
repo_id
stringlengths 4
110
| author
stringlengths 2
27
⌀ | model_type
stringlengths 2
29
⌀ | files_per_repo
int64 2
15.4k
| downloads_30d
int64 0
19.9M
| library
stringlengths 2
37
⌀ | likes
int64 0
4.34k
| pipeline
stringlengths 5
30
⌀ | pytorch
bool 2
classes | tensorflow
bool 2
classes | jax
bool 2
classes | license
stringlengths 2
30
| languages
stringlengths 4
1.63k
⌀ | datasets
stringlengths 2
2.58k
⌀ | co2
stringclasses 29
values | prs_count
int64 0
125
| prs_open
int64 0
120
| prs_merged
int64 0
15
| prs_closed
int64 0
28
| discussions_count
int64 0
218
| discussions_open
int64 0
148
| discussions_closed
int64 0
70
| tags
stringlengths 2
513
| has_model_index
bool 2
classes | has_metadata
bool 1
class | has_text
bool 1
class | text_length
int64 401
598k
| is_nc
bool 1
class | readme
stringlengths 0
598k
| hash
stringlengths 32
32
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Kuray107/librispeech-100h-supervised-meta
|
Kuray107
|
wav2vec2
| 7 | 6 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,280 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# librispeech-100h-supervised-meta
This model is a fine-tuned version of [Kuray107/librispeech-5h-supervised](https://huggingface.co/Kuray107/librispeech-5h-supervised) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0965
- Wer: 0.0330
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 0.1131 | 1.12 | 1000 | 0.0755 | 0.0487 |
| 0.0725 | 2.24 | 2000 | 0.0637 | 0.0404 |
| 0.0539 | 3.36 | 3000 | 0.0661 | 0.0389 |
| 0.0441 | 4.48 | 4000 | 0.0637 | 0.0371 |
| 0.0379 | 5.61 | 5000 | 0.0675 | 0.0356 |
| 0.0341 | 6.73 | 6000 | 0.0735 | 0.0360 |
| 0.0295 | 7.85 | 7000 | 0.0737 | 0.0362 |
| 0.0265 | 8.97 | 8000 | 0.0741 | 0.0350 |
| 0.0244 | 10.09 | 9000 | 0.0779 | 0.0337 |
| 0.0217 | 11.21 | 10000 | 0.0835 | 0.0343 |
| 0.0203 | 12.33 | 11000 | 0.0785 | 0.0339 |
| 0.0188 | 13.45 | 12000 | 0.0827 | 0.0344 |
| 0.0179 | 14.57 | 13000 | 0.0875 | 0.0332 |
| 0.0169 | 15.7 | 14000 | 0.0860 | 0.0330 |
| 0.0158 | 16.82 | 15000 | 0.0954 | 0.0330 |
| 0.0147 | 17.94 | 16000 | 0.0934 | 0.0329 |
| 0.0148 | 19.06 | 17000 | 0.0965 | 0.0330 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.2
- Datasets 1.18.2
- Tokenizers 0.10.3
|
79d9aaa2219667af98a8d4c2a8d54a6d
|
muhtasham/tiny-mlm-glue-rte-custom-tokenizer
|
muhtasham
|
bert
| 12 | 0 |
transformers
| 1 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,358 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tiny-mlm-glue-rte-custom-tokenizer
This model is a fine-tuned version of [google/bert_uncased_L-2_H-128_A-2](https://huggingface.co/google/bert_uncased_L-2_H-128_A-2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 7.3646
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 7.71 | 1.6 | 500 | 7.1503 |
| 6.8618 | 3.21 | 1000 | 7.2787 |
| 6.816 | 4.81 | 1500 | 7.2543 |
| 6.7094 | 6.41 | 2000 | 7.3646 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
04eb3d89b72f40c2b1b56a79ea92f755
|
lmqg/t5-large-subjqa-tripadvisor-qg
|
lmqg
|
t5
| 34 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
cc-by-4.0
|
['en']
|
['lmqg/qg_subjqa']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['question generation']
| true | true | true | 4,016 | false |
# Model Card of `lmqg/t5-large-subjqa-tripadvisor-qg`
This model is fine-tuned version of [lmqg/t5-large-squad](https://huggingface.co/lmqg/t5-large-squad) for question generation task on the [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (dataset_name: tripadvisor) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [lmqg/t5-large-squad](https://huggingface.co/lmqg/t5-large-squad)
- **Language:** en
- **Training data:** [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) (tripadvisor)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="en", model="lmqg/t5-large-subjqa-tripadvisor-qg")
# model prediction
questions = model.generate_q(list_context="William Turner was an English painter who specialised in watercolour landscapes", list_answer="William Turner")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/t5-large-subjqa-tripadvisor-qg")
output = pipe("generate question: <hl> Beyonce <hl> further expanded her acting career, starring as blues singer Etta James in the 2008 musical biopic, Cadillac Records.")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/lmqg/t5-large-subjqa-tripadvisor-qg/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_subjqa.tripadvisor.json)
| | Score | Type | Dataset |
|:-----------|--------:|:------------|:-----------------------------------------------------------------|
| BERTScore | 94.46 | tripadvisor | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_1 | 26.44 | tripadvisor | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_2 | 17.84 | tripadvisor | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_3 | 9.13 | tripadvisor | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| Bleu_4 | 5.35 | tripadvisor | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| METEOR | 27.45 | tripadvisor | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| MoverScore | 67.76 | tripadvisor | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
| ROUGE_L | 27.69 | tripadvisor | [lmqg/qg_subjqa](https://huggingface.co/datasets/lmqg/qg_subjqa) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_subjqa
- dataset_name: tripadvisor
- input_types: ['paragraph_answer']
- output_types: ['question']
- prefix_types: ['qg']
- model: lmqg/t5-large-squad
- max_length: 512
- max_length_output: 32
- epoch: 1
- batch: 16
- lr: 0.0001
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 4
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/t5-large-subjqa-tripadvisor-qg/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
f16ff422f4eeed8070d503b8e41bc8ee
|
CLAck/en-vi
|
CLAck
|
marian
| 11 | 25 |
transformers
| 0 |
translation
| true | false | false |
apache-2.0
|
['en', 'vi']
|
['ALT']
| null | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
['translation']
| false | true | true | 1,748 | false |
This is a finetuning of a MarianMT pretrained on English-Chinese. The target language pair is English-Vietnamese.
The first phase of training (mixed) is performed on a dataset containing both English-Chinese and English-Vietnamese sentences.
The second phase of training (pure) is performed on a dataset containing only English-Vietnamese sentences.
### Example
```
%%capture
!pip install transformers transformers[sentencepiece]
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
# Download the pretrained model for English-Vietnamese available on the hub
model = AutoModelForSeq2SeqLM.from_pretrained("CLAck/en-vi")
tokenizer = AutoTokenizer.from_pretrained("CLAck/en-vi")
# Download a tokenizer that can tokenize English since the model Tokenizer doesn't know anymore how to do it
# We used the one coming from the initial model
# This tokenizer is used to tokenize the input sentence
tokenizer_en = AutoTokenizer.from_pretrained('Helsinki-NLP/opus-mt-en-zh')
# These special tokens are needed to reproduce the original tokenizer
tokenizer_en.add_tokens(["<2zh>", "<2vi>"], special_tokens=True)
sentence = "The cat is on the table"
# This token is needed to identify the target language
input_sentence = "<2vi> " + sentence
translated = model.generate(**tokenizer_en(input_sentence, return_tensors="pt", padding=True))
output_sentence = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]
```
### Training results
MIXED
| Epoch | Bleu |
|:-----:|:-------:|
| 1.0 | 26.2407 |
| 2.0 | 32.6016 |
| 3.0 | 35.4060 |
| 4.0 | 36.6737 |
| 5.0 | 37.3774 |
PURE
| Epoch | Bleu |
|:-----:|:-------:|
| 1.0 | 37.3169 |
| 2.0 | 37.4407 |
| 3.0 | 37.6696 |
| 4.0 | 37.8765 |
| 5.0 | 38.0105 |
|
29a961ec256467dd85a5d89310a531d1
|
CVPR/FSPBT
|
CVPR
| null | 3 | 0 |
PyTorch Lightning
| 0 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['Image Translation']
| false | true | true | 599 | false |
## Model Details
This model is from [FSPBT-Image-Translation](https://github.com/rnwzd/FSPBT-Image-Translation)
## Citation Information
```bibtex
@Article{Texler20-SIG,
author = "Ond\v{r}ej Texler and David Futschik and Michal Ku\v{c}era and Ond\v{r}ej Jamri\v{s}ka and \v{S}\'{a}rka Sochorov\'{a} and Menglei Chai and Sergey Tulyakov and Daniel S\'{y}kora",
title = "Interactive Video Stylization Using Few-Shot Patch-Based Training",
journal = "ACM Transactions on Graphics",
volume = "39",
number = "4",
pages = "73",
year = "2020",
}
```
|
464e0e8ce5078d1f3ad9a684cd9ab127
|
Helsinki-NLP/opus-mt-sv-ilo
|
Helsinki-NLP
|
marian
| 10 | 7 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 776 | false |
### opus-mt-sv-ilo
* source languages: sv
* target languages: ilo
* OPUS readme: [sv-ilo](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/sv-ilo/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/sv-ilo/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-ilo/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/sv-ilo/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.sv.ilo | 34.8 | 0.578 |
|
31bc1bd048632b4a7f8635fccaa22619
|
monologg/koelectra-base-generator
|
monologg
|
electra
| 6 | 47 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
|
['ko']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['korean']
| false | true | true | 1,309 | false |
# KoELECTRA (Base Generator)
Pretrained ELECTRA Language Model for Korean (`koelectra-base-generator`)
For more detail, please see [original repository](https://github.com/monologg/KoELECTRA/blob/master/README_EN.md).
## Usage
### Load model and tokenizer
```python
>>> from transformers import ElectraModel, ElectraTokenizer
>>> model = ElectraModel.from_pretrained("monologg/koelectra-base-generator")
>>> tokenizer = ElectraTokenizer.from_pretrained("monologg/koelectra-base-generator")
```
### Tokenizer example
```python
>>> from transformers import ElectraTokenizer
>>> tokenizer = ElectraTokenizer.from_pretrained("monologg/koelectra-base-generator")
>>> tokenizer.tokenize("[CLS] 한국어 ELECTRA를 공유합니다. [SEP]")
['[CLS]', '한국어', 'E', '##L', '##EC', '##T', '##RA', '##를', '공유', '##합니다', '.', '[SEP]']
>>> tokenizer.convert_tokens_to_ids(['[CLS]', '한국어', 'E', '##L', '##EC', '##T', '##RA', '##를', '공유', '##합니다', '.', '[SEP]'])
[2, 18429, 41, 6240, 15229, 6204, 20894, 5689, 12622, 10690, 18, 3]
```
## Example using ElectraForMaskedLM
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="monologg/koelectra-base-generator",
tokenizer="monologg/koelectra-base-generator"
)
print(fill_mask("나는 {} 밥을 먹었다.".format(fill_mask.tokenizer.mask_token)))
```
|
88172dba26ef2bdf51cfcdd0c7b1cc72
|
mastergruffly/profile
|
mastergruffly
| null | 18 | 7 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 615 | false |
### profile Dreambooth model trained by mastergruffly with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
Sample pictures of this concept:
|
464476adf653f55519a15e38e4997e33
|
pyf98/voxforge_it_conformer_e12_linear2048
|
pyf98
| null | 21 | 2 |
espnet
| 0 |
automatic-speech-recognition
| false | false | false |
cc-by-4.0
|
['it']
|
['voxforge']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['espnet', 'audio', 'automatic-speech-recognition']
| false | true | true | 6,790 | false |
## ESPnet2 ASR model
### `pyf98/voxforge_it_conformer_e12_linear2048`
This model was trained by Yifan Peng using voxforge recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
Follow the [ESPnet installation instructions](https://espnet.github.io/espnet/installation.html)
if you haven't done that already.
```bash
cd espnet
git checkout bf8c8f00194bdfed8ca388d8b20d14791b7d270e
pip install -e .
cd egs2/voxforge/asr1
./run.sh --skip_data_prep false --skip_train true --download_model pyf98/voxforge_it_conformer_e12_linear2048
```
<!-- Generated by scripts/utils/show_asr_result.sh -->
# RESULTS
## Environments
- date: `Thu Dec 29 01:45:02 EST 2022`
- python version: `3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0]`
- espnet version: `espnet 202211`
- pytorch version: `pytorch 1.12.1`
- Git hash: `bf8c8f00194bdfed8ca388d8b20d14791b7d270e`
- Commit date: `Wed Dec 28 22:43:13 2022 -0500`
## asr_train_asr_conformer_e12_linear2048_raw_it_char_normalize_confnorm_varsFalse
### WER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_asr_model_valid.acc.ave/dt_it|1035|12587|70.3|24.6|5.1|3.3|33.0|95.4|
|decode_asr_asr_model_valid.acc.ave/et_it|1103|13699|72.4|22.5|5.1|2.9|30.5|91.5|
### CER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|decode_asr_asr_model_valid.acc.ave/dt_it|1035|75494|92.9|3.9|3.2|1.8|8.9|95.4|
|decode_asr_asr_model_valid.acc.ave/et_it|1103|81228|93.7|3.5|2.8|1.7|8.0|91.5|
### TER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
## ASR config
<details><summary>expand</summary>
```
config: conf/tuning/train_asr_conformer_e12_linear2048.yaml
print_config: false
log_level: INFO
dry_run: false
iterator_type: sequence
output_dir: exp/asr_train_asr_conformer_e12_linear2048_raw_it_char_normalize_confnorm_varsFalse
ngpu: 1
seed: 0
num_workers: 4
num_att_plot: 3
dist_backend: nccl
dist_init_method: env://
dist_world_size: null
dist_rank: null
local_rank: 0
dist_master_addr: null
dist_master_port: null
dist_launcher: null
multiprocessing_distributed: false
unused_parameters: false
sharded_ddp: false
cudnn_enabled: true
cudnn_benchmark: false
cudnn_deterministic: true
collect_stats: false
write_collected_feats: false
max_epoch: 100
patience: null
val_scheduler_criterion:
- valid
- loss
early_stopping_criterion:
- valid
- loss
- min
best_model_criterion:
- - valid
- acc
- max
keep_nbest_models: 10
nbest_averaging_interval: 0
grad_clip: 5.0
grad_clip_type: 2.0
grad_noise: false
accum_grad: 1
no_forward_run: false
resume: true
train_dtype: float32
use_amp: true
log_interval: null
use_matplotlib: true
use_tensorboard: true
create_graph_in_tensorboard: false
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
pretrain_path: null
init_param: []
ignore_init_mismatch: false
freeze_param: []
num_iters_per_epoch: null
batch_size: 128
valid_batch_size: null
batch_bins: 1000000
valid_batch_bins: null
train_shape_file:
- exp/asr_stats_raw_it_char/train/speech_shape
- exp/asr_stats_raw_it_char/train/text_shape.char
valid_shape_file:
- exp/asr_stats_raw_it_char/valid/speech_shape
- exp/asr_stats_raw_it_char/valid/text_shape.char
batch_type: folded
valid_batch_type: null
fold_length:
- 80000
- 150
sort_in_batch: descending
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
train_data_path_and_name_and_type:
- - dump/raw/tr_it/wav.scp
- speech
- sound
- - dump/raw/tr_it/text
- text
- text
valid_data_path_and_name_and_type:
- - dump/raw/dt_it/wav.scp
- speech
- sound
- - dump/raw/dt_it/text
- text
- text
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
valid_max_cache_size: null
optim: adam
optim_conf:
lr: 0.002
scheduler: warmuplr
scheduler_conf:
warmup_steps: 10000
token_list:
- <blank>
- <unk>
- <space>
- A
- E
- I
- O
- R
- N
- L
- S
- T
- C
- D
- U
- M
- P
- V
- G
- F
- H
- B
- Q
- Z
- ''''
- Ò
- À
- È
- Ú
- X
- W
- Í
- É
- Y
- K
- J
- '1'
- <sos/eos>
init: null
input_size: null
ctc_conf:
dropout_rate: 0.0
ctc_type: builtin
reduce: true
ignore_nan_grad: null
zero_infinity: true
joint_net_conf: null
use_preprocessor: true
token_type: char
bpemodel: null
non_linguistic_symbols: null
cleaner: null
g2p: null
speech_volume_normalize: null
rir_scp: null
rir_apply_prob: 1.0
noise_scp: null
noise_apply_prob: 1.0
noise_db_range: '13_15'
short_noise_thres: 0.5
frontend: default
frontend_conf:
fs: 16k
specaug: null
specaug_conf: {}
normalize: global_mvn
normalize_conf:
stats_file: exp/asr_stats_raw_it_char/train/feats_stats.npz
norm_vars: false
model: espnet
model_conf:
ctc_weight: 0.3
lsm_weight: 0.1
length_normalized_loss: false
preencoder: null
preencoder_conf: {}
encoder: conformer
encoder_conf:
output_size: 256
attention_heads: 4
linear_units: 2048
num_blocks: 12
dropout_rate: 0.1
positional_dropout_rate: 0.1
attention_dropout_rate: 0.1
input_layer: conv2d
normalize_before: true
macaron_style: true
rel_pos_type: latest
pos_enc_layer_type: rel_pos
selfattention_layer_type: rel_selfattn
activation_type: swish
use_cnn_module: true
cnn_module_kernel: 31
postencoder: null
postencoder_conf: {}
decoder: transformer
decoder_conf:
attention_heads: 4
linear_units: 2048
num_blocks: 6
dropout_rate: 0.1
positional_dropout_rate: 0.1
self_attention_dropout_rate: 0.0
src_attention_dropout_rate: 0.0
preprocessor: default
preprocessor_conf: {}
required:
- output_dir
- token_list
version: '202211'
distributed: false
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
95aa7c1cff51e692965b85954a8e8a11
|
bongsoo/albert-small-kor-cross-encoder-v1
|
bongsoo
|
albert
| 8 | 123 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['ko']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,916 | false |
# albert-small-kor-cross-encoder-v1
- albert-small-kor-v1 모델을 훈련시켜 cross-encoder로 파인튜닝한 모델
- This model was trained using [SentenceTransformers](https://sbert.net) [Cross-Encoder](https://www.sbert.net/examples/applications/cross-encoder/README.html) class.
# Training
- sts(10)-nli(3)-sts(10)-nli(3)-sts(10) 훈련 시킴 (**distil 훈련 없음**)
- STS : seed=111,epoch=10, lr=1e-4, eps=1e-6, warm_step=10%, max_seq_len=128, train_batch=128(small 모델=32) (albert 13m/7G) [훈련코드](https://github.com/kobongsoo/BERT/blob/master/sbert/cross-encoder/sbert-corossencoder-train-nli.ipynb)
- NLI 훈련 : seed=111,epoch=3, lr=3e-5, eps=1e-8, warm_step=10%, max_seq_len=128, train_batch=64, eval_bath=64(albert 2h/7G) [훈련코드](https://github.com/kobongsoo/BERT/blob/master/sbert/cross-encoder/sbert-corossencoder-train-sts.ipynb)
- [평가코드](https://github.com/kobongsoo/BERT/blob/master/sbert/cross-encoder/sbert-crossencoder-test3.ipynb),[테스트코드](https://github.com/kobongsoo/BERT/blob/master/sbert/cross-encoder/sbert-crossencoder-test.ipynb)
-
|모델 |korsts|klue-sts|glue(stsb)|stsb_multi_mt(en)|
|:--------|------:|--------:|--------------:|------------:|
|**albert-small-kor-cross-encoder-v1** |0.8455 |0.8526 |0.8513 |0.7976|
|klue-cross-encoder-v1 |0.8262 |0.8833 |0.8512 |0.7889|
|kpf-cross-encoder-v1 |0.8799 |0.9133 |0.8626 |0.8027|
## Usage and Performance
Pre-trained models can be used like this:
```
from sentence_transformers import CrossEncoder
model = CrossEncoder('bongsoo/albert-small-kor-cross-encoder-v1')
scores = model.predict([('오늘 날씨가 좋다', '오늘 등산을 한다'), ('오늘 날씨가 흐리다', '오늘 비가 내린다')])
print(scores)
```
```
[0.45417202 0.6294121 ]
```
The model will predict scores for the pairs `('Sentence 1', 'Sentence 2')` and `('Sentence 3', 'Sentence 4')`.
You can use this model also without sentence_transformers and by just using Transformers ``AutoModel`` class
|
d08ef34d72b0a23a3c85e27d5b94db65
|
facebook/m2m100-12B-last-ckpt
|
facebook
|
m2m_100
| 9 | 676 |
transformers
| 1 |
text2text-generation
| true | false | false |
mit
|
['multilingual', 'af', 'am', 'ar', 'ast', 'az', 'ba', 'be', 'bg', 'bn', 'br', 'bs', 'ca', 'ceb', 'cs', 'cy', 'da', 'de', 'el', 'en', 'es', 'et', 'fa', 'ff', 'fi', 'fr', 'fy', 'ga', 'gd', 'gl', 'gu', 'ha', 'he', 'hi', 'hr', 'ht', 'hu', 'hy', 'id', 'ig', 'ilo', 'is', 'it', 'ja', 'jv', 'ka', 'kk', 'km', 'kn', 'ko', 'lb', 'lg', 'ln', 'lo', 'lt', 'lv', 'mg', 'mk', 'ml', 'mn', 'mr', 'ms', 'my', 'ne', 'nl', False, 'ns', 'oc', 'or', 'pa', 'pl', 'ps', 'pt', 'ro', 'ru', 'sd', 'si', 'sk', 'sl', 'so', 'sq', 'sr', 'ss', 'su', 'sv', 'sw', 'ta', 'th', 'tl', 'tn', 'tr', 'uk', 'ur', 'uz', 'vi', 'wo', 'xh', 'yi', 'yo', 'zh', 'zu']
| null | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['m2m100-12B']
| false | true | true | 3,999 | false |
# M2M100 12B
M2M100 is a multilingual encoder-decoder (seq-to-seq) model trained for Many-to-Many multilingual translation.
It was introduced in this [paper](https://arxiv.org/abs/2010.11125) and first released in [this](https://github.com/pytorch/fairseq/tree/master/examples/m2m_100) repository.
The model that can directly translate between the 9,900 directions of 100 languages.
To translate into a target language, the target language id is forced as the first generated token.
To force the target language id as the first generated token, pass the `forced_bos_token_id` parameter to the `generate` method.
*Note: `M2M100Tokenizer` depends on `sentencepiece`, so make sure to install it before running the example.*
To install `sentencepiece` run `pip install sentencepiece`
```python
from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
chinese_text = "生活就像一盒巧克力。"
model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100-12B-last-ckpt")
tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100-12B-last-ckpt")
# translate Hindi to French
tokenizer.src_lang = "hi"
encoded_hi = tokenizer(hi_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "La vie est comme une boîte de chocolat."
# translate Chinese to English
tokenizer.src_lang = "zh"
encoded_zh = tokenizer(chinese_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Life is like a box of chocolate."
```
See the [model hub](https://huggingface.co/models?filter=m2m_100) to look for more fine-tuned versions.
## Languages covered
Afrikaans (af), Amharic (am), Arabic (ar), Asturian (ast), Azerbaijani (az), Bashkir (ba), Belarusian (be), Bulgarian (bg), Bengali (bn), Breton (br), Bosnian (bs), Catalan; Valencian (ca), Cebuano (ceb), Czech (cs), Welsh (cy), Danish (da), German (de), Greeek (el), English (en), Spanish (es), Estonian (et), Persian (fa), Fulah (ff), Finnish (fi), French (fr), Western Frisian (fy), Irish (ga), Gaelic; Scottish Gaelic (gd), Galician (gl), Gujarati (gu), Hausa (ha), Hebrew (he), Hindi (hi), Croatian (hr), Haitian; Haitian Creole (ht), Hungarian (hu), Armenian (hy), Indonesian (id), Igbo (ig), Iloko (ilo), Icelandic (is), Italian (it), Japanese (ja), Javanese (jv), Georgian (ka), Kazakh (kk), Central Khmer (km), Kannada (kn), Korean (ko), Luxembourgish; Letzeburgesch (lb), Ganda (lg), Lingala (ln), Lao (lo), Lithuanian (lt), Latvian (lv), Malagasy (mg), Macedonian (mk), Malayalam (ml), Mongolian (mn), Marathi (mr), Malay (ms), Burmese (my), Nepali (ne), Dutch; Flemish (nl), Norwegian (no), Northern Sotho (ns), Occitan (post 1500) (oc), Oriya (or), Panjabi; Punjabi (pa), Polish (pl), Pushto; Pashto (ps), Portuguese (pt), Romanian; Moldavian; Moldovan (ro), Russian (ru), Sindhi (sd), Sinhala; Sinhalese (si), Slovak (sk), Slovenian (sl), Somali (so), Albanian (sq), Serbian (sr), Swati (ss), Sundanese (su), Swedish (sv), Swahili (sw), Tamil (ta), Thai (th), Tagalog (tl), Tswana (tn), Turkish (tr), Ukrainian (uk), Urdu (ur), Uzbek (uz), Vietnamese (vi), Wolof (wo), Xhosa (xh), Yiddish (yi), Yoruba (yo), Chinese (zh), Zulu (zu)
## BibTeX entry and citation info
```
@misc{fan2020englishcentric,
title={Beyond English-Centric Multilingual Machine Translation},
author={Angela Fan and Shruti Bhosale and Holger Schwenk and Zhiyi Ma and Ahmed El-Kishky and Siddharth Goyal and Mandeep Baines and Onur Celebi and Guillaume Wenzek and Vishrav Chaudhary and Naman Goyal and Tom Birch and Vitaliy Liptchinsky and Sergey Edunov and Edouard Grave and Michael Auli and Armand Joulin},
year={2020},
eprint={2010.11125},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
c0eb5b950e8bbb7a70d452c10b0c9324
|
pere/norwegian-mt5
|
pere
|
t5
| 19 | 12 |
transformers
| 0 |
text2text-generation
| false | false | true |
cc-by-4.0
|
False
|
['Norwegian Nynorsk/Bokmål']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['seq2seq']
| false | true | true | 804 | false |
# 🇳🇴 Norwegian mT5 Base model 🇳🇴
This mT5-base model is trained from the mT5 checkpoint on a 19GB Balanced Bokmål-Nynorsk Corpus.
Parameters used in training:
```bash
python3 ./run_t5_mlm_flax_streaming.py
--model_name_or_path="./norwegian-t5-base"
--output_dir="./norwegian-t5-base"
--config_name="./norwegian-t5-base"
--tokenizer_name="./norwegian-t5-base"
--dataset_name="pere/nb_nn_balanced_shuffled"
--max_seq_length="512"
--per_device_train_batch_size="32"
--per_device_eval_batch_size="32"
--learning_rate="0.005"
--weight_decay="0.001"
--warmup_steps="2000"
--overwrite_output_dir
--logging_steps="100"
--save_steps="500"
--eval_steps="500"
--push_to_hub
--preprocessing_num_workers 96
--adafactor
```
|
aaaaee3fa7a262bbb28f7b09f79fec02
|
anas-awadalla/roberta-large-few-shot-k-128-finetuned-squad-seed-0
|
anas-awadalla
|
roberta
| 17 | 3 |
transformers
| 0 |
question-answering
| true | false | false |
mit
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 986 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-large-few-shot-k-128-finetuned-squad-seed-0
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 12
- eval_batch_size: 8
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 200
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
5683fc44762d42993e923c4839a5264e
|
paola-md/distilr2-lr2e05-wd0.05-bs64
|
paola-md
|
roberta
| 6 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,519 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilr2-lr2e05-wd0.05-bs64
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2722
- Rmse: 0.5217
- Mse: 0.2722
- Mae: 0.4092
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 512
- eval_batch_size: 512
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rmse | Mse | Mae |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| 0.2772 | 1.0 | 312 | 0.2741 | 0.5236 | 0.2741 | 0.4238 |
| 0.2737 | 2.0 | 624 | 0.2726 | 0.5221 | 0.2726 | 0.4078 |
| 0.2718 | 3.0 | 936 | 0.2727 | 0.5222 | 0.2727 | 0.4146 |
| 0.2697 | 4.0 | 1248 | 0.2722 | 0.5217 | 0.2722 | 0.4092 |
### Framework versions
- Transformers 4.19.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 2.4.0
- Tokenizers 0.12.1
|
73d48c32ceeb34906a21d1a62b8d72e7
|
lmqg/mt5-small-jaquad-qg-ae
|
lmqg
|
mt5
| 40 | 189 |
transformers
| 1 |
text2text-generation
| true | false | false |
cc-by-4.0
|
['ja']
|
['lmqg/qg_jaquad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['question generation', 'answer extraction']
| true | true | true | 7,174 | false |
# Model Card of `lmqg/mt5-small-jaquad-qg-ae`
This model is fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) for question generation and answer extraction jointly on the [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) (dataset_name: default) via [`lmqg`](https://github.com/asahi417/lm-question-generation).
### Overview
- **Language model:** [google/mt5-small](https://huggingface.co/google/mt5-small)
- **Language:** ja
- **Training data:** [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) (default)
- **Online Demo:** [https://autoqg.net/](https://autoqg.net/)
- **Repository:** [https://github.com/asahi417/lm-question-generation](https://github.com/asahi417/lm-question-generation)
- **Paper:** [https://arxiv.org/abs/2210.03992](https://arxiv.org/abs/2210.03992)
### Usage
- With [`lmqg`](https://github.com/asahi417/lm-question-generation#lmqg-language-model-for-question-generation-)
```python
from lmqg import TransformersQG
# initialize model
model = TransformersQG(language="ja", model="lmqg/mt5-small-jaquad-qg-ae")
# model prediction
question_answer_pairs = model.generate_qa("フェルメールの作品では、17世紀のオランダの画家、ヨハネス・フェルメールの作品について記述する。フェルメールの作品は、疑問作も含め30数点しか現存しない。現存作品はすべて油彩画で、版画、下絵、素描などは残っていない。")
```
- With `transformers`
```python
from transformers import pipeline
pipe = pipeline("text2text-generation", "lmqg/mt5-small-jaquad-qg-ae")
# answer extraction
answer = pipe("generate question: ゾフィーは貴族出身ではあったが王族出身ではなく、ハプスブルク家の皇位継承者であるフランツ・フェルディナントとの結婚は貴賤結婚となった。皇帝フランツ・ヨーゼフは、2人の間に生まれた子孫が皇位を継がないことを条件として結婚を承認していた。視察が予定されている<hl>6月28日<hl>は2人の14回目の結婚記念日であった。")
# question generation
question = pipe("extract answers: 『クマのプーさん』の物語はまず1925年12月24日、『イヴニング・ニュース』紙のクリスマス特集号に短編作品として掲載された。これは『クマのプーさん』の第一章にあたる作品で、このときだけは挿絵をJ.H.ダウドがつけている。その後作品10話と挿絵が整い、刊行に先駆けて「イーヨーの誕生日」のエピソードが1926年8月に『ロイヤルマガジン』に、同年10月9日に『ニューヨーク・イヴニング・ポスト』紙に掲載されたあと、同年10月14日にロンドンで(メシュエン社)、21日にニューヨークで(ダットン社)『クマのプーさん』が刊行された。<hl>前著『ぼくたちがとてもちいさかったころ』がすでに大きな成功を収めていたこともあり、イギリスでは初版は前著の7倍に当たる3万5000部が刷られた。<hl>他方のアメリカでもその年の終わりまでに15万部を売り上げている。ただし依然として人気のあった前著を売り上げで追い越すには数年の時間を要した。")
```
## Evaluation
- ***Metric (Question Generation)***: [raw metric file](https://huggingface.co/lmqg/mt5-small-jaquad-qg-ae/raw/main/eval/metric.first.sentence.paragraph_answer.question.lmqg_qg_jaquad.default.json)
| | Score | Type | Dataset |
|:-----------|--------:|:--------|:-----------------------------------------------------------------|
| BERTScore | 81.64 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| Bleu_1 | 56.94 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| Bleu_2 | 45.23 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| Bleu_3 | 37.37 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| Bleu_4 | 31.55 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| METEOR | 29.64 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| MoverScore | 59.42 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| ROUGE_L | 52.58 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
- ***Metric (Question & Answer Generation)***: [raw metric file](https://huggingface.co/lmqg/mt5-small-jaquad-qg-ae/raw/main/eval/metric.first.answer.paragraph.questions_answers.lmqg_qg_jaquad.default.json)
| | Score | Type | Dataset |
|:--------------------------------|--------:|:--------|:-----------------------------------------------------------------|
| QAAlignedF1Score (BERTScore) | 80.51 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| QAAlignedF1Score (MoverScore) | 56.28 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| QAAlignedPrecision (BERTScore) | 80.51 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| QAAlignedPrecision (MoverScore) | 56.28 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| QAAlignedRecall (BERTScore) | 80.51 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| QAAlignedRecall (MoverScore) | 56.28 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
- ***Metric (Answer Extraction)***: [raw metric file](https://huggingface.co/lmqg/mt5-small-jaquad-qg-ae/raw/main/eval/metric.first.answer.paragraph_sentence.answer.lmqg_qg_jaquad.default.json)
| | Score | Type | Dataset |
|:-----------------|--------:|:--------|:-----------------------------------------------------------------|
| AnswerExactMatch | 29.55 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| AnswerF1Score | 29.55 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| BERTScore | 78.12 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| Bleu_1 | 34.96 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| Bleu_2 | 31.92 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| Bleu_3 | 29.49 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| Bleu_4 | 27.55 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| METEOR | 26.22 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| MoverScore | 65.68 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
| ROUGE_L | 36.63 | default | [lmqg/qg_jaquad](https://huggingface.co/datasets/lmqg/qg_jaquad) |
## Training hyperparameters
The following hyperparameters were used during fine-tuning:
- dataset_path: lmqg/qg_jaquad
- dataset_name: default
- input_types: ['paragraph_answer', 'paragraph_sentence']
- output_types: ['question', 'answer']
- prefix_types: ['qg', 'ae']
- model: google/mt5-small
- max_length: 512
- max_length_output: 32
- epoch: 24
- batch: 64
- lr: 0.0005
- fp16: False
- random_seed: 1
- gradient_accumulation_steps: 1
- label_smoothing: 0.15
The full configuration can be found at [fine-tuning config file](https://huggingface.co/lmqg/mt5-small-jaquad-qg-ae/raw/main/trainer_config.json).
## Citation
```
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
```
|
65e098fcb0afd8f1053bcd3b228048af
|
ArafatBHossain/robert_base_fine_tuned_emotion_dataset
|
ArafatBHossain
|
roberta
| 10 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,322 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robert_base_fine_tuned_emotion_dataset
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1996
- Accuracy: 0.936
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.3438 | 1.0 | 2000 | 0.3140 | 0.921 |
| 0.1911 | 2.0 | 4000 | 0.1947 | 0.9315 |
| 0.1348 | 3.0 | 6000 | 0.1996 | 0.936 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
8daf54bcdc7600a5b2572be935631270
|
wietsedv/xlm-roberta-base-ft-udpos28-grc
|
wietsedv
|
xlm-roberta
| 8 | 13 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
|
['grc']
|
['universal_dependencies']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['part-of-speech', 'token-classification']
| true | true | true | 575 | false |
# XLM-RoBERTa base Universal Dependencies v2.8 POS tagging: Ancient Greek
This model is part of our paper called:
- Make the Best of Cross-lingual Transfer: Evidence from POS Tagging with over 100 Languages
Check the [Space](https://huggingface.co/spaces/wietsedv/xpos) for more details.
## Usage
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("wietsedv/xlm-roberta-base-ft-udpos28-grc")
model = AutoModelForTokenClassification.from_pretrained("wietsedv/xlm-roberta-base-ft-udpos28-grc")
```
|
67a3037a335508188f48a9f953278bc9
|
Ghost1/bert-finetuned-ner3
|
Ghost1
|
bert
| 12 | 5 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null |
['conll2003']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,519 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner3
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0603
- Precision: 0.9296
- Recall: 0.9490
- F1: 0.9392
- Accuracy: 0.9863
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0855 | 1.0 | 1756 | 0.0673 | 0.9130 | 0.9340 | 0.9234 | 0.9827 |
| 0.0345 | 2.0 | 3512 | 0.0590 | 0.9284 | 0.9445 | 0.9363 | 0.9855 |
| 0.0229 | 3.0 | 5268 | 0.0603 | 0.9296 | 0.9490 | 0.9392 | 0.9863 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu111
- Datasets 2.1.0
- Tokenizers 0.12.1
|
4cfec1bb35879750175ab8d6ab9d3c9d
|
mdroth/distilbert-base-uncased-finetuned-ner
|
mdroth
|
distilbert
| 13 | 9 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null |
['conll2003']
| null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,546 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0635
- Precision: 0.9300
- Recall: 0.9391
- F1: 0.9345
- Accuracy: 0.9841
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0886 | 1.0 | 1756 | 0.0676 | 0.9198 | 0.9233 | 0.9215 | 0.9809 |
| 0.0382 | 2.0 | 3512 | 0.0605 | 0.9271 | 0.9360 | 0.9315 | 0.9836 |
| 0.0247 | 3.0 | 5268 | 0.0635 | 0.9300 | 0.9391 | 0.9345 | 0.9841 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.9.0
- Datasets 2.0.0
- Tokenizers 0.11.6
|
91eb11adfe8e9644cf080c0bd7080be7
|
georgep4181/agp
|
georgep4181
| null | 34 | 26 |
diffusers
| 2 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['text-to-image']
| false | true | true | 2,052 | false |
### agp Dreambooth model trained by georgep4181 with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v2-512 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Sample pictures of:
agp (use that on your prompt)
Keywords: tatto, nychos, nychos art, exploded, grafity

|
e94bbca8f35f5730653bb793b9054834
|
schreon/gpt2-lhm-large-03
|
schreon
|
gpt2
| 11 | 14 |
transformers
| 0 |
text-generation
| true | false | false |
mit
| null |
['training_corpus']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 980 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-lhm-large-03
This model is a fine-tuned version of [schreon/gpt2-lhm-large-02](https://huggingface.co/schreon/gpt2-lhm-large-02) on the training_corpus dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.1+cu117
- Datasets 2.8.0
- Tokenizers 0.13.2
|
9b2ece690c4c022590333e9a7cdc2d4a
|
sd-concepts-library/mu-sadr
|
sd-concepts-library
| null | 14 | 0 | null | 0 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,510 | false |
### mu-sadr on Stable Diffusion
This is the `<783463b>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:









|
acef4ee9ac223924cfbe43af08b16e73
|
muhtasham/small-mlm-glue-cola-custom-tokenizer
|
muhtasham
|
bert
| 12 | 0 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,918 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# small-mlm-glue-cola-custom-tokenizer
This model is a fine-tuned version of [google/bert_uncased_L-4_H-512_A-8](https://huggingface.co/google/bert_uncased_L-4_H-512_A-8) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: nan
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- num_epochs: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.3833 | 0.47 | 500 | 6.0687 |
| 5.7664 | 0.94 | 1000 | 5.7078 |
| 5.4733 | 1.4 | 1500 | 5.6928 |
| 5.2967 | 1.87 | 2000 | 5.6740 |
| 5.0316 | 2.34 | 2500 | 5.5465 |
| 5.0508 | 2.81 | 3000 | nan |
| 5.003 | 3.27 | 3500 | 5.4421 |
| 4.7143 | 3.74 | 4000 | 5.3365 |
| 4.7795 | 4.21 | 4500 | 5.2115 |
| 4.6303 | 4.68 | 5000 | 5.0677 |
| 4.5267 | 5.14 | 5500 | 5.2197 |
| 4.5582 | 5.61 | 6000 | 5.0485 |
| 4.528 | 6.08 | 6500 | 5.1092 |
| 4.2633 | 6.55 | 7000 | 5.1459 |
| 4.2774 | 7.02 | 7500 | nan |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
0bc851b142606a57dc1abdf7afe8e399
|
glopez/cifar-10
|
glopez
|
vit
| 7 | 31 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['cifar10']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 931 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# cifar-10
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the cifar10 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
45248ae0ec8859feb3d414d07812e251
|
Isaacp/distilbert-base-uncased-finetuned-clinc
|
Isaacp
|
distilbert
| 12 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['clinc_oos']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 933 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
5c4be90ecdbdbedaddc06d0bd89b082c
|
coreml/coreml-dreamlike-diffusion
|
coreml
| null | 6 | 0 | null | 4 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
['coreml', 'stable-diffusion', 'text-to-image']
| false | true | true | 5,015 | false |
# Core ML Converted Model
This model was converted to Core ML for use on Apple Silicon devices by following Apple's instructions [here](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml).<br>
Provide the model to an app such as [Mochi Diffusion](https://github.com/godly-devotion/MochiDiffusion) to generate images.<br>
`split_einsum` version is compatible with all compute unit options including Neural Engine.<br>
`original` version is only compatible with CPU & GPU option.
Unfortunately, for this model the `split_einsum` version did not generate images correctly and was removed.
# Dreamlike Diffusion 1.0 is SD 1.5 fine tuned on high quality art, made by [dreamlike.art](https://dreamlike.art/).
Use the same prompts as you would for SD 1.5. Add **dreamlikeart** if the artstyle is too weak.
Non-square aspect ratios work better for some prompts. If you want a portrait photo, try using a 2:3 or a 9:16 aspect ratio. If you want a landscape photo, try using a 3:2 or a 16:9 aspect ratio.
Use slightly higher resolution for better results: 640x640px, 512x768px, 768x512px, etc.
### Examples
<img src="https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0/resolve/main/preview.jpg" style="max-width: 800px;" width="100%"/>
<img src="https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0/resolve/main/1.jpg" style="max-width: 800px;" width="100%"/>
<img src="https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0/resolve/main/2.jpg" style="max-width: 800px;" width="100%"/>
### dreamlike.art
You can use this model for free on [dreamlike.art](https://dreamlike.art/)!
<img src="https://huggingface.co/dreamlike-art/dreamlike-photoreal-1.0/resolve/main/dreamlike.jpg" style="max-width: 1000px;" width="100%"/>
### Gradio
We support a [Gradio](https://github.com/gradio-app/gradio) Web UI to run dreamlike-diffusion-1.0:
[](https://huggingface.co/spaces/akhaliq/dreamlike-diffusion-1.0)
### CompVis
[Download dreamlike-diffusion-1.0.ckpt (2.13GB)](https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0/resolve/main/dreamlike-diffusion-1.0.ckpt)
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion Pipeline](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "dreamlike-art/dreamlike-diffusion-1.0"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "dreamlikeart, a grungy woman with rainbow hair, travelling between dimensions, dynamic pose, happy, soft eyes and narrow chin, extreme bokeh, dainty figure, long hair straight down, torn kawaii shirt and baggy jeans, In style of by Jordan Grimmer and greg rutkowski, crisp lines and color, complex background, particles, lines, wind, concept art, sharp focus, vivid colors"
image = pipe(prompt).images[0]
image.save("./result.jpg")
```
# License
This model is licesed under a **modified** CreativeML OpenRAIL-M license.
- **You can't host or use the model or its derivatives on websites/apps/etc., from which you earn, will earn, or plan to earn revenue or donations. If you want to, please email us at contact@dreamlike.art**
- **You are free to host the model card and files (Without any actual inference or finetuning) on both commercial and non-commercial websites/apps/etc. Please state the full model name (Dreamlike Diffusion 1.0) and include a link to the model card (https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0)**
- **You are free to host the model or its derivatives on completely non-commercial websites/apps/etc (Meaning you are not getting ANY revenue or donations). Please state the full model name (Dreamlike Diffusion 1.0) and include a link to the model card (https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0)**
- **You are free to use the outputs of the model or the outputs of the model's derivatives for commercial purposes in teams of 10 or less**
- You can't use the model to deliberately produce nor share illegal or harmful outputs or content
- The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
- You may re-distribute the weights. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the **modified** CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here: https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0/blob/main/LICENSE.md
|
3b387abcabb6bacc6f2660c14e91ff18
|
renjithks/distilbert-cord-ner
|
renjithks
|
distilbert
| 12 | 5 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,215 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-cord-ner
This model is a fine-tuned version of [Geotrend/distilbert-base-en-fr-de-no-da-cased](https://huggingface.co/Geotrend/distilbert-base-en-fr-de-no-da-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1670
- Precision: 0.9128
- Recall: 0.9242
- F1: 0.9185
- Accuracy: 0.9656
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 113 | 0.1814 | 0.8480 | 0.8618 | 0.8548 | 0.9393 |
| No log | 2.0 | 226 | 0.1755 | 0.8669 | 0.9002 | 0.8832 | 0.9427 |
| No log | 3.0 | 339 | 0.1499 | 0.8800 | 0.8935 | 0.8867 | 0.9533 |
| No log | 4.0 | 452 | 0.1340 | 0.8975 | 0.9079 | 0.9027 | 0.9596 |
| 0.1812 | 5.0 | 565 | 0.1553 | 0.8999 | 0.9146 | 0.9072 | 0.9592 |
| 0.1812 | 6.0 | 678 | 0.1474 | 0.8961 | 0.9021 | 0.8991 | 0.9562 |
| 0.1812 | 7.0 | 791 | 0.1682 | 0.9135 | 0.9223 | 0.9179 | 0.9622 |
| 0.1812 | 8.0 | 904 | 0.1663 | 0.8960 | 0.9175 | 0.9066 | 0.9613 |
| 0.0199 | 9.0 | 1017 | 0.1753 | 0.9061 | 0.9261 | 0.9160 | 0.9635 |
| 0.0199 | 10.0 | 1130 | 0.1670 | 0.9128 | 0.9242 | 0.9185 | 0.9656 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
8175e147156d535ed5c681b5388bce73
|
xtlu/ddpm-butterflies-128
|
xtlu
| null | 15 | 2 |
diffusers
| 0 | null | false | false | false |
apache-2.0
|
['en']
|
['huggan/smithsonian_butterflies_subset']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,226 | false |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/xtlu/ddpm-butterflies-128/tensorboard?#scalars)
|
95a7ac52f45bd7397ced185f3edac3bf
|
google/t5-efficient-tiny-nl2
|
google
|
t5
| 12 | 7 |
transformers
| 0 |
text2text-generation
| true | true | true |
apache-2.0
|
['en']
|
['c4']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['deep-narrow']
| false | true | true | 6,244 | false |
# T5-Efficient-TINY-NL2 (Deep-Narrow version)
T5-Efficient-TINY-NL2 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5).
It is a *pretrained-only* checkpoint and was released with the
paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)**
by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures
of similar parameter count.
To quote the paper:
> We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased
> before considering any other forms of uniform scaling across other dimensions. This is largely due to
> how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a
> tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise,
> a tall base model might also generally more efficient compared to a large model. We generally find
> that, regardless of size, even if absolute performance might increase as we continue to stack layers,
> the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36
> layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e.,
> params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params,
> FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to
> consider.
To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially.
A sequence of word embeddings is therefore processed sequentially by each transformer block.
## Details model architecture
This model checkpoint - **t5-efficient-tiny-nl2** - is of model type **Tiny** with the following variations:
- **nl** is **2**
It has **11.9** million parameters and thus requires *ca.* **47.61 MB** of memory in full precision (*fp32*)
or **23.81 MB** of memory in half precision (*fp16* or *bf16*).
A summary of the *original* T5 model architectures can be seen here:
| Model | nl (el/dl) | ff | dm | kv | nh | #Params|
| ----| ---- | ---- | ---- | ---- | ---- | ----|
| Tiny | 4/4 | 1024 | 256 | 32 | 4 | 16M|
| Mini | 4/4 | 1536 | 384 | 32 | 8 | 31M|
| Small | 6/6 | 2048 | 512 | 32 | 8 | 60M|
| Base | 12/12 | 3072 | 768 | 64 | 12 | 220M|
| Large | 24/24 | 4096 | 1024 | 64 | 16 | 738M|
| Xl | 24/24 | 16384 | 1024 | 128 | 32 | 3B|
| XXl | 24/24 | 65536 | 1024 | 128 | 128 | 11B|
whereas the following abbreviations are used:
| Abbreviation | Definition |
| ----| ---- |
| nl | Number of transformer blocks (depth) |
| dm | Dimension of embedding vector (output vector of transformers block) |
| kv | Dimension of key/value projection matrix |
| nh | Number of attention heads |
| ff | Dimension of intermediate vector within transformer block (size of feed-forward projection matrix) |
| el | Number of transformer blocks in the encoder (encoder depth) |
| dl | Number of transformer blocks in the decoder (decoder depth) |
| sh | Signifies that attention heads are shared |
| skv | Signifies that key-values projection matrices are tied |
If a model checkpoint has no specific, *el* or *dl* than both the number of encoder- and decoder layers correspond to *nl*.
## Pre-Training
The checkpoint was pretrained on the [Colossal, Cleaned version of Common Crawl (C4)](https://huggingface.co/datasets/c4) for 524288 steps using
the span-based masked language modeling (MLM) objective.
## Fine-Tuning
**Note**: This model is a **pretrained** checkpoint and has to be fine-tuned for practical usage.
The checkpoint was pretrained in English and is therefore only useful for English NLP tasks.
You can follow on of the following examples on how to fine-tune the model:
*PyTorch*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization)
- [Question Answering](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_seq2seq_qa.py)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*Tensorflow*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*JAX/Flax*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/flax/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/flax/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
## Downstream Performance
TODO: Add table if available
## Computational Complexity
TODO: Add table if available
## More information
We strongly recommend the reader to go carefully through the original paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** to get a more nuanced understanding of this model checkpoint.
As explained in the following [issue](https://github.com/google-research/google-research/issues/986#issuecomment-1035051145), checkpoints including the *sh* or *skv*
model architecture variations have *not* been ported to Transformers as they are probably of limited practical usage and are lacking a more detailed description. Those checkpoints are kept [here](https://huggingface.co/NewT5SharedHeadsSharedKeyValues) as they might be ported potentially in the future.
|
be1a833c0d6f33587fce12e199a6dc81
|
Maseshi/Animistatics
|
Maseshi
| null | 28 | 176 |
diffusers
| 10 |
text-to-image
| false | false | false |
creativeml-openrail-m
|
['en']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers']
| false | true | true | 3,659 | false |

# Animistatics
Welcome to Animistatics - a latent diffusion model for weebs. This model is intended to produce high-quality, highly detailed anime style with just a few prompts. Like other anime-style Stable Diffusion models, it also supports danbooru tags to generate images.
e.g. **_girl, cafe, plants, coffee, lighting, steam, blue eyes, brown hair_**
## Gradio
We support a [Gradio](https://github.com/gradio-app/gradio) Web UI to run Animistatics:
[](https://huggingface.co/spaces/Maseshi/Animistatics)
## Google Colab
We support a [Google Colab](https://github.com/gradio-app/gradio) to run Animistatics:
[](https://colab.research.google.com/drive/1Qf7KGx7wCQ6XCs4ai_2riq68ip7mZw_t?usp=sharing)
## 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
import torch
repo_id = "Maseshi/Animistatics"
pipe = DiffusionPipeline.from_pretrained(repo_id, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
prompt = "girl, cafe, plants, coffee, lighting, steam, blue eyes, brown hair"
image = pipe(prompt, num_inference_steps=25).images[0]
image.save("girl.png")
```
## Examples
Below are some examples of images generated using this model:
**Anime Girl:**

```
girl, cafe, plants, coffee, lighting, steam, blue eyes, brown hair
Steps: 50, Sampler: DDIM, CFG scale: 12
```
**Anime Boy:**

```
boy, blonde hair, blue eyes, colorful, cumulonimbus clouds, lighting, medium hair, plants, city, hoodie, cool
Steps: 50, Sampler: DDIM, CFG scale: 12
```
**City:**

```
cityscape, concept art, sun shining through clouds, crepuscular rays, trending on art station, 8k
Steps: 50, Sampler: DDIM, CFG scale: 12
```
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
|
235d7d35c97baa83e51e116a8d6a15ff
|
jonatasgrosman/exp_w2v2t_de_vp-fr_s489
|
jonatasgrosman
|
wav2vec2
| 10 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['de']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'de']
| false | true | true | 469 | false |
# exp_w2v2t_de_vp-fr_s489
Fine-tuned [facebook/wav2vec2-large-fr-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-fr-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
a21aac3b46716961faf4de33bfe2d96c
|
Lucetepolis/TriPhaze
|
Lucetepolis
| null | 32 | 0 |
diffusers
| 21 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers']
| false | true | true | 4,985 | false |
# TriPhaze
ultracolor.v4 - <a href="https://huggingface.co/xdive/ultracolor.v4">Download</a> / <a href="https://arca.live/b/aiart/68609290">Sample</a><br/>
Counterfeit-V2.5 - <a href="https://huggingface.co/gsdf/Counterfeit-V2.5">Download / Sample</a><br/>
Treebark - <a href="https://huggingface.co/HIZ/aichan_pick">Download</a> / <a href="https://arca.live/b/aiart/67648642">Sample</a><br/>
EasyNegative and pastelmix-lora seem to work well with the models.
EasyNegative - <a href="https://huggingface.co/datasets/gsdf/EasyNegative">Download / Sample</a><br/>
pastelmix-lora - <a href="https://huggingface.co/andite/pastel-mix">Download / Sample</a>
# Formula
```
ultracolor.v4 + Counterfeit-V2.5 = temp1
U-Net Merge - 0.870333, 0.980430, 0.973645, 0.716758, 0.283242, 0.026355, 0.019570, 0.129667, 0.273791, 0.424427, 0.575573, 0.726209, 0.5, 0.726209, 0.575573, 0.424427, 0.273791, 0.129667, 0.019570, 0.026355, 0.283242, 0.716758, 0.973645, 0.980430, 0.870333
temp1 + Treebark = temp2
U-Net Merge - 0.752940, 0.580394, 0.430964, 0.344691, 0.344691, 0.430964, 0.580394, 0.752940, 0.902369, 0.988642, 0.988642, 0.902369, 0.666667, 0.902369, 0.988642, 0.988642, 0.902369, 0.752940, 0.580394, 0.430964, 0.344691, 0.344691, 0.430964, 0.580394, 0.752940
temp2 + ultracolor.v4 = TriPhaze_A
U-Net Merge - 0.042235, 0.056314, 0.075085, 0.100113, 0.133484, 0.177979, 0.237305, 0.316406, 0.421875, 0.5625, 0.75, 1, 0.5, 1, 0.75, 0.5625, 0.421875, 0.316406, 0.237305, 0.177979, 0.133484, 0.100113, 0.075085, 0.056314, 0.042235
ultracolor.v4 + Counterfeit-V2.5 = temp3
U-Net Merge - 0.979382, 0.628298, 0.534012, 0.507426, 0.511182, 0.533272, 0.56898, 0.616385, 0.674862, 0.7445, 0.825839, 0.919748, 0.5, 0.919748, 0.825839, 0.7445, 0.674862, 0.616385, 0.56898, 0.533272, 0.511182, 0.507426, 0.534012, 0.628298, 0.979382
temp3 + Treebark = TriPhaze_C
U-Net Merge - 0.243336, 0.427461, 0.566781, 0.672199, 0.751965, 0.812321, 0.857991, 0.892547, 0.918694, 0.938479, 0.953449, 0.964777, 0.666667, 0.964777, 0.953449, 0.938479, 0.918694, 0.892547, 0.857991, 0.812321, 0.751965, 0.672199, 0.566781, 0.427461, 0.243336
TriPhaze_A + TriPhaze_C = TriPhaze_B
U-Net Merge - 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5
```
# Converted weights
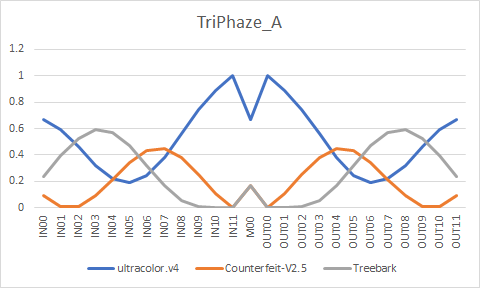
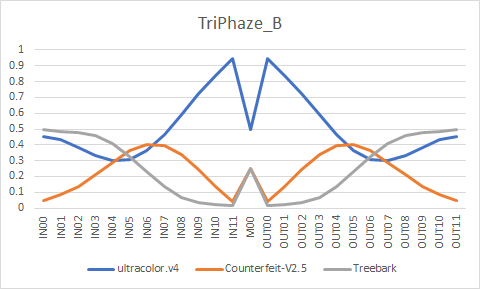
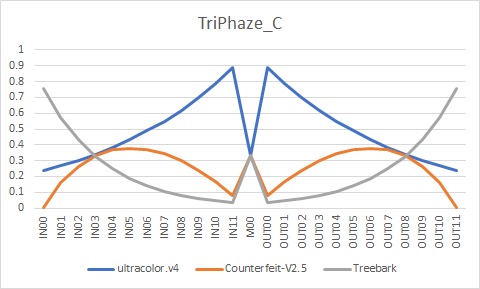
# Samples
All of the images use following negatives/settings. EXIF preserved.
```
Negative prompt: (worst quality, low quality:1.4), easynegative, bad anatomy, bad hands, error, missing fingers, extra digit, fewer digits, nsfw
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 1853114200, Size: 768x512, Model hash: 6bad0b419f, Denoising strength: 0.6, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: R-ESRGAN 4x+ Anime6B
```
# TriPhaze_A








# TriPhaze_B








# TriPhaze_C








|
dc3bebe3528bd4f11ec76d73983d9d3c
|
Helsinki-NLP/opus-mt-lua-sv
|
Helsinki-NLP
|
marian
| 10 | 10 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 776 | false |
### opus-mt-lua-sv
* source languages: lua
* target languages: sv
* OPUS readme: [lua-sv](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/lua-sv/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/lua-sv/opus-2020-01-09.zip)
* test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/lua-sv/opus-2020-01-09.test.txt)
* test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/lua-sv/opus-2020-01-09.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.lua.sv | 25.7 | 0.437 |
|
a45cee3cb2405ce17cb45e5e48d99da1
|
DOOGLAK/Article_100v3_NER_Model_3Epochs_UNAUGMENTED
|
DOOGLAK
|
bert
| 13 | 5 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null |
['article100v3_wikigold_split']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,537 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Article_100v3_NER_Model_3Epochs_UNAUGMENTED
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the article100v3_wikigold_split dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6272
- Precision: 0.0
- Recall: 0.0
- F1: 0.0
- Accuracy: 0.7772
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:---:|:--------:|
| No log | 1.0 | 11 | 0.7637 | 0.0 | 0.0 | 0.0 | 0.7772 |
| No log | 2.0 | 22 | 0.6651 | 0.0 | 0.0 | 0.0 | 0.7772 |
| No log | 3.0 | 33 | 0.6272 | 0.0 | 0.0 | 0.0 | 0.7772 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 2.4.0
- Tokenizers 0.11.6
|
f51f0d0f1709abd9639d1a3de3b94341
|
CavenLen/ddpm-Kaga-128
|
CavenLen
| null | 116 | 3 |
diffusers
| 0 | null | false | false | false |
apache-2.0
|
['en']
|
['CavenLen/Kaga']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,192 | false |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-Kaga-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `CavenLen/Kaga` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/CavenLen/ddpm-Kaga-128/tensorboard?#scalars)
|
0d4815d0110481d502557599e3df8a5c
|
Helsinki-NLP/opus-mt-ms-de
|
Helsinki-NLP
|
marian
| 11 | 7 |
transformers
| 0 |
translation
| true | true | false |
apache-2.0
|
['ms', 'de']
| null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['translation']
| false | true | true | 2,063 | false |
### msa-deu
* source group: Malay (macrolanguage)
* target group: German
* OPUS readme: [msa-deu](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/msa-deu/README.md)
* model: transformer-align
* source language(s): ind zsm_Latn
* target language(s): deu
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/msa-deu/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/msa-deu/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/msa-deu/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.msa.deu | 36.5 | 0.584 |
### System Info:
- hf_name: msa-deu
- source_languages: msa
- target_languages: deu
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/msa-deu/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['ms', 'de']
- src_constituents: {'zsm_Latn', 'ind', 'max_Latn', 'zlm_Latn', 'min'}
- tgt_constituents: {'deu'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/msa-deu/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/msa-deu/opus-2020-06-17.test.txt
- src_alpha3: msa
- tgt_alpha3: deu
- short_pair: ms-de
- chrF2_score: 0.584
- bleu: 36.5
- brevity_penalty: 0.966
- ref_len: 4198.0
- src_name: Malay (macrolanguage)
- tgt_name: German
- train_date: 2020-06-17
- src_alpha2: ms
- tgt_alpha2: de
- prefer_old: False
- long_pair: msa-deu
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
6db15e547a10193ee2ab8414a6df8708
|
Alireza1044/albert-base-v2-mnli
|
Alireza1044
|
albert
| 14 | 10 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| false | true | true | 994 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mnli
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the GLUE MNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5383
- Accuracy: 0.8501
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 64
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4.0
### Training results
### Framework versions
- Transformers 4.9.1
- Pytorch 1.9.0+cu102
- Datasets 1.10.2
- Tokenizers 0.10.3
|
b3b1bec91f5cc27cf91b8e0aaa1e5e35
|
jxuhf/Fine-tuning-text-classification-model-Habana-Gaudi
|
jxuhf
|
bert
| 14 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
|
['en']
|
['glue']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,086 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mrpc
This model is a fine-tuned version of [bert-large-uncased-whole-word-masking](https://huggingface.co/bert-large-uncased-whole-word-masking) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3680
- Accuracy: 0.8824
- F1: 0.9181
- Combined Score: 0.9002
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-06
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0a0+gitfe03f8c
- Datasets 2.1.0
- Tokenizers 0.12.1
|
0b9a440b68c08108ad846ed426986793
|
sd-concepts-library/tesla-bot
|
sd-concepts-library
| null | 12 | 0 | null | 1 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
[]
| false | true | true | 1,338 | false |
### Tesla Bot on Stable Diffusion
This is the `<tesla-bot>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as an `object`:







|
ec08bd4e2b6715cab96f3a0696b46e30
|
Harsit/bert-finetuned-squad
|
Harsit
|
bert
| 12 | 3 |
transformers
| 1 |
question-answering
| true | false | false |
apache-2.0
| null |
['squad']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 954 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
f47240a32efd469cca77e554184c5312
|
itaihay/wav2vec_asr_swbd_10_epochs
|
itaihay
|
wav2vec2
| 16 | 16 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 4,051 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec_asr_swbd_10_epochs
This model is a fine-tuned version of [facebook/wav2vec2-large-robust-ft-swbd-300h](https://huggingface.co/facebook/wav2vec2-large-robust-ft-swbd-300h) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: nan
- Wer: 0.9627
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:------:|:---------------:|:------:|
| 1.0682 | 0.22 | 5000 | 0.7383 | 0.4431 |
| 0.9143 | 0.44 | 10000 | 0.7182 | 0.4058 |
| 0.8905 | 0.66 | 15000 | 0.6291 | 0.3987 |
| 0.8354 | 0.87 | 20000 | 0.5976 | 0.3954 |
| 0.7749 | 1.09 | 25000 | 0.5773 | 0.3901 |
| 0.7336 | 1.31 | 30000 | 0.5812 | 0.3871 |
| 0.7314 | 1.53 | 35000 | 0.5802 | 0.3895 |
| 0.0 | 1.75 | 40000 | nan | 0.9627 |
| 0.0 | 1.97 | 45000 | nan | 0.9627 |
| 0.0 | 2.19 | 50000 | nan | 0.9627 |
| 0.0 | 2.4 | 55000 | nan | 0.9627 |
| 0.0 | 2.62 | 60000 | nan | 0.9627 |
| 0.0 | 2.84 | 65000 | nan | 0.9627 |
| 0.0 | 3.06 | 70000 | nan | 0.9627 |
| 0.0 | 3.28 | 75000 | nan | 0.9627 |
| 0.0 | 3.5 | 80000 | nan | 0.9627 |
| 0.0 | 3.72 | 85000 | nan | 0.9627 |
| 0.0 | 3.93 | 90000 | nan | 0.9627 |
| 0.0 | 4.15 | 95000 | nan | 0.9627 |
| 0.0 | 4.37 | 100000 | nan | 0.9627 |
| 0.0 | 4.59 | 105000 | nan | 0.9627 |
| 0.0 | 4.81 | 110000 | nan | 0.9627 |
| 0.0 | 5.03 | 115000 | nan | 0.9627 |
| 0.0 | 5.25 | 120000 | nan | 0.9627 |
| 0.0 | 5.46 | 125000 | nan | 0.9627 |
| 0.0 | 5.68 | 130000 | nan | 0.9627 |
| 0.0 | 5.9 | 135000 | nan | 0.9627 |
| 0.0 | 6.12 | 140000 | nan | 0.9627 |
| 0.0 | 6.34 | 145000 | nan | 0.9627 |
| 0.0 | 6.56 | 150000 | nan | 0.9627 |
| 0.0 | 6.78 | 155000 | nan | 0.9627 |
| 0.0 | 7.0 | 160000 | nan | 0.9627 |
| 0.0 | 7.21 | 165000 | nan | 0.9627 |
| 0.0 | 7.43 | 170000 | nan | 0.9627 |
| 0.0 | 7.65 | 175000 | nan | 0.9627 |
| 0.0 | 7.87 | 180000 | nan | 0.9627 |
| 0.0 | 8.09 | 185000 | nan | 0.9627 |
| 0.0 | 8.31 | 190000 | nan | 0.9627 |
| 0.0 | 8.53 | 195000 | nan | 0.9627 |
| 0.0 | 8.74 | 200000 | nan | 0.9627 |
| 0.0 | 8.96 | 205000 | nan | 0.9627 |
| 0.0 | 9.18 | 210000 | nan | 0.9627 |
| 0.0 | 9.4 | 215000 | nan | 0.9627 |
| 0.0 | 9.62 | 220000 | nan | 0.9627 |
| 0.0 | 9.84 | 225000 | nan | 0.9627 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 1.18.4
- Tokenizers 0.11.6
|
b3f12e7312845e90d2e587f5d53de21c
|
Chandanab/swin-tiny-patch4-window7-224-finetuned-eurosat
|
Chandanab
|
swin
| 11 | 4 |
transformers
| 0 |
image-classification
| true | false | false |
apache-2.0
| null |
['image_folder']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,491 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the image_folder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1677
- Accuracy: 0.9394
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 7 | 0.3554 | 0.8081 |
| 0.4819 | 2.0 | 14 | 0.2077 | 0.9091 |
| 0.1985 | 3.0 | 21 | 0.1677 | 0.9394 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cpu
- Datasets 2.2.0
- Tokenizers 0.12.1
|
04c41d9277cb0a89154c5551cbf954a8
|
tftransformers/t5-small
|
tftransformers
| null | 6 | 6 | null | 0 |
translation
| false | false | false |
apache-2.0
|
['en', 'fr', 'ro', 'de']
|
['c4']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['summarization', 'translation']
| false | true | true | 1,918 | false |
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html)
Pretraining Dataset: [C4](https://huggingface.co/datasets/c4)
Other Community Checkpoints: [here](https://huggingface.co/models?search=t5)
Paper: [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf)
Authors: *Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu*
## Abstract
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpusâ€Â, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.

## Usage
```
from tf_transformers.models import T5Model
# Any T5 model (t5-small, t5-base, t5-large etc)
model_name = 't5-small'
model = T5Model.from_pretrained(model_name)
```
|
7691059cd16936e462eab7e94ca5b74b
|
microsoft/tapex-base-finetuned-wikisql
|
microsoft
|
bart
| 12 | 209 |
transformers
| 3 |
table-question-answering
| true | false | false |
mit
|
['en']
|
['wikisql']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['tapex', 'table-question-answering']
| false | true | true | 3,054 | false |
# TAPEX (base-sized model)
TAPEX was proposed in [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou. The original repo can be found [here](https://github.com/microsoft/Table-Pretraining).
## Model description
TAPEX (**Ta**ble **P**re-training via **Ex**ecution) is a conceptually simple and empirically powerful pre-training approach to empower existing models with *table reasoning* skills. TAPEX realizes table pre-training by learning a neural SQL executor over a synthetic corpus, which is obtained by automatically synthesizing executable SQL queries.
TAPEX is based on the BART architecture, the transformer encoder-encoder (seq2seq) model with a bidirectional (BERT-like) encoder and an autoregressive (GPT-like) decoder.
This model is the `tapex-base` model fine-tuned on the [WikiSQL](https://huggingface.co/datasets/wikisql) dataset.
## Intended Uses
You can use the model for table question answering on relatively simple questions. Some **solveable** questions are shown below (corresponding tables now shown):
| Question | Answer |
|:---: |:---:|
| tell me what the notes are for south australia | no slogan on current series |
| what position does the player who played for butler cc (ks) play? | guard-forward |
| how many schools did player number 3 play at? | 1.0 |
| how many winning drivers in the kraco twin 125 (r2) race were there? | 1.0 |
| for the episode(s) aired in the u.s. on 4 april 2008, what were the names? | "bust a move" part one, "bust a move" part two |
### How to Use
Here is how to use this model in transformers:
```python
from transformers import TapexTokenizer, BartForConditionalGeneration
import pandas as pd
tokenizer = TapexTokenizer.from_pretrained("microsoft/tapex-base-finetuned-wikisql")
model = BartForConditionalGeneration.from_pretrained("microsoft/tapex-base-finetuned-wikisql")
data = {
"year": [1896, 1900, 1904, 2004, 2008, 2012],
"city": ["athens", "paris", "st. louis", "athens", "beijing", "london"]
}
table = pd.DataFrame.from_dict(data)
# tapex accepts uncased input since it is pre-trained on the uncased corpus
query = "In which year did beijing host the Olympic Games?"
encoding = tokenizer(table=table, query=query, return_tensors="pt")
outputs = model.generate(**encoding)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
# [' 2008.0']
```
### How to Eval
Please find the eval script [here](https://github.com/SivilTaram/transformers/tree/add_tapex_bis/examples/research_projects/tapex).
### BibTeX entry and citation info
```bibtex
@inproceedings{
liu2022tapex,
title={{TAPEX}: Table Pre-training via Learning a Neural {SQL} Executor},
author={Qian Liu and Bei Chen and Jiaqi Guo and Morteza Ziyadi and Zeqi Lin and Weizhu Chen and Jian-Guang Lou},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=O50443AsCP}
}
```
|
2041f81217becd72f8509293d6f0d9c9
|
amanm27/bert-base-uncased-sports
|
amanm27
|
bert
| 9 | 9 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,246 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-sports
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0064
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.4926 | 1.0 | 912 | 2.1186 |
| 2.2168 | 2.0 | 1824 | 2.0392 |
| 2.1327 | 3.0 | 2736 | 2.0081 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0
- Datasets 1.18.3
- Tokenizers 0.11.0
|
5acc9d65716dea7cc86f1e9ae10cee82
|
KarelDO/roberta-base.CEBaB_confounding.price_food_ambiance_negative.sa.5-class.seed_42
|
KarelDO
|
roberta
| 15 | 2 |
transformers
| 0 | null | true | false | false |
mit
|
['en']
|
['OpenTable']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,123 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base.CEBaB_confounding.price_food_ambiance_negative.sa.5-class.seed_42
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the OpenTable OPENTABLE dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6579
- Accuracy: 0.7352
- Macro-f1: 0.7190
- Weighted-macro-f1: 0.7313
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.2+cu102
- Datasets 2.5.2
- Tokenizers 0.12.1
|
847133ab849a8b5c6f4f5eb840419e53
|
chisun/mt5-small-finetuned-amazon-en-es
|
chisun
|
mt5
| 12 | 3 |
transformers
| 0 |
summarization
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['summarization', 'generated_from_trainer']
| true | true | true | 1,998 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-amazon-en-es
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6642
- Rouge1: 12.9097
- Rouge2: 3.2756
- Rougel: 12.2885
- Rougelsum: 12.3186
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|
| No log | 1.0 | 300 | 5.0305 | 4.4679 | 0.4134 | 4.3487 | 4.2807 |
| 9.3723 | 2.0 | 600 | 3.8535 | 10.6408 | 2.6198 | 10.5538 | 10.5819 |
| 9.3723 | 3.0 | 900 | 3.7590 | 12.1502 | 3.3079 | 12.013 | 12.1208 |
| 4.3429 | 4.0 | 1200 | 3.7019 | 13.0029 | 3.7708 | 12.9759 | 12.876 |
| 4.3429 | 5.0 | 1500 | 3.6782 | 13.1362 | 3.0904 | 12.561 | 12.5702 |
| 4.0043 | 6.0 | 1800 | 3.6698 | 12.8674 | 3.8026 | 12.3664 | 12.4216 |
| 4.0043 | 7.0 | 2100 | 3.6644 | 12.9581 | 3.3843 | 12.407 | 12.3956 |
| 3.872 | 8.0 | 2400 | 3.6642 | 12.9097 | 3.2756 | 12.2885 | 12.3186 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.0+cu116
- Datasets 2.4.0
- Tokenizers 0.12.1
|
d8bde60f9ca05ef08ceb6e4bd8663fd3
|
muhtasham/small-mlm-glue-rte-target-glue-sst2
|
muhtasham
|
bert
| 10 | 3 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,811 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# small-mlm-glue-rte-target-glue-sst2
This model is a fine-tuned version of [muhtasham/small-mlm-glue-rte](https://huggingface.co/muhtasham/small-mlm-glue-rte) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4047
- Accuracy: 0.8853
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- training_steps: 5000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.39 | 0.24 | 500 | 0.3545 | 0.8452 |
| 0.3071 | 0.48 | 1000 | 0.3333 | 0.8486 |
| 0.2584 | 0.71 | 1500 | 0.3392 | 0.8716 |
| 0.2388 | 0.95 | 2000 | 0.3082 | 0.8807 |
| 0.1863 | 1.19 | 2500 | 0.3273 | 0.8865 |
| 0.1691 | 1.43 | 3000 | 0.3945 | 0.8704 |
| 0.1675 | 1.66 | 3500 | 0.3601 | 0.8853 |
| 0.1713 | 1.9 | 4000 | 0.3341 | 0.8899 |
| 0.1368 | 2.14 | 4500 | 0.4622 | 0.8532 |
| 0.1251 | 2.38 | 5000 | 0.4047 | 0.8853 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
|
532e849193a5b9248745b134f283b308
|
darkstorm2150/Protogen_x5.8_Official_Release
|
darkstorm2150
| null | 23 | 18,179 |
diffusers
| 73 |
text-to-image
| false | false | false |
creativeml-openrail-m
|
['en']
| null | null | 11 | 6 | 2 | 3 | 1 | 1 | 0 |
['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'art', 'artistic', 'diffusers']
| false | true | true | 3,552 | false |
# Protogen_v5.8 by [darkstorm2150](https://instagram.com/officialvictorespinoza)
Protogen was warm-started with [Stable Diffusion v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) and
is rebuilt using dreamlikePhotoRealV2.ckpt as a core, adding small amounts during merge checkpoints.
## Model Weights
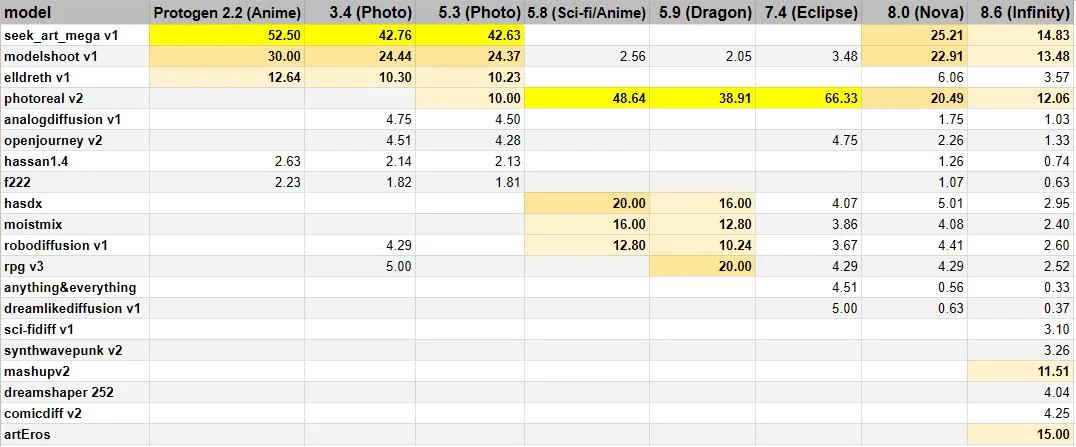
## Space
We support a [Gradio](https://github.com/gradio-app/gradio) Web UI:
[](https://huggingface.co/spaces/darkstorm2150/Stable-Diffusion-Protogen-webui)
### CompVis
[Download ProtoGen_X5.8.ckpt) (7.2GB)](https://huggingface.co/darkstorm2150/Protogen_v5.8_Official_Release/blob/main/ProtoGen_X5.8.ckpt)
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion Pipeline](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
```python
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
import torch
prompt = (
"modelshoot style, (extremely detailed CG unity 8k wallpaper), full shot body photo of the most beautiful artwork in the world, "
"english medieval witch, black silk vale, pale skin, black silk robe, black cat, necromancy magic, medieval era, "
"photorealistic painting by Ed Blinkey, Atey Ghailan, Studio Ghibli, by Jeremy Mann, Greg Manchess, Antonio Moro, trending on ArtStation, "
"trending on CGSociety, Intricate, High Detail, Sharp focus, dramatic, photorealistic painting art by midjourney and greg rutkowski"
)
model_id = "darkstorm2150/Protogen_v5.8_Official_Release"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
image = pipe(prompt, num_inference_steps=25).images[0]
image.save("./result.jpg")
```
License
This model is licesed under a modified CreativeML OpenRAIL-M license.
You are not allowed to host, finetune, or do inference with the model or its derivatives on websites/apps/etc. If you want to, please email us at contact@dreamlike.art
You are free to host the model card and files (Without any actual inference or finetuning) on both commercial and non-commercial websites/apps/etc. Please state the full model name (Dreamlike Photoreal 2.0) and include the license as well as a link to the model card (https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0)
You are free to use the outputs (images) of the model for commercial purposes in teams of 10 or less
You can't use the model to deliberately produce nor share illegal or harmful outputs or content
The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
You may re-distribute the weights. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the modified CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully) Please read the full license here: https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0/blob/main/LICENSE.md
|
0151ac25bcaf80f8f8504f4e6466cf2e
|
SetFit/distilbert-base-uncased__sst2__train-8-1
|
SetFit
|
distilbert
| 10 | 5 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,888 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased__sst2__train-8-1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6930
- Accuracy: 0.5047
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7082 | 1.0 | 3 | 0.7048 | 0.25 |
| 0.6761 | 2.0 | 6 | 0.7249 | 0.25 |
| 0.6653 | 3.0 | 9 | 0.7423 | 0.25 |
| 0.6212 | 4.0 | 12 | 0.7727 | 0.25 |
| 0.5932 | 5.0 | 15 | 0.8098 | 0.25 |
| 0.5427 | 6.0 | 18 | 0.8496 | 0.25 |
| 0.5146 | 7.0 | 21 | 0.8992 | 0.25 |
| 0.4356 | 8.0 | 24 | 0.9494 | 0.25 |
| 0.4275 | 9.0 | 27 | 0.9694 | 0.25 |
| 0.3351 | 10.0 | 30 | 0.9968 | 0.25 |
| 0.2812 | 11.0 | 33 | 1.0056 | 0.5 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2
- Tokenizers 0.10.3
|
d813d6e2cce202e2117663524dbc71c8
|
nvidia/stt_eo_conformer_ctc_large
|
nvidia
| null | 3 | 4 |
nemo
| 0 |
automatic-speech-recognition
| true | false | false |
cc-by-4.0
|
['eo']
|
['mozilla-foundation/common_voice_11_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'speech', 'audio', 'CTC', 'Conformer', 'Transformer', 'pytorch', 'NeMo', 'hf-asr-leaderboard', 'Riva']
| true | true | true | 5,889 | false |
# NVIDIA Conformer-CTC Large (Esperanto)
<style>
img {
display: inline;
}
</style>
| [](#model-architecture)
| [](#model-architecture)
| [](#datasets)
| [](#deployment-with-nvidia-riva) |
This model transcribes speech into lowercase Esperanto alphabet including spaces and apostroph. The model was obtained by finetuning from English SSL-pretrained model on Mozilla Common Voice Esperanto 11.0 dataset. It is a non-autoregressive "large" variant of Conformer [1], with around 120 million parameters. See the [model architecture](#model-architecture) section and [NeMo documentation](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#conformer-ctc) for complete architecture details.
It is also compatible with NVIDIA Riva for [production-grade server deployments](#deployment-with-nvidia-riva).
## Usage
The model is available for use in the NeMo toolkit [3], and can be used as a pre-trained checkpoint for inference or for finetuning on another dataset.
To train, finetune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest PyTorch version.
```
pip install nemo_toolkit['all']
```
### Automatically instantiate the model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.EncDecCTCModelBPE.from_pretrained("nvidia/stt_eo_conformer_ctc_large")
```
### Transcribing using Python
Simply do:
```
asr_model.transcribe(['<your_audio>.wav'])
```
### Transcribing many audio files
```shell
python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py
pretrained_name="nvidia/stt_eo_conformer_ctc_large"
audio_dir="<DIRECTORY CONTAINING AUDIO FILES>"
```
### Input
This model accepts 16 kHz mono-channel Audio (wav files) as input.
### Output
This model provides transcribed speech as a string for a given audio sample.
## Model Architecture
Conformer-CTC model is a non-autoregressive variant of Conformer model [1] for Automatic Speech Recognition which uses CTC loss/decoding instead of Transducer. You may find more info on the detail of this model here: [Conformer-CTC Model](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#conformer-ctc).
## Training
The NeMo toolkit [3] was used for finetuning from English SSL model for over several hundred epochs. The model is finetuning with this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_ctc/speech_to_text_ctc_bpe.py) and this [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/conformer/conformer_ctc_bpe.yaml). As pretrained English SSL model we use [ssl_en_conformer_large](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/nemo/models/ssl_en_conformer_large) which was trained using LibriLight corpus (~56k hrs of unlabeled English speech).
The tokenizer for the model was built using the text transcripts of the train set with this [script](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py).
Full config can be found inside the .nemo files.
More training details can be found at the [Esperanto ASR example](https://github.com/andrusenkoau/NeMo/blob/esperanto_example/docs/source/asr/examples/esperanto_asr/esperanto_asr.rst).
### Datasets
All the models were trained on Mozilla Common Voice Esperanto 11.0 dataset comprising of about 1400 validated hours of Esperanto speech. However, training set consists of a much smaller amount of data, because when forming the train.tsv, dev.tsv and test.tsv, repetitions of texts in train were removed by Mozilla developers.
- Train set: ~250 hours.
- Dev set: ~25 hours.
- Test: ~25 hours.
## Performance
The list of the available models in this collection is shown in the following table. Performances of the ASR models are reported in terms of Word Error Rate (WER%) with greedy decoding.
| Version | Tokenizer | Vocabulary Size | Dev WER| Test WER| Train Dataset |
|---------|-----------------------|-----------------|--------|---------|-----------------|
| 1.14.0 | SentencePiece [2] BPE | 128 | 2.9 | 4.8 | MCV-11.0 Train set |
## Limitations
Since this model was trained on publicly available speech datasets, the performance of this model might degrade for speech which includes technical terms, or vernacular that the model has not been trained on. The model might also perform worse for accented speech.
## Deployment with NVIDIA Riva
For the best real-time accuracy, latency, and throughput, deploy the model with [NVIDIA Riva](https://developer.nvidia.com/riva), an accelerated speech AI SDK deployable on-prem, in all clouds, multi-cloud, hybrid, at the edge, and embedded.
Additionally, Riva provides:
* World-class out-of-the-box accuracy for the most common languages with model checkpoints trained on proprietary data with hundreds of thousands of GPU-compute hours
* Best in class accuracy with run-time word boosting (e.g., brand and product names) and customization of acoustic model, language model, and inverse text normalization
* Streaming speech recognition, Kubernetes compatible scaling, and Enterprise-grade support
Check out [Riva live demo](https://developer.nvidia.com/riva#demos).
## References
- [1] [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100)
- [2] [Google Sentencepiece Tokenizer](https://github.com/google/sentencepiece)
- [3] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo)
|
c084d671bc4087675caa5f68fa2704f9
|
sd-concepts-library/moeb-style
|
sd-concepts-library
| null | 9 | 0 | null | 21 | null | false | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 1,018 | false |
### Moeb Style on Stable Diffusion
This is the `<moe-bius>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:




|
7a524bdc7258466f76df8c1e3372ad00
|
toasthans/Facebook_and_Twitter_Ohne_HPS
|
toasthans
|
bert
| 12 | 5 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,405 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Facebook_and_Twitter_Ohne_HPS
This model is a fine-tuned version of [bert-base-german-cased](https://huggingface.co/bert-base-german-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9218
- Accuracy: 0.8512
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4364 | 1.0 | 713 | 0.4107 | 0.8302 |
| 0.2843 | 2.0 | 1426 | 0.4316 | 0.8495 |
| 0.0869 | 3.0 | 2139 | 0.7700 | 0.8558 |
| 0.0443 | 4.0 | 2852 | 0.9218 | 0.8512 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
aa7cfda57d8a1bc17e38143d2cd7ec58
|
ashish23993/t5-small-finetuned-xsum-AB
|
ashish23993
|
t5
| 9 | 4 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,372 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum-AB
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8942
- Rouge1: 13.835
- Rouge2: 4.4916
- Rougel: 10.5998
- Rougelsum: 12.3225
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:-------:|:---------:|:-------:|
| 2.9182 | 1.0 | 625 | 2.8942 | 13.835 | 4.4916 | 10.5998 | 12.3225 | 19.0 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.13.0+cpu
- Datasets 2.6.1
- Tokenizers 0.13.1
|
9730088492af790e0f8d346df46cc693
|
lewtun/roberta-large-finetuned-clinc-12
|
lewtun
|
roberta
| 15 | 2 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null |
['clinc_oos']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,403 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-large-finetuned-clinc-12
This model is a fine-tuned version of [roberta-large](https://huggingface.co/roberta-large) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1429
- Accuracy: 0.9765
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.8662 | 1.0 | 954 | 0.3441 | 0.9339 |
| 0.158 | 2.0 | 1908 | 0.1498 | 0.9742 |
| 0.0469 | 3.0 | 2862 | 0.1429 | 0.9765 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.2+cu113
- Datasets 1.18.4
- Tokenizers 0.11.6
|
ac97eb3bb4836ff05fc5f5e7a5222477
|
tzvc/3647bbc5-4fbe-4a94-95ec-5aec23a04e73
|
tzvc
| null | 25 | 2 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image']
| false | true | true | 784 | false |
### training params
```json
{
"pretrained_model_name_or_path": "multimodalart/sd-fine-tunable",
"instance_data_dir": "./3647bbc5-4fbe-4a94-95ec-5aec23a04e73/instance_data",
"class_data_dir": "./class_data/person",
"output_dir": "./3647bbc5-4fbe-4a94-95ec-5aec23a04e73/",
"train_text_encoder": true,
"with_prior_preservation": false,
"prior_loss_weight": 1.0,
"instance_prompt": "sd-tzvc",
"class_prompt": "person",
"resolution": 512,
"train_batch_size": 1,
"gradient_accumulation_steps": 1,
"gradient_checkpointing": true,
"use_8bit_adam": true,
"learning_rate": 2e-06,
"lr_scheduler": "polynomial",
"lr_warmup_steps": 0,
"num_class_images": 500,
"max_train_steps": 1050,
"mixed_precision": "fp16"
}
```
|
d19316664557beb76ca272155a9d8bde
|
premsuresh/bart-finetuned-mathqa-moh
|
premsuresh
|
bart
| 8 | 6 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 960 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-finetuned-mathqa-moh
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 100
### Training results
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
|
c43b70a08a070c31e611a4413d75c257
|
willcai/wav2vec2_common_voice_accents_5
|
willcai
|
wav2vec2
| 11 | 6 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,436 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2_common_voice_accents_5
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0027
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 48
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 384
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.4163 | 1.34 | 400 | 0.5520 |
| 0.3305 | 2.68 | 800 | 0.1698 |
| 0.2138 | 4.03 | 1200 | 0.1104 |
| 0.1714 | 5.37 | 1600 | 0.0944 |
| 0.1546 | 6.71 | 2000 | 0.0700 |
| 0.1434 | 8.05 | 2400 | 0.0610 |
| 0.1272 | 9.4 | 2800 | 0.0493 |
| 0.1183 | 10.74 | 3200 | 0.0371 |
| 0.1113 | 12.08 | 3600 | 0.0468 |
| 0.1013 | 13.42 | 4000 | 0.0336 |
| 0.0923 | 14.77 | 4400 | 0.0282 |
| 0.0854 | 16.11 | 4800 | 0.0410 |
| 0.0791 | 17.45 | 5200 | 0.0252 |
| 0.0713 | 18.79 | 5600 | 0.0128 |
| 0.0662 | 20.13 | 6000 | 0.0252 |
| 0.0635 | 21.48 | 6400 | 0.0080 |
| 0.0607 | 22.82 | 6800 | 0.0098 |
| 0.0557 | 24.16 | 7200 | 0.0069 |
| 0.0511 | 25.5 | 7600 | 0.0057 |
| 0.0474 | 26.85 | 8000 | 0.0046 |
| 0.045 | 28.19 | 8400 | 0.0037 |
| 0.0426 | 29.53 | 8800 | 0.0027 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.2+cu102
- Datasets 1.18.4
- Tokenizers 0.11.6
|
4c7b82773b79ba94c4b08638d9f9aef3
|
jimregan/bert-base-irish-cased-v1-finetuned-ner
|
jimregan
|
bert
| 16 | 8 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
|
['ga']
|
['wikiann']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer', 'irish']
| true | true | true | 1,757 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-irish-cased-v1-finetuned-ner
This model is a fine-tuned version of [DCU-NLP/bert-base-irish-cased-v1](https://huggingface.co/DCU-NLP/bert-base-irish-cased-v1) on the wikiann dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2468
- Precision: 0.8191
- Recall: 0.8363
- F1: 0.8276
- Accuracy: 0.9307
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 63 | 0.4902 | 0.5579 | 0.5269 | 0.5420 | 0.8458 |
| No log | 2.0 | 126 | 0.3227 | 0.7169 | 0.7417 | 0.7291 | 0.8991 |
| No log | 3.0 | 189 | 0.2720 | 0.7895 | 0.7839 | 0.7867 | 0.9186 |
| No log | 4.0 | 252 | 0.2585 | 0.8128 | 0.8296 | 0.8211 | 0.9264 |
| No log | 5.0 | 315 | 0.2468 | 0.8191 | 0.8363 | 0.8276 | 0.9307 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
13d8958f90e9e5b3d560669be4d198fa
|
Ashenhard/Ashenhard-style
|
Ashenhard
| null | 13 | 0 | null | 2 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['text-to-image']
| false | true | true | 1,400 | false |
I'm a digital artist learning these new tools to work with, this is my first style model
I'm on Instagram: @ashenhard84 and Twitter: @ashenhard
This model was trained with 85 images, at 8500 steps 1e-6 in Shivam Shrirao Google colab.
I think the potential of this model is to merge it with others.
The token is **Ashenhard style**
**Generated by the model without merge:**




**Generated by the model merged with (A) Anything V3 at 0.4 - (B) Ashenhard:**


**Testing Img2Img with the model+anything**

**Generated by the model merged with (A) Ashenhard at 0.4 - (B) F222:**


|
2b86852ce24d083b9241897435960290
|
Nadav/bert-base-french-europeana-cased-squad-fr
|
Nadav
|
bert
| 10 | 23 |
transformers
| 0 |
question-answering
| true | false | false |
mit
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,292 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-french-europeana-cased-squad-fr
This model is a fine-tuned version of [dbmdz/bert-base-french-europeana-cased](https://huggingface.co/dbmdz/bert-base-french-europeana-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7031
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.9069 | 1.0 | 3539 | 1.7853 |
| 1.6263 | 2.0 | 7078 | 1.7031 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
|
f4609471e284cdc8cd2ec63e90b71575
|
elopezlopez/distilbert-base-uncased_fold_2_ternary
|
elopezlopez
|
distilbert
| 13 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,656 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased_fold_2_ternary
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5810
- F1: 0.7620
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 25
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 294 | 0.5886 | 0.7239 |
| 0.557 | 2.0 | 588 | 0.5085 | 0.7524 |
| 0.557 | 3.0 | 882 | 0.6332 | 0.7530 |
| 0.2456 | 4.0 | 1176 | 0.8749 | 0.7161 |
| 0.2456 | 5.0 | 1470 | 1.0601 | 0.7371 |
| 0.1112 | 6.0 | 1764 | 1.1885 | 0.7451 |
| 0.0484 | 7.0 | 2058 | 1.3027 | 0.7240 |
| 0.0484 | 8.0 | 2352 | 1.4647 | 0.7259 |
| 0.0259 | 9.0 | 2646 | 1.4476 | 0.7322 |
| 0.0259 | 10.0 | 2940 | 1.4826 | 0.7388 |
| 0.0164 | 11.0 | 3234 | 1.5869 | 0.7333 |
| 0.0109 | 12.0 | 3528 | 1.5954 | 0.7539 |
| 0.0109 | 13.0 | 3822 | 1.5810 | 0.7620 |
| 0.0082 | 14.0 | 4116 | 1.7165 | 0.7335 |
| 0.0082 | 15.0 | 4410 | 1.8152 | 0.7414 |
| 0.004 | 16.0 | 4704 | 1.7411 | 0.7474 |
| 0.004 | 17.0 | 4998 | 1.8692 | 0.7355 |
| 0.0034 | 18.0 | 5292 | 1.8727 | 0.7303 |
| 0.0009 | 19.0 | 5586 | 1.9813 | 0.7305 |
| 0.0009 | 20.0 | 5880 | 1.9764 | 0.7391 |
| 0.0012 | 21.0 | 6174 | 2.0170 | 0.7291 |
| 0.0012 | 22.0 | 6468 | 2.0240 | 0.7391 |
| 0.0004 | 23.0 | 6762 | 2.0311 | 0.7352 |
| 0.0014 | 24.0 | 7056 | 2.0174 | 0.7334 |
| 0.0014 | 25.0 | 7350 | 2.0282 | 0.7381 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
aea03357e491ac999c6e8dda7f882d20
|
Den4ikAI/rubert_large_squad_2
|
Den4ikAI
|
bert
| 11 | 3 |
transformers
| 0 |
question-answering
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 502 | false |
обученный rubert от sberbank-ai/ruBert-base.
размер выборки - 4.
Эпохи - 4.
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="Den4ikAI/rubert_large_squad_2",
tokenizer="Den4ikAI/rubert_large_squad_2"
)
predictions = qa_pipeline({
'context': "Пушкин родился 6 июля 1799 года",
'question': "Когда родился Пушкин?"
})
print(predictions)
# output:
#{'score': 0.8013797664642334, 'start': 15, 'end': 31, 'answer': '6 июля 1799 года'}
```
|
14eef434cecb6883b306dc777a051ec9
|
Pablo94/racism-finetuned-detests
|
Pablo94
|
roberta
| 13 | 0 |
transformers
| 0 |
text-classification
| true | false | false |
cc
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,760 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# racism-finetuned-detests
This model is a fine-tuned version of [davidmasip/racism](https://huggingface.co/davidmasip/racism) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0150
- Accuracy: 0.8560
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2659 | 1.0 | 153 | 0.3250 | 0.8429 |
| 0.1191 | 2.0 | 306 | 0.5344 | 0.8380 |
| 0.0074 | 3.0 | 459 | 0.8188 | 0.8396 |
| 0.0001 | 4.0 | 612 | 0.9264 | 0.8462 |
| 0.0001 | 5.0 | 765 | 0.9551 | 0.8462 |
| 0.0001 | 6.0 | 918 | 0.9771 | 0.8527 |
| 0.0001 | 7.0 | 1071 | 0.9937 | 0.8527 |
| 0.0001 | 8.0 | 1224 | 1.0054 | 0.8560 |
| 0.0 | 9.0 | 1377 | 1.0126 | 0.8560 |
| 0.0001 | 10.0 | 1530 | 1.0150 | 0.8560 |
### Framework versions
- Transformers 4.23.1
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
|
92c1f779ecf63012f2150153e8c67132
|
N75242/FloralMarbles_Model
|
N75242
| null | 25 | 0 | null | 7 | null | false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 3,053 | false |
### Model info
---
This is a dreambooth model trained with the data set of [FloralMarble](https://huggingface.co/datasets/spaablauw/FloralMarble_dataset) on top of stable diffusion 1.5, all creadits to [spaablauw](https://huggingface.co/spaablauw) for original images.
I left several models uploaded, all the intermediate steps + two anime models that I merged into.
I would recomend try [the 4000 steps model](https://huggingface.co/N75242/FloralMarbles_Model/resolve/main/FloralMarble_step_4000.ckpt) or the [7000 steps one](https://huggingface.co/N75242/FloralMarbles_Model/resolve/main/FloralMarble_step_7000.ckpt), it depends a bit in what you want, I had relly good result in booth.
For img2img 7000 step version is better.
[Download Eimis Merge](https://huggingface.co/N75242/FloralMarbles_Model/resolve/main/EimisAnimeDiffusion_1-0v_0-FloralMarble_step_3000.safetensors)
[Download Anything Merge](https://huggingface.co/N75242/FloralMarbles_Model/resolve/main/Anything-V3.0_0-FloralMarble_step_3000_1.safetensors)
Use whatever VAE you want.
---
### Examples, download images to get prompts from exif data














---
### Tag list
[Get the tag list images had here](https://huggingface.co/N75242/FloralMarbles_Model/resolve/main/tags.txt)
I used "flrmrbl" as an unique token, so it should activate the model traing data, also "floral marble" is present in all images, but its more generic si probably less powerfull.
But as an alternative use "in the style of flrmrbl" or "flrmrbl style".
Have fun!
|
a2eca7cfc4b3216175b4b668bb91edea
|
NinaXiao/distilroberta-base-finetuned-wikitext2
|
NinaXiao
|
roberta
| 8 | 2 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,267 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-finetuned-wikitext2
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9947
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 285 | 2.0524 |
| 2.2183 | 2.0 | 570 | 1.9742 |
| 2.2183 | 3.0 | 855 | 1.9947 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
3f4c37c9f9e3bd2be6cd8e4244c37bc4
|
rafiuddin/t5-end2end-questions-generation
|
rafiuddin
|
t5
| 6 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['squad_modified_for_t5_qg']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 993 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-end2end-questions-generation
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on the squad_modified_for_t5_qg dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
### Training results
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
33b86b0734902b0d4d6d751bb5c90ffd
|
Cinnamomo/unico
|
Cinnamomo
| null | 28 | 0 | null | 26 |
text-to-image
| false | false | false |
creativeml-openrail-m
|
['en']
| null | null | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
['stable-diffusion', 'text-to-image']
| false | true | true | 4,278 | false |
# i modelli 'Unico'
<img src=https://i.imgur.com/5KfDOik.png
width=100% height=100%>
Unico is the series of custom mixed models. Based on Inizio Unico and AbyssOrange2 models with U-Net Merge, and support .safetensors format only.
[WebUI](https://github.com/AUTOMATIC1111/stable-diffusion-webui)-amicable
## Summary
This model repository includes 5 main models currently:
1.
| Model: A | Model: B | Merge Weight | Base alpha | Merge Name |
| --- | --- | --- | --- | --- |
| [Inizio Fantasma+Inizio Inseguitore+Inizio Foschia](https://huggingface.co/Cinnamomo/inizio) | [Inizio Replicante+Inizio Skinjob+Inizio Deckard](https://huggingface.co/Cinnamomo/inizio) | weighted, M=0.66666666+M=0.66666666 | N/A | *Unico* |
Unico is another form of [Inizio Unico](https://huggingface.co/Cinnamomo/inizio).
2.
| Model: A | Model: B | Merge Weight | Base alpha | Merge Name |
| --- | --- | --- | --- | --- |
| [Inizio Unico](https://huggingface.co/Cinnamomo/inizio) | [AbyssOrange2 SFW](https://huggingface.co/WarriorMama777/OrangeMixs) | weighted, M=0.75. | N/A | *Unico Arancia* |
Unico Arancia('Orange🍊') is the closest model from AbyssOrange2 SFW. Anime~Semi-realistic.
3.
| Model: A | Model: B | U-Net Merge Weight | Base alpha | Merge Name |
| --- | --- | --- | --- | --- |
| Unico Arancia | [Openniji](https://huggingface.co/Korakoe/OpenNiji) | 1,1,1,1,0,0,1,1,0,0,0,1,0,0,0,0,1,1,1,0,0,0,0,1,1 | 0 | *Unico Bergamotto* |
Unico Bergamotto('Bergamot🍊') is significantly improved model of Unico Arancia for lightning and hand details. Anime~Semi-realistic.
4.
| Model: A | Model: B | U-Net Merge Weight | Base alpha | Merge Name |
| --- | --- | --- | --- | --- |
| Unico Vaniglia | [Openniji](https://huggingface.co/Korakoe/OpenNiji) | 1,1,1,1,0,0,1,1,0,0,0,1,0,0,0,0,1,1,1,0,0,0,0,1,1 | 0 | *Unico Vaniglia 1.5* |
Unico Vaniglia('Vanilla🍦') 1.5 is significantly improved model of Unico Vaniglia for lightning and hand details. Anime~Semi-realistic.
- NOTE: Another models are moved to legacy folder.
## Setting Reccomendation
```
##Basic prompts for anime
"txt2img/Prompt/value": "(best quality, extreme intricate detailed, octane render, very delicate cinematic light, colourful), (/*place tags*/), (solo girl/*character tags*/), (/*pose tags*/), (big breasts, big pelvis, slim waist, long legs, best ratio four finger and one thumb, /*body tags*/), (beautiful eyes and smooth radiant face, bishoujo), (/*colour of hair tag*/ hair, /*colour of eyes*/ eyes, thick lips, lip gloss), (/*clothing tags*/)",
"txt2img/Negative prompt/value": "(nsfw, worst quality, low quality:1.4), (greyscale), (fingers(missing, fused, interlocked, abnormal, too many, bad anatomy, fused, fusion, lose, bad detailed, mutated), digit(extra, fewer), hands(greater than 4 fingers, less than 4 fingers, cropped, mutated):1.4), (fat, chubby, curvy, watermark, signature:1.4), (3d, realistic)"
```
- Variational Automatic Encoder: [SD MSE 840k.vae.safetensors](https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.safetensors)
- Clip Skip: 2
- Resolution: 1024x576 w/ HighRes. Fix
- HighRes. Fix: R-ESRGAN General WDN 4xV3; upscale by 1.25
## Sample Images
>
> <img src=https://i.imgur.com/gYTQvrw.png
> width=100% height=100%>
> ▲ X/Y Plot #1
>
> <img src=https://i.imgur.com/HL6TfkD.png
> width=100% height=100%>
> ▲ X/Y Plot #2
>
> <img src=https://i.imgur.com/vrZmSLY.png
> width=100% height=100%>
> ▲ X/Y Plot #3
>
> <img src=https://i.imgur.com/aYIyVFJ.png
> width=100% height=100%>
>
> <img src=https://i.imgur.com/pKNd2XO.png
> width=100% height=100%>
>
> <img src=https://i.imgur.com/GknH4e0.png
> width=100% height=100%>
>
> <img src=https://i.imgur.com/rVblL4d.png
> width=100% height=100%>
> ▲ Unico Arancia
>
> <img src=https://i.imgur.com/8vCjbUK.png
> width=100% height=100%>
>
> <img src=https://i.imgur.com/HKvXAFx.png
> width=100% height=100%>
> ▲ Unico Bergamotto
## License Information
This model follows Creative ML Open RAIL-M: [Stable Diffusion License](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
But, You may use whatever you want. I don't like to set such restriction.
## Contact
*vitorriofungi@gmail.com* or [*Find Cinnamomo on Arcalive AI Art Channel*](https://arca.live/b/aiart)
|
b98be8a2fbab379a7ad3a1f873dc8ff4
|
erkam/sd-pokemon-model-lora
|
erkam
| null | 88 | 0 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['stable-diffusion', 'stable-diffusion-diffusers', 'text-to-image', 'diffusers', 'lora']
| false | true | true | 403 | false |
# LoRA text2image fine-tuning - https://huggingface.co/erkam/sd-pokemon-model-lora
These are LoRA adaption weights for https://huggingface.co/erkam/sd-pokemon-model-lora. The weights were fine-tuned on the lambdalabs/pokemon-blip-captions dataset. You can find some example images in the following.




|
3b7087edbdc98b684f9040e6985e7ebb
|
saattrupdan/xlmr-base-texas-squad-de
|
saattrupdan
|
xlm-roberta
| 12 | 7 |
transformers
| 0 |
question-answering
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 990 | false |
# TExAS-SQuAD-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the TExAS-SQuAD-de dataset.
It achieves the following results on the evaluation set:
- Exact match: 61.45%
- F1-score: 66.12%
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.8084 | 1.0 | 4233 | 1.5897 |
| 1.5696 | 2.0 | 8466 | 1.5478 |
| 1.4196 | 3.0 | 12699 | 1.5754 |
### Framework versions
- Transformers 4.12.2
- Pytorch 1.8.1+cu101
- Datasets 1.12.1
- Tokenizers 0.10.3
|
ba7e34ca964ec3b232a8635646e7a416
|
shivarama23/swin-tiny-patch4-window7-224-finetuned-image_quality
|
shivarama23
|
swin
| 16 | 32 |
transformers
| 1 |
image-classification
| true | false | false |
apache-2.0
| null |
['image_folder']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,934 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-image_quality
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the image_folder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5242
- Accuracy: 0.9091
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 1 | 0.6762 | 0.6364 |
| No log | 2.0 | 2 | 0.6309 | 0.7273 |
| No log | 3.0 | 3 | 0.6095 | 0.6364 |
| No log | 4.0 | 4 | 0.5775 | 0.6364 |
| No log | 5.0 | 5 | 0.5443 | 0.8182 |
| No log | 6.0 | 6 | 0.5242 | 0.9091 |
| No log | 7.0 | 7 | 0.5149 | 0.8182 |
| No log | 8.0 | 8 | 0.5094 | 0.8182 |
| No log | 9.0 | 9 | 0.5038 | 0.8182 |
| 0.4095 | 10.0 | 10 | 0.4992 | 0.8182 |
### Framework versions
- Transformers 4.19.4
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
bbcc2b9f394a54b9b7c59aa92461d892
|
jayantapaul888/smalldata-microsoft-deberta-base-mnli-eng-only-sentiment-single-finetuned-memes
|
jayantapaul888
|
deberta
| 15 | 4 |
transformers
| 0 |
text-classification
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,989 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# smalldata-microsoft-deberta-base-mnli-eng-only-sentiment-single-finetuned-memes
This model is a fine-tuned version of [jayantapaul888/twitter-data-microsoft-deberta-base-mnli-sentiment-finetuned-memes](https://huggingface.co/jayantapaul888/twitter-data-microsoft-deberta-base-mnli-sentiment-finetuned-memes) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7400
- Accuracy: 0.8816
- Precision: 0.8946
- Recall: 0.8937
- F1: 0.8937
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| No log | 1.0 | 378 | 0.2962 | 0.8764 | 0.8917 | 0.8881 | 0.8884 |
| 0.3387 | 2.0 | 756 | 0.2803 | 0.8831 | 0.8950 | 0.8942 | 0.8946 |
| 0.1693 | 3.0 | 1134 | 0.4289 | 0.8764 | 0.8912 | 0.8892 | 0.8886 |
| 0.0772 | 4.0 | 1512 | 0.5436 | 0.8690 | 0.8822 | 0.8823 | 0.8822 |
| 0.0772 | 5.0 | 1890 | 0.6566 | 0.8831 | 0.8960 | 0.8947 | 0.8949 |
| 0.024 | 6.0 | 2268 | 0.7400 | 0.8816 | 0.8946 | 0.8937 | 0.8937 |
### Framework versions
- Transformers 4.24.0.dev0
- Pytorch 1.11.0+cu102
- Datasets 2.6.1
- Tokenizers 0.13.1
|
194003f8df9464e82b5a7c790e973f2b
|
Kevincp560/bigbird-pegasus-large-arxiv-finetuned-pubmed
|
Kevincp560
|
bigbird_pegasus
| 10 | 1 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null |
['pub_med_summarization_dataset']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,921 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bigbird-pegasus-large-arxiv-finetuned-pubmed
This model is a fine-tuned version of [google/bigbird-pegasus-large-arxiv](https://huggingface.co/google/bigbird-pegasus-large-arxiv) on the pub_med_summarization_dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6049
- Rouge1: 45.4807
- Rouge2: 20.0199
- Rougel: 28.3621
- Rougelsum: 41.4618
- Gen Len: 219.144
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 2.594 | 1.0 | 500 | 1.9879 | 33.6364 | 13.5074 | 21.4286 | 29.7158 | 189.014 |
| 1.9146 | 2.0 | 1000 | 1.6494 | 44.0056 | 19.0069 | 27.5142 | 40.0492 | 210.528 |
| 1.7378 | 3.0 | 1500 | 1.6213 | 44.7071 | 19.3559 | 27.6806 | 40.6124 | 213.596 |
| 1.692 | 4.0 | 2000 | 1.6081 | 45.1505 | 19.7355 | 28.06 | 41.0108 | 213.674 |
| 1.6656 | 5.0 | 2500 | 1.6049 | 45.4807 | 20.0199 | 28.3621 | 41.4618 | 219.144 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.9.1
- Datasets 1.18.4
- Tokenizers 0.11.6
|
93be379e38e97cd0fe3d7fe703efc0bd
|
kazandaev/opus-mt-en-ru-finetuned_v2
|
kazandaev
|
marian
| 25 | 3 |
transformers
| 0 |
text2text-generation
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,583 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-en-ru-finetuned_v2
This model is a fine-tuned version of [kazandaev/opus-mt-en-ru-finetuned_v2](https://huggingface.co/kazandaev/opus-mt-en-ru-finetuned_v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8471
- Bleu: 37.5148
- Gen Len: 29.8495
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 49
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:------:|:---------------:|:-------:|:-------:|
| 0.7688 | 1.0 | 50906 | 0.8533 | 37.1941 | 29.8644 |
| 0.764 | 2.0 | 101812 | 0.8504 | 37.1506 | 29.8481 |
| 0.7637 | 3.0 | 152718 | 0.8485 | 37.3499 | 29.7743 |
| 0.7593 | 4.0 | 203624 | 0.8477 | 37.4428 | 29.8165 |
| 0.7579 | 5.0 | 254530 | 0.8471 | 37.5148 | 29.8495 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.6
|
c9fc70f1dcbe68979154a0b8652a0e06
|
Graphcore/bert-large-uncased
|
Graphcore
|
bert
| 13 | 1 |
transformers
| 6 | null | true | false | false |
apache-2.0
| null |
['Graphcore/wikipedia-bert-128', 'Graphcore/wikipedia-bert-512']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 5,734 | false |
# Graphcore/bert-large-uncased
Optimum Graphcore is a new open-source library and toolkit that enables developers to access IPU-optimized models certified by Hugging Face. It is an extension of Transformers, providing a set of performance optimization tools enabling maximum efficiency to train and run models on Graphcore’s IPUs - a completely new kind of massively parallel processor to accelerate machine intelligence. Learn more about how to take train Transformer models faster with IPUs at [hf.co/hardware/graphcore](https://huggingface.co/hardware/graphcore).
Through HuggingFace Optimum, Graphcore released ready-to-use IPU-trained model checkpoints and IPU configuration files to make it easy to train models with maximum efficiency in the IPU. Optimum shortens the development lifecycle of your AI models by letting you plug-and-play any public dataset and allows a seamless integration to our State-of-the-art hardware giving you a quicker time-to-value for your AI project.
## Model description
BERT (Bidirectional Encoder Representations from Transformers) is a transformers model which is designed to pretrain bidirectional representations from unlabelled texts. It enables easy and fast fine-tuning for different downstream tasks such as Sequence Classification, Named Entity Recognition, Question Answering, Multiple Choice and MaskedLM.
It was trained with two objectives in pretraining : Masked language modelling (MLM) and Next sentence prediction(NSP). First, MLM is different from traditional LM which sees the words one after another while BERT allows the model to learn a bidirectional representation. In addition to MLM, NSP is used for jointly pertaining text-pair representations.
It reduces the need of many engineering efforts for building task specific architectures through pre-trained representation. And achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks.
## Intended uses & limitations
This model is a pre-trained BERT-Large trained in two phases on the [Graphcore/wikipedia-bert-128](https://huggingface.co/datasets/Graphcore/wikipedia-bert-128) and [Graphcore/wikipedia-bert-512](https://huggingface.co/datasets/Graphcore/wikipedia-bert-512) datasets.
## Training and evaluation data
Trained on wikipedia datasets:
- [Graphcore/wikipedia-bert-128](https://huggingface.co/datasets/Graphcore/wikipedia-bert-128)
- [Graphcore/wikipedia-bert-512](https://huggingface.co/datasets/Graphcore/wikipedia-bert-512)
## Training procedure
Trained MLM and NSP pre-training scheme from [Large Batch Optimization for Deep Learning: Training BERT in 76 minutes](https://arxiv.org/abs/1904.00962).
Trained on 64 Graphcore Mk2 IPUs using [`optimum-graphcore`](https://github.com/huggingface/optimum-graphcore)
Command lines:
Phase 1:
```
python examples/language-modeling/run_pretraining.py \
--config_name bert-large-uncased \
--tokenizer_name bert-large-uncased \
--ipu_config_name Graphcore/bert-large-ipu \
--dataset_name Graphcore/wikipedia-bert-128 \
--do_train \
--logging_steps 5 \
--max_seq_length 128 \
--max_steps 10550 \
--is_already_preprocessed \
--dataloader_num_workers 64 \
--dataloader_mode async_rebatched \
--lamb \
--lamb_no_bias_correction \
--per_device_train_batch_size 8 \
--gradient_accumulation_steps 512 \
--pod_type pod64 \
--learning_rate 0.006 \
--lr_scheduler_type linear \
--loss_scaling 32768 \
--weight_decay 0.01 \
--warmup_ratio 0.28 \
--config_overrides "layer_norm_eps=0.001" \
--ipu_config_overrides "matmul_proportion=[0.14 0.19 0.19 0.19]" \
--output_dir output-pretrain-bert-large-phase1
```
Phase 2:
```
python examples/language-modeling/run_pretraining.py \
--config_name bert-large-uncased \
--tokenizer_name bert-large-uncased \
--model_name_or_path ./output-pretrain-bert-large-phase1 \
--ipu_config_name Graphcore/bert-large-ipu \
--dataset_name Graphcore/wikipedia-bert-512 \
--do_train \
--logging_steps 5 \
--max_seq_length 512 \
--max_steps 2038 \
--is_already_preprocessed \
--dataloader_num_workers 96 \
--dataloader_mode async_rebatched \
--lamb \
--lamb_no_bias_correction \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 512 \
--pod_type pod64 \
--learning_rate 0.002828 \
--lr_scheduler_type linear \
--loss_scaling 16384 \
--weight_decay 0.01 \
--warmup_ratio 0.128 \
--config_overrides "layer_norm_eps=0.001" \
--ipu_config_overrides "matmul_proportion=[0.14 0.19 0.19 0.19]" \
--output_dir output-pretrain-bert-large-phase2
```
### Training hyperparameters
The following hyperparameters were used during phase 1 training:
- learning_rate: 0.006
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: IPU
- gradient_accumulation_steps: 512
- total_train_batch_size: 65536
- total_eval_batch_size: 512
- optimizer: LAMB
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.28
- training_steps: 10550
- training precision: Mixed Precision
The following hyperparameters were used during phase 2 training:
- learning_rate: 0.002828
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- distributed_type: IPU
- gradient_accumulation_steps: 512
- total_train_batch_size: 16384
- total_eval_batch_size: 512
- optimizer: LAMB
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.128
- training_steps: 2038
- training precision: Mixed Precision
### Training results
```
train/epoch: 2.04
train/global_step: 2038
train/loss: 1.2002
train/train_runtime: 12022.3897
train/train_steps_per_second: 0.17
train/train_samples_per_second: 2777.367
```
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cpu
- Datasets 2.0.0
- Tokenizers 0.11.6
|
2f9c72bc7f5985b8697a4ee1d5159252
|
nicky007/stable-diffusion-trained-on-yujiro-hanma-images-baki-anime-fun-project
|
nicky007
| null | 16 | 66 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 426 | false |
### Stable_Diffusion-trained-on-YUJIRO-HANMA-images(Baki-anime)-Fun-project model trained by nicky007
Trained on YUJIRO HANMA character of Baki-the grappler anime ..its just a fun project coz i was bored..
try Text on the prompt like:
**'yujiro hanma clay statue'**,
**'yujiro hanma laughing and angry pose'**,
**'yujiro hanma posing very angry'** etc
Or you can try your own unique text
**Enjoy ,have a wonderfull day !!**
|
3b6c88b61314bdfc38358027de314e14
|
espnet/kan-bayashi_libritts_tts_train_gst_xvector_trasnformer_raw_phn_tacotro-truncated-250027
|
espnet
| null | 25 | 1 |
espnet
| 0 |
text-to-speech
| false | false | false |
cc-by-4.0
|
['en']
|
['libritts']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['espnet', 'audio', 'text-to-speech']
| false | true | true | 1,874 | false |
## Example ESPnet2 TTS model
### `kan-bayashi/libritts_tts_train_gst+xvector_trasnformer_raw_phn_tacotron_g2p_en_no_space_train.loss.ave`
♻️ Imported from https://zenodo.org/record/4409702/
This model was trained by kan-bayashi using libritts/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
f5a71214b2359a30c1536ccb90a5778c
|
jonatasgrosman/exp_w2v2t_es_wavlm_s26
|
jonatasgrosman
|
wavlm
| 10 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['es']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'es']
| false | true | true | 438 | false |
# exp_w2v2t_es_wavlm_s26
Fine-tuned [microsoft/wavlm-large](https://huggingface.co/microsoft/wavlm-large) for speech recognition using the train split of [Common Voice 7.0 (es)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
d623df325a740d552c18b99104957e25
|
sinu/IndoBERT-exam-qa
|
sinu
|
bert
| 12 | 9 |
transformers
| 0 |
question-answering
| true | false | false |
mit
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,272 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# IndoBERT-exam-qa
This model is a fine-tuned version of [indolem/indobert-base-uncased](https://huggingface.co/indolem/indobert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8274
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.395 | 1.0 | 8202 | 1.3536 |
| 1.1534 | 2.0 | 16404 | 1.4040 |
| 1.3661 | 3.0 | 24606 | 1.8274 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
a39fc30aa5bed0c41af95acef7e97243
|
jonatasgrosman/exp_w2v2t_it_vp-sv_s149
|
jonatasgrosman
|
wav2vec2
| 10 | 7 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['it']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'it']
| false | true | true | 469 | false |
# exp_w2v2t_it_vp-sv_s149
Fine-tuned [facebook/wav2vec2-large-sv-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-sv-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (it)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
b524a7f0739844445540e488f39f2f28
|
tnkmr/sfi_convtasnet_td_mgf_musdb18hq
|
tnkmr
| null | 2,230 | 0 | null | 0 |
audio-to-audio
| false | false | false |
mit
|
['ja']
|
['MUSDB18-HQ']
| null | 4 | 0 | 4 | 0 | 0 | 0 | 0 |
['music', 'audio', 'audio-to-audio', 'SFI']
| false | true | true | 1,248 | false |
# Sampling-frequency-independent (SFI) Conv-TasNet trained with the MUSDB18-HQ dataset for music source separation
This model was proposed in [our IEEE/ACM Trans. ASLP paper](https://doi.org/10.1109/TASLP.2022.3203907) and works well with untrained sampling frequencies by using sampling-frequency-independent convolutional layers with the time domain filter design.
The latent analog filter is a modulated Gaussian filter.
It was trained by Tomohiko Nakamura using [the codebase](https://github.com/TomohikoNakamura/sfi_convtasnet)).
This model was trained with 32 kHz-sampled data but works well with untrained sampling frequencies (e.g., 8, 16 kHz).
# License
MIT
# Citation
Please cite the following paper.
```
@article{KSaito2022IEEEACMTASLP,
author={Saito, Koichi and Nakamura, Tomohiko and Yatabe, Kohei and Saruwatari, Hiroshi},
journal = {IEEE/ACM Transactions on Audio, Speech, and Language Processing},
title = {Sampling-frequency-independent convolutional layer and its application to audio source separation},
year=2022,
month=sep,
volume=30,
pages={2928--2943},
doi={10.1109/TASLP.2022.3203907},
}
```
# Contents
- Four trained models (seed=40,42,44,47)
- Evaluation results (json files obtained with the museval library)
|
7a7132c3b0acf9de48ee931b1fad06eb
|
cjvt/gpt-sl-base
|
cjvt
|
gpt2
| 8 | 110 |
transformers
| 0 |
text-generation
| true | false | false |
apache-2.0
|
['sl']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['pytorch', 'causal-lm']
| false | true | true | 1,029 | false |
# GPT-sl-base
This model is a Slovene GPT model, based on the [bigscience workshop](https://github.com/bigscience-workshop/Megatron-DeepSpeed) fork of the Megatron. GPT-sl-base was trained on large Slovene corpora: Gigafida, KAS, slWaC, and MaCoCu.
## Model architecture
GPT-sl-base has about 110 million parameters. It consists of 12 transformer layers with a dimension of 768. It has 16 attention heads and can process sequences up to 1024 tokens in length.
The tokenizer was trained on a smaller subset of the corpora, and has the vocabulary of 60k tokens.
## Training
The model was trained for about 20 epochs, a total of 390k steps or 102B tokens seen during training.
| Step | Validation Perplexity |
|:------:|:---------------------:|
| 50000 | 26.801 |
| 100000 | 25.574 |
| 150000 | 24.773 |
| 200000 | 24.099 |
| 250000 | 23.336 |
| 300000 | 22.607 |
| 350000 | 22.329 |
| 390000 | 22.293 |
|
2ded5e8db2cca925ef703750d69d5082
|
eugenetanjc/wav2vec_mle
|
eugenetanjc
|
wav2vec2
| 12 | 1 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,249 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec_mle
This model is a fine-tuned version of [facebook/wav2vec2-base-960h](https://huggingface.co/facebook/wav2vec2-base-960h) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.3076
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 6
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 12
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 20
- num_epochs: 60
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| 7.3604 | 3.33 | 30 | 4.4612 | 1.0 |
| 4.502 | 6.67 | 60 | 4.5906 | 1.0 |
| 4.2842 | 10.0 | 90 | 4.4217 | 1.0 |
| 4.3833 | 13.33 | 120 | 4.3967 | 1.0 |
| 4.2631 | 16.67 | 150 | 4.3469 | 1.0 |
| 4.3357 | 20.0 | 180 | 4.3372 | 1.0 |
| 4.3941 | 23.33 | 210 | 4.3187 | 1.0 |
| 4.393 | 26.67 | 240 | 4.2981 | 1.0 |
| 4.3619 | 30.0 | 270 | 4.3049 | 1.0 |
| 4.3849 | 33.33 | 300 | 4.3138 | 1.0 |
| 4.3186 | 36.67 | 330 | 4.3123 | 1.0 |
| 4.3196 | 40.0 | 360 | 4.3097 | 1.0 |
| 4.3212 | 43.33 | 390 | 4.3279 | 1.0 |
| 4.3108 | 46.67 | 420 | 4.3249 | 1.0 |
| 4.3112 | 50.0 | 450 | 4.3093 | 1.0 |
| 4.2994 | 53.33 | 480 | 4.3198 | 1.0 |
| 4.2958 | 56.67 | 510 | 4.3071 | 1.0 |
| 4.2905 | 60.0 | 540 | 4.3076 | 1.0 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu113
- Datasets 1.18.3
- Tokenizers 0.12.1
|
2f1ccd57f6144b7a4159173e7f851a42
|
Kuaaangwen/bert-base-cased-finetuned-wikitext2
|
Kuaaangwen
|
bert
| 9 | 2 |
transformers
| 0 |
fill-mask
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,258 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-wikitext2
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6212
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.8335 | 1.0 | 2393 | 1.7164 |
| 1.738 | 2.0 | 4786 | 1.6589 |
| 1.7029 | 3.0 | 7179 | 1.6216 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
8fc344391458ee375ab6f8f5f2a44a7e
|
jonatasgrosman/wav2vec2-xls-r-1b-french
|
jonatasgrosman
|
wav2vec2
| 24 | 43 |
transformers
| 5 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['fr']
|
['mozilla-foundation/common_voice_8_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'fr', 'hf-asr-leaderboard', 'mozilla-foundation/common_voice_8_0', 'robust-speech-event']
| true | true | true | 3,092 | false |
# Fine-tuned XLS-R 1B model for speech recognition in French
Fine-tuned [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on French using the train and validation splits of [Common Voice 8.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0), [MediaSpeech](https://www.openslr.org/108/), [Multilingual TEDx](http://www.openslr.org/100), [Multilingual LibriSpeech](https://www.openslr.org/94/), and [Voxpopuli](https://github.com/facebookresearch/voxpopuli).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool, and thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
## Usage
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-xls-r-1b-french")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "fr"
MODEL_ID = "jonatasgrosman/wav2vec2-xls-r-1b-french"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
```
## Evaluation Commands
1. To evaluate on `mozilla-foundation/common_voice_8_0` with split `test`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-xls-r-1b-french --dataset mozilla-foundation/common_voice_8_0 --config fr --split test
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-xls-r-1b-french --dataset speech-recognition-community-v2/dev_data --config fr --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr-1b-french,
title={Fine-tuned {XLS-R} 1{B} model for speech recognition in {F}rench},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-xls-r-1b-french}},
year={2022}
}
```
|
f5a979e83291d25915710af60a5ae548
|
Sleoruiz/distilbert-base-uncased-finetuned-emotion
|
Sleoruiz
|
distilbert
| 14 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['emotion']
| null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,337 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2176
- Accuracy: 0.927
- F1: 0.9273
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8252 | 1.0 | 250 | 0.3121 | 0.916 | 0.9140 |
| 0.2471 | 2.0 | 500 | 0.2176 | 0.927 | 0.9273 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
091ba58af0f7e124a6a48605e907eb34
|
cobraxx/maherkou
|
cobraxx
| null | 18 | 3 |
diffusers
| 0 |
text-to-image
| false | false | false |
creativeml-openrail-m
| null | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
['text-to-image', 'stable-diffusion']
| false | true | true | 610 | false |
### maherkou Dreambooth model trained by cobraxx with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
Sample pictures of this concept:
|
cea626a0725e2a0f8e892e73d2fa90b5
|
jonatasgrosman/exp_w2v2t_et_vp-sv_s445
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['et']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'et']
| false | true | true | 469 | false |
# exp_w2v2t_et_vp-sv_s445
Fine-tuned [facebook/wav2vec2-large-sv-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-sv-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (et)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
3067d4fe1097374928b274104f8f490b
|
MultiBertGunjanPatrick/multiberts-seed-0-20k
|
MultiBertGunjanPatrick
|
bert
| 7 | 2 |
transformers
| 0 | null | true | false | false |
apache-2.0
|
['en']
|
['bookcorpus', 'wikipedia']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['exbert', 'multiberts', 'multiberts-seed-0']
| false | true | true | 6,479 | false |
# MultiBERTs Seed 0 Checkpoint 20k (uncased)
Seed 0 intermediate checkpoint 20k MultiBERTs (pretrained BERT) model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/pdf/2106.16163.pdf) and first released in
[this repository](https://github.com/google-research/language/tree/master/language/multiberts). This is an intermediate checkpoint.
The final checkpoint can be found at [multiberts-seed-0](https://hf.co/multberts-seed-0). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing MultiBERTs did not write a model card for this model so this model card has been written by [gchhablani](https://hf.co/gchhablani).
## Model description
MultiBERTs models are transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the MultiBERTs model as inputs.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=multiberts) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('multiberts-seed-0-20k')
model = BertModel.from_pretrained("multiberts-seed-0-20k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions. This bias will also affect all fine-tuned versions of this model. For an understanding of bias of this particular
checkpoint, please try out this checkpoint with the snippet present in the [Limitation and bias section](https://huggingface.co/bert-base-uncased#limitations-and-bias) of the [bert-base-uncased](https://huggingface.co/bert-base-uncased) checkpoint.
## Training data
The MultiBERTs models were pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038
unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The full model was trained on 16 Cloud TPU v2 chips for two million steps with a batch size
of 256. The sequence length was set to 512 throughout. The optimizer
used is Adam with a learning rate of 1e-4, \\(\beta_{1} = 0.9\\) and \\(\beta_{2} = 0.999\\), a weight decay of 0.01,
learning rate warmup for 10,000 steps and linear decay of the learning rate after.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2106-16163,
author = {Thibault Sellam and
Steve Yadlowsky and
Jason Wei and
Naomi Saphra and
Alexander D'Amour and
Tal Linzen and
Jasmijn Bastings and
Iulia Turc and
Jacob Eisenstein and
Dipanjan Das and
Ian Tenney and
Ellie Pavlick},
title = {The MultiBERTs: {BERT} Reproductions for Robustness Analysis},
journal = {CoRR},
volume = {abs/2106.16163},
year = {2021},
url = {https://arxiv.org/abs/2106.16163},
eprinttype = {arXiv},
eprint = {2106.16163},
timestamp = {Mon, 05 Jul 2021 15:15:50 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-16163.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<a href="https://huggingface.co/exbert/?model=multiberts">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
74cf9c25ed07d8487a47fbc9801aa2c8
|
CarpetCleaningArlingtonTX/CarpetCleaningArlingtonTX
|
CarpetCleaningArlingtonTX
| null | 2 | 0 | null | 0 | null | false | false | false |
other
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
[]
| false | true | true | 449 | false |
Carpet Cleaning Arlington TX
https://carpetcleaning-arlington-tx.com/
(817) 381-5072
At Rug Cleaning Plano in TX we likewise have a truck mounted cover cleaning framework. These versatile vehicles have a force to be reckoned with of hardware. They generally have these on them and they can finish any occupation properly. Whether it is a little home, an enormous house or a gigantic modern intricate, the undertaking is rarely too large or intense.
|
8a7990e09784ffb330cf660f3a526501
|
nepalprabin/xlm-roberta-base-finetuned-panx-de
|
nepalprabin
|
xlm-roberta
| 13 | 5 |
transformers
| 0 |
token-classification
| true | false | false |
mit
| null |
['xtreme']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,318 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1392
- F1: 0.8649
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2553 | 1.0 | 525 | 0.1616 | 0.8279 |
| 0.1284 | 2.0 | 1050 | 0.1419 | 0.8463 |
| 0.0813 | 3.0 | 1575 | 0.1392 | 0.8649 |
### Framework versions
- Transformers 4.22.2
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
a3030c1cc5303dc35a15e29135493b4c
|
kksukk/hubert_zeroth_gpu_freeze
|
kksukk
|
hubert
| 9 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['zeroth_korean_asr']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 13,354 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hubert_zeroth_gpu_freeze
This model is a fine-tuned version of [facebook/hubert-base-ls960](https://huggingface.co/facebook/hubert-base-ls960) on the zeroth_korean_asr dataset.
It achieves the following results on the evaluation set:
- Loss: 4.8310
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:---:|
| 26.2877 | 0.14 | 100 | 10.6810 | 1.0 |
| 6.4696 | 0.29 | 200 | 4.8799 | 1.0 |
| 4.841 | 0.43 | 300 | 4.8521 | 1.0 |
| 4.8366 | 0.57 | 400 | 4.8736 | 1.0 |
| 4.8311 | 0.72 | 500 | 4.8559 | 1.0 |
| 4.8383 | 0.86 | 600 | 4.8601 | 1.0 |
| 4.8288 | 1.01 | 700 | 4.8474 | 1.0 |
| 4.8283 | 1.15 | 800 | 4.8436 | 1.0 |
| 4.8283 | 1.29 | 900 | 4.8440 | 1.0 |
| 4.8299 | 1.44 | 1000 | 4.8518 | 1.0 |
| 4.8274 | 1.58 | 1100 | 4.8406 | 1.0 |
| 4.8308 | 1.72 | 1200 | 4.8384 | 1.0 |
| 4.8316 | 1.87 | 1300 | 4.8427 | 1.0 |
| 4.8298 | 2.01 | 1400 | 4.8423 | 1.0 |
| 4.8291 | 2.16 | 1500 | 4.8481 | 1.0 |
| 4.8326 | 2.3 | 1600 | 4.8426 | 1.0 |
| 4.83 | 2.44 | 1700 | 4.8362 | 1.0 |
| 4.8286 | 2.59 | 1800 | 4.8424 | 1.0 |
| 4.8269 | 2.73 | 1900 | 4.8362 | 1.0 |
| 4.8234 | 2.87 | 2000 | 4.8452 | 1.0 |
| 4.8179 | 3.02 | 2100 | 4.8416 | 1.0 |
| 4.825 | 3.16 | 2200 | 4.8519 | 1.0 |
| 4.8185 | 3.3 | 2300 | 4.8384 | 1.0 |
| 4.827 | 3.45 | 2400 | 4.8519 | 1.0 |
| 4.8316 | 3.59 | 2500 | 4.8467 | 1.0 |
| 4.825 | 3.74 | 2600 | 4.8465 | 1.0 |
| 4.8246 | 3.88 | 2700 | 4.8422 | 1.0 |
| 4.8228 | 4.02 | 2800 | 4.8326 | 1.0 |
| 4.8277 | 4.17 | 2900 | 4.8353 | 1.0 |
| 4.822 | 4.31 | 3000 | 4.8349 | 1.0 |
| 4.82 | 4.45 | 3100 | 4.8395 | 1.0 |
| 4.8252 | 4.6 | 3200 | 4.8350 | 1.0 |
| 4.8283 | 4.74 | 3300 | 4.8377 | 1.0 |
| 4.8229 | 4.89 | 3400 | 4.8344 | 1.0 |
| 4.8264 | 5.03 | 3500 | 4.8352 | 1.0 |
| 4.8237 | 5.17 | 3600 | 4.8337 | 1.0 |
| 4.8271 | 5.32 | 3700 | 4.8385 | 1.0 |
| 4.8332 | 5.46 | 3800 | 4.8392 | 1.0 |
| 4.8189 | 5.6 | 3900 | 4.8353 | 1.0 |
| 4.8209 | 5.75 | 4000 | 4.8355 | 1.0 |
| 4.8179 | 5.89 | 4100 | 4.8297 | 1.0 |
| 4.821 | 6.03 | 4200 | 4.8505 | 1.0 |
| 4.8243 | 6.18 | 4300 | 4.8371 | 1.0 |
| 4.8224 | 6.32 | 4400 | 4.8378 | 1.0 |
| 4.8261 | 6.47 | 4500 | 4.8368 | 1.0 |
| 4.8233 | 6.61 | 4600 | 4.8326 | 1.0 |
| 4.8252 | 6.75 | 4700 | 4.8364 | 1.0 |
| 4.8247 | 6.9 | 4800 | 4.8438 | 1.0 |
| 4.8139 | 7.04 | 4900 | 4.8435 | 1.0 |
| 4.8204 | 7.18 | 5000 | 4.8398 | 1.0 |
| 4.8197 | 7.33 | 5100 | 4.8382 | 1.0 |
| 4.82 | 7.47 | 5200 | 4.8371 | 1.0 |
| 4.8266 | 7.61 | 5300 | 4.8431 | 1.0 |
| 4.826 | 7.76 | 5400 | 4.8390 | 1.0 |
| 4.8216 | 7.9 | 5500 | 4.8381 | 1.0 |
| 4.82 | 8.05 | 5600 | 4.8339 | 1.0 |
| 4.8281 | 8.19 | 5700 | 4.8316 | 1.0 |
| 4.8246 | 8.33 | 5800 | 4.8361 | 1.0 |
| 4.8169 | 8.48 | 5900 | 4.8338 | 1.0 |
| 4.8175 | 8.62 | 6000 | 4.8341 | 1.0 |
| 4.8283 | 8.76 | 6100 | 4.8358 | 1.0 |
| 4.8232 | 8.91 | 6200 | 4.8356 | 1.0 |
| 4.8193 | 9.05 | 6300 | 4.8325 | 1.0 |
| 4.8146 | 9.2 | 6400 | 4.8297 | 1.0 |
| 4.8207 | 9.34 | 6500 | 4.8283 | 1.0 |
| 4.8221 | 9.48 | 6600 | 4.8334 | 1.0 |
| 4.8229 | 9.63 | 6700 | 4.8308 | 1.0 |
| 4.8239 | 9.77 | 6800 | 4.8352 | 1.0 |
| 4.8245 | 9.91 | 6900 | 4.8314 | 1.0 |
| 4.8173 | 10.06 | 7000 | 4.8300 | 1.0 |
| 4.8189 | 10.2 | 7100 | 4.8341 | 1.0 |
| 4.8209 | 10.34 | 7200 | 4.8287 | 1.0 |
| 4.823 | 10.49 | 7300 | 4.8320 | 1.0 |
| 4.8226 | 10.63 | 7400 | 4.8273 | 1.0 |
| 4.8241 | 10.78 | 7500 | 4.8308 | 1.0 |
| 4.8177 | 10.92 | 7600 | 4.8316 | 1.0 |
| 4.8235 | 11.06 | 7700 | 4.8274 | 1.0 |
| 4.8188 | 11.21 | 7800 | 4.8290 | 1.0 |
| 4.8183 | 11.35 | 7900 | 4.8355 | 1.0 |
| 4.8226 | 11.49 | 8000 | 4.8312 | 1.0 |
| 4.8209 | 11.64 | 8100 | 4.8307 | 1.0 |
| 4.8208 | 11.78 | 8200 | 4.8300 | 1.0 |
| 4.8221 | 11.93 | 8300 | 4.8281 | 1.0 |
| 4.82 | 12.07 | 8400 | 4.8306 | 1.0 |
| 4.8199 | 12.21 | 8500 | 4.8343 | 1.0 |
| 4.8212 | 12.36 | 8600 | 4.8314 | 1.0 |
| 4.8212 | 12.5 | 8700 | 4.8309 | 1.0 |
| 4.8228 | 12.64 | 8800 | 4.8310 | 1.0 |
| 4.8225 | 12.79 | 8900 | 4.8325 | 1.0 |
| 4.8146 | 12.93 | 9000 | 4.8364 | 1.0 |
| 4.8174 | 13.07 | 9100 | 4.8328 | 1.0 |
| 4.816 | 13.22 | 9200 | 4.8338 | 1.0 |
| 4.822 | 13.36 | 9300 | 4.8378 | 1.0 |
| 4.8253 | 13.51 | 9400 | 4.8411 | 1.0 |
| 4.8173 | 13.65 | 9500 | 4.8379 | 1.0 |
| 4.8227 | 13.79 | 9600 | 4.8374 | 1.0 |
| 4.8138 | 13.94 | 9700 | 4.8372 | 1.0 |
| 4.8191 | 14.08 | 9800 | 4.8327 | 1.0 |
| 4.8259 | 14.22 | 9900 | 4.8335 | 1.0 |
| 4.8098 | 14.37 | 10000 | 4.8301 | 1.0 |
| 4.8248 | 14.51 | 10100 | 4.8315 | 1.0 |
| 4.8199 | 14.66 | 10200 | 4.8304 | 1.0 |
| 4.8202 | 14.8 | 10300 | 4.8312 | 1.0 |
| 4.8159 | 14.94 | 10400 | 4.8316 | 1.0 |
| 4.8181 | 15.09 | 10500 | 4.8306 | 1.0 |
| 4.8217 | 15.23 | 10600 | 4.8350 | 1.0 |
| 4.8095 | 15.37 | 10700 | 4.8328 | 1.0 |
| 4.8249 | 15.52 | 10800 | 4.8329 | 1.0 |
| 4.8178 | 15.66 | 10900 | 4.8355 | 1.0 |
| 4.8192 | 15.8 | 11000 | 4.8342 | 1.0 |
| 4.8249 | 15.95 | 11100 | 4.8366 | 1.0 |
| 4.8096 | 16.09 | 11200 | 4.8385 | 1.0 |
| 4.8196 | 16.24 | 11300 | 4.8390 | 1.0 |
| 4.8271 | 16.38 | 11400 | 4.8352 | 1.0 |
| 4.8166 | 16.52 | 11500 | 4.8371 | 1.0 |
| 4.8206 | 16.67 | 11600 | 4.8348 | 1.0 |
| 4.817 | 16.81 | 11700 | 4.8347 | 1.0 |
| 4.8165 | 16.95 | 11800 | 4.8386 | 1.0 |
| 4.8159 | 17.1 | 11900 | 4.8376 | 1.0 |
| 4.8202 | 17.24 | 12000 | 4.8374 | 1.0 |
| 4.8157 | 17.39 | 12100 | 4.8370 | 1.0 |
| 4.8175 | 17.53 | 12200 | 4.8405 | 1.0 |
| 4.8189 | 17.67 | 12300 | 4.8321 | 1.0 |
| 4.8167 | 17.82 | 12400 | 4.8322 | 1.0 |
| 4.8229 | 17.96 | 12500 | 4.8353 | 1.0 |
| 4.8179 | 18.1 | 12600 | 4.8322 | 1.0 |
| 4.8183 | 18.25 | 12700 | 4.8379 | 1.0 |
| 4.8151 | 18.39 | 12800 | 4.8375 | 1.0 |
| 4.8211 | 18.53 | 12900 | 4.8355 | 1.0 |
| 4.8241 | 18.68 | 13000 | 4.8352 | 1.0 |
| 4.8185 | 18.82 | 13100 | 4.8350 | 1.0 |
| 4.8175 | 18.97 | 13200 | 4.8352 | 1.0 |
| 4.8094 | 19.11 | 13300 | 4.8337 | 1.0 |
| 4.8149 | 19.25 | 13400 | 4.8344 | 1.0 |
| 4.8131 | 19.4 | 13500 | 4.8386 | 1.0 |
| 4.8227 | 19.54 | 13600 | 4.8350 | 1.0 |
| 4.8175 | 19.68 | 13700 | 4.8325 | 1.0 |
| 4.8204 | 19.83 | 13800 | 4.8344 | 1.0 |
| 4.8228 | 19.97 | 13900 | 4.8322 | 1.0 |
| 4.8177 | 20.11 | 14000 | 4.8365 | 1.0 |
| 4.824 | 20.26 | 14100 | 4.8338 | 1.0 |
| 4.8151 | 20.4 | 14200 | 4.8342 | 1.0 |
| 4.8189 | 20.55 | 14300 | 4.8339 | 1.0 |
| 4.8115 | 20.69 | 14400 | 4.8325 | 1.0 |
| 4.8162 | 20.83 | 14500 | 4.8291 | 1.0 |
| 4.8182 | 20.98 | 14600 | 4.8321 | 1.0 |
| 4.8189 | 21.12 | 14700 | 4.8314 | 1.0 |
| 4.8123 | 21.26 | 14800 | 4.8318 | 1.0 |
| 4.8165 | 21.41 | 14900 | 4.8320 | 1.0 |
| 4.8247 | 21.55 | 15000 | 4.8315 | 1.0 |
| 4.8165 | 21.7 | 15100 | 4.8311 | 1.0 |
| 4.8151 | 21.84 | 15200 | 4.8352 | 1.0 |
| 4.8234 | 21.98 | 15300 | 4.8298 | 1.0 |
| 4.8136 | 22.13 | 15400 | 4.8282 | 1.0 |
| 4.8179 | 22.27 | 15500 | 4.8297 | 1.0 |
| 4.8128 | 22.41 | 15600 | 4.8307 | 1.0 |
| 4.8216 | 22.56 | 15700 | 4.8290 | 1.0 |
| 4.8177 | 22.7 | 15800 | 4.8286 | 1.0 |
| 4.8209 | 22.84 | 15900 | 4.8311 | 1.0 |
| 4.8183 | 22.99 | 16000 | 4.8276 | 1.0 |
| 4.8135 | 23.13 | 16100 | 4.8284 | 1.0 |
| 4.8116 | 23.28 | 16200 | 4.8279 | 1.0 |
| 4.8161 | 23.42 | 16300 | 4.8291 | 1.0 |
| 4.8202 | 23.56 | 16400 | 4.8292 | 1.0 |
| 4.8199 | 23.71 | 16500 | 4.8298 | 1.0 |
| 4.8203 | 23.85 | 16600 | 4.8293 | 1.0 |
| 4.8177 | 23.99 | 16700 | 4.8286 | 1.0 |
| 4.8153 | 24.14 | 16800 | 4.8273 | 1.0 |
| 4.8202 | 24.28 | 16900 | 4.8260 | 1.0 |
| 4.8189 | 24.43 | 17000 | 4.8289 | 1.0 |
| 4.8219 | 24.57 | 17100 | 4.8279 | 1.0 |
| 4.8148 | 24.71 | 17200 | 4.8284 | 1.0 |
| 4.8113 | 24.86 | 17300 | 4.8286 | 1.0 |
| 4.8133 | 25.0 | 17400 | 4.8299 | 1.0 |
| 4.8164 | 25.14 | 17500 | 4.8309 | 1.0 |
| 4.8231 | 25.29 | 17600 | 4.8279 | 1.0 |
| 4.8135 | 25.43 | 17700 | 4.8296 | 1.0 |
| 4.8118 | 25.57 | 17800 | 4.8293 | 1.0 |
| 4.8139 | 25.72 | 17900 | 4.8279 | 1.0 |
| 4.8144 | 25.86 | 18000 | 4.8281 | 1.0 |
| 4.8207 | 26.01 | 18100 | 4.8284 | 1.0 |
| 4.8096 | 26.15 | 18200 | 4.8285 | 1.0 |
| 4.8177 | 26.29 | 18300 | 4.8275 | 1.0 |
| 4.8221 | 26.44 | 18400 | 4.8288 | 1.0 |
| 4.8147 | 26.58 | 18500 | 4.8281 | 1.0 |
| 4.8148 | 26.72 | 18600 | 4.8281 | 1.0 |
| 4.819 | 26.87 | 18700 | 4.8282 | 1.0 |
| 4.8138 | 27.01 | 18800 | 4.8297 | 1.0 |
| 4.8094 | 27.16 | 18900 | 4.8291 | 1.0 |
| 4.8236 | 27.3 | 19000 | 4.8288 | 1.0 |
| 4.8208 | 27.44 | 19100 | 4.8292 | 1.0 |
| 4.816 | 27.59 | 19200 | 4.8279 | 1.0 |
| 4.8103 | 27.73 | 19300 | 4.8290 | 1.0 |
| 4.8152 | 27.87 | 19400 | 4.8296 | 1.0 |
| 4.8158 | 28.02 | 19500 | 4.8304 | 1.0 |
| 4.8122 | 28.16 | 19600 | 4.8293 | 1.0 |
| 4.8199 | 28.3 | 19700 | 4.8293 | 1.0 |
| 4.8185 | 28.45 | 19800 | 4.8287 | 1.0 |
| 4.8198 | 28.59 | 19900 | 4.8294 | 1.0 |
| 4.8102 | 28.74 | 20000 | 4.8291 | 1.0 |
| 4.8168 | 28.88 | 20100 | 4.8290 | 1.0 |
| 4.8117 | 29.02 | 20200 | 4.8303 | 1.0 |
| 4.8156 | 29.17 | 20300 | 4.8295 | 1.0 |
| 4.8127 | 29.31 | 20400 | 4.8298 | 1.0 |
| 4.8193 | 29.45 | 20500 | 4.8301 | 1.0 |
| 4.8174 | 29.6 | 20600 | 4.8301 | 1.0 |
| 4.8167 | 29.74 | 20700 | 4.8301 | 1.0 |
| 4.8137 | 29.89 | 20800 | 4.8310 | 1.0 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0+cu117
- Datasets 2.0.0
- Tokenizers 0.13.2
|
2596bf021ff2ee77b3b8df6a0138eb31
|
spacy/hr_core_news_md
|
spacy
| null | 32 | 1 |
spacy
| 0 |
token-classification
| false | false | false |
cc-by-sa-4.0
|
['hr']
| null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['spacy', 'token-classification']
| false | true | true | 42,189 | false |
### Details: https://spacy.io/models/hr#hr_core_news_md
Croatian pipeline optimized for CPU. Components: tok2vec, tagger, morphologizer, parser, lemmatizer (trainable_lemmatizer), senter, ner.
| Feature | Description |
| --- | --- |
| **Name** | `hr_core_news_md` |
| **Version** | `3.5.0` |
| **spaCy** | `>=3.5.0,<3.6.0` |
| **Default Pipeline** | `tok2vec`, `tagger`, `morphologizer`, `parser`, `lemmatizer`, `attribute_ruler`, `ner` |
| **Components** | `tok2vec`, `tagger`, `morphologizer`, `parser`, `lemmatizer`, `senter`, `attribute_ruler`, `ner` |
| **Vectors** | floret (50000, 300) |
| **Sources** | [Training corpus hr500k 1.0](http://hdl.handle.net/11356/1183) (Ljubešić, Nikola ; Agić, Željko ; Klubička, Filip ; Batanović, Vuk and Erjavec, Tomaž)<br />[Explosion Vectors (OSCAR 2109 + Wikipedia + OpenSubtitles + WMT News Crawl)](https://github.com/explosion/spacy-vectors-builder) (Explosion) |
| **License** | `CC BY-SA 4.0` |
| **Author** | [Explosion](https://explosion.ai) |
### Label Scheme
<details>
<summary>View label scheme (1518 labels for 4 components)</summary>
| Component | Labels |
| --- | --- |
| **`tagger`** | `Agcfpay`, `Agcfpdy`, `Agcfpgy`, `Agcfpiy`, `Agcfply`, `Agcfpny`, `Agcfsay`, `Agcfsdy`, `Agcfsgy`, `Agcfsiy`, `Agcfsly`, `Agcfsny`, `Agcmpay`, `Agcmpgy`, `Agcmpiy`, `Agcmpny`, `Agcmsany`, `Agcmsay`, `Agcmsayn`, `Agcmsdy`, `Agcmsgy`, `Agcmsiy`, `Agcmsly`, `Agcmsny`, `Agcnpay`, `Agcnpdy`, `Agcnpgy`, `Agcnpny`, `Agcnsay`, `Agcnsdy`, `Agcnsgy`, `Agcnsiy`, `Agcnsly`, `Agcnsny`, `Agpfpay`, `Agpfpdy`, `Agpfpgy`, `Agpfpiy`, `Agpfply`, `Agpfpny`, `Agpfsay`, `Agpfsdy`, `Agpfsgy`, `Agpfsin`, `Agpfsiy`, `Agpfsly`, `Agpfsny`, `Agpfsvy`, `Agpmpay`, `Agpmpdy`, `Agpmpgy`, `Agpmpiy`, `Agpmply`, `Agpmpny`, `Agpmsan`, `Agpmsann`, `Agpmsany`, `Agpmsay`, `Agpmsayn`, `Agpmsayy`, `Agpmsdy`, `Agpmsgn`, `Agpmsgy`, `Agpmsiy`, `Agpmsln`, `Agpmsly`, `Agpmsnn`, `Agpmsny`, `Agpmsvy`, `Agpnpay`, `Agpnpdy`, `Agpnpgy`, `Agpnpiy`, `Agpnply`, `Agpnpny`, `Agpnsay`, `Agpnsdy`, `Agpnsgn`, `Agpnsgy`, `Agpnsiy`, `Agpnsln`, `Agpnsly`, `Agpnsny`, `Agsfpay`, `Agsfpdy`, `Agsfpgy`, `Agsfpiy`, `Agsfply`, `Agsfpny`, `Agsfsay`, `Agsfsdy`, `Agsfsgy`, `Agsfsiy`, `Agsfsly`, `Agsfsny`, `Agsmpay`, `Agsmpdy`, `Agsmpgy`, `Agsmpiy`, `Agsmply`, `Agsmpny`, `Agsmsany`, `Agsmsayn`, `Agsmsayy`, `Agsmsdy`, `Agsmsgy`, `Agsmsiy`, `Agsmsly`, `Agsmsny`, `Agsnpay`, `Agsnpgy`, `Agsnply`, `Agsnpny`, `Agsnsay`, `Agsnsdy`, `Agsnsgy`, `Agsnsiy`, `Agsnsly`, `Agsnsny`, `Appfpay`, `Appfpdy`, `Appfpgy`, `Appfpiy`, `Appfply`, `Appfpny`, `Appfsay`, `Appfsgy`, `Appfsiy`, `Appfsly`, `Appfsny`, `Appmpay`, `Appmpdy`, `Appmpgy`, `Appmpiy`, `Appmply`, `Appmpny`, `Appmsann`, `Appmsany`, `Appmsayn`, `Appmsayy`, `Appmsdy`, `Appmsgn`, `Appmsgy`, `Appmsiy`, `Appmsly`, `Appmsnn`, `Appmsny`, `Appnpay`, `Appnpdy`, `Appnpgy`, `Appnpiy`, `Appnply`, `Appnpny`, `Appnsay`, `Appnsgy`, `Appnsly`, `Appnsny`, `Aspfpay`, `Aspfpgy`, `Aspfpiy`, `Aspfply`, `Aspfpny`, `Aspfsay`, `Aspfsdy`, `Aspfsgy`, `Aspfsly`, `Aspfsny`, `Aspmpay`, `Aspmpgy`, `Aspmply`, `Aspmpny`, `Aspmsayn`, `Aspmsayy`, `Aspmsdn`, `Aspmsdy`, `Aspmsgn`, `Aspmsgy`, `Aspmsiy`, `Aspmsln`, `Aspmsly`, `Aspmsnn`, `Aspnpay`, `Aspnpgy`, `Aspnpny`, `Aspnsay`, `Aspnsgn`, `Aspnsgy`, `Aspnsln`, `Aspnsly`, `Aspnsny`, `Cc`, `Cs`, `I`, `Mdc`, `Mdm`, `Mdo`, `Mds`, `Mlc`, `Mlc--g`, `Mlc--i`, `Mlc--l`, `Mlcf-a`, `Mlcf-d`, `Mlcf-g`, `Mlcf-n`, `Mlcfsa`, `Mlcfsd`, `Mlcfsg`, `Mlcfsi`, `Mlcfsl`, `Mlcfsn`, `Mlcm-a`, `Mlcm-g`, `Mlcm-l`, `Mlcm-n`, `Mlcmpn`, `Mlcmsan`, `Mlcmsay`, `Mlcmsg`, `Mlcmsi`, `Mlcmsl`, `Mlcmsn`, `Mlcn-n`, `Mlcnsa`, `Mlcnsg`, `Mlcnsn`, `Mlofpa`, `Mlofpd`, `Mlofpg`, `Mlofpi`, `Mlofpl`, `Mlofpn`, `Mlofsa`, `Mlofsd`, `Mlofsg`, `Mlofsi`, `Mlofsl`, `Mlofsn`, `Mlompa`, `Mlompd`, `Mlompg`, `Mlompi`, `Mlompl`, `Mlompn`, `Mlomsan`, `Mlomsay`, `Mlomsd`, `Mlomsg`, `Mlomsi`, `Mlomsl`, `Mlomsn`, `Mlonpa`, `Mlonpg`, `Mlonpl`, `Mlonpn`, `Mlonsa`, `Mlonsd`, `Mlonsg`, `Mlonsi`, `Mlonsl`, `Mlonsn`, `Mls`, `Mlsf-a`, `Mlsf-g`, `Mlsf-i`, `Mlsf-l`, `Mlsf-n`, `Mlsm-a`, `Mlsm-g`, `Mlsm-l`, `Mlsm-n`, `Mlsmpn`, `Mlsn-n`, `Mrc`, `Mro`, `Ncfpa`, `Ncfpd`, `Ncfpg`, `Ncfpi`, `Ncfpl`, `Ncfpn`, `Ncfpv`, `Ncfsa`, `Ncfsd`, `Ncfsg`, `Ncfsi`, `Ncfsl`, `Ncfsn`, `Ncfsv`, `Ncmpa`, `Ncmpd`, `Ncmpg`, `Ncmpi`, `Ncmpl`, `Ncmpn`, `Ncmpv`, `Ncmsan`, `Ncmsay`, `Ncmsd`, `Ncmsg`, `Ncmsi`, `Ncmsl`, `Ncmsn`, `Ncmsv`, `Ncnpa`, `Ncnpd`, `Ncnpg`, `Ncnpi`, `Ncnpl`, `Ncnpn`, `Ncnsa`, `Ncnsd`, `Ncnsg`, `Ncnsi`, `Ncnsl`, `Ncnsn`, `Ncnsv`, `Npfpa`, `Npfpg`, `Npfpl`, `Npfpn`, `Npfsa`, `Npfsd`, `Npfsg`, `Npfsi`, `Npfsl`, `Npfsn`, `Npmpa`, `Npmpd`, `Npmpg`, `Npmpi`, `Npmpl`, `Npmpn`, `Npmsan`, `Npmsay`, `Npmsd`, `Npmsg`, `Npmsi`, `Npmsl`, `Npmsn`, `Npmsv`, `Npnpg`, `Npnpn`, `Npnsa`, `Npnsd`, `Npnsg`, `Npnsi`, `Npnsl`, `Npnsn`, `Pd-fpa`, `Pd-fpd`, `Pd-fpg`, `Pd-fpi`, `Pd-fpl`, `Pd-fpn`, `Pd-fsa`, `Pd-fsd`, `Pd-fsg`, `Pd-fsi`, `Pd-fsl`, `Pd-fsn`, `Pd-mpa`, `Pd-mpd`, `Pd-mpg`, `Pd-mpi`, `Pd-mpl`, `Pd-mpn`, `Pd-msan`, `Pd-msay`, `Pd-msd`, `Pd-msg`, `Pd-msi`, `Pd-msl`, `Pd-msn`, `Pd-npa`, `Pd-npg`, `Pd-npi`, `Pd-npn`, `Pd-nsa`, `Pd-nsd`, `Pd-nsg`, `Pd-nsi`, `Pd-nsl`, `Pd-nsn`, `Pi-fpa`, `Pi-fpd`, `Pi-fpg`, `Pi-fpi`, `Pi-fpl`, `Pi-fpn`, `Pi-fsa`, `Pi-fsd`, `Pi-fsg`, `Pi-fsi`, `Pi-fsl`, `Pi-fsn`, `Pi-mpa`, `Pi-mpd`, `Pi-mpg`, `Pi-mpi`, `Pi-mpl`, `Pi-mpn`, `Pi-msan`, `Pi-msay`, `Pi-msd`, `Pi-msg`, `Pi-msi`, `Pi-msl`, `Pi-msn`, `Pi-npa`, `Pi-npd`, `Pi-npg`, `Pi-npi`, `Pi-npl`, `Pi-npn`, `Pi-nsa`, `Pi-nsd`, `Pi-nsg`, `Pi-nsi`, `Pi-nsl`, `Pi-nsn`, `Pi3m-a`, `Pi3m-d`, `Pi3m-g`, `Pi3m-i`, `Pi3m-n`, `Pi3n-a`, `Pi3n-d`, `Pi3n-g`, `Pi3n-i`, `Pi3n-l`, `Pi3n-n`, `Pp1-pa`, `Pp1-pd`, `Pp1-pg`, `Pp1-pi`, `Pp1-pl`, `Pp1-pn`, `Pp1-sa`, `Pp1-sd`, `Pp1-sg`, `Pp1-si`, `Pp1-sl`, `Pp1-sn`, `Pp2-pa`, `Pp2-pd`, `Pp2-pl`, `Pp2-pn`, `Pp2-sa`, `Pp2-sd`, `Pp2-sg`, `Pp2-sl`, `Pp2-sn`, `Pp3-pa`, `Pp3-pd`, `Pp3-pg`, `Pp3-pi`, `Pp3-pl`, `Pp3fpn`, `Pp3fsa`, `Pp3fsd`, `Pp3fsg`, `Pp3fsi`, `Pp3fsl`, `Pp3fsn`, `Pp3mpn`, `Pp3msa`, `Pp3msd`, `Pp3msg`, `Pp3msi`, `Pp3msl`, `Pp3msn`, `Pp3npn`, `Pp3nsa`, `Pp3nsi`, `Pp3nsn`, `Pq-fpa`, `Pq-fpn`, `Pq-fsa`, `Pq-fsi`, `Pq-fsl`, `Pq-fsn`, `Pq-mpn`, `Pq-msn`, `Pq-nsn`, `Pq3m-d`, `Pq3m-n`, `Pq3n-a`, `Pq3n-l`, `Pq3n-n`, `Ps1fpa`, `Ps1fpg`, `Ps1fpl`, `Ps1fpn`, `Ps1fsa`, `Ps1fsd`, `Ps1fsg`, `Ps1fsi`, `Ps1fsl`, `Ps1fsn`, _(truncated: full list in pipeline meta)_ |
| **`morphologizer`** | `Case=Nom\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Case=Loc\|POS=ADP`, `Case=Loc\|Gender=Neut\|Number=Sing\|POS=PROPN`, `Case=Ins\|POS=ADP`, `Case=Ins\|Gender=Neut\|Number=Sing\|POS=NOUN`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=PROPN`, `Degree=Pos\|POS=ADV`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Animacy=Inan\|Case=Acc\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Case=Loc\|Gender=Neut\|Number=Sing\|POS=NOUN`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Fem\|Number=Plur\|POS=NOUN`, `POS=PUNCT`, `POS=PART`, `Case=Loc\|Gender=Masc\|Number=Sing\|POS=NOUN`, `POS=SCONJ`, `Case=Nom\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=PROPN`, `Case=Acc\|Gender=Neut\|Number=Plur\|POS=NOUN`, `Case=Acc\|POS=PRON\|PronType=Prs\|Reflex=Yes`, `Case=Gen\|Gender=Neut\|Number=Sing\|POS=NOUN`, `Case=Gen\|Gender=Neut\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `POS=CCONJ`, `Case=Gen\|POS=ADP`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=NOUN`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Nom\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Nom\|Gender=Masc\|Number=Plur\|POS=NOUN`, `POS=VERB\|VerbForm=Inf`, `Case=Acc\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Acc\|Gender=Fem\|Number=Plur\|POS=NOUN`, `Case=Nom\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `POS=PART\|Polarity=Neg`, `Case=Acc\|Gender=Neut\|POS=PRON\|PronType=Neg`, `Case=Ins\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Degree=Pos\|POS=ADV\|PronType=Dem`, `Degree=Cmp\|POS=ADV`, `Case=Acc\|POS=ADP`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=PROPN`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Nom\|Gender=Masc\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Nom\|Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Gender=Masc\|Number=Sing\|POS=VERB\|Tense=Past\|VerbForm=Part\|Voice=Act`, `Case=Loc\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Case=Nom\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `NumType=Ord\|POS=ADJ`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Nom\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Nom\|Gender=Fem\|Number=Plur\|POS=NOUN`, `Gender=Fem\|Number=Plur\|POS=VERB\|Tense=Past\|VerbForm=Part\|Voice=Act`, `Animacy=Inan\|Case=Acc\|Gender=Masc\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Dem`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Polarity=Neg\|Tense=Pres\|VerbForm=Fin`, `Gender=Neut\|Number=Sing\|POS=VERB\|Tense=Past\|VerbForm=Part\|Voice=Act`, `Case=Loc\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Loc\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Case=Nom\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Gen\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Nom\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Case=Nom\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Nom\|Gender=Neut\|POS=PRON\|PronType=Int,Rel`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Case=Nom\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=NOUN`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=NOUN`, `Case=Nom\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Gender=Fem\|Number=Plur\|POS=AUX\|Tense=Past\|VerbForm=Part\|Voice=Act`, `NumType=Card\|POS=NUM`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Gender=Fem\|Number=Sing\|POS=VERB\|Tense=Past\|VerbForm=Part\|Voice=Act`, `Case=Loc\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Loc\|Gender=Fem\|Number=Plur\|POS=NOUN`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Animacy=Inan\|Case=Acc\|Gender=Masc\|Number=Sing\|POS=PROPN`, `Case=Acc\|Definite=Def\|Degree=Cmp\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Dem`, `Gender=Masc\|Number=Sing\|POS=AUX\|Tense=Past\|VerbForm=Part\|Voice=Act`, `Case=Nom\|Definite=Ind\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Animacy=Inan\|Case=Acc\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Case=Loc\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Degree=Pos\|POS=ADV\|PronType=Int,Rel`, `Gender=Neut\|Number=Sing\|POS=AUX\|Tense=Past\|VerbForm=Part\|Voice=Act`, `Case=Loc\|Gender=Neut\|Number=Plur\|POS=NOUN`, `Case=Nom\|Gender=Neut\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Case=Nom\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Nom\|Gender=Neut\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Nom\|Gender=Neut\|Number=Plur\|POS=NOUN`, `Case=Gen\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Nom\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Mood=Cnd\|Number=Plur\|POS=AUX\|Person=3\|Tense=Past\|VerbForm=Fin`, `Case=Nom\|Definite=Def\|Degree=Cmp\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Gender=Masc\|Number=Plur\|POS=VERB\|Tense=Past\|VerbForm=Part\|Voice=Act`, `Case=Gen\|Definite=Def\|Degree=Cmp\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|Polarity=Neg\|Tense=Pres\|VerbForm=Fin`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Acc\|Definite=Def\|Degree=Cmp\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Nom\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Case=Nom\|Definite=Ind\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Loc\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=PROPN`, `Case=Loc\|Gender=Neut\|Gender[psor]=Masc,Neut\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Loc\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Dat\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Case=Acc\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Mood=Cnd\|Number=Sing\|POS=AUX\|Person=3\|Tense=Past\|VerbForm=Fin`, `Case=Loc\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Dem`, `POS=X`, `Case=Nom\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Loc\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Loc\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Case=Loc\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=PROPN`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Nom\|Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Animacy=Anim\|Case=Acc\|Gender=Masc\|Number=Sing\|POS=PROPN`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=PROPN`, `Case=Nom\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Nom\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Int,Rel`, `Case=Gen\|Gender=Fem\|Number=Plur\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Loc\|Gender=Fem\|Number=Sing\|POS=PROPN`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Int,Rel`, `Case=Nom\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ\|Poss=Yes`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=2\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Animacy=Inan\|Case=Acc\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Loc\|Gender=Fem\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Acc\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Loc\|Definite=Def\|Degree=Sup\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Gen\|Definite=Def\|Degree=Sup\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Case=Loc\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Loc\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Ins\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Ins\|Gender=Fem\|Number=Plur\|POS=NOUN`, `Case=Dat\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Case=Nom\|Definite=Ind\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ\|Poss=Yes`, `Case=Gen\|Gender=Neut\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Ins\|Gender=Masc\|Number=Sing\|POS=PROPN`, `Animacy=Anim\|Case=Acc\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Animacy=Anim\|Case=Acc\|Gender=Masc\|NumType=Card\|Number=Sing\|POS=NUM`, `Animacy=Anim\|Case=Acc\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Case=Nom\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=1\|Tense=Pres\|VerbForm=Fin`, `POS=AUX\|VerbForm=Inf`, `Case=Loc\|Gender=Masc\|Number=Sing\|POS=PROPN`, `Case=Gen\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Ins\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Gender=Fem\|Number=Sing\|POS=AUX\|Tense=Past\|VerbForm=Part\|Voice=Act`, `Case=Ins\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Ins\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Ins\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Degree=Pos\|POS=ADV\|PronType=Ind`, `Animacy=Inan\|Case=Acc\|Definite=Ind\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Acc\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ\|Poss=Yes`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Degree=Pos\|POS=ADV\|PronType=Neg`, `Animacy=Inan\|Case=Acc\|Gender=Masc\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=PROPN`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Case=Acc\|Gender=Neut\|Gender[psor]=Masc,Neut\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=PROPN`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Nom\|Gender=Fem\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Ins\|Definite=Def\|Degree=Cmp\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Acc\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Nom\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Dat\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Nom\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Loc\|Gender=Neut\|Number=Plur\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Nom\|Gender=Masc\|POS=PRON\|PronType=Neg`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Neut\|Number=Plur\|POS=NOUN`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Tot`, `Mood=Cnd\|Number=Plur\|POS=AUX\|Person=1\|Tense=Past\|VerbForm=Fin`, `Case=Dat\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Nom\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Loc\|Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Definite=Def\|Degree=Cmp\|Gender=Fem\|Number=Sing\|POS=ADJ`, `POS=NOUN`, `Case=Voc\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Case=Gen\|Gender=Neut\|Number=Sing\|POS=PROPN`, `Case=Ins\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Loc\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Acc\|Gender=Masc\|Gender[psor]=Fem\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Ins\|Gender=Fem\|Number=Sing\|POS=PROPN`, `Case=Acc\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Acc\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Loc\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Loc\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Loc\|Gender=Masc\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Nom\|Gender=Fem\|NumType=Card\|Number=Plur\|POS=NUM`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Nom\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Acc\|Gender=Neut\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Loc\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Dat\|Gender=Fem\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Loc\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=2\|Tense=Pres\|VerbForm=Fin`, `Case=Ins\|Gender=Masc\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Dat\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Dat\|Gender=Fem\|Number=Plur\|POS=NOUN`, `POS=SPACE`, `Mood=Cnd\|Number=Sing\|POS=AUX\|Person=1\|Tense=Past\|VerbForm=Fin`, `Case=Loc\|Gender=Masc\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Nom\|Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Gen\|Gender=Fem\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=1\|Polarity=Neg\|Tense=Pres\|VerbForm=Fin`, `Case=Nom\|Definite=Def\|Degree=Cmp\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Fem\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Loc\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Masc\|POS=PRON\|PronType=Ind`, `Case=Acc\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Nom\|Gender=Neut\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Loc\|Gender=Neut\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Gen\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Dem`, `Animacy=Inan\|Case=Acc\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Ins\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Dat\|Gender=Masc\|POS=PRON\|PronType=Neg`, `Case=Ins\|Gender=Neut\|POS=PRON\|PronType=Int,Rel`, `Case=Dat\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Dat\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Acc\|Gender=Neut\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Animacy=Anim\|Case=Acc\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Dat\|POS=ADP`, `Degree=Sup\|POS=ADV`, `Case=Ins\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `POS=ADV\|Tense=Pres\|VerbForm=Conv`, `Case=Ins\|POS=PRON\|PronType=Prs\|Reflex=Yes`, `Case=Loc\|Gender=Neut\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Case=Loc\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Gender=Neut\|Number=Plur\|POS=VERB\|Tense=Past\|VerbForm=Part\|Voice=Act`, `Case=Nom\|Gender=Neut\|NumType=Card\|Number=Plur\|POS=NUM`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Loc\|Gender=Fem\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Ins\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Gen\|Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Ins\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ\|Poss=Yes`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ\|Poss=Yes`, `Case=Acc\|Gender=Fem\|NumType=Card\|Number=Plur\|POS=NUM`, `Case=Nom\|Gender=Fem\|Number=Plur\|POS=PROPN`, `Case=Ins\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Gen\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Case=Nom\|Gender=Fem\|NumType=Card\|Number=Sing\|POS=NUM`, `NumType=Mult\|POS=NUM`, `Case=Acc\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Ins\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Case=Gen\|Gender=Fem\|NumType=Mult\|POS=NUM`, `Case=Acc\|Gender=Neut\|POS=PRON\|PronType=Int,Rel`, `Animacy=Inan\|Case=Acc\|Definite=Def\|Degree=Cmp\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Fem\|NumType=Mult\|POS=NUM`, `Case=Ins\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Case=Loc\|Gender=Neut\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Fem\|NumType=Card\|Number=Plur\|POS=NUM`, `Case=Gen\|Gender=Masc\|Number=Plur\|POS=PROPN`, `Case=Nom\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Acc\|Gender=Fem\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Definite=Def\|Degree=Cmp\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Ins\|Gender=Neut\|Number=Sing\|POS=PROPN`, `Case=Nom\|Gender=Masc\|Number=Plur\|POS=PROPN`, `Case=Dat\|Gender=Masc\|Gender[psor]=Fem\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Animacy=Inan\|Case=Acc\|Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Masc\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Loc\|Gender=Neut\|POS=PRON\|PronType=Int,Rel`, `Animacy=Anim\|Case=Acc\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Acc\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Animacy=Inan\|Case=Acc\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Tot`, `Case=Ins\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `POS=ADV\|Tense=Past\|VerbForm=Conv`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Gen\|Gender=Fem\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Nom\|Definite=Def\|Degree=Cmp\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Masc\|POS=PRON\|PronType=Int,Rel`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Int,Rel`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ\|Poss=Yes`, `Case=Ins\|Gender=Neut\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Ins\|Gender=Neut\|Number=Plur\|POS=NOUN`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Gen\|Gender=Masc\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Loc\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Acc\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Gen\|Definite=Def\|Degree=Cmp\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Ins\|Gender=Masc\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Ins\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Nom\|Definite=Def\|Degree=Sup\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Gen\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Ins\|Gender=Fem\|NumType=Card\|Number=Sing\|POS=NUM`, `Degree=Pos\|POS=ADV\|PronType=Tot`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Dat\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Gen\|Gender=Neut\|NumType=Card\|Number=Sing\|POS=NUM`, `Gender=Masc\|Number=Plur\|POS=AUX\|Tense=Past\|VerbForm=Part\|Voice=Act`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Int,Rel`, `Case=Ins\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Nom\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Loc\|Gender=Fem\|Gender[psor]=Masc,Neut\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Ins\|Definite=Def\|Degree=Sup\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Gen\|Gender=Fem\|Gender[psor]=Fem\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender=Neut\|Number=Plur\|POS=NOUN`, `Case=Dat\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Dat\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Loc\|Gender=Fem\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Ins\|Gender=Fem\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Ins\|Definite=Def\|Degree=Sup\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Nom\|Gender=Neut\|POS=PRON\|PronType=Neg`, `Case=Gen\|Gender=Masc\|NumType=Mult\|POS=NUM`, `Case=Ins\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Animacy=Inan\|Case=Acc\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Gen\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Acc\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Fem\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Acc\|Gender=Fem\|Number=Plur\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Gender=Neut\|Number=Plur\|POS=AUX\|Tense=Past\|VerbForm=Part\|Voice=Act`, `Case=Ins\|Definite=Def\|Degree=Cmp\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Ins\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Loc\|Gender=Masc\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Gen\|Gender=Fem\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ\|Poss=Yes`, `Mood=Imp\|Number=Plur\|POS=VERB\|Person=2\|VerbForm=Fin`, `Case=Ins\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Gen\|Gender=Neut\|Gender[psor]=Masc,Neut\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Case=Ins\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Loc\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Ins\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Loc\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Gen\|Gender=Fem\|Number=Plur\|POS=PROPN`, `Case=Nom\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Loc\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Fem\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Ins\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Neut\|Number=Sing\|POS=PROPN`, `Case=Acc\|Gender=Neut\|POS=PRON\|PronType=Ind`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Int,Rel`, `Case=Loc\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ\|Poss=Yes`, `Case=Ins\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Dat\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=PROPN`, `Case=Acc\|Gender=Neut\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ\|Poss=Yes`, `Case=Dat\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Gen\|Gender=Masc\|Gender[psor]=Fem\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `NumType=Mult\|POS=SYM`, `Case=Loc\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Nom\|Gender=Masc\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Gender=Masc\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ\|Poss=Yes`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ\|Poss=Yes`, `Animacy=Anim\|Case=Acc\|Gender=Masc\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Nom\|Definite=Def\|Degree=Cmp\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Acc\|Gender=Masc\|NumType=Card\|Number=Plur\|POS=NUM`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Loc\|Gender=Masc\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Loc\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Acc\|Gender=Neut\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Ins\|Gender=Masc\|Number=Plur\|POS=PROPN`, `Case=Loc\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Nom\|Gender=Neut\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Ins\|Gender=Masc\|Number=Plur\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Gen\|Definite=Def\|Degree=Sup\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Gen\|Gender=Masc\|Number=Plur\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=PROPN`, `Case=Loc\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Loc\|Definite=Def\|Degree=Sup\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Gen\|Gender=Neut\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Ins\|Gender=Neut\|Number=Plur\|POS=DET\|PronType=Int,Rel`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Acc\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ\|Poss=Yes`, `Case=Loc\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Fem\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Gen\|Gender=Neut\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Loc\|Definite=Def\|Degree=Pos\|Gender=Neut\|Number=Plur\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Acc\|Definite=Def\|Degree=Sup\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Dat\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ\|Poss=Yes`, `Case=Nom\|Gender=Masc\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Gender=Fem\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Nom\|Definite=Def\|Degree=Sup\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Mood=Cnd\|Number=Sing\|POS=AUX\|Person=2\|Tense=Past\|VerbForm=Fin`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Dat\|Gender=Masc\|Number=Plur\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Gen\|Definite=Def\|Degree=Cmp\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Dat\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Gen\|Definite=Def\|Degree=Sup\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Nom\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Neg`, `Case=Loc\|Definite=Def\|Degree=Sup\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Dat\|Gender=Masc\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `POS=SYM`, `Case=Ins\|Definite=Def\|Degree=Cmp\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Nom\|Gender=Masc\|Gender[psor]=Masc,Neut\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Fem\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Dat\|Gender=Fem\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Definite=Def\|Degree=Sup\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ\|Poss=Yes`, `Case=Gen\|Gender=Fem\|Gender[psor]=Masc,Neut\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Animacy=Anim\|Case=Acc\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Dat\|Gender=Masc\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Loc\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Nom\|Gender=Neut\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Gen\|Gender=Neut\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Int,Rel`, `Case=Ins\|Definite=Def\|Degree=Cmp\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Dat\|Gender=Masc\|Number=Plur\|POS=PROPN`, `Case=Acc\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Loc\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Gen\|Gender=Neut\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Nom\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Nom\|Definite=Def\|Degree=Sup\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Gen\|Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ\|Poss=Yes`, `Case=Gen\|Definite=Def\|Degree=Sup\|Gender=Neut\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Neut\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Ins\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Gen\|Gender=Masc\|Gender[psor]=Masc,Neut\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|Polarity=Neg\|Tense=Pres\|VerbForm=Fin`, `Case=Ins\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Acc\|Definite=Def\|Degree=Sup\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Dat\|Gender=Fem\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Gen\|Gender=Neut\|Number=Plur\|POS=DET\|Poss=Yes\|PronType=Prs\|Reflex=Yes`, `Case=Acc\|Gender=Neut\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Gender=Fem\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Gen\|NumType=Card\|Number=Plur\|POS=NUM`, `Animacy=Anim\|Case=Acc\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Dat\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Animacy=Inan\|Case=Acc\|Gender=Masc\|Gender[psor]=Masc,Neut\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Gender=Masc\|Gender[psor]=Masc,Neut\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Nom\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ\|Poss=Yes`, `Case=Acc\|Definite=Def\|Degree=Cmp\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Animacy=Inan\|Case=Acc\|Definite=Def\|Degree=Sup\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Animacy=Anim\|Case=Acc\|Definite=Def\|Degree=Sup\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Gen\|Definite=Ind\|Degree=Pos\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Animacy=Inan\|Case=Acc\|Gender=Masc\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Loc\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Gen\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Ind`, `Animacy=Anim\|Case=Acc\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Nom\|Gender=Masc\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|Gender=Fem\|Gender[psor]=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Ins\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ\|VerbForm=Part\|Voice=Pass`, `Case=Loc\|POS=PRON\|PronType=Prs\|Reflex=Yes`, `Case=Loc\|Definite=Def\|Degree=Cmp\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Nom\|Definite=Def\|Degree=Cmp\|Gender=Neut\|Number=Sing\|POS=ADJ`, `Case=Acc\|Definite=Def\|Degree=Cmp\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Dat\|Definite=Def\|Degree=Cmp\|Gender=Masc\|Number=Sing\|POS=ADJ`, _(truncated: full list in pipeline meta)_ |
| **`parser`** | `ROOT`, `acl`, `advcl`, `advmod`, `advmod:emph`, `amod`, `appos`, `aux`, `aux:pass`, `case`, `cc`, `ccomp`, `compound`, `conj`, `cop`, `csubj`, `csubj:pass`, `dep`, `det`, `discourse`, `expl:pv`, `fixed`, `flat`, `flat:foreign`, `goeswith`, `iobj`, `mark`, `nmod`, `nsubj`, `nsubj:pass`, `nummod`, `obj`, `obl`, `orphan`, `parataxis`, `punct`, `xcomp` |
| **`ner`** | `DERIV_PER`, `LOC`, `MISC`, `ORG`, `PER` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `TOKEN_ACC` | 99.89 |
| `TOKEN_P` | 97.28 |
| `TOKEN_R` | 98.71 |
| `TOKEN_F` | 97.99 |
| `TAG_ACC` | 91.69 |
| `POS_ACC` | 97.33 |
| `MORPH_ACC` | 92.31 |
| `MORPH_MICRO_P` | 95.98 |
| `MORPH_MICRO_R` | 95.56 |
| `MORPH_MICRO_F` | 95.77 |
| `SENTS_P` | 95.12 |
| `SENTS_R` | 93.41 |
| `SENTS_F` | 94.25 |
| `DEP_UAS` | 86.45 |
| `DEP_LAS` | 80.05 |
| `LEMMA_ACC` | 92.81 |
| `ENTS_P` | 82.44 |
| `ENTS_R` | 81.34 |
| `ENTS_F` | 81.89 |
|
a9d1c84f9ba4b9f732b8400cbf847839
|
lschlessinger/bert-finetuned-math-prob-classification
|
lschlessinger
|
bert
| 12 | 1 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null |
['competition_math']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 2,334 | false |
# bert-finetuned-math-prob-classification
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the part of the [competition_math dataset](https://huggingface.co/datasets/competition_math). Specifically, it was trained as a multi-class multi-label model on the problem text. The problem types (labels) used here are "Counting & Probability", "Prealgebra", "Algebra", "Number Theory", "Geometry", "Intermediate Algebra", and "Precalculus".
## Model description
See the [bert-base-uncased](https://huggingface.co/bert-base-uncased) model for more details. The only architectural modification made was to the classification head. Here, 7 classes were used.
## Intended uses & limitations
This model is intended for demonstration purposes only. The problem type data was in English and contains many LaTeX tokens.
## Training and evaluation data
The `problem` field of [competition_math dataset](https://huggingface.co/datasets/competition_math) was used for training and evaluation input data. The target data was taken from the `type` field.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
This fine-tuned model achieves the following result on the problem type competition math test set:
```
precision recall f1-score support
Algebra 0.78 0.79 0.79 1187
Counting & Probability 0.75 0.81 0.78 474
Geometry 0.76 0.83 0.79 479
Intermediate Algebra 0.86 0.84 0.85 903
Number Theory 0.79 0.82 0.80 540
Prealgebra 0.66 0.61 0.63 871
Precalculus 0.95 0.89 0.92 546
accuracy 0.79 5000
macro avg 0.79 0.80 0.79 5000
weighted avg 0.79 0.79 0.79 5000
```
### Framework versions
- Transformers 4.22.2
- Pytorch 1.12.1+cu113
- Datasets 2.5.1
- Tokenizers 0.12.1
|
c2ef2b60923c1802a89517fbcd9901dc
|
jonatasgrosman/exp_w2v2t_ja_xlsr-53_s109
|
jonatasgrosman
|
wav2vec2
| 10 | 5 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
|
['ja']
|
['mozilla-foundation/common_voice_7_0']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['automatic-speech-recognition', 'ja']
| false | true | true | 461 | false |
# exp_w2v2t_ja_xlsr-53_s109
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) for speech recognition using the train split of [Common Voice 7.0 (ja)](https://huggingface.co/datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
|
5c9031be8d9a9480b1a541e3ac3afbd4
|
jiobiala24/wav2vec2-base-checkpoint-2
|
jiobiala24
|
wav2vec2
| 15 | 8 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['common_voice']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,531 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-TPU-cv-fine-tune-2
This model is a fine-tuned version of [jiobiala24/wav2vec2-base-TPU-cv-fine-tune](https://huggingface.co/jiobiala24/wav2vec2-base-TPU-cv-fine-tune) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6051
- Wer: 0.5484
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.522 | 6.45 | 400 | 1.2550 | 0.5649 |
| 0.2874 | 12.9 | 800 | 1.4235 | 0.6054 |
| 0.152 | 19.35 | 1200 | 1.5743 | 0.5806 |
| 0.0857 | 25.8 | 1600 | 1.6051 | 0.5484 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
9ce7e1332c13985f52adcc350946ff00
|
edumunozsala/roberta_bne_sentiment_analysis_es
|
edumunozsala
|
roberta
| 11 | 162 |
transformers
| 2 |
text-classification
| true | false | false |
apache-2.0
|
['es']
|
['IMDbreviews_es']
| null | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
['sagemaker', 'roberta-bne', 'TextClassification', 'SentimentAnalysis']
| true | true | true | 2,771 | false |
# Model roberta_bne_sentiment_analysis_es
## **A finetuned model for Sentiment analysis in Spanish**
This model was trained using Amazon SageMaker and the new Hugging Face Deep Learning container,
The base model is **RoBERTa-base-bne** which is a RoBERTa base model and has been pre-trained using the largest Spanish corpus known to date, with a total of 570GB.
It was trained by The [National Library of Spain (Biblioteca Nacional de España)](http://www.bne.es/en/Inicio/index.html)
**RoBERTa BNE Citation**
Check out the paper for all the details: https://arxiv.org/abs/2107.07253
```
@article{gutierrezfandino2022,
author = {Asier Gutiérrez-Fandiño and Jordi Armengol-Estapé and Marc Pàmies and Joan Llop-Palao and Joaquin Silveira-Ocampo and Casimiro Pio Carrino and Carme Armentano-Oller and Carlos Rodriguez-Penagos and Aitor Gonzalez-Agirre and Marta Villegas},
title = {MarIA: Spanish Language Models},
journal = {Procesamiento del Lenguaje Natural},
volume = {68},
number = {0},
year = {2022},
issn = {1989-7553},
url = {http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6405},
pages = {39--60}
}
```
## Dataset
The dataset is a collection of movie reviews in Spanish, about 50,000 reviews. The dataset is balanced and provides every review in english, in spanish and the label in both languages.
Sizes of datasets:
- Train dataset: 42,500
- Validation dataset: 3,750
- Test dataset: 3,750
## Intended uses & limitations
This model is intented for Sentiment Analysis for spanish corpus and finetuned specially for movie reviews but it can be applied to other kind of reviews.
## Hyperparameters
{
"epochs": "4",
"train_batch_size": "32",
"eval_batch_size": "8",
"fp16": "true",
"learning_rate": "3e-05",
"model_name": "\"PlanTL-GOB-ES/roberta-base-bne\"",
"sagemaker_container_log_level": "20",
"sagemaker_program": "\"train.py\"",
}
## Evaluation results
- Accuracy = 0.9106666666666666
- F1 Score = 0.9090909090909091
- Precision = 0.9063852813852814
- Recall = 0.9118127381600436
## Test results
## Model in action
### Usage for Sentiment Analysis
```python
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("edumunozsala/roberta_bne_sentiment_analysis_es")
model = AutoModelForSequenceClassification.from_pretrained("edumunozsala/roberta_bne_sentiment_analysis_es")
text ="Se trata de una película interesante, con un solido argumento y un gran interpretación de su actor principal"
input_ids = torch.tensor(tokenizer.encode(text)).unsqueeze(0)
outputs = model(input_ids)
output = outputs.logits.argmax(1)
```
Created by [Eduardo Muñoz/@edumunozsala](https://github.com/edumunozsala)
|
d927356df6f358778aacb03a698f32f6
|
Wiebke/bert-base-casedepoch3_sexist_baseline_with_reddit_and_gabfortest
|
Wiebke
|
bert
| 12 | 10 |
transformers
| 0 |
text-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,060 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-casedepoch3_sexist_baseline_with_reddit_and_gabfortest
This model is a fine-tuned version of [Wiebke/bert-base-casedepoch3_sexist_baseline_with_reddit_and_gab](https://huggingface.co/Wiebke/bert-base-casedepoch3_sexist_baseline_with_reddit_and_gab) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
6854e82e590efde22ceb1fce49625efc
|
akshaychaudhary/distilbert-base-uncased-finetuned-devops1-ner
|
akshaychaudhary
|
distilbert
| 13 | 5 |
transformers
| 0 |
token-classification
| true | false | false |
apache-2.0
| null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,559 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-devops1-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9870
- Precision: 0.0572
- Recall: 0.2689
- F1: 0.0944
- Accuracy: 0.7842
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 72 | 0.6027 | 0.0484 | 0.2269 | 0.0798 | 0.7861 |
| No log | 2.0 | 144 | 0.8631 | 0.0573 | 0.2857 | 0.0955 | 0.7771 |
| No log | 3.0 | 216 | 0.9870 | 0.0572 | 0.2689 | 0.0944 | 0.7842 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 1.18.4
- Tokenizers 0.11.6
|
49328b88c7d8f1ed5d970c4bb466a4bc
|
Ryna/wav2vec2-large-xlsr-53-Enlgish-FT-ASCEND-colab
|
Ryna
|
wav2vec2
| 12 | 3 |
transformers
| 0 |
automatic-speech-recognition
| true | false | false |
apache-2.0
| null |
['ascend']
| null | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
['generated_from_trainer']
| true | true | true | 1,147 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-53-Enlgish-FT-ASCEND-colab
This model is a fine-tuned version of [jonatasgrosman/wav2vec2-large-xlsr-53-english](https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-english) on the ascend dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 10000
- total_train_batch_size: 160000
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
342f484b026e49210b039674130eaf88
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.