
repo_id
stringlengths 4
110
| author
stringlengths 2
27
⌀ | model_type
stringlengths 2
29
⌀ | files_per_repo
int64 2
15.4k
| downloads_30d
int64 0
19.9M
| library
stringlengths 2
37
⌀ | likes
int64 0
4.34k
| pipeline
stringlengths 5
30
⌀ | pytorch
bool 2
classes | tensorflow
bool 2
classes | jax
bool 2
classes | license
stringlengths 2
30
| languages
stringlengths 4
1.63k
⌀ | datasets
stringlengths 2
2.58k
⌀ | co2
stringclasses 29
values | prs_count
int64 0
125
| prs_open
int64 0
120
| prs_merged
int64 0
15
| prs_closed
int64 0
28
| discussions_count
int64 0
218
| discussions_open
int64 0
148
| discussions_closed
int64 0
70
| tags
stringlengths 2
513
| has_model_index
bool 2
classes | has_metadata
bool 1
class | has_text
bool 1
class | text_length
int64 401
598k
| is_nc
bool 1
class | readme
stringlengths 0
598k
| hash
stringlengths 32
32
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
DrishtiSharma/wav2vec2-large-xls-r-300m-mr-v2
|
DrishtiSharma
|
wav2vec2
| 12 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['mr']
|
['mozilla-foundation/common_voice_8_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer', 'mr', 'robust-speech-event', 'hf-asr-leaderboard']
| true | true | true | 3,083 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-mr-v2
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - MR dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8729
- Wer: 0.4942
### Evaluation Commands
1. To evaluate on mozilla-foundation/common_voice_8_0 with test split
python eval.py --model_id DrishtiSharma/wav2vec2-large-xls-r-300m-mr-v2 --dataset mozilla-foundation/common_voice_8_0 --config mr --split test --log_outputs
2. To evaluate on speech-recognition-community-v2/dev_data
python eval.py --model_id DrishtiSharma/wav2vec2-large-xls-r-300m-mr-v2 --dataset speech-recognition-community-v2/dev_data --config mr --split validation --chunk_length_s 10 --stride_length_s 1
Note: Marathi language not found in speech-recognition-community-v2/dev_data!
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.000333
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 200
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:------:|
| 8.4934 | 9.09 | 200 | 3.7326 | 1.0 |
| 3.4234 | 18.18 | 400 | 3.3383 | 0.9996 |
| 3.2628 | 27.27 | 600 | 2.7482 | 0.9992 |
| 1.7743 | 36.36 | 800 | 0.6755 | 0.6787 |
| 1.0346 | 45.45 | 1000 | 0.6067 | 0.6193 |
| 0.8137 | 54.55 | 1200 | 0.6228 | 0.5612 |
| 0.6637 | 63.64 | 1400 | 0.5976 | 0.5495 |
| 0.5563 | 72.73 | 1600 | 0.7009 | 0.5383 |
| 0.4844 | 81.82 | 1800 | 0.6662 | 0.5287 |
| 0.4057 | 90.91 | 2000 | 0.6911 | 0.5303 |
| 0.3582 | 100.0 | 2200 | 0.7207 | 0.5327 |
| 0.3163 | 109.09 | 2400 | 0.7107 | 0.5118 |
| 0.2761 | 118.18 | 2600 | 0.7538 | 0.5118 |
| 0.2415 | 127.27 | 2800 | 0.7850 | 0.5178 |
| 0.2127 | 136.36 | 3000 | 0.8016 | 0.5034 |
| 0.1873 | 145.45 | 3200 | 0.8302 | 0.5187 |
| 0.1723 | 154.55 | 3400 | 0.9085 | 0.5223 |
| 0.1498 | 163.64 | 3600 | 0.8396 | 0.5126 |
| 0.1425 | 172.73 | 3800 | 0.8776 | 0.5094 |
| 0.1258 | 181.82 | 4000 | 0.8651 | 0.5014 |
| 0.117 | 190.91 | 4200 | 0.8772 | 0.4970 |
| 0.1093 | 200.0 | 4400 | 0.8729 | 0.4942 |
### Framework versions
- Transformers 4.16.1
- Pytorch 1.10.0+cu111
- Datasets 1.18.2
- Tokenizers 0.11.0
|
6e83d3525f7b641e6503765a14894a23
|
theojolliffe/bart-cnn-science-v3-e1-v4-e4-manual
|
theojolliffe
|
bart
| 13 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,790 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-cnn-science-v3-e1-v4-e4-manual
This model is a fine-tuned version of [theojolliffe/bart-cnn-science-v3-e1](https://huggingface.co/theojolliffe/bart-cnn-science-v3-e1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2615
- Rouge1: 53.36
- Rouge2: 32.0237
- Rougel: 33.2835
- Rougelsum: 50.7455
- Gen Len: 142.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 42 | 1.0675 | 51.743 | 31.3774 | 34.1939 | 48.7234 | 142.0 |
| No log | 2.0 | 84 | 1.0669 | 49.4166 | 28.1438 | 30.188 | 46.0289 | 142.0 |
| No log | 3.0 | 126 | 1.1799 | 52.6909 | 31.0174 | 35.441 | 50.0351 | 142.0 |
| No log | 4.0 | 168 | 1.2615 | 53.36 | 32.0237 | 33.2835 | 50.7455 | 142.0 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
ff8ab05385267dd05553bcb7c7e386d3
|
sujathass/distilbert-base-uncased-finetuned-cola
|
sujathass
|
distilbert
| 19 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,497 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5532
- Matthews Correlation: 0.5452
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5248 | 1.0 | 535 | 0.5479 | 0.3922 |
| 0.3503 | 2.0 | 1070 | 0.5148 | 0.4822 |
| 0.2386 | 3.0 | 1605 | 0.5532 | 0.5452 |
| 0.1773 | 4.0 | 2140 | 0.6818 | 0.5282 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
130df59874821f2d9ebf48d538947de5
|
jonatasgrosman/exp_w2v2t_es_unispeech_s767
|
jonatasgrosman
|
unispeech
| 10 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['es']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'es']
| false | true | true | 469 | false |
# exp_w2v2t_es_unispeech_s767
Fine-tuned [microsoft/unispeech-large-1500h-cv](https://huggingface.co/microsoft/unispeech-large-1500h-cv) for speech recognition using the train split of [Common Voice 7.0 (es)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
063f4b69e511feb90556fe95384c590c
|
rishabhjain16/whisper_large_to_pf10h
|
rishabhjain16
|
whisper
| 23 | 2 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,711 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-large
This model is a fine-tuned version of [openai/whisper-large](https://huggingface.co/openai/whisper-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1412
- Wer: 6.7893
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0475 | 2.03 | 500 | 0.1095 | 62.6591 |
| 0.0201 | 5.01 | 1000 | 0.1225 | 16.9285 |
| 0.0044 | 7.03 | 1500 | 0.1312 | 3.6701 |
| 0.0026 | 10.01 | 2000 | 0.1278 | 7.9506 |
| 0.0001 | 12.04 | 2500 | 0.1323 | 17.9186 |
| 0.0001 | 15.02 | 3000 | 0.1386 | 16.3031 |
| 0.0001 | 17.05 | 3500 | 0.1403 | 6.7074 |
| 0.0 | 20.02 | 4000 | 0.1412 | 6.7893 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.9.1.dev0
- Tokenizers 0.13.2
|
75ea4a3b12ef02bafcfa00fcab57474a
|
jayantapaul888/vit-base-patch16-224-finetuned-memes-v3
|
jayantapaul888
|
vit
| 12 | 9 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['imagefolder']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,527 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-finetuned-memes-v3
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3862
- Accuracy: 0.8478
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00012
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5649 | 0.99 | 40 | 0.6342 | 0.7488 |
| 0.3083 | 1.99 | 80 | 0.4146 | 0.8423 |
| 0.1563 | 2.99 | 120 | 0.3900 | 0.8547 |
| 0.0827 | 3.99 | 160 | 0.3862 | 0.8478 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
9c7e55749f4cdff0a07234ac3edfa792
|
ali2066/finetuned_token_3e-05_all_16_02_2022-16_25_56
|
ali2066
|
distilbert
| 13 | 10 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,791 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_token_3e-05_all_16_02_2022-16_25_56
This model is a fine-tuned version of [distilbert-base-uncased-finetuned-sst-2-english](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1630
- Precision: 0.3684
- Recall: 0.3714
- F1: 0.3699
- Accuracy: 0.9482
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 38 | 0.3339 | 0.1075 | 0.2324 | 0.1470 | 0.8379 |
| No log | 2.0 | 76 | 0.3074 | 0.1589 | 0.2926 | 0.2060 | 0.8489 |
| No log | 3.0 | 114 | 0.2914 | 0.2142 | 0.3278 | 0.2591 | 0.8591 |
| No log | 4.0 | 152 | 0.2983 | 0.1951 | 0.3595 | 0.2529 | 0.8454 |
| No log | 5.0 | 190 | 0.2997 | 0.1851 | 0.3528 | 0.2428 | 0.8487 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.1+cu113
- Datasets 1.18.0
- Tokenizers 0.10.3
|
af79ee7cbeb622fde1968682e8e9da46
|
osanseviero/tips
|
osanseviero
| null | 3 | 0 |
sklearn
| 0 | null | false | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 8,875 | false |
## Baseline Model trained on tips to predict sex
Metrics of the best model:
accuracy 0.647364
average_precision 0.481257
roc_auc 0.608805
recall_macro 0.588751
f1_macro 0.588435
Name: MultinomialNB(), dtype: float64
See model plot below:
<style>#sk-container-id-2 {color: black;background-color: white;}#sk-container-id-2 pre{padding: 0;}#sk-container-id-2 div.sk-toggleable {background-color: white;}#sk-container-id-2 label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-container-id-2 label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-container-id-2 label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-container-id-2 div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-container-id-2 div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-container-id-2 div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-container-id-2 input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-container-id-2 input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-container-id-2 div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-2 div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-2 input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-container-id-2 div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-container-id-2 div.sk-estimator:hover {background-color: #d4ebff;}#sk-container-id-2 div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-container-id-2 div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-2 div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: 0;}#sk-container-id-2 div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;position: relative;}#sk-container-id-2 div.sk-item {position: relative;z-index: 1;}#sk-container-id-2 div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;position: relative;}#sk-container-id-2 div.sk-item::before, #sk-container-id-2 div.sk-parallel-item::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: -1;}#sk-container-id-2 div.sk-parallel-item {display: flex;flex-direction: column;z-index: 1;position: relative;background-color: white;}#sk-container-id-2 div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-container-id-2 div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-container-id-2 div.sk-parallel-item:only-child::after {width: 0;}#sk-container-id-2 div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;}#sk-container-id-2 div.sk-label label {font-family: monospace;font-weight: bold;display: inline-block;line-height: 1.2em;}#sk-container-id-2 div.sk-label-container {text-align: center;}#sk-container-id-2 div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-container-id-2 div.sk-text-repr-fallback {display: none;}</style><div id="sk-container-id-2" class="sk-top-container"><div class="sk-text-repr-fallback"><pre>Pipeline(steps=[('easypreprocessor',EasyPreprocessor(types= continuous dirty_float low_card_int ... date free_string useless
total_bill True False False ... False False False
tip True False False ... False False False
smoker False False False ... False False False
day False False False ... False False False
time False False False ... False False False
size False False True ... False False False[6 rows x 7 columns])),('pipeline',Pipeline(steps=[('minmaxscaler', MinMaxScaler()),('multinomialnb', MultinomialNB())]))])</pre><b>In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. <br />On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.</b></div><div class="sk-container" hidden><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-4" type="checkbox" ><label for="sk-estimator-id-4" class="sk-toggleable__label sk-toggleable__label-arrow">Pipeline</label><div class="sk-toggleable__content"><pre>Pipeline(steps=[('easypreprocessor',EasyPreprocessor(types= continuous dirty_float low_card_int ... date free_string useless
total_bill True False False ... False False False
tip True False False ... False False False
smoker False False False ... False False False
day False False False ... False False False
time False False False ... False False False
size False False True ... False False False[6 rows x 7 columns])),('pipeline',Pipeline(steps=[('minmaxscaler', MinMaxScaler()),('multinomialnb', MultinomialNB())]))])</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-5" type="checkbox" ><label for="sk-estimator-id-5" class="sk-toggleable__label sk-toggleable__label-arrow">EasyPreprocessor</label><div class="sk-toggleable__content"><pre>EasyPreprocessor(types= continuous dirty_float low_card_int ... date free_string useless
total_bill True False False ... False False False
tip True False False ... False False False
smoker False False False ... False False False
day False False False ... False False False
time False False False ... False False False
size False False True ... False False False[6 rows x 7 columns])</pre></div></div></div><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-6" type="checkbox" ><label for="sk-estimator-id-6" class="sk-toggleable__label sk-toggleable__label-arrow">pipeline: Pipeline</label><div class="sk-toggleable__content"><pre>Pipeline(steps=[('minmaxscaler', MinMaxScaler()),('multinomialnb', MultinomialNB())])</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-7" type="checkbox" ><label for="sk-estimator-id-7" class="sk-toggleable__label sk-toggleable__label-arrow">MinMaxScaler</label><div class="sk-toggleable__content"><pre>MinMaxScaler()</pre></div></div></div><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-8" type="checkbox" ><label for="sk-estimator-id-8" class="sk-toggleable__label sk-toggleable__label-arrow">MultinomialNB</label><div class="sk-toggleable__content"><pre>MultinomialNB()</pre></div></div></div></div></div></div></div></div></div>
|
a714059d8d88f26113ba49c67eafc6a1
|
varadhbhatnagar/fc-claim-det-DPEGASUS
|
varadhbhatnagar
|
pegasus
| 10 | 6 |
transformers
| 0 |
summarization
| true | false | false |
apache-2.0
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 6,250 | false |
# Model Card for Pegasus for Claim Summarization
<!-- Provide a quick summary of what the model is/does. -->
This model can be used to summarize noisy claims on social media into clean and concise claims which can be used for downstream tasks in a fact-checking pipeline.
# Model Details
This is the fine-tuned D PEGASUS model with 'No Preprocessing (NP)' detailed in Table 2 in the paper.
This was the best performing model at the time of experimentation.
## Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Varad Bhatnagar, Diptesh Kanojia and Kameswari Chebrolu
- **Model type:** Summarization
- **Language(s) (NLP):** English
- **Finetuned from model:** https://huggingface.co/sshleifer/distill-pegasus-cnn-16-4
## Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/varadhbhatnagar/FC-Claim-Det
- **Paper:** https://aclanthology.org/2022.coling-1.259/
## Tokenizer
Same as https://huggingface.co/sshleifer/distill-pegasus-cnn-16-4
# Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
## Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
English to English summarization on noisy fact-checking worthy claims found on social media.
## Downstream Use
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
Can be used for other tasks in a fact-checking pipeline such as claim matching and evidence retrieval.
# Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
As the [Google Fact Check Explorer](https://toolbox.google.com/factcheck/explorer) is an ever growing and evolving system, the current Retrieval@k results may not exactly match
those in the corresponding paper as those experiments were conducted in the month of April and May 2022.
# Training Details
## Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[Data](https://github.com/varadhbhatnagar/FC-Claim-Det/blob/main/public_data/released_data.csv)
## Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
Finetuning the pretrained Distilled PEGASUS model on the 567 pairs released in our paper.
### Preprocessing
No preprocessing of input is done while fine-tuning this model.
# Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
Retrieval@5 and Mean Reciprocal Recall scores are reported.
## Results
Retrieval@5 = 34.91
MRR = 0.3
Further details can be found in the paper.
# Other Models from same work
[DBART](https://huggingface.co/varadhbhatnagar/fc-claim-det-DBART)
[T5-Base](https://huggingface.co/varadhbhatnagar/fc-claim-det-T5-base)
# Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
```
@inproceedings{bhatnagar-etal-2022-harnessing,
title = "Harnessing Abstractive Summarization for Fact-Checked Claim Detection",
author = "Bhatnagar, Varad and
Kanojia, Diptesh and
Chebrolu, Kameswari",
booktitle = "Proceedings of the 29th International Conference on Computational Linguistics",
month = oct,
year = "2022",
address = "Gyeongju, Republic of Korea",
publisher = "International Committee on Computational Linguistics",
url = "https://aclanthology.org/2022.coling-1.259",
pages = "2934--2945",
abstract = "Social media platforms have become new battlegrounds for anti-social elements, with misinformation being the weapon of choice. Fact-checking organizations try to debunk as many claims as possible while staying true to their journalistic processes but cannot cope with its rapid dissemination. We believe that the solution lies in partial automation of the fact-checking life cycle, saving human time for tasks which require high cognition. We propose a new workflow for efficiently detecting previously fact-checked claims that uses abstractive summarization to generate crisp queries. These queries can then be executed on a general-purpose retrieval system associated with a collection of previously fact-checked claims. We curate an abstractive text summarization dataset comprising noisy claims from Twitter and their gold summaries. It is shown that retrieval performance improves 2x by using popular out-of-the-box summarization models and 3x by fine-tuning them on the accompanying dataset compared to verbatim querying. Our approach achieves Recall@5 and MRR of 35{\%} and 0.3, compared to baseline values of 10{\%} and 0.1, respectively. Our dataset, code, and models are available publicly: https://github.com/varadhbhatnagar/FC-Claim-Det/.",
}
```
# Model Card Authors
Varad Bhatnagar
# Model Card Contact
Email: varadhbhatnagar@gmail.com
# How to Get Started with the Model
Use the code below to get started with the model.
```
from transformers import PegasusForConditionalGeneration, PegasusTokenizerFast
tokeizer = PegasusTokenizerFast.from_pretrained('varadhbhatnagar/fc-claim-det-DPEGASUS')
model = PegasusForConditionalGeneration.from_pretrained('varadhbhatnagar/fc-claim-det-DPEGASUS')
text ='world health organisation has taken a complete u turn and said that corona patients neither need isolate nor quarantine nor social distance and it can not even transmit from one patient to another'
tokenized_text = tokeizer.encode(text, return_tensors="pt")
summary_ids = model.generate(tokenized_text,
num_beams=6,
no_repeat_ngram_size=2,
min_length=5,
max_length=15,
early_stopping=True)
output = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
```
|
5b7c94c80f74d25dfe6e1045cdb944b5
|
yoavgur/gpt2-bash-history-baseline2
|
yoavgur
|
gpt2
| 13 | 4 |
transformers
| 0 |
text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,333 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-bash-history-baseline2
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6480
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 158 | 1.8653 |
| No log | 2.0 | 316 | 1.7574 |
| No log | 3.0 | 474 | 1.6939 |
| 1.9705 | 4.0 | 632 | 1.6597 |
| 1.9705 | 5.0 | 790 | 1.6480 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.6
|
ed795f6ccd0045793f6ba5368b572a09
|
microsoft/beit-base-patch16-384
|
microsoft
|
beit
| 6 | 387 |
transformers
| 0 |
image-classification
| true | false | true |
apache-2.0
| null |
['imagenet', 'imagenet-21k']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['image-classification', 'vision']
| false | true | true | 5,476 | false |
# BEiT (base-sized model, fine-tuned on ImageNet-1k)
BEiT model pre-trained in a self-supervised fashion on ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 384x384. It was introduced in the paper [BEIT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The BEiT model is a Vision Transformer (ViT), which is a transformer encoder model (BERT-like). In contrast to the original ViT model, BEiT is pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. The pre-training objective for the model is to predict visual tokens from the encoder of OpenAI's DALL-E's VQ-VAE, based on masked patches.
Next, the model was fine-tuned in a supervised fashion on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. Contrary to the original ViT models, BEiT models do use relative position embeddings (similar to T5) instead of absolute position embeddings, and perform classification of images by mean-pooling the final hidden states of the patches, instead of placing a linear layer on top of the final hidden state of the [CLS] token.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image. Alternatively, one can mean-pool the final hidden states of the patch embeddings, and place a linear layer on top of that.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=microsoft/beit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import BeitFeatureExtractor, BeitForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = BeitFeatureExtractor.from_pretrained('microsoft/beit-base-patch16-384')
model = BeitForImageClassification.from_pretrained('microsoft/beit-base-patch16-384')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The BEiT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/microsoft/unilm/blob/master/beit/datasets.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
For all pre-training related hyperparameters, we refer to page 15 of the [original paper](https://arxiv.org/abs/2106.08254).
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```@article{DBLP:journals/corr/abs-2106-08254,
author = {Hangbo Bao and
Li Dong and
Furu Wei},
title = {BEiT: {BERT} Pre-Training of Image Transformers},
journal = {CoRR},
volume = {abs/2106.08254},
year = {2021},
url = {https://arxiv.org/abs/2106.08254},
archivePrefix = {arXiv},
eprint = {2106.08254},
timestamp = {Tue, 29 Jun 2021 16:55:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-08254.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
```
|
1dbbc509c03ae588eaa3dffd2e241f61
|
WillHeld/bert-base-cased-stsb
|
WillHeld
|
bert
| 14 | 6 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,896 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-stsb
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the GLUE STSB dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4322
- Pearson: 0.9007
- Spearmanr: 0.8963
- Combined Score: 0.8985
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.06
- num_epochs: 10.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearson | Spearmanr | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:---------:|:--------------:|
| 1.6464 | 1.39 | 500 | 0.5662 | 0.8820 | 0.8814 | 0.8817 |
| 0.3329 | 2.78 | 1000 | 0.5070 | 0.8913 | 0.8883 | 0.8898 |
| 0.173 | 4.17 | 1500 | 0.4465 | 0.8988 | 0.8943 | 0.8966 |
| 0.1085 | 5.56 | 2000 | 0.4537 | 0.8958 | 0.8917 | 0.8937 |
| 0.0816 | 6.94 | 2500 | 0.4594 | 0.8977 | 0.8933 | 0.8955 |
| 0.0621 | 8.33 | 3000 | 0.4450 | 0.8997 | 0.8950 | 0.8974 |
| 0.0519 | 9.72 | 3500 | 0.4322 | 0.9007 | 0.8963 | 0.8985 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.7.1
- Datasets 1.18.3
- Tokenizers 0.11.6
|
1e0e5f307fccadc9cfac79f68b689af7
|
KoboldAI/fairseq-dense-6.7B-Shinen
|
KoboldAI
|
xglm
| 8 | 2,536 |
transformers
| 0 |
text-generation
| true | false | false |
mit
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,270 | false |
# Fairseq-dense 6.7B - Shinen
## Model Description
Fairseq-dense 6.7B-Shinen is a finetune created using Fairseq's MoE dense model. Compared to GPT-Neo-2.7-Horni, this model is much heavier on the sexual content.
**Warning: THIS model is NOT suitable for use by minors. The model will output X-rated content.**
## Training data
The training data contains user-generated stories from sexstories.com. All stories are tagged using the following way:
```
[Theme: <theme1>, <theme2> ,<theme3>]
<Story goes here>
```
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='KoboldAI/fairseq-dense-6.7B-Shinen')
>>> generator("She was staring at me", do_sample=True, min_length=50)
[{'generated_text': 'She was staring at me with a look that said it all. She wanted me so badly tonight that I wanted'}]
```
### Limitations and Biases
Based on known problems with NLP technology, potential relevant factors include bias (gender, profession, race and religion).
### BibTeX entry and citation info
```
Artetxe et al. (2021): Efficient Large Scale Language Modeling with Mixtures of Experts
```
|
e298e6401a1be407af94527004b4109f
|
Yuang/unilm-base-chinese-news-sum
|
Yuang
|
bert
| 7 | 19 |
transformers
| 1 |
text2text-generation
| true | false | false |
apache-2.0
|
['zh']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['unilm']
| false | true | true | 858 | false |
# unilm-base-chinese-news-sum
```sh
pip install git+https://github.com/Liadrinz/transformers-unilm # 安装兼容HuggingFace的UniLM模型代码
```
```py
from unilm import UniLMTokenizer, UniLMForConditionalGeneration
news_article = (
"12月23日,河北石家庄。8岁哥哥轻车熟路哄睡弟弟,姿势标准动作熟练。"
"妈妈杨女士表示:哥哥很喜欢弟弟,因为心思比较细,自己平时带孩子的习惯他都会跟着学习,"
"哄睡孩子也都会争着来,技巧很娴熟,两人在一块很有爱,自己感到很幸福,平时帮了自己很大的忙,感恩有这么乖的宝宝。"
)
tokenizer = UniLMTokenizer.from_pretrained("Yuang/unilm-base-chinese-news-sum")
model = UniLMForConditionalGeneration.from_pretrained("Yuang/unilm-base-chinese-news-sum")
inputs = tokenizer(news_article, return_tensors="pt")
output_ids = model.generate(**inputs, max_new_tokens=16)
output_text = tokenizer.decode(output_ids[0])
print(output_text) # "[CLS] <news_article> [SEP] <news_summary> [SEP]"
news_summary = output_text.split("[SEP]")[1].strip()
print(news_summary)
```
|
16675c0877927c8da4182bfdfa3700ae
|
deblagoj/distilbert-base-uncased-finetuned-emotion
|
deblagoj
|
distilbert
| 28 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['emotion']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,343 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2225
- Accuracy: 0.919
- F1: 0.9191
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.814 | 1.0 | 250 | 0.3153 | 0.904 | 0.9016 |
| 0.2515 | 2.0 | 500 | 0.2225 | 0.919 | 0.9191 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu116
- Datasets 2.6.1
- Tokenizers 0.13.1
|
e4ff784545aac7f2f902a872bc7c6536
|
mrm8488/t5-small-finetuned-text-simplification
|
mrm8488
|
t5
| 11 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['wiki_auto_asset_turk']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,859 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-text-simplification
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the wiki_auto_asset_turk dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1217
- Rouge2 Precision: 0.5537
- Rouge2 Recall: 0.4251
- Rouge2 Fmeasure: 0.4616
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:-----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 0.1604 | 1.0 | 15119 | 0.1156 | 0.5567 | 0.4266 | 0.4633 |
| 0.1573 | 2.0 | 30238 | 0.1163 | 0.5534 | 0.4258 | 0.462 |
| 0.1552 | 3.0 | 45357 | 0.1197 | 0.5527 | 0.4244 | 0.4608 |
| 0.1514 | 4.0 | 60476 | 0.1214 | 0.5528 | 0.4257 | 0.4617 |
| 0.1524 | 5.0 | 75595 | 0.1217 | 0.5537 | 0.4251 | 0.4616 |
### Framework versions
- Transformers 4.22.0
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
91b5322cd79ec24f9edbb93e41baa655
|
an303042/Jocelyn_Hobbie_Diffusion_v1
|
an303042
| null | 23 | 3 |
diffusers
| 1 |
text-to-image
| false | false | false |
creativeml-openrail-m
|
['en']
| null | null | 2 | 1 | 1 | 0 | 0 | 0 | 0 |
['stable-diffusion', 'text-to-image', 'image-to-image', 'diffusers']
| false | true | true | 1,643 | false |
### Jocelyn Hobbie Diffusion v1
This model was created to celebrate the works of Jocelyn Hobbie - A wonderful contemporary artist.
Check out her works @ www.jocelynhobbie.com and @jocelynhobbie
**Token to use is "jclnhbe style" **
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
### Examples



|
9188b06f898687a1aba05a90eb0493f3
|
Kaku0o0/distilbert-base-uncased-finetuned-squad
|
Kaku0o0
|
distilbert
| 16 | 3 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,279 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6090
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 274 | 1.5943 |
| 0.9165 | 2.0 | 548 | 1.5836 |
| 0.9165 | 3.0 | 822 | 1.6090 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.2
|
d72b717e9045dd10b1935091cc228aee
|
jonatasgrosman/exp_w2v2r_de_xls-r_accent_germany-8_austria-2_s452
|
jonatasgrosman
|
wav2vec2
| 10 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['de']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'de']
| false | true | true | 480 | false |
# exp_w2v2r_de_xls-r_accent_germany-8_austria-2_s452
Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
ace2107aff97558bfdd0b20289eec12f
|
luccazen/finetuning-sentiment-model-3000-samples
|
luccazen
|
distilbert
| 19 | 11 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['imdb']
| null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,055 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3026
- Accuracy: 0.8667
- F1: 0.8667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
b0c2608194605d909e3c6fefc09b6c05
|
jonatasgrosman/exp_w2v2t_zh-cn_no-pretraining_s805
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['zh-CN']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'zh-CN']
| false | true | true | 420 | false |
# exp_w2v2t_zh-cn_no-pretraining_s805
Fine-tuned randomly initialized wav2vec2 model for speech recognition using the train split of [Common Voice 7.0 (zh-CN)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
8a91a3682d09b46388d94c6315ab861a
|
nandysoham/Human_Development_Index-clustered
|
nandysoham
|
distilbert
| 8 | 0 |
transformers
| 0 |
question-answering
| false | true | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_keras_callback']
| true | true | true | 1,877 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# nandysoham/Human_Development_Index-clustered
This model is a fine-tuned version of [nandysoham16/4-clustered_aug](https://huggingface.co/nandysoham16/4-clustered_aug) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.2234
- Train End Logits Accuracy: 0.9410
- Train Start Logits Accuracy: 0.9479
- Validation Loss: 1.1060
- Validation End Logits Accuracy: 0.6667
- Validation Start Logits Accuracy: 0.6667
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 18, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch |
|:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:|
| 0.2234 | 0.9410 | 0.9479 | 1.1060 | 0.6667 | 0.6667 | 0 |
### Framework versions
- Transformers 4.26.0
- TensorFlow 2.9.2
- Datasets 2.9.0
- Tokenizers 0.13.2
|
84fceefdce7b88d4c94bcbc34365dc34
|
cwkeam/mctct-large
|
cwkeam
|
mctct
| 9 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['en']
|
['librispeech_asr', 'common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['speech']
| false | true | true | 2,641 | false |
# M-CTC-T
Massively multilingual speech recognizer from Meta AI. The model is a 1B-param transformer encoder, with a CTC head over 8065 character labels and a language identification head over 60 language ID labels. It is trained on Common Voice (version 6.1, December 2020 release) and VoxPopuli. After training on Common Voice and VoxPopuli, the model is trained on Common Voice only. The labels are unnormalized character-level transcripts (punctuation and capitalization are not removed). The model takes as input Mel filterbank features from a 16Khz audio signal.
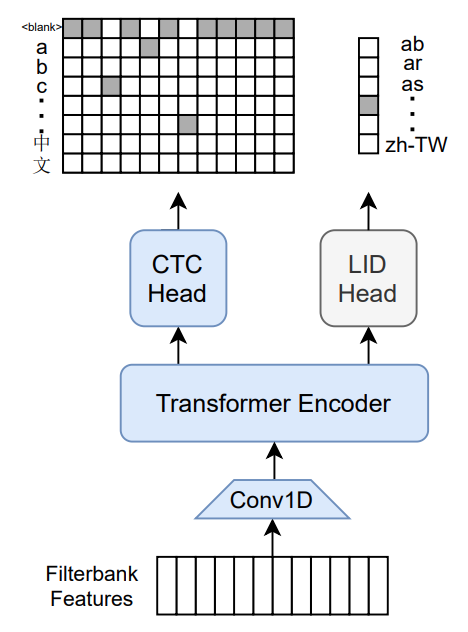
The original Flashlight code, model checkpoints, and Colab notebook can be found at https://github.com/flashlight/wav2letter/tree/main/recipes/mling_pl .
## Citation
[Paper](https://arxiv.org/abs/2111.00161)
Authors: Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, Ronan Collobert
```
@article{lugosch2021pseudo,
title={Pseudo-Labeling for Massively Multilingual Speech Recognition},
author={Lugosch, Loren and Likhomanenko, Tatiana and Synnaeve, Gabriel and Collobert, Ronan},
journal={ICASSP},
year={2022}
}
```
Additional thanks to [Chan Woo Kim](https://huggingface.co/cwkeam) and [Patrick von Platen](https://huggingface.co/patrickvonplaten) for porting the model from Flashlight to PyTorch.
# Training method
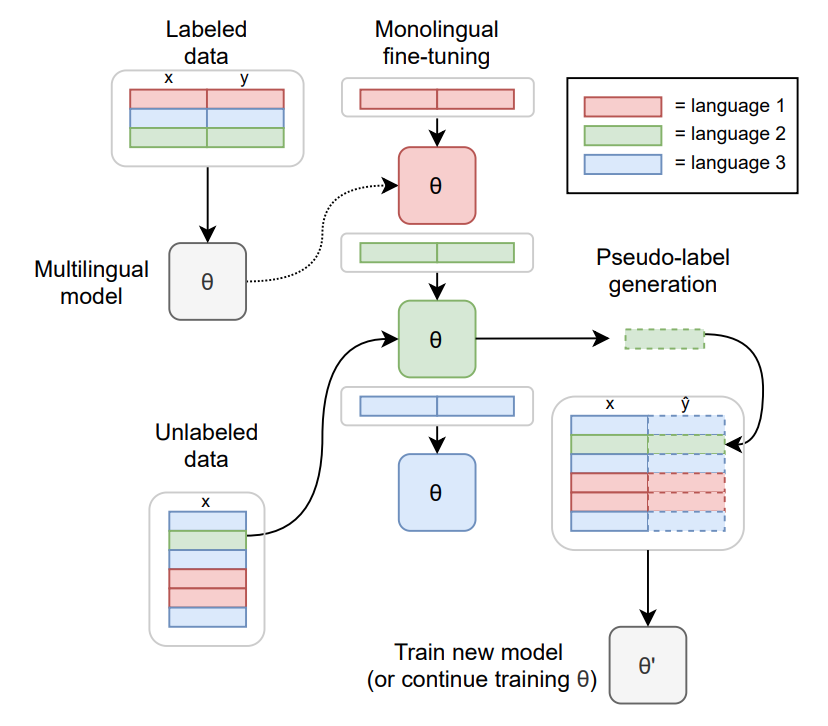 TO-DO: replace with the training diagram from paper
For more information on how the model was trained, please take a look at the [official paper](https://arxiv.org/abs/2111.00161).
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import MCTCTForCTC, MCTCTProcessor
model = MCTCTForCTC.from_pretrained("speechbrain/mctct-large")
processor = MCTCTProcessor.from_pretrained("speechbrain/mctct-large")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_features = processor(ds[0]["audio"]["array"], return_tensors="pt").input_features
# retrieve logits
logits = model(input_features).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
Results for Common Voice, averaged over all languages:
*Character error rate (CER)*:
| Valid | Test |
|-------|------|
| 21.4 | 23.3 |
|
ed65c127da6e0aa38494aefb4897f005
|
Helsinki-NLP/opus-mt-lue-en
|
Helsinki-NLP
|
marian
| 10 | 14 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 776 | false |
### opus-mt-lue-en
* source languages: lue
* target languages: en
* OPUS readme: [lue-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/lue-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/lue-en/opus-2020-01-09.zip)
* test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/lue-en/opus-2020-01-09.test.txt)
* test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/lue-en/opus-2020-01-09.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.lue.en | 31.7 | 0.469 |
|
f491a004b92f2843883c300950a40c6a
|
IIIT-L/hing-mbert-finetuned-code-mixed-DS
|
IIIT-L
|
bert
| 10 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
cc-by-4.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,380 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hing-mbert-finetuned-code-mixed-DS
This model is a fine-tuned version of [l3cube-pune/hing-mbert](https://huggingface.co/l3cube-pune/hing-mbert) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7248
- Accuracy: 0.7364
- Precision: 0.6847
- Recall: 0.7048
- F1: 0.6901
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.7277800745684633e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 43
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 0.6977 | 2.0 | 497 | 0.7248 | 0.7364 | 0.6847 | 0.7048 | 0.6901 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.1+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
e21f506810cb337315a23c35890a68f0
|
BAAI/AltCLIP-m9
|
BAAI
|
altclip
| 10 | 68 |
transformers
| 5 |
text-to-image
| true | false | false |
creativeml-openrail-m
|
['zh']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'zh', 'Chinese', 'multilingual', 'English(En)', 'Chinese(Zh)', 'Spanish(Es)', 'French(Fr)', 'Russian(Ru)', 'Japanese(Ja)', 'Korean(Ko)', 'Arabic(Ar)', 'Italian(It)']
| false | true | true | 4,172 | false |
# AltCLIP-m9
It supports English(En), Chinese(Zh), Spanish(Es), French(Fr), Russian(Ru), Japanese(Ja), Korean(Ko), Arabic(Ar) and Italian(It) languages.
| 名称 Name | 任务 Task | 语言 Language(s) | 模型 Model | Github |
|:------------------:|:----------:|:-------------------:|:--------:|:------:|
| AltCLIP-m9 | Text-Image | Multilingual | CLIP | [FlagAI](https://github.com/FlagAI-Open/FlagAI) |
## 简介 Brief Introduction
我们提出了一个简单高效的方法去训练更加优秀的九语CLIP模型。命名为AltCLIP-m9。AltCLIP训练数据来自 [WuDao数据集](https://data.baai.ac.cn/details/WuDaoCorporaText) 和 [LIAON](https://huggingface.co/datasets/ChristophSchuhmann/improved_aesthetics_6plus)
AltCLIP-m9模型可以为本项目中的AltDiffusion-m9模型提供支持,关于AltDiffusion-m9模型的具体信息可查看[此教程](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltDiffusion/README.md) 。
模型代码已经在 [FlagAI](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltCLIP) 上开源,权重位于我们搭建的 [modelhub](https://model.baai.ac.cn/model-detail/100077) 上。我们还提供了微调,推理,验证的脚本,欢迎试用。
We propose a simple and efficient method to train a better multilingua CLIP model. Named AltCLIP-m9. AltCLIP-m9 is trained with training data from [WuDao dataset](https://data.baai.ac.cn/details/WuDaoCorporaText) and [Liaon](https://huggingface.co/datasets/laion/laion2B-en).
The AltCLIP-m9 model can provide support for the AltDiffusion-m9 model in this project. Specific information on the AltDiffusion model can be found in [this tutorial](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltDiffusion/README.md).
The model code has been open sourced on [FlagAI](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltCLIP) and the weights are located on [modelhub](https://model.baai.ac.cn/model-detail/100077). We also provide scripts for fine-tuning, inference, and validation, so feel free to try them out.
## 引用
关于AltCLIP,我们已经推出了相关报告,有更多细节可以查阅,如对您的工作有帮助,欢迎引用。
If you find this work helpful, please consider to cite
```
@article{https://doi.org/10.48550/arxiv.2211.06679,
doi = {10.48550/ARXIV.2211.06679},
url = {https://arxiv.org/abs/2211.06679},
author = {Chen, Zhongzhi and Liu, Guang and Zhang, Bo-Wen and Ye, Fulong and Yang, Qinghong and Wu, Ledell},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences},
title = {AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
## 训练 Training
训练共有两个阶段。
在平行知识蒸馏阶段,我们只是使用平行语料文本来进行蒸馏(平行语料相对于图文对更容易获取且数量更大)。在多语对比学习阶段,我们使用少量的中-英 图像-文本对(每种语言6百万)来训练我们的文本编码器以更好地适应图像编码器。
There are two phases of training.
In the parallel knowledge distillation phase, we only use parallel corpus texts for distillation (parallel corpus is easier to obtain and larger in number compared to image text pairs). In the multilingual comparison learning phase, we use a small number of text-image pairs (about 6 million in each language) to train our text encoder to better fit the image encoder.
## 下游效果 Performance

## 可视化效果 Visualization effects
基于AltCLIP,我们还开发了AltDiffusion模型,可视化效果如下。
Based on AltCLIP, we have also developed the AltDiffusion model, visualized as follows.

## 模型推理 Inference
Please download the code from [FlagAI AltCLIP](https://github.com/FlagAI-Open/FlagAI/tree/master/examples/AltCLIP)
```python
from PIL import Image
import requests
# transformers version >= 4.21.0
from modeling_altclip import AltCLIP
from processing_altclip import AltCLIPProcessor
# now our repo's in private, so we need `use_auth_token=True`
model = AltCLIP.from_pretrained("BAAI/AltCLIP-m9")
processor = AltCLIPProcessor.from_pretrained("BAAI/AltCLIP-m9")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
|
68750b38809d102196dd00ad93645524
|
gabrielgmendonca/bert-base-portuguese-cased-finetuned-chico-xavier
|
gabrielgmendonca
|
bert
| 17 | 10 |
transformers
| 0 |
fill-mask
| true | true | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,357 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-portuguese-cased-finetuned-chico-xavier
This model is a fine-tuned version of [neuralmind/bert-base-portuguese-cased](https://huggingface.co/neuralmind/bert-base-portuguese-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7196
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.0733 | 1.0 | 561 | 1.8147 |
| 1.8779 | 2.0 | 1122 | 1.7624 |
| 1.8345 | 3.0 | 1683 | 1.7206 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.2
|
d5d143c8259c4d79cce030265b0aa0fc
|
Yagorka/ddpm-butterflies-256_new_data
|
Yagorka
| null | 13 | 0 |
diffusers
| 0 | null | false | false | false |
apache-2.0
|
['en']
|
['imagefolder']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,219 | false |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-256_new_data
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `imagefolder` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 2
- eval_batch_size: 2
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/Yagorka/ddpm-butterflies-256_new_data/tensorboard?#scalars)
|
1c9932db46508cc533b9cde330e7af62
|
DunnBC22/distilbert-base-uncased_research_articles_multilabel
|
DunnBC22
|
distilbert
| 10 | 2 |
transformers
| 1 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,647 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_research_articles_multilabel
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1956
- F1: 0.8395
- Roc Auc: 0.8909
- Accuracy: 0.6977
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:--------:|
| 0.3043 | 1.0 | 263 | 0.2199 | 0.8198 | 0.8686 | 0.6829 |
| 0.2037 | 2.0 | 526 | 0.1988 | 0.8355 | 0.8845 | 0.7010 |
| 0.1756 | 3.0 | 789 | 0.1956 | 0.8395 | 0.8909 | 0.6977 |
| 0.1579 | 4.0 | 1052 | 0.1964 | 0.8371 | 0.8902 | 0.6919 |
| 0.1461 | 5.0 | 1315 | 0.1991 | 0.8353 | 0.8874 | 0.6953 |
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
c76d52c9647733727a993ed42ba09e51
|
Helsinki-NLP/opus-mt-tc-big-en-cat_oci_spa
|
Helsinki-NLP
|
marian
| 13 | 7 |
transformers
| 1 |
translation
| true | true | false |
cc-by-4.0
|
['ca', 'en', 'es', 'oc']
| null | null | 2 | 1 | 1 | 0 | 0 | 0 | 0 |
['translation', 'opus-mt-tc']
| true | true | true | 6,454 | false |
# opus-mt-tc-big-en-cat_oci_spa
Neural machine translation model for translating from English (en) to Catalan, Occitan and Spanish (cat+oci+spa).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2022-03-13
* source language(s): eng
* target language(s): cat spa
* valid target language labels: >>cat<< >>spa<<
* model: transformer-big
* data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+bt_transformer-big_2022-03-13.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-cat+oci+spa/opusTCv20210807+bt_transformer-big_2022-03-13.zip)
* more information released models: [OPUS-MT eng-cat+oci+spa README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-cat+oci+spa/README.md)
* more information about the model: [MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)
This is a multilingual translation model with multiple target languages. A sentence initial language token is required in the form of `>>id<<` (id = valid target language ID), e.g. `>>cat<<`
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
">>spa<< Why do you want Tom to go there with me?",
">>spa<< She forced him to eat spinach."
]
model_name = "pytorch-models/opus-mt-tc-big-en-cat_oci_spa"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# ¿Por qué quieres que Tom vaya conmigo?
# Ella lo obligó a comer espinacas.
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-en-cat_oci_spa")
print(pipe(">>spa<< Why do you want Tom to go there with me?"))
# expected output: ¿Por qué quieres que Tom vaya conmigo?
```
## Benchmarks
* test set translations: [opusTCv20210807+bt_transformer-big_2022-03-13.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-cat+oci+spa/opusTCv20210807+bt_transformer-big_2022-03-13.test.txt)
* test set scores: [opusTCv20210807+bt_transformer-big_2022-03-13.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-cat+oci+spa/opusTCv20210807+bt_transformer-big_2022-03-13.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| eng-cat | tatoeba-test-v2021-08-07 | 0.66414 | 47.8 | 1631 | 12344 |
| eng-spa | tatoeba-test-v2021-08-07 | 0.73725 | 57.0 | 16583 | 134710 |
| eng-cat | flores101-devtest | 0.66071 | 41.5 | 1012 | 27304 |
| eng-oci | flores101-devtest | 0.56192 | 25.4 | 1012 | 27305 |
| eng-spa | flores101-devtest | 0.56288 | 28.1 | 1012 | 29199 |
| eng-spa | newssyscomb2009 | 0.58431 | 31.4 | 502 | 12503 |
| eng-spa | news-test2008 | 0.56622 | 30.0 | 2051 | 52586 |
| eng-spa | newstest2009 | 0.57988 | 30.5 | 2525 | 68111 |
| eng-spa | newstest2010 | 0.62343 | 37.4 | 2489 | 65480 |
| eng-spa | newstest2011 | 0.62424 | 39.1 | 3003 | 79476 |
| eng-spa | newstest2012 | 0.63006 | 39.6 | 3003 | 79006 |
| eng-spa | newstest2013 | 0.60291 | 35.8 | 3000 | 70528 |
| eng-spa | tico19-test | 0.73224 | 52.5 | 2100 | 66563 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 3405783
* port time: Wed Apr 13 16:40:45 EEST 2022
* port machine: LM0-400-22516.local
|
424dcc1893eb9b2aad20ff43c4edf4b9
|
RichardsonTXCarpetCleaning/AreaRugCleaningRichardsonTX
|
RichardsonTXCarpetCleaning
| null | 2 | 0 | null | 0 | null | false | false | false |
other
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 459 | false |
Area Rug Cleaning Richardson TX
https://carpetcleaning-richardson.com/area-rug-cleaning.html
(972) 454-9815
Do you need the best cleaning services in town from Rug Shampooers?Do you want to bring back the natural beauty of your rugs after they have lost their original appearance?By simply calling our professionals, Richardson TX Carpet Cleaning will be able to properly clean them for you, leaving them looking good and brightening up your home at any time.
|
694c0350332d4430ac749829753baccd
|
l3cube-pune/hi-random-twt-1m
|
l3cube-pune
|
bert
| 8 | 4 |
transformers
| 0 |
fill-mask
| true | false | false |
cc-by-4.0
|
['hi']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 551 | false |
A HindBERT (l3cube-pune/hindi-bert-v2) model finetuned on random 1 million Hindi Tweets.<br>
More details on the dataset, models, and baseline results can be found in our [paper] (<a href='https://arxiv.org/abs/2210.04267'> link </a>)<br>
```
@article{gokhale2022spread,
title={Spread Love Not Hate: Undermining the Importance of Hateful Pre-training for Hate Speech Detection},
author={Gokhale, Omkar and Kane, Aditya and Patankar, Shantanu and Chavan, Tanmay and Joshi, Raviraj},
journal={arXiv preprint arXiv:2210.04267},
year={2022}
}
```
|
3349905774dfdab2c24196023f189b4e
|
Lvxue/finetuned-mt5-base-10epoch
|
Lvxue
|
mt5
| 14 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
|
['en', 'ro']
|
['wmt16']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,003 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-mt5-base-10epoch
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the wmt16 ro-en dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2607
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 12
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
a65143b8c7e50ca50dab0697f67ae252
|
MultiBertGunjanPatrick/multiberts-seed-1-1900k
|
MultiBertGunjanPatrick
|
bert
| 7 | 3 |
transformers
| 0 | null | true | false | false |
apache-2.0
|
['en']
|
['bookcorpus', 'wikipedia']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['exbert', 'multiberts', 'multiberts-seed-1']
| false | true | true | 6,487 | false |
# MultiBERTs Seed 1 Checkpoint 1900k (uncased)
Seed 1 intermediate checkpoint 1900k MultiBERTs (pretrained BERT) model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/pdf/2106.16163.pdf) and first released in
[this repository](https://github.com/google-research/language/tree/master/language/multiberts). This is an intermediate checkpoint.
The final checkpoint can be found at [multiberts-seed-1](https://hf.co/multberts-seed-1). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing MultiBERTs did not write a model card for this model so this model card has been written by [gchhablani](https://hf.co/gchhablani).
## Model description
MultiBERTs models are transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the MultiBERTs model as inputs.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=multiberts) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('multiberts-seed-1-1900k')
model = BertModel.from_pretrained("multiberts-seed-1-1900k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions. This bias will also affect all fine-tuned versions of this model. For an understanding of bias of this particular
checkpoint, please try out this checkpoint with the snippet present in the [Limitation and bias section](https://huggingface.co/bert-base-uncased#limitations-and-bias) of the [bert-base-uncased](https://huggingface.co/bert-base-uncased) checkpoint.
## Training data
The MultiBERTs models were pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038
unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The full model was trained on 16 Cloud TPU v2 chips for two million steps with a batch size
of 256. The sequence length was set to 512 throughout. The optimizer
used is Adam with a learning rate of 1e-4, \\(\beta_{1} = 0.9\\) and \\(\beta_{2} = 0.999\\), a weight decay of 0.01,
learning rate warmup for 10,000 steps and linear decay of the learning rate after.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2106-16163,
author = {Thibault Sellam and
Steve Yadlowsky and
Jason Wei and
Naomi Saphra and
Alexander D'Amour and
Tal Linzen and
Jasmijn Bastings and
Iulia Turc and
Jacob Eisenstein and
Dipanjan Das and
Ian Tenney and
Ellie Pavlick},
title = {The MultiBERTs: {BERT} Reproductions for Robustness Analysis},
journal = {CoRR},
volume = {abs/2106.16163},
year = {2021},
url = {https://arxiv.org/abs/2106.16163},
eprinttype = {arXiv},
eprint = {2106.16163},
timestamp = {Mon, 05 Jul 2021 15:15:50 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-16163.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<a href="https://huggingface.co/exbert/?model=multiberts">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
663ace922b0b996678a08f74deb67fc9
|
huggingnft/boredapeyachtclub
|
huggingnft
| null | 5 | 47 |
transformers
| 1 |
unconditional-image-generation
| false | false | false |
mit
| null |
['huggingnft/boredapeyachtclub']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['huggingnft', 'nft', 'huggan', 'gan', 'image', 'images', 'unconditional-image-generation']
| false | true | true | 2,210 | false |
# Hugging NFT: boredapeyachtclub
## Disclaimer
All rights belong to their owners. Models and datasets can be removed from the site at the request of the copyright
holder.
## Model description
LightWeight GAN model for unconditional generation.
NFT collection available [here](https://opensea.io/collection/boredapeyachtclub).
Dataset is available [here](https://huggingface.co/datasets/huggingnft/boredapeyachtclub).
Check Space: [link](https://huggingface.co/spaces/AlekseyKorshuk/huggingnft).
Project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
[](https://github.com/AlekseyKorshuk/huggingnft)
## Intended uses & limitations
#### How to use
Check project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
#### Limitations and bias
Check project repository: [link](https://github.com/AlekseyKorshuk/huggingnft).
## Training data
Dataset is available [here](https://huggingface.co/datasets/huggingnft/boredapeyachtclub).
## Training procedure
Training script is available [here](https://github.com/AlekseyKorshuk/huggingnft).
## Generated Images
Check results with Space: [link](https://huggingface.co/spaces/AlekseyKorshuk/huggingnft).
## About
*Built by Aleksey Korshuk*
[](https://github.com/AlekseyKorshuk)
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
For more details, visit the project repository.
[](https://github.com/AlekseyKorshuk/huggingnft)
### BibTeX entry and citation info
```bibtex
@InProceedings{huggingnft,
author={Aleksey Korshuk}
year=2022
}
```
|
1f3c1d6d2f0cd0860896659206f084f3
|
jonatasgrosman/exp_w2v2r_de_xls-r_age_teens-5_sixties-5_s905
|
jonatasgrosman
|
wav2vec2
| 10 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['de']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'de']
| false | true | true | 475 | false |
# exp_w2v2r_de_xls-r_age_teens-5_sixties-5_s905
Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
ac1314255eb7b3a6bf1f2417270ff61c
|
DLochmelis33/22s-dl-sentiment-1
|
DLochmelis33
|
distilbert
| 10 | 6 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['yelp_review_full']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,033 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 22s-dl-sentiment-1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the yelp_review_full dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2574
- Accuracy: 0.9542
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.19.4
- Pytorch 1.11.0+cu113
- Datasets 2.3.0
- Tokenizers 0.12.1
|
d3c88d2135db8a2544841ea69f23b9e5
|
zannabethl/opus-mt-en-ro-finetuned-en-to-ro
|
zannabethl
|
marian
| 13 | 0 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['wmt16']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 927 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-en-ro-finetuned-en-to-ro
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-ro](https://huggingface.co/Helsinki-NLP/opus-mt-en-ro) on the wmt16 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Framework versions
- Transformers 4.22.2
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
76a413edc8df66c234a0f39348f724fa
|
MeshalAlamr/wav2vec2-xls-r-300m-arabic_speech_commands_half
|
MeshalAlamr
|
wav2vec2
| 10 | 3 |
transformers
| 0 |
audio-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,896 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-300m-arabic_speech_commands_half
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2678
- Accuracy: 0.9975
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 3.6816 | 0.99 | 28 | 3.4693 | 0.1575 |
| 3.0227 | 1.99 | 56 | 2.5330 | 0.2775 |
| 2.3345 | 2.99 | 84 | 1.8723 | 0.5925 |
| 1.6785 | 3.99 | 112 | 1.2944 | 0.8092 |
| 1.2606 | 4.99 | 140 | 0.8933 | 0.9425 |
| 1.0024 | 5.99 | 168 | 0.6041 | 0.9817 |
| 0.6478 | 6.99 | 196 | 0.3814 | 0.9933 |
| 0.4768 | 7.99 | 224 | 0.2678 | 0.9975 |
| 0.4143 | 8.99 | 252 | 0.2198 | 0.9967 |
| 0.3278 | 9.99 | 280 | 0.1993 | 0.9967 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1
|
837c135a53555b1a28b5536206baab65
|
jhaochenz/finetuned_gpt2-xl_sst2_negation0.01_pretrainedFalse_epochs10
|
jhaochenz
|
gpt2
| 16 | 0 |
transformers
| 0 |
text-generation
| true | false | false |
mit
| null |
['sst2']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,628 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned_gpt2-xl_sst2_negation0.01_pretrainedFalse_epochs10
This model is a fine-tuned version of [gpt2-xl](https://huggingface.co/gpt2-xl) on the sst2 dataset.
It achieves the following results on the evaluation set:
- Loss: 4.2831
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.7704 | 1.0 | 1323 | 3.1202 |
| 1.0733 | 2.0 | 2646 | 3.4126 |
| 0.867 | 3.0 | 3969 | 3.6512 |
| 0.7585 | 4.0 | 5292 | 3.7861 |
| 0.6945 | 5.0 | 6615 | 3.8881 |
| 0.6429 | 6.0 | 7938 | 3.9924 |
| 0.5997 | 7.0 | 9261 | 4.0998 |
| 0.5643 | 8.0 | 10584 | 4.1730 |
| 0.5279 | 9.0 | 11907 | 4.2446 |
| 0.4999 | 10.0 | 13230 | 4.2831 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.7.0
- Datasets 2.8.0
- Tokenizers 0.13.2
|
7fc5cb52fbb45a8f32b834c029cd52c6
|
tosin/dialogpt_mwoz
|
tosin
|
gpt2
| 9 | 16 |
transformers
| 3 |
conversational
| true | false | false |
cc-by-4.0
|
['en']
|
['multi_woz_v22']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['conversational', 'transformers']
| false | true | true | 2,435 | false |
## DialoGPT_MWOZ
This is a fine-tuned model of DialoGPT (medium) on the MultiWOZ v2.2 dataset. It is intended to be used as a conversational system.
The dataset it's trained on is limited in scope, as it covers only certain domains such as restaurants, hotel, taxi, train, hospital and police.
The perplexity achieved on the test and validation sets are 10.25 and 10.71, respectively. More information about the original pre-trained model can be found [here](https://huggingface.co/microsoft/DialoGPT-medium)
* Generation example from an interactive environment:
|Role | Response |
|---------|------------|
|User | I would like to have breakfast. |
|Bot | There are several options for Chinese in the city centre. Are you looking for a particular price range? |
|User | I'm looking for free food |
|Bot | There are 4 Chinese restaurants that are in the cheap price range. 3 in centre and one in north. |
|User | Not good enough |
|Bot | How about Charlie Chan? It is a Chinese restaurant in the centre of town. |
Please find the information about preprocessing, training and full details of the DialoGPT in the [original DialoGPT repository](https://github.com/microsoft/DialoGPT)
The paper for this work was accepted at the Northern Lights Deep Learning (NLDL) conference 2022. Arxiv paper: [https://arxiv.org/pdf/2110.06273.pdf](https://arxiv.org/pdf/2110.06273.pdf)
### How to use
Now we are ready to try out how the model works as a chatting partner!
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("tosin/dialogpt_mwoz")
model = AutoModelForCausalLM.from_pretrained("tosin/dialogpt_mwoz")
# Let's chat for 5 lines
for step in range(5):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id)
# pretty print last ouput tokens from bot
print("DialoGPT_MWOZ_Bot: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
|
a341239ce94becdd77f1d92edd3ab5ef
|
annahaz/bert-base-uncased-misogyny-sexism-4tweets-3e-05-0.05-3
|
annahaz
|
bert
| 10 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,773 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-misogyny-sexism-4tweets-3e-05-0.05-3
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8767
- Accuracy: 0.7094
- F1: 0.7184
- Precision: 0.6491
- Recall: 0.8043
- Mae: 0.2906
- Tn: 338
- Fp: 200
- Fn: 90
- Tp: 370
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall | Mae | Tn | Fp | Fn | Tp |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|:------:|:---:|:---:|:---:|:---:|
| 0.4767 | 1.0 | 1346 | 0.6853 | 0.6323 | 0.6501 | 0.5789 | 0.7413 | 0.3677 | 290 | 248 | 119 | 341 |
| 0.3783 | 2.0 | 2692 | 0.7041 | 0.6653 | 0.6528 | 0.6255 | 0.6826 | 0.3347 | 350 | 188 | 146 | 314 |
| 0.2803 | 3.0 | 4038 | 0.8767 | 0.7094 | 0.7184 | 0.6491 | 0.8043 | 0.2906 | 338 | 200 | 90 | 370 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
c9ee3a0ca85591b750f03ea027c7063d
|
farleyknight/patent-summarization-google-bigbird-pegasus-large-arxiv-2022-09-20
|
farleyknight
|
bigbird_pegasus
| 13 | 2 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['farleyknight/big_patent_5_percent']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,664 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# patent-summarization-google-bigbird-pegasus-large-arxiv-2022-09-20
This model is a fine-tuned version of [google/bigbird-pegasus-large-arxiv](https://huggingface.co/google/bigbird-pegasus-large-arxiv) on the farleyknight/big_patent_5_percent dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2617
- Rouge1: 37.3764
- Rouge2: 13.2442
- Rougel: 26.011
- Rougelsum: 31.0145
- Gen Len: 113.8789
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:--------:|
| 2.6121 | 0.08 | 5000 | 2.5652 | 35.0673 | 12.0073 | 24.5471 | 28.9315 | 119.9866 |
| 2.5182 | 0.17 | 10000 | 2.4797 | 34.6909 | 11.6432 | 24.87 | 28.1543 | 119.2043 |
| 2.5102 | 0.25 | 15000 | 2.4238 | 35.8574 | 12.2402 | 25.0712 | 29.5607 | 115.2890 |
| 2.4292 | 0.33 | 20000 | 2.3869 | 36.0133 | 12.2453 | 25.4039 | 29.483 | 112.5920 |
| 2.3678 | 0.41 | 25000 | 2.3594 | 35.238 | 11.6833 | 25.0449 | 28.3313 | 119.1739 |
| 2.3511 | 0.5 | 30000 | 2.3326 | 36.7755 | 12.8394 | 25.7218 | 30.2594 | 110.5819 |
| 2.3334 | 0.58 | 35000 | 2.3125 | 36.6317 | 12.7493 | 25.5388 | 30.094 | 115.5998 |
| 2.3833 | 0.66 | 40000 | 2.2943 | 37.1219 | 13.1564 | 25.7571 | 30.8666 | 113.8222 |
| 2.341 | 0.75 | 45000 | 2.2813 | 36.4962 | 12.6225 | 25.6904 | 29.9741 | 115.9845 |
| 2.3179 | 0.83 | 50000 | 2.2725 | 37.3535 | 13.1596 | 25.7385 | 31.056 | 117.7754 |
| 2.3164 | 0.91 | 55000 | 2.2654 | 36.9191 | 12.9316 | 25.7586 | 30.4691 | 116.1670 |
| 2.3046 | 0.99 | 60000 | 2.2618 | 37.3992 | 13.2731 | 26.0327 | 31.0338 | 114.5195 |
### Framework versions
- Transformers 4.23.0.dev0
- Pytorch 1.12.0
- Datasets 2.4.0
- Tokenizers 0.12.1
|
b92767257b5f485b805b057cfc637666
|
fathyshalab/all-roberta-large-v1-kitchen_and_dining-2-16-5
|
fathyshalab
|
roberta
| 11 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,523 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# all-roberta-large-v1-kitchen_and_dining-2-16-5
This model is a fine-tuned version of [sentence-transformers/all-roberta-large-v1](https://huggingface.co/sentence-transformers/all-roberta-large-v1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3560
- Accuracy: 0.2692
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.7421 | 1.0 | 1 | 2.5878 | 0.2012 |
| 2.1065 | 2.0 | 2 | 2.4975 | 0.2012 |
| 1.5994 | 3.0 | 3 | 2.4274 | 0.2249 |
| 1.1739 | 4.0 | 4 | 2.3808 | 0.2456 |
| 1.083 | 5.0 | 5 | 2.3560 | 0.2692 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
6e54ddf30303149db7d54742f5cf3fdd
|
hfl/chinese-electra-small-generator
|
hfl
|
electra
| 10 | 22 |
transformers
| 0 |
fill-mask
| true | true | false |
apache-2.0
|
['zh']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,963 | false |
**Please use `ElectraForPreTraining` for `discriminator` and `ElectraForMaskedLM` for `generator` if you are re-training these models.**
## Chinese ELECTRA
Google and Stanford University released a new pre-trained model called ELECTRA, which has a much compact model size and relatively competitive performance compared to BERT and its variants.
For further accelerating the research of the Chinese pre-trained model, the Joint Laboratory of HIT and iFLYTEK Research (HFL) has released the Chinese ELECTRA models based on the official code of ELECTRA.
ELECTRA-small could reach similar or even higher scores on several NLP tasks with only 1/10 parameters compared to BERT and its variants.
This project is based on the official code of ELECTRA: [https://github.com/google-research/electra](https://github.com/google-research/electra)
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find our resource or paper is useful, please consider including the following citation in your paper.
- https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
|
e069d866b48aaa5e05864080cb00307e
|
muhtasham/small-mlm-glue-qqp
|
muhtasham
|
bert
| 12 | 8 |
transformers
| 1 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,597 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# small-mlm-glue-qqp
This model is a fine-tuned version of [google/bert_uncased_L-4_H-512_A-8](https://huggingface.co/google/bert_uncased_L-4_H-512_A-8) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5151
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.8517 | 0.4 | 500 | 2.7156 |
| 2.8184 | 0.8 | 1000 | 2.6309 |
| 2.7461 | 1.2 | 1500 | 2.5335 |
| 2.5785 | 1.6 | 2000 | 2.5472 |
| 2.5753 | 2.0 | 2500 | 2.5667 |
| 2.4744 | 2.4 | 3000 | 2.4824 |
| 2.4448 | 2.8 | 3500 | 2.5490 |
| 2.476 | 3.2 | 4000 | 2.4906 |
| 2.3352 | 3.6 | 4500 | 2.5151 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
7440ec9b2bfe1419644995ce705d6ec1
|
jonatasgrosman/exp_w2v2r_fr_vp-100k_accent_france-8_belgium-2_s365
|
jonatasgrosman
|
wav2vec2
| 10 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['fr']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'fr']
| false | true | true | 501 | false |
# exp_w2v2r_fr_vp-100k_accent_france-8_belgium-2_s365
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (fr)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
3a6aade8201e30053f31f9afe284f8be
|
96harsh56/roberta-finetuned-subjqa-movies_1110pm
|
96harsh56
|
roberta
| 13 | 11 |
transformers
| 0 |
question-answering
| true | false | false |
cc-by-4.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 995 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-finetuned-subjqa-movies_1110pm
This model is a fine-tuned version of [deepset/roberta-base-squad2](https://huggingface.co/deepset/roberta-base-squad2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
f97a2db645f6d3404f1eab3568e7b9c5
|
shivam/xls-r-300m-marathi
|
shivam
|
wav2vec2
| 24 | 2 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['mr']
|
['mozilla-foundation/common_voice_8_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'generated_from_trainer', 'hf-asr-leaderboard', 'mozilla-foundation/common_voice_8_0', 'mr', 'robust-speech-event']
| true | true | true | 2,444 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - MR dataset.
It achieves the following results on the mozilla-foundation/common_voice_8_0 mr test set:
- Without LM
+ WER: 48.53
+ CER: 10.63
- With LM
+ WER: 38.27
+ CER: 8.91
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 400.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:------:|
| 4.2706 | 22.73 | 500 | 4.0174 | 1.0 |
| 3.2492 | 45.45 | 1000 | 3.2309 | 0.9908 |
| 1.9709 | 68.18 | 1500 | 1.0651 | 0.8440 |
| 1.4088 | 90.91 | 2000 | 0.5765 | 0.6550 |
| 1.1326 | 113.64 | 2500 | 0.4842 | 0.5760 |
| 0.9709 | 136.36 | 3000 | 0.4785 | 0.6013 |
| 0.8433 | 159.09 | 3500 | 0.5048 | 0.5419 |
| 0.7404 | 181.82 | 4000 | 0.5052 | 0.5339 |
| 0.6589 | 204.55 | 4500 | 0.5237 | 0.5897 |
| 0.5831 | 227.27 | 5000 | 0.5166 | 0.5447 |
| 0.5375 | 250.0 | 5500 | 0.5292 | 0.5487 |
| 0.4784 | 272.73 | 6000 | 0.5480 | 0.5596 |
| 0.4421 | 295.45 | 6500 | 0.5682 | 0.5467 |
| 0.4047 | 318.18 | 7000 | 0.5681 | 0.5447 |
| 0.3779 | 340.91 | 7500 | 0.5783 | 0.5347 |
| 0.3525 | 363.64 | 8000 | 0.5856 | 0.5367 |
| 0.3393 | 386.36 | 8500 | 0.5960 | 0.5359 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu113
- Datasets 1.18.1.dev0
- Tokenizers 0.11.0
|
60eb6938d5de282313300646ccf600ae
|
Helsinki-NLP/opus-mt-en-mkh
|
Helsinki-NLP
|
marian
| 11 | 17 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
|
['en', 'vi', 'km', 'mkh']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 2,387 | false |
### eng-mkh
* source group: English
* target group: Mon-Khmer languages
* OPUS readme: [eng-mkh](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-mkh/README.md)
* model: transformer
* source language(s): eng
* target language(s): kha khm khm_Latn mnw vie vie_Hani
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus-2020-07-27.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-mkh/opus-2020-07-27.zip)
* test set translations: [opus-2020-07-27.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-mkh/opus-2020-07-27.test.txt)
* test set scores: [opus-2020-07-27.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-mkh/opus-2020-07-27.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.eng-kha.eng.kha | 0.1 | 0.015 |
| Tatoeba-test.eng-khm.eng.khm | 0.2 | 0.226 |
| Tatoeba-test.eng-mnw.eng.mnw | 0.7 | 0.003 |
| Tatoeba-test.eng.multi | 16.5 | 0.330 |
| Tatoeba-test.eng-vie.eng.vie | 33.7 | 0.513 |
### System Info:
- hf_name: eng-mkh
- source_languages: eng
- target_languages: mkh
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-mkh/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['en', 'vi', 'km', 'mkh']
- src_constituents: {'eng'}
- tgt_constituents: {'vie_Hani', 'mnw', 'vie', 'kha', 'khm_Latn', 'khm'}
- src_multilingual: False
- tgt_multilingual: True
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-mkh/opus-2020-07-27.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-mkh/opus-2020-07-27.test.txt
- src_alpha3: eng
- tgt_alpha3: mkh
- short_pair: en-mkh
- chrF2_score: 0.33
- bleu: 16.5
- brevity_penalty: 1.0
- ref_len: 34734.0
- src_name: English
- tgt_name: Mon-Khmer languages
- train_date: 2020-07-27
- src_alpha2: en
- tgt_alpha2: mkh
- prefer_old: False
- long_pair: eng-mkh
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
1ee49bf659127fbeb0d8666783c21dcc
|
KarelDO/gpt2.CEBaB_confounding.observational.sa.5-class.seed_42
|
KarelDO
|
gpt2
| 15 | 2 |
transformers
| 0 | null | true | false | false |
mit
|
['en']
|
['OpenTable']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,084 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2.CEBaB_confounding.observational.sa.5-class.seed_42
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the OpenTable OPENTABLE dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9425
- Accuracy: 0.6091
- Macro-f1: 0.5206
- Weighted-macro-f1: 0.5595
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.2+cu102
- Datasets 2.5.2
- Tokenizers 0.12.1
|
575588f07f423ae923db8ec78fbb9bb2
|
dkasti/xlm-roberta-base-finetuned-panx-it
|
dkasti
|
xlm-roberta
| 10 | 11 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null |
['xtreme']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,314 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-it
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2388
- F1: 0.8233
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.8099 | 1.0 | 70 | 0.3035 | 0.7333 |
| 0.2766 | 2.0 | 140 | 0.2661 | 0.7948 |
| 0.1792 | 3.0 | 210 | 0.2388 | 0.8233 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.11.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
02684ba200c93ae4df77ce81e7c13054
|
nlp-waseda/roberta-base-japanese-with-auto-jumanpp
|
nlp-waseda
|
roberta
| 7 | 292 |
transformers
| 2 |
fill-mask
| true | false | false |
cc-by-sa-4.0
|
['ja']
|
['wikipedia', 'cc100']
| null | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
[]
| false | true | true | 2,188 | false |
# nlp-waseda/roberta-base-japanese-with-auto-jumanpp
## Model description
This is a Japanese RoBERTa base model pretrained on Japanese Wikipedia and the Japanese portion of CC-100.
## How to use
You can use this model for masked language modeling as follows:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("nlp-waseda/roberta-base-japanese-with-auto-jumanpp")
model = AutoModelForMaskedLM.from_pretrained("nlp-waseda/roberta-base-japanese-with-auto-jumanpp")
sentence = '早稲田大学で自然言語処理を[MASK]する。'
encoding = tokenizer(sentence, return_tensors='pt')
...
```
You can fine-tune this model on downstream tasks.
## Tokenization
`BertJapaneseTokenizer` now supports automatic tokenization for [Juman++](https://github.com/ku-nlp/jumanpp). However, if your dataset is large, you may take a long time since `BertJapaneseTokenizer` still does not supoort fast tokenization. You can still do the Juman++ tokenization by your self and use the old model [nlp-waseda/roberta-base-japanese](https://huggingface.co/nlp-waseda/roberta-base-japanese).
Juman++ 2.0.0-rc3 was used for pretraining. Each word is tokenized into tokens by [sentencepiece](https://github.com/google/sentencepiece).
## Vocabulary
The vocabulary consists of 32000 tokens including words ([JumanDIC](https://github.com/ku-nlp/JumanDIC)) and subwords induced by the unigram language model of [sentencepiece](https://github.com/google/sentencepiece).
## Training procedure
This model was trained on Japanese Wikipedia (as of 20210920) and the Japanese portion of CC-100. It took a week using eight NVIDIA A100 GPUs.
The following hyperparameters were used during pretraining:
- learning_rate: 1e-4
- per_device_train_batch_size: 256
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 2
- total_train_batch_size: 4096
- max_seq_length: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 700000
- warmup_steps: 10000
- mixed_precision_training: Native AMP
## Performance on JGLUE
See the [Baseline Scores](https://github.com/yahoojapan/JGLUE#baseline-scores) of JGLUE.
|
ee5ef6bef5d35ebc16a6e3898aed0490
|
kit-nlp/transformers-ud-japanese-electra-base-discriminator-irony
|
kit-nlp
|
electra
| 8 | 5 |
transformers
| 0 |
text-classification
| true | false | false |
cc-by-sa-4.0
|
['ja']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,198 | false |
# Electra Base Japanese Irony
This is an [ELECTRA](https://github.com/google-research/electra) Base model for the Japanese language finetuned for automatic irony detection.
The model was based on [transformers-ud-japanese-electra-ginza](https://huggingface.co/megagonlabs/transformers-ud-japanese-electra-base-discriminator/tree/main), and later finetuned on a dataset containing ironic and sarcastic tweets.
## Licenses
The finetuned model with all attached files is licensed under [CC BY-SA 4.0](http://creativecommons.org/licenses/by-sa/4.0/), or Creative Commons Attribution-ShareAlike 4.0 International License.
<a rel="license" href="http://creativecommons.org/licenses/by-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-sa/4.0/88x31.png" /></a>
## Citations
Please, cite this model using the following citation.
```
@inproceedings{dan2022electra-base-irony,
title={北見工業大学 テキスト情報処理研究室 ELECTRA Base 皮肉検出モデル (Megagon Labs ver.)},
author={団 俊輔 and プタシンスキ ミハウ and ジェプカ ラファウ and 桝井 文人},
publisher={HuggingFace},
year={2022},
url = "https://huggingface.co/kit-nlp/bert-base-japanese-basic-char-v2-irony"
}
```
|
689dc644faf1377cbd734eabffa6c260
|
Yuto01/distilbert-base-uncased-finetuned-imdb
|
Yuto01
|
distilbert
| 23 | 0 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null |
['imdb']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,278 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4442
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.6985 | 1.0 | 157 | 2.5612 |
| 2.562 | 2.0 | 314 | 2.4226 |
| 2.5316 | 3.0 | 471 | 2.4218 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1
- Datasets 2.9.1.dev0
- Tokenizers 0.13.2
|
d28467f6ba25ad4749d6fcec74c4e688
|
sd-dreambooth-library/metahuman-rkr
|
sd-dreambooth-library
| null | 29 | 2 |
diffusers
| 1 | null | false | false | false |
mit
| null | null | null | 2 | 2 | 0 | 0 | 1 | 1 | 0 |
[]
| false | true | true | 1,700 | false |
### metahuman rkr on Stable Diffusion via Dreambooth
#### model by hans120791
This your the Stable Diffusion model fine-tuned the metahuman rkr concept taught to Stable Diffusion with Dreambooth.
It can be used by modifying the `instance_prompt`: **a photo of sks rkr**
You can also train your own concepts and upload them to the library by using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_training.ipynb).
Here are the images used for training this concept:











|
f98d4ae3df5227b5b33e5a25d5330cde
|
FluxML/resnet18
|
FluxML
| null | 3 | 0 | null | 0 | null | false | false | false |
mit
| null | null | null | 4 | 0 | 3 | 1 | 0 | 0 | 0 |
[]
| false | true | true | 517 | false |
ResNet18 model ported from [torchvision](https://pytorch.org/vision/stable/index.html) for use with [Metalhead.jl](https://github.com/FluxML/Metalhead.jl). The scripts for creating this file can be found at [this gist](https://gist.github.com/darsnack/bfb8594cf5fdc702bdacb66586f518ef).
To use this model in Julia, [add the Metalhead.jl package to your environment](https://pkgdocs.julialang.org/v1/managing-packages/#Adding-packages). Then execute:
```julia
using Metalhead
model = ResNet(18; pretrain = true)
```
|
db581bb6bd39497eac67071d8c8b58c4
|
ufal/byt5-small-multilexnorm2021-tr
|
ufal
|
t5
| 6 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
|
['tr']
|
['mc4', 'wikipedia', 'multilexnorm']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['lexical normalization']
| false | true | true | 2,759 | false |
# Fine-tuned ByT5-small for MultiLexNorm (Turkish version)

This is the official release of the fine-tuned models for **the winning entry** to the [*W-NUT 2021: Multilingual Lexical Normalization (MultiLexNorm)* shared task](https://noisy-text.github.io/2021/multi-lexnorm.html), which evaluates lexical-normalization systems on 12 social media datasets in 11 languages.
Our system is based on [ByT5](https://arxiv.org/abs/2105.13626), which we first pre-train on synthetic data and then fine-tune on authentic normalization data. It achieves the best performance by a wide margin in intrinsic evaluation, and also the best performance in extrinsic evaluation through dependency parsing. In addition to these fine-tuned models, we also release the source files on [GitHub](https://github.com/ufal/multilexnorm2021) and an interactive demo on [Google Colab](https://colab.research.google.com/drive/1rxpI8IlKk-D2crFqi2hdzbTBIezqgsCg?usp=sharing).
## How to use
The model was *not* fine-tuned in a standard sentence-to-sentence setting – instead, it was tailored to the token-to-token definition of MultiLexNorm data. Please refer to [**the interactive demo on Colab notebook**](https://colab.research.google.com/drive/1rxpI8IlKk-D2crFqi2hdzbTBIezqgsCg?usp=sharing) to learn how to use these models.
## How to cite
```bibtex
@inproceedings{wnut-ufal,
title= "{ÚFAL} at {MultiLexNorm} 2021: Improving Multilingual Lexical Normalization by Fine-tuning {ByT5}",
author = "Samuel, David and Straka, Milan",
booktitle = "Proceedings of the 7th Workshop on Noisy User-generated Text (W-NUT 2021)",
year = "2021",
publisher = "Association for Computational Linguistics",
address = "Punta Cana, Dominican Republic"
}
```
## ByT5 - Small
ByT5 is a tokenizer-free version of [Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) and generally follows the architecture of [MT5](https://huggingface.co/google/mt5-small).
ByT5 was only pre-trained on [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual) excluding any supervised training with an average span-mask of 20 UTF-8 characters. Therefore, this model has to be fine-tuned before it is useable on a downstream task.
ByT5 works especially well on noisy text data,*e.g.*, `google/byt5-small` significantly outperforms [mt5-small](https://huggingface.co/google/mt5-small) on [TweetQA](https://arxiv.org/abs/1907.06292).
Paper: [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626)
Authors: *Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel*
|
9667530f8b3a767d6b7c589eef18494e
|
clu-ling/whisper-large-v2-japanese-5k-steps
|
clu-ling
|
whisper
| 33 | 1 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ja']
|
['mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,978 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-large-v2-japanese-5k-steps
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the Japanese CommonVoice dataset (v11)..
It achieves the following results on the evaluation set:
- Loss: 0.4200
- Wer: 0.7449
## Model description
This model is finetuned for 5000 steps for research purposes which means that the transcriptions might not be that satisfactory for users.
## Training and evaluation data
- Training Data: CommonVoice (v11) train split
- Validation Data: CommonVoice (v11) Validation split
- Test Data: CommonVoice (v11) Test split
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 50
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.0111 | 7.63 | 1000 | 0.3210 | 0.7888 |
| 0.0007 | 15.27 | 2000 | 0.3585 | 0.7478 |
| 0.0003 | 22.9 | 3000 | 0.3937 | 0.7432 |
| 0.0002 | 30.53 | 4000 | 0.4123 | 0.7443 |
| 0.0002 | 38.17 | 5000 | 0.4200 | 0.7449 |
### Transcription
```python
from datasets import load_dataset, Audio
import torch
from transformers import WhisperProcessor, WhisperForConditionalGeneration
# device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# load the model
processor = WhisperProcessor.from_pretrained("clu-ling/whisper-large-v2-japanese-5k-steps")
model = WhisperForConditionalGeneration.from_pretrained("clu-ling/whisper-large-v2-japanese-5k-steps").to(device)
forced_decoder_ids = processor.get_decoder_prompt_ids(language="ja", task="transcribe")
# load the dataset
commonvoice_eval = load_dataset("mozilla-foundation/common_voice_11_0", "ja", split="validation", streaming=True)
commonvoice_eval = commonvoice_eval.cast_column("audio", Audio(sampling_rate=16000))
sample = next(iter(commonvoice_eval))["audio"]
# features and generate token ids
input_features = processor(sample["array"], sampling_rate=input_speech["sampling_rate"], return_tensors="pt").input_features
predicted_ids = model.generate(input_features.to(device), forced_decoder_ids=forced_decoder_ids)
# decode
transcription = processor.batch_decode(predicted_ids)
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
print(transcription)
```
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.1
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
b92733fb94d2d94892f0c8301eca625f
|
misterneil/distilbert-base-uncased-finetuned-emotion
|
misterneil
|
distilbert
| 12 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['emotion']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,345 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2116
- Accuracy: 0.9295
- F1: 0.9293
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8487 | 1.0 | 250 | 0.3135 | 0.909 | 0.9051 |
| 0.2515 | 2.0 | 500 | 0.2116 | 0.9295 | 0.9293 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
6a276eb2c70616ccb70f5b2b13c01583
|
IDEA-CCNL/Wenzhong2.0-GPT2-110M-BertTokenizer-chinese
|
IDEA-CCNL
|
gpt2
| 6 | 171 |
transformers
| 3 |
text-generation
| true | false | false |
apache-2.0
|
['zh']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generate', 'gpt2']
| false | true | true | 3,494 | false |
# Wenzhong2.0-GPT2-110M-BertTokenizer-chinese
- Github: [Fengshenbang-LM](https://github.com/IDEA-CCNL/Fengshenbang-LM)
- Docs: [Fengshenbang-Docs](https://fengshenbang-doc.readthedocs.io/)
## 简介 Brief Introduction
善于处理NLG任务,中文版的GPT2-Small。基于BertTokenizer,实现字级别token,更便于受控文本生成。
Focused on handling NLG tasks, Chinese GPT2-Small.
## 模型分类 Model Taxonomy
| 需求 Demand | 任务 Task | 系列 Series | 模型 Model | 参数 Parameter | 额外 Extra |
| :----: | :----: | :----: | :----: | :----: | :----: |
| 通用 General | 自然语言生成 NLG | 闻仲 Wenzhong | GPT2 | 110M | 中文 Chinese |
## 模型信息 Model Information
类似于Wenzhong2.0-GPT2-3.5B-chinese,我们实现了一个small版本的12层的Wenzhong2.0-GPT2-110M-BertTokenizer-chinese,并在悟道(300G版本)上面进行预训练。本次开源别于之前开源的闻仲-GPT2系列,主要在于将BPE的分词换成了BertTokenzier的字级别分词。
Similar to Wenzhong2.0-GPT2-3.5B-chinese, we implement a small size Wenzhong2.0-GPT2-110M-BertTokenizer-chinese with 12 layers, which is pre-trained on Wudao Corpus (300G version).This open source version is different from the previous open source Wenzhong-GPT2 series, mainly because the word segmentation of BPE is replaced by the word level word segmentation of BertTokenzier.
## 使用 Usage
### 加载模型 Loading Models
```python
from transformers import BertTokenizer,GPT2LMHeadModel
hf_model_path = 'IDEA-CCNL/Wenzhong-GPT2-110M'
tokenizer = BertTokenizer.from_pretrained(hf_model_path)
model = GPT2LMHeadModel.from_pretrained(hf_model_path)
```
### 使用示例 Usage Examples
这里需要提一点,GPT在训练的时候是没有添加special_tokens的,BertTokenizer会默认补充special_tokens,所以在tokenzier的时候需要将add_special_tokens设置为false,这样生产效果会更好。
```python
def generate_word_level(input_text,n_return=5,max_length=128,top_p=0.9):
inputs = tokenizer(input_text,return_tensors='pt',add_special_tokens=False).to(model.device)
gen = model.generate(
inputs=inputs['input_ids'],
max_length=max_length,
do_sample=True,
top_p=top_p,
eos_token_id=21133,
pad_token_id=0,
num_return_sequences=n_return)
sentences = tokenizer.batch_decode(gen)
for idx,sentence in enumerate(sentences):
print(f'sentence {idx}: {sentence}')
print('*'*20)
return gen
outputs = generate_word_level('西湖的景色',n_return=5,max_length=128)
```
## 引用 Citation
如果您在您的工作中使用了我们的模型,可以引用我们的[论文](https://arxiv.org/abs/2209.02970):
If you are using the resource for your work, please cite the our [paper](https://arxiv.org/abs/2209.02970):
```text
@article{fengshenbang,
author = {Junjie Wang and Yuxiang Zhang and Lin Zhang and Ping Yang and Xinyu Gao and Ziwei Wu and Xiaoqun Dong and Junqing He and Jianheng Zhuo and Qi Yang and Yongfeng Huang and Xiayu Li and Yanghan Wu and Junyu Lu and Xinyu Zhu and Weifeng Chen and Ting Han and Kunhao Pan and Rui Wang and Hao Wang and Xiaojun Wu and Zhongshen Zeng and Chongpei Chen and Ruyi Gan and Jiaxing Zhang},
title = {Fengshenbang 1.0: Being the Foundation of Chinese Cognitive Intelligence},
journal = {CoRR},
volume = {abs/2209.02970},
year = {2022}
}
```
也可以引用我们的[网站](https://github.com/IDEA-CCNL/Fengshenbang-LM/):
You can also cite our [website](https://github.com/IDEA-CCNL/Fengshenbang-LM/):
```text
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
```
|
e36f706aec3695ee91445996bf69254c
|
anas-awadalla/bart-base-few-shot-k-512-finetuned-squad-seed-0
|
anas-awadalla
|
bart
| 16 | 3 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 988 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-base-few-shot-k-512-finetuned-squad-seed-0
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10.0
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.11.6
|
63cfe6f933e4a28487bc4aa7ddcd238f
|
Jethuestad/distilbert-base-uncased-test2
|
Jethuestad
|
distilbert
| 10 | 6 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null |
['wnut_17']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,545 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-test2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the wnut_17 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3055
- Precision: 0.5278
- Recall: 0.3957
- F1: 0.4523
- Accuracy: 0.9462
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 213 | 0.2889 | 0.5439 | 0.3503 | 0.4262 | 0.9453 |
| No log | 2.0 | 426 | 0.2938 | 0.5236 | 0.3800 | 0.4404 | 0.9457 |
| 0.0544 | 3.0 | 639 | 0.3055 | 0.5278 | 0.3957 | 0.4523 | 0.9462 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu102
- Datasets 2.4.0
- Tokenizers 0.12.1
|
3eddf0667a212d05ba094e44056024da
|
google/tapas-base-finetuned-wtq
|
google
|
tapas
| 8 | 31,285 |
transformers
| 63 |
table-question-answering
| true | true | false |
apache-2.0
|
['en']
|
['wikitablequestions']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['tapas']
| false | true | true | 7,105 | false |
# TAPAS base model fine-tuned on WikiTable Questions (WTQ)
This model has 2 versions which can be used. The default version corresponds to the `tapas_wtq_wikisql_sqa_inter_masklm_base_reset` checkpoint of the [original Github repository](https://github.com/google-research/tapas).
This model was pre-trained on MLM and an additional step which the authors call intermediate pre-training, and then fine-tuned in a chain on [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253), [WikiSQL](https://github.com/salesforce/WikiSQL) and finally [WTQ](https://github.com/ppasupat/WikiTableQuestions). It uses relative position embeddings (i.e. resetting the position index at every cell of the table).
The other (non-default) version which can be used is:
- `no_reset`, which corresponds to `tapas_wtq_wikisql_sqa_inter_masklm_base` (intermediate pre-training, absolute position embeddings).
Disclaimer: The team releasing TAPAS did not write a model card for this model so this model card has been written by
the Hugging Face team and contributors.
## Results
Size | Reset | Dev Accuracy | Link
-------- | --------| -------- | ----
LARGE | noreset | 0.5062 | [tapas-large-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-large-finetuned-wtq/tree/no_reset)
LARGE | reset | 0.5097 | [tapas-large-finetuned-wtq](https://huggingface.co/google/tapas-large-finetuned-wtq/tree/main)
**BASE** | **noreset** | **0.4525** | [tapas-base-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-base-finetuned-wtq/tree/no_reset)
**BASE** | **reset** | **0.4638** | [tapas-base-finetuned-wtq](https://huggingface.co/google/tapas-base-finetuned-wtq/tree/main)
MEDIUM | noreset | 0.4324 | [tapas-medium-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-medium-finetuned-wtq/tree/no_reset)
MEDIUM | reset | 0.4324 | [tapas-medium-finetuned-wtq](https://huggingface.co/google/tapas-medium-finetuned-wtq/tree/main)
SMALL | noreset | 0.3681 | [tapas-small-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-small-finetuned-wtq/tree/no_reset)
SMALL | reset | 0.3762 | [tapas-small-finetuned-wtq](https://huggingface.co/google/tapas-small-finetuned-wtq/tree/main)
MINI | noreset | 0.2783 | [tapas-mini-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-mini-finetuned-wtq/tree/no_reset)
MINI | reset | 0.2854 | [tapas-mini-finetuned-wtq](https://huggingface.co/google/tapas-mini-finetuned-wtq/tree/main)
TINY | noreset | 0.0823 | [tapas-tiny-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-tiny-finetuned-wtq/tree/no_reset)
TINY | reset | 0.1039 | [tapas-tiny-finetuned-wtq](https://huggingface.co/google/tapas-tiny-finetuned-wtq/tree/main)
## Model description
TAPAS is a BERT-like transformers model pretrained on a large corpus of English data from Wikipedia in a self-supervised fashion.
This means it was pretrained on the raw tables and associated texts only, with no humans labelling them in any way (which is why it
can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a (flattened) table and associated context, the model randomly masks 15% of the words in
the input, then runs the entire (partially masked) sequence through the model. The model then has to predict the masked words.
This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other,
or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional
representation of a table and associated text.
- Intermediate pre-training: to encourage numerical reasoning on tables, the authors additionally pre-trained the model by creating
a balanced dataset of millions of syntactically created training examples. Here, the model must predict (classify) whether a sentence
is supported or refuted by the contents of a table. The training examples are created based on synthetic as well as counterfactual statements.
This way, the model learns an inner representation of the English language used in tables and associated texts, which can then be used
to extract features useful for downstream tasks such as answering questions about a table, or determining whether a sentence is entailed
or refuted by the contents of a table. Fine-tuning is done by adding a cell selection head and aggregation head on top of the pre-trained model, and then jointly train these randomly initialized classification heads with the base model on SQa, WikiSQL and finally WTQ.
## Intended uses & limitations
You can use this model for answering questions related to a table.
For code examples, we refer to the documentation of TAPAS on the HuggingFace website.
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Question [SEP] Flattened table [SEP]
```
The authors did first convert the WTQ dataset into the format of SQA using automatic conversion scripts.
### Fine-tuning
The model was fine-tuned on 32 Cloud TPU v3 cores for 50,000 steps with maximum sequence length 512 and batch size of 512.
In this setup, fine-tuning takes around 10 hours. The optimizer used is Adam with a learning rate of 1.93581e-5, and a warmup
ratio of 0.128960. An inductive bias is added such that the model only selects cells of the same column. This is reflected by the
`select_one_column` parameter of `TapasConfig`. See the [paper](https://arxiv.org/abs/2004.02349) for more details (tables 11 and
12).
### BibTeX entry and citation info
```bibtex
@misc{herzig2020tapas,
title={TAPAS: Weakly Supervised Table Parsing via Pre-training},
author={Jonathan Herzig and Paweł Krzysztof Nowak and Thomas Müller and Francesco Piccinno and Julian Martin Eisenschlos},
year={2020},
eprint={2004.02349},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
```
```bibtex
@misc{eisenschlos2020understanding,
title={Understanding tables with intermediate pre-training},
author={Julian Martin Eisenschlos and Syrine Krichene and Thomas Müller},
year={2020},
eprint={2010.00571},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtex
@article{DBLP:journals/corr/PasupatL15,
author = {Panupong Pasupat and
Percy Liang},
title = {Compositional Semantic Parsing on Semi-Structured Tables},
journal = {CoRR},
volume = {abs/1508.00305},
year = {2015},
url = {http://arxiv.org/abs/1508.00305},
archivePrefix = {arXiv},
eprint = {1508.00305},
timestamp = {Mon, 13 Aug 2018 16:47:37 +0200},
biburl = {https://dblp.org/rec/journals/corr/PasupatL15.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
435a49fa91a4647f091568eac00ed51e
|
jlartey10/wav2vec2-large-xls-r-300m-tr-colab
|
jlartey10
|
wav2vec2
| 14 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,425 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-tr-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1786
- Wer: 0.5933
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.3421 | 14.81 | 400 | 1.1795 | 0.5922 |
| 0.113 | 29.63 | 800 | 1.1786 | 0.5933 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
1bf781f8a51f2c4e8813d1a0f7a9a232
|
eykarim/stable-diffusion-v1
|
eykarim
| null | 21 | 26 |
diffusers
| 1 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'endpoints-template']
| false | true | true | 2,061 | false |
# Fork of [CompVis/stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4)
> Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input.
> For more information about how Stable Diffusion functions, please have a look at [🤗's Stable Diffusion with 🧨Diffusers blog](https://huggingface.co/blog/stable_diffusion).
For more information about the model, license and limitations check the original model card at [CompVis/stable-diffusion-v1-4](https://huggingface.co/CompVis/stable-diffusion-v1-4).
### License (CreativeML OpenRAIL-M)
The full license can be found here: https://huggingface.co/spaces/CompVis/stable-diffusion-license
---
This repository implements a custom `handler` task for `text-to-image` for 🤗 Inference Endpoints. The code for the customized pipeline is in the [pipeline.py](https://huggingface.co/philschmid/stable-diffusion-v1-4-endpoints/blob/main/handler.py).
There is also a [notebook](https://huggingface.co/philschmid/stable-diffusion-v1-4-endpoints/blob/main/create_handler.ipynb) included, on how to create the `handler.py`
### expected Request payload
```json
{
"inputs": "A prompt used for image generation"
}
```
below is an example on how to run a request using Python and `requests`.
## Run Request
```python
import json
from typing import List
import requests as r
import base64
from PIL import Image
from io import BytesIO
ENDPOINT_URL = ""
HF_TOKEN = ""
# helper decoder
def decode_base64_image(image_string):
base64_image = base64.b64decode(image_string)
buffer = BytesIO(base64_image)
return Image.open(buffer)
def predict(prompt:str=None):
payload = {"inputs": code_snippet,"parameters": parameters}
response = r.post(
ENDPOINT_URL, headers={"Authorization": f"Bearer {HF_TOKEN}"}, json={"inputs": prompt}
)
resp = response.json()
return decode_base64_image(resp["image"])
prediction = predict(
prompt="the first animal on the mars"
)
```
expected output

|
02e252d8b8662adf82fe9de6d7455da4
|
jonatasgrosman/exp_w2v2t_th_vp-nl_s947
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['th']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'th']
| false | true | true | 469 | false |
# exp_w2v2t_th_vp-nl_s947
Fine-tuned [facebook/wav2vec2-large-nl-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-nl-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (th)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
28385eaceae96f7f37c0228ba47ea2e6
|
anuragshas/wav2vec2-large-xls-r-300m-bg
|
anuragshas
|
wav2vec2
| 25 | 9 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['bg']
|
['mozilla-foundation/common_voice_8_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'generated_from_trainer', 'hf-asr-leaderboard', 'mozilla-foundation/common_voice_8_0', 'robust-speech-event']
| true | true | true | 3,586 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLS-R-300M - Bulgarian
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - BG dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2473
- Wer: 0.3002
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 50.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.1589 | 3.48 | 400 | 3.0830 | 1.0 |
| 2.8921 | 6.96 | 800 | 2.6605 | 0.9982 |
| 1.3049 | 10.43 | 1200 | 0.5069 | 0.5707 |
| 1.1349 | 13.91 | 1600 | 0.4159 | 0.5041 |
| 1.0686 | 17.39 | 2000 | 0.3815 | 0.4746 |
| 0.999 | 20.87 | 2400 | 0.3541 | 0.4343 |
| 0.945 | 24.35 | 2800 | 0.3266 | 0.4132 |
| 0.9058 | 27.83 | 3200 | 0.2969 | 0.3771 |
| 0.8672 | 31.3 | 3600 | 0.2802 | 0.3553 |
| 0.8313 | 34.78 | 4000 | 0.2662 | 0.3380 |
| 0.8068 | 38.26 | 4400 | 0.2528 | 0.3181 |
| 0.7796 | 41.74 | 4800 | 0.2537 | 0.3073 |
| 0.7621 | 45.22 | 5200 | 0.2503 | 0.3036 |
| 0.7611 | 48.7 | 5600 | 0.2477 | 0.2991 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
#### Evaluation Commands
1. To evaluate on `mozilla-foundation/common_voice_8_0` with split `test`
```bash
python eval.py --model_id anuragshas/wav2vec2-large-xls-r-300m-bg --dataset mozilla-foundation/common_voice_8_0 --config bg --split test
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id anuragshas/wav2vec2-large-xls-r-300m-bg --dataset speech-recognition-community-v2/dev_data --config bg --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
### Inference With LM
```python
import torch
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoProcessor
import torchaudio.functional as F
model_id = "anuragshas/wav2vec2-large-xls-r-300m-bg"
sample_iter = iter(load_dataset("mozilla-foundation/common_voice_8_0", "bg", split="test", streaming=True, use_auth_token=True))
sample = next(sample_iter)
resampled_audio = F.resample(torch.tensor(sample["audio"]["array"]), 48_000, 16_000).numpy()
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
input_values = processor(resampled_audio, return_tensors="pt").input_values
with torch.no_grad():
logits = model(input_values).logits
transcription = processor.batch_decode(logits.numpy()).text
# => "и надутият му ката блоонкурем взе да се събира"
```
### Eval results on Common Voice 8 "test" (WER):
| Without LM | With LM (run `./eval.py`) |
|---|---|
| 30.07 | 21.195 |
|
84dd25bb62749346a323e6c010245e17
|
Pikachu/Crust
|
Pikachu
| null | 3 | 0 | null | 0 | null | false | false | false |
apache-2.0
|
['en']
|
["gathered from Uberduck's discord server, put together by Crust."]
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['synthesis', 'speech', 'speech synthesis']
| false | true | true | 3,183 | false |
# **CRUST - RELEASED** (Chungus Related Uberduck's Speech toy)
# Welcome to Crust 🍕⭕
Crust is a 168 speaker model based on uberduck's pipeline. We've noticed that having multiple speakers instead of having one speaker, improves the performance of the model and makes it be able to synthesize comparable results with only 1 minute of data. The results are surprisingly good and because of the lower dataset, batch size can be lowered and the model is generally faster than other models.
### What is a multispeaker model?
A multispeaker model is a model that has been trained on multiple speakers, the model first generates an "average" voice of all of the speakers and then tunes the different speakers on that average voice. If you have a lot of speakers, individual results won't be that great, as the model only has ~250+ mb to work with, but this is great for finetuning different voices on it because the model has learned an "average" voice. This average voice has the knowledge of all voices included in the dataset.
Core: A multispeaker model is a model trained on multiple speakers.
### How does this make training possible with 1 minute of training data?
The model has been trained on 168 datasets, ~20 hours of data, or ~19.8 thousand audio files. This is smaller than LJ speech but it has way more variety in voices, which LJ speech doesn't have. this variety allows the model to learn speech in different genders, accents, pitches, and other important factors, meaning that it knows a lot more in terms of voices. Finetuning this on 1 minute of data is possible because it already has a decently close match of your voice somewhere in its latent space.
Core: The multispeaker has more knowledge of multiple people speaking, making it surprisingly good at training on low-minute datasets.
### What are the downsides?
**-Training time.**
Training time sadly does still take a while, but considering you might only be training using 1 minute of data, it would take shorter than training it on the Lj-speech model, but would not come close to corentj's realtime voice cloning, it would be more accurate.
**-Clean datasets.**
We still doubt if the model would be able to be trained on datasets that have loud noise in them or have background music in them, realistically, it would not be able to be trained on these kinds of datasets, so before you train, please use a clean dataset.
**-Inference.**
Even though this model can be trained on 1 minute of data, we still recommend training it on more, we can't promise good results if the model doesn't have sufficient data, this would ideally be measured in syllables or phonemes, but minutes is a lot easier.
**-Audio quality.**
Sadly, the model has only been trained on 22050 hz and mono audio files, while this still sounds good when there's a Hi-Fi Gan vocoder, It's still going to not have stereo sound (which would not be that useful) or 44100 hz audio quality on its own. Sadly the Hi-Fi Gan vocoder does also bring in artifacts into the wav files which makes synthesis not as realistic.
We used [**Uberduck's TTS Pipeline on github**](https://github.com/uberduck-ai/uberduck-ml-dev) To train our model.
|
b4e2cbf3881321700051a97f3faf1cb1
|
chaitanya97/german_trained
|
chaitanya97
|
wav2vec2
| 12 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,568 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# german_trained
This model is a fine-tuned version of [flozi00/wav2vec-xlsr-german](https://huggingface.co/flozi00/wav2vec-xlsr-german) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.9367
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| 12.0352 | 5.0 | 5 | 12.6165 | 1.0 |
| 4.0249 | 10.0 | 10 | 6.6453 | 1.0 |
| 2.6661 | 15.0 | 15 | 5.7873 | 1.0 |
| 2.4123 | 20.0 | 20 | 4.3250 | 1.0 |
| 1.9481 | 25.0 | 25 | 3.9899 | 1.0 |
| 1.7533 | 30.0 | 30 | 3.9367 | 1.0 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu102
- Datasets 1.13.3
- Tokenizers 0.10.3
|
169b3cbebecb4672672b3e3d6123e16f
|
luigisaetta/whisper-tiny2-it
|
luigisaetta
|
whisper
| 17 | 2 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['it']
|
['mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer', 'whisper-event']
| true | true | true | 1,361 | false |
# luigisaetta/whisper-tiny2-it
This model is a fine-tuned version of [openai/whisper-tiny](https://huggingface.co/openai/whisper-tiny) on the common_voice_11_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4686
- Wer: 25.9110
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.5765 | 2.01 | 1000 | 0.5728 | 32.2181 |
| 0.3726 | 4.02 | 2000 | 0.5035 | 28.4606 |
| 0.2789 | 6.04 | 3000 | 0.4861 | 26.7894 |
| 0.2996 | 8.05 | 4000 | 0.4694 | 26.0279 |
| 0.2925 | 10.06 | 5000 | 0.4686 | 25.9110 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
5fbbe039ed45a8d11885f9a4f170f0b2
|
shizil/distilbert-base-uncased-finetuned-squad
|
shizil
|
distilbert
| 19 | 3 |
transformers
| 0 |
question-answering
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,285 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8489
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.7098 | 1.0 | 5681 | 2.3952 |
| 2.3633 | 2.0 | 11362 | 1.9956 |
| 2.1293 | 3.0 | 17043 | 1.8489 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
e8acf8ef09d24d168de5bf0646ab244a
|
uaritm/df_lik_n_mg_221
|
uaritm
|
t5
| 7 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
mit
|
['ru', 'uk', 'multilingual']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['russian', 'ukrainian']
| false | true | true | 512 | false |
# A little about the model
The model is trained to answer questions about health topics (Open-book question answering-comprehend).
cointegrated/rut5-base-multitask
For training, a compact T5 model was used: cointegrated/rut5-base-multitask
The training was conducted on a small set
out of 220 thousand pairs of question-answer sentences, so it still does not work as correctly as we would like.
The model is not a medical application and it is strongly discouraged to use the model for medical purposes!
|
e046b2b219e39c780ad78d166b5599b0
|
sanchit-gandhi/wav2vec2-large-tedlium
|
sanchit-gandhi
|
wav2vec2
| 9 | 6 |
transformers
| 1 |
automatic-speech-recognition
| true | false | true |
apache-2.0
|
['en']
|
['LIUM/tedlium']
| null | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
['speech']
| false | true | true | 2,881 | false |
# Wav2Vec2-Large-Tedlium
The Wav2Vec2 large model fine-tuned on the TEDLIUM corpus.
The model is initialised with Facebook's [Wav2Vec2 large LV-60k](https://huggingface.co/facebook/wav2vec2-large-lv60) checkpoint pre-trained on 60,000h of audiobooks from the LibriVox project. It is fine-tuned on 452h of TED talks from the [TEDLIUM](https://huggingface.co/datasets/LIUM/tedlium) corpus (Release 3). When using the model, make sure that your speech input is sampled at 16Khz.
The model achieves a word error rate (WER) of 8.4% on the dev set and 8.2% on the test set. [Training logs](https://wandb.ai/sanchit-gandhi/tedlium/runs/10c85yc4?workspace=user-sanchit-gandhi) document the training and evaluation progress over 50k steps of fine-tuning.
See [this notebook](https://colab.research.google.com/drive/1FjTsqbYKphl9kL-eILgUc-bl4zVThL8F?usp=sharing) for more information on how this model was fine-tuned.
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("sanchit-gandhi/wav2vec2-large-tedlium")
model = Wav2Vec2ForCTC.from_pretrained("sanchit-gandhi/wav2vec2-large-tedlium")
# load dummy dataset
ds = load_dataset("sanchit-gandhi/tedlium_dummy", split="validation")
# process audio inputs
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt", padding="longest").input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
print("Target: ", ds["text"][0])
print("Transcription: ", transcription[0])
```
## Evaluation
This code snippet shows how to evaluate **Wav2Vec2-Large-Tedlium** on the TEDLIUM test data.
```python
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import torch
from jiwer import wer
tedlium_eval = load_dataset("LIUM/tedlium", "release3", split="test")
model = Wav2Vec2ForCTC.from_pretrained("sanchit-gandhi/wav2vec2-large-tedlium").to("cuda")
processor = Wav2Vec2Processor.from_pretrained("sanchit-gandhi/wav2vec2-large-tedlium")
def map_to_pred(batch):
input_values = processor(batch["audio"]["array"], return_tensors="pt", padding="longest").input_values
with torch.no_grad():
logits = model(input_values.to("cuda")).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
batch["transcription"] = transcription
return batch
result = tedlium_eval.map(map_to_pred, batched=True, batch_size=1, remove_columns=["speech"])
print("WER:", wer(result["text"], result["transcription"]))
```
|
3f618c125b27ddc1d02470c6cb79ffe4
|
jannesg/takalane_zul_roberta
|
jannesg
|
roberta
| 8 | 7 |
transformers
| 0 |
fill-mask
| true | false | true |
mit
|
['zul']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['zul', 'fill-mask', 'pytorch', 'roberta', 'masked-lm']
| false | true | true | 1,060 | false |
# Takalani Sesame - Zulu 🇿🇦
<img src="https://pbs.twimg.com/media/EVjR6BsWoAAFaq5.jpg" width="600"/>
## Model description
Takalani Sesame (named after the South African version of Sesame Street) is a project that aims to promote the use of South African languages in NLP, and in particular look at techniques for low-resource languages to equalise performance with larger languages around the world.
## Intended uses & limitations
#### How to use
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("jannesg/takalane_zul_roberta")
model = AutoModelWithLMHead.from_pretrained("jannesg/takalane_zul_roberta")
```
#### Limitations and bias
Updates will be added continously to improve performance.
## Training data
Data collected from [https://wortschatz.uni-leipzig.de/en](https://wortschatz.uni-leipzig.de/en) <br/>
**Sentences:** 410000
## Training procedure
No preprocessing. Standard Huggingface hyperparameters.
## Author
Jannes Germishuys [website](http://jannesgg.github.io)
|
4c5357f5616807cc6a10f95039e94c24
|
zasheza/wav2vec2-base-timit-demo-colab-1
|
zasheza
|
wav2vec2
| 16 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,761 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-colab-1
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9634
- Wer: 0.4398
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 6
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 800
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.8991 | 5.26 | 500 | 1.4319 | 0.7522 |
| 0.8555 | 10.53 | 1000 | 0.7895 | 0.5818 |
| 0.4584 | 15.79 | 1500 | 0.7198 | 0.5211 |
| 0.3096 | 21.05 | 2000 | 0.7983 | 0.5118 |
| 0.2165 | 26.32 | 2500 | 0.7893 | 0.4745 |
| 0.163 | 31.58 | 3000 | 0.8779 | 0.4589 |
| 0.1144 | 36.84 | 3500 | 0.9256 | 0.4540 |
| 0.0886 | 42.11 | 4000 | 0.9184 | 0.4530 |
| 0.0668 | 47.37 | 4500 | 0.9634 | 0.4398 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.11.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
|
ea59332d428c9b0d3e6e6d9bf0c8489e
|
ashrielbrian/xlm-roberta-base-finetuned-panx-de-fr
|
ashrielbrian
|
xlm-roberta
| 10 | 4 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,315 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1636
- F1: 0.8567
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2905 | 1.0 | 715 | 0.1810 | 0.8263 |
| 0.1477 | 2.0 | 1430 | 0.1561 | 0.8488 |
| 0.095 | 3.0 | 2145 | 0.1636 | 0.8567 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
124653195a6a7520f21aee497db4b1a3
|
tomekkorbak/goofy_pasteur
|
tomekkorbak
|
gpt2
| 23 | 83 |
transformers
| 0 | null | true | false | false |
mit
|
['en']
|
['tomekkorbak/detoxify-pile-chunk3-0-50000', 'tomekkorbak/detoxify-pile-chunk3-50000-100000', 'tomekkorbak/detoxify-pile-chunk3-100000-150000', 'tomekkorbak/detoxify-pile-chunk3-150000-200000', 'tomekkorbak/detoxify-pile-chunk3-200000-250000', 'tomekkorbak/detoxify-pile-chunk3-250000-300000', 'tomekkorbak/detoxify-pile-chunk3-300000-350000', 'tomekkorbak/detoxify-pile-chunk3-350000-400000', 'tomekkorbak/detoxify-pile-chunk3-400000-450000', 'tomekkorbak/detoxify-pile-chunk3-450000-500000', 'tomekkorbak/detoxify-pile-chunk3-500000-550000', 'tomekkorbak/detoxify-pile-chunk3-550000-600000', 'tomekkorbak/detoxify-pile-chunk3-600000-650000', 'tomekkorbak/detoxify-pile-chunk3-650000-700000', 'tomekkorbak/detoxify-pile-chunk3-700000-750000', 'tomekkorbak/detoxify-pile-chunk3-750000-800000', 'tomekkorbak/detoxify-pile-chunk3-800000-850000', 'tomekkorbak/detoxify-pile-chunk3-850000-900000', 'tomekkorbak/detoxify-pile-chunk3-900000-950000', 'tomekkorbak/detoxify-pile-chunk3-950000-1000000', 'tomekkorbak/detoxify-pile-chunk3-1000000-1050000', 'tomekkorbak/detoxify-pile-chunk3-1050000-1100000', 'tomekkorbak/detoxify-pile-chunk3-1100000-1150000', 'tomekkorbak/detoxify-pile-chunk3-1150000-1200000', 'tomekkorbak/detoxify-pile-chunk3-1200000-1250000', 'tomekkorbak/detoxify-pile-chunk3-1250000-1300000', 'tomekkorbak/detoxify-pile-chunk3-1300000-1350000', 'tomekkorbak/detoxify-pile-chunk3-1350000-1400000', 'tomekkorbak/detoxify-pile-chunk3-1400000-1450000', 'tomekkorbak/detoxify-pile-chunk3-1450000-1500000', 'tomekkorbak/detoxify-pile-chunk3-1500000-1550000', 'tomekkorbak/detoxify-pile-chunk3-1550000-1600000', 'tomekkorbak/detoxify-pile-chunk3-1600000-1650000', 'tomekkorbak/detoxify-pile-chunk3-1650000-1700000', 'tomekkorbak/detoxify-pile-chunk3-1700000-1750000', 'tomekkorbak/detoxify-pile-chunk3-1750000-1800000', 'tomekkorbak/detoxify-pile-chunk3-1800000-1850000', 'tomekkorbak/detoxify-pile-chunk3-1850000-1900000', 'tomekkorbak/detoxify-pile-chunk3-1900000-1950000']
| null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 7,472 | false |
# goofy_pasteur
- **Repository: https://github.com/tomekkorbak/aligned-pretraining-objectives**
- **Paper: Arxiv link to be added**
## Model description
This model was trained using [pile-detoxify](https://huggingface.co/datasets/tomekkorbak/pile-detoxify), which is data from [The Pile](https://huggingface.co/datasets/the_pile), annotated based on toxicity detected by [Detoxify](https://github.com/unitaryai/detoxify).
## Intended uses & limitations
This model has been trained to generate text that receives a low score for toxicity from [Detoxify](https://github.com/unitaryai/detoxify).
While we have promising results with the methods used to avoid toxic text, we cannot guarantee that it will output text that is fully aligned with non-toxicity in every situation.
This model and its associated datasets are intended for research purposes only and should not be deployed anywhere.
Please take care to avoid misusing the datasets used to train this model (where toxicity and personal identifiable information are annotated) or putting anybody in danger by publicizing their information.
## Training and evaluation data
This model was trained using [pile-detoxify](https://huggingface.co/datasets/tomekkorbak/pile-detoxify).
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- training_steps: 50354
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.5.1
- Tokenizers 0.11.6
# Full config
{'dataset': {'datasets': ['tomekkorbak/detoxify-pile-chunk3-0-50000',
'tomekkorbak/detoxify-pile-chunk3-50000-100000',
'tomekkorbak/detoxify-pile-chunk3-100000-150000',
'tomekkorbak/detoxify-pile-chunk3-150000-200000',
'tomekkorbak/detoxify-pile-chunk3-200000-250000',
'tomekkorbak/detoxify-pile-chunk3-250000-300000',
'tomekkorbak/detoxify-pile-chunk3-300000-350000',
'tomekkorbak/detoxify-pile-chunk3-350000-400000',
'tomekkorbak/detoxify-pile-chunk3-400000-450000',
'tomekkorbak/detoxify-pile-chunk3-450000-500000',
'tomekkorbak/detoxify-pile-chunk3-500000-550000',
'tomekkorbak/detoxify-pile-chunk3-550000-600000',
'tomekkorbak/detoxify-pile-chunk3-600000-650000',
'tomekkorbak/detoxify-pile-chunk3-650000-700000',
'tomekkorbak/detoxify-pile-chunk3-700000-750000',
'tomekkorbak/detoxify-pile-chunk3-750000-800000',
'tomekkorbak/detoxify-pile-chunk3-800000-850000',
'tomekkorbak/detoxify-pile-chunk3-850000-900000',
'tomekkorbak/detoxify-pile-chunk3-900000-950000',
'tomekkorbak/detoxify-pile-chunk3-950000-1000000',
'tomekkorbak/detoxify-pile-chunk3-1000000-1050000',
'tomekkorbak/detoxify-pile-chunk3-1050000-1100000',
'tomekkorbak/detoxify-pile-chunk3-1100000-1150000',
'tomekkorbak/detoxify-pile-chunk3-1150000-1200000',
'tomekkorbak/detoxify-pile-chunk3-1200000-1250000',
'tomekkorbak/detoxify-pile-chunk3-1250000-1300000',
'tomekkorbak/detoxify-pile-chunk3-1300000-1350000',
'tomekkorbak/detoxify-pile-chunk3-1350000-1400000',
'tomekkorbak/detoxify-pile-chunk3-1400000-1450000',
'tomekkorbak/detoxify-pile-chunk3-1450000-1500000',
'tomekkorbak/detoxify-pile-chunk3-1500000-1550000',
'tomekkorbak/detoxify-pile-chunk3-1550000-1600000',
'tomekkorbak/detoxify-pile-chunk3-1600000-1650000',
'tomekkorbak/detoxify-pile-chunk3-1650000-1700000',
'tomekkorbak/detoxify-pile-chunk3-1700000-1750000',
'tomekkorbak/detoxify-pile-chunk3-1750000-1800000',
'tomekkorbak/detoxify-pile-chunk3-1800000-1850000',
'tomekkorbak/detoxify-pile-chunk3-1850000-1900000',
'tomekkorbak/detoxify-pile-chunk3-1900000-1950000'],
'is_split_by_sentences': True},
'generation': {'force_call_on': [25354],
'metrics_configs': [{}, {'n': 1}, {'n': 2}, {'n': 5}],
'scenario_configs': [{'generate_kwargs': {'do_sample': True,
'max_length': 128,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'unconditional',
'num_samples': 2048},
{'generate_kwargs': {'do_sample': True,
'max_length': 128,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'challenging_rtp',
'num_samples': 2048,
'prompts_path': 'resources/challenging_rtp.jsonl'}],
'scorer_config': {'device': 'cuda:0'}},
'kl_gpt3_callback': {'force_call_on': [25354],
'max_tokens': 64,
'num_samples': 4096},
'model': {'from_scratch': True,
'gpt2_config_kwargs': {'reorder_and_upcast_attn': True,
'scale_attn_by': True},
'path_or_name': 'gpt2'},
'objective': {'name': 'MLE'},
'tokenizer': {'path_or_name': 'gpt2'},
'training': {'dataloader_num_workers': 0,
'effective_batch_size': 64,
'evaluation_strategy': 'no',
'fp16': True,
'hub_model_id': 'goofy_pasteur',
'hub_strategy': 'all_checkpoints',
'learning_rate': 0.0005,
'logging_first_step': True,
'logging_steps': 1,
'num_tokens': 3300000000,
'output_dir': 'training_output104340',
'per_device_train_batch_size': 16,
'push_to_hub': True,
'remove_unused_columns': False,
'save_steps': 25354,
'save_strategy': 'steps',
'seed': 42,
'warmup_ratio': 0.01,
'weight_decay': 0.1}}
# Wandb URL:
https://wandb.ai/tomekkorbak/apo/runs/20d87pk8
|
3b21f10400385cc1fead2a991255332a
|
tyqiangz/xlm-roberta-base-finetuned-chaii
|
tyqiangz
|
xlm-roberta
| 12 | 9 |
transformers
| 0 |
question-answering
| true | false | false |
mit
| null |
[]
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| false | true | true | 1,256 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-chaii
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4651
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.92 | 1.0 | 899 | 0.4482 |
| 0.8055 | 2.0 | 1798 | 0.3225 |
| 0.7485 | 3.0 | 2697 | 0.4651 |
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
903c6f565f28b0dcd2212c9630e73d3d
|
LowGI/STT_Model_4
|
LowGI
|
wav2vec2
| 9 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,182 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# STT_Model_4
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2311
- Wer: 0.1373
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.4196 | 5.68 | 500 | 0.9866 | 0.6983 |
| 0.3696 | 11.36 | 1000 | 0.8788 | 0.4010 |
| 0.1182 | 17.05 | 1500 | 0.2187 | 0.1947 |
| 0.0658 | 22.73 | 2000 | 0.2578 | 0.1757 |
| 0.0421 | 28.41 | 2500 | 0.2178 | 0.1609 |
| 0.0346 | 34.09 | 3000 | 0.2038 | 0.1584 |
| 0.0285 | 39.77 | 3500 | 0.2187 | 0.1594 |
| 0.0228 | 45.45 | 4000 | 0.2114 | 0.1445 |
| 0.0262 | 51.14 | 4500 | 0.2201 | 0.1631 |
| 0.0162 | 56.82 | 5000 | 0.2078 | 0.1424 |
| 0.0135 | 62.5 | 5500 | 0.1989 | 0.1393 |
| 0.0128 | 68.18 | 6000 | 0.2118 | 0.1410 |
| 0.0104 | 73.86 | 6500 | 0.2158 | 0.1361 |
| 0.0081 | 79.55 | 7000 | 0.2154 | 0.1348 |
| 0.0067 | 85.23 | 7500 | 0.2107 | 0.1358 |
| 0.0067 | 90.91 | 8000 | 0.2161 | 0.1373 |
| 0.0056 | 96.59 | 8500 | 0.2311 | 0.1373 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
293c8686900c5fd418414e3ca9843a3e
|
ShihTing/PanJuOffset_TwoClass
|
ShihTing
|
vit
| 6 | 5 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['vision', 'image-classification']
| false | true | true | 1,560 | false |
# PanJu offset detect by image
Use fintune from google/vit-base-patch16-224(https://huggingface.co/google/vit-base-patch16-224)
## Dataset
```python
DatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 329
})
validation: Dataset({
features: ['image', 'label'],
num_rows: 56
})
})
```
36 Break and 293 Normal in train
5 Break and 51 Normal in validation
## Intended uses
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
# Load image
import torch
from transformers import ViTFeatureExtractor, ViTForImageClassification,AutoModel
from PIL import Image
import requests
url='https://datasets-server.huggingface.co/assets/ShihTing/IsCausewayOffset/--/ShihTing--IsCausewayOffset/validation/0/image/image.jpg'
image = Image.open(requests.get(url, stream=True).raw)
# Load model
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
device = torch.device('cpu')
extractor = AutoFeatureExtractor.from_pretrained('ShihTing/PanJuOffset_TwoClass')
model = AutoModelForImageClassification.from_pretrained('ShihTing/PanJuOffset_TwoClass')
# Predict
inputs = extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
Prob = outputs.logits.softmax(dim=-1).tolist()
print(Prob)
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
|
1d16f73b1de3059a040820e317f167de
|
okho0653/Bio_ClinicalBERT-zero-shot-finetuned-50cad
|
okho0653
|
bert
| 13 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,071 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT-zero-shot-finetuned-50cad
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1475
- Accuracy: 0.5
- F1: 0.6667
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
dbbbd8ac2dc99df7a1b90c7780cbd37b
|
augustocsc/gpt-m
|
augustocsc
|
gpt2
| 13 | 49 |
transformers
| 0 |
text-generation
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,102 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt-m
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0096
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.3775 | 0.06 | 500 | 0.0302 |
| 0.0207 | 0.11 | 1000 | 0.0188 |
| 0.0182 | 0.17 | 1500 | 0.0179 |
| 0.0171 | 0.22 | 2000 | 0.0152 |
| 0.0178 | 0.28 | 2500 | 0.0161 |
| 0.0147 | 0.33 | 3000 | 0.0150 |
| 0.0157 | 0.39 | 3500 | 0.0137 |
| 0.0137 | 0.44 | 4000 | 0.0126 |
| 0.0133 | 0.5 | 4500 | 0.0137 |
| 0.012 | 0.56 | 5000 | 0.0120 |
| 0.0122 | 0.61 | 5500 | 0.0117 |
| 0.0129 | 0.67 | 6000 | 0.0118 |
| 0.0113 | 0.72 | 6500 | 0.0114 |
| 0.0106 | 0.78 | 7000 | 0.0109 |
| 0.0119 | 0.83 | 7500 | 0.0108 |
| 0.0122 | 0.89 | 8000 | 0.0102 |
| 0.0105 | 0.94 | 8500 | 0.0101 |
| 0.0094 | 1.0 | 9000 | 0.0098 |
| 0.01 | 1.06 | 9500 | 0.0097 |
| 0.0097 | 1.11 | 10000 | 0.0096 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
380d15c66b02710e30b082e1a90405c7
|
anantoj/T5-summarizer-simple-wiki-v2
|
anantoj
|
t5
| 23 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,275 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# T5-summarizer-simple-wiki-v2
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0866
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.2575 | 1.0 | 14719 | 2.1173 |
| 2.2663 | 2.0 | 29438 | 2.0926 |
| 2.2092 | 3.0 | 44157 | 2.0866 |
### Framework versions
- Transformers 4.19.4
- Pytorch 1.11.0
- Datasets 2.3.2
- Tokenizers 0.12.1
|
bed1a5a45f8b90a202461269c7c821ed
|
Tsubame/ddpm-butterflies-64
|
Tsubame
| null | 17 | 0 |
diffusers
| 0 | null | false | false | false |
apache-2.0
|
['en']
|
['huggan/smithsonian_butterflies_subset']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,227 | false |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-64
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/Tsubame/ddpm-butterflies-64/tensorboard?#scalars)
|
248fd1bba82acb68669c346a9019a404
|
haesun/distilbert-base-uncased-distilled-clinc
|
haesun
|
distilbert
| 10 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['clinc_oos']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,792 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-distilled-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1894
- Accuracy: 0.9448
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.6133 | 1.0 | 318 | 1.0679 | 0.7290 |
| 0.8231 | 2.0 | 636 | 0.5164 | 0.8652 |
| 0.4289 | 3.0 | 954 | 0.3019 | 0.9168 |
| 0.2722 | 4.0 | 1272 | 0.2336 | 0.9335 |
| 0.214 | 5.0 | 1590 | 0.2117 | 0.94 |
| 0.1914 | 6.0 | 1908 | 0.2007 | 0.9445 |
| 0.1785 | 7.0 | 2226 | 0.1947 | 0.9435 |
| 0.1716 | 8.0 | 2544 | 0.1919 | 0.9468 |
| 0.1674 | 9.0 | 2862 | 0.1901 | 0.9452 |
| 0.1659 | 10.0 | 3180 | 0.1894 | 0.9448 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
a6e4be0233b77389f3b4b9c9737a6066
|
Hoax0930/kyoto_marian_mod_3
|
Hoax0930
|
marian
| 14 | 1 |
transformers
| 0 |
translation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation', 'generated_from_trainer']
| true | true | true | 1,071 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kyoto_marian_mod_3_5
This model is a fine-tuned version of [Hoax0930/kyoto_marian_mod_2](https://huggingface.co/Hoax0930/kyoto_marian_mod_2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8052
- Bleu: 18.4305
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 16
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
78deeef2e9b4896927745ca99503ea2c
|
royam0820/xlm-roberta-base-finetuned-panx-it
|
royam0820
|
xlm-roberta
| 10 | 23 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null |
['xtreme']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,320 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-it
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2630
- F1: 0.8124
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.8193 | 1.0 | 70 | 0.3200 | 0.7356 |
| 0.2773 | 2.0 | 140 | 0.2841 | 0.7882 |
| 0.1807 | 3.0 | 210 | 0.2630 | 0.8124 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
3a2879f06f18ad084d192880b27f74e4
|
devtanumisra/finetuning-insult-model-deberta
|
devtanumisra
|
deberta-v2
| 14 | 8 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,107 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-insult-model-deberta
This model is a fine-tuned version of [yangheng/deberta-v3-base-absa-v1.1](https://huggingface.co/yangheng/deberta-v3-base-absa-v1.1) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9472
- Accuracy: 0.7458
- F1: 0.7630
- Precision: 0.7332
- Recall: 0.7953
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.2
|
526444f17d845fe9f1d8bf0c457d8f50
|
Lvxue/distilled-mt5-small-0.02-0.5
|
Lvxue
|
mt5
| 14 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
|
['en', 'ro']
|
['wmt16']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,038 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilled-mt5-small-0.02-0.5
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the wmt16 ro-en dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8160
- Bleu: 7.448
- Gen Len: 44.2241
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
d53ff25017c6bbc8946f185c24d262af
|
muhtasham/tiny-mlm-glue-rte-target-glue-cola
|
muhtasham
|
bert
| 10 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,107 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-rte-target-glue-cola
This model is a fine-tuned version of [muhtasham/tiny-mlm-glue-rte](https://huggingface.co/muhtasham/tiny-mlm-glue-rte) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7986
- Matthews Correlation: 0.1168
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.6097 | 1.87 | 500 | 0.6209 | 0.0 |
| 0.6011 | 3.73 | 1000 | 0.6173 | 0.0 |
| 0.5827 | 5.6 | 1500 | 0.6197 | 0.0622 |
| 0.5534 | 7.46 | 2000 | 0.6410 | 0.0939 |
| 0.5244 | 9.33 | 2500 | 0.6664 | 0.1184 |
| 0.5087 | 11.19 | 3000 | 0.6684 | 0.1327 |
| 0.4867 | 13.06 | 3500 | 0.6789 | 0.0999 |
| 0.4693 | 14.93 | 4000 | 0.7124 | 0.1109 |
| 0.4483 | 16.79 | 4500 | 0.7333 | 0.1388 |
| 0.4303 | 18.66 | 5000 | 0.7486 | 0.1287 |
| 0.4105 | 20.52 | 5500 | 0.7961 | 0.1321 |
| 0.4046 | 22.39 | 6000 | 0.7986 | 0.1168 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
81ef4f9eae5b899e627580e496844142
|
skparida/wav2vec2-base-timit-demo-google-colab
|
skparida
|
wav2vec2
| 12 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,998 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-google-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5090
- Wer: 0.3435
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 3.5501 | 1.0 | 500 | 1.9752 | 0.9950 |
| 0.8608 | 2.01 | 1000 | 0.5051 | 0.5035 |
| 0.43 | 3.01 | 1500 | 0.4485 | 0.4525 |
| 0.2921 | 4.02 | 2000 | 0.4658 | 0.4332 |
| 0.2248 | 5.02 | 2500 | 0.4262 | 0.4268 |
| 0.1863 | 6.02 | 3000 | 0.4126 | 0.3977 |
| 0.1542 | 7.03 | 3500 | 0.4795 | 0.3987 |
| 0.1374 | 8.03 | 4000 | 0.4882 | 0.3982 |
| 0.1231 | 9.04 | 4500 | 0.4312 | 0.3790 |
| 0.1082 | 10.04 | 5000 | 0.4344 | 0.3679 |
| 0.0949 | 11.04 | 5500 | 0.4720 | 0.3769 |
| 0.0897 | 12.05 | 6000 | 0.5382 | 0.3706 |
| 0.0816 | 13.05 | 6500 | 0.4946 | 0.3618 |
| 0.0726 | 14.06 | 7000 | 0.5383 | 0.3630 |
| 0.0656 | 15.06 | 7500 | 0.4944 | 0.3693 |
| 0.059 | 16.06 | 8000 | 0.5096 | 0.3639 |
| 0.0572 | 17.07 | 8500 | 0.5066 | 0.3572 |
| 0.0559 | 18.07 | 9000 | 0.5366 | 0.3610 |
| 0.0468 | 19.08 | 9500 | 0.5103 | 0.3604 |
| 0.0413 | 20.08 | 10000 | 0.5126 | 0.3496 |
| 0.044 | 21.08 | 10500 | 0.5055 | 0.3524 |
| 0.0351 | 22.09 | 11000 | 0.5526 | 0.3515 |
| 0.0328 | 23.09 | 11500 | 0.4884 | 0.3512 |
| 0.032 | 24.1 | 12000 | 0.5167 | 0.3474 |
| 0.0271 | 25.1 | 12500 | 0.5027 | 0.3495 |
| 0.0229 | 26.1 | 13000 | 0.5076 | 0.3444 |
| 0.0252 | 27.11 | 13500 | 0.5122 | 0.3464 |
| 0.0224 | 28.11 | 14000 | 0.5133 | 0.3447 |
| 0.0236 | 29.12 | 14500 | 0.5090 | 0.3435 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.12.1+cu113
- Datasets 1.18.3
- Tokenizers 0.12.1
|
b73bc8068a38d9842a1a28aa5e1fccbd
|
jonatasgrosman/exp_w2v2r_de_vp-100k_age_teens-0_sixties-10_s50
|
jonatasgrosman
|
wav2vec2
| 10 | 0 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['de']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'de']
| false | true | true | 497 | false |
# exp_w2v2r_de_vp-100k_age_teens-0_sixties-10_s50
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
99ab1b4e801eeb604d455abf4166e5b3
|
sd-concepts-library/artist-yukiko-kanagai
|
sd-concepts-library
| null | 10 | 0 | null | 1 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,232 | false |
### Artist_Yukiko Kanagai on Stable Diffusion
This is the `<Yukiko Kanagai >` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:





|
490ed1b19eca329789151e9d49bec8da
|
reinoudbosch/xlm-roberta-base-finetuned-panx-en
|
reinoudbosch
|
xlm-roberta
| 10 | 11 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null |
['xtreme']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,313 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-en
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4025
- F1: 0.6778
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.1069 | 1.0 | 50 | 0.5201 | 0.5010 |
| 0.4975 | 2.0 | 100 | 0.4503 | 0.6198 |
| 0.3705 | 3.0 | 150 | 0.4025 | 0.6778 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.11.0
- Datasets 2.0.0
- Tokenizers 0.11.0
|
ece74ab822853eb0563103f75426e4f2
|
CLTL/MedRoBERTa.nl
|
CLTL
|
roberta
| 7 | 2,910 |
transformers
| 0 |
fill-mask
| true | false | false |
mit
|
['nl']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,229 | false |
# MedRoBERTa.nl
## Description
This model is a RoBERTa-based model pre-trained from scratch on Dutch hospital notes sourced from Electronic Health Records. The model is not fine-tuned. All code used for the creation of MedRoBERTa.nl can be found at https://github.com/cltl-students/verkijk_stella_rma_thesis_dutch_medical_language_model.
## Intended use
The model can be fine-tuned on any type of task. Since it is a domain-specific model trained on medical data, it is meant to be used on medical NLP tasks for Dutch.
## Data
The model was trained on nearly 10 million hospital notes from the Amsterdam University Medical Centres. The training data was anonymized before starting the pre-training procedure.
## Privacy
By anonymizing the training data we made sure the model did not learn any representative associations linked to names. Apart from the training data, the model's vocabulary was also anonymized. This ensures that the model can not predict any names in the generative fill-mask task.
## Authors
Stella Verkijk, Piek Vossen
## Reference
Paper: Verkijk, S. & Vossen, P. (2022) MedRoBERTa.nl: A Language Model for Dutch Electronic Health Records. Computational Linguistics in the Netherlands Journal, 11.
|
873d46ae03ff8457e2f7b42384fd2b5a
|
d2lee/finetuning-sentiment-model-3000-samples
|
d2lee
|
distilbert
| 13 | 12 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['imdb']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,049 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3150
- Accuracy: 0.8633
- F1: 0.8656
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1
- Datasets 2.6.1
- Tokenizers 0.13.1
|
c404266336f43fcb6ca4c8815ce452e6
|
lmqg/mt5-small-koquad-qag
|
lmqg
|
mt5
| 13 | 36 |
transformers
| 0 |
text2text-generation
| true | false | false |
cc-by-4.0
|
['ko']
|
['lmqg/qag_koquad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['questions and answers generation']
| true | true | true | 3,848 | false |
# Model Card of `lmqg/mt5-small-koquad-qag`
This model is fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) for question & answer pair generation task on the [lmqg/qag_koquad](https://huggingface.co/datasets/lmqg/qag_koquad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [google/mt5-small](https://huggingface.co/google/mt5-small)
- **Language:** ko
- **Training data:** [lmqg/qag_koquad](https://huggingface.co/datasets/lmqg/qag_koquad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="ko", model="lmqg/mt5-small-koquad-qag")
# model prediction
question_answer_pairs = model.generate_qa("1990년 영화 《 남부군 》에서 단역으로 영화배우 첫 데뷔에 이어 같은 해 KBS 드라마 《지구인》에서 단역으로 출연하였고 이듬해 MBC 《여명의 눈동자》를 통해 단역으로 출연하였다.")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/mt5-small-koquad-qag")
output = pipe("1990년 영화 《 남부군 》에서 단역으로 영화배우 첫 데뷔에 이어 같은 해 KBS 드라마 《지구인》에서 단역으로 출연하였고 이듬해 MBC 《여명의 눈동자》를 통해 단역으로 출연하였다.")
```
## Evaluation
- ***Metric (Question & Answer Generation)***: [raw metric file](https://huggingface.co/lmqg/mt5-small-koquad-qag/raw/main/eval/metric.first.answer.paragraph.questions_answers.lmqg_qag_koquad.default.json)
| | Score | Type | Dataset |
|:--------------------------------|--------:|:--------|:-------------------------------------------------------------------|
| QAAlignedF1Score (BERTScore) | 74.23 | default | [lmqg/qag_koquad](https://huggingface.co/datasets/lmqg/qag_koquad) |
| QAAlignedF1Score (MoverScore) | 75.06 | default | [lmqg/qag_koquad](https://huggingface.co/datasets/lmqg/qag_koquad) |
| QAAlignedPrecision (BERTScore) | 74.29 | default | [lmqg/qag_koquad](https://huggingface.co/datasets/lmqg/qag_koquad) |
| QAAlignedPrecision (MoverScore) | 75.14 | default | [lmqg/qag_koquad](https://huggingface.co/datasets/lmqg/qag_koquad) |
| QAAlignedRecall (BERTScore) | 74.2 | default | [lmqg/qag_koquad](https://huggingface.co/datasets/lmqg/qag_koquad) |
| QAAlignedRecall (MoverScore) | 75.04 | default | [lmqg/qag_koquad](https://huggingface.co/datasets/lmqg/qag_koquad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qag_koquad
- dataset_name: default
- input_types: ['paragraph']
- output_types: ['questions_answers']
- prefix_types: None
- model: google/mt5-small
- max_length: 512
- max_length_output: 256
- epoch: 13
- batch: 8
- lr: 0.0005
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 16
- label_smoothing: 0.0
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/mt5-small-koquad-qag/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
aef1594b8d22239d9dcc9334295d5bd1
|
Akanksha27/distilbert-base-uncased-finetuned-cola
|
Akanksha27
|
distilbert
| 18 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,275 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4969
- Matthews Correlation: 0.4354
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5287 | 1.0 | 535 | 0.4969 | 0.4354 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
ceca805ab9da6775e812ea83a342f1c3
|
KoichiYasuoka/roberta-classical-chinese-base-char
|
KoichiYasuoka
|
roberta
| 7 | 44 |
transformers
| 3 |
fill-mask
| true | false | false |
apache-2.0
|
['lzh']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['classical chinese', 'literary chinese', 'ancient chinese', 'masked-lm']
| false | true | true | 1,101 | false |
# roberta-classical-chinese-base-char
## Model Description
This is a RoBERTa model pre-trained on Classical Chinese texts, derived from [GuwenBERT-base](https://huggingface.co/ethanyt/guwenbert-base). Character-embeddings are enhanced into traditional/simplified characters. You can fine-tune `roberta-classical-chinese-base-char` for downstream tasks, such as [sentence-segmentation](https://huggingface.co/KoichiYasuoka/roberta-classical-chinese-base-sentence-segmentation), [POS-tagging](https://huggingface.co/KoichiYasuoka/roberta-classical-chinese-base-upos), [dependency-parsing](https://huggingface.co/KoichiYasuoka/roberta-classical-chinese-base-ud-goeswith), and so on.
## How to Use
```py
from transformers import AutoTokenizer,AutoModelForMaskedLM
tokenizer=AutoTokenizer.from_pretrained("KoichiYasuoka/roberta-classical-chinese-base-char")
model=AutoModelForMaskedLM.from_pretrained("KoichiYasuoka/roberta-classical-chinese-base-char")
```
## See Also
[SuPar-Kanbun](https://github.com/KoichiYasuoka/SuPar-Kanbun): Tokenizer POS-tagger and Dependency-parser for Classical Chinese
|
aaec20edf80480a0d79681f3ee60b9b7
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.