
ERGO: Efficient High-Resolution Visual Understanding for Vision-Language Models
ERGO (Efficient Reasoning & Guided Observation) is a large vision–language model trained with reinforcement learning on efficiency objectives, focusing on task-relevant regions to enhance accuracy and achieve up to a 3× speedup in inference.
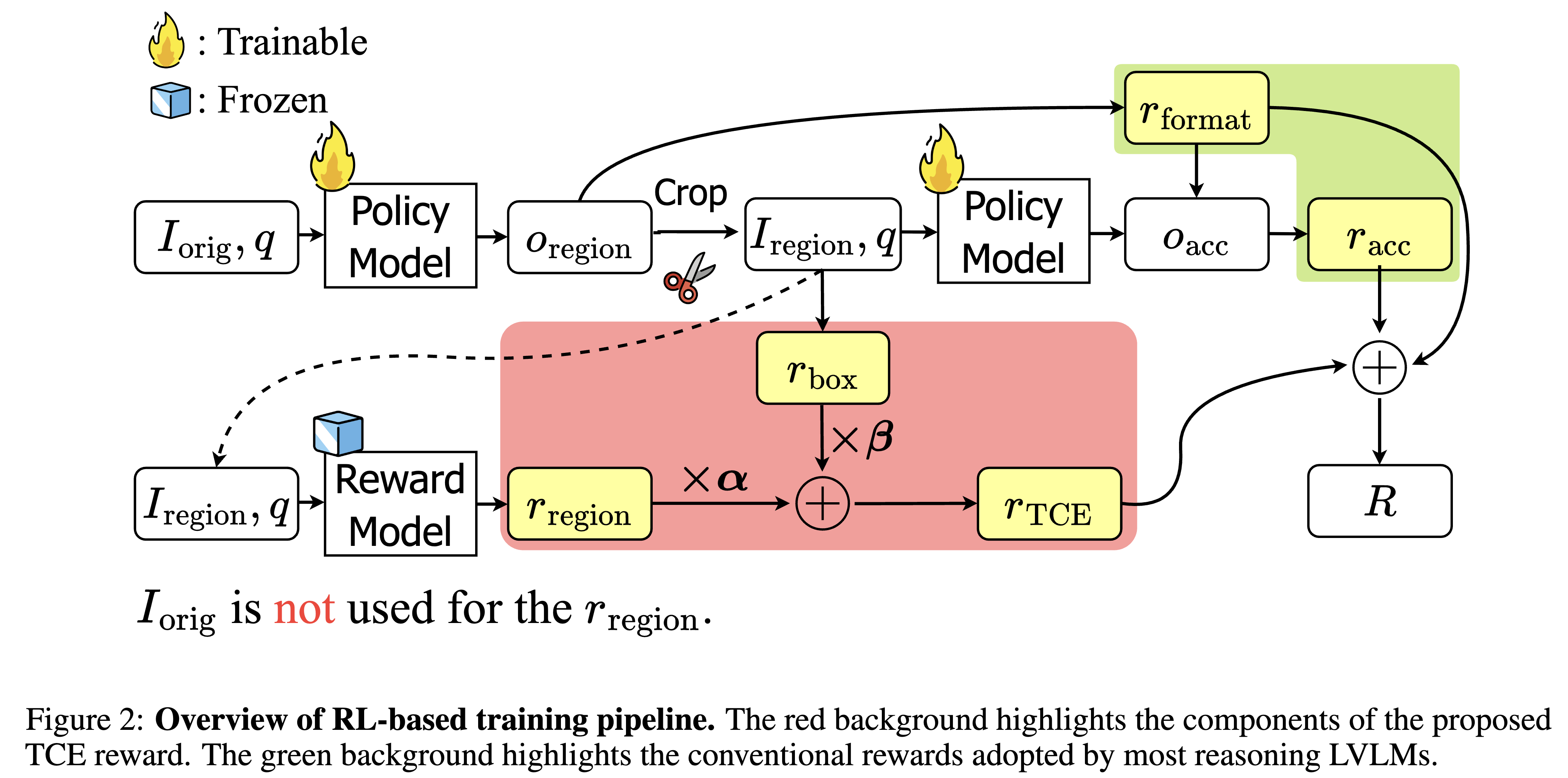
Installation
Python >= 3.10 is required.
curl -LsSf https://astral.sh/uv/install.sh | sh
git clone https://github.com/nota-github/ERGO.git
cd ERGO
uv venv
uv sync
source .venv/bin/activate
uv pip install -e .
Usage
We recommend using vLLM, as its
Automatic Prefix Cachingcan significantly improve inference speed.
This repository provides evaluation scripts for the following benchmarks:
See data/README.md for how to prepare datasets
Evaluation with vLLM
- Serving with vLLM
bash ./scripts/run_vllm.sh
- Run eval.py
export MAX_VISION_TOKEN_NUM=1280
export VLLM_ENDPOINT=http://127.0.0.1:8008/v1
export DATA_ROOT=./data
python ./src/ergo/eval.py \
--dataset {choose from [vstar, mmerwl, hrbench]} \
--data_root $DATA_ROOT\
--api_url $VLLM_ENDPOINT \
--max_vision_token_num $MAX_VISION_TOKEN_NUM
Inference with Hugging Face
python ./src/ergo/infer.py \
--input_path {default = "./data/demo/demo.jpg"} \
--question {default = "Is the orange luggage on the left or right side of the purple umbrella?"} \
{--save_output} # optional
License
This project is released under Apache 2.0 licence.
Acknowledgements
We would like to express our sincere appreciation to the following projects:
- Qwen2.5-VL: The base model we utilized. They are originally licensed under Apache 2.0 License.
- VLM-R1: The RL codebase we utilized. It is originally licensed under Apache 2.0 License.
- V*, HR-Bench, MME-RealWorld-lite : The evaluation benchmark dataset we utilized.
We also deeply appreciate the generous GPU resource support from Gwangju AICA.
Citation
@misc{lee2025ergoefficienthighresolutionvisual,
title={ERGO: Efficient High-Resolution Visual Understanding for Vision-Language Models},
author={Jewon Lee and Wooksu Shin and Seungmin Yang and Ki-Ung Song and DongUk Lim and Jaeyeon Kim and Tae-Ho Kim and Bo-Kyeong Kim},
year={2025},
eprint={2509.21991},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.21991},
}
- Downloads last month
- 105