
Serial Number
int64 1
6k
| Issue Number
int64 75.6k
112k
| Title
stringlengths 3
357
| Labels
stringlengths 3
241
⌀ | Body
stringlengths 9
74.5k
⌀ | Comments
int64 0
867
|
|---|---|---|---|---|---|
3,101 | 97,597 |
Insufficient MPS Documentation
|
module: docs, triaged, module: mps
|
### 📚 The doc issue
Whenever I try to have a look at MPS documentation for PyTorch, it is really difficult to figure it out and I couldn't find much in my way. On the other hand, when I look for CUDA documentation, every detail was set so that it can be understandable for everyday user. Checked that I have a functioning MPS.
### Suggest a potential alternative/fix
Creating a comprehensive documentation for MPS would be great.
cc @svekars @carljparker @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
3,102 | 97,595 |
can get_submodule be called within a ScriptFunction ?
|
oncall: jit, triaged
|
### 🚀 The feature, motivation and pitch
I'm writing a multi domain classifier where can first predict domains of a sentence, and then choose the corresponding sequence classifer to run. It can certainly save FPOP in inference stage.
```
class MultiDomainClassifier(nn.Module):
def __init__(self, classifiers: nn.ModuleDict, num_domain):
super().__init__()
self.classifiers = nn.ModuleList(classifiers.children())
self.num_domain = num_domain
def forward(self, inputs: Tensor, output_domains: Tensor) -> list[Tensor]:
return [self.classifiers.get_submodule(str(idx)).forward(inputs) for idx in output_domains]
```
But I got this:
```
RuntimeError:
Unknown type name 'Module':
File "/home/luka.bao/anaconda3/envs/cpu/lib/python3.9/site-packages/torch/nn/modules/module.py", line 617
def get_submodule(self, target: str) -> "Module":
~~~~~~~ <--- HERE
"""
Returns the submodule given by ``target`` if it exists,
'ModuleList.get_submodule' is being compiled since it was called from 'MultiDomainClassifier.forward'
File "/home/luka.bao/PycharmProjects/multitask-nlu-torch/torch_impl/output/classifier.py", line 109
def forward(self, inputs: Tensor, output_domains: Tensor) -> list[Tensor]:
return [self.classifiers.get_submodule(str(idx)).forward(inputs) for idx in output_domains]
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
```
### Alternatives
_No response_
### Additional context
_No response_
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 2 |
3,103 | 97,580 |
Torch 2.0 import hangs forever
|
module: build, module: cuda, triaged
|
### 🐛 Describe the bug
Importing torch 2.0 after importing tensorflow hangs forever. This does not happen with torch 1.13. It happens both with cuda 118 and cuda 117.
```bash
docker pull tensorflow/tensorflow:2.12.0-gpu
docker run -it tensorflow/tensorflow:2.12.0-gpu
pip install torch==2.0.0+cu118 torchvision==0.15.1+cu118 torchaudio==2.0.1+cu118 -f https://download.pytorch.org/whl/cu118/torch_stable.html
python
```
```python
import tensorflow as tf
import torch
```
### Versions
```
python collect_env.py
Collecting environment information...
PyTorch version: 2.0.0+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.26.1
Libc version: glibc-2.31
Python version: 3.8.10 (default, Mar 13 2023, 10:26:41) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-144-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA A100-SXM4-40GB
Nvidia driver version: 470.161.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 256
On-line CPU(s) list: 0-255
Thread(s) per core: 2
Core(s) per socket: 64
Socket(s): 2
NUMA node(s): 8
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7742 64-Core Processor
Stepping: 0
Frequency boost: enabled
CPU MHz: 3254.011
CPU max MHz: 2250.0000
CPU min MHz: 1500.0000
BogoMIPS: 4491.68
Virtualization: AMD-V
L1d cache: 4 MiB
L1i cache: 4 MiB
L2 cache: 64 MiB
L3 cache: 512 MiB
NUMA node0 CPU(s): 0-15,128-143
NUMA node1 CPU(s): 16-31,144-159
NUMA node2 CPU(s): 32-47,160-175
NUMA node3 CPU(s): 48-63,176-191
NUMA node4 CPU(s): 64-79,192-207
NUMA node5 CPU(s): 80-95,208-223
NUMA node6 CPU(s): 96-111,224-239
NUMA node7 CPU(s): 112-127,240-255
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Vulnerable
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate sme ssbd mba sev ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip rdpid overflow_recov succor smca
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0+cu118
[pip3] torchaudio==2.0.1+cu118
[pip3] torchvision==0.15.1+cu118
[pip3] triton==2.0.0
[conda] Could not collect
```
cc @malfet @seemethere @ngimel
| 4 |
3,104 | 97,575 |
Multi-output derivative formulas can save unnecessary tensors
|
module: autograd, triaged, module: nestedtensor, actionable
|
Usually when you have a derivative formula, e.g. `mm`:
```
- name: mm(Tensor self, Tensor mat2) -> Tensor
self: mm_mat1_backward(grad, mat2, self.sym_sizes(), self.sym_strides(), self.layout(), 1)
mat2: mm_mat2_backward(grad, self, mat2.sym_sizes(), mat2.sym_strides(), mat2.layout(), 1)
result: at::mm(self_t, mat2_p) + at::mm(self_p, mat2_t)
```
The structure informs autograd codegen what tensors need to be saved to compute which gradients, i.e. if only `self` requires grad, I only need to save `mat2`, and if only `mat2` requires grad, I only need to save `self`.
In VariableType, the following logic is generated for `mm`:
```cpp
if (_any_requires_grad) {
grad_fn = std::shared_ptr<MmBackward0>(new MmBackward0(), deleteNode);
grad_fn->set_next_edges(collect_next_edges( self, mat2 ));
if (grad_fn->should_compute_output(1)) {
grad_fn->self_ = SavedVariable(self, false);
}
...
if (grad_fn->should_compute_output(0)) {
grad_fn->mat2_ = SavedVariable(mat2, false);
}
}
```
However, when you have a single derivative formula that produces multiple outputs, autograd codegen no longer has visibility into what tensors need to be saved in order to compute which gradients.
```
- name: matmul(Tensor self, Tensor other) -> Tensor
self, other: matmul_backward(grad, self, other, grad_input_mask)
```
This yields the following unoptimized logic in autograd kernel:
```
if (_any_requires_grad) {
grad_fn = std::shared_ptr<MatmulBackward0>(new MatmulBackward0(), deleteNode);
grad_fn->set_next_edges(collect_next_edges( self, other ));
grad_fn->self_ = SavedVariable(self, false);
grad_fn->other_ = SavedVariable(other, false);
}
```
One common case where this can matter is if I'm doing some fine-tuning, e.g. I want to requires_grad=False for the parameters of a bunch of layers in the middle of a network.
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @Lezcano @Varal7 @cpuhrsch @jbschlosser @bhosmer @drisspg @gchanan
| 8 |
3,105 | 97,552 |
PackedSequence failure with MPS
|
triaged, module: mps
|
### 🐛 Describe the bug
Hi,
I have noticed recently that PyTorch fails in a specific way when using the PackedSequence Class with MPS. I've replicated the issue using a fresh minimal conda environment. I'm using PyTorch nightly because of the (recently closed) issues around LSTM and MPS (#96416) in PyTorch 2.0.0. The error doesn't seem to occur with PyTorch 1.13.1 (but I do get the old aten::nonzero flag with this version, so I don't know whether this version works only because the 'required' bit of code is being fed through the CPU instead of MPS).
The following code should hopefully replicate the problem I'm having. It generates some random sparsely populated time-series data (to replicate a series of padded samples), which is then packed via pack_padded_sequence, and fed into LSTM. The error occurs with larger sample sizes (like 1000), but not with smaller sample sizes (like 50).
```
import torch
from torch import nn, Tensor
from torch.nn.utils.rnn import pack_padded_sequence
# Make some sparsely populated synthetic data,
# mimicking padded time-series data
samples = 1000
input_data = torch.zeros((samples, 50, 3))
p = torch.rand((samples, 50, 3))
new_values = torch.normal(5, 3, size=(samples, 50, 3))
idx = torch.where(p < 0.05)
input_data[idx] = new_values[idx]
idx = input_data.sum(2).sum(1).nonzero().flatten()
input_data = input_data[idx]
# Set to mps
input_data = input_data.to('mps')
# Pack the data
lengths = Tensor([1 + arr.nonzero()[:, 0].max().item() - arr.nonzero()[:, 0].min().item()
for arr in input_data.cpu()])
packed_data = pack_padded_sequence(
input_data,
lengths,
batch_first=True,
enforce_sorted=False)
# Make our neural network
net = nn.Sequential(
nn.LSTM(input_size=3,
hidden_size=50)).to('mps')
output, (hn, cn) = net(packed_data)
print(output)
```
When the code is run, the following error is given, at the point of feeding the PackedSequence into the LSTM:
```
/AppleInternal/Library/BuildRoots/c651a45f-806e-11ed-a221-7ef33c48bc85/Library/Caches/com.apple.xbs/Sources/MetalPerformanceShaders/MPSCore/Types/MPSNDArray.mm:82: failed assertion `[MPSNDArrayDescriptor sliceDimension:withSubrange:] error: subRange.start (8192) is not less than length of dimension[1] (995)'
```
I'm not sure I fully understand what is going wrong. The code runs fine 1) with cpu and 2) with regular padded sequence (i.e., no packing) for much larger sample sizes.
### Versions
PyTorch version: 2.1.0.dev20230324
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.2.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: version 3.25.2
Libc version: N/A
Python version: 3.10.9 | packaged by conda-forge | (main, Feb 2 2023, 20:26:08) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-13.2.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M1 Pro
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.1.0.dev20230324
[conda] numpy 1.24.2 py310h3d2048e_0 conda-forge
[conda] pytorch 2.1.0.dev20230324 py3.10_0 pytorch-nightly
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 4 |
3,106 | 97,539 |
InfoNCE loss for contrastive learning
|
module: loss, triaged, enhancement
|
### 🚀 The feature, motivation and pitch
In the last couple of years contrastive self-supervised learning has been gaining popularity, as it allows one to use large amounts of unlabeled data to (pre) train a model. A loss function which is commonly used is the [InfoNCE](https://arxiv.org/abs/1807.03748) loss, having 4620 citations according to scholar. The loss is also used by [MoCo](https://arxiv.org/abs/1911.05722), which has 6416 citations, and [SimCLR](https://arxiv.org/abs/2002.05709), which has 8988 citations. I think this loss would be a good addition to PyTorch considering the popularity and the fact that a similar loss is not yet in PyTorch.
### Alternatives
There are slight variations in the literature. MoCo added the temperature, which wasn't present in the original definition. SimCLR uses more negative examples from both 'views'. But at it's core there is little difference between these, as the loss is still about applying softmax on the similarity of embeddings.
Other large papers in this field are [BYOL](https://arxiv.org/pdf/2006.07733.pdf) and [SimSiam](https://arxiv.org/abs/2011.10566), which calculate a mean squared error of embeddings, and [SwAV](https://arxiv.org/abs/2006.09882), which at a glance seems to use a similar loss although I haven't read the paper in detail yet.
### Additional context
For context: I have a repository with an implementation of this loss. Someone opened an issue there asking me to try to contribute it to PyTorch, hence this feature request. The goal of this feature request is to get the InfoNCE loss into PyTorch and not to get my implementation of it in particular in PyTorch. Although, I have no objection to that of course. I genuinely think that this loss, or a variant thereof, will make a valuable contribution.
| 0 |
3,107 | 97,532 |
TransformerEncoder fast path raises incorrect mask dtype warning
|
module: cuda, triaged, oncall: transformer/mha
|
### 🐛 Describe the bug
The following snippet shouldn't result in a warning, but does:
```python
import torch
import torch.nn as nn
encoder_layer = nn.TransformerEncoderLayer(
d_model=16,
nhead=2,
dim_feedforward=32,
dropout=0.1,
activation='relu',
batch_first=True,
)
encoder_norm = nn.LayerNorm(16)
encoder = nn.TransformerEncoder(
encoder_layer, 2, encoder_norm, enable_nested_tensor=True
).to('cuda')
inputs = torch.randn(2,3,16).to('cuda')
inputs.requires_grad=False
src_mask = torch.zeros(3, 3, dtype=torch.bool)#.triu_(diagonal=1)
input_seq_len = torch.tensor([3,2])
padding_mask = (torch.arange(3)[None, :].cpu() >= input_seq_len[:, None])
assert(src_mask.dtype == padding_mask.dtype)
assert(src_mask.dtype == torch.bool)
encoder.eval()
with torch.no_grad():
out = encoder(inputs,
mask=src_mask.cuda(),
src_key_padding_mask=padding_mask.cuda(),
)
```
```
env/lib/python3.9/site-packages/torch/nn/modules/transformer.py:562: UserWarning: Converting mask without torch.bool dtype to bool; this will negatively affect performance. Prefer to use a boolean mask directly. (Triggered internally at ../aten/src/ATen/native/transformers/attention.cpp:150.)
return torch._transformer_encoder_layer_fwd(
```
### Versions
Collecting environment information...
PyTorch version: 2.1.0.dev20230324+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.2 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.9.13 (main, Oct 13 2022, 21:15:33) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-67-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2080 Ti
Nvidia driver version: 525.85.05
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.2.2
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.2.2
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.2.2
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.2.2
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.2.2
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.2.2
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.2.2
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Vendor ID: GenuineIntel
Model name: Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz
CPU family: 6
Model: 158
Thread(s) per core: 1
Core(s) per socket: 8
Socket(s): 1
Stepping: 13
CPU max MHz: 4700.0000
CPU min MHz: 800.0000
BogoMIPS: 6000.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_
timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2
erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d arch_capabilities
Virtualisation: VT-x
L1d cache: 256 KiB (8 instances)
L1i cache: 256 KiB (8 instances)
L2 cache: 2 MiB (8 instances)
L3 cache: 12 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-7
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT disabled
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Mitigation; Microcode
Vulnerability Tsx async abort: Mitigation; TSX disabled
Versions of relevant libraries:
[pip3] mypy==1.0.1
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.4
[pip3] pytorch-lightning==2.0.0
[pip3] pytorch_revgrad==0.2.0
[pip3] pytorch-triton==2.1.0+e650d3708b
[pip3] torch==2.1.0.dev20230324+cu118
[pip3] torchaudio==2.0.0.dev20230312+cu118
[pip3] torchmetrics==0.11.4
[pip3] torchseq==3.0.0a0
[conda] numpy 1.21.5 pypi_0 pypi
[conda] pytorch-triton 2.0.0+b8b470bc59 pypi_0 pypi
[conda] torch 1.7.1 pypi_0 pypi
[conda] torchseq 3.0.0a0 dev_0 <develop>
cc @ptrblck @jbschlosser @bhosmer @cpuhrsch @erichan1 @drisspg @ngimel
| 2 |
3,108 | 97,504 |
Burn benchmark suites into CI docker image. Not only this saves test time, but also it will get rid of occasional model installation failures. (@weiwangmeta )
|
triaged
| null | 0 |
3,109 | 97,503 |
torch.cppExtension won't work with wsl2
|
triaged, module: wsl
|
### 🐛 Describe the bug
oper.cu:
`
#include <torch/torch.h>
#include <c10/cuda/CUDAStream.h>
#include <c10/cuda/CUDAGuard.h>
#include <torch/extension.h>
torch::Tensor TS_DELAY_FIXED_PERIOD(torch::Tensor &ten_x,int64_t period) {
torch::Tensor ten_re=torch::empty_like(ten_x);
return ten_re.squeeze();
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("TS_DELAY_FIXED_PERIOD", &TS_DELAY_FIXED_PERIOD,"TS_DELAY_FIXED_PERIOD kernel warpper");
}
`
test.py:
`
from torch.utils.cpp_extension import load
cuda_module = load(name="fm_oper", sources=["./oper.cu"], verbose=True, extra_cflags=['-O3'], extra_cuda_cflags=['-prec-sqrt=false','-O3'])
`
and I get:
/usr/local/cuda-12.0
/data/py_projects/pegasus/project/factor_mining/oper.cu
Using /root/.cache/torch_extensions/py39_cu117 as PyTorch extensions root...
Detected CUDA files, patching ldflags
Emitting ninja build file /root/.cache/torch_extensions/py39_cu117/fm_oper/build.ninja...
Building extension module fm_oper...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
[1/2] /usr/local/cuda-12.0/bin/nvcc -DTORCH_EXTENSION_NAME=fm_oper -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -isystem /root/anaconda3/lib/python3.9/site-packages/torch/include -isystem /root/anaconda3/lib/python3.9/site-packages/torch/include/torch/csrc/api/include -isystem /root/anaconda3/lib/python3.9/site-packages/torch/include/TH -isystem /root/anaconda3/lib/python3.9/site-packages/torch/include/THC -isystem /usr/local/cuda-12.0/include -isystem /root/anaconda3/include/python3.9 -D_GLIBCXX_USE_CXX11_ABI=0 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_86,code=compute_86 -gencode=arch=compute_86,code=sm_86 --compiler-options '-fPIC' -prec-sqrt=false -O3 -std=c++17 -c /data/py_projects/pegasus/project/factor_mining/oper.cu -o oper.cuda.o
FAILED: oper.cuda.o
/usr/local/cuda-12.0/bin/nvcc -DTORCH_EXTENSION_NAME=fm_oper -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -isystem /root/anaconda3/lib/python3.9/site-packages/torch/include -isystem /root/anaconda3/lib/python3.9/site-packages/torch/include/torch/csrc/api/include -isystem /root/anaconda3/lib/python3.9/site-packages/torch/include/TH -isystem /root/anaconda3/lib/python3.9/site-packages/torch/include/THC -isystem /usr/local/cuda-12.0/include -isystem /root/anaconda3/include/python3.9 -D_GLIBCXX_USE_CXX11_ABI=0 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_86,code=compute_86 -gencode=arch=compute_86,code=sm_86 --compiler-options '-fPIC' -prec-sqrt=false -O3 -std=c++17 -c /data/py_projects/pegasus/project/factor_mining/oper.cu -o oper.cuda.o
/root/anaconda3/lib/python3.9/site-packages/torch/include/pybind11/cast.h: In function ‘typename pybind11::detail::type_caster<typename pybind11::detail::intrinsic_type<T>::type>::cast_op_type<T> pybind11::detail::cast_op(make_caster<T>&)’:
/root/anaconda3/lib/python3.9/site-packages/torch/include/pybind11/cast.h:42:120: error: expected template-name before ‘<’ token
42 | return caster.operator typename make_caster<T>::template cast_op_type<T>();
| ^
/root/anaconda3/lib/python3.9/site-packages/torch/include/pybind11/cast.h:42:120: error: expected identifier before ‘<’ token
/root/anaconda3/lib/python3.9/site-packages/torch/include/pybind11/cast.h:42:123: error: expected primary-expression before ‘>’ token
42 | return caster.operator typename make_caster<T>::template cast_op_type<T>();
| ^
/root/anaconda3/lib/python3.9/site-packages/torch/include/pybind11/cast.h:42:126: error: expected primary-expression before ‘)’ token
42 | return caster.operator typename make_caster<T>::template cast_op_type<T>();
| ^
ninja: build stopped: subcommand failed.
Traceback (most recent call last):
File "/root/anaconda3/lib/python3.9/site-packages/torch/utils/cpp_extension.py", line 1893, in _run_ninja_build
subprocess.run(
File "/root/anaconda3/lib/python3.9/subprocess.py", line 528, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command '['ninja', '-v']' returned non-zero exit status 1.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/data/py_projects/pegasus/project/factor_mining/oper.py", line 567, in <module>
instance = FM_OPER(o, h, l, c, v, i, amt, vwap, indus_dummies, expire)
File "/data/py_projects/pegasus/project/factor_mining/oper.py", line 48, in __init__
self.cuda_module = load(name="fm_oper", sources=[util.abspath("./oper.cu")], verbose=True, extra_cflags=['-O3'], extra_cuda_cflags=['-prec-sqrt=false','-O3'])
File "/root/anaconda3/lib/python3.9/site-packages/torch/utils/cpp_extension.py", line 1284, in load
return _jit_compile(
File "/root/anaconda3/lib/python3.9/site-packages/torch/utils/cpp_extension.py", line 1509, in _jit_compile
_write_ninja_file_and_build_library(
File "/root/anaconda3/lib/python3.9/site-packages/torch/utils/cpp_extension.py", line 1624, in _write_ninja_file_and_build_library
_run_ninja_build(
File "/root/anaconda3/lib/python3.9/site-packages/torch/utils/cpp_extension.py", line 1909, in _run_ninja_build
raise RuntimeError(message) from e
### Versions
wsl2 pytorch2.0 cuda11.7
cc @peterjc123 @mszhanyi @skyline75489 @nbcsm
| 0 |
3,110 | 97,501 |
torch.compile not work in WSL
|
triaged, module: wsl, oncall: pt2
|
### 🐛 Describe the bug
``
`
`
`import torch
class TestSig(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return torch.sigmoid(x)
torch._dynamo.config.verbose=True
opt_cpu = torch.compile(TestSig())
print("cpu:", opt_cpu(torch.randn(1)))
cuda_eager = TestSig().cuda()
print("cuda eager:", cuda_eager(torch.randn(1).cuda()))
opt_cuda = torch.compile(TestSig()).cuda() #torch.compile(TestSig().cuda()) also fails
print("cuda opt:", opt_cuda(torch.randn(1).cuda()))`
and I get:
cpu: tensor([0.3198])
cuda eager: tensor([0.4224], device='cuda:0')
/usr/bin/ld: cannot find -lcuda: No such file or directory
collect2: error: ld returned 1 exit status
concurrent.futures.process._RemoteTraceback:
"""
Traceback (most recent call last):
File "/root/anaconda3/lib/python3.9/concurrent/futures/process.py", line 246, in _process_worker
r = call_item.fn(*call_item.args, **call_item.kwargs)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_inductor/codecache.py", line 549, in _worker_compile
kernel.precompile(warm_cache_only_with_cc=cc)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_inductor/triton_ops/autotune.py", line 69, in precompile
self.launchers = [
File "/root/anaconda3/lib/python3.9/site-packages/torch/_inductor/triton_ops/autotune.py", line 70, in <listcomp>
self._precompile_config(c, warm_cache_only_with_cc)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_inductor/triton_ops/autotune.py", line 83, in _precompile_config
triton.compile(
File "/root/anaconda3/lib/python3.9/site-packages/triton/compiler.py", line 1587, in compile
so_path = make_stub(name, signature, constants)
File "/root/anaconda3/lib/python3.9/site-packages/triton/compiler.py", line 1476, in make_stub
so = _build(name, src_path, tmpdir)
File "/root/anaconda3/lib/python3.9/site-packages/triton/compiler.py", line 1391, in _build
ret = subprocess.check_call(cc_cmd)
File "/root/anaconda3/lib/python3.9/subprocess.py", line 373, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['/usr/bin/gcc', '/tmp/tmphttesy02/main.c', '-O3', '-I/root/anaconda3/lib/python3.9/site-packages/triton/third_party/cuda/include', '-I/root/anaconda3/include/python3.9', '-I/tmp/tmphttesy02', '-shared', '-fPIC', '-lcuda', '-o', '/tmp/tmphttesy02/triton_.cpython-39-x86_64-linux-gnu.so']' returned non-zero exit status 1.
"""
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/output_graph.py", line 670, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/debug_utils.py", line 1055, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs)
File "/root/anaconda3/lib/python3.9/site-packages/torch/__init__.py", line 1390, in __call__
return compile_fx(model_, inputs_, config_patches=self.config)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_inductor/compile_fx.py", line 455, in compile_fx
return aot_autograd(
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/backends/common.py", line 48, in compiler_fn
cg = aot_module_simplified(gm, example_inputs, **kwargs)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 2805, in aot_module_simplified
compiled_fn = create_aot_dispatcher_function(
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 2498, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_args, aot_config)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 1713, in aot_wrapper_dedupe
return compiler_fn(flat_fn, leaf_flat_args, aot_config)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 1326, in aot_dispatch_base
compiled_fw = aot_config.fw_compiler(fw_module, flat_args_with_views_handled)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_inductor/compile_fx.py", line 430, in fw_compiler
return inner_compile(
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/debug_utils.py", line 595, in debug_wrapper
compiled_fn = compiler_fn(gm, example_inputs)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_inductor/debug.py", line 239, in inner
return fn(*args, **kwargs)
File "/root/anaconda3/lib/python3.9/contextlib.py", line 79, in inner
return func(*args, **kwds)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_inductor/compile_fx.py", line 177, in compile_fx_inner
compiled_fn = graph.compile_to_fn()
File "/root/anaconda3/lib/python3.9/site-packages/torch/_inductor/graph.py", line 586, in compile_to_fn
return self.compile_to_module().call
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_inductor/graph.py", line 575, in compile_to_module
mod = PyCodeCache.load(code)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_inductor/codecache.py", line 528, in load
exec(code, mod.__dict__, mod.__dict__)
File "/tmp/torchinductor_root/fl/cflyzetaelrdigwqk7eeqcd4ltjygnu2ngsoprkrcxeecyg274xg.py", line 42, in <module>
async_compile.wait(globals())
File "/root/anaconda3/lib/python3.9/site-packages/torch/_inductor/codecache.py", line 715, in wait
scope[key] = result.result()
File "/root/anaconda3/lib/python3.9/site-packages/torch/_inductor/codecache.py", line 573, in result
self.future.result()
File "/root/anaconda3/lib/python3.9/concurrent/futures/_base.py", line 446, in result
return self.__get_result()
File "/root/anaconda3/lib/python3.9/concurrent/futures/_base.py", line 391, in __get_result
raise self._exception
subprocess.CalledProcessError: Command '['/usr/bin/gcc', '/tmp/tmphttesy02/main.c', '-O3', '-I/root/anaconda3/lib/python3.9/site-packages/triton/third_party/cuda/include', '-I/root/anaconda3/include/python3.9', '-I/tmp/tmphttesy02', '-shared', '-fPIC', '-lcuda', '-o', '/tmp/tmphttesy02/triton_.cpython-39-x86_64-linux-gnu.so']' returned non-zero exit status 1.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/data/py_projects/pegasus/test4.py", line 15, in <module>
print("cuda opt:", opt_cuda(torch.randn(1).cuda()))
File "/root/anaconda3/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/eval_frame.py", line 82, in forward
return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/eval_frame.py", line 337, in catch_errors
return callback(frame, cache_size, hooks)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 404, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 104, in _fn
return fn(*args, **kwargs)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 262, in _convert_frame_assert
return _compile(
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 324, in _compile
out_code = transform_code_object(code, transform)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/bytecode_transformation.py", line 445, in transform_code_object
transformations(instructions, code_options)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 311, in transform
tracer.run()
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 1726, in run
super().run()
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 576, in run
and self.step()
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 540, in step
getattr(self, inst.opname)(inst)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 1792, in RETURN_VALUE
self.output.compile_subgraph(
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/output_graph.py", line 517, in compile_subgraph
self.compile_and_call_fx_graph(tx, list(reversed(stack_values)), root)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/output_graph.py", line 588, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/root/anaconda3/lib/python3.9/site-packages/torch/_dynamo/output_graph.py", line 675, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: debug_wrapper raised CalledProcessError: Command '['/usr/bin/gcc', '/tmp/tmphttesy02/main.c', '-O3', '-I/root/anaconda3/lib/python3.9/site-packages/triton/third_party/cuda/include', '-I/root/anaconda3/include/python3.9', '-I/tmp/tmphttesy02', '-shared', '-fPIC', '-lcuda', '-o', '/tmp/tmphttesy02/triton_.cpython-39-x86_64-linux-gnu.so']' returned non-zero exit status 1.
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
### Versions
wsl2 pytorch2.0 cuda11.7
cc @peterjc123 @mszhanyi @skyline75489 @nbcsm @vladimir-aubrecht @iremyux @Blackhex @cristianPanaite @ezyang @msaroufim @wconstab @bdhirsh @anijain2305 @soumith @ngimel
| 2 |
3,111 | 97,500 |
.set_ operation on a view (detach()) of the view tensor changes grad_fn of the original view tensor from ViewBackward0 to AsStridedBackward0
|
module: autograd, triaged, has workaround
|
### 🐛 Describe the bug
When I change the storage of the view tensor (x_detached) (in this case the result of .detach op), if the original (x) is itself a view tensor, the grad_fn of original tensor (x) is changed from ViewBackward0 to AsStridedBackward0, which is probably connected to [this](https://github.com/pytorch/pytorch/blob/v2.0.0/torch/csrc/autograd/variable.cpp#L657-L680).
However, I think this kind of behaviour was intended for inlace operations which alter the storage of the original tensor, and thus these changes should be recorded in its grad_fn. On the other hand, the whole point of set_ is to assign new storage to this view tensor (x_detached), so I don't alter the original storage, and, thus I don't see why the grad_fn should be updated.
```python
import torch
inp = torch.tensor(2., requires_grad=True)
x = inp.view(-1)
x_detached = x.detach()
y = torch.tensor(1.)
with torch.no_grad():
print(x, x_detached)
x_detached.set_(y)
print(x, x_detached)
```
```
tensor([2.], grad_fn=<ViewBackward0>) tensor([2.])
tensor([2.], grad_fn=<AsStridedBackward0>) tensor(1.)
```
### Versions
Collecting environment information...
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.23.3
Libc version: glibc-2.31
Python version: 3.8.13 | packaged by conda-forge | (default, Mar 25 2022, 06:04:10) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-65-generic-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: Tesla V100-SXM2-16GB
GPU 1: Tesla V100-SXM2-16GB
GPU 2: Tesla V100-SXM2-16GB
GPU 3: Tesla V100-SXM2-16GB
GPU 4: Tesla V100-SXM2-16GB
GPU 5: Tesla V100-SXM2-16GB
GPU 6: Tesla V100-SXM2-16GB
GPU 7: Tesla V100-SXM2-16GB
Nvidia driver version: 450.102.04
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.5.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 80
On-line CPU(s) list: 0-79
Thread(s) per core: 2
Core(s) per socket: 20
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20GHz
Stepping: 1
CPU MHz: 2634.591
CPU max MHz: 3600.0000
CPU min MHz: 1200.0000
BogoMIPS: 4390.11
Virtualization: VT-x
L1d cache: 1.3 MiB
L1i cache: 1.3 MiB
L2 cache: 10 MiB
L3 cache: 100 MiB
NUMA node0 CPU(s): 0-19,40-59
NUMA node1 CPU(s): 20-39,60-79
Vulnerability Itlb multihit: KVM: Mitigation: Split huge pages
Vulnerability L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Full generic retpoline, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; Clear CPU buffers; SMT vulnerable
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single pti intel_ppin ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt_a rdseed adx smap intel_pt xsaveopt cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts md_clear flush_l1d
Versions of relevant libraries:
[pip3] functorch==1.13.1
[pip3] numpy==1.23.5
[pip3] pytorch-quantization==2.1.2
[pip3] torch==1.13.1
[pip3] torch-tensorrt==1.2.0a0
[pip3] torchtext==0.11.0a0
[pip3] torchvision==0.14.0a0
[conda] functorch 1.13.1 pypi_0 pypi
[conda] mkl 2020.4 h726a3e6_304 conda-forge
[conda] mkl-include 2020.4 h726a3e6_304 conda-forge
[conda] numpy 1.23.5 pypi_0 pypi
[conda] pytorch-quantization 2.1.2 pypi_0 pypi
[conda] torch 1.13.1 pypi_0 pypi
[conda] torch-tensorrt 1.2.0a0 pypi_0 pypi
[conda] torchtext 0.11.0a0 pypi_0 pypi
[conda] torchvision 0.14.0a0 pypi_0 pypi
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 4 |
3,112 | 97,499 |
`onnxrt` fails with compilations
|
module: onnx, triaged, oncall: pt2
|
### 🐛 Describe the bug
```python
import timeit
import numpy as np
import timm
import torch
import torch._dynamo as dynamo
model = timm.create_model("resnext101_32x8d", pretrained=True, num_classes=2).to(
device="cuda:0"
)
cuda_backends = ["inductor", "onnxrt"]
def benchmark(backend="inductor"):
dummy_inputs = torch.randn(64, 3, 7, 7).to(device="cuda:0")
opt_model = torch.compile(model, backend=backend)
_ = opt_model(dummy_inputs)
runtimes = timeit.repeat(lambda: opt_model(dummy_inputs), number=1, repeat=25)
print(f"Average latency (seconds): {np.mean(runtimes)} for {backend}.")
torch._dynamo.reset()
for backend in cuda_backends:
print(benchmark(backend))
```
The above fails when the `backend` is set to `"onnxrt"`.
My `onnxruntime` version is: `1.14.1` and `onnx` version is `1.13.0`.
### Error logs
```
Average latency (seconds): 0.03335898948002068 for inductor.
None
/usr/local/lib/python3.8/dist-packages/torch/jit/_check.py:172: UserWarning: The TorchScript type system doesn't support instance-level annotations on empty non-base types in `__init__`. Instead, either 1) use a type annotation in the class body, or 2) wrap the type in `torch.jit.Attribute`.
warnings.warn("The TorchScript type system doesn't support "
============= Diagnostic Run torch.onnx.export version 2.0.0+cu117 =============
verbose: False, log level: Level.ERROR
======================= 0 NONE 0 NOTE 0 WARNING 0 ERROR ========================
Traceback (most recent call last):
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/output_graph.py", line 670, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/debug_utils.py", line 1055, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/backends/common.py", line 107, in wrapper
return fn(model, inputs, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/backends/onnxrt.py", line 51, in onnxrt
return onnxrt(gm, example_inputs, filename=tmp.name)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/backends/common.py", line 107, in wrapper
return fn(model, inputs, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/backends/onnxrt.py", line 76, in onnxrt
assert provider in onnxruntime.get_available_providers()
AssertionError
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "benchmark_backends.py", line 26, in <module>
print(benchmark(backend))
File "benchmark_backends.py", line 18, in benchmark
_ = opt_model(dummy_inputs)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/eval_frame.py", line 82, in forward
return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/eval_frame.py", line 337, in catch_errors
return callback(frame, cache_size, hooks)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/convert_frame.py", line 404, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/convert_frame.py", line 104, in _fn
return fn(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/convert_frame.py", line 262, in _convert_frame_assert
return _compile(
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/convert_frame.py", line 324, in _compile
out_code = transform_code_object(code, transform)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/bytecode_transformation.py", line 445, in transform_code_object
transformations(instructions, code_options)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/convert_frame.py", line 311, in transform
tracer.run()
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 1726, in run
super().run()
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 576, in run
and self.step()
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 540, in step
getattr(self, inst.opname)(inst)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 1792, in RETURN_VALUE
self.output.compile_subgraph(
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/output_graph.py", line 517, in compile_subgraph
self.compile_and_call_fx_graph(tx, list(reversed(stack_values)), root)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/output_graph.py", line 588, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/output_graph.py", line 675, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: onnxrt raised AssertionError:
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
### Minified repro
_No response_
### Versions
```
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.24.1
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-4.19.0-23-cloud-amd64-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 12.0.140
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA A100-SXM4-40GB
Nvidia driver version: 510.47.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 12
On-line CPU(s) list: 0-11
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) CPU @ 2.20GHz
Stepping: 7
CPU MHz: 2200.200
BogoMIPS: 4400.40
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 192 KiB
L1i cache: 192 KiB
L2 cache: 6 MiB
L3 cache: 38.5 MiB
NUMA node0 CPU(s): 0-11
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT Host state unknown
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; Clear CPU buffers; SMT Host state unknown
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves arat avx512_vnni md_clear arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.22.2
[pip3] pytorch-quantization==2.1.2
[pip3] torch==2.0.0
[pip3] torch-tensorrt==1.4.0.dev0
[pip3] torchtext==0.13.0a0+fae8e8c
[pip3] torchvision==0.15.1
[pip3] triton==2.0.0
[conda] Could not collect
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 2 |
3,113 | 97,498 |
Function Registry for extending collate_fn
|
module: dataloader, triaged, enhancement
|
### 🚀 The feature, motivation and pitch
Previous improvements on `collate_fn` has allow custom types in `collate_fn`
In this Enhancement Proposal, we would like to add Registry to take one step further to make extension even smoother.
Currently, to extend the `collate_fn`, we need to have the following code.
```python
from torch.utils import data
def collate_nested_tensor_fn(batch):
NestedTensor(batch)
data._utils.collate.default_collate_fn_map.update({PNTensor: collate_nested_tensor_fn})
```
However, `default_collate_fn_map` is not exported in `torch.utils.data` and is under a protected sub-package.
The process would be much smoother if we have a registry for `collate_fn`s, so that the process will become:
```python
from torch.utils import data
@data.collate_fns.register(PNTensor)
def collate_nested_tensor_fn(batch):
NestedTensor(batch)
```
### Alternatives
Alternatively, we could export `default_collate_fn_map` in `torch.utils.data` to avoid access of protected sub-package.
### Additional context
The following code demonstrates how we use registry in extending PyTorch functions:
```python
from functools import wraps
from typing import Callable
from ..registry import Registry
class TorchFuncRegistry(Registry):
"""
`TorchFuncRegistry` for extending PyTorch Tensor.
"""
def implement(self, torch_function: Callable) -> Callable:
r"""
Implement an implementation for a torch function.
Args:
function: The torch function to implement.
Returns:
function: The registered function.
Raises:
ValueError: If the function with the same name already registered and `TorchFuncRegistry.override=False`.
Examples:
```python
>>> import torch
>>> registry = TorchFuncRegistry("test")
>>> @registry.implement(torch.mean) # pylint: disable=E1101
... def mean(input):
... raise input.mean()
>>> registry # doctest: +ELLIPSIS
TorchFuncRegistry(
(<built-in method mean of type object at ...>): <function mean at ...>
)
```
"""
if torch_function in self and not self.override:
raise ValueError(f"Torch function {torch_function.__name__} already registered.")
@wraps(self.register)
def register(function):
self.set(torch_function, function)
return function
return register
NestedTensorFunc = TorchFuncRegistry()
@NestedTensorFunc.implement(torch.mean) # pylint: disable=E1101
def mean(
input, # pylint: disable=W0622
dim: Optional[int] = None,
keepdim: bool = False,
*,
dtype: Optional[torch.dtype] = None,
):
return input.mean(dim=dim, keepdim=keepdim, dtype=dtype)
@NestedTensorFunc.implement(torch.cat) # pylint: disable=E1101
def cat(tensors, dim: int = 0):
if dim != 0:
raise NotImplementedError(f"NestedTensor only supports cat when dim=0, but got {dim}")
return NestedTensor([t for tensor in tensors for t in tensor.storage])
```
Registry is basically a dict with some additional methods. The following code demonstrates how we define our registry:
Note that `NestedDict` is a subclass of `dict`, and can be considered as identical to `dict`.
```python
class Registry(NestedDict):
"""
`Registry` for components.
Notes:
`Registry` inherits from [`NestedDict`](https://chanfig.danling.org/nested_dict/).
Therefore, `Registry` comes in a nested structure by nature.
You could create a sub-registry by simply calling `registry.sub_registry = Registry`,
and access through `registry.sub_registry.register()`.
Examples:
```python
>>> registry = Registry("test")
>>> @registry.register
... @registry.register("Module1")
... class Module:
... def __init__(self, a, b):
... self.a = a
... self.b = b
>>> module = registry.register(Module, "Module2")
>>> registry
Registry(
('Module1'): <class 'danling.registry.Module'>
('Module'): <class 'danling.registry.Module'>
('Module2'): <class 'danling.registry.Module'>
)
>>> registry.lookup("Module")
<class 'danling.registry.Module'>
>>> config = {"module": {"name": "Module", "a": 1, "b": 2}}
>>> # registry.register(Module)
>>> module = registry.build(config["module"])
>>> type(module)
<class 'danling.registry.Module'>
>>> module.a
1
>>> module.b
2
```
"""
override: bool = False
def __init__(self, override: bool = False):
super().__init__()
self.setattr("override", override)
def register(self, component: Optional[Callable] = None, name: Optional[str] = None) -> Callable:
r"""
Register a new component.
Args:
component: The component to register.
name: The name of the component.
Returns:
component: The registered component.
Raises:
ValueError: If the component with the same name already registered and `Registry.override=False`.
Examples:
```python
>>> registry = Registry("test")
>>> @registry.register
... @registry.register("Module1")
... class Module:
... def __init__(self, a, b):
... self.a = a
... self.b = b
>>> module = registry.register(Module, "Module2")
>>> registry
Registry(
('Module1'): <class 'danling.registry.Module'>
('Module'): <class 'danling.registry.Module'>
('Module2'): <class 'danling.registry.Module'>
)
```
"""
if name in self and not self.override:
raise ValueError(f"Component with name {name} already registered.")
# Registry.register()
if name is not None:
self.set(name, component)
# @Registry.register()
@wraps(self.register)
def register(component, name=None):
if name is None:
name = component.__name__
self.set(name, component)
return component
# @Registry.register
if callable(component) and name is None:
return register(component)
return lambda x: register(x, component)
def lookup(self, name: str) -> Any:
r"""
Lookup for a component.
Args:
name:
Returns:
(Any): The component.
Raises:
KeyError: If the component is not registered.
Examples:
```python
>>> registry = Registry("test")
>>> @registry.register
... class Module:
... def __init__(self, a, b):
... self.a = a
... self.b = b
>>> registry.lookup("Module")
<class 'danling.registry.Module'>
```
"""
return self.get(name)
def build(self, name: Union[str, Mapping], *args, **kwargs) -> Any:
r"""
Build a component.
Args:
name (str | Mapping):
If its a `Mapping`, it must contain `"name"` as a member, the rest will be treated as `**kwargs`.
Note that values in `kwargs` will override values in `name` if its a `Mapping`.
*args: The arguments to pass to the component.
**kwargs: The keyword arguments to pass to the component.
Returns:
(Any):
Raises:
KeyError: If the component is not registered.
Examples:
```python
>>> registry = Registry("test")
>>> @registry.register
... class Module:
... def __init__(self, a, b):
... self.a = a
... self.b = b
>>> config = {"module": {"name": "Module", "a": 1, "b": 2}}
>>> # registry.register(Module)
>>> module = registry.build(**config["module"])
>>> type(module)
<class 'danling.registry.Module'>
>>> module.a
1
>>> module.b
2
>>> module = registry.build(config["module"], a=2)
>>> module.a
2
```
"""
if isinstance(name, Mapping):
name = deepcopy(name)
name, kwargs = name.pop("name"), dict(name, **kwargs) # type: ignore
return self.get(name)(*args, **kwargs) # type: ignore
def __wrapped__(self, *args, **kwargs):
pass
```
cc @SsnL @VitalyFedyunin @ejguan @NivekT @dzhulgakov
| 11 |
3,114 | 97,484 |
[DTensor] Add a unittest to cover default PG condition for DeviceMesh
|
oncall: distributed, triaged
|
### 🚀 The feature, motivation and pitch
There is no UT to cover the default PG condition for DeviceMesh. The detail of the past breakages can be found in https://github.com/pytorch/pytorch/pull/97384. A UT is required to cover this case.
### Alternatives
_No response_
### Additional context
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
3,115 | 97,474 |
make_fx(functionalize(f), tracing_mode='symbolic') breaks on torch.matmul
|
triaged, module: aotdispatch
|
### 🐛 Describe the bug
The following block of code takes a single `torch.matmul` call, functionalizes it, then calls `make_fx` with symbolic tracing:
```python
import torch
from torch.func import functionalize
from torch.fx.experimental.proxy_tensor import make_fx
y = torch.randn(1, 1)
def f(x):
return torch.matmul(x, y)
make_fx(
functionalize(f),
tracing_mode='symbolic',
_allow_non_fake_inputs=True,
)(torch.randn(1, 1, 1))
```
This fails with the following stack trace:
```
Traceback (most recent call last):
File "/.../bug.py", line 10, in <module>
make_fx(
File "/.../.venv/lib/python3.9/site-packages/torch/fx/experimental/proxy_tensor.py", line 756, in wrapped
t = dispatch_trace(wrap_key(func, args, fx_tracer, pre_autograd), tracer=fx_tracer, concrete_args=tuple(phs))
File "/.../.venv/lib/python3.9/site-packages/torch/fx/experimental/proxy_tensor.py", line 462, in dispatch_trace
graph = tracer.trace(root, concrete_args)
File "/.../.venv/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 778, in trace
(self.create_arg(fn(*args)),),
File "/.../.venv/lib/python3.9/site-packages/torch/fx/experimental/proxy_tensor.py", line 479, in wrapped
out = f(*tensors)
File "/.../.venv/lib/python3.9/site-packages/torch/_functorch/vmap.py", line 39, in fn
return f(*args, **kwargs)
File "/.../.venv/lib/python3.9/site-packages/torch/_functorch/eager_transforms.py", line 1600, in wrapped
func_outputs = func(*func_args, **func_kwargs)
File "/.../bug.py", line 7, in f
return torch.matmul(x, y)
RuntimeError: Cannot call sizes() on tensor with symbolic sizes/strides
```
Without the call to `functionalize`, everything works fine. Passing a 2-D tensor for `x` also works fine (if `x` is 3-D, it needs to be `aten.view`-ed then `aten.matmul`-ed).
[Output from Python dispatcher](https://github.com/pytorch/pytorch/blob/af440c427bffddd7edc2db800a0c34ae8f1107d0/torch/_ops.py#L531) prior to failure:
```
aten.randn.default DispatchKey.BackendSelect DispatchKey.BackendSelect
aten.empty.memory_format DispatchKey.BackendSelect DispatchKey.BackendSelect
aten.normal_.default DispatchKey.CPU DispatchKey.CPU
aten.empty_strided.default DispatchKey.BackendSelect DispatchKey.BackendSelect
aten.set_.source_Storage_storage_offset DispatchKey.AutogradMeta DispatchKey.Autograd
aten.set_.source_Storage_storage_offset DispatchKey.ADInplaceOrView DispatchKey.ADInplaceOrView
aten.set_.source_Storage_storage_offset DispatchKey.Meta DispatchKey.Meta
aten.detach.default DispatchKey.PythonTLSSnapshot DispatchKey.PythonTLSSnapshot
aten.detach.default DispatchKey.AutogradCPU DispatchKey.Autograd
aten.detach.default DispatchKey.ADInplaceOrView DispatchKey.ADInplaceOrView
aten.detach.default DispatchKey.Meta DispatchKey.Meta
aten.alias.default DispatchKey.Meta DispatchKey.Meta
aten.view.default DispatchKey.Meta DispatchKey.Meta
prims.view_of.default DispatchKey.Meta DispatchKey.Meta
aten.as_strided.default DispatchKey.Meta DispatchKey.Meta
aten.matmul.default DispatchKey.FuncTorchDynamicLayerFrontMode DispatchKey.FuncTorchDynamicLayerFrontMode
aten.matmul.default DispatchKey.Functionalize DispatchKey.Functionalize
```
### Versions
```
Collecting environment information...
PyTorch version: 2.1.0.dev20230323+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.6 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.9.13 (main, Aug 25 2022, 23:26:10) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.4.0-144-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 10.1.243
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090
Nvidia driver version: 530.30.02
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.8.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 57 bits virtual
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 106
Model name: Intel(R) Xeon(R) Silver 4314 CPU @ 2.40GHz
Stepping: 6
Frequency boost: enabled
CPU MHz: 1104.264
CPU max MHz: 3400.0000
CPU min MHz: 800.0000
BogoMIPS: 4800.00
Virtualization: VT-x
L1d cache: 768 KiB
L1i cache: 512 KiB
L2 cache: 20 MiB
L3 cache: 24 MiB
NUMA node0 CPU(s): 0-31
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 invpcid_single ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local wbnoinvd dtherm ida arat pln pts avx512vbmi umip pku ospke avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg tme avx512_vpopcntdq rdpid md_clear pconfig flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] pytorch-triton==2.1.0+e650d3708b
[pip3] torch==2.1.0.dev20230323+cu117
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.5 py39h6c91a56_3
[conda] numpy-base 1.21.5 py39ha15fc14_3
[conda] numpydoc 1.4.0 py39h06a4308_0
```
| 3 |
3,116 | 97,469 |
Improve collectives fingerprinting
|
good first issue, triaged, module: c10d
|
### 🚀 The feature, motivation and pitch
When using `TORCH_DISTRIBUTED_DEBUG=DETAIL` we collect collectives fingerprints and those are quite helpful when troubleshooting issues like stragglers.
One recurring problem in distributed jobs are stragglers and, in special, those triggered by python GC activity. We should extend CollectiveFingerPrint to include two pieces of information: python gc counts (for all 3 gens) and some monotonic clock source.
Those would enable us us to detect such issues as part of `TORCH_DISTRIBUTED_DEBUG=DETAIL`.
One complication of this idea is that we currently compare fingerprints in a bitwise fashion, which won't work since some of this information is just advisory.
### Alternatives
_No response_
### Additional context
_No response_
| 5 |
3,117 | 97,456 |
pytorch dynamic quantized model failed to convert to onnx
|
module: onnx, triaged
|
### 🐛 Describe the bug
I try to convert the dynamic quantized pytorch model to ONNX, but failed. The original float32 model can be successfully converted to onnx. I tried torch1.9 (CUDA) and torch2.0 (CPU), both have same issues.
Sample code:
```python
model_int8 = torch.quantization.quantize_dynamic(model, None, dtype=torch.qint8)
mic_audio = torch.randn((4, frame_number))* 32367
echo_ref_audio = torch.rand((1, frame_number))* 32367
cache_new = torch.zeros_like(cache) + 1.0e-8
export_inputs = (mic_audio, echo_ref_audio, cache_new)
torch.onnx.export(model_int8, export_inputs, output_filename, verbose=True, opset_version=16)
```
Error info:
```
export_onnx.py", line 125, in export_onnx_model
torch.onnx.export(model_int8, export_inputs, output_filename, verbose=True, opset_version=16)
File "/data1/*/myve_torch2_cpu/lib/python3.9/site-packages/torch/onnx/utils.py", line 506, in export
_export(
File "/data1/*/myve_torch2_cpu/lib/python3.9/site-packages/torch/onnx/utils.py", line 1550, in _export
graph, params_dict, torch_out = _model_to_graph(
File "/data1/*/myve_torch2_cpu/lib/python3.9/site-packages/torch/onnx/utils.py", line 1115, in _model_to_graph
graph, params, torch_out, module = _create_jit_graph(model, args)
File "/data1/*/myve_torch2_cpu/lib/python3.9/site-packages/torch/onnx/utils.py", line 975, in _create_jit_graph
in_vars, _ = torch.jit._flatten(args_params)
RuntimeError: Only tuples, lists and Variables are supported as JIT inputs/outputs. Dictionaries and strings are also accepted, but their usage is not recommended. Here, received an input of unsupported type: torch._C.ScriptObject
```
### Versions
PyTorch version: 2.0.0+cpu
Is debug build: False
CUDA used to build PyTorch: Could not collect
ROCM used to build PyTorch: N/A
OS: tlinux 2.6 (x86_64)
GCC version: (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44)
Clang version: Could not collect
CMake version: version 3.24.3
Libc version: glibc-2.17
Python version: 3.9.0 (default, Nov 17 2022, 07:27:34) [GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] (64-bit runtime)
Python platform: Linux-4.14.105-1-tlinux3-0019-x86_64-with-glibc2.17
Is CUDA available: False
CUDA runtime version: 11.2.142
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration:
GPU 0: Tesla P40
GPU 1: Tesla P40
GPU 2: Tesla P40
GPU 3: Tesla P40
GPU 4: Tesla P40
GPU 5: Tesla P40
GPU 6: Tesla P40
GPU 7: Tesla P40
Nvidia driver version: 460.32.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 88
On-line CPU(s) list: 0-87
Thread(s) per core: 2
Core(s) per socket: 22
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2699 v4 @ 2.20GHz
Stepping: 1
CPU MHz: 2799.841
CPU max MHz: 2201.0000
CPU min MHz: 1200.0000
BogoMIPS: 4399.69
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 56320K
NUMA node0 CPU(s): 0-21,44-65
NUMA node1 CPU(s): 22-43,66-87
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single pti intel_ppin tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt_a rdseed adx smap intel_pt xsaveopt cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==2.0.0+cpu
[pip3] torchaudio==2.0.1+cpu
[pip3] torchvision==0.15.1+cpu
[conda] Could not collect
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo @jgong5 @Xia-Weiwen @leslie-fang-intel
| 1 |
3,118 | 97,439 |
Change progressbar for hub
|
triaged, module: hub
|
### 🚀 The feature, motivation and pitch
i am changed progressbar for hub to use rich.progress, its more beautiful

### Alternatives
_No response_
### Additional context
I did it for myself, if you're interested - my pr https://github.com/pytorch/pytorch/pull/97438
cc @nairbv @NicolasHug @vmoens @jdsgomes
| 0 |
3,119 | 97,436 |
torch.compile not working with gradient checkpointing
|
module: checkpoint, triaged, oncall: pt2
|
### 🐛 Describe the bug
It looks like gradient checkpointing (activation checkpointing) it is not allowed if used with `torch.compile`. For example this code:
```
import torch
import torch.utils.checkpoint
import torch._dynamo
torch._dynamo.config.verbose=True
import argparse
import torch.utils.benchmark as benchmark
class myModel(torch.nn.Module):
def __init__(self, grad_checkpoint):
super().__init__()
self.conv1 = torch.nn.Conv2d(3, 128, kernel_size=3, padding=1)
self.conv2 = torch.nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.conv3 = torch.nn.Conv2d(128, 3, kernel_size=3, padding=1)
self.checkpoint = grad_checkpoint
def forward(self, x):
x = self.conv1(x)
x = torch.nn.functional.relu(x)
if self.checkpoint:
x = torch.utils.checkpoint.checkpoint(self.conv2, x)
else:
x = self.conv2(x)
x = torch.nn.functional.relu(x)
x = self.conv3(x)
return x
def run_forward(model_, x):
out = model_(x)
def run(grad_checkpoint):
device = "cuda" if torch.cuda.is_available() else "cpu"
model = myModel(grad_checkpoint).to(device)
x = torch.randn((2, 3, 640, 256), device=device)
model_opt = torch.compile(model, mode="reduce-overhead")
num_threads = torch.get_num_threads()
t = benchmark.Timer(
stmt='optim(x)',
globals={'optim': model_opt, 'x': x}, # When 'optim': model then it works
num_threads=num_threads,
label="Average Run Duration",
)
print(t.timeit(100))
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--grad_checkpoint", action='store_true')
args = parser.parse_args()
run(args.grad_checkpoint)
```
gives the following error:
```
File "timing.py", line 89, in <module>
run(args.grad_checkpoint)
File "timing.py", line 83, in run
print(t.timeit(100))
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/utils/benchmark/utils/timer.py", line 266, in timeit
self._timeit(number=max(int(number // 100), 2))
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/utils/benchmark/utils/timer.py", line 256, in _timeit
return max(self._timer.timeit(number), 1e-9)
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/timeit.py", line 177, in timeit
timing = self.inner(it, self.timer)
File "<timeit-src>", line 6, in inner
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 82, in forward
return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "timing.py", line 49, in forward
x = torch.utils.checkpoint.checkpoint(self.conv2, x)
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/utils/checkpoint.py", line 249, in checkpoint
return CheckpointFunction.apply(function, preserve, *args)
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/autograd/function.py", line 506, in apply
return super().apply(*args, **kwargs) # type: ignore[misc]
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/utils/checkpoint.py", line 81, in forward
ctx.fwd_cpu_state = torch.get_rng_state()
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 337, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 404, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 104, in _fn
return fn(*args, **kwargs)
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 262, in _convert_frame_assert
return _compile(
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 324, in _compile
out_code = transform_code_object(code, transform)
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/bytecode_transformation.py", line 445, in transform_code_object
transformations(instructions, code_options)
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 311, in transform
tracer.run()
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 1726, in run
super().run()
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 576, in run
and self.step()
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 540, in step
getattr(self, inst.opname)(inst)
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 342, in wrapper
return inner_fn(self, inst)
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 965, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 474, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/variables/torch.py", line 368, in call_function
return wrap_fx_proxy(
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/variables/builder.py", line 754, in wrap_fx_proxy
return wrap_fx_proxy_cls(
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/_dynamo/variables/builder.py", line 812, in wrap_fx_proxy_cls
assert "source" in options and options["source"] is not None
AssertionError:
from user code:
File "/home/manuel/anaconda3/envs/ldm/lib/python3.8/site-packages/torch/random.py", line 23, in get_rng_state
return default_generator.get_state()
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
### Versions
```
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.2 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.26.0
Libc version: glibc-2.35
Python version: 3.8.5 (default, Sep 4 2020, 07:30:14) [GCC 7.3.0] (64-bit runtime)
Python platform: Linux-5.19.0-35-generic-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2080 Ti
Nvidia driver version: 525.85.12
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Vendor ID: GenuineIntel
Model name: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
CPU family: 6
Model: 60
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
Stepping: 3
CPU max MHz: 4000.0000
CPU min MHz: 800.0000
BogoMIPS: 7195.66
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm cpuid_fault epb invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsaveopt dtherm ida arat pln pts md_clear flush_l1d
Virtualisation: VT-x
L1d cache: 128 KiB (4 instances)
L1i cache: 128 KiB (4 instances)
L2 cache: 1 MiB (4 instances)
L3 cache: 8 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-7
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Unknown: No mitigations
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Mitigation; Microcode
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] pytorch-lightning==1.6.3
[pip3] torch==2.0.0
[pip3] torch-fidelity==0.3.0
[pip3] torch-tb-profiler==0.4.1
[pip3] torchaudio==2.0.1
[pip3] torchmetrics==0.11.1
[pip3] torchvision==0.15.1
[pip3] triton==2.0.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py38h7f8727e_0
[conda] mkl_fft 1.3.1 py38hd3c417c_0
[conda] mkl_random 1.2.2 py38h51133e4_0
[conda] numpy 1.23.4 pypi_0 pypi
[conda] pytorch-lightning 1.6.3 pypi_0 pypi
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torch 2.0.0 pypi_0 pypi
[conda] torch-fidelity 0.3.0 pypi_0 pypi
[conda] torch-tb-profiler 0.4.1 pypi_0 pypi
[conda] torchaudio 2.0.1 pypi_0 pypi
[conda] torchmetrics 0.11.1 pypi_0 pypi
[conda] torchvision 0.15.1 pypi_0 pypi
[conda] triton 2.0.0 pypi_0 pypi
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 19 |
3,120 | 97,432 |
suspicious memory leak when increase DataLoader's prefetch_factor and enable pin_memory
|
module: dataloader, module: memory usage, triaged
|
### 🐛 Describe the bug
In my 8*V100 GPU training project I use torch's DataLoader and set partial arguments below.
`train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=8,
sampler=train_sampler,
num_workers=16,
pin_memory=True,
prefetch_factor=16,
persistent_workers=True)`
But while training I found the host memory cost too much(nearly 90% of total 768GB RAM), from our node's monitor.

When I set prefetch_factor back to 2 (default value), the memory problem disappeared.
Additional, I used NVIDIA Nsight Systems tool to profile my training job and found many cudaHostAlloc API calls even in 2000th+ steps, without any corresponding cudaFree calls, which also blocked execution of GPU Kernels.

In further analysis, I found these cudaHostAlloc were called from pin_memory_loop thread in DataLoader.
So I doubt there may be some pinned memory leak bugs? Need help from other developpers .
### Versions
torch.__version__ 1.13.1+cu117
torch.version.cuda : 11.7
torch.backends.cudnn.version() : 8500
python version : 3.7.13 (miniconda)
cuda driver version : 470.57.02
GPU : Tesla V100 * 8
cc @SsnL @VitalyFedyunin @ejguan @NivekT @dzhulgakov
| 0 |
3,121 | 97,426 |
Unsupported: ONNX export of operator group_norm, unknown input rank.
|
module: onnx, triaged, onnx-needs-info
|
### 🐛 Describe the bug
I try to export my script model to onnx format with `torch.onnx,export`, here's my export function:
```python
def export_onnx_model(model: Net, input_data: Tuple[Any], export_name: str):
input_names = [
"actors",
"actor_idcs",
"actor_ctrs",
"g_graph",
"g_ctrs",
"g_idcs",
"g_feats",
"g_turn",
"g_control",
"g_intersect",
"g_left",
"g_right",
]
output_names = ["output1"]
torch.onnx.export(
model.cuda(),
input_data,
f"{export_name}.onnx",
input_names=input_names,
output_names=output_names,
verbose=True,
opset_version=9,
)
```
And I get the error msgs as follow:
```
Exception has occurred: SymbolicValueError
Unsupported: ONNX export of operator group_norm, unknown input rank. Please feel free to request support or submit a pull request on PyTorch GitHub: https://github.com/pytorch/pytorch/issues [Caused by the value 'out defined in (%out : Tensor = onnx::Conv[dilations=[1], group=1, kernel_shape=annotate(List[int], []), pads=[1, 1], strides=[1]](%d_actors.1, %actor_net.groups.0.0.conv1.weight), scope: lane_gcn.lanegcn.Net::/lane_gcn.lanegcn.ActorNet::actor_net/torch.nn.modules.container.Sequential::groups.0/lane_gcn.layers.Res1dDownSample::0/torch.nn.modules.conv.Conv1d::conv1 # /home/zwj/miniconda3/envs/pt2/lib/python3.8/site-packages/torch/nn/modules/conv.py:309:15
)' (type 'Tensor') in the TorchScript graph. The containing node has kind 'onnx::Conv'.]
(node defined in File "/home/zwj/miniconda3/envs/pt2/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 309
weight, bias, self.stride,
_single(0), self.dilation, self.groups)
return F.conv1d(input, weight, bias, self.stride,
~~~~~~~~ <--- HERE
self.padding, self.dilation, self.groups)
Serialized File "code/__torch__/torch/nn/modules/conv.py", line 29
weight: Tensor,
bias: Optional[Tensor]) -> Tensor:
_1 = torch.conv1d(input, weight, bias, [1], [1], [1])
~~~~~~~~~~~~ <--- HERE
return _1
)
Inputs:
#0: d_actors.1 defined in (%d_actors.1 : Float(7, 3, 20, strides=[60, 20, 1], requires_grad=0, device=cuda:0), %d_actor_idcs : Long(7, strides=[1], requires_grad=0, device=cuda:0)[], %d_ctrs : Float(7, 2, strides=[2, 1], requires_grad=0, device=cuda:0)[], %d_graph : Dict(str, Dict(str, Tensor)[]), %g_ctrs : Long(1338, strides=[1], requires_grad=0, device=cuda:0)[], %g_idcs : Long(1380, strides=[1], requires_grad=0, device=cuda:0)[], %g_feats : Long(1380, strides=[1], requires_grad=0, device=cuda:0), %g_turn : Long(1460, strides=[1], requires_grad=0, device=cuda:0), %g_control : Long(1460, strides=[1], requires_grad=0, device=cuda:0), %g_intersect : Long(1456, strides=[1], requires_grad=0, device=cuda:0), %g_left : Dict(str, Tensor), %g_right : Dict(str, Tensor), %actor_net.groups.0.0.conv1.weight : Long(1163, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.bn1.weight : Long(53, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.bn1.bias : Long(53, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.conv2.weight : Long(1338, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.bn2.weight : Long(1338, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.bn2.bias : Long(1380, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.downsample.0.weight : Long(1380, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.downsample.1.weight : Long(1460, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.downsample.1.bias : Long(1460, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.conv1.weight : Long(1456, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.bn1.weight : Long(1456, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.bn1.bias : Long(1163, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.conv2.weight : Long(1163, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.bn2.weight : Long(53, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.bn2.bias : Long(53, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.conv1.weight : Float(1293, 2, strides=[2, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.bn1.weight : Long(1293, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.bn1.bias : Float(1293, 2, strides=[2, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.conv2.weight : Float(1293, 2, strides=[2, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.bn2.weight : Float(1293, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.bn2.bias : Float(1293, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.downsample.0.weight : Long(198, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.downsample.1.weight : Long(198, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.downsample.1.bias : Long(198, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.conv1.weight : Long(198, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.bn1.weight : Float(32, 3, 3, strides=[9, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.bn1.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.conv2.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.bn2.weight : Float(32, 32, 3, strides=[96, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.bn2.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.conv1.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.bn1.weight : Float(32, 3, 1, strides=[3, 1, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.bn1.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.conv2.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.bn2.weight : Float(32, 32, 3, strides=[96, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.bn2.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.downsample.0.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.downsample.1.weight : Float(32, 32, 3, strides=[96, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.downsample.1.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.conv1.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.bn1.weight : Float(64, 32, 3, strides=[96, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.bn1.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.conv2.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.bn2.weight : Float(64, 64, 3, strides=[192, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.bn2.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.2.conv.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.2.norm.weight : Float(64, 32, 1, strides=[32, 1, 1], requires_grad=0, device=cuda:0), %actor_net.lateral.2.norm.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.1.conv.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.1.norm.weight : Float(64, 64, 3, strides=[192, 3, 1], requires_grad=0, device=cuda:0), %actor_net.lateral.1.norm.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.0.conv.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.0.norm.weight : Float(64, 64, 3, strides=[192, 3, 1], requires_grad=0, device=cuda:0), %actor_net.lateral.0.norm.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.output.conv1.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.output.bn1.weight : Float(128, 64, 3, strides=[192, 3, 1], requires_grad=0, device=cuda:0), %actor_net.output.bn1.bias : Float(128, strides=[1], requires_grad=0, device=cuda:0), %actor_net.output.conv2.weight : Float(128, strides=[1], requires_grad=0, device=cuda:0), %actor_net.output.bn2.weight : Float(128, 128, 3, strides=[384, 3, 1], requires_grad=0, device=cuda:0), %actor_net.output.bn2.bias : Float(128, strides=[1], requires_grad=0, device=cuda:0) = prim::Param()
) (type 'Tensor')
#1: actor_net.groups.0.0.conv1.weight defined in (%d_actors.1 : Float(7, 3, 20, strides=[60, 20, 1], requires_grad=0, device=cuda:0), %d_actor_idcs : Long(7, strides=[1], requires_grad=0, device=cuda:0)[], %d_ctrs : Float(7, 2, strides=[2, 1], requires_grad=0, device=cuda:0)[], %d_graph : Dict(str, Dict(str, Tensor)[]), %g_ctrs : Long(1338, strides=[1], requires_grad=0, device=cuda:0)[], %g_idcs : Long(1380, strides=[1], requires_grad=0, device=cuda:0)[], %g_feats : Long(1380, strides=[1], requires_grad=0, device=cuda:0), %g_turn : Long(1460, strides=[1], requires_grad=0, device=cuda:0), %g_control : Long(1460, strides=[1], requires_grad=0, device=cuda:0), %g_intersect : Long(1456, strides=[1], requires_grad=0, device=cuda:0), %g_left : Dict(str, Tensor), %g_right : Dict(str, Tensor), %actor_net.groups.0.0.conv1.weight : Long(1163, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.bn1.weight : Long(53, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.bn1.bias : Long(53, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.conv2.weight : Long(1338, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.bn2.weight : Long(1338, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.bn2.bias : Long(1380, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.downsample.0.weight : Long(1380, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.downsample.1.weight : Long(1460, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.downsample.1.bias : Long(1460, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.conv1.weight : Long(1456, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.bn1.weight : Long(1456, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.bn1.bias : Long(1163, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.conv2.weight : Long(1163, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.bn2.weight : Long(53, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.bn2.bias : Long(53, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.conv1.weight : Float(1293, 2, strides=[2, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.bn1.weight : Long(1293, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.bn1.bias : Float(1293, 2, strides=[2, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.conv2.weight : Float(1293, 2, strides=[2, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.bn2.weight : Float(1293, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.bn2.bias : Float(1293, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.downsample.0.weight : Long(198, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.downsample.1.weight : Long(198, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.downsample.1.bias : Long(198, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.conv1.weight : Long(198, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.bn1.weight : Float(32, 3, 3, strides=[9, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.bn1.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.conv2.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.bn2.weight : Float(32, 32, 3, strides=[96, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.bn2.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.conv1.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.bn1.weight : Float(32, 3, 1, strides=[3, 1, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.bn1.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.conv2.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.bn2.weight : Float(32, 32, 3, strides=[96, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.bn2.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.downsample.0.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.downsample.1.weight : Float(32, 32, 3, strides=[96, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.downsample.1.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.conv1.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.bn1.weight : Float(64, 32, 3, strides=[96, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.bn1.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.conv2.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.bn2.weight : Float(64, 64, 3, strides=[192, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.bn2.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.2.conv.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.2.norm.weight : Float(64, 32, 1, strides=[32, 1, 1], requires_grad=0, device=cuda:0), %actor_net.lateral.2.norm.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.1.conv.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.1.norm.weight : Float(64, 64, 3, strides=[192, 3, 1], requires_grad=0, device=cuda:0), %actor_net.lateral.1.norm.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.0.conv.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.0.norm.weight : Float(64, 64, 3, strides=[192, 3, 1], requires_grad=0, device=cuda:0), %actor_net.lateral.0.norm.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.output.conv1.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.output.bn1.weight : Float(128, 64, 3, strides=[192, 3, 1], requires_grad=0, device=cuda:0), %actor_net.output.bn1.bias : Float(128, strides=[1], requires_grad=0, device=cuda:0), %actor_net.output.conv2.weight : Float(128, strides=[1], requires_grad=0, device=cuda:0), %actor_net.output.bn2.weight : Float(128, 128, 3, strides=[384, 3, 1], requires_grad=0, device=cuda:0), %actor_net.output.bn2.bias : Float(128, strides=[1], requires_grad=0, device=cuda:0) = prim::Param()
) (type 'Tensor')
Outputs:
#0: out defined in (%out : Tensor = onnx::Conv[dilations=[1], group=1, kernel_shape=annotate(List[int], []), pads=[1, 1], strides=[1]](%d_actors.1, %actor_net.groups.0.0.conv1.weight), scope: lane_gcn.lanegcn.Net::/lane_gcn.lanegcn.ActorNet::actor_net/torch.nn.modules.container.Sequential::groups.0/lane_gcn.layers.Res1dDownSample::0/torch.nn.modules.conv.Conv1d::conv1 # /home/zwj/miniconda3/envs/pt2/lib/python3.8/site-packages/torch/nn/modules/conv.py:309:15
) (type 'Tensor')
File "/home/zwj/Projects/senior_lanegcn/test/test_onnx_trt.py", line 114, in export_onnx_model
torch.onnx.export(
File "/home/zwj/Projects/senior_lanegcn/test/test_onnx_trt.py", line 77, in export_model
export_onnx_model(net, input_data, export_name)
File "/home/zwj/Projects/senior_lanegcn/test/test_onnx_trt.py", line 150, in <module>
export_model(ckpt_path, input_data, "lanegcn", export_format="onnx")
torch.onnx.errors.SymbolicValueError: Unsupported: ONNX export of operator group_norm, unknown input rank. Please feel free to request support or submit a pull request on PyTorch GitHub: https://github.com/pytorch/pytorch/issues [Caused by the value 'out defined in (%out : Tensor = onnx::Conv[dilations=[1], group=1, kernel_shape=annotate(List[int], []), pads=[1, 1], strides=[1]](%d_actors.1, %actor_net.groups.0.0.conv1.weight), scope: lane_gcn.lanegcn.Net::/lane_gcn.lanegcn.ActorNet::actor_net/torch.nn.modules.container.Sequential::groups.0/lane_gcn.layers.Res1dDownSample::0/torch.nn.modules.conv.Conv1d::conv1 # /home/zwj/miniconda3/envs/pt2/lib/python3.8/site-packages/torch/nn/modules/conv.py:309:15
)' (type 'Tensor') in the TorchScript graph. The containing node has kind 'onnx::Conv'.]
(node defined in File "/home/zwj/miniconda3/envs/pt2/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 309
weight, bias, self.stride,
_single(0), self.dilation, self.groups)
return F.conv1d(input, weight, bias, self.stride,
~~~~~~~~ <--- HERE
self.padding, self.dilation, self.groups)
Serialized File "code/__torch__/torch/nn/modules/conv.py", line 29
weight: Tensor,
bias: Optional[Tensor]) -> Tensor:
_1 = torch.conv1d(input, weight, bias, [1], [1], [1])
~~~~~~~~~~~~ <--- HERE
return _1
)
Inputs:
#0: d_actors.1 defined in (%d_actors.1 : Float(7, 3, 20, strides=[60, 20, 1], requires_grad=0, device=cuda:0), %d_actor_idcs : Long(7, strides=[1], requires_grad=0, device=cuda:0)[], %d_ctrs : Float(7, 2, strides=[2, 1], requires_grad=0, device=cuda:0)[], %d_graph : Dict(str, Dict(str, Tensor)[]), %g_ctrs : Long(1338, strides=[1], requires_grad=0, device=cuda:0)[], %g_idcs : Long(1380, strides=[1], requires_grad=0, device=cuda:0)[], %g_feats : Long(1380, strides=[1], requires_grad=0, device=cuda:0), %g_turn : Long(1460, strides=[1], requires_grad=0, device=cuda:0), %g_control : Long(1460, strides=[1], requires_grad=0, device=cuda:0), %g_intersect : Long(1456, strides=[1], requires_grad=0, device=cuda:0), %g_left : Dict(str, Tensor), %g_right : Dict(str, Tensor), %actor_net.groups.0.0.conv1.weight : Long(1163, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.bn1.weight : Long(53, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.bn1.bias : Long(53, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.conv2.weight : Long(1338, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.bn2.weight : Long(1338, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.bn2.bias : Long(1380, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.downsample.0.weight : Long(1380, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.downsample.1.weight : Long(1460, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.downsample.1.bias : Long(1460, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.conv1.weight : Long(1456, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.bn1.weight : Long(1456, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.bn1.bias : Long(1163, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.conv2.weight : Long(1163, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.bn2.weight : Long(53, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.bn2.bias : Long(53, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.conv1.weight : Float(1293, 2, strides=[2, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.bn1.weight : Long(1293, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.bn1.bias : Float(1293, 2, strides=[2, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.conv2.weight : Float(1293, 2, strides=[2, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.bn2.weight : Float(1293, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.bn2.bias : Float(1293, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.downsample.0.weight : Long(198, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.downsample.1.weight : Long(198, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.downsample.1.bias : Long(198, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.conv1.weight : Long(198, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.bn1.weight : Float(32, 3, 3, strides=[9, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.bn1.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.conv2.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.bn2.weight : Float(32, 32, 3, strides=[96, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.bn2.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.conv1.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.bn1.weight : Float(32, 3, 1, strides=[3, 1, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.bn1.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.conv2.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.bn2.weight : Float(32, 32, 3, strides=[96, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.bn2.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.downsample.0.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.downsample.1.weight : Float(32, 32, 3, strides=[96, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.downsample.1.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.conv1.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.bn1.weight : Float(64, 32, 3, strides=[96, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.bn1.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.conv2.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.bn2.weight : Float(64, 64, 3, strides=[192, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.bn2.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.2.conv.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.2.norm.weight : Float(64, 32, 1, strides=[32, 1, 1], requires_grad=0, device=cuda:0), %actor_net.lateral.2.norm.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.1.conv.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.1.norm.weight : Float(64, 64, 3, strides=[192, 3, 1], requires_grad=0, device=cuda:0), %actor_net.lateral.1.norm.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.0.conv.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.0.norm.weight : Float(64, 64, 3, strides=[192, 3, 1], requires_grad=0, device=cuda:0), %actor_net.lateral.0.norm.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.output.conv1.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.output.bn1.weight : Float(128, 64, 3, strides=[192, 3, 1], requires_grad=0, device=cuda:0), %actor_net.output.bn1.bias : Float(128, strides=[1], requires_grad=0, device=cuda:0), %actor_net.output.conv2.weight : Float(128, strides=[1], requires_grad=0, device=cuda:0), %actor_net.output.bn2.weight : Float(128, 128, 3, strides=[384, 3, 1], requires_grad=0, device=cuda:0), %actor_net.output.bn2.bias : Float(128, strides=[1], requires_grad=0, device=cuda:0) = prim::Param()
) (type 'Tensor')
#1: actor_net.groups.0.0.conv1.weight defined in (%d_actors.1 : Float(7, 3, 20, strides=[60, 20, 1], requires_grad=0, device=cuda:0), %d_actor_idcs : Long(7, strides=[1], requires_grad=0, device=cuda:0)[], %d_ctrs : Float(7, 2, strides=[2, 1], requires_grad=0, device=cuda:0)[], %d_graph : Dict(str, Dict(str, Tensor)[]), %g_ctrs : Long(1338, strides=[1], requires_grad=0, device=cuda:0)[], %g_idcs : Long(1380, strides=[1], requires_grad=0, device=cuda:0)[], %g_feats : Long(1380, strides=[1], requires_grad=0, device=cuda:0), %g_turn : Long(1460, strides=[1], requires_grad=0, device=cuda:0), %g_control : Long(1460, strides=[1], requires_grad=0, device=cuda:0), %g_intersect : Long(1456, strides=[1], requires_grad=0, device=cuda:0), %g_left : Dict(str, Tensor), %g_right : Dict(str, Tensor), %actor_net.groups.0.0.conv1.weight : Long(1163, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.bn1.weight : Long(53, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.bn1.bias : Long(53, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.conv2.weight : Long(1338, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.bn2.weight : Long(1338, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.bn2.bias : Long(1380, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.downsample.0.weight : Long(1380, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.downsample.1.weight : Long(1460, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.0.downsample.1.bias : Long(1460, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.conv1.weight : Long(1456, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.bn1.weight : Long(1456, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.bn1.bias : Long(1163, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.conv2.weight : Long(1163, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.bn2.weight : Long(53, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.0.1.bn2.bias : Long(53, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.conv1.weight : Float(1293, 2, strides=[2, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.bn1.weight : Long(1293, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.bn1.bias : Float(1293, 2, strides=[2, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.conv2.weight : Float(1293, 2, strides=[2, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.bn2.weight : Float(1293, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.bn2.bias : Float(1293, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.downsample.0.weight : Long(198, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.downsample.1.weight : Long(198, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.0.downsample.1.bias : Long(198, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.conv1.weight : Long(198, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.bn1.weight : Float(32, 3, 3, strides=[9, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.bn1.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.conv2.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.bn2.weight : Float(32, 32, 3, strides=[96, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.1.1.bn2.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.conv1.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.bn1.weight : Float(32, 3, 1, strides=[3, 1, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.bn1.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.conv2.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.bn2.weight : Float(32, 32, 3, strides=[96, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.bn2.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.downsample.0.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.downsample.1.weight : Float(32, 32, 3, strides=[96, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.0.downsample.1.bias : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.conv1.weight : Float(32, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.bn1.weight : Float(64, 32, 3, strides=[96, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.bn1.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.conv2.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.bn2.weight : Float(64, 64, 3, strides=[192, 3, 1], requires_grad=0, device=cuda:0), %actor_net.groups.2.1.bn2.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.2.conv.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.2.norm.weight : Float(64, 32, 1, strides=[32, 1, 1], requires_grad=0, device=cuda:0), %actor_net.lateral.2.norm.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.1.conv.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.1.norm.weight : Float(64, 64, 3, strides=[192, 3, 1], requires_grad=0, device=cuda:0), %actor_net.lateral.1.norm.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.0.conv.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.lateral.0.norm.weight : Float(64, 64, 3, strides=[192, 3, 1], requires_grad=0, device=cuda:0), %actor_net.lateral.0.norm.bias : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.output.conv1.weight : Float(64, strides=[1], requires_grad=0, device=cuda:0), %actor_net.output.bn1.weight : Float(128, 64, 3, strides=[192, 3, 1], requires_grad=0, device=cuda:0), %actor_net.output.bn1.bias : Float(128, strides=[1], requires_grad=0, device=cuda:0), %actor_net.output.conv2.weight : Float(128, strides=[1], requires_grad=0, device=cuda:0), %actor_net.output.bn2.weight : Float(128, 128, 3, strides=[384, 3, 1], requires_grad=0, device=cuda:0), %actor_net.output.bn2.bias : Float(128, strides=[1], requires_grad=0, device=cuda:0) = prim::Param()
) (type 'Tensor')
Outputs:
#0: out defined in (%out : Tensor = onnx::Conv[dilations=[1], group=1, kernel_shape=annotate(List[int], []), pads=[1, 1], strides=[1]](%d_actors.1, %actor_net.groups.0.0.conv1.weight), scope: lane_gcn.lanegcn.Net::/lane_gcn.lanegcn.ActorNet::actor_net/torch.nn.modules.container.Sequential::groups.0/lane_gcn.layers.Res1dDownSample::0/torch.nn.modules.conv.Conv1d::conv1 # /home/zwj/miniconda3/envs/pt2/lib/python3.8/site-packages/torch/nn/modules/conv.py:309:15
) (type 'Tensor')
```
I checked `group_norm` operator is supported from `opset=9`, and I try torch version 1.12 and 1.13, all gave the error...
Any ideas to fix that?
### Versions
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.6 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.10 (default, Jun 4 2021, 15:09:15) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-67-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
GPU 3: NVIDIA GeForce RTX 3090
GPU 4: NVIDIA GeForce RTX 3090
GPU 5: NVIDIA GeForce RTX 3090
GPU 6: NVIDIA GeForce RTX 3090
GPU 7: NVIDIA GeForce RTX 3090
Nvidia driver version: 515.65.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.2.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.2.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.2.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.2.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.2.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.2.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.2.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 2
Core(s) per socket: 32
Socket(s): 2
NUMA node(s): 2
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7502 32-Core Processor
Stepping: 0
Frequency boost: enabled
CPU MHz: 1745.438
CPU max MHz: 2500.0000
CPU min MHz: 1500.0000
BogoMIPS: 5000.36
Virtualization: AMD-V
L1d cache: 2 MiB
L1i cache: 2 MiB
L2 cache: 32 MiB
L3 cache: 256 MiB
NUMA node0 CPU(s): 0-31,64-95
NUMA node1 CPU(s): 32-63,96-127
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT enabled with STIBP protection
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP always-on, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate ssbd mba ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr rdpru wbnoinvd amd_ppin arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif v_spec_ctrl umip rdpid overflow_recov succor smca sme sev sev_es
Versions of relevant libraries:
[pip3] mypy-extensions==1.0.0
[pip3] mypy-protobuf==3.3.0
[pip3] numpy==1.23.5
[pip3] torch==1.13.1
[pip3] torch-tensorrt==1.3.0
[pip3] torch2trt==0.2.0
[pip3] torchaudio==2.0.0
[pip3] torchvision==0.15.0
[pip3] triton==2.0.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py38h7f8727e_0
[conda] mkl_fft 1.3.1 py38hd3c417c_0
[conda] mkl_random 1.2.2 py38h51133e4_0
[conda] numpy 1.23.5 py38h14f4228_0
[conda] numpy-base 1.23.5 py38h31eccc5_0
[conda] pytorch-cuda 11.7 h778d358_3 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torch 1.13.1 pypi_0 pypi
[conda] torch-tensorrt 1.3.0 pypi_0 pypi
[conda] torchaudio 2.0.0 py38_cu117 pytorch
[conda] torchtriton 2.0.0 py38 pytorch
[conda] torchvision 0.15.0 py38_cu117 pytorch
| 3 |
3,122 | 97,421 |
After the release of pytorch 2.0.0, the compilation of ACLs is problematic.
|
module: build, triaged
|
I found that when I installed torch2.0.0 using pip, I carried a torch.libs folder with three ACL so files and two libgomp files. I wanted to know the detailed compilation options and ACL versions of the three ACL so files. What are the sources of the other two libgomp files?
libarm_compute-860e7a78.so
libarm_compute_graph-ab857ce5.so
libgomp-d22c30c5.so.1.0.0
libarm_compute_core-0793f69d.so
libgomp-adceddde.so.1.0.0
As for why I want to know this, I want to compile pytorch in the source code to link my self-installed ACLs and find that it is much slower than the torch installed using pip, under the same version of torch.
My Compilation Environment:
GCC 10.2
ACL 23.0.1
torch 2.0.0
cc @malfet @seemethere
| 1 |
3,123 | 97,414 |
streamNone = get_cuda_stream(None) RuntimeError: invalid argument to getCurrentStream
|
triaged, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
Steps to repro:
Patch in https://github.com/pytorch/pytorch/pull/97275/
```
PYTORCH_TEST_WITH_INDUCTOR=1 python test/test_torch.py -k test_upsample_nearest2d_meta
```
fails with
```
======================================================================
ERROR: test_upsample_nearest2d_meta (__main__.TestTorch)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/data/users/ezyang/c/pytorch/test/test_torch.py", line 7594, in test_upsample_nearest2d_meta
def test_upsample_nearest2d_meta(self):
File "/data/users/ezyang/c/pytorch/torch/_dynamo/eval_frame.py", line 235, in _fn
return fn(*args, **kwargs)
File "/data/users/ezyang/c/pytorch/torch/_functorch/aot_autograd.py", line 3067, in forward
return compiled_fn(full_args)
File "/data/users/ezyang/c/pytorch/torch/_functorch/aot_autograd.py", line 1187, in g
return f(*args)
File "/data/users/ezyang/c/pytorch/torch/_functorch/aot_autograd.py", line 2098, in runtime_wrapper
all_outs = call_func_with_args(
File "/data/users/ezyang/c/pytorch/torch/_functorch/aot_autograd.py", line 1212, in call_func_with_args
out = normalize_as_list(f(args))
File "/tmp/torchinductor_ezyang/cr/ccratlcqupckmlekrr3wiwo4xs77rfbn2x47ii6wi3722dmjv52e.py", line 61, in call
streamNone = get_cuda_stream(None)
RuntimeError: invalid argument to getCurrentStream
----------------------------------------------------------------------
```
I don't see any user reports of this error so maybe low priority.
Generated code: https://gist.github.com/ezyang/199c5be44c0744f571620bfbc7d5993d
ATen graph looks valid, shouldn't be a bug in the DCE PR:
```
def forward(self):
# File: /data/users/ezyang/c/pytorch/test/test_torch.py:7602, code: x = torch.empty(4, 3, 8, 8, device='meta')
empty: f32[4, 3, 8, 8] = torch.ops.aten.empty.memory_format([4, 3, 8, 8], device = device(type='meta'), pin_memory = False)
# File: /data/users/ezyang/c/pytorch/test/test_torch.py:7604, code: torch._C._nn.upsample_nearest2d(x, (16, 16), out=out)
upsample_nearest2d: f32[4, 3, 16, 16] = torch.ops.aten.upsample_nearest2d.default(empty, [16, 16])
return (empty, upsample_nearest2d)
```
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 6 |
3,124 | 97,408 |
Further memcopy improvement at FX body level
|
triaged
|
We may consider to improve this further as the next step. In general, we don't have to care about what data type is when we do memory copy. Maybe we can do some pattern matching on the kernel fx body to figure out if it is a memory copy and just apply a common memory copy intrinsics.
_Originally posted by @jgong5 in https://github.com/pytorch/pytorch/pull/97147#discussion_r1145540933_
| 0 |
3,125 | 97,402 |
DISABLED test_checkpoint_trigger (__main__.TestCheckpoint)
|
triaged, module: flaky-tests, skipped, module: unknown
|
Platforms: dynamo
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_checkpoint_trigger&suite=TestCheckpoint) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/12205638073).
Over the past 3 hours, it has been determined flaky in 7 workflow(s) with 14 failures and 7 successes.
**Debugging instructions (after clicking on the recent samples link):**
DO NOT ASSUME THINGS ARE OKAY IF THE CI IS GREEN. We now shield flaky tests from developers so CI will thus be green but it will be harder to parse the logs.
To find relevant log snippets:
1. Click on the workflow logs linked above
2. Click on the Test step of the job so that it is expanded. Otherwise, the grepping will not work.
3. Grep for `test_checkpoint_trigger`
4. There should be several instances run (as flaky tests are rerun in CI) from which you can study the logs.
Test file path: `test_utils.py`
| 12 |
3,126 | 97,397 |
Import fails when both `USE_TENSORPIPE=OFF` and `USE_DISTRIBUTED=ON`.
|
module: build, triaged, module: tensorpipe
|
### 🐛 Describe the bug
Installation succeeds, but importing torch fails when pytorch is built with both `USE_TENSORPIPE=OFF` and `USE_DISTRIBUTED=ON`.
Error Message:
```
>>> import torch
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "lib/python3.10/site-packages/torch/__init__.py", line 831, in <module>
from .functional import * # noqa: F403
File "lib/python3.10/site-packages/torch/functional.py", line 8, in <module>
import torch.nn.functional as F
File "lib/python3.10/site-packages/torch/nn/__init__.py", line 1, in <module>
from .modules import * # noqa: F403
File "lib/python3.10/site-packages/torch/nn/modules/__init__.py", line 2, in <module>
from .linear import Identity, Linear, Bilinear, LazyLinear
File "lib/python3.10/site-packages/torch/nn/modules/linear.py", line 7, in <module>
from .. import functional as F
File "lib/python3.10/site-packages/torch/nn/functional.py", line 18, in <module>
from .._jit_internal import boolean_dispatch, _overload, BroadcastingList1, BroadcastingList2, BroadcastingList3
File "lib/python3.10/site-packages/torch/_jit_internal.py", line 39, in <module>
import torch.distributed.rpc
File "python3.10/site-packages/torch/distributed/rpc/__init__.py", line 30, in <module>
from torch._C._distributed_rpc import (
ImportError: cannot import name '_TensorPipeRpcBackendOptionsBase' from 'torch._C._distributed_rpc' (unknown location)
```
Missing symbols from that list include: `_TensorPipeRpcBackendOptionsBase`,
`TensorPipeAgent`, and `_DEFAULT_NUM_WORKER_THREADS`.
`grep TensorPipeRpcBackendOptionsBase lib/python3.10/site-packages/torch/lib/libtorch_python.so` turns up no matches.
Diagnosis: The bug's existence can be read off directly from the source code, since the `torch._C._distributed_rpc` imports those unconditionally, but https://github.com/pytorch/pytorch/blob/v1.13.1/torch/csrc/distributed/rpc/init.cpp#L532 injects _TensorPipeRpcBackendOptionsBase and some other things during `rpc_init()`, but only if `USE_TENSORPIPE` is defined.
### Versions
This issue has been noticed before #68002
The TensorPipe python import first appeared in 1.8.0.
The bug persists in v2.0.0:
https://github.com/pytorch/pytorch/blob/v2.0.0/torch/csrc/distributed/rpc/init.cpp#L532
https://github.com/pytorch/pytorch/blob/v2.0.0/torch/distributed/rpc/__init__.py#L54
cc @malfet @seemethere @osalpekar @jiayisuse @lw @beauby @pritamdamania87 @mrshenli @jjlilley @gqchen @rohan-varma
| 0 |
3,127 | 97,395 |
Expanded weights tests broken
|
triaged, module: functorch
|
### 🐛 Describe the bug
```
$ python pytorch/test/run_test.py -i test_expanded_weights -v
<omitted>
Ran 495 tests in 26.571s
FAILED (failures=29, errors=82, skipped=34)
FINISHED PRINTING LOG FILE of test_expanded_weights (/home/sclarkson/pytorch/test/test-reports/test_expanded_weights_24ydgznv.log)
test_expanded_weights failed!
Traceback (most recent call last):
File "/home/sclarkson/pytorch/test/run_test.py", line 1394, in <module>
main()
File "/home/sclarkson/pytorch/test/run_test.py", line 1352, in main
raise RuntimeError(
RuntimeError: test_expanded_weights failed!
Tip: You can keep running tests even on failure by passing --keep-going to run_test.py.
If running on CI, add the 'keep-going' label to your PR and rerun your jobs.
```
The errors all look like the example below
```
======================================================================
ERROR: test_Conv1d_cuda (__main__.TestExpandedWeightModuleCUDA)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/sclarkson/miniconda3/lib/python3.10/site-packages/torch/testing/_internal/common_utils.py", line 2069, in wrapper
method(*args, **kwargs)
File "/home/sclarkson/miniconda3/lib/python3.10/site-packages/torch/testing/_internal/common_device_type.py", line 401, in instantiated_test
result = test(self, **param_kwargs)
File "/home/sclarkson/pytorch/test/test_expanded_weights.py", line 695, in <lambda>
setattr(TestExpandedWeightModule, test_name, lambda self, test=test: test.test_context_manager(self, 'cpu'))
File "/home/sclarkson/pytorch/test/test_expanded_weights.py", line 661, in test_context_manager
test_case._do_test(module, input)
File "/home/sclarkson/pytorch/test/test_expanded_weights.py", line 412, in _do_test
actual_grads.append(input.grad.clone())
AttributeError: 'NoneType' object has no attribute 'clone'
```
And the failures all look like the example below.
```
======================================================================
FAIL: test_Conv1d_multiple_inputs_cuda (__main__.TestExpandedWeightModuleCUDA)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/sclarkson/miniconda3/lib/python3.10/site-packages/torch/testing/_internal/common_utils.py", line 2069, in wrapper
method(*args, **kwargs)
File "/home/sclarkson/miniconda3/lib/python3.10/site-packages/torch/testing/_internal/common_device_type.py", line 401, in instantiated_test
result = test(self, **param_kwargs)
File "/home/sclarkson/pytorch/test/test_expanded_weights.py", line 697, in <lambda>
lambda self, test=test: test.test_context_manager_multiple_inputs(self, 'cpu'))
File "/home/sclarkson/pytorch/test/test_expanded_weights.py", line 670, in test_context_manager_multiple_inputs
test_case._do_test_multi_input(module, input)
File "/home/sclarkson/pytorch/test/test_expanded_weights.py", line 476, in _do_test_multi_input
assert [self.assertEqual(actual, 2 * expected) for (actual, expected) in zip(actual_grads, expected_grads)]
File "/home/sclarkson/pytorch/test/test_expanded_weights.py", line 476, in <listcomp>
assert [self.assertEqual(actual, 2 * expected) for (actual, expected) in zip(actual_grads, expected_grads)]
File "/home/sclarkson/miniconda3/lib/python3.10/site-packages/torch/testing/_internal/common_utils.py", line 2967, in assertEqual
raise error_metas[0].to_error(
AssertionError: Tensor-likes are not close!
Mismatched elements: 80 / 80 (100.0%)
Greatest absolute difference: 2.188215970993042 at index (0, 0, 2) (up to 1e-05 allowed)
Greatest relative difference: 1.0000067267518076 at index (0, 2, 1) (up to 1.3e-06 allowed)
```
This didn't occur in the 1.13 release. I was able to bisect it back to #91807
It looks like the `TestExpandedWeightModule` is now overloaded to run two fundamentally different types of tests, some that are parameterized manually [here](https://github.com/pytorch/pytorch/blob/116a4f23016ecea430c947785d07702f20290bbd/test/test_expanded_weights.py#L679-L701) and others parameterized by device type [here](https://github.com/pytorch/pytorch/blob/116a4f23016ecea430c947785d07702f20290bbd/test/test_expanded_weights.py#L778)
This conflict is apparent in test names like `test_Conv1d_cuda_double_cpu (__main__.TestExpandedWeightModuleCPU)`
### Versions
```
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.2 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.9 (main, Jan 11 2023, 15:21:40) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.19.0-37-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce GTX 1080 Ti
GPU 1: NVIDIA GeForce GTX 1080 Ti
Nvidia driver version: 525.89.02
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz
CPU family: 6
Model: 79
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 1
Stepping: 1
CPU max MHz: 2900.0000
CPU min MHz: 1200.0000
BogoMIPS: 4400.12
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single pti intel_ppin ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt_a rdseed adx smap intel_pt xsaveopt cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts md_clear flush_l1d
Virtualization: VT-x
L1d cache: 384 KiB (12 instances)
L1i cache: 384 KiB (12 instances)
L2 cache: 3 MiB (12 instances)
L3 cache: 30 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-23
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; Clear CPU buffers; SMT vulnerable
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.5
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.0
[pip3] torchvision==0.15.0
[pip3] triton==2.0.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.5 py310hd5efca6_0
[conda] numpy-base 1.23.5 py310h8e6c178_0
[conda] pytorch 2.0.0 py3.10_cuda11.8_cudnn8.7.0_0 pytorch
[conda] pytorch-cuda 11.8 h7e8668a_3 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 2.0.0 py310_cu118 pytorch
[conda] torchtriton 2.0.0 py310 pytorch
[conda] torchvision 0.15.0 py310_cu118 pytorch
```
cc @zou3519 @Chillee @samdow @soumith @kshitij12345 @janeyx99
| 1 |
3,128 | 97,366 |
DISABLED test_vmapjvpvjp_svd_cuda_float32 (__main__.TestOperatorsCUDA)
|
triaged, skipped, module: functorch
|
Platforms: rocm
This test was disabled because it is failing on master ([recent examples](http://torch-ci.com/failure/functorch%2Ftest_ops.py%3A%3ATestOperatorsCUDA%3A%3Atest_vmapjvpvjp_svd_cuda_float32)).
cc @zou3519 @Chillee @samdow @soumith @kshitij12345 @janeyx99
| 2 |
3,129 | 97,365 |
inductor illegal memory access on indirect load on cpu
|
triaged, module: inductor, module: cpu inductor
|
### 🐛 Describe the bug
The following program proves an illegal memory access whereas the version without `torch.compile` works.
```
import torch
@torch.compile
def indexit(A, b):
return A[b - 1]
A = torch.rand(20)
b = torch.zeros(4)
print(indexit(A, b))
```
```
Traceback (most recent call last):
File "/scratch/zdevito/pytorch/hi.py", line 11, in <module>
print(indexit(A, b))
File "/scratch/zdevito/pytorch/torch/_tensor.py", line 426, in __repr__
return torch._tensor_str._str(self, tensor_contents=tensor_contents)
File "/scratch/zdevito/pytorch/torch/_tensor_str.py", line 636, in _str
return _str_intern(self, tensor_contents=tensor_contents)
File "/scratch/zdevito/pytorch/torch/_tensor_str.py", line 567, in _str_intern
tensor_str = _tensor_str(self, indent)
File "/scratch/zdevito/pytorch/torch/_tensor_str.py", line 327, in _tensor_str
formatter = _Formatter(get_summarized_data(self) if summarize else self)
File "/scratch/zdevito/pytorch/torch/_tensor_str.py", line 115, in __init__
nonzero_finite_vals = torch.masked_select(
RuntimeError: CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
```
Inductor kernel:
```
@triton.jit
def triton_(in_ptr0, in_ptr1, out_ptr0, xnumel, XBLOCK : tl.constexpr):
xnumel = 4
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:]
xmask = xindex < xnumel
x0 = xindex
tmp0 = tl.load(in_ptr0 + (x0), xmask)
tmp1 = 1
tmp2 = tmp0 - tmp1
tmp3 = tl.load(in_ptr1 + (tmp2), xmask)
tl.store(out_ptr0 + (x0 + tl.zeros([XBLOCK], tl.int32)), tmp3, xmask)
```
Note that indexing by -1 is valid and means to read the _last_ element similar to python, but the code being generated here does not appear to have any handling for this case.
This bug has been running in the GPT2ForSequenceClassification benchmark for some time but is covered up by the fact that slight reads off the end of tensors do not always generate illegal memory faults.
### Versions
Collecting environment information...
PyTorch version: 2.0.0a0+git6a6776f
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.2
Libc version: glibc-2.31
Python version: 3.10.9 (main, Jan 11 2023, 15:21:40) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-1019-aws-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.6.112
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA A100-SXM4-40GB
Nvidia driver version: 525.85.12
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8275CL CPU @ 3.00GHz
Stepping: 7
CPU MHz: 3000.042
BogoMIPS: 6000.08
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 1.5 MiB
L1i cache: 1.5 MiB
L2 cache: 48 MiB
L3 cache: 71.5 MiB
NUMA node0 CPU(s): 0-23,48-71
NUMA node1 CPU(s): 24-47,72-95
Vulnerability Itlb multihit: KVM: Mitigation: VMX unsupported
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Retbleed: Vulnerable
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, STIBP disabled, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq monitor ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single pti fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves ida arat pku ospke
Versions of relevant libraries:
[pip3] mypy==0.960
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.23.1
[pip3] torch==2.1.0a0+git797e31d
[pip3] torchvision==0.15.0a0+120e7af
[pip3] triton==2.0.0a2
[conda] numpy 1.23.1 pypi_0 pypi
[conda] torch 2.1.0a0+git797e31d dev_0 <develop>
[conda] torchvision 0.15.0a0+120e7af dev_0 <develop>
[conda] triton 2.0.0a2 pypi_0 pypi
cc @voznesenskym @penguinwu @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @ipiszy @ngimel @yf225 @chenyang78 @kadeng @muchulee8 @aakhundov @soumith @anijain2305 @desertfire
| 8 |
3,130 | 97,361 |
torch.compile()'d optimizer.step() has too many arguments in C++
|
triaged, oncall: pt2, module: aotdispatch, module: cpu inductor
|
### 🐛 Describe the bug
When one torch.compile()'s the optimizer.step() for the following models and optimizers on CPU, inductor generates a C++ kernel that takes in too many arguments for ctypes to handle and hits a "ctypes: too many arguments" error (https://github.com/microsoft/nnfusion/issues/399). The compiled optimizer step kernel unrolls the for loop of updates so that there are `num params` copies of the same code. The more parameters there are, the more likely it is to hit the error. Since it is just unrolling for-loops and the param updates do not interfere, the fix here would be to break up the kernels so that each take fewer arguments to avoid the error.
Models that ran into a 'too many arguments' error and their incompatible optimizers:
```
BERT_pytorch: AdamW, Rprop, Adam, ASGD, Adagrad, Adamax, Adadelta, NAdam
Background_Matting: AdamW, Rprop, Adam, ASGD, Adagrad, Adamax, Adadelta, NAdam
Super_SloMo: AdamW, Adamax, Adam, ASGD, NAdam
attention_is_all_you_need_pytorch: AdamW, Rprop, Adam, ASGD, Adagrad, Adamax, Adadelta, NAdam
densenet121: AdamW, Rprop, Adam, SGD, ASGD, Adagrad, Adamax, RMSprop, Adadelta, NAdam
detectron2_fasterrcnn_r_101_c4: AdamW, Adamax, Adam, ASGD, NAdam
detectron2_fasterrcnn_r_101_dc5: AdamW, Adamax, Adam, ASGD, NAdam
detectron2_fasterrcnn_r_101_fpn: AdamW, Rprop, Adamax, Adam, Adagrad, ASGD, NAdam
detectron2_fasterrcnn_r_50_fpn: Adamax, NAdam, ASGD
detectron2_maskrcnn: Adamax, NAdam, ASGD
detectron2_maskrcnn_r_101_c4: AdamW, Adamax, Adam, ASGD, NAdam
detectron2_maskrcnn_r_101_fpn: AdamW, Rprop, Adamax, Adam, Adagrad, ASGD, NAdam
detectron2_maskrcnn_r_50_fpn: Adamax, NAdam, ASGD
doctr_det_predictor: AdamW, Rprop, Adam, ASGD, Adagrad, Adamax, Adadelta, NAdam
fambench_xlmr: AdamW, Rprop, Adam, SGD, ASGD, Adagrad, Adamax, RMSprop, Adadelta, NAdam
fastNLP_Bert: AdamW, Rprop, Adam, ASGD, Adagrad, Adamax, Adadelta, NAdam
hf_Bart: AdamW, Rprop, Adam, ASGD, Adagrad, Adamax, RMSprop, Adadelta, NAdam
hf_Bert: AdamW, Rprop, Adam, ASGD, Adagrad, Adamax, Adadelta, NAdam
hf_Bert_large: AdamW, Rprop, Adam, SGD, ASGD, Adagrad, Adamax, RMSprop, Adadelta, NAdam
hf_BigBird: AdamW, Rprop, Adam, ASGD, Adagrad, Adamax, Adadelta, NAdam
hf_DistilBert: AdamW, Adamax, Adam, ASGD, NAdam
hf_GPT2: AdamW, Rprop, Adam, ASGD, Adagrad, Adamax, Adadelta, NAdam
hf_GPT2_large: AdamW, Rprop, Adam, SGD, ASGD, Adagrad, Adamax, RMSprop, Adadelta, NAdam
hf_Longformer: AdamW, Rprop, Adam, ASGD, Adagrad, Adamax, RMSprop, Adadelta, NAdam
hf_Reformer: Adamax, NAdam
hf_T5: AdamW, Rprop, Adamax, Adam, Adagrad, ASGD, NAdam
hf_T5_base: AdamW, Rprop, Adam, ASGD, Adagrad, Adamax, RMSprop, Adadelta, NAdam
hf_T5_large: AdamW, Rprop, Adam, SGD, ASGD, Adagrad, Adamax, RMSprop, Adadelta, NAdam
mnasnet1_0: Rprop, Adadelta
mobilenet_v2: Rprop, Adadelta
mobilenet_v2_quantized_qat: Rprop, Adadelta
mobilenet_v3_large: Rprop, Adadelta
phlippe_densenet: Rprop, Adadelta
resnet152: SGD, Rprop, RMSprop, Adadelta
resnet50: Rprop, Adadelta
resnet50_quantized_qat: Rprop, Adadelta
resnext50_32x4d: Rprop, Adadelta
shufflenet_v2_x1_0: Rprop, Adadelta
timm_efficientnet: Rprop, RMSprop, Adadelta
timm_nfnet: RMSprop, Adadelta
timm_regnet: Rprop, RMSprop, Adadelta
timm_vision_transformer: Rprop, Adadelta
```
### Error logs
Short error is: `ctypes.ArgumentError: too many arguments (1940), maximum is 1024` for running torch.compile on BERT_pytorch's parameters on CPU with default AdamW.
<details>
```
Traceback (most recent call last):
File "/fsx/users/janeyx/conda/envs/torchbenchmark/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/fsx/users/janeyx/conda/envs/torchbenchmark/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/scratch/janeyx/work/benchmark/userbenchmark/optim/__init__.py", line 414, in <module>
run(sys.argv[1:])
File "/scratch/janeyx/work/benchmark/userbenchmark/optim/__init__.py", line 405, in run
results = run_benchmarks(args.optims, args.funcs, args.models, args.devices)
File "/scratch/janeyx/work/benchmark/userbenchmark/optim/__init__.py", line 344, in run_benchmarks
bm = run_model(mn, d, O, defaults, func_str)
File "/scratch/janeyx/work/benchmark/userbenchmark/optim/__init__.py", line 320, in run_model
raise e
File "/scratch/janeyx/work/benchmark/userbenchmark/optim/__init__.py", line 317, in run_model
).blocked_autorange()
File "/fsx/users/janeyx/conda/envs/torchbenchmark/lib/python3.10/site-packages/torch/utils/benchmark/utils/timer.py", line 394, in blocked_autorange
number = self._estimate_block_size(min_run_time)
File "/fsx/users/janeyx/conda/envs/torchbenchmark/lib/python3.10/site-packages/torch/utils/benchmark/utils/timer.py", line 311, in _estimate_block_size
time_taken = self._timeit(number)
File "/fsx/users/janeyx/conda/envs/torchbenchmark/lib/python3.10/site-packages/torch/utils/benchmark/utils/timer.py", line 256, in _timeit
return max(self._timer.timeit(number), 1e-9)
File "/fsx/users/janeyx/conda/envs/torchbenchmark/lib/python3.10/timeit.py", line 178, in timeit
timing = self.inner(it, self.timer)
File "<timeit-src>", line 6, in inner
File "/scratch/janeyx/work/benchmark/userbenchmark/optim/__init__.py", line 268, in pt2_optimizer_step
f()
File "/fsx/users/janeyx/conda/envs/torchbenchmark/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 235, in _fn
return fn(*args, **kwargs)
File "/scratch/janeyx/work/benchmark/userbenchmark/optim/__init__.py", line 267, in f
optimizer.step()
File "/fsx/users/janeyx/conda/envs/torchbenchmark/lib/python3.10/site-packages/torch/optim/optimizer.py", line 33, in _use_grad
ret = func(self, *args, **kwargs)
File "/fsx/users/janeyx/conda/envs/torchbenchmark/lib/python3.10/site-packages/torch/optim/adamw.py", line 143, in step
self._cuda_graph_capture_health_check()
File "/fsx/users/janeyx/conda/envs/torchbenchmark/lib/python3.10/site-packages/torch/optim/adamw.py", line 171, in <resume in step>
adamw(
File "/fsx/users/janeyx/conda/envs/torchbenchmark/lib/python3.10/site-packages/torch/optim/adamw.py", line 264, in adamw
def adamw(
File "/fsx/users/janeyx/conda/envs/torchbenchmark/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 235, in _fn
return fn(*args, **kwargs)
File "/fsx/users/janeyx/conda/envs/torchbenchmark/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 3001, in forward
return compiled_fn(full_args)
File "/fsx/users/janeyx/conda/envs/torchbenchmark/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1175, in g
return f(*args)
File "/fsx/users/janeyx/conda/envs/torchbenchmark/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 2056, in runtime_wrapper
all_outs = call_func_with_args(
File "/fsx/users/janeyx/conda/envs/torchbenchmark/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1200, in call_func_with_args
out = normalize_as_list(f(args))
File "/tmp/torchinductor_janeyx/ch/cchgxveesattdyuylo65f32dgd33oz4dmmlxaimi3i6xyv2gbyh5.py", line 21373, in call
kernel_cpp_0(c_void_p(arg0_1.data_ptr()), c_void_p(arg388_1.data_ptr()), c_void_p(arg194_1.data_ptr()), c_void_p(arg582_1.data_ptr()), c_void_p(arg776_1.data_ptr()), c_void_p(arg1_1.data_ptr()), c_void_p(arg389_1.data_ptr()), ...c_void_p(arg967_1.data_ptr()), c_void_p(arg968_1.data_ptr()), c_void_p(arg969_1.data_ptr()))
ctypes.ArgumentError: too many arguments (1940), maximum is 1024
```
</details>
### Minified repro
Minimal repro with BERT_pytorch's param shapes:
```
def pt2_optimizer_step(optimizer):
@torch.compile()
def f():
optimizer.step()
f()
params = [torch.rand(20005, 768, dtype=torch.float32, device='cpu') for _ in range(194)]
for p in params:
p.grad = torch.rand_like(p)
o = torch.optim.AdamW(params)
pt2_optimizer_step(o)
```
Code reduced from https://github.com/pytorch/benchmark/pull/1473, look there if you want to pull params from models.
### Versions
2.0, nightlies
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 20 |
3,131 | 97,352 |
Sparse is not available on Windows
|
module: sparse, module: build, module: windows, triaged
|
### 🐛 Describe the bug
To track following:
https://github.com/pytorch/pytorch/blob/d850c33bfe3f1d1f0040738718cacb04ee449bdc/aten/src/ATen/mkl/Sparse.h#L5-L11
Copy-n-paste from 2y.o [comment](https://github.com/pytorch/pytorch/pull/50937#issuecomment-779272492):
## What's wrong there
The following error message is generated in the Windows build jobs for this PR (e.g. [this one](https://app.circleci.com/pipelines/github/pytorch/pytorch/273229/workflows/816eb750-45b5-4fb8-9e34-850e7608a3f2/jobs/10881331))
```
error LNK2038: mismatch detected for 'RuntimeLibrary': value 'MT_StaticRelease' doesn't match value 'MD_DynamicRelease' ...
```
## Root cause
The implementation of `mkl_sparse_d_create_csr` and `mkl_sparse_destroy` uses `malloc/new` and `free/delete` possibly, which requires UCRT. Currently, we link against the static variant of MKL with our code with /MD. With MSVC, you cannot have two copies of UCRT for a shared library / executable with different runtime library options (/MD and /MT).
## Possible solutions
### Solution 1
Remove the usages of `mkl_sparse_d_create_csr` and `mkl_sparse_destroy`
I don't know whether this is possible. But if possible, this is the easiest solution.
### Solution 2
Link against the dynamic variant of MKL instead.
In this solution, we have two choices.
#### Choice A
We depend on package managers completely.
But the difficulty is that MKL doesn't provide every release of MKL in PyPI and Anaconda Cloud. e.g. on PyPI, they have 2021.01 and 2019.0. However, on Anaconda Cloud, they have 2020.02 (defaults channel), 2020.04 (conda-forge channel) and 2021.01 (intel channel). So it is quite difficult for us to select the version of MKL to build PyTorch.
Another difficulty is that Anaconda Cloud doesn't provide the full set of development package for Windows. But we can install them through other package managers, e.g. nuget and choco.
#### Choice B
We copy the DLLs into the PyTorch package.
But the MKL DLLs are quite large. Uncompressed: 650M, Compressed: 128M
#### Choice C
A tradeoff between Choice A and B. But this still doesn't seem perfect.
cc @alexsamardzic @nikitaved @pearu @cpuhrsch @amjames @bhosmer @seemethere @peterjc123 @mszhanyi @skyline75489 @nbcsm
| 0 |
3,132 | 97,344 |
torch.onnx.export crashes on ReduceMax operator with onnx opset 18
|
module: onnx, triaged
|
If you have a question or would like help and support, please ask at our
[forums](https://discuss.pytorch.org/).
If you are submitting a feature request, please preface the title with [feature request].
If you are submitting a bug report, please fill in the following details.
## Issue description
Provide a short description.
I can successfully export my model with torch.onnx.export to onnx and run it with onnxruntime when selecting the onnx opset 17.
But when attempting to run torch.onnx.export on my model using onnx opset 18 , the export crashes in the ReduceMax operator.
here is the trace dump:
/usr/local/lib/python3.10/dist-packages/torch/onnx/symbolic_opset9.py:5589: UserWarning: Exporting aten::index operator of advanced indexing in opset 18 is achieved by combination of multiple ONNX operators, including Reshape, Transpose, Concat, and Gather. If indices include negative values, the exported graph will produce incorrect results.
warnings.warn(
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/torch/onnx/utils.py", line 1636, in _export
_C._check_onnx_proto(proto)
RuntimeError: Unrecognized attribute: axes for operator ReduceMax
==> Context: Bad node spec for node. Name: /model/ReduceMax OpType: ReduceMax
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/cad-engine/export_onnx.py", line 359, in
main()
File "/cad-engine/export_onnx.py", line 332, in main
onnx_model = export_tracing(torch_model, sample_inputs, args, logger)
File "/cad-engine/export_onnx.py", line 115, in export_tracing
torch.onnx.export(
File "/usr/local/lib/python3.10/dist-packages/torch/onnx/utils.py", line 506, in export
_export(
File "/usr/local/lib/python3.10/dist-packages/torch/onnx/utils.py", line 1638, in _export
raise errors.CheckerError(e) from e
torch.onnx.errors.CheckerError: Unrecognized attribute: axes for operator ReduceMax
==> Context: Bad node spec for node. Name: /model/ReduceMax OpType: ReduceMax
## Code example
Please try to provide a minimal example to repro the bug.
Error messages and stack traces are also helpful.
## System Info
Please copy and paste the output from our
[environment collection script](https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py)
(or fill out the checklist below manually).
python collect_env.py
Collecting environment information...
PyTorch version: 2.0.0+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.3.18-150300.59.63-default-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Quadro RTX 8000
Nvidia driver version: 515.76
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 45 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) Gold 6258R CPU @ 2.70GHz
CPU family: 6
Model: 85
Thread(s) per core: 1
Core(s) per socket: 8
Socket(s): 2
Stepping: 7
BogoMIPS: 5387.34
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves arat pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Hypervisor vendor: VMware
Virtualization type: full
L1d cache: 512 KiB (16 instances)
L1i cache: 512 KiB (16 instances)
L2 cache: 16 MiB (16 instances)
L3 cache: 77 MiB (2 instances)
NUMA node(s): 1
NUMA node0 CPU(s): 0-15
Vulnerability Itlb multihit: KVM: Mitigation: VMX unsupported
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
- PyTorch or Caffe2: PyTorch (there is no caffe module in my Pytorch install!)/ Use tracing , not torchscript
- How you installed PyTorch (conda, pip, source): pip
- Build command you used (if compiling from source): N/A
- OS: ununtu 22.04
- PyTorch version: 2.0.0
- Python version:3.10.6
- CUDA/cuDNN version:11.8
- GPU models and configuration: N/A for export
- GCC version (if compiling from source):N/A
- CMake version:N/A
Versions of relevant libraries:
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.24.2
[pip3] torch==2.0.0+cu118
[pip3] torchaudio==2.0.1+cu118
[pip3] torchvision==0.15.1+cu118
[pip3] triton==2.0.0
[pip3] detectron2 0.6
[conda] Could not collect
I have no idea where in the pytorch code (actually Detectron2 code) the exporter fails here is the export command)
#this is inspired from [detectron2 v0.6] detectron2/tree/main/tools/deploy/export_model.py
traceable_model = TracingAdapter(torch_model, inputs, inference)
with PathManager.open(os.path.join(args.output, "faster_rcnn_fpn.onnx"), "wb") as f:
torch.onnx.export(
traceable_model,
(image,),
f,
do_constant_folding=True,
export_params=True,
input_names=["image"], # the model's input names
output_names=["boxes", "labels", "scores", "image_dims"], # the model's output names
dynamic_axes={
"image" : {1: "height", 2: "width"},
"boxes" : {0: "findings"}, # boxes is a tensor of shape [number of findings, 4]
"labels" : {0: "findings"},
"scores" : {0: "findings"}
},
verbose=False,
opset_version=18)
| 7 |
3,133 | 97,343 |
Traced module shows non-deterministic behaviour on CUDA
|
oncall: jit
|
### 🐛 Describe the bug
Traced module produces inconsistent results when running multiple times on GPU even though the use of deterministic algorithms is enforced. The following code snippet demonstrates the issue:
```python
import torch
import numpy as np
from torch import nn
torch.use_deterministic_algorithms(True)
class Foo(nn.Module):
"""Simple CNN model."""
def __init__(self):
super().__init__()
self.prepro = nn.Sequential(
nn.Conv2d(3, 24, kernel_size=3, stride=1, padding="same"),
nn.BatchNorm2d(24),
nn.ReLU())
def forward(self, x):
return self.prepro(x)
# Random inputs
inputs = torch.randn([1, 3, 352, 224]).cuda()
# Create model and trace it
foo = Foo().eval().cuda()
foo = torch.jit.trace(foo, inputs)
# Add random bias to BatchNorm so it is not zero
params = foo.state_dict()
params['prepro.1.bias'] = torch.randn([24])
foo.load_state_dict(params)
out_foo = foo(inputs)
for i in range(2000):
out_curr = foo(inputs)
print(i, torch.equal(out_foo, out_curr))
assert torch.equal(out_foo, out_curr)
```
After a couple of iterations the model output differs from previous runs. Interestingly, the code above works just fine if the ReLU activation is removed from the module.
### Versions
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.2 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.26.0
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.17.0-1028-oem-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA RTX A3000 12GB Laptop GPU
Nvidia driver version: 525.85.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Vendor ID: GenuineIntel
Model name: 12th Gen Intel(R) Core(TM) i7-12850HX
CPU family: 6
Model: 151
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
Stepping: 2
CPU max MHz: 3519,2729
CPU min MHz: 800,0000
BogoMIPS: 4838.40
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid rdseed adx smap clflushopt clwb intel_pt sha_ni xsaveopt xsavec xgetbv1 xsaves split_lock_detect avx_vnni dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp hwp_pkg_req umip pku ospke waitpkg gfni vaes vpclmulqdq tme rdpid movdiri movdir64b fsrm md_clear serialize pconfig arch_lbr flush_l1d arch_capabilities
L1d cache: 640 KiB (16 instances)
L1i cache: 768 KiB (16 instances)
L2 cache: 14 MiB (10 instances)
L3 cache: 25 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-23
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.0.0
[pip3] torchvision==0.15.1
[conda] Could not collect
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 0 |
3,134 | 97,333 |
`torch.fmod` produces inconsistent results in eager and compile mode
|
module: cpu, triaged, module: half, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
The following program produces inconsistent results under eager mode and compile mode. Details for debugging are explained in the code. Note that we need a specific input tensor to trigger this issue (it may be not the only input that leads to inconsistency).
```python
import torch
def fn(x):
return torch.fmod(x, 2.3)
# "✔️" means that the program works fine with the substitution.
# ✔️ return torch.fmod(x, 2.5)
x = torch.tensor(
[[4.9805, 6.6445, 5.6836, 6.1055],
[3.4121, 4.1406, 5.1523, 5.9766],
[3.3691, 4.4102, 6.8008, 4.0156],
[6.8633, 6.8750, 6.9805, 5.7070]], dtype=torch.float16)
# ✔️ dtype=torch.float32
# ✔️ x = torch.rand([4, 4], dtype=torch.float16)
ret_eager = fn(x)
compiled = torch.compile(fn)
ret_compiled = compiled(x)
assert torch.allclose(
ret_eager, ret_compiled,
rtol=1e-2, atol=1e-3, equal_nan=True,
), '\n'.join([
'',
f'>>> ret_eager',
str(ret_eager),
f'>>> ret_compiled',
str(ret_compiled),
])
print('==== Check OK! ====')
"""
raceback (most recent call last):
File "repro.py", line 18, in <module>
assert torch.allclose(
AssertionError:
>>> ret_eager
tensor([[0.3789, 2.0430, 1.0820, 1.5039],
[1.1113, 1.8398, 0.5508, 1.3750],
[1.0684, 2.1094, 2.1992, 1.7148],
[2.2617, 2.2734, 0.0781, 1.1055]], dtype=torch.float16)
>>> ret_compiled
tensor([[0.3804, 2.0449, 1.0840, 1.5059],
[1.1123, 1.8408, 0.5522, 1.3770],
[1.0693, 2.1094, 2.2012, 1.7158],
[2.2637, 2.2754, 0.0804, 1.1074]], dtype=torch.float16)
"""
```
### Versions
<details><summary><b>Environment</b> <i>[Click to expand]</i></summary>
```
Collecting environment information...
PyTorch version: 2.1.0.dev20230321+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 14.0.0-1ubuntu1
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Mar 10 2023, 10:55:28) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 525.78.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.960
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.23.1
[pip3] pytorch-triton==2.1.0+e650d3708b
[pip3] torch==2.1.0.dev20230321+cu117
[pip3] torchaudio==2.1.0.dev20230321+cu117
[pip3] torchvision==0.16.0.dev20230322+cu117
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.5 py39he7a7128_1
[conda] numpy-base 1.21.5 py39hf524024_1
[conda] numpydoc 1.2 pyhd3eb1b0_0
```
</details>
cc @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10 @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @Guobing-Chen @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 4 |
3,135 | 97,329 |
torch.ops.aten.pow(2.0, 3) return unexpected value with complex type
|
module: internals, triaged, module: custom-operators
|
### 🐛 Describe the bug
torch.ops.aten.pow(2.0, 3) return unexpected value with complex type\
```python
torch.ops.aten.pow(2.0, 3)
```
Ideally it should return `8.0`, but it returns `(8.0+0j)`
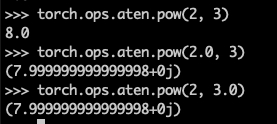
### Versions
torch==2.1.0.dev20230320+cpu
cc @ezyang @bhosmer @smessmer @ljk53 @bdhirsh
| 5 |
3,136 | 97,340 |
`torch.compile` + `torch.no_grad` not working for Mask R-CNN
|
triaged, ezyang's list, oncall: pt2, module: dynamic shapes
|
### 🐛 Describe the bug
Greetings,
I have been trying to get `torch.compile` to work with a Mask R-CNN model, but have not been able to do so in combination with gradient disabling. An error also occurs if I use `torch.inference_mode` instead of `torch.no_grad`. I've seen it mentioned that `torch.inference_mode` does not work with `torch.compile` ([here](https://github.com/pytorch/pytorch/issues/90882)), but not for gradient disabling in general. The following snippet should reproduce the error:
```python
import torch
import torchvision
device = "cuda:0"
x = torch.rand(1, 3, 800, 800, device=device)
model = torchvision.models.detection.maskrcnn_resnet50_fpn()
model = model.to(device)
model = torch.compile(model)
model.eval()
# This works
# _ = model(x)
# This does not
with torch.no_grad():
_ = model(x)
```
The output:
```
[2023-03-21 17:27:03,307] torch._inductor.utils: [WARNING] DeviceCopy in input program
[2023-03-21 17:27:03,307] torch._inductor.utils: [WARNING] DeviceCopy in input program
[2023-03-21 17:27:03,307] torch._inductor.utils: [WARNING] DeviceCopy in input program
[2023-03-21 17:27:03,307] torch._inductor.utils: [WARNING] DeviceCopy in input program
[2023-03-21 17:27:03,308] torch._inductor.utils: [WARNING] DeviceCopy in input program
/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/compile_fx.py:90: UserWarning: TensorFloat32 tensor cores for float32 matrix multiplication available but not enabled. Consider setting `torch.set_float32_matmul_precision('high')` for better performance.
warnings.warn(
[2023-03-21 17:27:06,965] torch._inductor.graph: [ERROR] Error from lowering
Traceback (most recent call last):
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/graph.py", line 333, in call_function
out = lowerings[target](*args, **kwargs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 225, in wrapped
out = decomp_fn(*args, **kwargs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 1431, in convolution
ir.Convolution.create(
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/ir.py", line 3244, in create
return Convolution(
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/ir.py", line 3088, in __init__
super().__init__(layout, inputs, constant_args)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/ir.py", line 2827, in __init__
super().__init__(None, layout, self.unwrap_storage(inputs), constant_args)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/ir.py", line 2378, in unwrap_storage
assert isinstance(x, (Buffer, ReinterpretView)), x
AssertionError: Pointwise(
'cuda',
torch.float32,
tmp0 = load(buf0, i3 + 14 * i2 + 196 * i1 + 50176 * i0)
tmp1 = load(arg1_1, i1)
tmp2 = tmp0 + tmp1
tmp3 = relu(tmp2)
return tmp3
,
ranges=[0, 256, 14, 14],
origins={arg0_1, relu, convolution, arg1_1, arg12_1}
)
Traceback (most recent call last):
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/graph.py", line 333, in call_function
out = lowerings[target](*args, **kwargs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 225, in wrapped
out = decomp_fn(*args, **kwargs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 1431, in convolution
ir.Convolution.create(
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/ir.py", line 3244, in create
return Convolution(
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/ir.py", line 3088, in __init__
super().__init__(layout, inputs, constant_args)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/ir.py", line 2827, in __init__
super().__init__(None, layout, self.unwrap_storage(inputs), constant_args)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/ir.py", line 2378, in unwrap_storage
assert isinstance(x, (Buffer, ReinterpretView)), x
AssertionError: Pointwise(
'cuda',
torch.float32,
tmp0 = load(buf0, i3 + 14 * i2 + 196 * i1 + 50176 * i0)
tmp1 = load(arg1_1, i1)
tmp2 = tmp0 + tmp1
tmp3 = relu(tmp2)
return tmp3
,
ranges=[0, 256, 14, 14],
origins={arg0_1, relu, convolution, arg1_1, arg12_1}
)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/output_graph.py", line 670, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/debug_utils.py", line 1055, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/__init__.py", line 1390, in __call__
return compile_fx(model_, inputs_, config_patches=self.config)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/compile_fx.py", line 455, in compile_fx
return aot_autograd(
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/backends/common.py", line 48, in compiler_fn
cg = aot_module_simplified(gm, example_inputs, **kwargs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 2805, in aot_module_simplified
compiled_fn = create_aot_dispatcher_function(
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 2498, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_args, aot_config)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 1713, in aot_wrapper_dedupe
return compiler_fn(flat_fn, leaf_flat_args, aot_config)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_functorch/aot_autograd.py", line 1326, in aot_dispatch_base
compiled_fw = aot_config.fw_compiler(fw_module, flat_args_with_views_handled)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/compile_fx.py", line 430, in fw_compiler
return inner_compile(
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/debug_utils.py", line 595, in debug_wrapper
compiled_fn = compiler_fn(gm, example_inputs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/debug.py", line 239, in inner
return fn(*args, **kwargs)
File "/usr/lib/python3.8/contextlib.py", line 75, in inner
return func(*args, **kwds)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/compile_fx.py", line 176, in compile_fx_inner
graph.run(*example_inputs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/graph.py", line 194, in run
return super().run(*args)
File "/tmp/a/env/lib/python3.8/site-packages/torch/fx/interpreter.py", line 136, in run
self.env[node] = self.run_node(node)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/graph.py", line 405, in run_node
result = self.call_function(n.target, args, kwargs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_inductor/graph.py", line 337, in call_function
raise LoweringException(e, target, args, kwargs) from e
torch._inductor.exc.LoweringException: AssertionError: Pointwise(
'cuda',
torch.float32,
tmp0 = load(buf0, i3 + 14 * i2 + 196 * i1 + 50176 * i0)
tmp1 = load(arg1_1, i1)
tmp2 = tmp0 + tmp1
tmp3 = relu(tmp2)
return tmp3
,
ranges=[0, 256, 14, 14],
origins={arg0_1, relu, convolution, arg1_1, arg12_1}
)
target: aten.convolution.default
args[0]: TensorBox(StorageBox(
Pointwise(
'cuda',
torch.float32,
tmp0 = load(buf0, i3 + 14 * i2 + 196 * i1 + 50176 * i0)
tmp1 = load(arg1_1, i1)
tmp2 = tmp0 + tmp1
tmp3 = relu(tmp2)
return tmp3
,
ranges=[0, 256, 14, 14],
origins={arg0_1, relu, convolution, arg1_1, arg12_1}
)
))
args[1]: TensorBox(StorageBox(
InputBuffer(name='arg2_1', layout=FixedLayout('cuda', torch.float32, size=[256, 256, 3, 3], stride=[2304, 9, 3, 1]))
))
args[2]: TensorBox(StorageBox(
InputBuffer(name='arg3_1', layout=FixedLayout('cuda', torch.float32, size=[256], stride=[1]))
))
args[3]: [1, 1]
args[4]: [1, 1]
args[5]: [1, 1]
args[6]: False
args[7]: [0, 0]
args[8]: 1
While executing %convolution_1 : [#users=1] = call_function[target=torch.ops.aten.convolution.default](args = (%relu, %arg2_1, %arg3_1, [1, 1], [1, 1], [1, 1], False, [0, 0], 1), kwargs = {})
Original traceback:
File "/tmp/a/env/lib/python3.8/site-packages/torchvision/models/detection/roi_heads.py", line 804, in <graph break in forward>
mask_features = self.mask_roi_pool(features, mask_proposals, image_shapes)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "nograd_compile_example.py", line 18, in <module>
_ = model(x)
File "/tmp/a/env/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 82, in forward
return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/tmp/a/env/lib/python3.8/site-packages/torchvision/models/detection/generalized_rcnn.py", line 83, in forward
images, targets = self.transform(images, targets)
File "/tmp/a/env/lib/python3.8/site-packages/torchvision/models/detection/generalized_rcnn.py", line 101, in <graph break in forward>
features = self.backbone(images.tensors)
File "/tmp/a/env/lib/python3.8/site-packages/torchvision/models/detection/generalized_rcnn.py", line 104, in <graph break in forward>
proposals, proposal_losses = self.rpn(images, features, targets)
File "/tmp/a/env/lib/python3.8/site-packages/torchvision/models/detection/generalized_rcnn.py", line 105, in <graph break in forward>
detections, detector_losses = self.roi_heads(features, proposals, images.image_sizes, targets)
File "/tmp/a/env/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/tmp/a/env/lib/python3.8/site-packages/torchvision/models/detection/roi_heads.py", line 761, in forward
box_features = self.box_roi_pool(features, proposals, image_shapes)
File "/tmp/a/env/lib/python3.8/site-packages/torchvision/models/detection/roi_heads.py", line 775, in <graph break in forward>
boxes, scores, labels = self.postprocess_detections(class_logits, box_regression, proposals, image_shapes)
File "/tmp/a/env/lib/python3.8/site-packages/torchvision/models/detection/roi_heads.py", line 804, in <graph break in forward>
mask_features = self.mask_roi_pool(features, mask_proposals, image_shapes)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 337, in catch_errors
return callback(frame, cache_size, hooks)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 404, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 104, in _fn
return fn(*args, **kwargs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 262, in _convert_frame_assert
return _compile(
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 324, in _compile
out_code = transform_code_object(code, transform)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/bytecode_transformation.py", line 445, in transform_code_object
transformations(instructions, code_options)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 311, in transform
tracer.run()
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 1726, in run
super().run()
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 576, in run
and self.step()
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 540, in step
getattr(self, inst.opname)(inst)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 1792, in RETURN_VALUE
self.output.compile_subgraph(
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/output_graph.py", line 541, in compile_subgraph
self.compile_and_call_fx_graph(tx, pass2.graph_output_vars(), root)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/output_graph.py", line 588, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/tmp/a/env/lib/python3.8/site-packages/torch/_dynamo/output_graph.py", line 675, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: debug_wrapper raised LoweringException: AssertionError: Pointwise(
'cuda',
torch.float32,
tmp0 = load(buf0, i3 + 14 * i2 + 196 * i1 + 50176 * i0)
tmp1 = load(arg1_1, i1)
tmp2 = tmp0 + tmp1
tmp3 = relu(tmp2)
return tmp3
,
ranges=[0, 256, 14, 14],
origins={arg0_1, relu, convolution, arg1_1, arg12_1}
)
target: aten.convolution.default
args[0]: TensorBox(StorageBox(
Pointwise(
'cuda',
torch.float32,
tmp0 = load(buf0, i3 + 14 * i2 + 196 * i1 + 50176 * i0)
tmp1 = load(arg1_1, i1)
tmp2 = tmp0 + tmp1
tmp3 = relu(tmp2)
return tmp3
,
ranges=[0, 256, 14, 14],
origins={arg0_1, relu, convolution, arg1_1, arg12_1}
)
))
args[1]: TensorBox(StorageBox(
InputBuffer(name='arg2_1', layout=FixedLayout('cuda', torch.float32, size=[256, 256, 3, 3], stride=[2304, 9, 3, 1]))
))
args[2]: TensorBox(StorageBox(
InputBuffer(name='arg3_1', layout=FixedLayout('cuda', torch.float32, size=[256], stride=[1]))
))
args[3]: [1, 1]
args[4]: [1, 1]
args[5]: [1, 1]
args[6]: False
args[7]: [0, 0]
args[8]: 1
While executing %convolution_1 : [#users=1] = call_function[target=torch.ops.aten.convolution.default](args = (%relu, %arg2_1, %arg3_1, [1, 1], [1, 1], [1, 1], False, [0, 0], 1), kwargs = {})
Original traceback:
File "/tmp/a/env/lib/python3.8/site-packages/torchvision/models/detection/roi_heads.py", line 804, in <graph break in forward>
mask_features = self.mask_roi_pool(features, mask_proposals, image_shapes)
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
I've tried the same test using a different model (`torchvision.models.resnet50`), and in
this case the error does not happen. So it could perhaps be specific to the Mask R-CNN
model.
### Versions
```
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.6 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.26.0
Libc version: glibc-2.31
Python version: 3.8.10 (default, Mar 13 2023, 10:26:41) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-67-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3060 Laptop GPU
Nvidia driver version: 525.85.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 20
On-line CPU(s) list: 0-19
Thread(s) per core: 1
Core(s) per socket: 14
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 154
Model name: 12th Gen Intel(R) Core(TM) i7-12700H
Stepping: 3
CPU MHz: 2700.000
CPU max MHz: 4700,0000
CPU min MHz: 400,0000
BogoMIPS: 5376.00
Virtualization: VT-x
L1d cache: 336 KiB
L1i cache: 224 KiB
L2 cache: 8,8 MiB
NUMA node0 CPU(s): 0-19
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid rdseed adx smap clflushopt clwb intel_pt sha_ni xsaveopt xsavec xgetbv1 xsaves split_lock_detect avx_vnni dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp hwp_pkg_req umip pku ospke waitpkg gfni vaes vpclmulqdq rdpid movdiri movdir64b fsrm md_clear serialize arch_lbr flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] pytorch-lightning==1.9.4
[pip3] torch==2.0.0
[pip3] torchmetrics==0.11.3
[pip3] torchvision==0.15.1
[conda] numpy 1.24.2 pypi_0 pypi
[conda] pytorch-lightning 1.9.3 pypi_0 pypi
[conda] torch 1.13.1 pypi_0 pypi
[conda] torchmetrics 0.11.3 pypi_0 pypi
[conda] torchvision 0.14.1 pypi_0 pypi
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 4 |
3,137 | 97,310 |
MPS: `unique` and `unique_consecutive` extremely slow when `return_counts=True`
|
module: performance, triaged, module: mps
|
### 🐛 Describe the bug
There appears to be a severe performance issue with `unique` and `unique_consecutive` when `return_counts=True` and the device is mps. I performed the following test:
```
import timeit
import torch
t = torch.randint(10, size=(100000,), device='mps')
t = t[t.argsort()]
t_cpu = t.cpu()
number = 10
print(timeit.timeit('t.unique()', globals=globals(), number=number))
print(timeit.timeit('t.unique(return_inverse=True)', globals=globals(), number=number))
print(timeit.timeit('t.unique(return_counts=True)', globals=globals(), number=number))
print(timeit.timeit('t_cpu.unique()', globals=globals(), number=number))
print(timeit.timeit('t_cpu.unique(return_inverse=True)', globals=globals(), number=number))
print(timeit.timeit('t_cpu.unique(return_counts=True)', globals=globals(), number=number))
print()
print(timeit.timeit('t.unique_consecutive()', globals=globals(), number=number))
print(timeit.timeit('t.unique_consecutive(return_inverse=True)', globals=globals(), number=number))
print(timeit.timeit('t.unique_consecutive(return_counts=True)', globals=globals(), number=number))
print(timeit.timeit('t_cpu.unique_consecutive()', globals=globals(), number=number))
print(timeit.timeit('t_cpu.unique_consecutive(return_inverse=True)', globals=globals(), number=number))
print(timeit.timeit('t_cpu.unique_consecutive(return_counts=True)', globals=globals(), number=number))
```
Output:
```
0.026759792000000004
0.035945208000000006
2.092266542
0.0016070839999997588
0.004217375000000079
0.006821041999999888
0.009870165999999791
0.010194499999999884
2.0578671660000003
0.0006946670000003152
0.0007299169999992472
0.0006608329999995277
```
As you can see, `unique` and `unique_consecutive` with `return_counts=True` on mps is around 100x slower. This gets even worse (can be 1000-10000x slower) if I increase the number of elements.
### Versions
Collecting environment information...
PyTorch version: 2.1.0.dev20230320
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.2.1 (arm64)
GCC version: Could not collect
Clang version: 12.0.0 (clang-1200.0.32.28)
CMake version: version 3.26.0
Libc version: N/A
Python version: 3.9.16 | packaged by conda-forge | (main, Feb 1 2023, 21:38:11) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-13.2.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M1 Pro
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.1.0.dev20230320
[conda] numpy 1.24.2 pypi_0 pypi
[conda] torch 2.1.0.dev20230320 pypi_0 pypi
cc @ngimel @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 1 |
3,138 | 97,295 |
Torch Dynamo allow_in_graph doesn't capture the custom function in graph
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
I tried running the following example to try out the torch dynamo allow_in_graph option, expecting a graph that contains 'my_custom_function' instead of torch.add operator, however, the graph returned by `make_fx` resolves to torch operator as shown in (2)
1. Example run:
```python
def my_custom_function(x):
return x + 1
def test_allow_in_graph():
torch._dynamo.allow_in_graph(my_custom_function)
@torch._dynamo.optimize("aot_eager")
def fn(a):
x = torch.add(a, 1)
x = torch.add(x, 1)
x = my_custom_function(x)
x = torch.add(x, 1)
x = torch.add(x, 1)
return x
fn(torch.randn(10))
```
2. Graph obtained from pdb session contains the torch operator instead of my_custom_function
```
-> return t
(Pdb) p t.print_readable()
class <lambda>(torch.nn.Module):
def forward(self, arg0_1: f32[10]):
add: f32[10] = torch.ops.aten.add.Tensor(arg0_1, 1); arg0_1 = None
add_1: f32[10] = torch.ops.aten.add.Tensor(add, 1); add = None
add_2: f32[10] = torch.ops.aten.add.Tensor(add_1, 1); add_1 = None
add_3: f32[10] = torch.ops.aten.add.Tensor(add_2, 1); add_2 = None
add_4: f32[10] = torch.ops.aten.add.Tensor(add_3, 1); add_3 = None
return (add_4,)
'class <lambda>(torch.nn.Module):\n def forward(self, arg0_1: f32[10]):\n
add: f32[10] = torch.ops.aten.add.Tensor(arg0_1, 1); arg0_1 = None\n \n
add_1: f32[10] = torch.ops.aten.add.Tensor(add, 1); add = None\n \n
add_2: f32[10] = torch.ops.aten.add.Tensor(add_1, 1); add_1 = None\n \n
add_3: f32[10] = torch.ops.aten.add.Tensor(add_2, 1); add_2 = None\n \n
add_4: f32[10] = torch.ops.aten.add.Tensor(add_3, 1); add_3 = None\n
return (add_4,)\n '
### Versions
python collect_env.py
Collecting environment information...
PyTorch version: 2.1.0.dev20230310+cpu
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.25.1
Libc version: glibc-2.31
Python version: 3.8.10 (default, Mar 13 2023, 10:26:41) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-53-generic-x86_64-with-glibc2.29
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 12
On-line CPU(s) list: 0-11
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) W-2235 CPU @ 3.80GHz
Stepping: 7
CPU MHz: 3800.000
CPU max MHz: 4600.0000
CPU min MHz: 1200.0000
BogoMIPS: 7599.80
Virtualization: VT-x
L1d cache: 192 KiB
L1i cache: 192 KiB
L2 cache: 6 MiB
L3 cache: 8.3 MiB
NUMA node0 CPU(s): 0-11
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.1.0.dev20230310+cpu
[pip3] torchvision==0.15.0.dev20230310+cpu
[conda] Could not collect
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 18 |
3,139 | 97,286 |
`jacrev` and `jacfwd` raise an error that `Sparse CSR tensors do not have strides`
|
module: sparse, triaged, module: functorch
|
### 🐛 Describe the bug
`jacrev` and `jacfwd` raise an error that `Sparse CSR tensors do not have strides` but the direct invocation will succeed
```py
import torch
from torch.func import jacrev, jacfwd
values = torch.tensor([1., 2., 3., 1., 2., 3., 4., 1., 2.])
def func(values):
crow_indices = [0, 3, 7, 9]
col_indices = torch.tensor([0, 1, 2, 0, 1, 2, 3, 0, 1])
size = (3, 4)
torch.sparse_csr_tensor(crow_indices,col_indices,values,size).to_dense()
crow_indices = torch.tensor(crow_indices)
return crow_indices
jacrev(func)(values)
# RuntimeError: Sparse CSR tensors do not have strides
```
### Versions
```
Collecting environment information...
PyTorch version: 2.1.0.dev20230311+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 14.0.0-1ubuntu1
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.9.16 (main, Mar 8 2023, 14:00:05) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 525.78.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Vendor ID: AuthenticAMD
Model name: AMD Ryzen Threadripper PRO 5975WX 32-Cores
CPU family: 25
Model: 8
Thread(s) per core: 2
Core(s) per socket: 32
Socket(s): 1
Stepping: 2
Frequency boost: enabled
CPU max MHz: 7006.6401
CPU min MHz: 1800.0000
BogoMIPS: 7186.68
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 invpcid_single hw_pstate ssbd mba ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr rdpru wbnoinvd amd_ppin arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif v_spec_ctrl umip pku ospke vaes vpclmulqdq rdpid overflow_recov succor smca fsrm
Virtualization: AMD-V
L1d cache: 1 MiB (32 instances)
L1i cache: 1 MiB (32 instances)
L2 cache: 16 MiB (32 instances)
L3 cache: 128 MiB (4 instances)
NUMA node(s): 1
NUMA node0 CPU(s): 0-63
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP always-on, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.1.0+2c32f43999
[pip3] torch==2.1.0.dev20230311+cu117
[pip3] torchaudio==2.0.0.dev20230311+cu117
[pip3] torchvision==0.15.0.dev20230311+cu117
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-triton 2.1.0+2c32f43999 pypi_0 pypi
[conda] torch 2.1.0.dev20230311+cu117 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230311+cu117 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230311+cu117 pypi_0 pypi
```
cc @alexsamardzic @nikitaved @pearu @cpuhrsch @amjames @bhosmer @zou3519 @Chillee @samdow @soumith @kshitij12345 @janeyx99
| 0 |
3,140 | 97,284 |
test_sparse_addmm fails on linux-bionic-py3.11-clang9 / test (crossref, 1, 2, linux.2xlarge)
|
module: sparse, module: autograd, triaged, module: decompositions
|
## Issue description
As in the title.
## Code example
A copy of the failure from https://github.com/pytorch/pytorch/actions/runs/4479543973/jobs/7874005200:
```
test_sparse.py::TestSparseCPU::test_sparse_addmm_masked_cpu_complex128 RERUN [ 58%]
test_sparse.py::TestSparseCPU::test_sparse_addmm_masked_cpu_complex128 RERUN [ 58%]
test_sparse.py::TestSparseCPU::test_sparse_addmm_masked_cpu_complex128 FAILED [ 58%]
==================================== RERUNS ====================================
____________ TestSparseCPU.test_sparse_addmm_masked_cpu_complex128 _____________
Traceback (most recent call last):
File "test_sparse.py", line 1613, in test_sparse_addmm
test_shape(7, 8, 9, 20, False, None)
File "test_sparse.py", line 1611, in test_shape
gradcheck(fn, (S, D1, D2))
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/testing/_internal/common_utils.py", line 3859, in gradcheck
return torch.autograd.gradcheck(fn, inputs, **kwargs)
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/autograd/gradcheck.py", line 1553, in gradcheck
return _gradcheck_helper(**args)
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/autograd/gradcheck.py", line 1567, in _gradcheck_helper
_gradcheck_real_imag(gradcheck_fn, func, func_out, tupled_inputs, outputs, eps,
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/autograd/gradcheck.py", line 1155, in _gradcheck_real_imag
gradcheck_fn(imag_fn, imag_func_out, tupled_inputs, imag_outputs, eps,
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/autograd/gradcheck.py", line 1402, in _fast_gradcheck
all_v, all_u, all_u_dense = _make_vectors(inp_tensors, outputs, use_forward_ad=use_forward_ad)
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/autograd/gradcheck.py", line 1360, in _make_vectors
ur = _vec_from_tensor(inp, g_cpu, True)
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/autograd/gradcheck.py", line 1257, in _vec_from_tensor
values = torch.rand(x_values.numel(), generator=generator) \
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/testing/_internal/common_utils.py", line 982, in __torch_function__
r = func(*args, **kwargs)
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/_subclasses/fake_utils.py", line 87, in __torch_dispatch__
fake_r = func(*fake_args, **fake_kwargs)
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/_ops.py", line 330, in __call__
return self._op(*args, **kwargs or {})
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/utils/_stats.py", line 20, in wrapper
return fn(*args, **kwargs)
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/_subclasses/fake_tensor.py", line 1057, in __torch_dispatch__
return self.dispatch(func, types, args, kwargs)
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/_subclasses/fake_tensor.py", line 1232, in dispatch
op_impl_out = op_impl(self, func, *args, **kwargs)
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/_subclasses/fake_tensor.py", line 362, in constructors
r = func(*args, **new_kwargs)
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/_ops.py", line 330, in __call__
return self._op(*args, **kwargs or {})
File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/_decomp/decompositions.py", line 1998, in uniform_
assert generator is None
AssertionError
```
## Temporary resolution
https://github.com/pytorch/pytorch/pull/97187 disables the test via `@unittest.skipIf(TEST_WITH_CROSSREF, "generator unsupport triggers assertion error")` decorator.
Previously, the test was skipped with a reference to https://github.com/pytorch/pytorch/issues/73145 .
## System Info
- PyTorch version: master
cc @alexsamardzic @nikitaved @cpuhrsch @amjames @bhosmer @ezyang @albanD @zou3519 @gqchen @soulitzer @Lezcano @Varal7 @SherlockNoMad @ngimel
| 0 |
3,141 | 97,283 |
`jacfwd` fails when computing the gradient for `channels_last` tensor
|
triaged, module: memory format, module: functorch
|
### 🐛 Describe the bug
`jacfwd` fails when computing the gradient for `channels_last` tensor but `jacrev` succeeds without any error
```py
import torch
from torch.func import jacrev, jacfwd
input = torch.randn(1, 2, 3, 4).to(memory_format=torch.channels_last)
def func(input):
input = input.reshape([1, 2, 3, 4])
input = input.to(memory_format=torch.channels_last)
return input
test_inputs = [input]
print(jacrev(func)(input))
# succeed
print(jacfwd(func)(input))
# RuntimeError: required rank 4 tensor to use channels_last format
```
`jacfwd` raises an error that "required rank 4 tensor to use channels_last format"
### Versions
```
Collecting environment information...
PyTorch version: 2.1.0.dev20230311+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 14.0.0-1ubuntu1
CMake version: version 3.25.0
Libc version: glibc-2.35
Python version: 3.9.16 (main, Mar 8 2023, 14:00:05) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-58-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 525.78.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Vendor ID: AuthenticAMD
Model name: AMD Ryzen Threadripper PRO 5975WX 32-Cores
CPU family: 25
Model: 8
Thread(s) per core: 2
Core(s) per socket: 32
Socket(s): 1
Stepping: 2
Frequency boost: enabled
CPU max MHz: 7006.6401
CPU min MHz: 1800.0000
BogoMIPS: 7186.68
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 invpcid_single hw_pstate ssbd mba ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr rdpru wbnoinvd amd_ppin arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif v_spec_ctrl umip pku ospke vaes vpclmulqdq rdpid overflow_recov succor smca fsrm
Virtualization: AMD-V
L1d cache: 1 MiB (32 instances)
L1i cache: 1 MiB (32 instances)
L2 cache: 16 MiB (32 instances)
L3 cache: 128 MiB (4 instances)
NUMA node(s): 1
NUMA node0 CPU(s): 0-63
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP always-on, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.1.0+2c32f43999
[pip3] torch==2.1.0.dev20230311+cu117
[pip3] torchaudio==2.0.0.dev20230311+cu117
[pip3] torchvision==0.15.0.dev20230311+cu117
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-triton 2.1.0+2c32f43999 pypi_0 pypi
[conda] torch 2.1.0.dev20230311+cu117 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230311+cu117 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230311+cu117 pypi_0 pypi
```
cc @jamesr66a @zou3519 @Chillee @samdow @soumith @kshitij12345 @janeyx99
| 0 |
3,142 | 97,271 |
[composable FSDP] clip_grad_norm
|
oncall: distributed, triaged, module: fsdp
|
### 🚀 The feature, motivation and pitch
FSDP clip_grad_norm should work with composable API: https://github.com/pytorch/pytorch/blob/master/torch/distributed/fsdp/fully_sharded_data_parallel.py#L962
### Alternatives
_No response_
### Additional context
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
3,143 | 97,268 |
Desync debugger encounters traceMap error
|
oncall: distributed, triaged, module: c10d, bug
|
### 🐛 Describe the bug
An internal user reported the following stack trace:
```
[ProcessGroupNCCL.cpp:847] [Rank 58] NCCL watchdog thread terminated with exception: traceMap[thisSeq][myRank].second == kEventStart INTERNAL ASSERT FAILED at "torch/csrc/distributed/c10d/TraceUtils.h":244, please report a bug to PyTorch. Timeout rank [58] last trace item must be kEventStart. thisSeq = 463038, col = ALLREDUCE
Exception raised from retrieveDesyncReport at torch/csrc/distributed/c10d/TraceUtils.h:244 (most recent call first):
# 2 c10::detail::torchCheckFail(char const*, char const*, unsigned int, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)
# 3 c10::detail::torchInternalAssertFail(char const*, char const*, unsigned int, char const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)
# 4 c10d::retrieveDesyncReport(c10::intrusive_ptr<c10d::Store, c10::detail::intrusive_target_default_null_type<c10d::Store> >&, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, int, int)
# 5 c10d::ProcessGroupNCCL::abortTimedOutCollectives(std::unordered_set<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >&)
# 6 c10d::ProcessGroupNCCL::ncclCommWatchdogInternal()
# 7 c10d::ProcessGroupNCCL::ncclCommWatchdog()
# 8 execute_native_thread_routine
# 9 start_thread
# 10 __clone3
```
It seems that the desync debugger missed to log the start of a collective, and hence when logging the completion it failed to find a match.
### Versions
master as of today
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @awgu
| 0 |
3,144 | 97,256 |
DISABLED test_vmapjvpvjp_linalg_svd_cuda_float32 (__main__.TestOperatorsCUDA)
|
triaged, skipped, module: functorch
|
Platforms: rocm
This test was disabled because it is failing on master ([recent examples](http://torch-ci.com/failure/functorch%2Ftest_ops.py%3A%3ATestOperatorsCUDA%3A%3Atest_vmapjvpvjp_linalg_svd_cuda_float32)).
Functorch test has recently been integrated into PyTorch default test suite, and this test starts to become flaky on ROCm
cc @zou3519 @Chillee @samdow @soumith @kshitij12345 @janeyx99
| 1 |
3,145 | 97,246 |
functorch roll-up issue for 2.1
|
triaged, module: functorch
|
P0 Critical (silent incorrectness, crashes)
- [x] https://github.com/pytorch/pytorch/issues/97161
- [x] https://github.com/pytorch/pytorch/issues/96887
- [x] https://github.com/pytorch/pytorch/issues/96854
P0 Interaction with PT2
- [ ] needs better error messages: https://github.com/pytorch/pytorch/issues/96041
UX
- [ ] Better error message for https://github.com/pytorch/pytorch/issues/94397
- [ ] https://github.com/pytorch/pytorch/issues/97248 (large)
Coverage
- [x] https://github.com/pytorch/pytorch/issues/95561
- [ ] https://github.com/pytorch/pytorch/issues/96855
- [x] https://github.com/pytorch/pytorch/issues/95888
- [x] https://github.com/pytorch/pytorch/issues/95738
- [x] https://github.com/pytorch/pytorch/issues/95057
- [x] https://github.com/pytorch/pytorch/issues/94630
- [x] https://github.com/pytorch/pytorch/issues/97558
- [x] https://github.com/pytorch/pytorch/issues/99187
| 0 |
3,146 | 97,241 |
Inductor "Original ATen:" doesn't work for backwards kernels
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
Example output:
```
# kernel path: /tmp/torchinductor_ezyang/rw/crwlqodm5jav743txhbrnyh5enri7mh6arxwt577cpal2zclclph.py
# Original ATen:·
triton_fused_8 = async_compile.triton('''
import triton
import triton.language as tl
from torch._inductor.ir import ReductionHint
from torch._inductor.ir import TileHint
from torch._inductor.triton_ops.autotune import reduction
from torch._inductor.utils import instance_descriptor
@reduction(
size_hints=[32, 65536],
reduction_hint=ReductionHint.DEFAULT,
filename=__file__,
meta={'signature': {0: '*fp32', 1: '*fp32', 2: 'i32', 3: 'i32', 4: 'i32', 5: 'i32', 6: 'i32'}, 'device': 0, 'constants': {}, 'mutated_arg_names': [], 'configs': [instance_descriptor(divisible_by_16=(0, 1, 3, 5, 6), equal_to_1=())]}
)
@triton.jit
def triton_(in_ptr0, out_ptr0, ks0, ks1, ks2, xnumel, rnumel, XBLOCK : tl.constexpr, RBLOCK : tl.constexpr):
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:, None]
xmask = xindex < xnumel
rbase = tl.arange(0, RBLOCK)[None, :]
x0 = xindex
_tmp1 = tl.zeros([XBLOCK, RBLOCK], tl.float32) + 0
```
### Versions
master
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @Chillee
| 1 |
3,147 | 97,236 |
Non-deterministic results when training a model on GPU with MPS backend
|
triaged, module: determinism, module: mps
|
### 🐛 Describe the bug
I previously posted this on PyTorch discussion forum and I was asked to raise an issue on GitHub.
This is my code to set the seed values right after the imports:
```
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
np.random.seed(seed) # Numpy module.
random.seed(seed) # Python random module.
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
torch.use_deterministic_algorithms(True)
seed_everything(42)
```
My model definition:
```
num_labels = 3
hidden_size = 768
intermediate_size = 800
class BertEncoder(nn.Module):
def __init__(self):
super(BertEncoder, self).__init__()
self.encoder = BertModel.from_pretrained('bert-base-multilingual-uncased')
def forward(self, x, mask=None):
outputs = self.encoder(x, attention_mask=mask)
feat = outputs[0][:, 0, :]
return feat
class BertClassifier(nn.Module):
def __init__(self, dropout=0.1):
super(BertClassifier, self).__init__()
self.dropout = nn.Dropout(p=dropout)
self.classifier = nn.Linear(hidden_size, num_labels)
# self.softmax = nn.Softmax(dim=1)
#self.apply(self.init_bert_weights)
def forward(self, x):
x = self.dropout(x)
out = self.classifier(x)
# out = self.softmax(x)
return out
def init_bert_weights(self, module):
""" Initialize the weights.
"""
if isinstance(module, (nn.Linear, nn.Embedding)):
module.weight.data.normal_(mean=0.0, std=0.02)
if isinstance(module, nn.Linear) and module.bias is not None:
module.bias.data.zero_()
src_encoder = BertEncoder()
src_classifier = BertClassifier()
src_encoder = src_encoder.to(device)
src_classifier = src_classifier.to(device)
```
I'm training the model using GPU on an MPS device. I have also set num_workers = 0 in the training and validation dataloaders. Despite all of this, the results are not reproducible.
My training output on the 1st run:
```
Epoch: 0/3
Epoch [00/03] Step [000/127]: cls_loss=1.0705
Epoch [00/03] Step [005/127]: cls_loss=0.9886
Epoch [00/03] Step [010/127]: cls_loss=0.8697
Epoch [00/03] Step [015/127]: cls_loss=1.1442
Epoch [00/03] Step [020/127]: cls_loss=0.9821
Epoch [00/03] Step [025/127]: cls_loss=0.8301
Epoch [00/03] Step [030/127]: cls_loss=0.9174
Epoch [00/03] Step [035/127]: cls_loss=0.8881
Epoch [00/03] Step [040/127]: cls_loss=0.7934
Epoch [00/03] Step [045/127]: cls_loss=1.0184
Epoch [00/03] Step [050/127]: cls_loss=1.0952
Epoch [00/03] Step [055/127]: cls_loss=0.9670
Epoch [00/03] Step [060/127]: cls_loss=0.8665
Epoch [00/03] Step [065/127]: cls_loss=0.7878
Epoch [00/03] Step [070/127]: cls_loss=0.6154
Epoch [00/03] Step [075/127]: cls_loss=0.8608
Epoch [00/03] Step [080/127]: cls_loss=0.7064
Epoch [00/03] Step [085/127]: cls_loss=0.7867
Epoch [00/03] Step [090/127]: cls_loss=0.7772
Epoch [00/03] Step [095/127]: cls_loss=0.6452
Epoch [00/03] Step [100/127]: cls_loss=0.5981
Epoch [00/03] Step [105/127]: cls_loss=0.7518
Epoch [00/03] Step [110/127]: cls_loss=0.7248
Epoch [00/03] Step [115/127]: cls_loss=1.0563
Epoch [00/03] Step [120/127]: cls_loss=0.7010
Epoch [00/03] Step [125/127]: cls_loss=0.7213
At the end of Epoch: 0
Validation loss: 0.6659477949142456
Accuracy: 0.6971046770601337
F1 score (Macro): 0.6691835627250752
F1 score (Per class): [0.61 0.62931034 0.76824034]
```
And, the training output after the 2nd run:
```
Epoch: 0/3
Epoch [00/03] Step [000/127]: cls_loss=1.0752
Epoch [00/03] Step [005/127]: cls_loss=0.9756
Epoch [00/03] Step [010/127]: cls_loss=0.9635
Epoch [00/03] Step [015/127]: cls_loss=1.1132
Epoch [00/03] Step [020/127]: cls_loss=0.9640
Epoch [00/03] Step [025/127]: cls_loss=0.9263
Epoch [00/03] Step [030/127]: cls_loss=0.9199
Epoch [00/03] Step [035/127]: cls_loss=0.9258
Epoch [00/03] Step [040/127]: cls_loss=0.9136
Epoch [00/03] Step [045/127]: cls_loss=1.1773
Epoch [00/03] Step [050/127]: cls_loss=1.2147
Epoch [00/03] Step [055/127]: cls_loss=1.0307
Epoch [00/03] Step [060/127]: cls_loss=0.9063
Epoch [00/03] Step [065/127]: cls_loss=0.7165
Epoch [00/03] Step [070/127]: cls_loss=0.7686
Epoch [00/03] Step [075/127]: cls_loss=0.9018
Epoch [00/03] Step [080/127]: cls_loss=0.7115
Epoch [00/03] Step [085/127]: cls_loss=0.8505
Epoch [00/03] Step [090/127]: cls_loss=0.7284
Epoch [00/03] Step [095/127]: cls_loss=0.6582
Epoch [00/03] Step [100/127]: cls_loss=0.6921
Epoch [00/03] Step [105/127]: cls_loss=0.8489
Epoch [00/03] Step [110/127]: cls_loss=0.7658
Epoch [00/03] Step [115/127]: cls_loss=0.9741
Epoch [00/03] Step [120/127]: cls_loss=0.9331
Epoch [00/03] Step [125/127]: cls_loss=0.7483
At the end of Epoch: 0
Validation loss: 0.7412455081939697
Accuracy: 0.6859688195991092
F1 score (Macro): 0.6511615399484937
F1 score (Per class): [0.55681818 0.63934426 0.75732218]
```
As seen above, the losses and F1 scores are not equal. But, if I run this on CPU, I get completely deterministic and reproducible results. The issue therefore is with either MPS/GPU training where the data is split into multiple workers. I have also installed the latest version of PyTorch (2.0), but it still doesn't resolve the issue.
Therefore, I kindly request that you investigate this issue and provide a solution.
### Versions
Collecting environment information...
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.6 (arm64)
GCC version: Could not collect
Clang version: 12.0.5 (clang-1205.0.22.11)
CMake version: version 3.22.2
Libc version: N/A
Python version: 3.9.16 | packaged by conda-forge | (main, Feb 1 2023, 21:38:11) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-12.6-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M1
Versions of relevant libraries:
[pip3] numpy==1.23.2
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.0
[pip3] torchmetrics==0.11.4
[pip3] torchvision==0.15.0
[conda] numpy 1.23.2 py39h3668e8b_0 conda-forge
[conda] pytorch 2.0.0 py3.9_0 pytorch
[conda] torchaudio 2.0.0 py39_cpu pytorch
[conda] torchmetrics 0.11.4 pypi_0 pypi
[conda] torchvision 0.15.0 py39_cpu pytorch
@ptrblck @cpuhrsch @fmassa @razarmehr @albanD @kulinseth
cc @mruberry @kurtamohler @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 2 |
3,148 | 97,225 |
Incompatibility with complex tensors
|
triaged, module: complex, oncall: pt2
|
### 🐛 Describe the bug
I am compiling a model that involves fourier transform and inverse fourier transform of tensors, which involves complex values after the transform. I am getting the error:
[2023-03-21 15:23:29,937] torch._dynamo.convert_frame: [ERROR] WON'T CONVERT <graph break in fft2d> /mnt/c/Users/Jin Yi/Documents/ArianaPHD/research/neural_operator/FNO2D.py line 87
due to:
Traceback (most recent call last):
File "/home/jinyi12/miniconda3/envs/phasefield/lib/python3.8/site-packages/torch/_ops.py", line 287, in __call__
return self._op(*args, **kwargs or {})
RuntimeError: aten::_conj() Expected a value of type 'Tensor' for argument 'self' but instead found type 'complex'.
Position: 0
Value: -6.283185307179586j
Declaration: aten::_conj(Tensor(a) self) -> Tensor(a)
Cast error details: Unable to cast -6.283185307179586j to Tensor
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/jinyi12/miniconda3/envs/phasefield/lib/python3.8/site-packages/torch/_dynamo/output_graph.py", line 675, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: debug_wrapper raised RuntimeError: aten::_conj() Expected a value of type 'Tensor' for argument 'self' but instead found type 'complex'.
Position: 0
Value: -6.283185307179586j
Declaration: aten::_conj(Tensor(a) self) -> Tensor(a)
Cast error details: Unable to cast -6.283185307179586j to Tensor
Set torch._dynamo.config.verbose=True for more information
### Error logs
Traceback (most recent call last):
File "/home/jinyi12/miniconda3/envs/phasefield/lib/python3.8/site-packages/torch/_ops.py", line 287, in __call__
return self._op(*args, **kwargs or {})
RuntimeError: aten::_conj() Expected a value of type 'Tensor' for argument 'self' but instead found type 'complex'.
Position: 0
Value: -6.283185307179586j
Declaration: aten::_conj(Tensor(a) self) -> Tensor(a)
Cast error details: Unable to cast -6.283185307179586j to Tensor
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/jinyi12/miniconda3/envs/phasefield/lib/python3.8/site-packages/torch/_dynamo/output_graph.py", line 675, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: debug_wrapper raised RuntimeError: aten::_conj() Expected a value of type 'Tensor' for argument 'self' but instead found type 'complex'.
Position: 0
Value: -6.283185307179586j
Declaration: aten::_conj(Tensor(a) self) -> Tensor(a)
Cast error details: Unable to cast -6.283185307179586j to Tensor
Set torch._dynamo.config.verbose=True for more information
[2023-03-21 15:23:30,775] torch._dynamo.convert_frame: [ERROR] WON'T CONVERT <graph break in forward> /mnt/c/Users/Jin Yi/Documents/ArianaPHD/research/neural_operator/FNO2D.py line 45
due to:
Traceback (most recent call last):
File "/home/jinyi12/miniconda3/envs/phasefield/lib/python3.8/site-packages/torch/_functorch/partitioners.py", line 220, in _tensor_nbytes
raise NotImplementedError("Don't know the size of dtype ", dtype)
NotImplementedError: ("Don't know the size of dtype ", torch.complex64)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/jinyi12/miniconda3/envs/phasefield/lib/python3.8/site-packages/torch/_dynamo/output_graph.py", line 675, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: debug_wrapper raised NotImplementedError: ("Don't know the size of dtype ", torch.complex64)
Set torch._dynamo.config.verbose=True for more information
### Minified repro
_No response_
### Versions
Collecting environment information...
PyTorch version: 2.0.0+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.8.16 (default, Jan 17 2023, 23:13:24) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.10.16.3-microsoft-standard-WSL2-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 12.1.66
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2070 SUPER
Nvidia driver version: 516.94
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 48 bits physical, 48 bits virtual
CPU(s): 24
On-line CPU(s) list: 0-23
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 1
Vendor ID: AuthenticAMD
CPU family: 23
Model: 1
Model name: AMD Ryzen Threadripper 1920X 12-Core Processor
Stepping: 1
CPU MHz: 3493.476
BogoMIPS: 6986.95
Hypervisor vendor: Microsoft
Virtualization type: full
L1d cache: 384 KiB
L1i cache: 768 KiB
L2 cache: 6 MiB
L3 cache: 24 MiB
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Full AMD retpoline, IBPB conditional, STIBP disabled, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl tsc_reliable nonstop_tsc cpuid extd_apicid pni pclmulqdq ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm cmp_legacy cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw topoext ssbd ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero xsaveerptr virt_ssbd arat
Versions of relevant libraries:
[pip3] adabelief-pytorch==0.2.0
[pip3] mypy==1.0.0
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.24.1
[pip3] pytorch-lightning==1.6.2
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0+cu118
[pip3] torchaudio==2.0.0.dev20230201+cu116
[pip3] torchmetrics==0.8.1
[pip3] torchsummary==1.5.1
[pip3] torchvision==0.15.0.dev20230201+cu116
[pip3] triton==2.0.0
[conda] adabelief-pytorch 0.2.0 pypi_0 pypi
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-lightning 1.6.2 pypi_0 pypi
[conda] pytorch-triton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torch 2.0.0+cu118 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230201+cu116 pypi_0 pypi
[conda] torchmetrics 0.8.1 pypi_0 pypi
[conda] torchsummary 1.5.1 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230201+cu116 pypi_0 pypi
[conda] triton 2.0.0 pypi_0 pypi
cc @ezyang @anjali411 @dylanbespalko @mruberry @Lezcano @nikitaved @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
3,149 | 97,210 |
INTERNAL ASSERT FAILED at "../c10/cuda/CUDAGraphsC10Utils.h":73, please report a bug to PyTorch. Unknown CUDA graph CaptureStatus32729
|
triaged, module: cuda graphs
|
how can i solve this error please
seed_value=42
random.seed(seed_value)
np.random.seed(seed_value) <--------- error
torch.manual_seed(seed_value)
torch.cuda.manual_seed_all(seed_value)
RuntimeError: false INTERNAL ASSERT FAILED at "../c10/cuda/CUDAGraphsC10Utils.h":73, please report a bug to PyTorch. Unknown CUDA graph CaptureStatus32729
_Originally posted by @cdmssa in https://github.com/pytorch/pytorch/issues/82886#issuecomment-1476349230_
cc @mcarilli
| 6 |
3,150 | 97,201 |
aten::sym_size is not using torch._ops.OpOverload in FX graph
|
triaged, module: dynamic shapes
|
### 🐛 Describe the bug
aten::sym_size has two overloads, but none of them are used. In FX graph, OverloadPacket itself seems to be used. Not sure if this is intended, or it's a bug, but it seems to be inconsistent to other ops.
```python
import torch
from torch.fx.experimental.proxy_tensor import make_fx
class MyModule(torch.nn.Module):
def forward(self, x):
return torch.flatten(x, start_dim=2, end_dim=3)
x = torch.randn(3, 5, 4, 5)
m = make_fx(MyModule(), tracing_mode="symbolic")(x)
for node in m.graph.nodes:
if isinstance(node.target, torch._ops.OpOverloadPacket):
print(type(node.target)) # <class 'torch._ops.OpOverloadPacket'>
print(node.target.overloads()) # ['default', 'int']
```
### Versions
Versions of relevant libraries:
[pip3] mypy==0.960
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.23.1
[pip3] pytorch==2.1.0a0+git3e6bde0
[pip3] torchaudio==0.13.0.dev20220912+cpu
[pip3] torchvision==0.15.0a0+511924c
[conda] blas 1.0 mkl
[conda] cpuonly 2.0 0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-include 2022.1.0 h06a4308_224
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.1 py39h6c91a56_0
[conda] numpy-base 1.23.1 py39ha15fc14_0
[conda] pytorch 2.1.0a0+git3e6bde0 dev_0 <develop>
[conda] pytorch-mutex 1.0 cpu pytorch
[conda] torchaudio 0.13.0.dev20220912+cpu pypi_0 pypi
[conda] torchvision 0.15.0a0+511924c pypi_0 pypi
cc @ezyang @BowenBao
| 5 |
3,151 | 97,196 |
Sequential/Partial unpickling and loading of models
|
module: pickle, triaged
|
### 🚀 The feature, motivation and pitch
Given a `90GB` model file that should not be run, but rather just inspected, you might want to load it partially.
Example usage:
```py
descriptors = torch.load_tensors_desc(filename)
# at this state, the memory usage should be close to zero.
for desc in descriptors:
tensor = torch.load_tensor_from_desc(filename, desc)
# at this state, the mamory usage should be about the size of the tensor.
```
This is **not** a suggestion regarding syntax. At the moment, this is hardly possible:
- A normal `torch.load` will use about `90GB` to load the model.
- Implementing a custom `pickle.Unpickler` still wants to construct the `torch.storage`'s for all tensors, which *conceptually* should not be neccessary (also, doesn't work as some tensors may share storage)
- Reimplementing the pickle-format is tedious.
I'm not sure this is an easy patch, or if it even is possible. Please leave any suggestions in the comments.
### Alternatives
_No response_
### Additional context
_No response_
| 1 |
3,152 | 97,189 |
torch.randint range for torch.int64 dtype seems wrong
|
triaged, topic: docs, module: python frontend
|
### 🐛 Describe the bug
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.10 (x86_64)
GCC version: (Ubuntu 12.2.0-3ubuntu1) 12.2.0
Clang version: Could not collect
CMake version: version 3.24.1
Libc version: glibc-2.36
Python version: 3.10.7 (main, Mar 10 2023, 10:47:39) [GCC 12.2.0] (64-bit runtime)
Python platform: Linux-5.19.0-38-generic-x86_64-with-glibc2.36
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1060 3GB
Nvidia driver version: 515.86.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 12
On-line CPU(s) list: 0-11
Vendor ID: GenuineIntel
Model name: Intel(R) Core(TM) i7-5930K CPU @ 3.50GHz
CPU family: 6
Model: 63
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
Stepping: 2
CPU(s) scaling MHz: 56%
CPU max MHz: 3700.0000
CPU min MHz: 1200.0000
BogoMIPS: 6999.64
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm cpuid_fault invpcid_single pti intel_ppin ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm xsaveopt cqm_llc cqm_occup_llc dtherm ida arat pln pts md_clear flush_l1d
Virtualization: VT-x
L1d cache: 192 KiB (6 instances)
L1i cache: 192 KiB (6 instances)
L2 cache: 1.5 MiB (6 instances)
L3 cache: 15 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-11
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] adan-pytorch==0.1.0
[pip3] numpy==1.24.2
[pip3] numpy-stl==2.8.0
[pip3] pytorch-ranger==0.1.1
[pip3] torch==2.0.0
[pip3] torch-optimizer==0.3.0
[pip3] torchaudio==2.0.1
[pip3] torchmetrics==0.9.3
[pip3] torchsort==0.1.9
[pip3] torchvision==0.15.1
[pip3] triton==2.0.0
[conda] Could not collect
### Versions
Is there something wrong here, or have I missed something?
```
>>> torch.randint(-2**7, 2**7, (1,), dtype=torch.int8)
tensor([-4], dtype=torch.int8)
>>> torch.randint(-2**15, 2**15, (1,), dtype=torch.int16)
tensor([13361], dtype=torch.int16)
>>> torch.randint(-2**31, 2**31, (1,), dtype=torch.int32)
tensor([-26865305], dtype=torch.int32)
>>> torch.randint(-2**63, 2**63, (1,), dtype=torch.int64)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: Overflow when unpacking long
```
cc @albanD
| 5 |
3,153 | 97,188 |
Building LibTorch on Ubuntu with Mac M1
|
module: build, triaged, module: torchbind, module: m1
|
I'm running into a similar issue as [#22116](https://github.com/pytorch/pytorch/issues/22116) but for a different setup:
Hardware: MacbookPro M1
OS: Ubuntu 20.04.5 via VMware Fusion (followed this [guide](https://dev.to/daud99/installing-ubuntu-using-vmware-fusion-tech-preview-on-mac-m1-silicon-4b0e))
Followed the official documentation [here](https://pytorch.org/cppdocs/installing.html) and received the following error after running "cmake --build . --config Release":
```
bmazotti@ubuntu20045:~/Documents/spslam/example-app/build$ cmake --build . --config Release
Scanning dependencies of target example-app
[ 50%] Building CXX object CMakeFiles/example-app.dir/example-app.cpp.o
[100%] Linking CXX executable example-app
/usr/bin/ld: /home/bmazotti/Documents/spslam/libtorch/lib/libtorch.so: error adding symbols: file in wrong format
collect2: error: ld returned 1 exit status
make[2]: *** [CMakeFiles/example-app.dir/build.make:88: example-app] Error 1
make[1]: *** [CMakeFiles/Makefile2:76: CMakeFiles/example-app.dir/all] Error 2
make: *** [Makefile:84: all] Error 2
```
Any help would be greatly appreciated, thanks in advance!
### Versions
cmake version 3.16.3
cc @malfet @seemethere @kulinseth @albanD @DenisVieriu97 @razarmehr @abhudev
| 1 |
3,154 | 97,177 |
Support 0-sized batches in SyncBatchNorm cuda ops
|
triaged, open source, ciflow/trunk, release notes: nn, merging
|
Fixes #78656
~~Haven't been able to build and therefore test this locally, hence the WIP status.~~
| 18 |
3,155 | 97,175 |
warn on future reshape alias mutation violations
|
module: internals, triaged, open source, module: viewing and reshaping, topic: bc breaking, topic: deprecation, ciflow/mps, no-stale, release notes: inductor
|
warn on future reshape alias mutation violations
Summary:
Copy-on-Write Storage
=====================
Motivation
----------
PyTorch inherited from NumPy an optimization on the reshape function
that produces a view as an output if it can be represented as
such. This complicates the work of the PyTorch compilation stack
because it needs to understand the representation of the input in
order to understand if the output will be a copy or an alias.
The compilation stack would rather not be concerned with such details,
motivating the Stride Agnostic PyTorch project.
To address reshape specifically, we wish to simplify the
implementation to *always* copy, but copy lazily upon modification if
we can represent the output as a view.
Implementation plan
-------------------
We have not implemented copy-on-write tensors yet, because this is a
backward incompatible change (see Backward Incompatible section
below). But this is the design.
A copy-on-write tensor, also known as a lazily-copied tensor, is
initially going to be created by an operation like reshape which would
historically have created a view. We wish to maintain the performance
of the view but drop the aliasing aspect. Note that there is desire
for copy-on-write tensors outside of reshape, so we will likely also
want to add a public operator that can do this. It could be named
"lazy_clone" or something similar.
The core tenet of the design is that we wish to maintain the invariant
that Tensors alias if and only if they share a storage. Thus when we
create a lazy-copy, we will need to create a new storage. We also will
have to modify the source storage, since it also must now be lazily
copied.
The algorithm for creating a new copy-on-write tensor (and also
converting the source to copy-on-write) is as follows:
```
def lazy_clone(src: Tensor) -> Tensor:
# First ensure that the source has a copy-on-write enabled storage.
# We implement this using a custom context on the DataPtr. The
# source tensor might already have this enabled, but if it doesn't,
# convert it.
if not has_copy_on_write_context(src.storage().storage_impl()):
if not(wrap_with_copy_on_write_context(src.storage().storage_impl())):
# For whatever reason, we weren't able to wrap the DataPtr.
# We have to do an eager copy.
return src.clone()
new_storage = fork_copy_on_write_storage(src.storage()) # can't fail
# Now just create a new tensor using the new storage.
return new Tensor(storage=new_storage, sizes_and_strides_like=src)
```
That's the high level algorithm. The copy-on-write context that we
introduce is morally just a refcount on the underlying physical data
pointer. Each unique storage represents a set of tensors that share a
view and thus will hold a single refcount on the context.
Now we just need to intercept writes to the storage and materialize
them. We can use a few mechanisms to do this:
1) autograd knows which operators write to which tensor inputs. We can
materialize at that point when autograd is enabled.
2) if autograd is not enabled, we can introduce a new dispatch key
that does the same trick
3) we can also materialize whenever there's mutable access to the data
pointer through any of `at::Tensor`, `c10::TensorImpl`,
`c10::Storage`, `c10::StorageImpl`, or `c10::DataPtr`. With the
current codebase, this will be too aggressive, but we will refactor
to have a minimal set of mutable accesses.
Backwards incompatibiility
--------------------------
Changing reshape to produce a copy is a backwards incompatible change,
because users could be relying on the aliasing behavior, intentionally
or not.
For one release, rather than returning copy-on-write tensors, we
instead warn when users have triggered behavior in their program that
relies on the aliasing of the output and input.
To do this, we must simulate the behavior in a backward compatible
way. To remain backward compatible, the aliases must preserve the
invariant that they have the same storage. This is a big deviation
from the design detailed above. To get closer to the real design and
implementation, we introduce a new `c10::TensorImpl` level concept
called "Shadow Storage". The shadow storage represents what the
storage would have looked like the view actually been a lazy copy.
In the instrumented world we thus maintain the formal invariant that
tensors that alias share a storage. But we have a new invariant:
tensors that are lazy-copies of each other will share a shadow
storage.
So what do we warn on? We warn if there is a write to a tensor in a
set that shares a shadow storage followed by a read or a write to a
different tensor that shares a physical storage but has a different
shadow storage. In the real implementation, the first write would have
triggered a copy, forever cleaving the two sets of tensors, but in the
current world we instead had behavior that relied on the view-ness of
the output of reshape.
We can track these violations simply by adding a generation number to
the shadow and physical storages, updating them both on writes and
observing if a read or write ever encounters values that are out of
sync.
We have a few mechanisms for tracking reads and writes:
* reads can be tracked by const accesses to the data pointer
* writes can be tracked by mutable accesses to the data pointer
* writes may also be tracked via autograd, using the same mechanism
to bump version numbers
Note that we presently are only checking via autograd, since we don't
have const access to the data pointer, so we would be way too
aggressive if we assumed every access was a real write.
### Optimizations to the instrumentation
Technically, every tensor will require a shadow storage, because if we
were to create a view of a tensor and then create a lazy-copy, both
the original tensor and the view would have to share the shadow
storage, and thus it has to be created and shared before we ever even
know we needed it.
But we don't want to pay the memory cost of this since we don't expect
it to be that common. We can get around this by saving the original
shadow storage on the physical storage itself. We will have an
asymmetrical rule that states that any tensor that has a null shadow
storage will instead get its shadow storage from the physical
storage. This allows us to avoid refcount bumps on the shadow storage
as well as deferring any generation number bumps until we actually
have an outstanding copy on write.
The simulation instrumentation itself will be unnecessary to maintain
once we can transition to enabling lazy copies. This may happen after
the first that goes out which contains the instrumentation and the
user warning.
Future work
-----------
* enrich the warning by flagging reads/writes to data pointer after a
big refactoring
* analyze violations of the warning and make a decision about whether
we require any coordination about the BC change or if we should just
let the warning run its course
* implement the actual copy on write
* simplify the compiler stack to no longer concern itself with this
Test Plan: Added new tests.
---
Stack created with [Sapling](https://sapling-scm.com). Best reviewed with [ReviewStack](https://reviewstack.dev/pytorch/pytorch/pull/97175).
* #98536
* __->__ #97175
cc @ezyang @bhosmer @smessmer @ljk53 @bdhirsh
| 15 |
3,156 | 97,174 |
Nightly conda binaries failed to pass tests since 2023-03-17
|
oncall: binaries, oncall: releng, module: ci, triaged
|
### 🐛 Describe the bug
Starting from 2023-03-17, the conda binary started to fail at "Test PyTorch Binary" step .
For example: https://github.com/pytorch/pytorch/actions/runs/4445030656/jobs/7805063867#step:15:1658
It failed to find sympy "No module named 'sympy'"

As a result: https://anaconda.org/pytorch-nightly/pytorch is showing 2023-03-16 being the latest linux binary.
### Versions
Nightly from 2023-03-17 and onwards till this issue is closed.
cc @ezyang @seemethere @malfet @pytorch/pytorch-dev-infra @atalman
| 2 |
3,157 | 97,163 |
[FSDP][optim_state_dict] Need more comprehensive tests for optim_state_dict interface
|
oncall: distributed, triaged, module: fsdp
|
### 🚀 The feature, motivation and pitch
FSDP optim_state_dict has many different APIs that confuse users a lot. In a recent PR, the two new APIs have been proposed to consolidate all the use cases -- `optim_state_dict` and `optim_state_dict_to_load`. However, current unittests do not have enough coverage of the new interfaces. More test coverage is required for `state_dict_type` and `optim_state_dict` and `optim_state_dict_to_load`.
https://github.com/pytorch/pytorch/pull/97110 fixes a breakage.
https://github.com/pytorch/pytorch/pull/96534 introduce some tests but need more.
cc., @wz3
### Alternatives
_No response_
### Additional context
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
3,158 | 97,156 |
Implement `torch.distributions.Poisson.cdf()`
|
module: distributions, feature, triaged
|
### 🚀 The feature, motivation and pitch
I'm currently working with Tobit Poisson loss functions, and I'm lacking the ability to calculate the Poisson CDF. Currently the `cdf` function for the Poisson distribution isn't implemented.
### Alternatives
I've tried using scipy to do this, but this doesn't go well when calculating grads. I'm currently using a very hacky workaround, which seems unnecessary.
### Additional context
If any efficient workarounds are known, feel free to share them here :)
I'm currently using `torch.special.gammaincc(torch.floor(k+1), lambda)`
cc @fritzo @neerajprad @alicanb @nikitaved
| 0 |
3,159 | 97,155 |
Custom recurrent network takes very long to compile for long sequences
|
triaged, ezyang's list, oncall: pt2, module: python dispatcher
|
### 🐛 Describe the bug
I am currently experimenting around `torch.compile` for use with a custom, pure-Python LiGRU implementation, which is a variant of the typical GRU architecture. This is not a crash/miscompile issue but a performance bug, resulting in really long compile times (>15 minutes for 1024 sequence length as an extreme example), ~~and worsened runtime performance (worse than eager even at a 64 sequence length on an A100 40GB)~~ (that part needs double checking).
For smaller sequences, the compiled variant is typically much faster than either eager mode or `torch.jit.script` compilation.
It seems likely to me that the recurrent architecture is being fully unrolled. Is this the expected behavior (e.g. at graph construction time)? If so, what can be done to work around the issue?
Note that I have been unable to try `dynamic=True` for now, as I am encountering an error with it enabled. If you believe dynamic shape support can help with this issue, I can also look deeper into that and report back.
The recurrent architecture in the below code is implemented as a `for`-loop over the sequence length as determined from the shape of the input.
I am not very familiar with `torch.compile`'s architecture, or with GPU compilers in general. However, I am wondering if something like partial unrolling in the CPU world could be applied here.
I have attached the full real-world code including the toy benchmark I've been using, which hopefully is correct.
I assumed it would not be helpful to create a smaller repro as this is not a crash/miscompile. If I'm wrong, I could try creating a smaller repro that shows similar behavior.
**`def _ligru_cell(self, w, ht):` is the relevant function.**
### Error logs
_No response_
### Repro
```python
import logging
logging.basicConfig(
format='%(asctime)s,%(msecs)03d %(levelname)-8s [%(filename)s:%(lineno)d] %(message)s',
datefmt='%Y-%m-%d:%H:%M:%S',
level=logging.INFO
)
logging.info("importing pytorch")
import torch
import torch._dynamo as dynamo
import torch.nn as nn
import time
from torch import Tensor
from typing import Optional
class LiGRU(torch.nn.Module):
""" This function implements a Light GRU (liGRU).
LiGRU is single-gate GRU model based on batch-norm + relu
activations + recurrent dropout. For more info see:
"M. Ravanelli, P. Brakel, M. Omologo, Y. Bengio,
Light Gated Recurrent Units for Speech Recognition,
in IEEE Transactions on Emerging Topics in Computational Intelligence,
2018" (https://arxiv.org/abs/1803.10225)
This is a custm RNN and to speed it up it must be compiled with
the torch just-in-time compiler (jit) right before using it.
You can compile it with:
compiled_model = torch.jit.script(model)
It accepts in input tensors formatted as (batch, time, fea).
In the case of 4d inputs like (batch, time, fea, channel) the tensor is
flattened as (batch, time, fea*channel).
Arguments
---------
hidden_size : int
Number of output neurons (i.e, the dimensionality of the output).
values (i.e, time and frequency kernel sizes respectively).
input_shape : tuple
The shape of an example input.
nonlinearity : str
Type of nonlinearity (tanh, relu).
normalization : str
Type of normalization for the ligru model (batchnorm, layernorm).
Every string different from batchnorm and layernorm will result
in no normalization.
num_layers : int
Number of layers to employ in the RNN architecture.
bias : bool
If True, the additive bias b is adopted.
dropout : float
It is the dropout factor (must be between 0 and 1).
re_init : bool
If True, orthogonal initialization is used for the recurrent weights.
Xavier initialization is used for the input connection weights.
bidirectional : bool
If True, a bidirectional model that scans the sequence both
right-to-left and left-to-right is used.
Example
-------
>>> inp_tensor = torch.rand([4, 10, 20])
>>> net = LiGRU(input_shape=inp_tensor.shape, hidden_size=5)
>>> out_tensor, _ = net(inp_tensor)
>>>
torch.Size([4, 10, 5])
"""
def __init__(
self,
hidden_size,
input_shape,
nonlinearity="relu",
normalization="batchnorm",
num_layers=1,
bias=True,
dropout=0.0,
re_init=True,
bidirectional=False,
):
super().__init__()
self.hidden_size = hidden_size
self.nonlinearity = nonlinearity
self.num_layers = num_layers
self.normalization = normalization
self.bias = bias
self.dropout = dropout
self.re_init = re_init
self.bidirectional = bidirectional
self.reshape = False
# Computing the feature dimensionality
if len(input_shape) > 3:
self.reshape = True
self.fea_dim = float(torch.prod(torch.tensor(input_shape[2:])))
self.batch_size = input_shape[0]
self.rnn = self._init_layers()
if self.re_init:
rnn_init(self.rnn)
def _init_layers(self):
"""Initializes the layers of the liGRU."""
rnn = torch.nn.ModuleList([])
current_dim = self.fea_dim
for i in range(self.num_layers):
rnn_lay = LiGRU_Layer(
current_dim,
self.hidden_size,
self.num_layers,
self.batch_size,
dropout=self.dropout,
nonlinearity=self.nonlinearity,
normalization=self.normalization,
bidirectional=self.bidirectional,
)
rnn.append(rnn_lay)
if self.bidirectional:
current_dim = self.hidden_size * 2
else:
current_dim = self.hidden_size
return rnn
def forward(self, x, hx: Optional[Tensor] = None):
"""Returns the output of the liGRU.
Arguments
---------
x : torch.Tensor
The input tensor.
hx : torch.Tensor
Starting hidden state.
"""
# Reshaping input tensors for 4d inputs
if self.reshape:
if x.ndim == 4:
x = x.reshape(x.shape[0], x.shape[1], x.shape[2] * x.shape[3])
# run ligru
output, hh = self._forward_ligru(x, hx=hx)
return output, hh
def _forward_ligru(self, x, hx: Optional[Tensor]):
"""Returns the output of the vanilla liGRU.
Arguments
---------
x : torch.Tensor
Input tensor.
hx : torch.Tensor
"""
h = []
if hx is not None:
if self.bidirectional:
hx = hx.reshape(
self.num_layers, self.batch_size * 2, self.hidden_size
)
# Processing the different layers
for i, ligru_lay in enumerate(self.rnn):
if hx is not None:
x = ligru_lay(x, hx=hx[i])
else:
x = ligru_lay(x, hx=None)
h.append(x[:, -1, :])
h = torch.stack(h, dim=1)
if self.bidirectional:
h = h.reshape(h.shape[1] * 2, h.shape[0], self.hidden_size)
else:
h = h.transpose(0, 1)
return x, h
def chunker(seq, size):
return (seq[pos:pos + size] for pos in range(0, len(seq), size))
class LiGRU_Layer(torch.nn.Module):
""" This function implements Light-Gated Recurrent Units (ligru) layer.
Arguments
---------
input_size : int
Feature dimensionality of the input tensors.
batch_size : int
Batch size of the input tensors.
hidden_size : int
Number of output neurons.
num_layers : int
Number of layers to employ in the RNN architecture.
nonlinearity : str
Type of nonlinearity (tanh, relu).
normalization : str
Type of normalization (batchnorm, layernorm).
Every string different from batchnorm and layernorm will result
in no normalization.
dropout : float
It is the dropout factor (must be between 0 and 1).
bidirectional : bool
if True, a bidirectional model that scans the sequence both
right-to-left and left-to-right is used.
"""
def __init__(
self,
input_size,
hidden_size,
num_layers,
batch_size,
dropout=0.0,
nonlinearity="relu",
normalization="batchnorm",
bidirectional=False,
):
super(LiGRU_Layer, self).__init__()
self.hidden_size = int(hidden_size)
self.input_size = int(input_size)
self.batch_size = batch_size
self.bidirectional = bidirectional
self.dropout = dropout
self.w = nn.Linear(self.input_size, 2 * self.hidden_size, bias=False)
self.u = nn.Linear(self.hidden_size, 2 * self.hidden_size, bias=False)
if self.bidirectional:
self.batch_size = self.batch_size * 2
# Initializing batch norm
self.normalize = False
if normalization == "batchnorm":
self.norm = nn.BatchNorm1d(2 * self.hidden_size, momentum=0.05)
self.normalize = True
elif normalization == "layernorm":
self.norm = torch.nn.LayerNorm(2 * self.hidden_size)
self.normalize = True
else:
# Normalization is disabled here. self.norm is only formally
# initialized to avoid jit issues.
self.norm = torch.nn.LayerNorm(2 * self.hidden_size)
self.normalize = True
# Initial state
self.register_buffer("h_init", torch.zeros(1, self.hidden_size))
# Preloading dropout masks (gives some speed improvement)
self._init_drop(self.batch_size)
# Setting the activation function
if nonlinearity == "tanh":
self.act = torch.nn.Tanh()
elif nonlinearity == "sin":
self.act = torch.sin
elif nonlinearity == "leaky_relu":
self.act = torch.nn.LeakyReLU()
else:
self.act = torch.nn.ReLU()
def forward(self, x, hx: Optional[Tensor] = None):
# type: (Tensor, Optional[Tensor]) -> Tensor # noqa F821
"""Returns the output of the liGRU layer.
Arguments
---------
x : torch.Tensor
Input tensor.
"""
if self.bidirectional:
x_flip = x.flip(1)
x = torch.cat([x, x_flip], dim=0)
# Change batch size if needed
self._change_batch_size(x)
# Feed-forward affine transformations (all steps in parallel)
w = self.w(x)
# Apply batch normalization
if self.normalize:
w_bn = self.norm(w.reshape(w.shape[0] * w.shape[1], w.shape[2]))
w = w_bn.reshape(w.shape[0], w.shape[1], w.shape[2])
# Processing time steps
if hx is not None:
h = self._ligru_cell(w, hx)
else:
h = self._ligru_cell(w, self.h_init)
if self.bidirectional:
h_f, h_b = h.chunk(2, dim=0)
h_b = h_b.flip(1)
h = torch.cat([h_f, h_b], dim=2)
return h
def _ligru_cell(self, w, ht):
"""Returns the hidden states for each time step.
Arguments
---------
wx : torch.Tensor
Linearly transformed input.
"""
hiddens = []
# Sampling dropout mask
drop_mask = self._sample_drop_mask(w)
# Loop over time axis
for k in range(w.shape[1]):
# HACK: compile: broadcast_to is necessary for the compiler to understand
# the initial shape of ht correctly
gates = w[:, k] + self.u(ht).broadcast_to(w[:, k].shape)
at, zt = gates.chunk(2, 1)
zt = torch.sigmoid(zt)
hcand = self.act(at) * drop_mask
ht = zt * ht + (1 - zt) * hcand
hiddens.append(ht)
# Stacking hidden states
h = torch.stack(hiddens, dim=1)
return h
def _init_drop(self, batch_size):
"""Initializes the recurrent dropout operation. To speed it up,
the dropout masks are sampled in advance.
"""
self.drop = torch.nn.Dropout(p=self.dropout, inplace=False)
self.N_drop_masks = 16000
self.drop_mask_cnt = 0
self.register_buffer(
"drop_masks",
self.drop(torch.ones(self.N_drop_masks, self.hidden_size)).data,
)
self.register_buffer("drop_mask_te", torch.tensor([1.0]).float())
def _sample_drop_mask(self, w):
"""Selects one of the pre-defined dropout masks"""
if self.training:
# Sample new masks when needed
if self.drop_mask_cnt + self.batch_size > self.N_drop_masks:
self.drop_mask_cnt = 0
self.drop_masks = self.drop(
torch.ones(
self.N_drop_masks, self.hidden_size, device=w.device
)
).data
# Sampling the mask
drop_mask = self.drop_masks[
self.drop_mask_cnt : self.drop_mask_cnt + self.batch_size
]
self.drop_mask_cnt = self.drop_mask_cnt + self.batch_size
else:
# FIXME: compile: breaks fullgraph capture
# self.drop_mask_te = self.drop_mask_te.to(w.device)
drop_mask = self.drop_mask_te.to(w.device)
return drop_mask
def _change_batch_size(self, x):
"""This function changes the batch size when it is different from
the one detected in the initialization method. This might happen in
the case of multi-gpu or when we have different batch sizes in train
and test. We also update the h_int and drop masks.
"""
if self.batch_size != x.shape[0]:
self.batch_size = x.shape[0]
if self.training:
self.drop_masks = self.drop(
torch.ones(
self.N_drop_masks, self.hidden_size, device=x.device,
)
).data
def rnn_init(module):
"""This function is used to initialize the RNN weight.
Recurrent connection: orthogonal initialization.
Arguments
---------
module: torch.nn.Module
Recurrent neural network module.
Example
-------
>>> inp_tensor = torch.rand([4, 10, 20])
>>> net = RNN(hidden_size=5, input_shape=inp_tensor.shape)
>>> out_tensor = net(inp_tensor)
>>> rnn_init(net)
"""
for name, param in module.named_parameters():
if "weight_hh" in name or ".u.weight" in name:
nn.init.orthogonal_(param)
def time_it(func):
start = time.time()
ret = func()
end = time.time()
logging.info(f"... took {end - start:.2f}s")
return ret
def benchmark(func, count=100):
logging.info("running 10 dry runs for function")
for _ in range(10):
func()
torch.cuda.synchronize()
logging.info("true runs:")
start = time.time()
for _ in range(count):
torch.cuda.synchronize()
func()
torch.cuda.synchronize()
end = time.time()
spent = end - start
logging.info(f"{spent / count:.4f}s/iter for {count} total")
if __name__ == "__main__":
batch, time_steps, feats = 128, 64, 512
hidden_size, num_layer, dropout = 1024, 4, 0.0
nonlinearity = "relu" # works also with sine, leakyrelu and tanh
device = "cuda"
# torch._dynamo.config.verbose=False
# smaller_toy = torch.randn((batch, 8, feats), requires_grad=False).to(device).half()
# frozen_toy_example = dynamo.run(toy_example)
logging.info("loading model & input onto device")
torch.manual_seed(0)
inp_tensor = torch.randn((batch, time_steps, feats), requires_grad=False).to(device).half()
net = LiGRU(
input_shape=inp_tensor.shape,
hidden_size=hidden_size,
num_layers=num_layer,
dropout=dropout,
nonlinearity=nonlinearity,
).to(device).half()
net.eval()
logging.info("=== evaluating model (not compiled)")
benchmark(lambda: net(inp_tensor)[0].sum().backward())
logging.info("=== torch.jit.script (JIT)")
net = time_it(lambda: torch.jit.script(net))
logging.info("=== testing JIT model")
benchmark(lambda: net(inp_tensor)[0].sum().backward())
logging.info("=== torch.compile (torchinductor)")
net = LiGRU(
input_shape=inp_tensor.shape,
hidden_size=hidden_size,
num_layers=num_layer,
dropout=dropout,
nonlinearity=nonlinearity,
).to(device).half()
net.eval()
net = time_it(lambda: torch.compile(net, mode="reduce-overhead", fullgraph=True))
logging.info("=== testing compiled model")
benchmark(lambda: net(inp_tensor)[0].sum().backward())
```
### Versions
```
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.10.2
Libc version: glibc-2.27
Python version: 3.10.9 (main, Mar 8 2023, 10:47:38) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.4.0-73-generic-x86_64-with-glibc2.27
Is CUDA available: False
CUDA runtime version: 11.3.58
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Probably one of the following:
/usr/local/cuda-10.1/targets/x86_64-linux/lib/libcudnn.so.7.2.1
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn.so.7.2.1
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn.so.8.2.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.0
/usr/local/cuda-9.2/lib64/libcudnn.so.7.2.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 44
Model name: Intel(R) Xeon(R) CPU E5640 @ 2.67GHz
Stepping: 2
CPU MHz: 1600.237
BogoMIPS: 5334.11
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 12288K
NUMA node0 CPU(s): 0,2,4,6,8,10,12,14
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid dca sse4_1 sse4_2 popcnt aes lahf_lm pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid dtherm ida arat flush_l1d
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.0
[pip3] torchvision==0.15.0
[pip3] triton==2.0.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.5 py310hd5efca6_0
[conda] numpy-base 1.23.5 py310h8e6c178_0
[conda] pytorch 2.0.0 py3.10_cuda11.8_cudnn8.7.0_0 pytorch
[conda] pytorch-cuda 11.8 h7e8668a_3 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 2.0.0 py310_cu118 pytorch
[conda] torchtriton 2.0.0 py310 pytorch
[conda] torchvision 0.15.0 py310_cu118 pytorch
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 8 |
3,160 | 97,154 |
RPC Tutorial can not profile the rpc operations communication between workers
|
oncall: distributed, triaged, module: rpc, oncall: profiler
|
### 🐛 Describe the bug
I followed the RPC profiling tutorial [PROFILING PYTORCH RPC-BASED WORKLOADS](https://pytorch.org/tutorials/prototype/distributed_rpc_profiling.html), trying to produce a clear rpc operation process between two workers like below.
```python
# Some columns are omitted for brevity, exact output subject to randomness
---------------------------------------------------------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg Number of Calls Node ID
---------------------------------------------------------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
rpc_async#aten::add(worker0 -> worker1) 0.00% 0.000us 0 20.462ms 20.462ms 1 0
rpc_async#aten::mul(worker0 -> worker1) 0.00% 0.000us 0 5.712ms 5.712ms 1 0
rpc_async#aten::mul(worker0 -> worker1)#remote_op: mul 1.84% 206.864us 2.69% 302.162us 151.081us 2 1
rpc_async#aten::add(worker0 -> worker1)#remote_op: add 1.41% 158.501us 1.57% 176.924us 176.924us 1 1
rpc_async#aten::mul(worker0 -> worker1)#remote_op: output_nr 0.04% 4.980us 0.04% 4.980us 2.490us 2 1
rpc_async#aten::mul(worker0 -> worker1)#remote_op: is_leaf 0.07% 7.806us 0.07% 7.806us 1.952us 4 1
rpc_async#aten::add(worker0 -> worker1)#remote_op: empty 0.16% 18.423us 0.16% 18.423us 18.423us 1 1
rpc_async#aten::mul(worker0 -> worker1)#remote_op: empty 0.14% 15.712us 0.14% 15.712us 15.712us 1 1
---------------------------------------------------------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------
Self CPU time total: 11.237ms
```
## Test1: Same as the Official Code
```python
def worker(rank, world_size):
# Above code omitted...
if rank == 0:
dst_worker_rank = (rank + 1) % world_size
dst_worker_name = f"worker{dst_worker_rank}"
t1, t2 = random_tensor(), random_tensor()
# Send and wait RPC completion under profiling scope.
with profiler.profile() as prof:
fut1 = rpc.rpc_async(dst_worker_name, torch.add, args=(t1, t2))
fut2 = rpc.rpc_async(dst_worker_name, torch.mul, args=(t1, t2))
# RPCs must be awaited within profiling scope.
fut1.wait()
fut2.wait()
print(prof.key_averages().table())
```
Profiling Logs show nothing!
```bash
DEBUG:root:worker1 successfully initialized RPC.
DEBUG:root:Rank 1 waiting for workers and shutting down RPC
DEBUG:root:worker0 successfully initialized RPC.
STAGE:2023-03-20 23:10:09 58750:58750 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
[W utils.cpp:173] Warning: Profiling a distributed call with the Kineto profiler will profile the caller, but not the worker. (function operator())
STAGE:2023-03-20 23:10:09 58750:58750 ActivityProfilerController.cpp:300] Completed Stage: Collection
DEBUG:root:Rank 0 waiting for workers and shutting down RPC
DEBUG:root:Rank 1 shutdown RPC
DEBUG:root:Rank 0 shutdown RPC
```
## Test2: Add print to show fut1/fu2 values()
```python
def worker(rank, world_size):
# Above code omitted...
if rank == 0:
dst_worker_rank = (rank + 1) % world_size
dst_worker_name = f"worker{dst_worker_rank}"
t1, t2 = random_tensor(), random_tensor()
# Send and wait RPC completion under profiling scope.
with profiler.profile() as prof:
fut1 = rpc.rpc_async(dst_worker_name, torch.add, args=(t1, t2))
fut2 = rpc.rpc_async(dst_worker_name, torch.mul, args=(t1, t2))
# RPCs must be awaited within profiling scope.
fut1.wait()
fut2.wait()
# print vals
print(fut1.value())
print(fut2.value())
print(prof.key_averages().table())
```
Profiling Logs show operations but not have rpc prefix!
```bash
DEBUG:root:worker1 successfully initialized RPC.
DEBUG:root:worker0 successfully initialized RPC.
DEBUG:root:Rank 1 waiting for workers and shutting down RPC
STAGE:2023-03-20 23:11:39 60149:60149 ActivityProfilerController.cpp:294] Completed Stage: Warm Up
[W utils.cpp:173] Warning: Profiling a distributed call with the Kineto profiler will profile the caller, but not the worker. (function operator())
tensor([[0.7637, 0.8160, 1.0736],
[0.8793, 1.3461, 0.9853],
[1.2276, 0.7834, 1.1987]], requires_grad=True)
tensor([[0.1369, 0.1664, 0.2245],
[0.0073, 0.3516, 0.1521],
[0.3742, 0.1182, 0.2851]], requires_grad=True)
STAGE:2023-03-20 23:11:39 60149:60149 ActivityProfilerController.cpp:300] Completed Stage: Collection
----------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg # of Calls
----------------------------- ------------ ------------ ------------ ------------ ------------ ------------
aten::reshape 3.42% 35.000us 5.08% 52.000us 26.000us 2
aten::_reshape_alias 1.66% 17.000us 1.66% 17.000us 8.500us 2
aten::isfinite 7.91% 81.000us 30.86% 316.000us 158.000us 2
aten::abs 8.01% 82.000us 12.60% 129.000us 16.125us 8
aten::empty 1.27% 13.000us 1.27% 13.000us 1.300us 10
aten::ne 9.38% 96.000us 16.89% 173.000us 28.833us 6
aten::to 2.54% 26.000us 12.11% 124.000us 10.333us 12
aten::_to_copy 4.59% 47.000us 9.57% 98.000us 12.250us 8
aten::empty_strided 1.56% 16.000us 1.56% 16.000us 2.000us 8
aten::copy_ 3.42% 35.000us 3.42% 35.000us 4.375us 8
aten::eq 2.15% 22.000us 2.15% 22.000us 11.000us 2
aten::mul 1.46% 15.000us 1.46% 15.000us 7.500us 2
aten::__and__ 0.59% 6.000us 3.12% 32.000us 16.000us 2
aten::bitwise_and 2.54% 26.000us 2.54% 26.000us 13.000us 2
aten::masked_select 4.88% 50.000us 15.72% 161.000us 80.500us 2
aten::sum 6.93% 71.000us 10.06% 103.000us 51.500us 2
aten::as_strided 1.46% 15.000us 1.46% 15.000us 0.326us 46
aten::fill_ 0.10% 1.000us 0.10% 1.000us 0.167us 6
aten::item 3.03% 31.000us 3.42% 35.000us 1.250us 28
aten::_local_scalar_dense 0.39% 4.000us 0.39% 4.000us 0.143us 28
aten::min 3.22% 33.000us 3.61% 37.000us 18.500us 2
aten::max 2.15% 22.000us 2.25% 23.000us 11.500us 2
aten::unbind 9.96% 102.000us 16.31% 167.000us 41.750us 4
aten::select 7.71% 79.000us 8.79% 90.000us 2.143us 42
aten::ceil 3.81% 39.000us 3.81% 39.000us 19.500us 2
aten::is_nonzero 0.98% 10.000us 1.95% 20.000us 2.500us 8
aten::div 1.76% 18.000us 1.76% 18.000us 9.000us 2
aten::gt 1.76% 18.000us 1.76% 18.000us 4.500us 4
aten::lt 1.37% 14.000us 1.37% 14.000us 7.000us 2
aten::resolve_conj 0.00% 0.000us 0.00% 0.000us 0.000us 6
aten::resolve_neg 0.00% 0.000us 0.00% 0.000us 0.000us 6
----------------------------- ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 1.024ms
DEBUG:root:Rank 0 waiting for workers and shutting down RPC
DEBUG:root:Rank 1 shutdown RPC
DEBUG:root:Rank 0 shutdown RPC
```
## Conclusion
After reading `torch.autograd.profiler` and `torch.autograd.profiler_util`, I guess that the rpc profiling feature may have been discarded but the tutorial did not change.
- https://github.com/pytorch/pytorch/blob/master/torch/autograd/profiler.py#L362, kineto_event.name() doesn't have works like `rpc_async# .. (worker0 -> worker1)#remote_op: mul` as prefix or suffix
- https://github.com/pytorch/pytorch/blob/master/torch/autograd/profiler.py#L382, node_id is not passed to FunctionEvent which makes _build_table() not show Node ID column.
- https://github.com/pytorch/pytorch/blob/master/torch/autograd/profiler_util.py#L756, Only append Node ID if any event has a valid (>= 0) Node ID
I'll be appropriate for the early replay.
### Versions
Env
```bash
Collecting environment information...
PyTorch version: 1.13.1+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: CentOS Linux 8 (Core) (x86_64)
GCC version: (GCC) 8.5.0 20210514 (Red Hat 8.5.0-4)
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.28
Python version: 3.8.16 | packaged by conda-forge | (default, Feb 1 2023, 16:01:55) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-4.18.0-193.el8.jd_025.x86_64-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: 11.2.152
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: Tesla V100-PCIE-16GB
GPU 1: Tesla V100-PCIE-16GB
GPU 2: Tesla V100-PCIE-16GB
GPU 3: Tesla V100-PCIE-16GB
Nvidia driver version: 460.32.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 40
On-line CPU(s) list: 0-39
Thread(s) per core: 2
Core(s) per socket: 10
Socket(s): 2
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz
Stepping: 1
CPU MHz: 2199.998
BogoMIPS: 4399.99
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 4096K
L3 cache: 16384K
NUMA node0 CPU(s): 0-39
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl xtopology cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ibrs ibpb fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt arat
Versions of relevant libraries:
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.24.2
[pip3] torch==1.13.1+cu116
[pip3] torchvision==0.14.1+cu116
[conda] numpy 1.24.2 pypi_0 pypi
[conda] torch 1.13.1+cu116 pypi_0 pypi
[conda] torchvision 0.14.1+cu116 pypi_0 pypi
```
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu @pietern @jjlilley @mrzzd @robieta @chaekit @aaronenyeshi @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git @tiffzhaofb @dzhulgakov @davidberard98
| 3 |
3,161 | 97,146 |
Problem with Hugging Face model that is not in training loop
|
triaged, oncall: pt2, module: cpu inductor
|
### 🐛 Describe the bug
I use the hugging face transformers and the DistilBert specifically. However, torch.compile fails because of it. The code associated with the bug:
```
from typing import List, Union
import pytorch_lightning as pl
import torch.nn as nn
import os
import torch
from torch import Tensor
from torch.distributions.distribution import Distribution
import hydra
class DistilbertEncoderBase(pl.LightningModule):
def __init__(self, modelpath: str, finetune: bool = False) -> None:
super().__init__()
from transformers import AutoTokenizer, AutoModel
from transformers import logging
logging.set_verbosity_error()
# Tokenizer
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# workaround to work from cluster and local
rel_p = modelpath.split('/')
rel_p = rel_p[rel_p.index('deps'):]
rel_p = '/'.join(rel_p)
modelpath = hydra.utils.get_original_cwd() + '/' + rel_p
self.tokenizer = AutoTokenizer.from_pretrained(modelpath)
# Text model
self.text_model = AutoModel.from_pretrained(modelpath)
# Don't train the model
if not finetune:
self.text_model.training = False
# for p in self.text_model.parameters():
# p.requires_grad = False
# Then configure the model
self.text_encoded_dim = self.text_model.config.dim
self.finetune = finetune
def train(self, mode: bool = True):
self.training = mode
for module in self.children():
# Don't put the model in
if module == self.text_model and not self.finetune:
continue
module.train(mode)
return self
def get_last_hidden_state(
self,
texts: List[str],
return_mask: bool = False) -> Union[Tensor, tuple[Tensor, Tensor]]:
encoded_inputs = self.tokenizer(texts,
return_tensors="pt",
padding=True)
output = self.text_model(**encoded_inputs.to(self.text_model.device))
if not return_mask:
return output.last_hidden_state
return output.last_hidden_state, encoded_inputs.attention_mask.to(
dtype=bool)
```
### Error logs
```
[20/03/23 12:24:41][pytorch_lightning.accelerators.cuda][INFO] - LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
[20/03/23 12:24:41][pytorch_lightning.callbacks.model_summary][INFO] -
| Name | Type | Params
-------------------------------------------------------
0 | textencoder | TextSpace | 71.3 M
1 | motionencoder | ActorAgnosticEncoder | 4.8 M
2 | motiondecoder | ActorAgnosticDecoder | 6.4 M
3 | metrics | ComputeMetricsSpace | 0
4 | _losses | ModuleDict | 0
5 | _tracker | ModuleDict | 0
-------------------------------------------------------
82.4 M Trainable params
0 Non-trainable params
82.4 M Total params
329.713 Total estimated model params size (MB)
[20/03/23 12:24:41][space.callback.progress][INFO] - Training started
Epoch 0: 0%| | 0/2 [00:00<?, ?it/s]cpu cpu cpu
cpu cpu cpu
cpu cpu cpu
cpu cpu cpu
cpu cpu cpu
cpu cpu cpu
cpu cpu cpu
cpu cpu cpu
cpu cpu cpu
cpu cpu cpu
[2023-03-20 12:24:41,463] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing training_step
[2023-03-20 12:24:41,809] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing allsplit_step
[2023-03-20 12:24:41,875] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing text_to_motion_forward
[2023-03-20 12:24:41,910] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-03-20 12:24:41,922] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing get_last_hidden_state
[2023-03-20 12:24:41,928] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in get_last_hidden_state>
[2023-03-20 12:24:42,027] torch._dynamo.convert_frame: [INFO] converting frame raised unsupported, leaving it unconverted
[2023-03-20 12:24:42,028] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing <graph break in get_last_hidden_state>
[2023-03-20 12:24:42,031] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing forward
[2023-03-20 12:24:42,559] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo done tracing forward (RETURN_VALUE)
[2023-03-20 12:24:42,571] torch._dynamo.output_graph: [INFO] Step 2: calling compiler function debug_wrapper
[2023-03-20 12:24:47,327] torch._inductor.compile_fx: [INFO] Step 3: torchinductor compiling FORWARDS graph 0
/tmp/tmps69d3bg_/main.c:4:10: fatal error: Python.h: No such file or directory
4 | #include <Python.h>
| ^~~~~~~~~~
/tmp/tmpwukh8f60/main.c:4:10: fatal error: Python.h: No such file or directory
4 | #include <Python.h>
| ^~~~~~~~~~
compilation terminated.
compilation terminated.
/tmp/tmpzui1vag_/main.c:4:10: fatal error: Python.h: No such file or directory
4 | #include <Python.h>
| ^~~~~~~~~~
compilation terminated.
/tmp/tmpnscxung2/main.c:4:10: fatal error: Python.h: No such file or directory
4 | #include <Python.h>
| ^~~~~~~~~~
compilation terminated.
/tmp/tmpnj6uttbb/main.c:4:10: fatal error: Python.h: No such file or directory
4 | #include <Python.h>
| ^~~~~~~~~~
compilation terminated.
/tmp/tmp7onv3nig/main.c:4:10: fatal error: Python.h: No such file or directory
4 | #include <Python.h>
| ^~~~~~~~~~
compilation terminated.
/tmp/tmpn8c04nql/main.c:4:10: fatal error: Python.h: No such file or directory
4 | #include <Python.h>
| ^~~~~~~~~~
compilation terminated.
/tmp/tmpm_pufzho/main.c:4:10: fatal error: Python.h: No such file or directory
4 | #include <Python.h>
| ^~~~~~~~~~
compilation terminated.
/tmp/tmpxk5ft47j/main.c:4:10: fatal error: Python.h: No such file or directory
4 | #include <Python.h>
| ^~~~~~~~~~
compilation terminated.
/tmp/tmp8ofizkry/main.c:4:10: fatal error: Python.h: No such file or directory
4 | #include <Python.h>
| ^~~~~~~~~~
compilation terminated.
/tmp/tmp5n2txqua/main.c:4:10: fatal error: Python.h: No such file or directory
4 | #include <Python.h>
| ^~~~~~~~~~
compilation terminated.
/tmp/tmpva88bonr/main.c:4:10: fatal error: Python.h: No such file or directory
4 | #include <Python.h>
| ^~~~~~~~~~
compilation terminated.
Error executing job with overrides: ['run_id=draft-extract-examples', 'experiment=debug-ps018', 'devices=1', 'data.dtype=spatial_pairs+seg+seq', 'model=space_joint', 'data.synthetic=true', 'data.proportion_synthetic=0.5', 'data.random_synthetic=True', 'machine.batch_size=8', 'model.optim.lr=0.0008', 'model.losses.loss_on_vertices=true', 'data.tiny=true', 'logger=none', 'machine.num_workers=0', 'trainer.log_every_n_steps=2']
An error occurred during Hydra's exception formatting:
TypeError("print_exception() got an unexpected keyword argument 'etype'")
concurrent.futures.process._RemoteTraceback:
"""
Traceback (most recent call last):
File "/usr/lib/python3.10/concurrent/futures/process.py", line 246, in _process_worker
r = call_item.fn(*call_item.args, **call_item.kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_inductor/codecache.py", line 549, in _worker_compile
kernel.precompile(warm_cache_only_with_cc=cc)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_inductor/triton_ops/autotune.py", line 69, in precompile
self.launchers = [
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_inductor/triton_ops/autotune.py", line 70, in <listcomp>
self._precompile_config(c, warm_cache_only_with_cc)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_inductor/triton_ops/autotune.py", line 83, in _precompile_config
triton.compile(
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/triton/compiler.py", line 1587, in compile
so_path = make_stub(name, signature, constants)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/triton/compiler.py", line 1476, in make_stub
so = _build(name, src_path, tmpdir)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/triton/compiler.py", line 1391, in _build
ret = subprocess.check_call(cc_cmd)
File "/usr/lib/python3.10/subprocess.py", line 369, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['/usr/bin/gcc', '/tmp/tmp7onv3nig/main.c', '-O3', '-I/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/triton/third_party/cuda/include', '-I/usr/include/python3.10', '-I/tmp/tmp7onv3nig', '-shared', '-fPIC', '-lcuda', '-o', '/tmp/tmp7onv3nig/triton_.cpython-310-x86_64-linux-gnu.so', '-L/usr/lib/x86_64-linux-gnu']' returned non-zero exit status 1.
"""
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 670, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/debug_utils.py", line 1055, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/__init__.py", line 1390, in __call__
return compile_fx(model_, inputs_, config_patches=self.config)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_inductor/compile_fx.py", line 455, in compile_fx
return aot_autograd(
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/backends/common.py", line 48, in compiler_fn
cg = aot_module_simplified(gm, example_inputs, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 2805, in aot_module_simplified
compiled_fn = create_aot_dispatcher_function(
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 2498, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_args, aot_config)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1713, in aot_wrapper_dedupe
return compiler_fn(flat_fn, leaf_flat_args, aot_config)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_functorch/aot_autograd.py", line 2133, in aot_dispatch_autograd
compiled_fw_func = aot_config.fw_compiler(
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_inductor/compile_fx.py", line 430, in fw_compiler
return inner_compile(
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/debug_utils.py", line 595, in debug_wrapper
compiled_fn = compiler_fn(gm, example_inputs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_inductor/debug.py", line 239, in inner
return fn(*args, **kwargs)
File "/usr/lib/python3.10/contextlib.py", line 79, in inner
return func(*args, **kwds)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_inductor/compile_fx.py", line 177, in compile_fx_inner
compiled_fn = graph.compile_to_fn()
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_inductor/graph.py", line 586, in compile_to_fn
return self.compile_to_module().call
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_inductor/graph.py", line 575, in compile_to_module
mod = PyCodeCache.load(code)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_inductor/codecache.py", line 528, in load
exec(code, mod.__dict__, mod.__dict__)
File "/tmp/torchinductor_nathanasiou/wr/cwrfi6svswnyoicfxggucqfgjge566oqd55uh5wriq3feqdgyibn.py", line 544, in <module>
async_compile.wait(globals())
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_inductor/codecache.py", line 715, in wait
scope[key] = result.result()
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_inductor/codecache.py", line 573, in result
self.future.result()
File "/usr/lib/python3.10/concurrent/futures/_base.py", line 458, in result
return self.__get_result()
File "/usr/lib/python3.10/concurrent/futures/_base.py", line 403, in __get_result
raise self._exception
subprocess.CalledProcessError: Command '['/usr/bin/gcc', '/tmp/tmp7onv3nig/main.c', '-O3', '-I/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/triton/third_party/cuda/include', '-I/usr/include/python3.10', '-I/tmp/tmp7onv3nig', '-shared', '-fPIC', '-lcuda', '-o', '/tmp/tmp7onv3nig/triton_.cpython-310-x86_64-linux-gnu.so', '-L/usr/lib/x86_64-linux-gnu']' returned non-zero exit status 1.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/nathanasiou/Desktop/conditional_action_gen/space/train.py", line 156, in <module>
_train()
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/hydra/main.py", line 48, in decorated_main
_run_hydra(
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/hydra/_internal/utils.py", line 377, in _run_hydra
run_and_report(
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/hydra/_internal/utils.py", line 294, in run_and_report
raise ex
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/hydra/_internal/utils.py", line 211, in run_and_report
return func()
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/hydra/_internal/utils.py", line 378, in <lambda>
lambda: hydra.run(
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/hydra/_internal/hydra.py", line 111, in run
_ = ret.return_value
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/hydra/core/utils.py", line 233, in return_value
raise self._return_value
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/hydra/core/utils.py", line 160, in run_job
ret.return_value = task_function(task_cfg)
File "/home/nathanasiou/Desktop/conditional_action_gen/space/train.py", line 50, in _train
return train(cfg, ckpt_ft)
File "/home/nathanasiou/Desktop/conditional_action_gen/space/train.py", line 145, in train
trainer.fit(compiled_model, datamodule=data_module, ckpt_path=ckpt_ft)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/trainer/trainer.py", line 520, in fit
call._call_and_handle_interrupt(
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/trainer/call.py", line 44, in _call_and_handle_interrupt
return trainer_fn(*args, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/trainer/trainer.py", line 559, in _fit_impl
self._run(model, ckpt_path=ckpt_path)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/trainer/trainer.py", line 935, in _run
results = self._run_stage()
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/trainer/trainer.py", line 978, in _run_stage
self.fit_loop.run()
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/loops/fit_loop.py", line 201, in run
self.advance()
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/loops/fit_loop.py", line 354, in advance
self.epoch_loop.run(self._data_fetcher)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/loops/training_epoch_loop.py", line 133, in run
self.advance(data_fetcher)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/loops/training_epoch_loop.py", line 218, in advance
batch_output = self.automatic_optimization.run(trainer.optimizers[0], kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/loops/optimization/automatic.py", line 185, in run
self._optimizer_step(kwargs.get("batch_idx", 0), closure)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/loops/optimization/automatic.py", line 261, in _optimizer_step
call._call_lightning_module_hook(
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/trainer/call.py", line 142, in _call_lightning_module_hook
output = fn(*args, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/core/module.py", line 1266, in optimizer_step
optimizer.step(closure=optimizer_closure)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/core/optimizer.py", line 158, in step
step_output = self._strategy.optimizer_step(self._optimizer, closure, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/strategies/strategy.py", line 224, in optimizer_step
return self.precision_plugin.optimizer_step(optimizer, model=model, closure=closure, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/plugins/precision/precision_plugin.py", line 114, in optimizer_step
return optimizer.step(closure=closure, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/optim/optimizer.py", line 33, in _use_grad
ret = func(self, *args, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/optim/adamw.py", line 148, in step
loss = closure()
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/plugins/precision/precision_plugin.py", line 101, in _wrap_closure
closure_result = closure()
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/loops/optimization/automatic.py", line 140, in __call__
self._result = self.closure(*args, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/loops/optimization/automatic.py", line 126, in closure
step_output = self._step_fn()
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/loops/optimization/automatic.py", line 308, in _training_step
training_step_output = call._call_strategy_hook(trainer, "training_step", *kwargs.values())
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/trainer/call.py", line 288, in _call_strategy_hook
output = fn(*args, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/pytorch_lightning/strategies/strategy.py", line 366, in training_step
return self.model.training_step(*args, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/home/nathanasiou/Desktop/conditional_action_gen/space/space/model/base.py", line 36, in training_step
return self.allsplit_step("train", batch, batch_idx)
File "/home/nathanasiou/Desktop/conditional_action_gen/space/space/model/space.py", line 377, in allsplit_step
datastruct_from_text, latent_vectors_text, distributions_from_text, mask_texts = self.text_to_motion_forward(gt_texts,
File "/home/nathanasiou/Desktop/conditional_action_gen/space/space/model/space.py", line 249, in text_to_motion_forward
distributions = self.textencoder(texts, mapping=indices)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/nathanasiou/Desktop/conditional_action_gen/space/space/model/textencoder/text_space.py", line 63, in forward
text_encoded, mask = self.get_last_hidden_state(texts, return_mask=True)
File "/home/nathanasiou/Desktop/conditional_action_gen/space/space/model/textencoder/distilbert.py", line 55, in get_last_hidden_state
encoded_inputs = self.tokenizer(texts,
File "/home/nathanasiou/Desktop/conditional_action_gen/space/space/model/textencoder/distilbert.py", line 58, in <graph break in get_last_hidden_state>
output = self.text_model(**encoded_inputs.to(self.text_model.device))
File "/home/nathanasiou/Desktop/conditional_action_gen/space/space/model/textencoder/distilbert.py", line 58, in <graph break in get_last_hidden_state>
output = self.text_model(**encoded_inputs.to(self.text_model.device))
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 337, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 404, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 104, in _fn
return fn(*args, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 262, in _convert_frame_assert
return _compile(
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 324, in _compile
out_code = transform_code_object(code, transform)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/bytecode_transformation.py", line 445, in transform_code_object
transformations(instructions, code_options)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 311, in transform
tracer.run()
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1726, in run
super().run()
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 576, in run
and self.step()
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 540, in step
getattr(self, inst.opname)(inst)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1792, in RETURN_VALUE
self.output.compile_subgraph(
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 541, in compile_subgraph
self.compile_and_call_fx_graph(tx, pass2.graph_output_vars(), root)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 588, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 675, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: debug_wrapper raised CalledProcessError: Command '['/usr/bin/gcc', '/tmp/tmp7onv3nig/main.c', '-O3', '-I/home/nathanasiou/.venvs/space/lib/python3.10/site-packages/triton/third_party/cuda/include', '-I/usr/include/python3.10', '-I/tmp/tmp7onv3nig', '-shared', '-fPIC', '-lcuda', '-o', '/tmp/tmp7onv3nig/triton_.cpython-310-x86_64-linux-gnu.so', '-L/usr/lib/x86_64-linux-gnu']' returned non-zero exit status 1.
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
### Minified repro
_No response_
### Versions
```
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.26.0
Libc version: glibc-2.31
Python version: 3.10.10 (main, Feb 8 2023, 14:50:01) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.15.0-67-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.7.64
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Quadro RTX 5000
Nvidia driver version: 525.89.02
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 12
On-line CPU(s) list: 0-11
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) W-2133 CPU @ 3.60GHz
Stepping: 4
CPU MHz: 3600.000
CPU max MHz: 3900,0000
CPU min MHz: 1200,0000
BogoMIPS: 7200.00
Virtualization: VT-x
L1d cache: 192 KiB
L1i cache: 192 KiB
L2 cache: 6 MiB
L3 cache: 8,3 MiB
NUMA node0 CPU(s): 0-11
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; Clear CPU buffers; SMT vulnerable
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single pti intel_ppin ssbd mba ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.22.3
[pip3] pytorch-lightning==2.0.0
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.1
[pip3] torchmetrics==0.9.3
[pip3] torchvision==0.15.1
[pip3] triton==2.0.0
[conda] No relevant packages
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 5 |
3,162 | 97,138 |
RuntimeError: NYI: Named tensors are not supported with the tracer
|
module: onnx, triaged
|
### 🐛 Describe the bug
Bug
While running the following script, I got the error: "RuntimeError: NYI: Named tensors are not supported with the tracer"
refer the onnx-model [mnist-1](https://github.com/onnx/models/blob/main/vision/classification/mnist/model/mnist-1.onnx)
To Reproduce
```
import torch.nn.functional as F
from torch import nn
from torchsummary import summary
import torch
device = torch.device("cuda:1" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu")
# device = torch.device("cpu")
print(device)
print(f"Using {device} device")
# Define model
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
constant1 = torch.tensor([
-0.1615397185087204,
-0.4338356554508209,
0.09164135903120041,
-0.01685221679508686,
-0.06502643972635269,
-0.1317378729581833,
0.020417550578713417,
-0.1211102306842804
])
constant2 = torch.tensor([
-0.08224882185459137,
-0.10886877775192261,
-0.14103959500789642,
-0.20486916601657867,
-0.17913565039634705,
-0.2154383808374405,
-0.1338050663471222,
-0.19572456181049347,
-0.26825064420700073,
-0.25821220874786377,
-0.07615606486797333,
0.01328414585441351,
-0.004444644320756197,
-0.41474083065986633,
-0.17879115045070648,
-0.03865588828921318])
constant3 = torch.randn(16,4,4,10)
constant4 = torch.tensor([[
-0.04485602676868439,
0.007791661191731691,
0.06810081750154495,
0.02999374084174633,
-0.1264096349477768,
0.14021874964237213,
-0.055284902453422546,
-0.04938381537795067,
0.08432205021381378,
-0.05454041436314583
]])
self.constant1 = nn.Parameter(data = constant1)
self.constant2 = nn.Parameter(data = constant2)
self.constant3 = nn.Parameter(data = constant3)
self.constant4 = nn.Parameter(data = constant4)
# self.conv1 = nn.Conv2d(in_channels=1,out_channels=8,kernel_size=(5,5),stride=(1,1),padding='same',dilation=(1,1),groups=1)
self.conv1 = nn.Conv2d(in_channels=1,out_channels=8,kernel_size=(5,5),stride=(1,1),padding=2,dilation=(1,1),groups=1)
self.relu1 = nn.ReLU()
self.reshape1 = nn.Unflatten(0,(1,8,1,1))
self.reshape2 = nn.Unflatten(0,(1,16,1,1))
self.reshape3 = nn.Sequential(
nn.Flatten(start_dim=0),
nn.Unflatten(0,(256,10))
)
self.reshape4 = nn.Sequential(
nn.Flatten()
)
self.maxpool1 = nn.MaxPool2d(kernel_size=(2,2),stride=(2,2))
# self.conv2 = nn.Conv2d(in_channels=8,out_channels=16,kernel_size=(5,5),stride=(1,1),padding='same',dilation=(1,1),groups=1)
self.conv2 = nn.Conv2d(in_channels=8,out_channels=16,kernel_size=(5,5),stride=(1,1),padding=2,dilation=(1,1),groups=1)
self.relu2 = nn.ReLU()
self.maxpool2 = nn.MaxPool2d(kernel_size=(3,3),stride=(3,3))
def forward(self, x):
x = x/255
x = self.conv1(x)
reshape1_output = self.reshape1(self.constant1)
x = x + reshape1_output
x = self.relu1(x)
x = self.maxpool1(x)
x = self.conv2(x)
reshape2_output = self.reshape2(self.constant2)
x = x + reshape2_output
x = self.relu2(x)
x = self.maxpool2(x)
# print(self.constant3.shape)
reshape3_output = self.reshape3(self.constant3)
# print(reshape3_output.shape)
x = self.reshape4(x)
# print(x.shape)
x = torch.mm(x,reshape3_output)
x = x + self.constant4
return x
#
print(device)
model = NeuralNetwork().to(device)
# input = torch.randn(1,28,28)
summary(model=model,input_data=(1,1,28,28),batch_dim = None,device=device)
dummy_input = torch.randn(1, 1, 28, 28, device='cuda:1')
input_names = [ "input73" ]
output_names = [ "output1" ]
torch.onnx.export(model, dummy_input, "mnist1.onnx", verbose=True, input_names=input_names, output_names=output_names)
```
Expected behavior
No error
Environment
PyTorch Version (e.g., 1.0): 1.10
OS (e.g., Linux): Ubuntu 18.04
How you installed PyTorch (conda, pip, source): conda
Build command you used (if compiling from source):
Python version: 3.7.13
CUDA/cuDNN version: 11.2
GPU models and configuration:
Any other relevant information:
### Versions
```
Collecting environment information...
PyTorch version: 1.10.0+cu111
Is debug build: False
CUDA used to build PyTorch: 11.1
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.19.5
Libc version: glibc-2.17
Python version: 3.7.13 (default, Mar 29 2022, 02:18:16) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-4.15.0-188-generic-x86_64-with-debian-buster-sid
Is CUDA available: True
CUDA runtime version: 11.2.67
CUDA_MODULE_LOADING set to:
GPU models and configuration:
GPU 0: Tesla V100-PCIE-32GB
GPU 1: Tesla V100-PCIE-32GB
Nvidia driver version: 460.27.04
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4110 CPU @ 2.10GHz
Stepping: 4
CPU MHz: 800.857
CPU max MHz: 2101.0000
CPU min MHz: 800.0000
BogoMIPS: 4200.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 11264K
NUMA node0 CPU(s): 0-7,16-23
NUMA node1 CPU(s): 8-15,24-31
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single pti intel_ppin ssbd mba ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts pku ospke md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.21.5
[pip3] torch==1.10.0+cu111
[pip3] torch-summary==1.4.5
[pip3] torchaudio==0.10.0+rocm4.1
[pip3] torchvision==0.11.0+cu111
[conda] numpy 1.21.6 pypi_0 pypi
[conda] torch 1.10.0+cu111 pypi_0 pypi
[conda] torch-summary 1.4.5 pypi_0 pypi
[conda] torchaudio 0.10.0+rocm4.1 pypi_0 pypi
[conda] torchvision 0.11.0+cu111 pypi_0 pypi
```
| 1 |
3,163 | 97,137 |
Errors using torch.compile() on Megatron-LM GPT model
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
enable torch2 on megatron-lm get model
```
def model_provider(pre_process=True, post_process=True):
"""Build the model."""
print_rank_0('building GPT model ...')
model = GPTModel(
num_tokentypes=0,
parallel_output=True,
pre_process=pre_process,
post_process=post_process
)
model = torch.compile(model)
return model
```
training script like:
```
#! /bin/bash
# Runs the "345M" parameter model
GPUS_PER_NODE=4
# Change for multinode config
NNODES=2
WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))
DATA_PATH=/share/project/Megatron-DeepSpeed-data/data/meg-gpt2-oscar-en-10k_text_document
CHECKPOINT_PATH=checkpoints/gpt2
DISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE --nnodes $NNODES --node_rank $RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT"
torchrun $DISTRIBUTED_ARGS \
pretrain_gpt.py \
--tensor-model-parallel-size 2 \
--pipeline-model-parallel-size 2 \
--no-async-tensor-model-parallel-allreduce \
--num-layers 24 \
--hidden-size 1024 \
--num-attention-heads 16 \
--micro-batch-size 4 \
--global-batch-size 16 \
--seq-length 1024 \
--max-position-embeddings 1024 \
--train-iters 500000 \
--lr-decay-iters 320000 \
--save $CHECKPOINT_PATH \
--load $CHECKPOINT_PATH \
--data-path $DATA_PATH \
--vocab-file /share/project/Megatron-DeepSpeed-data/data/gpt2-vocab.json \
--merge-file /share/project/Megatron-DeepSpeed-data/data/gpt2-merges.txt \
--data-impl mmap \
--split 949,50,1 \
--distributed-backend nccl \
--lr 0.00015 \
--lr-decay-style cosine \
--min-lr 1.0e-5 \
--weight-decay 1e-2 \
--clip-grad 1.0 \
--lr-warmup-fraction .01 \
--log-interval 100 \
--save-interval 10000 \
--eval-interval 1000 \
--eval-iters 10 \
--fp16
```
Got such error:
```
[after dataloaders are built] datetime: 2023-03-20 07:28:59
done with setup ...
training ...
[before the start of training step] datetime: 2023-03-20 07:28:59
[2023-03-20 07:29:05,653] torch._inductor.graph: [ERROR] Error from lowering
Traceback (most recent call last):
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/graph.py", line 333, in call_function
out = lowerings[target](*args, **kwargs)
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 225, in wrapped
out = decomp_fn(*args, **kwargs)
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 2020, in index_put
return index_put_(clone(x), indices, values, accumulate)
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 225, in wrapped
out = decomp_fn(*args, **kwargs)
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 2044, in index_put_
return index_put_as_masked_fill(self, indices, values, accumulate)
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 2028, in index_put_as_masked_fill
return mutate_to(self, where(indices[0], value, self))
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 225, in wrapped
out = decomp_fn(*args, **kwargs)
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 454, in where
for i, x in zip(indices, broadcast_tensors(*[args[i] for i in indices])):
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 225, in wrapped
out = decomp_fn(*args, **kwargs)
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 468, in broadcast_tensors
target = functools.reduce(
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 280, in broadcast_symbolic_shapes
V.graph.sizevars.guard_equals(a, b)
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/sizevars.py", line 253, in guard_equals
assert self.shape_env.evaluate_expr(sympy.Eq(left, right))
AssertionError
[2023-03-20 07:29:05,653] torch._inductor.graph: [ERROR] Error from lowering
Traceback (most recent call last):
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/graph.py", line 333, in call_function
out = lowerings[target](*args, **kwargs)
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 225, in wrapped
out = decomp_fn(*args, **kwargs)
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 2020, in index_put
return index_put_(clone(x), indices, values, accumulate)
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 225, in wrapped
out = decomp_fn(*args, **kwargs)
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 2044, in index_put_
return index_put_as_masked_fill(self, indices, values, accumulate)
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 2028, in index_put_as_masked_fill
return mutate_to(self, where(indices[0], value, self))
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 225, in wrapped
out = decomp_fn(*args, **kwargs)
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 454, in where
for i, x in zip(indices, broadcast_tensors(*[args[i] for i in indices])):
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 225, in wrapped
out = decomp_fn(*args, **kwargs)
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 468, in broadcast_tensors
target = functools.reduce(
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/lowering.py", line 280, in broadcast_symbolic_shapes
V.graph.sizevars.guard_equals(a, b)
File "/home/elrond/code/Megatron-LM/Megatron-LM/.env/lib/python3.8/site-packages/torch/_inductor/sizevars.py", line 253, in guard_equals
assert self.shape_env.evaluate_expr(sympy.Eq(left, right))
AssertionError
```
### Versions
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.26.0
Libc version: glibc-2.31
Python version: 3.8.13 | packaged by conda-forge | (default, Mar 25 2022, 06:04:10) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-113-generic-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-40GB
GPU 1: NVIDIA A100-SXM4-40GB
GPU 2: NVIDIA A100-SXM4-40GB
GPU 3: NVIDIA A100-SXM4-40GB
Nvidia driver version: 470.129.06
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.5.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 256
On-line CPU(s) list: 0-255
Thread(s) per core: 2
Core(s) per socket: 64
Socket(s): 2
NUMA node(s): 8
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7742 64-Core Processor
Stepping: 0
Frequency boost: enabled
CPU MHz: 3279.251
CPU max MHz: 2250.0000
CPU min MHz: 1500.0000
BogoMIPS: 4491.31
Virtualization: AMD-V
L1d cache: 4 MiB
L1i cache: 4 MiB
L2 cache: 64 MiB
L3 cache: 512 MiB
NUMA node0 CPU(s): 0-15,128-143
NUMA node1 CPU(s): 16-31,144-159
NUMA node2 CPU(s): 32-47,160-175
NUMA node3 CPU(s): 48-63,176-191
NUMA node4 CPU(s): 64-79,192-207
NUMA node5 CPU(s): 80-95,208-223
NUMA node6 CPU(s): 96-111,224-239
NUMA node7 CPU(s): 112-127,240-255
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate sme ssbd mba sev ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip rdpid overflow_recov succor smca
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.0.0
[pip3] torchvision==0.15.1
[pip3] triton==2.0.0
[conda] mkl 2020.4 h726a3e6_304 conda-forge
[conda] mkl-include 2020.4 h726a3e6_304 conda-forge
[conda] numpy 1.22.4 py38h99721a1_0 conda-forge
[conda] pytorch-quantization 2.1.2 pypi_0 pypi
[conda] torch 1.13.0a0+d321be6 pypi_0 pypi
[conda] torch-tensorrt 1.2.0a0 pypi_0 pypi
[conda] torchtext 0.11.0a0 pypi_0 pypi
[conda] torchvision 0.14.0a0 pypi_0 pypi
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 2 |
3,164 | 97,135 |
Incorrect gradient calculation for upsample nearest on CUDA
|
needs reproduction, module: autograd, module: nn, triaged, module: interpolation
|
### 🐛 Describe the bug
When I add test case to our device backend. The backward of nearest_upsample op confused me.
For a example, when a tensor of shape {1,3,2,4} resample to {1,3,2,5} using Upsample and scale_factor=1.295. The result only use the first row of input in each channel. But in its grad, the second row is not zeros.
Is it a feature of a bug? And is different from cuda impl.
```
# cpu
tensor([[[[1.4624, 0.9307, 0.2198, 0.6219],
[1.0367, 0.5511, 0.7772, 0.1279]],
[[0.8423, 0.5464, 0.4794, 0.2412],
[0.8416, 0.5206, 0.9406, 0.2007]],
[[1.0312, 0.7016, 0.3476, 0.3076],
[0.6786, 0.7558, 0.1232, 0.8883]]]])
# cuda
tensor([[[[2.4991, 1.4818, 0.9969, 0.7497],
[0.0000, 0.0000, 0.0000, 0.0000]],
[[1.6840, 1.0670, 1.4200, 0.4418],
[0.0000, 0.0000, 0.0000, 0.0000]],
[[1.7098, 1.4574, 0.4708, 1.1960],
[0.0000, 0.0000, 0.0000, 0.0000]]]], device='cuda:0')
```
Code:
```python
import torch
import numpy as np
import torch
np.random.seed(3693825160)
device = "cpu" # or "cuda"
tensor_0 = torch.from_numpy(np.random.uniform(0.0, 1.0, size=[1, 3, 2, 4])).to(torch.float32).to(device).requires_grad_(True)
# module_4 = torch.nn.Upsample(scale_factor=1.295275651786123, mode='nearest').to(device)
# tensor_6 = module_4(tensor_0)
tensor_6 = torch.nn.functional.interpolate(tensor_0, scale_factor=1.295275651786123, mode='nearest').to(device)
print("tensor_0:")
print(tensor_0)
print("tensor_6:")
print(tensor_6)
tensor_9 = torch.from_numpy(np.random.uniform(0.0, 1.0, size=[1, 3, 2, 5])).to(torch.float32).to(device).requires_grad_(False)
tensor_6.backward(tensor_9)
print("grad:")
print(tensor_0.grad)
```
Env:
```
PyTorch version: 1.12.1 (CPU only)
OS: CentOS Linux 7 (Core) (x86_64)
Python version: 3.8.8 (default, Apr 13 2021, 19:58:26) [GCC 7.3.0] (64-bit runtime)
```
### Versions
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: CentOS Linux 7 (Core) (x86_64)
GCC version: (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44)
Clang version: Could not collect
CMake version: version 3.20.6
Libc version: glibc-2.17
Python version: 3.8.8 (default, Apr 13 2021, 19:58:26) [GCC 7.3.0] (64-bit runtime)
Python platform: Linux-5.10.0-1.0.0.22-x86_64-with-glibc2.10
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 6271C CPU @ 2.60GHz
Stepping: 7
CPU MHz: 2945.419
CPU max MHz: 3900.0000
CPU min MHz: 1000.0000
BogoMIPS: 5200.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 33792K
NUMA node0 CPU(s): 0-23,48-71
NUMA node1 CPU(s): 24-47,72-95
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts pku avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.20.1
[pip3] numpydoc==1.1.0
[pip3] torch==1.12.1
[pip3] torchaudio==0.12.1
[pip3] torchvision==0.13.1
[conda] blas 1.0 mkl
[conda] cpuonly 2.0 0 pytorch
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.2.0 h06a4308_296
[conda] mkl-service 2.3.0 py38h27cfd23_1
[conda] mkl_fft 1.3.0 py38h42c9631_2
[conda] mkl_random 1.2.1 py38ha9443f7_2
[conda] numpy 1.20.1 py38h93e21f0_0
[conda] numpy-base 1.20.1 py38h7d8b39e_0
[conda] numpydoc 1.1.0 pyhd3eb1b0_1
[conda] pytorch 1.12.1 py3.8_cpu_0 pytorch
[conda] pytorch-mutex 1.0 cpu pytorch
[conda] torchaudio 0.12.1 py38_cpu pytorch
[conda] torchvision 0.13.1 py38_cpu pytorch
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @mruberry @jbschlosser @walterddr @mikaylagawarecki
| 7 |
3,165 | 97,130 |
Inconsistent results when mutating a tensor with shared storage in a nested function
|
triaged, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
Hi! I found the next snippet will generate different results before/after compilation. It exists for both CPU and CUDA backend. I'm not sure but it might be related to #97083 and #97115.
```
import torch
def forward():
a = torch.ones(2)
b = a.reshape(2)
c = a[0:2] # So a, b, c share the same storage?
def subfunc():
b[0] = 2
if b.sum() >= -1e5:
pass
subfunc()
return c
print(forward()) # [2., 1.]
fn_compiled = torch.compile(forward)
print(fn_compiled()) # [1., 1.]
```
### Error logs
_No response_
### Minified repro
_No response_
### Versions
<details>
PyTorch version: 2.1.0a0+gitfe05266
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.2
Libc version: glibc-2.31
Python version: 3.9.5 (default, Nov 23 2021, 15:27:38) [GCC 9.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-67-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.6.112
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2070
Nvidia driver version: 510.108.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.4
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.6.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 23
Model: 1
Model name: AMD Ryzen Threadripper 1950X 16-Core Processor
Stepping: 1
Frequency boost: enabled
CPU MHz: 2200.000
CPU max MHz: 3400.0000
CPU min MHz: 2200.0000
BogoMIPS: 6786.49
Virtualization: AMD-V
L1d cache: 512 KiB
L1i cache: 1 MiB
L2 cache: 8 MiB
L3 cache: 32 MiB
NUMA node0 CPU(s): 0-31
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT vulnerable
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid amd_dcm aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate ssbd ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif overflow_recov succor smca sme sev
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.1.0a0+git5d33f9c
[pip3] triton==2.0.0.post1
</details>
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 8 |
3,166 | 97,128 |
MultiHeadAttention, fast path broken with `bias=False` or uneven number of heads
|
triaged, oncall: transformer/mha
|
### 🐛 Describe the bug
Certain configurations of `MultiHeadAttention` fail during inference, because of issues in the fast execution path. These need to be added to the fast path, or else handled gracefully (i.e. revert to slow path).
The following configurations break:
1. `batch_first=True`, `bias=False`
2. `batch_first=True`, `num_heads` is odd, and `key_padding_mask` provided
### Example 1
```python
import torch
import torch.nn as nn
import contextlib
B, L, F = 8, 100, 128
nb_heads = 8
batch_first = True
bias = False
fast_path = True
use_pad_mask = False
mha = nn.MultiheadAttention(
embed_dim=F,
num_heads=nb_heads,
batch_first=batch_first,
bias=bias
).cuda()
mha.eval()
ctx = torch.no_grad if fast_path else contextlib.nullcontext
with ctx():
x = torch.randn(B, L, F).cuda()
if not batch_first:
x = x.transpose(0, 1)
pad_mask = None
if use_pad_mask:
pad_mask = torch.zeros((B, L), dtype=torch.bool).cuda()
mha(query=x, key=x, value=x, key_padding_mask=pad_mask)
```
Yields,
```
File ~/miniconda3/envs/py39/lib/python3.9/site-packages/torch/nn/modules/activation.py:1144, in MultiheadAttention.forward(self, query, key, value, key_padding_mask, need_weights, attn_mask, average_attn_weights, is_causal)
1141 if not why_not_fast_path:
1142 merged_mask, mask_type = self.merge_masks(attn_mask, key_padding_mask, query)
-> 1144 return torch._native_multi_head_attention(
1145 query,
1146 key,
1147 value,
1148 self.embed_dim,
1149 self.num_heads,
1150 self.in_proj_weight,
1151 self.in_proj_bias,
1152 self.out_proj.weight,
1153 self.out_proj.bias,
1154 merged_mask,
1155 need_weights,
1156 average_attn_weights,
1157 mask_type)
1159 any_nested = query.is_nested or key.is_nested or value.is_nested
1160 assert not any_nested, ("MultiheadAttention does not support NestedTensor outside of its fast path. " +
1161 f"The fast path was not hit because {why_not_fast_path}")
TypeError: _native_multi_head_attention(): argument 'qkv_bias' (position 7) must be Tensor, not NoneType
```
### Example 2
```python
B, L, F = 8, 100, 128
nb_heads = 1
batch_first = True
bias = True
fast_path = True
use_pad_mask = True
...
```
Yields,
```
...
RuntimeError: Only support when num_heads is even in transformer
```
### Versions
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.31
Python version: 3.9.16 (main, Mar 8 2023, 14:00:05) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-1029-gcp-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-40GB
GPU 1: NVIDIA A100-SXM4-40GB
GPU 2: NVIDIA A100-SXM4-40GB
GPU 3: NVIDIA A100-SXM4-40GB
Nvidia driver version: 495.29.05
cuDNN version: Probably one of the following:
/usr/local/cuda-11.5/targets/x86_64-linux/lib/libcudnn.so.8.3.1
/usr/local/cuda-11.5/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.3.1
/usr/local/cuda-11.5/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.3.1
/usr/local/cuda-11.5/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.3.1
/usr/local/cuda-11.5/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.3.1
/usr/local/cuda-11.5/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.3.1
/usr/local/cuda-11.5/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.3.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) CPU @ 2.20GHz
Stepping: 7
CPU MHz: 2200.220
BogoMIPS: 4400.44
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 768 KiB
L1i cache: 768 KiB
L2 cache: 24 MiB
L3 cache: 38.5 MiB
NUMA node0 CPU(s): 0-47
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT Host state unknown
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; Clear CPU buffers; SMT Host state unknown
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves arat avx512_vnni md_clear arch_capabilities
Versions of relevant libraries:
[pip3] mypy==0.991
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.21.6
[pip3] poptorch==3.11.0
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.0
[pip3] torchfile==0.1.0
[pip3] torchvision==0.15.0
[pip3] triton==2.0.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.6 pypi_0 pypi
[conda] poptorch 3.11.0 pypi_0 pypi
[conda] pytorch 2.0.0 py3.9_cuda11.8_cudnn8.7.0_0 pytorch
[conda] pytorch-cuda 11.8 h7e8668a_3 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 2.0.0 py39_cu118 pytorch
[conda] torchfile 0.1.0 pypi_0 pypi
[conda] torchtriton 2.0.0 py39 pytorch
[conda] torchvision 0.15.0 py39_cu118 pytorch
cc @jbschlosser @bhosmer @cpuhrsch @erichan1
| 4 |
3,167 | 97,123 |
[Compile] NameError: name 'buf0' is not defined (raised in ddp-training)
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
The demo code:
```python
from mmengine.dist import all_gather, broadcast, get_rank, init_dist
import torch
def batch_shuffle_ddp(x: torch.Tensor):
"""Batch shuffle, for making use of BatchNorm.
Args:
x (torch.Tensor): Data in each GPU.
Returns:
Tuple[torch.Tensor, torch.Tensor]: Output of shuffle operation.
- x_gather[idx_this]: Shuffled data.
- idx_unshuffle: Index for restoring.
"""
# gather from all gpus
batch_size_this = x.shape[0]
x_gather = torch.cat(all_gather(x), dim=0)
batch_size_all = x_gather.shape[0]
num_gpus = batch_size_all // batch_size_this
# random shuffle index
idx_shuffle = torch.randperm(batch_size_all)
# broadcast to all gpus
broadcast(idx_shuffle, src=0)
# index for restoring
idx_unshuffle = torch.argsort(idx_shuffle)
# shuffled index for this gpu
gpu_idx = get_rank()
idx_this = idx_shuffle.view(num_gpus, -1)[gpu_idx]
return x_gather[idx_this], idx_unshuffle
if __name__ == '__main__':
init_dist(launcher='pytorch')
func = torch.compile(batch_shuffle_ddp)
func(torch.ones(1, 1, 1, 1))
```
Training with `torchrun`
```python
torchrun --master_port 29501 --nproc_per_node 2 demo.py
```
### Versions
```bash
Collecting environment information...
PyTorch version: 2.1.0a0+git92eb9d3
Is debug build: True
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: CentOS Linux 7 (Core) (x86_64)
GCC version: (GCC) 8.5.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.17
Python version: 3.10.9 (main, Jan 11 2023, 15:21:40) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-3.10.0-957.el7.x86_64-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-80GB
GPU 1: NVIDIA A100-SXM4-80GB
GPU 2: NVIDIA A100-SXM4-80GB
GPU 3: NVIDIA A100-SXM4-80GB
GPU 4: NVIDIA A100-SXM4-80GB
GPU 5: NVIDIA A100-SXM4-80GB
GPU 6: NVIDIA A100-SXM4-80GB
GPU 7: NVIDIA A100-SXM4-80GB
Nvidia driver version: 515.65.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 256
On-line CPU(s) list: 0-255
Thread(s) per core: 2
Core(s) per socket: 64
Socket(s): 2
NUMA node(s): 2
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7742 64-Core Processor
Stepping: 0
CPU MHz: 2250.000
CPU max MHz: 2250.0000
CPU min MHz: 1500.0000
BogoMIPS: 4491.59
Virtualization: AMD-V
L1d cache: 32K
L1i cache: 32K
L2 cache: 512K
L3 cache: 16384K
NUMA node0 CPU(s): 0-63,128-191
NUMA node1 CPU(s): 64-127,192-255
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc art rep_good nopl xtopology nonstop_tsc extd_apicid aperfmperf eagerfpu pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_l2 cpb cat_l3 cdp_l3 hw_pstate sme retpoline_amd ssbd ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip overflow_recov succor smca
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.1.0a0+git92eb9d3
[pip3] torchvision==0.14.1
[pip3] triton==2.0.0
[conda] blas 1.0 mkl defaults
[conda] magma-cuda117 2.6.1 1 pytorch
[conda] mkl 2021.4.0 h06a4308_640 defaults
[conda] mkl-include 2022.1.0 h06a4308_224 defaults
[conda] mkl-service 2.4.0 py310h7f8727e_0 defaults
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0 defaults
[conda] mkl_random 1.2.2 py310h00e6091_0 defaults
[conda] numpy 1.23.5 py310hd5efca6_0 defaults
[conda] numpy-base 1.23.5 py310h8e6c178_0 defaults
[conda] torch 2.1.0a0+git92eb9d3 dev_0 <develop>
[conda] torchvision 0.14.1 pypi_0 pypi
[conda] triton 2.0.0 pypi_0 pypi
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
3,168 | 97,118 |
nn.Conv function to compute conv formula
|
module: docs, module: nn, triaged, actionable
|
### 🚀 The feature, motivation and pitch
When there is a `nn.Linear` after a `nn.ConvXd`, something like the below:
```python
nn.Sequential(
nn.ConvXd(...), # E.g. 2d or 3d
nn.Flatten(),
nn.Linear(input_shape, ...) # Requires knowing the Conv equation
)
```
One has to think about the Conv equation ([image source](https://pytorch.org/docs/1.13/generated/torch.nn.Conv3d.html#torch.nn.Conv3d)):
> 
On many different school projects, I find myself re-implementing this equation. It would be really useful if `torch` had a free function that could be `import`ed to accomplish this.
It would be well tested and just be a handy way to enable DRY model code with `torch`'s `Conv` layers.
Would `torch` be open to having a free function contributed for this? It could be a part of `nn` or `nn.functional`.
### Alternatives
Here is my current best function for this:
```python
def conv_conversion(
in_shape: tuple[int, ...],
kernel_size: int | tuple[int, ...],
padding: int | tuple[int, ...] = 0,
dilation: int | tuple[int, ...] = 1,
stride: int | tuple[int, ...] = 1,
) -> tuple[int, ...]:
"""Perform a Conv layer calculation matching nn.Conv's defaults."""
def to_tuple(value: int | tuple[int, ...]) -> tuple[int, ...]:
return (value,) * len(in_shape) if isinstance(value, int) else value
k, p = to_tuple(kernel_size), to_tuple(padding)
dil, s = to_tuple(dilation), to_tuple(stride)
return tuple(
int((in_shape[i] + 2 * p[i] - dil[i] * (k[i] - 1) - 1) / s[i] + 1)
for i in range(len(in_shape))
)
```
I would like to gather feedback on how it can be further generalized, and then write some unit tests for it.
Cheers!
### Additional context
_No response_
cc @svekars @carljparker @albanD @mruberry @jbschlosser @walterddr @mikaylagawarecki
| 4 |
3,169 | 97,115 |
[Dynamo] symbolic_convert returns ValueError: Cell is empty
|
good first issue, triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
Hi! I found the following snippet will trigger the `Cell is empty` error in the function `match_nested_cell`.
```
import torch
def forward():
x = torch.zeros(torch.Size([1]), device='cuda:0')
def subfunc():
x[0] = backup
if x[0] >= -1e5:
pass
backup = 1
subfunc()
return x
with torch.no_grad():
print(forward())
fn_compiled = torch.compile(forward)
print(fn_compiled())
```
### Error logs
```
Traceback (most recent call last):
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/convert_frame.py", line 331, in _compile
out_code = transform_code_object(code, transform)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/bytecode_transformation.py", line 530, in transform_code_object
transformations(instructions, code_options)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/convert_frame.py", line 318, in transform
tracer.run()
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/symbolic_convert.py", line 1848, in run
super().run()
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/symbolic_convert.py", line 604, in run
and self.step()
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/symbolic_convert.py", line 564, in step
getattr(self, inst.opname)(inst)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/symbolic_convert.py", line 347, in wrapper
return inner_fn(self, inst)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/symbolic_convert.py", line 1000, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/symbolic_convert.py", line 495, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/variables/functions.py", line 265, in call_function
return super().call_function(tx, args, kwargs)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/variables/functions.py", line 98, in call_function
return tx.inline_user_function_return(
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/symbolic_convert.py", line 531, in inline_user_function_return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/symbolic_convert.py", line 1941, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/symbolic_convert.py", line 1974, in inline_call_
sub_locals, closure_cells = func.bind_args(parent, args, kwargs)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/variables/functions.py", line 202, in bind_args
var = tx.match_nested_cell(name, cell)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/symbolic_convert.py", line 1852, in match_nested_cell
value = cell.cell_contents
ValueError: Cell is empty
from user code:
File "/home/su/accdiff/test.py", line 11, in <resume in forward>
subfunc()
Set torch._dynamo.config.verbose=True or TORCHDYNAMO_VERBOSE=1 for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/su/accdiff/test.py", line 17, in <module>
print(fn_compiled())
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/eval_frame.py", line 235, in _fn
return fn(*args, **kwargs)
File "/home/su/accdiff/test.py", line 2, in forward
def forward():
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/eval_frame.py", line 372, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/convert_frame.py", line 412, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/convert_frame.py", line 110, in _fn
return fn(*args, **kwargs)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/convert_frame.py", line 269, in _convert_frame_assert
return _compile(
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/utils.py", line 165, in time_wrapper
r = func(*args, **kwargs)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/convert_frame.py", line 402, in _compile
raise InternalTorchDynamoError() from e
torch._dynamo.exc.InternalTorchDynamoError
```
### Minified repro
_No response_
### Versions
PyTorch version: 2.1.0a0+gitfe05266
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.2
Libc version: glibc-2.31
Python version: 3.9.5 (default, Nov 23 2021, 15:27:38) [GCC 9.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-67-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.6.112
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2070
Nvidia driver version: 510.108.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.4
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.6.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 23
Model: 1
Model name: AMD Ryzen Threadripper 1950X 16-Core Processor
Stepping: 1
Frequency boost: enabled
CPU MHz: 2083.655
CPU max MHz: 3400.0000
CPU min MHz: 2200.0000
BogoMIPS: 6786.49
Virtualization: AMD-V
L1d cache: 512 KiB
L1i cache: 1 MiB
L2 cache: 8 MiB
L3 cache: 32 MiB
NUMA node0 CPU(s): 0-31
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT vulnerable
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid amd_dcm aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate ssbd ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif overflow_recov succor smca sme sev
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.1.0a0+git4805441
[pip3] triton==2.0.0.post1
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 13 |
3,170 | 97,114 |
[Feature Proposal: New Distributed Training Algorithms] LSGD and EASGD
|
oncall: distributed, triaged
|
### 🚀 The feature, motivation and pitch
Currently, PyTorch only offers support for DataParallelism. I am working on integrating two additional distributed training optimizers, EASGD and LSGD, into the codebase. The motivation is to enable a straightforward alternative of vanilla DataParallelism.
Vanilla DataParallelism:
``` python
model = DistributedDataParallel(model, device_ids=[args.gpu])
model.forward(data); model.backward(loss) ; optimizer.step()
```
Alternative Distributed Training:
``` python
optimizer = CommOptimizer(optimizer, dist_optim_name='LSGD+', comm_period=1, dist_pulling_strength=0.1, local_pulling_strength=0.1)
model.forward(data); model.backward(loss) ; optimizer.step()
```
The synchronous version could be implemented and wrapped up easily. A quick glance is available at [**SDTL GitHub**](https://github.com/yunfei-teng/SDTL).
The asynchronous version presents greater difficulty in implementation, but a prototype version could be found at [**LSGD GitHub**](https://github.com/yunfei-teng/LSGD).
### Alternatives
_No response_
### Additional context
LSGD:
* Paper: https://arxiv.org/abs/1905.10395
* LSGD Blog: https://yunfei-teng.github.io/LSGD-Blog
EASGD:
* Paper: https://arxiv.org/abs/1412.6651
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 4 |
3,171 | 97,111 |
TransformerEncoder truncates output when some token positions are masked by `src_key_padding_mask` across batch
|
triaged, module: nestedtensor, oncall: transformer/mha
|
### 🐛 Describe the bug
Original [post](https://discuss.pytorch.org/t/transformerencoder-src-key-padding-mask-truncates-output-when-some-token-positions-are-masked-across-batch/175316).
**THIS ONLY HAPPENS WHEN `enable_nested_tensor=True`.**
When `src_key_padding_mask` ([N, K]) has one column (k) all with value `True`, `TransformerEncoder` will remove this column in the output, causing inconsistency issues. Minimal example:
Class init
```python
encoder_layer = nn.TransformerEncoderLayer(d_model=256, nhead=4, dim_feedforward=512, activation='gelu', norm_first=False, batch_first=False)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=3, enable_nested_tensor=True)
```
Forward
```python
x = torch.randn(2000, 6, 256)
mask = torch.ones(2000, 6)
mask[:, 0] = 0 # here I masked 5 columns instead of just one
mask = mask.bool()
out = self.transformer_encoder(src = x, src_key_padding_mask = mask)
assert out.shape[1] == 6 # Error, the actual dim is only 1
```
Is this an expected behavior by design? If so, I don't think this is a good practice because oftentimes we want aggregation on the sequence level, and this kind of removal would make the use of scatter aggregation functions, e.g. `scatter_mean` difficult.
### Versions
```
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: CentOS Linux release 7.9.2009 (Core) (x86_64)
GCC version: (GCC) 9.2.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.17
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-3.10.0-1160.83.1.el7.x86_64-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Quadro RTX 8000
Nvidia driver version: 460.32.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 1
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 4
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 6240R CPU @ 2.40GHz
Stepping: 7
CPU MHz: 3688.476
CPU max MHz: 4000.0000
CPU min MHz: 1000.0000
BogoMIPS: 4800.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 36608K
NUMA node0 CPU(s): 0,4,8,12,16,20,24,28,32,36,40,44
NUMA node1 CPU(s): 1,5,9,13,17,21,25,29,33,37,41,45
NUMA node2 CPU(s): 2,6,10,14,18,22,26,30,34,38,42,46
NUMA node3 CPU(s): 3,7,11,15,19,23,27,31,35,39,43,47
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba rsb_ctxsw ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts pku ospke avx512_vnni md_clear spec_ctrl intel_stibp flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] denoising-diffusion-pytorch==0.31.1
[pip3] ema-pytorch==0.0.10
[pip3] numpy==1.21.5
[pip3] torch==1.13.1+cu117
[pip3] torch-cluster==1.6.1+pt113cu117
[pip3] torch-geometric==2.2.0
[pip3] torch-scatter==2.1.1+pt113cu117
[pip3] torch-sparse==0.6.17+pt113cu117
[pip3] torch-spline-conv==1.2.2+pt113cu117
[pip3] torchaudio==0.13.1+cu117
[pip3] torchdrug==0.2.0.post1
[pip3] torchvision==0.14.1+cu117
[conda] blas 1.0 mkl conda-forge
[conda] cudatoolkit 10.2.89 h713d32c_10 conda-forge
[conda] denoising-diffusion-pytorch 0.31.1 pypi_0 pypi
[conda] ema-pytorch 0.0.10 pypi_0 pypi
[conda] libblas 3.9.0 12_linux64_mkl conda-forge
[conda] libcblas 3.9.0 12_linux64_mkl conda-forge
[conda] liblapack 3.9.0 12_linux64_mkl conda-forge
[conda] mkl 2021.4.0 h8d4b97c_729 conda-forge
[conda] mkl-service 2.4.0 py38h95df7f1_0 conda-forge
[conda] mkl_fft 1.3.1 py38h8666266_1 conda-forge
[conda] mkl_random 1.2.2 py38h1abd341_0 conda-forge
[conda] numpy 1.21.5 py38h6c91a56_3
[conda] numpy-base 1.21.5 py38ha15fc14_3
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torch 1.12.0 pypi_0 pypi
[conda] torch-cluster 1.6.1+pt113cu117 pypi_0 pypi
[conda] torch-geometric 2.2.0 pypi_0 pypi
[conda] torch-scatter 2.1.1+pt113cu117 pypi_0 pypi
[conda] torch-sparse 0.6.17+pt113cu117 pypi_0 pypi
[conda] torch-spline-conv 1.2.2+pt113cu117 pypi_0 pypi
[conda] torchaudio 0.13.1+cu117 pypi_0 pypi
[conda] torchdrug 0.2.0.post1 pypi_0 pypi
[conda] torchvision 0.14.1+cu117 pypi_0 pypi
```
cc @cpuhrsch @jbschlosser @bhosmer @drisspg @erichan1
| 11 |
3,172 | 97,109 |
"Adaptive pool MPS: input sizes must be divisible by output sizes", I keep getting this error even when I try to adjust for size
|
triaged, module: mps
|
### 🐛 Describe the bug
I am running a facet-pytorch library for facial recognition. I initialised the mtcnn class and passed on MPS as the device so I can run the program on that GPU for faster results.
'''
device = torch.device("mps")
mtcnn1 = MTCNN(image_size=(160,160) device=device)
'''
The problem starts when I try to iterate though an image folder and pass it in the mtcnn i.e.
for imge, index in dataLoader:
face, prob = mtcnn0(image, return_prob=True)
it keeps coming up with this error:
RuntimeError: Adaptive pool MPS: input sizes must be divisible by output sizes
Can someone help please?
### Versions
wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 11 |
3,173 | 97,106 |
slow torch import on macos
|
module: performance, triaged, module: macos
|
### 🐛 Describe the bug
I’m having a hard time understanding the slow import of torch in later versions, including the most recent 2.0 release. I dug as deep as I could, and ran `cProfile` on torch's `__init__.py`:
```shell
ncalls tottime percall cumtime percall filename:lineno(function)
1287 1.824 0.001 1.824 0.001 {built-in method io.open_code} <--------------
45/25 1.045 0.023 1.579 0.063 {built-in method _imp.create_dynamic} <--------------
1287 0.136 0.000 0.136 0.000 {built-in method marshal.loads}
5408 0.064 0.000 0.064 0.000 {built-in method posix.stat}
2841/2785 0.050 0.000 0.240 0.000 {built-in method builtins.__build_class__}
424 0.047 0.000 0.080 0.000 assumptions.py:596(__init__)
1635/1 0.042 0.000 4.315 4.315 {built-in method builtins.exec}
2 0.040 0.020 0.040 0.020 {built-in method _ctypes.dlopen}
51906 0.026 0.000 0.062 0.000 {built-in method builtins.getattr}
1298 0.026 0.000 0.026 0.000 {method '__exit__' of '_io._IOBase' objects}
164 0.023 0.000 0.023 0.000 {built-in method posix.listdir}
1769 0.020 0.000 0.131 0.000 <frozen importlib._bootstrap_external>:1604(find_spec)
1287 0.019 0.000 0.019 0.000 {method 'read' of '_io.BufferedReader' objects}
```
The `_imp.create_dynamic` is part of `importlib.machinery.ModuleSpec` and is called once inside `package_importer.py` here:

I'm sorry in advance if this is not a bug, but I don't know where to post this and is becoming really annoying. I also ruled out is only on my end, a friend of mine has mac too, but he's on Big Sur, and uses python 3.10.
### Versions
```shell
Collecting environment information...
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.2.1 (x86_64)
GCC version: Could not collect
Clang version: 14.0.3 (clang-1403.0.22.14.1)
CMake version: version 3.25.2
Libc version: N/A
Python version: 3.11.0 (main, Mar 1 2023, 12:49:28) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Intel(R) Core(TM) i9-9880H CPU @ 2.30GHz
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.1
[pip3] torchvision==0.15.1
[conda] numpy 1.24.2 pypi_0 pypi
[conda] torch 2.0.0 pypi_0 pypi
[conda] torchaudio 2.0.1 pypi_0 pypi
[conda] torchvision 0.15.1 pypi_0 pypi
```
cc @ngimel @malfet @albanD
| 12 |
3,174 | 97,097 |
torch.cuda.FloatTensor().normal_() generate (partially) different sample on different gpu machines
|
module: docs, triaged
|
### 🐛 torch.cuda.FloatTensor().normal_() returns different results on different GPUs
So I executed a training script on two different machines and found that the data generated is actually (partially) different. The configs are as follows:
Machine 1:
* GPU: RTX A4000
* OS: Ubuntu 20.04 LTS
* Python: 3.10.9
* torch version: 2.0.0 with CUDA 11.7
* NVIDIA driver version: 470.161.03
Machine 2:
* GPU: RTX 2070 Super
* OS: Ubuntu 22.04 LTS
* Python: 3.10.9 (same)
* torch version: 2.0.0 with CUDA 11.7 (same)
* NVIDIA driver version: 470.161.03 (same)
Test code for replication:
```
import torch
torch.manual_seed(14)
x = torch.cuda.FloatTensor(1000, 100).normal_(5, 5**.5)
x
```
Machine 1 returns
```
tensor([[2.8731, 5.2727, 2.9889, ..., 1.6853, 9.6331, 6.6319],
[3.9968, 3.8097, 5.7328, ..., 4.4029, 3.9804, 7.4698],
[6.5552, 4.0857, 4.2315, ..., 2.7704, 3.5479, 3.3063],
...,
[8.6297, 2.3137, 6.2596, ..., 7.9358, 4.4697, 2.7475],
[7.0551, 7.8583, 3.9990, ..., 4.1139, 8.9315, 4.2042],
[2.7337, 2.2106, 7.7815, ..., 8.2207, 6.5395, 4.2604]],
device='cuda:0')
```
And machine 2 returns:
```
tensor([[2.8731, 5.2727, 2.9889, ..., 1.6853, 9.6331, 6.6319],
[3.9968, 3.8097, 5.7328, ..., 4.4029, 3.9804, 7.4698],
[6.5552, 4.0857, 4.2315, ..., 2.7704, 3.5479, 3.3063],
...,
[2.7640, 5.5319, 3.2799, ..., 3.0997, 2.1668, 5.0841],
[6.3256, 8.4741, 4.1051, ..., 2.6423, 7.7107, 3.3614],
[3.0485, 5.1392, 0.5328, ..., 3.0785, 4.5691, 3.4167]],
device='cuda:0')
```
Note that the first 3 rows shown are the same but starting from a certain row the numbers are different.
Also tested under torch 1.13.1 on both machines, doesn't make a difference.
### Versions
#### Machine 1
```
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.2 LTS (fossa-ditto X84) (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.31
Python version: 3.10.9 (main, Mar 8 2023, 10:47:38) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.14.0-1056-oem-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA RTX A4000
GPU 1: NVIDIA RTX A4000
GPU 2: NVIDIA RTX A4000
GPU 3: NVIDIA RTX A4000
Nvidia driver version: 470.161.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 64
On-line CPU(s) list: 0-63
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 6226R CPU @ 2.90GHz
Stepping: 7
CPU MHz: 2900.000
CPU max MHz: 3900.0000
CPU min MHz: 1200.0000
BogoMIPS: 5800.00
Virtualization: VT-x
L1d cache: 1 MiB
L1i cache: 1 MiB
L2 cache: 32 MiB
L3 cache: 44 MiB
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.0
[pip3] torchvision==0.15.0
[pip3] triton==2.0.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.5 py310hd5efca6_0
[conda] numpy-base 1.23.5 py310h8e6c178_0
[conda] pytorch 2.0.0 py3.10_cuda11.7_cudnn8.5.0_0 pytorch
[conda] pytorch-cuda 11.7 h778d358_3 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 2.0.0 py310_cu117 pytorch
[conda] torchtriton 2.0.0 py310 pytorch
[conda] torchvision 0.15.0 py310_cu117 pytorc
```
#### Machine 2
```
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.2 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.10.9 (main, Mar 8 2023, 10:47:38) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.19.0-35-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2070 SUPER
Nvidia driver version: 470.161.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 6
On-line CPU(s) list: 0-5
Vendor ID: GenuineIntel
Model name: Intel(R) Core(TM) i5-8400 CPU @ 2.80GHz
CPU family: 6
Model: 158
Thread(s) per core: 1
Core(s) per socket: 6
Socket(s): 1
Stepping: 10
CPU max MHz: 4000.0000
CPU min MHz: 800.0000
BogoMIPS: 5599.85
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d arch_capabilities
Virtualization: VT-x
L1d cache: 192 KiB (6 instances)
L1i cache: 192 KiB (6 instances)
L2 cache: 1.5 MiB (6 instances)
L3 cache: 9 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-5
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT disabled
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT disabled
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT disabled
Vulnerability Retbleed: Mitigation; IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Mitigation; Microcode
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.0
[pip3] torchvision==0.15.0
[pip3] triton==2.0.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.5 py310hd5efca6_0
[conda] numpy-base 1.23.5 py310h8e6c178_0
[conda] pytorch 2.0.0 py3.10_cuda11.7_cudnn8.5.0_0 pytorch
[conda] pytorch-cuda 11.7 h778d358_3 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 2.0.0 py310_cu117 pytorch
[conda] torchtriton 2.0.0 py310 pytorch
[conda] torchvision 0.15.0 py310_cu117 pytorch
```
cc @svekars @carljparker
| 1 |
3,175 | 97,088 |
A Segment Fault can be triggered in torch.embedding
|
triaged, module: edge cases
|
### 🐛 Describe the bug
The following code can triger a segment fault in `torch.embedding`:
````python
import torch
weight = torch.rand([13, 7], dtype=torch.float32)
indices = torch.rand([2, 0, 11, 3, 4, 2322065022462387218], dtype=torch.float32)
padding_idx = -53
scale_grad_by_freq = True
sparse = True
res = torch.embedding(
weight=weight,
indices=indices,
padding_idx=padding_idx,
scale_grad_by_freq=scale_grad_by_freq,
sparse=sparse,
)
````
The output:
````
Segmentation fault (core dumped)
````
The bug is similar to many issues I reported before, the 0 and the large value in input's shape might be the cause.
### Versions
PyTorch version: 2.1.0.dev20230307+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu120.04.1) 9.4.0
Clang version: 11.0.0-2ubuntu20.04.1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.8.16 (default, Mar 2 2023, 03:21:46) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-60-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla V100-PCIE-16GB
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4214 CPU @ 2.20GHz
Stepping: 7
CPU MHz: 2200.000
BogoMIPS: 4400.00
Virtualization: VT-x
L1d cache: 768 KiB
L1i cache: 768 KiB
L2 cache: 24 MiB
L3 cache: 33 MiB
NUMA node0 CPU(s): 0-11,24-35
NUMA node1 CPU(s): 12-23,36-47
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp_epp pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.0.0+b8b470bc59
[pip3] torch==2.1.0.dev20230307+cu117
[pip3] torchaudio==2.0.0.dev20230307+cu117
[pip3] torchvision==0.15.0.dev20230307+cu117
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-triton 2.0.0+b8b470bc59 pypi_0 pypi
[conda] torch 2.1.0.dev20230307+cu117 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230307+cu117 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230307+cu117 pypi_0 pypi
| 0 |
3,176 | 97,087 |
A Segment Fault can be triggered in torch.adjoint
|
triaged, module: edge cases
|
### 🐛 Describe the bug
The following code can triger a segment fault in `torch.adjoint`:
````python
import torch
input = torch.rand([0, 16, 3, 1, 4482056787832389139, 1], dtype=torch.float32)
res = torch.adjoint(
input=input,
)
````
The output:
````
Segmentation fault (core dumped)
````
The bug is similar to many issues I reported before, the 0 and the large value in `input`'s shape might be the cause.
### Versions
PyTorch version: 2.1.0.dev20230307+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu120.04.1) 9.4.0
Clang version: 11.0.0-2ubuntu20.04.1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.8.16 (default, Mar 2 2023, 03:21:46) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-60-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla V100-PCIE-16GB
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4214 CPU @ 2.20GHz
Stepping: 7
CPU MHz: 2200.000
BogoMIPS: 4400.00
Virtualization: VT-x
L1d cache: 768 KiB
L1i cache: 768 KiB
L2 cache: 24 MiB
L3 cache: 33 MiB
NUMA node0 CPU(s): 0-11,24-35
NUMA node1 CPU(s): 12-23,36-47
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp_epp pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.0.0+b8b470bc59
[pip3] torch==2.1.0.dev20230307+cu117
[pip3] torchaudio==2.0.0.dev20230307+cu117
[pip3] torchvision==0.15.0.dev20230307+cu117
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-triton 2.0.0+b8b470bc59 pypi_0 pypi
[conda] torch 2.1.0.dev20230307+cu117 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230307+cu117 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230307+cu117 pypi_0 pypi
| 0 |
3,177 | 97,086 |
A crash due to Floating Point Exception can be triggered in torch.index_select
|
module: crash, module: error checking, triaged, module: edge cases
|
### 🐛 Describe the bug
The following code can trigger a Floating Point Exception in `torch.index_select`:
````python
import torch
input = torch.rand([], dtype=torch.float32).cuda()
dim = 0
index = torch.rand([0], dtype=torch.float32).cuda()
res = torch.index_select(
input=input,
dim=dim,
index=index,
)
````
The output is:
````
Floating point exception (core dumped)
````
The bug is similar to #93877 .
### Versions
PyTorch version: 2.1.0.dev20230307+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 11.0.0-2~ubuntu20.04.1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.8.16 (default, Mar 2 2023, 03:21:46) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-60-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla V100-PCIE-16GB
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.1.1
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.1.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.1
/usr/local/cuda-11.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4214 CPU @ 2.20GHz
Stepping: 7
CPU MHz: 2200.000
BogoMIPS: 4400.00
Virtualization: VT-x
L1d cache: 768 KiB
L1i cache: 768 KiB
L2 cache: 24 MiB
L3 cache: 33 MiB
NUMA node0 CPU(s): 0-11,24-35
NUMA node1 CPU(s): 12-23,36-47
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp_epp pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.0.0+b8b470bc59
[pip3] torch==2.1.0.dev20230307+cu117
[pip3] torchaudio==2.0.0.dev20230307+cu117
[pip3] torchvision==0.15.0.dev20230307+cu117
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-triton 2.0.0+b8b470bc59 pypi_0 pypi
[conda] torch 2.1.0.dev20230307+cu117 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230307+cu117 pypi_0 pypi
[conda] torchvision 0.15.0.dev20230307+cu117 pypi_0 pypi
cc @malfet
| 5 |
3,178 | 97,085 |
[MPS] Fix and refactor unary/binary ops with non-zero offset or non-contiguous output
|
triaged, open source, Stale, release notes: mps, ciflow/mps
|
Fixes #100764
See the added test for repro.
| 4 |
3,179 | 97,084 |
timm models that are instantiated using timm's fast norm layer trigger graph breaks
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
timm has a modification to norm layers that forces their computation to run in lower precision. When this is enabled and the resulting model is compiled, the compiled model has graph breaks.
### Error logs
_No response_
### Minified repro
```python
import torch, timm
import torch._dynamo
timm.models.layers.fast_norm.set_fast_norm(enable=False)
model = timm.create_model("convnext_tiny")
print(torch._dynamo.explain(model, torch.randn(1,3,224,224))[0])
# Dynamo produced 1 graphs with 0 graph break and 59 ops
timm.models.layers.fast_norm.set_fast_norm(enable=True)
model = timm.create_model("convnext_tiny")
print(torch._dynamo.explain(model, torch.randn(1,3,224,224))[0])
# Dynamo produced 49 graphs with 48 graph break and 36 ops
```
### Versions
<details>
```
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.2
Libc version: glibc-2.31
Python version: 3.9.16 (main, Dec 7 2022, 01:11:51) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.10.147+-x86_64-with-glibc2.31
Is CUDA available: False
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 2
Core(s) per socket: 1
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU @ 2.20GHz
Stepping: 0
CPU MHz: 2199.998
BogoMIPS: 4399.99
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32 KiB
L1i cache: 32 KiB
L2 cache: 256 KiB
L3 cache: 55 MiB
NUMA node0 CPU(s): 0,1
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Vulnerable; SMT Host state unknown
Vulnerability Meltdown: Vulnerable
Vulnerability Mmio stale data: Vulnerable
Vulnerability Retbleed: Vulnerable
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Vulnerable: __user pointer sanitization and usercopy barriers only; no swapgs barriers
Vulnerability Spectre v2: Vulnerable, IBPB: disabled, STIBP: disabled, PBRSB-eIBRS: Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Vulnerable
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt arat md_clear arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.22.4
[pip3] torch==2.0.0+cu117
[pip3] torchaudio==2.0.1+cu117
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.14.1
[pip3] torchvision==0.15.1+cu117
[pip3] triton==2.0.0
[conda] Could not collect
```
`timm==0.6.12`
</details>
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
3,180 | 97,083 |
Inconsitent results before/after compilation for squeeze + tensor mutation + if statement
|
triaged, oncall: pt2, module: dynamic shapes
|
### 🐛 Describe the bug
Hi! I found the following snippet produces different result before/after compilation.
```
import torch
def forward():
a = torch.tensor([1])
a = a[0:1]
b = a.squeeze()
a[0] = 0 #(*)
if a[0] < 1e5:
pass
a[0] = 2
return b
with torch.no_grad():
print(forward()) # return 2
fn_compiled = torch.compile(forward)
print(fn_compiled()) # return 0
```
If commenting out the line highlighted with (*), we can get consistent results. However, a new warning emerges:
```
[2023-03-18 03:39:09,359] torch._inductor.graph: [WARNING] error in realize_users_of
Traceback (most recent call last):
File "/home/su/accdiff/thirdparty/pytorch/torch/_inductor/graph.py", line 254, in realize_users_of
visit(value)
File "/home/su/accdiff/thirdparty/pytorch/torch/_inductor/graph.py", line 248, in visit
if value.is_user_of(name):
File "/home/su/accdiff/thirdparty/pytorch/torch/_inductor/ir.py", line 353, in is_user_of
return any(name == dep.name for dep in self.get_reads())
File "/home/su/accdiff/thirdparty/pytorch/torch/_inductor/ir.py", line 3879, in __getattr__
fn = getattr(self.data, name)
File "/home/su/accdiff/thirdparty/pytorch/torch/_inductor/ir.py", line 3879, in __getattr__
fn = getattr(self.data, name)
AttributeError: 'bool' object has no attribute 'get_reads'
```
Is this normal?
### Error logs
_No response_
### Minified repro
_No response_
### Versions
PyTorch version: 2.1.0a0+gitfe05266
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.2
Libc version: glibc-2.31
Python version: 3.9.5 (default, Nov 23 2021, 15:27:38) [GCC 9.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-67-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.6.112
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2070
Nvidia driver version: 510.108.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.4
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.6.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 23
Model: 1
Model name: AMD Ryzen Threadripper 1950X 16-Core Processor
Stepping: 1
Frequency boost: enabled
CPU MHz: 2200.000
CPU max MHz: 3400.0000
CPU min MHz: 2200.0000
BogoMIPS: 6786.49
Virtualization: AMD-V
L1d cache: 512 KiB
L1i cache: 1 MiB
L2 cache: 8 MiB
L3 cache: 32 MiB
NUMA node0 CPU(s): 0-31
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT vulnerable
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid amd_dcm aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate ssbd ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif overflow_recov succor smca sme sev
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.1.0a0+git4805441
[pip3] triton==2.0.0
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @anijain2305
| 5 |
3,181 | 97,082 |
[Dynamo] aot_autograd throws IndexError
|
triaged, oncall: pt2, module: aotdispatch
|
### 🐛 Describe the bug
Hi! I found that the following snippet will trigger a `torch._dynamo.exc.BackendCompilerFailed`.
```
import torch
a = torch.tensor([1.], device='cuda:0')
b = torch.tensor(0., device='cuda:0')
def forward(a, b):
backup = a[0]
if b < 1e5:
a[0] = backup
a.max()
with torch.no_grad():
fn_compiled = torch.compile(forward)
print(fn_compiled(a, b))
```
### Error logs
```
[2023-03-18 03:16:07,705] torch._inductor.utils: [WARNING] make_fallback(aten.addmv): a decomposition exists, we should switch to it
Traceback (most recent call last):
File "/home/su/accdiff/test.py", line 13, in <module>
print(fn_compiled(a, b))
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/eval_frame.py", line 235, in _fn
return fn(*args, **kwargs)
File "/home/su/accdiff/test.py", line 5, in forward
def forward(a, b):
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/eval_frame.py", line 372, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/convert_frame.py", line 412, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/convert_frame.py", line 110, in _fn
return fn(*args, **kwargs)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/convert_frame.py", line 269, in _convert_frame_assert
return _compile(
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/utils.py", line 165, in time_wrapper
r = func(*args, **kwargs)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/convert_frame.py", line 331, in _compile
out_code = transform_code_object(code, transform)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/bytecode_transformation.py", line 530, in transform_code_object
transformations(instructions, code_options)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/convert_frame.py", line 318, in transform
tracer.run()
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/symbolic_convert.py", line 1848, in run
super().run()
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/symbolic_convert.py", line 604, in run
and self.step()
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/symbolic_convert.py", line 564, in step
getattr(self, inst.opname)(inst)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/symbolic_convert.py", line 1927, in RETURN_VALUE
self.output.compile_subgraph(
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/output_graph.py", line 574, in compile_subgraph
self.compile_and_call_fx_graph(tx, pass2.graph_output_vars(), root)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/output_graph.py", line 620, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/utils.py", line 165, in time_wrapper
r = func(*args, **kwargs)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/output_graph.py", line 690, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e).with_traceback(
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/output_graph.py", line 686, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/debug_utils.py", line 1064, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs)
File "/home/su/accdiff/thirdparty/pytorch/torch/__init__.py", line 1527, in __call__
return compile_fx(model_, inputs_, config_patches=self.config)
File "/home/su/accdiff/thirdparty/pytorch/torch/_inductor/compile_fx.py", line 534, in compile_fx
return aot_autograd(
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/backends/common.py", line 59, in compiler_fn
cg = aot_module_simplified(gm, example_inputs, **kwargs)
File "/home/su/accdiff/thirdparty/pytorch/torch/_functorch/aot_autograd.py", line 3004, in aot_module_simplified
compiled_fn = create_aot_dispatcher_function(
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/utils.py", line 165, in time_wrapper
r = func(*args, **kwargs)
File "/home/su/accdiff/thirdparty/pytorch/torch/_functorch/aot_autograd.py", line 2685, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_args, aot_config, fw_metadata=fw_metadata)
File "/home/su/accdiff/thirdparty/pytorch/torch/_functorch/aot_autograd.py", line 1791, in aot_wrapper_dedupe
return compiler_fn(flat_fn, leaf_flat_args, aot_config, fw_metadata=fw_metadata)
File "/home/su/accdiff/thirdparty/pytorch/torch/_functorch/aot_autograd.py", line 1970, in aot_wrapper_synthetic_base
create_synthetic_base_metadata(fw_metadata, synthetic_base_info, flat_args, flat_args_with_synthetic_bases)
File "/home/su/accdiff/thirdparty/pytorch/torch/_functorch/aot_autograd.py", line 1630, in create_synthetic_base_metadata
mutated_inp_require_grad_info.append(any(m.requires_grad_info[x] for x in outer_indices))
File "/home/su/accdiff/thirdparty/pytorch/torch/_functorch/aot_autograd.py", line 1630, in <genexpr>
mutated_inp_require_grad_info.append(any(m.requires_grad_info[x] for x in outer_indices))
torch._dynamo.exc.BackendCompilerFailed: backend='debug_wrapper' raised:
IndexError: list index out of range
```
### Minified repro
_No response_
### Versions
PyTorch version: 2.1.0a0+gitfe05266
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.2
Libc version: glibc-2.31
Python version: 3.9.5 (default, Nov 23 2021, 15:27:38) [GCC 9.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-67-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.6.112
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2070
Nvidia driver version: 510.108.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.4
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.6.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 23
Model: 1
Model name: AMD Ryzen Threadripper 1950X 16-Core Processor
Stepping: 1
Frequency boost: enabled
CPU MHz: 2200.000
CPU max MHz: 3400.0000
CPU min MHz: 2200.0000
BogoMIPS: 6786.49
Virtualization: AMD-V
L1d cache: 512 KiB
L1i cache: 1 MiB
L2 cache: 8 MiB
L3 cache: 32 MiB
NUMA node0 CPU(s): 0-31
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT vulnerable
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid amd_dcm aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate ssbd ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif overflow_recov succor smca sme sev
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.1.0a0+git4805441
[pip3] triton==2.0.0
cc @ezyang @msaroufim @wconstab @ngimel @bdhirsh @anijain2305 @soumith
| 1 |
3,182 | 97,081 |
[Dynamo] compile_check_fn throws IndexError
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
Hi! I found that the following snippet will trigger an InternalTorchDynamoError.
Some subtle modifications (as mentioned in the comments) might impede reproduction.
```
import torch
x = torch.tensor([1], device='cuda:0', dtype=torch.float64)
def forward():
a = torch.tensor([[0]], device='cuda:0', dtype=torch.float64)
# Move it out of the function will eliminate the error
a1 = a # This line and the next are required to reproduce the error
a2 = a1
if x[0] >= 0:
a.transpose(0, 1) # This line is required for reproduction
a2[0, 0] = 0
return (a1, ) # replace it with "return a1", and the error is eliminated.
print(forward())
fn_compiled = torch.compile(forward)
print(fn_compiled())
```
### Error logs
```
[2023-03-18 02:45:57,168] torch._inductor.utils: [WARNING] make_fallback(aten.addmv): a decomposition exists, we should switch to it
Traceback (most recent call last):
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/convert_frame.py", line 372, in _compile
check_fn = CheckFunctionManager(
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/guards.py", line 647, in __init__
self.check_fn = self.compile_check_fn(
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/guards.py", line 711, in compile_check_fn
assert self.output_graph.graphargs[
IndexError: list index out of range
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/su/accdiff/test.py", line 15, in <module>
print(fn_compiled())
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/eval_frame.py", line 235, in _fn
return fn(*args, **kwargs)
File "/home/su/accdiff/test.py", line 4, in forward
def forward():
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/eval_frame.py", line 372, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/convert_frame.py", line 412, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/convert_frame.py", line 110, in _fn
return fn(*args, **kwargs)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/convert_frame.py", line 269, in _convert_frame_assert
return _compile(
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/utils.py", line 165, in time_wrapper
r = func(*args, **kwargs)
File "/home/su/accdiff/thirdparty/pytorch/torch/_dynamo/convert_frame.py", line 402, in _compile
raise InternalTorchDynamoError() from e
torch._dynamo.exc.InternalTorchDynamoError
```
### Minified repro
_No response_
### Versions
PyTorch version: 2.1.0a0+gitfe05266
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.2
Libc version: glibc-2.31
Python version: 3.9.5 (default, Nov 23 2021, 15:27:38) [GCC 9.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-67-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.6.112
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2070
Nvidia driver version: 510.108.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.2.4
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.2.4
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.6.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 23
Model: 1
Model name: AMD Ryzen Threadripper 1950X 16-Core Processor
Stepping: 1
Frequency boost: enabled
CPU MHz: 2200.000
CPU max MHz: 3400.0000
CPU min MHz: 2200.0000
BogoMIPS: 6786.49
Virtualization: AMD-V
L1d cache: 512 KiB
L1i cache: 1 MiB
L2 cache: 8 MiB
L3 cache: 32 MiB
NUMA node0 CPU(s): 0-31
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT vulnerable
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid amd_dcm aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate ssbd ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif overflow_recov succor smca sme sev
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.1.0a0+git4805441
[pip3] triton==2.0.0
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 1 |
3,183 | 97,079 |
[compile] KeyError: example_value
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
`model.compile()` (defaults) gives me:
```
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing forward
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing wrapped_fn
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing range_push
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in range_push>
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in wrapped_fn>
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing _pre_forward_module_hook
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing pre_sub_module_forward_function
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing record_module
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in pre_sub_module_forward_function>
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing wrapped_fn
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in range_push>
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in wrapped_fn>
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing fetch_sub_module
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing iter_params
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing wrapped_fn
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in range_push>
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in wrapped_fn>
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing get_all_parameters
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing external_parameters
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing range_pop
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in range_pop>
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in fetch_sub_module>
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing is_initialized
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing get_rank
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo done tracing get_rank (RETURN_VALUE)
stderr: - 5597 - torch._dynamo.output_graph - Step 2: calling compiler function debug_wrapper
stderr: - 5597 - torch._dynamo.output_graph - Step 2: done compiler function debug_wrapper
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in range_push>
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing current_stream
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo done tracing current_stream (RETURN_VALUE)
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in pre_sub_module_forward_function>
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing _post_backward_module_hook
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing _post_backward_module_hook
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing _apply_to_tensors_only
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing forward
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in forward>
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo done tracing <graph break in forward> (RETURN_VALUE)
stderr: - 5597 - torch._dynamo.output_graph - Step 2: calling compiler function debug_wrapper
stderr: - 5597 - torch._inductor.compile_fx - Step 3: torchinductor compiling FORWARDS graph 1
stderr: - 5597 - torch._inductor.compile_fx - Step 3: torchinductor done compiling FORWARDS graph 1
stderr: - 5597 - torch._dynamo.output_graph - Step 2: done compiler function debug_wrapper
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing is_zero_param
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing forward
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing _pre_forward_module_hook
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing pre_sub_module_forward_function
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing record_module
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in pre_sub_module_forward_function>
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing fetch_sub_module
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing iter_params
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing get_all_parameters
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing register_external_parameter
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in register_external_parameter>
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing all_gather
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in range_push>
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing _all_gather
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing _ensure_availability_of_partitioned_params
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in _all_gather>
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing _allgather_params
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in _allgather_params>
stderr: - 5597 - torch._dynamo.output_graph - Step 2: calling compiler function debug_wrapper
stderr: - 5597 - torch._inductor.compile_fx - Step 3: torchinductor compiling FORWARDS graph 2
stderr: - 5597 - torch._inductor.compile_fx - Step 3: torchinductor done compiling FORWARDS graph 2
stderr: - 5597 - torch._dynamo.output_graph - Step 2: done compiler function debug_wrapper
stderr: - 5597 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing <graph break in _allgather_params>
stderr: Traceback (most recent call last):
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/convert_frame.py", line 324, in _compile
stderr: out_code = transform_code_object(code, transform)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/bytecode_transformation.py", line 445, in transform_code_object
stderr: transformations(instructions, code_options)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/convert_frame.py", line 311, in transform
stderr: tracer.run()
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 1726, in run
stderr: super().run()
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 576, in run
stderr: and self.step()
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 540, in step
stderr: getattr(self, inst.opname)(inst)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 342, in wrapper
stderr: return inner_fn(self, inst)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 965, in CALL_FUNCTION
stderr: self.call_function(fn, args, {})
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 474, in call_function
stderr: self.push(fn.call_function(self, args, kwargs))
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/variables/misc.py", line 744, in call_function
stderr: return self.obj.call_method(tx, self.name, args, kwargs).add_options(self)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/variables/tensor.py", line 424, in call_method
stderr: return wrap_fx_proxy(
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/variables/builder.py", line 754, in wrap_fx_proxy
stderr: return wrap_fx_proxy_cls(
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/variables/builder.py", line 789, in wrap_fx_proxy_cls
stderr: example_value = get_fake_value(proxy.node, tx)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/utils.py", line 1134, in get_fake_value
stderr: args, kwargs = torch.fx.node.map_arg((node.args, node.kwargs), visit)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/fx/node.py", line 621, in map_arg
stderr: return map_aggregate(a, lambda x: fn(x) if isinstance(x, Node) else x)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/fx/node.py", line 629, in map_aggregate
stderr: t = tuple(map_aggregate(elem, fn) for elem in a)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/fx/node.py", line 629, in <genexpr>
stderr: t = tuple(map_aggregate(elem, fn) for elem in a)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/fx/node.py", line 629, in map_aggregate
stderr: t = tuple(map_aggregate(elem, fn) for elem in a)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/fx/node.py", line 629, in <genexpr>
stderr: t = tuple(map_aggregate(elem, fn) for elem in a)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/fx/node.py", line 639, in map_aggregate
stderr: return fn(a)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/fx/node.py", line 621, in <lambda>
stderr: return map_aggregate(a, lambda x: fn(x) if isinstance(x, Node) else x)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/utils.py", line 1132, in visit
stderr: return n.meta["example_value"]
stderr: KeyError: example_value
stderr:
stderr: from user code:
stderr: File "/usr/local/lib/python3.8/dist-packages/deepspeed/runtime/zero/partition_parameters.py", line 1333, in <graph break in _allgather_params>
stderr: partitions[i].narrow(0,
```
### Versions
pt-2.0
@Chillee
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 3 |
3,184 | 97,078 |
[compile] TypeError: __init__() missing 1 required positional argument: 'parent_module'
|
triaged, ezyang's list, oncall: pt2
|
### 🐛 Describe the bug
`model.compile()` (defaults) gives me:
```
stderr: - 5543 - torch._dynamo.symbolic_convert - Step 1: torchdynamo start tracing forward
stderr: Traceback (most recent call last):
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/convert_frame.py", line 324, in _compile
stderr: out_code = transform_code_object(code, transform)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/bytecode_transformation.py", line 445, in transform_code_object
stderr: transformations(instructions, code_options)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/convert_frame.py", line 311, in transform
stderr: tracer.run()
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 1726, in run
stderr: super().run()
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 576, in run
stderr: and self.step()
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 540, in step
stderr: getattr(self, inst.opname)(inst)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 342, in wrapper
stderr: return inner_fn(self, inst)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 1014, in CALL_FUNCTION_KW
stderr: self.call_function(fn, args, kwargs)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 474, in call_function
stderr: self.push(fn.call_function(self, args, kwargs))
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/variables/nn_module.py", line 244, in call_function
stderr: return tx.inline_user_function_return(
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 510, in inline_user_function_return
stderr: result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 1806, in inline_call
stderr: return cls.inline_call_(parent, func, args, kwargs)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 1862, in inline_call_
stderr: tracer.run()
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 576, in run
stderr: and self.step()
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 540, in step
stderr: getattr(self, inst.opname)(inst)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 342, in wrapper
stderr: return inner_fn(self, inst)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 1014, in CALL_FUNCTION_KW
stderr: self.call_function(fn, args, kwargs)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 474, in call_function
stderr: self.push(fn.call_function(self, args, kwargs))
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/variables/nn_module.py", line 244, in call_function
stderr: return tx.inline_user_function_return(
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 510, in inline_user_function_return
stderr: result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 1806, in inline_call
stderr: return cls.inline_call_(parent, func, args, kwargs)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 1862, in inline_call_
stderr: tracer.run()
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 576, in run
stderr: and self.step()
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 540, in step
stderr: getattr(self, inst.opname)(inst)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 342, in wrapper
stderr: return inner_fn(self, inst)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 965, in CALL_FUNCTION
stderr: self.call_function(fn, args, {})
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 474, in call_function
stderr: self.push(fn.call_function(self, args, kwargs))
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/variables/nn_module.py", line 244, in call_function
stderr: return tx.inline_user_function_return(
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 510, in inline_user_function_return
stderr: result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 1806, in inline_call
stderr: return cls.inline_call_(parent, func, args, kwargs)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 1862, in inline_call_
stderr: tracer.run()
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 576, in run
stderr: and self.step()
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 540, in step
stderr: getattr(self, inst.opname)(inst)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 342, in wrapper
stderr: return inner_fn(self, inst)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 965, in CALL_FUNCTION
stderr: self.call_function(fn, args, {})
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/symbolic_convert.py", line 474, in call_function
stderr: self.push(fn.call_function(self, args, kwargs))
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/variables/nn_module.py", line 203, in call_function
stderr: return wrap_fx_proxy(
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/variables/builder.py", line 754, in wrap_fx_proxy
stderr: return wrap_fx_proxy_cls(
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/variables/builder.py", line 789, in wrap_fx_proxy_cls
stderr: example_value = get_fake_value(proxy.node, tx)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/utils.py", line 1143, in get_fake_value
stderr: nnmodule = deepcopy_to_fake_tensor(nnmodule, tx.fake_mode)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/utils.py", line 819, in deepcopy_to_fake_tensor
stderr: return wrap_fake_exception(lambda: copy.deepcopy(obj))
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/utils.py", line 808, in wrap_fake_exception
stderr: return fn()
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/utils.py", line 819, in <lambda>
stderr: return wrap_fake_exception(lambda: copy.deepcopy(obj))
stderr: File "/usr/lib/python3.8/copy.py", line 172, in deepcopy
stderr: y = _reconstruct(x, memo, *rv)
stderr: File "/usr/lib/python3.8/copy.py", line 270, in _reconstruct
stderr: state = deepcopy(state, memo)
stderr: File "/usr/lib/python3.8/copy.py", line 146, in deepcopy
stderr: y = copier(x, memo)
stderr: File "/usr/lib/python3.8/copy.py", line 230, in _deepcopy_dict
stderr: y[deepcopy(key, memo)] = deepcopy(value, memo)
stderr: File "/usr/lib/python3.8/copy.py", line 172, in deepcopy
stderr: y = _reconstruct(x, memo, *rv)
stderr: File "/usr/lib/python3.8/copy.py", line 264, in _reconstruct
stderr: y = func(*args)
stderr: TypeError: __init__() missing 1 required positional argument: 'parent_module'
tderr: Set torch._dynamo.config.verbose=True for more information
stderr:
stderr:
stderr: You can suppress this exception and fall back to eager by setting:
stderr: torch._dynamo.config.suppress_errors = True
stderr:
stderr:
stderr: The above exception was the direct cause of the following exception:
stderr:
stderr: Traceback (most recent call last):
stderr: File "/actions-runner/_work/m4/m4/m4/training/main.py", line 176, in <module>
stderr: train_logs = trainer.train()
stderr: File "/actions-runner/_work/m4/m4/m4/training/trainer.py", line 1438, in train
stderr: ) = self._do_batch(
stderr: File "/actions-runner/_work/m4/m4/m4/training/trainer.py", line 560, in _do_batch
stderr: vl_output = self.vl_model(
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
stderr: return forward_call(*args, **kwargs)
stderr: File "/usr/local/lib/python3.8/dist-packages/deepspeed/utils/nvtx.py", line 11, in wrapped_fn
stderr: ret_val = func(*args, **kwargs)
stderr: File "/usr/local/lib/python3.8/dist-packages/deepspeed/runtime/engine.py", line 1832, in forward
stderr: loss = self.module(*inputs, **kwargs)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1538, in _call_impl
stderr: result = forward_call(*args, **kwargs)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/eval_frame.py", line 82, in forward
stderr: return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
stderr: return fn(*args, **kwargs)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/eval_frame.py", line 337, in catch_errors
stderr: return callback(frame, cache_size, hooks)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/convert_frame.py", line 404, in _convert_frame
stderr: result = inner_convert(frame, cache_size, hooks)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/convert_frame.py", line 104, in _fn
stderr: return fn(*args, **kwargs)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/convert_frame.py", line 262, in _convert_frame_assert
stderr: return _compile(
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
stderr: r = func(*args, **kwargs)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/_dynamo/convert_frame.py", line 394, in _compile
stderr: raise InternalTorchDynamoError() from e
stderr: torch._dynamo.exc.InternalTorchDynamoError
stderr: ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 6786) of binary: /usr/bin/python3
stderr: Traceback (most recent call last):
stderr: File "/usr/local/bin/accelerate", line 8, in <module>
stderr: sys.exit(main())
stderr: File "/usr/local/lib/python3.8/dist-packages/accelerate/commands/accelerate_cli.py", line 45, in main
stderr: args.func(args)
stderr: File "/usr/local/lib/python3.8/dist-packages/accelerate/commands/launch.py", line 900, in launch_command
stderr: deepspeed_launcher(args)
stderr: File "/usr/local/lib/python3.8/dist-packages/accelerate/commands/launch.py", line 643, in deepspeed_launcher
stderr: distrib_run.run(args)
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/distributed/run.py", line 785, in run
stderr: elastic_launch(
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/distributed/launcher/api.py", line 134, in __call__
stderr: return launch_agent(self._config, self._entrypoint, list(args))
stderr: File "/usr/local/lib/python3.8/dist-packages/torch/distributed/launcher/api.py", line 250, in launch_agent
stderr: raise ChildFailedError(
stderr: torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
```
### Versions
pt-2.0
@Chillee
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 6 |
3,185 | 97,068 |
[RFC] CPU float16 performance optimization on eager mode.
|
feature, module: cpu, triaged, module: half
|
### 🚀 The feature, motivation and pitch
The RFC is to improve float16 performance as well as Op coverage on PyTorch CPU backend on eager mode.
Float16 and BFloat16 are both commonly used reduced floating point types for performance improvement in neural network inference/training. On the CPU side, previous optimization efforts have been placed more on BFloat16, which leaves float16 at a relatively primitive status.
On the 4th generation Intel® Xeon® Scalable processor (Sapphire Rapids), a new fp16 instruction set architecture for Intel® AVX-512 has been added, e.g. **avx512-fp16**. The instruction set supports a wide range of general-purpose numeric operations for fp16. One the next generation of Xeon, Intel® Advanced Matrix Extensions (AMX) will have fp16 support, e.g. **amx-fp16**.
This proposal would help the scenario when the model is pre trained on GPU with mixed precision of float16/float32 and users intend to do deployment on the CPU side without modifying the model weights, for instance, many HuggingFace models belong to this scenario.
**This project will be targeting at:**
* Improve float16 Op coverage on PT from 52% to ~80% (for reference, BFloat16 Op coverage ratio is 83%). Torchbench models and HuggingFace models will be prioritized.
* Improve float16 performance: Since the current fp16 performance on CPU is very low, we can use fp16 v.s. fp32 speedup as the metrics here. Performance speedup will match bf16, on average a 4x-5x performance speedup will be achieved on hardware with amx-fp16 support.
* Add Automatic Mixed Precision (AMP) support for float16 on CPU.
* Improve float16 numerical stability: use fp32 as accumulate type in reduction Ops, e.g. mean.
**Technically, the optimization will be carried out as below:**
Compute intensive Ops (e.g. Convolution, Gemm, and RNN):
* Rely on oneDNN for optimal performance when the hardware has float16 acceleration.
* Functional coverage will be added for hardware without float16 acceleration, no performance gain.
Generic ATen kernels:
* Extend avx256 and avx512 and vectorization utils for dtype `Half`. Add native convert intrinsics: `_mm256_cvtph_ps`/`_mm256_cvtps_ph` (Rounding mode: RNE).
* Unary and binary Op kernels: map to fp32 for computation.
* Non arithmetic Ops: do direct memory copy (no dtype conversion), e.g. cat, index_select.
* Reduction Ops: use fp32 as accumulate type.
* NN Ops: reuse kernels of BFloat16.
**Test Plan:**
* Extend `vec_test_all_types_AVX2` and `vec_test_all_types_AVX512` for float16.
* Add OpInfo at `torch/testing/_internal/common_methods_invocations.py`.
* Provide specific test cases for reduced floating point.
### Alternatives
_No response_
### Additional context
**Previous RFC on extending AMP fp16 on CPU:**
* https://github.com/pytorch/pytorch/issues/96093
**Float16 support in torch inductor** working in parallel (implemented in similar method as BFloat16 support), has dependency on explicit vectorization utils of `at::vec::Vectorized<Half>`.
**Pull Requests related to this feature requests:**
* https://github.com/pytorch/pytorch/pull/96076
* https://github.com/pytorch/pytorch/pull/96077
* https://github.com/pytorch/pytorch/pull/96078
* https://github.com/pytorch/pytorch/pull/96079
* https://github.com/pytorch/pytorch/pull/96080
* https://github.com/pytorch/pytorch/pull/96081
* https://github.com/pytorch/pytorch/pull/96082
cc @jgong5 @XiaobingSuper @sanchitintel @ashokei @jingxu10
| 1 |
3,186 | 97,047 |
Optimize for mobile produces incorrect result with INSERT_FOLD_PREPACK_OPS optimization
|
oncall: jit, oncall: mobile, actionable
|
### 🐛 Describe the bug
When my model is saved with default parameters for `optimize_for_mobile` it yields incorrect output.
If I add `INSERT_FOLD_PREPACK_OPS` to the blocklist, the result is correct.
```python
torchscript_model = torch.jit.script(model)
torchscript_model_optimized = optimize_for_mobile(torchscript_model, optimization_blocklist={MobileOptimizerType.INSERT_FOLD_PREPACK_OPS})
torchscript_model_optimized._save_for_lite_interpreter("model.ptl")
```
I'm happy to provide any additional info, including my source code and model weights. However, it's proprietary, so I won't post them to the public.
### Versions
PyTorch version: 1.14.0.dev20221110
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: version 3.25.0
Libc version: N/A
Python version: 3.9.12 (main, Jun 1 2022, 06:34:44) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-13.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M1 Pro
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] numpydoc==1.2
[pip3] torch==1.14.0.dev20221110
[pip3] torchaudio==0.14.0.dev20221110
[pip3] torchfile==0.1.0
[pip3] torchsummary==1.5.1
[pip3] torchvision==0.15.0.dev20221110
[conda] nomkl 3.0 0
[conda] numpy 1.23.4 pypi_0 pypi
[conda] numpydoc 1.2 pyhd3eb1b0_0
[conda] torch 1.14.0.dev20221110 pypi_0 pypi
[conda] torchaudio 0.14.0.dev20221110 pypi_0 pypi
[conda] torchfile 0.1.0 pypi_0 pypi
[conda] torchsummary 1.5.1 pypi_0 pypi
[conda] torchvision 0.15.0.dev20221110 pypi_0 pypi
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 1 |
3,187 | 97,030 |
DDP static graph fails for static model
|
oncall: distributed, triaged, module: ddp
|
### 🐛 Describe the bug
```
class M(nn.Module):
def __init__(self):
super().__init__()
self.a = nn.Linear(10, 10)
self.b = nn.Linear(10, 10)
def forward(self, x):
a = self.a(x)
b = self.b(x)
return (a, b)
m = M().cuda()
ddp = torch.nn.parallel.DistributedDataParallel(
m, device_ids=[self.rank], static_graph=True
)
inp = torch.rand(1, 10, device='cuda')
for _ in range(6):
out = ddp(inp)[0]
out.sum().backward()
# b's gradient should be None.
self.assertEqual(None, m.b.weight.grad)
self.assertEqual(None, m.b.bias.grad)
```
results in
```
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your training graph has changed in this iteration, e.g., one parameter is used in first iteration, but then got unused in the second iteration. this is not compatible with static_graph set to True.
```
### Versions
main
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 2 |
3,188 | 97,026 |
How to get list of all valid devices?
|
module: docs, triaged
|
### 📚 The doc issue
`torch.testing.get_all_device_types()`
yields all valid devices on the current machine however unlike `torch._tensor_classes` , `torch.testing.get_all_dtypes()`, and `import typing; typing.get_args(torch.types.Device)`, there doesn't seem to be a comprehensive list of all valid device types, which gets listed when I force an error
```
torch.devcie('asdasjdfas')
RuntimeError: Expected one of cpu, cuda, ipu, xpu, mkldnn, opengl, opencl, ideep, hip, ve, fpga, ort, xla, lazy, vulkan, mps, meta, hpu, privateuseone device type at start of device string: asdasjdfas
```
### Suggest a potential alternative/fix
```
torch._device_names = cpu, cuda, ipu, xpu, mkldnn, opengl, opencl, ideep, hip, ve, fpga, ort, xla, lazy, vulkan, mps, meta, hpu, privateuseone
```
cc @svekars @carljparker
| 0 |
3,189 | 97,018 |
Convnext breaks torch.compile
|
triaged, oncall: pt2
|
### 🐛 Describe the bug
Hi :wave:
Trying to `torch.compile` convnext results in a triton error.
It works for other models, e.g. vit and resnet.
I also would like to ask for help reading the error, I am not experienced but I'd like to understand what the error is telling me.
```python
import torch
from torchvision.models import convnext_base
model = convnext_base()
model = model.cuda().half()
model = torch.compile(model, mode="max-autotune")
x = torch.randn((1, 3, 224, 224), device="cuda").half()
with torch.no_grad():
model(x)
```
Error
```
[2023-03-17 14:18:03,439] torch._inductor.utils: [WARNING] using triton random, expect difference from eager
Traceback (most recent call last):
File "/home/zuppif/Documents/medium/pytorch-2.0-compile/convnext.py", line 13, in <module>
model(x)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/eval_frame.py", line 99, in __call__
return self.dynamo_ctx(self._orig_mod.__call__)(*args, **kwargs)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/eval_frame.py", line 235, in _fn
return fn(*args, **kwargs)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/eval_frame.py", line 372, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 405, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 105, in _fn
return fn(*args, **kwargs)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 263, in _convert_frame_assert
return _compile(
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 164, in time_wrapper
r = func(*args, **kwargs)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 325, in _compile
out_code = transform_code_object(code, transform)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/bytecode_transformation.py", line 530, in transform_code_object
transformations(instructions, code_options)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 312, in transform
tracer.run()
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 1842, in run
super().run()
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 598, in run
and self.step()
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 561, in step
getattr(self, inst.opname)(inst)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 1921, in RETURN_VALUE
self.output.compile_subgraph(
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/output_graph.py", line 545, in compile_subgraph
self.compile_and_call_fx_graph(tx, list(reversed(stack_values)), root)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/output_graph.py", line 615, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 164, in time_wrapper
r = func(*args, **kwargs)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/output_graph.py", line 701, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e).with_traceback(
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/output_graph.py", line 697, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/debug_utils.py", line 1064, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/__init__.py", line 1527, in __call__
return compile_fx(model_, inputs_, config_patches=self.config)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_inductor/compile_fx.py", line 411, in compile_fx
return compile_fx(
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_inductor/compile_fx.py", line 515, in compile_fx
return aot_autograd(
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/backends/common.py", line 59, in compiler_fn
cg = aot_module_simplified(gm, example_inputs, **kwargs)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 2987, in aot_module_simplified
compiled_fn = create_aot_dispatcher_function(
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 164, in time_wrapper
r = func(*args, **kwargs)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 2668, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_args, aot_config, fw_metadata=fw_metadata)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 1770, in aot_wrapper_dedupe
return compiler_fn(flat_fn, leaf_flat_args, aot_config, fw_metadata=fw_metadata)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 1943, in aot_wrapper_synthetic_base
return compiler_fn(flat_fn, flat_args, aot_config, fw_metadata=fw_metadata)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 1252, in aot_dispatch_base
compiled_fw = aot_config.fw_compiler(fw_module, flat_args)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 164, in time_wrapper
r = func(*args, **kwargs)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_inductor/compile_fx.py", line 483, in fw_compiler
return inner_compile(
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/contextlib.py", line 79, in inner
return func(*args, **kwds)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/debug_utils.py", line 598, in debug_wrapper
compiled_fn = compiler_fn(gm, example_inputs)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_inductor/debug.py", line 239, in inner
return fn(*args, **kwargs)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/contextlib.py", line 79, in inner
return func(*args, **kwds)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_inductor/compile_fx.py", line 182, in compile_fx_inner
compiled_fn = graph.compile_to_fn()
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_inductor/graph.py", line 648, in compile_to_fn
return self.compile_to_module().call
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 164, in time_wrapper
r = func(*args, **kwargs)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_inductor/graph.py", line 626, in compile_to_module
mod = PyCodeCache.load(code)
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_inductor/codecache.py", line 654, in load
exec(code, mod.__dict__, mod.__dict__)
File "/tmp/torchinductor_zuppif/kx/ckxfxxrav4eqlbxhp4vwjdwmi7wieclub23mynkqzi5d3lolcl6f.py", line 3106, in <module>
async_compile.wait(globals())
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_inductor/codecache.py", line 841, in wait
scope[key] = result.result()
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/site-packages/torch/_inductor/codecache.py", line 699, in result
self.future.result()
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/concurrent/futures/_base.py", line 439, in result
return self.__get_result()
File "/home/zuppif/miniconda3/envs/dl/lib/python3.9/concurrent/futures/_base.py", line 391, in __get_result
raise self._exception
torch._dynamo.exc.BackendCompilerFailed: backend='debug_wrapper' raised:
CompilationError: at 65:39:
def triton_(arg_A, arg_B, in_ptr2, in_ptr3, seed4, in_ptr5, out_ptr1):
GROUP_M : tl.constexpr = 8
EVEN_K : tl.constexpr = True
ALLOW_TF32 : tl.constexpr = False
ACC_TYPE : tl.constexpr = tl.float32
BLOCK_M : tl.constexpr = 64
BLOCK_N : tl.constexpr = 32
BLOCK_K : tl.constexpr = 32
A = arg_A
B = arg_B
M = 3136
N = 128
K = 512
stride_am = 512
stride_ak = 1
stride_bk = 1
stride_bn = 512
# based on triton.ops.matmul
pid = tl.program_id(0)
grid_m = (M + BLOCK_M - 1) // BLOCK_M
grid_n = (N + BLOCK_N - 1) // BLOCK_N
# re-order program ID for better L2 performance
width = GROUP_M * grid_n
group_id = pid // width
group_size = min(grid_m - group_id * GROUP_M, GROUP_M)
pid_m = group_id * GROUP_M + (pid % group_size)
pid_n = (pid % width) // (group_size)
rm = pid_m * BLOCK_M + tl.arange(0, BLOCK_M)
rn = pid_n * BLOCK_N + tl.arange(0, BLOCK_N)
ram = tl.max_contiguous(tl.multiple_of(rm % M, BLOCK_M), BLOCK_M)
rbn = tl.max_contiguous(tl.multiple_of(rn % N, BLOCK_N), BLOCK_N)
rk = tl.arange(0, BLOCK_K)
A = A + (ram[:, None] * stride_am + rk[None, :] * stride_ak)
B = B + (rk[:, None] * stride_bk + rbn[None, :] * stride_bn)
acc = tl.zeros((BLOCK_M, BLOCK_N), dtype=ACC_TYPE)
for k in range(K, 0, -BLOCK_K):
if EVEN_K:
a = tl.load(A)
b = tl.load(B)
else:
a = tl.load(A, mask=rk[None, :] < k, other=0.)
b = tl.load(B, mask=rk[:, None] < k, other=0.)
acc += tl.dot(a, b, allow_tf32=ALLOW_TF32)
A += BLOCK_K * stride_ak
B += BLOCK_K * stride_bk
# rematerialize rm and rn to save registers
rm = pid_m * BLOCK_M + tl.arange(0, BLOCK_M)
rn = pid_n * BLOCK_N + tl.arange(0, BLOCK_N)
idx_m = rm[:, None]
idx_n = rn[None, :]
mask = (idx_m < M) & (idx_n < N)
# inductor generates a suffix
xindex = idx_n + (128*idx_m)
tmp0 = tl.load(in_ptr2 + (idx_n + tl.zeros(mask.shape, tl.int32)), mask).to(tl.float32)
tmp1 = tl.load(in_ptr3 + (idx_n + tl.zeros(mask.shape, tl.int32)), mask).to(tl.float32)
tmp4_load = tl.load(seed4 + (0))
tmp4 = tl.broadcast_to(tmp4_load, [XBLOCK])
^
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
Cheers,
Fra
### Versions
Collecting environment information...
PyTorch version: 2.1.0.dev20230316+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.10 (x86_64)
GCC version: (Ubuntu 12.2.0-3ubuntu1) 12.2.0
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.36
Python version: 3.9.13 (main, Aug 25 2022, 23:26:10) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.19.0-35-generic-x86_64-with-glibc2.36
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090
Nvidia driver version: 525.60.11
cuDNN version: Probably one of the following:
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_train.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_train.so.8
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 43 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 7 2700X Eight-Core Processor
CPU family: 23
Model: 8
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
Stepping: 2
Frequency boost: enabled
CPU(s) scaling MHz: 78%
CPU max MHz: 3700,0000
CPU min MHz: 2200,0000
BogoMIPS: 7400.05
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate ssbd ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif overflow_recov succor smca sev sev_es
Virtualization: AMD-V
L1d cache: 256 KiB (8 instances)
L1i cache: 512 KiB (8 instances)
L2 cache: 4 MiB (8 instances)
L3 cache: 16 MiB (2 instances)
NUMA node(s): 1
NUMA node0 CPU(s): 0-15
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT vulnerable
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.24.1
[pip3] pytorch-lightning==2.0.0
[pip3] pytorch-triton==2.1.0+2c32f43999
[pip3] torch==2.1.0.dev20230316+cu117
[pip3] torchaudio==0.12.1+cu116
[pip3] torchmetrics==0.11.4
[pip3] torchtriton==2.0.0+0d7e753227
[pip3] torchvision==0.16.0.dev20230316+cu117
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-lightning 2.0.0 pypi_0 pypi
[conda] pytorch-triton 2.1.0+2c32f43999 pypi_0 pypi
[conda] torch 2.1.0.dev20230316+cu117 pypi_0 pypi
[conda] torchaudio 0.12.1+cu116 pypi_0 pypi
[conda] torchmetrics 0.11.4 pypi_0 pypi
[conda] torchtriton 2.0.0+0d7e753227 pypi_0 pypi
[conda] torchvision 0.16.0.dev20230316+cu117 pypi_0 pypi
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
3,190 | 97,016 |
[Inductor] atomic_add does not support bf16
|
triaged, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
This is may be known already, but triton does not support `atomic_add` with bf16, see https://github.com/openai/triton/blob/c9740f0870f6ae2480acd2a76a5fb4c920bc5ce5/python/triton/language/semantic.py#L904.
This is not a problem in eager mode, only with `torch.compile` as it works right now, ideally this op should not be currently selected?
I made a minified repro below, but there is probably an even easier way to replicate this, I'm just unsure how to exactly trigger `atomic_add`.
### Error logs
```
raise ValueError("atomic_" + op + " does not support " + str(element_ty))
ValueError: atomic_add does not support bf16
The above exception was the direct cause of the following exception:
```
```
triton.compiler.CompilationError: at 11:85:
def triton_(in_ptr0, in_ptr1, out_ptr0, xnumel, XBLOCK : tl.constexpr):
xnumel = 61440
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:]
xmask = xindex < xnumel
x1 = (xindex // 768)
x2 = xindex
x0 = xindex % 768
tmp0 = tl.load(in_ptr0 + (x1), None)
tmp1 = tl.load(in_ptr1 + (x2), None).to(tl.float32)
tl.atomic_add(out_ptr0 + (x0 + (768*tmp0) + tl.zeros([XBLOCK], tl.int32)), tmp1, None)
^
```
### Minified repro
```
import torch._inductor.overrides
import torch
from torch import tensor, device
import torch.fx as fx
from torch._dynamo.testing import rand_strided
from math import inf
from torch.fx.experimental.proxy_tensor import make_fx
import torch._dynamo.config
import torch._inductor.config
import torch._functorch.config
torch._dynamo.config.load_config(b'\x80\x02}q\x00(X\x0b\x00\x00\x00output_codeq\x01\x89X\r\x00\x00\x00log_file_nameq\x02NX\x07\x00\x00\x00verboseq\x03\x89X\x11\x00\x00\x00output_graph_codeq\x04\x89X\x12\x00\x00\x00verify_correctnessq\x05\x89X\x12\x00\x00\x00minimum_call_countq\x06K\x01X\x15\x00\x00\x00dead_code_eliminationq\x07\x88X\x10\x00\x00\x00cache_size_limitq\x08K@X\x0e\x00\x00\x00specialize_intq\t\x88X\x0e\x00\x00\x00dynamic_shapesq\n\x89X\x18\x00\x00\x00assume_static_by_defaultq\x0b\x89X\x10\x00\x00\x00guard_nn_modulesq\x0c\x89X\x1b\x00\x00\x00traceable_tensor_subclassesq\rc__builtin__\nset\nq\x0e]q\x0f\x85q\x10Rq\x11X\x0f\x00\x00\x00suppress_errorsq\x12\x89X\x15\x00\x00\x00replay_record_enabledq\x13\x89X \x00\x00\x00rewrite_assert_with_torch_assertq\x14\x88X\x12\x00\x00\x00print_graph_breaksq\x15\x89X\x07\x00\x00\x00disableq\x16\x89X*\x00\x00\x00allowed_functions_module_string_ignorelistq\x17h\x0e]q\x18(X\x0b\x00\x00\x00torch._refsq\x19X\x0c\x00\x00\x00torch._primsq\x1aX\x13\x00\x00\x00torch.distributionsq\x1bX\r\x00\x00\x00torch._decompq\x1cX\r\x00\x00\x00torch.testingq\x1de\x85q\x1eRq\x1fX\x12\x00\x00\x00repro_forward_onlyq \x89X\x0f\x00\x00\x00repro_toleranceq!G?PbM\xd2\xf1\xa9\xfcX\x16\x00\x00\x00capture_scalar_outputsq"\x89X \x00\x00\x00capture_dynamic_output_shape_opsq#\x89X\x19\x00\x00\x00enforce_cond_guards_matchq$\x88X\x0c\x00\x00\x00optimize_ddpq%\x88X\x1a\x00\x00\x00raise_on_ctx_manager_usageq&\x88X\x1c\x00\x00\x00raise_on_unsafe_aot_autogradq\'\x89X\x17\x00\x00\x00raise_on_backend_changeq(\x89X\x18\x00\x00\x00error_on_nested_fx_traceq)\x88X\t\x00\x00\x00allow_rnnq*\x89X\x08\x00\x00\x00base_dirq+X;\x00\x00\x00/home/jonas/miniconda3/envs/dl/lib/python3.10/site-packagesq,X\x0e\x00\x00\x00debug_dir_rootq-XN\x00\x00\x00/home/jonas/Dropbox/Documents_Hyperion/Python/cramming-dev/torch_compile_debugq.X)\x00\x00\x00DO_NOT_USE_legacy_non_fake_example_inputsq/\x89X\x13\x00\x00\x00_save_config_ignoreq0h\x0e]q1(X!\x00\x00\x00skipfiles_inline_module_allowlistq2X\x12\x00\x00\x00constant_functionsq3X\x0b\x00\x00\x00repro_levelq4X\x0b\x00\x00\x00repro_afterq5e\x85q6Rq7u.')
torch._inductor.config.load_config(b'\x80\x02}q\x00(X\x05\x00\x00\x00debugq\x01\x89X\x10\x00\x00\x00disable_progressq\x02\x88X\x10\x00\x00\x00verbose_progressq\x03\x89X\x0b\x00\x00\x00cpp_wrapperq\x04\x89X\x03\x00\x00\x00dceq\x05\x89X\x14\x00\x00\x00static_weight_shapesq\x06\x88X\x0c\x00\x00\x00size_assertsq\x07\x88X\x10\x00\x00\x00pick_loop_ordersq\x08\x88X\x0f\x00\x00\x00inplace_buffersq\t\x88X\x11\x00\x00\x00benchmark_harnessq\n\x88X\x0f\x00\x00\x00epilogue_fusionq\x0b\x89X\x15\x00\x00\x00epilogue_fusion_firstq\x0c\x89X\x0f\x00\x00\x00pattern_matcherq\r\x88X\n\x00\x00\x00reorderingq\x0e\x89X\x0c\x00\x00\x00max_autotuneq\x0f\x89X\x15\x00\x00\x00search_autotune_cacheq\x10\x89X\x17\x00\x00\x00realize_reads_thresholdq\x11K\x04X\x17\x00\x00\x00realize_bytes_thresholdq\x12M\xd0\x07X\x1b\x00\x00\x00realize_acc_reads_thresholdq\x13K\x08X\x0f\x00\x00\x00fallback_randomq\x14\x89X\x12\x00\x00\x00implicit_fallbacksq\x15\x88X\x0b\x00\x00\x00tune_layoutq\x16\x89X\x11\x00\x00\x00aggressive_fusionq\x17\x89X\x0f\x00\x00\x00max_fusion_sizeq\x18K@X\x1b\x00\x00\x00unroll_reductions_thresholdq\x19K\x08X\x0e\x00\x00\x00comment_originq\x1a\x89X\x10\x00\x00\x00benchmark_kernelq\x1b\x89X\x12\x00\x00\x00developer_warningsq\x1c\x89X\x0f\x00\x00\x00compile_threadsq\x1dK\x10X\x11\x00\x00\x00global_cache_pathq\x1eNX\x13\x00\x00\x00kernel_name_max_opsq\x1fK\nX\r\x00\x00\x00shape_paddingq \x89X\x0e\x00\x00\x00permute_fusionq!\x89X\x1a\x00\x00\x00profiler_mark_wrapper_callq"\x89X\x18\x00\x00\x00_raise_error_for_testingq#\x89X\x0c\x00\x00\x00_profile_varq$X\x00\x00\x00\x00q%X\x11\x00\x00\x00profile_bandwidthq&\x89X\x17\x00\x00\x00profile_bandwidth_regexq\'h%X\x0b\x00\x00\x00cpp.threadsq(J\xff\xff\xff\xffX\x13\x00\x00\x00cpp.dynamic_threadsq)\x89X\x0b\x00\x00\x00cpp.simdlenq*NX\x12\x00\x00\x00cpp.min_chunk_sizeq+M\x00\x10X\x07\x00\x00\x00cpp.cxxq,NX\x03\x00\x00\x00g++q-\x86q.X\x19\x00\x00\x00cpp.enable_kernel_profileq/\x89X\x12\x00\x00\x00cpp.weight_prepackq0\x88X\x11\x00\x00\x00triton.cudagraphsq1\x89X\x17\x00\x00\x00triton.debug_sync_graphq2\x89X\x18\x00\x00\x00triton.debug_sync_kernelq3\x89X\x15\x00\x00\x00triton.dense_indexingq4\x89X\x10\x00\x00\x00triton.max_tilesq5K\x02X\x19\x00\x00\x00triton.autotune_pointwiseq6\x88X\'\x00\x00\x00triton.tiling_prevents_pointwise_fusionq7\x88X\'\x00\x00\x00triton.tiling_prevents_reduction_fusionq8\x88X\x1b\x00\x00\x00triton.ordered_kernel_namesq9\x89X\x1f\x00\x00\x00triton.descriptive_kernel_namesq:\x89X\x1c\x00\x00\x00triton.persistent_reductionsq;\x88X\x10\x00\x00\x00triton.max_blockq<}q=(X\x01\x00\x00\x00Xq>M\x00\x08X\x01\x00\x00\x00Yq?M\x00\x04X\x01\x00\x00\x00Zq@M\x00\x04uX\r\x00\x00\x00trace.enabledqA\x89X\x0f\x00\x00\x00trace.debug_logqB\x88X\x0e\x00\x00\x00trace.info_logqC\x89X\x0e\x00\x00\x00trace.fx_graphqD\x88X\x1a\x00\x00\x00trace.fx_graph_transformedqE\x88X\x13\x00\x00\x00trace.ir_pre_fusionqF\x88X\x14\x00\x00\x00trace.ir_post_fusionqG\x88X\x11\x00\x00\x00trace.output_codeqH\x88X\x13\x00\x00\x00trace.graph_diagramqI\x89X\x15\x00\x00\x00trace.compile_profileqJ\x89X\x10\x00\x00\x00trace.upload_tarqKNu.')
torch._functorch.config.load_config(b'\x80\x02}q\x00(X\x11\x00\x00\x00use_functionalizeq\x01\x88X\x0f\x00\x00\x00use_fake_tensorq\x02\x88X\x16\x00\x00\x00fake_tensor_allow_metaq\x03\x88X\x0c\x00\x00\x00debug_assertq\x04\x88X\x14\x00\x00\x00debug_fake_cross_refq\x05\x89X\x11\x00\x00\x00debug_partitionerq\x06\x89X\x0c\x00\x00\x00debug_graphsq\x07\x89X\x0b\x00\x00\x00debug_jointq\x08\x89X\x14\x00\x00\x00static_weight_shapesq\t\x88X\x03\x00\x00\x00cseq\n\x88X\x10\x00\x00\x00max_dist_from_bwq\x0bK\x03X\t\x00\x00\x00log_levelq\x0cK\x14u.')
from torch.nn import *
class Repro(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, arg27_1, mm_1, full):
index_put = torch.ops.aten.index_put.default(full, [arg27_1], mm_1, True); full = arg27_1 = mm_1 = None
return (index_put,)
args = [((80,), (1,), torch.int64, 'cuda'), ((80, 768), (768, 1), torch.bfloat16, 'cuda'), ((512, 768), (768, 1), torch.bfloat16, 'cuda')]
args = [rand_strided(sh, st, dt, dev) for (sh, st, dt, dev) in args]
mod = make_fx(Repro(), tracing_mode='real')(*args)
from torch._inductor.compile_fx import compile_fx_inner
from torch._dynamo.debug_utils import same_two_models
compiled = compile_fx_inner(mod, args)
ref = compiled(args)
torch.cuda.synchronize() # Ensures that segfaults are surfaced
```
### Versions
```
PyTorch version: 2.1.0.dev20230316
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Pop!_OS 22.04 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.10.9 (main, Mar 1 2023, 18:23:06) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-6.2.0-76060200-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.5.119
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3050 Ti Laptop GPU
Nvidia driver version: 525.85.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.1.0.dev20230316
[pip3] torchaudio==2.0.0.dev20230317
[pip3] torchvision==0.16.0.dev20230317
[conda] blas 1.0 mkl
[conda] lion-pytorch 0.0.7 pypi_0 pypi
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.5 py310hd5efca6_0
[conda] numpy-base 1.23.5 py310h8e6c178_0
[conda] pytorch 2.1.0.dev20230316 py3.10_cuda11.8_cudnn8.7.0_0 pytorch-nightly
[conda] pytorch-cuda 11.8 h7e8668a_3 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] torchaudio 2.0.0.dev20230317 py310_cu118 pytorch-nightly
[conda] torchtriton 2.1.0+2c32f43999 py310 pytorch-nightly
[conda] torchvision 0.16.0.dev20230317 py310_cu118 pytorch-nightly
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 9 |
3,191 | 97,014 |
deprecate integral and boolean dtype support torch.logit and torch.special.logit
|
triaged, module: deprecation, module: special
|
### 🐛 Describe the bug
Valid domain for these functions is (0, 1). So it doesn't make sense to support integral or boolean inputs for them as there are only two valid values (which produce -inf and inf respectively).
Thanks @pmeier for finding this.
More context: https://github.com/pytorch/pytorch/pull/96124#issuecomment-1471973352
### Versions
master
cc @mruberry
| 0 |
3,192 | 97,006 |
[Feature Request] Compile compatible Neighborhood Algorithms for large Tensors
|
triaged, oncall: pt2
|
### 🚀 The feature, motivation and pitch
For large tensors, neighborhood algorithms are limited by large memory requirements, for example the squared-distance matrix of KNN.
Speaking from my field of 3D analysis, a pointcloud scan can easily have >100.000 coordinates. A reconstructed scene of 500m can have up to 1 Billion data points. Applying neighborhood algorithms on such data is only possible with specialized frameworks such as PyKeOps or FAISS. To my knowledge, this also affects graph convolutional networks
This request was denied in the past due to compatible frameworks. Now with the introduction of .compile() this has changed.
This request is for .compile() PyTorch native neighborhood algorithms, optimized for very large tensors.
### Alternatives
(Not .compile() compatible)
PyKeOps
Faiss
### Additional context
_No response_
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 8 |
3,193 | 97,004 |
Small learning rate with `capturable=True` causes Adam optimizer to blow up model parameters.
|
module: optimizer, triaged
|
### 🐛 Describe the bug
When setting the `capturable` argument of Adam optimizer to `True`, the call of `optimizer.step` will use the following routine (line 267~ 290 in `torch/optim/adam.py`):
```
if capturable:
......
step_size = lr / bias_correction1
step_size_neg = step_size.neg()
......
else:
denom = (exp_avg_sq.sqrt() / (bias_correction2_sqrt * step_size_neg)).add_(eps / step_size_neg)
param.addcdiv_(exp_avg, denom)
```
This will cause overflow when `lr` is very small.
### Versions
Below are some relevant version information.
```
PyTorch version: 1.12.0
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0] (64-bit runtime)
Versions of relevant libraries:
[pip3] torch==1.12.0
[conda] pytorch 1.12.0 py3.8_cuda11.3_cudnn8.3.2_0 pytorch
```
cc @vincentqb @jbschlosser @albanD @janeyx99
| 4 |
3,194 | 96,997 |
[Inductor] [CPU] Torchbench model hf_Reformer performance regression > 10% on 2023-03-15 nightly release
|
triaged, oncall: pt2, module: inductor, module: cpu inductor
|
### 🐛 Describe the bug
Compare with the benchmarks_update based on 2023-03-12, there is a performance regression on torchbench model **hf_Reformer** on [TorchInductor CPU Performance Dashboard](https://github.com/pytorch/pytorch/issues/93531#issuecomment-1473049949) on 2023-03-15 as bellow:
| 2023-03-15 | | | | update-2023-03-12 | | | | Result Comp | | |
| ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- |
| batch_size | speedup | inductor | eager | batch_size | speedup | inductor | eager | speedup ratio | eager ratio | inductor ratio |
|1 |0.9103 |0.4018883 |0.365838919 |1 |1.0173 |0.3548287 |0.360967237 |0.89 |0.99 |0.88
2023-03-15 nightly release SW information:
SW | Nightly commit | Master/Main commit
-- | -- | --
Pytorch|[4f7cbd0](https://github.com/pytorch/pytorch/commit/4f7cbd0)|[c6a82e4](https://github.com/pytorch/pytorch/commit/c6a82e4)
Torchbench|/|[83a316df](https://github.com/pytorch/benchmark/commit/83a316df)
torchaudio|[375e751](https://github.com/pytorch/audio/commit/375e751)|[a8f4e97](https://github.com/pytorch/audio/commit/a8f4e97)
torchtext|[9749082](https://github.com/pytorch/text/commit/9749082)| [46e7eef](https://github.com/pytorch/text/commit/46e7eef)
torchvision|[8d15ca7](https://github.com/pytorch/vision/commit/8d15ca7)|[98c5815](https://github.com/pytorch/vision/commit/98c5815)
torchdata|[b3048d5](https://github.com/pytorch/data/commit/b3048d5)|[f1283eb](https://github.com/pytorch/data/commit/f1283eb)
dynamo_benchmarks|[1238ae3](https://github.com/pytorch/pytorch/commit/1238ae3)|/
update 2023-03-12 nightly release SW information:
SW | Nightly commit | Master/Main commit
-- | -- | --
Pytorch|[1238ae3](https://github.com/pytorch/pytorch/commit/1238ae3)|[82d3d05](https://github.com/pytorch/pytorch/commit/82d3d05)
Torchbench|/|[83a316df](https://github.com/pytorch/benchmark/commit/83a316df)
torchaudio|[375e751](https://github.com/pytorch/audio/commit/375e751)|[a8f4e97](https://github.com/pytorch/audio/commit/a8f4e97)
torchtext|[9749082](https://github.com/pytorch/text/commit/9749082)| [46e7eef](https://github.com/pytorch/text/commit/46e7eef)
torchvision|[8d15ca7](https://github.com/pytorch/vision/commit/8d15ca7)|[98c5815](https://github.com/pytorch/vision/commit/98c5815)
torchdata|[b3048d5](https://github.com/pytorch/data/commit/b3048d5)|[f1283eb](https://github.com/pytorch/data/commit/f1283eb)
dynamo_benchmarks|[1238ae3](https://github.com/pytorch/pytorch/commit/1238ae3)|/
Graph dump by cosim:
2023-03-15:
[graph.txt](https://github.com/pytorch/pytorch/files/10997500/graph.txt)
update-2023-03-12:
[graph.txt](https://github.com/pytorch/pytorch/files/10997505/graph.txt)
Minified repro:
```bash
python -m torch.backends.xeon.run_cpu --core_list 0 --ncores_per_instance 1 benchmarks/dynamo/torchbench.py --performance --float32 -dcpu -n50 --inductor --no-skip --dashboard --only hf_Reformer --cold_start_latency --batch_size 1 --threads 1
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 1 |
3,195 | 96,996 |
Get error: "tuple index with non-constant index" when exporting a model to ONNX format
|
module: onnx, triaged, onnx-needs-info
|
### 🐛 Describe the bug
I’m trying to convert a model to onnx format. A function is wrapped by torch.jit.script() in the model forward method. No other torch.jit.script() is uesd. The forward method is following:
```
def forward(self, img):
img = self.onnx_trans(img)
x = self.backbone(img)
x = self.neck(x)
mask_feat_pred = self.mask_feat_head(x[self.mask_feat_head.start_level:self.mask_feat_head.end_level + 1])
cate_preds, kernel_preds = self.bbox_head(x)
get_seg = torch.jit.script(get_seg_scripted)
seg_result = get_seg(cate_preds, kernel_preds, mask_feat_pred)
print(seg_result)
return seg_result
```
I use the following code to export the model:
```
cfg = Custom_light_res50(mode='detect')
cfg.print_cfg()
model = SOLOv2(cfg).cuda()
model.load_state_dict(torch.load(cfg.val_weight), strict=True)
model.eval()
input_size = (512, 512)
input_img = cv2.imread('detect_imgs/test1.bmp', cv2.IMREAD_COLOR)
input_img = cv2.resize(input_img, input_size)
input_img = torch.from_numpy(input_img).cuda()
torch.onnx.export(model,
input_img,
'seg.onnx',
input_names=['seg'],
output_names=['output'],
verbose=False,
opset_version=14)
```
I can get the correct value of variable `seg_result`. But still I get the error:
```
Traceback (most recent call last):
File "/home/feiyu/SOLOv2_minimal/ttt.py", line 99, in <module>
torch.onnx.export(model,
File "/home/feiyu/.local/lib/python3.10/site-packages/torch/onnx/utils.py", line 504, in export
_export(
File "/home/feiyu/.local/lib/python3.10/site-packages/torch/onnx/utils.py", line 1529, in _export
graph, params_dict, torch_out = _model_to_graph(
File "/home/feiyu/.local/lib/python3.10/site-packages/torch/onnx/utils.py", line 1115, in _model_to_graph
graph = _optimize_graph(
File "/home/feiyu/.local/lib/python3.10/site-packages/torch/onnx/utils.py", line 582, in _optimize_graph
_C._jit_pass_lower_all_tuples(graph)
RuntimeError: tuple index with non-constant index
```
Did I do anything wrong? Since I can already get the correct value, which means the forward computation is totally right. Why there’s still an error? Besides, the variable `seg_result` is the final result that I want to get. It's structure: `[[torch.Tensor, torch.Tensor, torch.Tensor]]`. No other procedure after `seg_result` returned.
### Versions
Collecting environment information...
PyTorch version: 1.13.1+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.2 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.19.0-35-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090
Nvidia driver version: 510.108.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn.so.8
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_train.so.8
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_train.so.8
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 20
On-line CPU(s) list: 0-19
Vendor ID: GenuineIntel
Model name: Intel(R) Core(TM) i9-10900K CPU @ 3.70GHz
CPU family: 6
Model: 165
Thread(s) per core: 2
Core(s) per socket: 10
Socket(s): 1
Stepping: 5
CPU max MHz: 5300.0000
CPU min MHz: 800.0000
BogoMIPS: 7399.70
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp pku ospke md_clear flush_l1d arch_capabilities
Virtualization: VT-x
L1d cache: 320 KiB (10 instances)
L1i cache: 320 KiB (10 instances)
L2 cache: 2.5 MiB (10 instances)
L3 cache: 20 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-19
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Mitigation; Microcode
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==1.13.1+cu116
[pip3] torchvision==0.14.1+cu116
[conda] Could not collect
| 5 |
3,196 | 96,982 |
[mps] conv1d outputs zeros
|
triaged, module: mps
|
### 🐛 Describe the bug
HI! I'm getting tensors filled with zeros when using `mps`with "large" inputs and outputs.
```python
import torch
from torch.nn.functional import conv1d
device = "mps"
input_signal = torch.ones(size=(4, 1, 385360)).to(device)
kernel = torch.ones(size=(352, 1, 65536)).to(device)
output_signal = conv1d(input_signal, kernel)
print(output_signal) ## This should be full of ones, but it is however full of zeros.
#### This behaviour does not happen if, for example, the kernel is smaller
kernel = torch.ones(size=(1, 1, 1)).to(device)
output_signal = conv1d(input_signal, kernel)
print(output_signal) ## Has ones everywhere, as expected
```
I wonder if this is related to #88308 and #96716, as they are also resulting into matrices of zeros when using `mps`
### Versions
```PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.2.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: Could not collect
Libc version: N/A
Python version: 3.10.10 (main, Mar 4 2023, 23:23:44) [Clang 14.0.0 (clang-1400.0.29.202)] (64-bit runtime)
Python platform: macOS-13.2.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M2 Pro```
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.1
[pip3] torchmetrics==0.10.1
[conda] Could not collect
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
3,197 | 96,981 |
[ONNX] Export failed for Module with Keyword-only inputs
|
module: onnx, triaged, onnx-needs-info
|
### 🐛 Describe the bug
`torch.onnx.export` cannot export a Module which takes in Keyword-only arguments in its forward function.
Example:
```python
import torch
import torch.nn as nn
class MyModel(nn.Module):
def forward(self, *, inp):
# Must be called with inp=...
return inp
model = MyModel()
print("Forward pass works: ", model(inp=torch.zeros(4)), "\n")
# Keyword arguments given to torch.onnx.export as a dictionary
# See https://pytorch.org/docs/stable/onnx.html#torch.onnx.export
args = ({"inp": torch.zeros(4)},)
# Fails
torch.onnx.export(model, args, "pytorch_test.onnx")
```
Logs:
```
Forward pass works: tensor([0., 0., 0., 0.])
============= Diagnostic Run torch.onnx.export version 2.0.0+cu117 =============
verbose: False, log level: Level.ERROR
======================= 0 NONE 0 NOTE 0 WARNING 0 ERROR ========================
Traceback (most recent call last):
File "/home/isherstyuk/trt/unclippipeline_trt/pytorch_test.py", line 16, in <module>
torch.onnx.export(model, args, "pytorch_test.onnx")
File "/home/isherstyuk/.local/lib/python3.10/site-packages/torch/onnx/utils.py", line 506, in export
_export(
File "/home/isherstyuk/.local/lib/python3.10/site-packages/torch/onnx/utils.py", line 1548, in _export
graph, params_dict, torch_out = _model_to_graph(
File "/home/isherstyuk/.local/lib/python3.10/site-packages/torch/onnx/utils.py", line 1113, in _model_to_graph
graph, params, torch_out, module = _create_jit_graph(model, args)
File "/home/isherstyuk/.local/lib/python3.10/site-packages/torch/onnx/utils.py", line 989, in _create_jit_graph
graph, torch_out = _trace_and_get_graph_from_model(model, args)
File "/home/isherstyuk/.local/lib/python3.10/site-packages/torch/onnx/utils.py", line 893, in _trace_and_get_graph_from_model
trace_graph, torch_out, inputs_states = torch.jit._get_trace_graph(
File "/home/isherstyuk/.local/lib/python3.10/site-packages/torch/jit/_trace.py", line 1268, in _get_trace_graph
outs = ONNXTracedModule(f, strict, _force_outplace, return_inputs, _return_inputs_states)(*args, **kwargs)
File "/home/isherstyuk/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/isherstyuk/.local/lib/python3.10/site-packages/torch/jit/_trace.py", line 127, in forward
graph, out = torch._C._create_graph_by_tracing(
File "/home/isherstyuk/.local/lib/python3.10/site-packages/torch/jit/_trace.py", line 118, in wrapper
outs.append(self.inner(*trace_inputs))
File "/home/isherstyuk/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/isherstyuk/.local/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1488, in _slow_forward
result = self.forward(*input, **kwargs)
TypeError: MyModel.forward() takes 1 positional argument but 2 were given
```
The reason this is happening is that `torch.onnx.export` transforms the given keyword args into positional args, as seen here https://github.com/pytorch/pytorch/blob/v2.0.0/torch/onnx/utils.py#L821-L857. This works for 99% of cases since most keyword arguments can also be passed in as positional arguments, I think it is pretty rare to have keyword-only arguments. [Here](https://docs.python.org/3.10/library/inspect.html#inspect.Parameter.kind) is a reference about types of arguments in python I found useful.
### Versions
Versions of relevant libraries:
[pip3] numpy==1.23.1
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.1
[pip3] torchvision==0.15.1
[pip3] triton==2.0.0
[conda] Could not collect
| 4 |
3,198 | 96,972 |
Adding sparse `addmv` and `triangular_solve` support on CPU - Mac OS - Apple Silicon M2
|
module: sparse, triaged, module: macos, module: arm
|
### 🚀 The feature, motivation and pitch
As discussed in https://github.com/pytorch/pytorch/issues/77764#issuecomment-1472510169 it would be helpful to have a CPU fallback for [`torch.addmv`](https://pytorch.org/docs/stable/generated/torch.addmv.html?highlight=addmv#torch.addmv) on Mac OS when using sparse matrices.
### Alternatives
Run on google colab or similar
### Additional context
Steps to reproduce the issue on Mac OS:
```python
import torch
print(f"Running PyTorch version: {torch.__version__}")
dtype = torch.float32
device = torch.device("cpu")
#device = torch.device("mps")
print(f"Using device: {device}")
#mat = torch.randn((4,4), dtype=dtype, device=device)
mat = torch.randn((4,4), dtype=dtype, device=device).relu().to_sparse_csr()
mvec = torch.randn((4,), dtype=dtype, device=device)
avec = torch.randn((4,), dtype=dtype, device=device)
ovec = torch.addmv(avec, mat, mvec)
print(ovec)
```
leading to
```
UserWarning: Sparse CSR tensor support is in beta state. If you miss a functionality in the sparse tensor support, please submit a feature request to https://github.com/pytorch/pytorch/issues. (Triggered internally at /Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/SparseCsrTensorImpl.cpp:56.)
mat = torch.randn((4,4), dtype=dtype, device=device).relu().to_sparse_csr()
Traceback (most recent call last):
File "[...]/test.py", line 14, in <module>
ovec = torch.addmv(avec, mat, mvec)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
RuntimeError: Calling addmv on a sparse CPU tensor requires compiling PyTorch with MKL. Please use PyTorch built MKL support.
```
It may be that MKL can be compiled for Mac OS (and thus shipped in the default pytorch distribution for mac) or maybe an less optimised alternative needs to be found (e.g. Eigen).
cc @alexsamardzic @nikitaved @pearu @cpuhrsch @amjames @bhosmer @malfet @albanD
| 21 |
3,199 | 96,964 |
GPU:7900xtx Pytorch2.0.0 rocBLAS error:
|
oncall: binaries, module: rocm, triaged
|
### 🐛 Describe the bug
```python
import torch
A = torch.ones(5, 5).to('cuda')
B = torch.ones(5, 5).to('cuda')
C = torch.matmul(A, B)
```
when program runing to calc C,i get this Message:
```
rocBLAS error: Cannot read /home/kali/miniconda3/envs/pytorch2/lib/python3.9/site-packages/torch/lib/rocblas/library/TensileLibrary.dat: No such file or directory
```
It is found that the reason is the lack of the rocblas library file with the architecture of gfx1100, so putting the gxf1100 library file into the rocblas directory in the python environment of conda can solve this problem
### Versions
GPU:AMD 7900XTX
OS:Ubuntu 22.04
Pytorch: 2.0.0
install by: pip install
Compiling the source code or repackaging the whl file containing the gfx1100 library files can solve this problem
cc @ezyang @seemethere @malfet @jeffdaily @sunway513 @jithunnair-amd @pruthvistony @ROCmSupport
| 2 |
3,200 | 96,949 |
TensorStorage error when deepcopying FX graph_module of Adam optimizer
|
module: optimizer, triaged, oncall: pt2
|
### 🐛 Describe the bug
When there is Adam optimizer inside torch.compile'd function, it is not possible to do deepcopy of the module.

My assumption is that after AOT, FX graph module is just a program description that at most contains FakeTensors which do not have storage and depending on backend needs, we should be able to deepcopy such module. It's not the case now it seems.
Attaching very small reproducer (need to change .txt to .py):
[repro.txt](https://github.com/pytorch/pytorch/files/10989598/repro.txt)
Reproducer uses Adam optimizer, I did not see such issue with SGD.
### Error logs

### Minified repro
_No response_
### Versions
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.9.16 (main, Dec 7 2022, 01:11:51) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.10.147+-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla T4
Nvidia driver version: 525.85.12
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 2
Core(s) per socket: 1
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) CPU @ 2.00GHz
Stepping: 3
CPU MHz: 2000.164
BogoMIPS: 4000.32
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32 KiB
L1i cache: 32 KiB
L2 cache: 1 MiB
L3 cache: 38.5 MiB
NUMA node0 CPU(s): 0,1
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Vulnerable; SMT Host state unknown
Vulnerability Meltdown: Vulnerable
Vulnerability Mmio stale data: Vulnerable
Vulnerability Retbleed: Vulnerable
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Vulnerable: __user pointer sanitization and usercopy barriers only; no swapgs barriers
Vulnerability Spectre v2: Vulnerable, IBPB: disabled, STIBP: disabled, PBRSB-eIBRS: Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Vulnerable
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves arat md_clear arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==2.0.0+cu117
[pip3] torchaudio==2.0.1+cu117
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.14.1
[pip3] torchvision==0.15.1+cu117
[pip3] triton==2.0.0
[conda] Could not collect
cc @vincentqb @jbschlosser @albanD @janeyx99 @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @anijain2305
| 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.