(f)) == "y"
146 if remove:
147 filesize = os.stat(f).st_size
148 if i > 1:
149 eta = filesize / rate
150 eta_msg = " (ETA to remove {:d} bytes: {:.0f}s )".format(filesize, eta)
151 print("Securely removing file {}/{} {}{}...".format(i, filecount, f, eta_msg))
152 start = time.time()
153 secure_delete(f)
154 file_elapsed = time.time() - start
155 bytes_deleted += filesize
156 time_elapsed += file_elapsed
157 rate = bytes_deleted / time_elapsed
158 print(
159 "elapsed: {:.2f}s rate: {:.1f} MB/s overall rate: {:.1f} MB/s".format(
160 file_elapsed, filesize / 1048576 / file_elapsed, rate / 1048576
161 )
162 )
163 else:
164 print("Not removing {}.".format(f))
165
166
167 def were_there_submissions_today(args, context=None):
168 with context or app_context():
169 something = (
170 db.session.query(Source)
171 .filter(Source.last_updated > datetime.datetime.utcnow() - datetime.timedelta(hours=24))
172 .count()
173 > 0
174 )
175 count_file = os.path.join(args.data_root, "submissions_today.txt")
176 open(count_file, "w").write(something and "1" or "0")
177
178
179 def add_check_db_disconnect_parser(subps):
180 check_db_disconnect_subp = subps.add_parser(
181 "check-disconnected-db-submissions",
182 help="Check for submissions that exist in the database but not the filesystem.",
183 )
184 check_db_disconnect_subp.set_defaults(func=check_for_disconnected_db_submissions)
185
186
187 def add_check_fs_disconnect_parser(subps):
188 check_fs_disconnect_subp = subps.add_parser(
189 "check-disconnected-fs-submissions",
190 help="Check for submissions that exist in the filesystem but not in the database.",
191 )
192 check_fs_disconnect_subp.set_defaults(func=check_for_disconnected_fs_submissions)
193
194
195 def add_delete_db_disconnect_parser(subps):
196 delete_db_disconnect_subp = subps.add_parser(
197 "delete-disconnected-db-submissions",
198 help="Delete submissions that exist in the database but not the filesystem.",
199 )
200 delete_db_disconnect_subp.set_defaults(func=delete_disconnected_db_submissions)
201 delete_db_disconnect_subp.add_argument(
202 "--force", action="store_true", help="Do not ask for confirmation."
203 )
204
205
206 def add_delete_fs_disconnect_parser(subps):
207 delete_fs_disconnect_subp = subps.add_parser(
208 "delete-disconnected-fs-submissions",
209 help="Delete submissions that exist in the filesystem but not the database.",
210 )
211 delete_fs_disconnect_subp.set_defaults(func=delete_disconnected_fs_submissions)
212 delete_fs_disconnect_subp.add_argument(
213 "--force", action="store_true", help="Do not ask for confirmation."
214 )
215
216
217 def add_list_db_disconnect_parser(subps):
218 list_db_disconnect_subp = subps.add_parser(
219 "list-disconnected-db-submissions",
220 help="List submissions that exist in the database but not the filesystem.",
221 )
222 list_db_disconnect_subp.set_defaults(func=list_disconnected_db_submissions)
223
224
225 def add_list_fs_disconnect_parser(subps):
226 list_fs_disconnect_subp = subps.add_parser(
227 "list-disconnected-fs-submissions",
228 help="List submissions that exist in the filesystem but not the database.",
229 )
230 list_fs_disconnect_subp.set_defaults(func=list_disconnected_fs_submissions)
231
232
233 def add_were_there_submissions_today(subps):
234 parser = subps.add_parser(
235 "were-there-submissions-today",
236 help=("Update the file indicating " "whether submissions were received in the past 24h"),
237 )
238 parser.set_defaults(func=were_there_submissions_today)
239
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/securedrop/management/submissions.py b/securedrop/management/submissions.py
--- a/securedrop/management/submissions.py
+++ b/securedrop/management/submissions.py
@@ -9,11 +9,14 @@
from db import db
from rm import secure_delete
-from models import Source, Submission
+from models import Reply, Source, Submission
from management import app_context
def find_disconnected_db_submissions(path):
+ """
+ Finds Submission records whose file does not exist.
+ """
submissions = db.session.query(Submission).order_by(Submission.id, Submission.filename).all()
files_in_fs = {}
@@ -50,7 +53,7 @@
if disconnected_submissions:
print(
'Run "manage.py delete-disconnected-db-submissions" to delete these records.',
- file=sys.stderr
+ file=sys.stderr,
)
for s in disconnected_submissions:
print(s.id)
@@ -78,8 +81,14 @@
def find_disconnected_fs_submissions(path):
+ """
+ Finds files in the store that lack a Submission or Reply record.
+ """
submissions = Submission.query.order_by(Submission.id, Submission.filename).all()
- files_in_db = {s.filename: s for s in submissions}
+ files_in_db = {s.filename: True for s in submissions}
+
+ replies = Reply.query.order_by(Reply.id, Reply.filename).all()
+ files_in_db.update({r.filename: True for r in replies})
files_in_fs = {}
for directory, subdirs, files in os.walk(path):
@@ -99,7 +108,7 @@
def check_for_disconnected_fs_submissions(args):
"""
- Check for files without a corresponding Submission record in the database.
+ Check for files without a corresponding Submission or Reply record in the database.
"""
with app_context():
disconnected = find_disconnected_fs_submissions(args.store_dir)
@@ -114,14 +123,14 @@
def list_disconnected_fs_submissions(args):
"""
- List files without a corresponding Submission record in the database.
+ List files without a corresponding Submission or Reply record in the database.
"""
with app_context():
disconnected_files = find_disconnected_fs_submissions(args.store_dir)
if disconnected_files:
print(
'Run "manage.py delete-disconnected-fs-submissions" to delete these files.',
- file=sys.stderr
+ file=sys.stderr,
)
for f in disconnected_files:
print(f)
|
{"golden_diff": "diff --git a/securedrop/management/submissions.py b/securedrop/management/submissions.py\n--- a/securedrop/management/submissions.py\n+++ b/securedrop/management/submissions.py\n@@ -9,11 +9,14 @@\n \n from db import db\n from rm import secure_delete\n-from models import Source, Submission\n+from models import Reply, Source, Submission\n from management import app_context\n \n \n def find_disconnected_db_submissions(path):\n+ \"\"\"\n+ Finds Submission records whose file does not exist.\n+ \"\"\"\n submissions = db.session.query(Submission).order_by(Submission.id, Submission.filename).all()\n \n files_in_fs = {}\n@@ -50,7 +53,7 @@\n if disconnected_submissions:\n print(\n 'Run \"manage.py delete-disconnected-db-submissions\" to delete these records.',\n- file=sys.stderr\n+ file=sys.stderr,\n )\n for s in disconnected_submissions:\n print(s.id)\n@@ -78,8 +81,14 @@\n \n \n def find_disconnected_fs_submissions(path):\n+ \"\"\"\n+ Finds files in the store that lack a Submission or Reply record.\n+ \"\"\"\n submissions = Submission.query.order_by(Submission.id, Submission.filename).all()\n- files_in_db = {s.filename: s for s in submissions}\n+ files_in_db = {s.filename: True for s in submissions}\n+\n+ replies = Reply.query.order_by(Reply.id, Reply.filename).all()\n+ files_in_db.update({r.filename: True for r in replies})\n \n files_in_fs = {}\n for directory, subdirs, files in os.walk(path):\n@@ -99,7 +108,7 @@\n \n def check_for_disconnected_fs_submissions(args):\n \"\"\"\n- Check for files without a corresponding Submission record in the database.\n+ Check for files without a corresponding Submission or Reply record in the database.\n \"\"\"\n with app_context():\n disconnected = find_disconnected_fs_submissions(args.store_dir)\n@@ -114,14 +123,14 @@\n \n def list_disconnected_fs_submissions(args):\n \"\"\"\n- List files without a corresponding Submission record in the database.\n+ List files without a corresponding Submission or Reply record in the database.\n \"\"\"\n with app_context():\n disconnected_files = find_disconnected_fs_submissions(args.store_dir)\n if disconnected_files:\n print(\n 'Run \"manage.py delete-disconnected-fs-submissions\" to delete these files.',\n- file=sys.stderr\n+ file=sys.stderr,\n )\n for f in disconnected_files:\n print(f)\n", "issue": "New submission cleanup could delete valid files of replies\n## Description\r\n\r\nIn `securedrop/management/submissions.py`, the `find_disconnected_fs_submissions` returns any file found in the store that is not associated with a `Submission` record in the database. It should only return files that have neither a `Submission` nor `Reply` record, to avoid warning admins about and possibly deleting replies.\r\n\r\n## Steps to Reproduce\r\n\r\n- Run `make dev`\r\n- In another shell:\r\n - Run `docker container ls` to get the dev container's ID\r\n - Run `docker exec -it \"container-id\" bash`\r\n - Run `./manage.py list-disconnected-fs-submissions`\r\n\r\n## Expected Behavior\r\n\r\nWith a consistent database and filesystem, no disconnects should be reported. \r\n\r\n## Actual Behavior\r\n\r\nThe files of all replies in the database are reported as candidates for cleanup.\r\n\r\n## Comments\r\n\r\nThe function simply needs to build a list of reply files as it does for submissions, and check the files under the store against the complete set of valid files.\r\n\n", "before_files": [{"content": "from __future__ import print_function\n\nimport datetime\nimport os\nimport sys\nimport time\n\nfrom six.moves import input\n\nfrom db import db\nfrom rm import secure_delete\nfrom models import Source, Submission\nfrom management import app_context\n\n\ndef find_disconnected_db_submissions(path):\n submissions = db.session.query(Submission).order_by(Submission.id, Submission.filename).all()\n\n files_in_fs = {}\n for directory, subdirs, files in os.walk(path):\n for f in files:\n files_in_fs[f] = os.path.abspath(os.path.join(directory, f))\n\n disconnected_submissions = [s for s in submissions if s.filename not in files_in_fs]\n\n return disconnected_submissions\n\n\ndef check_for_disconnected_db_submissions(args):\n \"\"\"\n Check for Submission records whose files are missing.\n \"\"\"\n with app_context():\n disconnected = find_disconnected_db_submissions(args.store_dir)\n if disconnected:\n print(\n \"There are submissions in the database with no corresponding files. \"\n 'Run \"manage.py list-disconnected-db-submissions\" for details.'\n )\n else:\n print(\"No problems were found. All submissions' files are present.\")\n\n\ndef list_disconnected_db_submissions(args):\n \"\"\"\n List the IDs of Submission records whose files are missing.\n \"\"\"\n with app_context():\n disconnected_submissions = find_disconnected_db_submissions(args.store_dir)\n if disconnected_submissions:\n print(\n 'Run \"manage.py delete-disconnected-db-submissions\" to delete these records.',\n file=sys.stderr\n )\n for s in disconnected_submissions:\n print(s.id)\n\n\ndef delete_disconnected_db_submissions(args):\n \"\"\"\n Delete Submission records whose files are missing.\n \"\"\"\n with app_context():\n disconnected_submissions = find_disconnected_db_submissions(args.store_dir)\n ids = [s.id for s in disconnected_submissions]\n\n remove = args.force\n if not args.force:\n remove = input(\"Enter 'y' to delete all submissions missing files: \") == \"y\"\n if remove:\n print(\"Removing submission IDs {}...\".format(ids))\n db.session.query(Submission).filter(Submission.id.in_(ids)).delete(\n synchronize_session=\"fetch\"\n )\n db.session.commit()\n else:\n print(\"Not removing disconnected submissions in database.\")\n\n\ndef find_disconnected_fs_submissions(path):\n submissions = Submission.query.order_by(Submission.id, Submission.filename).all()\n files_in_db = {s.filename: s for s in submissions}\n\n files_in_fs = {}\n for directory, subdirs, files in os.walk(path):\n for f in files:\n files_in_fs[f] = os.path.abspath(os.path.join(directory, f))\n\n disconnected_files = []\n for f, p in files_in_fs.items():\n if f not in files_in_db:\n filesize = os.stat(p).st_size\n disconnected_files.append((p, filesize))\n\n disconnected_files = [t[0] for t in sorted(disconnected_files, key=lambda t: t[1])]\n\n return disconnected_files\n\n\ndef check_for_disconnected_fs_submissions(args):\n \"\"\"\n Check for files without a corresponding Submission record in the database.\n \"\"\"\n with app_context():\n disconnected = find_disconnected_fs_submissions(args.store_dir)\n if disconnected:\n print(\n \"There are files in the submission area with no corresponding records in the \"\n 'database. Run \"manage.py list-disconnected-fs-submissions\" for details.'\n )\n else:\n print(\"No unexpected files were found in the store.\")\n\n\ndef list_disconnected_fs_submissions(args):\n \"\"\"\n List files without a corresponding Submission record in the database.\n \"\"\"\n with app_context():\n disconnected_files = find_disconnected_fs_submissions(args.store_dir)\n if disconnected_files:\n print(\n 'Run \"manage.py delete-disconnected-fs-submissions\" to delete these files.',\n file=sys.stderr\n )\n for f in disconnected_files:\n print(f)\n\n\ndef delete_disconnected_fs_submissions(args):\n \"\"\"\n Delete files without a corresponding Submission record in the database.\n \"\"\"\n with app_context():\n disconnected_files = find_disconnected_fs_submissions(args.store_dir)\n bytes_deleted = 0\n time_elapsed = 0.0\n rate = 1.0\n filecount = len(disconnected_files)\n eta = 1.0\n eta_msg = \"\"\n for i, f in enumerate(disconnected_files, 1):\n remove = args.force\n if not args.force:\n remove = input(\"Enter 'y' to delete {}: \".format(f)) == \"y\"\n if remove:\n filesize = os.stat(f).st_size\n if i > 1:\n eta = filesize / rate\n eta_msg = \" (ETA to remove {:d} bytes: {:.0f}s )\".format(filesize, eta)\n print(\"Securely removing file {}/{} {}{}...\".format(i, filecount, f, eta_msg))\n start = time.time()\n secure_delete(f)\n file_elapsed = time.time() - start\n bytes_deleted += filesize\n time_elapsed += file_elapsed\n rate = bytes_deleted / time_elapsed\n print(\n \"elapsed: {:.2f}s rate: {:.1f} MB/s overall rate: {:.1f} MB/s\".format(\n file_elapsed, filesize / 1048576 / file_elapsed, rate / 1048576\n )\n )\n else:\n print(\"Not removing {}.\".format(f))\n\n\ndef were_there_submissions_today(args, context=None):\n with context or app_context():\n something = (\n db.session.query(Source)\n .filter(Source.last_updated > datetime.datetime.utcnow() - datetime.timedelta(hours=24))\n .count()\n > 0\n )\n count_file = os.path.join(args.data_root, \"submissions_today.txt\")\n open(count_file, \"w\").write(something and \"1\" or \"0\")\n\n\ndef add_check_db_disconnect_parser(subps):\n check_db_disconnect_subp = subps.add_parser(\n \"check-disconnected-db-submissions\",\n help=\"Check for submissions that exist in the database but not the filesystem.\",\n )\n check_db_disconnect_subp.set_defaults(func=check_for_disconnected_db_submissions)\n\n\ndef add_check_fs_disconnect_parser(subps):\n check_fs_disconnect_subp = subps.add_parser(\n \"check-disconnected-fs-submissions\",\n help=\"Check for submissions that exist in the filesystem but not in the database.\",\n )\n check_fs_disconnect_subp.set_defaults(func=check_for_disconnected_fs_submissions)\n\n\ndef add_delete_db_disconnect_parser(subps):\n delete_db_disconnect_subp = subps.add_parser(\n \"delete-disconnected-db-submissions\",\n help=\"Delete submissions that exist in the database but not the filesystem.\",\n )\n delete_db_disconnect_subp.set_defaults(func=delete_disconnected_db_submissions)\n delete_db_disconnect_subp.add_argument(\n \"--force\", action=\"store_true\", help=\"Do not ask for confirmation.\"\n )\n\n\ndef add_delete_fs_disconnect_parser(subps):\n delete_fs_disconnect_subp = subps.add_parser(\n \"delete-disconnected-fs-submissions\",\n help=\"Delete submissions that exist in the filesystem but not the database.\",\n )\n delete_fs_disconnect_subp.set_defaults(func=delete_disconnected_fs_submissions)\n delete_fs_disconnect_subp.add_argument(\n \"--force\", action=\"store_true\", help=\"Do not ask for confirmation.\"\n )\n\n\ndef add_list_db_disconnect_parser(subps):\n list_db_disconnect_subp = subps.add_parser(\n \"list-disconnected-db-submissions\",\n help=\"List submissions that exist in the database but not the filesystem.\",\n )\n list_db_disconnect_subp.set_defaults(func=list_disconnected_db_submissions)\n\n\ndef add_list_fs_disconnect_parser(subps):\n list_fs_disconnect_subp = subps.add_parser(\n \"list-disconnected-fs-submissions\",\n help=\"List submissions that exist in the filesystem but not the database.\",\n )\n list_fs_disconnect_subp.set_defaults(func=list_disconnected_fs_submissions)\n\n\ndef add_were_there_submissions_today(subps):\n parser = subps.add_parser(\n \"were-there-submissions-today\",\n help=(\"Update the file indicating \" \"whether submissions were received in the past 24h\"),\n )\n parser.set_defaults(func=were_there_submissions_today)\n", "path": "securedrop/management/submissions.py"}], "after_files": [{"content": "from __future__ import print_function\n\nimport datetime\nimport os\nimport sys\nimport time\n\nfrom six.moves import input\n\nfrom db import db\nfrom rm import secure_delete\nfrom models import Reply, Source, Submission\nfrom management import app_context\n\n\ndef find_disconnected_db_submissions(path):\n \"\"\"\n Finds Submission records whose file does not exist.\n \"\"\"\n submissions = db.session.query(Submission).order_by(Submission.id, Submission.filename).all()\n\n files_in_fs = {}\n for directory, subdirs, files in os.walk(path):\n for f in files:\n files_in_fs[f] = os.path.abspath(os.path.join(directory, f))\n\n disconnected_submissions = [s for s in submissions if s.filename not in files_in_fs]\n\n return disconnected_submissions\n\n\ndef check_for_disconnected_db_submissions(args):\n \"\"\"\n Check for Submission records whose files are missing.\n \"\"\"\n with app_context():\n disconnected = find_disconnected_db_submissions(args.store_dir)\n if disconnected:\n print(\n \"There are submissions in the database with no corresponding files. \"\n 'Run \"manage.py list-disconnected-db-submissions\" for details.'\n )\n else:\n print(\"No problems were found. All submissions' files are present.\")\n\n\ndef list_disconnected_db_submissions(args):\n \"\"\"\n List the IDs of Submission records whose files are missing.\n \"\"\"\n with app_context():\n disconnected_submissions = find_disconnected_db_submissions(args.store_dir)\n if disconnected_submissions:\n print(\n 'Run \"manage.py delete-disconnected-db-submissions\" to delete these records.',\n file=sys.stderr,\n )\n for s in disconnected_submissions:\n print(s.id)\n\n\ndef delete_disconnected_db_submissions(args):\n \"\"\"\n Delete Submission records whose files are missing.\n \"\"\"\n with app_context():\n disconnected_submissions = find_disconnected_db_submissions(args.store_dir)\n ids = [s.id for s in disconnected_submissions]\n\n remove = args.force\n if not args.force:\n remove = input(\"Enter 'y' to delete all submissions missing files: \") == \"y\"\n if remove:\n print(\"Removing submission IDs {}...\".format(ids))\n db.session.query(Submission).filter(Submission.id.in_(ids)).delete(\n synchronize_session=\"fetch\"\n )\n db.session.commit()\n else:\n print(\"Not removing disconnected submissions in database.\")\n\n\ndef find_disconnected_fs_submissions(path):\n \"\"\"\n Finds files in the store that lack a Submission or Reply record.\n \"\"\"\n submissions = Submission.query.order_by(Submission.id, Submission.filename).all()\n files_in_db = {s.filename: True for s in submissions}\n\n replies = Reply.query.order_by(Reply.id, Reply.filename).all()\n files_in_db.update({r.filename: True for r in replies})\n\n files_in_fs = {}\n for directory, subdirs, files in os.walk(path):\n for f in files:\n files_in_fs[f] = os.path.abspath(os.path.join(directory, f))\n\n disconnected_files = []\n for f, p in files_in_fs.items():\n if f not in files_in_db:\n filesize = os.stat(p).st_size\n disconnected_files.append((p, filesize))\n\n disconnected_files = [t[0] for t in sorted(disconnected_files, key=lambda t: t[1])]\n\n return disconnected_files\n\n\ndef check_for_disconnected_fs_submissions(args):\n \"\"\"\n Check for files without a corresponding Submission or Reply record in the database.\n \"\"\"\n with app_context():\n disconnected = find_disconnected_fs_submissions(args.store_dir)\n if disconnected:\n print(\n \"There are files in the submission area with no corresponding records in the \"\n 'database. Run \"manage.py list-disconnected-fs-submissions\" for details.'\n )\n else:\n print(\"No unexpected files were found in the store.\")\n\n\ndef list_disconnected_fs_submissions(args):\n \"\"\"\n List files without a corresponding Submission or Reply record in the database.\n \"\"\"\n with app_context():\n disconnected_files = find_disconnected_fs_submissions(args.store_dir)\n if disconnected_files:\n print(\n 'Run \"manage.py delete-disconnected-fs-submissions\" to delete these files.',\n file=sys.stderr,\n )\n for f in disconnected_files:\n print(f)\n\n\ndef delete_disconnected_fs_submissions(args):\n \"\"\"\n Delete files without a corresponding Submission record in the database.\n \"\"\"\n with app_context():\n disconnected_files = find_disconnected_fs_submissions(args.store_dir)\n bytes_deleted = 0\n time_elapsed = 0.0\n rate = 1.0\n filecount = len(disconnected_files)\n eta = 1.0\n eta_msg = \"\"\n for i, f in enumerate(disconnected_files, 1):\n remove = args.force\n if not args.force:\n remove = input(\"Enter 'y' to delete {}: \".format(f)) == \"y\"\n if remove:\n filesize = os.stat(f).st_size\n if i > 1:\n eta = filesize / rate\n eta_msg = \" (ETA to remove {:d} bytes: {:.0f}s )\".format(filesize, eta)\n print(\"Securely removing file {}/{} {}{}...\".format(i, filecount, f, eta_msg))\n start = time.time()\n secure_delete(f)\n file_elapsed = time.time() - start\n bytes_deleted += filesize\n time_elapsed += file_elapsed\n rate = bytes_deleted / time_elapsed\n print(\n \"elapsed: {:.2f}s rate: {:.1f} MB/s overall rate: {:.1f} MB/s\".format(\n file_elapsed, filesize / 1048576 / file_elapsed, rate / 1048576\n )\n )\n else:\n print(\"Not removing {}.\".format(f))\n\n\ndef were_there_submissions_today(args, context=None):\n with context or app_context():\n something = (\n db.session.query(Source)\n .filter(Source.last_updated > datetime.datetime.utcnow() - datetime.timedelta(hours=24))\n .count()\n > 0\n )\n count_file = os.path.join(args.data_root, \"submissions_today.txt\")\n open(count_file, \"w\").write(something and \"1\" or \"0\")\n\n\ndef add_check_db_disconnect_parser(subps):\n check_db_disconnect_subp = subps.add_parser(\n \"check-disconnected-db-submissions\",\n help=\"Check for submissions that exist in the database but not the filesystem.\",\n )\n check_db_disconnect_subp.set_defaults(func=check_for_disconnected_db_submissions)\n\n\ndef add_check_fs_disconnect_parser(subps):\n check_fs_disconnect_subp = subps.add_parser(\n \"check-disconnected-fs-submissions\",\n help=\"Check for submissions that exist in the filesystem but not in the database.\",\n )\n check_fs_disconnect_subp.set_defaults(func=check_for_disconnected_fs_submissions)\n\n\ndef add_delete_db_disconnect_parser(subps):\n delete_db_disconnect_subp = subps.add_parser(\n \"delete-disconnected-db-submissions\",\n help=\"Delete submissions that exist in the database but not the filesystem.\",\n )\n delete_db_disconnect_subp.set_defaults(func=delete_disconnected_db_submissions)\n delete_db_disconnect_subp.add_argument(\n \"--force\", action=\"store_true\", help=\"Do not ask for confirmation.\"\n )\n\n\ndef add_delete_fs_disconnect_parser(subps):\n delete_fs_disconnect_subp = subps.add_parser(\n \"delete-disconnected-fs-submissions\",\n help=\"Delete submissions that exist in the filesystem but not the database.\",\n )\n delete_fs_disconnect_subp.set_defaults(func=delete_disconnected_fs_submissions)\n delete_fs_disconnect_subp.add_argument(\n \"--force\", action=\"store_true\", help=\"Do not ask for confirmation.\"\n )\n\n\ndef add_list_db_disconnect_parser(subps):\n list_db_disconnect_subp = subps.add_parser(\n \"list-disconnected-db-submissions\",\n help=\"List submissions that exist in the database but not the filesystem.\",\n )\n list_db_disconnect_subp.set_defaults(func=list_disconnected_db_submissions)\n\n\ndef add_list_fs_disconnect_parser(subps):\n list_fs_disconnect_subp = subps.add_parser(\n \"list-disconnected-fs-submissions\",\n help=\"List submissions that exist in the filesystem but not the database.\",\n )\n list_fs_disconnect_subp.set_defaults(func=list_disconnected_fs_submissions)\n\n\ndef add_were_there_submissions_today(subps):\n parser = subps.add_parser(\n \"were-there-submissions-today\",\n help=(\"Update the file indicating \" \"whether submissions were received in the past 24h\"),\n )\n parser.set_defaults(func=were_there_submissions_today)\n", "path": "securedrop/management/submissions.py"}]}
| 2,908 | 562 |
gh_patches_debug_15959
|
rasdani/github-patches
|
git_diff
|
zulip__zulip-21059
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Race conditions in muting topics and users
Our pattern in [muting topics](https://github.com/zulip/zulip/blob/b4075b78eb6e128bce7ef3d36b86d176ef2ecfa5/zerver/views/muting.py#L39-L42) is to check if the topic is muted, and if not then to add a row:
```py3
if topic_is_muted(user_profile, stream.id, topic_name):
raise JsonableError(_("Topic already muted"))
do_mute_topic(user_profile, stream, topic_name, date_muted)
return json_success()
```
This pattern is inherently prone to race conditions. Luckily, we catch those due to database constraints, in the form of `UserTopic.objects.create` raising an IntegrityError, but those bubble up as 500's, not 400's.
We should catch those IntegrityError's and re-raise them as `JsonableError(_("Topic already muted"))`. That applies to the mute-topic codepath, as well as the mute-user codepath.
Though it doesn't affect correctness in this case, since the duplicate row is the first database change operation, these actions should be done inside of transactions.
Un-muting is technically also subject to this race, though it doesn't matter -- both processes calling `.delete()` on the same object is a mostly-silent no-op for the second process.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `zerver/views/muting.py`
Content:
```
1 import datetime
2 from typing import Optional
3
4 from django.http import HttpRequest, HttpResponse
5 from django.utils.timezone import now as timezone_now
6 from django.utils.translation import gettext as _
7
8 from zerver.lib.actions import do_mute_topic, do_mute_user, do_unmute_topic, do_unmute_user
9 from zerver.lib.exceptions import JsonableError
10 from zerver.lib.request import REQ, has_request_variables
11 from zerver.lib.response import json_success
12 from zerver.lib.streams import (
13 access_stream_by_id,
14 access_stream_by_name,
15 access_stream_for_unmute_topic_by_id,
16 access_stream_for_unmute_topic_by_name,
17 check_for_exactly_one_stream_arg,
18 )
19 from zerver.lib.topic_mutes import topic_is_muted
20 from zerver.lib.user_mutes import get_mute_object
21 from zerver.lib.users import access_user_by_id
22 from zerver.lib.validator import check_int
23 from zerver.models import UserProfile
24
25
26 def mute_topic(
27 user_profile: UserProfile,
28 stream_id: Optional[int],
29 stream_name: Optional[str],
30 topic_name: str,
31 date_muted: datetime.datetime,
32 ) -> None:
33 if stream_name is not None:
34 (stream, sub) = access_stream_by_name(user_profile, stream_name)
35 else:
36 assert stream_id is not None
37 (stream, sub) = access_stream_by_id(user_profile, stream_id)
38
39 if topic_is_muted(user_profile, stream.id, topic_name):
40 raise JsonableError(_("Topic already muted"))
41
42 do_mute_topic(user_profile, stream, topic_name, date_muted)
43
44
45 def unmute_topic(
46 user_profile: UserProfile,
47 stream_id: Optional[int],
48 stream_name: Optional[str],
49 topic_name: str,
50 ) -> None:
51 error = _("Topic is not muted")
52
53 if stream_name is not None:
54 stream = access_stream_for_unmute_topic_by_name(user_profile, stream_name, error)
55 else:
56 assert stream_id is not None
57 stream = access_stream_for_unmute_topic_by_id(user_profile, stream_id, error)
58
59 do_unmute_topic(user_profile, stream, topic_name)
60
61
62 @has_request_variables
63 def update_muted_topic(
64 request: HttpRequest,
65 user_profile: UserProfile,
66 stream_id: Optional[int] = REQ(json_validator=check_int, default=None),
67 stream: Optional[str] = REQ(default=None),
68 topic: str = REQ(),
69 op: str = REQ(),
70 ) -> HttpResponse:
71
72 check_for_exactly_one_stream_arg(stream_id=stream_id, stream=stream)
73
74 if op == "add":
75 mute_topic(
76 user_profile=user_profile,
77 stream_id=stream_id,
78 stream_name=stream,
79 topic_name=topic,
80 date_muted=timezone_now(),
81 )
82 return json_success(request)
83 elif op == "remove":
84 unmute_topic(
85 user_profile=user_profile,
86 stream_id=stream_id,
87 stream_name=stream,
88 topic_name=topic,
89 )
90 return json_success(request)
91
92
93 def mute_user(request: HttpRequest, user_profile: UserProfile, muted_user_id: int) -> HttpResponse:
94 if user_profile.id == muted_user_id:
95 raise JsonableError(_("Cannot mute self"))
96
97 muted_user = access_user_by_id(
98 user_profile, muted_user_id, allow_bots=False, allow_deactivated=True, for_admin=False
99 )
100 date_muted = timezone_now()
101
102 if get_mute_object(user_profile, muted_user) is not None:
103 raise JsonableError(_("User already muted"))
104
105 do_mute_user(user_profile, muted_user, date_muted)
106 return json_success(request)
107
108
109 def unmute_user(
110 request: HttpRequest, user_profile: UserProfile, muted_user_id: int
111 ) -> HttpResponse:
112 muted_user = access_user_by_id(
113 user_profile, muted_user_id, allow_bots=False, allow_deactivated=True, for_admin=False
114 )
115 mute_object = get_mute_object(user_profile, muted_user)
116
117 if mute_object is None:
118 raise JsonableError(_("User is not muted"))
119
120 do_unmute_user(mute_object)
121 return json_success(request)
122
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/zerver/views/muting.py b/zerver/views/muting.py
--- a/zerver/views/muting.py
+++ b/zerver/views/muting.py
@@ -1,6 +1,7 @@
import datetime
from typing import Optional
+from django.db import IntegrityError
from django.http import HttpRequest, HttpResponse
from django.utils.timezone import now as timezone_now
from django.utils.translation import gettext as _
@@ -39,7 +40,10 @@
if topic_is_muted(user_profile, stream.id, topic_name):
raise JsonableError(_("Topic already muted"))
- do_mute_topic(user_profile, stream, topic_name, date_muted)
+ try:
+ do_mute_topic(user_profile, stream, topic_name, date_muted)
+ except IntegrityError:
+ raise JsonableError(_("Topic already muted"))
def unmute_topic(
|
{"golden_diff": "diff --git a/zerver/views/muting.py b/zerver/views/muting.py\n--- a/zerver/views/muting.py\n+++ b/zerver/views/muting.py\n@@ -1,6 +1,7 @@\n import datetime\n from typing import Optional\n \n+from django.db import IntegrityError\n from django.http import HttpRequest, HttpResponse\n from django.utils.timezone import now as timezone_now\n from django.utils.translation import gettext as _\n@@ -39,7 +40,10 @@\n if topic_is_muted(user_profile, stream.id, topic_name):\n raise JsonableError(_(\"Topic already muted\"))\n \n- do_mute_topic(user_profile, stream, topic_name, date_muted)\n+ try:\n+ do_mute_topic(user_profile, stream, topic_name, date_muted)\n+ except IntegrityError:\n+ raise JsonableError(_(\"Topic already muted\"))\n \n \n def unmute_topic(\n", "issue": "Race conditions in muting topics and users\nOur pattern in [muting topics](https://github.com/zulip/zulip/blob/b4075b78eb6e128bce7ef3d36b86d176ef2ecfa5/zerver/views/muting.py#L39-L42) is to check if the topic is muted, and if not then to add a row:\r\n```py3\r\n if topic_is_muted(user_profile, stream.id, topic_name):\r\n raise JsonableError(_(\"Topic already muted\"))\r\n\r\n do_mute_topic(user_profile, stream, topic_name, date_muted)\r\n return json_success()\r\n```\r\n\r\nThis pattern is inherently prone to race conditions. Luckily, we catch those due to database constraints, in the form of `UserTopic.objects.create` raising an IntegrityError, but those bubble up as 500's, not 400's.\r\n\r\nWe should catch those IntegrityError's and re-raise them as `JsonableError(_(\"Topic already muted\"))`. That applies to the mute-topic codepath, as well as the mute-user codepath.\r\n\r\nThough it doesn't affect correctness in this case, since the duplicate row is the first database change operation, these actions should be done inside of transactions.\r\n\r\nUn-muting is technically also subject to this race, though it doesn't matter -- both processes calling `.delete()` on the same object is a mostly-silent no-op for the second process.\n", "before_files": [{"content": "import datetime\nfrom typing import Optional\n\nfrom django.http import HttpRequest, HttpResponse\nfrom django.utils.timezone import now as timezone_now\nfrom django.utils.translation import gettext as _\n\nfrom zerver.lib.actions import do_mute_topic, do_mute_user, do_unmute_topic, do_unmute_user\nfrom zerver.lib.exceptions import JsonableError\nfrom zerver.lib.request import REQ, has_request_variables\nfrom zerver.lib.response import json_success\nfrom zerver.lib.streams import (\n access_stream_by_id,\n access_stream_by_name,\n access_stream_for_unmute_topic_by_id,\n access_stream_for_unmute_topic_by_name,\n check_for_exactly_one_stream_arg,\n)\nfrom zerver.lib.topic_mutes import topic_is_muted\nfrom zerver.lib.user_mutes import get_mute_object\nfrom zerver.lib.users import access_user_by_id\nfrom zerver.lib.validator import check_int\nfrom zerver.models import UserProfile\n\n\ndef mute_topic(\n user_profile: UserProfile,\n stream_id: Optional[int],\n stream_name: Optional[str],\n topic_name: str,\n date_muted: datetime.datetime,\n) -> None:\n if stream_name is not None:\n (stream, sub) = access_stream_by_name(user_profile, stream_name)\n else:\n assert stream_id is not None\n (stream, sub) = access_stream_by_id(user_profile, stream_id)\n\n if topic_is_muted(user_profile, stream.id, topic_name):\n raise JsonableError(_(\"Topic already muted\"))\n\n do_mute_topic(user_profile, stream, topic_name, date_muted)\n\n\ndef unmute_topic(\n user_profile: UserProfile,\n stream_id: Optional[int],\n stream_name: Optional[str],\n topic_name: str,\n) -> None:\n error = _(\"Topic is not muted\")\n\n if stream_name is not None:\n stream = access_stream_for_unmute_topic_by_name(user_profile, stream_name, error)\n else:\n assert stream_id is not None\n stream = access_stream_for_unmute_topic_by_id(user_profile, stream_id, error)\n\n do_unmute_topic(user_profile, stream, topic_name)\n\n\n@has_request_variables\ndef update_muted_topic(\n request: HttpRequest,\n user_profile: UserProfile,\n stream_id: Optional[int] = REQ(json_validator=check_int, default=None),\n stream: Optional[str] = REQ(default=None),\n topic: str = REQ(),\n op: str = REQ(),\n) -> HttpResponse:\n\n check_for_exactly_one_stream_arg(stream_id=stream_id, stream=stream)\n\n if op == \"add\":\n mute_topic(\n user_profile=user_profile,\n stream_id=stream_id,\n stream_name=stream,\n topic_name=topic,\n date_muted=timezone_now(),\n )\n return json_success(request)\n elif op == \"remove\":\n unmute_topic(\n user_profile=user_profile,\n stream_id=stream_id,\n stream_name=stream,\n topic_name=topic,\n )\n return json_success(request)\n\n\ndef mute_user(request: HttpRequest, user_profile: UserProfile, muted_user_id: int) -> HttpResponse:\n if user_profile.id == muted_user_id:\n raise JsonableError(_(\"Cannot mute self\"))\n\n muted_user = access_user_by_id(\n user_profile, muted_user_id, allow_bots=False, allow_deactivated=True, for_admin=False\n )\n date_muted = timezone_now()\n\n if get_mute_object(user_profile, muted_user) is not None:\n raise JsonableError(_(\"User already muted\"))\n\n do_mute_user(user_profile, muted_user, date_muted)\n return json_success(request)\n\n\ndef unmute_user(\n request: HttpRequest, user_profile: UserProfile, muted_user_id: int\n) -> HttpResponse:\n muted_user = access_user_by_id(\n user_profile, muted_user_id, allow_bots=False, allow_deactivated=True, for_admin=False\n )\n mute_object = get_mute_object(user_profile, muted_user)\n\n if mute_object is None:\n raise JsonableError(_(\"User is not muted\"))\n\n do_unmute_user(mute_object)\n return json_success(request)\n", "path": "zerver/views/muting.py"}], "after_files": [{"content": "import datetime\nfrom typing import Optional\n\nfrom django.db import IntegrityError\nfrom django.http import HttpRequest, HttpResponse\nfrom django.utils.timezone import now as timezone_now\nfrom django.utils.translation import gettext as _\n\nfrom zerver.lib.actions import do_mute_topic, do_mute_user, do_unmute_topic, do_unmute_user\nfrom zerver.lib.exceptions import JsonableError\nfrom zerver.lib.request import REQ, has_request_variables\nfrom zerver.lib.response import json_success\nfrom zerver.lib.streams import (\n access_stream_by_id,\n access_stream_by_name,\n access_stream_for_unmute_topic_by_id,\n access_stream_for_unmute_topic_by_name,\n check_for_exactly_one_stream_arg,\n)\nfrom zerver.lib.topic_mutes import topic_is_muted\nfrom zerver.lib.user_mutes import get_mute_object\nfrom zerver.lib.users import access_user_by_id\nfrom zerver.lib.validator import check_int\nfrom zerver.models import UserProfile\n\n\ndef mute_topic(\n user_profile: UserProfile,\n stream_id: Optional[int],\n stream_name: Optional[str],\n topic_name: str,\n date_muted: datetime.datetime,\n) -> None:\n if stream_name is not None:\n (stream, sub) = access_stream_by_name(user_profile, stream_name)\n else:\n assert stream_id is not None\n (stream, sub) = access_stream_by_id(user_profile, stream_id)\n\n if topic_is_muted(user_profile, stream.id, topic_name):\n raise JsonableError(_(\"Topic already muted\"))\n\n try:\n do_mute_topic(user_profile, stream, topic_name, date_muted)\n except IntegrityError:\n raise JsonableError(_(\"Topic already muted\"))\n\n\ndef unmute_topic(\n user_profile: UserProfile,\n stream_id: Optional[int],\n stream_name: Optional[str],\n topic_name: str,\n) -> None:\n error = _(\"Topic is not muted\")\n\n if stream_name is not None:\n stream = access_stream_for_unmute_topic_by_name(user_profile, stream_name, error)\n else:\n assert stream_id is not None\n stream = access_stream_for_unmute_topic_by_id(user_profile, stream_id, error)\n\n do_unmute_topic(user_profile, stream, topic_name)\n\n\n@has_request_variables\ndef update_muted_topic(\n request: HttpRequest,\n user_profile: UserProfile,\n stream_id: Optional[int] = REQ(json_validator=check_int, default=None),\n stream: Optional[str] = REQ(default=None),\n topic: str = REQ(),\n op: str = REQ(),\n) -> HttpResponse:\n\n check_for_exactly_one_stream_arg(stream_id=stream_id, stream=stream)\n\n if op == \"add\":\n mute_topic(\n user_profile=user_profile,\n stream_id=stream_id,\n stream_name=stream,\n topic_name=topic,\n date_muted=timezone_now(),\n )\n return json_success(request)\n elif op == \"remove\":\n unmute_topic(\n user_profile=user_profile,\n stream_id=stream_id,\n stream_name=stream,\n topic_name=topic,\n )\n return json_success(request)\n\n\ndef mute_user(request: HttpRequest, user_profile: UserProfile, muted_user_id: int) -> HttpResponse:\n if user_profile.id == muted_user_id:\n raise JsonableError(_(\"Cannot mute self\"))\n\n muted_user = access_user_by_id(\n user_profile, muted_user_id, allow_bots=False, allow_deactivated=True, for_admin=False\n )\n date_muted = timezone_now()\n\n if get_mute_object(user_profile, muted_user) is not None:\n raise JsonableError(_(\"User already muted\"))\n\n do_mute_user(user_profile, muted_user, date_muted)\n return json_success(request)\n\n\ndef unmute_user(\n request: HttpRequest, user_profile: UserProfile, muted_user_id: int\n) -> HttpResponse:\n muted_user = access_user_by_id(\n user_profile, muted_user_id, allow_bots=False, allow_deactivated=True, for_admin=False\n )\n mute_object = get_mute_object(user_profile, muted_user)\n\n if mute_object is None:\n raise JsonableError(_(\"User is not muted\"))\n\n do_unmute_user(mute_object)\n return json_success(request)\n", "path": "zerver/views/muting.py"}]}
| 1,716 | 190 |
gh_patches_debug_36963
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-2161
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
remove transpile_dag
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. -->
### What is the expected enhancement?
Once we have pass_manager fully integrated we should remove the function transpile_dag from the transpiler.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `qiskit/transpiler/transpiler.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright 2018, IBM.
4 #
5 # This source code is licensed under the Apache License, Version 2.0 found in
6 # the LICENSE.txt file in the root directory of this source tree.
7
8 """Tools for compiling a batch of quantum circuits."""
9 import logging
10 import warnings
11
12 from qiskit.circuit import QuantumCircuit
13 from qiskit.mapper import CouplingMap
14 from qiskit.tools.parallel import parallel_map
15 from qiskit.converters import circuit_to_dag
16 from qiskit.converters import dag_to_circuit
17 from qiskit.mapper.layout import Layout
18 from qiskit.transpiler.exceptions import TranspilerError
19 from qiskit.transpiler.preset_passmanagers import default_pass_manager_simulator, \
20 default_pass_manager
21
22 logger = logging.getLogger(__name__)
23
24
25 def transpile(circuits, backend=None, basis_gates=None, coupling_map=None,
26 initial_layout=None, seed_mapper=None, pass_manager=None):
27 """transpile one or more circuits.
28
29 Args:
30 circuits (QuantumCircuit or list[QuantumCircuit]): circuits to compile
31 backend (BaseBackend): a backend to compile for
32 basis_gates (list[str]): list of basis gate names supported by the
33 target. Default: ['u1','u2','u3','cx','id']
34 coupling_map (list): coupling map (perhaps custom) to target in mapping
35 initial_layout (list): initial layout of qubits in mapping
36 seed_mapper (int): random seed for the swap_mapper
37 pass_manager (PassManager): a pass_manager for the transpiler stages
38
39 Returns:
40 QuantumCircuit or list[QuantumCircuit]: transpiled circuit(s).
41 """
42 return_form_is_single = False
43 if isinstance(circuits, QuantumCircuit):
44 circuits = [circuits]
45 return_form_is_single = True
46
47 # pass manager overrides explicit transpile options (basis_gates, coupling_map)
48 # explicit transpile options override options gotten from a backend
49 if not pass_manager and backend:
50 basis_gates = basis_gates or getattr(backend.configuration(), 'basis_gates', None)
51 # This needs to be removed once Aer 0.2 is out
52 coupling_map = coupling_map or getattr(backend.configuration(), 'coupling_map', None)
53
54 # Convert integer list format to Layout
55 if isinstance(initial_layout, list) and \
56 all(isinstance(elem, int) for elem in initial_layout):
57 if isinstance(circuits, list):
58 circ = circuits[0]
59 else:
60 circ = circuits
61 initial_layout = Layout.generate_from_intlist(initial_layout, *circ.qregs)
62
63 if initial_layout is not None and not isinstance(initial_layout, Layout):
64 initial_layout = Layout(initial_layout)
65
66 circuits = parallel_map(_transpilation, circuits,
67 task_kwargs={'basis_gates': basis_gates,
68 'coupling_map': coupling_map,
69 'initial_layout': initial_layout,
70 'seed_mapper': seed_mapper,
71 'pass_manager': pass_manager})
72 if return_form_is_single:
73 return circuits[0]
74 return circuits
75
76
77 def _transpilation(circuit, basis_gates=None, coupling_map=None,
78 initial_layout=None, seed_mapper=None,
79 pass_manager=None):
80 """Perform transpilation of a single circuit.
81
82 Args:
83 circuit (QuantumCircuit): A circuit to transpile.
84 basis_gates (list[str]): list of basis gate names supported by the
85 target. Default: ['u1','u2','u3','cx','id']
86 coupling_map (CouplingMap): coupling map (perhaps custom) to target in mapping
87 initial_layout (Layout): initial layout of qubits in mapping
88 seed_mapper (int): random seed for the swap_mapper
89 pass_manager (PassManager): a pass_manager for the transpiler stage
90
91 Returns:
92 QuantumCircuit: A transpiled circuit.
93
94 Raises:
95 TranspilerError: If the Layout does not matches the circuit
96 """
97 if initial_layout is not None and set(circuit.qregs) != initial_layout.get_registers():
98 raise TranspilerError('The provided initial layout does not match the registers in '
99 'the circuit "%s"' % circuit.name)
100
101 if pass_manager and not pass_manager.working_list:
102 return circuit
103
104 is_parametric_circuit = bool(circuit.unassigned_variables)
105
106 dag = circuit_to_dag(circuit)
107 del circuit
108
109 final_dag = transpile_dag(dag, basis_gates=basis_gates,
110 coupling_map=coupling_map,
111 initial_layout=initial_layout,
112 skip_numeric_passes=is_parametric_circuit,
113 seed_mapper=seed_mapper,
114 pass_manager=pass_manager)
115
116 out_circuit = dag_to_circuit(final_dag)
117
118 return out_circuit
119
120
121 # pylint: disable=redefined-builtin
122 def transpile_dag(dag, basis_gates=None, coupling_map=None,
123 initial_layout=None, skip_numeric_passes=None,
124 seed_mapper=None, pass_manager=None):
125 """Transform a dag circuit into another dag circuit (transpile), through
126 consecutive passes on the dag.
127
128 Args:
129 dag (DAGCircuit): dag circuit to transform via transpilation
130 basis_gates (list[str]): list of basis gate names supported by the
131 target. Default: ['u1','u2','u3','cx','id']
132 coupling_map (list): A graph of coupling::
133
134 [
135 [control0(int), target0(int)],
136 [control1(int), target1(int)],
137 ]
138
139 eg. [[0, 2], [1, 2], [1, 3], [3, 4]}
140
141 initial_layout (Layout or None): A layout object
142 skip_numeric_passes (bool): If true, skip passes which require fixed parameter values
143 seed_mapper (int): random seed_mapper for the swap mapper
144 pass_manager (PassManager): pass manager instance for the transpilation process
145 If None, a default set of passes are run.
146 Otherwise, the passes defined in it will run.
147 If contains no passes in it, no dag transformations occur.
148
149 Returns:
150 DAGCircuit: transformed dag
151 """
152 # TODO: `basis_gates` will be removed after we have the unroller pass.
153 # TODO: `coupling_map`, `initial_layout`, `seed_mapper` removed after mapper pass.
154
155 if basis_gates is None:
156 basis_gates = ['u1', 'u2', 'u3', 'cx', 'id']
157 if isinstance(basis_gates, str):
158 warnings.warn("The parameter basis_gates is now a list of strings. "
159 "For example, this basis ['u1','u2','u3','cx'] should be used "
160 "instead of 'u1,u2,u3,cx'. The string format will be "
161 "removed after 0.9", DeprecationWarning, 2)
162 basis_gates = basis_gates.split(',')
163
164 if pass_manager is None:
165 # default set of passes
166
167 # if a coupling map is given compile to the map
168 if coupling_map:
169 pass_manager = default_pass_manager(basis_gates,
170 CouplingMap(coupling_map),
171 initial_layout,
172 skip_numeric_passes,
173 seed_mapper=seed_mapper)
174 else:
175 pass_manager = default_pass_manager_simulator(basis_gates)
176
177 # run the passes specified by the pass manager
178 # TODO return the property set too. See #1086
179 name = dag.name
180 dag = pass_manager.run_passes(dag)
181 dag.name = name
182
183 return dag
184
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/qiskit/transpiler/transpiler.py b/qiskit/transpiler/transpiler.py
--- a/qiskit/transpiler/transpiler.py
+++ b/qiskit/transpiler/transpiler.py
@@ -106,22 +106,59 @@
dag = circuit_to_dag(circuit)
del circuit
- final_dag = transpile_dag(dag, basis_gates=basis_gates,
- coupling_map=coupling_map,
- initial_layout=initial_layout,
- skip_numeric_passes=is_parametric_circuit,
- seed_mapper=seed_mapper,
- pass_manager=pass_manager)
+ final_dag = _transpile_dag(dag, basis_gates=basis_gates,
+ coupling_map=coupling_map,
+ initial_layout=initial_layout,
+ skip_numeric_passes=is_parametric_circuit,
+ seed_mapper=seed_mapper,
+ pass_manager=pass_manager)
out_circuit = dag_to_circuit(final_dag)
return out_circuit
-# pylint: disable=redefined-builtin
def transpile_dag(dag, basis_gates=None, coupling_map=None,
initial_layout=None, skip_numeric_passes=None,
seed_mapper=None, pass_manager=None):
+ """Deprecated - Transform a dag circuit into another dag circuit
+ (transpile), through consecutive passes on the dag.
+
+ Args:
+ dag (DAGCircuit): dag circuit to transform via transpilation
+ basis_gates (list[str]): list of basis gate names supported by the
+ target. Default: ['u1','u2','u3','cx','id']
+ coupling_map (list): A graph of coupling::
+
+ [
+ [control0(int), target0(int)],
+ [control1(int), target1(int)],
+ ]
+
+ eg. [[0, 2], [1, 2], [1, 3], [3, 4]}
+
+ initial_layout (Layout or None): A layout object
+ skip_numeric_passes (bool): If true, skip passes which require fixed parameter values
+ seed_mapper (int): random seed_mapper for the swap mapper
+ pass_manager (PassManager): pass manager instance for the transpilation process
+ If None, a default set of passes are run.
+ Otherwise, the passes defined in it will run.
+ If contains no passes in it, no dag transformations occur.
+
+ Returns:
+ DAGCircuit: transformed dag
+ """
+
+ warnings.warn("transpile_dag has been deprecated and will be removed in the "
+ "0.9 release. Circuits can be transpiled directly to other "
+ "circuits with the transpile function.", DeprecationWarning)
+ return _transpile_dag(dag, basis_gates, coupling_map, initial_layout,
+ skip_numeric_passes, seed_mapper, pass_manager)
+
+
+def _transpile_dag(dag, basis_gates=None, coupling_map=None,
+ initial_layout=None, skip_numeric_passes=None,
+ seed_mapper=None, pass_manager=None):
"""Transform a dag circuit into another dag circuit (transpile), through
consecutive passes on the dag.
|
{"golden_diff": "diff --git a/qiskit/transpiler/transpiler.py b/qiskit/transpiler/transpiler.py\n--- a/qiskit/transpiler/transpiler.py\n+++ b/qiskit/transpiler/transpiler.py\n@@ -106,22 +106,59 @@\n dag = circuit_to_dag(circuit)\n del circuit\n \n- final_dag = transpile_dag(dag, basis_gates=basis_gates,\n- coupling_map=coupling_map,\n- initial_layout=initial_layout,\n- skip_numeric_passes=is_parametric_circuit,\n- seed_mapper=seed_mapper,\n- pass_manager=pass_manager)\n+ final_dag = _transpile_dag(dag, basis_gates=basis_gates,\n+ coupling_map=coupling_map,\n+ initial_layout=initial_layout,\n+ skip_numeric_passes=is_parametric_circuit,\n+ seed_mapper=seed_mapper,\n+ pass_manager=pass_manager)\n \n out_circuit = dag_to_circuit(final_dag)\n \n return out_circuit\n \n \n-# pylint: disable=redefined-builtin\n def transpile_dag(dag, basis_gates=None, coupling_map=None,\n initial_layout=None, skip_numeric_passes=None,\n seed_mapper=None, pass_manager=None):\n+ \"\"\"Deprecated - Transform a dag circuit into another dag circuit\n+ (transpile), through consecutive passes on the dag.\n+\n+ Args:\n+ dag (DAGCircuit): dag circuit to transform via transpilation\n+ basis_gates (list[str]): list of basis gate names supported by the\n+ target. Default: ['u1','u2','u3','cx','id']\n+ coupling_map (list): A graph of coupling::\n+\n+ [\n+ [control0(int), target0(int)],\n+ [control1(int), target1(int)],\n+ ]\n+\n+ eg. [[0, 2], [1, 2], [1, 3], [3, 4]}\n+\n+ initial_layout (Layout or None): A layout object\n+ skip_numeric_passes (bool): If true, skip passes which require fixed parameter values\n+ seed_mapper (int): random seed_mapper for the swap mapper\n+ pass_manager (PassManager): pass manager instance for the transpilation process\n+ If None, a default set of passes are run.\n+ Otherwise, the passes defined in it will run.\n+ If contains no passes in it, no dag transformations occur.\n+\n+ Returns:\n+ DAGCircuit: transformed dag\n+ \"\"\"\n+\n+ warnings.warn(\"transpile_dag has been deprecated and will be removed in the \"\n+ \"0.9 release. Circuits can be transpiled directly to other \"\n+ \"circuits with the transpile function.\", DeprecationWarning)\n+ return _transpile_dag(dag, basis_gates, coupling_map, initial_layout,\n+ skip_numeric_passes, seed_mapper, pass_manager)\n+\n+\n+def _transpile_dag(dag, basis_gates=None, coupling_map=None,\n+ initial_layout=None, skip_numeric_passes=None,\n+ seed_mapper=None, pass_manager=None):\n \"\"\"Transform a dag circuit into another dag circuit (transpile), through\n consecutive passes on the dag.\n", "issue": "remove transpile_dag\n<!-- \u26a0\ufe0f If you do not respect this template, your issue will be closed -->\r\n<!-- \u26a0\ufe0f Make sure to browse the opened and closed issues to confirm this idea does not exist. -->\r\n\r\n### What is the expected enhancement?\r\nOnce we have pass_manager fully integrated we should remove the function transpile_dag from the transpiler. \r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright 2018, IBM.\n#\n# This source code is licensed under the Apache License, Version 2.0 found in\n# the LICENSE.txt file in the root directory of this source tree.\n\n\"\"\"Tools for compiling a batch of quantum circuits.\"\"\"\nimport logging\nimport warnings\n\nfrom qiskit.circuit import QuantumCircuit\nfrom qiskit.mapper import CouplingMap\nfrom qiskit.tools.parallel import parallel_map\nfrom qiskit.converters import circuit_to_dag\nfrom qiskit.converters import dag_to_circuit\nfrom qiskit.mapper.layout import Layout\nfrom qiskit.transpiler.exceptions import TranspilerError\nfrom qiskit.transpiler.preset_passmanagers import default_pass_manager_simulator, \\\n default_pass_manager\n\nlogger = logging.getLogger(__name__)\n\n\ndef transpile(circuits, backend=None, basis_gates=None, coupling_map=None,\n initial_layout=None, seed_mapper=None, pass_manager=None):\n \"\"\"transpile one or more circuits.\n\n Args:\n circuits (QuantumCircuit or list[QuantumCircuit]): circuits to compile\n backend (BaseBackend): a backend to compile for\n basis_gates (list[str]): list of basis gate names supported by the\n target. Default: ['u1','u2','u3','cx','id']\n coupling_map (list): coupling map (perhaps custom) to target in mapping\n initial_layout (list): initial layout of qubits in mapping\n seed_mapper (int): random seed for the swap_mapper\n pass_manager (PassManager): a pass_manager for the transpiler stages\n\n Returns:\n QuantumCircuit or list[QuantumCircuit]: transpiled circuit(s).\n \"\"\"\n return_form_is_single = False\n if isinstance(circuits, QuantumCircuit):\n circuits = [circuits]\n return_form_is_single = True\n\n # pass manager overrides explicit transpile options (basis_gates, coupling_map)\n # explicit transpile options override options gotten from a backend\n if not pass_manager and backend:\n basis_gates = basis_gates or getattr(backend.configuration(), 'basis_gates', None)\n # This needs to be removed once Aer 0.2 is out\n coupling_map = coupling_map or getattr(backend.configuration(), 'coupling_map', None)\n\n # Convert integer list format to Layout\n if isinstance(initial_layout, list) and \\\n all(isinstance(elem, int) for elem in initial_layout):\n if isinstance(circuits, list):\n circ = circuits[0]\n else:\n circ = circuits\n initial_layout = Layout.generate_from_intlist(initial_layout, *circ.qregs)\n\n if initial_layout is not None and not isinstance(initial_layout, Layout):\n initial_layout = Layout(initial_layout)\n\n circuits = parallel_map(_transpilation, circuits,\n task_kwargs={'basis_gates': basis_gates,\n 'coupling_map': coupling_map,\n 'initial_layout': initial_layout,\n 'seed_mapper': seed_mapper,\n 'pass_manager': pass_manager})\n if return_form_is_single:\n return circuits[0]\n return circuits\n\n\ndef _transpilation(circuit, basis_gates=None, coupling_map=None,\n initial_layout=None, seed_mapper=None,\n pass_manager=None):\n \"\"\"Perform transpilation of a single circuit.\n\n Args:\n circuit (QuantumCircuit): A circuit to transpile.\n basis_gates (list[str]): list of basis gate names supported by the\n target. Default: ['u1','u2','u3','cx','id']\n coupling_map (CouplingMap): coupling map (perhaps custom) to target in mapping\n initial_layout (Layout): initial layout of qubits in mapping\n seed_mapper (int): random seed for the swap_mapper\n pass_manager (PassManager): a pass_manager for the transpiler stage\n\n Returns:\n QuantumCircuit: A transpiled circuit.\n\n Raises:\n TranspilerError: If the Layout does not matches the circuit\n \"\"\"\n if initial_layout is not None and set(circuit.qregs) != initial_layout.get_registers():\n raise TranspilerError('The provided initial layout does not match the registers in '\n 'the circuit \"%s\"' % circuit.name)\n\n if pass_manager and not pass_manager.working_list:\n return circuit\n\n is_parametric_circuit = bool(circuit.unassigned_variables)\n\n dag = circuit_to_dag(circuit)\n del circuit\n\n final_dag = transpile_dag(dag, basis_gates=basis_gates,\n coupling_map=coupling_map,\n initial_layout=initial_layout,\n skip_numeric_passes=is_parametric_circuit,\n seed_mapper=seed_mapper,\n pass_manager=pass_manager)\n\n out_circuit = dag_to_circuit(final_dag)\n\n return out_circuit\n\n\n# pylint: disable=redefined-builtin\ndef transpile_dag(dag, basis_gates=None, coupling_map=None,\n initial_layout=None, skip_numeric_passes=None,\n seed_mapper=None, pass_manager=None):\n \"\"\"Transform a dag circuit into another dag circuit (transpile), through\n consecutive passes on the dag.\n\n Args:\n dag (DAGCircuit): dag circuit to transform via transpilation\n basis_gates (list[str]): list of basis gate names supported by the\n target. Default: ['u1','u2','u3','cx','id']\n coupling_map (list): A graph of coupling::\n\n [\n [control0(int), target0(int)],\n [control1(int), target1(int)],\n ]\n\n eg. [[0, 2], [1, 2], [1, 3], [3, 4]}\n\n initial_layout (Layout or None): A layout object\n skip_numeric_passes (bool): If true, skip passes which require fixed parameter values\n seed_mapper (int): random seed_mapper for the swap mapper\n pass_manager (PassManager): pass manager instance for the transpilation process\n If None, a default set of passes are run.\n Otherwise, the passes defined in it will run.\n If contains no passes in it, no dag transformations occur.\n\n Returns:\n DAGCircuit: transformed dag\n \"\"\"\n # TODO: `basis_gates` will be removed after we have the unroller pass.\n # TODO: `coupling_map`, `initial_layout`, `seed_mapper` removed after mapper pass.\n\n if basis_gates is None:\n basis_gates = ['u1', 'u2', 'u3', 'cx', 'id']\n if isinstance(basis_gates, str):\n warnings.warn(\"The parameter basis_gates is now a list of strings. \"\n \"For example, this basis ['u1','u2','u3','cx'] should be used \"\n \"instead of 'u1,u2,u3,cx'. The string format will be \"\n \"removed after 0.9\", DeprecationWarning, 2)\n basis_gates = basis_gates.split(',')\n\n if pass_manager is None:\n # default set of passes\n\n # if a coupling map is given compile to the map\n if coupling_map:\n pass_manager = default_pass_manager(basis_gates,\n CouplingMap(coupling_map),\n initial_layout,\n skip_numeric_passes,\n seed_mapper=seed_mapper)\n else:\n pass_manager = default_pass_manager_simulator(basis_gates)\n\n # run the passes specified by the pass manager\n # TODO return the property set too. See #1086\n name = dag.name\n dag = pass_manager.run_passes(dag)\n dag.name = name\n\n return dag\n", "path": "qiskit/transpiler/transpiler.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright 2018, IBM.\n#\n# This source code is licensed under the Apache License, Version 2.0 found in\n# the LICENSE.txt file in the root directory of this source tree.\n\n\"\"\"Tools for compiling a batch of quantum circuits.\"\"\"\nimport logging\nimport warnings\n\nfrom qiskit.circuit import QuantumCircuit\nfrom qiskit.mapper import CouplingMap\nfrom qiskit.tools.parallel import parallel_map\nfrom qiskit.converters import circuit_to_dag\nfrom qiskit.converters import dag_to_circuit\nfrom qiskit.mapper.layout import Layout\nfrom qiskit.transpiler.exceptions import TranspilerError\nfrom qiskit.transpiler.preset_passmanagers import default_pass_manager_simulator, \\\n default_pass_manager\n\nlogger = logging.getLogger(__name__)\n\n\ndef transpile(circuits, backend=None, basis_gates=None, coupling_map=None,\n initial_layout=None, seed_mapper=None, pass_manager=None):\n \"\"\"transpile one or more circuits.\n\n Args:\n circuits (QuantumCircuit or list[QuantumCircuit]): circuits to compile\n backend (BaseBackend): a backend to compile for\n basis_gates (list[str]): list of basis gate names supported by the\n target. Default: ['u1','u2','u3','cx','id']\n coupling_map (list): coupling map (perhaps custom) to target in mapping\n initial_layout (list): initial layout of qubits in mapping\n seed_mapper (int): random seed for the swap_mapper\n pass_manager (PassManager): a pass_manager for the transpiler stages\n\n Returns:\n QuantumCircuit or list[QuantumCircuit]: transpiled circuit(s).\n \"\"\"\n return_form_is_single = False\n if isinstance(circuits, QuantumCircuit):\n circuits = [circuits]\n return_form_is_single = True\n\n # pass manager overrides explicit transpile options (basis_gates, coupling_map)\n # explicit transpile options override options gotten from a backend\n if not pass_manager and backend:\n basis_gates = basis_gates or getattr(backend.configuration(), 'basis_gates', None)\n # This needs to be removed once Aer 0.2 is out\n coupling_map = coupling_map or getattr(backend.configuration(), 'coupling_map', None)\n\n # Convert integer list format to Layout\n if isinstance(initial_layout, list) and \\\n all(isinstance(elem, int) for elem in initial_layout):\n if isinstance(circuits, list):\n circ = circuits[0]\n else:\n circ = circuits\n initial_layout = Layout.generate_from_intlist(initial_layout, *circ.qregs)\n\n if initial_layout is not None and not isinstance(initial_layout, Layout):\n initial_layout = Layout(initial_layout)\n\n circuits = parallel_map(_transpilation, circuits,\n task_kwargs={'basis_gates': basis_gates,\n 'coupling_map': coupling_map,\n 'initial_layout': initial_layout,\n 'seed_mapper': seed_mapper,\n 'pass_manager': pass_manager})\n if return_form_is_single:\n return circuits[0]\n return circuits\n\n\ndef _transpilation(circuit, basis_gates=None, coupling_map=None,\n initial_layout=None, seed_mapper=None,\n pass_manager=None):\n \"\"\"Perform transpilation of a single circuit.\n\n Args:\n circuit (QuantumCircuit): A circuit to transpile.\n basis_gates (list[str]): list of basis gate names supported by the\n target. Default: ['u1','u2','u3','cx','id']\n coupling_map (CouplingMap): coupling map (perhaps custom) to target in mapping\n initial_layout (Layout): initial layout of qubits in mapping\n seed_mapper (int): random seed for the swap_mapper\n pass_manager (PassManager): a pass_manager for the transpiler stage\n\n Returns:\n QuantumCircuit: A transpiled circuit.\n\n Raises:\n TranspilerError: If the Layout does not matches the circuit\n \"\"\"\n if initial_layout is not None and set(circuit.qregs) != initial_layout.get_registers():\n raise TranspilerError('The provided initial layout does not match the registers in '\n 'the circuit \"%s\"' % circuit.name)\n\n if pass_manager and not pass_manager.working_list:\n return circuit\n\n is_parametric_circuit = bool(circuit.unassigned_variables)\n\n dag = circuit_to_dag(circuit)\n del circuit\n\n final_dag = _transpile_dag(dag, basis_gates=basis_gates,\n coupling_map=coupling_map,\n initial_layout=initial_layout,\n skip_numeric_passes=is_parametric_circuit,\n seed_mapper=seed_mapper,\n pass_manager=pass_manager)\n\n out_circuit = dag_to_circuit(final_dag)\n\n return out_circuit\n\n\ndef transpile_dag(dag, basis_gates=None, coupling_map=None,\n initial_layout=None, skip_numeric_passes=None,\n seed_mapper=None, pass_manager=None):\n \"\"\"Deprecated - Transform a dag circuit into another dag circuit\n (transpile), through consecutive passes on the dag.\n\n Args:\n dag (DAGCircuit): dag circuit to transform via transpilation\n basis_gates (list[str]): list of basis gate names supported by the\n target. Default: ['u1','u2','u3','cx','id']\n coupling_map (list): A graph of coupling::\n\n [\n [control0(int), target0(int)],\n [control1(int), target1(int)],\n ]\n\n eg. [[0, 2], [1, 2], [1, 3], [3, 4]}\n\n initial_layout (Layout or None): A layout object\n skip_numeric_passes (bool): If true, skip passes which require fixed parameter values\n seed_mapper (int): random seed_mapper for the swap mapper\n pass_manager (PassManager): pass manager instance for the transpilation process\n If None, a default set of passes are run.\n Otherwise, the passes defined in it will run.\n If contains no passes in it, no dag transformations occur.\n\n Returns:\n DAGCircuit: transformed dag\n \"\"\"\n\n warnings.warn(\"transpile_dag has been deprecated and will be removed in the \"\n \"0.9 release. Circuits can be transpiled directly to other \"\n \"circuits with the transpile function.\", DeprecationWarning)\n return _transpile_dag(dag, basis_gates, coupling_map, initial_layout,\n skip_numeric_passes, seed_mapper, pass_manager)\n\n\ndef _transpile_dag(dag, basis_gates=None, coupling_map=None,\n initial_layout=None, skip_numeric_passes=None,\n seed_mapper=None, pass_manager=None):\n \"\"\"Transform a dag circuit into another dag circuit (transpile), through\n consecutive passes on the dag.\n\n Args:\n dag (DAGCircuit): dag circuit to transform via transpilation\n basis_gates (list[str]): list of basis gate names supported by the\n target. Default: ['u1','u2','u3','cx','id']\n coupling_map (list): A graph of coupling::\n\n [\n [control0(int), target0(int)],\n [control1(int), target1(int)],\n ]\n\n eg. [[0, 2], [1, 2], [1, 3], [3, 4]}\n\n initial_layout (Layout or None): A layout object\n skip_numeric_passes (bool): If true, skip passes which require fixed parameter values\n seed_mapper (int): random seed_mapper for the swap mapper\n pass_manager (PassManager): pass manager instance for the transpilation process\n If None, a default set of passes are run.\n Otherwise, the passes defined in it will run.\n If contains no passes in it, no dag transformations occur.\n\n Returns:\n DAGCircuit: transformed dag\n \"\"\"\n # TODO: `basis_gates` will be removed after we have the unroller pass.\n # TODO: `coupling_map`, `initial_layout`, `seed_mapper` removed after mapper pass.\n\n if basis_gates is None:\n basis_gates = ['u1', 'u2', 'u3', 'cx', 'id']\n if isinstance(basis_gates, str):\n warnings.warn(\"The parameter basis_gates is now a list of strings. \"\n \"For example, this basis ['u1','u2','u3','cx'] should be used \"\n \"instead of 'u1,u2,u3,cx'. The string format will be \"\n \"removed after 0.9\", DeprecationWarning, 2)\n basis_gates = basis_gates.split(',')\n\n if pass_manager is None:\n # default set of passes\n\n # if a coupling map is given compile to the map\n if coupling_map:\n pass_manager = default_pass_manager(basis_gates,\n CouplingMap(coupling_map),\n initial_layout,\n skip_numeric_passes,\n seed_mapper=seed_mapper)\n else:\n pass_manager = default_pass_manager_simulator(basis_gates)\n\n # run the passes specified by the pass manager\n # TODO return the property set too. See #1086\n name = dag.name\n dag = pass_manager.run_passes(dag)\n dag.name = name\n\n return dag\n", "path": "qiskit/transpiler/transpiler.py"}]}
| 2,457 | 712 |
gh_patches_debug_9218
|
rasdani/github-patches
|
git_diff
|
marshmallow-code__webargs-498
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Suggest including URL variable parameters in more examples
I'm totally new to Flask, Marshmallow, SQLAlchemy, webargs and this ecosystem. I was given a coding test and while trying to complete it, I had to use flaskparser together with an URL parameter. Not knowing how to configure them to be used together, I googled "flaskparser". The top 5 results are:
- https://webargs.readthedocs.io/en/latest/_modules/webargs/flaskparser.html
- https://webargs.readthedocs.io/en/latest/
- https://webargs.readthedocs.io/en/latest/api.html
- https://webargs.readthedocs.io/en/latest/advanced.html
- https://webargs.readthedocs.io/en/latest/quickstart.html
None of these include an example where an URL variable parameter and webargs are used together. I found the example that I need in [Framework Support](https://github.com/marshmallow-code/webargs/blob/dev/docs/framework_support.rst) (which does not appear on the first page of the Google results) as following:
```
from webargs import fields
from webargs.flaskparser import use_args
@app.route("/user/<int:uid>")
@use_args({"per_page": fields.Int()}, location="query")
def user_detail(args, uid):
return ("The user page for user {uid}, showing {per_page} posts.").format(
uid=uid, per_page=args["per_page"]
)
```
Since the simpler use can can be inferred from the more complex use case, but not vice-versa, I would suggest to either include this code example in [flaskparser.py example](https://github.com/marshmallow-code/webargs/edit/dev/src/webargs/flaskparser.py), or somehow tweak the SEO for https://webargs.readthedocs.io/en/latest/framework_support.html so that it will appear on the first page of Google search results.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/webargs/flaskparser.py`
Content:
```
1 """Flask request argument parsing module.
2
3 Example: ::
4
5 from flask import Flask
6
7 from webargs import fields
8 from webargs.flaskparser import use_args
9
10 app = Flask(__name__)
11
12 hello_args = {
13 'name': fields.Str(required=True)
14 }
15
16 @app.route('/')
17 @use_args(hello_args)
18 def index(args):
19 return 'Hello ' + args['name']
20 """
21 import flask
22 from werkzeug.exceptions import HTTPException
23
24 from webargs import core
25 from webargs.compat import MARSHMALLOW_VERSION_INFO
26 from webargs.multidictproxy import MultiDictProxy
27
28
29 def abort(http_status_code, exc=None, **kwargs):
30 """Raise a HTTPException for the given http_status_code. Attach any keyword
31 arguments to the exception for later processing.
32
33 From Flask-Restful. See NOTICE file for license information.
34 """
35 try:
36 flask.abort(http_status_code)
37 except HTTPException as err:
38 err.data = kwargs
39 err.exc = exc
40 raise err
41
42
43 def is_json_request(req):
44 return core.is_json(req.mimetype)
45
46
47 class FlaskParser(core.Parser):
48 """Flask request argument parser."""
49
50 __location_map__ = dict(
51 view_args="load_view_args",
52 path="load_view_args",
53 **core.Parser.__location_map__,
54 )
55
56 def _raw_load_json(self, req):
57 """Return a json payload from the request for the core parser's load_json
58
59 Checks the input mimetype and may return 'missing' if the mimetype is
60 non-json, even if the request body is parseable as json."""
61 if not is_json_request(req):
62 return core.missing
63
64 return core.parse_json(req.get_data(cache=True))
65
66 def _handle_invalid_json_error(self, error, req, *args, **kwargs):
67 abort(400, exc=error, messages={"json": ["Invalid JSON body."]})
68
69 def load_view_args(self, req, schema):
70 """Return the request's ``view_args`` or ``missing`` if there are none."""
71 return req.view_args or core.missing
72
73 def load_querystring(self, req, schema):
74 """Return query params from the request as a MultiDictProxy."""
75 return MultiDictProxy(req.args, schema)
76
77 def load_form(self, req, schema):
78 """Return form values from the request as a MultiDictProxy."""
79 return MultiDictProxy(req.form, schema)
80
81 def load_headers(self, req, schema):
82 """Return headers from the request as a MultiDictProxy."""
83 return MultiDictProxy(req.headers, schema)
84
85 def load_cookies(self, req, schema):
86 """Return cookies from the request."""
87 return req.cookies
88
89 def load_files(self, req, schema):
90 """Return files from the request as a MultiDictProxy."""
91 return MultiDictProxy(req.files, schema)
92
93 def handle_error(self, error, req, schema, *, error_status_code, error_headers):
94 """Handles errors during parsing. Aborts the current HTTP request and
95 responds with a 422 error.
96 """
97 status_code = error_status_code or self.DEFAULT_VALIDATION_STATUS
98 # on marshmallow 2, a many schema receiving a non-list value will
99 # produce this specific error back -- reformat it to match the
100 # marshmallow 3 message so that Flask can properly encode it
101 messages = error.messages
102 if (
103 MARSHMALLOW_VERSION_INFO[0] < 3
104 and schema.many
105 and messages == {0: {}, "_schema": ["Invalid input type."]}
106 ):
107 messages.pop(0)
108 abort(
109 status_code,
110 exc=error,
111 messages=error.messages,
112 schema=schema,
113 headers=error_headers,
114 )
115
116 def get_default_request(self):
117 """Override to use Flask's thread-local request object by default"""
118 return flask.request
119
120
121 parser = FlaskParser()
122 use_args = parser.use_args
123 use_kwargs = parser.use_kwargs
124
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/src/webargs/flaskparser.py b/src/webargs/flaskparser.py
--- a/src/webargs/flaskparser.py
+++ b/src/webargs/flaskparser.py
@@ -9,14 +9,16 @@
app = Flask(__name__)
- hello_args = {
- 'name': fields.Str(required=True)
+ user_detail_args = {
+ 'per_page': fields.Int()
}
- @app.route('/')
- @use_args(hello_args)
- def index(args):
- return 'Hello ' + args['name']
+ @app.route("/user/<int:uid>")
+ @use_args(user_detail_args)
+ def user_detail(args, uid):
+ return ("The user page for user {uid}, showing {per_page} posts.").format(
+ uid=uid, per_page=args["per_page"]
+ )
"""
import flask
from werkzeug.exceptions import HTTPException
|
{"golden_diff": "diff --git a/src/webargs/flaskparser.py b/src/webargs/flaskparser.py\n--- a/src/webargs/flaskparser.py\n+++ b/src/webargs/flaskparser.py\n@@ -9,14 +9,16 @@\n \n app = Flask(__name__)\n \n- hello_args = {\n- 'name': fields.Str(required=True)\n+ user_detail_args = {\n+ 'per_page': fields.Int()\n }\n \n- @app.route('/')\n- @use_args(hello_args)\n- def index(args):\n- return 'Hello ' + args['name']\n+ @app.route(\"/user/<int:uid>\")\n+ @use_args(user_detail_args)\n+ def user_detail(args, uid):\n+ return (\"The user page for user {uid}, showing {per_page} posts.\").format(\n+ uid=uid, per_page=args[\"per_page\"]\n+ )\n \"\"\"\n import flask\n from werkzeug.exceptions import HTTPException\n", "issue": "Suggest including URL variable parameters in more examples\nI'm totally new to Flask, Marshmallow, SQLAlchemy, webargs and this ecosystem. I was given a coding test and while trying to complete it, I had to use flaskparser together with an URL parameter. Not knowing how to configure them to be used together, I googled \"flaskparser\". The top 5 results are:\r\n\r\n- https://webargs.readthedocs.io/en/latest/_modules/webargs/flaskparser.html\r\n- https://webargs.readthedocs.io/en/latest/\r\n- https://webargs.readthedocs.io/en/latest/api.html\r\n- https://webargs.readthedocs.io/en/latest/advanced.html\r\n- https://webargs.readthedocs.io/en/latest/quickstart.html\r\n\r\nNone of these include an example where an URL variable parameter and webargs are used together. I found the example that I need in [Framework Support](https://github.com/marshmallow-code/webargs/blob/dev/docs/framework_support.rst) (which does not appear on the first page of the Google results) as following:\r\n\r\n```\r\nfrom webargs import fields\r\nfrom webargs.flaskparser import use_args\r\n\r\n\r\n@app.route(\"/user/<int:uid>\")\r\n@use_args({\"per_page\": fields.Int()}, location=\"query\")\r\ndef user_detail(args, uid):\r\n return (\"The user page for user {uid}, showing {per_page} posts.\").format(\r\n uid=uid, per_page=args[\"per_page\"]\r\n )\r\n```\r\n\r\nSince the simpler use can can be inferred from the more complex use case, but not vice-versa, I would suggest to either include this code example in [flaskparser.py example](https://github.com/marshmallow-code/webargs/edit/dev/src/webargs/flaskparser.py), or somehow tweak the SEO for https://webargs.readthedocs.io/en/latest/framework_support.html so that it will appear on the first page of Google search results.\n", "before_files": [{"content": "\"\"\"Flask request argument parsing module.\n\nExample: ::\n\n from flask import Flask\n\n from webargs import fields\n from webargs.flaskparser import use_args\n\n app = Flask(__name__)\n\n hello_args = {\n 'name': fields.Str(required=True)\n }\n\n @app.route('/')\n @use_args(hello_args)\n def index(args):\n return 'Hello ' + args['name']\n\"\"\"\nimport flask\nfrom werkzeug.exceptions import HTTPException\n\nfrom webargs import core\nfrom webargs.compat import MARSHMALLOW_VERSION_INFO\nfrom webargs.multidictproxy import MultiDictProxy\n\n\ndef abort(http_status_code, exc=None, **kwargs):\n \"\"\"Raise a HTTPException for the given http_status_code. Attach any keyword\n arguments to the exception for later processing.\n\n From Flask-Restful. See NOTICE file for license information.\n \"\"\"\n try:\n flask.abort(http_status_code)\n except HTTPException as err:\n err.data = kwargs\n err.exc = exc\n raise err\n\n\ndef is_json_request(req):\n return core.is_json(req.mimetype)\n\n\nclass FlaskParser(core.Parser):\n \"\"\"Flask request argument parser.\"\"\"\n\n __location_map__ = dict(\n view_args=\"load_view_args\",\n path=\"load_view_args\",\n **core.Parser.__location_map__,\n )\n\n def _raw_load_json(self, req):\n \"\"\"Return a json payload from the request for the core parser's load_json\n\n Checks the input mimetype and may return 'missing' if the mimetype is\n non-json, even if the request body is parseable as json.\"\"\"\n if not is_json_request(req):\n return core.missing\n\n return core.parse_json(req.get_data(cache=True))\n\n def _handle_invalid_json_error(self, error, req, *args, **kwargs):\n abort(400, exc=error, messages={\"json\": [\"Invalid JSON body.\"]})\n\n def load_view_args(self, req, schema):\n \"\"\"Return the request's ``view_args`` or ``missing`` if there are none.\"\"\"\n return req.view_args or core.missing\n\n def load_querystring(self, req, schema):\n \"\"\"Return query params from the request as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.args, schema)\n\n def load_form(self, req, schema):\n \"\"\"Return form values from the request as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.form, schema)\n\n def load_headers(self, req, schema):\n \"\"\"Return headers from the request as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.headers, schema)\n\n def load_cookies(self, req, schema):\n \"\"\"Return cookies from the request.\"\"\"\n return req.cookies\n\n def load_files(self, req, schema):\n \"\"\"Return files from the request as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.files, schema)\n\n def handle_error(self, error, req, schema, *, error_status_code, error_headers):\n \"\"\"Handles errors during parsing. Aborts the current HTTP request and\n responds with a 422 error.\n \"\"\"\n status_code = error_status_code or self.DEFAULT_VALIDATION_STATUS\n # on marshmallow 2, a many schema receiving a non-list value will\n # produce this specific error back -- reformat it to match the\n # marshmallow 3 message so that Flask can properly encode it\n messages = error.messages\n if (\n MARSHMALLOW_VERSION_INFO[0] < 3\n and schema.many\n and messages == {0: {}, \"_schema\": [\"Invalid input type.\"]}\n ):\n messages.pop(0)\n abort(\n status_code,\n exc=error,\n messages=error.messages,\n schema=schema,\n headers=error_headers,\n )\n\n def get_default_request(self):\n \"\"\"Override to use Flask's thread-local request object by default\"\"\"\n return flask.request\n\n\nparser = FlaskParser()\nuse_args = parser.use_args\nuse_kwargs = parser.use_kwargs\n", "path": "src/webargs/flaskparser.py"}], "after_files": [{"content": "\"\"\"Flask request argument parsing module.\n\nExample: ::\n\n from flask import Flask\n\n from webargs import fields\n from webargs.flaskparser import use_args\n\n app = Flask(__name__)\n\n user_detail_args = {\n 'per_page': fields.Int()\n }\n\n @app.route(\"/user/<int:uid>\")\n @use_args(user_detail_args)\n def user_detail(args, uid):\n return (\"The user page for user {uid}, showing {per_page} posts.\").format(\n uid=uid, per_page=args[\"per_page\"]\n )\n\"\"\"\nimport flask\nfrom werkzeug.exceptions import HTTPException\n\nfrom webargs import core\nfrom webargs.compat import MARSHMALLOW_VERSION_INFO\nfrom webargs.multidictproxy import MultiDictProxy\n\n\ndef abort(http_status_code, exc=None, **kwargs):\n \"\"\"Raise a HTTPException for the given http_status_code. Attach any keyword\n arguments to the exception for later processing.\n\n From Flask-Restful. See NOTICE file for license information.\n \"\"\"\n try:\n flask.abort(http_status_code)\n except HTTPException as err:\n err.data = kwargs\n err.exc = exc\n raise err\n\n\ndef is_json_request(req):\n return core.is_json(req.mimetype)\n\n\nclass FlaskParser(core.Parser):\n \"\"\"Flask request argument parser.\"\"\"\n\n __location_map__ = dict(\n view_args=\"load_view_args\",\n path=\"load_view_args\",\n **core.Parser.__location_map__,\n )\n\n def _raw_load_json(self, req):\n \"\"\"Return a json payload from the request for the core parser's load_json\n\n Checks the input mimetype and may return 'missing' if the mimetype is\n non-json, even if the request body is parseable as json.\"\"\"\n if not is_json_request(req):\n return core.missing\n\n return core.parse_json(req.get_data(cache=True))\n\n def _handle_invalid_json_error(self, error, req, *args, **kwargs):\n abort(400, exc=error, messages={\"json\": [\"Invalid JSON body.\"]})\n\n def load_view_args(self, req, schema):\n \"\"\"Return the request's ``view_args`` or ``missing`` if there are none.\"\"\"\n return req.view_args or core.missing\n\n def load_querystring(self, req, schema):\n \"\"\"Return query params from the request as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.args, schema)\n\n def load_form(self, req, schema):\n \"\"\"Return form values from the request as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.form, schema)\n\n def load_headers(self, req, schema):\n \"\"\"Return headers from the request as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.headers, schema)\n\n def load_cookies(self, req, schema):\n \"\"\"Return cookies from the request.\"\"\"\n return req.cookies\n\n def load_files(self, req, schema):\n \"\"\"Return files from the request as a MultiDictProxy.\"\"\"\n return MultiDictProxy(req.files, schema)\n\n def handle_error(self, error, req, schema, *, error_status_code, error_headers):\n \"\"\"Handles errors during parsing. Aborts the current HTTP request and\n responds with a 422 error.\n \"\"\"\n status_code = error_status_code or self.DEFAULT_VALIDATION_STATUS\n # on marshmallow 2, a many schema receiving a non-list value will\n # produce this specific error back -- reformat it to match the\n # marshmallow 3 message so that Flask can properly encode it\n messages = error.messages\n if (\n MARSHMALLOW_VERSION_INFO[0] < 3\n and schema.many\n and messages == {0: {}, \"_schema\": [\"Invalid input type.\"]}\n ):\n messages.pop(0)\n abort(\n status_code,\n exc=error,\n messages=error.messages,\n schema=schema,\n headers=error_headers,\n )\n\n def get_default_request(self):\n \"\"\"Override to use Flask's thread-local request object by default\"\"\"\n return flask.request\n\n\nparser = FlaskParser()\nuse_args = parser.use_args\nuse_kwargs = parser.use_kwargs\n", "path": "src/webargs/flaskparser.py"}]}
| 1,790 | 207 |
gh_patches_debug_4065
|
rasdani/github-patches
|
git_diff
|
conda-forge__conda-smithy-577
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
linter false positive with selectors
https://github.com/conda-forge/staged-recipes/pull/3992 got a `Selectors are suggested to take a <two spaces>#<one space>[<expression>] form.` error, when the only selector actually is spaced properly.
Looking at it a bit, `selector_lines` thinks that the following two lines have selectors:
```
- inotifywatch --help > /dev/null || [[ $? == 1 ]]
- inotifywait --help > /dev/null || [[ $? == 1 ]]
```
I guess that conda-build would actually identify this line as a selector, but the linter message is pretty confusing. Should we print line numbers or something?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conda_smithy/lint_recipe.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 from __future__ import unicode_literals
4
5 import io
6 import itertools
7 import os
8 import re
9 import github
10
11 import jinja2
12 import ruamel.yaml
13
14 from conda_build.metadata import ensure_valid_license_family
15
16
17 EXPECTED_SECTION_ORDER = ['package', 'source', 'build', 'requirements',
18 'test', 'app', 'about', 'extra']
19
20 REQUIREMENTS_ORDER = ['build', 'run']
21
22 TEST_KEYS = {'imports', 'commands'}
23
24
25 class NullUndefined(jinja2.Undefined):
26 def __unicode__(self):
27 return self._undefined_name
28
29 def __getattr__(self, name):
30 return '{}.{}'.format(self, name)
31
32 def __getitem__(self, name):
33 return '{}["{}"]'.format(self, name)
34
35
36 def get_section(parent, name, lints):
37 section = parent.get(name, {})
38 if not isinstance(section, dict):
39 lints.append('The "{}" section was expected to be a dictionary, but '
40 'got a {}.'.format(name, type(section).__name__))
41 section = {}
42 return section
43
44
45 def lintify(meta, recipe_dir=None, conda_forge=False):
46 lints = []
47 major_sections = list(meta.keys())
48
49 # If the recipe_dir exists (no guarantee within this function) , we can
50 # find the meta.yaml within it.
51 meta_fname = os.path.join(recipe_dir or '', 'meta.yaml')
52
53 source_section = get_section(meta, 'source', lints)
54 build_section = get_section(meta, 'build', lints)
55 requirements_section = get_section(meta, 'requirements', lints)
56 test_section = get_section(meta, 'test', lints)
57 about_section = get_section(meta, 'about', lints)
58 extra_section = get_section(meta, 'extra', lints)
59 package_section = get_section(meta, 'package', lints)
60
61 # 1: Top level meta.yaml keys should have a specific order.
62 section_order_sorted = sorted(major_sections,
63 key=EXPECTED_SECTION_ORDER.index)
64 if major_sections != section_order_sorted:
65 section_order_sorted_str = map(lambda s: "'%s'" % s,
66 section_order_sorted)
67 section_order_sorted_str = ", ".join(section_order_sorted_str)
68 section_order_sorted_str = "[" + section_order_sorted_str + "]"
69 lints.append('The top level meta keys are in an unexpected order. '
70 'Expecting {}.'.format(section_order_sorted_str))
71
72 # 2: The about section should have a home, license and summary.
73 for about_item in ['home', 'license', 'summary']:
74 # if the section doesn't exist, or is just empty, lint it.
75 if not about_section.get(about_item, ''):
76 lints.append('The {} item is expected in the about section.'
77 ''.format(about_item))
78
79 # 3a: The recipe should have some maintainers.
80 if not extra_section.get('recipe-maintainers', []):
81 lints.append('The recipe could do with some maintainers listed in '
82 'the `extra/recipe-maintainers` section.')
83
84 # 3b: Maintainers should be a list
85 if not isinstance(extra_section.get('recipe-maintainers', []), list):
86 lints.append('Recipe maintainers should be a json list.')
87
88 # 4: The recipe should have some tests.
89 if not any(key in TEST_KEYS for key in test_section):
90 test_files = ['run_test.py', 'run_test.sh', 'run_test.bat',
91 'run_test.pl']
92 a_test_file_exists = (recipe_dir is not None and
93 any(os.path.exists(os.path.join(recipe_dir,
94 test_file))
95 for test_file in test_files))
96 if not a_test_file_exists:
97 lints.append('The recipe must have some tests.')
98
99 # 5: License cannot be 'unknown.'
100 license = about_section.get('license', '').lower()
101 if 'unknown' == license.strip():
102 lints.append('The recipe license cannot be unknown.')
103
104 # 6: Selectors should be in a tidy form.
105 if recipe_dir is not None and os.path.exists(meta_fname):
106 bad_selectors = []
107 # Good selectors look like ".*\s\s#\s[...]"
108 good_selectors_pat = re.compile(r'(.+?)\s{2,}#\s\[(.+)\](?(2).*)$')
109 with io.open(meta_fname, 'rt') as fh:
110 for selector_line in selector_lines(fh):
111 if not good_selectors_pat.match(selector_line):
112 bad_selectors.append(selector_line)
113 if bad_selectors:
114 lints.append('Selectors are suggested to take a '
115 '``<two spaces>#<one space>[<expression>]`` form.')
116
117 # 7: The build section should have a build number.
118 if build_section.get('number', None) is None:
119 lints.append('The recipe must have a `build/number` section.')
120
121 # 8: The build section should be before the run section in requirements.
122 requirements_order_sorted = sorted(requirements_section,
123 key=REQUIREMENTS_ORDER.index)
124 if list(requirements_section.keys()) != requirements_order_sorted:
125 lints.append('The `requirements/build` section should be defined '
126 'before the `requirements/run` section.')
127
128 # 9: Files downloaded should have a hash.
129 if ('url' in source_section and
130 not ({'sha1', 'sha256', 'md5'} & set(source_section.keys()))):
131 lints.append('When defining a source/url please add a sha256, sha1 '
132 'or md5 checksum (sha256 preferably).')
133
134 # 10: License should not include the word 'license'.
135 license = about_section.get('license', '').lower()
136 if 'license' in license.lower():
137 lints.append('The recipe `license` should not include the word '
138 '"License".')
139
140 # 11: There should be one empty line at the end of the file.
141 if recipe_dir is not None and os.path.exists(meta_fname):
142 with io.open(meta_fname, 'r') as f:
143 lines = f.read().split('\n')
144 # Count the number of empty lines from the end of the file
145 empty_lines = itertools.takewhile(lambda x: x == '', reversed(lines))
146 end_empty_lines_count = len(list(empty_lines))
147 if end_empty_lines_count > 1:
148 lints.append('There are {} too many lines. '
149 'There should be one empty line at the end of the '
150 'file.'.format(end_empty_lines_count - 1))
151 elif end_empty_lines_count < 1:
152 lints.append('There are too few lines. There should be one empty '
153 'line at the end of the file.')
154
155 # 12: License family must be valid (conda-build checks for that)
156 try:
157 ensure_valid_license_family(meta)
158 except RuntimeError as e:
159 lints.append(str(e))
160
161 # 13: Check that the recipe name is valid
162 recipe_name = package_section.get('name', '').strip()
163 if re.match('^[a-z0-9_\-.]+$', recipe_name) is None:
164 lints.append('Recipe name has invalid characters. only lowercase alpha, numeric, '
165 'underscores, hyphens and dots allowed')
166
167 # 14: Run conda-forge specific lints
168 if conda_forge:
169 run_conda_forge_lints(meta, recipe_dir, lints)
170
171 # 15: Check if we are using legacy patterns
172 build_reqs = requirements_section.get('build', None)
173 if build_reqs and ('numpy x.x' in build_reqs):
174 lints.append('Using pinned numpy packages is a deprecated pattern. Consider '
175 'using the method outlined '
176 '[here](https://conda-forge.org/docs/meta.html#building-against-numpy).')
177
178 return lints
179
180
181 def run_conda_forge_lints(meta, recipe_dir, lints):
182 gh = github.Github(os.environ['GH_TOKEN'])
183 package_section = get_section(meta, 'package', lints)
184 extra_section = get_section(meta, 'extra', lints)
185 recipe_dirname = os.path.basename(recipe_dir) if recipe_dir else 'recipe'
186 recipe_name = package_section.get('name', '').strip()
187 is_staged_recipes = recipe_dirname != 'recipe'
188
189 # 1: Check that the recipe does not exist in conda-forge
190 if is_staged_recipes:
191 cf = gh.get_user(os.getenv('GH_ORG', 'conda-forge'))
192 try:
193 cf.get_repo('{}-feedstock'.format(recipe_name))
194 feedstock_exists = True
195 except github.UnknownObjectException as e:
196 feedstock_exists = False
197
198 if feedstock_exists:
199 lints.append('Feedstock with the same name exists in conda-forge')
200
201 # 2: Check that the recipe maintainers exists:
202 maintainers = extra_section.get('recipe-maintainers', [])
203 for maintainer in maintainers:
204 try:
205 gh.get_user(maintainer)
206 except github.UnknownObjectException as e:
207 lints.append('Recipe maintainer "{}" does not exist'.format(maintainer))
208
209
210 def selector_lines(lines):
211 # Using the same pattern defined in conda-build (metadata.py),
212 # we identify selectors.
213 sel_pat = re.compile(r'(.+?)\s*(#.*)?\[(.+)\](?(2).*)$')
214
215 for line in lines:
216 line = line.rstrip()
217 if line.lstrip().startswith('#'):
218 # Don't bother with comment only lines
219 continue
220 m = sel_pat.match(line)
221 if m:
222 m.group(3)
223 yield line
224
225
226 def main(recipe_dir, conda_forge=False):
227 recipe_dir = os.path.abspath(recipe_dir)
228 recipe_meta = os.path.join(recipe_dir, 'meta.yaml')
229 if not os.path.exists(recipe_dir):
230 raise IOError('Feedstock has no recipe/meta.yaml.')
231
232 env = jinja2.Environment(undefined=NullUndefined)
233
234 with io.open(recipe_meta, 'rt') as fh:
235 content = env.from_string(''.join(fh)).render(os=os)
236 meta = ruamel.yaml.load(content, ruamel.yaml.RoundTripLoader)
237 results = lintify(meta, recipe_dir, conda_forge)
238 return results
239
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/conda_smithy/lint_recipe.py b/conda_smithy/lint_recipe.py
--- a/conda_smithy/lint_recipe.py
+++ b/conda_smithy/lint_recipe.py
@@ -210,7 +210,7 @@
def selector_lines(lines):
# Using the same pattern defined in conda-build (metadata.py),
# we identify selectors.
- sel_pat = re.compile(r'(.+?)\s*(#.*)?\[(.+)\](?(2).*)$')
+ sel_pat = re.compile(r'(.+?)\s*(#.*)?\[([^\[\]]+)\](?(2).*)$')
for line in lines:
line = line.rstrip()
|
{"golden_diff": "diff --git a/conda_smithy/lint_recipe.py b/conda_smithy/lint_recipe.py\n--- a/conda_smithy/lint_recipe.py\n+++ b/conda_smithy/lint_recipe.py\n@@ -210,7 +210,7 @@\n def selector_lines(lines):\n # Using the same pattern defined in conda-build (metadata.py),\n # we identify selectors.\n- sel_pat = re.compile(r'(.+?)\\s*(#.*)?\\[(.+)\\](?(2).*)$')\n+ sel_pat = re.compile(r'(.+?)\\s*(#.*)?\\[([^\\[\\]]+)\\](?(2).*)$')\n \n for line in lines:\n line = line.rstrip()\n", "issue": "linter false positive with selectors\nhttps://github.com/conda-forge/staged-recipes/pull/3992 got a `Selectors are suggested to take a <two spaces>#<one space>[<expression>] form.` error, when the only selector actually is spaced properly.\r\n\r\nLooking at it a bit, `selector_lines` thinks that the following two lines have selectors:\r\n```\r\n - inotifywatch --help > /dev/null || [[ $? == 1 ]]\r\n - inotifywait --help > /dev/null || [[ $? == 1 ]]\r\n```\r\nI guess that conda-build would actually identify this line as a selector, but the linter message is pretty confusing. Should we print line numbers or something?\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport io\nimport itertools\nimport os\nimport re\nimport github\n\nimport jinja2\nimport ruamel.yaml\n\nfrom conda_build.metadata import ensure_valid_license_family\n\n\nEXPECTED_SECTION_ORDER = ['package', 'source', 'build', 'requirements',\n 'test', 'app', 'about', 'extra']\n\nREQUIREMENTS_ORDER = ['build', 'run']\n\nTEST_KEYS = {'imports', 'commands'}\n\n\nclass NullUndefined(jinja2.Undefined):\n def __unicode__(self):\n return self._undefined_name\n\n def __getattr__(self, name):\n return '{}.{}'.format(self, name)\n\n def __getitem__(self, name):\n return '{}[\"{}\"]'.format(self, name)\n\n\ndef get_section(parent, name, lints):\n section = parent.get(name, {})\n if not isinstance(section, dict):\n lints.append('The \"{}\" section was expected to be a dictionary, but '\n 'got a {}.'.format(name, type(section).__name__))\n section = {}\n return section\n\n\ndef lintify(meta, recipe_dir=None, conda_forge=False):\n lints = []\n major_sections = list(meta.keys())\n\n # If the recipe_dir exists (no guarantee within this function) , we can\n # find the meta.yaml within it.\n meta_fname = os.path.join(recipe_dir or '', 'meta.yaml')\n\n source_section = get_section(meta, 'source', lints)\n build_section = get_section(meta, 'build', lints)\n requirements_section = get_section(meta, 'requirements', lints)\n test_section = get_section(meta, 'test', lints)\n about_section = get_section(meta, 'about', lints)\n extra_section = get_section(meta, 'extra', lints)\n package_section = get_section(meta, 'package', lints)\n\n # 1: Top level meta.yaml keys should have a specific order.\n section_order_sorted = sorted(major_sections,\n key=EXPECTED_SECTION_ORDER.index)\n if major_sections != section_order_sorted:\n section_order_sorted_str = map(lambda s: \"'%s'\" % s,\n section_order_sorted)\n section_order_sorted_str = \", \".join(section_order_sorted_str)\n section_order_sorted_str = \"[\" + section_order_sorted_str + \"]\"\n lints.append('The top level meta keys are in an unexpected order. '\n 'Expecting {}.'.format(section_order_sorted_str))\n\n # 2: The about section should have a home, license and summary.\n for about_item in ['home', 'license', 'summary']:\n # if the section doesn't exist, or is just empty, lint it.\n if not about_section.get(about_item, ''):\n lints.append('The {} item is expected in the about section.'\n ''.format(about_item))\n\n # 3a: The recipe should have some maintainers.\n if not extra_section.get('recipe-maintainers', []):\n lints.append('The recipe could do with some maintainers listed in '\n 'the `extra/recipe-maintainers` section.')\n\n # 3b: Maintainers should be a list\n if not isinstance(extra_section.get('recipe-maintainers', []), list):\n lints.append('Recipe maintainers should be a json list.')\n\n # 4: The recipe should have some tests.\n if not any(key in TEST_KEYS for key in test_section):\n test_files = ['run_test.py', 'run_test.sh', 'run_test.bat',\n 'run_test.pl']\n a_test_file_exists = (recipe_dir is not None and\n any(os.path.exists(os.path.join(recipe_dir,\n test_file))\n for test_file in test_files))\n if not a_test_file_exists:\n lints.append('The recipe must have some tests.')\n\n # 5: License cannot be 'unknown.'\n license = about_section.get('license', '').lower()\n if 'unknown' == license.strip():\n lints.append('The recipe license cannot be unknown.')\n\n # 6: Selectors should be in a tidy form.\n if recipe_dir is not None and os.path.exists(meta_fname):\n bad_selectors = []\n # Good selectors look like \".*\\s\\s#\\s[...]\"\n good_selectors_pat = re.compile(r'(.+?)\\s{2,}#\\s\\[(.+)\\](?(2).*)$')\n with io.open(meta_fname, 'rt') as fh:\n for selector_line in selector_lines(fh):\n if not good_selectors_pat.match(selector_line):\n bad_selectors.append(selector_line)\n if bad_selectors:\n lints.append('Selectors are suggested to take a '\n '``<two spaces>#<one space>[<expression>]`` form.')\n\n # 7: The build section should have a build number.\n if build_section.get('number', None) is None:\n lints.append('The recipe must have a `build/number` section.')\n\n # 8: The build section should be before the run section in requirements.\n requirements_order_sorted = sorted(requirements_section,\n key=REQUIREMENTS_ORDER.index)\n if list(requirements_section.keys()) != requirements_order_sorted:\n lints.append('The `requirements/build` section should be defined '\n 'before the `requirements/run` section.')\n\n # 9: Files downloaded should have a hash.\n if ('url' in source_section and\n not ({'sha1', 'sha256', 'md5'} & set(source_section.keys()))):\n lints.append('When defining a source/url please add a sha256, sha1 '\n 'or md5 checksum (sha256 preferably).')\n\n # 10: License should not include the word 'license'.\n license = about_section.get('license', '').lower()\n if 'license' in license.lower():\n lints.append('The recipe `license` should not include the word '\n '\"License\".')\n\n # 11: There should be one empty line at the end of the file.\n if recipe_dir is not None and os.path.exists(meta_fname):\n with io.open(meta_fname, 'r') as f:\n lines = f.read().split('\\n')\n # Count the number of empty lines from the end of the file\n empty_lines = itertools.takewhile(lambda x: x == '', reversed(lines))\n end_empty_lines_count = len(list(empty_lines))\n if end_empty_lines_count > 1:\n lints.append('There are {} too many lines. '\n 'There should be one empty line at the end of the '\n 'file.'.format(end_empty_lines_count - 1))\n elif end_empty_lines_count < 1:\n lints.append('There are too few lines. There should be one empty '\n 'line at the end of the file.')\n\n # 12: License family must be valid (conda-build checks for that)\n try:\n ensure_valid_license_family(meta)\n except RuntimeError as e:\n lints.append(str(e))\n\n # 13: Check that the recipe name is valid\n recipe_name = package_section.get('name', '').strip()\n if re.match('^[a-z0-9_\\-.]+$', recipe_name) is None:\n lints.append('Recipe name has invalid characters. only lowercase alpha, numeric, '\n 'underscores, hyphens and dots allowed')\n\n # 14: Run conda-forge specific lints\n if conda_forge:\n run_conda_forge_lints(meta, recipe_dir, lints)\n\n # 15: Check if we are using legacy patterns\n build_reqs = requirements_section.get('build', None)\n if build_reqs and ('numpy x.x' in build_reqs):\n lints.append('Using pinned numpy packages is a deprecated pattern. Consider '\n 'using the method outlined '\n '[here](https://conda-forge.org/docs/meta.html#building-against-numpy).')\n\n return lints\n\n\ndef run_conda_forge_lints(meta, recipe_dir, lints):\n gh = github.Github(os.environ['GH_TOKEN'])\n package_section = get_section(meta, 'package', lints)\n extra_section = get_section(meta, 'extra', lints)\n recipe_dirname = os.path.basename(recipe_dir) if recipe_dir else 'recipe'\n recipe_name = package_section.get('name', '').strip()\n is_staged_recipes = recipe_dirname != 'recipe'\n\n # 1: Check that the recipe does not exist in conda-forge\n if is_staged_recipes:\n cf = gh.get_user(os.getenv('GH_ORG', 'conda-forge'))\n try:\n cf.get_repo('{}-feedstock'.format(recipe_name))\n feedstock_exists = True\n except github.UnknownObjectException as e:\n feedstock_exists = False\n\n if feedstock_exists:\n lints.append('Feedstock with the same name exists in conda-forge')\n\n # 2: Check that the recipe maintainers exists:\n maintainers = extra_section.get('recipe-maintainers', [])\n for maintainer in maintainers:\n try:\n gh.get_user(maintainer)\n except github.UnknownObjectException as e:\n lints.append('Recipe maintainer \"{}\" does not exist'.format(maintainer))\n\n\ndef selector_lines(lines):\n # Using the same pattern defined in conda-build (metadata.py),\n # we identify selectors.\n sel_pat = re.compile(r'(.+?)\\s*(#.*)?\\[(.+)\\](?(2).*)$')\n\n for line in lines:\n line = line.rstrip()\n if line.lstrip().startswith('#'):\n # Don't bother with comment only lines\n continue\n m = sel_pat.match(line)\n if m:\n m.group(3)\n yield line\n\n\ndef main(recipe_dir, conda_forge=False):\n recipe_dir = os.path.abspath(recipe_dir)\n recipe_meta = os.path.join(recipe_dir, 'meta.yaml')\n if not os.path.exists(recipe_dir):\n raise IOError('Feedstock has no recipe/meta.yaml.')\n\n env = jinja2.Environment(undefined=NullUndefined)\n\n with io.open(recipe_meta, 'rt') as fh:\n content = env.from_string(''.join(fh)).render(os=os)\n meta = ruamel.yaml.load(content, ruamel.yaml.RoundTripLoader)\n results = lintify(meta, recipe_dir, conda_forge)\n return results\n", "path": "conda_smithy/lint_recipe.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport io\nimport itertools\nimport os\nimport re\nimport github\n\nimport jinja2\nimport ruamel.yaml\n\nfrom conda_build.metadata import ensure_valid_license_family\n\n\nEXPECTED_SECTION_ORDER = ['package', 'source', 'build', 'requirements',\n 'test', 'app', 'about', 'extra']\n\nREQUIREMENTS_ORDER = ['build', 'run']\n\nTEST_KEYS = {'imports', 'commands'}\n\n\nclass NullUndefined(jinja2.Undefined):\n def __unicode__(self):\n return self._undefined_name\n\n def __getattr__(self, name):\n return '{}.{}'.format(self, name)\n\n def __getitem__(self, name):\n return '{}[\"{}\"]'.format(self, name)\n\n\ndef get_section(parent, name, lints):\n section = parent.get(name, {})\n if not isinstance(section, dict):\n lints.append('The \"{}\" section was expected to be a dictionary, but '\n 'got a {}.'.format(name, type(section).__name__))\n section = {}\n return section\n\n\ndef lintify(meta, recipe_dir=None, conda_forge=False):\n lints = []\n major_sections = list(meta.keys())\n\n # If the recipe_dir exists (no guarantee within this function) , we can\n # find the meta.yaml within it.\n meta_fname = os.path.join(recipe_dir or '', 'meta.yaml')\n\n source_section = get_section(meta, 'source', lints)\n build_section = get_section(meta, 'build', lints)\n requirements_section = get_section(meta, 'requirements', lints)\n test_section = get_section(meta, 'test', lints)\n about_section = get_section(meta, 'about', lints)\n extra_section = get_section(meta, 'extra', lints)\n package_section = get_section(meta, 'package', lints)\n\n # 1: Top level meta.yaml keys should have a specific order.\n section_order_sorted = sorted(major_sections,\n key=EXPECTED_SECTION_ORDER.index)\n if major_sections != section_order_sorted:\n section_order_sorted_str = map(lambda s: \"'%s'\" % s,\n section_order_sorted)\n section_order_sorted_str = \", \".join(section_order_sorted_str)\n section_order_sorted_str = \"[\" + section_order_sorted_str + \"]\"\n lints.append('The top level meta keys are in an unexpected order. '\n 'Expecting {}.'.format(section_order_sorted_str))\n\n # 2: The about section should have a home, license and summary.\n for about_item in ['home', 'license', 'summary']:\n # if the section doesn't exist, or is just empty, lint it.\n if not about_section.get(about_item, ''):\n lints.append('The {} item is expected in the about section.'\n ''.format(about_item))\n\n # 3a: The recipe should have some maintainers.\n if not extra_section.get('recipe-maintainers', []):\n lints.append('The recipe could do with some maintainers listed in '\n 'the `extra/recipe-maintainers` section.')\n\n # 3b: Maintainers should be a list\n if not isinstance(extra_section.get('recipe-maintainers', []), list):\n lints.append('Recipe maintainers should be a json list.')\n\n # 4: The recipe should have some tests.\n if not any(key in TEST_KEYS for key in test_section):\n test_files = ['run_test.py', 'run_test.sh', 'run_test.bat',\n 'run_test.pl']\n a_test_file_exists = (recipe_dir is not None and\n any(os.path.exists(os.path.join(recipe_dir,\n test_file))\n for test_file in test_files))\n if not a_test_file_exists:\n lints.append('The recipe must have some tests.')\n\n # 5: License cannot be 'unknown.'\n license = about_section.get('license', '').lower()\n if 'unknown' == license.strip():\n lints.append('The recipe license cannot be unknown.')\n\n # 6: Selectors should be in a tidy form.\n if recipe_dir is not None and os.path.exists(meta_fname):\n bad_selectors = []\n # Good selectors look like \".*\\s\\s#\\s[...]\"\n good_selectors_pat = re.compile(r'(.+?)\\s{2,}#\\s\\[(.+)\\](?(2).*)$')\n with io.open(meta_fname, 'rt') as fh:\n for selector_line in selector_lines(fh):\n if not good_selectors_pat.match(selector_line):\n bad_selectors.append(selector_line)\n if bad_selectors:\n lints.append('Selectors are suggested to take a '\n '``<two spaces>#<one space>[<expression>]`` form.')\n\n # 7: The build section should have a build number.\n if build_section.get('number', None) is None:\n lints.append('The recipe must have a `build/number` section.')\n\n # 8: The build section should be before the run section in requirements.\n requirements_order_sorted = sorted(requirements_section,\n key=REQUIREMENTS_ORDER.index)\n if list(requirements_section.keys()) != requirements_order_sorted:\n lints.append('The `requirements/build` section should be defined '\n 'before the `requirements/run` section.')\n\n # 9: Files downloaded should have a hash.\n if ('url' in source_section and\n not ({'sha1', 'sha256', 'md5'} & set(source_section.keys()))):\n lints.append('When defining a source/url please add a sha256, sha1 '\n 'or md5 checksum (sha256 preferably).')\n\n # 10: License should not include the word 'license'.\n license = about_section.get('license', '').lower()\n if 'license' in license.lower():\n lints.append('The recipe `license` should not include the word '\n '\"License\".')\n\n # 11: There should be one empty line at the end of the file.\n if recipe_dir is not None and os.path.exists(meta_fname):\n with io.open(meta_fname, 'r') as f:\n lines = f.read().split('\\n')\n # Count the number of empty lines from the end of the file\n empty_lines = itertools.takewhile(lambda x: x == '', reversed(lines))\n end_empty_lines_count = len(list(empty_lines))\n if end_empty_lines_count > 1:\n lints.append('There are {} too many lines. '\n 'There should be one empty line at the end of the '\n 'file.'.format(end_empty_lines_count - 1))\n elif end_empty_lines_count < 1:\n lints.append('There are too few lines. There should be one empty '\n 'line at the end of the file.')\n\n # 12: License family must be valid (conda-build checks for that)\n try:\n ensure_valid_license_family(meta)\n except RuntimeError as e:\n lints.append(str(e))\n\n # 13: Check that the recipe name is valid\n recipe_name = package_section.get('name', '').strip()\n if re.match('^[a-z0-9_\\-.]+$', recipe_name) is None:\n lints.append('Recipe name has invalid characters. only lowercase alpha, numeric, '\n 'underscores, hyphens and dots allowed')\n\n # 14: Run conda-forge specific lints\n if conda_forge:\n run_conda_forge_lints(meta, recipe_dir, lints)\n\n # 15: Check if we are using legacy patterns\n build_reqs = requirements_section.get('build', None)\n if build_reqs and ('numpy x.x' in build_reqs):\n lints.append('Using pinned numpy packages is a deprecated pattern. Consider '\n 'using the method outlined '\n '[here](https://conda-forge.org/docs/meta.html#building-against-numpy).')\n\n return lints\n\n\ndef run_conda_forge_lints(meta, recipe_dir, lints):\n gh = github.Github(os.environ['GH_TOKEN'])\n package_section = get_section(meta, 'package', lints)\n extra_section = get_section(meta, 'extra', lints)\n recipe_dirname = os.path.basename(recipe_dir) if recipe_dir else 'recipe'\n recipe_name = package_section.get('name', '').strip()\n is_staged_recipes = recipe_dirname != 'recipe'\n\n # 1: Check that the recipe does not exist in conda-forge\n if is_staged_recipes:\n cf = gh.get_user(os.getenv('GH_ORG', 'conda-forge'))\n try:\n cf.get_repo('{}-feedstock'.format(recipe_name))\n feedstock_exists = True\n except github.UnknownObjectException as e:\n feedstock_exists = False\n\n if feedstock_exists:\n lints.append('Feedstock with the same name exists in conda-forge')\n\n # 2: Check that the recipe maintainers exists:\n maintainers = extra_section.get('recipe-maintainers', [])\n for maintainer in maintainers:\n try:\n gh.get_user(maintainer)\n except github.UnknownObjectException as e:\n lints.append('Recipe maintainer \"{}\" does not exist'.format(maintainer))\n\n\ndef selector_lines(lines):\n # Using the same pattern defined in conda-build (metadata.py),\n # we identify selectors.\n sel_pat = re.compile(r'(.+?)\\s*(#.*)?\\[([^\\[\\]]+)\\](?(2).*)$')\n\n for line in lines:\n line = line.rstrip()\n if line.lstrip().startswith('#'):\n # Don't bother with comment only lines\n continue\n m = sel_pat.match(line)\n if m:\n m.group(3)\n yield line\n\n\ndef main(recipe_dir, conda_forge=False):\n recipe_dir = os.path.abspath(recipe_dir)\n recipe_meta = os.path.join(recipe_dir, 'meta.yaml')\n if not os.path.exists(recipe_dir):\n raise IOError('Feedstock has no recipe/meta.yaml.')\n\n env = jinja2.Environment(undefined=NullUndefined)\n\n with io.open(recipe_meta, 'rt') as fh:\n content = env.from_string(''.join(fh)).render(os=os)\n meta = ruamel.yaml.load(content, ruamel.yaml.RoundTripLoader)\n results = lintify(meta, recipe_dir, conda_forge)\n return results\n", "path": "conda_smithy/lint_recipe.py"}]}
| 3,303 | 160 |
gh_patches_debug_4665
|
rasdani/github-patches
|
git_diff
|
googleapis__google-api-python-client-906
|
We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Fix typo in positional decorator method docstring
Thanks for stopping by to let us know something could be better!
**PLEASE READ**: If you have a support contract with Google, please create an issue in the [support console](https://cloud.google.com/support/) instead of filing on GitHub. This will ensure a timely response.
Please run down the following list and make sure you've tried the usual "quick fixes":
- Search the issues already opened: https://github.com/googleapis/google-api-python-client/issues
- Search StackOverflow: https://stackoverflow.com/questions/tagged/google-cloud-platform+python
If you are still having issues, please be sure to include as much information as possible:
#### Environment details
- OS type and version: irrelevant
- Python version: irrelevant
- pip version: irrelevant
- `google-api-python-client` version: irrelevant
#### Steps to reproduce
irrelevant
#### Code example
irrelevant
#### Stack trace
irrelevant
Making sure to follow these steps will guarantee the quickest resolution possible.
Thanks!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `googleapiclient/_helpers.py`
Content:
```
1 # Copyright 2015 Google Inc. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Helper functions for commonly used utilities."""
16
17 import functools
18 import inspect
19 import logging
20 import warnings
21
22 import six
23 from six.moves import urllib
24
25
26 logger = logging.getLogger(__name__)
27
28 POSITIONAL_WARNING = "WARNING"
29 POSITIONAL_EXCEPTION = "EXCEPTION"
30 POSITIONAL_IGNORE = "IGNORE"
31 POSITIONAL_SET = frozenset(
32 [POSITIONAL_WARNING, POSITIONAL_EXCEPTION, POSITIONAL_IGNORE]
33 )
34
35 positional_parameters_enforcement = POSITIONAL_WARNING
36
37 _SYM_LINK_MESSAGE = "File: {0}: Is a symbolic link."
38 _IS_DIR_MESSAGE = "{0}: Is a directory"
39 _MISSING_FILE_MESSAGE = "Cannot access {0}: No such file or directory"
40
41
42 def positional(max_positional_args):
43 """A decorator to declare that only the first N arguments my be positional.
44
45 This decorator makes it easy to support Python 3 style keyword-only
46 parameters. For example, in Python 3 it is possible to write::
47
48 def fn(pos1, *, kwonly1=None, kwonly1=None):
49 ...
50
51 All named parameters after ``*`` must be a keyword::
52
53 fn(10, 'kw1', 'kw2') # Raises exception.
54 fn(10, kwonly1='kw1') # Ok.
55
56 Example
57 ^^^^^^^
58
59 To define a function like above, do::
60
61 @positional(1)
62 def fn(pos1, kwonly1=None, kwonly2=None):
63 ...
64
65 If no default value is provided to a keyword argument, it becomes a
66 required keyword argument::
67
68 @positional(0)
69 def fn(required_kw):
70 ...
71
72 This must be called with the keyword parameter::
73
74 fn() # Raises exception.
75 fn(10) # Raises exception.
76 fn(required_kw=10) # Ok.
77
78 When defining instance or class methods always remember to account for
79 ``self`` and ``cls``::
80
81 class MyClass(object):
82
83 @positional(2)
84 def my_method(self, pos1, kwonly1=None):
85 ...
86
87 @classmethod
88 @positional(2)
89 def my_method(cls, pos1, kwonly1=None):
90 ...
91
92 The positional decorator behavior is controlled by
93 ``_helpers.positional_parameters_enforcement``, which may be set to
94 ``POSITIONAL_EXCEPTION``, ``POSITIONAL_WARNING`` or
95 ``POSITIONAL_IGNORE`` to raise an exception, log a warning, or do
96 nothing, respectively, if a declaration is violated.
97
98 Args:
99 max_positional_arguments: Maximum number of positional arguments. All
100 parameters after the this index must be
101 keyword only.
102
103 Returns:
104 A decorator that prevents using arguments after max_positional_args
105 from being used as positional parameters.
106
107 Raises:
108 TypeError: if a key-word only argument is provided as a positional
109 parameter, but only if
110 _helpers.positional_parameters_enforcement is set to
111 POSITIONAL_EXCEPTION.
112 """
113
114 def positional_decorator(wrapped):
115 @functools.wraps(wrapped)
116 def positional_wrapper(*args, **kwargs):
117 if len(args) > max_positional_args:
118 plural_s = ""
119 if max_positional_args != 1:
120 plural_s = "s"
121 message = (
122 "{function}() takes at most {args_max} positional "
123 "argument{plural} ({args_given} given)".format(
124 function=wrapped.__name__,
125 args_max=max_positional_args,
126 args_given=len(args),
127 plural=plural_s,
128 )
129 )
130 if positional_parameters_enforcement == POSITIONAL_EXCEPTION:
131 raise TypeError(message)
132 elif positional_parameters_enforcement == POSITIONAL_WARNING:
133 logger.warning(message)
134 return wrapped(*args, **kwargs)
135
136 return positional_wrapper
137
138 if isinstance(max_positional_args, six.integer_types):
139 return positional_decorator
140 else:
141 args, _, _, defaults = inspect.getargspec(max_positional_args)
142 return positional(len(args) - len(defaults))(max_positional_args)
143
144
145 def parse_unique_urlencoded(content):
146 """Parses unique key-value parameters from urlencoded content.
147
148 Args:
149 content: string, URL-encoded key-value pairs.
150
151 Returns:
152 dict, The key-value pairs from ``content``.
153
154 Raises:
155 ValueError: if one of the keys is repeated.
156 """
157 urlencoded_params = urllib.parse.parse_qs(content)
158 params = {}
159 for key, value in six.iteritems(urlencoded_params):
160 if len(value) != 1:
161 msg = "URL-encoded content contains a repeated value:" "%s -> %s" % (
162 key,
163 ", ".join(value),
164 )
165 raise ValueError(msg)
166 params[key] = value[0]
167 return params
168
169
170 def update_query_params(uri, params):
171 """Updates a URI with new query parameters.
172
173 If a given key from ``params`` is repeated in the ``uri``, then
174 the URI will be considered invalid and an error will occur.
175
176 If the URI is valid, then each value from ``params`` will
177 replace the corresponding value in the query parameters (if
178 it exists).
179
180 Args:
181 uri: string, A valid URI, with potential existing query parameters.
182 params: dict, A dictionary of query parameters.
183
184 Returns:
185 The same URI but with the new query parameters added.
186 """
187 parts = urllib.parse.urlparse(uri)
188 query_params = parse_unique_urlencoded(parts.query)
189 query_params.update(params)
190 new_query = urllib.parse.urlencode(query_params)
191 new_parts = parts._replace(query=new_query)
192 return urllib.parse.urlunparse(new_parts)
193
194
195 def _add_query_parameter(url, name, value):
196 """Adds a query parameter to a url.
197
198 Replaces the current value if it already exists in the URL.
199
200 Args:
201 url: string, url to add the query parameter to.
202 name: string, query parameter name.
203 value: string, query parameter value.
204
205 Returns:
206 Updated query parameter. Does not update the url if value is None.
207 """
208 if value is None:
209 return url
210 else:
211 return update_query_params(url, {name: value})
212
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
|
diff --git a/googleapiclient/_helpers.py b/googleapiclient/_helpers.py
--- a/googleapiclient/_helpers.py
+++ b/googleapiclient/_helpers.py
@@ -40,7 +40,7 @@
def positional(max_positional_args):
- """A decorator to declare that only the first N arguments my be positional.
+ """A decorator to declare that only the first N arguments may be positional.
This decorator makes it easy to support Python 3 style keyword-only
parameters. For example, in Python 3 it is possible to write::
|
{"golden_diff": "diff --git a/googleapiclient/_helpers.py b/googleapiclient/_helpers.py\n--- a/googleapiclient/_helpers.py\n+++ b/googleapiclient/_helpers.py\n@@ -40,7 +40,7 @@\n \n \n def positional(max_positional_args):\n- \"\"\"A decorator to declare that only the first N arguments my be positional.\n+ \"\"\"A decorator to declare that only the first N arguments may be positional.\n \n This decorator makes it easy to support Python 3 style keyword-only\n parameters. For example, in Python 3 it is possible to write::\n", "issue": "Fix typo in positional decorator method docstring\nThanks for stopping by to let us know something could be better!\r\n\r\n**PLEASE READ**: If you have a support contract with Google, please create an issue in the [support console](https://cloud.google.com/support/) instead of filing on GitHub. This will ensure a timely response.\r\n\r\nPlease run down the following list and make sure you've tried the usual \"quick fixes\":\r\n\r\n - Search the issues already opened: https://github.com/googleapis/google-api-python-client/issues\r\n - Search StackOverflow: https://stackoverflow.com/questions/tagged/google-cloud-platform+python\r\n\r\nIf you are still having issues, please be sure to include as much information as possible:\r\n\r\n#### Environment details\r\n\r\n - OS type and version: irrelevant\r\n - Python version: irrelevant\r\n - pip version: irrelevant\r\n - `google-api-python-client` version: irrelevant\r\n\r\n#### Steps to reproduce\r\n\r\n irrelevant\r\n\r\n#### Code example\r\n\r\n irrelevant\r\n\r\n#### Stack trace\r\n\r\n irrelevant\r\n\r\nMaking sure to follow these steps will guarantee the quickest resolution possible.\r\n\r\nThanks!\r\n\n", "before_files": [{"content": "# Copyright 2015 Google Inc. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Helper functions for commonly used utilities.\"\"\"\n\nimport functools\nimport inspect\nimport logging\nimport warnings\n\nimport six\nfrom six.moves import urllib\n\n\nlogger = logging.getLogger(__name__)\n\nPOSITIONAL_WARNING = \"WARNING\"\nPOSITIONAL_EXCEPTION = \"EXCEPTION\"\nPOSITIONAL_IGNORE = \"IGNORE\"\nPOSITIONAL_SET = frozenset(\n [POSITIONAL_WARNING, POSITIONAL_EXCEPTION, POSITIONAL_IGNORE]\n)\n\npositional_parameters_enforcement = POSITIONAL_WARNING\n\n_SYM_LINK_MESSAGE = \"File: {0}: Is a symbolic link.\"\n_IS_DIR_MESSAGE = \"{0}: Is a directory\"\n_MISSING_FILE_MESSAGE = \"Cannot access {0}: No such file or directory\"\n\n\ndef positional(max_positional_args):\n \"\"\"A decorator to declare that only the first N arguments my be positional.\n\n This decorator makes it easy to support Python 3 style keyword-only\n parameters. For example, in Python 3 it is possible to write::\n\n def fn(pos1, *, kwonly1=None, kwonly1=None):\n ...\n\n All named parameters after ``*`` must be a keyword::\n\n fn(10, 'kw1', 'kw2') # Raises exception.\n fn(10, kwonly1='kw1') # Ok.\n\n Example\n ^^^^^^^\n\n To define a function like above, do::\n\n @positional(1)\n def fn(pos1, kwonly1=None, kwonly2=None):\n ...\n\n If no default value is provided to a keyword argument, it becomes a\n required keyword argument::\n\n @positional(0)\n def fn(required_kw):\n ...\n\n This must be called with the keyword parameter::\n\n fn() # Raises exception.\n fn(10) # Raises exception.\n fn(required_kw=10) # Ok.\n\n When defining instance or class methods always remember to account for\n ``self`` and ``cls``::\n\n class MyClass(object):\n\n @positional(2)\n def my_method(self, pos1, kwonly1=None):\n ...\n\n @classmethod\n @positional(2)\n def my_method(cls, pos1, kwonly1=None):\n ...\n\n The positional decorator behavior is controlled by\n ``_helpers.positional_parameters_enforcement``, which may be set to\n ``POSITIONAL_EXCEPTION``, ``POSITIONAL_WARNING`` or\n ``POSITIONAL_IGNORE`` to raise an exception, log a warning, or do\n nothing, respectively, if a declaration is violated.\n\n Args:\n max_positional_arguments: Maximum number of positional arguments. All\n parameters after the this index must be\n keyword only.\n\n Returns:\n A decorator that prevents using arguments after max_positional_args\n from being used as positional parameters.\n\n Raises:\n TypeError: if a key-word only argument is provided as a positional\n parameter, but only if\n _helpers.positional_parameters_enforcement is set to\n POSITIONAL_EXCEPTION.\n \"\"\"\n\n def positional_decorator(wrapped):\n @functools.wraps(wrapped)\n def positional_wrapper(*args, **kwargs):\n if len(args) > max_positional_args:\n plural_s = \"\"\n if max_positional_args != 1:\n plural_s = \"s\"\n message = (\n \"{function}() takes at most {args_max} positional \"\n \"argument{plural} ({args_given} given)\".format(\n function=wrapped.__name__,\n args_max=max_positional_args,\n args_given=len(args),\n plural=plural_s,\n )\n )\n if positional_parameters_enforcement == POSITIONAL_EXCEPTION:\n raise TypeError(message)\n elif positional_parameters_enforcement == POSITIONAL_WARNING:\n logger.warning(message)\n return wrapped(*args, **kwargs)\n\n return positional_wrapper\n\n if isinstance(max_positional_args, six.integer_types):\n return positional_decorator\n else:\n args, _, _, defaults = inspect.getargspec(max_positional_args)\n return positional(len(args) - len(defaults))(max_positional_args)\n\n\ndef parse_unique_urlencoded(content):\n \"\"\"Parses unique key-value parameters from urlencoded content.\n\n Args:\n content: string, URL-encoded key-value pairs.\n\n Returns:\n dict, The key-value pairs from ``content``.\n\n Raises:\n ValueError: if one of the keys is repeated.\n \"\"\"\n urlencoded_params = urllib.parse.parse_qs(content)\n params = {}\n for key, value in six.iteritems(urlencoded_params):\n if len(value) != 1:\n msg = \"URL-encoded content contains a repeated value:\" \"%s -> %s\" % (\n key,\n \", \".join(value),\n )\n raise ValueError(msg)\n params[key] = value[0]\n return params\n\n\ndef update_query_params(uri, params):\n \"\"\"Updates a URI with new query parameters.\n\n If a given key from ``params`` is repeated in the ``uri``, then\n the URI will be considered invalid and an error will occur.\n\n If the URI is valid, then each value from ``params`` will\n replace the corresponding value in the query parameters (if\n it exists).\n\n Args:\n uri: string, A valid URI, with potential existing query parameters.\n params: dict, A dictionary of query parameters.\n\n Returns:\n The same URI but with the new query parameters added.\n \"\"\"\n parts = urllib.parse.urlparse(uri)\n query_params = parse_unique_urlencoded(parts.query)\n query_params.update(params)\n new_query = urllib.parse.urlencode(query_params)\n new_parts = parts._replace(query=new_query)\n return urllib.parse.urlunparse(new_parts)\n\n\ndef _add_query_parameter(url, name, value):\n \"\"\"Adds a query parameter to a url.\n\n Replaces the current value if it already exists in the URL.\n\n Args:\n url: string, url to add the query parameter to.\n name: string, query parameter name.\n value: string, query parameter value.\n\n Returns:\n Updated query parameter. Does not update the url if value is None.\n \"\"\"\n if value is None:\n return url\n else:\n return update_query_params(url, {name: value})\n", "path": "googleapiclient/_helpers.py"}], "after_files": [{"content": "# Copyright 2015 Google Inc. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Helper functions for commonly used utilities.\"\"\"\n\nimport functools\nimport inspect\nimport logging\nimport warnings\n\nimport six\nfrom six.moves import urllib\n\n\nlogger = logging.getLogger(__name__)\n\nPOSITIONAL_WARNING = \"WARNING\"\nPOSITIONAL_EXCEPTION = \"EXCEPTION\"\nPOSITIONAL_IGNORE = \"IGNORE\"\nPOSITIONAL_SET = frozenset(\n [POSITIONAL_WARNING, POSITIONAL_EXCEPTION, POSITIONAL_IGNORE]\n)\n\npositional_parameters_enforcement = POSITIONAL_WARNING\n\n_SYM_LINK_MESSAGE = \"File: {0}: Is a symbolic link.\"\n_IS_DIR_MESSAGE = \"{0}: Is a directory\"\n_MISSING_FILE_MESSAGE = \"Cannot access {0}: No such file or directory\"\n\n\ndef positional(max_positional_args):\n \"\"\"A decorator to declare that only the first N arguments may be positional.\n\n This decorator makes it easy to support Python 3 style keyword-only\n parameters. For example, in Python 3 it is possible to write::\n\n def fn(pos1, *, kwonly1=None, kwonly1=None):\n ...\n\n All named parameters after ``*`` must be a keyword::\n\n fn(10, 'kw1', 'kw2') # Raises exception.\n fn(10, kwonly1='kw1') # Ok.\n\n Example\n ^^^^^^^\n\n To define a function like above, do::\n\n @positional(1)\n def fn(pos1, kwonly1=None, kwonly2=None):\n ...\n\n If no default value is provided to a keyword argument, it becomes a\n required keyword argument::\n\n @positional(0)\n def fn(required_kw):\n ...\n\n This must be called with the keyword parameter::\n\n fn() # Raises exception.\n fn(10) # Raises exception.\n fn(required_kw=10) # Ok.\n\n When defining instance or class methods always remember to account for\n ``self`` and ``cls``::\n\n class MyClass(object):\n\n @positional(2)\n def my_method(self, pos1, kwonly1=None):\n ...\n\n @classmethod\n @positional(2)\n def my_method(cls, pos1, kwonly1=None):\n ...\n\n The positional decorator behavior is controlled by\n ``_helpers.positional_parameters_enforcement``, which may be set to\n ``POSITIONAL_EXCEPTION``, ``POSITIONAL_WARNING`` or\n ``POSITIONAL_IGNORE`` to raise an exception, log a warning, or do\n nothing, respectively, if a declaration is violated.\n\n Args:\n max_positional_arguments: Maximum number of positional arguments. All\n parameters after the this index must be\n keyword only.\n\n Returns:\n A decorator that prevents using arguments after max_positional_args\n from being used as positional parameters.\n\n Raises:\n TypeError: if a key-word only argument is provided as a positional\n parameter, but only if\n _helpers.positional_parameters_enforcement is set to\n POSITIONAL_EXCEPTION.\n \"\"\"\n\n def positional_decorator(wrapped):\n @functools.wraps(wrapped)\n def positional_wrapper(*args, **kwargs):\n if len(args) > max_positional_args:\n plural_s = \"\"\n if max_positional_args != 1:\n plural_s = \"s\"\n message = (\n \"{function}() takes at most {args_max} positional \"\n \"argument{plural} ({args_given} given)\".format(\n function=wrapped.__name__,\n args_max=max_positional_args,\n args_given=len(args),\n plural=plural_s,\n )\n )\n if positional_parameters_enforcement == POSITIONAL_EXCEPTION:\n raise TypeError(message)\n elif positional_parameters_enforcement == POSITIONAL_WARNING:\n logger.warning(message)\n return wrapped(*args, **kwargs)\n\n return positional_wrapper\n\n if isinstance(max_positional_args, six.integer_types):\n return positional_decorator\n else:\n args, _, _, defaults = inspect.getargspec(max_positional_args)\n return positional(len(args) - len(defaults))(max_positional_args)\n\n\ndef parse_unique_urlencoded(content):\n \"\"\"Parses unique key-value parameters from urlencoded content.\n\n Args:\n content: string, URL-encoded key-value pairs.\n\n Returns:\n dict, The key-value pairs from ``content``.\n\n Raises:\n ValueError: if one of the keys is repeated.\n \"\"\"\n urlencoded_params = urllib.parse.parse_qs(content)\n params = {}\n for key, value in six.iteritems(urlencoded_params):\n if len(value) != 1:\n msg = \"URL-encoded content contains a repeated value:\" \"%s -> %s\" % (\n key,\n \", \".join(value),\n )\n raise ValueError(msg)\n params[key] = value[0]\n return params\n\n\ndef update_query_params(uri, params):\n \"\"\"Updates a URI with new query parameters.\n\n If a given key from ``params`` is repeated in the ``uri``, then\n the URI will be considered invalid and an error will occur.\n\n If the URI is valid, then each value from ``params`` will\n replace the corresponding value in the query parameters (if\n it exists).\n\n Args:\n uri: string, A valid URI, with potential existing query parameters.\n params: dict, A dictionary of query parameters.\n\n Returns:\n The same URI but with the new query parameters added.\n \"\"\"\n parts = urllib.parse.urlparse(uri)\n query_params = parse_unique_urlencoded(parts.query)\n query_params.update(params)\n new_query = urllib.parse.urlencode(query_params)\n new_parts = parts._replace(query=new_query)\n return urllib.parse.urlunparse(new_parts)\n\n\ndef _add_query_parameter(url, name, value):\n \"\"\"Adds a query parameter to a url.\n\n Replaces the current value if it already exists in the URL.\n\n Args:\n url: string, url to add the query parameter to.\n name: string, query parameter name.\n value: string, query parameter value.\n\n Returns:\n Updated query parameter. Does not update the url if value is None.\n \"\"\"\n if value is None:\n return url\n else:\n return update_query_params(url, {name: value})\n", "path": "googleapiclient/_helpers.py"}]}
| 2,483 | 126 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.