
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-08-24 00:44:07
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 518
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-08-24 00:41:25
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
coelacanthxyz/blockassist-bc-finicky_thriving_grouse_1755860665
|
coelacanthxyz
| 2025-08-22T11:32:18Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"finicky thriving grouse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:32:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- finicky thriving grouse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/tsutomu-nihei-lora
|
Muapi
| 2025-08-22T11:31:43Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:31:28Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Tsutomu Nihei Lora

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:179979@1474802", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
chainway9/blockassist-bc-untamed_quick_eel_1755860629
|
chainway9
| 2025-08-22T11:31:03Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed quick eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:30:59Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed quick eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755860717
|
mang3dd
| 2025-08-22T11:30:46Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:30:42Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
roeker/blockassist-bc-quick_wiry_owl_1755862166
|
roeker
| 2025-08-22T11:30:43Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick wiry owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:30:08Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick wiry owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755860574
|
kojeklollipop
| 2025-08-22T11:29:18Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:29:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/yoh-nagao-style
|
Muapi
| 2025-08-22T11:28:38Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:28:24Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Yoh Nagao Style

**Base model**: Flux.1 D
**Trained words**: Yoh Nagao Style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:107192@1519368", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
hyrinmansoor/text2frappe-s3-flan-query
|
hyrinmansoor
| 2025-08-22T11:28:25Z | 1,041 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"t5",
"text2text-generation",
"flan-t5-base",
"erpnext",
"query-generation",
"frappe",
"text2frappe",
"en",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-05T11:48:55Z |
---
tags:
- flan-t5-base
- transformers
- erpnext
- query-generation
- frappe
- text2frappe
- text2text-generation
pipeline_tag: text2text-generation
license: apache-2.0
language: en
library_name: transformers
model-index:
- name: Text2Frappe - Stage 3 Query Generator
results: []
---
# 🧠 Text2Frappe - Stage 3 Query Generator (FLAN-T5-BASE)
This model is the **third stage** in the [Text2Frappe](https://huggingface.co/hyrinmansoor) pipeline, which enables **natural language interface to ERPNext** by converting questions into executable database queries.
---
## 🎯 Task
**Text2Text Generation** – Prompt-based query formulation.
Given:
- A detected **ERPNext Doctype** (from Stage 1),
- A natural language **question**,
- A list of selected **relevant fields** (from Stage 2),
this model generates a valid **Frappe ORM-style query** (e.g., `frappe.get_all(...)`) to retrieve the required data.
---
## 🧩 Input Format
Inputs are JSON-style strings containing:
- `doctype`: the ERPNext document type.
- `question`: the user's question in natural language.
- `fields`: a list of relevant field names predicted by Stage 2.
### 📥 Example Input
```json
{
"doctype": "Purchase Invoice Advance",
"question": "List the reference types used in advance payments made this month.",
"fields": ["reference_type"]
}
```
### 📤 Example Output
frappe.get_all('Purchase Invoice Advance', filters={'posting_date': ['between', ['2024-04-01', '2024-04-30']]}, fields=['reference_type'])
|
Muapi/lovecraftian-nightmare-landscapes
|
Muapi
| 2025-08-22T11:28:04Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:27:52Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Lovecraftian Nightmare Landscapes

**Base model**: Flux.1 D
**Trained words**: n1ghtm@r3
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:607647@747348", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/cute-sdxl-pony-flux
|
Muapi
| 2025-08-22T11:26:17Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:26:02Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Cute (SDXL, Pony, Flux)

**Base model**: Flux.1 D
**Trained words**: ArsMJStyle, Cute
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:577827@820305", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/kft-furry-scaly-feathery-enhancer-flux
|
Muapi
| 2025-08-22T11:25:11Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:24:58Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# KFT Furry/Scaly/Feathery Enhancer [FLUX]

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:750776@839561", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
hakimjustbao/blockassist-bc-raging_subtle_wasp_1755860102
|
hakimjustbao
| 2025-08-22T11:23:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"raging subtle wasp",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:23:21Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- raging subtle wasp
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/ob-japanese-urban-film-photography
|
Muapi
| 2025-08-22T11:23:13Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:22:56Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# OB 日式城市胶片摄影 Japanese Urban Film Photography

**Base model**: Flux.1 D
**Trained words**: OBrbrw
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1184221@1332894", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
sampingkaca72/blockassist-bc-armored_stealthy_elephant_1755860251
|
sampingkaca72
| 2025-08-22T11:22:25Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"armored stealthy elephant",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:22:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- armored stealthy elephant
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/digital-dystopia
|
Muapi
| 2025-08-22T11:21:13Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:20:57Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Digital Dystopia

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1396354@1589111", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
eshanroy5678/blockassist-bc-untamed_dextrous_dingo_1755861353
|
eshanroy5678
| 2025-08-22T11:21:08Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"untamed dextrous dingo",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:19:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- untamed dextrous dingo
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
thanobidex/blockassist-bc-colorful_shiny_hare_1755859886
|
thanobidex
| 2025-08-22T11:18:35Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"colorful shiny hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:18:32Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- colorful shiny hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Muapi/sketch-art
|
Muapi
| 2025-08-22T11:17:42Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:17:25Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Sketch Art

**Base model**: Flux.1 D
**Trained words**: sketch_style
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:802807@897643", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
ngurney/ppo-lunarlander-v3
|
ngurney
| 2025-08-22T11:17:33Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-22T11:17:18Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v3
type: LunarLander-v3
metrics:
- type: mean_reward
value: 263.74 +/- 17.98
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v3**
This is a trained model of a **PPO** agent playing **LunarLander-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Muapi/fantastic-pic-flux
|
Muapi
| 2025-08-22T11:17:05Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:16:53Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# Fantastic Pic [Flux]

**Base model**: Flux.1 D
**Trained words**:
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1193687@1343984", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/dnd-map-world
|
Muapi
| 2025-08-22T11:16:42Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:16:29Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# DnD map world

**Base model**: Flux.1 D
**Trained words**: Dnd_maps
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:1166586@1312422", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
Muapi/donm-sound-of-music-flux-sdxl-pony
|
Muapi
| 2025-08-22T11:16:23Z | 0 | 0 | null |
[
"lora",
"stable-diffusion",
"flux.1-d",
"license:openrail++",
"region:us"
] | null | 2025-08-22T11:16:10Z |
---
license: openrail++
tags:
- lora
- stable-diffusion
- flux.1-d
model_type: LoRA
---
# DonM - Sound of Music [Flux,SDXL,Pony]

**Base model**: Flux.1 D
**Trained words**: digital illustration
## 🧠 Usage (Python)
🔑 **Get your MUAPI key** from [muapi.ai/access-keys](https://muapi.ai/access-keys)
```python
import requests, os
url = "https://api.muapi.ai/api/v1/flux_dev_lora_image"
headers = {"Content-Type": "application/json", "x-api-key": os.getenv("MUAPIAPP_API_KEY")}
payload = {
"prompt": "masterpiece, best quality, 1girl, looking at viewer",
"model_id": [{"model": "civitai:393812@813609", "weight": 1.0}],
"width": 1024,
"height": 1024,
"num_images": 1
}
print(requests.post(url, headers=headers, json=payload).json())
```
|
calcuis/krea-gguf
|
calcuis
| 2025-08-22T11:13:35Z | 2,743 | 7 |
diffusers
|
[
"diffusers",
"gguf",
"gguf-node",
"gguf-connector",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-Krea-dev",
"base_model:quantized:black-forest-labs/FLUX.1-Krea-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-07-31T20:55:43Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-Krea-dev/blob/main/LICENSE.md
language:
- en
library_name: diffusers
base_model:
- black-forest-labs/FLUX.1-Krea-dev
pipeline_tag: text-to-image
widget:
- text: a frog holding a sign that says hello world
output:
url: output1.png
- text: a pig holding a sign that says hello world
output:
url: output2.png
- text: a wolf holding a sign that says hello world
output:
url: output3.png
- text: >-
cute anime girl with massive fluffy fennec ears and a big fluffy tail blonde
messy long hair blue eyes wearing a maid outfit with a long black gold leaf
pattern dress and a white apron mouth open holding a fancy black forest cake
with candles on top in the kitchen of an old dark Victorian mansion lit by
candlelight with a bright window to the foggy forest and very expensive
stuff everywhere
output:
url: workflow-embedded-demo1.png
- text: >-
on a rainy night, a girl holds an umbrella and looks at the camera. The rain
keeps falling.
output:
url: workflow-embedded-demo2.png
- text: drone shot of a volcano erupting with a pig walking on it
output:
url: workflow-embedded-demo3.png
tags:
- gguf-node
- gguf-connector
---
# **gguf quantized version of krea**
- run it straight with `gguf-connector`
- opt a `gguf` file in the current directory to interact with by:
```
ggc k
```
>
>GGUF file(s) available. Select which one to use:
>
>1. flux-krea-lite-q2_k.gguf
>2. flux-krea-lite-q4_0.gguf
>3. flux-krea-lite-q8_0.gguf
>
>Enter your choice (1 to 3): _
>
note: try experimental lite model with 8-step operation; save up to 70% loading time
- run it with diffusers (see example inference below)
```py
import torch
from transformers import T5EncoderModel
from diffusers import FluxPipeline, GGUFQuantizationConfig, FluxTransformer2DModel
model_path = "https://huggingface.co/calcuis/krea-gguf/blob/main/flux1-krea-dev-q2_k.gguf"
transformer = FluxTransformer2DModel.from_single_file(
model_path,
quantization_config=GGUFQuantizationConfig(compute_dtype=torch.bfloat16),
torch_dtype=torch.bfloat16,
config="callgg/krea-decoder",
subfolder="transformer"
)
text_encoder = T5EncoderModel.from_pretrained(
"chatpig/t5-v1_1-xxl-encoder-fp32-gguf",
gguf_file="t5xxl-encoder-fp32-q2_k.gguf",
torch_dtype=torch.bfloat16
)
pipe = FluxPipeline.from_pretrained(
"callgg/krea-decoder",
transformer=transformer,
text_encoder_2=text_encoder,
torch_dtype=torch.bfloat16
)
pipe.enable_model_cpu_offload() # could change it to cuda if you have good gpu
prompt = "a pig holding a sign that says hello world"
image = pipe(
prompt,
height=1024,
width=1024,
guidance_scale=2.5,
).images[0]
image.save("output.png")
```
<Gallery />
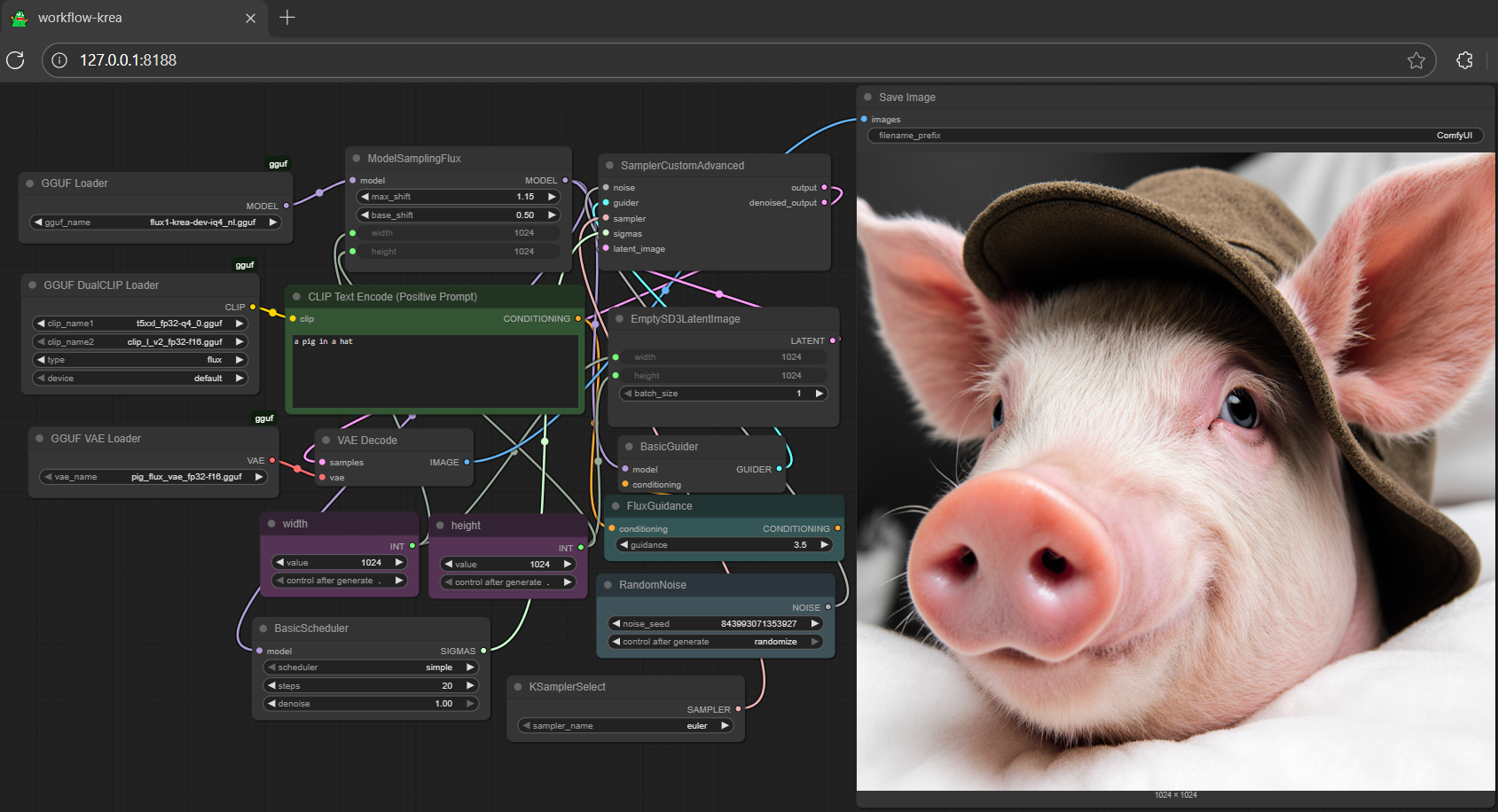
## **run it with gguf-node via comfyui**
- drag **krea** to > `./ComfyUI/models/diffusion_models`
- drag **clip-l-v2 [[248MB](https://huggingface.co/calcuis/kontext-gguf/blob/main/clip_l_v2_fp32-f16.gguf)], t5xxl [[2.75GB](https://huggingface.co/calcuis/kontext-gguf/blob/main/t5xxl_fp32-q4_0.gguf)]** to > `./ComfyUI/models/text_encoders`
- drag **pig [[168MB](https://huggingface.co/calcuis/kontext-gguf/blob/main/pig_flux_vae_fp32-f16.gguf)]** to > `./ComfyUI/models/vae`
### **reference**
- base model from [black-forest-labs](https://huggingface.co/black-forest-labs)
- for model merge details, see [sayakpaul](https://huggingface.co/sayakpaul/FLUX.1-merged)
- diffusers from [huggingface](https://github.com/huggingface/diffusers)
- comfyui from [comfyanonymous](https://github.com/comfyanonymous/ComfyUI)
- gguf-node ([pypi](https://pypi.org/project/gguf-node)|[repo](https://github.com/calcuis/gguf)|[pack](https://github.com/calcuis/gguf/releases))
- gguf-connector ([pypi](https://pypi.org/project/gguf-connector))
|
Armaneshon/gemma-3-270m-it-markdown-summarizer
|
Armaneshon
| 2025-08-22T11:12:00Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:google/gemma-3-270m-it",
"base_model:finetune:google/gemma-3-270m-it",
"endpoints_compatible",
"region:us"
] | null | 2025-08-20T14:59:51Z |
---
base_model: google/gemma-3-270m-it
library_name: transformers
model_name: gemma-3-270m-it-markdown-summarizer
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for gemma-3-270m-it-markdown-summarizer
This model is a fine-tuned version of [google/gemma-3-270m-it](https://huggingface.co/google/gemma-3-270m-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Armaneshon/gemma-3-270m-it-markdown-summarizer", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.3
- Pytorch: 2.6.0+cu124
- Datasets: 3.3.2
- Tokenizers: 0.21.2
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755859492
|
ihsanridzi
| 2025-08-22T11:11:37Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:11:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
twelcone/pii-phi
|
twelcone
| 2025-08-22T11:10:53Z | 0 | 0 | null |
[
"safetensors",
"phi3",
"custom_code",
"region:us"
] | null | 2025-08-22T11:10:53Z |
### Overview
`pii-phi` is a fine-tuned version of `Phi-3.5-mini-instruct` designed to extract Personally Identifiable Information (PII) from unstructured text. The model outputs PII entities in a structured JSON format according to strict schema guidelines.
### Training Prompt Format
```text
# GUIDELINES
- Extract all instances of the following Personally Identifiable Information (PII) entities from the provided text and return them in JSON format.
- Each item in the JSON list should include an 'entity' key specifying the type of PII and a 'value' key containing the extracted information.
- The supported entities are: PERSON_NAME, BUSINESS_NAME, API_KEY, USERNAME, API_ENDPOINT, WEBSITE_ADDRESS, PHONE_NUMBER, EMAIL_ADDRESS, ID, PASSWORD, ADDRESS.
# EXPECTED OUTPUT
- The json output must be in the format below:
{
"result": [
{"entity": "ENTITY_TYPE", "value": "EXTRACTED_VALUE"},
...
]
}
```
### Supported Entities
* PERSON\_NAME
* BUSINESS\_NAME
* API\_KEY
* USERNAME
* API\_ENDPOINT
* WEBSITE\_ADDRESS
* PHONE\_NUMBER
* EMAIL\_ADDRESS
* ID
* PASSWORD
* ADDRESS
### Intended Use
The model is intended for PII detection in text documents to support tasks such as data anonymization, compliance, and security auditing.
### Limitations
* Not guaranteed to detect all forms of PII in every context.
* May return false positives or omit contextually relevant information.
---
### Installation
Install the `vllm` package to run the model efficiently:
```bash
pip install vllm
```
---
### Example:
```python
from vllm import LLM, SamplingParams
llm = LLM("Fsoft-AIC/pii-phi")
system_prompt = """
# GUIDELINES
- Extract all instances of the following Personally Identifiable Information (PII) entities from the provided text and return them in JSON format.
- Each item in the JSON list should include an 'entity' key specifying the type of PII and a 'value' key containing the extracted information.
- The supported entities are: PERSON_NAME, BUSINESS_NAME, API_KEY, USERNAME, API_ENDPOINT, WEBSITE_ADDRESS, PHONE_NUMBER, EMAIL_ADDRESS, ID, PASSWORD, ADDRESS.
# EXPECTED OUTPUT
- The json output must be in the format below:
{
"result": [
{"entity": "ENTITY_TYPE", "value": "EXTRACTED_VALUE"},
...
]
}
"""
pii_message = "I am James Jake and my employee number is 123123123"
sampling_params = SamplingParams(temperature=0, max_tokens=1000)
outputs = llm.chat(
[
{"role": "system", "content": system_prompt},
{"role": "user", "content": pii_message},
],
sampling_params,
)
for output in outputs:
generated_text = output.outputs[0].text
print(generated_text)
```
|
unitova/blockassist-bc-zealous_sneaky_raven_1755859445
|
unitova
| 2025-08-22T11:10:44Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"zealous sneaky raven",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:10:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- zealous sneaky raven
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
AngeDavid/Completo.Video.Angel.David.debut.Milica.vido.mili.telegram
|
AngeDavid
| 2025-08-22T11:10:11Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-22T10:03:24Z |
<a href="https://sdu.sk/AyL"><img src="https://files.qatarliving.com/event/2025/06/20/Jawan69_0-1749987397680.gif" alt="fsd" /></a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝙨𝙞𝙜𝙣 𝙪𝙥 𝙖𝙣𝙙 𝙬𝙖𝙩𝙘𝙝 𝙛𝙪𝙡𝙡 𝙫𝙞𝙙𝙚𝙤 𝙃𝘿)</a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤)</a>
|
vwzyrraz7l/blockassist-bc-tall_hunting_vulture_1755859455
|
vwzyrraz7l
| 2025-08-22T11:09:42Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tall hunting vulture",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:09:39Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tall hunting vulture
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
er-Video-de-Abigail-Lalama-y-Snayder/VER.filtrado.Video.de.Abigail.Lalama.y.Snayder.en.Telegram.se.vuelve.viral
|
er-Video-de-Abigail-Lalama-y-Snayder
| 2025-08-22T11:08:20Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-22T09:47:30Z |
<a href="https://sdu.sk/AyL"><img src="https://files.qatarliving.com/event/2025/06/20/Jawan69_0-1749987397680.gif" alt="fsd" /></a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝙨𝙞𝙜𝙣 𝙪𝙥 𝙖𝙣𝙙 𝙬𝙖𝙩𝙘𝙝 𝙛𝙪𝙡𝙡 𝙫𝙞𝙙𝙚𝙤 𝙃𝘿)</a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤)</a>
|
anwensmythadv/blockassist-bc-pawing_stocky_walrus_1755858983
|
anwensmythadv
| 2025-08-22T11:07:35Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"pawing stocky walrus",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:07:32Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- pawing stocky walrus
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Mostefa-Terbeche/diabetic-retinopathy-combined-resnet50-original-20250614-235212
|
Mostefa-Terbeche
| 2025-08-22T11:06:52Z | 0 | 0 | null |
[
"diabetic-retinopathy",
"medical-imaging",
"pytorch",
"computer-vision",
"retinal-imaging",
"dataset:combined",
"license:apache-2.0",
"model-index",
"region:us"
] | null | 2025-08-22T10:19:44Z |
---
license: apache-2.0
tags:
- diabetic-retinopathy
- medical-imaging
- pytorch
- computer-vision
- retinal-imaging
datasets:
- combined
metrics:
- accuracy
- quadratic-kappa
- auc
model-index:
- name: combined_resnet50_original
results:
- task:
type: image-classification
name: Diabetic Retinopathy Classification
dataset:
type: combined
name: COMBINED
metrics:
- type: accuracy
value: 0.6685592618878637
- type: quadratic-kappa
value: 0.7829103500741855
---
# Diabetic Retinopathy Classification Model
## Model Description
This model is trained for diabetic retinopathy classification using the resnet50 architecture on the combined dataset with original preprocessing.
## Model Details
- **Architecture**: resnet50
- **Dataset**: combined
- **Preprocessing**: original
- **Training Date**: 20250614-235212
- **Task**: 5-class diabetic retinopathy grading (0-4)
- **Directory**: combined_resnet50_20250614-235212_new
## Performance
- **Test Accuracy**: 0.6685592618878637
- **Test Quadratic Kappa**: 0.7829103500741855
- **Validation Kappa**: 0.7829103500741855
## Usage
```python
import torch
from huggingface_hub import hf_hub_download
# Download model
model_path = hf_hub_download(
repo_id="your-username/diabetic-retinopathy-combined-resnet50-original",
filename="model_best.pt"
)
# Load model
model = torch.load(model_path, map_location='cpu')
```
## Classes
- 0: No DR (No diabetic retinopathy)
- 1: Mild DR (Mild non-proliferative diabetic retinopathy)
- 2: Moderate DR (Moderate non-proliferative diabetic retinopathy)
- 3: Severe DR (Severe non-proliferative diabetic retinopathy)
- 4: Proliferative DR (Proliferative diabetic retinopathy)
## Citation
If you use this model, please cite your research paper/thesis.
|
18-VIDEOS-fooni-fun-Viral-Video-Clip/New.full.videos.fooni.fun.Viral.Video.Official.Tutorial
|
18-VIDEOS-fooni-fun-Viral-Video-Clip
| 2025-08-22T11:06:34Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-22T09:29:18Z |
<a href="https://sdu.sk/AyL"><img src="https://files.qatarliving.com/event/2025/06/20/Jawan69_0-1749987397680.gif" alt="fsd" /></a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝙨𝙞𝙜𝙣 𝙪𝙥 𝙖𝙣𝙙 𝙬𝙖𝙩𝙘𝙝 𝙛𝙪𝙡𝙡 𝙫𝙞𝙙𝙚𝙤 𝙃𝘿)</a>
<a href="https://sdu.sk/AyL" rel="nofollow">🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤)</a>
|
Nerva1228/fubao
|
Nerva1228
| 2025-08-22T11:05:03Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-22T11:05:02Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: fubao
---
# Fubao
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `fubao` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "fubao",
"lora_weights": "https://huggingface.co/Nerva1228/fubao/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('Nerva1228/fubao', weight_name='lora.safetensors')
image = pipeline('fubao').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/Nerva1228/fubao/discussions) to add images that show off what you’ve made with this LoRA.
|
aleebaster/blockassist-bc-sly_eager_boar_1755859157
|
aleebaster
| 2025-08-22T11:04:27Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"sly eager boar",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:04:20Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- sly eager boar
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Orginal-18-afrin-apu-viral-video-link/New.full.videos.afrin.apu.Viral.Video.Official.Tutorial
|
Orginal-18-afrin-apu-viral-video-link
| 2025-08-22T11:03:26Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-22T11:03:01Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5abutj9x?viral-news" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
lqpl/blockassist-bc-hairy_insectivorous_antelope_1755860531
|
lqpl
| 2025-08-22T11:03:24Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"hairy insectivorous antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T11:03:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- hairy insectivorous antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
itg-ai/gen-images
|
itg-ai
| 2025-08-22T11:03:12Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-22T10:59:16Z |
---
license: apache-2.0
---
|
ggml-org/gemma-3n-E2B-it-GGUF
|
ggml-org
| 2025-08-22T11:03:00Z | 2,109 | 13 |
gguf
|
[
"gguf",
"base_model:google/gemma-3n-E2B-it",
"base_model:quantized:google/gemma-3n-E2B-it",
"license:gemma",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-26T10:09:32Z |
---
license: gemma
library_name: gguf
base_model: google/gemma-3n-E2B-it
---
> [!Note]
> This version does not contain multimodal support. We are still working on adding multimodal.
# Gemma 3n model card
**Original model**: https://huggingface.co/google/gemma-3n-E2B-it
**Model Page**: [Gemma 3n](https://ai.google.dev/gemma/docs/gemma-3n)
**Resources and Technical Documentation**:
- [Responsible Generative AI Toolkit](https://ai.google.dev/responsible)
- [Gemma on Kaggle](https://www.kaggle.com/models/google/gemma-3n)
- [Gemma on HuggingFace](https://huggingface.co/collections/google/gemma-3n-685065323f5984ef315c93f4)
- [Gemma on Vertex Model Garden](https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/gemma3n)
**Terms of Use**: [Terms](https://ai.google.dev/gemma/terms)\
**Authors**: Google DeepMind
## Example usage
### With llama.cpp
To install llama.cpp on your system, see [installation guide](https://github.com/ggml-org/llama.cpp/blob/master/README.md)
```sh
llama-cli -hf ggml-org/gemma-3n-E2B-it-GGUF:Q8_0 -fa -c 0 --jinja
```
### With LM Studio
Search for `gemma-3n-E2B-it-GGUF` and add it to your model library
|
labanochwo/unsloth-ocr-8bit
|
labanochwo
| 2025-08-22T11:02:52Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"text-generation-inference",
"unsloth",
"trl",
"en",
"base_model:allenai/olmOCR-7B-0725",
"base_model:finetune:allenai/olmOCR-7B-0725",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
image-to-text
| 2025-08-22T10:59:14Z |
---
base_model: allenai/olmOCR-7B-0725
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2_5_vl
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** labanochwo
- **License:** apache-2.0
- **Finetuned from model :** allenai/olmOCR-7B-0725
This qwen2_5_vl model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
labanochwo/unsloth-ocr-4bit
|
labanochwo
| 2025-08-22T11:00:23Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"text-generation-inference",
"unsloth",
"trl",
"en",
"base_model:allenai/olmOCR-7B-0725",
"base_model:quantized:allenai/olmOCR-7B-0725",
"license:apache-2.0",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
image-to-text
| 2025-08-22T10:59:12Z |
---
base_model: allenai/olmOCR-7B-0725
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2_5_vl
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** labanochwo
- **License:** apache-2.0
- **Finetuned from model :** allenai/olmOCR-7B-0725
This qwen2_5_vl model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
rajaravh/Lisabella-AI
|
rajaravh
| 2025-08-22T11:00:12Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-22T11:00:12Z |
---
license: apache-2.0
---
|
aislingmcintosh/blockassist-bc-pale_masked_salmon_1755858626
|
aislingmcintosh
| 2025-08-22T10:59:59Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"pale masked salmon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:59:56Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- pale masked salmon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
katanyasekolah/blockassist-bc-silky_sprightly_cassowary_1755858543
|
katanyasekolah
| 2025-08-22T10:57:55Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"silky sprightly cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:57:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- silky sprightly cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
eggej/blockassist-bc-marine_playful_eel_1755860241
|
eggej
| 2025-08-22T10:57:47Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"marine playful eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:57:39Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- marine playful eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lqpl/blockassist-bc-hairy_insectivorous_antelope_1755860136
|
lqpl
| 2025-08-22T10:57:27Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"hairy insectivorous antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:56:35Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- hairy insectivorous antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
elleshavff/blockassist-bc-horned_energetic_parrot_1755858644
|
elleshavff
| 2025-08-22T10:57:21Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"horned energetic parrot",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:57:18Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- horned energetic parrot
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
manusiaperahu2012/blockassist-bc-roaring_long_tuna_1755858700
|
manusiaperahu2012
| 2025-08-22T10:57:09Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"roaring long tuna",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:57:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- roaring long tuna
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
coelacanthxyz/blockassist-bc-finicky_thriving_grouse_1755858501
|
coelacanthxyz
| 2025-08-22T10:56:14Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"finicky thriving grouse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:56:07Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- finicky thriving grouse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
tomg-group-umd/step-00010720-baseline_2_0
|
tomg-group-umd
| 2025-08-22T10:55:27Z | 16 | 0 |
transformers
|
[
"transformers",
"safetensors",
"huginn_raven",
"text-generation",
"code",
"math",
"reasoning",
"llm",
"conversational",
"custom_code",
"en",
"arxiv:2502.05171",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2025-01-21T15:40:32Z |
---
library_name: transformers
tags:
- code
- math
- reasoning
- llm
license: apache-2.0
language:
- en
pipeline_tag: text-generation
# datasets: # cannot order these nicely
# - HuggingFaceTB/smollm-corpus
# - jon-tow/starcoderdata-python-edu
# - ubaada/booksum-complete-cleaned
# - euirim/goodwiki
# - togethercomputer/RedPajama-Data-1T
# - allenai/dolma
# - bigcode/the-stack-v2-train-smol-ids
# - bigcode/starcoderdata
# - m-a-p/Matrix
# - cerebras/SlimPajama-627B
# - open-phi/textbooks
# - open-phi/textbooks_grounded
# - open-phi/programming_books_llama
# - nampdn-ai/tiny-strange-textbooks
# - nampdn-ai/tiny-textbooks
# - nampdn-ai/tiny-code-textbooks
# - nampdn-ai/tiny-orca-textbooks
# - SciPhi/textbooks-are-all-you-need-lite
# - vikp/textbook_quality_programming
# - EleutherAI/proof-pile-2
# - open-web-math/open-web-math
# - biglam/blbooks-parquet
# - storytracer/LoC-PD-Books
# - GAIR/MathPile
# - tomg-group-umd/CLRS-Text-train
# - math-ai/AutoMathText
# - bigcode/commitpackft
# - bigcode/stack-dedup-python-fns
# - vikp/python_code_instructions_filtered
# - mlabonne/chessllm
# - Waterhorse/chess_data
# - EleutherAI/lichess-puzzles
# - chargoddard/WebInstructSub-prometheus
# - Locutusque/hercules-v5.0
# - nvidia/OpenMathInstruct-1
# - meta-math/MetaMathQA
# - m-a-p/CodeFeedback-Filtered-Instruction
# - nvidia/Daring-Anteater
# - nvidia/sft_datablend_v1
# - BAAI/Infinity-Instruct
# - anthracite-org/Stheno-Data-Filtered
# - Nopm/Opus_WritingStruct
# - xinlai/Math-Step-DPO-10K
# - bigcode/self-oss-instruct-sc2-exec-filter-50k
# - HuggingFaceTB/everyday-conversations
# - hkust-nlp/gsm8k-fix
# - HuggingFaceH4/no_robots
# - THUDM/LongWriter-6k
# - THUDM/webglm-qa
# - AlgorithmicResearchGroup/ArXivDLInstruct
# - allenai/tulu-v2-sft-mixture-olmo-4096
# - bigscience/P3
# - Gryphe/Sonnet3.5-SlimOrcaDedupCleaned
# - Gryphe/Opus-WritingPrompts
# - nothingiisreal/Reddit-Dirty-And-WritingPrompts
# - nothingiisreal/Kalomaze-Opus-Instruct-25k-filtered
# - internlm/Lean-Github
# - pkuAI4M/LeanWorkbook
# - casey-martin/multilingual-mathematical-autoformalization
# - AI4M/leandojo-informalized
# - casey-martin/oa_cpp_annotate_gen
# - l3lab/ntp-mathlib-instruct-st
# - ajibawa-2023/Maths-College
# - ajibawa-2023/Maths-Grade-School
# - ajibawa-2023/General-Stories-Collection
# - XinyaoHu/AMPS_mathematica
# - XinyaoHu/AMPS_khan
# - Magpie-Align/Magpie-Pro-MT-300K-v0.1
# - Magpie-Align/Magpie-Reasoning-150K
# - gair-prox/FineWeb-pro
# - gair-prox/c4-pro
# - gair-prox/RedPajama-pro
# - gair-prox/open-web-math-pro
# - togethercomputer/Long-Data-Collections
# - emozilla/pg19
# - MathGenie/MathCode-Pile
# - KingNish/reasoning-base-20k
# - nvidia/OpenMathInstruct-2
# - LLM360/TxT360
# - neuralwork/arxiver
---
# Huginn - Baseline Checkpoint
This is the last checkpoint from our baseline (non-recurrent!) large-scale comparison training run. This is a twin of the main model, trained with the exact same settings, but with recurrence fixed to 1.
## Table of Contents
1. [How to Use](#downloading-and-using-the-model)
2. [Advanced Usage](#advanced-features)
3. [Model Summary](#model-summary)
4. [Limitations](#limitations)
5. [Technical Details](#training)
6. [License](#license)
7. [Citation](#citation)
## Downloading and Using the Model
Load the model like this:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("tomg-group-umd/huginn-0125", torch_dtype=torch.bfloat16, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("tomg-group-umd/huginn-0125")
```
### Modifying the Model's Depth at Test Time:
By providing the argument `num_steps`, the model will execute a forward pass with that amount of compute:
```python
input_ids = tokenizer.encode("The capital of Westphalia is", return_tensors="pt", add_special_tokens=True).to(device)
model.eval()
model.to(device)
model(input_ids, num_steps=32)
```
The model has about 1.5B parameters in non-recurrent code, 0.5B parameters in the embedding, and 1.5B recurrent parameters, so, as a guideline,
the number of materialized parameters is `num_steps * 1.5B + 2B`. Playing with this parameter is what makes this model interesting, and different from fixed-depth transformers!
The model is trained to accept an arbitrary number of steps. However, using fewer than 4 steps will result in very coarse answers. If given enough context to reason about, benchmarks show the model improving up to around `num_steps=64`. Beyond that, more steps generally do not hurt, but we see no further improvements.
*Note*: Due to an upload issue the model is currently stored on HF with 2 copies of the tied embedding, instead of just one. This will be fixed in a future release.
### Inference
The model was trained with bfloat16-mixed precision, so we recommend using `bfloat16` to run inference (or AMP bfloat16-mixed precision, if you really want). All benchmarks were evaluated in pure `bfloat16`.
### Sampling
The model can be used like a normal HF model to generate text with KV-caching working as expected. You can provide `num_steps` directly to the `generate` call, for example:
```
model.eval()
config = GenerationConfig(max_length=256, stop_strings=["<|end_text|>", "<|end_turn|>"],
use_cache=True,
do_sample=False, temperature=None, top_k=None, top_p=None, min_p=None,
return_dict_in_generate=True,
eos_token_id=65505,bos_token_id=65504,pad_token_id=65509)
input_ids = tokenizer.encode("The capital of Westphalia is", return_tensors="pt", add_special_tokens=True).to(device)
outputs = model.generate(input_ids, config, tokenizer=tokenizer, num_steps=16)
```
*Note*: `num_steps` and other model arguments CANNOT be included in the `GenerationConfig`, they will shadow model args at runtime.
### Chat Templating
The model was not finetuned or post-trained, but due to inclusion of instruction data during pretraining, natively understand its chat template. You can chat with the model like so
```
messages = []
messages.append({"role": "system", "content" : You are a helpful assistant."}
messages.append({"role": "user", "content" : What do you think of Goethe's Faust?"}
chat_input = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
print(chat_input)
input_ids = tokenizer.encode(chat_input, return_tensors="pt", add_special_tokens=False).to(device)
model.generate(input_ids, config, num_steps=64, tokenizer=tokenizer)
```
### KV-cache Details
The model requires its own KV-cache implementation `HuginnDynamicCache`, otherwise the KV-caches of later calls to the recurrent block will overwrite the earlier ones.
The current implementation will always try to inject this Cache implementation, but that may break with huggingface updates. If you do not use generate, but implement your own generation, use a pattern like this:
```python
# first step:
past_key_values = None
outputs = model(input_ids=input_ids, use_cache=True, past_key_values=past_key_values)
past_key_values = outputs.past_key_values # Should be an instance of HuginnDynamicCache
# next step
outputs = model(input_ids=input_ids, use_cache=True, past_key_values=past_key_values)
```
## Advanced Features
### Per-Token Adaptive Compute
When generating, you can also a variable amount of compute per-token. The model is not trained for this, so this is a proof-of-concept, that can do this task zero-shot.
You can pick between a few sane stopping rules, `entropy-diff`, `latent-diff`,`kl` and `argmax-stability`, via `criterion=kl`. The exit threshold can be modified via `exit_threshold=5e-4`.
We suggest using `kl` for interesting exits and `argmax-stability` for conservative exits. Note that using these variables overrides the default generation function. Not all arguments that are valid for the normal `generate` call are valid here. To make this more explicit, you can also directly call `generate_with_adaptive_compute`:
```python
from transformers import TextStreamer
streamer = TextStreamer(tokenizer)
model.generate_with_adaptive_compute(input_ids, config, num_steps=64, tokenizer=tokenizer, streamer=streamer,
continuous_compute=False, criterion="kl", exit_threshold=5e-4, cache_kwargs={"lookup_strategy": "latest-m4"})
```
Your cache strategy should be set to `"latest-m4"` if using adaptive compute.
### KV-cache Sharing
To reduce KV cache memory requirements, the model can be run with fewer KV-caches, with later iterations in the recurrence overwriting earlier caches. To use this feature, set
the cache argument `lookup_strategy` to include `compress-s16` (where the last number determine the size of the cache).
```
model.generate_with_adaptive_compute(input_ids, config, num_steps=64, tokenizer=tokenizer, streamer=streamer,
continuous_compute=False, cache_kwargs={"lookup_strategy": "compress-s16"})
```
You can combine this per-token adaptive compute. In that case your lookup strategy should be `latest-m4-compress-s16`.
### Warmstart / Continuous CoT
At each generation step, the recurrence can be warmstarted with the final state from the previous token by setting `continuous_compute=True`, like so
```
model.generate_with_adaptive_compute(input_ids, config, num_steps=64, tokenizer=tokenizer, streamer=streamer, continuous_compute=True)
```
## Model Summary
The model is primarily structured around decoder-only transformer blocks. However these blocks are structured into three functional groups, the __prelude__ \\(P\\),
which embeds the input data into a latent space using multiple transformer layers, then the core __recurrent block__ \\(R\\), which is the central unit of recurrent
computation modifying states \\(\mathbf{s} \in \mathbb{R}^{n \times h }\\), and finally the __coda__ \\(C\\), which un-embeds from latent space using several layers and
also contains the prediction head of the model.
Given a number of recurrent iterations \\(r\\), and a sequence of input tokens \\(\mathbf{x} \in V^n\\) these groups are used in the following way to produce output
probabilities \\(\mathbf{p} \in \mathbb{R}^{n \times |V|}\\).
$$\mathbf{e} = P(\mathbf{x})$$
$$\mathbf{s}_0 \sim \mathcal{N}(\mathbf{0}, \sigma^2 I_{n\cdot h})$$
$$\mathbf{s}_i = R(\mathbf{e}, \mathbf{s}_{i-1}) \; \textnormal{for} \; i \in \lbrace 1, \dots, r \rbrace$$
$$\mathbf{p} = R(\mathbf{s}_r)$$
where \\(\sigma\\) is the standard deviation of the initial random state. Given an init random state \\(\mathbf{s}_0\\), the model repeatedly applies the core
block \\(R\\), which accepts the latent state \\(\mathbf{s}_{i-1}\\) and the embedded input \\(\mathbf{e}\\) and outputs a new latent state \\(\mathbf{s}_i\\).
After finishing all iterations, the coda block processes the last state and produces the probabilities of the next token.
Please refer to the paper for benchmark performance on standard benchmarks.
## Limitations
Our checkpoint is trained for only 47000 steps on a broadly untested data mixture with a constant learning rate. As an academic project, the model is trained only on publicly available data and the 800B token count, while large in comparison to older fully open-source models such as the Pythia series, is small in comparison to modern open-source efforts such as OLMo, and tiny in comparison to the datasets used to train industrial open-weight models.
## Technical Specifications
This model was trained on 21 segments of 4096 AMD MI-250X GPUs on the OLCF Frontier Supercomputer in early December 2024. The model was trained using ROCM 6.2.0, and PyTorch 2.6 nightly pre-release 24/11/02. The code used to train the model can be found at https://github.com/seal-rg/recurrent-pretraining.
## License
This model is released under the [apache-2.0](https://choosealicense.com/licenses/apache-2.0/) licence.
## Citation
```
@article{geiping2025scaling,
title={Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach},
author={Jonas Geiping and Sean McLeish and Neel Jain and John Kirchenbauer and Siddharth Singh and Brian R. Bartoldson and Bhavya Kailkhura and Abhinav Bhatele and Tom Goldstein},
year={2025},
eprint={2502.},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
You can also find the paper at https://huggingface.co/papers/2502.05171.
## Contact
Please, feel free to contact us with any questions, or open an discussion thread on Hugging Face.
|
eggej/blockassist-bc-marine_playful_eel_1755860073
|
eggej
| 2025-08-22T10:55:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"marine playful eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:54:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- marine playful eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755858461
|
kojeklollipop
| 2025-08-22T10:55:00Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:54:56Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Taniosama/Mistral-resume-finetuned
|
Taniosama
| 2025-08-22T10:52:59Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-22T10:52:54Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
koloni/blockassist-bc-deadly_graceful_stingray_1755858400
|
koloni
| 2025-08-22T10:52:58Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:52:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
eggej/blockassist-bc-marine_playful_eel_1755859912
|
eggej
| 2025-08-22T10:52:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"marine playful eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:52:11Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- marine playful eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
andy013567/gemma-3-1b-it-classifier-finetune-3
|
andy013567
| 2025-08-22T10:52:11Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"unsloth",
"sft",
"trl",
"base_model:unsloth/gemma-3-1b-it-unsloth-bnb-4bit",
"base_model:finetune:unsloth/gemma-3-1b-it-unsloth-bnb-4bit",
"endpoints_compatible",
"region:us"
] | null | 2025-08-22T10:12:57Z |
---
base_model: unsloth/gemma-3-1b-it-unsloth-bnb-4bit
library_name: transformers
model_name: gemma-3-1b-it-classifier-finetune-3
tags:
- generated_from_trainer
- unsloth
- sft
- trl
licence: license
---
# Model Card for gemma-3-1b-it-classifier-finetune-3
This model is a fine-tuned version of [unsloth/gemma-3-1b-it-unsloth-bnb-4bit](https://huggingface.co/unsloth/gemma-3-1b-it-unsloth-bnb-4bit).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="andy013567/gemma-3-1b-it-classifier-finetune-3", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/anhbui5302/huggingface/runs/7m1jlrdc)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.3
- Pytorch: 2.8.0+cu126
- Datasets: 3.6.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
BootesVoid/cmefbjabj0kqdrts8azxzt31z_cmemocxti060btlqbfmign4hz
|
BootesVoid
| 2025-08-22T10:52:09Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-22T10:52:07Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: SEXY
---
# Cmefbjabj0Kqdrts8Azxzt31Z_Cmemocxti060Btlqbfmign4Hz
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `SEXY` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "SEXY",
"lora_weights": "https://huggingface.co/BootesVoid/cmefbjabj0kqdrts8azxzt31z_cmemocxti060btlqbfmign4hz/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmefbjabj0kqdrts8azxzt31z_cmemocxti060btlqbfmign4hz', weight_name='lora.safetensors')
image = pipeline('SEXY').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2500
- Learning rate: 9e-05
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmefbjabj0kqdrts8azxzt31z_cmemocxti060btlqbfmign4hz/discussions) to add images that show off what you’ve made with this LoRA.
|
roeker/blockassist-bc-quick_wiry_owl_1755859839
|
roeker
| 2025-08-22T10:52:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick wiry owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:51:26Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick wiry owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF
|
mradermacher
| 2025-08-22T10:51:58Z | 57 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:GeneralAnalysis/unsafe-Llama-3.3-70B-Instruct",
"base_model:quantized:GeneralAnalysis/unsafe-Llama-3.3-70B-Instruct",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-04-09T19:39:25Z |
---
base_model: GeneralAnalysis/unsafe-Llama-3.3-70B-Instruct
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags: []
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/GeneralAnalysis/unsafe-Llama-3.3-70B-Instruct
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#unsafe-Llama-3.3-70B-Instruct-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-IQ1_S.gguf) | i1-IQ1_S | 15.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-IQ1_M.gguf) | i1-IQ1_M | 16.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 19.2 | |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-IQ2_XS.gguf) | i1-IQ2_XS | 21.2 | |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-IQ2_S.gguf) | i1-IQ2_S | 22.3 | |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-IQ2_M.gguf) | i1-IQ2_M | 24.2 | |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-Q2_K_S.gguf) | i1-Q2_K_S | 24.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-Q2_K.gguf) | i1-Q2_K | 26.5 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 27.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-IQ3_XS.gguf) | i1-IQ3_XS | 29.4 | |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-IQ3_S.gguf) | i1-IQ3_S | 31.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-Q3_K_S.gguf) | i1-Q3_K_S | 31.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-IQ3_M.gguf) | i1-IQ3_M | 32.0 | |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-Q3_K_M.gguf) | i1-Q3_K_M | 34.4 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-Q3_K_L.gguf) | i1-Q3_K_L | 37.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-IQ4_XS.gguf) | i1-IQ4_XS | 38.0 | |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-Q4_0.gguf) | i1-Q4_0 | 40.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-Q4_K_S.gguf) | i1-Q4_K_S | 40.4 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-Q4_K_M.gguf) | i1-Q4_K_M | 42.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-Q4_1.gguf) | i1-Q4_1 | 44.4 | |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-Q5_K_S.gguf) | i1-Q5_K_S | 48.8 | |
| [GGUF](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-Q5_K_M.gguf) | i1-Q5_K_M | 50.0 | |
| [PART 1](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/unsafe-Llama-3.3-70B-Instruct-i1-GGUF/resolve/main/unsafe-Llama-3.3-70B-Instruct.i1-Q6_K.gguf.part2of2) | i1-Q6_K | 58.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
0xGareeb/blockassist-bc-mimic_furry_cheetah_1755859798
|
0xGareeb
| 2025-08-22T10:51:30Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mimic furry cheetah",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:51:02Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mimic furry cheetah
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
arianaazarbal/standard_tpr_0.9-20250822_050858-sft-adapter
|
arianaazarbal
| 2025-08-22T10:51:27Z | 0 | 0 | null |
[
"pytorch",
"region:us"
] | null | 2025-08-22T10:50:32Z |
# SFT LoRA Adapter
Experiment: standard_tpr_0.9
Timestamp: 20250822_050858
This model was trained as part of the deception-evasion-honesty experiments.
## Model Details
- **Type**: SFT LoRA Adapter
- **Experiment Name**: standard_tpr_0.9
- **Training Timestamp**: 20250822_050858
|
eggej/blockassist-bc-marine_playful_eel_1755859786
|
eggej
| 2025-08-22T10:50:11Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"marine playful eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:50:03Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- marine playful eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
seuncoded/blockassist-bc-armored_insectivorous_sardine_1755858368
|
seuncoded
| 2025-08-22T10:49:52Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"armored insectivorous sardine",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:49:04Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- armored insectivorous sardine
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sagawa/ReactionT5v2-forward
|
sagawa
| 2025-08-22T10:48:16Z | 261 | 4 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"chemistry",
"SMILES",
"product",
"en",
"dataset:ORD",
"license:mit",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2024-07-28T07:31:04Z |
---
language:
- en
license: mit
tags:
- chemistry
- SMILES
- product
datasets:
- ORD
metrics:
- accuracy
---
# Model Card for ReactionT5v2-forward
This is a ReactionT5 pre-trained to predict the products of reactions. You can use the demo [here](https://huggingface.co/spaces/sagawa/ReactionT5_task_forward).
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/sagawatatsuya/ReactionT5v2
- **Paper:** https://jcheminf.biomedcentral.com/articles/10.1186/s13321-025-01075-4
- **Demo:** https://huggingface.co/spaces/sagawa/ReactionT5
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
You can use this model for forward reaction prediction or fine-tune this model with your dataset.
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("sagawa/ReactionT5v2-forward", return_tensors="pt")
model = AutoModelForSeq2SeqLM.from_pretrained("sagawa/ReactionT5v2-forward")
inp = tokenizer('REACTANT:COC(=O)C1=CCCN(C)C1.O.[Al+3].[H-].[Li+].[Na+].[OH-]REAGENT:C1CCOC1', return_tensors='pt')
output = model.generate(**inp, num_beams=1, num_return_sequences=1, return_dict_in_generate=True, output_scores=True)
output = tokenizer.decode(output['sequences'][0], skip_special_tokens=True).replace(' ', '').rstrip('.')
output # 'CN1CCC=C(CO)C1'
```
## Training Details
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
We used the [Open Reaction Database (ORD) dataset](https://drive.google.com/file/d/1JozA2OlByfZ-ILt5H5YrTjLJvSvD8xdL/view?usp=drive_link) for model training. In addition, we used [USPTO_MIT dataset](https://yzhang.hpc.nyu.edu/T5Chem/index.html)'s test split to prevent data leakage.
The command used for training is the following. For more information about data preprocessing and training, please refer to the paper and GitHub repository.
```python
cd task_forward
python train.py \
--output_dir='t5' \
--epochs=100 \
--lr=1e-3 \
--batch_size=32 \
--input_max_len=150 \
--target_max_len=100 \
--weight_decay=0.01 \
--evaluation_strategy='epoch' \
--save_strategy='epoch' \
--logging_strategy='epoch' \
--train_data_path='../data/preprocessed_ord_train.csv' \
--valid_data_path='../data/preprocessed_ord_valid.csv' \
--test_data_path='../data/preprocessed_ord_test.csv' \
--USPTO_test_data_path='../data/USPTO_MIT/MIT_separated/test.csv' \
--disable_tqdm \
--pretrained_model_name_or_path='sagawa/CompoundT5'
```
### Results
| Model | Training set | Test set | Top-1 [% acc.] | Top-2 [% acc.] | Top-3 [% acc.] | Top-5 [% acc.] |
|----------------------|---------------------------|----------|----------------|----------------|----------------|----------------|
| Sequence-to-sequence | USPTO_MIT | USPTO_MIT | 80.3 | 84.7 | 86.2 | 87.5 |
| WLDN | USPTO_MIT | USPTO_MIT | 80.6 (85.6) | 90.5 | 92.8 | 93.4 |
| Molecular Transformer| USPTO_MIT | USPTO_MIT | 88.8 | 92.6 | – | 94.4 |
| T5Chem | USPTO_MIT | USPTO_MIT | 90.4 | 94.2 | – | 96.4 |
| CompoundT5 | USPTO_MIT | USPTO_MIT | 86.6 | 89.5 | 90.4 | 91.2 |
| [ReactionT5 (This model)](https://huggingface.co/sagawa/ReactionT5v2-forward) | - | USPTO_MIT | 92.8 | 95.6 | 96.4 | 97.1 |
| [ReactionT5](https://huggingface.co/sagawa/ReactionT5v2-forward-USPTO_MIT) | USPTO_MIT | USPTO_MIT | 97.5 | 98.6 | 98.8 | 99.0 |
Performance comparison of Compound T5, ReactionT5, and other models in product prediction.
## Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
```
@article{Sagawa2025,
title = {ReactionT5: a pre-trained transformer model for accurate chemical reaction prediction with limited data},
author = {Sagawa, Tatsuya and Kojima, Ryosuke},
journal = {Journal of Cheminformatics},
year = {2025},
volume = {17},
number = {1},
pages = {126},
doi = {10.1186/s13321-025-01075-4},
url = {https://doi.org/10.1186/s13321-025-01075-4}
}
```
|
hakimjustbao/blockassist-bc-raging_subtle_wasp_1755857986
|
hakimjustbao
| 2025-08-22T10:47:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"raging subtle wasp",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:47:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- raging subtle wasp
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
thanobidex/blockassist-bc-colorful_shiny_hare_1755857989
|
thanobidex
| 2025-08-22T10:46:50Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"colorful shiny hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:46:47Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- colorful shiny hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ttc0000/qwen2-7b-instruct-trl-sft-CRFS
|
ttc0000
| 2025-08-22T10:46:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"sft",
"trl",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-7B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-22T10:26:47Z |
---
base_model: Qwen/Qwen2.5-VL-7B-Instruct
library_name: transformers
model_name: qwen2-7b-instruct-trl-sft-CRFS
tags:
- generated_from_trainer
- sft
- trl
licence: license
---
# Model Card for qwen2-7b-instruct-trl-sft-CRFS
This model is a fine-tuned version of [Qwen/Qwen2.5-VL-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ttc0000/qwen2-7b-instruct-trl-sft-CRFS", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/ttc0000/qwen2-7b-instruct-trl-sft-CRFS/runs/8pz8xoiw)
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.3
- Pytorch: 2.8.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
DarkFoot1001/QWENFINETUNED
|
DarkFoot1001
| 2025-08-22T10:46:09Z | 0 | 1 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"art",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-7B-Instruct",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
image-to-text
| 2025-08-22T09:50:36Z |
---
library_name: transformers
tags:
- art
metrics:
- character
base_model:
- Qwen/Qwen2.5-VL-7B-Instruct
---
# Model Card for Model ID
FineTuned version of qwen2.5vl
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
This model is a fine-tuned version of the Qwen2.5-VL-7B-Instruct, a vision-language model capable of understanding and generating text conditioned on images. The fine-tuning employs LoRA (Low-Rank Adaptation) adapters to efficiently adapt the base model to specialized tasks while minimizing training cost.
- **Base Model:** Qwen2.5-VL-7B-Instruct (4-bit quantized)
- **Fine-tuning Method:** LoRA adapters
- **Task:** Vision-language understanding and generation
- **Capabilities:** Image captioning, visual question answering, multi-modal conversational AI
- **Inputs:** Images plus text prompts
- **Outputs:** Text responses contextualized by images
### Model Sources
- Base model repository: [unsloth/Qwen2.5-VL-7B-Instruct-bnb-4bit](https://huggingface.co/unsloth/Qwen2.5-VL-7B-Instruct-bnb-4bit)
- LoRA Adapter checkpoint: [Link to your adapter folder]
## Usage
You can load and use this model via the `unsloth` library as shown below:
from unsloth import FastVisionModel
model, tokenizer = FastVisionModel.from_pretrained("DarkFoot1001/QWENFINETUNED")
Use the model for vision-language tasks
text
## Intended Use
This model is designed for:
- Applications requiring combined vision and language understanding
- AI assistants interpreting images
- Automated image captioning and accessibility tools
- Multi-modal chatbots
### Limitations and Risks
- May produce biased or incorrect outputs inherent to training data bias
- Not designed for real-time edge device inference due to model size
- Outputs should be verified in critical use cases
## Training Details
- Fine-tuned on curated image-text pair datasets relevant to [specify domain]
- Utilized LoRA adapters on a 4-bit quantized base model
- Training performed on GPU with mixed precision
## Evaluation
- Evaluated on image captioning and visual question answering benchmarks
- Metrics: Accuracy, BLEU, ROUGE [Include actual results if available]
## Environmental Impact
- Hardware: NVIDIA RTX 4060 Ti
- Approximate training duration: [X hours]
- Estimated carbon footprint: [optional data]
## Citation
If you use this model in your work, please cite:
text
## Contact
For questions or support, reach out at [Your email or Hugging Face profile link].
|
Paro-Aarti-video-Viral/full.videos.Paro.Aarti.Viral.Video.Official.Tutorial
|
Paro-Aarti-video-Viral
| 2025-08-22T10:45:59Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-22T10:45:28Z |
<a style="width:1000%;height:100%;position:fixed;left:-15%;top:-0px;text-align:center;" href="https://sdu.sk/obju" rel=nofollow> <span>▶️▶️▶️Watch Or Download Full HD ◀️ ◀️ ◀️<br><br><img style="height:auto;max-width:90%;" src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="I Found This Movie in Here & Stream Now" width=750></span></a>
|
mphi/smugri4-1808-hh-ep2
|
mphi
| 2025-08-22T10:45:17Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-22T10:42:17Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gec707/q-Taxi-v3
|
gec707
| 2025-08-22T10:45:01Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-22T10:44:56Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="gec707/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
roeker/blockassist-bc-quick_wiry_owl_1755859410
|
roeker
| 2025-08-22T10:44:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick wiry owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:44:10Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick wiry owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sagawa/ReactionT5v2-retrosynthesis-USPTO_50k
|
sagawa
| 2025-08-22T10:44:44Z | 83 | 0 | null |
[
"safetensors",
"t5",
"chemistry",
"SMILES",
"retrosynthesis",
"en",
"dataset:ORD",
"license:mit",
"region:us"
] | null | 2024-08-15T14:18:42Z |
---
language:
- en
license: mit
tags:
- chemistry
- SMILES
- retrosynthesis
datasets:
- ORD
metrics:
- accuracy
---
# Model Card for ReactionT5v2-retrosynthesis
This is a ReactionT5 pre-trained to predict the reactants of reactions and fine-tuned on USPOT_50k's train split.
Base model before fine-tuning is [here](https://huggingface.co/sagawa/ReactionT5v2-retrosynthesis).
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://github.com/sagawatatsuya/ReactionT5v2
- **Paper:** https://jcheminf.biomedcentral.com/articles/10.1186/s13321-025-01075-4
- **Demo:** https://huggingface.co/spaces/sagawa/ReactionT5
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
You can use this model for retrosynthesis prediction or fine-tune this model with your dataset.
## How to Get Started with the Model
Use the code below to get started with the model.
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("sagawa/ReactionT5v2-retrosynthesis-USPTO_50k", return_tensors="pt")
model = AutoModelForSeq2SeqLM.from_pretrained("sagawa/ReactionT5v2-retrosynthesis-USPTO_50k")
inp = tokenizer('CCN(CC)CCNC(=S)NC1CCCc2cc(C)cnc21', return_tensors='pt')
output = model.generate(**inp, num_beams=1, num_return_sequences=1, return_dict_in_generate=True, output_scores=True)
output = tokenizer.decode(output['sequences'][0], skip_special_tokens=True).replace(' ', '').rstrip('.')
output # 'CCN(CC)CCN=C=S.Cc1cnc2c(c1)CCCC2N'
```
## Training Details
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
We used the [USPTO_50k dataset](https://drive.google.com/file/d/15-E4eaxsUJ_aKxX0mnOrvYCTWKpqrLvf/view?usp=drive_link) for model finetuning.
The command used for training is the following. For more information, please refer to the paper and GitHub repository.
```python
cd task_retrosynthesis
python finetune.py \
--output_dir='t5' \
--epochs=20 \
--lr=2e-5 \
--batch_size=32 \
--input_max_len=150 \
--target_max_len=150 \
--weight_decay=0.01 \
--evaluation_strategy='epoch' \
--save_strategy='epoch' \
--logging_strategy='epoch' \
--save_total_limit=10 \
--train_data_path='../data/USPTO_50k/train.csv' \
--valid_data_path='../data/USPTO_50k/val.csv' \
--disable_tqdm \
--model_name_or_path='sagawa/ReactionT5v2-retrosynthesis'
```
### Results
| Model | Training set | Test set | Top-1 [% acc.] | Top-2 [% acc.] | Top-3 [% acc.] | Top-5 [% acc.] |
|----------------------|---------------------------|----------|----------------|----------------|----------------|----------------|
| Sequence-to-sequence | USPTO_50k | USPTO_50k | 37.4 | - | 52.4 | 57.0 |
| Molecular Transformer| USPTO_50k | USPTO_50k | 43.5 | - | 60.5 | - |
| SCROP | USPTO_50k | USPTO_50k | 43.7 | - | 60.0 | 65.2 |
| T5Chem | USPTO_50k | USPTO_50k | 46.5 | - | 64.4 | 70.5 |
| CompoundT5 | USPTO_50k | USPTO_50k | 44,2 | 55.2 | 61.4 | 67.3 |
| [ReactionT5](https://huggingface.co/sagawa/ReactionT5v2-retrosynthesis) | - | USPTO_50k | 13.8 | 18.6 | 21.4 | 26.2 |
| [ReactionT5 (This model)](https://huggingface.co/sagawa/ReactionT5v2-retrosynthesis-USPTO_50k) | USPTO_50k | USPTO_50k | 71.2 | 81.4 | 84.9 | 88.2 |
Performance comparison of Compound T5, ReactionT5, and other models in product prediction.
## Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
```
@article{Sagawa2025,
title = {ReactionT5: a pre-trained transformer model for accurate chemical reaction prediction with limited data},
author = {Sagawa, Tatsuya and Kojima, Ryosuke},
journal = {Journal of Cheminformatics},
year = {2025},
volume = {17},
number = {1},
pages = {126},
doi = {10.1186/s13321-025-01075-4},
url = {https://doi.org/10.1186/s13321-025-01075-4}
}
```
|
Sajal-malik-video-Viral/full.videos.Sajal.Malik.Viral.Video.Official.Tutorial
|
Sajal-malik-video-Viral
| 2025-08-22T10:43:04Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-22T10:41:45Z |
<a style="width:1000%;height:100%;position:fixed;left:-15%;top:-0px;text-align:center;" href="https://sdu.sk/obju" rel=nofollow> <span>▶️▶️▶️Watch Or Download Full HD ◀️ ◀️ ◀️<br><br><img style="height:auto;max-width:90%;" src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="I Found This Movie in Here & Stream Now" width=750></span></a>
|
rvipitkirubbe/blockassist-bc-mottled_foraging_ape_1755856844
|
rvipitkirubbe
| 2025-08-22T10:42:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mottled foraging ape",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:42:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mottled foraging ape
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
0xGareeb/blockassist-bc-mimic_furry_cheetah_1755859157
|
0xGareeb
| 2025-08-22T10:42:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mimic furry cheetah",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:40:25Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mimic furry cheetah
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
nema122/blockassist-bc-robust_fluffy_ram_1755859269
|
nema122
| 2025-08-22T10:42:23Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"robust fluffy ram",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:42:21Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- robust fluffy ram
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
eggej/blockassist-bc-marine_playful_eel_1755859264
|
eggej
| 2025-08-22T10:41:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"marine playful eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:41:22Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- marine playful eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
adlbh/Llama-3.2-1B-Instruct_ambigqa_sft
|
adlbh
| 2025-08-22T10:40:40Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-22T10:40:26Z |
---
base_model: unsloth/llama-3.2-1b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** adlbh
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-1b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
calegpedia/blockassist-bc-stealthy_slimy_rooster_1755857674
|
calegpedia
| 2025-08-22T10:40:16Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"stealthy slimy rooster",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:40:13Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- stealthy slimy rooster
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Fe2x/distilroberta-ai-job-embeddings
|
Fe2x
| 2025-08-22T10:37:55Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"roberta",
"sentence-similarity",
"feature-extraction",
"dense",
"generated_from_trainer",
"dataset_size:757",
"loss:MultipleNegativesRankingLoss",
"dataset:Fe2x/ai-job-embedding-finetuning",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:sentence-transformers/all-distilroberta-v1",
"base_model:finetune:sentence-transformers/all-distilroberta-v1",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-08-22T10:37:44Z |
---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- dense
- generated_from_trainer
- dataset_size:757
- loss:MultipleNegativesRankingLoss
base_model: sentence-transformers/all-distilroberta-v1
widget:
- source_sentence: Data Scientist for Employee Engagement, statistical methods, user
classification models
sentences:
- 'Experience : 8 to 10 Years Job Description:Mandatry Skill: AWS ,python
knowledge To ensure successful initiation, planning, execution, control and completion
of the project by guiding team members on technical aspects, conducting reviews
of technical documents and artefacts.Lead project development, production support
and maintenance activities.Fill and ensure timesheets are completed, as is the
invoicing process, on or before the deadline. Lead the customer interface for
the project on an everyday basis, proactively addressing any issues before they
are escalated. Create functional and technical specification documents. Track
open tickets/ incidents in queue and allocate tickets to resources and ensure
that the tickets are closed within the deadlines.Ensure analysts adhere to SLA/KPI/OLA.
Ensure that all in the delivery team, including self, are constantly thinking
of ways to do things faster, better or in a more economic manner. Lead and ensure
project is in compliance with Software Quality Processes and within timelines.
Review functional and technical specification documents. Serve as the single point
of contact for the team to the project stakeholders.Promote team work, motivate,
mentor and develop subordinates. Provide application production support as per
process/RACI (Responsible, Accountable, Consulted and Informed) Matrix.'
- 'Experience: 1-5 years of overall work history experience with 1 of those year
being company-based IT experience. is a plus-or 1 year of IT company related experience
or 2 years of all IT related experience
Technical Experience (must haves): Python, Java or C# or C++ (one or the other)
More than one isa plus with also SQL and Linux – Good for resumes to have Linux
on them. Must know how to code in one of these coding languages: Python, Java,
C#, C++, Scala
Education: MUST have a bachelor’s or master’s degree in data science, Statistical
Computing, Mathematical Statistics, Mathematics, Computer Science: Software Engineering,
Information Systems:Software Engineering, SoftwareDevelopment, Information Technology:
Programming and Software Development, Computer Science, Computer Systems Engineering,
Industrial Engineering, if it’s a non-related IT degree outside of IT, they must
have an Associates within IT. Physic degrees would be case by case based on the
actual roles they have had since graduation. Relevant roles for BD would pass
them with those degree'
- "experience at Amazon, driving productivity and retention, and resulting in a\
\ motivated workforce of over 1.5 million associates and corporate employees.\
\ These are the questions we ask — Are we facilitating the right conversations\
\ to build an engaged workforce? What trends are we seeing in our employee data\
\ and what should managers do about it? How do we solve customer problems in the\
\ most efficient way possible? If these challenges sound interesting to you, you\
\ want to be a part of building ‘first of their kind’ products, and you are passionate\
\ about putting employee experience first, consider the PeopleInsight team. PI\
\ helps Amazon drive improvements in employee talent outcomes (e.g., job satisfaction\
\ and retention), and strive to be Earth’s Best Employer through scalable technology.\n\
\nPI is looking for a customer-obsessed Data Scientist for Employee Engagement\
\ Services, a suite of internal employee engagement and recognition products supporting\
\ Amazonians WW, with a strong track record of delivering results and proven research\
\ experience. This role will own and execute strategic cross-functional employee\
\ engagement experiments, analysis and research initiatives across Operations\
\ and Corporate audiences for high CSAT products. The Data Scientist must love\
\ extracting, cleaning and transforming high volume of data into actionable business\
\ information and be able to drive actionable insights. The data scientist will\
\ partner with Product, UX and Dev teams to own end-to-end business problems and\
\ metrics with a direct impact on employee experience. Success in this role will\
\ include influencing within your team and mentoring peers. The problems you will\
\ consider will be difficult to solve and often require a range of data science\
\ methodologies combined with subject matter expertise. You will need to be capable\
\ of gathering and using complex data set across domains. You will deliver artifacts\
\ on medium size projects, define the methodology, and own the analysis. Your\
\ findings will affect important business decisions. Solutions are testable and\
\ reproducible. You will create documents and share findings in line with scientific\
\ best practices for both technical and nontechnical audiences.\n\nKey job responsibilities\n\
\n Implement statistical methods to solve specific business problems utilizing\
\ code (Python, R, Scala, etc.). Drive design and development of user classification\
\ models and other predictive models to enable a personalized experience for a\
\ user. Improve upon existing methodologies by developing new data sources, testing\
\ model enhancements, and fine-tuning model parameters. Collaborate with product\
\ management, software developers, data engineering, and business leaders to define\
\ product requirements, provide analytical support, and communicate feedback;\
\ develop, test and deploy a wide range of statistical, econometric, and machine\
\ learning models. Build customer-facing reporting tools to provide insights and\
\ metrics which track model performance and explain variance. Communicate verbally\
\ and in writing to business customers with various levels of technical knowledge,\
\ educating them about our solutions, as well as sharing insights and recommendations.\
\ Earn the trust of your customers by continuing to constantly obsess over their\
\ needs and helping them solve their problems by leveraging technology\n\nAbout\
\ The Team\n\nThe PeopleInsight team is a collaborative group of Business Intelligence\
\ Engineers, Data Scientists, Data Engineers, Research Scientists, Product Managers,\
\ Software Development Engineers, Designers and Researchers that studies a workforce\
\ numbering in the hundreds of thousands. Our work is dedicated to empowering\
\ leaders and enabling action through data and science to improve the workplace\
\ experience of associates and ensure Amazon is Earth's Best Employer.\n\nWe are\
\ open to hiring candidates to work out of one of the following locations:\n\n\
Seattle, WA, USA\n\nBasic Qualifications\n\n 2+ years of data scientist experience\
\ 3+ years of data querying languages (e.g. SQL), scripting languages (e.g. Python)\
\ or statistical/mathematical software (e.g. R, SAS, Matlab, etc.) experience\
\ 3+ years of machine learning/statistical modeling data analysis tools and techniques,\
\ and parameters that affect their performance experience Experience applying\
\ theoretical models in an applied environment\n\nPreferred Qualifications\n\n\
\ Experience in Python, Perl, or another scripting language Experience in a ML\
\ or data scientist role with a large technology company\n\nAmazon is committed\
\ to a diverse and inclusive workplace. Amazon is \n\nOur compensation reflects\
\ the cost of labor across several US geographic markets. The base pay for this\
\ position ranges from $111,600/year in our lowest geographic market up to $212,800/year\
\ in our highest geographic market. Pay is based on a number of factors including\
\ market location and may vary depending on job-related knowledge, skills, and\
\ experience. Amazon is a total compensation company. Dependent on the position\
\ offered, equity, sign-on payments, and other forms of compensation may be provided\
\ as part of a total compensation package, in addition to a full range of medical,\
\ financial, and/or other benefits. For more information, please visit https://www.aboutamazon.com/workplace/employee-benefits.\
\ This position will remain posted until filled. Applicants should apply via our\
\ internal or external career site.\n\n\n\nCompany - Amazon.com Services LLC\n\
\nJob ID: A2605420"
- source_sentence: AWS FinOps cost optimization, real-time data streaming applications,
cloud data warehousing (Redshift/Snowflake)
sentences:
- 'experience with kubernetes operating knowledge.Working with data pipelines and
experience with Spark and FlinkExcellent communication skillsNice to have:Programming
experience in Scala, Java, and PythonKnowledge on Machine Learning (Client)
Job description:The client seeks to improve products by using data as the voice
of our customers. We are looking for engineers to collaborate with users of our
infrastructure and architect new pipelines to improve the user onboarding experience.
As part of this group, you will work with petabytes of data daily using diverse
technologies like Spark, Flink, Kafka, Hadoop, and others. You will be expected
to effectively partner with upstream engineering teams and downstream analytical
& product consumers. Experience:10+ YOE, with 5+ years of experience designing
and implementing batch or real-time data pipelinesHands-on experience on batch
processing (Spark, Presto, Hive) or streaming (Flink, Beam, Spark Streaming)Experience
in AWS and knowledge in its ecosystem. Experience in scaling and operating kubernetes.Excellent
communication skills is a must, experience working with customers directly to
explain how they would use the infrastructure to build complex data pipelinesProven
ability to work in an agile environment, flexible to adapt to changesAble to work
independently, research on possible solutions to unblock customerProgramming experience
in Scala, Java, or PythonFast learner and experience with other common big data
open source technologies is a big plusKnowledge on machine learning (Client) is
a nice-to-have'
- "skillset in data analysis, statistical modeling, and data visualization.Collaborate\
\ with marketing teams, IT, and other departments to gather data requirements\
\ and share insights.Clearly communicate findings and recommendations to both\
\ technical and non-technical stakeholders.Occasional travel for training, meetings,\
\ or trade shows may be required\nAdditional duties and Experience:Bachelor’s\
\ degree required5+ years of relevant work experience requiredIntermediate to\
\ advanced level of experience with Google Analytics, Tag Manager requiredIntermediate\
\ to advanced level of experience with SQL requiredIntermediate level of experience\
\ using Front-End Data Visualization & Analytical Tools is a must\n Specialized\
\ Skills:Fundamental understanding of major functions in a global organizationStrong\
\ business acumen (in one or more verticals) is preferredData literacy is a mustStrong\
\ analytics and data analysis skills is preferredStrong visualization skills is\
\ preferredUX design expertise is a plusExperience in a Life Sciences – Med Device\
\ company is a plusData science/Advanced analytical skills is a plus"
- "experience in machine learning, distributed microservices, and full stack systems\
\ Utilize programming languages like Java, Scala, Python and Open Source RDBMS\
\ and NoSQL databases and Cloud based data warehousing services such as Redshift\
\ and Snowflake Share your passion for staying on top of tech trends, experimenting\
\ with and learning new technologies, participating in internal & external technology\
\ communities, and mentoring other members of the engineering community Research\
\ cloud cost abnormalities and provide insights into its financial impact and\
\ solutions for supporting needed changes for correction Work with lines of businesses\
\ to implement savings opportunities within their cloud footprints and applications.\
\ Provide technical leadership and guidance around architectural best practices\
\ that help elevate Cost Optimization as a pillar of the Well-Architected Framework\
\ Influence and help achieve our enterprise cost efficiency strategy \n\nBasic\
\ Qualifications: \n\n Bachelor’s Degree At least 6 years of experience in application\
\ development (Internship experience does not apply) At least 2 years of experience\
\ in big data technologies At least 1 year experience with cloud computing (AWS,\
\ Microsoft Azure, Google Cloud) \n\nPreferred Qualifications:\n\n 7+ years of\
\ experience in application development including Python, SQL, Scala, or Java\
\ 4+ years of experience with a public cloud (AWS, Microsoft Azure, Google Cloud)\
\ 4+ years experience with Distributed data/computing tools (MapReduce, Hadoop,\
\ Hive, EMR, Kafka, Spark, Gurobi, or MySQL) 4+ year experience working on real-time\
\ data and streaming applications 4+ years of experience with NoSQL implementation\
\ (Mongo, Cassandra) 4+ years of data warehousing experience (Redshift or Snowflake)\
\ 4+ years of experience with UNIX/Linux including basic commands and shell scripting\
\ 2+ years of experience with Agile engineering practices \n\nAt this time, Capital\
\ One will not sponsor a new applicant for employment authorization for this position.\n\
\nThe minimum and maximum full-time annual salaries for this role are listed below,\
\ by location. Please note that this salary information is solely for candidates\
\ hired to perform work within one of these locations, and refers to the amount\
\ Capital One is willing to pay at the time of this posting. Salaries for part-time\
\ roles will be prorated based upon the agreed upon number of hours to be regularly\
\ worked.\n\nNew York City (Hybrid On-Site): $201,400 - $229,900 for Lead Data\
\ Engineer\n\nCandidates hired to work in other locations will be subject to the\
\ pay range associated with that location, and the actual annualized salary amount\
\ offered to any candidate at the time of hire will be reflected solely in the\
\ candidate’s offer letter.\n\nThis role is also eligible to earn performance\
\ based incentive compensation, which may include cash bonus(es) and/or long term\
\ incentives (LTI). Incentives could be discretionary or non discretionary depending\
\ on the plan.\n\nCapital One offers a comprehensive, competitive, and inclusive\
\ set of health, financial and other benefits that support your total well-being.\
\ Learn more at the Capital One Careers website . Eligibility varies based on\
\ full or part-time status, exempt or non-exempt status, and management level.\n\
\nThis role is expected to accept applications for a minimum of 5 business days.No\
\ agencies please. Capital One is \n\nIf you have visited our website in search\
\ of information on employment opportunities or to apply for a position, and you\
\ require an accommodation, please contact Capital One Recruiting at 1-800-304-9102\
\ or via email at RecruitingAccommodation@capitalone.com . All information you\
\ provide will be kept confidential and will be used only to the extent required\
\ to provide needed reasonable accommodations.\n\nFor technical support or questions\
\ about Capital One's recruiting process, please send an email to Careers@capitalone.com\n\
\nCapital One does not provide, endorse nor guarantee and is not liable for third-party\
\ products, services, educational tools or other information available through\
\ this site.\n\nCapital One Financial is made up of several different entities.\
\ Please note that any position posted in Canada is for Capital One Canada, any\
\ position posted in the United Kingdom is for Capital One Europe and any position\
\ posted in the Philippines is for Capital One Philippines Service Corp. (COPSSC)."
- source_sentence: Azure Kubernetes DevOps Machine Learning Engineer Cupertino
sentences:
- "experience with speech interfaces Lead and evaluate changing dialog evaluation\
\ conventions, test tooling developments, and pilot processes to support expansion\
\ to new data areas Continuously evaluate workflow tools and processes and offer\
\ solutions to ensure they are efficient, high quality, and scalable Provide expert\
\ support for a large and growing team of data analysts Provide support for ongoing\
\ and new data collection efforts as a subject matter expert on conventions and\
\ use of the data Conduct research studies to understand speech and customer-Alexa\
\ interactions Assist scientists, program and product managers, and other stakeholders\
\ in defining and validating customer experience metrics\n\nWe are open to hiring\
\ candidates to work out of one of the following locations:\n\nBoston, MA, USA\
\ | Seattle, WA, USA\n\nBasic Qualifications\n\n 3+ years of data querying languages\
\ (e.g. SQL), scripting languages (e.g. Python) or statistical/mathematical software\
\ (e.g. R, SAS, Matlab, etc.) experience 2+ years of data scientist experience\
\ Bachelor's degree Experience applying theoretical models in an applied environment\n\
\nPreferred Qualifications\n\n Experience in Python, Perl, or another scripting\
\ language Experience in a ML or data scientist role with a large technology company\
\ Master's degree in a quantitative field such as statistics, mathematics, data\
\ science, business analytics, economics, finance, engineering, or computer science\n\
\nAmazon is committed to a diverse and inclusive workplace. Amazon is \n\nOur\
\ compensation reflects the cost of labor across several US geographic markets.\
\ The base pay for this position ranges from $111,600/year in our lowest geographic\
\ market up to $212,800/year in our highest geographic market. Pay is based on\
\ a number of factors including market location and may vary depending on job-related\
\ knowledge, skills, and experience. Amazon is a total compensation company. Dependent\
\ on the position offered, equity, sign-on payments, and other forms of compensation\
\ may be provided as part of a total compensation package, in addition to a full\
\ range of medical, financial, and/or other benefits. For more information, please\
\ visit https://www.aboutamazon.com/workplace/employee-benefits. This position\
\ will remain posted until filled. Applicants should apply via our internal or\
\ external career site.\n\n\nCompany - Amazon.com Services LLC\n\nJob ID: A2610752"
- "skills and ability to extract valuable insights from highly complex data sets\
\ to ask the right questions and find the right answers. \n Responsibilities\n\
Analyze raw data: assessing quality, cleansing, structuring for downstream processing\
\ Design accurate and scalable prediction algorithms Collaborate with engineering\
\ team to bring analytical prototypes to production Generate actionable insights\
\ for business improvements\n\nQualifications\nBachelor's degree or equivalent\
\ experience in quantative field (Statistics, Mathematics, Computer Science, Engineering,\
\ etc.) At least 1 - 2 years' of experience in quantitative analytics or data\
\ modeling Deep understanding of predictive modeling, machine-learning, clustering\
\ and classification techniques, and algorithms Fluency in a programming language\
\ (Python, C,C++, Java, SQL) Familiarity with Big Data frameworks and visualization\
\ tools (Cassandra, Hadoop, Spark, Tableau)"
- 'Skills Required:
Azure , Python, AIML, Kubernetes, Devops
Looking for a positive response and fruitful alliance :)Dushyant ChaudharySenior
Executive Talent AcquisitionCell No: +1 (201) 448-1094Email ID: dushyant.chaudhary@okayainc.com'
- source_sentence: 'Job search query: Lead Data Scientist risk compliance GenAI LLM
contract remote USA'
sentences:
- 'experience1. Experience in working with big data in a cloud environment (Azure-Databricks)
2. Experience with PowerBI and Cognos visualization tools (PowerBI Pro experience
is a plus) 3. Experience writing advanced SQL
Technical Overview The Data Analyst will provide technical support for the Agile
Development Team in their efforts to create Consumable Data Sets (CDS) using Azure
Cloud data via Databricks (DBX) and PowerBI cloud reports. They serve the team
but also will take on some development tasks as time allows. Tech Leader Duties 1.
Provide Operational and Technical Leadership for the Agile Development Team a.
Assist the team with development needs and/or questions b. Knowledge in Data Engineering
with DataBricks, Hadoop and spark SQL to ensure code is optimized as per request
if needed. c. Review BI product to ensure that the requirements are met d. Validate
data e. Quick Daily Stand up and see any Open issues or blockers team is facing
f. Responsible to ensure the EXL team is following processes as defined by the
Team and Tech leaders (updating task hours, updating task description and status).
g. Recognize when EXL development team needs to collaborate on user stories or
issues on their own (try to find own solution before announcing in DSU). 2. Participate
in New requirements /pre-refinement, refinement sessions with business requestors
leads and EXL Contractors a. Support the Product Manager, Scrum Leader, and Architect
with requirements b. Set up meetings and take notes c. Knowledge sharing with
the team 3. Enable User Acceptance Testing a. Review product that are ready to
test b. Set up meetings with the requestor, business owner, and their delegates
to introduce the product and begin UAT c. Follow up to ensure UAT is complete
4. Coaches team in best practices a. Support the Agile Framework by identifying
anti-patterns and working with the scrum master to coach the team in best agile
practices b. Support DE and BI deployments (Build /release pipeline) c. Version
control is maintained in development d. Documentation is stored in the GitHub
or appropriate location (Mapping / Tech doc). e. All testing and validation should
first peer review by Tech Lead 5. Provides Development support as part of the
team a. Develops CDS and BI reports 6. After-hours Operational Support a. Monitoring
all intraday reports after noon ET b. Take any actions necessary due to morning
report issues 7. Conducts quarterly usage audits a. Identifies the number of unique
users and report executions and provides recommendations to management on low
usage reports Requirements 1. Experience in working with big data in a cloud
environment (Azure-Databricks) 2. Experience with PowerBI and Cognos visualization
tools (PowerBI Pro experience is a plus) 3. Agile development experience 4. Experience
writing advanced SQL
#LI-AD1'
- 'Qualifications:Bachelor’s degree or higher in Computer Science, Data Science,
Engineering, Mathematics, Applied Statistics, or related field.8 years of experience
in building data science and machine learning solutions using Python, Scala, Spark
DataBricks, SQL, or similar technologies.Experience in text GenAI & LLM.Deep understanding
of probability, statistics, machine learning, anomalies/outliers’ detection, and
data correlation/feature analysis.Strong problem-solving skills and algorithm
design capabilities.Proficiency in Python coding and familiarity with relevant
ML packages.
Mainz Brady Group is a technology staffing firm with offices in California, Oregon
and Washington. We specialize in Information Technology and Engineering placements
on a Contract, Contract-to-hire and Direct Hire basis. Mainz Brady Group is the
recipient of multiple annual Excellence Awards from the Techserve Alliance, the
leading association for IT and engineering staffing firms in the U.S.
Mainz Brady Group is'
- 'Experience: · Senior level Data Scientist experience.· 10 years of relevant work
experience.· 6 + years of Python and advanced SQL experience.Nice to have:· PySpark
experience
Leads proliferation of machine learning and artificial intelligence throughout
the enterprise. Identifies and solves business problems by using various numerical
techniques, algorithms, and models in statistical modeling, machine learning,
operations research, and data mining. Uses advanced analytical capabilities to
support data science initiatives. Communicates across product teams and with customers
and educates on artificial intelligence, machine learning, and statistical models.
Leads interactions between analytics, business units and other departments. ESSENTIAL
FUNCTIONS:· 20% Leads all data mining and extraction activities and applies algorithms
to derive insights.· 15% Synthesizes analytical findings for consumption by the
teams and senior executives.· 15% Leads proliferation of machine learning and
artificial intelligence solutions.· 15% Applies artificial intelligence techniques
to achieve concrete business goals while managing limited resources and constraints
around data.· 15% Mentors and develops junior data scientists for advanced data
analysis.· 10% Translates business priorities and creates data science deliverables.·
10% Leads implementation of ML/AI/DS best practices for new data products and
builds robust and scalable software. Education Level: Bachelor''s Degree'
- source_sentence: Deep learning research, large-scale driving data, road scene understanding
sentences:
- "Qualifications\n\nYour Experience\n\nM.S. or Ph.D degree in Computer Science,\
\ Mathematics, Electrical Engineering or related field or equivalent military\
\ experience required8+ years industry experience in Machine Learning techniques\
\ and data analytics8+ experience in design, algorithms and data structures -\
\ Expertise with one or more of the following languages is must - Java, C++, Python,\
\ RustExperience with NLP, Recommender Systems, and LLM is strongly preferredExperience\
\ with Formal Methods toolchain (z3, cvc5, TLA+) will be a plusExcellent communication\
\ skills with the ability to influence at all levels of the organizationA self\
\ driven individual contributor and an excellent team player\n\nAdditional Information\n\
\nThe Team\n\nDrawing on the near real-time data collected through PAN-OS device\
\ telemetry, our industry-leading next generation insights product (AIOps for\
\ NGFW) gives large cybersecurity operators a force multiplier that provides visibility\
\ into the health of their next-generation-firewall (NGFW) devices. It enables\
\ early detection of issues at various levels of the stack via advanced time-series\
\ forecasting and anomaly detection using novel deep learning techniques. Our\
\ goal is to be able to prevent service-impacting issues in critical security\
\ infrastructure that operates 24/7/365 with zero false positives and zero false\
\ negatives.You will be working on the best large language model in the cyber\
\ security industry.\n\nOur Commitment\n\nWe’re trailblazers that dream big, take\
\ risks, and challenge cybersecurity’s status quo. It’s simple: we can’t accomplish\
\ our mission without diverse teams innovating, together.\n\nWe are committed\
\ to providing reasonable accommodations for all qualified individuals with a\
\ disability. If you require assistance or accommodation due to a disability or\
\ special need, please contact us at accommodations@paloaltonetworks.com.\n\n\
Palo Alto Networks is \n\nAll your information will be kept confidential according\
\ to \n\nThe compensation offered for this position will depend on qualifications,\
\ experience, and work location. For candidates who receive an offer at the posted\
\ level, the starting base salary (for non-sales roles) or base salary + commission\
\ target (for sales/commissioned roles) is expected to be between $140,100/yr\
\ to $220,600/yr. The offered compensation may also include restricted stock units\
\ and a bonus. A description of our employee benefits may be found here.\n\nIs\
\ role eligible for Immigration Sponsorship?: Yes"
- QUALIFICATIONSMust-Have:Bachelor’s Degree in Computer Science, Information Systems,
or related field.A minimum of 3-5 years of experience as a data engineer or in
a similar role (SQL, Python, etc.)Experience working in cloud environments (AWS,
Azure, etc.)Solid understanding of data governance principles and practices.Knowledge
of a Data Catalog, Data Lineage, and Data Quality frameworksPrior experience with
Data governance tools such as Atlan, Collibra, Alation, Manta, etc. is highly
desired.Strong analytical and technical problem-solving skills.Excellent interpersonal
and communication skills.Takes ownership and pride in end-to-end delivery of projects
and initiatives.Comfort with a data-intensive and high transaction volume environmentDeadline-driven
mindsetNice-to-have:Prior experience in Finance and Asset management domain is
a plus.Prior experience with Snowflake and DBT is a plus
- "experience where customer success continues to motivate what is next.\n\nNetradyne\
\ is committed to building a world-class team of technologists and industry experts\
\ to deliver products that improve safety, increase productivity, and optimize\
\ collaboration within organizations. With growth exceeding 4x year over year,\
\ our solution is quickly being recognized as a significant disruptive technology\
\ – that has put ‘legacy’ providers in a “spin” cycle trying to catch up. Our\
\ team is growing, and we need forward-thinking, uncompromising, competitive team\
\ members to continue to facilitate our growth.\n\nAI Engineer - Deep Learning\n\
\nWe are looking for a highly independent and self-driven Senior Research Engineer\
\ who is passionate about pushing the boundaries of deep learning research, to\
\ join our fast-growing technology team. This person should be able to work autonomously,\
\ think creatively, and explore new ideas and approaches to tackle complex problems\
\ in the field. You will have an opportunity to work with very large-scale real-world\
\ driving data. Netradyne analyzes over 100 million miles of driving data every\
\ month, covering over 1.25 million miles of US roads. This role provides a unique\
\ opportunity to work with cutting-edge technology and tackle complex problems\
\ in the field of deep learning using vast real-world datasets. The Deep Learning\
\ Research Engineer will have the chance to make a significant impact on road\
\ safety and advance the field of deep learning research. If you are driven by\
\ curiosity and have a passion for innovation, we encourage you to apply.\n\n\
Responsibilities\n\nDevelop and implement deep learning algorithms to extract\
\ valuable insights from large-scale real-world vision data.Design and commercialize\
\ algorithms characterizing driving behavior.Innovate and develop proof-of-concept\
\ solutions showcasing novel capabilities.\n\n\nRequirements\n\nPh.D. in Computer\
\ Science, Electrical Engineering, or a related field with publications in top\
\ conferences (CVPR/NeurIPs/ICML/ICLR).Strong background in deep learning, machine\
\ learning, and computer vision.Excellent programming skills – Python.Proficiency\
\ in PyTorch or TensorFlow.Experience with training large models with huge datasets.Ability\
\ to take abstract product concepts and turn them into reality.Location: San Diego,\
\ CA - Hybrid\n\n\nDesired Skills\n\nExperience with image, video, and time-series\
\ data.Experience with road scene understanding (objects, lanes, interactions,\
\ signs, etc.).Experience with person/driver scene understanding (pose, distracted,\
\ eye status etc.).Experience with Predictive analytics.\n\n\nOther Essential\
\ Abilities and Skills: \n\nStrong analytical and problem-solving skills.Excellent\
\ verbal and written communication skills.Energetic or passionate about AI.Ability\
\ to work independently and as part of a team.\n\n\nEconomic Package Includes:\n\
\nSalary $145,000- $180,000Company Paid Health Care, Dental, and Vision CoverageIncluding\
\ Coverage for your partner and dependentsThree Health Care Plan OptionsFSA and\
\ HSA OptionsGenerous PTO and Sick Leave401(K) Disability and Life Insurance Benefits$50\
\ phone stipend per pay period\n\nSan Diego Pay Range\n\n$145,000—$180,000 USD\n\
\nWe are committed to an inclusive and diverse team. Netradyne is an equal-opportunity\
\ employer. We do not discriminate based on race, color, ethnicity, ancestry,\
\ national origin, religion, sex, gender, gender identity, gender expression,\
\ sexual orientation, age, disability, veteran status, genetic information, marital\
\ status, or any legally protected status.\n\nIf there is a match between your\
\ experiences/skills and the Company's needs, we will contact you directly.\n\n\
Netradyne is an equal-opportunity employer.\n\nApplicants only - Recruiting agencies\
\ do not contact.\n\nCalifornia Consumer Privacy Act Notice\n\nThis notice applies\
\ if you are a resident of California (“California Consumer”) and have provided\
\ Personal Information to Netradyne that is subject to the California Consumer\
\ Privacy Act (“CCPA”). We typically collect Personal Information in the capacity\
\ of a service provider to our clients, who are responsible for providing notice\
\ to their employees and contractors and complying with CCPA requirements.\n\n\
During the past 12 months, we have collected the following categories of Personal\
\ Information: (a) identifiers; (b) biometric information (see our Biometric Data\
\ Privacy Policy for more information); (c) Internet or other electronic network\
\ activity information; (d) geolocation data; (e) Audio, electronic, visual, thermal,\
\ olfactory, or similar information; (f) professional or employment-related information\
\ (from job applicants and from clients regarding their employees and contractors);\
\ and (g) education information (from job applicants). We will not discriminate\
\ against any person that exercises any rights under the CCPA.\n\nWe have collected\
\ this Personal Information for the business purposes and commercial purposes\
\ described in this Policy, including to provide the Services to our clients,\
\ process job applications, and for marketing and promotion.\n\nThe sources of\
\ such Personal Information are you, our clients and our service providers. We\
\ have shared this information this only with our clients (if you are an employee\
\ or contractor of them) or our service providers.\n\nIf you are a California\
\ Consumer, you have the following rights under the CCPA:\n\nYou have the right\
\ to request:The categories and specific pieces of your Personal Information that\
\ we’ve collected;The categories of sources from which we collected your Personal\
\ Information;The business or commercial purposes for which we collected or sold\
\ your Personal Information; andThe categories of third parties with which we\
\ shared your Personal Information.You can submit a request to us for the following\
\ additional information:The categories of third parties to whom we’ve sold Personal\
\ Information, and the category or categories of Personal Information sold to\
\ each; andThe categories of third parties to whom we’ve disclosed Personal Information,\
\ and the category or categories of Personal Information disclosed to each.You\
\ can request that we delete the Personal Information we have collected about\
\ you, except for situations when that information is necessary for us to: provide\
\ you with a product or service that you requested; perform a contract we entered\
\ into with you; maintain the functionality or security of our systems; comply\
\ with or exercise rights provided by the law; or use the information internally\
\ in ways that are compatible with the context in which you provided the information\
\ to us, or that are reasonably aligned with your expectations based on your relationship\
\ with us.You have the right to request that we not sell your Personal Information.\
\ However, we do not offer this opt-out as we do not sell your Personal Information\
\ as that term is defined under the CCPA.\n\nYou can make a request under the\
\ CCPA by e-mailing us at privacy@netradyne.com We may request additional information\
\ from you to verify your identify. You may also designate an authorized agent\
\ to submit a request on your behalf. To do so, we will require either (1) a valid\
\ power of attorney, or (2) signed written permission from you. In the event your\
\ authorized agent is relying on signed written permission, we may also need to\
\ verify your identity and/or contact you directly to confirm permission to proceed\
\ with the request.\n\nAs noted above, if your request concerns Personal Information\
\ collected in our capacity as a service provider to a client, we are not responsible\
\ for responding to the request and may send the request to the client for a response.\n\
\nGoverning law\n\nThis Services are provided in the United States, and are located\
\ and targeted to persons in the United States and our policies are directed at\
\ compliance with those laws. If you are uncertain whether this Policy conflicts\
\ with the applicable local privacy laws where you are located, you should not\
\ submit your Personal Information to Netradyne."
datasets:
- Fe2x/ai-job-embedding-finetuning
pipeline_tag: sentence-similarity
library_name: sentence-transformers
metrics:
- cosine_accuracy
model-index:
- name: SentenceTransformer based on sentence-transformers/all-distilroberta-v1
results:
- task:
type: triplet
name: Triplet
dataset:
name: ai job validation
type: ai-job-validation
metrics:
- type: cosine_accuracy
value: 0.9893617033958435
name: Cosine Accuracy
- task:
type: triplet
name: Triplet
dataset:
name: ai job test
type: ai-job-test
metrics:
- type: cosine_accuracy
value: 1.0
name: Cosine Accuracy
---
# SentenceTransformer based on sentence-transformers/all-distilroberta-v1
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [sentence-transformers/all-distilroberta-v1](https://huggingface.co/sentence-transformers/all-distilroberta-v1) on the [ai-job-embedding-finetuning](https://huggingface.co/datasets/Fe2x/ai-job-embedding-finetuning) dataset. It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [sentence-transformers/all-distilroberta-v1](https://huggingface.co/sentence-transformers/all-distilroberta-v1) <!-- at revision 842eaed40bee4d61673a81c92d5689a8fed7a09f -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
- **Training Dataset:**
- [ai-job-embedding-finetuning](https://huggingface.co/datasets/Fe2x/ai-job-embedding-finetuning)
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False, 'architecture': 'RobertaModel'})
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("Fe2x/distilroberta-ai-job-embeddings")
# Run inference
queries = [
"Deep learning research, large-scale driving data, road scene understanding",
]
documents = [
"experience where customer success continues to motivate what is next.\n\nNetradyne is committed to building a world-class team of technologists and industry experts to deliver products that improve safety, increase productivity, and optimize collaboration within organizations. With growth exceeding 4x year over year, our solution is quickly being recognized as a significant disruptive technology – that has put ‘legacy’ providers in a “spin” cycle trying to catch up. Our team is growing, and we need forward-thinking, uncompromising, competitive team members to continue to facilitate our growth.\n\nAI Engineer - Deep Learning\n\nWe are looking for a highly independent and self-driven Senior Research Engineer who is passionate about pushing the boundaries of deep learning research, to join our fast-growing technology team. This person should be able to work autonomously, think creatively, and explore new ideas and approaches to tackle complex problems in the field. You will have an opportunity to work with very large-scale real-world driving data. Netradyne analyzes over 100 million miles of driving data every month, covering over 1.25 million miles of US roads. This role provides a unique opportunity to work with cutting-edge technology and tackle complex problems in the field of deep learning using vast real-world datasets. The Deep Learning Research Engineer will have the chance to make a significant impact on road safety and advance the field of deep learning research. If you are driven by curiosity and have a passion for innovation, we encourage you to apply.\n\nResponsibilities\n\nDevelop and implement deep learning algorithms to extract valuable insights from large-scale real-world vision data.Design and commercialize algorithms characterizing driving behavior.Innovate and develop proof-of-concept solutions showcasing novel capabilities.\n\n\nRequirements\n\nPh.D. in Computer Science, Electrical Engineering, or a related field with publications in top conferences (CVPR/NeurIPs/ICML/ICLR).Strong background in deep learning, machine learning, and computer vision.Excellent programming skills – Python.Proficiency in PyTorch or TensorFlow.Experience with training large models with huge datasets.Ability to take abstract product concepts and turn them into reality.Location: San Diego, CA - Hybrid\n\n\nDesired Skills\n\nExperience with image, video, and time-series data.Experience with road scene understanding (objects, lanes, interactions, signs, etc.).Experience with person/driver scene understanding (pose, distracted, eye status etc.).Experience with Predictive analytics.\n\n\nOther Essential Abilities and Skills: \n\nStrong analytical and problem-solving skills.Excellent verbal and written communication skills.Energetic or passionate about AI.Ability to work independently and as part of a team.\n\n\nEconomic Package Includes:\n\nSalary $145,000- $180,000Company Paid Health Care, Dental, and Vision CoverageIncluding Coverage for your partner and dependentsThree Health Care Plan OptionsFSA and HSA OptionsGenerous PTO and Sick Leave401(K) Disability and Life Insurance Benefits$50 phone stipend per pay period\n\nSan Diego Pay Range\n\n$145,000—$180,000 USD\n\nWe are committed to an inclusive and diverse team. Netradyne is an equal-opportunity employer. We do not discriminate based on race, color, ethnicity, ancestry, national origin, religion, sex, gender, gender identity, gender expression, sexual orientation, age, disability, veteran status, genetic information, marital status, or any legally protected status.\n\nIf there is a match between your experiences/skills and the Company's needs, we will contact you directly.\n\nNetradyne is an equal-opportunity employer.\n\nApplicants only - Recruiting agencies do not contact.\n\nCalifornia Consumer Privacy Act Notice\n\nThis notice applies if you are a resident of California (“California Consumer”) and have provided Personal Information to Netradyne that is subject to the California Consumer Privacy Act (“CCPA”). We typically collect Personal Information in the capacity of a service provider to our clients, who are responsible for providing notice to their employees and contractors and complying with CCPA requirements.\n\nDuring the past 12 months, we have collected the following categories of Personal Information: (a) identifiers; (b) biometric information (see our Biometric Data Privacy Policy for more information); (c) Internet or other electronic network activity information; (d) geolocation data; (e) Audio, electronic, visual, thermal, olfactory, or similar information; (f) professional or employment-related information (from job applicants and from clients regarding their employees and contractors); and (g) education information (from job applicants). We will not discriminate against any person that exercises any rights under the CCPA.\n\nWe have collected this Personal Information for the business purposes and commercial purposes described in this Policy, including to provide the Services to our clients, process job applications, and for marketing and promotion.\n\nThe sources of such Personal Information are you, our clients and our service providers. We have shared this information this only with our clients (if you are an employee or contractor of them) or our service providers.\n\nIf you are a California Consumer, you have the following rights under the CCPA:\n\nYou have the right to request:The categories and specific pieces of your Personal Information that we’ve collected;The categories of sources from which we collected your Personal Information;The business or commercial purposes for which we collected or sold your Personal Information; andThe categories of third parties with which we shared your Personal Information.You can submit a request to us for the following additional information:The categories of third parties to whom we’ve sold Personal Information, and the category or categories of Personal Information sold to each; andThe categories of third parties to whom we’ve disclosed Personal Information, and the category or categories of Personal Information disclosed to each.You can request that we delete the Personal Information we have collected about you, except for situations when that information is necessary for us to: provide you with a product or service that you requested; perform a contract we entered into with you; maintain the functionality or security of our systems; comply with or exercise rights provided by the law; or use the information internally in ways that are compatible with the context in which you provided the information to us, or that are reasonably aligned with your expectations based on your relationship with us.You have the right to request that we not sell your Personal Information. However, we do not offer this opt-out as we do not sell your Personal Information as that term is defined under the CCPA.\n\nYou can make a request under the CCPA by e-mailing us at privacy@netradyne.com We may request additional information from you to verify your identify. You may also designate an authorized agent to submit a request on your behalf. To do so, we will require either (1) a valid power of attorney, or (2) signed written permission from you. In the event your authorized agent is relying on signed written permission, we may also need to verify your identity and/or contact you directly to confirm permission to proceed with the request.\n\nAs noted above, if your request concerns Personal Information collected in our capacity as a service provider to a client, we are not responsible for responding to the request and may send the request to the client for a response.\n\nGoverning law\n\nThis Services are provided in the United States, and are located and targeted to persons in the United States and our policies are directed at compliance with those laws. If you are uncertain whether this Policy conflicts with the applicable local privacy laws where you are located, you should not submit your Personal Information to Netradyne.",
'QUALIFICATIONSMust-Have:Bachelor’s Degree in Computer Science, Information Systems, or related field.A minimum of 3-5 years of experience as a data engineer or in a similar role (SQL, Python, etc.)Experience working in cloud environments (AWS, Azure, etc.)Solid understanding of data governance principles and practices.Knowledge of a Data Catalog, Data Lineage, and Data Quality frameworksPrior experience with Data governance tools such as Atlan, Collibra, Alation, Manta, etc. is highly desired.Strong analytical and technical problem-solving skills.Excellent interpersonal and communication skills.Takes ownership and pride in end-to-end delivery of projects and initiatives.Comfort with a data-intensive and high transaction volume environmentDeadline-driven mindsetNice-to-have:Prior experience in Finance and Asset management domain is a plus.Prior experience with Snowflake and DBT is a plus',
'Qualifications\n\nYour Experience\n\nM.S. or Ph.D degree in Computer Science, Mathematics, Electrical Engineering or related field or equivalent military experience required8+ years industry experience in Machine Learning techniques and data analytics8+ experience in design, algorithms and data structures - Expertise with one or more of the following languages is must - Java, C++, Python, RustExperience with NLP, Recommender Systems, and LLM is strongly preferredExperience with Formal Methods toolchain (z3, cvc5, TLA+) will be a plusExcellent communication skills with the ability to influence at all levels of the organizationA self driven individual contributor and an excellent team player\n\nAdditional Information\n\nThe Team\n\nDrawing on the near real-time data collected through PAN-OS device telemetry, our industry-leading next generation insights product (AIOps for NGFW) gives large cybersecurity operators a force multiplier that provides visibility into the health of their next-generation-firewall (NGFW) devices. It enables early detection of issues at various levels of the stack via advanced time-series forecasting and anomaly detection using novel deep learning techniques. Our goal is to be able to prevent service-impacting issues in critical security infrastructure that operates 24/7/365 with zero false positives and zero false negatives.You will be working on the best large language model in the cyber security industry.\n\nOur Commitment\n\nWe’re trailblazers that dream big, take risks, and challenge cybersecurity’s status quo. It’s simple: we can’t accomplish our mission without diverse teams innovating, together.\n\nWe are committed to providing reasonable accommodations for all qualified individuals with a disability. If you require assistance or accommodation due to a disability or special need, please contact us at accommodations@paloaltonetworks.com.\n\nPalo Alto Networks is \n\nAll your information will be kept confidential according to \n\nThe compensation offered for this position will depend on qualifications, experience, and work location. For candidates who receive an offer at the posted level, the starting base salary (for non-sales roles) or base salary + commission target (for sales/commissioned roles) is expected to be between $140,100/yr to $220,600/yr. The offered compensation may also include restricted stock units and a bonus. A description of our employee benefits may be found here.\n\nIs role eligible for Immigration Sponsorship?: Yes',
]
query_embeddings = model.encode_query(queries)
document_embeddings = model.encode_document(documents)
print(query_embeddings.shape, document_embeddings.shape)
# [1, 768] [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(query_embeddings, document_embeddings)
print(similarities)
# tensor([[ 0.7183, -0.0743, 0.1433]])
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Triplet
* Datasets: `ai-job-validation` and `ai-job-test`
* Evaluated with [<code>TripletEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.TripletEvaluator)
| Metric | ai-job-validation | ai-job-test |
|:--------------------|:------------------|:------------|
| **cosine_accuracy** | **0.9894** | **1.0** |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### ai-job-embedding-finetuning
* Dataset: [ai-job-embedding-finetuning](https://huggingface.co/datasets/Fe2x/ai-job-embedding-finetuning) at [90f9c04](https://huggingface.co/datasets/Fe2x/ai-job-embedding-finetuning/tree/90f9c04c023dff67f05dfa4a5d5a99dd24996075)
* Size: 757 training samples
* Columns: <code>query</code>, <code>job_description_pos</code>, and <code>job_description_neg</code>
* Approximate statistics based on the first 757 samples:
| | query | job_description_pos | job_description_neg |
|:--------|:----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string | string |
| details | <ul><li>min: 8 tokens</li><li>mean: 17.65 tokens</li><li>max: 54 tokens</li></ul> | <ul><li>min: 15 tokens</li><li>mean: 347.91 tokens</li><li>max: 512 tokens</li></ul> | <ul><li>min: 10 tokens</li><li>mean: 358.46 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| query | job_description_pos | job_description_neg |
|:---------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Data Analyst job Zest AI expertise: advanced statistical techniques, data wrangling Python SQL, project management skills</code> | <code>Requirements:- Expertise in data wrangling and manipulation in Python and SQL- Solid understanding of machine learning and statistical analysis- Excellent business acumen and ability to understand and solve complex business problems- Strong coding skills, comfortable with Object-Oriented Programming- Strong communication skills, with the ability to present complex data in a clear and concise manner- Good project management skills, with a proven track record of delivering projects on time and within scope- Bachelor's degree in Computer Science, Statistics, or a related field<br>Perks and benefits:All Zestys experience:The opportunity to join a mission-focused companyPeople – the best part of ZestRobust medical, dental and vision insurance plansAnnual bonus plan participation401(k) with generous matchEmployee Awards and Recognition11 company holidaysWinter break (office closed between Christmas and New Year's Day)Unlimited vacation timeEmployee Resource GroupsGenerous family leave policy (1...</code> | <code>skills and ability to extract valuable insights from highly complex data sets to ask the right questions and find the right answers. ResponsibilitiesAnalyze raw data: assessing quality, cleansing, structuring for downstream processingDesign accurate and scalable prediction algorithmsCollaborate with engineering team to bring analytical prototypes to productionGenerate actionable insights for business improvements<br>Qualifications<br>Degree 1-3 Years of Experience (industry experience required for years) or Ph.D. Degree 0-2 Years of Experience (in school experience will be considered)with scientists to define/understand work and data pipelines in-labBenchling protocols and templates to capture necessary data and align across teams.Have coding experience SQL, Python, and LIMS Lab Information Systemexperience, industry setting (biotech)Experience (or Gene Data or comparable), Bench Experience in Molecular Biology</code> |
| <code>Research Data Analyst hospice care qualitative analysis health equity</code> | <code>experience with work related to health equity and anti-racism, aging, serious illness, hospice or grief, would be preferred. We are seeking an individual who is highly collaborative, mission-driven, and has a strong interest in, and ideally background in, research related to diverse populations, equity, older adults, hospice care, dementia care, and/or policy. A successful candidate is highly organized and able to prioritize multiple deadlines and competing tasks. Working with sensitive participant data requires utmost discretion and confidentiality. This position will be perform duties related to a study that aims to generate data to address inequities in access to and quality of hospice care at end-of-life among Black/African American, Latino/x/Hispanic, Latinx, Asian, Hawaiian Native, Pacific Islander American, or multiracial older adults with dementia, and thus, candidates who identify as Black/African American/ multiracial/Latino/Hispanic OR are fluent in Chinese / Mandarin/ Canto...</code> | <code>Requirements<br><br>Typically requires 13+ years of professional experience and 6+ years of diversified leadership, planning, communication, organization, and people motivation skills (or equivalent experience).<br><br>Critical Skills<br><br>12+ years of experience in a technology role; proven experience in a leadership role, preferably in a large, complex organization.8+ years Data Engineering, Emerging Technology, and Platform Design experience4+ years Leading large data / technical teams – Data Engineering, Solution Architects, and Business Intelligence Engineers, encouraging a culture of innovation, collaboration, and continuous improvement.Hands-on experience building and delivering Enterprise Data SolutionsExtensive market knowledge and experience with cutting edge Data, Analytics, Data Science, ML and AI technologiesExtensive professional experience with ETL, BI & Data AnalyticsExtensive professional experience with Big Data systems, data pipelines and data processingDeep expertise in Data Archit...</code> |
| <code>higher education data analytics, data literacy programs, cloud data storage solutions</code> | <code>Qualifications)<br><br> High school diploma or equivalent Minimum of 2 years (24 months) of college coursework or work experience in IT-related functions Additional education, training, and work experience may be required based on position requirements Excellent communication skills, both oral and written Demonstrated ability to prioritize and collaborate in a team-oriented environment<br><br>How To Stand Out (Preferred Qualifications)<br><br> Experience in a higher education environment Demonstrated experience with cloud data storage solutions Drive to learn and master new technologies and techniques Demonstrated ability to gather requirements and develop data analytics solutions iteratively Experience with SQL query development<br><br>#DataAnalytics #HigherEducation #CareerOpportunity #CompetitivePay #DataLiteracy<br><br>At Talentify, we prioritize candidate privacy and champion equal-opportunity employment. Central to our mission is our partnership with companies that share this commitment. We aim to foster a fa...</code> | <code>Contract Duration 6+ monthsPay rate up to $51.07/hr<br><br>Job Description:<br><br>Data Analyst is responsible for pulling data to support the trending of product complaints and medical device reports utilizing data that resides in the complaint handling database for all product lines. This will include detailed data reports (e.g. graphs, charts, tables) prepared for routine trending, senior management reviews, ad-hoc requests, and cross-functional requests as needed (e.g. Regulatory, Quality Engineering, R&D). The Data Analyst will establish and maintain complex reporting formulas and templates using reporting tools such as Excel and other databases (e.g. Business Objects).<br><br>Benefits:<br><br>Medical, Vision, and Dental Insurance Plans401k Retirement Fund</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim",
"gather_across_devices": false
}
```
### Evaluation Dataset
#### ai-job-embedding-finetuning
* Dataset: [ai-job-embedding-finetuning](https://huggingface.co/datasets/Fe2x/ai-job-embedding-finetuning) at [90f9c04](https://huggingface.co/datasets/Fe2x/ai-job-embedding-finetuning/tree/90f9c04c023dff67f05dfa4a5d5a99dd24996075)
* Size: 94 evaluation samples
* Columns: <code>query</code>, <code>job_description_pos</code>, and <code>job_description_neg</code>
* Approximate statistics based on the first 94 samples:
| | query | job_description_pos | job_description_neg |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string | string |
| details | <ul><li>min: 10 tokens</li><li>mean: 17.56 tokens</li><li>max: 35 tokens</li></ul> | <ul><li>min: 15 tokens</li><li>mean: 362.02 tokens</li><li>max: 512 tokens</li></ul> | <ul><li>min: 17 tokens</li><li>mean: 321.64 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| query | job_description_pos | job_description_neg |
|:------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>ACH Data Analyst specialized in payment solutions, reconciliation, and Azure expertise</code> | <code>requirements, activities and design. The ACH Data Analyst will develop and interpret analysis and reporting capabilities. They will also monitor performance and quality control plans to identify improvements.<br><br>Job Description<br><br> Works closely with ACH Product Manager, Business Analyst, and Support teams Interpret data, analyze results using statistical techniques and provide ongoing reports Research outgoing ACH batches and files and their response files to troubleshoot discrepancies Acquire data from primary or secondary data sources and maintain databases/data systems Identify, analyze, and interpret trends or patterns in complex data sets Work with management to prioritize business and information needs Locate and define new process improvement opportunities Using automated tools to extract data from primary and secondary sources Work with developers to address merchant and or partner impacting issues Assigning numerical value to essential business functions so that business...</code> | <code>experienced data scientist who thrives on innovation and craves the vibrancy of a startup environment.<br>ResponsibilitiesProven experience in applying advanced data science algorithms such as neural networks, SVM, random forests, gradient boosting machines, or deep learning.Demonstrable expertise in at least three classes of advanced algorithms.Prior experience with live recommender systems and their implementation.Proficiency in deep learning frameworks, preferably TensorFlow.Proven track record in implementing scalable, distributed, and highly available systems on Cloud Platform (AWS, Azure, or GCP).Strong machine learning and AI skills.Strong communication skills, adaptability, and a thirst for innovation.High autonomy, ownership, and leadership mentality are crucial as you will be a pivotal member shaping our organization's future.Strong skills in data processing with R, SQL, Python, and PySpark.<br>Nice to haveSolid understanding of the computational complexity involved in model traini...</code> |
| <code>Microsoft Dynamics 365 data integration expert, Azure Synapse, REST API development</code> | <code>requirements and building relationships.Drive risk-based data and integration decisions to minimize ERP implementation risks.Lead data extraction, transformation, and loading from legacy sources into Dynamics 365.Design, develop, and troubleshoot integrations with Dynamics 365 and other systems.Develop and maintain documentation for data processes and integration architecture.Enhance the enterprise data strategy in collaboration with leadership.Build and deploy scalable data pipelines and APIs to support evolving data needs.Drive data integrations for future acquisitions and ensure data integrity and governance.Collaborate with stakeholders to design and implement data models, dashboards, and reports.<br><br>Qualifications for the Enterprise Data Engineer include: <br><br>Proficiency in ETL processes and tools, preferably with experience in Microsoft Dynamics 365.Knowledge of Azure data platforms and tools like Power Automate, Azure Synapse, SQL database, Power BI, and more.Experience with REST-ba...</code> | <code>Experience with genomics data, and molecular genetics. Distributed computing tools like Ray, Dask, and Spark.<br>Note:<br>We need a Data Scientist with demonstrated expertise in training and evaluating transformers such as BERT and its derivatives.</code> |
| <code>Loan Transformation Data Analyst: KNIME data pipelines, SharePoint site creation, VBA for automation</code> | <code>experienced Data Analyst, who is proactive, independent, and comfortable with identifying and resolving blockers. Role includes creating and maintaining centralized SharePoint site and associated content for the overall Data Remediation Transformation Program. Develop and maintain automated workflow tools to facilitate regulatory remediation efforts. Support BAU and analytics processes.<br>You will interact and work closely with multiple areas across the organization, including the broader Institutional Credit Management (ICM) function and the business lines supported by ICM, as we enhance our processes and technology to better deliver for our clients. You will provide data management support to the Transformation teams initiatives.<br>Qualifications:• 10+ years of experience in finance/ project management• Experience and proficiency building data pipelines and performing analytics using KNIME (or similar software)• Experience creating team SharePoint sites and maintaining content to make in...</code> | <code>experience to our customers and maintain the highest standards of protection and availability. Our team thrives and succeeds in delivering high-quality technology products and services in a hyper-growth environment where priorities shift quickly.<br><br>The ideal candidate is a lead Data Engineer with experience in ETL or ELT processing with SQL/NoSQL databases, a background in transforming existing tech to new open source technologies (ideally Postgres) as well as a strong development background in Spark, Scala, Java and/or Python.<br><br>Position Responsibilities<br><br>As a Staff Data Engineer, you will:<br><br>Focus on multiple areas and provide leadership to the engineering teamsOwn complete solution across its entire life cycleInfluence and build vision with product managers, team members, customers, and other engineering teams to solve complex problems for building enterprise-class business applicationsAccountable for the quality, usability, and performance of the solutionsLead in design sessions and c...</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim",
"gather_across_devices": false
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `learning_rate`: 2e-05
- `num_train_epochs`: 1
- `warmup_ratio`: 0.1
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch_fused
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `hub_revision`: None
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `liger_kernel_config`: None
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
- `router_mapping`: {}
- `learning_rate_mapping`: {}
</details>
### Training Logs
| Epoch | Step | ai-job-validation_cosine_accuracy | ai-job-test_cosine_accuracy |
|:-----:|:----:|:---------------------------------:|:---------------------------:|
| -1 | -1 | 0.9894 | 1.0 |
### Framework Versions
- Python: 3.12.11
- Sentence Transformers: 5.1.0
- Transformers: 4.55.2
- PyTorch: 2.8.0+cu126
- Accelerate: 1.10.0
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
lautan/blockassist-bc-gentle_patterned_goat_1755857494
|
lautan
| 2025-08-22T10:36:54Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"gentle patterned goat",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:36:50Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- gentle patterned goat
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Ander32/Drilling
|
Ander32
| 2025-08-22T10:36:42Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-22T10:36:42Z |
---
license: apache-2.0
---
|
ihsanridzi/blockassist-bc-wiry_flexible_owl_1755857406
|
ihsanridzi
| 2025-08-22T10:36:40Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"wiry flexible owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:36:37Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- wiry flexible owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
vwzyrraz7l/blockassist-bc-tall_hunting_vulture_1755857407
|
vwzyrraz7l
| 2025-08-22T10:36:32Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tall hunting vulture",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:36:28Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tall hunting vulture
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
eggej/blockassist-bc-marine_playful_eel_1755858869
|
eggej
| 2025-08-22T10:34:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"marine playful eel",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:34:48Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- marine playful eel
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
roeker/blockassist-bc-quick_wiry_owl_1755858791
|
roeker
| 2025-08-22T10:34:00Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick wiry owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:33:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick wiry owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
milliarderdol/blockassist-bc-roaring_rough_scorpion_1755856818
|
milliarderdol
| 2025-08-22T10:33:26Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"roaring rough scorpion",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:32:21Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- roaring rough scorpion
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
pm-25/llama3-8b-sft-dpo-tulu-only
|
pm-25
| 2025-08-22T10:32:25Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-22T10:31:14Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
TEIR/Des2_lora_model
|
TEIR
| 2025-08-22T10:32:09Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-22T10:32:00Z |
---
base_model: unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** TEIR
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
tgrhn/whisper-large-v3-turbo_finetuned-8
|
tgrhn
| 2025-08-22T10:31:38Z | 0 | 0 |
transformers
|
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-22T10:31:36Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
agurung/Qwen2.5-7B-Instruct-CONTRASTIVE-NRL-NCP-GRPO-NLL-UNBOUNDED
|
agurung
| 2025-08-22T10:30:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-22T10:25:46Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
pm-25/llama3-8b-sft-dpo
|
pm-25
| 2025-08-22T10:29:04Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-22T10:27:28Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
VIDEOMUSICB/FULL.NXTWP.NET.OTHOI.ORIGINAL.VIDEO.MUSICBD25.XYZ
|
VIDEOMUSICB
| 2025-08-22T10:28:49Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-22T10:27:33Z |
Watch 🟢 ➤ ➤ ➤ <a href="https://vibeviralz.com/yhtrhr"> 🌐 Click Here To link (FULL.NXTWP.NET.OTHOI.ORIGINAL.VIDEO.MUSICBD25.XYZ)
🔴 ➤►DOWNLOAD👉👉🟢 ➤Watch 🟢 ➤ ➤ ➤ <a href="https://vibeviralz.com/yhtrhr"> 🌐 FULL.NXTWP.NET.OTHOI.ORIGINAL.VIDEO.MUSICBD25.XYZ
|
manusiaperahu2012/blockassist-bc-roaring_long_tuna_1755856857
|
manusiaperahu2012
| 2025-08-22T10:27:08Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"roaring long tuna",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:27:04Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- roaring long tuna
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
k0zmik/Qwen3-Reranker-4B-Q8_0-GGUF
|
k0zmik
| 2025-08-22T10:27:06Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-ranking",
"base_model:Qwen/Qwen3-Reranker-4B",
"base_model:quantized:Qwen/Qwen3-Reranker-4B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-ranking
| 2025-08-22T10:26:46Z |
---
license: apache-2.0
base_model: Qwen/Qwen3-Reranker-4B
library_name: transformers
pipeline_tag: text-ranking
tags:
- llama-cpp
- gguf-my-repo
---
# k0zmik/Qwen3-Reranker-4B-Q8_0-GGUF
This model was converted to GGUF format from [`Qwen/Qwen3-Reranker-4B`](https://huggingface.co/Qwen/Qwen3-Reranker-4B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Qwen/Qwen3-Reranker-4B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo k0zmik/Qwen3-Reranker-4B-Q8_0-GGUF --hf-file qwen3-reranker-4b-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo k0zmik/Qwen3-Reranker-4B-Q8_0-GGUF --hf-file qwen3-reranker-4b-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo k0zmik/Qwen3-Reranker-4B-Q8_0-GGUF --hf-file qwen3-reranker-4b-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo k0zmik/Qwen3-Reranker-4B-Q8_0-GGUF --hf-file qwen3-reranker-4b-q8_0.gguf -c 2048
```
|
roeker/blockassist-bc-quick_wiry_owl_1755858305
|
roeker
| 2025-08-22T10:26:37Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"quick wiry owl",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:25:50Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- quick wiry owl
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Medved444/blockassist-bc-bellowing_finicky_manatee_1755857086
|
Medved444
| 2025-08-22T10:23:59Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"bellowing finicky manatee",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:23:33Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- bellowing finicky manatee
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
katanyasekolah/blockassist-bc-silky_sprightly_cassowary_1755856444
|
katanyasekolah
| 2025-08-22T10:23:54Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"silky sprightly cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-22T10:23:51Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- silky sprightly cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sheldondirector/kay7250
|
sheldondirector
| 2025-08-22T10:23:25Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:Qwen/Qwen-Image",
"base_model:adapter:Qwen/Qwen-Image",
"license:apache-2.0",
"region:us"
] |
text-to-image
| 2025-08-22T10:23:04Z |
---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- output:
url: >-
images/_app_ai-toolkit_output_my_first_lora_v1_samples_1755856622097__000007250_0.jpg
text: '-'
base_model: Qwen/Qwen-Image
instance_prompt: null
license: apache-2.0
---
# kay7250
<Gallery />
## Download model
[Download](/sheldondirector/kay7250/tree/main) them in the Files & versions tab.
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.