
repo_id
stringlengths 4
110
| author
stringlengths 2
27
⌀ | model_type
stringlengths 2
29
⌀ | files_per_repo
int64 2
15.4k
| downloads_30d
int64 0
19.9M
| library
stringlengths 2
37
⌀ | likes
int64 0
4.34k
| pipeline
stringlengths 5
30
⌀ | pytorch
bool 2
classes | tensorflow
bool 2
classes | jax
bool 2
classes | license
stringlengths 2
30
| languages
stringlengths 4
1.63k
⌀ | datasets
stringlengths 2
2.58k
⌀ | co2
stringclasses 29
values | prs_count
int64 0
125
| prs_open
int64 0
120
| prs_merged
int64 0
15
| prs_closed
int64 0
28
| discussions_count
int64 0
218
| discussions_open
int64 0
148
| discussions_closed
int64 0
70
| tags
stringlengths 2
513
| has_model_index
bool 2
classes | has_metadata
bool 1
class | has_text
bool 1
class | text_length
int64 401
598k
| is_nc
bool 1
class | readme
stringlengths 0
598k
| hash
stringlengths 32
32
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
sd-concepts-library/carlitos-el-mago
|
sd-concepts-library
| null | 9 | 0 | null | 1 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,085 | false |
### carlitos el mago on Stable Diffusion
This is the `<carloscarbonell>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
b6ff16262f9c5abad876050d0a78c25d
|
sd-concepts-library/ingmar-bergman
|
sd-concepts-library
| null | 10 | 0 | null | 6 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,184 | false |
### ingmar-bergman on Stable Diffusion
This is the `<ingmar-bergman>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
0e7c79b6812c4c21d9b407cfba93d8b3
|
jonatasgrosman/exp_w2v2t_uk_hubert_s878
|
jonatasgrosman
|
hubert
| 10 | 4 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['uk']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'uk']
| false | true | true | 452 | false |
# exp_w2v2t_uk_hubert_s878
Fine-tuned [facebook/hubert-large-ll60k](https://huggingface.co/facebook/hubert-large-ll60k) for speech recognition using the train split of [Common Voice 7.0 (uk)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
ef822685940eee51935ef6ad0295dfa2
|
nmb-paperspace-hf/roberta-base-finetuned-swag
|
nmb-paperspace-hf
|
roberta
| 12 | 0 |
transformers
| 0 | null | true | false | false |
mit
| null |
['swag']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,467 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-swag
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the swag dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5161
- Accuracy: 0.8266
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: IPU
- gradient_accumulation_steps: 16
- total_train_batch_size: 32
- total_eval_batch_size: 10
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- training precision: Mixed Precision
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.1273 | 1.0 | 2298 | 0.5415 | 0.7898 |
| 0.2373 | 2.0 | 4596 | 0.4756 | 0.8175 |
| 0.1788 | 3.0 | 6894 | 0.5161 | 0.8266 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.0+cpu
- Datasets 2.7.1
- Tokenizers 0.12.1
|
3d67e58f42e4574c7910c80afc6063b8
|
vamads/distilbert-base-uncased-finetuned-preprint_full
|
vamads
|
distilbert
| 31 | 2 |
transformers
| 1 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,328 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-preprint_full
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3258
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7315 | 1.0 | 47 | 2.4462 |
| 2.577 | 2.0 | 94 | 2.3715 |
| 2.5386 | 3.0 | 141 | 2.3692 |
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.12.1
- Datasets 2.7.0
- Tokenizers 0.13.2
|
f21c09895cf0757659c4d67c94b64a74
|
gokuls/mobilebert_sa_GLUE_Experiment_logit_kd_wnli_256
|
gokuls
|
mobilebert
| 17 | 2 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,592 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_sa_GLUE_Experiment_logit_kd_wnli_256
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE WNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3453
- Accuracy: 0.5634
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3472 | 1.0 | 5 | 0.3453 | 0.5634 |
| 0.3469 | 2.0 | 10 | 0.3464 | 0.5634 |
| 0.3467 | 3.0 | 15 | 0.3465 | 0.5634 |
| 0.3465 | 4.0 | 20 | 0.3457 | 0.5634 |
| 0.3466 | 5.0 | 25 | 0.3453 | 0.5634 |
| 0.3466 | 6.0 | 30 | 0.3454 | 0.5634 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
|
92ec65ee171c7c22055c5a47601bc8df
|
IDEA-CCNL/Randeng-BART-139M
|
IDEA-CCNL
|
bart
| 9 | 166 |
transformers
| 2 |
text2text-generation
| true | false | false |
apache-2.0
|
['zh']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,703 | false |
# Randeng-BART-139M
- Github: [Fengshenbang-LM](https://github.com/IDEA-CCNL/Fengshenbang-LM)
- Docs: [Fengshenbang-Docs](https://fengshenbang-doc.readthedocs.io/)
## 简介 Brief Introduction
善于处理NLT任务,中文版的BART-base。
Good at solving NLT tasks, Chinese BART-base.
## 模型分类 Model Taxonomy
| 需求 Demand | 任务 Task | 系列 Series | 模型 Model | 参数 Parameter | 额外 Extra |
| :----: | :----: | :----: | :----: | :----: | :----: |
| 通用 General | 自然语言转换 NLT | 燃灯 Randeng | BART | 139M | 中文-Chinese |
## 模型信息 Model Information
参考论文:[BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/pdf/1910.13461.pdf)
为了得到一个中文版的BART-base,我们用悟道语料库(180G版本)进行预训练。具体地,我们在预训练阶段中使用了[封神框架](https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/main/fengshen)大概花费了8张A100约3天。
To get a Chinese BART-base, we use WuDao Corpora (180 GB version) for pre-training. Specifically, we use the [fengshen framework](https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/main/fengshen) in the pre-training phase which cost about 3 days with 8 A100 GPUs.
## 使用 Usage
```python
from transformers import BartForConditionalGeneration, AutoTokenizer, Text2TextGenerationPipeline
import torch
tokenizer=AutoTokenizer.from_pretrained('IDEA-CCNL/Randeng-BART-139M', use_fast=false)
model=BartForConditionalGeneration.from_pretrained('IDEA-CCNL/Randeng-BART-139M')
text = '桂林市是世界闻名<mask> ,它有悠久的<mask>'
text2text_generator = Text2TextGenerationPipeline(model, tokenizer)
print(text2text_generator(text, max_length=50, do_sample=False))
```
## 引用 Citation
如果您在您的工作中使用了我们的模型,可以引用我们的[论文](https://arxiv.org/abs/2209.02970):
If you are using the resource for your work, please cite the our [paper](https://arxiv.org/abs/2209.02970):
```text
@article{fengshenbang,
author = {Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen and Ruyi Gan and Jiaxing Zhang},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
```
也可以引用我们的[网站](https://github.com/IDEA-CCNL/Fengshenbang-LM/):
You can also cite our [website](https://github.com/IDEA-CCNL/Fengshenbang-LM/):
```text
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
```
|
660fc2b70146570a120537b48081c430
|
likejazz/xlm-roberta-base-finetuned-panx-de
|
likejazz
|
xlm-roberta
| 39 | 1 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null |
['xtreme']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,320 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1351
- F1: 0.8516
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 96
- eval_batch_size: 96
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 132 | 0.1641 | 0.8141 |
| No log | 2.0 | 264 | 0.1410 | 0.8399 |
| No log | 3.0 | 396 | 0.1351 | 0.8516 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.13.1+cu117
- Datasets 1.16.1
- Tokenizers 0.10.3
|
a4055cf8befa3cf2d9b6be08a2be911b
|
FredMath/distilbert-base-uncased-finetuned-ner
|
FredMath
|
distilbert
| 12 | 9 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null |
['conll2003']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,555 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0625
- Precision: 0.9243
- Recall: 0.9361
- F1: 0.9302
- Accuracy: 0.9835
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2424 | 1.0 | 878 | 0.0685 | 0.9152 | 0.9235 | 0.9193 | 0.9813 |
| 0.0539 | 2.0 | 1756 | 0.0621 | 0.9225 | 0.9333 | 0.9279 | 0.9828 |
| 0.0298 | 3.0 | 2634 | 0.0625 | 0.9243 | 0.9361 | 0.9302 | 0.9835 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
51e6594152a1c6d15d68944f6eeeb749
|
kejian/mighty-filtering
|
kejian
|
gpt2
| 36 | 4 |
transformers
| 0 | null | true | false | false |
apache-2.0
|
['en']
|
['kejian/codeparrot-train-more-filter-3.3b-cleaned']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 4,332 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mighty-filtering
This model was trained from scratch on the kejian/codeparrot-train-more-filter-3.3b-cleaned dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0008
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- training_steps: 50354
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.23.0
- Pytorch 1.13.0+cu116
- Datasets 2.0.0
- Tokenizers 0.12.1
# Full config
{'dataset': {'datasets': ['kejian/codeparrot-train-more-filter-3.3b-cleaned'],
'filter_threshold': 0.002361,
'is_split_by_sentences': True},
'generation': {'batch_size': 128,
'metrics_configs': [{}, {'n': 1}, {}],
'scenario_configs': [{'display_as_html': True,
'generate_kwargs': {'do_sample': True,
'eos_token_id': 0,
'max_length': 640,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'unconditional',
'num_hits_threshold': 0,
'num_samples': 2048},
{'display_as_html': True,
'generate_kwargs': {'do_sample': True,
'eos_token_id': 0,
'max_length': 272,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'functions',
'num_hits_threshold': 0,
'num_samples': 2048,
'prompts_path': 'resources/functions_csnet.jsonl',
'use_prompt_for_scoring': True}],
'scorer_config': {}},
'kl_gpt3_callback': {'gpt3_kwargs': {'model_name': 'code-cushman-001'},
'max_tokens': 64,
'num_samples': 4096},
'model': {'from_scratch': True,
'gpt2_config_kwargs': {'reorder_and_upcast_attn': True,
'scale_attn_by': True},
'path_or_name': 'codeparrot/codeparrot-small'},
'objective': {'name': 'MLE'},
'tokenizer': {'path_or_name': 'codeparrot/codeparrot-small'},
'training': {'dataloader_num_workers': 0,
'effective_batch_size': 64,
'evaluation_strategy': 'no',
'fp16': True,
'hub_model_id': 'mighty-filtering',
'hub_strategy': 'all_checkpoints',
'learning_rate': 0.0008,
'logging_first_step': True,
'logging_steps': 1,
'num_tokens': 3300000000.0,
'output_dir': 'training_output',
'per_device_train_batch_size': 16,
'push_to_hub': True,
'remove_unused_columns': False,
'save_steps': 25177,
'save_strategy': 'steps',
'seed': 42,
'warmup_ratio': 0.01,
'weight_decay': 0.1}}
# Wandb URL:
https://wandb.ai/kejian/uncategorized/runs/zk4rbxx0
|
c05203d9c3cb86c5758554a84dfd7035
|
Helsinki-NLP/opus-mt-fr-mt
|
Helsinki-NLP
|
marian
| 10 | 15 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 768 | false |
### opus-mt-fr-mt
* source languages: fr
* target languages: mt
* OPUS readme: [fr-mt](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fr-mt/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/fr-mt/opus-2020-01-09.zip)
* test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-mt/opus-2020-01-09.test.txt)
* test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-mt/opus-2020-01-09.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.fr.mt | 28.7 | 0.466 |
|
ee9b50ff1b5224148594871dffd8d953
|
racai/e4a-covid-bert-base-romanian-cased-v1
|
racai
|
bert
| 9 | 4 |
transformers
| 0 |
fill-mask
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,791 | false |
The model generated in the Enrich4All project.<br>
Evaluated the perplexity of MLM Task fine-tuned for COVID-related corpus.<br>
Baseline model: https://huggingface.co/dumitrescustefan/bert-base-romanian-cased-v1 <br>
Scripts and corpus used for training: https://github.com/racai-ai/e4all-models
Corpus
---------------
The COVID-19 datasets we designed are a small corpus and a question-answer dataset. The targeted sources were official websites of Romanian institutions involved in managing the COVID-19 pandemic, like The Ministry of Health, Bucharest Public Health Directorate, The National Information Platform on Vaccination against COVID-19, The Ministry of Foreign Affairs, as well as of the European Union. We also harvested the website of a non-profit organization initiative, in partnership with the Romanian Government through the Romanian Digitization Authority, that developed an ample platform with different sections dedicated to COVID-19 official news and recommendations. News websites were avoided due to the volatile character of the continuously changing pandemic situation, but a reliable source of information was a major private medical clinic website (Regina Maria), which provided detailed medical articles on important subjects of immediate interest to the readers and patients, like immunity, the emergent treating protocols or the new Omicron variant of the virus.
The corpus dataset was manually collected and revised. Data were checked for grammatical correctness, and missing diacritics were introduced.
<br><br>
The corpus is structured in 55 UTF-8 documents and contains 147,297 words.
Results
-----------------
| MLM Task | Perplexity |
| ------------- | ------------- |
| Baseline | 5.13 |
| COVID Fine-tuning| 2.74 |
|
cf9bc0b7d216501f87651daf1797ec43
|
huggingnft/nftrex
|
huggingnft
| null | 5 | 19 |
transformers
| 1 |
unconditional-image-generation
| false | false | false |
mit
| null |
['huggingnft/nftrex']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['huggingnft', 'nft', 'huggan', 'gan', 'image', 'images', 'unconditional-image-generation']
| false | true | true | 2,166 | false |
# Hugging NFT: nftrex
## Disclaimer
All rights belong to their owners. Models and datasets can be removed from the site at the request of the copyright
holder.
## Model description
LightWeight GAN model for unconditional generation.
NFT collection available [here](https://opensea.io/collection/nftrex).
Dataset is available [here](https://huggingface.co/datasets/huggingnft/nftrex).
Check Space: [link](https://huggingface.co/spaces/AlekseyKorshuk/huggingnft).
Project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
[](https://github.com/AlekseyKorshuk/huggingnft)
## Intended uses & limitations
#### How to use
Check project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
#### Limitations and bias
Check project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
## Training data
Dataset is available [here](https://huggingface.co/datasets/huggingnft/nftrex).
## Training procedure
Training script is available [here](https://github.com/AlekseyKorshuk/huggingnft).
## Generated Images
Check results with Space: [link](https://huggingface.co/spaces/AlekseyKorshuk/huggingnft).
## About
*Built by Aleksey Korshuk*
[](https://github.com/AlekseyKorshuk)
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
For more details, visit the project repository.
[](https://github.com/AlekseyKorshuk/huggingnft)
### BibTeX entry and citation info
```bibtex
@InProceedings{huggingnft,
author={Aleksey Korshuk}
year=2022
}
```
|
a2bd66f446d154e09747382c687d806d
|
jonatasgrosman/exp_w2v2t_en_xls-r_s468
|
jonatasgrosman
|
wav2vec2
| 10 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['en']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'en']
| false | true | true | 459 | false |
# exp_w2v2t_en_xls-r_s468
Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition on English using the train split of [Common Voice 7.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
8d9c38df256e5f0953102f2a39b863c9
|
google/t5-efficient-small-el8-dl2
|
google
|
t5
| 12 | 7 |
transformers
| 0 |
text2text-generation
| true | true | true |
apache-2.0
|
['en']
|
['c4']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['deep-narrow']
| false | true | true | 6,281 | false |
# T5-Efficient-SMALL-EL8-DL2 (Deep-Narrow version)
T5-Efficient-SMALL-EL8-DL2 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5).
It is a *pretrained-only* checkpoint and was released with the
paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)**
by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures
of similar parameter count.
To quote the paper:
> We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased
> before considering any other forms of uniform scaling across other dimensions. This is largely due to
> how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a
> tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise,
> a tall base model might also generally more efficient compared to a large model. We generally find
> that, regardless of size, even if absolute performance might increase as we continue to stack layers,
> the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36
> layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e.,
> params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params,
> FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to
> consider.
To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially.
A sequence of word embeddings is therefore processed sequentially by each transformer block.
## Details model architecture
This model checkpoint - **t5-efficient-small-el8-dl2** - is of model type **Small** with the following variations:
- **el** is **8**
- **dl** is **2**
It has **50.03** million parameters and thus requires *ca.* **200.11 MB** of memory in full precision (*fp32*)
or **100.05 MB** of memory in half precision (*fp16* or *bf16*).
A summary of the *original* T5 model architectures can be seen here:
| Model | nl (el/dl) | ff | dm | kv | nh | #Params|
| ----| ---- | ---- | ---- | ---- | ---- | ----|
| Tiny | 4/4 | 1024 | 256 | 32 | 4 | 16M|
| Mini | 4/4 | 1536 | 384 | 32 | 8 | 31M|
| Small | 6/6 | 2048 | 512 | 32 | 8 | 60M|
| Base | 12/12 | 3072 | 768 | 64 | 12 | 220M|
| Large | 24/24 | 4096 | 1024 | 64 | 16 | 738M|
| Xl | 24/24 | 16384 | 1024 | 128 | 32 | 3B|
| XXl | 24/24 | 65536 | 1024 | 128 | 128 | 11B|
whereas the following abbreviations are used:
| Abbreviation | Definition |
| ----| ---- |
| nl | Number of transformer blocks (depth) |
| dm | Dimension of embedding vector (output vector of transformers block) |
| kv | Dimension of key/value projection matrix |
| nh | Number of attention heads |
| ff | Dimension of intermediate vector within transformer block (size of feed-forward projection matrix) |
| el | Number of transformer blocks in the encoder (encoder depth) |
| dl | Number of transformer blocks in the decoder (decoder depth) |
| sh | Signifies that attention heads are shared |
| skv | Signifies that key-values projection matrices are tied |
If a model checkpoint has no specific, *el* or *dl* than both the number of encoder- and decoder layers correspond to *nl*.
## Pre-Training
The checkpoint was pretrained on the [Colossal, Cleaned version of Common Crawl (C4)](https://huggingface.co/datasets/c4) for 524288 steps using
the span-based masked language modeling (MLM) objective.
## Fine-Tuning
**Note**: This model is a **pretrained** checkpoint and has to be fine-tuned for practical usage.
The checkpoint was pretrained in English and is therefore only useful for English NLP tasks.
You can follow on of the following examples on how to fine-tune the model:
*PyTorch*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization)
- [Question Answering](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_seq2seq_qa.py)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*Tensorflow*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*JAX/Flax*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/flax/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/flax/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
## Downstream Performance
TODO: Add table if available
## Computational Complexity
TODO: Add table if available
## More information
We strongly recommend the reader to go carefully through the original paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** to get a more nuanced understanding of this model checkpoint.
As explained in the following [issue](https://github.com/google-research/google-research/issues/986#issuecomment-1035051145), checkpoints including the *sh* or *skv*
model architecture variations have *not* been ported to Transformers as they are probably of limited practical usage and are lacking a more detailed description. Those checkpoints are kept [here](https://huggingface.co/NewT5SharedHeadsSharedKeyValues) as they might be ported potentially in the future.
|
f2d7609c090e479af8fcd242783b441f
|
anuragshas/wav2vec2-large-xlsr-53-rm-vallader
|
anuragshas
|
wav2vec2
| 9 | 9 |
transformers
| 0 |
automatic-speech-recognition
| true | false | true |
apache-2.0
|
['rm-vallader']
|
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week']
| true | true | true | 3,527 | false |
# Wav2Vec2-Large-XLSR-53-Romansh Vallader
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Romansh Vallader using the [Common Voice](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "rm-vallader", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-rm-vallader")
model = Wav2Vec2ForCTC.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-rm-vallader")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Romansh Vallader test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "rm-vallader", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-rm-vallader")
model = Wav2Vec2ForCTC.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-rm-vallader")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\”\„\–\…\«\»]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub('’ ',' ',batch["sentence"])
batch["sentence"] = re.sub(' ‘',' ',batch["sentence"])
batch["sentence"] = re.sub('’|‘','\'',batch["sentence"])
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 32.89 %
## Training
The Common Voice `train` and `validation` datasets were used for training.
|
90e2f95ff3f3656395b7874e929794db
|
aapot/wav2vec2-xlsr-1b-finnish-lm
|
aapot
|
wav2vec2
| 21 | 4 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['fi']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'fi', 'finnish', 'generated_from_trainer', 'hf-asr-leaderboard', 'robust-speech-event']
| true | true | true | 9,461 | false |
# Wav2Vec2 XLS-R for Finnish ASR
This acoustic model is a fine-tuned version of [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) for Finnish ASR. The model has been fine-tuned with 259.57 hours of Finnish transcribed speech data. Wav2Vec2 XLS-R was introduced in
[this paper](https://arxiv.org/abs/2111.09296) and first released at [this page](https://github.com/pytorch/fairseq/tree/main/examples/wav2vec#wav2vec-20).
This repository also includes Finnish KenLM language model used in the decoding phase with the acoustic model.
**Note**: this model is exactly the same as the [Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm](https://huggingface.co/Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm) model so this model has just been copied/moved to the `Finnish-NLP` Hugging Face organization.
**Note**: there is a better V2 version of this model which has been fine-tuned longer with 16 hours of more data: [Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm-v2](https://huggingface.co/Finnish-NLP/wav2vec2-xlsr-1b-finnish-lm-v2)
## Model description
Wav2Vec2 XLS-R is Facebook AI's large-scale multilingual pretrained model for speech. It is pretrained on 436k hours of unlabeled speech, including VoxPopuli, MLS, CommonVoice, BABEL, and VoxLingua107. It uses the wav2vec 2.0 objective, in 128 languages.
You can read more about the pretrained model from [this blog](https://ai.facebook.com/blog/xls-r-self-supervised-speech-processing-for-128-languages) and [this paper](https://arxiv.org/abs/2111.09296).
This model is fine-tuned version of the pretrained model (1 billion parameter variant) for Finnish ASR.
## Intended uses & limitations
You can use this model for Finnish ASR (speech-to-text) task.
### How to use
Check the [run-finnish-asr-models.ipynb](https://huggingface.co/aapot/wav2vec2-xlsr-1b-finnish-lm/blob/main/run-finnish-asr-models.ipynb) notebook in this repository for an detailed example on how to use this model.
### Limitations and bias
This model was fine-tuned with audio samples which maximum length was 20 seconds so this model most likely works the best for quite short audios of similar length. However, you can try this model with a lot longer audios too and see how it works. If you encounter out of memory errors with very long audio files you can use the audio chunking method introduced in [this blog post](https://huggingface.co/blog/asr-chunking).
A vast majority of the data used for fine-tuning was from the Finnish Parliament dataset so this model may not generalize so well to very different domains like common daily spoken Finnish with dialects etc. In addition, audios of the datasets tend to be adult male dominated so this model may not work as well for speeches of children and women, for example.
The Finnish KenLM language model used in the decoding phase has been trained with text data from the audio transcriptions. Thus, the decoder's language model may not generalize to very different language, for example to spoken daily language with dialects. It may be beneficial to train your own KenLM language model for your domain language and use that in the decoding.
## Training data
This model was fine-tuned with 259.57 hours of Finnish transcribed speech data from following datasets:
| Dataset | Hours | % of total hours |
|:----------------------------------------------------------------------------------------------------------------------------------|:--------:|:----------------:|
| [Common Voice 7.0 Finnish train + evaluation + other splits](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0) | 9.70 h | 3.74 % |
| [Finnish parliament session 2](https://b2share.eudat.eu/records/4df422d631544ce682d6af1d4714b2d4) | 0.24 h | 0.09 % |
| [VoxPopuli Finnish](https://github.com/facebookresearch/voxpopuli) | 5.94 h | 2.29 % |
| [CSS10 Finnish](https://github.com/kyubyong/css10) | 10.32 h | 3.98 % |
| [Aalto Finnish Parliament ASR Corpus](http://urn.fi/urn:nbn:fi:lb-2021051903) | 228.00 h | 87.84 % |
| [Finnish Broadcast Corpus](http://urn.fi/urn:nbn:fi:lb-2016042502) | 5.37 h | 2.07 % |
Datasets were filtered to include maximum length of 20 seconds long audio samples.
## Training procedure
This model was trained during [Robust Speech Challenge Event](https://discuss.huggingface.co/t/open-to-the-community-robust-speech-recognition-challenge/13614) organized by Hugging Face. Training was done on a Tesla V100 GPU, sponsored by OVHcloud.
Training script was provided by Hugging Face and it is available [here](https://github.com/huggingface/transformers/blob/main/examples/research_projects/robust-speech-event/run_speech_recognition_ctc_bnb.py). We only modified its data loading for our custom datasets.
For the KenLM language model training, we followed the [blog post tutorial](https://huggingface.co/blog/wav2vec2-with-ngram) provided by Hugging Face. Training data for the 5-gram KenLM were text transcriptions of the audio training data.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: [8-bit Adam](https://github.com/facebookresearch/bitsandbytes) with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 5
- mixed_precision_training: Native AMP
The pretrained `facebook/wav2vec2-xls-r-1b` model was initialized with following hyperparameters:
- attention_dropout: 0.094
- hidden_dropout: 0.047
- feat_proj_dropout: 0.04
- mask_time_prob: 0.082
- layerdrop: 0.041
- activation_dropout: 0.055
- ctc_loss_reduction: "mean"
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.968 | 0.18 | 500 | 0.4870 | 0.4720 |
| 0.6557 | 0.36 | 1000 | 0.2450 | 0.2931 |
| 0.647 | 0.54 | 1500 | 0.1818 | 0.2255 |
| 0.5297 | 0.72 | 2000 | 0.1698 | 0.2354 |
| 0.5802 | 0.9 | 2500 | 0.1581 | 0.2355 |
| 0.6351 | 1.07 | 3000 | 0.1689 | 0.2336 |
| 0.4626 | 1.25 | 3500 | 0.1719 | 0.3099 |
| 0.4526 | 1.43 | 4000 | 0.1434 | 0.2069 |
| 0.4692 | 1.61 | 4500 | 0.1645 | 0.2192 |
| 0.4584 | 1.79 | 5000 | 0.1483 | 0.1987 |
| 0.4234 | 1.97 | 5500 | 0.1499 | 0.2178 |
| 0.4243 | 2.15 | 6000 | 0.1345 | 0.2070 |
| 0.4108 | 2.33 | 6500 | 0.1383 | 0.1850 |
| 0.4048 | 2.51 | 7000 | 0.1338 | 0.1811 |
| 0.4085 | 2.69 | 7500 | 0.1290 | 0.1780 |
| 0.4026 | 2.87 | 8000 | 0.1239 | 0.1650 |
| 0.4033 | 3.04 | 8500 | 0.1346 | 0.1657 |
| 0.3986 | 3.22 | 9000 | 0.1310 | 0.1850 |
| 0.3867 | 3.4 | 9500 | 0.1273 | 0.1741 |
| 0.3658 | 3.58 | 10000 | 0.1219 | 0.1672 |
| 0.382 | 3.76 | 10500 | 0.1306 | 0.1698 |
| 0.3847 | 3.94 | 11000 | 0.1230 | 0.1577 |
| 0.3691 | 4.12 | 11500 | 0.1310 | 0.1615 |
| 0.3593 | 4.3 | 12000 | 0.1296 | 0.1622 |
| 0.3619 | 4.48 | 12500 | 0.1285 | 0.1601 |
| 0.3361 | 4.66 | 13000 | 0.1261 | 0.1569 |
| 0.3603 | 4.84 | 13500 | 0.1235 | 0.1533 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.3
- Tokenizers 0.11.0
## Evaluation results
Evaluation was done with the [Common Voice 7.0 Finnish test split](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
To evaluate this model, run the `eval.py` script in this repository:
```bash
python3 eval.py --model_id aapot/wav2vec2-xlsr-1b-finnish-lm --dataset mozilla-foundation/common_voice_7_0 --config fi --split test
```
This model (the second row of the table) achieves the following WER (Word Error Rate) and CER (Character Error Rate) results compared to our other models:
| | WER (with LM) | WER (without LM) | CER (with LM) | CER (without LM) |
|-----------------------------------------|---------------|------------------|---------------|------------------|
|aapot/wav2vec2-xlsr-1b-finnish-lm-v2 |**4.09** |**9.73** |**0.88** |**1.65** |
|aapot/wav2vec2-xlsr-1b-finnish-lm |5.65 |13.11 |1.20 |2.23 |
|aapot/wav2vec2-xlsr-300m-finnish-lm |8.16 |17.92 |1.97 |3.36 |
## Team Members
- Aapo Tanskanen, [Hugging Face profile](https://huggingface.co/aapot), [LinkedIn profile](https://www.linkedin.com/in/aapotanskanen/)
- Rasmus Toivanen, [Hugging Face profile](https://huggingface.co/RASMUS), [LinkedIn profile](https://www.linkedin.com/in/rasmustoivanen/)
Feel free to contact us for more details 🤗
|
d2612bbc04ae5ef76b3e637a86f3d84b
|
jgammack/roberta-base-squad
|
jgammack
|
roberta
| 15 | 6 |
transformers
| 0 |
question-answering
| true | false | false |
mit
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 947 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-squad
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
970cd456f7ce21b118ac7fc86adbb360
|
SEUNGWON1/distilgpt2-finetuned-wikitext2
|
SEUNGWON1
|
gpt2
| 9 | 4 |
transformers
| 0 |
text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,243 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-wikitext2
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6421
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.7602 | 1.0 | 2334 | 3.6669 |
| 3.653 | 2.0 | 4668 | 3.6472 |
| 3.6006 | 3.0 | 7002 | 3.6421 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
5aa385f2eeb9ea184e37123362c16e6b
|
garyw/clinical-embeddings-100d-w2v-cr
|
garyw
| null | 5 | 0 | null | 1 | null | false | false | false |
gpl-3.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,547 | false |
Pre-trained word embeddings using the text of published clinical case reports. These embeddings use 100 dimensions and were trained using the word2vec algorithm on published clinical case reports found in the [PMC Open Access Subset](https://www.ncbi.nlm.nih.gov/pmc/tools/openftlist/). See the paper here: https://pubmed.ncbi.nlm.nih.gov/34920127/
Citation:
```
@article{flamholz2022word,
title={Word embeddings trained on published case reports are lightweight, effective for clinical tasks, and free of protected health information},
author={Flamholz, Zachary N and Crane-Droesch, Andrew and Ungar, Lyle H and Weissman, Gary E},
journal={Journal of Biomedical Informatics},
volume={125},
pages={103971},
year={2022},
publisher={Elsevier}
}
```
## Quick start
Word embeddings are compatible with the [`gensim` Python package](https://radimrehurek.com/gensim/) format.
First download the files from this archive. Then load the embeddings into Python.
```python
from gensim.models import FastText, Word2Vec, KeyedVectors # KeyedVectors are used to load the GloVe models
# Load the model
model = Word2Vec.load('w2v_oa_cr_100d.bin')
# Return 100-dimensional vector representations of each word
model.wv.word_vec('diabetes')
model.wv.word_vec('cardiac_arrest')
model.wv.word_vec('lymphangioleiomyomatosis')
# Try out cosine similarity
model.wv.similarity('copd', 'chronic_obstructive_pulmonary_disease')
model.wv.similarity('myocardial_infarction', 'heart_attack')
model.wv.similarity('lymphangioleiomyomatosis', 'lam')
```
|
e3317287015960343723950784a550a8
|
beyond/genius-large-k2t
|
beyond
|
bart
| 9 | 4 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
|
['en']
|
['wikipedia']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['GENIUS', 'conditional text generation', 'sketch-based text generation', 'keywords-to-text generation', 'data augmentation']
| false | true | true | 1,710 | false |
# 💡GENIUS – generating text using sketches!
- **Paper: [GENIUS: Sketch-based Language Model Pre-training via Extreme and Selective Masking for Text Generation and Augmentation](https://github.com/beyondguo/genius/blob/master/GENIUS_gby_arxiv.pdf)**
💡**GENIUS** is a powerful conditional text generation model using sketches as input, which can fill in the missing contexts for a given **sketch** (key information consisting of textual spans, phrases, or words, concatenated by mask tokens). GENIUS is pre-trained on a large- scale textual corpus with a novel *reconstruction from sketch* objective using an *extreme and selective masking* strategy, enabling it to generate diverse and high-quality texts given sketches.
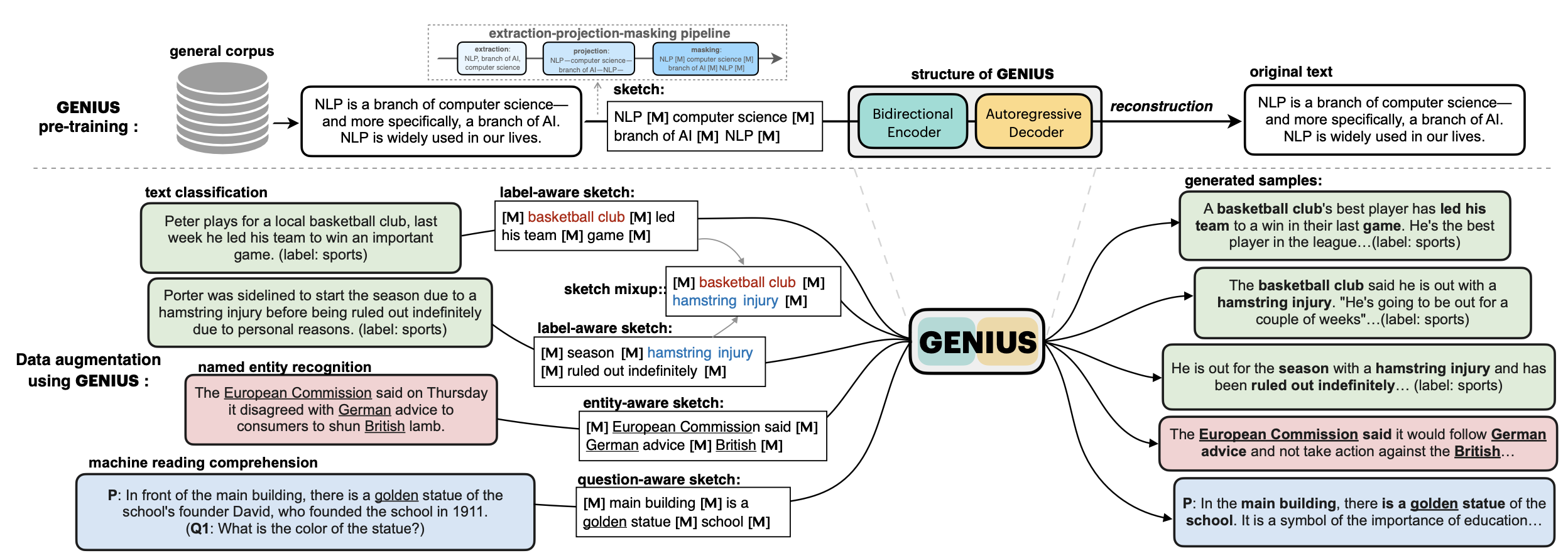
- Models hosted in 🤗 Huggingface:
**Model variations:**
| Model | #params | Language | comment|
|------------------------|--------------------------------|-------|---------|
| [`genius-large`](https://huggingface.co/beyond/genius-large) | 406M | English | The version used in **paper** (recommend) |
| [`genius-large-k2t`](https://huggingface.co/beyond/genius-large-k2t) | 406M | English | keywords-to-text |
| [`genius-base`](https://huggingface.co/beyond/genius-base) | 139M | English | smaller version |
| [`genius-base-ps`](https://huggingface.co/beyond/genius-base) | 139M | English | pre-trained both in paragraphs and short sentences |
| [`genius-base-chinese`](https://huggingface.co/beyond/genius-base-chinese) | 116M | 中文 | 在一千万纯净中文段落上预训练|
|
b2ef5692dd12757b03402d8a7bce21ee
|
sd-concepts-library/eastward
|
sd-concepts-library
| null | 20 | 0 | null | 3 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,162 | false |
### Eastward on Stable Diffusion
This is the `<eastward>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:














|
0a2f80e8cbd7757ca3445d9f95583e43
|
BN87/sample
|
BN87
| null | 2 | 0 | null | 0 | null | false | false | false |
openrail
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 4,739 | false |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
# Model Details
## Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
## Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
# Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
## Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
## Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
## Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
# Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
## Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
# Training Details
## Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
## Training Procedure [optional]
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
### Preprocessing
[More Information Needed]
### Speeds, Sizes, Times
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
# Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
## Testing Data, Factors & Metrics
### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
## Results
[More Information Needed]
### Summary
# Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
# Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
# Technical Specifications [optional]
## Model Architecture and Objective
[More Information Needed]
## Compute Infrastructure
[More Information Needed]
### Hardware
[More Information Needed]
### Software
[More Information Needed]
# Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
# Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
# More Information [optional]
[More Information Needed]
# Model Card Authors [optional]
[More Information Needed]
# Model Card Contact
[More Information Needed]
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
[More Information Needed]
</details>
|
8c16c88e1125fe4658d8e75ce6d9fbea
|
jonatasgrosman/exp_w2v2t_pl_vp-es_s840
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['pl']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'pl']
| false | true | true | 469 | false |
# exp_w2v2t_pl_vp-es_s840
Fine-tuned [facebook/wav2vec2-large-es-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-es-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (pl)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
a9dd3fdf9afbf47f3ee7335bfc80d10b
|
kyo/distilbert-base-uncased-finetuned-imdb
|
kyo
|
distilbert
| 12 | 4 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null |
['imdb']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,319 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4718
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.707 | 1.0 | 157 | 2.4883 |
| 2.572 | 2.0 | 314 | 2.4240 |
| 2.5377 | 3.0 | 471 | 2.4355 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
b53e956660a729299fcb42621c1a188f
|
eduardopds/mt5-small-finetuned-amazon-en-es
|
eduardopds
|
mt5
| 8 | 1 |
transformers
| 0 |
text2text-generation
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,651 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# eduardopds/mt5-small-finetuned-amazon-en-es
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 4.0870
- Validation Loss: 3.3925
- Epoch: 7
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5.6e-05, 'decay_steps': 9672, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 9.8646 | 4.3778 | 0 |
| 5.9307 | 3.8057 | 1 |
| 5.1494 | 3.6458 | 2 |
| 4.7430 | 3.5501 | 3 |
| 4.4782 | 3.4870 | 4 |
| 4.2922 | 3.4339 | 5 |
| 4.1536 | 3.4037 | 6 |
| 4.0870 | 3.3925 | 7 |
### Framework versions
- Transformers 4.18.0
- TensorFlow 2.8.0
- Datasets 2.2.1
- Tokenizers 0.12.1
|
a5a12122524bd20a37dbe9b117f8141b
|
huiziy/my_awesome_qa_model
|
huiziy
|
distilbert
| 12 | 1 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,279 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_qa_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an High School Health Science dataset.
It achieves the following results on the evaluation set:
- Loss: 5.2683
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 3 | 5.6569 |
| No log | 2.0 | 6 | 5.3967 |
| No log | 3.0 | 9 | 5.2683 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
dafdc56c0ad3508daadc75bc4cc28d1c
|
KoichiYasuoka/roberta-base-vietnamese-ud-goeswith
|
KoichiYasuoka
|
roberta
| 10 | 4 |
transformers
| 0 |
token-classification
| true | false | false |
cc-by-sa-4.0
|
['vi']
|
['universal_dependencies']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['vietnamese', 'token-classification', 'pos', 'dependency-parsing']
| false | true | true | 2,759 | false |
# roberta-base-vietnamese-ud-goeswith
## Model Description
This is a RoBERTa model pre-trained on Vietnamese texts for POS-tagging and dependency-parsing (using `goeswith` for subwords), derived from [roberta-base-vietnamese-upos](https://huggingface.co/KoichiYasuoka/roberta-base-vietnamese-upos).
## How to Use
```py
class UDgoeswith(object):
def __init__(self,bert):
from transformers import AutoTokenizer,AutoModelForTokenClassification
self.tokenizer=AutoTokenizer.from_pretrained(bert)
self.model=AutoModelForTokenClassification.from_pretrained(bert)
def __call__(self,text):
import numpy,torch,ufal.chu_liu_edmonds
w=self.tokenizer(text,return_offsets_mapping=True)
v=w["input_ids"]
x=[v[0:i]+[self.tokenizer.mask_token_id]+v[i+1:]+[j] for i,j in enumerate(v[1:-1],1)]
with torch.no_grad():
e=self.model(input_ids=torch.tensor(x)).logits.numpy()[:,1:-2,:]
r=[1 if i==0 else -1 if j.endswith("|root") else 0 for i,j in sorted(self.model.config.id2label.items())]
e+=numpy.where(numpy.add.outer(numpy.identity(e.shape[0]),r)==0,0,numpy.nan)
g=self.model.config.label2id["X|_|goeswith"]
r=numpy.tri(e.shape[0])
for i in range(e.shape[0]):
for j in range(i+2,e.shape[1]):
r[i,j]=r[i,j-1] if numpy.nanargmax(e[i,j-1])==g else 1
e[:,:,g]+=numpy.where(r==0,0,numpy.nan)
m=numpy.full((e.shape[0]+1,e.shape[1]+1),numpy.nan)
m[1:,1:]=numpy.nanmax(e,axis=2).transpose()
p=numpy.zeros(m.shape)
p[1:,1:]=numpy.nanargmax(e,axis=2).transpose()
for i in range(1,m.shape[0]):
m[i,0],m[i,i],p[i,0]=m[i,i],numpy.nan,p[i,i]
h=ufal.chu_liu_edmonds.chu_liu_edmonds(m)[0]
if [0 for i in h if i==0]!=[0]:
m[:,0]+=numpy.where(m[:,0]==numpy.nanmax(m[[i for i,j in enumerate(h) if j==0],0]),0,numpy.nan)
m[[i for i,j in enumerate(h) if j==0]]+=[0 if i==0 or j==0 else numpy.nan for i,j in enumerate(h)]
h=ufal.chu_liu_edmonds.chu_liu_edmonds(m)[0]
u="# text = "+text+"\n"
v=[(s,e) for s,e in w["offset_mapping"] if s<e]
for i,(s,e) in enumerate(v,1):
q=self.model.config.id2label[p[i,h[i]]].split("|")
u+="\t".join([str(i),text[s:e],"_",q[0],"_","|".join(q[1:-1]),str(h[i]),q[-1],"_","_" if i<len(v) and e<v[i][0] else "SpaceAfter=No"])+"\n"
return u+"\n"
nlp=UDgoeswith("KoichiYasuoka/roberta-base-vietnamese-ud-goeswith")
print(nlp("Hai cái đầu thì tốt hơn một."))
```
with [ufal.chu-liu-edmonds](https://pypi.org/project/ufal.chu-liu-edmonds/).
Or without ufal.chu-liu-edmonds:
```
from transformers import pipeline
nlp=pipeline("universal-dependencies","KoichiYasuoka/roberta-base-vietnamese-ud-goeswith",trust_remote_code=True,aggregation_strategy="simple")
print(nlp("Hai cái đầu thì tốt hơn một."))
```
|
62a24c63e77528313450ebf9ce8c82f3
|
IDEA-CCNL/Erlangshen-TCBert-1.3B-Classification-Chinese
|
IDEA-CCNL
|
bert
| 5 | 34 |
transformers
| 1 | null | true | false | false |
apache-2.0
|
['zh']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['classification']
| false | true | true | 8,644 | false |
# Erlangshen-TCBert-1.3B-Classification-Chinese
- Github: [Fengshenbang-LM](https://github.com/IDEA-CCNL/Fengshenbang-LM)
- Docs: [Fengshenbang-Docs](https://fengshenbang-doc.readthedocs.io/)
## 简介 Brief Introduction
1.3BM参数的Topic Classification BERT (TCBert)。
The TCBert with 1.3BM parameters is pre-trained for, not limited to, Chinese topic classification tasks.
## 模型分类 Model Taxonomy
| 需求 Demand | 任务 Task | 系列 Series | 模型 Model | 参数 Parameter | 额外 Extra |
| :----: | :----: | :----: | :----: | :----: | :----: |
| 通用 General | 自然语言理解 NLU | 二郎神 Erlangshen | TCBert | 1.3BM | Chinese |
## 模型信息 Model Information
为了提高模型在话题分类上的效果,我们收集了大量话题分类数据进行基于prompts的预训练。
To improve the model performance on the topic classification task, we collected numerous topic classification datasets for pre-training based on general prompts.
### 下游效果 Performance
我们为每个数据集设计了两个prompt模板。
We customize two prompts templates for each dataset.
第一个prompt模板:
For ***prompt template 1***:
| Dataset | Prompt template 1 |
|---------|:------------------------:|
| TNEWS | 下面是一则关于__的新闻: |
| CSLDCP | 这一句描述__的内容如下: |
| IFLYTEK | 这一句描述__的内容如下: |
第一个prompt模板的微调实验结果:
The **fine-tuning** results for prompt template 1:
| Model | TNEWS | CLSDCP | IFLYTEK |
|-----------------|:------:|:------:|:-------:|
| Macbert-base | 55.02 | 57.37 | 51.34 |
| Macbert-large | 55.77 | 58.99 | 50.31 |
| Erlangshen-1.3B | 57.36 | 62.35 | 53.23 |
| TCBert-base<sub>110M-Classification-Chinese | 55.57 | 58.60 | 49.63 |
| TCBert-large<sub>330M-Classification-Chinese | 56.17 | 60.06 | 51.34 |
| TCBert-1.3B<sub>1.3B-Classification-Chinese | 57.41 | 65.10 | 53.75 |
| TCBert-base<sub>110M-Sentence-Embedding-Chinese | 54.68 | 59.78 | 49.40 |
| TCBert-large<sub>330M-Sentence-Embedding-Chinese | 55.32 | 62.07 | 51.11 |
| TCBert-1.3B<sub>1.3B-Sentence-Embedding-Chinese | 57.46 | 65.04 | 53.06 |
第一个prompt模板的句子相似度结果:
The **sentence similarity** results for prompt template 1:
| | TNEWS | | CSLDCP | | IFLYTEK | |
|-----------------|:--------:|:---------:|:---------:|:---------:|:---------:|:---------:|
| Model | referece | whitening | reference | whitening | reference | whitening |
| Macbert-base | 43.53 | 47.16 | 33.50 | 36.53 | 28.99 | 33.85 |
| Macbert-large | 46.17 | 49.35 | 37.65 | 39.38 | 32.36 | 35.33 |
| Erlangshen-1.3B | 45.72 | 49.60 | 40.56 | 44.26 | 29.33 | 36.48 |
| TCBert-base<sub>110M-Classification-Chinese | 48.61 | 51.99 | 43.31 | 45.15 | 33.45 | 37.28 |
| TCBert-large<sub>330M-Classification-Chinese | 50.50 | 52.79 | 52.89 | 53.89 | 34.93 | 38.31 |
| TCBert-1.3B<sub>1.3B-Classification-Chinese | 50.80 | 51.59 | 51.93 | 54.12 | 33.96 | 38.08 |
| TCBert-base<sub>110M-Sentence-Embedding-Chinese | 45.82 | 47.06 | 42.91 | 43.87 | 33.28 | 34.76 |
| TCBert-large<sub>330M-Sentence-Embedding-Chinese | 50.10 | 50.90 | 53.78 | 53.33 | 37.62 | 36.94 |
| TCBert-1.3B<sub>1.3B-Sentence-Embedding-Chinese | 50.70 | 53.48 | 52.66 | 54.40 | 36.88 | 38.48 |
第二个prompt模板:
For ***prompt template 2***:
| Dataset | Prompt template 2 |
|---------|:------------------------:|
| TNEWS | 接下来的新闻,是跟__相关的内容: |
| CSLDCP | 接下来的学科,是跟__相关: |
| IFLYTEK | 接下来的生活内容,是跟__相关: |
第二个prompt模板的微调结果:
The **fine-tuning** results for prompt template 2:
| Model | TNEWS | CLSDCP | IFLYTEK |
|-----------------|:------:|:------:|:-------:|
| Macbert-base | 54.78 | 58.38 | 50.83 |
| Macbert-large | 56.77 | 60.22 | 51.63 |
| Erlangshen-1.3B | 57.81 | 62.80 | 52.77 |
| TCBert-base<sub>110M-Classification-Chinese | 54.58 | 59.16 | 49.80 |
| TCBert-large<sub>330M-Classification-Chinese | 56.22 | 61.23 | 50.77 |
| TCBert-1.3B<sub>1.3B-Classification-Chinese | 57.41 | 64.82 | 53.34 |
| TCBert-base<sub>110M-Sentence-Embedding-Chinese | 54.68 | 59.78 | 49.40 |
| TCBert-large<sub>330M-Sentence-Embedding-Chinese | 55.32 | 62.07 | 51.11 |
| TCBert-1.3B<sub>1.3B-Sentence-Embedding-Chinese | 56.87 | 65.83 | 52.94 |
第二个prompt模板的句子相似度结果:
The **sentence similarity** results for prompt template 2:
| | TNEWS | | CSLDCP | | IFLYTEK | |
|-----------------|:--------:|:---------:|:---------:|:---------:|:---------:|:---------:|
| Model | referece | whitening | reference | whitening | reference | whitening |
| Macbert-base | 42.29 | 45.22 | 34.23 | 37.48 | 29.62 | 34.13 |
| Macbert-large | 46.22 | 49.60 | 40.11 | 44.26 | 32.36 | 35.16 |
| Erlangshen-1.3B | 46.17 | 49.10 | 40.45 | 45.88 | 30.36 | 36.88 |
| TCBert-base<sub>110M-Classification-Chinese | 48.31 | 51.34 | 43.42 | 45.27 | 33.10 | 36.19 |
| TCBert-large<sub>330M-Classification-Chinese | 51.19 | 51.69 | 52.55 | 53.28 | 34.31 | 37.45 |
| TCBert-1.3B<sub>1.3B-Classification-Chinese | 52.14 | 52.39 | 51.71 | 53.89 | 33.62 | 38.14 |
| TCBert-base<sub>110M-Sentence-Embedding-Chinese | 46.72 | 48.86 | 43.19 | 43.53 | 34.08 | 35.79 |
| TCBert-large<sub>330M-Sentence-Embedding-Chinese | 50.65 | 51.94 | 53.84 | 53.67 | 37.74 | 36.65 |
| TCBert-1.3B<sub>1.3B-Sentence-Embedding-Chinese | 50.75 | 54.78 | 51.43 | 54.34 | 36.48 | 38.36 |
更多关于TCBERTs的细节,请参考我们的技术报告。基于新的数据,我们会更新TCBERTs,请留意我们仓库的更新。
For more details about TCBERTs, please refer to our paper. We may regularly update TCBERTs upon new coming data, please keep an eye on the repo!
## 使用 Usage
### 使用示例 Usage Examples
```python
# Prompt-based MLM fine-tuning
from transformers import BertForMaskedLM, BertTokenizer
import torch
# Loading models
tokenizer=BertTokenizer.from_pretrained("IDEA-CCNL/Erlangshen-TCBert-1.3B-Classification-Chinese")
model=BertForMaskedLM.from_pretrained("IDEA-CCNL/Erlangshen-TCBert-1.3B-Classification-Chinese")
# Prepare the data
inputs = tokenizer("下面是一则关于[MASK][MASK]的新闻:怎样的房子才算户型方正?", return_tensors="pt")
labels = tokenizer("下面是一则关于房产的新闻:怎样的房子才算户型方正?", return_tensors="pt")["input_ids"]
labels = torch.where(inputs.input_ids == tokenizer.mask_token_id, labels, -100)
# Output the loss
outputs = model(**inputs, labels=labels)
loss = outputs.loss
```
```python
# Prompt-based Sentence Similarity
# To extract sentence representations.
from transformers import BertForMaskedLM, BertTokenizer
import torch
# Loading models
tokenizer=BertTokenizer.from_pretrained("IDEA-CCNL/Erlangshen-TCBert-1.3B-Classification-Chinese")
model=BertForMaskedLM.from_pretrained("IDEA-CCNL/Erlangshen-TCBert-1.3B-Classification-Chinese")
# Cosine similarity function
cos = torch.nn.CosineSimilarity(dim=0, eps=1e-8)
with torch.no_grad():
# To extract sentence representations for training data
training_input = tokenizer("怎样的房子才算户型方正?", return_tensors="pt")
training_output = BertForMaskedLM(**token_text, output_hidden_states=True)
training_representation = torch.mean(training_outputs.hidden_states[-1].squeeze(), dim=0)
# To extract sentence representations for training data
test_input = tokenizer("下面是一则关于[MASK][MASK]的新闻:股票放量下趺,大资金出逃谁在接盘?", return_tensors="pt")
test_output = BertForMaskedLM(**token_text, output_hidden_states=True)
test_representation = torch.mean(training_outputs.hidden_states[-1].squeeze(), dim=0)
# Calculate similarity scores
similarity_score = cos(training_input, test_input)
```
## 引用 Citation
如果您在您的工作中使用了我们的模型,可以引用我们的[技术报告](https://arxiv.org/abs/2211.11304):
If you use for your work, please cite the following paper
```
@article{han2022tcbert,
title={TCBERT: A Technical Report for Chinese Topic Classification BERT},
author={Han, Ting and Pan, Kunhao and Chen, Xinyu and Song, Dingjie and Fan, Yuchen and Gao, Xinyu and Gan, Ruyi and Zhang, Jiaxing},
journal={arXiv preprint arXiv:2211.11304},
year={2022}
}
```
如果您在您的工作中使用了我们的模型,可以引用我们的[网站](https://github.com/IDEA-CCNL/Fengshenbang-LM/):
You can also cite our [website](https://github.com/IDEA-CCNL/Fengshenbang-LM/):
```text
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
```
|
b5a6bc8e567dd7a5a19190c181f37a44
|
moussaKam/barthez-sentiment-classification
|
moussaKam
|
mbart
| 6 | 1,792 |
transformers
| 2 |
text-classification
| true | false | false |
apache-2.0
|
['fr']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text-classification', 'bart']
| false | true | true | 405 | false |
### Barthez model finetuned on opinion classification task.
paper: https://arxiv.org/abs/2010.12321 \
github: https://github.com/moussaKam/BARThez
```
@article{eddine2020barthez,
title={BARThez: a Skilled Pretrained French Sequence-to-Sequence Model},
author={Eddine, Moussa Kamal and Tixier, Antoine J-P and Vazirgiannis, Michalis},
journal={arXiv preprint arXiv:2010.12321},
year={2020}
}
```
|
16d2dbc7628a380ea91baddf4718fc9d
|
EIStakovskii/bert-base-german-cased_fluency
|
EIStakovskii
|
bert
| 8 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
other
|
['de']
|
['news_commentary']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 895 | false |
This model was trained for evaluating linguistic acceptability and grammaticality. The finetuning was carried out based off [the bert-base-german-cased](https://huggingface.co/bert-base-german-cased).
Label_1 means ACCEPTABLE - the sentence is perfectly understandable by native speakers and has no serious grammatic and syntactic flaws.
Label_0 means NOT ACCEPTABLE - the sentence is flawed both orthographically and grammatically.
The model was trained on 50 thousand German sentences from [the news_commentary dataset](https://huggingface.co/datasets/news_commentary). Out of 50 thousand 25 thousand sentences were algorithmically corrupted using [the open source Python library](https://github.com/eistakovskii/text_corruption_plus). The library was originally developed by [aylliote](https://github.com/aylliote/corruption), but it was slightly adapted for the purposes of this model.
|
ff1df663a37a7163ffa95b01b937802d
|
dperezjr/wav2vec2-large-xls-r-300m-turkish-colab
|
dperezjr
|
wav2vec2
| 13 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,791 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-turkish-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3783
- Wer: 0.3036
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.0054 | 3.67 | 400 | 0.7096 | 0.6999 |
| 0.4061 | 7.34 | 800 | 0.4152 | 0.4637 |
| 0.1797 | 11.01 | 1200 | 0.4008 | 0.4164 |
| 0.1201 | 14.68 | 1600 | 0.4275 | 0.4152 |
| 0.0937 | 18.35 | 2000 | 0.4297 | 0.3978 |
| 0.074 | 22.02 | 2400 | 0.3670 | 0.3618 |
| 0.0602 | 25.69 | 2800 | 0.3875 | 0.3129 |
| 0.0472 | 29.36 | 3200 | 0.3783 | 0.3036 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
d0931be344cbe0069767cff0679443b6
|
chcaa/xls-r-300m-danish
|
chcaa
|
wav2vec2
| 5 | 48 |
transformers
| 4 | null | true | false | false |
apache-2.0
|
['da']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['speech', 'xls_r', 'xls_r_pretrained', 'danish']
| false | true | true | 724 | false |
## XLS-R-300m-danish
Continued pretraining of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for 120.000 steps on 141.000 hours of speech from Danish radio (DR P1 and Radio24Syv from 2005 to 2021).
The model was pretrained on 16kHz audio using fairseq and should be fine-tuned to perform speech recognition.
A fine-tuned version of this model for ASR can be found [here](https://huggingface.co/chcaa/xls-r-300m-danish-nst-cv9).
The model was trained by [Lasse Hansen](https://github.com/HLasse) ([CHCAA](https://chcaa.io)) and [Alvenir](https://alvenir.ai) on the [UCloud](https:/cloud.sdu.dk) platform. Many thanks to the Royal Danish Library for providing access to the data.
|
bdfaf4e339a732168646125fa3ca7ff8
|
espnet/kan-bayashi_jsut_transformer_accent_with_pause
|
espnet
| null | 19 | 4 |
espnet
| 0 |
text-to-speech
| false | false | false |
cc-by-4.0
|
['ja']
|
['jsut']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['espnet', 'audio', 'text-to-speech']
| false | true | true | 1,814 | false |
## Example ESPnet2 TTS model
### `kan-bayashi/jsut_transformer_accent_with_pause`
♻️ Imported from https://zenodo.org/record/4433196/
This model was trained by kan-bayashi using jsut/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
a1c73951a17514e6838f04cbca221652
|
qsnell/distilbert-base-uncased-finetuned-emotion
|
qsnell
|
distilbert
| 30 | 7 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['emotion']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,342 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1560
- Accuracy: 0.94
- F1: 0.9403
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 1000 | 0.2056 | 0.928 | 0.9284 |
| 0.3151 | 2.0 | 2000 | 0.1560 | 0.94 | 0.9403 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.10.2+cu102
- Datasets 2.4.0
- Tokenizers 0.12.1
|
5d1df4ecfffa22f69985ac63ae64ae70
|
google/bigbird-roberta-base
|
google
|
big_bird
| 8 | 23,736 |
transformers
| 26 | null | true | false | true |
apache-2.0
|
['en']
|
['bookcorpus', 'wikipedia', 'cc_news']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,765 | false |
# BigBird base model
BigBird, is a sparse-attention based transformer which extends Transformer based models, such as BERT to much longer sequences. Moreover, BigBird comes along with a theoretical understanding of the capabilities of a complete transformer that the sparse model can handle.
It is a pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in this [paper](https://arxiv.org/abs/2007.14062) and first released in this [repository](https://github.com/google-research/bigbird).
Disclaimer: The team releasing BigBird did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
BigBird relies on **block sparse attention** instead of normal attention (i.e. BERT's attention) and can handle sequences up to a length of 4096 at a much lower compute cost compared to BERT. It has achieved SOTA on various tasks involving very long sequences such as long documents summarization, question-answering with long contexts.
## How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BigBirdModel
# by default its in `block_sparse` mode with num_random_blocks=3, block_size=64
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base")
# you can change `attention_type` to full attention like this:
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base", attention_type="original_full")
# you can change `block_size` & `num_random_blocks` like this:
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base", block_size=16, num_random_blocks=2)
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
## Training Data
This model is pre-trained on four publicly available datasets: **Books**, **CC-News**, **Stories** and **Wikipedia**. It used same sentencepiece vocabulary as RoBERTa (which is in turn borrowed from GPT2).
## Training Procedure
Document longer than 4096 were split into multiple documents and documents that were much smaller than 4096 were joined. Following the original BERT training, 15% of tokens were masked and model is trained to predict the mask.
Model is warm started from RoBERTa’s checkpoint.
## BibTeX entry and citation info
```tex
@misc{zaheer2021big,
title={Big Bird: Transformers for Longer Sequences},
author={Manzil Zaheer and Guru Guruganesh and Avinava Dubey and Joshua Ainslie and Chris Alberti and Santiago Ontanon and Philip Pham and Anirudh Ravula and Qifan Wang and Li Yang and Amr Ahmed},
year={2021},
eprint={2007.14062},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
542ab2457e809e5b3b07c6c59156eb35
|
sd-concepts-library/aadhav-face
|
sd-concepts-library
| null | 9 | 0 | null | 0 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,040 | false |
### aadhav face on Stable Diffusion
This is the `<aadhav-face>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
0e3d5a2fdb959f6c1966db6b2774304d
|
npc-engine/t5-base-mse-summarization
|
npc-engine
|
t5
| 18 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 3,638 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-mse-summarization
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8743
- Rouge1: 45.9597
- Rouge2: 26.8086
- Rougel: 39.935
- Rougelsum: 43.8897
- Bleurt: -0.7132
- Gen Len: 18.464
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Bleurt | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|:-------:|
| 1.2568 | 1.0 | 267 | 1.0472 | 41.6829 | 21.9654 | 35.4264 | 39.5556 | -0.8231 | 18.522 |
| 1.1085 | 2.0 | 534 | 0.9840 | 43.1479 | 23.3351 | 36.9244 | 40.886 | -0.7843 | 18.534 |
| 1.0548 | 3.0 | 801 | 0.9515 | 44.1511 | 24.4912 | 37.9549 | 41.9984 | -0.7702 | 18.528 |
| 1.0251 | 4.0 | 1068 | 0.9331 | 44.426 | 24.9439 | 38.2978 | 42.1731 | -0.7633 | 18.619 |
| 0.9888 | 5.0 | 1335 | 0.9201 | 45.0385 | 25.524 | 38.8681 | 42.8998 | -0.7497 | 18.523 |
| 0.9623 | 6.0 | 1602 | 0.9119 | 44.8648 | 25.469 | 38.9281 | 42.7798 | -0.7496 | 18.537 |
| 0.9502 | 7.0 | 1869 | 0.9015 | 44.9668 | 25.5041 | 38.9463 | 42.9368 | -0.7412 | 18.48 |
| 0.9316 | 8.0 | 2136 | 0.8973 | 45.3028 | 25.7232 | 39.1533 | 43.277 | -0.7318 | 18.523 |
| 0.9191 | 9.0 | 2403 | 0.8921 | 45.2901 | 25.916 | 39.2909 | 43.3022 | -0.7296 | 18.529 |
| 0.9122 | 10.0 | 2670 | 0.8889 | 45.3535 | 26.1369 | 39.4861 | 43.28 | -0.7271 | 18.545 |
| 0.8993 | 11.0 | 2937 | 0.8857 | 45.5345 | 26.1669 | 39.5656 | 43.4664 | -0.7269 | 18.474 |
| 0.8905 | 12.0 | 3204 | 0.8816 | 45.7796 | 26.4145 | 39.8117 | 43.734 | -0.7185 | 18.503 |
| 0.8821 | 13.0 | 3471 | 0.8794 | 45.7163 | 26.4314 | 39.719 | 43.6407 | -0.7211 | 18.496 |
| 0.8789 | 14.0 | 3738 | 0.8784 | 45.9097 | 26.7281 | 39.9071 | 43.8105 | -0.7127 | 18.452 |
| 0.8665 | 15.0 | 4005 | 0.8765 | 46.1148 | 26.8882 | 40.1006 | 43.988 | -0.711 | 18.443 |
| 0.8676 | 16.0 | 4272 | 0.8766 | 45.9119 | 26.7674 | 39.9001 | 43.8237 | -0.718 | 18.491 |
| 0.8637 | 17.0 | 4539 | 0.8758 | 45.9158 | 26.7153 | 39.9463 | 43.8323 | -0.7183 | 18.492 |
| 0.8622 | 18.0 | 4806 | 0.8752 | 45.9508 | 26.75 | 39.9533 | 43.8795 | -0.7144 | 18.465 |
| 0.8588 | 19.0 | 5073 | 0.8744 | 45.9192 | 26.7352 | 39.8921 | 43.8204 | -0.7148 | 18.462 |
| 0.8554 | 20.0 | 5340 | 0.8743 | 45.9597 | 26.8086 | 39.935 | 43.8897 | -0.7132 | 18.464 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
6e07ca32a283a6c1b14d16b34a9a8d7d
|
sepidmnorozy/sentiment-10Epochs-3
|
sepidmnorozy
|
xlm-roberta
| 9 | 2 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,170 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sentiment-10Epochs-3
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7703
- Accuracy: 0.8568
- F1: 0.8526
- Precision: 0.8787
- Recall: 0.8279
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 0.3637 | 1.0 | 7088 | 0.3830 | 0.8571 | 0.8418 | 0.9429 | 0.7603 |
| 0.37 | 2.0 | 14176 | 0.4128 | 0.8676 | 0.8582 | 0.9242 | 0.8010 |
| 0.325 | 3.0 | 21264 | 0.4656 | 0.8737 | 0.8664 | 0.9189 | 0.8197 |
| 0.2948 | 4.0 | 28352 | 0.4575 | 0.8703 | 0.8652 | 0.9007 | 0.8324 |
| 0.3068 | 5.0 | 35440 | 0.4751 | 0.8705 | 0.8653 | 0.9016 | 0.8317 |
| 0.2945 | 6.0 | 42528 | 0.5509 | 0.8668 | 0.8618 | 0.8956 | 0.8305 |
| 0.2568 | 7.0 | 49616 | 0.6201 | 0.8632 | 0.8567 | 0.8994 | 0.8178 |
| 0.2107 | 8.0 | 56704 | 0.6836 | 0.8614 | 0.8576 | 0.8819 | 0.8346 |
| 0.1966 | 9.0 | 63792 | 0.7030 | 0.8583 | 0.8532 | 0.8848 | 0.8238 |
| 0.1675 | 10.0 | 70880 | 0.7703 | 0.8568 | 0.8526 | 0.8787 | 0.8279 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0
- Datasets 2.0.0
- Tokenizers 0.11.6
|
2312fe41ef93bdd7a9470920174a643c
|
henryscheible/eval_masked_v4_mrpc
|
henryscheible
| null | 13 | 0 | null | 0 | null | true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,048 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eval_masked_v4_mrpc
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6346
- Accuracy: 0.7941
- F1: 0.8595
- Combined Score: 0.8268
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1
- Datasets 2.6.1
- Tokenizers 0.13.1
|
8ef90d37700a2e82e6a9507f2c68c064
|
gokuls/mobilebert_sa_GLUE_Experiment_logit_kd_pretrain_mrpc
|
gokuls
|
mobilebert
| 17 | 2 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 3,109 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_sa_GLUE_Experiment_logit_kd_pretrain_mrpc
This model is a fine-tuned version of [gokuls/mobilebert_sa_pre-training-complete](https://huggingface.co/gokuls/mobilebert_sa_pre-training-complete) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2291
- Accuracy: 0.8578
- F1: 0.8993
- Combined Score: 0.8786
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------------:|
| 0.536 | 1.0 | 29 | 0.4134 | 0.7279 | 0.8284 | 0.7782 |
| 0.3419 | 2.0 | 58 | 0.3005 | 0.8284 | 0.8801 | 0.8543 |
| 0.2413 | 3.0 | 87 | 0.2707 | 0.8235 | 0.8780 | 0.8507 |
| 0.1852 | 4.0 | 116 | 0.3247 | 0.8284 | 0.8837 | 0.8561 |
| 0.1524 | 5.0 | 145 | 0.2856 | 0.8431 | 0.8900 | 0.8666 |
| 0.1297 | 6.0 | 174 | 0.2999 | 0.8456 | 0.8948 | 0.8702 |
| 0.1219 | 7.0 | 203 | 0.2797 | 0.8529 | 0.8986 | 0.8758 |
| 0.1141 | 8.0 | 232 | 0.2462 | 0.8603 | 0.9005 | 0.8804 |
| 0.1127 | 9.0 | 261 | 0.2557 | 0.8578 | 0.8982 | 0.8780 |
| 0.1091 | 10.0 | 290 | 0.2853 | 0.8480 | 0.8967 | 0.8724 |
| 0.1007 | 11.0 | 319 | 0.2472 | 0.8554 | 0.8981 | 0.8767 |
| 0.0979 | 12.0 | 348 | 0.2431 | 0.8505 | 0.8950 | 0.8727 |
| 0.0954 | 13.0 | 377 | 0.2456 | 0.8578 | 0.9007 | 0.8793 |
| 0.0946 | 14.0 | 406 | 0.2526 | 0.8578 | 0.9017 | 0.8798 |
| 0.0946 | 15.0 | 435 | 0.2291 | 0.8578 | 0.8993 | 0.8786 |
| 0.0938 | 16.0 | 464 | 0.2452 | 0.8603 | 0.9029 | 0.8816 |
| 0.0919 | 17.0 | 493 | 0.2365 | 0.8652 | 0.9050 | 0.8851 |
| 0.0916 | 18.0 | 522 | 0.2363 | 0.8652 | 0.9060 | 0.8856 |
| 0.0915 | 19.0 | 551 | 0.2432 | 0.8652 | 0.9063 | 0.8857 |
| 0.0905 | 20.0 | 580 | 0.2297 | 0.8652 | 0.9057 | 0.8854 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
|
c16a6beb442224eccd0766866f2ca43c
|
SkyR/albert-base-ours-run-5
|
SkyR
|
albert
| 9 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 3,064 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-base-ours-run-5
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6151
- Accuracy: 0.675
- Precision: 0.6356
- Recall: 0.6360
- F1: 0.6356
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.9766 | 1.0 | 200 | 0.8865 | 0.645 | 0.5935 | 0.5872 | 0.5881 |
| 0.7725 | 2.0 | 400 | 1.0650 | 0.665 | 0.7143 | 0.5936 | 0.5556 |
| 0.6018 | 3.0 | 600 | 0.8558 | 0.7 | 0.6637 | 0.6444 | 0.6456 |
| 0.3838 | 4.0 | 800 | 0.9796 | 0.67 | 0.6220 | 0.6219 | 0.6218 |
| 0.2135 | 5.0 | 1000 | 1.4533 | 0.675 | 0.6611 | 0.5955 | 0.6055 |
| 0.1209 | 6.0 | 1200 | 1.4688 | 0.67 | 0.6392 | 0.6474 | 0.6398 |
| 0.072 | 7.0 | 1400 | 1.8395 | 0.695 | 0.6574 | 0.6540 | 0.6514 |
| 0.0211 | 8.0 | 1600 | 2.0849 | 0.7 | 0.6691 | 0.6607 | 0.6603 |
| 0.0102 | 9.0 | 1800 | 2.3042 | 0.695 | 0.6675 | 0.6482 | 0.6533 |
| 0.0132 | 10.0 | 2000 | 2.2390 | 0.685 | 0.6472 | 0.6423 | 0.6439 |
| 0.004 | 11.0 | 2200 | 2.3779 | 0.68 | 0.6435 | 0.6481 | 0.6443 |
| 0.0004 | 12.0 | 2400 | 2.4575 | 0.675 | 0.6397 | 0.6352 | 0.6357 |
| 0.0003 | 13.0 | 2600 | 2.4676 | 0.675 | 0.6356 | 0.6360 | 0.6356 |
| 0.0003 | 14.0 | 2800 | 2.5109 | 0.68 | 0.6427 | 0.6424 | 0.6422 |
| 0.0002 | 15.0 | 3000 | 2.5470 | 0.675 | 0.6356 | 0.6360 | 0.6356 |
| 0.0002 | 16.0 | 3200 | 2.5674 | 0.675 | 0.6356 | 0.6360 | 0.6356 |
| 0.0001 | 17.0 | 3400 | 2.5889 | 0.685 | 0.6471 | 0.6488 | 0.6474 |
| 0.0001 | 18.0 | 3600 | 2.6016 | 0.675 | 0.6356 | 0.6360 | 0.6356 |
| 0.0001 | 19.0 | 3800 | 2.6108 | 0.675 | 0.6356 | 0.6360 | 0.6356 |
| 0.0001 | 20.0 | 4000 | 2.6151 | 0.675 | 0.6356 | 0.6360 | 0.6356 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Tokenizers 0.13.2
|
e4b23406c62dde5697691c219891a4b7
|
Bauyrjan/wav2vec2-kazakh-16K-af
|
Bauyrjan
|
wav2vec2
| 10 | 8 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,047 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-kazakh-16K-af
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
### Training results
### Framework versions
- Transformers 4.11.3
- Pytorch 1.13.0+cu117
- Datasets 1.13.3
- Tokenizers 0.10.3
|
e6e57c5309ef596ee15c5bfec75c64c9
|
scasutt/wav2vec2-large-xlsr-53_toy_train_data
|
scasutt
|
wav2vec2
| 7 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,807 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-53_toy_train_data
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6357
- Wer: 0.5496
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.6073 | 2.1 | 250 | 3.5111 | 1.0 |
| 3.0828 | 4.2 | 500 | 3.5133 | 1.0 |
| 1.9969 | 6.3 | 750 | 1.3924 | 0.9577 |
| 0.9279 | 8.4 | 1000 | 0.8378 | 0.7243 |
| 0.6692 | 10.5 | 1250 | 0.7367 | 0.6394 |
| 0.5273 | 12.6 | 1500 | 0.6703 | 0.5907 |
| 0.4314 | 14.7 | 1750 | 0.6594 | 0.5718 |
| 0.3809 | 16.8 | 2000 | 0.6138 | 0.5559 |
| 0.3934 | 18.9 | 2250 | 0.6357 | 0.5496 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu102
- Datasets 2.0.0
- Tokenizers 0.11.6
|
c8405a6c6d11908c0f42846b93a219bb
|
hugosousa/es_tei2go
|
hugosousa
| null | 14 | 1 |
spacy
| 0 |
token-classification
| false | false | false |
mit
|
['es']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['spacy', 'token-classification']
| true | true | true | 800 | false |
| Feature | Description |
| --- |-----------------------------------------|
| **Name** | `es_tei2go` |
| **Version** | `0.0.0` |
| **spaCy** | `>=3.2.4,<3.3.0` |
| **Default Pipeline** | `ner` |
| **Components** | `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | MIT |
| **Author** | [n/a]() |
### Label Scheme
<details>
<summary>View label scheme (1 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `TIMEX` |
</details>
|
74c3dae5ee0e1a8785029e619f633540
|
jimbung/bert-finetuned-ner
|
jimbung
|
bert
| 12 | 1 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null |
['conll2003']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,518 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0616
- Precision: 0.9302
- Recall: 0.9493
- F1: 0.9397
- Accuracy: 0.9863
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0878 | 1.0 | 1756 | 0.0657 | 0.9247 | 0.9340 | 0.9293 | 0.9828 |
| 0.0343 | 2.0 | 3512 | 0.0627 | 0.9291 | 0.9498 | 0.9393 | 0.9862 |
| 0.018 | 3.0 | 5268 | 0.0616 | 0.9302 | 0.9493 | 0.9397 | 0.9863 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
04ca05686ea0b7eb5f8532071fe10446
|
domenicrosati/deberta-v3-large-finetuned-synthetic-generated-only
|
domenicrosati
|
deberta-v2
| 13 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text-classification', 'generated_from_trainer']
| true | true | true | 1,566 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-v3-large-finetuned-synthetic-generated-only
This model is a fine-tuned version of [microsoft/deberta-v3-large](https://huggingface.co/microsoft/deberta-v3-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0094
- F1: 0.9839
- Precision: 0.9849
- Recall: 0.9828
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-06
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Precision | Recall |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:---------:|:------:|
| 0.009 | 1.0 | 10387 | 0.0104 | 0.9722 | 0.9919 | 0.9533 |
| 0.0013 | 2.0 | 20774 | 0.0067 | 0.9825 | 0.9844 | 0.9805 |
| 0.0006 | 3.0 | 31161 | 0.0077 | 0.9843 | 0.9902 | 0.9786 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
f017d24faf76ee343869b0108120f3db
|
KoichiYasuoka/roberta-large-japanese-char-luw-upos
|
KoichiYasuoka
|
roberta
| 9 | 12 |
transformers
| 0 |
token-classification
| true | false | false |
cc-by-sa-4.0
|
['ja']
|
['universal_dependencies']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['japanese', 'token-classification', 'pos', 'dependency-parsing']
| false | true | true | 1,413 | false |
# roberta-large-japanese-char-luw-upos
## Model Description
This is a RoBERTa model pre-trained on 青空文庫 texts for POS-tagging and dependency-parsing, derived from [roberta-large-japanese-aozora-char](https://huggingface.co/KoichiYasuoka/roberta-large-japanese-aozora-char). Every long-unit-word is tagged by [UPOS](https://universaldependencies.org/u/pos/) (Universal Part-Of-Speech) and [FEATS](https://universaldependencies.org/u/feat/).
## How to Use
```py
from transformers import AutoTokenizer,AutoModelForTokenClassification,TokenClassificationPipeline
tokenizer=AutoTokenizer.from_pretrained("KoichiYasuoka/roberta-large-japanese-char-luw-upos")
model=AutoModelForTokenClassification.from_pretrained("KoichiYasuoka/roberta-large-japanese-char-luw-upos")
pipeline=TokenClassificationPipeline(tokenizer=tokenizer,model=model,aggregation_strategy="simple")
nlp=lambda x:[(x[t["start"]:t["end"]],t["entity_group"]) for t in pipeline(x)]
print(nlp("国境の長いトンネルを抜けると雪国であった。"))
```
or
```py
import esupar
nlp=esupar.load("KoichiYasuoka/roberta-large-japanese-char-luw-upos")
print(nlp("国境の長いトンネルを抜けると雪国であった。"))
```
## Reference
安岡孝一: [Transformersと国語研長単位による日本語係り受け解析モデルの製作](http://id.nii.ac.jp/1001/00216223/), 情報処理学会研究報告, Vol.2022-CH-128, No.7 (2022年2月), pp.1-8.
## See Also
[esupar](https://github.com/KoichiYasuoka/esupar): Tokenizer POS-tagger and Dependency-parser with BERT/RoBERTa/DeBERTa models
|
1a749067e210f104e0970df0d7980618
|
lewtun/bert-base-uncased-finetuned-imdb
|
lewtun
|
bert
| 8 | 2 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null |
['imdb']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| false | true | true | 1,300 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0284
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.2244 | 1.0 | 958 | 2.0726 |
| 2.1537 | 2.0 | 1916 | 2.0381 |
| 2.1183 | 3.0 | 2874 | 2.0284 |
### Framework versions
- Transformers 4.10.3
- Pytorch 1.9.1+cu111
- Datasets 1.12.1
- Tokenizers 0.10.3
|
f1cdab297b6b3cf6cbcca28e440010ee
|
lapix/segformer-b3-finetuned-ccagt-400-300
|
lapix
|
segformer
| 7 | 20 |
transformers
| 2 |
image-segmentation
| true | false | false |
other
| null |
['lapix/CCAgT']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['vision', 'image-segmentation']
| false | true | true | 3,432 | false |
# SegFormer (b3-sized) model fine-tuned on CCAgT dataset
SegFormer model fine-tuned on CCAgT dataset at resolution 400x300. It was introduced in the paper [Semantic Segmentation for the Detection of Very Small Objects on Cervical Cell Samples Stained with the {AgNOR} Technique](https://doi.org/10.2139/ssrn.4126881) by [J. G. A. Amorim](https://huggingface.co/johnnv) et al.
This model was trained in a subset of [CCAgT dataset](https://huggingface.co/datasets/lapix/CCAgT/), so perform a evaluation of this model on the dataset available at HF will differ from the results presented in the paper. For more information about how the model was trained, read the paper.
Disclaimer: This model card has been written based on the SegFormer [model card](https://huggingface.co/nvidia/mit-b3/blob/main/README.md) by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
This repository only contains the pre-trained hierarchical Transformer, hence it can be used for fine-tuning purposes.
## Intended uses & limitations
You can use the model for fine-tuning of semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to segment an image of the CCAgT dataset:
```python
from transformers import AutoFeatureExtractor, SegformerForSemanticSegmentation
from PIL import Image
import requests
url = "https://huggingface.co/lapix/segformer-b3-finetuned-ccagt-400-300/resolve/main/sampleB.png"
image = Image.open(requests.get(url, stream=True).raw))
model = SegformerForSemanticSegmentation.from_pretrained("lapix/segformer-b3-finetuned-ccagt-400-300")
feature_extractor = AutoFeatureExtractor.from_pretrained("lapix/segformer-b3-finetuned-ccagt-400-300")
pixel_values = feature_extractor(images=image, return_tensors="pt")
outputs = model(pixel_values=pixel_values)
logits = outputs.logits
# Rescale logits to original image size (400, 300)
upsampled_logits = nn.functional.interpolate(
logits,
size=img.size[::-1], # (height, width)
mode="bilinear",
align_corners=False,
)
segmentation_mask = upsampled_logits.argmax(dim=1)[0]
print("Predicted mask:", segmentation_mask)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### License
The license for this model can be found [here](https://github.com/NVlabs/SegFormer/blob/master/LICENSE).
### BibTeX entry and citation info
```bibtex
@article{AtkinsonSegmentationAgNORSSRN2022,
author= {Jo{\~{a}}o Gustavo Atkinson Amorim and Andr{\'{e}} Vict{\'{o}}ria Matias and Allan Cerentini and Fabiana Botelho de Miranda Onofre and Alexandre Sherlley Casimiro Onofre and Aldo von Wangenheim},
doi = {10.2139/ssrn.4126881},
url = {https://doi.org/10.2139/ssrn.4126881},
year = {2022},
publisher = {Elsevier {BV}},
title = {Semantic Segmentation for the Detection of Very Small Objects on Cervical Cell Samples Stained with the {AgNOR} Technique},
journal = {{SSRN} Electronic Journal}
}
```
|
0bec281f2cb4719e359bf693a7b3dc4a
|
Helsinki-NLP/opus-mt-tc-big-itc-itc
|
Helsinki-NLP
|
marian
| 13 | 33 |
transformers
| 0 |
translation
| true | true | false |
cc-by-4.0
|
['ast', 'ca', 'es', 'fr', 'gl', 'it', 'lad', 'oc', 'pms', 'pt', 'ro']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['translation', 'opus-mt-tc']
| true | true | true | 17,972 | false |
# opus-mt-tc-big-itc-itc
## Table of Contents
- [Model Details](#model-details)
- [Uses](#uses)
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
- [How to Get Started With the Model](#how-to-get-started-with-the-model)
- [Training](#training)
- [Evaluation](#evaluation)
- [Citation Information](#citation-information)
- [Acknowledgements](#acknowledgements)
## Model Details
Neural machine translation model for translating from Italic languages (itc) to Italic languages (itc).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
**Model Description:**
- **Developed by:** Language Technology Research Group at the University of Helsinki
- **Model Type:** Translation (transformer-big)
- **Release**: 2022-08-10
- **License:** CC-BY-4.0
- **Language(s):**
- Source Language(s): ast cat cbk fra fro glg hat ita lad lad_Latn lat lat_Latn lij lld oci pms por ron spa
- Target Language(s): ast cat fra gcf glg hat ita lad lad_Latn lat lat_Latn oci por ron spa
- Language Pair(s): ast-cat ast-fra ast-glg ast-ita ast-oci ast-por ast-ron ast-spa cat-ast cat-fra cat-glg cat-ita cat-oci cat-por cat-ron cat-spa fra-ast fra-cat fra-glg fra-ita fra-oci fra-por fra-ron fra-spa glg-ast glg-cat glg-fra glg-ita glg-oci glg-por glg-ron glg-spa ita-ast ita-cat ita-fra ita-glg ita-oci ita-por ita-ron ita-spa lad-spa lad_Latn-spa oci-ast oci-cat oci-fra oci-glg oci-ita oci-por oci-ron oci-spa pms-ita por-ast por-cat por-fra por-glg por-ita por-oci por-ron por-spa ron-ast ron-cat ron-fra ron-glg ron-ita ron-oci ron-por ron-spa spa-cat spa-fra spa-glg spa-ita spa-por spa-ron
- Valid Target Language Labels: >>acf<< >>aoa<< >>arg<< >>ast<< >>cat<< >>cbk<< >>cbk_Latn<< >>ccd<< >>cks<< >>cos<< >>cri<< >>crs<< >>dlm<< >>drc<< >>egl<< >>ext<< >>fab<< >>fax<< >>fra<< >>frc<< >>frm<< >>frm_Latn<< >>fro<< >>fro_Latn<< >>frp<< >>fur<< >>fur_Latn<< >>gcf<< >>gcf_Latn<< >>gcr<< >>glg<< >>hat<< >>idb<< >>ist<< >>ita<< >>itk<< >>kea<< >>kmv<< >>lad<< >>lad_Latn<< >>lat<< >>lat_Grek<< >>lat_Latn<< >>lij<< >>lld<< >>lld_Latn<< >>lmo<< >>lou<< >>mcm<< >>mfe<< >>mol<< >>mwl<< >>mxi<< >>mzs<< >>nap<< >>nrf<< >>oci<< >>osc<< >>osp<< >>osp_Latn<< >>pap<< >>pcd<< >>pln<< >>pms<< >>pob<< >>por<< >>pov<< >>pre<< >>pro<< >>qbb<< >>qhr<< >>rcf<< >>rgn<< >>roh<< >>ron<< >>ruo<< >>rup<< >>ruq<< >>scf<< >>scn<< >>sdc<< >>sdn<< >>spa<< >>spq<< >>spx<< >>src<< >>srd<< >>sro<< >>tmg<< >>tvy<< >>vec<< >>vkp<< >>wln<< >>xfa<< >>xum<<
- **Original Model**: [opusTCv20210807_transformer-big_2022-08-10.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/itc-itc/opusTCv20210807_transformer-big_2022-08-10.zip)
- **Resources for more information:**
- [OPUS-MT-train GitHub Repo](https://github.com/Helsinki-NLP/OPUS-MT-train)
- More information about released models for this language pair: [OPUS-MT itc-itc README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/itc-itc/README.md)
- [More information about MarianNMT models in the transformers library](https://huggingface.co/docs/transformers/model_doc/marian)
- [Tatoeba Translation Challenge](https://github.com/Helsinki-NLP/Tatoeba-Challenge/
This is a multilingual translation model with multiple target languages. A sentence initial language token is required in the form of `>>id<<` (id = valid target language ID), e.g. `>>ast<<`
## Uses
This model can be used for translation and text-to-text generation.
## Risks, Limitations and Biases
**CONTENT WARNING: Readers should be aware that the model is trained on various public data sets that may contain content that is disturbing, offensive, and can propagate historical and current stereotypes.**
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
## How to Get Started With the Model
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
">>fra<< Charras anglés?",
">>fra<< Vull veure't."
]
model_name = "pytorch-models/opus-mt-tc-big-itc-itc"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# Conversations anglaises ?
# Je veux te voir.
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-itc-itc")
print(pipe(">>fra<< Charras anglés?"))
# expected output: Conversations anglaises ?
```
## Training
- **Data**: opusTCv20210807 ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
- **Pre-processing**: SentencePiece (spm32k,spm32k)
- **Model Type:** transformer-big
- **Original MarianNMT Model**: [opusTCv20210807_transformer-big_2022-08-10.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/itc-itc/opusTCv20210807_transformer-big_2022-08-10.zip)
- **Training Scripts**: [GitHub Repo](https://github.com/Helsinki-NLP/OPUS-MT-train)
## Evaluation
* test set translations: [opusTCv20210807_transformer-big_2022-08-10.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/itc-itc/opusTCv20210807_transformer-big_2022-08-10.test.txt)
* test set scores: [opusTCv20210807_transformer-big_2022-08-10.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/itc-itc/opusTCv20210807_transformer-big_2022-08-10.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| cat-fra | tatoeba-test-v2021-08-07 | 0.71201 | 54.6 | 700 | 5664 |
| cat-ita | tatoeba-test-v2021-08-07 | 0.74198 | 58.4 | 298 | 2028 |
| cat-por | tatoeba-test-v2021-08-07 | 0.74930 | 57.4 | 747 | 6119 |
| cat-spa | tatoeba-test-v2021-08-07 | 0.87844 | 78.1 | 1534 | 12094 |
| fra-cat | tatoeba-test-v2021-08-07 | 0.66525 | 46.2 | 700 | 5342 |
| fra-ita | tatoeba-test-v2021-08-07 | 0.72742 | 53.8 | 10091 | 62060 |
| fra-por | tatoeba-test-v2021-08-07 | 0.68413 | 48.6 | 10518 | 77650 |
| fra-ron | tatoeba-test-v2021-08-07 | 0.65009 | 44.0 | 1925 | 12252 |
| fra-spa | tatoeba-test-v2021-08-07 | 0.72080 | 54.8 | 10294 | 78406 |
| glg-por | tatoeba-test-v2021-08-07 | 0.76720 | 61.1 | 433 | 3105 |
| glg-spa | tatoeba-test-v2021-08-07 | 0.82362 | 71.7 | 2121 | 17443 |
| ita-cat | tatoeba-test-v2021-08-07 | 0.72529 | 56.4 | 298 | 2109 |
| ita-fra | tatoeba-test-v2021-08-07 | 0.77932 | 65.2 | 10091 | 66377 |
| ita-por | tatoeba-test-v2021-08-07 | 0.72798 | 54.0 | 3066 | 25668 |
| ita-ron | tatoeba-test-v2021-08-07 | 0.70814 | 51.1 | 1005 | 6209 |
| ita-spa | tatoeba-test-v2021-08-07 | 0.77455 | 62.9 | 5000 | 34937 |
| lad_Latn-spa | tatoeba-test-v2021-08-07 | 0.59363 | 42.6 | 239 | 1239 |
| lad-spa | tatoeba-test-v2021-08-07 | 0.52243 | 34.7 | 276 | 1448 |
| oci-fra | tatoeba-test-v2021-08-07 | 0.49660 | 29.6 | 806 | 6302 |
| pms-ita | tatoeba-test-v2021-08-07 | 0.40221 | 20.0 | 232 | 1721 |
| por-cat | tatoeba-test-v2021-08-07 | 0.71146 | 52.2 | 747 | 6149 |
| por-fra | tatoeba-test-v2021-08-07 | 0.75565 | 60.9 | 10518 | 80459 |
| por-glg | tatoeba-test-v2021-08-07 | 0.75348 | 59.0 | 433 | 3016 |
| por-ita | tatoeba-test-v2021-08-07 | 0.76883 | 58.8 | 3066 | 24897 |
| por-ron | tatoeba-test-v2021-08-07 | 0.67838 | 46.6 | 681 | 4521 |
| por-spa | tatoeba-test-v2021-08-07 | 0.79336 | 64.8 | 10947 | 87335 |
| ron-fra | tatoeba-test-v2021-08-07 | 0.70307 | 55.0 | 1925 | 13347 |
| ron-ita | tatoeba-test-v2021-08-07 | 0.73862 | 53.7 | 1005 | 6352 |
| ron-por | tatoeba-test-v2021-08-07 | 0.70889 | 50.7 | 681 | 4593 |
| ron-spa | tatoeba-test-v2021-08-07 | 0.73529 | 57.2 | 1959 | 12679 |
| spa-cat | tatoeba-test-v2021-08-07 | 0.82758 | 67.9 | 1534 | 12343 |
| spa-fra | tatoeba-test-v2021-08-07 | 0.73113 | 57.3 | 10294 | 83501 |
| spa-glg | tatoeba-test-v2021-08-07 | 0.77332 | 63.0 | 2121 | 16581 |
| spa-ita | tatoeba-test-v2021-08-07 | 0.77046 | 60.3 | 5000 | 34515 |
| spa-lad_Latn | tatoeba-test-v2021-08-07 | 0.40084 | 14.7 | 239 | 1254 |
| spa-por | tatoeba-test-v2021-08-07 | 0.75854 | 59.1 | 10947 | 87610 |
| spa-ron | tatoeba-test-v2021-08-07 | 0.66679 | 45.5 | 1959 | 12503 |
| ast-cat | flores101-devtest | 0.57870 | 31.8 | 1012 | 27304 |
| ast-fra | flores101-devtest | 0.56761 | 31.1 | 1012 | 28343 |
| ast-glg | flores101-devtest | 0.55161 | 27.9 | 1012 | 26582 |
| ast-ita | flores101-devtest | 0.51764 | 22.1 | 1012 | 27306 |
| ast-oci | flores101-devtest | 0.49545 | 20.6 | 1012 | 27305 |
| ast-por | flores101-devtest | 0.57347 | 31.5 | 1012 | 26519 |
| ast-ron | flores101-devtest | 0.52317 | 24.8 | 1012 | 26799 |
| ast-spa | flores101-devtest | 0.49741 | 21.2 | 1012 | 29199 |
| cat-ast | flores101-devtest | 0.56754 | 24.7 | 1012 | 24572 |
| cat-fra | flores101-devtest | 0.63368 | 38.4 | 1012 | 28343 |
| cat-glg | flores101-devtest | 0.59596 | 32.2 | 1012 | 26582 |
| cat-ita | flores101-devtest | 0.55886 | 26.3 | 1012 | 27306 |
| cat-oci | flores101-devtest | 0.54285 | 24.6 | 1012 | 27305 |
| cat-por | flores101-devtest | 0.62913 | 37.7 | 1012 | 26519 |
| cat-ron | flores101-devtest | 0.56885 | 29.5 | 1012 | 26799 |
| cat-spa | flores101-devtest | 0.53372 | 24.6 | 1012 | 29199 |
| fra-ast | flores101-devtest | 0.52696 | 20.7 | 1012 | 24572 |
| fra-cat | flores101-devtest | 0.60492 | 34.6 | 1012 | 27304 |
| fra-glg | flores101-devtest | 0.57485 | 30.3 | 1012 | 26582 |
| fra-ita | flores101-devtest | 0.56493 | 27.3 | 1012 | 27306 |
| fra-oci | flores101-devtest | 0.57449 | 28.2 | 1012 | 27305 |
| fra-por | flores101-devtest | 0.62211 | 36.9 | 1012 | 26519 |
| fra-ron | flores101-devtest | 0.56998 | 29.4 | 1012 | 26799 |
| fra-spa | flores101-devtest | 0.52880 | 24.2 | 1012 | 29199 |
| glg-ast | flores101-devtest | 0.55090 | 22.4 | 1012 | 24572 |
| glg-cat | flores101-devtest | 0.60550 | 32.6 | 1012 | 27304 |
| glg-fra | flores101-devtest | 0.62026 | 36.0 | 1012 | 28343 |
| glg-ita | flores101-devtest | 0.55834 | 25.9 | 1012 | 27306 |
| glg-oci | flores101-devtest | 0.52520 | 21.9 | 1012 | 27305 |
| glg-por | flores101-devtest | 0.60027 | 32.7 | 1012 | 26519 |
| glg-ron | flores101-devtest | 0.55621 | 27.8 | 1012 | 26799 |
| glg-spa | flores101-devtest | 0.53219 | 24.4 | 1012 | 29199 |
| ita-ast | flores101-devtest | 0.50741 | 17.1 | 1012 | 24572 |
| ita-cat | flores101-devtest | 0.57061 | 27.9 | 1012 | 27304 |
| ita-fra | flores101-devtest | 0.60199 | 32.0 | 1012 | 28343 |
| ita-glg | flores101-devtest | 0.55312 | 25.9 | 1012 | 26582 |
| ita-oci | flores101-devtest | 0.48447 | 18.1 | 1012 | 27305 |
| ita-por | flores101-devtest | 0.58162 | 29.0 | 1012 | 26519 |
| ita-ron | flores101-devtest | 0.53703 | 24.2 | 1012 | 26799 |
| ita-spa | flores101-devtest | 0.52238 | 23.1 | 1012 | 29199 |
| oci-ast | flores101-devtest | 0.53010 | 20.2 | 1012 | 24572 |
| oci-cat | flores101-devtest | 0.59946 | 32.2 | 1012 | 27304 |
| oci-fra | flores101-devtest | 0.64290 | 39.0 | 1012 | 28343 |
| oci-glg | flores101-devtest | 0.56737 | 28.0 | 1012 | 26582 |
| oci-ita | flores101-devtest | 0.54220 | 24.2 | 1012 | 27306 |
| oci-por | flores101-devtest | 0.62127 | 35.7 | 1012 | 26519 |
| oci-ron | flores101-devtest | 0.55906 | 28.0 | 1012 | 26799 |
| oci-spa | flores101-devtest | 0.52110 | 22.8 | 1012 | 29199 |
| por-ast | flores101-devtest | 0.54539 | 22.5 | 1012 | 24572 |
| por-cat | flores101-devtest | 0.61809 | 36.4 | 1012 | 27304 |
| por-fra | flores101-devtest | 0.64343 | 39.7 | 1012 | 28343 |
| por-glg | flores101-devtest | 0.57965 | 30.4 | 1012 | 26582 |
| por-ita | flores101-devtest | 0.55841 | 26.3 | 1012 | 27306 |
| por-oci | flores101-devtest | 0.54829 | 25.3 | 1012 | 27305 |
| por-ron | flores101-devtest | 0.57283 | 29.8 | 1012 | 26799 |
| por-spa | flores101-devtest | 0.53513 | 25.2 | 1012 | 29199 |
| ron-ast | flores101-devtest | 0.52265 | 20.1 | 1012 | 24572 |
| ron-cat | flores101-devtest | 0.59689 | 32.6 | 1012 | 27304 |
| ron-fra | flores101-devtest | 0.63060 | 37.4 | 1012 | 28343 |
| ron-glg | flores101-devtest | 0.56677 | 29.3 | 1012 | 26582 |
| ron-ita | flores101-devtest | 0.55485 | 25.6 | 1012 | 27306 |
| ron-oci | flores101-devtest | 0.52433 | 21.8 | 1012 | 27305 |
| ron-por | flores101-devtest | 0.61831 | 36.1 | 1012 | 26519 |
| ron-spa | flores101-devtest | 0.52712 | 24.1 | 1012 | 29199 |
| spa-ast | flores101-devtest | 0.49008 | 15.7 | 1012 | 24572 |
| spa-cat | flores101-devtest | 0.53905 | 23.2 | 1012 | 27304 |
| spa-fra | flores101-devtest | 0.57078 | 27.4 | 1012 | 28343 |
| spa-glg | flores101-devtest | 0.52563 | 22.0 | 1012 | 26582 |
| spa-ita | flores101-devtest | 0.52783 | 22.3 | 1012 | 27306 |
| spa-oci | flores101-devtest | 0.48064 | 16.3 | 1012 | 27305 |
| spa-por | flores101-devtest | 0.55736 | 25.8 | 1012 | 26519 |
| spa-ron | flores101-devtest | 0.51623 | 21.4 | 1012 | 26799 |
| fra-ita | newssyscomb2009 | 0.60995 | 32.1 | 502 | 11551 |
| fra-spa | newssyscomb2009 | 0.60224 | 34.2 | 502 | 12503 |
| ita-fra | newssyscomb2009 | 0.61237 | 33.7 | 502 | 12331 |
| ita-spa | newssyscomb2009 | 0.60706 | 35.4 | 502 | 12503 |
| spa-fra | newssyscomb2009 | 0.61290 | 34.6 | 502 | 12331 |
| spa-ita | newssyscomb2009 | 0.61632 | 33.3 | 502 | 11551 |
| fra-spa | news-test2008 | 0.58939 | 33.9 | 2051 | 52586 |
| spa-fra | news-test2008 | 0.58695 | 32.4 | 2051 | 52685 |
| fra-ita | newstest2009 | 0.59764 | 31.2 | 2525 | 63466 |
| fra-spa | newstest2009 | 0.58829 | 32.5 | 2525 | 68111 |
| ita-fra | newstest2009 | 0.59084 | 31.6 | 2525 | 69263 |
| ita-spa | newstest2009 | 0.59669 | 33.5 | 2525 | 68111 |
| spa-fra | newstest2009 | 0.59096 | 32.3 | 2525 | 69263 |
| spa-ita | newstest2009 | 0.60783 | 33.2 | 2525 | 63466 |
| fra-spa | newstest2010 | 0.62250 | 37.8 | 2489 | 65480 |
| spa-fra | newstest2010 | 0.61953 | 36.2 | 2489 | 66022 |
| fra-spa | newstest2011 | 0.62953 | 39.8 | 3003 | 79476 |
| spa-fra | newstest2011 | 0.61130 | 34.9 | 3003 | 80626 |
| fra-spa | newstest2012 | 0.62397 | 39.0 | 3003 | 79006 |
| spa-fra | newstest2012 | 0.60927 | 34.3 | 3003 | 78011 |
| fra-spa | newstest2013 | 0.59312 | 34.9 | 3000 | 70528 |
| spa-fra | newstest2013 | 0.59468 | 33.6 | 3000 | 70037 |
| cat-ita | wmt21-ml-wp | 0.69968 | 47.8 | 1743 | 42735 |
| cat-oci | wmt21-ml-wp | 0.73808 | 51.6 | 1743 | 43736 |
| cat-ron | wmt21-ml-wp | 0.51178 | 29.0 | 1743 | 42895 |
| ita-cat | wmt21-ml-wp | 0.70538 | 48.9 | 1743 | 43833 |
| ita-oci | wmt21-ml-wp | 0.59025 | 32.0 | 1743 | 43736 |
| ita-ron | wmt21-ml-wp | 0.51261 | 28.9 | 1743 | 42895 |
| oci-cat | wmt21-ml-wp | 0.80908 | 66.1 | 1743 | 43833 |
| oci-ita | wmt21-ml-wp | 0.63584 | 39.6 | 1743 | 42735 |
| oci-ron | wmt21-ml-wp | 0.47384 | 24.6 | 1743 | 42895 |
| ron-cat | wmt21-ml-wp | 0.52994 | 31.1 | 1743 | 43833 |
| ron-ita | wmt21-ml-wp | 0.52714 | 29.6 | 1743 | 42735 |
| ron-oci | wmt21-ml-wp | 0.45932 | 21.3 | 1743 | 43736 |
## Citation Information
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 8b9f0b0
* port time: Fri Aug 12 23:57:49 EEST 2022
* port machine: LM0-400-22516.local
|
c6695efcd40239c9085b0d3ebf6641a3
|
OFA-Sys/ofa-huge-vqa
|
OFA-Sys
|
ofa
| 6 | 17 |
transformers
| 3 | null | true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,932 | false |
# OFA-huge-vqa
## Introduction
This is the **huge** version of OFA model finetuned for **VQA**. OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image generation, visual grounding, image captioning, image classification, text generation, etc.) to a simple sequence-to-sequence learning framework.
The directory includes 4 files, namely `config.json` which consists of model configuration, `vocab.json` and `merge.txt` for our OFA tokenizer, and lastly `pytorch_model.bin` which consists of model weights. There is no need to worry about the mismatch between Fairseq and transformers, since we have addressed the issue yet.
## How to use
To use it in transformers, please refer to https://github.com/OFA-Sys/OFA/tree/feature/add_transformers. Install the transformers and download the models as shown below.
```
git clone --single-branch --branch feature/add_transformers https://github.com/OFA-Sys/OFA.git
pip install OFA/transformers/
git clone https://huggingface.co/OFA-Sys/OFA-huge-vqa
```
After, refer the path to OFA-large to `ckpt_dir`, and prepare an image for the testing example below. Also, ensure that you have pillow and torchvision in your environment.
```python
>>> from PIL import Image
>>> from torchvision import transforms
>>> from transformers import OFATokenizer, OFAModel
>>> from generate import sequence_generator
>>> mean, std = [0.5, 0.5, 0.5], [0.5, 0.5, 0.5]
>>> resolution = 480
>>> patch_resize_transform = transforms.Compose([
lambda image: image.convert("RGB"),
transforms.Resize((resolution, resolution), interpolation=Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)
])
>>> tokenizer = OFATokenizer.from_pretrained(ckpt_dir)
>>> txt = " what does the image describe?"# or any of your specified questions
>>> inputs = tokenizer([txt], return_tensors="pt").input_ids
>>> img = Image.open(path_to_image)
>>> patch_img = patch_resize_transform(img).unsqueeze(0)
# using the generator of fairseq version
>>> model = OFAModel.from_pretrained(ckpt_dir, use_cache=True)
>>> generator = sequence_generator.SequenceGenerator(
tokenizer=tokenizer,
beam_size=5,
max_len_b=16,
min_len=0,
no_repeat_ngram_size=3,
)
>>> data = {}
>>> data["net_input"] = {"input_ids": inputs, 'patch_images': patch_img, 'patch_masks':torch.tensor([True])}
>>> gen_output = generator.generate([model], data)
>>> gen = [gen_output[i][0]["tokens"] for i in range(len(gen_output))]
# using the generator of huggingface version
>>> model = OFAModel.from_pretrained(ckpt_dir, use_cache=False)
>>> gen = model.generate(inputs, patch_images=patch_img, num_beams=5, no_repeat_ngram_size=3)
>>> print(tokenizer.batch_decode(gen, skip_special_tokens=True))
```
|
c57447b757bbc8f610e44cde49a9db75
|
facebook/wav2vec2-large-xlsr-53-french
|
facebook
|
wav2vec2
| 9 | 16,985 |
transformers
| 9 |
automatic-speech-recognition
| true | false | true |
apache-2.0
|
['fr']
|
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['speech', 'audio', 'automatic-speech-recognition']
| false | true | true | 1,730 | false |
## Evaluation on Common Voice FR Test
```python
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
import torch
import re
import sys
model_name = "facebook/wav2vec2-large-xlsr-53-french"
device = "cuda"
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"]' # noqa: W605
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(model_name)
ds = load_dataset("common_voice", "fr", split="test", data_dir="./cv-corpus-6.1-2020-12-11")
resampler = torchaudio.transforms.Resample(orig_freq=48_000, new_freq=16_000)
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
return batch
ds = ds.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)
batch["target"] = batch["sentence"]
return batch
result = ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=list(ds.features.keys()))
wer = load_metric("wer")
print(wer.compute(predictions=result["predicted"], references=result["target"]))
```
**Result**: 25.2 %
|
0793203133e7a4bf5020c7adc9c2c492
|
rsuwaileh/IDRISI-LMR-EN-timebased-typebased
|
rsuwaileh
|
bert
| 8 | 7 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,757 | false |
This model is a BERT-based Location Mention Recognition model that is adopted from the [TLLMR4CM GitHub](https://github.com/rsuwaileh/TLLMR4CM/). The model identifies the toponyms' spans in the text and predicts their location types. The location type can be coarse-grained (e.g., country, city, etc.) and fine-grained (e.g., street, POI, etc.)
The model is trained using the training splits of all events from [IDRISI-R dataset](https://github.com/rsuwaileh/IDRISI) under the `Type-based` LMR mode and using the `Time-based` version of the data. You can download this data in `BILOU` format from [here](https://github.com/rsuwaileh/IDRISI/tree/main/data/LMR/EN/gold-random-bilou/). More details about the models are available [here](https://github.com/rsuwaileh/IDRISI/tree/main/models).
* Different variants of the model are available through HuggingFace:
- [rsuwaileh/IDRISI-LMR-EN-random-typeless](https://huggingface.co/rsuwaileh/IDRISI-LMR-EN-random-typeless/)
- [rsuwaileh/IDRISI-LMR-EN-random-typebased](https://huggingface.co/rsuwaileh/IDRISI-LMR-EN-random-typebased/)
- [rsuwaileh/IDRISI-LMR-EN-timebased-typeless](https://huggingface.co/rsuwaileh/IDRISI-LMR-EN-timebased-typeless/)
* Arabic models are also available:
- [rsuwaileh/IDRISI-LMR-AR-random-typeless](https://huggingface.co/rsuwaileh/IDRISI-LMR-AR-random-typeless/)
- [rsuwaileh/IDRISI-LMR-AR-random-typebased](https://huggingface.co/rsuwaileh/IDRISI-LMR-AR-random-typebased/)
- [rsuwaileh/IDRISI-LMR-AR-timebased-typeless](https://huggingface.co/rsuwaileh/IDRISI-LMR-AR-timebased-typeless/)
- [rsuwaileh/IDRISI-LMR-AR-timebased-typebased](https://huggingface.co/rsuwaileh/IDRISI-LMR-AR-timebased-typebased/)
To cite the models:
```
@article{suwaileh2022tlLMR4disaster,
title={When a Disaster Happens, We Are Ready: Location Mention Recognition from Crisis Tweets},
author={Suwaileh, Reem and Elsayed, Tamer and Imran, Muhammad and Sajjad, Hassan},
journal={International Journal of Disaster Risk Reduction},
year={2022}
}
@inproceedings{suwaileh2020tlLMR4disaster,
title={Are We Ready for this Disaster? Towards Location Mention Recognition from Crisis Tweets},
author={Suwaileh, Reem and Imran, Muhammad and Elsayed, Tamer and Sajjad, Hassan},
booktitle={Proceedings of the 28th International Conference on Computational Linguistics},
pages={6252--6263},
year={2020}
}
```
To cite the IDRISI-R dataset:
```
@article{rsuwaileh2022Idrisi-r,
title={IDRISI-R: Large-scale English and Arabic Location Mention Recognition Datasets for Disaster Response over Twitter},
author={Suwaileh, Reem and Elsayed, Tamer and Imran, Muhammad},
journal={...},
volume={...},
pages={...},
year={2022},
publisher={...}
}
```
|
f2528daf36ee5f448ab907589179224b
|
jonatasgrosman/exp_w2v2r_de_xls-r_gender_male-8_female-2_s293
|
jonatasgrosman
|
wav2vec2
| 10 | 1 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['de']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'de']
| false | true | true | 476 | false |
# exp_w2v2r_de_xls-r_gender_male-8_female-2_s293
Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
9e3a975b9ba0f11590d5bb96be8d3350
|
dbmdz/electra-base-turkish-mc4-cased-discriminator
|
dbmdz
|
electra
| 8 | 71 |
transformers
| 0 | null | true | true | false |
mit
|
['tr']
|
['allenai/c4']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,540 | false |
# 🇹🇷 Turkish ELECTRA model
<p align="center">
<img alt="Logo provided by Merve Noyan" title="Awesome logo from Merve Noyan" src="https://raw.githubusercontent.com/stefan-it/turkish-bert/master/merve_logo.png">
</p>
[](https://zenodo.org/badge/latestdoi/237817454)
We present community-driven BERT, DistilBERT, ELECTRA and ConvBERT models for Turkish 🎉
Some datasets used for pretraining and evaluation are contributed from the
awesome Turkish NLP community, as well as the decision for the BERT model name: BERTurk.
Logo is provided by [Merve Noyan](https://twitter.com/mervenoyann).
# Stats
We've also trained an ELECTRA (cased) model on the recently released Turkish part of the
[multiligual C4 (mC4) corpus](https://github.com/allenai/allennlp/discussions/5265) from the AI2 team.
After filtering documents with a broken encoding, the training corpus has a size of 242GB resulting
in 31,240,963,926 tokens.
We used the original 32k vocab (instead of creating a new one).
# mC4 ELECTRA
In addition to the ELEC**TR**A base model, we also trained an ELECTRA model on the Turkish part of the mC4 corpus. We use a
sequence length of 512 over the full training time and train the model for 1M steps on a v3-32 TPU.
# Model usage
All trained models can be used from the [DBMDZ](https://github.com/dbmdz) Hugging Face [model hub page](https://huggingface.co/dbmdz)
using their model name.
Example usage with 🤗/Transformers:
```python
tokenizer = AutoTokenizer.from_pretrained("dbmdz/electra-base-turkish-mc4-cased-discriminator")
model = AutoModel.from_pretrained("dbmdz/electra-base-turkish-mc4-cased-discriminator")
```
# Citation
You can use the following BibTeX entry for citation:
```bibtex
@software{stefan_schweter_2020_3770924,
author = {Stefan Schweter},
title = {BERTurk - BERT models for Turkish},
month = apr,
year = 2020,
publisher = {Zenodo},
version = {1.0.0},
doi = {10.5281/zenodo.3770924},
url = {https://doi.org/10.5281/zenodo.3770924}
}
```
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
We would like to thank [Merve Noyan](https://twitter.com/mervenoyann) for the
awesome logo!
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
|
3c6a5a353dfc7aa149c800e01a2ca185
|
espnet/GunnarThor_talromur_g_tacotron2
|
espnet
| null | 18 | 3 |
espnet
| 0 |
text-to-speech
| false | false | false |
cc-by-4.0
|
['en']
|
['talromur']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['espnet', 'audio', 'text-to-speech']
| false | true | true | 6,097 | false |
## ESPnet2 TTS model
### `espnet/GunnarThor_talromur_g_tacotron2`
This model was trained by Gunnar Thor using talromur recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```bash
cd espnet
git checkout 49a284e69308d81c142b89795de255b4ce290c54
pip install -e .
cd egs2/talromur/tts1
./run.sh --skip_data_prep false --skip_train true --download_model espnet/GunnarThor_talromur_g_tacotron2
```
## TTS config
<details><summary>expand</summary>
```
config: ./conf/tuning/train_tacotron2.yaml
print_config: false
log_level: INFO
dry_run: false
iterator_type: sequence
output_dir: exp/g/tts_train_tacotron2_raw_phn_none
ngpu: 1
seed: 0
num_workers: 1
num_att_plot: 3
dist_backend: nccl
dist_init_method: env://
dist_world_size: 2
dist_rank: 0
local_rank: 0
dist_master_addr: localhost
dist_master_port: 39151
dist_launcher: null
multiprocessing_distributed: true
unused_parameters: false
sharded_ddp: false
cudnn_enabled: true
cudnn_benchmark: false
cudnn_deterministic: true
collect_stats: false
write_collected_feats: false
max_epoch: 100
patience: null
val_scheduler_criterion:
- valid
- loss
early_stopping_criterion:
- valid
- loss
- min
best_model_criterion:
- - valid
- loss
- min
- - train
- loss
- min
keep_nbest_models: 5
nbest_averaging_interval: 0
grad_clip: 1.0
grad_clip_type: 2.0
grad_noise: false
accum_grad: 1
no_forward_run: false
resume: true
train_dtype: float32
use_amp: false
log_interval: null
use_matplotlib: true
use_tensorboard: true
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
pretrain_path: null
init_param: []
ignore_init_mismatch: false
freeze_param: []
num_iters_per_epoch: 500
batch_size: 20
valid_batch_size: null
batch_bins: 2560000
valid_batch_bins: null
train_shape_file:
- exp/g/tts_stats_raw_phn_none/train/text_shape.phn
- exp/g/tts_stats_raw_phn_none/train/speech_shape
valid_shape_file:
- exp/g/tts_stats_raw_phn_none/valid/text_shape.phn
- exp/g/tts_stats_raw_phn_none/valid/speech_shape
batch_type: numel
valid_batch_type: null
fold_length:
- 150
- 204800
sort_in_batch: descending
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
train_data_path_and_name_and_type:
- - dump/raw/train_g_phn/text
- text
- text
- - dump/raw/train_g_phn/wav.scp
- speech
- sound
valid_data_path_and_name_and_type:
- - dump/raw/dev_g_phn/text
- text
- text
- - dump/raw/dev_g_phn/wav.scp
- speech
- sound
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
valid_max_cache_size: null
optim: adam
optim_conf:
lr: 0.001
eps: 1.0e-06
weight_decay: 0.0
scheduler: null
scheduler_conf: {}
token_list:
- <blank>
- <unk>
- ','
- .
- r
- t
- n
- a0
- s
- I0
- D
- l
- Y0
- m
- v
- h
- E1
- k
- a:1
- E:1
- f
- G
- j
- T
- a1
- p
- c
- au:1
- i:1
- O:1
- I:1
- E0
- I1
- r_0
- t_h
- k_h
- Y1
- ei1
- i0
- ou:1
- ei:1
- u:1
- O1
- N
- l_0
- '91'
- ai0
- au1
- ou0
- n_0
- ei0
- O0
- ou1
- ai:1
- '9:1'
- ai1
- i1
- '90'
- au0
- c_h
- x
- 9i:1
- C
- p_h
- u0
- Y:1
- J
- 9i1
- u1
- 9i0
- N_0
- m_0
- J_0
- Oi1
- Yi0
- Yi1
- Oi0
- au:0
- '9:0'
- E:0
- <sos/eos>
odim: null
model_conf: {}
use_preprocessor: true
token_type: phn
bpemodel: null
non_linguistic_symbols: null
cleaner: null
g2p: null
feats_extract: fbank
feats_extract_conf:
n_fft: 1024
hop_length: 256
win_length: null
fs: 22050
fmin: 80
fmax: 7600
n_mels: 80
normalize: global_mvn
normalize_conf:
stats_file: exp/g/tts_stats_raw_phn_none/train/feats_stats.npz
tts: tacotron2
tts_conf:
embed_dim: 512
elayers: 1
eunits: 512
econv_layers: 3
econv_chans: 512
econv_filts: 5
atype: location
adim: 512
aconv_chans: 32
aconv_filts: 15
cumulate_att_w: true
dlayers: 2
dunits: 1024
prenet_layers: 2
prenet_units: 256
postnet_layers: 5
postnet_chans: 512
postnet_filts: 5
output_activation: null
use_batch_norm: true
use_concate: true
use_residual: false
dropout_rate: 0.5
zoneout_rate: 0.1
reduction_factor: 1
spk_embed_dim: null
use_masking: true
bce_pos_weight: 5.0
use_guided_attn_loss: true
guided_attn_loss_sigma: 0.4
guided_attn_loss_lambda: 1.0
pitch_extract: null
pitch_extract_conf: {}
pitch_normalize: null
pitch_normalize_conf: {}
energy_extract: null
energy_extract_conf: {}
energy_normalize: null
energy_normalize_conf: {}
required:
- output_dir
- token_list
version: 0.10.7a1
distributed: true
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
82fadb5a8435156bb2efeb5c36bcdd99
|
Narshion/mWACH_mBERT_System
|
Narshion
|
bert
| 9 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,001 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on mWACH NEO dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6344
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.12.4
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
8d20c9bf3e603c33335a7f8a54d8aa27
|
shahriarebrampour/distilbert-base-uncased-finetuned-imdb
|
shahriarebrampour
|
distilbert
| 15 | 3 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null |
['imdb']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,318 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4303
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.5274 | 1.0 | 157 | 2.4476 |
| 2.5259 | 2.0 | 314 | 2.4390 |
| 2.5134 | 3.0 | 471 | 2.4330 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
259d486bd75f25f54bc9620507e8c556
|
DeadBeast/mbert-base-cased-finetuned-bengali-fakenews
|
DeadBeast
|
bert
| 8 | 6 |
transformers
| 1 |
text-classification
| true | false | false |
apache-2.0
|
['bengali']
|
['BanFakeNews']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 804 | false |
# **mBERT-base-cased-finetuned-bengali-fakenews**
This model is a fine-tune checkpoint of mBERT-base-cased over **[Bengali-fake-news Dataset](https://www.kaggle.com/cryptexcode/banfakenews)** for Text classification. This model reaches an accuracy of 96.3 with an f1-score of 79.1 on the dev set.
### **How to use?**
**Task**: binary-classification
- LABEL_1: Authentic (*Authentic means news is authentic*)
- LABEL_0: Fake (*Fake means news is fake*)
```
from transformers import pipeline
print(pipeline("sentiment-analysis",model="DeadBeast/mbert-base-cased-finetuned-bengali-fakenews",tokenizer="DeadBeast/mbert-base-cased-finetuned-bengali-fakenews")("অভিনেতা আফজাল শরীফকে ২০ লাখ টাকার অনুদান অসুস্থ অভিনেতা আফজাল শরীফকে চিকিৎসার জন্য ২০ লাখ টাকা অনুদান দিয়েছেন প্রধানমন্ত্রী শেখ হাসিনা।"))
```
|
d5bed2918df870de0a9dbb3dca27c05c
|
AlekseyKorshuk/dalio-all-io-1.3b
|
AlekseyKorshuk
|
opt
| 13 | 5 |
transformers
| 0 |
text-generation
| true | false | false |
other
| null |
['AlekseyKorshuk/dalio-all-io']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 3,062 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dalio-all-io-1.3b
This model is a fine-tuned version of [facebook/opt-1.3b](https://huggingface.co/facebook/opt-1.3b) on the AlekseyKorshuk/dalio-all-io dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3652
- Accuracy: 0.0558
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 16
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.6543 | 0.03 | 1 | 2.6113 | 0.0513 |
| 2.6077 | 0.07 | 2 | 2.6113 | 0.0513 |
| 2.5964 | 0.1 | 3 | 2.5605 | 0.0519 |
| 2.7302 | 0.14 | 4 | 2.5234 | 0.0527 |
| 2.7 | 0.17 | 5 | 2.5078 | 0.0528 |
| 2.5674 | 0.21 | 6 | 2.4941 | 0.0532 |
| 2.6406 | 0.24 | 7 | 2.4883 | 0.0534 |
| 2.5315 | 0.28 | 8 | 2.4805 | 0.0536 |
| 2.7202 | 0.31 | 9 | 2.4727 | 0.0537 |
| 2.5144 | 0.34 | 10 | 2.4648 | 0.0536 |
| 2.4983 | 0.38 | 11 | 2.4512 | 0.0537 |
| 2.7029 | 0.41 | 12 | 2.4414 | 0.0539 |
| 2.5198 | 0.45 | 13 | 2.4336 | 0.0540 |
| 2.5706 | 0.48 | 14 | 2.4258 | 0.0545 |
| 2.5688 | 0.52 | 15 | 2.4180 | 0.0548 |
| 2.3793 | 0.55 | 16 | 2.4102 | 0.0552 |
| 2.4785 | 0.59 | 17 | 2.4043 | 0.0554 |
| 2.4688 | 0.62 | 18 | 2.3984 | 0.0553 |
| 2.5674 | 0.66 | 19 | 2.3984 | 0.0553 |
| 2.5054 | 0.69 | 20 | 2.3945 | 0.0554 |
| 2.452 | 0.72 | 21 | 2.3887 | 0.0555 |
| 2.5999 | 0.76 | 22 | 2.3828 | 0.0556 |
| 2.3665 | 0.79 | 23 | 2.3789 | 0.0556 |
| 2.6223 | 0.83 | 24 | 2.375 | 0.0557 |
| 2.3562 | 0.86 | 25 | 2.3711 | 0.0557 |
| 2.429 | 0.9 | 26 | 2.3691 | 0.0557 |
| 2.563 | 0.93 | 27 | 2.3672 | 0.0558 |
| 2.4573 | 0.97 | 28 | 2.3652 | 0.0558 |
| 2.4883 | 1.0 | 29 | 2.3652 | 0.0558 |
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
3868877e1bc69347bd974c551b64a03f
|
theojolliffe/bart-large-cnn-finetuned-roundup-3-1
|
theojolliffe
|
bart
| 13 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,293 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-cnn-finetuned-roundup-3-1
This model is a fine-tuned version of [facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 258 | 1.3238 | 50.228 | 29.5898 | 30.1054 | 47.1265 | 142.0 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
35ecae7a28341de9a06dee1ab5d35ab0
|
sd-concepts-library/smurf-style
|
sd-concepts-library
| null | 15 | 0 | null | 3 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,643 | false |
### Smurf Style on Stable Diffusion
This is the `<smurfy>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:










|
974909a98ef7f26509972b9fbed3f00e
|
jonatasgrosman/exp_w2v2t_uk_wav2vec2_s646
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['uk']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'uk']
| false | true | true | 456 | false |
# exp_w2v2t_uk_wav2vec2_s646
Fine-tuned [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) for speech recognition using the train split of [Common Voice 7.0 (uk)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
04b3b3d60a8e440d5ac583e30e88516e
|
MohamedRashad/diffusion_fashion
|
MohamedRashad
| null | 17 | 268 |
diffusers
| 4 |
text-to-image
| false | false | false |
openrail
|
['en']
| null | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['stable-diffusion', 'diffusers', 'text-to-image', 'fashion', 'diffusion', 'openjourney']
| false | true | true | 878 | false |
# Stable Diffusion fine-tuned for [Fashion Product Images Dataset](https://www.kaggle.com/datasets/paramaggarwal/fashion-product-images-dataset)
This model is a fine-tuned version of [openjourney](https://huggingface.co/prompthero/openjourney) that is based on Stable Diffusion targeting fashion and clothing.
## How to use ?
```python
from diffusers import StableDiffusionPipeline
import torch
pipeline = StableDiffusionPipeline.from_pretrained("MohamedRashad/diffusion_fashion", torch_dtype=torch.float16)
pipeline.to("cuda")
prompt = "A photo of a dress, made in 2019, color is Red, Casual usage, Women's cloth, something for the summer season, on white background"
images = pipeline(prompt).images[0]
image.save("red_dress.png")
```
## Any feedback or questions are welcomed on the [community](https://huggingface.co/MohamedRashad/diffusion_fashion/discussions) tab
|
e1a31e041e803f5cc9bc9728e8f98615
|
stopdoingmath/opus-mt-sla-en-finetuned-uk-to-en
|
stopdoingmath
|
marian
| 13 | 2 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['opus100']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,318 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-sla-en-finetuned-uk-to-en
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-sla-en](https://huggingface.co/Helsinki-NLP/opus-mt-sla-en) on the opus100 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7232
- Bleu: 27.7684
- Gen Len: 12.2485
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|
| 1.5284 | 1.0 | 62500 | 1.7232 | 27.7684 | 12.2485 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
158e74da4b9e02f21fc7bdf82f10bc82
|
ufal/byt5-small-multilexnorm2021-nl
|
ufal
|
t5
| 6 | 4 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
|
['nl']
|
['mc4', 'wikipedia', 'multilexnorm']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['lexical normalization']
| false | true | true | 2,757 | false |
# Fine-tuned ByT5-small for MultiLexNorm (Dutch version)

This is the official release of the fine-tuned models for **the winning entry** to the [*W-NUT 2021: Multilingual Lexical Normalization (MultiLexNorm)* shared task](https://noisy-text.github.io/2021/multi-lexnorm.html), which evaluates lexical-normalization systems on 12 social media datasets in 11 languages.
Our system is based on [ByT5](https://arxiv.org/abs/2105.13626), which we first pre-train on synthetic data and then fine-tune on authentic normalization data. It achieves the best performance by a wide margin in intrinsic evaluation, and also the best performance in extrinsic evaluation through dependency parsing. In addition to these fine-tuned models, we also release the source files on [GitHub](https://github.com/ufal/multilexnorm2021) and an interactive demo on [Google Colab](https://colab.research.google.com/drive/1rxpI8IlKk-D2crFqi2hdzbTBIezqgsCg?usp=sharing).
## How to use
The model was *not* fine-tuned in a standard sentence-to-sentence setting – instead, it was tailored to the token-to-token definition of MultiLexNorm data. Please refer to [**the interactive demo on Colab notebook**](https://colab.research.google.com/drive/1rxpI8IlKk-D2crFqi2hdzbTBIezqgsCg?usp=sharing) to learn how to use these models.
## How to cite
```bibtex
@inproceedings{wnut-ufal,
title= "{ÚFAL} at {MultiLexNorm} 2021: Improving Multilingual Lexical Normalization by Fine-tuning {ByT5}",
author = "Samuel, David and Straka, Milan",
booktitle = "Proceedings of the 7th Workshop on Noisy User-generated Text (W-NUT 2021)",
year = "2021",
publisher = "Association for Computational Linguistics",
address = "Punta Cana, Dominican Republic"
}
```
## ByT5 - Small
ByT5 is a tokenizer-free version of [Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) and generally follows the architecture of [MT5](https://huggingface.co/google/mt5-small).
ByT5 was only pre-trained on [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual) excluding any supervised training with an average span-mask of 20 UTF-8 characters. Therefore, this model has to be fine-tuned before it is useable on a downstream task.
ByT5 works especially well on noisy text data,*e.g.*, `google/byt5-small` significantly outperforms [mt5-small](https://huggingface.co/google/mt5-small) on [TweetQA](https://arxiv.org/abs/1907.06292).
Paper: [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626)
Authors: *Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel*
|
7645032b3257faa5d78cbf841cc1f828
|
Rocketknight1/bert-base-cased-finetuned-wikitext2
|
Rocketknight1
|
bert
| 22 | 7 |
transformers
| 0 |
fill-mask
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,248 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Rocketknight1/bert-base-cased-finetuned-wikitext2
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 6.3982
- Validation Loss: 6.2664
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 7.0679 | 6.4768 | 0 |
| 6.3982 | 6.2664 | 1 |
### Framework versions
- Transformers 4.21.0.dev0
- TensorFlow 2.9.1
- Datasets 2.3.3.dev0
- Tokenizers 0.11.0
|
dede3f9d1face4030ba314f44722da0b
|
Jethuestad/dat259-nor-wav2vec2
|
Jethuestad
|
wav2vec2
| 17 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice_8_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,661 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dat259-nor-wav2vec2
This model is a fine-tuned version of [NbAiLab/nb-wav2vec2-300m-nynorsk](https://huggingface.co/NbAiLab/nb-wav2vec2-300m-nynorsk) on the common_voice_8_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 10.9446
- Wer: 1.1259
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 84.8696 | 1.57 | 5 | 91.5942 | 1.0 |
| 62.5471 | 3.29 | 10 | 33.8515 | 1.0068 |
| 20.2215 | 4.86 | 15 | 17.4461 | 1.0017 |
| 15.2892 | 6.57 | 20 | 13.5454 | 1.0034 |
| 12.8086 | 8.29 | 25 | 12.0084 | 1.0408 |
| 11.0168 | 9.86 | 30 | 10.9446 | 1.1259 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.10.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
751b3979ea8a68ba2cbef3399ae8df69
|
lmqg/mt5-base-esquad-qg
|
lmqg
|
mt5
| 20 | 101 |
transformers
| 0 |
text2text-generation
| true | false | false |
cc-by-4.0
|
['es']
|
['lmqg/qg_esquad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['question generation']
| true | true | true | 6,392 | false |
# Model Card of `lmqg/mt5-base-esquad-qg`
This model is fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) for question generation task on the [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [google/mt5-base](https://huggingface.co/google/mt5-base)
- **Language:** es
- **Training data:** [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="es", model="lmqg/mt5-base-esquad-qg")
# model prediction
questions = model.generate_q(list_context="a noviembre , que es también la estación lluviosa.", list_answer="noviembre")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/mt5-base-esquad-qg")
output = pipe("del <hl> Ministerio de Desarrollo Urbano <hl> , Gobierno de la India.")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/lmqg/mt5-base-esquad-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_esquad.default.json)
| | Score | Type | Dataset |
|:-----------|--------:|:--------|:-----------------------------------------------------------------|
| BERTScore | 84.47 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| Bleu_1 | 26.73 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| Bleu_2 | 18.46 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| Bleu_3 | 13.5 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| Bleu_4 | 10.15 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| METEOR | 23.43 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| MoverScore | 59.62 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| ROUGE_L | 25.45 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
- ***Metric (Question & Answer Generation, Reference Answer)***: Each question is generated from *the gold answer*. [raw metric file](https://huggingface.co/lmqg/mt5-base-esquad-qg/raw/main/eval/metric.first.answer.paragraph.questions_answers.lmqg_qg_esquad.default.json)
| | Score | Type | Dataset |
|:--------------------------------|--------:|:--------|:-----------------------------------------------------------------|
| QAAlignedF1Score (BERTScore) | 89.68 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| QAAlignedF1Score (MoverScore) | 64.22 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| QAAlignedPrecision (BERTScore) | 89.7 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| QAAlignedPrecision (MoverScore) | 64.24 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| QAAlignedRecall (BERTScore) | 89.66 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| QAAlignedRecall (MoverScore) | 64.21 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
- ***Metric (Question & Answer Generation, Pipeline Approach)***: Each question is generated on the answer generated by [`lmqg/mt5-base-esquad-ae`](https://huggingface.co/lmqg/mt5-base-esquad-ae). [raw metric file](https://huggingface.co/lmqg/mt5-base-esquad-qg/raw/main/eval_pipeline/metric.first.answer.paragraph.questions_answers.lmqg_qg_esquad.default.lmqg_mt5-base-esquad-ae.json)
| | Score | Type | Dataset |
|:--------------------------------|--------:|:--------|:-----------------------------------------------------------------|
| QAAlignedF1Score (BERTScore) | 80.79 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| QAAlignedF1Score (MoverScore) | 55.25 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| QAAlignedPrecision (BERTScore) | 78.45 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| QAAlignedPrecision (MoverScore) | 53.7 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| QAAlignedRecall (BERTScore) | 83.34 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
| QAAlignedRecall (MoverScore) | 56.99 | default | [lmqg/qg_esquad](https://huggingface.co/datasets/lmqg/qg_esquad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_esquad
- dataset_name: default
- input_types: ['paragraph_answer']
- output_types: ['question']
- prefix_types: None
- model: google/mt5-base
- max_length: 512
- max_length_output: 32
- epoch: 10
- batch: 4
- lr: 0.0005
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 16
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/mt5-base-esquad-qg/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
eb9be155dc782e0985f16dc80f6ea2db
|
nlp04/kobart_32_3e-5_datav2_min30_lp5.0_temperature1.0
|
nlp04
|
bart
| 17 | 0 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,591 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kobart_32_3e-5_datav2_min30_lp5.0_temperature1.0
This model is a fine-tuned version of [gogamza/kobart-base-v2](https://huggingface.co/gogamza/kobart-base-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5958
- Rouge1: 35.6403
- Rouge2: 13.1314
- Rougel: 23.8946
- Bleu1: 29.625
- Bleu2: 17.4903
- Bleu3: 10.6018
- Bleu4: 6.0498
- Gen Len: 50.697
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Bleu1 | Bleu2 | Bleu3 | Bleu4 | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:------:|:-------:|:-------:|:------:|:-------:|
| 1.8239 | 3.78 | 5000 | 2.5958 | 35.6403 | 13.1314 | 23.8946 | 29.625 | 17.4903 | 10.6018 | 6.0498 | 50.697 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
|
56585eac002f308bacc6c29965ba09e7
|
XSY/albert-base-v2-fakenews-discriminator
|
XSY
|
albert
| 9 | 26 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,438 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-base-v2-fakenews-discriminator
The dataset: Fake and real news dataset https://www.kaggle.com/clmentbisaillon/fake-and-real-news-dataset
I use title and label to train the classifier
label_0 : Fake news
label_1 : Real news
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0910
- Accuracy: 0.9758
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0452 | 1.0 | 1768 | 0.0910 | 0.9758 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
89b057bc317cc8e6dd17669f1c2c2e28
|
nvidia/segformer-b0-finetuned-ade-512-512
|
nvidia
|
segformer
| 6 | 26,404 |
transformers
| 29 |
image-segmentation
| true | true | false |
other
| null |
['scene_parse_150']
| null | 2 | 1 | 1 | 0 | 1 | 1 | 0 |
['vision', 'image-segmentation']
| false | true | true | 2,849 | false |
# SegFormer (b0-sized) model fine-tuned on ADE20k
SegFormer model fine-tuned on ADE20k at resolution 512x512. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
Disclaimer: The team releasing SegFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
from PIL import Image
import requests
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### License
The license for this model can be found [here](https://github.com/NVlabs/SegFormer/blob/master/LICENSE).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
0f75a39da0ea20bb0b5c6f8eac9c191f
|
p1atdev/pd-archive
|
p1atdev
| null | 14 | 0 | null | 6 | null | false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 778 | false |
# Plat Diffusion Archive
## v1.3.1

- [`plat-v1-3-1.safetensors`](https://huggingface.co/p1atdev/pd-archive/blob/main/plat-v1-3-1.safetensors)
- [`plat-v1-3-1.ckpt`](https://huggingface.co/p1atdev/pd-archive/blob/main/plat-v1-3-1.ckpt)
- [`plat-v1-3-1.yaml`](https://huggingface.co/p1atdev/pd-archive/blob/main/plat-v1-3-1.yaml)
## v1.3.0

- [`plat-v1-3-0.safetensors`](https://huggingface.co/p1atdev/pd-archive/blob/main/plat-v1-3-0.safetensors)
- [`plat-v1-3-0.ckpt`](https://huggingface.co/p1atdev/pd-archive/blob/main/plat-v1-3-0.ckpt)
- [`plat-v1-3-0.yaml`](https://huggingface.co/p1atdev/pd-archive/blob/main/plat-v1-3-0.yaml)
|
fa45c12c0f66eb7c665121bfaf662704
|
jonatasgrosman/exp_w2v2t_ru_vp-nl_s131
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ru']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'ru']
| false | true | true | 469 | false |
# exp_w2v2t_ru_vp-nl_s131
Fine-tuned [facebook/wav2vec2-large-nl-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-nl-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (ru)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
3a226d10d62a48da3c21f41c0b307c37
|
mio/hiten
|
mio
| null | 7 | 0 |
diffusers
| 4 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers']
| false | true | true | 4,108 | false |
# Hiten Diffusion
**Welcome to Hiten Diffusion** - a latent diffusion model that has been trained on Chinese TaiWan Artist artwork, [hiten](https://www.pixiv.net/users/490219). The current model has been fine-tuned with a learning rate of `2.0e-6` for `10 Epochs` on `467 images` collected from Danbooru. The model is trained using [NovelAI Aspect Ratio Bucketing Tool](https://github.com/NovelAI/novelai-aspect-ratio-bucketing) so that it can be trained at non-square resolutions. Like other anime-style Stable Diffusion models, it also supports Danbooru tags to generate images.
e.g. **_1girl, white hair, golden eyes, beautiful eyes, detail, flower meadow, cumulonimbus clouds, lighting, detailed sky, garden_**
## 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "mio/hiten"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "1girl,solo,miku"
image = pipe(prompt).images[0]
image.save("./miku.png")
```
## Examples
Below are some examples of images generated using this model:




### Prompt and settings for Example Images
**Anime Girl:**
```
(((masterpiece))),(((best quality))),((ultra-detailed)), ((illustration)),floating, ((an extremely delicate and beautiful)),(beautiful detailed eyes),((disheveled hair)),1girl, bangs, black_hair, blue_sailor_collar, blurry, blurry_background, depth_of_field, eyebrows_visible_through_hair, long_hair, looking_at_viewer, parted_lips, sailor_collar, school_uniform, serafuku, shirt, solo, yoroizuka_mizore,medium_chest,colourful_stages,crown,masterpiece,full_body,white_thighhighs,extremely_detailed_CG_unity_8k_wallpaper,solo,1girl,lights
Negative prompt: nsfw,nipples,lowres,bad anatomy,bad hands, text, error, missing fingers,extra digit, fewer digits, cropped, worstquality, low quality, normal quality,jpegartifacts,signature, watermark, username,blurry,bad feet, (((mutilated))),(((((too many fingers))))),((((fused fingers)))),(((extra fingers))),(((mutated hands))),extra limbs,(bad_prompt), (((mutilated))),(((((too many fingers))))),((((fused fingers)))),(((extra fingers)))
Steps: 24, Sampler: DPM2 a Karras, CFG scale: 7, Seed: 3722281017, Size: 512x768, Model hash: 53a39f6a, Model: hiten_epoch10, Batch size: 4, Batch pos: 3, Clip skip: 2, ENSD: 31337
```
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
## Big Thanks to
- [Linaqruf](https://huggingface.co/Linaqruf) for his first step.
- [Kohya](https://twitter.com/kohya_ss) with their [Kohya Trainer](https://note.com/kohya_ss/n/ne17e34dd51bf)
|
8174115d5ff7ea0aefea701097e3635b
|
Chituyi/wav2vec2-large-xls-r-300m-tr-colab
|
Chituyi
|
wav2vec2
| 15 | 24 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,058 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-tr-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 20
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 40
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
b4c5de0c50c84f825fb90e694b3f1a1a
|
fathyshalab/all-roberta-large-v1-kitchen_and_dining-4-16-5
|
fathyshalab
|
roberta
| 11 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,523 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# all-roberta-large-v1-kitchen_and_dining-4-16-5
This model is a fine-tuned version of [sentence-transformers/all-roberta-large-v1](https://huggingface.co/sentence-transformers/all-roberta-large-v1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3560
- Accuracy: 0.2692
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.7421 | 1.0 | 1 | 2.5878 | 0.2012 |
| 2.1065 | 2.0 | 2 | 2.4975 | 0.2012 |
| 1.5994 | 3.0 | 3 | 2.4274 | 0.2249 |
| 1.1739 | 4.0 | 4 | 2.3808 | 0.2456 |
| 1.083 | 5.0 | 5 | 2.3560 | 0.2692 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
79ce2cee829768cc03e8748ccf227dfd
|
sd-concepts-library/captainkirb
|
sd-concepts-library
| null | 11 | 0 | null | 0 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,258 | false |
### CaptainKirb on Stable Diffusion
This is the `<captainkirb>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:






|
c25042be9771e6103bf6776a84502c7d
|
Helsinki-NLP/opus-mt-fr-tvl
|
Helsinki-NLP
|
marian
| 10 | 7 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 776 | false |
### opus-mt-fr-tvl
* source languages: fr
* target languages: tvl
* OPUS readme: [fr-tvl](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fr-tvl/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/fr-tvl/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-tvl/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-tvl/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.fr.tvl | 32.6 | 0.497 |
|
70eb1692186ab8090685fb19be7f49d8
|
dundar/wav2vec2-large-xlsr-53-lithuanian
|
dundar
|
wav2vec2
| 9 | 8 |
transformers
| 0 |
automatic-speech-recognition
| true | false | true |
apache-2.0
|
['lt']
|
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week']
| true | true | true | 3,351 | false |
# Wav2Vec2-Large-XLSR-53-Lithuanian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Lithuanian using the [Common Voice](https://huggingface.co/datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "lt", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("dundar/wav2vec2-large-xlsr-53-lithuanian")
model = Wav2Vec2ForCTC.from_pretrained("dundar/wav2vec2-large-xlsr-53-lithuanian")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Lithuanian test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "lt", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("dundar/wav2vec2-large-xlsr-53-lithuanian")
model = Wav2Vec2ForCTC.from_pretrained("dundar/wav2vec2-large-xlsr-53-lithuanian")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 35.87 %
## Training
The Common Voice datasets `except the test` set were used for training.
The script used for training can be found [here](https://github.com/ebdundar/)
|
207e6bbe7486b198c5f4a947860140a9
|
erwanlc/t5-cocktails_recipe-base
|
erwanlc
|
t5
| 16 | 2 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 906 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-cocktails_recipe-base
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
3bb7c91e0c1ab5700767c8b31a156aee
|
laurabernardy/LuxGPT2-basedGER
|
laurabernardy
|
gpt2
| 8 | 2 |
transformers
| 0 |
text-generation
| true | false | false |
mit
|
['lb']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['luxembourgish', 'lëtzebuergesch', 'text generation', 'transfer learning']
| true | true | true | 1,065 | false |
## LuxGPT-2 based GER
GPT-2 model for Text Generation in luxembourgish language, trained on 711 MB of text data, consisting of RTL.lu news articles, comments, parlament speeches, the luxembourgish Wikipedia, Newscrawl, Webcrawl and subtitles. Created via transfer learning with an German base model, feature space mapping from LB on Base feature space and gradual layer freezing.
The training took place on a 32 GB Nvidia Tesla V100
- with One Cycle policy for the learning rate
- with the help of fastai's LR finder
- for 53.4 hours
- for 20 epochs and 7 cycles
- using the fastai library
## Usage
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("laurabernardy/LuxGPT2-basedGER")
model = AutoModelForCausalLM.from_pretrained("laurabernardy/LuxGPT2-basedGER")
```
## Limitations and Biases
See the [GPT2 model card](https://huggingface.co/gpt2) for considerations on limitations and bias. See the [GPT2 documentation](https://huggingface.co/transformers/model_doc/gpt2.html) for details on GPT2.
|
124bc2200da741856fe0b90ed435d86a
|
ss756/bert-base-cased-finetuned-squad
|
ss756
|
bert
| 24 | 2 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,153 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0081
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.0071 | 1.0 | 22183 | 1.0081 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.9.0+cu111
- Datasets 2.1.0
- Tokenizers 0.12.1
|
33578cd24298bf967b7cdb25098b2e21
|
eliotm/t5-small-finetuned-en-to-ro-LR_1e-3
|
eliotm
|
t5
| 12 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['wmt16']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,274 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-en-to-ro-LR_1e-3
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the wmt16 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5215
- Bleu: 7.1606
- Gen Len: 18.2451
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|
| 0.6758 | 1.0 | 7629 | 1.5215 | 7.1606 | 18.2451 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
b2957ed7d83bc1e2ba040f36c3f97dd7
|
Helsinki-NLP/opus-mt-bg-sv
|
Helsinki-NLP
|
marian
| 10 | 17 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 768 | false |
### opus-mt-bg-sv
* source languages: bg
* target languages: sv
* OPUS readme: [bg-sv](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/bg-sv/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/bg-sv/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/bg-sv/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/bg-sv/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.bg.sv | 29.1 | 0.494 |
|
6429a4dcb3928cef6ac7838939bee22b
|
jonatasgrosman/exp_w2v2t_es_hubert_s459
|
jonatasgrosman
|
hubert
| 10 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['es']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'es']
| false | true | true | 452 | false |
# exp_w2v2t_es_hubert_s459
Fine-tuned [facebook/hubert-large-ll60k](https://huggingface.co/facebook/hubert-large-ll60k) for speech recognition using the train split of [Common Voice 7.0 (es)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
0ad035b8e2d58abbde753ffca4fbf826
|
Duskfallcrew/duskfall-s-animanga-model
|
Duskfallcrew
| null | 21 | 5 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text-to-image']
| false | true | true | 914 | false |
### Duskfall's Animanga Model Dreambooth model trained by Duskfallcrew with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
If you want to donate towards costs and don't want to subscribe:
https://ko-fi.com/DUSKFALLcrew
If you want to monthly support the EARTH & DUSK media projects and not just AI:
https://www.patreon.com/earthndusk
Discord https://discord.gg/Da7s8d3KJ7
Rules
Do not sell merges, or this model.
Do share, and credit if you use this model.
DO PLS REVIEW AND YELL AT ME IF IT SUCKS!
We never update the images on here anymore
see civit https://civitai.com/user/duskfallcrew
|
c37cd1c092a31809d6da941dd33fda77
|
yanaiela/roberta-base-epoch_55
|
yanaiela
|
roberta
| 9 | 3 |
transformers
| 0 |
fill-mask
| true | false | false |
mit
|
['en']
|
['wikipedia', 'bookcorpus']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['roberta-base', 'roberta-base-epoch_55']
| false | true | true | 2,102 | false |
# RoBERTa, Intermediate Checkpoint - Epoch 55
This model is part of our reimplementation of the [RoBERTa model](https://arxiv.org/abs/1907.11692),
trained on Wikipedia and the Book Corpus only.
We train this model for almost 100K steps, corresponding to 83 epochs.
We provide the 84 checkpoints (including the randomly initialized weights before the training)
to provide the ability to study the training dynamics of such models, and other possible use-cases.
These models were trained in part of a work that studies how simple statistics from data,
such as co-occurrences affects model predictions, which are described in the paper
[Measuring Causal Effects of Data Statistics on Language Model's `Factual' Predictions](https://arxiv.org/abs/2207.14251).
This is RoBERTa-base epoch_55.
## Model Description
This model was captured during a reproduction of
[RoBERTa-base](https://huggingface.co/roberta-base), for English: it
is a Transformers model pretrained on a large corpus of English data, using the
Masked Language Modelling (MLM).
The intended uses, limitations, training data and training procedure for the fully trained model are similar
to [RoBERTa-base](https://huggingface.co/roberta-base). Two major
differences with the original model:
* We trained our model for 100K steps, instead of 500K
* We only use Wikipedia and the Book Corpus, as corpora which are publicly available.
### How to use
Using code from
[RoBERTa-base](https://huggingface.co/roberta-base), here is an example based on
PyTorch:
```
from transformers import pipeline
model = pipeline("fill-mask", model='yanaiela/roberta-base-epoch_83', device=-1, top_k=10)
model("Hello, I'm the <mask> RoBERTa-base language model")
```
## Citation info
```bibtex
@article{2207.14251,
Author = {Yanai Elazar and Nora Kassner and Shauli Ravfogel and Amir Feder and Abhilasha Ravichander and Marius Mosbach and Yonatan Belinkov and Hinrich Schütze and Yoav Goldberg},
Title = {Measuring Causal Effects of Data Statistics on Language Model's `Factual' Predictions},
Year = {2022},
Eprint = {arXiv:2207.14251},
}
```
|
a65460a0e4877d56952b4f50599bc910
|
Helsinki-NLP/opus-mt-sm-fr
|
Helsinki-NLP
|
marian
| 10 | 8 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 768 | false |
### opus-mt-sm-fr
* source languages: sm
* target languages: fr
* OPUS readme: [sm-fr](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/sm-fr/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/sm-fr/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/sm-fr/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/sm-fr/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.sm.fr | 24.6 | 0.419 |
|
1a5d1192d71b0a79626586f59952a6f6
|
nlpaueb/sec-bert-num
|
nlpaueb
|
bert
| 8 | 8 |
transformers
| 4 |
fill-mask
| true | true | false |
cc-by-sa-4.0
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['finance', 'financial']
| false | true | true | 15,128 | false |
# SEC-BERT
<img align="center" src="https://i.ibb.co/0yz81K9/sec-bert-logo.png" alt="sec-bert-logo" width="400"/>
<div style="text-align: justify">
SEC-BERT is a family of BERT models for the financial domain, intended to assist financial NLP research and FinTech applications.
SEC-BERT consists of the following models:
* [**SEC-BERT-BASE**](https://huggingface.co/nlpaueb/sec-bert-base): Same architecture as BERT-BASE trained on financial documents.
* **SEC-BERT-NUM** (this model): Same as SEC-BERT-BASE but we replace every number token with a [NUM] pseudo-token handling all numeric expressions in a uniform manner, disallowing their fragmentation).
* [**SEC-BERT-SHAPE**](https://huggingface.co/nlpaueb/sec-bert-shape): Same as SEC-BERT-BASE but we replace numbers with pseudo-tokens that represent the number’s shape, so numeric expressions (of known shapes) are no longer fragmented, e.g., '53.2' becomes '[XX.X]' and '40,200.5' becomes '[XX,XXX.X]'.
</div>
## Pre-training corpus
The model was pre-trained on 260,773 10-K filings from 1993-2019, publicly available at <a href="https://www.sec.gov/">U.S. Securities and Exchange Commission (SEC)</a>
## Pre-training details
<div style="text-align: justify">
* We created a new vocabulary of 30k subwords by training a [BertWordPieceTokenizer](https://github.com/huggingface/tokenizers) from scratch on the pre-training corpus.
* We trained BERT using the official code provided in [Google BERT's GitHub repository](https://github.com/google-research/bert)</a>.
* We then used [Hugging Face](https://huggingface.co)'s [Transformers](https://github.com/huggingface/transformers) conversion script to convert the TF checkpoint in the desired format in order to be able to load the model in two lines of code for both PyTorch and TF2 users.
* We release a model similar to the English BERT-BASE model (12-layer, 768-hidden, 12-heads, 110M parameters).
* We chose to follow the same training set-up: 1 million training steps with batches of 256 sequences of length 512 with an initial learning rate 1e-4.
* We were able to use a single Google Cloud TPU v3-8 provided for free from [TensorFlow Research Cloud (TRC)](https://sites.research.google/trc), while also utilizing [GCP research credits](https://edu.google.com/programs/credits/research). Huge thanks to both Google programs for supporting us!
</div>
## Load Pretrained Model
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("nlpaueb/sec-bert-num")
model = AutoModel.from_pretrained("nlpaueb/sec-bert-num")
```
## Pre-process Text
<div style="text-align: justify">
To use SEC-BERT-NUM, you have to pre-process texts replacing every numerical token with [NUM] pseudo-token.
Below there is an example of how you can pre-process a simple sentence. This approach is quite simple; feel free to modify it as you see fit.
</div>
```python
import re
import spacy
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("nlpaueb/sec-bert-num")
spacy_tokenizer = spacy.load("en_core_web_sm")
sentence = "Total net sales decreased 2% or $5.4 billion during 2019 compared to 2018."
def sec_bert_num_preprocess(text):
tokens = [t.text for t in spacy_tokenizer(text)]
processed_text = []
for token in tokens:
if re.fullmatch(r"(\d+[\d,.]*)|([,.]\d+)", token):
processed_text.append('[NUM]')
else:
processed_text.append(token)
return ' '.join(processed_text)
tokenized_sentence = tokenizer.tokenize(sec_bert_num_preprocess(sentence))
print(tokenized_sentence)
"""
['total', 'net', 'sales', 'decreased', '[NUM]', '%', 'or', '$', '[NUM]', 'billion', 'during', '[NUM]', 'compared', 'to', '[NUM]', '.']
"""
```
## Using SEC-BERT variants as Language Models
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales [MASK] 2% or $5.4 billion during 2019 compared to 2018. | decreased
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | increased (0.221), were (0.131), are (0.103), rose (0.075), of (0.058)
| **SEC-BERT-BASE** | increased (0.678), decreased (0.282), declined (0.017), grew (0.016), rose (0.004)
| **SEC-BERT-NUM** | increased (0.753), decreased (0.211), grew (0.019), declined (0.010), rose (0.006)
| **SEC-BERT-SHAPE** | increased (0.747), decreased (0.214), grew (0.021), declined (0.013), rose (0.002)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased 2% or $5.4 [MASK] during 2019 compared to 2018. | billion
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | billion (0.841), million (0.097), trillion (0.028), ##m (0.015), ##bn (0.006)
| **SEC-BERT-BASE** | million (0.972), billion (0.028), millions (0.000), ##million (0.000), m (0.000)
| **SEC-BERT-NUM** | million (0.974), billion (0.012), , (0.010), thousand (0.003), m (0.000)
| **SEC-BERT-SHAPE** | million (0.978), billion (0.021), % (0.000), , (0.000), millions (0.000)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased [MASK]% or $5.4 billion during 2019 compared to 2018. | 2
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | 20 (0.031), 10 (0.030), 6 (0.029), 4 (0.027), 30 (0.027)
| **SEC-BERT-BASE** | 13 (0.045), 12 (0.040), 11 (0.040), 14 (0.035), 10 (0.035)
| **SEC-BERT-NUM** | [NUM] (1.000), one (0.000), five (0.000), three (0.000), seven (0.000)
| **SEC-BERT-SHAPE** | [XX] (0.316), [XX.X] (0.253), [X.X] (0.237), [X] (0.188), [X.XX] (0.002)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased 2[MASK] or $5.4 billion during 2019 compared to 2018. | %
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | % (0.795), percent (0.174), ##fold (0.009), billion (0.004), times (0.004)
| **SEC-BERT-BASE** | % (0.924), percent (0.076), points (0.000), , (0.000), times (0.000)
| **SEC-BERT-NUM** | % (0.882), percent (0.118), million (0.000), units (0.000), bps (0.000)
| **SEC-BERT-SHAPE** | % (0.961), percent (0.039), bps (0.000), , (0.000), bcf (0.000)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased 2% or $[MASK] billion during 2019 compared to 2018. | 5.4
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | 1 (0.074), 4 (0.045), 3 (0.044), 2 (0.037), 5 (0.034)
| **SEC-BERT-BASE** | 1 (0.218), 2 (0.136), 3 (0.078), 4 (0.066), 5 (0.048)
| **SEC-BERT-NUM** | [NUM] (1.000), l (0.000), 1 (0.000), - (0.000), 30 (0.000)
| **SEC-BERT-SHAPE** | [X.X] (0.787), [X.XX] (0.095), [XX.X] (0.049), [X.XXX] (0.046), [X] (0.013)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased 2% or $5.4 billion during [MASK] compared to 2018. | 2019
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | 2017 (0.485), 2018 (0.169), 2016 (0.164), 2015 (0.070), 2014 (0.022)
| **SEC-BERT-BASE** | 2019 (0.990), 2017 (0.007), 2018 (0.003), 2020 (0.000), 2015 (0.000)
| **SEC-BERT-NUM** | [NUM] (1.000), as (0.000), fiscal (0.000), year (0.000), when (0.000)
| **SEC-BERT-SHAPE** | [XXXX] (1.000), as (0.000), year (0.000), periods (0.000), , (0.000)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased 2% or $5.4 billion during 2019 compared to [MASK]. | 2018
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | 2017 (0.100), 2016 (0.097), above (0.054), inflation (0.050), previously (0.037)
| **SEC-BERT-BASE** | 2018 (0.999), 2019 (0.000), 2017 (0.000), 2016 (0.000), 2014 (0.000)
| **SEC-BERT-NUM** | [NUM] (1.000), year (0.000), last (0.000), sales (0.000), fiscal (0.000)
| **SEC-BERT-SHAPE** | [XXXX] (1.000), year (0.000), sales (0.000), prior (0.000), years (0.000)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| During 2019, the Company [MASK] $67.1 billion of its common stock and paid dividend equivalents of $14.1 billion. | repurchased
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | held (0.229), sold (0.192), acquired (0.172), owned (0.052), traded (0.033)
| **SEC-BERT-BASE** | repurchased (0.913), issued (0.036), purchased (0.029), redeemed (0.010), sold (0.003)
| **SEC-BERT-NUM** | repurchased (0.917), purchased (0.054), reacquired (0.013), issued (0.005), acquired (0.003)
| **SEC-BERT-SHAPE** | repurchased (0.902), purchased (0.068), issued (0.010), reacquired (0.008), redeemed (0.006)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| During 2019, the Company repurchased $67.1 billion of its common [MASK] and paid dividend equivalents of $14.1 billion. | stock
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | stock (0.835), assets (0.039), equity (0.025), debt (0.021), bonds (0.017)
| **SEC-BERT-BASE** | stock (0.857), shares (0.135), equity (0.004), units (0.002), securities (0.000)
| **SEC-BERT-NUM** | stock (0.842), shares (0.157), equity (0.000), securities (0.000), units (0.000)
| **SEC-BERT-SHAPE** | stock (0.888), shares (0.109), equity (0.001), securities (0.001), stocks (0.000)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| During 2019, the Company repurchased $67.1 billion of its common stock and paid [MASK] equivalents of $14.1 billion. | dividend
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | cash (0.276), net (0.128), annual (0.083), the (0.040), debt (0.027)
| **SEC-BERT-BASE** | dividend (0.890), cash (0.018), dividends (0.016), share (0.013), tax (0.010)
| **SEC-BERT-NUM** | dividend (0.735), cash (0.115), share (0.087), tax (0.025), stock (0.013)
| **SEC-BERT-SHAPE** | dividend (0.655), cash (0.248), dividends (0.042), share (0.019), out (0.003)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| During 2019, the Company repurchased $67.1 billion of its common stock and paid dividend [MASK] of $14.1 billion. | equivalents
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | revenue (0.085), earnings (0.078), rates (0.065), amounts (0.064), proceeds (0.062)
| **SEC-BERT-BASE** | payments (0.790), distributions (0.087), equivalents (0.068), cash (0.013), amounts (0.004)
| **SEC-BERT-NUM** | payments (0.845), equivalents (0.097), distributions (0.024), increases (0.005), dividends (0.004)
| **SEC-BERT-SHAPE** | payments (0.784), equivalents (0.093), distributions (0.043), dividends (0.015), requirements (0.009)
## Publication
<div style="text-align: justify">
If you use this model cite the following article:<br>
[**FiNER: Financial Numeric Entity Recognition for XBRL Tagging**](https://arxiv.org/abs/2203.06482)<br>
Lefteris Loukas, Manos Fergadiotis, Ilias Chalkidis, Eirini Spyropoulou, Prodromos Malakasiotis, Ion Androutsopoulos and George Paliouras<br>
In the Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL 2022) (Long Papers), Dublin, Republic of Ireland, May 22 - 27, 2022
</div>
```
@inproceedings{loukas-etal-2022-finer,
title = {FiNER: Financial Numeric Entity Recognition for XBRL Tagging},
author = {Loukas, Lefteris and
Fergadiotis, Manos and
Chalkidis, Ilias and
Spyropoulou, Eirini and
Malakasiotis, Prodromos and
Androutsopoulos, Ion and
Paliouras George},
booktitle = {Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL 2022)},
publisher = {Association for Computational Linguistics},
location = {Dublin, Republic of Ireland},
year = {2022},
url = {https://arxiv.org/abs/2203.06482}
}
```
## About Us
<div style="text-align: justify">
[AUEB's Natural Language Processing Group](http://nlp.cs.aueb.gr) develops algorithms, models, and systems that allow computers to process and generate natural language texts.
The group's current research interests include:
* question answering systems for databases, ontologies, document collections, and the Web, especially biomedical question answering,
* natural language generation from databases and ontologies, especially Semantic Web ontologies,
text classification, including filtering spam and abusive content,
* information extraction and opinion mining, including legal text analytics and sentiment analysis,
* natural language processing tools for Greek, for example parsers and named-entity recognizers,
machine learning in natural language processing, especially deep learning.
The group is part of the Information Processing Laboratory of the Department of Informatics of the Athens University of Economics and Business.
</div>
[Manos Fergadiotis](https://manosfer.github.io) on behalf of [AUEB's Natural Language Processing Group](http://nlp.cs.aueb.gr)
|
f34f9c86a043ec59964816eda0c36b3e
|
jonatasgrosman/exp_w2v2r_fr_vp-100k_gender_male-8_female-2_s500
|
jonatasgrosman
|
wav2vec2
| 10 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['fr']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'fr']
| false | true | true | 498 | false |
# exp_w2v2r_fr_vp-100k_gender_male-8_female-2_s500
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (fr)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
435c7ed7a5f1c273590d0da79bd2d194
|
gokuls/mobilebert_add_GLUE_Experiment_qqp_128
|
gokuls
|
mobilebert
| 17 | 6 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,103 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_add_GLUE_Experiment_qqp_128
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5071
- Accuracy: 0.7568
- F1: 0.6361
- Combined Score: 0.6965
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:--------------:|
| 0.6507 | 1.0 | 2843 | 0.6497 | 0.6318 | 0.0 | 0.3159 |
| 0.6311 | 2.0 | 5686 | 0.5445 | 0.7259 | 0.5622 | 0.6441 |
| 0.5153 | 3.0 | 8529 | 0.5153 | 0.7493 | 0.5892 | 0.6693 |
| 0.4912 | 4.0 | 11372 | 0.5071 | 0.7568 | 0.6361 | 0.6965 |
| 0.4805 | 5.0 | 14215 | nan | 0.6318 | 0.0 | 0.3159 |
| 0.0 | 6.0 | 17058 | nan | 0.6318 | 0.0 | 0.3159 |
| 0.0 | 7.0 | 19901 | nan | 0.6318 | 0.0 | 0.3159 |
| 0.0 | 8.0 | 22744 | nan | 0.6318 | 0.0 | 0.3159 |
| 0.0 | 9.0 | 25587 | nan | 0.6318 | 0.0 | 0.3159 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.8.0
- Tokenizers 0.13.2
|
e20d4b0b57e39d30f8973ee1ff6f4f41
|
CAiRE/wav2vec2-large-xlsr-53-cantonese
|
CAiRE
|
wav2vec2
| 12 | 15 |
transformers
| 2 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['yue']
|
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week']
| true | true | true | 3,956 | false |
# Wav2Vec2-Large-XLSR-53-Cantonese
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Cantonese using the [Common Voice Corpus 8.0](https://commonvoice.mozilla.org/en/datasets).
When using this model, make sure that your speech input is sampled at 16kHz.
The Common Voice's validated `train` and `dev` were used for training.
The script used for training can be found at [https://github.com/holylovenia/wav2vec2-pretraining](https://github.com/holylovenia/wav2vec2-pretraining).
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "zh-HK", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("CAiRE/wav2vec2-large-xlsr-53-cantonese")
model = Wav2Vec2ForCTC.from_pretrained("CAiRE/wav2vec2-large-xlsr-53-cantonese")
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
resampler = torchaudio.transforms.Resample(sampling_rate, 16_000)
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset[:2]["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset[:2]["sentence"])
```
## Evaluation
The model can be evaluated as follows on the zh-HK test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "zh-HK", split="test")
wer = load_metric("cer")
processor = Wav2Vec2Processor.from_pretrained("CAiRE/wav2vec2-large-xlsr-53-cantonese")
model = Wav2Vec2ForCTC.from_pretrained("CAiRE/wav2vec2-large-xlsr-53-cantonese")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\'\”\�]'
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
resampler = torchaudio.transforms.Resample(sampling_rate, 16_000)
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("CER: {:2f}".format(100 * cer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: CER: 18.55 %
## Citation
If you use our code/model, please cite us:
```
@inproceedings{lovenia2022ascend,
title={ASCEND: A Spontaneous Chinese-English Dataset for Code-switching in Multi-turn Conversation},
author={Lovenia, Holy and Cahyawijaya, Samuel and Winata, Genta Indra and Xu, Peng and Yan, Xu and Liu, Zihan and Frieske, Rita and Yu, Tiezheng and Dai, Wenliang and Barezi, Elham J and others},
booktitle={Proceedings of the 13th Language Resources and Evaluation Conference (LREC)},
year={2022}
}
```
|
2c315f5cba4b9337a523c686b6ccda97
|
FortWorthCarpetCleaning/FortWorthCarpetCleaning
|
FortWorthCarpetCleaning
| null | 2 | 0 | null | 0 | null | false | false | false |
other
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 610 | false |
Fort Worth Carpet Cleaning
https://txfortworthcarpetcleaning.com/
(817) 523-1237
Save your wellbeing and your family wellbeing with Floor covering cleaning Stronghold worth TX as our administration will assist you with staying away from yourself and your family from asthma and sensitivity by eliminating the residue and the soil from your rug, let me let you know that you can clean your rug however clean it professionality and ensure that it turns out to be clear of any soil even the intense soil as the blood stains or wine stains needs our administration. We are here to accomplish Worth TX fulfillments.
|
6728cce49e091f74fb3d6c7327cb2376
|
Helsinki-NLP/opus-mt-sv-he
|
Helsinki-NLP
|
marian
| 10 | 12 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 768 | false |
### opus-mt-sv-he
* source languages: sv
* target languages: he
* OPUS readme: [sv-he](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/sv-he/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/sv-he/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-he/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-he/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.sv.he | 23.1 | 0.440 |
|
bfa4fccaa4fd741dac5fba31a31feeb3
|
htermotto/distilbert-base-uncased-finetuned-squad
|
htermotto
|
distilbert
| 12 | 3 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null |
['squad_v2']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,287 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad_v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4909
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2236 | 1.0 | 8235 | 1.2651 |
| 0.9496 | 2.0 | 16470 | 1.2313 |
| 0.7572 | 3.0 | 24705 | 1.4909 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.0
- Tokenizers 0.13.2
|
4141fd3d94463454d875ae9235f256f7
|
joheras/mt5-small-clara-med
|
joheras
|
mt5
| 16 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
|
['es']
|
['lcampillos/CLARA-MeD']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['simplification', 'generated_from_trainer']
| true | true | true | 4,103 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-clara-med
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the [CLARA-MeD](https://huggingface.co/lcampillos/CLARA-MeD) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9850
- Rouge1: 33.0363
- Rouge2: 19.0613
- Rougel: 30.295
- Rougelsum: 30.2898
- SARI: 40.7094
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|
| No log | 1.0 | 190 | 3.0286 | 18.0709 | 7.727 | 16.1995 | 16.3348 |
| No log | 2.0 | 380 | 2.4754 | 24.9167 | 13.0501 | 22.3889 | 22.4724 |
| 6.79 | 3.0 | 570 | 2.3542 | 29.9908 | 15.9829 | 26.3751 | 26.4343 |
| 6.79 | 4.0 | 760 | 2.2894 | 30.4435 | 16.3176 | 27.1801 | 27.1926 |
| 3.1288 | 5.0 | 950 | 2.2440 | 30.8602 | 16.8033 | 27.8195 | 27.8355 |
| 3.1288 | 6.0 | 1140 | 2.1772 | 31.4202 | 17.3253 | 28.3394 | 28.3699 |
| 3.1288 | 7.0 | 1330 | 2.1584 | 31.5591 | 17.7302 | 28.618 | 28.6189 |
| 2.7919 | 8.0 | 1520 | 2.1286 | 31.6211 | 17.7423 | 28.7218 | 28.7462 |
| 2.7919 | 9.0 | 1710 | 2.1031 | 31.9724 | 18.017 | 29.0754 | 29.0744 |
| 2.6007 | 10.0 | 1900 | 2.0947 | 32.1588 | 18.2474 | 29.2957 | 29.2956 |
| 2.6007 | 11.0 | 2090 | 2.0914 | 32.4959 | 18.4197 | 29.6052 | 29.609 |
| 2.6007 | 12.0 | 2280 | 2.0726 | 32.6673 | 18.8962 | 29.9145 | 29.9122 |
| 2.4911 | 13.0 | 2470 | 2.0487 | 32.4461 | 18.6804 | 29.6224 | 29.6274 |
| 2.4911 | 14.0 | 2660 | 2.0436 | 32.8393 | 19.0315 | 30.1024 | 30.1097 |
| 2.4168 | 15.0 | 2850 | 2.0229 | 32.8235 | 18.9549 | 30.0699 | 30.0605 |
| 2.4168 | 16.0 | 3040 | 2.0253 | 32.8584 | 18.8602 | 30.0582 | 30.0712 |
| 2.4168 | 17.0 | 3230 | 2.0177 | 32.7145 | 18.9059 | 30.0436 | 30.0771 |
| 2.3452 | 18.0 | 3420 | 2.0151 | 32.6874 | 18.8339 | 29.9739 | 30.0004 |
| 2.3452 | 19.0 | 3610 | 2.0138 | 32.516 | 18.6562 | 29.7823 | 29.7951 |
| 2.302 | 20.0 | 3800 | 2.0085 | 32.8117 | 18.8208 | 30.0902 | 30.1282 |
| 2.302 | 21.0 | 3990 | 2.0043 | 32.7633 | 18.8364 | 30.0619 | 30.0781 |
| 2.302 | 22.0 | 4180 | 1.9972 | 32.9786 | 19.0354 | 30.2166 | 30.2286 |
| 2.2641 | 23.0 | 4370 | 1.9927 | 33.0222 | 19.0501 | 30.2716 | 30.2951 |
| 2.2641 | 24.0 | 4560 | 1.9905 | 32.9557 | 18.9958 | 30.1988 | 30.2004 |
| 2.2366 | 25.0 | 4750 | 1.9897 | 33.0429 | 18.9806 | 30.2861 | 30.3012 |
| 2.2366 | 26.0 | 4940 | 1.9850 | 33.047 | 19.118 | 30.3437 | 30.3368 |
| 2.2366 | 27.0 | 5130 | 1.9860 | 33.0736 | 19.0805 | 30.3311 | 30.3476 |
| 2.2157 | 28.0 | 5320 | 1.9870 | 33.0698 | 19.0649 | 30.2959 | 30.3093 |
| 2.2157 | 29.0 | 5510 | 1.9844 | 33.0376 | 19.0397 | 30.299 | 30.2839 |
| 2.2131 | 30.0 | 5700 | 1.9850 | 33.0363 | 19.0613 | 30.295 | 30.2898 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0
- Datasets 2.8.0
- Tokenizers 0.12.1
|
9c4f14a67a28cdf777fc1fcde23a1b41
|
indobenchmark/indobart-v2
|
indobenchmark
|
mbart
| 7 | 277 |
transformers
| 3 |
text2text-generation
| true | false | false |
mit
|
['id']
|
['Indo4B+']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['indogpt', 'indobenchmark', 'indonlg']
| false | true | true | 1,281 | false |
# IndoBART-v2 Model
[IndoBART-v2](https://arxiv.org/abs/2104.08200) is a state-of-the-art language model for Indonesian based on the BART model. The pretrained model is trained using the BART training objective.
## All Pre-trained Models
| Model | #params | Training data |
|--------------------------------|--------------------------------|-----------------------------------|
| `indobenchmark/indobart-v2` | 132M | Indo4B-Plus (26 GB of text) |
## Authors
<b>IndoBART</b> was trained and evaluated by Samuel Cahyawijaya*, Genta Indra Winata*, Bryan Wilie*, Karissa Vincentio*, Xiaohong Li*, Adhiguna Kuncoro*, Sebastian Ruder, Zhi Yuan Lim, Syafri Bahar, Masayu Leylia Khodra, Ayu Purwarianti, Pascale Fung
## Citation
If you use our work, please cite:
```bibtex
@article{cahyawijaya2021indonlg,
title={IndoNLG: Benchmark and Resources for Evaluating Indonesian Natural Language Generation},
author={Cahyawijaya, Samuel and Winata, Genta Indra and Wilie, Bryan and Vincentio, Karissa and Li, Xiaohong and Kuncoro, Adhiguna and Ruder, Sebastian and Lim, Zhi Yuan and Bahar, Syafri and Khodra, Masayu Leylia and others},
journal={arXiv preprint arXiv:2104.08200},
year={2021}
}
```
|
d82b47ff522066b8649d911c4717a9bf
|
ncoop57/DiGPTame-medium
|
ncoop57
|
gpt2
| 11 | 30 |
transformers
| 1 |
conversational
| true | false | true |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['conversational']
| false | true | true | 2,304 | false |
## Finetuned DialoGPT model on Spanish Conversations
This model was finetuned from the original [DialoGPT-medium](https://huggingface.co/microsoft/DialoGPT-medium) model on subtitles from Spanish movies and telenovelas from the awesome [OpenSubtitle dataset](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/opensubtitles).
DialoGPT paper: [https://arxiv.org/abs/1911.00536](https://arxiv.org/abs/1911.00536)
Some example dialog from the model:
|Role | Response |
|---------|--------|
|User | ¿Cómo está el clima hoy? |
| Bot | Muy bien. |
|User | Eso es bueno escuchar. ¿Vas a ir a la playa? |
| Bot | No, también puedo regresar. |
|User | Oh bien, bueno, iré a la playa más tarde. |
| Bot | ¡No! |
|User | ¿Qué está mal con eso? |
| Bot | ¡Cómo que no! |
|User | Estoy confundido, ¿por qué no puedo ir a la playa? |
| Bot | ¡Cómo que no! |
|User | Explícamelo por favor. |
| Bot | ¡No! |
## Using the model
Example code for trying out the model (taken directly from the [DialoGPT-medium](https://huggingface.co/microsoft/DialoGPT-medium) model card):
```python
from transformers import AutoModelWithLMHead, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("ncoop57/DiGPTame-medium")
model = AutoModelWithLMHead.from_pretrained("ncoop57/DiGPTame-medium")
# Let's chat for 5 lines
for step in range(5):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id)
# pretty print last ouput tokens from bot
print("DialoGPT: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
## Training your own model
If you would like to finetune your own model or finetune this Spanish model, please checkout my blog post on that exact topic!
https://nathancooper.io/i-am-a-nerd/chatbot/deep-learning/gpt2/2020/05/12/chatbot-part-1.html
|
2ea97827dc29f2ffac7cc5b0ab9cf215
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.