
Serial Number
int64 1
6k
| Issue Number
int64 75.6k
112k
| Title
stringlengths 3
357
| Labels
stringlengths 3
241
⌀ | Body
stringlengths 9
74.5k
⌀ | Comments
int64 0
867
|
|---|---|---|---|---|---|
4,401 | 87,597 |
ninja: build stopped: subcommand failed
|
needs reproduction, module: build, triaged
|
### 🐛 Describe the bug
Getting the following output when running `setup.py install` which results in the build failing.

### Versions

cc @malfet @seemethere
| 1 |
4,402 | 93,573 |
sebotnet33ts_256 fails with TORCHDYNAMO_DYNAMIC_SHAPES=1: sympy infinite loop
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
```
File "/raid/ezyang/pytorch-scratch2/torch/fx/graph_module.py", line 279, in __call__
raise e
File "/raid/ezyang/pytorch-scratch2/torch/fx/graph_module.py", line 269, in __call__
return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
File "/raid/ezyang/pytorch-scratch2/torch/nn/modules/module.py", line 1363, in _call_impl
return forward_call(*input, **kwargs)
File "<eval_with_key>.54", line 7, in forward
_unsafe_view = torch.ops.aten._unsafe_view.default(clone, [8192, 32]); clone = None
File "/raid/ezyang/pytorch-scratch2/torch/_ops.py", line 257, in __call__
return self._op(*args, **kwargs or {})
RuntimeError: shape '[8192, 32]' is invalid for input of size 131072
```
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @eellison
### Error logs
https://gist.github.com/da80e0d407c464a21cc49b84ce51ba74
### Minified repro
minifier didn't work
(it looks like it works but the resulting repro doesn't actually trigger error; after patching in [fix minifier 1](https://github.com/pytorch/pytorch/pull/84246/commits/55dfd189542df88860abe99897e42b97794d10e9) and [minor improvements to minifier 1](https://github.com/pytorch/pytorch/pull/84246/commits/d5d8240d66a651d471b0893c6fa601a5fe41597b) the minifier no longer runs.
| 1 |
4,403 | 87,589 |
#error "Expected GLOO_USE_CUDA to be defined"
|
module: build, triaged, module: third_party
|
### 🐛 Describe the bug
when I compiled torch 1.8.0a0+d1cb4a1 from source on GeForce RTX 4090, I always encountered following error:

I was helpless...
### Versions
driver version: 520.56.06
cudatoolkit: 11.3.1
cuda-nvcc: 11.3.122
cc @malfet @seemethere
| 2 |
4,404 | 87,579 |
Crash on backwards step when using `batch_first=True` for LSTMs on MPS (1.14 nightly build)
|
module: rnn, triaged, module: mps
|
### 🐛 Describe the bug
When using `batch_first=True` for LSTM layers, attempting to compute gradients causes a crash when running pytorch on MPS. This crash does not happen when running on CPU.
```python
import torch
import torch.nn as nn
device = "mps" if torch.backends.mps.is_available() else "cpu"
print("Running on", device)
data = torch.zeros((5, 3, 10), device=device)
lstm = nn.LSTM(10, 20, 1, batch_first=True).to(device)
h0 = torch.zeros((1, 5, 20), device=device)
c0 = torch.zeros((1, 5, 20), device=device)
expected = torch.randn((5, 3, 20), device=device)
output, _ = lstm(data, (h0, c0))
output = output.sum()
# crash occurs here
output.backward()
```
This produces the following crash, when running on MPS:
```
loc("total derivative last state"("(mpsFileLoc): /AppleInternal/Library/BuildRoots/a0876c02-1788-11ed-b9c4-96898e02b808/Library/Caches/com.apple.xbs/Sources/MetalPerformanceShadersGraph/mpsgraph/MetalPerformanceShadersGraph/Core/Files/MPSGraphUtilities.mm":219:0)): error: input types 'tensor<1x3x20xf32>' and 'tensor<1x5x20xf32>' are not broadcast compatible
LLVM ERROR: Failed to infer result type(s).
```
Additionally, I searched through the other issues, it seems there is a closed issue [here](https://github.com/pytorch/pytorch/issues/80306) which has a similar bug. However, despite being closed, it seems like it is still broken
### Versions
```
Collecting environment information...
PyTorch version: 1.14.0.dev20221023
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.6 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.102)
CMake version: version 3.24.1
Libc version: N/A
Python version: 3.10.7 (main, Sep 14 2022, 22:38:23) [Clang 14.0.0 (clang-1400.0.29.102)] (64-bit runtime)
Python platform: macOS-12.6-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.4
[pip3] pytorch-lightning==1.4.2
[pip3] torch==1.14.0.dev20221023
[pip3] torch-fidelity==0.3.0
[pip3] torchaudio==0.14.0.dev20221023
[pip3] torchmetrics==0.6.0
[pip3] torchvision==0.15.0.dev20221023
[conda] Could not collect
```
cc @zou3519 @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
4,405 | 87,576 |
Dynamic shapes exhaustive tests should fail (not xfail) if data mismatch
|
triaged, module: dynamic shapes
|
### 🐛 Describe the bug
In other words, it's OK to fail if you fail with an error message, but NOT ok to return silently incorrect outputs. I'm hoping to catch other occurrences of things like https://github.com/pytorch/pytorch/issues/87575 and https://github.com/pytorch/pytorch/issues/87571
### Versions
master
| 0 |
4,406 | 87,575 |
Functionalization does something wrong with pad backward when it uses as_strided
|
triaged, module: functionalization
|
### 🐛 Describe the bug
On master, make sure the unit test is using functionalization:
```
diff --git a/test/functorch/test_aotdispatch.py b/test/functorch/test_aotdispatch.py
index c058b3618e..d848068f3c 100644
--- a/test/functorch/test_aotdispatch.py
+++ b/test/functorch/test_aotdispatch.py
@@ -1317,7 +1317,7 @@ class TestEagerFusionOpInfo(AOTTestCase):
@skipIfNoSympy
@patch("functorch.compile.config.use_dynamic_shapes", True)
@patch("functorch.compile.config.use_fake_tensor", True)
- @patch("functorch.compile.config.use_functionalize", False)
+ @patch("functorch.compile.config.use_functionalize", True)
@skipOps('TestEagerFusionOpInfo', 'test_aot_autograd_symbolic_exhaustive',
aot_autograd_failures | symbolic_aot_autograd_failures)
def test_aot_autograd_symbolic_exhaustive(self, device, dtype, op):
```
and then run this test:
```
python test/functorch/test_aotdispatch.py -k test_aot_autograd_symbolic_exhaustive_nn_functional_pad_circular_cpu_float32
```
It fails with a value mismatch error.
If you patch in (from https://github.com/pytorch/pytorch/issues/86427)
```
diff --git a/tools/autograd/gen_inplace_or_view_type.py b/tools/autograd/gen_inplace_or_view_type.py
index d79212a093..f9334d8c5b 100644
--- a/tools/autograd/gen_inplace_or_view_type.py
+++ b/tools/autograd/gen_inplace_or_view_type.py
@@ -158,7 +158,7 @@ at::_ops::${unambiguous_name}::call(${unpacked_args})"""
SETUP_REPLAY_VIEW_IF_NOT_SUPPORT_AS_STRIDED_OR_VIEW_WITH_METADATA_CHANGE = CodeTemplate(
"""\
std::function<at::Tensor(const at::Tensor&)> func=nullptr;
-if (${is_view_with_metadata_change} || !self.unsafeGetTensorImpl()->support_as_strided()) {
+if (${is_view_with_metadata_change} || !self.unsafeGetTensorImpl()->support_as_strided() || true) {
${replay_view_func}
}
"""
```
the test starts passing. So it would seem that functionalization is not handling as_strided completely correctly in all cases.
cc @bdhirsh @soumith
### Versions
master
| 0 |
4,407 | 87,574 |
DCE produced obviously wrong graph for pad, but test did not catch it
|
triaged, module: aotdispatch
|
### 🐛 Describe the bug
To reproduce, run on master:
```
AOT_FX_GRAPHS_JOINT=1 AOT_FX_GRAPHS=1 python test/functorch/test_aotdispatch.py -k test_aot_autograd_symbolic_exhaustive_nn_functional_pad_circular_cpu_float32
```
Inspect the third joint graph. You can see the operator is implemented with a bunch of slices and then mutations on the slices. Now, inspect the final forward/backward graph. All of the slice mutation code has been DCE'd away, and you're just returning empty tensors.
Yet somehow, the test passes! Very puzzling.
cc @Chillee
### Versions
master
| 0 |
4,408 | 87,571 |
Testing insufficient to catch incorrect dispatch key for bernoulli.p re functionalization
|
triaged, module: functionalization
|
### 🐛 Describe the bug
I was investigating this dynamic shapes test failure:
```
python test/functorch/test_aotdispatch.py -k test_aot_autograd_symbolic_exhaustive_nn_functional_feature_alpha_dropout_with_train_cpu_float32
```
The bug boiled down to functionalization. Pre functionalization:
```
new_empty: f32[s0, s0, 1, 1] = torch.ops.aten.new_empty.default(primals_1, [sym_size, sym_size_1, 1, 1]
); sym_size = sym_size_1 = None
bernoulli_: f32[s0, s0, 1, 1] = torch.ops.aten.bernoulli_.float(new_empty)
```
post functionalization:
```
new_empty: f32[s0, s0, 1, 1] = torch.ops.aten.new_empty.default(primals_1, [sym_size, sym_size_1, 1, 1]); sym_size = sym_size_1 = None
empty_like: f32[s0, s0, 1, 1] = torch.ops.aten.empty_like.default(new_empty, memory_format = torch.cont
iguous_format); new_empty = None
bernoulli_: f32[s0, s0, 1, 1] = torch.ops.aten.bernoulli_.float(empty_like)
```
The `bernoulli_` never got functionalized! However, the empty_like is a clue: it kind of looks like the functional bernoulli did get applied, but we failed to trace it.
```
- func: bernoulli.p(Tensor self, float p, *, Generator? generator=None) -> Tensor
device_check: NoCheck # TensorIterator
variants: function, method
tags: nondeterministic_seeded
```
Bingo.
I have a fix for this, nbd. (Just add CompositeExplicitAutogradNonFunctional.) What is concerning, however, is the fact that we weren't able to catch this in testing. This is an "obvious" problem, maybe the functionalization codegen should have some test to make sure you aren't registering the functional variants as CompositeImplicitAutograd. Or maybe, why didn't composite compliance catch this? Hmm...
Another useful lint that would have caught this is, after functionalization, assert no more mutable ops in graph.
cc @bdhirsh @soumith @zou3519
### Versions
master
| 3 |
4,409 | 87,559 |
diagonal of Jacobian matrix
|
module: autograd, triaged, enhancement
|
### 🚀 The feature, motivation and pitch
I'd like to calculate the diagonal of the jacobian matrix.
[d z_1/d x_1, d z_2/d x_2, ..., d z_n/d x_n]
This operator is widely used in the diffusion model.
### Alternatives
My current solution is calculating the whole Jacobian matrix, which takes a large memory and is slow.
### Additional context
_No response_
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
| 10 |
4,410 | 87,556 |
The behavior of cast `NaN` is different on cpu and cuda
|
triaged, module: NaNs and Infs, module: edge cases
|
### 🐛 Describe the bug
The behavior of cast `NaN` is different on cpu and cuda. CPU will return INT_MIN but CUDA returns 0
```py
a = torch.tensor(float('nan'))
b = a.clone().cpu().type(torch.int32)
c = a.clone().cuda().type(torch.int32)
print(b) # tensor(-2147483648, dtype=torch.int32)
print(c) # tensor(0, device='cuda:0', dtype=torch.int32)
```
### Versions
torch: 1.12.1
cuda: 11.6
| 0 |
4,411 | 87,555 |
Improve `c10d::ReduceOp` & `torch.distributed.distributed_c10d.ReduceOp`
|
oncall: distributed, triaged
|
`c10d::ReduceOp` is now a struct which contains an enum class of `RedOptype` in order to support `PREMUL_SUM` (premul_sum is only supported by NCCL backend).
This new reduce op type takes either a Python scalar or a Tensor and that scaling value needs to be stored somewhere while keeping the compatibility with dispatchable reduce ops (note that TorchScript compiler's support is limited) and keeping `torch.distributed.ReduceOp` instances enum like as possible (to name a few, allowing for `__members__` and `isinstance`).
As the op type itself is marked experimental for now but with this requirements and the changes caused, we have to improve the API.
The question is how to have users pass a scale value and how to create ReduceOp (while before premul_sum, there was no need to create a ReduceOp instance as it was closer to Python enum).
Related:
- https://github.com/pytorch/pytorch/pull/87303
- https://github.com/pytorch/pytorch/issues/87191
- https://github.com/pytorch/pytorch/pull/84243
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu @wanchaol @carmocca
| 2 |
4,412 | 87,551 |
`bmm` will return wrong result on cpu with in-place
|
triaged, module: edge cases
|
### 🐛 Describe the bug
`bmm` will return wrong result on cpu with in-place. For example, when trying to output the result to the original input, the result is wrong.
More interestingly, the gpu will return the correct value given the same input
```py
import torch
input_1 = torch.randn(2, 1, 5)
def f(input_1):
y = torch.bmm(input_1, input_1.transpose((- 1), (- 2)), out=input_1)
return y
inp_cpu = input_1.clone().detach().cpu()
inp_gpu = input_1.clone().detach().cuda()
print(f(inp_cpu))
print(f(inp_gpu))
```
```
tensor([[[0.]], [[0.]]])
tensor([[[ 0.3501]], [[-0.2560]]], device='cuda:0')
```
### Versions
pytorch: 1.12.1
cuda: 11.6
| 2 |
4,413 | 87,550 |
[onnx] export repeat_interleave TypeError: z_(): incompatible function arguments
|
needs reproduction, module: onnx, triaged, onnx-triaged
|
### 🐛 Describe the bug
I was able to export my model to TorchScript but trying to export it to ONNX gives me a cryptic error I don't understand. I managed to reproduce the error with this small example:
```python
import torch
import torch.nn.functional as F
from torch import nn
print(torch.__version__)
class RepeatedTokenEmbedding(nn.Module):
def __init__(self, label_count=16):
super().__init__()
self.embed = nn.Embedding(label_count, 2)
def forward(self, x, durs):
# problem goes away with pad lines removed
x = F.pad(x, [0, 2, 0, 0], value=0)
durs = F.pad(durs, [0, 2, 0, 0], value=0)
repeats = torch.repeat_interleave(x[0], durs[0]).unsqueeze(0)
embedding = self.embed(repeats)
return embedding
rte = RepeatedTokenEmbedding()
x = torch.randint(low=1, high=16, size=(1, 16)).long()
durs = torch.randint(low=1, high=4, size=(1, 16)).long()
out = rte(x, durs)
torch.onnx.export(rte, (x, durs), 'test.onnx', verbose=True)
```
It works with the pad line removed, but breaks again if I try to specify the axis as dynamic like this:
```python
torch.onnx.export(
rte,
(x, durs),
'test.onnx',
verbose=True,
input_names=["x", "durs"],
output_names=["embedding"],
# problem goes away with this removed
dynamic_axes={
"x": {1: "sequence"}
}
)
```
The traceback:
```
1.14.0.dev20221021+cu116
/usr/local/lib/python3.7/dist-packages/torch/onnx/_internal/jit_utils.py:258: UserWarning: Constant folding - Only steps=1 can be constant folded for opset >= 10 onnx::Slice op. Constant folding not applied. (Triggered internally at ../torch/csrc/jit/passes/onnx/constant_fold.cpp:179.)
_C._jit_pass_onnx_node_shape_type_inference(node, params_dict, opset_version)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
[<ipython-input-1-aedf6a6a2a21>](https://localhost:8080/#) in <module>
27 out = rte(x, durs)
28
---> 29 torch.onnx.export(rte, (x, durs), 'test.onnx', verbose=True)
16 frames
[/usr/local/lib/python3.7/dist-packages/torch/onnx/utils.py](https://localhost:8080/#) in export(model, args, f, export_params, verbose, training, input_names, output_names, operator_export_type, opset_version, do_constant_folding, dynamic_axes, keep_initializers_as_inputs, custom_opsets, export_modules_as_functions)
517 keep_initializers_as_inputs=keep_initializers_as_inputs,
518 custom_opsets=custom_opsets,
--> 519 export_modules_as_functions=export_modules_as_functions,
520 )
521
[/usr/local/lib/python3.7/dist-packages/torch/onnx/utils.py](https://localhost:8080/#) in _export(model, args, f, export_params, verbose, training, input_names, output_names, operator_export_type, export_type, opset_version, do_constant_folding, dynamic_axes, keep_initializers_as_inputs, fixed_batch_size, custom_opsets, add_node_names, onnx_shape_inference, export_modules_as_functions)
1537 fixed_batch_size=fixed_batch_size,
1538 training=training,
-> 1539 dynamic_axes=dynamic_axes,
1540 )
1541
[/usr/local/lib/python3.7/dist-packages/torch/onnx/utils.py](https://localhost:8080/#) in _model_to_graph(model, args, verbose, input_names, output_names, operator_export_type, do_constant_folding, _disable_torch_constant_prop, fixed_batch_size, training, dynamic_axes)
1121 dynamic_axes=dynamic_axes,
1122 input_names=input_names,
-> 1123 module=module,
1124 )
1125 except Exception as e:
[/usr/local/lib/python3.7/dist-packages/torch/onnx/utils.py](https://localhost:8080/#) in _optimize_graph(graph, operator_export_type, _disable_torch_constant_prop, fixed_batch_size, params_dict, dynamic_axes, input_names, module)
661 _C._jit_pass_onnx_lint(graph)
662
--> 663 graph = _C._jit_pass_onnx(graph, operator_export_type)
664 _C._jit_pass_onnx_lint(graph)
665 _C._jit_pass_lint(graph)
[/usr/local/lib/python3.7/dist-packages/torch/onnx/utils.py](https://localhost:8080/#) in _run_symbolic_function(graph, block, node, inputs, env, operator_export_type)
1865 k: symbolic_helper._node_get(node, k) for k in node.attributeNames()
1866 }
-> 1867 return symbolic_fn(graph_context, *inputs, **attrs)
1868
1869 attrs = {
[/usr/local/lib/python3.7/dist-packages/torch/onnx/symbolic_opset13.py](https://localhost:8080/#) in repeat_interleave(g, self, repeats, dim, output_size)
536 # If input size is dynamic or repeats vector is dynamic
537 if output_sizes[dim] == 0 or cond_dynamic_repeats:
--> 538 reps = symbolic_helper._size_helper(g, input, dim)
539 reps = opset11.unsqueeze(g, reps, 0)
540 # Check if repeats vector is a single integer value
[/usr/local/lib/python3.7/dist-packages/torch/onnx/symbolic_helper.py](https://localhost:8080/#) in _size_helper(g, self, dim)
1307 from torch.onnx.symbolic_opset9 import select
1308
-> 1309 return select(g, full_shape, g.op("Constant", value_t=torch.tensor([0])), dim)
1310
1311
[/usr/local/lib/python3.7/dist-packages/torch/onnx/symbolic_helper.py](https://localhost:8080/#) in wrapper(g, *args, **kwargs)
378 for descriptor, arg in descriptor_args
379 ):
--> 380 return fn(g, *args, **kwargs)
381
382 # Dequantize arguments that are quantized
[/usr/local/lib/python3.7/dist-packages/torch/onnx/symbolic_helper.py](https://localhost:8080/#) in wrapper(g, *args, **kwargs)
301 f"{FILE_BUG_MSG}"
302 )
--> 303 return fn(g, *args, **kwargs)
304
305 return wrapper
[/usr/local/lib/python3.7/dist-packages/torch/onnx/symbolic_opset9.py](https://localhost:8080/#) in select(g, self, dim, index)
1138 else:
1139 # FIXME(justinchuby): can index be an int and not a value?
-> 1140 return g.op("Gather", self, index, axis_i=dim)
1141
1142
[/usr/local/lib/python3.7/dist-packages/torch/onnx/_internal/jit_utils.py](https://localhost:8080/#) in op(self, opname, outputs, *raw_args, **kwargs)
83 """
84 # FIXME(justinchuby): Add the return type back once we know how to handle mypy
---> 85 return _add_op(self, opname, *raw_args, outputs=outputs, **kwargs)
86
87 @_beartype.beartype
[/usr/local/lib/python3.7/dist-packages/torch/onnx/_internal/jit_utils.py](https://localhost:8080/#) in _add_op(graph_context, opname, outputs, *args, **kwargs)
187 keyword argument for multi-return nodes).
188 """
--> 189 inputs = [_const_if_tensor(graph_context, arg) for arg in args]
190 # Filter out None attributes, this can be convenient client side because
191 # now they can pass through None attributes, and have them not show up
[/usr/local/lib/python3.7/dist-packages/torch/onnx/_internal/jit_utils.py](https://localhost:8080/#) in <listcomp>(.0)
187 keyword argument for multi-return nodes).
188 """
--> 189 inputs = [_const_if_tensor(graph_context, arg) for arg in args]
190 # Filter out None attributes, this can be convenient client side because
191 # now they can pass through None attributes, and have them not show up
[/usr/local/lib/python3.7/dist-packages/torch/onnx/_internal/jit_utils.py](https://localhost:8080/#) in _const_if_tensor(graph_context, arg)
218 return arg
219
--> 220 return _add_op(graph_context, "onnx::Constant", value_z=arg)
221
222
[/usr/local/lib/python3.7/dist-packages/torch/onnx/_internal/jit_utils.py](https://localhost:8080/#) in _add_op(graph_context, opname, outputs, *args, **kwargs)
203 opset_version=graph_context.opset,
204 n_outputs=outputs,
--> 205 shape_inference=GLOBALS.onnx_shape_inference,
206 )
207
[/usr/local/lib/python3.7/dist-packages/torch/onnx/_internal/jit_utils.py](https://localhost:8080/#) in _create_node(graph_or_block, domain_op, inputs, attributes, params_dict, opset_version, n_outputs, shape_inference)
254 if key in _SKIP_NODE_ATTRIBUTES:
255 continue
--> 256 _add_attribute(node, key, value, aten=aten)
257 if shape_inference:
258 _C._jit_pass_onnx_node_shape_type_inference(node, params_dict, opset_version)
[/usr/local/lib/python3.7/dist-packages/torch/onnx/_internal/jit_utils.py](https://localhost:8080/#) in _add_attribute(node, key, value, aten)
307 else:
308 kind = "i"
--> 309 return getattr(node, f"{kind}_")(name, value)
310
311
TypeError: z_(): incompatible function arguments. The following argument types are supported:
1. (self: torch._C.Node, arg0: str, arg1: at::Tensor) -> torch._C.Node
Invoked with: %41 : Tensor = onnx::Constant(), scope: __main__.RepeatedTokenEmbedding::
, 'value', 0
(Occurred when translating repeat_interleave).
```
### Versions
```
Collecting environment information...
PyTorch version: 1.14.0.dev20221021+cu116
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.22.6
Libc version: glibc-2.26
Python version: 3.7.15 (default, Oct 12 2022, 19:14:55) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.10.133+-x86_64-with-Ubuntu-18.04-bionic
Is CUDA available: False
CUDA runtime version: 11.2.152
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.6
[pip3] pytorch-lightning==1.7.7
[pip3] torch==1.14.0.dev20221021+cu116
[pip3] torch-stft==0.1.4
[pip3] torchaudio==0.14.0.dev20221021+cu116
[pip3] torchmetrics==0.10.0
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.14.0.dev20221021
[pip3] torchvision==0.15.0.dev20221021+cu116
[conda] Could not collect
```
| 1 |
4,414 | 87,542 |
DISABLED test_numpy_ref_mps_nn_functional_conv_transpose1d_mps_float32 (__main__.TestCommonMPS)
|
triaged, skipped
|
Platforms: macos
This test was disabled because it is failing on master.
Example:
https://hud.pytorch.org/pytorch/pytorch/commit/838b699e1082791d5e838ca0de0d72c4b6120e14
This appears to be part of a larger pattern of flaky tests failing with the error `AssertionError: Tensor-likes are not close!` and may have a deeper root cause than just this one test
Failing run on GitHub: https://github.com/pytorch/pytorch/actions/runs/3300182413/jobs/5446436403
Relevant logs:
```
2022-10-22T00:13:06.9665930Z ======================================================================
2022-10-22T00:13:06.9666150Z FAIL [0.247s]: test_numpy_ref_mps_nn_functional_conv_transpose1d_mps_float32 (__main__.TestCommonMPS)
2022-10-22T00:13:06.9666640Z ----------------------------------------------------------------------
2022-10-22T00:13:06.9666860Z Traceback (most recent call last):
2022-10-22T00:13:06.9667220Z File "/Users/ec2-user/runner/_work/_temp/conda_environment_3300182413/lib/python3.9/site-packages/torch/testing/_internal/common_device_type.py", line 381, in instantiated_test
2022-10-22T00:13:06.9667470Z result = test(self, **param_kwargs)
2022-10-22T00:13:06.9667800Z File "/Users/ec2-user/runner/_work/_temp/conda_environment_3300182413/lib/python3.9/site-packages/torch/testing/_internal/common_device_type.py", line 831, in test_wrapper
2022-10-22T00:13:06.9668040Z return test(*args, **kwargs)
2022-10-22T00:13:06.9668340Z File "/Users/ec2-user/runner/_work/_temp/conda_environment_3300182413/lib/python3.9/site-packages/torch/testing/_internal/common_device_type.py", line 991, in only_fn
2022-10-22T00:13:06.9668570Z return fn(slf, *args, **kwargs)
2022-10-22T00:13:06.9668880Z File "/Users/ec2-user/runner/_work/_temp/conda_environment_3300182413/lib/python3.9/site-packages/torch/testing/_internal/common_utils.py", line 1307, in wrapper
2022-10-22T00:13:06.9669090Z fn(*args, **kwargs)
2022-10-22T00:13:06.9669340Z File "/Users/ec2-user/runner/_work/pytorch/pytorch/test/test_mps.py", line 7875, in test_numpy_ref_mps
2022-10-22T00:13:06.9669550Z self.compare_with_reference(op, op.ref, sample_input)
2022-10-22T00:13:06.9670100Z File "/Users/ec2-user/runner/_work/_temp/conda_environment_3300182413/lib/python3.9/site-packages/torch/testing/_internal/common_utils.py", line 2361, in compare_with_reference
2022-10-22T00:13:06.9670370Z self.assertEqual(actual, expected, exact_device=False, **kwargs)
2022-10-22T00:13:06.9670710Z File "/Users/ec2-user/runner/_work/_temp/conda_environment_3300182413/lib/python3.9/site-packages/torch/testing/_internal/common_utils.py", line 2464, in assertEqual
2022-10-22T00:13:06.9670910Z assert_equal(
2022-10-22T00:13:06.9671180Z File "/Users/ec2-user/runner/_work/_temp/conda_environment_3300182413/lib/python3.9/site-packages/torch/testing/_comparison.py", line 1093, in assert_equal
2022-10-22T00:13:06.9671400Z raise error_metas[0].to_error(msg)
2022-10-22T00:13:06.9671580Z AssertionError: Tensor-likes are not close!
2022-10-22T00:13:06.9671670Z
2022-10-22T00:13:06.9671730Z Mismatched elements: 1 / 56 (1.8%)
2022-10-22T00:13:06.9671960Z Greatest absolute difference: 1.1682510375976562e-05 at index (0, 7, 3) (up to 1e-05 allowed)
2022-10-22T00:13:06.9672350Z Greatest relative difference: 1.2376390796915803e-05 at index (0, 7, 3) (up to 1.3e-06 allowed)
2022-10-22T00:13:06.9672480Z
2022-10-22T00:13:06.9672600Z ----------------------------------------------------------------------
```
| 1 |
4,415 | 87,539 |
RAM leak when copying tensor from cpu to cuda
|
module: cuda, module: memory usage, triaged
|
### 🐛 Describe the bug
If you profile run the following code then you'll see that line 8 grabs ~2GB of RAM, but it doesn't get released:
`
import gc
import torch
from memory_profiler import profile
@profile
def test(n):
t1 = torch.ones(n)
t2 = torch.ones(n).to("cuda")
del t1
del t2
gc.collect()
torch.cuda.empty_cache()
if __name__ == "__main__":
test(3000000)
`
### Versions
PyTorch version: 1.12.0+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: Could not collect
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.27
Python version: 3.8.12 (default, Sep 10 2021, 00:16:05) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.214-120.368.amzn2.x86_64-x86_64-with-glibc2.27
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: Tesla T4
Nvidia driver version: 510.47.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] botorch==0.2.1
[pip3] gpytorch==1.4.2
[pip3] mypy==0.982
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.4
[pip3] pytorch-lightning==1.7.7
[pip3] torch==1.12.0
[pip3] torchmetrics==0.10.0
[pip3] torchvision==0.13.1
cc @ngimel
| 4 |
4,416 | 87,514 |
invalid_arguments.cpp is busted
|
module: bootcamp, triaged, actionable, module: python frontend
|
### 🐛 Describe the bug
This file is responsible for multi-overload error printing when arguments mismatch. It is supposed to have color formatting, where it tells you which argument mismatched, where green says it matched, and red says it mismatched. It is also completely broken.
<img width="946" alt="image" src="https://user-images.githubusercontent.com/13564/197295055-befa59a9-4de3-4dd3-bd95-5a3bd91d4c6a.png">
Notice that tuple is red, even though it actually is correctly matching for the second argument.
The brokenness appears to stem from the fact that, to determine how to match up the arguments, invalid_arguments.cpp *re-parses* the string names that the python arg parser assigns:
```
std::string FunctionParameter::type_name() const {
switch (type_) {
case ParameterType::TENSOR:
return "Tensor";
case ParameterType::SCALAR:
return "Number";
case ParameterType::INT64:
return "int";
case ParameterType::SYM_INT:
return "int (or SymInt)";
case ParameterType::DOUBLE:
return "float";
case ParameterType::COMPLEX:
return "complex";
case ParameterType::TENSOR_LIST:
return "tuple of Tensors";
```
however, this parsing is completely busted; for example, to parse a tuple appropriately, you should must return a string `tuple[int]`. Furthermore, the names must exactly match what Python typename reports for the type in question.
This is completely bonkers because we have a type system for the parameters already in python_arg_parser.cpp, invalid_arguments.cpp should have reused it.
This would be a good starter task for someone, I think.
### Versions
master
cc @albanD
| 0 |
4,417 | 87,504 |
Loading model trained on MPS cannot be opened on non MPS system
|
triaged, module: mps
|
### 🐛 Describe the bug
When loading a model saved on an "mps" system on a "non-mps" system the following error is thrown.
The code I have run on the "non-mps" system (and other variations that throw the same error)
```python
device = torch.device("cuda")
model = AutoEncoder()
model.to(torch.device("cuda"))
model.load_state_dict(torch.load("model.pt"), map_location=device)
```
The model (model.pt) was saved on an Apple Sillicon M1 Pro using the "mps" backend.
The full error message:
```python
RuntimeError Traceback (most recent call last)
/home/alexandervialabellander/ssy340-deep-machine-learning/project/project_final_gcp.ipynb Cell 31 in <cell line: 4>()
[2](vscode-notebook-cell://ssh-remote%2Bgcp-ssy340/home/alexandervialabellander/ssy340-deep-machine-learning/project/project_final_gcp.ipynb#X54sdnNjb2RlLXJlbW90ZQ%3D%3D?line=1) model = AutoEncoder()
[3](vscode-notebook-cell://ssh-remote%2Bgcp-ssy340/home/alexandervialabellander/ssy340-deep-machine-learning/project/project_final_gcp.ipynb#X54sdnNjb2RlLXJlbW90ZQ%3D%3D?line=2) model.to(torch.device("cuda"))
----> [4](vscode-notebook-cell://ssh-remote%2Bgcp-ssy340/home/alexandervialabellander/ssy340-deep-machine-learning/project/project_final_gcp.ipynb#X54sdnNjb2RlLXJlbW90ZQ%3D%3D?line=3) model.load_state_dict(torch.load("model.pt"), map_location="cuda:0")
File /opt/conda/envs/dml/lib/python3.9/site-packages/torch/serialization.py:712, in load(f, map_location, pickle_module, **pickle_load_args)
710 opened_file.seek(orig_position)
711 return torch.jit.load(opened_file)
--> 712 return _load(opened_zipfile, map_location, pickle_module, **pickle_load_args)
713 return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File /opt/conda/envs/dml/lib/python3.9/site-packages/torch/serialization.py:1046, in _load(zip_file, map_location, pickle_module, pickle_file, **pickle_load_args)
1044 unpickler = UnpicklerWrapper(data_file, **pickle_load_args)
1045 unpickler.persistent_load = persistent_load
-> 1046 result = unpickler.load()
1048 torch._utils._validate_loaded_sparse_tensors()
1050 return result
File /opt/conda/envs/dml/lib/python3.9/site-packages/torch/_utils.py:198, in _rebuild_device_tensor_from_numpy(data, dtype, device, requires_grad)
197 def _rebuild_device_tensor_from_numpy(data, dtype, device, requires_grad):
--> 198 tensor = torch.from_numpy(data).to(dtype=dtype, device=device)
199 tensor.requires_grad = requires_grad
200 return tensor
RuntimeError: Expected one of cpu, cuda, xpu, mkldnn, opengl, opencl, ideep, hip, ve, ort, mlc, xla, lazy, vulkan, meta, hpu device type at start of device string: mps
```
The error can be avoided by first on the "mps" system moving the model to the cpu "cpu".
Example that I ran
```python
model.to(torch.device("cpu"))
torch.save(model.state_dict(), "model_cpu.pt")
discriminator.to(torch.device("cpu"))
torch.save(discriminator.state_dict(), "disc_cpu.pt")
```
### Versions
**MPS Env**
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.3 (arm64)
GCC version: Could not collect
Clang version: 13.1.6 (clang-1316.0.21.2.5)
CMake version: Could not collect
Libc version: N/A
Python version: 3.9.13 | packaged by conda-forge | (main, May 27 2022, 17:00:33) [Clang 13.0.1 ] (64-bit runtime)
Python platform: macOS-12.3-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.3
[pip3] pytorch-model-summary==0.1.1
[pip3] torch==1.12.1
[pip3] torchsummary==1.5.1
[pip3] torchvision==0.13.0a0
[conda] numpy 1.23.3 py39hcb4b507_0 conda-forge
[conda] pytorch 1.12.1 cpu_py39hf1faf6a_1 conda-forge
[conda] pytorch-model-summary 0.1.1 py_0 conda-forge
[conda] torchsummary 1.5.1 pypi_0 pypi
[conda] torchvision 0.13.0 cpu_py39h80956b8_0 conda-forge
**Non MPS Env**
```
PyTorch version: 1.11.0
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Debian GNU/Linux 10 (buster) (x86_64)
GCC version: (Debian 8.3.0-6) 8.3.0
Clang version: Could not collect
CMake version: version 3.13.4
Libc version: glibc-2.28
Python version: 3.9.13 (main, Oct 13 2022, 21:15:33) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-4.19.0-22-cloud-amd64-x86_64-with-glibc2.28
Is CUDA available: True
CUDA runtime version: 11.3.109
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA A100-SXM4-40GB
Nvidia driver version: 510.47.03
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.3
[pip3] torch==1.11.0
[pip3] torchsummary==1.5.1
[pip3] torchvision==0.12.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.3 py39h14f4228_0
[conda] numpy-base 1.23.3 py39h31eccc5_0
[conda] pytorch 1.11.0 py3.9_cuda11.3_cudnn8.2.0_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchsummary 1.5.1 pypi_0 pypi
[conda] torchvision 0.12.0 py39_cu113 pytorch
```
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 1 |
4,418 | 87,501 |
Synchronize domain builds to be executed after core build have completed
|
module: ci, triaged
|
Synchronize domain builds to be executed after core build have completed for nightly
Somethimes audio and vision nightly is kicked before pytorch core is complete hence we need to synchronize these builds in order to make sure we have up to date and correct nightlies
cc @seemethere @malfet @pytorch/pytorch-dev-infra
| 0 |
4,419 | 87,499 |
built from source windows static library with multiple "unresolved external symbol"
|
module: build, module: windows, triaged
|
### 🐛 Describe the bug
We are building the static libtorch library from source (`release/1.12` branch, we also tried the `master` branch. both of them have the identical issues), we are using the conda environment (python 3.7).
After following the installation guide at `https://github.com/pytorch/pytorch/blob/master/README.md`, installing all the cuda, cudnn dependencies, we set out to build the library.
Here's how we build the library
``` bash
set BUILD_SHARED_LIBS=OFF
set USE_NINJA=OFF
set CMAKE_GENERATOR=Visual Studio 16 2019
set BUILD_TEST=False
python ../tools/build_libtorch.py
```
It builds fine, but when we link it into a visual studio project to run a demo code, it has the following error msgs.
The code demo:
``` cpp
#include <iostream>
#include <ATen/ATen.h>
#include <torch/torch.h>
int main() {
torch::Tensor tensor = torch::rand({ 2, 3 });
std::cout << torch::cuda::is_available() << std::endl;
torch::Tensor tensor2 = at::tensor({ -1, 1 }, at::kCUDA);
std::cout << tensor2 << std::endl;
std::cout << tensor << std::endl;
return 0;
}
```
Error messages:
```
1>C:\Users\tingwuw\pytorch\build_libtorch\libtorch-install\include\ATen\TensorIterator.h(541): message : see reference to class template instantiation 'c10::SmallVector<at::OperandInfo,4>' being compiled
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "private: static void __cdecl caffe2::TypeMeta::error_unsupported_typemeta(class caffe2::TypeMeta)" (?error_unsupported_typemeta@TypeMeta@caffe2@@CAXV12@@Z)
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "class std::basic_ostream<char,struct std::char_traits<char> > & __cdecl at::print(class std::basic_ostream<char,struct std::char_traits<char> > &,class at::Tensor const &,__int64)" (?print@at@@YAAEAV?$basic_ostream@DU?$char_traits@D@std@@@std@@AEAV23@AEBVTensor@1@_J@Z)
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "public: static class at::Tensor __cdecl at::_ops::rand::call(class c10::ArrayRef<__int64>,class c10::optional<enum c10::ScalarType>,class c10::optional<enum c10::Layout>,class c10::optional<struct c10::Device>,class c10::optional<bool>)" (?call@rand@_ops@at@@SA?AVTensor@3@V?$ArrayRef@_J@c10@@V?$optional@W4ScalarType@c10@@@6@V?$optional@W4Layout@c10@@@6@V?$optional@UDevice@c10@@@6@V?$optional@_N@6@@Z)
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "class at::Tensor __cdecl at::tensor(class c10::ArrayRef<int>,struct c10::TensorOptions const &)" (?tensor@at@@YA?AVTensor@1@V?$ArrayRef@H@c10@@AEBUTensorOptions@4@@Z)
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "public: void __cdecl c10::TensorImpl::set_autograd_meta(class std::unique_ptr<struct c10::AutogradMetaInterface,struct std::default_delete<struct c10::AutogradMetaInterface> >)" (?set_autograd_meta@TensorImpl@c10@@QEAAXV?$unique_ptr@UAutogradMetaInterface@c10@@U?$default_delete@UAutogradMetaInterface@c10@@@std@@@std@@@Z)
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "public: virtual __cdecl c10::AutogradMetaInterface::~AutogradMetaInterface(void)" (??1AutogradMetaInterface@c10@@UEAA@XZ)
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "public: __cdecl c10::impl::ExcludeDispatchKeyGuard::~ExcludeDispatchKeyGuard(void)" (??1ExcludeDispatchKeyGuard@impl@c10@@QEAA@XZ)
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "public: __cdecl c10::impl::ExcludeDispatchKeyGuard::ExcludeDispatchKeyGuard(class c10::DispatchKeySet)" (??0ExcludeDispatchKeyGuard@impl@c10@@QEAA@VDispatchKeySet@2@@Z)
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "protected: void __cdecl c10::SmallVectorBase<unsigned int>::grow_pod(void *,unsigned __int64,unsigned __int64)" (?grow_pod@?$SmallVectorBase@I@c10@@IEAAXPEAX_K1@Z)
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "private: static struct c10::UndefinedTensorImpl c10::UndefinedTensorImpl::_singleton" (?_singleton@UndefinedTensorImpl@c10@@0U12@A)
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "void __cdecl c10::detail::torchInternalAssertFail(char const *,char const *,unsigned int,char const *,char const *)" (?torchInternalAssertFail@detail@c10@@YAXPEBD0I00@Z)
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "void __cdecl c10::detail::torchInternalAssertFail(char const *,char const *,unsigned int,char const *,class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> > const &)" (?torchInternalAssertFail@detail@c10@@YAXPEBD0I0AEBV?$basic_string@DU?$char_traits@D@std@@V?$allocator@D@2@@std@@@Z)
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "void __cdecl c10::detail::torchCheckFail(char const *,char const *,unsigned int,char const *)" (?torchCheckFail@detail@c10@@YAXPEBD0I0@Z)
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "bool __cdecl torch::cuda::is_available(void)" (?is_available@cuda@torch@@YA_NXZ)
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "public: virtual void __cdecl torch::autograd::AutogradMeta::set_fw_grad(class at::TensorBase const &,class at::TensorBase const &,unsigned __int64,bool)" (?set_fw_grad@AutogradMeta@autograd@torch@@UEAAXAEBVTensorBase@at@@0_K_N@Z)
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "public: virtual class at::Tensor const & __cdecl torch::autograd::AutogradMeta::fw_grad(unsigned __int64,class at::TensorBase const &)const " (?fw_grad@AutogradMeta@autograd@torch@@UEBAAEBVTensor@at@@_KAEBVTensorBase@5@@Z)
1>ConsoleApplication1.obj : error LNK2001: unresolved external symbol "public: static class std::shared_ptr<struct torch::autograd::ForwardADLevel> __cdecl torch::autograd::ForwardADLevel::try_get_by_idx(unsigned __int64)" (?try_get_by_idx@ForwardADLevel@autograd@torch@@SA?AV?$shared_ptr@UForwardADLevel@autograd@torch@@@std@@_K@Z)
1>C:\Users\tingwuw\source\repos\ConsoleApplication1\x64\Release\ConsoleApplication1.exe : fatal error LNK1120: 17 unresolved externals
1>Done building project "ConsoleApplication1.vcxproj" -- FAILED.
========== Build: 0 succeeded, 1 failed, 0 up-to-date, 0 skipped ==========
```
My colleague and I have tried different machines also tried different building methods on separate machines,
and the error messages are consistent though different setup.
Also, we can build the dynamic library and use it successfully for the example code. Only the static one does not work.
No sure what's happening. Is there anything missing that could be helpful?
Let me know and I can update the info asap :)
### Versions
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 11 Enterprise
GCC version: Could not collect
Clang version: Could not collect
CMake version: version 3.24.1
Libc version: N/A
Python version: 3.7.13 (default, Mar 28 2022, 08:03:21) [MSC v.1916 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.22621-SP0
Is CUDA available: N/A
CUDA runtime version: 11.5.50
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090 Ti
Nvidia driver version: 512.16
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] numpy==1.21.5
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 haa95532_640
[conda] mkl-include 2022.1.0 haa95532_193
[conda] mkl-service 2.4.0 py37h2bbff1b_0
[conda] mkl_fft 1.3.1 py37h277e83a_0
[conda] mkl_random 1.2.2 py37hf11a4ad_0
[conda] numpy 1.21.5 py37h7a0a035_3
[conda] numpy-base 1.21.5 py37hca35cd5_3
cc @malfet @seemethere @peterjc123 @mszhanyi @skyline75489 @nbcsm
| 0 |
4,420 | 87,497 |
Gloo errors when process's batch only indexes padding_idx of sparse embedding
|
oncall: distributed
|
### 🐛 Describe the bug
When a model uses embeddings that are sparse and padded (using padded_idx). Multi-process CPU training via DDP will produce Gloo errors of the form `op.preamble.length <= op.nbytes. 20 vs 16` any time a process's entire batch indexes the padded index.
I suspect this causes problems during gradient reduction because the process in question has an empty gradient tensor while the other processes have non-empty gradient tensors.
The error doesn't occur when embeddings are dense, unpadded, or when the entire batch indexes a single unpadded index.
## Repro
```python
import pytorch_lightning as pl
import torch
class TestModule(pl.LightningModule):
def __init__(self, emb_size, padded, sparse, offset):
super().__init__()
self.offset = offset
self.embedding = torch.nn.Embedding(
emb_size, 1, padding_idx=0 if padded else None, sparse=sparse
)
self.criterion = torch.nn.MSELoss()
def forward(self, x):
# simulate a batch that only indexes one element in the embedding
rnk = torch.distributed.get_rank()
a = self.embedding(torch.ones(x[:, 0].size()).int() * (rnk + self.offset))
return a
def training_step(self, batch, batch_idx):
x, y = batch
x_hat = self.forward(x)
loss = self.criterion(x_hat.flatten(), y.flatten())
return loss
def configure_optimizers(self):
optimizer = torch.optim.Adagrad(
self.parameters(),
lr=0.5,
)
return optimizer
def train(padded: bool, sparse: bool, offset: int):
emb_size = 12
data_size = 1000
ds = torch.utils.data.TensorDataset(
torch.randint(0, emb_size, [data_size, 1]),
torch.rand([data_size, 1]),
)
dl = torch.utils.data.DataLoader(ds, batch_size=10)
model = TestModule(emb_size, padded, sparse, offset)
trainer = pl.Trainer(
num_nodes=3,
devices=4,
max_epochs=3,
accelerator="cpu",
)
trainer.fit(model, dl)
train(True, True, 0) # fails
train(False, True, 0) # not padded, succeeds
train(True, False, 0) # not sparse, succeeds
train(True, True, 1) # doesn't index the padded_idx, succeeds
```
## Error message
```
E1020 12:56:59.375689 1777 ExceptionTracer.cpp:222] exception stack complete
terminate called after throwing an instance of 'gloo::EnforceNotMet'
what(): [enforce fail at gloo/transport/tcp/pair.cc:510] op.preamble.length <= op.nbytes. 16 vs 8
*** Aborted at 1666295819 (Unix time, try 'date -d @1666295819') ***
*** Signal 6 (SIGABRT) (0x8068200000507) received by PID 1287 (pthread TID 0x7f6b53e00640) (linux TID 1777) (maybe from PID 1287, UID 525954) (code: -6), stack trace: ***
@ 000000002f76a238 folly::symbolizer::(anonymous namespace)::signalHandler(int, siginfo_t*, void*)
@ 0000000000000000 (unknown)
@ 000000000009c9d3 __GI___pthread_kill
@ 00000000000444ec __GI_raise
@ 000000000002c432 __GI_abort
@ 00000000000a3fd4 __gnu_cxx::__verbose_terminate_handler()
@ 0000000016af6900 aiplatform::error_reporting::(anonymous namespace)::logExceptionDetailsAndExit(folly::exception_wrapper const&, bool, std::optional<int>, aiplatform::error_reporting::TerminationLogger const*)
@ 0000000016af25f7 aiplatform::error_reporting::(anonymous namespace)::terminateHandler()
@ 00000000000a1b39 __cxxabiv1::__terminate(void (*)())
@ 00000000000a1ba4 std::terminate()
@ 00000000000a1e6f __cxa_throw
@ 0000000000003c6e __cxa_throw
@ 0000000031b7a283 gloo::transport::tcp::Pair::prepareRead(gloo::transport::tcp::Op&, gloo::NonOwningPtr<gloo::transport::tcp::UnboundBuffer>&, iovec&)
@ 0000000031b7a398 gloo::transport::tcp::Pair::read()
@ 0000000031b7b728 gloo::transport::tcp::Pair::handleReadWrite(int)
@ 0000000031b7f7c3 gloo::transport::tcp::Pair::handleEvents(int)
@ 0000000031b7622d gloo::transport::tcp::Loop::run()
@ 00000000000df4e4 execute_native_thread_routine
@ 000000000009ac0e start_thread
@ 000000000012d1db __clone3
Fatal Python error: Aborted
```
### Versions
collect_env.py failed, but I'm running on trunk
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu
| 0 |
4,421 | 87,494 |
Missing docstring for resize_as
|
module: docs, triaged
|
### 📚 The doc issue
As per the title, there is no docstring for `resize_as`.
```python
In [2]: t = torch.randn(6)
In [3]: t.resize_as?
Signature: t.resize_as(tensor)
Docstring: <no docstring>
File: /usr/local/Caskroom/miniconda/base/envs/book/lib/python3.10/site-packages/torch/_tensor.py
Type: method
In [4]: torch.resize_as_?
Docstring: <no docstring>
Type: builtin_function_or_method
```
### Suggest a potential alternative/fix
Add docstring.
cc @svekars @carljparker
| 0 |
4,422 | 87,491 |
TorchDynamo fails to trace the graph when custom op is being used
|
triaged, module: aotdispatch, module: dynamo
|
### 🐛 Describe the bug
TorchDynamo does not trace the graph when using custom APEX LayerNorm and this results in no fusion of other elementwise operations. The issue can be reproduced using the code below.
```
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.parameter import Parameter
from apex.contrib.layer_norm.layer_norm import FastLayerNorm
import torchdynamo
tensor_dtype = torch.float16
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(768, 768, bias=False)
self.fc2 = nn.Linear(768, 2048, bias=False)
self.fast_layer_norm = FastLayerNorm(768)
self.bias = Parameter(torch.rand(768))
def forward(self, x, residuals):
out = self.fc1(x)
out = out + self.bias
out = F.dropout(out, p=0.1, training=True)
ln_input = out + residuals
ln_out = self.fast_layer_norm(ln_input)
out1 = self.fc2(ln_out)
return out1
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = Net()
net.cuda()
net = net.half()
input_shapes = [(512, 64, 768),
(512, 64, 768)]
def generate_io_tensor(net, input_shapes):
input_tensors = []
for shape in input_shapes:
tensor = torch.rand(shape, dtype=torch.float16, requires_grad=True, device='cuda')
input_tensors.append(tensor)
target_tensor_size = net(*input_tensors).size()
target_tensor = torch.rand(target_tensor_size, dtype=torch.float16, device='cuda')
return input_tensors, target_tensor
network_fn = torchdynamo.optimize("aot_nvfuser")(net)
bench_iters = 10
for idx in range(bench_iters):
input_tensors, target_tensor = generate_io_tensor(net, input_shapes)
for tensor in input_tensors:
tensor.grad = None
network_fn.zero_grad(set_to_none=True)
outputs = network_fn(*input_tensors)
outputs.backward(target_tensor)
```
Using `AOT_FX_GRAPHS=1` I see the following output
```
====== Forward (only) graph ======
class <lambda>(torch.nn.Module):
def forward(self, arg0_1: f16[512, 64, 768], arg1_1: f16[768], arg2_1: f16[768]):
# Module stack: {}, File: /opt/conda/lib/python3.8/site-packages/apex/contrib/layer_norm/layer_norm.py:15, code: xmat = x.view((-1, hidden_size))
view: f16[32768, 768] = torch.ops.aten.view.default(arg0_1, [-1, 768])
return (view, arg1_1, arg2_1, arg0_1)
```
The expected output would have the graph and could fuse the remaining ops using NvFuser.
### Versions
```
Collecting environment information...
PyTorch version: 1.14.0a0+gite85dbcc
Is debug build: False
CUDA used to build PyTorch: 11.8
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.5 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.24.1
Libc version: glibc-2.31
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-91-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA A100 80GB PCIe
Nvidia driver version: 515.65.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] bert-pytorch==0.0.1a4
[pip3] clip-anytorch==2.5.0
[pip3] CoCa-pytorch==0.0.6
[pip3] dalle2-pytorch==1.10.5
[pip3] ema-pytorch==0.0.10
[pip3] functorch==1.14.0a0+408bcf1
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.21.5
[pip3] pytorch-transformers==1.2.0
[pip3] pytorch-warmup==0.1.0
[pip3] rotary-embedding-torch==0.1.5
[pip3] torch==1.14.0a0+gite85dbcc
[pip3] torch-fidelity==0.3.0
[pip3] torch-struct==0.5
[pip3] torchdynamo==1.14.0.dev0
[pip3] torchmetrics==0.10.0
[pip3] torchrec-nightly==2022.10.14
[pip3] torchtext==0.14.0a0+4570a56
[pip3] torchvision==0.15.0a0+f467349
[pip3] torchx-nightly==2022.10.17
[pip3] vector-quantize-pytorch==0.9.2
[conda] bert-pytorch 0.0.1a4 dev_0 <develop>
[conda] clip-anytorch 2.5.0 pypi_0 pypi
[conda] coca-pytorch 0.0.6 pypi_0 pypi
[conda] dalle2-pytorch 1.10.5 pypi_0 pypi
[conda] ema-pytorch 0.0.10 pypi_0 pypi
[conda] functorch 1.14.0a0+408bcf1 pypi_0 pypi
[conda] mkl 2019.1 144
[conda] mkl-include 2019.1 144
[conda] nomkl 3.0 0
[conda] numpy 1.21.2 pypi_0 pypi
[conda] numpy-base 1.21.5 py38hb8be1f0_2
[conda] pytorch-transformers 1.2.0 pypi_0 pypi
[conda] pytorch-warmup 0.1.0 pypi_0 pypi
[conda] rotary-embedding-torch 0.1.5 pypi_0 pypi
[conda] torch 1.14.0a0+gite85dbcc dev_0 <develop>
[conda] torch-fidelity 0.3.0 pypi_0 pypi
[conda] torch-struct 0.5 pypi_0 pypi
[conda] torchdynamo 1.14.0.dev0 dev_0 <develop>
[conda] torchmetrics 0.10.0 pypi_0 pypi
[conda] torchrec-nightly 2022.10.14 pypi_0 pypi
[conda] torchtext 0.14.0a0+4570a56 dev_0 <develop>
[conda] torchvision 0.15.0a0+f467349 dev_0 <develop>
[conda] torchx-nightly 2022.10.17 pypi_0 pypi
[conda] vector-quantize-pytorch 0.9.2 pypi_0 pypi
```
cc @mlazos @soumith @voznesenskym @yanboliang @penguinwu @anijain2305 @EikanWang @jgong5 @Guobing-Chen @chunyuan-w @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @desertfire
| 0 |
4,423 | 87,487 |
[JIT] Inconsistent handling of tracing dict output leads to assertion
|
oncall: jit
|
### 🐛 Describe the bug
Repro:
```python
import torch
from typing import Dict, List, Optional, Tuple
def impl(
values: torch.Tensor,
) -> List[List[torch.Tensor]]:
jt_tensors: List[List[torch.Tensor]] = []
for i in range(2):
jt_tensors.append([values[:], values[1:], values[2:], values[3:]])
return jt_tensors
@torch.jit.script
def scripted_impl(
keys: List[str],
values: torch.Tensor,
) -> Dict[str, Tuple[torch.Tensor, torch.Tensor, torch.Tensor, Optional[torch.Tensor]]]:
jt_tensors = impl(values)
ret = torch.jit.annotate(
Dict[str, Tuple[torch.Tensor, torch.Tensor, torch.Tensor, Optional[torch.Tensor]]],
{k: (v[0], v[1], v[2], v[3]) for (k, v) in zip(keys, jt_tensors)},
)
return ret
def thing(values):
return scripted_impl(["asdf", "fdsa"], values)
values = torch.rand((5))
traced_thing = torch.jit.trace(thing, (values,), strict=False)
```
The tracer seems like it tries to guess the return type based on the ivalue return type (https://github.com/pytorch/pytorch/blob/master/torch/csrc/jit/frontend/tracer.cpp#L293) and apparently it guesses wrong... perhaps there's a better way to do the annotations here, but I couldn't figure out a way to get around it.
### Versions
master branch
| 0 |
4,424 | 87,468 |
Categorical fails simplex validation after its own normalisation on CUDA
|
module: distributions, triaged
|
### 🐛 Describe the bug
`torch.distributions.Categorical` fails on simplex validation after normalising the input probabilities.
So far, I could only reproduce this bug with CUDA.
I have uploaded two tensors to reproduce the behaviour here: https://oc.embl.de/index.php/s/fAhBE8KESs0i6vm
```python
import torch
p = torch.load("fishy_tensor.pt")
torch.distributions.Categorical(p) # fails with simplex check
torch.distributions.constraints.simplex.check(p) # yields all true
```

I raised this issue in the forum already https://discuss.pytorch.org/t/distributions-categorical-fails-with-constraint-simplex-but-manual-check-passes/163209/3
### Versions
## Environment
cudatoolkit 11.3.1 h9edb442_10 conda-forge
python 3.10.5 h582c2e5_0_cpython conda-forge
python_abi 3.10 2_cp310 conda-forge
pytorch 1.12.0 py3.10_cuda11.3_cudnn8.3.2_0 pytorch
pytorch-lightning 1.6.5 pypi_0 pypi
pytorch-mutex 1.0 cuda pytorch
complete env here: https://oc.embl.de/index.php/s/UwFFBFDJy6s71t0
cc @fritzo @neerajprad @alicanb @nikitaved
| 4 |
4,425 | 93,566 |
[BUG] moco fails without suppress errors: RuntimeError: Tensors must be CUDA and dense
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
Patch in https://github.com/pytorch/pytorch/pull/87440 to turn off error suppression
run `python benchmarks/dynamo/torchbench.py --accuracy --backend eager --training --only moco`
fails with
```
File "/raid/ezyang/pytorch-scratch2/torch/_dynamo/variables/tensor.py", line 132, in <lambda>
lambda: _run_node(tx.output, node, args, kwargs, nnmodule)
File "/raid/ezyang/pytorch-scratch2/torch/_dynamo/variables/tensor.py", line 51, in _run_node
return node.target(*args, **kwargs)
File "/raid/ezyang/pytorch-scratch2/torch/distributed/distributed_c10d.py", line 2264, in all_gather
work = default_pg.allgather([tensor_list], [tensor])
File "/raid/ezyang/pytorch-scratch2/torch/utils/_python_dispatch.py", line 101, in __torch_dispatch__
return old.__torch_dispatch__(func, types, args, kwargs)
File "/raid/ezyang/pytorch-scratch2/torch/_subclasses/fake_tensor.py", line 822, in __torch_dispatch__
r = func(*args, **kwargs)
File "/raid/ezyang/pytorch-scratch2/torch/_ops.py", line 257, in __call__
return self._op(*args, **kwargs or {})
RuntimeError: Tensors must be CUDA and dense
```
### Error logs
https://gist.github.com/5a54f01612589820947d15ac2256a9a2
### Minified repro
minifier does not work because captured dynamo graph has distributed operations in it, but process groups are not initialized
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 3 |
4,426 | 87,458 |
Placeholder tensor is empty
|
triaged, module: mps
|
### 🐛 Describe the bug
I am running detectron2 on a MacBook 14" with and M1 Pro processor, using the MPS GPU support.
When running inference on an image using the detection2 predictor as follows
```python
im = cv2.imread(d["file_name"])
outputs = predictor(im)
```
I get the following error, which suggests to report a bug to PyTorch, therefore this issue.
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In [9], line 7
5 print(im.shape)
6 #im = np.array(Image.open(d["file_name"]))
----> 7 outputs = predictor(im) # format is documented at https://detectron2.readthedocs.io/tutorials/models.html#model-output-format
8 v = Visualizer(im[:, :, ::-1],
9 metadata=balloon_metadata,
10 scale=0.5,
11 instance_mode=ColorMode.IMAGE_BW # remove the colors of unsegmented pixels. This option is only available for segmentation models
12 )
13 out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
File ~/opt/anaconda3/envs/torch-gpu/lib/python3.8/site-packages/detectron2/engine/defaults.py:317, in DefaultPredictor.__call__(self, original_image)
314 image = torch.as_tensor(image.astype("float32").transpose(2, 0, 1))
316 inputs = {"image": image, "height": height, "width": width}
--> 317 predictions = self.model([inputs])[0]
318 return predictions
File ~/opt/anaconda3/envs/torch-gpu/lib/python3.8/site-packages/torch/nn/modules/module.py:1357, in Module._call_impl(self, *input, **kwargs)
1352 # If we don't have any hooks, we want to skip the rest of the logic in
1353 # this function, and just call forward.
1354 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1355 or _global_backward_pre_hooks or _global_backward_hooks
1356 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1357 return forward_call(*input, **kwargs)
1358 # Do not call functions when jit is used
1359 full_backward_hooks, non_full_backward_hooks = [], []
File ~/opt/anaconda3/envs/torch-gpu/lib/python3.8/site-packages/detectron2/modeling/meta_arch/rcnn.py:150, in GeneralizedRCNN.forward(self, batched_inputs)
127 """
128 Args:
129 batched_inputs: a list, batched outputs of :class:`DatasetMapper` .
(...)
147 "pred_boxes", "pred_classes", "scores", "pred_masks", "pred_keypoints"
148 """
149 if not self.training:
--> 150 return self.inference(batched_inputs)
152 images = self.preprocess_image(batched_inputs)
153 if "instances" in batched_inputs[0]:
File ~/opt/anaconda3/envs/torch-gpu/lib/python3.8/site-packages/detectron2/modeling/meta_arch/rcnn.py:213, in GeneralizedRCNN.inference(self, batched_inputs, detected_instances, do_postprocess)
210 assert "proposals" in batched_inputs[0]
211 proposals = [x["proposals"].to(self.device) for x in batched_inputs]
--> 213 results, _ = self.roi_heads(images, features, proposals, None)
214 else:
215 detected_instances = [x.to(self.device) for x in detected_instances]
File ~/opt/anaconda3/envs/torch-gpu/lib/python3.8/site-packages/torch/nn/modules/module.py:1357, in Module._call_impl(self, *input, **kwargs)
1352 # If we don't have any hooks, we want to skip the rest of the logic in
1353 # this function, and just call forward.
1354 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1355 or _global_backward_pre_hooks or _global_backward_hooks
1356 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1357 return forward_call(*input, **kwargs)
1358 # Do not call functions when jit is used
1359 full_backward_hooks, non_full_backward_hooks = [], []
File ~/opt/anaconda3/envs/torch-gpu/lib/python3.8/site-packages/detectron2/modeling/roi_heads/roi_heads.py:750, in StandardROIHeads.forward(***failed resolving arguments***)
747 pred_instances = self._forward_box(features, proposals)
748 # During inference cascaded prediction is used: the mask and keypoints heads are only
749 # applied to the top scoring box detections.
--> 750 pred_instances = self.forward_with_given_boxes(features, pred_instances)
751 return pred_instances, {}
File ~/opt/anaconda3/envs/torch-gpu/lib/python3.8/site-packages/detectron2/modeling/roi_heads/roi_heads.py:776, in StandardROIHeads.forward_with_given_boxes(self, features, instances)
773 assert not self.training
774 assert instances[0].has("pred_boxes") and instances[0].has("pred_classes")
--> 776 instances = self._forward_mask(features, instances)
777 instances = self._forward_keypoint(features, instances)
778 return instances
File ~/opt/anaconda3/envs/torch-gpu/lib/python3.8/site-packages/detectron2/modeling/roi_heads/roi_heads.py:846, in StandardROIHeads._forward_mask(self, features, instances)
844 else:
845 features = {f: features[f] for f in self.mask_in_features}
--> 846 return self.mask_head(features, instances)
File ~/opt/anaconda3/envs/torch-gpu/lib/python3.8/site-packages/torch/nn/modules/module.py:1357, in Module._call_impl(self, *input, **kwargs)
1352 # If we don't have any hooks, we want to skip the rest of the logic in
1353 # this function, and just call forward.
1354 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1355 or _global_backward_pre_hooks or _global_backward_hooks
1356 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1357 return forward_call(*input, **kwargs)
1358 # Do not call functions when jit is used
1359 full_backward_hooks, non_full_backward_hooks = [], []
File ~/opt/anaconda3/envs/torch-gpu/lib/python3.8/site-packages/detectron2/modeling/roi_heads/mask_head.py:197, in BaseMaskRCNNHead.forward(self, x, instances)
183 def forward(self, x, instances: List[Instances]):
184 """
185 Args:
186 x: input region feature(s) provided by :class:`ROIHeads`.
(...)
195 A dict of losses in training. The predicted "instances" in inference.
196 """
--> 197 x = self.layers(x)
198 if self.training:
199 return {"loss_mask": mask_rcnn_loss(x, instances, self.vis_period) * self.loss_weight}
File ~/opt/anaconda3/envs/torch-gpu/lib/python3.8/site-packages/detectron2/modeling/roi_heads/mask_head.py:289, in MaskRCNNConvUpsampleHead.layers(self, x)
287 def layers(self, x):
288 for layer in self:
--> 289 x = layer(x)
290 return x
File ~/opt/anaconda3/envs/torch-gpu/lib/python3.8/site-packages/torch/nn/modules/module.py:1357, in Module._call_impl(self, *input, **kwargs)
1352 # If we don't have any hooks, we want to skip the rest of the logic in
1353 # this function, and just call forward.
1354 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1355 or _global_backward_pre_hooks or _global_backward_hooks
1356 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1357 return forward_call(*input, **kwargs)
1358 # Do not call functions when jit is used
1359 full_backward_hooks, non_full_backward_hooks = [], []
File ~/opt/anaconda3/envs/torch-gpu/lib/python3.8/site-packages/detectron2/layers/wrappers.py:119, in Conv2d.forward(self, x)
117 x = self.norm(x)
118 if self.activation is not None:
--> 119 x = self.activation(x)
120 return x
File ~/opt/anaconda3/envs/torch-gpu/lib/python3.8/site-packages/torch/nn/modules/module.py:1357, in Module._call_impl(self, *input, **kwargs)
1352 # If we don't have any hooks, we want to skip the rest of the logic in
1353 # this function, and just call forward.
1354 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1355 or _global_backward_pre_hooks or _global_backward_hooks
1356 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1357 return forward_call(*input, **kwargs)
1358 # Do not call functions when jit is used
1359 full_backward_hooks, non_full_backward_hooks = [], []
File ~/opt/anaconda3/envs/torch-gpu/lib/python3.8/site-packages/torch/nn/modules/activation.py:102, in ReLU.forward(self, input)
101 def forward(self, input: Tensor) -> Tensor:
--> 102 return F.relu(input, inplace=self.inplace)
File ~/opt/anaconda3/envs/torch-gpu/lib/python3.8/site-packages/torch/nn/functional.py:1457, in relu(input, inplace)
1455 result = torch.relu_(input)
1456 else:
-> 1457 result = torch.relu(input)
1458 return result
RuntimeError: [srcBuf length] > 0 INTERNAL ASSERT FAILED at "/Users/runner/work/_temp/anaconda/conda-bld/pytorch_1666163570052/work/aten/src/ATen/native/mps/OperationUtils.mm":242, please report a bug to PyTorch. Placeholder tensor is empty!
```
Thanks
### Versions
PyTorch version: 1.14.0.dev20221019
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.6 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.102)
CMake version: version 3.24.2
Libc version: N/A
Python version: 3.8.13 | packaged by conda-forge | (default, Mar 25 2022, 06:04:14) [Clang 12.0.1 ] (64-bit runtime)
Python platform: macOS-12.6-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.1
[pip3] pytorch-lightning==1.7.7
[pip3] torch==1.14.0.dev20221019
[pip3] torchaudio==0.13.0.dev20221019
[pip3] torchmetrics==0.10.0
[pip3] torchnet==0.0.4
[pip3] torchvision==0.15.0.dev20221019
[conda] numpy 1.23.1 py38h42add53_0
[conda] numpy-base 1.23.1 py38hadd41eb_0
[conda] pytorch 1.14.0.dev20221019 py3.8_0 pytorch-nightly
[conda] pytorch-lightning 1.7.7 pypi_0 pypi
[conda] torchaudio 0.13.0.dev20221019 py38_cpu pytorch-nightly
[conda] torchmetrics 0.10.0 pypi_0 pypi
[conda] torchnet 0.0.4 pypi_0 pypi
[conda] torchvision 0.15.0.dev20221019 py38_cpu pytorch-nightly
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 1 |
4,427 | 87,451 |
Some operations do not keep `channels_last` memory format which yields accuracy drop
|
triaged, module: memory format
|
### 🐛 Describe the bug
I tried to switch to `torch.channels_last` in order to reduce the training time but I noticed that the new training shows quite a performance drop. While looking deeper into the cause, I noticed that there are some modules which do not keep the `torch.channels_last` memory format:
```python
from functools import partial
import itertools
import torch
import torch.nn as nn
devices = ['cpu', 'cuda']
modules = [partial(nn.ConvTranspose2d, in_channels=3, out_channels=3, kernel_size=(2, 2), stride=(2, 2), bias=False),
partial(nn.Conv2d, in_channels=3, out_channels=3, kernel_size=(2, 2), stride=(2, 2), bias=False),
partial(nn.Linear, in_features=5, out_features=5, bias=False),
partial(nn.Conv2d, in_channels=3, out_channels=3, kernel_size=(3, 3), stride=1, padding=(1, 1), bias=False),
partial(nn.Conv2d, in_channels=3, out_channels=3, kernel_size=(1, 1)),
partial(nn.Conv2d, in_channels=3, out_channels=3, kernel_size=(1, 2), stride=1, bias=False),
partial(nn.Conv2d, in_channels=3, out_channels=3, kernel_size=(1, 2), stride=1, padding=(0, 1)),
nn.GELU,
partial(nn.BatchNorm2d, num_features=3)]
for device, module in itertools.product(devices, modules):
m = module()
# create random input
inp = torch.randn(2, 3, 4, 5)
# cast input and module to device/memory format
inp = inp.to(memory_format=torch.channels_last).to(device=device)
m = m.to(memory_format=torch.channels_last).to(device=device)
out = m(inp)
if not out.is_contiguous(memory_format=torch.channels_last):
print(f'Operation does not keep channels_last for '
f'device = {device}, module = {module} but has now stride {out.stride()}')
```
which yields
```bash
Operation does not keep channels_last for device = cpu, module = functools.partial(<class 'torch.nn.modules.conv.ConvTranspose2d'>, in_channels=3, out_channels=3, kernel_size=(2, 2), stride=(2, 2), bias=False) but has now stride (240, 80, 10, 1)
Operation does not keep channels_last for device = cpu, module = functools.partial(<class 'torch.nn.modules.linear.Linear'>, in_features=5, out_features=5, bias=False) but has now stride (60, 20, 5, 1)
Operation does not keep channels_last for device = cuda, module = functools.partial(<class 'torch.nn.modules.linear.Linear'>, in_features=5, out_features=5, bias=False) but has now stride (60, 20, 5, 1)
```
As `nn.Linear` does not keep the channels_last memory layout on the GPU, this then causes a problem, as the following modules are now in `torch.channels_last` but the input is not anymore:
```python
from functools import partial
import itertools
import torch
import torch.nn as nn
devices = ['cpu', 'cuda']
memory_formats = [torch.contiguous_format, torch.channels_last]
modules = [partial(nn.ConvTranspose2d, in_channels=3, out_channels=3, kernel_size=(2, 2), stride=(2, 2), bias=False),
partial(nn.Conv2d, in_channels=3, out_channels=3, kernel_size=(2, 2), stride=(2, 2), bias=False),
partial(nn.Linear, in_features=5, out_features=5, bias=False),
partial(nn.Conv2d, in_channels=3, out_channels=3, kernel_size=(3, 3), stride=1, padding=(1, 1), bias=False),
partial(nn.Conv2d, in_channels=3, out_channels=3, kernel_size=(1, 1)),
partial(nn.Conv2d, in_channels=3, out_channels=3, kernel_size=(1, 2), stride=1, bias=False),
partial(nn.Conv2d, in_channels=3, out_channels=3, kernel_size=(1, 2), stride=1, padding=(0, 1)),
nn.GELU,
partial(nn.BatchNorm2d, num_features=3)]
for device, memory_format, module in itertools.product(devices, memory_formats, modules):
m1 = module()
m2 = module()
# use identical weights for both modules
m2.load_state_dict(m1.state_dict())
# create random input
inp = torch.randn(2, 3, 4, 5)
# cast module to device/memory format
m1 = m1.to(device=device)
m2 = m2.to(memory_format=memory_format).to(device=device)
# cast input to device (keeping `contiguous` memory format)
inp = inp.to(device=device)
out1 = m1(inp)
out2 = m2(inp)
if not torch.allclose(out1, out2):
print(f'Results differ for device = {device}, memory_format = {memory_format}, module = {module} '
f'with max difference {torch.max(torch.abs(out1 - out2)).item()}')
```
which is a problem for the `Conv2d`:
```bash
Results differ for device = cuda, memory_format = torch.channels_last, module = functools.partial(<class 'torch.nn.modules.conv.Conv2d'>, in_channels=3, out_channels=3, kernel_size=(2, 2), stride=(2, 2), bias=False) with max difference 0.0002925097942352295
Results differ for device = cuda, memory_format = torch.channels_last, module = functools.partial(<class 'torch.nn.modules.conv.Conv2d'>, in_channels=3, out_channels=3, kernel_size=(1, 1)) with max difference 0.0007414817810058594
Results differ for device = cuda, memory_format = torch.channels_last, module = functools.partial(<class 'torch.nn.modules.conv.Conv2d'>, in_channels=3, out_channels=3, kernel_size=(1, 2), stride=1, bias=False) with max difference 0.000747382640838623
Results differ for device = cuda, memory_format = torch.channels_last, module = functools.partial(<class 'torch.nn.modules.conv.Conv2d'>, in_channels=3, out_channels=3, kernel_size=(1, 2), stride=1, padding=(0, 1)) with max difference 0.0005008578300476074
```
So I think the `nn.Conv2d` silently assumes that the input has the correct memory layout which is not the case due to a previous module that brought it back to be contiguous.
### Versions
PyTorch version: 1.12.1+cu113
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.3 (default, Jul 2 2020, 16:21:59) [GCC 7.3.0] (64-bit runtime)
Python platform: Linux-5.4.0-107-generic-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: 11.2.152
CUDA_MODULE_LOADING set to:
GPU models and configuration:
GPU 0: NVIDIA RTX A6000
GPU 1: NVIDIA RTX A6000
GPU 2: NVIDIA RTX A6000
GPU 3: NVIDIA RTX A6000
GPU 4: NVIDIA RTX A6000
GPU 5: NVIDIA RTX A6000
GPU 6: NVIDIA RTX A6000
GPU 7: NVIDIA RTX A6000
Nvidia driver version: 470.103.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.20.3
[pip3] torch==1.12.1+cu113
[pip3] torchaudio==0.12.1+cu113
[pip3] torchinfo==1.7.1
[pip3] torchvision==0.13.1+cu113
[pip3] torchviz==0.0.2
[conda] Could not collect
cc @VitalyFedyunin @jamesr66a
| 1 |
4,428 | 87,449 |
pytorch could not build from source with cudnn 8.0.5
|
module: build, module: cudnn, module: cuda, triaged
|
### 🐛 Describe the bug
pytorch could not build from source with cudnn 8.0.5, since cudnn-frontend in thirdparty will use `CUDNN_DATA_INT64` and other API such as `CUDNN_POINTWISE_RELU_BWD`, whereas CUDNN 8.0.5 API seems not to have (https://docs.nvidia.com/deeplearning/cudnn/archives/cudnn-805/api/index.html).
```
pytorch/cmake/../third_party/cudnn_frontend/include/cudnn_frontend_utils.h: In function 'std::__cxx11::string cudnn_frontend::to_string(cudnnDataType_t)':
pytorch/cmake/../third_party/cudnn_frontend/include/cudnn_frontend_utils.h:93:14: error: 'CUDNN_DATA_INT64' was not declared in this scope
case CUDNN_DATA_INT64:
^~~~~~~~~~~~~~~~
pytorch/cmake/../third_party/cudnn_frontend/include/cudnn_frontend_utils.h:93:14: note: suggested alternative: 'CUDNN_DATA_INT8x4'
case CUDNN_DATA_INT64:
^~~~~~~~~~~~~~~~
CUDNN_DATA_INT8x4
pytorch/cmake/../third_party/cudnn_frontend/include/cudnn_frontend_utils.h:95:14: error: 'CUDNN_DATA_BFLOAT16' was not declared in this scope
case CUDNN_DATA_BFLOAT16:
^~~~~~~~~~~~~~~~~~~
pytorch/cmake/../third_party/cudnn_frontend/include/cudnn_frontend_utils.h:95:14: note: suggested alternative: 'CUDNN_DATA_FLOAT'
case CUDNN_DATA_BFLOAT16:
^~~~~~~~~~~~~~~~~~~
CUDNN_DATA_FLOAT
```
### Versions
Pytorch 1.12.0
cc @malfet @seemethere @csarofeen @ptrblck @xwang233 @ngimel
| 4 |
4,429 | 87,448 |
Semantics of sparse operations clarification - Sparsity of the gradient with respect to a sparse tensor input
|
module: sparse, module: docs, module: autograd, triaged, enhancement, module: masked operators
|
### 🚀 The feature, motivation and pitch
In many applications involving sparse matrices, one may be interested in imposing the sparsity pattern and using the gradient with repect to the "non-zero" elements of the sparse tensor only.
As a motivating toy example, let us consider tridiagonal matrices and let L be a (loss) function mapping such matrices to a scalar value, it may be of interest to find:
T_opt = argmin_{T ∈ Tridiagonal} L(T)
Using autodiff in such a context should ideally be straighforward with PyTorch. At the moment, however, the semantics of sparse matrix operations when it comes to the gradient with respect to the sparse matrix are not made explicit in the [documentation](https://pytorch.org/docs/stable/sparse.html) and may thus not match user expectations.
After discussion in several issues (see e.g. https://github.com/pytorch/pytorch/issues/87358#issuecomment-1285755188), I realised that the default (implicit) semantics of sparse tensors in PyTorch is that the sparse representation only affects the way the data is stored. Results of any operation with a sparse matrix, including backwards, should be equivalent to that of the operation applied to a dense view of the sparse matrix.
While this "transparent storage layout" semantics (as referred to it in https://github.com/pytorch/maskedtensor/issues/71#issuecomment-1286305562) makes sense in some setups, it may not be the semantics expected from a linear algebra perspective. In the latter case, the expectation of the user may typically be that the gradient of a sparse op with repect to the sparse input should be a sparse tensor (let's call this "sparsity-preserving gradient" semantics).
Despite "transparent storage layout" semantics being the default in PyTorch, "sparsity-preserving gradient" semantics is already used in some cases, in particular in [`torch.sparse.mm`](https://pytorch.org/docs/stable/generated/torch.sparse.mm.html), see e.g. discussion in #41128 and https://github.com/pytorch/pytorch/issues/2389#issuecomment-1006557121 but also usage in https://github.com/rusty1s/pytorch_sparse and https://github.com/flaport/torch_sparse_solve.
It was argued in https://github.com/pytorch/pytorch/issues/87358#issuecomment-1285797058 that [`torch.masked`](https://pytorch.org/docs/master/masked.html) would provide semantics more aligned with "sparsity-preserving gradient", however, as per https://github.com/pytorch/maskedtensor/issues/71#issuecomment-1286305562, it seems unclear how MaskedTensors should deal with non-trivial sparse ops such as sparse @ dense. Furthermore, as illustrated in #41128, "sparsity-preserving gradient" semantics can be particularly useful to manage memory requirements when dealing with large sparse matrices. It's unclear to me how MaskedTensors can provide optimal memory and computational usage in this case in comparison to directly using sparse tenors.
Given the above, it would be great to:
- Clarify the default semantics for sparse tensors in the documentation
- Provide options to support "sparsity-preserving gradient" in key operations (as done for `torch.sparse.mm`)
### Alternatives
Alternatives include:
- Rely on a third-party sparse matrix library supporting "sparsity-preserving gradient" semantics such as https://github.com/rusty1s/pytorch_sparse
- Expand generic third-party library for abstract linear operators such as https://github.com/cornellius-gp/linear_operator to take advantage of efficient sparse operations
- Only work on small-scale problems (to ensure the dense gradient matrices can fit in memory) for which "sparsity-preserving gradient" can be achieved in two steps: 1) dense gradient; 2) subsample
### Additional context
Related issues: #87358 #41128 https://github.com/pytorch/maskedtensor/issues/71 #9674 #86963
cc @nikitaved @pearu @cpuhrsch @amjames @bhosmer @svekars @carljparker @ezyang @albanD @zou3519 @gqchen @soulitzer @Lezcano @Varal7
| 0 |
4,430 | 87,446 |
ipykernel crash importing torch after scipy in .ipynb file
|
needs reproduction, module: crash, triaged
|
### 🐛 Describe the bug
I'm working in a .ipynb notebook in VSCode on an Intel MacBook (late 2016 MBP)
Conda environment setup as:
```
% conda create --prefix ./envs/scipy
% conda activate ./envs/scipy
% conda install pytorch=1.12.1 -c pytorch
% conda install scipy
% conda install ipython ipykernel
```
As first cell in notebook, this causes kernel crash
```
from scipy.optimize import least_squares
import torch
```
This does not:
```
import torch
from scipy.optimize import least_squares
```
### Versions
Collecting environment information...
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.6 (x86_64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.102)
CMake version: Could not collect
Libc version: N/A
Python version: 3.10.6 (main, Oct 7 2022, 15:17:23) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.3
[pip3] torch==1.12.1
[conda] blas 1.0 mkl
[conda] mkl 2021.4.0 hecd8cb5_637
[conda] mkl-service 2.4.0 py310hca72f7f_0
[conda] mkl_fft 1.3.1 py310hf879493_0
[conda] mkl_random 1.2.2 py310hc081a56_0
[conda] numpy 1.23.3 py310hc1140d4_0
[conda] numpy-base 1.23.3 py310h2a77c02_0
[conda] pytorch 1.12.1 py3.10_0 pytorch
| 3 |
4,431 | 93,565 |
[Bug]: AssertionError: ABCMeta
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
Turn off error suppression and run test_sort_out in test_sort_out
```
File "/raid/ezyang/pytorch-scratch2/torch/_dynamo/variables/functions.py", line 62, in call_function
return tx.inline_user_function_return(
File "/raid/ezyang/pytorch-scratch2/torch/_dynamo/symbolic_convert.py", line 293, in inline_user_function_
return
result = InliningInstructionTranslator.inline_call(self, fn, args, kwargs)
File "/raid/ezyang/pytorch-scratch2/torch/_dynamo/symbolic_convert.py", line 1519, in inline_call
return cls.inline_call_(parent, func, args, kwargs)
File "/raid/ezyang/pytorch-scratch2/torch/_dynamo/symbolic_convert.py", line 1547, in inline_call_
sub_locals, closure_cells = func.bind_args(parent, args, kwargs) File "/raid/ezyang/pytorch-scratch2/torch/_dynamo/variables/functions.py", line 126, in bind_args
fake_func.__kwdefaults__ = {
File "/raid/ezyang/pytorch-scratch2/torch/_dynamo/variables/functions.py", line 127, in <dictcomp>
k: wrap(v) for k, v in fn.__kwdefaults__.items() File "/raid/ezyang/pytorch-scratch2/torch/_dynamo/variables/functions.py", line 23, in wrap_bound_arg
return cls([wrap_bound_arg(x, options) for x in val], **options)
File "/raid/ezyang/pytorch-scratch2/torch/_dynamo/variables/functions.py", line 23, in <listcomp>
return cls([wrap_bound_arg(x, options) for x in val], **options) File "/raid/ezyang/pytorch-scratch2/torch/_dynamo/variables/functions.py", line 29, in wrap_bound_arg
assert isinstance(val, VariableTracker), typestr(val)
AssertionError: ABCMeta
```
### Error logs
na
### Did Dynamo succeed?
- [ ] Does dynamo.optimize("eager") succeed?
### Did AOT succeed?
- [ ] Did dynamo.optimize("aot_eager") succeed?
### Did Inductor succeed?
- [ ] Does dynamo.optimize("inductor") succeed?
### Minified repro
na
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
4,432 | 87,433 |
index_select() applied in sparse tensor can't backprop
|
module: sparse, triaged
|
### 🐛 Describe the bug
index_select() applied in sparse tensor can't backprop.
As the example below demostrates:
```
import torch
i = torch.tensor([[0, 1]])
v = torch.tensor([2., 2.], requires_grad=True)
s = torch.sparse_coo_tensor(i, v, size=[4], requires_grad=True)
print(s)
idx = torch.tensor([1, 2])
r = torch.index_select(s, 0, idx.detach()).to_dense()
print(r)
a = torch.sum(r)
a.backward()
print(v.grad)
```
When executed, it occurs an error:
```
Traceback (most recent call last):
File "/home/xiahongchi/test/test.py", line 12, in <module>
a.backward()
File "/home/xiahongchi/anaconda3/envs/mininet/lib/python3.8/site-packages/torch/_tensor.py", line 396, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/home/xiahongchi/anaconda3/envs/mininet/lib/python3.8/site-packages/torch/autograd/__init__.py", line 173, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: Tensors of type SparseTensorImpl do not have strides
```
### Versions
PyTorch version: 1.12.1+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.16.3
Libc version: glibc-2.31
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.15.0-48-generic-x86_64-with-glibc2.17
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] torch==1.12.1
[conda] torch 1.12.1 pypi_0 pypi
cc @nikitaved @pearu @cpuhrsch @amjames @bhosmer
| 1 |
4,433 | 87,412 |
[be] Change the structure of BackendConfig so that we don't need to write helper functions
|
oncall: quantization, triaged
|
### 🐛 Describe the bug
we probably want to change how the backend configs are stored so that we don't need to write these helper functions: https://github.com/pytorch/pytorch/blob/master/torch/ao/quantization/backend_config/utils.py#L24
e.g. changing it from a list to a dictionary
### Versions
master
cc @jianyuh @raghuramank100 @jamesr66a @vkuzo
| 0 |
4,434 | 87,402 |
`lower_cholesky` constraint incorrectly fails on MPS
|
triaged, module: mps
|
### 🐛 Describe the bug
```python
import torch
from torch.distributions.constraints import lower_cholesky
x = torch.tensor([[1.4142]])
print("CPU:", lower_cholesky.check(x).item())
print("MPS:", lower_cholesky.check(x.to("mps")).item())
```
Outputs
```
CPU: True
MPS: False
```
### Versions
PyTorch version: 1.14.0.dev20221020
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.4 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.201)
CMake version: Could not collect
Libc version: N/A
Python version: 3.8.13 (default, Mar 28 2022, 06:13:39) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-12.4-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.14.0.dev20221020
[pip3] torchaudio==0.14.0.dev20221020
[pip3] torchcde==0.2.5
[pip3] torchdiffeq==0.2.3
[pip3] torchsde==0.2.5
[pip3] torchvision==0.15.0.dev20221020
[conda] numpy 1.23.4 pypi_0 pypi
[conda] torch 1.14.0.dev20221020 pypi_0 pypi
[conda] torchaudio 0.14.0.dev20221020 pypi_0 pypi
[conda] torchcde 0.2.5 pypi_0 pypi
[conda] torchdiffeq 0.2.3 pypi_0 pypi
[conda] torchsde 0.2.5 pypi_0 pypi
[conda] torchvision 0.15.0.dev20221020 pypi_0 pypi
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 0 |
4,435 | 93,562 |
[Bug]: TorchInductor Input As_Strided Calls Dont Compose With Offset Inputs
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
Torchinductor will compile some operators like `aten.select.int` to `as_strided` calls which have the signature:
`as_strided(Tensor(a) self, SymInt[] size, SymInt[] stride, SymInt? storage_offset=None) -> Tensor(a)`
When the input has a non-zero storage offset that offset is ignored.
### Error logs
...
### Did Dynamo succeed?
- [X] Does dynamo.optimize("eager") succeed?
### Did AOT succeed?
- [X] Did dynamo.optimize("aot_eager") succeed?
### Did Inductor succeed?
- [ ] Does dynamo.optimize("inductor") succeed?
### Minified repro
```
import torch
def foo(x):
return torch.ops.aten.select.int(x, 1, 2)
foo_opt = torch._dynamo.optimize("inductor")(foo)
y = torch.rand([3, 4, 5, 6])
z = y[2]
out_opt = foo_opt(z)
out_eager = foo(z)
print(out_opt.storage_offset() == out_eager.storage_offset())
print(torch.allclose(out_opt, out_eager))
```
> False
False
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
4,436 | 87,395 |
Quantized Inference on GPU summary of resources
|
oncall: quantization, triaged
|
### 🚀 The feature, motivation and pitch
Quantized Inference on GPU
### Additional context
Quantization support for GPU inference is an area of active development with two existing protypes
1) PyTorch quantization + fx2trt lowering, inference in TensorRT.
You can read more about TRT at https://pytorch.org/TensorRT/#getting-started
A PTQ tutorial using TRT can be found at https://pytorch.org/TensorRT/tutorials/ptq.html#ptq
You can also find examples in https://github.com/pytorch/TensorRT/blob/master/py/torch_tensorrt/fx/test/quant/test_quant_trt.py
2) Integration with cudnn through native quantized cuda ops which is an early prototype that's been paused.
See test_qconv2d_cudnn at https://github.com/pytorch/pytorch/blob/master/test/quantization/core/test_quantized_op.py#L4608
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo @jgong5 @Xia-Weiwen @leslie-fang-intel
| 7 |
4,437 | 87,390 |
`chunk` a 0-dim tensor will crash in JIT script w/o profiling executor
|
oncall: jit
|
### 🐛 Describe the bug
`chunk` a 0-dim tensor will crash in JIT script w/o profiling executor
```py
import torch
class M(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, inp):
fn_res = torch.chunk(inp, 1, dim=0)[0]
return fn_res
fn = M().to('cpu')
inp = torch.rand([], dtype=torch.float32, device='cpu')
torch._C._jit_set_profiling_executor(False)
jit_fn = torch.jit.script(fn)
print(jit_fn.graph)
jit_fn(inp.clone())
```
```
segmentation fault (core dumped)
```
### Versions
```
Collecting environment information...
PyTorch version: 1.14.0.dev20221020
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.2.0-19ubuntu1) 11.2.0
Clang version: 14.0.0-1ubuntu1
CMake version: version 3.24.1
Libc version: glibc-2.35
Python version: 3.9.13 (main, Aug 25 2022, 23:26:10) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.19.5-051905-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.6.124
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3060
Nvidia driver version: 515.76
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] functorch==0.2.1
[pip3] numpy==1.23.3
[pip3] torch==1.14.0.dev20221020
[pip3] torchaudio==0.14.0.dev20221020
[pip3] torchvision==0.15.0.dev20221020
[conda] _tflow_select 2.3.0 mkl
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] functorch 0.2.1 pypi_0 pypi
[conda] libblas 3.9.0 12_linux64_mkl conda-forge
[conda] libcblas 3.9.0 12_linux64_mkl conda-forge
[conda] liblapack 3.9.0 12_linux64_mkl conda-forge
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py39h7f8727e_0
[conda] mkl_fft 1.3.1 py39hd3c417c_0
[conda] mkl_random 1.2.2 py39h51133e4_0
[conda] numpy 1.23.3 pypi_0 pypi
[conda] numpy-base 1.23.1 py39ha15fc14_0
[conda] pytorch 1.14.0.dev20221020 py3.9_cuda11.6_cudnn8.3.2_0 pytorch-nightly
[conda] pytorch-cuda 11.6 h867d48c_0 pytorch-nightly
[conda] pytorch-mutex 1.0 cuda pytorch-nightly
[conda] tensorflow-base 2.9.1 mkl_py39h353358b_0
[conda] torchaudio 0.13.0.dev20220923+cu116 pypi_0 pypi
[conda] torchvision 0.14.0.dev20220923+cu116 pypi_0 pypi
```
| 0 |
4,438 | 87,389 |
Installing PyTorch with BUILD_SPLIT_CUDA=ON and CUDNN fails on linker error
|
module: build, module: cudnn, module: cuda, triaged, actionable
|
### 🐛 Describe the bug
Environment:
OS: Fedora 36, x86_64
Device: GeForce RTX 3070 Mobile
GCC: 10
Cuda: 11.6
I tried to install PyTorch with the following command:
```
(pytorch10) DEBUG=0 USE_DISTRIBUTED=0 TORCH_CUDA_ARCH_LIST="8.6" BUILD_SPLIT_CUDA=ON USE_MKLDNN=0 USE_CUDA=1 BUILD_TEST=0 USE_FBGEMM=0 USE_OPENMP=0 BUILD_CAFFE2_OPS=0 BUILD_CAFFE2=0 USE_EXPERIMENTAL_CUDNN_V8_API=0 USE_NNPACK=0 USE_QNNPACK=0 USE_NCCL=0 USE_XNNPACK=0 CMAKE_CXX_COMPILER=/home/linuxbrew/.linuxbrew/bin/g++-10 CMAKE_C_COMPILER=/home/linuxbrew/.linuxbrew/bin/gcc-10 python setup.py develop
```
the script failed on linking :
```
[2206/2210] Linking CXX executable bin/torch_shm_manager
FAILED: bin/torch_shm_manager
:
undefined reference to `at::native::cudnn_batch_norm(at::Tensor const&, at::Tensor const&, c10::optional<at::Tensor> const&, c10::optional<at::Tensor> const&, c10::optional<at::Tensor> const&, bool, double, double)'
```
I installed CUDNN and it resolved the issue. I think instead there should be an error that this library is required before trying to create the cuda shared library. The symbol it complains about is a PyTorch symbol, not a CUDNN symbol.
### Versions
torch 1.14.0a0+git440f734
cc @malfet @seemethere @csarofeen @ptrblck @xwang233 @ngimel
| 4 |
4,439 | 87,388 |
Document dist.new_subgroups
|
oncall: distributed, module: docs, triaged
|
### 📚 The doc issue
This is currently undocumented.
### Suggest a potential alternative/fix
_No response_
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu @svekars @carljparker
| 0 |
4,440 | 87,371 |
Better type annotations for `torch.Tensor` subclasses
|
module: typing, triaged, actionable, tensor subclass
|
### 🚀 The feature, motivation and pitch
In the spirit of #86105, I think `torch.Tensor` type annotations can be improved to better support tensor subclasses.
For example, consider
```python
class Subclass(torch.Tensor):
pass
subclass = Subclass()
reveal_type(subclass.clone())
# note: Revealed type is "torch._tensor.Tensor"
print(type(subclass.clone())
# __main__.Subclass
```
It's clear that the underlying logic preserves the subclass, but the type annotations don't. There are many methods which would benefit from improved hints: `clone`, `detach`, `new_full`, `new_ones`, `new_empty`, `new_zero`, and `new_tensor`, to name a few.
### Alternatives
_No response_
### Additional context
_No response_
cc @ezyang @malfet @rgommers @xuzhao9 @gramster
| 3 |
4,441 | 93,561 |
[Bug]: OPTForCausalLM failing with TORCHDYNAMO_DYNAMIC_SHAPES=1: UNPACK_SEQUENCE AssertionError: assert len(seq.items) == inst.argval
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
```
File "/raid/ezyang/pytorch-scratch2/torch/_dynamo/symbolic_convert.py", line 349, in run
and self.step()
File "/raid/ezyang/pytorch-scratch2/torch/_dynamo/symbolic_convert.py", line 322, in step
getattr(self, inst.opname)(inst)
File "/raid/ezyang/pytorch-scratch2/torch/_dynamo/symbolic_convert.py", line 1000, in UNPACK_SEQUENCE
assert len(seq.items) == inst.argval
AssertionError
```
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh @voznesenskym
### Error logs
https://gist.github.com/db994c33e9020d15e4c2ae8dbcf91d2a
### Did Dynamo succeed?
- [ ] Does dynamo.optimize("eager") succeed?
### Did AOT succeed?
- [ ] Did dynamo.optimize("aot_eager") succeed?
### Did Inductor succeed?
- [ ] Does dynamo.optimize("inductor") succeed?
### Minified repro
```
TORCHDYNAMO_DYNAMIC_SHAPES=1 AOT_DYNAMIC_SHAPES=0 time python benchmarks/dynamo/huggingface.py --accuracy --backend eager --training --only OPTForCausalLM
```
minifier did not work (minifier ran, but resulting program did not actually fail)
| 0 |
4,442 | 93,560 |
[Bug]: speech_transformer failing with TORCHDYNAMO_DYNAMIC_SHAPES=1: RuntimeError: expand(CUDABoolType{[10, 1, 204, 320]}, size=[-1, 204, -1]): the number of sizes provided (3) must be greater or equal to the number of dimensions in the tensor (4)
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
```
RuntimeError: expand(CUDABoolType{[10, 1, 204, 320]}, size=[-1, 204, -1]): the number of sizes provided (3) must be greater or equal to the number of dimensions in the tensor (4)
```
Cannot minify as the exception occurs outside of dynamo compiled code
### Error logs
https://gist.github.com/110f0d3706cee14947dd8c4eed9a4c72
### Did Dynamo succeed?
- [ ] Does dynamo.optimize("eager") succeed?
### Did AOT succeed?
- [ ] Did dynamo.optimize("aot_eager") succeed?
### Did Inductor succeed?
- [ ] Does dynamo.optimize("inductor") succeed?
### Minified repro
```
TORCHDYNAMO_DYNAMIC_SHAPES=1 python benchmarks/dynamo/torchbench.py --accuracy --backend eager --training --only speech_transformer
```
minifier doesn't work on this example
cc @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
4,443 | 87,366 |
Implementation of CG, and BICGSTAB methods
|
module: optimizer, triaged, needs research
|
### 🚀 The feature, motivation, and pitch
I want to contribute to the PyTorch community with my implementation of CG and BICGSTAB methods; I believe this will immensely help research students who work in optimization theory, as they can just use these modules which have GPU support, and who have their training scripts written in PyTorch, instead of implementing them from scratch every time.
Thanks, and regards.
### Alternatives
_No response_
### Additional context
Krylov subspace methods are crucial in conjugate gradient solvers, and are a significant part of the optimization theory. Any update rule can be formulated as Ax = b; solving this system of equations iteratively with GPU support is crucial to many research students; this is especially true when they just want to approximate the solutions; an example of such a use case is the implementation of second order methods, especially newton descent methods. In deep learning, it is not feasible to completely solve the equation, hence an iterative solver is necessary.
cc @vincentqb @jbschlosser @albanD
| 1 |
4,444 | 87,364 |
test_ao_sparsity fails when build without FBGEMM
|
triaged
|
### 🐛 Describe the bug
All tests from https://github.com/pytorch/pytorch/blob/master/test/ao/sparsity/test_composability.py (imported in `test_ao_sparsity`) fail when PyTorch is build without FBGEMM, e.g. on POWER.
The test suite/cases should have a `skipIfNoFBGEMM` decorator
### Versions
1.12, 1.13 and current master
| 1 |
4,445 | 87,358 |
Triangular solver for sparse matrices
|
module: sparse, triaged, module: linear algebra
|
### 🚀 The feature, motivation and pitch
Despite not being explicitly documented, [`torch.triangular_solve`](https://pytorch.org/docs/stable/generated/torch.triangular_solve.html) appears to support sparse matrices in CSR and BSR format.
`torch.triangular_solve` is marked deprecated in favour of [`torch.linalg.solve_triangular`](https://pytorch.org/docs/stable/generated/torch.linalg.solve_triangular.html). However `torch.linalg.solve_triangular` does not seem to currently support sparse matrices.
It woud be great to have at least feature parity between `torch.triangular_solve` and `torch.linalg.solve_triangular`. It would also be very helpful to document the existing support for sparse matrices. I indeed only incidentally found out about `torch.triangular_solve` supporting BSR inputs when reading about it in an issue https://github.com/pytorch/pytorch/issues/9222#issuecomment-1006591190. I then found out about CSR support by "random" trial and error.
Additionally, the gradient computed using `torch.triangular_solve` is dense whcih is unexpected. The gradient with respect to the non-zero values only would be more in line with other sparse ops.
### Alternatives
Alternative 1: Relying on the deprecated function until it gets removed
Alternative 2: Implementing a workaround through [`cupyx.scipy.sparse.linalg.spsolve_triangular`](https://docs.cupy.dev/en/stable/reference/generated/cupyx.scipy.sparse.linalg.spsolve_triangular.html) and a custom backward op similar to what I suggested here for generic sparse matrices:
https://github.com/pytorch/pytorch/issues/69538#issuecomment-1010956880
### Additional context
Related issues include: #53441 #9222 #69538 #28341 #10043 #87085
Rough test script:
```python
# Try with the nightly version of PyTorch
!pip3 install --pre torch torchvision torchaudio torchtext --extra-index-url https://download.pytorch.org/whl/nightly/cu117 --upgrade
import torch
print(f'Running PyTorch version: {torch.__version__}')
torchdevice = torch.device('cpu')
if torch.cuda.is_available():
torchdevice = torch.device('cuda')
print('Default GPU is ' + torch.cuda.get_device_name(torch.device('cuda')))
print('Running on ' + str(torchdevice))
# Dimension of the square sparse matrix
n = 5
# Number of non-zero elements (up to duplicates)
nnz = 8
rowidx = torch.randint(low=0, high=n, size=(nnz,), device=torchdevice)
colidx = torch.randint(low=0, high=n, size=(nnz,), device=torchdevice)
itemidx = torch.vstack((rowidx,colidx))
xvalues = torch.randn(nnz, dtype=torch.double, device=torchdevice)
x_coo = torch.sparse_coo_tensor(itemidx, xvalues, size=(n,n)).coalesce()
x_csr = x_coo.to_sparse_csr()
t_dense = torch.triu(x_coo.to_dense())+torch.eye(n,device=torchdevice)
t_coo = t_dense.to_sparse_coo()
t_csr = t_dense.to_sparse_csr()
t_bsr = t_csr.to_sparse_bsr(1)
b = torch.randn(n, dtype=torch.double, device=torchdevice).unsqueeze(1)
print('\ntorch.triangular_solve dense:\n===\n',torch.triangular_solve(b,t_dense,upper=True))
print('\ntorch.linalg.solve_triangular dense:\n===\n',torch.linalg.solve_triangular(t_dense,b,upper=True))
try:
print('\ntorch.triangular_solve coo:\n===\n',torch.triangular_solve(b,t_coo,upper=True))
except Exception as err:
print('\nException - torch.triangular_solve coo:\n===\n')
print(Exception, err)
try:
print('\ntorch.linalg.solve_triangular coo:\n===\n',torch.linalg.solve_triangular(t_coo,b,upper=True))
except Exception as err:
print('\nException - torch.linalg.solve_triangular coo:\n===\n')
print(Exception, err)
print('\ntorch.triangular_solve csr:\n===\n',torch.triangular_solve(b,t_csr,upper=True))
try:
print('\ntorch.linalg.solve_triangular csr:\n===\n',torch.linalg.solve_triangular(t_csr,b,upper=True))
except Exception as err:
print('\nException - torch.linalg.solve_triangular csr:\n===\n')
print(Exception, err)
print('\ntorch.triangular_solve bsr:\n===\n',torch.triangular_solve(b.unsqueeze(0),t_bsr,upper=True))
try:
print('\ntorch.triangular_solve bsr:\n===\n',torch.linalg.solve_triangular(t_bsr,b,upper=True))
except Exception as err:
print('\nException - torch.triangular_solve bsr:\n===\n')
print(Exception, err)
try:
tt_csr= t_csr.detach().clone().requires_grad_(True)
bb = b.detach().clone().requires_grad_(True)
test = torch.autograd.gradcheck(torch.triangular_solve, (bb,tt_csr), check_sparse_nnz=True, eps=1e-6, atol=1e-4)
print('\n=\ncsr torch.triangular_solve',test)
except Exception as err:
print('\n=\ncsr torch.triangular_solve except')
print(Exception, err)
```
cc @nikitaved @pearu @cpuhrsch @amjames @bhosmer @jianyuh @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
| 20 |
4,446 | 93,557 |
[Inductor] Task Tracker for CPU Backend Optimization
|
triaged, oncall: pt2, module: cpu inductor
|
This issue summarizes all the completed, WIP and planned tasks about (or related to) TorchInductor CPU backend optimization. Note that the list is not fixed and would grow per benchmark result and feedbacks from maintainers and the community.
### Completed
- [x] https://github.com/pytorch/torchdynamo/pull/1452
- [x] https://github.com/pytorch/torchdynamo/pull/1468
- [x] https://github.com/pytorch/torchdynamo/pull/1486, https://github.com/pytorch/pytorch/pull/87037
### WIP
- [x] https://github.com/pytorch/pytorch/issues/93552 (FP32 data type as first stage)
- [x] https://github.com/pytorch/pytorch/pull/87068
- [x] https://github.com/pytorch/pytorch/pull/87356
- [x] https://github.com/pytorch/pytorch/pull/88160
- [x] https://github.com/pytorch/pytorch/pull/88482
- [x] https://github.com/pytorch/pytorch/pull/88736
- [x] https://github.com/pytorch/pytorch/issues/93522
- [x] Conv/Linear post-op fusion for inference
- [x] https://github.com/pytorch/pytorch/pull/87063
- [x] https://github.com/pytorch/pytorch/pull/87064
- [x] https://github.com/pytorch/pytorch/pull/87065
- [x] https://github.com/pytorch/pytorch/pull/87066
- [x] Conv/Linear weight prepack for inference
### Planned (short-term)
- [x] Explicit vectorization support for BF16 data type
- [x] Explicit vectorization support for INT8 data type
### Planned (longer than short-term)
- [ ] Codegen for conv/gemm
- [ ] Autotune
- [ ] clang/llvm integration
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
4,447 | 87,353 |
Speed of torch.istft
|
module: performance, triaged, module: fft
|
### 🐛 Describe the bug
It is well-known that the complexity of FFT is O(NlogN) with respect to the sequence length N.
The complexity of STFT given N/T windows of length T is O(N/T * Tlog(T))~O(N).
As such, STFT should be theoretically faster than FFT given large sequence length N.
It can be backed up by the test as follow:
```
import torch
import time
device = torch.device('cuda')
length = 10000
hidden = 6
batch = 256
signal = torch.tensor([[[i for i in range(length)] for dim in range(hidden)] for b in range(batch)], device=device).float()
time_ls = []
for i in range(100):
torch.cuda.synchronize()
start = time.time()
spec = torch.fft.rfft(signal)
# torch.fft.irfft(spec)
torch.cuda.synchronize()
end = time.time()
time_ls.append(end - start)
time_ls = torch.tensor(time_ls)
time_ls = time_ls.sort()[0]
time_ls = time_ls[5:-5]
print(time_ls.mean(), time_ls.std())
time_ls = []
signal = signal.reshape(-1, length)
n_fft = 256
for i in range(100):
torch.cuda.synchronize()
start = time.time()
spec = torch.stft(signal, n_fft=n_fft, hop_length=n_fft, center=False, onesided=True)
# torch.istft(spec, n_fft=n_fft, hop_length=n_fft, center=False, onesided=True)
torch.cuda.synchronize()
end = time.time()
time_ls.append(end - start)
time_ls = torch.tensor(time_ls)
time_ls = time_ls.sort()[0]
time_ls = time_ls[5:-5]
print(time_ls.mean(), time_ls.std())
```
where the time of fft is 0.0008, and the time of stft is 0.0005. That is great!
However, if you uncomment the istft lines, the results are strange,
where the time of fft + ifft is 0.0019, and the time of stft + istft is 0.003.
Why does istft consume so much time?
### Versions
pytorch nightly-release.
**In pytorch 1.12.1 (stable version), the istft function behaves even more poorly due to #84407**
cc @VitalyFedyunin @ngimel @mruberry @peterbell10
| 9 |
4,448 | 87,352 |
RuntimeError: Tensors of type TensorImpl do not have numel
|
module: build, module: cuda, triaged, module: docker
|
### 📚 The doc issue
I was trying to build a docker with pytorch versions as follows
RUN pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 torchaudio==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu113
and nvidia/cuda:11.0-base
and found the error log as follows
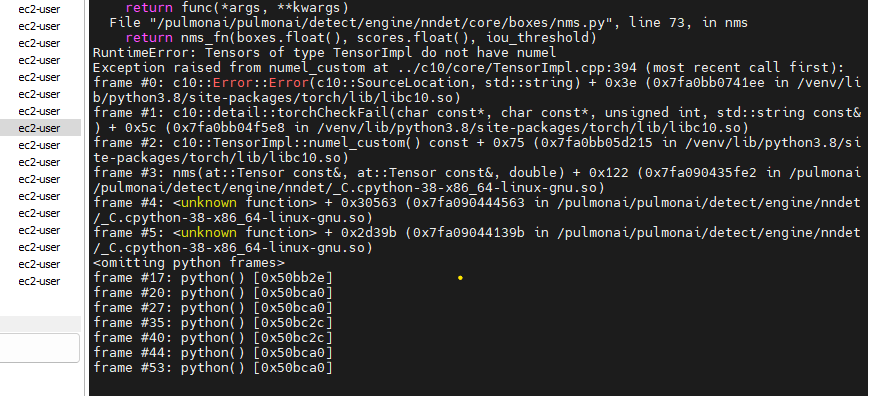
### Suggest a potential alternative/fix
_No response_
cc @malfet @seemethere @ngimel
| 0 |
4,449 | 87,351 |
buffer is not large enough when running pytorch on M1 mps
|
triaged, module: mps
|
### 🐛 Describe the bug
(update: look at next comments for easier reproductions)
As #78496 fix I thought I can use mps using nightly version of torch so when using `torch-1.14.0.dev20221019` I ran
```bash
# preparations
pip3 install --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cpu
pip3 install git+https://github.com/openai/whisper.git # OpenAI's whisper project
wget https://cdn-media.huggingface.co/speech_samples/sample2.flac # just a sample audio file
# actual run
whisper sample2.flac --language=en --device=mps
```
I got, `Error: buffer is not large enough. Must be 29000 bytes`,
```bash
/opt/homebrew/lib/python3.10/site-packages/whisper/decoding.py:629: UserWarning: The operator 'aten::repeat_interleave.self_int' is not currently supported on the MPS backend and will fall back to run on the CPU. This may have performance implications. (Triggered internally at /Users/runner/work/pytorch/pytorch/pytorch/aten/src/ATen/mps/MPSFallback.mm:11.)
audio_features = audio_features.repeat_interleave(self.n_group, dim=0)
/AppleInternal/Library/BuildRoots/a0876c02-1788-11ed-b9c4-96898e02b808/Library/Caches/com.apple.xbs/Sources/MetalPerformanceShaders/MPSCore/Types/MPSNDArray.mm:782: failed assertion `[MPSNDArray, initWithBuffer:descriptor:] Error: buffer is not large enough. Must be 29000 bytes
'
[1] 32842 abort whisper sample2.flac --device=mps --language=en
/opt/homebrew/Cellar/python@3.10/3.10.8/Frameworks/Python.framework/Versions/3.10/lib/python3.10/multiprocessing/resource_tracker.py:224: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown
warnings.warn('resource_tracker: There appear to be %d '
```
Just to note, I don't have the issue with the code https://github.com/pytorch/pytorch/issues/78247 so possibly this is a different issue.
### Versions
```bash
Collecting environment information...
PyTorch version: 1.14.0.dev20221019
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.6 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.102)
CMake version: version 3.24.2
Libc version: N/A
Python version: 3.10.8 (main, Oct 13 2022, 09:48:40) [Clang 14.0.0 (clang-1400.0.29.102)] (64-bit runtime)
Python platform: macOS-12.6-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.4
[pip3] torch==1.14.0.dev20221019
[pip3] torchaudio==0.13.0.dev20221019
[pip3] torchvision==0.15.0.dev20221019
[conda] Could not collect
```
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 9 |
4,450 | 87,350 |
OpenCL 3.0 support: support every GPU on earth through rusticl
|
feature, triaged
|
### 🚀 The feature, motivation and pitch
I know openCL has been requested quite a few times in the past, and it would be a fairly sizable effort to port all of the hundreds of small primitives required. Usually the complaints seem to break down into spotty support and bad performance.
However, with the rapid development of rusticl I think the landscape has changed significantly.
Rusticl is a translation layer in Mesa written in rust, in much the same vein as zink. It provides openCL support on top of gallium 3D, implementing OpenCL 3.0. It was merged into Mesa in mid September and has developed extremely rapidly. It's already useful for running 3D renders in luxmark, GIMP, darktable, with OpenCL image support unlike Clover. It also reportedly passes the OpenCL 3.0 conformance tests.
In terms of hardware support,
It's been fixed up for dGPU support: https://www.phoronix.com/news/Rusticl-Discrete-GPU-Fixes
It's being ported to RadeonSI: https://www.phoronix.com/news/Rusticl-RadeonSI-WIP
to Intel Iris: https://www.phoronix.com/news/Intel-Iris-Rusticl-Prep
and can even run on top of Vulcan drivers, for example intel's ANV: https://www.phoronix.com/news/Rusticl-Zink-Vulkan-Works
It's looking like this is a great way to get PyTorch running _**everywhere.**_
Both major vendors' open drivers, RdeonSI and Iris, but also to the plethora of Vulcan drivers as well.
It can also now outperform ROCm in some cases, and will probably continue to get faster with ongoing optimization work: https://www.phoronix.com/news/Rusticl-Outperformed-ROCm
### Alternatives
There is work on AMD ROCm and partial Vulkan support, but with rusticl already running on ANV through zink, you'd get full support on both AMD and all Vulcan drivers with the same API, with full-featured support on the latter basically for free.
As I understand it, spotty support for ROCm across AMD cards has been a major hurdle (there are plenty of people out there trying to hack PyTorch/ROCm to run on an RX 580, for example), but rusticl already runs equally well on all of them: https://twitter.com/illwieckz/status/1582803118093635585
### Additional context
_No response_
| 8 |
4,451 | 93,556 |
Tracker for manually running pytorch/examples
|
triaged, oncall: pt2
|
- [x] imagenet
- https://github.com/pytorch/torchdynamo/issues/1687 and https://github.com/pytorch/torchdynamo/issues/1701 were filed and fixed.
- [x] word_language_model
- https://github.com/pytorch/torchdynamo/issues/1712 was filed and fixed
- [ ] time_sequence_prediction
- https://github.com/pytorch/pytorch/issues/93558 was filed
- [ ] fast_neural_style
- [ ] mnist
- [ ] mnist_hogwild
- [ ] regression
- [ ] reinforcement_learning
- [ ] siamese_network
- [ ] super_resolution
- [ ] vae
- [ ] dcgan
cc @ezyang @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
4,452 | 93,555 |
LSTM and RNN fail dynamo lowering in eval mode due to FakeTensor issues
|
triaged, oncall: pt2
|
Fails to lower for the `validation` function, but doesn't really crash or anything.
```
$ python main.py --cuda --model LSTM
make_fallback(aten.unfold): a decomposition exists, we should switch to it
make_fallback(aten.unfold_backward): a decomposition exists, we should switch to it
[2022-10-19 22:33:01,885] torch._inductor.lowering: [WARNING] using triton random, expect difference from eager
[2022-10-19 22:33:02,712] torch._inductor.lowering: [WARNING] using triton random, expect difference from eager
| epoch 1 | 200/ 2983 batches | lr 20.00 | ms/batch 19.71 | loss 7.62 | ppl 2039.35
| epoch 1 | 400/ 2983 batches | lr 20.00 | ms/batch 11.68 | loss 6.85 | ppl 943.85
| epoch 1 | 600/ 2983 batches | lr 20.00 | ms/batch 12.93 | loss 6.48 | ppl 650.65
| epoch 1 | 800/ 2983 batches | lr 20.00 | ms/batch 8.14 | loss 6.29 | ppl 537.32
| epoch 1 | 1000/ 2983 batches | lr 20.00 | ms/batch 8.09 | loss 6.14 | ppl 464.14
| epoch 1 | 1200/ 2983 batches | lr 20.00 | ms/batch 8.10 | loss 6.06 | ppl 429.59
| epoch 1 | 1400/ 2983 batches | lr 20.00 | ms/batch 8.03 | loss 5.94 | ppl 379.93
| epoch 1 | 1600/ 2983 batches | lr 20.00 | ms/batch 7.97 | loss 5.93 | ppl 377.54
| epoch 1 | 1800/ 2983 batches | lr 20.00 | ms/batch 8.02 | loss 5.80 | ppl 329.85
| epoch 1 | 2000/ 2983 batches | lr 20.00 | ms/batch 8.03 | loss 5.77 | ppl 320.32
| epoch 1 | 2200/ 2983 batches | lr 20.00 | ms/batch 8.06 | loss 5.65 | ppl 285.32
| epoch 1 | 2400/ 2983 batches | lr 20.00 | ms/batch 8.03 | loss 5.66 | ppl 287.72
| epoch 1 | 2600/ 2983 batches | lr 20.00 | ms/batch 7.99 | loss 5.65 | ppl 284.09
| epoch 1 | 2800/ 2983 batches | lr 20.00 | ms/batch 8.13 | loss 5.54 | ppl 254.32
[2022-10-19 22:33:29,785] torch._dynamo.convert_frame: [ERROR] WON'T CONVERT forward /home/soumith/code/examples/word_language_model/model.py line 48
due to:
Traceback (most recent call last):
File "/home/soumith/code/pytorch/torch/_subclasses/fake_tensor.py", line 701, in __torch_dispatch__
raise Exception(
Exception: Invoking operators with non-Fake Tensor inputs in FakeTensorMode is not yet supported. Please convert all Tensors to FakeTensors first. Found in aten._cudnn_rnn.default(*(FakeTensor(FakeTensor(..., device='meta', size=(25, 20, 200),
grad_fn=<NativeDropoutBackward0>), cuda:0), [FakeTensor(Parameter(FakeTensor(..., device='meta', size=(800, 200), requires_grad=True)), cuda:0), FakeTensor(Parameter(FakeTensor(..., device='meta', size=(800, 200), requires_grad=True)), cuda:0), FakeTensor(Parameter(FakeTensor(..., device='meta', size=(800,), requires_grad=True)), cuda:0), FakeTensor(Parameter(FakeTensor(..., device='meta', size=(800,), requires_grad=True)), cuda:0), FakeTensor(Parameter(FakeTensor(..., device='meta', size=(800, 200), requires_grad=True)), cuda:0), FakeTensor(Parameter(FakeTensor(..., device='meta', size=(800, 200), requires_grad=True)), cuda:0), FakeTensor(Parameter(FakeTensor(..., device='meta', size=(800,), requires_grad=True)), cuda:0), FakeTensor(Parameter(FakeTensor(..., device='meta', size=(800,), requires_grad=True)), cuda:0)], 4, None, FakeTensor(FakeTensor(..., device='meta', size=(2, 20, 200)), cuda:0), FakeTensor(FakeTensor(..., device='meta', size=(2, 20, 200)), cuda:0), 2, 200, 0, 2, False, 0.2, True, False, [], tensor([196, 214, 156, ..., 0, 0, 0], device='cuda:0',
dtype=torch.uint8)), **{})
from user code:
File "/home/soumith/code/examples/word_language_model/model.py", line 50, in forward
output, hidden = self.rnn(emb, hidden)
Set torch._dynamo.config.verbose=True for more information
==========
```
cc @ezyang @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
4,453 | 93,554 |
[Bug]: the custom op cannot be included in the FX graph captured by torchdynamo
|
triaged, bug, oncall: pt2, module: cpu inductor
|
### 🐛 Describe the bug
The custom op registered via PyTorch registration mechanism cannot be included in the FX graph captured by torchdynamo.
### Error logs
the graph of JIT trace includes "torch_ipex::convolution_forward", but the graph of dynamo doesn't include it and got a warnning "Graph break: inline in skipfiles".
the graph of JIT trace:
graph(%self.1 : __torch__.torch.fx.graph_module.___torch_mangle_2.GraphModule,
%x : Tensor):
%self.conv.ctx : __torch__.torch.classes.ipex_prepack.ConvolutionOpContext = prim::Constant[value=object(0x556930639580)]()
%self.conv.weight : Tensor = prim::Constant[value=<Tensor>]()
%self.conv.bias : Tensor = prim::Constant[value=0.01 * -7.6438 3.1947 -6.6860 [ CPUFloatType{3} ]]()
%5 : Tensor = prim::CallMethod[name="get_data_handle"](%self.conv.ctx), scope: __module.conv
%8 : Tensor = prim::profile[profiled_type=Float(3, 6, 10, 10, strides=[600, 1, 60, 6], requires_grad=0, device=cpu), seen_none=0](%x)
%9 : Tensor = prim::profile[profiled_type=Float(1, 6, 3, 3, 16, strides=[864, 144, 48, 16, 1], requires_grad=0, device=cpu), seen_none=0](%self.conv.weight)
%10 : Tensor = prim::profile[profiled_type=Float(3, strides=[1], requires_grad=0, device=cpu), seen_none=0](%self.conv.bias)
%11 : Tensor = prim::profile[profiled_type=Long(1, strides=[1], requires_grad=0, device=cpu), seen_none=0](%5)
%input : Tensor = torch_ipex::convolution_forward(%8, %9, %10, %11), scope: __module.conv # /home/jiayisun/anaconda3/envs/ipex/lib/python3.8/site-packages/torch/_ops.py:175:0
%12 : Tensor = prim::profile[profiled_type=Float(3, 3, 8, 8, strides=[192, 1, 24, 3], requires_grad=0, device=cpu), seen_none=0](%input)
%7 : Tensor = aten::relu_(%12) # /home/jiayisun/anaconda3/envs/ipex/lib/python3.8/site-packages/torch/nn/functional.py:1455:0
%13 : Tensor = prim::profile[profiled_type=Float(3, 3, 8, 8, strides=[192, 1, 24, 3], requires_grad=0, device=cpu), seen_none=0](%7)
= prim::profile()
return (%13)
the graph of dynamo with JIT backend:
torchdynamo.symbolic_convert: [WARNING] Graph break: inline in skipfiles: forward /home/jiayisun/gitlab/frameworks.ai.pytorch.ipex-cpu/build/Release/packages/intel_extension_for_pytorch/nn/utils/_weight_prepack.py from user code at File "<eval_with_key>.4", line 5, in forward
conv = self.conv(x); x = None
graph(%self : __torch__.torch.fx.graph_module.___torch_mangle_6.GraphModule,
%_stack0 : Tensor):
%4 : Tensor = prim::profile[profiled_type=Float(3, 3, 8, 8, strides=[192, 1, 24, 3], requires_grad=0, device=cpu), seen_none=0](%_stack0)
%2 : Tensor = aten::relu_(%4) # /home/jiayisun/anaconda3/envs/ipex/lib/python3.8/site-packages/torch/nn/functional.py:1455:0
%5 : Tensor = prim::profile[profiled_type=Float(3, 3, 8, 8, strides=[192, 1, 24, 3], requires_grad=0, device=cpu), seen_none=0](%2)
%3 : (Tensor) = prim::TupleConstruct(%5)
= prim::profile()
return (%3)
### Minified repro
Here is the example:
```python
class Conv_Bn_Relu(nn.Module):
def __init__(self):
super(Conv_Bn_Relu, self).__init__()
self.conv = torch.nn.Conv2d(6, 3, 3)
self.bn = torch.nn.BatchNorm2d(3, eps=0.001)
def forward(self, x):
return F.relu(self.bn(self.conv(x)), inplace=True)
def compiler(gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor]):
traced_gm = torch.jit.trace(gm.eval(), example_inputs).eval()
traced_gm = torch.jit.freeze(traced_gm)
print(traced_gm.graph_for(*example_inputs))
return traced_gm
model = Conv_Bn_Relu().to(memory_format=torch.channels_last).eval()
x = torch.randn(3, 6, 10, 10).to(memory_format=torch.channels_last)
# In the weight prepack process, aten::conv is replaced by their optimized counterparts in Intel® Extension for PyTorch* via the registration mechanism.
model = ipex.optimize(model)
# jit
with torch.no_grad():
traced_gm = torch.jit.trace(model, x).eval()
traced_gm = torch.jit.freeze(traced_gm)
print(traced_gm.graph_for(x))
# dynamo
m = torchdynamo.optimize(compiler)(model)
with torch.no_grad():
m(x)
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
4,454 | 93,553 |
Better error message when attempting to `torch.save` an optimized model
|
triaged, oncall: pt2
|
A bunch of examples directly do `torch.save(model)`. For example https://github.com/pytorch/examples/blob/main/word_language_model/main.py#L234-L235
Right now, if a dynamo-optimized model is attempted to be saved, this is the error message.
Fixing this IMO is not a priority.
But, at the very least, a better error message should be displayed.
```
-----------------------------------------------------------------------------------------
| end of epoch 1 | time: 26.86s | valid loss 7.29 | valid ppl 1467.68
-----------------------------------------------------------------------------------------
Traceback (most recent call last):
File "/home/soumith/code/examples/word_language_model/main.py", line 237, in <module>
torch.save(model, f)
File "/home/soumith/code/pytorch/torch/serialization.py", line 422, in save
_save(obj, opened_zipfile, pickle_module, pickle_protocol)
File "/home/soumith/code/pytorch/torch/serialization.py", line 634, in _save
pickler.dump(obj)
AttributeError: Can't pickle local object '_TorchDynamoContext.__call__.<locals>.TorchDynamoNNModuleWrapper'
```
cc @ezyang @msaroufim @wconstab @ngimel @bdhirsh
| 0 |
4,455 | 87,298 |
[Quant] There is no default_qconfig_mapping for dynamic quantization
|
oncall: quantization, low priority, triaged
|
https://github.com/pytorch/pytorch/blob/86a581928a4f5065a79771a7a2d87c6999c452e9/torch/ao/quantization/qconfig_mapping.py#L65
`get_default_qconfig_mapping` today only uses static qconfigs. Users who wish to use dynamic qconfigs will have to do something like the following (similar to https://github.com/pytorch/pytorch/pull/87002):
```
qconfig_mapping = get_default_qconfig_mapping().set_global(default_dynamic_qconfig)
for pattern in qconfig_mapping.object_type_qconfigs.keys():
if pattern not in _FIXED_QPARAMS_OP_TO_OBSERVER:
qconfig_mapping.set_object_type(pattern, default_dynamic_qconfig)
```
Maybe we should have `get_default_qconfig_mapping` accept a `default_qconfig` argument.
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo @jgong5 @Xia-Weiwen @leslie-fang-intel
| 1 |
4,456 | 87,289 |
'str' object has no attribute '__module__' in jit is_final
|
oncall: jit
|
### 🐛 Describe the bug
A minimal code to reproduce this error is:
```python
from __future__ import annotations
import torch
from torch import nn
class Name:
pass
class Model(nn.Module):
name: Name
def __init__(self) -> None:
super().__init__()
self.module = nn.Conv2d(3, 3, kernel_size=1)
def forward(self, x):
return self.module(x)
model = Model()
torch.jit.script(model)
```
It crashes with:
```
Traceback (most recent call last):
File "test.py", line 20, in <module>
torch.jit.script(model)
File "/home/azureuser/miniconda3/envs/nni/lib/python3.8/site-packages/torch/jit/_script.py", line 1286, in script
return torch.jit._recursive.create_script_module(
File "/home/azureuser/miniconda3/envs/nni/lib/python3.8/site-packages/torch/jit/_recursive.py", line 455, in create_script_module
concrete_type = get_module_concrete_type(nn_module, share_types)
File "/home/azureuser/miniconda3/envs/nni/lib/python3.8/site-packages/torch/jit/_recursive.py", line 406, in get_module_concrete_type
concrete_type = concrete_type_store.get_or_create_concrete_type(nn_module)
File "/home/azureuser/miniconda3/envs/nni/lib/python3.8/site-packages/torch/jit/_recursive.py", line 347, in get_or_create_concrete_type
concrete_type_builder = infer_concrete_type_builder(nn_module)
File "/home/azureuser/miniconda3/envs/nni/lib/python3.8/site-packages/torch/jit/_recursive.py", line 222, in infer_concrete_type_builder
if torch._jit_internal.is_final(ann):
File "/home/azureuser/miniconda3/envs/nni/lib/python3.8/site-packages/torch/_jit_internal.py", line 943, in is_final
return ann.__module__ in {'typing', 'typing_extensions'} and \
AttributeError: 'str' object has no attribute '__module__'
```
The same script works fine when `from __future__ import annotations` is removed, or `name: Name` is removed.
### Versions
Collecting environment information...
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.10.2
Libc version: glibc-2.27
Python version: 3.8.12 (default, Oct 12 2021, 13:49:34) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-1090-azure-x86_64-with-glibc2.17
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.961
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.3
[pip3] pytorch-lightning==1.6.1
[pip3] torch==1.12.1
[pip3] torchaudio==0.12.1
[pip3] torchmetrics==0.6.0
[pip3] torchvision==0.13.1
[conda] blas 1.0 mkl
[conda] cpuonly 2.0 0 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py38h7f8727e_0
[conda] mkl_fft 1.3.1 py38hd3c417c_0
[conda] mkl_random 1.2.2 py38h51133e4_0
[conda] numpy 1.23.3 py38h14f4228_0
[conda] numpy-base 1.23.3 py38h31eccc5_0
[conda] pytorch 1.12.1 py3.8_cpu_0 pytorch
[conda] pytorch-lightning 1.6.1 pypi_0 pypi
[conda] pytorch-mutex 1.0 cpu pytorch
[conda] torchaudio 0.12.1 py38_cpu pytorch
[conda] torchmetrics 0.6.0 pypi_0 pypi
[conda] torchvision 0.13.1 py38_cpu pytorch
| 0 |
4,457 | 87,283 |
Missing string parsing for some parameter types in python arg parsing logic
|
high priority, triaged, module: pybind
|
### 🐛 Describe the bug
This bug was uncovered while working on https://github.com/pytorch/pytorch/pull/87095. We were accessing garbage value for the default symint argument while directly calling into python bindings code (`torch._C`). Unfortunately symint and symintlist weren't the only parameter types that weren't handled properly in `set_default_str`, which scans the string and sets the default value as well as throws an error if it sees something unexpected (e.g., `None` for device).
Currently, the following argument types are not handled:
```
ParameterType::TENSOR_LIST
ParameterType::GENERATOR
ParameterType::PYOBJECT
ParameterType::MEMORY_FORMAT
ParameterType::DIMNAME
ParameterType::DIMNAME_LIST
ParameterType::SCALAR_LIST
ParameterType::STORAGE
ParameterType::QSCHEME
```
This was only discovered with the above PR because before, we weren't throwing error by default if a parameter type wasn't handled.
Granted that most of them probably don't need to store anything in the default case because they usually default to empty containers, but we should have a hard check for this in `set_default_str`. (added a fallthrough for now: https://github.com/pytorch/pytorch/pull/87095/files#diff-bb8fc823d2ddc10e38cabfc113c4aa0682b6082089079209abab27b7715d1e3eR1062-R1086)
### Versions
Master
cc @ezyang @gchanan @zou3519
| 1 |
4,458 | 93,552 |
Enable TorchInductor to support more vectorization operators
|
triaged, oncall: pt2, module: cpu inductor
|
### 🚀 The feature, motivation and pitch
Currently, we are working on the TorchInductor optimization by using `aten::vec` to accelerate the operator performance.
Regarding the mathematic functions like `exp`, `tanh` and etc, TorchInductor runs into C++ std function now. Its performance is much worse than `aten::vec` because `aten::vec` leverages `Sleef` functions.
We have submitted a PR to establish the infrastructure - https://github.com/pytorch/pytorch/pull/87068. Besides that, we need to implement more features as follows.
- [x] Support reduction
- [ ] Vectorize the tail loop with `aten::vec`
- [x] Lower `angle`, `acos`, `asin`, `atan`, `atan2`, `erfc`, `erfinv`, `expm1`, `log10`, `frac`, `sinh`, `cosh`, `hypot`, `igamma`, `igammac`, `nextafter`, `tan`
- [ ] `round`, `log2`, `log1p`: couldn't find symbolic meta function/decomposition
- [x] Support BF16
- [ ] Optimize the loop condition and loop index calculation by replacing `div` with `add`
### Alternatives
To use OMP SIMD to vectorize the kernel. But it is hard to force the SIMD to run into the `Sleef` function to get better performance.
### Additional context
N/A
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh @jansel @lezcano @fdrocha
| 0 |
4,459 | 93,549 |
[Bug]: GoogleFnet failed to load with amp
|
triaged, bug, oncall: pt2
|
### 🐛 Describe the bug
Command that fails:
```bash
python benchmarks/huggingface.py --performance --training -d cuda --backend=aot_eager --skip-accuracy-check --only GoogleFnet --amp
```
### Error logs
```py
File "/opt/conda/lib/python3.8/site-packages/transformers/models/fnet/modeling_fnet.py", line 220, in forward
self_outputs = self.self(hidden_states)
File "/opt/pytorch/pytorch/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/transformers/models/fnet/modeling_fnet.py", line 199, in forward
outputs = self.fourier_transform(hidden_states).real
RuntimeError: cuFFT only supports dimensions whose sizes are powers of two when computing in half precision, but got a signal size of[512, 768]
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/opt/pytorch/torchdynamo/benchmarks/common.py", line 1881, in main
device, name, model, example_inputs, batch_size = runner.load_model(
File "benchmarks/huggingface.py", line 402, in load_model
self.validate_model(model, example_inputs)
File "/opt/pytorch/torchdynamo/benchmarks/common.py", line 1009, in validate_model
raise NotImplementedError("Eager model failed to run")
NotImplementedError: Eager model failed to run
WARNING:root:GoogleFnet failed to load
```
### Did Dynamo succeed?
- [ ] Does dynamo.optimize("eager") succeed?
### Did AOT succeed?
- [ ] Did dynamo.optimize("aot_eager") succeed?
### Did Inductor succeed?
- [ ] Does dynamo.optimize("inductor") succeed?
### Minified repro
.
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 3 |
4,460 | 87,276 |
torch.save throws ValueError: ctypes objects containing pointers cannot be pickled
|
module: serialization, triaged
|
### 🐛 Describe the bug
I have tried saving my dataloader object, but it throws me ValueError: ctypes objects containing pointers cannot be pickled
Here is the code:
```
batch_size = 16
do_flip = True
flip_vert = True
max_rotate = 90
max_zoom = 1.1
max_lighting = 0.2
max_warp = 0.2
p_affine = 0.75
p_lighting = 0.75
tfms = get_transforms(do_flip=do_flip,
flip_vert=flip_vert,
max_rotate=max_rotate,
max_zoom=max_zoom,
max_lighting=max_lighting,
max_warp=max_warp,
p_affine=p_affine,
p_lighting=p_lighting)
train, valid,test = ObjectItemListSlide(train_images) ,ObjectItemListSlide(valid_images),ObjectItemListSlide(test_images)
item_list = ItemLists(".", valid, test)
lls = item_list.label_from_func(lambda x: x.y, label_cls=SlideObjectCategoryList)
lls = lls.transform(tfms, tfm_y=True, size=patch_size)
data_test= lls.databunch(bs=batch_size, collate_fn=bb_pad_collate,num_workers=0).normalize()
torch.save(data_test.valid_dl,"test_dl.pt")
```
ValueError Traceback (most recent call last)
[<ipython-input-18-91b8a8dc1f71>](https://localhost:8080/#) in <module>
----> 1 torch.save(data_test.valid_dl,"test_dl.pt")
1 frames
[/usr/local/lib/python3.7/dist-packages/torch/serialization.py](https://localhost:8080/#) in save(obj, f, pickle_module, pickle_protocol, _use_new_zipfile_serialization)
378 if _use_new_zipfile_serialization:
379 with _open_zipfile_writer(opened_file) as opened_zipfile:
--> 380 _save(obj, opened_zipfile, pickle_module, pickle_protocol)
381 return
382 _legacy_save(obj, opened_file, pickle_module, pickle_protocol)
[/usr/local/lib/python3.7/dist-packages/torch/serialization.py](https://localhost:8080/#) in _save(obj, zip_file, pickle_module, pickle_protocol)
587 pickler = pickle_module.Pickler(data_buf, protocol=pickle_protocol)
588 pickler.persistent_id = persistent_id
--> 589 pickler.dump(obj)
590 data_value = data_buf.getvalue()
591 zip_file.write_record('data.pkl', data_value, len(data_value))
ValueError: ctypes objects containing pointers cannot be pickled
### Versions
torch-1.11.0 torchvision-0.12.0
cc @mruberry
| 0 |
4,461 | 93,548 |
Use new input clearing mechanism for aot_eager
|
triaged, oncall: pt2
|
@Chillee
Is this optimization already enabled for `aot_eager`? The numbers seem to suggest that it's not. Should we try to enable it with `aot_eager` first just as a confirmation that nothing new has creeped into the memory footprint?
_Originally posted by @anijain2305 in https://github.com/pytorch/torchdynamo/issues/1600#issuecomment-1275613843_
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
4,462 | 93,547 |
dynamo/aot fails when run with autograd.detect_anomaly context manager
|
triaged, oncall: pt2
|
I was trying to debug https://github.com/pytorch/torchdynamo/issues/1712 and more specifically why it was doing "double" backward() call.
We have a context manager called [autograd.detect_anomaly](https://pytorch.org/docs/stable/autograd.html#torch.autograd.detect_anomaly) which allows you to see which part of "forward" made the "backward" error out.
Enabling that context manager errors out.
```
$ python main.py --cuda --model Transformer
/home/soumith/code/examples/word_language_model/main.py:232: UserWarning: Anomaly Detection has been enabled. This mode will increase the runtime and should only be enabled for debugging.
with torch.autograd.detect_anomaly():
/home/soumith/code/pytorch/torch/autograd/__init__.py:300: UserWarning: Error detected in LogSoftmaxBackward0. Traceback of forward call that caused the error:
Module stack: {}
File "/home/soumith/code/examples/word_language_model/model.py", line 151, in forward
return F.log_softmax(output, dim=-1)
(Triggered internally at /home/soumith/code/pytorch/torch/csrc/autograd/python_anomaly_mode.cpp:114.)
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
Traceback (most recent call last):
File "/home/soumith/code/examples/word_language_model/main.py", line 233, in <module>
train()
File "/home/soumith/code/examples/word_language_model/main.py", line 188, in train
output = model(data)
File "/home/soumith/code/pytorch/torch/_dynamo/eval_frame.py", line 137, in __call__
return self.forward(*args, **kwargs)
File "/home/soumith/code/pytorch/torch/_dynamo/eval_frame.py", line 134, in forward
return optimized_forward(*args, **kwargs)
File "/home/soumith/code/pytorch/torch/_dynamo/eval_frame.py", line 157, in _fn
return fn(*args, **kwargs)
File "/home/soumith/code/examples/word_language_model/model.py", line 138, in forward
def forward(self, src, has_mask=True):
File "/home/soumith/code/pytorch/torch/_dynamo/eval_frame.py", line 157, in _fn
return fn(*args, **kwargs)
File "/home/soumith/code/pytorch/functorch/_src/aot_autograd.py", line 858, in forward
return compiled_f(
File "/home/soumith/code/pytorch/functorch/_src/aot_autograd.py", line 844, in new_func
compiled_fn = create_aot_dispatcher_function(
File "/home/soumith/code/pytorch/functorch/_src/aot_autograd.py", line 564, in create_aot_dispatcher_function
aot_dispatch_autograd(flat_fn, fake_flat_tensor_args, aot_config)
File "/home/soumith/code/pytorch/functorch/_src/aot_autograd.py", line 390, in aot_dispatch_autograd
fx_g = make_fx(joint_forward_backward)(*joint_inputs)
File "/home/soumith/code/pytorch/torch/fx/experimental/proxy_tensor.py", line 663, in wrapped
t = dispatch_trace(wrap_key(func, args, fx_tracer), tracer=fx_tracer, concrete_args=tuple(phs))
File "/home/soumith/code/pytorch/torch/_dynamo/eval_frame.py", line 157, in _fn
return fn(*args, **kwargs)
File "/home/soumith/code/pytorch/torch/fx/experimental/proxy_tensor.py", line 413, in dispatch_trace
graph = tracer.trace(root, concrete_args)
File "/home/soumith/code/pytorch/torch/_dynamo/eval_frame.py", line 157, in _fn
return fn(*args, **kwargs)
File "/home/soumith/code/pytorch/torch/fx/_symbolic_trace.py", line 739, in trace
(self.create_arg(fn(*args)),),
File "/home/soumith/code/pytorch/torch/fx/_symbolic_trace.py", line 614, in flatten_fn
tree_out = root_fn(*tree_args)
File "/home/soumith/code/pytorch/torch/fx/experimental/proxy_tensor.py", line 427, in wrapped
out = f(*tensors)
File "/home/soumith/code/pytorch/functorch/_src/aot_autograd.py", line 166, in joint_forward_backward
backward_out = torch.autograd.grad(
File "/home/soumith/code/pytorch/torch/autograd/__init__.py", line 300, in grad
return Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
File "/home/soumith/code/pytorch/torch/utils/_python_dispatch.py", line 101, in __torch_dispatch__
return old.__torch_dispatch__(func, types, args, kwargs)
File "/home/soumith/code/pytorch/torch/fx/experimental/proxy_tensor.py", line 453, in __torch_dispatch__
return self.inner_torch_dispatch(func, types, args, kwargs)
File "/home/soumith/code/pytorch/torch/fx/experimental/proxy_tensor.py", line 478, in inner_torch_dispatch
out = proxy_call(self, func, args, kwargs)
File "/home/soumith/code/pytorch/torch/fx/experimental/proxy_tensor.py", line 256, in proxy_call
raise RuntimeError(
RuntimeError: It appears that you're trying to get value out of a tracing tensor with aten._local_scalar_dense.default - erroring out! It's likely that this is caused by data-dependent control flow or similar.
```
cc @ezyang @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
4,463 | 87,268 |
register_package has no further documentation
|
module: docs, oncall: package/deploy
|
### 📚 The doc issue
There is a page describing how to save and load torch models. It briefly mentions
```
User extensions can register their own location tags and tagging and deserialization methods using torch.serialization.register_package().
```
However, there is no further explanation beyond that.
https://pytorch.org/docs/stable/generated/torch.load.html?highlight=register_package
### Suggest a potential alternative/fix
If there's a convenient way to extend the capabilities of load & save, it would be useful to know more about it. `register_package` sounds potentially useful, but there is no documentation on it, and the pydoc for that function is empty as well
https://github.com/pytorch/pytorch/blob/c413a32135b745d29e555069d7cd8f6e6527b59f/torch/serialization.py#L89
cc @svekars @carljparker
| 0 |
4,464 | 87,267 |
The installation commands given on the pytorch website will not install properly
|
oncall: binaries, triaged
|
Description: The command to install torch 1.10.0 on the pytorch website is
pip install torch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0
Impact: Following the commands on the official website will result in an error that prevents installation
Solution: Change the installation command to the following, and change torchvision==0.11.0 to 0.11.1
pip install torch==1.10.0 torchvision==0.11.1 torchaudio==0.10.0
<img width="844" alt="图片3" src="https://user-images.githubusercontent.com/60139005/196588665-48a49c8e-b13e-44b6-bc1a-6390a027b24b.png">
<img width="936" alt="图片4" src="https://user-images.githubusercontent.com/60139005/196588671-7ab5d603-9873-4c50-a4b7-c7e5d55f85b6.png">

cc @ezyang @seemethere @malfet
| 4 |
4,465 | 87,236 |
nvprims.div doesn't work with FakeTensor cpu scalars
|
triaged, module: nvfuser, module: fakeTensor
|
### 🐛 Describe the bug
```py
import torch
from torch.fx.experimental.proxy_tensor import make_fx
from torch._subclasses.fake_tensor import FakeTensor
meta_scalar = torch.zeros((), device="meta")
meta_tensor = torch.zeros((3, 3), device="meta")
with torch._subclasses.fake_tensor.FakeTensorMode() as mode:
fake_cpu_scalar = FakeTensor(mode, meta_scalar, torch.device("cpu"))
fake_cuda_tensor = FakeTensor(mode, meta_tensor, torch.device("cuda"))
gm = make_fx(lambda a, b: torch.ops.nvprims.div(a, b))(fake_cuda_tensor, fake_cpu_scalar)
```
```py
File ~/dev/pytorch/master/torch/_prims_common/__init__.py:612, in check_same_shape(allow_cpu_scalar_tensors, *args)
608 if not is_same_shape(shape, arg.shape):
609 msg = "Shape {0} is not the expected shape {1}!".format(
610 arg.shape, shape
611 )
--> 612 raise RuntimeError(msg)
613 else:
614 msg = (
615 "Unexpected type when checking for same shape, " + str(type(arg)) + "!"
616 )
RuntimeError: Shape torch.Size([]) is not the expected shape torch.Size([3, 3])!
```
It works fine with `torch.ops.prims.div`.
### Versions
Latest master.
cc @kevinstephano @jjsjann123
| 2 |
4,466 | 93,546 |
Dynamo+FSDP overall triage
|
triaged, module: fsdp, oncall: pt2
|
Let me post various issues here first and then graduate some of them to their own issue rather than opening tons of issues in the beginning, since some of these may be minor/cosmetic/easy to fix.
- [ ] FakeTensor + FlatParamsWrapper Bug (WIP: pytorch/pytorch#93688 )
- [ ] `[WARNING] Graph break: inline in skipfiles: forward` -- triaging below
- [ ] toy_model: `RuntimeError: The size of tensor a (159567000) must match the size of tensor b (319134000) at non-singleton dimension 0` -- triaging below
- [ ] hf_Bert/hf_T5: `NotImplementedError: UserDefinedObjectVariable(_GenericAlias) is not a constant` -- possible dupe of pytorch/pytorch#93695 ?
cc @zhaojuanmao @mrshenli @rohan-varma @awgu @ezyang @soumith @msaroufim @ngimel @bdhirsh
| 0 |
4,467 | 87,222 |
`custom_jvp` and `custom_vjp`
|
triaged, module: functorch
|
### 🚀 The feature, motivation and pitch
`functorch` equivalents to [jax.custom_jvp](https://jax.readthedocs.io/en/latest/_autosummary/jax.custom_jvp.html#jax.custom_jvp) and [jax.custom_vjp](https://jax.readthedocs.io/en/latest/_autosummary/jax.custom_vjp.html#jax.custom_vjp), i.e., decorators to define custom derivatives:
#### PyTorch API
```Python
class F(Function):
@staticmethod
def jvp():
pass
@staticmethod
def vjp():
pass
f = F()
```
#### Hypothetical functorch API
```Python
@functorch.custom_jvp
@functorch.custom_vjp
def f(x: Tensor) -> Tensor:
pass
@f.x_jvp
def f_x_jvp():
pass
@f.x_vjp
def f_x_vjp():
pass
```
### Alternatives
_No response_
### Additional context
_No response_
cc @zou3519 @Chillee @samdow @soumith
| 3 |
4,468 | 87,209 |
Reproducible "CUDA error: an illegal memory access was encountered"
|
needs reproduction, module: crash, module: cuda, triaged
|
### 🐛 Describe the bug
I get a "CUDA error: an illegal memory access was encountered" error 100% of the time with the following code.
The error seems to occur only when `input_length` is 249 or 250. For other values, it doesn't seem to happen.
I'm guessing this is hitting some edge case in tensor manipulation & indexing, but I have no idea where.
```
#!/usr/bin/env python3
import torch
from torch import nn
from torchaudio.models import Conformer
class Model(nn.Module):
def __init__(self):
super().__init__()
encoder_dim = 272
num_heads = 8
num_layers = 18
conv_kernel_size = 31
num_labels = 500
conv_layers = [
nn.Conv1d(
in_channels=80, out_channels=encoder_dim * 2,
kernel_size=3, stride=1, padding=0, dilation=1),
nn.GLU(dim=1),
nn.Conv1d(
in_channels=encoder_dim, out_channels=encoder_dim * 2,
kernel_size=3, stride=2, padding=0, dilation=1),
nn.GLU(dim=1),
nn.Conv1d(
in_channels=encoder_dim, out_channels=encoder_dim * 2,
kernel_size=3, stride=1, padding=0, dilation=1),
nn.GLU(dim=1),
nn.Conv1d(
in_channels=encoder_dim, out_channels=encoder_dim * 2,
kernel_size=3, stride=2, padding=0, dilation=1),
nn.GLU(dim=1),
]
self.conv_subsampler = nn.Sequential(*conv_layers)
self.conformer = Conformer(
input_dim=encoder_dim, num_heads=num_heads, ffn_dim=4 * encoder_dim,
num_layers=num_layers, depthwise_conv_kernel_size=conv_kernel_size,
)
self.output_layer = nn.Linear(encoder_dim, num_labels + 1)
def forward(self, input_t: torch.Tensor):
output = self.conv_subsampler(input_t.unsqueeze(1).transpose(2, 3).squeeze(1)).transpose(1, 2)
output, output_lengths = self.conformer(output, torch.tensor([output.shape[1]]).cuda())
output = self.output_layer(output)
return output, output_lengths
# 249 or 250 here causes "RuntimeError: CUDA error: an illegal memory access was encountered"
input_length = 250
input_tensor = torch.rand((1, input_length, 80), dtype=torch.float32).cuda()
model = Model().cuda()
output, output_len = model(input_tensor)
output = nn.functional.log_softmax(output, dim=2).transpose(0, 1)
lossfun = nn.CTCLoss(blank=0, reduction='mean')
print(output.shape)
loss = lossfun(output, torch.cuda.IntTensor([[1, 2]]), output_len, torch.cuda.IntTensor([2]))
loss.backward()
```
Output:
```
$ reproduce_250_bug.py
torch.Size([60, 1, 501])
Traceback (most recent call last):
File "reproduce_250_bug.py", line 62, in <module>
loss.backward()
File "/home/wjeon/miniconda3/envs/py38/lib/python3.8/site-packages/torch/_tensor.py", line 396, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/home/wjeon/miniconda3/envs/py38/lib/python3.8/site-packages/torch/autograd/__init__.py", line 173, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: CUDA error: an illegal memory access was encountered
```
### Versions
```
$ python collect_env.py
Collecting environment information...
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.10.2
Libc version: glibc-2.27
Python version: 3.8.13 (default, Mar 28 2022, 11:38:47) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-4.15.0-194-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.7.99
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: Tesla V100-SXM2-32GB
Nvidia driver version: 515.65.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.4.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.4.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.2
[pip3] torch==1.12.1
[pip3] torchaudio==0.12.1
[pip3] torchvision==0.13.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h2bc3f7f_2
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] libblas 3.9.0 12_linux64_mkl conda-forge
[conda] libcblas 3.9.0 12_linux64_mkl conda-forge
[conda] liblapack 3.9.0 12_linux64_mkl conda-forge
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-service 2.4.0 py38h7f8727e_0
[conda] mkl_fft 1.3.1 py38hd3c417c_0
[conda] mkl_random 1.2.2 py38h51133e4_0
[conda] numpy 1.23.2 pypi_0 pypi
[conda] numpy-base 1.23.1 py38ha15fc14_0
[conda] pytorch 1.12.1 py3.8_cuda11.3_cudnn8.3.2_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.12.1 py38_cu113 pytorch
[conda] torchvision 0.13.1 py38_cu113 pytorch
```
cc @ezyang @gchanan @zou3519 @ngimel
| 7 |
4,469 | 87,196 |
Missing `docker` directory in `tools/`
|
module: docs, triaged, module: docker
|
### 🐛 Describe the bug
The `docker` directory mentioned in README of build `tools` is missing
https://github.com/pytorch/pytorch/blob/dbccccb7a2f724fc57e42bd1f347212f12984a67/tools/README.md?plain=1#L56
The link listing all runtime Docker images could be used here.
cc @svekars @holly1238
| 1 |
4,470 | 87,178 |
The autogenerated out variants via `autogen:` do not check that the dtype of the `out` kwarg via `canCast`.
|
triaged, module: codegen
|
### 🐛 Describe the bug
As per title. cc @ezyang @bhosmer @bdhirsh
### Versions
master
| 0 |
4,471 | 87,172 |
Unstable results in sin/arcsin/arccos calls
|
module: numerical-stability, triaged, module: edge cases
|
### 🐛 Describe the bug
I get unstable results when sin, arcsin, arccos are called sequentially. sin followed by arcsin should give by the same value, however the calculation is not exactly the same and we get unstable results after arccos: `0.0003` on CPU and `nan` on CUDA.
Here is the code to reproduce the issue:
```
import torch
x = torch.ones(2)
y = torch.sin(x)
y = torch.arcsin(y) # inverse operations, gives [1.0000, 1.0000]
y = torch.arccos(y)
print(y) # gives [0.0003, 0.0003]
x1 = x.clone().cuda()
y1 = torch.sin(x1)
y1 = torch.arcsin(y1) # gives [1.0000, 1.0000]
y1 = torch.arccos(y1)
print(y1) # gives [nan, nan]
```
### Versions
1.12.1+cu113
| 1 |
4,472 | 87,170 |
torch.linalg.cond gives inconsistent results on CPU/CUDA
|
triaged, module: NaNs and Infs, module: linear algebra
|
### 🐛 Describe the bug
`torch.linalg.cond` computes the conditional number of a matrix. But if the matrix is not invertiable it should give back infinity but we can get different results on cpu and gpu:
- CPU: 1.4825e+08
- GPU: 9.8031e+14
- numpy: inf
Code to reproduce:
```
import torch
import numpy as np
torch.manual_seed(420)
torch.cuda.manual_seed_all(420)
input = torch.ones(2, 2)
output = torch.linalg.cond(input)
cuda_input = torch.ones(2, 2).cuda()
cuda_output = torch.linalg.cond(cuda_input)
print(output) # gives large number (1.4825e+08)
print(cuda_output) # gives even larger number (9.8031e+14)
print(np.linalg.cond(input)) # gives inf
```
### Versions
torch 1.12.1+cu113
cc @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
| 2 |
4,473 | 87,163 |
New APIs for cuda graph inspection and manipulation
|
triaged, module: cuda graphs
|
A stalled #85519 adds capabilities to dump cuda graphs for inspection. We would like to extend it to
1) provide a way to get all nodes from the graph
2) modify nodes to patch in addresses for the inputs to avoid copying inputs. Note, this is more complicated than just comparing old and new pointers and swapping one for another because kernels could operate on input slices, so one would need to inspect if kernel argument falls within the range of the original input tensor and, if so, replace it with the corresponding new address + offset.
cc @mcarilli @ezyang @eqy
| 3 |
4,474 | 93,543 |
DDPOptimizer+inductor OOMs with hf_GPT2_large and timm_vision_transformer_large
|
triaged, oncall: pt2
|
Repro:
`gpui --oversubscribe python run_benchmark.py distributed --ngpus 1 --model torchbenchmark.models.hf_GPT2_large.Model --trainer torchbenchmark.util.distributed.core_model.trainer.Trainer --job_dir /fsx/users/dberard/scratch-local/bench-fast/benchmark/logs --cluster local --torchdynamo inductor --optimize_dynamo_ddp`
Error:
```
Traceback (most recent call last):
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/site-packages/submitit/core/submission.py", line 54, in process_job
result = delayed.result()
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/site-packages/submitit/core/utils.py", line 133, in result
self._result = self.function(*self.args, **self.kwargs)
File "/fsx/users/dberard/scratch-local/bench-fast/benchmark/torchbenchmark/util/distributed/submit.py", line 123, in __call__
return trainer_class(self.args, model_class, model_args=self.model_args).measure()
File "/fsx/users/dberard/scratch-local/bench-fast/benchmark/torchbenchmark/util/distributed/core_model/trainer.py", line 90, in measure
self.benchmark.invoke()
File "/fsx/users/dberard/scratch-local/bench-fast/benchmark/torchbenchmark/util/model.py", line 243, in invoke
self.train()
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/site-packages/torch/_dynamo/eval_frame.py", line 157, in _fn
return fn(*args, **kwargs)
File "/fsx/users/dberard/scratch-local/bench-fast/benchmark/torchbenchmark/util/framework/huggingface/model_factory.py", line 123, in train
def train(self):
File "/fsx/users/dberard/scratch-local/bench-fast/benchmark/torchbenchmark/util/framework/huggingface/model_factory.py", line 124, in <graph break in train>
outputs = self.model(**self.example_inputs)
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/site-packages/torch/_tensor.py", line 488, in backward
torch.autograd.backward(
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/site-packages/torch/autograd/__init__.py", line 197, in backward
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/site-packages/torch/autograd/function.py", line 270, in apply
return user_fn(self, *args)
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/site-packages/functorch/_src/aot_autograd.py", line 464, in backward
CompiledFunction.compiled_bw = aot_config.bw_compiler(
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/site-packages/torch/_dynamo/optimizations/backends.py", line 555, in _wrapped_bw_compiler
return disable(bw_compiler(*args, **kwargs))
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 85, in time_wrapper
r = func(*args, **kwargs)
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/site-packages/torch/_inductor/compile_fx.py", line 353, in bw_compiler
return compile_fx_inner(
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/site-packages/torch/_dynamo/debug_utils.py", line 450, in debug_wrapper
compiled_fn = compiler_fn(gm, example_inputs, **kwargs)
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/site-packages/torch/_inductor/debug.py", line 178, in inner
return fn(*args, **kwargs)
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/contextlib.py", line 75, in inner
return func(*args, **kwds)
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/site-packages/torch/_inductor/compile_fx.py", line 120, in compile_fx_inner
compiled_fn = cudagraphify(
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/site-packages/torch/_dynamo/utils.py", line 85, in time_wrapper
r = func(*args, **kwargs)
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/site-packages/torch/_inductor/compile_fx.py", line 183, in cudagraphify
return cudagraphify_impl(model, inputs, static_input_idxs)
File "/data/home/dberard/miniconda/envs/bench-fast/lib/python3.8/site-packages/torch/_inductor/compile_fx.py", line 249, in cudagraphify_impl
model(list(static_inputs))
File "/tmp/torchinductor_dberard/wm/cwmx6z66cmrszqbfpvgyixq7nrq23aagw7qu7or5ijuzlvwfucn4.py", line 470, in call
buf9 = empty_strided((1280, 1280), (1280, 1), device='cuda', dtype=torch.float32)
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 39.41 GiB total capacity; 31.47 GiB already allocated; 7.50 MiB free; 38.03 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try sett
ing max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
4,475 | 87,159 |
torch/csrc/utils/python_arg_parser.h:424:94: error: format ‘%ld’ expects argument of type ‘long int’, but argument 7 has type ‘int’
|
module: build, triaged, module: arm
|
### 🐛 Describe the bug
I'm trying to compile the latest but it failed, then I tried to ```git checkout v1.12.1``` but it failed with the same error. The gcc setting for the CPU are `-march=armv7ve+simd -mfpu=neon-vfpv4` and it fails in the same way on the original hardware and while compiling it with `qemu-arm-static` on a different machine. There are a lot of errors like this:
```
/rstorage/drone/pytorch_install/pytorch/torch/csrc/utils/python_arg_parser.h: In member function ‘std::vector<double, std::allocator<double> > torch::PythonArgs::getDoublelist(int)’:
/rstorage/drone/pytorch_install/pytorch/torch/csrc/utils/python_arg_parser.h:751:82: error: format ‘%ld’ expects argument of type ‘long int’, but argument 7 has type ‘int’ [-Werror=format=]
751 | "%s(): argument '%s' must be %s, but found element of type %s at pos %ld",
| ~~^
| |
| long int
| %d
......
756 | idx + 1);
| ~~~~~~~
| |
| int
```
But even if i "fix" that by changing %ld to %d then i get this :
```
In file included from /rstorage/drone/pytorch_install/pytorch/torch/csrc/jit/python/python_list.cpp:3:
/rstorage/drone/pytorch_install/pytorch/third_party/pybind11/include/pybind11/detail/common.h: In instantiation of ‘pybind11::ssize_t pybind11::ssize_t_cast(const IntType&) [with IntType = long long int; pybind11::ssize_t = int]’:
/rstorage/drone/pytorch_install/pytorch/third_party/pybind11/include/pybind11/pytypes.h:1985:68: required from ‘pybind11::list::list(SzType) [with SzType = long long int; typename std::enable_if<std::is_integral<_Tp>::value, int>::type <anonymous> = 0]’
/rstorage/drone/pytorch_install/pytorch/torch/csrc/jit/python/python_list.cpp:32:25: required from here
/rstorage/drone/pytorch_install/pytorch/third_party/pybind11/include/pybind11/detail/common.h:410:35: error: static assertion failed: Implicit narrowing is not permitted.
410 | static_assert(sizeof(IntType) <= sizeof(ssize_t), "Implicit narrowing is not permitted.");
| ~~~~~~~~~~~~~~~~^~~~~~~~~~~~~~~~~~
/rstorage/drone/pytorch_install/pytorch/third_party/pybind11/include/pybind11/detail/common.h:410:35: note: ‘(sizeof (long long int) <= sizeof (pybind11::ssize_t))’ evaluates to false
```
It seem like some kind of an integer auto-sizing error somewhere.
### Versions
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (armv7l)
GCC version: (Ubuntu 11.2.0-19ubuntu1) 11.2.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Aug 10 2022, 11:40:04) [GCC 11.3.0] (32-bit runtime)
Python platform: Linux-5.15.72-sunxi-armv7l-with-glibc2.35
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] numpy==1.21.5
[conda] Could not collect
cc @malfet @seemethere
| 5 |
4,476 | 87,157 |
DISABLED test_expanded_reduction_cpu (__main__.CpuTests)
|
triaged, skipped, module: inductor, module: dynamo
|
Platforms: linux
This test was disabled because it is failing on master ([recent examples](http://torch-ci.com/failure/test_expanded_reduction_cpu%2CCpuTests)).
cc @jansel @lezcano @fdrocha @mlazos @soumith @voznesenskym @yanboliang
| 2 |
4,477 | 87,145 |
Unrecognized data format when using release libtorch libraries in debug build
|
oncall: jit
|
## Issue description
Once the model has been created, trained and evaluated (in Python using PyTorch), it is exported to a PT file (using TorchScript). It is then simply loaded using libtorch C++ to see if an error occurs.
The error (see **Code example** below) states that there is an issue with the format of the data supplied. However once the build type for the application that uses libtorch is switched to release, the issue disappears.
It appears that at least for VS2017 (MSVC v141, CMake 3.12) combining different build versions (release with debug and vice versa) is not working. Using the release version of libtorch in a debug build of a 3rd party software should be allowed for two main reasons:
* libtorch debug version (especially GPU) is huge
* Developer may not want to actually debug libtorch and only debug code that is calling libtorch functionality.
## Code example
Standard project with CMake using the following code (taken from the examples in the documentation):
```
#include <torch/script.h>
#include <iostream>
#include <memory>
int main(int argc, const char* argv[])
{
torch::jit::script::Module module;
try {
std::cout << "Trying to load model..." << std::endl;
module = torch::jit::load("test_model.pt");
}
catch (const c10::Error& e) {
std::cerr << "Loading failed" << std::endl;
std::cerr << e.what() << std::endl;
return -1;
}
std::cout << "Loading successful" << std::endl;
}
```
Creating a debug build, while linking at the release libraries of libtorch, creates and error:
```
Trying to load model...
Loading failed
Unrecognized data format
Exception raised from load at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\torch\csrc\jit\serialization\import.cpp:449 (most recent call first):
00007FF84F79DA2200007FF84F79D9C0 c10.dll!c10::Error::Error [<unknown file> @ <unknown line number>]
00007FF84F79D43E00007FF84F79D3F0 c10.dll!c10::detail::torchCheckFail [<unknown file> @ <unknown line number>]
00007FFFD64CB54700007FFFD64CB4E0 torch_cpu.dll!torch::jit::load [<unknown file> @ <unknown line number>]
00007FFFD64CB42A00007FFFD64CB380 torch_cpu.dll!torch::jit::load [<unknown file> @ <unknown line number>]
00007FF762B5682B00007FF762B566E0 pytroch_load_model.exe!main [c:\users\USER\projects\cmake dx cuda pytorch\cmake_integration_examples\pytorch\src\pytroch_load_model.cpp @ 17]
00007FF762B81BF400007FF762B81BC0 pytroch_load_model.exe!invoke_main [d:\agent\_work\2\s\src\vctools\crt\vcstartup\src\startup\exe_common.inl @ 79]
00007FF762B81A9E00007FF762B81970 pytroch_load_model.exe!__scrt_common_main_seh [d:\agent\_work\2\s\src\vctools\crt\vcstartup\src\startup\exe_common.inl @ 288]
00007FF762B8195E00007FF762B81950 pytroch_load_model.exe!__scrt_common_main [d:\agent\_work\2\s\src\vctools\crt\vcstartup\src\startup\exe_common.inl @ 331]
00007FF762B81C8900007FF762B81C80 pytroch_load_model.exe!mainCRTStartup [d:\agent\_work\2\s\src\vctools\crt\vcstartup\src\startup\exe_main.cpp @ 17]
00007FF884C6703400007FF884C67020 KERNEL32.DLL!BaseThreadInitThunk [<unknown file> @ <unknown line number>]
00007FF884F4265100007FF884F42630 ntdll.dll!RtlUserThreadStart [<unknown file> @ <unknown line number>]
```
The error, even if it had something to do with the loaded data, is not helpful at all since `unknown file` and `unknown line number` is as vague as it gets.
Switching to a release build (linking against the release libtorch libraries) resolves the problem and the model is loaded successfully. Note that the model itself is not important here. Multiple both self-made as well as download from various "Paper with Code" sources and repositories for PyTorch models suffer from the same issue.
## System Info
Environment (using Python script to collect data):
```
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 10 Enterprise
GCC version: Could not collect
Clang version: Could not collect
CMake version: version 3.25.0-rc1
Libc version: N/A
Python version: 3.10.6 | packaged by conda-forge | (main, Oct 7 2022, 20:14:50) [MSC v.1916 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.19043-SP0
Is CUDA available: True
CUDA runtime version: 11.2.67
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3080 Laptop GPU
Nvidia driver version: 516.94
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.23.1
[pip3] torch==1.12.1
[pip3] torchaudio==0.12.1
[pip3] torchvision==0.13.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h59b6b97_2
[conda] mkl 2021.4.0 haa95532_640
[conda] mkl-service 2.4.0 py310h2bbff1b_0
[conda] mkl_fft 1.3.1 py310ha0764ea_0
[conda] mkl_random 1.2.2 py310h4ed8f06_0
[conda] numpy 1.23.1 py310h6d2d95c_0
[conda] numpy-base 1.23.1 py310h206c741_0
[conda] pytorch 1.12.1 py3.10_cuda11.3_cudnn8_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.12.1 py310_cu113 pytorch
[conda] torchvision 0.13.1 py310_cu113 pytorch
```
- PyTorch: latest, libtorch 1.12.1 (release build, cpu and gpu versions)
- How you installed PyTorch (conda, pip, source): PyTorch is installed via conda (miniconda environment)
- CUDA/cuDNN version: CUDA 11.2, latest cuDNN
- CMake version: 3.12 (supplied by Visual Studio 2017 Pro installation)
- Compiler: MSVC v141 (supplied by Visual Studio 2017 Pro installation)
| 1 |
4,478 | 87,131 |
torch.clamp does not clamp out of -0 from 0 when ran on the CPU
|
triaged, module: numpy, module: edge cases
|
### 🐛 Describe the bug
when ran on the CPU, `torch.clamp` does not clamp out of -0 from 0 (i.e. when min is 0, it does not change -0 to 0 as it should).
- output on cpu: -0.
- output on gpu: 0.
- output with numpy: 0.
See this code snippet to produce the bug:
```
import torch
import numpy as np
torch.manual_seed(420)
torch.cuda.manual_seed_all(420)
x = torch.tensor([-0., 0., 0.])
y = torch.clamp(x, min=0, max=1) # prints [-0., 0., 0.]
print(y)
x = x.cuda()
y = torch.clamp(x, min=0, max=1) # prints [0., 0., 0.]
print(y)
x = np.array([-0., 0., 0.])
y = np.clip(x, 0, 1)
print(y) # prints [0., 0., 0.]
```
### Versions
torch 1.12.1
cc @mruberry @rgommers
| 0 |
4,479 | 87,129 |
[MPS] sum on a size=1 dim is ~5x slower than squeeze
|
triaged, module: mps
|
### 🐛 Describe the bug
For a dimension with size 1, MPS's implementation of sum is ~5x slower than squeeze. This becomes more painful when the tensor is larger, as shown in the benchmarks below.
## Proposed Solution:
Would it help to have MPS's kernel for sum call squeeze when the size of the sum'd dimension is already 1 (for the case where dimensions should not be kept)? --> I have not checked whether this is already the case.
## Benchmarks

[sum_benchmark.txt](https://github.com/pytorch/pytorch/files/9804411/sum_benchmark.txt) --> changed this to a TXT so GH would let me upload it, but to run, change the extension back to .py.
### Versions
master
```
Collecting environment information...
PyTorch version: 1.14.0a0+gitb40f443
Is debug build: True
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.5 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.102)
CMake version: version 3.22.1
Libc version: N/A
Python version: 3.10.6 (main, Oct 7 2022, 15:17:36) [Clang 12.0.0 ] (64-bit runtime)
Python platform: macOS-12.5-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: False
Versions of relevant libraries:
[pip3] numpy==1.23.1
[pip3] torch==1.14.0a0+gitb40f443
[conda] numpy 1.23.1 py310h220015d_0
[conda] numpy-base 1.23.1 py310h742c864_0
[conda] torch 1.14.0a0+gitb40f443 dev_0 <develop>
```
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 5 |
4,480 | 87,126 |
Bug in Histogram Observer Implementation
|
oncall: quantization, triaged
|
### 🐛 Describe the bug
It seems to me that the `HistogramObserver` implementation has a bug. In [L 1181](https://github.com/pytorch/pytorch/blob/e85dbcc9b075961ab082975348c5cf1d99b7da76/torch/ao/quantization/observer.py#L1181) the forward pass is as follows:
```
combined_histogram = self._combine_histograms(
combined_histogram,
self.histogram,
self.upsample_rate,
downsample_rate,
start_idx,
self.bins,
)
```
Where `_combine_histograms` is defined as:
```
def _combine_histograms(
self,
orig_hist: torch.Tensor,
new_hist: torch.Tensor,
upsample_rate: int,
downsample_rate: int,
start_idx: int,
Nbins: int,
) -> torch.Tensor:
```
Therefore, ` combined_histogram` gets mapped to `orig_hist` while `self.histogram` gets mapped to `new_hist`. It seems to me like it should be the other way around given the variable names.
Can someone clarify?
Thank you!!
### Versions
latest main
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo @jgong5 @Xia-Weiwen @leslie-fang-intel
| 2 |
4,481 | 87,090 |
MPS memory usage significantly higher than on CPU
|
module: memory usage, triaged, module: mps
|
### 🐛 Describe the bug
Thanks for the MPS backend! I've started to use it more but one issue I've been running into is that I OOM much more easily when using `device=mps` than `device=cpu`. I've included a fairly small example that reproduces this behavior:
```python
# bug.py
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalMultiheadAttention(nn.Module):
def __init__(self, d_model, n_heads, n_ctx):
super().__init__()
assert d_model % n_heads == 0
self.n_heads = n_heads
self.d_head = d_head = d_model // n_heads
self.n_ctx = n_ctx
self.linear_q = nn.Linear(d_model, n_heads * d_head)
self.linear_k = nn.Linear(d_model, n_heads * d_head)
self.linear_v = nn.Linear(d_model, n_heads * d_head)
self.output = nn.Linear(n_heads * d_head, d_model)
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, T, D = x.size()
q = self.linear_q(x).view(B, T, self.n_heads, self.d_head)
k = self.linear_k(x).view(B, T, self.n_heads, self.d_head)
v = self.linear_v(x).view(B, T, self.n_heads, self.d_head)
q = q.transpose(1, 2) # [B, n_heads, T, d_head]
k = k.transpose(1, 2).transpose(2, 3) # [B, n_heads, d_head, T]
v = v.transpose(1, 2) # [B, n_heads, T, d_head]
x = q @ k # [B, n_heads, T, T]
x.mul_(self.d_head**-0.5)
x = F.softmax(x, dim=-1)
x = x @ v # [B, n_heads, T, d_head]
x = x.transpose(1, 2).contiguous() # [B, T, n_heads, d_head]
x = x.view(B, T, self.n_heads * self.d_head)
x = self.output(x)
assert x.size() == (B, T, D)
return x
d_model = 128
n_heads = 8
n_ctx = 2048
batch_size = 32
argparse = argparse.ArgumentParser()
argparse.add_argument("--device", type=str, default="cpu")
args = argparse.parse_args()
device = torch.device(args.device)
attn = CausalMultiheadAttention(d_model, n_heads, n_ctx).to(device)
for idx in range(2000):
print(idx)
ins = torch.randn(batch_size, n_ctx, d_model).to(device)
out = attn(ins)
```
Running it on my M1 Max gives me roughly:
* `python bug.py --device cpu` has a peak memory usage of about 10GB
* `python bug.py --device mps` has a peak memory usage of about 17GB
(I'm actually unsure how to best report the memory size in use since MPS will use shared GPU memory; the above figures are from what Activity Monitor reports for the python process)
Beyond this toy example, I find that I consistently cannot train models on MPS that I can fit when training on CPU (with the exact same code, the only difference being the `device` used).
### Versions
Collecting environment information...
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.6 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.102)
CMake version: version 3.24.2
Libc version: N/A
Python version: 3.10.5 (main, Jul 9 2022, 10:15:34) [Clang 13.1.6 (clang-1316.0.21.2.5)] (64-bit runtime)
Python platform: macOS-12.6-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.971
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.22.4
[pip3] torch==1.12.1
[conda] Could not collect
cc @kulinseth @albanD @malfet @DenisVieriu97 @razarmehr @abhudev
| 2 |
4,482 | 87,089 |
Failing periodic test: test_comprehensive_masked_cumprod_cuda_float16 (__main__.TestInductorOpInfoCUDA)
|
module: cuda, triaged, module: inductor
|
### 🐛 Describe the bug
This test started failing periodic:
cuda11.6-py3.10-gcc7-sm86 / test (default, 1, 4, linux.g5.4xlarge.nvidia.gpu):
- test_comprehensive_masked_cumprod_cuda_float16 (__main__.TestInductorOpInfoCUDA)
(Probably unrelated, but the tests in https://github.com/pytorch/pytorch/issues/87087 started failing a few prs before this one)
You can find the logs from the failure here:
https://hud.pytorch.org/pytorch/pytorch/commit/30f6f6903c7e68d2105d5b8dfe8841a788bab051
Specifically:
```
2022-10-16T21:39:26.1245187Z ======================================================================
2022-10-16T21:39:26.1245375Z FAIL [0.262s]: test_comprehensive_masked_cumprod_cuda_float16 (__main__.TestInductorOpInfoCUDA)
2022-10-16T21:39:26.1245591Z ----------------------------------------------------------------------
2022-10-16T21:39:26.1245691Z Traceback (most recent call last):
2022-10-16T21:39:26.1245973Z File "/opt/conda/lib/python3.10/site-packages/torch/testing/_internal/common_utils.py", line 2008, in wrapper
2022-10-16T21:39:26.1246061Z method(*args, **kwargs)
2022-10-16T21:39:26.1246368Z File "/opt/conda/lib/python3.10/site-packages/torch/testing/_internal/common_device_type.py", line 378, in instantiated_test
2022-10-16T21:39:26.1246471Z result = test(self, **param_kwargs)
2022-10-16T21:39:26.1246763Z File "/opt/conda/lib/python3.10/site-packages/torch/testing/_internal/common_device_type.py", line 824, in test_wrapper
2022-10-16T21:39:26.1246858Z return test(*args, **kwargs)
2022-10-16T21:39:26.1247149Z File "/opt/conda/lib/python3.10/site-packages/torch/testing/_internal/common_device_type.py", line 1020, in only_fn
2022-10-16T21:39:26.1247240Z return fn(self, *args, **kwargs)
2022-10-16T21:39:26.1247516Z File "/opt/conda/lib/python3.10/site-packages/torch/testing/_internal/common_utils.py", line 1315, in wrapper
2022-10-16T21:39:26.1247606Z fn(*args, **kwargs)
2022-10-16T21:39:26.1247756Z File "/opt/conda/lib/python3.10/unittest/mock.py", line 1369, in patched
2022-10-16T21:39:26.1247864Z return func(*newargs, **newkeywargs)
2022-10-16T21:39:26.1248063Z File "/var/lib/jenkins/workspace/test/inductor/test_torchinductor_opinfo.py", line 599, in test_comprehensive
2022-10-16T21:39:26.1248134Z raise e
2022-10-16T21:39:26.1248331Z File "/var/lib/jenkins/workspace/test/inductor/test_torchinductor_opinfo.py", line 557, in test_comprehensive
2022-10-16T21:39:26.1248415Z self.check_model_cuda(
2022-10-16T21:39:26.1248565Z File "/opt/conda/lib/python3.10/unittest/mock.py", line 1369, in patched
2022-10-16T21:39:26.1248674Z return func(*newargs, **newkeywargs)
2022-10-16T21:39:26.1248864Z File "/var/lib/jenkins/workspace/test/inductor/test_torchinductor.py", line 332, in check_model_cuda
2022-10-16T21:39:26.1248941Z check_model(
2022-10-16T21:39:26.1249088Z File "/opt/conda/lib/python3.10/unittest/mock.py", line 1369, in patched
2022-10-16T21:39:26.1249196Z return func(*newargs, **newkeywargs)
2022-10-16T21:39:26.1249377Z File "/var/lib/jenkins/workspace/test/inductor/test_torchinductor.py", line 288, in check_model
2022-10-16T21:39:26.1249458Z self.assertEqual(
2022-10-16T21:39:26.1249743Z File "/opt/conda/lib/python3.10/site-packages/torch/testing/_internal/common_utils.py", line 2472, in assertEqual
2022-10-16T21:39:26.1249822Z assert_equal(
2022-10-16T21:39:26.1250089Z File "/opt/conda/lib/python3.10/site-packages/torch/testing/_comparison.py", line 1093, in assert_equal
2022-10-16T21:39:26.1250190Z raise error_metas[0].to_error(msg)
2022-10-16T21:39:26.1250380Z AssertionError: Tensor-likes are not close!
2022-10-16T21:39:26.1250387Z
2022-10-16T21:39:26.1250487Z Mismatched elements: 1 / 5 (20.0%)
2022-10-16T21:39:26.1250689Z Greatest absolute difference: 0.03125 at index (1,) (up to 1e-05 allowed)
2022-10-16T21:39:26.1250841Z Greatest relative difference: 0.0011210762331838565 at index (1,) (up to 0.001 allowed)
2022-10-16T21:39:26.1250867Z
2022-10-16T21:39:26.1250969Z The failure occurred for item [0]
```
### Versions
n/a
cc @ngimel @jansel @lezcano @fdrocha @mlazos @soumith @voznesenskym @yanboliang
| 2 |
4,483 | 87,087 |
Failing periodic tests: test_dense_mask_index_cpu (__main__.CpuTests) & est_expanded_reduction_cpu (__main__.CpuTests)
|
triaged, module: flaky-tests
|
### 🐛 Describe the bug
The following two tests started failing periodic builds together
cuda11.6-py3.10-gcc7-sm86 / test (default, 4, 4, linux.g5.4xlarge.nvidia.gpu):
- test_dense_mask_index_cpu (__main__.CpuTests)
- est_expanded_reduction_cpu (__main__.CpuTests)
Logs showing the failing tests:
https://hud.pytorch.org/pytorch/pytorch/commit/a0c2a7f2eda788a48f1d243940297f1467faf138
Specifically, the failing tests are:
```
2022-10-16T05:48:45.7754229Z ======================================================================
2022-10-16T05:48:45.7754367Z FAIL [0.031s]: test_dense_mask_index_cpu (__main__.CpuTests)
2022-10-16T05:48:45.7754584Z ----------------------------------------------------------------------
2022-10-16T05:48:45.7754690Z Traceback (most recent call last):
2022-10-16T05:48:45.7754974Z File "/var/lib/jenkins/workspace/test/inductor/test_torchinductor.py", line 3214, in test_dense_mask_index
2022-10-16T05:48:45.7755108Z self.common(fn, [torch.randn(102400), torch.randn(3)])
2022-10-16T05:48:45.7755264Z File "/opt/conda/lib/python3.10/unittest/mock.py", line 1369, in patched
2022-10-16T05:48:45.7755376Z return func(*newargs, **newkeywargs)
2022-10-16T05:48:45.7755564Z File "/var/lib/jenkins/workspace/test/inductor/test_torchinductor.py", line 256, in check_model
2022-10-16T05:48:45.7755652Z self.assertEqual(
2022-10-16T05:48:45.7755940Z File "/opt/conda/lib/python3.10/site-packages/torch/testing/_internal/common_utils.py", line 2472, in assertEqual
2022-10-16T05:48:45.7756023Z assert_equal(
2022-10-16T05:48:45.7756287Z File "/opt/conda/lib/python3.10/site-packages/torch/testing/_comparison.py", line 1093, in assert_equal
2022-10-16T05:48:45.7756392Z raise error_metas[0].to_error(msg)
2022-10-16T05:48:45.7756505Z AssertionError: Scalars are not close!
2022-10-16T05:48:45.7756513Z
2022-10-16T05:48:45.7756700Z Absolute difference: 0.0002899169921875 (up to 1e-05 allowed)
2022-10-16T05:48:45.7756900Z Relative difference: 1.3709022109477941e-06 (up to 1.3e-06 allowed)
2022-10-16T05:48:45.7756905Z
2022-10-16T05:48:45.7757017Z ======================================================================
2022-10-16T05:48:45.7757162Z FAIL [0.026s]: test_expanded_reduction_cpu (__main__.CpuTests)
2022-10-16T05:48:45.7757369Z ----------------------------------------------------------------------
2022-10-16T05:48:45.7757465Z Traceback (most recent call last):
2022-10-16T05:48:45.7757662Z File "/var/lib/jenkins/workspace/test/inductor/test_torchinductor.py", line 766, in test_expanded_reduction
2022-10-16T05:48:45.7757807Z self.common(fn, (torch.randn(2, 197, 256), torch.randn(2, 1, 256)))
2022-10-16T05:48:45.7757959Z File "/opt/conda/lib/python3.10/unittest/mock.py", line 1369, in patched
2022-10-16T05:48:45.7758070Z return func(*newargs, **newkeywargs)
2022-10-16T05:48:45.7758305Z File "/var/lib/jenkins/workspace/test/inductor/test_torchinductor.py", line 256, in check_model
2022-10-16T05:48:45.7758397Z self.assertEqual(
2022-10-16T05:48:45.7758708Z File "/opt/conda/lib/python3.10/site-packages/torch/testing/_internal/common_utils.py", line 2472, in assertEqual
2022-10-16T05:48:45.7758782Z assert_equal(
2022-10-16T05:48:45.7759056Z File "/opt/conda/lib/python3.10/site-packages/torch/testing/_comparison.py", line 1093, in assert_equal
2022-10-16T05:48:45.7759155Z raise error_metas[0].to_error(msg)
2022-10-16T05:48:45.7759317Z AssertionError: Tensor-likes are not close!
2022-10-16T05:48:45.7759323Z
2022-10-16T05:48:45.7759424Z Mismatched elements: 1 / 256 (0.4%)
2022-10-16T05:48:45.7759657Z Greatest absolute difference: 2.002716064453125e-05 at index (36,) (up to 1e-05 allowed)
2022-10-16T05:48:45.7759892Z Greatest relative difference: 4.907013266928203e-06 at index (36,) (up to 1.3e-06 allowed)
2022-10-16T05:48:45.7759903Z
2022-10-16T05:48:45.7760111Z ----------------------------------------------------------------------
```
Probably unrelated, but the following test also started failing a few PRs later (tracked in https://github.com/pytorch/pytorch/issues/87089):
This test started failing a few PRs later
cuda11.6-py3.10-gcc7-sm86 / test (default, 1, 4, linux.g5.4xlarge.nvidia.gpu):
- test_comprehensive_masked_cumprod_cuda_float16 (__main__.TestInductorOpInfoCUDA)
### Versions
n/a
| 1 |
4,484 | 87,085 |
gradcheck failure with sparse matrix multiplication
|
module: sparse, module: autograd, triaged
|
### 🐛 Describe the bug
As detailed in #86963, sparse @ dense matrix mutiplication fails to pass gradcheck. A manual inspection of the gradient seems to indicate that this is a bug with gradcheck rather than the matrix multiplication itself.
Steps to reproduce:
```python
# Try with the nightly version of PyTorch
!pip3 install --pre torch torchvision torchaudio torchtext --extra-index-url https://download.pytorch.org/whl/nightly/cu117 --upgrade
import torch
print(f'Running PyTorch version: {torch.__version__}')
torchdevice = torch.device('cpu')
if torch.cuda.is_available():
torchdevice = torch.device('cuda')
print('Default GPU is ' + torch.cuda.get_device_name(torch.device('cuda')))
print('Running on ' + str(torchdevice))
# Dimension of the square sparse matrix
n = 5
# Number of non-zero elements (up to duplicates)
nnz = 8
rowidx = torch.randint(low=0, high=n, size=(nnz,), device=torchdevice)
colidx = torch.randint(low=0, high=n, size=(nnz,), device=torchdevice)
itemidx = torch.vstack((rowidx,colidx))
xvalues = torch.randn(nnz, dtype=torch.double, device=torchdevice)
x_coo = torch.sparse_coo_tensor(itemidx, xvalues, size=(n,n)).coalesce()
#print('x_coo:',x_coo)
#print(x_coo.to_dense())
x_csr = x_coo.to_sparse_csr()
b = torch.randn(n, dtype=torch.double, device=torchdevice).unsqueeze(1)
try:
xx_coo = x_coo.detach().clone().requires_grad_(True)
bb = b.detach().clone().requires_grad_(True)
test = torch.autograd.gradcheck(torch.sparse.mm, (xx_coo, bb), check_sparse_nnz=True, eps=1e-6, atol=1e-4)
print('\n=\ncoo torch.sparse.mm gradcheck',test)
except Exception as err:
print('\n=\ncoo torch.sparse.mm gradcheck except')
print(Exception, err)
try:
xx_csr = x_csr.detach().clone().requires_grad_(True)
bb = b.detach().clone().requires_grad_(True)
test = torch.autograd.gradcheck(torch.sparse.mm, (xx_csr, bb), check_sparse_nnz=True, eps=1e-6, atol=1e-4)
print('\n=\ncsr torch.sparse.mm gradcheck',test)
except Exception as err:
print('\n=\ncsr torch.sparse.mm gradcheck except')
print(Exception, err)
try:
xx_coo = x_coo.detach().clone().requires_grad_(True)
bb = b.detach().clone().requires_grad_(True)
test = torch.autograd.gradcheck(torch.mm, (xx_coo, bb), check_sparse_nnz=True, eps=1e-6, atol=1e-4)
print('\n=\ncoo torch.mm gradcheck',test)
except Exception as err:
print('\n=\ncoo torch.mm gradcheck except')
print(Exception, err)
try:
xx_csr = x_csr.detach().clone().requires_grad_(True)
bb = b.detach().clone().requires_grad_(True)
test = torch.autograd.gradcheck(torch.mm, (xx_csr, bb), check_sparse_nnz=True, eps=1e-6, atol=1e-4)
print('\n=\ncsr torch.mm gradcheck',test)
except Exception as err:
print('\n=\ncsr torch.mm gradcheck except')
print(Exception, err)
try:
xx_coo = x_coo.detach().clone().requires_grad_(True)
bb = b.detach().clone().requires_grad_(True)
test = torch.autograd.gradcheck(torch.smm, (xx_coo, bb), check_sparse_nnz=True, eps=1e-6, atol=1e-4)
print('\n=\ncoo torch.smm gradcheck',test)
except Exception as err:
print('\n=\ncoo torch.smm gradcheck except')
print(Exception, err)
try:
xx_csr = x_csr.detach().clone().requires_grad_(True)
bb = b.detach().clone().requires_grad_(True)
test = torch.autograd.gradcheck(torch.smm, (xx_csr, bb), check_sparse_nnz=True, eps=1e-6, atol=1e-4)
print('\n=\ncsr torch.smm gradcheck',test)
except Exception as err:
print('\n=\ncsr torch.smm gradcheck except')
print(Exception, err)
try:
xx_coo = x_coo.detach().clone().requires_grad_(True)
bb = b.detach().clone().requires_grad_(True)
test = torch.autograd.gradcheck(torch.nn.functional.linear, (bb.squeeze(), xx_coo), check_sparse_nnz=True, eps=1e-6, atol=1e-4)
print('\n=\ncoo torch.nn.functional.linear gradcheck',test)
except Exception as err:
print('\n=\ncoo torch.nn.functional.linear gradcheck except')
print(Exception, err)
try:
xx_csr = x_csr.detach().clone().requires_grad_(True)
bb = b.detach().clone().requires_grad_(True)
test = torch.autograd.gradcheck(torch.nn.functional.linear, (bb.squeeze(), xx_csr), check_sparse_nnz=True, eps=1e-6, atol=1e-4)
print('\n=\ncsr torch.nn.functional.linear gradcheck',test)
except Exception as err:
print('\n=\ncsr torch.nn.functional.linear gradcheck except')
print(Exception, err)
```
### Versions
Based on current google colab with manually updated pytorch version:
```
PyTorch version: 1.14.0.dev20221017+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.22.6
Libc version: glibc-2.26
Python version: 3.7.14 (default, Sep 8 2022, 00:06:44) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.10.133+-x86_64-with-Ubuntu-18.04-bionic
Is CUDA available: True
CUDA runtime version: 11.2.152
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: Tesla T4
Nvidia driver version: 460.32.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.6
[pip3] torch==1.14.0.dev20221017+cu117
[pip3] torchaudio==0.13.0.dev20221017+cu117
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.14.0.dev20221017
[pip3] torchvision==0.15.0.dev20221017+cu117
[conda] Could not collect
```
cc @nikitaved @pearu @cpuhrsch @amjames @bhosmer @ezyang @albanD @zou3519 @gqchen @soulitzer @Lezcano @Varal7
| 1 |
4,485 | 87,080 |
cppextension host compiler check ignores executable symbolic link in CUDA bin directory
|
module: build, module: cpp-extensions, triaged
|
### 🐛 Describe the bug
PyTorch 1.12 added a [host compiler version check](https://github.com/pytorch/pytorch/blob/b40f4434ac3512a21dcec91467df1b179898503f/torch/utils/cpp_extension.py#L409-L420) when building PyTorch extensions. However, one way of specifying the host compiler executable used by nvcc is to include a symbolic link to the desired compiler executable in the CUDA home directory, and it seems that the compiler version check does not take this into account. This results in an error, even though nvcc may well be setup to use the correct host compiler version.
It may well be good to check for other ways that nvcc may be informed which compiler to use and factor these into the version check too.
It seems a simple workaround is to simply to set the ```TORCH_DONT_CHECK_COMPILER_ABI``` environment variable. But it would be nice to not rely on this, as it is useful to know when the compiler version is genuinely wrong.
### Versions
PyTorch 1.12
cc @malfet @seemethere @zou3519
| 0 |
4,486 | 87,076 |
Nandense layer for missing values
|
module: sparse, module: nn, triaged, module: masked operators
|
### 🚀 The feature, motivation and pitch
This paper has an interesting Tensorflow implementation of a nan aware layer so that the neural network can handle missing values natively. Code provided in the paper, might be interesting to implement in Pytorch for inclusion in this library.
https://arxiv.org/pdf/2206.01640.pdf
### Alternatives
_No response_
### Additional context
_No response_
cc @nikitaved @pearu @cpuhrsch @amjames @bhosmer @albanD @mruberry @jbschlosser @walterddr @kshitij12345 @saketh-are
| 1 |
4,487 | 87,070 |
DISABLED test_variant_consistency_jit_linalg_lu_cuda_complex64 (__main__.TestJitCUDA)
|
module: cuda, triaged, module: flaky-tests, skipped, module: unknown
|
Platforms: linux
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_variant_consistency_jit_linalg_lu_cuda_complex64&suite=TestJitCUDA) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/8924896021).
Over the past 3 hours, it has been determined flaky in 1 workflow(s) with 1 failures and 1 successes.
**Debugging instructions (after clicking on the recent samples link):**
DO NOT BE ALARMED IF THE CI IS GREEN. We now shield flaky tests from developers so CI will thus be green but it will be harder to parse the logs.
To find relevant log snippets:
1. Click on the workflow logs linked above
2. Click on the Test step of the job so that it is expanded. Otherwise, the grepping will not work.
3. Grep for `test_variant_consistency_jit_linalg_lu_cuda_complex64`
4. There should be several instances run (as flaky tests are rerun in CI) from which you can study the logs.
cc @ngimel
| 9 |
4,488 | 93,540 |
more cudagraphs tests
|
triaged, oncall: pt2
|
After https://github.com/pytorch/pytorch/pull/87058 and https://github.com/pytorch/pytorch/pull/87060 and the issues that prompted those PRs, I can think of a bunch of edge-cases that we should add tests for within the cudagraph codepath:
1. Inputs are views of a larger storage
```python
input_parent = torch.randn(1000, requires_grad=True)
input1 = input_parent[0:100]
input2 = input_parent[300:400]
out = model(input1, input2)
out.sum().backward()
```
2. Same as (1), but model parameters share storage
```python
class Repro(torch.nn.Module):
def __init__(self):
super(Repro, self).__init__(device)
self.weight1 = torch.nn.Parameter(
torch.randn(2, 2, requires_grad=True, device=device)
)
self.weight2 = nn.Parameter(self.weight1.detach())
# the weights wont remain tied across a `model.to(device)` or `model.cuda()` call, so this has to be carefully constructed with the weights already on the target device
def forward(self, x):
# assert(self.weight1.data_ptr() == self.weight2.data_ptr())
x = torch.matmul(x, self.weight1)
x = torch.matmul(x, self.weight2)
return x
```
3. Inputs have actual overlap
```python
input_parent = torch.randn(1000, requires_grad=True)
input1 = input_parent[0:100]
input2 = input_parent[50:200]
out = model(input1, input2)
out.sum().backward()
```
cc: @eellison
cc @ezyang @msaroufim @wconstab @ngimel @bdhirsh
| 1 |
4,489 | 87,056 |
Pipe conveys inconsistent value in GPU env
|
module: multiprocessing, triaged
|
### 🐛 Describe the bug
The Pipe and Queue of multiprocessing module conveys inconsistent value in GPU env while run correctly in non-heterogeneous env.
For the code below, the values on two sides of the Pipe are inconsistent. However, if the env is non-heterogeneous (do not .to('cuda:0')), the result is correct.
```python
import multiprocessing
import torch
import time
def genData(pipeIn):
for i in range(2):
t=torch.ones(3,).to('cuda:0')
#t=torch.ones(3,)
pipeIn.send(t)
time.sleep(1)
if __name__ == '__main__':
pout, pin = multiprocessing.Pipe(duplex=False)
temp = multiprocessing.Process(target=genData, args=(pin,))
temp.start()
for i in range(2):
r = pout.recv()
print(r)
del r
```
### Versions
- CPython versions: 3.8.10
- Operating system and architecture:
- Windows 11 (Version: 21H2) on 11th Gen Intel(R) Core(TM) i7-11800H @ 2.30GHz 2.30 GHz
- GPU: NVIDIA GeForce RTX 3060 Laptop GPU
- Dependecies: Torch (1.11.0+cu113)
cc @VitalyFedyunin
| 0 |
4,490 | 87,041 |
Segmentation fault: 11 when running "import torch" on Mac OS X
|
triaged, module: macos
|
### 🐛 Describe the bug
Hi team, I'm getting `Segmentation fault: 11` when trying to import torch in my local machine:
```
Python 3.7.12 | packaged by conda-forge | (default, Oct 26 2021, 05:59:23)
[Clang 11.1.0 ] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
Segmentation fault: 11
```
I have looked through past issues and tried to look for similar errors, but haven't found anything related to seg fault 11.
I installed `gdb` and tried to debug, but I'm not sure if it has some issues and the output looks correct:
`gdb python
r -c "import torch"`
```
Reading symbols from python...
warning: `/tmp/lto.o': can't open to read symbols: No such file or directory.
(No debugging symbols found in python)
(gdb)
(gdb) r -c "import torch"
Starting program: /Users/Darren/opt/miniconda3/envs/computer-vision/bin/python -c "import torch"
[New Thread 0x1803 of process 21505]
[New Thread 0x1a03 of process 21505]
warning: unhandled dyld version (17)
File "<string>", line 1
"import
^
SyntaxError: EOL while scanning string literal
[Inferior 1 (process 21505) exited with code 01]
```
Also tried running [collect_env.py](https://github.com/pytorch/pytorch/blob/master/torch/utils/collect_env.py), but it gave the same "Segmentation fault: 11" error from the line `import torch`.
I installed PyTorch with `pip3 install torch torchvision`, the versions are torch 1.12.1 and torchvision 0.13.1. I was trying to install for CPU only since I don't have a GPU.
Any idea on what might be causing the seg fault? Thanks
### Versions
I had to manually set `TORCH_AVAILABLE` to false to bypass `import torch`, which would otherwise cause a seg fault 11 error.
```
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: macOS 11.4 (x86_64)
GCC version: Could not collect
Clang version: 14.0.4
CMake version: version 3.22.1
Libc version: N/A
Python version: 3.7.12 | packaged by conda-forge | (default, Oct 26 2021, 05:59:23) [Clang 11.1.0 ] (64-bit runtime)
Python platform: Darwin-20.5.0-x86_64-i386-64bit
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] numpy==1.21.6
[pip3] torch==1.12.1
[pip3] torchvision==0.13.1
[conda] numpy 1.21.6 py37h345d48f_0 conda-forge
[conda] torch 1.12.1 pypi_0 pypi
[conda] torchvision 0.13.1 pypi_0 pypi
```
cc @malfet @albanD
| 4 |
4,491 | 87,033 |
Saving and loading from physical storage
|
module: memory usage, module: serialization, triaged
|
### 🚀 The feature, motivation and pitch
Physical storage allows us to work with very large tensors.
Ideally, saving a tensor from physical storage into a file would not create a copy of the full tensor in memory. I believe that a call to `torch.save` will already do that.
However, when loading the tensor, it will be directly loaded on memory, not on physical storage. This is a problem if the tensor is too big.
A nice feature would be that a tensor that was saved on physical storage would be loaded on physical storage again, without creating a full copy in memory:
```python
x = torch.zeros(10).share_memory_()
torch.save(x, "x.pt")
x_loaded = torch.load("x.pt")
x.is_shared() # the tensor is on physical storage again
```
cc @mruberry @suo
### Alternatives
TorchSnapshot offers an alternative where we can directly save a tensor from physical to physical storage, then load a tensor in place on another one in any memory location without creating a full copy in memory (hence solving this problem). I don't think PyTorch intends to do in-place tensor loading but still, I think that keeping the memory location (as we keep the device) would be a nice-to-have feature.
### Additional context
We have implemented in TorchRL a buffer API where big tensors that would not fit in RAM are stored on disk (say > 1Tb). Through the use of memmap arrays, we can quickly access any given set of rows of these tensors during sampling from the buffer. This is much faster than accessing shared tensors stored in a list for instance.
When checkpointing, we'd like to save directly those tensors from disk storage to disk storage, without loading the full tensor on RAM. We would also like to load tensors that were saved on physical storage on the same storage location, without loading the full tensor in memory.
| 2 |
4,492 | 87,031 |
Improve Readability of error(s) when provided unexpected keyword arguments.
|
module: error checking, triaged, actionable, module: python frontend
|
### 🐛 Describe the bug
Just went through first time using PyTorch and got so confused with the error.
I was trying to figure out how the `mean()` was working, and there I provided wrong keyword argument:
```python
import torch
a = torch.tensor([[7.0, 7.0, 7.0],
[2.0, 2.0, 2.0],
[3.0, 3.0, 3.0]])
torch.mean(a, dims=(0, 1), keepdim=True) # `dims` instead of `dim`
```
The error that I got, which not only confused me but the readability is debatable.
```text
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
[<ipython-input-9-5db8329df866>](https://localhost:8080/#) in <module>
4 [2.0, 2.0, 2.0],
5 [3.0, 3.0, 3.0]])
----> 6 torch.mean(a, dims=(0, 1), keepdim=True)
TypeError: mean() received an invalid combination of arguments - got (Tensor, keepdim=bool, dims=tuple), but expected one of:
* (Tensor input, *, torch.dtype dtype)
didn't match because some of the keywords were incorrect: keepdim, dims
* (Tensor input, tuple of ints dim, bool keepdim, *, torch.dtype dtype, Tensor out)
* (Tensor input, tuple of names dim, bool keepdim, *, torch.dtype dtype, Tensor out)
```
`didn't match because some of the keywords were incorrect: keepdim, dims`. I get it `dims` was incorrect. Was `keepdim` also incorrect?
Can we improve the readability of errors in PyTorch.
Coming from TF background, and this is what I see:
```python
import tensorflow as tf
tf.reduce_mean([1, 2, 3], axs=None) # `axs` instead of `axis`
```
```text
[/usr/local/lib/python3.7/dist-packages/tensorflow/python/util/dispatch.py](https://localhost:8080/#) in op_dispatch_handler(*args, **kwargs)
1074 if iterable_params is not None:
1075 args, kwargs = replace_iterable_params(args, kwargs, iterable_params)
-> 1076 result = api_dispatcher.Dispatch(args, kwargs)
1077 if result is not NotImplemented:
1078 return result
TypeError: Got an unexpected keyword argument 'axs'
```
Straight to the point!
> The above example was ran on Colab environment.
### Versions
PyTorch version: 1.12.1+cu113
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.22.6
Libc version: glibc-2.26
Python version: 3.7.14 (default, Sep 8 2022, 00:06:44) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.10.133+-x86_64-with-Ubuntu-18.04-bionic
Is CUDA available: False
CUDA runtime version: 11.2.152
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.1.1
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.1.1
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.21.6
[pip3] torch==1.12.1+cu113
[pip3] torchaudio==0.12.1+cu113
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.13.1
[pip3] torchvision==0.13.1+cu113
[conda] Could not collect
cc @albanD
| 2 |
4,493 | 87,019 |
Rewrite `narrow_copy_dense_cpu_out` using `copy_` and `narrow`
|
triaged, module: functionalization
|
### 🚀 The feature, motivation and pitch
Looks like the current implementation of `narrow_copy_dense_cpu_out` wasn't fully reviewed before being merged. Alban suggested a potential alternative implementation [here](https://github.com/pytorch/pytorch/pull/49502#issuecomment-759421583):
```cpp
Tensor& narrow_copy_dense_cpu_out(
const Tensor& self, int64_t dim, int64_t start, int64_t length, Tensor& output
) {
// resize output
auto output_sizes = self.sizes().vec();
output_sizes[dim] = length;
at::native::resize_(output, output_sizes);
// write the content into output
return output.copy_(at::narrow(self, dim, start, length));
}
```
I see two advantages:
- the code is much simpler
- it will use the same error checking logic as `narrow` (currently, the checks and error messages are slightly different).
Perf impact of this rewrite needs to be investigated first.
### Alternatives
_No response_
### Additional context
_No response_
cc @bdhirsh @ezyang @soumith
| 2 |
4,494 | 87,003 |
Multiprocessing DataLoader pickles multiprocessing.Queues incorrectly
|
module: dataloader, triaged
|
### 🐛 Describe the bug
If a `DataPipe` instance passed to a `DataLoader` contains a member of `multiprocessing.Queue` when `num_workers>0`, the `Queue` object is not correctly "deserialized" in worker processes, when the start method for sub-processes is "spawn" (the default on MacOS).
The example below works under Linux, but not MacOS.
```
import torchdata
from multiprocessing import Queue
import itertools
import torch
# Lead (worker 0) gives out data to followers. Lame, but to show that workers can
# communicate.
class LeadFollowerDataPipe(torchdata.datapipes.iter.IterDataPipe):
def __init__(self, group_size):
self._group_size = group_size
self._queues = [Queue() for _ in range(self._group_size)]
def __iter__(self):
worker_id = torch.utils.data.get_worker_info().id
assert worker_id < self._group_size
if worker_id != 0:
q = self._queues[worker_id]
while True:
yield worker_id, q.get()
else:
for i in itertools.count(0):
dst_worker = i % self._group_size
if dst_worker == 0:
yield 0, i
self._queues[dst_worker].put(i)
if __name__ == '__main__':
dp = LeadFollowerDataPipe(3)
dl = torch.utils.data.DataLoader(dp, num_workers=3)
for v, _ in zip(dl, range(100)):
print(v)
```
On MacOS, the following occurs:
```
Original Traceback (most recent call last):
File "/lib/python3.8/site-packages/torch/utils/data/datapipes/_typing.py", line 514, in wrap_generator
response = gen.send(None)
File "lead_follower.py", line 22, in __iter__
yield worker_id, q.get()
File "/opt/homebrew/Cellar/python@3.8/3.8.13_1/Frameworks/Python.framework/Versions/3.8/lib/python3.8/multiprocessing/queues.py", line 97, in get
res = self._recv_bytes()
File "/opt/homebrew/Cellar/python@3.8/3.8.13_1/Frameworks/Python.framework/Versions/3.8/lib/python3.8/multiprocessing/connection.py", line 216, in recv_bytes
buf = self._recv_bytes(maxlength)
File "/opt/homebrew/Cellar/python@3.8/3.8.13_1/Frameworks/Python.framework/Versions/3.8/lib/python3.8/multiprocessing/connection.py", line 414, in _recv_bytes
buf = self._recv(4)
File "/opt/homebrew/Cellar/python@3.8/3.8.13_1/Frameworks/Python.framework/Versions/3.8/lib/python3.8/multiprocessing/connection.py", line 379, in _recv
chunk = read(handle, remaining)
OSError: [Errno 9] Bad file descriptor
```
This is because Python's multiprocessing pickles the arguments to the multiprocessing target function, and it has special treatment when pickling sockets (thus, multiprocessing.Queues) [1]. However, DataPipes are wrapped in _DataPipeSerializationWrapper [2]. When pickling the wrapper, the default pickler is always used and that prevents the aforementioned special pickler from doing its job.
Removing these two lines line [3] makes the above code work under MacOS.
[1] https://github.com/python/cpython/blob/f4c03484da59049eb62a9bf7777b963e2267d187/Lib/multiprocessing/reduction.py#L33
[2] https://github.com/pytorch/pytorch/blob/1a7409c77199403153f1260e2281bae2f76745f6/torch/utils/data/datapipes/datapipe.py#L317
[3] https://github.com/pytorch/pytorch/blob/d29c8c0ffa68f11790fc2e9fd78778bb8e9bc281/torch/utils/data/dataloader.py#L259
### Versions
```
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.6 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.102)
CMake version: Could not collect
Libc version: N/A
Python version: 3.8.13 (default, May 8 2022, 17:48:02) [Clang 13.1.6 (clang-1316.0.21.2)] (64-bit runtime)
Python platform: macOS-12.6-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.22.4
[pip3] torch==1.12.1
[pip3] torchdata==0.4.1
[conda] No relevant packages
```
cc @SsnL @VitalyFedyunin @ejguan @NivekT
| 4 |
4,495 | 86,989 |
Error: unknown architecture `armv7-a;' and Error: selected processor does not support `command' in ARM mode
|
oncall: quantization, triaged, module: arm, topic: build
|
### 🐛 Describe the bug
I'm trying to build PyTorch on OprangePi PC (H3 Quad-core Cortex-A7) but for some reason I get
```
Error: unknown architecture `armv7-a;'
```
is that semicolon in a wrong place ? The actual -march is:
```
$:> gcc -c -Q -march=native --help=target | grep march
-march= armv7ve+simd
```
After which I get about a thousand similar errors like this: Error: selected processor does not support 'command' in ARM mode'
Is there a way to force/change -march or is it a bug in the auto-detecting code of `setup.py` / cmake(s) ?
```
/rstorage/pytorch_install/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack/src/q8gemm_sparse/4x8c1x4-dq-packedA-aarch32-neon.S: Assembler messages:
/rstorage/drone/pytorch_install/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack/src/q8gemm_sparse/4x8c1x4-dq-packedA-aarch32-neon.S:471: Error: unknown architecture `armv7-a;'
/rstorage/pytorch_install/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack/src/q8gemm_sparse/4x8c1x4-dq-packedA-aarch32-neon.S:471: Error: selected processor does not support `vpush {d8-d15}' in ARM mode
/rstorage/pytorch_install/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack/src/q8gemm_sparse/4x8c1x4-dq-packedA-aarch32-neon.S:471: Error: selected processor does not support `vld1.8 {d16[]},[r7]' in ARM mode
/rstorage/pytorch_install/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack/src/q8gemm_sparse/4x8c1x4-dq-packedA-aarch32-neon.S:471: Error: selected processor does not support `veor q10,q10,q10' in ARM mode
/rstorage/pytorch_install/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack/src/q8gemm_sparse/4x8c1x4-dq-packedA-aarch32-neon.S:471: Error: selected processor does not support `vld1.8 {d17[]},[r4]!' in ARM mode
/rstorage/pytorch_install/pytorch/aten/src/ATen/native/quantized/cpu/qnnpack/src/q8gemm_sparse/4x8c1x4-dq-packedA-aarch32-neon.S:471: Error: selected processor does not support `vld1.8 {d0},[r6]!' in ARM mode
```
### Versions
Collecting environment information...
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (armv7l)
GCC version: (Ubuntu 11.2.0-19ubuntu1) 11.2.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.10.6 (main, Aug 10 2022, 11:40:04) [GCC 11.3.0] (32-bit runtime)
Python platform: Linux-5.15.72-sunxi-armv7l-with-glibc2.35
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
Versions of relevant libraries:
[pip3] numpy==1.21.5
[conda] Could not collect
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo @malfet
| 5 |
4,496 | 86,968 |
Drop deprecated behavior from NumPy-style `T`
|
triaged, module: numpy, module: deprecation
|
### 🚀 The feature, motivation and pitch
See `numpy_T` in core. The deprecation warning has been there for 12 months and for more than 2 releases, so it can be removed IIUC.
```cpp
if (n != 2 && n != 0) {
TORCH_WARN_ONCE(
"The use of `x.T` on tensors of dimension other than 2 to reverse their shape is deprecated ",
"and it will throw an error in a future release. Consider `x.mT` to transpose batches of matrices ",
"or `x.permute(*torch.arange(x.ndim - 1, -1, -1))` to reverse the dimensions of a tensor."
);
}
```
See the BC policy:
https://github.com/pytorch/pytorch/wiki/PyTorch's-Python-Frontend-Backward-and-Forward-Compatibility-Policy
Maybe `T` can be made into an alias of `t`, but they have slightly different constraints:
- `T` checks for `n != 2 && n != 0`, `t` (in `check_t`) checks sparse dims and has a check for `<= 2`.
- `T` is implemented using `permute`, `t` is implemented using `transpose`.
### Alternatives
_No response_
### Additional context
_No response_
cc @mruberry @rgommers
| 2 |
4,497 | 86,965 |
Upgrade to a newer llvm-openmp version to avoid `/dev/shm` pollution
|
oncall: binaries, triaged, module: openmp
|
### 🐛 Describe the bug
In the following conda environment, on linux:
```sh
conda create -n test
conda activate test
conda install pytorch==1.12.0 torchvision torchaudio cudatoolkit=11.3 -c pytorch
```
You will notice that the `llvm-openmp` package will be installed as well.
Now, consider the following python code executed inside that environment
```py
import subprocess
import torch # imports llvm-openmp which is compiled with #define KMP_USE_SHM, this creates a file in /dev/shm
subprocess.run("ls") # leaks a file in /dev/shm, since this invocation forks a new process
subprocess.run("/bin/ls", close_fds=False) # doesn't leak, since this invocation will spawn a new process
```
This is resolved with [[OpenMP][libomp] Fix /dev/shm pollution after forked child process terminates
](https://reviews.llvm.org/D125996), which is in the 15.0.0 release of openmp, the version pytorch is compiled with is 14.0.x.
### Versions
Collecting environment information...
PyTorch version: 1.12.0
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.2.0-19ubuntu1) 11.2.0
Clang version: 14.0.0-1ubuntu1
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.9.13 | packaged by conda-forge | (main, May 27 2022, 16:56:21) [GCC 10.3.0] (64-bit runtime)
Python platform: Linux-5.15.0-50-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.3.109
CUDA_MODULE_LOADING set to:
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3080 Ti Laptop GPU
Nvidia driver version: 520.61.05
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.6.0
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.6.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.1
[pip3] torch==1.12.0
[pip3] torchaudio==0.12.0
[pip3] torchmetrics==0.9.3
[pip3] torchvision==0.13.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 11.3.1 h9edb442_10 conda-forge
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2021.4.0 h8d4b97c_729 conda-forge
[conda] mkl-service 2.4.0 py39h7e14d7c_0 conda-forge
[conda] mkl_fft 1.3.1 py39h0c7bc48_1 conda-forge
[conda] mkl_random 1.2.2 py39hde0f152_0 conda-forge
[conda] numpy 1.23.1 py39h6c91a56_0
[conda] numpy-base 1.23.1 py39ha15fc14_0
[conda] pytorch 1.12.0 py3.9_cuda11.3_cudnn8.3.2_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.12.0 py39_cu113 pytorch
[conda] torchvision 0.13.0 py39_cu113 pytorch
cc @ezyang @seemethere @malfet
| 0 |
4,498 | 86,962 |
PyTorch RPC crashed when using IB
|
oncall: distributed, module: rpc
|
### 🐛 Describe the bug
Hi. I am using PyTorch's RPC with tensorpipe backend for my project and encounter a weird bug. Bascially, there are two workers on two machines. Worker A invoked rpc on worker B, and all of a sudden, worker B just crashed.
I compile the PyTorch from scratch to dig into the position where it crashed with gdb. The figure below shows that it crashes due to deference a nullptr pointer. It seems related to IB. But I have no idea why it happened.
However, when I run my program in machines without IB, it works well.
Can you give some clues about this issue? Thanks!

### Versions
```sh
(jasper) ➜ ~ python collect_env.py
Collecting environment information...
PyTorch version: 1.12.0a0+git664058f
Is debug build: False
CUDA used to build PyTorch: 11.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.31
Python version: 3.8.12 (default, Oct 12 2021, 13:49:34) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.0-110-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: 11.3.109
CUDA_MODULE_LOADING set to:
GPU models and configuration:
GPU 0: Tesla P100-PCIE-12GB
GPU 1: Tesla P100-PCIE-12GB
Nvidia driver version: 515.43.04
cuDNN version: Probably one of the following:
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn.so.8.4.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8.4.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_adv_train.so.8.4.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8.4.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8.4.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8.4.0
/usr/local/cuda-11.3/targets/x86_64-linux/lib/libcudnn_ops_train.so.8.4.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.22.3
[pip3] numpydoc==1.3.1
[pip3] torch==1.12.0a0+git664058f
[pip3] torch-scatter==2.0.9
[pip3] torchaudio==0.12.1+cu113
[pip3] torchvision==0.13.1+cu113
[conda] blas 1.0 mkl
[conda] magma-cuda113 2.5.2 1 pytorch
[conda] mkl 2021.4.0 h06a4308_640
[conda] mkl-include 2022.1.0 h06a4308_224
[conda] mkl-service 2.4.0 py38h7f8727e_0
[conda] mkl_fft 1.3.1 py38hd3c417c_0
[conda] mkl_random 1.2.2 py38h51133e4_0
[conda] numpy 1.22.3 pypi_0 pypi
[conda] numpy-base 1.21.5 py38hf524024_2
[conda] numpydoc 1.3.1 pypi_0 pypi
[conda] torch 1.12.0a0+git664058f dev_0 <develop>
[conda] torch-scatter 2.0.9 dev_0 <develop>
[conda] torchaudio 0.12.1+cu113 pypi_0 pypi
[conda] torchvision 0.13.1+cu113 pypi_0 pypi
```
cc @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @H-Huang @kwen2501 @awgu @pietern @jjlilley @mrzzd
| 3 |
4,499 | 86,929 |
DISABLED test_vmapvjpvjp_linalg_lu_cuda_float32 (__main__.TestOperatorsCUDA)
|
triaged, module: flaky-tests, skipped, module: functorch
|
Platforms: linux
This test was disabled because it is failing in CI. See [recent examples](https://hud.pytorch.org/flakytest?name=test_vmapvjpvjp_linalg_lu_cuda_float32&suite=TestOperatorsCUDA) and the most recent trunk [workflow logs](https://github.com/pytorch/pytorch/runs/8873086538).
Over the past 3 hours, it has been determined flaky in 1 workflow(s) with 1 failures and 1 successes.
**Debugging instructions (after clicking on the recent samples link):**
DO NOT BE ALARMED IF THE CI IS GREEN. We now shield flaky tests from developers so CI will thus be green but it will be harder to parse the logs.
To find relevant log snippets:
1. Click on the workflow logs linked above
2. Click on the Test step of the job so that it is expanded. Otherwise, the grepping will not work.
3. Grep for `test_vmapvjpvjp_linalg_lu_cuda_float32`
4. There should be several instances run (as flaky tests are rerun in CI) from which you can study the logs.
cc @zou3519 @Chillee @samdow @soumith
| 9 |
4,500 | 93,535 |
[opbench] NameError: name 'tensor' is not defined
|
triaged, oncall: pt2
|
Opbench doesn't seem to handle inputs with lists correctly.
Command to reproduce
```
python operatorbench.py --op=aten.cat.default --dtype=float16
```
Stacktrace
```
Traceback (most recent call last):
File "/home/villedepommes/miniconda3/envs/torchdynamo2/lib/python3.10/site-packages/torch/fx/graph_module.py", line 269, in __call__
return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
File "/home/villedepommes/miniconda3/envs/torchdynamo2/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1190, in _call_impl
return forward_call(*input, **kwargs)
File "<eval_with_key>.0", line 5, in forward
cat_default = torch.ops.aten.cat.default([tensor([[[[-7.1172, -0.0527, 4.3867, ..., -3.2422, -2.5586, 2.8047],
NameError: name 'tensor' is not defined
Call using an FX-traced Module, line 5 of the traced Module's generated forward function:
def forward(self):
cat_default = torch.ops.aten.cat.default([tensor([[[[-7.1172, -0.0527, 4.3867, ..., -3.2422, -2.5586, 2.8047],
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
[ 1.7490, 3.8242, 1.8721, ..., -5.0781, -7.3281, 4.6953],
[ 1.3975, -2.2070, 3.8047, ..., 5.4141, 8.4844, 3.2266],
error aten.cat.default
name 'tensor' is not defined
Traceback (most recent call last):
File "/home/villedepommes/github/torchdynamo2/benchmarks/microbenchmarks/operatorbench.py", line 281, in <module>
benchmark()
File "/home/villedepommes/miniconda3/envs/torchdynamo2/lib/python3.10/site-packages/click/core.py", line 1130, in __call__
return self.main(*args, **kwargs)
File "/home/villedepommes/miniconda3/envs/torchdynamo2/lib/python3.10/site-packages/click/core.py", line 1055, in main
rv = self.invoke(ctx)
File "/home/villedepommes/miniconda3/envs/torchdynamo2/lib/python3.10/site-packages/click/core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/villedepommes/miniconda3/envs/torchdynamo2/lib/python3.10/site-packages/click/core.py", line 760, in invoke
return __callback(*args, **kwargs)
File "/home/villedepommes/github/torchdynamo2/benchmarks/microbenchmarks/operatorbench.py", line 262, in benchmark
raise e
File "/home/villedepommes/github/torchdynamo2/benchmarks/microbenchmarks/operatorbench.py", line 247, in benchmark
microbenchmark(
File "/home/villedepommes/github/torchdynamo2/benchmarks/microbenchmarks/operatorbench.py", line 78, in microbenchmark
cudagraphs_eager = cudagraphs_inner(gm, gm_args, copy_outputs=False)
File "/home/villedepommes/github/torchdynamo2/torchdynamo/optimizations/backends.py", line 526, in cudagraphs_inner
model(*inputs)
File "/home/villedepommes/miniconda3/envs/torchdynamo2/lib/python3.10/site-packages/torch/fx/graph_module.py", line 660, in call_wrapped
return self._wrapped_call(self, *args, **kwargs)
File "/home/villedepommes/miniconda3/envs/torchdynamo2/lib/python3.10/site-packages/torch/fx/graph_module.py", line 277, in __call__
raise e.with_traceback(None)
NameError: name 'tensor' is not defined
```
cc @ezyang @soumith @msaroufim @wconstab @ngimel @bdhirsh
| 3 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.