
CoInteract: Physically-Consistent Human-Object Interaction Video Synthesis via Spatially-Structured Co-Generation
Paper • 2604.19636 • Published • 59
Physically-Consistent Human-Object Interaction Video Synthesis
via Spatially-Structured Co-Generation
Alibaba Group & Tsinghua University
CoInteract is the first end-to-end framework that generates physically-consistent human-object interaction (HOI) videos with zero additional inference cost. Given a person image, a product image, text prompts, and optional speech audio, CoInteract produces realistic videos where humans naturally grasp, wear, present, and manipulate objects — with no hand-object interpenetration or geometric misalignment.
🔥 Key Results:
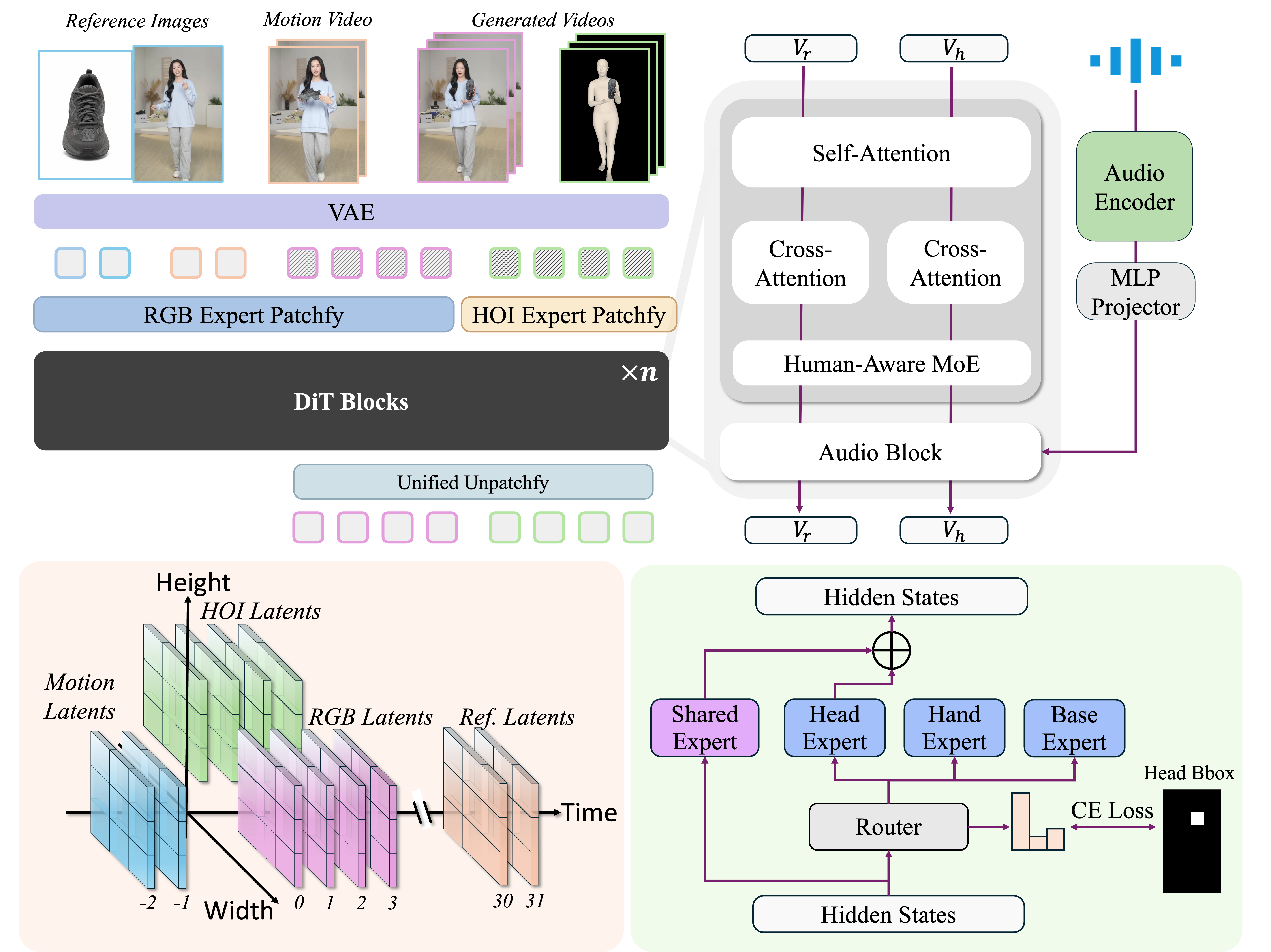
CoInteract embeds structural priors and interaction geometry directly into a Diffusion Transformer (DiT) backbone through three core innovations:
🧠 Human-Aware MoE — Spatially-supervised Mixture-of-Experts routes tokens to region-specialized experts (Head, Hand, Base), ensuring high structural fidelity for hands and faces with minimal parameter overhead.
🔗 Dual-Stream Co-Generation — An auxiliary HOI structure stream is jointly trained with the RGB stream within a shared DiT backbone, forcing the model to learn spatial and interaction relationships.
✨ Asymmetric Co-Attention — A two-stage training strategy with asymmetric attention masks embeds physical interaction rules, enabling the HOI branch to be completely removed at inference with zero overhead.
Our model handles diverse real-world products across various scenarios. Visit our Project Page for full video demos.
Supported Interaction Types:
| Category | Examples |
|---|---|
| 🤲 Grasping | Macaron box · Teapot · Skincare serum · Coffee mug |
| 👜 Presenting | Leather handbag · Eyeshadow palette · Decorative plate |
| 👗 Wearing | Emerald necklace · Sports jacket |
| 🌵 Holding | Cactus pot · Various daily objects |
Application Scenarios:
| Property | Value |
|---|---|
| Backbone | Diffusion Transformer (DiT) |
| Resolution | 720p 480p |
| Frame Count | Up to 81 frames per chunk |
| Multi-Chunk | Supported for long-form video |
| Inputs | Person image + Object image + Text prompt + Audio + (Optional) Pose |
| Training Data | Large-scale HOI video dataset with structure annotations |
| Precision | FP16 / BF16 |
| License | Apache 2.0 |

Full quantitative results will be released upon paper acceptance.
If you find CoInteract useful for your research, please consider citing:
@article{luo2025cointeract,
title={CoInteract: Physically-Consistent Human-Object Interaction Video Synthesis via Spatially-Structured Co-Generation},
author={Luo, Xiangyang and Xin, Xiaozhe and Feng, Tao and Guo, Xu and Jin, Meiguang and Ma, Junfeng},
journal={arXiv preprint arXiv:2604.19636},
year={2026}
}
This work is supported by Taobao Live Tech, Alibaba Group and Tsinghua University.
Project Page · Paper · Code · Demo
If you like this project, please give us a ⭐!