
Chinda Thai LLM
Collection
Chinda Opensource Thai LLM for Everyone
•
2 items
•
Updated
Latest Model, Think in Thai, Answer in Thai, Built by Thai Startup
Chinda Opensource Thai LLM 4B is iApp Technology's cutting-edge Thai language model that brings advanced thinking capabilities to the Thai AI ecosystem. Built on the latest Qwen3-4B architecture, Chinda represents our commitment to developing sovereign AI solutions for Thailand.
Chinda LLM 4B is completely free and open-source, enabling developers, researchers, and businesses to build Thai AI applications without restrictions.
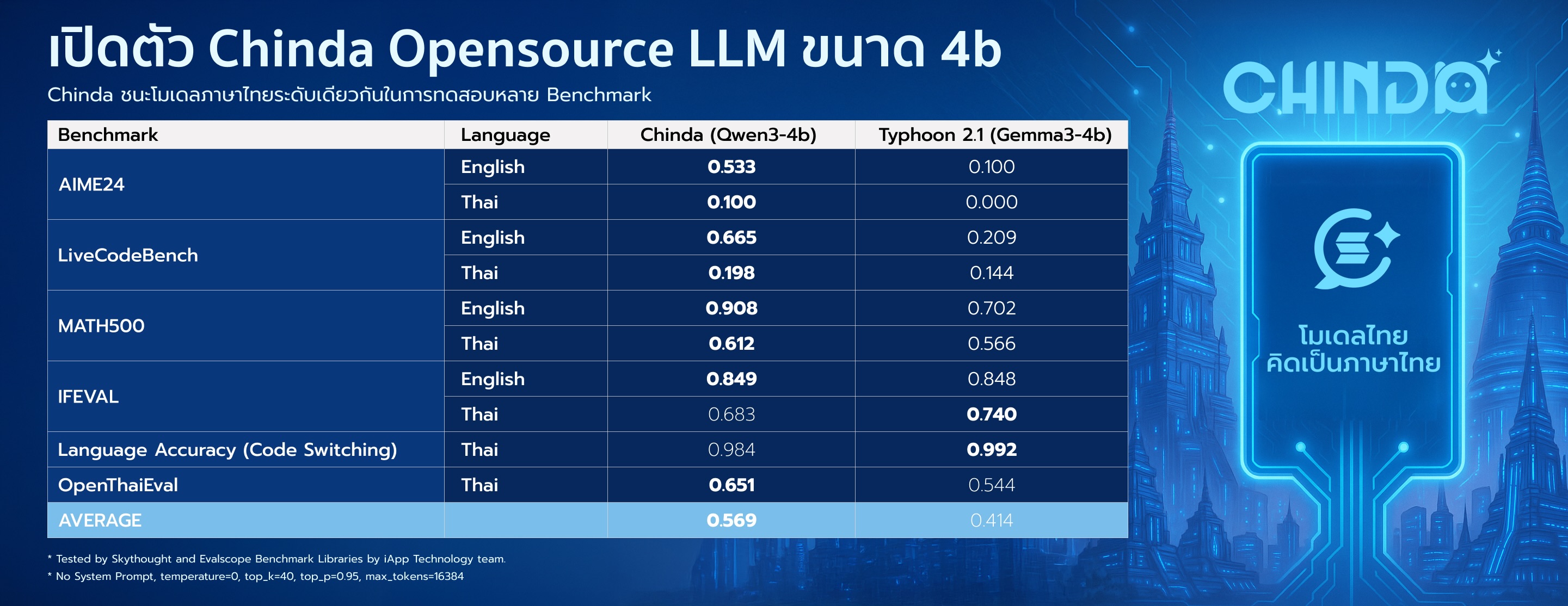
Chinda LLM 4B demonstrates superior performance compared to other Thai language models in its category:
| Benchmark | Language | Chinda LLM 4B | Alternative* |
|---|---|---|---|
| AIME24 | English | 0.533 | 0.100 |
| Thai | 0.100 | 0.000 | |
| LiveCodeBench | English | 0.665 | 0.209 |
| Thai | 0.198 | 0.144 | |
| MATH500 | English | 0.908 | 0.702 |
| Thai | 0.612 | 0.566 | |
| IFEVAL | English | 0.849 | 0.848 |
| Thai | 0.683 | 0.740 | |
| Language Accuracy | Thai | 0.984 | 0.992 |
| OpenThaiEval | Thai | 0.651 | 0.544 |
| AVERAGE | 0.569 | 0.414 |
Perfect for building Retrieval-Augmented Generation systems that keep data processing within Thai sovereignty.
Reliable Small Language Model optimized for edge computing and personal devices.
Excellent performance in mathematical reasoning and problem-solving.
Strong capabilities in code generation and programming assistance.
Very fast inference with minimal GPU memory consumption, ideal for production deployments.
As a 4B parameter model, it may hallucinate when asked for specific facts without provided context. Always use with RAG or provide relevant context for factual queries.
pip install transformers torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "iapp/chinda-qwen3-4b"
# Load the tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# Prepare the model input
prompt = "อธิบายเกี่ยวกับปัญญาประดิษฐ์ให้ฟังหน่อย"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Enable thinking mode for better reasoning
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# Generate response
generated_ids = model.generate(
**model_inputs,
max_new_tokens=1024,
temperature=0.6,
top_p=0.95,
top_k=20,
do_sample=True
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# Parse thinking content (if enabled)
try:
# Find </think> token (151668)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("🧠 Thinking:", thinking_content)
print("💬 Response:", content)
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Enable detailed reasoning
)
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # Fast response mode
)
pip install vllm>=0.8.5
vllm serve iapp/chinda-qwen3-4b --enable-reasoning --reasoning-parser deepseek_r1
pip install sglang>=0.4.6.post1
python -m sglang.launch_server --model-path iapp/chinda-qwen3-4b --reasoning-parser qwen3
Installation:
# Install Ollama (if not already installed)
curl -fsSL https://ollama.com/install.sh | sh
# Pull Chinda LLM 4B model
ollama pull iapp/chinda-qwen3-4b
Basic Usage:
# Start chatting with Chinda LLM
ollama run iapp/chinda-qwen3-4b
# Example conversation
ollama run iapp/chinda-qwen3-4b "อธิบายเกี่ยวกับปัญญาประดิษฐ์ให้ฟังหน่อย"
API Server:
# Start Ollama API server
ollama serve
# Use with curl
curl http://localhost:11434/api/generate -d '{
"model": "iapp/chinda-qwen3-4b",
"prompt": "สวัสดีครับ",
"stream": false
}'
Model Specifications:
Chinda LLM 4B natively supports up to 32,768 tokens. For longer contexts, enable YaRN scaling:
{
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
}
For Thinking Mode:
For Non-Thinking Mode:
Chinda LLM 4B uses a standardized chat template format for consistent interactions:
# Basic template structure
messages = [
{"role": "system", "content": "You are a helpful Thai AI assistant."},
{"role": "user", "content": "สวัสดีครับ"},
{"role": "assistant", "content": "สวัสดีค่ะ! มีอะไรให้ช่วยเหลือบ้างคะ"},
{"role": "user", "content": "ช่วยอธิบายเรื่อง AI ให้ฟังหน่อย"}
]
# Apply template with thinking mode
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True
)
The template follows the standard conversational format:
<|im_start|>system
You are a helpful Thai AI assistant.<|im_end|>
<|im_start|>user
สวัสดีครับ<|im_end|>
<|im_start|>assistant
สวัสดีค่ะ! มีอะไรให้ช่วยเหลือบ้างคะ<|im_end|>
<|im_start|>user
ช่วยอธิบายเรื่อง AI ให้ฟังหน่อย<|im_end|>
<|im_start|>assistant
# Multi-turn conversation with thinking control
def create_conversation(messages, enable_thinking=True):
# Add system message if not present
if not messages or messages[0]["role"] != "system":
system_msg = {
"role": "system",
"content": "คุณเป็น AI ผู้ช่วยที่ฉลาดและเป็นประโยชน์ พูดภาษาไทยได้อย่างเป็นธรรมชาติ"
}
messages = [system_msg] + messages
# Apply chat template
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=enable_thinking
)
return text
# Example usage
conversation = [
{"role": "user", "content": "คำนวณ 15 × 23 = ?"},
]
prompt = create_conversation(conversation, enable_thinking=True)
You can control thinking mode within conversations using special commands:
# Enable thinking for complex problems
messages = [
{"role": "user", "content": "/think แก้สมการ: x² + 5x - 14 = 0"}
]
# Disable thinking for quick responses
messages = [
{"role": "user", "content": "/no_think สวัสดี"}
]
def manage_context(messages, max_tokens=30000):
"""Simple context management function"""
total_tokens = sum(len(tokenizer.encode(msg["content"])) for msg in messages)
while total_tokens > max_tokens and len(messages) > 2:
# Keep system message and remove oldest user/assistant pair
if messages[1]["role"] == "user":
messages.pop(1) # Remove user message
if len(messages) > 1 and messages[1]["role"] == "assistant":
messages.pop(1) # Remove corresponding assistant message
total_tokens = sum(len(tokenizer.encode(msg["content"])) for msg in messages)
return messages
For enterprise deployments, custom training, or commercial support, contact us at:
The name "Chinda" (จินดา) comes from "จินดามณี" (Chindamani), which is considered the first book of Thailand written by Phra Horathibodi (Sri Dharmasokaraja) in the Sukhothai period. Just as จินดามณี was a foundational text for Thai literature and learning, Chinda LLM represents our foundation for Thai sovereign AI - a model that truly understands and thinks in Thai, preserving and advancing Thai language capabilities in the digital age.
Yes! Chinda LLM 4B is released under the Apache 2.0 License, which allows:
No restrictions on commercial applications - build and deploy freely!
Thinking Mode (enable_thinking=True):
<think>...</think> blocksNon-Thinking Mode (enable_thinking=False):
You can switch between modes or let users control it dynamically using /think and /no_think commands.
Chinda LLM 4B achieves 37% better overall performance compared to the nearest alternative:
It's currently the highest-scoring Thai LLM in the 4B parameter category.
Minimum Requirements:
Recommended for Production:
CPU-Only Mode: Possible but significantly slower (not recommended for production)
Yes! As an open-source model under Apache 2.0 license, you can:
Popular fine-tuning frameworks that work with Chinda:
Need help with fine-tuning? Contact our team at sale@iapp.co.th
Primary Languages:
Additional Languages:
Special Features:
The model weights are open-source, but the specific training datasets are not publicly released. However:
For research collaborations or dataset inquiries, contact our research team.
For Technical Issues:
For Commercial Support:
Community Support:
Model Specifications:
Download Options:
huggingface.co/iapp/chinda-qwen3-4bQuantization Options:
If you use Chinda LLM 4B in your research or projects, please cite:
@misc{chinda-llm-4b,
title={Chinda LLM 4B: Thai Sovereign AI Language Model},
author={iApp Technology},
year={2025},
publisher={Hugging Face},
url={https://huggingface.co/iapp/chinda-qwen3-4b}
}
Built with 🇹🇭 by iApp Technology - Empowering Thai Businesses with Sovereign AI Excellence

Powered by iApp Technology
Disclaimer: Provided responses are not guaranteed.