
repo_id
stringlengths 4
110
| author
stringlengths 2
27
⌀ | model_type
stringlengths 2
29
⌀ | files_per_repo
int64 2
15.4k
| downloads_30d
int64 0
19.9M
| library
stringlengths 2
37
⌀ | likes
int64 0
4.34k
| pipeline
stringlengths 5
30
⌀ | pytorch
bool 2
classes | tensorflow
bool 2
classes | jax
bool 2
classes | license
stringlengths 2
30
| languages
stringlengths 4
1.63k
⌀ | datasets
stringlengths 2
2.58k
⌀ | co2
stringclasses 29
values | prs_count
int64 0
125
| prs_open
int64 0
120
| prs_merged
int64 0
15
| prs_closed
int64 0
28
| discussions_count
int64 0
218
| discussions_open
int64 0
148
| discussions_closed
int64 0
70
| tags
stringlengths 2
513
| has_model_index
bool 2
classes | has_metadata
bool 1
class | has_text
bool 1
class | text_length
int64 401
598k
| is_nc
bool 1
class | readme
stringlengths 0
598k
| hash
stringlengths 32
32
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
spacy/en_core_web_trf
|
spacy
| null | 26 | 699 |
spacy
| 10 |
token-classification
| false | false | false |
mit
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['spacy', 'token-classification']
| false | true | true | 2,830 | false |
### Details: https://spacy.io/models/en#en_core_web_trf
English transformer pipeline (roberta-base). Components: transformer, tagger, parser, ner, attribute_ruler, lemmatizer.
| Feature | Description |
| --- | --- |
| **Name** | `en_core_web_trf` |
| **Version** | `3.5.0` |
| **spaCy** | `>=3.5.0,<3.6.0` |
| **Default Pipeline** | `transformer`, `tagger`, `parser`, `attribute_ruler`, `lemmatizer`, `ner` |
| **Components** | `transformer`, `tagger`, `parser`, `attribute_ruler`, `lemmatizer`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | [OntoNotes 5](https://catalog.ldc.upenn.edu/LDC2013T19) (Ralph Weischedel, Martha Palmer, Mitchell Marcus, Eduard Hovy, Sameer Pradhan, Lance Ramshaw, Nianwen Xue, Ann Taylor, Jeff Kaufman, Michelle Franchini, Mohammed El-Bachouti, Robert Belvin, Ann Houston)<br />[ClearNLP Constituent-to-Dependency Conversion](https://github.com/clir/clearnlp-guidelines/blob/master/md/components/dependency_conversion.md) (Emory University)<br />[WordNet 3.0](https://wordnet.princeton.edu/) (Princeton University)<br />[roberta-base](https://github.com/pytorch/fairseq/tree/master/examples/roberta) (Yinhan Liu and Myle Ott and Naman Goyal and Jingfei Du and Mandar Joshi and Danqi Chen and Omer Levy and Mike Lewis and Luke Zettlemoyer and Veselin Stoyanov) |
| **License** | `MIT` |
| **Author** | [Explosion](https://explosion.ai) |
### Label Scheme
<details>
<summary>View label scheme (112 labels for 3 components)</summary>
| Component | Labels |
| --- | --- |
| **`tagger`** | `$`, `''`, `,`, `-LRB-`, `-RRB-`, `.`, `:`, `ADD`, `AFX`, `CC`, `CD`, `DT`, `EX`, `FW`, `HYPH`, `IN`, `JJ`, `JJR`, `JJS`, `LS`, `MD`, `NFP`, `NN`, `NNP`, `NNPS`, `NNS`, `PDT`, `POS`, `PRP`, `PRP$`, `RB`, `RBR`, `RBS`, `RP`, `SYM`, `TO`, `UH`, `VB`, `VBD`, `VBG`, `VBN`, `VBP`, `VBZ`, `WDT`, `WP`, `WP$`, `WRB`, `XX`, ```` |
| **`parser`** | `ROOT`, `acl`, `acomp`, `advcl`, `advmod`, `agent`, `amod`, `appos`, `attr`, `aux`, `auxpass`, `case`, `cc`, `ccomp`, `compound`, `conj`, `csubj`, `csubjpass`, `dative`, `dep`, `det`, `dobj`, `expl`, `intj`, `mark`, `meta`, `neg`, `nmod`, `npadvmod`, `nsubj`, `nsubjpass`, `nummod`, `oprd`, `parataxis`, `pcomp`, `pobj`, `poss`, `preconj`, `predet`, `prep`, `prt`, `punct`, `quantmod`, `relcl`, `xcomp` |
| **`ner`** | `CARDINAL`, `DATE`, `EVENT`, `FAC`, `GPE`, `LANGUAGE`, `LAW`, `LOC`, `MONEY`, `NORP`, `ORDINAL`, `ORG`, `PERCENT`, `PERSON`, `PRODUCT`, `QUANTITY`, `TIME`, `WORK_OF_ART` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `TOKEN_ACC` | 99.86 |
| `TOKEN_P` | 99.57 |
| `TOKEN_R` | 99.58 |
| `TOKEN_F` | 99.57 |
| `TAG_ACC` | 97.79 |
| `SENTS_P` | 95.04 |
| `SENTS_R` | 84.92 |
| `SENTS_F` | 89.69 |
| `DEP_UAS` | 95.27 |
| `DEP_LAS` | 93.95 |
| `ENTS_P` | 89.78 |
| `ENTS_R` | 90.49 |
| `ENTS_F` | 90.13 |
|
d3bb3f6ccc7732cce4ce4544f36046db
|
netsvetaev/netsvetaev-black
|
netsvetaev
| null | 12 | 0 | null | 0 |
text-to-image
| false | false | false |
mit
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['diffusion', 'netsvetaev', 'dreambooth', 'stable-diffusion', 'text-to-image']
| false | true | true | 1,885 | false |
Hello!
This is the model, based on my paintings on a black background and SD 1.5. This is the second onw, trained with 29 images and 2900 steps.
The token is «netsvetaev black style».
Best suited for: abstract seamless patterns, images similar to my original paintings with blue triangles, and large objects like «cat face» or «girl face».
It works well with landscape orientation and embiggen.
It has MIT license, you can use it for free.
Best used with Invoke AI: https://github.com/invoke-ai/InvokeAI (The examples below contain metadata for it)



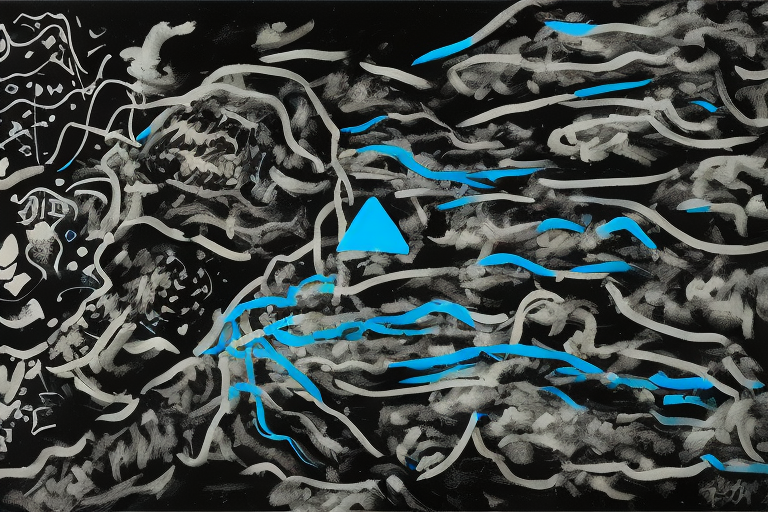




________________________
Artur Netsvetaev, 2022
https://netsvetaev.com
|
095ceb5e80f95d76f1b4a8cb782848d7
|
flood/distilbert-base-uncased-finetuned-clinc
|
flood
|
distilbert
| 10 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['clinc_oos']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,481 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7793
- Accuracy: 0.9161
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 4.2926 | 1.0 | 318 | 3.2834 | 0.7374 |
| 2.6259 | 2.0 | 636 | 1.8736 | 0.8303 |
| 1.5511 | 3.0 | 954 | 1.1612 | 0.8913 |
| 1.0185 | 4.0 | 1272 | 0.8625 | 0.91 |
| 0.8046 | 5.0 | 1590 | 0.7793 | 0.9161 |
### Framework versions
- Transformers 4.19.3
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
5486ae3503f9737683e6ae1ef1399064
|
ychu4/distilbert-base-uncased-finetuned-cola
|
ychu4
|
distilbert
| 10 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,571 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7512
- Matthews Correlation: 0.5097
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5237 | 1.0 | 535 | 0.5117 | 0.4469 |
| 0.3496 | 2.0 | 1070 | 0.5538 | 0.4965 |
| 0.2377 | 3.0 | 1605 | 0.6350 | 0.4963 |
| 0.1767 | 4.0 | 2140 | 0.7512 | 0.5097 |
| 0.1383 | 5.0 | 2675 | 0.8647 | 0.5056 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.8.1+cu102
- Datasets 1.15.1
- Tokenizers 0.10.1
|
b9b875b63ab2df93af7c92c6910bbb29
|
Helsinki-NLP/opus-mt-de-hr
|
Helsinki-NLP
|
marian
| 10 | 102 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 770 | false |
### opus-mt-de-hr
* source languages: de
* target languages: hr
* OPUS readme: [de-hr](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/de-hr/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-26.zip](https://object.pouta.csc.fi/OPUS-MT-models/de-hr/opus-2020-01-26.zip)
* test set translations: [opus-2020-01-26.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-hr/opus-2020-01-26.test.txt)
* test set scores: [opus-2020-01-26.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-hr/opus-2020-01-26.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.de.hr | 42.6 | 0.643 |
|
d0c270513d89d9b266baea2a48da2e0e
|
lizaboiarchuk/bert-tiny-oa-finetuned
|
lizaboiarchuk
|
bert
| 8 | 2 |
transformers
| 0 |
fill-mask
| false | true | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,823 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# lizaboiarchuk/bert-tiny-oa-finetuned
This model is a fine-tuned version of [prajjwal1/bert-tiny](https://huggingface.co/prajjwal1/bert-tiny) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 4.0626
- Validation Loss: 3.7514
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -525, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 4.6311 | 4.1088 | 0 |
| 4.2579 | 3.7859 | 1 |
| 4.0635 | 3.7253 | 2 |
| 4.0658 | 3.6842 | 3 |
| 4.0626 | 3.7514 | 4 |
### Framework versions
- Transformers 4.22.1
- TensorFlow 2.8.2
- Tokenizers 0.12.1
|
31a99ed4917ff2e63d6cc3366110de3c
|
google/t5-efficient-large-nh12
|
google
|
t5
| 12 | 7 |
transformers
| 0 |
text2text-generation
| true | true | true |
apache-2.0
|
['en']
|
['c4']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['deep-narrow']
| false | true | true | 6,258 | false |
# T5-Efficient-LARGE-NH12 (Deep-Narrow version)
T5-Efficient-LARGE-NH12 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5).
It is a *pretrained-only* checkpoint and was released with the
paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)**
by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures
of similar parameter count.
To quote the paper:
> We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased
> before considering any other forms of uniform scaling across other dimensions. This is largely due to
> how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a
> tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise,
> a tall base model might also generally more efficient compared to a large model. We generally find
> that, regardless of size, even if absolute performance might increase as we continue to stack layers,
> the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36
> layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e.,
> params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params,
> FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to
> consider.
To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially.
A sequence of word embeddings is therefore processed sequentially by each transformer block.
## Details model architecture
This model checkpoint - **t5-efficient-large-nh12** - is of model type **Large** with the following variations:
- **nh** is **12**
It has **662.23** million parameters and thus requires *ca.* **2648.91 MB** of memory in full precision (*fp32*)
or **1324.45 MB** of memory in half precision (*fp16* or *bf16*).
A summary of the *original* T5 model architectures can be seen here:
| Model | nl (el/dl) | ff | dm | kv | nh | #Params|
| ----| ---- | ---- | ---- | ---- | ---- | ----|
| Tiny | 4/4 | 1024 | 256 | 32 | 4 | 16M|
| Mini | 4/4 | 1536 | 384 | 32 | 8 | 31M|
| Small | 6/6 | 2048 | 512 | 32 | 8 | 60M|
| Base | 12/12 | 3072 | 768 | 64 | 12 | 220M|
| Large | 24/24 | 4096 | 1024 | 64 | 16 | 738M|
| Xl | 24/24 | 16384 | 1024 | 128 | 32 | 3B|
| XXl | 24/24 | 65536 | 1024 | 128 | 128 | 11B|
whereas the following abbreviations are used:
| Abbreviation | Definition |
| ----| ---- |
| nl | Number of transformer blocks (depth) |
| dm | Dimension of embedding vector (output vector of transformers block) |
| kv | Dimension of key/value projection matrix |
| nh | Number of attention heads |
| ff | Dimension of intermediate vector within transformer block (size of feed-forward projection matrix) |
| el | Number of transformer blocks in the encoder (encoder depth) |
| dl | Number of transformer blocks in the decoder (decoder depth) |
| sh | Signifies that attention heads are shared |
| skv | Signifies that key-values projection matrices are tied |
If a model checkpoint has no specific, *el* or *dl* than both the number of encoder- and decoder layers correspond to *nl*.
## Pre-Training
The checkpoint was pretrained on the [Colossal, Cleaned version of Common Crawl (C4)](https://huggingface.co/datasets/c4) for 524288 steps using
the span-based masked language modeling (MLM) objective.
## Fine-Tuning
**Note**: This model is a **pretrained** checkpoint and has to be fine-tuned for practical usage.
The checkpoint was pretrained in English and is therefore only useful for English NLP tasks.
You can follow on of the following examples on how to fine-tune the model:
*PyTorch*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization)
- [Question Answering](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_seq2seq_qa.py)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*Tensorflow*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*JAX/Flax*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/flax/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/flax/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
## Downstream Performance
TODO: Add table if available
## Computational Complexity
TODO: Add table if available
## More information
We strongly recommend the reader to go carefully through the original paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** to get a more nuanced understanding of this model checkpoint.
As explained in the following [issue](https://github.com/google-research/google-research/issues/986#issuecomment-1035051145), checkpoints including the *sh* or *skv*
model architecture variations have *not* been ported to Transformers as they are probably of limited practical usage and are lacking a more detailed description. Those checkpoints are kept [here](https://huggingface.co/NewT5SharedHeadsSharedKeyValues) as they might be ported potentially in the future.
|
4ec890fd73f0c992b43a7913e18eeb2b
|
sd-concepts-library/female-kpop-singer
|
sd-concepts-library
| null | 10 | 0 | null | 5 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,436 | false |
### female kpop singer on Stable Diffusion
This is the `<female-kpop-star>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Simple test model I made with images of Choerry, Hwasa, Nancy, and last 2 are Hyuna.
Placeholder token: <female-kpop-star>
Initializer token: musician
Here is the new concept you will be able to use as an `object`:





Feel free to modify / further train this model without credit.
|
98fd16d131ba13128ff02d5ae5397111
|
cahya/whisper-large-id
|
cahya
|
whisper
| 27 | 32 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['id']
|
['mozilla-foundation/common_voice_11_0', 'magic_data', 'TITML']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['whisper-event', 'generated_from_trainer']
| true | true | true | 1,891 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Large Indonesian
This model is a fine-tuned version of [openai/whisper-large](https://huggingface.co/openai/whisper-large) on the mozilla-foundation/common_voice_11_0, magic_data, titml id dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2034
- Wer: 6.2483
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 10000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.1516 | 0.5 | 1000 | 0.1730 | 6.5664 |
| 0.1081 | 1.0 | 2000 | 0.1638 | 6.3682 |
| 0.0715 | 1.49 | 3000 | 0.1803 | 6.2713 |
| 0.1009 | 1.99 | 4000 | 0.1796 | 6.2667 |
| 0.0387 | 2.49 | 5000 | 0.2054 | 6.4927 |
| 0.0494 | 2.99 | 6000 | 0.2034 | 6.2483 |
| 0.0259 | 3.48 | 7000 | 0.2226 | 6.3497 |
| 0.0265 | 3.98 | 8000 | 0.2274 | 6.4004 |
| 0.0232 | 4.48 | 9000 | 0.2443 | 6.5618 |
| 0.015 | 4.98 | 10000 | 0.2413 | 6.4927 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
74b8270fc623df3b7fea9f8ea5a476cf
|
sd-concepts-library/gram-tops
|
sd-concepts-library
| null | 12 | 0 | null | 0 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,338 | false |
### gram-tops on Stable Diffusion
This is the `<gram-tops>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:







|
af6f1a1fddfc382747711f1fd157184a
|
AndyChiang/cdgp-csg-bart-cloth
|
AndyChiang
|
bart
| 9 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
|
['en']
|
['cloth']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['bart', 'cloze', 'distractor', 'generation']
| false | true | true | 3,710 | false |
# cdgp-csg-bart-cloth
## Model description
This model is a Candidate Set Generator in **"CDGP: Automatic Cloze Distractor Generation based on Pre-trained Language Model", Findings of EMNLP 2022**.
Its input are stem and answer, and output is candidate set of distractors. It is fine-tuned by [**CLOTH**](https://www.cs.cmu.edu/~glai1/data/cloth/) dataset based on [**facebook/bart-base**](https://huggingface.co/facebook/bart-base) model.
For more details, you can see our **paper** or [**GitHub**](https://github.com/AndyChiangSH/CDGP).
## How to use?
1. Download the model by hugging face transformers.
```python
from transformers import BartTokenizer, BartForConditionalGeneration, pipeline
tokenizer = BartTokenizer.from_pretrained("AndyChiang/cdgp-csg-bart-cloth")
csg_model = BartForConditionalGeneration.from_pretrained("AndyChiang/cdgp-csg-bart-cloth")
```
2. Create a unmasker.
```python
unmasker = pipeline("fill-mask", tokenizer=tokenizer, model=csg_model, top_k=10)
```
3. Use the unmasker to generate the candidate set of distractors.
```python
sent = "I feel <mask> now. </s> happy"
cs = unmasker(sent)
print(cs)
```
## Dataset
This model is fine-tuned by [CLOTH](https://www.cs.cmu.edu/~glai1/data/cloth/) dataset, which is a collection of nearly 100,000 cloze questions from middle school and high school English exams. The detail of CLOTH dataset is shown below.
| Number of questions | Train | Valid | Test |
| ------------------- | ----- | ----- | ----- |
| **Middle school** | 22056 | 3273 | 3198 |
| **High school** | 54794 | 7794 | 8318 |
| **Total** | 76850 | 11067 | 11516 |
You can also use the [dataset](https://huggingface.co/datasets/AndyChiang/cloth) we have already cleaned.
## Training
We use a special way to fine-tune model, which is called **"Answer-Relating Fine-Tune"**. More detail is in our paper.
### Training hyperparameters
The following hyperparameters were used during training:
- Pre-train language model: [facebook/bart-base](https://huggingface.co/facebook/bart-base)
- Optimizer: adam
- Learning rate: 0.0001
- Max length of input: 64
- Batch size: 64
- Epoch: 1
- Device: NVIDIA® Tesla T4 in Google Colab
## Testing
The evaluations of this model as a Candidate Set Generator in CDGP is as follows:
| P@1 | F1@3 | F1@10 | MRR | NDCG@10 |
| ----- | ----- | ----- | ----- | ------- |
| 14.20 | 11.07 | 11.37 | 24.29 | 31.74 |
## Other models
### Candidate Set Generator
| Models | CLOTH | DGen |
| ----------- | ----------------------------------------------------------------------------------- | -------------------------------------------------------------------------------- |
| **BERT** | [cdgp-csg-bert-cloth](https://huggingface.co/AndyChiang/cdgp-csg-bert-cloth) | [cdgp-csg-bert-dgen](https://huggingface.co/AndyChiang/cdgp-csg-bert-dgen) |
| **SciBERT** | [cdgp-csg-scibert-cloth](https://huggingface.co/AndyChiang/cdgp-csg-scibert-cloth) | [cdgp-csg-scibert-dgen](https://huggingface.co/AndyChiang/cdgp-csg-scibert-dgen) |
| **RoBERTa** | [cdgp-csg-roberta-cloth](https://huggingface.co/AndyChiang/cdgp-csg-roberta-cloth) | [cdgp-csg-roberta-dgen](https://huggingface.co/AndyChiang/cdgp-csg-roberta-dgen) |
| **BART** | [*cdgp-csg-bart-cloth*](https://huggingface.co/AndyChiang/cdgp-csg-bart-cloth) | [cdgp-csg-bart-dgen](https://huggingface.co/AndyChiang/cdgp-csg-bart-dgen) |
### Distractor Selector
**fastText**: [cdgp-ds-fasttext](https://huggingface.co/AndyChiang/cdgp-ds-fasttext)
## Citation
None
|
538cd8db3aa5cc4b6e121358f763768b
|
deepiit98/Pub-clustered
|
deepiit98
|
distilbert
| 8 | 10 |
transformers
| 0 |
question-answering
| false | true | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,855 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# deepiit98/Pub-clustered
This model is a fine-tuned version of [nandysoham16/16-clustered_aug](https://huggingface.co/nandysoham16/16-clustered_aug) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.3787
- Train End Logits Accuracy: 0.8715
- Train Start Logits Accuracy: 0.8924
- Validation Loss: 0.1505
- Validation End Logits Accuracy: 1.0
- Validation Start Logits Accuracy: 0.9231
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 18, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch |
|:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:|
| 0.3787 | 0.8715 | 0.8924 | 0.1505 | 1.0 | 0.9231 | 0 |
### Framework versions
- Transformers 4.26.0
- TensorFlow 2.9.2
- Datasets 2.9.0
- Tokenizers 0.13.2
|
07b0c2b3af54d701409d6043048ff3be
|
rishabhjain16/whisper_medium_to_pf10h
|
rishabhjain16
|
whisper
| 23 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,725 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-medium
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1594
- Wer: 21.8343
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0269 | 5.0 | 500 | 0.1069 | 118.0302 |
| 0.0049 | 10.01 | 1000 | 0.1263 | 135.2788 |
| 0.0009 | 15.01 | 1500 | 0.1355 | 94.5731 |
| 0.0001 | 20.01 | 2000 | 0.1413 | 7.5188 |
| 0.0001 | 25.01 | 2500 | 0.1515 | 7.2508 |
| 0.0001 | 30.02 | 3000 | 0.1568 | 24.8493 |
| 0.0 | 35.02 | 3500 | 0.1588 | 22.1470 |
| 0.0 | 40.02 | 4000 | 0.1594 | 21.8343 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.9.1.dev0
- Tokenizers 0.13.2
|
bd7d5d769b59f9440273c7bb88d63ecf
|
sd-concepts-library/kodakvision500t
|
sd-concepts-library
| null | 9 | 0 | null | 13 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,222 | false |
### KodakVision500T on Stable Diffusion
This is the `<kodakvision_500T>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
This concept was trained on **6** photographs taken with **Kodak Vision 3 500T**, through **1800** steps.
Here are some generated images from the concept that you will be able to use as a `style`:




|
75d2bdca72eef586f7ff1c3b8150ab78
|
Robertooo/ELL_pretrained
|
Robertooo
|
roberta
| 6 | 7 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,243 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ELL_pretrained
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9006
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.1542 | 1.0 | 1627 | 2.1101 |
| 2.0739 | 2.0 | 3254 | 2.0006 |
| 2.0241 | 3.0 | 4881 | 1.7874 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu102
- Datasets 2.6.1
- Tokenizers 0.13.1
|
d8f5079101ebdef7f79abbdf0b8f4f1b
|
shashank2123/t5-finetuned-for-GEC
|
shashank2123
|
t5
| 10 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| false | true | true | 1,537 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-finetuned-for-GEC
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on an unkown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3949
- Bleu: 0.3571
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:-------:|
| 0.3958 | 1.0 | 4053 | 0.4236 | 0.3493 | 19.0 |
| 0.3488 | 2.0 | 8106 | 0.4076 | 0.3518 | 19.0 |
| 0.319 | 3.0 | 12159 | 0.3962 | 0.3523 | 19.0 |
| 0.3105 | 4.0 | 16212 | 0.3951 | 0.3567 | 19.0 |
| 0.3016 | 5.0 | 20265 | 0.3949 | 0.3571 | 19.0 |
### Framework versions
- Transformers 4.9.1
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
e9a98bc915e3de98fef4984774dd17a9
|
ncats/EpiExtract4GARD-v2
|
ncats
|
bert
| 17 | 114 |
transformers
| 0 |
token-classification
| true | false | false |
other
|
['en']
|
['ncats/EpiSet4NER']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['token-classification', 'ncats']
| false | true | true | 9,493 | false |
## DOCUMENTATION UPDATES IN PROGRESS
## Model description
**EpiExtract4GARD-v2** is a fine-tuned [BioBERT-base-cased](https://huggingface.co/dmis-lab/biobert-base-cased-v1.1) model that is ready to use for **Named Entity Recognition** of locations (LOC), epidemiologic types (EPI), and epidemiologic rates (STAT). This model was fine-tuned on EpiSet4NER-v2 for epidemiological information from rare disease abstracts. See dataset documentation for details on the weakly supervised teaching methods and dataset biases and limitations. See [EpiExtract4GARD on GitHub](https://github.com/ncats/epi4GARD/tree/master/EpiExtract4GARD#epiextract4gard) for details on the entire pipeline.
#### How to use
You can use this model with the Hosted inference API to the right with this [test sentence](https://pubmed.ncbi.nlm.nih.gov/21659675/): "27 patients have been diagnosed with PKU in Iceland since 1947. Incidence 1972-2008 is 1/8400 living births."
See code below for use with Transformers *pipeline* for NER.:
~~~
from transformers import pipeline, AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("ncats/EpiExtract4GARD")
tokenizer = AutoTokenizer.from_pretrained("ncats/EpiExtract4GARD")
NER_pipeline = pipeline('ner', model=model, tokenizer=tokenizer,aggregation_strategy='simple')
sample = "The live-birth prevalence of mucopolysaccharidoses in Estonia. Previous studies on the prevalence of mucopolysaccharidoses (MPS) in different populations have shown considerable variations. There are, however, few data with regard to the prevalence of MPSs in Fenno-Ugric populations or in north-eastern Europe, except for a report about Scandinavian countries. A retrospective epidemiological study of MPSs in Estonia was undertaken, and live-birth prevalence of MPS patients born between 1985 and 2006 was estimated. The live-birth prevalence for all MPS subtypes was found to be 4.05 per 100,000 live births, which is consistent with most other European studies. MPS II had the highest calculated incidence, with 2.16 per 100,000 live births (4.2 per 100,000 male live births), forming 53% of all diagnosed MPS cases, and was twice as high as in other studied European populations. The second most common subtype was MPS IIIA, with a live-birth prevalence of 1.62 in 100,000 live births. With 0.27 out of 100,000 live births, MPS VI had the third-highest live-birth prevalence. No cases of MPS I were diagnosed in Estonia, making the prevalence of MPS I in Estonia much lower than in other European populations. MPSs are the third most frequent inborn error of metabolism in Estonia after phenylketonuria and galactosemia."
sample2 = "Early Diagnosis of Classic Homocystinuria in Kuwait through Newborn Screening: A 6-Year Experience. Kuwait is a small Arabian Gulf country with a high rate of consanguinity and where a national newborn screening program was expanded in October 2014 to include a wide range of endocrine and metabolic disorders. A retrospective study conducted between January 2015 and December 2020 revealed a total of 304,086 newborns have been screened in Kuwait. Six newborns were diagnosed with classic homocystinuria with an incidence of 1:50,000, which is not as high as in Qatar but higher than the global incidence. Molecular testing for five of them has revealed three previously reported pathogenic variants in the <i>CBS</i> gene, c.969G>A, p.(Trp323Ter); c.982G>A, p.(Asp328Asn); and the Qatari founder variant c.1006C>T, p.(Arg336Cys). This is the first study to review the screening of newborns in Kuwait for classic homocystinuria, starting with the detection of elevated blood methionine and providing a follow-up strategy for positive results, including plasma total homocysteine and amino acid analyses. Further, we have demonstrated an increase in the specificity of the current newborn screening test for classic homocystinuria by including the methionine to phenylalanine ratio along with the elevated methionine blood levels in first-tier testing. Here, we provide evidence that the newborn screening in Kuwait has led to the early detection of classic homocystinuria cases and enabled the affected individuals to lead active and productive lives."
#Sample 1 is from: Krabbi K, Joost K, Zordania R, Talvik I, Rein R, Huijmans JG, Verheijen FV, Õunap K. The live-birth prevalence of mucopolysaccharidoses in Estonia. Genet Test Mol Biomarkers. 2012 Aug;16(8):846-9. doi: 10.1089/gtmb.2011.0307. Epub 2012 Apr 5. PMID: 22480138; PMCID: PMC3422553.
#Sample 2 is from: Alsharhan H, Ahmed AA, Ali NM, Alahmad A, Albash B, Elshafie RM, Alkanderi S, Elkazzaz UM, Cyril PX, Abdelrahman RM, Elmonairy AA, Ibrahim SM, Elfeky YME, Sadik DI, Al-Enezi SD, Salloum AM, Girish Y, Al-Ali M, Ramadan DG, Alsafi R, Al-Rushood M, Bastaki L. Early Diagnosis of Classic Homocystinuria in Kuwait through Newborn Screening: A 6-Year Experience. Int J Neonatal Screen. 2021 Aug 17;7(3):56. doi: 10.3390/ijns7030056. PMID: 34449519; PMCID: PMC8395821.
NER_pipeline(sample)
NER_pipeline(sample2)
~~~
Or if you download [*classify_abs.py*](https://github.com/ncats/epi4GARD/blob/master/EpiExtract4GARD/classify_abs.py), [*extract_abs.py*](https://github.com/ncats/epi4GARD/blob/master/EpiExtract4GARD/extract_abs.py), and [*gard-id-name-synonyms.json*](https://github.com/ncats/epi4GARD/blob/master/EpiExtract4GARD/gard-id-name-synonyms.json) from GitHub then you can test with this [*additional* code](https://github.com/ncats/epi4GARD/blob/master/EpiExtract4GARD/Case%20Study.ipynb):
~~~
import pandas as pd
import extract_abs
import classify_abs
pd.set_option('display.max_colwidth', None)
NER_pipeline = extract_abs.init_NER_pipeline()
GARD_dict, max_length = extract_abs.load_GARD_diseases()
nlp, nlpSci, nlpSci2, classify_model, classify_tokenizer = classify_abs.init_classify_model()
def search(term,num_results = 50):
return extract_abs.search_term_extraction(term, num_results, NER_pipeline, GARD_dict, max_length,nlp, nlpSci, nlpSci2, classify_model, classify_tokenizer)
a = search(7058)
a
b = search('Santos Mateus Leal syndrome')
b
c = search('Fellman syndrome')
c
d = search('GARD:0009941')
d
e = search('Homocystinuria')
e
~~~
#### Limitations and bias
## Training data
It was trained on [EpiSet4NER](https://huggingface.co/datasets/ncats/EpiSet4NER). See dataset documentation for details on the weakly supervised teaching methods and dataset biases and limitations. The training dataset distinguishes between the beginning and continuation of an entity so that if there are back-to-back entities of the same type, the model can output where the second entity begins. As in the dataset, each token will be classified as one of the following classes:
Abbreviation|Description
---------|--------------
O |Outside of a named entity
B-LOC | Beginning of a location
I-LOC | Inside of a location
B-EPI | Beginning of an epidemiologic type (e.g. "incidence", "prevalence", "occurrence")
I-EPI | Epidemiologic type that is not the beginning token.
B-STAT | Beginning of an epidemiologic rate
I-STAT | Inside of an epidemiologic rate
+More | Description pending
### EpiSet Statistics
Beyond any limitations due to the EpiSet4NER dataset, this model is limited in numeracy due to BERT-based model's use of subword embeddings, which is crucial for epidemiologic rate identification and limits the entity-level results. Recent techniques in numeracy could be used to improve the performance of the model without improving the underlying dataset.
## Training procedure
This model was trained on a [AWS EC2 p3.2xlarge](https://aws.amazon.com/ec2/instance-types/), which utilized a single Tesla V100 GPU, with these hyperparameters:
4 epochs of training (AdamW weight decay = 0.05) with a batch size of 16. Maximum sequence length = 192. Model was fed one sentence at a time.
<!--- Full config [here](https://wandb.ai/wzkariampuzha/huggingface/runs/353prhts/files/config.yaml). --->
<!--- THIS IS NOT THE UPDATED RESULTS --->
<!--- ## Hold-out validation results --->
<!--- metric| entity-level result --->
<!--- -|- --->
<!--- f1 | 83.8 --->
<!--- precision | 83.2 --->
<!--- recall | 84.5 --->
<!--- ## Test results --->
<!--- | Dataset for Model Training | Evaluation Level | Entity | Precision | Recall | F1 | --->
<!--- |:--------------------------:|:----------------:|:------------------:|:---------:|:------:|:-----:| --->
<!--- | EpiSet | Entity-Level | Overall | 0.556 | 0.662 | 0.605 | --->
<!--- | | | Location | 0.661 | 0.696 | 0.678 | --->
<!--- | | | Epidemiologic Type | 0.854 | 0.911 | 0.882 | --->
<!--- | | | Epidemiologic Rate | 0.143 | 0.218 | 0.173 | --->
<!--- | | Token-Level | Overall | 0.811 | 0.713 | 0.759 | --->
<!--- | | | Location | 0.949 | 0.742 | 0.833 | --->
<!--- | | | Epidemiologic Type | 0.9 | 0.917 | 0.908 | --->
<!--- | | | Epidemiologic Rate | 0.724 | 0.636 | 0.677 | --->
Thanks to [@William Kariampuzha](https://github.com/wzkariampuzha) at Axle Informatics/NCATS for contributing this model.
|
bf4976e91400ee73838550905b8a7e0d
|
Khalsuu/english-filipino-wav2vec2-l-xls-r-test-08
|
Khalsuu
|
wav2vec2
| 13 | 8 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['filipino_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,888 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# english-filipino-wav2vec2-l-xls-r-test-08
This model is a fine-tuned version of [jonatasgrosman/wav2vec2-large-xlsr-53-english](https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-english) on the filipino_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5968
- Wer: 0.4255
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.3434 | 2.09 | 400 | 2.2857 | 0.9625 |
| 1.6304 | 4.19 | 800 | 1.1547 | 0.7268 |
| 0.9231 | 6.28 | 1200 | 1.0252 | 0.6186 |
| 0.6098 | 8.38 | 1600 | 0.9371 | 0.5494 |
| 0.4922 | 10.47 | 2000 | 0.7092 | 0.5478 |
| 0.3652 | 12.57 | 2400 | 0.7358 | 0.5149 |
| 0.2735 | 14.66 | 2800 | 0.6270 | 0.4646 |
| 0.2038 | 16.75 | 3200 | 0.5717 | 0.4506 |
| 0.1552 | 18.85 | 3600 | 0.5968 | 0.4255 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
5eda547dc16e02d5cbf848c5bb79cbd5
|
dweb/deberta-base-CoLA
|
dweb
|
deberta
| 13 | 9 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,180 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-base-CoLA
This model is a fine-tuned version of [microsoft/deberta-base](https://huggingface.co/microsoft/deberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1655
- Accuracy: 0.8482
- F1: 0.8961
- Roc Auc: 0.8987
- Mcc: 0.6288
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Roc Auc | Mcc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:-------:|:------:|
| 0.5266 | 1.0 | 535 | 0.4138 | 0.8159 | 0.8698 | 0.8627 | 0.5576 |
| 0.3523 | 2.0 | 1070 | 0.3852 | 0.8387 | 0.8880 | 0.9041 | 0.6070 |
| 0.2479 | 3.0 | 1605 | 0.3981 | 0.8482 | 0.8901 | 0.9120 | 0.6447 |
| 0.1712 | 4.0 | 2140 | 0.4732 | 0.8558 | 0.9008 | 0.9160 | 0.6486 |
| 0.1354 | 5.0 | 2675 | 0.7181 | 0.8463 | 0.8938 | 0.9024 | 0.6250 |
| 0.0876 | 6.0 | 3210 | 0.8453 | 0.8520 | 0.8992 | 0.9123 | 0.6385 |
| 0.0682 | 7.0 | 3745 | 1.0282 | 0.8444 | 0.8938 | 0.9061 | 0.6189 |
| 0.0431 | 8.0 | 4280 | 1.1114 | 0.8463 | 0.8960 | 0.9010 | 0.6239 |
| 0.0323 | 9.0 | 4815 | 1.1663 | 0.8501 | 0.8970 | 0.8967 | 0.6340 |
| 0.0163 | 10.0 | 5350 | 1.1655 | 0.8482 | 0.8961 | 0.8987 | 0.6288 |
### Framework versions
- Transformers 4.11.0
- Pytorch 1.9.0+cu102
- Datasets 1.12.1
- Tokenizers 0.10.3
|
ac8fa12d2c41b12d5aad9e72086b5748
|
espnet/kan-bayashi_jsut_tts_train_transformer_raw_phn_jaconv_pyopenjtalk_prosody_train.loss.ave
|
espnet
| null | 20 | 0 |
espnet
| 0 |
text-to-speech
| false | false | false |
cc-by-4.0
|
['ja']
|
['jsut']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['espnet', 'audio', 'text-to-speech']
| false | true | true | 1,859 | false |
## ESPnet2 TTS pretrained model
### `kan-bayashi/jsut_tts_train_transformer_raw_phn_jaconv_pyopenjtalk_prosody_train.loss.ave`
♻️ Imported from https://zenodo.org/record/5499040/
This model was trained by kan-bayashi using jsut/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
0eb689d7bfc3433a0acf40fbb681bf82
|
Helsinki-NLP/opus-mt-en-kwn
|
Helsinki-NLP
|
marian
| 10 | 7 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 776 | false |
### opus-mt-en-kwn
* source languages: en
* target languages: kwn
* OPUS readme: [en-kwn](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-kwn/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-kwn/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-kwn/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-kwn/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.en.kwn | 27.6 | 0.513 |
|
aeee6eb87d1d6b766b4a8a2a0bd16b87
|
jonatasgrosman/exp_w2v2t_ar_vp-nl_s103
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ar']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'ar']
| false | true | true | 469 | false |
# exp_w2v2t_ar_vp-nl_s103
Fine-tuned [facebook/wav2vec2-large-nl-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-nl-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (ar)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
90d0f3a6a25dc6430040c3df00e40823
|
jonatasgrosman/exp_w2v2t_de_hubert_s921
|
jonatasgrosman
|
hubert
| 10 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['de']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'de']
| false | true | true | 452 | false |
# exp_w2v2t_de_hubert_s921
Fine-tuned [facebook/hubert-large-ll60k](https://huggingface.co/facebook/hubert-large-ll60k) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
b88c8a04b69f8ebac733f1b04d5e89e9
|
sd-concepts-library/karl-s-lzx-1
|
sd-concepts-library
| null | 9 | 0 | null | 0 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,003 | false |
### karl's lzx 1 on Stable Diffusion
This is the `<lzx>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
2d522dfb442f6f2e2524168113891e96
|
jonatasgrosman/exp_w2v2r_de_xls-r_age_teens-0_sixties-10_s113
|
jonatasgrosman
|
wav2vec2
| 10 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['de']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'de']
| false | true | true | 476 | false |
# exp_w2v2r_de_xls-r_age_teens-0_sixties-10_s113
Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
2df71a7511737286b41d7e63aa418607
|
maesneako/ES_corlec_DeepESP-gpt2-spanish
|
maesneako
|
gpt2
| 8 | 2 |
transformers
| 0 |
text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,029 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ES_corlec_DeepESP-gpt2-spanish
This model is a fine-tuned version of [DeepESP/gpt2-spanish](https://huggingface.co/DeepESP/gpt2-spanish) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.0360
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 4.2471 | 0.4 | 2000 | 4.2111 |
| 4.1503 | 0.79 | 4000 | 4.1438 |
| 4.0749 | 1.19 | 6000 | 4.1077 |
| 4.024 | 1.59 | 8000 | 4.0857 |
| 3.9855 | 1.98 | 10000 | 4.0707 |
| 3.9465 | 2.38 | 12000 | 4.0605 |
| 3.9277 | 2.78 | 14000 | 4.0533 |
| 3.9159 | 3.17 | 16000 | 4.0482 |
| 3.8918 | 3.57 | 18000 | 4.0448 |
| 3.8789 | 3.97 | 20000 | 4.0421 |
| 3.8589 | 4.36 | 22000 | 4.0402 |
| 3.8554 | 4.76 | 24000 | 4.0387 |
| 3.8509 | 5.15 | 26000 | 4.0377 |
| 3.8389 | 5.55 | 28000 | 4.0370 |
| 3.8288 | 5.95 | 30000 | 4.0365 |
| 3.8293 | 6.34 | 32000 | 4.0362 |
| 3.8202 | 6.74 | 34000 | 4.0360 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.1+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
3777a0b48e15aa83fbfcc3a8d58367f1
|
kadirnar/RRDB_ESRGAN_x4
|
kadirnar
| null | 3 | 0 | null | 0 | null | false | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['Super-Resolution', 'computer-vision', 'ESRGAN', 'gan']
| false | true | true | 1,229 | false |
### Model Description
[ESRGAN](https://arxiv.org/abs/2107.10833): ECCV18 Workshops - Enhanced SRGAN. Champion PIRM Challenge on Perceptual Super-Resolution
[Paper Repo](https://github.com/xinntao/ESRGAN): Implementation of paper.
### Installation
```
pip install bsrgan
```
### BSRGAN Usage
```python
from bsrgan import BSRGAN
model = BSRGAN(weights='kadirnar/RRDB_ESRGAN_x4', device='cuda:0', hf_model=True)
model.save = True
pred = model.predict(img_path='data/image/test.png')
```
### BibTeX Entry and Citation Info
```
@inproceedings{zhang2021designing,
title={Designing a Practical Degradation Model for Deep Blind Image Super-Resolution},
author={Zhang, Kai and Liang, Jingyun and Van Gool, Luc and Timofte, Radu},
booktitle={IEEE International Conference on Computer Vision},
pages={4791--4800},
year={2021}
}
```
```
@InProceedings{wang2018esrgan,
author = {Wang, Xintao and Yu, Ke and Wu, Shixiang and Gu, Jinjin and Liu, Yihao and Dong, Chao and Qiao, Yu and Loy, Chen Change},
title = {ESRGAN: Enhanced super-resolution generative adversarial networks},
booktitle = {The European Conference on Computer Vision Workshops (ECCVW)},
month = {September},
year = {2018}
}
```
|
7d1bdaa4ecfd1abdd5fd07d706828baf
|
gchhablani/bert-base-cased-finetuned-qnli
|
gchhablani
|
bert
| 52 | 75 |
transformers
| 1 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer', 'fnet-bert-base-comparison']
| true | true | true | 2,215 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-qnli
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the GLUE QNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3986
- Accuracy: 0.9099
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path bert-base-cased \\n --task_name qnli \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir bert-base-cased-finetuned-qnli \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Accuracy | Validation Loss |
|:-------------:|:-----:|:-----:|:--------:|:---------------:|
| 0.337 | 1.0 | 6547 | 0.9013 | 0.2448 |
| 0.1971 | 2.0 | 13094 | 0.9143 | 0.2839 |
| 0.1175 | 3.0 | 19641 | 0.9099 | 0.3986 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
3cdfb6d834695135d2121ce917efadfe
|
kamilali/distilbert-base-uncased-finetuned-custom
|
kamilali
|
bert
| 12 | 5 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,338 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-custom
This model is a fine-tuned version of [bert-large-uncased-whole-word-masking-finetuned-squad](https://huggingface.co/bert-large-uncased-whole-word-masking-finetuned-squad) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7808
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 368 | 1.1128 |
| 2.1622 | 2.0 | 736 | 0.8494 |
| 1.2688 | 3.0 | 1104 | 0.7808 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 1.18.4
- Tokenizers 0.11.6
|
d2e58228e74b9ef3f6fe20b0f21751c6
|
vitorgrs/MyModel
|
vitorgrs
| null | 20 | 15 |
diffusers
| 1 |
text-to-image
| false | false | false |
openrail
| null | null | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 1,400 | false |
# Welcome to MY MODEL!
Hi! Dreambooth model for me. Use it as you want and respect the license model.
## How do I use it?
The keyword for this model is **vitordeluccagrs**.
Try to use "*portrait of vitordeluccagrs shirtless reading a book in a chair, art by artgerm*".
Be creative. Specify the faces features you want, hair style, the environment, if is a art, it's in which artist style? Want it realistic? Say it! And also say which ISO, camera, etc. Want to look like 500px and unsplash pictures? Say it too! Want it to look like Blade Runner? Say it. **Be creative**.
USE NEGATIVE PROMPT! Stable Diffusion works best if you use negative prompt. With negative prompt, you are saying what things you don't want in picture, like you know... extra fingers!.
# My social networks
[Mastodon](https://bolha.us/vitordelucca)
[Instagram](https://instagram.com/vitor_dlucca)
[Twitter](https://twitter.com/vitor_dlucca)
[Telegram](https://vitordelucca.t.me)
# Sample pictures




|
666eb99b6a7ebe5c40c670b750a35b96
|
sd-concepts-library/bob-dobbs
|
sd-concepts-library
| null | 19 | 0 | null | 2 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,128 | false |
### Bob Dobbs on Stable Diffusion
This is the `<bob>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:














|
19c82a393e0dae7c5f0b7004ba42f542
|
figfig/local_test_model
|
figfig
|
whisper
| 10 | 1 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['en']
|
['figfig/restaurant_order_local_test']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['hf-asr-leaderboard', 'generated_from_trainer']
| true | true | true | 1,476 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# restaurant_local_test_model
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the local_test_data dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5435
- Wer: 78.5714
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5
- training_steps: 40
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| No log | 10.0 | 10 | 2.2425 | 7.1429 |
| No log | 20.0 | 20 | 0.6651 | 0.0 |
| 2.4375 | 30.0 | 30 | 0.5776 | 35.7143 |
| 2.4375 | 40.0 | 40 | 0.5435 | 78.5714 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
9b7c2631cbd37143750ea1036e1c2bea
|
sd-concepts-library/lego-astronaut
|
sd-concepts-library
| null | 9 | 0 | null | 3 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,070 | false |
### Lego astronaut on Stable Diffusion
This is the `<lego-astronaut>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
44a2655b30c3724d1ab3d54e61eb1e24
|
sd-concepts-library/monster-toy
|
sd-concepts-library
| null | 9 | 0 | null | 4 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,042 | false |
### <monster-toy> on Stable Diffusion
This is the `<monster-toy>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:




|
381ec11a3c238585e8dd29a5918888b6
|
gustavecortal/distilcamembert-cae-feeling
|
gustavecortal
|
camembert
| 6 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,673 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilcamembert-cae-feeling
This model is a fine-tuned version of [cmarkea/distilcamembert-base](https://huggingface.co/cmarkea/distilcamembert-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9307
- Precision: 0.6783
- Recall: 0.6835
- F1: 0.6767
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|
| 1.1901 | 1.0 | 40 | 1.0935 | 0.1963 | 0.4430 | 0.2720 |
| 1.0584 | 2.0 | 80 | 0.8978 | 0.6304 | 0.6076 | 0.5776 |
| 0.6805 | 3.0 | 120 | 0.8577 | 0.6918 | 0.6709 | 0.6759 |
| 0.3938 | 4.0 | 160 | 1.0034 | 0.6966 | 0.6582 | 0.6586 |
| 0.2713 | 5.0 | 200 | 0.9307 | 0.6783 | 0.6835 | 0.6767 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
16f29d1e63eb3b0a6a8b8d93e0d6a15c
|
plai-edp-test/distilbert_base_uncased
|
plai-edp-test
|
distilbert
| 8 | 0 |
transformers
| 0 |
fill-mask
| false | true | false |
apache-2.0
|
['en']
|
['bookcorpus', 'wikipedia']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['exbert']
| false | true | true | 8,470 | false |
# DistilBERT base model (uncased)
This model is a distilled version of the [BERT base model](https://huggingface.co/bert-base-uncased). It was
introduced in [this paper](https://arxiv.org/abs/1910.01108). The code for the distillation process can be found
[here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation). This model is uncased: it does
not make a difference between english and English.
## Model description
DistilBERT is a transformers model, smaller and faster than BERT, which was pretrained on the same corpus in a
self-supervised fashion, using the BERT base model as a teacher. This means it was pretrained on the raw texts only,
with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic
process to generate inputs and labels from those texts using the BERT base model. More precisely, it was pretrained
with three objectives:
- Distillation loss: the model was trained to return the same probabilities as the BERT base model.
- Masked language modeling (MLM): this is part of the original training loss of the BERT base model. When taking a
sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the
model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that
usually see the words one after the other, or from autoregressive models like GPT which internally mask the future
tokens. It allows the model to learn a bidirectional representation of the sentence.
- Cosine embedding loss: the model was also trained to generate hidden states as close as possible as the BERT base
model.
This way, the model learns the same inner representation of the English language than its teacher model, while being
faster for inference or downstream tasks.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=distilbert) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='distilbert-base-uncased')
>>> unmasker("Hello I'm a [MASK] model.")
[{'sequence': "[CLS] hello i'm a role model. [SEP]",
'score': 0.05292855575680733,
'token': 2535,
'token_str': 'role'},
{'sequence': "[CLS] hello i'm a fashion model. [SEP]",
'score': 0.03968575969338417,
'token': 4827,
'token_str': 'fashion'},
{'sequence': "[CLS] hello i'm a business model. [SEP]",
'score': 0.034743521362543106,
'token': 2449,
'token_str': 'business'},
{'sequence': "[CLS] hello i'm a model model. [SEP]",
'score': 0.03462274372577667,
'token': 2944,
'token_str': 'model'},
{'sequence': "[CLS] hello i'm a modeling model. [SEP]",
'score': 0.018145186826586723,
'token': 11643,
'token_str': 'modeling'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import DistilBertTokenizer, DistilBertModel
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertModel.from_pretrained("distilbert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import DistilBertTokenizer, TFDistilBertModel
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions. It also inherits some of
[the bias of its teacher model](https://huggingface.co/bert-base-uncased#limitations-and-bias).
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='distilbert-base-uncased')
>>> unmasker("The White man worked as a [MASK].")
[{'sequence': '[CLS] the white man worked as a blacksmith. [SEP]',
'score': 0.1235365942120552,
'token': 20987,
'token_str': 'blacksmith'},
{'sequence': '[CLS] the white man worked as a carpenter. [SEP]',
'score': 0.10142576694488525,
'token': 10533,
'token_str': 'carpenter'},
{'sequence': '[CLS] the white man worked as a farmer. [SEP]',
'score': 0.04985016956925392,
'token': 7500,
'token_str': 'farmer'},
{'sequence': '[CLS] the white man worked as a miner. [SEP]',
'score': 0.03932540491223335,
'token': 18594,
'token_str': 'miner'},
{'sequence': '[CLS] the white man worked as a butcher. [SEP]',
'score': 0.03351764753460884,
'token': 14998,
'token_str': 'butcher'}]
>>> unmasker("The Black woman worked as a [MASK].")
[{'sequence': '[CLS] the black woman worked as a waitress. [SEP]',
'score': 0.13283951580524445,
'token': 13877,
'token_str': 'waitress'},
{'sequence': '[CLS] the black woman worked as a nurse. [SEP]',
'score': 0.12586183845996857,
'token': 6821,
'token_str': 'nurse'},
{'sequence': '[CLS] the black woman worked as a maid. [SEP]',
'score': 0.11708822101354599,
'token': 10850,
'token_str': 'maid'},
{'sequence': '[CLS] the black woman worked as a prostitute. [SEP]',
'score': 0.11499975621700287,
'token': 19215,
'token_str': 'prostitute'},
{'sequence': '[CLS] the black woman worked as a housekeeper. [SEP]',
'score': 0.04722772538661957,
'token': 22583,
'token_str': 'housekeeper'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
DistilBERT pretrained on the same data as BERT, which is [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset
consisting of 11,038 unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia)
(excluding lists, tables and headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The model was trained on 8 16 GB V100 for 90 hours. See the
[training code](https://github.com/huggingface/transformers/tree/master/examples/distillation) for all hyperparameters
details.
## Evaluation results
When fine-tuned on downstream tasks, this model achieves the following results:
Glue test results:
| Task | MNLI | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE |
|:----:|:----:|:----:|:----:|:-----:|:----:|:-----:|:----:|:----:|
| | 82.2 | 88.5 | 89.2 | 91.3 | 51.3 | 85.8 | 87.5 | 59.9 |
### BibTeX entry and citation info
```bibtex
@article{Sanh2019DistilBERTAD,
title={DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter},
author={Victor Sanh and Lysandre Debut and Julien Chaumond and Thomas Wolf},
journal={ArXiv},
year={2019},
volume={abs/1910.01108}
}
```
<a href="https://huggingface.co/exbert/?model=distilbert-base-uncased">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
a75c71419364c4b880f611067bf63823
|
brashandplucky/ddpm-butterflies-128
|
brashandplucky
| null | 13 | 0 |
diffusers
| 0 | null | false | false | false |
apache-2.0
|
['en']
|
['huggan/smithsonian_butterflies_subset']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,236 | false |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/brashandplucky/ddpm-butterflies-128/tensorboard?#scalars)
|
fe41e696d38935f845b976da2c142a4d
|
Buseak/my_awesome_wnut_model
|
Buseak
|
bert
| 12 | 1 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,546 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_wnut_model
This model is a fine-tuned version of [dbmdz/bert-base-turkish-cased](https://huggingface.co/dbmdz/bert-base-turkish-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2661
- Precision: 0.8999
- Recall: 0.8933
- F1: 0.8966
- Accuracy: 0.9264
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 488 | 0.3614 | 0.8731 | 0.8606 | 0.8668 | 0.9043 |
| 0.6843 | 2.0 | 976 | 0.2872 | 0.8927 | 0.8856 | 0.8891 | 0.9209 |
| 0.3517 | 3.0 | 1464 | 0.2661 | 0.8999 | 0.8933 | 0.8966 | 0.9264 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
16f8e05c8486deb6e3eabcb4d2eb7752
|
huggan/pix2pix-night2day
|
huggan
| null | 5 | 0 | null | 1 | null | true | false | false |
mit
| null |
['huggan/night2day']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['huggan', 'gan']
| false | true | true | 2,374 | false |
# MyModelName
## Model description
[Pix2pix Model](https://arxiv.org/abs/1611.07004) is a conditional adversarial networks, a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This makes it possible to apply the same generic approach to problems that traditionally would require very different loss formulations. We demonstrate that this approach is effective at synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing images, among other tasks.
## Intended uses & limitations:
Used for reconstruction of images from edges
#### How to use
```python
from torchvision.transforms import Compose, Resize, ToTensor, Normalize
from PIL import Image
from torchvision.utils import save_image
import cv2
from huggan.pytorch.pix2pix.modeling_pix2pix import GeneratorUNet
transform = Compose(
[
Resize((256, 256), Image.BICUBIC),
ToTensor(),
Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
)
model = GeneratorUNet.from_pretrained('huggan/pix2pix-night2day')
def predict_fn(img):
inp = transform(img).unsqueeze(0)
out = model(inp)
save_image(out, 'out.png', normalize=True)
return 'out.png'
predict_fn(img)
```
#### Limitations and bias
* Gives unrealistic colors in the image
* Gives Blurry image sometimes
## Training data
* [night2day](https://huggingface.co/datasets/huggan/night2day)
## Training procedure
```
# clone the repository
git clone https://github.com/huggingface/community-events.git
pip install .
# change directory
cd community-events/huggan/pytorch/pix2pix/
# define config
accelerate config
# launch training with required parameters
accelerate launch train.py --checkpoint_interval 5 --dataset huggan/night2day --push_to_hub --model_name pix2pix-night2day --batch_size 128 --n_epochs 50
```
## Generated Images
Here,
* First Image Row: Input Image
* Second Image Row: Generated Image
* Third Image Row: Target Image


### BibTeX entry and citation info
```bibtex
@article{pix2pix2017,
title={Image-to-Image Translation with Conditional Adversarial Networks},
author={Isola, Phillip and Zhu, Jun-Yan and Zhou, Tinghui and Efros, Alexei A},
journal={CVPR},
year={2017}
}
```
|
ae24493af07785bdfe4487e58e51a850
|
ultra-coder54732/comment-detection-prop-16
|
ultra-coder54732
|
bert
| 30 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 922 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# comment-detection-prop-16
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
74b516b7c244ef0dfaa9e26e31033edf
|
Prem11100/donut-base-Label-studio-200-invoices
|
Prem11100
|
vision-encoder-decoder
| 14 | 3 |
transformers
| 0 | null | true | false | false |
mit
| null |
['imagefolder']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,002 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# donut-base-Label-studio-200-invoices
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.2
|
0c9e525fb1ef8ef88a6fe54ed9a5e93e
|
thammarat-th/distilbert-base-uncased-finetuned-imdb
|
thammarat-th
|
distilbert
| 14 | 3 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null |
['imdb']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,319 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2591
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.4216 | 1.0 | 782 | 2.2803 |
| 2.3719 | 2.0 | 1564 | 2.2577 |
| 2.3407 | 3.0 | 2346 | 2.2320 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.12.1+cu113
- Datasets 1.17.0
- Tokenizers 0.10.3
|
250d46085d1ae14b38e0bf6e82ca7aff
|
NeuroSenko/abyss_orange_mix_senko_by_rimukoro_hyper
|
NeuroSenko
| null | 34 | 0 | null | 0 | null | false | false | false |
mit
| null |
['NeuroSenko/senko_by_rimukoro']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['Stable Diffusion', 'Senko', 'Hypernetwork']
| false | true | true | 2,784 | false |
## Description
This hypernetwork will help you to make your Senko-san be look like she was drawn by Rimukoro. This model was trained using [AbyssOrangeMix_base](https://huggingface.co/WarriorMama777/OrangeMixs/blob/main/Models/AbyssOrangeMix/AbyssOrangeMix_base.ckpt) model so it should work fine with that specific model or with other relative models.
## Usage
For using this hypernetwork just place .pt file in your `models\hypernetworks` directory and then depends on your UI you will need to choose this hypernetwork in settings or use it directly in your positive prompt like `<hypernet:abyss_orange_mix_senko_by_rimukoro:1.0>`
## Dataset
Feel free to use a dataset I used for training this model. You can find it [here](https://huggingface.co/datasets/NeuroSenko/senko_by_rimukoro).
## Examples

## PNG Info Example
masterpiece, best quality, 1girl, solo, cinematic lighting, 1girl, solo, senko \(sewayaki kitsune no senko-san\), senko-san, sewayaki kitsune no senko-san, animal ears, fox ears, fox girl, fox tail, hair flower, hair ornament, orange eyes, orange hair, rimukoro, short hair, tail, flat chest, looking at viewer, light smile, full body, forest, rain, darkness, moon, wet clothes, blush, jacket, T-shirt, skirt
Negative prompt: ugly, old, amateur drawing, odd, fat, lowres, text, error, worst quality, low quality, jpeg artifacts, signature, watermark, username, (blurry:1.3), out of focus, cropped, out of frame, cloned face, mutilated, deformed, gross proportions, disfigured, mutated hands, poorly drawn hands, bad anatomy, (bad hands:1.4), missing fingers, extra digit, (extra fingers:1.3), fewer digits, poorly drawn face, fused fingers, long neck, extra limbs, broken limb, asymmetrical eyes cell shading, watercolor
Steps: 30, Sampler: DDIM, CFG scale: 12, Seed: 1393421640, Size: 640x832, Model hash: ffa7b160, Model: AbyssOrangeMix_base, Hypernet: abyss_orange_mix_senko_by_rimukoro, Hypernet hash: f3753abd, Denoising strength: 0.7, Eta: 0.69, Clip skip: 2, Hires upscale: 2, Hires upscaler: Latent
## Chosing a hypernetwork with non-default amount of steps
Hypernetwork `abyss_orange_mix_senko_by_rimukoro.pt` presents a model which was trained on 4000 amount of steps (which I personally prefer). I also published hypernetworks which were trained on different amount of steps (up to 15000).
You can find these hypernetworks in [models folder](https://huggingface.co/NeuroSenko/abyss_orange_mix_senko_by_rimukoro_hyper/tree/main/models).
To make it easier for you to choose a hypernetwork I publish [this grid](https://neurosenko.github.io/sd-grid-viewer/?configUrl=https://neurosenko.github.io/sd-grids/orange-senko-by-rimukoro/config.json) which you can use for comparing these hypernetworks using 5 different seeds.
|
e9db635631c2a79fb0c0af09d7ee1220
|
OpenMatch/ance-tele_nq_qry-encoder
|
OpenMatch
|
bert
| 7 | 3 |
transformers
| 0 |
feature-extraction
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 897 | false |
This model is the **query** encoder of ANCE-Tele trained on NQ, described in the EMNLP 2022 paper ["Reduce Catastrophic Forgetting of Dense Retrieval Training with Teleportation Negatives"](https://arxiv.org/pdf/2210.17167.pdf). The associated GitHub repository is available at https://github.com/OpenMatch/ANCE-Tele.
ANCE-Tele only trains with self-mined negatives (teleportation negatives) without using additional negatives (e.g., BM25, other DR systems) and eliminates the dependency on filtering strategies and distillation modules.
|NQ (Test)|R@5|R@20|R@20|
|:---|:---|:---|:---|
|ANCE-Tele|77.0|84.9|89.7|
```
@inproceedings{sun2022ancetele,
title={Reduce Catastrophic Forgetting of Dense Retrieval Training with Teleportation Negatives},
author={Si Sun, Chenyan Xiong, Yue Yu, Arnold Overwijk, Zhiyuan Liu and Jie Bao},
booktitle={Proceedings of EMNLP 2022},
year={2022}
}
```
|
494f8866ada1f9e3ec7361acb9adbb52
|
uck/distilbert-base-uncased-finetuned-emotion
|
uck
|
distilbert
| 14 | 0 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['emotion']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,335 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2245
- Accuracy: 0.92
- F1: 0.9203
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8171 | 1.0 | 250 | 0.3222 | 0.907 | 0.9055 |
| 0.2546 | 2.0 | 500 | 0.2245 | 0.92 | 0.9203 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.8.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
51561382d9e9903534e8dfb1ade9ad86
|
cyburn/gauzy_storms
|
cyburn
| null | 8 | 0 | null | 0 | null | false | false | false |
unknown
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 760 | false |
# Gauzy Storm finetuned style Model
Produced from publicly available pictures in landscape, portrait and square format. This model is focussed on creating animal hybrid artwork.
## Model info
The models included was trained on "multi-resolution" images.
## Using the model
* common subject prompt tokens: `<wathever> by gauzy storms`
## Example prompts
`bear deer by gauzy storms`:
<img src="https://huggingface.co/cyburn/gauzy_storms/resolve/main/1.png" alt="Picture." width="500"/>
`pinguin by gauzy storms`:
<img src="https://huggingface.co/cyburn/gauzy_storms/resolve/main/2.png" alt="Picture." width="500"/>
`unicorn zebra by gauzy storms`:
<img src="https://huggingface.co/cyburn/gauzy_storms/resolve/main/3.png" alt="Picture." width="500"/>
|
1c039a60103a4955b61ff5ff244542c8
|
chenglu/caicai-dog-heywhale
|
chenglu
| null | 17 | 39 |
diffusers
| 2 |
text-to-image
| true | false | false |
creativeml-openrail-m
| null | null | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['pytorch', 'diffusers', 'stable-diffusion', 'text-to-image', 'diffusion-models-class', 'dreambooth-hackathon', 'animal']
| false | true | true | 838 | false |
# DreamBooth model for the caicai concept trained by chenglu.
This is a Stable Diffusion model fine-tuned on the caicai concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of caicai dog**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `dog` images for the animal theme,
for the Hugging Face DreamBooth Hackathon, from the HF CN Community,
corporated with the HeyWhale.
Thanks to @hhhxynh in the HF China community.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('chenglu/caicai-dog-heywhale')
image = pipeline().images[0]
image
```
|
9c6c5bb4477d9f6e3c368904b83358db
|
ZhiyuanQiu/camembert-base-finetuned-Train_RAW10-dd
|
ZhiyuanQiu
|
camembert
| 12 | 6 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,448 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# camembert-base-finetuned-Train_RAW10-dd
This model is a fine-tuned version of [camembert-base](https://huggingface.co/camembert-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2175
- Precision: 0.8744
- Recall: 0.9056
- F1: 0.8897
- Accuracy: 0.9357
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1873 | 1.0 | 9930 | 0.2088 | 0.8652 | 0.8927 | 0.8788 | 0.9326 |
| 0.1533 | 2.0 | 19860 | 0.2175 | 0.8744 | 0.9056 | 0.8897 | 0.9357 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
05bfd4b3ecc3358ed23fac0a1a31703e
|
09panesara/distilbert-base-uncased-finetuned-cola
|
09panesara
|
distilbert
| 13 | 29 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,572 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7580
- Matthews Correlation: 0.5406
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5307 | 1.0 | 535 | 0.5094 | 0.4152 |
| 0.3545 | 2.0 | 1070 | 0.5230 | 0.4940 |
| 0.2371 | 3.0 | 1605 | 0.6412 | 0.5087 |
| 0.1777 | 4.0 | 2140 | 0.7580 | 0.5406 |
| 0.1288 | 5.0 | 2675 | 0.8494 | 0.5396 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
8049a4a9534380cfa876b5fd9f798304
|
betelgeux/bert-base-uncased-issues-128
|
betelgeux
|
bert
| 10 | 6 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,930 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-issues-128
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0348
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.3932 | 1.0 | 1409 | 2.0750 |
| 2.1659 | 2.0 | 2818 | 1.9781 |
| 2.0364 | 3.0 | 4227 | 2.1215 |
| 1.9399 | 4.0 | 5636 | 2.1018 |
| 1.8857 | 5.0 | 7045 | 1.9919 |
| 1.813 | 6.0 | 8454 | 2.2653 |
| 1.7505 | 7.0 | 9863 | 2.0857 |
| 1.7196 | 8.0 | 11272 | 1.9211 |
| 1.672 | 9.0 | 12681 | 1.9853 |
| 1.6379 | 10.0 | 14090 | 2.0391 |
| 1.6037 | 11.0 | 15499 | 1.9305 |
| 1.5699 | 12.0 | 16908 | 2.0291 |
| 1.5363 | 13.0 | 18317 | 2.0492 |
| 1.5155 | 14.0 | 19726 | 1.8807 |
| 1.4999 | 15.0 | 21135 | 1.8604 |
| 1.4784 | 16.0 | 22544 | 2.0348 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
5945eeff94e28a30394bbd6accfe6da0
|
google/t5-efficient-tiny-ff6000
|
google
|
t5
| 12 | 9 |
transformers
| 0 |
text2text-generation
| true | true | true |
apache-2.0
|
['en']
|
['c4']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['deep-narrow']
| false | true | true | 6,257 | false |
# T5-Efficient-TINY-FF6000 (Deep-Narrow version)
T5-Efficient-TINY-FF6000 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5).
It is a *pretrained-only* checkpoint and was released with the
paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)**
by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures
of similar parameter count.
To quote the paper:
> We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased
> before considering any other forms of uniform scaling across other dimensions. This is largely due to
> how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a
> tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise,
> a tall base model might also generally more efficient compared to a large model. We generally find
> that, regardless of size, even if absolute performance might increase as we continue to stack layers,
> the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36
> layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e.,
> params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params,
> FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to
> consider.
To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially.
A sequence of word embeddings is therefore processed sequentially by each transformer block.
## Details model architecture
This model checkpoint - **t5-efficient-tiny-ff6000** - is of model type **Tiny** with the following variations:
- **ff** is **6000**
It has **36.55** million parameters and thus requires *ca.* **146.21 MB** of memory in full precision (*fp32*)
or **73.1 MB** of memory in half precision (*fp16* or *bf16*).
A summary of the *original* T5 model architectures can be seen here:
| Model | nl (el/dl) | ff | dm | kv | nh | #Params|
| ----| ---- | ---- | ---- | ---- | ---- | ----|
| Tiny | 4/4 | 1024 | 256 | 32 | 4 | 16M|
| Mini | 4/4 | 1536 | 384 | 32 | 8 | 31M|
| Small | 6/6 | 2048 | 512 | 32 | 8 | 60M|
| Base | 12/12 | 3072 | 768 | 64 | 12 | 220M|
| Large | 24/24 | 4096 | 1024 | 64 | 16 | 738M|
| Xl | 24/24 | 16384 | 1024 | 128 | 32 | 3B|
| XXl | 24/24 | 65536 | 1024 | 128 | 128 | 11B|
whereas the following abbreviations are used:
| Abbreviation | Definition |
| ----| ---- |
| nl | Number of transformer blocks (depth) |
| dm | Dimension of embedding vector (output vector of transformers block) |
| kv | Dimension of key/value projection matrix |
| nh | Number of attention heads |
| ff | Dimension of intermediate vector within transformer block (size of feed-forward projection matrix) |
| el | Number of transformer blocks in the encoder (encoder depth) |
| dl | Number of transformer blocks in the decoder (decoder depth) |
| sh | Signifies that attention heads are shared |
| skv | Signifies that key-values projection matrices are tied |
If a model checkpoint has no specific, *el* or *dl* than both the number of encoder- and decoder layers correspond to *nl*.
## Pre-Training
The checkpoint was pretrained on the [Colossal, Cleaned version of Common Crawl (C4)](https://huggingface.co/datasets/c4) for 524288 steps using
the span-based masked language modeling (MLM) objective.
## Fine-Tuning
**Note**: This model is a **pretrained** checkpoint and has to be fine-tuned for practical usage.
The checkpoint was pretrained in English and is therefore only useful for English NLP tasks.
You can follow on of the following examples on how to fine-tune the model:
*PyTorch*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization)
- [Question Answering](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_seq2seq_qa.py)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*Tensorflow*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*JAX/Flax*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/flax/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/flax/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
## Downstream Performance
TODO: Add table if available
## Computational Complexity
TODO: Add table if available
## More information
We strongly recommend the reader to go carefully through the original paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** to get a more nuanced understanding of this model checkpoint.
As explained in the following [issue](https://github.com/google-research/google-research/issues/986#issuecomment-1035051145), checkpoints including the *sh* or *skv*
model architecture variations have *not* been ported to Transformers as they are probably of limited practical usage and are lacking a more detailed description. Those checkpoints are kept [here](https://huggingface.co/NewT5SharedHeadsSharedKeyValues) as they might be ported potentially in the future.
|
e4d9f3e9d4591523e8227ee21b3d44ac
|
Graphcore/convnext-base-ipu
|
Graphcore
| null | 3 | 203 | null | 0 | null | false | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,486 | false |
# Graphcore/convnext-base-ipu
Optimum Graphcore is a new open-source library and toolkit that enables developers to access IPU-optimized models certified by Hugging Face. It is an extension of Transformers, providing a set of performance optimization tools enabling maximum efficiency to train and run models on Graphcore’s IPUs - a completely new kind of massively parallel processor to accelerate machine intelligence. Learn more about how to take train Transformer models faster with IPUs at [hf.co/hardware/graphcore](https://huggingface.co/hardware/graphcore).
Through HuggingFace Optimum, Graphcore released ready-to-use IPU-trained model checkpoints and IPU configuration files to make it easy to train models with maximum efficiency in the IPU. Optimum shortens the development lifecycle of your AI models by letting you plug-and-play any public dataset and allows a seamless integration to our State-of-the-art hardware giving you a quicker time-to-value for your AI project.
## Model description
Paper link : [A ConvNet for the 2020s](https://arxiv.org/pdf/2201.03545.pdf)
## Intended uses & limitations
This model contains just the `IPUConfig` files for running the [facebook/convnext-base-224](https://huggingface.co/facebook/convnext-base-224) model on Graphcore IPUs.
**This model contains no model weights, only an IPUConfig.**
## Usage
```
from optimum.graphcore import IPUConfig
ipu_config = IPUConfig.from_pretrained("Graphcore/convnext-base-ipu")
```
|
78681aa9ef055be24159893d5f7beac6
|
MultiBertGunjanPatrick/multiberts-seed-2-2000k
|
MultiBertGunjanPatrick
|
bert
| 7 | 5 |
transformers
| 0 | null | true | false | false |
apache-2.0
|
['en']
|
['bookcorpus', 'wikipedia']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['exbert', 'multiberts', 'multiberts-seed-2']
| false | true | true | 6,487 | false |
# MultiBERTs Seed 2 Checkpoint 2000k (uncased)
Seed 2 intermediate checkpoint 2000k MultiBERTs (pretrained BERT) model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/pdf/2106.16163.pdf) and first released in
[this repository](https://github.com/google-research/language/tree/master/language/multiberts). This is an intermediate checkpoint.
The final checkpoint can be found at [multiberts-seed-2](https://hf.co/multberts-seed-2). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing MultiBERTs did not write a model card for this model so this model card has been written by [gchhablani](https://hf.co/gchhablani).
## Model description
MultiBERTs models are transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the MultiBERTs model as inputs.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=multiberts) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('multiberts-seed-2-2000k')
model = BertModel.from_pretrained("multiberts-seed-2-2000k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions. This bias will also affect all fine-tuned versions of this model. For an understanding of bias of this particular
checkpoint, please try out this checkpoint with the snippet present in the [Limitation and bias section](https://huggingface.co/bert-base-uncased#limitations-and-bias) of the [bert-base-uncased](https://huggingface.co/bert-base-uncased) checkpoint.
## Training data
The MultiBERTs models were pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038
unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The full model was trained on 16 Cloud TPU v2 chips for two million steps with a batch size
of 256. The sequence length was set to 512 throughout. The optimizer
used is Adam with a learning rate of 1e-4, \\(\beta_{1} = 0.9\\) and \\(\beta_{2} = 0.999\\), a weight decay of 0.01,
learning rate warmup for 10,000 steps and linear decay of the learning rate after.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2106-16163,
author = {Thibault Sellam and
Steve Yadlowsky and
Jason Wei and
Naomi Saphra and
Alexander D'Amour and
Tal Linzen and
Jasmijn Bastings and
Iulia Turc and
Jacob Eisenstein and
Dipanjan Das and
Ian Tenney and
Ellie Pavlick},
title = {The MultiBERTs: {BERT} Reproductions for Robustness Analysis},
journal = {CoRR},
volume = {abs/2106.16163},
year = {2021},
url = {https://arxiv.org/abs/2106.16163},
eprinttype = {arXiv},
eprint = {2106.16163},
timestamp = {Mon, 05 Jul 2021 15:15:50 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-16163.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<a href="https://huggingface.co/exbert/?model=multiberts">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
321dbfeac1abc4a1112e5e39558bb185
|
jonatasgrosman/exp_w2v2t_ja_vp-it_s544
|
jonatasgrosman
|
wav2vec2
| 10 | 4 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ja']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'ja']
| false | true | true | 469 | false |
# exp_w2v2t_ja_vp-it_s544
Fine-tuned [facebook/wav2vec2-large-it-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-it-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (ja)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
e80dec13aee31fa52e5416345ff47b2c
|
paola-md/recipe-lr0.0001-wd0.05-bs64
|
paola-md
|
roberta
| 6 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,470 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# recipe-lr0.0001-wd0.05-bs64
This model is a fine-tuned version of [paola-md/recipe-distilroberta-Is](https://huggingface.co/paola-md/recipe-distilroberta-Is) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2792
- Rmse: 0.5284
- Mse: 0.2792
- Mae: 0.4268
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 256
- eval_batch_size: 256
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rmse | Mse | Mae |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| 0.2798 | 1.0 | 623 | 0.2789 | 0.5281 | 0.2789 | 0.4219 |
| 0.2786 | 2.0 | 1246 | 0.2795 | 0.5287 | 0.2795 | 0.4287 |
| 0.2785 | 3.0 | 1869 | 0.2792 | 0.5284 | 0.2792 | 0.4268 |
### Framework versions
- Transformers 4.19.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 2.4.0
- Tokenizers 0.12.1
|
e76c2db5ea81b6b5e9d091b3ccf49a8b
|
salihkavaf/distilbert-base-uncased-finetuned-imdb
|
salihkavaf
|
distilbert
| 8 | 2 |
transformers
| 0 |
fill-mask
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,610 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# salihkavaf/distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [salihkavaf/distilbert-base-uncased-finetuned-imdb](https://huggingface.co/salihkavaf/distilbert-base-uncased-finetuned-imdb) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.6769
- Validation Loss: 2.5848
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -688, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 2.6769 | 2.5848 | 0 |
### Framework versions
- Transformers 4.18.0
- TensorFlow 2.8.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
be4080f3d0638bb876999aea5fea30bf
|
goharava/bart-large-fine-tuned-large_
|
goharava
|
bart
| 11 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,431 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-finetuned-large
This model is a fine-tuned version of [facebook/bart-large](https://huggingface.co/facebook/bart-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6397
- Rouge1: 88.2870
- Rouge2: 26.4705
- Rougel: 88.1924
- Rougelsum: 88.3415
- Gen Len: 6.0323
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 121 | 0.8676 | 67.7680 | 19.6386 | 67.5697 | 67.5758 | 6.2774 |
| No log | 2.0 | 242 | 0.6661 | 73.6309 | 21.6079 | 73.2496 | 73.5335 | 5.3957 |
| No log | 3.0 | 363 | 0.6649 | 82.6362 | 21.4663 | 82.3944 | 82.6107 | 5.6624 |
| No log | 4.0 | 484 | 0.6598 | 86.4811 | 25.3580 | 86.1949 | 86.3580 | 5.7914 |
| 0.5135 | 5.0 | 605 | 0.8032 | 86.0334 | 25.1510 | 85.8895 | 85.9038 | 6.5634 |
| 0.5135 | 6.0 | 726 | 0.6981 | 88.0139 | 25.6152 | 87.9025 | 87.9932 | 6.3591 |
| 0.5135 | 7.0 | 847 | 0.6991 | 88.7421 | 25.6469 | 88.5959 | 88.7255 | 6.3376 |
| 0.5135 | 8.0 | 968 | 0.5995 | 88.9180 | 26.9917 | 88.6984 | 88.8878 | 5.8538 |
| 0.1613 | 9.0 | 1089 | 0.5973 | 88.5923 | 26.7081 | 88.4593 | 88.6287 | 5.8387 |
| 0.1613 | 10.0 | 1210 | 0.6397 | 88.2870 | 26.4705 | 88.1924 | 88.3415 | 6.0323 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
05205cc18c7a92baccfca8c2a97e0df1
|
jonatasgrosman/exp_w2v2t_ar_r-wav2vec2_s779
|
jonatasgrosman
|
wav2vec2
| 10 | 2 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ar']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'ar']
| false | true | true | 462 | false |
# exp_w2v2t_ar_r-wav2vec2_s779
Fine-tuned [facebook/wav2vec2-large-robust](https://huggingface.co/facebook/wav2vec2-large-robust) for speech recognition using the train split of [Common Voice 7.0 (ar)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
1c2ed4b3d32ac43575044a51b6d3a76c
|
juancopi81/course-bert-finetuned-squad
|
juancopi81
|
bert
| 8 | 3 |
transformers
| 0 |
question-answering
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,275 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# juancopi81/course-bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.0547
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 5546, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Epoch |
|:----------:|:-----:|
| 1.0547 | 0 |
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.8.2
- Datasets 2.3.2
- Tokenizers 0.12.1
|
9b49412836fba3c01b35d01b615fe652
|
viktor-enzell/wav2vec2-large-voxrex-swedish-4gram
|
viktor-enzell
|
wav2vec2
| 12 | 29 |
transformers
| 5 |
automatic-speech-recognition
| true | false | false |
cc0-1.0
|
['sv']
|
['common_voice', 'NST_Swedish_ASR_Database', 'P4', 'The_Swedish_Culturomics_Gigaword_Corpus']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['audio', 'automatic-speech-recognition', 'speech', 'hf-asr-leaderboard', 'sv']
| true | true | true | 2,972 | false |
# KBLab's wav2vec 2.0 large VoxRex Swedish (C) with 4-gram model
Training of the acoustic model is the work of KBLab. See [VoxRex-C](https://huggingface.co/KBLab/wav2vec2-large-voxrex-swedish) for more details. This repo extends the acoustic model with a social media 4-gram language model for boosted performance.
## Model description
VoxRex-C is extended with a 4-gram language model estimated from a subset extracted from [The Swedish Culturomics Gigaword Corpus](https://spraakbanken.gu.se/resurser/gigaword) from Språkbanken. The subset contains 40M words from the social media genre between 2010 and 2015.
## How to use
#### Simple usage example with pipeline
```python
import torch
from transformers import pipeline
# Load the model. Using GPU if available
model_name = 'viktor-enzell/wav2vec2-large-voxrex-swedish-4gram'
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
pipe = pipeline(model=model_name).to(device)
# Run inference on an audio file
output = pipe('path/to/audio.mp3')['text']
```
#### More verbose usage example with audio pre-processing
Example of transcribing 1% of the Common Voice test split. The model expects 16kHz audio, so audio with another sampling rate is resampled to 16kHz.
```python
from transformers import Wav2Vec2ForCTC, Wav2Vec2ProcessorWithLM
from datasets import load_dataset
import torch
import torchaudio.functional as F
# Import model and processor. Using GPU if available
model_name = 'viktor-enzell/wav2vec2-large-voxrex-swedish-4gram'
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device);
processor = Wav2Vec2ProcessorWithLM.from_pretrained(model_name)
# Import and process speech data
common_voice = load_dataset('common_voice', 'sv-SE', split='test[:1%]')
def speech_file_to_array(sample):
# Convert speech file to array and downsample to 16 kHz
sampling_rate = sample['audio']['sampling_rate']
sample['speech'] = F.resample(torch.tensor(sample['audio']['array']), sampling_rate, 16_000)
return sample
common_voice = common_voice.map(speech_file_to_array)
# Run inference
inputs = processor(common_voice['speech'], sampling_rate=16_000, return_tensors='pt', padding=True).to(device)
with torch.no_grad():
logits = model(**inputs).logits
transcripts = processor.batch_decode(logits.cpu().numpy()).text
```
## Training procedure
Text data for the n-gram model is pre-processed by removing characters not part of the wav2vec 2.0 vocabulary and uppercasing all characters. After pre-processing and storing each text sample on a new line in a text file, a [KenLM](https://github.com/kpu/kenlm) model is estimated. See [this tutorial](https://huggingface.co/blog/wav2vec2-with-ngram) for more details.
## Evaluation results
The model was evaluated on the full Common Voice test set version 6.1. VoxRex-C achieved a WER of 9.03% without the language model and 6.47% with the language model.
|
e8c141b6e2a3f64297ccf1ac8dbacab4
|
irena/whisper-small-sv-SE
|
irena
|
whisper
| 21 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['hi']
|
['mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['hf-asr-leaderboard', 'generated_from_trainer']
| true | true | true | 1,005 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small sv-SE - irena
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
a991b6665cb435767fb82a6dcef68a51
|
anas-awadalla/bert-base-uncased-few-shot-k-32-finetuned-squad-seed-10
|
anas-awadalla
|
bert
| 16 | 5 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,001 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-few-shot-k-32-finetuned-squad-seed-10
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 200
### Training results
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.17.0
- Tokenizers 0.10.3
|
5416cd6d9215167053ee5a78bbf5d4e7
|
timm/maxxvitv2_rmlp_base_rw_224.sw_in12k
|
timm
| null | 4 | 64 |
timm
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['imagenet-12k']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['image-classification', 'timm']
| false | true | true | 22,237 | false |
# Model card for maxxvitv2_rmlp_base_rw_224.sw_in12k
A timm specific MaxxViT-V2 (w/ a MLP Log-CPB (continuous log-coordinate relative position bias motivated by Swin-V2) image classification model. Trained in `timm` on ImageNet-12k (a 11821 class subset of full ImageNet-22k) by Ross Wightman.
### Model Variants in [maxxvit.py](https://github.com/rwightman/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 127.2
- GMACs: 24.2
- Activations (M): 62.8
- Image size: 224 x 224
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545
- Swin Transformer V2: Scaling Up Capacity and Resolution: https://arxiv.org/abs/2111.09883
- **Dataset:** ImageNet-12k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model('maxxvitv2_rmlp_base_rw_224.sw_in12k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'maxxvitv2_rmlp_base_rw_224.sw_in12k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 128, 192, 192])
# torch.Size([1, 128, 96, 96])
# torch.Size([1, 256, 48, 48])
# torch.Size([1, 512, 24, 24])
# torch.Size([1, 1024, 12, 12])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(
urlopen('https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'))
model = timm.create_model(
'maxxvitv2_rmlp_base_rw_224.sw_in12k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, num_features, H, W) tensor
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/rwightman/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
|
660729bb96af7dec7358daafbf51e7d2
|
valurank/finetuned-distilbert-news-article-categorization
|
valurank
|
distilbert
| 8 | 524 |
transformers
| 0 |
text-classification
| true | false | false |
other
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,163 | false |
### finetuned-distilbert-news-article-catgorization
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the news_article_categorization dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1548
- F1_score(weighted): 0.96
### Model description
More information needed
### Intended uses & limitations
More information needed
### Training and evaluation data
The model was trained on some subset of the news_article_categorization dataset and it was validated on the remaining subset of the data
### Training procedure
More information needed
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-5
- train_batch_size: 3
- eval_batch_size: 3
- seed: 17
- optimizer: AdamW(lr=1e-5 and epsilon=1e-08)
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 0
- num_epochs: 2
### Training results
| Training Loss | Epoch | Validation Loss | f1 score |
|:-------------:|:-----:|:---------------: |:------:|
| 0.6359 | 1.0 | 0.1739 | 0.9619 |
| 0.1548 | 2.0 | 0.1898 | 0.9648 |
|
4efec8ebaf02b7e6fab82722fa71cf5f
|
kika2000/wav2vec2-large-xls-r-300m-kika5_my-colab
|
kika2000
|
wav2vec2
| 13 | 8 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,513 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-kika5_my-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3860
- Wer: 0.3505
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.0007 | 4.82 | 400 | 0.6696 | 0.8283 |
| 0.2774 | 9.64 | 800 | 0.4231 | 0.5476 |
| 0.1182 | 14.46 | 1200 | 0.4253 | 0.5102 |
| 0.0859 | 19.28 | 1600 | 0.4600 | 0.4866 |
| 0.0693 | 24.1 | 2000 | 0.4030 | 0.4533 |
| 0.0611 | 28.92 | 2400 | 0.4189 | 0.4412 |
| 0.0541 | 33.73 | 2800 | 0.4272 | 0.4380 |
| 0.0478 | 38.55 | 3200 | 0.4537 | 0.4505 |
| 0.0428 | 43.37 | 3600 | 0.4349 | 0.4181 |
| 0.038 | 48.19 | 4000 | 0.4562 | 0.4199 |
| 0.0345 | 53.01 | 4400 | 0.4209 | 0.4310 |
| 0.0316 | 57.83 | 4800 | 0.4336 | 0.4058 |
| 0.0288 | 62.65 | 5200 | 0.4004 | 0.3920 |
| 0.025 | 67.47 | 5600 | 0.4115 | 0.3857 |
| 0.0225 | 72.29 | 6000 | 0.4296 | 0.3948 |
| 0.0182 | 77.11 | 6400 | 0.3963 | 0.3772 |
| 0.0165 | 81.93 | 6800 | 0.3921 | 0.3687 |
| 0.0152 | 86.75 | 7200 | 0.3969 | 0.3592 |
| 0.0133 | 91.57 | 7600 | 0.3803 | 0.3527 |
| 0.0118 | 96.39 | 8000 | 0.3860 | 0.3505 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
73b50fce7acb6a58a4cec4b7cd5c238f
|
miangoar/esm2_t12_35M_UR50D-finetuned-secondary-structure-classification
|
miangoar
|
esm
| 7 | 1 |
transformers
| 0 |
token-classification
| false | true | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,650 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# esm2_t12_35M_UR50D-finetuned-secondary-structure-classification
This model is a fine-tuned version of [facebook/esm2_t12_35M_UR50D](https://huggingface.co/facebook/esm2_t12_35M_UR50D) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.4076
- Train Masked Accuracy: 0.8342
- Validation Loss: 0.4714
- Validation Masked Accuracy: 0.8060
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.0}
- training_precision: float32
### Training results
| Train Loss | Train Masked Accuracy | Validation Loss | Validation Masked Accuracy | Epoch |
|:----------:|:---------------------:|:---------------:|:--------------------------:|:-----:|
| 0.5874 | 0.7454 | 0.4908 | 0.7962 | 0 |
| 0.4503 | 0.8156 | 0.4703 | 0.8043 | 1 |
| 0.4076 | 0.8342 | 0.4714 | 0.8060 | 2 |
### Framework versions
- Transformers 4.25.1
- TensorFlow 2.9.2
- Datasets 2.7.1
- Tokenizers 0.13.2
|
73f1e0199fe1deb2ba621021d978f960
|
theblackcat102/electra-large-webgpt-rm
|
theblackcat102
|
electra
| 10 | 3 |
transformers
| 2 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['openai/webgpt_comparisons']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['webgpt', 'regression', 'reward-model']
| false | true | true | 1,274 | false |
# Reward Model pretrained on openai/webgpt_comparison
Reward model finetuned from existing pretrain model.
Things that aligned with the orignal papers
* Overfits easily using rank loss
* Small learning rate
Different from the papers
* Small model performs bad due to lack of world knowledge, since the validation accuracy doesn't even reach 60%. OpenAI RM had 6B parameters.
* Train using a 80-20 train-validation split on torch AMP settings
Other models I had tried
* bloomz-560m : embedding size doesn't worth the training, since this dataset only contain english prompt
* gpt2-large : not stable
* gpt2-base : not stable
# Performance on validation split
| model | val acc | val loss (rank loss) |
|---|---|---|
| [roberta-base](https://huggingface.co/theblackcat102/roberta-base-webgpt-rm) | 56.21 | 0.71 |
| [roberta-large](https://huggingface.co/theblackcat102/roberta-large-webgpt-rm) | 57.89 | 0.67 |
| [electra-base](https://huggingface.co/theblackcat102/electra-base-webgpt-rm) | 57.02 | 0.70 |
| [electra-large](https://huggingface.co/theblackcat102/electra-large-webgpt-rm) | 58.75 | 0.69 |
Tensorboard logs are located under runs/
# Note:
* You will have to reweight this model output such that the mean rewards equals to 0
|
82de84b1327cb88c7f9e708a34673b36
|
google/multiberts-seed_1-step_1500k
|
google
|
bert
| 8 | 12 |
transformers
| 0 | null | true | true | false |
apache-2.0
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['multiberts', 'multiberts-seed_1', 'multiberts-seed_1-step_1500k']
| false | true | true | 3,527 | false |
# MultiBERTs, Intermediate Checkpoint - Seed 1, Step 1500k
MultiBERTs is a collection of checkpoints and a statistical library to support
robust research on BERT. We provide 25 BERT-base models trained with
similar hyper-parameters as
[the original BERT model](https://github.com/google-research/bert) but
with different random seeds, which causes variations in the initial weights and order of
training instances. The aim is to distinguish findings that apply to a specific
artifact (i.e., a particular instance of the model) from those that apply to the
more general procedure.
We also provide 140 intermediate checkpoints captured
during the course of pre-training (we saved 28 checkpoints for the first 5 runs).
The models were originally released through
[http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our
paper
[The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163).
This is model #1, captured at step 1500k (max: 2000k, i.e., 2M steps).
## Model Description
This model was captured during a reproduction of
[BERT-base uncased](https://github.com/google-research/bert), for English: it
is a Transformers model pretrained on a large corpus of English data, using the
Masked Language Modelling (MLM) and the Next Sentence Prediction (NSP)
objectives.
The intended uses, limitations, training data and training procedure for the fully trained model are similar
to [BERT-base uncased](https://github.com/google-research/bert). Two major
differences with the original model:
* We pre-trained the MultiBERTs models for 2 million steps using sequence
length 512 (instead of 1 million steps using sequence length 128 then 512).
* We used an alternative version of Wikipedia and Books Corpus, initially
collected for [Turc et al., 2019](https://arxiv.org/abs/1908.08962).
This is a best-effort reproduction, and so it is probable that differences with
the original model have gone unnoticed. The performance of MultiBERTs on GLUE after full training is oftentimes comparable to that of original
BERT, but we found significant differences on the dev set of SQuAD (MultiBERTs outperforms original BERT).
See our [technical report](https://arxiv.org/abs/2106.16163) for more details.
### How to use
Using code from
[BERT-base uncased](https://huggingface.co/bert-base-uncased), here is an example based on
Tensorflow:
```
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_1-step_1500k')
model = TFBertModel.from_pretrained("google/multiberts-seed_1-step_1500k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
PyTorch version:
```
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_1-step_1500k')
model = BertModel.from_pretrained("google/multiberts-seed_1-step_1500k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
## Citation info
```bibtex
@article{sellam2021multiberts,
title={The MultiBERTs: BERT Reproductions for Robustness Analysis},
author={Thibault Sellam and Steve Yadlowsky and Jason Wei and Naomi Saphra and Alexander D'Amour and Tal Linzen and Jasmijn Bastings and Iulia Turc and Jacob Eisenstein and Dipanjan Das and Ian Tenney and Ellie Pavlick},
journal={arXiv preprint arXiv:2106.16163},
year={2021}
}
```
|
dbcce8ee071c2181030fa458d3c8e266
|
muhtasham/small-mlm-glue-qnli-target-glue-rte
|
muhtasham
|
bert
| 10 | 4 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,441 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# small-mlm-glue-qnli-target-glue-rte
This model is a fine-tuned version of [muhtasham/small-mlm-glue-qnli](https://huggingface.co/muhtasham/small-mlm-glue-qnli) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.3314
- Accuracy: 0.6101
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4059 | 6.41 | 500 | 1.5081 | 0.6209 |
| 0.0562 | 12.82 | 1000 | 2.5424 | 0.5921 |
| 0.0258 | 19.23 | 1500 | 2.7425 | 0.6209 |
| 0.0161 | 25.64 | 2000 | 3.3314 | 0.6101 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
96ca1d01f1203350b40b9ecbdd2a9b46
|
anas-awadalla/bert-base-uncased-few-shot-k-16-finetuned-squad-seed-42
|
anas-awadalla
|
bert
| 18 | 7 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,055 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-few-shot-k-16-finetuned-squad-seed-42
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 200
### Training results
{'exact_match': 3.207190160832545, 'f1': 6.680463956037787}
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
f77de9bcdf912ca0e9cadaef1199c2c7
|
MayaGalvez/bert-base-multilingual-cased-finetuned-multilingual_pos
|
MayaGalvez
|
bert
| 10 | 11 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 3,510 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-multilingual-cased-finetuned-multilingual-pos
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1999
- Precision: 0.9438
- Recall: 0.9438
- F1: 0.9438
- Accuracy: 0.9541
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 1.0385 | 0.29 | 100 | 0.4411 | 0.8523 | 0.8473 | 0.8498 | 0.8739 |
| 0.3849 | 0.57 | 200 | 0.3275 | 0.8907 | 0.8913 | 0.8910 | 0.9103 |
| 0.2976 | 0.86 | 300 | 0.2879 | 0.9034 | 0.9037 | 0.9036 | 0.9203 |
| 0.2487 | 1.14 | 400 | 0.2599 | 0.9132 | 0.9115 | 0.9123 | 0.9285 |
| 0.2027 | 1.43 | 500 | 0.2444 | 0.9224 | 0.9198 | 0.9211 | 0.9349 |
| 0.1899 | 1.71 | 600 | 0.2287 | 0.9239 | 0.9246 | 0.9243 | 0.9378 |
| 0.18 | 2.0 | 700 | 0.2184 | 0.9282 | 0.9297 | 0.9289 | 0.9418 |
| 0.1351 | 2.29 | 800 | 0.2214 | 0.9297 | 0.9291 | 0.9294 | 0.9424 |
| 0.134 | 2.57 | 900 | 0.2123 | 0.9337 | 0.9333 | 0.9335 | 0.9458 |
| 0.1294 | 2.86 | 1000 | 0.1993 | 0.9359 | 0.9344 | 0.9352 | 0.9476 |
| 0.1156 | 3.14 | 1100 | 0.2018 | 0.9377 | 0.9377 | 0.9377 | 0.9494 |
| 0.1007 | 3.43 | 1200 | 0.2027 | 0.9375 | 0.9384 | 0.9380 | 0.9495 |
| 0.0959 | 3.71 | 1300 | 0.1971 | 0.9387 | 0.9394 | 0.9390 | 0.9505 |
| 0.0982 | 4.0 | 1400 | 0.1953 | 0.9408 | 0.9414 | 0.9411 | 0.9522 |
| 0.0761 | 4.29 | 1500 | 0.1987 | 0.9404 | 0.9412 | 0.9408 | 0.9517 |
| 0.0788 | 4.57 | 1600 | 0.1994 | 0.9405 | 0.9411 | 0.9408 | 0.9518 |
| 0.0755 | 4.86 | 1700 | 0.2009 | 0.9413 | 0.9420 | 0.9417 | 0.9525 |
| 0.0671 | 5.14 | 1800 | 0.2011 | 0.9421 | 0.9423 | 0.9422 | 0.9527 |
| 0.0636 | 5.43 | 1900 | 0.2002 | 0.9428 | 0.9431 | 0.9430 | 0.9532 |
| 0.0628 | 5.71 | 2000 | 0.1993 | 0.9422 | 0.9433 | 0.9428 | 0.9532 |
| 0.0645 | 6.0 | 2100 | 0.1979 | 0.9434 | 0.9430 | 0.9432 | 0.9536 |
| 0.0543 | 6.29 | 2200 | 0.2017 | 0.9427 | 0.9434 | 0.9430 | 0.9532 |
| 0.0558 | 6.57 | 2300 | 0.1992 | 0.9427 | 0.9432 | 0.9430 | 0.9534 |
| 0.0529 | 6.86 | 2400 | 0.1999 | 0.9438 | 0.9438 | 0.9438 | 0.9541 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu102
- Datasets 2.4.0
- Tokenizers 0.12.1
|
4826183159e09ea8157460f6a38bfa91
|
tillschwoerer/distilbert-base-uncased-finetuned-tagesschau-subcategories
|
tillschwoerer
|
distilbert
| 21 | 5 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,743 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-tagesschau-subcategories
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7723
- Accuracy: 0.7267
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.4 | 30 | 1.3433 | 0.5667 |
| No log | 0.8 | 60 | 1.0861 | 0.6933 |
| No log | 1.2 | 90 | 0.9395 | 0.7067 |
| No log | 1.6 | 120 | 0.8647 | 0.68 |
| No log | 2.0 | 150 | 0.8018 | 0.72 |
| No log | 2.4 | 180 | 0.7723 | 0.7267 |
| No log | 2.8 | 210 | 0.7616 | 0.72 |
| No log | 3.2 | 240 | 0.7348 | 0.7067 |
| No log | 3.6 | 270 | 0.7747 | 0.72 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
7b6203bb795313d67299a451a9d0d574
|
Gladiator/distilbert-base-uncased_swag_mqa
|
Gladiator
|
distilbert
| 12 | 0 |
transformers
| 0 |
multiple-choice
| true | false | false |
apache-2.0
| null |
['swag']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,254 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_swag_mqa
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the swag dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8556
- Accuracy: 0.6494
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.9234 | 1.0 | 2000 | 0.8556 | 0.6494 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
059819cb0140c0c3a911c03d957148f5
|
fpuentes/gpt2-galician
|
fpuentes
|
gpt2
| 9 | 3 |
transformers
| 0 |
text-generation
| true | false | false |
apache-2.0
|
['gl']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 888 | false |
Modelo de 125M de parámetros, adestrado e afinado desde un modelo preentrenado (GPT2-Spanish), usando un dataset en galego de 387MB obtido da wikipedia en galego.
No contexto da
**[Resolución do 22 de decembro de 2021 da Secretaría Xeral de Educación e Formación Profesional pola que se convocan premios para o desenvolvemento de proxectos de innovación tecnolóxica ou científica e proxectos de innovación didáctica no ámbito da formación profesional en centros públicos dependentes da Consellería de Cultura, Educación e Universidade](http://www.edu.xunta.gal/fp/sites/fp/files/pi2022__resolucion_de_convocatoria.pdf)**,
baixo o nome de
"*Creación dun modelo de linguaxe adestrado previamente mediante técnicas de autoatención para explorar arquitecturas que permitan o seu uso en solucións de procesamento da linguaxe natural en galego tanto na docencia como na contorna empresarial*"
|
6ebaddbee7b681dff2c5e995f2b31745
|
Tirendaz/sentiment-model-on-imdb-dataset
|
Tirendaz
|
distilbert
| 19 | 6 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['imdb']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,043 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sentiment-model-on-imdb-dataset
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3694
- Accuracy: 0.85
- F1: 0.8544
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
8d25b34e1843191cbf333e326e58dcd2
|
Haakf/allsides_right_text_headline_padded_overfit
|
Haakf
|
distilbert
| 8 | 4 |
transformers
| 0 |
fill-mask
| false | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 2,338 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Haakf/allsides_right_text_headline_padded_overfit
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.8995
- Validation Loss: 1.7970
- Epoch: 19
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -797, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.9722 | 1.8914 | 0 |
| 1.9552 | 1.8628 | 1 |
| 1.9303 | 1.8589 | 2 |
| 1.9311 | 1.8490 | 3 |
| 1.9168 | 1.8710 | 4 |
| 1.8825 | 1.8630 | 5 |
| 1.8841 | 1.8935 | 6 |
| 1.8924 | 1.8301 | 7 |
| 1.8940 | 1.8391 | 8 |
| 1.9021 | 1.8450 | 9 |
| 1.8821 | 1.8698 | 10 |
| 1.8958 | 1.8886 | 11 |
| 1.8891 | 1.8550 | 12 |
| 1.8849 | 1.8777 | 13 |
| 1.8809 | 1.8690 | 14 |
| 1.8859 | 1.8723 | 15 |
| 1.8932 | 1.8602 | 16 |
| 1.9025 | 1.8583 | 17 |
| 1.8853 | 1.7923 | 18 |
| 1.8995 | 1.7970 | 19 |
### Framework versions
- Transformers 4.24.0
- TensorFlow 2.9.2
- Datasets 2.7.1
- Tokenizers 0.13.2
|
1c4245bb79bca8e84f0eda93c96885e3
|
milyiyo/paraphraser-german-mt5-small
|
milyiyo
|
mt5
| 14 | 58 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
|
['de']
|
['paws-x', 'tapaco']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,079 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# paraphraser-german-mt5-small
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the paws-x (de) and tapaco (de) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7678
- Perplexity: 5.86
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 3.7064 | 0.05 | 2000 | 2.0731 |
| 2.8673 | 0.11 | 4000 | 2.0420 |
| 2.6133 | 0.16 | 6000 | 2.0080 |
| 2.4563 | 0.21 | 8000 | 1.9556 |
| 2.385 | 0.27 | 10000 | 1.9090 |
| 2.3122 | 0.32 | 12000 | 1.9127 |
| 2.2775 | 0.38 | 14000 | 1.8658 |
| 2.2323 | 0.43 | 16000 | 1.8407 |
| 2.17 | 0.48 | 18000 | 1.8342 |
| 2.1672 | 0.54 | 20000 | 1.8328 |
| 2.1488 | 0.59 | 22000 | 1.8071 |
| 2.1026 | 0.64 | 24000 | 1.8328 |
| 2.1036 | 0.7 | 26000 | 1.7979 |
| 2.0854 | 0.75 | 28000 | 1.7895 |
| 2.0594 | 0.81 | 30000 | 1.7944 |
| 2.0793 | 0.86 | 32000 | 1.7726 |
| 2.0661 | 0.91 | 34000 | 1.7762 |
| 2.0722 | 0.97 | 36000 | 1.7714 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
2068239718ac0014097bc521a74a4e47
|
pooyaphoenix/distilbert-base-uncased-finetuned-cola
|
pooyaphoenix
|
distilbert
| 13 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,571 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7904
- Matthews Correlation: 0.5227
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.528 | 1.0 | 535 | 0.5180 | 0.4003 |
| 0.3508 | 2.0 | 1070 | 0.5120 | 0.5019 |
| 0.2409 | 3.0 | 1605 | 0.6374 | 0.5128 |
| 0.1806 | 4.0 | 2140 | 0.7904 | 0.5227 |
| 0.1311 | 5.0 | 2675 | 0.8824 | 0.5227 |
### Framework versions
- Transformers 4.12.2
- Pytorch 1.9.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
|
46e7217a07a70ba879055cedd2927df8
|
ali2066/finetuned_sentence_itr3_2e-05_all_27_02_2022-17_44_32
|
ali2066
|
distilbert
| 13 | 6 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,615 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_sentence_itr3_2e-05_all_27_02_2022-17_44_32
This model is a fine-tuned version of [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4095
- Accuracy: 0.8263
- F1: 0.8865
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 195 | 0.3685 | 0.8293 | 0.8911 |
| No log | 2.0 | 390 | 0.3495 | 0.8415 | 0.8992 |
| 0.4065 | 3.0 | 585 | 0.3744 | 0.8463 | 0.9014 |
| 0.4065 | 4.0 | 780 | 0.4260 | 0.8427 | 0.8980 |
| 0.4065 | 5.0 | 975 | 0.4548 | 0.8366 | 0.8940 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.1+cu113
- Datasets 1.18.0
- Tokenizers 0.10.3
|
325725c826e0273c119e51fc8dcfb139
|
Seznam/small-e-czech
|
Seznam
|
electra
| 9 | 4,903 |
transformers
| 6 | null | true | true | false |
cc-by-4.0
|
['cs']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 2,117 | false |
# Small-E-Czech
Small-E-Czech is an [Electra](https://arxiv.org/abs/2003.10555)-small model pretrained on a Czech web corpus created at [Seznam.cz](https://www.seznam.cz/) and introduced in an [IAAI 2022 paper](https://arxiv.org/abs/2112.01810). Like other pretrained models, it should be finetuned on a downstream task of interest before use. At Seznam.cz, it has helped improve [web search ranking](https://blog.seznam.cz/2021/02/vyhledavani-pomoci-vyznamovych-vektoru/), query typo correction or clickbait titles detection. We release it under [CC BY 4.0 license](https://creativecommons.org/licenses/by/4.0/) (i.e. allowing commercial use). To raise an issue, please visit our [github](https://github.com/seznam/small-e-czech).
### How to use the discriminator in transformers
```python
from transformers import ElectraForPreTraining, ElectraTokenizerFast
import torch
discriminator = ElectraForPreTraining.from_pretrained("Seznam/small-e-czech")
tokenizer = ElectraTokenizerFast.from_pretrained("Seznam/small-e-czech")
sentence = "Za hory, za doly, mé zlaté parohy"
fake_sentence = "Za hory, za doly, kočka zlaté parohy"
fake_sentence_tokens = ["[CLS]"] + tokenizer.tokenize(fake_sentence) + ["[SEP]"]
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
outputs = discriminator(fake_inputs)
predictions = torch.nn.Sigmoid()(outputs[0]).cpu().detach().numpy()
for token in fake_sentence_tokens:
print("{:>7s}".format(token), end="")
print()
for prediction in predictions.squeeze():
print("{:7.1f}".format(prediction), end="")
print()
```
In the output we can see the probabilities of particular tokens not belonging in the sentence (i.e. having been faked by the generator) according to the discriminator:
```
[CLS] za hory , za dol ##y , kočka zlaté paro ##hy [SEP]
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.8 0.3 0.2 0.1 0.0
```
### Finetuning
For instructions on how to finetune the model on a new task, see the official HuggingFace transformers [tutorial](https://huggingface.co/transformers/training.html).
|
8145a4b7721103ce9c96a7f22399b5b0
|
abkbvknv/bert-finetuned-ner
|
abkbvknv
|
bert
| 12 | 11 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null |
['conll2003']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 893 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
2133aa02c3f70e9cd147a315438e7d1e
|
fathyshalab/all-roberta-large-v1-banking-5-16-5
|
fathyshalab
|
roberta
| 11 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,512 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# all-roberta-large-v1-banking-5-16-5
This model is a fine-tuned version of [sentence-transformers/all-roberta-large-v1](https://huggingface.co/sentence-transformers/all-roberta-large-v1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2920
- Accuracy: 0.3982
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.7211 | 1.0 | 1 | 2.5748 | 0.2301 |
| 2.2722 | 2.0 | 2 | 2.4566 | 0.3009 |
| 1.9185 | 3.0 | 3 | 2.3596 | 0.3805 |
| 1.667 | 4.0 | 4 | 2.2920 | 0.3982 |
| 1.4704 | 5.0 | 5 | 2.2565 | 0.3982 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
f3aa4580bcdfccdf51924d6ed1203e95
|
aioxlabs/dvoice-swahili
|
aioxlabs
|
wav2vec2
| 8 | 16 |
speechbrain
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['sw']
|
['commonvoice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['CTC', 'pytorch', 'speechbrain', 'Transformer']
| false | true | true | 5,832 | false |
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# wav2vec 2.0 with CTC/Attention trained on DVoice Swahili (No LM)
This repository provides all the necessary tools to perform automatic speech
recognition from an end-to-end system pretrained on a [DVoice-VoxLingua107](https://zenodo.org/record/6342622) Swahili dataset within
SpeechBrain. For a better experience, we encourage you to learn more about
[SpeechBrain](https://speechbrain.github.io).
| DVoice Release | Val. CER | Val. WER | Test CER | Test WER |
|:-------------:|:---------------------------:| -----:| -----:| -----:|
| v2.0 | 8.83 | 22.78 | 9.46 | 23.16 |
# Pipeline description
This ASR system is composed of 2 different but linked blocks:
- Tokenizer (unigram) that transforms words into subword units and trained with
the train transcriptions.
- Acoustic model (wav2vec2.0 + CTC). A pretrained wav2vec 2.0 model ([facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)) is combined with two DNN layers and finetuned on the Darija dataset.
The obtained final acoustic representation is given to the CTC greedy decoder.
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *transcribe_file* if needed.
# Install SpeechBrain
First of all, please install tranformers and SpeechBrain with the following command:
```
pip install speechbrain transformers
```
Please notice that we encourage you to read the SpeechBrain tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
# Transcribing your own audio files (in Swahili)
```python
from speechbrain.pretrained import EncoderASR
asr_model = EncoderASR.from_hparams(source="aioxlabs/dvoice-swahili", savedir="pretrained_models/asr-wav2vec2-dvoice-sw")
asr_model.transcribe_file('./the_path_to_your_audio_file')
```
# Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
# Training
To train the model from scratch, please see our GitHub tutorial [here](https://github.com/AIOXLABS/DVoice).
# Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
# About DVoice
DVoice is a community initiative that aims to provide Africa low resources languages with data and models to facilitate their use of voice technologies. The lack of data on these languages makes it necessary to collect data using methods that are specific to each one. Two different approaches are currently used: the DVoice platforms ([https://dvoice.ma](https://dvoice.ma) and [https://dvoice.sn](https://dvoice.sn)), which are based on Mozilla Common Voice, for collecting authentic recordings from the community, and transfer learning techniques for automatically labeling recordings that are retrived from social medias. The DVoice platform currently manages 7 languages including Darija (Moroccan Arabic dialect) whose dataset appears on this version, Wolof, Mandingo, Serere, Pular, Diola and Soninke.
For this project, AIOX Labs the SI2M Laboratory are joining forces to build the future of technologies together.
# About AIOX Labs
Based in Rabat, London and Paris, AIOX-Labs mobilizes artificial intelligence technologies to meet the business needs and data projects of companies.
- He is at the service of the growth of groups, the optimization of processes or the improvement of the customer experience.
- AIOX-Labs is multi-sector, from fintech to industry, including retail and consumer goods.
- Business ready data products with a solid algorithmic base and adaptability for the specific needs of each client.
- A complementary team made up of doctors in AI and business experts with a solid scientific base and international publications.
Website: [https://www.aiox-labs.com/](https://www.aiox-labs.com/)
# SI2M Laboratory
The Information Systems, Intelligent Systems and Mathematical Modeling Research Laboratory (SI2M) is an academic research laboratory of the National Institute of Statistics and Applied Economics (INSEA). The research areas of the laboratories are Information Systems, Intelligent Systems, Artificial Intelligence, Decision Support, Network and System Security, Mathematical Modelling.
Website: [SI2M Laboratory](https://insea.ac.ma/index.php/pole-recherche/equipe-de-recherche/150-laboratoire-de-recherche-en-systemes-d-information-systemes-intelligents-et-modelisation-mathematique)
# About SpeechBrain
SpeechBrain is an open-source and all-in-one speech toolkit. It is designed to be simple, extremely flexible, and user-friendly. Competitive or state-of-the-art performance is obtained in various domains.
Website: https://speechbrain.github.io/
GitHub: https://github.com/speechbrain/speechbrain
# Referencing SpeechBrain
```
@misc{SB2021,
author = {Ravanelli, Mirco and Parcollet, Titouan and Rouhe, Aku and Plantinga, Peter and Rastorgueva, Elena and Lugosch, Loren and Dawalatabad, Nauman and Ju-Chieh, Chou and Heba, Abdel and Grondin, Francois and Aris, William and Liao, Chien-Feng and Cornell, Samuele and Yeh, Sung-Lin and Na, Hwidong and Gao, Yan and Fu, Szu-Wei and Subakan, Cem and De Mori, Renato and Bengio, Yoshua },
title = {SpeechBrain},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\\\\url{https://github.com/speechbrain/speechbrain}},
}
```
# Acknowledgements
This research was supported through computational resources of HPC-MARWAN (www.marwan.ma/hpc) provided by CNRST, Rabat, Morocco. We deeply thank this institution.
|
5c8951ad65175ee81b9dee63de4071fd
|
malmarz/whisper_small_s5k_b64_nofreeze_mgb2cv11
|
malmarz
|
whisper
| 61 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,528 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-small
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4429
- Wer: 52.7568
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.3629 | 1.03 | 1000 | 0.4917 | 53.1291 |
| 0.289 | 2.06 | 2000 | 0.4747 | 61.3855 |
| 0.2996 | 3.08 | 3000 | 0.4542 | 55.4692 |
| 0.2331 | 4.11 | 4000 | 0.4353 | 51.4917 |
| 0.1566 | 5.14 | 5000 | 0.4429 | 52.7568 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
e0de70fbbad9a68b91936cb3a610eab8
|
luigisaetta/whisper-small-it
|
luigisaetta
|
whisper
| 22 | 2 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['it']
|
['mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer', 'whisper-event']
| true | true | true | 1,714 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-it
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1919
- Wer: 11.72
## Model description
More information needed
## Intended uses & limitations
I have left this model here. BUt the "small3-it", produced later, has better performance.
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 2
- total_train_batch_size: 256
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.1441 | 1.68 | 1000 | 0.1912 | 0.1256 |
| 0.0653 | 3.36 | 2000 | 0.1845 | 0.1182 |
| 0.0374 | 5.03 | 3000 | 0.1919 | 0.1172 |
| 0.0238 | 6.71 | 4000 | 0.2069 | 0.1202 |
| 0.0162 | 8.39 | 5000 | 0.2184 | 0.1223 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
d89545f5d2aa1688abcc63e688b74685
|
google/t5-efficient-small-dl12
|
google
|
t5
| 12 | 9 |
transformers
| 0 |
text2text-generation
| true | true | true |
apache-2.0
|
['en']
|
['c4']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['deep-narrow']
| false | true | true | 6,254 | false |
# T5-Efficient-SMALL-DL12 (Deep-Narrow version)
T5-Efficient-SMALL-DL12 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5).
It is a *pretrained-only* checkpoint and was released with the
paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)**
by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures
of similar parameter count.
To quote the paper:
> We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased
> before considering any other forms of uniform scaling across other dimensions. This is largely due to
> how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a
> tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise,
> a tall base model might also generally more efficient compared to a large model. We generally find
> that, regardless of size, even if absolute performance might increase as we continue to stack layers,
> the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36
> layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e.,
> params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params,
> FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to
> consider.
To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially.
A sequence of word embeddings is therefore processed sequentially by each transformer block.
## Details model architecture
This model checkpoint - **t5-efficient-small-dl12** - is of model type **Small** with the following variations:
- **dl** is **12**
It has **85.7** million parameters and thus requires *ca.* **342.82 MB** of memory in full precision (*fp32*)
or **171.41 MB** of memory in half precision (*fp16* or *bf16*).
A summary of the *original* T5 model architectures can be seen here:
| Model | nl (el/dl) | ff | dm | kv | nh | #Params|
| ----| ---- | ---- | ---- | ---- | ---- | ----|
| Tiny | 4/4 | 1024 | 256 | 32 | 4 | 16M|
| Mini | 4/4 | 1536 | 384 | 32 | 8 | 31M|
| Small | 6/6 | 2048 | 512 | 32 | 8 | 60M|
| Base | 12/12 | 3072 | 768 | 64 | 12 | 220M|
| Large | 24/24 | 4096 | 1024 | 64 | 16 | 738M|
| Xl | 24/24 | 16384 | 1024 | 128 | 32 | 3B|
| XXl | 24/24 | 65536 | 1024 | 128 | 128 | 11B|
whereas the following abbreviations are used:
| Abbreviation | Definition |
| ----| ---- |
| nl | Number of transformer blocks (depth) |
| dm | Dimension of embedding vector (output vector of transformers block) |
| kv | Dimension of key/value projection matrix |
| nh | Number of attention heads |
| ff | Dimension of intermediate vector within transformer block (size of feed-forward projection matrix) |
| el | Number of transformer blocks in the encoder (encoder depth) |
| dl | Number of transformer blocks in the decoder (decoder depth) |
| sh | Signifies that attention heads are shared |
| skv | Signifies that key-values projection matrices are tied |
If a model checkpoint has no specific, *el* or *dl* than both the number of encoder- and decoder layers correspond to *nl*.
## Pre-Training
The checkpoint was pretrained on the [Colossal, Cleaned version of Common Crawl (C4)](https://huggingface.co/datasets/c4) for 524288 steps using
the span-based masked language modeling (MLM) objective.
## Fine-Tuning
**Note**: This model is a **pretrained** checkpoint and has to be fine-tuned for practical usage.
The checkpoint was pretrained in English and is therefore only useful for English NLP tasks.
You can follow on of the following examples on how to fine-tune the model:
*PyTorch*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization)
- [Question Answering](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_seq2seq_qa.py)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*Tensorflow*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*JAX/Flax*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/flax/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/flax/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
## Downstream Performance
TODO: Add table if available
## Computational Complexity
TODO: Add table if available
## More information
We strongly recommend the reader to go carefully through the original paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** to get a more nuanced understanding of this model checkpoint.
As explained in the following [issue](https://github.com/google-research/google-research/issues/986#issuecomment-1035051145), checkpoints including the *sh* or *skv*
model architecture variations have *not* been ported to Transformers as they are probably of limited practical usage and are lacking a more detailed description. Those checkpoints are kept [here](https://huggingface.co/NewT5SharedHeadsSharedKeyValues) as they might be ported potentially in the future.
|
b5c80e88ee2399fb6fe00346070fad06
|
alxdfy/noggles-v21-5900
|
alxdfy
| null | 16 | 3 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 767 | false |
### noggles_v21_5900 Dreambooth model trained by alxdfy with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
Sample pictures of this concept:

|
a3737015e8d0100fdeca8744955a0794
|
nc33/finetune_deberta_small_model
|
nc33
|
deberta-v2
| 15 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null |
['super_glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,367 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetune_deberta_small_model
This model is a fine-tuned version of [nc33/finetune_deberta_small_model](https://huggingface.co/nc33/finetune_deberta_small_model) on the super_glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6788
- Accuracy: 0.8021
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3666 | 1.0 | 590 | 0.5625 | 0.8003 |
| 0.2501 | 2.0 | 1180 | 0.6762 | 0.7976 |
| 0.2343 | 3.0 | 1770 | 0.6788 | 0.8021 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
99717ae010bc9e03cb4a459ca8ec44a6
|
marcop/musika_techno
|
marcop
| null | 8 | 0 |
keras
| 1 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['audio', 'music', 'generation', 'tensorflow']
| false | true | true | 1,089 | false |
# Musika Techno Model
Pretrained Techno GAN model for the [Musika system](https://github.com/marcoppasini/musika) for fast infinite waveform music generation.
Introduced in [this paper](https://arxiv.org/abs/2208.08706).
## Model description
This pretrained GAN system consists of a ResNet-style generator and discriminator. During training, stability is controlled by adapting the strength of gradient penalty regularization on-the-fly. The gradient penalty weighting term is contained in *switch.npy*. The generator is conditioned on a latent coordinate system to produce samples of arbitrary length. The latent representations produced by the generator are then passed to a decoder which converts them into waveform audio.
The generator has a context window of about 12 seconds of audio.
### How to use
This pretrained Techno GAN system is automatically downloaded at the first execution of the system. Try Musika [here](https://github.com/marcoppasini/musika)!
## Training data
The Techno GAN system was trained on 1000 hours of music with the *techno* tag from *jamendo.com*.
|
e1d88b71620ac2b7f027e86ed4350195
|
pinot/wav2vec2-large-xls-r-300m-ja-colab
|
pinot
|
wav2vec2
| 23 | 6 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice_10_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,910 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-ja-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice_10_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1407
- Wer: 0.2456
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 637 | 5.3238 | 0.9663 |
| No log | 2.0 | 1274 | 4.1785 | 0.7662 |
| No log | 3.0 | 1911 | 2.3701 | 0.4983 |
| No log | 4.0 | 2548 | 1.8443 | 0.4090 |
| 6.5781 | 5.0 | 3185 | 1.4892 | 0.3363 |
| 6.5781 | 6.0 | 3822 | 1.3229 | 0.2995 |
| 6.5781 | 7.0 | 4459 | 1.2418 | 0.2814 |
| 6.5781 | 8.0 | 5096 | 1.1928 | 0.2647 |
| 1.0184 | 9.0 | 5733 | 1.1584 | 0.2520 |
| 1.0184 | 10.0 | 6370 | 1.1407 | 0.2456 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.10.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
53ad0726b0eba90d7c59b488149907a8
|
ScandinavianMrT/gpt2_prefinetune_SARC_1epoch_withcontext
|
ScandinavianMrT
|
gpt2
| 11 | 5 |
transformers
| 0 |
text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,140 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2_prefinetune_SARC_1epoch_withcontext
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.7899
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 3.8788 | 1.0 | 14028 | 3.7899 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
273bdcfc2b5c263a6a489844d0b38e78
|
sd-dreambooth-library/spacecat
|
sd-dreambooth-library
| null | 28 | 9 |
diffusers
| 0 | null | false | false | false |
mit
| null | null | null | 2 | 2 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,860 | false |
### spacecat on Stable Diffusion via Dreambooth
#### model by Unev3n
This your the Stable Diffusion model fine-tuned the spacecat concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks spacecat**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
Here are the images used for training this concept:










|
c55858028a3a27802d653695ae3bd60d
|
NYTK/translation-bart-en-hu
|
NYTK
|
bart
| 9 | 36 |
transformers
| 0 |
translation
| true | false | false |
apache-2.0
|
['en', 'hu']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 1,160 | false |
# BART Translation model
For further models, scripts and details, see [our repository](https://github.com/nytud/machine-translation) or [our demo site](https://juniper.nytud.hu/demo/nlp).
- Source language: English
- Target language: Hungarian
- Pretrained on English WikiText-103 and Hungarian Wikipedia
- Finetuned on subcorpora from OPUS
- Segments: 56.837.602
## Limitations
- tokenized input text (tokenizer: [HuSpaCy](https://huggingface.co/huspacy))
## Results
| Model | BLEU | chrF-3 |
| ------------- | ------------- | ------------- |
| Google en-hu | 25.30 | 54.08 |
| **BART-base-enhu** | **34.38** | **58.88** |
| Google hu-en| 34.48 | 59.59 |
| **BART-base-huen** | **38.03** | **61,37** |
## Citation
If you use this model, please cite the following paper:
```
@inproceedings {yang-bart,
title = {{BARTerezzünk! Messze, messze, messze a világtól, - BART kísérleti modellek magyar nyelvre}},
booktitle = {XVIII. Magyar Számítógépes Nyelvészeti Konferencia},
year = {2022},
publisher = {Szegedi Tudományegyetem, Informatikai Intézet},
address = {Szeged, Magyarország},
author = {Yang, Zijian Győző},
pages = {15--29}
}
```
|
459e23f448b49b2f3204512d67860df9
|
Helsinki-NLP/opus-mt-tr-es
|
Helsinki-NLP
|
marian
| 10 | 111 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 770 | false |
### opus-mt-tr-es
* source languages: tr
* target languages: es
* OPUS readme: [tr-es](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/tr-es/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-26.zip](https://object.pouta.csc.fi/OPUS-MT-models/tr-es/opus-2020-01-26.zip)
* test set translations: [opus-2020-01-26.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/tr-es/opus-2020-01-26.test.txt)
* test set scores: [opus-2020-01-26.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/tr-es/opus-2020-01-26.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.tr.es | 56.3 | 0.722 |
|
0819fbc5fa91665d251d099b3543ca22
|
alikanakar/wav2vec2-large-xls-r-300m-turkish-colab-2
|
alikanakar
|
wav2vec2
| 13 | 8 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,553 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-turkish-colab-2
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4152
- Wer: 0.3686
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.9382 | 7.4 | 400 | 0.6296 | 0.7016 |
| 0.2837 | 14.81 | 800 | 0.4440 | 0.5161 |
| 0.1185 | 22.22 | 1200 | 0.4217 | 0.4007 |
| 0.0701 | 29.62 | 1600 | 0.4152 | 0.3686 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
943c38409683f3169c7eb19e69fcd017
|
nateraw/huggingpics-package-demo-2
|
nateraw
|
vit
| 12 | 13 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['image-classification', 'huggingpics', 'generated_from_trainer']
| false | true | true | 1,429 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# huggingpics-package-demo-2
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3761
- Acc: 0.9403
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Acc |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.0328 | 1.0 | 24 | 0.9442 | 0.7463 |
| 0.8742 | 2.0 | 48 | 0.7099 | 0.9403 |
| 0.6451 | 3.0 | 72 | 0.5050 | 0.9403 |
| 0.508 | 4.0 | 96 | 0.3761 | 0.9403 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0+cu111
- Tokenizers 0.10.3
|
df2c043ccfdc7e27258341761cab6e19
|
HPL/roberta-large-unlabeled-labeled-gab-reddit-task-semeval2023-t10-210000sample
|
HPL
|
roberta
| 11 | 314 |
transformers
| 0 |
fill-mask
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,101 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-large-unlabeled-labeled-gab-reddit-task-semeval2023-t10-210000sample
This model is a fine-tuned version of [HPL/roberta-large-unlabeled-labeled-gab-reddit-task-semeval2023-t10-150000sample](https://huggingface.co/HPL/roberta-large-unlabeled-labeled-gab-reddit-task-semeval2023-t10-150000sample) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.13.0
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.10.3
|
db307b5656793a6b1dfe70e516e1332c
|
HIZ/aichan_pick
|
HIZ
| null | 5 | 0 | null | 6 | null | false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 845 | false |
Stable diffusion models removed EMA version from the ai image channel and elsewhere.
Feel free to download.
<font size="6">**Treebark**</font>
This model was made by 나무껍질맛 in arcalive AI channel.
1. Anything V.3, add-difference 0.2 (animefull prevgood - animesfw prevgood)
2. Add-difference 1 (Gape60 - Animefull)
3. U-net merge with BasilMix (1,0.9,0.7,0.5,0.3,0.1,1,1,1,1,1,1,0,0,0,0,0,0,0,0.1,0.3,0.5,0.7,0.9,1_base alpha 0)
4. Add-difference 0.2 (SXD v1.0 - SD1.5)
Treebark is more **gape** style than other 2.5D style models.
<font size="6">**AniDosmix**</font>
This model was made by DiaryOfSta in arcalive AI channel.
And the original model is uploaded on https://civitai.com/models/6437/anidosmix
I permitted uploading this pruned fp16 version.
AniDosmix is a 2.5D style model and balanced for making people and **background**.
|
e40f4d0dd3a4aa8490ddc07b7ed9979f
|
DOOGLAK/Article_500v1_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
|
bert
| 13 | 5 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null |
['article500v1_wikigold_split']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,561 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_500v1_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article500v1_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2058
- Precision: 0.6615
- Recall: 0.6746
- F1: 0.6680
- Accuracy: 0.9326
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 58 | 0.3029 | 0.3539 | 0.3790 | 0.3660 | 0.8967 |
| No log | 2.0 | 116 | 0.2191 | 0.6223 | 0.6488 | 0.6353 | 0.9262 |
| No log | 3.0 | 174 | 0.2058 | 0.6615 | 0.6746 | 0.6680 | 0.9326 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
216d020f08d3f36e8ec06d4c994ddade
|
ali2066/finetuned_token_2e-05_all_16_02_2022-15_50_54
|
ali2066
|
distilbert
| 13 | 10 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,791 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_token_2e-05_all_16_02_2022-15_50_54
This model is a fine-tuned version of [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1750
- Precision: 0.3286
- Recall: 0.3334
- F1: 0.3310
- Accuracy: 0.9447
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 38 | 0.3355 | 0.0975 | 0.2358 | 0.1380 | 0.8361 |
| No log | 2.0 | 76 | 0.3177 | 0.1359 | 0.2709 | 0.1810 | 0.8398 |
| No log | 3.0 | 114 | 0.3000 | 0.1542 | 0.3043 | 0.2047 | 0.8471 |
| No log | 4.0 | 152 | 0.3033 | 0.1589 | 0.3060 | 0.2091 | 0.8434 |
| No log | 5.0 | 190 | 0.3029 | 0.1629 | 0.3110 | 0.2138 | 0.8447 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.1+cu113
- Datasets 1.18.0
- Tokenizers 0.10.3
|
0cb4c3d371ea45d673cf514a6639c1dc
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.