
Serial Number
int64 1
6k
| Issue Number
int64 75.6k
112k
| Title
stringlengths 3
357
| Labels
stringlengths 3
241
⌀ | Body
stringlengths 9
74.5k
⌀ | Comments
int64 0
867
|
|---|---|---|---|---|---|
2,701 | 100,733 |
Nightly torch.compile fails with dynamically patched `nn.module.forward`
|
high priority, module: nn, triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
When an `nn.Module` forward is modified during runtime, `torch.compile` fails.
```
import torch
import torch.nn as nn
import functools
model = nn.Linear(5, 5)
old_forward = model.forward
@functools.wraps(old_forward)
def new_forward(*args, **kwargs):
return old_forward(*args, **kwargs)
model.forward = new_forward
model = torch.compile(model, backend='eager')
model(torch.randn(1, 5))
```
Output
```
Traceback (most recent call last):
File "/home/jgu/Projects/dynamite/env/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 1228, in get_fake_value
return wrap_fake_exception(
File "/home/jgu/Projects/dynamite/env/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 848, in wrap_fake_exception
return fn()
File "/home/jgu/Projects/dynamite/env/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 1229, in <lambda>
lambda: run_node(tx.output, node, args, kwargs, nnmodule)
File "/home/jgu/Projects/dynamite/env/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 1292, in run_node
raise RuntimeError(
RuntimeError: Failed running call_method forward(*(Linear(in_features=5, out_features=5, bias=True), FakeTensor(..., size=(1, 5))), **{}):
Please convert all Tensors to FakeTensors first or instantiate FakeTensorMode with 'allow_non_fake_inputs'. Found in aten.t.default(*(Parameter containing:
tensor([[ 0.1118, 0.2579, 0.2571, -0.2395, 0.2391],
[-0.3907, -0.2695, 0.2111, -0.4282, -0.2784],
[ 0.1674, 0.3213, -0.1111, 0.2801, 0.3222],
[-0.0022, 0.2045, -0.2440, 0.2014, -0.3790],
[ 0.4095, -0.2653, -0.2879, 0.2875, -0.1032]], requires_grad=True),), **{})
(scroll up for backtrace)
```
Expected Output: exit 0
### Impact
I accidentally hit this when running a model that implicitly uses hugging face's accelerate module with torch.compile. HF's accelerate dynamically patches model.forward to do device offload. https://github.com/huggingface/accelerate/blob/main/src/accelerate/hooks.py#L118
### Versions
torch==2.1.0.dev20230428+cu117
The above example works with torch2.0 but fails on nightly
cc @ezyang @gchanan @zou3519 @albanD @mruberry @jbschlosser @walterddr @mikaylagawarecki @msaroufim @wconstab @ngimel @bdhirsh @anijain2305 @voznesenskym @penguinwu @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @soumith @desertfire
| 6 |
2,702 | 100,730 |
`torch::jit::EliminateExceptions` lowering pass never completes on specific model
|
oncall: jit
|
### 🐛 Describe the bug
## Bug Description and Overview
When running the `torch::jit::EliminateExceptions` lowering pass on a specific model, the program never completes.
https://github.com/pytorch/pytorch/blob/40df6e164777e834b5f5b50e066632ed40bd25ef/torch/csrc/jit/passes/remove_exceptions.h#L20
A simple model which elicits this error (when run through the `torch::jit::EliminateExceptions` lowering pass), as adapted from https://github.com/pytorch/TensorRT/issues/1823 is:
```python
import torch
class UpSample(torch.nn.Module):
def __init__(self):
super(UpSample, self).__init__()
self.upsample = torch.nn.Upsample(
scale_factor=2, mode="bilinear", align_corners=False
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.upsample(x) + self.upsample(x)
model = torch.jit.script(UpSample().eval().to("cuda"))
input = torch.randn((5, 5, 5, 5)).to("cuda")
```
The corresponding IR for the above code is reproduced here: https://github.com/pytorch/TensorRT/issues/1823#issuecomment-1509005086.
## Context and Findings
The bug was traced to the use of `replaceAllUsesWith` (see https://github.com/pytorch/TensorRT/pull/1859#issuecomment-1534153675), which can cause invalid IR to be generated, especially in cases where there are nested `prim::If` calls. https://github.com/pytorch/TensorRT/pull/1859 gives a sample solution to this issue, substituting the `replaceAllUsesWith` operator with `replaceFirstUseWith`.
Would this substitution retain the original functionality/intent of the `torch::jit::EliminateExceptions` lowering pass?
### Versions
Versions of relevant libraries:
```
[pip3] torch==2.1.0.dev20230419+cu117
```
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
2,703 | 100,725 |
[CUDA RPC] Incorrect messages in CUDA Support RPC when parallelized with other GPU programs
|
oncall: distributed
|
### 🐛 Describe the bug
### Issue Summary
When running the official example of [DISTRIBUTED PIPELINE PARALLELISM USING RPC](https://pytorch.org/tutorials/intermediate/dist_pipeline_parallel_tutorial.html) and modifying the transferred tensors into GPU tensors (i.e., return out.cpu() -> return out), inconsistencies in the transferred tensor values are observed. Specifically, there are discrepancies in the loss values for the same inputs and model parameters.
These discrepancies only occur when running other GPU programs, such as a pure computation task in the backend using PyTorch or nccl-tests tasks. When the other GPU task is stopped, the loss values become consistent.
This suggests that other GPU programs could be interfering with the CUDA Support RPC, leading to incorrect message transfers.
**Could anyone provide some insight or guidance on how to prevent other GPU programs from interfering with the CUDA Support RPC and ensure correct message transfers?**
Any help or suggestions would be greatly appreciated.
### Steps to Reproduce
1. Run a pure computation task in the backend using PyTorch.
```python
import torch
import time
from multiprocessing import Pool, set_start_method
def run_on_single_gpu(device):
a = torch.randn(20000,20000).cuda(device)
b = torch.randn(20000,20000).cuda(device)
ta = a
tb = b
while True:
a = ta
b = tb
a = torch.sin(a)
b = torch.sin(b)
a = torch.cos(a)
b = torch.cos(b)
a = torch.tan(a)
b = torch.tan(b)
a = torch.exp(a)
b = torch.exp(b)
a = torch.log(a)
b = torch.log(b)
b = torch.matmul(a, b)
#time.sleep(0.000005)
if __name__ == '__main__':
set_start_method('spawn')
print('start running')
num_gpus = torch.cuda.device_count()
pool = Pool(processes=num_gpus)
pool.map(run_on_single_gpu, range(num_gpus))
pool.close()
pool.join()
```
2. Run the official example of [DISTRIBUTED PIPELINE PARALLELISM USING RPC](https://pytorch.org/tutorials/intermediate/dist_pipeline_parallel_tutorial.html) and modifying the transferred tensors into GPU tensors (i.e., return out.cpu() -> return out),
```python
import os
import threading
import time
from functools import wraps
import torch
import torch.nn as nn
import torch.distributed.autograd as dist_autograd
import torch.distributed.rpc as rpc
import torch.multiprocessing as mp
import torch.optim as optim
from torch.distributed.optim import DistributedOptimizer
from torch.distributed.rpc import RRef
from torchvision.models.resnet import Bottleneck
#########################################################
# Define Model Parallel ResNet50 #
#########################################################
# In order to split the ResNet50 and place it on two different workers, we
# implement it in two model shards. The ResNetBase class defines common
# attributes and methods shared by two shards. ResNetShard1 and ResNetShard2
# contain two partitions of the model layers respectively.
num_classes = 1000
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class ResNetBase(nn.Module):
def __init__(self, block, inplanes, num_classes=1000,
groups=1, width_per_group=64, norm_layer=None):
super(ResNetBase, self).__init__()
self._lock = threading.Lock()
self._block = block
self._norm_layer = nn.BatchNorm2d
self.inplanes = inplanes
self.dilation = 1
self.groups = groups
self.base_width = width_per_group
def _make_layer(self, planes, blocks, stride=1):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if stride != 1 or self.inplanes != planes * self._block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * self._block.expansion, stride),
norm_layer(planes * self._block.expansion),
)
layers = []
layers.append(self._block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * self._block.expansion
for _ in range(1, blocks):
layers.append(self._block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def parameter_rrefs(self):
r"""
Create one RRef for each parameter in the given local module, and return a
list of RRefs.
"""
return [RRef(p) for p in self.parameters()]
class ResNetShard1(ResNetBase):
"""
The first part of ResNet.
"""
def __init__(self, device, *args, **kwargs):
super(ResNetShard1, self).__init__(
Bottleneck, 64, num_classes=num_classes, *args, **kwargs)
self.device = device
self.seq = nn.Sequential(
nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False),
self._norm_layer(self.inplanes),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
self._make_layer(64, 3),
self._make_layer(128, 4, stride=2)
).to(self.device)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
def forward(self, x_rref):
x = x_rref.to_here().to(self.device)
with self._lock:
out = self.seq(x)
# return out.cpu()
return out
class ResNetShard2(ResNetBase):
"""
The second part of ResNet.
"""
def __init__(self, device, *args, **kwargs):
super(ResNetShard2, self).__init__(
Bottleneck, 512, num_classes=num_classes, *args, **kwargs)
self.device = device
self.seq = nn.Sequential(
self._make_layer(256, 6, stride=2),
self._make_layer(512, 3, stride=2),
nn.AdaptiveAvgPool2d((1, 1)),
).to(self.device)
self.fc = nn.Linear(512 * self._block.expansion, num_classes).to(self.device)
def forward(self, x_rref):
x = x_rref.to_here().to(self.device)
with self._lock:
out = self.fc(torch.flatten(self.seq(x), 1))
# return out.cpu()
return out
class DistResNet50(nn.Module):
"""
Assemble two parts as an nn.Module and define pipelining logic
"""
def __init__(self, split_size, workers, *args, **kwargs):
super(DistResNet50, self).__init__()
self.split_size = split_size
# Put the first part of the ResNet50 on workers[0]
self.p1_rref = rpc.remote(
workers[0],
ResNetShard1,
args = ("cuda:0",) + args,
kwargs = kwargs
)
# Put the second part of the ResNet50 on workers[1]
self.p2_rref = rpc.remote(
workers[1],
ResNetShard2,
args = ("cuda:1",) + args,
kwargs = kwargs
)
def forward(self, xs):
# Split the input batch xs into micro-batches, and collect async RPC
# futures into a list
out_futures = []
for x in iter(xs.split(self.split_size, dim=0)):
x_rref = RRef(x)
y_rref = self.p1_rref.remote().forward(x_rref)
z_fut = self.p2_rref.rpc_async().forward(y_rref)
out_futures.append(z_fut)
# collect and cat all output tensors into one tensor.
return torch.cat(torch.futures.wait_all(out_futures))
def parameter_rrefs(self):
remote_params = []
remote_params.extend(self.p1_rref.remote().parameter_rrefs().to_here())
remote_params.extend(self.p2_rref.remote().parameter_rrefs().to_here())
return remote_params
#########################################################
# Run RPC Processes #
#########################################################
num_batches = 3
batch_size = 120
image_w = 128
image_h = 128
def run_master(split_size):
# put the two model parts on worker1 and worker2 respectively
model = DistResNet50(split_size, ["worker1", "worker2"])
loss_fn = nn.MSELoss()
opt = DistributedOptimizer(
optim.SGD,
model.parameter_rrefs(),
lr=0.05,
)
one_hot_indices = torch.LongTensor(batch_size) \
.random_(0, num_classes) \
.view(batch_size, 1)
for i in range(num_batches):
print(f"Processing batch {i}")
# generate random inputs and labels
torch.manual_seed(123)
inputs = torch.randn(batch_size, 3, image_w, image_h)
labels = torch.zeros(batch_size, num_classes) \
.scatter_(1, one_hot_indices, 1)
# The distributed autograd context is the dedicated scope for the
# distributed backward pass to store gradients, which can later be
# retrieved using the context_id by the distributed optimizer.
with dist_autograd.context() as context_id:
outputs = model(inputs)
loss = loss_fn(outputs, labels.to("cuda:0"))
print(f"loss: {loss.item()}")
dist_autograd.backward(context_id, [loss])
# opt.step(context_id)
def run_worker(rank, world_size, num_split):
os.environ['MASTER_ADDR'] = '11.218.124.179'
# os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29000'
# Higher timeout is added to accommodate for kernel compilation time in case of ROCm.
options = rpc.TensorPipeRpcBackendOptions(num_worker_threads=256, rpc_timeout=300)
if rank == 0:
options.set_device_map("master", {rank: 0})
options.set_device_map("worker1", {rank: 0})
options.set_device_map("worker2", {rank: 1})
rpc.init_rpc(
"master",
rank=rank,
world_size=world_size,
rpc_backend_options=options
)
run_master(num_split)
else:
options.set_device_map("master", {rank-1: 0})
options.set_device_map("worker1", {rank-1: 0})
options.set_device_map("worker2", {rank-1: 1})
rpc.init_rpc(
f"worker{rank}",
rank=rank,
world_size=world_size,
rpc_backend_options=options
)
pass
# block until all rpcs finish
rpc.shutdown()
if __name__=="__main__":
world_size = 3
for num_split in [1, 2, 4, 8]:
tik = time.time()
mp.spawn(run_worker, args=(world_size, num_split), nprocs=world_size, join=True)
tok = time.time()
print(f"number of splits = {num_split}, execution time = {tok - tik}")
```
3. Observe the log of the RPC task and note that the loss values are inconsistent. For example, the losses in 'number of splits = 4 and 8' of my log.
```Processing batch 0
loss: 0.3522467613220215
Processing batch 1
loss: 0.3522467613220215
Processing batch 2
loss: 0.3522467613220215
number of splits = 1, execution time = 30.63558030128479
Processing batch 0
loss: 0.37125730514526367
Processing batch 1
loss: 0.37125730514526367
Processing batch 2
loss: 0.37125730514526367
number of splits = 2, execution time = 25.16931390762329
Processing batch 0
loss: 0.3850472569465637
Processing batch 1
loss: 0.3850732445716858
Processing batch 2
loss: 0.38506922125816345
number of splits = 4, execution time = 24.290683269500732
Processing batch 0
loss: 0.38254597783088684
Processing batch 1
loss: 0.38254597783088684
Processing batch 2
loss: 0.35708141326904297
number of splits = 8, execution time = 22.055739402770996
```
4. Close the pure computation task and only run the RPC task. Observe that the loss values become consistent.
```
Processing batch 0
loss: 0.3423759937286377
Processing batch 1
loss: 0.3423759937286377
Processing batch 2
loss: 0.3423759937286377
number of splits = 1, execution time = 19.911068439483643
Processing batch 0
loss: 0.40370798110961914
Processing batch 1
loss: 0.40370798110961914
Processing batch 2
loss: 0.40370798110961914
number of splits = 2, execution time = 14.234280824661255
Processing batch 0
loss: 0.36699122190475464
Processing batch 1
loss: 0.36699122190475464
Processing batch 2
loss: 0.36699122190475464
number of splits = 4, execution time = 12.719268560409546
Processing batch 0
loss: 0.3601795434951782
Processing batch 1
loss: 0.3601795434951782
Processing batch 2
loss: 0.3601795434951782
number of splits = 8, execution time = 11.449119329452515
```
### Versions
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Tencent tlinux 2.2 (Final) (x86_64)
GCC version: (GCC) 8.3.0
Clang version: Could not collect
CMake version: version 3.26.1
Libc version: glibc-2.17
Python version: 3.8.12 (default, Jun 13 2022, 19:37:57) [GCC 8.3.0] (64-bit runtime)
Python platform: Linux-4.14.105-1-tlinux3-0013-x86_64-with-glibc2.2.5
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: A100-SXM4-40GB
GPU 1: A100-SXM4-40GB
GPU 2: A100-SXM4-40GB
GPU 3: A100-SXM4-40GB
GPU 4: A100-SXM4-40GB
GPU 5: A100-SXM4-40GB
GPU 6: A100-SXM4-40GB
GPU 7: A100-SXM4-40GB
Nvidia driver version: 450.156.00
cuDNN version: Probably one of the following:
/usr/lib64/libcudnn.so.8.5.0
/usr/lib64/libcudnn_adv_infer.so.8.5.0
/usr/lib64/libcudnn_adv_train.so.8.5.0
/usr/lib64/libcudnn_cnn_infer.so.8.5.0
/usr/lib64/libcudnn_cnn_train.so.8.5.0
/usr/lib64/libcudnn_ops_infer.so.8.5.0
/usr/lib64/libcudnn_ops_train.so.8.5.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 192
On-line CPU(s) list: 0-191
Thread(s) per core: 2
Core(s) per socket: 48
Socket(s): 2
NUMA node(s): 2
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7K62 48-Core Processor
Stepping: 0
CPU MHz: 3292.824
CPU max MHz: 2600.0000
CPU min MHz: 1500.0000
BogoMIPS: 5190.52
Virtualization: AMD-V
L1d cache: 32K
L1i cache: 32K
L2 cache: 512K
L3 cache: 16384K
NUMA node0 CPU(s): 0-47,96-143
NUMA node1 CPU(s): 48-95,144-191
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate ssbd ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip rdpid overflow_recov succor smca
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.1
[pip3] torchpippy==0.1.0
[pip3] torchvision==0.12.0
[pip3] triton==2.0.0
[conda] Could not collect
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
2,704 | 100,705 |
torch.cuda.amp.GradScaler initialization
|
triaged, module: amp (automated mixed precision)
|
### 🐛 Describe the bug
If I just create a scaler using the following code
`scaler = torch.cuda.amp.GradScaler()`
and do not use this `scaler` in my code, then somehow training faces issue with convergence.
I have faced it with at least 2 models.
### Versions
I have faced this in torch-1.6, torch-1.12.
cc @mcarilli @ptrblck @leslie-fang-intel @jgong5
| 2 |
2,705 | 100,704 |
[Discussion] Investigate possibilities for Windows Arm64 BLAS and LAPACK
|
module: windows, triaged, module: linear algebra
|
We are trying to investigate what implementations of BLAS/LAPACK are compatible with PyTorch and Windows Arm64.
Considering the options listed [here](https://github.com/pytorch/pytorch/blob/master/cmake/Dependencies.cmake#L246), we have the following conclusions:
- [ATLAS](https://math-atlas.sourceforge.net/): outdated (last update was in 2015)
- [BLIS](https://github.com/flame/blis): prebuild Windows [binaries](https://ci.appveyor.com/project/shpc/blis), [instructions](https://github.com/flame/blis/blob/e14424f55b15d67e8d18384aea45a11b9b772e02/docs/FAQ.md#can-i-build-blis-on-windows) on how to build it on Windows
- When running the instructions for building on Windows on an Arm64 machine, there is a SEH unwinding issue in the LLVM
- [OpenBLAS](https://github.com/xianyi/OpenBLAS): Compiled with PyTorch and it seems to be working:
- Some core tests are failing on access violation or similar issues
- WIP testing pipeline is [here](https://github.com/Windows-on-ARM-Experiments/pytorch-ci/actions/runs/4587922322)
- Generic BLAS: TBD
- [EigenBLAS](https://eigen.tuxfamily.org/dox/index.html): [here](https://gist.github.com/danielTobon43/8ef3d15f84a43fb15f1f4a49de5fcc75) are some instructions about building Eigen on Windows. There is also some Windows Arm64 option on https://vcpkg.io/en/packages.html
- [MKL](https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl.html): for Intel processors
- [VecLib](https://developer.apple.com/documentation/accelerate/veclib): for Apple devices
- [Nvidia MAGMA](https://developer.nvidia.com/magma): optimization for GPU (out of our scope for now)
- [FlexiBLAS](https://github.com/mpimd-csc/flexiblas): no Windows support https://github.com/mpimd-csc/flexiblas/issues/9
- [libflame](https://github.com/flame/libflame): It is a sister project to BLIS. Last update in August 2019
- [Netlib Reference Implementation](https://github.com/flame/libflame): [how to build on windows](https://icl.utk.edu/lapack-for-windows/lapack/)
- [APL](https://developer.arm.com/Tools%20and%20Software/Arm%20Performance%20Libraries#:~:text=Arm%20Performance%20Libraries%20provide%20optimized,performance%20in%20multi%2Dprocessor%20environments.): No support for Windows
## Open questions
- What did we miss with the implementations described above?
- What other implementations are worth being taken into consideration?
cc @peterjc123 @mszhanyi @skyline75489 @nbcsm @vladimir-aubrecht @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
| 0 |
2,706 | 100,675 |
DISABLED test_inplace_gradgrad_remainder_cuda_float64 (__main__.TestBwdGradientsCUDA)
|
module: autograd, triaged, module: flaky-tests, skipped
|
Platforms: linux
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_inplace_gradgrad_remainder_cuda_float64&suite=TestBwdGradientsCUDA) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/undefined).
Over the past 3 hours, it has been determined flaky in 7 workflow(s) with 7 failures and 7 successes.
**Debugging instructions (after clicking on the recent samples link):**
DO NOT ASSUME THINGS ARE OKAY IF THE CI IS GREEN. We now shield flaky tests from developers so CI will thus be green but it will be harder to parse the logs.
To find relevant log snippets:
1. Click on the workflow logs linked above
2. Click on the Test step of the job so that it is expanded. Otherwise, the grepping will not work.
3. Grep for `test_inplace_gradgrad_remainder_cuda_float64`
4. There should be several instances run (as flaky tests are rerun in CI) from which you can study the logs.
Test file path: `test_ops_gradients.py`
ConnectionTimeoutError: Connect timeout for 5000ms, GET https://raw.githubusercontent.com/pytorch/pytorch/master/test/test_ops_gradients.py -2 (connected: false, keepalive socket: false, socketHandledRequests: 1, socketHandledResponses: 0)
headers: {}
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 1 |
2,707 | 100,674 |
Add support for MaxPool3D on the MPS backend
|
triaged, module: mps
|
### 🚀 The feature, motivation and pitch
Currently, Pooling operations are only supported on MPS for 1D and 2D inputs. While MPS doesn't have native support for 3d pooling operations, it does support 4d pooling operations (e.g. [`maxPooling4DWithSourceTensor()`](https://developer.apple.com/documentation/metalperformanceshadersgraph/mpsgraph/3750695-maxpooling4dwithsourcetensor?language=objc)). 3d tensors can be expanded to become 4d tensors, passed to 4d pooling operations, and then squeezed back to 3d tensors. This wouldn't affect the accuracy of the results when compared to direct 3d pooling operations. So, we can start working to add support for 3d pooling operations on the MPS backend.
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev @mattiaspaul
### Alternatives
_No response_
### Additional context
This feature, along with the introduction of 3d convolutions in #99246 would open up lots of possible model architectures for 3D inputs.
Full disclosure: I already have a working implementation of MaxPool3D support for MPS, and @mattiaspaul already has something in the works to address this as well.
| 0 |
2,708 | 100,656 |
On UMA systems, pytorch fails to reserve memory exceeding the initial memory size
|
module: rocm, module: memory usage, triaged
|
### 🐛 Describe the bug
When using pytorch with ROCm / HIP on systems with unified memory, eg. AMD APUs, pytorch seems to stick to the inital reported GPU memory (which is 512 MB on my system for example), even if plenty of system RAM (and so candidate VRAM) is available. It seems the available memory is only polled once (or with an unreliable method), and after using up this memory, torch bails out like:
"HIP out of memory. Tried to allocate 2.00 MiB (GPU 0; 512.00 MiB total capacity; 455.97 MiB already allocated; 42.00 MiB free; 470.00 MiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_HIP_ALLOC_CONF"
Other applications on my system (eg. OpenGL) manage to use 4GB+ of GPU memory. So it seems pytorch is stuck to the initial reported "free" GPU memory forever.
### Versions
PyTorch version: 2.0.0+rocm5.4.2
Is debug build: False
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: 5.4.22803-474e8620
OS: Ubuntu 22.10 (x86_64)
GCC version: (Ubuntu 12.2.0-3ubuntu1) 12.2.0
Clang version: Could not collect
CMake version: version 3.26.3
Libc version: glibc-2.36
Python version: 3.10.7 (main, Mar 10 2023, 10:47:39) [GCC 12.2.0] (64-bit runtime)
Python platform: Linux-6.2.0-060200-generic-x86_64-with-glibc2.36
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: AMD Radeon Graphics
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: 5.4.22803
MIOpen runtime version: 2.19.0
Is XNNPACK available: True
CPU:
Architektur: x86_64
CPU Operationsmodus: 32-bit, 64-bit
Adressgrößen: 48 bits physical, 48 bits virtual
Byte-Reihenfolge: Little Endian
CPU(s): 16
Liste der Online-CPU(s): 0-15
Anbieterkennung: AuthenticAMD
Modellname: AMD Ryzen 9 6900HX with Radeon Graphics
Prozessorfamilie: 25
Modell: 68
Thread(s) pro Kern: 2
Kern(e) pro Socket: 8
Sockel: 1
Stepping: 1
BogoMIPS: 6587.65
Markierungen: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate ssbd mba ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr rdpru wbnoinvd cppc arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif v_spec_ctrl umip pku ospke vaes vpclmulqdq rdpid overflow_recov succor smca fsrm
Virtualisierung: AMD-V
L1d Cache: 256 KiB (8 instances)
L1i Cache: 256 KiB (8 instances)
L2 Cache: 4 MiB (8 instances)
L3 Cache: 16 MiB (1 instance)
NUMA-Knoten: 1
NUMA-Knoten0 CPU(s): 0-15
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP always-on, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] clip-anytorch==2.5.2
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.23.5
[pip3] open-clip-torch==2.16.0
[pip3] pytorch-lightning==1.7.7
[pip3] pytorch-triton-rocm==2.0.2
[pip3] torch==2.0.0+rocm5.4.2
[pip3] torch-fidelity==0.3.0
[pip3] torchaudio==2.0.0+rocm5.4.2
[pip3] torchcontrib==0.0.2
[pip3] torchdiffeq==0.2.3
[pip3] torchlibrosa==0.0.9
[pip3] torchmetrics==0.11.4
[pip3] torchsde==0.2.5
[pip3] torchvision==0.15.1+rocm5.4.2
[conda] No relevant packages
cc @jeffdaily @sunway513 @jithunnair-amd @pruthvistony @ROCmSupport
| 0 |
2,709 | 100,654 |
UserWarning: must run observer before calling calculate_qparams. Returning default values.
|
oncall: quantization, triaged
|
### 🐛 Describe the bug
I am testing out quantization results for a resnet based model. I started with resnet18. Using both eager and fx mode, I get the below warning, and the subsequent accuracy of the quantized model is close to zero, making me suspicious whether calibration is happening correctly if at all.
**/home/chinmay/anaconda3/envs/v_pytorch2/lib/python3.8/site-packages/torch/ao/quantization/utils.py:302: UserWarning: must run observer before calling calculate_qparams. Returning default values.
warnings.warn(**
I follow the code shown in the tutorials, pasting the fx code below, but the same issue occurs with eager as well.
[Code](https://gist.github.com/chinmayjog13/c66226681d538382014a9140e0bc8de1)
```[tasklist]
### Tasks
- [ ] Add a draft title or issue reference here
```
### Versions
```
Collecting environment information...
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.6 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.16 (default, Mar 2 2023, 03:21:46) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.8.0-63-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100 80GB PCIe
GPU 1: NVIDIA A100 80GB PCIe
GPU 2: NVIDIA A100 80GB PCIe
GPU 3: NVIDIA A100 80GB PCIe
GPU 4: NVIDIA A100 80GB PCIe
GPU 5: NVIDIA A100 80GB PCIe
GPU 6: NVIDIA A100 80GB PCIe
GPU 7: NVIDIA A100 80GB PCIe
Nvidia driver version: 515.105.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.5.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 1
Core(s) per socket: 32
Socket(s): 2
NUMA node(s): 2
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7502 32-Core Processor
Stepping: 0
Frequency boost: enabled
CPU MHz: 1498.611
CPU max MHz: 3354.4919
CPU min MHz: 1500.0000
BogoMIPS: 5000.33
Virtualization: AMD-V
L1d cache: 2 MiB
L1i cache: 2 MiB
L2 cache: 32 MiB
L3 cache: 256 MiB
NUMA node0 CPU(s): 0-31
NUMA node1 CPU(s): 32-63
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Full AMD retpoline, IBPB conditional, IBRS_FW, STIBP disabled, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate sme ssbd mba sev ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr rdpru wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip rdpid overflow_recov succor smca
Versions of relevant libraries:
[pip3] numpy==1.24.3
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.0
[pip3] torchvision==0.15.0
[pip3] triton==2.0.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py38h7f8727e_0
[conda] mkl_fft 1.3.1 py38hd3c417c_0
[conda] mkl_random 1.2.2 py38h51133e4_0
[conda] numpy 1.24.3 py38h14f4228_0
[conda] numpy-base 1.24.3 py38h31eccc5_0
[conda] pytorch 2.0.0 py3.8_cuda11.7_cudnn8.5.0_0 pytorch
[conda] pytorch-cuda 11.7 h778d358_3 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 2.0.0 py38_cu117 pytorch
[conda] torchtriton 2.0.0 py38 pytorch
[conda] torchvision 0.15.0 py38_cu117 pytorch
```
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo @jgong5 @Xia-Weiwen @leslie-fang-intel
| 25 |
2,710 | 100,637 |
Optimal Batch Size Selection in Torchdynamo Benchmarks for Different GPU Memory Sizes
|
triaged, oncall: pt2
|
### 🚀 The feature, motivation and pitch
The torchdynamo benchmarking scripts come with default batch size for each model based on A100 40GB GPU tests. When adapting these scripts for training on smaller sized GPUs, we see OOM errors. The performance and accuracy tests will fail for most models and the benchmarking results becomes less informative. Thus it makes more sense to assign an optimal batch size according to the actual GPU memory size for each model, where the optimal batch size map will be kept as a list in the directory `benchmarks/dynamo`. By adding this batch size selection feature in the benchmarking scripts for all model suites, the benchmarking can be adapted by wider communities and suits their needs for testing and comparison among different GPU types.
### Alternatives
_No response_
### Additional context
_No response_
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @anijain2305
| 7 |
2,711 | 100,636 |
tracing does not work when torch.distributions is involved
|
oncall: jit
|
### 🐛 Describe the bug
Basically the title, i am working on a reinforcement learning model and wanted to trace it to a scriptmodel to use it in C++, but it wont trace when torch.distributions, specifically the MultivariateNormal distribution (i have not tried the others).
I define a module that uses the distribution like this
```python
class ActorModel(torch.nn.Module):
def __init__(self, actor):
super().__init__()
self.actor = actor
def forward(self, x):
logits = self.actor(x)[0]
batch_size = logits.shape[0]
action_dim = 3
# Split the logits into the mean and Cholesky factor
tril_flat = logits[:, action_dim:]
mean = logits[:, :action_dim]
tril_flat = torch.where(tril_flat == 0, 1e-8, tril_flat).detach()
tril = torch.zeros(batch_size, action_dim, action_dim, device=logits.device)
tril[:, torch.tril(torch.ones(action_dim, action_dim, device=logits.device)).bool()] = tril_flat
# Construct the multivariate normal distribution
dist = MultivariateNormal(mean, scale_tril=tril)
return dist.sample()
```
and I then (try to) trace it like this
```python
actor.load_state_dict(policy.actor.state_dict())
actor = actor.to(torch.device('cpu'))
actor_module = ActorModel(actor)
actor_module.eval()
for param in actor_module.parameters():
param.requires_grad = False
with torch.no_grad():
example_input = torch.rand((1, 2, 290))
traced_script_last_model = torch.jit.script(actor_module, example_input)
```
The result is a fail in the sanity check, along with a warning about non-deterministic nodes
```
/home/bigbaduser/.local/lib/python3.11/site-packages/torch/jit/_trace.py:1084: TracerWarning: Trace had nondeterministic nodes. Did you forget call .eval() on your model? Nodes:
%bvec : Float(1, 3, strides=[3, 1], requires_grad=0, device=cpu) = aten::normal(%588, %596, %597) # /home/bigbaduser/.local/lib/python3.11/site-packages/torch/distributions/u
tils.py:48:0
This may cause errors in trace checking. To disable trace checking, pass check_trace=False to torch.jit.trace()
_check_trace(
/home/bigbaduser/.local/lib/python3.11/site-packages/torch/jit/_trace.py:1084: TracerWarning: Output nr 1. of the traced function does not match the corresponding output of the Pytho
n function. Detailed error:
Tensor-likes are not close!
Mismatched elements: 3 / 3 (100.0%)
Greatest absolute difference: 6.103819370269775 at index (0, 2) (up to 1e-05 allowed)
Greatest relative difference: 9.780014123811462 at index (0, 1) (up to 1e-05 allowed)
_check_trace(
```
And I know that the issue is in the distributions because when I try to trace the model itself with
```python
with torch.no_grad():
example_input = torch.rand((1, 2, 290))
traced_script_last_model = torch.jit.script(lambda x: actor(x)[0], example_input)
```
it works without issue. I thought it could be the `torch.where` since that is (at least in my head, i dont know how it is implemented) a control flow operation, but i tried deleting that line and it didn't matter, same error
### Versions
```
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Arch Linux (x86_64)
GCC version: (GCC) 13.1.1 20230429
Clang version: 15.0.7
CMake version: version 3.26.3
Libc version: glibc-2.37
Python version: 3.11.3 (main, Apr 5 2023, 15:52:25) [GCC 12.2.1 20230201] (64-bit runtime)
Python platform: Linux-6.3.1-arch1-1-x86_64-with-glibc2.37
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3080 Ti
Nvidia driver version: 530.41.03
cuDNN version: Probably one of the following:
/usr/lib/libcudnn.so.8.8.0
/usr/lib/libcudnn_adv_infer.so.8.8.0
/usr/lib/libcudnn_adv_train.so.8.8.0
/usr/lib/libcudnn_cnn_infer.so.8.8.0
/usr/lib/libcudnn_cnn_train.so.8.8.0
/usr/lib/libcudnn_ops_infer.so.8.8.0
/usr/lib/libcudnn_ops_train.so.8.8.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 6
On-line CPU(s) list: 0-5
Vendor ID: GenuineIntel
Model name: Intel(R) Core(TM) i5-8400 CPU @ 2.80GHz
CPU family: 6
Model: 158
Thread(s) per core: 1
Core(s) per socket: 6
Socket(s): 1
Stepping: 10
CPU(s) scaling MHz: 95%
CPU max MHz: 4000.0000
CPU min MHz: 800.0000
BogoMIPS: 5602.18
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single pti ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp
Virtualization: VT-x
L1d cache: 192 KiB (6 instances)
L1i cache: 192 KiB (6 instances)
L2 cache: 1.5 MiB (6 instances)
L3 cache: 9 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-5
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT disabled
Vulnerability Mds: Vulnerable: Clear CPU buffers attempted, no microcode; SMT disabled
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Vulnerable: Clear CPU buffers attempted, no microcode; SMT disabled
Vulnerability Retbleed: Mitigation; IBRS
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; IBRS, IBPB conditional, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Vulnerable: No microcode
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.24.3
[pip3] torch==2.0.0
[pip3] triton==2.0.0
[conda] Could not collect
```
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
2,712 | 100,626 |
Will Deep Implicit Models ever become first class citizens in PyTorch?
|
module: autograd, triaged, oncall: pt2, module: functorch
|
### 🚀 The feature, motivation and pitch
PyTorch makes it unnecessarily difficult to work with [Deep Implicit Models](https://implicit-layers-tutorial.org/). Deep Implicit Layers/Models are characterized by the need to implement custom backward passes to be efficient, making use of the [implicit function theorem](https://en.wikipedia.org/wiki/Implicit_function_theorem).
In particular, the following issues persist:
- JIT is incompatible with custom backwards. The only way around this is writing custom C++ extensions. https://github.com/pytorch/pytorch/issues/35749
- Implementing custom backward hooks for a whole `nn.Module` is extremely counter-intuitive, consider this example from Chapter 4:
```python
def forward(self, x):
# compute forward pass and re-engage autograd tape
with torch.no_grad():
z, self.forward_res = self.solver(
lambda z : self.f(z, x), torch.zeros_like(x), **self.kwargs)
z = self.f(z,x)
# set up Jacobian vector product (without additional forward calls)
z0 = z.clone().detach().requires_grad_()
f0 = self.f(z0,x)
def backward_hook(grad):
g, self.backward_res = self.solver(
lambda y : autograd.grad(f0, z0, y, retain_graph=True)[0] + grad,
grad, **self.kwargs)
return g
z.register_hook(backward_hook)
return z
```
One needs to `no_grad` the forward, and then manually surgically insert the custom backward.
- Custom backward of nn.Modules are also incompatible with JIT, and it's unclear how to work around it.
### Alternatives
JAX supports per-function custom backward overrides via decorators: https://jax.readthedocs.io/en/latest/notebooks/Custom_derivative_rules_for_Python_code.html
```python
import jax.numpy as jnp
from jax import custom_jvp
@custom_jvp
def f(x, y):
return jnp.sin(x) * y
@f.defjvp
def f_jvp(primals, tangents):
x, y = primals
x_dot, y_dot = tangents
primal_out = f(x, y)
tangent_out = jnp.cos(x) * x_dot * y + jnp.sin(x) * y_dot
return primal_out, tangent_out
```
If supported, this would solve all 3 issues.
### Additional context
_No response_
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @soumith @msaroufim @wconstab @ngimel @bdhirsh @Chillee @samdow @kshitij12345 @janeyx99
| 12 |
2,713 | 100,623 |
Fix static lib
|
triaged, open source, ciflow/binaries, release notes: releng
|
Fix linking issues when building with BUILD_SHARED_LIBS=OFF.
Added 2 CI jobs: one that builds with BUILD_SHARED_LIBS=OFF with cuda12.1, and another job that creates a project from a cmake file using the previously built libtorch and runs it.
This PR is using https://github.com/pytorch/builder/pull/1465 to test the changes work.
The third commit changes the builder branch to my branch in order to do the test.
Fixes #87499
| 10 |
2,714 | 100,617 |
GPU VRAM usage significantly higher for Lenet5 models when compared to other frameworks
|
triaged, better-on-discuss-forum
|
### 🐛 Describe the bug
Hello everybody.
I’ve been experimenting with different models and different frameworks, and I’ve noticed that, when using GPU, training Lenet-5 on the MNIST dataset on PyTorch leads to higher GPU VRAM usage when compared to the Keras and TensorFlow v1.X implementations.
I'm on a Ubuntu 18.04.4 system equipped with an NVIDIA Quadro RTX 4000 GPU with 8GB of VRAM and an Intel(R) Core(TM) i9-9900K CPU running at 3.60GHz.
Here are boxplots that showcase the performance of numerous Lenet5:
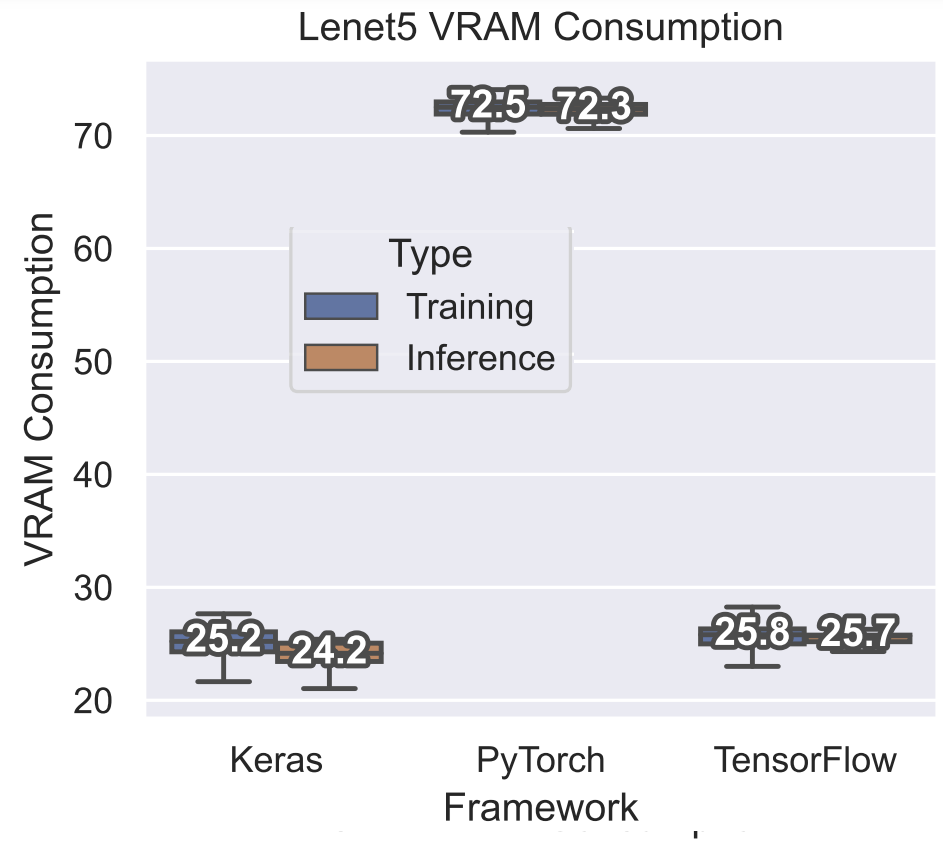
Any ideas on what may be causing this?
### Versions
The version of relevant libraries are:
numpy==1.19.5
torch==1.10.0
torchaudio==0.10.0
torchvision==0.11.1
mkl==2022.2.1
mkl-fft==1.3.0
mkl-random==1.2.1
mkl-service==2.4.0
| 2 |
2,715 | 100,584 |
[doc] torch.scalar_tensor doc is missing
|
module: docs, triaged
|
### 📚 The doc issue
```python
>>> import torch
>>> k = 4
>>> torch.scalar_tensor(k)
tensor(4.)
>>> torch.scalar_tensor.__doc__
>>>
```
Main branch: `2.1.0a0+git2ac6ee7`
cc @svekars @carljparker
| 0 |
2,716 | 100,582 |
Synchronization issue when combining DPP and RPC - "Parameter marked twice"
|
oncall: distributed
|
### 🐛 Describe the bug
I'm using DDP in conjunction with RPC to create a master-worker setup to train a DQN agent using multiple GPUs in parallel. The master process manages the game and memory buffer and fits one of the partitions of the data, while the workers only fit their respective partitions of the data. I'm training on 2 NVIDIA 3090 GPUs within a single machine.
The minimal code to reproduce the error is shown below. The problem appears to be that the master process triggers a second call to the worker's `_train_on_batch` before the first call is completed. As a result, the parameters of the worker get marked twice, which throws the error. This seems like a race condition since the error isn't reproduced 100% of the time. I added some prints to the code (not shown in the example for clarity purposes) which confirm this is the issue:
```
2023-05-03 20:48:59,315 [INFO] rank=0 | start local_iter=0 | master_iter=0
2023-05-03 20:48:59,330 [INFO] rank=1 | start local_iter=0 | master_iter=0
2023-05-03 20:48:59,935 [INFO] rank=0 | bckwd done local_iter=0 | master_iter=0
2023-05-03 20:48:59,937 [INFO] rank=0 | optim done local_iter=0 | master_iter=0
2023-05-03 20:48:59,938 [INFO] rank=0 | start local_iter=1 | master_iter=1
2023-05-03 20:48:59,939 [INFO] rank=1 | start local_iter=0 | master_iter=1
2023-05-03 20:48:59,959 [INFO] rank=1 | bckwd done local_iter=0 | master_iter=0
2023-05-03 20:48:59,959 [INFO] rank=1 | bckwd done local_iter=0 | master_iter=1
On WorkerInfo(id=1, name=worker_1):
RuntimeError('Expected to mark a variable ready only once. This error is caused [...]
```
In the logs above, `rank` is the process rank (`0` for master, `1` for worker), `local_iter` is the `_train_on_batch` call number (i.e `0` for the first call, `1` for the second call), and `master_iter` is the number of `_train_on_batch` calls the master process has completed (iterations numbers are incremented just before exiting `_train_on_batch`). `backwd done` and `optim done` means the process has returned from the `loss.backward` and `optimizer.step` calls, respectively. We see that the master process has finished it's first training iteration when it signals the worker to start its second iteration, while the latter hasn't finished its first iteration yet.
The error is fixed adding a `dist.barrier` before exiting `_train_on_batch` method, which points towards this being a process synchronization issue. However, the DDP documentation states that
> Constructor, forward method, and differentiation of the output (or a function of the output of this module) are distributed synchronization points. Take that into account in case different processes might be executing different code.
Thus, shouldn't the processes be synchronized on the `preds = self.model(batch.data.to(self.rank))` call? Or is the `dist.barrier` usage intended in this use case?
Minimal code to reproduce the error (might not be reproduced 100% of the time - bigger models tend to show more failures):
```python
import os
from dataclasses import dataclass
import torch
import torch.nn as nn
import torch.distributed as dist
import torch.distributed.rpc as rpc
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.optim import Optimizer
MASTER_ADDR = "localhost"
MASTER_PORT = "29500"
BACKEND = "nccl"
def _set_master_addr() -> None:
os.environ["MASTER_ADDR"] = MASTER_ADDR
os.environ["MASTER_PORT"] = MASTER_PORT
@dataclass
class Batch:
data: torch.Tensor
labels: torch.Tensor
class TrainOnBatchMixin:
def _train_on_batch(self, batch: Batch) -> float:
preds = self.model(batch.data.to(self.rank))
self.optimizer.zero_grad()
batch_loss = self.loss(preds, batch.labels.to(self.rank))
batch_loss.backward()
self.optimizer.step()
class Trainer(TrainOnBatchMixin):
def __init__(
self,
model: nn.Module,
optimizer: Optimizer,
in_feats: int,
out_feats: int,
loss: nn.Module = nn.MSELoss(),
num_workers: int = 1,
num_epochs: int = 5,
) -> None:
self.model = model
self.optimizer = optimizer
self.in_feats = in_feats
self.out_feats = out_feats
self.loss = loss
self.num_workers = num_workers
self.num_epochs = num_epochs
self.rank = 0
self.world_size = self.num_workers + 1
self._setup()
def _setup(self) -> None:
# spawn workers
for rank in range(1, self.world_size):
worker_process = mp.Process(
target=Worker.init_process,
kwargs={"rank": 1, "world_size": self.world_size},
)
worker_process.start()
# initialize self
_set_master_addr()
# init self RPC
rpc.init_rpc("master", rank=0, world_size=self.world_size)
# init self DDP
dist.init_process_group(rank=0, world_size=self.world_size, backend=BACKEND)
self.worker_rrefs = [
rpc.remote(
f"worker_{rank}",
Worker,
kwargs={
"rank": rank,
"model": self.model,
"optimizer": self.optimizer,
"loss": self.loss,
},
)
for rank in range(1, self.world_size)
]
self.model = DDP(self.model.to(0), device_ids=[0])
def train(self) -> None:
for num_epoch in range(self.num_epochs):
# create fake data
data = torch.tensor(
[[1] * self.in_feats, [12] * self.in_feats], dtype=torch.float32
)
labels = torch.tensor(
[[1] * self.out_feats, [13] * self.out_feats], dtype=torch.float32
)
batch = Batch(data, labels)
# execute workers
for worker_rref in self.worker_rrefs:
rpc.rpc_async(
worker_rref.owner(),
worker_rref.rpc_sync()._train_on_batch,
args=(batch,),
)
# execute self
self._train_on_batch(batch)
rpc.shutdown()
class Worker(TrainOnBatchMixin):
def __init__(
self,
rank: int,
model: nn.Module,
optimizer: Optimizer,
loss: nn.Module,
) -> None:
self.rank = rank
self.model = DDP(model.to(rank), device_ids=[rank])
self.optimizer = self._copy_optimizer(optimizer, self.model)
self.loss = type(loss)()
@staticmethod
def _copy_optimizer(optimizer: Optimizer, model: nn.Module) -> Optimizer:
return type(optimizer)(
params=[p for p in model.parameters()], **optimizer.defaults
)
@staticmethod
def init_process(
rank: int,
world_size: int,
) -> None:
_set_master_addr()
# init RPC
rpc.init_rpc(name=f"worker_{rank}", rank=rank, world_size=world_size)
# init DDP
dist.init_process_group(rank=rank, world_size=world_size, backend=BACKEND)
# block until trainer has given shut down signal
rpc.shutdown()
if __name__ == "__main__":
in_feats = int(1e5)
out_feats = 10
model = nn.Linear(in_feats, out_feats)
optimizer = torch.optim.SGD(params=model.parameters(), lr=1e-3)
trainer = Trainer(
model=model, optimizer=optimizer, in_feats=in_feats, out_feats=out_feats
)
trainer.train()
```
### Versions
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.26.3
Libc version: glibc-2.31
Python version: 3.9.4 (default, Apr 23 2023, 21:06:21) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-144-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 10.1.243
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
Nvidia driver version: 495.29.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 158
Model name: Intel(R) Core(TM) i9-9900K CPU @ 3.60GHz
Stepping: 12
CPU MHz: 4868.364
CPU max MHz: 5000.0000
CPU min MHz: 800.0000
BogoMIPS: 7200.00
Virtualization: VT-x
L1d cache: 256 KiB
L1i cache: 256 KiB
L2 cache: 2 MiB
L3 cache: 16 MiB
NUMA node0 CPU(s): 0-15
Vulnerability Itlb multihit: KVM: Mitigation: Split huge pages
Vulnerability L1tf: Not affected
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Mitigation; Microcode
Vulnerability Tsx async abort: Mitigation; Clear CPU buffers; SMT vulnerable
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] flake8==4.0.1
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.24.3
[pip3] torch==2.0.0
[pip3] triton==2.0.0
[conda] Could not collect
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 3 |
2,717 | 100,578 |
Add support for aten::tril_indices for MPS backend
|
feature, triaged, module: linear algebra, module: mps
|
### 🐛 Describe the bug
First time contributors are welcome! 🙂
Add support for 'aten::tril_indices' for MPS backend. Generic support for adding operations to MPS backend is captured here: https://github.com/pytorch/pytorch/wiki/MPS-Backend#adding-op-for-mps-backend
### Versions
N/A
cc @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
2,718 | 100,574 |
undocumented error on torch.autograd.Function.jvp for non-Tensor forward returns
|
module: docs, module: autograd, triaged, actionable
|
### 🐛 Describe the bug
Returning non-Tensor values from torch.autograd.Function.forward works fine with backpropoagation but breaks jvp with the obscure error "RuntimeError: bad optional access". Either forward should require Tensor return values or this should work.
```
from torch import randn
from torch.autograd import Function
from torch.autograd.forward_ad import dual_level
from torch.autograd.forward_ad import make_dual
class TestFunc1(Function):
@staticmethod
def forward(ctx, x):
return 1, x
@staticmethod
def backward(ctx, dy, dz):
return dz
@staticmethod
def jvp(ctx, dz):
return None, dz
x = randn(5, requires_grad=True)
# this works
z2 = TestFunc1.apply(x)[1].sum().backward()
assert x.grad is not None
# this breaks
dx = randn(5)
with dual_level():
x2 = make_dual(x, dx)
z2 = TestFunc1.apply(x2) # raises RuntimeError: bad optional access
```
### Versions
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Manjaro Linux (x86_64)
GCC version: (GCC) 12.2.1 20230201
Clang version: 15.0.7
CMake version: version 3.26.3
Libc version: glibc-2.37
Python version: 3.11.3 (main, Apr 13 2023, 18:03:05) [GCC 12.2.1 20230201] (64-bit runtime)
Python platform: Linux-6.1.25-1-MANJARO-x86_64-with-glibc2.37
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3080
Nvidia driver version: 530.41.03
cuDNN version: Probably one of the following:
/usr/lib/libcudnn.so.8.8.0
/usr/lib/libcudnn_adv_infer.so.8.8.0
/usr/lib/libcudnn_adv_train.so.8.8.0
/usr/lib/libcudnn_cnn_infer.so.8.8.0
/usr/lib/libcudnn_cnn_train.so.8.8.0
/usr/lib/libcudnn_ops_infer.so.8.8.0
/usr/lib/libcudnn_ops_train.so.8.8.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 43 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 9 3900X 12-Core Processor
CPU family: 23
Model: 113
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 1
Stepping: 0
Frequency boost: enabled
CPU(s) scaling MHz: 78%
CPU max MHz: 4672,0698
CPU min MHz: 2200,0000
BogoMIPS: 7588,32
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate ssbd mba ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr rdpru wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif v_spec_ctrl umip rdpid overflow_recov succor smca sev sev_es
Virtualization: AMD-V
L1d cache: 384 KiB (12 instances)
L1i cache: 384 KiB (12 instances)
L2 cache: 6 MiB (12 instances)
L3 cache: 64 MiB (4 instances)
NUMA node(s): 1
NUMA node0 CPU(s): 0-23
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT enabled with STIBP protection
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP always-on, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] flake8==6.0.0
[pip3] mypy==1.1.1
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.24.2
[pip3] torch==2.0.0
[pip3] triton==2.0.0
[conda] Could not collect
cc @svekars @carljparker @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 2 |
2,719 | 100,562 |
Use a label instead of body text for merge blocking CI SEVs
|
module: ci, triaged
|
See https://github.com/pytorch/pytorch/pull/100559#pullrequestreview-1411334737
cc @seemethere @malfet @pytorch/pytorch-dev-infra
| 0 |
2,720 | 100,561 |
[ONNX] Opset 18 support for TorchScript exporter
|
module: onnx, triaged
|
* Modified ONNX Ops
- [ ] Reduce ops. E.g., https://onnx.ai/onnx/operators/text_diff_ReduceMax_13_18.html#l-onnx-op-reducemax-d13-18
- [ ] Pad. https://onnx.ai/onnx/operators/text_diff_Pad_13_18.html#l-onnx-op-pad-d13-18
- [ ] Resize. https://onnx.ai/onnx/operators/text_diff_Resize_13_18.html#l-onnx-op-resize-d13-18
- [ ] ScatterElements, ScatterND. Native reduction mode https://onnx.ai/onnx/operators/text_diff_ScatterElements_16_18.html#l-onnx-op-scatterelements-d16-18
- [ ] Split. New attribute `num_outputs`. https://onnx.ai/onnx/operators/text_diff_Split_13_18.html#l-onnx-op-split-d13-18
* New ONNX Ops
- [ ] CenterCropPad
- [ ] Col2Im
- [ ] Mish
- [ ] BitwiseAnd, BitwiseNot, BitwiseOr, BitwiseXor
- [ ] GroupNormalization
| 1 |
2,721 | 100,528 |
Backward hook execution order changes when input.requires_grad is False
|
module: docs, module: autograd, module: nn, triaged, actionable
|
### 🐛 Describe the bug
When using the `register_module_full_backward_pre_hook` and `register_module_full_backward_hook` functions, the order of hooks execution is affected by whether the input requires gradient or not. If the input does not require a gradient, then the order of execution becomes incorrect.
```
------ train_data.requires_grad = True ------
Push: MSELoss
Pop: MSELoss
-->Push: Sequential
Push: Sequential<--
Push: Linear
Pop: Linear
Push: ReLU
Pop: ReLU
Push: Linear
Pop: Linear
Pop: Sequential
Push: Sequential
Push: Linear
Pop: Linear
Push: ReLU
Pop: ReLU
Push: Linear
Pop: Linear
Pop: Sequential
Pop: Sequential
------ train_data.requires_grad = False ------
Push: MSELoss
Pop: MSELoss
-->Push: Sequential
Pop: Sequential
Push: Sequential<--
Push: Linear
Pop: Linear
Push: ReLU
Pop: ReLU
Push: Linear
Pop: Linear
Pop: Sequential
Push: Sequential
Pop: Sequential
Push: Linear
Pop: Linear
Push: ReLU
Pop: ReLU
Push: Linear
Pop: Linear
Finished Training
```
Code to reproduce:
```python
import torch
import torch.nn as nn
import torch.optim as optim
# Define the neural network architecture
net = nn.Sequential(nn.Sequential(
nn.Linear(10, 20),
nn.ReLU(),
nn.Linear(20, 1)
), nn.Sequential(
nn.Linear(1, 20),
nn.ReLU(),
nn.Linear(20, 1)))
# Create dummy data
train_data = torch.randn(100, 10, requires_grad=True)
train_labels = torch.randn(100, 1)
# Define the loss function and optimizer
criterion = nn.MSELoss()
# Train the neural network
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = net.to(device)
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
def _pre_hook(module, *_, **__):
print('Push: ', f'{module.__class__.__name__}')
def _after_hook(module, *_, **__):
print('Pop: ', f'{module.__class__.__name__}')
torch.nn.modules.module.register_module_full_backward_pre_hook(_pre_hook)
torch.nn.modules.module.register_module_full_backward_hook(_after_hook)
print('------ train_data.requires_grad = True ------')
for epoch in range(1):
running_loss = 0.0
for i in range(1):
inputs, labels = train_data[i].to(device), train_labels[i].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# print('Epoch %d loss: %.3f' % (epoch + 1, running_loss / 100))
running_loss = 0.0
print('------ train_data.requires_grad = False ------')
train_data.requires_grad = False
for epoch in range(1):
running_loss = 0.0
for i in range(1):
inputs, labels = train_data[i].to(device), train_labels[i].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# print('Epoch %d loss: %.3f' % (epoch + 1, running_loss / 100))
running_loss = 0.0
print('Finished Training')
```
### Versions
```
Collecting environment information...
PyTorch version: 1.14.0a0+44dac51
Is debug build: False
CUDA used to build PyTorch: 12.0
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.24.1
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-77-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 12.0.140
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A30
GPU 1: NVIDIA A30
GPU 2: NVIDIA A30
GPU 3: NVIDIA A30
GPU 4: NVIDIA A30
GPU 5: NVIDIA A30
GPU 6: NVIDIA A30
GPU 7: NVIDIA A30
Nvidia driver version: 525.85.12
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 256
On-line CPU(s) list: 0-255
Thread(s) per core: 2
Core(s) per socket: 64
Socket(s): 2
NUMA node(s): 8
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7742 64-Core Processor
Stepping: 0
Frequency boost: enabled
CPU MHz: 1500.048
CPU max MHz: 2250.0000
CPU min MHz: 1500.0000
BogoMIPS: 4500.40
Virtualization: AMD-V
L1d cache: 4 MiB
L1i cache: 4 MiB
L2 cache: 64 MiB
L3 cache: 512 MiB
NUMA node0 CPU(s): 0-15,128-143
NUMA node1 CPU(s): 16-31,144-159
NUMA node2 CPU(s): 32-47,160-175
NUMA node3 CPU(s): 48-63,176-191
NUMA node4 CPU(s): 64-79,192-207
NUMA node5 CPU(s): 80-95,208-223
NUMA node6 CPU(s): 96-111,224-239
NUMA node7 CPU(s): 112-127,240-255
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Vulnerable, IBPB: disabled, STIBP: disabled
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate sme ssbd mba sev ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip rdpid overflow_recov succor smca
Versions of relevant libraries:
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.22.2
[pip3] pytorch-lightning==1.9.4
[pip3] pytorch-quantization==2.1.2
[pip3] torch==1.14.0a0+44dac51
[pip3] torch-automated-profiler==1.10.0
[pip3] torch-performance-linter==0.2.1.dev36+gd3906c3
[pip3] torch-tb-profiler==0.4.1
[pip3] torch-tensorrt==1.4.0.dev0
[pip3] torchmetrics==0.9.1
[pip3] torchtext==0.13.0a0+fae8e8c
[pip3] torchvision==0.15.0a0
[pip3] triton==2.0.0
[pip3] tritonclient==2.22.4
[conda] Could not collect
```
cc @svekars @carljparker @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @mruberry @jbschlosser @walterddr @mikaylagawarecki
| 3 |
2,722 | 100,520 |
DISABLED test_inplace_grad_div_floor_rounding_cuda_float64 (__main__.TestBwdGradientsCUDA)
|
triaged, module: flaky-tests, skipped, oncall: pt2, module: inductor
|
Platforms: inductor
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_inplace_grad_div_floor_rounding_cuda_float64&suite=TestBwdGradientsCUDA) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/undefined).
Over the past 3 hours, it has been determined flaky in 7 workflow(s) with 7 failures and 7 successes.
**Debugging instructions (after clicking on the recent samples link):**
DO NOT ASSUME THINGS ARE OKAY IF THE CI IS GREEN. We now shield flaky tests from developers so CI will thus be green but it will be harder to parse the logs.
To find relevant log snippets:
1. Click on the workflow logs linked above
2. Click on the Test step of the job so that it is expanded. Otherwise, the grepping will not work.
3. Grep for `test_inplace_grad_div_floor_rounding_cuda_float64`
4. There should be several instances run (as flaky tests are rerun in CI) from which you can study the logs.
Test file path: `test_ops_gradients.py`
cc @ezyang @msaroufim @wconstab @bdhirsh @anijain2305 @voznesenskym @penguinwu @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @ipiszy @ngimel @yf225 @chenyang78 @kadeng @muchulee8 @aakhundov @soumith @desertfire @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 10 |
2,723 | 100,468 |
Accuracy repro extraction, constants in graph are not preserved exactly
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
If the repro graph contains a constant (e.g., due to use of torch.tensor), this constant is not serialized faithfully when we extract repros. I plan on fixing it so that if the constant is not too big (<= 4) we'll just print it into the graph, but ideally we would use the same ContentStore mechanism to store these constants exactly.
Comment on this issue if this is affecting you.
### Versions
master
cc @msaroufim @wconstab @ngimel @bdhirsh @anijain2305 @soumith
| 0 |
2,724 | 100,461 |
Arithmetic of single-element Tensors with different dtypes on 'cpu' and 'mps' results in obscure/unhelpful `TypeError`
|
triaged, module: mps
|
### 🐛 Describe the bug
The following snippet raises a TypeError with a rather unhelpful error message
```python
import torch
cpu_tensor = torch.mean(torch.rand(2).double()) # float64 tensor on cpu
mps_tensor = torch.mean(torch.rand(2, device='mps')) # float32 tensor on mps
cpu_tensor + mps_tensor # TypeError: unsupported operand type(s) for +: 'Tensor' and 'Tensor'
```
It would be more sensible to raise either of the usual `RuntimeError`s stating that the operation is impossible because the Tensors are on different devices and/or that the data types are incompatible.
### Versions
```
Collecting environment information...
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.0 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.102)
CMake version: version 3.25.2
Libc version: N/A
Python version: 3.10.0 (default, Mar 3 2022, 03:54:28) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-13.0-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M1
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] pytorch-ident==0.2.5
[pip3] pytorch-lightning==1.9.4
[pip3] torch==2.0.0
[pip3] torchcast==0.3.0
[pip3] torchfilter==0.0
[pip3] torchmetrics==0.11.4
[conda] numpy 1.23.5 py310hb93e574_0
[conda] numpy-base 1.23.5 py310haf87e8b_0
[conda] pytorch-ident 0.2.5 pypi_0 pypi
[conda] pytorch-lightning 1.9.4 pyhd8ed1ab_0 conda-forge
[conda] torch 2.0.0 pypi_0 pypi
[conda] torchcast 0.3.0 pypi_0 pypi
[conda] torchfilter 0.0 pypi_0 pypi
[conda] torchmetrics 0.11.4 pyhd8ed1ab_0 conda-forge
```
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 2 |
2,725 | 100,459 |
DISABLED test_wait_i_3 (__main__.TestMultiThreadedWait)
|
oncall: distributed, module: flaky-tests, skipped
|
Platforms: linux
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_wait_i_3&suite=TestMultiThreadedWait) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/undefined).
Over the past 3 hours, it has been determined flaky in 7 workflow(s) with 14 failures and 7 successes.
**Debugging instructions (after clicking on the recent samples link):**
DO NOT ASSUME THINGS ARE OKAY IF THE CI IS GREEN. We now shield flaky tests from developers so CI will thus be green but it will be harder to parse the logs.
To find relevant log snippets:
1. Click on the workflow logs linked above
2. Click on the Test step of the job so that it is expanded. Otherwise, the grepping will not work.
3. Grep for `test_wait_i_3`
4. There should be several instances run (as flaky tests are rerun in CI) from which you can study the logs.
Test file path: `distributed/test_store.py` or `distributed/test_store.py`
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 8 |
2,726 | 100,452 |
[Inductor] Fuse Attention pattern match doesn't work with masking or dropout or FP16
|
triaged, oncall: pt2, module: inductor, inductor_pattern_match
|
### 🐛 Describe the bug
fuse_attention fx pass for replacing various dot product attention modules with scaled_dot_product_attention does not work when
1. Using Mask
2. Using Dropout
3. Using FP16
Here's the code snippet to reproduce the first two cases. Change float.32 to float16 to reproduce third case.
```
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class Net(nn.Module):
def __init__(self, config):
super().__init__()
def forward(self, q, k, v):
attn_weight = torch.softmax(
(q @ k.transpose(-2, -1) / math.sqrt(q.size(-1))),
dim=-1,
)
return attn_weight @ v
class Net_w_dropout(nn.Module):
def __init__(self, config):
super().__init__()
def forward(self, q, k, v):
attn_weight = torch.softmax(
(q @ k.transpose(-2, -1) / math.sqrt(q.size(-1))),
dim=-1,
)
attn_weight = torch.dropout(attn_weight, 0.1, True)
return attn_weight @ v
class Net_w_mask(nn.Module):
def __init__(self, config):
super().__init__()
def forward(self, q, k, v):
attn_mask = torch.ones(
q.size(-2), k.size(-2), dtype=torch.bool, device=q.device
).tril(diagonal=0)
attn_mask = attn_mask.masked_fill(
torch.logical_not(attn_mask), -float("inf")
)
attn_weight = torch.softmax(
(q @ k.transpose(-2, -1) / math.sqrt(q.size(-1))) + attn_mask,
dim=-1,
)
return attn_weight @ v
def generate_io_tensor():
input_tensors = []
for idx, shape in enumerate(input_shapes):
tensor = torch.rand(shape, dtype=torch.float32, requires_grad=True, device='cuda')
input_tensors.append(tensor)
return input_tensors
config = {'seq_len': 2048, 'num_attn_heads':16, 'batch_size': 4, 'kv_channels': 64}
input_shapes = [(config['batch_size'], config['num_attn_heads'], config['seq_len'], config['kv_channels']),
(config['batch_size'], config['num_attn_heads'], config['seq_len'], config['kv_channels']),
(config['batch_size'], config['num_attn_heads'], config['seq_len'], config['kv_channels'])]
input_tensors = generate_io_tensor()
for inp_tensor in input_tensors:
inp_tensor.grad = None
net = Net(config)
net.cuda()
network_fn = torch.compile(net, fullgraph=True)
from torch._inductor.utils import run_and_get_code
result, (source_code,) = run_and_get_code(
network_fn, *input_tensors)
print(source_code)
net_w_dropout = Net_w_dropout(config)
net_w_dropout.cuda()
network_fn_dropout = torch.compile(net_w_dropout, fullgraph=True)
from torch._inductor.utils import run_and_get_code
result, (source_code,) = run_and_get_code(
network_fn_dropout, *input_tensors)
print(source_code)
net_w_mask = Net_w_mask(config)
net_w_mask.cuda()
network_fn_mask = torch.compile(net_w_mask, fullgraph=True)
from torch._inductor.utils import run_and_get_code
result, (source_code,) = run_and_get_code(
network_fn_mask, *input_tensors)
print(source_code)
```
### Error logs
And here is the output for all the three source code. Only no-mask, no-dropout module gets pattern matched completely.
[debug_fuse_attn_report.log](https://github.com/pytorch/pytorch/files/11369564/debug_fuse_attn_report.log)
### Minified repro
_No response_
### Versions
```
[pip3] numpy==1.23.5
[pip3] pytorch-lightning==1.9.4
[pip3] torch==2.1.0a0+git100a25d
[pip3] torchmetrics==0.11.4
[pip3] torchvision==0.16.0a0+0d75d9e
[pip3] triton==2.1.0
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 3 |
2,727 | 100,448 |
DISABLED test_wait_i_4 (__main__.TestMultiThreadedWait)
|
oncall: distributed, module: flaky-tests, skipped
|
Platforms: linux
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_wait_i_4&suite=TestMultiThreadedWait) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/undefined).
Over the past 3 hours, it has been determined flaky in 11 workflow(s) with 22 failures and 11 successes.
**Debugging instructions (after clicking on the recent samples link):**
DO NOT ASSUME THINGS ARE OKAY IF THE CI IS GREEN. We now shield flaky tests from developers so CI will thus be green but it will be harder to parse the logs.
To find relevant log snippets:
1. Click on the workflow logs linked above
2. Click on the Test step of the job so that it is expanded. Otherwise, the grepping will not work.
3. Grep for `test_wait_i_4`
4. There should be several instances run (as flaky tests are rerun in CI) from which you can study the logs.
Test file path: `distributed/test_store.py` or `distributed/test_store.py`
ConnectionTimeoutError: Connect timeout for 5000ms, GET https://raw.githubusercontent.com/pytorch/pytorch/master/test/distributed/test_store.py -2 (connected: false, keepalive socket: false, socketHandledRequests: 1, socketHandledResponses: 0)
headers: {}
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 7 |
2,728 | 100,425 |
Higher GPU consumption for Lenet-5 and LSTM models when compared to other frameworks
|
module: cuda, module: memory usage, triaged
|
### 🐛 Describe the bug
Hello everybody.
I’ve been experimenting with different models and different frameworks, and I’ve noticed that, when using GPU, training Lenet-5 and LSTM models on the IMDB dataset and the MNIST, respectively, leads to higher GPU usage to the Keras and TensorFlow v1.X implementations. Moreover, I’ve also noticed that higher GPU consumption leads to faster training and inference times, and improved accuracy for the Lenet-5 model, while it leads to a slower training time, faster inference time, and consistent accuracy, when compared to the other frameworks
I'm on a Ubuntu 18.04.4 system equipped with an NVIDIA Quadro RTX 4000 GPU with 8GB of VRAM and an Intel(R) Core(TM) i9-9900K CPU running at 3.60GHz.
Here are boxplots that showcase the performance of numerous Lenet5 and LSTM models. Note that the blue boxplots represent training time while the orange ones represent the inference time:

Any ideas on what may be causing this?
### Versions
The version of relevant libraries are:
numpy==1.19.5
torch==1.10.0
torchaudio==0.10.0
torchvision==0.11.1
mkl==2022.2.1
mkl-fft==1.3.0
mkl-random==1.2.1
mkl-service==2.4.0
cc @ngimel
| 1 |
2,729 | 100,419 |
Subgraph rewriter: Unable to match constant args
|
triaged, module: dynamo
|
**Summary:**
I want to match `nn.Conv2d` with arbitrary strides, paddings, and other constant fields. However, when I try to do this the constants are inlined into the graph, and `replace_pattern` complains that these constant args are dead code (i.e. have no users in the graph). For my use case, both the original model and patterns need to be dynamo exported.
**Minimal repro:**
```
import torch
import torch._dynamo as torchdynamo
import torch.nn.functional as F
from torch.fx import replace_pattern
class M(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv = torch.nn.Conv2d(1, 1, 1, stride=(1, 1), padding=(1, 1))
def forward(self, x):
return self.conv(x)
def match_pattern(x, weight, bias, stride, padding):
return F.conv2d(x, weight, bias, stride, padding)
def replacement_pattern(x, weight, bias, stride, padding):
return F.relu(F.conv2d(x, weight, bias, stride, padding))
model_example_inputs = (torch.randn(1, 1, 3, 3),)
pattern_example_inputs = (
torch.randn(1, 1, 3, 3), # x
torch.randn(1, 1, 1, 1), # weight
torch.randn(1), # bias
(1, 1), # stride
(0, 0), # padding
)
m = M()
m, _ = torchdynamo.export(m, *model_example_inputs, aten_graph=True)
match_pattern , _ = torchdynamo.export(match_pattern, *pattern_example_inputs, aten_graph=True)
replacement_pattern , _ = torchdynamo.export(replacement_pattern, *pattern_example_inputs, aten_graph=True)
replace_pattern(m, match_pattern, replacement_pattern) # This line fails with the following stacktrace
```
**Outcome:**
```
Traceback (most recent call last):
File "/home/andrewor/repro.py", line 33, in <module>
replace_pattern(m, match_pattern, replacement_pattern)
File "/home/andrewor/local/miniconda3/envs/pytorch/lib/python3.9/site-packages/torch/fx/subgraph_rewriter.py", line 195, in replace_pattern
match_and_replacements = _replace_pattern(gm, pattern, replacement)
File "/home/andrewor/local/miniconda3/envs/pytorch/lib/python3.9/site-packages/torch/fx/subgraph_rewriter.py", line 245, in _replace_pattern
matcher = SubgraphMatcher(pattern_graph, match_output=False, match_placeholder=False,
File "/home/andrewor/local/miniconda3/envs/pytorch/lib/python3.9/site-packages/torch/fx/passes/utils/matcher_utils.py", line 81, in __init__
assert len(node.users) > 0, \
AssertionError: SubgraphMatcher cannot be initialized with an pattern with dead code
```
cc @soumith @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 0 |
2,730 | 100,414 |
Can't export onnx model from a torch script model
|
oncall: jit, module: onnx, triaged
|
### 🐛 Describe the bug
Trying to run to do an onnx export of a torch script model, got
RuntimeError: input_values.size() == param_count_list.size() INTERNAL ASSERT FAILED
```
/home/go22670/.conda/envs/torch/lib/python3.10/site-packages/torch/onnx/utils.py:825: UserWarning: no signature found for <torch.ScriptMethod object at 0x7f3115072ac0>, skipping _decide_input_format
warnings.warn(f"{e}, skipping _decide_input_format")
================ Diagnostic Run torch.onnx.export version 2.0.0 ================
verbose: False, log level: Level.ERROR
======================= 0 NONE 0 NOTE 0 WARNING 0 ERROR ========================
Traceback (most recent call last):
File "/home/go22670/Projects/test2/test.py", line 25, in <module>
out, vad, enhFile = enh.process(file,outFile=myout)
File "/home/go22670/Projects/test2/src/ourcode/enhance.py", line 242, in process
self.convert(self.model, tWin)
File "/home/go22670/Projects/test2/src/ourcode/enhance.py", line 184, in convert
Th.onnx.export(model, input, seamnet_onnx, verbose=True, input_names=input_names, output_names=output_names)
File "/home/go22670/.conda/envs/torch/lib/python3.10/site-packages/torch/onnx/utils.py", line 506, in export
_export(
File "/home/go22670/.conda/envs/torch/lib/python3.10/site-packages/torch/onnx/utils.py", line 1548, in _export
graph, params_dict, torch_out = _model_to_graph(
File "/home/go22670/.conda/envs/torch/lib/python3.10/site-packages/torch/onnx/utils.py", line 1113, in _model_to_graph
graph, params, torch_out, module = _create_jit_graph(model, args)
File "/home/go22670/.conda/envs/torch/lib/python3.10/site-packages/torch/onnx/utils.py", line 974, in _create_jit_graph
graph = _C._propagate_and_assign_input_shapes(
RuntimeError: input_values.size() == param_count_list.size() INTERNAL ASSERT FAILED at "/opt/conda/conda-bld/pytorch_1678402411778/work/torch/csrc/jit/ir/graph_utils.cpp":57, please report a bug to PyTorch. input_values:194 vs param_count_list:193
```
I wish I could provide a minimal example, but our network is pretty big.
### Versions
```
Collecting environment information...
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Red Hat Enterprise Linux 8.7 (Ootpa) (x86_64)
GCC version: (GCC) 8.5.0 20210514 (Red Hat 8.5.0-15)
Clang version: Could not collect
CMake version: version 3.20.2
Libc version: glibc-2.28
Python version: 3.10.11 (main, Apr 20 2023, 19:02:41) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-4.18.0-425.3.1.el8.x86_64-x86_64-with-glibc2.28
Is CUDA available: True
CUDA runtime version: 11.1.105
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: GRID A100-40C
GPU 1: GRID A100-40C
Nvidia driver version: 510.85.02
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 1
Core(s) per socket: 2
Socket(s): 8
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 25
Model: 1
Model name: AMD EPYC 7713 64-Core Processor
Stepping: 1
CPU MHz: 1996.249
BogoMIPS: 3992.49
Hypervisor vendor: VMware
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 512K
L3 cache: 32768K
NUMA node0 CPU(s): 0-15
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl tsc_reliable nonstop_tsc cpuid extd_apicid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm cmp_legacy extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw topoext invpcid_single ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves clzero wbnoinvd arat umip pku ospke vaes vpclmulqdq rdpid overflow_recov succor
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.0
[pip3] torchvision==0.15.0
[pip3] triton==2.0.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-fft 1.3.1 pypi_0 pypi
[conda] mkl-random 1.2.2 pypi_0 pypi
[conda] mkl-service 2.4.0 pypi_0 pypi
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.5 pypi_0 pypi
[conda] numpy-base 1.23.5 py310h8e6c178_0
[conda] pytorch 2.0.0 py3.10_cuda11.8_cudnn8.7.0_0 pytorch
[conda] pytorch-cuda 11.8 h7e8668a_3 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torch 2.0.0 pypi_0 pypi
[conda] torchaudio 2.0.0 pypi_0 pypi
[conda] torchtriton 2.0.0 py310 pytorch
[conda] torchvision 0.15.0 pypi_0 pypi
[conda] triton 2.0.0 pypi_0 pypi
```
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 2 |
2,731 | 100,411 |
Sparse Matrix nnz Overflow when casting from COO to CSR
|
module: sparse, triaged
|
### 🐛 Describe the bug
Casting torch.sparse_coo_tensor to torch.sparse_csr_tensor with .to_sparse_csr() causes an integer overflow in nnz for sufficiently large tensors. See below example where COO tensor has nnz = 3_000_000_000, and CSR tensor has nnz=-1294967296 (expected overflow result from int32).
```python
# sample code to reproduce the problem
nnz = 3_000_000_000
coo_idxs = torch.stack([torch.arange(nnz),torch.zeros(nnz,dtype=torch.long)])
coo_vals = torch.ones(nnz,dtype=torch.long)
coo_tensor = torch.sparse_coo_tensor(coo_idxs,coo_vals)
print(coo_tensor) # has correct nnz
csr_tensor = coo_tensor.to_sparse_csr()
print(csr_tensor) # has negative nnz due to overflow
```
### Versions
Collecting environment information...
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.17
Python version: 3.7.13 (default, Mar 29 2022, 02:18:16) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-3.10.0-1160.88.1.el7.x86_64-x86_64-with-debian-buster-sid
Is CUDA available: False
CUDA runtime version: 11.3.109
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-80GB
GPU 1: NVIDIA A100-SXM4-80GB
GPU 2: NVIDIA A100-SXM4-80GB
GPU 3: NVIDIA DGX Display
GPU 4: NVIDIA A100-SXM4-80GB
Nvidia driver version: 470.129.06
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.2.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.2.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.2.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.2.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.2.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.2.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.2.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 2
Core(s) per socket: 64
Socket(s): 1
NUMA node(s): 4
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7742 64-Core Processor
Stepping: 0
CPU MHz: 2250.000
CPU max MHz: 2250.0000
CPU min MHz: 1500.0000
BogoMIPS: 4491.74
Virtualization: AMD-V
L1d cache: 32K
L1i cache: 32K
L2 cache: 512K
L3 cache: 16384K
NUMA node0 CPU(s): 0-15,64-79
NUMA node1 CPU(s): 16-31,80-95
NUMA node2 CPU(s): 32-47,96-111
NUMA node3 CPU(s): 48-63,112-127
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc art rep_good nopl nonstop_tsc extd_apicid aperfmperf eagerfpu pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_l2 cpb cat_l3 cdp_l3 hw_pstate sme ssbd rsb_ctxsw ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip overflow_recov succor smca
Versions of relevant libraries:
[pip3] numpy==1.21.5
[pip3] torch==1.12.1
[pip3] torchtext==0.13.1
[pip3] torchvision==0.13.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 ha36c431_9 nvidia
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py37h7f8727e_0
[conda] mkl_fft 1.3.1 py37hd3c417c_0
[conda] mkl_random 1.2.2 py37h51133e4_0
[conda] numpy 1.21.5 py37he7a7128_2
[conda] numpy-base 1.21.5 py37hf524024_2
[conda] pytorch 1.12.1 py3.7_cuda11.3_cudnn8.3.2_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchtext 0.13.1 py37 pytorch
[conda] torchvision 0.13.1 py37_cu113 pytorch
cc @alexsamardzic @nikitaved @pearu @cpuhrsch @amjames @bhosmer
| 2 |
2,732 | 100,386 |
Stop importing HuggingFace transformers in DataClassVariable
|
triaged, oncall: pt2, module: dynamo, module: startup time
|
### 🐛 Describe the bug
There are some HF specific hacks here:
```
class DataClassVariable(ConstDictVariable):
"""
This is a bit of a hack to deal with
transformers.file_utils.ModelOutput() from huggingface.
ModelOutput causes trouble because it a a mix of a dataclass and a
OrderedDict and it calls super() methods implemented in C.
"""
# ModelOutput() excludes None, though generic datclasses don't
include_none = False
@staticmethod
@functools.lru_cache(None)
def _patch_once():
from transformers.file_utils import ModelOutput
for obj in ModelOutput.__dict__.values():
if callable(obj):
skip_code(obj.__code__)
@staticmethod
def is_matching_cls(cls):
try:
from transformers.file_utils import ModelOutput
return issubclass(cls, ModelOutput)
except ImportError:
return False
```
Importing transformers takes about 0.5s; it would be much better if we could avoid importing it at all if the model in question doesn't involve transformers.
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 1 |
2,733 | 100,385 |
Import setuptools.command.build_ext from torch.utils.cpp_extension somehow indirectly imports Cython when it is installed
|
triaged, oncall: pt2, module: startup time
|
### 🐛 Describe the bug
I noticed this when inspecting profiles of a simple torch.compile invocation. cpp_extension is pulled in by torch/_inductor/codecache.py. I'm not exactly sure why Cython is automatically getting imported from setuptools. The Cython import is somewhat expensive. A dirty workaround that saves you a half second or so is to uninstall Cython.
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
2,734 | 100,378 |
VecISA.__bool__ is very expensive (nearly a second) on startup
|
triaged, oncall: pt2, module: cpu inductor, module: startup time
|
### 🐛 Describe the bug
VecISA currently requires compiling a cpp program to test for capabilities, similar to `./configure`. We do this compilation **on every new process invocation**, dissimilar to `./configure`. After performing the capability query, we should cache it and reuse the cache entry. This will save us about 1s cold start time on CPU inductor.
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
2,735 | 100,376 |
_sfdp_init is extremely expensive for startup time, even on networks that don't benefit from it
|
triaged, oncall: pt2, module: startup time
|
### 🐛 Describe the bug
<img width="1488" alt="image" src="https://user-images.githubusercontent.com/13564/235464215-6867ef63-1cdf-4054-a622-d5da14642e18.png">
In this speedscope profile, compiling a relatively trivial CPU program from cold start, sfdp_init is taking up a whopping three seconds, out of eight seconds end to end compile time.
To reproduce, I was just profiling this script:
```
import torch
import torch._dynamo
torch._inductor.config.cpp.inject_relu_bug_TESTING_ONLY = 'accuracy'
torch._dynamo.config.repro_after = "aot"
torch._dynamo.config.repro_level = 4
torch._dynamo.config.debug_dir_root = "/tmp/tmp5qmh2x01"
@torch.compile()
def inner(x):
for _ in range(3):
x = torch.sin(x)
x = torch.relu(x)
for _ in range(3):
x = torch.cos(x)
return x
inner(torch.randn(20, 20).to("cpu"))
```
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @jansel
### Versions
master
| 1 |
2,736 | 100,370 |
[BUG] add 1 to different tensor but get same value
|
triaged, module: correctness (silent), module: mps
|
## Issue description
Generating a list of random tensors using device mps (M2 gpu), then I add a value on each by index, but it feedbacks the same value. Which means `data[1] + 1 = data[2] + 1` but of course `data[1]` is not equal to `data[2]`
So so so weird!!!
## Code example
```
import torch
d = torch.randint(0, 50000, size=(32, ), device=torch.device("mps"))
# d = torch.rand(size=(32, ), device=torch.device("mps"))
print(d)
print(d.dtype)
print("d1", d[1])
print("d1 + 1", d[1] + 1)
print("d2", d[2])
print("d2 + 1", d[2] + 1)
```
the output is
```
tensor([ 6343, 1605, 28616, 2264, 12151, 13417, 1629, 32512, 4441, 43177,
6520, 18301, 3608, 35951, 17655, 6629, 21160, 35743, 44574, 16854,
24114, 26402, 16203, 26529, 45812, 46216, 19513, 30223, 37758, 14296,
5785, 19335], device='mps:0')
torch.int64
d1 tensor(1605, device='mps:0')
d1 + 1 tensor(6344, device='mps:0')
d2 tensor(28616, device='mps:0')
d2 + 1 tensor(6344, device='mps:0')
```
So when you add 1 on each item in the tensor, it gives back the same value.
other Arithmetic operations are not correct as well
```
import torch
d = torch.randint(0, 50000, size=(32, ), device=torch.device("mps"))
# d = torch.rand(size=(32, ), device=torch.device("mps"))
print(d)
print(d.dtype)
print("d1", d[1])
print("d1 * 2", d[1] * 2)
print("d2", d[2])
print("d2 * 2", d[2] * 2)
```
## System Info
PyTorch version: 1.13.0.dev20220718
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.3 (arm64)
GCC version: Could not collect
Clang version: 14.0.3 (clang-1403.0.22.14.1)
CMake version: Could not collect
Libc version: N/A
Python version: 3.9.12 (main, Apr 5 2022, 01:52:34) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-13.3-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M2
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
2,737 | 100,366 |
some of the enteries in the previous version of pytorch section are invalid
|
oncall: binaries, module: docs
|
### 🐛 Describe the bug
The links used for installing some of the previous versions of pytorch are invalid and fail to install the packages.
1.10.0 and 1.9.0 have these issues.
For example to install 1.10.0+cu113 or 1.10.0+cu111 the following given statements fail:
```
# CUDA 11.3
pip install torch==1.10.0+cu113 torchvision==0.11.0+cu113 torchaudio==0.10.0 -f https://download.pytorch.org/whl/torch_stable.html
```
Or
```
# CUDA 11.1
pip install torch==1.10.0+cu111 torchvision==0.11.0+cu111 torchaudio==0.10.0 -f https://download.pytorch.org/whl/torch_stable.html
```
To fix that the url at the end must be fixed accordingly so the following now work:
```
# CUDA 11. 3
pip install torch==1.10.0+cu113 torchvision==0.11.0+cu113 torchaudio==0.10.0 -f https://download.pytorch.org/whl/cu113/torch_stable.html
```
```
# CUDA 11. 3
pip install torch==1.10.0+cu111 torchvision==0.11.0+cu111 torchaudio==0.10.0 -f https://download.pytorch.org/whl/cu111/torch_stable.html
```
### Versions
1.10.0, 1.9.0
cc @seemethere @malfet @svekars @carljparker
| 1 |
2,738 | 100,358 |
Tensor on shared memory is set to 0 when using concurrent.futures and CUDA
|
oncall: distributed, triaged
|
### 🐛 Describe the bug
The following code works perfectly on CPU. On CUDA, the second print shows that the weights are all 0.
If I pass `l` to `goo` through the pool, then in the thread its weights are 0. Without the pool it works.
This happens only on CUDA.
```
import torch
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import ProcessPoolExecutor
from torch import multiprocessing as mp
def goo(l):
return l(torch.rand(2, device='cuda'))
def run():
ctx = mp.get_context('spawn')
pool1 = ProcessPoolExecutor(1)
l = torch.nn.Linear(2, 2).to('cuda').share_memory()
print(vars(l))
pool1.submit(goo, l)
def foo():
print(vars(l))
thread = ThreadPoolExecutor(1)
thread.submit(foo)
if __name__ == '__main__':
run()
```
### Versions
This is on a Windows computer, but the issue happens also on a SLURM-based cluster with older version of python and pytorch.
Collecting environment information...
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 11 Home
GCC version: Could not collect
Clang version: Could not collect
CMake version: Could not collect
Libc version: N/A
Python version: 3.10.9 | packaged by conda-forge | (main, Jan 11 2023, 15:15:40) [MSC v.1916 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.22621-SP0
Is CUDA available: True
CUDA runtime version: 12.0.76
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1650 with Max-Q Design
Nvidia driver version: 527.41
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture=9
CurrentClockSpeed=2000
DeviceID=CPU0
Family=198
L2CacheSize=7680
L2CacheSpeed=
Manufacturer=GenuineIntel
MaxClockSpeed=2000
Name=12th Gen Intel(R) Core(TM) i7-1280P
ProcessorType=3
Revision=
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] numpy-quaternion==2022.4.2
[pip3] pytorch-lightning==2.0.2
[pip3] pytorch-memlab==0.2.4
[pip3] torch==2.0.0
[pip3] torch-tb-profiler==0.4.1
[pip3] torchaudio==2.0.0
[pip3] torchmetrics==0.11.4
[pip3] torchvision==0.15.0
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 haa95532_640
[conda] mkl-service 2.4.0 py310h2bbff1b_0
[conda] mkl_fft 1.3.1 py310ha0764ea_0
[conda] mkl_random 1.2.2 py310h4ed8f06_0
[conda] numpy 1.23.5 py310h60c9a35_0
[conda] numpy-base 1.23.5 py310h04254f7_0
[conda] numpy-quaternion 2022.4.2 pypi_0 pypi
[conda] pytorch 2.0.0 py3.10_cuda11.7_cudnn8_0 pytorch
[conda] pytorch-cuda 11.7 h16d0643_3 pytorch
[conda] pytorch-lightning 2.0.2 pypi_0 pypi
[conda] pytorch-memlab 0.2.4 pypi_0 pypi
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torch 1.13.1 pypi_0 pypi
[conda] torch-tb-profiler 0.4.1 pypi_0 pypi
[conda] torchaudio 2.0.0 pypi_0 pypi
[conda] torchmetrics 0.11.4 pypi_0 pypi
[conda] torchvision 0.15.0 pypi_0 pypi
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
2,739 | 100,347 |
nn.MultiheadAttention doesn't use efficient scaled_dot_product_attention
|
module: docs, oncall: transformer/mha
|
### 📚 The doc issue
The default `forward()` of `nn.MultiheadAttention` has `need_weights==True`. But in this case `scaled_dot_product_attention` does not use one of the efficient fused kernels and silently uses the native implementation. It would be good if this was documented since it took me a while to figure out why I was not seeing the expected performance.
### Suggest a potential alternative/fix
_No response_
cc @svekars @carljparker @jbschlosser @bhosmer @cpuhrsch @erichan1 @drisspg
| 2 |
2,740 | 100,343 |
[torch.compile] `sum` out-of-bound read
|
triaged, module: cpu inductor
|
### 🐛 Describe the bug
`torch.compile` makes `sum` out-of-bound read
```py
import torch
torch.manual_seed(420)
batch_size = 2
input_tensor = torch.randn((batch_size, 10))
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.idx = torch.tensor([[1, 3, 2],[1, 4, 3]])
def forward(self, x):
return torch.sum(x[self.idx], dim=1)
func = Model().to('cpu')
test_inputs = [input_tensor]
with torch.no_grad():
func.train(False)
jit_func = torch.compile(func)
res2 = jit_func(input_tensor)
print(res2)
# success, out-of-bound read
# tensor([[ 6.1276e-01, -9.3005e-01, 1.3646e+00, -7.3723e-01, -7.0839e-01,
# -2.8423e-01, -1.4816e+00, 3.2976e-01, 4.8557e-01, 4.1309e-01],
# [ 6.1276e-01, -9.3005e-01, 1.3646e+00, nan, -7.0839e-01,
# -1.7412e+38, -1.4816e+00, nan, 4.8557e-01, 4.1309e-01]])
func(input_tensor) # without jit
# IndexError: index 3 is out of bounds for dimension 0 with size 2
```
### Versions
```
Collecting environment information...
PyTorch version: 2.1.0.dev20230419+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 14.0.0-1ubuntu1
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.9.16 (main, Mar 8 2023, 14:00:05) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.19.5-051905-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.5.119
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3060
Nvidia driver version: 510.108.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Vendor ID: GenuineIntel
Model name: 12th Gen Intel(R) Core(TM) i9-12900K
CPU family: 6
Model: 151
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
Stepping: 2
CPU max MHz: 6700.0000
CPU min MHz: 800.0000
BogoMIPS: 6374.40
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault cat_l2 invpcid_single cdp_l2 ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid rdt_a rdseed adx smap clflushopt clwb intel_pt sha_ni xsaveopt xsavec xgetbv1 xsaves split_lock_detect avx_vnni dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp hwp_pkg_req hfi umip pku ospke waitpkg gfni vaes vpclmulqdq tme rdpid movdiri movdir64b fsrm md_clear serialize pconfig arch_lbr ibt flush_l1d arch_capabilities
Virtualization: VT-x
L1d cache: 640 KiB (16 instances)
L1i cache: 768 KiB (16 instances)
L2 cache: 14 MiB (10 instances)
L3 cache: 30 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-23
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.1.0+46672772b4
[pip3] torch==2.1.0.dev20230419+cu118
[pip3] torchaudio==2.1.0.dev20230419+cu118
[pip3] torchvision==0.16.0.dev20230419+cu118
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-triton 2.1.0+46672772b4 pypi_0 pypi
[conda] torch 2.1.0.dev20230419+cu118 pypi_0 pypi
[conda] torchaudio 2.1.0.dev20230419+cu118 pypi_0 pypi
[conda] torchvision 0.16.0.dev20230419+cu118 pypi_0 pypi
```
| 8 |
2,741 | 100,334 |
MPS device inference all same value
|
triaged, module: mps
|
### 🐛 Describe the bug
Hi all,
I have the problem where inference in my model gives different results if I use `mps` device. The inference result are all the same, just for instance. I will share 2 images, they are using **cpu** and **mps** respectively. (The code is exactly the same, except the device ofc)
<img width="619" alt="torch-cpu" src="https://user-images.githubusercontent.com/3484029/235360481-ee0982b7-75f1-42c1-95b2-7416baa04b3e.png">
<img width="617" alt="torch-mps" src="https://user-images.githubusercontent.com/3484029/235360488-f58e4b97-a1ef-4289-9304-78f1085a3dcb.png">
### Versions
ollecting environment information...
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.3.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.3 (clang-1403.0.22.14.1)
CMake version: Could not collect
Libc version: N/A
Python version: 3.11.0 | packaged by conda-forge | (main, Oct 25 2022, 06:21:25) [Clang 14.0.4 ] (64-bit runtime)
Python platform: macOS-13.3.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M1 Pro
Versions of relevant libraries:
[pip3] numpy==1.24.3
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.1
[pip3] torchvision==0.15.1
[conda] numpy 1.24 py311hb8f3215_0 conda-forge
[conda] torch 2.0.0 pypi_0 pypi
[conda] torchaudio 2.0.1 pypi_0 pypi
[conda] torchvision 0.15.1 pypi_0 pypi
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 3 |
2,742 | 100,331 |
[inductor] Move loop ordering after fusion
|
topic: not user facing, module: inductor, module: dynamo, ciflow/inductor, ciflow/inductor-perf-compare
|
Stack from [ghstack](https://github.com/ezyang/ghstack) (oldest at bottom):
* #108755
* __->__ #100331
* #108193
cc @soumith @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 6 |
2,743 | 100,320 |
Compiled function inside vmap
|
triaged, oncall: pt2, module: functorch, module: aotdispatch
|
### 🐛 Describe the bug
It seems like vmap can work inside `torch.compile` (https://github.com/pytorch/pytorch/issues/100105, https://github.com/pytorch/pytorch/issues/98822), but in my tests the other way around seems not to work, which would be a wonderful thing to have.
### Error logs
```
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py:324, in _compile(code, globals, locals, builtins, compiler_fn, one_graph, export, hooks, frame)
323 try:
--> 324 out_code = transform_code_object(code, transform)
325 orig_code_map[out_code] = code
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/bytecode_transformation.py:445, in transform_code_object(code, transformations, safe)
443 propagate_line_nums(instructions)
--> 445 transformations(instructions, code_options)
446 return clean_and_assemble_instructions(instructions, keys, code_options)[1]
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py:299, in _compile.<locals>.transform(instructions, code_options)
298 nonlocal output
--> 299 tracer = InstructionTranslator(
300 instructions,
301 code,
302 locals,
303 globals,
304 builtins,
305 code_options,
306 compiler_fn,
307 one_graph,
308 export,
309 mutated_closure_cell_contents,
310 )
311 tracer.run()
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py:1670, in InstructionTranslator.__init__(self, instructions, f_code, f_locals, f_globals, f_builtins, code_options, compiler_fn, one_graph, export, mutated_closure_cell_contents)
1668 vars.extend(x for x in self.cell_and_freevars() if x not in vars)
-> 1670 self.symbolic_locals = collections.OrderedDict(
1671 (
1672 k,
1673 VariableBuilder(
1674 self,
1675 LocalInputSource(k, code_options["co_varnames"].index(k))
1676 if k in code_options["co_varnames"]
1677 else LocalSource((k)),
1678 )(f_locals[k]),
1679 )
1680 for k in vars
1681 if k in f_locals
1682 )
1684 # symbolic_locals contains the mapping from original f_locals to the
1685 # Variable objects. During the Variable building phase, each object also
1686 # has its associated guards. At the end, we will accumulate these
(...)
1699 # next invocation when args is not a list, and args[0] is a runtime
1700 # error. Therefore, we recursively add guards for list/dict variable here.
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py:1673, in <genexpr>(.0)
1668 vars.extend(x for x in self.cell_and_freevars() if x not in vars)
1670 self.symbolic_locals = collections.OrderedDict(
1671 (
1672 k,
-> 1673 VariableBuilder(
1674 self,
1675 LocalInputSource(k, code_options["co_varnames"].index(k))
1676 if k in code_options["co_varnames"]
1677 else LocalSource((k)),
1678 )(f_locals[k]),
1679 )
1680 for k in vars
1681 if k in f_locals
1682 )
1684 # symbolic_locals contains the mapping from original f_locals to the
1685 # Variable objects. During the Variable building phase, each object also
1686 # has its associated guards. At the end, we will accumulate these
(...)
1699 # next invocation when args is not a list, and args[0] is a runtime
1700 # error. Therefore, we recursively add guards for list/dict variable here.
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/variables/builder.py:172, in VariableBuilder.__call__(self, value)
171 return self.tx.output.side_effects[value]
--> 172 return self._wrap(value).clone(**self.options())
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/variables/builder.py:238, in VariableBuilder._wrap(self, value)
237 if istensor(value):
--> 238 return self.wrap_tensor(value)
239 elif istype(value, (tuple, list, odict_values)) or is_namedtuple(value):
240 # One can index a tensor with a list/tuple. Therefore, we need to
241 # have a stricter match.
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/variables/builder.py:639, in VariableBuilder.wrap_tensor(self, value)
636 tensor_proxy = self.tx.output.create_graph_input(
637 re.sub(r"[^a-zA-Z0-9]+", "_", self.name), type(value)
638 )
--> 639 tensor_variable = wrap_fx_proxy(
640 tx=self.tx,
641 proxy=tensor_proxy,
642 example_value=value,
643 guards=self.make_guards(GuardBuilder.TENSOR_MATCH),
644 should_specialize=self.tensor_should_specialize(),
645 ignore_subclass=ignore_subclass,
646 source=self.get_source(),
647 )
648 assert "tensor_dict" not in tensor_proxy.node.meta
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/variables/builder.py:754, in wrap_fx_proxy(tx, proxy, example_value, **options)
753 def wrap_fx_proxy(tx, proxy, example_value=None, **options):
--> 754 return wrap_fx_proxy_cls(
755 target_cls=TensorVariable,
756 tx=tx,
757 proxy=proxy,
758 example_value=example_value,
759 **options,
760 )
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/variables/builder.py:814, in wrap_fx_proxy_cls(target_cls, tx, proxy, example_value, ignore_subclass, **options)
813 kwargs["source"] = options["source"]
--> 814 example_value = wrap_to_fake_tensor_and_record(
815 example_value, tx=tx, **kwargs
816 )
818 if isinstance(example_value, torch.Tensor):
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/variables/builder.py:957, in wrap_to_fake_tensor_and_record(e, tx, ignore_subclass, source, is_tensor)
951 static_shapes = (
952 source is None
953 or type(e) is torch.nn.Parameter
954 or config.dynamic_shapes is False
955 or not is_tensor
956 )
--> 957 fake_e = wrap_fake_exception(
958 lambda: tx.fake_mode.from_tensor(
959 e,
960 static_shapes=static_shapes,
961 ignore_subclass=ignore_subclass,
962 source=source,
963 )
964 )
965 if is_tensor:
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/utils.py:808, in wrap_fake_exception(fn)
807 try:
--> 808 return fn()
809 except UnsupportedFakeTensorException as e:
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/variables/builder.py:958, in wrap_to_fake_tensor_and_record.<locals>.<lambda>()
951 static_shapes = (
952 source is None
953 or type(e) is torch.nn.Parameter
954 or config.dynamic_shapes is False
955 or not is_tensor
956 )
957 fake_e = wrap_fake_exception(
--> 958 lambda: tx.fake_mode.from_tensor(
959 e,
960 static_shapes=static_shapes,
961 ignore_subclass=ignore_subclass,
962 source=source,
963 )
964 )
965 if is_tensor:
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_subclasses/fake_tensor.py:1324, in FakeTensorMode.from_tensor(self, tensor, static_shapes, ignore_subclass, source)
1323 if static_shapes:
-> 1324 return self.fake_tensor_converter(
1325 self, tensor, ignore_subclass=ignore_subclass, source=source
1326 )
1327 return self.fake_tensor_converter(
1328 self,
1329 tensor,
(...)
1332 source=source,
1333 )
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_subclasses/fake_tensor.py:314, in FakeTensorConverter.__call__(self, fake_mode, t, make_constant, shape_env, ignore_subclass, source)
304 def __call__(
305 self,
306 fake_mode,
(...)
312 source=None,
313 ):
--> 314 return self.from_real_tensor(
315 fake_mode,
316 t,
317 make_constant,
318 shape_env=shape_env,
319 ignore_subclass=ignore_subclass,
320 source=source,
321 )
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_subclasses/fake_tensor.py:272, in FakeTensorConverter.from_real_tensor(self, fake_mode, t, make_constant, shape_env, ignore_subclass, source)
265 return FakeTensor(
266 fake_mode,
267 make_meta_t(),
268 existing_device,
269 constant=t if make_constant else None,
270 )
--> 272 out = self.meta_converter(
273 t,
274 shape_env=shape_env,
275 callback=mk_fake_tensor,
276 ignore_subclass=ignore_subclass,
277 source=source,
278 )
279 if out is NotImplemented:
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_subclasses/meta_utils.py:502, in MetaConverter.__call__(self, t, shape_env, callback, ignore_subclass, source)
501 with ctx:
--> 502 r = self.meta_tensor(
503 t, shape_env=shape_env, callback=callback, source=source
504 )
505 # TODO: this is suspicious, now that we have callback argument
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_subclasses/meta_utils.py:381, in MetaConverter.meta_tensor(self, t, shape_env, callback, source)
379 r = r.clone(memory_format=torch.preserve_format)
--> 381 s = t.untyped_storage()
382 swr = StorageWeakRef(s)
NotImplementedError: Cannot access storage of BatchedTensorImpl
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
The above exception was the direct cause of the following exception:
InternalTorchDynamoError Traceback (most recent call last)
Cell In[7], line 3
1 xs = torch.ones(10, 3)
2 vmap_norm = vmap(norm)
----> 3 vmap_norm(xs)
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_functorch/vmap.py:434, in vmap.<locals>.wrapped(*args, **kwargs)
430 return _chunked_vmap(func, flat_in_dims, chunks_flat_args,
431 args_spec, out_dims, randomness, **kwargs)
433 # If chunk_size is not specified.
--> 434 return _flat_vmap(
435 func, batch_size, flat_in_dims, flat_args, args_spec, out_dims, randomness, **kwargs
436 )
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_functorch/vmap.py:39, in doesnt_support_saved_tensors_hooks.<locals>.fn(*args, **kwargs)
36 @functools.wraps(f)
37 def fn(*args, **kwargs):
38 with torch.autograd.graph.disable_saved_tensors_hooks(message):
---> 39 return f(*args, **kwargs)
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_functorch/vmap.py:619, in _flat_vmap(func, batch_size, flat_in_dims, flat_args, args_spec, out_dims, randomness, **kwargs)
617 try:
618 batched_inputs = _create_batched_inputs(flat_in_dims, flat_args, vmap_level, args_spec)
--> 619 batched_outputs = func(*batched_inputs, **kwargs)
620 return _unwrap_batched(batched_outputs, out_dims, vmap_level, batch_size, func)
621 finally:
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py:209, in _TorchDynamoContext.__call__.<locals>._fn(*args, **kwargs)
207 dynamic_ctx.__enter__()
208 try:
--> 209 return fn(*args, **kwargs)
210 finally:
211 set_eval_frame(prior)
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py:337, in catch_errors_wrapper.<locals>.catch_errors(frame, cache_size)
334 return hijacked_callback(frame, cache_size, hooks)
336 with compile_lock:
--> 337 return callback(frame, cache_size, hooks)
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py:404, in convert_frame.<locals>._convert_frame(frame, cache_size, hooks)
402 counters["frames"]["total"] += 1
403 try:
--> 404 result = inner_convert(frame, cache_size, hooks)
405 counters["frames"]["ok"] += 1
406 return result
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py:104, in wrap_convert_context.<locals>._fn(*args, **kwargs)
102 torch.fx.graph_module._forward_from_src = fx_forward_from_src_skip_result
103 try:
--> 104 return fn(*args, **kwargs)
105 finally:
106 torch._C._set_grad_enabled(prior_grad_mode)
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py:262, in convert_frame_assert.<locals>._convert_frame_assert(frame, cache_size, hooks)
259 global initial_grad_state
260 initial_grad_state = torch.is_grad_enabled()
--> 262 return _compile(
263 frame.f_code,
264 frame.f_globals,
265 frame.f_locals,
266 frame.f_builtins,
267 compiler_fn,
268 one_graph,
269 export,
270 hooks,
271 frame,
272 )
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/utils.py:163, in dynamo_timed.<locals>.dynamo_timed_inner.<locals>.time_wrapper(*args, **kwargs)
161 compilation_metrics[key] = []
162 t0 = time.time()
--> 163 r = func(*args, **kwargs)
164 time_spent = time.time() - t0
165 # print(f"Dynamo timer: key={key}, latency={latency:.2f} sec")
File ~/mambaforge/envs/b/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py:394, in _compile(code, globals, locals, builtins, compiler_fn, one_graph, export, hooks, frame)
392 except Exception as e:
393 exception_handler(e, code, frame)
--> 394 raise InternalTorchDynamoError() from e
InternalTorchDynamoError:
```
### Minified repro
```python
import torch
from torch import vmap
@torch.compile
def norm(g):
return torch.linalg.norm(g)
norm(torch.ones(3)) # => works, tensor(1.7321)
# fails with error in log
xs = torch.ones(10, 3)
vmap_norm = vmap(norm)
vmap_norm(xs)
```
### Versions
Collecting environment information...
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.2.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: version 3.25.2
Libc version: N/A
Python version: 3.10.10 | packaged by conda-forge | (main, Mar 24 2023, 20:12:31) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-13.2.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M1 Pro
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.0
[pip3] torchvision==0.15.0
[conda] numpy 1.23.5 py310hb93e574_0
[conda] numpy-base 1.23.5 py310haf87e8b_0
[conda] pytorch 2.0.0 py3.10_0 pytorch
[conda] torchaudio 2.0.0 py310_cpu pytorch
[conda] torchvision 0.15.0 py310_cpu pytorch
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @zou3519 @Chillee @samdow @kshitij12345 @janeyx99
| 2 |
2,744 | 100,316 |
[torch.compile] raises RuntimeError in `sdfp_pattern_1` that `Expected size for first two dimensions of batch2 tensor`
|
triaged, oncall: pt2, module: inductor, inductor_pattern_match
|
### 🐛 Describe the bug
`torch.compile` raises RuntimeError in `sdfp_pattern_1` that `Expected size for first two dimensions of batch2 tensor`
```py
import torch
torch.manual_seed(420)
class Attention(torch.nn.Module):
def __init__(self, hidden_size, num_heads):
super(Attention, self).__init__()
self.hidden_size = hidden_size
self.num_heads = num_heads
self.head_size = hidden_size // num_heads
self.query = torch.nn.Linear(hidden_size, hidden_size)
self.key = torch.nn.Linear(hidden_size, hidden_size)
self.value = torch.nn.Linear(hidden_size, hidden_size)
self.inv_scale = torch.nn.Parameter(torch.Tensor([1 / self.head_size ** 0.5]), requires_grad=False)
def forward(self, x):
query = self.query(x)
key = self.key(x)
value = self.value(x)
(batch_size, seq_len, hidden_size) = query.size()
query = query.view(batch_size, seq_len, self.num_heads, self.head_size).permute(0, 2, 1, 3)
key = key.view(batch_size, seq_len, self.num_heads, self.head_size).permute(0, 2, 3, 1)
value = value.view(batch_size, seq_len, self.num_heads, self.head_size).permute(0, 2, 1, 3)
attention_weights = torch.matmul(query, key).div(self.inv_scale).softmax(dim=-1)
# print(attention_weights.shape)
# print(value.shape)
output = torch.matmul(attention_weights, value)
return output
hidden_size = 16
num_heads = 1
seq_len = 4
batch_size = 1
x = torch.randn(batch_size, seq_len, hidden_size)
func = Attention(hidden_size, num_heads).to('cpu')
with torch.no_grad():
res1 = func(x)
print(res1)
jit_func = torch.compile(func)
res2 = jit_func(x)
print(res2)
# RuntimeError: Expected size for first two dimensions of batch2 tensor to be: [4, 1] but got: [4, 4].
```
### Versions
```
Collecting environment information...
PyTorch version: 2.1.0.dev20230419+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 14.0.0-1ubuntu1
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.9.16 (main, Mar 8 2023, 14:00:05) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.19.5-051905-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.5.119
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3060
Nvidia driver version: 510.108.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Vendor ID: GenuineIntel
Model name: 12th Gen Intel(R) Core(TM) i9-12900K
CPU family: 6
Model: 151
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
Stepping: 2
CPU max MHz: 6700.0000
CPU min MHz: 800.0000
BogoMIPS: 6374.40
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault cat_l2 invpcid_single cdp_l2 ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid rdt_a rdseed adx smap clflushopt clwb intel_pt sha_ni xsaveopt xsavec xgetbv1 xsaves split_lock_detect avx_vnni dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp hwp_pkg_req hfi umip pku ospke waitpkg gfni vaes vpclmulqdq tme rdpid movdiri movdir64b fsrm md_clear serialize pconfig arch_lbr ibt flush_l1d arch_capabilities
Virtualization: VT-x
L1d cache: 640 KiB (16 instances)
L1i cache: 768 KiB (16 instances)
L2 cache: 14 MiB (10 instances)
L3 cache: 30 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-23
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.1.0+46672772b4
[pip3] torch==2.1.0.dev20230419+cu118
[pip3] torchaudio==2.1.0.dev20230419+cu118
[pip3] torchvision==0.16.0.dev20230419+cu118
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-triton 2.1.0+46672772b4 pypi_0 pypi
[conda] torch 2.1.0.dev20230419+cu118 pypi_0 pypi
[conda] torchaudio 2.1.0.dev20230419+cu118 pypi_0 pypi
[conda] torchvision 0.16.0.dev20230419+cu118 pypi_0 pypi
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 1 |
2,745 | 100,310 |
Using ddp training with different machine
|
oncall: distributed, module: elastic
|
### 🐛 Describe the bug
I train the project with different machine
https://github.com/ultralytics/yolov5
machine 1
```
docker run -it --gpus all --rm -v $(pwd):/mnt --network=host nvcr.io/nvidia/pytorch:21.09-py3
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=2 --node_rank=0 --master_addr="192.0.1.1" --master_port=1234 train.py --device 0,1 --workers 1
```
machine 2
```
docker run -it --gpus all --rm -v $(pwd):/mnt --network=host nvcr.io/nvidia/pytorch:21.09-py3
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=2 --node_rank=1 --master_addr="192.0.1.1" --master_port=1234 train.py --device 2,3 --workers 1
```
The machine 2 error then it hang
```
warnings.warn(
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: -7) local_rank: 0 (pid: 449) of binary: /opt/conda/bin/python
```
I try to ping the master address, it is ok.
### Versions
using ngc docker
FROM pytorch/pytorch:2.0.0-cuda11.7-cudnn8-runtime
If I use the command with the same machine, it will be training successfully.
machine 1 on docker1
```
docker run -it --gpus all --rm -v $(pwd):/mnt --network=host nvcr.io/nvidia/pytorch:21.09-py3
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=2 --node_rank=0 --master_addr="192.0.1.1" --master_port=1234 train.py --device 0,1 --workers 1
```
machine 1 on docker2
```
docker run -it --gpus all --rm -v $(pwd):/mnt --network=host nvcr.io/nvidia/pytorch:21.09-py3
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=2 --node_rank=1 --master_addr="192.0.1.1" --master_port=1234 train.py --device 2,3 --workers 1
```
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu @dzhulgakov
| 3 |
2,746 | 100,289 |
graph._export_onnx() incorrect data types in the binary string representation
|
module: onnx, triaged
|
### 🐛 Describe the bug
This bug was aroused in the comments sections of this [post](https://github.com/pytorch/pytorch/issues/100097)
The model converted from torch to onnx is represented by a binary string through the `torch.onnx.export()` function, that function uses a private bounded function [graph._export_onnx](https://github.com/pytorch/pytorch/blob/9e1f46d55b9dfb48effdaf8eb3aa87ba5d072662/torch/onnx/utils.py#L1606) to construct the binary string. It works as expected except for the the data type of the output tensors, it is not accurate, it casts the int32 dtype to int64.
you can find tests [here](https://github.com/pytorch/pytorch/issues/100097)
### Versions
```
pytorch version: 2.0.0+cu118
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: None
onnx version: 1.13.1
```
| 0 |
2,747 | 100,278 |
Dynamo capture for HigherOrderOperators, followups
|
triaged, oncall: pt2, module: dynamo
|
General higher order operators tracking issue. @voznesenskym, @Chillee
## General UX
- [x] calling nn.Modules or using nn.Module parameters should not graph break
- [x] HigherOrderOperator body functions should not all be named "cond_body"
- [x] body functions with non-single Tensor output
- [x] https://github.com/pytorch/pytorch/pull/103870
- [x] HigherOrderOperator fallback should fallback on the entire HigherOrderOperator instead of letting Dynamo introspect `HigherOrderOperator.__call__`. Likely needs some sort of bytecode rewriting.
- [x] HigherOrderOperator side effect handling (e.g. https://github.com/pytorch/pytorch/issues/103613)
- [x] https://github.com/pytorch/pytorch/issues/104298
- [ ] body functions with non-Tensor inputs
- [ ] HigherOrderOperators should accept pytree input/output
- [ ] Constants should probably not be inputs to the body function
- [ ] Unification: torch.utils.checkpoint and torch.func.grad use a slightly different mechanism for lifting the APIs into a HigherOrderOperator. Ideally we would have a single mechanism.
## autograd.Function
- Nothing here
## checkpoint
- [ ] Revisit why we need to add guards for constants - see ctx here - https://github.com/pytorch/pytorch/pull/102448
## Control flow operators
- [ ] Get cond, map to use the new mechanism, delete the old mechanism
- [ ] Decide on the stable {cond, map, scan, while_loop, for_i_loop} APIs. Fix existing APIs (cond, map) to match what we want.
- [ ] Turn Dynamo on by default for control flow operators in eager-mode PyTorch.
- [ ] differentiable cond
- [ ] capturable while-loop
- [ ] Integrate Brian's AOTExport API to stop doing recomputation in the backwards pass.
## functorch transforms
### grad
- [ ] func which takes kwargs is not supported (currently graph-break) : Fix (speculate_subgraph should support kwargs)
- [ ] Implement support for `torch.func.grad_and_value` (we would get `grad` for free that)
- [ ] speculate_subgraph should ideally support pytrees
- [ ] functools.wraps nested function use leads to graph-break (https://github.com/pytorch/pytorch/issues/103913)
- [ ] side-effect handling in dynamo is incomplete/buggy (mainly related to how it handles closure), fixing this would should help us avoid modelling grad mode for `torch.func.grad` in `speculate_subgraph` (see also https://github.com/pytorch/pytorch/pull/102264#discussion_r1231112556)
- [ ] figure out why we need to disable(func) to actually get this to work. disable(func) has the side effect of disabling func when it is used outside of grad, which is undesirable
- [ ] Some mutations are not treated as side-effects leading to incorrect graph (see `test_escaped_wrappers_are_marked_as_dead`). Also, ref https://github.com/pytorch/pytorch/issues/103613
- [ ] Lifted tensor are treated as side-effect (see `test_grad_freevar_tensor`)
## # vmap
- [ ] API to allow tracing through `torch` functions (which don't deal with tensors) https://github.com/pytorch/pytorch/pull/101707#discussion_r1283429266
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 0 |
2,748 | 100,270 |
[Performance] Potential Performance optimization for SDPA
|
triaged, module: inductor, module: multi-headed-attention
|
# Summary
### Eager
The interface for SDPA is (batch, num_heads, seq_len, head_dim) to more closely align with the Attention is All You Need Paper. For most transformers architectures SDPA is called following an input Linear projection and this projection is done on a tensor of shape (batch, seq_len, num_heads, head_dim).
For instance take a look at the CausalSelfAttention module used in the tutorial:
https://pytorch.org/tutorials/intermediate/scaled_dot_product_attention_tutorial.html#causal-self-attention.
This requires the query, key, value's to be transposed prior to calling SDPA.
Both FlashAttention and MemEfficientAttention accept input q,k,v in the form: (batch, seq_len, num_heads, head_dim). Within sdpa{flash, mem_eff} we call transpose here:
For flash the following is the code pointer:
https://github.com/pytorch/pytorch/blob/c4bed869d16e9e0b761b82dda9130cfc14479141/aten/src/ATen/native/transformers/cuda/attention.cu#L715
In eager this manifests itself as two back-to-back view operations. This is not ideal but view ops are generally fairly cheap.
### PT2
Now we go to torch_compile which is great at removing this framework overhead. However, since https://github.com/pytorch/pytorch/blob/c4bed869d16e9e0b761b82dda9130cfc14479141/aten/src/ATen/native/transformers/cuda/attention.cu#L688
is an aten operation that inductor doesn't know how to compile( this is good), inductor will fallback to the aten op. However the transposes inside this ops which are potentially fusable can not be.
### Question:
We could probably make sdpa_flash composite and just have at::_flash_forward as an aten op. This should in theory allow for the transposes to be compiled. Is there a good way to figure out the potential of this change before doing it? -> There is potential complexity with handling NestedTensors but I think we could avoid the dispatcher and just do it manually.
| 3 |
2,749 | 100,253 |
profiler.export_stacks doesn't return stack trace unless experimental_config is provided
|
high priority, module: regression, oncall: profiler
|
### 🐛 Describe the bug
Since I upgraded torch from `1.13.0+cu117` to `2.0.0+cu117`, the following code isn't logging nor printing the stack trace.
```python
import torch
from torch.profiler import profile, record_function
a = torch.rand(100, 100)
b = torch.rand(100, 100)
with profile(with_stack=True, profile_memory=True) as prof:
with record_function("model_inference"):
torch.add(a, b)
prof.export_stacks("myFile", "self_cpu_time_total")
print(prof.key_averages(group_by_stack_n=5))
```
for `1.13.0+cu117` the file is logged correctly:
```
test_prof.py(8):_<module>;torch/autograd/profiler.py(478):___init__;<built-in_method_zeros_of_type_object_at_0x7f55776329c0> 45
test_prof.py(8):_<module>;torch/autograd/profiler.py(478):___init__;<built-in_method_zeros_of_type_object_at_0x7f55776329c0> 30
test_prof.py(8):_<module>;torch/autograd/profiler.py(478):___init__;<built-in_method_zeros_of_type_object_at_0x7f55776329c0> 5
test_prof.py(8):_<module>;torch/autograd/profiler.py(487):___enter__;torch/_ops.py(437):___call__;<built-in_method__record_function_enter_of_PyCapsule_object_at_0x7f549a9189f0> 143
test_prof.py(8):_<module>;torch/autograd/profiler.py(487):___enter__;torch/_ops.py(437):___call__;<built-in_method__record_function_enter_of_PyCapsule_object_at_0x7f549a9189f0> 3
test_prof.py(8):_<module>;<built-in_method_add_of_type_object_at_0x7f55776329c0> 85
test_prof.py(8):_<module>;torch/profiler/profiler.py(475):___exit__;torch/profiler/profiler.py(484):_stop;torch/profiler/profiler.py(511):__transit_action;torch/profiler/profiler.py(117):_stop_trace;torch/autograd/profiler.py(223):___exit__;torch/cuda/__init__.py(556):_synchronize;torch/cuda/__init__.py(201):__lazy_init;<built-in_function__cuda_init> 1269
test_prof.py(8):_<module>;torch/profiler/profiler.py(475):___exit__;torch/profiler/profiler.py(484):_stop;torch/profiler/profiler.py(511):__transit_action;torch/profiler/profiler.py(117):_stop_trace;torch/autograd/profiler.py(223):___exit__;torch/cuda/__init__.py(556):_synchronize;torch/cuda/__init__.py(201):__lazy_init;torch/cuda/__init__.py(108):__check_capability;torch/cuda/__init__.py(344):_get_device_capability;torch/cuda/__init__.py(361):_get_device_properties;<built-in_method__get_device_properties_of_PyCapsule_object_at_0x7f5597a3d8d0> 175
test_prof.py(8):_<module>;torch/profiler/profiler.py(475):___exit__;torch/profiler/profiler.py(484):_stop;torch/profiler/profiler.py(511):__transit_action;torch/profiler/profiler.py(117):_stop_trace;torch/autograd/profiler.py(223):___exit__;torch/cuda/__init__.py(556):_synchronize;<built-in_function__cuda_synchronize> 252937
```
for `2.0.0+117cu` however, I get an empty file. Is there something I'm missing?
### Versions
For the env with torch 1.13.0
```bash
Collecting environment information...
PyTorch version: 1.13.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.10.2
Libc version: glibc-2.27
Python version: 3.9.15 (main, Nov 24 2022, 14:31:59) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.4.0-147-generic-x86_64-with-glibc2.27
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1650
Nvidia driver version: 525.105.17
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.8.1
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_train.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_train.so.8
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 158
Model name: Intel(R) Core(TM) i9-9980HK CPU @ 2.40GHz
Stepping: 13
CPU MHz: 964.671
CPU max MHz: 5000.0000
CPU min MHz: 800.0000
BogoMIPS: 4800.00
Virtualisation: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 16384K
NUMA node0 CPU(s): 0-15
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==1.13.0
[pip3] torchaudio==0.13.0
[pip3] torchvision==0.14.0
[conda] cudatoolkit 11.0.3 h88f8997_10 conda-forge
[conda] numpy 1.23.5 pypi_0 pypi
[conda] torch 1.13.0 pypi_0 pypi
[conda] torchaudio 0.13.0 pypi_0 pypi
[conda] torchvision 0.14.0 pypi_0 pypi
```
For torch 2.0.0:
```bash
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.26.3
Libc version: glibc-2.27
Python version: 3.9.16 (main, Mar 8 2023, 14:00:05) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.4.0-147-generic-x86_64-with-glibc2.27
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1650
Nvidia driver version: 525.105.17
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.8.1
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_train.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_train.so.8
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 158
Model name: Intel(R) Core(TM) i9-9980HK CPU @ 2.40GHz
Stepping: 13
CPU MHz: 1672.804
CPU max MHz: 5000.0000
CPU min MHz: 800.0000
BogoMIPS: 4800.00
Virtualisation: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 16384K
NUMA node0 CPU(s): 0-15
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.24.3
[pip3] torch==2.0.0
[pip3] torchvision==0.15.1
[pip3] triton==2.0.0
[conda] numpy 1.24.3 pypi_0 pypi
[conda] torch 2.0.0 pypi_0 pypi
[conda] torchvision 0.15.1 pypi_0 pypi
[conda] triton 2.0.0 pypi_0 pypi
```
cc @ezyang @gchanan @zou3519 @robieta @chaekit @aaronenyeshi @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git @tiffzhaofb @dzhulgakov @davidberard98
| 12 |
2,750 | 100,249 |
[discussion] "TensorList" as first-class abstraction (including python frontend) and as key for dispatch for merging `torch._foreach_*` into regular `torch.*` functions
|
feature, triaged, module: nestedtensor
|
### 🚀 The feature, motivation and pitch
There currently exist NestedTensor which accepts a list of tensors but copies them into a new storage
There currently are a bunch of _foreach methods which accept and return tensor lists (e.g. https://github.com/pytorch/pytorch/issues/100248) - these do not force copies into a new storage and often operate inplace. Another usecase: https://github.com/pytorch/pytorch/issues/27522 where copies can be more costly than the operation itself + when copies are taking the precious memory (which is important in academic settings)
I'm proposing to make lists of tensors somehow a first-class abstraction similar to NestedTensor. Maybe it could be done by introducing a new class TensorList or by making existing dispatch to foreach functions if they are fed a python list of tensors
This was discussed in some other places before with @cpuhrsch, but maybe now with proliferation of _foreach methods, it may make sense to absorb them into existing `torch.*` methods and just dispatch properly? As I understand, some TensorList abstraction already exists at the C++ / dispatch level
### Alternatives
_No response_
### Additional context
_No response_
cc @cpuhrsch @jbschlosser @bhosmer @drisspg
| 5 |
2,751 | 100,244 |
torch.utils._content_store will deduplicate storage with identical contents; may be problematic for mutation
|
module: serialization, triaged
|
### 🐛 Describe the bug
Maybe we need a mode where we maintain aliases
### Versions
master
cc @mruberry
| 0 |
2,752 | 100,241 |
Interaction of torch.no_grad and torch.autocast context managers with torch.compile
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
Originally discussed at:
https://discuss.pytorch.org/t/torch-compile-interaction-with-autocast-and-no-grad/178648/2?u=vadimkantorov
`Where should I put no_grad and autocast contexts? Inside the function that will be torch.compile’d? Or should I torch.compile first and then wrap the calls with autocast / no_grad? In theory knowing the autocast context and if we don’t need to save intermediate tensors can lead to stonger optimization and more aggressive inplace / economic memory placement`
I think this is an important question as during optimizing for best fp16 perf, e.g. inductor can pre-allocate smaller buffers and use inplace codegen if it knows that it's in no_grad. So the question is coming up naturally. @ezyang @albanD What are your current ideas on interaction of compilation with these important aspects: no_grad-ness and low_precision-ness? And how can we currently hint compilation for MAX brrr (in training) and smaller memory footprints (in inference) :) Also, if we keep using the compiled function in these contexts, it should not trigger a re-compilation every time
@bdhirsh in the original discuss thread:
`Today, if you try to torch.compile a module / function that internally uses autocast/no_grad context managers, dynamo will graph break on them.`
So I’d recommend putting them outside for now:
```python
@torch.compile
def f(args):
...
with torch.cuda.amp.autocast():
out = f(...)
with torch.no_grad():
out = f(...)
```
`I think we want to fix this though, and avoid graph breaking on these context managers. So longer term the answer is “it shouldn’t matter” - feel free to file an issue though!`
### Versions
N/A
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @anijain2305 @voznesenskym @penguinwu @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 6 |
2,753 | 100,239 |
torch.compile is not compatible with DPP with torch.nn.SyncBatchNorm.convert_sync_batchnorm()
|
triaged, module: ddp, module: norms and normalization, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
The error was triggered during training using torch.compile with DDP and SyncBatchNorm.
Circumstances:
1. DDP + SyncBatchNorm, working normally
2. torch.compile + DDP, working normally
3. torch.compile + single gpu, working normally
4. torch.compile + DDP + SyncBatchNorm, not working and raised error below
### Error logs
Brief logs:
Traceback (most recent call last):
File "/home/cg/zzt/midepth/train.py", line 419, in <module>
mp.spawn(main_worker, nprocs=ngpus_per_node, args=(ngpus_per_node, args))
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/multiprocessing/spawn.py", line 239, in spawn
return start_processes(fn, args, nprocs, join, daemon, start_method='spawn')
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/multiprocessing/spawn.py", line 197, in start_processes
while not context.join():
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/multiprocessing/spawn.py", line 160, in join
raise ProcessRaisedException(msg, error_index, failed_process.pid)
torch.multiprocessing.spawn.ProcessRaisedException:
-- Process 0 terminated with the following error:
Traceback (most recent call last):
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/multiprocessing/spawn.py", line 69, in _wrap
fn(i, *args)
File "/home/cg/zzt/midepth/train.py", line 104, in main_worker
train(model, args, epochs=args.epochs, lr=args.lr, device=args.gpu, root=args.root,
File "/home/cg/zzt/midepth/train.py", line 197, in train
loss.backward()
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_tensor.py", line 487, in backward
torch.autograd.backward(
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/autograd/__init__.py", line 200, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/autograd/function.py", line 274, in apply
return user_fn(self, *args)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 2310, in backward
list(ctx.symints) + list(ctx.saved_tensors) + list(contiguous_args)
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [6, 3072, 13, 17]], which is output 0 of torch::autograd::CopyBackwards, is at version 1; expected version 0 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
Verbose logs:
/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/autograd/__init__.py:303: UserWarning: Error detected in ConvolutionBackward0. Traceback of forward call that caused the error:
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/geffnet/conv2d_layers.py", line 72, in conv2d_same
return F.conv2d(x, weight, bias, stride, (0, 0), dilation, groups)
| File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/geffnet/conv2d_layers.py", line 86, in forward
return conv2d_same(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
(Triggered internally at /opt/conda/conda-bld/pytorch_1678411187366/work/torch/csrc/autograd/python_anomaly_mode.cpp:114.)
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/autograd/__init__.py:303: UserWarning: Error detected in ConvolutionBackward0. Traceback of forward call that caused the error:
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/geffnet/conv2d_layers.py", line 72, in conv2d_same
return F.conv2d(x, weight, bias, stride, (0, 0), dilation, groups)
| File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/geffnet/conv2d_layers.py", line 86, in forward
return conv2d_same(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
(Triggered internally at /opt/conda/conda-bld/pytorch_1678411187366/work/torch/csrc/autograd/python_anomaly_mode.cpp:114.)
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
Epoch: 1/30. Loop: Train: 0%| | 0/4234 [00:05<?, ?it/s]
Traceback (most recent call last):
File "/home/cg/zzt/midepth/train.py", line 419, in <module>
mp.spawn(main_worker, nprocs=ngpus_per_node, args=(ngpus_per_node, args))
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/multiprocessing/spawn.py", line 239, in spawn
return start_processes(fn, args, nprocs, join, daemon, start_method='spawn')
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/multiprocessing/spawn.py", line 197, in start_processes
while not context.join():
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/multiprocessing/spawn.py", line 160, in join
raise ProcessRaisedException(msg, error_index, failed_process.pid)
torch.multiprocessing.spawn.ProcessRaisedException:
-- Process 1 terminated with the following error:
Traceback (most recent call last):
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 670, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/backends/distributed.py", line 203, in compile_fn
return self.backend_compile_fn(gm, example_inputs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/debug_utils.py", line 1055, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/__init__.py", line 1390, in __call__
return compile_fx(model_, inputs_, config_patches=self.config)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_inductor/compile_fx.py", line 455, in compile_fx
return aot_autograd(
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/backends/common.py", line 48, in compiler_fn
cg = aot_module_simplified(gm, example_inputs, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 2805, in aot_module_simplified
compiled_fn = create_aot_dispatcher_function(
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 2498, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_args, aot_config)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1713, in aot_wrapper_dedupe
return compiler_fn(flat_fn, leaf_flat_args, aot_config)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 2087, in aot_dispatch_autograd
fx_g = make_fx(joint_forward_backward, aot_config.decompositions)(
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/fx/experimental/proxy_tensor.py", line 714, in wrapped
t = dispatch_trace(wrap_key(func, args, fx_tracer), tracer=fx_tracer, concrete_args=tuple(phs))
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/fx/experimental/proxy_tensor.py", line 443, in dispatch_trace
graph = tracer.trace(root, concrete_args)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/fx/_symbolic_trace.py", line 778, in trace
(self.create_arg(fn(*args)),),
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/fx/_symbolic_trace.py", line 652, in flatten_fn
tree_out = root_fn(*tree_args)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/fx/experimental/proxy_tensor.py", line 459, in wrapped
out = f(*tensors)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1156, in traced_joint
return functionalized_f_helper(primals, tangents)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1108, in functionalized_f_helper
f_outs = flat_fn_no_input_mutations(fn, f_primals, f_tangents, meta, keep_input_mutations)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1076, in flat_fn_no_input_mutations
outs = flat_fn_with_synthetic_bases_expanded(fn, primals, primals_after_cloning, maybe_tangents, meta, keep_input_mutations)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1048, in flat_fn_with_synthetic_bases_expanded
outs = forward_or_joint(fn, primals_before_cloning, primals, maybe_tangents, meta, keep_input_mutations)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1017, in forward_or_joint
backward_out = torch.autograd.grad(
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/autograd/__init__.py", line 269, in grad
return handle_torch_function(
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/overrides.py", line 1534, in handle_torch_function
result = mode.__torch_function__(public_api, types, args, kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_inductor/overrides.py", line 38, in __torch_function__
return func(*args, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/autograd/__init__.py", line 303, in grad
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/utils/_stats.py", line 20, in wrapper
return fn(*args, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/fx/experimental/proxy_tensor.py", line 487, in __torch_dispatch__
return self.inner_torch_dispatch(func, types, args, kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/fx/experimental/proxy_tensor.py", line 512, in inner_torch_dispatch
out = proxy_call(self, func, args, kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/fx/experimental/proxy_tensor.py", line 345, in proxy_call
out = func(*args, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_ops.py", line 287, in __call__
return self._op(*args, **kwargs or {})
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/utils/_stats.py", line 20, in wrapper
return fn(*args, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_subclasses/fake_tensor.py", line 987, in __torch_dispatch__
return self.dispatch(func, types, args, kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_subclasses/fake_tensor.py", line 1162, in dispatch
op_impl_out = op_impl(self, func, *args, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_subclasses/fake_tensor.py", line 410, in local_scalar_dense
raise DataDependentOutputException(func)
torch._subclasses.fake_tensor.DataDependentOutputException: aten._local_scalar_dense.default
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/multiprocessing/spawn.py", line 69, in _wrap
fn(i, *args)
File "/home/cg/zzt/midepth/train.py", line 104, in main_worker
train(model, args, epochs=args.epochs, lr=args.lr, device=args.gpu, root=args.root,
File "/home/cg/zzt/midepth/train.py", line 190, in train
pred = model(img) * args.max_depth
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/nn/parallel/distributed.py", line 1156, in forward
output = self._run_ddp_forward(*inputs, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/nn/parallel/distributed.py", line 1110, in _run_ddp_forward
return module_to_run(*inputs[0], **kwargs[0]) # type: ignore[index]
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 82, in forward
return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/home/cg/zzt/midepth/models/unet.py", line 20, in forward
features = self.encoder(x)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/cg/zzt/midepth/models/unet.py", line 44, in forward
features.append(v(features[-1]))
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 334, in catch_errors
return hijacked_callback(frame, cache_size, hooks)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 404, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 104, in _fn
return fn(*args, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 262, in _convert_frame_assert
return _compile(
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 324, in _compile
out_code = transform_code_object(code, transform)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/bytecode_transformation.py", line 445, in transform_code_object
transformations(instructions, code_options)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 311, in transform
tracer.run()
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1726, in run
super().run()
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 576, in run
and self.step()
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 540, in step
getattr(self, inst.opname)(inst)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1792, in RETURN_VALUE
self.output.compile_subgraph(
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 517, in compile_subgraph
self.compile_and_call_fx_graph(tx, list(reversed(stack_values)), root)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 588, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/home/cg/anaconda3/envs/tc2/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 675, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: compile_fn raised DataDependentOutputException: aten._local_scalar_dense.default
### Minified repro
_No response_
### Versions
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.1 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.31
Python version: 3.10.11 (main, Apr 20 2023, 19:02:41) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-69-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.7.64
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
Nvidia driver version: 525.105.17
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz
Stepping: 7
CPU MHz: 2100.000
CPU max MHz: 3200.0000
CPU min MHz: 800.0000
BogoMIPS: 4200.00
Virtualization: VT-x
L1d cache: 1 MiB
L1i cache: 1 MiB
L2 cache: 32 MiB
L3 cache: 44 MiB
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.24.3
[pip3] torch==2.0.0
[pip3] torchinfo==1.7.2
[pip3] torchvision==0.15.0
[pip3] triton==2.0.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.24.3 py310hd5efca6_0
[conda] numpy-base 1.24.3 py310h8e6c178_0
[conda] pytorch 2.0.0 py3.10_cuda11.7_cudnn8.5.0_0 pytorch
[conda] pytorch-cuda 11.7 h778d358_3 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchinfo 1.7.2 pypi_0 pypi
[conda] torchtriton 2.0.0 py310 pytorch
[conda] torchvision 0.15.0 py310_cu117 pytorch
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 5 |
2,754 | 100,223 |
Add missing `OpInfo`s for prims ops
|
module: tests, triaged, module: primTorch
|
### 🚀 The feature, motivation and pitch
Some prims ops don't have OpInfos:
- [x] bessel_i0
- [x] bessel_i0e
- [x] bessel_i1
- [x] bessel_i1e
- [x] bessel_j0
- [x] bessel_j1
- [ ] broadcast_in_dim
- [ ] cbrt
- [ ] collapse
- [ ] collapse_view
- [ ] convert_element_type
- [ ] copy_strided
- [ ] copy_to
- [ ] device_put
- [x] empty_strided
- [ ] erf_inv
- [x] erfcx
- [ ] fft_c2c
- [ ] fft_c2r
- [ ] fft_r2c
- [ ] iota
- [x] item
- [ ] maximum_value
- [ ] minimum_value
- [ ] name
- [x] ndtri
- [ ] resize
- [ ] rev
- [ ] shift_left
- [ ] shift_right_arithmetic
- [ ] slice_in_dim
- [x] spherical_bessel_j0
- [ ] split_dim
- [ ] view_of
- [x] zeta
### Alternatives
_No response_
### Additional context
_No response_
cc @mruberry @ezyang @ngimel @Lezcano @peterbell10
| 5 |
2,755 | 100,220 |
tensor with dims marked with torch._dynamo.mark_dynamic loses dynamic dim marks after being moved to a different device
|
triaged, oncall: pt2, module: dynamic shapes
|
### 🐛 Describe the bug
I'm trying to mark some tensor dims as dynamic with `torch._dynamo.mark_dynamic`, and later move it to a target device. If the target device and the device the tensor was on when `torch._dynamo.mark_dynamic` called, `_dynamo_dynamic_indices` is lost on the new tensor.
Repro1 (cpu -> cuda):
```
import torch._dynamo
t = torch.ones((1, 20))
assert not hasattr(t, "_dynamo_dynamic_indices")
torch._dynamo.mark_dynamic(t, 0)
assert t._dynamo_dynamic_indices == {0}
t_cuda = t.to("cuda")
assert t_cuda._dynamo_dynamic_indices == {0}
```
Repro2 (cuda -> cpu):
```
import torch._dynamo
t = torch.ones((1, 20)).to("cuda")
assert not hasattr(t, "_dynamo_dynamic_indices")
torch._dynamo.mark_dynamic(t, 0)
assert t._dynamo_dynamic_indices == {0}
t_cpu = t.to("cpu")
assert t_cpu._dynamo_dynamic_indices == {0}
```
Both repros yield the same error log
```
Traceback (most recent call last):
File "*****", line *, in <module>
assert t_cuda._dynamo_dynamic_indices == {0}
AttributeError: 'Tensor' object has no attribute '_dynamo_dynamic_indices'
```
### Expected Output:
No Errors
### Versions
torch version: `2.1.0.dev20230427+cu117`
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
2,756 | 100,158 |
`torch.sparse_csc_tensor` matrix multiplication produces MKL error SPARSE_STATUS_ALLOC_FAILED when density is too high
|
module: sparse, triaged
|
### 🐛 Describe the bug
I create 2 random sparse matrices with `s` elements in each column, and perform matrix multiplication. I do this in AWS SageMaker Studio jupyter notebook, on a large instance (ml.r5.8xlarge with 32 vCPUs and 256GB RAM).
My code:
```
import numpy as np
import pandas as pd
import sys, torch
print(f"Python {sys.version.split()[0]} torch {torch.__version__}")
def rand_mat_sp(m, n, s):
"""Create a sparse mxn matrix, in which every column has exactly s nonzero entries, with randomly chosen positions and random values from the interval (0,1]."""
I = np.concatenate([[0],np.full(n,s)]).cumsum().astype(np.int32)
uu = np.zeros(n*s, dtype=np.int32)
for j in range(n): uu[j*s:(j+1)*s] = np.sort(np.random.default_rng().choice(m, size=s, replace=False, shuffle=False))
ww = (1-np.random.rand(n*s)).astype(np.float32) # entries have uniform distribution on interval (0,1]
return torch.sparse_csc_tensor(I,uu,ww,size=(m,n),dtype=torch.float32)
print(rand_mat_sp(5,5,3).to_dense())
for s in [150,160]:
%time x, y = [rand_mat_sp(10**5,10**5,s) for i in [1,2]]
%time z = torch.mm(x,y) # matrix multiplication
print(z._nnz()/10**5) # nr nonzero entries per column
```
When `s` is too large, the code produces the error:
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<timed exec> in <module>
RuntimeError: MKL error: SPARSE_STATUS_ALLOC_FAILED when calling `mkl_sparse_spmm( SPARSE_OPERATION_NON_TRANSPOSE, mkl_sparse_mat1.descriptor(), mkl_sparse_mat2.descriptor(), &result_desc)`
20161.82454
```
Note that doing the same multiplication with `scipy.sparse.csc_array` instead, produces no error, for arbitrarily large `s`.
Screenshot:

### Versions
Code:
```
! wget https://raw.githubusercontent.com/pytorch/pytorch/main/torch/utils/collect_env.py
%run collect_env.py
```
Output:
```
--2023-04-27 09:22:48-- https://raw.githubusercontent.com/pytorch/pytorch/main/torch/utils/collect_env.py
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.110.133, 185.199.109.133, 185.199.108.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.110.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 21550 (21K) [text/plain]
Saving to: ‘collect_env.py.2’
collect_env.py.2 100%[===================>] 21.04K --.-KB/s in 0s
2023-04-27 09:22:48 (124 MB/s) - ‘collect_env.py.2’ saved [21550/21550]
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.6 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.26.3
Libc version: glibc-2.31
Python version: 3.9.16 | packaged by conda-forge | (main, Feb 1 2023, 21:39:03) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-4.14.311-233.529.amzn2.x86_64-x86_64-with-glibc2.31
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8259CL CPU @ 2.50GHz
Stepping: 7
CPU MHz: 3072.166
BogoMIPS: 4999.99
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 512 KiB
L1i cache: 512 KiB
L2 cache: 16 MiB
L3 cache: 35.8 MiB
NUMA node0 CPU(s): 0-31
Vulnerability Itlb multihit: KVM: Vulnerable
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Retbleed: Vulnerable
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single pti fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves ida arat pku ospke
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] sagemaker-pytorch-training==2.7.0
[pip3] torch==2.0.0
[pip3] torchaudio==0.13.1+cpu
[pip3] torchdata==0.5.1
[pip3] torchvision==0.14.1+cpu
[pip3] triton==2.0.0
[conda] mkl 2022.2.1 h84fe81f_16997 conda-forge
[conda] mkl-include 2023.0.0 h84fe81f_26648 conda-forge
[conda] numpy 1.23.5 pypi_0 pypi
[conda] sagemaker-pytorch-training 2.7.0 pypi_0 pypi
[conda] torch 2.0.0 pypi_0 pypi
[conda] torchaudio 0.13.1+cpu pypi_0 pypi
[conda] torchdata 0.5.1 pypi_0 pypi
[conda] torchvision 0.14.1+cpu pypi_0 pypi
[conda] triton 2.0.0 pypi_0 pypi
```
cc @alexsamardzic @nikitaved @pearu @cpuhrsch @amjames @bhosmer
| 6 |
2,757 | 100,156 |
Illegal instruction in ARM64 (ver 2.0.0)
|
oncall: binaries, triaged, module: arm
|
### 🐛 Describe the bug
Illegal instruction while importing torch. (version 2.0.0)
AWS Machine: a1.large
AMI: amzn2-ami-kernel-5.10-hvm-2.0.20230418.0-arm64-gp2
python code:
import torch
example:
>>> import torch
Illegal instruction
Note: Downgrading to 1.13.1 solves the issue.
### Versions
Can't run collect_env.py on version 2.0.0 cause I can't import torch.
But, downgrading to 1.13.1 solves the issue, so here are the details:
Collecting environment information...
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Amazon Linux 2 (aarch64)
GCC version: (GCC) 7.3.1 20180712 (Red Hat 7.3.1-15)
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.26
Python version: 3.9.0 (default, Apr 27 2023, 08:22:43) [GCC 7.3.1 20180712 (Red Hat 7.3.1-15)] (64-bit runtime)
Python platform: Linux-5.10.177-158.645.amzn2.aarch64-aarch64-with-glibc2.26
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: aarch64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 1
Core(s) per socket: 2
Socket(s): 1
NUMA node(s): 1
Vendor ID: ARM
Model: 3
Model name: Cortex-A72
Stepping: r0p3
BogoMIPS: 166.66
L1d cache: 32K
L1i cache: 48K
L2 cache: 2048K
NUMA node0 CPU(s): 0,1
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 cpuid
Versions of relevant libraries:
[pip3] torch==1.13.1
[conda] Could not collect
cc @seemethere @malfet
| 2 |
2,758 | 100,152 |
DISABLED test_open_device_registration (__main__.TestCppExtensionOpenRgistration)
|
module: cpp-extensions, triaged, module: flaky-tests, skipped
|
Platforms: asan, linux, win, windows, dynamo, mac, macos
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_open_device_registration&suite=TestCppExtensionOpenRgistration) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/undefined).
Over the past 3 hours, it has been determined flaky in 22 workflow(s) with 44 failures and 22 successes.
**Debugging instructions (after clicking on the recent samples link):**
DO NOT ASSUME THINGS ARE OKAY IF THE CI IS GREEN. We now shield flaky tests from developers so CI will thus be green but it will be harder to parse the logs.
To find relevant log snippets:
1. Click on the workflow logs linked above
2. Click on the Test step of the job so that it is expanded. Otherwise, the grepping will not work.
3. Grep for `test_open_device_registration`
4. There should be several instances run (as flaky tests are rerun in CI) from which you can study the logs.
Test file path: `test_cpp_extensions_open_device_registration.py`
cc @malfet @zou3519
| 5 |
2,759 | 100,145 |
This flag not work : torch.backends.cudnn.allow_tf32 = False
|
module: cuda, triaged
|
### 🐛 Describe the bug
import torch
>>> torch.backends.cuda.matmul.allow_tf32
True
>>> torch.backends.cuda.matmul.allow_tf32=False
>>> torch.backends.cuda.matmul.allow_tf32
True
torch 1.13.0a0+08820cb
### Versions
torch 1.13.0a0+08820cb
cc @ngimel
| 2 |
2,760 | 100,125 |
Error saving MONAI pytorch model to ONNX
|
module: onnx, triaged
|
### 🐛 Describe the bug
Hi, I have trained a pytorch RetinaNet3D model using the MONAI framework and would like to serialize it so it can be run with BentoML. However I get the following error using torch.onnx.export:
```
Cell In[12], line 1
torch.onnx.export(detector, # model being run
File ~\AppData\Local\anaconda3\lib\site-packages\torch\onnx\utils.py:506 in export
_export(
File ~\AppData\Local\anaconda3\lib\site-packages\torch\onnx\utils.py:1548 in _export
graph, params_dict, torch_out = _model_to_graph(
File ~\AppData\Local\anaconda3\lib\site-packages\torch\onnx\utils.py:1113 in _model_to_graph
graph, params, torch_out, module = _create_jit_graph(model, args)
File ~\AppData\Local\anaconda3\lib\site-packages\torch\onnx\utils.py:989 in _create_jit_graph
graph, torch_out = _trace_and_get_graph_from_model(model, args)
File ~\AppData\Local\anaconda3\lib\site-packages\torch\onnx\utils.py:893 in _trace_and_get_graph_from_model
trace_graph, torch_out, inputs_states = torch.jit._get_trace_graph(
File ~\AppData\Local\anaconda3\lib\site-packages\torch\jit\_trace.py:1268 in _get_trace_graph
outs = ONNXTracedModule(f, strict, _force_outplace, return_inputs, _return_inputs_states)(*args, **kwargs)
File ~\AppData\Local\anaconda3\lib\site-packages\torch\nn\modules\module.py:1501 in _call_impl
return forward_call(*args, **kwargs)
File ~\AppData\Local\anaconda3\lib\site-packages\torch\jit\_trace.py:127 in forward
graph, out = torch._C._create_graph_by_tracing(
File ~\AppData\Local\anaconda3\lib\site-packages\torch\jit\_trace.py:114 in wrapper
tuple(x.clone(memory_format=torch.preserve_format) for x in args)
File ~\AppData\Local\anaconda3\lib\site-packages\torch\jit\_trace.py:114 in <genexpr>
tuple(x.clone(memory_format=torch.preserve_format) for x in args)
TypeError: MetaTensor.clone() got an unexpected keyword argument 'memory_format'
```
Here is code to reproduce that error, although I can't include the actual model file or example tensor.
```
import torch
from monai.apps.detection.networks.retinanet_detector import RetinaNetDetector
from monai.apps.detection.networks.retinanet_network import RetinaNet
from monai.apps.detection.utils.anchor_utils import AnchorGeneratorWithAnchorShape
anchor_generator = AnchorGeneratorWithAnchorShape(
feature_map_scales=[2**l for l in range(len([1,2]) + 1)],
base_anchor_shapes=[[6,8,4],[8,6,5],[10,10,6]]
)
_example_path = r'example_tensor.pt'
_inference_model_path = r'trained_retinanet_model.pt'
example = torch.load(_example_path, map_location='cpu')
net = torch.jit.load(_inference_model_path, map_location='cpu')
detector = RetinaNetDetector(network=net, anchor_generator=anchor_generator, debug=False)
def __getstate__(self):
state = self.__dict__.copy(
state.pop("_thread_local", None)
state.pop("_metrics_lock", None)
return state
RetinaNetDetector.__getstate__ = __getstate__
RetinaNet.__getstate__ = __getstate__
torch.jit._script.RecursiveScriptModule.__getstate__ = __getstate__
patch_size = (192,192,96)
detector.set_box_selector_parameters(
score_thresh=0.02,
topk_candidates_per_level=1000,
nms_thresh=0.22,
detections_per_img=1,
)
detector.set_sliding_window_inferer(
roi_size=patch_size,
overlap=0.25,
sw_batch_size=1,
mode="gaussian",
device="cpu",
# device=device,
)
detector.eval()
torch.onnx.export(detector,
example.float().cpu(),
"onnx_test.onnx"
export_params=True)
```
What could cause this error? Thanks!
### Versions
wget does not work on my Windows machine. I am using the following:
torch=2.0.0
monai=1.1.0
| 0 |
2,761 | 100,123 |
Error building Pytorch from source
|
module: build, module: rocm, triaged
|
### 🐛 Describe the bug
I'm trying to build Pytorch 1.13 from source in order to use Yolov5 on my AMD GPU with ROCm. I followed the steps:
```
git clone -b release/1.13 https://github.com/pytorch/pytorch
cd pytorch
python tools/amd_build/build_amd.py
MAX_JOBS=1 python setup.py install # MAX_JOBS=1 to prevent freezing on my PC while building
```
I got the following output :
```
[6385/6833] Linking CXX shared library lib/libtorch_hip.so
FAILED: lib/libtorch_hip.so
: && /usr/bin/c++ -fPIC -Wno-deprecated -fvisibility-inlines-hidden -DUSE_PTHREADPOOL -fopenmp -DNDEBUG -DUSE_KINETO -DLIBKINETO_NOCUPTI -DUSE_FBGEMM -DUSE_QNNPACK -DUSE_PYTORCH_QNNPACK -DUSE_XNNPACK -DSYMBOLICATE_MOBILE_DEBUG_HANDLE -DEDGE_PROFILER_USE_KINETO -O2 -fPIC -Wno-narrowing -Wall -Wextra -Werror=return-type -Werror=non-virtual-dtor -Wno-missing-field-initializers -Wno-type-limits -Wno-array-bounds -Wno-unknown-pragmas -Wunused-local-typedefs -Wno-unused-parameter -Wno-unused-function -Wno-unused-result -Wno-strict-overflow -Wno-strict-aliasing -Wno-error=deprecated-declarations -Wno-stringop-overflow -Wno-psabi -Wno-error=pedantic -Wno-error=redundant-decls -Wno-error=old-style-cast -fdiagnostics-color=always -faligned-new -Wno-unused-but-set-variable -Wno-maybe-uninitialized -fno-math-errno -fno-trapping-math -Werror=format -Werror=cast-function-type -Wno-stringop-overflow -DHAVE_AVX2_CPU_DEFINITION -O3 -DNDEBUG -DNDEBUG -Wl,--no-as-needed -rdynamic -shared -Wl,-soname,libtorch_hip.so -o lib/libtorch_hip.so caffe2/CMakeFiles/torch_hip.dir/__/build/aten/src/ATen/torch_hip_generated_UfuncCUDA_add.cu.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/torch_hip_generated_Sleep.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/torch_hip_generated_cub-RadixSortKeys.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/torch_hip_generated_cub-RadixSortPairs.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/torch_hip_generated_cub.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/detail/torch_hip_generated_IndexUtils.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/torch_hip_generated_jiterator.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_AbsKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ActivationEluKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ActivationGeluKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ActivationGluKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ActivationHardshrinkKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ActivationHardsigmoidKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ActivationHardswishKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ActivationHardtanhKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ActivationLeakyReluKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ActivationLogSigmoidKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ActivationMishKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ActivationPreluKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ActivationSiluKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ActivationSoftplusKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ActivationSoftshrinkKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ActivationThresholdKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_AdaptiveAveragePooling.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_AdaptiveAveragePooling3d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_AdaptiveMaxPooling2d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_AdaptiveMaxPooling3d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_AmpKernels.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_AveragePool2d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_AveragePool3d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_BinaryBitwiseOpsKernels.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_BinaryDivFloorKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_BinaryDivTrueKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_BinaryDivTruncKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_BinaryGeometricKernels.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_BinaryLogicalOpsKernels.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_BinaryMiscBackwardOpsKernels.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_BinaryMiscOpsKernels.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_BinaryMulKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_BinaryRemainderKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_BinaryShiftOpsKernels.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Bucketization.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Col2Im.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_CompareEQKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_CompareKernels.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ComplexKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ConvolutionMM2d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Copy.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_CopysignKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_CrossKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_CumminmaxKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_CumprodKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_CumsumKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_DepthwiseConv2d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_DepthwiseConv3d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_DilatedMaxPool2d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_DilatedMaxPool3d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_DistanceKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_DistributionBernoulli.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_DistributionCauchyKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_DistributionExponentialKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_DistributionGeometricKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_DistributionLogNormalKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_DistributionNormal.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_DistributionRandomKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_DistributionUniform.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Distributions.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Dropout.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Embedding.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_EmbeddingBackwardKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_EmbeddingBag.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_FillKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ForeachBinaryOpList.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ForeachBinaryOpScalar.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ForeachBinaryOpScalarList.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ForeachPointwiseOp.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ForeachReduceOp.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ForeachUnaryOp.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_FractionalMaxPool2d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_FractionalMaxPool3d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_FunctionOfAMatrixUtilsKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_FusedAdamKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_GcdLcmKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_GridSampler.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_HIPScalar.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_IGammaKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Im2Col.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_IndexKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Indexing.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_LegacyThrustHelpers.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Lerp.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_LinearAlgebra.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_LogAddExpKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_LogcumsumexpKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Loss.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_LossCTC.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_MaxMinElementwiseKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_MaxUnpooling.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_MultiLabelMarginCriterion.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_MultiMarginLoss.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_MultinomialKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_NLLLoss2d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_NaiveConvolutionTranspose2d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_NaiveConvolutionTranspose3d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_NaiveDilatedConvolution.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Nonzero.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Normalization.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_PointwiseOpsKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_PowKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_RNN.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Randperm.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_RangeFactories.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_RecordStream.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Reduce.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ReduceAMinMaxKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ReduceArgMaxKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ReduceArgMinKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ReduceLogicKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ReduceMaxValuesKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ReduceMinValuesKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ReduceMomentKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ReduceNormKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ReduceSumProdKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ReflectionPad.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_RenormKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Repeat.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ReplicationPadding.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_RreluWithNoise.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ScatterGatherKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_SegmentReduce.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Shape.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_SoftMax.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Sort.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_SortImpl.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_SortStable.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Sorting.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_SparseBinaryOpIntersectionKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_SparseMM.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_SpectralOps.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_StepKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_SummaryOps.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_TensorCompare.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_TensorFactories.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_TensorModeKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_TensorTopK.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_TensorTransformations.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_TriangularOps.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryComplexKernels.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryFractionKernels.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryGammaKernels.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryGeometricAcosKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryGeometricAcoshKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryGeometricAsinKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryGeometricAsinhKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryGeometricAtanKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryGeometricAtanhKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryGeometricCosKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryGeometricCoshKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryGeometricSinKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryGeometricSinhKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryGeometricTanKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryGeometricTanhKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryLogKernels.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnaryOpsKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnarySignKernels.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnarySpecialOpsKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UnfoldBackwardKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_Unique.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UniqueCub.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UpSampleBicubic2d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UpSampleBilinear2d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UpSampleLinear1d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UpSampleNearest1d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UpSampleNearest2d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UpSampleNearest3d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_UpSampleTrilinear3d.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ValidateCompressedIndicesKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_WeightNorm.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_ZetaKernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_airy_ai.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_bessel_j0.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_bessel_j1.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_bessel_y0.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_bessel_y1.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_chebyshev_polynomial_t.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_chebyshev_polynomial_u.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_chebyshev_polynomial_v.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_chebyshev_polynomial_w.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_fused_adam_amsgrad_impl.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_fused_adam_impl.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_group_norm_kernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_hermite_polynomial_h.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_hermite_polynomial_he.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_laguerre_polynomial_l.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_layer_norm_kernel.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_legendre_polynomial_p.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_modified_bessel_i0.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_modified_bessel_i1.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_modified_bessel_k0.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_modified_bessel_k1.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_scaled_modified_bessel_k0.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_scaled_modified_bessel_k1.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_shifted_chebyshev_polynomial_t.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_shifted_chebyshev_polynomial_u.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_shifted_chebyshev_polynomial_v.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_shifted_chebyshev_polynomial_w.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/torch_hip_generated_spherical_bessel_j0.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/nested/hip/torch_hip_generated_NestedTensorTransformerFunctions.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/sparse/hip/torch_hip_generated_SoftMax.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/sparse/hip/torch_hip_generated_SparseCsrTensorMath.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/sparse/hip/torch_hip_generated_SparseHIPTensor.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/sparse/hip/torch_hip_generated_SparseHIPTensorMath.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/sparse/hip/torch_hip_generated_SparseMatMul.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/quantized/hip/torch_hip_generated_Activation.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/quantized/hip/torch_hip_generated_AffineQuantizer.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/quantized/hip/torch_hip_generated_EmbeddingBag.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/quantized/hip/torch_hip_generated_FakeQuantizeCore.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/quantized/hip/torch_hip_generated_FusedObsFakeQuant.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/quantized/hip/torch_hip_generated_IntReprQuant.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/quantized/hip/torch_hip_generated_MakePerTensorQuantizedTensor.hip.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/transformers/hip/torch_hip_generated_attention.hip.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/distributed/c10d/quantization/torch_hip_generated_quantization_gpu.cu.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/miopen/BatchNorm_miopen.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/miopen/Conv_miopen.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/miopen/RNN_miopen.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/cudnn/hip/AffineGridGenerator.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/cudnn/hip/BatchNorm.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/cudnn/hip/ConvPlaceholders.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/cudnn/hip/ConvShared.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/cudnn/hip/Conv_v7.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/cudnn/hip/Conv_v8.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/cudnn/hip/GridSampler.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/cudnn/hip/LossCTC.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/cudnn/hip/RNN.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/miopen/Descriptors.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/miopen/Handle.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/miopen/Types.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/nested/hip/NestedTensorTransformerFunctions.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/sparse/hip/SparseBlas.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/sparse/hip/SparseBlasImpl.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/sparse/hip/SparseBlasLegacy.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/sparse/hip/SparseHIPBlas.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/sparse/hip/SparseHIPTensor.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/quantized/hip/Activation.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/quantized/cudnn/hip/BinaryOps.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/quantized/cudnn/hip/Conv.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/quantized/cudnn/hip/ConvPrepack.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/quantized/cudnn/hip/ConvUnpackImpl.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/quantized/cudnn/hip/Linear.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/quantized/cudnn/hip/LinearPrepack.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/quantized/cudnn/hip/LinearUnpackImpl.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/quantized/cudnn/hip/Pooling.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/CachingHostAllocator.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/CuSparseHandlePool.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/CublasHandlePool.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/EmptyTensor.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/Exceptions.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/HIPBlas.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/HIPContext.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/HIPGeneratorImpl.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/HIPGraph.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/HIPSparseBlas.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/HIPSparseDescriptors.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/PeerToPeerAccess.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/PinnedMemoryAllocator.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/detail/HIPHooks.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/impl/HIPCachingAllocatorMasqueradingAsCUDA.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/impl/HIPGuardImplMasqueradingAsCUDA.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/llvm_basic.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/hip/llvm_complex.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/Activation.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/Blas.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/Distributions.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/Equal.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/GridSampler.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/IndexKernel.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/LinearAlgebraStubs.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/ReduceOps.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/Resize.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/ScanKernels.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/Sort.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/Sorting.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/SpectralOps.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/TensorCompare.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/TensorModeKernel.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/TensorShapeHIP.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/TensorTopK.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/jit_utils.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/linalg/BatchLinearAlgebra.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/linalg/BatchLinearAlgebraLib.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/linalg/CusolverDnHandlePool.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/native/hip/linalg/HIPSolver.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/RegisterCUDA.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/RegisterNestedTensorCUDA.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/RegisterQuantizedCUDA.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/RegisterSparseCUDA.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/aten/src/ATen/RegisterSparseCsrCUDA.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/CudaIPCTypes.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/cuda/comm.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/cuda/memory_snapshot.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/fuser/cuda/fused_kernel.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/profiler/cuda.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/autograd/functions/comm.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/arith.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/compute_at.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/inline_propagator.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/compute_at_map.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/codegen.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/contiguity.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/dispatch.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/expr_evaluator.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/executor.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/executor_kernel_arg.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/executor_launch_params.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/evaluator_common.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/executor_utils.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/fusion.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/graph_fuser.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/grouped_reduction.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/index_compute.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_index_compute.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/instrumentation.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/ir_base_nodes.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/ir_builder.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/ir_cloner.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/ir_container.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/ir_graphviz.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/ir_nodes.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/ir_iostream.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/ir_utils.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/iter_visitor.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/kernel.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/kernel_cache.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/kernel_expr_evaluator.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/kernel_ir.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/kernel_ir_dispatch.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_alias_memory.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_allocation.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_double_buffer.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_expr_sort.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_fused_reduction.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_fusion_simplifier.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_index.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_index_hoist.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_insert_syncs.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_instrument.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_loops.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_magic_zero.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_misaligned_vectorization.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_predicate.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_predicate_elimination.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_replace_size.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_shift.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_sync_information.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_thread_predicate.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_trivial_broadcast.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_trivial_reductions.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_unroll.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_utils.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_validation.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower_warp_reduce.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/lower2device.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/manager.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/maxinfo_propagator.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/mutator.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/non_divisible_split.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/ops/alias.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/ops/composite.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/ops/normalization.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/parallel_dimension_map.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/parallel_type_bitmap.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/parser.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/partial_split_map.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/partition.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/predicate_compute.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/python_frontend/fusion_cache.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/python_frontend/fusion_definition.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/python_frontend/fusion_interface.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/register_interface.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/root_domain_map.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/scheduler/pointwise.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/scheduler/pointwise_utils.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/scheduler/transpose.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/scheduler/normalization.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/scheduler/reduction.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/scheduler/matmul.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/scheduler/reduction_utils.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/scheduler/registry.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/scheduler/utils.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/type_inference.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/type_promotion.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/fusion_segmenter.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/tensor_view.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/transform_iter.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/transform_replay.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/transform_rfactor.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/transform_view.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/type.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/utils.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/mma_type.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/codegen/cuda/scheduler/mma_utils.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/passes/frozen_conv_add_relu_fusion_cuda.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/tensorexpr/cuda_codegen.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/jit/runtime/register_cuda_ops.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/cuda/nccl.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/distributed/c10d/reducer_cuda.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/distributed/c10d/NCCLUtils.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/distributed/c10d/ProcessGroupNCCL.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/distributed/c10d/ProcessGroupUCC.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/distributed/c10d/UCCTracing.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/distributed/c10d/UCCUtils.cpp.o caffe2/CMakeFiles/torch_hip.dir/__/torch/csrc/distributed/rpc/tensorpipe_cuda.cpp.o -Wl,-rpath,/home/guilherme/pytorch/build/lib:/opt/rocm/hip/lib:/opt/rocm-5.4.3/lib:/opt/rocm/roctracer/lib:/opt/rocm/rccl/lib:/opt/rocm/lib:/usr/lib/x86_64-linux-gnu/openmpi/lib: lib/libc10_hip.so /opt/rocm/hip/lib/libamdhip64.so /opt/rocm-5.4.3/lib/libMIOpen.so.1.0.50403 /opt/rocm/hip/lib/libamdhip64.so /opt/rocm/roctracer/lib/libroctx64.so /opt/rocm-5.4.3/lib/librocblas.so.0.1.50403 /opt/rocm-5.4.3/lib/libhipfft.so /opt/rocm-5.4.3/lib/libhiprand.so.1.1.50403 /opt/rocm-5.4.3/lib/libhipsparse.so.0.1.50403 lib/libgloo_hip.a /opt/rocm/rccl/lib/librccl.so lib/libc10.so -Wl,--no-as-needed,"/home/guilherme/pytorch/build/lib/libtorch_cpu.so" -Wl,--as-needed lib/libprotobuf.a -pthread /usr/lib/x86_64-linux-gnu/librt.so /opt/rocm/lib/libamdhip64.so.5.4.50403 /opt/rocm/llvm/lib/clang/15.0.0/lib/linux/libclang_rt.builtins-x86_64.a /opt/rocm/hip/lib/libamdhip64.so -lrccl -ldl -lrt lib/libgloo.a /usr/lib/x86_64-linux-gnu/openmpi/lib/libmpi_cxx.so /usr/lib/x86_64-linux-gnu/openmpi/lib/libmpi.so -lpthread -Wl,-rpath-link,/opt/rocm-5.4.3/lib && :
/usr/bin/ld: não foi possível localizar -lrccl
collect2: error: ld returned 1 exit status
ninja: build stopped: subcommand failed.
```
I did not build ROCm from source. I'm not sure what is causing this error.
Thanks in advance.
### Versions
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.8.10 (default, Mar 13 2023, 10:26:41) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-52-generic-x86_64-with-glibc2.29
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
CPU:
Arquitetura: x86_64
Modo(s) operacional da CPU: 32-bit, 64-bit
Ordem dos bytes: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 12
Lista de CPU(s) on-line: 0-11
Thread(s) per núcleo: 2
Núcleo(s) por soquete: 6
Soquete(s): 1
Nó(s) de NUMA: 1
ID de fornecedor: GenuineIntel
Família da CPU: 6
Modelo: 165
Nome do modelo: Intel(R) Core(TM) i5-10400F CPU @ 2.90GHz
Step: 3
CPU MHz: 2900.000
CPU MHz máx.: 4300,0000
CPU MHz mín.: 800,0000
BogoMIPS: 5799.77
Virtualização: VT-x
cache de L1d: 192 KiB
cache de L1i: 192 KiB
cache de L2: 1,5 MiB
cache de L3: 12 MiB
CPU(s) de nó0 NUMA: 0-11
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Mitigation; Microcode
Vulnerability Tsx async abort: Not affected
Opções: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.24.3
[pip3] pytorch-triton-rocm==2.0.0
[pip3] torchaudio==0.13.1+rocm5.2
[pip3] torchvision==0.14.1+rocm5.2
[pip3] triton==2.0.0
[conda] Could not collect
cc @malfet @seemethere @jeffdaily @sunway513 @jithunnair-amd @pruthvistony @ROCmSupport
| 4 |
2,762 | 100,116 |
'pip install triton' from pinned hash gives unreliable triton
|
module: build, triaged, oncall: pt2
|
Needs further investigation, but several users have reported that the following comand, which is supposedly fine to use, produces triton builds that sometimes segfault with pytorch+benchmarks.
`pip install "git+https://github.com/openai/triton@7d1a95b04654ff9c216afe08a454ad0822f05370#subdirectory=python"`
(replace 7d1a... with any valid pinned hash)
Instead, the `make triton` command which calls [install_triton_wheel.sh](https://github.com/pytorch/pytorch/blob/main/scripts/install_triton_wheel.sh) installs from our CI's build of triton, and this works reliably.
`pip install --extra-index-url https://download.pytorch.org/whl/nightly/ "pytorch-triton==$(cat .ci/docker/triton_version.txt)+$(head -c 10 .ci/docker/ci_commit_pins/triton.txt)"`
The difference is not the triton hash version as the same pinned hash was used with the working/broken install.
We should figure out if there is a missing or wrong config in the setup script for the regular pip build and make sure it works.
cc @malfet @seemethere @ezyang @soumith @msaroufim @ngimel @bdhirsh
| 5 |
2,763 | 100,105 |
[pt2-functorch] torch.func.functional_call works with func.vmap but breaks for func.grad
|
triaged, oncall: pt2, module: functorch
|
### 🐛 Describe the bug
```python
import torch
from torch import nn
from torchvision.models import resnet18
from torch._dynamo import allow_in_graph
from functools import wraps
from functorch import make_functional_with_buffers, vmap, grad
def traceable(f):
f = allow_in_graph(f)
@wraps(f)
def wrapper(*args, **kwargs):
return f(*args, **kwargs)
return wrapper
x = torch.randn(3, 3)
class Net(torch.nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
def forward(self, x):
return x.sum()
net = Net()
f = lambda param, buffer, x: torch.func.functional_call(net, (param, buffer), x)
p = dict(net.named_parameters())
b = dict(net.named_buffers())
grad(f)(p, b, x)
# RuntimeError: Cannot access data pointer of Tensor that doesn't have storage
torch.compile(traceable(grad(f)))(p, b, x)
vmap(f)(p, b, x)
# Works
torch.compile(traceable(vmap(f)))(p, b, x)
```
But if one uses legacy `make_functional_with_buffers` then both cases work.
```python
import torch
from torch import nn
from torchvision.models import resnet18
from torch._dynamo import allow_in_graph
from functools import wraps
from functorch import make_functional_with_buffers, vmap, grad
def traceable(f):
f = allow_in_graph(f)
@wraps(f)
def wrapper(*args, **kwargs):
return f(*args, **kwargs)
return wrapper
x = torch.randn(3, 3)
class Net(torch.nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
def forward(self, x):
return x.sum()
net = Net()
fnet, p, b = make_functional_with_buffers(net)
f = lambda param, buffer, x: fnet(param, buffer, x)
grad(f)(p, b, x)
torch.compile(traceable(grad(f)))(p, b, x)
vmap(f)(p, b, x)
torch.compile(traceable(vmap(f)))(p, b, x)
```
### Versions
master
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @anijain2305 @zou3519 @Chillee @samdow @janeyx99
| 0 |
2,764 | 100,096 |
Inductor origins still not accurate
|
triaged, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
Given
```
import torch
@torch.compile()
def f(x):
y = x * 2
z = torch.cumsum(y, 0)
return z + 1
f(torch.randn(3, device='cuda'))
```
you end up with
```
def call(args):
arg0_1, = args
args.clear()
with torch.cuda._DeviceGuard(0):
torch.cuda.set_device(0) # no-op to ensure context
buf0 = empty_strided((3, ), (1, ), device='cuda', dtype=torch.float32)
stream0 = get_cuda_stream(0)
triton_poi_fused_cumsum_mul_0.run(arg0_1, buf0, 3, grid=grid(3), stream=stream0)
del arg0_1
buf1 = aten.cumsum(buf0, 0)
del buf0
buf2 = buf1
assert_size_stride(buf2, (3, ), (1, ))
del buf1
buf3 = buf2; del buf2 # reuse
triton_poi_fused_add_1.run(buf3, 3, grid=grid(3), stream=stream0)
return (buf3, )
```
cumsum should not be attributed to the first kernel, which doesn't actually do cumsum.
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire @Chillee
### Versions
master
| 3 |
2,765 | 100,092 |
detectron2_fcos_r_50_fpn shape error with inductor
|
triaged, oncall: pt2, module: dynamic shapes, module: inductor
|
### 🐛 Describe the bug
```bash
+ python torchbench.py --performance --float32 -dcpu --output=/workspace/pytorch/benchmarks/dynamo/benchmark_logs/inductor_torchbench_float32_inference_cpu_performance.csv -n50 --inductor --no-skip --dashboard -x detectron2_fasterrcnn_r_50_fpn -x detectron2_fasterrcnn_r_50_dc5 -x detectron2_maskrcnn_r_101_c4 -x timm_efficientdet -x detectron2_fasterrcnn_r_101_c4 -x pyhpc_equation_of_state -x detectron2_fasterrcnn_r_50_c4 -x detectron2_maskrcnn -x detectron2_maskrcnn_r_101_fpn -x opacus_cifar10 -x pyhpc_isoneutral_mixing -x maml -x pyhpc_turbulent_kinetic_energy -x detectron2_fasterrcnn_r_101_dc5 -x detectron2_fasterrcnn_r_101_fpn -x fambench_xlmr -x detectron2_maskrcnn_r_50_fpn -k 'resnet..$' --cold-start-latency --only=detectron2_fcos_r_50_fpn
cpu eval detectron2_fcos_r_50_fpn ERROR:common:Backend dynamo failed in warmup()
Traceback (most recent call last):
File "/workspace/pytorch/benchmarks/dynamo/common.py", line 1375, in warmup
fn(model, example_inputs)
File "/home/dy_new/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "torchbench.py", line 363, in forward_pass
return mod(*inputs)
File "/home/dy_new/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/dy_new/lib/python3.8/site-packages/detectron2/modeling/meta_arch/dense_detector.py", line 92, in forward
images = self.preprocess_image(batched_inputs)
File "/home/dy_new/lib/python3.8/site-packages/detectron2/modeling/meta_arch/dense_detector.py", line 93, in <graph break in forward>
features = self.backbone(images.tensor)
File "/home/dy_new/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/dy_new/lib/python3.8/site-packages/detectron2/modeling/backbone/fpn.py", line 126, in forward
bottom_up_features = self.bottom_up(x)
File "/home/dy_new/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/dy_new/lib/python3.8/site-packages/detectron2/modeling/backbone/resnet.py", line 443, in forward
assert x.dim() == 4, f"ResNet takes an input of shape (N, C, H, W). Got {x.shape} instead!"
File "/home/dy_new/lib/python3.8/site-packages/detectron2/modeling/backbone/resnet.py", line 443, in <graph break in forward>
assert x.dim() == 4, f"ResNet takes an input of shape (N, C, H, W). Got {x.shape} instead!"
AssertionError: ResNet takes an input of shape (N, C, H, W). Got (1, 1, 1, 3, 800, 1216) instead!
```
### Versions
DynamoBenchmark(PyTorch): 6c43e9fdbd76ebaa0ae85351bc39116eb7b45ad4
TorchBench: 4a1df233ec934b17318c37be8634161ae312d799
```
Collecting environment information...
PyTorch version: 2.0.0+cpu
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.22.3
Libc version: glibc-2.31
Python version: 3.8.10 (default, Mar 13 2023, 10:26:41) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.10.9-051009-generic-x86_64-with-glibc2.29
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7262 8-Core Processor
Stepping: 0
Frequency boost: enabled
CPU MHz: 1793.895
CPU max MHz: 3200.0000
CPU min MHz: 1500.0000
BogoMIPS: 6387.66
Virtualization: AMD-V
L1d cache: 256 KiB
L1i cache: 256 KiB
L2 cache: 4 MiB
L3 cache: 128 MiB
NUMA node0 CPU(s): 0-15
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Full AMD retpoline, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate sme ssbd mba sev ibrs ibpb stibp vmmcall sev_es fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr rdpru wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip rdpid overflow_recov succor smca
Versions of relevant libraries:
[pip3] bert-pytorch==0.0.1a4
[pip3] clip-anytorch==2.5.2
[pip3] CoCa-pytorch==0.0.7
[pip3] dalle2-pytorch==1.12.4
[pip3] ema-pytorch==0.2.3
[pip3] functorch==1.14.0a0+b71aa0b
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.21.2
[pip3] open-clip-torch==2.17.2
[pip3] pytorch-transformers==1.2.0
[pip3] pytorch-warmup==0.1.1
[pip3] rotary-embedding-torch==0.2.1
[pip3] torch==2.0.0+cpu
[pip3] torch-fidelity==0.3.0
[pip3] torch-struct==0.5
[pip3] torchaudio==2.0.1+cpu
[pip3] torchdata==0.6.0
[pip3] torchmetrics==0.11.4
[pip3] torchrec-nightly==2023.4.26
[pip3] torchtext==0.15.1+cpu
[pip3] torchvision==0.15.1+cpu
[pip3] vector-quantize-pytorch==1.2.2
[conda] No relevant packages
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 3 |
2,766 | 100,087 |
TransformerEncoderLayer behavior inconsistent between training and evaluation mode
|
oncall: transformer/mha
|
### 🐛 Describe the bug
Hi,
TransformerEncoderLayer is behaving differently in training and evaluation mode. In training mode, it expects the src_mask to be of shape (N⋅num_heads, S, S) and throws an error if the shape is (N, num_heads, S, S). This behavior is consistent with the documentation. However, in evaluation mode with gradients disabled and batch_first set to true, it takes the "sparsity fast path", which shows the opposite behavior: a src_mask of shape (N⋅num_heads, S, S) throws an error while (N, num_heads, S, S) works as expected.
See the code below for a minimum example.
```python
import torch
from torch.nn import TransformerEncoderLayer
heads = 8
bs = 64
input_dim = 16
seq_len = 4
layer = TransformerEncoderLayer(input_dim, heads, 32, batch_first=True)
# Works
res = layer(torch.zeros(bs, seq_len, input_dim), torch.zeros((bs * heads, seq_len, seq_len), dtype=torch.bool))
# Does not work
# res = layer(torch.zeros(bs, seq_len, input_dim), torch.zeros((bs, heads, seq_len, seq_len), dtype=torch.bool))
layer.eval()
with torch.no_grad():
# Does not work
# res = layer(torch.zeros(bs, seq_len, input_dim), torch.zeros((bs * heads, seq_len, seq_len), dtype=torch.bool))
# Works
res = layer(torch.zeros(bs, seq_len, input_dim), torch.zeros((bs, heads, seq_len, seq_len), dtype=torch.bool))
```
I personally think the second behavior is more intuitive, as I don't understand why the head and batch dimensions should be merged into one.
A workaround is to prevent TransformerEncoderLayer from being set to evaluation mode, which probably comes at a performance penalty.
Best,
Tim
### Versions
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.6 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.26.1
Libc version: glibc-2.31
Python version: 3.8.10 (default, Mar 13 2023, 10:26:41) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-69-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3080 Ti
Nvidia driver version: 525.105.17
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 48 bits physical, 48 bits virtual
CPU(s): 24
On-line CPU(s) list: 0-23
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 1
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 25
Model: 33
Model name: AMD Ryzen 9 5900X 12-Core Processor
Stepping: 0
Frequency boost: enabled
CPU MHz: 2200.000
CPU max MHz: 3700,0000
CPU min MHz: 2200,0000
BogoMIPS: 7400.21
Virtualization: AMD-V
L1d cache: 384 KiB
L1i cache: 384 KiB
L2 cache: 6 MiB
L3 cache: 64 MiB
NUMA node0 CPU(s): 0-23
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP always-on, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate ssbd mba ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr rdpru wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif v_spec_ctrl umip pku ospke vaes vpclmulqdq rdpid overflow_recov succor smca fsrm
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.0.0
[pip3] torchvision==0.15.1
[pip3] triton==2.0.0
[conda] Could not collect
cc @jbschlosser @bhosmer @cpuhrsch @erichan1
| 0 |
2,767 | 100,085 |
[regression] torch.norm with out dtype bfloat16 cause runtime error
|
triaged, module: regression, module: norms and normalization
|
### 🐛 Describe the bug
As per torch.norm documentation, it can take out tensor. If we set out tensor to be bfloat16 and in input to be float32 then it fails with error:
```
RuntimeError: Expected out tensor to have dtype float, but got c10::BFloat16 instead
```
It used to work for PT 1.13. Use below code to reproduce the issue.
```
torch.norm(torch.tensor([3.]), 2, [0], False, out=torch.tensor([], dtype=torch.bfloat16))
```
### Versions
Name: torch
Version: 2.0.0
Summary: Tensors and Dynamic neural networks in Python with strong GPU acceleration
Home-page: https://pytorch.org/
Author: PyTorch Team
Author-email: [packages@pytorch.org](mailto:packages@pytorch.org)
License: BSD-3
Location: /home/jthakur/.pt_2_0/lib/python3.8/site-packages
Requires: filelock, jinja2, networkx, nvidia-cublas-cu11, nvidia-cuda-cupti-cu11, nvidia-cuda-nvrtc-cu11, nvidia-cuda-runtime-cu11, nvidia-cudnn-cu11, nvidia-cufft-cu11, nvidia-curand-cu11, nvidia-cusolver-cu11, nvidia-cusparse-cu11, nvidia-nccl-cu11, nvidia-nvtx-cu11, sympy, triton, typing-extensions
Required-by: torchaudio, torchvision, triton
| 3 |
2,768 | 100,080 |
[Indexing] Incoherent Tensor indexing for nested lists
|
triaged, module: numpy, module: advanced indexing, module: edge cases
|
### 🐛 Describe the bug
The behavior of `pytorch.tensor.__getitem__()` is incoherent when using nested lists:
```python
import torch
t = torch.tensor([1, 2])
t[0].shape # torch.Size([])
t[[0]].shape # torch.Size([1])
t[[[0]]].shape # torch.Size([1]) <--- No dimension added here
t[[[[0]]]].shape # torch.Size([1, 1]) <--- Subsequent shapes are thus off by 1 dimension
```
That behavior is not observed with tensordict or numpy, where dimensions are added as expected.
```python
import numpy as np
nd = np.array([1, 2])
nd[0].shape # ()
nd[[0]].shape # (1,)
nd[[[0]]].shape # (1, 1)
nd[[[[0]]]].shape # (1, 1, 1)
```
### Versions
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.3.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.3 (clang-1403.0.22.14.1)
CMake version: Could not collect
Libc version: N/A
Python version: 3.10.8 (main, Nov 24 2022, 08:08:27) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-13.3.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M1 Pro
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.0.0
[pip3] torchrl==0.1.0+9a85f45
[conda] numpy 1.24.2 pypi_0 pypi
[conda] torch 2.0.0 pypi_0 pypi
[conda] torchrl 0.1.0+9a85f45 dev_0 <develop>
cc @mruberry @rgommers @ezyang @gchanan @zou3519
| 2 |
2,769 | 100,075 |
[compile] output does not match eager mode
|
high priority, triaged, oncall: pt2, module: functorch, module: pt2 accuracy
|
### 🐛 Describe the bug
```python
import torch
from torch import nn
from torchvision.models import resnet18
from torch._dynamo import allow_in_graph
from functools import wraps
from functorch import make_functional_with_buffers, vmap, grad
def traceable(f):
f = allow_in_graph(f)
@wraps(f)
def wrapper(*args, **kwargs):
return f(*args, **kwargs)
return wrapper
torch.manual_seed(42)
device = 'cpu' # also fails on CUDA
model = resnet18(pretrained=False, norm_layer=(lambda c: nn.GroupNorm(min(c, 32), c)))
model.to(device)
model.eval()
fnet, params, buffers = make_functional_with_buffers(model)
x = torch.randn(10, 3, 224, 224, device=device)
f = lambda p, b, x : fnet(p, b, x).sum()
# Works for this simpler function
# f = lambda p, b, x: (torch.sin(x) + torch.cos(x) + torch.exp(x)).sum()
f = grad(f)
expected = f(params, buffers, x)
actual = torch.compile(traceable(f))(params, buffers, x)
torch.testing.assert_close(actual, expected)
```
Output
```
AssertionError: Tensor-likes are not close!
Mismatched elements: 9406 / 9408 (100.0%)
Greatest absolute difference: 0.12333643436431885 at index (0, 2, 3, 4) (up to 1e-05 allowed)
Greatest relative difference: 41.227630615234375 at index (5, 0, 0, 6) (up to 1.3e-06 allowed)
```
### Versions
master
cc @ezyang @gchanan @zou3519 @soumith @msaroufim @wconstab @ngimel @bdhirsh @Chillee @samdow @janeyx99
| 21 |
2,770 | 100,074 |
DISABLED test_checkpointing_resets_persistent_refs (__main__.CudaGraphTreeTests)
|
triaged, module: flaky-tests, skipped, module: inductor
|
Platforms: linux
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_checkpointing_resets_persistent_refs&suite=CudaGraphTreeTests) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/undefined).
Over the past 3 hours, it has been determined flaky in 2 workflow(s) with 3 failures and 2 successes.
**Debugging instructions (after clicking on the recent samples link):**
DO NOT ASSUME THINGS ARE OKAY IF THE CI IS GREEN. We now shield flaky tests from developers so CI will thus be green but it will be harder to parse the logs.
To find relevant log snippets:
1. Click on the workflow logs linked above
2. Click on the Test step of the job so that it is expanded. Otherwise, the grepping will not work.
3. Grep for `test_checkpointing_resets_persistent_refs`
4. There should be several instances run (as flaky tests are rerun in CI) from which you can study the logs.
Test file path: `inductor/test_cudagraph_trees.py` or `inductor/test_cudagraph_trees.py`
cc @soumith @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 4 |
2,771 | 100,069 |
Issue with FSDP + HuggingFace generate
|
triaged, module: fsdp
|
### 🐛 Describe the bug
Calling `.generate` on a HuggingFace model that has been FSDP wrapped results in an error. I was able to work around this error by summoning full params without recurse, which just summons the LM head and avoids the issue.
Script with a minimal(ish) repro:
```python
import torch
import transformers
from composer.utils import dist
def _auto_wrap_policy(module: torch.nn.Module, recurse: bool, nonwrapped_numel: int) -> bool:
if recurse:
return True
if hasattr(module, '_fsdp_wrap'):
return bool(module._fsdp_wrap)
return False
def main():
# initialize dist
dist.initialize_dist(None)
# load base model and tokenizer from Hugging Face
gpt = transformers.AutoModelForCausalLM.from_pretrained('EleutherAI/gpt-neo-125m')
gptt = transformers.AutoTokenizer.from_pretrained('EleutherAI/gpt-neo-125m')
from torch.distributed.fsdp.fully_sharded_data_parallel import FullyShardedDataParallel as FSDP
# This seems to cause other problems...
# for module in gpt.modules():
# module._fsdp_wrap = True
gpt._fsdp_wrap = True
# move model to gpu
gpt.to(torch.cuda.current_device())
# FSDP wrap
fsdp_wrapped_gpt = FSDP(gpt, auto_wrap_policy=_auto_wrap_policy, use_orig_params=False)
print(fsdp_wrapped_gpt)
# create the input
input_dict = gptt('hello', return_tensors='pt')
input_dict['input_ids'] = input_dict['input_ids'].to(torch.cuda.current_device())
input_dict['attention_mask'] = input_dict['attention_mask'].to(torch.cuda.current_device())
# THIS CODE IS NECESSARY IN ORDER FOR .generate TO NOT ERROR BELOW (THIS WAS A PREVIOUS WORKAROUND FROM TORCH 1.13 THAT STILL SEEMS TO BE NECESSARY)
with torch.no_grad():
fsdp_wrapped_gpt.forward(input_ids=input_dict['input_ids'])
# call generate
generation = fsdp_wrapped_gpt.generate(input_ids=input_dict['input_ids'], attention_mask=input_dict['attention_mask'], max_new_tokens=5)
print(generation)
if __name__ == '__main__':
main()
```
resulting error:
```python
Traceback (most recent call last):
File "/mnt/workdisk/danielking/github/composer/scripts/fsdp_gen_repro.py", line 49, in <module>
main()
File "/mnt/workdisk/danielking/github/composer/scripts/fsdp_gen_repro.py", line 45, in main
generation = fsdp_wrapped_gpt.generate(input_ids=input_dict['input_ids'], attention_mask=input_dict['attention_mask'], max_new_tokens=5)
File "/mnt/workdisk/danielking/miniconda3/envs/composer-dev-torch2/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/mnt/workdisk/danielking/miniconda3/envs/composer-dev-torch2/lib/python3.10/site-packages/transformers/generation/utils.py", line 1437, in generate
return self.greedy_search(
File "/mnt/workdisk/danielking/miniconda3/envs/composer-dev-torch2/lib/python3.10/site-packages/transformers/generation/utils.py", line 2248, in greedy_search
outputs = self(
File "/mnt/workdisk/danielking/miniconda3/envs/composer-dev-torch2/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/mnt/workdisk/danielking/miniconda3/envs/composer-dev-torch2/lib/python3.10/site-packages/transformers/models/gpt_neo/modeling_gpt_neo.py", line 741, in forward
transformer_outputs = self.transformer(
File "/mnt/workdisk/danielking/miniconda3/envs/composer-dev-torch2/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/mnt/workdisk/danielking/miniconda3/envs/composer-dev-torch2/lib/python3.10/site-packages/transformers/models/gpt_neo/modeling_gpt_neo.py", line 578, in forward
inputs_embeds = self.wte(input_ids)
File "/mnt/workdisk/danielking/miniconda3/envs/composer-dev-torch2/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/mnt/workdisk/danielking/miniconda3/envs/composer-dev-torch2/lib/python3.10/site-packages/torch/nn/modules/sparse.py", line 162, in forward
return F.embedding(
File "/mnt/workdisk/danielking/miniconda3/envs/composer-dev-torch2/lib/python3.10/site-packages/torch/nn/functional.py", line 2210, in embedding
return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
RuntimeError: 'weight' must be 2-D
```
workaround is to wrap the `.generate` call with `with FSDP.summon_full_params(self.model, writeback=False, recurse=False):`
### Versions
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.26.3
Libc version: glibc-2.31
Python version: 3.10.10 (main, Mar 21 2023, 18:45:11) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.4.0-137-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-40GB
GPU 1: NVIDIA A100-SXM4-40GB
Nvidia driver version: 515.48.07
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.5.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 48 bits physical, 48 bits virtual
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 1
Core(s) per socket: 32
Socket(s): 2
NUMA node(s): 8
Vendor ID: AuthenticAMD
CPU family: 25
Model: 1
Model name: AMD EPYC 7513 32-Core Processor
Stepping: 1
Frequency boost: enabled
CPU MHz: 1777.500
CPU max MHz: 2600.0000
CPU min MHz: 1500.0000
BogoMIPS: 5200.14
Virtualization: AMD-V
L1d cache: 2 MiB
L1i cache: 2 MiB
L2 cache: 32 MiB
L3 cache: 256 MiB
NUMA node0 CPU(s): 0-7
NUMA node1 CPU(s): 8-15
NUMA node2 CPU(s): 16-23
NUMA node3 CPU(s): 24-31
NUMA node4 CPU(s): 32-39
NUMA node5 CPU(s): 40-47
NUMA node6 CPU(s): 48-55
NUMA node7 CPU(s): 56-63
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 invpcid_single hw_pstate ssbd mba ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 invpcid cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold v_vmsave_vmload vgif umip pku ospke vaes vpclmulqdq rdpid overflow_recov succor smca
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] pytorch-ranger==0.1.1
[pip3] torch==2.0.0+cu117
[pip3] torch-optimizer==0.3.0
[pip3] torchdata==0.6.0
[pip3] torchmetrics==0.11.3
[pip3] torchtext==0.15.1+cpu
[pip3] torchvision==0.15.1+cu117
[pip3] triton==2.0.0
[pip3] vit-pytorch==0.35.8
[conda] numpy 1.24.2 pypi_0 pypi
[conda] pytorch-ranger 0.1.1 pypi_0 pypi
[conda] torch 2.0.0+cu117 pypi_0 pypi
[conda] torch-optimizer 0.3.0 pypi_0 pypi
[conda] torchdata 0.6.0 pypi_0 pypi
[conda] torchmetrics 0.11.3 pypi_0 pypi
[conda] torchtext 0.15.1+cpu pypi_0 pypi
[conda] torchvision 0.15.1+cu117 pypi_0 pypi
[conda] triton 2.0.0 pypi_0 pypi
[conda] vit-pytorch 0.35.8 pypi_0 pypi
cc @zhaojuanmao @mrshenli @rohan-varma @awgu
| 14 |
2,772 | 100,062 |
add github check that diffs generated code
|
triaged, module: infra, module: codegen
|
### 🚀 The feature, motivation and pitch
PyTorch relies heavily on generated code. We should make the experience around that in CI better for authors and reviewers both.
We should add a check that generates all the code at the base ref and the head ref and diffs them. If there are differences we should add a link to a page that renders the diffs and perhaps also add a label on the PR.
We may want to go even further by requiring review and approval of diffs to generated code through some mechanism.
### Alternatives
An alternative could be to provide a command that authors and reviewers both can run to generate and compare the generated code, but I think it's even better if that is done automatically as proposed.
### Additional context
_No response_
cc @ezyang @bhosmer @bdhirsh
| 3 |
2,773 | 100,061 |
torch.compile() drops the performance of validation / Dynamo is not guarding on attributes on NN modules
|
high priority, triaged, ezyang's list, oncall: pt2, module: pt2 accuracy
|
### 🐛 Describe the bug
I encountered that after adding torch.compile(model), the performance of the model on the verification set has been declining as the training progresses.

When I remove torch.compile(model), the model is back to normal:
epoch 1/1000, train: loss=0.0767, val: psnr=27.5813, 1.4m 1.4m/24.2h
epoch 2/1000, train: loss=0.0438, val: psnr=28.2431, 1.6m 3.0m/25.3h
epoch 3/1000, train: loss=0.0428, val: psnr=28.2909, 1.6m 4.6m/25.5h
epoch 4/1000, train: loss=0.0417, val: psnr=28.4744, 1.6m 6.2m/25.9h
epoch 5/1000, train: loss=0.0406, val: psnr=28.7785, 1.6m 7.8m/26.1h
epoch 6/1000, train: loss=0.0404, val: psnr=28.5917, 1.6m 9.5m/26.3h
epoch 7/1000, train: loss=0.0395, val: psnr=28.6923, 1.6m 11.1m/26.3h
epoch 8/1000, train: loss=0.0393, val: psnr=28.9986, 1.5m 12.6m/26.2h
epoch 9/1000, train: loss=0.0382, val: psnr=28.8534, 1.7m 14.2m/26.4h
### Error logs
Those two things do not work. You can reproduce the similar result with this [repro](https://github.com/XieQi2015/F-Conv/tree/main/MinistExp).
You can implement with the simple case, by adding the model = torch.compile(model) below [here](https://github.com/XieQi2015/F-Conv/blob/c55c4184a0cf6e7a30be62217c781264853a0515/MinistExp/Rotated_MNIST_simpleCase_Main.py#L46).
After training 30 epochs, the model begin to test. If you add the torch.compile, the test accuracy will not increase. While for the version without torch.compile is normal.
### Minified repro
env TORCHDYNAMO_REPRO_AFTER="aot" TORCHDYNAMO_REPRO_LEVEL=4
System prompts the body is too long, so I unload the repro.py in [here](https://drive.google.com/file/d/1cD1NV3ucDpHxn9unu04kmlTnjNVAgWRt/view)
### Versions
Collecting environment information...
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.1 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.31
Python version: 3.10.11 (main, Apr 20 2023, 19:02:41) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.4.0-42-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.1.74
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 4090
GPU 1: NVIDIA GeForce RTX 4090
GPU 2: NVIDIA GeForce RTX 4090
GPU 3: NVIDIA GeForce RTX 4090
GPU 4: NVIDIA GeForce RTX 4090
GPU 5: NVIDIA GeForce RTX 4090
GPU 6: NVIDIA GeForce RTX 4090
GPU 7: NVIDIA GeForce RTX 4090
Nvidia driver version: 525.105.17
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 48 bits physical, 48 bits virtual
CPU(s): 256
On-line CPU(s) list: 0-254
Off-line CPU(s) list: 255
Thread(s) per core: 1
Core(s) per socket: 64
Socket(s): 2
NUMA node(s): 8
Vendor ID: AuthenticAMD
CPU family: 25
Model: 1
Model name: AMD EPYC 7763 64-Core Processor
Stepping: 1
Frequency boost: enabled
CPU MHz: 1502.643
CPU max MHz: 2450.0000
CPU min MHz: 1500.0000
BogoMIPS: 4900.14
Virtualization: AMD-V
L1d cache: 2 MiB
L1i cache: 2 MiB
L2 cache: 32 MiB
L3 cache: 256 MiB
NUMA node0 CPU(s): 0-15,128-143
NUMA node1 CPU(s): 16-31,144-159
NUMA node2 CPU(s): 32-47,160-175
NUMA node3 CPU(s): 48-63,176-191
NUMA node4 CPU(s): 64-79,192-207
NUMA node5 CPU(s): 80-95,208-223
NUMA node6 CPU(s): 96-111,224-239
NUMA node7 CPU(s): 112-127,240-254
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Full AMD retpoline, IBPB conditional, IBRS_FW, STIBP always-on, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 invpcid_single hw_pstate ssbd mba ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 invpcid cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold v_vmsave_vmload vgif umip pku ospke vaes vpclmulqdq rdpid overflow_recov succor smca
Versions of relevant libraries:
[pip3] natten==0.14.6+torch200cu118
[pip3] numpy==1.23.5
[pip3] pytorch-ssim==0.1
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.0
[pip3] torchvision==0.15.0
[pip3] triton==2.0.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] natten 0.14.6+torch200cu118 pypi_0 pypi
[conda] numpy 1.23.5 py310hd5efca6_0
[conda] numpy-base 1.23.5 py310h8e6c178_0
[conda] pytorch 2.0.0 py3.10_cuda11.8_cudnn8.7.0_0 pytorch
[conda] pytorch-cuda 11.8 h7e8668a_3 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] pytorch-ssim 0.1 pypi_0 pypi
[conda] torchaudio 2.0.0 py310_cu118 pytorch
[conda] torchtriton 2.0.0 py310 pytorch
[conda] torchvision 0.15.0 py310_cu118 pytorch
cc @ezyang @gchanan @zou3519 @msaroufim @wconstab @ngimel @bdhirsh @anijain2305 @soumith
| 17 |
2,774 | 100,055 |
pre_autograd `make_fx` broken with simple F.linear with symbolic shape
|
triaged, oncall: pt2, module: dynamic shapes
|
### 🐛 Describe the bug
I'm trying to get a `pre_autograd` aten_graph from dynamo with dynamic shape. The following code sort of works on `torch==2.1.0.dev20230425` but is broken with '2.1.0a0+git1c11065'
```
import torch
import torch.nn as nn
import torch._dynamo as dynamo
from torch.fx.experimental.proxy_tensor import make_fx
from torch._dispatch.python import enable_python_dispatcher
from torch._guards import detect_fake_mode
def compiler(gm, example_inputs):
fake_mode = detect_fake_mode(example_inputs)
fake_inputs = [fake_mode.from_tensor(i) if isinstance(i, torch.Tensor) else i
for i in example_inputs]
with fake_mode, enable_python_dispatcher():
fx_graph = make_fx(gm, pre_autograd=True)(*fake_inputs)
print(fx_graph.graph)
return gm.forward
@dynamo.optimize(compiler, dynamic=True)
def f(x, w, b):
z = torch.nn.functional.linear(x, w, b)
return z
w = torch.randn(20, 10)
b = torch.randn(20)
f(torch.randn(1, 2, 10), w, b)
f(torch.randn(1, 3, 10), w, b)
```
Output from `torch==2.1.0.dev20230425`
```
graph():
%arg0_1 : [#users=2] = placeholder[target=arg0_1]
%arg1_1 : [#users=1] = placeholder[target=arg1_1]
%arg2_1 : [#users=1] = placeholder[target=arg2_1]
%arg3_1 : [#users=1] = placeholder[target=arg3_1]
%t : [#users=1] = call_function[target=torch.ops.aten.t.default](args = (%arg2_1,), kwargs = {})
%view : [#users=1] = call_function[target=torch.ops.aten.view.default](args = (%arg1_1, [%arg0_1, 10]), kwargs = {})
%addmm : [#users=1] = call_function[target=torch.ops.aten.addmm.default](args = (%arg3_1, %view, %t), kwargs = {})
%view_1 : [#users=1] = call_function[target=torch.ops.aten.view.default](args = (%addmm, [1, %arg0_1, 20]), kwargs = {})
```
Output from '2.1.0a0+git1c11065'
```
torch._dynamo.exc.BackendCompilerFailed: backend='compiler' raised:
RuntimeError: s0 is not tracked with proxy for <torch.fx.experimental.proxy_tensor.PythonKeyTracer object at 0x7f25897eed7
0>
```
Expected Output:
FX graph that contains "call_function[target=torch.ops.aten.linear.default]".
With `torch==2.1.0.dev20230425`, the problem is that `aten.linear.default` did not go through python dispatch, so we have a graph with "transpose + view + admm".
With '2.1.0a0+git1c11065', we have `aten.linear.default` properly go through python dispatch, and `transpose + view + admm` is going through `inside_mode` of `ProxyTorchDispatchMode`. However, within Linear.cpp, we have the following code
```
static inline Tensor _flatten_3d_linear(const Tensor& input, const Tensor& weight, const Tensor& bias) {
const auto input_sizes = input.sym_sizes();
const auto result = at::addmm(bias, input.view_symint({input_sizes[0] * input_sizes[1], input_sizes[2]}), weight.t()); return result.view_symint({input_sizes[0], input_sizes[1], result.sym_size(1)});
}
```
So the input to `aten::view` is a new symbol `s0 = 1 * s0` but it is somehow not tracked by `ProxyTorchDispatchMode.symnode_tracker`.
### Versions
'2.1.0a0+git1c11065'
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 21 |
2,775 | 100,054 |
Add compile option -Werror=return-type compile error
|
module: build, triaged, actionable
|
### 🐛 Describe the bug
When I add -Werror=return-type to the compilation option, the following error occurs during compilation.
```
/data/vcpkg/buildtrees/libtorch/src/v1.12.1-d15308d103.clean/aten/src/ATen/native/Convolution.cpp: In function ‘at::Tensor at::native::_convolution_mode(const at::Tensor&, const at::Tensor&, const c10::optional<at::Tensor>&, at::IntArrayRef, c10::string_view, at::IntArrayRef, int64_t)’:
/data/vcpkg/buildtrees/libtorch/src/v1.12.1-d15308d103.clean/aten/src/ATen/native/Convolution.cpp:920:1: error: control reaches end of non-void function [-Werror=return-type]
920 | }
| ^
cc1plus: some warnings being treated as errors
```
### Versions
The version I am using is 1.12.1
cc @malfet @seemethere
| 2 |
2,776 | 100,052 |
nn.Transformer out[0:-1] not precisely equal to last_out when predicting in tgt mask
|
oncall: transformer/mha
|
### 🐛 Describe the bug
Should nn.Transformer output keep the same last values when using tgt mask to predict current value?
```python
import torch
from torch import nn
transformer = nn.Transformer(nhead=16, num_encoder_layers=12)
src = torch.randn((10, 32, 512))
tgt = torch.randn((20, 32, 512))
out_sequence_list = []
seq_tgt = tgt[0:1, :, :]
# predict
with torch.no_grad():
for _ in range(src.size(0)):
tgt_mask = transformer.generate_square_subsequent_mask(seq_tgt.size(0))
seq_out = transformer(src=src,
tgt=seq_tgt,
tgt_mask=tgt_mask)
latest_out = seq_out[-1, :, :].unsqueeze(0)
out_sequence_list.append(latest_out)
# AssertError when seq_out.size(0) >= 2
# In [1]: seq_out - torch.cat(out_sequence_list, dim=0)
# Out[1]:
# tensor([[[-0.2359, 1.1037, -0.4994, ..., -1.6979, 1.0394, 0.7114],
# [-0.2334, -0.2180, 2.1017, ..., -0.6985, 1.3802, 0.6556],
# [-0.0134, 2.5504, 1.7151, ..., -0.2102, -0.3800, 0.3372],
# ...,
# [ 0.1166, -0.5099, 0.4002, ..., 0.4912, 0.3495, 0.2175],
# [ 1.3356, 0.9382, -0.0159, ..., 0.1846, -1.5192, 1.2687],
# [-0.5507, 0.4309, 0.5729, ..., -0.5270, -0.8455, -1.1845]],
# [[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
# [ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
# [ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
# ...,
# [ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
# [ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
# [ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]])
assert torch.all(seq_out == torch.cat(out_sequence_list, dim=0))
seq_tgt = torch.cat([seq_tgt, latest_out], dim=0)
```
### Versions
```
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.3.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.28.1)
CMake version: version 3.26.3
Libc version: N/A
Python version: 3.10.4 (main, Mar 31 2022, 03:37:37) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-13.3.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M1 Pro
Versions of relevant libraries:
[pip3] numpy==1.21.5
[pip3] pytorch-crf==0.7.2
[pip3] pytorch-ignite==0.5.0.dev20221205
[pip3] pytorch-lightning==1.9.3
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.0
[pip3] torchdata==0.6.0
[pip3] torchmetrics==0.11.4
[pip3] torchtext==0.3.1
[pip3] torchvision==0.15.0
[conda] ignite 0.5.0.dev20221205 py_0 pytorch-nightly
[conda] numpy 1.21.5 py310h220015d_3 defaults
[conda] numpy-base 1.21.5 py310h742c864_3 defaults
[conda] pytorch 2.0.0 py3.10_0 pytorch
[conda] pytorch-crf 0.7.2 pypi_0 pypi
[conda] pytorch-lightning 1.9.3 pypi_0 pypi
[conda] torch 2.0.0 pypi_0 pypi
[conda] torchaudio 2.0.0 py310_cpu pytorch
[conda] torchdata 0.6.0 py310 pytorch
[conda] torchmetrics 0.11.4 pypi_0 pypi
[conda] torchtext 0.3.1 pypi_0 pypi
[conda] torchvision 0.15.0 py310_cpu pytorch
```
cc @jbschlosser @bhosmer @cpuhrsch @erichan1
| 0 |
2,777 | 100,051 |
Issue of HistogramObserver to handle abnormal value
|
oncall: quantization, triaged
|
### 🐛 Describe the bug
There is a issue in `HistogramObserver ` when the input has abnormal values. Here is the script to reproduce this issue
```
import torch
from torch.ao.quantization.observer import HistogramObserver
def test():
obser = HistogramObserver.with_args(reduce_range=False)()
input1 = torch.tensor([-3.4028234663852886, -0.0])
obser(input1)
input2 = torch.tensor([-3.4028234663852886 * 10**38, -0.0])
obser(input2)
if __name__ == "__main__":
test()
```
and the corresponding error message is:
```
Traceback (most recent call last):
File "/home/lesliefang/pytorch_1_7_1/quantization/customer_issue/MLDL-883/test2.py", line 54, in <module>
test()
File "/home/lesliefang/pytorch_1_7_1/quantization/customer_issue/MLDL-883/test2.py", line 50, in test
obser(input2)
File "/home/lesliefang/pytorch_1_7_1/quantization/frameworks.ai.pytorch.private-cpu/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/lesliefang/pytorch_1_7_1/quantization/frameworks.ai.pytorch.private-cpu/torch/ao/quantization/observer.py", line 1176, in forward
) = self._adjust_min_max(combined_min, combined_max, self.upsample_rate)
File "/home/lesliefang/pytorch_1_7_1/quantization/frameworks.ai.pytorch.private-cpu/torch/ao/quantization/observer.py", line 1095, in _adjust_min_max
downsample_rate = int(
OverflowError: cannot convert float infinity to integer
```
### Versions
Collecting environment information...
PyTorch version: 2.1.0a0+gita15539d
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: CentOS Linux 7 (Core) (x86_64)
GCC version: (GCC) 9.3.1 20200408 (Red Hat 9.3.1-2)
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.17
Python version: 3.9.10 (main, Mar 2 2022, 12:02:00) [GCC 9.3.0] (64-bit runtime)
Python platform: Linux-4.19.5-1.el7.elrepo.x86_64-x86_64-with-glibc2.17
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 56
On-line CPU(s) list: 0-55
Thread(s) per core: 1
Core(s) per socket: 28
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel Genuine CPU
Stepping: 10
CPU MHz: 1199.859
CPU max MHz: 2900.0000
CPU min MHz: 1200.0000
BogoMIPS: 5800.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 39424K
NUMA node0 CPU(s): 0-27
NUMA node1 CPU(s): 28-55
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req pku ospke avx512_vnni flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] intel-extension-for-pytorch==2.1.0+git8e7c2b9
[pip3] numpy==1.22.3
[pip3] torch==2.1.0a0+git72daade
[pip3] torchvision==0.16.0a0+5579995
[conda] mkl 2023.0.0 intel_25398 intel
[conda] mkl-include 2023.0.0 <pip>
[conda] mkl-include 2023.0.0 intel_25398 intel
[conda] mkl-service 2.4.0 py39h3605609_14 intel
[conda] mkl-static 2023.0.0 <pip>
[conda] mkl_fft 1.3.1 py39hcab1719_22 intel
[conda] mkl_random 1.2.2 py39hbf47bc3_22 intel
[conda] mkl_umath 0.1.1 py39hf66a691_32 intel
[conda] numpy 1.22.3 py39hf0956d0_5 intel
[conda] numpy-base 1.22.3 py39h45c9ace_5 intel
[conda] torchvision 0.16.0a0+5579995 <pip>
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo @jgong5 @Xia-Weiwen @Guobing-Chen
| 3 |
2,778 | 100,044 |
[Tensor Parallel] Clarify docs
|
oncall: distributed
|
### 📚 The doc issue
Some enhancements when reading through tensor parallel docs: https://github.com/pytorch/pytorch/blob/main/torch/distributed/tensor/parallel/api.py#L35
- Example should include DeviceMesh creation
- > ``PairwiseParallel`` comes with constraints for now. --> we should add a description of what sort of constraints these are.
-
### Suggest a potential alternative/fix
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
2,779 | 100,012 |
Dataloader multiprocess loading with num_worker > 0 calls __main__ file to run
|
module: dataloader, triaged
|
### 🐛 Describe the bug
A conditional bug -- All the imports are used apart from tqdm
I am not using tqdm directly But if I don't use it code never runs, for more [reference](https://discuss.pytorch.org/t/error-while-multiprocessing-in-dataloader/46845/27)
When I import it, it sometimes runs but not always.
But when it runs, all print statement in the script are called. Other people solved this problem without understanding the problem in this [thread](https://discuss.pytorch.org/t/errors-when-using-num-workers-0-in-dataloader/97564/3)
Hope you can replicate the bug on your end because it seems to be very conditional!
```
#%%
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from pathlib import Path
import matplotlib.pyplot as plt
from tqdm import tqdm
import requests
import zipfile
from pathlib import Path
import os
data_path = Path("data/")
image_path = data_path/ 'pizza_steak_sushi'
if not image_path.is_dir():
print(f'{image_path} does not exist, creating one ...')
image_path.mkdir(parents=True, exist_ok=True)
url = 'https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi.zip'
local_zip_file = data_path / 'pizza_steak_sushi.zip'
print(f'Downloading pizza, steak, sushi data from {url}')
response = requests.get(url)
with open(local_zip_file, 'wb') as f:
f.write(response.content)
with zipfile.ZipFile(local_zip_file, 'r') as zip_ref:
print('Unzipping pizza, steak, sushi data ...')
zip_ref.extractall(image_path)
os.remove(local_zip_file)
print(f'Removed {local_zip_file} after extraction')
else:
print(f'{image_path} directory already exists, skipping download')
#%%
data_path = Path("data/")
image_path = data_path/ 'pizza_steak_sushi'
train_dir = image_path / "train"
test_dir = image_path / "test"
device = 'cuda' if torch.cuda.is_available() else 'cpu'
data_transforms = transforms.Compose([
transforms.Resize(size=(64,64)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
])
train_data = datasets.ImageFolder(root= train_dir,
transform=data_transforms,
target_transform=None)
# %%
from torch.utils.data import DataLoader
BATCH_SIZE = 1
train_dataloader = DataLoader(dataset=train_data,
batch_size=BATCH_SIZE,
num_workers=1,
shuffle=True)
test_dataloader = DataLoader(dataset=test_data,
batch_size=BATCH_SIZE,
num_workers=1,
shuffle=False)
len(train_dataloader), len(test_dataloader)
#%%
img, label = next(iter(train_dataloader))
print(f"Image shape: {img.shape} -> [batch_size, height, width]")
print(f"Label shape: {label.shape}")
print("Why are you running the full script")
# %%
```

### Versions
Collecting environment information...
PyTorch version: 1.13.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N[/A](https://file+.vscode-resource.vscode-cdn.net/A)
OS: macOS 13.3.1 (x86_64)
GCC version: Could not collect
Clang version: Could not collect
CMake version: Could not collect
Libc version: N[/A](https://file+.vscode-resource.vscode-cdn.net/A)
Python version: 3.9.15 (main, Nov 4 2022, 11:11:31) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N[/A](https://file+.vscode-resource.vscode-cdn.net/A)
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N[/A](https://file+.vscode-resource.vscode-cdn.net/A)
MIOpen runtime version: N[/A](https://file+.vscode-resource.vscode-cdn.net/A)
Is XNNPACK available: True
CPU:
Apple M1
Versions of relevant libraries:
[pip3] flake8==4.0.1
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] numpydoc==1.5.0
[pip3] torch==1.13.1
[pip3] torchmetrics==0.11.4
[pip3] torchvision==0.14.1
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 h0a44026_0 pytorch
[conda] mkl 2021.4.0 hecd8cb5_637
[conda] mkl-service 2.4.0 py39h9ed2024_0
[conda] mkl_fft 1.3.1 py39h4ab4a9b_0
[conda] mkl_random 1.2.2 py39hb2f4e1b_0
[conda] numpy 1.21.5 py39h2e5f0a9_3
[conda] numpy-base 1.21.5 py39h3b1a694_3
[conda] numpydoc 1.5.0 py39hecd8cb5_0
[conda] pytorch 1.13.1 py3.9_0 pytorch
[conda] torchmetrics 0.11.4 pypi_0 pypi
[conda] torchvision 0.14.1 py39_cpu pytorch
cc @SsnL @VitalyFedyunin @ejguan @NivekT @dzhulgakov
| 1 |
2,780 | 100,006 |
Revive multigpu testing
|
module: ci, triaged
|
### 🐛 Describe the bug
@ngimel brought to my attention, that we do not have multigpu testing for `test_ops` and `test_jit`
It would be good idea to move all test decorated with `@needsMultiGPU` to a separate file and create its own periodic config for multigpu tests
### Versions
CI
cc @seemethere @pytorch/pytorch-dev-infra
| 3 |
2,781 | 100,005 |
torch.triu() may returns wrong values using MPS
|
high priority, triaged, module: NaNs and Infs, module: correctness (silent), module: mps
|
### 🐛 Describe the bug
Using MPS, torch.triu() may returns tensor with incorrect values.
It works as expected on CPU:
```
>>> import torch
>>>
>>> mask = torch.full((1, 1, 10, 10), float("-inf"), device=torch.device("cpu"))
>>> result = torch.triu(mask, diagonal=1)
>>> print(result)
tensor([[[[0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]]])
```
But on MPS, it return tensor with NaN:
```
>>> import torch
>>>
>>> mask = torch.full((1, 1, 10, 10), float("-inf"), device=torch.device("mps"))
>>> result = torch.triu(mask, diagonal=1)
>>> print(result)
tensor([[[[nan, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[nan, nan, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[nan, nan, nan, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[nan, nan, nan, nan, -inf, -inf, -inf, -inf, -inf, -inf],
[nan, nan, nan, nan, nan, -inf, -inf, -inf, -inf, -inf],
[nan, nan, nan, nan, nan, nan, -inf, -inf, -inf, -inf],
[nan, nan, nan, nan, nan, nan, nan, -inf, -inf, -inf],
[nan, nan, nan, nan, nan, nan, nan, nan, -inf, -inf],
[nan, nan, nan, nan, nan, nan, nan, nan, nan, -inf],
[nan, nan, nan, nan, nan, nan, nan, nan, nan, nan]]]],
device='mps:0')
```
Also, it works correct on CUDA:
```
>>> import torch
>>>
>>> mask = torch.full((1, 1, 10, 10), float("-inf"), device=torch.device("cuda"))
>>> result = torch.triu(mask, diagonal=1)
>>> print(result)
tensor([[[[0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]]], device='cuda:0')
```
This behavior is reproducible on both pytorch 2.0 and pytorch 1.12.x
### Versions
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.3.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.3 (clang-1403.0.22.14.1)
CMake version: version 3.26.3
Libc version: N/A
Python version: 3.10.10 | packaged by conda-forge | (main, Mar 24 2023, 20:12:31) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-13.3.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M1 Ultra
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.0.0
[conda] numpy 1.24.2 pypi_0 pypi
[conda] pytorch 2.0.0 py3.10_0 pytorch
cc @ezyang @gchanan @zou3519 @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 4 |
2,782 | 99,999 |
Runtime Error
|
triaged, bug
|
### 🐛 Describe the bug
Hi!, While using the simpletransformers library, I've had the following bug:
``` Bash
/opt/conda/lib/python3.7/site-packages/simpletransformers/t5/t5_model.py in train(self, train_dataset, output_dir, show_running_loss, eval_data, verbose, **kwargs)
603 verbose=verbose and args.evaluate_during_training_verbose,
604 silent=args.evaluate_during_training_silent,
--> 605 **kwargs,
606 )
607
/opt/conda/lib/python3.7/site-packages/simpletransformers/t5/t5_model.py in eval_model(self, eval_data, output_dir, verbose, silent, **kwargs)
700 self._move_model_to_device()
701
--> 702 eval_dataset = self.load_and_cache_examples(eval_data, evaluate=True, verbose=verbose, silent=silent)
...
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]))]'. Reason: 'RuntimeError('falseINTERNAL ASSERT FAILED at "/opt/conda/conda-bld/pytorch_1634272178570/work/aten/src/ATen/MapAllocator.cpp":300, please report a bug to PyTorch. unable to write to file </torch_4843_2733>')'
```
### Versions
Collecting environment information...
PyTorch version: 1.10.0
Is debug build: False
CUDA used to build PyTorch: 11.1
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: Could not collect
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.17
Python version: 3.7.11 (default, Jul 27 2021, 14:32:16) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.19.0-38-generic-x86_64-with-debian-buster-sid
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 4090
Nvidia driver version: 525.105.17
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 158
Model name: Intel(R) Core(TM) i9-9900K CPU @ 3.60GHz
Stepping: 12
CPU MHz: 4794.428
CPU max MHz: 5000.0000
CPU min MHz: 800.0000
BogoMIPS: 7200.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 16384K
NUMA node0 CPU(s): 0-15
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.20.2
[pip3] torch==1.10.0
[pip3] torchelastic==0.2.0
[pip3] torchtext==0.11.0
[pip3] torchvision==0.11.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.1.74 h6bb024c_0 nvidia
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py37h7f8727e_0
[conda] mkl_fft 1.3.1 py37hd3c417c_0
[conda] mkl_random 1.2.2 py37h51133e4_0
[conda] numpy 1.20.2 pypi_0 pypi
[conda] pytorch 1.10.0 py3.7_cuda11.1_cudnn8.0.5_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchelastic 0.2.0 pypi_0 pypi
[conda] torchtext 0.11.0 py37 pytorch
[conda] torchvision 0.11.1 py37_cu111 pytorch
| 1 |
2,783 | 99,994 |
OpInfo missing for `prims.convert_element_type`
|
triaged, module: primTorch, oncall: pt2
|
`prims.convert_element_type` does not have an OpInfo
cc @ezyang @mruberry @ngimel @Lezcano @peterbell10 @soumith @msaroufim @wconstab @bdhirsh
| 0 |
2,784 | 99,989 |
Copying an MPS tensor to a CPU tensor using a for loop fails
|
triaged, module: mps
|
### 🐛 Describe the bug
A simple copy from an MPS tensor to a CPU tensor leads to only the first element of the CPU tensor being modified and being assigned the last value of the MPS tensor.
Simple example:
```python
import torch
mv = torch.arange(5,device=torch.device('mps'),dtype=torch.float32)
cv = torch.zeros(5,dtype=torch.float32)
for i in range(5):
cv[i] = mv[i]
print(f'mv={mv.cpu().numpy()}')
print(f'cv={cv.numpy()}')
```
leading to
```
mv=[0. 1. 2. 3. 4.]
cv=[4. 0. 0. 0. 0.]
```
Results are even stranger if the dtypes are different:
```python
import torch
mv = torch.arange(5,device=torch.device('mps'),dtype=torch.int32)
cv = torch.zeros(5,dtype=torch.float32)
for i in range(5):
cv[i] = mv[i]
print(f'mv={mv.cpu().numpy()}')
print(f'cv={cv.numpy()}')
```
leading to
```
mv=[0 1 2 3 4]
cv=[6.e-45 0.e+00 0.e+00 0.e+00 0.e+00]
```
### Versions
PyTorch version: 2.1.0.dev20230422
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.3.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.3 (clang-1403.0.22.14.1)
CMake version: version 3.26.3
Libc version: N/A
Python version: 3.11.2 (main, Mar 15 2023, 21:30:06) [Clang 14.0.0 (clang-1400.0.29.202)] (64-bit runtime)
Python platform: macOS-13.3.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M2 Pro
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==2.1.0.dev20230422
[pip3] torchaudio==2.1.0.dev20230424
[pip3] torchvision==0.16.0.dev20230424
[conda] Could not collect
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
2,785 | 99,982 |
torch.cuda.is_available() crashes python in systems with disabled gpu
|
module: crash, module: cuda, triaged, module: edge cases
|
### 🐛 Describe the bug
Recently, whenever I call torch.cuda.is_available(), my python interpreter suddenly crashes. However, this only happens when using it in the "wild", when calling it in PyCharm, everything works fine.
It might be because of the laptop I'm using, which disables the nvidia gpu when in battery mode, however, it worked before. _This crash only happens in battery mode with the disabled gpu._
**Although this might be a strangely unusual setup, this call should still not crash the entire interpreter.**
This happened in torch 1.13 as well as in 2.0.0.
I updated the python interpreter as well as all packages, but it did not help so far.
I'm using python 3.10.11 in a venv with CUDA 11.7.1 on Win11.
I also tried surrounding the call with try-except, to catch possible uncaught exceptions, however with no success.
Whenever I execute the file containing the cuda-check, or type it directly into the interpreter, the process crashes and exits, without any further message, except for the exit code: -1073740791 (0xC0000409).
```
import torch.cuda
torch.cuda.is_available()
```
### Versions
```
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 11 Home
GCC version: Could not collect
Clang version: Could not collect
CMake version: version 3.24.0
Libc version: N/A
Python version: 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.22621-SP0
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1650 with Max-Q Design
Nvidia driver version: 531.61
cuDNN version: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\bin\cudnn_ops_train64_8.dll
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture=9
CurrentClockSpeed=3201
DeviceID=CPU0
Family=107
L2CacheSize=4096
L2CacheSpeed=
Manufacturer=AuthenticAMD
MaxClockSpeed=3201
Name=AMD Ryzen 7 5800HS with Radeon Graphics
ProcessorType=3
Revision=20480
Versions of relevant libraries:
[pip3] numpy==1.24.3
[pip3] torch==2.0.0+cu117
[pip3] torchvision==0.15.1+cu117
[conda] Could not collect
```
cc @ngimel
| 3 |
2,786 | 99,981 |
Group Norm crashes on Apple M1/MPS devices for versions 2.0+
|
needs reproduction, triaged, module: regression, module: mps
|
### 🐛 Describe the bug
I ran the following notebook locally under 3 versions of PyTorch (1.13.1, 2.0.0, and local build of main 2.1.0a0+git466adab) https://colab.research.google.com/drive/1gxdkgRVfM55zihY9TFLja97cSVZOZq2B?usp=sharing
I isolated the error to the group norm layer (nn.GroupNorm(n_groups, out_channels)). With a group norm (regardless of if the network is on cpu or sent to mps) the very first loss.backwards() causing the python kernel to crash. If you swap this layer out with a batch norm or instance norm, training proceeds as normal
### Versions
Collecting environment information...
PyTorch version: 2.1.0a0+git466adab
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.3.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.3 (clang-1403.0.22.14.1)
CMake version: version 3.22.1
Libc version: N/A
Python version: 3.8.16 (default, Mar 1 2023, 21:18:45) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-13.3.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M1 Max
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.1.0a0+git466adab
[conda] numpy 1.23.5 pypi_0 pypi
[conda] torch 2.1.0a0+git466adab dev_0 <develop>
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 8 |
2,787 | 99,979 |
I encountered an error while trying to save the stylegan2 network as torch. onnx. export
|
module: onnx, triaged
|
### 🐛 Describe the bug
Hello, I encountered an error while trying to save the stylegan2 network as torch. onnx. export
The input for Stylgen2 is [1,512], but whether I input [1,512] or [1,1,512], I cannot obtain the correct network.
[stylegan2 address](https://github.com/rosinality/stylegan2-pytorch)
mycode
```
def to_onnx_zdim(model,onnx_name):
dummy_input=torch.randn(1,1,512,device='cuda')
torch.onnx.export(model,dummy_input,onnx_name,verbose=True)
```
```
sample_z = torch.randn(args.sample, args.latent, device=device)
sample, _ = g_ema(
[sample_z], truncation=args.truncation, truncation_latent=mean_latent
)
to_onnx_zdim(g_ema, 'output/stylegan2_net.onnx')
```

torch version

### Versions
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.26.3
Libc version: glibc-2.31
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.14.0-1059-oem-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.6.55
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
Nvidia driver version: 470.141.03
cuDNN version: /usr/local/cuda-11.1/targets/x86_64-linux/lib/libcudnn.so.5.1.10
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
架构: x86_64
CPU 运行模式: 32-bit, 64-bit
字节序: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU: 80
在线 CPU 列表: 0-79
每个核的线程数: 2
每个座的核数: 20
座: 2
NUMA 节点: 2
厂商 ID: GenuineIntel
CPU 系列: 6
型号: 85
型号名称: Intel(R) Xeon(R) Gold 5218R CPU @ 2.10GHz
步进: 7
CPU MHz: 2100.000
CPU 最大 MHz: 4000.0000
CPU 最小 MHz: 800.0000
BogoMIPS: 4200.00
虚拟化: VT-x
L1d 缓存: 1.3 MiB
L1i 缓存: 1.3 MiB
L2 缓存: 40 MiB
L3 缓存: 55 MiB
NUMA 节点0 CPU: 0-19,40-59
NUMA 节点1 CPU: 20-39,60-79
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
标记: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rgood nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.23.2
[pip3] stylegan2-pytorch==1.8.9
[pip3] torch==2.0.0
[pip3] torchaudio==0.8.0
[pip3] torchsummary==1.5.1
[pip3] torchvision==0.15.1
[pip3] triton==2.0.0
[pip3] vector-quantize-pytorch==0.1.0
[conda] numpy 1.23.2 pypi_0 pypi
[conda] stylegan2-pytorch 1.8.9 pypi_0 pypi
[conda] torch 2.0.0 pypi_0 pypi
[conda] torchaudio 0.8.0 pypi_0 pypi
[conda] torchsummary 1.5.1 pypi_0 pypi
[conda] torchvision 0.15.1 pypi_0 pypi
[conda] triton 2.0.0 pypi_0 pypi
[conda] vector-quantize-pytorch 0.1.0 pypi_0 pypi
| 0 |
2,788 | 99,978 |
torch.jit.trace can not trace buffer by Module.register_buffer() when use DDP Module.
|
oncall: distributed
|
### 🐛 Describe the bug
I want to use Tensorboard add_graph func to draw the network structure, but when my module have a buffer by Module.register_buffer() setting, the add_graph func raise an error and tell me "Modules that are called during a trace must be registered as submodules of the thing being traced."
But if I don't use DDP model, I don't have this error.
At the same time, if my network has no buffer, there will be no error if I use ddp.
```python
import torch
from torch import Tensor, nn
from torch.nn.parallel import DistributedDataParallel as DDP
from torch import distributed, nn
import os
import torch
import torch.multiprocessing as mp
from torch import distributed
import torch
from torch.utils.tensorboard import SummaryWriter
class Demo(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
A = torch.rand(4, 4, 4)
self.register_buffer('A', A)
self.conv = nn.Conv2d(3, 32, 3)
def forward(self, x: Tensor):
x = x.mul(self.A)
x = self.conv(x)
return x
def parallel_network(network: nn.Module) -> DDP:
distributed.barrier()
network_ = nn.SyncBatchNorm.convert_sync_batchnorm(network)
network_ = DDP(network_,
device_ids=[0],
output_device=0)
return network_
def main(local_rank):
torch.cuda.set_device(local_rank)
if distributed.is_nccl_available():
backend = 'nccl'
else:
backend = 'gloo'
distributed.init_process_group(
backend=backend,
init_method='env://',
world_size=torch.cuda.device_count(),
rank=local_rank
)
distributed.barrier()
demo = Demo()
demo = parallel_network(demo.cuda())
writer = SummaryWriter()
input_ = torch.rand(2, 3, 4, 4).cuda()
writer.add_graph(demo, input_)
if __name__ == '__main__':
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '8880'
mp.spawn(main, nprocs=torch.cuda.device_count())
```
Run the code and you'll get an error like this:
```
RuntimeError: Tried to trace <__torch__.torch.classes.c10d.ProcessGroup object at 000002DD0FA310E0> but it is not part of the active trace. Modules that are called during a trace must be registered as submodules of the thing being traced.
```
Specifically, the error is raised by the line.
The specific location is : torch\nn\parallel\distributed.py", line 1689.
```
dist._broadcast_coalesced(
self.process_group, tensors, buffer_size, authoritative_rank
)
```
### Versions
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 10 专业版
GCC version: Could not collect
Clang version: Could not collect
CMake version: Could not collect
Libc version: N/A
Python version: 3.11.2 | packaged by Anaconda, Inc. | (main, Mar 27 2023, 23:35:04) [MSC v.1916 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.19045-SP0
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1060
Nvidia driver version: 512.78
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture=9
CurrentClockSpeed=2808
DeviceID=CPU0
Family=198
L2CacheSize=1024
L2CacheSpeed=
Manufacturer=GenuineIntel
MaxClockSpeed=2808
Name=Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz
ProcessorType=3
Revision=
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==2.0.0+cu117
[pip3] torchaudio==2.0.1+cu117
[pip3] torchvision==0.15.1+cu117
[conda] numpy 1.24.1 pypi_0 pypi
[conda] torch 2.0.0+cu117 pypi_0 pypi
[conda] torchaudio 2.0.1+cu117 pypi_0 pypi
[conda] torchvision 0.15.1+cu117 pypi_0 pypi
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 3 |
2,789 | 99,968 |
`print` statement causes inplace error
|
module: autograd, triaged, needs design
|
### 🐛 Describe the bug
Reported in: https://discuss.pytorch.org/t/error-with-view-no-grad-and-inplace-modify/173082
but I couldn't find the created GitHub issue and the author didn't follow up.
Code to reproduce the issue:
```python
net = nn.Sequential(
nn.Linear(10, 10),
nn.ReLU(),
nn.Linear(10, 10),
nn.ReLU(),
nn.Linear(10, 10),
nn.ReLU(),
)
with torch.no_grad():
for param in net.parameters():
for j in param.flatten():
#print("current j", j)
j += 1
```
Comment the `print` statement in and the code will fail with:
```python
RuntimeError: A view was created in no_grad mode and its base or another view of its base has been modified inplace with grad mode enabled. Given that this use case is ambiguous and error-prone, it is forbidden. You can clarify your code by moving both the view and the inplace either both inside the no_grad block (if you don't want the inplace to be tracked) or both outside (if you want the inplace to be tracked).
```
I would assume the inplace operation is allowed as it's in a `no_grad` block and no computation graph was ever created.
Also, maybe related to: https://discuss.pytorch.org/t/old-problem-but-strange-things-trying-to-backward-through-the-graph-a-second-time/178369
but no executable code snippet was posted yet.
### Versions
Reproduced in a nightly build: `2.1.0.dev20230407+cu118`.
CC @albanD as we talked about this issue before.
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 2 |
2,790 | 99,949 |
[inductor] Autotuning leads to non determinism
|
triaged, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
https://github.com/pytorch/pytorch/pull/99851 disables autotuning when torch.use_deterministic_algorithms are ON.
However, we should due diligence to see if we can remove or alteast reduce non-determinism with autotuning.
### Error logs
_No response_
### Minified repro
_No response_
### Versions
NA
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 1 |
2,791 | 99,932 |
FSDP + gradient clipping raises an odd warning with the simplest model on torch 2.0
|
oncall: distributed, triaged, module: fsdp
|
### 🐛 Describe the bug
if I wrap a model really simply e.g.
```
model = FullyShardedDataParallel(model,
auto_wrap_policy=_auto_wrap_policy,
device_id=torch.cuda.current_device(),
)
```
do some training, then clip gradients via:
```
for module in model.modules():
if isinstance(module, FullyShardedDataParallel):
module.clip_grad_norm_(max_norm=0.1197)
```
It gives me this scary warning:
/mnt/workdisk/brandon/envs/fsdp_generate/lib/python3.10/site-packages/torch/distributed/fsdp/_common_utils.py:291: UserWarning: An unexpected prefix is detected. This case should only happen when using DMP with FSDP. prefix = _fsdp_wrapped_module.softmax., submodule_name = _fsdp_wrapped_module
To minimally repo:
```
import os
from datetime import timedelta
import torch
import torch.nn as nn
import torch.distributed as dist
from torch.distributed.fsdp import FullyShardedDataParallel
from torch.distributed.fsdp.api import ShardingStrategy
import torch.multiprocessing as mp
import logging
DEVICE_TYPE="cuda"
def setup(rank, world_size, use_cuda=True):
logging.getLogger().setLevel(logging.DEBUG if rank == 0 else logging.CRITICAL)
print(f"init for rank {rank}")
if use_cuda:
dist.init_process_group("nccl", rank=rank, world_size=world_size, timeout=timedelta(seconds=5))
else:
dist.init_process_group("gloo", rank=rank, world_size=world_size, timeout=timedelta(seconds=5))
# set device for nccl pg for collectives
if use_cuda == "nccl":
print(f"--> init device for rank {rank}")
torch.cuda.set_device(rank)
print (f"finished init for rank {rank}")
def _auto_wrap_policy(module: torch.nn.Module, recurse: bool, nonwrapped_numel: int) -> bool:
if recurse:
return True
if hasattr(module, '_fsdp_wrap'):
return bool(module._fsdp_wrap)
return False
def simple_model_with_grads():
# Set up small NN with one linear layer with no bias + softmax, so only
# one set of params and get some gradients.
N, hin, num_classes = 8, 4, 3
x = torch.rand((N, hin))
y = torch.randint(high=num_classes - 1, size=(N,))
model = nn.Sequential(nn.Linear(hin, num_classes, bias=False), nn.Softmax(dim=1))
# Force wrap every module in FSDP, to allow for testing FSDP
# gradient clipping properly.
for module in model.modules():
module._fsdp_wrap = True
model._fsdp_wrap = True
model = FullyShardedDataParallel(model,
sharding_strategy=ShardingStrategy.FULL_SHARD,
auto_wrap_policy=_auto_wrap_policy,
device_id=torch.cuda.current_device(),
)
o = model(x)
loss_fn = nn.CrossEntropyLoss()
loss = loss_fn(o, y)
loss.backward()
return model
def work_main(rank):
model = simple_model_with_grads()
for module in model.modules():
if isinstance(module, FullyShardedDataParallel):
module.clip_grad_norm_(max_norm=0.1197)
def main(rank, world_size, use_cuda=True):
setup(rank, world_size, use_cuda)
work_main(rank)
if __name__ == "__main__":
os.environ["MASTER_ADDR"] = "localhost"
# os.environ["MASTER_PORT"] = "29506"
world_size = 2
use_cuda = DEVICE_TYPE == "cuda"
print(f"use_cuda == {use_cuda}")
process = mp.spawn(main, args=(world_size,), nprocs=world_size, join=True)
process.join()
```
### Versions
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.26.3
Libc version: glibc-2.31
Python version: 3.10.10 (main, Feb 8 2023, 14:50:01) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-137-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-40GB
GPU 1: NVIDIA A100-SXM4-40GB
GPU 2: NVIDIA A100-SXM4-40GB
GPU 3: NVIDIA A100-SXM4-40GB
Nvidia driver version: 515.48.07
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.5.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 48 bits physical, 48 bits virtual
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 1
Core(s) per socket: 32
Socket(s): 2
NUMA node(s): 8
Vendor ID: AuthenticAMD
CPU family: 25
Model: 1
Model name: AMD EPYC 7513 32-Core Processor
Stepping: 1
Frequency boost: enabled
CPU MHz: 1499.770
CPU max MHz: 2600.0000
CPU min MHz: 1500.0000
BogoMIPS: 5200.48
Virtualization: AMD-V
L1d cache: 2 MiB
L1i cache: 2 MiB
L2 cache: 32 MiB
L3 cache: 256 MiB
NUMA node0 CPU(s): 0-7
NUMA node1 CPU(s): 8-15
NUMA node2 CPU(s): 16-23
NUMA node3 CPU(s): 24-31
NUMA node4 CPU(s): 32-39
NUMA node5 CPU(s): 40-47
NUMA node6 CPU(s): 48-55
NUMA node7 CPU(s): 56-63
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 invpcid_single hw_pstate ssbd mba ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 invpcid cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold v_vmsave_vmload vgif umip pku ospke vaes vpclmulqdq rdpid overflow_recov succor smca
Versions of relevant libraries:
[pip3] numpy==1.22.4
[pip3] pytorch-ranger==0.1.1
[pip3] torch==2.0.0
[pip3] torch-optimizer==0.3.0
[pip3] torchaudio==2.0.1
[pip3] torchmetrics==0.11.3
[pip3] torchtext==0.14.1
[pip3] torchvision==0.15.1
[pip3] triton==2.0.0
[pip3] vit-pytorch==0.35.8
[conda] Could not collect
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 2 |
2,792 | 99,923 |
benchmarks/dynamo/ci_expected_accuracy/update_expected.py truncates file if only one shard succeeds
|
triaged, module: benchmark, oncall: pt2
|
### 🐛 Describe the bug
If you run benchmarks/dynamo/ci_expected_accuracy/update_expected.py on a run where one shard failed for some reason, it will delete all the entries associated with that shard. We should instead merge the entries from the shard
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
2,793 | 99,922 |
ciflow/inductor should run both inference and training even if inference fails
|
module: ci, triaged, module: inductor
|
### 🐛 Describe the bug
Otherwise `benchmarks/dynamo/ci_expected_accuracy/update_expected.py` cannot get all the updates; you have to run once, update, and then run it again
### Versions
master
cc @seemethere @malfet @pytorch/pytorch-dev-infra @soumith @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 0 |
2,794 | 99,918 |
[RFC] DebugMode
|
triaged
|
### 🚀 The feature, motivation and pitch
## RFC: Debug Mode
Inspired by issue https://github.com/pytorch/pytorch/issues/93880, this RFC proposes to design a DEBUG mode for PyTorch eager mode.
A lot of CUDA kernels fail with device assert but understanding this assert maybe tricky. We rely on device side asserts so that the performance is not degraded due to syncs and extra checks. But this leads to a problem when user sees an error which is not easy to understand.
With debug mode, users would be able to get comprehensive error messages at the cost of decreased performance. This would be an opt-in mechanism which could be used via setting an ENVIRONMENT variable or used directly in code by running under a context manager.
**We will provide a bunch of checks (especially for indexing ops) that users can utilise as well as the ability for the user to add their own checks.**
**NOTE** : Operators compiled by PT2 stack doesn't dispatch via the dispatcher (compiled functions directly called by Python) and hence we won't probably support checks on them in first iteration (Thoughts?).
### Usage with Environment Variable:
Enviroment variable `TORCH_EAGER_DEBUG` (emphasizing that eager ops would be checked) would be one way of running the under debug mode.
Examples
1. Running with debug mode
```bash
TORCH_EAGER_DEBUG=1 python my_script.py
```
2. Specifying the checks to run
```bash
TORCH_EAGER_DEBUG="inf, index" python my_script.py
```
### Usage with Context Manager:
We will also expose context manager which will run only the relevant code under debug mode.
```python
with DebugMode():
y = model(x)
```
### Design
In terms of design, we want to enable user to register their own checks besides the ones provided by PyTorch.
#### 1. Context Manager which accepts user defined checks.
```python
class DebugMode(TorchDispatchMode):
def __init__(self,
checks: Union[str, List[str]] = 'all', # Selection of checks provided by PyTorch
# Additional pre-checks (callables) user can pass
# Arguments to the callable are op, op_args, op_kwargs
pre_checks: Optional[Union[Iterable[Callable], Callable]] = None,
# Additional post-checks (callables) user can pass
# Arguments to the callable are op, op_args, op_kwargs, result
post_checks: Optional[Union[Iterable[Callable], Callable]] = None,
# custom_error_handler for an uncaught error
custom_error_handler: Optional[Callable] = None) -> None:
```
Observation: With this design, it will probably not be simple to share checks between users (there can't be a third party package which you can just install and get new checks).
#### 2. Context Manager with registration mechanism.
```python
class DebugMode(TorchDispatchMode):
def __init__(self,
# Selection of checks provided by PyTorch (as well as user defined checks)
checks: Union[str, List[str]] = 'all') -> None:
```
Registration helpers (class methods)
```python
# Arguments to the callable are op, op_args, op_kwargs
DebugMode.register_debug_mode_pre_check(name, callable)
# Arguments to the callable are op, op_args, op_kwargs, result
DebugMode.register_debug_mode_post_check(name, callable)
# Arguments to the callable are exception, op, op_args, op_kwargs
DebugMode.register_debug_mode_error_handler(callable)
```
With this design, users can easily share their checks (even as third party libraries).
#### 3. C++ Macro for Debug Checks in an Operator
```c++
// one debug check
TORCH_DEBUG_CHECK(TORCH_CHECK(condition, "some error message"));
// multiple debug check
TORCH_DEBUG_CHECK({
TORCH_CHECK(condition1, "some error message");
TORCH_CHECK(condition2, "some other error message");
});
```
These checks will only be triggered if the asked by the user. User will use ENVIRONMENT variable or DebugMode context manager from above to turn on these checks.
### Implementation
We will be leveraging the `TorchDispatchMode` to implement this utility. This will allow us to intercept and add checks for both forward and backward operators. For C++ macro, we will use an internal runtime global flag to turn the macro on and off.
**Draft PR [WIP]**: https://github.com/pytorch/pytorch/pull/95952
**Thanks @chillee, @zou3519 and @albanD for help and review of the design.**
### Alternatives
_No response_
### Additional context
_No response_
cc @ZainRizvi @kit1980 @huydhn @clee2000
| 5 |
2,795 | 99,908 |
Deprecate torch.distributed.algorithms._optimizer_overlap
|
oncall: distributed
|
### 🚀 The feature, motivation and pitch
After a discussion with @rohan-varma, we agreed we should deprecate and remove [torch.distributed.algorithms._optimizer_overlap](https://github.com/pytorch/pytorch/blob/7d2a18da0b3427fcbe44b461a0aa508194535885/torch/distributed/algorithms/_optimizer_overlap/optimizer_overlap.py) in favor of [torch.distributed.optim.apply_optimizer_in_backward](https://github.com/pytorch/pytorch/blob/7d2a18da0b3427fcbe44b461a0aa508194535885/torch/distributed/optim/apply_optimizer_in_backward.py).
This deprecation would involve:
- [ ] Adding a deprecation warning for its usage
- [ ] Offboarding any use cases to use the other API
- [ ] Removing the extra code that came along with it, for example any documentation and helpers like [torch.distributed.algorithms.ddp_comm_hooks](https://github.com/pytorch/pytorch/blob/7d2a18da0b3427fcbe44b461a0aa508194535885/torch/distributed/algorithms/ddp_comm_hooks/optimizer_overlap_hooks.py)
### Alternatives
_No response_
### Additional context
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
2,796 | 99,903 |
Can the CUDA device LUID be exposed as part of _CudaDeviceProperties?
|
module: cuda, triaged, enhancement, actionable, needs design
|
### 🚀 The feature, motivation and pitch
CUDA devices can be ordered in a few different ways (FASTEST_FIRST, PCI_BUS_ID). The device LUID is the more modern way of describing a GPU in a unique way. It's particularly useful when using CUDA along with other APIs such as Vulkan or DirectX.
Can the LUID that the cudaDeviceProp structure contains be made visible in _CudaDeviceProperties as well?
https://docs.nvidia.com/cuda/cuda-runtime-api/structcudaDeviceProp.html#structcudaDeviceProp_1b1fe931f3f41d1b97c8679c8b15d94e3
Thanks
### Alternatives
_No response_
### Additional context
_No response_
cc @ngimel
| 4 |
2,797 | 99,893 |
Many models are failing on periodic dynamic shape benchmark tests dynamic_aot_eager
|
triaged, oncall: pt2, module: dynamic shapes
|
### 🐛 Describe the bug
For example, https://hud.pytorch.org/pytorch/pytorch/commit/ab0a8215bb73c508ecfaabead6f3118beef2547f. There are more than one root cause here I think. I have moved the test to unstable in the meantime https://github.com/pytorch/pytorch/pull/99895
### Versions
PyTorch CI
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
2,798 | 99,883 |
HashTest.Scalar from test_lazy is broken
|
triaged, module: lazy
|
### 🐛 Describe the bug
HashTest.Scalar from test_lazy is broken.
Here are lines in question:
https://github.com/pytorch/pytorch/blob/09b189edc36235ad96816904adb2c230351b9ac8/test/cpp/lazy/test_misc.cpp#L23-L37
Line 30 modifies `b.tag`, not anything in the data union.
On little endian systems before this assignment tag has value `0x00000001`, or `c10::Scalar::Tag::HAS_i`, and after assignment it keeps old value. Nothing changed and test actually tests nothing it intended to.
It's worse on big endian systems. Before assignment tag also has value `0x00000001`, or `c10::Scalar::Tag::HAS_i`. But after assignment it becomes `0x01000001`, an invalid value. And when accessing data, an exception about this is thrown:
```
unknown file: Failure
C++ exception with description "Expected false to be true, but got false. (Could this error message be improved? If so, please report an enhancement request to PyTorch.)
Exception raised from toLong at /home/user/pytorch/c10/core/Scalar.h:99 (most recent call first):
frame #0: <unknown function> + 0xbbf42 (0x3ffea5bbf42 in /home/user/pytorch/build/lib/libc10.so)
...
```
This test is better to be reworked or to be deleted.
### Versions
pytorch current main branch
Collecting environment information...
PyTorch version: 2.1.0a0+gitab0a821
Is debug build: True
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Gentoo Linux (s390x)
GCC version: (Gentoo 11.3.1_p20230303 p8) 11.3.1 20230303
Clang version: Could not collect
CMake version: version 3.26.0
Libc version: glibc-2.37
Python version: 3.10.10 (main, Mar 21 2023, 10:36:56) [GCC 11.3.1 20230120] (64-bit runtime)
Python platform: Linux-5.16.5-200.fc35.s390x-s390x-8561-with-glibc2.37
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: False
CPU:
Architecture: s390x
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Big Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Vendor ID: IBM/S390
Model name: -
Machine type: 8561
Thread(s) per core: 1
Core(s) per socket: 1
Socket(s) per book: 1
Book(s) per drawer: 1
Drawer(s): 8
CPU dynamic MHz: 5200
CPU static MHz: 5200
BogoMIPS: 24038.00
Dispatching mode: horizontal
Flags: esan3 zarch stfle msa ldisp eimm dfp edat etf3eh highgprs te vx vxd vxe gs vxe2 vxp sort dflt sie
Hypervisor: z/VM 7.3.0
Hypervisor vendor: IBM
Virtualization type: full
L1d cache: 1 MiB (8 instances)
L1i cache: 1 MiB (8 instances)
L2d cache: 32 MiB (8 instances)
L2i cache: 32 MiB (8 instances)
L3 cache: 256 MiB
L4 cache: 960 MiB
NUMA node(s): 1
NUMA node0 CPU(s): 0-7
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Not affected
Vulnerability Spectre v1: Mitigation; __user pointer sanitization
Vulnerability Spectre v2: Mitigation; etokens
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.24.2
[conda] Could not collect
| 0 |
2,799 | 99,874 |
[torch.compile] unsupported operand type(s) for @: 'Tensor' and 'Tensor' when enabling `shape_padding`
|
triaged, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
`torch.compile` raises the error that unsupported operand type(s) for @: 'Tensor' and 'Tensor' when enabling `shape_padding` (TORCHINDUCTOR_SHAPE_PADDING=1)
```py
import torch
torch.manual_seed(420)
class Model(torch.nn.Module):
def forward(self, x, y):
out = x @ y
return out
input_dim = 20
seq_length = 10
batch_size = 4
x = torch.randn(batch_size, seq_length, input_dim).cuda()
y = torch.zeros((batch_size, input_dim, seq_length)).cuda()
func = Model().to('cuda')
res1 = func(x, y)
print(res1)
jit_func = torch.compile(func)
res2 = jit_func(x, y)
# TypeError: unsupported operand type(s) for @: 'Tensor' and 'Tensor'
# While executing %matmul : [#users=1] = call_function[target=operator.matmul](args = (%l_x_, %l_y_), kwargs = {})
```
### Versions
```
Collecting environment information...
PyTorch version: 2.1.0.dev20230419+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 14.0.0-1ubuntu1
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.9.16 (main, Mar 8 2023, 14:00:05) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.19.5-051905-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.5.119
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3060
Nvidia driver version: 510.108.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Vendor ID: GenuineIntel
Model name: 12th Gen Intel(R) Core(TM) i9-12900K
CPU family: 6
Model: 151
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
Stepping: 2
CPU max MHz: 6700.0000
CPU min MHz: 800.0000
BogoMIPS: 6374.40
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault cat_l2 invpcid_single cdp_l2 ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid rdt_a rdseed adx smap clflushopt clwb intel_pt sha_ni xsaveopt xsavec xgetbv1 xsaves split_lock_detect avx_vnni dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp hwp_pkg_req hfi umip pku ospke waitpkg gfni vaes vpclmulqdq tme rdpid movdiri movdir64b fsrm md_clear serialize pconfig arch_lbr ibt flush_l1d arch_capabilities
Virtualization: VT-x
L1d cache: 640 KiB (16 instances)
L1i cache: 768 KiB (16 instances)
L2 cache: 14 MiB (10 instances)
L3 cache: 30 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-23
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.1.0+46672772b4
[pip3] torch==2.1.0.dev20230419+cu118
[pip3] torchaudio==2.1.0.dev20230419+cu118
[pip3] torchvision==0.16.0.dev20230419+cu118
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-triton 2.1.0+46672772b4 pypi_0 pypi
[conda] torch 2.1.0.dev20230419+cu118 pypi_0 pypi
[conda] torchaudio 2.1.0.dev20230419+cu118 pypi_0 pypi
[conda] torchvision 0.16.0.dev20230419+cu118 pypi_0 pypi
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 1 |
2,800 | 99,873 |
Dynamo config patching in our code is brittle
|
triaged, oncall: pt2, module: dynamo, module: export
|
### 🐛 Describe the bug
Concretely, the other day, I was trying to change the default setting of `assume_static_by_default` for export only: https://github.com/pytorch/pytorch/pull/99554 The easiest way to do this was to modify _dynamo.export to patch this to False on entry.
However, this resulted in something very awkward: it's now *no longer possible* to override this setting via external configuration! Because the config setting always gets overwritten by the patch on the inside.
In general, it's awkward to have config settings that default one way for eager and another export. It would be nice to figure out some robust mechanism for doing this
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.