
Serial Number
int64 1
6k
| Issue Number
int64 75.6k
112k
| Title
stringlengths 3
357
| Labels
stringlengths 3
241
⌀ | Body
stringlengths 9
74.5k
⌀ | Comments
int64 0
867
|
|---|---|---|---|---|---|
3,001 | 98,269 |
Inconsistent nn.KLDivLoss behavior: 0s in target OK on cpu, but gives nan on mps
|
triaged, module: mps
|
### 🐛 Describe the bug
KLDivLoss is supposed to take the log of a probability distribution as target, sometimes this target contains 0s. This is handled correctly when device='cpu', but when device='mps' we get nans. Current workaround is to add some small eps to the target.
```python
torch.manual_seed(1)
x = torch.rand(10, 8, device='mps')
x = x / x.sum(dim=1, keepdim=True)
x = log_softmax(x, dim=-1)
y = torch.rand(10, 8, device='mps')
y = y / y.sum(dim=1, keepdim=True)
criterion = nn.KLDivLoss(reduction="sum")
print(criterion(x, y), criterion(x.to('cpu'), y.to('cpu')))
# mask out random entries of y
mask = torch.rand(10, 8, device='mps') < 0.5
y = y * mask
print(criterion(x, y), criterion(x.to('cpu'), y.to('cpu')))
```
Outputs:
```tensor(1.6974, device='mps:0') tensor(1.6974)```
```tensor(nan, device='mps:0') tensor(1.0370)```
### Versions
```
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.2.1 (x86_64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: Could not collect
Libc version: N/A
Python version: 3.10.10 (main, Mar 21 2023, 13:41:39) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M1 Pro
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.0
[pip3] torchvision==0.15.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 h0a44026_0 pytorch
[conda] mkl 2021.4.0 hecd8cb5_637
[conda] mkl-service 2.4.0 py310hca72f7f_0
[conda] mkl_fft 1.3.1 py310hf879493_0
[conda] mkl_random 1.2.2 py310hc081a56_0
[conda] numpy 1.23.5 py310h9638375_0
[conda] numpy-base 1.23.5 py310ha98c3c9_0
[conda] pytorch 2.0.0 py3.10_0 pytorch
[conda] torchaudio 2.0.0 py310_cpu pytorch
[conda] torchvision 0.15.0 py310_cpu pytorch```
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 5 |
3,002 | 98,268 |
hf_Longformer regression caused by https://github.com/pytorch/pytorch/pull/98119
|
triaged, oncall: pt2
|
Bisect points to https://github.com/pytorch/pytorch/pull/98119 and reverting it makes the error go away.
Repro:
```
python benchmarks/dynamo/torchbench.py --inductor --amp --training --accuracy --device cuda --only hf_Longformer
```
Error msg:
```
ValueError: Cannot view a tensor with shape torch.Size([4, 12, 1024, 513]) and strides (6303744, 513, 6156, 1) as a tensor with shape (48, 4, 256, 513)!
```
Q: Why is this not caught by CI?
A: Because `hf_Longformer` uses more than 24GB GPU memory, it is currently skipped on CI. I will fix this by running larger models on A100 instances.
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 5 |
3,003 | 98,260 |
Broken mypy check in test_type_hints.py::TestTypeHints::test_doc_examples
|
module: typing, triaged
|
### 🐛 Describe the bug
There are two problems with this test that surfaces today:
1. The `mypy==0.960` version we are using has a bug with Python 3.10.6+ https://github.com/python/mypy/issues/13627. It breaks for Python 3.11 in CI. The fix requires an upgrade to 0.981 or newer. The bug is that mypy not only checks stuffs in PyTorch, but also PyTorch dependencies. Specifically, it's numpy `/opt/conda/envs/py_3.11/lib/python3.11/site-packages/numpy/__init__.pyi:638:48: error: Positional-only parameters are only supported in Python 3.8 and greater [syntax]`. For example, https://hud.pytorch.org/pytorch/pytorch/commit/73b06a0268bb89c09a86f16fa0f72818baa4b250. I found a PR https://github.com/pytorch/pytorch/pull/91983 to upgrade mypy. Could we go ahead with that? (cc @ezyang @malfet @rgommers @xuzhao9 @gramster)
2. The test has been broken on ASAN after https://github.com/pytorch/pytorch/pull/94525 (cc @wanchaol) with the following error `mypy.ini:5:1: error: Error importing plugin "numpy.typing.mypy_plugin": No module named 'numpy.typing.mypy_plugin' [misc]`, for example https://github.com/pytorch/pytorch/actions/runs/4601886643/jobs/8130489457
So why today you ask? As these changes have been in trunk for a while. It turns out that `test_doc_examples` was slow, so it wasn't run in these jobs till now.
```
test_type_hints.py::TestTypeHints::test_doc_examples SKIPPED [0.0002s] (test is slow; run with PYTORCH_TEST_WITH_SLOW to enable test)
```
The test is run as part of [slow jobs](https://github.com/pytorch/pytorch/blob/master/.github/workflows/slow.yml) but they don't cover 3.11 nor ASAN to trigger those bugs (Ouch!)
I have disabled the test in the mean time while we take actions https://github.com/pytorch/pytorch/issues/98259
### Versions
PyTorch CI
| 0 |
3,004 | 98,259 |
DISABLED test_doc_examples (__main__.TestTypeHints)
|
module: typing, triaged, skipped
|
Platforms: linux
This test was disabled because it is failing on master ([recent examples](https://hud.pytorch.org/failure/%2Fopt%2Fconda%2Fenvs%2Fpy_3.11%2Flib%2Fpython3.11%2Fsite-packages%2Fnumpy%2F__init__.pyi%3A638%3A48%3A%20error%3A%20Positional-only%20parameters%20are%20only%20supported%20in%20Python%203.8%20and%20greater%20%20%5Bsyntax%5D)).
This looks like an upstream mypy issue https://github.com/python/mypy/issues/13627 as documented in https://github.com/pytorch/pytorch/pull/94255. Disable the test to investigate further
cc @ezyang @malfet @rgommers @xuzhao9 @gramster
| 4 |
3,005 | 98,256 |
[CUDA][MAGMA][Linalg] Remove MAGMA from CUDA linear algebra dependencies
|
triaged, open source, ciflow/trunk, release notes: releng, ciflow/periodic, no-stale, keep-going
|
# wip
linear algebra on CUDA (non-ROCM) devices will only use cuSOLVER library; magma will be removed
Todo:
- [ ] remove this has_magma check in pytorch/builder for cuda build https://github.com/pytorch/builder/blob/3df3313b12e91a9feae40f15681f505b9f3d1354/check_binary.sh#L392-L393, and make sure https://github.com/pytorch/pytorch/pull/98256/commits/34194b8f3b42f0a63098cddefa565cb20aa0b171 is reverted
| 4 |
3,006 | 98,251 |
[Dynamo] Enable `dynamo.export` for huggingface models w/ `ModelOutput`
|
feature, triaged, module: pytree, oncall: pt2, module: dynamo, module: export
|
### 🚀 The feature, motivation and pitch
Initially reported at #96386, `dynamo.export` raises for any huggingface model that returns a subclass of `ModelOutput`.
Here is an experimental patch I have done to unblock `dynamo.export` based ONNX export. The idea is to extend `pytree` to be able to flatten/unflatten `ModelOutput` and its subclasses.
https://github.com/pytorch/pytorch/blob/95de585a7f208476ae06894acbcc897a0bf9abed/torch/onnx/_internal/fx/exporter.py#L21-L68
I wonder if it is a good idea to bring this native into `pytree`? The context of this patch needs to cover not only `dynamo.export` but any other subsequent fx pass that may interact with the formatted output, otherwise it won't recognize the output structure.
Feedbacks and suggestions are welcomed. Feel free to let me know if there are other more suitable solutions.
@jansel @voznesenskym @wconstab
### Alternatives
_No response_
### Additional context
_No response_
cc @zou3519 @ezyang @msaroufim @wconstab @ngimel @bdhirsh @anijain2305 @voznesenskym @penguinwu @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @soumith @desertfire
| 5 |
3,007 | 98,237 |
inductor `compile_fx_inner()` segfaults on `torch.isinf`
|
triaged, oncall: pt2, module: inductor
|
minimal repro:
```
import torch
from torch._inductor.compile_fx import compile_fx_inner
from torch._subclasses import FakeTensorMode
from torch.fx.experimental.proxy_tensor import make_fx
def f(x):
isinf = torch.isinf(x)
return [isinf]
with FakeTensorMode():
inp = torch.ones(2048, device='cuda')
fx_g = make_fx(f)(inp)
fx_inner = compile_fx_inner(fx_g, [inp])
```
This fails with:
```
File "/tmp/torchinductor_hirsheybar/3h/c3hkvftvlgct3scdmbgllet56gcfozfyloqidc57nlxmixrk5ioq.py", line 45, in <module>
async_compile.wait(globals())
File "/scratch/hirsheybar1/work/pytorch/torch/_inductor/codecache.py", line 876, in wait
scope[key] = result.result()
File "/scratch/hirsheybar1/work/pytorch/torch/_inductor/codecache.py", line 734, in result
self.future.result()
File "/scratch/hirsheybar1/work/py38/lib/python3.8/concurrent/futures/_base.py", line 444, in result
return self.__get_result()
File "/scratch/hirsheybar1/work/py38/lib/python3.8/concurrent/futures/_base.py", line 389, in __get_result
raise self._exception
concurrent.futures.process.BrokenProcessPool: A process in the process pool was terminated abruptly while the future was running or pending.
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 5 |
3,008 | 98,222 |
aten::_linalg_solve_ex.result' is not currently implemented for the MPS
|
feature, triaged, module: mps
|
### 🐛 Describe the bug
I would like to request an implementation to fix "aten::_linalg_solve_ex.result' is not currently implemented for the MPS"
### Versions
aten::_linalg_solve_ex.result
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 10 |
3,009 | 98,212 |
Wrong results for GELU forward pass (CPU vs MPS) while inferencing a GLPN model from huggingface
|
high priority, triaged, module: correctness (silent), module: mps
|
### 🐛 Describe the bug
Hi, there. I've discovered strange behaviour when using MPS device. When infer the same model with the same input on "mps" device, the result is numerically wrong and meaningless.
@amyeroberts from huggingface narrowed down the scope of the problem to GELU layer, more information is here: https://github.com/huggingface/transformers/issues/22468
The issue makes it impossible to use GLPN architecture with MPS device.
Here are some examples:
MPS | CPU
:-------------------------:|:-------------------------:
 | 
Thanks in advance for the help!
### Versions
PyTorch version: 2.1.0.dev20230329
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.3 (arm64)
GCC version: Could not collect
Clang version: 14.0.3 (clang-1403.0.22.14.1)
CMake version: Could not collect
Libc version: N/A
Python version: 3.9.6 (default, Mar 10 2023, 20:16:38) [Clang 14.0.3 (clang-1403.0.22.14.1)] (64-bit runtime)
Python platform: macOS-13.3-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M2 Max
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.1.0.dev20230329
[pip3] torchaudio==2.1.0.dev20230329
[pip3] torchvision==0.16.0.dev20230329
[conda] Could not collect
cc @ezyang @gchanan @zou3519 @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 2 |
3,010 | 98,210 |
torch.jit.script + legacy executor mode has diff in some pattern
|
oncall: jit
|
### 🐛 Describe the bug
# there is output diff between origin and script
``` python
import torch
import os
os.environ['TORCH_JIT_DISABLE_NEW_EXECUTOR'] = '1'
torch._C._jit_set_nvfuser_enabled(False)
class TempModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.head_size = 64
def forward(self, x):
score_scale1 = torch.rsqrt(torch.tensor(self.head_size) * 3)
return score_scale1
module = TempModule()
x = module(torch.randn(4, 5))
print(x) # print 0.0722
ts_module = torch.jit.script(module)
y = ts_module(torch.randn(4, 5))
print(y) # print 0, unexpectly
```
### Versions
torch==2.0.0
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 1 |
3,011 | 98,208 |
Add a deterministic version of reflection_pad2d_backward_cuda
|
module: nn, triaged, enhancement, module: determinism, actionable
|
Running ResViT model in deterministic mode i face
UserWarning: reflection_pad2d_backward_cuda does not have a deterministic implementation, but you set 'torch.use_deterministic_algorithms(True, warn_only=True)'. You can file an issue at https://github.com/pytorch/pytorch/issues to help us prioritize adding deterministic support for this operation. (Triggered internally at ../aten/src/ATen/Context.cpp:82.)
pytorch version 1.13.1
Thank you!
### Alternatives
_No response_
### Additional context
_No response_
cc @albanD @mruberry @jbschlosser @walterddr @mikaylagawarecki @kurtamohler
| 4 |
3,012 | 98,204 |
NaN appears when initializing tensor
|
needs reproduction, triaged, module: NaNs and Infs
|
### 🐛 Describe the bug
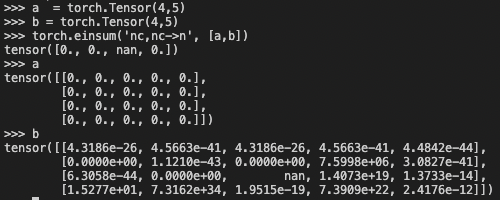
When I initialize a tensor, Nan appears such as the picture below. But I can't reimplement this bug again. Can anyone tell me why?
### Versions
PyTorch version: 1.12.0
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: CentOS Linux 7 (Core) (x86_64)
GCC version: (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44)
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.17
Python version: 3.9.12 (main, Apr 5 2022, 06:56:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-4.14.0_1-0-0-41-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration:
GPU 0: Tesla V100-SXM2-32GB
GPU 1: Tesla V100-SXM2-32GB
GPU 2: Tesla V100-SXM2-32GB
GPU 3: Tesla V100-SXM2-32GB
GPU 4: Tesla V100-SXM2-32GB
GPU 5: Tesla V100-SXM2-32GB
GPU 6: Tesla V100-SXM2-32GB
GPU 7: Tesla V100-SXM2-32GB
Nvidia driver version: 460.32.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 6271C CPU @ 2.60GHz
Stepping: 7
CPU MHz: 1000.000
CPU max MHz: 2601.0000
CPU min MHz: 1000.0000
BogoMIPS: 5200.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 33792K
NUMA node0 CPU(s): 0-23,48-71
NUMA node1 CPU(s): 24-47,72-95
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts pku avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] flake8==3.9.2
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] numpydoc==1.2
[pip3] pytorch-metric-learning==1.5.0
[pip3] torch==1.12.0
[pip3] torchvision==0.13.0
[pip3] tritonclient==2.31.0
[conda] blas 1.0 mkl defaults
[conda] cudatoolkit 11.3.1 h2bc3f7f_2 defaults
[conda] faiss-gpu 1.7.3 py3.9_h28a55e0_0_cuda11.3 pytorch
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] libfaiss 1.7.3 hfc2d529_0_cuda11.3 pytorch
[conda] mkl 2021.4.0 h06a4308_640 defaults
[conda] mkl-service 2.4.0 py39h7f8727e_0 defaults
[conda] mkl_fft 1.3.1 py39hd3c417c_0 defaults
[conda] mkl_random 1.2.2 py39h51133e4_0 defaults
[conda] numpy 1.21.5 py39he7a7128_1 defaults
[conda] numpy-base 1.21.5 py39hf524024_1 defaults
[conda] numpydoc 1.2 pyhd3eb1b0_0 defaults
[conda] pytorch 1.12.0 py3.9_cuda11.3_cudnn8.3.2_0 pytorch
[conda] pytorch-metric-learning 1.5.0 pypi_0 pypi
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchvision 0.13.0 py39_cu113 pytorch
[conda] tritonclient 2.31.0 pypi_0 pypi
| 0 |
3,013 | 98,203 |
AssertionError: was expecting embedding dimension of 22, but got 1320
|
oncall: transformer/mha
|
### 🐛 Describe the bug
I am new to pytorch on Colab. I used Transformer encoder as feature extractor to build DQN. The input shape of DQN is (60,22), and the output is one of the three numbers of 0,1,2. model.learn completed successfully. But model.predict is wrong. How can I change it?
code:
class TransformerFeaturesExtractor(BaseFeaturesExtractor):
def __init__(self, observation_space, features_dim=128):
super(TransformerFeaturesExtractor, self).__init__(observation_space, features_dim)
self.transformer_encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=features_dim, nhead=2), num_layers=6
)
self.flatten = nn.Flatten()
def forward(self, observations):
x = self.flatten(observations)
x = self.transformer_encoder(x.unsqueeze(0))
return x.squeeze(0)
policy_kwargs = dict(
features_extractor_class=TransformerFeaturesExtractor,
features_extractor_kwargs=dict(features_dim=22), #, action_space=env.action_space),
)
# Create an instance of the DQN agent
model = DQN("MlpPolicy", env,policy_kwargs=policy_kwargs, verbose=1)
#model = DQN('MlpPolicy', stock_trade_env, verbose=1)
#model = PPO('MlpPolicy', env, verbose=1)
# Train the agent
# pdb.set_trace()
model.learn(total_timesteps=10_000, progress_bar=True)
obs = env.reset()
for i in range(100):
action, _states = model.predict(obs)
#action = env.action_space.sample()
obs, rewards, dones, info = env.step(action)
if dones:
break
env.render()
### Versions
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-8-b1d23f2bc043> in <cell line: 366>()
365 obs = env.reset()
366 for i in range(100):
--> 367 action, _states = model.predict(obs)
368 #action = env.action_space.sample()
369 obs, rewards, dones, info = env.step(action)
16 frames
/usr/local/lib/python3.9/dist-packages/torch/nn/functional.py in multi_head_attention_forward(query, key, value, embed_dim_to_check, num_heads, in_proj_weight, in_proj_bias, bias_k, bias_v, add_zero_attn, dropout_p, out_proj_weight, out_proj_bias, training, key_padding_mask, need_weights, attn_mask, use_separate_proj_weight, q_proj_weight, k_proj_weight, v_proj_weight, static_k, static_v, average_attn_weights)
5024 raise AssertionError(
5025 "only bool and floating types of key_padding_mask are supported")
-> 5026 assert embed_dim == embed_dim_to_check, \
5027 f"was expecting embedding dimension of {embed_dim_to_check}, but got {embed_dim}"
5028 if isinstance(embed_dim, torch.Tensor):
AssertionError: was expecting embedding dimension of 22, but got 1320
cc @jbschlosser @bhosmer @cpuhrsch @erichan1
| 3 |
3,014 | 98,200 |
torch.nn.init functions with `generator` argument
|
module: nn, triaged, module: random, actionable
|
### 🚀 The feature, motivation and pitch
I might have a custom random generator (`torch.Generator`). All the low-level random functions support a `generator` argument for this. All the functions in `torch.nn.init` just call the low-level functions.
It would be useful if I can pass `generator` to those `torch.nn.init` functions and it would just pass it on to the low-level functions.
In my case, I'm mostly interested in `torch.nn.init.trunc_normal_`, as there is no such low-level `trunc_normal_` function.
### Alternatives
For my use case, it would also be fine if you add a `Tensor.trunc_normal_` low-level function, next to the `Tensor.normal_` function.
However, I think having `generator` as an argument for the `torch.nn.init` functions can anyway be helpful.
### Additional context
_No response_
cc @albanD @mruberry @jbschlosser @walterddr @mikaylagawarecki @pbelevich
| 5 |
3,015 | 98,194 |
add register_default_collate_for
|
triaged, open source, release notes: dataloader
|
Fixes #97498
| 9 |
3,016 | 98,193 |
RuntimeError: CUDA error: an illegal memory access was encountered, torch/cuda/streams.py", line 94, in synchronize
|
module: cuda, triaged
|
Hi.
I get a torch.cuda.synchronize() error, when i infer the TRT plugin. The detailed error information is as follows.
Building TRT engine....
[04/03/2023-06:52:48] [TRT] [V] Applying generic optimizations to the graph for inference.
[04/03/2023-06:52:48] [TRT] [V] Original: 1 layers
[04/03/2023-06:52:48] [TRT] [V] After dead-layer removal: 1 layers
[04/03/2023-06:52:48] [TRT] [V] After Myelin optimization: 1 layers
[04/03/2023-06:52:48] [TRT] [V] Applying ScaleNodes fusions.
[04/03/2023-06:52:48] [TRT] [V] After scale fusion: 1 layers
[04/03/2023-06:52:48] [TRT] [V] After dupe layer removal: 1 layers
[04/03/2023-06:52:48] [TRT] [V] After final dead-layer removal: 1 layers
[04/03/2023-06:52:48] [TRT] [V] After tensor merging: 1 layers
[04/03/2023-06:52:48] [TRT] [V] After vertical fusions: 1 layers
[04/03/2023-06:52:48] [TRT] [V] After dupe layer removal: 1 layers
[04/03/2023-06:52:48] [TRT] [V] After final dead-layer removal: 1 layers
[04/03/2023-06:52:48] [TRT] [V] After tensor merging: 1 layers
[04/03/2023-06:52:48] [TRT] [V] After slice removal: 1 layers
[04/03/2023-06:52:48] [TRT] [V] After concat removal: 1 layers
[04/03/2023-06:52:48] [TRT] [V] Trying to split Reshape and strided tensor
[04/03/2023-06:52:48] [TRT] [V] Graph construction and optimization completed in 0.109626 seconds.
[04/03/2023-06:52:49] [TRT] [V] Using cublasLt as a tactic source
[04/03/2023-06:52:49] [TRT] [I] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +67, GPU +8, now: CPU 4520, GPU 3365 (MiB)
[04/03/2023-06:52:49] [TRT] [V] Using cuDNN as a tactic source
[04/03/2023-06:52:49] [TRT] [I] [MemUsageChange] Init cuDNN: CPU +0, GPU +10, now: CPU 4520, GPU 3375 (MiB)
[04/03/2023-06:52:49] [TRT] [I] Local timing cache in use. Profiling results in this builder pass will not be stored.
[04/03/2023-06:52:49] [TRT] [V] Constructing optimization profile number 0 [1/1].
[04/03/2023-06:52:49] [TRT] [V] Reserving memory for host IO tensors. Host: 0 bytes
[04/03/2023-06:52:49] [TRT] [V] =============== Computing reformatting costs
[04/03/2023-06:52:49] [TRT] [V] =============== Computing reformatting costs
[04/03/2023-06:52:49] [TRT] [V] =============== Computing costs for
[04/03/2023-06:52:49] [TRT] [V] *************** Autotuning format combination: Float(1327104,20736,144,1) -> Float(165888,512,1) ***************
[04/03/2023-06:52:49] [TRT] [V] Formats and tactics selection completed in 0.0748828 seconds.
[04/03/2023-06:52:49] [TRT] [V] After reformat layers: 1 layers
[04/03/2023-06:52:49] [TRT] [V] Pre-optimized block assignment.
[04/03/2023-06:52:49] [TRT] [V] Block size 8589934592
[04/03/2023-06:52:49] [TRT] [V] Total Activation Memory: 8589934592
[04/03/2023-06:52:49] [TRT] [I] Detected 1 inputs and 1 output network tensors.
[04/03/2023-06:52:49] [TRT] [V] Layer: (Unnamed Layer* 0) [PluginV2DynamicExt] Host Persistent: 112 Device Persistent: 0 Scratch Memory: 0
[04/03/2023-06:52:49] [TRT] [I] Total Host Persistent Memory: 112
[04/03/2023-06:52:49] [TRT] [I] Total Device Persistent Memory: 0
[04/03/2023-06:52:49] [TRT] [I] Total Scratch Memory: 0
[04/03/2023-06:52:49] [TRT] [I] [MemUsageStats] Peak memory usage of TRT CPU/GPU memory allocators: CPU 0 MiB, GPU 0 MiB
[04/03/2023-06:52:49] [TRT] [V] Optimized block assignment.
[04/03/2023-06:52:49] [TRT] [I] Total Activation Memory: 0
[04/03/2023-06:52:49] [TRT] [V] Disabling unused tactic source: EDGE_MASK_CONVOLUTIONS
[04/03/2023-06:52:49] [TRT] [V] Using cublasLt as a tactic source
[04/03/2023-06:52:49] [TRT] [I] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +1, GPU +8, now: CPU 4619, GPU 3821 (MiB)
[04/03/2023-06:52:49] [TRT] [V] Using cuDNN as a tactic source
[04/03/2023-06:52:49] [TRT] [I] [MemUsageChange] Init cuDNN: CPU +0, GPU +8, now: CPU 4619, GPU 3829 (MiB)
[04/03/2023-06:52:49] [TRT] [V] Engine generation completed in 0.842963 seconds.
[04/03/2023-06:52:49] [TRT] [V] Engine Layer Information:
Layer(PluginV2): (Unnamed Layer* 0) [PluginV2DynamicExt], Tactic: 0x0000000000000000, input_img[Float(-2,64,144,144)] -> vision_transformer_output[Float(-2,324,512)]
[04/03/2023-06:52:49] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in building engine: CPU +0, GPU +0, now: CPU 0, GPU 0 (MiB)
[04/03/2023-06:52:49] [TRT] [V] Using cublasLt as a tactic source
[04/03/2023-06:52:49] [TRT] [I] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +8, now: CPU 4573, GPU 3681 (MiB)
[04/03/2023-06:52:49] [TRT] [V] Using cuDNN as a tactic source
[04/03/2023-06:52:49] [TRT] [I] [MemUsageChange] Init cuDNN: CPU +0, GPU +8, now: CPU 4573, GPU 3689 (MiB)
[04/03/2023-06:52:49] [TRT] [V] Total per-runner device persistent memory is 0
[04/03/2023-06:52:49] [TRT] [V] Total per-runner host persistent memory is 112
[04/03/2023-06:52:49] [TRT] [V] Allocated activation device memory of size 0
[04/03/2023-06:52:49] [TRT] [I] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +0, now: CPU 0, GPU 0 (MiB)
Traceback (most recent call last):
File "examples/infer_visiontransformer_plugin.py", line 310, in <module>
main(args)
File "examples/infer_visiontransformer_plugin.py", line 128, in main
plugin_output = run_trt_plugin(p_loader, images_tensor, engine)
File "/opt/conda/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "examples/infer_visiontransformer_plugin.py", line 166, in run_trt_plugin
stream.synchronize()
File "/opt/conda/lib/python3.8/site-packages/torch/cuda/streams.py", line 94, in synchronize
super(Stream, self).synchronize()
RuntimeError: CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
- PyTorch or Caffe2:
- How you installed PyTorch (conda, pip, source):
- Build command you used (if compiling from source):
- OS:
- PyTorch version:
- Python version:
- CUDA/cuDNN version:
- GPU models and configuration:
- GCC version (if compiling from source):
- CMake version:
- Versions of any other relevant libraries:
cc @ngimel
| 0 |
3,017 | 98,189 |
[onnx] AdaptiveMaxPool2d can not convert to GlobalMaxPool
|
module: onnx, triaged
|
### 🐛 Describe the bug
I try to convert the cbam block to onnx. The nn.AdaptiveMaxPool2d([1, 1]) used in ChannelAttention is expected to be a GlobalMaxPool in onnx accodring to according to https://github.com/pytorch/pytorch/blob/ff4569ae2939c3e81092fdf43c9d5f2f08453c42/torch/onnx/symbolic_opset9.py#L981, but i got onnx::MaxPool. Is there any way to solve this problem?
python script:
~~~python
import torch
import torch.nn as nn
def conv3x3(in_planes, out_planes, stride=1):
"3x3 convolution with padding"
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d([1, 1])
self.max_pool = nn.AdaptiveMaxPool2d([1, 1])
self.fc = nn.Sequential(nn.Conv2d(in_planes, in_planes // 16, 1, bias=False),
nn.ReLU(),
nn.Conv2d(in_planes // 16, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class CBAM(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(CBAM, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.ca = ChannelAttention(planes)
self.sa = SpatialAttention()
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.ca(out) * out
out = self.sa(out) * out
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
if __name__ == '__main__':
model = CBAM(16, 16)
device = 'cuda:0'
model.to(device)
model.eval()
dummpy_input = torch.zeros([1, 16, 400, 640], device=device)
torch.onnx.export(
model,
dummpy_input,
'model.onnx',
verbose=True,
input_names=["input"],
output_names=["output"],
opset_version=14,
)
~~~
script output:
~~~
Exported graph: graph(%input : Float(1, 16, 400, 640, strides=[4096000, 256000, 640, 1], requires_grad=0, device=cuda:0),
%ca.fc.0.weight : Float(1, 16, 1, 1, strides=[16, 1, 1, 1], requires_grad=1, device=cuda:0),
%ca.fc.2.weight : Float(16, 1, 1, 1, strides=[1, 1, 1, 1], requires_grad=1, device=cuda:0),
%sa.conv1.weight : Float(1, 2, 7, 7, strides=[98, 49, 7, 1], requires_grad=1, device=cuda:0),
%onnx::Conv_41 : Float(16, 16, 3, 3, strides=[144, 9, 3, 1], requires_grad=0, device=cuda:0),
%onnx::Conv_42 : Float(16, strides=[1], requires_grad=0, device=cuda:0),
%onnx::Conv_44 : Float(16, 16, 3, 3, strides=[144, 9, 3, 1], requires_grad=0, device=cuda:0)):
%onnx::Conv_45 : Float(16, strides=[1], requires_grad=0, device=cuda:0) = onnx::Identity(%onnx::Conv_42)
%/conv1/Conv_output_0 : Float(1, 16, 400, 640, strides=[4096000, 256000, 640, 1], requires_grad=1, device=cuda:0) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[3, 3], pads=[1, 1, 1, 1], strides=[1, 1], onnx_name="/conv1/Conv"](%input, %onnx::Conv_41, %onnx::Conv_42), scope: __main__.CBAM::/torch.nn.modules.conv.Conv2d::conv1 # /home/oem/anaconda3/envs/torch/lib/python3.10/site-packages/torch/nn/modules/conv.py:459:0
%/relu/Relu_output_0 : Float(1, 16, 400, 640, strides=[4096000, 256000, 640, 1], requires_grad=1, device=cuda:0) = onnx::Relu[onnx_name="/relu/Relu"](%/conv1/Conv_output_0), scope: __main__.CBAM::/torch.nn.modules.activation.ReLU::relu # /home/oem/anaconda3/envs/torch/lib/python3.10/site-packages/torch/nn/functional.py:1455:0
%/conv2/Conv_output_0 : Float(1, 16, 400, 640, strides=[4096000, 256000, 640, 1], requires_grad=1, device=cuda:0) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[3, 3], pads=[1, 1, 1, 1], strides=[1, 1], onnx_name="/conv2/Conv"](%/relu/Relu_output_0, %onnx::Conv_44, %onnx::Conv_45), scope: __main__.CBAM::/torch.nn.modules.conv.Conv2d::conv2 # /home/oem/anaconda3/envs/torch/lib/python3.10/site-packages/torch/nn/modules/conv.py:459:0
%/ca/avg_pool/GlobalAveragePool_output_0 : Float(1, 16, 1, 1, strides=[16, 1, 1, 1], requires_grad=1, device=cuda:0) = onnx::GlobalAveragePool[onnx_name="/ca/avg_pool/GlobalAveragePool"](%/conv2/Conv_output_0), scope: __main__.CBAM::/__main__.ChannelAttention::ca/torch.nn.modules.pooling.AdaptiveAvgPool2d::avg_pool # /home/oem/anaconda3/envs/torch/lib/python3.10/site-packages/torch/nn/functional.py:1214:0
%/ca/fc/fc.0/Conv_output_0 : Float(1, 1, 1, 1, strides=[1, 1, 1, 1], requires_grad=0, device=cuda:0) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[1, 1], pads=[0, 0, 0, 0], strides=[1, 1], onnx_name="/ca/fc/fc.0/Conv"](%/ca/avg_pool/GlobalAveragePool_output_0, %ca.fc.0.weight), scope: __main__.CBAM::/__main__.ChannelAttention::ca/torch.nn.modules.container.Sequential::fc/torch.nn.modules.conv.Conv2d::fc.0 # /home/oem/anaconda3/envs/torch/lib/python3.10/site-packages/torch/nn/modules/conv.py:459:0
%/ca/fc/fc.1/Relu_output_0 : Float(1, 1, 1, 1, strides=[1, 1, 1, 1], requires_grad=1, device=cuda:0) = onnx::Relu[onnx_name="/ca/fc/fc.1/Relu"](%/ca/fc/fc.0/Conv_output_0), scope: __main__.CBAM::/__main__.ChannelAttention::ca/torch.nn.modules.container.Sequential::fc/torch.nn.modules.activation.ReLU::fc.1 # /home/oem/anaconda3/envs/torch/lib/python3.10/site-packages/torch/nn/functional.py:1457:0
%/ca/fc/fc.2/Conv_output_0 : Float(1, 16, 1, 1, strides=[16, 1, 1, 1], requires_grad=0, device=cuda:0) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[1, 1], pads=[0, 0, 0, 0], strides=[1, 1], onnx_name="/ca/fc/fc.2/Conv"](%/ca/fc/fc.1/Relu_output_0, %ca.fc.2.weight), scope: __main__.CBAM::/__main__.ChannelAttention::ca/torch.nn.modules.container.Sequential::fc/torch.nn.modules.conv.Conv2d::fc.2 # /home/oem/anaconda3/envs/torch/lib/python3.10/site-packages/torch/nn/modules/conv.py:459:0
%/ca/max_pool/MaxPool_output_0 : Float(1, 16, 1, 1, strides=[16, 1, 1, 1], requires_grad=1, device=cuda:0) = onnx::MaxPool[kernel_shape=[400, 640], pads=[0, 0, 0, 0], strides=[400, 640], onnx_name="/ca/max_pool/MaxPool"](%/conv2/Conv_output_0), scope: __main__.CBAM::/__main__.ChannelAttention::ca/torch.nn.modules.pooling.AdaptiveMaxPool2d::max_pool # /home/oem/anaconda3/envs/torch/lib/python3.10/site-packages/torch/nn/functional.py:1121:0
%/ca/fc/fc.0_1/Conv_output_0 : Float(1, 1, 1, 1, strides=[1, 1, 1, 1], requires_grad=0, device=cuda:0) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[1, 1], pads=[0, 0, 0, 0], strides=[1, 1], onnx_name="/ca/fc/fc.0_1/Conv"](%/ca/max_pool/MaxPool_output_0, %ca.fc.0.weight), scope: __main__.CBAM::/__main__.ChannelAttention::ca/torch.nn.modules.container.Sequential::fc/torch.nn.modules.conv.Conv2d::fc.0 # /home/oem/anaconda3/envs/torch/lib/python3.10/site-packages/torch/nn/modules/conv.py:459:0
%/ca/fc/fc.1_1/Relu_output_0 : Float(1, 1, 1, 1, strides=[1, 1, 1, 1], requires_grad=1, device=cuda:0) = onnx::Relu[onnx_name="/ca/fc/fc.1_1/Relu"](%/ca/fc/fc.0_1/Conv_output_0), scope: __main__.CBAM::/__main__.ChannelAttention::ca/torch.nn.modules.container.Sequential::fc/torch.nn.modules.activation.ReLU::fc.1 # /home/oem/anaconda3/envs/torch/lib/python3.10/site-packages/torch/nn/functional.py:1457:0
%/ca/fc/fc.2_1/Conv_output_0 : Float(1, 16, 1, 1, strides=[16, 1, 1, 1], requires_grad=0, device=cuda:0) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[1, 1], pads=[0, 0, 0, 0], strides=[1, 1], onnx_name="/ca/fc/fc.2_1/Conv"](%/ca/fc/fc.1_1/Relu_output_0, %ca.fc.2.weight), scope: __main__.CBAM::/__main__.ChannelAttention::ca/torch.nn.modules.container.Sequential::fc/torch.nn.modules.conv.Conv2d::fc.2 # /home/oem/anaconda3/envs/torch/lib/python3.10/site-packages/torch/nn/modules/conv.py:459:0
%/ca/Add_output_0 : Float(1, 16, 1, 1, strides=[16, 1, 1, 1], requires_grad=1, device=cuda:0) = onnx::Add[onnx_name="/ca/Add"](%/ca/fc/fc.2/Conv_output_0, %/ca/fc/fc.2_1/Conv_output_0), scope: __main__.CBAM::/__main__.ChannelAttention::ca # /home/oem/Downloads/test.py:23:0
%/ca/sigmoid/Sigmoid_output_0 : Float(1, 16, 1, 1, strides=[16, 1, 1, 1], requires_grad=1, device=cuda:0) = onnx::Sigmoid[onnx_name="/ca/sigmoid/Sigmoid"](%/ca/Add_output_0), scope: __main__.CBAM::/__main__.ChannelAttention::ca/torch.nn.modules.activation.Sigmoid::sigmoid # /home/oem/anaconda3/envs/torch/lib/python3.10/site-packages/torch/nn/modules/activation.py:295:0
%/Mul_output_0 : Float(1, 16, 400, 640, strides=[4096000, 256000, 640, 1], requires_grad=1, device=cuda:0) = onnx::Mul[onnx_name="/Mul"](%/ca/sigmoid/Sigmoid_output_0, %/conv2/Conv_output_0), scope: __main__.CBAM:: # /home/oem/Downloads/test.py:67:0
%/sa/ReduceMean_output_0 : Float(1, 1, 400, 640, strides=[256000, 256000, 640, 1], requires_grad=1, device=cuda:0) = onnx::ReduceMean[axes=[1], keepdims=1, onnx_name="/sa/ReduceMean"](%/Mul_output_0), scope: __main__.CBAM::/__main__.SpatialAttention::sa # /home/oem/Downloads/test.py:34:0
%/sa/ReduceMax_output_0 : Float(1, 1, 400, 640, strides=[256000, 256000, 640, 1], requires_grad=1, device=cuda:0) = onnx::ReduceMax[axes=[1], keepdims=1, onnx_name="/sa/ReduceMax"](%/Mul_output_0), scope: __main__.CBAM::/__main__.SpatialAttention::sa # /home/oem/Downloads/test.py:35:0
%/sa/Concat_output_0 : Float(1, 2, 400, 640, strides=[512000, 256000, 640, 1], requires_grad=1, device=cuda:0) = onnx::Concat[axis=1, onnx_name="/sa/Concat"](%/sa/ReduceMean_output_0, %/sa/ReduceMax_output_0), scope: __main__.CBAM::/__main__.SpatialAttention::sa # /home/oem/Downloads/test.py:36:0
%/sa/conv1/Conv_output_0 : Float(1, 1, 400, 640, strides=[256000, 256000, 640, 1], requires_grad=0, device=cuda:0) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[7, 7], pads=[3, 3, 3, 3], strides=[1, 1], onnx_name="/sa/conv1/Conv"](%/sa/Concat_output_0, %sa.conv1.weight), scope: __main__.CBAM::/__main__.SpatialAttention::sa/torch.nn.modules.conv.Conv2d::conv1 # /home/oem/anaconda3/envs/torch/lib/python3.10/site-packages/torch/nn/modules/conv.py:459:0
%/sa/sigmoid/Sigmoid_output_0 : Float(1, 1, 400, 640, strides=[256000, 256000, 640, 1], requires_grad=1, device=cuda:0) = onnx::Sigmoid[onnx_name="/sa/sigmoid/Sigmoid"](%/sa/conv1/Conv_output_0), scope: __main__.CBAM::/__main__.SpatialAttention::sa/torch.nn.modules.activation.Sigmoid::sigmoid # /home/oem/anaconda3/envs/torch/lib/python3.10/site-packages/torch/nn/modules/activation.py:295:0
%/Mul_1_output_0 : Float(1, 16, 400, 640, strides=[4096000, 256000, 640, 1], requires_grad=1, device=cuda:0) = onnx::Mul[onnx_name="/Mul_1"](%/sa/sigmoid/Sigmoid_output_0, %/Mul_output_0), scope: __main__.CBAM:: # /home/oem/Downloads/test.py:68:0
%/Add_output_0 : Float(1, 16, 400, 640, strides=[4096000, 256000, 640, 1], requires_grad=1, device=cuda:0) = onnx::Add[onnx_name="/Add"](%/Mul_1_output_0, %input), scope: __main__.CBAM:: # /home/oem/Downloads/test.py:73:0
%output : Float(1, 16, 400, 640, strides=[4096000, 256000, 640, 1], requires_grad=1, device=cuda:0) = onnx::Relu[onnx_name="/relu_1/Relu"](%/Add_output_0), scope: __main__.CBAM::/torch.nn.modules.activation.ReLU::relu # /home/oem/anaconda3/envs/torch/lib/python3.10/site-packages/torch/nn/functional.py:1455:0
return (%output)
================ Diagnostic Run torch.onnx.export version 2.0.0 ================
verbose: False, log level: Level.ERROR
======================= 0 NONE 0 NOTE 0 WARNING 0 ERROR ========================
~~~
### Versions
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] pytorch-lightning==2.0.0
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.0
[pip3] torchmetrics==0.11.4
[pip3] torchvision==0.15.0
[pip3] triton==2.0.0
[conda] blas 1.0 mkl
[conda] libblas 3.9.0 12_linux64_mkl conda-forge
[conda] libcblas 3.9.0 12_linux64_mkl conda-forge
[conda] liblapack 3.9.0 12_linux64_mkl conda-forge
[conda] liblapacke 3.9.0 12_linux64_mkl conda-forge
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.5 py310hd5efca6_0
[conda] numpy-base 1.23.5 py310h8e6c178_0
[conda] pytorch 2.0.0 py3.10_cuda11.8_cudnn8.7.0_0 pytorch
[conda] pytorch-cuda 11.8 h7e8668a_3 pytorch
[conda] pytorch-lightning 2.0.0 pyhd8ed1ab_1 conda-forge
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 2.0.0 py310_cu118 pytorch
[conda] torchmetrics 0.11.4 pyhd8ed1ab_0 conda-forge
[conda] torchtriton 2.0.0 py310 pytorch
[conda] torchvision 0.15.0 py310_cu118 pytorch
| 2 |
3,018 | 98,187 |
how can i load seperate pytorch_model.bin?
|
module: serialization, triaged
|
If you have a question or would like help and support, please ask at our
[forums](https://discuss.pytorch.org/).
If you are submitting a feature request, please preface the title with [feature request].
If you are submitting a bug report, please fill in the following details.
## Issue description
Provide a short description.
## Code example
Please try to provide a minimal example to repro the bug.
Error messages and stack traces are also helpful.
## System Info
Please copy and paste the output from our
[environment collection script](https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py)
(or fill out the checklist below manually).
You can get the script and run it with:
```
wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
```
- PyTorch or Caffe2:
- How you installed PyTorch (conda, pip, source):
- Build command you used (if compiling from source):
- OS:
- PyTorch version: 1.13.1
- Python version: 3.8
- CUDA/cuDNN version:
- GPU models and configuration:
- GCC version (if compiling from source):
- CMake version:
- Versions of any other relevant libraries:
I have a separate binary file (pytorch_model-00001-of-00002.bin, pytorch_model-00002-of-00002.bin, pytorch_model.bin.index.json).
When I substitute path into torch.load, I get an error.
How can I get this into torch.load?
cc @mruberry
| 0 |
3,019 | 98,169 |
The operator 'aten::_weight_norm_interface' is not currently implemented for the MPS device.
|
feature, triaged, module: mps
|
### 🐛 Describe the bug
NotImplementedError: The operator 'aten::_weight_norm_interface' is not currently implemented for the MPS device. If you want this op to be added in priority during the prototype phase of this feature, please comment on https://github.com/pytorch/pytorch/issues/77764. As a temporary fix, you can set the environment variable `PYTORCH_ENABLE_MPS_FALLBACK=1` to use the CPU as a fallback for this op. WARNING: this will be slower than running natively on MPS.
### Versions
NotImplementedError: The operator 'aten::_weight_norm_interface' is not currently implemented for the MPS device. If you want this op to be added in priority during the prototype phase of this feature, please comment on https://github.com/pytorch/pytorch/issues/77764. As a temporary fix, you can set the environment variable `PYTORCH_ENABLE_MPS_FALLBACK=1` to use the CPU as a fallback for this op. WARNING: this will be slower than running natively on MPS.
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
3,020 | 98,164 |
forward AD implimentation : _scaled_dot_product_efficient_attention
|
triaged, module: forward ad
|
### 🚀 The feature, motivation and pitch
Hi there,
I encountered an error message that requests me to file an issue regarding a feature implementation. The error message is as follows:
NotImplementedError: Trying to use forward AD with _scaled_dot_product_efficient_attention that does not support it because it has not been implemented yet.
Please file an issue to PyTorch at https://github.com/pytorch/pytorch/issues/new?template=feature-request.yml so that we can prioritize its implementation.
Note that forward AD support for some operators require PyTorch to be built with TorchScript and for JIT to be enabled. If the environment var PYTORCH_JIT=0 is set or if the
library is not built with TorchScript, some operators may no longer be used with forward AD.
I would appreciate it if you could prioritize the implementation of this feature. Thank you for your help.
### Alternatives
_No response_
### Additional context
I ran forward AD of Stable-Diffusion with diffusers library, dtype = torch.float32, device=cuda.
| 3 |
3,021 | 98,161 |
Compiling complex-valued functions fails
|
triaged, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
Compiling fails for even very simple functions when tensors are complex-valued. See e.g.
```python
import torch
@torch.compile
def foo(X, Y):
Z = X + Y
return Z
X = torch.zeros(10, dtype=torch.complex128)
Y = torch.zeros(10, dtype=torch.complex128)
foo(X, Y)
```
### Error logs
```python
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
File [~/torch/_dynamo/output_graph.py:670](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/output_graph.py:670), in OutputGraph.call_user_compiler(self, gm)
[669](/torch/_dynamo/output_graph.py?line=668) else:
--> [670](/torch/_dynamo/output_graph.py?line=669) compiled_fn = compiler_fn(gm, self.fake_example_inputs())
[671](/torch/_dynamo/output_graph.py?line=670) _step_logger()(logging.INFO, f"done compiler function {name}")
File [~/torch/_dynamo/debug_utils.py:1055](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/debug_utils.py:1055), in wrap_backend_debug..debug_wrapper(gm, example_inputs, **kwargs)
[1054](/torch/_dynamo/debug_utils.py?line=1053) else:
-> [1055](/torch/_dynamo/debug_utils.py?line=1054) compiled_gm = compiler_fn(gm, example_inputs)
[1057](/torch/_dynamo/debug_utils.py?line=1056) return compiled_gm
File [~/torch/__init__.py:1390](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/__init__.py:1390), in _TorchCompileInductorWrapper.__call__(self, model_, inputs_)
[1388](/torch/__init__.py?line=1387) from torch._inductor.compile_fx import compile_fx
-> [1390](/torch/__init__.py?line=1389) return compile_fx(model_, inputs_, config_patches=self.config)
File [~/torch/_inductor/compile_fx.py:455](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_inductor/compile_fx.py:455), in compile_fx(model_, example_inputs_, inner_compile, config_patches)
[450](/torch/_inductor/compile_fx.py?line=449) with overrides.patch_functions():
[451](/torch/_inductor/compile_fx.py?line=450)
[452](/torch/_inductor/compile_fx.py?line=451) # TODO: can add logging before[/after](https://file+.vscode-resource.vscode-cdn.net/after) the call to create_aot_dispatcher_function
[453](/torch/_inductor/compile_fx.py?line=452) # in torch._functorch[/aot_autograd.py](https://file+.vscode-resource.vscode-cdn.net/aot_autograd.py)::aot_module_simplified::aot_function_simplified::new_func
[454](/torch/_inductor/compile_fx.py?line=453) # once torchdynamo is merged into pytorch
--> [455](/torch/_inductor/compile_fx.py?line=454) return aot_autograd(
[456](/torch/_inductor/compile_fx.py?line=455) fw_compiler=fw_compiler,
[457](/torch/_inductor/compile_fx.py?line=456) bw_compiler=bw_compiler,
[458](/torch/_inductor/compile_fx.py?line=457) decompositions=select_decomp_table(),
[459](/torch/_inductor/compile_fx.py?line=458) partition_fn=functools.partial(
[460](/torch/_inductor/compile_fx.py?line=459) min_cut_rematerialization_partition, compiler="inductor"
[461](/torch/_inductor/compile_fx.py?line=460) ),
[462](/torch/_inductor/compile_fx.py?line=461) keep_inference_input_mutations=True,
[463](/torch/_inductor/compile_fx.py?line=462) )(model_, example_inputs_)
File [~/torch/_dynamo/backends/common.py:48](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/backends/common.py:48), in aot_autograd..compiler_fn(gm, example_inputs)
[47](/torch/_dynamo/backends/common.py?line=46) with enable_aot_logging():
---> [48](/torch/_dynamo/backends/common.py?line=47) cg = aot_module_simplified(gm, example_inputs, **kwargs)
[49](/torch/_dynamo/backends/common.py?line=48) counters["aot_autograd"]["ok"] += 1
File [~/torch/_functorch/aot_autograd.py:2805](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_functorch/aot_autograd.py:2805), in aot_module_simplified(mod, args, fw_compiler, bw_compiler, partition_fn, decompositions, hasher_type, static_argnums, keep_inference_input_mutations)
[2803](/torch/_functorch/aot_autograd.py?line=2802) full_args.extend(args)
-> [2805](/torch/_functorch/aot_autograd.py?line=2804) compiled_fn = create_aot_dispatcher_function(
[2806](/torch/_functorch/aot_autograd.py?line=2805) functional_call,
[2807](/torch/_functorch/aot_autograd.py?line=2806) full_args,
[2808](/torch/_functorch/aot_autograd.py?line=2807) aot_config,
[2809](/torch/_functorch/aot_autograd.py?line=2808) )
[2811](/torch/_functorch/aot_autograd.py?line=2810) # TODO: There is something deeply wrong here; compiled_fn running with
[2812](/torch/_functorch/aot_autograd.py?line=2811) # the boxed calling convention, but aot_module_simplified somehow
[2813](/torch/_functorch/aot_autograd.py?line=2812) # historically returned a function that was not the boxed calling
[2814](/torch/_functorch/aot_autograd.py?line=2813) # convention. This should get fixed...
File [~/torch/_dynamo/utils.py:163](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/utils.py:163), in dynamo_timed..dynamo_timed_inner..time_wrapper(*args, **kwargs)
[162](/torch/_dynamo/utils.py?line=161) t0 = time.time()
--> [163](/torch/_dynamo/utils.py?line=162) r = func(*args, **kwargs)
[164](/torch/_dynamo/utils.py?line=163) time_spent = time.time() - t0
File [~/torch/_functorch/aot_autograd.py:2498](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_functorch/aot_autograd.py:2498), in create_aot_dispatcher_function(flat_fn, flat_args, aot_config)
[2496](/torch/_functorch/aot_autograd.py?line=2495) # You can put more passes here
-> [2498](/torch/_functorch/aot_autograd.py?line=2497) compiled_fn = compiler_fn(flat_fn, fake_flat_args, aot_config)
[2500](/torch/_functorch/aot_autograd.py?line=2499) if not hasattr(compiled_fn, "_boxed_call"):
File [~/torch/_functorch/aot_autograd.py:1713](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_functorch/aot_autograd.py:1713), in aot_wrapper_dedupe(flat_fn, flat_args, aot_config, compiler_fn)
[1712](/torch/_functorch/aot_autograd.py?line=1711) if ok:
-> [1713](/torch/_functorch/aot_autograd.py?line=1712) return compiler_fn(flat_fn, leaf_flat_args, aot_config)
[1715](/torch/_functorch/aot_autograd.py?line=1714) # Strategy 2: Duplicate specialize.
[1716](/torch/_functorch/aot_autograd.py?line=1715) #
[1717](/torch/_functorch/aot_autograd.py?line=1716) # In Haskell types, suppose you have:
(...)
[1749](/torch/_functorch/aot_autograd.py?line=1748) # }
[1750](/torch/_functorch/aot_autograd.py?line=1749) # keep_arg_mask = [True, True, False, True]
File [~/torch/_functorch/aot_autograd.py:1326](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_functorch/aot_autograd.py:1326), in aot_dispatch_base(flat_fn, flat_args, aot_config)
[1325](/torch/_functorch/aot_autograd.py?line=1324) with context(), track_graph_compiling(aot_config, "inference"):
-> [1326](/torch/_functorch/aot_autograd.py?line=1325) compiled_fw = aot_config.fw_compiler(fw_module, flat_args_with_views_handled)
[1328](/torch/_functorch/aot_autograd.py?line=1327) compiled_fn = create_runtime_wrapper(
[1329](/torch/_functorch/aot_autograd.py?line=1328) compiled_fw,
[1330](/torch/_functorch/aot_autograd.py?line=1329) runtime_metadata=metadata_,
[1331](/torch/_functorch/aot_autograd.py?line=1330) trace_joint=False,
[1332](/torch/_functorch/aot_autograd.py?line=1331) keep_input_mutations=aot_config.keep_inference_input_mutations
[1333](/torch/_functorch/aot_autograd.py?line=1332) )
File [~/torch/_dynamo/utils.py:163](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/utils.py:163), in dynamo_timed..dynamo_timed_inner..time_wrapper(*args, **kwargs)
[162](/torch/_dynamo/utils.py?line=161) t0 = time.time()
--> [163](/torch/_dynamo/utils.py?line=162) r = func(*args, **kwargs)
[164](/torch/_dynamo/utils.py?line=163) time_spent = time.time() - t0
File [~/torch/_inductor/compile_fx.py:430](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_inductor/compile_fx.py:430), in compile_fx..fw_compiler(model, example_inputs)
[429](/torch/_inductor/compile_fx.py?line=428) model = convert_outplace_to_inplace(model)
--> [430](/torch/_inductor/compile_fx.py?line=429) return inner_compile(
[431](/torch/_inductor/compile_fx.py?line=430) model,
[432](/torch/_inductor/compile_fx.py?line=431) example_inputs,
[433](/torch/_inductor/compile_fx.py?line=432) num_fixed=fixed,
[434](/torch/_inductor/compile_fx.py?line=433) cudagraphs=cudagraphs,
[435](/torch/_inductor/compile_fx.py?line=434) graph_id=graph_id,
[436](/torch/_inductor/compile_fx.py?line=435) )
File [~/torch/_dynamo/debug_utils.py:595](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/debug_utils.py:595), in wrap_compiler_debug..debug_wrapper(gm, example_inputs, **kwargs)
[594](/torch/_dynamo/debug_utils.py?line=593) else:
--> [595](/torch/_dynamo/debug_utils.py?line=594) compiled_fn = compiler_fn(gm, example_inputs)
[597](/torch/_dynamo/debug_utils.py?line=596) return compiled_fn
File [~/torch/_inductor/debug.py:239](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_inductor/debug.py:239), in DebugContext.wrap..inner(*args, **kwargs)
[238](/torch/_inductor/debug.py?line=237) with DebugContext():
--> [239](/torch/_inductor/debug.py?line=238) return fn(*args, **kwargs)
File [~/miniconda3/lib/python3.9/contextlib.py:79](https://file+.vscode-resource.vscode-cdn.net/Users/~/miniconda3/lib/python3.9/contextlib.py:79), in ContextDecorator.__call__..inner(*args, **kwds)
[78](/miniconda3/lib/python3.9/contextlib.py?line=77) with self._recreate_cm():
---> [79](/miniconda3/lib/python3.9/contextlib.py?line=78) return func(*args, **kwds)
File [~/torch/_inductor/compile_fx.py:177](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_inductor/compile_fx.py:177), in compile_fx_inner(gm, example_inputs, cudagraphs, num_fixed, is_backward, graph_id)
[176](/torch/_inductor/compile_fx.py?line=175) graph.run(*example_inputs)
--> [177](/torch/_inductor/compile_fx.py?line=176) compiled_fn = graph.compile_to_fn()
[179](/torch/_inductor/compile_fx.py?line=178) if cudagraphs:
File [~/torch/_inductor/graph.py:586](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_inductor/graph.py:586), in GraphLowering.compile_to_fn(self)
[585](/torch/_inductor/graph.py?line=584) def compile_to_fn(self):
--> [586](/torch/_inductor/graph.py?line=585) return self.compile_to_module().call
File [~/torch/_dynamo/utils.py:163](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/utils.py:163), in dynamo_timed..dynamo_timed_inner..time_wrapper(*args, **kwargs)
[162](/torch/_dynamo/utils.py?line=161) t0 = time.time()
--> [163](/torch/_dynamo/utils.py?line=162) r = func(*args, **kwargs)
[164](/torch/_dynamo/utils.py?line=163) time_spent = time.time() - t0
File [~/torch/_inductor/graph.py:571](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_inductor/graph.py:571), in GraphLowering.compile_to_module(self)
[569](/torch/_inductor/graph.py?line=568) from .codecache import PyCodeCache
--> [571](/torch/_inductor/graph.py?line=570) code = self.codegen()
[572](/torch/_inductor/graph.py?line=571) if config.debug:
File [~/torch/_inductor/graph.py:522](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_inductor/graph.py:522), in GraphLowering.codegen(self)
[521](/torch/_inductor/graph.py?line=520) assert self.scheduler is not None # mypy can't figure this out
--> [522](/torch/_inductor/graph.py?line=521) self.scheduler.codegen()
[523](/torch/_inductor/graph.py?line=522) assert self.wrapper_code is not None
File [~/torch/_dynamo/utils.py:163](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/utils.py:163), in dynamo_timed..dynamo_timed_inner..time_wrapper(*args, **kwargs)
[162](/torch/_dynamo/utils.py?line=161) t0 = time.time()
--> [163](/torch/_dynamo/utils.py?line=162) r = func(*args, **kwargs)
[164](/torch/_dynamo/utils.py?line=163) time_spent = time.time() - t0
File [~/torch/_inductor/scheduler.py:1177](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_inductor/scheduler.py:1177), in Scheduler.codegen(self)
[1175](/torch/_inductor/scheduler.py?line=1174) self.available_buffer_names.update(node.get_names())
-> [1177](/torch/_inductor/scheduler.py?line=1176) self.flush()
File [~/torch/_inductor/scheduler.py:1095](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_inductor/scheduler.py:1095), in Scheduler.flush(self)
[1094](/torch/_inductor/scheduler.py?line=1093) for backend in self.backends.values():
-> [1095](/torch/_inductor/scheduler.py?line=1094) backend.flush()
[1096](/torch/_inductor/scheduler.py?line=1095) self.free_buffers()
File [~/torch/_inductor/codegen/cpp.py:1975](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_inductor/codegen/cpp.py:1975), in CppScheduling.flush(self)
[1974](/torch/_inductor/codegen/cpp.py?line=1973) def flush(self):
-> [1975](/torch/_inductor/codegen/cpp.py?line=1974) self.kernel_group.codegen_define_and_call(V.graph.wrapper_code)
[1976](/torch/_inductor/codegen/cpp.py?line=1975) self.get_kernel_group()
File [~/torch/_inductor/codegen/cpp.py:2004](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_inductor/codegen/cpp.py:2004), in KernelGroup.codegen_define_and_call(self, wrapper)
[2003](/torch/_inductor/codegen/cpp.py?line=2002) kernel_name = "kernel_cpp_" + wrapper.next_kernel_suffix()
-> [2004](/torch/_inductor/codegen/cpp.py?line=2003) arg_defs, call_args, arg_types = self.args.cpp_argdefs()
[2005](/torch/_inductor/codegen/cpp.py?line=2004) arg_defs = ",\n".ljust(25).join(arg_defs)
File [~/torch/_inductor/codegen/common.py:330](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_inductor/codegen/common.py:330), in KernelArgs.cpp_argdefs(self)
[329](/torch/_inductor/codegen/common.py?line=328) dtype = buffer_types[outer]
--> [330](/torch/_inductor/codegen/common.py?line=329) cpp_dtype = DTYPE_TO_CPP[dtype]
[331](/torch/_inductor/codegen/common.py?line=330) arg_defs.append(f"const {cpp_dtype}* __restrict__ {inner}")
KeyError: torch.complex128
The above exception was the direct cause of the following exception:
BackendCompilerFailed Traceback (most recent call last)
[/Users/notebooks/test_compile.py](https://file+.vscode-resource.vscode-cdn.net/Users/notebooks/test_compile.py) in line 9
[7](/notebooks/test_compile.py?line=6) X = torch.zeros(10, dtype=torch.complex128)
[8](/notebooks/test_compile.py?line=7) Y = torch.zeros(10, dtype=torch.complex128)
----> [9](/notebooks/test_compile.py?line=8) foo(X, Y)
File [~/torch/_dynamo/eval_frame.py:209](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/eval_frame.py:209), in _TorchDynamoContext.__call__.._fn(*args, **kwargs)
[207](/torch/_dynamo/eval_frame.py?line=206) dynamic_ctx.__enter__()
[208](/torch/_dynamo/eval_frame.py?line=207) try:
--> [209](/torch/_dynamo/eval_frame.py?line=208) return fn(*args, **kwargs)
[210](/torch/_dynamo/eval_frame.py?line=209) finally:
[211](/torch/_dynamo/eval_frame.py?line=210) set_eval_frame(prior)
File [~/torch/_dynamo/eval_frame.py:337](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/eval_frame.py:337), in catch_errors_wrapper..catch_errors(frame, cache_size)
[334](/torch/_dynamo/eval_frame.py?line=333) return hijacked_callback(frame, cache_size, hooks)
[336](/torch/_dynamo/eval_frame.py?line=335) with compile_lock:
--> [337](/torch/_dynamo/eval_frame.py?line=336) return callback(frame, cache_size, hooks)
File [~/torch/_dynamo/convert_frame.py:404](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/convert_frame.py:404), in convert_frame.._convert_frame(frame, cache_size, hooks)
[402](/torch/_dynamo/convert_frame.py?line=401) counters["frames"]["total"] += 1
[403](/torch/_dynamo/convert_frame.py?line=402) try:
--> [404](/torch/_dynamo/convert_frame.py?line=403) result = inner_convert(frame, cache_size, hooks)
[405](/torch/_dynamo/convert_frame.py?line=404) counters["frames"]["ok"] += 1
[406](/torch/_dynamo/convert_frame.py?line=405) return result
File [~/torch/_dynamo/convert_frame.py:104](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/convert_frame.py:104), in wrap_convert_context.._fn(*args, **kwargs)
[102](/torch/_dynamo/convert_frame.py?line=101) torch.fx.graph_module._forward_from_src = fx_forward_from_src_skip_result
[103](/torch/_dynamo/convert_frame.py?line=102) try:
--> [104](/torch/_dynamo/convert_frame.py?line=103) return fn(*args, **kwargs)
[105](/torch/_dynamo/convert_frame.py?line=104) finally:
[106](/torch/_dynamo/convert_frame.py?line=105) torch._C._set_grad_enabled(prior_grad_mode)
File [~/torch/_dynamo/convert_frame.py:262](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/convert_frame.py:262), in convert_frame_assert.._convert_frame_assert(frame, cache_size, hooks)
[259](/torch/_dynamo/convert_frame.py?line=258) global initial_grad_state
[260](/torch/_dynamo/convert_frame.py?line=259) initial_grad_state = torch.is_grad_enabled()
--> [262](/torch/_dynamo/convert_frame.py?line=261) return _compile(
[263](/torch/_dynamo/convert_frame.py?line=262) frame.f_code,
[264](/torch/_dynamo/convert_frame.py?line=263) frame.f_globals,
[265](/torch/_dynamo/convert_frame.py?line=264) frame.f_locals,
[266](/torch/_dynamo/convert_frame.py?line=265) frame.f_builtins,
[267](/torch/_dynamo/convert_frame.py?line=266) compiler_fn,
[268](/torch/_dynamo/convert_frame.py?line=267) one_graph,
[269](/torch/_dynamo/convert_frame.py?line=268) export,
[270](/torch/_dynamo/convert_frame.py?line=269) hooks,
[271](/torch/_dynamo/convert_frame.py?line=270) frame,
[272](/torch/_dynamo/convert_frame.py?line=271) )
File [~/torch/_dynamo/utils.py:163](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/utils.py:163), in dynamo_timed..dynamo_timed_inner..time_wrapper(*args, **kwargs)
[161](/torch/_dynamo/utils.py?line=160) compilation_metrics[key] = []
[162](/torch/_dynamo/utils.py?line=161) t0 = time.time()
--> [163](/torch/_dynamo/utils.py?line=162) r = func(*args, **kwargs)
[164](/torch/_dynamo/utils.py?line=163) time_spent = time.time() - t0
[165](/torch/_dynamo/utils.py?line=164) # print(f"Dynamo timer: key={key}, latency={latency:.2f} sec")
File [~/torch/_dynamo/convert_frame.py:324](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/convert_frame.py:324), in _compile(code, globals, locals, builtins, compiler_fn, one_graph, export, hooks, frame)
[322](/torch/_dynamo/convert_frame.py?line=321) for attempt in itertools.count():
[323](/torch/_dynamo/convert_frame.py?line=322) try:
--> [324](/torch/_dynamo/convert_frame.py?line=323) out_code = transform_code_object(code, transform)
[325](/torch/_dynamo/convert_frame.py?line=324) orig_code_map[out_code] = code
[326](/torch/_dynamo/convert_frame.py?line=325) break
File [~/torch/_dynamo/bytecode_transformation.py:445](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/bytecode_transformation.py:445), in transform_code_object(code, transformations, safe)
[442](/torch/_dynamo/bytecode_transformation.py?line=441) instructions = cleaned_instructions(code, safe)
[443](/torch/_dynamo/bytecode_transformation.py?line=442) propagate_line_nums(instructions)
--> [445](/torch/_dynamo/bytecode_transformation.py?line=444) transformations(instructions, code_options)
[446](/torch/_dynamo/bytecode_transformation.py?line=445) return clean_and_assemble_instructions(instructions, keys, code_options)[1]
File [~/torch/_dynamo/convert_frame.py:311](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/convert_frame.py:311), in _compile..transform(instructions, code_options)
[298](/torch/_dynamo/convert_frame.py?line=297) nonlocal output
[299](/torch/_dynamo/convert_frame.py?line=298) tracer = InstructionTranslator(
[300](/torch/_dynamo/convert_frame.py?line=299) instructions,
[301](/torch/_dynamo/convert_frame.py?line=300) code,
(...)
[309](/torch/_dynamo/convert_frame.py?line=308) mutated_closure_cell_contents,
[310](/torch/_dynamo/convert_frame.py?line=309) )
--> [311](/torch/_dynamo/convert_frame.py?line=310) tracer.run()
[312](/torch/_dynamo/convert_frame.py?line=311) output = tracer.output
[313](/torch/_dynamo/convert_frame.py?line=312) assert output is not None
File [~/torch/_dynamo/symbolic_convert.py:1726](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/symbolic_convert.py:1726), in InstructionTranslator.run(self)
[1724](/torch/_dynamo/symbolic_convert.py?line=1723) def run(self):
[1725](/torch/_dynamo/symbolic_convert.py?line=1724) _step_logger()(logging.INFO, f"torchdynamo start tracing {self.f_code.co_name}")
-> [1726](/torch/_dynamo/symbolic_convert.py?line=1725) super().run()
File [~/torch/_dynamo/symbolic_convert.py:576](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/symbolic_convert.py:576), in InstructionTranslatorBase.run(self)
[571](/torch/_dynamo/symbolic_convert.py?line=570) try:
[572](/torch/_dynamo/symbolic_convert.py?line=571) self.output.push_tx(self)
[573](/torch/_dynamo/symbolic_convert.py?line=572) while (
[574](/torch/_dynamo/symbolic_convert.py?line=573) self.instruction_pointer is not None
[575](/torch/_dynamo/symbolic_convert.py?line=574) and not self.output.should_exit
--> [576](/torch/_dynamo/symbolic_convert.py?line=575) and self.step()
[577](/torch/_dynamo/symbolic_convert.py?line=576) ):
[578](/torch/_dynamo/symbolic_convert.py?line=577) pass
[579](/torch/_dynamo/symbolic_convert.py?line=578) except BackendCompilerFailed:
File [~/torch/_dynamo/symbolic_convert.py:540](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/symbolic_convert.py:540), in InstructionTranslatorBase.step(self)
[538](/torch/_dynamo/symbolic_convert.py?line=537) if not hasattr(self, inst.opname):
[539](/torch/_dynamo/symbolic_convert.py?line=538) unimplemented(f"missing: {inst.opname}")
--> [540](/torch/_dynamo/symbolic_convert.py?line=539) getattr(self, inst.opname)(inst)
[542](/torch/_dynamo/symbolic_convert.py?line=541) return inst.opname != "RETURN_VALUE"
[543](/torch/_dynamo/symbolic_convert.py?line=542) except BackendCompilerFailed:
File [~/torch/_dynamo/symbolic_convert.py:1792](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/symbolic_convert.py:1792), in InstructionTranslator.RETURN_VALUE(self, inst)
[1787](/torch/_dynamo/symbolic_convert.py?line=1786) _step_logger()(
[1788](/torch/_dynamo/symbolic_convert.py?line=1787) logging.INFO,
[1789](/torch/_dynamo/symbolic_convert.py?line=1788) f"torchdynamo done tracing {self.f_code.co_name} (RETURN_VALUE)",
[1790](/torch/_dynamo/symbolic_convert.py?line=1789) )
[1791](/torch/_dynamo/symbolic_convert.py?line=1790) log.debug("RETURN_VALUE triggered compile")
-> [1792](/torch/_dynamo/symbolic_convert.py?line=1791) self.output.compile_subgraph(
[1793](/torch/_dynamo/symbolic_convert.py?line=1792) self, reason=GraphCompileReason("return_value", [self.frame_summary()])
[1794](/torch/_dynamo/symbolic_convert.py?line=1793) )
[1795](/torch/_dynamo/symbolic_convert.py?line=1794) self.output.add_output_instructions([create_instruction("RETURN_VALUE")])
File [~/torch/_dynamo/output_graph.py:517](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/output_graph.py:517), in OutputGraph.compile_subgraph(self, tx, partial_convert, reason)
[503](/torch/_dynamo/output_graph.py?line=502) self.add_output_instructions(random_calls_instructions)
[505](/torch/_dynamo/output_graph.py?line=504) if (
[506](/torch/_dynamo/output_graph.py?line=505) stack_values
[507](/torch/_dynamo/output_graph.py?line=506) and all(
(...)
[514](/torch/_dynamo/output_graph.py?line=513)
[515](/torch/_dynamo/output_graph.py?line=514) # optimization to generate better code in a common case
[516](/torch/_dynamo/output_graph.py?line=515) self.add_output_instructions(
--> [517](/torch/_dynamo/output_graph.py?line=516) self.compile_and_call_fx_graph(tx, list(reversed(stack_values)), root)
[518](/torch/_dynamo/output_graph.py?line=517) + [create_instruction("UNPACK_SEQUENCE", len(stack_values))]
[519](/torch/_dynamo/output_graph.py?line=518) )
[520](/torch/_dynamo/output_graph.py?line=519) else:
[521](/torch/_dynamo/output_graph.py?line=520) graph_output_var = self.new_var("graph_out")
File [~/torch/_dynamo/output_graph.py:588](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/output_graph.py:588), in OutputGraph.compile_and_call_fx_graph(self, tx, rv, root)
[586](/torch/_dynamo/output_graph.py?line=585) assert_no_fake_params_or_buffers(gm)
[587](/torch/_dynamo/output_graph.py?line=586) with tracing(self.tracing_context):
--> [588](/torch/_dynamo/output_graph.py?line=587) compiled_fn = self.call_user_compiler(gm)
[589](/torch/_dynamo/output_graph.py?line=588) compiled_fn = disable(compiled_fn)
[591](/torch/_dynamo/output_graph.py?line=590) counters["stats"]["unique_graphs"] += 1
File [~/torch/_dynamo/utils.py:163](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/utils.py:163), in dynamo_timed..dynamo_timed_inner..time_wrapper(*args, **kwargs)
[161](/torch/_dynamo/utils.py?line=160) compilation_metrics[key] = []
[162](/torch/_dynamo/utils.py?line=161) t0 = time.time()
--> [163](/torch/_dynamo/utils.py?line=162) r = func(*args, **kwargs)
[164](/torch/_dynamo/utils.py?line=163) time_spent = time.time() - t0
[165](/torch/_dynamo/utils.py?line=164) # print(f"Dynamo timer: key={key}, latency={latency:.2f} sec")
File [~/torch/_dynamo/output_graph.py:675](https://file+.vscode-resource.vscode-cdn.net/Users/~/torch/_dynamo/output_graph.py:675), in OutputGraph.call_user_compiler(self, gm)
[673](/torch/_dynamo/output_graph.py?line=672) except Exception as e:
[674](/torch/_dynamo/output_graph.py?line=673) compiled_fn = gm.forward
--> [675](/torch/_dynamo/output_graph.py?line=674) raise BackendCompilerFailed(self.compiler_fn, e) from e
[676](/torch/_dynamo/output_graph.py?line=675) return compiled_fn
BackendCompilerFailed: debug_wrapper raised KeyError: torch.complex128
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
### Minified repro
_No response_
### Versions
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.2.1 (x86_64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: Could not collect
Libc version: N/A
Python version: 3.9.16 (main, Jan 11 2023, 10:02:19) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
Versions of relevant libraries:
[pip3] flake8==6.0.0
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.24.2
[pip3] pytorch-lightning==2.0.0
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.1
[pip3] torchcde==0.2.5
[pip3] torchdiffeq==0.2.3
[pip3] torchmetrics==0.11.4
[pip3] torchqdynamics==0.1.0
[pip3] torchsde==0.2.5
[pip3] torchvision==0.15.1
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 hecd8cb5_637
[conda] mkl-service 2.4.0 py39h9ed2024_0
[conda] mkl_fft 1.3.1 py39h4ab4a9b_0
[conda] mkl_random 1.2.2 py39hb2f4e1b_0
[conda] numpy 1.24.2 pypi_0 pypi
[conda] pytorch-lightning 2.0.0 pypi_0 pypi
[conda] torch 2.0.0 pypi_0 pypi
[conda] torchaudio 2.0.1 pypi_0 pypi
[conda] torchcde 0.2.5 pypi_0 pypi
[conda] torchdiffeq 0.2.3 pypi_0 pypi
[conda] torchmetrics 0.11.4 pypi_0 pypi
[conda] torchqdynamics 0.1.0 pypi_0 pypi
[conda] torchsde 0.2.5 pypi_0 pypi
[conda] torchvision 0.15.1 pypi_0 pypi
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 22 |
3,022 | 98,142 |
double free or corruption (fasttop)
|
needs reproduction, triaged
|
### 🐛 Describe the bug
pytoch 2.0
conda install pytorch torchvision torchaudio cpuonly -c pytorch
Based on C ++ custom class, TORCH TENSOR as the inherent attribute, when the program executes the completion of the object degeneration, there is an error **Double Free or Corruption (Fasttop)**. Theoretically TORCH Tensor memory is managed and released by TORCH itself.
torch::TensorOptions options(torch::kFloat32);
if (is_train) { options.requires_grad(); }
if (normal) {
auto gen_opt = c10::optional<at::Generator>();
value_tensor = torch::normal(mean, std, {1, dim_size}, gen_opt, options = torch::kFloat32);
} else {
value_tensor = torch::rand({1, dim_size}, options = options);
}
// torch::DeviceType device = torch::DeviceType::CPU
value_tensor.to(torch::kCPU);
valgrind log:
```
==1989799== 8 bytes in 1 blocks are still reachable in loss record 299 of 3,796
==1989799== at 0x483DF0F: operator new(unsigned long) (vg_replace_malloc.c:434)
==1989799== by 0x9398B29: char const* c10::demangle_type<torch::jit::SRNativeOperatorFunctor_prim_TupleIndex>() (in /App/conda/envs/conda_xmake_cpu/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so)
==1989799== by 0x5C55771: __static_initialization_and_destruction_0(int, int) [clone .constprop.0] (in /App/conda/envs/conda_xmake_cpu/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so)
==1989799== by 0x4011B99: call_init.part.0 (dl-init.c:72)
==1989799== by 0x4011CA0: call_init (dl-init.c:30)
==1989799== by 0x4011CA0: _dl_init (dl-init.c:119)
==1989799== by 0x4001139: ??? (in /usr/lib/x86_64-linux-gnu/ld-2.31.so)
==1989799==
==1989799== 8 bytes in 1 blocks are still reachable in loss record 300 of 3,796
==1989799== at 0x483DF0F: operator new(unsigned long) (vg_replace_malloc.c:434)
==1989799== by 0x9398BD9: char const* c10::demangle_type<torch::jit::SRNativeOperatorFunctor_prim_RaiseException>() (in /App/conda/envs/conda_xmake_cpu/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so)
==1989799== by 0x5C55812: __static_initialization_and_destruction_0(int, int) [clone .constprop.0] (in /App/conda/envs/conda_xmake_cpu/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so)
==1989799== by 0x4011B99: call_init.part.0 (dl-init.c:72)
==1989799== by 0x4011CA0: call_init (dl-init.c:30)
==1989799== by 0x4011CA0: _dl_init (dl-init.c:119)
==1989799== by 0x4001139: ??? (in /usr/lib/x86_64-linux-gnu/ld-2.31.so)
==1989799==
==1989799== 8 bytes in 1 blocks are still reachable in loss record 301 of 3,796
==1989799== at 0x483DF0F: operator new(unsigned long) (vg_replace_malloc.c:434)
==1989799== by 0x9398C89: char const* c10::demangle_type<torch::jit::SRNativeOperatorFunctor_prim_Uninitialized>() (in /App/conda/envs/conda_xmake_cpu/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so)
==1989799== by 0x5C558B3: __static_initialization_and_destruction_0(int, int) [clone .constprop.0] (in /App/conda/envs/conda_xmake_cpu/lib/python3.9/site-packages/torch/lib/libtorch_cpu.so)
==1989799== by 0x4011B99: call_init.part.0 (dl-init.c:72)
==1989799== by 0x4011CA0: call_init (dl-init.c:30)
==1989799== by 0x4011CA0: _dl_init (dl-init.c:119)
==1989799== by 0x4001139: ??? (in /usr/lib/x86_64-linux-gnu/ld-2.31.so)
==1989799==
```
### Versions
Collecting environment information...
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: Could not collect
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.6 LTS (x86_64)
GCC version: (conda-forge gcc 12.2.0-19) 12.2.0
Clang version: 15.0.6 (https://github.com/conda-forge/clangdev-feedstock b6cf7124da893bcb57ab1f38c768ea825fabbdb1)
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.9.16 (main, Mar 8 2023, 14:00:05) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.4.0-128-generic-x86_64-with-glibc2.31
Is CUDA available: False
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration:
GPU 0: Tesla V100-SXM2-32GB
GPU 1: Tesla V100-SXM2-32GB
GPU 2: Tesla V100-SXM2-32GB
GPU 3: Tesla V100-SXM2-32GB
GPU 4: Tesla V100-SXM2-32GB
GPU 5: Tesla V100-SXM2-32GB
GPU 6: Tesla V100-SXM2-32GB
GPU 7: Tesla V100-SXM2-32GB
Nvidia driver version: 450.203.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 72
On-line CPU(s) list: 0-71
Thread(s) per core: 2
Core(s) per socket: 18
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 6140 CPU @ 2.30GHz
Stepping: 4
CPU MHz: 1000.141
CPU max MHz: 3700.0000
CPU min MHz: 1000.0000
BogoMIPS: 4600.00
Virtualization: VT-x
L1d cache: 1.1 MiB
L1i cache: 1.1 MiB
L2 cache: 36 MiB
L3 cache: 49.5 MiB
NUMA node0 CPU(s): 0-17,36-53
NUMA node1 CPU(s): 18-35,54-71
Vulnerability Itlb multihit: KVM: Mitigation: Split huge pages
Vulnerability L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; Clear CPU buffers; SMT vulnerable
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single pti intel_ppin ssbd mba ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req pku ospke md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.0
[pip3] torchvision==0.15.0
[conda] blas 1.0 mkl defaults
[conda] cpuonly 2.0 0 pytorch
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640 defaults
[conda] mkl-service 2.4.0 py39h7f8727e_0 defaults
[conda] mkl_fft 1.3.1 py39hd3c417c_0 defaults
[conda] mkl_random 1.2.2 py39h51133e4_0 defaults
[conda] numpy 1.23.5 py39h14f4228_0 defaults
[conda] numpy-base 1.23.5 py39h31eccc5_0 defaults
[conda] pytorch 2.0.0 py3.9_cpu_0 pytorch
[conda] pytorch-mutex 1.0 cpu pytorch
[conda] torchaudio 2.0.0 py39_cpu pytorch
[conda] torchvision 0.15.0 py39_cpu pytorch
| 4 |
3,023 | 98,136 |
A Segment Fault can be triggered in torch._grid_sampler_2d_cpu_fallback
|
module: crash, module: nn, triaged
|
### 🐛 Describe the bug
The following code can triger a segment fault `in torch._grid_sampler_2d_cpu_fallback`:
````python
import torch
input = torch.rand([16, 5, 8, 16], dtype=torch.float32).cuda()
grid = torch.rand([16, 1, 1, 2], dtype=torch.float32).cuda()
interpolation_mode = 8
padding_mode = -78
align_corners = False
res = torch._grid_sampler_2d_cpu_fallback(
input=input,
grid=grid,
interpolation_mode=interpolation_mode,
padding_mode=padding_mode,
align_corners=align_corners,
)
````
The output:
````
Segmentation fault (core dumped)
````
### Versions
Collecting environment information...
PyTorch version: 2.1.0.dev20230331+cu118
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 11.0.0-2~ubuntu20.04.1
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.8.16 (default, Mar 2 2023, 03:21:46) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-67-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 12.1.66
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla V100-PCIE-16GB
Nvidia driver version: 530.30.02
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.8.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.8.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Silver 4214 CPU @ 2.20GHz
Stepping: 7
CPU MHz: 2200.000
BogoMIPS: 4400.00
Virtualization: VT-x
L1d cache: 768 KiB
L1i cache: 768 KiB
L2 cache: 24 MiB
L3 cache: 33 MiB
NUMA node0 CPU(s): 0-11,24-35
NUMA node1 CPU(s): 12-23,36-47
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp_epp pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-triton==2.1.0+46672772b4
[pip3] torch==2.1.0.dev20230331+cu118
[pip3] torchaudio==2.1.0.dev20230401+cu118
[pip3] torchvision==0.16.0.dev20230331+cu118
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-triton 2.1.0+46672772b4 pypi_0 pypi
[conda] torch 2.1.0.dev20230331+cu118 pypi_0 pypi
[conda] torchaudio 2.1.0.dev20230401+cu118 pypi_0 pypi
[conda] torchvision 0.16.0.dev20230331+cu118 pypi_0 pypi
cc @albanD @mruberry @jbschlosser @walterddr @mikaylagawarecki
| 2 |
3,024 | 98,133 |
[interoperability] zero-size cuda arrays do not look supported
|
module: cuda, triaged
|
### 🐛 Describe the bug
https://numba.readthedocs.io/en/stable/cuda/cuda_array_interface.html says zero-size cuda arrays' data pointer is 0.
It doesn't seem like https://github.com/pytorch/pytorch/blob/553bb01df965d30ebfb3ef4dad68f911764b71d6/torch/csrc/utils/tensor_numpy.cpp#L362 treat such case differently.
Script to reproduce:
```python
import torch
class Foo:
__cuda_array_interface__ = {
"data": (0, False),
"typestr": "|i",
"shape": (0, ),
}
foo = Foo()
t = torch.asarray(foo, device="cuda")
assert t.is_cuda, t.device
print(t)
```
Output I got
```console
Traceback (most recent call last):
File "/home/mkozuki/cuda_array_interface_sample.py", line 13, in <module>
t = torch.asarray(foo, device="cuda")
RuntimeError: The specified pointer resides on host memory and is not registered with any CUDA device.
```
### Versions
```
Collecting environment information...
PyTorch version: 2.1.0a0+git7f22cf6
Is debug build: False
CUDA used to build PyTorch: 12.0
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.31
Python version: 3.9.12 (main, Jun 1 2022, 11:38:51) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.14.0-1057-oem-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 12.0.140
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3070 Ti
Nvidia driver version: 525.85.12
cuDNN version: Probably one of the following:
/usr/local/cuda-12.0/targets/x86_64-linux/lib/libcudnn.so.8
/usr/local/cuda-12.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8
/usr/local/cuda-12.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8
/usr/local/cuda-12.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8
/usr/local/cuda-12.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8
/usr/local/cuda-12.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8
/usr/local/cuda-12.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: False
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 36
On-line CPU(s) list: 0-35
Thread(s) per core: 2
Core(s) per socket: 18
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz
Stepping: 7
CPU MHz: 3000.000
CPU max MHz: 4800.0000
CPU min MHz: 1200.0000
BogoMIPS: 6000.00
Virtualization: VT-x
L1d cache: 576 KiB
L1i cache: 576 KiB
L2 cache: 18 MiB
L3 cache: 24.8 MiB
NUMA node0 CPU(s): 0-35
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] flake8==6.0.0
[pip3] flake8-bugbear==23.3.23
[pip3] flake8-comprehensions==3.11.1
[pip3] flake8-executable==2.1.3
[pip3] flake8-logging-format==0.9.0
[pip3] flake8-pyi==23.3.1
[pip3] mypy==0.960
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.1
[pip3] torch==2.0.0a0+gitcb67d94
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-include 2022.0.1 h06a4308_117
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.1 pypi_0 pypi
[conda] torch 2.1.0a0+gitc7f93ec dev_0 <develop>
```
cc @ngimel @ptrblck @leofang
| 1 |
3,025 | 98,124 |
PyTorch Profiler fails recording functions
|
oncall: profiler
|
### 🐛 Describe the bug
Using PyTorchProfiler with PyTorch 2.0 for training GPT2LMHeadModel from hugging face, mostly fails. Kineto init does not seem to throw error but nvtx captures fails with the following error and the runs ends with a report `RuntimeError: Can't disable Kineto profiler when it's not running` when `_disable_profiler()` is called on teardown.
The profiler works fine for other networks I have tried.
```
[W record_function.cpp:497] Exception in RecordFunction callback: state_ptr INTERNAL ASSERT FAILED at "../torch/csrc/profiler/standalone/nvtx_observer.cpp":116, please report a bug to PyTorch. Expected profiler state set
Exception raised from updateOutputTensorTracker at ../torch/csrc/profiler/standalone/nvtx_observer.cpp:116 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x57 (0x7fb9cbcba4d7 in /wks/.venv/lib/python3.8/site-packages/torch/lib/libc10.so)
frame #1: c10::detail::torchCheckFail(char const*, char const*, unsigned int, std::string const&) + 0x64 (0x7fb9cbc8436b in /wks/.venv/lib/python3.8/site-packages/torch/lib/libc10.so)
frame #2: c10::detail::torchInternalAssertFail(char const*, char const*, unsigned int, char const*, char const*) + 0x43 (0x7fb9cbcb8413 in /wks/.venv/lib/python3.8/site-packages/torch/lib/libc10.so)
frame #3: <unknown function> + 0x524314e (0x7fb9f708e14e in /wks/.venv/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #4: at::RecordFunction::end() + 0x51 (0x7fb9f38d75f1 in /wks/.venv/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #5: <unknown function> + 0x4a12fa6 (0x7fb9f685dfa6 in /wks/.venv/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #6: c10::Dispatcher::callBoxed(c10::OperatorHandle const&, std::vector<c10::IValue, std::allocator<c10::IValue> >*) const + 0x222 (0x7fb9f36d8f62 in /wks/.venv/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #7: torch::jit::invokeOperatorFromPython(std::vector<std::shared_ptr<torch::jit::Operator>, std::allocator<std::shared_ptr<torch::jit::Operator> > > const&, pybind11::args, pybind11::kwargs const&, c10::optional<c10::DispatchKey>) + 0x483 (0x7fba0b5be553 in /wks/.venv/lib/python3.8/site-packages/torch/lib/libtorch_python.so)
frame #8: torch::jit::_get_operation_for_overload_or_packet(std::vector<std::shared_ptr<torch::jit::Operator>, std::allocator<std::shared_ptr<torch::jit::Operator> > > const&, c10::Symbol, pybind11::args, pybind11::kwargs const&, bool, c10::optional<c10::DispatchKey>) + 0x5a2 (0x7fba0b5bee42 in /wks/.venv/lib/python3.8/site-packages/torch/lib/libtorch_python.so)
frame #9: <unknown function> + 0x784a07 (0x7fba0b4b3a07 in /wks/.venv/lib/python3.8/site-packages/torch/lib/libtorch_python.so)
frame #10: <unknown function> + 0x3b7050 (0x7fba0b0e6050 in /wks/.venv/lib/python3.8/site-packages/torch/lib/libtorch_python.so)
frame #11: PyCFunction_Call + 0x59 (0x5f5b39 in /wks/.venv/bin/python3)
frame #12: _PyEval_EvalFrameDefault + 0x6465 (0x5717f5 in /wks/.venv/bin/python3)
frame #13: _PyEval_EvalCodeWithName + 0x26a (0x569d8a in /wks/.venv/bin/python3)
frame #14: _PyFunction_Vectorcall + 0x393 (0x5f60c3 in /wks/.venv/bin/python3)
frame #15: /wks/.venv/bin/python3() [0x59cb2e]
frame #16: _PyObject_MakeTpCall + 0x296 (0x5f6706 in /wks/.venv/bin/python3)
frame #17: _PyEval_EvalFrameDefault + 0x5db3 (0x571143 in /wks/.venv/bin/python3)
frame #18: _PyFunction_Vectorcall + 0x1b6 (0x5f5ee6 in /wks/.venv/bin/python3)
frame #19: _PyEval_EvalFrameDefault + 0x851 (0x56bbe1 in /wks/.venv/bin/python3)
frame #20: _PyFunction_Vectorcall + 0x1b6 (0x5f5ee6 in /wks/.venv/bin/python3)
frame #21: _PyEval_EvalFrameDefault + 0x851 (0x56bbe1 in /wks/.venv/bin/python3)
frame #22: _PyFunction_Vectorcall + 0x1b6 (0x5f5ee6 in /wks/.venv/bin/python3)
frame #23: /wks/.venv/bin/python3() [0x50b849]
frame #24: PyObject_Call + 0x62 (0x5f52b2 in /wks/.venv/bin/python3)
frame #25: _PyEval_EvalFrameDefault + 0x1f2c (0x56d2bc in /wks/.venv/bin/python3)
frame #26: _PyEval_EvalCodeWithName + 0x26a (0x569d8a in /wks/.venv/bin/python3)
```
Still working through why it only happens for GPT2LMHeadModel while others work fine. Confirming that creasing to recording nvtx emits leads to successful captures for other metrics.
### Versions
PyTorch 2.0 with cuda 11.7 and cupti 11.7
cc @robieta @chaekit @aaronenyeshi @ngimel @nbcsm @guotuofeng @guyang3532 @gaoteng-git @tiffzhaofb @dzhulgakov @davidberard98
| 2 |
3,026 | 98,122 |
[pt2] `movedim` + `add_` + `cat` triggers exception
|
triaged, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
The following program works fine in eager mode but triggers RuntimeError when using `torch.compile`.
* On GPU the issue still exists.
* All the three operators are necessary for triggering the exception.
```python
import torch
def fn(x):
# x: (2, 2, 3, 3, 2)
v1_0 = torch.movedim(x, source=1, destination=2)
v4_0 = x.add_(1)
v0_0 = torch.cat([v4_0, v4_0], dim=2) # v0_0: (2, 2, 6, 3, 2)
return [v1_0, v0_0]
x = torch.rand([2, 2, 3, 3, 2])
ret_eager = fn(x)
print('==== Eager mode OK! ====')
compiled = torch.compile(fn)
print('==== torchcomp compilation OK! ====')
ret_compiled = compiled(x)
print('==== torchcomp mode OK! ====')
"""
==== Eager mode OK! ====
==== torchcomp compilation OK! ====
Traceback (most recent call last):
File "repro.py", line 18, in <module>
ret_compiled = compiled(x)
File "python3.10/site-packages/torch/_dynamo/eval_frame.py", line 237, in _fn
return fn(*args, **kwargs)
File "/home/yuyao/bug_repro/repro.py", line 3, in fn
def fn(v3_0):
File "python3.10/site-packages/torch/_dynamo/eval_frame.py", line 237, in _fn
return fn(*args, **kwargs)
File "python3.10/site-packages/torch/_functorch/aot_autograd.py", line 3065, in forward
return compiled_fn(full_args)
File "python3.10/site-packages/torch/_functorch/aot_autograd.py", line 1182, in g
return f(*args)
File "python3.10/site-packages/torch/_functorch/aot_autograd.py", line 2202, in runtime_wrapper
regenerated_out = gen_alias_from_base(aliased_base_tensor, o_, o_grad)
File "python3.10/site-packages/torch/_functorch/aot_autograd.py", line 576, in gen_alias_from_base
reshaped_base_tensor = aliased_base_tensor.as_strided(
RuntimeError: setStorage: sizes [2, 2, 6, 3, 2], strides [72, 36, 6, 2, 1], storage offset 0, and itemsize 4 requiring a storage size of 576 are out of bounds for storage of size 288
"""
```
### Versions
<details><summary><b>Environment</b> <i>[Click to expand]</i></summary>
```
PyTorch version: 2.1.0.dev20230331+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: 14.0.0-1ubuntu1
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Mar 10 2023, 10:55:28) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.19.0-35-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
Nvidia driver version: 525.78.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.960
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.23.1
[pip3] pytorch-triton==2.1.0+46672772b4
[pip3] torch==2.1.0.dev20230331+cu117
[pip3] torchaudio==2.1.0.dev20230331+cu117
[pip3] torchvision==0.16.0.dev20230331+cu117
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.21.5 py39he7a7128_1
[conda] numpy-base 1.21.5 py39hf524024_1
[conda] numpydoc 1.2 pyhd3eb1b0_0
```
</details>
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 1 |
3,027 | 98,115 |
Request to cherrypick a fix into v1.13.1 (v1.8 has a CVE)
|
oncall: binaries, triaged
|
### 🐛 Describe the bug
We ran into a CVE on v1.8, details at https://nvd.nist.gov/vuln/detail/CVE-2022-45907. The CVE got fixed in v1.13.1 but this version has a bazel bug which stops us from using it: https://github.com/pytorch/pytorch/issues/92096#issuecomment-1492771044.
Since, 1.8 -> 2.0.0 is a major version upgrade (which is a risk for us), the request is to cherrypick the fix for the bazel issue to 1.13: Fix is https://github.com/pytorch/pytorch/pull/92122.
### Versions
N/A
cc @seemethere @malfet
| 6 |
3,028 | 98,100 |
Unable to run session using exported ONNX model using dictionary input
|
module: onnx, triaged
|
### 🐛 Describe the bug
The following example tries to export CustomAdd ONNX model and tries to run using onnxruntime session. I have tried a few variations of passing the inputs with the run call. But I keep getting errors.
Traceback (most recent call last):
File "add.py", line 23, in <module>
ort_outputs = ort_sess.run(None, d)
File "/home/sajandhy/.conda/envs/py38/lib/python3.8/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 200, in run
return self._sess.run(output_names, input_feed, run_options)
RuntimeError: Input must be a list of dictionaries or a single numpy array for input 'x'.
Not clear what I am missing
```
import numpy
import onnxruntime
import torch
class CustomAdd(torch.nn.Module):
def forward(self, d):
x = d["x"]
y = d["y"]
return torch.add(x, y)
x = torch.randn(3, 3)
y = torch.randn(3, 3)
d = {"x":x, "y":y}
model = CustomAdd()
pt_outputs = model(d)
torch.onnx.export(CustomAdd(), (d, {}), "add.onnx")
ort_sess = onnxruntime.InferenceSession("add.onnx")
ort_inputs = (x, y)
ort_outputs = ort_sess.run(None, d)
```
### Versions
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.6 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.26.1
Libc version: glibc-2.31
Python version: 3.8.16 (default, Mar 2 2023, 03:21:46) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-1035-azure-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: Tesla V100-PCIE-16GB
GPU 1: Tesla V100-PCIE-16GB
GPU 2: Tesla V100-PCIE-16GB
GPU 3: Tesla V100-PCIE-16GB
Nvidia driver version: 525.89.02
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 24
On-line CPU(s) list: 0-23
Thread(s) per core: 1
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2690 v4 @ 2.60GHz
Stepping: 1
CPU MHz: 2593.992
BogoMIPS: 5187.98
Hypervisor vendor: Microsoft
Virtualization type: full
L1d cache: 768 KiB
L1i cache: 768 KiB
L2 cache: 6 MiB
L3 cache: 70 MiB
NUMA node0 CPU(s): 0-11
NUMA node1 CPU(s): 12-23
Vulnerability Itlb multihit: KVM: Mitigation: VMX unsupported
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT Host state unknown
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; Clear CPU buffers; SMT Host state unknown
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single pti fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt md_clear
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] pytorch-lightning==1.1.4
[pip3] torch==2.0.0
[pip3] torchvision==0.15.1
[pip3] triton==2.0.0
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py38h7f8727e_0
[conda] mkl_fft 1.3.1 py38hd3c417c_0
[conda] mkl_random 1.2.2 py38h51133e4_0
[conda] numpy 1.23.5 py38h14f4228_0
[conda] numpy-base 1.23.5 py38h31eccc5_0
[conda] pytorch-lightning 1.1.4 pypi_0 pypi
[conda] torch 2.0.0 pypi_0 pypi
[conda] torchvision 0.15.1 pypi_0 pypi
[conda] triton 2.0.0 pypi_0 pypi
| 1 |
3,029 | 98,089 |
GroupNorm cpu/gpu parity tests fail with pretty large differences
|
module: nn, triaged, needs research
|
### 🐛 Describe the bug
Differences look too big to be tolerance errors, investigate why this is the case. Skipping the test for now but filing this issue to track
```
=================================== FAILURES ===================================
2023-03-31T17:42:23.8945917Z _________ TestModuleCUDA.test_cpu_gpu_parity_nn_GroupNorm_cuda_float32 _________
2023-03-31T17:42:23.8946180Z Traceback (most recent call last):
2023-03-31T17:42:23.8946431Z File "test_modules.py", line 578, in test_cpu_gpu_parity
2023-03-31T17:42:23.8946690Z check_backward(cpu_outputs, gpu_outputs)
2023-03-31T17:42:23.8946944Z File "test_modules.py", line 570, in check_backward
2023-03-31T17:42:23.8947185Z self.assertEqual(cpu_p.grad, gpu_p.grad)
2023-03-31T17:42:23.8947635Z File "/opt/conda/envs/py_3.8/lib/python3.8/site-packages/torch/testing/_internal/common_utils.py", line 3023, in assertEqual
2023-03-31T17:42:23.8947942Z raise error_metas[0].to_error(
2023-03-31T17:42:23.8948212Z AssertionError: Tensor-likes are not close!
2023-03-31T17:42:23.8948359Z
2023-03-31T17:42:23.8948451Z Mismatched elements: 6 / 6 (100.0%)
2023-03-31T17:42:23.8948716Z Greatest absolute difference: 9.029479503631592 at index (4,) (up to 0.05 allowed)
2023-03-31T17:42:23.8949112Z Greatest relative difference: 1.9686480656500926 at index (2,) (up to 1.3e-06 allowed)
```
### Versions
master
cc @albanD @mruberry @jbschlosser @walterddr
| 1 |
3,030 | 98,087 |
[dynamo] hf_Reformer's graph break has increased
|
low priority, triaged, oncall: pt2, module: dynamo
|
https://github.com/pytorch/pytorch/pull/98003 updated the torchbench version that CI uses. While it does pick up a transformers upstream change which fixes graph break in Bert, it increase hf_Reformer's graph break from 5 to 26 for inference and from 51 to 67 for training.
cc: @ngimel
cc @ezyang @msaroufim @wconstab @bdhirsh @anijain2305 @voznesenskym @penguinwu @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @chenyang78 @aakhundov @kadeng @soumith @ngimel
| 2 |
3,031 | 98,077 |
Is there a recommended implementation of yuv2RGB for the current torch?
|
module: onnx, module: nn, triaged, module: python frontend
|
### 🚀 The feature, motivation and pitch
I need to convert the YUV420SP image to RGB, and then I built a network by torch. However, when I turned to the onnx frame model at last, I found it was very large. Is there a good way to do this?

### Alternatives
_No response_
### Additional context
_No response_
cc @albanD @mruberry @jbschlosser @walterddr @mikaylagawarecki
| 6 |
3,032 | 98,075 |
Unexpected results with torch.nn.functional.layer_norm
|
module: numerical-stability, triaged, module: norms and normalization
|
### 🐛 Describe the bug
Consider the following inputs:
```
a = torch.tensor([-3.], dtype=torch.float64)
weight = torch.tensor([1e10], dtype=torch.float64)
bias = torch.tensor([-1], dtype=torch.float64)
normalaxis = (1,)
eps = 0.1
torch.nn.functional.layer_norm(a, normalaxis, weight= weight, bias=bias, eps=eps)
```
This returns -1. as expected. In fact, when the weight is between 1e0 to 1e10, the return value is -1. However, when the weight is further increased from 1e10, the return value changes (first decreases and then increases). This makes no sense to me since the mean in every case is -3 and therefore, the weight will always get multiplied by 0 according to the layer_norm update equation which means the answer should always be -1 (equal to bias). What am I missing here?
https://discuss.pytorch.org/t/unexpected-results-with-torch-nn-functional-layer-norm/176064?u=hello-fri-end
### Versions
```
--2023-03-31 10:35:36-- https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 21501 (21K) [text/plain]
Saving to: ‘collect_env.py’
collect_env.py 100%[===================>] 21.00K --.-KB/s in 0.001s
2023-03-31 10:35:36 (22.6 MB/s) - ‘collect_env.py’ saved [21501/21501]
Collecting environment information...
PyTorch version: 1.13.1+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.2
Libc version: glibc-2.31
Python version: 3.9.16 (main, Dec 7 2022, 01:11:51) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.10.147+-x86_64-with-glibc2.31
Is CUDA available: False
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 2
On-line CPU(s) list: 0,1
Thread(s) per core: 2
Core(s) per socket: 1
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU @ 2.20GHz
Stepping: 0
CPU MHz: 2200.164
BogoMIPS: 4400.32
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32 KiB
L1i cache: 32 KiB
L2 cache: 256 KiB
L3 cache: 55 MiB
NUMA node0 CPU(s): 0,1
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Vulnerable; SMT Host state unknown
Vulnerability Meltdown: Vulnerable
Vulnerability Mmio stale data: Vulnerable
Vulnerability Retbleed: Vulnerable
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Vulnerable: __user pointer sanitization and usercopy barriers only; no swapgs barriers
Vulnerability Spectre v2: Vulnerable, IBPB: disabled, STIBP: disabled, PBRSB-eIBRS: Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Vulnerable
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx smap xsaveopt arat md_clear arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.22.4
[pip3] torch==1.13.1+cu116
[pip3] torchaudio==0.13.1+cu116
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.14.1
[pip3] torchvision==0.14.1+cu116
[conda] Could not collect
```
| 4 |
3,033 | 98,073 |
Add PrivateUse1 folder in aten/src/ATen
|
triaged, module: backend
|
### 🚀 The feature, motivation and pitch
I am going to add a PrivateUse1 folder to contain all the feature adaptations for PrivateUse1 under Aten,For example GetGeneratorPrivate which is used for the three-party backend to register his own Generator implementation.This makes it easier for us to centrally manage these features, and it will increase the convenience of adaptation for different back-end manufacturers.This is an immature idea, please give your valuable advice.
### Alternatives
_No response_
### Additional context
_No response_
| 8 |
3,034 | 98,070 |
Request custom backend device memory Allocator.
|
module: memory usage, triaged, module: backend, module: CUDACachingAllocator
|
### 🚀 The feature, motivation and pitch
For newly registered backend users, the framework is expected to support a device lining pool mechanism. Users only need to register malloc and free functions related to devices to reduce the development cost of the new backend.
### Alternatives
I think the support for this feature can be divided into the following steps
1. Currently, the cachingAllocator mechanism of the CUDA is mature. We can extract classes from the cachingAllocator mechanism and provide them for users to inherit during implementation, such as DeviceStats, Block, BlockInfo, THCcachingAllocator and DeviceCachingAllocator.
2. We can pre-register a device CachingAllocator for the privateuse1 backend. New users only need to register the free and malloc functions of their backend.
3. The CachingAllocator policy can be replaced and extended for capable users.
### Additional context
_No response_
| 1 |
3,035 | 98,064 |
Module 'Sequential' has no attribute '_modules' :
|
oncall: jit
|
### 🐛 Describe the bug
```pythons
import torch
import torch.nn as nn
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.seq = nn.Sequential(
nn.Linear(10, 20),
nn.ReLU(),
nn.Linear(20, 5)
)
def forward(self, x):
return self.seq(x)
my_module = MyModule()
scripted_module = torch.jit.script(my_module)
```
```
RuntimeError:
Module 'Sequential' has no attribute '_modules' :
File "/home/zhou/.local/lib/python3.10/site-packages/torch/nn/modules/container.py", line 251
@property
def modules(self):
return self._modules
~~~~~~~~~~~~~ <--- HERE
```
### Versions
__version__ = '2.0.0+cu117'
debug = False
cuda = '11.7'
git_version = 'c263bd43e8e8502d4726643bc6fd046f0130ac0e'
hip = None
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 4 |
3,036 | 98,059 |
DISABLED test_scatter_1d (__main__.DeviceMeshCollectiveTest)
|
oncall: distributed, module: flaky-tests, skipped
|
Platforms: linux
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_scatter_1d&suite=DeviceMeshCollectiveTest) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/12412570135).
Over the past 3 hours, it has been determined flaky in 2 workflow(s) with 3 failures and 2 successes.
**Debugging instructions (after clicking on the recent samples link):**
DO NOT ASSUME THINGS ARE OKAY IF THE CI IS GREEN. We now shield flaky tests from developers so CI will thus be green but it will be harder to parse the logs.
To find relevant log snippets:
1. Click on the workflow logs linked above
2. Click on the Test step of the job so that it is expanded. Otherwise, the grepping will not work.
3. Grep for `test_scatter_1d`
4. There should be several instances run (as flaky tests are rerun in CI) from which you can study the logs.
Test file path: `distributed/_tensor/test_device_mesh.py` or `distributed/_tensor/test_device_mesh.py`
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 5 |
3,037 | 98,039 |
OpClassTensorOp for fp32 torch.bmm(NT, NT)
|
Stale, release notes: cuda
|
An attempt to further improve performance
| 2 |
3,038 | 98,013 |
Automate aarch64 builds
|
oncall: releng, triaged
|
Automate aarch64 builds: https://github.com/pytorch/builder/tree/main/aarch64_linux
| 0 |
3,039 | 98,012 |
[Nova] Add metadata validation step to the smoke tests for core and domains
|
oncall: releng, triaged
|
Consider using: https://pypi.org/project/check-wheel-contents/
| 0 |
3,040 | 98,008 |
Write Binary Builds oncall runbook
|
oncall: releng, triaged
|
- Add a point about failure Alerts
| 0 |
3,041 | 98,007 |
Create release checklist template for the Launch Date
|
oncall: releng, triaged
| null | 0 |
3,042 | 98,006 |
Create a plan on removing conda dependency from CI/CD
|
oncall: releng, triaged
|
Try POC having single conda env but all dependencies come from pypi
Wheel builds
Try starting change in Nova
Provide design document
Mostly wheel related
| 0 |
3,043 | 98,004 |
matmul with CSR matrix in inference mode throws an exception
|
module: sparse, module: autograd, triaged
|
### 🐛 Describe the bug
```
# BUG: matmul with CSR matrix in inference mode throws an exception
import torch;
x = torch.randn((4,8,5),dtype=torch.float);
M = torch.Tensor.to_sparse_csr(torch.eye(8));
# non-inference mode works
y = torch.matmul(M,x);
# inference mode throws RuntimeError: Cannot set version_counter for inference tensor
with torch.inference_mode():
y = torch.matmul(M,x);
```
### Versions
Collecting environment information...
PyTorch version: 1.13.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-137-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 12.0.76
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA TITAN Xp
Nvidia driver version: 525.60.13
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 12
On-line CPU(s) list: 0-11
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 158
Model name: Intel(R) Core(TM) i7-8700K CPU @ 3.70GHz
Stepping: 10
CPU MHz: 4300.000
CPU max MHz: 4700.0000
CPU min MHz: 800.0000
BogoMIPS: 7399.70
Virtualization: VT-x
L1d cache: 192 KiB
L1i cache: 192 KiB
L2 cache: 1.5 MiB
L3 cache: 12 MiB
NUMA node0 CPU(s): 0-11
Vulnerability Itlb multihit: KVM: Vulnerable
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Mitigation; Microcode
Vulnerability Tsx async abort: Mitigation; Clear CPU buffers; SMT vulnerable
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.21.1
[pip3] numpydoc==0.7.0
[pip3] torch==1.13.1
[pip3] torchaudio==0.13.1
[pip3] torchvision==0.14.1
[conda] Could not collect
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7 @alexsamardzic @cpuhrsch @amjames @bhosmer
| 12 |
3,044 | 98,002 |
DataLoader with collate_fn that returns tensors in GPU memory raises warnings when deleted
|
module: dataloader, triaged
|
### 🐛 Describe the bug
I defined a `DataLoader` with `collate_fn` that returns tensors in GPU memory, with `num_workers=1` and `prefetch_factor=2` so that as I iterate through the `DataLoader`, the tensors it returns are already in GPU memory. When the `DataLoader` is deleted, a lot of warnings are raised from [`CUDAGuardImpl.h`](https://github.com/pytorch/pytorch/blob/master/c10/cuda/impl/CUDAGuardImpl.h). For example:
```python
import torch
import torchvision
def collate_gpu(batch):
x, t = torch.utils.data.default_collate(batch)
return x.to(device=0), t.to(device=0)
train_dataset = torchvision.datasets.MNIST(
'./data',
train=True,
download=True,
transform=torchvision.transforms.ToTensor(),
)
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=100,
num_workers=1,
prefetch_factor=2,
persistent_workers=True,
collate_fn=collate_gpu,
)
if __name__ == "__main__":
x, t = next(iter(train_loader))
print("About to call `del train_loader`...")
del train_loader
print("Finished `del train_loader`")
```
Console output:
```
About to call `del train_loader`...
[W C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\torch\csrc\CudaIPCTypes.cpp:15] Producer process has been terminated before all shared CUDA tensors released. See Note [Sharing CUDA tensors]
[W CUDAGuardImpl.h:46] Warning: CUDA warning: driver shutting down (function uncheckedGetDevice)
[W CUDAGuardImpl.h:62] Warning: CUDA warning: driver shutting down (function uncheckedSetDevice)
[W CUDAGuardImpl.h:46] Warning: CUDA warning: driver shutting down (function uncheckedGetDevice)
[W CUDAGuardImpl.h:62] Warning: CUDA warning: invalid device ordinal (function uncheckedSetDevice)
[W CUDAGuardImpl.h:46] Warning: CUDA warning: driver shutting down (function uncheckedGetDevice)
[W CUDAGuardImpl.h:62] Warning: CUDA warning: invalid device ordinal (function uncheckedSetDevice)
[W CUDAGuardImpl.h:46] Warning: CUDA warning: driver shutting down (function uncheckedGetDevice)
[W CUDAGuardImpl.h:62] Warning: CUDA warning: invalid device ordinal (function uncheckedSetDevice)
[W CUDAGuardImpl.h:46] Warning: CUDA warning: driver shutting down (function uncheckedGetDevice)
[W CUDAGuardImpl.h:62] Warning: CUDA warning: invalid device ordinal (function uncheckedSetDevice)
[W CUDAGuardImpl.h:46] Warning: CUDA warning: driver shutting down (function uncheckedGetDevice)
[W CUDAGuardImpl.h:62] Warning: CUDA warning: invalid device ordinal (function uncheckedSetDevice)
Finished `del train_loader`
```
In reality I don't call `del train_loader`, but I initialise `train_loader` inside a function, and when the function exits, the result is the same. (Weirdly, if I don't call `del train_loader` and `train_loader` is not defined inside a function, then there are no warning messages at all).
PS am I being silly? I would have assumed it would be a very common use case to want to pre-fetch data in GPU memory with a DataLoader rather than waiting in the main process for data to be copied to the GPU, but I can't seem to find many posts on this topic at all (one example is [this thread](https://discuss.pytorch.org/t/moving-data-to-gpu-in-collate-fn-fails/49021), but it's 4 years old and the error message is different)
### Versions
Versions/OS:
Python 3.7.6
Cuda 11.7
PyTorch 1.13.0+cu117
Windows 10
(sorry I don't fancy running a >600 line Python script downloaded from the internet, regardless of the author)
cc @SsnL @VitalyFedyunin @ejguan @NivekT @dzhulgakov
| 6 |
3,045 | 97,992 |
torch.compile not compatible with multiprocessing pool
|
triaged, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
Attempting to call `torch.compile()` within a multiprocessing pool results in:
```sh
torch._dynamo.exc.BackendCompilerFailed: debug_wrapper raised AssertionError: daemonic processes are not allowed to have children
```
I am using `transformers` `ViTModel` to encode images and cache them to disk inside my DataLoader transform. To improve performance, I was hoping to use `torch.compile()` since I perform this pre-processing transform on CPU. However, compiling in my transform's `__init__` runs into pickling issues when the DataLoader forks the workers. As for compiling after the workers have forked, I run into the issue above.
### Error logs
```sh
RuntimeError: Caught BackendCompilerFailed in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/home/jovyan/.conda/envs/videocv/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 670, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "/home/jovyan/.conda/envs/videocv/lib/python3.10/site-packages/torch/_dynamo/debug_utils.py", line 1055, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs)
File "/home/jovyan/.conda/envs/videocv/lib/python3.10/site-packages/torch/__init__.py", line 1388, in __call__
from torch._inductor.compile_fx import compile_fx
File "/home/jovyan/.conda/envs/videocv/lib/python3.10/site-packages/torch/_inductor/compile_fx.py", line 21, in <module>
from . import config, metrics, overrides, pattern_matcher
File "/home/jovyan/.conda/envs/videocv/lib/python3.10/site-packages/torch/_inductor/pattern_matcher.py", line 19, in <module>
from .lowering import lowerings as L
File "/home/jovyan/.conda/envs/videocv/lib/python3.10/site-packages/torch/_inductor/lowering.py", line 3868, in <module>
import_submodule(kernel)
File "/home/jovyan/.conda/envs/videocv/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 1304, in import_submodule
importlib.import_module(f"{mod.__name__}.{filename[:-3]}")
File "/home/jovyan/.conda/envs/videocv/lib/python3.10/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "/home/jovyan/.conda/envs/videocv/lib/python3.10/site-packages/torch/_inductor/kernel/bmm.py", line 4, in <module>
from ..select_algorithm import (
File "/home/jovyan/.conda/envs/videocv/lib/python3.10/site-packages/torch/_inductor/select_algorithm.py", line 20, in <module>
from .codecache import code_hash, DiskCache, PyCodeCache
File "/home/jovyan/.conda/envs/videocv/lib/python3.10/site-packages/torch/_inductor/codecache.py", line 721, in <module>
AsyncCompile.warm_pool()
File "/home/jovyan/.conda/envs/videocv/lib/python3.10/site-packages/torch/_inductor/codecache.py", line 660, in warm_pool
pool._adjust_process_count()
File "/home/jovyan/.conda/envs/videocv/lib/python3.10/concurrent/futures/process.py", line 692, in _adjust_process_count
self._spawn_process()
File "/home/jovyan/.conda/envs/videocv/lib/python3.10/concurrent/futures/process.py", line 709, in _spawn_process
p.start()
File "/home/jovyan/.conda/envs/videocv/lib/python3.10/multiprocessing/process.py", line 118, in start
assert not _current_process._config.get('daemon'), \
AssertionError: daemonic processes are not allowed to have children
```
### Minified repro
_No response_
### Versions
```sh
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.6 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.26.0
Libc version: glibc-2.31
Python version: 3.10.9 | packaged by conda-forge | (main, Feb 2 2023, 20:20:04) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-121-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.6.112
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA A40
Nvidia driver version: 470.57.02
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.3.3
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.3.3
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.3.3
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.3.3
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.3.3
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.3.3
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.3.3
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU: removed
Versions of relevant libraries:
[pip3] mypy==1.0.1
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.24.2
[pip3] pytorch-optimizer==2.5.0
[pip3] pytorch-triton==2.0.0+b8b470bc59
[pip3] torch==2.0.0
[pip3] torchinfo==1.7.2
[pip3] torchvision==0.15.1
[pip3] triton==2.0.0
[conda] numpy 1.24.2 pypi_0 pypi
[conda] pytorch-optimizer 2.5.0 pypi_0 pypi
[conda] pytorch-triton 2.0.0+b8b470bc59 pypi_0 pypi
[conda] torch 2.0.0 pypi_0 pypi
[conda] torchinfo 1.7.2 pypi_0 pypi
[conda] torchvision 0.15.1 pypi_0 pypi
[conda] triton 2.0.0 pypi_0 pypi
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 1 |
3,046 | 97,991 |
functional collective should respect the whole mesh
|
oncall: distributed, triaged
|
### 🚀 The feature, motivation and pitch
See discussion of this PR, when passing the whole mesh to the functional collective (without meshdim), it should be able to see the whole mesh ranks and run collective on all the ranks, instead of only 0 mesh dim.
### Alternatives
_No response_
### Additional context
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
3,047 | 97,990 |
Relax version dependencies on CUDA pip wheels?
|
oncall: binaries, module: cuda
|
### 🐛 Describe the bug
A JAX user noted that `torch` and `jax` have conflicting requirements for NVIDIA's CUDA pip wheels.
Torch specifies exact version pins in its wheels:
```
Requires-Dist: nvidia-cuda-nvrtc-cu11 (==11.7.99) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-cuda-runtime-cu11 (==11.7.99) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-cuda-cupti-cu11 (==11.7.101) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-cudnn-cu11 (==8.5.0.96) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-cublas-cu11 (==11.10.3.66) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-cufft-cu11 (==10.9.0.58) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-curand-cu11 (==10.2.10.91) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-cusolver-cu11 (==11.4.0.1) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-cusparse-cu11 (==11.7.4.91) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-nccl-cu11 (==2.14.3) ; platform_system == "Linux" and platform_machine == "x86_64"
Requires-Dist: nvidia-nvtx-cu11 (==11.7.91) ; platform_system == "Linux" and platform_machine == "x86_64"
```
These are non-overlapping with some of JAX's dependencies. JAX currently ships wheels that require:
* CUDA 11.8+ and cudnn 8.6+, or
* CUDA 12.0+ and cudnn 8.8+.
For CUDA 11 wheels, JAX requires:
```
"nvidia-cublas-cu11>=11.11",
"nvidia-cuda-nvcc-cu11>=11.8",
"nvidia-cuda-runtime-cu11>=11.8",
"nvidia-cudnn-cu11>=8.6",
"nvidia-cufft-cu11>=10.9",
"nvidia-cusolver-cu11>=11.4",
"nvidia-cusparse-cu11>=11.7",
```
I'm wondering if you would be open to relaxing some or all of the CUDA version pins in `torch` to be `>=` constraints. NVIDIA promise backward compatibility for CUDA and CUDNN minor releases, so in theory this is safe. Theory and practice may differ, however.
My fall back is to tell users to do the following, which works because `pip` doesn't actually enforce the version constraints:
```
pip install torch
pip install --upgrade nvidia-cublas-cu11 nvidia-cuda-runtime-cu11 # ... etc.
# then install JAX
```
but it's not optimal: it means one cannot really release a package that depends on both `jax` and `torch`.
### Versions
2.0
cc @seemethere @malfet @ngimel
| 8 |
3,048 | 97,985 |
Can libtorch be used for quantization-aware training of models?
|
oncall: quantization, triaged
|
### 🚀 The feature, motivation and pitch
We want to use C++ to develop a software for deep learning model training and quantification. Users can fine-tune and train the model by themselves. In order to facilitate deployment, we don't want to use python language, so we want to implement it based on libtorch.
However, libtorch does not seem to support quantization-aware training at present. Is it possible to add this function to libtorch?
### Alternatives
_No response_
### Additional context
_No response_
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo @jgong5 @Xia-Weiwen @leslie-fang-intel
| 3 |
3,049 | 97,976 |
Dynamo doesn't report accurate line numbers for <resume> in some situations
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
Steps to reproduce:
1. Patch in https://github.com/pytorch/pytorch/pull/97884
2. Run `TORCH_LOGS=dynamo benchmarks/dynamo/huggingface.py --devices cuda --inductor --accuracy --print-graph-breaks --only PegasusForConditionalGeneration`
Here are the full logs https://gist.github.com/ezyang/01254a7e14d17ad9f9843c22676cb1fc
In the logs, you will see:
```
[2023-03-30 05:27:57,270] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing file "<string>", line 3, in <resume in __init__>
[2023-03-30 05:27:57,270] torch._dynamo.output_graph: [WARNING] Graph break: call_method DataClassVariable() __setitem__ [ConstantVariable(str), ConstantVariable(NoneType)] {} from user code at:
File "<string>", line 4, in <resume in __init__>
[2023-03-30 05:27:57,277] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing file "<string>", line 4, in <resume in __init__>
[2023-03-30 05:27:57,277] torch._dynamo.output_graph: [WARNING] Graph break: call_method DataClassVariable() __setitem__ [ConstantVariable(str), ConstantVariable(NoneType)] {} from user code at:
File "<string>", line 5, in <resume in __init__>
[2023-03-30 05:27:57,284] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing file "<string>", line 5, in <resume in __init__>
[2023-03-30 05:27:57,284] torch._dynamo.output_graph: [WARNING] Graph break: call_method DataClassVariable() __setitem__ [ConstantVariable(str), ConstantVariable(NoneType)] {} from user code at:
File "<string>", line 6, in <resume in __init__>
[2023-03-30 05:27:57,291] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing file "<string>", line 6, in <resume in __init__>
[2023-03-30 05:27:57,291] torch._dynamo.output_graph: [WARNING] Graph break: call_method DataClassVariable() __setitem__ [ConstantVariable(str), ConstantVariable(NoneType)] {} from user code at:
File "<string>", line 7, in <resume in __init__>
[2023-03-30 05:27:57,298] torch._dynamo.symbolic_convert: [INFO] Step 1: torchdynamo start tracing file "<string>", line 7, in <resume in __init__>
[2023-03-30 05:27:57,298] torch._dynamo.output_graph: [WARNING] Graph break: call_method DataClassVariable() __setitem__ [ConstantVariable(str), TensorVariable()] {} from user code at:
File "<string>", line 8, in <resume in __init__>
```
This is really bad. Really want real file line numbers here.
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire @jansel
### Versions
master
| 0 |
3,050 | 97,966 |
torch.randn signature is missing generator
|
module: docs, triaged, enhancement, module: random, module: python frontend
|
### 📚 The doc issue
[torch.randn](https://pytorch.org/docs/stable/generated/torch.randn.html) lacks `generator` argument in the signature `torch.randn(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False, pin_memory=False)`.
### Suggest a potential alternative/fix
Add `generator`, like in [torch.rand](https://pytorch.org/docs/stable/generated/torch.rand.html#torch.rand):
`torch.randn(*size, *, generator=None, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False, pin_memory=False)`
cc @svekars @carljparker @pbelevich @albanD
| 1 |
3,051 | 97,961 |
[CI/Infra] Record keeping: runner shutdown spike
|
triaged
|
### 🐛 Describe the bug
https://hud.pytorch.org/failure/The%20runner%20has%20received%20a%20shutdown%20signal.%20This%20can%20happen%20when%20the%20runner%20service%20is%20stopped%2C%20or%20a%20manually%20started%20runner%20is%20canceled. shows skyrocketing number of instances "runner shutdown" on Mar 29, 2023. Because they got self-disconnected via "sudo ./svc.sh stop" usually after main action step's failure. When the actions was already failing, there was logic to determine whether the error was "unrecoverable" or not. If the error was indeed unrecoverable, then disconnecting is good because it prevents pollution of future jobs. Though such disconnection should be aligned with the underlying infra (e.g. as it currently stands, a courtesy notification may be needed for GCP runners). If the error was not "unrecoverable", we should make sure the runner does not get disconnected from GHA (or maybe this does not matter, but developers would be redirected to runner cancellation error first).
<img width="797" alt="image" src="https://user-images.githubusercontent.com/109318740/228754623-4524e2a1-2a7b-4450-8b0e-577972ec44bd.png">
We know the related PR (#97585), and a follow-up forward fix (#97929) ,. but I want to make sure we address the following issues:
1) For GCP A100 runners that were affected, the error should not be categorized "unrecoverable", e.g. in this action https://github.com/pytorch/pytorch/actions/runs/4560162853/jobs/8045132304 , it was transient SSH error, should be recoverable. And for this https://github.com/pytorch/pytorch/actions/runs/4558849401/jobs/8042466592
that was software caused core-dump and is non-deterministic. The runner should not be disconnected from the GHA. Though after the disconnection, manual intervention was needed as the auto-scaler does not yet have the knowledge that the still online busy runner decided to silently disconnect from GHA without telling auto-scaler (e.g. set /tmp/runner_status to "idle" for auto-scaler to shut it down)
2) For AWS runners that were affected, we need to also make sure those instances go through "garbage collection" procedure so they do not become at large. cc @jeanschmidt
3) If we allow runner self-disconnect, depending on how we implemented auto-scaler, we should make sure the auto-scaler get the opportunity to reclaim them and take care of the runners.
cc @huydhn @seemethere @malfet
### Versions
After #97585, maybe resolved by now, or maybe not. Needs confirmation.
| 3 |
3,052 | 97,915 |
Investigate Lazy{*}Norm{*}d modules no batch dim support
|
module: nn, triaged
|
### 🐛 Describe the bug
LazyInstanceNorm is documented to support no_batch_dim (e.g. (C, L) is listed as a valid input shape [here](https://pytorch.org/docs/stable/generated/torch.nn.LazyInstanceNorm1d.html)) but in _LazyNormBase, [`in_features` is initialized as `.shape[1]`](https://github.com/pytorch/pytorch/blob/099b2801dbcf23aba0b5c6862451b7b18272afd0/torch/nn/modules/batchnorm.py#L221), which should be incorrect when there is no batch dimension.
e.g. the following snippet fails
```
import torch
lazy_instance_norm = torch.nn.LazyInstanceNorm()
lazy_instance_norm(torch.randn(3, 15))
# ValueError: expected input's size at dim=0 to match num_features (15), but got: 3.
```
This might also apply to batchnorm which also uses _LazyNormBase and needs further investigation.
### Versions
master
cc @albanD @mruberry @jbschlosser @walterddr
| 0 |
3,053 | 97,913 |
BUG torch.jit.annotate on List + torch.stack give wrong DTYPE
|
oncall: jit
|
### 🐛 Describe the bug
Hi, we are switching to pytorch2.0; we have some internal LSTM implem with JIT and are using `torch.jit.annotate`; here is a small example to reproduce the error;
`torch.jit.annote` are giving a value of 6 in the dtype after torch.stack the list.
Reproduce bug:
```
from typing import List
import torch
from torch import Tensor
class Example(torch.nn.Module):
def __init__(self,i_size) -> None:
super().__init__()
self.layer_norm = torch.nn.LayerNorm(i_size)
@torch.jit.script
def do_stuff_with_jit_annotate(input):
# pad output x times
outputs = torch.jit.annotate(List[Tensor], [])
for i in range(5):
outputs = outputs.append(input)
print(torch.stack(outputs).dtype)
# It print always value 6.
# This make the onnx fail when this value is used by other modules.
# I solve it in our JITLSTM by
# torch.stack(outputs).float()
return torch.stack(outputs)
def forward(self,input):
output = self.do_stuff_with_jit_annotate(input)
return self.layer_norm(output)
model = Example(10)
torch.onnx.export(model,
torch.randn(1,10),
"model.onnx",
input_names=["input"],
output_names=["output"],
do_constant_folding=True,
verbose=True,
opset_version=11,
)
```
Error:
```
Traceback (most recent call last):
File "example.py", line 30, in <module>
torch.onnx.export(model,
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/utils.py", line 506, in export
_export(
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/utils.py", line 1548, in _export
graph, params_dict, torch_out = _model_to_graph(
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/utils.py", line 1117, in _model_to_graph
graph = _optimize_graph(
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/utils.py", line 665, in _optimize_graph
graph = _C._jit_pass_onnx(graph, operator_export_type)
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/utils.py", line 1891, in _run_symbolic_function
return symbolic_fn(graph_context, *inputs, **attrs)
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/symbolic_helper.py", line 392, in wrapper
return fn(g, *args, **kwargs)
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/symbolic_helper.py", line 306, in wrapper
return fn(g, *args, **kwargs)
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/symbolic_opset9.py", line 2837, in layer_norm
normalized, _, _ = native_layer_norm(g, input, normalized_shape, weight, bias, eps)
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/symbolic_helper.py", line 392, in wrapper
return fn(g, *args, **kwargs)
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/symbolic_helper.py", line 306, in wrapper
return fn(g, *args, **kwargs)
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/symbolic_opset9.py", line 2774, in native_layer_norm
_type_utils.JitScalarType.from_value(numerator)
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/_type_utils.py", line 197, in from_value
raise errors.SymbolicValueError(
torch.onnx.errors.SymbolicValueError: Cannot determine scalar type for this '<class 'torch.TensorType'>' instance and a default value was not provided. [Caused by the value '21 defined in (%21 : Tensor = onnx::Sub(%input, %20), scope: __main__.Example::/torch.nn.modules.normalization.LayerNorm::layer_norm
)' (type 'Tensor') in the TorchScript graph. The containing node has kind 'onnx::Sub'.]
Inputs:
#0: input defined in (%input : Tensor = onnx::ConcatFromSequence[axis=0, new_axis=1](%outputs) # example.py:22:15
) (type 'Tensor')
#1: 20 defined in (%20 : Tensor = onnx::ReduceMean[axes=[-1]](%input), scope: __main__.Example::/torch.nn.modules.normalization.LayerNorm::layer_norm
) (type 'Tensor')
Outputs:
#0: 21 defined in (%21 : Tensor = onnx::Sub(%input, %20), scope: __main__.Example::/torch.nn.modules.normalization.LayerNorm::layer_norm
) (type 'Tensor')
```
### Versions
```
[pip3] flake8==4.0.1
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.22.4
[pip3] pytorch-lightning==1.9.3
[pip3] torch==2.0.0
[pip3] torch-nebula==0.16.2
[pip3] torch-ort==1.14.0
[pip3] torch-tb-profiler==0.4.0
[pip3] torchmetrics==0.11.3
[pip3] torchsnapshot==0.1.0
[pip3] torchvision==0.15.1+cu117
[pip3] triton==2.0.0
[conda] magma-cuda117 2.6.1 1 pytorch
[conda] mkl 2023.0.0 pypi_0 pypi
[conda] mkl-fft 1.3.1 pypi_0 pypi
[conda] mkl-include 2021.4.0 pypi_0 pypi
[conda] numpy 1.22.4 pypi_0 pypi
[conda] pytorch-lightning 1.9.3 pypi_0 pypi
[conda] torch 2.0.0 pypi_0 pypi
[conda] torch-nebula 0.16.2 pypi_0 pypi
[conda] torch-ort 1.14.0 pypi_0 pypi
[conda] torch-tb-profiler 0.4.0 pypi_0 pypi
[conda] torchmetrics 0.11.3 pypi_0 pypi
[conda] torchsnapshot 0.1.0 pypi_0 pypi
[conda] torchvision 0.15.1+cu117 pypi_0 pypi
[conda] triton 2.0.0 pypi_0 pypi
```
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 1 |
3,054 | 97,909 |
`torch.func.functional_call` doesn't work with compiled models
|
high priority, triaged, module: correctness (silent), oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
When creating a custom model with `nn.Module` and compiling it with `torch.compile()`, the output of `torch.func.functional_call()` remains the same even if providing different `parameter_and_buffer_dicts`. Below is an example:
```python
import torch
import torch.nn as nn
class LinearNet(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 3)
def forward(self, x):
return self.linear(x)
inputs = torch.randn(1, 1)
print('instantiate w/ nn.Module + compile:')
model = torch.compile(LinearNet())
params = dict(model.named_parameters())
print(torch.func.functional_call(model, params, inputs))
# set parameters to 0 so that outputs should also be 0
for name, param in params.items():
params[name] = torch.zeros_like(param)
print(torch.func.functional_call(model, params, inputs))
print('instantiate w/ nn.Linear + compile:')
model = torch.compile(nn.Linear(1, 3))
params = dict(model.named_parameters())
print(torch.func.functional_call(model, params, inputs))
for name, param in params.items():
params[name] = torch.zeros_like(param)
print(torch.func.functional_call(model, params, inputs))
print('instantiate w/ nn.Module + no compile:')
model = LinearNet()
params = dict(model.named_parameters())
print(torch.func.functional_call(model, params, inputs))
for name, param in params.items():
params[name] = torch.zeros_like(param)
print(torch.func.functional_call(model, params, inputs))
```
Outputs:
```
instantiate w/ nn.Module + compile:
tensor([[-0.2246, 0.4658, 0.3510]], grad_fn=<CompiledFunctionBackward>)
tensor([[-0.2246, 0.4658, 0.3510]], grad_fn=<CompiledFunctionBackward>)
instantiate w/ nn.Linear + compile:
tensor([[ 0.3361, 0.3872, -0.6998]], grad_fn=<AddmmBackward0>)
tensor([[0., 0., 0.]])
instantiate w/ nn.Module + no compile:
tensor([[-0.2540, -0.5778, 1.1222]], grad_fn=<AddmmBackward0>)
tensor([[0., 0., 0.]])
```
<details>
<summary>Versions</summary>
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.2 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.35
Python version: 3.10.10 (main, Mar 21 2023, 18:45:11) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.19.0-38-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA RTX A5000
Nvidia driver version: 530.30.02
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 20
On-line CPU(s) list: 0-19
Vendor ID: GenuineIntel
Model name: 12th Gen Intel(R) Core(TM) i7-12700
CPU family: 6
Model: 151
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 1
Stepping: 2
CPU max MHz: 4900.0000
CPU min MHz: 800.0000
BogoMIPS: 4224.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid rdseed adx smap clflushopt clwb intel_pt sha_ni xsaveopt xsavec xgetbv1 xsaves split_lock_detect avx_vnni dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp hwp_pkg_req hfi umip pku ospke waitpkg gfni vaes vpclmulqdq tme rdpid movdiri movdir64b fsrm md_clear serialize pconfig arch_lbr ibt flush_l1d arch_capabilities
Virtualization: VT-x
L1d cache: 512 KiB (12 instances)
L1i cache: 512 KiB (12 instances)
L2 cache: 12 MiB (9 instances)
L3 cache: 25 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-19
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.23.5
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.0
[pip3] torchvision==0.15.0
[pip3] triton==2.0.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.23.5 py310hd5efca6_0
[conda] numpy-base 1.23.5 py310h8e6c178_0
[conda] pytorch 2.0.0 py3.10_cuda11.7_cudnn8.5.0_0 pytorch
[conda] pytorch-cuda 11.7 h778d358_3 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 2.0.0 py310_cu117 pytorch
[conda] torchtriton 2.0.0 py310 pytorch
[conda] torchvision 0.15.0 py310_cu117 pytorch
</details>
cc @ezyang @gchanan @zou3519 @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 6 |
3,055 | 97,902 |
Multiple model init using OpenMP in c++ does not speed up
|
module: multiprocessing, triaged
|
### 🐛 Describe the bug
I parallelized the creation of multiple Linear models using OpenMP below.
```c++
#include <iostream>
#include <torch/torch.h>
#include <chrono>
#include <omp.h>
using namespace std;
int main() {
int dim = 20000;
int world_size = 10;
{
auto begin = std::chrono::high_resolution_clock::now();
for (int i = 0; i < world_size; ++i) {
torch::nn::Linear(dim, dim);
}
auto end = std::chrono::high_resolution_clock::now();
auto elapsed = std::chrono::duration_cast<std::chrono::nanoseconds>(end - begin);
printf("sequential time: %.3f s\n", elapsed.count() * 1e-9);
}
{
auto begin = std::chrono::high_resolution_clock::now();
#pragma omp parallel for num_threads(omp_get_max_threads()) schedule(static)
for (int i = 0; i < world_size; ++i) {
torch::nn::Linear(dim, dim);
}
auto end = std::chrono::high_resolution_clock::now();
auto elapsed = std::chrono::duration_cast<std::chrono::nanoseconds>(end - begin);
printf("parallel time: %.3f s\n", elapsed.count() * 1e-9);
}
}
```
However, the time is taken the same in parallel and sequential. 17.5s
I tried the same thing in Python using torch.multiprocessing.
```python
import torch
import torch.nn as nn
import torch.multiprocessing as mp
import time
def f(rank, dim):
nn.Linear(dim, dim, device=torch.device('cpu'))
if __name__ == "__main__":
world_size = 10
dim = 20000
# seq
tic = time.perf_counter()
for i in range(world_size):
nn.Linear(dim, dim, device=torch.device('cpu'))
toc = time.perf_counter()
print(f"Seq in {toc - tic:0.4f} seconds")
# par
tic = time.perf_counter()
mp.spawn(f,
args=(dim,),
nprocs=world_size,
join=True)
toc = time.perf_counter()
print(f"Par in {toc - tic:0.4f} seconds")
```
In python, sequential takes 17.5s while parallel takes 6.5s.
My guess is parameter initialization operation in C++ is serialized using multi-threading.
Any solution to speed this up in C++? I'm implementing multi-gpu training (data parallelism) in c++ (actually in java using javacpp torch preset).
### Versions
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Linux Mint 20.3 (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.26.1
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 14 2022, 12:59:47) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.4.0-139-generic-x86_64-with-glibc2.29
Is CUDA available: True
CUDA runtime version: 11.3.109
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2070 with Max-Q Design
Nvidia driver version: 515.86.01
cuDNN version: Probably one of the following:
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn.so.8.6.0
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.6.0
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.6.0
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.6.0
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.6.0
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.6.0
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.6.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn.so.8.6.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.6.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.6.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.6.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.6.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.6.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 12
On-line CPU(s) list: 0-11
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 165
Model name: Intel(R) Core(TM) i7-10750H CPU @ 2.60GHz
Stepping: 2
CPU MHz: 4130.787
CPU max MHz: 5000.0000
CPU min MHz: 800.0000
BogoMIPS: 5199.98
Virtualization: VT-x
L1d cache: 192 KiB
L1i cache: 192 KiB
L2 cache: 1.5 MiB
L3 cache: 12 MiB
NUMA node0 CPU(s): 0-11
Vulnerability Itlb multihit: KVM: Mitigation: Split huge pages
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Mitigation; Microcode
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp pku ospke md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.0.0
[pip3] triton==2.0.0
[conda] Could not collect
cc @VitalyFedyunin @ejguan
| 5 |
3,056 | 97,894 |
Dropout traces poorly with AotAutograd/make_fx
|
triaged, oncall: pt2, module: aotdispatch
|
## Issue 1: probability can't be a tensor
```py
from torch.fx.experimental.proxy_tensor import make_fx
import torch
print(make_fx(
lambda x,p: torch.nn.functional.dropout(x, p),
decomposition_table={},
tracing_mode="fake")(torch.randn(10), torch.tensor(0.5)))
```
output:
```py
Traceback (most recent call last):
File "repro.py", line 4, in <module>
print(make_fx(
File "/home/jansel/pytorch/torch/fx/experimental/proxy_tensor.py", line 756, in wrapped
t = dispatch_trace(wrap_key(func, args, fx_tracer, pre_autograd), tracer=fx_tracer, concrete_args=tuple(phs))
File "/home/jansel/pytorch/torch/fx/experimental/proxy_tensor.py", line 462, in dispatch_trace
graph = tracer.trace(root, concrete_args)
File "/home/jansel/pytorch/torch/fx/_symbolic_trace.py", line 778, in trace
(self.create_arg(fn(*args)),),
File "/home/jansel/pytorch/torch/fx/experimental/proxy_tensor.py", line 479, in wrapped
out = f(*tensors)
File "repro.py", line 5, in <lambda>
lambda x, p: torch.nn.functional.dropout(x, p),
File "/home/jansel/pytorch/torch/nn/functional.py", line 1250, in dropout
if p < 0.0 or p > 1.0:
File "/home/jansel/pytorch/torch/utils/_stats.py", line 20, in wrapper
return fn(*args, **kwargs)
File "/home/jansel/pytorch/torch/fx/experimental/proxy_tensor.py", line 528, in __torch_dispatch__
return self.inner_torch_dispatch(func, types, args, kwargs)
File "/home/jansel/pytorch/torch/fx/experimental/proxy_tensor.py", line 553, in inner_torch_dispatch
return proxy_call(self, func, self.pre_autograd, args, kwargs)
File "/home/jansel/pytorch/torch/fx/experimental/proxy_tensor.py", line 364, in proxy_call
out = func(*args, **kwargs)
File "/home/jansel/pytorch/torch/_ops.py", line 394, in __call__
return self._op(*args, **kwargs or {})
File "/home/jansel/pytorch/torch/utils/_stats.py", line 20, in wrapper
return fn(*args, **kwargs)
File "/home/jansel/pytorch/torch/_subclasses/fake_tensor.py", line 1062, in __torch_dispatch__
return self.dispatch(func, types, args, kwargs)
File "/home/jansel/pytorch/torch/_subclasses/fake_tensor.py", line 1244, in dispatch
op_impl_out = op_impl(self, func, *args, **kwargs)
File "/home/jansel/pytorch/torch/_subclasses/fake_tensor.py", line 415, in local_scalar_dense
raise DataDependentOutputException(func)
torch._subclasses.fake_tensor.DataDependentOutputException: aten._local_scalar_dense.default
```
You can also hit this issue with `mode="real"`
```py
print(make_fx(
lambda x, p: torch.nn.functional.dropout(x, p),
decomposition_table={},
tracing_mode="real")(torch.randn(10, device="cuda"), torch.tensor(0.235, device="cuda")))
```
outputs:
```py
Traceback (most recent call last):
File "repro.py", line 4, in <module>
print(make_fx(
File "/home/jansel/pytorch/torch/fx/experimental/proxy_tensor.py", line 756, in wrapped
t = dispatch_trace(wrap_key(func, args, fx_tracer, pre_autograd), tracer=fx_tracer, concrete_args=tuple(phs))
File "/home/jansel/pytorch/torch/fx/experimental/proxy_tensor.py", line 462, in dispatch_trace
graph = tracer.trace(root, concrete_args)
File "/home/jansel/pytorch/torch/fx/_symbolic_trace.py", line 778, in trace
(self.create_arg(fn(*args)),),
File "/home/jansel/pytorch/torch/fx/experimental/proxy_tensor.py", line 479, in wrapped
out = f(*tensors)
File "repro.py", line 5, in <lambda>
lambda x, p: torch.nn.functional.dropout(x, p),
File "/home/jansel/pytorch/torch/nn/functional.py", line 1250, in dropout
if p < 0.0 or p > 1.0:
File "/home/jansel/pytorch/torch/utils/_stats.py", line 20, in wrapper
return fn(*args, **kwargs)
File "/home/jansel/pytorch/torch/fx/experimental/proxy_tensor.py", line 528, in __torch_dispatch__
return self.inner_torch_dispatch(func, types, args, kwargs)
File "/home/jansel/pytorch/torch/fx/experimental/proxy_tensor.py", line 553, in inner_torch_dispatch
return proxy_call(self, func, self.pre_autograd, args, kwargs)
File "/home/jansel/pytorch/torch/fx/experimental/proxy_tensor.py", line 294, in proxy_call
raise RuntimeError(
RuntimeError: It appears that you're trying to get value out of a tracing tensor with aten._local_scalar_dense.default - erroring out! It's likely that this is caused by data-dependent control flow or similar. It may be possible to trace this with dynamic shapes; try setting tracing_mode='symbolic' in your make_fx call.
```
## Issue 2: it gets decomposed unconditionally on CPU
```py
print(make_fx(
lambda x, p: torch.nn.functional.dropout(x, p),
decomposition_table={},
tracing_mode="real")(torch.randn(10), 0.5))
```
results in:
```py
def forward(self, x_1, p_1):
empty_like = torch.ops.aten.empty_like.default(x_1, memory_format = torch.contiguous_format)
bernoulli_ = torch.ops.aten.bernoulli_.float(empty_like); empty_like = None
div_ = torch.ops.aten.div_.Scalar(bernoulli_, 0.5); bernoulli_ = None
mul = torch.ops.aten.mul.Tensor(x_1, div_); x_1 = div_ = None
return mul
```
I set `decomposition_table={}` why am I getting `bernoulli_`???
## Issue 3: GPU does something completely different
```py
print(make_fx(
lambda x, p: torch.nn.functional.dropout(x, p),
decomposition_table={},
tracing_mode="real")(torch.randn(10, device="cuda"), 0.5))
```
outputs:
```py
def forward(self, x_1, p_1):
native_dropout = torch.ops.aten.native_dropout.default(x_1, 0.5, True); x_1 = None
getitem = native_dropout[0]
getitem_1 = native_dropout[1]; native_dropout = None
return getitem
```
This is almost right, except 0.5 got burned in rather than passed as an arg.
cc @ezyang @msaroufim @wconstab @ngimel @bdhirsh @anijain2305 @gchanan @zou3519 @soumith
| 16 |
3,057 | 97,892 |
A parameterized fill value for triu and tril functions
|
triaged, enhancement, module: viewing and reshaping
|
### 🚀 The feature, motivation and pitch
to mask the multihead attention layers we must store a mask tensor and perform additive or fill operations on the attention matrix, this tensor occupies memory. For the cases where we need to apply a causal mask, we can simply select the lower part of the attention matrix, filling the rest of the matrix with the value -inf. Currently our tril function does not allow this simple functionality.
I propose to add the fill_value parameter, default zero, to both functions.
`torch.tril(input, diagonal=0, *, fill_value=0, out=None) → [Tensor]`
`torch.triu(input, diagonal=0, *, fill_value=0, out=None) → [Tensor]`
```python
def multi_head_attention(q, k, v, /, heads, causal = None):
q = rearrange(q, '... l (h k) -> h ... l k', h=heads)
k = rearrange(k, '... t (h k) -> h ... t k', h=heads)
v = rearrange(v, '... t (h v) -> h ... t v', h=heads)
attn = einsum(q, k, 'h ... l k, h ... t k -> h ... l t')
attn = attn / np.sqrt(q.shape[-1])
if causal is not None:
attn = attn.tril(fill_value=-np.inf)
# we dont need this anymore:
# mask = view_for_broadcast(mask, to=attn)
# attn = attn.masked_fill(mask, -np.inf)
# or:
# attn = attn - mask * (-1e10)
attn = pt.softmax(attn, dim=-1)
output = einsum(attn, v, 'h ... l t, h ... t v -> h ... l v')
return rearrange(output, 'h ... l v -> ... l (h v)'), attn
```
### Alternatives
_No response_
### Additional context
_No response_
cc @gchanan @mruberry
| 3 |
3,058 | 97,888 |
Type conversion between float/complex
|
triaged, module: complex, enhancement
|
### 🚀 The feature, motivation and pitch
It would be nice to have a simple way to convert between float and complex types of the same precision. Something like
```python
dtype = torch.float32
print(dtype.to_complex())
# torch.complex64
dtype = torch.complex128
print(dtype.to_float())
# torch.float64
dtype = torch.float64
print(dtype.to_float())
# torch.float64
```
### Alternatives
1. building a dictionnary that stores conversions from float to complex types of the same precision
2. using this unpleasant/difficult to read workaround: `getattr(torch, torch.finfo(dtype).dtype)`
### Additional context
We are building a library for the simulation of quantum systems built on torch (see [torchqdynamics](https://github.com/PierreGuilmin/torchqdynamics)), and conversion between float and complex types happens all the time. Quantum objects are always complex, but time is always float-like, and it's essential that they are of the same precision.
cc @ezyang @anjali411 @dylanbespalko @mruberry @Lezcano @nikitaved
| 4 |
3,059 | 97,876 |
Missing torch import in _contextlib.py when using torch.jit._recursive
|
needs reproduction, oncall: jit
|
### 🐛 Describe the bug
When attempting to use `torch.jit.script()`, we see the following `ImportError`.
```
10:47:31 modest/modest/serialize/serialize.py:275: in serialize_vocoder
10:47:31 vocoder = torch.jit.script(vocoder)
10:47:31 env/lib/python3.10/site-packages/torch/jit/_script.py:1284: in script
10:47:31 return torch.jit._recursive.create_script_module(
10:47:31 env/lib/python3.10/site-packages/torch/jit/_recursive.py:480: in create_script_module
10:47:31 return create_script_module_impl(nn_module, concrete_type, stubs_fn)
10:47:31 env/lib/python3.10/site-packages/torch/jit/_recursive.py:542: in create_script_module_impl
10:47:31 script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
10:47:31 env/lib/python3.10/site-packages/torch/jit/_script.py:614: in _construct
10:47:31 init_fn(script_module)
10:47:31 env/lib/python3.10/site-packages/torch/jit/_recursive.py:520: in init_fn
10:47:31 scripted = create_script_module_impl(orig_value, sub_concrete_type, stubs_fn)
10:47:31 env/lib/python3.10/site-packages/torch/jit/_recursive.py:546: in create_script_module_impl
10:47:31 create_methods_and_properties_from_stubs(concrete_type, method_stubs, property_stubs)
10:47:31 _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
10:47:31
10:47:31 concrete_type = <torch.ConcreteModuleType object at 0x7ff8ec4d5cb0>
10:47:31 method_stubs = [ScriptMethodStub(resolution_callback=<function createResolutionCallbackFromEnv.<locals>.<lambda> at 0x7ff8e6b3a680>, ...
10:47:31 (last_conv): Sequential(
10:47:31 (0): ReLU()
10:47:31 (1): Conv1d(2, 1, kernel_size=(3,), stride=(1,), padding=(1,))
10:47:31 )
10:47:31 )>)]
10:47:31 property_stubs = []
10:47:31
10:47:31 def create_methods_and_properties_from_stubs(concrete_type, method_stubs, property_stubs):
10:47:31 method_defs = [m.def_ for m in method_stubs]
10:47:31 method_rcbs = [m.resolution_callback for m in method_stubs]
10:47:31 method_defaults = [get_default_args(m.original_method) for m in method_stubs]
10:47:31
10:47:31 property_defs = [p.def_ for p in property_stubs]
10:47:31 property_rcbs = [p.resolution_callback for p in property_stubs]
10:47:31
10:47:31 > concrete_type._create_methods_and_properties(property_defs, property_rcbs, method_defs, method_rcbs, method_defaults)
10:47:31 E RuntimeError:
10:47:31 E undefined value torch:
10:47:31 E File "/code/env/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 56
10:47:31 E self.n_frames_per_step - (features.shape[2] % self.n_frames_per_step)
10:47:31 E ) % self.n_frames_per_step
10:47:31 E features = torch.nn.functional.pad(features, (0, padding))
10:47:31 E ~~~~~ <--- HERE
10:47:31 E
10:47:31 E # Start with all zeros as conditioning
10:47:31
10:47:31 env/lib/python3.10/site-packages/torch/jit/_recursive.py:397: RuntimeError
```
No idea what's going on, sadly. However, adding `import torch` to the `/code/env/lib/python3.10/site-packages/torch/utils/_contextlib.py` file makes the error go away.
### Versions
```
Collecting environment information...
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.31
Python version: 3.10.10 (main, Mar 21 2023, 18:45:11) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-1020-aws-x86_64-with-glibc2.31
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8275CL CPU @ 3.00GHz
Stepping: 7
CPU MHz: 3461.119
BogoMIPS: 5999.99
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 1.5 MiB
L1i cache: 1.5 MiB
L2 cache: 48 MiB
L3 cache: 71.5 MiB
NUMA node0 CPU(s): 0-23,48-71
NUMA node1 CPU(s): 24-47,72-95
Vulnerability Itlb multihit: KVM: Mitigation: VMX unsupported
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Retbleed: Vulnerable
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, STIBP disabled, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq monitor ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single pti fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves ida arat pku ospke
Versions of relevant libraries:
[pip3] fft-conv-pytorch==1.1.3
[pip3] flake8==3.9.2
[pip3] k2==1.23.4.dev20230324+cuda11.8.torch2.0.0
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.22.3
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.0
[pip3] torchvision==0.15.0
[pip3] triton==2.0.0
[pip3] tritonclient==2.19.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] fft-conv-pytorch 1.1.3 pypi_0 pypi
[conda] k2 1.23.4.dev20230324+cuda11.8.torch2.0.0 pypi_0 pypi
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py310h7f8727e_0
[conda] mkl_fft 1.3.1 py310hd6ae3a3_0
[conda] mkl_random 1.2.2 py310h00e6091_0
[conda] numpy 1.22.3 py310hfa59a62_0
[conda] numpy-base 1.22.3 py310h9585f30_0
[conda] pytorch 2.0.0 py3.10_cuda11.8_cudnn8.7.0_0 pytorch
[conda] pytorch-cuda 11.8 h7e8668a_3 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 2.0.0 py310_cu118 pytorch
[conda] torchtriton 2.0.0 py310 pytorch
[conda] torchvision 0.15.0 py310_cu118 pytorch
[conda] tritonclient 2.19.0 pypi_0 pypi
```
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 2 |
3,060 | 97,872 |
nn.linear not support bfloat16
|
needs reproduction, oncall: distributed, triaged
|
### 🐛 Describe the bug
from torch.distributed.fsdp import (
FullyShardedDataParallel as FSDP,
MixedPrecision,
BackwardPrefetch,
ShardingStrategy,
FullStateDictConfig,
StateDictType, CPUOffload,
)
class Model(nn.Module):
def __init__(
self,
):
super().__init__()
self.to_pred = nn.Linear(dim, 1, bias = False)
def forward(
self,
input
):
pred = self.to_pred(input)
return pred
bfSixteen = MixedPrecision(
param_dtype=torch.bfloat16,
# Gradient communication precision.
reduce_dtype=torch.bfloat16,
# Buffer precision.
buffer_dtype=torch.bfloat16,
)
model = Model()
model = FSDP(model,
auto_wrap_policy=opt_auto_wrap_policy,
mixed_precision=bfSixteen ,
device_id=torch.cuda.current_device())
res = model(input)
File "/nfs/users/weisongwei/miniconda3/envs/tf2.9/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
pred = self.to_pred(pooled)
File "/nfs/users/weisongwei/miniconda3/envs/tf2.9/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
pred = self.to_pred(pooled)
File "/nfs/users/weisongwei/miniconda3/envs/tf2.9/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/nfs/users/weisongwei/miniconda3/envs/tf2.9/lib/python3.8/site-packages/torch/nn/modules/linear.py", line 114, in forward
pred = self.to_pred(pooled)
File "/nfs/users/weisongwei/miniconda3/envs/tf2.9/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/nfs/users/weisongwei/miniconda3/envs/tf2.9/lib/python3.8/site-packages/torch/nn/modules/linear.py", line 114, in forward
return forward_call(*input, **kwargs)
File "/nfs/users/weisongwei/miniconda3/envs/tf2.9/lib/python3.8/site-packages/torch/nn/modules/linear.py", line 114, in forward
return forward_call(*input, **kwargs)return forward_call(*input, **kwargs)
File "/nfs/users/weisongwei/miniconda3/envs/tf2.9/lib/python3.8/site-packages/torch/nn/modules/linear.py", line 114, in forward
File "/nfs/users/weisongwei/miniconda3/envs/tf2.9/lib/python3.8/site-packages/torch/nn/modules/linear.py", line 114, in forward
return forward_call(*input, **kwargs)
File "/nfs/users/weisongwei/miniconda3/envs/tf2.9/lib/python3.8/site-packages/torch/nn/modules/linear.py", line 114, in forward
return forward_call(*input, **kwargs)
File "/nfs/users/weisongwei/miniconda3/envs/tf2.9/lib/python3.8/site-packages/torch/nn/modules/linear.py", line 114, in forward
return forward_call(*input, **kwargs)
File "/nfs/users/weisongwei/miniconda3/envs/tf2.9/lib/python3.8/site-packages/torch/nn/modules/linear.py", line 114, in forward
return F.linear(input, self.weight, self.bias)
RuntimeErrorreturn F.linear(input, self.weight, self.bias) :
return F.linear(input, self.weight, self.bias)expected scalar type Float but found BFloat16return F.linear(input, self.weight, self.bias)
RuntimeErrorreturn F.linear(input, self.weight, self.bias) : RuntimeError
return F.linear(input, self.weight, self.bias)RuntimeErrorexpected scalar type Float but found BFloat16:
: RuntimeError
expected scalar type Float but found BFloat16expected scalar type Float but found BFloat16:
RuntimeError
expected scalar type Float but found BFloat16 :
### Versions
torch2.0 and torch1.13
when use fsdp wrap a model which have nn.Linear , if mixed_precision use bfloat16, it will be an error.
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu @albanD @mruberry @jbschlosser @walterddr @mikaylagawarecki
| 2 |
3,061 | 97,865 |
Unable to install torch on python 3.8.16
|
needs reproduction, oncall: binaries, triaged
|
### 🐛 Describe the bug
We have the ci pipeline which will install python 3.8.16 and on top of that we install torch package.
python -m pip install -r requirements.txt
requirements.txt contains
torch==2.0.0
Error we getting is
ERROR: Ignored the following versions that require a different python version: 1.9.5 Requires-Python >=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, <3.7
ERROR: Could not find a version that satisfies the requirement torch==2.0.0 (from versions: none)
ERROR: No matching distribution found for torch==2.0.0
### Versions
3.8.16
cc @seemethere @malfet
| 4 |
3,062 | 97,861 |
torch.onnx.errors.OnnxExporterError: Unsupported: ONNX export of operator unsafe_chunk, unknown dimension size.
|
module: onnx, triaged
|
### 🐛 Describe the bug
from speechbrain.pretrained import Tacotron2
from speechbrain.pretrained import HIFIGAN
tacotron2 = Tacotron2.from_hparams(source="speechbrain/tts-tacotron2-ljspeech", savedir="tmpdir_tractron2")
hifi_gan = HIFIGAN.from_hparams(source="speechbrain/tts-hifigan-ljspeech", savedir="tmpdir_hifi")
torch.onnx.export(tacotron2.mods.model )
### Versions
torch=2.0
| 2 |
3,063 | 97,856 |
make tensor data const correct
|
module: internals, triaged
|
### 🚀 The feature, motivation and pitch
The layers of tensor data throughout our stack have historically been lax about const correctness. We don't, for example, consistently distinguish between a data accessor granting mutable vs const access. This makes it challenging to add instrumentation that can distinguish data reads from data writes.
Furthermore, we mark methods const that give out mutable handles to class internals.
We should be strict on our tensor class and its internals about these accesses.
There is a straightforward migration path that forces us to make a decision at each callsite: change the existing method to return a const pointer and introduce an equivalent variant named `mutable_<original_method_name>` that gives a non-const pointer. Then we just fix what breaks.
While doing this, we need to be careful about not just blindly changing to the mutable variant: we should only do so when we must.
Challenges:
Some of our libraries were designed without considering this and will require some redesign to accommodate this distinction. For example, TensorIterator levels all of its arguments to non-const. JIT function calls do the same.
### Alternatives
_No response_
### Additional context
We want this right now to instrument reads/writes with high fidelity to accurately simulate and also implement copy-on-write tensors.
cc @ezyang @bhosmer @smessmer @ljk53 @bdhirsh
| 4 |
3,064 | 97,852 |
Functionalize crashes on train_step GraphModule
|
triaged, module: functionalization
|
### 🐛 Describe the bug
When apply functionalize to `train_step` with a single linear forward, backward and an SGD optimizer, it crashes with the following error:
1. with `torch._enable_functionalization(reapply_views=True)`:
```
File "/fsx/users/shenli/pytorch/test/distributed/_spmd/test_tracing.py", line 533, in _test_optimizer
train_step(mod, opt, inp)
File "/fsx/users/shenli/pytorch/torch/distributed/_spmd/api.py", line 313, in wrapper
gm = make_fx(
File "/fsx/users/shenli/pytorch/torch/fx/experimental/proxy_tensor.py", line 739, in wrapped
args = pytree.tree_map(wrap_fn_map[tracing_mode], args)
File "/fsx/users/shenli/pytorch/torch/utils/_pytree.py", line 196, in tree_map
return tree_unflatten([fn(i) for i in flat_args], spec)
File "/fsx/users/shenli/pytorch/torch/utils/_pytree.py", line 196, in <listcomp>
return tree_unflatten([fn(i) for i in flat_args], spec)
File "/fsx/users/shenli/pytorch/torch/fx/experimental/proxy_tensor.py", line 728, in wrap_fake
return fake_tensor_mode.from_tensor(x, source=source) # type: ignore[attr-defined]
File "/fsx/users/shenli/pytorch/torch/_subclasses/fake_tensor.py", line 1398, in from_tensor
return self.fake_tensor_converter(
File "/fsx/users/shenli/pytorch/torch/_subclasses/fake_tensor.py", line 314, in __call__
return self.from_real_tensor(
File "/fsx/users/shenli/pytorch/torch/_subclasses/fake_tensor.py", line 272, in from_real_tensor
out = self.meta_converter(
File "/fsx/users/shenli/pytorch/torch/_subclasses/meta_utils.py", line 501, in __call__
r = self.meta_tensor(
File "/fsx/users/shenli/pytorch/torch/_subclasses/meta_utils.py", line 364, in meta_tensor
r = callback(
File "/fsx/users/shenli/pytorch/torch/_subclasses/fake_tensor.py", line 267, in mk_fake_tensor
make_meta_t(),
File "/fsx/users/shenli/pytorch/torch/_subclasses/meta_utils.py", line 365, in <lambda>
lambda: torch.empty_strided(
RuntimeError: Cannot call storage_offset() on tensor with symbolic sizes/strides
Exception raised from storage_offset_default at /fsx/users/shenli/pytorch/c10/core/TensorImpl.h:770 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >) + 0x6c (0x7f6e977fd1ac in /fsx/u
sers/shenli/pytorch/torch/lib/libc10.so)
```
2. with `torch._functorch.eager_transforms.functionalize`
```
File "/fsx/users/shenli/pytorch/torch/distributed/_spmd/api.py", line 256, in wrapper
gm = functionalize(make_fx(
File "/fsx/users/shenli/pytorch/torch/_functorch/vmap.py", line 39, in fn
return f(*args, **kwargs)
File "/fsx/users/shenli/pytorch/torch/_functorch/eager_transforms.py", line 1600, in wrapped
func_outputs = func(*func_args, **func_kwargs)
File "/fsx/users/shenli/pytorch/torch/fx/experimental/proxy_tensor.py", line 715, in wrapped
args = pytree.tree_map(wrap_fn_map[tracing_mode], args)
File "/fsx/users/shenli/pytorch/torch/utils/_pytree.py", line 196, in tree_map
return tree_unflatten([fn(i) for i in flat_args], spec)
File "/fsx/users/shenli/pytorch/torch/utils/_pytree.py", line 196, in <listcomp>
return tree_unflatten([fn(i) for i in flat_args], spec)
File "/fsx/users/shenli/pytorch/torch/fx/experimental/proxy_tensor.py", line 704, in wrap_fake
return fake_tensor_mode.from_tensor(x, source=source) # type: ignore[attr-defined]
File "/fsx/users/shenli/pytorch/torch/_subclasses/fake_tensor.py", line 1398, in from_tensor
return self.fake_tensor_converter(
File "/fsx/users/shenli/pytorch/torch/_subclasses/fake_tensor.py", line 314, in __call__
return self.from_real_tensor(
File "/fsx/users/shenli/pytorch/torch/_subclasses/fake_tensor.py", line 280, in from_real_tensor
raise UnsupportedFakeTensorException("meta converter nyi")
torch._subclasses.fake_tensor.UnsupportedFakeTensorException: meta converter nyi
```
To reproduce, wrap the following line with functionalize.
https://github.com/pytorch/pytorch/blob/91166ef7e75fc5fb94fb56ec6679a1744cf0f28c/torch/distributed/_spmd/api.py#L311
Then run `pytest test/distributed/_spmd/test_tracing.py -k test_sgd -vs`
### Versions
PyTorch version: 2.1.0a0+gitff807e7
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.24.1
Libc version: glibc-2.31
Python version: 3.9.12 (main, Apr 5 2022, 06:56:58) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-1019-aws-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.6.112
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-40GB
GPU 1: NVIDIA A100-SXM4-40GB
GPU 2: NVIDIA A100-SXM4-40GB
GPU 3: NVIDIA A100-SXM4-40GB
GPU 4: NVIDIA A100-SXM4-40GB
GPU 5: NVIDIA A100-SXM4-40GB
GPU 6: NVIDIA A100-SXM4-40GB
GPU 7: NVIDIA A100-SXM4-40GB
Nvidia driver version: 525.85.12
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8275CL CPU @ 3.00GHz
Stepping: 7
CPU MHz: 2999.998
BogoMIPS: 5999.99
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 1.5 MiB
L1i cache: 1.5 MiB
L2 cache: 48 MiB
L3 cache: 71.5 MiB
NUMA node0 CPU(s): 0-23,48-71
NUMA node1 CPU(s): 24-47,72-95
Vulnerability Itlb multihit: KVM: Mitigation: VMX unsupported
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Mmio stale data: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Retbleed: Vulnerable
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, STIBP disabled, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq monitor ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single pti fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves ida arat pku ospke
Versions of relevant libraries:
[pip3] flake8==3.8.2
[pip3] flake8-bugbear==20.1.4
[pip3] flake8-comprehensions==3.3.0
[pip3] flake8-executable==2.0.4
[pip3] flake8-logging-format==0.9.0
[pip3] flake8-pyi==20.5.0
[pip3] mypy==0.960
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.1
[pip3] torch==2.1.0a0+gitff807e7
[pip3] torchdynamo==1.13.0.dev0
[pip3] torchmetrics==0.9.3
[pip3] torchrec==0.2.0
[pip3] torchvision==0.13.0a0+ecbff88
[pip3] torchx-nightly==2022.9.28
[pip3] triton==2.0.0.dev20221202
[pip3] vit-pytorch==0.33.2
[conda] mkl 2022.0.1 h06a4308_117
[conda] mkl-include 2022.0.1 h06a4308_117
[conda] numpy 1.23.1 pypi_0 pypi
[conda] torch 2.1.0a0+gitff807e7 dev_0 <develop>
[conda] torchdynamo 1.13.0.dev0 dev_0 <develop>
[conda] torchmetrics 0.9.3 pypi_0 pypi
[conda] torchrec 0.2.0 pypi_0 pypi
[conda] torchvision 0.13.0a0+ecbff88 pypi_0 pypi
[conda] torchx-nightly 2022.9.28 pypi_0 pypi
[conda] triton 2.0.0.dev20221202 pypi_0 pypi
cc @bdhirsh @ezyang @soumith
| 0 |
3,065 | 97,849 |
TORCH_LIBRARIES variable leads to undefined reference function error in compiling while using libtorch in c++
|
module: cpp, triaged
|
### 🐛 Describe the bug
I'm using cmake to build my c++ project. When i add ${TORCH_LIBRARIES} into target_link_libraries's parameters, the compiling fails.
Here's some of my cmake codes:
> set(CMAKE_CXX_STANDARD 14)
> set(THIRD_PARTY_PATH "${PROJECT_SOURCE_DIR}/third_party")
> set(Torch_DIR /opt/libtorch_1.13/share/cmake/Torch)
> find_package(Torch REQUIRED)
> include_directories(${PROJECT_SOURCE_DIR}/third_party/include)
>
> add_executable(torch_test main.cpp)
> target_link_libraries(torch_test ${PROJECT_SOURCE_DIR}/third_party/lib/libjsoncpp.so)
> target_link_libraries(torch_test -Wl,--no-as-needed /opt/torch_tensorrt/lib/libtorchtrt.so)
>
> target_link_libraries(torch_test ${TORCH_LIBRARIES}
> /opt/TensorRT-8.5.3.1/lib/libnvinfer.so
> /opt/TensorRT-8.5.3.1/lib/libnvinfer_plugin.so
> /opt/libtorch_1.13/lib/libtorch_global_deps.so
> /opt/libtorch_1.13/lib/libc10_cuda.so
> )
### Versions
system: ubuntu2204
libtorch version: 1.13
cuda version: 11.7
cc @jbschlosser
| 10 |
3,066 | 97,848 |
Document _wrap_fx_args_as_onnxscript_args
|
module: onnx, triaged
|
`_wrap_fx_args_as_onnxscript_args` needs some documentation.
| 0 |
3,067 | 97,847 |
CUDA 10.2 cudnn 8.2.4 run Conv2d error
|
needs reproduction, module: cudnn, module: cuda, triaged
|
### 🐛 Describe the bug
File "/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 399, in forward
return self._conv_forward(input, self.weight, self.bias)
File "/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 395, in _conv_forward
return F.conv2d(input, weight, bias, self.stride,
RuntimeError: cuDNN error: CUDNN_STATUS_NOT_INITIALIZED
### Versions
i try cudnn 7.6 8.0 as well
pytorch 1.8.0
cudnn 8.2.4
cuda 10.2
2080ti
cc @csarofeen @ptrblck @xwang233 @ngimel
| 1 |
3,068 | 97,846 |
[WIP] _nested_view_from_buffer.cont, torch.cat([NTs], dim=0)
|
Stale
|
TODO
- Tests
| 6 |
3,069 | 97,827 |
Memory leak when saving an input tensor returned as-is if mark_dirty and running with dual tensors
|
module: autograd, triaged, module: edge cases, module: forward ad
|
```python
import weakref
import torch
import torch.autograd.forward_ad as fwAD
import gc
def scope():
saved_tensors = []
class A(torch.autograd.Function):
@staticmethod
def forward(x):
return x
@staticmethod
def setup_context(ctx, inputs, output):
ctx.mark_dirty(inputs[0])
ctx.save_for_backward(output)
saved_tensors.append(output)
@staticmethod
def backward(ctx, grad_output):
return grad_output
@staticmethod
def jvp(ctx, x_t):
x_t.add_(0)
return x_t
a = torch.tensor(2., device="cpu", requires_grad=True).clone()
a_t = torch.tensor(2., device="cpu", requires_grad=True).clone()
with fwAD.dual_level():
a_dual = fwAD.make_dual(a, a_t)
A.apply(a_dual)
class Test():
pass
test = Test()
ref = weakref.ref(test)
saved_tensors[0].grad_fn.metadata["test"] = test
return ref
ref = scope()
gc.collect()
print(ref())
```
The reason this happens is that the output node is actually an AsStridedBackward node, but the logic testing for whether saved tensors are outputs checks that the grad_fn is ABackward.
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @Lezcano @Varal7
| 0 |
3,070 | 97,825 |
Support sparse COO/CSR/CSC/BSR/BSC return values in gradcheck input function
|
module: sparse, module: autograd, open source, release notes: autograd, release notes: sparse, skip-pr-sanity-checks, no-stale
|
As in the title.
Previously, the input functions to gradcheck were expected to return strided tensors: say, when the result of an input function would be a sparse tensor, it had to be converted to strided via `.to_dense(masked=...)` method call. With this PR, the conversion of input function return values to strided tensors is not required anymore.
Stack from [ghstack](https://github.com/ezyang/ghstack) (oldest at bottom):
* __->__ #97825
* #98292
* #98288
cc @alexsamardzic @nikitaved @cpuhrsch @amjames @bhosmer @ezyang @albanD @zou3519 @gqchen @soulitzer @Lezcano @Varal7
| 8 |
3,071 | 97,823 |
Using `param in param_list` can trigger `non-singleton dimension` error?
|
triaged, module: python frontend
|
### 🐛 Describe the bug
Let's say I have a parameter, and a list of other parameters; if I check `param in others`, I can get an error about `non-singleton dimension`:
```py
param = nn.Parameter(torch.zeros(2))
others = [nn.Parameter(torch.zeros(3, 4))]
param in others # Throws error
```
It's unclear to me why. I can workaround it by explicitly calling `id()` or `hash()`, e.g.
```py
def param_in(p_check, params):
ids = [id(p) for p in params]
return id(p_check) in ids
```
This happens in both PyTorch v1.12.0 and v2.0.0
See small but more complete unittest:
https://github.com/EricCousineau-TRI/repro/blob/9cbd37f6b/python/torch/torch_param_bug.py
### Versions
<details>
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.2 LTS (x86_64)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.26.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Mar 10 2023, 10:55:28) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.19.0-35-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
Nvidia driver version: 525.78.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 64
On-line CPU(s) list: 0-63
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) Gold 6226R CPU @ 2.90GHz
CPU family: 6
Model: 85
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 2
Stepping: 7
CPU max MHz: 3900.0000
CPU min MHz: 1200.0000
BogoMIPS: 5800.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Virtualization: VT-x
L1d cache: 1 MiB (32 instances)
L1i cache: 1 MiB (32 instances)
L2 cache: 32 MiB (32 instances)
L3 cache: 44 MiB (2 instances)
NUMA node(s): 2
NUMA node0 CPU(s): 0-15,32-47
NUMA node1 CPU(s): 16-31,48-63
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.0.0
[pip3] triton==2.0.0
[conda] Could not collect
</details>
cc @albanD
| 1 |
3,072 | 97,807 |
Compile error when using consecutive pad
|
triaged, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
Hi! This is a bug found by a fuzzer which might be uncommon in the real world. However, it looks like an unseen internal error. So I still report it in case it might lead to other problems.
```
import torch
x = torch.rand([1,2,1], device='cuda')
def forward():
a = torch.nn.functional.pad(x, (0, 1))
b = torch.nn.functional.pad(a, (0, 0, 0, 1), 'reflect')
b[0, 0, 0] = 0.1
return b
with torch.no_grad():
print(forward())
fn_compiled = torch.compile(forward)
print(fn_compiled())
```
### Error logs
<details>
```
Traceback (most recent call last):
File "/home/su/accdiff/test.py", line 13, in <module>
print(fn_compiled())
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/eval_frame.py", line 235, in _fn
return fn(*args, **kwargs)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/eval_frame.py", line 372, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 412, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 110, in _fn
return fn(*args, **kwargs)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 269, in _convert_frame_assert
return _compile(
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 166, in time_wrapper
r = func(*args, **kwargs)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 331, in _compile
out_code = transform_code_object(code, transform)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/bytecode_transformation.py", line 530, in transform_code_object
transformations(instructions, code_options)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 318, in transform
tracer.run()
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 1854, in run
super().run()
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 604, in run
and self.step()
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 564, in step
getattr(self, inst.opname)(inst)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 1933, in RETURN_VALUE
self.output.compile_subgraph(
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/output_graph.py", line 581, in compile_subgraph
self.compile_and_call_fx_graph(tx, list(reversed(stack_values)), root)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/output_graph.py", line 651, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 166, in time_wrapper
r = func(*args, **kwargs)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/output_graph.py", line 730, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e).with_traceback(
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/output_graph.py", line 726, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/debug_utils.py", line 1088, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/__init__.py", line 1527, in __call__
return compile_fx(model_, inputs_, config_patches=self.config)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_inductor/compile_fx.py", line 568, in compile_fx
return aot_autograd(
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/backends/common.py", line 62, in compiler_fn
cg = aot_module_simplified(gm, example_inputs, **kwargs)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 3044, in aot_module_simplified
compiled_fn = create_aot_dispatcher_function(
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 166, in time_wrapper
r = func(*args, **kwargs)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 2687, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_args, aot_config, fw_metadata=fw_metadata)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 1794, in aot_wrapper_dedupe
return compiler_fn(flat_fn, leaf_flat_args, aot_config, fw_metadata=fw_metadata)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 1960, in aot_wrapper_synthetic_base
return compiler_fn(flat_fn, flat_args, aot_config, fw_metadata=fw_metadata)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 1260, in aot_dispatch_base
compiled_fw = compiler(fw_module, flat_args)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 166, in time_wrapper
r = func(*args, **kwargs)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_inductor/compile_fx.py", line 532, in fw_compiler_base
return inner_compile(
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/debug_utils.py", line 622, in debug_wrapper
compiled_fn = compiler_fn(gm, example_inputs)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_inductor/debug.py", line 239, in inner
return fn(*args, **kwargs)
File "/usr/lib/python3.9/contextlib.py", line 79, in inner
return func(*args, **kwds)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_inductor/compile_fx.py", line 184, in compile_fx_inner
compiled_fn = graph.compile_to_fn()
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_inductor/graph.py", line 651, in compile_to_fn
return self.compile_to_module().call
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 166, in time_wrapper
r = func(*args, **kwargs)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_inductor/graph.py", line 627, in compile_to_module
mod = PyCodeCache.load(code, linemap=linemap)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_inductor/codecache.py", line 645, in load
return cls.load_by_key_path(key, path, linemap)
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_inductor/codecache.py", line 660, in load_by_key_path
exec(code, mod.__dict__, mod.__dict__)
File "/tmp/torchinductor_su/4z/c4zfyhvmhdxtexf7nlasmfuwk6v57f47ujeyfvxymet23zqho5w7.py", line 88, in <module>
async_compile.wait(globals())
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_inductor/codecache.py", line 876, in wait
scope[key] = result.result()
File "/home/su/accdiff/accdiff_env/lib/python3.9/site-packages/torch/_inductor/codecache.py", line 734, in result
self.future.result()
File "/usr/lib/python3.9/concurrent/futures/_base.py", line 445, in result
return self.__get_result()
File "/usr/lib/python3.9/concurrent/futures/_base.py", line 390, in __get_result
raise self._exception
torch._dynamo.exc.BackendCompilerFailed: backend='debug_wrapper' raised:
CompilationError: at 29:39: tmp9 = tl.abs(tmp8)
tmp10 = tmp7 - tmp9
tmp11 = tl.abs(tmp10)
tmp12 = tmp7 - tmp11
tmp13 = tmp4 - tmp0
tmp14 = tl.abs(tmp13)
tmp15 = tmp7 - tmp14
tmp16 = tl.abs(tmp15)
tmp17 = tmp7 - tmp16
tmp18 = tmp17
tmp19 = tmp18 < tmp7
tmp20 = tl.load(in_ptr0 + (tmp12), tmp19, other=0)
^
ValueError('Mask argument cannot be block type if pointer argument is not a block')
```
</details>
### Minified repro
_No response_
### Versions
<details>
```
Collecting environment information...
PyTorch version: 2.1.0a0+gitfe05266
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.2
Libc version: glibc-2.31
Python version: 3.9.5 (default, Nov 23 2021, 15:27:38) [GCC 9.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-67-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.6.112
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2070
Nvidia driver version: 510.108.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.6.0
/usr/local/cuda-11.6/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.6.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.7.0
/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 43 bits physical, 48 bits virtual
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 23
Model: 1
Model name: AMD Ryzen Threadripper 1950X 16-Core Processor
Stepping: 1
Frequency boost: enabled
CPU MHz: 2200.000
CPU max MHz: 3400.0000
CPU min MHz: 2200.0000
BogoMIPS: 6786.49
Virtualization: AMD-V
L1d cache: 512 KiB
L1i cache: 1 MiB
L2 cache: 8 MiB
L3 cache: 32 MiB
NUMA node0 CPU(s): 0-31
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT vulnerable
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, STIBP disabled, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid amd_dcm aperfmperf rapl pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate ssbd ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif overflow_recov succor smca sme sev
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.1.0a0+gitc1a6dde
[pip3] triton==2.1.0
```
</details>
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 0 |
3,073 | 97,802 |
Some c++ library docstrings incorrectly linked/repeated
|
module: docs, module: cpp, triaged, module: mps
|
### 📚 The doc issue
For example, the docstring for [torch::mps::is_available()](https://pytorch.org/cppdocs/api/function_namespacetorch_1_1mps_1ac04d09cc0c1b3c42588745c70b9c7cac.html):
```
Returns true if MPS device is available.
Returns true if MPS device is available.
Returns true if at least one CUDA device is available.
If we compiled with CUDA but there is a driver problem, etc., this function will report CUDA is not available (rather than raise an error.)
```
Looks incorrect.
Another example: [at::cuda::is_available()](https://pytorch.org/cppdocs/api/function_namespaceat_1_1cuda_1abdf5679016d4e4149f80f3fe2e80890f.html).
```
CUDA is available if we compiled with CUDA, and there are one or more devices.
Returns true if MPS device is available.
Returns true if at least one CUDA device is available.
If we compiled with CUDA but there is a driver problem, etc., this function will report CUDA is not available (rather than raise an error.)
```
### Suggest a potential alternative/fix
_No response_
cc @svekars @carljparker @jbschlosser @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
3,074 | 97,788 |
Add SSIM as Loss Function
|
feature, module: loss, triaged, needs research
|
### 🚀 The feature, motivation and pitch
Hello, I am doing research in the field of Unsupervised Anomaly Detection. In Unsupervised Anomaly Detection, you can segment an anomaly area through Reconstruction Error, but in the case of areas with ambiguous boundaries, better performance is shown when using loss using SSIM than using existing losses. Therefore, I would like to be able to use SSIM as the loss function of pytorch. Thank you :)
### Alternatives
_No response_
### Additional context
_No response_
| 1 |
3,075 | 97,784 |
torch.compile fails with torch._dynamo.exc.TorchRuntimeError on a function that contains a torch script module
|
triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
When calling `torch.compile` on a function that contains a torch script module, it raises `torch._dynamo.exc.TorchRuntimeError`. When calling directly on the torch script module it works fine.
```
import torch
import torch.nn.functional as F
from torch.nn import Linear, ReLU, Sequential
def works():
model = Sequential(Linear(100, 200), ReLU(), Linear(200, 10))
model = torch.jit.trace(model, (torch.randn(1, 100), ))
model = torch.compile(model)
return model(torch.randn(1, 100))
def fails():
model = Sequential(Linear(100, 200), ReLU(), Linear(200, 10))
model = torch.jit.trace(model, (torch.randn(1, 100), ))
def predict(x):
return model(x)
predict = torch.compile(predict)
return predict(torch.randn(1, 100))
works() # works on nightly but fails on 2.0 stable for a different reason
fails() # fails on both nightly and 2.0 stable
```
Output:
```
Traceback (most recent call last):
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 1233, in run_node
return nnmodule(*args, **kwargs)
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/nn/modules/linear.py(114): forward
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/nn/modules/module.py(1488): _slow_forward
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/nn/modules/module.py(1501): _call_impl
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/nn/modules/container.py(217): forward
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/nn/modules/module.py(1488): _slow_forward
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/nn/modules/module.py(1501): _call_impl
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/jit/_trace.py(1056): trace_module
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/jit/_trace.py(794): trace
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py(235): _fn
repro.py(15): fails
repro.py(22): <module>
RuntimeError:
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 1186, in get_fake_value
return wrap_fake_exception(
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 827, in wrap_fake_exception
return fn()
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 1187, in <lambda>
lambda: run_node(tx.output, node, args, kwargs, nnmodule)
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 1240, in run_node
raise RuntimeError(
RuntimeError: Failed running call_module model(*(FakeTensor(FakeTensor(..., device='meta', size=(1, 100)), cpu),), **{}):
The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/nn/modules/linear.py(114): forward
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/nn/modules/module.py(1488): _slow_forward
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/nn/modules/module.py(1501): _call_impl
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/nn/modules/container.py(217): forward
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/nn/modules/module.py(1488): _slow_forward
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/nn/modules/module.py(1501): _call_impl
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/jit/_trace.py(1056): trace_module
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/jit/_trace.py(794): trace
/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py(235): _fn
repro.py(15): fails
repro.py(22): <module>
RuntimeError:
(scroll up for backtrace)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "repro.py", line 22, in <module>
fails()
File "repro.py", line 19, in fails
return predict(torch.randn(1, 100))
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 235, in _fn
return fn(*args, **kwargs)
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 372, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 412, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 110, in _fn
return fn(*args, **kwargs)
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 269, in _convert_frame_assert
return _compile(
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 166, in time_wrapper
r = func(*args, **kwargs)
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 331, in _compile
out_code = transform_code_object(code, transform)
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/bytecode_transformation.py", line 530, in transform_code_object
transformations(instructions, code_options)
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/convert_frame.py", line 318, in transform
tracer.run()
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 1854, in run
super().run()
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 604, in run
and self.step()
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 564, in step
getattr(self, inst.opname)(inst)
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 347, in wrapper
return inner_fn(self, inst)
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 1003, in CALL_FUNCTION
self.call_function(fn, args, {})
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/symbolic_convert.py", line 495, in call_function
self.push(fn.call_function(self, args, kwargs))
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/variables/nn_module.py", line 238, in call_function
return wrap_fx_proxy(
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/variables/builder.py", line 902, in wrap_fx_proxy
return wrap_fx_proxy_cls(
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/variables/builder.py", line 937, in wrap_fx_proxy_cls
example_value = get_fake_value(proxy.node, tx)
File "/home/jgu/miniconda3/envs/torch-nightly/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 1207, in get_fake_value
raise TorchRuntimeError() from e
torch._dynamo.exc.TorchRuntimeError:
from user code:
File "repro.py", line 17, in predict
return model(x)
Set torch._dynamo.config.verbose=True or TORCHDYNAMO_VERBOSE=1 for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
### Versions
Tested both 2.0 stable and nightly torch==2.1.0.dev20230328+cpu
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 9 |
3,076 | 97,783 |
The first epoch is very slow when using torch.compile
|
triaged, oncall: pt2, module: dynamic shapes
|
### 🐛 Describe the bug
We tried using torch.compile on our training code and the first epoch was very slow.
### Error logs
```bash
# uncompiled mode: out = model(x)
$ python torch2_compile.py
```
2.0.0+cu117
/mnt/nfs/env/py-venv/py39_cuda117_torch200/lib/python3.9/site-packages/torch/autograd/__init__.py:200: UserWarning: CUDA initialization: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 803: system has unsupported display driver / cuda driver combination (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:109.)
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
**Epoch 0/10 time: 0.09859752655029297**
Epoch 1/10 time: 0.09461498260498047
Epoch 2/10 time: 0.09749722480773926
Epoch 3/10 time: 0.09946417808532715
Epoch 4/10 time: 0.09831523895263672
Epoch 5/10 time: 0.0978553295135498
Epoch 6/10 time: 0.09766864776611328
Epoch 7/10 time: 0.0983278751373291
Epoch 8/10 time: 0.09094047546386719
Epoch 9/10 time: 0.09506630897521973
Epoch avg time: 0.09683477878570557
```bash
# compiled mode: out = compiled_model(x)
$ python torch2_compile.py
```
2.0.0+cu117
/mnt/nfs/env/py-venv/py39_cuda117_torch200/lib/python3.9/site-packages/torch/cuda/__init__.py:107: UserWarning: CUDA initialization: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 803: system has unsupported display driver / cuda driver combination (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:109.)
return torch._C._cuda_getDeviceCount() > 0
No CUDA runtime is found, using CUDA_HOME='/mnt/nfs/env/cuda/cuda-11.7'
[2023-03-28 22:20:57,063] torch._inductor.utils: [WARNING] using triton random, expect difference from eager
**Epoch 0/10 time: 18.54069495201111**
Epoch 1/10 time: 0.10959434509277344
Epoch 2/10 time: 0.10520339012145996
Epoch 3/10 time: 0.10396909713745117
Epoch 4/10 time: 0.10267758369445801
Epoch 5/10 time: 0.10393261909484863
Epoch 6/10 time: 0.10507917404174805
Epoch 7/10 time: 0.10506296157836914
Epoch 8/10 time: 0.10470414161682129
Epoch 9/10 time: 0.10574936866760254
Epoch avg time: 1.948666763305664
### Minified repro
```bash
$ CUDA_VISIBLE_DEVICES=0
$ python torch2_compile.py
```
```bash
$ cat torch2_compile.py
#!/usr/bin/env python3
import time
import torch
import torch._dynamo as dynamo
import torchvision.models as models
model = models.alexnet()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
compiled_model = torch.compile(model)
x = torch.randn(16, 3, 224, 224)
optimizer.zero_grad()
epoches=10
count = []
for epoch in range(epoches):
start = time.time()
#out = model(x)
out = compiled_model(x)
out.sum().backward()
optimizer.step()
end = time.time()
count.append(end - start)
print(f"Epoch {epoch}/{epoches} time: {end - start}")
print(f"Epoch avg time: {sum(count)/len(count)}")
```
### Versions
$ python ~/env/bin/collect_env.py
Collecting environment information...
/mnt/nfs/env/py-venv/py39_cuda117_torch200/lib/python3.9/site-packages/torch/cuda/__init__.py:107: UserWarning: CUDA initialization: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 803: system has unsupported display driver / cuda driver combination (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:109.)
return torch._C._cuda_getDeviceCount() > 0
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: CentOS Linux release 7.3.1611 (Core) (x86_64)
GCC version: (GCC) 7.5.0
Clang version: Could not collect
CMake version: version 3.26.1
Libc version: glibc-2.17
Python version: 3.9.15 (main, Nov 12 2022, 16:52:40) [GCC 5.5.0] (64-bit runtime)
Python platform: Linux-3.10.0-693.21.1.std7a.el7.0.x86_64-x86_64-with-glibc2.17
Is CUDA available: False
CUDA runtime version: 11.7.64
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration:
GPU 0: NVIDIA A100-SXM4-80GB
GPU 1: NVIDIA A100-SXM4-80GB
GPU 2: NVIDIA A100-SXM4-80GB
GPU 3: NVIDIA A100-SXM4-80GB
GPU 4: NVIDIA A100-SXM4-80GB
GPU 5: NVIDIA A100-SXM4-80GB
GPU 6: NVIDIA A100-SXM4-80GB
GPU 7: NVIDIA A100-SXM4-80GB
Nvidia driver version: 530.30.02
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 2
Core(s) per socket: 32
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 106
Model name: Intel(R) Xeon(R) Platinum 8350C CPU @ 2.60GHz
Stepping: 6
CPU MHz: 3500.000
BogoMIPS: 5206.54
Virtualization: VT-x
L1d cache: 48K
L1i cache: 32K
L2 cache: 1280K
L3 cache: 49152K
NUMA node0 CPU(s): 0-31,64-95
NUMA node1 CPU(s): 32-63,96-127
Versions of relevant libraries:
[pip3] audio2numpy==0.1.2
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.23.5
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.1
[pip3] torchvision==0.15.1
[pip3] triton==2.0.0
[conda] Could not collect
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 17 |
3,077 | 97,778 |
inductor: NameError: name 'math_floor' is not defined when running fx_graph_runnable.py
|
triaged, oncall: pt2, module: dynamic shapes, module: inductor, module: minifier
|
### 🐛 Describe the bug
For inductor dynamic shape case, when running the debug code ```fx_graph_runnable.py```, some models always meet the following error:
```
NameError: name 'math_floor' is not defined
```
or
```
NameError: name 'math_ceil' is not defined
```
you can directly run https://gist.github.com/XiaobingSuper/4592434a70779eca591f0cc5cf3a02e7#file-fx_graph_runnable-py, and will report ```NameError```.
### Versions
Collecting environment information...
PyTorch version: 2.1.0a0+git33dfded
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.31
Python version: 3.9.16 (main, Mar 8 2023, 14:00:05) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.13.0-30-generic-x86_64-with-glibc2.31
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] bert-pytorch==0.0.1a4
[pip3] clip-anytorch==2.5.2
[pip3] CoCa-pytorch==0.0.7
[pip3] dalle2-pytorch==1.10.5
[pip3] ema-pytorch==0.2.2
[pip3] functorch==1.14.0a0+408bcf1
[pip3] mypy==0.960
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.23.1
[pip3] pytorch-transformers==1.2.0
[pip3] pytorch-warmup==0.1.1
[pip3] rotary-embedding-torch==0.2.1
[pip3] torch==2.1.0a0+git5aa4046
[pip3] torch-fidelity==0.3.0
[pip3] torch-struct==0.5
[pip3] torchaudio==2.0.0a0+a8f4e97
[pip3] torchdata==0.7.0a0+f1283eb
[pip3] torchmetrics==0.11.4
[pip3] torchrec-nightly==2023.3.23
[pip3] torchtext==0.15.0a0+46e7eef
[pip3] torchvision==0.15.0a0+98c5815
[pip3] vector-quantize-pytorch==1.1.2
[conda] bert-pytorch 0.0.1a4 dev_0 <develop>
[conda] clip-anytorch 2.5.2 pypi_0 pypi
[conda] coca-pytorch 0.0.7 pypi_0 pypi
[conda] dalle2-pytorch 1.10.5 pypi_0 pypi
[conda] ema-pytorch 0.2.2 pypi_0 pypi
[conda] functorch 1.14.0a0+408bcf1 pypi_0 pypi
[conda] mkl 2023.0.0 h6d00ec8_25399
[conda] mkl-include 2023.0.0 h06a4308_25399
[conda] numpy 1.23.1 pypi_0 pypi
[conda] pytorch-transformers 1.2.0 pypi_0 pypi
[conda] pytorch-warmup 0.1.1 pypi_0 pypi
[conda] rotary-embedding-torch 0.2.1 pypi_0 pypi
[conda] torch 2.1.0a0+git5aa4046 dev_0 <develop>
[conda] torch-fidelity 0.3.0 pypi_0 pypi
[conda] torch-struct 0.5 pypi_0 pypi
[conda] torchaudio 2.0.0a0+a8f4e97 pypi_0 pypi
[conda] torchdata 0.6.0 pypi_0 pypi
[conda] torchmetrics 0.11.4 pypi_0 pypi
[conda] torchrec-nightly 2023.3.23 pypi_0 pypi
[conda] torchtext 0.15.0a0+46e7eef pypi_0 pypi
[conda] torchvision 0.15.0a0+98c5815 dev_0 <develop>
[conda] vector-quantize-pytorch 1.1.2 pypi_0 pypi
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 7 |
3,078 | 97,772 |
consider bumping `DEFAULT_PROTOCOL`
|
module: serialization, triaged
|
### 🐛 Describe the bug
As per https://github.com/pytorch/pytorch/releases/tag/v2.0.0, PyTorch 2.0 dropped support for Python versions up to and including 3.7, but it's unclear whether `DEFAULT_PROTOCOL` in `torch/serialization.py` is intended to keep its current value (originally set in August 2016!) or was simply overlooked.
https://github.com/pytorch/pytorch/blob/08766b23de8ed50a8f52973df78114426500cb65/torch/serialization.py#L23
https://docs.python.org/3/library/pickle.html#data-stream-format says:
> * Protocol version 2 was introduced in Python 2.3. It provides much more efficient pickling of [new-style classes](https://docs.python.org/3/glossary.html#term-new-style-class). Refer to [PEP 307](https://peps.python.org/pep-0307/) for information about improvements brought by protocol 2.
> * Protocol version 3 was added in Python 3.0. It has explicit support for [bytes](https://docs.python.org/3/library/stdtypes.html#bytes) objects and cannot be unpickled by Python 2.x. This was the default protocol in Python 3.0–3.7.
> * Protocol version 4 was added in Python 3.4. It adds support for very large objects, pickling more kinds of objects, and some data format optimizations. It is the default protocol starting with Python 3.8. Refer to [PEP 3154](https://peps.python.org/pep-3154/) for information about improvements brought by protocol 4.
> * Protocol version 5 was added in Python 3.8. It adds support for out-of-band data and speedup for in-band data. Refer to [PEP 574](https://peps.python.org/pep-0574/) for information about improvements brought by protocol 5.
As such, it seems worthwhile to consider bumping `DEFAULT_PROTOCOL`. Otherwise, it would be worth at least documenting the reasoning for **_not_** bumping it?
### Versions
PyTorch 2.0 (`v2.0.0`)
cc @mruberry
| 0 |
3,079 | 97,761 |
torch.testing.assert_close: allow check to fail on part on the input
|
triaged, module: testing
|
### 🚀 The feature, motivation and pitch
**Request**: A feature in `torch.testing.assert_close()` that allows users to state: "It's OK if the assertion fails on less than x% of the input (or y entries in absolute terms)" e.g. `assert_close(a, b, atol=atol, rtol=rtol, ignore_failure_rate_below=.02)` (name TBD)
**Why**:
Very often in torchvision we have equality checks that *almost* pass, except for a tiny (negligible) portion of the input. E.g.:
```
Mismatched elements: 1 / 50 (2.0%)
Greatest absolute difference: 3.0863037109375 at index (0, 22) (up to 0.1 allowed)
Greatest relative difference: 0.16271504955728078 at index (0, 22) (up to 0.1 allowed)
```
In the example above we don't really mind that 2% of the input fails, we'd want to test to pass instead of fail.
### Alternatives
Increasing atol or rtol aren't viable alternative in most cases, nor is computing the MAE or other metrics (because the difference between the few values that differ might be arbitrarily high, and that should still be OK).
### Additional context
CC @pmeier as discussed offline
| 3 |
3,080 | 97,760 |
Test Failure: TestUnaryUfuncsCPU.test_reference_numerics_normal_cos_cpu_float32 on s390x
|
triaged, module: numpy
|
### 🐛 Describe the bug
When I execute the following test case on s390x, I got the failure.
```python
$ python test/test_unary_ufuncs.py TestUnaryUfuncsCPU.test_reference_numerics_normal_cos_cpu_float32
...
======================================================================
FAIL: test_reference_numerics_normal_cos_cpu_float32 (__main__.TestUnaryUfuncsCPU)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/ishizaki/PyTorch/master/torch/testing/_internal/common_device_type.py", line 401, in instantiated_test
result = test(self, **param_kwargs)
File "/home/ishizaki/PyTorch/master/torch/testing/_internal/common_device_type.py", line 851, in test_wrapper
return test(*args, **kwargs)
File "/home/ishizaki/PyTorch/master/torch/testing/_internal/common_utils.py", line 1390, in wrapper
fn(*args, **kwargs)
File "/home/ishizaki/PyTorch/master/test/test_unary_ufuncs.py", line 284, in test_reference_numerics_normal
self._test_reference_numerics(dtype, op, tensors)
File "/home/ishizaki/PyTorch/master/test/test_unary_ufuncs.py", line 265, in _test_reference_numerics
_helper_reference_numerics(
File "/home/ishizaki/PyTorch/master/test/test_unary_ufuncs.py", line 217, in _helper_reference_numerics
self.assertEqualHelper(
File "/home/ishizaki/PyTorch/master/test/test_unary_ufuncs.py", line 171, in assertEqualHelper
self.assertEqual(
File "/home/ishizaki/PyTorch/master/torch/testing/_internal/common_utils.py", line 3023, in assertEqual
raise error_metas[0].to_error(
AssertionError: Tensor-likes are not close!
Mismatched elements: 42 / 943593 (0.0%)
Greatest absolute difference: 0.9999842047691345 at index (814, 548) (up to 1e-05 allowed)
Greatest relative difference: inf at index (28, 413) (up to 1.3e-06 allowed)
----------------------------------------------------------------------
Ran 1 test in 132.550s
FAILED (failures=1)
```
I realized that elements at particular positions (e.g. 28, 413) have different values. The expected value (generated by numpy) is 0 while the non-zero value is expected.
I can reproduce this problem by using the following code (Python 3.10.6, numpy 1.24.2). The value of `tc[28][414]` must be `0.5403023` rather than `0.0`.
```python
$ python -c "import torch; import numpy; t = torch.Tensor(1029,917).cpu().numpy(); t[0][0]=1; t[28][413]=1; tc = numpy.cos(t); print(t[0][0], tc[0][0], t[28][413], tc[28][413])"
1.0 0.5403023 1.0 0.0
$ python -c "import torch; import numpy; t = torch.Tensor(1029,917).cpu().numpy(); t[0][0]=1; t[28][414]=1; tc = numpy.cos(t); print(t[0][0], tc[0][0], t[28][414], tc[28][414])"
1.0 0.5403023 1.0 0.0
$ python -c "import torch; import numpy; t = torch.Tensor(1029,917).cpu(); t[0][0]=1; t[28][413]=1; tc = torch.cos(t); print(t[0][0], tc[0][0], t[28][413], tc[28][413])"
tensor(1.) tensor(0.5403) tensor(1.) tensor(0.5403)
$ python -c "import torch; import numpy; t = torch.Tensor(1029,917).cpu(); t[0][0]=1; t[28][414]=1; tc = torch.cos(t); print(t[0][0], tc[0][0], t[28][414], tc[28][414])"
tensor(1.) tensor(0.5403) tensor(1.) tensor(0.5403)
```
### Versions
```
Collecting environment information...
PyTorch version: 2.1.0a0+gite3df6a7
Is debug build: True
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (s390x)
GCC version: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-144-generic-s390x-with-glibc2.35
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: False
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.1.0a0+gite3df6a7
[conda] Could not collect
```
cc @mruberry @rgommers
| 3 |
3,081 | 97,757 |
oneDNN 3.0+ support
|
triaged, module: intel
|
### 🚀 The feature, motivation and pitch
MKLDNN was renamed to oneDNN a long time ago and the cmake name is also different.
The internal copy of MKLDNN in PyTorch is very outdated.
While PyTorch can be built with external oneDNN 2.x (with patches to look for the new cmake name), oneDNN 3.0 may also be found that way but PyTorch doesn't build because of API differences in oneDNN.
Please support oneDNN 3.0+
### Alternatives
_No response_
### Additional context
_No response_
cc @frank-wei @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10
| 3 |
3,082 | 97,750 |
irrelevant error output for Minified repro
|
triaged, oncall: pt2, module: minifier
|
### 🐛 Describe the bug
I am trying to locate the error after using `torch.compile()` to my unet.
The scope of `torch.compile()` is added to `self.unet` only.
The error:
```
發生例外狀況: BackendCompilerFailed
debug_wrapper raised DataDependentOutputException: aten._local_scalar_dense.default
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
torch._subclasses.fake_tensor.DataDependentOutputException: aten._local_scalar_dense.default
The above exception was the direct cause of the following exception:
File "/code/EnlightDiff/diffusion.py", line 216, in p_losses
noise_pred = self.unet(x_t, t, cond)
File "/code/EnlightDiff/diffusion.py", line 223, in forward
noise_pred, noise = self.p_losses(x_start, t, cond, center, noise=noise)
File "/code/EnlightDiff/diffusion.py", line 489, in training_step
noise_pred, noise = self.model(x_start, t, cond, center)
File "/code/EnlightDiff/main.py", line 341, in main
trainer.fit(model=litmodel, datamodule=litdataModule)
File "/code/EnlightDiff/main.py", line 363, in <module>
main(use_LOL4K=use_LOL4K, on_diffusion=on_diffusion, on_encoder=on_encoder,
torch._dynamo.exc.BackendCompilerFailed: debug_wrapper raised DataDependentOutputException: aten._local_scalar_dense.default
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
Therefore, follow up issue #97749, I used cuda:0 to produce the minified repro again.
The exception raised seems to be irrelevant and helpless to locate the runtime error for `torch.compile()`
### Error logs
[2023-03-28 14:21:39,824] torch._dynamo.debug_utils: [WARNING] Compiled Fx GraphModule failed. Creating script to minify the error.
[2023-03-28 14:21:39,828] torch._dynamo.debug_utils: [WARNING] Writing checkpoint with 19 nodes to /code/EnlightDiff/torch_compile_debug/run_2023_03_28_13_58_25_580581-pid_1719185/minifier/checkpoints/minified_19_nodes.py
[2023-03-28 14:21:39,829] torch._dynamo.debug_utils: [WARNING] Copying /code/EnlightDiff/torch_compile_debug/run_2023_03_28_13_58_25_580581-pid_1719185/minifier/checkpoints/minified_19_nodes.py to /code/EnlightDiff/torch_compile_debug/run_2023_03_28_13_58_25_580581-pid_1719185/minifier/repro.py for convenience
Traceback (most recent call last):
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/debug_utils.py", line 1073, in dynamo_minifier_backend
raise ValueError("No issue was detected")
ValueError: No issue was detected
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 666, in call_user_compiler
compiled_fn = compiler_fn(gm, self.example_inputs())
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/debug_utils.py", line 1055, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs)
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/debug_utils.py", line 1088, in dynamo_minifier_backend
minifier(
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_functorch/fx_minifier.py", line 97, in minifier
raise RuntimeError("Input graph did not fail the tester")
RuntimeError: Input graph did not fail the tester
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/code/EnlightDiff/torch_compile_debug/run_2023_03_28_13_58_25_580581-pid_1719185/minifier/minifier_launcher.py", line 69, in <module>
opt_mod(*args)
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 82, in forward
return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 337, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 404, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 104, in _fn
return fn(*args, **kwargs)
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 262, in _convert_frame_assert
return _compile(
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 324, in _compile
out_code = transform_code_object(code, transform)
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/bytecode_transformation.py", line 445, in transform_code_object
transformations(instructions, code_options)
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/convert_frame.py", line 311, in transform
tracer.run()
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1726, in run
super().run()
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 576, in run
and self.step()
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 540, in step
getattr(self, inst.opname)(inst)
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/symbolic_convert.py", line 1792, in RETURN_VALUE
self.output.compile_subgraph(
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 541, in compile_subgraph
self.compile_and_call_fx_graph(tx, pass2.graph_output_vars(), root)
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 588, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packages/torch/_dynamo/output_graph.py", line 675, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: debug_wrapper raised RuntimeError: Input graph did not fail the tester
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
### Minified repro
```
import os
from math import inf
import torch
from torch import tensor, device
import torch.fx as fx
import functools
import torch._dynamo
from torch._dynamo.debug_utils import run_fwd_maybe_bwd
from torch._dynamo.backends.registry import lookup_backend
from torch._dynamo.testing import rand_strided
import torch._dynamo.config
import torch._inductor.config
import torch._functorch.config
torch._dynamo.config.load_config(b'\x80\x02}q\x00(X\x0b\x00\x00\x00output_codeq\x01\x89X\r\x00\x00\x00log_file_nameq\x02NX\x07\x00\x00\x00verboseq\x03\x88X\x11\x00\x00\x00output_graph_codeq\x04\x89X\x12\x00\x00\x00verify_correctnessq\x05\x89X\x12\x00\x00\x00minimum_call_countq\x06K\x01X\x15\x00\x00\x00dead_code_eliminationq\x07\x88X\x10\x00\x00\x00cache_size_limitq\x08K@X\x14\x00\x00\x00specialize_int_floatq\t\x88X\x0e\x00\x00\x00dynamic_shapesq\n\x89X\x10\x00\x00\x00guard_nn_modulesq\x0b\x89X\x1b\x00\x00\x00traceable_tensor_subclassesq\x0cc__builtin__\nset\nq\r]q\x0e\x85q\x0fRq\x10X\x0f\x00\x00\x00suppress_errorsq\x11\x89X\x15\x00\x00\x00replay_record_enabledq\x12\x88X \x00\x00\x00rewrite_assert_with_torch_assertq\x13\x88X\x12\x00\x00\x00print_graph_breaksq\x14\x89X\x07\x00\x00\x00disableq\x15\x89X*\x00\x00\x00allowed_functions_module_string_ignorelistq\x16h\r]q\x17(X\x0b\x00\x00\x00torch._refsq\x18X\r\x00\x00\x00torch._decompq\x19X\x13\x00\x00\x00torch.distributionsq\x1aX\r\x00\x00\x00torch.testingq\x1bX\x0c\x00\x00\x00torch._primsq\x1ce\x85q\x1dRq\x1eX\x12\x00\x00\x00repro_forward_onlyq\x1f\x89X\x0f\x00\x00\x00repro_toleranceq G?PbM\xd2\xf1\xa9\xfcX\x16\x00\x00\x00capture_scalar_outputsq!\x89X\x19\x00\x00\x00enforce_cond_guards_matchq"\x88X\x0c\x00\x00\x00optimize_ddpq#\x88X\x1a\x00\x00\x00raise_on_ctx_manager_usageq$\x88X\x1c\x00\x00\x00raise_on_unsafe_aot_autogradq%\x89X\x17\x00\x00\x00raise_on_backend_changeq&\x89X\x18\x00\x00\x00error_on_nested_fx_traceq\'\x88X\t\x00\x00\x00allow_rnnq(\x89X\x08\x00\x00\x00base_dirq)X>\x00\x00\x00/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packagesq*X\x0e\x00\x00\x00debug_dir_rootq+X%\x00\x00\x00/code/EnlightDiff/torch_compile_debugq,X)\x00\x00\x00DO_NOT_USE_legacy_non_fake_example_inputsq-\x89X\x13\x00\x00\x00_save_config_ignoreq.h\r]q/(X\x0b\x00\x00\x00repro_afterq0X!\x00\x00\x00skipfiles_inline_module_allowlistq1X\x12\x00\x00\x00constant_functionsq2X\x0b\x00\x00\x00repro_levelq3e\x85q4Rq5u.')
torch._inductor.config.load_config(b'\x80\x02}q\x00(X\x05\x00\x00\x00debugq\x01\x89X\x10\x00\x00\x00disable_progressq\x02\x88X\x10\x00\x00\x00verbose_progressq\x03\x89X\x0b\x00\x00\x00cpp_wrapperq\x04\x89X\x03\x00\x00\x00dceq\x05\x89X\x14\x00\x00\x00static_weight_shapesq\x06\x88X\x0c\x00\x00\x00size_assertsq\x07\x88X\x10\x00\x00\x00pick_loop_ordersq\x08\x88X\x0f\x00\x00\x00inplace_buffersq\t\x88X\x11\x00\x00\x00benchmark_harnessq\n\x88X\x0f\x00\x00\x00epilogue_fusionq\x0b\x89X\x15\x00\x00\x00epilogue_fusion_firstq\x0c\x89X\x0f\x00\x00\x00pattern_matcherq\r\x88X\n\x00\x00\x00reorderingq\x0e\x89X\x0c\x00\x00\x00max_autotuneq\x0f\x89X\x17\x00\x00\x00realize_reads_thresholdq\x10K\x04X\x17\x00\x00\x00realize_bytes_thresholdq\x11M\xd0\x07X\x1b\x00\x00\x00realize_acc_reads_thresholdq\x12K\x08X\x0f\x00\x00\x00fallback_randomq\x13\x89X\x12\x00\x00\x00implicit_fallbacksq\x14\x88X\x0b\x00\x00\x00tune_layoutq\x15\x89X\x11\x00\x00\x00aggressive_fusionq\x16\x89X\x0f\x00\x00\x00max_fusion_sizeq\x17K@X\x1b\x00\x00\x00unroll_reductions_thresholdq\x18K\x08X\x0e\x00\x00\x00comment_originq\x19\x89X\x12\x00\x00\x00developer_warningsq\x1a\x89X\x0f\x00\x00\x00compile_threadsq\x1bK X\x13\x00\x00\x00kernel_name_max_opsq\x1cK\nX\r\x00\x00\x00shape_paddingq\x1d\x89X\x0e\x00\x00\x00permute_fusionq\x1e\x89X\x1a\x00\x00\x00profiler_mark_wrapper_callq\x1f\x89X\x18\x00\x00\x00_raise_error_for_testingq \x89X\x0b\x00\x00\x00cpp.threadsq!J\xff\xff\xff\xffX\x13\x00\x00\x00cpp.dynamic_threadsq"\x89X\x0b\x00\x00\x00cpp.simdlenq#NX\x12\x00\x00\x00cpp.min_chunk_sizeq$M\x00\x10X\x07\x00\x00\x00cpp.cxxq%NX\x03\x00\x00\x00g++q&\x86q\'X\x19\x00\x00\x00cpp.enable_kernel_profileq(\x89X\x12\x00\x00\x00cpp.weight_prepackq)\x88X\x11\x00\x00\x00triton.cudagraphsq*\x89X\x17\x00\x00\x00triton.debug_sync_graphq+\x89X\x18\x00\x00\x00triton.debug_sync_kernelq,\x89X\x15\x00\x00\x00triton.dense_indexingq-\x89X\x10\x00\x00\x00triton.max_tilesq.K\x02X\x19\x00\x00\x00triton.autotune_pointwiseq/\x88X\'\x00\x00\x00triton.tiling_prevents_pointwise_fusionq0\x88X\'\x00\x00\x00triton.tiling_prevents_reduction_fusionq1\x88X\x1b\x00\x00\x00triton.ordered_kernel_namesq2\x89X\x1f\x00\x00\x00triton.descriptive_kernel_namesq3\x89X\x1c\x00\x00\x00triton.persistent_reductionsq4\x89X\r\x00\x00\x00trace.enabledq5\x89X\x0f\x00\x00\x00trace.debug_logq6\x88X\x0e\x00\x00\x00trace.info_logq7\x89X\x0e\x00\x00\x00trace.fx_graphq8\x88X\x1a\x00\x00\x00trace.fx_graph_transformedq9\x88X\x13\x00\x00\x00trace.ir_pre_fusionq:\x88X\x14\x00\x00\x00trace.ir_post_fusionq;\x88X\x11\x00\x00\x00trace.output_codeq<\x88X\x13\x00\x00\x00trace.graph_diagramq=\x89X\x15\x00\x00\x00trace.compile_profileq>\x89X\x10\x00\x00\x00trace.upload_tarq?Nu.')
torch._functorch.config.load_config(b'\x80\x02}q\x00(X\x11\x00\x00\x00use_functionalizeq\x01\x88X\x0f\x00\x00\x00use_fake_tensorq\x02\x88X\x16\x00\x00\x00fake_tensor_allow_metaq\x03\x88X\x0c\x00\x00\x00debug_assertq\x04\x88X\x14\x00\x00\x00debug_fake_cross_refq\x05\x89X\x11\x00\x00\x00debug_partitionerq\x06\x89X\x0c\x00\x00\x00debug_graphsq\x07\x89X\x0b\x00\x00\x00debug_jointq\x08\x89X\x12\x00\x00\x00use_dynamic_shapesq\t\x89X\x14\x00\x00\x00static_weight_shapesq\n\x88X\x03\x00\x00\x00cseq\x0b\x88X\x10\x00\x00\x00max_dist_from_bwq\x0cK\x03X\t\x00\x00\x00log_levelq\rK\x14u.')
# REPLACEABLE COMMENT FOR TESTING PURPOSES
args = [((32, 3, 160, 160), (76800, 25600, 160, 1), torch.float32, 'cuda', False), ((32,), (1,), torch.int64, 'cuda', False), ((32, 3, 160, 160), (76800, 25600, 160, 1), torch.float16, 'cuda', False)]
args = [rand_strided(sh, st, dt, dev).requires_grad_(rg) for (sh, st, dt, dev, rg) in args]
from torch.nn import *
class Repro(torch.nn.Module):
def __init__(self):
super().__init__()
self.self_mlp_0 = Linear(in_features=64, out_features=256, bias=True).cuda()
self.self_mlp_2 = Linear(in_features=256, out_features=64, bias=True).cuda()
def forward(self, x : torch.Tensor, time : torch.Tensor, cond : torch.Tensor):
arange = torch.arange(32, device = device(type='cuda', index=0))
mul = arange * -0.2971077539347156; arange = None
exp = torch.exp(mul); mul = None
getitem = time[(slice(None, None, None), None)]; time = None
getitem_1 = exp[(None, slice(None, None, None))]; exp = None
mul_1 = getitem * getitem_1; getitem = getitem_1 = None
sin = mul_1.sin()
cos = mul_1.cos(); mul_1 = None
cat = torch.cat((sin, cos), dim = -1); sin = cos = None
self_mlp_0 = self.self_mlp_0(cat); cat = None
softplus = torch._C._nn.softplus(self_mlp_0)
tanh = torch.tanh(softplus); softplus = None
mul_2 = self_mlp_0 * tanh; self_mlp_0 = tanh = None
self_mlp_2 = self.self_mlp_2(mul_2); mul_2 = None
cat_1 = torch.cat((x, cond), dim = 1); x = cond = None
return (cat_1, self_mlp_2)
mod = Repro()
# Setup debug minifier compiler
torch._dynamo.debug_utils.MINIFIER_SPAWNED = True
compiler_fn = lookup_backend("dynamo_minifier_backend")
dynamo_minifier_backend = functools.partial(
compiler_fn,
compiler_name="inductor",
)
opt_mod = torch._dynamo.optimize(dynamo_minifier_backend)(mod)
with torch.cuda.amp.autocast(enabled=True):
opt_mod(*args)
```
### Versions
please refer to #97749
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
3,083 | 97,749 |
Bug on Minified repro example
|
triaged, oncall: pt2, module: minifier
|
### 🐛 Describe the bug
I created a minified repro to examine the cause of the runtime error (as the compiler seems to have no error report).
The card used to generate the repro is cuda:7.
Then I ran the gerenreated repro. Now the repro complain runtime error as Unhandled FakeTensor Device Propagation for aten.mul.Tensor, found two different devices cuda:0, cuda:7
(scroll up for backtrace)
As I think we cant ensure to use cuda:0 to debug every time. I think it should be fixed on Minified repro.
### Error logs
發生例外狀況: TorchRuntimeError
from user code:
File "/code/EnlightDiff/torch_compile_debug/run_2023_03_28_13_57_57_112729-pid_1716815/minifier/minifier_launcher.py", line 43, in forward
mul_1 = getitem * getitem_1; getitem = getitem_1 = None
Last frame execution written to /code/EnlightDiff/torch_compile_debug/run_2023_03_28_14_01_45_743159-pid_1727270/error_recordings/forward_TorchRuntimeError_37.rec. To run only this frame while debugging, run torch._dynamo.replay('/code/EnlightDiff/torch_compile_debug/run_2023_03_28_14_01_45_743159-pid_1727270/error_recordings/forward_TorchRuntimeError_37.rec').
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
RuntimeError: Unhandled FakeTensor Device Propagation for aten.mul.Tensor, found two different devices cuda:0, cuda:7
The above exception was the direct cause of the following exception:
RuntimeError: Failed running call_function <built-in function mul>(*(FakeTensor(FakeTensor(..., device='meta', size=(32, 1), dtype=torch.int64), cuda:0), FakeTensor(FakeTensor(..., device='meta', size=(1, 32)), cuda:7)), **{}):
Unhandled FakeTensor Device Propagation for aten.mul.Tensor, found two different devices cuda:0, cuda:7
(scroll up for backtrace)
The above exception was the direct cause of the following exception:
File "/code/EnlightDiff/torch_compile_debug/run_2023_03_28_13_57_57_112729-pid_1716815/minifier/minifier_launcher.py", line 69, in <module>
opt_mod(*args)
torch._dynamo.exc.TorchRuntimeError:
from user code:
File "/code/EnlightDiff/torch_compile_debug/run_2023_03_28_13_57_57_112729-pid_1716815/minifier/minifier_launcher.py", line 43, in forward
mul_1 = getitem * getitem_1; getitem = getitem_1 = None
Last frame execution written to /code/EnlightDiff/torch_compile_debug/run_2023_03_28_14_01_45_743159-pid_1727270/error_recordings/forward_TorchRuntimeError_37.rec. To run only this frame while debugging, run torch._dynamo.replay('/code/EnlightDiff/torch_compile_debug/run_2023_03_28_14_01_45_743159-pid_1727270/error_recordings/forward_TorchRuntimeError_37.rec').
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
### Minified repro
```
import os
from math import inf
import torch
from torch import tensor, device
import torch.fx as fx
import functools
import torch._dynamo
from torch._dynamo.debug_utils import run_fwd_maybe_bwd
from torch._dynamo.backends.registry import lookup_backend
from torch._dynamo.testing import rand_strided
import torch._dynamo.config
import torch._inductor.config
import torch._functorch.config
torch._dynamo.config.load_config(b'\x80\x02}q\x00(X\x0b\x00\x00\x00output_codeq\x01\x89X\r\x00\x00\x00log_file_nameq\x02NX\x07\x00\x00\x00verboseq\x03\x88X\x11\x00\x00\x00output_graph_codeq\x04\x89X\x12\x00\x00\x00verify_correctnessq\x05\x89X\x12\x00\x00\x00minimum_call_countq\x06K\x01X\x15\x00\x00\x00dead_code_eliminationq\x07\x88X\x10\x00\x00\x00cache_size_limitq\x08K@X\x14\x00\x00\x00specialize_int_floatq\t\x88X\x0e\x00\x00\x00dynamic_shapesq\n\x89X\x10\x00\x00\x00guard_nn_modulesq\x0b\x89X\x1b\x00\x00\x00traceable_tensor_subclassesq\x0cc__builtin__\nset\nq\r]q\x0e\x85q\x0fRq\x10X\x0f\x00\x00\x00suppress_errorsq\x11\x89X\x15\x00\x00\x00replay_record_enabledq\x12\x88X \x00\x00\x00rewrite_assert_with_torch_assertq\x13\x88X\x12\x00\x00\x00print_graph_breaksq\x14\x89X\x07\x00\x00\x00disableq\x15\x89X*\x00\x00\x00allowed_functions_module_string_ignorelistq\x16h\r]q\x17(X\r\x00\x00\x00torch.testingq\x18X\r\x00\x00\x00torch._decompq\x19X\x0c\x00\x00\x00torch._primsq\x1aX\x13\x00\x00\x00torch.distributionsq\x1bX\x0b\x00\x00\x00torch._refsq\x1ce\x85q\x1dRq\x1eX\x12\x00\x00\x00repro_forward_onlyq\x1f\x89X\x0f\x00\x00\x00repro_toleranceq G?PbM\xd2\xf1\xa9\xfcX\x16\x00\x00\x00capture_scalar_outputsq!\x89X\x19\x00\x00\x00enforce_cond_guards_matchq"\x88X\x0c\x00\x00\x00optimize_ddpq#\x88X\x1a\x00\x00\x00raise_on_ctx_manager_usageq$\x88X\x1c\x00\x00\x00raise_on_unsafe_aot_autogradq%\x89X\x17\x00\x00\x00raise_on_backend_changeq&\x89X\x18\x00\x00\x00error_on_nested_fx_traceq\'\x88X\t\x00\x00\x00allow_rnnq(\x89X\x08\x00\x00\x00base_dirq)X>\x00\x00\x00/home/cychan/mambaforge/envs/ldm3/lib/python3.10/site-packagesq*X\x0e\x00\x00\x00debug_dir_rootq+X%\x00\x00\x00/code/EnlightDiff/torch_compile_debugq,X)\x00\x00\x00DO_NOT_USE_legacy_non_fake_example_inputsq-\x89X\x13\x00\x00\x00_save_config_ignoreq.h\r]q/(X\x0b\x00\x00\x00repro_levelq0X\x0b\x00\x00\x00repro_afterq1X\x12\x00\x00\x00constant_functionsq2X!\x00\x00\x00skipfiles_inline_module_allowlistq3e\x85q4Rq5u.')
torch._inductor.config.load_config(b'\x80\x02}q\x00(X\x05\x00\x00\x00debugq\x01\x89X\x10\x00\x00\x00disable_progressq\x02\x88X\x10\x00\x00\x00verbose_progressq\x03\x89X\x0b\x00\x00\x00cpp_wrapperq\x04\x89X\x03\x00\x00\x00dceq\x05\x89X\x14\x00\x00\x00static_weight_shapesq\x06\x88X\x0c\x00\x00\x00size_assertsq\x07\x88X\x10\x00\x00\x00pick_loop_ordersq\x08\x88X\x0f\x00\x00\x00inplace_buffersq\t\x88X\x11\x00\x00\x00benchmark_harnessq\n\x88X\x0f\x00\x00\x00epilogue_fusionq\x0b\x89X\x15\x00\x00\x00epilogue_fusion_firstq\x0c\x89X\x0f\x00\x00\x00pattern_matcherq\r\x88X\n\x00\x00\x00reorderingq\x0e\x89X\x0c\x00\x00\x00max_autotuneq\x0f\x89X\x17\x00\x00\x00realize_reads_thresholdq\x10K\x04X\x17\x00\x00\x00realize_bytes_thresholdq\x11M\xd0\x07X\x1b\x00\x00\x00realize_acc_reads_thresholdq\x12K\x08X\x0f\x00\x00\x00fallback_randomq\x13\x89X\x12\x00\x00\x00implicit_fallbacksq\x14\x88X\x0b\x00\x00\x00tune_layoutq\x15\x89X\x11\x00\x00\x00aggressive_fusionq\x16\x89X\x0f\x00\x00\x00max_fusion_sizeq\x17K@X\x1b\x00\x00\x00unroll_reductions_thresholdq\x18K\x08X\x0e\x00\x00\x00comment_originq\x19\x89X\x12\x00\x00\x00developer_warningsq\x1a\x89X\x0f\x00\x00\x00compile_threadsq\x1bK X\x13\x00\x00\x00kernel_name_max_opsq\x1cK\nX\r\x00\x00\x00shape_paddingq\x1d\x89X\x0e\x00\x00\x00permute_fusionq\x1e\x89X\x1a\x00\x00\x00profiler_mark_wrapper_callq\x1f\x89X\x18\x00\x00\x00_raise_error_for_testingq \x89X\x0b\x00\x00\x00cpp.threadsq!J\xff\xff\xff\xffX\x13\x00\x00\x00cpp.dynamic_threadsq"\x89X\x0b\x00\x00\x00cpp.simdlenq#NX\x12\x00\x00\x00cpp.min_chunk_sizeq$M\x00\x10X\x07\x00\x00\x00cpp.cxxq%NX\x03\x00\x00\x00g++q&\x86q\'X\x19\x00\x00\x00cpp.enable_kernel_profileq(\x89X\x12\x00\x00\x00cpp.weight_prepackq)\x88X\x11\x00\x00\x00triton.cudagraphsq*\x89X\x17\x00\x00\x00triton.debug_sync_graphq+\x89X\x18\x00\x00\x00triton.debug_sync_kernelq,\x89X\x15\x00\x00\x00triton.dense_indexingq-\x89X\x10\x00\x00\x00triton.max_tilesq.K\x02X\x19\x00\x00\x00triton.autotune_pointwiseq/\x88X\'\x00\x00\x00triton.tiling_prevents_pointwise_fusionq0\x88X\'\x00\x00\x00triton.tiling_prevents_reduction_fusionq1\x88X\x1b\x00\x00\x00triton.ordered_kernel_namesq2\x89X\x1f\x00\x00\x00triton.descriptive_kernel_namesq3\x89X\x1c\x00\x00\x00triton.persistent_reductionsq4\x89X\r\x00\x00\x00trace.enabledq5\x89X\x0f\x00\x00\x00trace.debug_logq6\x88X\x0e\x00\x00\x00trace.info_logq7\x89X\x0e\x00\x00\x00trace.fx_graphq8\x88X\x1a\x00\x00\x00trace.fx_graph_transformedq9\x88X\x13\x00\x00\x00trace.ir_pre_fusionq:\x88X\x14\x00\x00\x00trace.ir_post_fusionq;\x88X\x11\x00\x00\x00trace.output_codeq<\x88X\x13\x00\x00\x00trace.graph_diagramq=\x89X\x15\x00\x00\x00trace.compile_profileq>\x89X\x10\x00\x00\x00trace.upload_tarq?Nu.')
torch._functorch.config.load_config(b'\x80\x02}q\x00(X\x11\x00\x00\x00use_functionalizeq\x01\x88X\x0f\x00\x00\x00use_fake_tensorq\x02\x88X\x16\x00\x00\x00fake_tensor_allow_metaq\x03\x88X\x0c\x00\x00\x00debug_assertq\x04\x88X\x14\x00\x00\x00debug_fake_cross_refq\x05\x89X\x11\x00\x00\x00debug_partitionerq\x06\x89X\x0c\x00\x00\x00debug_graphsq\x07\x89X\x0b\x00\x00\x00debug_jointq\x08\x89X\x12\x00\x00\x00use_dynamic_shapesq\t\x89X\x14\x00\x00\x00static_weight_shapesq\n\x88X\x03\x00\x00\x00cseq\x0b\x88X\x10\x00\x00\x00max_dist_from_bwq\x0cK\x03X\t\x00\x00\x00log_levelq\rK\x14u.')
# REPLACEABLE COMMENT FOR TESTING PURPOSES
args = [((32, 3, 160, 160), (76800, 25600, 160, 1), torch.float32, 'cuda', False), ((32,), (1,), torch.int64, 'cuda', False), ((32, 3, 160, 160), (76800, 25600, 160, 1), torch.float16, 'cuda', False)]
args = [rand_strided(sh, st, dt, dev).requires_grad_(rg) for (sh, st, dt, dev, rg) in args]
from torch.nn import *
class Repro(torch.nn.Module):
def __init__(self):
super().__init__()
self.self_mlp_0 = Linear(in_features=64, out_features=256, bias=True).cuda()
self.self_mlp_2 = Linear(in_features=256, out_features=64, bias=True).cuda()
def forward(self, x : torch.Tensor, time : torch.Tensor, cond : torch.Tensor):
arange = torch.arange(32, device = device(type='cuda', index=7))
mul = arange * -0.2971077539347156; arange = None
exp = torch.exp(mul); mul = None
getitem = time[(slice(None, None, None), None)]; time = None
getitem_1 = exp[(None, slice(None, None, None))]; exp = None
mul_1 = getitem * getitem_1; getitem = getitem_1 = None
sin = mul_1.sin()
cos = mul_1.cos(); mul_1 = None
cat = torch.cat((sin, cos), dim = -1); sin = cos = None
self_mlp_0 = self.self_mlp_0(cat); cat = None
softplus = torch._C._nn.softplus(self_mlp_0)
tanh = torch.tanh(softplus); softplus = None
mul_2 = self_mlp_0 * tanh; self_mlp_0 = tanh = None
self_mlp_2 = self.self_mlp_2(mul_2); mul_2 = None
cat_1 = torch.cat((x, cond), dim = 1); x = cond = None
return (cat_1, self_mlp_2)
mod = Repro()
# Setup debug minifier compiler
torch._dynamo.debug_utils.MINIFIER_SPAWNED = True
compiler_fn = lookup_backend("dynamo_minifier_backend")
dynamo_minifier_backend = functools.partial(
compiler_fn,
compiler_name="inductor",
)
opt_mod = torch._dynamo.optimize(dynamo_minifier_backend)(mod)
with torch.cuda.amp.autocast(enabled=True):
opt_mod(*args)
```
### Versions
Collecting environment information...
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.10.9 | packaged by conda-forge | (main, Feb 2 2023, 20:20:04) [GCC 11.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-67-generic-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
GPU 2: NVIDIA GeForce RTX 3090
GPU 3: NVIDIA GeForce RTX 3090
GPU 4: NVIDIA GeForce RTX 3090
GPU 5: NVIDIA GeForce RTX 3090
GPU 6: NVIDIA GeForce RTX 3090
GPU 7: NVIDIA GeForce RTX 3090
Nvidia driver version: 525.85.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 6256 CPU @ 3.60GHz
Stepping: 7
CPU MHz: 1713.576
CPU max MHz: 4500.0000
CPU min MHz: 1200.0000
BogoMIPS: 7200.00
Virtualization: VT-x
L1d cache: 768 KiB
L1i cache: 768 KiB
L2 cache: 24 MiB
L3 cache: 66 MiB
NUMA node0 CPU(s): 0-11,24-35
NUMA node1 CPU(s): 12-23,36-47
Vulnerability Itlb multihit: KVM: Mitigation: VMX disabled
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Mitigation; TSX disabled
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single intel_ppin ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts pku ospke avx512_vnni md_clear flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] lion-pytorch==0.0.7
[pip3] numpy==1.24.2
[pip3] pytorch-lightning==2.0.0
[pip3] torch==2.0.0
[pip3] torchmetrics==0.11.4
[pip3] torchvision==0.15.0
[pip3] triton==2.0.0
[conda] blas 1.0 mkl conda-forge
[conda] cudatoolkit 11.8.0 h37601d7_11 conda-forge
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] libblas 3.9.0 16_linux64_mkl conda-forge
[conda] libcblas 3.9.0 16_linux64_mkl conda-forge
[conda] liblapack 3.9.0 16_linux64_mkl conda-forge
[conda] lion-pytorch 0.0.7 pypi_0 pypi
[conda] mkl 2022.2.1 h84fe81f_16997 conda-forge
[conda] numpy 1.24.2 py310h8deb116_0 conda-forge
[conda] pytorch 2.0.0 py3.10_cuda11.8_cudnn8.7.0_0 pytorch
[conda] pytorch-cuda 11.8 h7e8668a_3 pytorch
[conda] pytorch-lightning 2.0.0 pyhd8ed1ab_1 conda-forge
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchmetrics 0.11.4 pyhd8ed1ab_0 conda-forge
[conda] torchtriton 2.0.0 py310 pytorch
[conda] torchvision 0.15.0 py310_cu118 pytorch
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
3,084 | 97,748 |
TypeError: 'torch._C._TensorMeta' object is not iterable
|
module: windows, module: rocm, triaged
|
### 🐛 Describe the bug
Error on initial use
pip install torch
import torch
x = torch.rand(5,3)
print(x)
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "D:\Clouds\OneDrive\Documents\dev\github\openai\ChatGPT-at-Home\env\lib\site-packages\torch\__init__.py", line 934, in <module>
from .storage import _StorageBase, TypedStorage, _LegacyStorage, UntypedStorage, _warn_typed_storage_removal
File "D:\Clouds\OneDrive\Documents\dev\github\openai\ChatGPT-at-Home\env\lib\site-packages\torch\storage.py", line 230, in <module>
class UntypedStorage(torch._C.StorageBase, _StorageBase):
TypeError: 'torch._C._TensorMeta' object is not iterable
Running on -
# Python 3.10.0b2
# GNU bash, version 5.1.16(1)-release (x86_64-pc-msys)
# VS Code Version: 1.76.2 (system setup)
Commit: ee2b180d582a7f601fa6ecfdad8d9fd269ab1884
Date: 2023-03-14T17:55:54.936Z
Electron: 19.1.11
Chromium: 102.0.5005.196
Node.js: 16.14.2
V8: 10.2.154.26-electron.0
OS: Windows_NT x64 10.0.19045
Sandboxed: No
# Hardware - Nitro AN515-43
Processor AMD Ryzen 5 3550H with Radeon Vega Mobile Gfx 2.10 GHz
Installed RAM 40.0 GB (37.9 GB usable)
# OS
Edition Windows 10 Home Single Language
Version 22H2
OS build 19045.2728
Experience Windows Feature Experience Pack 120.2212.4190.0
### Versions
$ python collect_env.py
Traceback (most recent call last):
File "D:\Clouds\OneDrive\Documents\dev\github\openai\ChatGPT-at-Home\collect_env.py", line 15, in <module>
import torch
File "D:\Clouds\OneDrive\Documents\dev\github\openai\ChatGPT-at-Home\env\lib\site-packages\torch\__init__.py", line 934, in <module>
from .storage import _StorageBase, TypedStorage, _LegacyStorage, UntypedStorage, _warn_typed_storage_removal
File "D:\Clouds\OneDrive\Documents\dev\github\openai\ChatGPT-at-Home\env\lib\site-packages\torch\storage.py", line 230, in <module>
class UntypedStorage(torch._C.StorageBase, _StorageBase):
TypeError: 'torch._C._TensorMeta' object is not iterable
cc @peterjc123 @mszhanyi @skyline75489 @nbcsm @jeffdaily @sunway513 @jithunnair-amd @pruthvistony @ROCmSupport
| 8 |
3,085 | 97,718 |
Dynamo generates invalid frame when graph-breaking due to opacus_cifar10 hooks
|
triaged, bug, module: dynamo, release notes: dynamo
|
### 🐛 Describe the bug
When running torchbench opacus_cifar10 today in CI, hooks are silently ignored on modules such as `torch.nn.modules.conv.Conv2d` since this is 'allowed' in graph and hooks aren't traced by dynamo. Some of the hook behavior might actually be burned into the AOT trace, and this is at best shaky or more likely incorrect (I didn't read carefully what the hooks do but it's not trivial) - [capture_activations_hook](https://github.com/pytorch/opacus/blob/main/opacus/grad_sample/grad_sample_module.py#L267), [capture_backprops_hook](https://github.com/pytorch/opacus/blob/main/opacus/grad_sample/grad_sample_module.py#L290)
There is a related gh issue (#96722) where dynamo skips hooks on 'allowed' modules. PR #97184 fixes this by graph-breaking on allowed_modules that have hooks. See the PR desc for more discussion on alternative fixes.
After graph-breaking on allowed modules with hooks, opacus fails with what looks like an invalid dynamo frame generated.
Checkout: `ghstack checkout https://github.com/pytorch/pytorch/pull/97184`
Repro:
`TORCH_COMPILE_DEBUG=1 python benchmarks/dynamo/torchbench.py --only opacus_cifar10 --performance --backend aot_eager > opacus.log 2>&1`
Log: https://gist.github.com/wconstab/50e752cc4a6db010549c2f5cdfff67ac
**Notable excerpts from log:**
This graphbreak is expected, due to the change in #97184
```
[2023-03-27 23:34:30,451] torch._dynamo.output_graph: [DEBUG] COMPILING GRAPH due to GraphCompileReason(reason="Can't support hooks on 'allowed' modules (<class 'torch.nn.modules.conv.Conv2d'>) becuase allowed modules don't get traced through.",
```
Not sure why getattr fails here, unless it's becuase the hook didn't modify the dynamo's copy of the module and the hook is actually mutating the module via setattr. (The hook does actually store stuff on the module)
```
[2023-03-27 23:34:30,456] torch._dynamo.symbolic_convert: [DEBUG] FAILED INLINING <code object __getattr__ at 0x7ff33221e3a0, file "/scratch/whc/work/pytorch/torch/nn/modules/module.py", line 1601>
[2023-03-27 23:34:30,456] torch._dynamo.output_graph: [DEBUG] restore_graphstate: removed 0 nodes
[2023-03-27 23:34:30,457] torch._dynamo.symbolic_convert: [DEBUG] step triggered compile
```
?
```
torch._dynamo.exc.Unsupported: class property GradSampleModule getset_descriptor
[2023-03-27 23:34:30,457] torch._dynamo.output_graph: [DEBUG] restore_graphstate: removed 0 nodes
[2023-03-27 23:34:30,457] torch._dynamo.output_graph: [DEBUG] COMPILING GRAPH due to GraphCompileReason(reason='step_unsupported', user_stack=[<FrameSummary file /scratch/whc/work/py38/lib/python3.8/site-packages/opacus/grad_sample/gsm_base.py, line 71 in __getattr__>])
ERROR:common:Backend dynamo failed in warmup()
```
And finally we bottom out with a stackframe that's invalid.
```
File "/scratch/whc/work/pytorch/torch/_dynamo/bytecode_analysis.py", line 185, in stacksize_analysis
assert low >= 0
AssertionError:
```
### Versions
PR (see above)
cc @soumith @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 2 |
3,086 | 97,711 |
dynamo sometimes hits the cache size limit due to the foreach flag in optimizer.step()
|
module: optimizer, triaged, oncall: pt2, module: dynamo
|
### 🐛 Describe the bug
When one torch.compile()'s the optimizer.step() for certain models and optimizers, dynamo sometimes hits the cache size limit due to the foreach flag. It should not try recompiling a graph for the foreach flag currently since we should just be tracing single-tensor for now. This will likely be fixed by @mlazos's foreach + optimizer changes and this issue is a tracker to make sure it is not forgotten.
### Error logs
```
Warning: 27 21:42:30,628] torch._dynamo.convert_frame: [WARNING] torch._dynamo hit config.cache_size_limit (64)
function: 'nadam' (/home/ubuntu/miniconda3/envs/userbenchmarks-ci/lib/python3.10/site-packages/torch/optim/nadam.py:160)
reasons: ___check_obj_id(foreach, 7698112)
to diagnose recompilation issues, see https://pytorch.org/docs/master/compile/troubleshooting.html.
```
### Repro
I'm not sure this is easy to repro in a small way, but this happens when I run my benchmarking script from https://github.com/pytorch/benchmark/pull/1473 with `python -m userbenchmark.optim.__init__`.
### Versions
2.0, nightlies
cc @vincentqb @jbschlosser @albanD @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire @lazos
| 1 |
3,087 | 97,693 |
Compile targts cuda:0 rather than the device the model is on
|
triaged, oncall: pt2, module: inductor
|
### 🐛 Describe the bug
The pytorch compile works great when I only have one GPU (gtx 1660 super, no tensor cores) installed on my computer. However, when I installed a new GPU card RTX 3060 (has tensor cores), which becomes the new “cuda:0”, even though I still chose gtx 1660 (“cuda:1” now) to run the model, the pytorch compile still choose rtx 3060, which has tensor cores as the targeted archecture. And I got the following warning:
```
compile_fx.py:90: UserWarning: TensorFloat32 tensor cores for float32 matrix multiplication available but not enabled. Consider setting `torch.set_float32_matmul_precision('high')` for better performance.
```
and error:
```
compiler.py", line 1671, in _init_handles
mod, func, n_regs, n_spills = cuda_utils.load_binary(self.metadata["name"], self.asm["cubin"], self.shared, device)
RuntimeError: Triton Error [CUDA]: device kernel image is invalid
```
Would be great if the compile function can either detect which GPU the model is on or has a device option.
### Versions
pytorch 2.0
cuda 11.8
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @desertfire
| 12 |
3,088 | 97,681 |
[FSDP] Consolidate test_fsdp_state_dict.py
|
oncall: distributed, triaged, module: fsdp
|
### 🚀 The feature, motivation and pitch
One issue today is that our test_fsdp_state_dict.py file was incrementally developed and now there is a nontrivial amount of redundancy between tests. It would be great if we can consolidate the tests to reduce time to signal and also improve developer efficiency (e.g. if adding a new feature, which test(s) should I test my feature with).
### Alternatives
_No response_
### Additional context
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
3,089 | 97,676 |
Pytorch 2 compile + fsdp + transformers crash
|
triaged, module: xla
|
### 🐛 Describe the bug
Hello,
I am trying to combine both pytorch 2.0 compile + fsdp on TPU but it doesn't work.
What does work on TPU:
base training.
base training + PyTorch compile.
base training + FSDP.
But it doesn't work when I combine both FSDP + PyTorch compile.
I have created an example here to reproduce the problem:
https://colab.research.google.com/drive/1RmarhGBIjeWHIngO7fAp239eqt5Za8bZ?usp=sharing
### Versions
```
Collecting environment information...
PyTorch version: 2.1.0.dev20230327+cpu-cxx11-abi
Is debug build: False
CUDA used to build PyTorch: Could not collect
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: 10.0.0-4ubuntu1
CMake version: version 3.25.2
Libc version: glibc-2.31
Python version: 3.9.16 (main, Dec 7 2022, 01:11:51) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.10.147+-x86_64-with-glibc2.31
Is CUDA available: False
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.7.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.7.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 40
On-line CPU(s) list: 0-39
Thread(s) per core: 2
Core(s) per socket: 20
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU @ 2.30GHz
Stepping: 0
CPU MHz: 2299.998
BogoMIPS: 4599.99
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 640 KiB
L1i cache: 640 KiB
L2 cache: 5 MiB
L3 cache: 45 MiB
NUMA node0 CPU(s): 0-39
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Vulnerable; SMT Host state unknown
Vulnerability Meltdown: Vulnerable
Vulnerability Mmio stale data: Vulnerable
Vulnerability Retbleed: Vulnerable
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Vulnerable: __user pointer sanitization and usercopy barriers only; no swapgs barriers
Vulnerability Spectre v2: Vulnerable, IBPB: disabled, STIBP: disabled, PBRSB-eIBRS: Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid tsc_known_freq pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm abm invpcid_single ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid xsaveopt arat md_clear arch_capabilities
Versions of relevant libraries:
[pip3] numpy==1.24.2
[pip3] torch==2.1.0.dev20230327+cpu.cxx11.abi
[pip3] torch-xla==2.1.0+abccaab
[pip3] torchaudio==0.13.1+cu116
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.14.1
[pip3] torchvision==0.14.1+cu116
[conda] Could not collect
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 3 |
3,090 | 97,670 |
[FSDP] test model.eval() + keep_low_precision_grads
|
oncall: distributed, triaged
|
### 🚀 The feature, motivation and pitch
Need to test that keep_low_precision_grads in mixed_precision is nullified in model.eval() mode.
### Alternatives
_No response_
### Additional context
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
3,091 | 97,668 |
sparse_csr_tensor matmul wrong output in bfloat16
|
module: sparse, triaged
|
### 🐛 Describe the bug
Trying to do a sparse-dense matrix multiplication in with bfloat16 dtype produces incorrect output.
More specifically, I would like to use torch.sparse_csr_tensor to implement conditional matrix multiplication (I have an index selecting which matrix to use, in the sample below I'm simulating this by multiplying each slice of the batch with a different matrix. sparse_bsc_tensor would be more optimal for this, but unfortunately, matmul is not supported with it currently).
The code below tests the output of the operation for different data types and prints the max relative and absolute error:
```python
import torch
n_blocks = 16
n_channels = 128
block_size = 8
bs = 32
device = torch.device("cuda")
# Generate test data
testvec_g = torch.randn(bs, n_channels)
mat_g = torch.randn(n_blocks, n_channels, block_size)
# calculate reference output
olist = []
sample_per_block = bs // n_blocks
for b in range(n_blocks):
olist.append(testvec_g.float()[b*sample_per_block: (b+1)*sample_per_block] @ mat_g[b].float())
reference = torch.cat(olist, dim=0)
# Do the test
def test(dtype):
mat = mat_g.to(dtype).to(device)
testvec = testvec_g.to(dtype).to(device)
sel = torch.arange(n_blocks)[..., None].expand(-1, bs // n_blocks).flatten().to(device)
out = torch.sparse_csr_tensor(
crow_indices=torch.arange(0, testvec.nelement() + 1, testvec.shape[-1], device=mat.device),
col_indices=(torch.arange(0, testvec.shape[-1], device=mat.device) + sel[:, None] * n_channels).flatten(),
values=testvec.flatten(),
size=(testvec.shape[0], testvec.shape[1] * n_blocks)
)
scores = out @ mat.flatten(0,1)
ref = reference.type(dtype).to(device)
print(" Max forward abs diff: ", (scores - ref).abs().max())
print(" Max forward rel diff: ", ((scores - ref) / ref).abs().max())
print("float32")
test(torch.float32)
print("float16")
test(torch.float16)
print("bfloat16")
test(torch.bfloat16)
```
It produces the following output (which varies due to the randomly generated inputs):
```
float32
/home/robert/test/min_bfloat16_fail.py:30: UserWarning: Sparse CSR tensor support is in beta state. If you miss a functionality in the sparse tensor support, please submit a feature request to https://github.com/pytorch/pytorch/issues. (Triggered internally at ../aten/src/ATen/SparseCsrTensorImpl.cpp:54.)
out = torch.sparse_csr_tensor(
Max forward abs diff: tensor(7.6294e-06, device='cuda:0')
Max forward rel diff: tensor(1.8543e-05, device='cuda:0')
float16
Max forward abs diff: tensor(0.0312, device='cuda:0', dtype=torch.float16)
Max forward rel diff: tensor(0.1309, device='cuda:0', dtype=torch.float16)
bfloat16
Max forward abs diff: tensor(0.2500, device='cuda:0', dtype=torch.bfloat16)
Max forward rel diff: tensor(2.0156, device='cuda:0', dtype=torch.bfloat16)
```
Bfloat16 has max 200% error, and just by looking at the matrices by hand, it is clear that the output has nothing like the correct one.
Thanks in advance for any suggestions!
### Versions
```
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
OS: Manjaro Linux (x86_64)
GCC version: (GCC) 12.2.0
Clang version: 14.0.6
CMake version: version 3.25.0
Python version: 3.10 (64-bit runtime)
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090
Nvidia driver version: 525.60.11
cuDNN version: Probably one of the following:
/usr/lib/libcudnn.so.8.6.0
/usr/lib/libcudnn_adv_infer.so.8.6.0
/usr/lib/libcudnn_adv_train.so.8.6.0
/usr/lib/libcudnn_cnn_infer.so.8.6.0
/usr/lib/libcudnn_cnn_train.so.8.6.0
/usr/lib/libcudnn_ops_infer.so.8.6.0
/usr/lib/libcudnn_ops_train.so.8.6.0
Versions of relevant libraries:
[pip3] kmeans-pytorch==0.3
[pip3] numpy==1.23.5
[pip3] pytorch-lightning==1.9.0
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0
[pip3] torch-dct==0.1.6
[pip3] torchaudio==2.0.0.dev20230131+cu118
[pip3] torchmetrics==0.11.0
[pip3] torchvision==0.15.0.dev20230131+cu118
[conda] Could not collect
```
cc @alexsamardzic @nikitaved @pearu @cpuhrsch @amjames @bhosmer
| 2 |
3,092 | 97,659 |
How do I get the original object wrapped by the torch.fx.proxy class?
|
triaged, oncall: fx
|
I want quant the swin transformers. This model need get some shape of tensors in the forward function, but the args is a proxy object, How do I get the original object(It is the window tensor below) wrapped by the Proxy class?Thanks.
## Issue description
Provide a short description.
## Code example


## Traceback
**the windows is a tensor wrapped by the proxy, Is there some method to get the original tensor or its shape?**
## System Info
Versions of relevant libraries:
[pip3] numpy==1.23.3
[pip3] torch==1.12.0+cu116
[pip3] torchaudio==0.12.0+cu116
[pip3] torchvision==0.13.0+cu116
[conda] blas 1.0 mkl defaults
[conda] cudatoolkit 11.3.1 h2bc3f7f_2 defaults
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640 defaults
[conda] mkl-service 2.4.0 py38h7f8727e_0 defaults
[conda] mkl_fft 1.3.1 py38hd3c417c_0 defaults
[conda] mkl_random 1.2.2 py38h51133e4_0 defaults
[conda] numpy 1.23.3 py38h14f4228_0 defaults
[conda] numpy-base 1.23.3 py38h31eccc5_0 defaults
[conda] pytorch 1.13.0 py3.8_cpu_0 pytorch
[conda] pytorch-mutex 1.0 cpu pytorch
[conda] torch 1.12.0+cu116 <pip>
[conda] torchaudio 0.12.0+cu116 <pip>
[conda] torchaudio 0.13.0 py38_cpu pytorch
[conda] torchvision 0.14.0 py38_cpu pytorch
[conda] torchvision 0.13.0+cu116 <pip>
cc @ezyang @SherlockNoMad @EikanWang @jgong5 @wenzhe-nrv
| 2 |
3,093 | 97,656 |
[bug] Internal assert failed when using pyro
|
module: distributions, triaged, module: macos, module: linear algebra, module: python frontend
|
### 🐛 Describe the bug
The initialization of a wishart distribution below fails. Reproducing example:
```python
import pyro, torch
torch.manual_seed(42)
print(pyro.__version__) # 1.8.4
print(torch.__version__) # 2.0.0
n = 5000
X = pyro.param(f'X', torch.randn(n, 2))
log_s = pyro.param(f's', torch.randn(1))
M_mean = X @ X.T + log_s.exp() * torch.eye(n)
pyro.distributions.Wishart(n, M_mean)
```
The error that is thrown:
```python
** On entry to SSYEVD, parameter number 8 had an illegal value
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In [1], line 12
10 log_s = pyro.param(f's', torch.randn(1))
11 M_mean = X @ X.T + log_s.exp() * torch.eye(n)
---> 12 pyro.distributions.Wishart(n, M_mean)
File ~/miniconda3/lib/python3.9/site-packages/pyro/distributions/distribution.py:24, in DistributionMeta.__call__(cls, *args, **kwargs)
22 if result is not None:
23 return result
---> 24 return super().__call__(*args, **kwargs)
File ~/miniconda3/lib/python3.9/site-packages/torch/distributions/wishart.py:109, in Wishart.__init__(self, df, covariance_matrix, precision_matrix, scale_tril, validate_args)
106 if self.df.lt(event_shape[-1]).any():
107 warnings.warn("Low df values detected. Singular samples are highly likely to occur for ndim - 1 < df < ndim.")
--> 109 super().__init__(batch_shape, event_shape, validate_args=validate_args)
110 self._batch_dims = [-(x + 1) for x in range(len(self._batch_shape))]
112 if scale_tril is not None:
File ~/miniconda3/lib/python3.9/site-packages/torch/distributions/distribution.py:60, in Distribution.__init__(self, batch_shape, event_shape, validate_args)
58 continue # skip checking lazily-constructed args
59 value = getattr(self, param)
---> 60 valid = constraint.check(value)
61 if not valid.all():
62 raise ValueError(
63 f"Expected parameter {param} "
64 f"({type(value).__name__} of shape {tuple(value.shape)}) "
(...)
67 f"but found invalid values:\n{value}"
68 )
File ~/miniconda3/lib/python3.9/site-packages/pyro/distributions/torch_patch.py:81, in _PositiveDefinite_check(self, value)
78 batch_shape = value.shape[:-2]
79 flattened_value = value.reshape((-1,) + matrix_shape)
80 return torch.stack(
---> 81 [torch.linalg.eigvalsh(v)[:1] > 0.0 for v in flattened_value]
82 ).view(batch_shape)
File ~/miniconda3/lib/python3.9/site-packages/pyro/distributions/torch_patch.py:81, in <listcomp>(.0)
78 batch_shape = value.shape[:-2]
79 flattened_value = value.reshape((-1,) + matrix_shape)
80 return torch.stack(
---> 81 [torch.linalg.eigvalsh(v)[:1] > 0.0 for v in flattened_value]
82 ).view(batch_shape)
RuntimeError: false INTERNAL ASSERT FAILED at "/Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/native/BatchLinearAlgebra.cpp":1539, please report a bug to PyTorch. linalg.eigh: Argument 8 has illegal value. Most certainly there is a bug in the implementation calling the backend library.
```
### Versions
```
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.6 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.102)
CMake version: version 3.26.0
Libc version: N/A
Python version: 3.9.15 | packaged by conda-forge | (main, Nov 22 2022, 08:52:10) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-12.6-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M2
Versions of relevant libraries:
[pip3] botorch==0.7.2
[pip3] gpytorch==1.9.0
[pip3] mypy==1.1.1
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.23.5
[pip3] numpyro==0.10.1
[pip3] pytorch-lightning==1.7.7
[pip3] torch==2.0.0
[pip3] torch-cluster==1.6.0
[pip3] torch-geometric==2.2.0
[pip3] torch-scatter==2.1.0
[pip3] torch-sparse==0.6.16
[pip3] torch-spline-conv==1.2.1
[pip3] torchmetrics==0.10.2
[pip3] torchpwl==0.2.0
[pip3] torchsde==0.2.5
[pip3] torchvision==0.14.0
[conda] botorch 0.7.2 pypi_0 pypi
[conda] gpytorch 1.9.0 pypi_0 pypi
[conda] numpy 1.23.5 pypi_0 pypi
[conda] numpy-base 1.21.5 py39hadd41eb_3
[conda] numpyro 0.10.1 pypi_0 pypi
[conda] pytorch-lightning 1.7.7 pypi_0 pypi
[conda] torch 2.0.0 pypi_0 pypi
[conda] torch-cluster 1.6.0 pypi_0 pypi
[conda] torch-geometric 2.2.0 pypi_0 pypi
[conda] torch-scatter 2.1.0 pypi_0 pypi
[conda] torch-sparse 0.6.16 pypi_0 pypi
[conda] torch-spline-conv 1.2.1 pypi_0 pypi
[conda] torchmetrics 0.10.2 pypi_0 pypi
[conda] torchpwl 0.2.0 pypi_0 pypi
[conda] torchsde 0.2.5 pypi_0 pypi
[conda] torchvision 0.14.0 pypi_0 pypi
```
cc @fritzo @neerajprad @alicanb @nikitaved @malfet @albanD @jianyuh @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
| 0 |
3,094 | 97,653 |
transposed 2d copy bfloat16 support
|
triaged, intel
|
@zhuhaozhe BTW, transposed 2d copy only supports float currently. Will you add bfloat16 support later?
_Originally posted by @jgong5 in https://github.com/pytorch/pytorch/issues/97147#issuecomment-1484523680_
cc @jgong5 @mingfeima @XiaobingSuper @sanchitintel @ashokei @jingxu10
| 0 |
3,095 | 97,652 |
torch.onnx.export support sparse tensor format
|
module: onnx, triaged
|
### 🚀 The feature, motivation and pitch
I have a simply model just like a conv2d with a sparse weight in my case. The forward like following
```
# self.weight is sparsed with coo format
x = torch.sparse.mm(self.weight, x)
```
When i want to convert to onnx model. This error occur.
```
tuple(x.clone(memory_format=torch.preserve_format) for x in args)
RuntimeError: unsupported memory format option Preserve
```
I think maybe torch.onnx.export module doesn't support SparseTensor?
### Alternatives
_No response_
### Additional context
_No response_
| 1 |
3,096 | 97,638 |
Regression in jit for f-strings with new lines
|
oncall: jit, triaged
|
### 🐛 Describe the bug
Consider the following code. It executes without error on v1.13.1 and python3.7
```python
import torch
@torch.jit.script
def xxx(
box_preds: torch.Tensor, cls_scores: torch.Tensor, cls_labels: torch.Tensor
) -> None:
assert (
1 == 2
), f'"cls_labels" should have the same shape as "cls_scores", but got {cls_labels.shape} and \
{cls_scores.shape}'
print(xxx)
```
But it fails with the following error on v1.13.1 and python3.9
```
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
[<ipython-input-4-7faa743d235b>](https://localhost:8080/#) in <module>
2
3 @torch.jit.script
----> 4 def xxx(
5 box_preds: torch.Tensor, cls_scores: torch.Tensor, cls_labels: torch.Tensor
6 ) -> None:
11 frames
[/usr/local/lib/python3.9/dist-packages/torch/jit/frontend.py](https://localhost:8080/#) in get_char(index)
730
731 def get_char(index):
--> 732 return chr(source[index])
733
734 start_pos = base.range().end + 1
IndexError: index out of range
```
### Versions
v1.13.1
cc @EikanWang @jgong5 @wenzhe-nrv @sanchitintel
| 3 |
3,097 | 97,635 |
JAX + PyTorch produces `OMP: Error #13: Assertion failure at kmp_affinity.cpp(532)`
|
needs reproduction, triaged
|
### 🐛 Describe the bug
On my machine, running:
```python
import jax
import torch
```
produces
```
OMP: Error #13: Assertion failure at kmp_affinity.cpp(532).
OMP: Hint Please submit a bug report with this message, compile and run commands used, and machine configuration info including native compiler and operating system versions. Faster response will be obtained by including all program sources. For information on submitting this issue, please see http://www.intel.com/software/products/support/.
fish: “ipython” terminated by signal SIGABRT (Abort)
```
I've tested this for all versions `(jax,jaxlib,pytorch) ∈ {(0.3.25, 0.3.25, 1.13.1), (0.4.6, 0.4.6, 1.13.1), (0.4.6, 0.4.6, 2.0.0)}`
JAX is installed via `pip install jax jaxlib`; PyTorch is installed via `conda install pytorch cpuonly -c pytorch`.
Switching the import order seems to fix things.
### Versions
```
PyTorch version: 2.0.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Debian GNU/Linux 11 (bullseye) (x86_64)
GCC version: (Debian 10.2.1-6) 10.2.1 20210110
Clang version: Could not collect
CMake version: version 3.18.4
Libc version: glibc-2.31
Python version: 3.8.16 (default, Mar 2 2023, 03:21:46) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.89-16172-g8db7d2810659-x86_64-with-glibc2.17
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 39 bits physical, 48 bits virtual
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 1
Core(s) per socket: 1
Socket(s): 8
<Snipped, not sure I should be publicly sharing my robustness to certain vulnerabilities! Let me know if anything here is particularly needed.>
Versions of relevant libraries:
[pip3] mypy==1.0.1
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.24.2
[pip3] torch==2.0.0
[pip3] torchvision==0.15.0
[conda] blas 1.0 mkl
[conda] cpuonly 2.0 0 pytorch
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py38h7f8727e_0
[conda] mkl_fft 1.3.1 py38hd3c417c_0
[conda] mkl_random 1.2.2 py38h51133e4_0
[conda] numpy 1.24.2 pypi_0 pypi
[conda] numpy-base 1.23.5 py38h31eccc5_0
[conda] pytorch 2.0.0 py3.8_cpu_0 pytorch
[conda] pytorch-mutex 1.0 cpu pytorch
[conda] torchvision 0.15.0 py38_cpu pytorch
```
| 2 |
3,098 | 97,631 |
torch.zeros_like on a zero-sized BSR/BSC tensor results invalid tensor
|
module: sparse, triaged, module: correctness (silent)
|
## Issue description
As in the title.
## Code example
```python
>>> torch.sparse.check_sparse_tensor_invariants.enable()
>>> x=torch.sparse_bsr_tensor([0, 3], [0, 1, 2], torch.arange(12).reshape(3, 2, 1, 2))
>>> torch._validate_sparse_bsr_tensor_args(x.crow_indices(), x.col_indices(), x.values(), x.shape)
>>> z=torch.zeros_like(x)
>>> z
tensor(crow_indices=tensor([0, 0]),
col_indices=tensor([], size=(0,)),
values=tensor([], size=(0, 2, 2, 1)), size=(2, 3, 2), nnz=0,
layout=torch.sparse_bsr)
>>> torch._validate_sparse_bsr_tensor_args(z.crow_indices(), z.col_indices(), z.values(), z.shape)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
RuntimeError: tensor shape[1] (=3) must be divisible with blocksize[1] (=2) as defined by values shape
```
The expected result is
```python
>>> z=torch.sparse_bsr_tensor(torch.zeros(x.crow_indices().shape, dtype=torch.int64), torch.zeros(0, dtype=torch.int64), torch.zeros(0, *x.values().shape[1:]), x.shape)
>>> torch._validate_sparse_bsr_tensor_args(z.crow_indices(), z.col_indices(), z.values(), z.shape)
>>> z
tensor(crow_indices=tensor([0, 0]),
col_indices=tensor([], size=(0,)),
values=tensor([], size=(0, 2, 1, 2)), size=(2, 3, 2), nnz=0,
layout=torch.sparse_bsr)
```
## System Info
- PyTorch version: master
cc @alexsamardzic @nikitaved @cpuhrsch @amjames @bhosmer
| 1 |
3,099 | 97,623 |
Compile dynamic does not support GroupNorm in module
|
triaged, oncall: pt2, module: dynamic shapes
|
### 🐛 Describe the bug
If my module simply wraps group norm, it does not compile with dynamic=True.
```python
import torch
from torch import nn
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self.norm = nn.GroupNorm(32, 512)
def forward(self, x):
return self.norm(x)
model = MyModule().cuda().eval()
model = torch.compile(model, dynamic=True)
x = torch.randn([1, 512, 32, 32], device="cuda")
y = model(x)
```
Error:
```
Traceback (most recent call last):
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/output_graph.py", line 670, in call_user_compiler
compiled_fn = compiler_fn(gm, self.fake_example_inputs())
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/debug_utils.py", line 1055, in debug_wrapper
compiled_gm = compiler_fn(gm, example_inputs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/__init__.py", line 1390, in __call__
return compile_fx(model_, inputs_, config_patches=self.config)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_inductor/compile_fx.py", line 401, in compile_fx
return compile_fx(
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_inductor/compile_fx.py", line 455, in compile_fx
return aot_autograd(
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/backends/common.py", line 48, in compiler_fn
cg = aot_module_simplified(gm, example_inputs, **kwargs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 2805, in aot_module_simplified
compiled_fn = create_aot_dispatcher_function(
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 2498, in create_aot_dispatcher_function
compiled_fn = compiler_fn(flat_fn, fake_flat_args, aot_config)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 1713, in aot_wrapper_dedupe
return compiler_fn(flat_fn, leaf_flat_args, aot_config)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 2087, in aot_dispatch_autograd
fx_g = make_fx(joint_forward_backward, aot_config.decompositions)(
File "/home/tiger/.local/lib/python3.9/site-packages/torch/fx/experimental/proxy_tensor.py", line 714, in wrapped
t = dispatch_trace(wrap_key(func, args, fx_tracer), tracer=fx_tracer, concrete_args=tuple(phs))
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/fx/experimental/proxy_tensor.py", line 443, in dispatch_trace
graph = tracer.trace(root, concrete_args)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 778, in trace
(self.create_arg(fn(*args)),),
File "/home/tiger/.local/lib/python3.9/site-packages/torch/fx/_symbolic_trace.py", line 652, in flatten_fn
tree_out = root_fn(*tree_args)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/fx/experimental/proxy_tensor.py", line 459, in wrapped
out = f(*tensors)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 1156, in traced_joint
return functionalized_f_helper(primals, tangents)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 1108, in functionalized_f_helper
f_outs = flat_fn_no_input_mutations(fn, f_primals, f_tangents, meta, keep_input_mutations)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 1076, in flat_fn_no_input_mutations
outs = flat_fn_with_synthetic_bases_expanded(fn, primals, primals_after_cloning, maybe_tangents, meta, keep_input_mutations)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 1048, in flat_fn_with_synthetic_bases_expanded
outs = forward_or_joint(fn, primals_before_cloning, primals, maybe_tangents, meta, keep_input_mutations)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_functorch/aot_autograd.py", line 1017, in forward_or_joint
backward_out = torch.autograd.grad(
File "/home/tiger/.local/lib/python3.9/site-packages/torch/autograd/__init__.py", line 269, in grad
return handle_torch_function(
File "/home/tiger/.local/lib/python3.9/site-packages/torch/overrides.py", line 1534, in handle_torch_function
result = mode.__torch_function__(public_api, types, args, kwargs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_inductor/overrides.py", line 38, in __torch_function__
return func(*args, **kwargs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/autograd/__init__.py", line 303, in grad
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
File "/home/tiger/.local/lib/python3.9/site-packages/torch/utils/_stats.py", line 20, in wrapper
return fn(*args, **kwargs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/fx/experimental/proxy_tensor.py", line 487, in __torch_dispatch__
return self.inner_torch_dispatch(func, types, args, kwargs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/fx/experimental/proxy_tensor.py", line 512, in inner_torch_dispatch
out = proxy_call(self, func, args, kwargs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/fx/experimental/proxy_tensor.py", line 248, in proxy_call
r = CURRENT_DECOMPOSITION_TABLE[func](*args, **kwargs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_decomp/decompositions.py", line 70, in inner
r = f(*tree_map(increase_prec, args), **tree_map(increase_prec, kwargs))
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_decomp/decompositions.py", line 1171, in native_group_norm_backward
cpg, _rem = divmod(C, group)
TypeError: unsupported operand type(s) for divmod(): 'SymInt' and 'int'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/opt/tiger/code/test.py", line 16, in <module>
y = model(x)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/eval_frame.py", line 82, in forward
return self.dynamo_ctx(self._orig_mod.forward)(*args, **kwargs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/eval_frame.py", line 209, in _fn
return fn(*args, **kwargs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/eval_frame.py", line 337, in catch_errors
return callback(frame, cache_size, hooks)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 404, in _convert_frame
result = inner_convert(frame, cache_size, hooks)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 104, in _fn
return fn(*args, **kwargs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 262, in _convert_frame_assert
return _compile(
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 324, in _compile
out_code = transform_code_object(code, transform)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/bytecode_transformation.py", line 445, in transform_code_object
transformations(instructions, code_options)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/convert_frame.py", line 311, in transform
tracer.run()
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 1726, in run
super().run()
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 576, in run
and self.step()
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 540, in step
getattr(self, inst.opname)(inst)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/symbolic_convert.py", line 1792, in RETURN_VALUE
self.output.compile_subgraph(
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/output_graph.py", line 517, in compile_subgraph
self.compile_and_call_fx_graph(tx, list(reversed(stack_values)), root)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/output_graph.py", line 588, in compile_and_call_fx_graph
compiled_fn = self.call_user_compiler(gm)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/utils.py", line 163, in time_wrapper
r = func(*args, **kwargs)
File "/home/tiger/.local/lib/python3.9/site-packages/torch/_dynamo/output_graph.py", line 675, in call_user_compiler
raise BackendCompilerFailed(self.compiler_fn, e) from e
torch._dynamo.exc.BackendCompilerFailed: debug_wrapper raised TypeError: unsupported operand type(s) for divmod(): 'SymInt' and 'int'
Set torch._dynamo.config.verbose=True for more information
You can suppress this exception and fall back to eager by setting:
torch._dynamo.config.suppress_errors = True
```
### Versions
```
Collecting environment information...
PyTorch version: 2.0.0+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Debian GNU/Linux 11 (bullseye) (x86_64)
GCC version: (Debian 10.2.1-6) 10.2.1 20210110
Clang version: Could not collect
CMake version: version 3.25.0
Libc version: glibc-2.31
Python version: 3.9.2 (default, Feb 28 2021, 17:03:44) [GCC 10.2.1 20210110] (64-bit runtime)
Python platform: Linux-5.4.143.bsk.7-amd64-x86_64-with-glibc2.31
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: A100-SXM-80GB
Nvidia driver version: 450.191.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.5.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.5.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 57 bits virtual
CPU(s): 128
On-line CPU(s) list: 0-127
Thread(s) per core: 2
Core(s) per socket: 32
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 106
Model name: Intel(R) Xeon(R) Platinum 8336C CPU @ 2.30GHz
Stepping: 6
CPU MHz: 3000.000
CPU max MHz: 3500.0000
CPU min MHz: 800.0000
BogoMIPS: 4600.00
Virtualization: VT-x
L1d cache: 3 MiB
L1i cache: 2 MiB
L2 cache: 80 MiB
L3 cache: 108 MiB
NUMA node0 CPU(s): 0-31,64-95
NUMA node1 CPU(s): 32-63,96-127
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 invpcid_single ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local wbnoinvd dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req avx512vbmi umip pku ospke avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg tme avx512_vpopcntdq rdpid md_clear pconfig flush_l1d arch_capabilities
Versions of relevant libraries:
[pip3] byted-torch==2.0.0.post0
[pip3] byted-torch-monitor==0.0.1
[pip3] numpy==1.24.2
[pip3] pytorch-triton==2.0.0+0d7e753227
[pip3] torch==2.0.0
[pip3] torchaudio==2.0.1
[pip3] torchvision==0.15.1
[pip3] triton==2.0.0
[conda] Could not collect
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 11 |
3,100 | 97,606 |
MPS: grid_sampler_2d falls back to CPU, even though warning says it is natively supported on macOS >=13.1
|
triaged, module: mps
|
### 🐛 Describe the bug
The following script runs with a warning that the grid_sampler_2d op is falling back to CPU, but is supported natively on MPS with macOS >=13.1:
```python
import torch
import torchvision.transforms as transforms
img = torch.rand([1, 1, 256, 256], device="mps");
transform = transforms.RandomPerspective();
img = transform(img);
```
I ran the script on macOS 13.3, so it should run without warnings, as the op is apparently supported on versions equal to or above 13.1.
Either the warning is wrong about what versions it is supported on, or the compatibility check is not working correctly. I'll look into it and make a PR if I can figure it out.
### Versions
PyTorch version: 2.1.0.dev20230317
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.3 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: version 3.25.2
Libc version: N/A
Python version: 3.10.8 (main, Nov 24 2022, 08:08:27) [Clang 14.0.6 ] (64-bit runtime)
Python platform: macOS-13.3-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Apple M1 Pro
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] pytorch-lightning==1.8.6
[pip3] torch==2.1.0.dev20230317
[pip3] torchaudio==2.0.0.dev20230317
[pip3] torchmetrics==0.11.0
[pip3] torchvision==0.16.0.dev20230317
[conda] numpy 1.24.1 pypi_0 pypi
[conda] pytorch-lightning 1.8.6 pypi_0 pypi
[conda] torch 2.1.0.dev20230317 pypi_0 pypi
[conda] torchaudio 2.0.0.dev20230317 pypi_0 pypi
[conda] torchmetrics 0.11.0 pypi_0 pypi
[conda] torchvision 0.16.0.dev20230317 pypi_0 pypi
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 4 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.