|
|
--- |
|
|
license: llama3 |
|
|
library_name: terratorch |
|
|
datasets: |
|
|
- embed2scale/SSL4EO-S12-v1.1 |
|
|
- ibm-esa-geospatial/Llama3-SSL4EO-S12-v1.1-captions |
|
|
base_model: |
|
|
- laion/CLIP-ViT-B-16-laion2B-s34B-b88K |
|
|
--- |
|
|
|
|
|
[](https://arxiv.org/abs/2503.15969) |
|
|
[](https://github.com/IBM/MS-CLIP) |
|
|
|
|
|
# Llama3-MS-CLIP ViT-B/16 |
|
|
|
|
|
Llama3-MS-CLIP is the first Vision-Language Model in the CLIP family that understands multispectral imagery. |
|
|
It is trained on one million image-text pairs from the SSL4EO-S12-v1.1 dataset with generated captions. |
|
|
|
|
|
## Architecture |
|
|
|
|
|
The CLIP model consists of two encoders for text and images. We extended the RGB patch embeddings to multispectral input and initialized the weights of the additional input channels with zeros. During the continual pre-training, the images and texts of each batch are encoded and combined. The loss increases the similarity of matching pairs while decreasing other combinations. |
|
|
|
|
|
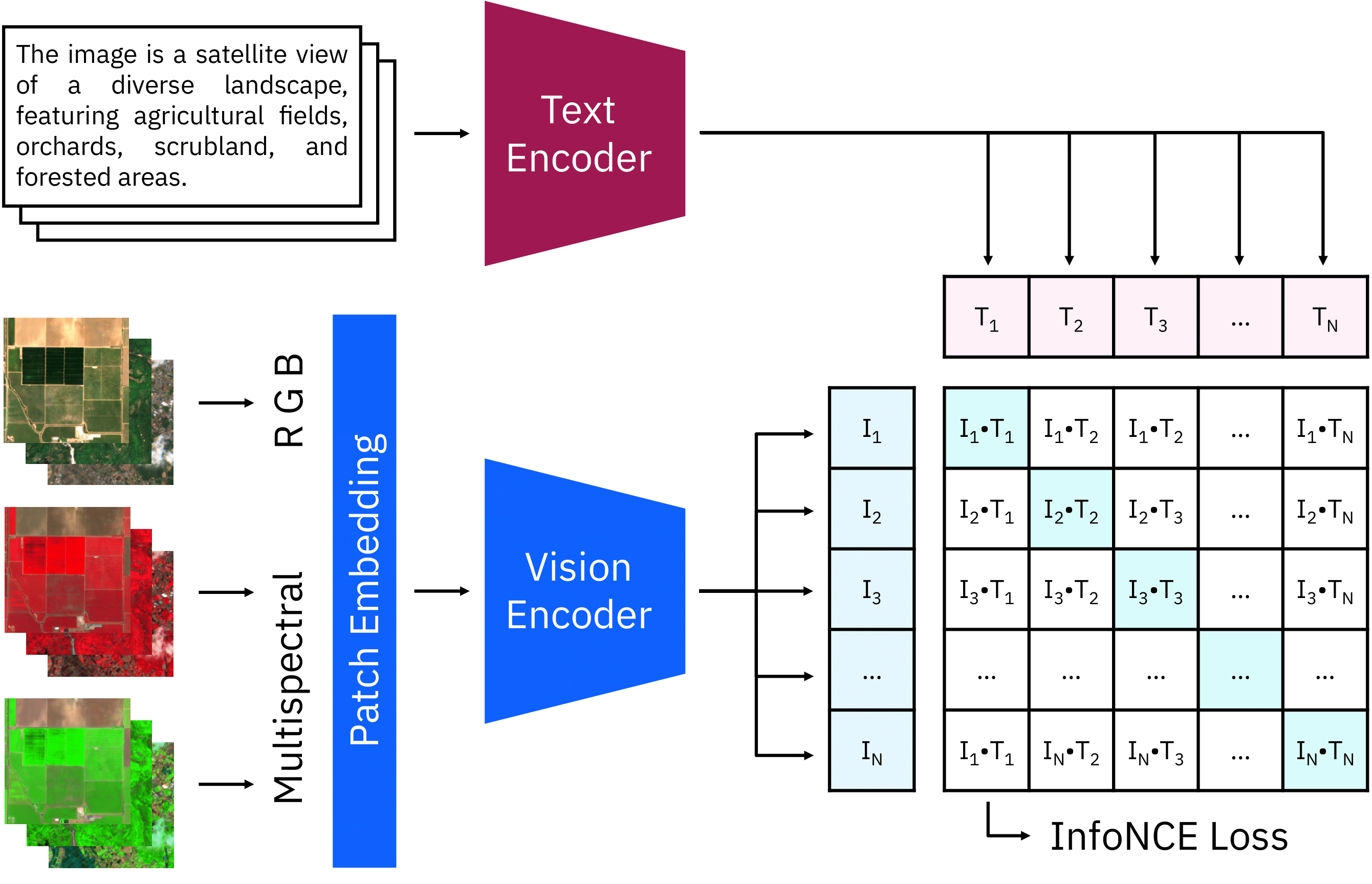 |
|
|
|
|
|
## Evaluation |
|
|
|
|
|
We evaluated Llama3-MS-CLIP with zero-shot classification and text-to-image retrieval results, measured in accuracy (%) ↑ and mAP@100 (%) ↑, respectively. |
|
|
The following Figure compares our model with the OpenCLIP baselines and other EO-VLMs. |
|
|
We applied a smoothed min-max scaling and annotated the lowest and highest scores. |
|
|
Our multispectral CLIP model is outperforming other RGB-based models on most benchmarks. |
|
|
|
|
|
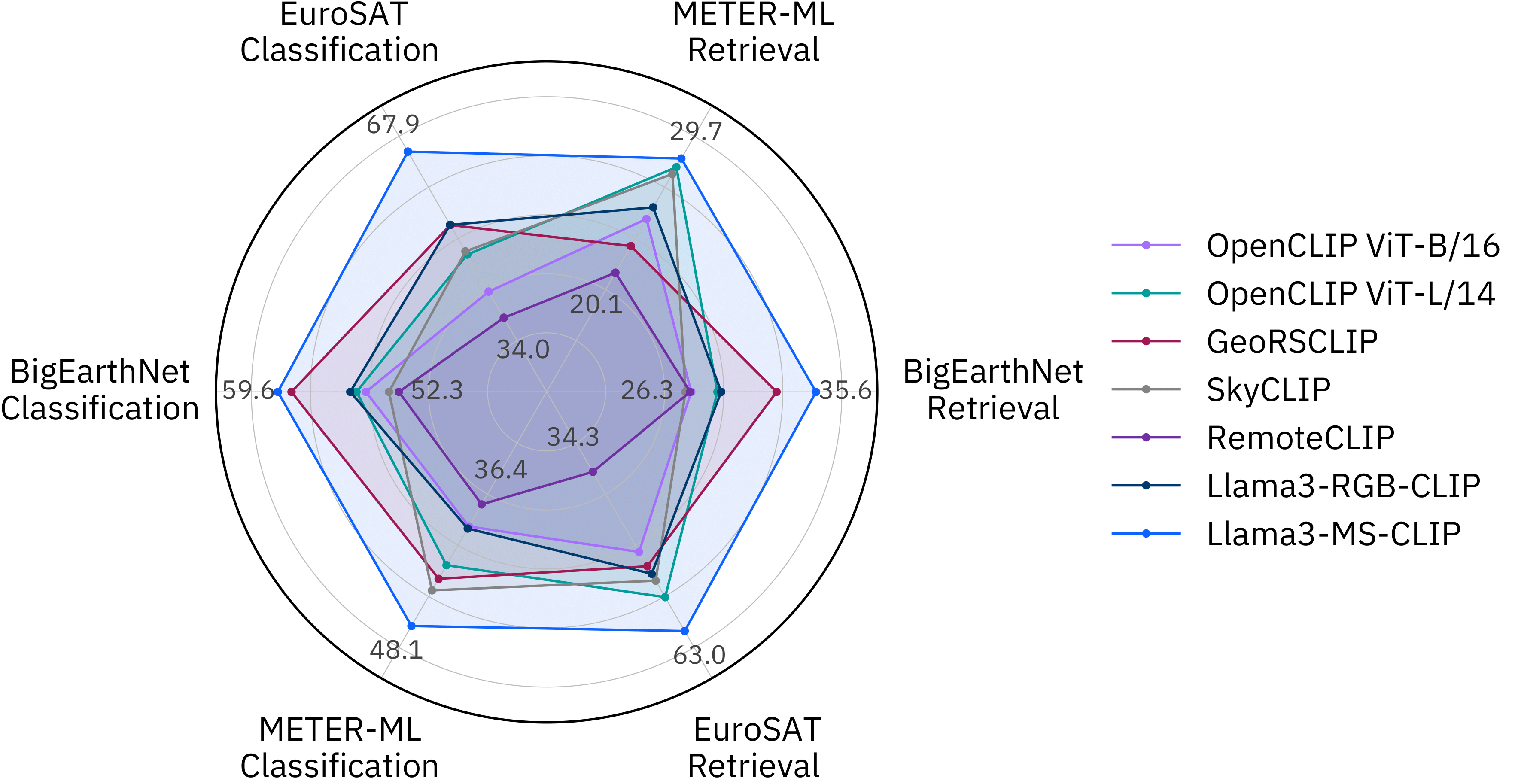 |
|
|
|
|
|
## Usage |
|
|
|
|
|
You can use the model out of the box for zero-shot classification and text-to-image retrieval with Sentinel-2 L2A images. |
|
|
|
|
|
### Setup |
|
|
|
|
|
Clone the repository and set up a new env: |
|
|
```shell |
|
|
git clone https://github.com/IBM/MS-CLIP |
|
|
cd MS-CLIP |
|
|
python -m venv venv |
|
|
source venv/bin/activate |
|
|
pip install -e . |
|
|
``` |
|
|
|
|
|
### Infernece |
|
|
|
|
|
We provide an easy-to-use inference script that automatically downloads the weights from Hugging Face. You just need to provide a path to folder with Sentinel-2 L2A files (all 12 bands) and `class_names` or a `query`. |
|
|
|
|
|
Run zero-shot classification with: |
|
|
```shell |
|
|
python inference.py --run-classification \ |
|
|
--model-name "Llama3-MS-CLIP-Base" \ |
|
|
--images "path/to/sentinel2_l2a_files/" \ |
|
|
--class-names "class 1" "class 2" "class 3" |
|
|
``` |
|
|
|
|
|
Run text-to-image retrieval with: |
|
|
```shell |
|
|
python inference.py --run_retrieval\ |
|
|
--model-name "Llama3-MS-CLIP-Base" \ |
|
|
--images "path/to/sentinel2_l2a_files/" \ |
|
|
--query "Your query text" \ |
|
|
--top-k 5 # Number of retrieved images |
|
|
``` |
|
|
|
|
|
More information is provided in the GitHub repository [MS-CLIP](https://github.com/IBM/MS-CLIP). |
|
|
|
|
|
## Citation |
|
|
|
|
|
Please cite the following paper, if you use Llama3-MS-CLIP in your research: |
|
|
|
|
|
``` |
|
|
@article{marimo2025beyond, |
|
|
title={Beyond the Visible: Multispectral Vision-Language Learning for Earth Observation}, |
|
|
author={Marimo, Clive Tinashe and Blumenstiel, Benedikt and Nitsche, Maximilian and Jakubik, Johannes and Brunschwiler, Thomas}, |
|
|
journal={arXiv preprint arXiv:2503.15969}, |
|
|
year={2025} |
|
|
} |
|
|
``` |
|
|
|
|
|
## License |
|
|
|
|
|
Built with Meta Llama 3. |
|
|
|
|
|
While the model itself is not based on Llama 3 but OpenCLIP B/16, it is trained on captions generated by a Llama 3-derivative model (License: https://github.com/meta-llama/llama3/blob/main/LICENSE). |

